3 questions à Marie-Cécile Godwin Paccard de la #TeamMobilizon
Marie-Cécile Godwin Paccard est designer indépendante et chercheuse UX. Elle accompagne des personnes et des organisations dans la définition de leurs fondamentaux et objectifs, en apportant un regard systémique. Elle s’occupe de comprendre les usages en profondeur et de concevoir des outils utilisables, éthiques et inclusifs. Elle fait partie de l’équipe qui travaille sur le logiciel Mobilizon. Nous lui avons posé 3 questions pour qu’elle nous explique son rôle sur le projet.
Bonjour Marie-Cécile ! Vous avez accompagné le projet Mobilizon, afin que celui-ci corresponde, dès sa conception, aux besoins et usages des personnes qui sont vouées à l’utiliser. Pouvez-vous nous expliquer en quoi il est particulièrement important pour ce projet de prendre en compte les besoins et attentes des futur⋅es utilisateur⋅ices ?
Bonjour à toute l’équipe ! Étudier les besoins et les usages, c’est essentiel si l’on veut concevoir un logiciel, un service ou même un objet qui soit utilisable, et donc utilisé. Mobilizon a pour ambition de permettre aux personnes de s’organiser et de se rassembler, et de leur donner le pouvoir de le faire librement et respectueusement. Rien de mieux pour commencer à parler « usages » dès le début de la réflexion autour du projet ! Toute l’équipe qui travaille sur Mobilizon a le souhait que les communautés existantes s’en emparent et que de nouvelles communautés s’y créent. On ne pourra pas atteindre cet objectif si on ne fait pas l’effort d’aller à la rencontre des personnes pour comprendre ce dont elles ont besoin, quels problèmes elles rencontrent et comment elles ont fait pour y pallier jusqu’à présent.
Quand on conçoit des choses destinées à être utilisées par d’autres personnes, il est très important de ne pas se contenter de nos propres suppositions, croyances ou idées fixes et d’ouvrir notre esprit à la perception et à l’expérience d’autres personnes. Une courte phase de recherche en usages peut donner des résultats rapides et précieux et permettre d’identifier très en amont des problématiques et des objectifs auxquels on n’avait pas forcément pensé et qui vont nous aider à questionner nos présupposés de départ.
Quelle a été votre démarche pour recueillir la parole de ces utilisateur⋅ices (ou communautés) ?
D’abord, nous avons passé un temps de réflexion ensemble à bien cadrer le projet, ses ambitions, mais aussi ses implications politiques (car TOUT est politique, surtout dans le design et le logiciel, qui plus est libre !) et comment Mobilizon s’inscrivait dans la mission de Framasoft. Nous avons fait le point sur les plateformes d’organisation existantes et ce qu’elles engendraient comme problèmes qui empêchaient les gens de s’organiser librement. J’ai ensuite proposé un plan de recherche à l’équipe, pour bien définir ce vers quoi nous allions orienter la phase de recherche. Nous avons lancé une première enquête en ligne, qui a recueilli pas loin de 300 réponses. Dans cette enquête, nous demandions aux personnes répondantes comment elles s’organisaient en général pour se rassembler à l’aide des plateformes numériques, soit en tant qu’invitées, soit en tant qu’organisatrices elles-mêmes. Nous avons recueilli des informations précieuses sur les problèmes qu’elles pouvaient rencontrer, et pourquoi elles utilisaient ou pas tel ou tel outil numérique pour le faire.
Dans un deuxième temps, nous avons défini des typologies de communautés à qui nous souhaitions nous adresser. À nouveau, il fallait partir des usages : des communautés très grandes avec différents niveaux d’organisation qui créent des rassemblements publics, des communautés spécialisées qui organisent des événements thématiques, des organisations qui souhaitent assurer respect de la vie privée à elles et aux personnes qui participent à leurs événements, etc. Je suis ensuite partie à la recherche de personnes qui correspondaient à ces cas d’usages pour leur poser des questions sur leur manière de s’organiser. On ne parle pas encore de logiciel, de code ou de graphisme à ce point : on se focalise encore et toujours sur les usages, sur la réalité de l’organisation d’événements et aux problèmes bien concrets qui se posent aux personnes qui les mettent en place.
Comment ces éléments alimentent-ils la réflexion sur les fonctionnalités de Mobilizon ?
Une fois que la phase de recherche est bouclée, il est temps de tirer des conclusions sur les données recueillies. Quelle est la réalité des usages des personnes et comment concevoir un logiciel qui ira dans leur sens ? On va ensuite arbitrer nos décisions avec ces données.
Certaines choses parlent tout de suite d’elles-mêmes : si je me rends compte à travers quasiment tous les entretiens qu’une problématique revient tout le temps, cela veut dire qu’il faut la garder en tête tout au long de la conception et du développement et trouver la meilleure manière d’y répondre. Certes, il y a des problèmes très humains que Mobilizon ne pourra pas résoudre, par exemple les « no-show », les personnes qui indiquent qu’elles participeront à l’événement mais finissent par ne pas venir. Même si l’on a pas de solution logicielle pour résoudre ce souci, comprendre pourquoi il embête les organisateurs et organisatrices permet de prendre de meilleures décisions par la suite.
Mobilizon ne pourra pas être « one-size-fits-all » (taille unique). Seront couvertes en priorité les fonctionnalités que nous pensons indispensables aux petites communautés qui n’ont pas les moyens techniques de se rassembler ailleurs. On ne remplacera pas un Mattermost ou un WhatsApp, et on n’aura jamais la même force de frappe que Facebook. Mais Mobilizon proposera les fonctionnalités essentielles pour que les communautés les plus exposées au capitalisme de surveillance puissent migrer hors de Facebook, mais ne pourra pas remplacer les centaines de pads imbriqués ou les conversations vocales de Discord à plus de 30 personnes !
En ce moment, je suis en train de concevoir le « back office » de Mobilizon, et toute l’articulation de la « tuyauterie » qui va permettre de créer un événement, un groupe, d’inviter des personnes dans ledit groupe pour s’organiser en amont de l’événement, de définir les différentes identités avec lesquelles on pourra dire que l’on participe à un événement en cloisonnant son activité, de modérer les participations ou les questions et commentaires…
Avec le reste de l’équipe, nous nous posons également plein de questions sur la manière dont Mobilizon va accompagner les personnes dans la compréhension des principes de la fédération et des instances. Le but est de nous assurer que dans tous les cas, la personne qui souhaite utiliser une instance Mobilizon pour créer un événement sur le web accède simplement aux tenants et aboutissants de tel ou tel choix, pour prendre la décision qui lui convient le mieux. Cela va se traduire dans plein d’aspects de la conception du logiciel : comment va se dérouler l’inscription (« on boarding »), quels éléments vont permettre de comprendre le principe des instances dans le texte et dans l’interface, etc.
Pour en savoir plus sur le logiciel Mobilizon, c’est sur https://joinmobilizon.org/. Vous pouvez aussi vous inscrire à la newsletter Mobilizon pour recevoir les informations sur l’évolution du logiciel.
C’est quoi, l’interopérabilité, et pourquoi est-ce beau et bien ?
Protocole, HTTP, interopérabilité, ça vous parle ? Et normes, spécifications, RFC, ça va toujours ? Si vous avez besoin d’y voir un peu plus clair, l’article ci-dessous est un morceau de choix rédigé par Stéphane Bortzmeyer qui s’est efforcé de rendre accessibles ces notions fondamentales.
Protocoles
Le 21 mai 2019, soixante-neuf organisations, dont Framasoft, ont signé un appel à ce que soit imposé, éventuellement par la loi, un minimum d’interopérabilité pour les gros acteurs commerciaux du Web.
« Interopérabilité » est un joli mot, mais qui ne fait pas forcément partie du vocabulaire de tout le monde, et qui mérite donc d’être expliqué. On va donc parler d’interopérabilité, de protocoles, d’interfaces, de normes, et j’espère réussir à le faire tout en restant compréhensible (si vous êtes informaticien·ne professionnel·le, vous savez déjà tout cela ; mais l’appel des 69 organisations concerne tout le monde).
Le Web, ou en fait tout l’Internet, repose sur des protocoles de communication. Un protocole, c’est un ensemble de règles qu’il faut suivre si on veut communiquer. Le terme vient de la communication humaine, par exemple, lorsqu’on rencontre quelqu’un, on se serre la main, ou bien on se présente si l’autre ne vous connaît pas, etc. Chez les humains, le protocole n’est pas rigide (sauf en cas de réception par la reine d’Angleterre dans son palais, mais cela doit être rare chez les lectrices et lecteurs du Framablog). Si la personne avec qui vous communiquez ne respecte pas exactement le protocole, la communication peut tout de même avoir lieu, quitte à se dire que cette personne est bien impolie. Mais les logiciels ne fonctionnent pas comme des humains. Contrairement aux humains, ils n’ont pas de souplesse, les règles doivent être suivies exactement. Sur un réseau comme l’Internet, pour que deux logiciels puissent communiquer, chacun doit donc suivre exactement les mêmes règles, et c’est l’ensemble de ces règles qui fait un protocole.
Un exemple concret ? Sur le Web, pour que votre navigateur puisse afficher la page web désirée, il doit demander à un serveur web un ou plusieurs fichiers. La demande se fait obligatoirement en envoyant au serveur le mot GET (« donne », en anglais) suivi du nom du fichier, suivi du mot « HTTP/1.1 ». Si un navigateur web s’avisait d’envoyer le nom du fichier avant le mot GET, le serveur ne comprendrait rien, et renverrait plutôt un message d’erreur. En parlant d’erreurs, vous avez peut-être déjà rencontré le nombre 404 qui est simplement le code d’erreur qu’utilisent les logiciels qui parlent HTTP pour signaler que la page demandée n’existe pas. Ces codes numériques, conçus pour être utilisés entre logiciels, ont l’avantage sur les textes de ne pas être ambigus, et de ne pas dépendre d’une langue humaine particulière. Cet exemple décrit une toute petite partie du protocole nommé HTTP (pour Hypertext Transfer Protocol) qui est le plus utilisé sur le Web.
Il existe des protocoles bien plus complexes. Le point important est que, derrière votre écran, les logiciels communiquent entre eux en utilisant ces protocoles. Certains servent directement aux logiciels que vous utilisez (comme HTTP, qui permet à votre navigateur Web de communiquer avec le serveur qui détient les pages désirées), d’autres protocoles relèvent de l’infrastructure logicielle de l’Internet ; vos logiciels n’interagissent pas directement avec eux, mais ils sont indispensables.
Le protocole, ces règles de communication, sont indispensables dans un réseau comme l’Internet. Sans protocole, deux logiciels ne pourraient tout simplement pas communiquer, même si les câbles sont bien en place et les machines allumées. Sans protocole, les logiciels seraient dans la situation de deux humains, un Français ne parlant que français, et un Japonais ne parlant que japonais. Même si chacun a un téléphone et connaît le numéro de l’autre, aucune vraie communication ne pourra prendre place. Tout l’Internet repose donc sur cette notion de protocole.
Le protocole permet l’interopérabilité. L’interopérabilité est la capacité à communiquer de deux logiciels différents, issus d’équipes de développement différentes. Si une université bolivienne peut échanger avec une entreprise indienne, c’est parce que toutes les deux utilisent des protocoles communs.
Seuls les protocoles ont besoin d’être communs : l’Internet n’oblige pas à utiliser les mêmes logiciels, ni à ce que les logiciels aient la même interface avec l’utilisateur. Si je prends l’exemple de deux logiciels qui parlent le protocole HTTP, le navigateur Mozilla Firefox (que vous êtes peut-être en train d’utiliser pour lire cet article) et le programme curl (utilisé surtout par les informaticiens pour des opérations techniques), ces deux logiciels ont des usages très différents, des interfaces avec l’utilisateur reposant sur des principes opposés, mais tous les deux parlent le même protocole HTTP. Le protocole, c’est ce qu’on parle avec les autres logiciels (l’interface avec l’utilisateur étant, elle, pour les humain·e·s.).
La distinction entre protocole et logiciel est cruciale. Si j’utilise le logiciel A parce que je le préfère et vous le logiciel B, tant que les deux logiciels parlent le même protocole, aucun problème, ce sera juste un choix individuel. Malgré leurs différences, notamment d’interface utilisateur, les deux logiciels pourront communiquer. Si, en revanche, chaque logiciel vient avec son propre protocole, il n’y aura pas de communication, comme dans l’exemple du Français et du Japonais plus haut.
Babel
Alors, est-ce que tous les logiciels utilisent des protocoles communs, permettant à tout le monde de communiquer avec bonheur ? Non, et ce n’est d’ailleurs pas obligatoire. L’Internet est un réseau à « permission facultative ». Contrairement aux anciennes tentatives de réseaux informatiques qui étaient contrôlés par les opérateurs téléphoniques, et qui décidaient de quels protocoles et quelles applications tourneraient sur leurs réseaux, sur l’Internet, vous pouvez inventer votre propre protocole, écrire les logiciels qui le parlent et les diffuser en espérant avoir du succès. C’est d’ailleurs ainsi qu’a été inventé le Web : Tim Berners-Lee (et Robert Cailliau) n’ont pas eu à demander la permission de qui que ce soit. Ils ont défini le protocole HTTP, ont écrit les applications et leur invention a connu le succès que l’on sait.
Cette liberté d’innovation sans permission est donc une bonne chose. Mais elle a aussi des inconvénients. Si chaque développeur ou développeuse d’applications invente son propre protocole, il n’y aura plus de communication ou, plus précisément, il n’y aura plus d’interopérabilité. Chaque utilisatrice et chaque utilisateur ne pourra plus communiquer qu’avec les gens ayant choisi le même logiciel. Certains services sur l’Internet bénéficient d’une bonne interopérabilité, le courrier électronique, par exemple. D’autres sont au contraire composés d’un ensemble de silos fermés, ne communiquant pas entre eux. C’est par exemple le cas des messageries instantanées. Chaque application a son propre protocole, les personnes utilisant WhatsApp ne peuvent pas échanger avec celles utilisant Telegram, qui ne peuvent pas communiquer avec celles qui préfèrent Signal ou Riot. Alors que l’Internet était conçu pour faciliter la communication, ces silos enferment au contraire leurs utilisateurs et utilisatrices dans un espace clos.
La situation est la même pour les réseaux sociaux commerciaux comme Facebook. Vous ne pouvez communiquer qu’avec les gens qui sont eux-mêmes sur Facebook. Les pratiques de la société qui gère ce réseau sont déplorables, par exemple en matière de captation et d’utilisation des données personnelles mais, quand on suggère aux personnes qui utilisent Facebook de quitter ce silo, la réponse la plus courante est « je ne peux pas, tou·te·s mes ami·e·s y sont, et je ne pourrais plus communiquer avec eux et elles si je partais ». Cet exemple illustre très bien les dangers des protocoles liés à une entreprise et, au contraire, l’importance de l’interopérabilité.
Mais pourquoi existe-t-il plusieurs protocoles pour un même service ? Il y a différentes raisons. Certaines sont d’ordre technique. Je ne les développerai pas ici, ce n’est pas un article technique, mais les protocoles ne sont pas tous équivalents, il y a des raisons techniques objectives qui peuvent faire choisir un protocole plutôt qu’un autre. Et puis deux personnes différentes peuvent estimer qu’en fait deux services ne sont pas réellement identiques et méritent donc des protocoles séparés, même si tout le monde n’est pas d’accord.
Mais il peut aussi y avoir des raisons commerciales : l’entreprise en position dominante n’a aucune envie que des acteurs plus petits la concurrencent, et ne souhaite pas permettre à des nouveaux entrants d’arriver. Elle a donc une forte motivation à n’utiliser qu’un protocole qui lui est propre, que personne d’autre ne connaît.
Enfin, il peut aussi y avoir des raisons plus psychologiques, comme la conviction chez l·e·a créat·eur·rice d’un protocole que son protocole est bien meilleur que les autres.
Un exemple d’un succès récent en termes d’adoption d’un nouveau protocole est donné par le fédivers. Ce terme, contraction de « fédération » et « univers » (et parfois écrit « fédiverse » par anglicisme) regroupe tous les serveurs qui échangent entre eux par le protocole ActivityPub, que l’appel des soixante-neuf organisations mentionne comme exemple. ActivityPub permet d’échanger des messages très divers. Les logiciels Mastodon et Pleroma se servent d’ActivityPub pour envoyer de courts textes, ce qu’on nomme du micro-blogging (ce que fait Twitter). PeerTube utilise ActivityPub pour permettre de voir les nouvelles vidéos et les commenter. WriteFreely fait de même avec les textes que ce logiciel de blog permet de rédiger et diffuser. Et, demain, Mobilizon utilisera ActivityPub pour les informations sur les événements qu’il permettra d’organiser. Il s’agit d’un nouvel exemple de la distinction entre protocole et logiciel. Bien que beaucoup de gens appellent le fédivers « Mastodon », c’est inexact. Mastodon n’est qu’un des logiciels qui permettent l’accès au fédivers.
Le terme d’ActivityPub n’est d’ailleurs pas idéal. Il y a en fait un ensemble de protocoles qui sont nécessaires pour communiquer au sein du fédivers. ActivityPub n’est que l’un d’entre eux, mais il a un peu donné son nom à l’ensemble.
Tous les logiciels de la mouvance des « réseaux sociaux décentralisés » n’utilisent pas ActivityPub. Par exemple, Diaspora ne s’en sert pas et n’est donc pas interopérable avec les autres.
Appel
Revenons maintenant l’appel cité au début, Que demande-t-il ? Cet appel réclame que l’interopérabilité soit imposée aux GAFA, ces grosses entreprises capitalistes qui sont en position dominante dans la communication. Tous sont des silos fermés. Aucun moyen de commenter une vidéo YouTube si on a un compte PeerTube, de suivre les messages sur Twitter ou Facebook si on est sur le fédivers. Ces GAFA ne changeront pas spontanément : il faudra les y forcer.
Il ne s’agit que de la communication externe. Cet appel est modéré dans le sens où il ne demande pas aux GAFA de changer leur interface utilisateur, ni leur organisation interne, ni leurs algorithmes de sélection des messages, ni leurs pratiques en matière de gestion des données personnelles. Il s’agit uniquement d’obtenir qu’ils permettent l’interopérabilité avec des services concurrents, de façon à permettre une réelle liberté de choix par les utilisateurs. Un tel ajout est simple à implémenter pour ces entreprises commerciales, qui disposent de fonds abondants et de nombreu·ses-x programmeur·e·s compétent·e·s. Et il « ouvrirait » le champ des possibles. Il s’agit donc de défendre les intérêts des utilisateurs et utilisatrices. (Alors que le gouvernement, dans ses commentaires, n’a cité que les intérêts des GAFA, comme si ceux-ci étaient des espèces menacées qu’il fallait défendre.)
Qui commande ?
Mais au fait, qui décide des protocoles, qui les crée ? Il n’y a pas de réponse simple à cette question. Il existe plein de protocoles différents et leurs origines sont variées. Parfois, ils sont rédigés, dans un texte qui décrit exactement ce que doivent faire les deux parties. C’est ce que l’on nomme une spécification. Mais parfois il n’y a pas vraiment de spécification, juste quelques vagues idées et un programme qui utilise ce protocole. Ainsi, le protocole BitTorrent, très utilisé pour l’échange de fichiers, et pour lequel il existe une très bonne interopérabilité, avec de nombreux logiciels, n’a pas fait l’objet d’une spécification complète. Rien n’y oblige développeurs et développeuses : l’Internet est « à permission facultative ». Dans de tels cas, celles et ceux qui voudraient créer un programme interopérable devront lire le code source (les instructions écrites par le ou la programmeur·e) ou analyser le trafic qui circule, pour essayer d’en déduire en quoi consiste le protocole (ce qu’on nomme la rétro-ingénierie). C’est évidemment plus long et plus difficile et il est donc très souhaitable, pour l’interopérabilité, qu’il existe une spécification écrite et correcte (il s’agit d’un exercice difficile, ce qui explique que certains protocoles n’en disposent pas).
Parfois, la spécification est adoptée formellement par un organisme dont le rôle est de développer et d’approuver des spécifications. C’est ce qu’on nomme la normalisation. Une spécification ainsi approuvée est une norme. L’intérêt d’une norme par rapport à une spécification ordinaire est qu’elle reflète a priori un consensus assez large d’une partie des acteurs, ce n’est plus un acte unilatéral. Les normes sont donc une bonne chose mais, rien n’étant parfait, leur développement est parfois laborieux et lent.
Toutes les normes ne se valent pas. Certaines sont publiquement disponibles (comme les normes importantes de l’infrastructure de l’Internet, les RFC – Request For Comments), d’autres réservées à ceux qui paient, ou à ceux qui sont membres d’un club fermé. Certaines normes sont développées de manière publique, où tout le monde a accès aux informations, d’autres sont créées derrière des portes soigneusement closes. Lorsque la norme est développée par une organisation ouverte à tous et toutes, selon des procédures publiques, et que le résultat est publiquement disponible, on parle souvent de normes ouvertes. Et, bien sûr, ces normes ouvertes sont préférables pour l’interopérabilité.
L’une des organisations de normalisation ouverte les plus connues est l’IETF (Internet Engineering Task Force, qui produit notamment la majorité des RFC). L’IETF a développé et gère la norme décrivant le protocole HTTP, le premier cité dans cet article. Mais d’autres organisations de normalisation existent comme le W3C (World-Wide Web Consortium) qui est notamment responsable de la norme ActivityPub.
Par exemple, pour le cas des messageries instantanées que j’avais citées, il y a bien une norme, portant le doux nom de XMPP (Extensible Messaging and Presence Protocol). Google l’utilisait, puis l’a abandonnée, jouant plutôt le jeu de la fermeture.
Difficultés
L’interopérabilité n’est évidemment pas une solution magique à tous les problèmes. On l’a dit, l’appel des soixante-neuf organisations est très modéré puisqu’il demande seulement une ouverture à des tiers. Si cette demande se traduisait par une loi obligeant à cette interopérabilité, tout ne serait pas résolu.
D’abord, il existe beaucoup de moyens pour respecter la lettre d’un protocole tout en violant son esprit. On le voit pour le courrier électronique où Gmail, en position dominante, impose régulièrement de nouvelles exigences aux serveurs de messagerie avec lesquels il daigne communiquer. Le courrier électronique repose, contrairement à la messagerie instantanée, sur des normes ouvertes, mais on peut respecter ces normes tout en ajoutant des règles. Ce bras de fer vise à empêcher les serveurs indépendants de communiquer avec Gmail. Si une loi suivant les préconisations de l’appel était adoptée, nul doute que les GAFA tenteraient ce genre de jeu, et qu’il faudrait un mécanisme de suivi de l’application de la loi.
Plus subtil, l’entreprise qui voudrait « tricher » avec les obligations d’interopérabilité peut aussi prétendre vouloir « améliorer » le protocole. On ajoute deux ou trois choses qui n’étaient pas dans la norme et on exerce alors une pression sur les autres organisations pour qu’elles aussi ajoutent ces fonctions. C’est un exercice que les navigateurs web ont beaucoup pratiqué, pour réduire la concurrence.
Jouer avec les normes est d’autant plus facile que certaines normes sont mal écrites, laissant trop de choses dans le vague (et c’est justement le cas d’ActivityPub). Écrire une norme est un exercice difficile. Si on laisse beaucoup de choix aux programmeuses et programmeurs qui créeront les logiciels, il y a des risques de casser l’interopérabilité, suite à des choix trop différents. Mais si on contraint ces programmeuses et programmeurs, en imposant des règles très précises pour tous les détails, on empêche les logiciels d’évoluer en réponse aux changements de l’Internet ou des usages. La normalisation reste donc un art difficile, pour lequel on n’a pas de méthode parfaite.
Conclusion
Voilà, désolé d’avoir été long, mais les concepts de protocole et d’interopérabilité sont peu enseignés, alors qu’ils sont cruciaux pour le fonctionnement de l’Internet et surtout pour la liberté des citoyen·ne·s qui l’utilisent. J’espère les avoir expliqués clairement, et vous avoir convaincu⋅e de l’importance de l’interopérabilité. Pensez à soutenir l’appel des soixante-neuf organisations !
Après
Et si vous voulez d’autres informations sur ce sujet, il y a :
Mastodon a déjà deux ans, et il est toujours vivant, n’en déplaise aux oiseaux de mauvais augure. Il est inadéquat de le comparer aux plateformes sociales, et Peter 0’Shaughnessy nous explique bien pourquoi…
Pourquoi Mastodon se moque de la « masse critique »
C’est une erreur de juger la Fediverse comme s’il s’agissait d’une startup de la Silicon Valley.
Mastodon a maintenant plus de deux ans et (pour emprunter une expression à Terry Pratchett), il n’est toujours pas mort. D’une manière ou d’une autre, il a réussi à défier les premiers critiques qui disaient qu’il « ne survivrait pas » et qu’il était « mort dans l’œuf ». Même certains de ceux qui postaient sur Mastodon à ses débuts doutaient de sa longévité :
Plus récemment, un article sur l’écosystème plus vaste qui comprend Mastodon, appelé La Fediverse, a fait la une de Hacker News : Qu’est-ce que ActivityPub, et comment changera-t-il l’Internet ? par Jeremy Dormitzer. C’est un bon argument en faveur de l’importance de la norme ActivityPub, sur laquelle reposent Mastodon et d’autres plateformes sociales. Cependant, il commet toujours la même erreur que ces premiers prophètes de malheur :
Le plus gros problème à l’heure actuelle, c’est l’adoption par les utilisateurs. Le réseau ActivityPub n’est viable que si les gens l’utilisent, et pour concurrencer de manière significative Facebook et Twitter, nous avons besoin de beaucoup de gens pour l’utiliser. Pour rivaliser avec les grands, nous avons besoin de beaucoup d’argent…
Des arguments similaires ont été présentés dans de nombreux articles au cours des derniers mois. Ils impliquent :
que la valeur du réseau n’est proportionnelle qu’au nombre d’utilisateurs ;
que ce ne sera vraiment un succès que s’il devient un remplacement massif pour Twitter et Facebook ;
que si vous ne le rejoignez pas, il ne survivra pas.
Mais tout cela est faux. Voici pourquoi…
1. La Fediverse n’est pas une startup
Nous sommes tellement conditionnés de nos jours par le monde du capital-risque et des startups que nous pensons intuitivement que toutes les nouvelles entreprises technologiques doivent réussir ou faire faillite. Mais ce n’est pas la nature du modèle économique qui se cache derrière le Fediverse, qui est déjà durable, tout en continuant de fonctionner comme si de rien n’était.
Nous devons cesser de juger la Fediverse comme s’il s’agissait d’une startup de la Silicon Valley en concurrence avec Twitter et Facebook.
Jeremy a raison de dire que la plupart des instances sont « créées et administrées par des bénévoles avec des budgets minuscules », mais il implique que cela doit changer, alors que la plupart des administrateurs et utilisateurs de Mastodon que je connais sont très satisfaits de ce modèle, qui nous libère des intérêts acquis et contradictoires des régies publicitaires.
C’est facile à dire pour moi, car je n’héberge pas ma propre instance et mon administrateur a gentiment refusé les offres de dons jusqu’ici. Cependant, dans la plupart des cas, il semble que tout se passe très bien, la plupart du temps grâce au financement participatif. Même si certaines instances ont été fermées à un moment donné (et c’est malheureusement le cas), il y en a d’autres qui se présentent à leur place. Malgré les fortes fluctuations à chaque nouvelle vague d’utilisateurs venant de Twitter, la trajectoire globale est à la hausse, et c’est ce qui importe — pas la vitesse de la croissance, ni l’atteinte d’un certain niveau de masse critique. Michael Mahemoff l’a bien dit :
« Mastodon est déjà « assez bon » dans sa forme initiale pour satisfaire plusieurs besoins de niche (les personnes qui veulent plus ou moins de modération ou des critères différents de modération, celles qui ne veulent pas de publicités, celles qui veulent des participant⋅e⋅s qui sont libres d’innover, celles qui veulent posséder et/ou héberger leur propre contenu, etc.). Comme Mastodon a un modèle de mécénat durable, il peut se développer au fil du temps et être capable de continuer à innover. »
En fait, si Mastodon se développait trop rapidement, cela pourrait avoir des conséquences plus négatives que positives. La croissance progressive permet aux instances existantes de mieux faire face à la charge et permet à de nouvelles instances d’émerger et de faire face à une partie du flux.
2. C’est aussi une question de qualité (d’expérience), pas seulement de quantité (d’utilisateurs et utilisatrices)
Lorsque j’ai rejoint Mastodon pour la première fois, j’ai été enthousiasmé par chaque nouvelle vague d’utilisateurs et utilisatrices venant de Twitter. Je voulais prêcher à ce sujet à autant de gens que possible et essayer d’amener autant d’amis que possible à « déménager ». Au bout d’un moment, j’ai pris conscience que je me concentrais trop sur la comparaison avec Twitter et que j’essayais d’en faire un remplaçant de Twitter. En fait, j’avais déjà un réseau précieux là-bas et suffisamment de raisons de le visiter régulièrement, même si j’ai continué à utiliser Twitter aussi.
Mastodon s’articule autour des communautés. Ces communautés peuvent être des réseaux spécialisés selon les sujets qui vous intéressent. Vous n’avez pas besoin de tous vos amis pour être au sein de ces communautés, pour trouver des gens intéressants, du contenu utile et des interactions intéressantes.
Comme Vee Satayamas l’a noté, si vous êtes un utilisateur de Twitter, vous le trouverez peut-être utile même si peu de membres de votre famille ou d’amis réels sont présents. Vous n’avez pas besoin que tout le monde soit disponible sur chaque réseau. J’ai récemment quitté Facebook et j’ai quand même pu entrer en contact avec mes amis, par courriel ou par texto. Ce serait bien mieux si davantage de mes amis étaient sur Mastodon, mais ce n’est pas un gros problème.
En réalité, il y a quelque chose de positif dans la petite taille de mon réseau sur Mastodon. Je peux suivre ma chronologie, mon « fil », sans me sentir dépassé. C’est moins stressant d’y poster, comparé à Twitter, où chaque message que vous envoyez risque d’être republié par une horde géante ! Je suppose que c’est comparable à l’effet ressenti par les YouTubers, tel que détaillé dans cet intéressant article du Guardian, qui cite Matt Lees :
« Le cerveau humain n’est pas vraiment conçu pour interagir avec des centaines de personnes chaque jour… Lorsque des milliers de personnes vous envoient des commentaires directs sur votre travail, vous avez vraiment l’impression que quelque chose vous vient à l’esprit. Nous ne sommes pas faits pour gérer l’empathie et la sympathie à cette échelle. »
Pour moi, Mastodon offre un moyen terme heureux entre les conversations intimes des groupes WhatsApp, par exemple, et le potentiel sans limites de Twitter pour découvrir de nouvelles personnes et de nouveaux contenus.
