Depuis les années 1950 et l’apparition des premiers hackers, l’informatique est porteuse d’un message d’émancipation. Sans ces pionniers, notre dépendance aux grandes firmes technologiques aurait déjà été scellée.
Aujourd’hui, l’avènement de l’Internet des objets remet en question l’autonomisation des utilisateurs en les empêchant de « bidouiller » à leur gré. Pire encore, les modèles économiques apparus ces dernières années remettent même en question la notion de propriété. Les GAFAM et compagnie sont-ils devenus nos nouveaux seigneurs féodaux ?
Une traduction de Framalang : Relec’, Redmood, FranBAG, Ostrogoths, simon, Moutmout, Edgar Lori, Luc, jums, goofy, Piup et trois anonymes
Est-ce vraiment ainsi que se définissent maintenant nos rapports avec les entreprises de technologie numérique ? Queen Mary Master
Les appareils connectés à Internet sont si courants et si vulnérables que des pirates informatiques ont récemment pénétré dans un casino via… son aquarium ! Le réservoir était équipé de capteurs connectés à Internet qui mesuraient sa température et sa propreté. Les pirates sont entrés dans les capteurs de l’aquarium puis dans l’ordinateur utilisé pour les contrôler, et de là vers d’autres parties du réseau du casino. Les intrus ont ainsi pu envoyer 10 gigaoctets de données quelque part en Finlande.
En observant plus attentivement cet aquarium, on découvre le problème des appareils de « l’Internet des objets » : on ne les contrôle pas vraiment. Et il n’est pas toujours évident de savoir qui tire les ficelles, bien que les concepteurs de logiciels et les annonceurs soient souvent impliqués.
Dans mon livre récent intitulé Owned : Property, Privacy, and the New Digital Serfdom (Se faire avoir : propriété, protection de la vie privée et la nouvelle servitude numérique), je définis les enjeux liés au fait que notre environnement n’a jamais été truffé d’autant de capteurs. Nos aquariums, téléviseurs intelligents, thermostats d’intérieur reliés à Internet, Fitbits (coachs électroniques) et autres téléphones intelligents recueillent constamment des informations sur nous et notre environnement. Ces informations sont précieuses non seulement pour nous, mais aussi pour les gens qui veulent nous vendre des choses. Ils veillent à ce que les appareils connectés soient programmés de manière à ce qu’ils partagent volontiers de l’information…
Les atteintes à la sécurité et à la vie privée sont intégrées
Comme le Roomba, d’autres appareils intelligents peuvent être programmés pour partager nos informations privées avec les annonceurs publicitaires par le biais de canaux dissimulés. Dans un cas bien plus intime que le Roomba, un appareil de massage érotique contrôlable par smartphone, appelé WeVibe, recueillait des informations sur la fréquence, les paramètres et les heures d’utilisation. L’application WeVibe renvoyait ces données à son fabricant, qui a accepté de payer plusieurs millions de dollars dans le cadre d’un litige juridique lorsque des clients s’en sont aperçus et ont contesté cette atteinte à la vie privée.
Ces canaux dissimulés constituent également une grave faille de sécurité. Il fut un temps, le fabricant d’ordinateurs Lenovo, par exemple, vendait ses ordinateurs avec un programme préinstallé appelé Superfish. Le programme avait pour but de permettre à Lenovo — ou aux entreprises ayant payé — d’insérer secrètement des publicités ciblées dans les résultats de recherches web des utilisateurs. La façon dont Lenovo a procédé était carrément dangereuse : l’entreprise a modifié le trafic des navigateurs à l’insu de l’utilisateur, y compris les communications que les utilisateurs croyaient chiffrées, telles que des transactions financières via des connexions sécurisées à des banques ou des boutiques en ligne.
Le problème sous-jacent est celui de la propriété
L’une des principales raisons pour lesquelles nous ne contrôlons pas nos appareils est que les entreprises qui les fabriquent semblent penser que ces appareils leur appartiennent toujours et agissent clairement comme si c’était le cas, même après que nous les avons achetés. Une personne peut acheter une jolie boîte pleine d’électronique qui peut fonctionner comme un smartphone, selon les dires de l’entreprise, mais elle achète une licence limitée à l’utilisation du logiciel installé. Les entreprises déclarent qu’elles sont toujours propriétaires du logiciel et que, comme elles en sont propriétaires, elles peuvent le contrôler. C’est comme si un concessionnaire automobile vendait une voiture, mais revendiquait la propriété du moteur.
Ce genre de disposition anéantit le fondement du concept de propriété matérielle. John Deere a déjà annoncé aux agriculteurs qu’ils ne possèdent pas vraiment leurs tracteurs, mais qu’ils ont, en fait, uniquement le droit d’en utiliser le logiciel — ils ne peuvent donc pas réparer leur propre matériel agricole ni même le confier à un atelier de réparation indépendant. Les agriculteurs s’y opposent, mais il y a peut-être des personnes prêtes à l’accepter, lorsqu’il s’agit de smartphones, souvent achetés avec un plan de paiement échelonné et échangés à la première occasion.
Combien de temps faudra-t-il avant que nous nous rendions compte que ces entreprises essaient d’appliquer les mêmes règles à nos maisons intelligentes, aux téléviseurs intelligents dans nos salons et nos chambres à coucher, à nos toilettes intelligentes et à nos voitures connectées à Internet ?
Un retour à la féodalité ?
La question de savoir qui contrôle la propriété a une longue histoire. Dans le système féodal de l’Europe médiévale, le roi possédait presque tout, et l’accès à la propriété des autres dépendait de leurs relations avec le roi. Les paysans vivaient sur des terres concédées par le roi à un seigneur local, et les ouvriers ne possédaient même pas toujours les outils qu’ils utilisaient pour l’agriculture ou d’autres métiers comme la menuiserie et la forge.
Au fil des siècles, les économies occidentales et les systèmes juridiques ont évolué jusqu’à notre système commercial moderne : les individus et les entreprises privées achètent et vendent souvent eux-mêmes des biens de plein droit, possèdent des terres, des outils et autres objets. Mis à part quelques règles gouvernementales fondamentales comme la protection de l’environnement et la santé publique, la propriété n’est soumise à aucune condition.
Ce système signifie qu’une société automobile ne peut pas m’empêcher de peindre ma voiture d’une teinte rose pétard ou de faire changer l’huile dans le garage automobile de mon choix. Je peux même essayer de modifier ou réparer ma voiture moi-même. Il en va de même pour ma télévision, mon matériel agricole et mon réfrigérateur.
Pourtant, l’expansion de l’Internet des objets semble nous ramener à cet ancien modèle féodal où les gens ne possédaient pas les objets qu’ils utilisaient tous les jours. Dans cette version du XXIe siècle, les entreprises utilisent le droit de la propriété intellectuelle — destiné à protéger les idées — pour contrôler les objets physiques dont les utilisateurs croient être propriétaires.
Mainmise sur la propriété intellectuelle
Mon téléphone est un Samsung Galaxy. Google contrôle le système d’exploitation ainsi que les applications Google Apps qui permettent à un smartphone Android de fonctionner correctement. Google en octroie une licence à Samsung, qui fait sa propre modification de l’interface Android et me concède le droit d’utiliser mon propre téléphone — ou du moins c’est l’argument que Google et Samsung font valoir. Samsung conclut des accords avec de nombreux fournisseurs de logiciels qui veulent prendre mes données pour leur propre usage.
Mais ce modèle est déficient, à mon avis. C’est notre droit de pouvoir réparer nos propres biens. C’est notre droit de pouvoir chasser les annonceurs qui envahissent nos appareils. Nous devons pouvoir fermer les canaux d’information détournés pour les profits des annonceurs, pas simplement parce que nous n’aimons pas être espionnés, mais aussi parce que ces portes dérobées constituent des failles de sécurité, comme le montrent les histoires de Superfish et de l’aquarium piraté. Si nous n’avons pas le droit de contrôler nos propres biens, nous ne les possédons pas vraiment. Nous ne sommes que des paysans numériques, utilisant les objets que nous avons achetés et payés au gré des caprices de notre seigneur numérique.
Même si les choses ont l’air sombres en ce moment, il y a de l’espoir. Ces problèmes deviennent rapidement des cauchemars en matière de relations publiques pour les entreprises concernées. Et il y a un appui bipartite important en faveur de projets de loi sur le droit à la réparation qui restaurent certains droits de propriété pour les consommateurs.
Ces dernières années, des progrès ont été réalisés dans la reconquête de la propriété des mains de magnats en puissance du numérique. Ce qui importe, c’est que nous identifiions et refusions ce que ces entreprises essaient de faire, que nous achetions en conséquence, que nous exercions vigoureusement notre droit d’utiliser, de réparer et de modifier nos objets intelligents et que nous appuyions les efforts visant à renforcer ces droits. L’idée de propriété est encore puissante dans notre imaginaire culturel, et elle ne mourra pas facilement. Cela nous fournit une opportunité. J’espère que nous saurons la saisir.
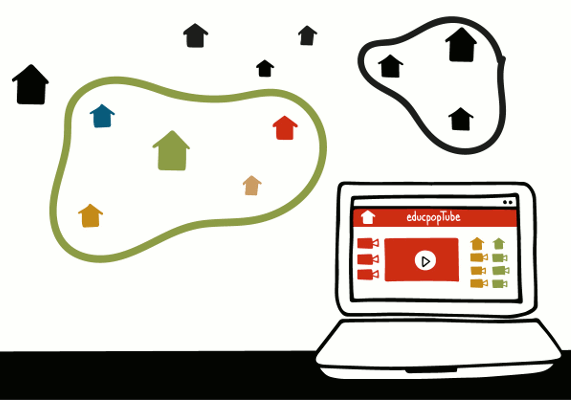
Framatube : aidez-nous à briser l’hégémonie de YouTube
Ceci est une révolution. OK : l’expression nous a été confisquée par un célèbre vendeur de pommes, mais dans ce cas, elle est franchement juste. Et si, ensemble, nous pouvions nous libérer de l’hégémonie de YouTube en innovant dans la manière dont on visionne et diffuse des vidéos ? Chez Framasoft, nous croyons que c’est possible… mais ça ne se fera pas sans vous.
