Des ateliers solarpunk pour imaginer un avenir low-tech
Cette semaine, à l’Université de Technologie de Compiègne, des ateliers originaux vont mobiliser une quarantaine de participant⋅es (dont plusieurs membres de Framasoft) pour imaginer un monde low-tech en 2042 !
Dans cette université qui forme des ingénieurs existe une unité de valeur « lowtechisation et numérique » animée par Stéphane Crozat, qui par ailleurs est membre de Framasoft et l’initiateur de l’atelier pédagogique UPLOAD/solarpunk. De quoi s’agit-il exactement ?
Solarpunk ?
Dérèglement climatique, pollution, inégalités sociales, extinction des énergies fossiles… dans un monde menacé, à quoi peut ressembler une civilisation durable et comment y parvenir ? Le solarpunk est un genre de la science-fiction qui envisage des réponses à cette question dans une perspective utopique ou simplement optimiste, sans jamais être dystopique.
Voici les trois premiers articles du manifeste solarpunk :
Nous sommes solarpunk parce que l’optimisme nous a été volé et que nous cherchons à le récupérer.
Nous sommes solarpunk parce que les seules autres options sont le déni et le désespoir.
L’essence du Solarpunk est une vision de l’avenir qui incarne le meilleur de ce que l’humanité peut accomplir : un monde post-pénurie, post-hiérarchie, post-capitalisme où l’humanité se considère comme une partie de la nature et où les énergies propres remplacent les combustibles fossiles.
Si vous souhaitez en savoir plus, le manifeste est à votre disposition.
Low-tech ?
On comprend mieux pourquoi proposer d’imaginer des fictions low-techà de futurs ingénieurs, qui seront plus enclins à agir en génération frugale (suivant ce scénario pour 2050 de l’ADEME) qu’en technosolutionnistes.
Le principe de lowtechisation est résumé en une formule dans le cours de Stéphane :
Vaste programme, bigrement idéaliste, direz-vous, mais pourquoi ne pas envisager collectivement et concrètement des scénarios possibles qui répondent à ces idéaux ? Voici la proposition-cadre qui est faite aux participant⋅es (et à vous si vous souhaitez y ajouter votre contribution) :
Nous sommes en 2042. La mauvaise nouvelle c’est que l’effondrement est vécu au quotidien (pénurie, épidémies, énergie et matières premières raréfiées, réchauffement climatique…). La bonne nouvelle c’est que notre société n’investit plus majoritairement sur le techno-solutionnisme et la croissance […] mais que peuvent émerger de nouveaux projets désirables : réappropriation de savoir-faire technologiques, réaffectation des ressources, création de communs, décentralisation, autonomisation, débats publics…
Parmi ces initiatives qui émergent, il y a la création de l’UPLOAD (Université Populaire Libre Ouverte Autonome Décentralisée, à Compiègne). On imaginera et publiera des récits courts qui mettront en scène une activité pédagogique (un cours sur la post-croissance ? des ateliers d’imagination de nouveaux métiers ?), un projet low-tech (un éco-bâtiment passif à réaliser soi-même ?) ou high-tech (une IA pour parler avec des animaux ?).
Une semaine de réflexions, échanges, créations
Du lundi au vendredi un programme diversifié et appétissant est proposé sur place… il sera question bien sûr de low-tech, de décroissance, de décentralisation d’internet, de lectures partagées, de divers scénarios pour demain, souhaitables ou non, et d’élaborer par étapes et ensemble des récits grands ou petits qui seront résumés sur Mastodon et publiés une fois élaborés… ici même sur le Framablog !
À suivre : dès mardi, les groupes auront choisi un thème et le publieront sur Mastodon…
Il y a déjà des suggestions qu’on peut utiliser, dépasser ou ignorer…
Crédits de l’illustration : CC BY-NC-SA 4.0 · par Cix · Bâtir aussi, Ateliers de l’Antémonde · https://antemonde.org/ (adaptée par stph)
et vous, le clavier vous démange ?
Bien sûr, vous n’êtes pas à Compiègne, mais l’idée de proposer un avenir qui ne soit pas post-apocalyptique vous plaît… vous pouvez apporter une contribution à ce projet avec une fiction solarpunk en élaborant :
un format 500 caractères pour Mastodon avec les hashtag #solarPunk et #UPLOAD
IA génératives : la fin des exercices rédactionnels à l’université ?
En décembre 2022 le magazine États-unien The Atlantic titre : « The College Essay Is Dead » ( Marche, 2022 [1] ). L’auteur de l’article, écrivain, attribue un B+ à une rédaction produite avec le LLM [2] GPT-3 dans le cadre du cours de Mike Sharples, enseignant en sciences humaines. J’ai moi même attribué la note de 14/15 à un exercice rédactionnel réalisé avec ChatpGPT en février 2023 à l’UTC ( Turcs mécaniques ou magie noire ? ). Une enseignante de philosophie lui a attribué une note de 11/20 au baccalauréat ( Lellouche, 2023 [3] ).
J’ai depuis observé plusieurs cas de « triche » avec des LLM à l’UTC en 2023.
Se pose donc la question de la réaction à court terme pour les enseignants concernant les exercices rédactionnels qui sont réalisés par les étudiants à distance.
Je parlerai de LLM
Je parlerai de LLM [2] dans cet article plutôt que de ChatGPT.
ChatGPT est un outil de l’entreprise OpenIA basé sur un LLM [2] à vocation de conversation généraliste (capable d’aborder n’importe quel sujet) et le premier à avoir introduit une rupture d’usage dans ce domaine. Le problème abordé ici concerne bien cette classe d’outils, mais pas seulement ceux d’OpenIA : des outils concurrents existent à présent (certains pourront devenir plus puissants), des outils plus spécialisés existent (pour la traduction par exemple), d’autres sont probablement amenés à voir le jour (orientés vers la production de textes universitaires, pourquoi pas ?).
Les LLM [2] ne génèrent pas que des textes à la demande, ils génèrent aussi de nombreuses opinions parmi les spécialistes et les usagers ; j’essaierai de me borner aux faits présents, à ce que l’on peut raisonnablement anticiper à court terme (sans faire de science-fiction) et à la seule question de l’évaluation en contexte pédagogique (mais je n’y arriverai pas totalement…).
Je ne parlerai donc pas :
des autres enjeux pédagogiques : quel est le rôle de l’université face au développement des LLM ? doit-on former à leurs usages ? les enseignants doivent-il utiliser des LLM eux-mêmes ? est-ce que ça a du sens d’apprendre à rédiger à l’ère des LLM ?
des enjeux technico-fonctionnels : qu’est-ce que les LLM ne savent pas faire aujourd’hui ? qu’est-ce qu’on pense qu’ils ne seront jamais capables de faire ?
des enjeux politiques et éthiques : est-ce un progrès ? est-ce qu’on peut arrêter le progrès ? que penser de la dépendance croissante aux entreprises de la tech États-uniennes ? du déploiement du capitalisme de surveillance ?
des enjeux socio-écologiques : à quoi ça sert ? quels humains ça remplace ? quel est l’impact environnemental des LLM ?
des enjeux philosophiques : les LLM sont-ils neutres ? est-ce que ça dépend comment on s’en sert ? ou bien l’automatisation introduite change-t-elle radicalement notre rapport au langage et à la raison ? compléter des textes en utilisant des fonctions statistiques, est-ce penser ? qu’est-ce que l’intelligence ?
des enjeux juridiques : est-ce que les LLM respectent le droit d’auteur ? un texte produit avec un LLM est-il une création originale ?
…
TL;DR
Cet article étant un peu long, cette page en propose un résumé (TL;DR signifiant : « Too Long; Didn’t Read ») : Résumé du présent article.
Problématique et hypothèse
Problématique
Peut-on continuer à faire faire des exercices rédactionnels « à la maison » comme avant ?
Sans statuer sur la dimension de rupture des LLM — est-ce une nouvelle évolution liée au numérique qui percute le monde de la pédagogie, comme les moteurs de recherche ou Wikipédia avant elle, ou bien une révolution qui va changer radicalement les règles du jeu — il parait nécessaire de réinterroger nos pratiques : « sans sombrer dans le catastrophisme, il serait tout aussi idiot de ne pas envisager que nous sommes une nouvelle fois devant un changement absolument majeur de notre manière d’enseigner, de transmettre, et d’interagir dans un cadre éducatif, a fortiori lorsque celui-ci est asynchrone et/ou à distance. ( Ertzscheid, 2023 [6]) »
Hypothèse
L’automatisation permise par les LLM rend raisonnable une triche automatisée dont le rapport coût/bénéfice est beaucoup plus avantageux qu’une triche manuelle.
De nombreux modules universitaires comportent des exercices rédactionnels à réaliser chez soi. Ces travaux sont généralement évalués et cette évaluation compte pour la validation du module et donc in fine, pour l’attribution d’un diplôme.
Dans certains contextes, il n’y a pas d’évaluation en présentiel sans ordinateur et donc la totalité de la note peut bénéficier d’une « aide extérieure ».
Souvent à l’université la présence et/ou la participation effective des étudiants lors des cours et TD n’est pas elle-même évaluée, et parfois il n’y a pas d’examen classique, en conséquence un étudiant a la possibilité de valider un cours sans y assister en produisant des rendus écrits qualitatifs à domicile.
Cette situation pré-existe à l’arrivée des LLM, mais nous faisons l’hypothèse suivante :
sans LLM il reste un travail significatif pour se faire aider par un humain ou copier des contenus glanés sur le Web ;
sans LLM il reste un risque important d’une production de qualité insuffisante (l’humain qui a aidé ou fait à la place n’est pas assez compétent, les contenus Web copiés ont été mal sélectionnés, ou mal reformulés, etc.) ;
avec un LMM il est possible de produire un écrit standard sans aucun effort, pour exemple la copie de philo évaluée à 11 a été produite en 1,5 minute ( Lellouche, 2023 [3]).
Triche ?
J’utilise le terme de triche car si la consigne est de produire un texte original soi-même alors le faire produire par un tiers est de la triche. L’existence d’un moyen simple pour réaliser un exercice n’est pas en soi une autorisation à l’utiliser dans un contexte d’apprentissage. C’est similaire à ce qu’on peut trouver dans un contexte sportif par exemple, si vous faites une course à vélo, vous ne devez pas être aidé d’un moteur électrique.
LLM et moteurs de recherche : différence de degré ou de nature ?
J’écrivais en 2015 à propos de l’usage des moteurs de recherche ( Le syndrome de la Bibliothèque de Babel) : « La question intéressante qui se pose aux pédagogues n’est tant de savoir si l’élève va copier ou pas, s’il va « tricher ». La question est de savoir comment maintenir un travail d’élaboration d’une démarche et de production sensément originale et personnelle qui repose explicitement sur une recherche – donc une recherche sur le web – alors que la réponse à la question posée s’invite sur l’écran, formulée très exactement telle qu’attendue. C’est à peine une simplification en l’espèce de dire que la réponse a été jointe à la question, par celui même qui a posé cette question. »
Les LLM font sauter cette barrière : là où les moteurs de recherche permettaient une réponse facile à une question récurrente, les LLM permettent une réponse immédiate à une question originale.
L’évaluation de tout travail avec un ordinateur
Notons que le problème se pose pour tous les travaux rédactionnels avec ordinateur, même en présentiel ou en synchrone. En effet dès lors que l’on veut que nos exercices s’appuient sur un accès à un traitement de texte, des recherches Web ou d’autres outils numériques, alors ils ouvrent l’accès aux LLM.
Il existe des solutions humaines ou techniques de surveillance des examens pour ouvrir l’accès à certains outils seulement, mais d’une part elles posent des problèmes pratiques, éthiques et juridiques, et d’autre part les LLM s’introduisent progressivement au sein des autres outils, ainsi par exemple le moteur de recherche.
Les LLM et les étudiants
Les LLM sont utilisés par les étudiants
Lors de mes cours du semestre dernier (mars à juillet 2023), j’ai rencontré plusieurs cas d’usage de LLM.
Ces cas s’apparentent à de la triche.
Les étudiants n’ont pas facilement admis leur usage (allant dans certains cas jusqu’à nier des évidences).
Ce sont des cas d’usages stupides de la part des étudiants, car non nécessaires pour la validation du cours, sans intérêt du point de vue pédagogique, et facilement détectables.
On peut retenir les arguments principaux revendiqués par les étudiants :
Le gain de temps (même si je sais faire, « flemme » ou « retard »).
La nécessité de ne pas échouer et la peur d’être pénalisé sur le niveau d’expression écrite.
Le fait de ne pas être « sûr » de tricher (ce n’est pas explicitement interdit).
Des étudiants qui n’utilisent pas encore les LLM pour les exercices rédactionnels les utilisent plus facilement pour la traduction automatique.
UTC : Un premier étudiant utilise ChatGPT (IS03)
Au sein du cours de l’UTC IS03 (« Low-technicisation et numérique »), les étudiants doivent réaliser des notes de lecture sur la base d’articles scientifiques. Un étudiant étranger non-francophone utilise grossièrement un LLM (probablement ChatGPT) pour produire en une semaine le résumé de plusieurs dizaines de pages de lectures d’articles scientifiques difficiles et de rapports longs. J’avais donné une liste de plusieurs lectures possibles, mais n’attendais évidemment des notes que concernant un ou deux documents.
Il faut plusieurs minutes de discussion pour qu’il reconnaisse ne pas être l’auteur des notes. Mon premier argument étant sur le niveau de langue obtenue (aucune faute, très bonne expression…) l’étudiant commencera par reconnaître qu’il utilise des LLM pour corriger son français (on verra que cette « excuse » sera souvent mobilisée). Sur le volume de travail fournit, il reconnaît alors utiliser des LLM pour « résumer ».
In fine, il se justifiera en affirmant qu’il n’a pas utilisé ChatGPT mais d’autres outils (ce qui est très probablement faux, mais en l’espèce n’a pas beaucoup d’importance).
C’était un cas tout à fait « stupide », l’étudiant avait produit des notes sur près d’une dizaine de rapports et articles, sous-tendant plusieurs heures de lectures scientifiques et autant de résumés, et avait produit des énoncés sans aucune faute, tout cela en maîtrisant mal le français.
UTC : 6 cas identifiés lors de l’Api Libre Culture
Une Activité Pédagogique d’Intersemestre (Api) est un cours que les étudiants choisissent au lieu de partir en vacances, en général par intérêt, dont les conditions d’obtention sont faciles : les étudiants sont en mode stage pendant une semaine (ils ne suivent que l’Api) et leur présence régulière suffit en général pour valider le cours et obtenir les 2 crédits ECTS associés. Un devoir individuel était à réaliser sur machine pour clôturer l’Api Libre Culture de juillet 2023. Il consistait essentiellement en un retour personnel sur la semaine de formation.
Lors de ce devoir de fin d’Api, 6 étudiantes et étudiants (parmi 20 participants en tout) ont mobilisé de façon facilement visible un LLM (ChatGPT ou un autre). Pour 4 d’entre eux c’était un usage partiel (groupe 1), pour 2 d’entre eux un usage massif pour répondre à certaines questions (groupe 2). J’ai communiqué avec ces 6 personnes par mail.
3 des étudiants du groupe 1 ont avoué spontanément, en s’excusant, conscients donc d’avoir certainement transgressé les règles de l’examen. La 4e personne a reconnu les faits après que j’ai insisté (envoi d’un second mail en réponse à un premier mail de déni).
