Podcast Projets Libres ! Des humain⋅es derrière les projets !
Le podcast est un média particulièrement consommé en France, comme le rappelait l’interview de Benjamin Bellamy de Castopod en mai 2022 sur ce même blog (aussi disponible en… podcast !). Il permet d’écouter une interview en faisant la vaisselle, des crêpes, ou du roller (mais pas en milieu urbain – ceci est un message de la sécurité routière). Cela veut dire, par exemple, que vous pouvez écouter cette interview de Pouhiou et Booteille sur le projet PeerTube par… Walid de Podcast Projets Libres ! tout en changeant le joint de culasse de votre ordinateur ! C’est dingue cette coïncidence, non ?!
Un petit micro interview un grand micro. CC-BY-SA JJJJOOOOOOOOOOEEEEEEEEEEEPINO
Peux-tu te présenter ? Qui es-tu ? D’où viens-tu ? Quelle est ta couleur préférée ?
Je m’appelle Walid Nouh, mon surnom est wawa (ou wawax).
J’ai découvert l’informatique (et le roller) à l’âge de huit ans. Depuis, je n’ai jamais arrêté 🙂
J’habite actuellement en région parisienne et je travaille dans une entreprise de l’économie sociale et solidaire dans la réparation et le reconditionnement de gros électroménager.
Ma couleur préférée est le noir.
À quel moment, dans ton parcours, as-tu croisé le logiciel libre ?
Durant mes années d’IUT. En cours, nous avions des ordinateurs sous Red Hat Linux.
Mon premier ordinateur personnel sous Linux c’était en 2000, il tournait sur une MandrakeLinux.
C’est à la sortie de mes études que j’ai vraiment découvert le libre et compris que c’était ce que j’allais faire dans les années à venir.
C’est lors de ma première expérience professionnelle, dans une ESN nommée Atos, que j’ai eu l’occasion de rejoindre le Centre Open Source de la compagnie, et de rencontrer d’autres personnes passionnées et qui avaient l’habitude de contribuer sur des projets libres.
Pourquoi le format podcast ?
Le podcast est ma manière préférée de consommer de l’information. J’écoute entre 10 et 20 heures de podcasts par semaine…
J’aime le fait que le format est libre, qu’on peut trouver des podcasts de niche, et que l’on peut aller très en profondeur dans les sujets.
Je suis un très grand fan des podcasts longs (entre 45 minutes et deux heures), j’ai d’ailleurs du mal à écouter des épisodes de 15 minutes.
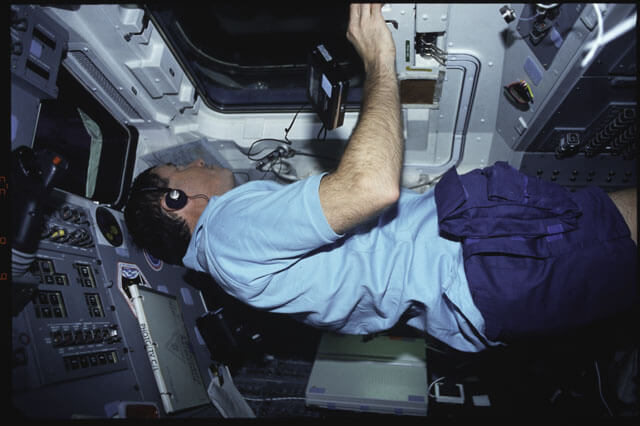
On peut vraiment faire ce qu’on veut en écoutant un podcast – ici, un astronaute jouant avec l’apesanteur en écoutant un podcast
D’ailleurs, tes podcasts font très pros (format, montage) : des astuces ou bons logiciels à conseiller ?
Chaque épisode me prend 6 à 10 heures de travail !
Pour arriver à ce résultat je passe énormément de temps à me documenter, écouter des podcasts ou vidéos, afin de réaliser une trame.
Je soumets ensuite cette trame au(x) invité(s), afin qu’ils puissent se préparer ou ajuster celle-ci.
Cette phase préparatoire peut prendre des semaines, car elle est nourrie par mes rencontres, réflexions ou lectures. Chaque épisode commence, pour moi, par la découverte du sujet et un questionnement sur l’angle que je veux donner à l’interview, et comment celle-ci s’inscrit dans la suite des précédentes.
Pour le montage j’utilise Audacity, c’est très classique (il faut que j’essaye Ardour…).
Pour la mise en ligne je passe par la plateforme libre Castopod, qui est très bien et nativement connectée au Fediverse.
Si je devais donner des conseils :
bien réfléchir à sa ligne éditoriale, ce que l’on veut faire, et en quoi ses épisodes vont se distinguer de ce qui existe déjà dans l’univers du podcast.
être clair sur l’objectif de son podcast : est-ce que l’on veut un podcast plutôt “live” ? (donc sans montage par la suite). Est-ce qu’on se fixe des limites en temps à passer par épisode ?
est-ce que tu veux vivre ou te rémunérer avec ton podcast ? (Auquel cas renseigne-toi bien, regarde ce que font les autres pour trouver un modèle qui te convient).
De mon côté, je me suis fixé plusieurs règles :
la durée de l’épisode n’est pas un problème
je ne m’interdis aucun sujet : le podcast reflète mes intérêts. Je suis conscient que certains épisodes ne vont pas intéresser la majorité des gens, mais du moment que j’ai envie de le faire, alors il n’y a pas de raison de s’en priver 🙂
je ne m’astreint à aucun calendrier de sortie fixe (même si j’aime bien le format de 2 par mois, mais ça risque de glisser plutôt vers 1 toute les trois semaines)
je fais le minimum en termes de communication sur les réseaux sociaux et je laisse faire le bouche-à-oreille
des épisodes peuvent être super techniques et d’autres grand public, à mon appréciation
Pourquoi le sujet du libre et non celui du roller ?
J’ai commencé les podcasts il y a deux ans par collaborer sur un podcast de roller, nommé Balado Roller. Dans ce podcast nous interviewons des personnes qui ont contribué à l’essor du roller. J’ai commencé par y être invité, puis co-animateur et aujourd’hui je réalise une partie des montages des épisodes auxquels je participe. Son audience est bien supérieure à celle de Projets Libres! et nous savons qu’il est écouté par les professionnels de ce sport.
Le podcast Projets libres!, reprend le même concept mais appliqué à ma seconde passion, qui est le logiciel libre. La différence c’est que pour celui de roller nous sommes deux, et nous nous appuyons sur un site qui existe depuis 20 ans.
Pour Projets Libres!, je suis tout seul, c’est moi qui fait tout de A à Z, suivant mes propres désirs (je suis assez perfectionniste).
Une autre différence est que sur nos interviews roller, le travail de préparation a soit été déjà fait en amont sur le site rollerenligne.com au fil des années, soit il est minimal car nous connaissons personnellement la plupart de nos invités. Sur Projets Libres! je dois faire beaucoup plus de recherche pour éviter de dire des bêtises, et aussi pour être sûr de la qualité de l’échange de l’on va avoir.
Comment choisis-tu qui tu vas interviewer ? En fonction des affinités ? Parce que tu utilises le logiciel ou projet ? Du buzz ?
C’est une combinaison de plusieurs facteurs :
mes propres passions, sujets de fond. Principalement : la cartographie des projets francophones, les financements des projets, les transports, le Fediverse, les forks et les ERPs
les personnes qui me contactent pour me proposer un sujet ou une mise en relation
les rencontres que je fais sur les salons ou conférences, et qui alimentent mes réflexions
les outils que j’utilise et dont je suis fan
mon travail, dans le métier du reconditionnement, qui m’amène à vouloir creuser certains sujets qui m’intéressent
J’essaye de n’interviewer que des personnes qui sont au coeur des projets. Ma stratégie est de proposer un contenu original, que j’espère de qualité, et que les personnes concernées feront tourner dans leur communauté. Je ne souhaite pas faire de publicité. Ma communication est plutôt du type LinuxFR que du type LinkedIn.
Je fais des podcasts en français car c’est ma langue natale et aussi parce qu’il y a déjà de très bons podcasts en anglais.
Dans tes podcasts, tu te concentres sur l’histoire humaine derrière les projets : c’est important pour toi ?
Pas de logiciel libre sans femmes et hommes !
J’ai eu la chance d’être un professionnel du logiciel libre, actif dans l’univers francophone pendant plus de 10 ans, d’être core developer sur un logiciel, d’avoir participé au fork d’un autre, d’avoir travaillé en ESN spécialisées dans le libre. Partout où je suis passé j’ai rencontré des femmes et des hommes passionnés par le libre et ses valeurs.
C’est en partie ce que je cherche à mettre en valeur, en m’appuyant sur ma propre expérience.
Pour faire simple, je cherche à produire le contenu que j’aimerais entendre. Je suis souvent frustré à la fin d’une interview car personnellement j’aurais posé d’autres questions, ou creusé d’autres sujets !
Mes podcasts ont pour but d’être complémentaires avec ceux qui existent déjà, que j’écoute régulièrement et que j’aprécie.
Qui aimerais-tu interviewer pour un prochain épisode ?
J’ai comme projet d’essayer interviewer toutes les associations historiques du libre.
L’idée serait de pouvoir faire une cartographie ou une frise temporelle de l’apparition des unes par rapport aux autres.
Je vais aussi me concentrer sur la notion de fork, et ce que cela veut dire au niveau humain (pour les personnes qui forkent, et pour les mainteneurs qui se font forker).
Bref, j’ai déjà une feuille de route pour les 6 mois à venir ^^
Page Castopod de Projets Podcasts Libres !
Quels sont les défis à venir pour le podcast ?
Durer. Je me suis fixé 1 an sous cette forme et seul. Le podcast est un travail journalier, qui me prend presque tout mon temps libre.
En 2024, il va falloir que je constitue une équipe, pour aider à monter en qualité et garder un rythme raisonnable.
La parité femme/homme dans les interviews. Ce n’est pas si simple, mais j’y travaille et c’est très important pour moi.
Se renouveler, d’avoir toujours des bonnes personnes avec du contenu intéressant.
Il va falloir que je me finance mes besoins en me basant sur le don : je ne suis pas intéressé par mettre la publication ou du sponsoring dans le podcast. Comment donc faire en sorte que les gens acceptent de me financer, sans que cela ne me demande plus de travail supplémentaire (par exemple faire du contenu exclusif pour ses donateurs). Dans une démarche bénévole, tout contenu que je produis est du temps que je ne passe pas pour d’autres projets ou dans ma vie personnelle
Réaliser un épisode avec sa transcription : c’est un défi permanent, car cela ajoute plusieurs heures de travail par épisode 🙂
La transcription des épisodes doit effectivement prendre un temps fou. C’est important pour toi ?
C’est une des premières choses qui m’a été demandé, et j’avais mis le sujet de côté car je ne pouvais pas tout faire. C’est en lisant le manifeste de Julie Moynat, relayé par Frédéric Couchet que j’ai remis le sujet au goût du jour.
La transcription a plusieurs fonctions :
permettre aux gens qui ne veulent pas ou ne peuvent pas écouter le podcast de suivre notre conversation. Je dois avouer que, dans le cadre de mon travail, je déteste les tutoriels vidéos car tu ne peux pas rechercher dedans pour trouver exactement ce que tu veux…
elle améliore le référencement du texte
elle participe à la démarche “de ne pas juste avoir un podcast” mais d’avoir un media
Techniquement je passe par un service (non libre) de transcription. Je dois ensuite retravailler les phrases pour en faire un texte lisible. Cela pose des questions sur le niveau de retravail, entre avoir un texte en bon français et garder le sens et l’atmosphère de l’interview. J’ai bien essayé de demander une IA de me corriger les phrases sans les modifier, mais je n’ai pas encore atteint le bon résultat. J’ai des échanges avec Benjamin Bellamy de Castopod, car c’est un de leurs axes de travail actuel.
N’étant pas un professionnel, la correction transcription d’un épisode d’un heure me prend 2 à 3 heures de travail (avec la mise en forme sur le site). C’est une des raisons pour lesquelles je pense changer le rythme de sortie des épisodes.
Je voudrais faire quelques remerciements :
ma femme qui supporte tous mes enregistrements et mes conversations autour du podcast !
mes amis et collègues pour les idées, écoutes et commentaires
mon ami Emilien Martinoty pour son aide et pour création et maintenance du site
l’équipe de Castopod pour la migration sur leur plate-forme et les discussions régulières
tous les invités qui m’ont fait confiance
pour finir toute l’équipe framasoft pour leur accueil et la promotion de mon podcast
Nous avons profité de la sortie d’une nouvelle version de l’application mobile pour interroger l’équipe de Piwigo, et plus particulièrement Pierrick, le créateur de ce logiciel libre qui a fêté ses vingt ans et qui est, c’est incroyable, rentable.
Moi je note que «Piwigo» c’est plus sympa que « PhpWebGallery », comme nom de logiciel. Enfin, un logiciel libre qui n’a pas un nom trop tordu. Qu’est-ce que vous pouvez nous apprendre sur Piwigo, le logiciel ?
Piwigo est un logiciel libre de gestion de photothèque. Il s’agit d’une application web, donc accessible depuis un navigateur web, que l’on peut également consulter et administrer avec des applications mobiles. Au-delà des photos, Piwigo permet d’organiser et indexer tout type de média : images, vidéos, documents PDF et autres fichiers de travail des graphistes. Originellement conçu pour les particuliers, il s’est au fil des ans trouvé un public auprès des organisations de toutes tailles.
Le logo de Piwigo, le logiciel
La gestation du projet PhpWebGallery démarre fin 2001 et la première version sortira aux vacances de Pâques 2002. Pendant les vacances, car j’étais étudiant en école d’ingénieur à Lyon et j’ai eu besoin de temps libre pour finaliser la première version. Le logiciel a tout de suite rencontré un public et des contributeurs ont rejoint l’aventure. En 2009, « PhpWebGallery » est renommé « Piwigo » mais seul le nom a changé, il s’agit du même projet.
Les huit premières années, le projet était entièrement bénévole, avec des contributeurs (de qualité) qui donnaient de leur temps libre et de leurs compétences. Le passage d’étudiant à salarié m’a donné du temps libre, vraiment beaucoup. Je faisais pas mal d’heures pour mon employeur mais en comparaison avec le rythme prépa/école, c’était très tranquille : pas de devoirs à faire le soir ! Donc Piwigo a beaucoup avancé durant cette période. Devenu parent puis propriétaire d’un appartement, avec les travaux à faire… mon temps libre a fondu et il a fallu faire des choix. Soit j’arrêtais le projet et il aurait été repris par la communauté, soit je trouvais un modèle économique viable et compatible avec le projet pour en faire mon métier. Si je suis ici pour en parler douze ans plus tard, c’est que cette deuxième option a été retenue.
En 2010 vous lancez le service piwigo.com ; un logiciel libre dont les auteurs ne crèvent pas de faim, c’est plutôt bien. Est-ce que c’est vrai ? Avez-vous trouvé votre modèle économique ?
Le logo de Piwigo, le service
Pour ce qui me concerne, je ne crève pas du tout de faim. J’ai pu rapidement retrouver des revenus équivalents à mon ancien salaire. Et davantage aujourd’hui. J’estime vivre très confortablement et ne manquer de rien. Ceci est très subjectif et mon mode de vie pourrait paraître « austère » pour certains et « extravagant » pour d’autres. En tout cas moi cela me convient 🙂
Notre modèle économique a un peu évolué en 12 ans. Si l’objectif est depuis le départ de se concentrer sur la vente d’abonnements, il a fallu quelques années pour que cela couvre mon salaire. J’ai eu l’opportunité de réaliser des prestations de dev en parallèle de Piwigo les premières années pour compenser la croissance lente des ventes d’abonnements.
