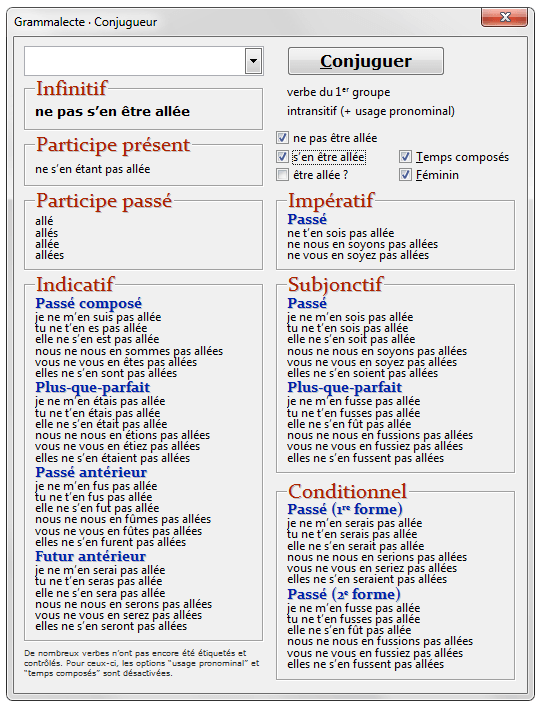
La thermodynamique peut-elle casser des briques ?
L’équipe Framabook est très fière de vous annoncer la sortie de son premier manuel scolaire : Thermodynamique de l’ingénieur. Ce manuel universitaire, à destination des étudiant-e-s comme de leurs enseignant-e-s, est signé Olivier Cleynen, et disponible sous la licence CC-BY-SA…
L’occasion d’une rencontre drôle et intéressante avec cet auteur qui a fait le pari du livre Libre !

Bon, Olivier, je serai honnête, on se demande comment tu as pu en arriver là. Tu n’es pas un poussin de l’année qui découvre le monde du Libre : si j’en crois ton ancien blog, dès ton premier billet en 2007 tu déclares ta flamme au logiciel libre, en établissant du reste un lien très net entre logiciel libre et société libre. Pourrais-tu te présenter succinctement et évoquer ta trajectoire de libriste ?
Ma trajectoire n’est en fait pas réellement exceptionnelle. Je suis ingénieur aéronautique de formation et j’ai découvert le logiciel libre et son univers pendant mes études. Il y a des gens pour qui ça « prend » plus que pour d’autres… en 2006 j’ai co-fondé puis dirigé à plein temps pendant deux ans une association à but non-lucratif de promotion du logiciel libre qui ressemblait un peu à Framasoft. J’ai essayé sans succès d’en vivre, puis, je suis devenu prof en école d’ingénieurs : c’est là que j’ai commencé ce livre. J’effectue maintenant une thèse de doctorat dans l’espoir de me faire une petite place dans l’enseignement supérieur.
Question No124 (mais, à la demande d’Olivier, la voici en 2e position) : pourrais-tu résumer la thermodynamique en un tweet (140 signes) ?
Bon, je tente l’expérience, mais j’ai droit à plusieurs essais, alors…
« Tiens, je me demande comment le frigo fait pour refroidir le pack de bières alors qu’il est déjà plus froid que dehors… »
« Comment ça, le moteur de voiture n’a que 30% d’efficacité ? On est obligés de rejeter 70% de la chaleur par le pot d’échappement ? »
« @JamesPrescottJoule Au fait, c’est quoi, chaud ? Une sorte de fluide bizarre invisible ? Est-ce qu’on peut fabriquer du chaud ? »
« @WilliamThomsonKelvin Et 40°C, c’est deux fois plus chaud que 20°C ? Et si oui, alors qu’est-ce qui est deux fois plus chaud que -10°C ? »
« @LudwigEduardBoltzmann Pourquoi ma tasse de thé chaud va toujours se refroidir toute seule, et jamais se réchauffer ? HEIN, POURQUOI ???? »
La réponse à chacun de ces tweets demande de comprendre ce que c’est que la chaleur, comment on la fabrique, comment on la détruit, comment on la transforme. C’est ce qu’on appelle thermodynamique. De là, les physiciens enchaînent sur tout un tas de questionnements : la notion d’échelle microscopique ou macroscopique, la notion d’état, d’équilibre, le sens des transformations, etc. Les ingénieurs (le camp dont je fais partie) cherchent plutôt à bidouiller la chaleur dans des machines, et se servent de la thermodynamique pour comprendre les moteurs et les rendre plus efficaces, ou plus puissants, ou plus réactifs, etc. Quoi qu’il en soit, c’est passionnant : on commence par étudier de petits ballons de gaz, et on finit par prédire la fin de l’univers ! Ah zut, la réponse fait plus de 140 caractères !