Pour les 2 étudiants du groupe 2 :
le premier n’a reconnu les faits qu’après plusieurs mails et que je lui aie montré l’historique d’un pad (traitement de texte en ligne) qui comportait un copie/coller évident de ChatGPT.
le second, étudiant étranger parlant très bien français, n’a jamais vraiment reconnu les faits, s’en tenant à un usage partiel « pour s’aider en français » (loin de ce que j’ai constaté).
À noter qu’aucun étudiant ne niait avoir utilisé un LLM, leur défense était un usage non déterminant pour s’aider à formuler des choses qu’ils avaient produites eux-mêmes.
Pour les deux étudiants du groupe 2, j’ai décidé de ne pas valider l’Api, ils n’ont donc pas eu les crédits qu’ils auraient eu facilement en me rendant un travail de leur fait, même de faible niveau. Ils n’ont pas contesté ma décision, l’un des deux précisera même : « d’autant plus que j’ai déjà les compétences du fait du cours suivi dans un semestre précédent ».
Un étudiant en Nouvelle-Zélande reconnaît utiliser ChatGPT
« In May, a student in New Zealand confessed to using AI to write their papers, justifying it as a tool like Grammarly or spell-check: “I have the knowledge, I have the lived experience, I’m a good student, I go to all the tutorials and I go to all the lectures and I read everything we have to read but I kind of felt I was being penalised because I don’t write eloquently and I didn’t feel that was right,” they told a student paper in Christchurch. They don’t feel like they’re cheating, because the student guidelines at their university state only that you’re not allowed to get somebody else to do your work for you. GPT-3 isn’t “somebody else”—it’s a program. » ( Marche, 2022 [1] )
On note les deux arguments principaux produits :
je l’utilise car je ne suis pas très fort à l’écrit et je ne trouve pas normal que cela ma pénalise ;
ce n’est pas clairement interdit à l’université.
J’ai interviewé des collégiens et lycéens
ChatGPT est déjà utilisé au collège et au lycée : surtout par les « mauvais » élèves (selon les bons élèves)…
…et par les bons élèves occasionnellement, mais pour une « bonne raison » : manque de temps, difficultés rencontrées, etc.
Des outils d’IA dédiés à la traduction sont plus largement utilisés, y compris par les bons élèves.
À l’école « l’échec c’est mal » donc le plus important est de rendre un bon devoir (voire un devoir parfait).
Cet article fait suite à « Turcs mécaniques ou magie noire ? » un autre article écrit en janvier sur la base d’un test de ChatGPT à qui j’avais fait passer un de mes examens. Pour mémoire ChatGPT obtenait selon ma correction 14/15 à cet examen second, égalité donc avec les meilleurs étudiants du cours.
B+ à un exercice rédactionnel en Grande-Bretagne
En mai 2022, Mike Sharples utilise le LLM [2] GPT-3 pour produire une rédaction dans le cadre de son cours de pédagogie ( Sharples, 2022 [7] ). Il estime qu’un étudiant qui aurait produit ce résultat aurait validé son cours. Il en conclut que les LLM sont capables de produire des travaux rédactionnels du niveau attendu des étudiants et qu’il faut revoir nos façons d’évaluer (et même, selon lui, nos façons d’enseigner).
Le journaliste et écrivain qui rapport l’expérience dans The Antlantic attribue un B+ à la rédaction mise à disposition par Mike Sharples ( Marche, 2022 [1] ).
11 au bac de philo
ChatGPT s’est vu attribué la note de 11/20 par une correctrice (qui savait qu’elle corrigeait le produit d’une IA) au bac de philosophie 2023. Le protocole n’est pas rigoureux, mais le plus important, comme le note l’article de Numerama ( Lellouche, 2023 [3] ) c’est que le texte produit est loin d’être nul, alors même que le LLM n’est pas spécifiquement programmé pour cet exercice. Un « GPTphilo » aurait indubitablement obtenu une meilleure note, et la version 2024 aura progressé. Probablement pas assez pour être capable de réaliser de vraie productions de philosophe, mais certainement assez pour être capable de rendre caduque un tel exercice d’évaluation (s’il était réalisé à distance avec un ordinateur).
66% de réussite dans le cadre d’une étude comparative
Farazouli et al. ( 2023 [8] ) ont mené un travail plus rigoureux pour évaluer dans quelle mesure ChatGPT est capable de réussir dans le cadre de travaux réalisés à la maison, et quelles conséquences cela a sur les pratiques d’évaluation. 22 enseignants ont eu à corriger 6 copies dont 3 étaient des copies ChatGPT et 3 des copies d’étudiants ayant préalablement obtenu les notes A, C et E (pour 4 de ces enseignants, ils n’avaient que 5 copies dont 2 écrites avec ChatGPT).
« ChatGPT achieved a high passing grade rate of more than 66% in home examination questions in the fields of humanities, social sciences and law. »
Dont :
1 travail noté A sans suspicion que c’était une copie ChatGPT ;
4 rendus notés B, dont 1 seul était suspecté d’avoir été réalisé avec ChatGPT.
On observe des disparités assez importantes en fonction des domaines :
Les notes obtenues par ChatGPT ont été meilleures en philosophie et en sociologie et moins bonnes en droits et en éducation
F
E
D
C
B
A
Philosophie
3
2
7
6
3
0
Droit
9
4
0
2
0
0
Sociologie
6
6
1
1
3
1
Éducation
5
2
0
1
0
0
Remarque
On observe une grande disparité dans les évaluations d’un même travail (humain ou ChatGPT) par des évaluateurs différents (de F à A), ce qui interroge sur le protocole suivi et/ou sur la nature même de l’évaluation.
Corriger c’était déjà chiant…
La plupart des enseignants s’accordent sur le fait que le plus ennuyeux dans leur métier est la correction des travaux étudiants. Savoir que l’on corrige potentiellement des travaux qui n’ont même pas été produits par les étudiants est tout à fait démobilisant…
« La question c’est celle d’une dilution exponentielle des heuristiques de preuve. Celle d’une loi de Brandolini dans laquelle toute production sémiotique, par ses conditions de production même (ces dernières étant par ailleurs souvent dissimulées ou indiscernables), poserait la question de l’énergie nécessaire à sa réfutation ou à l’établissement de ses propres heuristiques de preuve. » ( Ertzscheid, 2023 [6] ).
Il est coûteux pour un évaluateur de détecter du ChatGPT
Prenons un exemple, Devereaux ( 2023 [9] ) nous dit qu’il devrait être facile pour un évaluateur de savoir si une source existe ou non. Il prend cet exemple car ChatGPT produit des références bibliographiques imaginaires.
C’est en effet possible, mais ce n’est pas « facile », au sens où si vous avez beaucoup de rédactions avec beaucoup de références à lire, cela demande un travail important et a priori inutile ; lors de la correction de l’exercice de ChatGPT ( Turcs mécaniques ou magie noire ?), je me suis moi-même « fait avoir » y compris avec un auteur que je connaissais très bien : je ne connaissais pas les ouvrages mentionnés, mais les titres et co-auteurs était crédibles (et l’auteur prolifique !).
C’est aussi un bon exemple de limite conjoncturelle de l’outil, il paraît informatiquement assez facile de coupler un LLM avec des bases de données bibliographiques pour produire des références à des sources qui soient existantes. La détection ne supposera pas seulement de vérifier que la référence existe mais qu’on soit capable de dire à quel point elle est utilisée à propos. Le correcteur se retrouve alors plus proche d’une posture de révision d’article scientifique, ce qui suppose un travail beaucoup plus important, de plusieurs heures contre plusieurs minutes pour la correction d’un travail d’étudiant.
À quoi sert la rédaction à l’école ?
À quoi sert la rédaction à l’école ?
L’exercice rédactionnel est un moyen pour faire travailler un contenu, mais c’est surtout un moyen pour les étudiants d’apprendre à travailler leur raisonnement.
On peut penser que la généralisation de l’usage de LLM conduise à la perte de compétences à l’écrit, mais surtout à la perte de capacités de raisonnement, pour lesquelles l’écrit est un mode d’entraînement
Pourquoi faire écrire ?
Bret Devereaux ( 2023 [9] ) s’est posé la même question — à quoi sert un exercice rédactionnel ( « teaching essay ») — dans le même contexte de l’arrivée de ChatGPT ? Il propose trois fonctions pour cet exercice.
L’exercice est un moyen pour travailler (chercher, lire, explorer, étudier…) un contenu tiers (histoire, idée…) : l’usage de ChatGPT rend l’exercice totalement inutile, mais on peut assez facilement imaginer d’autres façon de faire travailler le contenu.
L’exercice est un moyen d’apprendre à faire des rédactions : l’usage de ChatGPT rend aussi l’exercice inutile, mais une part importante des étudiants n’aura plus à produire de rédaction en dehors de l’école.
L’exercice est un moyen d’apprendre à mettre en forme des idées par écrit. Ici encore l’usage de ChatGPT rend l’exercice inutile, puisque bien entendu, le résultat final obtenu n’a aucune importance (le contenu sera détruit après usage), et que seul compte le processus suivi (analyse des idées, organisation…). On peut considérer que l’usage d’un LLM est ici plus dommageable en ce sens qu’apprendre à penser via l’exercice rédactionnel est un processus d’apprentissage assez fondamental.
Exemple
Un étudiant qui a utilisé ChatGPT pour un exercice rédactionnel à l’UTC m’a transmis un de ses exemples d’usage, pour me montrer qu’il n’avait pas « triché » puisque le contenu venait de lui.
Il a ainsi donné en entrée à ChatGPT le texte suivant : « Le droit d’auteur, est une licence qui protège les œuvres artistiques et intellectuelles, genre les bouquins, les musiques, les films ou les tableaux. Ça donne aux créateurs le pouvoir de décider comment on peut utiliser, copier ou diffuser leur travail, et ça leur assure d’être reconnus comme ceux qui l’ont créé. »
Si l’on demande une reformulation à ChatGPT on obtient : « Le droit d’auteur est une forme de protection légale qui s’applique aux œuvres artistiques et intellectuelles, telles que les livres, la musique, les films et les œuvres d’art. Il accorde aux créateurs le pouvoir de contrôler l’utilisation, la reproduction et la diffusion de leur travail, tout en garantissant qu’ils soient reconnus en tant que créateurs de ces œuvres. »
On observe une correction de style, mais aussi une correction de fond. Le droit d’auteur n’est pas une « licence » (cette phrase n’a pas de sens) comme l’écrit l’étudiant, mais bien « une forme de protection légale » . En outre le même texte écrit avec beaucoup de fautes ressortira parfaitement écrit en français (l’étudiant qui m’écrivait avait certainement déjà corrigé préalablement son texte car le mail qui l’accompagnait comportait beaucoup de fautes d’orthographe et de formulation).
Si ChatGPT peut l’écrire, ça ne sert à rien ?
Un argument que produit Bret Devereaux et pas mal d’autres commentateurs devant les résultats obtenus par ChatGPT est le suivant : si une machine y arrive c’est que l’exercice est sans intérêt. « If your essay prompt can be successfully answered using nothing but vague ChatGPT generated platitudes, it is a bad prompt » ( Devereaux, 2023 [9] ).
C’est discutable :
Cette assertion suppose que l’exercice n’avait pas de sens en soi, même s’il était pratiqué avec intérêt avant, et la preuve qui est donnée est qu’une machine peut le faire. On peut faire l’analogie avec le fait de s’entraîner à faire de la course à pied à l’ère de la voiture (des arts martiaux à l’ère du fusil, du jardinage à l’ère de l’agriculture industrielle, etc.), ce n’est pas parce qu’une machine peut réaliser une tâche qu’il est inutile pour un humain de s’entraîner à la réaliser.
Farazouli et al. ( 2023 [8]) relèvent que les qualités mise en avant par les évaluateurs après correction de copies produites par ChatGPT étaient notamment : la qualité du langage, la cohérence, et la créativité. Dans certains contextes les productions de ChatGPT ne sont donc pas évaluées comme médiocres.
Ce que ChatGPT ne fait pas bien
À l’inverse Farazouli et al. ( 2023 [8] ) ont identifié des lacunes dans l’argumentation, le manque de références au cours et au contraire la présence de contenus extérieurs au cours.
La faiblesse argumentative est peut-être un défaut intrinsèque au sens où la mécanique statistique des LLM ne serait pas capable de simuler certains raisonnements. En revanche on note que le manque de références au cours et la présence de références extérieures est discutable (ça peut rester un moyen de détecter, mais c’est un assez mauvais objectif en soi).
En premier cycle universitaire on ne souhaite pas en général cette relation étroite au cours (il existe plusieurs approches, et un étudiant qui ferait le travail par lui-même serait tout à fait dans son rôle).
En second cycle, cela peut être le cas lorsque le cours porte sur un domaine en lien avec la recherche de l’enseignant typiquement. Mais la recherche est en général publiée et le LLM peut tout à fait être entraîné sur ces données et donc « connaître » ce domaine.
À quoi servent les évaluations à l’école ?
L’évaluation joue un double rôle : l’évaluation formative sert à guider l’apprenant (elle a vocation à lui rendre service), tandis que l’évaluation sommative joue un rôle de certification (elle a vocation à rendre service à un tiers).
Or on est souvent en situation de confusion de ces deux fonctions et cela conduit l’apprenant à se comporter comme s’il était en situation d’évaluation sommative et à chercher à maximiser ses résultats.
On note en particulier :
la fonction de classement entre les élèves des notes ;
la confusion entre l’exercice rédactionnel comme moyen (c’est le processus qui compte) ou comme fin (c’est le résultat qui compte).
Certifier (évaluation sommative) afin de statuer sur les acquis, valider un module de cours, délivrer un diplôme ; cette évaluation se situe après la formation.
Réguler (évaluation formative) afin de guider l’apprenant dans son processus d’apprentissage ; cette évaluation se situe pendant la formation.
Orienter (évaluation diagnostique) afin d’aider à choisir les modalités d’étude les plus appropriées en fonction des intérêts, des aptitudes et de l’acquisition des pré-requis ; cette évaluation se situe avant la formation (et en cela l’évaluation diagnostique se distingue bien de l’évaluation sommative en ce qu’elle se place avant la formation du point de vue de l’évaluateur).
« L’évaluation survient souvent à un moment trop précoce par rapport au processus d’apprentissage en cours ( Astofi, 1992 [11]) ».
C’est un défaut du contrôle continu, arrivant tôt, dès le début du cours même, il nous place d’emblée en posture sommative. Celui qui ne sait pas encore faire est donc potentiellement stressé par l’évaluation dont il refuse ou minore la dimension formative.
Entraîner ou arbitrer ? (confusion des rôles)
« Les fonctions d’entraîneur et d’arbitre sont trop souvent confondues. C’est toujours celle d’entraîneur dont le poids est minoré. ( Astofi, 1992 [11]) »
« Il reste à articuler les deux logiques de l’évaluation, dont l’une exige la confiance alors que l’autre oppose évaluateur et évalué ( Perrenoud, 1997 [12]) ».
