Glyn Moody sur l’article 13 – Mensonges et mauvaise foi
Glyn Moody est un journaliste, blogueur et écrivain spécialisé dans les questions de copyright et droits numériques. Ses combats militants le placent en première ligne dans la lutte contre l’article 13 de la directive européenne sur le droit d’auteur, dont le vote final est prévu ce mois-ci. Cet article a été combattu par des associations en France telles que La Quadrature du Net, dénoncé pour ses effet délétères par de nombreuses personnalités (cette lettre ouverte par exemple, signée de Vinton Cerf, Tim Berners-lee, Bruce Schneier, Jimmy Wales…) et a fait l’objet de pétitions multiples.
Dans une suite d’articles en cours (en anglais) ou dans diverses autres interventions (celle-ci traduite en français) que l’on parcourra avec intérêt, Glyn Moody démonte un à un les éléments de langage des lobbyistes des ayants droit. Le texte que Framalang a traduit pour vous met l’accent sur la mauvaise foi des défenseurs de l’article 13 qui préparent des réponses biaisées aux objections qui leur viennent de toutes parts, et notamment de 4 millions d’Européens qui ont manifesté leur opposition.
Pour Glyn Moody, manifestement l’article 13 est conçu pour donner des pouvoirs exorbitants (qui vont jusqu’à une forme de censure automatisée) aux ayants droit au détriment des utilisateurs et utilisatrices « ordinaires »
L’article 13 n’est pas seulement un travail législatif dangereux, mais aussi foncièrement malhonnête
par Glyn Moody
La directive sur Copyright de l’Union Européenne est maintenant en phase d’achèvement au sein du système législatif européen. Étant donné la nature avancée des discussions, il est déjà très surprenant que le comité des affaires juridiques (JURI), responsable de son pilotage à travers le Parlement Européen, ait récemment publié une session de « Questions et Réponses » sur la proposition de « Directive au sujet du Copyright numérique ». Mais il n’est pas difficile de deviner pourquoi ce document a été publié maintenant. De plus en plus de personnes prennent conscience que la directive sur le Copyright en général, et l’Article 13 en particulier, vont faire beaucoup de tort à l’Internet en Europe. Cette session de Q & R tente de contrer les objections relevées et d’étouffer le nombre grandissant d’appels à l’abandon de l’Article 13.
La première question de cette session de Q & R, « En quoi consiste la directive sur le Copyright ? », souligne le cœur du problème de la loi proposée.
La réponse est la suivante : « La proposition de directive sur le Copyright dans le marché unique numérique » cherche à s’assurer que les artistes (en particulier les petits artistes, par exemple les musiciens), les éditeurs de contenu ainsi que les journalistes, bénéficient autant du monde connecté et d’Internet que du monde déconnecté. »
Il n’est fait mention nulle part des citoyens européens qui utilisent l’Internet, ou de leurs priorités. Donc, il n’est pas surprenant qu’on ne règle jamais le problème du préjudice que va causer la directive sur le Copyright à des centaines de millions d’utilisateurs d’Internet, car les défenseurs de la directive sur le Copyright ne s’en préoccupent pas. La session de Q & R déclare : « Ce qu’il est actuellement légal et permis de partager, restera légal et permis de partager. » Bien que cela soit sans doute correct au sens littéral, l’exigence de l’Article 13 concernant la mise en place de filtres sur la mise en ligne de contenus signifie en pratique que c’est loin d’être le cas. Une information parfaitement légale à partager sera bloquée par les filtres, qui seront forcément imparfaits, et parce que les entreprises devant faire face à des conséquences juridiques, feront toujours preuve d’excès de prudence et préféreront trop bloquer.
La question suivante est : « Quel impact aura la directive sur les utilisateurs ordinaires ? ».
Là encore, la réponse est correcte mais trompeuse : « Le projet de directive ne cible pas les utilisateurs ordinaires. »
Personne ne dit qu’elle cible les utilisateurs ordinaires, en fait, ils sont complètement ignorés par la législation. Mais le principal, c’est que les filtres sur les chargements de contenu vont affecter les utilisateurs ordinaires, et de plein fouet. Que ce soit ou non l’intention n’est pas la question.
« Est-ce que la directive affecte la liberté sur Internet ou mène à une censure d’Internet ? » demande la session de Q & R.
La réponse ici est « Un utilisateur pourra continuer d’envoyer du contenu sur les plateformes d’Internet et (…) ces plateformes / agrégateurs d’informations pourront continuer à héberger de tels chargements, tant que ces plateformes respectent les droits des créateurs à une rémunération décente. »
Oui, les utilisateurs pourront continuer à envoyer du contenu, mais une partie sera bloquée de manière injustifiable parce que les plateformes ne prendront pas le risque de diffuser du contenu qui ne sera peut-être couvert par l’une des licences qu’elles ont signées.
La question suivante concerne le mensonge qui est au cœur de la directive sur le Copyright, à savoir qu’il n’y a pas besoin de filtre sur les chargements. C’est une idée que les partisans ont mise en avant pendant un temps, et il est honteux de voir le Parlement Européen lui-même répéter cette contre-vérité. Voici l’élément de la réponse :
« La proposition de directive fixe un but à atteindre : une plateforme numérique ou un agrégateur de presse ne doit pas gagner d’argent grâce aux productions de tierces personnes sans les indemniser. Par conséquent, une plateforme ou un agrégateur a une responsabilité juridique si son site diffuse du contenu pour lequel il n’aurait pas correctement rémunéré le créateur. Cela signifie que ceux dont le travail est illégalement utilisé peuvent poursuivre en justice la plateforme ou l’agrégateur. Toutefois, le projet de directive ne spécifie pas ni ne répertorie quels outils, moyens humains ou infrastructures peuvent être nécessaires afin d’empêcher l’apparition d’une production non rémunérée sur leur site. Il n’y a donc pas d’obligation de filtrer les chargements.
Toutefois, si de grandes plateformes ou agrégateurs de presse ne proposent pas de solutions innovantes, ils pourraient finalement opter pour le filtrage. »
La session Q & R essaye d’affirmer qu’il n’est pas nécessaire de filtrer les chargements et que l’apport de « solutions innovantes » est à la charge des entreprises du web. Elle dit clairement que si une entreprise utilise des filtres sur les chargements, on doit lui reprocher de ne pas être suffisamment « innovante ». C’est une absurdité. D’innombrables experts ont signalé qu’il est impossible « d’empêcher la diffusion de contenu non-rémunéré sur un site » à moins de vérifier, un à un, chacun les fichiers et de les bloquer si nécessaire : il s’agit d’un filtrage des chargements. Aucune “innovation” ne permettra de contourner l’impossibilité logique de se conformer à la directive sur le Copyright, sans avoir recours au filtrage des chargements.
En plus de donner naissance à une législation irréfléchie, cette approche montre aussi la profonde inculture technique de nombreux politiciens européens. Ils pensent encore manifestement que la technologie est une sorte de poudre de perlimpinpin qui peut être saupoudrée sur les problèmes afin de les faire disparaître. Ils ont une compréhension médiocre du domaine numérique et sont cependant assez arrogants pour ignorer les meilleurs experts mondiaux en la matière lorsque ceux-ci disent que ce que demande la Directive sur le Copyright est impossible.
Pour couronner le tout, la réponse à la question : « Pourquoi y a-t-il eu de nombreuses contestations à l’encontre de cette directive ? » constitue un terrible affront pour le public européen. La réponse reconnaît que : « Certaines statistiques au sein du Parlement Européen montrent que les parlementaires ont rarement, voire jamais, été soumis à un tel niveau de lobbying (appels téléphoniques, courriels, etc.). » Mais elle écarte ce niveau inégalé de contestation de la façon suivante :
« De nombreuses campagnes antérieures de lobbying ont prédit des conséquences désastreuses qui ne se sont jamais réalisées.
Par exemple, des entreprises de télécommunication ont affirmé que les factures téléphoniques exploseraient en raison du plafonnement des frais d’itinérance ; les lobbies du tabac et de la restauration ont prétendu que les personnes allaient arrêter d’aller dans les restaurants et dans les bars suite à l’interdiction d’y fumer à l’intérieur ; des banques ont dit qu’elles allaient arrêter de prêter aux entreprises et aux particuliers si les lois devenaient plus strictes sur leur gestion, et le lobby de la détaxe a même argué que les aéroports allaient fermer, suite à la fin des produits détaxés dans le marché intérieur. Rien de tout ceci ne s’est produit. »
Il convient de remarquer que chaque « contre-exemple » concerne des entreprises qui se plaignent de lois bénéficiant au public. Mais ce n’est pas le cas de la vague de protestation contre la directive sur le Copyright, qui vient du public et qui est dirigée contre les exigences égoïstes de l’industrie du copyright. La session de Q & R tente de monter un parallèle biaisé entre les pleurnichements intéressés des industries paresseuses et les attentes d’experts techniques inquiets, ainsi que de millions de citoyens préoccupés par la préservation des extraordinaires pouvoirs et libertés de l’Internet ouvert.
