Partout en France, des personnes dynamiques s’investissent pour accompagner celles et ceux qui le désirent vers davantage de maîtrise et d’émancipation dans leurs usages numériques.
Framasoft a choisi de mettre en lumière et de soutenir l’activité exemplaire de celle qui se fait appeler « la Reine des Elfes » sur son média social favori. Si nous la connaissons bien et l’apprécions, c’est parce qu’au-delà de son activité régulière au Centre des Abeilles à Quimper, elle a organisé une première session d’Entrée libre, qui a réuni des intervenants du monde du Libre pour 3 jours en août 2019, un événement ouvert à toutes et gratuit « pour comprendre internet, découvrir les logiciels libres et protéger sa vie privée » (voir l’affiche 2019).
Eh bien voilà que notre chère « rainette » bretonne récidive cette année ! Voici dans l’interview ci-dessous les raisons qui la poussent à organiser et réussir un événement qui nous est cher. Et puis comme le budget est plus important cette année, elle a lancé un appel aux dons auquel nous vous invitons à répondre comme nous venons de le faire…
Mat ar jeu, Brigitte ?
Demat Framasoft. Tu te colles au brezhonneg ? Je ne te suivrai pas dans cette langue, car même si j’habite en terre bretonnante, je ne le maîtrise pas. Je te répondrais donc en Gallec : je vais bien ! 🙂
D’où est venue l’idée d’Entrée Libre ?
Ouh là ! Il faut revenir à la première édition en 2019. Je voulais faire un cadeau à mon pote @reunigkozh qui a initié les distributions gratuites d’ordinateurs au Centre des abeilles. Cela faisait 10 ans en 2019. Et je trouvais que nous devions fêter cela.
Mon expérience personnelle m’avait montré que tout le monde ne comprend pas ce qu’iel fait lors de l’utilisation d’un ordinateur. C’est compliqué de comprendre qu’alors que l’on est seul face à un écran, il se passe plein d’autres choses. De comprendre aussi qu’il peut y avoir aussi de l’éthique dans le numérique et qu’on peut choisir quoi utiliser, si on est suffisamment informé.
Le premier Entrée Libre était donc axé sur une présentation d’assos ou de logiciels qui pouvaient aider à prendre sa vie numérique en main.
Est-ce que c’est facile de faire venir des intervenant·e·s de qualitay à Quimper ? (question de Parisien-tête-de-chien qui se croit au centre du monde… libre 🙂 )
J’ai eu beaucoup de chance d’utiliser le Fédiverse, en l’occurrence, Mastodon. Avant, j’étais surtout sur Diaspora* et quand Framasoft a dit « ça vous dit d’essayer un nouvel outil de microblogging ? » ben, je suis allée tester !… et j’y ai rencontré des gens super, qui m’ont appris plein de trucs et qui répondaient à mes questions de noob. Alors, quand j’ai parlé de mon projet d’informer les gens de ce qui existait, Iels ont répondu présent. C’était très émouvant de voir que non seulement personne ne démontait ce projet mais qu’en plus il y avait du monde à répondre à mon appel. J’suis ni connue ni de ce monde-là… Et iels sont forcément de qualitay puisque ce sont mes mastopotes ! 😀
C’est le numéro 2, pourquoi ? Le 1 ne t’a pas suffi ? 😀
J’avais dit que je ne referai plus ! 😛 . C’est beaucoup de boulot mine de rien et beaucoup de stress ! Mais voilà, suite au premier confinement, j’ai rencontré beaucoup de gens « malades du numérique ». Je veux dire que beaucoup de personnes ont été obligées d’utiliser des outils qu’iels ne comprenaient pas. C’était devenu une obligation et iels ont galéré pensant que c’était de leur faute… « parce que je suis nul ! ». J’aimerais donc qu’iels comprennent que ce n’est pas le cas. Qu’il existe des outils plus accessibles que d’autres. Qu’iels ne vont pas casser Internet en allant « dessus ».
Quelles attentes est-ce que tu perçois lors des ateliers que tu réalises ? (je pense à la fois aux tiens et aux distributions d’ordis de LinuxQuimper)
Vaste question !
Pour les distributions, c’est facile. Les gens veulent s’équiper ! Leur besoin est simple, pouvoir accéder aux mails et pour beaucoup, pouvoir s’actualiser à Pôle Emploi. Mais nous n’avons pas beaucoup de retour quand à leur utilisation par la suite.
Pour les ateliers que j’anime, en tant que salariée maintenant, je mets bien les choses au clair. Je ne donne pas de cours, je fais un accompagnement. C’est-à-dire que je ne touche que très peu à la machine, sauf pour voir parfois où sont cachés les trucs (ben oui, n’utilisant qu’Ubuntu, je ne sais pas forcément utiliser un Windows ou un Mac.).
L’avantage de leur montrer cela, c’est que du coup, iels s’aperçoivent qu’il n’y a pas de science infuse et que non, l’apposition des mains ne leur fera pas venir le savoir. Quant à leurs attentes, une fois qu’iels ont compris cela , elles deviennent plus sympas. Les discussions sur la vie privée arrivent très vite, d’autant que j’ai accroché les belles affiches de la Quadrature du net dans la salle où je suis . Et une fois les angoisses passées, la curiosité arrive et tu les vois passer le curseur sur les icônes, pour savoir ce que c’est avant de cliquer. Et faire la différence entre Internet et leur machine. C’est génial !
Et puis ensuite, quand je les accompagne sur Internet, il y a plein de questions auxquelles je les force à trouver la réponse par rapport à leurs attentes. Notamment pour les cookies… Je leur explique que ce n’est pas à moi de décider pour elleux, cela leur semble étonnant au début, et puis je les vois décider, se demander pourquoi telle ou telle extension a été ajoutée la dernière fois qu’iels ont amené leur ordi à réparer… C’est très sympa !
D’où te vient cette curiosité pour apprendre et progresser en compétences dans un domaine qui ne t’était pas trop familier il y a peu d’années encore ?
Je crois que je suis curieuse par nature. Pas de cette curiosité pour savoir qui fait quoi. Mais de comment ça marche et du pourquoi, cela épuisait parfois mes instits même si elles aimaient bien cela.
J’ai toujours démonté mes machines, pas quand j’étais enfant, « les filles ne font pas ça » (déjà que je jouais au foot et que je grimpais aux arbres !), pour essayer de les réparer car souvent ce n’était pas grand-chose qui les empêchait de fonctionner (un tout petit jouet glissé dans le magnétoscope par exemple). Et on va dire que c’est grâce ou à cause de Windows que j’ai rencontré le Libre. Puisque j’en avais assez de le casser parce que je retirais des fichiers qui ne me semblaient pas clairs et de ces virus qui revenaient malgré les antivirus qu’ils soient gratuits ou payants. J’ai donc commencé par chercher sur internet « par quoi remplacer Windows ». À l’époque je ne connaissais pas le mot « système d’exploitation » et j’ai lu des trucs qui parlaient d’un bidule qui s’appelait Linux. J’ai fouillé, cherché, et au bout d’un an j’ai dit à un de mes fils : « tu te débrouilles mais je veux ça sur l’ordi ». Il a gravé un disque et la libération est arrivée. 😀
Puis j’ai vu qu’il existait un groupe LinuxQuimper (sur FB à l’époque où je l’utilisais) et qu’il y avait au centre social des Abeilles des gens de ce groupe (j’ai appris plus tard qu’on disait un GUL) distribuaient des ordis sous Linux. Je les ai donc contactés et je suis entrée dans l’équipe de distribution. Et j’ai recommencé à poser des questions ;-). Et un jour, ils m’ont parlé de Diaspora* où j’ai créé un compte…
Pour nous, tu es la figure de proue d’Entrée Libre, mais est-ce que tu es soutenue et aidée localement pour cette opération par une association ?
Le centre social est effectivement géré par une association « Centre des abeilles ».
Pour la prépa, je suis toute seule à bord, avec l’aval des intervenants et des aides ponctuelles sur les mises en forme. Je prépare cela bénévolement, et ensuite je me fais aider pour la diffusion et tous les petits détails pratiques.
Quand le projet prend forme, le directeur du centre le présente au conseil d’administration du Centre des Abeilles qui valide ou pas le projet. C.A où je suis convoquée pour le présenter aussi.
C’est donc toujours beaucoup d’incertitude et cette année j’ai trouvé cela plus compliqué que la première année. Un C.A. en visio manque de chaleur et d’interaction. En plus le budget est plus lourd que la dernière fois…
Le budget est/a été difficile à boucler, est-ce parce que les frais d’hébergement et déplacement de tous les invités sont trop importants cette fois-ci ?
Déjà on a plus du double d’intervenants. La dernière fois Entrée Libre finissait à 18h chaque soir sur 3 jours. Ce coup-ci , ça commence à la même heure mais ça va finir à 20h30, voire 21h le temps de tout ranger pour le lendemain, pour les bénévoles. Il y a donc un repas supplémentaire à prévoir.
Ce n’est pas tant les déplacements et l’hébergement (iels sont nombreux à ne pas vouloir de défraiement et d’hébergement, ouf !) qui vont coûter le plus mais bien les repas pour plus de trente personnes midi et soir (mon premier prévisionnel comptait tout le monde et arrivait à 9868,05€ t’imagines la tête des gens du CA 😛
Entrée Libre N°2 bénéficie d’une subvention du fonds de soutien à la vie associative, mais il reste de l’argent à trouver…
Est-ce qu’il y aura des crêpes ?
Au moins pour les intervenantes et intervenants ! Pourquoi vous croyez qu’iels viennent ? 😀
Mais je crois bien que j’ai un mastopote qui veut en faire pour le public aussi ! J’ai même prévu des repas et des crêpes véganes pour les bénévoles et le public.
On te laisse le mot de la fin !
Personnellement je trouve que c’est un beau projet que celui de permettre à des gens de s’émanciper, de pouvoir comprendre ce qui se passe avec leurs données numériques, de pouvoir choisir des outils respectueux. Mais pour pouvoir choisir il faut avoir du choix et sans informations on n’en a pas !
Parce que cette belle phrase « si tu ne sais pas demande, et si tu sais, partage » n’a de sens que si il y a du monde pour poser des questions et du monde pour recevoir les partages.
Si ce projet a du sens pour vous aussi n’hésitez pas, si vous le pouvez, à faire un don au « Centre des Abeilles » . Pour plus d’infos sur le programme n’hésitez pas à aller visiter sa page.
Merci à mes mastopotes et à Framasoft de m’avoir permis de tester plein de trucs et de croire en moi. Et bien sûr, un grand merci à celles et ceux qui ont déjà participé à la collecte de dons.
Pour assurer le succès de l’événement, Framasoft, qui animera plusieurs conférences et ateliers, a mis la main à la poche et contribué financièrement. Vous pouvez consulter le détail du budget prévisionnel.
Avec un ton acerbe contre les géants du numérique, Aral Balkan nourrit depuis plusieurs années une analyse lucide et sans concession du capitalisme de surveillance. Nous avons maintes fois publié des traductions de ses diatribes.
Ce qui fait la particularité de ce nouvel article, c’est qu’au-delà de l’adieu à Twitter, il retrace les étapes de son cheminement.
Sa trajectoire est mouvementée, depuis l’époque où il croyait (« quel idiot j’étais ») qu’il suffisait d’améliorer le système. Il revient donc également sur ses années de lutte contre les plateformes prédatrices et les startups .
Il explique quelle nouvelle voie constructive il a adoptée ces derniers temps, jusqu’à la conviction qu’il faut d’urgence « construire l’infrastructure technologique alternative qui sera possédée et contrôlée par des individus, pas par des entreprises ou des gouvernements ». Dans cette perspective, le Fediverse a un rôle important à jouer selon lui.
Sur le Fédiverse, ils ont un terme pour Twitter.
Ils l’appellent « le site de l’enfer ».
C’est très approprié.
Lorsque je m’y suis inscrit, il y a environ 15 ans, vers fin 2006, c’était un espace très différent. Un espace modeste, pas géré par des algorithmes, où on pouvait mener des discussions de groupe avec ses amis.
Ce que je ne savais pas à l’époque, c’est que Twitter, Inc. était une start-up financée avec du capital risque.
Même si j’avais su, ça n’aurait rien changé, vu que je n’avais aucune idée sur le financement ou les modèles commerciaux. Je pensais que tout le monde dans la tech essayait simplement de fabriquer les nouvelles choses du quotidien pour améliorer la vie des gens.
Même six ans après, en 2012, j’en étais encore à me concentrer sur l’amélioration de l’expérience des utilisateurs avec le système actuel :
« Les objets ont de la valeur non par ce qu’ils sont, mais par ce qu’ils nous permettent de faire. Et, en tant que personnes qui fabriquons des objets, nous avons une lourde responsabilité. La responsabilité de ne pas tenir pour acquis le temps limité dont chacun d’entre nous dispose en ce monde. La responsabilité de rendre ce temps aussi beau, aussi confortable, aussi indolore, aussi exaltant et aussi agréable que possible à travers les expériences que nous créons.
Parce que c’est tout ce qui compte.
Et il ne tient qu’à nous de le rendre meilleur. »
– C’est tout ce qui compte.
Quel idiot j’étais, pas vrai ?
Vous pouvez prendre autant de temps que nécessaire pour me montrer du doigt et ricaner.
Ok, c’est fait ? Continuons…
Privilège est simplement un autre mot pour dire qu’on s’en fiche
À cette époque, je tenais pour acquis que le système en général est globalement bon. Ou du moins je ne pensais pas qu’il était activement mauvais 1.
Bien sûr, j’étais dans les rues à Londres, avec des centaines de milliers de personnes manifestant contre la guerre imminente en Irak. Et bien sûr, j’avais conscience que nous vivions dans une société inégale, injuste, raciste, sexiste et classiste (j’ai étudié la théorie critique des médias pendant quatre ans, du coup j’avais du Chomsky qui me sortait de partout), mais je pensais, je ne sais comment, que la tech existait en dehors de cette sphère. Enfin, s’il m’arrivait de penser tout court.
Ce qui veut clairement dire que les choses n’allaient pas assez mal pour m’affecter personnellement à un point où je ressentais le besoin de me renseigner à ce sujet. Et ça, tu sais, c’est ce qu’on appelle privilège.
Il est vrai que ça me faisait bizarre quand l’une de ces start-ups faisait quelque chose qui n’était pas dans notre intérêt. Mais ils nous ont dit qu’ils avaient fait une erreur et se sont excusés alors nous les avons crus. Pendant un certain temps. Jusqu’à ce que ça devienne impossible.
Et, vous savez quoi, j’étais juste en train de faire des « trucs cools » qui « améliorent la vie des gens », d’abord en Flash puis pour l’IPhone et l’IPad…
Mais je vais trop vite.
Retournons au moment où j’étais complètement ignorant des modèles commerciaux et du capital risque. Hum, si ça se trouve, vous en êtes à ce point-là aujourd’hui. Il n’y a pas de honte à avoir. Alors écoutez bien, voici le problème avec le capital risque.