YouTube est un ogre qui coûte cher
YouTube est avant tout un symbole. Celui de ces plateformes (Dailymotion, Vimeo, Facebook vidéos…) qui centralisent nos créations vidéos pour offrir nos données et notre temps de cerveau disponible aux multinationales qui se sont payé ces sites d’hébergement.
Il faut dire que capter nos vidéos et nos attentions coûte affreusement cher à ces ogres du web. Les fichiers vidéo pèsent lourd, il leur faut donc constamment financer l’ajout de disques durs dans leurs fermes de serveurs. Sans compter que, lorsque toutes ces vidéos sont centralisées et donc envoyées depuis les mêmes machines, il leur faut agrandir la taille et le débit du tuyau qui transporte ces flux de données, ce qui, encore une fois, se traduit en terme de pépètes, ou plutôt de méga-thunes.
Techniquement et financièrement, centraliser de la vidéo est probablement la méthode la moins pertinente, digne de l’époque des Minitels. Si, en revanche, votre but est de devenir l’unique chaîne de télé du Minitel 2.0 (donc d’un Internet gouverné par les plateformes)… Si votre but est d’avoir le pouvoir d’influencer les contenus et les habitudes du monde entier… Et si votre but est de collecter de précieuses informations sur nos intérêts, nos créations et nos échanges… Alors là, cela devient carrément rentable !
Dans nos vies, YouTube s’est hissé au rang de Facebook : un mal nécessaire, un site que l’on adore détester, un service « dont j’aimerais bien me passer, mais… ». À tel point que, si seules des « Licornes » (des entreprises milliardaires) peuvent s’offrir le succès de telles plateformes, beaucoup d’autres tentent d’imiter leur fonctionnement, jusque dans le logiciel libre. Comme si nous ne ne pouvions même plus imaginer comment faire autrement…
Je ne veux pas que vous le poussiez ou l’ébranliez [le tyran], mais seulement ne le soutenez plus, et vous le verrez, comme un grand colosse à qui on a dérobé sa base, de son poids même fondre en bas et se rompre. Étienne de LA BOÉTIE, Discours de la servitude volontaire, 1574
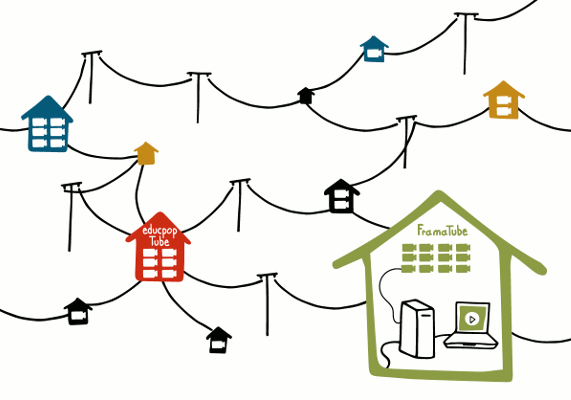
Réapproprions-nous les moyens de diffusion
Nous aurions pu proposer un Framatube centralisant des vidéos libres et libristes sur nos serveurs, basé sur les logiciels libres Mediadrop, Mediagoblin ou Mediaspip, qui sont très efficaces lorsqu’il s’agit d’héberger sa vidéothèque perso. Mais, en cas de succès et donc face à un très grand nombre de vidéos et de vues, nous aurions dû en payer le prix fort : or (on a fait les calculs) nous sommes 350 000 fois plus pauvres que Google-Alphabet, à qui appartient YouTube. Nous ne voulons pas utiliser leurs méthodes, et ça tombe bien : nous n’en avons pas les moyens.
Le logiciel libre a, en revanche, la capacité de penser hors de ce Google-way-of-life. L’intérêt principal de Google, son capital, ce sont nos données. C’est précisément ce qui l’empêche de mettre en place des solutions différentes, innovantes. Une vraie innovation serait d’utiliser, par exemple, des techniques de diffusion presque aussi vieilles qu’Internet et qui ont fait leurs preuves : la fédération d’hébergements et le pair-à-pair, par exemple.
Avec les fédérations, l’union fait la force, et la force est avec nous ! Dessins : CC-By-SA Emma Lidbury
La fédération, on connaît ça grâce aux emails (et nous en avons parlé en présentant l’alternative libre à Twitter qu’est Mastodon). Le fait que l’email de Camille soit hébergé par son entreprise et que la boite mail de Dominique lui soit fournie par son université ne les empêche pas de communiquer, bien au contraire !
Le visionnage en pair à pair, pour mieux répartir les flux dans le réseau (promis : ce n’est pas sale.) Dessins : Emma Lidbury
Le pair-à-pair, nous le connaissons avec eMule, les Torrents ou plus récemment Pop-corn Time : c’est quand l’ordinateur de chaque personne qui reçoit un fichier (par exemple la vidéo qui s’affiche dans un lecteur sur votre écran) l’envoie en même temps aux autres personnes. Cela permet, tout simplement, de répartir les flux d’information et de soulager le réseau.
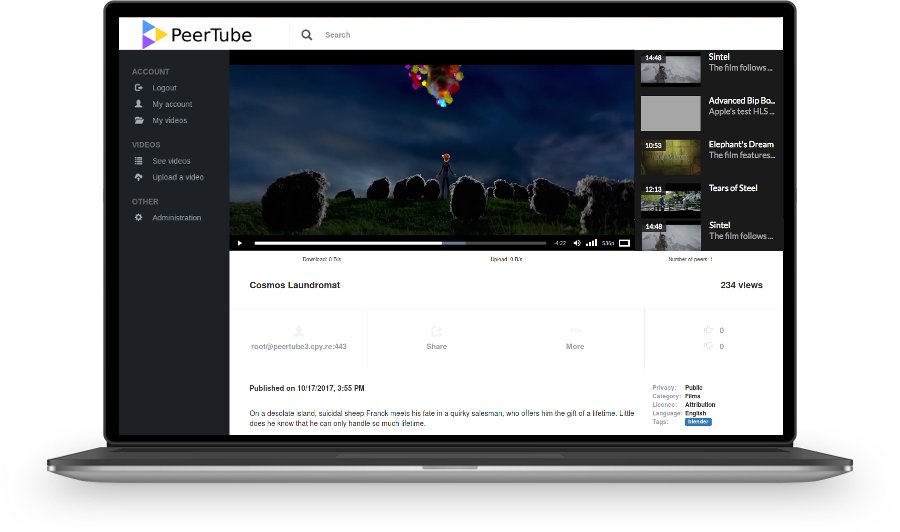
Avec PeerTube, libérons-nous des chaînes de YouTube
PeerTube est un logiciel libre qui démocratise l’hébergement de vidéos en créant un réseau d’hébergeurs, dont les vidéos vues sont partagées en direct entre internautes, de pairs à pairs. Son développeur, Chocobozzz, y travaille bénévolement depuis deux ans, sur son temps libre.
Chez Framasoft, lors de la campagne Dégooglisons Internet, nous nous sommes souvent creusé la tête sur la meilleure façon de créer une alternative à YouTube qui libère à la fois les internautes, les vidéastes et les hébergeurs, sans pénaliser le confort de chacun. Lorsque nous avons eu vent de PeerTube, nous étions émerveillé·e·s : sa conception, bien qu’encore en cours de développement, laisse entrevoir un logiciel qui peut tout changer.
Nous aurons, à un moment donné, besoin de contributions sur le design de PeerTube.
Pour le spectateur, aller sur un des hébergements PeerTube lui permettra de voir et d’interagir avec les vidéos de cet hébergeur mais aussi de tous ses « hébergeurs amis » (principe de fédération). Un·e vidéaste aura la liberté de choisir entre plusieurs hébergements, chacun ayant ses centres d’intérêts, ses conditions générales, ses règles de modération voire de monétisation. Une hébergeuse (un jour prochain nous dirons peut-être une PeerTubeuse ?) quant à elle, n’aura pas besoin d’héberger les vidéos du monde entier afin d’attirer un large public, et ne craindra plus qu’une vidéo vue massivement ne fasse tomber son serveur.
Depuis octobre 2017, nous avons accueilli Chocobozzz au sein de notre équipe de salarié·e·s afin de financer son temps de travail sur le logiciel PeerTube, et donc d’accélérer son développement en l’accompagnant du mieux que nous pouvons. L’objectif ? Sortir une version bêta de PeerTube (utilisable publiquement) dès mars 2018, dans le cadre de notre campagne Contributopia.
Les premiers moyens de contribuer à PeerTube
Clairement, PeerTube ne sera pas (pas tout de suite) aussi beau, fonctionnel et fourni qu’un YouTube de 2017 (qui bénéficie depuis 10 ans des moyens de Google, une des entreprises les plus riches au monde). Mais les fonctionnalités, présentes ou prévues, mettent déjà l’eau à la bouche… et si vous voulez en savoir plus, vous pouvez déjà poser toutes vos questions sur PeerTube sur notre forum. Ces questions nous permettront de mieux cerner vos attentes sur un tel projet, et de publier prochainement une foire aux questions sur ce blog.
Une autre manière de contribuer dès maintenant sur ce projet, c’est avec votre argent, par un don à Framasoft, qui en plus est toujours défiscalisable à 66 % pour les contribuables français (ce qui fait qu’un don de 100 € revient, après impôts, à 34 €). Mine de rien, c’est un moyen pour vous de consacrer une petite partie de vos contributions publiques à ces biens communs que sont les logiciels libres, dont PeerTube est un exemple.