Voici finalement la raison pour laquelle la directive sur le Copyright est si pernicieuse : elle ignore totalement les droits des usagers d’Internet. Le fait que la nouvelle session de Q & R soit incapable de répondre à aucune des critiques sérieuses sur la loi autrement qu’en jouant sur les mots, dans une argumentation pitoyable, est la confirmation que tout ceci n’est pas seulement un travail législatif dangereux, mais aussi profondément malhonnête. Si l’Article 13 est adopté, il fragilisera l’Internet dans les pays de l’UE, entraînera la zone dans un marasme numérique et, par le refus réitéré de l’Union Européenne d’écouter les citoyens qu’elle est censée servir, salira le système démocratique tout entier.
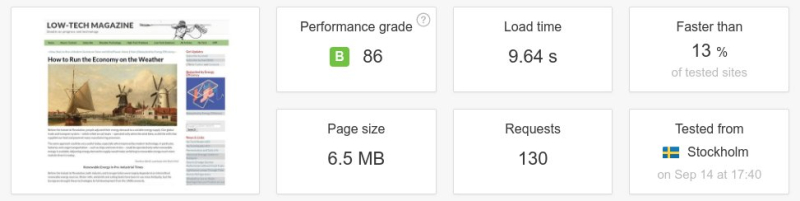
Sites lourds, sites lents, pages web obèses qui exigent pour être consultées dans un délai raisonnable une carte graphique performante, un processeur rapide et autant que possible une connexion par fibre optique… tel est le quotidien de l’internaute ordinaire.
Nul besoin de remonter aux débuts du Web pour comparer : c’est d’une année sur l’autre que la taille moyenne des pages web s’accroît désormais de façon significative.
Quant à la consommation en énergie de notre vie en ligne, elle prend des proportions qui inquiètent à juste titre : des lointains datacenters aux hochets numériques dont nous aimons nous entourer, il y a de quoi se poser des questions sur la nocivité environnementale de nos usages collectifs et individuels.
Bien sûr, les solutions économes à l’échelle de chacun sont peut-être dérisoires au regard des gigantesques gaspillages d’un système consumériste insatiable et énergivore.
Cependant nous vous invitons à prendre en considération l’expérience de l’équipe barcelonaise de Low-Tech Magazine dont nous avons traduit pour vous un article. Un peu comme l’association Framasoft l’avait fait en ouverture de la campagne dégooglisons… en se dégooglisant elle-même, les personnes de Low-tech Magazine ont fait de leur mieux pour appliquer à leur propre site les principes de frugalité qu’elles défendent : ce ne sont plus seulement les logiciels mais aussi les matériels qui ont fait l’objet d’une cure d’amaigrissement au régime solaire.
En espérant que ça donnera des idées à tous les bidouilleurs…
article original : How to build a Low-tech website Traduction Framalang : Khrys, Mika, Bidouille, Penguin, Eclipse, Barbara, Mannik, jums, Mary, Cyrilus, goofy, simon, xi, Lumi, Suzy + 2 auteurs anonymes
Comment créer un site web basse technologie
Low-tech Magazine a été créé en 2007 et n’a que peu changé depuis. Comme une refonte du site commençait à être vraiment nécessaire, et comme nous essayons de mettre en œuvre ce que nous prônons, nous avons décidé de mettre en place une version de Low Tech Magazine en basse technologie, auto-hébergée et alimentée par de l’énergie solaire. Le nouveau blog est conçu pour réduire radicalement la consommation d’énergie associée à l’accès à notre contenu.
Premier prototype du serveur alimenté à l’énergie solaire sur lequel tourne le nouveau site.
Pour éviter les conséquences négatives d’une consommation énergivore, les énergies renouvelables seraient un moyen de diminuer les émissions des centres de données. Par exemple, le rapport annuel ClickClean de Greenpeace classe les grandes entreprises liées à Internet en fonction de leur consommation d’énergies renouvelables.
Cependant, faire fonctionner des centres de données avec des sources d’énergie renouvelables ne suffit pas à compenser la consommation d’énergie croissante d’Internet. Pour commencer, Internet utilise déjà plus d’énergie que l’ensemble des énergies solaire et éolienne mondiales. De plus, la réalisation et le remplacement de ces centrales électriques d’énergies renouvelables nécessitent également de l’énergie, donc si le flux de données continue d’augmenter, alors la consommation d’énergies fossiles aussi.
Cependant, faire fonctionner les centres de données avec des sources d’énergie renouvelables ne suffit pas à combler la consommation d’énergie croissante d’Internet.
Enfin, les énergies solaire et éolienne ne sont pas toujours disponibles, ce qui veut dire qu’un Internet fonctionnant à l’aide d’énergies renouvelables nécessiterait une infrastructure pour le stockage de l’énergie et/ou pour son transport, ce qui dépend aussi des énergies fossiles pour sa production et son remplacement. Alimenter les sites web avec de l’énergie renouvelable n’est pas une mauvaise idée, mais la tendance vers l’augmentation de la consommation d’énergie doit aussi être traitée.
Des sites web qui enflent toujours davantage
Tout d’abord, le contenu consomme de plus en plus de ressources. Cela a beaucoup à voir avec l’importance croissante de la vidéo, mais une tendance similaire peut s’observer sur les sites web.
La taille moyenne d’une page web (établie selon les pages des 500 000 domaines les plus populaires) est passée de 0,45 mégaoctets en 2010 à 1,7 mégaoctets en juin 2018. Pour les sites mobiles, le poids moyen d’une page a décuplé, passant de 0,15 Mo en 2011 à 1,6 Mo en 2018. En utilisant une méthode différente, d’autres sources évoquent une moyenne autour de 2,9 Mo en 2018.
La croissance du transport de données surpasse les avancées en matière d’efficacité énergétique (l’énergie requise pour transférer 1 mégaoctet de données sur Internet), ce qui engendre toujours plus de consommation d’énergie. Des sites plus « lourds » ou plus « gros » ne font pas qu’augmenter la consommation d’énergie sur l’infrastructure du réseau, ils raccourcissent aussi la durée de vie des ordinateurs, car des sites plus lourds nécessitent des ordinateurs plus puissants pour y accéder. Ce qui veut dire que davantage d’ordinateurs ont besoin d’être fabriqués, une production très coûteuse en énergie.
Être toujours en ligne ne fait pas bon ménage avec des sources d’énergies renouvelables telles que l’éolien ou le solaire, qui ne sont pas toujours disponibles.
La deuxième raison de l’augmentation de la consommation énergétique d’Internet est que nous passons de plus en plus de temps en ligne. Avant l’arrivée des ordinateurs portables et du Wi-Fi, nous n’étions connectés au réseau que lorsque nous avions accès à un ordinateur fixe au bureau, à la maison ou à la bibliothèque. Nous vivons maintenant dans un monde où quel que soit l’endroit où nous nous trouvons, nous sommes toujours en ligne, y compris, parfois, sur plusieurs appareils à la fois.
Un accès Internet en mode « toujours en ligne » va de pair avec un modèle d’informatique en nuage, permettant des appareils plus économes en énergie pour les utilisateurs au prix d’une dépense plus importante d’énergie dans des centres de données. De plus en plus d’activités qui peuvent très bien se dérouler hors-ligne nécessitent désormais un accès Internet en continu, comme écrire un document, remplir une feuille de calcul ou stocker des données. Tout ceci ne fait pas bon ménage avec des sources d’énergies renouvelables telles que l’éolien ou le solaire, qui ne sont pas disponibles en permanence.
Conception d’un site internet basse technologie
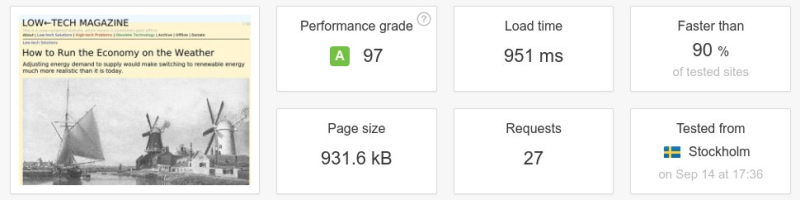
La nouvelle mouture de notre site répond à ces deux problématiques. Grâce à une conception simplifiée de notre site internet, nous avons réussi à diviser par cinq la taille moyenne des pages du blog par rapport à l’ancienne version, tout en rendant le site internet plus agréable visuellement (et plus adapté aux mobiles). Deuxièmement, notre nouveau site est alimenté à 100 % par l’énergie solaire, non pas en théorie, mais en pratique : il a son propre stockage d’énergie et sera hors-ligne lorsque le temps sera couvert de manière prolongée.