Ce qui se passe dans le Capital Risque reste dans le Capital Risque
Le capital risque est un jeu de roulette dont les enjeux sont importants, et la Silicon Valley en est le casino.
Un capital risqueur va investir, disons, 5 millions de dollars dans dix start-ups tout en sachant pertinemment que neuf d’entre elles vont échouer. Ce dont a besoin ce monsieur (c’est presque toujours un « monsieur »), c’est que celle qui reste soit une licorne qui vaudra des milliards. Et il (c’est presque toujours il) n’investit pas son propre argent non plus. Il investit l’argent des autres. Et ces personnes veulent récupérer 5 à 10 fois plus d’argent, parce que ce jeu de roulette est très risqué.
Alors, comment une start-up devient-elle une licorne ? Eh bien, il y a un modèle commercial testé sur le terrain qui est connu pour fonctionner : l’exploitation des personnes.
Voici comment ça fonctionne:
1. Rendez les gens accros
Offrez votre service gratuitement à vos « utilisateurs » et essayez de rendre dépendants à votre produit le plus de gens possible.
Pourquoi?
Parce qu’il vous faut croître de manière exponentielle pour obtenir l’effet de réseau, et vous avez besoin de l’effet de réseau pour enfermer les gens que vous avez attirés au début.
Bon dieu, des gens très importants ont même écrit des guides pratiques très vendus sur cette étape, comme Hooked : comment créer un produit ou un service qui ancre des habitudes.
Voilà comment la Silicon Valley pense à vous.
2. Exploitez-les
Collectez autant de données personnelles que possible sur les gens.
Pistez-les sur votre application, sur toute la toile et même dans l’espace physique, pour créer des profils détaillés de leurs comportements. Utilisez cet aperçu intime de leurs vies pour essayer de les comprendre, de les prédire et de les manipuler.
Monétisez tout ça auprès de vos clients réels, qui vous paient pour ce service.
C’est ce que certains appellent le Big Data, et que d’autres appellent le capitalisme de surveillance.
3. Quittez la scène (vendez)
Une start-up est une affaire temporaire, dont le but du jeu est de se vendre à une start-up en meilleure santé ou à une entreprise existante de la Big Tech, ou au public par le biais d’une introduction en Bourse.
Si vous êtes arrivé jusque-là, félicitations. Vous pourriez fort bien devenir le prochain crétin milliardaire et philanthrope en Bitcoin de la Silicon Valley.
De nombreuses start-ups échouent à la première étape, mais tant que le capital risque a sa précieuse licorne, ils sont contents.
Des conneries (partie 1)
Je ne savais donc pas que le fait de disposer de capital risque signifiait que Twitter devait connaître une croissance exponentielle et devenir une licorne d’un milliard de dollars. Je n’avais pas non plus saisi que ceux d’entre nous qui l’utilisaient – et contribuaient à son amélioration à ce stade précoce – étaient en fin de compte responsables de son succès. Nous avons été trompés. Du moins, je l’ai été et je suis sûr que je ne suis pas le seul à ressentir cela.
Tout cela pour dire que Twitter était bien destiné à devenir le Twitter qu’il est aujourd’hui dès son premier « investissement providentiel » au tout début.
C’est ainsi que se déroule le jeu du capital risque et des licornes dans la Silicon Valley. Voilà ce que c’est. Et c’est tout ce à quoi j’ai consacré mes huit dernières années : sensibiliser, protéger les gens et construire des alternatives à ce modèle.
Voici quelques enregistrements de mes conférences datant de cette période, vous pouvez regarder :
Dans le cadre de la partie « sensibilisation », j’essayais également d’utiliser des plateformes comme Twitter et Facebook à contre-courant.
Comme je l’ai écrit dans Spyware vs Spyware en 2014 : « Nous devons utiliser les systèmes existants pour promouvoir nos alternatives, si nos alternatives peuvent exister tout court. » Même pour l’époque, c’était plutôt optimiste, mais une différence cruciale était que Twitter, au moins, n’avait pas de timeline algorithmique.
Les timelines algorithmiques (ou l’enfumage 2.0)
Qu’est-ce qu’une timeline algorithmique ? Essayons de l’expliquer.
Ce que vous pensez qu’il se passe lorsque vous tweetez: « j’ai 44 000 personnes qui me suivent. Quand j’écris quelque chose, 44 000 personnes vont le voir ».
Ce qui se passe vraiment lorsque vous tweetez : votre tweet pourrait atteindre zéro, quinze, quelques centaines, ou quelques milliers de personnes.
Et ça dépend de quoi?
Dieu seul le sait, putain.
(Ou, plus exactement, seul Twitter, Inc. le sait.)
Donc, une timeline algorithmique est une boîte noire qui filtre la réalité et décide de qui voit quoi et quand, sur la base d’un lot de critères complètement arbitraires déterminés par l’entreprise à laquelle elle appartient.
En d’autres termes, une timeline algorithmique est simplement un euphémisme pour parler d’un enfumage de masse socialement acceptable. C’est de l’enfumage 2.0.
L’algorithme est un trouduc
La nature de l’algorithme reflète la nature de l’entreprise qui en est propriétaire et l’a créé.
Étant donné que les entreprises sont sociopathes par nature, il n’est pas surprenant que leurs algorithmes le soient aussi. En bref, les algorithmes d’exploiteurs de personnes comme Twitter et Facebook sont des connards qui remuent la merde et prennent plaisir à provoquer autant de conflits et de controverses que possible.
Hé, qu’attendiez-vous exactement d’un milliardaire qui a pour bio #Bitcoin et d’un autre qui qualifie les personnes qui utilisent sont utilisées par son service de « pauvres cons » ?
Ces salauds se délectent à vous montrer des choses dont ils savent qu’elles vont vous énerver dans l’espoir que vous riposterez. Ils se délectent des retombées qui en résultent. Pourquoi ? Parce que plus il y a d’« engagement » sur la plateforme – plus il y a de clics, plus leurs accros («utilisateurs») y passent du temps – plus leurs sociétés gagnent de l’argent.
Eh bien, ça suffit, merci bien.
Des conneries (partie 2)
Certes je considère important de sensibiliser les gens aux méfaits des grandes entreprises technologiques, et j’ai probablement dit et écrit tout ce qu’il y a à dire sur le sujet au cours des huit dernières années. Rien qu’au cours de cette période, j’ai donné plus d’une centaine de conférences, sans parler des interviews dans la presse écrite, à la radio et à la télévision.
Voici quelques liens vers une poignée d’articles que j’ai écrits sur le sujet au cours de cette période :
Est-ce que ça a servi à quelque chose ?
Je ne sais pas.
J’espère que oui.
J’ai également interpellé d’innombrables personnes chez les capitalistes de la surveillance comme Google et Facebook sur Twitter et – avant mon départ il y a quelques années – sur Facebook, et ailleurs. (Quelqu’un se souvient-il de la fois où j’ai réussi à faire en sorte que Samuel L. Jackson interpelle Eric Schmidt sur le fait que Google exploite les e-mails des gens?) C’était marrant. Mais je m’égare…
Est-ce que tout cela a servi à quelque chose ?
Je ne sais pas.
J’espère que oui.
Mais voici ce que je sais :
Est-ce que dénoncer les gens me rend malheureux ? Oui.
Est-ce que c’est bien ? Non.
Est-ce que j’aime les conflits ? Non.
Alors, trop c’est trop.
Les gens viennent parfois me voir pour me remercier de « parler franchement ». Eh bien, ce « parler franchement » a un prix très élevé. Alors peut-être que certaines de ces personnes peuvent reprendre là où je me suis arrêté. Ou pas. Dans tous les cas, j’en ai fini avec ça.
Dans ta face
Une chose qu’il faut comprendre du capitalisme de surveillance, c’est qu’il s’agit du courant dominant. C’est le modèle dominant. Toutes les grandes entreprises technologiques et les startups en font partie2. Et être exposé à leurs dernières conneries et aux messages hypocrites de personnes qui s’y affilient fièrement tout en prétendant œuvrer pour la justice sociale n’est bon pour la santé mentale de personne.
C’est comme vivre dans une ferme industrielle appartenant à des loups où les partisans les plus bruyants du système sont les poulets qui ont été embauchés comme chefs de ligne.
J’ai passé les huit dernières années, au moins, à répondre à ce genre de choses et à essayer de montrer que la Big Tech et le capitalisme de surveillance ne peuvent pas être réformés.
Et cela me rend malheureux.
J’en ai donc fini de le faire sur des plates-formes dotées d’algorithmes de connards qui s’amusent à m’infliger autant de misère que possible dans l’espoir de m’énerver parce que cela «fait monter les chiffres».
Va te faire foutre, Twitter !
J’en ai fini avec tes conneries.
« fuck twitter » par mowl.eu, licence CC BY-NC-ND 2.0
Et après ?
À bien des égards, cette décision a été prise il y a longtemps. J’ai créé mon propre espace sur le fediverse en utilisant Mastodon il y a plusieurs années et je l’utilise depuis. Si vous n’avez jamais entendu parler du fediverse, imaginez-le de la manière suivante :
Imaginez que vous (ou votre groupe d’amis) possédez votre propre copie de twitter.com. Mais au lieu de twitter.com, le vôtre se trouve sur votre-place.org. Et à la place de Jack Dorsey, c’est vous qui fixez les règles.
Vous n’êtes pas non plus limité à parler aux gens sur votre-place.org.
Je possède également mon propre espace sur mon-espace.org (disons que je suis @moi@mon-espace.org). Je peux te suivre @toi@ton-espace.org et aussi bien @eux@leur.site et @quelquun-dautre@un-autre.espace. Ça marche parce que nous parlons tous un langage commun appelé ActivityPub.
Donc imaginez un monde où il y a des milliers de twitter.com qui peuvent tous communiquer les uns avec les autres et Jack n’a rien à foutre là-dedans.
Eh bien, c’est ça, le Fediverse.
Et si Mastodon n’est qu’un moyen parmi d’autres d’avoir son propre espace dans le Fediverse, joinmastodon.org est un bon endroit pour commencer à se renseigner sur le sujet et mettre pied à l’étrier de façon simple sans avoir besoin de connaissances techniques. Comme je l’ai déjà dit, je suis sur le Fediverse depuis les débuts de Mastodon et j’y copiais déjà manuellement les posts sur Twitter.
Maintenant j’ai automatisé le processus via moa.party et, pour aller de l’avant, je ne vais plus me connecter sur Twitter ou y répondre3.
Vu que mes posts sur Mastodon sont maintenant automatiquement transférés là-bas, vous pouvez toujours l’utiliser pour me suivre, si vous en avez envie. Mais pourquoi ne pas utiliser cette occasion de rejoindre le Fediverse et vous amuser ?
Small is beautiful
Si je pense toujours qu’avoir des bonnes critiques de la Big Tech est essentiel pour peser pour une régulation efficace, je ne sais pas si une régulation efficace est même possible étant donné le niveau de corruption institutionnelle que nous connaissons aujourd’hui (lobbies, politique des chaises musicales, partenariats public-privé, captation de réglementation, etc.)
Ce que je sais, c’est que l’antidote à la Big Tech est la Small Tech.
Nous devons construire l’infrastructure technologique alternative qui sera possédée et contrôlée par des individus, pas par des entreprises ou des gouvernements. C’est un prérequis pour un futur qui respecte la personne humaine, les droits humains, la démocratie et la justice sociale.
Dans le cas contraire, nous serons confrontés à des lendemains sombres où notre seul recours sera de supplier un roi quelconque, de la Silicon Valley ou autre, « s’il vous plaît monseigneur, soyez gentil ».
Je sais aussi que travailler à la construction de telles alternatives me rend heureux alors que désespérer sur l’état du monde ne fait que me rendre profondément malheureux. Je sais que c’est un privilège d’avoir les compétences et l’expérience que j’ai, et que cela me permet de travailler sur de tels projets. Et je compte bien les mettre à contribution du mieux possible.
Pour aller de l’avant, je prévois de concentrer autant que possible de mon temps et de mon énergie à la construction d’un Small Web.
Si vous avez envie d’en parler (ou d’autre chose), vous pouvez me trouver sur le Fediverse.
Vous pouvez aussi discuter avec moi pendant mes live streams S’update et pendant nos live streams Small is beautiful avec Laura.
Des jours meilleurs nous attendent…
Prenez soin de vous.
Portez-vous bien.
Aimez-vous les uns les autres.
À 23 ans, cURL se rend utile partout
Non, ce n’est pas une marque de biscuits apéritifs aux cacahuètes, mais un outil logiciel méconnu qui mérite pourtant de faire partie de notre culture numérique. On révise ?
Bien qu’ignoré de la plupart des internautes, il est d’un usage familier pour celles et ceux qui travaillent en coulisses pour le Web. L’adage : « si un site web n’est pas « curlable », ce n’est pas du Web » fait de curl un outil majeur pour définir ce qu’est le Web aujourd’hui.
Son développeur principal suédois Daniel Stenberg retrace ici la genèse de cURL, son continu développement et surtout, ce qui devrait intéresser les moins geeks de nos lecteurs, son incroyable diffusion, à travers sa bibliothèque libcurl, au cœur de tant d’objets et appareils familiers. Après des débuts fort modestes, « la quasi-totalité des appareils connectés à Internet exécutent curl » !
Si vous n’êtes pas développeur et que les caractéristiques techniques de curl sont pour vous un peu obscures, allez directement à la deuxième partie de l’article pour en comprendre facilement l’importance.
Article original sur le blog de l’auteur : curl is 23 years old today
Traduction : Fabrice, Goofy, Julien/Sphinx, jums, NGFChristian, tTh,
curl fête son 23e anniversaire
par Daniel Stenberg La date de naissance officielle de curl, le 20 mars 1998, marque le jour de la toute première archive tar qui pouvait installer un outil nommé curl. Je l’ai créé et nommé curl 4.0 car je voulais poursuivre la numérotation de versions que j’avais déjà utilisée pour les noms précédents de l’outil. Ou plutôt, j’ai fait un saut depuis la 3.12, qui était la dernière version que j’avais utilisée avec le nom précédent : urlget.
Bien sûr, curl n’a pas été créé à partir de rien ce jour-là. Son histoire commence une petite année plus tôt : le 11 novembre 1996 a été publié un outil appelé httpget, développé par Rafael Sagula. C’est un projet j’avais trouvé et auquel j’avais commencé à contribuer. httpget 0.1 était un fichier de code C de moins de 300 lignes. (La plus ancienne version dont j’aie encore le code source est httpget 1.3, retrouvée ici)
Comme je l’ai évoqué à de multiples reprises, j’ai commencé à m’attaquer à ce projet parce que je voulais avoir un petit outil pour télécharger des taux de change régulièrement depuis un site internet et les fournir via mon petit bot4 de taux de change sur IRC5.