Cette confusion des temps entraîne une confusion des rôles : l’enseignant est toujours de fait un certificateur, celui qui permet la validation du cours, la poursuite des études, l’orientation…
Se faire confiance
La question de la confiance au sein de la relation apprenant-enseignant était également relevée par Farazouli et al. ( 2023 [8] ) qui insistait sur la dégradation potentielle introduite par les LLM :
« The presence of AI chatbots may prompt teachers to ask “who has written the text?” and thereby question students’ authorship, potentially reinforcing mistrust at the core of teacher–student relationship »
Évaluation des compétences
Philippe Perrenoud ( 1997 [12]) défend une approche par compétences qui s’écarte d’une « comparaison entre les élèves » pour se diriger vers une comparaison entre « ce que l’élève a fait, et qu’il ferait s’il était plus compétent ». L’auteur souligne que ce système est moins simple et moins économique : « l’évaluation par les compétences ne peut qu’être complexe, personnalisée, imbriquée au travail de formation proprement dit ». Il faut, nous dit-il, renoncer à organiser un « examen de compétence en plaçant tous les concurrents sur la même ligne ».
Cet éloignement à la fonction de classement est intéressante à interroger. La fonction de classement des évaluations n’est pas, en général, revendiquée comme telle, mais elle persiste à travers les notes (A, B, C, D, E), la courbe de Gauss attendue de la répartition de ces notes, le taux de réussite, d’échec, de A. Ces notes ont également une fonction de classement pour l’accès à des semestres d’étude à l’étranger par exemple, ou pour des stages.
Il ne s’agit donc pas seulement de la fonction formative et de l’apprenant face à sa note.
La tâche n’est qu’un prétexte
« La tâche n’est qu’un prétexte », nous rappelle Philippe Meirieu ( Meirieu, 2004 [13]), pour s’exercer en situation d’apprentissage ou pour vérifier qu’on a acquis certaines habiletés.
Il est déterminant de différencier les deux situations :
dans le premier cas on peut travailler à apprendre avec l’apprenant sans se focaliser sur ce qu’on produit ;
dans le second, en revanche, cas l’énergie de l’apprenant est concentrée sur le résultat, il cherche à se conformer aux attentes de l’évaluation.
On oublie que la tâche n’est qu’un prétexte, le « livrable » qu’on demande est un outil et non un objectif, dans l’immense majorité des cas la dissertation ne sera pas lue pour ce qu’elle raconte, mais uniquement pour produire une évaluation. La résolution du problème de mathématique ou le compte-rendu d’expérience de chimie ne revêt aucun intérêt en soi, puisque, par construction, le lecteur connaît déjà la réponse. C’est à la fois une évidence et quelque chose que le processus évaluatif fait oublier, et in fine, c’est bien au résultat qui est produit que l’étudiant, comme souvent l’enseignant, prête attention, plutôt qu’au processus d’apprentissage.
Évaluation des moyens mis en œuvre et non d’un niveau atteint
À travers l’étude des travaux de Joseph Jacotot, Jacques Rancière ( 1987 [14]) propose que ce qui compte n’est pas ce qu’on apprend mais le fait qu’on apprenne et qu’on sache que l’on peut apprendre, avec sa propre intelligence. Le « maître ignorant » n’est pas celui qui transmet le savoir, il est celui qui provoque l’engagement de l’apprenant, qui s’assure qu’il y a engagement. Selon ce dispositif, la notion même d’évaluation sommative n’est pas possible, puisque le maître est ignorant de ce que l’élève apprend (Jacotot enseigne ainsi les mathématiques ou la musique dont il n’a pas la connaissance).
Cette approche pourrait inspirer à l’évaluation un rôle de suivi de l’engagement (présence, travail…) décorrélé de toute évaluation de résultat : présence et participation en cours et en TD. Notons que le système ECTS [15] est déjà basé sur une charge de travail requise (25 à 30 heures pour 1 crédit).
Remise en question de l’évaluation sommative
L’évaluation via des examens et des notes est un processus peu fiable, en témoignent les variations que l’on observe entre différents évaluateurs, et les variations dans le temps observées auprès d’un même évaluateur ( Hadji, 1989 [10]). On peut donc minorer l’importance de la fonction certifiante de certaines notes. Or les notes coûtent cher à produire par le temps et l’attention qu’elles exigent des enseignants et des apprenants.
On peut donc se poser la question du supprimer, ou diminuer, l’évaluation sommative. Cela pour une partie des enseignements au moins, quitte à garder des espaces sommatifs pour répondre à des nécessités de classement ou certification.
Qu’est-ce qu’on peut faire maintenant ?
Interdire l’usage des LLM par défaut dans le règlement des études (en sachant que ça va devenir difficile d’identifier quand ils sont mobilisés) ?
Utiliser des moyens techniques de détection de fraude (et entrer dans une « course à l’armement ») ?
Améliorer nos exercices rédactionnel pour « échapper aux LLM » tout en restant en veille sur ce qu’ils savent adresser de nouveau ?
Renoncer aux travaux rédactionnels évalués à la maison ?
Évaluer uniquement en fin de module, voire en dehors des modules et/ou procéder à des évaluations de compétence individuelles ?
Organiser des évaluations certifiantes en dehors des cours (évaluation de compétences, examens transversaux…) ?
Diminuer la pression sur les étudiants et modifier le contrat pédagogique passé avec eux ?
Simplifier la notation, ne conserver que les résultats admis ou non admis, pour évacuer toute idée de classement ?
Passer d’une obligation de résultat à une obligation de moyen, c’est à dire valider les cours sur la base de la présence ?
Ne plus du tout évaluer certains cours (en réfléchissant contextuellement à la fonction de l’évaluation sommative) ?
Interdire ChatGPT ?
« And that’s the thing: in a free market, a competitor cannot simply exclude a disruptive new technology. But in a classroom, we can absolutely do this thing ( Devereaux, 2023 [9]) »
C’est vrai, et le règlement des études peut intégrer cette interdiction a priori. Mais les LLM vont s’immiscer au sein de tous les outils numériques, a commencer par les moteurs de recherche, et cela va être difficile de maintenir l’usage d’outils numériques sans LLM.
Utiliser des moyens techniques de détection de fraude ?
Des systèmes de contrôle dans le contexte de l’évaluation à distance ou des logiciels anti-plagiat existent, mais :
cela pose des problèmes de surveillance et d’intrusion dans les machines des apprenants ;
cela suppose une « course à l’armement » entre les systèmes de détection et les systèmes de triche.
Il faut des résultats fiables pour être en mesure d’accuser un étudiant de fraude.
Adapter nos exercices et rester en veille ?
« Likewise, poorly designed assignments will be easier for students to cheat on, but that simply calls on all of us to be more careful and intentional with our assignment design ( Devereaux, 2023 [9]). »
Certains exercices pourront être en effet aménagés pour rendre plus difficile l’usage de LLM. On peut avoir une exigence argumentative plus élevée et/ou poser des questions plus complexes (en réfléchissant à pourquoi on ne le faisait pas avant, ce qui doit être modifié pour atteindre ce nouvel objectif, etc.). On peut augmenter le niveau d’exigence demandé (en réfléchissant au fait que cela puisse exclure des étudiants, au fait qu’il faille relâcher d’autres exercices par ailleurs…).
Mais pour certains exercices ce ne sera pas possible (thème et version en langue par exemple). Et de plus cela implique une logique de veille active entre la conception de ces exercices et l’évolution rapide des capacités des outils qui intégreront des LLM.
Renoncer aux travaux à la maison (ou à leur évaluation)
On peut décider de ne plus évaluer les travaux réalisés à la maison.
On peut alors imaginer plusieurs formes de substitution : retour aux devoirs sur table et sans ordinateur, passage à l’oral…
Évaluer en dehors des cours ?
On peut imaginer :
des évaluations certifiantes totalement en dehors des cours (sur le modèle du TOEIC ou du baccalauréat, par exemple pour les langues donc, pour l’expression française, pour des connaissances dans certains domaines, des compétences rédactionnelles…) ;
des évaluations certifiantes calées uniquement en fin d’UV (examen final de sortie de cours, avec éventuellement rattrapage, sans plus aucune note intermédiaire) ;
des évaluations de compétences individuelles (intéressantes pédagogiquement, mais coûteuses à organiser et demandant des compétences avancées de la part des évaluateurs).
Diminuer la pression sur les étudiants ?
Le contrat ECTS est très exigeant. 30 crédits par semestre c’est 750 à 900 heures attendues de travail en 16 semaines, vacances comprises, soit 45h à 55h par semaine. Plus la pression sur le temps est importante plus la tentation de tricher est grande.
On peut imaginer de renouer un contrat pédagogique d’un autre ordre avec les étudiants, fondé sur la confiance réciproque et la recherche de leur intérêt.
Simplifier la notation (pass or fail) ?
L’UTC a connu un système à 3 notes : « admis », « non admis » et « mention » (équivalent à A). Dans ce système, on prête moins d’attention à la fonction sommative des évaluations. Si un apprenant obtient une note suffisante à un premier examen par exemple, il sait qu’il validera le module et il n’a pas d’intérêt particulier à optimiser ses autres évaluations sommatives.
Passer d’une obligation de résultat à une obligation de moyen ?
De fait certains cours sont mobilisés pour la validation du diplôme, voire la sélection et le classement des étudiants, et d’autres comptent très peu pour cet objectif en pratique.
Certains cours pourraient donc être exclus du processus d’évaluation sommative (comme en formation professionnelle). On économiserait le temps de travail d’évaluation sommative qui pourrait être réinvesti ailleurs. Quelques étudiants en profiteraient certainement pour « passer au travers » de certains contenus, il faudrait pouvoir évaluer dans quelle mesure cela serait pire qu’aujourd’hui.
Renoncer à noter ? (pourquoi note-t-on ?)
Certains cours, sinon tous, pourraient donc échapper totalement à la notation.
À quelle fin évalue-t-on les étudiants dans une école qui a sélectionné à l’entrée comme l’UTC ?
Pour valider que les étudiants ont été « bien » sélectionnés ?
Pour les « forcer » à travailler ?
Pour faire « sérieux » ?
Pour répondre aux demandes d’organismes de certification du diplôme ?
[2] – LLM (Large Language Model) : Les grands modèles de langage (ou LLM, pour « Large Language Model ») sont des mécanismes d’Intelligence Artificielle. Une de leurs applications les plus connues est la génération de textes ou d’images. L’ouverture au public de ChatGPT, en novembre 2022, a popularisé cette application. Chaque grande entreprise de l’informatique sort désormais son propre modèle, son propre LLM.
[8] – Farazouli Alexandra, Cerratto-Pargman Teresa, Bolander-Laksov Klara, McGrath Cormac. 2023. Hello GPT! Goodbye home examination? An exploratory study of AI chatbots impact on university teachers’ assessment practicesHello GPT! Goodbye home examination?. in Assessment & Evaluation in Higher Education. vol.0 n°0 pp1-13.https://doi.org/10.1080/02602938.2023.2241676.
[10] – Hadji C.. 1989. L’évaluation, règles du jeu: des intentions aux outils. ESF.
[11] – Astolfi Jean-Pierre. 1992. L’école pour apprendre: l’élève face aux savoirsL’école pour apprendre. ESF.
[12] – Perrenoud Philippe. 1997. Construire des compétences dès l’école. ESF.
[13] – Meirieu Philippe. 2004. Faire l’école, faire la classe: démocratie et pédagogieFaire l’école, faire la classe. ESF.
[14] – Rancière Jacques. 1987. Le maître ignorant: cinq leçons sur l’émancipation intellectuelleLe maître ignorant. Fayard.
[15] – ECTS (European Credit Transfer and accumulation System). Le système européen de transfert et d’accumulation de crédits a pour objectif de faciliter la comparaison des programmes d’études au sein des différents pays européens. Le système ECTS s’applique principalement à la formation universitaire. Il a remplacé le système des unités de valeur (UV) jusque-là utilisé en France. wikipedia.org
Contribuer à un logiciel libre dans une formation en école d’ingénieur
Des étudiants de l’Université de Technologie de Compiègne effectuent, dans le cadre de leur cursus, des Travaux de Laboratoire consistant à avancer sur des tickets du projet Framadate (qui n’en manque pas), avec le soutien de leur enseignant Stéphane Crozat (dont on vous reparlera) et du CHATONS local Picasoft. Leurs travaux sont documentés dans un wiki et leur avancement dans des pads.
De la belle contribution utile !
Pour commencer, une petite présentation s’impose : je m’appelle Justine et je suis en première année de formation ingénieur en informatique à l’UTC (Université de Technologie de Compiègne). Lors de ce semestre, c’est-à-dire lors des quatre derniers mois, et dans le cadre de ma formation (ce travail, après évaluation, pourra m’apporter 5 crédits ECTS), j’ai eu l’occasion de contribuer au logiciel libre Framadate. Cet article se veut être un bilan de mon expérience.
Contribuer à un logiciel libre, était-ce différent d’un projet « classique » ?
À l’UTC, les étudiants sont évalués selon des barèmes différents d’une matière à l’autre. En informatique, l’évaluation comprend souvent un projet (qui ne correspond pas souvent à plus de 20% de la note finale). Ce projet a des objectifs largement pertinents, comme vérifier sur un cas pratique que les étudiants ont assimilé la théorie qui leur a été enseignée. Cependant, j’ai souvent éprouvé une certaine frustration vis-à-vis de ces projets. En effet, une fois rendu, évalué et donc noté, le projet tombe dans l’oubli : pas d’utilisation réelle, pas d’amélioration, une sorte de produit déjà mort à sa sortie. Ainsi, l’idée de travailler sur un logiciel libre, avec des utilisateurs bien réels derrière, m’a semblé extrêmement pertinente et bien différente des projets que j’avais déjà pu mener.
Est ce que ces différences ont entraîné des difficultés ?
Les premières difficultés rencontrées ont été celles posées par l’installation et la prise en main de l’environnement de travail, proposé par les suiveurs. Alors que la plupart du temps, pour mener à bien les projets classiques, les installations des environnements sont déjà faites sur les machines de l’UTC, cela n’était pas le cas cette fois. Composé de nombreux outils (principalement Docker et Git au sein de Linux), l’installation de notre environnement a été relativement lourde et laborieuse. Une fois installé, l’environnement est au premier abord difficile à prendre en main : de nombreuses lignes sont à exécuter dans l’interpréteur de commandes avant de pouvoir tester le code.
Mais les difficultés les plus compliquées à surmonter ont été celles posées par le projet en lui-même. D’abord parce que les langages utilisés (SQL, PHP orienté objet, Javascript, HTML via le moteur de templates Smarty…) ne m’étaient pas ou peu connus. Ensuite, et surtout, parce qu’il m’a paru très compliqué de m’insérer dans un projet déjà bien développé (dans un projet « classique » à l’UTC, on part de rien, on développe tout), projet dont l’architecture n’est pas (ou très peu) documentée. Sa compréhension a donc nécessité beaucoup de temps et d’efforts, j’y reviendrai.
Comment s’est organisée ta contribution ?
Cette contribution a été organisée selon une méthode de type agile : le travail est découpé en itérations de six heures chacune, une itération par semaine. Le semestre a ainsi été rythmé par des réunions de suivi hebdomadaires avec les suiveurs, Stéphane Crozat et Andrés Maldonado, chargés d’accompagner et d’évaluer le travail. Sur chaque itération, nous déterminions donc ensemble l’objectif à atteindre pour la semaine suivante, et je déterminais seule l’articulation de mon travail (combien d’heures je devais passer à réaliser telle tâche). La contribution s’est articulée en deux volets : un volet de développement (qui consistait en la résolution de trois issues ouvertes sur le projet) et un volet de documentation (via le wiki de l’association Picasoft).
Concrètement, qu’as-tu apporté à Framadate ?