Internet n’est pas une entité autonome. Sa consommation grandissante d’énergie est la résultante de décisions prises par des développeurs logiciels, des concepteurs de site internet, des départements marketing, des annonceurs et des utilisateurs d’internet. Avec un site internet poids plume alimenté par l’énergie solaire et déconnecté du réseau, nous voulons démontrer que d’autres décisions peuvent être prises.
Avec 36 articles en ligne sur environ une centaine, le poids moyen d’une page sur le site internet alimenté par énergie solaire est environ cinq fois inférieur à celui de la version précédente.
Pour commencer, la nouvelle conception du site va à rebours de la tendance à des pages plus grosses. Sur 36 articles actuellement en ligne sur environ une centaine, le poids moyen d’une page sur le site internet alimenté par énergie solaire est 0,77 Mo – environ cinq fois inférieur à celui de la version précédente, et moins de la moitié du poids moyen d’une page établi sur les 500 000 blogs les plus populaires en juin 2018.
Ci-dessous : un test de vitesse d’une page web entre l’ancienne et la nouvelle version du magazine Low-Tech. La taille de la page a été divisée par plus de six, le nombre de requêtes par cinq, et la vitesse de téléchargement a été multipliée par dix. Il faut noter que l’on n’a pas conçu le site internet pour être rapide, mais pour une basse consommation d’énergie. La vitesse aurait été supérieure si le serveur avait été placé dans un centre de données et/ou à une position plus centrale de l’infrastructure d’Internet.
Ci-dessous sont détaillées plusieurs des décisions de conception que nous avons faites pour réduire la consommation d’énergie. Des informations plus techniques sont données sur une page distincte. Nous avons aussi libéré le code source pour la conception de notre site internet.
Site statique
Un des choix fondamentaux que nous avons faits a été d’élaborer un site internet statique. La majorité des sites actuels utilisent des langages de programmation côté serveur qui génèrent la page désirée à la volée par requête à une base de données. Ça veut dire qu’à chaque fois que quelqu’un visite une page web, elle est générée sur demande.
Au contraire, un site statique est généré une fois pour toutes et existe comme un simple ensemble de documents sur le disque dur du serveur. Il est toujours là, et pas seulement quand quelqu’un visite la page. Les sites internet statiques sont donc basés sur le stockage de fichiers quand les sites dynamiques dépendent de calculs récurrents. En conséquence, un site statique nécessite moins de puissance de calcul, donc moins d’énergie.
Le choix d’un site statique nous permet d’opérer la gestion de notre site de manière économique depuis notre bureau de Barcelone. Faire la même chose avec un site web généré depuis une base de données serait quasiment impossible, car cela demanderait trop d’énergie. Cela présenterait aussi des risques importants de sécurité. Bien qu’un serveur avec un site statique puisse toujours être piraté, il y a significativement moins d’attaques possibles et les dommages peuvent être plus facilement réparés.
Images optimisées pour en réduire le « poids »
Le principal défi a été de réduire la taille de la page sans réduire l’attractivité du site. Comme les images consomment l’essentiel de la bande passante il serait facile d’obtenir des pages très légères et de diminuer l’énergie nécessaire en supprimant les images, en réduisant leur nombre ou en réduisant considérablement leur taille. Néanmoins, les images sont une part importante de l’attractivité de Low-tech Magazine et le site ne serait pas le même sans elles.
Par optimisation, on peut rendre les images dix fois moins gourmandes en ressources, tout en les affichant bien plus largement que sur l’ancien site.
Nous avons plutôt choisi d’appliquer une ancienne technique de compression d’image appelée « diffusion d’erreur ». Le nombre de couleurs d’une image, combiné avec son format de fichier et sa résolution, détermine la taille de cette image. Ainsi, plutôt que d’utiliser des images en couleurs à haute résolution, nous avons choisi de convertir toutes les images en noir et blanc, avec quatre niveaux de gris intermédiaires.
Ces images en noir et blanc sont ensuite colorées en fonction de la catégorie de leur contenu via les capacités de manipulation d’image natives du navigateur. Compressées par ce module appelé dithering, les images présentées dans ces articles ajoutent beaucoup moins de poids au contenu ; par rapport à l’ancien site web, elles sont environ dix fois moins consommatrices de ressources.
Police de caractère par défaut / Pas de logo
Toutes les ressources chargées, y compris les polices de caractères et les logos, le sont par une requête supplémentaire au serveur, nécessitant de l’espace de stockage et de l’énergie. Pour cette raison, notre nouveau site web ne charge pas de police personnalisée et enlève toute déclaration de liste de polices de caractères, ce qui signifie que les visiteurs verront la police par défaut de leur navigateur.
Une page du magazine en version basse consommation
Nous utilisons une approche similaire pour le logo. En fait, Low-tech Magazine n’a jamais eu de véritable logo, simplement une bannière représentant une lance, considérée comme une arme low-tech (technologie sobre) contre la supériorité prétendue des « high-tech » (hautes technologies).
Au lieu d’un logo dessiné, qui nécessiterait la production et la distribution d’image et de polices personnalisées, la nouvelle identité de Low-Tech Magazine consiste en une unique astuce typographique : utiliser une flèche vers la gauche à la place du trait d’union dans le nom du blog : LOW←TECH MAGAZINE.
Pas de pistage par un tiers, pas de services de publicité, pas de cookies
Les logiciels d’analyse de sites tels que Google Analytics enregistrent ce qui se passe sur un site web, quelles sont les pages les plus vues, d’où viennent les visiteurs, etc. Ces services sont populaires car peu de personnes hébergent leur propre site. Cependant l’échange de ces données entre le serveur et l’ordinateur du webmaster génère du trafic de données supplémentaire et donc de la consommation d’énergie.
Avec un serveur auto-hébergé, nous pouvons obtenir et visualiser ces mesures de données avec la même machine : tout serveur génère un journal de ce qui se passe sur l’ordinateur. Ces rapports (anonymes) ne sont vus que par nous et ne sont pas utilisés pour profiler les visiteurs.
Avec un serveur auto-hébergé, pas besoin de pistage par un tiers ni de cookies.
Low-tech Magazine a utilisé des publicités Google Adsense depuis ses débuts en 2007. Bien qu’il s’agisse d’une ressource financière importante pour maintenir le blog, elles ont deux inconvénients importants. Le premier est la consommation d’énergie : les services de publicité augmentent la circulation des données, ce qui consomme de l’énergie.
Deuxièmement, Google collecte des informations sur les visiteurs du blog, ce qui nous contraint à développer davantage les déclarations de confidentialité et les avertissements relatifs aux cookies, qui consomment aussi des données et agacent les visiteurs. Nous avons donc remplacé Adsense par d’autres sources de financement (voir ci-dessous pour en savoir plus). Nous n’utilisons absolument aucun cookie.
À quelle fréquence le site web sera-t-il hors-ligne ?
Bon nombre d’entreprises d’hébergement web prétendent que leurs serveurs fonctionnent avec de l’énergie renouvelable. Cependant, même lorsqu’elles produisent de l’énergie solaire sur place et qu’elles ne se contentent pas de « compenser » leur consommation d’énergie fossile en plantant des arbres ou autres, leurs sites Web sont toujours en ligne.
Cela signifie soit qu’elles disposent d’un système géant de stockage sur place (ce qui rend leur système d’alimentation non durable), soit qu’elles dépendent de l’énergie du réseau lorsqu’il y a une pénurie d’énergie solaire (ce qui signifie qu’elles ne fonctionnent pas vraiment à 100 % à l’énergie solaire).
Le panneau photo-voltaïque solaire de 50 W. Au-dessus, un panneau de 10 W qui alimente un système d’éclairage.
En revanche, ce site web fonctionne sur un système d’énergie solaire hors réseau avec son propre stockage d’énergie et hors-ligne pendant les périodes de temps nuageux prolongées. Une fiabilité inférieure à 100 % est essentielle pour la durabilité d’un système solaire hors réseau, car au-delà d’un certain seuil, l’énergie fossile utilisée pour produire et remplacer les batteries est supérieure à l’énergie fossile économisée par les panneaux solaires.
Reste à savoir à quelle fréquence le site sera hors ligne. Le serveur web est maintenant alimenté par un nouveau panneau solaire de 50 Wc et une batterie plomb-acide (12V 7Ah) qui a déjà deux ans. Comme le panneau solaire est à l’ombre le matin, il ne reçoit la lumière directe du soleil que 4 à 6 heures par jour. Dans des conditions optimales, le panneau solaire produit ainsi 6 heures x 50 watts = 300 Wh d’électricité.
Le serveur web consomme entre 1 et 2,5 watts d’énergie (selon le nombre de visiteurs), ce qui signifie qu’il consomme entre 24 et 60 Wh d’électricité par jour. Dans des conditions optimales, nous devrions donc disposer de suffisamment d’énergie pour faire fonctionner le serveur web 24 heures sur 24. La production excédentaire d’énergie peut être utilisée pour des applications domestiques.
