L’équipe de traduction des bénévoles de Framalang vous propose aujourd’hui le bref témoignage de Silvia, une designeuse indépendante1, qui avait atteint comme beaucoup un degré d’addiction élevé aux réseaux sociaux. Comme d’autres aussi, elle a renoncé progressivement à ces réseaux, et fait le bilan après six mois du nouvel état d’esprit dont elle a bénéficié, une sorte de sentiment de soulagement, celui d’avoir retrouvé un peu de liberté… Bien sûr chacun a une trajectoire différente et la démarche peut n’être pas aussi facile, mais pourquoi ne pas tenter ?
Article original sur le blog de l’autrice : Life off social media, six months in
Traduction Framalang : Bromind, Diane, Florence, goofy, Marius, ngfchristian, Penguin
Six mois hors réseaux sociaux, six mois dans ma vie
par Silvia Maggi
J’étais vraiment partout. Citez-moi un réseau social, et sans doute, j’y avais un compte… Internet a toujours été important pour moi, et un certain degré de présence en ligne était bon pour mon travail, mes hobbies et mes relations sociales.
Mes préférés étaient Twitter, Flickr et LinkedIn. J’ai été une utilisatrice plutôt précoce. Puis sont arrivés Facebook et Instagram, qui sont ensuite devenus les principales raisons pour lesquelles j’ai fermé la plupart de mes comptes. Dès l’origine, j’ai eu une relation d’amour-haine avec Facebook. La première fois que je m’y suis connectée, j’ai détesté l’interface, les couleurs, et j’avais du mal à voir l’intérêt. D’ailleurs, j’ai aussitôt fermé le compte que je venais d’ouvrir, et je n’y suis revenue que plus tard, poussée par des amis qui me disaient « on y est tous et c’est marrant ».
Avec Instagram, le ressentiment est monté progressivement. Mon amour pour la photographie aurait pu être satisfait par l’application mais c’était également une période où les filtres étaient utilisés à outrance – à l’époque, l’autre application en vogue pour la prise de photos était Hipstamatic – et je préférais de toute façon prendre des clichés plutôt avec un appareil photo.
À mesure que la popularité d’Instagram augmentait, associée à la qualité du contenu, je suis devenue accro. Je n’ai jamais effacé mon compte Flickr, mais je ne visitais que rarement la plateforme : à un moment, on a eu l’impression que tout le monde avait migré vers l’application aux photos carrées. Cependant, quand Facebook a acheté Instagram pour 1 milliard de dollars en 2012, son avenir est devenu malheureusement évident. Avance rapide jusqu’à janvier 2021 : j’ai désactivé ce que je considérais à une époque comme mon précieux compte Instagram, et j’ai également fermé mon compte WhatsApp. Avant cela, j’avais fermé mes comptes Twitter, Facebook et Pinterest. Six mois plus tard, je peux dire comment les choses se sont passées.
Le bruit de fond s’est tu
Au début, c’était une sensation étrange : quelque chose manquait. Dans ma vie, je m’étais habituée à un certain niveau de bruit, au point de ne plus m’en rendre compte. Une fois qu’il a disparu, cela est devenu si évident que je m’en suis sentie soulagée. J’ai désormais moins d’opportunités de distractions et ainsi, il m’est devenu progressivement, plus facile de rester concentrée plus longtemps. En conséquence, cela a considérablement amélioré ma productivité et désormais, je suis à même de commencer et terminer la lecture de livres.
Le monde a continué de tourner
Je ne prête plus l’oreille aux mèmes, scandales ni à tout ce qui devient viral ou tendance sur les réseaux sociaux. Au lieu d’avoir peur de rater quelque chose, j’y suis indifférente. Le temps que je passais à suivre ce qui arrivait en ligne, je le passe ailleurs. Et le mieux dans tout ça, c’est que je ne me sens pas obligée de donner mon avis. J’ai des opinions précises sur les choses qui me tiennent à cœur, mais je doute que le monde entier ait besoin de les connaître.
En ce moment historique, tout peut être source de division, et les réseaux sociaux sont un endroit où la plupart des gens choisissent un camp. C’est un triste spectacle à voir car les arguments clivants sont amplifiés mais jamais réellement apaisés.
Ma santé mentale s’est améliorée
Il y a quelques années, je pensais qu’avoir du succès sur Instagram pourrait devenir mon boulot d’appoint. C’est arrivé à beaucoup de gens, alors pourquoi pas moi ? J’avais acheté un cours en ligne, proposé par un influenceur célèbre, pour comprendre comment rendre mon compte Instagram digne d’intérêt, et faire monter mes photos tout en haut grâce à l’algorithme.
À partir de ce moment, je me suis retrouvée enfermée dans une boucle. Je sortais et prenais avec frénésie plein de photos, les publiais puis je vérifiais les statistiques pour voir comment elles évoluaient. J’ai eu de bons moments, rencontré des personnes géniales, mais ce n’était jamais assez. En tant que photographe, je n’en faisais jamais assez. Les statistiques sont devenues un problème : j’en étais obsédée. Je les vérifiais tout le temps, me demandant ce que je faisais mal. Quand tout cela est devenu trop, je suis passée à un compte personnel, espérant résoudre mon problème en cliquant sur un simple bouton. Ça ne s’est pas passé ainsi : les chiffres n’étaient pas le vrai problème.
À chaque fois que j’éprouvais comme une démangeaison de photographier, et que je ne pouvais pas prendre de photos, je me sentais coupable parce que je n’avais rien à poster. Ma passion pour la photographie est passée d’une activité qui ne m’a jamais déçue, à une source d’anxiété et de sentiment d’infériorité. Depuis que j’ai désactivé mon compte Instagram, je prends des photos quand j’en ai envie. Je les poste sur Flickr, ou bien je les garde pour moi. Ça ne compte plus vraiment, tant que c’est un exutoire créatif.
Chaque fois que j’avais quelque chose à dire ou à montrer, je postais presque immédiatement sur un réseau social. C’était la chose normale à faire. Même si cela a diminué pendant les dernières années, je vois cela comme une attitude étrange de ma part. C’est peut-être une réflexion due au fait que je me connais un peu mieux désormais, mais il m’a toujours fallu du temps pour assimiler des concepts et me forger des opinions. C’est pour cela que je préfère écrire sur mon blog et que j’ai réduit récemment ma fréquence de publication : je donne davantage de détails sur mes apprentissages et mes réalisations récentes.
Conclusion
Quitter les réseaux sociaux a été une bonne décision pour moi. Je suis plus concentrée, moins anxieuse et j’ai à présent plus de temps libre. Cela, en plus des divers confinements, m’a permis de mieux me concentrer et réfléchir davantage à ce qui compte vraiment. Prendre cette décision ne conviendrait certainement pas à tout le monde, mais il est important de réaliser à quel point les réseaux sociaux influencent nos vies, et à quel point ils peuvent changer nos habitudes ainsi que notre manière de penser. Et ainsi, prendre des décisions à notre place.
Des très nombreux témoignages en français qui mettent souvent l’accent sur la difficulté à se « sevrer »…
Mise à jour
22 Novembre 2021. Il y a deux mois, je me suis connectée à Instagram et n’ai rien ressenti. J’ai vu une vidéo d’un ami, mais je n’ai nullement éprouvé le besoin de regarder plus loin.
Il n’y avait aucun intérêt à maintenir ce compte en mode inactif, alors j’ai demandé sa suppression.
Maintenant c’est fini.
Détestons Facebook, mais pour de bonnes raisons…
Même si Facebook Meta s’est efforcé de démentir rapidement, la nouvelle a eu le temps de recueillir un beau succès : ne serait-ce qu’envisager de priver l’Europe de Facebook et Instagram a semblé une si plaisante perspective que beaucoup sur les rézosocios ont crié « chiche ! » ou » bon débarras » en assortissant les messages ironiques d’une quantité de mèmes. C’est l’occasion pour Aral Balkan, qui se réjouit d’un tel rejet implicite de facebook, d’examiner les bonnes raisons de renoncer non seulement à Facebook, mais aussi à toutes sortes de services qui nous asservissent. Tous jouent la même partition, celle du capitalisme de surveillance prédateur de nos données. Dans ce bref article traduit par Framalang, il invite aussi à adopter des solutions alternatives plus respectueuses de l’humain et de la démocratie.
Tout le monde déteste Facebook (mais le problème n’est pas seulement Facebook)
par Aral Balkan
— Mark Zuckerberg et son équipe envisagent de fermer Facebook et Instagram en Europe si Meta ne peut pas traiter les données des Européens sur des serveurs américains.
« C’est alors que mon fil Twitter a pris feu avec une rare unanimité, la gauche et la droite, les riches et les pauvres, les bien portants et les malades, tous d’accord et acquiesçant pour répondre oui, mais oui, allez-y, faites-le. »
Bon, c’est désormais officiel, tout le monde déteste Facebook.
Mais les raisons de cette détestation ont leur importance. Il en va de même pour ce que nous voulons en faire.
D’autres bonnes raisons de détester Facebook et les éleveurs d’humains, dans ma conférence : The Camera Panopticon
Parce qu’il ne censure pas ce que votre gouvernement souhaite qu’il censure ;
Parce qu’il a censuré votre néonazi préféré ;
Parce que vous souhaitez créer le prochain Facebook en étant aussi malveillant qu’eux, mais qu’ils sont en travers de votre chemin (on parle bien de vous, les investisseurs en capital risque et les startups, on vous a vus).
Nous sommes donc toutes et tous d’accord pour dire que Facebook est un problème.
Certains pour de bonnes raisons, d’autres pour de mauvaises raisons…
Mais il ne s’agit pas que de Facebook : cela concerne toute société qui utilise le même modèle économique que Facebook.
Ce modèle économique que j’appelle « un élevage d’humains ».
Il s’agit donc également de Google. Et de Snapchat. Et de TikTok. Et aussi de… et de… ad nauseam. Car tel est le modèle économique utilisé aujourd’hui par les technologies grand public.
Nous avons donc un plus gros problème, systémique, sur les bras (youpi !). Et tout le monde semble avoir une idée ou une autre sur la façon dont nous devrions agir différemment à l’avenir.
Obliger Facebook à partager ses données avec d’autres éleveurs d’humains afin que davantage d’éleveurs d’humains puissent partager vos données (essayez de répéter ça cinq fois, pour voir)
Eh oui, c’est exactement l’actuelle stratégie de canard sans tête de la Commission européenne, vu que ses membres sont incapables de voir au-delà des marchés et de l’antitrust.
D’autres bonnes raisons encore
Regardez mon intervention au Parlement européen dans laquelle je résume le problème et propose une solution.
Soutenir les actuelles alternatives fédérées non commerciales (le « fediverse »), dans lesquelles existent déjà des alternatives viables à Twitter, YouTube et Instagram ;
Soutenir les actuelles alternatives individuelles et non commerciales pour les personnes, comme Owncast pour la diffusion de vidéos en ligne ;
Soutenir la recherche et le développement du Small web — un Web non commercial, à échelle humaine, fait d’espaces d’espaces détenus et contrôlés par des individus, et non par des entreprises.
Regardez les enregistrements de Small is Beautiful, l’émission mensuelle de la Small Technology Foundation, pour en savoir plus à propos de mes travaux sur le Small Web. Détester Facebook, c’est très bien, mais surtout n’oublions pas qu’il n’est pas seulement question de Facebook. Il s’agit plus largement d’élevage d’humains.
Si Facebook disparaît demain mais qu’un autre Facebook le remplace, nous n’aurons rien gagné au change.
Alors, je vous en prie, assurons-nous de bien comprendre les différences entre les diverses alternatives et choisissons celles qui aboutiront à un progrès significatif dans la protection de l’identité individuelle et de la démocratie.
(Un indice ? Regardez l’intention qui est derrière l’organisation. Est-ce que son but, c’est de gagner des milliards de dollars ou de protéger les droits humains et la démocratie ? Et oui, peu importe ce que les capitalistes vous diront, les deux buts sont diamétralement opposés et mutuellement exclusifs.)
Si vous avez aimé cet article, vous pouvez soutenir la fondation de son auteur, Small Technology, qui est petite, indépendante, et à but non-lucratif.
Le but de cette fondation de 2 personnes est de protéger les personnes et la démocratie à l’ère numérique.
Infoclimat : un commun météorologique et climatologique à préserver !