Comme évoqué plus haut, l’architecture du projet n’était que très peu documentée. Ainsi, afin de travailler efficacement sur le projet, j’ai préféré commencer par passer plusieurs heures (concrètement une vingtaine) à explorer le projet et documenter au maximum ce que j’en comprenais (les classes implémentées, leur articulation au sein du projet…). Un travail étudiant comme celui-ci est aussi l’occasion d’apprendre à formaliser et documenter, mon travail est disponible ici.
Ce n’est que dans un second temps que j’ai réellement commencé mon travail de résolution d’issues, et donc de développement et de documentation du travail réalisé. J’ai préféré travailler ces deux volets en parallèle, afin de restituer le travail réalisé lorsque tout était encore frais dans mon esprit. J’ai ainsi pu travailler sur trois issues :
Issue #38 : collecter les adresses e-mail des sondés
L’idée est de permettre à l’administrateur de choisir de collecter (ou non) les adresses e-mail des sondés. Si l’administrateur choisit la collecte, alors la saisie d’une adresse de courriel valide (respectant le format e-mail) est obligatoire pour voter. La collecte s’accompagne d’une fonctionnalité permettant à l’administrateur de récupérer efficacement l’ensemble des adresses des personnes sondées.
A la création d’un sondage, l’administrateur choisit s’il collecte ou non les adresses emails des sondés.
Un avertissement informe que, dans le cas où les votes sont modifiables par tous, n’importe qui ayant accès au sondage peut récupérer les adresses emails des sondés.
Pour voter, lorsque la collecte des adresses emails est active, une adresse email valide doit être renseignée. L’administrateur peut récupérer la liste des adresses emails des sondés grâce aux boutons enveloppe situés au dessus de chaque colonne. Si la collecte est active et que quiconque peut modifier tous les votes, un avertissement informe que n’importe qui peut accéder aux adresses emails des sondés.
En cliquant sur un bouton enveloppe, l’administrateur récupère les adresses emails des sondés triées selon leur choix (‘oui’, ‘si besoin’ ou ‘non’).
Issue#324 (et #61) : Amélioration de l’option de collecte des adresses e-mail des personnes sondées. L’idée était d’améliorer le travail réalisé précédemment en passant la collecte des adresses de courriel sous quatre options différentes :
option 1 : la collecte est désactivée ;
option 2 : la collecte est activée ;
option 3 : la collecte est activée et la saisie est obligatoire ;
option 4 : la collecte est activée, la saisie est obligatoire et le vote doit être confirmé par un clic sur le lien envoyé dans un mail à l’adresse renseignée (cette dernière option n’a pas été implémentée car le service d’envoi d’e-mail est inutilisable au sein de l’installation).
A la création d’un sondage, l’administrateur choisit une des quatre options pour son sondage. De même que précédemment, un avertissement informe si les adresses emails des sondés ne sont pas protégées.
Issue#208 : permettre la finalisation d’un sondage par l’administrateur
L’idée était d’ajouter une fonctionnalité pour l’administrateur de clôture de sondage et de lui permettre :
de sélectionner le choix retenu ;
de justifier son choix.
Dans les informations du sondage, l’administrateur et l’utilisateur sait si le sondage est encore ouvert ou s’il est fermé (ici, il est encore ouvert). L’administrateur peut fermer le sondage en cliquant sur le bouton.
Une fois le sondage fermé, l’administrateur peut sélectionner le choix qu’il retient grâce au bouton au dessus de chaque colonne. La valeur de ce choix est visible dans les informations du sondage, côté administrateur et côté utilisateur.
Une fois un choix sélectionné, l’administrateur peut justifier son choix. La valeur de cette explication est visible dans les informations du sondage, côté administrateur et côté utilisateur.
Chacune de ces résolutions d’issues a fait l’objet d’une merge-request. C’est un processus itératif très intéressant à découvrir au sein duquel on peut interagir avec les développeurs logiciel et web de Framasoft qui vont vérifier le travail proposé et en demander des corrections.
Tout au long de mon travail, j’ai pu ainsi interagir avec différents interlocuteurs : les suiveurs bien sûr, Stéphane Crozat et Andrés Maldonado, mais aussi Thomas Citharel, développeur logiciel web chez Framasoft, et Kyâne Pichou, diplômé de l’UTC. Je tiens à remercier tous ces interlocuteurs pour leur soutien et leurs conseils, je pense qu’il est indispensable d’être bien accompagnés dans ce processus de contribution afin qu’il soit efficace et utile à tous.
Finalement, quels sont les apports au sein de ta formation ?
Contribuer à Framadate m’a d’abord permis de gagner en compétences d’utilisation des outils utilisés (Docker, Git, Linux) et en développement web : interface, base de données,…. Mais cette contribution m’a surtout fait gagner énormément d’indépendance et d’autonomie vis-à-vis d’un projet déjà existant et bien développé, ce qui est très formateur et pertinent en amont de mon futur stage (six mois en entreprise à partir de septembre).
Que faudrait-il retenir de cet article ?
Contribuer à un logiciel libre au sein de la formation en école d’ingénieur constitue une expérience très pertinente pour compléter le profil théorique et « scolaire » d’un étudiant. Cette expérience permet de faire face à de nouvelles difficultés, et ainsi développer de toutes nouvelles aptitudes.
En savoir plus :
ECTS : European Credits Transfer System, calculés en fonction de la charge de travail de l’étudiant , ils permettent l’obtention des diplômes français (et européens).
Picasoft est le CHATON créé par les étudiants de l’UTC.
Des routes et des ponts (15) – les institutions et l’open source
Voici le plus long des chapitres de Des routes et des ponts de Nadia Ehgbal que nous traduisons pour vous semaine après semaine (si vous avez raté les épisodes précédents). Il s’agit cette fois-ci des institutions (ici nord-américaines) qui par diverses formes de mécénat, contribuent au développement et au maintien des projets d’infrastructure numérique open source parce qu’elles y trouvent leur intérêt. Pas sûr qu’en Europe et en France ces passerelles et ces coopérations bien comprises entre entreprises et open source soient aussi habituelles…
Les efforts institutionnels pour financer les infrastructures numériques
Il existe des institutions qui s’efforcent d’organiser collectivement les projets open source et aider à leur financement. Il peut s’agir de fondations indépendantes liées aux logiciels, ou d’entreprises de logiciels elles-mêmes qui apportent leur soutien.
Soutien administratif et mécénat financier
Plusieurs fondations fournissent un soutien organisationnel, comme le mécénat financier, aux projets open source : en d’autres termes, la prise en charge des tâches autres que le code, dont beaucoup de développeurs se passent volontiers. L’Apache Software Foundation, constituée en 1999, a été créée en partie pour soutenir le développement du serveur Apache HTTP, qui dessert environ 55 % de la totalité des sites internet dans le monde.
Depuis lors, la fondation Apache est devenue un foyer d’ancrage pour plus de 350 projets open source. Elle se structure comme une communauté décentralisée de développeurs, sans aucun employé à plein temps et avec presque 3000 bénévoles. Elle propose de multiples services aux projets qu’elle héberge, consistant principalement en un soutien organisationnel, juridique et de développement. En 2011, Apache avait un budget annuel de plus de 500 000 $, issu essentiellement de subventions et de donations.
Le Software Freedom Conservancy, fondée en 2006, fournit également des services administratifs non-lucratifs à plus de 30 projets libres et open source. Parmi les projets que cette fondation soutient, on retrouve notamment Git, le système de contrôle de versions dont nous avons parlé plus haut et sur lequel GitHub a bâti sa plateforme, et Twisted, une librairie Python déjà citée précédemment.
On trouve encore d’autres fondations fournissant un soutien organisationnel, par exemple The Eclipse Foundation et Software in the Public Interest. La Fondation Linux et la Fondation Mozilla soutiennent également des projets open source externes de diverses façons (dont nous parlerons plus loin dans ce chapitre), bien que ce ne soit pas le but principal de leur mission.
Il est important de noter que ces fondations fournissent une aide juridique et administrative, mais rarement financière. Ainsi, être sponsorisé par Apache ou par le Software Freedom Conservancy ne suffit pas en soi à financer un projet ; les fondations ne font que faciliter le traitement des dons et la gestion du projet.
Un autre point important à noter, c’est que ces initiatives soutiennent le logiciel libre et open source d’un point de vue philosophique, mais ne se concentrent pas spécifiquement sur ses infrastructures. Par exemple, OpenTripPlanner, projet soutenu par le Software Freedom Conservancy, est un logiciel pour planifier les voyages : même son code est open source, il s’agit d’une application destinée aux consommateurs, pas d’une infrastructure.
La coopération est nécessaire pour construire et maintenir une infrastructure – photo par An en Alain (licence CC By 2.0)
Créer une fondation pour aider un projet
Certains projets sont suffisamment importants pour être gérés à travers leurs propres fondations. Python, Node.js, Django et jQuery sont tous adossés à des fondations.
Il y a deux conditions fondamentales à remplir pour qu’une fondation fonctionne : accéder au statut d’exemption fiscale et trouver des financements.
Réussir à accéder au statut 501(c), la loi américaine qui définit les organismes sans but lucratif, peut s’avérer difficile pour ces projets, à cause du manque de sensibilisation autour de la technologie open source et de la tendance à voir l’open source comme une activité non-caritative. En 2013, une controverse a révélé que l’IRS (Internal Revenue Service, service des impôts américain) avait dressé une liste de groupes postulant au statut d’exemption fiscale qui nécessiteraient davantage de surveillance : l’open source en faisait partie. Malheureusement, ces contraintes ne facilitent pas l’institutionnalisation de ces projets.
Par exemple, Russell Keith-Magee, qui était jusqu’à une époque récente président de la Django Software Foundation, a expliqué que la fondation ne pouvait pas directement financer le développement logiciel de Django, sans prendre le risque de perdre son statut 501(c). La fondation soutient plutôt le développement via des activités communautaires.
En juin 2014, la Fondation Yorba, qui a créé des logiciels de productivité qui tournent sous Linux, s’est vu refuser le statut 501(c) après avoir attendu la décision pendant presque quatre ans et demi. Jim Nelson, son directeur exécutif, a été particulièrement inquiété par le raisonnement de l’IRS : parce que leur logiciel pouvait potentiellement être utilisé par des entités commerciales, le travail de Yorba ne pouvait pas être considéré comme caritatif. Une lettre de l’IRS explique :
« Se contenter de publier sous une licence open source tous usages ne signifie pas que les pauvres et les moins privilégiés utiliseront effectivement les outils. […] On ne peut pas savoir qui utilise les outils, et encore moins quel genre de contenus sont créés avec ces outils. »
Nelson a pointé les failles de ce raisonnement dans un billet de blog, comparant la situation à celle d’autres biens publics :
« Il y a une organisation caritative ici à San Francisco qui plante des arbres pour le bénéfice de tous. Si l’un de leurs arbres… rafraîchit les clients d’un café pendant qu’ils profitent de leur expresso, cela signifie-t-il que l’organisation qui plante des arbres n’est plus caritative ? »
Les projets qui accèdent au statut 501(c) ont tendance à insister sur l’importance de la communauté, comme la Python Software Foundation, dont l’objet est de « promouvoir, protéger et faire progresser le langage de programmation Python, ainsi que de soutenir et faciliter la croissance d’une communauté diversifiée et internationale de programmeurs Python ».
En parallèle, certains projets candidatent pour devenir une association de commerce au sens du statut 501(c)(6). La Fondation jQuery en est un exemple, se décrivant comme « une association de commerce à but non-lucratif pour développeurs web, financée par ses membres ». La Fondation Linux est également une association de commerce.
Le deuxième aspect de la formalisation de la gouvernance d’un projet à travers une fondation est la recherche de la source de financement adéquate. Certaines fondations sont financées par des donations individuelles, mais ont proportionnellement de petits budgets.
La Django Software Foundation, par exemple, gère Django, le plus populaire des frameworks web écrits en Python, utilisé par des entreprises comme Instagram et Pinterest. La Fondation est dirigée par des bénévoles, et reçoit moins de 60 000 $ de donations par an. L’année dernière, la Django Software Foundation a reçu une subvention ponctuelle de la part de la Fondation Mozilla.
Parmi les autres sources habituelles de financement on trouve les entreprises mécènes. En effet, les entreprises privées sont bien placées pour financer ces projets logiciels, puisqu’elles les utilisent elles-mêmes. La Fondation Linux est l’un de ces cas particuliers qui rencontrent le succès, et ce grâce la valeur fondamentale du noyau Linux pour les activités de quasiment toutes les entreprises. La Fondation Linux dispose de 30 millions de dollars d’un capital géré sur une base annuelle, alimenté par des entreprises privées comme IBM, Intel, Oracle et Samsung – et ce chiffre continue d’augmenter.
Créer une fondation pour soutenir un projet est une bonne idée pour les projets d’infrastructure très conséquents. Mais cette solution est moins appropriée pour de plus petits projets, en raison de la quantité de travail, des ressources, et du soutien constant des entreprises, nécessaires pour créer une organisation durable.
Node.js est un exemple récent d’utilisation réussie d’une fondation pour soutenir un gros projet. Node.js est un framework JavaScript, développé en 2009 par Ryan Dahl et différents autres développeurs employés par Joyent, une entreprise privée du secteur logiciel. Ce framework est devenu extrêmement populaire, mais a commencé à souffrir de contraintes de gouvernance liées à l’encadrement par Joyent, que certaines personnes estimaient incapable de représenter pleinement la communauté enthousiaste et en pleine croissance de Node.js.
En 2014, un groupe de contributeurs de Node.js menaça de forker le projet. Joyent essaya de gérer ces problèmes de gouvernance en créant un conseil d’administration pour le projet, mais la scission eut finalement lieu, le nouveau fork prenant le nom d’io.js. En février 2015 fut annoncée l’intention de créer une organisation 501(c) (6) en vue d’extraire Node.js de la mainmise de Joyent. Les communautés Node.js et io.js votèrent pour travailler ensemble sous l’égide de cette nouvelle entité, appelée la Fondation Node.js. La Fondation Node.js, structurée suivant les conseils de la Fondation Linux, dispose d’un certain nombre d’entreprises mécènes qui contribuent financièrement à son budget, notamment IBM, Microsoft et payPal. Ces sponsors pensent retirer une certaine influence de leur soutien au développement d’un projet logiciel populaire qui fait avancer le web, et ils ont des ressources à mettre à disposition.
Montage d’une yourte, photo par Armel (CC BY SA 2.0)
Un autre exemple prometteur est Ruby Together, une organisation initiée par plusieurs développeurs Ruby pour soutenir des projets d’infrastructure Ruby. Ruby Together est structuré en tant qu’association commerciale, dans laquelle chaque donateur, entreprise ou individu, investit de l’argent pour financer le travail à temps plein de développeurs chargés d’améliorer le cœur de l’infrastructure Ruby. Les donateurs élisent un comité de direction bénévole, qui aide à décider chaque mois sur quels projets les membres de Ruby Together devraient travailler.
Ruby Together fut conçue par deux développeurs et finance leur travail de : André Arko et David Radcliffe. Aujourd’hui, en avril 2016, est également rémunéré le travail de quatre autres mainteneurs d’infrastructure. Le budget mensuel en mars 2016 était d’un peu plus de 18 000 dollars par mois, couvert entièrement par des dons. La création de Ruby Together fut annoncée en mars 2015 et reste un projet récent, mais pourrait bien servir de base à un modèle davantage orienté vers la communauté pour financer la création d’autres projets d’infrastructure.