Ce n’est pas le logiciel qui est libre, c’est vous, c’est nous ! Dessins : CC-By-SA Emma Lidbury
Car si le logiciel libre est diffusé gratuitement, il n’est pas gratuit : il est, en général, financé à la source. Là, nous vous proposons une expérience de financement participatif assez intéressante. Il ne s’agit pas de faire un crowdfunding en mode « Si vous payez suffisamment, alors on le fait. » Nous avons d’ores et déjà embauché Chocobozzz, et nous mènerons PeerTube au moins jusqu’à sa version bêta.
Sachant cela, et si vous croyez en ce projet aussi fort que nous y croyons : est-ce que vous allez participer à cet effort, qui est aussi un effort financier ?
L’état des dons au moment où nous publions cet article.
Bien entendu, cela n’est pas aussi tranché : si nous n’atteignons pas cet objectif-là, nous devrons simplement revoir l’ensemble de nos activités à la baisse (et nous inquiéter sérieusement en 2018). Néanmoins, nous n’avons aucune envie d’être alarmistes car nous vous faisons confiance. Nous savons qu’il est possible de contribuer, ensemble, à réaliser les mondes et les projets de Contributopia.
Le logiciel « open source » a gagné, tant mieux, c’est un préalable pour une informatique éthique, explique Daniel Pascot, qui a tout au long d’une carrière bien remplie associé enseignement et pratique de l’informatique, y compris en créant une entreprise.
Du côté de nos cousins d’Outre-Atlantique, on lui doit notamment d’avoir présidé aux destinées de l’association libriste FACIL (c’est un peu l’April du Québec) et milité activement pour la promotion de solutions libres jusqu’aux instances gouvernementales.
On peut se réjouir de l’ubiquité du logiciel libre mais les fameuses quatre libertés du logiciel libre (merci Mr Stallman) ne semblent en réalité concerner que les créateurs de logiciels. Les utilisateurs, peu réceptifs au potentiel ouvert par les licences libres, sont intéressés essentiellement par l’usage libre des logiciels et les services proposés par des entreprises intermédiaires. Hic jacet lupus… Quand ces services échappent à la portée des licences libres, comment garantir qu’ils sont éthiques ? La réflexion qu’entame Daniel Pascot à la lumière d’exemples concrets porte de façon très intéressante sur les conditions d’un contrat équilibré entre utilisateurs et fournisseurs de services. Les propositions de charte qu’il élabore ressemblent d’ailleurs plutôt à une liste des droits des utilisateurs et utilisatrices 😉
Chez Framasoft, nous trouvons que ce sont là des réflexions et propositions fort bien venues pour le mouvement de CHATONS qui justement vous proposent des services divers en s’engageant par une charte.
Comme toujours sur le Framablog, les commentaires sont ouverts…
Le logiciel « open source » a gagné, oui mais…
Photo Yann Doublet
Les « libristes »1 se rendent progressivement compte que bien des combats qu’ils ont livrés étaient une cause perdue d’avance car ils sous-estimaient les conséquences de la complexité des logiciels. Quels que soient les bienfaits des logiciels libres, les utiliser exige une compétence et un entretien continu qui ne sont pas envisageables pour la grande majorité des individus ou organisations2.
Richard Stallman a fait prendre conscience de la nécessité de contrôler les programmes pour garantir notre liberté. La dimension éthique était importante : il parlait du bon et du mauvais logiciel. L’importance de ce contrôle a été mise en évidence par Lawrence Lessig avec son « Code is law »3. La nature immatérielle et non rivale du logiciel faisait que les libristes le considéraient naturellement comme un bien commun. Il leur semblait évident qu’il devait être partagé. Comme on vivait alors dans un monde où les ordinateurs étaient autonomes, la licence GPL avec ses libertés offrait un socle satisfaisant sur lequel les libristes s’appuyaient.
J’ai depuis plus de 20 ans enseigné et milité pour le logiciel libre que j’utilise quotidiennement. Comme tout bon libriste convaincu, j’ai présenté les quatre libertés de la GPL, et je reconnais que je n’ai pas convaincu grand monde avec ce discours. Qu’il faille garder contrôle sur le logiciel, parfait ! Les gens comprennent, mais la solution GPL ne les concerne pas parce que ce n’est absolument pas dans leur intention d’installer, étudier, modifier ou distribuer du logiciel. Relisez les licences et vous conviendrez qu’elles sont rédigées du point de vue des producteurs de logiciels plus que des utilisateurs qui n’envisagent pas d’en produire eux-mêmes.
Mais un objet technique et complexe, c’est naturellement l’affaire des professionnels et de l’industrie. Pour eux, la morale ou l’éthique n’est pas une préoccupation première, ce sont des techniciens et des marchands qui font marcher l’économie dans leur intérêt. Par contre, la liberté du partage du code pour des raisons d’efficacité (qualité et coût) les concerne. Ils se sont alors débarrassés de la dimension éthique en créant le modèle open source4. Et ça a marché rondement au point que ce modèle a gagné la bataille du logiciel. Les cinq plus grandes entreprises au monde selon leurs capitalisations boursières, les GAFAM, reposent sur ce modèle. Microsoft n’est plus le démon privatif à abattre, mais est devenu un acteur du libre. Enlevez le code libre et plus de Web, plus de courrier électronique, plus de réseaux sociaux comme Facebook, plus de service Google ou Amazon, ou de téléphone Apple ou Android. Conclusion : le logiciel libre a gagné face au logiciel propriétaire, c’est une question de temps pour que la question ne se pose plus.
Oui, mais voilà, c’est du logiciel libre débarrassé de toute évidence de sa dimension éthique, ce qui fait que du point de vue de l’utilisateur qui dépend d’un prestataire, le logiciel libre n’apporte rien. En effet, les prestataires de services, comme les réseaux sociaux ou les plates-formes de diffusion, ne distribuent pas de logiciel, ils en utilisent et donc échappent tout à fait légalement aux contraintes éthiques associées aux licences libres. Ce qui importe aux utilisateurs ce ne sont pas les logiciels en tant qu’objets, mais le service qu’ils rendent qui, lui, n’est pas couvert par les licences de logiciel libre. Circonstance aggravante, la gratuité apparente de bien des services de logiciel anesthésie leurs utilisateurs face aux conséquences de leur perte de liberté et de l’appropriation de leurs données et comportements (méta données) souvent à leur insu5.
Pourtant, aujourd’hui, nous ne pouvons plus nous passer de logiciel, tout comme nous ne pouvons pas nous passer de manger. Le logiciel libre c’est un peu comme le « bio » : de plus en plus de personnes veulent manger bio, tout simplement parce que c’est bon pour soi (ne pas s’empoisonner), bon pour la planète (la préserver de certaines pollutions) ou aussi parce que cela permet d’évoluer vers une économie plus humaine à laquelle on aspire (économie de proximité). Le « bio » est récent, mais en pleine expansion, il y a de plus en plus de producteurs, de marchands, et nos gouvernements s’en préoccupent par des lois, des règlements, des certifications ou la fiscalité. Ainsi le « bio » ce n’est pas seulement un produit, mais un écosystème complexe qui repose sur des valeurs : si le bio s’était limité à des « écolos » pour auto-consommation, on n’en parlerait pas. Eh bien le logiciel c’est comme le bio, ce n’est pas seulement un produit mais aussi un écosystème complexe qui concerne chacun de nous et la société avec tous ses acteurs.
Dans l’écosystème logiciel, les éditeurs et les prestataires de service qui produisent et opèrent le logiciel, ont compris que le logiciel libre (au sens open source) est bon pour eux et s’en servent, car ils le contrôlent. Par contre il n’en va pas de même pour ceux qui ne contrôlent pas directement le logiciel. La licence du logiciel ne suffit pas à leur donner contrôle. Mais alors que faire pour s’assurer que le service rendu par le logiciel via un prestataire soit bon pour nous, les divers utilisateurs dans cet écosystème numérique complexe ?
Je vais ici commenter la dimension éthique de deux projets de nature informatique qui s’appuient sur du logiciel libre sur lesquels je travaille actuellement en tentant d’intégrer ma réflexion de militant, d’universitaire et de praticien. PIAFS concerne les individus et donc le respect de nos vies privées pour des données sensibles, celles de notre santé dans un contexte de partage limité, la famille. REA vise à garantir à une organisation le contrôle de son informatisation dans le cadre d’une relation contractuelle de nature coopérative.
Deux cas qui ont alimenté ma réflexion
PIAFS : Partage des Informations Avec la Famille en Santé
PIAFS est projet qui répond à un besoin non satisfait : un serveur privé pour partager des données de santé au sein d’une unité familiale à des fins d’entr’aide (http://piafs.org/). Cette idée, dans un premier temps, a débouché sur un projet de recherche universitaire pour en valider et préciser la nature. Pour cela il nous fallait un prototype.
Au-delà de la satisfaction d’un besoin réel, je cherchais en tant que libriste comment promouvoir le logiciel libre. Je constatais que mes proches n’étaient pas prêts à renoncer à leurs réseaux sociaux même si je leur en montrais les conséquences. Il fallait éviter une première grande difficulté : changer leurs habitudes. J’avais là une opportunité : mes proches, comme beaucoup de monde, n’avaient pas encore osé organiser leurs données de santé dans leur réseau social.