Infoclimat est une association de passionné·es de météo, qui agit pour favoriser et vulgariser l’échange de données et de connaissances autour de la météo et du climat. Nous baignons dans les mêmes eaux et partageons les mêmes valeurs : les communs culturels doivent être ouverts à toutes et tous pour l’intérêt général !
L’association va fêter ses 20 ans et se lancer dans un nouveau projet : le recrutement de son·sa premier·ère salarié·e. C’est l’occasion de donner la parole à Frédéric Ameye et Sébastien Brana, tous deux bénévoles.
Bonjour Frédéric et Sébastien, pouvez-vous vous présenter ?
Frédéric Ameye (FA), 27 ans, je suis ingénieur dans les systèmes embarqués pendant les heures ouvrables… et en-dehors de ça, je suis depuis longtemps « Linuxien » et (modeste) défenseur du logiciel libre, mais aussi de l’égalité des chances à l’école — issu d’une famille ouvrière très modeste, c’est quelque chose qui me tient beaucoup à cœur. Le reste du temps (quand il en reste), vous me trouverez principalement en rando au fin fond de la montagne…
J’ai intégré l’aventure Infoclimat en 2009 (j’avais alors 15 ans), période à laquelle j’ai « refondu » le site web de l’asso à partir de l’ordinateur familial à écran cathodique, que je monopolisais des dizaines d’heures par semaine, jusqu’à très tard dans la nuit. J’ai continué ce rôle jusqu’à aujourd’hui (avec un écran plat, et moins d’heures dans la nuit car la trentaine arrive vite). Entre-temps, j’ai rejoint le Conseil d’Administration, et je suis ensuite devenu Vice-Président en 2015.
Sébastien Brana (SB), 42 ans. Dans la vie « hors Infoclimat », je suis chef de projet informatique à la Direction générale des finances publiques… et comme Frédéric, en dehors de « ça », j’occupe une grande partie de mon temps libre (soirées, week-end et congés) au profit du site et de l’association que j’ai rejoint en 2005 et dont je suis également Vice-Président depuis 12 ans. Au-delà des phénomènes météo (orages et chutes de neige notamment) qui m’ont toujours fasciné depuis aussi loin que je me souvienne, je suis également passionné par la communauté que nous avons formée depuis une vingtaines d’années, rassemblant des personnes de tous âges (des gamins de 10 ans aux retraités) et de tous milieux, amateurs ou professionnels, scientifiques ou littéraires, ou simplement amoureux de beaux paysages et de photographies. La météo touche tout le monde, les questions liées au climat interrogent tout le monde – bref, ces sujets intéressent voire passionnent bien au-delà des barrières sociales habituelles !
Vous êtes membres bénévoles de Infoclimat, pouvez-vous nous parler du projet de l’association ?
SB : Initialement, Infoclimat était un petit groupe de passionnés de météo et de climat, qui partageaient leurs relevés entre-eux à la fin des années 90, sur un site web appelé « OrageNet ». Tout cela a progressivement grossi, jusqu’à l’année 2003, où l’association a été créée principalement pour subvenir aux besoins d’hébergement du site web. A l’époque, nous étions déjà (et sans le savoir!) en « Web 2.0 » et pratiquions les sciences participatives puisque l’essentiel du contenu était apporté par les passionnés ; nous étions alors bien loin d’imaginer que les problématiques liées au climat deviendraient un enjeu mondial avec une telle résonance médiatique.
Infoclimat a beaucoup évoluée, entre les débuts sur un internet confidentiel des années 90 dédié au partage, au web d’aujourd’hui.
FA : Depuis, l’objet social s’est considérablement diversifié, avec la montée en puissance de notre asso. Aujourd’hui, nous visons trois thématiques particulières :
L’engagement citoyen au service de la météo et du climat : partager ses relevés, ses observations météo, installer des stations météorologiques,… au service de tous ! Cela permet de comprendre comment le climat change, mais aussi de déceler des particularités locales que les modèles de prévision ne savent pas bien prendre en compte, ou qui ne peuvent pas être mesurées facilement.
Valoriser la donnée météo et climato, qu’elle soit issue de services officiels ou diffusée en « OpenData » par nous ou nos passionnés, et en particulier en faire des outils utiles autant aux « pros » et chercheurs, qu’au service de la vulgarisation des sujets climatiques pour le grand public. Les utilisations sont très nombreuses : agriculture, viabilité hivernale, thermique dans l’habitat, recherches sur le changement climatique, production électrique, journalistes…
Former et transmettre les connaissances, par la production de contenus de vulgarisation scientifique, l’organisation de « rencontres météo », ou encore des interventions auprès des écoles, dans des événements sur le terrain ou sur les réseaux sociaux. Bref, contrer la désinformation et le buzz !
Quand Infoclimat débarque quelque part, c’est rarement pour pique-niquer… Mais plutôt pour installer du matériel météo !
Vous faites donc des prévisions météo ?
SB : Même si le forum est largement animé par des prévisionnistes amateurs, nous parlons finalement assez peu de prévisions météo : le cœur du site, c’est l’observation météo en temps réel et la climatologie qui résulte des données collectées, qui sont des sujets bien différents ! Il y aurait tant à dire sur le monde de la prévision météo, mais cela mériterait un article à lui seul, car il y a un gros sujet là aussi sur l’ouverture des données et la paternité des algorithmes… Souvent négligée, l’observation météorologique est pourtant fondamentale pour produire une bonne prévision. Pour faire court, la donnée météo « observée » est la nourriture qu’il faut pour entraîner les modèles climatiques, et faire tourner les modèles numériques qui vous diront s’il faut un parapluie demain sur votre pixel de 1km².
Quantité d’observations météo intégrées dans le modèle de prévisions français « AROME », source principale de toutes les prévisions en France métropolitaine. La performance des modèles météorologiques est fortement corrélée à la quantité, la fréquence, et à la qualité de leurs données d’entrées (observations radar, satellite, avions, stations météo au sol,…). La quantité d’observations des stations Météo-France est à peu près équivalente à la quantité de données produites par les passionnés d’Infoclimat. Graphique simplifié, hors données radar. Avec l’aimable autorisation de Météo-France et du CNRM.
FA : Ce qu’il faut savoir, c’est que l’immense majorité des sites internet ou appli que vous consultez ne font pas de prévisions météo, mais utilisent des algorithmes automatisés qui traitent des données fournies (gratuitement ou avec redevance) par les organismes publics (Météo-France, la NOAA, le Met-Office, l’organisme européen ECMWF,…). La qualité des prévisions est en gros corrélée à l’argent que les créateurs des sites et des applis peuvent injecter pour récolter des données brutes de ces modèles numériques. Par exemple, pour avoir les données du modèle de Météo-France « AROME », c’est à peu près gratuit car les données sont sous licence Etalab, mais si vous voulez des données plus complètes, permettant d’affiner vos algorithmes et de proposer « mieux », c’est sur devis.
Dès lors, Infoclimat ne souhaite pas se lancer dans cette surenchère, et propose uniquement des prévisions automatisées issues de données ouvertes de Météo-France et de la NOAA, et indique très clairement la différence entre prévisions automatisées et bulletins rédigés par des passionnés.
La Terre est découpée en petits cubes dans lesquels les modèles météo estiment les paramètres de l’atmosphère à venir. Les cubes sont généralement bien plus gros lorsque les échéances sont lointaines (J+4, J+5…), ce qui empêche les modèles météorologiques de discerner les phénomènes météo de petite échelle (averses, orages, neige, effets des reliefs et des côtes). Pourtant, de nombreuses appli météo se contentent de vous fournir grossièrement ces données sans l’explication qui va avec. Chez Infoclimat, on laisse volontairement la résolution native, pour ne pas induire le lecteur en erreur sur la résolution réelle des données.
Cela me fait toujours rire (jaune) quand j’entends « [site ou appli] a de meilleures prévisions à chaque fois, et en plus, on les a à 15 jours ! » : lorsqu’il s’agit de prévisions « automatiques », par ville, il est probable qu’il utilise les mêmes données que tous les autres, présentées légèrement différemment, et qu’il s’agisse juste d’un biais de confirmation. Il existe bien sûr quelques exceptions, certaines entreprises faisant un vrai travail de fusion de données, d’analyse, de suppression des biais, pour proposer des informations de très grande qualité, généralement plutôt payantes ou pour les pros. Mais même chez ceux qui vous vendent du service d’aide à la décision, de protection des biens et des personnes, des données expertisées ou à vocation assurantielles, vous seriez très surpris de la piètre qualité de l’exploitation qui est faite de ces données brutes.
Les modélisateurs météo ont plein de techniques pour prendre en compte les incertitudes dans les observations et les modèles, notamment ce que l’on appelle la « prévision ensembliste ». Mais ces incertitudes sont rarement présentées ou expliquées au public. Ici par exemple, le graphique présente la quantité de pluie prédite par un modèle météo le 6 janvier, pour la période entre le 6 janvier et le 16 janvier 2022, sur un point de la France. Le modèle considère plusieurs scénarios d’évolution possible des futurs météorologiques. Source : ECMWF, CC BY 4.0.
Malheureusement, cette situation rend très délicate la perception des prévisions météo par le grand public (« ils se trompent tout le temps ») : la majorité des applis prend des données gratuites, de faible qualité, sur le monde entier, qui donnent une prévision différente 4 fois par jour au fil des calculs. Cela ne met vraiment pas en valeur le travail des modélisateurs, qui font pourtant un travail formidable, les modèles numériques s’améliorant considérablement, et décrédibilisent aussi les conclusions des organismes de recherche pour le climat (« ils ne savent pas prévoir à 3 jours, pourquoi ils sauraient dans 50 ans ?! »), alors qu’il s’agit surtout d’une exploitation maladroite de données brutes, sans accompagnement dans leur lecture.
Ce graphique présente, grosso-modo, l’amélioration de la qualité des prévisions de l’état de l’atmosphère au fil des années, à diverses échéances de temps (jaune = J+10, vert = J+7, rouge = J+5, bleu = J+3) et selon les hémisphères terrestres. Plus c’est proche de 100%, meilleures sont les prévisions ! Source : ECMWF, CC BY 4.0.
Du coup, quelles actions menez-vous ?
FA : Notre action principale, c’est la fourniture d’une plateforme sur le web, qu’on assimile souvent au « Wikipédia de la météo », ou à un « hub de données » : nous récoltons toutes sortes de données climatiques et météorologiques de par le monde, pour les décoder, les rendre digestes pour différents publics, et la mettre en valeur pour l’analyse du changement climatique. Ce sont par exemple des cartographies, ou des indices d’évolution du climat. C’est notre rôle initial, qui aujourd’hui compile plus de 6 milliards de données météo, à la qualité souvent rigoureusement contrôlée par des passionnés ! Il faut savoir que nous n’intégrons pas toutes les stations météo : nous respectons des normes de qualité du matériel et de l’environnement, pour que les données soient exploitables et comparables entre-elles, comparables avec des séries climatiques historiques, et assimilables dans des modèles numériques de prévision.
Infoclimat propose l’accès à toutes les informations météo et climatiques dans des interfaces qui se veulent simples d’accès, mais suffisamment complètes pour les plus experts. Dur équilibre !
SB : Avec l’accroissement de notre budget, nous avons pu passer à l’étape supérieure : installer nos propres stations météo, et soutenir les associations locales et les passionnés qui en installent et qui souhaitent mettre leurs données au service d’une base de données commune et libre.
Les passionnés ne reculent devant rien pour l’intérêt général. Aller installer une station météo à Casterino, village des Alpes Maritimes qui s’est retrouvé isolé de tout après la tempête Alex ? C’est fait, et avec le sourire malgré les kilomètres avec le matériel sur le dos ! Retrouvez l’article ici
Il faut savoir que la donnée météo se « monnaye », et chèrement: Météo-France, par exemple, ne met à disposition du grand public que quelques pourcents de ses données, le reste étant soumis à des redevances de plusieurs centaines de milliers d’euros par an (on y reviendra). Ce n’est d’ailleurs pas le cas dans tous les pays du monde, les États-Unis (NOAA) ont été précurseurs, beaucoup de pays Européens s’y mettent, mais la France est un peu en retard… Nous sommes partenaires de Météo-France, participons à des travaux communs dans le cadre du « Conseil Supérieur de la Météorologie », mais c’est très long, trop long, et cela prive Météo-France d’une source de revenus importante dans un contexte de stricte restriction budgétaire. L’établissement public administratif se retrouve en effet pris dans une injonction contradictoire par son autorité de tutelle (le Ministère de la Transition écologique et solidaire) : d’un côté il doit « libérer » les données publiques et mettre en place les infrastructures nécessaires, de l’autre, on lui intime l’ordre de trouver de nouvelles sources de financement par sa branche commerciale, et on lui réduit ses effectifs !