Programmes d’entreprises
Les éditeurs de logiciels soutiennent les projets d’infrastructure de différentes manières.
En tant que bénéficiaires des projets d’infrastructures, ils contribuent en faisant remonter des dysfonctionnements et des bugs, en proposant ou soumettant de nouvelles fonctionnalités ou par d’autres moyens. Certaines entreprises encouragent leurs employés à contribuer à des projets d’une importance critique sur leur temps de travail. De nombreux employés contribuent ainsi de manière significative à des projets open source extérieurs à l’entreprise. Pour certains employés, travailler sur de l’open source fait clairement partie de leur travail. L’allocation de temps de travail de leurs salariés est une des plus importantes façons de contribuer à l’open source pour les entreprises.
Les grandes entreprises comme Google ou Facebook adhèrent avec enthousiasme à l’open source, de façon à inspirer confiance et renforcer leur influence ; elles sont de fait les seuls acteurs institutionnels assez importants qui peuvent assumer son coût sans avoir besoin d’un retour financier sur investissement. Les projets open source aident à renforcer l’influence d’une entreprise, que ce soit en publiant son propre projet open source ou en embauchant des développeurs de premier plan pour qu’ils travaillent à plein temps sur un projet open source.
Ces pratiques ne sont pas limitées aux entreprises purement logicielles. Walmart, par exemple, qui est un soutien majeur de l’open source, a investi plus de deux millions de dollars dans un projet open source nommé hapi. Eran Hammer, développeur senior à Walmart Labs, s’est empressé de préciser que « l’open source, ce n’est pas du caritatif » et que les ressources d’ingénierie gratuites sont proportionnelles à la taille des entreprises qui utilisent hapi. Dion Almaer, l’ancien vice-président en ingénierie de Walmart Labs, a remarqué que leur engagement envers l’open source les aidait à recruter, à construire une solide culture d’entreprise, et à gagner « une série d’effets de levier ».
En termes de soutien direct au maintien du projet, il arrive que des entreprises embauchent une personne pour travailler à plein temps à la maintenance d’un projet open source. Les entreprises donnent aussi occasionnellement à des campagnes de financement participatif pour un projet particulier. Par exemple, récemment, une campagne sur Kickstarter pour financer un travail essentiel sur Django a reçu 32 650 £ (environ 40 000 €) ; Tom Christie, l’organisateur de la campagne, a déclaré que 80 % du total venait d’entreprises. Cependant, ces efforts sont toujours consacrés à des projets spécifiques et les infrastructures numériques ne sont pas encore vues communément comme une question de responsabilité sociale par les entreprises de logiciel à but lucratif. Cela laisse encore beaucoup de marge aux actions de défense et promotion.
L’un des programmes d’entreprise les plus connus est le Summer of Code de Google (été de programmation, souvent nommé GSoC), déjà mentionné dans ce livre, qui offre de l’argent à des étudiant⋅e⋅s pour travailler sur des projets open source pendant un été. Les étudiant⋅e⋅s sont associé⋅e⋅s à des mentors qui vont les aider à se familiariser avec le projet. Le Summer of Code est maintenu par le bureau des programmes open source de Google, et il a financé des milliers d’étudiant⋅e⋅s.
Le but du Summer of Code est de donner à des étudiants la possibilité d’écrire du code pour des projets open source, non de financer les projets eux-mêmes.
L’an dernier, Stripe, une entreprise de traitement des paiements, a annoncé une « retraite open source », offrant un salaire mensuel d’un maximum de 7500 dollars pour une session de trois mois dans les locaux de Stripe. À l’origine, l’entreprise voulait uniquement offrir deux bourses, mais après avoir reçu 120 candidatures, le programme a été ouvert à quatre bénéficiaires.
Ces derniers ont été enchantés par cette expérience. L’un d’entre eux, Andrey Petrov, continue de maintenir la bibliothèque Python urllib3 dont nous avons déjà parlé, et qui est largement utilisée dans l’écosystème Python.
À propos de cette expérience, Andrey a écrit :
« La publication et la contribution au code open source vont continuer que je sois payé pour ou non, mais le processus sera lent et non ciblé. Ce qui n’est pas un problème, car c’est ainsi que l’open source a toujours fonctionné. Mais on n’est pas obligé d’en rester là. […]
Si vous êtes une entreprise liée à la technologie, allouez s’il vous plaît un budget pour du financement et des bourses dans le domaine de l’open source. Distribuez-le sur Gittip [Note : Gittip est maintenant dénommé Gratipay. Le produit a été quelque peu modifié depuis la publication originelle du billet d’Andrew] si vous voulez, ou faites ce qu’a fait Stripe et financez des sprints ambitieux pour atteindre des objectifs de haute valeur.
Considérez ceci comme une demande solennelle de parrainage : s’il vous plaît, aidez au financement du développement d’urllib3. »
La retraite open source de Stripe peut servir de modèle aux programmes de soutien. Stripe a décidé de reconduire le programme pour une deuxième année consécutive en 2015. Malgré la popularité de leur programme et la chaude réception qu’il a reçue chez les développeurs et développeuses, cette pratique n’est toujours pas répandue dans les autres entreprises.
Les entreprises montrent un intérêt croissant pour l’open source, et personne ne peut prédire au juste ce que cela donnera sur le long terme. Les entreprises pourraient régler le problème du manque de support à long terme en consacrant des ressources humaines et un budget aux projets open source. Des programmes de bourse formalisés pourraient permettre de mettre en contact des entreprises avec des développeurs open source ayant besoin d’un soutien à plein temps. Alors que les équipes de contributeurs à un projet étaient souvent composées d’une diversité de développeurs venant de partout, peut-être seront-elles bientôt composées par un groupe d’employés d’une même entreprise. Les infrastructures numériques deviendront peut-être une série de « jardins clos », chacun d’entre eux étant techniquement ouvert et bénéficiant d’un soutien solide, mais en réalité, grâce à ses ressources illimitées, une seule entreprise et de ses employés en assureront le soutien.
Mais si on pousse la logique jusqu’au bout, ce n’est pas de très bon augure pour l’innovation. Jeff Lindsay, un architecte logiciel qui a contribué à mettre en place l’équipe de Twilio, une entreprise performante de solutions de communication dans le cloud, livrait l’an dernier ses réflexions dans une émission :
« À Twilio, on est incité à améliorer le fonctionnement de Twilio, à Amazon on est incité à améliorer le fonctionnement d’Amazon. Mais qui est incité à mieux les faire fonctionner ensemble et à offrir plus de possibilités aux usagers en combinant les deux ? Il n’y a personne qui soit vraiment incité à faire ça. »
Timothy Fuzz, un ingénieur système, ajoute :
« Pour Bruce Schneier, cette situation tient du servage. Nous vivons dans un monde où Google est une cité-état, où Apple est une cité-état et… si je me contente de continuer à utiliser les produits Google, si je reste confiné dans l’environnement Google, tout me paraît bénéfique. Mais il est quasi impossible de vivre dans un monde où je change d’environnement : c’est très pénible, vous tombez sur des bugs, et aucune de ces entreprises ne cherche vraiment à vous aider. Nous sommes dans ce monde bizarre, mais si vous regardez du côté des cités-états, l’un des problèmes majeurs c’est le commerce inter-étatique : si on doit payer des droits de douane parce qu’on cherche à exporter quelque chose d’Austin pour le vendre à Dallas, ce n’est pas un bon modèle économique. On pâtit de l’absence d’innovation et de partage des idées. On en est là, aujourd’hui. »
Bien que l’argument du « servage » se réfère généralement aux produits d’une entreprise, comme l’addiction à l’iPhone ou à Android, il pourrait être tout aussi pertinent pour les projets open source parrainés. Les améliorations prioritaires seront toujours celles qui bénéficient directement à l’entreprise qui paie le développeur. Cette remarque ne relève pas de la malveillance ou de la conspiration : simplement, être payé par une entreprise pour travailler à un projet qui ne fait pas directement partie de ses affaires est une contrainte à prendre en compte.
Mais personne, pas plus Google que la Fondation Linux ou qu’un groupe de développeurs indépendants, ne peut contrôler l’origine d’un bon projet open source. Les nouveaux projets de valeur peuvent germer n’importe où, et quand ils rendent un service de qualité aux autres développeurs, ils sont largement adoptés. C’est une bonne chose et cela alimente l’innovation.
Aide spécifique de fondation
Deux fondations ont récemment fait part de leur décision de financer plus spécifiquement l’infrastructure numérique : la Fondation Linux et la Fondation Mozilla.
Après la découverte de la faille Heartbleed, la Fondation Linux a annoncé qu’elle mettait en place l’Initiative pour les infrastructures essentielles (Core Infrastructure Initiative, CII) pour éviter que ce genre de problème ne se reproduise. Jim Zemlin, le directeur-général de la Fondation Linux, a réuni près de 4 millions de dollars en promesses de dons provenant de treize entreprises privées, dont Amazon Web Services, IBM et Microsoft, pour financer des projets liés à la sécurité des infrastructures pour les trois ans à venir. La Fondation Linux s’occupe également d’obtenir des financements gouvernementaux, y compris de la Maison-Blanche.
La CII est officiellement un projet de la fondation Linux. Depuis sa création en avril 2014, la CII a sponsorisé du travail de développement d’un certain nombre de projets, dont OpenSSL, NTP, GnuPG (un système de chiffrement des communications) et OpenSSH (un ensemble de protocoles relatifs à la sécurité). La CII se concentre en priorité sur une partie de l’infrastructure numérique : les projets relatifs à la sécurité.
Au mois d’octobre 2015, Mitchell Baker, la présidente de la Fondation Mozilla, a annoncé la création du Programme de soutien à l’open source de Mozilla (Mozilla Open Source Support Program, MOSS) et a promis de consacrer un million de dollars au financement de logiciels libres et open source. Selon Baker, ce programme aura deux volets : un volet « rétribution » pour les projets qu’utilise Mozilla et un volet « contribution » pour les projets libres et open source en général. Grâce aux suggestions de la communauté, Mozilla a sélectionné neuf projets pour la première série de bourses. Ils se disent également prêts à financer des audits de sécurité pour les projets open source importants.
Enfin, certaines fondations contribuent ponctuellement à des projets de développement logiciel. Par exemple, la Python Software Foundation propose aux individus et aux associations des bourses modestes destinées pour la plupart aux actions pédagogiques et de sensibilisation.
Autres acteurs institutionnels
Il existe plusieurs autres acteurs qui apportent diverses formes de soutien aux infrastructures numériques : Github, le capital-risque et le monde universitaire. Si Facebook est un « utilitaire social » et Google un « utilitaire de recherche », tous deux régulant de facto les corps dans leur domaine respectif – alors Github a une chance de devenir « l’utilitaire open source ». Son modèle économique l’empêche de devenir un mastodonte financier (contrairement à Facebook ou Google dont le modèle est basé sur la publicité, alors que Github se monétise par l’hébergement de code pour les clients professionnels, et par l’hébergement individuel de code privé), mais Github est toujours un endroit où aujourd’hui encore l’open source est créée et maintenue.
GitHub s’adresse aux entreprises aussi – Image par Evan (licence CC BY 2.0)
Github s’est doté de grandes aspirations avec une levée de fonds de capital-risque de 350 millions de dollars, même si l’entreprise était déjà rentable. Si Github assume pleinement son rôle d’administrateur du code open source, l’organisation peut avoir une énorme influence sur le soutien apporté à ces projets. Par exemple, elle peut créer de meilleurs outils de gestion de projets open source, défendre certaines catégories de licences, ou aider les gestionnaires de projets à gérer efficacement leurs communautés.
Github a subi de grosses pressions venant des développeurs qui gèrent certains projets, ces pressions incluent une lettre ouverte collective intitulée « Cher Github », principalement issue de la communauté Javascript. Cette lettre explique : « Beaucoup sont frustrés. Certains parmi nous qui déploient des projets très populaires sur Github se sentent totalement ignoré par vous ». La lettre inclut une liste de requêtes pour l’amélioration de produits, qui pourrait les aider à gérer plus efficacement leurs projets.
Github se confronte de plus en plus à des difficultés largement documentées dans les médias. Auparavant, l’entreprise était connue pour sa hiérarchie horizontale, sans aucun manager ni directive venant d’en haut. Les employés de Github avaient aussi la liberté de choisir de travailler sur les projets qu’ils souhaitaient. Ces dernières années, tandis que Github s’est développée pour atteindre presque 500 employés, l’entreprise a réorienté sa stratégie vers une orientation plus commerciale en recrutant des équipes de vente et des dirigeants, insérés dans un système hiérarchique plus traditionnel. Cette transition d’une culture décentralisée vers plus de centralité s’est faite dans la douleur chez Github : au moins 10 dirigeants ont quitté l’organisation durant les quelques mois de l’hiver 2015-2016, ces départs incluant l’ingénieur en chef, le directeur des affaires financières, le directeur stratégique et le directeur des ressources humaines. En raison de ces conflits internes, Github n’a toujours pas pris position publiquement pour jouer un rôle de promoteur de l’open source et assumer un leadership à même de résoudre les questions pressantes autour de l’open source, mais le potentiel est bel et bien là.
Pour le capital-risque, abordé précédemment, il y a un enjeu particulier dans l’avenir des infrastructures numériques. Comme les outils des développeurs aident les entreprises du secteur technologique à créer plus rapidement et plus efficacement, meilleurs sont les outils, meilleures sont les startups, meilleure sera la rentabilité du capital-risque. Néanmoins, l’infrastructure, d’un point de vue capitaliste, n’est en rien limitée à l’open source mais plus largement focalisée sur les plateformes qui aident d’autres personnes à créer. C’est pour cela que les investissements dans Github ou npm, qui sont des plateformes qui aident à diffuser du code source, ont un sens, mais tout aussi bien les investissements dans Slack, une plateforme de travail collaboratif que les développeurs peuvent utiliser pour construire des applications en ligne de commande connectées à la plateforme (à ce propos, le capital-risque a constitué un fonds de 80 millions dédié au support de projets de développement qui utilisent Slack). Même si le capital-risque apprécie les mécaniques sous-jacentes de l’infrastructure, il est limité dans ses catégories d’actifs : un capitaliste ne peut pas investir dans un projet sans modèle économique.
Enfin, les institutions universitaires ont joué un rôle historique éminent dans le soutien aux infrastructures numériques, tout particulièrement le développement de nouveaux projets. Par exemple, LLVM, un projet de compilateur pour les langages C et C++, a démarré en tant que projet de recherche au sein de l’Université de l’Illinois, à Urbana-Champaign. Il est maintenant utilisé par les outils de développement de Mac OS X et iOS d’Apple, mais aussi dans le kit de développement de la Playstation 4 de Sony.
Un autre exemple, R, un langage de programmation répandu dans la statistique assistée par ordinateur et l’analyse de données, a été d’abord écrit par Robert Gentleman et Ross Ihaka à l’Université d’Auckland. R n’est pas uniquement utilisé par des entreprises logicielles comme Facebook ou Google, mais aussi par la Bank of America, l’Agence américaine des produits alimentaires et médicamenteux et le Service météorologique national américain, entre autres.