Si ce projet avait dès le départ une dimension éthique, il n’était pas question de confier ces données sensibles à un réseau social. J’étais dès le départ confronté à une dimension pratique au-delà de la disponibilité du logiciel. De plus, pour les utilisateurs de PIAFS, l’auto-hébergement n’est pas une solution envisageable. Il fallait recourir à un fournisseur car un tel service doit être assuré d’une manière responsable et pérenne. Même si l’on s’appuyait sur des coopératives de santé pour explorer le concept, il est rapidement apparu qu’il fallait recourir à un service professionnel classique dont il faut alors assumer les coûts6. Il fallait transposer les garanties apportées par le logiciel libre au fournisseur de service : l’idée de charte que l’on voyait émerger depuis quelques années semblait la bonne approche pour garantir une informatique éthique, et en même temps leur faire comprendre qu’ils devaient eux-mêmes assurer les coûts du service.
REA : Pour donner au client le contrôle de son informatisation
J’ai enseigné la conception des systèmes d’information dans l’université pendant près de 40 ans (à Aix-en-Provence puis à Québec), et eu l’occasion de travailler dans des dizaines de projets. J’ai eu connaissance de nombreux dérapages de coût ou de calendrier et j’ai étudié la plupart des méthodologies qui tentent d’y remédier. J’ai aussi appris qu’une des stratégies commerciales de l’industrie informatique (ils ne sont pas les seuls !) est la création de situations de rente pas toujours à l’avantage du client. Dans tout cela je n’ai pas rencontré grande préoccupation éthique.
J’ai eu, dès le début de ma carrière de professeur en systèmes d’information (1971), la chance d’assister, sinon participer, à la formalisation de la vision de Jean-Louis Le Moigne7 : un système d’information consiste à capturer, organiser et conserver puis distribuer et parfois traiter les informations créées par l’organisation. Cette vision s’opposait aux méthodologies naissantes de l’analyse structurée issues de la programmation structurée. Elle établissait que l’activité de programmation devait être précédée par une compréhension du fonctionnement de l’organisation à partir de ses processus. L’approche qui consiste à choisir une « solution informatique » sans vraiment repenser le problème est encore largement dominante. J’ai ainsi été conduit à développer, enseigner et pratiquer une approche dite à partir des données qui s’appuie sur la réalisation précoce de prototypes fonctionnels afin de limiter les dérapages coûteux (je l’appelle maintenant REA pour Référentiel d’Entreprise Actif, le code de REA est bien sûr libre).
Mon but est, dans ma perspective libriste, de redonner le contrôle au client dans la relation client-fournisseur de services d’intégration. Si ce contrôle leur échappe trop souvent du fait de leur incompétence technique, il n’en reste pas moins que ce sont eux qui subissent les conséquences des systèmes informatiques « mal foutus ». Là encore le logiciel libre ne suffit pas à garantir le respect du client et le besoin d’une charte pour une informatique éthique s’impose8 .
Vers une charte de l’informatique libre, c’est-à-dire bonne pour l’écosystème numérique
Dans les deux cas, si l’on a les ressources et la compétence pour se débrouiller seul, les licences libres comme la GPL ou une licence Creative Commons pour la méthodologie garantissent une informatique éthique (respect de l’utilisateur, contribution à un bien commun). S’il faut recourir à un hébergeur ou un intégrateur, les garanties dépendent de l’entente contractuelle entre le client-utilisateur et le fournisseur.
Il y a une différence fondamentale entre le logiciel et le service. Le logiciel est non rival, il ne s’épuise pas à l’usage, car il peut être reproduit sans perte pour l’original, alors que le service rendu est à consommation unique. Le logiciel relève de l’abondance alors que le service relève de la rareté qui est le fondement de l’économie qui nous domine, c’est la rareté qui fait le prix. Le logiciel peut être mis en commun et partagé alors que le service ne le peut pas. L’économie d’échelle n’enlève pas le caractère rival du service. Et c’est là que la réalité nous rattrape : la mise en commun du logiciel est bonne pour nous tous, mais cela n’a pas de sens pour le service car aucun fournisseur ne rendra ce service gratuitement hormis le pur bénévolat.
Des propositions balisant un comportement éthique existent, en voici quelques exemples:
dans Le Manifeste pour le développement Agile de logiciels, des informaticiens ont proposé une démarche dite agile qui repose sur 4 valeurs et 12 principes. Sans être explicitement une charte éthique, la démarche est clairement définie dans l’optique du respect du client. Ce manifeste est utile dans le cas REA ;
la charte du collectif du mouvement CHATONS concerne les individus, elle est pensée dans un contexte d’économie sociale et solidaire, elle est inspirante pour le cas PIAFS ;
la charte de Framasoft définit un internet éthique, elle est inspirante pour le cas PIAFS mais aussi pour la définition d’un cadre global;
dernièrement sous forme de lettre ouverte, un collectif issu du Techfestival de Copenhague propose une pratique éthique, utile pour les deux cas et qui permet de réfléchir au cadre global.
Les libristes, mais dieu merci ils ne sont pas les seuls, ont une bonne idée des valeurs qui président à une informatique éthique, bonne pour eux, à laquelle ils aspirent lorsqu’ils utilisent les services d’un fournisseur. Les exigences éthiques ne sont cependant pas les mêmes dans les deux cas car l’un concerne un service qui n’inclut pas de développement informatique spécifique et l’autre implique une activité de développement significative (dans le tableau ci-dessous seuls des critères concernant l’éthique sont proposés):
Critères pour le client
Dans le cas de PIAFS
Dans le cas d’un projet REA
Respect de leur propriété
Les données qu’ils produisent leur appartiennent, ce n’est pas négociable
Tout document produit (analyse, …) est propriété du client
Respect de leur identité
Essentiel
Le client doit contrôler la feuille de route, ce sont ses besoins que l’on doit satisfaire par ceux du fournisseur
Respect de leur indépendance vis à vis du fournisseur
Important, préside au choix des logiciels et des formats
Critique : mais difficile à satisfaire.
Proximité du service : favoriser l’économie locale et protection contre les monopoles
Important
Important
Pérennité du service
Important, mais peut être tempéré par la facilité du changement
Essentiel : le changement est difficile et coûteux, mais la « prise en otage » est pire
Payer le juste prix
Important
Important
Partage équitable des risques
Risque faible
Essentiel car le risque est élevé
Mise en réseau
Essentiel : la connexion « sociale » est impérative mais dans le respect des autres valeurs
Plus aucune organisation vit en autarcie
Contribution (concerne le fournisseur)
Non discutable, obligatoire
Important mais aménageable
Entente sur le logiciel
Le client, individu ou organisation, doit avoir l’assurance que les logiciels utilisés par le fournisseur de services font bien et seulement ce qu’ils doivent faire. Comme il n’a pas la connaissance requise pour cette expertise, il doit faire confiance au fournisseur. Or, parce que celui-ci n’offre pas toute la garantie requise (volonté et capacité de sa part), il faut, dans cette situation, recourir à un tiers de confiance. Cette expertise externe par un tiers de confiance est très problématique. Il faut d’une part que le fournisseur donne accès aux logiciels et d’autre part trouver un expert externe qui accepte d’étudier les logiciels, autrement dit résoudre la quadrature du cercle !
Le logiciel libre permet de la résoudre. Il est accessible puisqu’il est public, il est produit par une communauté qui a les qualités requises pour jouer ce rôle de tiers de confiance. Ainsi, pour une informatique éthique :
tout logiciel utilisé par le fournisseur doit être public, couvert par une licence libre, ce qui le conduit à ne pas redévelopper un code existant ou le moins possible,
s’il est amené à produire du nouveau code,
le fournisseur doit le rendre libre. C’est à l’avantage de la société mais aussi du client dans un contexte de partage et de protection contre les situations de rente qui le tiennent en otage,
ou du moins le rendre accessible au client,
garantir que seul le code montré est utilisé,
utiliser des formats de données et documents libres.
L’éthique est complexe, il est difficile sinon impossible d’anticiper tous les cas. L’exigence de logiciel libre peut être adaptée à des situations particulières, par exemple si le prestataire est engagé pour un logiciel que le client ne désire pas partager il en prend alors la responsabilité, ou si la nécessité de poursuivre l’utilisation de logiciels non libres est non contournable temporairement.
Entente sur le bien ou service
Le critère du coût est propre au service. Dans une approche éthique le juste coût n’est pas la résultante du jeu de l’offre et de la demande, ni d’un jeu de négociation basé sur des secrets, et encore moins le résultat d’une rente de situation. Il s’agit pour le fournisseur de couvrir ses coûts et de rentabiliser son investissement (matériel, formation…). Une approche éthique impose de la transparence, le client :
doit savoir ce qu’il paye,
doit avoir la garantie que le contrat couvre tous les frais pour l’ensemble du service (pas de surprise à venir),
doit être capable d’estimer la valeur de ce qu’il paye,
doit connaître les coûts de retrait du service et en estimer les conséquences.
Le partage équitable du risque concerne essentiellement les projets d’informatisation avec un intégrateur. Il est rare que l’on puisse estimer correctement l’ampleur d’un projet avant de l’avoir au moins partiellement réalisé. Une part du risque provient de l’organisation et de son environnement, une autre part du risque provient des capacités du fournisseur et de ses outils. Ceci a un impact sur le découpage du projet, chaque étape permet d’estimer les suivantes :
tout travail réalisé par le fournisseur contributif au projet :
doit être payé,
appartient au client,
doit pouvoir être utilisé indépendamment du fournisseur.
le travail dont le volume est dépendant du client est facturé au temps,
le travail sous le contrôle du fournisseur doit si possible être facturé sur une base forfaitaire,
le client est maître de la feuille de route,
tout travail entamé par le fournisseur doit être compris et accepté par le client,
la relation entre le client et le fournisseur est de nature collaborative, le client participe au projet qui évolue au cours de la réalisation à la différence d’une relation contractuelle dans laquelle le client commande puis le fournisseur livre ce qui est commandé.