Redevances demandées par Météo-France pour accéder aux données météo de son réseau « RADOME » (90% des stations françaises). Hors de portée de notre association ! Source
Le réseau de stations en France, avec les données ouvertes de Météo-France (à gauche), et avec les données Infoclimat et partenaires en plus (à droite). Remarquez le contraste avec certains autres pays Européens !
Aujourd’hui, Infoclimat c’est donc un bon millier de stations météo (les nôtres, celles des passionnés, et de nos associations partenaires), qui complètent les réseaux nationaux dans des zones non couvertes, et qui permettront à l’avenir d’améliorer la fiabilité des modèles météo de Météo-France, dans des travaux que nous menons avec eux sur l’assimilation des réseaux de données partenaires. Parfois d’ailleurs, nous réinstallons des stations météo là où Météo-France est parti ou n’a pas souhaité améliorer ou maintenir des installations, comme au Mont-Ventoux (84), ou à Castérino (06). Et ces données intéressent une multitude d’acteurs, que nous découvrons souvent au hasard des installations : au-delà de l’intérêt pour la météo des particuliers (« combien fait-il au soleil? » « quelle quantité de pluie est tombée la nuit dernière? »), les activités professionnelles météo-sensibles allant de l’agriculture à l’expertise en assurance, en passant par les études de risques et/ou d’impacts jusqu’aux recherches sur les « ICU » (ilots de chaleurs urbains observés dans les milieux urbanisés) se montrent très demandeuses et n’hésitent pas à se tourner vers nous pour leur fournir de la « bonne data-météo ».
Enfin, le troisième pilier, c’est la pédagogie. Nous avons repris en 2018, à nos frais et sans aucune subvention, l’initiative « Météo à l’École », qui avait été lancée en 2008 par le Ministère de l’Éducation Nationale avec Météo-France et l’Observatoire de Paris, mais qui a failli disparaître faute de budget à la fin du « Grand Emprunt ». L’objectif : sensibiliser de manière ludique les publics du primaire et du secondaire aux enjeux de la météo et du climat. Installer une station météo dans un collège permet de faire un peu de techno, traiter les données en faisant des maths, des stats et de l’informatique, et enfin les analyser pour parler climat et Système Terre.
Aujourd’hui, nous hébergeons les données des quelques 60 stations, ainsi que les contenus pédagogiques de Météo À l’École, permettant aux profs d’échanger entre eux.
Installer des stations météo dans les écoles, expliquer les concepts de la météo et du climat, « jouer » avec des données, et discuter entre profs : c’est ce que permet le programme Météo à l’École
Depuis de nombreuses années, nous complétons cela avec des interventions auprès des jeunes et moins jeunes, sous forme d’ateliers ou de journées à thème (« Rencontres Météo et Espace », « Nuit des Chercheurs », « Fête du Vent »,…), un peu partout en France selon la disponibilité de nos bénévoles !
Lors des Rencontres Météo et Espace organisées par le CNES, Infoclimat et Météo-France, les enfants apprennent par exemple comment on mesure les paramètres en altitude dans l’atmosphère, grâce aux ballons sondes.
Nous aimons autant apprendre des choses aux très jeunes (à gauche), qu’aux moins jeunes (à droite), lors d’événements tout-publics.
Quelles valeurs défendez-vous ?
FA : La première de nos valeurs, c’est l’intérêt général ! Ce que nous avons conçu au cours de ces vingt dernières années n’appartient à personne, c’est un commun au service de tous, et pour certaines informations, c’est même le point de départ d’un cercle vertueux de réutilisation, par la libération des données en Open-Data.
La page OpenData d’Infoclimat, qui permet de s’abstraire des complexités des formats météo, des différents fournisseurs, et tente de résoudre au mieux la problématique des licences des données.
Comme on l’a dit plus haut, le monde de la météo est un juteux business. Vous trouverez pléthore de sites et applis météo, et leur composante commune, c’est que ce sont des sociétés à but lucratif qui en font un business, sous couvert d’engagement citoyen et de « communauté ». Vous y postez vos données et vos photos, et ils en tirent en retour des revenus publicitaires, quand ils ne revendent pas les données météo à d’autres sociétés (qui les mâchouillent et en font de l’analyse pour d’autres secteurs d’activité).
Parmi les initiatives similaires, on peut citer parmi les plus connues « Weather Underground » (appartenant à IBM et destinée à alimenter Watson) ou encore « Awekas » (Gmbh allemande), « Windy » (société tchèque), « Météociel » (SAS française), qui sont des sociétés privées à plusieurs centaines de milliers ou quelques millions d’euros de CA. On notera d’ailleurs que toutes ces initiatives ont des sites souvent moins complets que le notre !
On se retrouve dans une situation parfois ubuesque : ces types de sociétés peuvent acheter des données payantes à l’établissement public Météo-France (pour quelques centaines de milliers d’euros par an), et les proposent ensuite à tous sur leur site web, rémunéré par la publicité ou par abonnement à des fonctionnalités « premium ». Alors qu’elles pourraient bénéficier à tous dans une base de données librement gérée comme celle d’Infoclimat, et aussi servir nos outils d’analyse du changement climatique ; il faut passer obligatoirement par les sites de ces sociétés privées pour bénéficier des données produites par l’établissement public… et donc en partie avec l’argent public. D’autres acteurs de notre communauté en faisant déjà echo il y a bien des années, et la situation n’a pas changé : https://blog.bacpluszero.com/2014/06/comment-jai-failli-faire-doubler-le.html.
Nos adhérents et administrateurs lors d’une visite chez Météo-France, en 2016. Malgré un partenariat depuis 2009, l’établissement public éprouve toujours des difficultés à partager ses données avec la communauté, mais s’engage à ses côtés dans la formation et le support technique. En mémoire de nos bénévoles disparus Pouic, Mich’, Enzo.
SB : Notre force, c’est de pouvoir bénéficier d’une totale indépendance, grâce à nos adhérents, mécènes et donateurs. On a réalisé le site dont on a toujours rêvé, pas celui qui générera le plus de trafic possible pour en tirer un revenu. Les données des stations météo que nous finançons sont toutes placées sous licences ouvertes, et nos communications sont rigoureuses et factuelles plutôt que « putaclic » (ce qui nous vaut d’ailleurs une notoriété encore assez limitée chez le grand public, en dehors des photos de nos contributeurs reprises dans les bulletins météo de France TV notamment).
Trouvez-vous aussi votre indépendance vis-à-vis des GAFAM ?
FA : Cela reste encore perfectible : si nous croyons à notre indépendance et au respect des utilisateurs, il y aurait encore des reproches à nous faire. Nous mettons vraiment beaucoup en place pour respecter les données (qu’elles soient météo, personnelles, ou les droits des photographes), nous auto-hébergeons l’immense majorité des contenus (sur 12 serveurs dédiés OVH, du cloud Scaleway, et des machines gracieusement prêtées par Gandi, et même un NAS chez un administrateur fibré !), et essayons d’éviter les services tiers, et les fuyons au possible lorsqu’ils sont hébergés ou contrôlés à l’étranger. Mais tout n’est pas toujours si simple.
Par exemple, nous utilisions jusqu’à très récemment encore Google Analytics, par « simplicité » : tout notre historique depuis 2008 y est stocké, et une instance Matomo assez dimensionnée pour 150M de pages vues par an, ça veut dire gérer une nouvelle machine, et des coûts supplémentaires… pour une utilisation assez marginale, notre exploitation des statistiques étant très basique, puisque pas de publicités et pas de « conversions » ou « cibles d’audience »… Mais tout de même appréciée des bénévoles pour analyser la fréquentation et l’usage des rubriques du site. Il doit aussi traîner quelques polices de caractères hébergées par Google, mais tout le reste est 100% auto-hébergé et/ou « fait maison ».
Nos cartes sont complexes et nécessitent des données géospatiales de bonne qualité, et à jour. Maintenir à jour une telle base, seuls, et à l’échelle mondiale, est… un projet à lui tout seul.
Nous sommes aussi de gros consommateurs de contenus cartographiques, et proposons des interfaces de visualisation mondiales plutôt jolies (basées sur OpenLayers plutôt que GoogleMaps), mais qui nécessitent des extractions de données particulières (juste les villes, un modèle de terrain haute résolution, ou bien juste les rivières ou limites administratives). C’est un sujet qui peut aussi être vite difficile à gérer.
À une époque, on stockait donc une copie partielle de la base de données OpenStreetMap sur l’Europe, et je générais moi-même des carto avec Tilemill / Mapserver / Geowebcache et des styles personnalisés. Les ressources nécessaires pour faire ça étaient immenses (disque et CPU), la complexité technique était grande, et que dire quand il faut tenir toutes ces bases à jour. C’est un projet à lui tout seul, et on ne peut pas toujours réinventer la roue. Bref, pour le moment, nous utilisons les coûteux services de Mapbox.
Vous nous avez parlé de certaines limites dans votre travail bénévole, qu’est-ce qui vous pose problème ?
FA : Le problème majeur, c’est le développement web du site. La majorité de nos outils sont basés sur le site web : cartes, graphiques, statistiques climatiques, espaces d’échange, contenus pédagogiques, tout est numérique. Aujourd’hui, et depuis 13 ans, le développement et la maintenance du site et de ses serveurs repose sur un seul bénévole (moi !). Déjà, ce n’est pas soutenable humainement, mais c’est aussi assez dangereux.
La raison est simple : un logiciel avec 400.000 lignes de code, 12 serveurs, des technologies « compliquées » (formats de fichiers spécifiques à la météo, cartes interactives, milliards d’enregistrements, bases de données de plusieurs téraoctets,…), ce n’est pas à la portée du premier bénévole qui se pointe ! Et il faut aussi beaucoup d’accompagnement, ce qui est difficile à combiner avec la charge de travail existante.
Pour les plus geeks d’entre-vous, concrètement, voici les technos sur lesquelles sont basées nos plateformes : PHP (sans framework ni ORM !), Javascript/jQuery, OpenLayers, Leaflet, Highcharts, Materialize (CSS), pas mal de Python pour le traitement de données météo (Scipy/Numpy) du NGINX, et pour les spécifiques à notre monde, énormément de GDAL et mapserver, geowebcache, des outils loufoques comme NCL, des librairies pour lire et écrire des formats de fichiers dans tous les sens (BUFR, SYNOP, METAR, GRIB2, NetCDF).
Et bien sûr surtout MariaDB, en mode réplication (et bientôt on aura besoin d’un mode « cluster » pour scaler), des protocoles de passage de message (RabbitMQ, WebSockets), de l’ElasticSearch et SphinxSearch pour la recherche fulltext, et du Redis + Memcached pour les caches applicatifs.
Au niveau infra, évidemment de la gestion de firewall, de bannissement automatique des IP, un peu de répartition de charge, de l’IP-failover, un réseau dédié entre machines (« vRack » chez OVH), beaucoup de partages NFS ou de systèmes de fichiers distribués (GlusterFS, mais c’est compliqué à maintenir donc on essaie de migrer vers de l’Object-Storage type S3).
Et on a aussi une appli mobile Android en Java, et iOS en Swift, mais elles sont vieillissantes, fautes de moyens (leur développement a été sous-traité), et la majorité des fonctionnalités est de toutes façons destinée à être intégrée sur le site en mode « responsive design ».
Je passe sur la nécessité de s’interfacer avec des API externes (envois de mails, récupération de données météo sur des serveurs OpenData, parsing de données météo, API de la banque pour les paiements d’adhésions), des outils de gestion interne (Google Workspace, qui est « gratuit » pour les assos, hé oui !), des serveurs FTP et VPN pour connecter nos stations météo, un Gitlab auto-hébergé pour le ticketing et le code source …
SB : On a aussi des difficultés à dégager du temps pour d’autres actions : installer des stations météo par exemple, ce n’est pas négligeable. Il faut démarcher des propriétaires, obtenir des autorisations, parfois signer des conventions compliquées avec des collectivités locales, gérer des problématiques « Natura 2000 » ou « Bâtiments de France », aller sur site,… c’est assez complexe. Nous essayons de nous reposer au maximum sur notre communauté de bénévoles et adhérents pour nous y assister.