D’après mon expérience, la plupart des utilisateurs actifs de Mastodon ne veulent pas qu’il ressemble davantage à Twitter — et ne ressentent pas le besoin que tous ceux qui sont sur Twitter les rejoignent. Par exemple, ces personnes apprécient le fait qu’il n’y a pas de publicitaires et très peu de marques. Pour les gens qui ne s’inquiètent que de leur « influence », alors c’est sûr, Mastodon n’aura pas autant de valeur. Mais la plupart de celles et ceux qui sont sur Mastodon ne regretteront pas trop de ce genre de personnes venues de Twitter !
Nous devons cesser de considérer Mastodon comme un substitut potentiel de Twitter. C’est différent, et c’est délibéré. Je comprends qu’on se plaise à imaginer que la Fediverse pourrait un jour écraser Twitter et Facebook, mais je ne pense pas que ce soit réaliste (du moins pas dans un avenir proche). Je pense que ce sera toujours l’outsider et c’est très bien ainsi, d’une certaine façon.
3. C’est un écosystème ouvert
La Fediverse ne gagne pas seulement de la valeur à partir de la quantité d’utilisateurs, elle en gagne aussi à partir de la quantité de services. S’appuyer sur le standard ActivityPub implique que nous pouvons utiliser Mastodon, PeerTube (un service semblable à YouTube), PixelFed (un service semblable à Instagram) et beaucoup d’autres, qui peuvent tous interopérer. Cela donne à la Fediverse un avantage d’échelle par rapport aux plateformes propriétaires closes. C’est un point que l’article de Jeremy a bien fait ressortir :
« Parce qu’il parle le même « langage », un utilisateur de Mastodon peut suivre un utilisateur de PeerTube. Si l’utilisateur de PeerTube envoie une nouvelle vidéo, elle apparaîtra dans le flux de l’utilisateur Mastodon. L’utilisatrice de Mastodon peut commenter la vidéo PeerTube directement depuis Mastodon. Pensez-y une seconde. Toute application qui implémente ActivityPub fait partie d’un réseau social étendu, qui conserve le choix de l’utilisateur et pulvérise les jardins propriétaires clos. Imaginez que vous puissiez vous connecter à Facebook et voir les messages de vos amis sur Instagram et Twitter, sans avoir besoin de compte Instagram ni de compte Twitter. »
Cela signifie également que si nous avons l’impression que le service que nous utilisons ne va pas dans la direction qui nous convient (coucou, utilisateurs de Twitter 👋), alors nous pouvons passer à une autre instance et conserver l’accès à l’écosystème global.
La Fediverse s’accroît et c’est une bonne chose. Mais elle n’a pas besoin de davantage d’utilisatrices. Transmettre l’idée qu’on pourrait échouer sans une migration massive à partir d’autres plateformes sociales est une perspective trompeuse. Et défendre cette idée donnerait aux gens la fausse impression, lorsqu’ils rejoindront ce réseau social, qu’on devrait rechercher la quantité d’utilisateurs et utilisatrices, plutôt que la qualité de l’expérience.
Alors ne comptons pas trop le nombre d’inscrit⋅e⋅s sur Mastodon. Allons doucement en le comparant à Twitter. Arrêtons de le traiter comme s’il s’agissait d’une situation à la Highlander où « il n’y a de la place que pour un seul ». Et commençons à profiter de la Fediverse pour ce qu’elle est — quelque chose de différent.
Merci à Jeremy Dormit d’avoir été très gentil avec moi en critiquant cette partie de son billet de blog (qui m’a beaucoup plu par ailleurs) – voici sa réponse à mon pouet qui a mené à ce billet. Merci aussi à mes anciens collègues de Samsung Internet qui ont jeté un coup d’œil à une version antérieure de ce post.
Libre adaptation avec le Geektionerd generator d’un mastodon dessiné par Peter O’Saughnessy
Comment les entreprises surveillent notre quotidien
Vous croyez tout savoir déjà sur l’exploitation de nos données personnelles ? Parcourez plutôt quelques paragraphes de ce très vaste dossier…
Il s’agit du remarquable travail d’enquête procuré par Craked Labs, une organisation sans but lucratif qui se caractérise ainsi :
… un institut de recherche indépendant et un laboratoire de création basé à Vienne, en Autriche. Il étudie les impacts socioculturels des technologies de l’information et développe des innovations sociales dans le domaine de la culture numérique.
… Il a été créé en 2012 pour développer l’utilisation participative des technologies de l’information et de la communication, ainsi que le libre accès au savoir et à l’information – indépendamment des intérêts commerciaux ou gouvernementaux. Cracked Labs se compose d’un réseau interdisciplinaire et international d’experts dans les domaines de la science, de la théorie, de l’activisme, de la technologie, de l’art, du design et de l’éducation et coopère avec des parties publiques et privées.
Bien sûr, vous connaissez les GAFAM omniprésents aux avant-postes pour nous engluer au point que s’en déprendre complètement est difficile… Mais connaissez-vous Acxiom et LiveRamp, Equifax, Oracle, Experian et TransUnion ? Non ? Pourtant il y a des chances qu’ils nous connaissent bien…
Il existe une industrie très rentable et très performante des données « client ».
Dans ce long article documenté et qui déploie une vaste gamme d’exemples dans tous les domaines, vous ferez connaissance avec les coulisses de cette industrie intrusive pour laquelle il semble presque impossible de « passer inaperçu », où notre personnalité devient un profil anonyme mais tellement riche de renseignements que nos nom et prénom n’ont aucun intérêt particulier.
L’article est long, vous pouvez préférer le lire à votre rythme en format .PDF (2,3 Mo)
avec les contributions de : Katharina Kopp, Patrick Urs Riechert / Illustrations de Pascale Osterwalder.
Comment des milliers d’entreprises surveillent, analysent et influencent la vie de milliards de personnes. Quels sont les principaux acteurs du pistage numérique aujourd’hui ? Que peuvent-ils déduire de nos achats, de nos appels téléphoniques, de nos recherches sur le Web, de nos Like sur Facebook ? Comment les plateformes en ligne, les entreprises technologiques et les courtiers en données font-ils pour collecter, commercialiser et exploiter nos données personnelles ?
Ces dernières années, des entreprises dans de nombreux secteurs se sont mises à surveiller, pister et suivre les gens dans pratiquement tous les aspects de leur vie. les comportements, les déplacements, les relations sociales, les centres d’intérêt, les faiblesses et les moments les plus intimes de milliards de personnes sont désormais continuellement enregistrés, évalués et analysés en temps réel. L’exploitation des données personnelles est devenue une industrie pesant plusieurs milliards de dollars. Pourtant, de ce pistage numérique omniprésent, on ne voit que la partie émergée de l’iceberg ; la majeure partie du processus se déroule dans les coulisses et reste opaque pour la plupart d’entre nous.
Ce rapport de Cracked Labs examine le fonctionnement interne et les pratiques en vigueur dans cette industrie des données personnelles. S’appuyant sur des années de recherche et sur un précédent rapport de 2016, l’enquête donne à voir la circulation cachée des données entre les entreprises. Elle cartographie la structure et l’étendue de l’écosystème numérique de pistage et de profilage et explore tout ce qui s’y rapporte : les technologies, les plateformes, les matériels ainsi que les dernières évolutions marquantes.
Le rapport complet (93 pages, en anglais) est disponible en téléchargement au format PDF, et cette publication web en présente un résumé en dix parties.
En 2007, Apple a lancé le smartphone, Facebook a atteint les 30 millions d’utilisateurs, et des entreprises de publicité en ligne ont commencé à cibler les internautes en se basant sur des données relatives à leurs préférences individuelles et leurs centres d’intérêt. Dix ans plus tard, un large ensemble d’entreprises dont le cœur de métier est les données (les data-companies ou entreprises de données en français) a émergé, on y trouve de très gros acteurs comme Facebook ou Google mais aussi des milliers d’autres entreprises, qui sans cesse, se partagent et se vendent les unes aux autres des profils numériques. Certaines entreprises ont commencé à combiner et à relier des données du web et des smartphones avec les données clients et les informations hors-ligne qu’elles avaient accumulées pendant des décennies.
La machine omniprésente de surveillance en temps réel qui a été développée pour la publicité en ligne s’étend rapidement à d’autres domaines, de la tarification à la communication politique en passant par le calcul de solvabilité et la gestion des risques. Des plateformes en ligne énormes, des entreprises de publicité numérique, des courtiers en données et des entreprises de divers secteurs peuvent maintenant identifier, trier, catégoriser, analyser, évaluer et classer les utilisateurs via les plateformes et les matériels. Chaque clic sur un site web et chaque mouvement du doigt sur un smartphone peut activer un large éventail de mécanismes de partage de données distribuées entre plusieurs entreprises, ce qui, en définitive, affecte directement les choix offerts aux gens. Le pistage numérique et le profilage, en plus de la personnalisation ne sont pas seulement utilisés pour surveiller, mais aussi pour influencer les comportements des personnes.
Vous devez vous battre pour votre vie privée, sinon vous la perdrez.
Eric Schmidt, Google/Alphabet, 2013
Analyser les individus
Des études scientifiques démontrent que de nombreux aspects de la personnalité des individus peuvent être déduits des données générées par des recherches sur Internet, des historiques de navigation, des comportements lors du visionnage d’une vidéo, des activités sur les médias sociaux ou des achats. Par exemple, des données personnelles sensibles telles que l’origine ethnique, les convictions religieuses ou politiques, la situation amoureuse, l’orientation sexuelle, ou l’usage d’alcool, de cigarettes ou de drogues peuvent être assez précisément déduites des Like sur Facebook d’une personne. L’analyse des profils de réseaux sociaux peut aussi prédire des traits de personnalité comme la stabilité émotionnelle, la satisfaction individuelle, l’impulsivité, la dépression et l’intérêt pour le sensationnel.
Analyser les like Facebook, les données des téléphones, et les styles de frappe au clavier
Pour plus de détails, se référer à Christl and Spiekermann 2016 (p. 14-20). Sources : Kosinski et al 2013, Chittaranjan et al 2011, Epp at al 2011.
De la même façon, il est possible de déduire certains traits de caractères d’une personne à partir de données sur les sites Web qu’elle a visités, sur les appels téléphoniques qu’elle a passés, et sur les applis qu’elle a utilisées. L’historique de navigation peut donner des informations sur la profession et le niveau d’étude. Des chercheurs canadiens ont même réussi à évaluer des états émotionnels comme la confiance, la nervosité, la tristesse ou la fatigue en analysant la façon dont on tape sur le clavier de l’ordinateur.
Analyser les individus dans la finance, les assurances et la santé
Les résultats des méthodes actuelles d’extraction et d’analyse des données reposent sur des corrélations statistiques avec un certain niveau de probabilité. Bien qu’ils soient significativement plus fiables que le hasard dans la prédiction des caractéristiques ou des traits de caractère d’un individu, ils ne sont évidemment pas toujours exacts. Néanmoins, ces méthodes sont déjà mises en œuvre pour trier, catégoriser, étiqueter, évaluer, noter et classer les personnes, non seulement dans une approche marketing mais aussi pour prendre des décisions dans des domaines riches en conséquence comme la finance, l’assurance, la santé, pour ne citer qu’eux.
L’évaluation de crédit basée sur les données de comportement numérique
Des startups comme Lenddo, Kreditech, Cignifi et ZestFinance utilisent déjà les données récoltées sur les réseaux sociaux, lors de recherches sur le web ou sur les téléphones portables pour calculer la solvabilité d’une personne sans même utiliser de données financières. D’autres se basent sur la façon dont quelqu’un va remplir un formulaire en ligne ou naviguer sur un site web, sur la grammaire et la ponctuation de ses textos, ou sur l’état de la batterie de son téléphone. Certaines entreprises incluent même des données sur les amis avec lesquels une personne est connectée sur un réseau social pour évaluer sa solvabilité.
Cignifi, qui calcule la solvabilité des clients en fonction des horaires et de la fréquence des appels téléphoniques, se présente comme « la plateforme ultime de monétisation des données pour les opérateurs de réseaux mobiles ». De grandes entreprises, notamment MasterCard, le fournisseur d’accès mobile Telefonica, les agences d’évaluation de solvabilité Experian et Equifax, ainsi que le géant chinois de la recherche web Baidu, ont commencé à nouer des partenariats avec des startups de ce genre. L’application à plus grande échelle de services de cette nature est particulièrement en croissance dans les pays du Sud, ainsi qu’auprès de groupes de population vulnérables dans d’autres régions.
Réciproquement, les données de crédit nourrissent le marketing en ligne. Sur Twitter, par exemple, les annonceurs peuvent cibler leurs publicités en fonction de la solvabilité supposée des utilisateurs de Twitter sur la base des données client fournies par le courtier en données Oracle. Allant encore plus loin dans cette logique, Facebook a déposé un brevet pour une évaluation de crédit basée sur la cote de solvabilité de vos amis sur un réseau social. Personne ne sait s’ils ont l’intention de réellement mettre en application cette intégration totale des réseaux sociaux, du marketing et de l’évaluation des risques.
On peut dire que toutes les données sont des données sur le crédit, mais il manque encore la façon de les utiliser.
Douglas Merrill, fondateur de ZestFinance et ancien directeur des systèmes d’informations chez Google, 2012
Prédire l’état de santé à partir des données client
Les entreprises de données et les assureurs travaillent sur des programmes qui utilisent les informations sur la vie quotidienne des consommateurs pour prédire leurs risques de santé. Par exemple, l’assureur Aviva, en coopération avec la société de conseil Deloitte, a utilisé des données clients achetées à un courtier en données et habituellement utilisées pour le marketing, pour prédire les risques de santé individuels (comme le diabète, le cancer, l’hypertension et la dépression) de 60 000 personnes souhaitant souscrire une assurance.
La société de conseil McKinsey a aidé à prédire les coûts hospitaliers de patients en se basant sur les données clients d’une « grande compagnie d’assurance » santé américaine. En utilisant les informations concernant la démographie, la structure familiale, les achats, la possession d’une voiture et d’autres données, McKinsey a déclaré que ces « renseignements peuvent aider à identifier des sous-groupes stratégiques de patients avant que des périodes de coûts élevés ne surviennent ».
L’entreprise d’analyse santé GNS Healthcare a aussi calculé les risques individuels de santé de patients à partir d’un large champ de données tel que la génétique, les dossiers médicaux, les analyses de laboratoire, les appareils de santé mobiles et le comportement du consommateur. Les sociétés partenaires des assureurs tels que Aetna donnent une note qui identifie « les personnes susceptibles de subir une opération » et proposent de prédire l’évolution de la maladie et les résultats des interventions. D’après un rapport sectoriel, l’entreprise « classe les patients suivant le retour sur investissement » que l’assureur peut espérer s’il les cible pour des interventions particulières.
LexisNexis Risk Solutions, à la fois, un important courtier en données et une société d’analyse de risque, fournit un produit d’évaluation de santé qui calcule les risques médicaux ainsi que les frais de santé attendus individuellement, en se basant sur une importante quantité de données consommateurs, incluant les achats.
Collecte et utilisation massives de données client
Les plus importantes plates-formes connectées d’aujourd’hui, Google et Facebook en premier lieu, ont des informations détaillées sur la vie quotidienne de milliards de personnes dans le monde. Ils sont les plus visibles, les plus envahissants et, hormis les entreprises de renseignement, les publicitaires en ligne et les services de détection des fraudes numériques, peut-être les acteurs les plus avancés de l’industrie de l’analyse et des données personnelles. Beaucoup d’autres agissent en coulisse et hors de vue du public.
Le cœur de métier de la publicité en ligne consiste en un écosystème de milliers d’entreprises concentrées sur la traque constante et le profilage de milliards de personnes. À chaque fois qu’une publicité est affichée sur un site web ou une application mobile, un profil d’utilisateur vient juste d’être vendu au plus gros enchérisseur dans les millisecondes précédentes. Contrairement à ces nouvelles pratiques, les agences d’analyse de solvabilité et les courtiers en données clients exploitent des données personnelles depuis des décennies. Ces dernières années, ils ont commencé à combiner les très nombreuses données dont ils disposent sur la vie hors-ligne des personnes avec les bases de données utilisateurs et clients utilisées par de grandes plateformes, par des entreprises de publicité et par une multitude d’autres entreprises dans de nombreuses secteurs.
Les entreprises de données ont des informations détaillées sur des milliards de personnes
Plateformes en ligne grand public
Facebook dispose
des profils de
1,9 milliards d’utilisateurs de Facebook
1,2 milliards d’utilisateurs de Whatsapp
600 millions d’utilisateurs d’Instagram
Google dispose
des profils de
2 milliards d’utilisateurs d’Android
+ d’un milliard d’utilisateurs de Gmail
+ d’un milliard d’utilisateurs de Youtube
Apple dispose
des profils de
1 milliard d’utilisateurs d’iOS
Sociétés d’analyse de la solvabilité
Experian
dispose des données de solvabilité de 918 millions de personnes
dispose des données marketing de 700 millions de personnes
a un “aperçu” sur 2,3 milliards de personnes
Equifax
dispose des données de 820 millions de personnes
et d’1 milliard d’appareils
TransUnion
dispose des données d’1 milliard de personnes
Courtiers en données clients
Acxiom
dispose des données de
700 millions de personnes
1 milliard de cookies et d’appareils mobiles
3,7 milliards de profils clients
Oracle
dispose des données de
1 milliard d’utilisateurs d’appareils mobiles
1,7 milliards d’internautes
donne accès à
5 milliards d’identifiants uniques client
Facebook utilise au moins 52 000 caractéristiques personnelles pour trier et classer ses 1,9 milliard d’utilisateurs suivant, par exemple, leur orientation politique, leur origine ethnique et leurs revenus. Pour ce faire, la plateforme analyse leurs messages, leurs Likes, leurs partages, leurs amis, leurs photos, leurs mouvements et beaucoup d’autres comportements. De plus, Facebook acquiert à d’autres entreprises des données sur ses utilisateurs. En 2013, la plateforme démarre son partenariat avec les quatre courtiers en données Acxiom, Epsilon, Datalogix et BlueKai, les deux derniers ont ensuite été rachetés par le géant de l’informatique Oracle. Ces sociétés aident Facebook à pister et profiler ses utilisateurs bien mieux qu’il le faisait déjà en lui fournissant des données collectées en dehors de sa plateforme.
Les courtiers en données et le marché des données personnelles
Les courtiers en données client ont un rôle clé dans le marché des données personnelles actuel. Ils agrègent, combinent et échangent des quantités astronomiques d’informations sur des populations entières, collectées depuis des sources en ligne et hors-ligne. Les courtiers en données collectent de l’information disponible publiquement et achètent le droit d’utiliser les données clients d’autres entreprises. Leurs données proviennent en général de sources qui ne sont pas les individus eux-mêmes, et sont collectées en grande partie sans que le consommateur soit au courant. Ils analysent les données, en font des déductions, construisent des catégories de personnes et fournissent à leurs clients des informations sur des milliers de caractéristiques par individu.
Dans les profils individuels créés par les courtiers en données, on trouve non seulement des informations à propos de l’éducation, de l’emploi, des enfants, de la religion, de l’origine ethnique, de la position politique, des loisirs, des centres d’intérêts et de l’usage des médias, mais aussi à propos du comportement en ligne, par exemple les recherches sur Internet. Sont également collectées les données sur les achats, l’usage de carte bancaire, le revenu et l’endettement, la gestion bancaire et les polices d’assurance, la propriété immobilière et automobile, et tout un tas d’autres types d’information. Les courtiers en données calculent et attribuent aussi des notes aux individus afin de prédire leur comportement futur, par exemple en termes de stabilité économique, de projet de grossesse ou de changement d’emploi.
Quelques exemples de données clients fournies par Acxiom et Oracle
exemples de données clients fournies par Axciom et Oracle (en avril/mai 2017) – sources : voir le rapport
Acxiom, un important courtier en données
Fondée en 1969, Acxiom gère l’une des plus grandes bases de données client commerciales au monde. Disposant de milliers de sources, l’entreprise fournit jusqu’à 3000 types de données sur 700 millions de personnes réparties dans de nombreux pays, dont les États-Unis, le Royaume-Uni et l’Allemagne. Née sous la forme d’une entreprise de marketing direct, Acxiom a développé ses bases de données client centralisées à la fin des années 1990.
À l’aide de son système Abilitek Link, l’entreprise tient à jour une sorte de registre de la population dans lequel chaque personne, chaque foyer et chaque bâtiment reçoit un identifiant unique. En permanence, l’entreprise met à jour ses bases de données sur la base d’informations concernant les naissances et les décès, les mariages et les divorces, les changements de nom ou d’adresse et aussi bien sûr de nombreuses autres données de profil. Quand on lui demande des renseignements sur une personne, Acxiom peut par exemple donner une appartenance religieuse parmi l’une des 13 retenues comme « catholique », « juif », ou « musulman » et une appartenance ethnique sur quasiment 200 possibles.
Acxiom commercialise l’accès aux profils détaillés des consommateurs et aide ses clients à trouver, cibler, identifier, analyser, trier, noter et classer les gens. L’entreprise gère aussi directement pour ses propres clients 15 000 bases de données clients représentant des milliards de profils consommateurs. Les clients d’Acxiom sont des grandes banques, des assureurs, des services de santé et des organismes gouvernementaux. En plus de son activité de commercialisation de données, Acxiom fournit également des services de vérification d’identité, de gestion du risque et de détection de fraude.
Acxiom et ses fournisseurs de données, ses partenaires et ses services
Axciom et ses fournisseurs de données, ses partenaires et ses clients (en avril/mai 2017) – sources : voir le rapport
Depuis l’acquisition en 2014 de la société de données en ligne LiveRamp, Acxiom a déployé d’importants efforts pour connecter son dépôt de données – couvrant une dizaine d’années – au monde numérique. Par exemple, Acxiom était parmi les premiers courtiers en données à fournir de l’information additionnelle à Facebook, Google et Twitter afin d’aider ces plateformes à mieux pister ou catégoriser les utilisateurs en fonction de leurs achats mais aussi en fonction d’autres comportements qu’ils ne savaient pas encore eux-mêmes pister.
LiveRamp de Acxiom connecte et combine les profils numériques issus de centaines d’entreprises de données et de publicité. Au centre se trouve son système IdentityLink, qui aide à reconnaître les individus et à relier les informations les concernant, dans les bases de données, les plateformes et les appareils en se basant sur leur adresse de courriel, leur numéro de téléphone, l’identifiant de leur téléphone, ou d’autres identifiants. Bien que l’entreprise assure que les correspondances et les associations se fassent de manière « anonyme » et « dé-identifiée », elle dit aussi pouvoir « connecter des données hors-ligne et en ligne sur un seul identifiant ».
Parmi les entreprises qui ont récemment été reconnues comme étant des fournisseurs de données par LiveRamp, on trouve les géants de l’analyse de solvabilité Equifax, Experian et TransUnion. De plus, de nombreux services de pistage numérique collectant des données par Internet, par les applications mobiles, et même par des capteurs placés dans le monde réel, fournissent des données à LiveRamp. Certains d’entre eux utilisent les base de données de LiveRamp, qui permettent aux entreprises « d’acheter et de vendre des données client précieuses ». D’autres fournissent des données afin que Acxiom et LiveRamp puissent reconnaître des individus et relier les informations enregistrées avec les profils numériques d’autres provenances. Mais le plus préoccupant, c’est sans doute le partenariat entre Acxiom et Crossix, une entreprise avec des données détaillées sur la santé de 250 millions de consommateurs américains. Crossix figure parmi les fournisseurs de données de LiveRamp.
Quiconque enregistrant des données sur les consommateurs peut potentiellement être un fournisseur de données. »
Travis May, Directeur général de Acxiom-LiveRamp
Oracle, un géant des technologies de l’information pénètre le marché des données client
En faisant l’acquisition de plusieurs entreprises de données telles que Datalogix, BlueKai, AddThis et CrossWise, Oracle, un des premiers fournisseurs de logiciels d’entreprises et de bases de données dans le monde, est également récemment devenu un des premiers courtiers en données clients. Dans son « cloud », Oracle rassemble 3 milliards de profils utilisateurs issus de 15 millions de sites différents, les données d’un milliard d’utilisateurs mobiles, des milliards d’historiques d’achats dans des chaînes de supermarchés et 1500 détaillants, ainsi que 700 millions de messages par jour issus des réseaux sociaux, des blogs et des sites d’avis de consommateurs.
Oracle rassemble des données sur des milliards de consommateurs
Oracle et ses fournisseurs de données, ses partenaires et ses clients (en avril/mai 2017) – sources : voir le rapport
Oracle catalogue près de 100 fournisseurs de données dans son répertoire de données, parmi lesquels figurent Acxiom et des agences d’analyse de solvabilité telles que Experian et TransUnion, ainsi que des entreprises qui tracent les visites de sites Internet, l’utilisation d’applications mobiles et les déplacements, ou qui collectent des données à partir de questionnaires en ligne. Visa et MasterCard sont également référencés comme fournisseurs de données. En coopération avec ses partenaires, Oracle fournit plus de 30 000 catégories de données différentes qui peuvent être attribuées aux consommateurs. Réciproquement, l’entreprise partage des données avec Facebook et aide Twitter à calculer la solvabilité de ses utilisateurs.
Le Graphe d’Identifiants Oracle détermine et combine des profils utilisateur provenant de différentes entreprises. Il est le « trait d’union entre les interactions » à travers les différentes bases de données, services et appareils afin de « créer un profil client adressable » et « d’identifier partout les clients et les prospects ». D’autres entreprises peuvent envoyer à Oracle, des clés de correspondance construites à partir d’adresses courriel, de numéros de téléphone, d’adresse postale ou d’autres identifiants, Oracle les synchronisera ensuite à son « réseau d’identifiants utilisateurs et statistiques, connectés ensemble dans le Graphe d’Identifiants Oracle ». Bien que l’entreprise promette de n’utiliser que des identifiants utilisateurs anonymisés et des profils d’utilisateurs anonymisés, ceux-ci font tout de même référence à certains individus et peuvent être utilisés pour les reconnaître et les cibler dans de nombreux contextes de la vie.
Le plus souvent, les clients d’Oracle peuvent télécharger dans le « cloud » d’Oracle leurs propres données concernant : leurs clients, les visites sur leur site ou les utilisateurs d’une application ; ils peuvent les combiner avec des données issues de nombreuses autres entreprises, puis les transférer et les utiliser en temps réel sur des centaines d’autres plateformes de commerce et de publicité. Ils peuvent par exemple les utiliser pour trouver et cibler des personnes sur tous les appareils et plateformes, personnaliser leurs interactions, et le cas échéant mesurer la réaction des clients qui ont été personnellement ciblés.
La surveillance en temps réel des comportements quotidiens
Les plateformes en ligne, les fournisseurs de technologies publicitaires, les courtiers en données, et les négociants de toutes sortes d’industries peuvent maintenant surveiller, reconnaître et analyser des individus dans de nombreuses situations. Ils peuvent étudier ce qui intéresse les gens, ce qu’ils ont fait aujourd’hui, ce qu’ils vont sûrement faire demain, et leur valeur en tant que client.
Les données concernant les vies en ligne et hors ligne des personnes
Une large spectre d’entreprises collecte des informations sur les personnes depuis des décennies. Avant l’existence d’Internet, les agences de crédit et les agences de marketing direct servaient de point d’intégration principal entre les données provenant de différentes sources. Une première étape importante dans la surveillance systématique des consommateurs s’est produite dans les années 1990, par la commercialisation de bases de données, les programmes de fidélité et l’analyse poussée de solvabilité. Après l’essor d’Internet et de la publicité en ligne au début des années 2000, et la montée des réseaux sociaux, des smartphones et de la publicité en ligne à la fin des années 2000, on voit maintenant dans les années 2010 l’industrie des données clients s’intégrer avec le nouvel écosystème de pistage et de profilage numérique.
Cartographie de la collecte de données clients
Différents niveaux, domaines et sources de collecte de données clients par les entreprises
De longue date, les courtiers en données clients et d’autres entreprises acquièrent des informations sur les abonnés à des journaux et à des magazines, sur les membres de clubs de lecture et de ciné-clubs, sur les acheteurs de catalogues de vente par correspondance, sur les personnes réservant dans les agences de voyage, sur les participants à des séminaires et à des conférences, et sur les consommateurs qui remplissent les cartes de garantie pour leurs achats. La collecte de données d’achats grâce à des programmes de fidélité est, de ce point de vue, une pratique établie depuis longtemps.
En complément des données provenant directement des individus, sont utilisées, par exemple les informations concernant le type quartiers et d’immeubles où résident les personnes afin de décrire, étiqueter, trier et catégoriser ces personnes. De même, les entreprises utilisent maintenant des profils de consommateurs s’appuyant sur les métadonnées concernant le type de sites Internet fréquentés, les vidéos regardées, les applications utilisées et les zones géographiques visitées. Au cours de ces dernières années, l’échelle et le niveau de détail des flux de données comportementales générées par toutes sortes d’activités du quotidien, telles que l’utilisation d’Internet, des réseaux sociaux et des équipements, ont rapidement augmenté.
Ce n’est pas un téléphone, c’est mon mouchard /pisteur/. New York Times, 2012
Un pistage et un profilage omniprésents
Une des principales raisons pour lesquelles le pistage et le profilage commerciaux sont devenus si généralisés c’est que quasiment tous les sites Internet, les fournisseurs d’applications mobiles, ainsi que de nombreux vendeurs d’équipements, partagent activement des données comportementales avec d’autres entreprises.
Il y a quelques années, la plupart des sites Internet ont commencé à inclure dans leur propre site des services de pistage qui transmettent des données à des tiers. Certains de ces services fournissent des fonctions visibles aux utilisateurs. Par exemple, lorsqu’un site Internet montre un bouton Facebook « j’aime » ou une vidéo YouTube encapsulée, des données utilisateur sont transmises à Facebook ou à Google. En revanche, de nombreux autres services ayant trait à la publicité en ligne demeurent cachés et, pour la plupart, ont pour seul objectif de collecter des données utilisateur. Le type précis de données utilisateur partagées par les éditeurs numériques et la façon dont les tierces parties utilisent ces données reste largement méconnus. Une partie de ces activités de pistage peut être analysée par n’importe qui ; par exemple en installant l’extension pour navigateur Lightbeam, il est possible de visualiser le réseau invisible des trackers des parties tierces.