Quelques universités emploient également des programmeurs qui ont alors la liberté de travailler à des projets open source. Par exemple, le protocole d’heure réseau ou NTP (Network Time Protocol) utilisé pour synchroniser le temps via Intrenet, fut d’abord développé par David Mills, maintenant professeur émérite de l’université du Delaware — le projet continuant à être maintenu par un groupe de volontaires conduit par Harlan Stenn. Bash, l’outil de développement dont nous parlions dans un chapitre précédent, est actuellement maintenu par Chet Ramsay, qui est employé par le département des technologies de l’information de l’université Case Western.
Les institutions universitaires ont le potentiel pour jouer un rôle important dans le soutien de nouveaux projets, parce que cela coïncide avec leurs missions et types de donation, mais elles peuvent aussi manquer de la réactivité nécessaire pour attirer les nouveaux programmeurs open source. NumFOCUS est un exemple d’une fondation 501(c)(3) qui soutient les logiciels scientifiques open source à travers des donations et parrainages financiers. Le modèle de la fondation externe peut aider à fournir le soutien dont les logiciels scientifiques ont besoin dans un contexte d’environnement universitaire. Les fondations Alfred P. Sloan et Gordon & Betty Moore expérimentent aussi des manières de connecter les institutions universitaires avec les mainteneurs de logiciels d’analyse des données, dans le but de soutenir un écosystème ouvert et durable.
Les universitaires ont intérêt à contribuer à Wikipédia — qui a intérêt à ce qu’ils contribuent…
présenté par Christophe Masutti
Le moins que l’on puisse dire, lorsqu’on fréquente les milieux universitaires, c’est que les enseignants-chercheurs partagent des avis très différents à propos de l’encyclopédie en ligne libre Wikipédia. Pour certains, c’est un non-sujet puisqu’il s’agit seulement de permettre à n’importe qui d’écrire n’importe quoi. Pour d’autres, il faut savoir y contribuer parfois pour corriger des erreurs, parfois parce qu’il est aussi du devoir du chercheur que de partager ses connaissances, et pour d’autres encore la pertinence de Wikipédia ne saurait être valide à cause de l’anonymat des contributeurs et de l’absence d’un comité éditorial dans les règles de l’art des revues universitaires classiques.
Une quatrième catégorie, en revanche, prend du recul par rapport aux régimes de publication académiques et considère que ce n’est pas parce que les règles de publications sont universitaires qu’elles doivent être universelles. Ceux-là proposent de contribuer activement à Wikipédia mais en tâchant d’opérer la distinction entre les objectifs et les normes de Wikipédia et les attentes habituelles des publications académiques.
L’American Historical Association est l’une des plus anciennes sociétés savantes aux États-Unis. L’une de ses publications mensuelles, Perspectives on History, a 50 ans d’existence et reste l’une des revues historiques les plus lues au niveau mondial. Stephen W. Campbell, un jeune chercheur, vient d’y publier un article-témoignage dont nous vous proposons ci-dessous une traduction. Il y synthétise rapidement l’attitude classique des historiens vis-à-vis de Wikipédia et propose justement de prendre un peu de recul par rapport aux questions épistémologiques de la neutralité et de l’objectivité.
Certains arguments sont bien entendus discutables, mais le plus important est que, en publiant ce témoignage dans une telle revue, on assiste certainement à une déclaration d’intérêt. Cela montre aussi que l’attitude des chercheurs par rapport à Wikipédia n’est pas un phénomène générationnel. William Cronon, le président de l’AHA en 2012, y est cité comme ayant encouragé la participation à Wikipédia.
La question est plutôt à entrevoir du point de vue de la participation active et volontaire : il y a une vie au-delà du régime de l’évaluation permanente et épuisante des instances de “valorisation” de la recherche académique…
Améliorer Wikipédia : Notes d’un sceptique éclairé
En tant qu’historien américain qui étudie l’économie politique de la période d’avant la guerre de Sécession, j’ai toujours été fasciné par le mouvement de panique de 1837 – un cataclysme financier qui mérite son nom de « première grande dépression américaine », suivant l’expression employée dans un livre récent. Pendant les congés d’hiver 2012-1013, j’ai cherché « Crise de 1837 » sur Wikipédia et n’ai trouvé qu’une entrée assez décousue qui ne pointait que sur bien peu de sources secondaires. C’était fâcheux, c’est le moins qu’on puisse dire. Les rédacteurs de Wikipédia avaient marqué l’article comme partial ou incomplet et demandaient à un « spécialiste » de l’histoire des États-Unis de l’améliorer.
J’ai pris la décision d’améliorer l’entrée, et dans ce processus j’ai découvert des détails importants concernant les règles de Neutralité du point de vue de Wikipédia, les sous-cultures idéologiquement chargées qui, souvent, altèrent et falsifient ces entrées et une explication probable de mon aptitude à réhabiliter l’entrée avec succès. Depuis deux ans et jusque très récemment, j’ai été un critique véhément à l’encontre de Wikipédia, étant frustré par de trop nombreuses réponses dérivées de Wikipédia aux examens. Mais comme je vais le montrer plus loin, je suis devenu plus optimiste concernant la mission de Wikipédia et je crois qu’elle incarne de nombreuses valeurs auxquelles sont très attachés les universitaires.
Parmi ces derniers on trouve un large éventail d’opinions sur l’utilité de Wikipédia. L’ancien président de l’AHA William Cronon ne voyait que des avantages au fait d’encourager les historiens à contribuer davantage à Wikipédia, tandis que Timothy Messer-Kruse émet un jugement sévère en soulignant les écueils d’un site web qui ne fait pas la différence entre les opinions d’un expert et celles d’un profane, et dont la politique de vérification exclut les contenus seulement fondés sur des sources primaires inaccessibles – ce qui fait de lui un critique virulent de Wikipédia(1). Ma position se situe quelque part entre les deux.
En examinant de plus près cet article sur la Crise de 1837, j’ai remarqué que pratiquement tous les auteurs cités dans les références étaient des libertariens radicaux. La seule « référence externe » était un article écrit de façon informelle, aux sources sélectives, écrit par un obscur historien ne citant pas ses références, et rendu publique lors d’une conférence au Ludwig Von Mises Institute (LVMI), un think-tank d’Alabama qui n’est rattaché à aucune université ni soumis à un système de révision par des pairs.
Tenant son nom de l’économiste autrichien Ludwig Von Mises (1881-1973), l’organisation sponsorise des chercheurs prônant le « laissez-faire » économique et les théories du cycle économique de Friedrich Hayek. Certains LVMIstes (« membres » du LVMI) ont réduit à néant Abraham Lincoln, promu l’étalon-or, et donné une vision romantique du Vieux Sud en omettant l’esclavage. Le groupe rejette catégoriquement, d’après son site web, toute forme de régulation par l’État comme dangereuse pour « la science de la liberté ». Cela semble simpliste. La plupart des historiens reconnaissent que le terme « liberté » a plusieurs significations. L’accès à une assurance-maladie, la protection de l’environnement, ou celle des droits civiques, relèvent de la « liberté », mais nécessitent l’intervention de l’État
J’ai passé plusieurs jours de mes congés d’hiver à ajouter du contenu et des références sur le site, et les éditeurs de Wikipédia, vraisemblablement après avoir approuvé mes modifications, ont supprimé la mention qui fait référence à des informations partiales et incomplètes. Quant à savoir pourquoi cette expérience a été un succès, la réponse pourrait se trouver dans la politique de Wikipédia sur la neutralité de point de vue : les contributeurs doivent s’efforcer de « ne pas donner une fausse impression de parité, ni ne donner trop de poids à un point de vue particulier »(2). Tout économiste chevronné qu’ait été Hayek, l’interprétation de Von Mises était encore en minorité.
La façon dont j’ai édité pourrait expliquer pourquoi je ne me suis pas retrouvé dans une guerre d’édition chronophage. J’ai plus que doublé le nombre de références monographiques et d’articles de journaux révisés par des pairs tout en supprimant très peu du texte préexistant même si je le jugeais suspect. J’ai plutôt restructuré la prose pour la rendre plus lisible. Cette formule ne fonctionne peut être pas toujours, mais les historiens devraient essayer d’écrire autant que possible d’une manière descriptive sur Wikipédia et non de façon analytique, bien que cela puisse être contre-intuitif par rapport à notre formation et que la frontière entre description et analyse soit incertaine.
Les détracteurs de Wikipédia ont beaucoup d’objections valides. Il n’y a pas de rédacteur en chef ayant le dernier mot sur le contenu. La sagesse collective peut renforcer certains préjugés innés ou se révéler erronée au cours du temps. C’est le problème que Messer-Kruse a judicieusement mis en exergue dans ses recherches approfondies sur l’attentat de Haymarket Square – même lorsqu’un contributeur-expert, comme Messer-Kruse, élabore un argumentaire basé sur de solides preuves, les éditeurs bénévoles de Wikipédia peuvent tergiverser ou amoindrir le nouveau point de vue « minoritaire ». Enfin, il existe une possibilité pour que l’existence même de Wikipédia dévalue l’art et le travail d’enseigner et publier. Il y a quelques années, j’ai rédigé un article pour un projet d’encyclopédie sur l’esclavage américain d’un éditeur de référence bien connu. L’éditeur m’informa, après que j’eus fini mon article, que le projet serait interrompu pour une durée indéterminée, en partie en raison de la concurrence avec Wikipédia.
Il n’y a peut-être aucun sujet qui mène autant à la controverse que la pierre fondatrice de Wikipédia sur la neutralité. Les détracteurs se demandent si cet objectif peut être atteint ou même s’il est désirable(3). En décrivant ses règles qui mettent l’accent sur le double verrou de la « vérifiabilité » et du refus des « travaux inédits », Wikipédia indique qu’il vise à décrire les débats, mais pas à s’y engager. C’est cela qui fait hésiter les historiens. À partir du moment où nous sélectionnons un sujet de recherche et que nous collationnons des faits dans un ordre particulier, nous nous engageons involontairement dans un débat. Ajoutons à cela que les faits ne sont jamais vraiment neutres puisque ils sont toujours compris à l’intérieur d’un contexte idéologique plus vaste(4).
De plus, le plus surprenant parmi les règles de Wikipédia est la façon dont le site gère les approches complexes de ces nombreux problèmes philosophiques. Les contributeurs de Wikipédia insistent sur le fait que la neutralité n’est pas la même chose que l’objectivité. Le site évite de traiter les peudo-sciences, les fausses équivalences et soutient les principes de la revue par les pairs. Pour valider des arguments contradictoires, il donne la primauté à l’argument dans les publications érudites, et non à la validation par le grand public. Le règlement de Wikipédia reconnaît même que l’on ne peut pas considérer le principe de neutralité au sens le plus strict car les tentatives d’élimination de toute partialité peuvent se faire au détriment de la signification(5). Ce sont toutes ces normes que les universitaires devraient applaudir. Les rédacteurs de Wikipédia ont sans doute répondu aux critiques de Messer-Kruse, et bien qu’il n’incorporera jamais correctement des informations trop innovantes et récentes uniquement connues dans les milieux scientifiques, la beauté du site est qu’il contient les outils de ses propres améliorations.
Ayant conscience que certains de ces problèmes ne trouveront jamais vraiment de solution, j’en appelle aux historiens pour qu’ils consacrent quelques heures de leur précieux temps libre à l’amélioration de Wikipédia ; à titre d’encouragement, je demande aux administrateurs d’intégrer les contributions à Wikipédia dans leurs exigences de publication concernant l’attribution de poste de professeurs. Les docteurs récemment diplômés font face actuellement à une terrible crise de l’emploi et l’objectif tant convoité d’obtenir un poste de professeur à temps plein s’avère de plus en plus difficile à atteindre. Les contributions à Wikipédia pourraient être un bon moyen de valoriser leur CV en prévision d’un prochain entretien d’embauche. Les détails pour y parvenir restent probablement à régler.
Peut-être des historiens pourraient-ils s’identifier publiquement sur Wikipédia, sauvegarder leurs contributions, et être crédités si Wikipédia conserve leurs corrections. Publier ouvertement peut réduire le risque de troll, l’anonymat protégeant souvent les internautes des répercussions de commentaires indésirables. Les articles Wikipédia doivent venir en complément, et non en substitution, des articles traditionnels (dans des revues) et monographies, et les comités de validation devraient prendre en compte un certain quota d’articles en ligne par rapport aux articles traditionnels – peut-être quatre ou cinq entrées validées dans Wikipédia pour chaque article dans un journal traditionnel spécialisé.
Une des critiques récurrentes à l’égard des monographies est qu’elles conviennent seulement à un public spécialisé et limité, et finissent par s’empoussiérer sur des étagères de bibliothèques endormies. Peut-être que Wikipédia est le lieu idéal pour diffuser nos propres recherches et expertises à destination d’un public plus vaste, ce qui, théoriquement, permettrait d’améliorer la conception de l’histoire qu’a le public et la façon dont on en parle. Nombreux sont les représentants des sciences dures qui ont déjà pris en compte la publication électronique et comme d’autres l’ont souligné, nous risquons d’être marginalisés comme discipline si nous ne nous joignons pas à ce mouvement(6).
Au moment où j’écris ceci, environ un tiers du texte et la moitié des citations de l’article sur la crise de 1837 sont de ma main. J’ai dû mettre de côté ce précieux projet parce que le nouveau semestre venait de commencer, ce qui est bien regrettable parce que la page pouvait encore être améliorée, du moins ai-je procuré les lignes directrices aux autres spécialistes. Le site compte cinquante-huit « abonnés à cette page » et la section « Historique » affiche un grand nombre de suppressions qui ont été réintroduites – ce qui est peut-être l’indice de l’incorrigible obstination des partisans de Wikipédia. Les étudiants, les passionnés d’économie politique et le grand public disposeront toutefois de meilleures informations historiques, du moins je l’espère, à mesure que Wikipédia s’améliorera de façon continue.
Stephen W. Campbell est maître de conférence au Pasadena City College. Sa thèse de doctorat, terminée en 2013 à l’Université de Santa Barbara, analyse l’interaction entre les journaux, les institutions financières et le renforcement de l’État avant la guerre de Sécession.
Notes (Les ouvrages référencés en liens sont en anglais)
3. Jeremy Brown et Benedicte Melanie Olsen, « Using Wikipedia in the Undergraduate Classroom to Learn How to Write about Recent History », Perspectives on History, 50, Avril 2012 (consulté le 23 avril 2013).
Logiciels et matériels libres font le bonheur de l’éducation
Avec du logiciel et du matériel libres, on est aujourd’hui en mesure de proposer des cours tout à fait passionnants, ouverts, modulables et sans entrave à la création.
Le témoignage d’un prof qu’on aurait bien aimé avoir lorsqu’on était jeune.
Un programme universitaire qui enseigne l’interaction homme-machine avec du logiciel et du matériel libres
Jonathan Muckell – 28 mars 2014 – OpenSource.com (Traduction : Omegax, Mounoux, lamessen, Piup, aKa, lumi, Kcchouette, ton, Gatitac)
La plupart des gens considèrent que leurs interactions avec les systèmes informatiques se passent via un clavier, une souris ou un écran tactile. Cependant, les humains ont évolué pour interagir avec leur environnement et leurs congénères de manière bien plus complexe. Réduire l’écart entre les systèmes informatiques du monde numérique et le réel est en train d’être étudié et testé dans le cours de Physical Computing(NdT : Difficile à traduire, informatique physique/démonstrative) de l’université d’État de New-York (SUNY) à Albany.