Ces petites décisions prises rapidement à cette époque allaient avoir plus tard un impact significatif et influencer ma vie. curl a depuis toujours été l’un de mes passe-temps principaux. Et bien sûr il s’agit aussi d’un travail à plein temps depuis quelques années désormais.
En ce même jour de novembre 1996 a été distribué pour la première fois le programme Wget(1.4.0). Ce projet existait déjà sous un autre nom avant d’être distribué, et je crois me souvenir que je ne le connaissais pas, j’utilisais httpget pour mon robogiciel. Peut-être que j’avais vu Wget et que je ne l’utilisais pas à cause de sa taille : l’archive tar de Wget 1.4.0 faisait 171 ko.
Peu de temps après, je suis devenu le responsable de httpget et j’ai étendu ses fonctionnalités. Il a ensuite été renommé urlget quand je lui ai ajouté le support de Gopher et de FTP (ce que j’ai fait parce que j’avais trouvé des taux de change sur des serveurs qui utilisaient ces protocoles). Au printemps 1998, j’ai ajouté le support de l’envoi par FTP et comme le nom du programme ne correspondait plus clairement à ses fonctionnalités j’ai dû le renommer une fois de plus6.
Nommer les choses est vraiment difficile. Je voulais un nom court dans le style d’Unix. Je n’ai pas planché très longtemps puisque j’ai trouvé un mot marrant assez rapidement. L’outil fonctionne avec des URL, et c’est un client Internet. « c » pour client et URL ont fait que « cURL » semblait assez pertinent et marrant. Et court. Bien dans de style d’Unix.
J’ai toujours voulu que curl soit un citoyen qui s’inscrive dans la tradition Unix d’utiliser des pipes7, la sortie standard, etc. Je voulais que curl fonctionne comme la commande cat, mais avec des URL. curl envoie donc par défaut le contenu de l’URL sur la sortie standard dans le terminal. Tout comme le fait cat. Il nous permettra donc de « voir » le contenu de l’URL. La lettre C se prononce si (Ndt : ou see, « voir » en anglais) donc « see URL » fonctionne aussi. Mon esprit blagueur n’en demande pas plus, mais je dis toujours « kurl ».
Le logo original, créé en 1998 par Henrik Hellerstedt
J’ai créé le paquet curl 4.0 et l’ai rendu public ce vendredi-là. Il comprenait alors 2 200 lignes de code. Dans la distribution de curl 4.8 que j’ai faite quelques mois plus tard, le fichier THANKS mentionnait 7 contributeurs[Note] Daniel Stenberg, Rafael Sagula, Sampo Kellomaki, Linas Vepstas, Bjorn Reese, Johan Anderson, Kjell Ericson[/note]. Ça nous a pris presque sept ans pour atteindre une centaine de contributeurs. Aujourd’hui, ce fichier liste plus de 2 300 noms et nous ajoutons quelques centaines de noms chaque année. Ce n’est pas un projet solo !
Il ne s’est rien passé de spécial
curl n’a pas eu un succès massif. Quelques personnes l’ont découvert et deux semaines après cette première distribution, j’ai envoyé la 4.1 avec quelques corrections de bugs et une tradition de plusieurs décennies a commencé : continuer à publier des mises à jour avec des corrections de bug. « Distribuer tôt et souvent » est un mantra auquel nous nous sommes conformés.
Plus tard en 1998, après plus de quinze distributions, notre page web présentait cette excellente déclaration :
Capture d’écran : Liste de diffusion. Pour cause de grande popularité, nous avons lancé une liste de diffusion pour parler de cet outil. (La version 4.8.4 a été téléchargée à elle seule plus de 300 fois depuis ce site.)
Trois cents téléchargements !
Je n’ai jamais eu envie de conquérir le monde ou nourri de visions idylliques pour ce projet et cet outil. Je voulais juste que les transferts sur Internet soient corrects, rapides et fiables, et c’est ce sur quoi j’ai travaillé.
Afin de mieux procurer au monde entier de quoi réaliser de bons transferts sur Internet, nous avons lancé la bibliothèque libcurl, publiée pour la première fois à l’été 2000. Cela a permis au projet de se développer sous un autre angle 8. Avec les années, libcurl est devenue de facto une API de transfert Internet.
Aujourd’hui, alors qu’il fête son 23e anniversaire, c’est toujours principalement sous cet angle que je vois le cœur de mon travail sur curl et ce que je dois y faire. Je crois que si j’ai atteint un certain succès avec curl avec le temps, c’est principalement grâce à une qualité spécifique. En un mot :
Persistance
Nous tenons bon. Nous surmontons les problèmes et continuons à perfectionner le produit. Nous sommes dans une course de fond. Il m’a fallu deux ans (si l’on compte à partir des précurseurs) pour atteindre 300 téléchargements. Il en a fallu dix ou presque pour qu’il soit largement disponible et utilisé.
En 2008, le site web pour curl a servi 100 Go de données par mois. Ce mois-ci, c’est 15 600 Go (soit fait 156 fois plus en 156 mois) ! Mais bien entendu, la plupart des utilisatrices et utilisateurs ne téléchargent rien depuis notre site, c’est leur distribution ou leur système d’exploitation qui leur met à disposition curl.
curl a été adopté au sein de Red Hat Linux à la fin de l’année 1998, c’est devenu un paquet Debian en mai 1999 et faisait partie de Mac OS X 10.1 en août 2001. Aujourd’hui, il est distribué par défaut dans Windows 10 et dans les appareils iOS et Android. Sans oublier les consoles de jeux comme la Nintendo Switch, la Xbox et la PS5 de Sony.
Ce qui est amusant, c’est que libcurl est utilisé par les deux principaux systèmes d’exploitation mobiles mais que ces derniers n’exposent pas d’API pour ses fonctionnalités. Aussi, de nombreuses applications, y compris celles qui sont largement diffusées, incluent-elles leur propre version de libcurl : YouTube, Skype, Instagram, Spotify, Google Photos, Netflix, etc. Cela signifie que la plupart des personnes qui utilisent un smartphone ont curl installé plusieurs fois sur leur téléphone.
Par ailleurs, libcurl est utilisé par certains des jeux vidéos les plus populaires : GTA V, Fortnite, PUBG mobile, Red Dead Redemption 2, etc.
libcurl alimente les fonctionnalités de lecteurs média ou de box comme Roku, Apple TV utilisés par peut-être un demi milliard de téléviseurs.
curl et libcurl sont pratiquement intégrés dans chaque serveur Internet, c’est le moteur de transfert par défaut de PHP qui est lui-même utilisé par environ 80% des deux milliards de sites web.
Maintenant que les voitures sont connectées à Internet, libcurl est utilisé dans presque chaque voiture moderne pour le transfert de données depuis et vers les véhicules.
À cela s’ajoutent les lecteurs média, les appareils culinaires ou médicaux, les imprimantes, les montres intelligentes et les nombreux objets « intelligents » connectés à Internet. Autrement dit, la quasi-totalité des appareils connectés à Internet exécutent curl.
Je suis convaincu que je n’exagère pas quand je déclare que curl existe sur plus de dix milliards d’installations sur la planète.
Seuls et solides
À plusieurs reprises lors de ces années, j’ai essayé de voir si curl pouvait rejoindre une organisation cadre mais aucune n’a accepté et, en fin de compte, je pense que c’est mieux ainsi. Nous sommes complètement seuls et indépendants de toute organisation ou entreprise. Nous faisons comme nous l’entendons et nous ne suivons aucune règle édictée par d’autres. Ces dernières années, les dons et les soutiens financiers se sont vraiment accélérés et nous sommes désormais en situation de pouvoir confortablement payer des récompenses pour la chasse aux bugs de sécurité par exemple.
Le support commercial que nous proposons, wolfSSL et moi-même, a je crois renforcé curl : cela me laisse encore plus de temps pour travailler sur curl, et permet à davantage d’entreprises d’utiliser curl sereinement, ce qui en fin de compte le rend meilleur pour tous.
Ces 300 lignes de code fin 1996 sont devenues 172 000 lignes en mars 2021.
L’avenir
Notre travail le plus important est de ne pas « faire chavirer le navire ». Fournir la meilleure et la plus solide bibliothèque de transfert par Internet, sur le plus de plateformes possible.
Mais pour rester attractifs, nous devons vivre avec notre temps, c’est à dire de nous adapter aux nouveaux protocoles et aux nouvelles habitudes au fur et à mesure qu’ils apparaissent. Prendre en charge de nouvelles versions de protocoles, permettre de meilleures manières de faire les choses et, au fur et à mesure, abandonner les mauvaises choses de manière responsable pour ne pas nuire aux personnes qui utilisent le logiciel.
À court terme je pense que nous voulons travailler à nous assurer du fonctionnement d’HTTP/3, faire de Hyper 9 une brique de très bonne qualité et voir ce que devient la brique rustls.
Après 23 ans, nous n’avons toujours pas de vision idéale ni de feuille de route pour nous guider. Nous allons là où Internet et nos utilisatrices nous mènent. Vers l’avant, toujours plus haut !
La feuille de route de curl 😉
23 ans de curl en 23 nombres
Pendant les jours qui ont précédé cet anniversaire, j’ai tweeté 23 « statistiques de curl » en utilisant le hashtag #curl23. Ci-dessous ces vingt-trois nombres et faits.
2 200 lignes de code en mars 1998 sont devenues 170 000 lignes en 2021 alors que curl fête ses 23 ans
14 bibliothèques TLS différentes sont prises en charge par curl alors qu’il fête ses 23 ans
2 348 contributrices et contributeurs ont participé au développement de curl alors qu’il fête ses 23 ans
197 versions de curl ont été publiées alors que curl fête ses 23 ans
6 787 correctifs de bug ont été enregistrés alors que curl fête ses 23 ans
10 000 000 000 d’installations dans le monde font que curl est l’un des jeunes hommes de 23 ans des plus distribués au monde
871 personnes ont contribué au code de curl pour en faire un projet vieux de 23 ans
935 000 000 récupérations pour l’image docker officielle de curl (83 récupérations par seconde) alors que curl fête ses 23 ans
22 marques de voitures, au moins, exécutent curl dans leurs véhicules alors que curl fête ses 23 ans
100 tâches d’intégration continue sont exécutées pour chaque commit et pull request sur le projet curl alors qu’il fête ses 23 ans
15 000 heures de son temps libre ont été passés sur le projet curl par Daniel alors qu’il fête ses 23 ans
2 systèmes d’exploitation mobile les plus utilisés intègrent et utilisent curl dans leur architecture alors que curl fête ses 23 ans
86 systèmes d’exploitation différents font tourner curl alors qu’il fête ses 23 ans
250 000 000 de télévisions utilisent curl alors qu’il fête ses 23 ans
26 protocoles de transport sont pris en charge alors que curl fête ses 23 ans
36 bibliothèques tierces différentes peuvent être compilées afin d’être utilisées par curl alors qu’il fête ses 23 ans
22 architectures différentes de processeurs exécutent curl alors qu’il fête ses 23 ans
4 400 dollars américains ont été payés au total pour la découverte de bugs alors que curl fête ses 23 ans
240 options de ligne de commandes existent lorsque curl fête ses 23 ans
15 600 Go de données sont téléchargées chaque mois depuis le site web de curl alors que curl fête ses 23 ans
60 passerelles vers d’autres langages existent pour permettre aux programmeurs de transférer des données facilement en utilisant n’importe quel langage alors que curl fête ses 23 ans
1 327 449 mots composent l’ensemble des RFC pertinentes qu’il faut lire pour les opérations effectuées par curl alors que curl fête ses 23 ans
1 fondateur et développeur principal est resté dans les parages du projet alors que curl fête ses 23 ans
Les médias sociaux ne sont pas des espaces démocratiques
On peut rêver d’une solution technologique ou juridique pour limiter ou interdire l’utilisation d’un logiciel à des groupes ou personnes qui ne partagent pas les valeurs auxquelles on tient ou pire veulent les détruire. L’entreprise est bien plus délicate qu’il n’y paraît, y compris pour les réseaux alternatifs décentralisés (ou plutôt acentrés) qu’on regroupe sous le terme de Fediverse. Il ne suffit pas en effet de dire que chaque instance décide de ses propres règles pour se débarrasser des difficultés.
Dans l’article qui suit, Christophe Masutti prend acte de la fin d’une illusion : l’idéal d’un grand espace de communication démocratique, égalitaire et ouvert à tous n’existe pas plus avec les Gafam qu’avec le Fediverse et ses réseaux alternatifs.
Face aux grandes plateformes centralisées de médias sociaux qui ne recherchent nullement à diffuser ou promouvoir le débat démocratique éclairé comme elles le prétendent mais à monétiser le spectacle d’un pseudo-débat, nous sommes confrontées au grand fourre-tout où distinguer le pire du meilleur renvoie chacun à une tâche colossale et indéfiniment renouvelée.
Cependant ce qui change la donne avec le Fediverse, c’est que la question de la fermeture à d’autres ne prend en compte ni le profit ni le facteur nombre : les instances sans objectif lucratif ont leurs qualités et leurs défauts propres, qu’elles aient deux ou deux cent mille utilisatrices. Et selon Christophe, les rapports entre les instances restent à écrire, à la manière dont les rapports variables entre les habitants d’un quartier déterminent leurs rapports individuels et collectifs…
Les médias sociaux ne sont pas des espaces démocratiques
par Christophe Masutti
Lors d’une récente interview avec deux autres framasoftiennes à propos du Fediverse et des réseaux sociaux dits « alternatifs », une question nous fut posée :
dans la mesure où les instances de service de micro-blogging (type Mastodon) ou de vidéo (comme Peertube) peuvent afficher des « lignes éditoriales » très différentes les unes des autres, comment gérer la modération en choisissant de se fédérer ou non avec une instance peuplée de fachos ou comment se comporter vis-à-vis d’une instance communautaire et exclusive qui choisit délibérément de ne pas être fédérée ou très peu ?
De manière assez libérale et pour peu que les conditions d’utilisation du service soient clairement définies dans chaque instance, on peut répondre simplement que la modération demande plus ou moins de travail, que chaque instance est tout à fait libre d’adopter sa propre politique éditoriale, et qu’il s’agit de choix individuels (ceux du propriétaire du serveur qui héberge l’instance) autant que de choix collectifs (si l’hébergeur entretient des relations diplomatiques avec les membres de son instance). C’est une évidence.
La difficulté consistait plutôt à expliquer pourquoi, dans la conception même des logiciels (Mastodon ou Peertube, en l’occurrence) ou dans les clauses de la licence d’utilisation, il n’y a pas de moyen mis en place par l’éditeur du logiciel (Framasoft pour Peertube, par exemple) afin de limiter cette possibilité d’enfermement de communautés d’utilisateurs dans de grandes bulles de filtres en particulier si elles tombent dans l’illégalité. Est-il légitime de faire circuler un logiciel qui permet à ♯lesgens de se réunir et d’échanger dans un entre-soi homogène tout en prétendant que le Fediverse est un dispositif d’ouverture et d’accès égalitaire ?