Une étude récente a examiné un million de sites Internet différents et a trouvé plus de 80 000 services tiers recevant des données concernant les visiteurs de ces sites. Environ 120 de ces services de pistage ont été trouvés sur plus de 10 000 sites, et six entreprises surveillent les utilisateurs sur plus de 100 000 sites, dont Google, Facebook, Twitter et BlueKai d’Oracle. Une étude sur 200 000 utilisateurs allemands visitant 21 millions de pages Internet a montré que les trackers tiers étaient présents sur 95 % des pages visitées. De même, la plupart des applications mobiles partagent des informations sur leurs utilisateurs avec d’autres entreprises. Une étude menée en 2015 sur les applications à la mode en Australie, en Allemagne et aux États-Unis a trouvé qu’entre 85 et 95 % des applications gratuites, et même 60 % des applications payantes se connectaient à des tierces parties recueillant des données personnelles.
Une carte interactive des services cachés de pistage tiers sur les applications Android créée par des chercheurs européens et américains peut être explorée à l’adresse suivante : haystack.mobi/panopticon
En matière d’appareils, ce sont peut-être les smartphones qui actuellement contribuent le plus au recueil omniprésent données. L’information enregistrée par les téléphones portables fournit un aperçu détaillé de la personnalité et de la vie quotidienne d’un utilisateur. Puisque les consommateurs ont en général besoin d’un compte Google, Apple ou Microsoft pour les utiliser, une grande partie de l’information est déjà reliée à l’identifiant d’une des principales plateformes.
La vente de données utilisateurs ne se limite pas aux éditeurs de sites Internet et d’applications mobiles. Par exemple, l’entreprise d’intelligence commerciale SimilarWeb reçoit des données issues non seulement de centaines de milliers de sources de mesures directes depuis les sites et les applications, mais aussi des logiciels de bureau et des extensions de navigateur. Au cours des dernières années, de nombreux autres appareils avec des capteurs et des connexions réseau ont intégré la vie de tous les jours, cela va des liseuses électroniques et autres accessoires connectés aux télés intelligentes, compteurs, thermostats, détecteurs de fumée, imprimantes, réfrigérateurs, brosses à dents, jouets et voitures. À l’instar des smartphones, ces appareils donnent aux entreprises un accès sans précédent au comportement des consommateurs dans divers contextes de leur vie.
Publicité programmatique et technologie marketing
La plus grande partie de la publicité numérique prend aujourd’hui la forme d’enchères en temps réel hautement automatisées entre les éditeurs et les publicitaires ; on appelle cela la publicité programmatique. Lorsqu’une personne se rend sur un site Internet, les données utilisateur sont envoyées à une kyrielle de services tiers, qui cherchent ensuite à reconnaître la personne et extraire l’information disponible sur le profil. Les publicitaires souhaitant livrer une publicité à cet individu, en particulier du fait de certains attributs ou comportements, placent une enchère. En quelques millisecondes, le publicitaire le plus offrant gagne et place la pub. Les publicitaires peuvent de la même façon enchérir sur les profils utilisateurs et le placement de publicités au sein des applications mobiles.
Néanmoins, ce processus ne se déroule pas, la plupart du temps, entre les éditeurs et les publicitaires. L’écosystème est constitué d’une pléthore de toutes sortes de données différentes et de fournisseurs de technologies en interaction les uns avec les autres, parmi lesquels des réseaux publicitaires, des marchés publicitaires, des plateformes côté vente et des plateformes côté achat. Certains se spécialisent dans le pistage et la publicité suivant les résultats de recherche, dans la publicité généraliste sur Internet, dans la pub sur mobile, dans les pubs vidéos, dans les pubs sur les réseaux sociaux, ou dans les pubs au sein des jeux. D’autres se concentrent sur l’approvisionnement en données, en analyse ou en services de personnalisation.
Pour tracer le portrait des utilisateurs d’Internet et d’applications mobiles, toutes les parties impliquées ont développé des méthodes sophistiquées pour accumuler, regrouper et relier les informations provenant de différentes entreprises afin de suivre les individus dans tous les aspects de leur vie. Nombre d’entre elles recueillent et utilisent des profils numériques sur des centaines de millions de consommateurs, leurs navigateurs Internet et leurs appareils.
De nombreux secteurs rejoignent l’économie de pistage
Au cours de ces dernières années, des entreprises dans plusieurs secteurs ont commencé à partager et à utiliser à très grande échelle des données concernant leurs utilisateurs et clients.
La plupart des détaillants vendent des formes agrégées de données sur les habitudes d’achat auprès des entreprises d’études de marchés et des courtiers en données. Par exemple, l’entreprise de données IRI accède aux données de plus de 85 000 magasins (‘alimentation, grande distribution, médicaments, d’alcool et d’animaux de compagnie, magasin à prix unique et magasin de proximité). Nielsen déclare recueillir les informations concernant les ventes de 900 000 magasins dans le monde dans plus de 100 pays. L’enseigne de grande distribution britannique Tesco sous-traite son programme de fidélité et ses activités en matière de données auprès d’une filiale, Dunnhumby, dont le slogan est « transformer les données consommateur en régal pour le consommateur ». Lorsque Dunnhumby a fait l’acquisition de l’entreprise technologique de publicité allemande Sociomantic, il a été annoncé que Dunnhumby « conjuguerait ses connaissances étendues au sujet sur les préférences d’achat de 400 millions de consommateurs » avec les « données en temps réel de plus de 700 millions de consommateurs en ligne » de Sociomantic afin personnaliser et d’évaluer les publicités.
Cartographie de l’écosystème du pistage et du profilage commercial
Aujourd’hui de nombreux industriels dans divers secteurs ont rejoint l’écosystème de pistage et de profilage numérique, aux cotés des grandes plateformes en ligne et des professionnels de l’analyse des données clients.
De grands groupes médiatiques sont aussi fortement intégrés dans l’écosystème de pistage et de profilage numérique actuel. Par exemple, Time Inc. a fait l’acquisition d’Adelphic, une importante société de pistage et de technologies publicitaires multi-support, mais aussi de Viant, une entreprise qui déclare avoir accès à plus de 1,2 milliard d’utilisateurs enregistrés. La plateforme de streaming Spotify est un exemple célèbre d’éditeur numérique qui vend les données de ses utilisateurs. Depuis 2016, la société partage avec le département données du géant du marketing WPP des informations à propos de ce que les utilisateurs écoutent, sur leur humeur ainsi que sur leur comportement et leur activité en termes de playlist. WPP a maintenant accès « aux préférences et comportements musicaux des 100 millions d’utilisateurs de Spotify ».
De nombreuses grandes entreprises de télécom et de fournisseurs d’accès Internet ont fait l’acquisition d’entreprises de technologies publicitaires et de données. Par exemple, Millennial Media, une filiale d’AOL-Verizon, est une plateforme de publicité mobile qui collecte les données de plus de 65 000 applications de différents développeurs, et prétend avoir accès à environ 1 milliard d’utilisateurs actifs distincts dans le monde. Singtel, l’entreprise de télécoms basée à Singapour, a acheté Turn, une plateforme de technologies publicitaires qui donne accès aux distributeurs à 4,3 milliards d’appareils pouvant être ciblés et d’identifiants de navigateurs et à 90 000 attributs démographiques, comportementaux et psychologiques.
Comme les compagnies aériennes, les hôtels, les commerces de détail et les entreprises de beaucoup d’autres secteur, le secteur des services financiers a commencé à agréger et utiliser des données clients supplémentaires grâce à des programmes de fidélité dans les années 80 et 90. Les entreprises dont la clientèle cible est proche et complémentaires partagent depuis longtemps certaines de leurs données clients entre elles, un processus souvent géré par des intermédiaires. Aujourd’hui, l’un de ces intermédiaires est Cardlytics, une entreprise qui gère des programmes de fidélité pour plus de 1 500 institutions financières, telles que Bank of America et MasterCard. Cardlytics s’engage auprès des institutions financières à « générer des nouvelles sources de revenus en exploitant le pouvoir de [leurs] historiques d’achat ». L’entreprise travaille aussi en partenariat avec LiveRamp, la filiale d’Acxiom qui combine les données en ligne et hors ligne des consommateurs.
Pour MasterCard, la vente de produits et de services issus de l’analyse de données pourrait même devenir son cœur de métier, sachant que la production d’informations, dont la vente de données, représentent une part considérable et croissante de ses revenus. Google a récemment déclaré qu’il capture environ 70 % des transactions par carte de crédit aux États-Unis via « partenariats tiers » afin de tracer les achats, mais n’a pas révélé ses sources.
Ce sont vos données. Vous avez le droit de les contrôler, de les partager et de les utiliser comme bon vous semble.
C’est ainsi que le courtier en données Lotame s’adresse sur son site Internet à ses entreprises clientes en 2016.
Relier, faire correspondre et combiner des profils numériques
Jusqu’à récemment, les publicitaires, sur Facebook, Google ou d’autres réseaux de publicité en ligne, ne pouvaient cibler les individus qu’en analysant leur comportement en ligne. Mais depuis quelques années, grâce aux moyens offerts par les entreprises de données, les profils numériques issus de différentes plateformes, de différentes bases de données clients et du monde de la publicité en ligne peuvent désormais être associés et combinés entre eux.
Connecter les identités en ligne et hors ligne
Cela a commencé en 2012, quand Facebook a permis aux entreprises de télécharger leurs propres listes d’adresses de courriel et de numéros de téléphone sur la plateforme. Bien que les adresses et numéros de téléphone soient convertis en pseudonyme, Facebook est en mesure de relier directement ces données client provenant d’entreprises tierces avec ses propres comptes utilisateur. Cela permet par exemple aux entreprises de trouver et de cibler très précisément sur Facebook les personnes dont elles possèdent les adresses de courriel ou les numéros de téléphone. De la même façon, il leur est éventuellement possible d’exclure certaines personnes du ciblage de façon sélective, ou de déléguer à la plateforme le repérage des personnes qui ont des caractéristiques, centre d’intérêts, et comportements communs.
C’est une fonctionnalité puissante, peut-être plus qu’il n’y paraît au premier abord. Elle permet en effet aux entreprises d’associer systématiquement leurs données client avec les données Facebook. Mieux encore, d’autres publicitaires et marchands de données peuvent également synchroniser leurs bases avec celles de la plateforme et en exploiter les ressources, ce qui équivaut à fournir une sorte de télécommande en temps réel pour manipuler l’univers des données Facebook. Les entreprises peuvent maintenant capturer en temps réel des données comportementales extrêmement précises comme un clic de souris sur un site, le glissement d’un doigt sur une application mobile ou un achat en magasin, et demander à Facebook de trouver et de cibler aussitôt les personnes qui viennent de se livrer à ces activités. Google et Twitter ont mis en place des fonctionnalités similaires en 2015.
Les plateformes de gestion de données
De nos jours, la plupart des entreprises de technologie publicitaire croisent en continu plusieurs sources de codage relatives aux individus. Les plateformes de gestion de données permettent aux entreprises de tous les domaines d’associer et de relier leurs propres données clients, comprenant des informations en temps réel sur les achats, les sites web consultés, les applications utilisées et les réponses aux courriels, avec des profils numériques fournis par une multitude de fournisseurs tiers de données. Les données associées peuvent alors être analysées, triées et classées, puis utilisées pour envoyer un message donné à des personnes précises via des réseaux ou des appareils particuliers. Une entreprise peut, par exemple, cibler un groupe de clients existants ayant visité une page particulière sur son site ; ils sont alors perçus comme pouvant devenir de bons clients, bénéficiant alors de contenus personnalisés ou d’une réduction, que ce soit sur Facebook, sur une appli mobile ou sur le site même de l’entreprise.
L’émergence des plateformes de gestion de données marque un tournant dans le développement d’un envahissant pistage des comportements d’achat. Avec leur aide, les entreprises dans tous les domaines et partout dans le monde peuvent très facilement associer et relier les données qu’elles ont collectées depuis des années sur leurs clients et leurs prospects avec les milliards de profils collectés dans le monde numérique. Les principales entreprises faisant tourner ces plateformes sont : Oracle, Adobe, Salesforce (Krux), Wunderman (KBM Group/Zipline), Neustar, Lotame et Cxense.
Nous vous afficherons des publicités basées sur votre identité, mais cela ne veut pas dire que vous serez identifiable.
Erin Egan, Directeur de la protection de la vie privée chez Facebook, 2012
Identifier les gens et relier les profils numériques
Pour surveiller et suivre les gens dans les différentes situations de leur vie, pour leur associer des profils et toujours les reconnaître comme un seul et même individu, les entreprises amassent une grande variété de types de données qui, en quelque sorte, les identifient.
Parce qu’il est ambigu, le nom d’une personne a toujours été un mauvais identifiant pour un recueil de données. L’adresse postale, par contre, a longtemps été et est encore, une indication clé qui permet d’associer et de relier des données de différentes origines sur les consommateurs et leur famille. Dans le monde numérique, les identifiants les plus pertinents pour relier les profils et les comportements sur les différentes bases de données, plateformes et appareils sont : l’adresse de courriel, le numéro de téléphone, et le code propre à chaque smartphone ou autre appareil.
Les identifiants de compte utilisateur sur les immenses plateformes comme Google, Facebook, Apple et Microsoft jouent aussi un rôle important dans le suivi des gens sur Internet. Google, Apple, Microsoft et Roku attribuent un « identifiant publicitaire » aux individus, qui est maintenant largement utilisé pour faire correspondre et relier les données d’appareils tels que les smartphones avec les autres informations issues du monde numérique. Verizon utilise son propre identifiant pour pister les utilisateurs sur les sites web et les appareils. Certaines grandes entreprises de données comme Acxiom, Experian et Oracle disposent, au niveau mondial, d’un identifiant unique par personne qu’elles utilisent pour relier des dizaines d’années de données clients avec le monde numérique. Ces identifiants d’entreprise sont constitués le plus souvent de deux identifiants ou plus qui sont attachés à différents aspects de la vie en ligne et hors ligne d’une personne et qui peuvent être d’une certaine façon reliés l’un à l’autre.
Des Identifiants utilisés pour pister les gens sur les sites web, les appareils et les lieux de vie
Comment les entreprises identifient les consommateurs et les relient à des informations de profils – sources : voir le rapport
Les entreprises de pistage utilisent également des identifiants plus ou moins temporaires, comme les cookies qui sont attachés aux utilisateurs surfant sur le web. Depuis que les utilisateurs peuvent ne pas autoriser ou supprimer les cookies dans leur navigateur, elles ont développé des méthodes sophistiquées permettant de calculer une empreinte numérique unique basée sur diverses caractéristiques du navigateur et de l’ordinateur d’une personne. De la même manière, les entreprises amassent les empreintes sur les appareils tels que les smartphones. Les cookies et les empreintes numériques sont continuellement synchronisés entre les différents services de pistage et ensuite reliés à des identifiants plus permanents.
D’autres entreprises fournissent des services de pistage multi-appareils qui utilisent le machine learning (voir Wikipédia) pour analyser de grandes quantités de données. Par exemple, Tapad, qui a été acheté par le géant des télécoms norvégiens Telenor, analyse les données de deux milliards d’appareils dans le monde et utilise des modèles basés sur les comportements et les relations pour trouver la probabilité qu’un ordinateur, une tablette, un téléphone ou un autre appareil appartienne à la même personne.
Un profilage « anonyme » ?
Les entreprises de données suppriment les noms dans leurs profils détaillés et utilisent des fonctions de hachage (voir Wikipedia) pour convertir les adresses de courriel et les numéros de téléphone en code alphanumérique comme “e907c95ef289”. Cela leur permet de déclarer sur leur site web et dans leur politique de confidentialité qu’elles recueillent, partagent et utilisent uniquement des données clients « anonymisées » ou « dé-identifiées ».
Néanmoins, comme la plupart des entreprises utilisent les mêmes process déterministes pour calculer ces codes alphanumériques, on devrait les considérer comme des pseudonymes qui sont en fait bien plus pratiques que les noms réels pour identifier les clients dans le monde numérique. Même si une entreprise partage des profils contenant uniquement des adresses de courriels ou des numéros de téléphones chiffrés, une personne peut toujours être reconnue dès qu’elle utilise un autre service lié avec la même adresse de courriel ou le même numéro de téléphone. De cette façon, bien que chaque service de pistage impliqué ne connaissent qu’une partie des informations du profil d’une personne, les entreprises peuvent suivre et interagir avec les gens au niveau individuel via les services, les plateformes et les appareils.
Si une entreprise peut vous suivre et interagir avec vous dans le monde numérique – et cela inclut potentiellement votre téléphone mobile ou votre télé – alors son affirmation que vous êtes anonyme n’a aucun sens, en particulier quand des entreprises ajoutent de temps à autre des informations hors-ligne aux données en ligne et masquent simplement le nom et l’adresse pour rendre le tout « anonyme ».
Joseph Turow, spécialiste du marketing et de la vie privée dans son livre « The Daily You », 2011
Gérer les clients et les comportements : personnalisation et évaluation
S’appuyant sur les méthodes sophistiquées d’interconnexion et de combinaison de données entre différents services, les entreprises de tous les secteurs d’activité peuvent utiliser les flux de données comportementales actuellement omniprésents afin de surveiller et d’analyser une large gamme d’activités et de comportements de consommateurs pouvant être pertinents vis-à-vis de leurs intérêts commerciaux.
Avec l’aide des vendeurs de données, les entreprises tentent d’entrer en contact avec les clients tout au long de leurs parcours autant de fois que possible, à travers les achats en ligne ou en boutique, le publipostage, les pubs télé et les appels des centres d’appels. Elles tentent d’enregistrer et de mesurer chaque interaction avec un consommateur, y compris sur les sites Internet, plateformes et appareils qu’ils ne contrôlent pas eux-mêmes. Elles peuvent recueillir en continu une abondance de données concernant leurs clients et d’autres personnes, les améliorer avec des informations provenant de tiers, et utiliser les profils améliorés au sein de l’écosystème de commercialisation et de technologie publicitaire. À l’heure actuelle, les plateformes de gestion des données clients permettent la définition de jeux complexes de règles qui régissent la façon de réagir automatiquement à certains critères tels que des activités ou des personnes données ou une combinaison des deux.
Par conséquent, les individus ne savent jamais si leur comportement a déclenché une réaction de l’un de ces réseaux de pistage et de profilage constamment mis à jour, interconnectés et opaques, ni, le cas échéant, comment cela influence les options qui leur sont proposées à travers les canaux de communication et dans les situations de vie.
Tracer, profiler et influencer les individus en temps réel
Chaque interaction enclenche un large éventail de flux de données entre de nombreuses entreprises.
Personnalisation en série
Les flux de données échangés entre les publicitaires en ligne, les courtiers en données, et les autres entreprises ne sont pas seulement utilisés pour diffuser de la publicité ciblée sur les sites web ou les applis mobiles. Ils sont de plus en plus utilisés pour personnaliser les contenus, les options et les choix offerts aux consommateurs sur le site d’une entreprise par exemple. Les entreprises de technologie des données, comme par exemple Optimizely, peuvent aider à personnaliser un site web spécialement pour les personnes qui le visitent pour la première fois, en s’appuyant sur les profils numériques de ces visiteurs fournis par Oracle.
Les boutiques en ligne, par exemple, personnalisent l’accueil des visiteurs : quels produits seront mis en évidence, quelles promotions seront proposées, et même le prix et des produits ou des services peuvent être différents selon la personne qui visite le site. Les services de détection de la fraude évaluent les utilisateurs en temps réel et décident quels moyens de paiement et de transport peuvent être proposés.
Les entreprises développent des technologies pour calculer et évaluer en continu le potentiel de valeur à long terme d’un client en s’appuyant sur son historique de navigation, de recherche et de localisation, mais aussi sur son usage des applis, sur les produits achetés et sur ses amis sur les réseaux sociaux. Chaque clic, chaque glissement de doigt, chaque Like, chaque partage est susceptible d’influencer la manière dont une personne est traitée en tant que client, combien de temps elle va attendre avant que la hotline ne lui réponde, ou si elle sera complètement exclue des relances et des services marketing.
L’Internet des riches n’est pas le même que celui des pauvres.
Michael Fertik, fondateur de reputation.com, 2013
Trois types de plateformes technologiques jouent un rôle important dans cette sorte de personnalisation instantanée. Premièrement, les entreprises utilisent des systèmes de gestion de la relation client pour gérer leurs données sur les clients et les prospects. Deuxièmement, elles utilisent des plateformes de gestion de données pour connecter leurs propres données à l’écosystème de publicité numérique et obtiennent ainsi des informations supplémentaires sur le profil de leurs clients. Troisièmement, elles peuvent utiliser des plateformes de marketing prédictif qui les aident à produire le bon message pour la bonne personne au bon moment, calculant comment convaincre quelqu’un en exploitant ses faiblesses et ses préjugés.
Par exemple, l’entreprise de données RocketFuel promet à ses clients de « leur apporter des milliers de milliards de signaux numériques ou non pour créer des profils individuels et pour fournir aux consommateurs une expérience personnalisée, toujours actualisée et toujours pertinente » s’appuyant sur les 2,7 milliards de profils uniques de son dépôt de données. Selon RocketFuel, il s’agit « de noter chaque signal selon sa propension à influencer le consommateur ».
La plateforme de marketing prédictif TellApart, qui appartient à Twitter, associe une valeur à chaque couple client/produit acheté, une « synthèse entre la probabilité d’achat, l’importance de la commande et la valeur à long terme », s’appuyant sur « des centaines de signaux en ligne et en magasin sur un consommateur anonyme unique ». En conséquence, TellApart regroupe automatiquement du contenu tel que « l’image du produit, les logos, les offres et toute autre métadonnée » pour construire des publicités, des courriels, des sites web et des offres personnalisées.
Tarifs personnalisés et campagnes électorales
Des méthodes identiques peuvent être utilisées pour personnaliser les tarifs dans les boutiques en ligne, par exemple, en prédisant le niveau d’achat d’un client à long terme ou le montant qu’il sera probablement prêt à payer un peu plus tard. Des preuves sérieuses suggèrent que les boutiques en ligne affichent déjà des tarifs différents selon les consommateurs, ou même des prix différents pour le même produit, en s’appuyant sur leur comportement et leurs caractéristiques. Un champ d’action similaire est la personnalisation lors des campagnes électorales. Le ciblage des électeurs avec des messages personnalisés, adaptés à leur personnalité, et à leurs opinions politiques sur des problèmes donnés a fait monter les débats sur une possible manipulation politique.
Utiliser les données, les analyser et les personnaliser pour gérer les consommateurs
Actuellement, dans tous les domaines, les entreprises peuvent mobiliser les réseaux de suivi et de profilage pour trouver, évaluer, contacter, trier et gérer les consommateurs
Tests et expériences sur les personnes
La personnalisation s’appuyant sur de riches informations de profil et sur du suivi invasif en temps réel est devenue un outil puissant pour influencer le comportement du consommateur quand il visite une page web, clique sur une pub, s’inscrit à un service, s’abonne à une newsletter, télécharge une application ou achète un produit.
Pour améliorer encore cela, les entreprises ont commencé à faire des expériences en continu sur les individus. Elles procèdent à des tests en faisant varier les fonctionnalités, le design des sites web, l’interface utilisateur, les titres, les boutons, les images ou mêmes les tarifs et les remises, surveillent et mesurent avec soin comment les différents groupes d’utilisateurs interagissent avec ces modifications. De cette façon, les entreprises optimisent sans arrêt leur capacité à encourager les personnes à agir comme elles veulent qu’elles agissent.
Les organes de presse, y compris à grand tirage comme le Washington Post, utilisent différentes versions des titres de leurs articles pour voir laquelle est la plus performante. Optimizely, un des principaux fournisseurs de technologies pour ce genre de tests, propose à ses clients la capacité de « faire des tests sur l’ensemble de l’expérience client sur n’importe quel canal, n’importe quel appareil, et n’importe quelle application ». Expérimenter sur des usagers qui l’ignorent est devenu la nouvelle norme.
En 2014, Facebook a déclaré faire tourner « plus d’un millier d’expérimentations chaque jour » afin « d’optimiser des résultats précis » ou pour « affiner des décisions de design sur le long terme ». En 2010 et 2012, la plateforme a mené des expérimentations sur des millions d’utilisateurs et montré qu’en manipulant l’interface utilisateur, les fonctionnalités et le contenu affiché, Facebook pouvait augmenter significativement le taux de participation électorale d’un groupe de personnes. Leur célèbre expérimentation sur l’humeur des internautes, portant sur 700 000 individus, consistait à manipuler secrètement la quantité de messages émotionnellement positifs ou négatifs présents dans les fils d’actualité des utilisateurs : il s’avéra que cela avait un impact sur le nombre de messages positifs ou négatifs que les utilisateurs postaient ensuite eux-mêmes.
Suite à la critique massive de Facebook par le public concernant cette expérience, la plateforme de rendez-vous OkCupid a publié un article de blog provocateur défendant de telles pratiques, déclarant que « nous faisons des expériences sur les êtres humains » et « c’est ce que font tous les autres ». OkCupid a décrit une expérimentation dans laquelle a été manipulé le pourcentage de « compatibilité » montré à des paires d’utilisateurs. Quand on affichait un taux de 90 % entre deux utilisateurs qui en fait étaient peu compatibles, les utilisateurs échangeaient nettement plus de messages entre eux. OkCupid a déclaré que quand elle « dit aux gens » qu’ils « vont bien ensemble », alors ils « agissent comme si c’était le cas ».
Toutes ces expériences qui posent de vraies questions éthiques montrent le pouvoir de la personnalisation basée sur les données pour influer sur les comportements.
Dans les mailles du filet : vie quotidienne, données commerciales et analyse du risque
Les données concernant les comportements des personnes, les liens sociaux, et les moments les plus intimes sont de plus en plus utilisées dans des contextes ou à des fins complètement différents de ceux dans lesquels elles ont été enregistrées. Notamment, elles sont de plus en plus utilisées pour prendre des décisions automatisées au sujet d’individus dans des domaines clés de la vie tels que la finance, l’assurance et les soins médicaux.
Données relatives aux risques pour le marketing et la gestion client
Les agences d’évaluation de la solvabilité, ainsi que d’autres acteurs clés de l’évaluation du risque, principalement dans des domaines tels que la vérification des identités, la prévention des fraudes, les soins médicaux et l’assurance fournissent également des solutions commerciales. De plus, la plupart des courtiers en données s’échangent divers types d’informations sensibles, par exemple des informations concernant la situation financière d’un individu, et ce à des fins commerciales. L’utilisation de l’évaluation de solvabilité à des fins de marketing afin soit de cibler soit d’exclure des ensembles vulnérables de la population a évolué pour devenir des produits qui associent le marketing et la gestion du risque.
L’agence d’évaluation de la solvabilité TransUnion fournit, par exemple, un produit d’aide à la décision piloté par les données à destination des commerces de détail et des services financiers qui leur permet « de mettre en œuvre des stratégies de marketing et de gestion du risque sur mesure pour atteindre les objectifs en termes de clients, canaux de vente et résultats commerciaux », il inclut des données de crédit et promet « un aperçu inédit du comportement, des préférences et des risques du consommateur. » Les entreprises peuvent alors laisser leurs clients « choisir parmi une gamme complète d’offres sur mesure, répondant à leurs besoins, leurs préférences et leurs profils de risque » et « évaluer leurs clients sur divers produits et canaux de vente et leur présenter uniquement la ou les offres les plus pertinente pour eux et les plus rentables » pour l’entreprise. De même, Experian fournit un produit qui associe « crédit à la consommation et informations commerciales, fourni avec plaisir par Experian. »
En matière de surveillance, il n’est pas question de connaître vos secrets, mais de gérer des populations, de gérer des personnes.
Katarzyna Szymielewicz, Vice-Présidente EDRi, 2015
Vérification des identités en ligne et détection de la fraude
Outre la machine de surveillance en temps réel qui a été développée au travers de la publicité en ligne, d’autres formes de pistage et de profilage généralisées ont émergé dans les domaines de l’analyse de risque, de la détection de fraudes et de la cybersécurité.
De nos jours, les services de détection de fraude en ligne utilisent des technologies hautement intrusives afin d’évaluer des milliards de transactions numériques. Ils recueillent d’énormes quantités d’informations concernant les appareils, les individus et les comportements. Les fournisseurs habituels dans l’évaluation de solvabilité, la vérification d’identité, et la prévention des fraudes ont commencé à surveiller et à évaluer la façon dont les personnes surfent sur le web et utilisent leurs appareils mobiles. En outre, ils ont entrepris de relier les données comportementales en ligne avec l’énorme quantité d’information hors-connexion qu’ils recueillent depuis des dizaines d’années.
Avec l’émergence de services passant par l’intermédiaire d’objets technologiques, la vérification de l’identité des consommateurs et la prévention de la fraude sont devenues de plus en plus importantes et de plus en plus contraignantes, notamment au vu de la cybercriminalité et de la fraude automatisée. Dans un même temps, les systèmes actuels d’analyse du risque ont agrégé des bases de données gigantesques contenant des informations sensibles sur des pans entiers de population. Nombre de ces systèmes répondent à un grand nombre de cas d’utilisation, parmi lesquels la preuve d’identité pour les services financiers, l’évaluation des réclamations aux compagnies d’assurance et des demandes d’indemnités, de l’analyse des transactions financières et l’évaluation de milliards de transactions en ligne.
De tels systèmes d’analyse du risque peuvent décider si une requête ou une transaction est acceptée ou rejetée ou décider des options de livraison disponibles pour une personne lors d’une transaction en ligne. Des services marchands de vérification d’identité et d’analyse de la fraude sont également employés dans des domaines tels que les forces de l’ordre et la sécurité nationale. La frontière entre les applications commerciales de l’analyse de l’identité et de la fraude et celles utilisées par les agences gouvernementales de renseignement est de plus en plus floue.
Lorsque des individus sont ciblés par des systèmes aussi opaques, ils peuvent être signalés comme étant suspects et nécessitant un traitement particulier ou une enquête, ou bien ils peuvent être rejetés sans plus d’explication. Ils peuvent recevoir un courriel, un appel téléphonique, une notification, un message d’erreur, ou bien le système peut tout simplement ne pas indiquer une option, sans que l’utilisateur ne connaisse son existence pour d’autres. Des évaluations erronées peuvent se propager d’un système à l’autre. Il est souvent difficile, voire impossible de faire recours contre ces évaluations négatives qui excluent ou rejettent, notamment à cause de la difficulté de s’opposer à quelque chose dont on ne connaît pas l’existence.