En tant que professeurs de ce cours, nous profitons en ce moment d’une grande variété de projets de logiciels et matériels libres pour en apprendre plus sur les principaux concepts fondamentaux grâce à des expériences pratiques et la mise en place d’outils libres. Côté logiciel, nous utilisons un environnement de développement intégré (Arduino Sketch) et nous développons des modélisations pour les imprimantes 3D en utilisant OpenSCAD. Pour la partie matériel libre du cours, nous utilisons des Arduino et la PrintrBot Simple.
Le cours de Physical computing associe l’utilisation du matériel et du logiciel pour détecter et contrôler les interactions entre les utilisateurs et l’environnement. Elle peut repérer et répondre à des actions, par exemple en détectant la localisation des véhicules à une intersection et en ajustant le réglage des feux. Le domaine de l’informatique physique est relativement vaste, englobant des spécialités telles que la robotique, les microcontrôleurs, l’impression 3D et les vêtements intelligents.
D’après mon expérience, les étudiants aiment avoir la possibilité de combiner la pensée créative et sa mise en œuvre pratique. Il naît un sentiment d’émerveillement et d’accomplissement quand ils sont capables de faire quelque chose qui se passe dans le monde physique. L’une des premières activités du cours est simplement d’écrire du code et de créer un circuit pour faire clignoter une ampoule LED. Je ne me lasse jamais de voir leur joie quand ils y arrivent la première fois. L’un des objectifs principaux est de maintenir cet état d’émerveillement et d’excitation. Quand le cours progresse, nous avons les « Jeux olympiques des robots » où les étudiants se font rivalisent avec leurs robots construits sur mesure dans différentes catégories. Plus tard, nous plongeons dans l’impression 3D, où ils créent des objets personnalisés.
Chaque fois que nous abordons un nouveau domaine, je vois cette étincelle, cette excitation sur le visage de mes étudiants. Je veux que la passion et un véritable intérêt pour le matériel se développent. Je veux qu’ils expérimentent en rentrant dans leurs dortoirs. Si je réussis, les étudiants ne devraient pas avoir la sensation de travailler comme dans une école traditionnelle. Durant le processus et spécialement pour leur projet de fin d’étude, j’insiste sur l’inovation et la pensée créatrice. Quelle est la valeur de ce qu’ils génèrent à travers les conceptions qu’ils proposent ? Je veux que les étudiants pensent de façon créative et non pas qu’ils suivent un processus établi ou des tâches séquentielles prédéfinies.
J’utilise souvent le circuit imprimé Arduino pour enseigner car c’est un moyen fantastique pour apprendre. Non seulement il est très utile pour introduire des sujets tels que la programmation embarquée et l’électronique, mais c’est aussi une plateforme phénoménale pour le prototypage rapide et l’innovation. Des étudiants ont accompli des projets de fin d’étude vraiment innovants. Deux de mes étudiants ont utilisé une commande WiiMote de Nintendo pour jouer à pierre-feuille-ciseaux contre l’ordinateur. Si vous jouez suffisamment longtemps, l’ordinateur mémorise vos précédents mouvements et prédit ce que vous allez choisir avant vous. Des étudiants ont controlé une voiture à partir d’un smartphone et un autre groupe a programmé l’envoi automatique d’informations de détecteurs sur Twitter. Au début du semestre, les cours sont basés sur les concepts fondamentaux, avec du temps dédié aux travaux pratiques en équipes réduites. La dernière partie du semestre est basée sur des projets intégrés et créatifs.
Ce semestre, nous avons introduit l’impression 3D comme sujet principal du programme scolaire. C’est l’occasion pour les étudiants de construire des objets physiques, ainsi que de combiner capteurs, pièces mécaniques et processeurs pour donner vie aux objets. D’un point de vue éducatif, le Printrbot Simple est vraiment l’idéal. Nous avons commandé l’imprimante en kit et avons demandé aux élèves d’effectuer l’assemblage. Ce procédé a non seulement fourni une occasion pour les étudiants d’apprendre les mécanismes de fonctionnement d’une imprimante 3D, mais leur a aussi donné un sentiment d’appropriation par l’utilisation et l’entretien des imprimantes au fil du temps. Les imprimantes 3D ont des problèmes similaires à ceux des imprimantes 2D — elles se bloquent, elles ont des problèmes mécaniques et d’entretien. Toutefois, le Printrbot Simple est conçu de façon à faire participer les élèves. Et ils ont acquis les compétences nécessaires pour corriger et résoudre les problèmes quand ils surviennent.
Le Libre en classe
La plupart des élèves ont une certaine expérience du Libre et de l’open source. Le Département Informatique de l’Université d’Albany repose sur ??l’utilisation d’outils libres. En particulier, de nombreux étudiants utilisent GitHub, qui est exploité dès les premiers cours. Le département donne aussi des cours spéciaux qui sont purement focalisés sur le logiciels libre. L’élément nouveau pour les étudiants est la notion de matériel libre.
La majorité des gens ont tendance à penser que le Libre ne concerne que le développement logiciel. Le matériel libre est un concept novateur et passionnant pour les étudiants.
Le matériel et les logiciels libres ont permis à notre cours de Physical Computing d’éviter les problèmes de licences, et donc de pouvoir évoluer librement. Cela nous a aussi apporté de la flexibilité : nous se sommes pas enfermés sur une seule plateforme ou un outil unique. Le Libre autorise les modifications sans être bloqué par les modalités de contrat de licence du vendeur.
The Open Access Button : cartographions les entraves au Libre Accès
Il est souvent question de libre accès sur le Framablog. Par exemple avec ce manifeste du regretté Aaron Swartz ou cette limpide explication vidéo de Jean-Claude Guédon.
Avec Internet et la numérisation, il est désormais possible de consulter l’ensemble des ressources scientifiques et académiques. En théorie oui mais il peut en aller tout autrement dans la pratique, ce qui n’est pas sans poser de nombreux problèmes. Deux étudiants proposent ici de signaler tout péage rencontré pour accéder à ces ressources et de le mentionner sur un site commun.
On notera au passage que c’est OpenStreetMap qui fournit la carte.
Des étudiants lancent le « Bouton » pour mettre en lumière l’accès refusé aux articles scientifiques
18 novembre 2013 – Open Acess Button (Traduction : Penguin, Gilles, r0u, sinma, Paul)
Traquer et cartographier l’impact des péages, un clic à la fois.
Aujourd’hui, lors d’un congrès international d’étudiants défendant un accès plus important aux publications universitaires, deux étudiants anglais de premier cycle ont annoncé le lancement fortement attendu du bouton Open Access(NdT : Accès libre), un outil adossé au navigateur qui permet de cartographier l’épidémie de refus d’accès aux articles de la recherche universitaire et qui aide les utilisateurs à trouver les recherches dont ils ont besoin.
Les étudiants David Carroll et Joseph McArthur ont créé le bouton Open Access en réaction au sentiment de frustration que leur causait l’impossibilité d’accéder aux travaux de la recherche universitaire.
« J’ai réalisé qu’il y avait un problème à force de continuellement me heurter à des obstacles pour accéder à des articles pertinents pour mes recherches », explique Carroll, étudiant en médecine à l’université Queen’s de Belfast. « Mon université peut s’offrir un abonnement à de nombreuses publications et, pourtant, je ne peux pas accéder à tout ce dont j’ai besoin. Cela m’a amené à me demander combien d’autres que moi rencontraient le même problème et comment cela affectait les gens partout dans le monde ».
Chaque jour, des personnes essaient d’accéder à des articles de la recherche universitaire – des médecins cherchant de nouveaux traitements, des scientifiques travaillant à la mise au point de nouvelles technologies, des étudiants essayant de parfaire leur formation. Or au lieu d’avoir immédiatement accès aux informations essentielles qu’ils cherchent, ces personnes se retrouvent trop souvent confrontées à un système de péage qui subordonne leur accès à l’information leur demandant un paiement en échange de l’accès, parfois jusqu’à 40$ par article. Ces péages existent parce qu’une grande partie des ressources académiques est publiée dans des journaux onéreux, basés sur des abonnements dont les augmentations de prix ont largement dépassé l’inflation depuis plusieurs décennies.
« Vu la capacité actuelle de partager la connaissance sur le Web, il est absurde que la majorité de la population dans le monde se voit barrer l’accès à de si nombreux travaux » indique McArthur, étudiant en pharmacologie au University College de Londres. « Jusqu’à maintenant, ce déni d’accès était invisible car chacun le vivait de son côté. Nous avons créé le bouton Open Access pour rassembler toutes ces expériences séparées et mettre en lumière l’ampleur mondiale du problème ».
Le bouton Open Access est un outil adossé au navigateur qui permet aux utilisateurs de garder la trace d’un refus d’accès à une publication, puis de chercher des moyens alternatifs d’accéder à ladite publication. Chaque fois qu’un utilisateur se heurte à un péage, il clique simplement sur le bouton dans sa barre de favoris, remplit ,s’il le souhaite, une boîte de dialogue optionnelle, et son expérience vient s’ajouter à celle des autres utilisateurs sur une carte. Il reçoit ensuite un lien pour rechercher un accès libre et gratuit à l’article en utilisant par exemple des ressources comme Google Scholar. L’initiative Open Access Button espère créer une carte mondiale montrant l’impact du refus d’accès aux publications scientifiques.
Le bouton Open Access tire son nom du mouvement mondial pour le libre accès(NdT : Open Access en anglais) : la disponibilité gratuite et immédiate en ligne d’articles de recherche, accompagnés du droit intégral d’utilisation de ces articles dans l’espace numérique.
« Le mouvement pour l’Open Access est une solution puissante contre les barrières auxquelles se heurtent les chercheurs des pays en développement ou en phase de transition économique dans leurs tentatives d’accéder et de partager des recherches cruciales pour l’amélioration de la vie », déclare Iryna Kuchma, responsable du programme Open Acces à l’EIFL (Electronic Information for Libraries ou Information électronique pour bibliothèques), une organisation qui travaille avec des bibliothèques à travers le monde pour permettre l’accès des populations des pays en voie de développement ou en phase de transition économique aux informations numériques. « L’accès aux dernières publications scientifiques ne doit pas être confiné à la sphère universitaire, mais ouvert à tout personne intéressée : médecins et patients, agriculteurs* et entrepreneurs, formateurs et étudiants ».
Pour Jack Andraka, étudiant américain de 16 ans, récompensé par l’Intel Science Fair pour avoir inventé un test révolutionnaire de diagnostic du cancer du pancréas, « Le bouton Open Access aide à démocratiser la connaissance ». Andraka a raconté comment il s’était lui-même heurté aux les refus d’accès aux publications scientifiques quand il développait son test. « La connaissance ne doit pas être une marchandise. Elle doit être librement accessible pour permettre aux patients et familles d’être pleinement parties prenantes. »
David Carroll et Joseph McArthur ont annoncé le lancement du bouton Open Access aujourd’hui devant un parterre de plus de 80 personnes réunies à l’occasion de la Berlin 11 Student and Early Stage Researcher Satellite Conference, une rencontre internationale pour les étudiants intéressés par la promotion de l’Open Access. Cette rencontre précède la conférence Open Access de Berlin, une convention de leaders d’opinion à travers le monde sur la question de l’Open Access, qui a débuté mardi.
« Ne perdons jamais de vue que nous tenons trop souvent pour immuable ce qui n’est qu’un état de fait, mais les développeurs du bouton Open Access nous rappellent qu’en tant qu’individus, nous avons réellement le pouvoir de changer les choses », déclare Heither Joseph, directeur exécutif de la coalition SPARC (Scholarly Publishing and Academic Resources Coalition), un regroupement international de bibliothèques universitaires et de recherche) et leader de renommée internationale au sein du mouvement Open Access. « C’est une idée simple, mais incroyablement créative, qui devrait nous aider à montrer combien l’accès libre répond à un véritable besoin ».
Plus d’informations à propos du bouton Open Access ainsi que des instructions pour son installation sont disponibles sur le site www.OpenAccessButton.org.
Suivez la conversation sur Twitter à @OA_Button avec le hashtag #aobuttonlaunch.
Un étudiant nous propose un appareil photo libre en impression 3D pour 25 €
Léo Marius vient à peine de sortir diplômé de l’École supérieure d’art et design de Saint Etienne. Son projet de recherche consistait à créer de toutes pièces (l’expression est bien trouvée) rien moins qu’un appareil photo en impression 3D !
Le plus simple est encore d’illustrer tout de suite cela par une image explicite.
Il ne s’agit donc pas de photo numérique mais argentique, avec de vieilles pellicules dedans, et il reste le coût (non négligeable) des objectifs. Il n’empêche que le résultat est saisissant, fonctionnel et surtout mis à disposition de tous grâce au choix du Libre.
Nous avons évidemment eu envie d’en savoir plus en interviewant ci-dessous ce jeune créateur.
On voit ici, une nouvelle fois, combien le Libre peut être utile en situation d’étude et d’apprentissage. Combiné avec une accessibilité croissante des nouvelles technologies, il permet à tout un chacun, ayant un peu d’imagination, de réaliser puis partager des choses formidables.
On voit également se dessiner une nouvelle génération de makers/hackers, qui n’a pas eu à batailler (comme nous) pour faire connaître et exister le Libre, et qui l’adopte presque naturellement. Une génération qui donne, somme toute, espoir et confiance en l’avenir 😉
Entretien avec Léo Marius
Léo Marius, bonjour, peux-tu te présenter succinctement ?
Je suis un jeune designer tout juste diplômé de l’École supérieure d’art et design de Saint Etienne. Passionné par les nouvelles technologies et en particulier l’impression 3D dans laquelle je vois des opportunités de créations incroyables souvent sous-exploitées (je milite contre les têtes de Yoda et les coques pour smartphone imprimés !).
Libriste et actif dans le milieu associatif depuis quelques années. J’apprécie beaucoup la photographie mais je ne suis pas moi-même photographe.
Qu’est-ce donc que le projet O3DPC ? Comment est-il né ? Et en quoi est-il relié à tes études ?
Le projet O3DPC (pour Open 3D Printed Camera) est un travail de recherche que j’ai mené en rapprochant l’impression 3D libre et la photographie, il rassemble plusieurs projets sur lesquels j’ai travaillé, dont plusieurs sténopés et dernièrement le reflex imprimé.
J’ai mené ce travail en tant que projet personnel tout au long de mes études en design, c’était l’occasion pour moi de rapprocher deux domaines qui m’intéressent : l’impression 3D et la photographie.
De ce projet est donc sorti le prototype OR-01, quelles sont ces principales caractéristiques ? ces atouts ? ces améliorations futures (j’ai cru lire un projet avec la carte Arduino) ?
C’est un reflex argentique classique avec une visée directe (on peut voir directement ce que l’ont vise sur le petit rectangle dessus et un obturateur manuel qui fonctionne à environ 1/60° de seconde).
Son atout principal c’est que l’ensemble de ses sources sont libres, et donc adaptable, il est ainsi facile de le modifier pour l’adapter si certaines choses fonctionnement mal ou si on souhaite l’adapter pour des usages particuliers.
Dans sa forme actuelle je retiendrai deux éléments particulièrement intéressants :
En premier la bague d’adaptation pour les optiques est démontable, on peut donc facilement s’imprimer des baïonnettes différentes pour s’adapter a plusieurs types d’objectifs sans avoir à changer de boîtier.
