There was one more present left at the foot of the Christmas tree… The French free software directory and founding project of Framasoft is evolving once again, into a site that’s nicer, simpler, more ergonomic… and a lot more practical for recommending your favourite free software!
🦆 VS 😈: Let’s take back some ground from the tech giants!
There was one more present left at the foot of the Christmas tree… The free software directory and founding project of Framasoft is evolving once again, into a site that’s nicer, simpler, more ergonomic… and a lot more practical for recommending your favourite free software!
So, for people who were used to the previous version of Framalibre, we warn you: it’s going to leave a gap… You have every right to exclaim “but where’s all my junk?” … But for many newcomers to the world of free software, that was the problem!
Maiwann has done a lot of usability testing for us, especially at conferences and at the stands where we meet. These tests helped her to realise, for example, that putting a simple ‘mail’ label on the home page wasn’t helping people who were ‘looking for an alternative to Gmail’.
So for this new version, we’ve made a radical choice: simplicity. So we’ve gone to great lengths to simplify menus, sub-menus, drop-down menus, labels, boxes, notes, buttons, and so on.
This radical choice for simplicity came at a price: we had to refocus the Framalibre directory on digital tools. The previous version wanted to open up to free culture, objects and structures. But the problem with doing a bit of everything is that it’s hard to do everything well: presenting all open source resources meant multiplying menus and categories, while increasing the complexity of creating a listing.
The new Framalibre site is deliberately bare bones. It welcomes you with a page displaying tags (the most frequently used search terms) and a search bar. Goodbye the meta-categories, categories, sub-categories and sub-category filters… In short, the tree structure inherited from the 2001 directory!
Our aim is to respond as quickly as possible to your need to find free software to do what you need to do, or to find an alternative to the service provided by the web giants that you want to free yourself from: you search, you find.
Results for Photoshop search on Framalibre 2024
📃 Under the hood, the pages 📃
Click on GNU and Tux to support Framalibre! – illustration David Revoy – License : CC-By 4.0
For the more technical among you (the rest of you can skip straight to the next part ^^), this simplicity can also be found under the hood.
Framalibre 2017’s Drupal 7 needed a good upgrade, which takes time and energy. The entries database was difficult to access: while we’d done a good job of tinkering with something so that it could be used by others, we would have had to spend more time and energy developing a practical, documented API…
Instead, we decided to devote this energy to applying this choice of simplicity to the software itself, by making the new Framalibre a static site, which we hope will be lighter and faster. The code for this tool, based on Jekyll software, was developed by the talents of l’Échappée Belle (thanks to Fanny and David <3), and of course it’s free and available online.
This choice of static allowed us to modify the structure of the entries and the database. Now written in markdown, these records can be read by both humans and scripts (as long as your robots remain well-behaved, of course :p). As the Framalibre records are CC-By SA, we hope that making them more accessible and readable will lead to some interesting re-uses!
We’ve also taken the opportunity to simplify the manuals as much as possible: you won’t find any screenshots of the software, for example. After a few years, these images are often outdated and misleading. From now on, the information presented in a manual will be simple and concise, and if you like this first look at a particular free software product, we invite you to find out more on the official website.
Entry for Krita on Framalibre 2024
🎁 “Here, this is what I use to free myself…” 🎁.
Click to support us and help to push back MS Blue Scream – Illustration CC-By David Revoy
Because our goal is not for you to stay on Framalibre as long as possible (yes, in the game of attention economy, Framasoft is frankly – and deliberately – bad 😉 ). On the contrary, Framalibre aims to be a mediator, a ramp to take you to the official site of the free tool that meets your needs.
In addition to being a search tool, we have designed this new Framalibre as a tool for recommending free and ethical alternatives. Whether it’s during the preliminary surveys and tests for this redesign of Framalibre, during the regular meetings we attend, or even when we look at how we operate ourselves… we observe the same constant:
It’s much easier to adopt a free tool when it comes highly recommended by people we trust.
This is how we came up with the idea of adding a “used by Framasoft members” box at the top of certain search pages. This doesn’t mean that other software isn’t as good, or that it won’t meet your specific needs: it just shows the free software and services that we use regularly.
[capture mini-site]
💝 Framalibre mini-sites: offer your choices! 💝
With this new version of Framalibre, we wanted to go even further to encourage peer-to-peer recommendations. We know from experience that a person who uses free software today is a person who will help those around him or her to liberate their digital use tomorrow.
On the new Framalibre, you can make your own selection of free tools and get a link to a page that you can share with your friends and family!
Just for fun, here are a few examples we’ve put together for you:
We look forward to hearing your choice of free tools!
GNU and Tux against MB Blue Scream – Illustration David Revoy – License : CC-By 4.0
🤝 Collaboration is about sharing! 🤝
Of course, Framalibre is and will remain a collaborative directory. Whether you want to add a record to the directory or correct an existing record, contributions are just a click away!
What’s more, we’ve made the whole process a lot easier (you can see there’s a theme here!). The downside is that your submissions will be reviewed by our team of moderators before they are published (rather than being moderated after submission, as was previously the case).
The upside is that there are already almost 1,019 entries to discover, like so many of the solutions that open source communities offer each of us to make our digital practices better.
And if you can’t find the entry for that great free software or application that freed you from the web giants… feel free to add it: you’ll see, it’s (unsurprisingly) easy!
So now it’s up to you!
It’s up to you to use Framalibre to find, share and, above all, recommend the free tools that make your digital life easier… and life in general!
Because, yes, at the end of the year, we need you, your support and your sharing to help us regain ground on the toxic GAFAM web and create more ethical digital spaces.
So we’ve asked David Revoy to help us present this on our ‘Support Framasoft’ page, which we invite you to visit (because it’s beautiful) and above all to share as widely as possible:
If we are to balance our budget for 2024, we have just 5 days left to raise € 71 398 : we can’t do it without your help !
Offrez le cadeau du logiciel libre, avec Framalibre !
Il restait un cadeau au pied du sapin… L’annuaire du logiciel libre et projet fondateur de Framasoft évolue à nouveau, en un site plus beau, plus simple, plus ergonomique… et beaucoup plus pratique pour recommander ses logiciels libres préférés !
C’est donc riches de tous ces enseignements que nous avons concocté cette nouvelle version « 2024 » de Framalibre que nous vous présentons aujourd’hui, avec fierté, sur Framalibre.org
Alors pour les personnes qui étaient habituées à la version précédente de Framalibre, on vous prévient : ça va faire un vide… Vous êtes tout à fait en droit de vous écrier « mais il est où, tout mon bazar ? » … Or, pour beaucoup de nouvelles et de nouveaux dans le monde du libre, c’était bien ça le problème !
Maiwann a réalisé pour nous des tests d’utilisation, notamment lors de conférences, ou sur des stands où l’on se rencontre. Ces tests lui ont, par exemple, permis de réaliser qu’afficher une simple étiquette « mail » sur la page d’accueil n’aidait pas pour autant les personnes dont le besoin serait « trouver une alternative à Gmail ».
Pour cette nouvelle mouture, nous avons donc fait un choix radical : celui de la simplicité. Nous avons donc réalisé un grand travail pour simplifier les menus, sous-menus, menus secondaires, étiquettes, encadrés, affichages de notices, boutons…
Ce choix radical de la simplicité a un coût : nous avons dû recentrer l’annuaire Framalibre sur les outils numériques. La version précédente avait voulu s’ouvrir à la culture, aux objets et aux structures du libre. Mais le problème quand on fait un peu de tout, c’est que c’est dur de faire tout bien : présenter tout le Libre induisait de multiplier les menus et les catégories tout en augmentant la complexité pour créer une notice.
Le nouveau site Framalibre est volontairement dépouillé. Il vous accueille par une page affichant des étiquettes (les recherches les plus utilisées) et une barre de recherche. Finies les méta-catégories, catégories, sous catégories, et filtres de sous-catégories… Bref, l’arborescence héritée de l’annuaire de 2001 !
Notre d’objectif est de répondre au plus vite à votre besoin de trouver un logiciel libre pour faire ce que vous avez à faire, ou de trouver une alternative pour remplacer ce service des géants du web dont vous voulez vous libérer : vous cherchez, vous trouvez.
résultats d’une recherche photoshop sur Framalibre 2024
📃 Sous le capot, les pages 📃
Cliquez sur GNU et Tux pour soutenir Framalibre ! – illustration David Revoy – Licence : CC-By 4.0
Pour les plus techniques d’entre vous (les autres, vous pouvez passer directement à la partie suivante ^^), cette simplicité se retrouve aussi sous le capot.
Le Drupal 7 de Framalibre 2017 avait besoin d’une bonne mise à niveau, ce qui demande du temps et de l’énergie. La base de données des notices était difficile d’accès : si nous avions bien bricolé quelque chose pour que cela puisse être utilisé par d’autres, il nous aurait fallu mettre plus de temps et d’énergie à développer une API pratique et documentée…
Nous avons préféré consacrer cette énergie à appliquer ce choix de la simplicité dans le logiciel même, en faisant du nouveau Framalibre un site statique, que l’on espère plus léger et rapide. Le code de cet outil, basé sur le logiciel Jekyll, a été développé par les talents de l’Échappée Belle (merci à Fanny et David <3), et bien entendu il est libre et disponible en ligne.
Ce choix du statique nous a permis de modifier la structure des notices et de la base de données. Désormais écrites en markdown, ces notices sont lisibles aussi bien par des humaines que par des scripts (tant que vos robots restent bien élevés, ça va de soi :p). Les notices de Framalibre étant sous CC-By SA, nous espérons que faciliter leur accès et leur lisibilité permettra des réutilisations intéressantes !
Nous en avons d’ailleurs profité pour simplifier au maximum les notices : vous n’y trouverez plus, par exemple, de capture d’écran du logiciel. En effet, au bout de quelques années, ces images sont souvent périmées et trompeuses. Désormais, les informations présentées dans une notice sont simples, succinctes, et si ce premier regard sur tel ou tel logiciel libre vous plaît, on vous invite à trouver plus d’informations sur le site officiel.
Notice de Krita sur Framalibre 2024
🎁 « Tiens, voici ce que j’utilise pour me libérer… » 🎁
Cliquez pour nous soutenir et aider à repousser MS Blue Scream – Illustration CC-By David Revoy
Car notre objectif n’est pas que vous restiez sur Framalibre le plus longtemps possible (oui, au jeu de l’économie de l’attention, Framasoft est franchement -et volontairement- mauvaise 😉 ). Au contraire, Framalibre se veut un intermédiaire, une rampe pour vous élancer vers le site officiel de l’outil libre qui répond à votre besoin.
Au-delà d’être un outil de recherche, nous avons pensé ce nouveau Framalibre comme un outil de recommandation d’alternatives libres et éthiques. Que ce soit lors des enquêtes et tests préliminaires à cette refonte de Framalibre, durant les rencontres régulières auxquelles nous participons ou même lorsque l’on regarde nos fonctionnements à nous.… nous observons la même constante :
Il est beaucoup plus facile d’adopter un outil libre lorsqu’il nous est chaudement recommandé par des personnes en qui nous avons confiance.
C’est comme cela que nous avons eu l’idée d’ajouter un encadré « utilisé par les membres de Framasoft » en haut de certaines pages de recherche. Cela ne veut pas dire que les autres logiciels soient moins bien, ni qu’ils ne répondent pas à votre attente spécifique : cela permet juste de montrer les logiciels et services libres que nous utilisons régulièrement.
Un mini-site de recommandations Framalibre
💝 Les mini-sites Framalibre : offrez vos sélections ! 💝
Avec cette nouvelle version de Framalibre, nous avions envie d’aller encore plus loin pour favoriser la recommandation de pair à pair. Nous savons, d’expérience, qu’une personne qui utilise du libre aujourd’hui est une personne qui, demain, aidera ses proches à libérer leurs usages numériques.
Sur le nouveau Framalibre, vous pouvez faire votre sélection d’outils libres, et obtenir le lien d’une page à partager avec vos proches !
Rien que pour le plaisir, voici quelques exemples que nous vous avons concoctés :
Nous avons hâte de vous voir partager vos sélections d’outils libres !
GNU & Tux contre MB Blue Scream – Illustration David Revoy – Licence : CC-By 4.0
🤝 Le collaboratif, ça se partage ! 🤝
Bien entendu, Framalibre est et reste un annuaire collaboratif. Que vous vouliez ajouter une notice à l’annuaire ou corriger une notice existante, la contribution est à portée de clic !
Nous avons d’ailleurs rendu tout le processus plus… simple (vous sentiez qu’il y a comme un thème, là !). La contrepartie, c’est que vos contributions seront vérifiées avant publication par notre équipe de modératrices et modérateurs (et non plus modérées a posteriori comme avant).
L’avantage, c’est qu’il y a déjà près de 1 019 notices à aller découvrir, comme autant de solutions que les communautés du Libre offrent à chacune et chacun d’entre nous pour mieux émanciper ses pratiques numériques.
Et si vous n’y trouvez pas la fiche de ce super logiciel libre ou de cette app formidable qui vous a émancipé des géants du web… Libre à vous de l’ajouter : vous allez voir, c’est (sans trop de surprise) simple !
Alors désormais, c’est à vous de jouer !
À vous de vous emparer de Framalibre pour trouver, partager mais surtout pour recommander les outils libres qui vous facilitent la vie numérique… et la vie tout court !
Car oui : cette fin d’année encore, nous avons besoin de vous, de votre soutien, de vos partages, pour nous aider à reprendre du terrain sur le web toxique des GAFAM, et multiplier les espaces de numérique éthique.
Nous avons donc demandé à David Revoy de nous aider à montrer cela sur notre site Soutenir Framasoft, que nous vous invitons à visiter (parce que c’est beau) et surtout à partager le plus largement possible :
Si nous voulons boucler notre budget pour 2024, il ne nous reste plus que 5 jours pour récolter 71 398 € : nous n’y arriverons pas sans votre aide !
Depuis plusieurs années, Framasoft est honoré et enchanté des illustrations que lui fournit David Revoy, comme sont ravi⋅es les lectrices et lecteurs qui apprécient les aventures de Pepper et Carrot et les graphistes qui bénéficient de ses tutoriels. Ses créations graphiques sont sous licence libre (CC-BY), ce qui est un choix courageux compte tenu des « éditeurs » dépourvus de scrupules comme on peut le lire dans cet article.
