DIFFUser bientôt vos articles dans le Fediverse ?
Chaque mois le Fediverse s’enrichit de nouveaux projets, probablement parce nous désirons toujours plus de maîtrise de notre vie numérique.
Décentralisé et fédéré, ce réseau en archipel s’articule autour de briques technologiques qui permettent à ses composantes diverses de communiquer. Au point qu’à chaque rumeur de projet nouveau dans le monde du Libre la question est vite posée de savoir s’il sera « fédéré » et donc relié à d’autres projets.
Si vous désirez approfondir vos connaissances au plan technique et au plan de la réflexion sur la fédération, vous trouverez matière à vous enrichir dans les deux mémoires de Nathalie, stagiaire chez Framasoft l’année dernière.
Aujourd’hui, alors que l’idée de publier sur un blog semble en perte de vitesse, apparaît un nouvel intérêt pour la publication d’articles sur des plateformes libres et fédérées, comme Plume et WriteFreely. Maîtriser ses publications sans traqueurs ni publicités parasites, sans avoir à se plier aux injonctions des GAFAM pour se connecter et publier, sans avoir à brader ses données personnelles pour avoir un espace numérique d’expression, tout en étant diffusé dans un réseau de confiance et pouvoir interagir avec lui, voilà dans quelle mouvance se situe le projet DIFFU auquel nous vous invitons à contribuer et que vous présente l’interviewé du jour…
Bonjour, peux-tu te présenter, ainsi que tes activités ?