Exemples de détection de fraude en ligne et de service d’analyse des risques
L’entreprise de cybersécurité ThreatMetrix traite les données concernant 1,4 milliard de « comptes utilisateur uniques » sur des « milliers de sites dans le monde. » Son Digital Identity Network (Réseau d’Identité Numérique) enregistre des « millions d’opérations faites par des consommateurs chaque jour, notamment des connexions, des paiements et des créations de nouveaux comptes », et cartographie les « associations en constante évolution entre les individus et leurs appareils, leurs positions, leurs identifiants et leurs comportements » à des fins de vérification des identités et de prévention des fraudes. L’entreprise collabore avec Equifax et TransUnion. Parmi ses clients se trouvent Netflix, Visa et des entreprises dans des secteurs tels que le jeu vidéo, les services gouvernementaux et la santé.
De façon analogue, l’entreprise de données ID Analytics, qui a récemment été achetée par Symantec, exploite un Réseau d’Identifiants fait de « 100 millions de nouveaux éléments d’identité quotidiens issus des principales organisations interprofessionnelles. ». L’entreprise agrège des données concernant 300 millions de consommateurs, sur les prêts à haut risque, les achats en ligne et les demandes de carte de crédit ou de téléphone portable. Son Indice d’Identité, ID Score, prend en compte les appareils numériques ainsi que les noms, les numéros de sécurité sociale et les adresses postales et courriel.
Trustev, une entreprise en ligne de détection de la fraude dont le siège se situe en Irlande et qui a été rachetée par l’agence d’évaluation de la solvabilité TransUnion en 2015, juge des transactions en ligne pour des clients dans les secteurs des services financiers, du gouvernement, de la santé et de l’assurance en s’appuyant sur l’analyse des comportements numériques, les identités et les appareils tels que les téléphones, les tablettes, les ordinateurs portables, les consoles de jeux, les télés et même les réfrigérateurs. L’entreprise propose aux entreprises clientes la possibilité d’analyser la façon dont les visiteurs cliquent et interagissent avec les sites Internets et les applications. Elle utilise une large gamme de données pour évaluer les utilisateurs, y compris les numéros de téléphone, les adresses courriel et postale, les empreintes de navigateur et d’appareil, les vérifications de la solvabilité, les historiques d’achats sur l’ensemble des vendeurs, les adresses IP, les opérateurs mobiles et la géolocalisation des téléphones. Afin d’aider à « accepter les transactions futures », chaque appareil se voit attribuer une empreinte digitale d’appareil unique. Trustev propose aussi une technologie de marquage d’empreinte digitale sociale qui analyse le contenu des réseaux sociaux, notamment une « analyse de la liste d’amis » et « l’identification des schémas ». TransUnion a intégré la technologie Trustev dans ses propres solutions identifiantes et anti-fraude.
Selon son site Internet, Trustev utilise une large gamme de données pour évaluer les personnes
Capture d’écran du site Internet de Trustev, 2 juin 2016
De façon similaire, l’agence d’évaluation de la solvabilité Equifax affirme qu’elle possède des données concernant près de 1 milliard d’appareils et peut affirmer « l’endroit où se situe en fait un appareil et s’il est associé à d’autres appareils utilisés dans des fraudes connues ». En associant ces données avec « des milliards d’identités et d’événements de crédit pour trouver les activités douteuses » dans tous les secteurs, et en utilisant des informations concernant la situation d’emploi et les liens entre les ménages, les familles et les partenaires, Equifax prétend être capable « de distinguer les appareils ainsi que les individus ».
Je ne suis pas un robot
Le produit reCaptcha de Google fournit en fait un service similaire, du moins en partie. Il est incorporé dans des millions de sites Internets et aide les fournisseurs de sites Internets à décider si un visiteur est un être humain ou non. Jusqu’à récemment, les utilisateurs devaient résoudre diverses sortes de défis rapides tels que le déchiffrage de lettres dans une image, la sélection d’images dans une grille, ou simplement en cochant la case « Je ne suis pas un robot ». En 2017, Google a présenté une version invisible de reCaptcha, en expliquant qu’à partir de maintenant, les utilisateurs humains pourront passer « sans aucune interaction utilisateur, contrairement aux utilisateurs douteux et aux robots ». L’entreprise ne révèle pas le type de données et de comportements utilisateurs utilisés pour reconnaître les humains. Des analyses laissent penser que Google, outre les adresses IP, les empreintes de navigateur, la façon dont l’utilisateur frappe au clavier, déplace la souris ou utilise l’écran tactile « avant, pendant et après » une interaction reCaptcha, utilise plusieurs témoins Google. On ne sait pas exactement si les individus sans compte utilisateur sont désavantagés, si Google est capable d’identifier des individus particuliers plutôt que des « humains » génériques, ou si Google utilise les données enregistrées par reCaptcha à d’autres fins que la détection de robots.
Le pistage numérique à des fins publicitaires et de détection de la fraude ?
Les flux omniprésents de données comportementales enregistrées pour la publicité en ligne s’écoulent vers les systèmes de détection de la fraude. Par exemple, la plateforme de données commerciales Segment propose à ses clients des moyens faciles d’envoyer des données concernant leurs clients, leur site Internet et les utilisateurs mobiles à une kyrielle de services de technologies commerciales, ainsi qu’à des entreprises de détection de fraude. Castle est l’une d’entre-elles et utilise « les données comportementales des consommateurs pour prédire les utilisateurs qui présentent vraisemblablement un risque en matière de sécurité ou de fraude ». Une autre entreprise, Smyte, aide à « prévenir les arnaques, les messages indésirables, le harcèlement et les fraudes par carte de crédit ».
La grande agence d’analyse de la solvabilité Experian propose un service de pistage multi-appareils qui fournit de la reconnaissance universelle d’appareils, sur mobile, Internet et les applications pour le marketing numérique. L’entreprise s’engage à concilier et à associer les « identifiants numériques existants » de leurs clients, y compris des « témoins, identifiants d’appareil, adresses IP et d’autres encore », fournissant ainsi aux commerciaux un « lien omniprésent, cohérent et permanent sur tous les canaux ».
La technologie d’identification d’appareils provient de 41st parameter (le 41e paramètre), une entreprise de détection de la fraude rachetée par Experian en 2013. En s’appuyant sur la technologie développée par 41st parameter, Experian propose aussi une solution d’intelligence d’appareil pour la détection de la fraude au cours des paiements en ligne. Cette solution qui « créé un identifiant fiable pour l’appareil et recueille des données appareil abondantes » « identifie en quelques millisecondes chaque appareil à chaque visite » et « fournit une visibilité jamais atteinte de l’individu réalisant le paiement ». On ne sait pas exactement si Experian utilise les mêmes données pour ses services d’identification d’appareils pour détecter la fraude que pour le marketing.
Cartographie de l’écosystème du pistage et du profilage commercial
Au cours des dernières années, les pratiques déjà existantes de surveillance commerciale ont rapidement muté en un large éventail d’acteurs du secteur privé qui surveillent en permanence des populations entières. Certains des acteurs de l’écosystème actuel de pistage et de profilage, tels que les grandes plateformes et d’autres entreprises avec un grand nombre de clients, tiennent une position unique en matière d’étendue et de niveau de détail de leurs profils de consommateurs. Néanmoins, les données utilisées pour prendre des décisions concernant les individus sur de nombreux sujets ne sont généralement pas centralisées en un lieu, mais plutôt assemblées en temps réel à partir de plusieurs sources selon les besoins.
Un large éventail d’entreprises de données et de services d’analyse en marketing, en gestion client et en analyse du risque recueillent, analysent, partagent et échangent de façon uniforme des données client et les associent avec des informations supplémentaires issues de milliers d’autres entreprises. Tandis que l’industrie des données et des services d’analyse fournissent les moyens pour déployer ces puissantes technologies, les entreprises dans de nombreuses industries contribuent à augmenter la quantité et le niveau de détail des données collectées ainsi que la capacité à les utiliser.
Cartographie de l’écosystème du pistage et du profilage commercial numérique
En plus des grandes plateformes en ligne et de l’industrie des données et des services d’analyse des consommateurs, des entreprises dans de nombreux secteurs ont rejoint les écosystèmes de pistage et de profilage numérique généralisé.
Google et Facebook, ainsi que d’autres grandes plateformes telles que Apple, Microsoft, Amazon et Alibaba ont un accès sans précédent à des données concernant les vies de milliards de personnes. Bien qu’ils aient des modèles commerciaux différents et jouent par conséquent des rôles différents dans l’industrie des données personnelles, ils ont le pouvoir de dicter dans une large mesure les paramètres de base des marchés numériques globaux. Les grandes plateformes limitent principalement la façon dont les autres entreprises peuvent obtenir leurs données. Ainsi, ils les obligent à utiliser les données utilisateur de la plateforme dans leur propre écosystème et recueillent des données au-delà de la portée de la plateforme.
Bien que les grandes multinationales de différents secteurs ayant des interactions fréquentes avec des centaines de millions de consommateurs soient en quelque sorte dans une situation semblable, elles ne font pas qu’acheter des données clients recueillies par d’autres, elles en fournissent aussi. Bien que certaines parties des secteurs des services financiers et des télécoms ainsi que des domaines sociétaux critiques tels que la santé, l’éducation et l’emploi soient soumis à une réglementation plus stricte dans la plupart des juridictions, un large éventail d’entreprises a commencé à utiliser ou fournissent des données aux réseaux actuels de surveillance commerciale.
Les détaillants et d’autres entreprises qui vendent des produits et services aux consommateurs vendent pour la plupart les données concernant les achats de leurs clients. Les conglomérats médiatiques et les éditeurs numériques vendent des données au sujet de leur public qui sont ensuite utilisées par des entreprises dans la plupart des autres secteurs. Les fournisseurs de télécoms et d’accès haut débit ont entrepris de suivre leurs clients sur Internet. Les grandes groupes de distribution, de médias et de télécoms ont acheté ou achètent des entreprises de données, de pistage et de technologie publicitaire. Avec le rachat de NBC Universal par Comcast et le rachat probable de Time Warner par AT&T, les grands groupes de télécoms aux États-Unis sont aussi en train de devenir des éditeurs gigantesques, créant par là même des portefeuilles puissants de contenu, de données et de capacité de pistage. Avec l’acquisition de AOL et de Yahoo, Verizon aussi est devenu une « plateforme ».
Les institutions financières ont longtemps utilisé des données sur les consommateurs pour la gestion du risque, notamment dans l’évaluation de la solvabilité et la détection de fraude, ainsi que pour le marketing, l’acquisition et la rétention de clientèle. Elles complètent leurs propres données avec des données externes issues d’agences d’évaluation de la solvabilité, de courtiers en données et d’entreprises de données commerciales. PayPal, l’entreprise de paiements en ligne la plus connue, partage des informations personnelles avec plus de 600 tiers, parmi lesquels d’autres fournisseurs de paiements, des agences d’évaluation de la solvabilité, des entreprises de vérification de l’identité et de détection de la fraude, ainsi qu’avec les acteurs les plus développés au sein de l’écosystème de pistage numérique. Tandis que les réseaux de cartes de crédit et les banques ont partagé des informations financières sur leurs clients avec les fournisseurs de données de risque depuis des dizaines d’années, ils ont maintenant commencé à vendre des données sur les transactions à des fins publicitaires.
Une myriade d’entreprises, grandes ou petites, fournissant des sites Internets, des applications mobiles, des jeux et d’autres solutions sont étroitement liées à l’écosystème de données commerciales. Elles utilisent des services qui leur permettent de facilement transmettre à des services tiers des données concernant leurs utilisateurs. Pour nombre d’entre elles, la vente de flux de données comportementales concernant leurs utilisateurs constitue un élément clé de leur business model. De façon encore plus inquiétante, les entreprises qui fournissent des services tels que les enregistreurs d’activité physique intègrent des services qui transmettent les données utilisateurs à des tierces parties.
L’envahissante machine de surveillance en temps réel qui a été développée pour la publicité en ligne est en train de s’étendre vers d’autres domaines dont la politique, la tarification, la notation des crédits et la gestion des risques. Partout dans le monde, les assureurs commencent à proposer à leurs clients des offres incluant du suivi en temps réel de leur comportement : comment ils conduisent, quelles sont leurs activités santé ou leurs achats alimentaires et quand ils se rendent au club de gym. Des nouveaux venus dans l’analyse assurantielle et les technologies financières prévoient les risques de santé d’un individu en s’appuyant sur les données de consommation, mais évaluent aussi la solvabilité à partir de données de comportement via les appels téléphoniques ou les recherches sur Internet.
Les courtiers en données sur les consommateurs, les entreprises de gestion de clientèle et les agences de publicité comme Acxiom, Epsilon, Merkle ou Wunderman/WPP jouent un rôle prépondérant en assemblant et reliant les données entre les plateformes, les multinationales et le monde de la technologie publicitaire. Les agences d’évaluation de crédit comme Experian qui fournissent de nombreux services dans des domaines très sensibles comme l’évaluation de crédit, la vérification d’identité et la détection de la fraude jouent également un rôle prépondérant dans l’actuel envahissant écosystème de la commercialisation des données.
Des entreprises particulièrement importantes qui fournissent des données, des analyses et des solutions logicielles sont également appelées « plateforme ». Oracle, un fournisseur important de logiciel de base de données est, ces dernières années, devenu un courtier en données de consommation. Salesforce, le leader sur le marché de la gestion de la relation client qui gère les bases de données commerciales de millions de clients qui ont chacun de nombreux clients, a récemment acquis Krux, une grande entreprise de données, connectant et combinant des données venant de l’ensemble du monde numérique. L’entreprise de logiciels Adobe joue également un rôle important dans le domaine des technologies de profilage et de publicité.
En plus, les principales grandes entreprises du conseil, de l’analyse et du logiciel commercial, comme IBM, Informatica, SAS, FICO, Accenture, Capgemini, Deloitte et McKinsey et même des entreprises spécialisées dans le renseignement et la défense comme Palantir, jouent également un rôle significatif dans la gestion et l’analyse des données personnelles, de la gestion de la relation client à celle de l’identité, du marketing à l’analyse de risque pour les assureurs, les banques et les gouvernements.
Vers une société du contrôle social numérique généralisé ?
Ce rapport montre qu’aujourd’hui, les réseaux entre plateformes en ligne, fournisseurs de technologies publicitaires, courtiers en données, et autres peuvent suivre, reconnaître et analyser des individus dans de nombreuses situations de la vie courante. Les informations relatives aux comportements et aux caractéristiques d’un individu sont reliées entre elles, assemblées, et utilisées en temps réel par des entreprises, des bases de données, des plateformes, des appareils et des services. Des acteurs uniquement motivés par des buts économiques ont fait naître un environnement de données dans lequel les individus sont constamment sondés et évalués, catégorisés et regroupés, notés et classés, numérotés et comptés, inclus ou exclus, et finalement traités de façon différente.
Ces dernières années, plusieurs évolutions importantes ont donné de nouvelles capacités sans précédent à la surveillance omniprésente par les entreprises. Cela comprend l’augmentation des médias sociaux et des appareils en réseau, le pistage et la mise en relation en temps réel de flux de données comportementales, le rapprochement des données en ligne et hors ligne, et la consolidation des données commerciales et de gestion des risques. L’envahissant pistage et profilage numériques, mélangé à la personnalisation et aux tests, ne sont pas seulement utilisés pour surveiller, mais aussi pour influencer systématiquement le comportement des gens. Quand les entreprises utilisent les données sur les situations du quotidien pour prendre des décisions parfois triviales, parfois conséquente sur les gens, cela peut conduire à des discriminations, et renforcer voire aggraver des inégalités existantes.
Malgré leur omniprésence, seul le haut de l’iceberg des données et des activités de profilage est visible pour les particuliers. La plupart d’entre elles restent opaques et à peine compréhensible par la majorité des gens. Dans le même temps, les gens ont de moins en moins de solutions pour résister au pouvoir de cet ecosystème de données ; quitter le pistage et le profilage envahissant, est devenu synonyme de quitter la vie moderne. Bien que les responsables des entreprises affirment que la vie privée est morte (tout en prenant soin de préserver leur propre vie privée), Mark Andrejevic suggère que les gens perçoivent en fait l’asymétrie du pouvoir dans le monde numérique actuel, mais se sentent « frustrés par un sentiment d’impuissance face à une collecte et à une exploitation de données de plus en plus sophistiquées et exhaustives. »
Au regard de cela, ce rapport se concentre sur le fonctionnement interne et les pratiques en vigueur dans l’actuelle industrie des données personnelles. Bien que l’image soit devenue plus nette, de larges portions du système restent encore dans le noir. Renforcer la transparence sur le traitement des données par les entreprises reste un prérequis indispensable pour résoudre le problème de l’asymétrie entre les entreprises de données et les individus. Avec un peu de chance, les résultats de ce rapport encourageront des travaux ultérieurs de la part de journalistes, d’universitaires, et d’autres personnes concernés par les libertés civiles, la protection des données et celle des consommateurs ; et dans l’idéal des travaux des législateurs et des entreprises elles-mêmes.
En 1999, Lawrence Lessig, avait bien prédit que, laissé à lui-même, le cyberespace, deviendrait un parfait outil de contrôle façonné principalement par la « main invisible » du marché. Il avait dit qu’il était possible de « construire, concevoir, ou programmer le cyberespace pour protéger les valeurs que nous croyons fondamentales, ou alors de construire, concevoir, ou programmer le cyberespace pour permettre à toutes ces valeurs de disparaître. » De nos jours, la deuxième option est presque devenue réalité au vu des milliards de dollars investis dans le capital-risque pour financer des modèles économiques s’appuyant sur une exploitation massive et sans scrupule des données. L’insuffisance de régulation sur la vie privée aux USA et l’absence de son application en Europe ont réellement gêné l’émergence d’autres modèles d’innovation numérique, qui seraient fait de pratiques, de technologies, de modèles économiques qui protègent la liberté, la démocratie, la justice sociale et la dignité humaine.
À un niveau plus global, la législation sur la protection des données ne pourra pas, à elle seule, atténuer les conséquences qu’un monde « conduit par les données » a sur les individus et la société que ce soit aux USA ou en Europe. Bien que le consentement et le choix soient des principes cruciaux pour résoudre les problèmes les plus urgents liés à la collecte massive de données, ils peuvent également mener à une illusion de volontarisme. En plus d’instruments de régulation supplémentaires sur la non-discrimination, la protection du consommateur, les règles de concurrence, il faudra en général un effort collectif important pour donner une vision positive d’une future société de l’information. Sans quoi, on pourrait se retrouver bientôt dans une société avec un envahissant contrôle social numérique, dans la laquelle la vie privée deviendrait, si elle existe encore, un luxe pour les riches. Tous les éléments en sont déjà en place.
La production de ce rapport, matériaux web et illustrations a été soutenue par Open Society Foundations.
Bibliographie
Christl, W. (2017, juin). Corporate surveillance in everyday life. Cracked Labs.
Christl, W., & Spiekermann, S. (2016). Networks of Control, a Report on Corporate Surveillance, Digital Tracking, Big Data & Privacy (p. 14‑20). Consulté à l’adresse https://www.privacylab.at/wp-content/uploads/2016/09/Christl-Networks__K_o.pdf
Epp, C., Lippold, M., & Mandryk, R. L. (2011). Identifying emotional states using keystroke dynamics (p. 715). ACM Press. https://doi.org/10.1145/1978942.1979046
Kosinski, M., Stillwell, D., & Graepel, T. (2013). Private traits and attributes are predictable from digital records of human behavior. Proceedings of the National Academy of Sciences, 110(15), 5802‑5805. https://doi.org/10.1073/pnas.1218772110
Turow, J. (s. d.). Daily You | Yale University Press. Consulté 25 septembre 2017, à l’adresse https://yalebooks.yale.edu/book/9780300188011/daily-you
Décodons le discours anti-chiffrement
La secrétaire d’État à l’Intérieur du Royaume-Uni demandait fin juillet aux entreprises du numérique de renoncer au chiffrement de bout en bout. Aral Balkan a vivement réagi à ses propos.
L’intérêt de son analyse sans concessions n’est ni anecdotique ni limité au Royaume-Uni. Il s’agit bien de décoder le discours contre le chiffrement dont on abreuve les médias majeurs, que ce soit outre-Manche ou ici même en France, comme presque partout ailleurs en Europe. Un discours qui repose sur le terrorisme comme épouvantail et sur Internet comme bouc-émissaire. Alors que s’empilent des lois répressives qui rendent légale une surveillance de tous de plus en plus intrusive, sans pour autant hélas éradiquer le terrorisme, il est urgent de dénoncer avec force et publiquement la manipulation des esprits par le discours sécuritaire. Il en va de notre liberté.
Ce travail qu’assument courageusement des associations comme la Quadrature du Net et que nous devons tous soutenir est ici plutôt bien mené par Aral Balkan qui « traduit » les déclarations de la ministre pour ce qu’elles signifient réellement : l’appel à la collusion entre le capitalisme de surveillance et le contrôle étatique de la vie de chacun.
Article original paru sur le blog d’Aral Balkan : Decrypting Amber Rudd Traduction Framalang : hello, mo, FranBAG, goofy, Éric, Bromind, Lumibd, audionuma, karlmo, Todd
où elle déclare en substance qu’elle n’a pas besoin de connaître les technologies comme le chiffrement pour… les interdire !
Amber Rudd entre les lignes
par Aral Balkan
Facebook, Microsoft, Twitter et YouTube (Google/Alphabet, Inc) viennent de créer le Forum Internet Global Contre le Terrorisme et Amber Rudd, la ministre de l’Intérieur britannique, leur demande de renoncer discrètement à assurer le chiffrement de bout en bout de leurs produits. Ne croyez plus un traître mot de ce que ces entreprises racontent sur le chiffrement de bout en bout ou le respect de la vie privée sur leurs plateformes. PS : WhatsApp appartient à Facebook.
Amber Rudd : « les discussions entre les entreprises IT et le gouvernement… doivent rester confidentielles. » Crédit photo : The Independent
Ruddement fouineuse
La tribune sur le chiffrement qu’Amber Rudd a fait paraître dans le Telegraph (article en anglais, payant) est tellement tordue qu’elle a de quoi donner le vertige à une boule de billard. Il est évident que Rudd (célèbre pour avoir un jour confondu le concept cryptographique de hachage avec les hashtags) est tout sauf naïve sur ce sujet. Elle est mal intentionnée.
Étant donné l’importance de ce qui est en jeu (rien moins que l’intégrité de la personne à l’ère numérique et l’avenir de la démocratie en Europe), je voudrais prendre un moment pour disséquer son article et y répondre point par point.
Petit spoiler pour ceux qui manquent de temps : la partie la plus inquiétante de son article est la deuxième, dans laquelle elle révèle qu’elle a créé le Forum Internet Global Contre le Terrorisme avec Facebook, Microsoft, Twitter et YouTube (Google/Alphabet, Inc.), et qu’elle leur a demandé de supprimer le chiffrement de bout en bout de leurs produits (souvenez vous que c’est Facebook qui détient WhatsApp) sans prévenir personne. Cela a de graves conséquences sur ce que l’on peut attendre de la protection contre la surveillance étatique sur ces plateformes. Si vous n’avez pas le temps de tout lire, n’hésitez pas à sauter directement à la partie II.
Partie I : entente public-privé ; surveillance de masse et contrôle traditionnel.
Amber commence par poser une équivalence entre la lutte contre la propagande publique en ligne des organisations terroristes et la nécessité d’accéder aux communications privées de la population dans son ensemble. Elle prône aussi la surveillance de masse, dont nous savons qu’elle est inefficace, et reste étrangement silencieuse sur la police de proximité, dont nous savons qu’elle est efficace.
Rudd : Nous ne cherchons pas à interdire le chiffrement, mais si nous sommes dans l’impossibilité de voir ce que préparent les terroristes, cela met en danger notre sécurité.
Traduction : Nous voulons interdire le chiffrement parce que si nous le faisons nous serons mieux armés pour attraper les terroristes.
En raison de la très faible occurrence des attaques terroristes, les faux positifs submergent complètement le système, quel qu’en soit le degré de précision. Et quand je dis « complètement », je n’exagère pas : pour chacun des complots terroristes détectés par le système, si tant est qu’il en découvre jamais, des millions de gens seront accusés à tort.
Si vous n’êtes toujours pas convaincu et pensez que le gouvernement britannique devrait avoir le droit d’espionner tout un chacun, ne vous inquiétez pas : il le fait déjà. Il a le pouvoir de contraindre les entreprises IT à introduire des portes dérobées dans tous les moyens de communication grâce à l’Investigatory Powers Act (d’abord connu sous le nom de projet de loi IP et plus familièrement appelé charte des fouineurs). Peut-être n’avez-vous jamais entendu parler de cette loi car elle est passée relativement inaperçue et n’a pas suscité d’opposition dans les rangs du parti travailliste.
Toujours est-il que vos droits sont déjà passés à la trappe. Amber Rudd s’occupe maintenant de désamorcer vos réactions pour le jour où ils décideront d’appliquer les droits qu’ils ont déjà.
Rudd : Les terribles attentats terroristes de cette année confirment que les terroristes utilisent les plateformes Internet pour répandre leur détestable idéologie et planifier des attaques.
Traduction : Nous voulons faire d’internet un bouc émissaire, en faire la source de nos problèmes avec le terrorisme.
Les chercheurs spécialisés dans le terrorisme ont remarqué que la violence en Europe et au Royaume-Uni suit un schéma classique. Cela peut donner des clés aux gouvernements pour contrer le problème, à condition d’allouer les crédits et les ressources là où ils sont le plus utiles. La plupart des djihadistes européens sont de jeunes musulmans, souvent masculins, vivant dans des quartiers pauvres défavorisés où le taux de chômage est élevé. Ils sont souvent de la deuxième ou troisième génération de migrants, issus de pays où ils n’ont jamais vécu ; ils ne sont pas bien intégrés dans la société ; quand ils ne sont pas au chômage, leur niveau d’éducation est faible. Leurs vies sont dépourvues de sens, de but.
Rudd déroule son argument :
Rudd : Le numérique est présent dans quasi tous les complots que nous mettons au jour. En ligne, vous pouvez trouver en un clic de souris votre propre set du « parfait petit djihadiste. » Les recruteurs de Daesh (État islamique) déploient leurs tentacules jusque dans les ordinateurs portables des chambres de garçons (et, de plus en plus souvent, celles des filles), dans nos villes et nos cités, d’un bout à l’autre du pays. Les fournisseurs d’extrémisme de droite abreuvent la planète de leur marque de haine sans jamais avoir à sortir de chez eux.
Tous les exemples qui précèdent concernent des informations publiques librement accessibles en ligne. Pas besoin de portes dérobées, pas besoin de fragiliser le chiffrement pour que les services judiciaires y aient accès. Tout l’intérêt, justement, c’est qu’elles soient faciles à trouver et à lire. La propagande n’aurait pas beaucoup d’intérêt si elle restait cachée.
Rudd : On ne saurait sous-estimer l’ampleur du phénomène.
Traduction : Il est impossible d’exagérer davantage l’ampleur du phénomène.
Vous vous souvenez qu’on court davantage de risques de mourir en tombant de son lit qu’en tombant aux mains d’un terroriste ? Tout est dit.
Premièrement, l’article du Telegraph dont Amber Rudd fournit le lien ne fait nulle part mention de vidéos extrémistes que Khalid Masood aurait regardées (que ce soit en ligne, sur le Web, grâce à un quelconque service chiffré, ni où que ce soit d’autre). Peut-être Rudd s’imaginait-elle que personne ne le lirait pour vérifier. À vrai dire, en cherchant sur le Web, je n’ai pas pu trouver un seul article qui mentionne des vidéos extrémistes visionnées par Khalid Massood. Et même si c’était le cas, ce ne serait qu’un exemple de plus de contenu public auquel le gouvernement a accès sans l’aide de portes dérobées et sans compromettre le chiffrement.
On se heurte régulièrement au problème de l’analyse et de la hiérarchisation des informations déjà amassées. Il n’est plus rare d’apprendre qu’un terroriste était déjà connu des services de police et de renseignement. C’était le cas des kamikazes du 7 juillet 2005 à Londres, Mohammed Siddique Khan et Shezhad Tanweer, et de certains des présumés coupables des attentats de Paris, Brahim Abdeslam, Omar Ismail Mostefai et Samy Amimour.
Rudd: Daesh prétend avoir ouvert 11000 nouveaux comptes sur les réseaux sociaux durant le seul mois de mai dernier. Notre analyse montre que trois quarts des récits de propagande de Daesh sont partagés dans les trois heures qui suivent leur publication – une heure de moins qu’il y a un an.
Une fois encore, ce sont des comptes publics. Utilisés à des fins de propagande. Les messages ne sont pas chiffrés et les portes dérobées ne seraient d’aucun secours.
Rudd: Souvent, les terroristes trouvent leur public avant que nous ayons le temps de réagir.
Les forces de l’ordre ont du mal à gérer le nombre de suspects recherchés. Le HMIC (NDLT : police des polices anglaise) s’est rendu compte que 67000 suspects recherchés n’avaient pas été enregistrés dans le PNC (Police National Computer, le fichier national de la police). En outre, à la date d’août 2017, le PNC comptait 45960 suspects, où figurent pêle-mêle ceux qui sont recherchés pour terrorisme, pour meurtre et pour viol.
Au lieu de se concentrer là-dessus, Amber cherche à détourner notre attention sur le Grand Méchant Internet. Quand on parle du loup…
Rudd : L’ennemi connecté est rapide. Il est impitoyable. Il cible les faibles et les laissés-pour-compte. Il utilise le meilleur de l’innovation à des fins on ne peut plus maléfiques.
Grandiloquence ! Hyperbole ! Sensationnalisme !
Tremblez… tremblez de peur…
(Non merci, sans façon.)
Rudd : C’est pour cela que j’ai réuni les entreprises IT en mars : pour commencer à réfléchir à la façon de renverser la vapeur. Elles comprennent les enjeux.
De quelles entreprises Internet s’agit-il, Amber ? Serait-ce par hasard celles qui suivent, analysent et monnaient déjà nos moindres faits et gestes ? Les mêmes qui, jour après jour, sapent notre droit à la vie privée ? Un peu, qu’elles comprennent les enjeux ! C’est leur business. Pour reprendre la fameuse analyse de Bruce Schneier : « La NSA ne s’est pas tout à coup réveillée en se disant « On n’a qu’à espionner tout le monde ». Ils ont regardé autour d’eux et se sont dit : « Waouh, il y a des entreprises qui fliquent tout le monde. Il faut qu’on récupère une copie des données. » »
Ne vous méprenez pas, Google et Facebook (pour prendre deux des plus gros siphonneurs de données perso) se contrefichent de notre vie privée, tout autant que Rudd. Mais ce que réclame Amber, c’est de pouvoir taper gratuitement dans leur butin (et le butin, pour eux, ce sont nos données). Ils n’apprécient pas forcément, mais on les a déjà vus s’en accommoder s’il le faut.