Cet artiste talentueux autant que généreux explique aujourd’hui son embarras face aux IA génératives et pourquoi son éthique ainsi que son processus créatif personnel l’empêchent de les utiliser comme le font les « IArtistes »…
« C’est cool, vous avez utilisé quel IA pour faire ça ? »
« Son travail est sans aucun doute de l’IA »
« C’est de l’art fait avec de l’IA et je trouve ça déprimant… »
… voilà un échantillon des commentaires que je reçois de plus en plus sur mon travail artistique.
Et ce n’est pas agréable.
Dans un monde où des légions d’IArtistes envahissent les plateformes comme celles des médias sociaux, de DeviantArt ou ArtStation, je remarque que dans l’esprit du plus grand nombre on commence à mettre l’Art-par-IA et l’art numérique dans le même panier. En tant qu’artiste numérique qui crée son œuvre comme une vraie peinture, je trouve cette situation très injuste. J’utilise une tablette graphique, des layers (couches d’images), des peintures numériques et des pinceaux numériques. J’y travaille dur des heures et des heures. Je ne me contente pas de saisir au clavier une invite et d’appuyer sur Entrée pour avoir mes images.
C’est pourquoi j’ai commencé à ajouter les hashtags #HumanArt puis #HumanMade à mes œuvres sur les réseaux sociaux pour indiquer clairement que mon art est « fait à la main » et qu’il n’utilise pas Stable Diffusion, Dall-E, Midjourney ou n’importe quel outil de génération automatique d’images disponible aujourd’hui. Je voulais clarifier cela pour ne plus recevoir le genre de commentaires que j’ai cités au début de mon intro. Mais quel est le meilleur hashtag pour cela ?
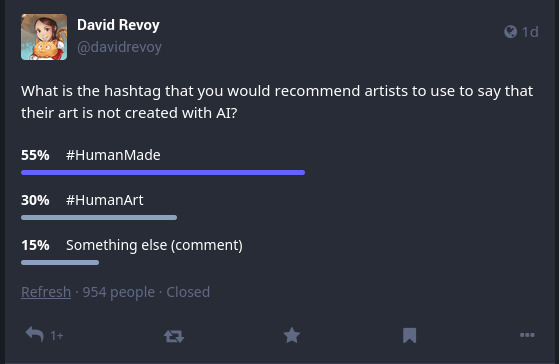
Je ne savais pas trop, alors j’ai lancé un sondage sur mon fil Mastodon
Sur 954 personnes qui ont voté (je les remercie), #HumanMade l’emporte par 55 % contre 30 % pour #HumanArt. Mais ce qui m’a fait changer d’idée c’est la diversité et la richesse des points de vue que j’ai reçus en commentaires. Bon nombre d’entre eux étaient privés et donc vous ne pouvez pas les parcourir. Mais ils m’ont vraiment fait changer d’avis sur la question. C’est pourquoi j’ai décidé de rédiger cet article pour en parler un peu.
Critiques des hashtags #HumanMade et #HumanArt
Tout d’abord, #HumanArt sonne comme une opposition au célèbre tag #FurryArt de la communauté Furry. Bien vu, ce n’est pas ce que je veux.
Et puis #HumanMade est un choix qui a été critiqué parce que l’IA aussi était une création humaine, ce qui lui faisait perdre sa pertinence. Mais la plupart des personnes pouvaient facilement comprendre ce que #HumanMade signifierait sous une création artistique. Donc 55 % des votes était un score cohérent.
J’ai aussi reçu pas mal de propositions d’alternatives comme #HandCrafted, #HandMade, #Art et autres suggestions.
Le succès de #NoAI
J’ai également reçu beaucoup de suggestions en faveur du hashtag #NoAI, ainsi que des variantes plus drôles et surtout plus crues. C’était tout à fait marrant, mais je n’ai pas l’intention de m’attaquer à toute l’intelligence artificielle. Certains de ses usages qui reposent sur des jeux de données éthiques pourraient à l’avenir s’avérer de bons outils. J’y reviendrai plus loin dans cet article.
De toutes façons, j’ai toujours essayé d’avoir un état d’esprit « favorable à » plutôt que « opposé à » quelque chose.
C’est aux artistes qui utilisent l’IA de taguer leur message
Ceci est revenu aussi très fréquemment dans les commentaires. Malheureusement, les IArtistes taguent rarement leur travail, comme on peut le voir sur les réseaux sociaux, DeviantArt ou ArtStation. Et je les comprends, vu le nombre d’avantages qu’ils ont à ne pas le faire.
Pour commencer, ils peuvent se faire passer pour des artistes sans grand effort. Ensuite, ils peuvent conférer à leur art davantage de légitimité à leurs yeux et aux yeux de leur public. Enfin, ils peuvent probablement éviter les commentaires hostiles et les signalements des artistes anti-IA des diverses plateformes.
Je n’ai donc pas l’espoir qu’ils le feront un jour. Je déteste cette situation parce qu’elle est injuste.
Mais récemment j’ai commencé à apprécier ce comportement sous un autre angle, dans la mesure où ces impostures pourraient ruiner tous les jeux de données et les modèles d’apprentissage : les IA se dévorent elles-mêmes.
Quand David propose de saboter les jeux de données… 😛
Pas de hashtag du tout
La dernière suggestion que j’ai fréquemment reçue était de ne pas utiliser de hashtag du tout.
En effet, écrire #HumanArt, #HumanMade ou #NoAI signalerait immédiatement le message et l’œuvre comme une cible de qualité pour l’apprentissage sur les jeux de données à venir. Comme je l’ai écrit plus haut, obtenir des jeux de données réalisées par des humains est le futur défi des IA. Je ne veux surtout pas leur faciliter la tâche.
Il m’est toujours possible d’indiquer mon éthique personnelle en écrivant « Œuvre réalisée sans utilisation de générateur d’image par IA qui repose sur des jeux de données non éthiques » dans la section d’informations de mon profil de média social, ou bien d’ajouter simplement un lien vers l’article que j’écris en ce moment même.
Conclusion et considérations sur les IA
J’ai donc pris ma décision : je n’utiliserai pour ma création artistique aucun hashtag, ni #HumanArt, ni #HumanMade, ni #NoAI.
Je continuerai à publier en ligne mes œuvres numériques, comme je le fais depuis le début des années 2000.
Je continuerai à tout publier sous une licence permissive Creative Commons et avec les fichiers sources, parce que c’est ainsi que j’aime qualifier mon art : libre et gratuit.
Malheureusement, je ne serai jamais en mesure d’empêcher des entreprises dépourvues d’éthique de siphonner complètement mes collections d’œuvres. Le mal est en tout cas déjà fait : des centaines, voire des milliers de mes illustrations et cases de bandes dessinées ont été utilisées pour entraîner leurs IA. Il est facile d’en avoir la preuve (par exemple sur haveibeentrained.com ou bien en parcourant le jeu de données d’apprentissage Laion5B).
Je ne suis pas du tout d’accord avec ça.
Quelles sont mes possibilités ? Pas grand-chose… Je ne peux pas supprimer mes créations une à une de leur jeu de données. Elles ont été copiées sur tellement de sites de fonds d’écran, de galeries, forums et autres projets. Je n’ai pas les ressources pour me lancer là-dedans. Je ne peux pas non plus exclure mes créations futures des prochaines moissons par scans. De plus, les méthodes de protection comme Glaze me paraissent une piètre solution au problème, je ne suis pas convaincu. Pas plus que par la perspective d’imposer des filigranes à mes images…
Ne vous y trompez pas : je n’ai rien contre la technologie des IA en elle-même.On la trouve partout en ce moment. Dans le smartphones pour améliorer les photos, dans les logiciels de 3D pour éliminer le « bruit » des processeurs graphiques, dans les outils de traduction [N. de T. la présente traduction a en effet été réalisée avec l’aide DeepL pour le premier jet], derrière les moteurs de recherche etc. Les techniques de réseaux neuronaux et d’apprentissage machine sur les jeux de données s’avèrent très efficaces pour certaines tâches.
Les projets FLOSS (Free Libre and Open Source Software) eux-mêmes comme GMIC développent leurs propres bibliothèques de réseaux neuronaux. Bien sûr elles reposeront sur des jeux de données éthiques. Comme d’habitude, mon problème n’est pas la technologie en elle-même. Mon problème, c’est le mode de gouvernance et l’éthique de ceux qui utilisent de telles technologies.
Pour ma part, je continuerai à ne pas utiliser d’IA génératives dans mon travail (Stable Diffusion, Dall-E, Midjourney et Cie). Je les ai expérimentées sur les médias sociaux par le passé, parfois sérieusement, parfois en étant impressionné, mais le plus souvent de façon sarcastique .
Je n’aime pas du tout le processus des IA…
Quand je crée une nouvelle œuvre, je n’exprime pas mes idées avec des mots.
Quand je crée une nouvelle œuvre, je n’envoie pas l’idée par texto à mon cerveau.
C’est un mixage complexe d’émotions, de formes, de couleurs et de textures. C’est comme saisir au vol une scène éphémère venue d’un rêve passager rendant visite à mon cerveau. Elle n’a nul besoin d’être traduite en une formulation verbale. Quand je fais cela, je partage une part intime de mon rêve intérieur. Cela va au-delà des mots pour atteindre certaines émotions, souvenirs et sensations.
Avec les IA, les IArtistes se contentent de saisir au clavier un certains nombre de mots-clés pour le thème. Ils l’agrémentent d’autres mots-clés, ciblent l’imitation d’un artiste ou d’un style. Puis ils laissent le hasard opérer pour avoir un résultat. Ensuite ils découvrent que ce résultat, bien sûr, inclut des émotions sous forme picturale, des formes, des couleurs et des textures. Mais ces émotions sont-elles les leurs ou bien un sous-produit de leur processus ? Quoi qu’il en soit, ils peuvent posséder ces émotions.
Les IArtistes sont juste des mineurs qui forent dans les œuvres d’art générées artificiellement, c’est le nouveau Readymade numérique de notre temps. Cette technologie recherche la productivité au moindre coût et au moindre effort. Je pense que c’est très cohérent avec notre époque. Cela fournit à beaucoup d’écrivains des illustrations médiocres pour les couvertures de leurs livres, aux rédacteurs pour leurs articles, aux musiciens pour leurs albums et aux IArtistes pour leurs portfolios…
Je comprends bien qu’on ne peut pas revenir en arrière, ce public se sent comme empuissanté par les IA. Il peut finalement avoir des illustrations vite et pas cher. Et il va traiter de luddites tous les artistes qui luttent contre ça…
Mais je vais persister ici à déclarer que personnellement je n’aime pas cette forme d’art, parce qu’elle ne dit rien de ses créateurs. Ce qu’ils pensent, quel est leur goût esthétique, ce qu’ils ont en eux-mêmes pour tracer une ligne ou donner tel coup de pinceau, quelle lumière brille en eux, comment ils masquent leurs imperfections, leurs délicieuses inexactitudes en les maquillant… Je veux voir tout cela et suivre la vie des personnes, œuvre après œuvre.
Vous pouvez soutenir la travail de David Revoy en devenant un mécène ou en parcourant sa boutique.
Piwigo, la photo en liberté
Nous avons profité de la sortie d’une nouvelle version de l’application mobile pour interroger l’équipe de Piwigo, et plus particulièrement Pierrick, le créateur de ce logiciel libre qui a fêté ses vingt ans et qui est, c’est incroyable, rentable.
Moi je note que «Piwigo» c’est plus sympa que « PhpWebGallery », comme nom de logiciel. Enfin, un logiciel libre qui n’a pas un nom trop tordu. Qu’est-ce que vous pouvez nous apprendre sur Piwigo, le logiciel ?
Piwigo est un logiciel libre de gestion de photothèque. Il s’agit d’une application web, donc accessible depuis un navigateur web, que l’on peut également consulter et administrer avec des applications mobiles. Au-delà des photos, Piwigo permet d’organiser et indexer tout type de média : images, vidéos, documents PDF et autres fichiers de travail des graphistes. Originellement conçu pour les particuliers, il s’est au fil des ans trouvé un public auprès des organisations de toutes tailles.
Le logo de Piwigo, le logiciel
La gestation du projet PhpWebGallery démarre fin 2001 et la première version sortira aux vacances de Pâques 2002. Pendant les vacances, car j’étais étudiant en école d’ingénieur à Lyon et j’ai eu besoin de temps libre pour finaliser la première version. Le logiciel a tout de suite rencontré un public et des contributeurs ont rejoint l’aventure. En 2009, « PhpWebGallery » est renommé « Piwigo » mais seul le nom a changé, il s’agit du même projet.
Les huit premières années, le projet était entièrement bénévole, avec des contributeurs (de qualité) qui donnaient de leur temps libre et de leurs compétences. Le passage d’étudiant à salarié m’a donné du temps libre, vraiment beaucoup. Je faisais pas mal d’heures pour mon employeur mais en comparaison avec le rythme prépa/école, c’était très tranquille : pas de devoirs à faire le soir ! Donc Piwigo a beaucoup avancé durant cette période. Devenu parent puis propriétaire d’un appartement, avec les travaux à faire… mon temps libre a fondu et il a fallu faire des choix. Soit j’arrêtais le projet et il aurait été repris par la communauté, soit je trouvais un modèle économique viable et compatible avec le projet pour en faire mon métier. Si je suis ici pour en parler douze ans plus tard, c’est que cette deuxième option a été retenue.
En 2010 vous lancez le service piwigo.com ; un logiciel libre dont les auteurs ne crèvent pas de faim, c’est plutôt bien. Est-ce que c’est vrai ? Avez-vous trouvé votre modèle économique ?
Le logo de Piwigo, le service
Pour ce qui me concerne, je ne crève pas du tout de faim. J’ai pu rapidement retrouver des revenus équivalents à mon ancien salaire. Et davantage aujourd’hui. J’estime vivre très confortablement et ne manquer de rien. Ceci est très subjectif et mon mode de vie pourrait paraître « austère » pour certains et « extravagant » pour d’autres. En tout cas moi cela me convient 🙂
Notre modèle économique a un peu évolué en 12 ans. Si l’objectif est depuis le départ de se concentrer sur la vente d’abonnements, il a fallu quelques années pour que cela couvre mon salaire. J’ai eu l’opportunité de réaliser des prestations de dev en parallèle de Piwigo les premières années pour compenser la croissance lente des ventes d’abonnements.
Ce qui a beaucoup changé c’est notre cible : on est passé d’une cible B2C (à destination des individus) à une cible B2B (à destination des organisations). Et cela a tout changé en terme de chiffre d’affaires. Malheureusement ou plutôt « factuellement » nous plafonnons depuis longtemps sur les particuliers. Nos offres Entreprise quant à elles sont en croissance continue, sans que l’on atteigne encore de plafond. Nous avons donc décidé de communiquer vers cette cible. Piwigo reste utilisable pour des particuliers bien sûr, mais ce sont prioritairement les organisations qui vont orienter notre feuille de route.