Ce qui a beaucoup changé c’est notre cible : on est passé d’une cible B2C (à destination des individus) à une cible B2B (à destination des organisations). Et cela a tout changé en terme de chiffre d’affaires. Malheureusement ou plutôt « factuellement » nous plafonnons depuis longtemps sur les particuliers. Nos offres Entreprise quant à elles sont en croissance continue, sans que l’on atteigne encore de plafond. Nous avons donc décidé de communiquer vers cette cible. Piwigo reste utilisable pour des particuliers bien sûr, mais ce sont prioritairement les organisations qui vont orienter notre feuille de route.
Grâce à la réorientation de notre modèle économique, il a été possible de faire grossir l’équipe.
Donc on a Piwigo.org qui fournit le logiciel libre que chacun⋅e peut installer à condition d’en avoir les compétences, et Piwigo.com, service commercial géré par ton équipe et toi. Vous vous chargez de la maintenance, des mises à jour, des sauvegardes.
Qui est vraiment derrière Piwigo.com aujourd’hui ? Et combien de gens est-ce que ça fait vivre ?
Une petite équipe mêlant des salariés, dont plusieurs alternants, des freelances dans les domaines du support, de la communication, du design ou encore de la gestion administrative. Cela représente 8 personnes, certaines à temps plein, d’autres à temps partiel. J’exclus le cabinet comptable, même s’il y passe du temps compte tenu du nombre de transactions que les abonnements représentent…
Qu’est-ce qui est lourd ?
Certains aspects purement comptables de l’activité. La gestion de la TVA par exemple. Non pas le principe de la TVA mais les règles autour de la TVA. Nous vendons en France, dans la zone Euro et hors zone Euro : à chaque situation sa règle d’application des taxes. Les PCA (produits constatés d’avance) sont aussi une petite source de tracas qu’il a fallu gérer proprement. Jamais je n’aurais imaginé passer autant de temps sur ce genre de sujets en lançant le projet commercial.
Qu’est-ce qui est cool ?
Constater que Piwigo est leur principal outil de travail de nombreux clients. On comprend alors que certains choix de design, certaines optimisations de performances font pour eux une grande différence au quotidien.
Création d’un⋅e utilisateur⋅ice
Nous avons lancé depuis quelques semaines une série d’entretiens utilisateurs durant lesquels des clients nous montrent comment ils utilisent Piwigo et c’est assez génial de les voir utiliser voire détourner les fonctionnalités que l’on a développées.
D’un point de vue vraiment personnel, ce que je trouve cool c’est qu’un projet démarré sur mon temps libre pendant mes études soit devenu créateur d’emplois. Et j’espère un emploi « intéressant » pour les personnes concernées. Qu’elles soient participantes à l’aventure ou utilisatrices dans leur métier. Je crois vraiment au rôle social de l’entreprise et je suis particulièrement fier que Piwigo figure dans le parcours professionnel de nombreuses personnes.
Oui, je suis d’accord : ça claque ! et bien sûr tout est absolument authentique. Évidemment on n’affiche qu’une portion microscopique de notre liste de clients.
Recevez-vous des commandes spécifiques des gros clients pour développer certaines fonctionnalités ?
Pourquoi des « gros » ? Certaines entreprises « pas très grosses » ont des demandes spécifiques aussi. Bon, en pratique c’est vrai que certains « gros » ont l’habitude que l’outil s’adapte à leur besoin et pas le contraire. Donc parfois on adapte : en personnalisant l’interface quasiment toujours, en développant des plugins parfois. C’est moins de 5% de nos clients qui vont payer une prestation de développement. Vendre ce type de prestation n’est pas au cœur de notre modèle économique mais ne pas le proposer pourrait nuire à la vente d’abonnements, donc on est ouverts aux demandes.
Est-ce que vous refusez de faire certaines choses ?
D’un point de vue du développement ? Pas souvent. Je n’ai pas souvenir de demandes suffisamment farfelues… pardon « spécifiques » pour qu’on les refuse a priori. En revanche il y a des choses qu’on refuse systématiquement : répondre à des appels d’offre et autre « marchés publics ». Quand une administration nous contacte et nous envoie des « dossiers » avec des listes de questions à rallonge, on s’assure qu’il n’y a pas d’appel d’offre derrière car on ne rentrera pas dans le processus. Nous ne vendons pas assez cher pour nous permettre de répondre à des appels d’offre. Je comprends que les entreprises qui vendent des tickets à 50k€+ se permettent ce genre de démarche administrative, mais avec notre ticket entre 500€ et 4 000€, on serait perdant à tous les coups. Le « coût administratif » d’un appel d’offre est plus élevé que le coût opérationnel de la solution proposée. C’est aberrant et on refuse de rentrer là-dedans.
Bien que nous refusions de répondre à cette complexité administrative (très française), nous avons de nombreuses administrations comme clients : ministère, mairies, conseils départementaux, offices de tourisme… Comme quoi c’est possible (et légal) de ne pas gaspiller de l’énergie et du temps à remplir des dossiers.
Y a-t-il beaucoup de particuliers qui, comme moi, vous confient leurs photos ? Faites péter les chiffres qui décoiffent !
Environ 2000 particuliers sont clients de notre offre hébergée. Ils sont bien plus nombreux à confier leurs photos à Piwigo, mais ils ne sont pas hébergés sur nos serveurs. Notre dernière enquête en 2020 indiquait qu’environ un utilisateur sur dix était client de Piwigo.com [donc 90% des gens qui utilisent le logiciel Piwigo s’auto-hébergent ou s’hébergent ailleurs, NDLR] .
Si on élargit un peu le champ de vision, on estime qu’il y a entre 50 000 et 500 000 installations de Piwigo dans le monde. Avec une énorme majorité d’installations hors Piwigo.com donc. Difficile à chiffrer précisément car Piwigo ne traque pas les installations.
La page d’administration de Piwigo
Pour des chiffres qui « décoiffent », je dirais qu’on a fait 30% de croissance en 2020. Puis encore 30% de croissance en 2021 (merci les confinements…) et qu’on revient à notre rythme de croisière de +15% par an en 2022. Dans le contexte actuel de difficulté des entreprises, je trouve qu’on s’en sort bien !
Autre chiffre qui décoiffe : on n’a pas levé un seul euro. Aucun business angel, aucune levée de fonds auprès d’investisseurs. Notre croissance est douce mais sereine. Attention pour autant : je ne dénigre pas le principe de lever des fonds. Cela permet d’aller beaucoup plus vite. Vers le succès ou l’échec, mais beaucoup plus vite ! Rien ne dit que si c’était à refaire, je n’essaierais pas de lever des fonds.
Encore un chiffre respectable : Piwigo a soufflé sa vingtième bougie en 2022. Le projet a connu plusieurs phases et nous vivons actuellement celle de la professionnalisation. Beaucoup de projets libres s’arrêtent avant et disparaissent car ils ne franchissent pas cette étape. Si certains voient dans l’arrivée de l’argent une « trahison » de la communauté, je trouve au contraire que c’est sain et gage de pérennité. Lorsque les fondateurs d’un projet ont besoin d’un modèle économique viable pour payer leurs propres factures, vous pouvez être sûrs que le projet ne va pas être abandonné sur un coup de tête.
Est-ce que les réseaux sociaux axés sur la photographie concurrencent Piwigo ? On pense à Instagram mais aussi à Pixelfed, évidemment.
J’ai regardé rapidement ce qu’était Pixelfed. Ma conclusion au bout de quelques minutes : c’est un clone opensource à Instagram, en mode décentralisé.
Piwigo n’est pas un réseau social. Pour certains utilisateurs, Piwigo a perdu de son intérêt dès lors que Facebook et ses albums photos sont arrivés. Pour d’autres, Piwigo constitue au contraire une solution pour ceux qui refusent la centralisation/uniformisation telle que proposée par Facebook ou Google. Enfin pour de nombreux clients pro (photographes ou entreprises) Piwigo est un outil à usage interne de l’équipe communication pour organiser les ressources média qui seront ensuite utilisées sur les réseaux sociaux. Il faut comprendre que pour les chargés de communication d’un office de tourisme, mettre sa photothèque sur Facebook n’a aucun sens. Ils ou elles publient quelques photos sur Facebook, sur Instagram ou autres, mais leur photothèque est organisée sur leur Piwigo.
Bref, même si les premières années je me suis demandé si Piwigo était encore pertinent face à l’émergence de ces nouvelles formes de communication, je sais aujourd’hui que Piwigo n’est pas en concurrence frontale avec ces derniers mais qu’au contraire, l’existence de ces réseaux nécessite pour les marques/entreprises qu’elles organisent leurs photothèques. Piwigo est là pour les y aider.
Quelles sont les différences ?
La toute première des choses, c’est la temporalité. Les réseaux sociaux sont excellents pour obtenir une exposition forte et éphémère de votre « actualité ». À l’inverse, Piwigo va exceller pour vous permettre de retrouver un lot de photos parmi des centaines de milliers, organisées au fil des années. Piwigo permet de gérer son patrimoine photo (et autres médias) sur le temps long.
L’autre aspect important c’est le travail en équipe. Un réseau social est généralement conçu autour d’une seule personne qui administre le compte. Dans Piwigo, plusieurs administrateurs collaborent (à un instant T ou dans la durée) pour construire la photothèque : classification, indexation (tags, titre, descriptions…)
Enfin, certaines fonctionnalités n’ont tout simplement rien à voir. Par exemple, dans un réseau social le cœur de métier va être d’obtenir des likes. Dans un Piwigo, vous allez pouvoir mettre en place un moteur de recherche multicritères avec vos propres critères. Par exemple on a un client qui fabrique des matériaux acoustiques. Ses critères de recherche sont collection, coloris, lieu d’implantation… Cela n’aurait aucun sens sur l’interface uniformisée d’un Instagram.
Qui apporte des contributions à Piwigo ? Est-ce que c’est surtout la core team ?
Cela a beaucoup changé avec le temps. Et même ce qu’on appelle aujourd’hui « équipe » n’est plus la même chose que ce qu’on appelait « équipe » il y a 10 ans. Aujourd’hui, l’équipe c’est essentiellement celle du projet commercial. Pas uniquement mais quand même pas mal.
On a donc beaucoup de contributions « internes » mais ce serait trop simplificateur d’ignorer l’énorme apport de la communauté de contributeurs au sens large. Déjà parce que l’état actuel de Piwigo repose sur les fondations créées par une communauté de développeurs bénévoles. Ensuite parce qu’on reçoit bien sûr des contributions sous forme de rapports de bugs, des pull-requests mais aussi grâce à des bénévoles qui aident des utilisateurs sur les forums communautaires, les bêta-testeurs… sans oublier les centaines de traducteurs.
Petite anecdote dont je suis fier : Rasmus Lerdorf, créateur de PHP (le langage de programmation principalement utilisé dans Piwigo) nous a plusieurs fois envoyé des patches pour que Piwigo soit compatibles avec les dernières versions de PHP.
Quel est votre lien avec le monde du Libre ? (<troll>y a-t-il un monde du Libre ?</troll>)
Je ne sais pas s’il y a un « monde du libre ». Historiquement Les contributeurs sont d’abord des utilisateurs du logiciel qui ont voulu le faire évoluer. Je ne suis pas certain qu’il s’agisse de fervents défenseurs du logiciel libre.
Franchement je ne sais pas trop comment répondre à cette question. Je sais que Piwigo est une brique de ce monde du libre mais je ne suis pas sûr que l’on conscientise le fait de faire partie d’un mouvement global. Je pense qu’on est pragmatique plutôt qu’idéologique.
En tant que client, je viens de recevoir le mail qui annonce le changement de tarif. Pouvez-vous nous expliquer l’origine de cette décision ?
Là on est vraiment sur l’actualité « à chaud ». Le changement de tarif pour les nouveaux/futurs clients a fait l’objet d’une longue réflexion et préparation. Je dirais qu’on le prépare depuis 18 mois.
Si j’ai bien compris la clientèle particulière est un tout petit pourcentage de la clientèle de Piwigo.com ?
Les clients de l’ancienne offre « individuelle » représentent 30 % du chiffre d’affaires des abonnements pour 91% des clients. J’exclus les prestations de dev, qui sont exclusivement ordonnées par des entreprises. Donc « tout petit pourcentage », ça dépend du point de vue 🙂
Est-ce que l’offre de stockage illimité devient trop chère ?
En moyenne sur l’ensemble des clients individuels, on est à ~30 Go de stockage utilisé. La médiane est quant à elle de 5Go. Si la marge financière dégagée n’est pas folle, on ne perd pas d’argent pour autant, car nous avons réussi à ne pas payer le stockage trop cher. Pour faire simple : on n’utilise pas de stockage cloud type Amazon Web Services, Google Cloud ou Microsoft Azure. Sinon on serait clairement perdant.
Ceci est vrai tant qu’on propose de l’illimité sur les photos. Sauf que la première demande au support, devant toutes les autres, c’est : « puis-je ajouter mes vidéos ? », et cela change la donne. Hors de question de proposer de l’illimité sur les vidéos. De l’autre côté, on entend et on comprend la demande des utilisateurs concernant les vidéos. Donc on veut proposer les vidéos, mais il faut en parallèle introduire un quota de stockage.
Ensuite nous avions un souci de cohérence entre l’offre individuelle (stockage illimité mais photos uniquement) et les offres entreprise (quota de stockage et tout type de fichiers). La solution qui nous paraît la meilleure est d’imposer un quota pour toutes les offres, mais un quota généreux. L’offre « Perso » est à 50 Go de stockage, donc largement au-delà de la conso moyenne.
Enfin la principe de l’illimité est problématique. En 12 ans, la perception du grand public sur le numérique a évolué. Je parle spécifiquement de la consommation de ressources que le numérique représente. Le cloud, ce sont des serveurs dans des centres de données qui consomment de l’électricité, etc. En 2023, je pense que tout le monde a intégré le fait que nous vivons dans un monde fini. Ceci n’est pas compatible avec la notion de stockage infini. Je peux vous assurer que certains utilisateurs n’ont pas conscience de cette finitude.
Est-ce que des pros ont utilisé cette offre destinée aux particuliers pour «abuser» ?
Il y a des abus sur l’utilisation de l’espace de stockage, mais pas spécialement par des pros. On a des particuliers qui scannent des documents en haute résolution par dizaine de milliers pour des téraoctets stockés… On a des particuliers qui sont fans de telle ou telle star de cinéma et qui font des captures d’écran chaque seconde de chaque film de cet acteur. Ne rigolez pas, cela existe.
En revanche on avait un soucis de positionnement : l’offre « individuelle » n’était pas très appropriée pour les photographes pros mais l’offre entreprise était trop chère. On a maintenant des offres mieux étagées et on espère que cela sera plus pertinent pour ce type de client.
Enfin on a des entreprises qui essaient de prendre l’offre individuelle en se faisant passer pour des particuliers. Et là on est obligés de faire les gendarmes. On a même détecté des « patterns » de ses entreprises et on annulait les commandes « individuelles » de ces clients. J’en avais personnellement un petit peu ras le bol 🙂
Les nouvelles offres, même « Perso » sont accessibles même à des multinationales. Évidemment, les limites qu’on a fixées devraient naturellement les orienter vers nos offres Entreprise (nouvelle génération) voire VIP.