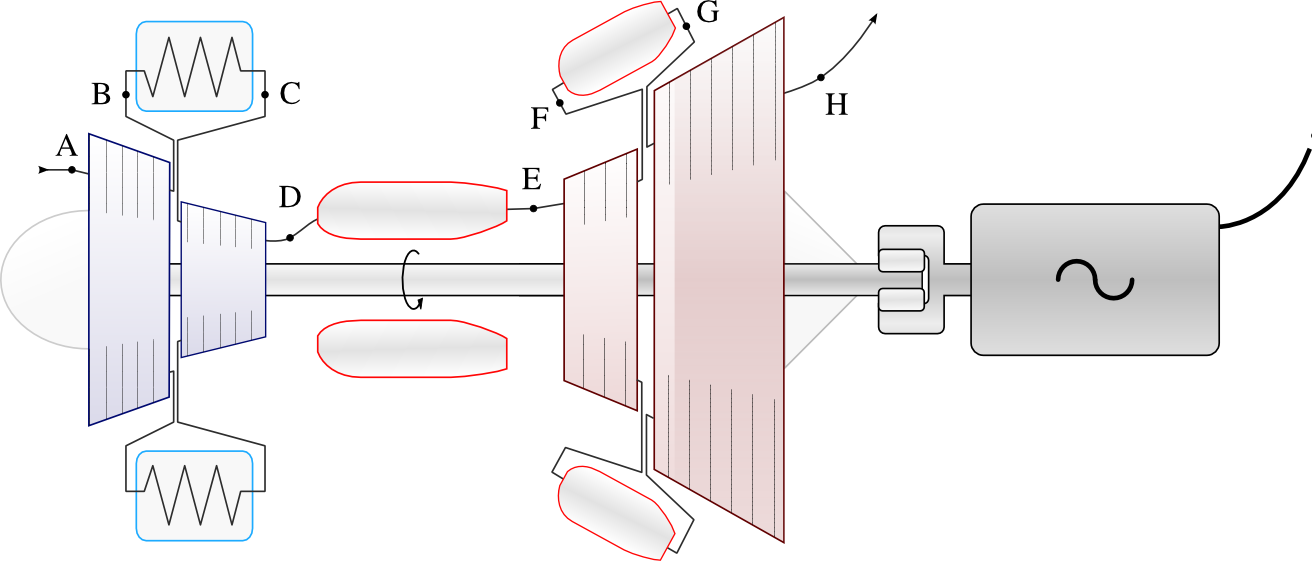
(CC-BY-SA Olivier Cleynen)
Pourquoi avoir choisi de porter tout ton effort et pendant si longtemps (plusieurs années tout de même !) sur ce manuel de thermodynamique ? Les livres existants n’étaient pas suffisants ?
Il y deux faces à la réponse. D’une part, je trouve la plupart des livres français de thermodynamique terriblement tristes et ennuyeux. Je trouve dommage de se casser la tête à résoudre des équations qu’on comprend à peine pendant deux semestres, si c’est pour ressortir de la thermodynamique sans jamais avoir étudié le fonctionnement d’un turboréacteur. J’avais envie de faire un cours « pour futur-es ingénieur-es curieux-ses », et avec le temps le cours a pris la forme d’un livre.