Grâce à la réorientation de notre modèle économique, il a été possible de faire grossir l’équipe.
Donc on a Piwigo.org qui fournit le logiciel libre que chacun⋅e peut installer à condition d’en avoir les compétences, et Piwigo.com, service commercial géré par ton équipe et toi. Vous vous chargez de la maintenance, des mises à jour, des sauvegardes.
Qui est vraiment derrière Piwigo.com aujourd’hui ? Et combien de gens est-ce que ça fait vivre ?
Une petite équipe mêlant des salariés, dont plusieurs alternants, des freelances dans les domaines du support, de la communication, du design ou encore de la gestion administrative. Cela représente 8 personnes, certaines à temps plein, d’autres à temps partiel. J’exclus le cabinet comptable, même s’il y passe du temps compte tenu du nombre de transactions que les abonnements représentent…
Qu’est-ce qui est lourd ?
Certains aspects purement comptables de l’activité. La gestion de la TVA par exemple. Non pas le principe de la TVA mais les règles autour de la TVA. Nous vendons en France, dans la zone Euro et hors zone Euro : à chaque situation sa règle d’application des taxes. Les PCA (produits constatés d’avance) sont aussi une petite source de tracas qu’il a fallu gérer proprement. Jamais je n’aurais imaginé passer autant de temps sur ce genre de sujets en lançant le projet commercial.
Qu’est-ce qui est cool ?
Constater que Piwigo est leur principal outil de travail de nombreux clients. On comprend alors que certains choix de design, certaines optimisations de performances font pour eux une grande différence au quotidien.
Création d’un⋅e utilisateur⋅ice
Nous avons lancé depuis quelques semaines une série d’entretiens utilisateurs durant lesquels des clients nous montrent comment ils utilisent Piwigo et c’est assez génial de les voir utiliser voire détourner les fonctionnalités que l’on a développées.
D’un point de vue vraiment personnel, ce que je trouve cool c’est qu’un projet démarré sur mon temps libre pendant mes études soit devenu créateur d’emplois. Et j’espère un emploi « intéressant » pour les personnes concernées. Qu’elles soient participantes à l’aventure ou utilisatrices dans leur métier. Je crois vraiment au rôle social de l’entreprise et je suis particulièrement fier que Piwigo figure dans le parcours professionnel de nombreuses personnes.
Oui, je suis d’accord : ça claque ! et bien sûr tout est absolument authentique. Évidemment on n’affiche qu’une portion microscopique de notre liste de clients.
Recevez-vous des commandes spécifiques des gros clients pour développer certaines fonctionnalités ?
Pourquoi des « gros » ? Certaines entreprises « pas très grosses » ont des demandes spécifiques aussi. Bon, en pratique c’est vrai que certains « gros » ont l’habitude que l’outil s’adapte à leur besoin et pas le contraire. Donc parfois on adapte : en personnalisant l’interface quasiment toujours, en développant des plugins parfois. C’est moins de 5% de nos clients qui vont payer une prestation de développement. Vendre ce type de prestation n’est pas au cœur de notre modèle économique mais ne pas le proposer pourrait nuire à la vente d’abonnements, donc on est ouverts aux demandes.
Est-ce que vous refusez de faire certaines choses ?
D’un point de vue du développement ? Pas souvent. Je n’ai pas souvenir de demandes suffisamment farfelues… pardon « spécifiques » pour qu’on les refuse a priori. En revanche il y a des choses qu’on refuse systématiquement : répondre à des appels d’offre et autre « marchés publics ». Quand une administration nous contacte et nous envoie des « dossiers » avec des listes de questions à rallonge, on s’assure qu’il n’y a pas d’appel d’offre derrière car on ne rentrera pas dans le processus. Nous ne vendons pas assez cher pour nous permettre de répondre à des appels d’offre. Je comprends que les entreprises qui vendent des tickets à 50k€+ se permettent ce genre de démarche administrative, mais avec notre ticket entre 500€ et 4 000€, on serait perdant à tous les coups. Le « coût administratif » d’un appel d’offre est plus élevé que le coût opérationnel de la solution proposée. C’est aberrant et on refuse de rentrer là-dedans.
Bien que nous refusions de répondre à cette complexité administrative (très française), nous avons de nombreuses administrations comme clients : ministère, mairies, conseils départementaux, offices de tourisme… Comme quoi c’est possible (et légal) de ne pas gaspiller de l’énergie et du temps à remplir des dossiers.
Y a-t-il beaucoup de particuliers qui, comme moi, vous confient leurs photos ? Faites péter les chiffres qui décoiffent !
Environ 2000 particuliers sont clients de notre offre hébergée. Ils sont bien plus nombreux à confier leurs photos à Piwigo, mais ils ne sont pas hébergés sur nos serveurs. Notre dernière enquête en 2020 indiquait qu’environ un utilisateur sur dix était client de Piwigo.com [donc 90% des gens qui utilisent le logiciel Piwigo s’auto-hébergent ou s’hébergent ailleurs, NDLR] .
Si on élargit un peu le champ de vision, on estime qu’il y a entre 50 000 et 500 000 installations de Piwigo dans le monde. Avec une énorme majorité d’installations hors Piwigo.com donc. Difficile à chiffrer précisément car Piwigo ne traque pas les installations.
La page d’administration de Piwigo
Pour des chiffres qui « décoiffent », je dirais qu’on a fait 30% de croissance en 2020. Puis encore 30% de croissance en 2021 (merci les confinements…) et qu’on revient à notre rythme de croisière de +15% par an en 2022. Dans le contexte actuel de difficulté des entreprises, je trouve qu’on s’en sort bien !
Autre chiffre qui décoiffe : on n’a pas levé un seul euro. Aucun business angel, aucune levée de fonds auprès d’investisseurs. Notre croissance est douce mais sereine. Attention pour autant : je ne dénigre pas le principe de lever des fonds. Cela permet d’aller beaucoup plus vite. Vers le succès ou l’échec, mais beaucoup plus vite ! Rien ne dit que si c’était à refaire, je n’essaierais pas de lever des fonds.
Encore un chiffre respectable : Piwigo a soufflé sa vingtième bougie en 2022. Le projet a connu plusieurs phases et nous vivons actuellement celle de la professionnalisation. Beaucoup de projets libres s’arrêtent avant et disparaissent car ils ne franchissent pas cette étape. Si certains voient dans l’arrivée de l’argent une « trahison » de la communauté, je trouve au contraire que c’est sain et gage de pérennité. Lorsque les fondateurs d’un projet ont besoin d’un modèle économique viable pour payer leurs propres factures, vous pouvez être sûrs que le projet ne va pas être abandonné sur un coup de tête.
Est-ce que les réseaux sociaux axés sur la photographie concurrencent Piwigo ? On pense à Instagram mais aussi à Pixelfed, évidemment.
J’ai regardé rapidement ce qu’était Pixelfed. Ma conclusion au bout de quelques minutes : c’est un clone opensource à Instagram, en mode décentralisé.
Piwigo n’est pas un réseau social. Pour certains utilisateurs, Piwigo a perdu de son intérêt dès lors que Facebook et ses albums photos sont arrivés. Pour d’autres, Piwigo constitue au contraire une solution pour ceux qui refusent la centralisation/uniformisation telle que proposée par Facebook ou Google. Enfin pour de nombreux clients pro (photographes ou entreprises) Piwigo est un outil à usage interne de l’équipe communication pour organiser les ressources média qui seront ensuite utilisées sur les réseaux sociaux. Il faut comprendre que pour les chargés de communication d’un office de tourisme, mettre sa photothèque sur Facebook n’a aucun sens. Ils ou elles publient quelques photos sur Facebook, sur Instagram ou autres, mais leur photothèque est organisée sur leur Piwigo.
Bref, même si les premières années je me suis demandé si Piwigo était encore pertinent face à l’émergence de ces nouvelles formes de communication, je sais aujourd’hui que Piwigo n’est pas en concurrence frontale avec ces derniers mais qu’au contraire, l’existence de ces réseaux nécessite pour les marques/entreprises qu’elles organisent leurs photothèques. Piwigo est là pour les y aider.
Quelles sont les différences ?
La toute première des choses, c’est la temporalité. Les réseaux sociaux sont excellents pour obtenir une exposition forte et éphémère de votre « actualité ». À l’inverse, Piwigo va exceller pour vous permettre de retrouver un lot de photos parmi des centaines de milliers, organisées au fil des années. Piwigo permet de gérer son patrimoine photo (et autres médias) sur le temps long.
L’autre aspect important c’est le travail en équipe. Un réseau social est généralement conçu autour d’une seule personne qui administre le compte. Dans Piwigo, plusieurs administrateurs collaborent (à un instant T ou dans la durée) pour construire la photothèque : classification, indexation (tags, titre, descriptions…)
Enfin, certaines fonctionnalités n’ont tout simplement rien à voir. Par exemple, dans un réseau social le cœur de métier va être d’obtenir des likes. Dans un Piwigo, vous allez pouvoir mettre en place un moteur de recherche multicritères avec vos propres critères. Par exemple on a un client qui fabrique des matériaux acoustiques. Ses critères de recherche sont collection, coloris, lieu d’implantation… Cela n’aurait aucun sens sur l’interface uniformisée d’un Instagram.
Qui apporte des contributions à Piwigo ? Est-ce que c’est surtout la core team ?
Cela a beaucoup changé avec le temps. Et même ce qu’on appelle aujourd’hui « équipe » n’est plus la même chose que ce qu’on appelait « équipe » il y a 10 ans. Aujourd’hui, l’équipe c’est essentiellement celle du projet commercial. Pas uniquement mais quand même pas mal.
On a donc beaucoup de contributions « internes » mais ce serait trop simplificateur d’ignorer l’énorme apport de la communauté de contributeurs au sens large. Déjà parce que l’état actuel de Piwigo repose sur les fondations créées par une communauté de développeurs bénévoles. Ensuite parce qu’on reçoit bien sûr des contributions sous forme de rapports de bugs, des pull-requests mais aussi grâce à des bénévoles qui aident des utilisateurs sur les forums communautaires, les bêta-testeurs… sans oublier les centaines de traducteurs.
Petite anecdote dont je suis fier : Rasmus Lerdorf, créateur de PHP (le langage de programmation principalement utilisé dans Piwigo) nous a plusieurs fois envoyé des patches pour que Piwigo soit compatibles avec les dernières versions de PHP.
Quel est votre lien avec le monde du Libre ? (<troll>y a-t-il un monde du Libre ?</troll>)
Je ne sais pas s’il y a un « monde du libre ». Historiquement Les contributeurs sont d’abord des utilisateurs du logiciel qui ont voulu le faire évoluer. Je ne suis pas certain qu’il s’agisse de fervents défenseurs du logiciel libre.
Franchement je ne sais pas trop comment répondre à cette question. Je sais que Piwigo est une brique de ce monde du libre mais je ne suis pas sûr que l’on conscientise le fait de faire partie d’un mouvement global. Je pense qu’on est pragmatique plutôt qu’idéologique.
En tant que client, je viens de recevoir le mail qui annonce le changement de tarif. Pouvez-vous nous expliquer l’origine de cette décision ?
Là on est vraiment sur l’actualité « à chaud ». Le changement de tarif pour les nouveaux/futurs clients a fait l’objet d’une longue réflexion et préparation. Je dirais qu’on le prépare depuis 18 mois.
Si j’ai bien compris la clientèle particulière est un tout petit pourcentage de la clientèle de Piwigo.com ?
Les clients de l’ancienne offre « individuelle » représentent 30 % du chiffre d’affaires des abonnements pour 91% des clients. J’exclus les prestations de dev, qui sont exclusivement ordonnées par des entreprises. Donc « tout petit pourcentage », ça dépend du point de vue 🙂
Est-ce que l’offre de stockage illimité devient trop chère ?
En moyenne sur l’ensemble des clients individuels, on est à ~30 Go de stockage utilisé. La médiane est quant à elle de 5Go. Si la marge financière dégagée n’est pas folle, on ne perd pas d’argent pour autant, car nous avons réussi à ne pas payer le stockage trop cher. Pour faire simple : on n’utilise pas de stockage cloud type Amazon Web Services, Google Cloud ou Microsoft Azure. Sinon on serait clairement perdant.
Ceci est vrai tant qu’on propose de l’illimité sur les photos. Sauf que la première demande au support, devant toutes les autres, c’est : « puis-je ajouter mes vidéos ? », et cela change la donne. Hors de question de proposer de l’illimité sur les vidéos. De l’autre côté, on entend et on comprend la demande des utilisateurs concernant les vidéos. Donc on veut proposer les vidéos, mais il faut en parallèle introduire un quota de stockage.
Ensuite nous avions un souci de cohérence entre l’offre individuelle (stockage illimité mais photos uniquement) et les offres entreprise (quota de stockage et tout type de fichiers). La solution qui nous paraît la meilleure est d’imposer un quota pour toutes les offres, mais un quota généreux. L’offre « Perso » est à 50 Go de stockage, donc largement au-delà de la conso moyenne.
Enfin la principe de l’illimité est problématique. En 12 ans, la perception du grand public sur le numérique a évolué. Je parle spécifiquement de la consommation de ressources que le numérique représente. Le cloud, ce sont des serveurs dans des centres de données qui consomment de l’électricité, etc. En 2023, je pense que tout le monde a intégré le fait que nous vivons dans un monde fini. Ceci n’est pas compatible avec la notion de stockage infini. Je peux vous assurer que certains utilisateurs n’ont pas conscience de cette finitude.
Est-ce que des pros ont utilisé cette offre destinée aux particuliers pour «abuser» ?
Il y a des abus sur l’utilisation de l’espace de stockage, mais pas spécialement par des pros. On a des particuliers qui scannent des documents en haute résolution par dizaine de milliers pour des téraoctets stockés… On a des particuliers qui sont fans de telle ou telle star de cinéma et qui font des captures d’écran chaque seconde de chaque film de cet acteur. Ne rigolez pas, cela existe.
En revanche on avait un soucis de positionnement : l’offre « individuelle » n’était pas très appropriée pour les photographes pros mais l’offre entreprise était trop chère. On a maintenant des offres mieux étagées et on espère que cela sera plus pertinent pour ce type de client.