Nous prévoyons de maintenir le site web en ligne pendant un ou deux jours de mauvais temps, après quoi il sera mis hors ligne.
Cependant, par temps nuageux, surtout en hiver, la production quotidienne d’énergie pourrait descendre à 4 heures x 10 watts = 40 watts-heures par jour, alors que le serveur nécessite entre 24 et 60 Wh par jour. La capacité de stockage de la batterie est d’environ 40 Wh, en tenant compte de 30 % des pertes de charge et de décharge et de 33 % de la profondeur ou de la décharge (le régulateur de charge solaire arrête le système lorsque la tension de la batterie tombe à 12 V).
Par conséquent, le serveur solaire restera en ligne pendant un ou deux jours de mauvais temps, mais pas plus longtemps. Cependant, il s’agit d’estimations et nous pouvons ajouter une deuxième batterie de 7 Ah en automne si cela s’avère nécessaire. Nous visons un uptime, c’est-à-dire un fonctionnement sans interruption, de 90 %, ce qui signifie que le site sera hors ligne pendant une moyenne de 35 jours par an.
Premier prototype avec batterie plomb-acide (12 V 7 Ah) à gauche et batterie Li-Po UPS (3,7V 6600 mA) à droite. La batterie au plomb-acide fournit l’essentiel du stockage de l’énergie, tandis que la batterie Li-Po permet au serveur de s’arrêter sans endommager le matériel (elle sera remplacée par une batterie Li-Po beaucoup plus petite).
Quel est la période optimale pour parcourir le site ?
L’accessibilité à ce site internet dépend de la météo à Barcelone en Espagne, endroit où est localisé le serveur. Pour aider les visiteurs à « planifier » leurs visites à Low-tech Magazine, nous leur fournissons différentes indications.
Un indicateur de batterie donne une information cruciale parce qu’il peut indiquer au visiteur que le site internet va bientôt être en panne d’énergie – ou qu’on peut le parcourir en toute tranquillité. La conception du site internet inclut une couleur d’arrière-plan qui indique la charge de la batterie qui alimente le site Internet grâce au soleil. Une diminution du niveau de charge indique que la nuit est tombée ou que la météo est mauvaise.
Outre le niveau de batterie, d’autres informations concernant le serveur du site web sont affichées grâce à un tableau de bord des statistiques. Celui-ci inclut des informations contextuelles sur la localisation du serveur : heure, situation du ciel, prévisions météorologiques, et le temps écoulé depuis la dernière fois où le serveur s’est éteint à cause d’un manque d’électricité.
SERVEUR : Ce site web fonctionne sur un ordinateur Olimex A20. Il est doté de 2 GHz de vitesse de processeur, 1 Go de RAM et 16 Go d’espace de stockage. Le serveur consomme 1 à 2,5 watts de puissance.
SOFTWARE DU SERVEUR : le serveur web tourne sur Armbian Stretch, un système d’exploitation Debian construit sur un noyau SUNXI. Nous avons rédigé une documentation technique sur la configuration du serveur web.
LOGICIEL DE DESIGN : le site est construit avec Pelican, un générateur de sites web statiques. Nous avons publié le code source de « solar », le thème que nous avons développé.
CONNEXION INTERNET. Le serveur est connecté via une connexion Internet fibre 100 MBps. Voici comment nous avons configuré le routeur. Pour l’instant, le routeur est alimenté par le réseau électrique et nécessite 10 watts de puissance. Nous étudions comment remplacer ce routeur gourmand en énergie par un routeur plus efficace qui pourrait également être alimenté à l’énergie solaire.
SYSTÈME SOLAIRE PHOTOVOLTAÏQUE. Le serveur fonctionne avec un panneau solaire de 50 Wc et une batterie plomb-acide 12 V 7 Ah. Cependant, nous continuons de réduire la taille du système et nous expérimentons différentes configurations. L’installation photovoltaïque est gérée par un régulateur de charge solaire 20A.
Qu’est-il arrivé à l’ancien site ?
Le site Low-tech Magazine alimenté par énergie solaire est encore en chantier. Pour le moment, la version alimentée par réseau classique reste en ligne. Nous encourageons les lecteurs à consulter le site alimenté par énergie solaire, s’il est disponible. Nous ne savons pas trop ce qui va se passer ensuite. Plusieurs options se présentent à nous, mais la plupart dépendront de l’expérience avec le serveur alimenté par énergie solaire.
Tant que nous n’avons pas déterminé la manière d’intégrer l’ancien et le nouveau site, il ne sera possible d’écrire et lire des commentaires que sur notre site internet alimenté par réseau, qui est toujours hébergé chez TypePad. Si vous voulez envoyer un commentaire sur le serveur web alimenté en énergie solaire, vous pouvez en commentant cette page ou en envoyant un courriel à solar (at) lowtechmagazine (dot) com.
Est-ce que je peux aider ?
Bien sûr, votre aide est la bienvenue.
D’une part, nous recherchons des idées et des retours d’expérience pour améliorer encore plus le site web et réduire sa consommation d’énergie. Nous documenterons ce projet de manière détaillée pour que d’autres personnes puissent aussi faire des sites web basse technologie.
D’autre part, nous espérons recevoir des contributions financières pour soutenir ce projet. Les services publicitaires qui ont maintenu Low-tech Magazine depuis ses débuts en 2007 sont incompatibles avec le design de notre site web poids plume. C’est pourquoi nous cherchons d’autres moyens de financer ce site :
1. Nous proposerons bientôt un service de copies du blog imprimées à la demande. Grâce à ces publications, vous pourrez lire le Low-tech Magazine sur papier, à la plage, au soleil, où vous voulez, quand vous voulez.
2. Vous pouvez nous soutenir en envoyant un don sur PayPal, Patreon ou LiberaPay.
3. Nous restons ouverts à la publicité, mais nous ne pouvons l’accepter que sous forme d’une bannière statique qui renvoie au site de l’annonceur. Nous ne travaillons pas avec les annonceurs qui ne sont pas en phase avec notre mission.
Un navigateur pour diffuser votre site web en pair à pair
Les technologies qui permettent la décentralisation du Web suscitent beaucoup d’intérêt et c’est tant mieux. Elles nous permettent d’échapper aux silos propriétaires qui collectent et monétisent les données que nous y laissons.
Vous connaissez probablement Mastodon, peerTube, Pleroma et autres ressources qui reposent sur le protocole activityPub. Mais connaissez-vous les projets Aragon, IPFS, ou ScuttleButt ?
Aujourd’hui nous vous proposons la traduction d’un bref article introducteur à une technologie qui permet de produire et héberger son site web sur son ordinateur et de le diffuser sans le moindre serveur depuis un navigateur.
Nous sommes Blue Link Labs, une équipe de trois personnes qui travaillent à améliorer le Web avec le protocole Dat et un navigateur expérimental pair à pair qui s’appelle Beaker.
L’équipe Blue Link Labs
Nous travaillons sur Beaker car publier et partager est l’essence même du Web. Cependant pour publier votre propre site web ou seulement diffuser un document, vous avez besoin de savoir faire tourner un serveur ou de pouvoir payer quelqu’un pour le faire à votre place.
Nous nous sommes donc demandé « Pourquoi ne pas partager un site Internet directement depuis votre navigateur ? »
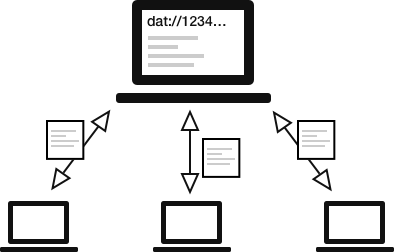
Un protocole pair-à-pair comme dat:// permet aux appareils des utilisateurs ordinaires d’héberger du contenu, donc nous utilisons dat:// dans Beaker pour pouvoir publier depuis le navigateur et donc au lieu d’utiliser un serveur, le site web d’un auteur et ses visiteurs l’aident à héberger ses fichiers. C’est un peu comme BitTorrent, mais pour les sites web !
Architecture
Beaker utilise un réseau pair-à-pair distribué pour publier des sites web et des jeux de données (parfois nous appelons ça des « dats »).
Les sites web dat:// sont joignables avec une clé publique faisant office d’URL, et chaque donnée ajoutée à un site web dat:// est attachée à un log signé.
Les visiteurs d’un site web dat:// peuvent se retrouver grâce à une table de hachage distribuée1, puis ils synchronisent les données entre eux, agissant à la fois comme téléchargeurs et téléverseurs, et vérifiant que les données n’ont pas été altérées pendant le transit.
Une illustration basique du réseau dat://
Techniquement, un site Web dat:// n’est pas tellement différent d’un site web https:// . C’est une collection de fichiers et de dossiers qu’un navigateur Internet va interpréter suivant les standards du Web. Mais les sites web dat:// sont spéciaux avec Beaker parce que nous avons ajouté une API (interface de programmation) qui permet aux développeurs de faire des choses comme lire, écrire, regarder des fichiers dat:// et construire des applications web pair-à-pair.