Quels sont vos besoins actuels ?
SB : Dans l’idéal, et pour venir en renfort de Frédéric, nous aurions besoin d’un développeur « full-stack » PHP à plein temps, et d’un DevOps pour pouvoir améliorer l’architecture de tout ça (qui n’est plus au goût des stacks technologiques modernes, et sent un peu trop l’année 2010 plutôt que 2022, ce qui rend la maintenance compliquée alors que le trafic web généré suppose de la perf’ et des optimisations à tous les niveaux).
Ce n’était pas immédiatement possible au vu des revenus de l’association, qui atteignaient environ 60.000€ en 2021, dont 15.000€ sont dépensés en frais de serveurs dédiés chez OVH (passer au tout-cloud coûte trop cher, en temps comme en argent,… mais gérer des serveurs aussi !).
FA : On développe aussi deux applis Android et iOS, qui reprennent les contenus du site dans un format simplifié, et surtout permettent de recevoir des alertes « push » selon les conditions météo, et d’afficher des widgets. Elles sont dans le même esprit que le site (pas de pubs, le moins de contenus tiers possibles), cependant ce sont des applis que l’on a sous-traité à un freelance, ce qui finit par coûter très cher. Nous réfléchissons à quelle direction donner à celles-ci, surtout au vu de l’essor de la version « responsive » de notre site.
Nous aimerions commencer à donner une direction européenne à notre plateforme, et la mettre à disposition des communautés d’autres pays. Il y a un gros travail de traduction, mais surtout de travaux techniques pour rendre les pages de notre site « traduisibles » dans différentes langues.
Vous ouvrez cette année un premier poste salarié, quelle a été votre démarche ?
SB : Dès lors, nous avions surtout un besoin intermédiaire, qui vise à faire progresser nos revenus. Pour cela, notre première marche sur l’escalier de la réussite, c’est de recruter un·e chargé·e de développement associatif, chargé d’épauler les bénévoles du Conseil d’Administration à trouver des fonds : mécènes et subventionneurs publics. Les sujets climat sont au cœur du débat public aujourd’hui, l’engagement citoyen aussi (on l’a vu avec CovidTracker !), nous y participons depuis 20 ans, mais sans savoir nous « vendre ».
FA : Cette première marche, nous l’avons franchie grâce à Gandi, dans le cadre de son programme « Gandi Soutient », qui nous a mis en relation avec vous, Framasoft. Vous êtes gentiment intervenus auprès de nos membres de Conseil d’Administration, et vous nous avez rassurés sur la capacité d’une petite association à se confronter aux monopoles commerciaux, en gardant ses valeurs fondatrices. Sans votre intervention, nous n’aurions probablement pas franchi le pas, du moins pas aussi vite !
Intervention de Framasoft pendant une réunion du CA de Infoclimat
SB : Cela va nous permettre de faire souffler une partie de nos bénévoles. Même si cela nous fait peur, car c’est une étape que nous n’osions pas franchir pour préserver nos valeurs, c’est avec une certaine fierté que nous pouvons aujourd’hui dire : « nous sommes une asso d’intérêt général, nous proposons un emploi au bénéfice de tous, et qui prend sa part dans la mobilisation contre le changement climatique, en en donnant des clés de compréhension aux citoyens ».
FA : La seconde étape, c’est recruter un⋅e dév’ web full-stack PHP/JS, quelqu’un qui n’aurait pas été impressionné par ma liste de technos évoquée précédemment ! Comme nous avons eu un soutien particulièrement fort de notre communauté en ce début d’année, et que notre trésorerie le permet, nous avons accéléré le mouvement, et la fiche de poste est d’ores-et-déjà disponible, pour un recrutement envisagé à l’été 2022.
Comment pouvons-nous soutenir Infoclimat, même sans s’y connaître en stations météo ?
FA : Pour celles et ceux qui en ont les moyens, ils peuvent nous soutenir financièrement : c’est le nerf de la guerre. Quelques euros sont déjà un beau geste ; et pour les entreprises qui utilisent quotidiennement nos données (on vous voit !), un soutien plus important permet à nos outils de continuer à exister. C’est par exemple le cas d’un de nos mécènes, la Compagnie Nationale du Rhône, qui produit de l’électricité hydroélectrique et éolienne, et est donc légitimement intéressée de soutenir une asso qui contribue au développement des données météo !
Pour cela, nous avons un dossier tout prêt pour expliquer le détail de nos actions auprès des décideurs. Pour aller plus loin, une seule adresse : association@infoclimat.fr
Et pour ceux qui veulent aussi s’investir, nous avons une page spécifique qui détaille le type de tâches bénévoles réalisables : https://www.infoclimat.fr/contribuer.
Ce n’est pas exhaustif, il y a bien d’autres moyens de nous épauler bénévolement, pour celles et ceux qui sont prêts à mettre les mains dans le cambouis : des webdesigners, développeurs aguerris, experts du traitement de données géographique, « datavizualisateurs », ou même des gens qui veulent faire de l’IA sur des séries de données pour en trouver les erreurs et biais : il y a d’infinies possibilités ! Je ne vous cacherai pas que le ticket d’entrée est assez élevé du point de vue de la technique, cela dit…
SB : Pour les autres, il reste l’énorme possibilité de participer au site en reportant des observations via le web ou l’appli mobile (une paire d’yeux suffit!) ainsi que des photos, ou… simplement nous faire connaître ! Une fois comprise la différence entre Infoclimat et tous les sites météo, dans le mode de fonctionnement et l’exploitation commerciale ou non des données, on comprend vite que notre association produit vraiment de la valeur au service des citoyens, sans simplement profiter des données des autres, sans apporter sa pierre à l’édifice, comme le font nonchalamment d’autres initiatives. Par ailleurs, nous avions pour projet d’avoir une page sur Wikipédia, refusée par manque de notoriété 🙁 . Idem pour la demande de certification du compte Twitter de l’Association, qui pourtant relaie de l’information vérifiée et montre son utilité lors des événements météo dangereux ou inhabituels, comme lors de l’éruption tout récente du volcan Hunga Tonga-Hunga Ha’apai sur les Iles Tonga qui a été détectée 15h plus tard et 17.000 km plus loin par nos stations météo lors du passage de l’onde de choc sur la métropole!
FA : Infoclimat, c’est un peu l’OpenFoodFacts du Yuka, l’OpenStreetMap du GoogleMaps, le PeerTube du YouTube, le Wikipédia de l’Encarta (pour les plus vieux)… et surtout une formidable communauté, que l’on en profite pour remercier ici !
On vous laisse maintenant le mot de la fin !
SB : Bien sûr, on aimerait remercier tous ceux qui ont permis à cette aventure de progresser : tous les bénévoles qui ont œuvré depuis 20 ans, tous les adhérent⋅e⋅s qui ont apporté leur pierre, nos mécènes et donateurs, ainsi que les passionnés qui alimentent le site et nous soutiennent depuis toutes ces années!
FA : Le soutien de Gandi et Framasoft a aussi été un déclencheur, et j’espère que cela pourra continuer à être fructueux, au service d’un monde meilleur et désintéressé. Des initiatives comme la notre montrent qu’être une asso, ça permet de produire autant voire plus de valeur que bien des start-up ou qu’un gros groupe qu’on voit passer dans le paysage météo. Et pourtant, nous sommes souvent bien moins soutenus, ou compris.
Mais où sont les livres universitaires open-source ?
Où sont les livres universitaires libres, ceux qu’on pourrait télécharger gratuitement à la façon d’un logiciel open-source ? Les lecteurs et lectrices du Framablog qui étudient ou travaillent à l’université se sont probablement posé la question.
Olivier Cleynen vous soumet ici quelques réponses auxquelles nous ouvrons bien volontiers nos colonnes.
Les manuels universitaires libres, j’en ai fabriqué un : Thermodynamique de l’ingénieur, publié en 2015 au sein du projet Framabook. Cette année, alors que Framabook se métamorphose en Des livres en commun et abandonne le format papier, je reprends le livre à mon nom et j’expérimente avec différentes formes de commercialisation pour sa troisième édition. C’est pour moi l’occasion de me poser un peu et de partager avec vous ce que j’ai appris sur ce monde au cours des sept dernières années.
Bon, je vais commencer par prendre le problème à l’envers. Un manuel universitaire, c’est d’abord un livre et comme tout autre livre il faut qu’il parte d’un désir fort de la part de l’auteur/e, car c’est une création culturelle au même titre qu’une composition musicale par exemple. Et d’autre part c’est un outil de travail, il faut qu’il soit très cohérent, structuré, qu’il justifie constamment l’effort qu’il demande au lecteur ou à la lectrice, en l’aidant à accomplir quelque chose de précis. Ces deux facettes font qu’il doit être le produit du travail d’un nombre faible de personnes très impliquées. On le voit bien avec les projets Wikibooks et Wikiversity par exemple, qui à mes yeux ne peuvent pas décoller, par contraste avec Wikipédia où le fait que certains articles soient plus touffus que d’autres et utilisent des conventions de notation différentes ne pose aucun problème.
Leonardo da Vinci (1452-1519), Codex Leicester, un manuel italien écrit en miroir, ayant un peu vieilli, mais heureusement déjà dans le domaine public.
Pour écrire un livre comme Thermodynamique de l’ingénieur j’estime (à la louche) qu’il faut un an de travail à quelqu’un de niveau ingénieur. En plus de ça il faut au moins deux personne-mois de travail pour mettre le tout en page et avoir un livre prêt à l’impression.
Je n’aime pas beaucoup ce genre de calculs qui ont tendance à tout réduire à des échanges mercantiles, mais dans un monde où l’équipe d’en face loue l’accès à un PDF en ligne à 100 euros par semestre, on peut se permettre d’écrire quelques nombres au dos d’une enveloppe, pour se faire une idée. Un an de travail pour une ingénieur médiane coûte 58 k€ brut en France. Pour deux personnes-mois de mise en page, on peut certainement compter 5 k€ de rémunération brute, soit au total: 63 000 euros.
Maintenant en partant sur la base de 1000 livres vendus on voit qu’il faudrait récolter 63 euros par livre pour financer au “prix du marché”, si je peux me permettre, le travail purement créatif. C’est une mesure (très approximative…) de ce que les créateurs choisissent de ne pas gagner ailleurs, lorsqu’ils/elles font un livre en accès gratuit ou en vente à prix coûtant, comme l’a été le Framabook de thermodynamique.
Thermodynamique de l’ingénieur – troisième édition
Bien sûr, si l’on reprend le problème à l’endroit, le prix d’un livre acheté par un étudiant ou une universitaire n’est pas du tout calculé sur cette base, car il faut aussi et surtout rémunérer les autres acteurs entre l’auteure et la lectrice.
La part du lion est assurément réservée aux distributeurs, et parmi eux Amazon, qui sont passés progressivement de purs agents logistiques à de véritables plateformes éditoriales. Les distributeurs ont ainsi dépassé leur rôle initial (être une réponse à la question : « où vais-je me procurer ce livre qui m’intéresse ? ») et saturé le niveau d’au-dessus, en proposant de facto toutes les réponses les plus pertinentes à la question : « quel est le meilleur livre sur ce sujet ? ».
Au milieu de tout ça, il y a les éditeurs. Un peu comme les producteurs dans le monde de la musique, leur rôle est de résoudre l’équation qui va lier et satisfaire tous les acteurs impliqués dans l’arrivée du livre entre les mains de la lectrice. Ils sont ceux qui devraient le mieux connaître les particularités de ce produit pas tout à fait comme les autres, et pourtant…
Dans notre exploration du monde des manuels universitaires, je vais choisir de diviser les éditeurs en trois groupes.
tout un patrimoine est rendu légalement inaccessible.
Au centre, nous avons les petits. Ils sont écrasés par tous les autres, mais je peux dire d’emblée qu’ils n’ont que ce qu’ils méritent. Leurs outils et méthodes de travail sont désuets voire archaïques, et ils saisissent très mal les mécanismes du succès éditorial. Donc, ils se contentent de sortir beaucoup de livres pour espérer en réussir quelques-uns. Contactez-les avec votre projet, et ils vous proposeront un contrat dans lequel vous renoncez ad vitam à tout contrôle, et à 93% des revenus de la vente. Faites le calcul : même avec un prix de vente élevé, disons 40€, ce qu’ils vous présenteront sans sourciller comme un succès (mille livres vendus) ne vous rapportera même pas 3000 euros bruts, étalés sur dix ans.