Mais la plus grande motivation est que je n’ai rien trouvé de libre à me mettre sous la dent ! La thermodynamique de l’ingénieur est terminée depuis 150 ans et les technologies que l’on y étudie aujourd’hui ont toutes au moins 50 ans : un livre de thermo, c’est donc essentiellement un remix. C’est dur de voir que ces équations, ces raisonnements et ces schémas qui font partie du patrimoine scientifique et public au sens large, sont affublés d’une mention « reproduction interdite ». Dans certains livres, c’est même écrit à toutes les pages…
De ce point de vue, non, les livres existants n’étaient pas suffisants. Je trouve que ce n’est pas assez bien de pousser des étudiants à acheter un livre vendu quarante euros (un par matière…) qui leur défend solennellement d’en repiquer le contenu. C’est triste de voir un éditeur distribuer les JPG des figures aux seuls profs qui engendreront quarante ventes d’un livre. Et c’est frustrant, lorsqu’on débute un cours, de devoir tout ré-écrire et dessiner depuis zéro, du premier diagramme pression-volume jusqu’au dernier schéma de turbine.
J’ai construit le livre que j’avais envie de trouver quand j’ai commencé. Tu peux le copier, le reprendre, le ré-utiliser. Un schéma t’intéresse ? Tu télécharges le PDF, tu cliques sur la légende, et te voilà face au fichier source sur Wikimedia Commons, que tu peux modifier selon tes besoins. Tu préfères un format « polycopié » du chapitre 8 avec des grandes marges ? Tu pointes ton navigateur sur http://thermodynamique.ninja/ et tu imprimes. Tu veux reprendre une série d’équations en LaTeX sans les retaper, ou tu veux soumettre un patch pour corriger une erreur ? La même page web te pointe vers le dépôt git du projet. Tout ça se fait sans demander de permission, il suffit de respecter les termes de la licence Creative Commons : BY-SA pour le texte et la plupart des figures, et CC-0 pour les schémas les plus simples.
Dis-donc je l’ai parcouru ton ouvrage, d’accord il est parfaitement bien rangé dans des tiroirs avec un sommaire et des sous-parties aux petits oignons mais tout de même ça déborde de partout : histoire des sciences, biographies de quelques savants, une série de cours progressifs, des schémas et des croquis, des trucs pour aller plus loin… et surtout des exercices avec des cas de figure qui impliquent l’étudiant… brr ça fait un peu peur tout ça non ?
Alors, il ne faut pas avoir peur : c’est un gros livre, on n’est pas obligé de tout lire ! On s’y retrouve facilement, il est construit pour qu’on puisse aussi le survoler rapidement.
En ce qui concerne les exemples résolus et les exercices, j’admets que c’est parfois un peu riche, mais c’est le prix à payer pour qui veut étudier des cas concrets, car il faut plus de contexte. Six années d’enseignement en école d’ingénieurs ont fait le tri : les exercices qui « percutent » sont aussi ceux pour lesquels il faut un peu s’impliquer. Et puis je trouve juste plus cool d’avoir sous les yeux une photo de l’hélicoptère dont je calcule la consommation de carburant.
Les parties historiques (une par chapitre) sont, elles, parfaitement accessoires. Le but est de se construire une culture d’ingénieur/e et de scientifique : comprendre que pendant longtemps, on comprenait à peine ce que l’on faisait en thermodynamique, et voir aussi comment la technologie des moteurs a chamboulé le monde. Philippe Depondt, enseignant-chercheur en physique (à qui je voue une admiration sans fin pour avoir écrit le génial L’entropie et tout ça), a accepté d’écrire la moitié d’entre elles, et j’ai complété l’autre moitié. Peut-être est-ce que nous nous sommes laissé emporter ? Mais regrette-t-on d’apprendre, après avoir étudié un chapitre difficile, que la première personne à avoir montré que la chaleur n’a pas de poids a aussi été agent secret, architecte, instituteur et ministre de guerre philanthrope ? Ou qu’un geek thermodynamicien frustré s’est construit sa propre turbine à vapeur pour pouvoir ridiculiser toute la Royal Navy avec son bateau ?