Créer un site Web pair-à-pair
Beaker rend facile pour quiconque de créer un nouveau site web dat:// en un clic (faire le tour des fonctionnalités). Si vous êtes familier avec le HTML, les CSS ou le JavaScript (même juste un peu !) alors vous êtes prêt⋅e à publier votre premier site Web dat://.
L’exemple ci-dessous montre comment fabriquer le site Web lui-même via la création et la sauvegarde d’un fichier JSON. Cet exemple est fictif mais fournit un modèle commun pour stocker des données, des profils utilisateurs, etc. pour un site Web dat:// : au lieu d’envoyer les données de l’application sur un serveur, elles peuvent être stockées sur le site web lui-même !
// index.js // first get an instance of the website's files var files = new DatArchive(window.location) document.getElementById('create-json-button').addEventListener('click', saveMessage) async function saveMessage () { var timestamp = Date.now() var filename = timestamp + '.json' var content = { timestamp, message: document.getElementById('message').value }
// write the message to a JSON file // this file can be read later using the DatArchive.readFile API await files.writeFile(filename, JSON.stringify(content)) }
Pour aller plus loin
Nous avons hâte de voir ce que les gens peuvent faire de dat:// et de Beaker. Nous apprécions tout spécialement quand quelqu’un crée un site web personnel ou un blog, ou encore quand on expérimente l’interface de programmation pour créer une application.
Beaucoup de choses sont à explorer avec le Web pair-à-pair !
Vous trouverez ci-dessous en un seul document sous deux formats (.odt et .pdf) non seulement l’ensemble des chapitres publiés précédemment mais aussi les copieuses annexes qui référencent les recherches menées par l’équipe ainsi que les éléments qui ne pouvaient être détaillés dans les chapitres précédents.
Traduction Framalang pour l’ensemble du document :
Nous avons fait de notre mieux, mais des imperfections de divers ordres peuvent subsister, n’hésitez pas à vous emparer de la version en .odt pour opérer les rectifications que vous jugerez nécessaires.
.PDF Version 3.2 (2,6 Mo)
.ODT Version 3.2 (3,3 Mo)
Les données que récolte Google – Ch.7 et conclusion
Voici déjà la traduction du septième chapitre et de la brève conclusion de Google Data Collection, l’étude élaborée par l’équipe du professeur Douglas C. Schmidt, spécialiste des systèmes logiciels, chercheur et enseignant à l’Université Vanderbilt. Si vous les avez manqués, retrouvez les chapitres précédents déjà publiés.
Il s’agit cette fois-ci de tous les récents produits de Google (ou plutôt Alphabet) qui investissent nos pratiques et nos habitudes : des pages AMP aux fournisseurs de services tiers en passant par les assistants numériques, tout est prétexte à collecte de données directement ou non.
VII. Des produits avec un haut potentiel futur d’agrégation de données
83. Google a d’autres produits qui pourraient être adoptés par le marché et pourraient bientôt servir à la collecte de données, tels que AMP, Photos, Chromebook Assistant et Google Pay. Il faut ajouter à cela que Google est capable d’utiliser les données provenant de partenaires pour collecter les informations de l’utilisateur. La section suivante les décrit plus en détail.
84. Il existe également d’autres applications Google qui peuvent ne pas être largement utilisées. Toutefois, par souci d’exhaustivité, la collecte de données par leur intermédiaire est présentée dans la section VIIII.B de l’annexe.
A. Pages optimisées pour les mobiles (AMP)
85. Les Pages optimisées pour les mobiles (AMP) sont une initiative open source menée par Google pour réduire le temps de chargement des sites Web et des publicités. AMP convertit le HTML standard et le code JavaScript en une version simplifiée développée par Google2 qui stocke les pages validées dans un cache des serveurs du réseau Google pour un accès plus rapide3. AMP fournit des liens vers les pages grâce aux résultats de la recherche Google mais également via des applications tierces telles que LinkedIn et Twitter. D’après AMP : « L’ecosystème AMP compte 25 millions de domaines, plus de 100 fournisseurs de technologie et plateformes de pointe qui couvrent les secteurs de la publication de contenu, les publicités, le commerce en ligne, les petits commerces, le commerce local etc. »4
86. L’illustration 17a décrit les étapes menant à la fourniture d’une page AMP accessible via la recherche Google. Merci de noter que le fournisseur de contenu à travers AMP n’a pas besoin de fournir ses propres caches serveur, car c’est quelque chose que Google fournit pour garantir un délai optimal de livraison aux utilisateurs. Dans la mesure où le cache AMP est hébergé sur les serveurs de Google, lors d’un clic sur un lien AMP produit par la recherche Google, le nom de domaine vient du domaine google.com et non pas du domaine du fournisseur. Ceci est montré grâce aux captures prises lors d’un exemple de recherche de mots clés dans l’illustration 17b.
Illustration 17 : une page web normale qui devient une page AMP.
87. Les utilisateurs peuvent accéder au contenu depuis de multiples fournisseurs dont les articles apparaissent dans les résultats de recherche pendant qu’ils naviguent dans le carrousel AMP, tout en restant dans le domaine de Google. En effet, le cache AMP opère comme un réseau de distribution de contenu (RDC, ou CDN en anglais) appartenant à Google et géré par Google.
88. En créant un outil open source, complété avec un CDN, Google a attiré une large base d’utilisateurs à qui diffuser les sites mobiles et la publicité et cela constitue une quantité d’information significative (p.ex. le contenu lui-même, les pages vues, les publicités, et les informations de celui à qui ce contenu est fourni). Toutes ces informations sont disponibles pour Google parce qu’elles sont collectées sur les serveurs CDN de Google, fournissant ainsi à Google beaucoup plus de données que par tout autre moyen d’accès.
89. L’AMP est très centré sur l’utilisateur, c’est-à-dire qu’il offre aux utilisateurs une expérience de navigation beaucoup plus rapide et améliorée sans l’encombrement des fenêtres pop-up et des barres latérales. Bien que l’AMP représente un changement majeur dans la façon dont le contenu est mis en cache et transmis aux utilisateurs, la politique de confidentialité de Google associée à l’AMP est assez générale5. En particulier, Google est en mesure de recueillir des informations sur l’utilisation des pages Web (par exemple, les journaux de serveur et l’adresse IP) à partir des requêtes envoyées aux serveurs de cache AMP. De plus, les pages standards sont converties en AMP via l’utilisation des API AMP6. Google peut donc accéder à des applications ou à des sites Web (« clients API ») et utiliser toute information soumise par le biais de l’API conformément à ses politiques générales7.
90. Comme les pages Web ordinaires, les pages Web AMP pistent les données d’utilisation via Google Analytics et DoubleClick. En particulier, elles recueillent des informations sur les données de page (par exemple : domaine, chemin et titre de page), les données d’utilisateur (par exemple : ID client, fuseau horaire), les données de navigation (par exemple : ID et référence de page uniques), l’information du navigateur et les données sur les interactions et les événements8. Bien que les modes de collecte de données de Google n’aient pas changé avec l’AMP, la quantité de données recueillies a augmenté puisque les visiteurs passent 35 % plus de temps sur le contenu Web qui se charge avec Google AMP que sur les pages mobiles standard.9
B. Google Assistant
91. Google Assistant est un assistant personnel virtuel auquel on accède par le biais de téléphones mobiles et d’appareils dits intelligents. C’est un assistant virtuel populaire, comme Siri d’Apple, Alexa d’Amazon et Cortana de Microsoft. 10 Google Assistant est accessible via le bouton d’accueil des appareils mobiles sous Android 6.0 ou versions ultérieures. Il est également accessible via une application dédiée sur les appareils iOS11, ainsi que par l’intermédiaire de haut-parleurs intelligents, tel Google Home, qui offre de nombreuses fonctions telles que l’envoi de textes, la recherche de courriels, le contrôle de la musique, la recherche de photos, les réponses aux questions sur la météo ou la circulation, et le contrôle des appareils domestiques intelligents11.
92. Google collecte toutes les requêtes de Google Assistant, qu’elles soient audio ou saisies au clavier. Il collecte également l’emplacement où la requête a été effectuée. L’illustration 18 montre le contenu d’une requête enregistrée par Google. Outre son utilisation via les haut-parleurs de Google Home, Google Assistant est activé sur divers autres haut-parleurs produits par des tiers (par exemple, les casques sans fil de Bose). Au total, Google Assistant est disponible sur plus de 400 millions d’appareils12. Google peut collecter des données via l’ensemble de ces appareils puisque les requêtes de l’Assistant passent par les serveurs de Google.
Figure 18 : Exemple de détails collectés à partir de la requête Google Assistant.