Enfin on a des entreprises qui essaient de prendre l’offre individuelle en se faisant passer pour des particuliers. Et là on est obligés de faire les gendarmes. On a même détecté des « patterns » de ses entreprises et on annulait les commandes « individuelles » de ces clients. J’en avais personnellement un petit peu ras le bol 🙂
Les nouvelles offres, même « Perso » sont accessibles même à des multinationales. Évidemment, les limites qu’on a fixées devraient naturellement les orienter vers nos offres Entreprise (nouvelle génération) voire VIP.
Est-ce qu’il s’agissait d’une offre qui se voulait temporaire et que vous avez laissé filer parce que vous étiez sur autre chose ?
Pendant 12 ans ? Non non, le choix de proposer de l’illimité en 2010 était réfléchi et « à durée indéterminée ». Les besoins et les possibilités et surtout les demandes ont changé. On s’adapte. On espère ne pas se tromper et si c’est le cas on fera des ajustements.
L’important c’est de pas mettre nos clients au pied du mur : ils peuvent renouveler sur leur offre d’origine. On a toujours proposé cela et on ne compte pas changer cette règle. C’est assez unique dans notre secteur d’activité mais on y tient.
Nous avons vu que votre actualité c’était la nouvelle version de Piwigo NG. Je crois que vous avez besoin d’aide. Vous pouvez nous en parler ?
Nous avons plusieurs actualités et effectivement côté logiciel, c’est la sortie de la version 2 de l’application mobile pour Android. Piwigo NG (comme Next Generation) est le résultat du travail de Rémi, qui travaille sur Piwigo depuis deux ans. Après avoir voulu faire évoluer l’application « native » sans succès, il a créé en deux semaines un prototype d’application mobile en Flutter. Ce qu’il avait fait en deux semaines était meilleur que ce que l’on galérait à obtenir avec l’application native en plusieurs mois. On a donc décidé de basculer sur cette nouvelle technologie. Un an après la sortie de Piwigo NG, Rémi sort une version 2 toujours sur Flutter mais avec une nouvelle architecture « plus propice aux évolutions ». Le fameux « il faut refactorer tous les six mois », devise des développeurs Java.
CLIC : Un projet pour des apprentissages numériques plus interactifs
La proposition de CLIC est de s’auto-héberger (de faire fonctionner des services web libres sur son propre matériel) et de disposer de ses contenus et données localement, et/ou sur le grand Internet avec un système technique pré-configuré. Le dispositif s’adresse plutôt à des militant⋅es, des chercheur⋅euses, des formateur⋅ices… amené⋅es à se rendre sur le terrain, où la connexion Internet n’est pas toujours stable, voire est inexistante.
Note grammaticale : nous n’avons pas réussi à trancher entre « le CLIC » ou « la CLIC » pour le nom du dispositif, alors en attendant de décider, nous alternons entre les deux tout au long de l’article.
Depuis décembre 2022, un an après une première rencontre, la clique du projet CLIC s’est retrouvée deux fois :
à Paris au CICP et en ligne pour une nouvelle session de travail et d’échange avec des chercheur⋅ses de l’IRD.
à Montpellier au Mas Cobado dans une ambiance de fablab éphémère
À la fin de la session de novembre 2021, l’objectif pour 2022 était d’avoir testé le dispositif dans plusieurs contextes. Des CLICs ont ainsi été mis en place pour les labs d’innovation pédagogique, et pour les territoires d’expérimentation Colibris, des contenus accessibles hors ligne ont été ajoutés avec kiwix.
Une difficulté s’est cependant vite posée, liée à l’état de développement du dispositif : l’installation nécessitait alors un accompagnement humain qui manquait une fois de retour sur le terrain, si la CLIC ne fonctionnait plus. Pour les CLICs livré⋅es clé en main, la maintenance et parfois l’usage lui-même étaient donc dépendants des humain⋅es de la clique. Enfin, la pénurie de nano-ordinateurs comme les Raspberry Pi a empêché de s’approvisionner en matériel à déployer. Le projet a donc peu avancé, mais l’intérêt est resté présent.
Premiers retours d’usage
Une priorité pour les retrouvailles de décembre 2022 a donc été d’identifier la cause des problèmes surgissant à l’installation d’une part, et de rédiger un tutoriel pour accompagner l’installation pour les personnes souhaitant plonger dans le projet d’autre part.
Des premiers retours d’usages des chercheur⋅ses de l’IRD ont permis de soulever plusieurs questions :
celle de l’usage d’un logiciel d’enquête non-libre en lien avec un CLIC,
celle de la récupération de sauvegarde de ce qui a été travaillé localement en vue de le publier en ligne,
celle de la compatibilité avec différentes bases de données.
Sur la question de l’usage de solutions techniques non-libres, le projet CLIC s’appuyant sur YunoHost, rapidement la réponse a été qu’on ne chercherait pas de compatibilité avec de telles solutions, préservant nos ressources pour la recherche sur des solutions libres.
Concernant la récupération « facile » des sauvegardes, la réponse reste à être identifiée et implémentée, car il n’y a pour le moment pas de solution clé en main le permettant, autre que l’outil de sauvegarde intégré à YunoHost. Si l’utilisateur⋅ice peut se passer d’une aide graphique, le transfert vers une autre CLIC ou vers un YesWiki devrait pouvoir se faire sans trop de difficultés.
Pour la compatibilité avec les bases de données, plusieurs sont supportées par le projet CLIC : MariaDB (ou MySQL), PostGreSQL. Pour des solutions personnalisées (par exemple à partir d’openHDS), des installations supplémentaires sont à envisager, mais pas impossibles.
En un CLIC, une installation simplifiée et ergonomique.
Les discussions tout au long de 2022 ont mis en évidence un intérêt pour plusieurs cas d’usage :
pour un usage pédagogique en classe, en formation (apprendre à administrer un serveur, se former à l’utilisation de logiciels…),
pour réaliser un travail de terrain en Sciences Humaines et Sociales (anthropologie, démographie, linguistique, etc.) sans connexion,
pour s’affranchir du recours à la 4G en cas de connexion Internet défaillante ou restreinte (réseaux d’université par exemple),
pour mettre à disposition des contenus (supports pédagogiques, informations utiles dans un contexte précis, partages au sein d’une communauté…).
Si vous vous retrouvez dans ces cas, ou que vous en identifiez d’autres et que vous souhaitez participer aux tests du prototype du CLIC, contactez-nous sur contact AT projetclic.cc. Nous pouvons vous accompagner dans les premières étapes, et vos retours seront très utiles pour avancer ce projet.
Vous pouvez aussi regarder par vous-même, auquel cas vous aurez besoin :
Après ces deux rencontres, on compte cinq grosses améliorations :
Un site a été créé pour le projet pour y retrouver actus, communauté, images à télécharger et tutoriels : https://projetclic.cc.
Le hotspot wifi affiche une popup permettant de retrouver le portail sans connaitre son adresse url d’avance,
L’installateur permet de choisir les applications qu’on veut utiliser parmi une sélection,
Le portail de sélection de service a été travaillé graphiquement et une démo est disponible,
Des images sont mises à disposition pour les modèle de nano-ordinateurs Odroid en plus des RaspberryPi.
Le portail de sélection des services a été travaillé graphiquement.
Les améliorations matérielles ne sont pas en reste :
Design et impressions 3D de boîtiers pour nano-ordinateur Odroid
Des boîtiers pour nano-ordinateurs Odroid.
Travail sur la Chatravane avec des ateliers pédagogiques sur la consommation énergétique en autonomie avec des panneaux solaires.
La chatravane, un prototype de serveur nomade alimenté par des panneaux solaires.
Pour la suite, il est prévu :
De continuer de travailler sur le système et son installation, notamment pour s’approcher au maximum d’une installation « en un clic ».
D’ajouter une facilitation graphique au tutoriel, pour aider à la compréhension du fonctionnement d’une CLIC.
De continuer les tests sur le terrain (et adapter la documentation en fonction des observations).
De prévoir un hackathon axé sur le design et la communication.
Le projet CLIC avance doucement mais sûrement, grâce à du temps de travail bénévole et rémunéré (ritimo, Mouvement Colibris, YunoHost) et au soutien de Framasoft.
Nos prochaines retrouvailles seront aux Journées du Logicel Libre (JDLL) les 1er et 2 avril 2023, où vous nous retrouverez en déambulation et de manière plus posée, au stand de nos ami·es de YunoHost.
Crédit photos : 12b Fabrice Bellamy et Mathieu Wostyn Crédit vidéo : Mouvement Colibris Licence CC BY SA
Gao & Blaze : le jeu mobile immersif qui utilise et respecte vos données personnelles
Nous avons été contacté·es récemment par l’équipe de la coopérative « La Boussole », pour nous parler d’un tout nouveau projet : le jeu Gao & Blaze.
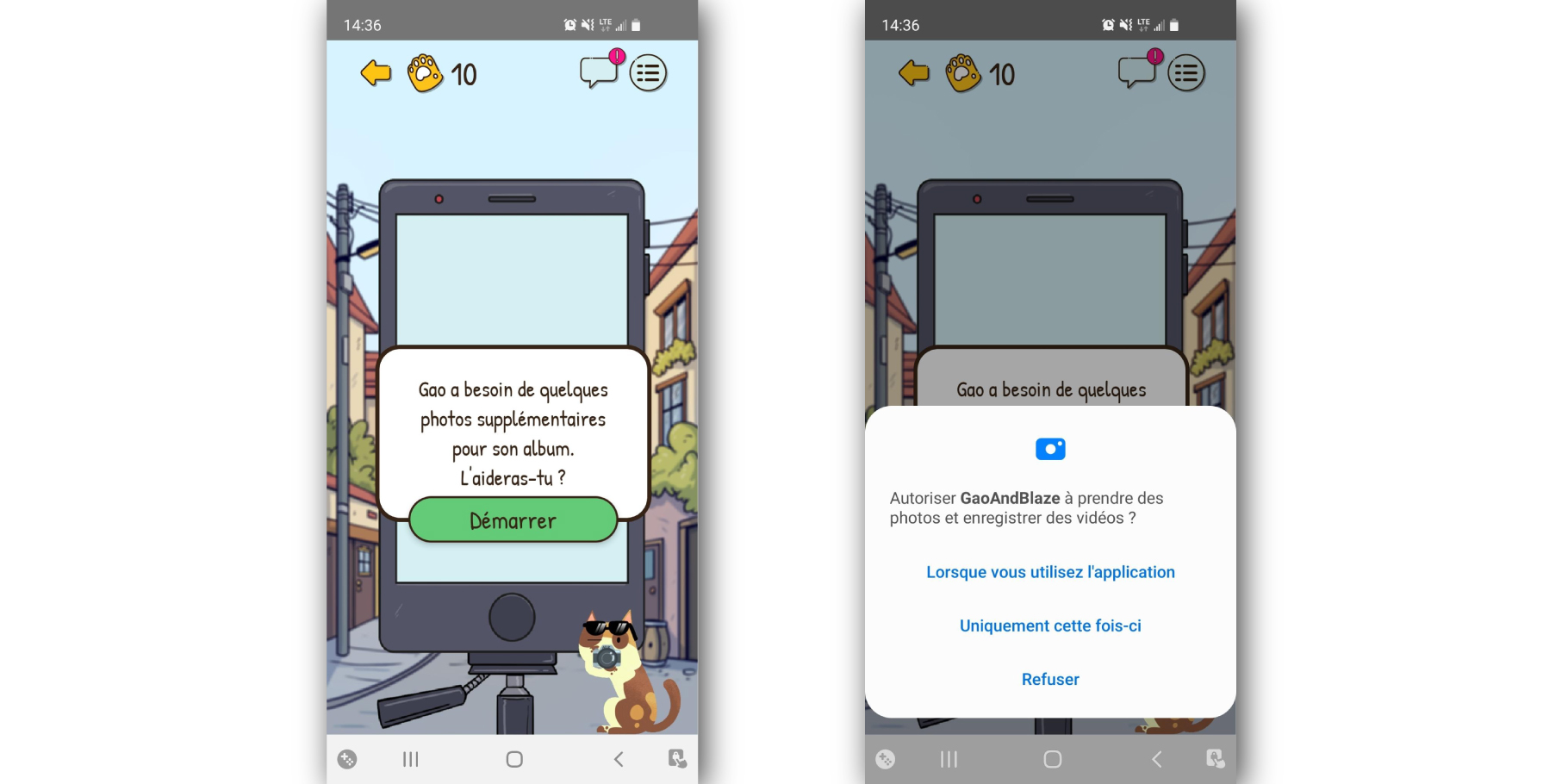
Gao & Blaze, est un jeu libre et gratuit pour smartphone, qui permet de prendre conscience et agir sur la protection de vos données et le respect de votre vie privée. Au fur et à mesure du jeu, vous réalisez l’ampleur des données personnelles et sociales qui peuvent être divulguées avec l’installation d’une simple appli (mais sans collecte cachée de données, promis !).
Bel exemple d’éducation populaire aux enjeux du numérique, cet ovni dans le monde du jeu vidéo nous a grandement intéressé·es. Nous avons donc posé quelques questions à l’équipe de la coopérative « La Boussole ».
Bonjour l’équipe de la coopérative « La Boussole » ! À Framasoft, on vous connaît déjà un peu depuis quelques années, mais pourriez-vous vous présenter aux lecteur⋅ices du Framablog ?
Bonjour à Framasoft et merci pour cet espace ! Nous sommes plein de choses, mais avant tout 3 :
Une coopérative, c’est-à-dire que nous avons fait le choix de créer une structure qui appartient uniquement à celles et ceux qui y travaillent (pas d’actionnaires, pas de patron·nes).
D’éducation populaire, c’est-à-dire que nous voulons rendre certaines connaissances issues de la recherche académique (nous gardons un pied dans la recherche et l’université) accessibles au plus grand nombre sans que les bagages éducatifs soient un frein.
Et nous portons des valeurs d’émancipation, c’est-à-dire que nous avons pour ambition de donner du pouvoir d’agir aux individus et aux collectifs : nous croyons que le savoir est un pouvoir fort et voulons partager nos savoirs, autour de l’informatique libre, autour de la lutte contre les discriminations et sur les formes de travail alternatives.
Super ! Vous pouvez nous en dire un peu plus sur les types d’actions que vous réalisez ?
Principalement nous réalisons des projets de recherche autour de nos thématiques mais également des formations courtes pour donner des outils pratiques. Nous explorons aussi lors d’ateliers pédagogiques des nouvelles formes de transmettre des connaissances car nous nous préoccupons souvent de savoir comment nos savoirs académiques peuvent avoir un impact concret et positif sur les gens que nous rencontrons. Nous voyons aussi comment dans des domaines comme le numérique la concentration des savoirs et savoir-faire peut créer d’importantes inégalités de pouvoir.