Il y a également le dos autonome et démontable que j’apprécie, la partie où l’on met sa pellicule. Lorsque j’utilise le mien j’ai deux dos prêts avec deux pellicules différentes et je peux les changer rapidement pour m’adapter à la luminosité (ou switcher entre une pellicule noir et blanc et couleur, tout cela en plein milieu du rouleau d’une pellicule)
Le choix de l’open source, c’est un choix pragmatique, éthique ou les deux mon général ? Je lis (avec joie) une licence CC by-sa pour tes pièces, pourquoi n’as-tu pas retenu la clause non commerciale NC ?
Un peu des deux. À mon arrivée à l’école, j’ai intégré l’association Le_Garage (dont j’ai été président pendant deux ans) qui fait de la sensibilisation dans l’école aux questions du libre en art et design. Ça a donc été assez naturel pour moi de redistribuer ce travail sous licence libre.
L’idée principale derrière l’OR-01 c’est la réappropriation et la compréhension des nos appareils quotidiens, fermer les sources aurait interdit et contredit cet objectif
Pour ce qui est des la clause NC je préfère ne pas l’utiliser car je la trouve trop floue et contraignante dans la pratique. Si on souhaite qu’un projet se diffuse il ne faut pas lui mettre des bâtons dans les roues. Je n’ai aucune raison de m opposer à ce que quelqu’un souhaite se rapproprier le projet, l’améliorer et le vendre, s’il a lui même fourni un travail et qu’il respecte les conditions de redistribution de la licence copyleft.
Quelle imprimante 3D utilises-tu ? La « full libre » RepRap ou la « moins libre » MakerBot[1] ?
J’ai commencé le projet O3DPC il y a un peu plus de trois ans avec une Makerbot de 1ere génération (la numéro 660 ! une pièce de collection) que nous avions acquis avec notre association libriste et qui était encore libre à l’époque. Le reflex a été réalisé avec une Makerbot de dernière génération, la Replicator 2X qui a été achetée par notre école en complément d’une imprimante 3D haut de gamme que nous avions déjà.
L’utilisation de la Makerbot est un moindre mal, les technologies utilisées sont les même que sur les RepRaps traditionnels et les pièces qu’il est possible d’imprimer avec une Makerbot le seront aussi sur une RepRap bien calibrée. Je souhaitais, pour aider à sa diffusion, que le boîtier soit imprimable sur une imprimante de type RepRap. Si j’avais pu choisir je pense que j’aurais opté pour une Lulzbot. 😉
Au niveau logiciel, quels sont ceux que tu utilises et pourquoi ? Sont-ils tous libres ?
J’ai essentiellement utilisé Blender, c’est un logiciel que je connais bien et que je trouve extrêmement polyvalent et flexible. Les formes produites avec ce logiciel sont souvent très souples, et on déplace avec aisance les points pour adapter nos formes et nos courbes. Souvent en design on nous fait utiliser l’application propriétaire Rhino qui est beaucoup plus stricte dans son utilisation (« un tout petit peu plus haut » sur Blender correspond à un « Z+0,23mm » sur un Rhino mais il faut alors redessiner toute sa courbe avant de refaire sa révolution). Avec Blender on peut se permettre des approximations, ce qui est bien pratique dans une démarche de recherche.
J’ai également utilisé le libre OpenScad pour certaines pièces qui nécessitaient des formes et des distances très précises. Le fait de pouvoir coder ses pièces s’est avéré très utile. La pièce ne correspond pas ? Il suffit de changer quelques lignes de code pour tout modifier ! L’ensemble est libre 😉
Ce qui était particulièrement pratique c’est que, n’ayant pas d’ordinateur portable performant, je me déplaçais avec mon disque dur et les versions mobiles de toutes mes application pour les principaux OS dessus et je pouvais alors travailler où je le souhaitais.
Tu déposes les fichiers numériques de tes pièces sur Thingiverse et Instructables. Aujourd’hui quand on est développeur et qu’on cherche du boulot, on peut mettre dans son CV ses contributions sur GitHub. Penses-tu qu’il en ira de même demain dans le design sur ce type de dépôts ?
Oui, et de plus en plus. Je prends par exemple le designer Samuel Bernier qui a diffusé une partie de son travail en libre sur Instructables et que j’ai interogé pour mon mémoire (sur les Designers/Makers). Lorsque je lui ai demandé ce que lui avait apporté le libre, il m’a répondu : « des contacts et beaucoup d’opportunités ».
J’ai d’ailleurs mis récemment une note sur mon compte Instructables précisant que je cherchais un emploi, et j’ai reçu une proposition assez intéressante la semaine dernière (rien de défini, mais on verra). Ça fonctionne. Et si cela n’aboutit pas je peux me dire que 95% de mes employeurs potentiels auront vu mon projet de diplôme avant que je les contacte, ce qui est pas mal déjà comme entrée en matière.
25 euros en pièces détachées pour une appareil photo, c’est possible ? Et si oui, ne crains-tu pas pas qu’une société s’en empare et commercialise ton projet sans toi puisque c’est open source (question troll-piège :)) ?
Comme je l’ai mentionné plus haut, tant qu’ils respectent la clause de redistribution à l’identique (SA), cela me va. Je pourrais ainsi à mon tour récupérer leurs sources (que j’espère améliorées) pour mes propres boîtiers 😉
Éprouves-tu une certaine « nostalgie » de la photo argentique ?
Pas vraiment de la nostalgie, mais c’est une sensibilité différente à l’image que l’on ne retrouve pas avec le numérique : l’attente et l’incertitude de la photo, le coût aussi qui limite l’utilisation abusive. On réfléchit avant d’appuyer sur le bouton, on n’en prend pas cinquante à la volée comme cela se fait trop souvent.
Je me souviens du temps où les objectifs étaient obligatoirement reliés à une marque (ceux pour Canon, Nikon, etc.). Avec ton OR-01 et sa bague adaptable, tu donnes en quelque sorte de l’interopérabilité aux appareils photos, non ?
Oui, toujours dans l’idée de se rapproprier la technologies. Si l’appareil avait été dépendant d’un type d’objectifs, cela n’aurait pas fonctionné.
Techniquement, comment réussis-tu avec des pièces à monter à rendre l’appareil totalement opaque ?
Le tout est imprimé avec du plastique opaque et, en mettant des rebords et des emboîtements bien placés, l’étanchéité se fait sans trop de difficultés. Pour certaines zones, un peu plus sensibles, j’ai ajouté de la patafix noire pour combler les trous potentiels.
Toutes les parties étant autonomes c’est surtout le dos dans lequel se trouve la pellicule qu’il faut rendre étanche à la lumière, on peut se permettre des petits jours dans les autres. Ça reste un appareil DIY. 🙂
Un petit mot sur Framasoft que tu sembles connaître ?
Merci ! Continuez ce que vous faites. Le libre l’emportera ! 😉
Un appel à lancer ? Une actualité à annoncer ?
Peut être une nouvelle version plus aboutie de l’OpenReflex qui devrait être disponible en financement participatif en septembre ou octobre (selon mes engagements professionnels). N’hésitez pas à suivre mon blog ou à me poster un message sur le dépôt Instructables pour être tenus au courant.
Et sinon, permettez-moi un petit clin d’oeil hommage à Gilles Roussi, le professeur à l’origine de l’association Le_Garage qui nous lira surement 😉









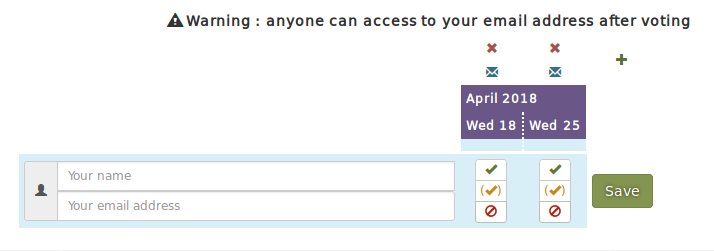
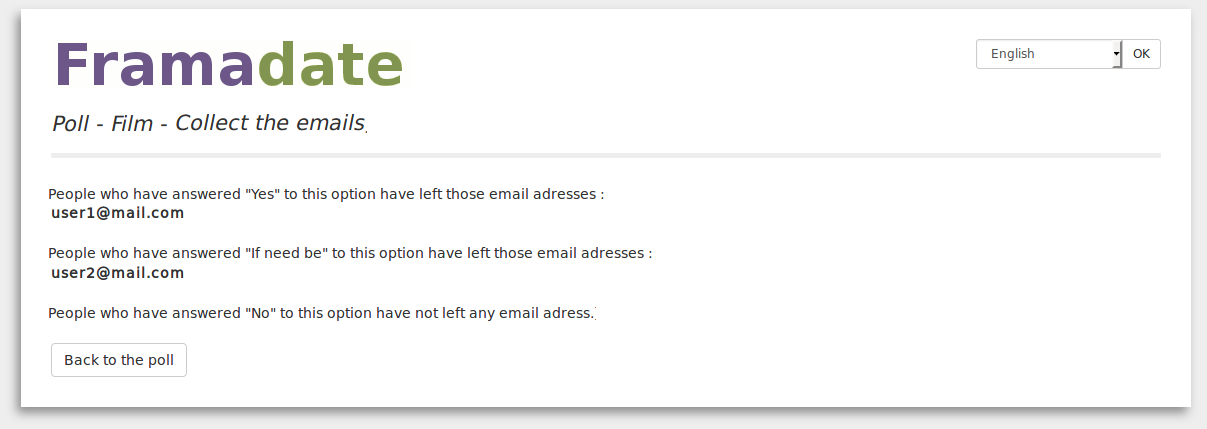


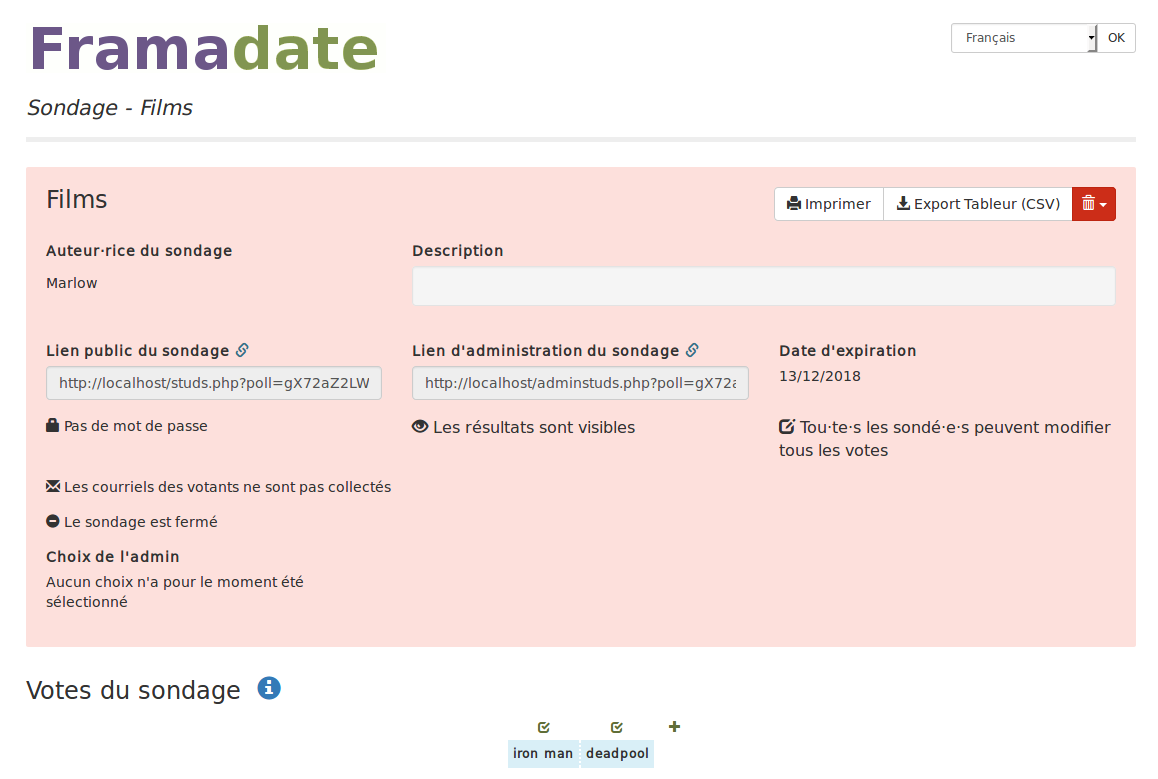
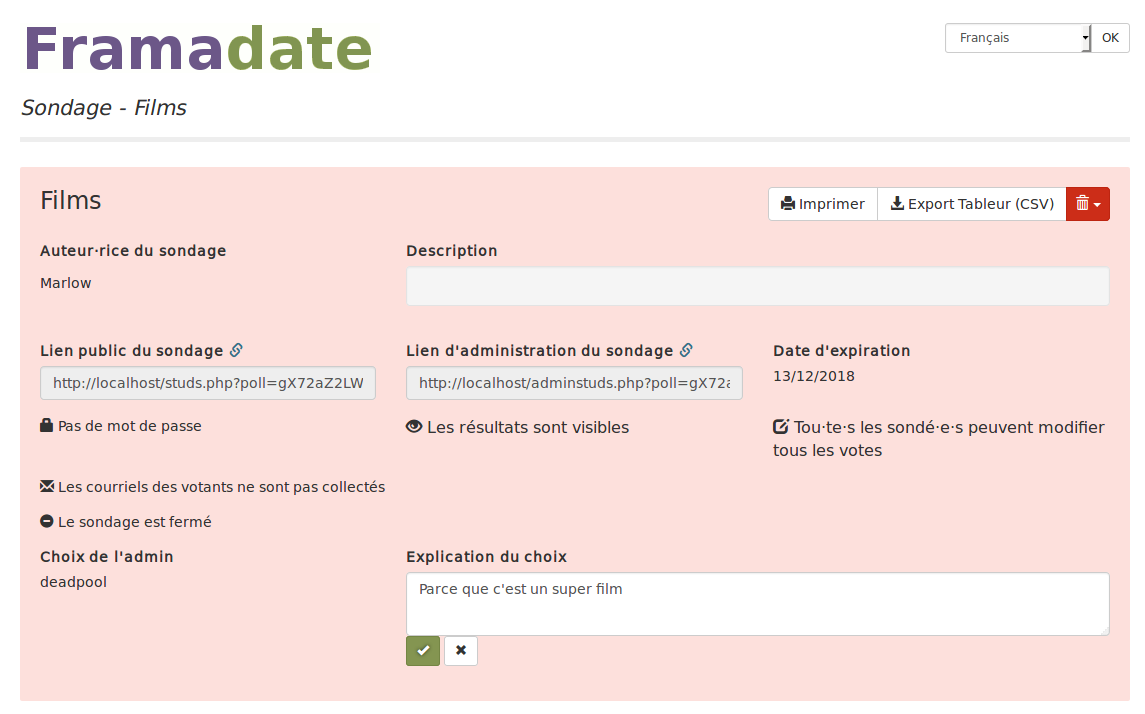








 De ce projet est donc sorti le prototype OR-01, quelles sont ces principales caractéristiques ? ces atouts ? ces améliorations futures (j’ai cru lire un projet avec la carte Arduino) ?
De ce projet est donc sorti le prototype OR-01, quelles sont ces principales caractéristiques ? ces atouts ? ces améliorations futures (j’ai cru lire un projet avec la carte Arduino) ?