C. Photos
93. Google Photos est utilisé par plus de 500 millions de personnes dans le monde et stocke plus de 1,2 milliard de photos et vidéos chaque jour13. Google enregistre l’heure et les coordonnées GPS de chaque photo prise.Google télécharge des images dans le Google cloud et effectue une analyse d’images pour identifier un large éventail d’objets, tels que les modes de transport, les animaux, les logos, les points de repère, le texte et les visages14. Les capacités de détection des visages de Google permettent même de détecter les états émotionnels associés aux visages dans les photos téléchargées et stockées dans leur cloud14.
94. Google Photos effectue cette analyse d’image par défaut lors de l’utilisation du produit, mais ne fera pas de distinction entre les personnes, sauf si l’utilisateur donne l’autorisation à l’application15. Si un utilisateur autorise Google à regrouper des visages similaires, Google identifie différentes personnes à l’aide de la technologie de reconnaissance faciale et permet aux utilisateurs de partager des photos grâce à sa technologie de « regroupement de visages »1316. Des exemples des capacités de classification d’images de Google avec et sans autorisation de regroupement des visages de l’utilisateur sont présentés dans l’illustration 19. Google utilise Photos pour assembler un vaste ensemble d’informations d’identifications faciales, qui a récemment fait l’objet de poursuites judiciaires17 de la part de certains États.
Illustration : Exemple de reconnaissance d’images dans Google Photos.
D. Chromebook
95. Chromebook est la tablette-ordinateur de Google qui fonctionne avec le système d’exploitation Chrome (Chrome OS) et permet aux utilisateurs d’accéder aux applications sur le cloud. Bien que Chromebook ne détienne qu’une très faible part du marché des PC, il connaît une croissance rapide, en particulier dans le domaine des appareils informatiques pour la catégorie K-12, où il détenait 59,8 % du marché au deuxième trimestre 201718. La collecte de données de Chromebook est similaire à celle du navigateur Google Chrome, qui est décrite dans la section II.A. Chromebooks permet également aux cookies de Google et de domaines tiers de pister l’activité de l’utilisateur, comme pour tout autre ordinateur portable ou PC.
96. De nombreuses écoles de la maternelle à la terminale utilisent des Chromebooks pour accéder aux produits Google via son service GSuite for Education. Google déclare que les données recueillies dans le cadre d’une telle utilisation ne sont pas utilisées à des fins de publicité ciblée19. Toutefois, les étudiants reçoivent des publicités s’ils utilisent des services supplémentaires (tels que YouTube ou Blogger) sur les Chromebooks fournis par leur établissement d’enseignement.
E. Google Pay
97. Google Pay est un service de paiement numérique qui permet aux utilisateurs de stocker des informations de carte de crédit, de compte bancaire et de PayPal pour effectuer des paiements en magasin, sur des sites Web ou dans des applications utilisant Google Chrome ou un appareil Android connecté20. Pay est le moyen par lequel Google collecte les adresses et numéros de téléphone vérifiés des utilisateurs, car ils sont associés aux comptes de facturation. En plus des renseignements personnels, Pay recueille également des renseignements sur la transaction, comme la date et le montant de la transaction, l’emplacement et la description du marchand, le type de paiement utilisé, la description des articles achetés, toute photo qu’un utilisateur choisit d’associer à la transaction, les noms et adresses électroniques du vendeur et de l’acheteur, la description du motif de la transaction par l’utilisateur et toute offre associée à la transaction21. Google traite ses informations comme des informations personnelles en fonction de sa politique générale de confidentialité. Par conséquent il peut utiliser ces informations sur tous ses produits et services pour fournir de la publicité très ciblée21. Les paramètres de confidentialité de Google l’autorisent par défaut à utiliser ces données collectées22.
F. Données d’utilisateurs collectées auprès de fournisseurs de données tiers
98. Google collecte des données de tiers en plus des informations collectées directement à partir de leurs services et applications. Par exemple, en 2014, Google a annoncé qu’il commencerait à suivre les ventes dans les vrais commerces réels en achetant des données sur les transactions par carte de crédit et de débit. Ces données couvraient 70 % de toutes les opérations de crédit et de débit aux États-Unis23. Elles contenaient le nom de l’individu, ainsi que l’heure, le lieu et le montant de son achat24.
99. Les données de tiers sont également utilisées pour aider Google Pay, y compris les services de vérification, les informations résultant des transactions Google Pay chez les commerçants, les méthodes de paiement, l’identité des émetteurs de cartes, les informations concernant l’accès aux soldes du compte de paiement Google, les informations de facturation des opérateurs et transporteurs et les rapports des consommateurs21. Pour les vendeurs, Google peut obtenir des informations des organismes de crédit aux particuliers ou aux entreprises.
100. Bien que l’information des utilisateurs tiers que Google reçoit actuellement soit de portée limitée, elle a déjà attiré l’attention des autorités gouvernementales. Par exemple, la FTC a annoncé une injonction contre Google en juillet 2017 concernant la façon dont la collecte par Google de données sur les achats des consommateurs porte atteinte à la vie privée électronique25. L’injonction conteste l’affirmation de Google selon laquelle il peut protéger la vie privée des consommateurs tout au long du processus en utilisant son algorithme. Bien que d’autres mesures n’aient pas encore été prises, l’injonction de la FTC est un exemple des préoccupations du public quant à la quantité de données que Google recueille sur les consommateurs.
VIII. CONCLUSION
101. Google compte un pourcentage important de la population mondiale parmi ses clients directs, avec de multiples produits en tête de leurs marchés mondiaux et de nombreux produits qui dépassent le milliard d’utilisateurs actifs par mois. Ces produits sont en mesure de recueillir des données sur les utilisateurs au moyen d’une variété de techniques qui peuvent être difficiles à comprendre pour un utilisateur moyen. Une grande partie de la collecte de données de Google a lieu lorsque l’utilisateur n’utilise aucun de ses produits directement. L’ampleur d’une telle collecte est considérable, en particulier sur les appareils mobiles Android. Et bien que ces informations soient généralement recueillies sans identifier un utilisateur unique, Google a la possibilité d’utiliser les données recueillies auprès d’autres sources pour désanonymiser une telle collecte.
Il s’agit cette fois de comprendre comment Google complète les données collectées avec les données provenant des applications et des comptes connectés des utilisateurs.
VI. Données collectées par les applications clés de Google destinées aux particuliers
67. Google a des dizaines de produits et services qui évoluent en permanence (une liste est disponible dans le tableau 4, section IX.B de l’annexe). On accède souvent à ces produits grâce à un compte Google (ou on l’y associe), ce qui permet à Google de relier directement les détails des activités de l’utilisateur de ses produits et services à un profil utilisateur. En plus des données d’usage de ses produits, Google collecte également des identificateurs et des données de localisation liés aux appareils lorsqu’on accède aux services Google. 26
68. Certaines applications de Google (p.ex. YouTube, Search, Gmail et Maps) occupent une place centrale dans les tâches de base qu’une multitude d’utilisateurs effectuent quotidiennement sur leurs appareils fixes ou mobiles. Le tableau 2 décrit la portée de ces produits clés. Cette section explique comment chacune de ces applications majeures collecte les informations des utilisateurs.
Tableau 2 : Portée mondiale des principales applications Google
Produits
Utilisateurs actifs
Search
Plus d’un milliard d’utilisateurs actifs par mois, 90.6 % de part de marché des moteurs de recherche 27
Youtube
Plus de 1,8 milliard d’utilisateurs inscrits et actifs par mois 28
Maps
Plus d’un milliard d’utilisateurs actifs par mois 29
69. Google Search est le moteur de recherche sur internet le plus populaire au monde 27, avec plus de 11 milliards de requêtes par mois aux États-Unis 31. En plus de renvoyer un classement de pages web en réponse aux requêtes globales des utilisateurs, Google exploite d’autres outils basés sur la recherche, tels que Google Finance, Flights (vols), News (actualités), Scholar (recherche universitaire), Patents (brevets), Books (livres), Images, Videos et Hotels. Google utilise ses applications de recherche afin de collecter des données liées aux recherches, à l’historique de navigation ainsi qu’aux activités d’achats et de clics sur publicités. Par exemple, Google Finance collecte des informations sur le type d’actions que les utilisateurs peuvent suivre, tandis que Google Flight piste leurs réservations et recherches de voyage.
70. Dès lors que Search est utilisé, Google collecte les données de localisation par différents biais, sur ordinateur ou sur mobile, comme décrit dans les sections précédentes. Google enregistre toute l’activité de recherche d’un utilisateur ou utilisatrice et la relie à son compte Google si cette personne est connectée. L’illustration 13 montre un exemple d’informations collectées par Google sur une recherche utilisateur par mot-clé et la navigation associée.