et maintenant (roulements de tambour) dis-nous pourquoi c’est devenu un framabook, pourquoi cet éditeur ? tu es grillé chez les éditeurs classiques ? Travailler avec des gens qui n’avaient jamais fait de thermodynamique, ça ne t’a pas posé problème ?
Je n’ai pas eu l’occasion de chercher d’autres éditeurs, mais dans la mesure où la publication sous licence libre a toujours fait partie intégrante du projet, j’imagine que je n’aurais pas eu beaucoup de succès. Je suis et soutiens la progression de Framasoft depuis longtemps, et je suis très honoré que le comité ait accepté de produire un Framabook pour étudiants ingénieurs.
Quant au processus d’édition, il n’y a pas que les connaissances en thermodynamique qui comptent. Le comité m’a encouragé pour trouver un confrère, Nicolas Horny, qui veuille bien relire le livre sous son aspect technique (qu’il en soit remercié…). Mais je compte surtout le travail incroyable de Mireille Bernex, qui est à l’origine de centaines d’améliorations de langage et de clarifications dans le livre, et de beaucoup d’autres contributeurs que je n’ai pas la place de citer ici. Enfin, après quinze mois d’édition, je ne suis toujours pas venu à bout de la patience de Christophe Masutti, qui coordonne le projet Framabook. Bref, le plus important est de partager le désir de produire un manuel de qualité, et de ce point de vue, je suis comblé.
On dit souvent que le Libre et l’éducation portent plusieurs valeurs communes. Pour toi, quel est l’intérêt pour les enseignants et les étudiants de disposer d’un ouvrage sous licence libre ?
L’avantage pratique du livre libre est bien sûr sa gratuité. L’étudiant/e et l’enseignant/e peuvent le télécharger à tout moment, sur n’importe quel équipement, et s’en servir, en repiquant/reprenant/remixant le contenu du livre, sans demander la permission à qui que ce soit ni rentrer dans l’illégalité.
Il me semble que cette gratuité est un point important. Dans l’enseignement, le véritable ajout de valeur économique se fait dans la transmission, la réappropriation, et la création du savoir et des connaissances : en classe, en amphithéâtre, pendant le travail de groupe ou le travail personnel. En revanche, il n’y a aucune valeur économique intrinsèque à l’accès à la connaissance : sinon, il suffirait de s’acheter des livres pour devenir ingénieur ! Je préfère donc que l’argent dans l’éducation, privée ou publique, soit consacré aux activités (payer cher les profs et l’environnement de travail) plutôt que l’accès à l’information (faire chuter le coût des livres et ouvrir l’accès aux bibliothèques).
L’utilisation de contenus sous licence libre est aussi, selon moi, une démarche intellectuelle plus claire et pérenne. Lorsqu’un/e prof ou étudiant/e reprend une image du site internet d’Airbus, par exemple, il y a toute une liste de restrictions associées à sa réutilisation : on ne peut s’en servir que pour dire du bien d’Airbus, on ne peut pas la modifier comme on le veut, les conditions de l’utilisation commerciale sont floues, et la permission peut être retirée à tout moment. La reprise de documents dans le cadre de la courte citation française, ou du fair use américain, ou des innombrables accords particuliers passés par l’un ou l’autre éditeur avec tel ou tel gouvernement, est un véritable casse-tête juridique et laisse beaucoup d’incertitudes. Je préfère dire : tiens, reprends mon beau schéma de centrale à vapeur pour en faire ce que tu veux : les termes de la licence CC-BY-SA sont clairs et elle est irrévocable. C’est un bon ingrédient pour cuisiner quelque chose qui, fondamentalement, n’est qu’un remix des connaissances humaines actuelles.
