RGPD : la Quadrature au carré
Classé dans : Dégooglisons Internet (2014-2017), Droits numériques, Enjeux du numérique, G.A.F.A.M., Libertés numériques |
2
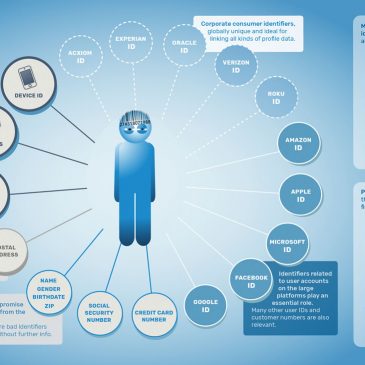
Le 16 avril dernier, la Quadrature du Net a lancé un appel inédit en France pour une action de groupe contre les GAFAM. Cette action s’appuiera sur l’application prochaine du Règlement général sur la protection des données (RGPD).