Illustration 13 : Un exemple de collecte de données de recherche extrait de la page My Activity (Mon Activité) d’un utilisateur
71. Non seulement c’est le moteur de recherche par défaut sur Chrome et les appareils Google, mais Google Search est aussi l’option par défaut sur d’autres navigateurs internet et applications grâce à des arrangements de distribution. Ainsi, Google est récemment devenu le moteur de recherche par défaut sur le navigateur internet Mozilla Firefox 32 dans des régions clés (dont les USA et le Canada), une position occupée auparavant par Yahoo. De même, Apple est passé de Microsoft Bing à Google pour les résultats de recherche via Siri sur les appareils iOS et Mac 33. Google a des accords similaires en place avec des OEM (fabricants d’équipement informatique ou électronique) 34, ce qui lui permet d’atteindre les consommateurs mobiles.
B. YouTube
72. YouTube met à disposition des utilisateurs et utilisatrices une plateforme pour la mise en ligne et la visualisation de contenu vidéo. Il attire plus de 180 millions de personnes rien qu’aux États-Unis et a la particularité d’être le deuxième site le plus visité des États-Unis 35, juste derrière Google Search. Au sein des entreprises de streaming multimédia, YouTube possède près de 80 % de parts de marché en termes de visites mensuelles (comme décrit dans l’illustration 14). La quantité de contenu mis en ligne et visualisé sur YouTube est conséquente : 400 heures de vidéo sont mises en ligne chaque minute 36 et 1 milliard d’heures de vidéo sont visualisées quotidiennement sur la plateforme YouTube.37
Illustration 14 : Comparaison d’audiences mensuelles des principaux sites multimédia aux États-Unis 38
73. Les utilisateurs peuvent accéder à YouTube sur l’ordinateur (navigateur internet), sur leurs appareils mobiles (application et/ou navigateur internet) et sur Google Home (via un abonnement payant appelé YouTube Red). Google collecte et sauvegarde l’historique de recherche, l’historique de visualisation, les listes de lecture, les abonnements et les commentaires aux vidéos. La date et l’horaire de chaque activité sont ajoutés à ces informations.
74. Si un utilisateur se connecte à son compte Google pour accéder à n’importe quelle application Google via un navigateur internet (par ex. Chrome, Firefox, Safari), Google reconnaît l’identité de l’utilisateur, même si l’accès à la vidéo est réalisé par un site hors Google (ex. : vidéos YouTube lues sur cnn.com). Cette fonctionnalité permet à Google de pister l’utilisation YouTube d’un utilisateur à travers différentes plateformes tierces. L’illustration 15 montre un exemple de données YouTube collectées.
Illustration 15 : Exemple de collecte de données YouTube dans My Activity (Mon Activité)
75. Google propose également un produit YouTube différencié pour les enfants, appelé YouTube Kids, dans l’intention d’offrir une version « familiale » de YouTube avec des fonctionnalités de contrôle parental et de filtres vidéos. Google collecte des informations de YouTube Kids, notamment le type d’appareil, le système d’exploitation, l’identifiant unique de l’appareil, les informations de journalisation et les détails d’utilisation du service. Google utilise ensuite ces informations pour fournir des annonces publicitaires limitées, qui ne sont pas cliquables et dont le format, la durée et le site sont limités.39.
C. Maps
76. Maps est l’application phare de navigation routière de Google. Google Maps peut déterminer les trajets et la vitesse d’un utilisateur et ses lieux de fréquentation régulière (ex. : domicile, travail, restaurants et magasins). Cette information donne à Google une idée des intérêts (ex. : préférences d’alimentation et d’achats), des déplacements et du comportement de l’utilisateur.
77. Maps utilise l’adresse IP, le GPS, le signal cellulaire et les points d’accès au Wi-Fi pour calculer la localisation d’un appareil. Les deux dernières informations sont collectées par le biais de l’appareil où Maps est utilisé, puis envoyées à Google pour évaluer la localisation via son interface de localisation (Location API). Cette interface fournit de nombreux détails sur un utilisateur, dont les coordonnées géographiques, son état stationnaire ou en mouvement, sa vitesse et la détermination probabiliste de son mode de transport (ex. : en vélo, voiture, train, etc.).
78. Maps sauvegarde un historique des lieux qu’un utilisateur connecté à Maps par son compte Googe a visités. L’illustration 16. montre un exemple d’un tel historique 40. Les points rouges indiquent les coordonnées géographiques recueillies par Maps lorsque l’utilisateur se déplace ; les lignes bleues représentent les projections de Maps sur le trajet réel de l’utilisateur.
Illustration 16 : Exemple d’un historique Google Maps (« Timeline ») d’un utilisateur réel
79. La précision des informations de localisation recueillies par les applications de navigation routière permet à Google de non seulement cibler des audiences publicitaires, mais l’aide aussi à fournir des annonces publicitaires aux utilisateurs lorsqu’ils s’approchent d’un magasin 41. Google Maps utilise de plus ces informations pour générer des données de trafic routier en temps réel.42
D. Gmail
80. Gmail sauvegarde tous les messages (envoyés et reçus), le nom de l’expéditeur, son adresse email et la date et l’heure des messages envoyés ou reçus. Puisque Gmail représente pour beaucoup un répertoire central pour la messagerie électronique, il peut déterminer leurs intérêts en scannant le contenu de leurs courriels, identifier les adresses de commerçants grâce à leurs courriels publicitaires ou les factures envoyées par message électronique, et connaître l’agenda d’un utilisateur (ex. : réservations à dîner, rendez-vous médicaux…). Étant donné que les utilisateurs utilisent leur identifiant Gmail pour des plateformes tierces (Facebook, LinkedIn…), Google peut analyser tout contenu qui leur parvient sous forme de courriel (ex. : notifications, messages).
81. Depuis son lancement en 2004 jusqu’à la fin de l’année 2017 (au moins), Google peut avoir analysé le contenu des courriels Gmail pour améliorer le ciblage publicitaire et les résultats de recherche ainsi que ses filtres de pourriel. Lors de l’été 2016, Google a franchi une nouvelle étape et a modifié sa politique de confidentialité pour s’autoriser à fusionner les données de navigation, autrefois anonymes, de sa filiale DoubleClick (qui fournit des publicités personnalisées sur internet) avec les données d’identification personnelles qu’il amasse à travers ses autres produits, dont Gmail 43. Le résultat : « les annonces publicitaires DoubleClick qui pistent les gens sur Internet peuvent maintenant leur être adaptées sur mesure, en se fondant sur les mots-clés qu’ils ont utilisés dans leur messagerie Gmail. Cela signifie également que Google peut à présent reconstruire le portrait complet d’une utilisatrice ou utilisateur par son nom, en fonction de tout ce qui est écrit dans ses courriels, sur tous les sites visités et sur toutes les recherches menées. » 44
82. Vers la fin de l’année 2017, Google a annoncé qu’il arrêterait la personnalisation des publicités basées sur les messages Gmail 45. Cependant, Google a annoncé récemment qu’il continue à analyser les messages Gmail pour certaines raisons 46.
Les données que récolte Google – Ch.5
Voici déjà la traduction du cinquième chapitre de Google Data Collection, l’étude élaborée par l’équipe du professeur Douglas C. Schmidt, spécialiste des systèmes logiciels, chercheur et enseignant à l’Université Vanderbilt. Si vous les avez manqués, retrouvez les chapitres précédents déjà publiés. Il s’agit cette fois d’explorer la quantité de données que Google collecte lorsque l’on a désactivé tout ce qui pouvait l’être…
V. Quantité de données collectées lors d’une utilisation minimale des produits Google
58. Cette section montre les détails de la collecte de données par Google à travers ses services de publication et d’annonces. Afin de comprendre une telle collecte de données, une expérience est réalisée impliquant un utilisateur qui se sert de son téléphone dans sa vie de tous les jours mais qui évite délibérément d’utiliser les produits Google (Search, Gmail, YouTube, Maps, etc.), exception faite du navigateur Chrome.
59. Pour que l’expérience soit aussi réaliste que possible, plusieurs études sur les usages de consommateurs47, 48 ont été utilisées pour créer le profil d’usage journalier d’un utilisateur lambda. Ensuite, toutes les interactions directes avec les services Google ont été retirées du profil. La section IX.F dans les annexes liste les sites internet et applications utilisés pendant l’expérience.
60. L’expérience a été reproduite sur des appareils Android et iOS et les données HTTPS envoyées aux serveurs Google et Apple ont été tracées et analysées en utilisant une méthode similaire à celle expliquée dans la section précédente. Les résultats sont résumés dans la figure 12. Pendant la période de 24 h (qui inclut la période de repos nocturne), la majorité des appels depuis le téléphone Android ont été effectués vers les services Google de localisation et de publication de publicités (DoubleClick, Analytics). Google a enregistré la géolocalisation de l’utilisateur environ 450 fois, ce qui représente 1,4 fois le volume de l’expérience décrite dans la section III.C, qui se basait sur un téléphone immobile.