Est-ce qu’il s’agissait d’une offre qui se voulait temporaire et que vous avez laissé filer parce que vous étiez sur autre chose ?
Pendant 12 ans ? Non non, le choix de proposer de l’illimité en 2010 était réfléchi et « à durée indéterminée ». Les besoins et les possibilités et surtout les demandes ont changé. On s’adapte. On espère ne pas se tromper et si c’est le cas on fera des ajustements.
L’important c’est de pas mettre nos clients au pied du mur : ils peuvent renouveler sur leur offre d’origine. On a toujours proposé cela et on ne compte pas changer cette règle. C’est assez unique dans notre secteur d’activité mais on y tient.
Nous avons vu que votre actualité c’était la nouvelle version de Piwigo NG. Je crois que vous avez besoin d’aide. Vous pouvez nous en parler ?
Nous avons plusieurs actualités et effectivement côté logiciel, c’est la sortie de la version 2 de l’application mobile pour Android. Piwigo NG (comme Next Generation) est le résultat du travail de Rémi, qui travaille sur Piwigo depuis deux ans. Après avoir voulu faire évoluer l’application « native » sans succès, il a créé en deux semaines un prototype d’application mobile en Flutter. Ce qu’il avait fait en deux semaines était meilleur que ce que l’on galérait à obtenir avec l’application native en plusieurs mois. On a donc décidé de basculer sur cette nouvelle technologie. Un an après la sortie de Piwigo NG, Rémi sort une version 2 toujours sur Flutter mais avec une nouvelle architecture « plus propice aux évolutions ». Le fameux « il faut refactorer tous les six mois », devise des développeurs Java.
Le 12 janvier dernier, PVH éditions a annoncé la libération de sa collection Ludomire. Vu la faible fréquence de ce genre de démarche dans le milieu de l’édition traditionnelle, nous avons eu envie d’aller interroger ce courageux éditeur suisse.
Rencontre avec un éditeur qui libère
Bonjour, pourriez-vous tout d’abord présenter rapidement PVH éditions, son histoire et catalogue ?
PVH éditions est une maison d’édition franco-suisse spécialisée dans la science-fiction, la fantasy et le fantastique, qu’on appelle parfois « littérature de l’Imaginaire » mais je préfère dire SFFF qui rend mieux compte de tous les genres et sous-genres qu’il renferme. Notre activité éditoriale a démarré en 2014, mais nous nous sommes réellement professionnalisés fin 2020. C’est à ce moment où tout s’est accéléré : en deux ans nous avons doublé la taille de notre catalogue, embauché six personnes et obtenu un contrat de diffusion auprès de CED-CEDIF (distribution Pollen).
Pendant les premières années, nous avons beaucoup expérimenté : livre de voyage, jeu de société, etc. Mais en 2021, nous avons resserré notre catalogue qui comprend essentiellement la collection Ludomire (16 romans et recueils de nouvelles), la collection Bretteur (4 romans et recueils de contes), quelques coéditions en jeu de rôle (Mississippi et Oreinidia) et des essais décalés autour de Bitcoin (Objective Thune et La monnaie à pétales).
Malgré les évolutions de ces dernières années, l’ADN de PVH éditions reste celle du début : il s’agit d’un projet artistique un peu fou de deux amis, Christophe Gérard et moi. Le caractère bicéphale et binational s’incarne dans deux structures : PVH éditions, dirigé par moi-même à Neuchâtel en Suisse, et PVH Labs, dirigé par Christophe à Montboillon en Haute-Saône (France). L’équipe de quatre personnes de PVH éditions se charge du développement éditorial : édition de livres, projets de traduction, etc. Celle de PVH Labs, quatre personnes également, se charge du développement software, de la commercialisation dans l’UE et un studio de production de nouveaux formats pour nos romans.
Ainsi en ce début 2023, nous commençons une nouvelle phase de la pérennisation de notre structure. L’enjeu est de faire connaître nos auteurs et nos livres et mener à bien deux projets d’envergure : les développements et le lancement de notre boutique en ligne p2p, La Bookinerie, et de nos Romans augmentés. Ces deux projets, basés sur des logiciels libres, sont liés à la libération de la collection Ludomire.
Vous avez décidé de basculer une partie de votre catalogue, à savoir la collection Ludomire, sous licence libre, comment est née cette envie, et pourquoi le faire ?
L’envie a toujours été là. La question devrait être : pourquoi ne l’avons-nous pas fait avant ? Pour ma part, je m’intéresse aux logiciels libres depuis bien longtemps et j’en utilise autant que possible. Je me suis beaucoup intéressé aux licences Creative Commons bien avant d’être éditeur. J’ai suivi les expériences créatives de Ploum et Thierry Crouzet sur leurs blogs. Ce n’est d’ailleurs pas un hasard si j’ai édité certaines de leurs œuvres. Dès 2020, nous avons inscrit dans notre ligne éditoriale notre « intérêt pour la culture libre ». En 2021, nous avons lancé le format print@home sous licence CC BY-NC-SA. La libération des œuvres s’inscrit dans notre ADN, dans une suite logique.
Alors je la pose : pourquoi ne l’avez-vous pas fait avant ?
Quand on a démarré l’édition, on avait beaucoup de choses à apprendre, à mettre en place. Notre objectif était avant tout de sortir des beaux livres et de rentrer dans nos sous. Rester dans les clous est clairement un confort, on discute avec d’autres éditeurs, on reprend les modèles de contrats que l’on nous partage. L’utilisation de licences libres n’était pas une priorité, même si c’était une envie.
J’avais également le sentiment que libérer des œuvres, comme ça, sans projet, ça aurait été un peu bidon. Pourquoi libérer des œuvres si on continue à fonctionner de la même manière que quand on utilisait un copyright ? Je pense que j’avais besoin de réfléchir au sens d’une telle démarche selon le prisme de l’éditeur. Nous avions également besoin d’arriver à un point de stabilité chez PVH éditions qui nous permette de nous investir dans une telle transformation. Et surtout, je voulais inscrire cette libération dans un projet éditorial ambitieux et cohérent.
C’est ainsi que notre diffusion en France et en Belgique (signée en juillet et en place depuis novembre 2022) a apporté le temps et la stabilité qui m’a permis de préparer cette libération pendant le deuxième semestre 2022. En décembre, nous avons obtenu un financement public important pour la mise en place de notre boutique en ligne p2p, La Bookinerie, sur 2023 et 2024. À présent, si j’ose dire, je déroule un programme mûrement réfléchi.
Vous parlez de la question des répercussions avec les partenaires, quel accueil a reçu votre idée ? Comment ont réagi les collègues éditeurs ? David Revoy avait eu pas mal de souci à l’époque de la première édition chez Glénat de Pepper & Carrot, vous n’êtes pas inquiets ?
Pour le moment, je n’ai pas de retour négatif. Mon diffuseur semble intrigué et il y voit une opportunité pour encore mieux mettre en valeur la collection Ludomire auprès des libraires. Dernièrement, j’ai eu des discussions avec un éditeur européen pour faire traduire certaines œuvres, et il m’a dit : « No problem, I like copyleft ». J’ai également l’impression que le choix d’une telle licence peut être bien vu pour obtenir de l’argent public, même si je pense qu’ils s’en fichent un peu. C’est plutôt encourageant non ?
Clairement, j’avais certaines inquiétudes mais je n’en ai plus vraiment. En réalité, on en fait une énormité mais j’ai surtout l’impression que la plupart des gens se fichent bien de la licence. C’est surtout dans des projets d’adaptation que ça aura de l’importance. Je vous tiendrai au courant.
Pour beaucoup, libérer des œuvres, cela revient à dire qu’elles sont gratuites. Vous venez de l’édition traditionnelle, n’êtes pas des utopistes et avez dû faire quelques calculs. Comment envisagez-vous les choses, financièrement parlant ?
Bien entendu que j’ai fait mes calculs (même si parfois on navigue au doigt mouillé). En réalité, il était important d’assurer une base solide : une belle collection proposée en librairie, des sorties régulières déjà planifiées. La libération de la collection Ludomire n’aura pas d’effet négatif sur ce socle. Le fait que le livre sera disponible gratuitement en version numérique n’aura pas d’influence sur les ventes en librairie. C’est ce que j’ai aussi constaté avec les œuvres de Ploum, qui invitait (avec ma bénédiction) à télécharger gratuitement les e-books. Ça n’a pas empêché Printeurs d’être notre meilleure vente e-book.
Clairement, je pense que cette libération ne peut qu’avoir un effet bénéfique : gagner en visibilité dans les médias, toucher de nouveaux publics, renforcer l’engagement de nos lecteurs. La Bookinerie, qui sera en gros un outil de crowdfunding autohébergé et sans intermédiaire, pourrait être une source financière complémentaire. On est clairement dans l’expérimentation.
Vous avez choisi la licence CC BY SA, qui place les œuvres dans les Communs, et qui est donc plus complexe à intégrer dans des circuits classiques, alors que d’autres licences libres moins engagées existaient (CC BY notamment). Qu’est ce qui a motivé ce choix ?
Nous avons publié un article pour expliquer le choix de notre licence. J’y explique en gros que selon moi pour un éditeur, il y a le choix du copyright ou le choix du copyleft. Le CC BY n’offre aucun avantage et permet la prédation. En tant qu’éditeur, notre métier consiste à exploiter des œuvres et leurs dérivés, soit on les conserve jalousement, soit on espère que d’autres nous aideront à les exploiter. Laisser la possibilité à d’autres de refermer la licence ne nous est donc d’aucune aide.
Après oui, c’est aussi un choix engagé. Si cela ne tenait qu’à moi, la propriété intellectuelle serait abolie, c’est selon moi un archaïsme. Mais c’est aussi un choix pragmatique qui permet de me démarquer des autres éditeurs de SFFF. J’ai également l’intime conviction que le monde de l’édition a besoin de se réinventer pour survivre. La propriété intellectuelle ne sert que les grands acteurs qui ont les moyens de le défendre. Comme challenger, nous avons tout à gagner de sortir du cadre.
Vous allez très loin dans la mise en commun, en proposant une version à imprimer soi-même. Pourquoi aller jusque là ?
Parce que nous nous intéressons à tous les lecteurs potentiels et que plus de la moitié des francophones sont en Afrique. Dans cette région du monde, l’accès au livre est compliqué pour des raisons logistiques et à cause du pouvoir d’achat. Le print@home, inspiré par la difficile accessibilité de nos livres pendant le premier confinement, est un moyen d’offrir un accès imprimé à nos livres pour ces populations. Il sera l’un des formats au cœur de notre boutique online p2p, La Bookinerie.
Et en réalité, si on réfléchit bien à la décision de libérer une œuvre, le but est de la rendre accessible soi-même dans tous les formats pertinents et d’en être la source originelle. C’est ainsi qu’on peut cultiver un public et promouvoir les autres œuvres dans les mêmes formats. La logique commerciale change, je pense. Mais c’est l’expérience qui permettra d’y répondre.
Avez-vous un workflow basé sur des outils libres, également ? Si oui, envisagez-vous de le partager ?
La boutique online p2p est un projet de logiciel libre. Il sera bien entendu partagé dès qu’il aura une version stable. Nous développons également des romans augmentés avec le logiciel Ren’Py et nous allons développer des fonctionnalités nouvelles à nos frais qui seront partagées également.
En interne, nous utilisons autant que possible Ubuntu et des logiciels libres, mais ce n’est pas très structuré. J’espère en faire une seconde étape dans le projet de libération de nos collections et de nos outils. Mais, la priorité est déjà de mener à bien la première étape et survivre. Mais il est évident que tout ce que nous développerons de solide sera partagé : contrats, logiciels, procédures, etc.
Parmi les auteurices impliqués, on retrouve des personnes comme Aquilegia Nox, Thierry Crouzet ou Ploum que tu as cités et qui avaient déjà réfléchi aux licences libres. Comment se sont déroulés les échanges avec celleux qui découvraient ? Quelles étaient leurs plus grandes interrogations, leurs plus grandes craintes ?
Effectivement, Thierry, Ploum et Aquilegia Nox sont des vétérans dans le domaine. Il n’y a pas eu besoin de beaucoup d’efforts pour les convaincre. Mais, pour les autres auteurs·rices, ça a été finalement assez facile aussi. Ils nous font confiance. Il y a deux questions qui reviennent souvent : Qu’est-ce que ça change ? Ben pas grand chose en réalité. Dans un contrat d’édition classique, l’auteur cède tous les droits (à l’exception des droits moraux inaliénables) à l’éditeur. Ils perdent de facto le contrôle de leur œuvre et ses adaptations, à discrétion de leur éditeur. L’édition sous licence libre leur redonne en partie ce droit. En gros, avant ils perdaient le contrôle de leur œuvre et ses adaptations, maintenant ils perdent toujours le contrôle mais ils récupèrent le droit de se réapproprier l’œuvre sans l’accord de l’éditeur. C’est donc une amélioration.
La seconde question concerne les détournements immoraux de l’œuvre. Sur ce point, je leur dis qu’ils conservent le droit moral pour s’opposer à des utilisations scandaleuses. Mais je les préviens surtout que dans les faits, c’est très compliqué d’empêcher des adaptations scandaleuses. Même Disney n’arrive pas à les empêcher… Il faut surtout dédramatiser et éviter l’effet Streisand.
Avez-vous des espoirs, des attentes, sur ce qui pourrait advenir des œuvres ainsi libérées ? Parmi les auteurices, en connaissez-vous qui souhaitent profiter de cette opportunité pour enrichir, développer leur travail originel ?
Je n’ai pas vraiment d’attente car je ne veux pas être déçu. Je pense que la plupart des développements ou adaptations des œuvres libérées viendront des impulsions de PVH éditions ou des auteur·rices. L’approfondissement des œuvres fait partie de notre ligne éditoriale, on y travaille indépendamment du type de licence. Nous avons toujours encouragé nos auteurs à le faire et nous sommes toujours ouverts à aider à l’éclosion de projets connexes.
Dernièrement, ce n’était pas sur un roman de la collection Ludomire mais sur l’essai La monnaie à pétales nous avons reçu la contribution d’une interprétation audio du texte. Nous avons ouvert la licence de ce livre audio en CC BY-SA et il sera diffusé sur la chaîne youtube de l’interprète. Ce serait génial d’avoir de telles initiatives pour la collection Ludomire et j’espère qu’on pourra s’y associer de la même manière.
Mais mon expérience et mon instinct me disent que des initiatives personnelles externes sont rares, je pense qu’il faut surtout chercher à développer un réseau professionnel et un corpus libre commun, où tout le réseau peut piocher dedans pour développer ses propres projets. Je me dis que c’est ainsi que le copyleft pourra peut-être révéler tout son potentiel.
Comme souvent dans nos interviews, avez-vous envie de répondre à une question qui ne vous a pas été posée ? Vous pouvez le faire en conclusion.
On a parlé de beaucoup de licence, de projets mais nous n’avons pas parlé des livres. Et la première source de fierté dans cette collection Ludomire n’est pas sa licence mais sa qualité littéraire. Et comme vous m’en donnez l’occasion, je vais vous la présenter.