Vous me direz que ce n’est pas bien grave, qu’avoir une haute rentabilité, une haute efficacité, n’est pas un but en soi : tout le monde ne veut pas être Jeff Bezos, et le monde a bien besoin de petits acteurs, de diversité éditoriale, de tentatives risquées, tout comme le secteur de la musique. Certes ! Mais voyons les conséquences en aval. Lorsque le contrat est signé, le copyright sur l’œuvre passe irréversiblement dans les mains de l’éditeur, qui ne l’exploitera vraisemblablement que dix ans. Que se passe-t-il après ? Le livre n’est plus imprimé, il sort de la sphère commerciale, et… il est envoyé en prison. Il rejoint la montagne de livres abandonnés, qui attendent, sous l’œil du gendarme copyright, le premier janvier de la 71ème année après la mort de leur auteur, que l’on puisse les réutiliser. Un siècle de punition ! Quelle bibliothèque en aura encore un exemplaire en rayon lorsqu’ils en sortiront ?
Et voilà comment nous entretenons cette situation absurde, dans laquelle une masse de travail faramineuse, sans plus aucune valeur commerciale, est mise hors d’accès de ceux qui en ont besoin. Il y a des manuels universitaires par centaines, parfaitement fonctionnels, dont le contenu aurait juste besoin d’un petit dépoussiérage pour servir dans les amphis après une mise à jour. Ils pourraient aussi être traduits en d’autres langues, ou bien dépecés pour servir à construire de nouvelles choses. Au lieu de ça, en thermodynamique les petits éditeurs sortent chaque année de nouveaux manuels dans lesquels les auteurs décrivent une nouvelle fois l’expérience de Joule et Gay-Lussac de 1807, condamnés à refaire eux-mêmes le même schéma, les mêmes diagrammes pression-volume, donner les mêmes explications sans pouvoir utiliser ce qui a déjà été fait par leurs prédécesseurs. Certes, d’autres disciplines évoluent plus vite que la mienne, mais partout il y a des fondamentaux qu’il n’est pas nécessaire de revisiter très souvent, et pour lesquels tout un patrimoine est rendu légalement inaccessible. Quel gâchis !
des pratiques difficiles à accepter pour ceux pour qui un livre doit aussi être un outil d’émancipation.
Grimpons maintenant d’un étage. Au dessus des petits éditeurs, les gros ; eux résolvent l’équation autrement, en partant du point de vue qu’un manuel universitaire est un outil de travail professionnel : un produit pointu, hyper-spécialisé et qui coûte cher. Aux États-Unis, ce sont eux qui mènent la course. Pour pouvoir suivre un cours de thermodynamique ou de chimie organique, l’étudiant/e lambda est forcée d’utiliser un manuel qui coûte entre 100 et 300 euros par le/la prof, qui va baser tous ses cours, diapositives, sessions d’exercices et examens dessus. Nous parlons de pavés de 400 pages, écrits par plusieurs auteur/es et illustrés par des professionnels, des outils magnifiques qui non seulement attisent votre curiosité, mais aussi vous rassasient d’applications concrètes et récentes, en vous permettant de progresser à votre rythme. On est loin des petits aides-mémoire français avec leurs résumés de cours abscons !
Ces manuels sont de véritables navires, conduits avec soin pour maximiser leur potentiel commercial, avec des pratiques pas toujours très éthiques. Par exemple, les nouvelles éditions s’enchaînent à un rythme rapide, et les données et la numérotation des exercices sont souvent modifiés, pour rendre plus difficile l’utilisation des éditions antérieures. Pour pouvoir capter de nouveaux marchés, en Asie notamment, les éditeurs impriment pour eux des versions beaucoup moins chères, dont ils tentent après par tous les moyens d’interdire la vente dans les autres pays.
Le prix de vente des livres est en fait tel que pour les étudiants, la location devient le moyen d’accès principal. Les distributeurs (comme Amazon US ou Chegg) vous envoient l’enveloppe de retour affranchie directement avec le livre. Vous pouvez tout de même surligner et annoter l’intérieur du livre : il ne sera probablement pas reloué plus d’une fois. Après tout, le coût de fabrication est faible au regard des autres sommes en jeu : il s’agit surtout de pouvoir contrôler le nombre de livres en circulation (lire : empêcher la revente de livres récents et bon marché).
Les éditeurs tentent aussi de ne pas louper le virage (très lent…) de la dématérialisation, en louant l’accès au contenu du livre via leur site Internet ou leur appli. Pensiez-vous que l’on vous donnerait un PDF à télécharger ? Que nenni. Nos amis francophones au Canada ont déjà testé pour vous : « Les étudiants sont pris en otage avec une plateforme difficile d’utilisation à un prix très élevé. Difficile de faire des recherches, difficile de naviguer, difficile de zoomer, difficile d’imprimer. Difficile de toute. En plus, on perd l’accès au livre après un certain temps, alors qu’on paie presque la totalité du prix d’un livre physique. Il y a un problème. »
En bref, cet étage combine le meilleur et le pire : des outils pédagogiques de très bon niveau, empaquetés dans des pratiques difficiles à accepter pour ceux pour qui un livre doit aussi être un outil d’émancipation.
l’émergence de créateurs et créatrices de biens culturels plus indépendants et plus justement rétribués
En dessous de ces deux groupes, il y a tout un ensemble désordonné d’entreprises qui proposent aux auteurs potentiels de court-circuiter les voies d’édition traditionnelles (j’expérimente en ce moment avec plusieurs de ces acteurs pour mon livre). On peut mentionner Lulu, qui fournit un service d’impression à la demande (Framabook l’a longtemps utilisé), mais aussi Amazon qui accepte de plus en plus facilement dans son catalogue physique et immatériel (Kindle) des livres auto-édités. En marge, il y a un grand nombre d’acteurs qui facilitent la rémunération des créateurs et créatrices en tout genre, par exemple en permettant la vente de fichiers informatiques, de services en ligne, et le financement ponctuel ou régulier de leur travail par leur audience. Ces choses étaient très difficiles à mettre en pratique il y a quinze ans ; maintenant ces entreprises érodent par le bas les piliers financiers de l’édition traditionnelle. Elles permettent, d’une part, l’émergence de créateurs et créatrices de biens culturels plus indépendants et plus justement rétribués, qui ne se feront pas manger tout/es cru/es par les machines de l’édition traditionnelle. Elles permettent aussi, et c’est plus regrettable, la monétisation d’échanges qui auraient dû rester non-commerciaux ; par exemple on ne peut que grincer des dents en voyant des enseignants fonctionnaires de l’éducation nationale, sur une plateforme quelconque, se vendre les uns aux autres l’accès à leurs fiches de travaux pratiques de collège. Dans l’ensemble toutefois, je pense que la balance penche franchement dans le bon sens, et je me réjouis de savoir que de plus en plus de personnes se voient offrir la possibilité de se demander : « tiens, et si j’en faisais un livre ? ».
Alors toi, petit/e prof de l’enseignement supérieur, qui voudrais bien faire un livre de ce que tu as déjà construit avec tes cours, et qui regardes ce paysage, tu te demandes si tu ne devrais pas faire un manuel universitaire open-source, un truc que les étudiants et les autres profs pourraient télécharger et réadapter sans rien devoir demander. Qu’est-ce que je peux te recommander ?
Pour commencer, le plus important — fonce ! Tu ne le regretteras pas. Je partage volontiers avec toi quelques chiffres et quelques retours, sept ans après m’être lancé (mais sans avoir jamais travaillé sur la communication ou la diffusion). Une trentaine de personnes télécharge le PDF de mon livre depuis mon site Internet chaque jour, la moitié depuis les pays d’Afrique francophone, et une sur cinq-cent met la main à sa poche pour acheter un exemplaire imprimé. Après six ans, ça représente 250 livres vendus (250 kilos de papier !). Je retrouve des traces de mon livre un peu partout sur Internet, pour le meilleur et pour le pire. Il y a eu un gros lot de mauvaises surprises, parce qu’il y a beaucoup de dilution : le PDF du livre est repris, en entier ou en petits morceaux, par de nombreux acteurs plus ou moins bien intentionnés. Le plus souvent ce sont simplement des banques de PDFs et miroirs informes qui s’efforcent de bien se positionner dans les résultats des moteurs de recherche, puis génèrent un revenu en apposant de la publicité à côté du contenu qu’ils reproduisent. Il y a aussi des plateformes (par exemple Academia.edu pour ne pas les nommer) qui encouragent leurs utilisateurs à republier comme les leurs les travaux des autres, et mon livre fait partie de milliers d’autres qui sont partagés sous une nouvelle licence et en étant mal attribués. Le plus désagréable est certainement de voir mon travail occasionnellement plagié par des universitaires qui ont voulu croire que le livre était simplement déposé dans le domaine public et qu’il n’était pas nécessaire d’en mentionner l’auteur. Mais je pense que ces problèmes sont propres à tous les livres et pas seulement ceux que l’on diffuse sous licence Creative Commons.
Il y a aussi de bonnes surprises ! Recevoir un paquet de correctifs par quelqu’un qui a pris le temps de refaire tes exercices. Recevoir un compliment et un remerciement d’une consœur que tu n’as jamais pu rencontrer. Voir ton PDF téléchargé depuis des adresses IP associées à une ville au milieu du désert algérien, ou bien d’endroits où personne ne n’a jamais vu une librairie universitaire ou une camionnette Amazon. Ces moments à eux seuls font du projet un succès à mes yeux, et ils te porteront toi aussi dans tes efforts.
Dans tout cela, il faut bien voir que les quantités d’argent mises en jeu dans la circulation du livre sont dérisoires, à des années-lumières de la valeur que vont créer les étudiants ingénieurs avec ce qu’ils ont appris à l’aide du manuel. Et surtout, après avoir de bon cœur mis son livre en libre téléchargement et la version papier en vente à prix coûtant, l’auteur/e réalise un matin, comme certainement beaucoup de programmeurs libristes avant lui/elle, que des œuvres concurrentes objectivement bien moins bonnes et beaucoup plus chères se vendent bien mieux.
Où trouver notre place alors dans ce paysage compliqué ? Un livre sous licence Creative Commons peut-il être une bonne réponse au problème ?
Cette treizième édition du livre, préférez-vous l’acheter neuve pour 190 euros, ou d’occasion pour 100 euros ? Sinon, je vous propose de la louer pour 37 euros…
Je pense qu’une bonne recette de fabrication pour livre universitaire doit en tout premier satisfaire trois groupes : les auteur/es, les enseignant/es et les étudiant/es. De quoi ont-ils/elles besoin ? Je propose ici mes réponses (évidemment toutes biaisées par mon expérience), en listant les points les plus importants en premier.
Ce que veulent les auteur/es :
Fabriquer une œuvre qui n’est pas cloisonnée, qui peut servir à d’autres si je disparais ou si le projet ne m’intéresse plus (donc quelque chose de ré-éditable, qu’on peut corriger, remettre à jour, traduisible en japonais et tout ça sans devoir obtenir de permission).
Une reconnaissance de mon travail, quelque chose que je peux valoriser dans un CV académique (donc quelque chose qui va être cité par ceux qui s’en servent).
De l’argent, mais pas cent-douze euros par an. Soit le livre contribue significativement à mes revenus, soit je préfère renoncer à gagner de l’argent avec (pour maximiser sa diffusion et m’éviter les misères administratives, la contribution à la sécu des artistes-auteurs ou à l’Urssaf etc).
Ce que veulent les enseignant/es :
Un contenu fiable (un livre bien ancré dans la littérature scientifique existante et dans lequel l’auteur/e n’essaie pas de glisser un point de vue « alternatif » ou personnel).
Un livre remixable, dont on peut reprendre le contenu dans ses diapos ou son polycopié, de façon flexible (ne pas devoir scanner les pages du livre ou bien tout redessiner).
Un livre dont le prix est supportable pour les étudiant/es.
Et enfin, ce que veulent les étudiant/es :
Un livre qui les aide à s’en sortir dans leur cours. C’est d’abord un outil, et il faut survivre aux examens ! Si le livre rend le sujet intéressant, c’est un plus.
Un livre très bon marché, ou encore mieux, gratuit.
Un livre déjà désigné pour elles et eux, et qui correspond bien au programme : personne n’a envie d’arpenter les rayons de bibliothèque ou le catalogue d’Amazon en espérant trouver de l’aide.