Ce qui est plus grave, c’est que la requête de Rudd exclut l’existence même de services qui cherchent vraiment à protéger notre vie privée : les outils de communication chiffrée de bout en bout comme Signal, par exemple ; ou les outils de communication décentralisés comme Tox.chat.
Rudd : Grâce au travail accompli avec la cellule anti-terroriste du gouvernement, nous avons pu dépublier 280000 documents à caractère terroriste depuis 2010 et fermer des millions de comptes.
Ok, donc, si je comprends bien, Amber, ce que vous nous expliquez, c’est que les mesures que vous prenez en collaboration avec les entreprises IT pour lutter contre la propagande publique des organisations terroristes fonctionnent bien. Le tout sans le moindre besoin de compromettre le chiffrement ou d’implémenter des portes dérobées dans les systèmes de communication. Mais continuez donc comme ça !
Rudd : Mais il y a bien plus à faire. Voilà pourquoi, lors de la réunion de mars dernier, les entreprises IT les plus puissantes de la planète se sont portées volontaires pour créer le Forum Internet Global Contre le Terrorisme.
Les multinationales n’ont pas à fliquer les citoyens du monde, ce n’est pas leur rôle. Elles aimeraient bien amasser encore plus de données et de renseignements sur la population mondiale, légitimer les structures de surveillance déjà en place et exercer un contrôle encore plus grand. Ça va sans dire. Mais c’est cet avenir que nous devons à tout prix éviter.
Sous prétexte de nous préserver d’un risque statistiquement négligeable, ce qui est envisagé est un panoptique mondial sans précédent. Dans un tel système, nous pourrons dire adieu à nos libertés individuelles (la liberté de parole, le droit à la vie privée…) et à notre démocratie.
Rudd : Le Forum se réunit aujourd’hui pour la première fois et je suis dans la Silicon Valley pour y assister.
Non seulement vous plaidez pour que les entreprises privées s’acoquinent avec les gouvernements pour jouer un rôle actif dans le flicage des citoyens ordinaires, mais vous faites appel à des entreprises américaines, ce qui revient à donner un sceau d’approbation officiel à l’implication d’entreprises étrangères dans le flicage des citoyens britanniques. (Merkel et Macron ont l’intention de saper les droits des citoyens européens de la même façon si on les laisse faire.)
Rudd : Les entreprises IT veulent aller plus vite et plus loin dans la mise au point de solutions technologiques susceptibles d’identifier, de faire disparaître, d’endiguer la diffusion de contenus extrémistes.
Soit ! Mais ça ne nécessite toujours pas de portes dérobées ni de chiffrement moins performant. Encore une fois, il s’agit de contenus publics.
Il faudrait un jour prendre le temps de débattre beaucoup plus longuement de qui est habilité à décréter qu’un contenu est extrémiste, et de ce qui arrive quand les algorithmes se plantent et stigmatisent quelqu’un à tort comme auteur de propos extrémistes en laissant sous-entendre que cette personne est extrémiste alors qu’elle ne l’est pas.
À l’heure actuelle, ce sont des entreprises américaines qui définissent ce qui est acceptable ou pas sur Internet. Et le problème est bien plus vaste que ça : il nous manque une sphère publique numérique, puisque les Facebook et autres Google de la planète sont des espaces privés (pas publics) – ce sont des centres commerciaux, pas des parcs publics.
Rudd : Leur attitude mérite félicitations mais ils doivent également savoir que nous leur demanderons des comptes. Cependant notre défi ne se limite pas à cela. Car au-delà des contenus pernicieux auxquels tout le monde a accès, il y a ceux que nous ne voyons pas, ceux qui sont chiffrés.
Ah, nous y voilà ! Après avoir consacré la moitié de l’article au combat victorieux du gouvernement contre l’expansion en ligne de la propagande publique des organisations terroristes, Rudd passe à son dada : la nécessité d’espionner les communications privées en ligne de chaque citoyen pour garantir notre sécurité.
Partie II : la guerre contre le chiffrement de bout en bout avec la complicité de Facebook, Microsoft, Twitter et YouTube (Google/Alphabet, Inc.)
C’est là qu’il faut prendre un siège si vous êtes sujet au vertige car Mme Rudd va faire mieux qu’un derviche tourneur. Elle va également lâcher une bombe qui aura de graves répercussions sur votre vie privée si vous êtes adeptes des services fournis par Facebook, Microsoft, Twitter ou YouTube (Google/Alphabet, Inc.)
Parfaitement, Amber. La discussion devrait s’arrêter là. Il n’y a pas de « mais » qui tienne.
Mais …
Rudd : Mais, comme beaucoup d’autres technologies efficaces, les services de chiffrement sont utilisés et détournés par une petite minorité d’utilisateurs.
Oui, et donc ?
Rudd : Il existe un enjeu particulier autour de ce qu’on appelle le « chiffrement de bout en bout » qui interdit même au fournisseur de service d’accéder au contenu d’une communication.
Le chiffrement de bout en bout a aussi un autre nom : le seul qui protège votre vie privée à l’heure actuelle (au moins à court terme, jusqu’à ce que la puissance de calcul soit démultipliée de façon exponentielle ou que de nouvelles vulnérabilités soient découvertes dans les algorithmes de chiffrement).
Incidemment, l’autre garant important de la vie privée, dont on parle rarement, est la décentralisation. Plus nos données privées échappent aux silos de centralisation, plus le coût de la surveillance de masse augmente – exactement comme avec le chiffrement.
Rudd : Que ce soit bien clair : le gouvernement soutient le chiffrement fort et n’a pas l’intention d’interdire le chiffrement de bout en bout.
Ah bon, alors est-ce qu’on peut en rester là et rentrer chez nous maintenant … ?
Rudd : Mais l’impossibilité d’accéder aux données chiffrées dans certains cas ciblés et bien particuliers (même avec un mandat signé par un ministre et un haut magistrat) constitue un obstacle de taille dans la lutte anti-terroriste et la traduction en justice des criminels.
Oui, mais c’est la vie. On ne peut pas avoir le beurre et l’argent du beurre.
Rudd : Je sais que certains vont soutenir qu’on ne peut pas avoir le beurre et l’argent du beurre, que si un système est chiffré de bout en bout, il est à jamais impossible d’accéder au contenu d’une communication. C’est peut-être vrai en théorie. Mais la réalité est différente.
Vrai en théorie ? Mme Rudd, c’est vrai en théorie, en pratique, ici sur Terre, sur la Lune et dans l’espace. C’est vrai, point final.
« Mais la réalité est différente », ce doit être la glorieuse tentative d’Amber Rudd pour battre le premier ministre australien, Malcolm Turnbull, dans la course aux âneries sur le chiffrement . M. Turnbull a en effet récemment fait remarquer que « les lois mathématiques sont tout à fait estimables, mais que la seule loi qui s’applique en Australie est la loi australienne. »
Turnbull et Rudd, bien sûr, suivent la même partition. C’est aussi celle que suivent May, Merkel et Macron. Et, après sa remarque illogique, Turnbull a laissé entendre de quelle musique il s’agit quand il a ajouté : « Nous cherchons à nous assurer de leur soutien. » (« leur », en l’occurrence, fait référence aux entreprises IT).
Rudd développe son idée dans le paragraphe qui suit :
Rudd : Dans la vraie vie, la plupart des gens sont prêts à troquer la parfaite inviolabilité de leurs données contre une certaine facilité d’utilisation et un large éventail de fonctionnalités. Il ne s’agit donc pas de demander aux entreprises de compromettre le chiffrement ou de créer de prétendues « portes dérobées ». Qui utilise WhatsApp parce qu’il est chiffré de bout en bout ? On l’utilise plutôt que parce que c’est un moyen incroyablement convivial et bon marché de rester en contact avec les amis et la famille. Les entreprises font constamment des compromis entre la sécurité et la « facilité d’utilisation » et c’est là que nos experts trouvent des marges de manœuvres possibles.
Traduction : Ce que nous voulons, c’est que les entreprises n’aient pas recours au chiffrement de bout en bout.
Voilà donc la pierre angulaire de l’argumentaire de Rudd : les entreprises IT devraient décider d’elles-mêmes de compromettre la sécurité et la protection de la vie privée de leurs usagers, en n’implémentant pas le chiffrement de bout en bout. Et, pour faire bonne mesure, détourner l’attention des gens en créant des services pratiques et divertissants.
Inutile de préciser que ce n’est pas très loin de ce que font aujourd’hui les entreprises de la Silicon Valley qui exploitent les données des gens. En fait, ce que dit Rudd aux entreprises comme Facebook et Google, c’est : « Hé, vous appâtez déjà les gens avec des services gratuits pour pouvoir leur soutirer des données. Continuez, mais faites en sorte que nous aussi, nous puissions accéder à la fois aux métadonnées et aux contenus de leurs communications. Ne vous inquiétez pas, ils ne s’en apercevront pas, comme ils ne se rendent pas compte aujourd’hui que vous leur offrez des bonbons pour mieux les espionner. »
De même, l’argument de l’indispensable « compromis entre la sécurité et la facilité d’utilisation » relève d’un choix fallacieux. Une nouvelle génération d’apps sécurisées et respectueuses de la vie privée, comme Signal, prouvent qu’un tel compromis n’est pas nécessaire. En fait c’est Rudd, ici, qui perpétue ce mythe à dessein et incite les entreprises IT à s’en servir pour justifier leur décision d’exposer leurs usagers à la surveillance gouvernementale.
Pas besoin de réfléchir bien longtemps pour se rendre compte que l’argumentation d’Amber s’écroule d’elle-même. Elle demande « Qui utilise WhatsApp parce que c’est chiffré de bout en bout et non parce que c’est un moyen incroyablement convivial et bon marché de rester en contact avec les amis et la famille ? » Retournons-lui la question : « Qui s’abstient d’utiliser WhatsApp aujourd’hui sous prétexte que le chiffrement de bout en bout le rendrait moins convivial ? » (Et, tant que nous y sommes, n’oublions pas que Facebook, propriétaire de Whatsapp, fait son beurre en récoltant le plus d’informations possible sur vous et en exploitant cet aperçu de votre vie privée pour satisfaire son avidité financière et ses objectifs politiques. N’oublions pas non plus que les métadonnées – interlocuteurs, fréquence et horaires des appels – ne sont pas chiffrées dans WhatsApp, que WhatsApp partage ses données avec Facebook et que votre profil de conversation et votre numéro de téléphone sont liés à votre compte Facebook.`
Rudd : Donc, nous avons le choix. Mais ces choix seront le fruit de discussions réfléchies entre les entreprises IT et le gouvernement – et ils doivent rester confidentiels.
Traduction : Quand les entreprises supprimeront le chiffrement de bout en bout de leurs produits, nous ne souhaitons pas qu’elles en avertissent leurs usagers.
Voilà qui devrait vous faire froid dans le dos.
Les services dont Amber Rudd parle (comme WhatsApp) sont des applications propriétaires dont le code source est privé. Cela signifie que même d’autres programmeurs n’ont aucune idée précise de ce que font ces services (même si certaines techniques de rétro-ingénierie permettent d’essayer de le découvrir). Si la plupart des gens font confiance au chiffrement de bout en bout de WhatsApp c’est qu’un cryptographe très respecté du nom de Moxie Marlinspikel’a implémenté et nous a dit qu’il n’y avait pas de problème. Or, le problème avec les applications, c’est qu’elles peuvent être modifiées en un clin d’œil… et qu’elles le sont. WhatsApp peut très bien supprimer le chiffrement de bout en bout de ses outils demain sans nous en avertir et nous n’en saurons rien. En fait, c’est précisément ce que demande Amber Rudd à Facebook et compagnie.
À la lumière de ces informations, il y a donc deux choses à faire :
Regardez quelles entreprises participent au Forum Internet Global Contre le Terrorisme et cessez de croire un traître mot de ce qu’elles disent sur le chiffrement et les garanties de protection de la vie privée qu’offrent leurs produits. Ces entreprises sont Facebook, Microsoft, Twitter et YouTube (Google/Alphabet, Inc.)
Les experts en sécurité informatique ne doivent pas se porter garants du chiffrement de bout en bout de ces produits sauf s’ils peuvent s’engager à vérifier individuellement chaque nouvelle version exécutable. Pour limiter la casse, les individus comme Moxie Marlinspike, qui a pu se porter garant d’entreprises comme Facebook et WhatsApp, doivent publiquement prendre leurs distances par rapport à ces entreprises et les empêcher de devenir complices de la surveillance gouvernementale. Il suffit d’une seule compilation de code pour supprimer discrètement le chiffrement de bout en bout, et c’est exactement ce que souhaite Amber Rudd.
Rudd : Ce qu’il faut bien comprendre c’est qu’il ne s’agit pas de compromettre la sécurité en général.
Ces actions compromettraient totalement la vie privée et la sécurité des militants et des groupes les plus vulnérables de la société.
Rudd : Il s’agit travailler ensemble pour que, dans des circonstances bien particulières, nos services de renseignement soient en mesure d’obtenir plus d’informations sur les agissements en ligne de grands criminels et de terroristes.
Une fois encore, ni la suppression du chiffrement de bout en bout ni la mise en place de portes dérobées ne sont nécessaires pour combattre le terrorisme. Si Rudd veut arrêter des terroristes, elle devrait plutôt cesser de raboter le budget de la police de proximité, le seul moyen qui ait fait ses preuves. Je me demande si Rudd se rend seulement compte qu’en appelant à la suppression du chiffrement de bout en bout dans les outils de communications en ligne, ce qu’elle fait en réalité, c’est exposer le contenu des communications de tout un chacun à la surveillance continue par – au minimum – les fournisseurs et les hébergeurs de ces services. Sans parler du fait que ces communications peuvent être manipulées par d’autres acteurs peu recommandables, y compris des gouvernements étrangers ennemis.
Rudd : Parer à cette menace à tous les niveaux relève de la responsabilité conjointe des gouvernements et des entreprises. Et nous avons un intérêt commun : nous voulons protéger nos citoyens et ne voulons pas que certaines plateformes puissent servir à planifier des attaques contre eux. La réunion du Forum qui a lieu aujourd’hui est un premier pas dans la réalisation de cette mission.
Je n’ai rien de plus à ajouter, pas plus que Rudd.
Pour conclure, je préfère insister sur ce que j’ai déjà dit :
Ce que souhaite Amber Rudd ne vous apportera pas plus de sécurité. Ça ne vous protégera pas des terroristes. Ça permettra aux gouvernements d’espionner plus facilement les militants et les minorités. Ça compromettra la sécurité de tous et aura des effets glaçants, dont la destruction du peu de démocratie qui nous reste. Ça nous conduira tout droit à un État Surveillance et à un panoptique mondial, tels que l’humanité n’en a jamais encore connu.
Quant aux entreprises membres du Forum Internet Global Contre le Terrorisme (Facebook, Microsoft, Twitter et YouTube (Google/Alphabet, Inc.) – il faudrait être fou pour croire ce qu’elles disent du chiffrement de bout en bout sur leur plateformes ou des fonctionnalités « vie privée » de leurs apps. Vu ce qu’a dit Amber Rudd, sachez désormais que le chiffrement de bout en bout dont elles se targuent aujourd’hui peut être désactivé et compromis à tout moment lors d’une prochaine mise à jour, et que vous n’en serez pas informés.
Vu ce qu’a dit Amber Rudd et ce que nous savons à présent du Forum Internet Global Contre le Terrorisme, continuer à recommander WhatsApp comme moyen de communication sécurisé à des militants et à d’autres groupes vulnérables est profondément irresponsable et menace directement le bien-être, voire peut-être la vie, de ces gens.
P.S. Merci pour ce beau travail, Amber. Espèce de marionnette !
(Un grand merci, non ironique cette fois, à Laura Kalbag pour sa relecture méticuleuse et ses corrections.)
À propos de l’auteur
Aral Balkan est militant, designer et développeur. Il représente ⅓ de Ind.ie, une petite entreprise sociale œuvrant à la justice sociale à l’ère du numérique.
Contacter Aral Balkan
Email(pour les questions urgentes, merci de mettre laura@ind.ie en CC)
En 2015, après une longue période d’hésitation, j’ai sauté le pas. J’ai décidé que Google, Facebook ou encore Microsoft seraient pour moi des connaissances lointaines, et non des compagnons de route.
On a du mal à croire qu’il soit possible d’envisager sérieusement une telle transformation sans se couper du monde et du confort que nous offre le Web. Pourtant, ça l’est.
Nous sommes en juillet 2017. Ça fait deux ans. J’ai mes repères, mes marques et aucune sensation de manque. Lorsque je choisis de faire une entorse à mes principes et d’utiliser Google, ou de démarrer mon PC sous Windows, c’est une option ; j’ai toujours le choix. Je crois que c’est ça, l’idée : avoir le choix. La décentralisation, ce n’est pas juste quitter le navire : c’est choisir sur lequel on embarque en connaissance de cause.
Depuis 2015, alors que la moitié du marché des smartphones est contrôlé par Google et son système d’exploitation Android, que tout le monde connaît GMail, utilise Google Docs, se localise avec Google Maps et partage des choses sur Google+ (lol nope), je n’utilise pas tout cela. Ou plutôt, je n’utilise plus.
Bon, OK, j’ai une chaîne YouTube, donc je mets des vidéos en ligne. Promis, c’est tout. Vous verrez plus bas que même pour gérer mes abonnements YouTube, je me passe de compte Google !
Ni pour mes recherches. Ni pour mes mails. Ni pour partager des photos avec mes ami⋅e⋅s ou pour héberger une page web. Ni pour me géolocaliser. Ni pour faire fonctionner mon smartphone.
Depuis 2015, et quand Skype est le moyen le plus commun de discuter en audio/vidéo, quand choisir un ordinateur se résume à choisir entre Microsoft ou Apple, qu’on utilise le pack Office, voire qu’on est aventureux et qu’on a investi dans un Windows Phone (désolé), je n’utilise pas Microsoft. Ou plutôt, je n’utilise plus. Et même si les hipsters et les web-designers (sont-ce les mêmes personnes ?) investissent dans du matériel Apple, moi, je n’ai jamais touché à ça.
Alors je me suis dit que peut-être, ça vous intéresserait de savoir COMMENT j’ai pu réussir sans faire une syncope. Et comment j’ai découvert des alternatives qui me respectent et ne me traitent pas comme une donnée à vendre.
Allez, ferme Hangout, Messenger, Skype, Whatsapp, viens t’asseoir près du feu, et prends le temps de me lire, un peu. Ouais, je te tutoie, on n’est pas bien, là, entre internautes ?
Chapitre 1 : Pourquoi ?
Normalement, je dialogue avec un mec lambda qui a la critique facile dans mes articles, mais ici, c’est le Framablog ; il faut un peu de prestance. Ce sera donc Jean-Michel Pouetpouet qui prendra la parole. Donc, introducing Jean-Michel Pouetpouet :
« Haha, cocasse, cet individu se prend pour plus grand qu’il n’est et ose chapitrer son contenu tel un véritable auteur »
Oui, c’est plus cool que de mettre juste un « 1. ». Il y a beaucoup à dire, et faire juste un énorme pavé, c’est pas terrible. Puis j’ai l’âme littéraire.
Ce que je pense important de signaler dans ce retour d’expérience, c’est que j’ai longtemps été très Googlophile. Très content d’utiliser leurs outils. C’est joli, c’est simple, c’est très chouette, et tout le monde utilise les mêmes. Et quand on me disait, au détour d’une conversation sur le logiciel libre : « mais Google te surveille, Google est méchant, Google est tout vilain pas beau ! »
Je répondais : « Et il va en faire quoi, de mes données, Google ? Je m’en fous. »
J’étais un membre de la team #RienÀCacher et fier de l’être. Quand je m’étais demandé ce qui se faisait d’autre, j’étais allé sur le site de Framasoft (c’était il y a fort longtemps) et j’avais soupiré « pfeuh, c’est pas terrible comme même ». J’écris « comme même » afin de me ridiculiser efficacement, merci de ne pas commenter à ce sujet.
Puis un jour, au détour d’une Assemblée Nationale, j’ai entendu parler de surveillance généralisée par des boîtes noires. On en a tou⋅te⋅s, je pense, entendu parler.
« Nom d’une pipe, mais ceci n’a aucun lien avec la dégooglisation ! »
Tut-tut. C’est moi qui raconte. Et tu vas voir que si, ça a à voir ; du moins, dans mon esprit de jeune chèvre numérique.
Parce que quand j’ai entendu parler de ça, je me suis dit « mince, j’ai pas envie qu’on voie tout ce que je fais sous prétexte que trois clampins ont un pet au casque ». D’un seul coup, mon « rien à cacher » venait de s’effriter. Et il s’est ensuite effondré tel un tunnel mal foutu sous une montagne coréenne dans un film de Kim Seong-hun.
Mes certitudes sur la vie privée en ligne, allégorie
Dans ma tête, une alarme pleine de poussière s’est mise à hurler, une ampoule à moitié grillée a viré au rouge, et je me suis soudain inquiété de ma vie privée en ligne.
J’ai commencé à voir, la sueur au front, circuler des alertes de La Quadrature du Net concernant le danger potentiel que représenterait un tel dispositif d’espionnage massif. Et j’ai fini par tomber sur plusieurs conférences. Plein de conférences. Dont la fameuse « sexe, alcool et vie privée » : une merveille.
Après cela, deux conclusions :
La vie privée, c’est important et on la laisse facilement nous échapper ;
Les grandes entreprises qui ont mainmise sur ta vie privée, c’est pas tip top caviar.
Mais d’abord, avant de parler Google ou Facebook, il me fallait fuir le flicage étatique automatisé. Alors j’ai acheté une Brique Internet (powered by le génial système d’auto-hébergement YunoHost) et j’ai adhéré à l’association Aquilenet.
Une Brique Internet dans son milieu naturel
Aquilenet, c’est un FAI (Fournisseur d’Accès à Internet) géré par des copains qui n’ont rien de mieux à faire que d’aider les gens à avoir accès à un Internet neutre, propre. J’ai donc souscrit à un VPN chez eux (chez nous, devrais-je maintenant dire). Pour avoir une protection contre les boîtes noires qui squatteront un jour (peut-être, vu comme ça avance vite) chez SFR, Free, Bouygues, Orange, et voudront savoir ce que je fais.
« Mais bon », me suis-je dit, « c’est très cool, mais ça n’empêche pas Google et Facebook de me renifler le derrière tout ça ».
Et j’ai entrepris la terrible, l’effroyable, l’inimaginable, la mythique, l’inaccessible… DéGooglisation.
Chapitre 2 : Poser les bases – Linux, Firefox, Searx
2.1/ Microsoft, l’OS privateur
Étrangement, le plus simple, c’était de dire au revoir à Microsoft.
Se dire que son système entier est couvert de trous (aka backdoors) pour laisser rentrer quiconque Microsoft veut bien laisser entrer, ce n’est pas agréable. Savoir que la nouvelle version gratuite qu’il te propose est bourrée de trackers, c’est pas mieux.
Pour bien comprendre, imagine que ton ordinateur soit comme un appartement.
Donc, on te vend un appartement sans serrure. On te dit « eh, vous pouvez en faire installer une si vous le voulez, mais alors, il faudra faire appel à une entreprise ».
Option n°1 : je n’ai pas besoin de serrure
« Je m’en fiche. J’ai confiance, et je sais quand je pars et comment je pars. Personne ne voudra entrer chez moi. »
Vraiment, est-ce qu’on peut croire une seconde à cette phrase ? Tu y vas au feeling ? Y a pas de raison que quelqu’un ne veuille entrer ? Tu partiras au travail ou en vacances le cœur léger ?
Option n°2 : je fais poser une serrure par un serrurier qui met un point d’honneur à ne pas me laisser voir son intervention
« Hop, me voilà protégé ! »
Et s’il garde un double de la clé ?
S’il décide de faire une copie de la clé et de l’envoyer à quelqu’un qui veut entrer chez vous sur simple demande ?
Elle fait quoi exactement cette serrure ?
Elle ferme vraiment ma porte ?
Option n°3 : je connais un gars très cool, il fabrique la serrure, me montre comment il la fait, et me prouve qu’il n’a pas de double de ma clé
« Je connais ma serrure, je connais ma clé, et je sais combien il en existe »
Ok, c’est super ça ! Dommage : je l’ai fait dans un appartement dont les murs sont en papier mâché. En plus, j’ai une fenêtre pétée, tout le monde peut rentrer. J’avais pas vu quand j’ai pris l’appart’. Bon, je rappelle mon pote, faut inspecter tout l’appartement et faire les travaux qui s’imposent.
Option n°4 : et si je prenais un appartement où tout est clean et sous contrôle ?
Ah, bah de suite, on se sent mieux. Et c’est ça l’intérêt d’un système d’exploitation (OS) libre. Parce que c’est bien sympa, Microsoft, mais concrètement, c’est eux qui ont tout mis en place. Et quand on veut voir comment c’est fait, s’il y a un vice caché, c’est non. C’est leur business, ça les regarde.
Alors pourquoi leur faire confiance ? La solution, c’est le logiciel libre : tout le monde peut trifouiller dedans et voir si c’est correct.
Comme point d’entrée Ubuntu (et surtout ses variantes) est un OS très simple d’accès, et qui ne demande pas de connaissances formidables d’un point de vue technique.
« Huées depuis mon manoir ! Ubuntu n’est pas libre, il utilise des drivers propriétaires, et de surcroît, l’ensemble est produit par Canonical ! Moi, Jean-Michel Pouetpouet, j’utilise uniquement FreeBSD, ce qui me permet d’avoir une pilosité soyeuse ! »
C’est super cool, mais FreeBSD, c’est pas vraiment l’accessibilité garantie et la compatibilité parfaite avec le monde extérieur (mais ça a plein d’avantages, ne me tuez pas, s’il vous plaît). Ubuntu, c’est grand public, et tout public. C’est fait pour, excusez-les du peu !
Dans la majorité des cas, il suffit d’une installation bien faite et tout ronronne. Le plus compliqué, c’est finalement de se dire : « allez, hop, j’y vais ».
En 2016, je jouais à League of Legends et à Hearthstone sur mon PC sous Linux. Je n’y joue plus parce que je ne joue plus. Mais j’y regarde les même lives que les autres, visite les mêmes sites web.
Et j’utilise mutt pour avoir moi aussi une pilosité soyeuse.
« Comme quoi, vous n’êtes finalement qu’un traître à vos valeurs ! Vous faites l’apologie du terrorisme du logiciel propriétaire, vous faites des trous dans votre coffre fort, quelle honte, quel scandale, démission ! »
J’entendais moins ce type de commentaires concernant Pokémon Go qui envoie des données à Nintendo. Comme quoi, les compromis, ça n’est pas que mon apanage.
Soit, je passerai sur ces menus détails ! Mais pourriez-vous cesser de tergiverser en toute véhémence avec un individu dont l’existence est factice ?
Non.
Une fois sous Ubuntu, le nom de mes logiciels change. Leur interface aussi. Et oui, il faut le temps de s’habituer. Mais qui ne s’est pas senti désemparé devant Windows 8.1 et son absence de bureau ? Un peu de temps d’adaptation. Et c’est tout.
On est pas bien, là ? (Xubuntu 17.04) [Fond d’écran par Lewisdowsett]Certes, parfois, la compatibilité n’est pas au rendez-vous. Soit on se bat, soit on se résout à faire un dual-boot (deux systèmes d’exploitation installés) sur son ordinateur, soit on virtualise (l’OS dans l’OS). C’est ce que j’ai fait : j’ai un Windows qui prend un tiers de mon disque dur, tout formaté et tout vide ou presque.
Ce filet de sécurité en place, la majorité du travail doit être fait sous Linux. Une fois qu’on en a l’habitude, un retour sous Windows n’est même plus tentant.
2.2/ La recherche : fondamental
Google, en premier lieu, c’est quoi ?
Un moteur de recherche. Un moteur de recherche qui sait absolument tout sur ce que je cherche. Parce que j’utilise un compte. Avec un historique. Parce qu’il utilise des trackers. Parce qu’il retient mon IP.
On parle donc d’une entreprise qui sait qui je suis, ce que je cherche, sur quoi je clique. Une entreprise qui détermine ma personnalité pour vendre le résultat à des régies publicitaires.
Non, désolé, ça ne me convient pas. Je n’ai pas envie qu’une entreprise puisse me profiler à tel point qu’elle sache si j’ai le VIH avant que j’en sois informé. Qu’elle sache que je déménage. Que je cherche un emploi. Où. Si je suis célibataire ou non. Depuis quand. Quel animal de compagnie j’ai chez moi. Qui est ma famille. Quels sont mes goûts.
Ah non, vraiment, une seule entité, privée, capitaliste, qui vit de la vente de pub, et qui me connaît aussi bien, ça ne me plaît pas.
« Et quelle fut ta réponse à cette situation ? »
J’utilise Bing.
« ?! *fait tomber son monocle dans sa tasse de thé* »
Non, pas du tout.
J’utilisais au départ Startpage. Le principe est simple : ce moteur de recherches ne garde aucune donnée, et envoie la recherche à Google avant d’afficher le résultat.
La différence est énorme. Google sait que Startpage a fait une recherche. Mais il ne sait pas QUI a utilisé Startpage. Il ne sait pas QUI je suis, juste ce que je cherche. Google ne peut plus me profiler, et moi, j’ai mes résultats.
Et voilà, je n’utilise plus Google Search. Juste comme ça. Pouf.
Il existe aussi Framabee qui utilise également Searx, ou encore Qwant (mais c’est pas du libre, et c’est une entreprise, alors j’aime moins).
À noter que cette étape n’est pas du tout dure à franchir : nombreux sont celleux qui utilisent Ecosia au lieu de Google, ou Duck Duck Go, et ne se sentent pas gênés dans leur recherche quotidienne de recettes de crêpes.
2.3/ Navigateur web et add-ons
Je naviguais avec Google Chrome. Comme beaucoup de monde (en dehors des admirateurs d’Internet Explorer, dont je ne comprendrai jamais les tendances auto-mutilatoires).
Je suis donc passé sous Firefox, et avec lui, j’ai ajouté pléthore d’extensions orientées vers la protection de la vie privée.
Au-revoir-UTM est une extension très simple qui va virer automatiquement les balises « utm » laissées par les régies publicitaires ou trackers pour savoir d’où vous venez lors de l’accès au contenu.
Decentraleyes remplace à la volée les contenus que vous auriez normalement dû aller chercher sur des CDN centralisés et généralement très enclins à violer votre vie privée, tels Google, CloudFlare, Akamai et j’en passe.
Disconnect supprime tout le contenu traçant comme le contenu publicitaire, les outils d’analyse de trafic et les boutons sociaux.