Le coffret Les Chroniques des Regards perdus, de Pascal Lovis, est une série d’heroic fantasy. Best-seller suisse, il s’agit de deux romans et une nouvelle qui séduiront les lecteurs qui aiment l’aventure et des fils narratifs entrecroisés. Pour les amateurs de fantasy, c’est une valeur sure.
Le même auteur a écrit également le diptyque Terre hantée. Il s’agit d’une œuvre de science-fiction tirant ses inspirations de films où la réalité ne semble pas être ce qu’elle est tel que The Truman Show et Matrix. Une plume efficace et expérimentée.
Le roman Printeurs et le recueil de nouvelles Le stagiaire au spatioport Omega 3000 et autres joyeusetés que nous réserve le futur sont les œuvres du libriste et blogueur Ploum, Lionel Dricot. Il s’agit d’œuvres engagées qui aborde avec un humour parfois grinçant, parfois absurde les travers de nos sociétés consuméristes basées sur le capitalisme de surveillance. Allez-y les yeux fermés, vous allez passer un bon moment !
Le coffret ONE MINUTE de Thierry Crouzet est sans doute l’opus le plus extraordinaire de la collection. Ouvrage de science-fiction inclassable, il décrit la minute la plus cruciale de l’humanité du point de vue de 380 personnes différentes à travers le monde. Comme un tableau impressionniste, chaque très court chapitre représente un point dans une fresque qui se révèle au fur et à mesure que l’on tourne les pages. Il y aborde et combine de manière surprenante des thématiques classiques de la SF, tel que le premier contact extraterrestre, la singularité informatique, l’hyperconnexion et le rapport de l’humanité avec la nature. Cette série est une expérience de lecture unique.
La série Adjaï aux mille visages, d’Aquilegia Nox, présente la vie chaotique et aventureuse d’un changelin dans le roman Ceux qui changent. Avec naturel, il aborde des questions de transidentité, de tolérance et de rapport au corps, tout en proposant un parcours de vie pleine de rebondissement et d’intrigues. Dans le recueil de nouvelles Ceux qui viennent, l’autrice approfondit son univers en y présentant d’autres lieux, d’autres cultures et d’autres personnages au destin exceptionnel. Une exploration bouleversante.
D’autres livres sortiront en mars et mai, tel qu’Hoc est corpus, roman historique fantastique pendant les croisades au royaume de Jérusalem, ou La couronne boréale, aventure littéraire et loufoque d’une bande d’archéologues à la recherche d’un artefact légendaire (ils n’ont pas de fouet, mais il y a un chat).
Vous pourriez bien découvrir nos livres chez votre libraire et, si ce n’est pas le cas, il pourra vous les commander. Ils sont également en vente en e-book et en papier sur notre site.
Et promis, on vous tiendra au courant de nos projets liés à l’art et le logiciel libres.
par JULIA ANGWIN Si vous avez parcouru tout le battage médiatique sur ChatGPT le dernier robot conversationnel qui repose sur l’intelligence artificielle, vous pouvez avoir quelque raison de croire que la fin du monde est proche.
Même le PDG de l’entreprise qui a lancé ChatGPT, Sam Altman, a déclaré aux médias que le pire scénario pour l’IA pourrait signifier « notre extinction finale ».
Alors, jusqu’à quel point devrions-nous nous inquiéter ? Pour recueillir un avis autorisé, je me suis adressée au professeur d’informatique de Princeton Arvind Narayanan, qui est en train de co-rédiger un livre sur « Le charlatanisme de l’IA ». En 2019, Narayanan a fait une conférence au MIT intitulée « Comment identifier le charlatanisme del’IA » qui exposait une classification des IA en fonction de leur validité ou non. À sa grande surprise, son obscure conférence universitaire est devenue virale, et ses diapos ont été téléchargées plusieurs dizaines de milliers de fois ; ses messages sur twitter qui ont suivi ont reçu plus de deux millions de vues.
Narayanan s’est alors associé à l’un de ses étudiants, Sayash Kapoor, pour développer dans un livre la classification des IA. L’année dernière, leur duo a publié une liste de 18 pièges courants dans lesquels tombent régulièrement les journalistes qui couvrent le sujet des IA. Presque en haut de la liste : « illustrer des articles sur l’IA avec de chouettes images de robots ». La raison : donner une image anthropomorphique des IA implique de façon fallacieuse qu’elles ont le potentiel d’agir dans le monde réel.
Voici notre échange, édité par souci de clarté et brièveté.
Angwin : vous avez qualifié ChatGPT de « générateur de conneries ». Pouvez-vous expliquer ce que vous voulez dire ?
Narayanan : Sayash Kapoor et moi-même l’appelons générateur de conneries et nous ne sommes pas les seuls à le qualifier ainsi. Pas au sens strict mais dans un sens précis. Ce que nous voulons dire, c’est qu’il est entraîné pour produire du texte vraisemblable. Il est très bon pour être persuasif, mais n’est pas entraîné pour produire des énoncés vrais ; s’il génère souvent des énoncés vrais, c’est un effet collatéral du fait qu’il doit être plausible et persuasif, mais ce n’est pas son but.
Cela rejoint vraiment ce que le philosophe Harry Frankfurt a appelé du bullshit, c’est-à-dire du langage qui a pour objet de persuader sans égards pour le critère de vérité. Ceux qui débitent du bullshit se moquent de savoir si ce qu’ils disent est vrai ; ils ont en tête certains objectifs. Tant qu’ils persuadent, ces objectifs sont atteints. Et en effet, c’est ce que fait ChatGPT. Il tente de persuader, et n’a aucun moyen de savoir à coup sûr si ses énoncés sont vrais ou non.
Angwin : Qu’est-ce qui vous inquiète le plus avec ChatGPT ?
Narayanan : il existe des cas très clairs et dangereux de mésinformation dont nous devons nous inquiéter. Par exemple si des personnes l’utilisent comme outil d’apprentissage et accidentellement apprennent des informations erronées, ou si des étudiants rédigent des essais en utilisant ChatGPT quand ils ont un devoir maison à faire. J’ai appris récemment que le CNET a depuis plusieurs mois maintenant utilisé des outils d’IA générative pour écrire des articles. Même s’ils prétendent que des éditeurs humains ont vérifié rigoureusement les affirmations de ces textes, il est apparu que ce n’était pas le cas. Le CNET a publié des articles écrits par une IA sans en informer correctement, c’est le cas pour 75 articles, et plusieurs d’entre eux se sont avérés contenir des erreurs qu’un rédacteur humain n’aurait très probablement jamais commises. Ce n’était pas dans une mauvaise intention, mais c’est le genre de danger dont nous devons nous préoccuper davantage quand des personnes se tournent vers l’IA en raison des contraintes pratiques qu’elles affrontent. Ajoutez à cela le fait que l’outil ne dispose pas d’une notion claire de la vérité, et vous avez la recette du désastre.
Angwin : Vous avez développé une classification des l’IA dans laquelle vous décrivez différents types de technologies qui répondent au terme générique de « IA ». Pouvez-vous nous dire où se situe ChatGPT dans cette taxonomie ?
Narayanan : ChatGPT appartient à la catégorie des IA génératives. Au plan technologique, elle est assez comparable aux modèles de conversion de texte en image, comme DALL-E [qui crée des images en fonction des instructions textuelles d’un utilisateur]. Ils sont liés aux IA utilisées pour les tâches de perception. Ce type d’IA utilise ce que l’on appelle des modèles d’apprentissage profond. Il y a environ dix ans, les technologies d’identification par ordinateur ont commencé à devenir performantes pour distinguer un chat d’un chien, ce que les humains peuvent faire très facilement.
Ce qui a changé au cours des cinq dernières années, c’est que, grâce à une nouvelle technologie qu’on appelle des transformateurs et à d’autres technologies associées, les ordinateurs sont devenus capables d’inverser la tâche de perception qui consiste à distinguer un chat ou un chien. Cela signifie qu’à partir d’un texte, ils peuvent générer une image crédible d’un chat ou d’un chien, ou même des choses fantaisistes comme un astronaute à cheval. La même chose se produit avec le texte : non seulement ces modèles prennent un fragment de texte et le classent, mais, en fonction d’une demande, ces modèles peuvent essentiellement effectuer une classification à l’envers et produire le texte plausible qui pourrait correspondre à la catégorie donnée.
Angwin : une autre catégorie d’IA dont vous parlez est celle qui prétend établir des jugements automatiques. Pouvez-vous nous dire ce que ça implique ?
Narayanan : je pense que le meilleur exemple d’automatisation du jugement est celui de la modération des contenus sur les médias sociaux. Elle est nettement imparfaite ; il y a eu énormément d’échecs notables de la modération des contenus, dont beaucoup ont eu des conséquences mortelles. Les médias sociaux ont été utilisés pour inciter à la violence, voire à la violence génocidaire dans de nombreuses régions du monde, notamment au Myanmar, au Sri Lanka et en Éthiopie. Il s’agissait dans tous les cas d’échecs de la modération des contenus, y compris de la modération du contenu par l’IA.
Toutefois les choses s’améliorent. Il est possible, du moins jusqu’à un certain point, de s’emparer du travail des modérateurs de contenus humains et d’entraîner des modèles à repérer dans une image de la nudité ou du discours de haine. Il existera toujours des limitations intrinsèques, mais la modération de contenu est un boulot horrible. C’est un travail traumatisant où l’on doit regarder en continu des images atroces, de décapitations ou autres horreurs. Si l’IA peut réduire la part du travail humain, c’est une bonne chose.
Je pense que certains aspects du processus de modération des contenus ne devraient pas être automatisés. Définir où passe la frontière entre ce qui est acceptable et ce qui est inacceptable est chronophage. C’est très compliqué. Ça demande d’impliquer la société civile. C’est constamment mouvant et propre à chaque culture. Et il faut le faire pour tous les types possibles de discours. C’est à cause de tout cela que l’IA n’a pas de rôle à y jouer.
Angwin : vous décrivez une autre catégorie d’IA qui vise à prédire les événements sociaux. Vous êtes sceptique sur les capacités de ce genre d’IA. Pourquoi ?
Narayanan : c’est le genre d’IA avec laquelle les décisionnaires prédisent ce que pourraient faire certaines personnes à l’avenir, et qu’ils utilisent pour prendre des décisions les concernant, le plus souvent pour exclure certaines possibilités. On l’utilise pour la sélection à l’embauche, c’est aussi célèbre pour le pronostic de risque de délinquance. C’est aussi utilisé dans des contextes où l’intention est d’aider des personnes. Par exemple, quelqu’un risque de décrocher de ses études ; intervenons pour suggérer un changement de filière.
Ce que toutes ces pratiques ont en commun, ce sont des prédictions statistiques basées sur des schémas et des corrélations grossières entre les données concernant ce que des personnes pourraient faire. Ces prédictions sont ensuite utilisées dans une certaine mesure pour prendre des décisions à leur sujet et, dans de nombreux cas, leur interdire certaines possibilités, limiter leur autonomie et leur ôter la possibilité de faire leurs preuves et de montrer qu’elles ne sont pas définies par des modèles statistiques. Il existe de nombreuses raisons fondamentales pour lesquelles nous pourrions considérer la plupart de ces applications de l’IA comme illégitimes et moralement inadmissibles.
Lorsqu’on intervient sur la base d’une prédiction, on doit se demander : « Est-ce la meilleure décision que nous puissions prendre ? Ou bien la meilleure décision ne serait-elle pas celle qui ne correspond pas du tout à une prédiction ? » Par exemple, dans le scénario de prédiction du risque de délinquance, la décision que nous prenons sur la base des prédictions est de refuser la mise en liberté sous caution ou la libération conditionnelle, mais si nous sortons du cadre prédictif, nous pourrions nous demander : « Quelle est la meilleure façon de réhabiliter cette personne au sein de la société et de diminuer les risques qu’elle ne commette un autre délit ? » Ce qui ouvre la possibilité d’un ensemble beaucoup plus large d’interventions.
Angwin : certains s’alarment en prétendant que ChatGPT conduit à “l’apocalypse,” pourrait supprimer des emplois et entraîner une dévalorisation des connaissances. Qu’en pensez-vous ?
Narayanan : Admettons que certaines des prédictions les plus folles concernant ChatGPT se réalisent et qu’il permette d’automatiser des secteurs entiers de l’emploi. Par analogie, pensez aux développements informatiques les plus importants de ces dernières décennies, comme l’internet et les smartphones. Ils ont remodelé des industries entières, mais nous avons appris à vivre avec. Certains emplois sont devenus plus efficaces. Certains emplois ont été automatisés, ce qui a permis aux gens de se recycler ou de changer de carrière. Il y a des effets douloureux de ces technologies, mais nous apprenons à les réguler.
Même pour quelque chose d’aussi impactant que l’internet, les moteurs de recherche ou les smartphones, on a pu trouver une adaptation, en maximisant les bénéfices et minimisant les risques, plutôt qu’une révolution. Je ne pense pas que les grands modèles de langage soient même à la hauteur. Il peut y avoir de soudains changements massifs, des avantages et des risques dans de nombreux secteurs industriels, mais je ne vois pas de scénario catastrophe dans lequel le ciel nous tomberait sur la tête.
NB : cet article existe aussi en version anglaise (traduction automatique)
Dans notre Lettre d’informations #28 (Automne 2021), nous vous parlions de Romain, stagiaire à Framasoft, dont nous savions que le sujet de stage allait tourner autour du logiciel libre Nextcloud.
Puis, une fois les résultats analysés (nous vous en proposons une version brute anonymisée et une analyse synthétique en fin d’article), nous avons pu identifier un besoin utilisateur non satisfait, sur lequel pourrait travailler Romain.
En effet, Nextcloud comporte de (très) nombreuses fonctionnalités, mais celle qui demeure centrale est probablement le stockage et partage de fichiers. Or, la navigation parmi les fichiers dans l’interface web est assez fastidieuse : un clic à chaque fois que l’on change de dossier, et donc un rechargement plus ou moins rapide de la page et de l’arborescence des dossiers et fichiers. Et parfois de nombreux clics pour passer d’un rameau de l’arborescence à l’autre.
Il y avait sans doute moyen de faire plus accessible et plus naturel.
Romain, qui ne connaissait ni le langage informatique PHP ni la solution Nextcloud au début de son stage, s’est donc lancé dans le développement d’un prototype d’application tierce, qui permettrait non seulement de pouvoir « développer l’arborescence de fichiers » au sein d’une même interface, mais aussi de pouvoir faire des recherches avancées.
Deux mois plus tard naissait le plugin « Sorts », dont nous vous racontons l’histoire ci-dessous.
Bonjour Romain, peux-tu te présenter ?
Je m’appelle Romain et j’ai 24 ans. J’ai grandi en Guadeloupe avant de venir étudier à Villeurbanne, à l’Institut National des Sciences Appliquées de Lyon, dont je serai diplômé en 2022 en tant qu’Ingénieur Télécom.
Quand je ne suis pas occupé par mes études, je passe pas mal de temps à bricoler et réparer des vieilles machines, et à m’investir dans des projets collectifs ! Je suis notamment très engagé au Karnaval Humanitaire, une asso étudiante qui organise un festival de musique dont j’ai été le régisseur site en 2021 et 2022.
Photographie de Romain, stagiaire INSA Lyon à Framasoft de Septembre 2021 à Février 2022
Concernant ton stage, tu as choisi Framasoft. Pourquoi ?
Je voulais un stage en accord avec mes valeurs de libre partage des connaissances, et en rupture avec le capital et les grandes entreprises !