Une autre façon de poser la question pourrait être la suivante : comment est-il possible qu’un logiciel libre puisse permettre à des fachos d’ouvrir leurs propres instance de microblogging en déversant impunément sur le réseau leurs flots de haine et de frustrations ?1
Bien sûr nous avons répondu à ces questions, mais à mon avis de manière trop vague. C’est qu’en réalité, il y a plusieurs niveaux de compréhension que je vais tâcher de décrire ici.
Il y a trois aspects :
l’éthique du logiciel libre n’inclut pas la destination morale des logiciels libres, tant que la loyauté des usages est respectée, et la première clause des 4 libertés du logiciel libre implique la liberté d’usage : sélectionner les utilisateurs finaux en fonction de leurs orientations politique, sexuelles, etc. contrevient fondamentalement à cette clause…
… mais du point de vue technique, on peut en discuter car la conception du logiciel pourrait permettre de repousser ces limites éthiques2,
et la responsabilité juridique des hébergeurs implique que ces instances fachos sont de toute façon contraintes par l’arsenal juridique adapté ; ce à quoi on pourra toujours rétorquer que cela n’empêche pas les fachos de se réunir dans une cave (mieux : un local poubelle) à l’abri des regards.
Mais est-ce suffisant ? se réfugier derrière une prétendue neutralité de la technique (qui n’est jamais neutre), les limites éthiques ou la loi, ce n’est pas une bonne solution. Il faut se poser la question : que fait-on concrètement non pour interdire certains usages du Fediverse, mais pour en limiter l’impact social négatif ?
La principale réponse, c’est que le modèle économique du Fediverse ne repose pas sur la valorisation lucrative des données, et que se détacher des modèles centralisés implique une remise en question de ce que sont les « réseaux » sociaux. La vocation d’un dispositif technologique comme le Fediverse n’est pas d’éliminer les pensées fascistes et leur expression, pas plus que la vocation des plateformes Twitter et Facebook n’est de diffuser des modèles démocratiques, malgré leur prétention à cet objectif. La démocratie, les échanges d’idées, et de manière générale les interactions sociales ne se décrètent pas par des modèles technologiques, pas plus qu’elles ne s’y résument.
Prétendre le contraire serait les restreindre à des modèles et des choix imposés (et on voit bien que la technique ne peut être neutre). Si Facebook, Twitter et consorts ont la prétention d’être les gardiens de la liberté d’expression, c’est bien davantage pour exploiter les données personnelles à des fins lucratives que pour mettre en place un débat démocratique.
Exit le vieux rêve du global village ? En fait, cette vieille idée de Marshall McLuhan ne correspond pas à ce que la plupart des gens en ont retenu. En 1978, lorsque Murray Turoff et Roxanne Hiltz publient The Network Nation, ils conceptualisent vraiment ce qu’on entend par « Communication médiée par ordinateur » : échanges de contenus (volumes et vitesse), communication sociale-émotionnelle (les émoticônes), réduction des distances et isolement, communication synchrone et asynchrone, retombées scientifiques, usages domestiques de la communication en ligne, etc. Récompensés en 1994 par l’EFF Pioneer Award, Murray Turoff et Roxanne Hiltz sont aujourd’hui considérés comme les « parents » des systèmes de forums et de chat massivement utilisés aujourd’hui. Ce qu’on a retenu de leurs travaux, et par la suite des nombreuses applications, c’est que l’avenir du débat démocratique, des processus de décision collective (M. Turoff travaillait pour des institutions publiques) ou de la recherche de consensus, reposent pour l’essentiel sur les technologies de communication. C’est vrai en un sens, mais M. Turoff mettait en garde3 :
Dans la mesure où les communications humaines sont le mécanisme par lequel les valeurs sont transmises, tout changement significatif dans la technologie de cette communication est susceptible de permettre ou même de générer des changements de valeur.
Communiquer avec des ordinateurs, bâtir un système informatisé de communication sociale-émotionnelle ne change pas seulement l’organisation sociale, mais dans la mesure où l’ordinateur se fait de plus en plus le support exclusif des communications (et les prédictions de Turoff s’avéreront très exactes), la communication en réseau fini par déterminer nos valeurs.
Aujourd’hui, communiquer dans un espace unique globalisé, centralisé et ouvert à tous les vents signifie que nous devons nous protéger individuellement contre les atteintes morales et psychiques de celleux qui s’immiscent dans nos échanges. Cela signifie que nos écrits puissent être utilisés et instrumentalisés plus tard à des fins non souhaitées. Cela signifie qu’au lieu du consensus et du débat démocratique nous avons en réalité affaire à des séries de buzz et des cancans. Cela signifie une mise en concurrence farouche entre des contenus discursifs de qualité et de légitimités inégales mais prétendument équivalents, entre une casserole qui braille La donna è mobile et la version Pavarotti, entre une conférence du Collège de France et un historien révisionniste amateur dans sa cuisine, entre des contenus journalistiques et des fake news, entre des débats argumentés et des plateaux-télé nauséabonds.
Tout cela ne relève en aucun cas du consensus et encore moins du débat, mais de l’annulation des chaînes de valeurs (quelles qu’elles soient) au profit d’une mise en concurrence de contenus à des fins lucratives et de captation de l’attention. Le village global est devenu une poubelle globale, et ce n’est pas brillant.
Là où les médias sociaux centralisés impliquaient une ouverture en faveur d’une croissance lucrative du nombre d’utilisateurs, le Fediverse se fout royalement de ce nombre, pourvu qu’il puisse mettre en place des chaînes de confiance.
Dans cette perspective, le Fediverse cherche à inverser la tendance. Non par la technologie (le protocole ActivityPub ou autre), mais par le fait qu’il incite à réfléchir sur la manière dont nous voulons conduire nos débats et donc faire circuler l’information.
On pourrait aussi bien affirmer qu’il est normal de se voir fermer les portes (ou du moins être exclu de fait) d’une instance féministe si on est soi-même un homme, ou d’une instance syndicaliste si on est un patron, ou encore d’une instance d’un parti politique si on est d’un autre parti. C’est un comportement tout à fait normal et éminemment social de faire partie d’un groupe d’affinités, avec ses expériences communes, pour parler de ce qui nous regroupe, d’actions, de stratégies ou simplement un partage d’expériences et de subjectivités, sans que ceux qui n’ont pas les mêmes affinités ou subjectivités puissent s’y joindre. De manière ponctuelle on peut se réunir à l’exclusion d’autre groupes, pour en sortir à titre individuel et rejoindre d’autre groupes encore, plus ouverts, tout comme on peut alterner entre l’intimité d’un salon et un hall de gare.
Dans ce texte paru sur le Framablog, A. Mansoux et R. R. Abbing montrent que le Fediverse est une critique de l’ouverture. Ils ont raison. Là où les médias sociaux centralisés impliquaient une ouverture en faveur d’une croissance lucrative du nombre d’utilisateurs, le Fediverse se fout royalement de ce nombre, pourvu qu’il puisse mettre en place des chaînes de confiance.
Un premier mouvement d’approche consiste à se débarrasser d’une conception complètement biaisée d’Internet qui fait passer cet ensemble de réseaux pour une sorte de substrat technique sur lequel poussent des services ouverts aux publics de manière égalitaire. Évidemment ce n’est pas le cas, et surtout parce que les réseaux ne se ressemblent pas, certains sont privés et chiffrés (surtout dans les milieux professionnels), d’autres restreints, d’autres plus ouverts ou complètement ouverts. Tous dépendent de protocoles bien différents. Et concernant les médias sociaux, il n’y a aucune raison pour qu’une solution technique soit conçue pour empêcher la première forme de modération, à savoir le choix des utilisateurs. Dans la mesure où c’est le propriétaire de l’instance (du serveur) qui reste in fine responsable des contenus, il est bien normal qu’il puisse maîtriser l’effort de modération qui lui incombe. Depuis les années 1980 et les groupes usenet, les réseaux sociaux se sont toujours définis selon des groupes d’affinités et des règles de modération clairement énoncées.
À l’inverse, avec des conditions générales d’utilisation le plus souvent obscures ou déloyales, les services centralisés tels Twitter, Youtube ou Facebook ont un modèle économique tel qu’il leur est nécessaire de drainer un maximum d’utilisateurs. En déléguant le choix de filtrage à chaque utilisateur, ces médias sociaux ont proposé une représentation faussée de leurs services :
Faire croire que c’est à chaque utilisateur de choisir les contenus qu’il veut voir alors que le système repose sur l’économie de l’attention et donc sur la multiplication de contenus marchands (la publicité) et la mise en concurrence de contenus censés capter l’attention. Ces contenus sont ceux qui totalisent plus ou moins d’audience selon les orientations initiales de l’utilisateur. Ainsi on se voit proposer des contenus qui ne correspondent pas forcément à nos goûts mais qui captent notre attention parce de leur nature attrayante ou choquante provoquent des émotions.
Faire croire qu’ils sont des espaces démocratiques. Ils réduisent la démocratie à la seule idée d’expression libre de chacun (lorsque Trump s’est fait virer de Facebook les politiques se sont sentis outragés… comme si Facebook était un espace public, alors qu’il s’agit d’une entreprise privée).
Les médias sociaux mainstream sont tout sauf des espaces où serait censée s’exercer la démocratie bien qu’ils aient été considérés comme tels, dans une sorte de confusion entre le brouhaha débridé des contenus et la liberté d’expression. Lors du « printemps arabe » de 2010, par exemple, on peut dire que les révoltes ont beaucoup reposé sur la capacité des réseaux sociaux à faire circuler l’information. Mais il a suffi aux gouvernements de censurer les accès à ces services centralisés pour brider les révolutions. Ils se servent encore aujourd’hui de cette censure pour mener des négociations diplomatiques qui tantôt cherchent à attirer l’attention pour obtenir des avantages auprès des puissances hégémoniques tout en prenant la « démocratie » en otage, et tantôt obligent les GAFAM à se plier à la censure tout en facilitant la répression. La collaboration est le sport collectif des GAFAM. En Turquie, Amnesty International s’en inquiète et les exemples concrets ne manquent pas comme au Vietnam récemment.
Si les médias sociaux comme Twitter et Facebook sont devenus des leviers politiques, c’est justement parce qu’ils se sont présentés comme des supports technologiques à la démocratie. Car tout dépend aussi de ce qu’on entend par « démocratie ». Un mot largement privé de son sens initial comme le montre si bien F. Dupuis-Déri4. Toujours est-il que, de manière très réductrice, on tient pour acquis qu’une démocratie s’exerce selon deux conditions : que l’information circule et que le débat public soit possible.
Même en réduisant la démocratie au schéma techno-structurel que lui imposent les acteurs hégémoniques des médias sociaux, la question est de savoir s’il permettent la conjonction de ces conditions. La réponse est non. Ce n’est pas leur raison d’être.
Alors qu’Internet et le Web ont été élaborés au départ pour être des dispositifs égalitaires en émission et réception de pair à pair, la centralisation des accès soumet l’émission aux conditions de l’hébergeur du service. Là où ce dernier pourrait se contenter d’un modèle marchand basique consistant à faire payer l’accès et relayer à l’aveugle les contenus (ce que fait La Poste, encadrée par la loi sur les postes et télécommunications), la salubrité et la fiabilité du service sont fragilisés par la responsabilisation de l’hébergeur par rapport à ces contenus et la nécessité pour l’hébergeur à adopter un modèle économique de rentabilité qui repose sur la captation des données des utilisateurs à des fins de marketing pour prétendre à une prétendue gratuité du service5. Cela implique que les contenus échangés ne sont et ne seront jamais indépendants de toute forme de censure unilatéralement décidée (quoi qu’en pensent les politiques qui entendent légiférer sur l’emploi des dispositifs qui relèveront toujours de la propriété privée), et jamais indépendants des impératifs financiers qui justifient l’économie de surveillance, les atteintes à notre vie privée et le formatage comportemental qui en découlent.
Paradoxalement, le rêve d’un espace public ouvert est tout aussi inatteignable pour les médias sociaux dits « alternatifs », où pour des raisons de responsabilité légale et de choix de politique éditoriale, chaque instance met en place des règles de modération qui pourront toujours être considérées par les utilisateurs comme abusives ou au moins discutables. La différence, c’est que sur des réseaux comme le Fediverse (ou les instances usenet qui reposent sur NNTP), le modèle économique n’est pas celui de l’exploitation lucrative des données et n’enferme pas l’utilisateur sur une instance en particulier. Il est aussi possible d’ouvrir sa propre instance à soi, être le seul utilisateur, et néanmoins se fédérer avec les autres.
De même sur chaque instance, les règles d’usage pourraient être discutées à tout moment entre les utilisateurs et les responsables de l’instance, de manière à créer des consensus. En somme, le Fediverse permet le débat, même s’il est restreint à une communauté d’utilisateurs, là où la centralisation ne fait qu’imposer un état de fait tout en tâchant d’y soumettre le plus grand nombre. Mais dans un pays comme le Vietnam où l’essentiel du trafic Internet passe par Facebook, les utilisateurs ont-ils vraiment le choix ?
Ce sont bien la centralisation et l’exploitation des données qui font des réseaux sociaux comme Facebook, YouTube et Twitter des instruments extrêmement sensibles à la censure d’État, au service des gouvernements totalitaires, et parties prenantes du fascisme néolibéral.
L’affaire Cambridge Analytica a bien montré combien le débat démocratique sur les médias sociaux relève de l’imaginaire, au contraire fortement soumis aux effets de fragmentation discursive. Avant de nous demander quelles idéologies elles permettent de véhiculer nous devons interroger l’idéologie des GAFAM. Ce que je soutiens, c’est que la structure même des services des GAFAM ne permet de véhiculer vers les masses que des idéologies qui correspondent à leurs modèles économiques, c’est-à-dire compatibles avec le profit néolibéral.
En reprenant des méthodes d’analyse des années 1970-80, le marketing psychographique et la socio-démographie6, Cambridge Analytica illustre parfaitement les trente dernières années de perfectionnement de l’analyse des données comportementales des individus en utilisant le big data. Ce qui intéresse le marketing, ce ne sont plus les causes, les déterminants des choix des individus, mais la possibilité de prédire ces choix, peu importent les causes. La différence, c’est que lorsqu’on applique ces principes, on segmente la population par stéréotypage dont la granularité est d’autant plus fine que vous disposez d’un maximum de données. Si vous voulez influencer une décision, dans un milieu où il est possible à la fois de pomper des données et d’en injecter (dans les médias sociaux, donc), il suffit de voir quels sont les paramètres à changer. À l’échelle de millions d’individus, changer le cours d’une élection présidentielle devient tout à fait possible derrière un écran.