On le voit, finalement nous ne sommes pas loin du compte avec des livres sous licence Creative Commons ! Tous les outils importants sont déjà à portée de main, pour créer le livre (avec des logiciels libres en tout genre), l’encadrer (avec des contrats de licence solides) et le distribuer (avec l’Internet pour sa forme numérique et, si nécessaire d’autres plateformes pour sa forme physique). C’est peut-être un évidence, mais il est bon de se rappeler parfois qu’on vit une époque formidable.
Alors, que manque-t-il ? Pourquoi les livres libres n’ont-ils toujours pas envahi les amphis ? Quels sont les points faibles qui rendent l’équation si difficile à résoudre ? Je pense qu’une partie de la réponse vient de nous-mêmes, nous dans les communautés impliquées autour des concepts de culture libre, de partage des connaissances et de logiciels open-source. Voici quelques éléments de critique, que je propose avec beaucoup de respect et en grimaçant un peu car je m’identifie avec ces communautés et m’inclus parmi les responsables.
la monnaie de cette reconnaissance est la citation académique
Je voudrais d’abord me tourner vers les enseignant/es du supérieur. Confrères, consœurs, nous devons citer nos sources dans nos documents de cours, et les publier ! Je sais que construire un cours est un travail très chronophage, souvent fait seul/e et à la volée — comment pourrait-il en être autrement, puisque souvent seul le travail de recherche est valorisé à l’université. Mais trop de nos documents (résumés de cours, exercices, diapositives) ne citent aucune source, et restent en plus coincés dans un intranet universitaire, cachés dans un serveur Moodle, invisibles depuis l’extérieur. Sous nos casquettes de chercheurs, nous sommes déjà les premiers responsables d’une crise sans fin dans l’édition des publications scientifiques. Nous devons faire mieux avec nos chapeaux d’enseignants. Nous le devons à nos étudiants, à qui nous reprochons souvent de faire la même chose que nous. Et nous le devons à ceux et celles dont nous reprenons le travail (les plans de cours, les schémas, les exercices…), qui ont besoin de reconnaissance pour leur partage ; la monnaie de cette reconnaissance est la citation académique. Il faut surmonter le syndrome de l’imposteur : mentionner un livre dans la bibliographie officielle de la fiche descriptive du cours ne suffit pas. Il faut aussi le citer dans ses documents de travail, et les laisser en libre accès ensuite.
Quant aux institutions de l’enseignement supérieur (écoles, instituts, universités en tous genres), je souhaite qu’elles acceptent l’idée que la création de supports de cours universitaires est un processus qui demande de l’argent au même titre que la création de savoir par l’activité de recherche. Il faut y consacrer du temps, et il y a des frais de fonctionnement. Sans cela, on laisse les enseignants perpétuellement réinventer la roue, coincés entre des livres trop courts ou trop chers pour leurs étudiants. Il manque plus généralement une prise de conscience que l’enseignement supérieur a tout d’un processus industriel (il se fait à grande échelle, il a de très nombreux aspects qui sont mesurables directement etc.): nous devons arrêter d’enseigner avec des méthodes de travail qui relèvent de l’artisanat, chacun avec ses petits outils, ses méthodes et son expérience.
Un peu plus loin, au cœur-même des communautés libristes, il y a aussi beaucoup d’obstacles à franchir pour l’auteur/e universitaire : ainsi les défauts de la bibliothèque multimédia communautaire Wikimedia Commons, et du projet Creative Commons en général, pourraient faire chacun l’objet d’un article entier.
Ce que j’ai appris avec ce projet de livre, c’est que travailler à l’intersection de tous ces groupes consomme une certaine quantité d’énergie, parce que mon espoir n’est pas que le fruit de tout ce travail reste à l’intérieur. J’ai envie d’envoyer mon livre de l’autre côté de la colline, où il se retrouve en concurrence avec des manuels de gros éditeurs, parce que c’est ce public que je veux rencontrer — l’espoir n’est pas de faire un livre pour geeks libristes, mais plutôt d’arriver dans les mains d’étudiants qui n’ont pas l’habitude de copier légalement des trucs. Créer ce pont entre deux mondes est un travail en soi. En le réalisant, j’ai appris deux choses.
un travail de communication et de présence en amont.
La première, c’est que nous dépendons toujours d’une plate-forme ou d’une autre. Comme beaucoup d’autres avant moi, je me suis hissé sur les épaules de géants depuis une chambre d’étudiant, en montant une pile de logiciels libres sur mon ordinateur et en me connectant à un réseau informatique global décentralisé. L’euphorie perdure encore jusqu’à ce jour, mais elle ne doit pas m’empêcher d’accepter qu’on ne peut pas toujours tout faire soi-même, et qu’une activité qui implique des transactions financières se fait toujours à l’intérieur d’un ou plusieurs systèmes. Quel que soit son métier, avocate, auteure, chauffagiste, restaurantiste, une personne qui veut s’adresser à un public doit passer par une plate-forme : il faut une boutique avec vitrine sur rue, ou un emplacement dans une galerie commerciale, ou une fiche dans un annuaire professionnel, ou bien un emplacement publicitaire physique ou numérique, ou encore être présent dans un salon professionnel. Chaque public a des attentes particulières. Pour que quelqu’un pense à vous même sans se tourner activement vers une plateforme (simplement en pensant silencieusement « bon il me faut un livre de thermodynamique » ou « bon il faut que quelqu’un répare cette chaudière ») il faut que vous ayez fait un travail de communication et de présence en amont. Toutes les plateformes ne sont pas équivalentes, loin de là ! Le web est certainement une des toutes meilleures, mais là aussi nous voulons trop souvent oublier qu’elle est de facto mécaniquement couplée à une autre, celle du moteur de recherche duquel émanent 92% des requêtes mondiales : c’est ce moteur qu’il faut satisfaire pour y grandir.
Autre plateforme, Amazon: l’utiliser pour distribuer ses livres, c’est participer à beaucoup de choses difficiles à accepter sociétalement. Framasoft a fait le choix de ne plus l’utiliser, et c’est tout à leur honneur, d’autant plus lorsqu’on voit le travail qu’ils abattent pour en construire de meilleures, des plateformes ! Personnellement, j’ai choisi de continuer à y vendre mon livre, car il y a des publics pour lesquels un livre qui n’est pas sur Amazon n’existe pas. Idem pour Facebook, sur lequel je viens bon gré mal gré de me connecter pour la première fois, parce que mon livre s’y partage que je le veuille ou non et que je voudrais bien voir ça de plus près. Ainsi, au cours des dernières années j’ai appris à observer les flux au delà de la connexion entre mon petit serveur et mon petit ordinateur.
La seconde chose que j’ai apprise, c’est que nous avons, nous au sein des communautés du logiciel et de la culture libres, une relation assez dysfonctionnelle à l’argent. Il nous manque globalement de l’argent, ça je le savais déjà (j’ai fondé et travaillé à plein temps pour une association sont les objectifs ressemblaient un peu à ceux de Framasoft il y a 15 ans), mais j’avais toujours attribué cela à de vagues circonstances extérieures. Maintenant, je suis convaincu qu’une grande part de responsabilité nous revient : il nous manque de la culture et de la sensibilité autour de l’argent et du commerce. Dès que l’on professionnalise son activité, on vient à bout du credo « il est seulement interdit d’interdire » que nous avons adopté pour encadrer le partage des biens communs culturels. Nos licences et nos organisations sont en décalage avec la réalité et nous faisons collectivement un amalgame entre « amateur », « non-commercial » et « à but non-lucratif ». — j’y reviendrai dans un autre article.
Voilà tout ce que j’ai en tête lors que je me demande où sont les livres universitaires libres. Qui sera là pour faire un pont entre tous ces mondes ? Il y a quelques années, le terme “Open Educationnal Resource” (OER ou en français REL) a pris de l’essor un peu comme le mot-clé “MOOC”, une idée intéressante pas toujours suivie d’applications concrètes. Plusieurs projets ont été lancés pour éditer des livres et cours universitaires libres. Aujourd’hui beaucoup on jeté l’éponge : Lyryx, Boundless, Flatworld, Tufts OpenCourseWare, Bookboon se sont arrêtés ou tournés vers d’autres modèles. Il reste, à ma connaissance, un seul éditeur avec un catalogue substantiel et à jour (je ne vous cache pas que je rêve d’y contribuer un jour) : c’est OpenStax, une organisation américaine à but non-lucratif, avec une quarantaine de manuels en anglais. Et dans la sphère francophone ? Un groupe de geeks de culture libre arrivera-t-il jamais à faire peur à tout le monde en mettant dans les mains des étudiants des outils qu’ils peuvent utiliser comme ils le veulent ?
CLIC ! : une plateforme de coopération tout terrain
Fin novembre, des commoners (militant·e·s des communs), artistes, animateurs et animatrices de rues se sont retrouvé·e·s au Vigan (dans les Cévennes gardoises), pour travailler sur le #ProjetCLIC! (Contenus et Logiciels pour des Internets Conviviaux !), une plateforme numérique pour essaimer des pratiques numériques et coopératives, solidaires et émancipatrices grâce à des logiciels, ressources et formations librement partageables.
Que ce soit dans le secteur associatif, en entreprise, ou dans tout autre collectif, les besoins en outillage informatique sont prégnants. Les géants de l’Internet savent proposer des solutions qui paraissent convenir mais cela a un certain prix, que ce soit en termes monétaires ou d’abandon de notre vie privée. Heureusement, certaines initiatives, telles que celles portées par Framasoft et les CHATONS, permettent de répondre à ces besoins sans concession. Cependant, ces solutions nous font dépendre de tiers, qui doivent être de confiance, et elles sont limitées à la présence d’une connexion internet et à la capacité du tiers à maintenir son service en ligne. En outre, ces outils sont livrés « nus » : il nous faut alors les alimenter en contenus afin de partager nos savoirs et connaissances.
Comment permettre que ces contenus et outils soient facilement accessibles, utilisés et réutilisables dans tous les contextes, y compris les plus éloignés de l’Internet ?
La proposition de CLIC! est de s’auto-héberger (d’installer les services sur son matériel, chez soi) et d’avoir ses outils libres et contenus disponibles localement, et/ou sur le grand Internet avec un système technique pré-configuré. On vous explique.
L’interface de sélection des services dans CLIC!
Entre Chatons et PirateBox : CLIC!
CLIC! pourrait être vu comme un mix entre un CHATONS (hébergeur de logiciel et service libre) et une Piratebox (dispositif électronique accessible par wifi, permettant de partager des contenus libres) pour mettre l’auto-hébergement à la portée de toutes et tous.
Coté logiciel, CLIC! est une distribution Linux issue de Yunohost qui propose déjà des services et des contenus libres préinstallés. L’idée est de proposer en plus des contenus thématiques installables en un clic (fichiers multimédias, parcours pédagogiques, …)
Coté matériel, il pourrait s’installer sur différentes machines: le gros serveur dans un datacenter, un nano-ordinateur type Raspberry Pi, ou encore sur des « ordinosaures » (de vieilles tours d’ordinateurs ou d’anciens ordinateurs portables réutilisés).
Un schéma de Frédérique pour y voir plus clair (ou pas)
Une coding party pour faire avancer le projet
La semaine du 22 au 28 novembre 2021, un groupe éclectique de développeur·euses, facilitateur·rices, bricoleur·euses et artistes issu·es de divers horizons se sont retrouvé·es pour imaginer des usages, adapter l’ergonomie, travailler l’interface, réaliser des installations artistiques dans l’espace public et poursuivre les développements de la distribution CLIC!
Le groupe s’est retrouvé à la Fabrègue (la fabrique en occitan), un écolieu du Vigan associé à la ressourcerie locale.
Une vidéo timelapse pour voir l’ambiance et comment on collaborait
Appréhender ce que pourrait être un Internet low-tech
Qu’est-ce qu’un Internet low-tech ? Le simple fait de trouver une définition des concepts et de se mettre d’accord sur le degré d’autonomie souhaité est un vaste sujet !
De nombreuses personnes réfléchissent déjà au sujet. Notre approche est très concrète : comment faire du mieux avec les ressources à disposition près de chez nous (récupérer du vieux matos dans ses placards ou dans les ressourceries) et tester du matériel peu gourmand en énergie (comme un nano-ordinateur) pour s’auto-alimenter en électricité.