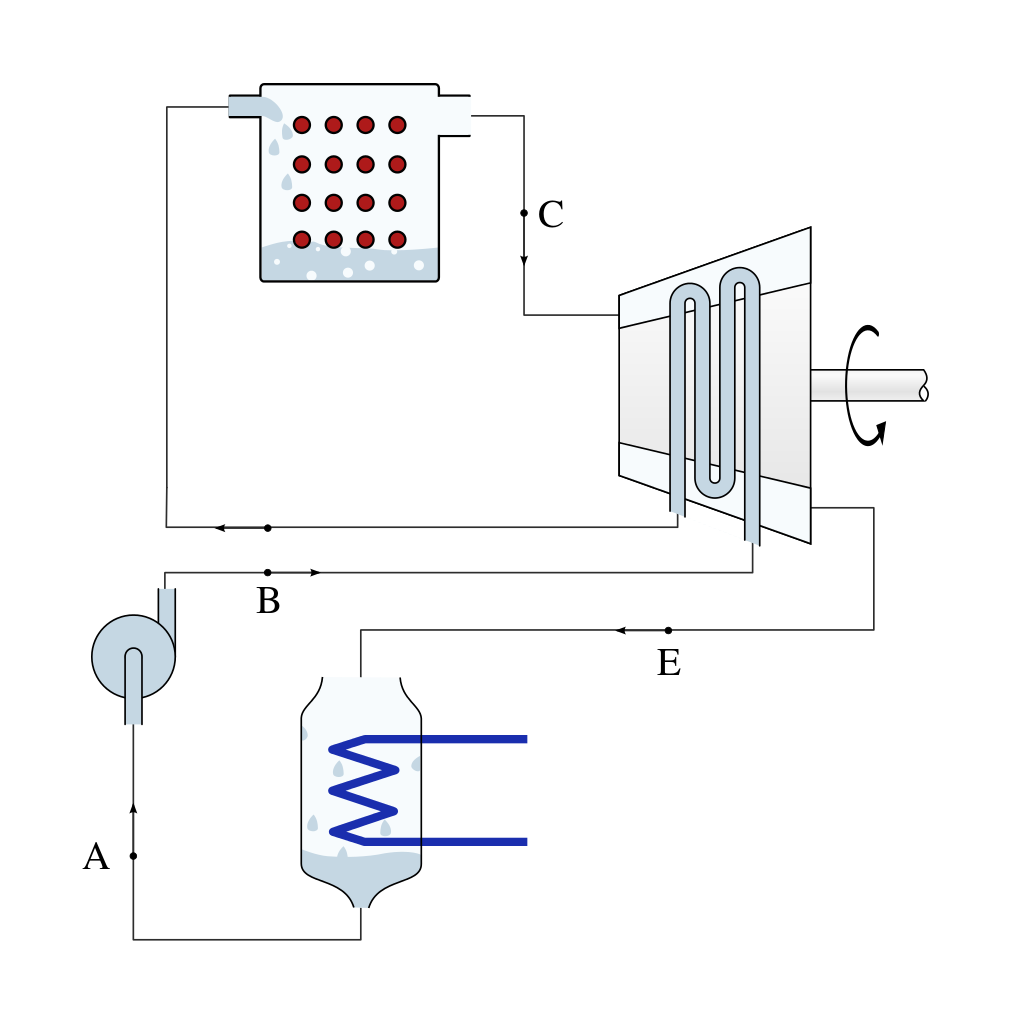 Un autre schéma qui devient évident une fois qu’on a lu le manuel… si, si !
Un autre schéma qui devient évident une fois qu’on a lu le manuel… si, si !
(CC-BY-SA Olivier Cleynen)
Pour vendre beaucoup d’exemplaires, j’espère que tu feras comme certains profs d’université et que ton cours sera incompréhensible si tes étudiants n’achètent pas ton livre…
Ce serait sournois, n’est-ce pas ? Et pourtant, c’est une pratique courante dans les universités aux États-Unis : beaucoup de cours sont ancrés sur un livre particulier, que les étudiants doivent absolument avoir sous la main s’ils veulent réussir.