HTTPS Everywhere force votre navigateur à utiliser les versions HTTPS (donc chiffrés) des sites web que vous consultez, même si vous cliquez sur un lien HTTP (en clair).
uBlock Origin, qu’on ne présente plus, un super bloqueur de publicité et de traqueurs, juste un must-have.
Blender est une extension qui va tricher sur l’identité de votre navigateur, pour tenter de le faire passer pour celui le plus utilisé à l’heure actuelle, et ainsi se noyer dans la masse.
Smart Referer permet de masquer son référent. En effet, par défaut, votre navigateur envoie au serveur l’URL du site duquel vous venez. L’extension permet de remplacer cette valeur par l’URL du site sur lequel on va, voire carrément de supprimer l’information.
uMatrix est THE extension ultime pour la protection de sa vie privée sur Internet. Elle va en effet bloquer tout appel externe au site visité, vous protégeant de tout le pistage ambiant du net.
uMatrix : filtre par type de contenu et par domaine !
Une fois qu’on est à l’aise avec ça, on a déjà un meilleur contrôle de sa présence en ligne et des traces qu’on laisse.
Chapitre 3 : OK Google, déGooglise-toi
3.1 : Google Docs, Google Sheets, Google machins, le pack, quoi.
Il n’y a rien de plus simple que de se débarrasser de Google Docs. Des outils d’aussi bonne qualité sont disponibles chez Framasoft. Rien à installer (sauf si vous souhaitez héberger vous-même le contenu), accessible à tout le monde. Et en plus, depuis quelques temps, il y a Framaestro, le Google Drive de Framasoft. Tout comme Google. Sauf que…
… Bah c’est Framasoft, quoi. Si c’est la première fois que vous entendez ce nom, déjà : bienvenue. Ensuite, Framasoft ne va pas faire attention à vos données. Ou plutôt si, mais au sens de « les protéger ». Il s’agit de bénévoles qui souhaitent proposer des outils de qualité ; Framasoft s’en fiche de ce que vous saisissez dans vos documents. Et ne s’en approprie pas les droits ; Google, oui.
Pour trouver l’outil qu’il vous faut, rendez-vous simplement sur https://degooglisons-internet.org/alternatives et choisissez la ligne correspondant à l’outil Google dont vous souhaitez vous débarrasser.
3.2 : Google Maps / Google Street View
Google Maps peut être aisément remplacé par Open Street Map. Sur votre smartphone, l’application OSMAnd~ fait très bien son travail.
Pour Google Street View, Open Street Maps a lancé Open Street Cam. L’idée est tout bonnement GÉ-NIALE : on a pas les moyens de faire se promener une « OSM Car » ? Alors les utilisateurs seront l’OSM Car !
Moins utilisés que mes précédents amis mais tout de même existants, ces outils de stockage en ligne d’images ou de fichiers sont tenus par des entreprises en lesquels on ne peut pas avoir confiance.
Les services d’hébergement de fichiers ne manquent pas. Et ceux que je vais proposer ici n’ont pas mainmise sur vos fichiers.
Ça n’a l’air de rien comme ça, mais une entreprise qui peut regarder vos fichiers, est-ce que ce n’est pas problématique ? Lui avez-vous donné l’autorisation de s’introduire ainsi dans vos échanges de données ?
Pour les albums, au revoir Picasa, préférez Piwigo.
Pour un simple partage d’image(s), pourquoi pas Framapic ou Lutim ?
Pour stocker vos fichiers et les envoyer, dégagez WeTransfer de là et choisissez plutôt Framadrop. Abandonnez votre Dropbox, et rendez-vous sur un Nextcloud installé chez un pote ou une asso (ou directement chez vous ?) !
Les alternatives sont là, et sont bien plus diverses. La seule nuance, c’est que vous ne les connaissez pas, et n’avez pas le réflexe de les chercher.
Dans mon cas, ayant une Brique (je vous ai dit que j’avais une Brique ?), j’utilise Jirafeau pour héberger mes images, Nextcloud pour le reste. Ça me va très bien, et au moins, ça reste chez moi.
3.4 : Discuter en instantané
Rendez-vous sur Jabber (XMPP). Skype ne vous respecte pas, Hangout non plus. Messenger ? Pfeuh-cebook ! La messagerie directe de Twitter ? Ne comptez pas trop protéger vos données là-dessus non plus. Whatsapp ? C’est encore Facebook derrière !
Au lieu d’installer Google Hangouts et d’utiliser votre compte Google, installez Xabber ou Conversation sur votre téléphone et créez un compte Jabber. Vous voici à utiliser XMPP, le même protocole que derrière Hangout ou Messenger, mais sans la méchante boîte qui vit de publicité ciblée et de vente de données personnelles.
Au lieu d’utiliser Skype, pourquoi pas Tox ? Ou en ligne, vous pouvez utiliser Vroom, et même Framatalk !
J’ai un peu de mal à conseiller Telegram car récemment, la sécurité qu’il promet a été remise en question, et qu’il s’agit toujours d’une entreprise qui peut vouloir jouer avec vos données.
3.5 : GMail
On attaque le côté le plus effrayant : les e-mails. Je ne sais pas pour vous, mais moi, je n’imaginais pas pouvoir dire au revoir à mon GMail.
Cela faisait 5 ans que TOUS mes échanges se faisaient par son biais. Que tous mes comptes, sur tous les sites où j’étais inscrit, connaissaient cet e-mail comme étant le mien.
En réalité… je me suis rendu compte que mes mails déjà envoyés étaient sacrifiables, et que ceux déjà lus l’étaient également. Je me suis rendu compte que je recevais plus de spam et de newsletters (auxquelles je n’étais pas forcément inscrit) que de nouvelles de mes proches.
Et puis surtout, bon sang : Google lisait mes mails. Une entreprise lisait ma correspondance privée pour mieux me connaître. Pour mieux me profiler. Pour me vendre à des régies publicitaires. Non, ce n’est pas acceptable.
Étant alors devenu membre d’un FAI associatif, je lui ai confié mes mails. Mais avant cela, j’avais prévu de me tourner vers Protonmail. C’est certes une entreprise, mais vos messages sont chiffrés, et il n’est pas possible (dans le cas où c’est bien fait ;)) pour l’entreprise de lire vos mails. Contrairement à Google qui lit bien tout ce qu’il veut.
J’y reviens, mais… De la publicité ciblée à partir de vos échanges privés. Comment peut-on accepter ça ?
Protonmail est un service qui m’a l’air fiable. Ça reste néanmoins une entreprise, dont le code est partiellement consultable. Si vous souhaitez abandonner Google, c’est une alternative viable.
Envoyez un mail à tous vos contacts, mettez (ou non) en place une réponse automatique Google indiquant « voici ma nouvelle adresse e-mail », et changez votre adresse e-mail sur tous les sites la connaissant. Après tout, vous l’aviez peut-être fait avec votre adresse @aol.fr ou @wanadoo.fr sans vous interroger plus longtemps sur ce changement.
En consultant ses mails GMail de temps en temps, on peut en voir un qui s’est perdu et indiquer la bonne adresse e-mail à laquelle écrire.
Vous verrez, contrairement à ce qu’on croit, c’est simple, rapide, et on ne rencontre quasiment aucun obstacle.
Je ne sais pas si je vous ai dit que j’avais une brique Internet chez moi, d’ailleurs ; mais du coup, maintenant, elle héberge aussi une partie de mes e-mails (je jongle entre les adresses). Vous imaginez ? Ces mails sont stockés directement dans un petit boîtier posé par terre chez moi. Nulle part ailleurs !
3.6 : YouTube
Je poste des vidéos sur YouTube, étant vidéaste. Bon, OK. Mais je n’ai pas pour autant envie d’utiliser un compte Google le reste du temps. Et je ne voulais évidemment pas perdre mes abonnements.
La solution à cela ? L’oublié flux RSS. Comme quand on suivait les blogs, tu te rappelles ?
Pour celleux qui n’auraient pas connu ou utilisé RSS à l’époque où c’était la star d’Internet, il s’agit, en gros, d’abonnement à des sites/blogs. Dès qu’un nouvel article paraît, vous le recevez sur votre lecteur de flux RSS, où se rassemblent vos abonnements.
J’ai donc installé FreshRSS sur ma Brique (vous saviez que j’avais une brique ?), et y ai importé ce fameux fichier .opml. J’en ai profité pour ajouter Chroma, qui sort sur Dailymotion (eh ouais : on peut croiser les flux !). Et j’ai une sorte de boîte mail de mes abonnements vidéo ! C’est beau, non ?
Des abonnements YouTube sans compte YouTube <3
J’y ai ajouté un plugin nommé « FreshRSS-Youtube » qui me permet d’ouvrir les vidéos YouTube directement dans mon lecteur RSS. Donc j’ai un YouTube sans compte, avec juste mes abonnements, le tout chez moi.
Histoire de simplifier tout ça, j’ai développé une extension Firefox qui permet de s’abonner plus facilement à une chaîne en RSS. Il est disponible ici
Récupérer un flux RSS avec RSS-Tube !
3.7 : Android
Ton smartphone est sous Android ? Chouette. Mais Android utilise en permanence des services Google. Pour te géolocaliser, pour faire fonctionner tes applications, pour t’entendre quand tu chuchotes sous la couette un « OK, Google ».
Au début, j’ai été dérouté par cette prise de conscience. Alors j’ai simplement abandonné l’idée d’avoir un smartphone. J’ai acheté un téléphone tout pourri-pourrave pour quelques 30€ qui envoyait des SMS, recevait des MMS quand il était de bonne humeur, et téléphonait. C’était tout. Il y avait aussi le pire appareil photo qu’on ait vu depuis 2005.
Puis, un jour, au hasard d’une rencontre, on m’a parlé de Replicant. J’ai regardé, et j’ai constaté que ce n’était malheureusement pas compatible avec le Samsung Galaxy S3 Mini que j’avais abandonné précédemment.
Le hasard a fait le reste.
Un jour, j’ai commandé un t-shirt chez la Free Software Foundation Europe et reçu un papier « Free your Android ! » dans le colis.
En allant sur leur site, j’ai pu découvrir CyanogenMod (devenu maintenant LineageOS). Un Android, mais sans Google, créé par la communauté pour la communauté. Comme d’habitude, tout n’est pas tout blanc, mais c’est toujours mieux que rien.
Je l’ai installé (en suivant simplement des tutos, rien d’incroyable), installé F-Droid (qui remplace Google Play) pour télécharger les applications dont j’avais besoin, et j’installe directement les fichiers .apk comme on installe un .exe sur son Windows ou un .deb sur son Ubuntu.
Mon téléphone sous CyanogenMod 13
Conclusion
Bravo. Si vous êtes arrivé jusque là sans tricher, vous avez le droit de vous féliciter. J’espère que vous n’avez pas trouvé le temps trop long !
Courage, plus que quelques lignes. Les dernières pensées.
Au final, ce qui ressort de mon expérience, c’est que me préparer psychologiquement à quitter Google et Microsoft m’a pris plus de temps que pour m’en passer réellement, trouver des alternatives, et m’y faire.
On n’a pas besoin d’eux. Les alternatives existent, sont nombreuses, variées, et nous respectent pour ce que nous sommes : des êtres humains, avec des droits, qui souhaitons simplement utiliser Internet pour notre plaisir personnel quotidien.
Je pense que j’ai oublié plein de choses. Je pense que de nouveaux outils grandissent chaque jour et attendent qu’on les découvre.
En parallèle de tout ça, j’ai appris beaucoup sur l’auto-hébergement. J’ai aussi beaucoup appris sur l’anonymat, sur le chiffrement, sur le fonctionnement d’Internet. J’ai rejoint une association formidable, et en m’intéressant à la technique et au numérique, j’ai fait des rencontres nombreuses et toutes plus géniales les unes que les autres.
Je vous ai dit que quand j’ai commencé tout ça, je ne savais pas faire autre chose qu’un « apt-get install » sous GNU/Linux ? Que j’avais une peur bleue du code (malgré ma formation dans ce domaine) ?
Maintenant, j’en fais, j’en lis, et j’en redemande.
Mon Internet est propre. Ma vie privée, si elle n’est pas à l’abri, reçoit le maximum que je peux lui donner. Je vis d’outils décentralisés et d’auto-hébergement.
DÉGOOGLISONS L’INTERNET.
With Datalove,
Korbak <3
Si on laissait tomber Facebook ?
Le travail de Salim Virani que nous vous invitons à parcourir est remarquable parce qu’il a pris la peine de réunir et classer le très grand nombre de « petites » atteintes de Facebook à notre vie privée. Ce n’est donc pas ici une révélation fracassante mais une patiente mise en série qui constitue une sorte de dossier accablant sur Facebook et ses pratiques avouées ou inavouables. Vous trouverez donc de nombreux liens dans l’article et au bas de l’article, qui sont autant de sources.
Si comme nous le souhaitons, vous avez déjà renoncé à Facebook, il est temps d’en libérer vos proches : les références et les faits évoqués ici par Salim Virani seront pour vous un bon réservoir d’arguments.
Par quoi remplacer Facebook lorsqu’on va supprimer son compte ? Telle est la question qui reste le point bloquant pour un certain nombre de personnes. Bien sûr il existe entre autres Diaspora et ses divers pods (dont Framasphère bien sûr), mais Salim Virani répond plutôt : par de vrais contacts sociaux ! Avons-nous vraiment besoin de Facebook pour savoir qui sont nos véritables amis et pouvoir échanger avec eux ?
N’hésitez pas à nous faire part de votre expérience de Facebook et de ses dangers, dont le moindre n’est pas l’addiction. Saurons-nous nous dé-facebook-iser ?
Dites à ceux que vous aimez de laisser tomber Facebook
par Salim Virani
J’ai écrit ce qui suit pour ma famille et mes proches, afin de leur expliquer pourquoi les dernières clauses de la politique de confidentialité de Facebook sont vraiment dangereuses. Cela pourra peut-être vous aider aussi. Une série de références externes, et des suggestions pour en sortir correctement, se trouvent au bas de cet article.
Mise à jour 2017 : beaucoup des inquiétudes que j’avais se sont avérées fondées. Facebook a persévéré dans sa logique de mépris envers ses utilisateurs. J’ai actualisé cet article en y ajoutant quelques liens et arguments supplémentaires.
« Ah au fait, j’avais envie de te demander pourquoi tu quittes Facebook », telle est la question embarrassée qu’on me pose du bout des lèvres très fréquemment ces temps-ci. Genre vous savez plus ou moins que Facebook c’est mal, mais vous n’avez pas trop envie de savoir jusqu’à quel point.
J’ai été un grand supporter de Facebook – un des premiers utilisateurs de mon entourage à défendre ce moyen génial de rester en contact, c’était en 2006. J’ai fait s’inscrire ma mère et mes frères, ainsi qu’environ vingt autres personnes. J’ai même enseigné le marketing de Facebook à l’un des plus prestigieux programmes technologiques du Royaume-Uni, la Digital Business Academy. Je suis un technico-commercial – donc je peux voir les implications – et jusqu’à maintenant elles ne m’avaient pas inquiété plus que ça. Je ne prenais pas au sérieux les personnes qui hésitaient en invoquant des questions de vie privée.
Juste pour vérifier…
Pendant les vacances 2014/2015, j’ai voulu passer quelques minutes à vérifier les prochains changements dans la politique de confidentialité, avec une attitude prudente en me demandant « et si… ? ». Certaines éventualités étaient inquiétantes, en particulier concernant nos informations financières et de localisation, sans oublier tout le reste. En fait, ce que je soupçonnais a déjà eu lieu il y a deux ans, depuis 2011 ! Ces quelques minutes se sont changées en quelques jours de lecture. J’ai ignoré beaucoup d’affirmationspas qui, selon moi, peuvent être expliquées comme des accidents (« techniquement plausibles » ou « techniquement fainéantes »).
Après tout, je suis moi-même le fondateur d’une start-up, et je sais à quel point les questions techniques peuvent être complexes. Par exemple, les droits d’accès excessifs demandés par l’application Facebook pour Android proviennent d’un problème technique étroitement lié à Android. Mais il restait encore beaucoup de préoccupations concernant la protection de la vie privée, et j’ai croisé ces faits avec des techniques que je sais être standards dans le marketing basé sur les données.
Avec ces derniers changements de confidentialité le 30 janvier 2015, j’ai peur.
Facebook a toujours été légèrement pire que toutes les autres entreprises technologiques avec une gestion louche de la confidentialité ; mais maintenant, on est passé à un autre niveau. Quitter Facebook n’est plus simplement nécessaire pour vous protéger vous-même, c’est devenu aussi nécessaire pour protéger vos amis et votre famille. Cela pourrait être le point de non-retour – mais il n’est pas encore trop tard pour reprendre le contrôle.
Une petite liste de pratiques de Facebook
Il ne s’agit plus simplement des informations que Facebook dit qu’il va prendre et ce qu’il va en faire ; il s’agit de tout ce qu’il ne dit pas, et qu’il fait tout de même grâce aux failles qu’ils se sont créées dans les Conditions de Service, et la facilité avec laquelle ils reviennent sur leurs promesses. Nous n’avons même plus besoin de cliquer sur « J’accepte ». Ils modifient simplement la politique de confidentialité, et en restant sur Facebook, vous acceptez. Et hop !
Aucune de vos données sur Facebook n’est sécurisée ni anonyme, quels que soient vos paramètres de confidentialité. Ces réglages sont juste des diversions. Il y a des violations de confidentialité très sérieuses, comme la vente de listes des produits que vous recommandez à des annonceurs et des politiciens, le pistage de tout ce que vous lisez sur Internet, ou l’utilisation des données de vos amis pour apprendre des informations privées sur vous – aucune de ces pratiques n’a de bouton « off ». Pire encore, Facebook agit ainsi sans vous le dire, et sans vous révéler les dommages que vous subissez, même si vous le demandez.
Facebook donne vos données à des « tiers » via les applications que vous utilisez, puis il affirme que c’est vous qui le faites, pas eux. À chaque fois que vous utilisez une application connectée à Facebook, vous autorisez Facebook à échapper à sa propre politique de confidentialité avec vous et vos amis. C’est comme quand mon frère me forçait à me frapper moi-même, puis me demandait « Pourquoi tu te frappes tout seul ? ». Et il allait dire à ma mère que ce n’était pas de sa faute.
En creusant un peu, j’ai découvert tout le pistage que fait Facebook – et je l’ai vérifié avec des articles de sources connues et réputées, ainsi qu’avec des études qui ont été examinées minutieusement. Les liens sont dans la section Source à la fin de ce post.
Ça semble fou quand on met le tout bout à bout !
Facebook crée de fausses recommandations de produits venant de vous pour vos amis – et ils ne vous le disent jamais.
Quand vous voyez un bouton « J’aime » sur le web, Facebook est en train de repérer que vous êtes en train de lire cette page. Il parcourt les mots-clés de cette page et les associe avec vous. Il sait combien de temps vous passez sur les différents sites et les différents sujets.
Ils repèrent votre localisation et l’utilisent pour trouver des informations sur vous, si par exemple vous êtes malade (si vous êtes chez un médecin ou un spécialiste), avec qui vous couchez (qui est à vos côtés pendant la nuit), où vous travaillez, si vous êtes en recherche d’emploi (un rendez-vous d’une heure dans les bureaux de la concurrence), etc.
Ils ont organisé des campagnes de quasi-dénonciation pour inciter par la ruse les amis des gens à révéler des informations sur eux, alors qu’ils avaient décidé de les garder secrètes.
Ils utilisent l’énorme quantité de données qu’ils ont sur vous (avec vos « J’aime », ce que vous lisez, ce que vous écrivez mais que vous ne publiez pas) pour créer des profils très précis de qui vous êtes – même si vous faites tout pour garder ces choses secrètes. Il y a des techniques statistiques, qui existent depuis des décennies en marketing, pour trouver des modèles comportementaux en corrélant les actions et les caractéristiques d’une personne. Même si vous n’avez jamais publié quoi que ce soit, ils peuvent facilement déduire vos âge, sexe, orientation sexuelle et opinions politiques. Quand vous publiez, ils en déduisent beaucoup plus. Puis ils le révèlent aux banques, aux compagnies d’assurances, aux gouvernements et, évidemment, aux annonceurs.
« Je n’ai rien à cacher »
Pourtant, beaucoup de gens ne s’en inquiètent pas, estimant qu’ils n’ont rien à cacher. Pourquoi s’intéresseraient-ils à ma petite personne ? Pourquoi devrais-je m’inquiéter de cela alors que je ne fais rien de mal ?
L’histoire est désormais célèbre : une adolescente enceinte a vu sa grossesse révélée au grand jour par le magasin Target, après que ce dernier a analysé ses données d’achat (sacs à main plus grands, pilules contre le mal de tête, mouchoirs…) et a envoyé par erreur un message de félicitations à son père, qui n’était pas au courant. Oups !
Il arrive la même chose à vos données, qui sont révélées à n’importe quelle entreprise sans contrôle de votre part. Et cela se traduit par les différentes manières dont vos données peuvent révéler des choses vous concernant à des entités que vous ne souhaitez pas mettre au courant.
L’un des problèmes les plus évidents ici concerne les compagnies d’assurance. Les données qu’elles récoltent sur vous sont exploitées pour prédire votre futur. Aimeriez-vous qu’on vous refuse une assurance santé sous prétexte qu’un algorithme a prédit à tort que vous aviez commencé à consulter un cardiologue ?
Et si votre employeur ou futur employeur savait que vous êtes peut-être enceinte ?
Aimeriez-vous que votre patron soit au courant quand vous n’êtes pas réellement cloué au lit, ou quand vous cherchez un autre job ?
Aimeriez-vous que n’importe qui soit au courant si vous avez des difficultés à payer votre prêt ? Si vous vendez votre maison, les acheteurs sauront qu’ils sont en position de force.
Même si nous avons pour la plupart d’entre nous le sentiment que nous n’avons rien à cacher, nous nous retrouvons tous parfois dans des situations où nous avons besoin que certaines choses restent secrètes, au moins pendant un temps. Mais nous renonçons à cela – et pour quelle raison ?
Extraits des « Conditions d’utilisation » (et non « Politique de confidentialité », vous voyez l’astuce ?)
Vous nous donnez permission d’utiliser votre nom, image de votre profil, le contenu et les informations en lien avec des activités commerciales, soutiens sponsorisés et autres contenus (comme les marques que vous aimez), proposés ou mis en avant par nos soins.
Plus bas :
Par « information » nous voulons dire les données et autres informations qui vous concernent, ce qui inclut les faits et gestes des utilisateurs et des non-utilisateurs qui interagissent avec Facebook.
Donc cela inclut tout ce qu’ils collectent sur vous mais sans vous le dire. Tout ce que vous lisez sur Internet, tout ce qu’on a jamais publié à votre propos, toutes vos transactions financières privées.
De plus, vos données commencent à être combinées avec les données de vos amis pour faire un modèle encore plus précis. Il ne s’agit pas que de vos données, mais ce que l’on obtient quand on combine tout ensemble.
Le problème n’est pas ce que nous avons à cacher, il s’agit de garantir le droit fondamental à notre liberté – lequel est notre droit à la vie privée
Nul ne sera l’objet d’immixtions arbitraires dans sa vie privée, sa famille, son domicile ou sa correspondance, ni d’atteintes à son honneur et à sa réputation.
Nous avons le droit de dire un mot sur la façon dont ces informations seront utilisées. Mais en utilisant Facebook, nous les abandonnons volontairement, pas seulement les nôtres mais aussi celle de nos amis, de notre famille !
Si vous admettez avoir commis quelque chose d’illégal dans les messages privés de Facebook, ou si vous avez simplement mentionné un soutien à une action politique, cela pourra être utilisé contre vous à l’avenir, tout particulièrement par un gouvernement étranger. Vous pouvez être arrêté simplement parce que vous étiez au mauvais endroit au mauvais moment, ou être mis à l’écart à l’aéroport un jour, pour risquer de la prison car vous avez révélé que vous avez fait quelque chose d’illégal il y a 5 ans. Un comédien New Yorkais a vu une équipe SWAT (un groupe d’intervention policière américaine musclé) entrer dans son appartement pour une blague sur Facebook. Les forces de l’ordre commettent souvent des erreurs, et vous leur donnez plus de pouvoir et plus de chance d’être dans l’erreur. Vous rechargez le fusil, le pointez sur votre tempe, et le donnez à n’importe quel « applicateur de la loi » à la gâchette facile capable d’acheter vos données personnelles.
Pas besoin de parler d’une hypothétique surveillance gouvernementale ici. L’un des premiers investisseurs de Facebook, Greylock, a un conseil d’administration en lien avec la CIA via une entreprise appelée In-Q-Tel. Selon leur site web, ils « identifient les technologies de pointe pour aider la CIA et plus largement l’intelligence américaine à poursuivre leur mission ». Et si vous n’êtes toujours pas au courant, il a été révélé que les données de Facebook ont été livrées directement au programme PRISM.
Les courtiers en données commerciales
Et comme je l’explique plus loin, ces informations se retrouvent de toute façon en grande partie publiquement accessible. Pas besoin des programmes de la NSA, les entreprises de données marketing s’en occupent, en dés-anonymisant toutes vos données pour les vendre encore et encore. C’est fait systématiquement et automatiquement. Il y a toute une industrie autour de ça. Il y a des places de marché pour acheter et vendre les données des consommateurs, qui étaient bâties originellement autour des agences de crédit et des entreprises de publipostage, puis qui ont évolué avec l’industrie de la barre d’outil de navigateur, quand Internet Explorer était répandu – maintenant il y a encore plus d’informations qu’avant. Un exemple récent est RapLeaf qui a collecté et publié des informations identifiables personnellement, y compris des identifiants Facebook et MySpace.
Ils ont arrêté suite à une sérieuse controverse, mais non seulement le mal avait été fait, mais il y a eu d’autres entreprises qui ont échappé à cette mauvaise publicité et ont continué ces pratiques. Il ne s’agit pas de la façon dont les commerciaux vous adressent des publicités ciblées : le problème, c’est que vos données sont achetées et vendues pour cela.
Dans quel pays envisagez-vous de partir en voyage ? Êtes-vous d’accord pour confier toutes ces informations sur vous aux forces de l’ordre de ce pays ? Parce que, sachez-le : elles les achètent.
Le truc, c’est qu’il n’y a pas besoin d’approuver une théorie du complot pour être concerné. Mark Zuckerburg lui-même a été très clair publiquement avec ses investisseurs à propos de ses intentions :
1) Être l’intermédiaire de toutes les communications personnelles.
C’est pour cela qu’ils ont conçu Messenger et acheté WhatsApp, mais n’oubliez pas qu’ils ont essayé pire. Quand ils ont lancé les emails Facebook, ils ont profité des utilisateurs qui avaient synchronisé leurs contacts Facebook. Ils ont fait en sorte que l’adresse @facebook.com soit l’adresse par défaut pour tout le monde. Pourquoi ? Pour que vos amis vous envoient des e-mails sur votre adresse @facebook.com au lieu de votre adresse normale, ce qui leur permettra de lire vos correspondances.
2) Rendre publiques toutes les communications privées au fil du temps.
C’est pour cela qu’ils ont lentement changé les paramètres de vie privée par défaut vers public, rendu les configurations de la vie privée de plus en plus difficiles à utiliser, et prétendent maintenant que leur outil d’aide à la vie privée va changer cela.
En réalité, il y a une foule de violations de la vie privée qui ne peuvent être désactivées, comme permettre aux publicitaires d’utiliser votre liste de contacts, couper la façon dont Facebook suit ce que vous lisez sur Internet, ou empêcher Facebook de collecter d’autres informations sur vous. Vous ne pouvez pas les désactiver !
Facebook ne vous laisse pas partager ce que vous voulez
Même si vous n’avez rien à cacher, inquiétez-vous du contraire, ce que Facebook choisit de cacher quand vous souhaitez le partager. Ils vous filtrent.
« Je voulais te demander pourquoi tu quittes Facebook » arrive généralement après quelque chose comme « Tu n’as pas vu mon post la semaine dernière ? ».
Si vous avez déjà eu cette conversation, vous aurez noté qu’il y a une grande différence entre vos attentes lorsque vous communiquez sur Facebook et ce qui arrive réellement. En gros, Facebook filtre vos posts suivant que les utilisateurs utiliseront plus Facebook ou non s’ils ne le voient pas.
On a l’impression que Facebook est la seule manière de rester en contact. Avec les photos et les commentaires. On a l’impression que tout le monde y est et qu’on y voit une bonne partie de leur vie.
En fait, un grand nombre de vos messages ne sont jamais vus par personne !
Et vous en manquez plein aussi. Même si ceux de vos amis vous arrivent, cela ne veut pas dire que les vôtres leur parviennent.
Les messages privés puent aussi. Combien de messages Facebook envoyés sans réponse ? À combien de messages Facebook pensez-vous avoir oublié de revenir plus tard, combien en manquez-vous simplement ? Est-ce comme ça que vous voulez traiter vos amis ?
Facebook est un moyen vraiment peu fiable pour rester en contact.
Le mois dernier (NdT : en 2015), j’ai simplement cessé d’utiliser Facebook. Quelque chose d’incroyable est arrivé. Les gens m’ont téléphoné, et on s’est vraiment donné de nos nouvelles. Ma famille était plus en contact. Mon frère m’a envoyé des courriels avec des nouvelles. Des amis sont venus chez moi me dire bonjour.
C’était, disons, social.
Censure politique
Facebook bloque des publications s’il y a du contenu politique qu’il n’aime pas. Ils ont bloqué des publications concernant Ferguson et d’autres manifestations politiques. Quand Zuckerberg a prétendument pété un câble et a banni les mots « vie privée » des réunions à Facebook, cela a aussi été censuré dans toutes les publications Facebook. Vous aviez juste un message d’erreur à propos de « contenu inapproprié ». Ouais, c’est ça ! Inapproprié pour qui ?
Pourtant, nous ne devrions pas être surpris. Facebook n’est pas une plate-forme neutre – nous devons être conscients des objectifs des gens qui sont derrière. Zuckerberg a révélé ses intentions publiquement. Le premier membre du conseil de Facebook aussi, Peter Thiel, un conservateur. Quand il était plus jeune, il a écrit un livre remettant en question le multiculturalisme à Stanford, et il soutient maintenant une théorie appelée le « Désir Mimétique » qui, parmi d’autres choses positives, peut utiliser les groupes sociaux des gens pour manipuler leurs désirs et leurs intentions (je suis un fan de Thiel quand il parle des startups – mais on oublie souvent que beaucoup de gens ne connaissent pas tout ceci).
Facebook va jusqu’à laisser des organisations politiques bloquer vos communications. Il suffit de quelques personnes pour classer comme offensant un article d’actualité, et il est supprimé du flux de tout le monde. Cette fonctionnalité est souvent détournée. Je peux bloquer n’importe quel article sur Facebook en convainquant quelques amis de le classer comme offensant. C’est de la censure facile et pas chère.