C’est la raison pour laquelle les politiques du moment ont surréagi face au bannissement de Trump des plateformes comme Twitter et Facebook (voir ici ou là). Si ces plateformes ont le pouvoir de faire taire le président des États-Unis, c’est que leur capacité de caisse de résonance accrédite l’idée qu’elles sont les principaux espaces médiatiques réellement utiles aux démarches électoralistes. En effet, nulle part ailleurs il n’est possible de s’adresser en masse, simultanément et de manière segmentée (ciblée) aux populations. Ce faisant, le discours politique ne s’adresse plus à des groupes d’affinité (un parti parle à ses sympathisants), il ne cherche pas le consensus dans un espace censé servir d’agora géante où aurait lieu le débat public. Rien de tout cela. Le discours politique s’adresse désormais et en permanence à chaque segment électoral de manière assez fragmentée pour que chacun puisse y trouver ce qu’il désire, orienter et conforter ses choix en fonction de ce que les algorithmes qui scandent les contenus pourront présenter (ou pas). Dans cette dynamique, seul un trumpisme ultra-libéral pourra triompher, nulle place pour un débat démocratique, seules triomphent les polémiques, la démagogie réactionnaire et ce que les gauches ont tant de mal à identifier7 : le fascisme.
Face à cela, et sans préjuger de ce qu’il deviendra, le Fediverse propose une porte de sortie sans toutefois remettre au goût du jour les vieilles représentations du village global. J’aime à le voir comme une multiplication d’espaces (d’instances) plus où moins clos (ou plus ou moins ouverts, c’est selon) mais fortement identifiés et qui s’affirment les uns par rapport aux autres, dans leurs différences ou leurs ressemblances, en somme dans leurs diversités.
C’est justement cette diversité qui est à la base du débat et de la recherche de consensus, mais sans en constituer l’alpha et l’oméga. Les instances du Fediverse, sont des espaces communs d’immeubles qui communiquent entre eux, ou pas, ni plus ni moins. Ils sont des lieux où l’on se regroupe et où peuvent se bâtir des collectifs éphémères ou non. Ils sont les supports utilitaires où des pratiques d’interlocution non-concurrentielles peuvent s’accomplir et s’inventer : microblog, blog, organiseur d’événement, partage de vidéo, partage de contenus audio, et toute application dont l’objectif consiste à outiller la liberté d’expression et non la remplacer.
Angélisme ? Peut-être. En tout cas, c’est ma manière de voir le Fediverse aujourd’hui. L’avenir nous dira ce que les utilisateurs en feront.
On peut se référer au passage de la plateforme suprémaciste Gab aux réseaux du Fediverse, mais qui finalement fut bloquée par la plupart des instances du réseau.↩
Par exemple, sans remplacer les outils de modération par du machine learning plus ou moins efficace, on peut rendre visible davantage les procédures de reports de contenus haineux, mais à condition d’avoir une équipe de modérateurs prête à réceptionner le flux : les limites deviennent humaines.↩
Turoff, Murray, and Starr Roxane Hiltz. 1994. The Network Nation: Human Communication via Computer. Cambridge: MIT Press, p. 401.↩
Dupuis-Déri, Francis. Démocratie, histoire politique d’un mot: aux États-Unis et en France. Montréal (Québec), Canada: Lux, 2013.↩
Et même si le service était payant, l’adhésion supposerait un consentement autrement plus poussé à l’exploitation des données personnelles sous prétexte d’une qualité de service et d’un meilleur ciblage marketing ou de propagande. Pire encore s’il disposait d’une offre premium ou de niveaux d’abonnements qui segmenteraient encore davantage les utilisateurs.↩
J’en parlerai dans un article à venir au sujet du courtage de données et de la société Acxiom.↩
…pas faute d’en connaître les symptômes depuis longtemps. Comme ce texte de Jacques Ellul paru dans la revue Esprit en 1937, intitulé « Le fascisme fils du libéralisme », dont voici un extrait : « [Le fascisme] s’adresse au sentiment et non à l’intelligence, il n’est pas un effort vers un ordre réel mais vers un ordre fictif de la réalité. Il est précédé par tout un courant de tendances vers le fascisme : dans tous les pays nous retrouvons ces mesures de police et de violence, ce désir de restreindre les droits du parlement au profit du gouvernement, décrets-lois et pleins pouvoirs, affolement systématique obtenu par une lente pression des journaux sur la mentalité courante, attaques contre tout ce qui est pensée dissidente et expression de cette pensée, limitation de liberté de parole et de droit de réunion, restriction du droit de grève et de manifester, etc. Toutes ces mesures de fait constituent déjà le fascisme. ».↩
Sauvegardez !
Régulièrement, un accident qui entraine la perte de données importantes nous rappelle l’importance des sauvegardes. L’incendie du centre de données d’OVH à Strasbourg le 10 mars dernier a été particulièrement spectaculaire, car de nombreuses personnes et organisations ont été touchées, mais des incidents de ce genre sont fréquents, quoique moins médiatisés. Un ami vient de m’écrire pour me demander mon numéro de téléphone car il a perdu son ordiphone avec son carnet d’adresses, un étudiant a perdu son ordinateur portable dans le métro, avec tout son mémoire de master dessus, et met une petite annonce dans la station de métro, une graphiste s’aperçoit que son ordinateur, avec tous ses travaux dessus, ne démarre plus un matin, une ville a perdu ses données suite au passage d’un rançongiciel, une utilisatrice de Facebook demande de l’aide car son compte a été piraté et elle ne peut plus accéder à ses photos de famille… Des appels au secours sur les réseaux sociaux comme celui-ci ou celui-là sont fréquents. Dans tous ces cas, le problème était l’absence de sauvegardes. Mais c’est quoi, les sauvegardes, et comment faut-il les faire ?
Le principe est simple : une sauvegarde (backup, en anglais) est une copie des données effectuée sur un autre support. Le but est de pouvoir récupérer ses données en cas de perte. Les causes de perte sont innombrables : vol de l’ordinateur portable ou de l’ordiphone (ces engins, étant mobiles, sont particulièrement exposés à ces risques), effacement par un logiciel malveillant ou par une erreur humaine, panne matérielle. Les causes possibles sont trop nombreuses pour être toutes citées. Retenons plutôt ce principe : les données peuvent devenir inaccessibles du jour au lendemain. Même si vous n’utilisez qu’un ordinateur fixe, parfaitement sécurisé, dans un local à l’abri des incendies (qui peut vraiment prétendre avoir une telle sécurité ?), un composant matériel peut toujours lâcher, vous laissant dans l’angoisse face à vos fichiers irrécupérables. Ne pensons donc pas aux causes de perte, pensons aux précautions à prendre.
(Au passage, saviez-vous que Lawrence d’Arabie avait perdu lors d’un voyage en train un manuscrit qu’il avait dû retaper complètement ? Il n’avait pas de sauvegardes. À sa décharge, avant le numérique, faire des sauvegardes était long et compliqué.)
La règle est simple : il faut sauvegarder ses données. Ou, plus exactement, ce qui n’est pas sauvegardé peut être perdu à tout instant, sans préavis. Si vous êtes absolument certain ou certaine que vos données ne sont pas importantes, vous pouvez vous passer de sauvegardes. À l’inverse, si vous êtes en train d’écrire l’œuvre de votre vie et que dix ans de travail sont sur votre ordinateur, arrêter de lire cet article et aller faire tout de suite une sauvegarde est impératif. Entre les deux, c’est à vous de juger de l’importance de vos données, mais l’expérience semble indiquer que la plupart des utilisateurices sous-estiment le risque de panne, de vol ou de perte. Dans le doute, il vaut donc mieux sauvegarder.
Comment on sauvegarde ?
Là, je vais vous décevoir, je ne vais pas donner de mode d’emploi tout fait. D’abord, cela dépend beaucoup de votre environnement informatique. On n’utilisera pas les mêmes logiciels sur macOS et sur Ubuntu. Je ne connais pas tous les environnements et je ne peux donc pas vous donner des procédures exactes. (Mais, connaissant les lecteurices du Framablog, je suis certain qu’ielles vont ajouter dans les commentaires plein de bons conseils pratiques.) Ensuite, une autre raison pour laquelle je ne donne pas de recettes toutes faites est que la stratégie de sauvegarde va dépendre de votre cas particulier. Par exemple, si vous travaillez sur des données confidentielles (données personnelles, par exemple), certaines stratégies ne pourront pas être appliquées.
Je vais plutôt me focaliser sur quelques principes souvent oubliés. Le premier est d’éviter de mettre tous ses œufs dans le même panier. J’ai déjà vu le cas d’une étudiante ayant bien mis sa thèse en cours de rédaction sur une clé USB mais qui avait la clé et l’ordinateur portable dans le même sac… qui fut volé à l’arrachée dans la rue. Dans ce cas, il n’y a pas de réelle sauvegarde, puisque le même problème (le vol) entraîne la perte du fichier et de la sauvegarde. Même chose si la sauvegarde est accessible depuis la machine principale, par exemple parce qu’elle est sur un serveur de fichiers. Certes, dans ce cas, une panne matérielle de la machine n’entrainerait pas la perte des données sauvegardées sur le serveur, en revanche, une fausse manœuvre (destruction accidentelle des fichiers) ou une malveillance (rançongiciel chiffrant tout ce qu’il trouve, pour le rendre inutilisable) frapperait la sauvegarde aussi bien que l’original. Enfin, si vous travaillez à la maison, et que la sauvegarde est chez vous, rappelez-vous que le même incendie peut détruire les deux. (Il n’est pas nécessaire que tout brûle pour que tous les fichiers soient perdus ; un simple début de fumée peut endommager le matériel au point de rendre les données illisibles.) Rappelez-vous : il y a plusieurs causes de pertes de données, pas juste la panne d’un disque dur, et la stratégie de sauvegarde doit couvrir toutes ces causes. On parle parfois de « règle 3-2-1 » : les données doivent être sauvegardées en trois exemplaires, sur au moins deux supports physiques différents, et au moins une copie doit être dans un emplacement séparé. Bref, il faut être un peu paranoïaque et imaginer tout ce qui pourrait aller mal.
Donc, pensez à séparer données originelles et sauvegardes. Si vous utilisez un disque dur externe pour vos sauvegardes, débranchez-le physiquement une fois la sauvegarde faite. Si vous utilisez un serveur distant, déconnectez-vous après la copie.
(Si vous êtes programmeureuse, les systèmes de gestion de versions gardent automatiquement les précédentes versions de vos programmes, ce qui protège contre certaines erreurs humaines, comme d’effacer un fichier. Et, si ce système de gestion de versions est décentralisé, comme git, cela permet d’avoir facilement des copies en plusieurs endroits. Toutefois, tous ces endroits sont en général accessibles et donc vulnérables à, par exemple, un logiciel malveillant. Le système de gestion de versions ne dispense pas de sauvegardes.)
Ensuite, ne faites pas d’économies : il est très probable que vos données valent davantage que les quelques dizaines d’euros que coûte un disque dur externe ou une clé USB. Toutefois, il vaut mieux des sauvegardes imparfaites que pas de sauvegardes du tout. Simplement envoyer un fichier par courrier électronique à un autre compte (par exemple celui d’un ami) est simple, rapide et protège mieux que de ne rien faire du tout.
Enfin, faites attention à ce que la sauvegarde elle-même peut faire perdre des données, si vous copiez sur un disque ou une clé où se trouvent déjà des fichiers. C’est une des raisons pour lesquelles il est recommandé d’automatiser les sauvegardes, ce que permettent la plupart des outils. L’automatisation n’a pas pour but que de vous fatiguer moins, elle sert aussi à limiter les risques de fausse manœuvre.
« Five Days’ Backup » par daryl_mitchell, licence CC BY-SA 2.0
À quel rythme ?
La règle est simple : si vous faites des sauvegardes tous les jours, vous pouvez perdre une journée de travail. Si vous en faites toutes les semaines, vous pouvez perdre une semaine de travail. À vous de voir quel rythme vous préférez.
Et le cloud magique qui résout tout ?
Quand on parle de sauvegardes, beaucoup de gens répondent tout de suite « ah, mais pas de problème, moi, tout est sauvegardé dans le cloud ». Mais ce n’est pas aussi simple. D’abord, le cloud n’existe pas : il s’agit d’ordinateurs comme les autres, susceptibles des mêmes pannes, comme l’a tristement démontré l’incendie d’OVH. Il est d’ailleurs intéressant de noter que beaucoup de clients d’OVH supposaient acquis que leurs données étaient recopiées sur plusieurs centres de données, pour éviter la perte, malgré les conditions d’utilisation d’OVH qui disaient clairement que la sauvegarde était de la responsabilité du client. (Mais qui lit les conditions d’utilisation ?)
Parfois, la croyance dans la magie du cloud va jusqu’à dire que leurs centres de données ne peuvent pas brûler, que des copies sont faites, bref que ce qui est stocké dans le nuage ne peut pas être perdu. Mais rappelez-vous qu’il existe d’innombrables causes de perte de données. Combien d’utilisateurs d’un service en ligne ont eu la mauvaise surprise de découvrir un matin qu’ils n’avaient plus accès à leur compte parce qu’un pirate avait deviné leur mot de passe (ou détourné leur courrier ou leurs SMS) ou parce que la société gestionnaire avait délibérément fermé le compte, en raison d’un changement de politique de leur part ou tout simplement parce que le logiciel qui contrôle automatiquement les accès a décidé que votre compte était problématique ? Il n’est pas nécessaire que la société qui contrôle vos fichiers perde les données pour que vous n’y ayez plus accès. Là aussi, c’est une histoire fréquente (témoignage en anglais) et elle l’est encore plus en cas d’hébergement gratuit où vous n’êtes même pas un client.
Ah, et un autre problème avec la sous-traitance (le terme correct pour cloud), la confidentialité. Si vous travaillez avec des données confidentielles (s’il s’agit de données personnelles, vous avez une responsabilité légale, n’oubliez pas), il n’est pas prudent de les envoyer à l’extérieur sans précautions, surtout vers les fournisseurs états-uniens (ou chinois, mais ce cas est plus rare). Une bonne solution est de chiffrer vos fichiers avant l’envoi. Mais comme rien n’est parfait dans le monde cruel où nous vivons, il faut se rappeler que c’est moins pratique et surtout que cela introduit un risque de perte : si vous perdez ou oubliez la clé de chiffrement, vos sauvegardes ne serviront à rien.
Tester
Un adage ingénierie classique est que ce qui n’a pas été testé ne marche jamais, quand on essaie de s’en servir. Appliqué aux sauvegardes, cela veut dire qu’il faut tester que la sauvegarde fonctionne, en essayant une restauration (le contraire d’une sauvegarde : mettre les fichiers sur l’ordinateur, à partir de la copie).
Une bonne discipline, par exemple, est de profiter de l’achat d’une nouvelle machine pour essayer de restaurer les fichiers à partir de la copie. Vous serez peut-être surpris·e de constater à ce moment qu’il manque des fichiers importants, qui avaient été négligés lors de la sauvegarde, ou bien que la sauvegarde la plus récente n’est… pas très récente. Ou bien tout simplement que la clé USB où vous aviez fait la sauvegarde a disparu, ou bien ne fonctionne plus.