Je connaissais déjà un peu les actions de Framasoft et notamment les services en ligne et le développement logiciel, et je savais que j’y trouverais des projets intéressants dans un cadre super… et je n’ai pas été déçu !
Venons-en au sujet de ton stage. Quel était l’objectif général ?
Mon stage s’est déroulé au début d’un projet plus large, dont le nom de code est « Framacloud » [Note de Framasoft : on vous reparlera de ce projet ambitieux à la rentrée], dont l’objectif est de permettre aux structures luttant pour le progrès social et la justice sociale de s’approprier, maîtriser et contrôler les processus de collaboration numérique.
Ce projet de Framasoft est centré sur un logiciel de collaboration en ligne et de partage de fichiers : Nextcloud.
Cependant, bien que ce soit une des solutions libres les plus abouties et complètes dans ce domaine, il est avant tout conçu pour répondre aux besoins des clients de « Nextcloud GmbH« , la société allemande éditrice du logiciel. Ces clients, ce sont de grosses structures, publiques, universitaires ou privées. Du coup, il y a un risque de différences entre les attentes des petites structures associatives et les priorités de développement de Nextcloud GmbH.
Le but de mon stage était donc de trouver comment améliorer ce logiciel afin de le rendre plus utile et plus accessible pour les structures alternatives.
Eh bien d’abord, il fallait à la fois que je me forme sur le développement de Nextcloud, et qu’on en apprenne davantage sur ce logiciel : son fonctionnement, ses défauts et surtout ce qui manquait aux utilisateurs qu’on visait.
Après plusieurs tests du logiciel et plusieurs hypothèses sur comment l’améliorer, on a décidé de se rapprocher de nos utilisateurs cibles. On a donc mis en place une enquête visant des personnes faisant parties de structures engagées pour le progrès social et la justice sociale qui utilisaient déjà Nextcloud. Cette enquête questionnait leurs usages de l’informatique collaborative au sein du collectif, leurs usages de Nextcloud, leurs frustrations et leurs attentes.
C’est grâce aux presque 200 réponses de cette enquête qu’on a décidé des développements logiciels que j’ai réalisés au cours de ce stage et qui ont abouti à la création d’un plugin Nextcloud appelé « Sorts » !
Arrêtons nous déjà sur ce travail d’enquête. Quels en ont été les résultats ?
Les préoccupations principales qui ressortaient de cette enquête étaient, au final, des préoccupations d’ordre plutôt général sur l’outil Nextcloud. Mais ça nous a permis de voir ce qui est important pour le public qu’on souhaite impacter.
Parmi la vingtaine de sujets que j’ai pu identifier dans les réponses, les deux premiers étaient des sujets sur lesquels on ne pouvait pas faire grand-chose : l’édition collaborative de documents et la « lenteur » générale de l’outil.
Par contre, parmi les sujets qui suivaient on avait plus de perspective pour aider à changer les choses en quelques mois de stage : prise en main et ergonomie du logiciel, problèmes de synchronisation ou encore aide aux utilisateurs pour s’y retrouver parmi les fichiers du collectif.
C’est cette dernière préoccupation de s’y retrouver dans l’arborescence des fichiers qui m’intéressait le plus, et qui m’a mené au développement de « Sorts« .
Pour ceux qui souhaitent jeter un œil aux détails de l’enquête, nous avons publié les résultats anonymisés, ainsi qu’une synthèse des différents sujets abordés que j’ai réalisée pour affiner le sujet du stage (c’est sans doute plus digeste que le tableur de résultats bruts).
[Note de Framasoft : Retrouvez les résultats de l’enquête en fin d’article]
Donc, tu es parti sur la création de l’application Nextcloud « Sorts » . Mais… il fait quoi, ce plugin, en fait ?
L’idée derrière Sorts, c’est d’aider les gens à retrouver les fichiers qu’ils cherchent et à comprendre comment les dossiers et les fichiers ont été organisés par le collectif dont ils font partie.
Pour régler le premier problème on a profité de toutes les informations relatives à chaque fichier que Nextcloud stockait déjà (date de modification, poids, « étiquetage » du fichier par l’utilisateur, …) et on a codé une interface qui permet de faire une recherche qui mélange ces différents attributs. Par exemple « Trouve-moi tous les fichiers dans le dossier « Subvention » et ses sous-dossiers qui sont marqués comme étant importants, et qui sont des .pdf ».
Recherche par filtres dans Sorts
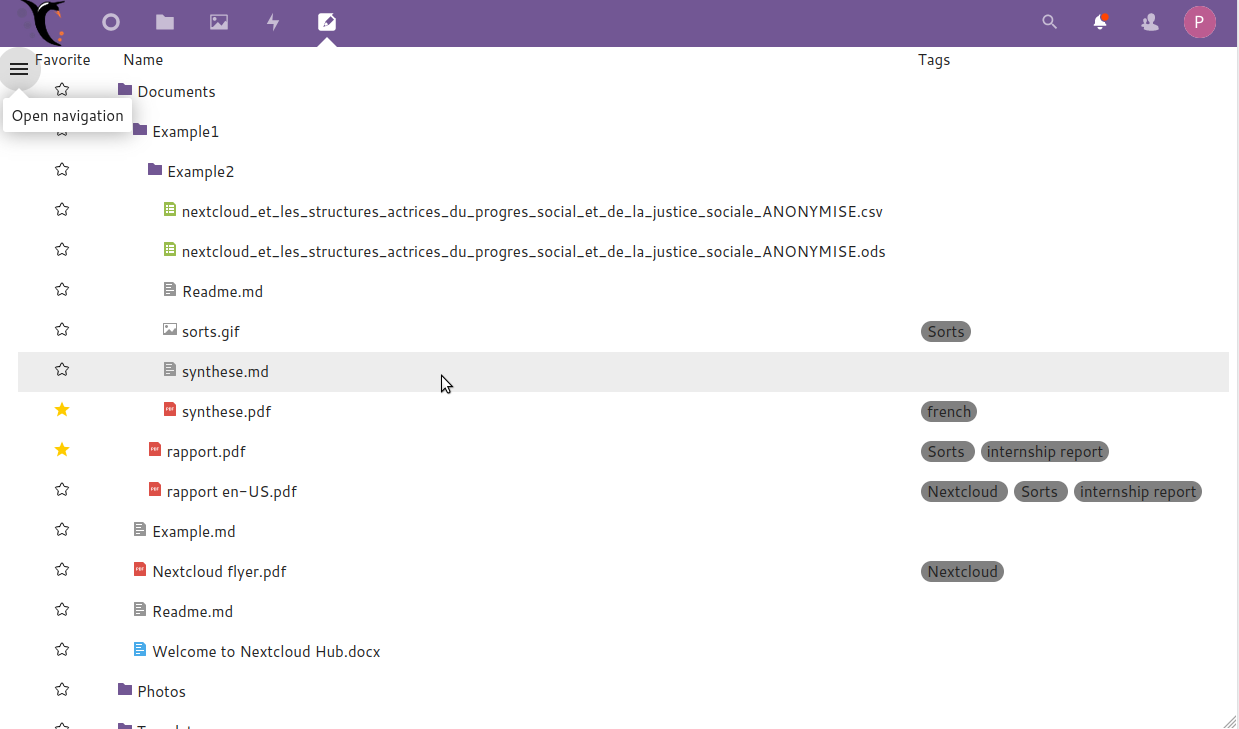
Pour régler le deuxième problème on a décidé de présenter les dossiers, sous-dossiers et fichiers d’une manière qui n’était pas encore présente dans Nextcloud : en liste arborescente. C’est-à-dire que lorsqu’on clique sur un dossier, au lieu de « rentrer » dans ce dossier et de ne voir que son contenu direct, le dossier est « déroulé » et on voit son contenu ainsi que les dossiers et fichiers qui sont « à coté » de lui. Cette liste arborescente prend plus de place qu’une liste simple mais elle permet de bien comprendre où on se situe dans les dossiers, ce qui aide à comprendre la façon dont ils sont rangés.
Navigation par arborescence : un clic sur un dossier ouvre le contenu de ce dossier sous forme arborescente.
Techniquement, tu as rencontré des soucis ?
Oui, comme dans tout processus de développement. Je pense qu’une des grosses difficultés a été de trouver quelle partie des API de Nextcloud utiliser, quelles étaient ses limites et comment faire avec. La recherche Nextcloud est pensée autour d’une recherche « groupée » (« unified search ») où l’utilisateur cherche une chaîne de caractères, et Nextcloud renvoie comme résultats tout ce qui correspond à cette chaîne de caractères parmi les ressources diverses et variées de Nextcloud (fichiers, todo, évènements, mails, conversations, …). Autant dire que ça ne correspond pas du tout à ce qu’on souhaite faire : chercher parmi les fichiers uniquement selon plusieurs conditions, dont certaines ne sont pas des chaînes de caractères (dates, nombres, …). Mais, heureusement pour nous, il y avait une autre API de recherche propre aux fichiers. Cette autre API paraissait très prometteuse parce qu’elle était déjà pensée pour permettre de combiner des conditions de recherches sur des attributs propres aux fichiers. Cependant, cette API était assez vieille et peu utilisée, ce qui m’a parfois donné un peu de fil à retordre.
De plus, je me suis rendu compte assez tard que l’API ne prenait pas en compte deux des différents attributs des fichiers : les « étiquettes » (tags) et les informations sur les partages de fichiers. Ces informations sont gérées dans des API totalement séparées. Je me suis donc retrouvé face à un dilemme : soit je réécris une API qui fait elle-même les requêtes en base de données avec tous les attributs, soit je complète l’API présente, soit je bricole quelque-chose où je fais 3 requêtes en base de données par recherche et je combine les résultats. La première solution m’aurait pris trop de temps et la deuxième solution aurait été refusée par Nextcloud GmbH (on ne modifie pas les APIs de Nextcloud à la légère), donc j’ai bricolé quelque-chose, et tant pis pour les performances de l’application.
As-tu eu des contacts avec la communauté Nextcloud ou son entreprise éditrice (Nextcloud Gmbh), et si oui, comment ça s’est passé ?
Oui bien sûr, lorsqu’on a commencé à avoir une bonne idée de ce qu’on souhaitait faire de Sorts j’ai écrit une note d’intention avec un lien vers un prototype sur le forum dédié au développement de plugin Nextcloud. Ça a mené à quelques échanges avec des développeurs salariés de Nextcloud qui étaient intéressés par le projet et qui m’ont fait quelques retours constructifs. On a même fait une réunion en visio avec eux pour discuter du plugin mais aussi du projet plus large, mais avec les plannings des uns et des autres cette réunion a eu lieu assez tard dans le développement de Sorts et elle n’a pas beaucoup impacté le plugin.
Et donc, la question qui pique : Sorts, ça marche ou pas ?
Eh bien OUI ! Sorts propose une vue de l’arborescence des fichiers « dépliante » et permet déjà de faire des recherches combinées sur une bonne variété des caractéristiques que peuvent avoir des fichiers !
Cependant, il s’agit d’une version Bêta qui présente quelques limites… J’ai dû faire quelques arrangements avec les problèmes techniques évoqués dans la question précédente, et si la version actuelle fonctionne sur des petites instances Nextcloud, elle aura sans doute du mal à « passer à l’échelle » pour fonctionner avec des instances réelles avec des centaines d’utilisateurs et des milliers de fichiers.
Vidéo de démonstration des fonctionnalités de Nextcloud Sorts 0.1.0-beta (source)
Et la suite ? C’est quoi à ton avis, et pour quand ?
Nous souhaitons continuer à maintenir cette application et à traiter et accepter toutes les contributions éventuelles, mais ni moi ni Framasoft n’avons prévu de développer à plein temps dessus pour le moment. Sorts rentre maintenant dans le monde du développement bénévole, ce qui veut dire que les développements portés par Framasoft et moi-même se feront au fil des envies et des disponibilités, sans agenda particulier (ce qui veut aussi dire que nous n’annoncerons pas de « date de sortie » quelconque).
On arrive à la fin de cette interview. Souhaites-tu nous partager un sentiment sur le travail effectué pendant ce stage ?
Résumer un stage en une émotion ? C’est difficile ! Développer un programme, c’est passer de la frustration quand ça ne marche pas, à l’excitation d’enquêter sur pourquoi ça ne marche pas, à la satisfaction de voir la fonctionnalité fonctionner quand on a trouvé.
Non, plus sérieusement, il y a eu quelques frustrations comme ne pas avoir beaucoup de temps pour développer ou ne pas retrouver autant de temps et de motivation que ce que j’aurais souhaité pour boucler le projet après le stage, mais je suis satisfait. Satisfait d’avoir fait quelque-chose qui marche mais surtout d’avoir pu concevoir ce plugin du presque début à la presque fin, en prenant le temps d’identifier ce qu’on pouvait faire d’utile, de réfléchir à quoi ça devait ressembler, et d’ensuite réfléchir à comment le réaliser techniquement.
Dernière question, récurrente dans nos interviews : quelle est la question que tu aurais aimé qu’on te pose, et quelle serait ta réponse ?
Mais pourquoi ne pas avoir publié Sorts plus tôt ?
C’est mon grand regret ! Et je pense que les personnes qui s’étaient intéressées à l’application lors de la note d’intention se sont aussi posées la question. Mais ma vie associative et personnelle était assez chargée après le stage et ne m’a pas laissé beaucoup de temps pour m’occuper de Sorts, c’est aussi ça le développement bénévole.
Merci Romain ! Ainsi qu’à toutes les personnes qui auront rendu ce travail possible, notamment en répondant au questionnaire !
Rappel des différents liens évoqués dans l’article :
Application Sorts sur l’App store Nextcloud à télécharger (Attention : version beta, à utiliser à vos risques et périls. Cependant, les risques sont limités car l’application Sorts ne fait pas de modification sur vos fichiers)
Nextcloud Sorts : a Nextcloud application prototype to navigate your files more easily
Then, once the results were analyzed (you will find an anonymized raw version and a synthetic analysis at the end of the article), we were able to identify a set of unmet user needs, on which Romain could work.
Nextcloud provides loads of features, but the one that remains the most central is probably the storage and sharing of files. However, browsing files in the web interface is quite tedious: a click each time you change folder, and thus a more or less fast reloading of the tree structure. And sometimes many clicks to go from one branch of the tree to another.
There was probably a way to make it more accessible and more intuitive.
Romain, who knew neither the PHP computer language nor the Nextcloud software solution when beginning his internship, indulged himself with the development of a prototype of a third-party application, which would not only allow to « open the file tree » within the same interface, but also to be able to make advanced searches.
Two months later, the « Sorts » plugin was born, and we would like to share its story below.
Hello Romain, can you introduce yourself?
My name is Romain and I am 24 years old. I grew up in Guadeloupe (French West Indies) before coming to study in Villeurbanne, at the Institut National des Sciences Appliquées in Lyon, where I will graduate in 2022 as a Telecom Engineer.
When I’m not busy with my studies, I spend a lot of time tinkering and repairing old machines, and getting involved in community projects! I am particularly involved in Karnaval Humanitaire, a student association that organizes a music festival for which I was the site manager in 2021 and 2022.
Picture of Romain, INSA Lyon intern at Framasoft from September 2021 to February 2022
Why did you choose Framasoft for your internship?
I wanted my internship to be in line with my values of free sharing of knowledge, and away from capitalism and big companies!