Mise à jour de 2017 : on a vu combien cela a affecté les élections des États-Unis. Les fils d’actualité des gens qui avaient des idées opposées étaient souvent filtrés, et pourtant des fausses actualités se sont facilement répandues facilement, parce que ces faux gros-titres renforcent nos convictions et nous sommes contents de les partager.
Tout cela confirme que c’est une mauvaise idée de compter sur Facebook pour communiquer avec des gens qui sont importants pour vous. Votre habitude d’utiliser Facebook implique que d’autres personnes doivent utiliser Facebook.
C’est un cercle vicieux.
En fait, cela nuit à vos relations avec beaucoup de gens, parce que vous pensez que vous êtes en contact avec eux, mais vous ne l’êtes pas. Au mieux, vous êtes en contact avec une version filtrée de vos amis. Ces relations s’affaiblissent, alors que vos relations avec des personnes qui publient du contenu qui plaît à Facebook prennent leur place.
Non seulement Facebook veut lire toutes vos communications, mais il veut aussi les contrôler.
Vous balancez vos amis
Même si vous pensez que tout ça ne vous pose pas trop de problèmes, en utilisant Facebook, vous forcez vos amis et votre famille à accepter la même chose. Même ceux qui ne sont pas sur Facebook, ou qui vont jusqu’à utiliser des faux noms.
Si vous avez déjà utilisé la synchronisation des contacts Facebook, ou si vous avez déjà utilisé Facebook sur votre téléphone, alors Facebook a récupéré la totalité de votre liste de contacts. Les noms, les numéros de téléphone, les adresses, les adresses électroniques, tout. Puis ils utilisent tout ça pour créer des « profils fantômes » des gens que vous connaissez et qui ne sont pas sur Facebook. Les internautes qui n’utilisent pas Facebook s’en aperçoivent souvent en recevant des e-mails qui contiennent leurs informations personnelles de la part de Facebook. Les internautes qui utilisent Facebook s’en aperçoivent aussi quand ils publient une photo d’un ami qui n’est pas sur Facebook, et qu’elle se retrouve automatiquement taguée. Mon ami n’est pas sur Facebook, mais comme d’autres amis et moi avons utilisé Facebook sur nos téléphones, Facebook connaît son nom et ses informations de contact, et sait aussi qui sont ses amis, puisqu’il peut le voir dans leur liste de contacts et leur journal d’appel. Il suffit de publier quelques photos avec son visage (ils peuvent l’identifier sur des photos), et voilà, ils peuvent ajouter les données de géolocalisation tirées des photos à son profil fantôme. Beaucoup d’autres techniques de Facebook fonctionnent aussi avec les profils fantômes. Et par-dessus le marché, ils peuvent déduire beaucoup de choses sur lui très précisément en s’appuyant sur des similitudes statistiques avec ses amis.
Donc en gros, on a tous balancé accidentellement nos amis qui voulaient préserver leur vie privée. Facebook nous a piégés.
Mais les pièges de Facebook vont encore plus loin.
La « vie privée » ne s’applique pas à ce que Facebook déterre
Tout comme les profils fantômes des gens, Facebook peut « deviner un like » en fonction d’autres informations qu’il possède sur vous, comme ce que vous lisez sur Internet ou ce que vous faites dans les applications quand vous vous y authentifiez avec Facebook ou ce qu’il y a sur votre facture de carte bleue (j’en parlerai davantage plus loin). Appelez cela un « like fantôme ». Cela leur permet de vous vendre à plus d’annonceurs.
Il y a déjà une vaste documentation sur la collecte de ces informations par Facebook. La technique du « like fantôme » est simplement une utilisation standard des techniques statistiques en marketing de base de données. Si vous lisez beaucoup sur ce sujet, vous l’aimez probablement. Ce genre de chose. Ces techniques sont utilisées en marketing depuis les années 80 et vous pouvez embaucher des étudiants en statistiques pour le faire, même si bien sûr, Facebook embauche les meilleurs du domaine et cherchent à faire avancer l’état de l’art en intelligence artificielle pour cela. En Europe, Facebook est légalement obligé de partager toutes les informations qu’il a sur vous, mais il refuse. Donc il y a encore une autre action en justice contre eux.
Les permissions
Au travers de son labyrinthe de redéfinitions des mots comme « information », « contenu » et « données », vous permettez à Facebook de collecter toutes sortes d’informations sur vous et de les donner à des annonceurs. Avec votre permission seulement, disent-ils, mais la définition de « permission » contient l’utilisation d’une application ou qui sait quoi d’autre.
Et vous pensiez que ces requêtes Farmville étaient embêtantes. À chaque fois que vous en voyez une, cet ami révèle vos informations à des « tiers ».
Vous voyez comment ça marche ? Vous dites à Facebook que c’est « uniquement pour vos amis », mais vos amis peuvent le révéler à un « tiers ». Et la plupart des applications qu’ils utilisent sont des « tiers ».
Donc en fait, tout ce que vous marquiez en « amis seulement » n’a pas grande importance. En étant sur Facebook, il y a bien plus d’informations à votre propos qui sont collectées, combinées, partagées et utilisées.
Ils disent qu’ils « anonymisent » ça, mais en réalité il n’y a qu’une étape pour le dés-anonymiser. Beaucoup de données anonymes, comme ce que vous postez et quand, vos photos, votre localisation à tel moment est suffisant pour un grand nombre d’entreprises qui relient ces données anonymes à vous – et les revendent (c’est pour cela que ça n’a pas d’importance que vous utilisiez un faux nom sur Facebook, vos données sont comme une empreinte digitale et permettront de vous associer à votre vrai nom).
En plus, ils permettent à toutes les applications Facebook d’avoir un accès complet à vos informations – avec votre nom et tout. Et même si vous n’utilisez jamais d’application sur Facebook, vos amis le font. Lorsqu’ils utilisent ces applications, ces amis partagent toutes vos informations pour vous. Il y a toute une industrie derrière.
Certaines choses ont bien un bouton « off », mais rappelez-vous que c’est temporaire, et comme Facebook l’a fait dans le passé, ils les réactiveront sans vous en avertir. Lorsque Facebook a démarré (et sans doute quand vous vous êtes inscrit) c’était clairement un endroit sûr pour partager avec vos amis. C’était leur grande promesse. Avec le temps, ils ont passé les paramètres de confidentialité à « public par défaut ». De cette façon, si vous vouliez toujours garder Facebook mais seulement pour vos amis, vous deviez trouver manuellement plus d’une centaine de paramètres sur d’innombrables pages cachées. Ensuite, ils ont abandonné ces paramètres pour forcer les informations à être publiques de toute façon.
Pourquoi est-ce que vous vous frappez tout seul ? 🙂
Vente de vos recommandations sans votre accord
Vous avez sûrement déjà remarqué des publicités Facebook avec une recommandation de vos amis en dessous. En gros, Facebook donne aux annonceurs le droit d’utiliser vos recommandations, mais vous n’avez aucun contrôle dessus. Cela ne concerne pas simplement quand vous cliquez sur un bouton « J’aime ». Il y a des cas connus de végétariens qui recommandent McDonald’s, d’une femme mariée heureuse qui recommande des sites de rencontres, et même un jeune garçon qui recommande un sex club à sa propre mère !
Ces cas étaient si embarrassants que les personnes concernées s’en sont rendu compte. Les gens les ont appelées. Mais dans la plupart des cas, ces « recommandations » ne sont pas découvertes – les gens pensent qu’elles sont vraies. C’est encore plus effrayant, car Facebook est largement utilisé pour la promotion politique, et la recommandation de produits. Les gens savent que j’ai déjà collecté des fonds pour le soutien d’enfants malades du cancer, donc cela ne les étonnera peut-être pas de voir une publicité où je recommande un programme chrétien d’aide aux enfants pauvres en Afrique. Mais je ne soutiens absolument pas les programmes qui ont une tendance religieuse, car ils sont connus pour favoriser les gens qui se convertissent. Pire, des gens pourraient s’imaginer des choses fausses sur mes convictions religieuses à partir de ces fausses recommandations. Et je passe sur tous les trucs à la mode sur les startups que je ne cautionne pas !
Ils profitent de la confiance que vos proches ont en vous
Nous n’avons aucun moyen de savoir si notre cautionnement a été utilisé pour vendre des conneries ineptes en notre nom. Je n’ai pas envie d’imaginer ma mère gâcher son argent en achetant quelque chose qu’elle pensait que je cautionnais, ou les investisseurs financiers de ma startup voir des publicités pour des produits inutiles avec mon visage en dessous.
Utiliser Facebook signifie que ce genre de chose se produit à tout moment. Les publicitaires peuvent acheter votre cautionnement sur Facebook et vos informations à des revendeurs de données extérieurs. Vous n’êtes jamais mis au courant de ça et vous ne pouvez pas le désactiver.
Les derniers changements en matière de vie privée
Finalement, je veux expliquer comment ce dernier changement dans nos vies privées engendre des choses encore pires, et la manière dont vous continuerez à en perdre le contrôle si vous restez sur Facebook.
L’usage de Facebook exige de vous suivre à la trace, de connaître ce que vous achetez, vos informations financières comme les comptes bancaires et les numéros de carte de crédit. Vous avez donné votre accord dans les nouvelles « conditions de service ». Ils ont déjà commencé à partager des données avec Mastercard. Ils utiliseront le fait que vous êtes restés sur Facebook comme « la permission » d’échanger avec toutes sortes de banques et institutions financières afin d’obtenir vos données d’eux. Ils diront que c’est anonyme, mais comme ils dupent vos amis pour qu’ils dévoilent vos données aux tiers avec des applications, ils créeront des échappatoires ici aussi.
Facebook insiste aussi pour suivre à la trace votre emplacement via le GPS de votre téléphone, partout et tout le temps. Il saura exactement avec qui vous passez votre temps. Il connaîtra vos habitudes, il saura quand vous appelez au travail pour vous déclarer malade, alors que vous êtes au bowling. « Machin a aimé : « bowling à Secret Lanes a 14h. » ». Ils sauront si vous faites partie d’un groupe d’entraide de toxicomanes, ou allez chez un psychiatre, ou un médium, ou votre maîtresse. Ils sauront combien de fois vous êtes allé chez le médecin ou à l’hôpital et peuvent le partager avec d’éventuels assureurs ou employeurs. Ils sauront quand vous serez secrètement à la recherche d’un travail, et vendront votre intérêt pour des sites de recherche de travail à vos amis et collègues – vous serez dévoilé.
Ils sauront tout ce qui peut être révélé par votre emplacement et ils l’utiliseront pour faire de l’argent.
Et – tout sera fait rétrospectivement. Si vous restez sur Facebook après le 30 janvier, il n’y a rien qui empêchera tout vos emplacements et vos données financières passés d’être utilisées. Ils obtiendront vos localisations passées avec vos amis vérifiés – donc avec vous, et les données GPS stockées dans les photos ou vous êtes identifiés ensemble. Ils extrairont vos vieux relevés financiers – ce médicament embarrassant que vous avez acheté avec votre carte de crédit il y a 5 ans sera ajouté à votre profil pour être utilisé selon les choix de Facebook. Il sera vendu à maintes reprises et probablement utilisé contre vous. Il sera partagé avec des gouvernements et sera librement disponible pour des tas d’entreprises « tierces » qui ne vendent rien que de données personnelles et éliminent irréversiblement votre vie privée.
Désormais c’est irréversible.
Les données relatives à votre géolocalisation et vos moyens financiers ne sont pas seulement sensibles, elles permettent à des entreprises tierces (extérieures à Facebook) de dés-anonymiser des informations vous concernant. Cela permet de récolter toutes sortes d’informations disponibles sur vous, y compris des informations recoupées que vous n’avez pas spécifiées. C’est un fait que même Facebook lui-même ne parvient pas à maintenir totalement le caractère privé des données – on ne peut pas dire que ça les préoccupe, d’ailleurs.
C’est sans précédent, et de même que vous n’avez jamais pensé que Facebook puisse revendre vos libertés lorsque vous vous êtes inscrits en 2009, il est trop difficile de prédire quels revenus Facebook et les vendeurs de données tiers vont tirer de cette nouvelle énergie dormante.
C’est simplement une conséquence de leurs nouveaux modèles économiques. Facebook vous vend au plus offrant, parce que c’est comme cela qu’ils font leur beurre. Et ils subissent des pressions monstrueuses de leurs investisseurs pour en faire plus.
Qu’est-ce que vous pouvez faire de plus à ce sujet ? Facebook vous offre deux possibilités : accepter tout cela ou sauter du bus Facebook.
Pour être honnête, ce bus est de plus en plus fou et pue un peu, n’est-ce pas ? Il y a de plus en plus de problèmes qui prennent des proportions sidérantes. Entre vous et moi, je doute que les choses s’orientent vers quelque chose de rationnel un jour…
Comment se tirer de ce pétrin
Image par Kvarki1 (CC BY-SA 3.0 ), via Wikimedia Commons
D’après la décision de justice rendue il y a quelques années par le FTC (Federal Trade Commission, NdT), après que Facebook a été poursuivi par le gouvernement des États-Unis pour ses pratiques en matière de vie privée, Facebook est « tenu d’empêcher que quiconque puisse accéder aux informations d’un utilisateur plus de 30 jours après que cet utilisateur a supprimé son compte ».
On peut l’interpréter de différentes façons. Certains disent qu’il faut supprimer chacune de vos publications, une par une ; d’autres disent qu’il faut supprimer votre compte, et d’autres disent qu’ils garderont vos données quand même – tout ce que vous pouvez faire, c’est arrêter de leur donner plus d’informations. Et puis, il y a les courtiers en données qui travaillent avec Facebook, qui ont déjà récupéré vos informations.
Donc supprimer votre compte Facebook (pas simplement le désactiver) est nécessaire pour arrêter tout ça, puis il y a quelques autres étapes à suivre pour tenter de réparer les dégâts :
Récupérez vos photos. J’ai utilisé cette application Android puisque l’outil Facebook ne vous permet pas de récupérer toutes vos photos, ni dans leur résolution maximale (j’ai aussi téléchargé la page avec ma liste d’amis, simplement en faisant défiler la page jusqu’en bas pour charger tout le monde, puis en cliquant sur Fichier -> Enregistrer. Honnêtement, je n’ai pas eu besoin du fichier jusqu’à présent. Il s’avère que je n’ai pas besoin d’un ordinateur pour savoir qui sont mes amis).
Ensuite, il y a toutes les applications que vous avez utilisées. C’est l’une des plus grosses failles de Facebook, car cela leur permet de dire qu’ils ne peuvent pas contrôler ce que les applications font avec vos données une fois que vous les leur avez données. Du coup, j’ai sauvegardé sur mon disque dur la page de paramètres qui montre quelles applications j’ai utilisées, et j’ai désactivé l’accès de chacune d’elles manuellement. Chacune de ces applications a sa propre politique de confidentialité – la plupart sont une cause perdue et prétendent avoir des droits illimités sur mes informations, donc je les coupe simplement et je passe à autre chose.
Facebook pourra toujours vous pister avec un « compte fantôme », mais cela peut-être bloqué.
Pour empêcher Facebook (et consort) de surveiller ce que je lis sur internet (ils le font même si vous n’avez pas de compte), j’utilise Firefox avec l’option « Ne pas me pister » activée.
Si vous n’utilisez pas Firefox, EFF a un plugin pour votre navigateur appelé Privacy Badger (et pendant que l’on y est, l’EEF a fait en sorte que ce plugin génial choisisse automatiquement le serveur qui dispose de la connexion la plus sécurisée, cela rend plus difficile d’intercepter votre activité numérique pour l’industrie de l’information).
Mise à jour 2017 : au début, je pensais essayer des alternatives à Facebook. Je ressentais un besoin de remplacer Facebook par quelque chose de similaire comme Diaspora, mais l’e-mail et le téléphone se sont révélés bien meilleurs ! Après un mois sans Facebook, je n’ai plus ressenti le besoin de le remplacer. Les coups de téléphone ont suffi, figurez-vous. Tout le monde en a déjà un, et on oublie combien ils sont super faciles et pratiques à utiliser. Je vois moins de photos, mais je parle à des gens pour de vrai. Plus récemment, nous sommes tous allés sur un grand salon de messagerie instantanée. Je recommande actuellement Signal pour faire ça. Vous pouvez faire des appels, chatter et partager des photos de façon chiffrée, et très peu de choses sont stockées sur leurs serveurs. En fait, c’est bien mieux que Facebook, puisque c’est plus instantané et personnel.
Si vous avez d’autres idées ou conseils, merci de me joindre. Je considère ceci comme une étape responsable pour éviter qu’on me prive de ma liberté, et celle de ma famille et mes amis, et que nos relations personnelles en pâtissent.
Gardez bien à l’esprit que ce n’est pas juste une question technique. En restant sur Facebook, vous leur donnez l’autorisation de collecter et d’utiliser des informations sur vous, même si vous n’utilisez pas Internet. Et en y restant, les données qu’ils collectent sur vous sont utilisées pour créer des modèles sur vos amis proches et votre famille, même ceux qui ont quitté Facebook.
Internet est libre et ouvert, mais ça ne veut pas dire que nous acceptons d’être espionnés
Pour finir, le monde est rempli de gens qui disent « ça n’arrivera jamais », et quand cela finit par arriver, cela se change en « on ne peut rien y faire ». Si, on peut. Internet a été décentralisé pendant 50 ans, et contient un tas de fonctionnalités faites pour nous aider à protéger nos vies privées. Nous avons notre mot à dire sur le monde dans lequel nous voulons vivre – si nous commençons par agir à notre niveau. Et en plus, nous pouvons aider tout le monde à comprendre, et faire en sorte que chacun puisse faire son propre choix éclairé.
Cet article a maintenant été lu par 1 000 000 personnes. C’est un signe fort que nous pouvons nous informer et nous éduquer nous-mêmes !
Merci de partager ceci avec les gens qui vous sont importants. Mais honnêtement, même si cet article est vraiment populaire, il est clair que beaucoup de gens pensent savoir ce qu’il contient. Partager un lien n’est jamais aussi efficace que de parler aux gens.
Si vous avez lu jusqu’ici et que vous voulez partager avec un proche, je vous suggère de faire ce que j’ai fait – décrochez votre téléphone.
Une question pour vous
Cet article a été écrit en réaction à la politique de confidentialité de janvier 2015, il y a 2 ans. Ça a toujours été un article populaire, mais en janvier 2017, il a connu un pic de popularité. Je me demande bien pourquoi, et ça serait sympa si vous pouviez me dire ce que vous en pensez, par Twitter ou par e-mail.
Je me demande pourquoi mon article sur la vie privée sur Facebook (qui date de plusieurs années) subit une vague de popularité depuis la semaine dernière. Des idées ?
– Salim Virani (@SaintSal) 8 janvier 2017
Sources
Une petite note sur la qualité de ces sources : j’ai essayé de trouver des références dans des médias majeurs, avec tout un échantillon de biais politiques. Ces articles sont moins précis techniquement, mais on peut s’attendre à ce qu’ils soient plus rigoureux que les blogs pour vérifier leurs sources. Pour les aspects plus techniques, d’autres sources comme The Register sont certainement plus crédibles, et Techcrunch est notoirement peu fiable en matière de fact-checking. J’ai toutefois inclus certains de leurs articles, parce qu’ils sont doués pour expliquer les choses.
Articles en anglais
Facebook likes reveal sensitive personal information eff.org
Private traits and attributes are predictable from digital records of human behavior pnas.org table of top likes
New Facebook Policies Sell Your Face And Whatever It Infers forbes.com
Quand il n’y avait pas (ou peu) d’autres choix éthiques, ce dialogue était inimaginable. Mais ça, c’était avant.
Conjuguons l’affreux verbe « Skaïper » au passé !
Mais si, vous connaissez Skype ! C’est un de ces logiciels/réseaux sociaux/services qui, par défaut, ne se ferment pas quand vous appuyez sur la croix, s’allument dès le démarrage de votre ordi, sont retors à désinstaller et à quitter, vous collent des notifications à tout va et sont installés de base sur votre ordinateur (qu’on vous a forcé à acheter avec un Windows dessus)…
Normal : ce cauchemar de libriste, ce logiciel qui veut contrôler vos comportements au lieu de vous laisser « maîtres » de votre machine, est un des fleurons de Microsoft. Au-delà de la faute de goût linguistique (« Skaïper »… -_- ), le danger est grand. Chaque compte Skype est désormais un compte Microsoft, et leur nouvelle fonctionnalité de traduction automatique de vos échanges audio nous apprend que Microsoft est désormais capable de scanner vos conversations et les transformer en textes. Le texte, c’est facile et très peu coûteux à archiver, à indexer, à analyser… Une manne incroyable pour les publicitaires qui enrichissent les GAFAM sur notre dos !
Au-delà de Microsoft-Skype, le monde des conversations audio/vidéo en ligne n’est pas beaucoup plus reluisant… Facebook déguise son Messenger en appli de téléphone tout en captant vos données sur Whatsapp (sauf si vous faites cela), Google ressert ses Hangouts à toutes les sauces (non mais Allo, quoi !), Apple ne jure que par Facetime… Pendant que Discord (qui a néanmoins le bon goût d’utiliser la technologie WebRTC) grimpe en flèche chez les gamers. Avec plus de 11 millions d’utilisateurs il détrône de fait Teamspeak, et Mumble l’outsider libre… Or nous avons déjà vu avec Microsoft-Skype ce qu’il se passe lorsqu’on laisse trop de monde mettre sa vie numérique dans le panier d’un seul et même logiciel non-libre…
De son côté, la fondation Mozilla annonce la fin de la prise en charge de Hello, un outil de conversations audio/vidéo qui était inclus dans leur navigateur Firefox… mais qui ne le sera plus à partir de la version 49 du panda roux. Et nous, on a envie de lui faire des câlins, au panda roux, tant il en faut pour le consoler.
Framatalk : une conversation audio/vidéo en deux clics
Voici donc une solution imparfaite mais libre… et simple ! C’est un des gros avantages de Framatalk : sa simplicité d’utilisation. Nul besoin de créer un compte, il vous suffit d’aller sur Framatalk.org pour :
Créer un salon en saisissant votre nom (l’adresse Web sera framatalk.org/NomQueVousAvezChoisi)
Autoriser votre navigateur à utiliser votre micro et votre caméra
Partager l’adresse Web du salon avec votre interlocuteur pour qu’il vous rejoigne
… et discuter !
C’est aussi simple que ça.
Bien entendu, vous trouverez tout un tas de petites options faciles à comprendre, dont :
Un tchat pour discuter en mode texte (il vous faudra entrer un pseudo)
Un bouton d’invitation à la conversation (partage par email de l’adresse web du salon)
Des boutons pour activer/désactiver le micro, la caméra, le mode plein écran
Un accès aux paramètres (modifier son pseudo, sa caméra, son micro)
La possibilité que Framatalk retienne votre profil de paramètres (il créera un cookie)
Les droits de modération du salon (pour la première personne arrivée)
La possibilité de protéger le salon par mot de passe (pour le modérateur)
Tous ces détails sont d’un usage intuitif et sont résumés dans la barre des boutons en haut ou à gauche de l’écran de votre salon Framatalk. Tant de simplicité nous permet de tenter un record, ici et maintenant (appelez le Guiness Book !) :
4. Partagez l’adresse web pour converser avec vos ami-e-s !
Oui, c’est tout.
Avec Framatalk, vous n’aurez plus à accepter de vous faire skyper contre votre gré.
Libre et imparfait ? — On va quand même le faire…
Soyons honnêtes : la solution que nous vous proposons n’est pas parfaite. Depuis plus de neuf mois, nous avons testé de nombreux services libres, et aucun n’est (pour l’instant et à nos yeux) parfait. Alors entre Vroom.im, Spreed.me, Hubl.in et bien d’autres… nous avons choisi Jitsi Meet !
Framatalk est donc une instance de Jitsi Meet (une parmi d’autres, dont celle des développeurs). C’est un logiciel développé en JavaScript, qui utilise la technologie WebRTC, et qui est sous licence Apache 2.0. C’est surtout le logiciel permettant de créer des salons de discussions audio/vidéo qui a le mieux supporté nos tests et notre cahier des charges.
Par ailleurs, nous vous conseillons de désactiver l’affichage de la vidéo (le petit bouton « caméra ») si vous n’avez pas une connexion bien solide. Tout simplement parce que les échanges vidéos fonctionnent, mais demandent une bande passante importante (un abonnement Internet de type fibre) si on ne veut pas souffrir de ralentissements et autres voix mécaniques…
Donc voilà : Framatalk est imparfait, et a des limitations que les géants du Web ne connaissent pas. Le problème, c’est que les GAFAM investissent grandement pour s’enrichir grâce à vos données (et donc vos vies) numériques, et qu’il faut réagir et proposer une alternative sans espionnage / profilage publicitaire.
Notre espoir, c’est que plus nous serons nombreuses et nombreux à utiliser Jitsi Meet (ou d’autres solutions libres), plus cela motivera les communautés à trouver des solutions et des moyens. Donc, si le principe vous plaît, n’hésitez pas à aller participer au code de Jitsi Meet !