Conclusion
Il faut sauvegarder. Je l’ai déjà dit, non ? Pour vous motiver, posez-vous les questions suivantes :
Si, un matin, mon ordinateur fait entendre un bruit de casserole et ne démarre pas, saurais-je facilement restaurer des données sauvegardées ?
Si toutes mes données sont chez un hébergeur extérieur et que je perds l’accès à mon compte, comment restaurerais-je mes données ?
Si je travaille sur un ordinateur portable que je trimballe souvent, et qu’il est volé ou perdu, où et comment restaurer les données ?
Si vous préférez les messages en vidéo, j’ai bien aimé cette vidéo qui, en dépit de son nom, n’est pas faite que pour les geeks.
Développeurs, développeuses, nettoyez le Web !
Voici la traduction d’une nouvelle initiative d’Aral Balkan intitulée : Clean up the web! : et si on débarrassait les pages web de leurs nuisances intrusives ?
En termes parfois fleuris (mais il a de bonnes raisons de hausser le ton) il invite toutes les personnes qui font du développement web à agir pour en finir avec la soumission aux traqueurs des GAFAM. Pour une fois, ce n’est pas seulement aux internautes de se méfier de toutes parts en faisant des choix éclairés, mais aussi à celles et ceux qui élaborent les pages web de faire face à leurs responsabilités, selon lui…
Développeurs, développeuses, c’est le moment de choisir votre camp : voulez-vous contribuer à débarrasser le Web du pistage hostile à la confidentialité, ou bien allez-vous en être complices ?
Que puis-je faire ?
🚮️ Supprimer les scripts tiers de Google, Facebook, etc.
Ces scripts permettent à des éleveurs de moutons numériques comme Google et Facebook de pister les utilisatrices d’un site à l’autre sur tout le Web. Si vous les incorporez à votre site, vous êtes complice en permettant ce pistage par des traqueurs.
Face à la pression montante des mécontents, Google a annoncé qu’il allait à terme bloquer les traqueurs tiers dans son navigateur Chrome. Ça a l’air bien non ? Et ça l’est, jusqu’à ce que l’on entende que l’alternative proposée est de faire en sorte que Chrome lui-même traque les gens sur tous les sites qu’ils visitent…sauf si les sites lui demandent de ne pas le faire, en incluant le header suivant dans leur réponse :
Permissions-Policy: interest-cohort=()
Bon, maintenant, si vous préférez qu’on vous explique à quel point c’est un coup tordu…
Aucune page web au monde ne devrait avoir à supplier Google : « s’il vous plaît, monsieur, ne violez pas la vie privée de la personne qui visite mon site » mais c’est exactement ce que Google nous oblige à faire avec sa nouvelle initiative d’apprentissage fédéré des cohortes (FLoC).
Si jamais vous avez du mal à retenir le nom, n’oubliez pas que « flock » veut dire « troupeau » en anglais, comme dans « troupeau de moutons, » parce que c’est clairement l’image qu’ils se font de nous chez Google s’ils pensent qu’on va accepter cette saloperie.
Donc c’est à nous, les développeurs, de coller ce header dans tous les serveurs web (comme nginx, Caddy, etc.), tous les outils web (comme WordPress, Wix, etc.)… bref dans tout ce qui, aujourd’hui, implique une réponse web à une requête, partout dans le monde.
Notre petit serveur web, Site.js, l’a déjà activé par défaut.
Si jamais il y a des politiciens qui ont les yeux ouverts en ce 21e siècle et qui ne sont pas trop occupés à se frotter les mains ou à saliver à l’idée de fricoter, voire de se faire embaucher par Google et Facebook, c’est peut-être le moment de faire attention et de faire votre putain de taf pour changer.
🚮️ Arrêter d’utiliser Chrome et conseiller aux autres d’en faire autant, si ça leur est possible.
Rappelons qui est le méchant ici : c’est Google (Alphabet, Inc.), pas les gens qui pour de multiples raisons pourraient être obligés d’utiliser le navigateur web de Google (par exemple, ils ne savent pas forcément comment télécharger et installer un nouveau navigateur, ou peuvent être obligés de l’utiliser au travail, etc.)
Donc, attention de ne pas vous retrouver à blâmer la victime, mais faites comprendre aux gens quel est le problème avec Google (« c’est une ferme industrielle pour les êtres humains ») et conseillez-leur d’utiliser, s’ils le peuvent, un navigateur différent.
C’est décourageant de voir les tentacules de ce foutu monstre marin s’étendre partout et s’il a jamais été temps de créer une organisation indépendante financée par des fonds publics pour mettre au point un navigateur sans cochonnerie, c’est le moment.
🚮️ Protégez-vous et montrez aux autres comment en faire autant
Pointez vers cette page avec les hashtags #CleanUpTheWeb et#FlocOffGoogle.
🚮️ Choisissez un autre business model
En fin de compte, on peut résumer les choses ainsi : si votre business model est fondé sur le pistage et le profilage des gens, vous faites partie du problème.
Les mecs de la tech dans la Silicon Valley vous diront qu’il n’y a pas d’autre façon de faire de la technologie que la leur.
C’est faux.
Ils vous diront que votre « aventure extraordinaire » commence par une startup financée par des business angels et du capital risque et qu’elle se termine soit quand vous êtes racheté par un Google ou un Facebook, soit quand vous en devenez un vous-même. Licornes et compagnie…
Vous pouvez créer de petites entreprises durables. Vous pouvez créer des coopératives. Vous pouvez créer des associations à but non lucratif, comme nous.
Si vous vous demandez ce qui vous rend heureux, est-ce que ce n’est pas ça, par hasard ?
Est-ce que vous voulez devenir milliardaire ? Est-ce que vous avez envie de traquer, de profiler, de manipuler les gens ? Ou est-ce que vous avec juste envie de faire de belles choses qui améliorent la vie des gens et rendent le monde plus équitable et plus sympa ?
Nous faisons le pari que vous préférez la seconde solution.
Si vous manquez d’inspiration, allez voir ce qui se fait chez Plausible, par exemple, et comment c’est fait, ou chez HEY, Basecamp, elementary OS, Owncast, Pine64, StarLabs, Purism, ou ce à quoi nous travaillons avec Site.js et le Small Web… vous n’êtes pas les seuls à dire non aux conneries de la Silicon Valley
On existe en partie grâce au soutien de gens comme vous. Si vous partagez notre vision et désirez soutenir notre travail, faites une don aujourd’hui et aidez-nous à continuer à exister.
Google chante le requiem pour les cookies, mais le grand chœur du pistage résonnera encore
Google va cesser de nous pister avec des cookies tiers ! Une bonne nouvelle, oui mais… Regardons le projet d’un peu plus près avec un article de l’EFF.
La presse en ligne s’en est fait largement l’écho : par exemple siecledigital, generation-nt ou lemonde. Et de nombreux articles citent un éminent responsable du tout-puissant Google :
Chrome a annoncé son intention de supprimer la prise en charge des cookies tiers et que nous avons travaillé avec l’ensemble du secteur sur le Privacy Sandbox afin de mettre au point des innovations qui protègent l’anonymat tout en fournissant des résultats aux annonceurs et aux éditeurs. Malgré cela, nous continuons à recevoir des questions pour savoir si Google va rejoindre d’autres acteurs du secteur des technologies publicitaires qui prévoient de remplacer les cookies tiers par d’autres identifiants de niveau utilisateur. Aujourd’hui, nous précisons qu’une fois les cookies tiers supprimés, nous ne créerons pas d’identifiants alternatifs pour suivre les individus lors de leur navigation sur le Web et nous ne les utiliserons pas dans nos produits.
David Temkin, Director of Product Management, Ads Privacy and Trust (source)
« Pas d’identifiants alternatifs » voilà de quoi nous réjouir : serait-ce la fin d’une époque ?
Comme d’habitude avec Google, il faut se demander où est l’arnaque lucrative. Car il semble bien que le Béhémoth du numérique n’ait pas du tout renoncé à son modèle économique qui est la vente de publicité.
Dans cet article de l’Electronic Frontier Foundation, que vous a traduit l’équipe de Framalang, il va être question d’un projet déjà entamé de Google dont l’acronyme est FLoC, c’est-à-dire Federated Learning of Cohorts. Vous le trouverez ici traduit AFC pour « Apprentissage Fédéré de Cohorte » (voir l’article de Wikipédia Apprentissage fédéré).
Pour l’essentiel, ce dispositif donnerait au navigateur Chrome la possibilité de créer des groupes de milliers d’utilisateurs ayant des habitudes de navigation similaires et permettrait aux annonceurs de cibler ces « cohortes ».
Les cookies tiers se meurent, mais Google essaie de créer leur remplaçant.
Personne ne devrait pleurer la disparition des cookies tels que nous les connaissons aujourd’hui. Pendant plus de deux décennies, les cookies tiers ont été la pierre angulaire d’une obscure et sordide industrie de surveillance publicitaire sur le Web, brassant plusieurs milliards de dollars ; l’abandon progressif des cookies de pistage et autres identifiants tiers persistants tarde à arriver. Néanmoins, si les bases de l’industrie publicitaire évoluent, ses acteurs les plus importants sont déterminés à retomber sur leurs pieds.
Google veut être en première ligne pour remplacer les cookies tiers par un ensemble de technologies permettant de diffuser des annonces ciblées sur Internet. Et certaines de ses propositions laissent penser que les critiques envers le capitalisme de surveillance n’ont pas été entendues. Cet article se concentrera sur l’une de ces propositions : l’Apprentissage Fédéré de Cohorte (AFC, ou FLoC en anglais), qui est peut-être la plus ambitieuse – et potentiellement la plus dangereuse de toutes.
L’AFC est conçu comme une nouvelle manière pour votre navigateur d’établir votre profil, ce que les pisteurs tiers faisaient jusqu’à maintenant, c’est-à-dire en retravaillant votre historique de navigation récent pour le traduire en une catégorie comportementale qui sera ensuite partagée avec les sites web et les annonceurs. Cette technologie permettra d’éviter les risques sur la vie privée que posent les cookies tiers, mais elle en créera de nouveaux par la même occasion. Une solution qui peut également exacerber les pires attaques sur la vie privée posées par les publicités comportementales, comme une discrimination accrue et un ciblage prédateur.
La réponse de Google aux défenseurs de la vie privée a été de prétendre que le monde de demain avec l’AFC (et d’autres composants inclus dans le « bac à sable de la vie privée » sera meilleur que celui d’aujourd’hui, dans lequel les marchands de données et les géants de la tech pistent et profilent en toute impunité. Mais cette perspective attractive repose sur le présupposé fallacieux que nous devrions choisir entre « le pistage à l’ancienne » et le « nouveau pistage ». Au lieu de réinventer la roue à espionner la vie privée, ne pourrait-on pas imaginer un monde meilleur débarrassé des problèmes surabondants de la publicité ciblée ?
Nous sommes à la croisée des chemins. L’ère des cookies tiers, peut-être la plus grande erreur du Web, est derrière nous et deux futurs possibles nous attendent.
Dans l’un d’entre eux, c’est aux utilisateurs et utilisatrices que revient le choix des informations à partager avec chacun des sites avec lesquels il ou elle interagit. Plus besoin de s’inquiéter du fait que notre historique de navigation puisse être utilisé contre nous-mêmes, ou employé pour nous manipuler, lors de l’ouverture d’un nouvel onglet.
Dans l’autre, le comportement de chacune et chacun est répercuté de site en site, au moyen d’une étiquette, invisible à première vue mais riche de significations pour celles et ceux qui y ont accès. L’historique de navigation récent, concentré en quelques bits, est « démocratisé » et partagé avec les dizaines d’interprètes anonymes qui sont partie prenante des pages web. Les utilisatrices et utilisateurs commencent chaque interaction avec une confession : voici ce que j’ai fait cette semaine, tenez-en compte.
Les utilisatrices et les personnes engagées dans la défense des droits numériques doivent rejeter l’AFC et les autres tentatives malvenues de réinventer le ciblage comportemental. Nous exhortons Google à abandonner cette pratique et à orienter ses efforts vers la construction d’un Web réellement favorable aux utilisateurs.
Qu’est-ce que l’AFC ?
En 2019, Google présentait son bac à sable de la vie privée qui correspond à sa vision du futur de la confidentialité sur le Web. Le point central de ce projet est un ensemble de protocoles, dépourvus de cookies, conçus pour couvrir la multitude de cas d’usage que les cookies tiers fournissent actuellement aux annonceurs. Google a soumis ses propositions au W3C, l’organisme qui forge les normes du Web, où elles ont été principalement examinées par le groupe de commerce publicitaire sur le Web, un organisme essentiellement composé de marchands de technologie publicitaire. Dans les mois qui ont suivi, Google et d’autres publicitaires ont proposé des dizaines de standards techniques portant des noms d’oiseaux : pigeon, tourterelle, moineau, cygne, francolin, pélican, perroquet… et ainsi de suite ; c’est très sérieux ! Chacune de ces propositions aviaires a pour objectif de remplacer différentes fonctionnalités de l’écosystème publicitaire qui sont pour l’instant assurées par les cookies.
L’AFC est conçu pour aider les annonceurs à améliorer le ciblage comportemental sans l’aide des cookies tiers. Un navigateur ayant ce système activé collecterait les informations sur les habitudes de navigation de son utilisatrice et les utiliserait pour les affecter à une « cohorte » ou à un groupe. Les utilisateurs qui ont des habitudes de navigations similaires – reste à définir le mot « similaire » – seront regroupés dans une même cohorte. Chaque navigateur partagera un identifiant de cohorte, indiquant le groupe d’appartenance, avec les sites web et les annonceurs. D’après la proposition, chaque cohorte devrait contenir au moins plusieurs milliers d’utilisatrices et utilisateurs (ce n’est cependant pas une garantie).
Si cela vous semble complexe, imaginez ceci : votre identifiant AFC sera comme un court résumé de votre activité récente sur le Web.
La démonstration de faisabilité de Google utilisait les noms de domaines des sites visités comme base pour grouper les personnes. Puis un algorithme du nom de SimHash permettait de créer les groupes. Il peut tourner localement sur la machine de tout un chacun, il n’y a donc pas besoin d’un serveur central qui collecte les données comportementales. Toutefois, un serveur administrateur central pourrait jouer un rôle dans la mise en œuvre des garanties de confidentialité. Afin d’éviter qu’une cohorte soit trop petite (c’est à dire trop caractéristique), Google propose qu’un acteur central puisse compter le nombre de personnes dans chaque cohorte. Si certaines sont trop petites, elles pourront être fusionnées avec d’autres cohortes similaires, jusqu’à ce qu’elles représentent suffisamment d’utilisateurs.
Pour que l’AFC soit utile aux publicitaires, une cohorte d’utilisateurs ou utilisatrices devra forcément dévoiler des informations sur leur comportement.