Conclusion : l’informatique éthique est possible
Pour tous les utilisateurs de l’informatique, c’est à dire pratiquement tout le monde et toutes les organisations de notre société numérique, il est aussi difficile de nier l’intérêt d’une informatique éthique que de rejeter le « bio », mais encore faut-il en être conscient. Le débat au sein des producteurs de logiciels reste difficile à comprendre. Ce qui est bon pour un libriste c’est un logiciel qui avant tout le respecte, alors que pour les autres informaticiens, c’est à dire la grande majorité, c’est un logiciel qui ne bogue pas. Fait aggravant : la vérité des coûts nous est cachée. Cependant au-delà de cette différence philosophique, l’intérêt du logiciel partagé est tel qu’un immense patrimoine de logiciel libre ou open source est disponible. Ce patrimoine est le socle sur lequel une informatique éthique est possible. Les deux cas présentés nous montent que les conditions existent dès maintenant.
Une informatique éthique est possible, mais elle ne sera que si nous l’exigeons. Les géants du Net sont de véritables états souverains devant lesquels même nos états baissent pavillon. La route est longue, chaotique et pleine de surprises, comme elle l’a été depuis la naissance de l’ordinateur, mais un fait est acquis, elle doit reposer sur le logiciel libre.
Le chemin se fait en marchant, comme l’écrivait le poète Antonio Machado, et c’est à nous libristes de nous donner la main et de la tendre aux autres. Ce ne sera pas facile car il faudra mettre la main à la poche et la bataille est politique. Il nous faut exiger, inspirés par le mouvement « bio », un label informatique éthique et pourquoi pas un forum mondial de l’écosystème numérique. La piste est tracée (à l’instar de la Quadrature du Net), à nous de l’emprunter.
Notes
J’ai utilisé ce mot de libriste pour rendre compte de la dimension militante et à certains égards repliée sur elle-même, qu’on leur reproche souvent à raison.↩
Dans un article paru en 2000, Lawrence Lessig -auquel on doit les licences Creative Commons- a clairement mis en lumière que l’usage d’internet (et donc des logiciels) nous contraint, tout comme nous sommes contraint par les lois. Il nous y a alerté sur les conséquences relatives à notre vie privée. Voir la traduction française sur Framablog « Le code fait loi – De la liberté dans le cyberespace » (publié le 22/05/2010),↩
Dans l’optique open source, un bon logiciel est un logiciel qui n’a pas de bogue. Dans l’optique logiciel libre, un bon logiciel est un logiciel éthique qui respecte son utilisateur et contribue au patrimoine commun. Dans les deux cas il est question d’accès au code source mais pour des raisons différentes, ce qui au plan des licences peut sembler des nuances : « Né en 1998 d’une scission de la communauté du logiciel libre (communauté d’utilisateurs et de développeurs) afin de conduire une politique jugée plus adaptée aux réalités économiques et techniques, le mouvement open source défend la liberté d’accéder aux sources des programmes qu’ils utilisent, afin d’aboutir à une économie du logiciel dépendant de la seule vente de prestations et non plus de celle de licences d’utilisation ». Voir la page Wikipédia, « Open Source Initiative ».↩
La question de recourir à une organisation de l’économie sociale et solidaire s’est posée et ce n’est pas exclu.Cela n’a pas été retenu pour des raisons pratiques et aussi parce que la démarche visait à promouvoir une informatique éthique de la part des fournisseurs traditionnels locaux.↩
Avant d’être connu comme un constructiviste Jean-Louis Le Moigne, alors professeur à l’IAE d’Aix-en-Provence, créait un enseignement de systèmes d’information organisationnels et lançait avec Huber Tardieu la recherche qui a conduit à la méthode Merise à laquelle j’ai participé car j’étais alors assistant dans sa petite équipe universitaire et il a été mon directeur de doctorat.↩
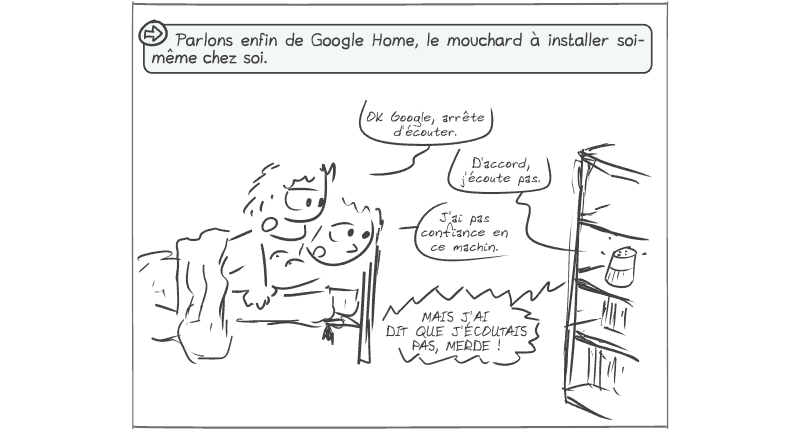
Eh bien comme souvent avec les GAFAM, la réalité rejoint la caricature : le blogueur Artem Russakovskii a révélé sur AndroidPolice.com avoir remarqué un « bug » qui faisait que son Google Home enregistrait absolument tout le son qu’il captait 24 heures sur 24, 7 jours sur 7 et l’envoyait sur son compte Google…
Le truc « drôle » ici, c’est que le seul vrai « bug » que l’on peut constater, c’est l’enregistrement des fichiers dans l’espace perso de l’utilisateur.
Tout le reste, ça n’est pas un bug : c’est la fonctionnalité !
Google Home enregistre et analyse absolument TOUT ce que son microphone capte, 24 heures sur 24, 7 jours sur 7, et c’est son fonctionnement NORMAL.
C’est toute l’absurdité de la notion « d’écoute » dans ce cas-là !
Pour détecter que vous avez prononcé « OK Google » (ou, par exemple, « Alexa » dans le cas de l’équivalent d’Amazon), le Google Home doit enregistrer et analyser tout ce que son microphone capte…
Sinon, ce serait un peu comme si un médecin vous disait cela :
La seule différence, dans le cas de Google Home, c’est que si son analyse révèle que la phrase ne commence pas par « OK Google », les éventuelles commandes données après ne seront pas traitées comme des commandes à exécuter.
Mais il les enregistre tout autant que celles qu’il exécute !
Dans le même genre d’idée, Google (oui, encore) a dévoilé un appareil photo, Clips, dont le principe est de détecter lui-même le meilleur moment pour prendre une photo.
En gros, il reconnaît les visages de votre famille, estime à quel moment vous êtes les plus photogéniques et prend alors une photo tout seul comme un grand.
Eh bien que les choses soient claires : pour pouvoir faire son analyse (dont je ne doute pas qu’elle doit être une prouesse technique remarquable), le Google Clips vous filme. Oui.
Il.
Vous.
Filme.
En.
Permanence.
Pour finir, rappelons que cette problématique du « on doit écouter pour savoir s’il fallait écouter », on la retrouve jusque dans les fameuses lois liberticides qu’on se mange en boucle depuis quelques années (Loi Renseignement, Loi Terrorisme, Loi Machintruc, etc.).
En effet, quand bien même votre algorithme de détection des terroristes serait efficace, cela signifie quoi qu’il arrive une perte de vie privée radicale pour 100 % de la population.
De la même manière que même si moins d’un millième des mots que vous prononcez sont « OK Google », Google Home enregistrera quand même tous les autres.
Et que même si vous n’êtes photogénique que quelques secondes dans la journée…
… Google Clips vous filmera en permanence.
Eh oui, le pire, c’est que les algos de détection des terroristes fonctionnent très mal !
D’après une étude sur de tels algos (menée par Timme Bisgaard Munk, chercheur de l’Université de Copenhague), il y a en moyenne 100 000 faux positifs – innocents identifiés comme terroristes – pour 1 terroriste réel détecté. Quant aux faux négatifs – terroristes réels non-détectés –, eh bien… il suffit de suivre l’actu.
C’est donc la double peine, car non seulement les dominants sacrifient nos vies privées, mais en plus l’hypothétique gain (détection des terroristes avant le passage à l’acte) est non-existant !
Ayant atteint le point binouze (qui indique l’heure de l’apéro), j’arrête donc là cette petite revue des oreilles, de plus en plus nombreuses, qui parsèment nos murs.
En conclusion : il y a un mouvement général de surveillance massive de la population qui se met en place à la fois par des acteurs privés et étatiques. La première étape pour lutter contre ça, c’est de ne pas participer à notre propre surveillance…
L’article qui suit n’est pas une traduction intégrale mais un survol aussi fidèle que possible de la conférence TED effectuée par la sociologue des technologies Zeynep Tufecki. Cette conférence intitulée : « Nous créons une dystopie simplement pour obliger les gens à cliquer sur des publicités » (We’re building a dystopia just to make people click on ads) est en cours de traduction sur la plateforme Amara préconisée par TED, mais la révision n’étant pas effectuée, il faudra patienter pour en découvrir l’intégralité sous-titrée en français. est maintenant traduite en français \o/
En attendant, voici 4 minutes de lecture qui s’achèvent hélas sur des perspectives assez vagues ou plutôt un peu vastes : il faut tout changer. Du côté de Framasoft, nous proposons de commencer par outiller la société de contribution avec la campagne Contributopia… car dégoogliser ne suffira pas !
Mettez un peu à jour vos contre-modèles, demande Zeynep : oubliez les références aux menaces de Terminator et du 1984 d’Orwell, ces dystopies ne sont pas adaptées à notre débutant XXIe siècle.