Vous nous avez contactés récemment au sujet d’un projet un peu particulier : Gao & Blaze. Mais… c’est quoi ?!
Nous sommes parti·e·s d’une frustration : nous avions passé du temps et mis de l’énergie à essayer de convaincre du bien-fondé de la protection des données interpersonnelles, de sensibiliser aux questions liées à la sécurité informatique, mais le constat était que beaucoup de gens étaient d’accord avec nous sans pour autant changer leurs pratiques dans les faits.
Dit de manière brutale : nous voulions savoir comment faire pour que des gens aient envie d’aller à des chiffrofêtes car il nous semblait que seuls des gens déjà sensibilisés y participaient, et nous avions l’ambition d’aller chercher plus loin.
Bien évidemment, le panorama a évolué au cours des dernières années de différentes manières notamment avec des scandales de plus en plus audibles et relayés, mais également des initiatives enthousiasmantes qui ont marqué un avant et un après dans les usages courants (nous pensons notamment à votre campagne Dégooglisons internet). Pourtant, il nous semblait y avoir un chaînon manquant autour du « passage à l’action ». Nous avons donc voulu proposer un jeu qui utilise l’émotion avant d’utiliser la raison – autrement dit qui passe par l’expérience personnelle avant la connaissance concrète. C’est là que nous avons eu l’idée d’imaginer un jeu pour donner à voir les conséquences concrètes de l’exploitation et l’usage des données de Madame et Monsieur Tout-le-monde.
Cette frustration nous trottait à l’esprit quand nous avions vu un appel à projet de recherche sur la protection des données. Nous avions proposé un projet qui n’entrait pas dans les cases, mais nous avons réussi à monter un partenariat qui nous a permis de créer un ovni. À notre connaissance c’est le premier jeu autour de la sensibilisation à la protection des données interpersonnelles sur Android.
C’est un ovni car nous avions 4 conditions non négociables :
Exploiter le système des permissions Android pour proposer une expérience immersive
Utiliser les données des joueuses et des joueurs, tout en respectant ces données.
Faire un jeu 100% en logiciel libre sans utiliser des interfaces intermédiaires obscures (le jeu est en React Native)
Faire un vrai jeu : c’est-à-dire que nous voulions que les gens y jouent pour l’intérêt ludique et que ce ne soit pas le « volet sensibilisation » qui prenne le dessus.
C’est qui Gao et Blaze ? Des personnages ?
Exactement ! Gao est un chat, appartenant à Blaze. Il s’inspire de son chat et l’a converti en l’icône des Gao Games. Les Gao games sont un univers de mini-jeux gratuits sur smartphone autour duquel toute communauté s’est construite. Blaze, est le dev principal de ces jeux. Toute ressemblance avec certains petits jeux mignons, « gratuits » et très célèbres est purement accidentelle… 0:o)
C’est aussi et avant tout le chat de Blaze, le développeur des jeux, qui l’a rendu célèbre.
D’autres personnages et non des moindres, font partie de la communauté, Alex, Nikki, Masako, Amin, Ally…. nous vous laissons les découvrir en allant leur parler !
La question des données personnelles, vous pensez que ça intéresse réellement les jeunes ? Est-ce que la vie privée ce n’est pas « Un problème de vieux cons ? »
Question intéressante, nous pouvons rétorquer par facilité qu’en 2010 c’était une question de « vieux cons », mais c’était il y a déjà 12 ans ! Plus sérieusement, nous constatons que beaucoup d’eau a coulé sous les ponts depuis le début des années 2010 en termes de révélations (E. Snowden, Wikileaks, Cambridge Analytica, Pegasus…), en termes d’ampleur des scandales, de leur couverture médiatique, mais aussi du côté de la marche triomphante des multinationales des données dans la prédation et l’exploitation des données des individus.
Il y a également de nouveaux freins légaux (comme le RGPD, par exemple), et une jeune génération qui a ses propres stratégies d’appropriation et d’usage des technologies numériques…
Nous croyons que l’intérêt pour la vie privée est là, simplement qu’il se configure de nouvelles façons. Avec Gao&Blaze nous tentons d’apporter une réponse à la demande et aux questionnements d’un public peu expert et réfractaire aux approches classiques de sensibilisation.
Parlons maintenant des licences du jeu : sous quelle(s) licence(s) est publié le jeu, et surtout… Pourquoi ?
La question des licences a mérité un peu de réflexion, car un jeu vidéo présente la particularité de mêler plein de composantes différentes : code, œuvres graphiques, dialogues, musiques… Certaines licences (comme la GPL par exemple) sont conçues pour du code informatique, et conviendraient pas vraiment pour une illustration, par exemple.
Pour essayer de couvrir tous ces usages, Gao&Blaze est donc diffusé sous licence GNU AGPL 3.0 pour le code et sous licence Creative Commons BY-SA 4.0 pour les autres créations. Il embarque aussi des polices d’écriture et musiques sous licences tierces compatibles.
Vous n’avez pas peur de vous faire « voler » les innombrables heures de travail que vous avez passées en développement ?
C’est une vraie question !
En premier lieu, nous concevons notre création comme une contribution aux biens communs, et en soi, ça ne se « possède » pas – ça ne peut donc pas se voler.
En revanche, il existe deux risques auxquels nous avons pensé :
La prédation des biens communs pour en faire des biens privés. Pour un logiciel, ça pourrait être le fait de modifier légèrement le code, puis d’en faire un logiciel privateur. Mais ce sont aussi des choses qui arrivent dans d’autres domaines : privatiser des biens qui bénéficient à tous les êtres vivants (l’eau, l’air, les forêts…) au profit de quelques uns, etc.
L’usurpation, qui consisterait à respecter « à la marge » la licence, mais à s’approprier le travail de création qui a été fait (en faisant croire plus ou moins explicitement qu’une autre personne serait l’autrice du jeu). Un exemple de ça serait de reprendre le jeu tel quel, et remplacer tous les logos et mentions visibles des autrices et auteurs par ceux de quelqu’un d’autre, et se contenter de nous citer de façon obscure, avec une petite phrase en caractère 6 au fin fond d’un menu.
Une idée reçue est que les licences libres ne protègent pas bien les œuvres et/ou les autrices/auteurs mais c’est faux. Les licences que nous avons choisies protègent normalement de ces deux risques car :
Elles sont contaminantes, c’est-à-dire qu’elles obligent à repartager les modifications et travaux dérivés sous des licences similaires. On ne peut donc pas se les approprier en faisant de la prédation, on ne peut que permettre de nouvelles contributions aux biens communs.
Elles peuvent protéger efficacement de l’usurpation. C’est un dispositif juridique méconnu, mais il faut savoir que des licences comme la GNU AGPL permettent l’ajout de « termes additionnels » (qui doivent rester en conformité avec la licence). Nous avons utilisé ces termes additionnels pour nous prémunir de toute tentative de maquillage / « re-branding » du jeu.
Le seul risque qui existe serait que des gens créent une version dérivée avec laquelle nous serions en désaccord éthiquement, mais bon, c’est la vie. Dans le fond, créer des œuvres libres implique aussi de changer de point de vue : même si nous avons une parenté sur l’œuvre, ce n’est pas « notre » bébé, c’est le bébé de tout le monde. Mais ça tombe bien, ça fait potentiellement plus de bonnes volontés pour s’en occuper. 🙂
Quel rôle joue la MAIF dans votre projet ? Partenariat financier ou davantage ?
La MAIF est un assureur militant de poids et nous avons collaboré avec deux structures satellites de ce géant de l’assurance : la Fondation MAIF pour la recherche, et l’association Prévention MAIF dédiée aux actions de prévention. Ces deux structures non-lucratives ont co-financé avec nous la partie production et la partie recherche, et nous avons eu le plaisir d’avoir des échanges enrichissants pour consolider le projet et qu’il voie le jour.
Impossible de dire que l’engagement n’était que financier : les structures de la MAIF étaient intimement convaincues de la pertinence de la démarche et de l’urgence sociétale du sujet. Ils tenaient à ce que ce projet se fasse sous forme de logiciel libre mais qu’il ne puisse pas être approprié par d’autres.
Merci pour cet impressionnant travail ! 🙂 Quelles sont les prochaines étapes et vos attentes vis-à-vis de Gao & Blaze ?
C’est le cas de le dire ! C’était assez fou de créer un studio de jeu vidéo éphémère, de vouloir avancer masqué·e·s avec un jeu visuellement très mainstream, et pourtant codé « en dur », alors même que la production logicielle n’est pas notre cœur de métier.
La suite est la partie recherche de ce projet ! Nous avons besoin qu’il soit joué jusqu’au bout, nous avons envie de comprendre et constater comment oui ou non notre pari de sensibiliser à la protection des données via le jeu était pertinent ou pas.
Le jeu demande au fur et à mesure différentes autorisations.
Et pour vos autres projets (on se doute que vous en avez !) : quels sont-ils ? Quels sont vos espoirs ? Comment peut-on vous aider ?
Nous continuons dans nos projets de recherche (autour des formes de sensibilisation) et de formations auprès d’autres publics. Aujourd’hui nous réfléchissons à la sensibilisation aux questions de la vie privée pour des personnes peu ou pas lettrées qui pourtant sont contraintes à l’utilisation de téléphones portables.
Nous avons aussi d’autres chantiers académiques car il est important pour nous de nous maintenir à la page, de lire et de produire des recherches au long cours. Une participation à projet de documentaire sur les low-tech (basses-technologies) est dans les cartons et nous vous en parlerons plus tard quand il sera plus avancé !
Une question traditionnelle pour conclure : quelle est la question que l’on ne vous a pas posée, à laquelle vous auriez aimé répondre ? Et quelle serait-votre réponse, tant qu’à faire ! 🙂
Nous aurions voulu que vous nous demandiez si nous avons choisi exprès le 30 novembre pour lancer le jeu car c’est la journée mondiale de la sécurité informatique. Nous vous dirions que oui, nous avions tout savamment calculé 😉
Ou peut-être une autre question sur les autres personnages, surtout Nikki, hackeuse badass mais pas très genrée, ou sur Alex, une femme noire qui commence « Madame Tout-le-monde » et finit héroïne. Nous voulions fuir certaines caricatures et avions envie de personnages vraisemblables mais peu courants dans le monde du jeu vidéo.
Retour sur le Contribatelier « Accessibilité numérique » organisé lors de la Journée Mondiale des Mobilités et de l’Accessibilité
Le 30 avril 2022, à l’occasion de la Journée Mondiale des Mobilités et de l’Accessibilité, deux structures membres du collectif CHATONS, Alsace Réseau Neutre et Le Cloud Girofle, ainsi que le hackerspace associatif strasbourgeois Hackstub, se sont mobilisées pour organiser simultanément un Contribatelier sur l’Accessibilité numérique à Strasbourg et Villebon-sur-Yvette (91). Nous leur laissons le clavier pour nous partager un compte-rendu de cette action et des pistes envisagées pour la suite.
À cette occasion, une douzaine de tests ont été menés sur des logiciels libres, dont la plupart sont proposés comme services en ligne par des membres du collectif CHATONS. Les audits consistaient en des tests d’usage réalisés par binômes, composés d’une personne malvoyante en charge du test et d’une personne voyante en charge de sa captation. L’objectif de ces tests utilisateurices fut double : permettre aux personnes qui créent ou hébergent ces solutions de prendre conscience des problèmes et des solutions possibles, et identifier les éventuels services accessibles sur https://entraide.chatons.org et https://chatons.org.
Cet article est l’occasion de détailler comment les tests se sont passés et de mettre en avant les principaux soucis et perspectives liés à l’accessibilité des services libres, dans l’optique de structurer un groupe parlant d’accessibilité au sein du collectif.
Comptes-rendus des sessions
CR du contribatelier animé par ARN et Hackstub à la médiathèque Neudorf de Strasbourg
Avec :
Irina (organisatrice et participante), utilisatrice expérimentée d’outils libres et contributrice, membre d’Alsace Réseau Neutre, atteinte de déficience visuelle
Gabriel (participant), président de C’Cité (Fédération des Aveugles Alsace Lorraine Grand Est), à l’aise avec le numérique au quotidien, atteint de déficience visuelle proche du stade aveugle
Sylvain (participant), ingénieur logiciel
Valentin (organisateur et participant), ingénieur libriste militant, gérant de ReflexLibre, membre d’Alsace Réseau Neutre et contributeur de YunoHost
Marjorie (organisatrice et participante), graphiste, artiste et programmeuse libriste, membre d’Hackstub et du collectif cyberféministe Hacqueen
Avec le soutien également d’Éric et Thomas qui sont passés nous voir. Éric est graphiste et programmeur libriste, membre d’ARN, et Thomas est un usager régulier du hackerspace Hackstub qui s’intéresse à l’informatique, au Libre, et à leurs enjeux.
14 tests ont été effectués sur 13 logiciels en deux demi-journées. Nous avons été surprises et surpris du nombre de tests qui ont pu être conduits en si peu de temps, avec très peu de personnes testeuses. Parmi les possibilités de tests, nous n’avons pas sélectionné les outils collaboratifs car nous redoutions une faible accessibilité de ces outils : écrire dans un document collaboratif en ligne prive généralement la personne déficiente visuelle des raccourcis de son outil d’assistance. Les résultats sont mitigés : sur 14 tests, 8 se sont soldés par un succès et 6 ont posé problème (deux réussites partielles et 4 échecs). Les services qui ont posé le plus de problèmes sont les outils de sondage. Certains des tests partiellement réussis ont nécessité une assistance, due à des défauts d’accessibilité non liés à l’outil testé. Exemple : lors du test de Mumble, un logiciel d’audioconférence libre, l’activation du micro a été ardue. Il y avait donc des problèmes liés davantage aux fonctionnalités du navigateur ou à d’autres paramètres (configuration des outils d’assistance ou des interfaces).
Un autre constat intéressant à faire est que les tests ont été effectués avec un système d’exploitation et un navigateur propriétaire (OS Windows + navigateur Edge ou Chrome). L’outil d’assistance était quant à lui libre (NVDA). On peut s’interroger sur le rapport entre le taux de réussite et l’utilisation d’outils qui ne sont pas libres : y a-t-il plus de moyens injectés pour l’accessibilité dans les outils propriétaires ?