Selon la proposition formulée par Google, la plupart des spécifications sont déjà à l’étude. Le projet de spécification prévoit que l’identification d’une cohorte sera accessible via JavaScript, mais on ne peut pas savoir clairement s’il y aura des restrictions, qui pourra y accéder ou si l’identifiant de l’utilisateur sera partagé par d’autres moyens. L’AFC pourra constituer des groupes basés sur l’URL ou le contenu d’une page au lieu des noms domaines ; également utiliser une synergie de « système apprentissage » (comme le sous-entend l’appellation AFC) afin de créer des regroupements plutôt que de se baser sur l’algorithme de SimHash. Le nombre total de cohortes possibles n’est pas clair non plus. Le test de Google utilise une cohorte d’utilisateurs avec des identifiants sur 8 bits, ce qui suppose qu’il devrait y avoir une limite de 256 cohortes possibles. En pratique, ce nombre pourrait être bien supérieur ; c’est ce que suggère la documentation en évoquant une « cohorte d’utilisateurs en 16 bits comprenant 4 caractères hexadécimaux ». Plus les cohortes seront nombreuses, plus elles seront spécialisées – plus les identifiants de cohortes seront longs, plus les annonceurs en apprendront sur les intérêts de chaque utilisatrice et auront de facilité pour cibler leur empreinte numérique.
Mais si l’un des points est déjà clair c’est le facteur temps. Les cohortes AFC seront réévaluées chaque semaine, en utilisant chaque fois les données recueillies lors de la navigation de la semaine précédente.
Ceci rendra les cohortes d’utilisateurs moins utiles comme identifiants à long terme, mais les rendra plus intrusives sur les comportements des utilisatrices dans la durée.
De nouveaux problèmes pour la vie privée.
L’AFC fait partie d’un ensemble qui a pour but d’apporter de la publicité ciblée dans un futur où la vie privée serait préservée. Cependant la conception même de cette technique implique le partage de nouvelles données avec les annonceurs. Sans surprise, ceci crée et ajoute des risques concernant la donnée privée.
Le Traçage par reconnaissance d’ID.
Le premier enjeu, c’est le pistage des navigateurs, une pratique qui consiste à collecter de multiples données distinctes afin de créer un identifiant unique, personnalisé et stable lié à un navigateur en particulier. Le projet Cover Your Tracks (Masquer Vos Traces) de l’Electronic Frontier Foundation (EFF) montre comment ce procédé fonctionne : pour faire simple, plus votre navigateur paraît se comporter ou agir différemment des autres, plus il est facile d’en identifier l’empreinte unique.
Google a promis que la grande majorité des cohortes AFC comprendrait chacune des milliers d’utilisatrices, et qu’ainsi on ne pourra vous distinguer parmi le millier de personnes qui vous ressemblent. Mais rien que cela offre un avantage évident aux pisteurs. Si un pistage commence avec votre cohorte, il doit seulement identifier votre navigateur parmi le millier d’autres (au lieu de plusieurs centaines de millions). En termes de théorie de l’information, les cohortes contiendront quelques bits d’entropie jusqu’à 8, selon la preuve de faisabilité. Cette information est d’autant plus éloquente sachant qu’il est peu probable qu’elle soit corrélée avec d’autres informations exposées par le navigateur. Cela va rendre la tâche encore plus facile aux traqueurs de rassembler une empreinte unique pour les utilisateurs de l’AFC.
Google a admis que c’est un défi et s’est engagé à le résoudre dans le cadre d’un plan plus large, le « Budget vie privée » qui doit régler le problème du pistage par l’empreinte numérique sur le long terme. Un but admirable en soi, et une proposition qui va dans le bon sens ! Mais selon la Foire Aux Questions, le plan est « une première proposition, et n’a pas encore d’implémentation dans un navigateur ». En attendant, Google a commencé à tester l’AFC dès ce mois de mars.
Le pistage par l’empreinte numérique est évidemment difficile à arrêter. Des navigateurs comme Safari et Tor se sont engagés dans une longue bataille d’usure contre les pisteurs, sacrifiant une grande partie de leurs fonctionnalités afin de réduire la surface des attaques par traçage. La limitation du pistage implique généralement des coupes ou des restrictions sur certaines sources d’entropie non nécessaires. Il ne faut pas que Google crée de nouveaux risques d’être tracé tant que les problèmes liés aux risques existants subsistent.
L’exposition croisée
Un second problème est moins facile à expliquer : la technologie va partager de nouvelles données personnelles avec des pisteurs qui peuvent déjà identifier des utilisatrices. Pour que l’AFC soit utile aux publicitaires, une cohorte devra nécessairement dévoiler des informations comportementales.
La page Github du projet aborde ce sujet de manière très directe :
Cette API démocratise les accès à certaines informations sur l’historique de navigation général des personnes (et, de fait, leurs intérêts principaux) à tous les sites qui le demandent… Les sites qui connaissent les Données à Caractère Personnel (c’est-à-dire lorsqu’une personne s’authentifie avec son adresse courriel) peuvent enregistrer et exposer leur cohorte. Cela implique que les informations sur les intérêts individuels peuvent éventuellement être rendues publiques.
Comme décrit précédemment, les cohortes AFC ne devraient pas fonctionner en tant qu’identifiant intrinsèque. Cependant, toute entreprise capable d’identifier un utilisateur d’une manière ou d’une autre – par exemple en offrant les services « identifiez-vous via Google » à différents sites internet – seront à même de relier les informations qu’elle apprend de l’AFC avec le profil de l’utilisateur.
Deux catégories d’informations peuvent alors être exposées :
1. Des informations précises sur l’historique de navigation. Les pisteurs pourraient mettre en place une rétro-ingénierie sur l’algorithme d’assignation des cohortes pour savoir si une utilisatrice qui appartient à une cohorte spécifique a probablement ou certainement visité des sites spécifiques.
2. Des informations générales relatives à la démographie ou aux centres d’intérêts. Par exemple, une cohorte particulière pourrait sur-représenter des personnes jeunes, de sexe féminin, ou noires ; une autre cohorte des personnes d’âge moyen votant Républicain ; une troisième des jeunes LGBTQ+, etc.
Cela veut dire que chaque site que vous visitez se fera une bonne idée de quel type de personne vous êtes dès le premier contact avec ledit site, sans avoir à se donner la peine de vous suivre sur le Net. De plus, comme votre cohorte sera mise à jour au cours du temps, les sites sur lesquels vous êtes identifié⋅e⋅s pourront aussi suivre l’évolution des changements de votre navigation. Souvenez-vous, une cohorte AFC n’est ni plus ni moins qu’un résumé de votre activité récente de navigation.
Vous devriez pourtant avoir le droit de présenter différents aspects de votre identité dans différents contextes. Si vous visitez un site pour des informations médicales, vous pourriez lui faire confiance en ce qui concerne les informations sur votre santé, mais il n’y a pas de raison qu’il ait besoin de connaître votre orientation politique. De même, si vous visitez un site de vente au détail, ce dernier n’a pas besoin de savoir si vous vous êtes renseigné⋅e récemment sur un traitement pour la dépression. L’AFC érode la séparation des contextes et, au contraire, présente le même résumé comportemental à tous ceux avec qui vous interagissez.
Au-delà de la vie privée
L’AFC est conçu pour éviter une menace spécifique : le profilage individuel qui est permis aujourd’hui par le croisement des identifiants contextuels. Le but de l’AFC et des autres propositions est d’éviter de laisser aux pisteurs l’accès à des informations qu’ils peuvent lier à des gens en particulier. Alors que, comme nous l’avons montré, cette technologie pourrait aider les pisteurs dans de nombreux contextes. Mais même si Google est capable de retravailler sur ses conceptions et de prévenir certains risques, les maux de la publicité ciblée ne se limitent pas aux violations de la vie privée. L’objectif même de l’AFC est en contradiction avec d’autres libertés individuelles.
Pouvoir cibler c’est pouvoir discriminer. Par définition, les publicités ciblées autorisent les annonceurs à atteindre certains types de personnes et à en exclure d’autres. Un système de ciblage peut être utilisé pour décider qui pourra consulter une annonce d’emploi ou une offre pour un prêt immobilier aussi facilement qu’il le fait pour promouvoir des chaussures.
Au fur et à mesure des années, les rouages de la publicité ciblée ont souvent été utilisés pour l’exploitation, la discrimination et pour nuire. La capacité de cibler des personnes en fonction de l’ethnie, la religion, le genre, l’âge ou la compétence permet des publicités discriminatoires pour l’emploi, le logement ou le crédit. Le ciblage qui repose sur l’historique du crédit – ou des caractéristiques systématiquement associées – permet de la publicité prédatrice pour des prêts à haut taux d’intérêt. Le ciblage basé sur la démographie, la localisation et l’affiliation politique aide les fournisseurs de désinformation politique et la suppression des votants. Tous les types de ciblage comportementaux augmentent les risques d’abus de confiance.
Au lieu de réinventer la roue du pistage, nous devrions imaginer un monde sans les nombreux problèmes posés par les publicités ciblées.
Google, Facebook et beaucoup d’autres plateformes sont en train de restreindre certains usages sur de leur système de ciblage. Par exemple, Google propose de limiter la capacité des annonceurs de cibler les utilisatrices selon des « catégories de centres d’intérêt à caractère sensible ». Cependant, régulièrement ces tentatives tournent court, les grands acteurs pouvant facilement trouver des compromis et contourner les « plateformes à usage restreint » grâce à certaines manières de cibler ou certains types de publicité.
Même un imaginant un contrôle total sur quelles informations peuvent être utilisées pour cibler quelles personnes, les plateformes demeurent trop souvent incapables d’empêcher les usages abusifs de leur technologie. Or l’AFC utilisera un algorithme non supervisé pour créer ses propres cohortes. Autrement dit, personne n’aura un contrôle direct sur la façon dont les gens seront regroupés.
Idéalement (selon les annonceurs), les cohortes permettront de créer des regroupements qui pourront avoir des comportements et des intérêts communs. Mais le comportement en ligne est déterminé par toutes sortes de critères sensibles : démographiques comme le genre, le groupe ethnique, l’âge ou le revenu ; selon les traits de personnalités du « Big 5 »; et même la santé mentale. Ceci laisse à penser que l’AFC regroupera aussi des utilisateurs parmi n’importe quel de ces axes.
L’AFC pourra aussi directement rediriger l’utilisatrice et sa cohorte vers des sites internet qui traitent l’abus de substances prohibées, de difficultés financières ou encore d’assistance aux victimes d’un traumatisme.
Google a proposé de superviser les résultats du système pour analyser toute corrélation avec ces catégories sensibles. Si l’on découvre qu’une cohorte spécifique est étroitement liée à un groupe spécifique protégé, le serveur d’administration pourra choisir de nouveaux paramètres pour l’algorithme et demander aux navigateurs des utilisateurs concernés de se constituer en un autre groupe.
Cette solution semble à la fois orwellienne et digne de Sisyphe. Pour pouvoir analyser comment les groupes AFC seront associés à des catégories sensibles, Google devra mener des enquêtes gigantesques en utilisant des données sur les utilisatrices : genre, race, religion, âge, état de santé, situation financière. Chaque fois que Google trouvera qu’une cohorte est associée trop fortement à l’un de ces facteurs, il faudra reconfigurer l’ensemble de l’algorithme et essayer à nouveau, en espérant qu’aucune autre « catégorie sensible » ne sera impliquée dans la nouvelle version. Il s’agit d’une variante bien plus compliquée d’un problème que Google s’efforce déjà de tenter de résoudre, avec de fréquents échecs.
Dans un monde numérique doté de l’AFC, il pourrait être plus difficile de cibler directement les utilisatrices en fonction de leur âge, genre ou revenu. Mais ce ne serait pas impossible. Certains pisteurs qui ont accès à des informations secondaires sur les utilisateurs seront capables de déduire ce que signifient les groupes AFC, c’est-à-dire quelles catégories de personnes appartiennent à une cohorte, à force d’observations et d’expérimentations. Ceux qui seront déterminés à le faire auront la possibilité de la discrimination. Pire, les plateformes auront encore plus de mal qu’aujourd’hui à contrôler ces pratiques. Les publicitaires animés de mauvaises intentions pourront être dans un déni crédible puisque, après tout, ils ne cibleront pas directement des catégories protégées, ils viseront seulement les individus en fonction de leur comportement. Et l’ensemble du système sera encore plus opaque pour les utilisatrices et les régulateurs.
Avec Google les instruments changent, mais c’est toujours la même musique…
Google, ne faites pas ça, s’il vous plaît
Nous nous sommes déjà prononcés sur l’AFC et son lot de propositions initiales lorsque tout cela a été présenté pour la première fois, en décrivant l’AFC comme une technologie « contraire à la vie privée ». Nous avons espéré que les processus de vérification des standards mettraient l’accent sur les défauts de base de l’AFC et inciteraient Google à renoncer à son projet. Bien entendu, plusieurs problèmes soulevés sur leur GitHub officiel exposaient exactement les mêmespréoccupations que les nôtres. Et pourtant, Google a poursuivi le développement de son système, sans pratiquement rien changer de fondamental. Ils ont commencé à déployer leur discours sur l’AFC auprès des publicitaires, en vantant le remplacement du ciblage basé sur les cookies par l’AFC « avec une efficacité de 95 % ». Et à partir de la version 89 de Chrome, depuis le 2 mars, la technologie est déployée pour un galop d’essai. Une petite fraction d’utilisateurs de Chrome – ce qui fait tout de même plusieurs millions – a été assignée aux tests de cette nouvelle technologie.
Ne vous y trompez pas, si Google poursuit encore son projet d’implémenter l’AFC dans Chrome, il donnera probablement à chacun les « options » nécessaires. Le système laissera probablement le choix par défaut aux publicitaires qui en tireront bénéfice, mais sera imposé par défaut aux utilisateurs qui en seront affectés. Google se glorifiera certainement de ce pas en avant vers « la transparence et le contrôle par l’utilisateur », en sachant pertinemment que l’énorme majorité de ceux-ci ne comprendront pas comment fonctionne l’AFC et que très peu d’entre eux choisiront de désactiver cette fonctionnalité. L’entreprise se félicitera elle-même d’avoir initié une nouvelle ère de confidentialité sur le Web, débarrassée des vilains cookies tiers, cette même technologie que Google a contribué à développer bien au-delà de sa date limite, engrangeant des milliards de dollars au passage.
Ce n’est pas une fatalité. Les parties les plus importantes du bac-à-sable de la confidentialité comme l’abandon des identificateurs tiers ou la lutte contre le pistage des empreintes numériques vont réellement améliorer le Web. Google peut choisir de démanteler le vieil échafaudage de surveillance sans le remplacer par une nouveauté nuisible.
Nous rejetons vigoureusement le devenir de l’AFC. Ce n’est pas le monde que nous voulons, ni celui que méritent les utilisatrices. Google a besoin de tirer des leçons pertinentes de l’époque du pistage par des tiers et doit concevoir son navigateur pour l’activité de ses utilisateurs et utilisatrices, pas pour les publicitaires.