Avant de nous indigner, il faut comprendre le pourquoi du comment de la chose. Construire un cours universitaire, c’est un travail pharaonique. Structurer un corps de connaissances, le sectionner en morceaux de 120 minutes digestes, ré-exprimer des notions complexes, illustrer tout cela, et construire des exercices intéressants : on peut y consacrer un temps infini, que les profs n’ont pas. Ancrer un cours sur un manuel en particulier, et donc sur une « recette » déjà éprouvée, permet à un/e prof de se consacrer au véritable apport de valeur qu’il/elle doit générer : rendre un cours passionnant, créer un environnement de travail où les étudiants vont se prendre au jeu et s’épanouir. On ne peut tout de même pas demander à chaque prof de ré-écrire toute la thermodynamique !
En enjoignant tous les étudiants à travailler sur un seul livre, le problème de l’accès à l’information est réglé dès le premier cours du semestre, et le reste du temps est consacré à l’exploration, l’appropriation des connaissances. L’alternative classique à la française, le tableau à craie et le maigre polycopié, n’a rien de mirobolant. Qui aurait cru qu’en 2015, l’apprentissage de la thermodynamique puisse encore se faire en recopiant au stylo sur du papier l’information qu’un prof trace avec un caillou blanc poussiéreux sur un mur noir devant 200 personnes ?
En parallèle, les revenus importants qui découlent de ces ventes poussent les éditeurs et les auteurs à produire des manuels de très haute qualité. Nous parlons de pavés de 500 ou 1000 pages, magnifiquement illustrés, soigneusement structurés, hyper accessibles, bref, de vrais outils de travail et de découverte qui donnent immédiatement envie de s’y plonger. On se prend vite de passion pour n’importe quelle discipline avec cela !
Le revers de la médaille est le prix supporté par les étudiants, en termes économiques et de libertés.
L’argent, d’abord : à 200 dollars le livre, l’accès à l’information indispensable au suivi d’un cours devient un obstacle très important à franchir, quel que soit le mode de financement (état, bourses, fonds propres ou emprunts).
En termes de libertés, le coût est plus subtil. Les éditeurs et distributeurs ont tout intérêt à restreindre le marché du livre d’occasion, et font mettre à jour les livres à un rythme effréné ; à chaque fois, la numérotation et l’énoncé de nombreux exercices est modifié (ce qui décourage l’utilisation d’anciennes éditions en cours). Les livres sont couramment proposés en location, sous forme papier (par Amazon notamment) mais aussi sous forme numérique. Voilà des livres dans le nuage, qui ne marchent que lorsqu’on est connecté sur le campus, ou bien seulement pendant un semestre. Certains livres en ligne sont financés avec de la publicité, et on peut imaginer que l’ensemble des données personnelles recueillies à propos des lecteurs est exploité. On retrouve les éditeurs dans les tribunaux et au Congrès, où ils tentent de faire interdire la revente aux USA des livres qu’ils commercialisent au quart du prix en Inde. Bref, on retrouve là l’ensemble des problèmes éthiques et sociétaux associés à un système de distribution fermé, et qui s’immisce dans les ordinateurs et les tablettes des étudiants.
Vu d’ici le problème peut sembler être très étatsunien, mais je suis convaincu que la recherche d’une meilleure qualité d’enseignement nous y confrontera tous tôt ou tard (en fait, à l’instant même où nous abandonnerons cette cochonnerie de tableau à craie…). Je pense que la publication de livres universitaires libres peut être une partie de la réponse. Un programme d’études où tu peux télécharger, remixer, imprimer librement tous les livres ? — Vous pensez, c’est comme construire toute une pile de logiciels libres qui fonctionne sur n’importe quel ordinateur, ou bien écrire toute une encyclopédie sous licence libre : c’est totalement impossible…