Cliquez sur l’image pour afficher la vidéo sur le site de TED (vous pourrez afficher les sous-titres via un bouton en bas de la vidéo)
Ce qui est à craindre aujourd’hui, car c’est déjà là, c’est plutôt comment ceux qui détiennent le pouvoir utilisent et vont utiliser l’intelligence artificielle pour exercer sur nous des formes de contrôle nouvelles et malheureusement peu détectables. Les technologies qui menacent notre liberté et notre jardin secret (celui de notre bulle d’intimité absolue) sont développées par des entreprises-léviathans qui le font d’abord pour vendre nos données et notre attention aux GAFAM (Tristan Nitot, dans sa veille attentive, signale qu’on les appelle les frightful five, les 5 qui font peur, aux États-Unis). Zeynep ajoute d’ailleurs Alibaba et Tencent. D’autres à venir sont sur les rangs, peut-on facilement concevoir.
Ne pas se figurer que c’est seulement l’étape suivante qui prolonge la publicité en ligne, c’est au contraire un véritable saut vers une autre catégorie « un monde différent » à la fois exaltant par son potentiel extraordinaire mais aussi terriblement dangereux.
Voyons un peu la mécanique de la publicité. Dans le monde physique, les friandises à portée des enfants au passage en caisse de supermarché sont un procédé d’incitation efficace, mais dont la portée est limitée. Dans le monde numérique, ce que Zeynep appelle l’architecture de la persuasion est à l’échelle de plusieurs milliards de consommateurs potentiels. Qui plus est, l’intelligence artificielle peut cibler chacun distinctement et envoyer sur l’écran de son smartphone (on devrait dire spyphone, non ?) un message incitatif qui ne sera vu que par chacun et le ciblera selon ses points faibles identifiés par algorithmes.
Prenons un exemple : quand hier l’on voulait vendre des billets d’avion pour Las Vegas, on cherchait la tranche d’âge idéale et la carte de crédit bien garnie. Aujourd’hui, les mégadonnées et l’apprentissage machine (machine learning) s’appuient sur tout ce que Facebook peut avoir collecté sur vous à travers messages, photos, « likes », même sur les textes qu’on a commencés à saisir au clavier et qu’on a ensuite effacés, etc. Tout est analysé en permanence, complété avec ce que fournissent des courtiers en données.
Les algos d’apprentissage, comme leur nom l’indique, apprennent ainsi non seulement votre profil personnel mais également, face à un nouveau compte, à quel type déjà existant on peut le rapprocher. Pour reprendre l’exemple, ils peuvent deviner très vite si telle ou telle personne est susceptible d’acheter un billet pour un séjour à Las Vegas.
Vous pensez que ce n’est pas très grave si on nous propose un billet pour Vegas.
Le problème n’est pas là.
Le problème c’est que les algorithmes complexes à l’œuvre deviennent opaques pour tout le monde, y compris les programmeurs, même s’ils ont accès aux données qui sont généralement propriétaires donc inaccessibles.
« Comme si nous cessions de programmer pour laisser se développer une forme d’intelligence que nous ne comprenons pas véritablement. Et tout cela marche seulement s’il existe une énorme quantité de données, donc ils encouragent une surveillance étendue : pour que les algos de machine learning puissent opérer. Voilà pourquoi Facebook veut absolument collecter le plus de données possible sur vous. Les algos fonctionneront bien mieux »
Que se passerait-il, continue Zeynep avec l’exemple de Las Vegas, si les algos pouvaient repérer les gens bipolaires, soumis à des phases de dépenses compulsives et donc bons clients pour Vegas, capitale du jeu d’argent ? Eh bien un chercheur qui a contacté Zeynep a démontré que les algos pouvaient détecter les profils à risques psychologiques avec les médias sociaux avant que des symptômes cliniques ne se manifestent…
Les outils de détection existent et sont accessibles, les entreprises s’en servent et les développent.
L’exemple de YouTube est également très intéressant : nous savons bien, continue Zeynep, que nous sommes incités par un algo à écouter/regarder d’autres vidéos sur la page où se trouve celle que nous avons choisie.
Eh bien en 2016, témoigne Zeynep, j’ai reçu de suggestions par YouTube : comme j’étudiais la campagne électorale en sociologue, je regardais des vidéos des meetings de Trump et YouTube m’a suggéré des vidéos de suprématistes (extrême-droite fascisante aux USA) !
Ce n’est pas seulement un problème de politique. L’algorithme construit une idée du comportement humain, en supposant que nous allons pousser toujours notre curiosité vers davantage d’extrêmes, de manière à nous faire demeurer plus longtemps sur un site pendant que Google vous sert davantage de publicités.
Pire encore, comme l’ont prouvé des expériences faites par ProPublica et BuzzFeed, que ce soit sur Facebook ou avec Google, avec un investissement minime, on peut présenter des messages et profils violemment antisémites à des personnes qui ne sont pas mais pourraient (toujours suivant les algorithmes) devenir antisémites.
L’année dernière, le responsable médias de l’équipe de Trump a révélé qu’ils avaient utilisé de messages « non-publics » de Facebook pour démobiliser les électeurs, les inciter à ne pas voter, en particulier dans des villes à forte population d’Afro-américains. Qu’y avait-il dans ces messages « non-publics » ? On ne le saura pas, Twitter ne le dira pas.
Les algorithmes peuvent donc aussi influencer le comportement des électeurs.
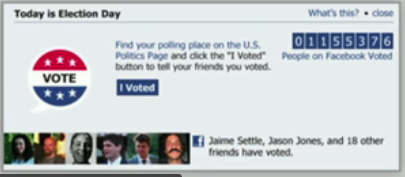
Facebook a fait une expérience en 2010 qui a été divulguée après coup.
Certains ont vu ce message les incitant à voter. Voici la version basique :
et d’autres ont vu cette version (avec les imagettes des contacts qui ont cliqué sur « j’ai voté »)
Ce message n’a été présenté qu’une fois mais 340 000 électeurs de plus ont voté lors de cette élection, selon cette recherche, confirmée par les listes électorales.
En 2012, même expérience, résultats comparables : 270 000 électeurs de plus.
De quoi laisser songeur quand on se souvient que l’élection présidentielle américaine de 2016 s’est décidée à environ 100 000 voix près…
« Si une plate-forme dotée d’un tel pouvoir décide de faire passer les partisans d’un candidat avant les autres, comment le saurions-nous ? »
Les algorithmes peuvent facilement déduire notre appartenance à une communauté ethnique, nos opinions religieuses et politiques, nos traits de personnalité, l’intelligence, la consommation de substances addictives, la séparation parentale, l’âge et le sexe, en se fondant sur les « j’aime » de Facebook. Ces algorithmes peuvent identifier les manifestants même si leurs visages sont partiellement dissimulés, et même l’orientation sexuelle des gens à partir de leurs photos de leur profil de rencontres.
Faut-il rappeler que la Chine utilise déjà la technologie de détection des visages pour identifier et arrêter les personnes ?
Le pire, souligne Zeynep est que
« Nous construisons cette infrastructure de surveillance autoritaire uniquement pour inciter les gens à cliquer sur les publicités. »
Si nous étions dans l’univers terrifiant de 1984 nous aurions peur mais nous saurions de quoi, nous détesterions et pourrions résister. Mais dans ce nouveau monde, si un état nous observe et nous juge, empêche par anticipation les potentiels fauteurs de trouble de s’opposer, manipule individus et masses avec la même facilité, nous n’en saurons rien ou très peu…
« Les mêmes algorithmes que ceux qui nous ont été lancés pour nous rendre plus flexibles en matière de publicité organisent également nos flux d’informations politiques, personnelles et sociales… »
Les dirigeants de Facebook ou Google multiplient les déclarations bien intentionnées pour nous convaincre qu’ils ne nous veulent aucun mal. Mais le problème c’est le business model qu’ils élaborent. Ils se défendent en prétendant que leur pouvoir d’influence est limité, mais de deux choses l’une : ou bien Facebook est un énorme escroquerie et les publicités ne fonctionnent pas sur leur site (et dans ce cas pourquoi des entreprises paieraient-elles pour leur publicité sur Facebook ?), ou bien leur pouvoir d’influence est terriblement préoccupant. C’est soit l’un, soit l’autre. Même chose pour Google évidemment.
Que faire ?
C’est toute la structure et le fonctionnement de notre technologie numérique qu’il faudrait modifier…
« Nous devons faire face au manque de transparence créé par les algorithmes propriétaires, au défi structurel de l’opacité de l’apprentissage machine, à toutes ces données qui sont recueillies à notre sujet. Nous avons une lourde tâche devant nous. Nous devons mobiliser notre technologie, notre créativité et aussi notre pouvoir politique pour construire une intelligence artificielle qui nous soutienne dans nos objectifs humains, mais qui soit aussi limitée par nos valeurs humaines. »
« Nous avons besoin d’une économie numérique où nos données et notre attention ne sont pas destinées à la vente aux plus offrants autoritaires ou démagogues. »
Caliopen, la messagerie libre sur la rampe de lancement
Le projet Caliopen, lancé il y a trois ans, est un projet ambitieux. Alors qu’il est déjà complexe de créer un nouveau logiciel de messagerie, il s’agit de proposer un agrégateur de correspondance qui permette à chacun d’ajuster son niveau de confidentialité.
Ce logiciel libre mûrement réfléchi est tout à fait en phase avec ce que Framasoft s’efforce de promouvoir à chaque fois que des libristes donnent aux utilisateurs et utilisatrices plus d’autonomie et de maîtrise, plus de sécurité et de confidentialité.
Après une nécessaire période d’élaboration, le projet Caliopen invite tout le monde à tester la version alpha et à faire remonter les observations et suggestions. La première version grand public ce sera pour dans un an environ.
Vous êtes curieux de savoir ce que ça donne ? Nous l’étions aussi, et nous avons demandé à Laurent Chemla, qui bidouillait déjà dans l’Internet alors que vous n’étiez même pas né⋅e, de nous expliquer tout ça, puisqu’il est le père tutélaire du projet Caliopen, un projet que nous devons tous soutenir et auquel nous pouvons contribuer.