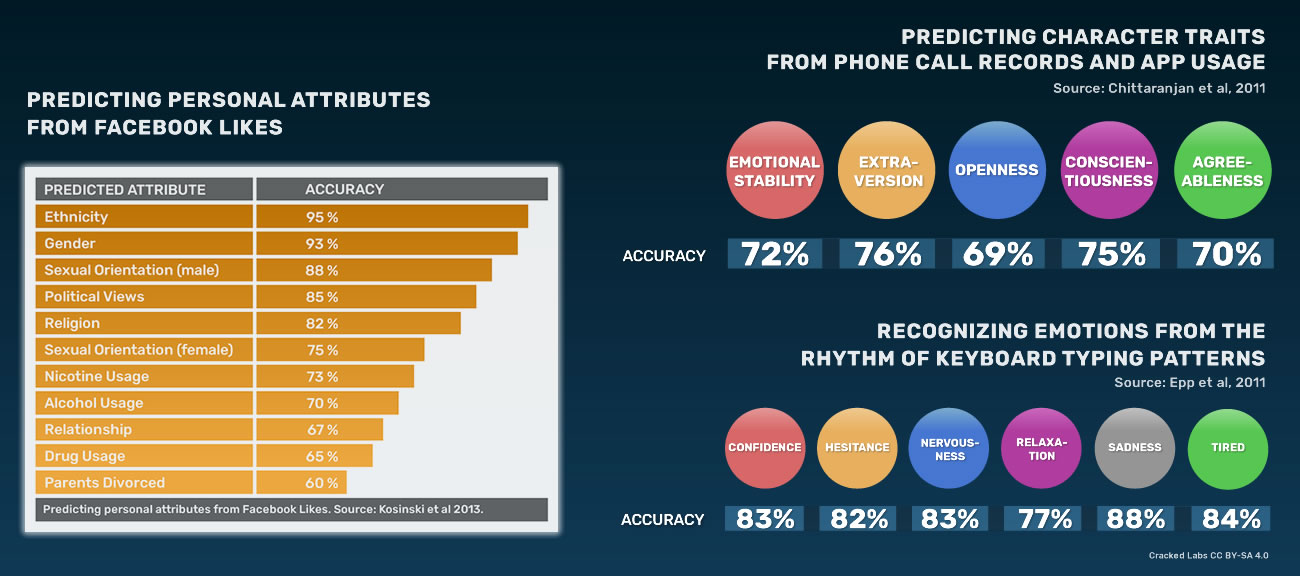
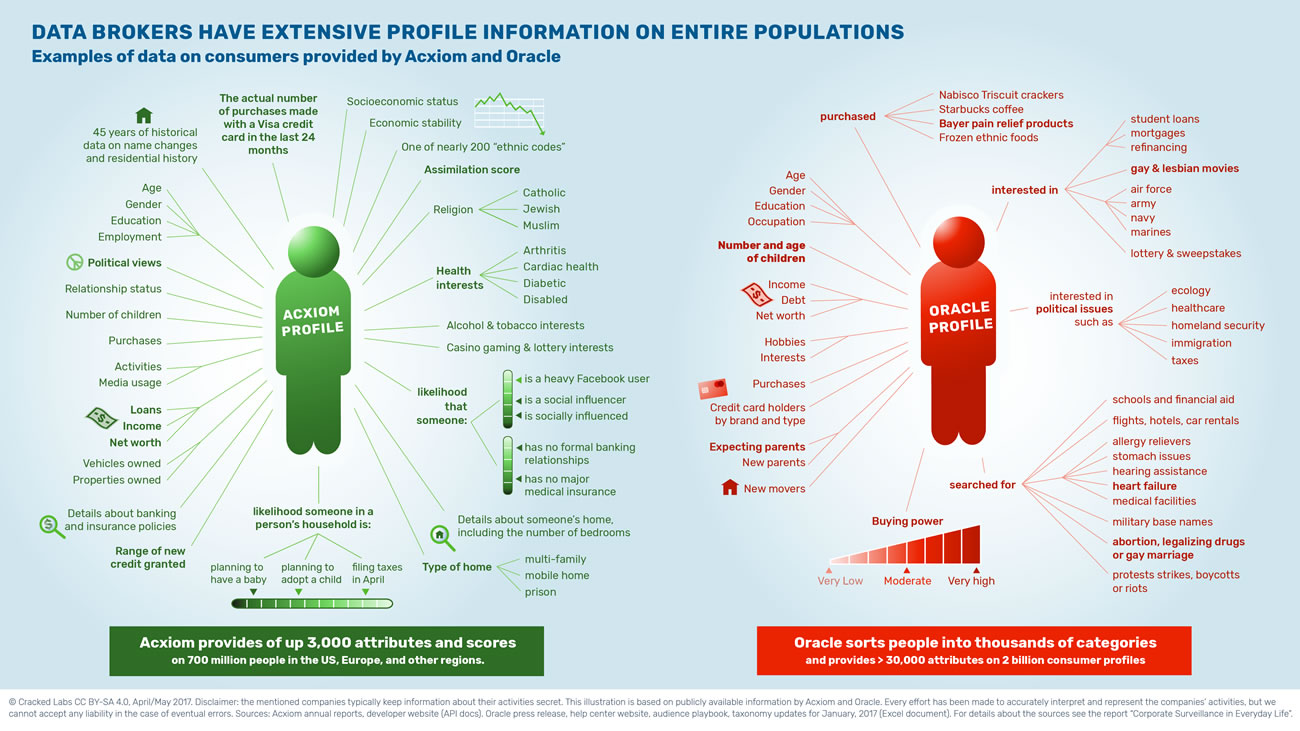
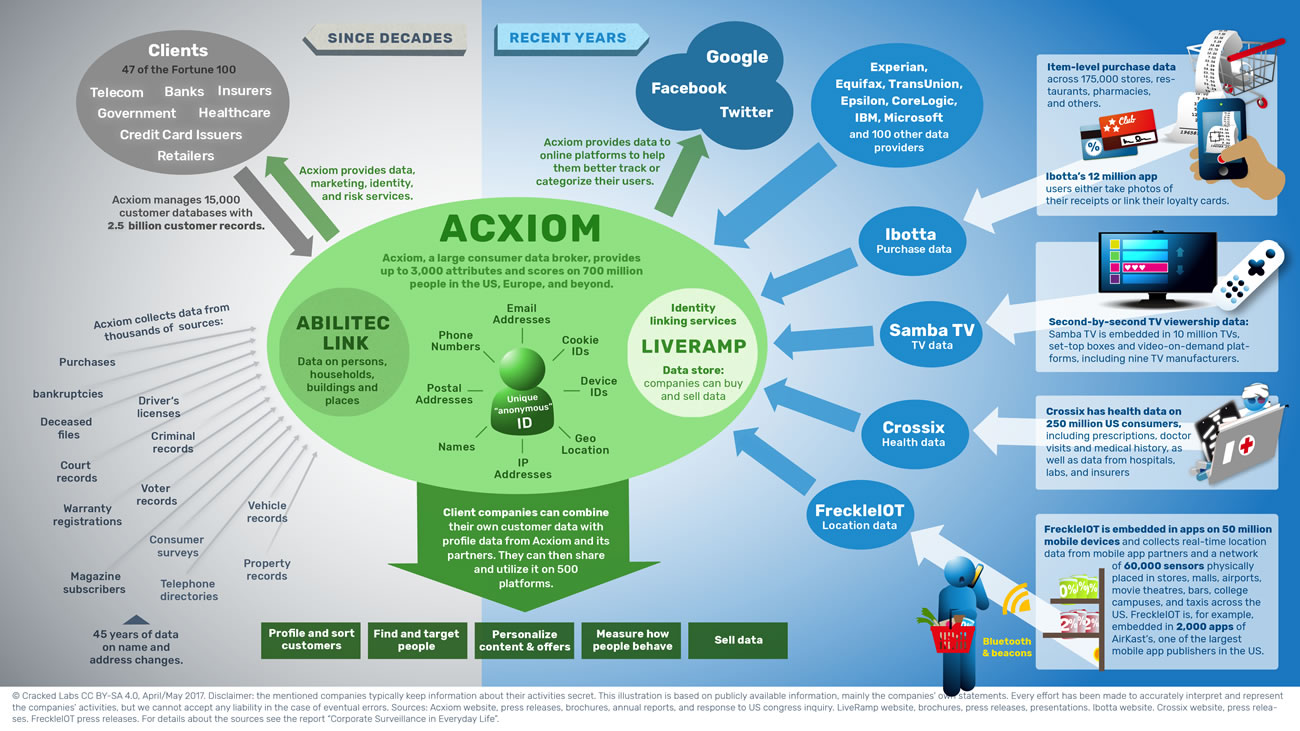
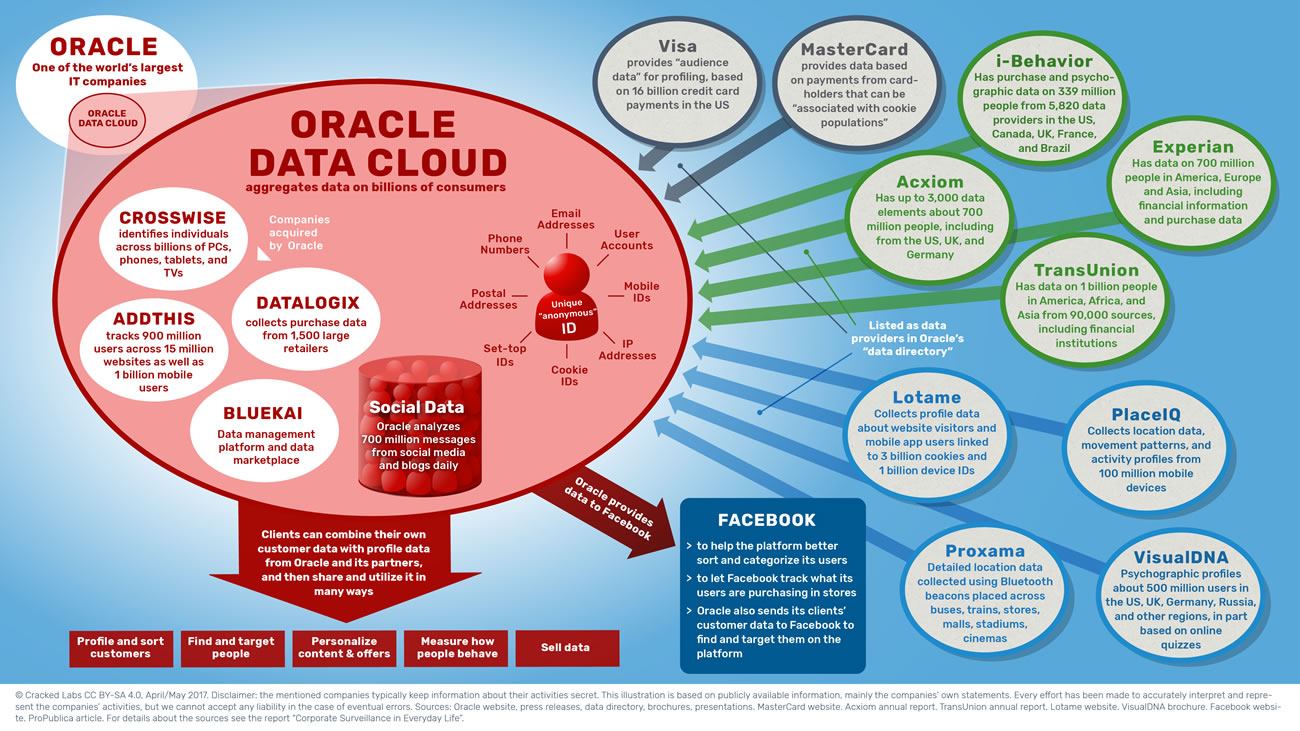
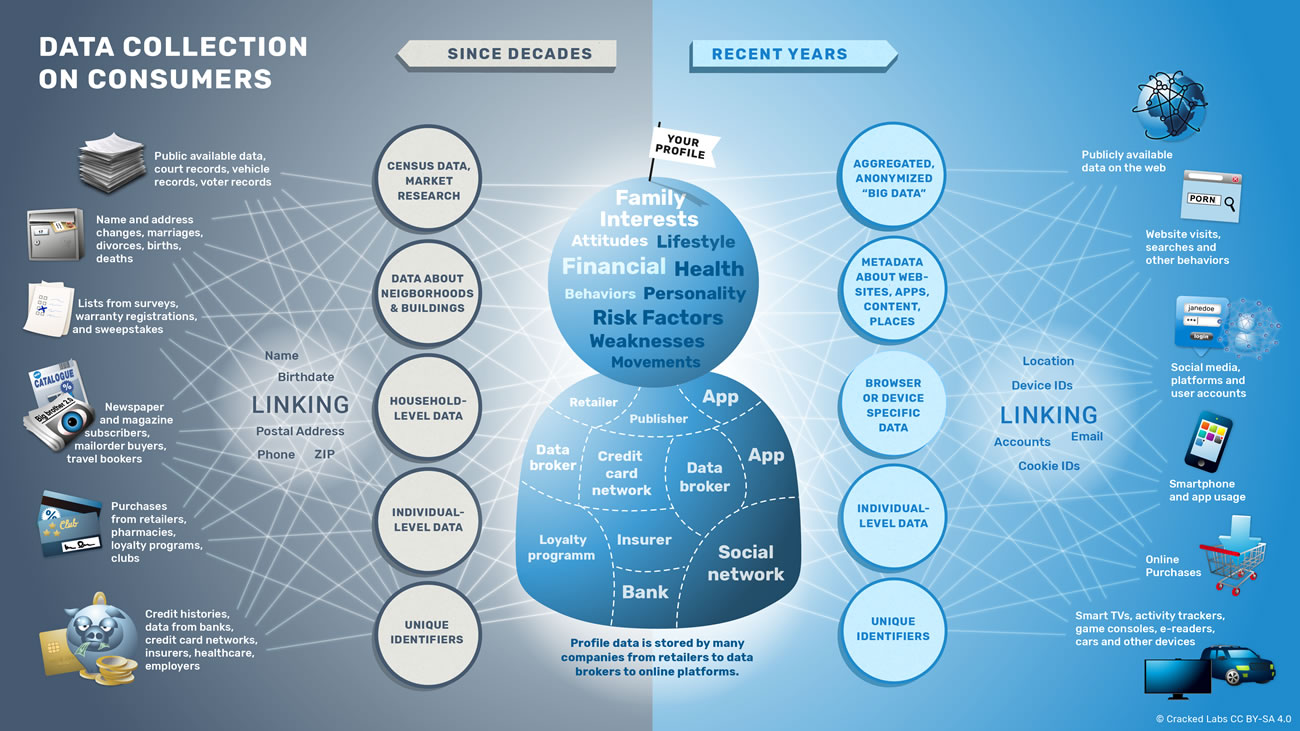

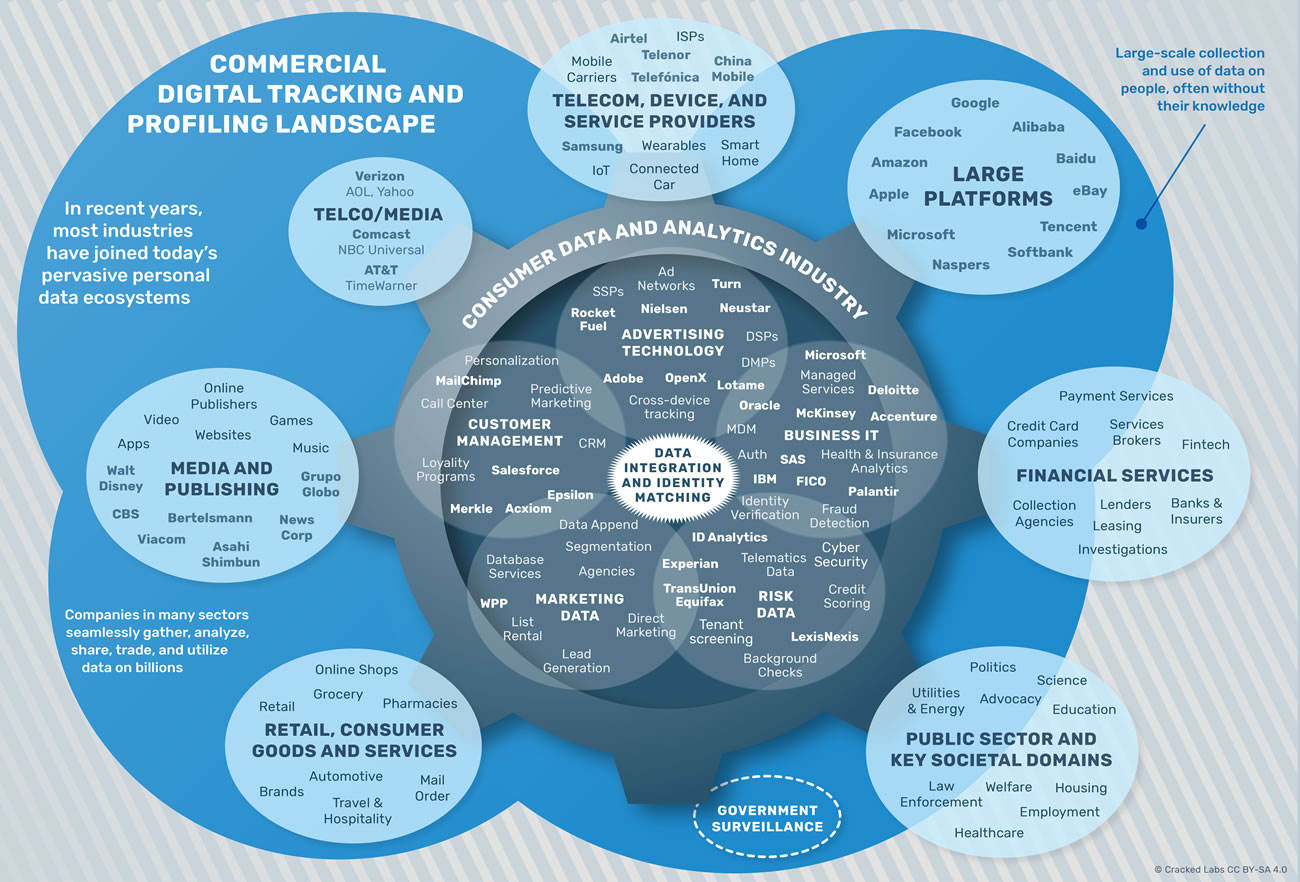
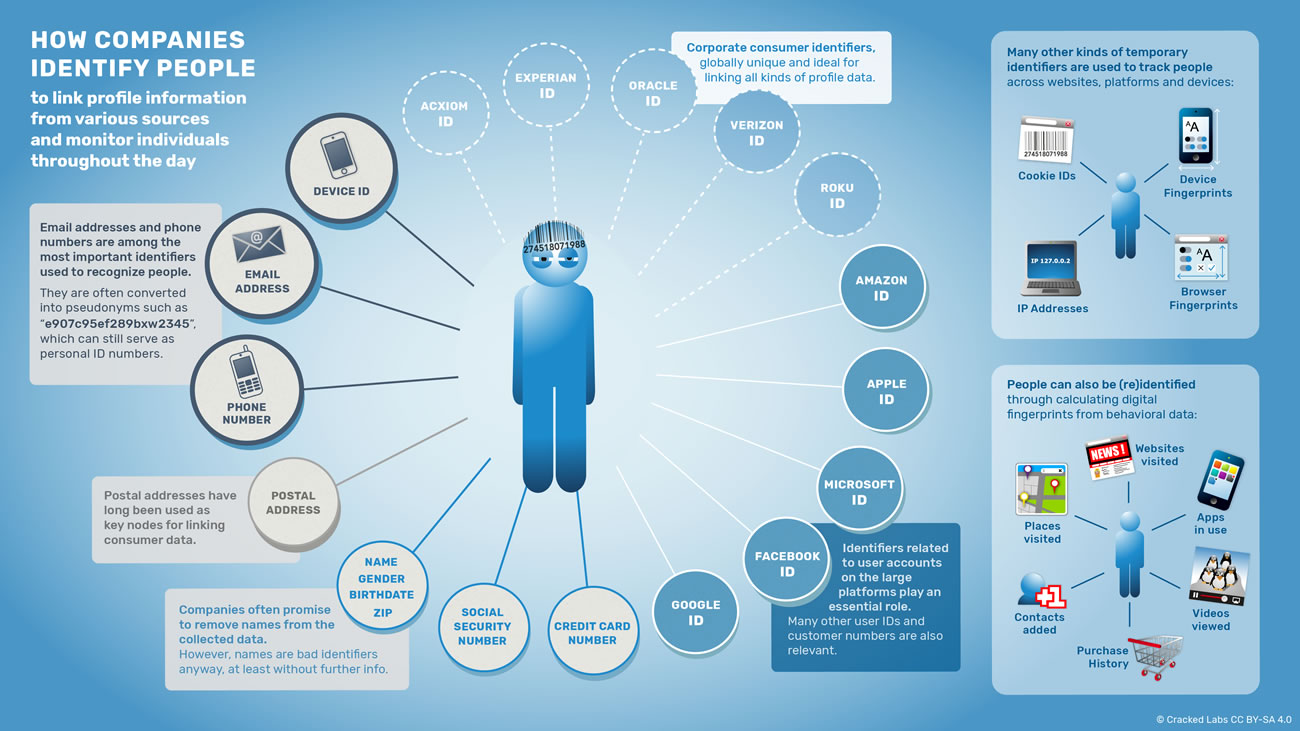
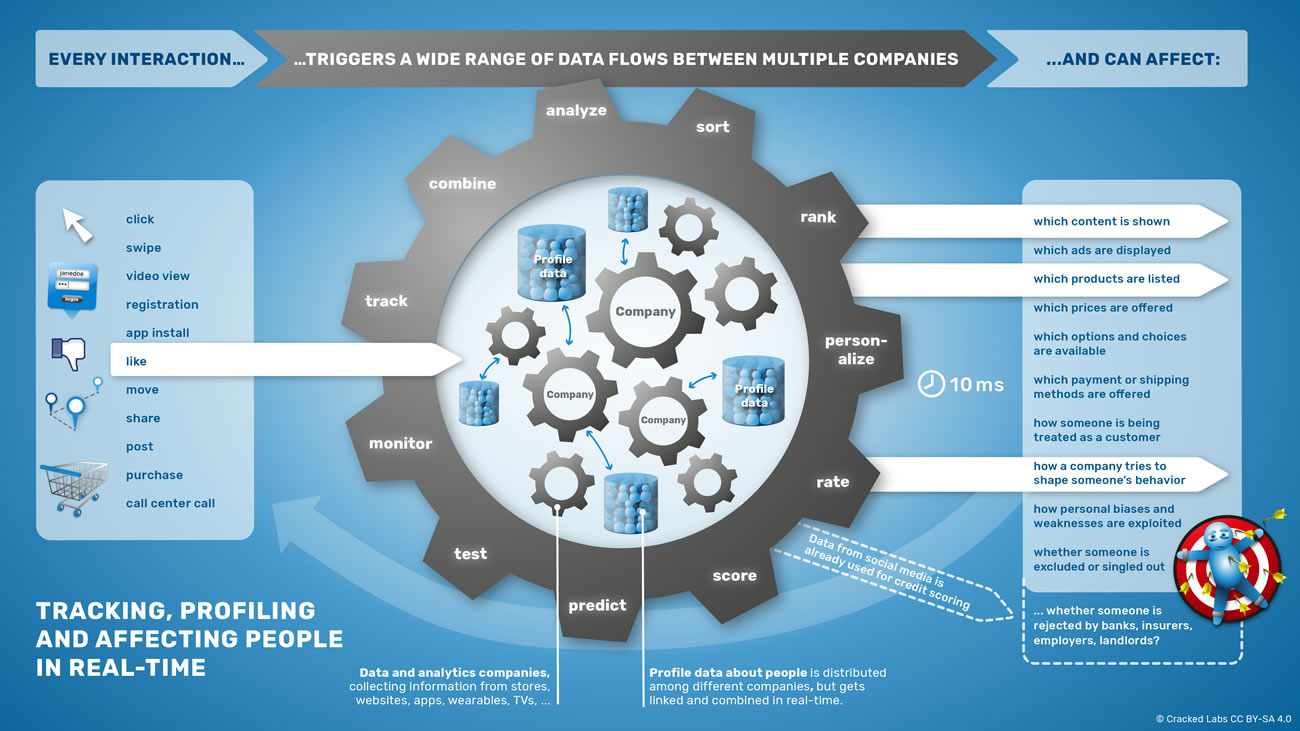
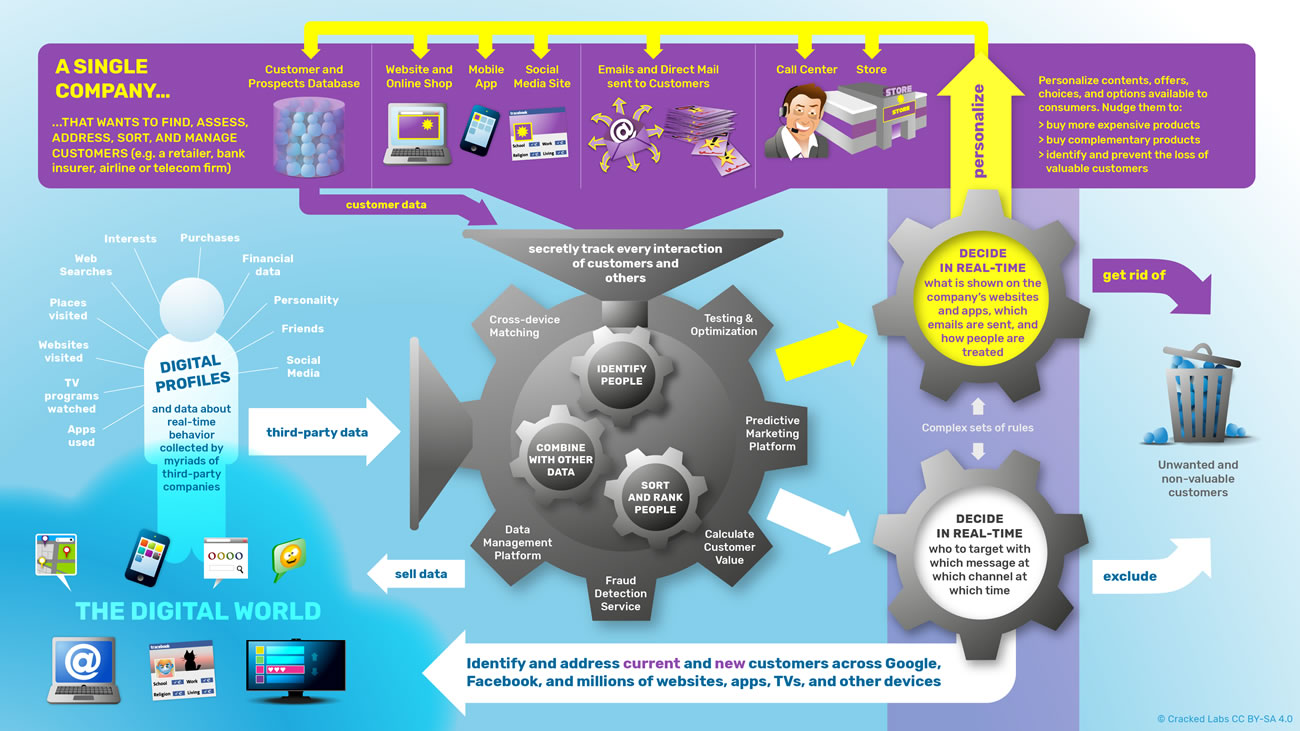
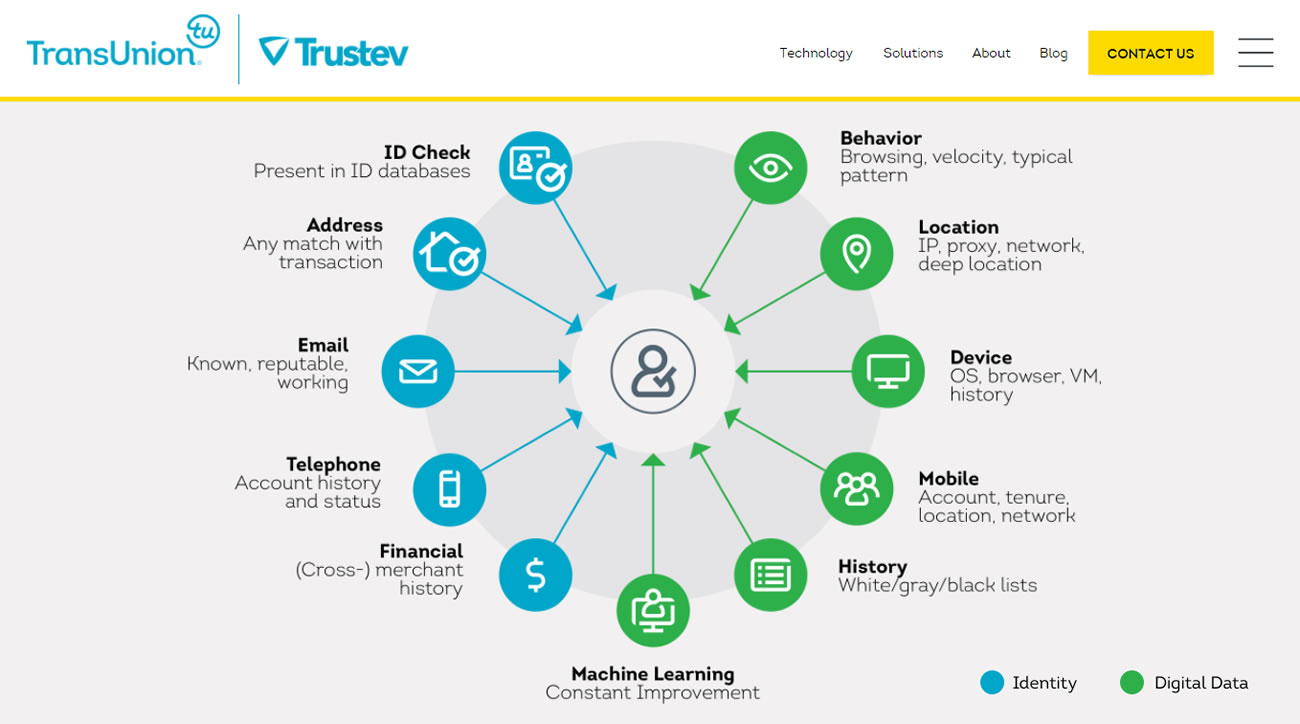
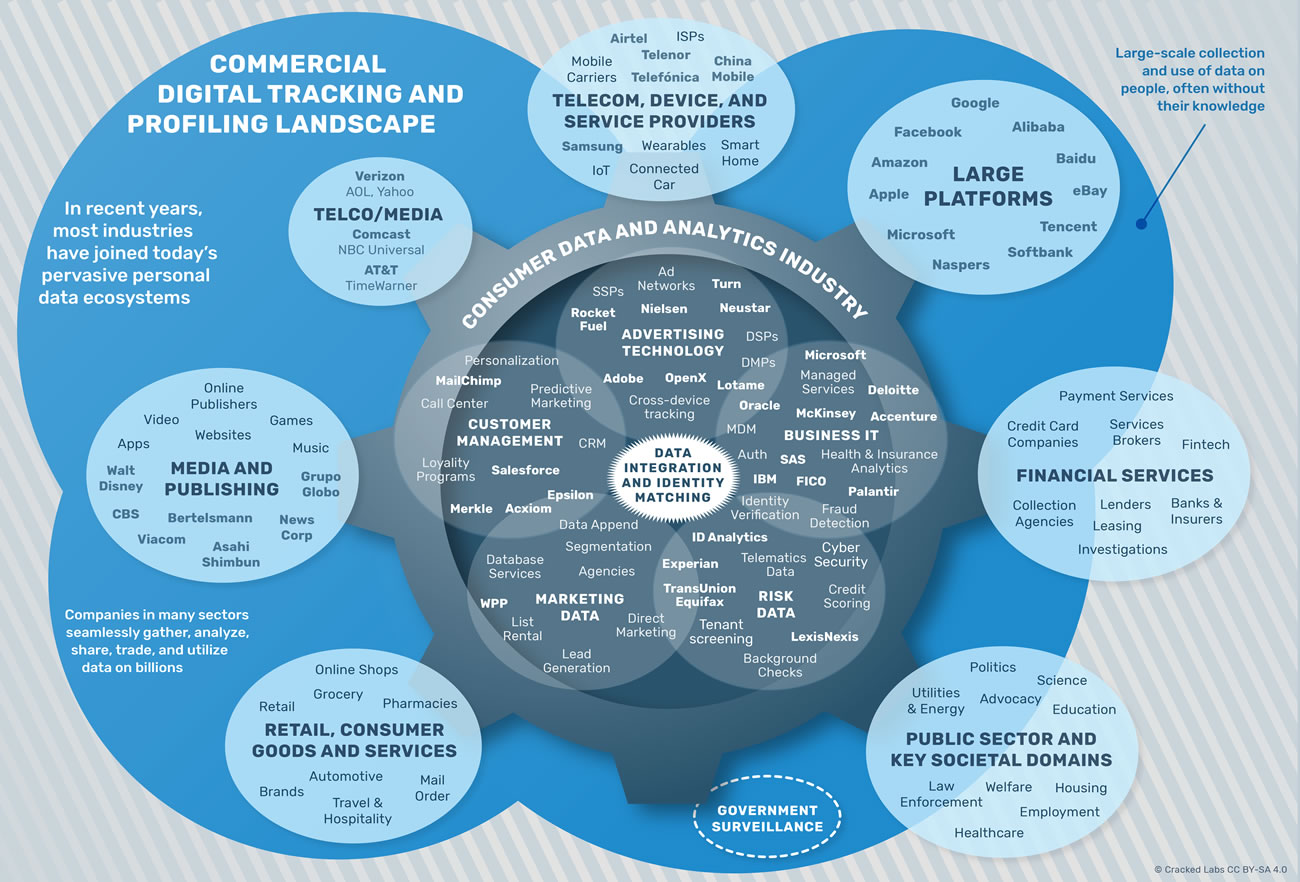
 par Aral Balkan
par Aral Balkan



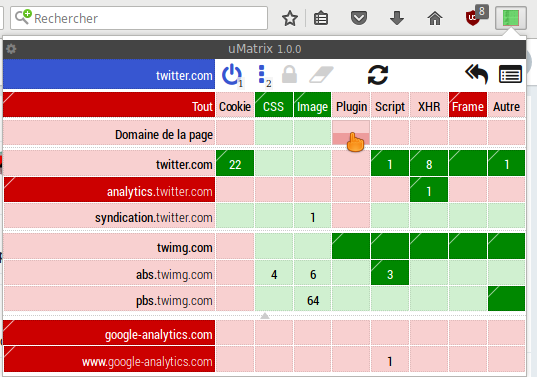

 J’ai écrit ce qui suit pour ma famille et mes proches, afin de leur expliquer pourquoi les dernières clauses de la politique de confidentialité de Facebook sont vraiment dangereuses. Cela pourra peut-être vous aider aussi. Une série de références externes, et des suggestions pour en sortir correctement, se trouvent au bas de cet article.
J’ai écrit ce qui suit pour ma famille et mes proches, afin de leur expliquer pourquoi les dernières clauses de la politique de confidentialité de Facebook sont vraiment dangereuses. Cela pourra peut-être vous aider aussi. Une série de références externes, et des suggestions pour en sortir correctement, se trouvent au bas de cet article.





![Kae [CC BY-SA 3.0 (https://creativecommons.org/licenses/by-sa/3.0)], via Wikimedia Commons](https://commons.wikimedia.org/wiki/File:Power_connector_Legrand_32A.jpg){kind=link}
_-_Google_Art_Project_-_edited.jpg){kind=link}
![Codex Bodmer – Frater Rufillus (wohl tätig im Weißenauer Skriptorium) [Public domain]](https://commons.wikimedia.org/wiki/File:Codex_Bodmer_127_244r_detail_Rufillus.jpg){kind=link}