I already knew a bit about Framasoft’s projects, especially the online services and software development, and I knew I would find interesting projects in a great environment… and I was not disappointed!
Let’s come to the subject of your internship. What was the main goal?
My internship took place at the beginning of a larger project, codenamed « Framacloud » [Framasoft’s note: we’ll be telling you more about this ambitious project in the upcoming months], whose goal is to allow structures fighting for social progress and social justice to gain ownership, master and control over digital collaboration processes.
This Framasoft project is focused on an online collaboration and file sharing software solution: Nextcloud.
However, although it is one of the most successful and complete open source solutions in this field, it is primarily designed to meet the needs of customers of « Nextcloud GmbH« , the German company that publishes the software. These customers are large structures, public, university or private. As a result, there is a risk of differences between the expectations of small associations and the development priorities of Nextcloud GmbH.
The goal of my internship was therefore to find out how to improve this software in order to make it more useful and more accessible for alternative organisations.
OK, that’s a big topic! How did you manage about it?
Well, first of all, I had to learn about the development of Nextcloud, and we had to learn more about this software: how it works, its flaws and especially what was missing for the users we were targeting.
After several tests of the software and several hypotheses on how to improve it, we decided to get closer to our target users. So we set up a survey targeting people who were part of organisations committed to social progress and social justice and who were already using Nextcloud. This survey questioned their uses of collaborative computing within the collective, their uses of Nextcloud, their frustrations and expectations.
Thanks to the almost 200 answers of this survey we decided on the software developments to be achieved during this internship and that led to the creation of a Nextcloud plugin called « Sorts »!
Let’s focus a moment on this survey work. What were the results?
The main concerns that came out of this survey were rather general concerns about the Nextcloud tool. But it allowed us to see what is important for the public we wanted to address.
Of the 20 or so topics I was able to identify in the responses, the first two were topics we couldn’t do much about: collaborative document editing and the general « slowness » of the tool.
On the other hand, among the following subjects we had more perspective to help change things in a few months of training: handling and ergonomics of the software, synchronization problems or help to users to find their way among the files of the collective.
It is this last concern: « finding one’s way in the tree of files more easily » that interested me the most, and that led me to the development of « Sorts ».
For those who want to have a look at the details of the survey, we have published the anonymized results, as well as a synthesis of the different subjects I have discussed in order to refine the subject of the workshop (it is probably easier to digest than the spreadsheet of raw results).
[Framasoft’s note: You can find the results of the survey at the end of the article]
So, you decided to create the Nextcloud application « Sorts ». But… what does this plugin actually do?
The idea behind Sorts is to help people find the files they are looking for and to understand how the folders and files have been organized by the collective they are part of.
To solve the first problem we took advantage of all the information about each file that Nextcloud was already storing (modification date, weight, « tagging » of the file by the user, …) and I coded an interface that allows users to perform a search mixing these different attributes. For example « Find me all the files in the folder « Grant » and its subfolders that are marked as important, and that are in PDF format ».
Search by filters in Sorts
To solve the second problem we decided to present the folders, subfolders and files in a way that was not yet present in Nextcloud: in a tree list. That is to say that when you click on a folder, instead of « entering » this folder and seeing only its direct content, the folder is « expanded » and you see its content as well as the folders and files which are « next to » it. This tree-like list takes up more space than a simple list but it allows you to understand where you are in the folders, which helps you to understand how they are arranged.
Tree navigation: clicking on a folder opens the contents of that folder in tree form.
Technically, did you encounter any issues?
Yes, like in any development process. I think one of the big challenges was to find out which part of the Nextcloud APIs to use, what were its limitations and how to deal with it. The Nextcloud current search feature is designed around a « grouped » search (« unified search ») where the user searches for a string of characters, and Nextcloud returns everything that matches this string among the various resources (files, todos, events, emails, conversations, …). This is not at all what we wanted to do: search among files only according to several conditions, some of which are not strings (dates, numbers, …). But, fortunately for us, there was another search API specific to files. This other API looked very promising because it was already thought to allow combining search conditions on file-specific attributes. However, this API was quite old and not widely used, which sometimes gave me a bit of trouble.
Moreover, I realized quite lately that the API did not take into account two of the different file attributes: « tags » and file sharing information. This information is managed in totally separate APIs. So I faced this dilemma: either I rewrite an API that does the database queries itself with all the attributes, or I complete the existing API, or I cobble together something where I do 3 database queries per search and combine the results. The first solution would have taken too much time and the second solution would have been rejected by Nextcloud GmbH (you don’t change Nextcloud APIs so easily), so I cobbled something together, and so much for the performance of the application.
Did you have contacts with the Nextcloud community or its editor (Nextcloud Gmbh), and if so, how did it go ?
Yes of course, when we started to have a clear idea of what we wanted to do with Sorts I wrote a note of intent with a link to a prototype on the Nextcloud plugin development forum. This led to some exchanges with Nextcloud’s employed developers who were interested in the project and sent me some constructive feedback. We even had a video meeting with them to discuss the plugin but also the wider project, but with everyone’s schedules this meeting took place quite late in the development of Sorts and it didn’t impact the plugin much.
And now, the nagging question: is Sorts really working?
Well YES ! 🎉 Sorts offers an « unfolding » file tree view and already allows combined searches on a good variety of characteristics that files can have!
However, this is a Beta version and it has some limitations… I had to make some accommodations with the technical issues mentioned in the previous question, and while the current version works on small Nextcloud instances, it will likely have trouble to scale when working with real instances counting hundreds of users and thousands of files.
Nextcloud Sorts 0.1.0-beta feature demo video (source)
We want to continue to maintain this application and to process and accept all possible contributions, but neither I nor Framasoft have plans to develop it full time at the moment. Sorts is now entering the world of community/voluntary development, which means that the developments carried by Framasoft and myself will be done according to our desires and availabilities, without any particular agenda (which also means that we won’t announce any « release date »).
We are coming to the end of this interview. Would you like to share with us a feeling about the work done during this workshop?
Summarize an internship in one emotion? That’s a tough one! Developing a program goes from frustration when it doesn’t work, to the excitement of investigating why it doesn’t work, to the satisfaction of seeing the feature work when you’ve found it.
No, more seriously, there were some frustrations like not having much time to develop or not finding as much time and motivation as I would have liked to complete the project after the internship, but I am satisfied. Satisfied to have made something that works but especially to have been able to design this plugin from almost the beginning to almost the end, taking the time to identify what could be useful, to think about what it should look like, and then to think about how to realize it technically.
Last question, recurrent in our interviews: what is the question you would have liked to be asked, and what would be your answer?
Why didn’t you publish Sorts earlier?
That’s my big regret! And I think that the people who were interested in the application during the note of intent also asked themselves that question. But my associative and personal life was quite busy after the internship and didn’t leave me much time to take care of Sorts, that’s also what volunteer development is about.
Thank you Romain! And to all the people who made this work possible, especially by answering the questionnaire!
Reminder of the different links mentioned in the article :
Download and install Sorts application on the Nextcloud App store (Warning: beta version, use at your own risk. However, the risks are limited because the Sorts application does not make any modification on your files)
Gao & Blaze : le jeu mobile immersif qui utilise et respecte vos données personnelles
Nous avons été contacté·es récemment par l’équipe de la coopérative « La Boussole », pour nous parler d’un tout nouveau projet : le jeu Gao & Blaze.
Gao & Blaze, est un jeu libre et gratuit pour smartphone, qui permet de prendre conscience et agir sur la protection de vos données et le respect de votre vie privée. Au fur et à mesure du jeu, vous réalisez l’ampleur des données personnelles et sociales qui peuvent être divulguées avec l’installation d’une simple appli (mais sans collecte cachée de données, promis !).
Bel exemple d’éducation populaire aux enjeux du numérique, cet ovni dans le monde du jeu vidéo nous a grandement intéressé·es. Nous avons donc posé quelques questions à l’équipe de la coopérative « La Boussole ».
Bonjour l’équipe de la coopérative « La Boussole » ! À Framasoft, on vous connaît déjà un peu depuis quelques années, mais pourriez-vous vous présenter aux lecteur⋅ices du Framablog ?
Bonjour à Framasoft et merci pour cet espace ! Nous sommes plein de choses, mais avant tout 3 :
Une coopérative, c’est-à-dire que nous avons fait le choix de créer une structure qui appartient uniquement à celles et ceux qui y travaillent (pas d’actionnaires, pas de patron·nes).
D’éducation populaire, c’est-à-dire que nous voulons rendre certaines connaissances issues de la recherche académique (nous gardons un pied dans la recherche et l’université) accessibles au plus grand nombre sans que les bagages éducatifs soient un frein.
Et nous portons des valeurs d’émancipation, c’est-à-dire que nous avons pour ambition de donner du pouvoir d’agir aux individus et aux collectifs : nous croyons que le savoir est un pouvoir fort et voulons partager nos savoirs, autour de l’informatique libre, autour de la lutte contre les discriminations et sur les formes de travail alternatives.
Super ! Vous pouvez nous en dire un peu plus sur les types d’actions que vous réalisez ?
Principalement nous réalisons des projets de recherche autour de nos thématiques mais également des formations courtes pour donner des outils pratiques. Nous explorons aussi lors d’ateliers pédagogiques des nouvelles formes de transmettre des connaissances car nous nous préoccupons souvent de savoir comment nos savoirs académiques peuvent avoir un impact concret et positif sur les gens que nous rencontrons. Nous voyons aussi comment dans des domaines comme le numérique la concentration des savoirs et savoir-faire peut créer d’importantes inégalités de pouvoir.
Vous nous avez contactés récemment au sujet d’un projet un peu particulier : Gao & Blaze. Mais… c’est quoi ?!
Nous sommes parti·e·s d’une frustration : nous avions passé du temps et mis de l’énergie à essayer de convaincre du bien-fondé de la protection des données interpersonnelles, de sensibiliser aux questions liées à la sécurité informatique, mais le constat était que beaucoup de gens étaient d’accord avec nous sans pour autant changer leurs pratiques dans les faits.
Dit de manière brutale : nous voulions savoir comment faire pour que des gens aient envie d’aller à des chiffrofêtes car il nous semblait que seuls des gens déjà sensibilisés y participaient, et nous avions l’ambition d’aller chercher plus loin.
Bien évidemment, le panorama a évolué au cours des dernières années de différentes manières notamment avec des scandales de plus en plus audibles et relayés, mais également des initiatives enthousiasmantes qui ont marqué un avant et un après dans les usages courants (nous pensons notamment à votre campagne Dégooglisons internet). Pourtant, il nous semblait y avoir un chaînon manquant autour du « passage à l’action ». Nous avons donc voulu proposer un jeu qui utilise l’émotion avant d’utiliser la raison – autrement dit qui passe par l’expérience personnelle avant la connaissance concrète. C’est là que nous avons eu l’idée d’imaginer un jeu pour donner à voir les conséquences concrètes de l’exploitation et l’usage des données de Madame et Monsieur Tout-le-monde.
Cette frustration nous trottait à l’esprit quand nous avions vu un appel à projet de recherche sur la protection des données. Nous avions proposé un projet qui n’entrait pas dans les cases, mais nous avons réussi à monter un partenariat qui nous a permis de créer un ovni. À notre connaissance c’est le premier jeu autour de la sensibilisation à la protection des données interpersonnelles sur Android.
C’est un ovni car nous avions 4 conditions non négociables :
Exploiter le système des permissions Android pour proposer une expérience immersive
Utiliser les données des joueuses et des joueurs, tout en respectant ces données.
Faire un jeu 100% en logiciel libre sans utiliser des interfaces intermédiaires obscures (le jeu est en React Native)
Faire un vrai jeu : c’est-à-dire que nous voulions que les gens y jouent pour l’intérêt ludique et que ce ne soit pas le « volet sensibilisation » qui prenne le dessus.
C’est qui Gao et Blaze ? Des personnages ?
Exactement ! Gao est un chat, appartenant à Blaze. Il s’inspire de son chat et l’a converti en l’icône des Gao Games. Les Gao games sont un univers de mini-jeux gratuits sur smartphone autour duquel toute communauté s’est construite. Blaze, est le dev principal de ces jeux. Toute ressemblance avec certains petits jeux mignons, « gratuits » et très célèbres est purement accidentelle… 0:o)
C’est aussi et avant tout le chat de Blaze, le développeur des jeux, qui l’a rendu célèbre.
D’autres personnages et non des moindres, font partie de la communauté, Alex, Nikki, Masako, Amin, Ally…. nous vous laissons les découvrir en allant leur parler !
La question des données personnelles, vous pensez que ça intéresse réellement les jeunes ? Est-ce que la vie privée ce n’est pas « Un problème de vieux cons ? »
Question intéressante, nous pouvons rétorquer par facilité qu’en 2010 c’était une question de « vieux cons », mais c’était il y a déjà 12 ans ! Plus sérieusement, nous constatons que beaucoup d’eau a coulé sous les ponts depuis le début des années 2010 en termes de révélations (E. Snowden, Wikileaks, Cambridge Analytica, Pegasus…), en termes d’ampleur des scandales, de leur couverture médiatique, mais aussi du côté de la marche triomphante des multinationales des données dans la prédation et l’exploitation des données des individus.
Il y a également de nouveaux freins légaux (comme le RGPD, par exemple), et une jeune génération qui a ses propres stratégies d’appropriation et d’usage des technologies numériques…
Nous croyons que l’intérêt pour la vie privée est là, simplement qu’il se configure de nouvelles façons. Avec Gao&Blaze nous tentons d’apporter une réponse à la demande et aux questionnements d’un public peu expert et réfractaire aux approches classiques de sensibilisation.
Parlons maintenant des licences du jeu : sous quelle(s) licence(s) est publié le jeu, et surtout… Pourquoi ?
La question des licences a mérité un peu de réflexion, car un jeu vidéo présente la particularité de mêler plein de composantes différentes : code, œuvres graphiques, dialogues, musiques… Certaines licences (comme la GPL par exemple) sont conçues pour du code informatique, et conviendraient pas vraiment pour une illustration, par exemple.
Pour essayer de couvrir tous ces usages, Gao&Blaze est donc diffusé sous licence GNU AGPL 3.0 pour le code et sous licence Creative Commons BY-SA 4.0 pour les autres créations. Il embarque aussi des polices d’écriture et musiques sous licences tierces compatibles.
Vous n’avez pas peur de vous faire « voler » les innombrables heures de travail que vous avez passées en développement ?
C’est une vraie question !
En premier lieu, nous concevons notre création comme une contribution aux biens communs, et en soi, ça ne se « possède » pas – ça ne peut donc pas se voler.
En revanche, il existe deux risques auxquels nous avons pensé :
La prédation des biens communs pour en faire des biens privés. Pour un logiciel, ça pourrait être le fait de modifier légèrement le code, puis d’en faire un logiciel privateur. Mais ce sont aussi des choses qui arrivent dans d’autres domaines : privatiser des biens qui bénéficient à tous les êtres vivants (l’eau, l’air, les forêts…) au profit de quelques uns, etc.
L’usurpation, qui consisterait à respecter « à la marge » la licence, mais à s’approprier le travail de création qui a été fait (en faisant croire plus ou moins explicitement qu’une autre personne serait l’autrice du jeu). Un exemple de ça serait de reprendre le jeu tel quel, et remplacer tous les logos et mentions visibles des autrices et auteurs par ceux de quelqu’un d’autre, et se contenter de nous citer de façon obscure, avec une petite phrase en caractère 6 au fin fond d’un menu.