Figure 12 : Requêtes du téléphone portable durant une journée typique d’utilisation
61. Les serveurs de Google communiquent significativement moins souvent avec un appareil iPhone qu’avec Android (45 % moins). En revanche, le nombre d’appels aux régies publicitaires de Google reste les mêmes pour les deux appareils — un résultat prévisible puisque l’utilisation de pages web et d’applications tierces était la même sur chacun des périphériques. À noter, une différence importante est que l’envoi de données de géolocalisation à Google depuis un appareil iOS est pratiquement inexistant. En absence des plateformes Android et Chrome — ou de l’usage d’un des autres produits de Google — Google perd significativement sa capacité à pister la position des utilisateurs.
62. Le nombre total d’appels aux serveurs Apple depuis un appareil iOS était bien moindre, seulement 19 % des appels aux serveurs de Google depuis l’appareil Android. De plus, il n’y a pas d’appels aux serveurs d’Apple liés à la publicité, ce qui pourrait provenir du fait que le modèle économique d’Apple ne dépend pas autant de la publicité que celui de Google. Même si Apple obtient bien certaines données de localisation des utilisateurs d’appareil iOS, le volume de données collectées est bien moindre (16 fois moins) que celui collecté par Google depuis Android.
63. Au total, les téléphones Android ont communiqué 11.6 Mo de données par jour (environ 350 Mo par mois) avec les serveurs de Google. En comparaison, l’iPhone n’a envoyé que la moitié de ce volume. La quantité de données spécifiques aux régies publicitaires de Google est restée pratiquement identique sur les deux appareils.
64. L’appareil iPhone a communiqué bien moins de données aux serveurs Apple que l’appareil Android n’a échangé avec les serveurs Google.
65. De manière générale, même en l’absence d’interaction utilisateur avec les applications Google les plus populaires, un utilisateur de téléphone Android muni du navigateur Chrome a tout de même tendance à envoyer une quantité non négligeable de données à Google, dont la majorité est liée à la localisation et aux appels aux serveurs de publicité. Bien que, dans le cadre limité de cette expérience, un utilisateur d’iPhone soit protégé de la collecte des données de localisation par Google, Google recueille tout de même une quantité comparable de données liées à la publicité.
66. La section suivante décrit les données collectées par les applications les plus populaires de Google, telles que Gmail, Youtube, Maps et la recherche.
Framasoft : les chiffres à connaître
Chaque année, nous nous rappelons à votre bon souvenir pour vous inciter à soutenir financièrement nos actions. Vous voyez au fil du temps de nouveaux services et des campagnes ambitieuses se mettre en place. Mais peut-être voudriez-vous savoir en chiffres ce que nous avons réalisé jusqu’à présent. Voilà de quoi vous satisfaire.
Par souci de transparence, nos bilans financiers sont publiés chaque année et nous offrons en temps réel l’accès à certaines statistiques d’usage de nos services. Mais cela ne couvre pas l’ensemble de nos actions et nous nous sommes dit que vous pourriez en vouloir plus que ce qui se trouve sur Framastats.
Libre à vous de picorer un chiffre ou l’autre, d’en faire des quizz ou de les reprendre pour votre argumentaire afin de démontrer l’efficacité du monde associatif. Nous espérons que vous y verrez l’illustration de notre engagement à promouvoir le libre sous toutes ses formes.
1 : Depuis son lancement voilà un an, chaque heure un nouveau site naît sur Framasite.
2,5 : Les 5 000 utilisatrices de Framadrive utilisent 2,5 To de données pour leurs 3 millions de fichiers.
5 : Toutes les 5 secondes en moyenne, un utilisateur se connecte sur les services Framasoft.
10 : Toutes les 10 minutes à peine, une nouvelle visioconférence est créée sur Framatalk, qui accueille environ 400 participant⋅es par jour.
Framatalk, la vision-conférence Libre, vue par Pëhà
11 : C’est le nombre de pizzas, additionné aux 47 plateaux-repas et 25 couscous qu’ont avalé les 25 personnes présentes pendant les 4 jours de l’AG Framasoft 2018.
33 : Framasoft vous propose 33 services en ligne alternatifs, respectueux de vos données et sans publicité.
35 : Grâce aux 300 abonné·e·s à la liste Framalang, ce ne sont pas moins de 35 traductions qui ont été effectuées et publiées sur le Framablog en un an.
252 : http://joinpeertube.org , c’est une fédération de 252 instances (déclarées) affichant 23 017 vidéos libérées de YouTube
750 : Chaque mois, notre support répond à environ 750 demandes, questions et problèmes. Avec un seul salarié !
Framalibre, l’annuaire à l’origine de Framasoft
871 : Framalibre, l’annuaire du libre vous présente 871 projets, logiciels ou créations artistiques sous licence libre à l’aide de courtes notices.
1 000 : Framaforms c’est environ 1000 formulaires créés quotidiennement et plus de 44 000 formulaires hébergés.
1 800 : Chaque jour, ce sont près de 1 800 images qui viennent s’ajouter aux 770 000 déjà présentes sur les serveurs de Framapic.
2 236 : Le Framablog c’est 2 236 articles et 28 919 commentaires depuis 2006, faisant le lien entre logiciel libre et société/culture libres.
3 000 : 4 000 utilisatrices réparties en 250 groupes ont créé plus de 3 000 présentations et conférences grâce à Framaslides alors qu’il n’est encore qu’en beta !
6 000 : Framemo héberge 6 000 tableaux qui ont aidé des utilisateurs à mettre leurs idées au clair, sans avoir à s’inscrire.
Framacarte, pour ne pas se perdre en chemin
6 000 : Sur Framacarte ajoutez votre propre fond de carte aux 6 000 qui existent déjà, en partenariat avec OpenStreetMap.
6 579 : Framapiaf, c’est 6 579 utilisateurs ayant « pouetté » 734 500 messages sur cette instance Mastodon, elle-même fédérée avec près de 4 000 autres instances (totalisant environ 1,5 million de comptes).
11 000 : Avec Framanews, ce sont 500 lecteurs (limite qu’on a nous même fixée pour restreindre la charge du serveur) qui accèdent régulièrement à leurs 11 000 flux RSS.
13 000 : Près de 4 000 utilisatrices accèdent à leur 13 000 notes depuis n’importe quel navigateur, avec un accès sécurisé, sur Framanotes.
15 000 : Avec Framabag 15 000 personnes ont pu sauvegarder et classer 1,5 million d’articles.
Framagit, pour partager librement votre code
25 000 : Notre forge logicielle, Framagit, héberge plus de 25 000 projets (et autant d’utilisateurs).
35 000 : Avec MyFrama, 35 000 utilisatrices partagent librement leurs liens Internet.
43 000 : Accédez à une des 43 000 adresses Web abrégées ou créez-en une grâce au raccourcisseur d’URL Framalink qui ne traque pas vos visiteurs.
52 000 : Découvrez Framasphère, membre du réseau social libre et fédéré Diaspora*, où 52 000 utilisatrices ont échangé environ 600 000 messages et autant de commentaires.
75 000 : Près de 75 000 joueurs ont pu faire une petite pause ludique sans s’exposer à de la publicité sur Framagames.
Framadrop, le partage aisé de gros fichier, en sécurité
100 000 : Sur Framadrop plus de 100 000 fichiers ont pu être échangés en toute confidentialité.
130 000 : Framacalc accueille plus de 130 000 feuilles de calcul, où vos données ne sont pas espionnées ni revendues
142 600 : Sur Framapad, c’est en moyenne plus de 142 600 pads actifs chaque jour et presque 8 millions d’utilisateurs depuis ses débuts.
150 000 : Les serveurs de Framalistes adressent en moyenne 150 000 courriels chaque jour aux 280 000 inscrites à des listes de discussion.
200 000 : Êtes-vous l’une des 200 000 personnes à avoir consulté un des 23 000 messages chiffrés de Framabin ?
500 000 : Framadate c’est plus de 500 000 visites par mois et plus de 1 000 sondages créés chaque jour.
Framapiaf, notre instance Mastodon
2 500 000 : Plus de 2 millions et demi de personnes ont développé leurs idées, échafaudé des projets sur Framindmap depuis sa mise en place.
3 350 000 : Grâce à Framabook, 3 350 000 lecteurs ont pu télécharger en toute légalité un des 47 ouvrages librement publiés.
5 000 000 : Sur Framagenda environ 35 000 utilisateurs gèrent un million de contacts. Ils organisent et partagent près de cinq millions d’événements.
10 000 000 : Comme près de 40 000 personnes, travaillez en équipe sur Framateam et rejoignez un des 80 000 canaux avec presque 10 millions de messages !
Et le chiffre essentiel pour que tout cela soit possible, c’est celui de nos donatrices et donateurs (2381 en moyenne chaque année) : appuyez sur ce bouton pour le faire croître de 1