PeerTube : Y’a déjà plein de vidéos !
Hier, nous avons publié un long article présentant la bêta de PeerTube. C’est bien. Mais si ce logiciel sert à créer et fédérer plein de petits « YouTube maison », autant parler des vidéos aussi, non… ?

... mais ce serait peut-être l'une des plus grandes opportunités manquées de notre époque si le logiciel libre ne libérait rien d'autre que du code
Quand les GAFAM et consorts proposent un internet privatif, fermé, centralisateur et espionnant… On a envie de tendre vers des solutions Libres, Ethiques Décentralisées et Solidaires…
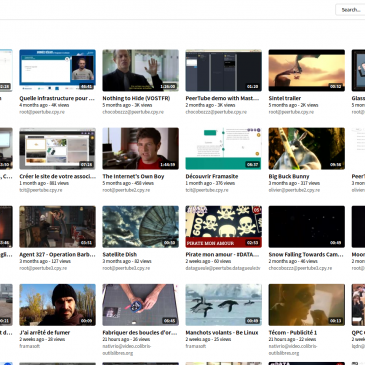
Hier, nous avons publié un long article présentant la bêta de PeerTube. C’est bien. Mais si ce logiciel sert à créer et fédérer plein de petits « YouTube maison », autant parler des vidéos aussi, non… ?
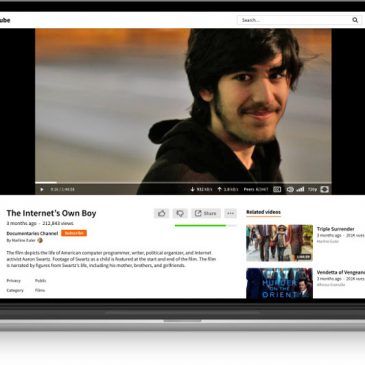
Le 21 novembre dernier, nous annoncions notre volonté de développer PeerTube, un logiciel libre qui pose les bases d’une alternative aux YouTubes et autres plateformes centralisant les vidéos.

Consulter des ouvrages en bibliothèque était hier une opération dont les bibliothécaires défendaient ardemment le caractère confidentiel. Aujourd’hui toutes nos recherches d’informations nous pistent. Voici déjà le 7e article de la série écrite par Rick Falkvinge. Le fondateur du Parti … Lire la suite

Hier nous n’étions surveillés que suite à un soupçon, aujourd’hui nous sommes surveillés en permanence. Voici déjà le 6e article de la série écrite par Falkvinge. Le fondateur du Parti Pirate suédois s’attaque aujourd’hui à la question de notre liberté … Lire la suite

Aujourd’hui 19 février nous célébrons un anniversaire symbolique : voici exactement un an qu’un certain Eugen Roschko a répondu publiquement à Mark Zuckerberg et mentionné le réseau social Mastodon qu’il avait créé quelques mois auparavant.

Hier nous pouvions facilement rencontrer qui nous voulions physiquement de façon privée et être à l’abri des oreilles indiscrètes si nous l’avions décidé. C’est devenu presque impossible aujourd’hui dans l’espace numérique.

Tristan Nitot est un compagnon de route de longue date pour l’association Framasoft et nous suivons régulièrement ses aventures libristes, depuis son implication désormais « historique » pour Mozilla jusqu’à ses fonctions actuelles au sein de Cozy, en passant par la publication … Lire la suite

Dans ce quatrième numéro de la série Nouveaux Léviathans, nous allons voir dans quelle mesure le modèle économique a développé son besoin vital de la captation des données relatives à la vie privée. De fait, nous vivons dans le même … Lire la suite