Une idée reçue est que les licences libres ne protègent pas bien les œuvres et/ou les autrices/auteurs mais c’est faux. Les licences que nous avons choisies protègent normalement de ces deux risques car :
Elles sont contaminantes, c’est-à-dire qu’elles obligent à repartager les modifications et travaux dérivés sous des licences similaires. On ne peut donc pas se les approprier en faisant de la prédation, on ne peut que permettre de nouvelles contributions aux biens communs.
Elles peuvent protéger efficacement de l’usurpation. C’est un dispositif juridique méconnu, mais il faut savoir que des licences comme la GNU AGPL permettent l’ajout de « termes additionnels » (qui doivent rester en conformité avec la licence). Nous avons utilisé ces termes additionnels pour nous prémunir de toute tentative de maquillage / « re-branding » du jeu.
Le seul risque qui existe serait que des gens créent une version dérivée avec laquelle nous serions en désaccord éthiquement, mais bon, c’est la vie. Dans le fond, créer des œuvres libres implique aussi de changer de point de vue : même si nous avons une parenté sur l’œuvre, ce n’est pas « notre » bébé, c’est le bébé de tout le monde. Mais ça tombe bien, ça fait potentiellement plus de bonnes volontés pour s’en occuper. 🙂
Quel rôle joue la MAIF dans votre projet ? Partenariat financier ou davantage ?
La MAIF est un assureur militant de poids et nous avons collaboré avec deux structures satellites de ce géant de l’assurance : la Fondation MAIF pour la recherche, et l’association Prévention MAIF dédiée aux actions de prévention. Ces deux structures non-lucratives ont co-financé avec nous la partie production et la partie recherche, et nous avons eu le plaisir d’avoir des échanges enrichissants pour consolider le projet et qu’il voie le jour.
Impossible de dire que l’engagement n’était que financier : les structures de la MAIF étaient intimement convaincues de la pertinence de la démarche et de l’urgence sociétale du sujet. Ils tenaient à ce que ce projet se fasse sous forme de logiciel libre mais qu’il ne puisse pas être approprié par d’autres.
Merci pour cet impressionnant travail ! 🙂 Quelles sont les prochaines étapes et vos attentes vis-à-vis de Gao & Blaze ?
C’est le cas de le dire ! C’était assez fou de créer un studio de jeu vidéo éphémère, de vouloir avancer masqué·e·s avec un jeu visuellement très mainstream, et pourtant codé « en dur », alors même que la production logicielle n’est pas notre cœur de métier.
La suite est la partie recherche de ce projet ! Nous avons besoin qu’il soit joué jusqu’au bout, nous avons envie de comprendre et constater comment oui ou non notre pari de sensibiliser à la protection des données via le jeu était pertinent ou pas.
Le jeu demande au fur et à mesure différentes autorisations.
Et pour vos autres projets (on se doute que vous en avez !) : quels sont-ils ? Quels sont vos espoirs ? Comment peut-on vous aider ?
Nous continuons dans nos projets de recherche (autour des formes de sensibilisation) et de formations auprès d’autres publics. Aujourd’hui nous réfléchissons à la sensibilisation aux questions de la vie privée pour des personnes peu ou pas lettrées qui pourtant sont contraintes à l’utilisation de téléphones portables.
Nous avons aussi d’autres chantiers académiques car il est important pour nous de nous maintenir à la page, de lire et de produire des recherches au long cours. Une participation à projet de documentaire sur les low-tech (basses-technologies) est dans les cartons et nous vous en parlerons plus tard quand il sera plus avancé !
Une question traditionnelle pour conclure : quelle est la question que l’on ne vous a pas posée, à laquelle vous auriez aimé répondre ? Et quelle serait-votre réponse, tant qu’à faire ! 🙂
Nous aurions voulu que vous nous demandiez si nous avons choisi exprès le 30 novembre pour lancer le jeu car c’est la journée mondiale de la sécurité informatique. Nous vous dirions que oui, nous avions tout savamment calculé 😉
Ou peut-être une autre question sur les autres personnages, surtout Nikki, hackeuse badass mais pas très genrée, ou sur Alex, une femme noire qui commence « Madame Tout-le-monde » et finit héroïne. Nous voulions fuir certaines caricatures et avions envie de personnages vraisemblables mais peu courants dans le monde du jeu vidéo.
Plus de soixante-quinze millions de podcasts sont téléchargés chaque mois dans notre pays par plus de douze millions de personnes.
Qui les fait ? Qui les écoute ? Nous avons interrogé Benjamin Bellamy, co-créateur de Castopod —en audio, s’il vous plaît.
Illustration CC-BY-SA Benjamin Bellamy
La transcription de l’entretien
Bonjour ! Selon une enquête Médiamétrie sortie en décembre 2022 « Les chiffres clés de la consommation de podcasts en France », plus de soixante-quinze millions de podcasts sont téléchargés chaque mois dans notre pays par plus de douze millions de personnes. C’est donc un phénomène qui a conquis toute la Gaule. Toute, pas tout à fait puisqu’il reste au moins un indi… irréductible, voilà, je commence à bafouiller, c’est bien, qui est passé à côté c’est-à-dire moi.
Aujourd’hui nous avons eu l’idée d’interviewer Benjamin qui, lui, est très impliqué dans le monde du podcast et pour lui faire honneur nous faisons donc cet entretien en audio, ce qui n’est pas l’habitude dans le Framablog.
Benjamin, est-ce que tu peux te présenter ?
Oui, bien sûr, Frédéric. Bonjour. Donc je m’appelle Benjamin Bellamy.
En deux mots je suis né longtemps avant les réseaux sociaux mais après les cartes perforées et tout petit je suis tombé dans la marmite informatique.
J’écoute des podcasts depuis pas mal de temps et il y a deux ans avec trois associés j’ai créé une société qui y est exclusivement consacrée, Ad Aures.
Est-ce que tu peux présenter Castopod ? C’est quoi ? Un logiciel, une plate-forme, un oiseau, une fusée ?
Castopod qui donc est développée par Ad Aures, c’est un peu tout ça à la fois.
C’est d’abord un logiciel codé en PHP qui permet à toutes et à tous d’héberger plusieurs podcasts. Une fois en place, c’est-à-dire cinq minutes après avoir dézippé le paquet et lancé l’assistant d’installation c’est une plateforme d’hébergement de podcasts multipodcasts multi-utilisatrices multi-utilisateurs et enfin peu de gens le savent mais en imprimant le code source de Castopod sur une feuille A4 on obtient un superbe oiseau.
Illustration CC-BY-SA Benjamin Bellamy
Pour la fusée en revanche j’avoue on est super en retard et rien n’est prêt.
Enfin, plus sérieusement, Castopod permet à tout le monde de mettre des podcasts en ligne afin qu’ils soient disponibles sur n’importe quelle plateforme d’écoute donc ça peut être évidemment Apple Podcast, Google Podcast, Deezer, Spotify, Podcast-Addict, PostFriends, Overcast,… Il y en a plein d’autres, donc vraiment partout. Castopod apporte tout ce dont on a besoin donc de la gestion de fichiers sonores MP3 évidemment à la gestion des métadonnées, des titres, des descriptions, la génération du fameux RSS, l’export de clips vidéo à partager sur les réseaux sociaux, les mesures d’audience etc.
Et d’autre part, Castopod est adapté tout autant aux podcastrices et aux podcasteurs en herbe qu’aux professionnels les plus chevronnés puisque avec une seule installation on peut avoir autant de podcasts qu’on veut autant de comptes utilisateurs qu’on veut et enfin Castopod est open source, libre et gratuit, et il promeut et intègre des initiatives ouvertes telles que celles de Podcasting 2.0 qui permet entre autres la gestion de transcription et de sous-titrage de liens de financement de chapitres de géolocalisation de contenu de gestion des intervenants et de commentaires inter-plateforme et encore plein d’autres choses.
Qu’est-ce qui t’a poussé à lancer Casopod ?
Qu’est-ce qui m’a poussé à lancer Castopod, tu veux dire : qui m’a poussé à lancer Castopod ? D’une certaine manière c’est Framasoft.
En fait en mars 2019 alors que je cherchais une plateforme de podcasts compatible avec le fédivers j’ai contacté Framasoft pour savoir si vous aviez pas ça dans les tuyaux. Naïvement j’étais persuadé que la réponse serait « ben oui, évidemment » et là la douche froide : « non pas du tout ».
Et à ce moment-là Chocobozzz m’avait expliqué qu’avec les développements de Peertube et Mobilizon qui avaient été lancés un petit peu avant en décembre 2018 Framasoft n’avait pas le temps de se consacrer à un autre projet.
Heureuse coïncidence, à ce moment-là Ludovic Dubost le créateur de Xwiki m’a raconté comment il avait obtenu un financement de NLnet pour CryptPad. Donc j’ai déposé un dossier qui a été accepté immédiatement et qui en plus de nous faire très plaisir nous a confortés quant à la pertinence du projet.
Les podcasts m’ont l’air d’être gratuits dans la majorité des cas. Quel est le modèle économique ? Comment est-ce qu’ils en vivent, les gens ?
Il y a plusieurs modèles économiques du podcast.
Déjà effectivement il est important de noter qu’aujourd’hui quatre-vingt-dix-neuf pour cent des podcasts n’ont pas de modèle au sens capitaliste du terme, ce qui ne veut pas pour autant dire qu’ils sont gratuits.
Les podcastrices et les podcasteurs se rémunèrent de façon indirecte par le plaisir que ça procure, pour la promotion d’un autre produit ou service, pour l’exposition médiatique, etc. et quant au pourcent restant… Il existe plein de manières de gagner de l’argent.
On peut vendre un abonnement, encourager ses auditrices et ses auditeurs à donner des pourboires, on peut gagner des bitcoins par seconde d’écoute, on peut lire de la publicité, on peut produire un podcast de marque, on peut insérer automatiquement des spots publicitaires sonores, on peut afficher de la publicité à l’écran… par exemple chez Ad Aures notre spécialité c’est l’affichage publicitaire de recommandations contextuelles donc sans cookie ni profilage de l’internaute.
Et quel est le modèle économique de Castopod, alors ? Si je te dis que la société Ad Aures est l’équivalent de Canonical pour Ubuntu, est-ce que tu le prends mal ?
En fait c’est plutôt flatteur. On n’a pas du tout la prétention de devenir le Canonical du podcast même si effectivement on peut y voir des similitudes.
Pour répondre à ta question comme je l’ai laissé entendre plus tôt Castopod a bénéficié d’une subvention européenne qui a permis de financer le démarrage du développement. Ad Aures, la société que j’ai créée avec mes associés a également financé une grosse part du développement.
On compte sur les contributions de toutes celles et ceux qui souhaitent qu’on puisse continuer à maintenir et à faire grandir Castopod au travers de la plateforme Open Collective et enfin à on lance à l’heure où on parle tout juste d’une offre d’hébergement payante clés en main qui va donc permettre à toutes et à tous d’utiliser Castopod sans avoir à s’occuper du moindre aspect technique de l’hébergement.
On se rapproche plutôt du modèle de Piwigo, alors ?
Euh, exactement, ouais.
Alors la question qui pique. Moi je te connais, on s’est rencontrés, euh, il n’y a pas si longtemps que ça, au salon Open-Source Experience et je te connais comme un vrai libriste très engagé… et tu proposes de mettre de la pub sur les «postcasses» des gens ! J’arriverai jamais à prononcer «podcast» correctement ! Alors est-ce que la pub c’est compatible avec ton engagement libriste ?
Alors je vois pas pourquoi ça ne serait pas parce que en fait publicité et open source, ces deux concepts ont absolument rien à voir, même si je comprends ce que tu veux dire.
Personnellement, moi, je considère que la publicité en soi déjà ce n’est pas sale et c’est pas honteux et… Ce qui lui a donné une mauvaise réputation c’est le profilage à outrance des internautes est ça ouais c’est pas terrible, je suis d’accord mais justement nous ce qu’on propose c’est des publicités qui sont non invasives sans profilage sans cookie, pertinentes parce que en relation directe avec le contenu qui les héberge et ça permet d’offrir une rémunération à celles et à ceux qui produisent les contenus.
Chez nous il n’y a pas de pub pour le tout dernier jeu super addictif ou le top dix des choses qu’on ignorait pouvoir faire avec un cure-dent et un balai de chiottes.
Nous on va plutôt mettre en avant un bouquin en lien direct avec les métadonnées et avec le contenu sonore du podcast grâce au concept que notre moteur d’analyse sémantique aura détecté.
Alors d’un point de vue pratique comment est-ce qu’on fait pour avoir des podcasts dans son smartphone sans blinder sa mémoire ? Parce que moi j’oublie pas que je suis toujours à court de mémoire.
Eh eh, c’est là que que je vois qu’effectivement tu n’es pas un expert du podcast parce que un podcast en moyenne c’est quarante minutes.
Pour avoir une bonne qualité, voire même une très bonne qualité il faut compter 192 kilobits par seconde. Ce qui fait que un bon gros podcast ça fait moins de 100 méga-octets. Si en plus tu considères que aujourd’hui on est connecté la plupart du temps à Internet du coup pour écouter un podcast il n’y a pas nécessairement besoin de le pré-télécharger. On se rend vite compte que l’espace de stockage nécessaire c’est pas vraiment le souci.
OK, alors moi j’ai un autre problème quand est-ce que les gens ont le temps d’écouter des podcasts ? En faisant autre chose en même temps ?
Bah ça c’est la magie du podcast. Le podcast il laisse les mains et les pieds et les yeux totalement libres. Si tu fais le bilan d’une journée, en fait, tu te rends compte que les occasions elles sont super nombreuses.
Tu as le petit-déj, dans ta voiture, dans les transports, en faisant du sport, en attendant un rendez-vous, en faisant son ménage. Personnellement je ne fais plus la vaisselle sans mon podcast.
OK, mais le temps d’une vaisselle suffit pour écouter un podcast ? C’est quoi la durée idéale d’un podcast ?
Alors… J’ai envie dire déjà ça dépend de ta dextérité à faire la vaisselle. Peut-être que la mienne est pas au top et que justement comme j’écoute des podcasts, eh bien, je ne progresse pas beaucoup. La durée idéale d’un podcast, ben, c’est un peu comme la longueur idéale des jambes, c’est quand elles touchent bien le sol. C’est affaire de contexte parce que si euh les statistiques font état donc d’une durée moyenne de quarante minutes il y a tout plein de circonstances pour écouter un podcast. Donc en fait il y a plein de durées idéales.
Le contexte d’écoute c’est un critère déterminant.
Je ne vais pas chercher le même type et la même longueur, la même durée, de podcast pour le café du matin que pour le café du TGV Paris-Biarritz ! À chaque contexte d’écoute il y a une durée idéale.
Alors, qui produit des podcasts ? Est-ce qu’il y a une grosse offre française ? Moi je ne connais que celui de Tristan Nitot mais en effet je ne suis pas spécialiste.
Sur les quatre millions de podcasts dans le monde il y en a 72 000 qui sont francophones ce qui veut dire qu’il y en a beaucoup et qui a beaucoup plus d’heures de podcasts francophones publiés chaque jour qu’il y a d’heures dans une journée. Même si tu les écoutes en vitesse deux fois sans dormir tu ne pourras pas tout écouter.