Voici les pistes explorées durant cette semaine au Vigan :
Alimentation autonome via panneaux solaires
Quelques tests ont été réalisés pour discuter des problématiques d’alimentation d’un petit ordinateur ARM avec une batterie lithium et un panneau solaire USB.
Une caractéristique importante des batteries est la puissance maximale qu’elles peuvent absorber quand on les charge. C’est ce qui permettra de déterminer s’il est possible de les recharger en une seule journée via un panneau solaire ou s’il faudra compter plusieurs jours de soleil pour une charge complète.
12b prend des mesures d’un Raspberry Pi sur batterie, avec un écran portable branché.
Récupération de batteries lithium d’anciens ordinateurs portables
Un beau travail a été mené pour détailler les opérations nécessaires pour récupérer des batteries depuis des vieilles batteries d’ordinateurs portables. Toutes les opérations sont détaillées dans un tutoriel accessible sur le wiki du Distrilab.
Les piles lithium rondes que l’on peut trouver dans les batteries d’ordinateurs portables
Réemploi de vieux ordinateurs (ordinosaures)
La délégation partie faire ses courses à la Ressourcerie du Pont pour faire le plein d’ordinosaures qui deviendront autant de kiosques autonomes mettant à disposition autant de services numériques que des livres électroniques ou des MOOCs
Hack-design
Des plasticien·nes locaux ont fait parler leur imagination pour créer de nouveaux looks pour différents usages :
Yeahman : un crieur de rue qui enregistrera des paroles publiques et les rediffusera, faisant office de jukebox actionnable par liens mp3 dans des QR-codes
Mouche à facette: un Raspberry Pi volant, avec des ailes en boule à facettes
Girafe rose : une statue de girafe en bois cachant un point d’accès wifi et un serveur CLIC!
Autre piste explorée : un lecteur d’annonces connecté au web par flux RSS, à base de raspberry pi zéro et écran e-ink (comme sur les liseuses d’e-book, l’écran noir et blanc continue d’afficher du contenu sans avoir besoin d’énergie)
Améliorer les outils pour permettre l’usage en local et déconnecté du grand internet
Nous avons profité de la présence d’éminents contributeur·ices Yunohost et Chatons, pour contribuer au code de projets libres. Ainsi :
Ljf a pu corriger des bugs du hotspot wifi dans Yunohost et faire en sorte qu’il propose les services du serveur CLIC même sans connexion internet ✨
Tobias a ajouté le support de Framemo dans le dépot d’applications de YunoHost. Il a également travaillé sur une app permettant de remonter des informations vers l’outil de statistiques des chatons
12b a créé des images Raspberry Pi et Odroid « clé en main » pour avoir un Yunohost avec des services installés, et une sélection de contenus de formations, de vidéos et de textes préinstallés, et accessibles en mode wifi « hotspot » local.
Penser les usages et les contenus pour être au plus proche des besoins des gens
Le temps nous a manqué pour réaliser tout ce que nous avions imaginé, en partie parce que nous avons pris du temps pour avoir des moments de restitution et d’échange avec les personnes en visite sur le lieu, ce qui fut riche !
Des graines de projets ont donc été semées et pousseront en 2022 :
une rubrique « Participation citoyenne » est apparue dans CLIC!, pour permettre d’effectuer des votes, des sondages et d’autres échanges locaux ;
initier les bénévoles de la ressourcerie à l’installation de ces kiosques sur des vieux ordinateurs et mettre la formation à disposition de toutes et tous ;
faire des tests utilisateur·ices en direct sur un marché avec un nano-ordi nomade et un kiosque à la ressourcerie.
Une affiche de présentation des bornes Recy’clic par Uto de R(d)évolution
Expérimenter de nouvelles manières de travailler ensemble
Se voir en vrai, vivre ensemble, prendre soin des besoins de toutes et tous, s’amuser, passer du bon temps entre et avec des personnes inspirant·es… Cette rencontre a provoqué une envie de continuer à travailler ensemble sur ce projet. Voici quelques ingrédients, que nous pouvons partager, pour des rencontres réussies :
Liberté de rythme et de présence : certains étaient là pour quelques jours, d’autres pour une semaine. Certains actifs tôt le matin, d’autres (et iels étaient nombreux⋅ses) tard dans la nuit.
Un lieu inspirant et des hôtes accueillant·e·s, merci R(d)évolution du Vigan!
Un cadre de travail mêlant grand repas auto-organisés, discussions enflammées, temps de travail collectif et présentation croisées des avancées
Des animateur·ice·s soucieux·ses de l’inclusion des participant·es, de nombreux points de synchronisation
Faire du commun, trouver du sens dans nos collaborations
Vous avez envie de participer au projet ? Vous pouvez nous contacter via notre formulaire de contact, et nous vous tiendrons informé·es de nos prochains petits pas, et rencontres!
Le mot de la fin
Comme d’habitude sur le framablog, un petit mot des participant·es pour conclure :
ljf : Il reste de nombreux défis à relever pour proposer de l’auto-hébergement facile, itinérant et déconnectable, cette résidence était un pas de plus, longue vie au projet CLIC! et merci aux habitant⋅es de la Fabrègue et à leur énergie inspirante.
12b : De belles rencontres et un projet inspirant. On continue en 2022!
Simon : Une chouette rencontre avec une belle diversité et plein d’idées, vivement la suite !
Tobias : Une rencontre hors du temps qui crée autant de code que d’idées et de liens entre les personnes.
Frédéric : Une belle parenthèse pour moi qui cours toujours après le temps et de super rencontres! Ce fut un vrai moment de bonheur de pouvoir participer au développement de cette solution. Merci à tous·tes
Christian : un chouette moment d’échange, pour découvrir, expérimenter, tester et discuter. Un grand merci aux organisateurs.
Lilian : Il y a encore du travail pour que cela soit accessible à tous·tes, mais un énorme potentiel pour permettre à chacun·e d’avoir facilement accès à des outils éthiques.
Ulysse : Une très belle aventure, qui va essaimer, et pas forcément là où on l’imagine, et c’est ça qui est beau !
Florian: merci Framasoft de nous avoir soutenus dans cette démarche et au plaisir de vous voir à notre prochain sprint IRL avec ce super groupe <3
Mathieu : un dispositif dont ritimo rêvait depuis de nombreuses années, qui est en train d’aboutir avec les précieuses contributions de chouettes personnes, et un soutien extra de Framasoft : la recette pour créer du lien, de l’interconnaissance, de la confiance – et construire ensemble du commun !
Crédit photos et vidéos : 12b Fabrice Bellamy – licence CC BY SA
PENSA, un projet universitaire européen autour de la citoyenneté numérique
En février 2020, nous avons été contacté par Marco Cappellini, d’Aix-Marseille Université, qui nous proposait de participer à un projet européen – qui n’avait, à l’époque, pas encore de nom – sur la thématique de la citoyenneté numérique dans une perspective plurilingue. Intriguées, nous avons voulu en savoir plus et, après un temps d’échanges, nous avons convenu que Framasoft serait l’un des partenaires associés de ce projet, spécifiquement sur la production de séquences de formations. Et puis, une pandémie mondiale est passée par là ! Ce n’est donc qu’en février 2021 que le projet PENSA (c’est son petit nom) a eu confirmation de son financement et que nous avons pu préciser notre participation : nous animerons une session de formation sur les logiciels libres dans l’enseignement en juin 2022. Maintenant que le projet est lancé, il était temps qu’on vous en parle. Et pour cela, nous avons proposé aux personnes qui coordonnent ce projet de répondre à une petite interview.
Bonjour Elisabeth et Marco ! Pouvez-vous vous présenter ?
Bonjour, je suis Elisabeth Sanchez, Ingénieure d’études au Centre de Formation et d’Autoformation en Langues (CFAL) à Aix Marseille Université. Je suis en charge de l’animation et de l’ingénierie du projet PENSA.
Bonjour, je suis Marco Cappellini, enseignant chercheur à Aix Marseille Université et coordonnateur du projet PENSA.
Vous faites tous les deux partie de l’équipe de coordination du projet PENSA. Vous pouvez nous expliquer de quoi il s’agit ?
Le projet pour une Professionnalisation des Enseignants utilisant le Numérique pour un Soutien à l’Autonomie et à la citoyenneté (PENSA), soutenu par le programme Erasmus+ de la Commission européenne, aborde deux questions d’actualité dans l’enseignement supérieur et la société.
La première est le besoin de formation et d’infrastructure pour dispenser un enseignement mixte, distant et/ou co-modal (c’est-à-dire un enseignement en classe diffusé simultanément à des étudiants en ligne) qui s’est fait à la suite de la pandémie. Pendant les lockdowns nationaux et pour dispenser un enseignement co-modal, les enseignants se sont souvent tournés vers les plateformes en ligne classiques telles que Zoom sans être conscients du modèle économique de ces plateformes en termes de traitement des données personnelles.
La deuxième question est la nécessité d’éduquer les jeunes aux implications de l’utilisation des sites de réseaux sociaux (Facebook, YouTube, etc.) sur les plans psychologique, sociologique, économique et social. En effet, le déploiement de ces plateformes s’est accompagné de discours d’émancipation, les utilisateurs ayant pu exprimer et échanger leurs idées en ligne, générant ainsi davantage de dialogue public. Parfois, des dérives extrêmes ont démontré la fragilité du système d’où la nécessité de sensibiliser les étudiants aux logiques inhérentes à ces plateformes.
Le projet PENSA aborde ces questions avec une approche globale d’ouverture, à la fois dans le sens de l’éducation ouverte et des plateformes open source. Le cœur du projet est constitué de 30 enseignants et formateurs d’enseignants dans sept universités, la plupart faisant partie de l’Université européenne CIVIS, une association académique et une entreprise.
Au cours du projet, une centaine d’enseignants seront formés à l’intégration de l’enseignement mixte et co-modal dans leurs classes, avec l’intégration de la télécollaboration et de l’échange virtuel sur des sujets liés à la citoyenneté numérique. Grâce à ces actions, PENSA permettra à 400 élèves de toute l’Europe de développer leurs compétences numériques, leurs compétences plurilingues, leurs capacités de collaboration et leur autonomie d’apprentissage.
Pouvez-vous nous préciser comment les étudiant⋅es travaillent en collaboration ?
Les étudiants vont travailler en classe avec leurs enseignants et en ligne en petits groupes avec leurs camarades d’une université partenaire. Les échanges en ligne se déroulent dans la plupart des cas en trois phases. La première est une phase de prise de contact pour briser la glace. Les étudiants peuvent se présenter et comparer leurs environnements, d’études et personnels par exemple. Dans la deuxième phase, les étudiants travaillent pour analyser ensemble des « textes parallèles ». De manière générale, ces textes peuvent être des remakes de films, par exemple un groupe franco-italien comparant Bienvenue chez les Ch’tis et Benvenuti al Sud. Dans le cadre du projet PENSA, il s’agira plus spécifiquement par exemple de législations pour le déploiement de la reconnaissance faciale dans les pays respectifs. Cette deuxième phase se veut une entrée dans l’interculturel. Dans la troisième phase, les étudiants collaborent pour réaliser une production commune, un article de blog ou un poster sur une thématique en lien avec le projet, par exemple la gestion des données sur un site de réseautage social. C’est dans cette phase qu’il vont apprendre à développer leur communication et la gestion de la diversité dans une équipe, pour aller encore davantage dans l’interculturel.
Comment vous est venue l’idée de travailler sur ces thématiques ?
Marco : Personnellement, de deux choses. Tout d’abord, ce sont plusieurs lectures qui ont éclairé chez moi les aspects problématiques de certains outils et plateformes numériques. Je pense aux écrits de Bernard Harcourt et plus spécifiquement son essai La Société d’exposition : désir et désobéissance à l’ère numérique, à ceux de Frank Pasquale sur l’opacité du fonctionnement des entreprises qui dominent sur Internet, ou encore les écrits sur l’autodéfense numérique du collectif italien Ippolita, également partenaire associé de PENSA.
La deuxième dynamique a été un ensemble de discussions avec des collègues et des amis, qui ont montré d’une part qu’il y avait une connaissance vague des dynamiques sur Internet et une connaissance presque nulle des outils alternatifs à disposition. À partir de là, avec plusieurs collègues on s’est réunis en février 2019 et on a travaillé à une proposition pour les appels à projet de la Commission Européenne. Puis est venue la pandémie, qui n’a fait que renforcer le besoin de développer une culture numérique chez les étudiants, mais aussi chez beaucoup de collègues.