Remarque : nous avons contacté Google pour vérifier certains éléments exposés dans ce billet ainsi que pour demander davantage d’informations sur le test initial en cours. Nous n’avons reçu aucune réponse à ce jour.
Libres bulles pour que décollent les contributions
Comme beaucoup d’associations libristes, nous recevons fréquemment ce genre de demandes « je vous suis depuis longtemps et je voudrais contribuer un peu au Libre, comment commencer ? »
Pour y répondre, ce qui n’est pas toujours facile, une dynamique équipe s’est constituée avec le soutien de Framasoft et a fondé le projet Contribulle qui propose déjà d’aiguiller chacun⋅e vers des contributions à sa mesure. Pour comprendre comment ça marche et quel intérêt vous avez à les rejoindre, nous leur avons posé des questions…
« Bulles de savon » par Daniel_Hache, licence CC BY-ND 2.0
Bonjour la team Contribulle ! On vous a rencontré⋅e⋅s sur l’archipel de Contributopia, mais pouvez-vous vous présenter, nous dire de quels horizons vous venez ?
– Hello, je suis llaq (ou lelibreauquotidien), je suis dans le logiciel libre depuis quelques années depuis qu’un ami m’a offert un PC sous Linux (bon, quand j’étais sous Windows, j’utilisais déjà des logiciels libres mais c’était pas un argument rédhibitoire).
— Yo ! Oui on se baladait dans le coin, l’horizon qui se présentait à nous paraissait bien prometteur ! Je suis Mélanie mais vous pouvez m’appeler méli, j’ai bientôt 25 ans et je viens du monde du design UX et UI. En explorant le numérique, j’ai pas mal gravité autour du Libre et mon mémoire de master de l’année dernière m’a bien fait plonger dans ce sujet super passionnant ! Fun fact : je me demandais comment rendre le logiciel libre plus ouvert (!), pour mieux accueillir une diversité de contributions et il faut dire que votre campagne Contributopia m’a pas mal guidée héhé. Le projet Contribulle a en partie émergé à cette période-là et je suis contente de le poursuivre, toujours en tant que designeuse UX/UI !
– Hello ! Je suis Maiwann, membre de Framasoft… une petite asso que vous connaissez peut-être ? Et je suis designer.
Laissez-moi deviner : Contribulle, c’est un dispositif pour enfermer les contributeurs et contributrices d’un projet dans une bulle et alors quand ça monte ça éclate et le projet explose ? Non, c’est pas ça ?
llaq : C’est presque ça. Contribulle est une plateforme qui permet de mettre en relation des projets aux besoins assez spécifiques avec des contributeur·rice·s intéressé·e·s, qu’iels soient dans le domaine technique ou non. Un des buts du site est d’ailleurs de permettre aux non-techniques de contribuer à des projets libres et surtout de démontrer que la contribution, c’est pas seulement pour les codeur·se·s.
méli : Haha, ce nom a été voté par jugement majoritaire ! Perso, j’imagine une bulle qui est amenée à grossir grâce aux contributions des personnes et qui sera tellement géante qu’il sera impossible de la rater. Et peut-être qu’elle pourrait attirer d’autres contributions !
Maiwann : … Et moi j’imagine plein de petites bulles comme un nuage de bulles de savon quand on souffle dans le petit cercle ! Et elles s’envolent… loin… loiiiiiin ! Jusqu’à ce qu’on en fasse une nouvelle fournée 🙂
« Bubbles » by bogenfreund, licence CC BY-SA 2.0
Ah mais c’est tout neuf cette plateforme ? Comment est venue l’idée de proposer ça ? Et d’ailleurs ça paraît tellement utile qu’on se demande pourquoi ça n’existait pas avant.
méli : Pendant mon mémoire, j’avais retenu qu’il était compliqué de s’y retrouver parmi tous les projets libres créés et qu’il était encore plus difficile de savoir où et comment contribuer au Libre, surtout en tant que non-développeur·se. J’avais donc rapidement imaginé un site qui recenserait des projets libres à la recherche de compétences et qui permettrait d’attirer des contributeur·rice·s de tous horizons. Je ne savais pas s’il existait déjà une plateforme de ce type dans laquelle je pourrais m’inscrire.
Quelques déambulations plus tard, je suis tombée sur la restitution du fameux événement coorganisé par Framasoft et la Quadrature du Net « Fabulous Contribution Camp » de novembre 2017. J’y ai trouvé une idée similaire au site que j’imaginais et je contacte donc Maiwann pour avoir des nouvelles sur l’évolution de ce projet. On s’appelle en janvier 2020 (merci BigBlueButton) et il s’avère que rien n’avait été mis en place et qu’il manquait un tremplin pour lancer le projet. C’est donc à partir de là que ça a décollé. Si la suite intéresse : J’ai ensuite réalisé une maquette de la plateforme, qui avait pour nom de code « Meetic du Libre ». J’ai pu la présenter au cours d’un Confinatelier en juin 2020 avec Maiwann. On avait pour objectifs de valider la pertinence du projet et ensuite de mobiliser des personnes qui souhaiteraient bien y contribuer. Les retours nous ont rassuré⋅e⋅s et on a pu monter un groupe de travail rapidement.
Cependant, avec l’été qui se profilait, le site était juste débutant jusqu’à ce que Maiwann nous relance fin octobre. Depuis novembre, l’équipe est un peu plus réduite : on est 2 designeuses, 1 développeur front et 1 développeur back et on s’organise des rendez-vous hebdomadaires pour avancer. Des personnes nous ont aussi aidé⋅e⋅s ponctuellement, que ce soit aux niveaux code, graphisme et design, on leur en est super reconnaissant·e·s ! Grâce aux efforts et la bonne humeur de tou·te·s les contributeur·rices, on a pu mettre en ligne Contribulle en février 2021, une grande fierté !
Est-ce qu’il faut s’inscrire avec ses coordonnées et tout ?
llaq : Pour les personnes qui créent une demande de contribution, il n’est pas nécessaire de créer de compte. Il faut simplement renseigner une adresse email valide et un pseudo pour que les contributeur·rice·s qui le souhaitent puissent contacter la personne qui a créé l’annonce.
Maiwann : On a fait en sorte d’être le plus minimalistes possibles dans le nombre d’infos demandées. Du coup, exit la création de compte pour ne pas se farcir un énième identifiant-mot-de-passe ! En revanche, on demande un moyen de contact aux personnes qui recherchent des contributeurices, pour être sûres qu’elles vont pouvoir s’adresser à un humain !
Combien ça coûte ?
llaq : Rien. Plus sérieusement, dans le projet, nous sommes tou·te·s bénévoles et les ressources techniques servant à l’hébergement de contribulle.org nous ont gracieusement été offertes par notre partenaire Framasoft, donc aucun frais pour nous, aucune raison de faire payer la plateforme donc 🙂
méli : Dans la perspective de mettre en avant des projets qui participent à l’émancipation individuelle et collective des individus et qui sont bien évidemment respectueux de nos libertés, on ne souhaite pas faire payer pour poster une annonce. On veut inviter le plus grand nombre à mettre la main à la pâte donc on préfère éviter de poser des contraintes financières dès le départ !
Maiwann : Ça a coûté du temps et de l’énergie à des gens compétents de se retrouver, de décider d’une direction pour le projet, de faire des choix, de les maquetter / coder, + les frais d’hébergement. Et ça va coûter de l’énergie dans le futur pour faire vivre Contribulle, donc si vous en parlez le plus possible autour de vous, ça nous aidera beaucoup et ça contribuera à faire vivre Contribulle !
Si j’ai un projet génial mais que je ne sais rien faire du tout, je peux juste vous donner mon idée géniale et vous allez vous en charger et tout faire pour moi ?
méli : Mmmh Contribulle n’est pas un service de travail gratuit… mais c’est chouette si tu as une bonne idée de projet, si tu sens qu’elle a du potentiel et qu’elle est valide…
À quel(s) besoin(s) répond-elle ?
Quelle est sa valeur ajoutée pour les futur·e·s utilisateur·rices ?
…
…tu peux lister précisément les compétences requises. Contribulle a vocation de faciliter la compréhension de contributions auprès des personnes qui veulent aider. C’est pour ça qu’il nous semble nécessaire dans le formulaire de demande de contribution de bien présenter le projet et de donner plus d’indications sur la contribution souhaitée. Un projet se doit d’être sérieux et conscient du temps et de l’effort qu’un·e contributeur·rice y consacrera.
logo du projet Contribulle
Un point qu’il est important de mentionner est l’accueil des contributeur·rice·s au sein d’un projet. Il ne faut pas prendre l’aide d’une personne externe comme acquise et surtout la surexploiter parce que (friendly reminder) : on a nos vies et nos priorités à gérer.
Un projet doit mettre en place un dispositif pour faciliter l’accès à la contribution, que ce soit une page dédiée, une conversation épistolaire, le format est libre et à adapter selon les parties prenantes !
Attention cependant aux renvois directs vers les forges logicielles comme GitHub ou GitLab qui ne sont pas si accessibles pour les non-techniques. Peut-être qu’un tutorat personnalisé peut s’envisager ?
Bref, soyons plus à l’écoute des contributeur·rice·s ! Et pour les contributeur·rice·s : écoutez-vous et n’hésitez pas à dire quand un truc vous gêne, la communication fait tout.
Comment je vais savoir que d’autres sont intéressée⋅es par mon projet ou que ma contribution intéresse d’autres ?
llaq : On n’a pas de messagerie intégrée, tout se fait par le mail que vous avez indiqué dans votre annonce. Maiwann : comme ça, pas besoin de revenir sur la plateforme, ouf ! Vous postez et c’est réglé !
Attention c’est le moment trollifère : les projets sur lesquels on peut contribuer c’est du libre ou open source ou bien osef ?
llaq : Nous comptons justement implémenter un bandeau qui s’affichera si le projet est libre ou pas (c’est-à-dire bénéficiant d’une licence libre) ! Mais sa place sur Contribulle va dépendre de l’équipe de modération composée de 4 personnes pour l’instant.
méli : La valeur (politique) des projets publiés sera prise en compte. Parmi les questions à se poser : pour qui est le projet ? Participe-t-il au bien collectif ? Comment permettrait-il à tou·te·s les utilisateur·rices de disposer de leurs appareils ainsi que de leurs données personnelles ?
Maiwann : On voudrait que tous les projets soient sous licence libre, mais on est aussi conscient·es que tout le monde n’est pas forcément au clair sur l’intérêt que ça peut avoir, l’importance… donc on se dit qu’on poussera les personnes à s’y intéresser à l’aide du bandeau, mais sans les disqualifier forcément d’entrée (et on verra ça au cas par cas !)
C’est évalué comment et par qui, le « sérieux » ou la pertinence des projets et contributions ? Chacun⋅e s’autonomise et hop ?
llaq : Nous avons décidé de faire de la modération à posteriori. Ton annonce est directement publiée et visible par tout le monde mais si l’équipe de modération estime que le projet n’a pas sa place sur Contribulle, il sera supprimé de la plateforme. Maiwann : et si c’est trop relou, on passera à de la modération a priori ! Et pour faire des choix, ça sera sans doute au doigt mouillé, au « comment chacune le sent » et puis on verra sur le tas comment se structure l’équipe de modération ! Pour l’instant, RAS 🙂
« bubbles » par Mycatkins, licence CC BY 2.0
Et donc si je veux contribuller au projet, je peux faire quoi ?
méli : Pour l’instant, nous faire des retours sur vos usages de Contribulle et la promouvoir autour de vous seraient de belles contributions ! On souhaite l’améliorer au mieux selon les besoins ressentis de chacun·e.
La question de rétribution n’a pas encore été abordée mais selon l’évolution de la plateforme et des ressources mobilisées, des formes sont à réfléchir je pense. Qu’il s’agisse de don financier, d’un retour d’utilisateur·rice, ou autre.
Maiwann : Je pense que ce qui va être primordial ça va être de faire vivre Contribulle. Quelqu’un dit qu’il voudrait aider le Libre ? glissez lui un mot sur Contribulle. Quelqu’un vient à un contrib’atelier ? N’oubliez pas de parler de Contribulle. Comme ça le projet vivra grâce aux visites des contributeurices !
Ah mais il y a déjà un paquet de demandes, ça fait un peu peur, je vois bien que je ne vais servir à rien pour tous ces trucs de techies ! Au secours ! (Pour l’instant dans l’équipe c’est orienté web développement non) ?
méli : c’est 50/50 moitié dev et moitié design/conception. Oui, on a dépassé les 20 annonces depuis sa mise en ligne il y a un mois, c’est trop bien ! Et on cherche vraiment à mettre en avant des contributions non-techniques parce que tu es super utile justement ! Prochainement tu pourras filtrer les annonces selon tes propres savoir-faire, en espérant qu’il y aura des demandes à ce niveau-là. En attendant, on te propose des contributions faciles. Tu seras renvoyé·e vers des sites sélectionnés par nos soins et auxquelles tu peux directement contribuer. Bonne contribution !
Maiwann : C’est tout à fait ça, grâce aux filtres tu vas pouvoir plus facilement mettre de côté les choses qui font peur !
Et si je regarde, il y a déjà quelques projets qui sont chouettes et que tu peux aider sans compétences techniques, par exemple :











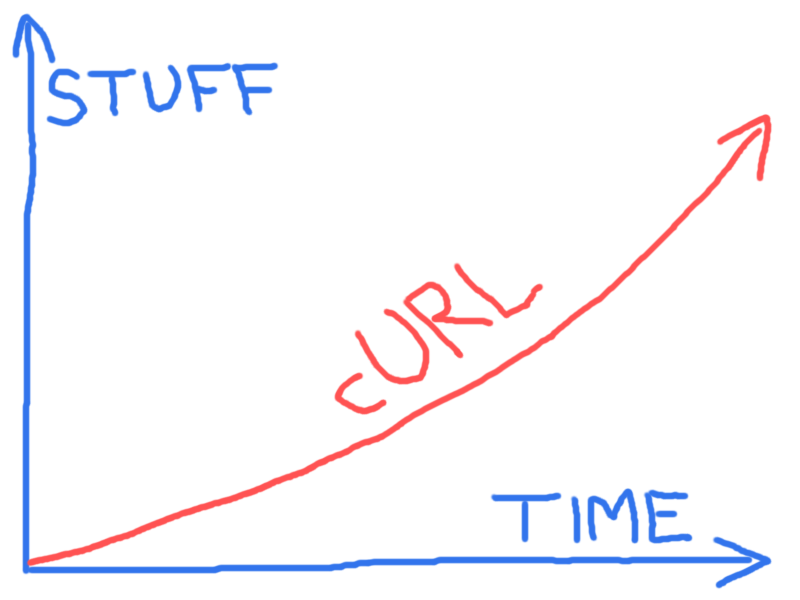











{kind=link}