Bonjour, pourrais-tu te présenter brièvement ?
J’ai 53 ans, dont 35 passés dans les mondes de l’informatique et des réseaux. Presque une éternité dans ce milieu – en tous cas le temps d’y vivre plusieurs vies (« pirate », programmeur, hacktiviste, entrepreneur…). Mais ces temps-ci je suis surtout le porteur du projet Caliopen, même si je conserve une petite activité au sein du CA de la Quadrature du Net. Et je fais des macarons.
Le projet Caliopen arrive ce mois-ci au stade de la version alpha, mais comment ça a commencé ?
Jérémie Zimmermann est venu me sortir de ma retraite nîmoise en me poussant à relancer un très ancien projet de messagerie après les révélations de Snowden. Ça faisait déjà un petit moment que je me demandais si je pouvais encore être utile à la communauté autrement qu’en publiant quelques billets de temps en temps, alors j’ai lancé l’idée en public, pour voir, et il y a eu un tel retour que je n’ai pas pu faire autrement que d’y aller, malgré ma flemme congénitale.
Quand tu as lancé le projet publiquement (sur une liste de diffusion il me semble) quelle était la feuille de route, ou plutôt la « bible » des spécifications que tu souhaitais voir apparaître dans Caliopen ?
Très vite on a vu deux orientations se dessiner : la première, très technique, allait vers une vision maximaliste de la sécurité (réinventer SMTP pour protéger les métadonnées, garantir l’anonymat, passer par du P2P, ce genre de choses), tandis que la seconde visait à améliorer la confidentialité des échanges sans tout réinventer. Ça me semblait plus réaliste – parce que compatible avec les besoins du grand public – et c’est la direction que j’ai choisi de suivre au risque de fâcher certains contributeurs.
J’ai alors essayé de lister toutes les fonctionnalités (aujourd’hui on dirait les « User Stories ») qui sont apparues dans les échanges sur cette liste, puis de les synthétiser, et c’est avec ça que je suis allé voir Stephan Ramoin, chez Gandi, pour lui demander une aide qu’il a aussitôt accepté de donner. Le projet a ensuite évolué au rythme des échanges que j’ai pu avoir avec les techos de Gandi, puis de façon plus approfondie avec Thomas Laurent pendant la longue étape durant laquelle nous avons imaginé le design de Caliopen. C’est seulement là, après avoir défini le « pourquoi » et le « quoi » qu’on a pu vraiment commencer à réfléchir au « comment » et à chercher du monde pour le réaliser.
La question qui fâche : quand on lit articles et interviews sur Caliopen, on a l’impression que le concept est encore super flou. C’est quoi l’elevator pitch pour vendre le MVP de la start-up aux business angels des internets digitaux ? (en français : tu dis quoi pour convaincre de nouveaux partenaires financiers ?)
Ça fait bien 3 ans que le concept de base n’a pas bougé : un agrégateur de correspondances qui réunit tous nos échanges privés (emails, message Twitter ou Facebook, messageries instantanées…), sous forme de conversations, définies par ceux avec qui on discute plutôt que par le protocole utilisé pour le faire. Voilà pour ton pitch.
Ce qui est vrai c’est qu’en fonction du public auquel on s’adresse on ne présente pas forcément le même angle. Le document qui a été soumis à BPI France pour obtenir le financement actuel fait 23 pages, très denses. Il aborde les aspects techniques, financiers, l’état du marché, la raison d’être de Caliopen, ses objectifs sociétaux, ses innovations, son design, les différents modèles économiques qui peuvent lui être appliqués… ce n’est pas quelque chose qu’on peut développer en un article ou une interview unique.
Si j’aborde Caliopen sous l’angle de la vie privée, alors j’explique par exemple le rôle des indices de confidentialité, la façon dont le simple fait d’afficher le niveau de confidentialité d’un message va influencer l’utilisateur dans ses pratiques: on n’écrit pas la même chose sur une carte postale que dans une lettre sous enveloppe. Rien que sur ce sujet, on vient de faire une conférence entière (à Paris Web et à BlendWebMix) sans aborder aucun des autres aspects du projet.
Si je l’aborde sous l’angle technique, alors je vais peut-être parler d’intégration « verticale ». Du fait qu’on ne peut pas se contenter d’un nouveau Webmail, ou d’un nouveau protocole, si on veut tenir compte de tous les aspects qui font qu’un échange est plus ou moins secret. Ce qui fait de Caliopen un ensemble de différentes briques plutôt qu’une unique porte ou fenêtre. Ou alors je vais parler de la question du chiffrement, de la diffusion des clés publiques, de TOFU et du RFC 7929…
Mais on peut aussi débattre du public visé, de design, d’économie du Web, de décentralisation… tous ces angles sont pertinents, et chacun peut permettre de présenter Caliopen avec plus ou moins de détails.
Caliopen est un projet complexe, fondé sur un objectif (la lutte contre la surveillance de masse) et basé sur un moyen (proposer un service utile à tous), qui souhaite changer les habitudes des gens en les amenant à prendre réellement conscience du niveau d’exposition de leur vie privée. Il faut plus de talent que je n’en ai pour le décrire en quelques mots.
Il reste un intérêt pour les mails ? On a l’impression que tout passe par les webmails ou encore dans des applis de communication sur mobile, non ?
Même si je ne crois pas à la disparition de l’email, c’est justement parce qu’on a fait le constat qu’aujourd’hui la correspondance numérique passe par de très nombreux services qu’on a imaginé Caliopen comme un agrégateur de tous ces échanges.
C’est un outil qui te permet de lire et d’écrire à tes contacts sans avoir à te préoccuper du service, ou de l’application, où la conversation a commencé. Tu peux commencer un dialogue avec quelqu’un par message privé sur Twitter, la poursuivre par email, puis par messagerie instantanée… ça reste une conversation: un échange privé entre deux humains, qui peuvent aborder différents sujets, partager différents contenus. Et quand tu vas vouloir chercher l’information que l’autre t’a donné l’année passée, tu vas faire comment ?
C’est à ça que Caliopen veut répondre. Pour parler moderne, c’est l’User Story centrale du projet.
C’est quoi exactement cette histoire de niveaux de confidentialité ? Quel est son but ?
Il faut revenir à l’objectif principal du projet : lutter contre la surveillance de masse que les révélations d’Edward Snowden ont démontrée.
Pour participer à cette lutte, Caliopen vise à convaincre un maximum d’utilisateurs de la valeur de leur vie privée. Et pour ça, il faut d’abord leur montrer, de manière évidente, que leurs conversations sont très majoritairement espionnables, sinon espionnées. Notre pari, c’est que quand on voit le risque d’interception, on réagit autrement que lorsqu’on est seulement informé de son existence. C’est humain : regarde l’exemple de la carte postale que je te donne plus haut.
D’où l’idée d’associer aux messages (mais aussi aux contacts, aux terminaux, et même à l’utilisateur lui-même) un niveau de confidentialité. Représenté par une icône, des couleurs, des chiffres, c’est une question de design, mais ce qui est important c’est qu’en voyant le niveau de risque, l’utilisateur ne va plus pouvoir faire semblant de l’ignorer et qu’il va accepter de changer – au moins un peu – ses pratiques et ses habitudes pour voir ce niveau augmenter.
Bien sûr, il faudra l’accompagner. Lui proposer des solutions (techniques, comportementales, contextuelles) pour améliorer son « score ». Sans le culpabiliser (ce n’est pas la bonne manière de faire) mais en le récompensant – par une meilleure note, de nouvelles fonctionnalités, des options gratuites si le service est payant… bref par une ludification de l’expérience utilisateur. C’est notre piste en tous cas.
Et c’est en augmentant le niveau global de confidentialité des échanges qu’on veut rendre plus difficile (donc plus chère) la surveillance de tous, au point de pousser les états – et pourquoi pas les GAFAM – à changer de pratiques, eux aussi.
Financièrement, comment vit le projet Caliopen ? C’était une difficulté qui a retardé l’avancement ?
Sans doute un peu, mais je voudrais quand même dire que, même si je suis bien conscient de l’impression de lenteur que peut donner le projet, il faut se rendre compte qu’on parle d’un outil complexe, qui a démarré de zéro, avec aucun moyen, et qui s’attaque à un problème dont les racines datent de plusieurs dizaines d’années. Si c’était facile et rapide à résoudre, ça se saurait.
Dès l’instant où nous avons pris conscience qu’on n’allait pas pouvoir continuer sur le modèle du bénévolat, habituel au milieu du logiciel libre, nous avons réagi assez vite : Gandi a décidé d’embaucher à plein temps un développeur front end, sur ses fonds propres. Puis nous avons répondu à un appel à projet de BPI France qui tombait à pic et auquel Caliopen était bien adapté. Nous avons défendu notre dossier, devant un comité de sélection puis devant un panel d’experts, et nous avons obtenu de quoi financer deux ans de développement, avec une équipe dédiée et des partenaires qui nous assurent de disposer de compétences techniques rares. Et tout ça est documenté sur notre blog, depuis le début (tout est public depuis le début, d’ailleurs, même si tous les documents ne sont pas toujours faciles à retrouver, même pour nous).
Et finalement c’est qui les partenaires ?
Gandi reste le partenaire principal, auquel se sont joints Qwant et l’UPMC (avec des rôles moins larges mais tout aussi fondamentaux).
Quel est le modèle économique ? Les développeurs (ou développeuses, y’en a au fait dans l’équipe ?) sont rémunérés autrement qu’en macarons ? Combien faudra-t-il payer pour ouvrir un compte ?
Je ne suis pas sûr qu’on puisse parler de « modèle économique » pour un logiciel libre : après tout chacun pourra en faire ce qu’il voudra et lui imaginer tel ou tel modèle (économique ou non d’ailleurs).