Pour ce qui est de l’ambiance, nous avons apprécié l’accueil de la médiathèque Neudorf avec laquelle il a été facile de travailler dans une dynamique de coopération. Gabriel nous a également fait part de son enthousiasme quant à la convivialité de l’événement, malgré le peu de participation. Ce faible taux de participation, tant du côté des personnes malvoyantes que des personnes développeuses, nous a questionné sur les liens que nous entretenons avec les associations et publics déficients visuels, et nous a démontré qu’il y avait un vrai travail de sensibilisation à mener auprès de la communauté libriste. Il a toutefois permis un cadre assez intimiste, favorisant l’attention portée aux personnes participantes.
CR du contribatelier animé par Le cloud de Girofle à Villebon-sur-Yvette (91)
Avec :
Nicolas (participant), informaticien de métier atteint d’une déficience visuelle dégénérescente
Agathe (participante), libriste expérimentée et vidéaste à ses heures perdues
Maxime (organisateur et participant), membre du Cloud Girofle, libriste militant
Margaux (organisatrice et participante), membre du Cloud Girofle
Nous nous sommes retrouvés à 4 à la MJC Bobby Lapointe de Villebon-sur-Yvette (91), gentiment mise à disposition par Charles, également membre du Cloud Girofle. Avec l’aide d’Agathe, libriste et vidéaste à ses heures perdues, nous avons accueilli Nicolas, « informaticien d’avant Windows ! » atteint d’une déficience visuelle dégénérescente. Son ordinateur tourne sous Debian et le passage à la ligne de commande a été plus aisé pour lui quand sa vue a commencé à se détériorer. Il utilise encore des outils visuels, des fonctionnalités intégrées au gestionnaire de fenêtres Compiz comme le zoom et l’inversion de contraste. Mais il utilise de plus en plus les outils vocaux, qui représentent environ 80 % de son usage : le lecteur d’écran libre Orca et la synthèse vocale propriétaire Baratinoo, en attendant de trouver une synthèse vocale libre, en français, de qualité suffisante. Par ailleurs, Nicolas utilise EMACS, un éditeur de texte libre navigable intégralement au clavier développé par Richard Stallman, qui dispose de son propre lecteur d’écran (dans ces cas-là, il coupe Orca, qui est le lecteur d’écran pour systèmes GNU Linux). Il l’utilise beaucoup parce que c’est très adapté à son usage, mais ce n’est malheureusement pas toujours possible : en effet, le navigateur EWW intégré dans cet outil n’interprète pas le Javascript, un langage qui est aujourd’hui massivement présent sur le web !
Le cadre intimiste nous a permis d’échanger de manière très qualitative, et nous nous sommes concentrés sur Nicolas toute l’après-midi. Il nous aura fallu vivre cet atelier pour prendre conscience de la difficulté (pour être honnête, de la quasi-impossibilité) d’utiliser beaucoup de services libres en ligne quand on est déficient⋅e visuel⋅le (malvoyant⋅e, non-voyant⋅e).
Une dizaine de tests filmés ont été effectués par Nicolas, sans assistance extérieure, sur des services proposés par le Cloud Girofle : créer un compte sur Nextcloud, accéder à un espace de discussion Mattermost, lire un document OnlyOffice partagé par email, etc. Un protocole de test et des scénarios de tests avaient été préparé en amont et étaient mis à disposition. Les captations rendent compte de ce qui se passe sur l’écran et de la synthèse vocale.
Navigation sur Nextcloud lors du Contribatelier : l’utilisateur doit utiliser un niveau de zoom très élevé, en plus d’une synthèse vocale (enregistrée par l’enregistreur visible à droite).
Conclusion : c’est pas glorieux
Alors, les logiciels des CHATONS, c’est accessible comment ? Pour nous, les résultats sont édifiants (et décevants). La quasi-totalité des missions a échoué du côté de Villebon-sur-Yvette et le taux de réussite à Strasbourg ne dépasse pas 50%. Les tests qui ont rencontré le plus de succès ont été menés avec du matériel et des outils propriétaires (à l’exception du logiciel d’assistance), et il s’agissait aussi des manœuvres les plus simples.
Quelques exemples :
un test consistant à se créer un compte Nextcloud en recevant une invitation par email a pris une demi-heure (et nous parlons d’un test réalisé par un informaticien) !
un autre test sur le service Framadate (outil de planification de date) ne propose pas « oui/non/peut-être » comme réponses, mais « chaussure de ski » et « drapeau dans un trou » !
toujours sur Framadate, un autre testeur nous indique que la seule manière qu’il a trouvé de l’utiliser est de copier-coller les options dans un tableur, de le remplir, puis de reporter les options dans le tableau en ligne. Une gageure !
Et lors d’un test pour éditer un document en ligne (OnlyOffice) partagé avec Nextcloud, on se rend compte que le bouton pour ouvrir le document n’est pas accessible à la navigation au clavier, que même si on pose le curseur dessus, les options pour l’ouvrir ne sont pas lues par la synthèse vocale et que même si le document est ouvert, la synthèse vocale ne lit pas le document. On découvre ainsi que, même s’il y a un plugin de synthèse vocale installé dans OnlyOffice, le menu pour y accéder n’est pas accessible et que même si on clique sur ce bouton, la synthèse vocale ne fonctionne pas.
À chaque fois, la tentation d’abandonner est forte : impossible de savoir si la fonction qu’on essaye d’utiliser va réussir, ou si l’on va échouer pour une raison parfois bête (un bouton sans label, un message d’erreur qui s’affiche mais qui n’est pas lu). Assister en direct aux difficultés rencontrées par une personne malvoyante sur un ordinateur est une expérience édifiante. Nous pensons que tout le monde devrait la faire au moins une fois, pour se rendre compte des enjeux associés à l’accessibilité numérique.
Lecture d’un mail lors du Contribatelier : l’utilisateur doit utiliser un niveau de zoom très élevé, en plus d’une synthèse vocale (enregistrée par l’enregistreur visible à droite).
Bilan et perspectives
Le contribatelier, un outil de sensibilisation à l’accessibilité
Participer à ce contribatelier a été très éclairant à la fois sur l’urgence de la situation des personnes déficientes visuelles (beaucoup de services restent bloquants, et pour certains sur des points assez élémentaires), et sur ce qu’implique concrètement la manipulation d’outils d’assistance tels que les lecteurs d’écran. On se sent plus outillé et plus armé pour défendre ce grand sujet. C’est un format idéal pour provoquer une prise de conscience auprès de personnes non initiées, qui a le double avantage de sensibiliser tout en étant dans le “faire” (en l’occurrence, contribuer au libre). Les expériences ont globalement été appréciées de toustes les participantes. Que ce soit du point de vue de l’accueil ou du travail réalisé, ces séances ont offert un cadre convivial, surtout en petits groupes.
Le point sur les difficultés rencontrées
Nous nous sommes interrogés sur le degré d’intervention des personnes qui ne sont pas en situation de handicap lors d’un blocage pendant un test. Nous avons conclu de cet échange qu’il valait mieux laisser du temps pour dénouer la situation avant d’intervenir, afin de véritablement éprouver l’accessibilité de l’outil, mais que si on se retrouvait face à une impasse, il fallait accompagner la résolution du problème rencontré.
Si la personne déficiente visuelle ne prend pas aisément le service en main, il y a différents types d’échec :
celui où elle devra d’abord explorer l’interface pour la comprendre et consulter la documentation ;
celui où des astuces/manipulations lui sont indiquées par une autre personne ;
celui où elle ne pourra jamais accéder au service par ses propres moyens.
Côté développement, on peut aussi distinguer différents cas :
celui où il suffirait de corriger quelques détails ;
celui où les modifications sont complexes mais le service partiellement utilisable ;
celui où il faudrait quasiment tout revoir.
On découvre ainsi plusieurs catégories de problèmes :
des problèmes de conception : pages web trop complexes (comment s’y retrouver quand des centaines d’informations non hiérarchisées – il n’y a pas de couleurs en synthèse vocale – sont lues ?), notifications non accessibles ou synthèse vocale indisponible dans certains environnements (canevas notamment) ;
des erreurs d’implémentation : boutons sans label, titres des vidéos qui ne sont pas indiqués, parties du logiciel non navigables au clavier ;
des problèmes de version : avec la course aux fonctionnalités, les navigateurs web un peu anciens sont de moins en moins supportés. Or ce sont souvent ces navigateurs qui équipent les systèmes adaptés aux non-voyant⋅es. Choisir de ne pas les prendre en compte, c’est se priver de certain⋅es utilisateurices qui utilisent des systèmes spécifiques, pour lesquels les mises à jour sont parfois compliquées.
De manière générale, bien qu’une bonne moitié des interfaces graphiques des logiciels « en dur » sont inutilisables ou difficilement utilisables, elles restent mieux gérées par la synthèse vocale que dans les applications web, qui sont d’expérience peu accessibles. Les standards d’accessibilité sont peu respectés et la conception de pages complexes rend la lecture des pages plus difficile encore.
Par ailleurs, alors qu’aujourd’hui la majorité des personnes utilisent un très petit nombre de navigateurs web (Firefox, Chrome et Safari, qui se partagent la majorité du marché et concentrent toute l’attention des personnes développeuses), les personnes déficientes visuelles utilisent parfois d’autres navigateurs (Edge, Lynx, etc.), en plus de matériels d’assistance variés. Suivant les profils, on peut trouver des plages ou afficheurs braille, de la vocalisation, des outils visuels (zoom, couleurs, contraste), etc. Certains logiciels d’assistance définissent leurs propres raccourcis clavier, qui peuvent entrer en conflit avec les raccourcis natifs du système ou ceux d’autres programmes. L’interopérabilité de tous ces équipements n’est donc pas triviale.
Il y a également un autre paradoxe : la plupart des logiciels libres populaires dédient une partie de leur documentation à l’accessibilité, chacun expliquant comment les logiciels sont accessibles. Nous reconnaissons les efforts faits pour améliorer la situation, pourtant, en regardant les cas de OnlyOffice et de Mattermost, nous regrettons :
que ces pages ne soient pas plus mises en avant, par exemple au moment de se connecter au logiciel, et pas seulement en faisant une recherche sur le site de l’entreprise qui développe le logiciel ;
que les informations fournies dans ces pages soient parfois incomplètes, par exemple en ne précisant pas les limitations induites par le mode lecture ;
que ces procédures ne fonctionnent souvent pas ! Mattermost peut se naviguer au clavier, mais sur la version de Firefox utilisée par un de nos testeurs, celle-ci ne fonctionne pas. Autre exemple : le plugin de synthèse vocale d’OnlyOffice ne peut pas être activé facilement, et nécessite une configuration administrateur qui n’est pas faite par défaut.
Une personne dans le groupe strasbourgeois a rencontré des difficultés liées au verrouillage de son système, configuré par une entreprise qui fournit des systèmes adaptés aux personnes déficientes visuelles. Cette dernière n’installe que des versions de logiciels dont l’accessibilité a été évaluée, et parfois légèrement modifiées pour les rendre plus accessibles. L’entreprise dispose donc de son propre dépôt de paquets Debian, et configure les machines de ses clients et clientes pour utiliser ce dépôt en priorité, afin d’éviter qu’iels ne fassent des mises à jour non testées. L’inconvénient de cette méthode “verrouillée” est qu’il est ardu d’accéder aux dernières versions logicielles, faute de mises à jour, qui sont souvent disponibles sur le tard (plusieurs années sont parfois nécessaires). Le principe est pertinent, mais la prudence excessive, ou peut-être le manque de personnel compétent pour le travail d’adaptation, rend l’utilisation d’une machine sous ce système laborieuse. Par ailleurs, ce contrôle à distance du paramétrage peut donner le sentiment d’être dépossédé de sa machine, d’autant plus si la communication sur les changements apportés fait défaut. Il est possible de contourner le verrouillage “à la main”, mais cela demande une certaine aisance en informatique, et lève la garantie d’assistance en cas de soucis. Ainsi, des problèmes sont persistants avec Firefox car la version fournie n’est pas la dernière, ce qui a été bloquant pour mener à bien les tests : la personne est mobilisée pour la résolution du problème plutôt que pour la réalisation des tests. Ça pose la question du processus de développement logiciel : aujourd’hui on fournit des logiciels qui évoluent sans cesse, dont les anciennes versions ne sont pas supportées facilement, voire pas supportées du tout.
Et après ?
Nous souhaitons proposer à nouveaux des contribateliers sur l’accessibilité numérique afin de finir les tests prévus. De plus, nous préparerons d’autres tests à mener, avec comme priorité les services qui répondent à des usages du quotidien (communication, collaboration, sondage, traitement de texte, etc.). Nous envisageons néanmoins des tests sur des outils plus techniques dans un second temps (services proposés par YunoHost par exemple, un système d’exploitation qui facilite l’administration d’un serveur et participe à la démocratisation de l’auto-hébergement).
Par ailleurs, il est intéressant de noter que réaliser plusieurs fois un même test n’est pas futile. Au contraire, cela rend compte des différences rencontrées en fonction des systèmes et configurations, mais aussi selon les handicaps. La diversité des profils est très importante pour les tests. Il faut bien prendre en compte la différence de handicaps et de niveaux de culture numérique.
Nous pensons aussi qu’il serait pertinent de mettre en avant les manipulations qui facilitent la prise en main des outils et logiciels. Il y a parfois des astuces simples, qui s’avèrent très utiles pour contourner les difficultés rencontrées, même s’il est regrettable de devoir presque recourir au hack pour pouvoir utiliser un service.
Beaucoup de documentation à été produite lors de ces ateliers : des vidéos et des notes principalement. Nous entrons désormais dans la phase de restitution de ces tests, nous allons créer et publier des reports de bugs d’accessibilité sur les forges Git des logiciels concernés et les suivre. Deux personnes parmi nous, Irina et Valentin, ont fait deux rapports de bug antérieurement autour de Network Manager et de Mumble. Les protocoles pour soumettre les bugs d’accessibilité peuvent être laborieux, selon leur retour.
Lors de notre débrief, nous nous sommes demandés comment mobiliser davantage sur l’accessibilité numérique, au regard du faible nombre de personnes participantes. Nous aurions en effet souhaité que l’opération se déroule simultanément au sein de multiples structures membres du collectif CHATONS en France, afin de fédérer sur la question, et de lui donner plus de résonance.