L’une des particularités du marché français c’est l’importance de l’offre radiophonique parce que les Françaises et les Français sont très attachés à leurs radios, bien plus que dans les autres pays du monde, d’ailleurs. Et donc c’est naturellement qu’on retrouve les radios en bonne place dans les études d’écoute de podcasts. En France il y a également beaucoup de studios de podcasts d’une très grande qualité, vraiment beaucoup, et enfin et c’est ce qui est génial avec le podcasting : n’importe qui peut se lancer que ce soit pour une heure une semaine un an ou dix.
Ma fille a lancé le sien à dix ans !
Ah oui, les poésies d’Héloïse, tu m’as dit ça tout à l’heure.
C’est ça !
Est-ce qu’on a besoin de beaucoup de matériel pour faire un podcast ?
On a besoin que d’un bon micro, des idées, évidemment, euh, d’Audacity, Castopod, et ça suffit, hop-là, on se lance ?
La première chose dont on a besoin c’est l’envie puis l’idée et euh… et c’est tout !
Aujourd’hui n’importe quel téléphone moderne est capable d’enregistrer une voix bien mieux que les enregistreurs hors de prix qu’on avait dans les années quatre-vingts !
Si tu savais combien de podcasts sont en fait enregistrés au téléphone sous une couette ou dans une taie d’oreiller ! Bien entendu, et ce n’est pas valable que pour le podcast, hein, plus on avance et plus on devient exigeant et un bon microphone et une bonne carte son, ça fera vite la différence. Mais les contraintes techniques ne doivent pas brider la créativité.
En ce qui concerne le montage donc tu as cité Audacity. Je l’utilise de temps à autre mais je suis plutôt «Team Ardour». La grosse différence c’est qu’Audacity est destructif. C’est-à-dire que tu ne peux pas annuler une manipulation que tu as faite il y a deux heures alors qu’avec Ardour qui est non-destructif… deux ans après avoir bossé sur un montage tu peux encore tout corriger et revenir sur n’importe quelle opération.
Et enfin sur l’hébergement bah il y en a pour tous les besoins, tous les goûts, tous les profils, tous les podcasts, mais la seule solution qui à la fois open source certifié podcasting 2.0 et connectée au fédiverse c’est Castopod.
Qu’est-ce que tu écoutes, toi, comme podcasts ? Est-ce que tu as des conseils pour les personnes qui souhaitent une sélection ? On mettra les liens dans les commentaires.
Ah c’est un peu audacieux de demander à un inconnu un conseil podcast, c’est un peu comme demander un conseil gastronomique à un inconnu dans la rue.
Surtout que personnellement j’ai une sélection qui est assez éclectique et pas très originale.
Dans les podcasts que j’écoute régulièrement… Il y a Podland, Podnews, Podcasting 2.0, The Europeans, Décryptualité, Libre à vous, L’Octet vert que tu as cité et Sans Algo. Et puis j’écoute aussi beaucoup de d’émission de radio du service public podcastées quand elles sont pas sauvagement supprimées des plateformes ouvertes, suivez mon regard…
Alors c’est quoi ton regard ? Tu peux les citer ou… ?
Non je ne veux me fâcher avec personne.
J’ai vu que Castopod était compatibles Activitypub. Alors ça veut dire quoi concrètement pour les gens qui nous écoutent ?
Alors
Activitypub c’est un protocole… c’est un protocole standard normalisé par le W3C, donc c’est pas vraiment des rigolos quand il s’agit de définir une norme, qui permet à toutes les plateformes de réseaux sociaux qui l’implémente de connecter leur contenu et leurs utilisatrices et leurs utilisateurs entre eux l’ensemble des plateformes qui utilisent Activitypub est appelé le fédiverse qui est un mot-valise contraction de «univers» et «fédérer». La plus emblématique de ces plateformes c’est Mastodon quel est donc une plateforme de microblogging semblable à Twitter qui connaît un succès considérable depuis 2017 et récemment on en entend beaucoup parler suite au rachat de Twitter et on compte aujourd’hui plusieurs milliers de serveurs Mastodon et plusieurs millions d’utilisatrices et utilisateurs.
Là où franchement ça devient génial et même au-delà de Mastodon c’est que le fédiverse permet de mutualiser et d’interconnecter plein plein plein de serveurs sur des technologies diverses, différentes, pourvu qu’il implémente Activitypub. Par exemple une utilisatrice ou un utilisateur pourra depuis un un compte Mastodon donc un unique compte Mastodon interagir avec d’autres qui sont connectés depuis un ou plusieurs serveurs Pixelfed, du partage de photos façon Instagram depuis des serveurs Peertube partage de vidéos façon Youtube depuis des serveurs Bookwyrm qui est un service de partage de critiques littéraires depuis les serveurs Funkwhale qui permet du partage de musique depuis Mobilizon, nous en parlions tout à l’heure, qui permet de partager de l’organisation d’événements et depuis Castopod qui permet le partage de podcasts.
Illustration CC-BY-SA Benjamin Bellamy
Donc concrètement imagine c’est comme si depuis ton compte Twitter tu pouvais « liker » une photo Instagram, commenter une vidéo Youtube, partager une musique SoundCloud.
Alors évidemment bah ça c’est pas possible. C’est pas possible chez les GAFAM.
Mais sur le fédivers ça l’est ! C’est possible, et c’est possible aujourd’hui ! Ce qui fait que ben avec Castopod le podcast est le réseau social donc tes auditrices et tes auditeurs peuvent commenter, partager ou aimer un épisode directement sans aucun intermédiaire. Aucun intermédiaire, qu’il soit technique ou juridique, hein sans GAFAM, sans plateforme privative entre les deux tu as la garantie de ne pas te prendre un «strike» parce que tu as fait usage de ton droit de citation tu ne vas pas avoir ton compte bloqué parce que t’as utilisé des mots-clefs qui sont indésirables et pas de censure automatique par un idiot de «bot» qui ne sait dialoguer qu’en éructant des réponses pré-formatées.
Et tout cela en étant accessible à des millions d’utilisatrices et utilisateurs sur des milliers de serveurs du fédivers. Honnêtement, n’ayons pas peur de le dire, l’avenir des réseaux sociaux sera fédivers ou ne sera pas !
Ça me rappelle quelqu’un, tiens… Alors tu as mentionné, quand on a parlé de podcast, tout à l’heure, tu vois je n’arrive pas à le prononcer, décidément.
Tu as mentionné Podcast-Index quand on s’est parlé en préparant l’interview et tu as parlé de Podcasting 2.0 tout à l’heure. Qu’est-ce que c’est ?
Fred répète pour prononcer « podcast » correctement.
Alors…
Hum…
Laisse-moi chausser mes lunettes parce que cette question nécessite qu’on s’arrête une petite heure, une petite heure et demie sur
l’histoire du podcast.
Je ne suis pas sûr qu’il nous reste autant (de temps).
Alors là je vais… je vais abréger.
Bien avant les iPods, en 1989, l’émission « l’illusion d’une radio indépendante » (“Иллюзия независимого радио”) ouvre la voie aux podcasts qu’on connaît aujourd’hui en proposant en URSS des émissions sonores qui à l’époque étaient diffusées sur des cassettes et des bandes magnétiques et de « URSS » à « RSS » il n’y a qu’un U, celui de « Uuuuuuh ! quel jeu de mot tout pourri !» jeux de mots que je m’abstiendrai donc de faire.
Trop tard !…
Et donc sans jeu de mots et bien plus tard c’est en octobre 2000 que Tristan Louis, comme son nom peut le laisser penser il est français, il a l’idée d’inclure des fichiers MP3 dans un flux RSS. RSS lui-même créé et promu par des véritables légendes tel que Ramanathan V. Guha, Dave Winer ou Aaron Swartz.
Et donc il crée la technologie qui est celle que tous les podcasts du monde utilisent encore aujourd’hui. Après ça alors qu’on parlait plutôt d’audio blogging à l’époque, Ben Hammersley, journaliste au Guardian, est le premier à lancer le mot podcast en février 2004 qui est un mot-valise entre « iPod » et broadcasting, broadcasting pour « diffusion » en anglais.
Ce qui fera vraiment connaître le podcast au grand public c’est d’abord les contenus par exemple “Daily Source Code” d’Adam Curry lancé à l’été 2004, et ensuite l’intégration des podcasts par Apple dans iTunes 4.9 en juin 2005.
Et puis pas grand-chose pendant toute une décennie ! En fait l’histoire du podcast elle aurait pu s’arrêter là.
Mais en 2014, Sarah Koenig va bousculer littéralement un écosystème un peu moribond en publiant Serial le podcast aux 350 millions de téléchargements et c’est à ce moment-là qu’un véritable engouement populaire pour les podcasts apparaît.
C’est impressionnant, comme chiffre !
Ah oui, c’est impressionnant, oui… C’est impressionnant surtout que ça n’arrête pas de croître ! C’est un très bon podcast d’ailleurs Serial, j’adore. Il y a trois saisons et les trois sont très très bien. Si on comprend l’anglais c’est vraiment un podcast à écouter, Serial.
Néanmoins malgré ce renouveau force est de constater que,en plus de quinze ans, pas une seule – et alors que les usages du web entre-temps ont été révolutionnées par le haut débit les smartphones les réseaux sociaux le cloud etc. – donc pas une seule innovation technologique n’est venue bousculer le podcast.
Statu quo fonctionnel et technologique.
Apple règne toujours en maître absolu sur son annuaire de podcasts et rien n’a évolué et à l’été 2019 Adam Curry le même que cité tout à l’heure et Dave Jones, insatisfaits de cette situation, décident de lancer en parallèle, non pas un non pas deux, mais bien trois projets afin de secouer un peu tout ça.
Premièrement et pour mettre fin à la dépendance vis-à-vis de l’index d’Apple ils créent un index de podcasts qui s’appelle Podcast-Index, pas super original, mais au moins on comprend ce que c’est. Il faut comprendre que là où l’index d’Apple requiert une validation d’Apple pour ajouter le moindre podcast mais également pour lire le contenu de l’index ce qui fait qu’Apple en fait a le pouvoir de vie ou de mort sur n’importe quelle application d’écoute qui n’utiliserait que son index.
Là où l’index d’Apple est soumis au bon vouloir d’Apple, Podcast-index est libre.
Il est libre en lecture et en écriture mais attention, vraiment libre par exemple la base de données de Podcast-index, elle est librement téléchargeable dans son intégralité en un clic depuis la page d’accueil. Tu n’as même pas besoin de créer un compte, de filer ton adresse mail, ton numéro de portable, ou le nom de jeune fille de ta mère. Et en plus de ça des API sont librement disponibles pour les applications mobiles Podcast-index référence aujourd’hui plus de quatre millions de podcasts. Apple aujourd’hui en a deux millions et demi.
Deuxièmement et pour rattraper le temps perdu, Adam et Dave décident de proposer de nouvelles fonctionnalités en créant des nouvelles méta-données, le « Podcast Namespace », qui ouvre la voie à ce qu’ils appellent « Podcasting 2.0 ».
Parmi les nombreuses fonctionnalités qui comprend comment on peut noter ben donc la gestion de transcription et de sous-titrage les liens de financement le chapitrage la géolocalisation contenus la gestion d’un intervenant. Il y en a plein d’autres ayant des nouvelles tout le temps, l’ensemble de ces spécifications euh et de ses innovations est librement consultable en ligne sur Github (on mettra le lien dans l’article, dans la description) et librement consultable encore une fois en lecture et en écriture.
C’est là en fait le troisième volet la troisième révolution, le mot est à peine exagéré hein qu’Adam et Dave vont apporter aux podcasts ; ils ont créé une communauté libre et ouverte où tout le monde peut apporter son temps son talent ou son trésor et force est de constater que ça fonctionne du tonnerre. En moins de six mois, alors que je rappelle qu’aucune innovation n’avait bousculé le podcast en quinze ans, en moins de six mois il y a plein d’applications d’écoute et d’hébergeurs évidemment dont Castopod qui ont rejoint le mouvement et qui ont intégré tout ou partie de ces nouvelles fonctionnalités. Donc cette communauté elle se rassemble sur Github sur Mastodon sur podcastindex.social dans un podcast éponyme et lors de réunions où on parle plutôt «techos».
Enfin le résultat c’est que la liste des applications et des services qui sont compatibles podcasting 2.0 est disponible sur le site podcasting.com. Clairement c’est sur ce site et sur podcastindex.org qui faut aujourd’hui choisir son application ou son hébergeur.
Alors moi je suis allé tourner un peu sur les sites de Castopod, je suis allé voir blog.castopod.org mais alors tout est en anglais là-dedans !
J’ai cherché un un petit bouton pour changer de langue et il n’y en a pas. Je croyais que le projet était français ? Pourquoi ça cause pas la langue de Molière ?
Le projet est français mais il est avant tout européen, enfin en tous cas d’un point de vue chronologique et et donc naturellement on a commencé par l’anglais et on n’a pas eu le temps de traduire cette partie-là mais ça va venir vite, c’est promis.
Oui parce que la doc en revanche elle a son site en français doc.castopod.org/fr et là j’étais content j’aurais dû commencer par là parce que il y a plein d’explications dans la doc.
Oui, alors la doc, on a pris le temps de la traduire en français et en plus la communauté aidant elle est également disponible en plus de l’anglais en brésilien1 et en norvégien et d’autres langues arriveront derrière.
Mais alors je suppose que c’est en fonction des contributeurs et des contributrices que le projet évolue ? Vous avez besoin de contributeurs de contributrices ? Comment est-ce qu’on peut faire pour vous aider ?
Ouais tout à fait mais Castopod c’est avant tout un projet ouvert hein donc le le code source est ouvert mais pas seulement on a besoin de développeuses et de développeurs mais également de traductrices de traducteurs de testeuses de testeurs de prescriptrices et de prescripteurs qui prêchent la bonne parole (merci Framasoft !) et puis de financement via Open Collective.
D’accord ! Alors comme d’habitude on te laisse le mot de la fin dans le Framablog. Est-ce qu’il y a des questions qu’on ne t’a pas posées ? Est-ce qu’il y a des choses que tu as envie d’ajouter ?
Écoute, je trouve que tu as mené cette interview d’une main de maître.
Merci de m’avoir reçu ! En fait je voudrais juste dire aux gens : essayez le podcast.
Vous avez un téléphone vous pouvez vous y mettre ; il ne faut pas être timides hein lancez-vous attendez pas des mois avant de créer le premier épisode car une fois qu’on a une idée on enregistre on publie et puis c’est ce que j’aime avec le podcast, on peut changer de modèle on peut changer de format on peut changer ce qu’on veut on peut tester il y a des hébergeurs pour tout le monde. Évidemment moi je vous engage à aller sur castopod.org pour voir ce que c’est pour voir ce qu’on propose.
Ah, si vous avez un peu la fibre technique eh bien n’hésitez pas à le télécharger et à l’installer, sachant que si vous avez pas la fibre technique et bah allez plutôt sur castopod.com où on propose des prestations d’hébergement clé en main. Et puis bon podcasting et bonne écoute !
Ah bah je vais m’y mette du coup je vais essayer de trouver quelques podcasts intéressants parce que c’est pas du tout ma culture ! En tout cas voilà grâce à toi je vais écouter des podcasts.
Merci beaucoup d’être venu parler avec nous et puis on espère longue vie à Castopod.
L’illustration « Fred répète » a été réalisée avec Gégé, le générateur de Geektionnerd basé sur des dessins sous licence libre de SImon « Gee » Giraudot