Une fois qu’on a dit ça, on peut quand même dire qu’il ne serait pas cohérent de baser des services Caliopen sur l’exploitation des données personnelles des utilisateurs, et donc que le modèle « gratuité contre données » n’est pas adapté. Nous imaginons plutôt des services ouverts au public de type freemium, d’autres fournis par des entreprises pour leurs salariés, ou par des associations pour leurs membres. On peut aussi supposer que se créeront des services pour adapter Caliopen à des situations particulières, ou encore qu’il deviendra un outil fourni en Saas, ou vendu sous forme de package associé, par exemple, à la vente d’un nom de domaine.
Bref : les modèles économiques ce n’est pas ce qui manque le plus.
L’équipe actuelle est salariée, elle comporte des développeuses, et tu peux voir nos trombinettes sur https://www.caliopen.org
L’équipe de Caliopen
Trouver des développeurs ou développeuses n’est jamais une mince affaire dans le petit monde de l’open source, comment ça s’est passé pour Caliopen ?
Il faut bien comprendre que – pour le moment – Caliopen n’a pas d’existence juridique propre. Les gens qui bossent sur le projet sont des employés de Gandi (et bientôt de Qwant et de l’UPMC) qui ont soit choisi de consacrer une partie de leur temps de travail à Caliopen (ce que Gandi a rendu possible) soit été embauchés spécifiquement pour le projet. Et parfois nous avons des bénévoles qui nous rejoignent pour un bout de chemin 🙂
Le projet est encore franco-français. Tu t’en félicites (cocorico) ou ça t’angoisse ?
J’ai bien des sujets d’angoisse, mais pas celui-là. C’est un problème, c’est vrai, et nous essayons de le résoudre en allant, par exemple, faire des conférences à l’étranger (l’an dernier au FOSDEM, et cette année au 34C3 si notre soumission est acceptée). Et le site est totalement trilingue (français, anglais et italien) grâce au travail (bénévole) de Daniele Pitrolo.
D’un autre côté il faut quand même reconnaître que bosser au quotidien dans sa langue maternelle est un vrai confort dont il n’est pas facile de se passer. Même si on est tous conscients, je crois, qu’il faudra bien passer à l’anglais quand l’audience du projet deviendra un peu plus internationale, et nous comptons un peu sur les premières versions publiques pour que ça se produise.
Et au fait, c’est codé en quoi, Caliopen ? Du JavaScript surtout, d’après ce qu’on voit sur GitHub, mais nous supposons qu’il y a pas mal de technos assez pointues pour un tel projet ?
Sur GitHub, le code de Caliopen est dans un mono-repository, il n’y a donc pas de paquet (ou dépôt) spécifique au front ou au back. Le client est développé en JavaScript avec la librarie ReactJS. Le backend (l’API ReST, les workers …) sont développés en python et en Go. On n’a pas le détail mais ce doit être autour de 50% JS+css, 25% python, 25% Go. L’architecture est basée sur Cassandra et ElasticSearch.
Ce n’est pas que l’on utilise des technos pointues, mais plutôt qu’ on évite autant que possible la dette technique en intégrant le plus rapidement possible les évolutions des langages et des librairies que l’on utilise.
Donc il faut vraiment un haut niveau de compétences pour contribuer ?
Difficile à dire. Si on s’arrête sur l’aspect développement pur, les technos employées sont assez grand public, et si on a suivi un cursus standard on va facilement retrouver ses habitudes (cf. https://github.com/kamranahmedse/developer-roadmap).
Effectivement quelqu’un qui n’a pas l’habitude de développer sur ces outils (docker, Go, webpack, ES6+ …) risque d’être un peu perdu au début. Mais on est très souvent disponibles sur IRC pour répondre directement aux questions.
Néanmoins nous avons de « simples » contributions qui ne nécessitent pas de connaître les patrons de conception par cœur ou de devoir monter un cluster; par exemple proposer des corrections orthographiques, de nouvelles traductions, décrire des erreurs JavaScript dans des issues sur github, modifier un bout de css…
Qu’est-ce qui différencie le projet Caliopen d’un projet comme Protonmail ?
Protonmail est un Gmail-like orienté vers la sécurité. Caliopen est un agrégateur de correspondance privée (ce qui n’est rien-like) orienté vers l’amélioration des pratiques du grand public via l’expérience utilisateur. Protonmail est centralisé, Caliopen a prévu tout un (futur) écosystème exclusivement destiné à garantir la décentralisation des échanges. Et puis Caliopen est un logiciel libre, pas Protonmail.
Mais au-delà de ces différences techniques et philosophiques, ce sont surtout deux visions différentes, et peut-être complémentaires, de la lutte contre la surveillance de masse: Protonmail s’attaque à la protection de ceux qui sont prêts à changer leurs habitudes (et leur adresse email) parce qu’ils sont déjà convaincus qu’il faut faire certains efforts pour leur vie privée. Caliopen veut changer les habitudes de tous les autres, en leur proposant un service différent (mais utile) qui va les sensibiliser à la question. Parce qu’il faut bien se rendre compte que, malgré son succès formidable, aujourd’hui le nombre d’utilisateurs de Protonmail ne représente qu’à peine un millième du nombre d’utilisateurs de Gmail, et que quand les premiers échangent avec les seconds ils ne sont pas mieux protégés que M. Michu.
Maintenant, si tu veux bien imaginer que Caliopen est aussi un succès (on a le droit de rêver) et qu’il se crée un jour disons une dizaine de milliers de services basés sur noooootre proooojet, chacun ne gérant qu’un petit dixième du nombre d’utilisateurs de Protonmail… Eh ben sauf erreur on équilibre le nombre d’utilisateurs de Gmail et – si on a raison de croire que l’affichage des indices de confidentialité va produire un effet – on a significativement augmenté le niveau global de confidentialité.
Et peut-être même assez pour que la surveillance de masse devienne hors de prix.
Est-ce que dans la future version de Caliopen les messages seront chiffrés de bout en bout ?
À chaque fois qu’un utilisateur de Caliopen va vouloir écrire à un de ses contacts, c’est le protocole le plus sécurisé qui sera choisi par défaut pour transporter son message. Prenons un exemple et imaginons que tu m’ajoutes à tes contacts dans Caliopen : tu vas renseigner mon adresse email, mon compte Twitter, mon compte Mastodon, mon Keybase… plus tu ajouteras de moyens de contact plus Caliopen aura de choix pour m’envoyer ton message. Et il choisira le plus sécurisé par défaut (mais tu pourras décider de ne pas suivre son choix).
Plus tes messages auront pu être sécurisés, plus hauts seront leurs indices de confidentialité affichés. Et plus les indices de confidentialité de tes échanges seront hauts, plus haut sera ton propre indice global (ce qui devrait te motiver à mieux renseigner ma fiche contact afin d’y ajouter l’adresse de mon email hébergé sur un service Caliopen, parce qu’alors le protocole choisi sera le protocole intra-caliopen qui aura un très fort indice de confidentialité).
Mais l’utilisateur moyen n’aura sans doute même pas conscience de tout ça. Simplement le système fera en sorte de ne pas envoyer un message en clair s’il dispose d’un moyen plus sûr de le faire pour tel ou tel contact.
Est-ce qu’on pourra (avec un minimum de compétences, par exemple pour des CHATONS) installer Caliopen sur un serveur et proposer à des utilisateurs et utilisatrices une messagerie à la fois sécurisée et respectueuse ?
C’est fondamental, et c’est un des enjeux de Caliopen. Souvent quand je parle devant un public technique je pose la question : « combien de temps mettez-vous à installer un site Web en partant de zéro, et combien de temps pour une messagerie complète ? ». Et les réponses aujourd’hui sont bien sûr diamétralement opposées à ce qu’elle auraient été 15 ans plus tôt, parce qu’on a énormément travaillé sur la facilité d’installation d’un site, depuis des années, alors qu’on a totalement négligé la messagerie.
Si on veut que Caliopen soit massivement adopté, et c’est notre objectif, alors il faudra qu’il soit – relativement – facile à installer. Au moins assez facile pour qu’une entreprise, une administration, une association… fasse le choix de l’installer plutôt que de déléguer à Google la gestion du courrier de ses membres. Il faudra aussi qu’il soit facilement administrable, et facile à mettre à jour. Et tout ceci a été anticipé, et analysé, durant tout ce temps où tu crois qu’on n’a pas été assez vite !
On te laisse le dernier mot comme il est de coutume dans nos interviews pour le blog…
À lire tes questions j’ai conscience qu’on a encore beaucoup d’efforts à faire en termes de communication. Heureusement pour nous, Julien Dubedout nous a rejoints récemment, et je suis sûr qu’il va beaucoup améliorer tout ça. 🙂

 Les appareils connectés à Internet sont si courants et si vulnérables que des pirates informatiques ont récemment pénétré dans un casino via… son aquarium ! Le réservoir était équipé de capteurs connectés à Internet qui mesuraient sa température et sa propreté. Les pirates sont entrés dans les capteurs de l’aquarium puis dans l’ordinateur utilisé pour les contrôler, et de là vers d’autres parties du réseau du casino. Les intrus ont ainsi pu envoyer 10 gigaoctets de données quelque part en Finlande.
Les appareils connectés à Internet sont si courants et si vulnérables que des pirates informatiques ont récemment pénétré dans un casino via… son aquarium ! Le réservoir était équipé de capteurs connectés à Internet qui mesuraient sa température et sa propreté. Les pirates sont entrés dans les capteurs de l’aquarium puis dans l’ordinateur utilisé pour les contrôler, et de là vers d’autres parties du réseau du casino. Les intrus ont ainsi pu envoyer 10 gigaoctets de données quelque part en Finlande.



















{kind=link}
{kind=link}