Actions envisagées
Nous avons relevé plusieurs type d’action à envisager, en dehors de la reconduite de contribateliers sur le sujet et de la publication de ce communiqué :
Faire émerger un groupe “Accessibilité”. Une interstructure Accessibilité a déjà été créée sur la Litière, le wiki des CHATONS. Il serait intéressant de constituer un groupe national de travail, s’étendant à des structures telles que la FFDN, et qui peut-être ne se cantonnerait pas qu’au Libre pour réellement servir l’accessibilité numérique, qui dépend aujourd’hui de beaucoup d’outils propriétaires déployant les moyens.
Un atelier sur cette thématique sera proposé lors du camp CHATONS 2022 (18-22 août).
Rédiger des rapports de bug à destination des développeur⋅euses de logiciels.
Mettre à disposition sur les mails de connexion envoyés par les logiciels un lien vers des page décrivant les raccourcis clavier et options d’accessibilité proposées par le logiciel, ainsi que la liste des fonctions qui sont inopérantes.
Mettre plus en évidence l’accessibilité dans les critères pour intégrer le collectif CHATONS.
Faire infuser l’accessibilité numérique dans la communauté libriste à travers des ateliers de sensibilisation et d’auto-formation, en organisant des permanences en milieux associatifs rassemblant des publics déficients visuels, en veillant à ce que les formats proposés considèrent l’accessibilité et en parlent, etc.
Construire une relation de confiance et créer du lien entre associations de personnes déficientes visuelles et développeuses.
Aller chercher des gens plus compétents sur ces questions, et saisir des structures telles que les tiers-lieux numériques, les universités, les milieux étudiants, etc.
Compiler et traduire la documentation et les ressources existantes sur l’accessibilité numérique.
Quelques parti-pris non consensuels
L’inaccessibilité numérique renforce la fracture numérique et ne concerne pas que les personnes atteintes d’un handicap visuel mais aussi les personnes éloignées du numérique de manière générale, comme les personnes âgées ou les personnes neurodifférentes. Renforcer l’accessibilité numérique pour les personnes déficientes visuelles renforce aussi l’accessibilité numérique tout court !
L’accessibilité numérique n’est pas un patch, un plugin à ajouter, mais bien une philosophie, une manière de voir les choses qui doit infuser dès la base du développement (on parle d’accessibilité native).
Que choisir : du libre à tout prix, ou l’accessibilité ?
En tant que défenseur⋅euses des logiciels libres, on s’interroge : la liberté numéro zéro, c’est celle d’utiliser le logiciel libre.
Que faire quand une partie de la population se retrouve exclue contre son gré de l’utilisation de logiciels libres ? Voulons-nous des logiciels qui ne libèrent que les développeur⋅euses ou permettent aussi d’autonomiser les utilisateurices ?
Plus de soixante-quinze millions de podcasts sont téléchargés chaque mois dans notre pays par plus de douze millions de personnes.
Qui les fait ? Qui les écoute ? Nous avons interrogé Benjamin Bellamy, co-créateur de Castopod —en audio, s’il vous plaît.
Illustration CC-BY-SA Benjamin Bellamy
La transcription de l’entretien
Bonjour ! Selon une enquête Médiamétrie sortie en décembre 2022 « Les chiffres clés de la consommation de podcasts en France », plus de soixante-quinze millions de podcasts sont téléchargés chaque mois dans notre pays par plus de douze millions de personnes. C’est donc un phénomène qui a conquis toute la Gaule. Toute, pas tout à fait puisqu’il reste au moins un indi… irréductible, voilà, je commence à bafouiller, c’est bien, qui est passé à côté c’est-à-dire moi.
Aujourd’hui nous avons eu l’idée d’interviewer Benjamin qui, lui, est très impliqué dans le monde du podcast et pour lui faire honneur nous faisons donc cet entretien en audio, ce qui n’est pas l’habitude dans le Framablog.
Benjamin, est-ce que tu peux te présenter ?
Oui, bien sûr, Frédéric. Bonjour. Donc je m’appelle Benjamin Bellamy.
En deux mots je suis né longtemps avant les réseaux sociaux mais après les cartes perforées et tout petit je suis tombé dans la marmite informatique.
J’écoute des podcasts depuis pas mal de temps et il y a deux ans avec trois associés j’ai créé une société qui y est exclusivement consacrée, Ad Aures.
Est-ce que tu peux présenter Castopod ? C’est quoi ? Un logiciel, une plate-forme, un oiseau, une fusée ?
Castopod qui donc est développée par Ad Aures, c’est un peu tout ça à la fois.
C’est d’abord un logiciel codé en PHP qui permet à toutes et à tous d’héberger plusieurs podcasts. Une fois en place, c’est-à-dire cinq minutes après avoir dézippé le paquet et lancé l’assistant d’installation c’est une plateforme d’hébergement de podcasts multipodcasts multi-utilisatrices multi-utilisateurs et enfin peu de gens le savent mais en imprimant le code source de Castopod sur une feuille A4 on obtient un superbe oiseau.
Illustration CC-BY-SA Benjamin Bellamy
Pour la fusée en revanche j’avoue on est super en retard et rien n’est prêt.
Enfin, plus sérieusement, Castopod permet à tout le monde de mettre des podcasts en ligne afin qu’ils soient disponibles sur n’importe quelle plateforme d’écoute donc ça peut être évidemment Apple Podcast, Google Podcast, Deezer, Spotify, Podcast-Addict, PostFriends, Overcast,… Il y en a plein d’autres, donc vraiment partout. Castopod apporte tout ce dont on a besoin donc de la gestion de fichiers sonores MP3 évidemment à la gestion des métadonnées, des titres, des descriptions, la génération du fameux RSS, l’export de clips vidéo à partager sur les réseaux sociaux, les mesures d’audience etc.
Et d’autre part, Castopod est adapté tout autant aux podcastrices et aux podcasteurs en herbe qu’aux professionnels les plus chevronnés puisque avec une seule installation on peut avoir autant de podcasts qu’on veut autant de comptes utilisateurs qu’on veut et enfin Castopod est open source, libre et gratuit, et il promeut et intègre des initiatives ouvertes telles que celles de Podcasting 2.0 qui permet entre autres la gestion de transcription et de sous-titrage de liens de financement de chapitres de géolocalisation de contenu de gestion des intervenants et de commentaires inter-plateforme et encore plein d’autres choses.
Qu’est-ce qui t’a poussé à lancer Casopod ?
Qu’est-ce qui m’a poussé à lancer Castopod, tu veux dire : qui m’a poussé à lancer Castopod ? D’une certaine manière c’est Framasoft.
En fait en mars 2019 alors que je cherchais une plateforme de podcasts compatible avec le fédivers j’ai contacté Framasoft pour savoir si vous aviez pas ça dans les tuyaux. Naïvement j’étais persuadé que la réponse serait « ben oui, évidemment » et là la douche froide : « non pas du tout ».
Et à ce moment-là Chocobozzz m’avait expliqué qu’avec les développements de Peertube et Mobilizon qui avaient été lancés un petit peu avant en décembre 2018 Framasoft n’avait pas le temps de se consacrer à un autre projet.
Heureuse coïncidence, à ce moment-là Ludovic Dubost le créateur de Xwiki m’a raconté comment il avait obtenu un financement de NLnet pour CryptPad. Donc j’ai déposé un dossier qui a été accepté immédiatement et qui en plus de nous faire très plaisir nous a confortés quant à la pertinence du projet.
Les podcasts m’ont l’air d’être gratuits dans la majorité des cas. Quel est le modèle économique ? Comment est-ce qu’ils en vivent, les gens ?
Il y a plusieurs modèles économiques du podcast.
Déjà effectivement il est important de noter qu’aujourd’hui quatre-vingt-dix-neuf pour cent des podcasts n’ont pas de modèle au sens capitaliste du terme, ce qui ne veut pas pour autant dire qu’ils sont gratuits.
Les podcastrices et les podcasteurs se rémunèrent de façon indirecte par le plaisir que ça procure, pour la promotion d’un autre produit ou service, pour l’exposition médiatique, etc. et quant au pourcent restant… Il existe plein de manières de gagner de l’argent.
On peut vendre un abonnement, encourager ses auditrices et ses auditeurs à donner des pourboires, on peut gagner des bitcoins par seconde d’écoute, on peut lire de la publicité, on peut produire un podcast de marque, on peut insérer automatiquement des spots publicitaires sonores, on peut afficher de la publicité à l’écran… par exemple chez Ad Aures notre spécialité c’est l’affichage publicitaire de recommandations contextuelles donc sans cookie ni profilage de l’internaute.
Et quel est le modèle économique de Castopod, alors ? Si je te dis que la société Ad Aures est l’équivalent de Canonical pour Ubuntu, est-ce que tu le prends mal ?
En fait c’est plutôt flatteur. On n’a pas du tout la prétention de devenir le Canonical du podcast même si effectivement on peut y voir des similitudes.
Pour répondre à ta question comme je l’ai laissé entendre plus tôt Castopod a bénéficié d’une subvention européenne qui a permis de financer le démarrage du développement. Ad Aures, la société que j’ai créée avec mes associés a également financé une grosse part du développement.
On compte sur les contributions de toutes celles et ceux qui souhaitent qu’on puisse continuer à maintenir et à faire grandir Castopod au travers de la plateforme Open Collective et enfin à on lance à l’heure où on parle tout juste d’une offre d’hébergement payante clés en main qui va donc permettre à toutes et à tous d’utiliser Castopod sans avoir à s’occuper du moindre aspect technique de l’hébergement.
On se rapproche plutôt du modèle de Piwigo, alors ?
Euh, exactement, ouais.
Alors la question qui pique. Moi je te connais, on s’est rencontrés, euh, il n’y a pas si longtemps que ça, au salon Open-Source Experience et je te connais comme un vrai libriste très engagé… et tu proposes de mettre de la pub sur les «postcasses» des gens ! J’arriverai jamais à prononcer «podcast» correctement ! Alors est-ce que la pub c’est compatible avec ton engagement libriste ?
Alors je vois pas pourquoi ça ne serait pas parce que en fait publicité et open source, ces deux concepts ont absolument rien à voir, même si je comprends ce que tu veux dire.
Personnellement, moi, je considère que la publicité en soi déjà ce n’est pas sale et c’est pas honteux et… Ce qui lui a donné une mauvaise réputation c’est le profilage à outrance des internautes est ça ouais c’est pas terrible, je suis d’accord mais justement nous ce qu’on propose c’est des publicités qui sont non invasives sans profilage sans cookie, pertinentes parce que en relation directe avec le contenu qui les héberge et ça permet d’offrir une rémunération à celles et à ceux qui produisent les contenus.
Chez nous il n’y a pas de pub pour le tout dernier jeu super addictif ou le top dix des choses qu’on ignorait pouvoir faire avec un cure-dent et un balai de chiottes.
Nous on va plutôt mettre en avant un bouquin en lien direct avec les métadonnées et avec le contenu sonore du podcast grâce au concept que notre moteur d’analyse sémantique aura détecté.
Alors d’un point de vue pratique comment est-ce qu’on fait pour avoir des podcasts dans son smartphone sans blinder sa mémoire ? Parce que moi j’oublie pas que je suis toujours à court de mémoire.
Eh eh, c’est là que que je vois qu’effectivement tu n’es pas un expert du podcast parce que un podcast en moyenne c’est quarante minutes.
Pour avoir une bonne qualité, voire même une très bonne qualité il faut compter 192 kilobits par seconde. Ce qui fait que un bon gros podcast ça fait moins de 100 méga-octets. Si en plus tu considères que aujourd’hui on est connecté la plupart du temps à Internet du coup pour écouter un podcast il n’y a pas nécessairement besoin de le pré-télécharger. On se rend vite compte que l’espace de stockage nécessaire c’est pas vraiment le souci.
OK, alors moi j’ai un autre problème quand est-ce que les gens ont le temps d’écouter des podcasts ? En faisant autre chose en même temps ?
Bah ça c’est la magie du podcast. Le podcast il laisse les mains et les pieds et les yeux totalement libres. Si tu fais le bilan d’une journée, en fait, tu te rends compte que les occasions elles sont super nombreuses.
Tu as le petit-déj, dans ta voiture, dans les transports, en faisant du sport, en attendant un rendez-vous, en faisant son ménage. Personnellement je ne fais plus la vaisselle sans mon podcast.
OK, mais le temps d’une vaisselle suffit pour écouter un podcast ? C’est quoi la durée idéale d’un podcast ?
Alors… J’ai envie dire déjà ça dépend de ta dextérité à faire la vaisselle. Peut-être que la mienne est pas au top et que justement comme j’écoute des podcasts, eh bien, je ne progresse pas beaucoup. La durée idéale d’un podcast, ben, c’est un peu comme la longueur idéale des jambes, c’est quand elles touchent bien le sol. C’est affaire de contexte parce que si euh les statistiques font état donc d’une durée moyenne de quarante minutes il y a tout plein de circonstances pour écouter un podcast. Donc en fait il y a plein de durées idéales.
Le contexte d’écoute c’est un critère déterminant.
Je ne vais pas chercher le même type et la même longueur, la même durée, de podcast pour le café du matin que pour le café du TGV Paris-Biarritz ! À chaque contexte d’écoute il y a une durée idéale.
Alors, qui produit des podcasts ? Est-ce qu’il y a une grosse offre française ? Moi je ne connais que celui de Tristan Nitot mais en effet je ne suis pas spécialiste.
Sur les quatre millions de podcasts dans le monde il y en a 72 000 qui sont francophones ce qui veut dire qu’il y en a beaucoup et qui a beaucoup plus d’heures de podcasts francophones publiés chaque jour qu’il y a d’heures dans une journée. Même si tu les écoutes en vitesse deux fois sans dormir tu ne pourras pas tout écouter.
L’une des particularités du marché français c’est l’importance de l’offre radiophonique parce que les Françaises et les Français sont très attachés à leurs radios, bien plus que dans les autres pays du monde, d’ailleurs. Et donc c’est naturellement qu’on retrouve les radios en bonne place dans les études d’écoute de podcasts. En France il y a également beaucoup de studios de podcasts d’une très grande qualité, vraiment beaucoup, et enfin et c’est ce qui est génial avec le podcasting : n’importe qui peut se lancer que ce soit pour une heure une semaine un an ou dix.
Ma fille a lancé le sien à dix ans !
Ah oui, les poésies d’Héloïse, tu m’as dit ça tout à l’heure.
C’est ça !
Est-ce qu’on a besoin de beaucoup de matériel pour faire un podcast ?
On a besoin que d’un bon micro, des idées, évidemment, euh, d’Audacity, Castopod, et ça suffit, hop-là, on se lance ?
La première chose dont on a besoin c’est l’envie puis l’idée et euh… et c’est tout !