Bonjour Framasoft. Je m’appelle Jean-Pierre Morfin, on me connaît aussi sur les réseaux sociaux et dans le monde du libre sous le pseudo jpfox. J’ai 46 ans, je vis avec ma tribu familiale recomposée dans un village ardéchois où je pratique un peu (pas assez) le vélo. Informaticien depuis mon enfance, je suis membre du GULL G3L basé à Valence, où je gère avec d’autres l’activité C.H.A.T.O.N.S qui propose plusieurs services comme Mastodon, Diaspora, TT-Rss, boite mail, owncloud…
Passionnés par le libre, Michaël, un ami de longue date et moi-même avons créé en 2010 ce qui s’appelle désormais une Entreprise du Numérique Libre nommée Befox qui propose ses services aux TPE/PME dans la Drôme et l’Ardèche principalement : réalisation de sites à base de solutions libres comme Prestashop, Drupal ou autres, installation Dolibarr et interconnexion entre différents logiciels ou plateformes, hébergement applicatif, évolutions chez nos fidèles clients constituent l’essentiel de notre activité.
Et donc, vous voulez vous lancer dans le développement d’un nouveau logiciel fédéré, « Diffu ». Pourquoi ?
Tout d’abord nous avons ressenti tous les deux le besoin de retourner aux fondamentaux du Libre, et quoi de plus fondamental que le développement d’un logiciel ? Lors de nos divagations sur le Fédiverse, les remarques récurrentes qu’on y trouve ici ou là contre l’utilisation de Medium, nous ont fait penser qu’une alternative pouvait être intéressante. De plus, l’ouverture d’un compte Medium se fait nécessairement avec un compte Facebook ou Google, c’est leur façon d’authentifier un utilisateur ; en bons adeptes de la dégafamisation, c’est une raison de plus de créer une alternative à cette plateforme.
Voyant le succès et tout le potentiel de la Fédération, il fallait que cette nouvelle solution entre de ce cadre-là, car recréer une plateforme unique de publication ou un nouveau moteur de blog avec une gestion interne des commentaires ne présente aucun intérêt. Avec Diffu, la publication d’un article sur une des instances du réseau sera poussée sur le Fédiverse et les commentaires et réactions faits sur Mastodon, Pleroma, Hubzilla ou autre… seront agrégés pour être restitués directement sur la page de l’article. J’invite les lecteurs à jeter un œil à la maquette que nous avons réalisée pour se faire une idée, elle n’est pas fonctionnelle car cela reste encore un projet.
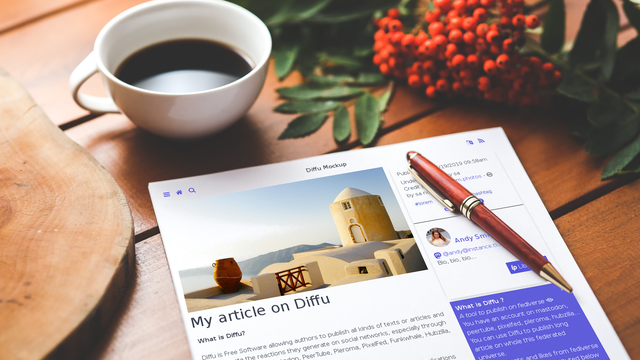
Quant au nom Diffu, on lui trouve deux sens : abréviation de Diffusion, ce qui reste l’objectif d’une plateforme de publication d’articles. Et dans sa prononciation à l’anglaise Diff You qui peut se comprendre Differentiate yourself – Différenciez vous ! C’est un peu ce que l’on fait lorsqu’on livre son avis, son expertise, ses opinions ou ses pensées dans un article.
Il existe déjà des logiciels fédérés de publication, tels que Plume ou WriteFreely. Quelles différences entre Diffu et ces projets ?
Absolument, ces deux applications libres, elles aussi, proposent de nombreux points de similitude avec Diffu notamment dans l’interconnexion avec le Fediverse et la possibilité de réagir aux articles avec un simple compte compatible avec ActivityPub.
La première différence est que pour Plume et WriteFreely, il est nécessaire de créer un compte sur l’instance que l’on souhaite utiliser. Avec Diffu, suivant les restrictions définies par l’administrateur⋅e de l’instance, il sera possible de créer un article juste en donnant son identifiant Mastodon par exemple (pas le mot de passe, hein, juste le pseudo et le nom de l’instance). L’auteur recevra un lien secret par message direct sur son compte Mastodon lui permettant d’accéder à son environnement de publication et de rédiger un nouvel article. Ce dernier sera associé à son auteur ou autrice, son profil Mastodon s’affichant en signature de l’article. Lors de la publication de l’article sur le Fediverse, l’autrice ou l’auteur sera mentionné⋅e dans le pouet qu’il n’aura plus qu’à repartager. L’adresse de la page de l’article sera utilisable sur les autres réseaux sociaux bien évidemment.
Nous voyons plus les instances Diffu comme des services proposés aux possesseurs de comptes ActivityPub. Comme on crée un Framadate ou un Framapad en deux clics, on pourra créer un article.
Les modes de modération et de workflow proposés par Diffu, la thématique choisie, les langues acceptées, la définition des règles de gestion permettront aux administrateurs de définir le public pouvant poster sur leur instance. Il sera par exemple possible de n’autoriser que les auteurs ayant un compte sur telle instance Mastodon, Diffu devenant un service complémentaire que pourrait proposer un CHATONS à ses utilisateurs Mastodon.
Ou, à l’opposé, un défenseur de la liberté d’expression peut laisser son instance Diffu open bar, au risque de voir son instance bloquée par d’autres acteurs du Fediverse, la régulation se faisant à plusieurs niveaux. Nous travaillons encore sur la définition des options de modération possibles, le but étant de laisser à l’administrateur⋅e toute la maîtrise des règles du jeu.
Les options retenues seront clairement explicites sur son instance pour que chacun⋅e puisse choisir la bonne plateforme qui lui convient le mieux. On imagine déjà faire un annuaire reprenant les règles de chaque instance pour aider les auteurs et autrices à trouver la plus appropriée à leur publication. Quitte à écrire sur plusieurs instances en fonction du sujet de l’article : « J’ai testé un nouveau vélo à assistance électrique » sur diffu.velo-zone.fr et « Comment installer LineageOS sur un Moto G4 » sur diffu.g3l.org.
L’autre différence avec Plume et WriteFreely est le langage retenu pour le développement de Diffu. Nous avons choisi PHP car il reste à nos yeux le plus simple à installer dans un environnement web et nous allons tout faire pour que ce soit vraiment le cas. Le locataire d’un simple hébergement mutualisé pourra installer Diffu : on dézippe le fichier de la dernière version, on envoie le tout par ftp sur le site, on accède à la page de configuration pour définir les options de son instance et ça fonctionne. Idem pour les mises à jour.
Nous avons déjà des contacts avec les dev de Plume qui sont tout aussi motivés que nous pour connecter nos plateformes et permettre une interaction entre les utilisateurs. C’est la magie du Fediverse !
Vous êtes en phase de crowdfunding pour le projet Diffu. À quoi va servir cet argent ?
Tout simplement à nous libérer du temps pour développer ce logiciel. On ne peut malheureusement pas se permettre de laisser en plan l’activité de Befox pendant des semaines car cela correspondrait à une absence complète de revenu pour nous deux. C’est donc notre société Befox qui va récolter le fruit de cette campagne et le transformer en rémunération. Nous avons visé au plus juste l’objectif de cette campagne de financement même si on sait que l’on va passer pas mal de temps en plus sur ce projet mais quand on aime…
Il faut aussi mentionner les 8 % de la campagne destinés à rétribuer la plateforme de financement Ulule.
Comment envisages-tu l’avenir de Diffu ?
Comme tout projet libre, après la publication des premières versions, la mise en ligne du code source, nous allons être à l’écoute des utilisateurs pour ajouter les fonctionnalités les plus attendues, garder la compatibilité avec le maximum d’acteurs du Fediverse. On sait que le protocole ActivityPub et ceux qui s’y rattachent peuvent avoir des interprétations différentes. On le voit pour les plateformes déjà en places comme Pleroma, Mastodon, Hubzilla, GNUSocial, PeerTube, PixelFed, WriteFreely et Plume… c’est une nécessité de collaborer avec les autres équipes de développement pour une meilleure expérience des utilisateurs.
Comme souvent ici, on te laisse le mot de la fin, pour poser LA question que tu aurais aimé qu’on te pose, et à laquelle tu aimerais répondre…
La question que l’on peut poser à tous les développeurs du Libre : quel éditeur de sources, Vim ou Emacs ?

La réponse en ce qui me concerne, c’est Vim bien sûr.
Plus sérieusement, cela me permet d’évoquer ce que je trouve génial avec les Logiciels Libres, le fait qu’il y en a pour tous les goûts, que si un outil ne te convient pas, tu peux en utiliser un autre ou modifier/faire modifier celui qui existe pour l’adapter à tes attentes.
Alors même si Plume et WriteFreely existent et font très bien certaines choses, ils sont tous les deux différents et je suis convaincu que Diffu a sa place et viendra en complément de ceux-ci. J’ai hâte de pouvoir m’investir à fond dans ce projet.
Merci pour cette interview, à bientôt sur le Fediverse !





![Kae [CC BY-SA 3.0 (https://creativecommons.org/licenses/by-sa/3.0)], via Wikimedia Commons](https://commons.wikimedia.org/wiki/File:Power_connector_Legrand_32A.jpg){kind=link}
_-_Google_Art_Project_-_edited.jpg){kind=link}
![Codex Bodmer – Frater Rufillus (wohl tätig im Weißenauer Skriptorium) [Public domain]](https://commons.wikimedia.org/wiki/File:Codex_Bodmer_127_244r_detail_Rufillus.jpg){kind=link}