Aujourd’hui n’importe quel téléphone moderne est capable d’enregistrer une voix bien mieux que les enregistreurs hors de prix qu’on avait dans les années quatre-vingts !
Si tu savais combien de podcasts sont en fait enregistrés au téléphone sous une couette ou dans une taie d’oreiller ! Bien entendu, et ce n’est pas valable que pour le podcast, hein, plus on avance et plus on devient exigeant et un bon microphone et une bonne carte son, ça fera vite la différence. Mais les contraintes techniques ne doivent pas brider la créativité.
En ce qui concerne le montage donc tu as cité Audacity. Je l’utilise de temps à autre mais je suis plutôt «Team Ardour». La grosse différence c’est qu’Audacity est destructif. C’est-à-dire que tu ne peux pas annuler une manipulation que tu as faite il y a deux heures alors qu’avec Ardour qui est non-destructif… deux ans après avoir bossé sur un montage tu peux encore tout corriger et revenir sur n’importe quelle opération.
Et enfin sur l’hébergement bah il y en a pour tous les besoins, tous les goûts, tous les profils, tous les podcasts, mais la seule solution qui à la fois open source certifié podcasting 2.0 et connectée au fédiverse c’est Castopod.
Qu’est-ce que tu écoutes, toi, comme podcasts ? Est-ce que tu as des conseils pour les personnes qui souhaitent une sélection ? On mettra les liens dans les commentaires.
Ah c’est un peu audacieux de demander à un inconnu un conseil podcast, c’est un peu comme demander un conseil gastronomique à un inconnu dans la rue.
Surtout que personnellement j’ai une sélection qui est assez éclectique et pas très originale.
Dans les podcasts que j’écoute régulièrement… Il y a Podland, Podnews, Podcasting 2.0, The Europeans, Décryptualité, Libre à vous, L’Octet vert que tu as cité et Sans Algo. Et puis j’écoute aussi beaucoup de d’émission de radio du service public podcastées quand elles sont pas sauvagement supprimées des plateformes ouvertes, suivez mon regard…
Alors c’est quoi ton regard ? Tu peux les citer ou… ?
Non je ne veux me fâcher avec personne.
J’ai vu que Castopod était compatibles Activitypub. Alors ça veut dire quoi concrètement pour les gens qui nous écoutent ?
Alors
Activitypub c’est un protocole… c’est un protocole standard normalisé par le W3C, donc c’est pas vraiment des rigolos quand il s’agit de définir une norme, qui permet à toutes les plateformes de réseaux sociaux qui l’implémente de connecter leur contenu et leurs utilisatrices et leurs utilisateurs entre eux l’ensemble des plateformes qui utilisent Activitypub est appelé le fédiverse qui est un mot-valise contraction de «univers» et «fédérer». La plus emblématique de ces plateformes c’est Mastodon quel est donc une plateforme de microblogging semblable à Twitter qui connaît un succès considérable depuis 2017 et récemment on en entend beaucoup parler suite au rachat de Twitter et on compte aujourd’hui plusieurs milliers de serveurs Mastodon et plusieurs millions d’utilisatrices et utilisateurs.
Là où franchement ça devient génial et même au-delà de Mastodon c’est que le fédiverse permet de mutualiser et d’interconnecter plein plein plein de serveurs sur des technologies diverses, différentes, pourvu qu’il implémente Activitypub. Par exemple une utilisatrice ou un utilisateur pourra depuis un un compte Mastodon donc un unique compte Mastodon interagir avec d’autres qui sont connectés depuis un ou plusieurs serveurs Pixelfed, du partage de photos façon Instagram depuis des serveurs Peertube partage de vidéos façon Youtube depuis des serveurs Bookwyrm qui est un service de partage de critiques littéraires depuis les serveurs Funkwhale qui permet du partage de musique depuis Mobilizon, nous en parlions tout à l’heure, qui permet de partager de l’organisation d’événements et depuis Castopod qui permet le partage de podcasts.
Illustration CC-BY-SA Benjamin Bellamy
Donc concrètement imagine c’est comme si depuis ton compte Twitter tu pouvais « liker » une photo Instagram, commenter une vidéo Youtube, partager une musique SoundCloud.
Alors évidemment bah ça c’est pas possible. C’est pas possible chez les GAFAM.
Mais sur le fédivers ça l’est ! C’est possible, et c’est possible aujourd’hui ! Ce qui fait que ben avec Castopod le podcast est le réseau social donc tes auditrices et tes auditeurs peuvent commenter, partager ou aimer un épisode directement sans aucun intermédiaire. Aucun intermédiaire, qu’il soit technique ou juridique, hein sans GAFAM, sans plateforme privative entre les deux tu as la garantie de ne pas te prendre un «strike» parce que tu as fait usage de ton droit de citation tu ne vas pas avoir ton compte bloqué parce que t’as utilisé des mots-clefs qui sont indésirables et pas de censure automatique par un idiot de «bot» qui ne sait dialoguer qu’en éructant des réponses pré-formatées.
Et tout cela en étant accessible à des millions d’utilisatrices et utilisateurs sur des milliers de serveurs du fédivers. Honnêtement, n’ayons pas peur de le dire, l’avenir des réseaux sociaux sera fédivers ou ne sera pas !
Ça me rappelle quelqu’un, tiens… Alors tu as mentionné, quand on a parlé de podcast, tout à l’heure, tu vois je n’arrive pas à le prononcer, décidément.
Tu as mentionné Podcast-Index quand on s’est parlé en préparant l’interview et tu as parlé de Podcasting 2.0 tout à l’heure. Qu’est-ce que c’est ?
Fred répète pour prononcer « podcast » correctement.
Alors…
Hum…
Laisse-moi chausser mes lunettes parce que cette question nécessite qu’on s’arrête une petite heure, une petite heure et demie sur
l’histoire du podcast.
Je ne suis pas sûr qu’il nous reste autant (de temps).
Alors là je vais… je vais abréger.
Bien avant les iPods, en 1989, l’émission « l’illusion d’une radio indépendante » (“Иллюзия независимого радио”) ouvre la voie aux podcasts qu’on connaît aujourd’hui en proposant en URSS des émissions sonores qui à l’époque étaient diffusées sur des cassettes et des bandes magnétiques et de « URSS » à « RSS » il n’y a qu’un U, celui de « Uuuuuuh ! quel jeu de mot tout pourri !» jeux de mots que je m’abstiendrai donc de faire.
Trop tard !…
Et donc sans jeu de mots et bien plus tard c’est en octobre 2000 que Tristan Louis, comme son nom peut le laisser penser il est français, il a l’idée d’inclure des fichiers MP3 dans un flux RSS. RSS lui-même créé et promu par des véritables légendes tel que Ramanathan V. Guha, Dave Winer ou Aaron Swartz.
Et donc il crée la technologie qui est celle que tous les podcasts du monde utilisent encore aujourd’hui. Après ça alors qu’on parlait plutôt d’audio blogging à l’époque, Ben Hammersley, journaliste au Guardian, est le premier à lancer le mot podcast en février 2004 qui est un mot-valise entre « iPod » et broadcasting, broadcasting pour « diffusion » en anglais.
Ce qui fera vraiment connaître le podcast au grand public c’est d’abord les contenus par exemple “Daily Source Code” d’Adam Curry lancé à l’été 2004, et ensuite l’intégration des podcasts par Apple dans iTunes 4.9 en juin 2005.
Et puis pas grand-chose pendant toute une décennie ! En fait l’histoire du podcast elle aurait pu s’arrêter là.
Mais en 2014, Sarah Koenig va bousculer littéralement un écosystème un peu moribond en publiant Serial le podcast aux 350 millions de téléchargements et c’est à ce moment-là qu’un véritable engouement populaire pour les podcasts apparaît.
C’est impressionnant, comme chiffre !
Ah oui, c’est impressionnant, oui… C’est impressionnant surtout que ça n’arrête pas de croître ! C’est un très bon podcast d’ailleurs Serial, j’adore. Il y a trois saisons et les trois sont très très bien. Si on comprend l’anglais c’est vraiment un podcast à écouter, Serial.
Néanmoins malgré ce renouveau force est de constater que,en plus de quinze ans, pas une seule – et alors que les usages du web entre-temps ont été révolutionnées par le haut débit les smartphones les réseaux sociaux le cloud etc. – donc pas une seule innovation technologique n’est venue bousculer le podcast.
Statu quo fonctionnel et technologique.
Apple règne toujours en maître absolu sur son annuaire de podcasts et rien n’a évolué et à l’été 2019 Adam Curry le même que cité tout à l’heure et Dave Jones, insatisfaits de cette situation, décident de lancer en parallèle, non pas un non pas deux, mais bien trois projets afin de secouer un peu tout ça.
Premièrement et pour mettre fin à la dépendance vis-à-vis de l’index d’Apple ils créent un index de podcasts qui s’appelle Podcast-Index, pas super original, mais au moins on comprend ce que c’est. Il faut comprendre que là où l’index d’Apple requiert une validation d’Apple pour ajouter le moindre podcast mais également pour lire le contenu de l’index ce qui fait qu’Apple en fait a le pouvoir de vie ou de mort sur n’importe quelle application d’écoute qui n’utiliserait que son index.
Là où l’index d’Apple est soumis au bon vouloir d’Apple, Podcast-index est libre.
Il est libre en lecture et en écriture mais attention, vraiment libre par exemple la base de données de Podcast-index, elle est librement téléchargeable dans son intégralité en un clic depuis la page d’accueil. Tu n’as même pas besoin de créer un compte, de filer ton adresse mail, ton numéro de portable, ou le nom de jeune fille de ta mère. Et en plus de ça des API sont librement disponibles pour les applications mobiles Podcast-index référence aujourd’hui plus de quatre millions de podcasts. Apple aujourd’hui en a deux millions et demi.
Deuxièmement et pour rattraper le temps perdu, Adam et Dave décident de proposer de nouvelles fonctionnalités en créant des nouvelles méta-données, le « Podcast Namespace », qui ouvre la voie à ce qu’ils appellent « Podcasting 2.0 ».
Parmi les nombreuses fonctionnalités qui comprend comment on peut noter ben donc la gestion de transcription et de sous-titrage les liens de financement le chapitrage la géolocalisation contenus la gestion d’un intervenant. Il y en a plein d’autres ayant des nouvelles tout le temps, l’ensemble de ces spécifications euh et de ses innovations est librement consultable en ligne sur Github (on mettra le lien dans l’article, dans la description) et librement consultable encore une fois en lecture et en écriture.
C’est là en fait le troisième volet la troisième révolution, le mot est à peine exagéré hein qu’Adam et Dave vont apporter aux podcasts ; ils ont créé une communauté libre et ouverte où tout le monde peut apporter son temps son talent ou son trésor et force est de constater que ça fonctionne du tonnerre. En moins de six mois, alors que je rappelle qu’aucune innovation n’avait bousculé le podcast en quinze ans, en moins de six mois il y a plein d’applications d’écoute et d’hébergeurs évidemment dont Castopod qui ont rejoint le mouvement et qui ont intégré tout ou partie de ces nouvelles fonctionnalités. Donc cette communauté elle se rassemble sur Github sur Mastodon sur podcastindex.social dans un podcast éponyme et lors de réunions où on parle plutôt «techos».
Enfin le résultat c’est que la liste des applications et des services qui sont compatibles podcasting 2.0 est disponible sur le site podcasting.com. Clairement c’est sur ce site et sur podcastindex.org qui faut aujourd’hui choisir son application ou son hébergeur.
Alors moi je suis allé tourner un peu sur les sites de Castopod, je suis allé voir blog.castopod.org mais alors tout est en anglais là-dedans !
J’ai cherché un un petit bouton pour changer de langue et il n’y en a pas. Je croyais que le projet était français ? Pourquoi ça cause pas la langue de Molière ?
Le projet est français mais il est avant tout européen, enfin en tous cas d’un point de vue chronologique et et donc naturellement on a commencé par l’anglais et on n’a pas eu le temps de traduire cette partie-là mais ça va venir vite, c’est promis.
Oui parce que la doc en revanche elle a son site en français doc.castopod.org/fr et là j’étais content j’aurais dû commencer par là parce que il y a plein d’explications dans la doc.
Oui, alors la doc, on a pris le temps de la traduire en français et en plus la communauté aidant elle est également disponible en plus de l’anglais en brésilien1 et en norvégien et d’autres langues arriveront derrière.
Mais alors je suppose que c’est en fonction des contributeurs et des contributrices que le projet évolue ? Vous avez besoin de contributeurs de contributrices ? Comment est-ce qu’on peut faire pour vous aider ?
Ouais tout à fait mais Castopod c’est avant tout un projet ouvert hein donc le le code source est ouvert mais pas seulement on a besoin de développeuses et de développeurs mais également de traductrices de traducteurs de testeuses de testeurs de prescriptrices et de prescripteurs qui prêchent la bonne parole (merci Framasoft !) et puis de financement via Open Collective.
D’accord ! Alors comme d’habitude on te laisse le mot de la fin dans le Framablog. Est-ce qu’il y a des questions qu’on ne t’a pas posées ? Est-ce qu’il y a des choses que tu as envie d’ajouter ?
Écoute, je trouve que tu as mené cette interview d’une main de maître.
Merci de m’avoir reçu ! En fait je voudrais juste dire aux gens : essayez le podcast.
Vous avez un téléphone vous pouvez vous y mettre ; il ne faut pas être timides hein lancez-vous attendez pas des mois avant de créer le premier épisode car une fois qu’on a une idée on enregistre on publie et puis c’est ce que j’aime avec le podcast, on peut changer de modèle on peut changer de format on peut changer ce qu’on veut on peut tester il y a des hébergeurs pour tout le monde. Évidemment moi je vous engage à aller sur castopod.org pour voir ce que c’est pour voir ce qu’on propose.
Ah, si vous avez un peu la fibre technique eh bien n’hésitez pas à le télécharger et à l’installer, sachant que si vous avez pas la fibre technique et bah allez plutôt sur castopod.com où on propose des prestations d’hébergement clé en main. Et puis bon podcasting et bonne écoute !
Ah bah je vais m’y mette du coup je vais essayer de trouver quelques podcasts intéressants parce que c’est pas du tout ma culture ! En tout cas voilà grâce à toi je vais écouter des podcasts.
Merci beaucoup d’être venu parler avec nous et puis on espère longue vie à Castopod.
L’illustration « Fred répète » a été réalisée avec Gégé, le générateur de Geektionnerd basé sur des dessins sous licence libre de SImon « Gee » Giraudot