PENSA est un projet ERASMUS+. Pouvez-vous nous en dire davantage sur ce programme européen ? Erasmus+ est un programme connu surtout pour ses actions liées à la mobilité. Moins connues, mais tout aussi intéressantes, sont les actions liées à la coopération, tant au niveau scolaire qu’universitaire. PENSA est un projet qui s’insère dans les actions clés, pour des partenariats stratégiques dans l’enseignement supérieur. L’idée principale est de réunir plusieurs partenaires aux expertises complémentaires pour répondre à un ou plusieurs défis sociétaux.
Dans PENSA, le noyau de l’équipe est composé d’enseignants de 7 universités, de collègues d’une entreprise spécialisée dans les open coursware et d’une association internationale. Dans une formation qui s’est tenue en juin 2021, chaque membre de l’équipe a apporté quelque chose aux autres. Par exemple, j’ai pu apprendre davantage sur les outils libres spécifiques à la formation et à mieux intégrer des échanges en ligne entre mes étudiants et des étudiants ailleurs. A partir de cette collaboration, dans chacune des universités on formera d’autres collègues pour diffuser des idées et des outils pour améliorer la pédagogie universitaire.
Puisque PENSA est un projet européen, quelles sont les langues utilisées ?
Il y a 7 langues présentes dans le projet : allemand, anglais, catalan, espagnol, français, italien, roumain. Dans les échanges entre étudiants, ils utilisent soit une langue comme langue véhiculaire (typiquement l’anglais), soit les deux langues des pays concernés (par exemple allemand et français pour un échange entre étudiants à Tübingen et Aix en Provence). Pour les autres initiatives du projet, comme la formation de formateurs, on a utilisé l’anglais dans un premier temps, les langues locales ensuite.
Le plus intéressant se passe au niveau de la gestion du projet : le comité de pilotage communique en intercompréhension des langues romanes. Par les similarités entre langues latines, et avec des stratégies de communication, chacun parle dans une langue romane et les autres comprennent et répondent en d’autres langues. Dans ces réunions, on parle donc français, italien et espagnol principalement, avec des touches en catalan et roumain. Au début, ça peut être un peu déstabilisant et surtout fatiguant, mais avec la pratique on s’y fait assez vite. C’est une manière pour nous de faire vivre le plurilinguisme européen, au-delà des séparations entre langues que l’on peut avoir apprises.
Crédit : Université Aix-Marseille
Quelle place accordez-vous au logiciel libre dans ce projet ?
Une place assez importante. D’abord, on vise à faire comprendre la différence entre « gratuit » et « libre », qui n’est pas évidente pour beaucoup de monde. Ensuite, dans la formation de formateurs on fait connaître des alternatives libres, parfois même institutionnelles, pour différents outils. Par exemple BigBlueButton comme une alternative à Zoom ou Skype. D’ailleurs, ces formations sont très intéressantes pour découvrir de nouveaux outils, même pour les personnes le plus expérimentées de l’équipe.
On prévoit aussi de développer et publier des extensions à des outils libres tels que la plateforme Moodle pour les cours hybrides ou à distance. Chez les étudiants, les formations que nous sommes en train de mettre en place visent aussi à les rendre plus conscients des enjeux de l’utilisation de plateformes gratuites grand public, par exemple sur comment elles sont conçues pour capter l’attention et extraire des données, les positionnant en tant que consommateurs. Nous espérons que cette prise de conscience contribuera à des changements dans leurs usages numériques, particulièrement par rapport aux plateformes de réseautage social.
Le côté « open » du projet se fait aussi au niveau des productions de matériel pédagogique, lequel sera mis en ligne sur les sites de la Commission Européenne et du projet.
Donc, le matériel pédagogique sera diffusé sous licence libre ? Si oui, laquelle ?
Oui, il sera diffusé en libre accès. Pour la ou les licences utilisées, ce n’est pas encore défini : ce sera discuté et décidé lors du prochain comité de pilotage.
Dernière question, traditionnelle : y a-t-il une question que l’on ne vous a pas posée ou un élément que vous souhaiteriez ajouter ?
On a probablement fait le tour. Merci bien pour cette occasion de parler de PENSA. Pour la suite et pour suivre l’évolution du projet et profiter des productions, ce sera sur le site https://pensa.univ-amu.fr/, dans la langue de votre choix 🙂
Les Métacartes « Numérique Éthique » : une boîte à outils pour s’émanciper
Faire le point sur son utilisation du numérique et améliorer ses pratiques : mais par où commencer ? Les Métacartes « Numérique Éthique » permettent d’accompagner ces réflexions, de se poser des questions pertinentes et d’évaluer ses priorités.
Pour animer leurs formations, Mélanie et Lilian (facilitateur⋅ices et formateur⋅ices, notamment dansAnimacoop), ont souhaité expérimenter un nouveau format facilement transportable, utilisable à plusieurs et dans l’espace. Iels ont ainsi créé les Métacartes (sous licence CC BY-SA), un jeu réel où chaque carte est reliée à une ressource en ligne régulièrement actualisée. Cela permet d’avoir un contenu à jour et non-obsolète (particulièrement intéressant dans le domaine du numérique). Framasoft avait souhaité soutenir leur initiative pleine de sens, nous vous en parlions sur le Framablog dans cet article.
Nous voulons maintenant vous aider à prendre les cartes en main pour facilement utiliser le jeu. Pour illustrer nos propos, nous allons prendre l’exemple d’un collectif qui souhaite questionner ses usages numériques : l’orchestre universitaire de l’Université Populaire Libre Ouverte Autonome et Décentralisée (que nous écrirons pour simplifier la lecture : l’orchestre UPLOAD).
Utiliser les cartes selon vos besoins
Pour commencer à utiliser les cartes, il est important de comprendre qu’il y a de nombreuses façons de les aborder et tout va dépendre du contexte général dans lequel vous vous trouvez. Vos valeurs sont-elles bien définies ? Les outils internes actuellement utilisés posent-ils des problèmes particuliers ? Les Métacartes peuvent ainsi être vues comme une boîte à outils sous forme de cartes : vous utiliserez une partie des outils, selon vos besoins, afin de faciliter un passage à l’action.
Les cartes « Ingrédients » : définir vos priorités
Les cartes « Ingrédients » sont les cartes violettes du jeu. Celles-ci présentent des éléments clés à prendre en compte pour vos réflexions. Elles comportent deux sous catégories : #critère et #usage.
Les cartes #critère pour affirmer vos valeurs
Une entrée par les cartes #critère est intéressante pour approfondir votre éthique et vos valeurs. En parcourant l’ensemble des cartes #critère, vous pouvez sélectionner 3 à 5 critères qui vous semblent les plus importants. Vous allez ainsi prioriser les critères à prendre en compte lors du choix d’un outil.
Les membres de l’orchestre UPLOAD ont ainsi choisit trois critères à prioriser dans l’évaluation de leurs outils actuels et/ou dans la recherche d’alternatives :
Logiciel libre : l’orchestre prône depuis sa création la mise sous licence libres d’œuvres musicales. Utiliser des logiciels libres est donc un choix essentiel pour le groupe, pour être en accord avec ses valeurs ;
Facilité de changement : les musicien⋅nes préfèrent de loin jouer de la musique plutôt que de passer des heures à changer leurs pratiques. Il faudra s’informer sur la facilité de migration et de prise en main des outils pour ne pas frustrer le groupe ;
Interopérabilité : il est essentiel pour les membres de l’orchestre de pouvoir partager du contenu sans avoir à penser à qui utilise quel logiciel. L’interopérabilité sera donc essentielle, pour que différents outils puissent communiquer entre eux.
Les cartes #usage pour identifier vos besoins concrets
Les cartes #usage permettent de définir les besoins réels en terme d’outils numériques. Vous pouvez ainsi commencer à sélectionner les cartes représentant vos besoins réguliers. Cette étape va permettre de démêler les outils numériques actuellement utilisés, de les nommer et de les questionner. Cet outil est-il en accord avec vos critères préalablement établis ? Ou voulez-vous le changer ? Les cartes #usage proposent justement des alternatives sur les ressources en ligne : une bonne manière de rapidement trouver des solutions !
L’orchestre UPLOAD a ainsi choisi les cartes #usage suivantes :
Diffusion d’information : diffusion d’info toutes les semaines aux membres de l’orchestre sur l’organisation interne (répétitions, week-ends, déroulé des concerts…)
Actuellement utilisé : envois par mail à tous les membres de l’asso.
OK avec les critères définis ? Non, le logiciel mail utilisé n’est pas libre.
Alternative : utiliser par exemple une liste de diffusion avant de penser à changer d’hébergeur de mail (moins contraignant pour commencer).
Les outils à garder et à changer sont ainsi définis. Le groupe a pris le temps de questionner pourquoi garder ou changer chaque outil. Les alternatives ont été proposées, il faudra maintenant les mettre en place et les tester.
Les cartes « Recettes » : des méthodes d’animation
Les cartes jaunes ou cartes « Recettes », proposent des idées d’animation pour amorcer des réflexions et sensibiliser sur certaines pratiques numériques. Elles peuvent demander plus ou moins de préparation pour l’animation (le niveau indiqué sur la carte, de 1 à 3).
Exemple de la carte « Vous êtes ici »
La carte « Vous êtes ici » est associée à une trame graphique en ligne pour voir où vous en êtes sur votre parcours vers un numérique éthique. Le chemin va appeler d’autres cartes du jeu pour avoir des réflexions approfondies, et comprendre dans quelle direction vous allez.
L’orchestre UPLOAD s’est positionné sur cette image sur l’étape « Faire le point » : la prise de conscience des enjeux a amené le groupe à agir pour changer ses pratiques !
Soutenir le projet
Ça leur a plu !
Dans un atelier avec ses étudiant⋅es de l’UTC, Stéphane Crozat nous partage son point de vue : « J’ai eu un ressenti positif en tant que prof, les étudiant⋅es faisaient ce que j’attendais. Iels souriaient, riaient, avaient l’air de prendre plaisir à l’exo. L’éval des étudiant·es est bonne. » (leurs commentaires sont ici).
Dans le cadre d’une formation pour des des conseiller⋅es numériques, Julie Brillet, bibliothécaire, formatrice et facilitatrice a exprimé sur Twitter « que les métacartes étaient vraiment un outil adapté, notamment comme porte d’entrée au site metacartes.cc qui comprend plein de contenus. »
La recherche et ses publications : le long chemin vers un libre accès
« Si la recherche universitaire est financée par des fonds publics, il n’y a aucune raison pour que ses publications soient privées ». Et pourtant…
La diffusion des publications universitaires dépend le plus souvent d’éditeurs qui tirent profit de situations de quasi-monopole en imposant une sorte de péage.
Pour échapper à ce contrôle marchand qui rend inaccessible l’accès aux connaissances à une part importante de la communauté scientifique mondiale, un nombre significatif de chercheuses et chercheurs désirent rendre le fruit de leur travail intellectuel disponible en Open Access.
La lutte pour le partage des connaissances est déjà ancienne. Retour rapide…
Il y a un peu plus de 10 ans maintenant, Aaron Swartz subissait la pression de poursuites judiciaires, qui allait le mener au suicide, pour avoir téléchargé et mis à disposition gratuitement 4,8 millions d’articles scientifiques de JSTOR, une plateforme de publication universitaire payante. Aaron Swartz était partisan d’un libre accès aux connaissances scientifiques, levier d’émancipation et de justice.
C’est à peu près à la même époque qu’Alexandra Elbakyan a lancé Sci-Hub, animée du même désir de donner un large accès aux publications universitaires à tous ceux qui comme elle, n’avaient pas les moyens d’acquitter le péage imposé par des éditeurs comme la multinationale Elsevier.
Une large majorité de chercheurs, en France comme dans le monde entier, est favorable à l’accès libre à leurs publications. Citons par exemple Céline Barthonnat, éditrice au CNRS :
la diffusion du savoir scientifique fait partie du travail des personnels de la recherche [article L411-1 du code de la recherche]. Beaucoup de ces recherches qui sont financées par l’argent public sont diffusées ensuite par ces éditeurs prédateurs”.
Le billet de Glyn Moody que Framalang a traduit pour vous marque peut-être une étape dans ce long combat où la volonté de partager les connaissances se heurte constamment aux logiques propriétaires mercantiles qui veulent faire de la circulation des publications scientifiques un marché lucratif.
Glyn Moody indique ici qu’il existe désormais une possibilité pour que les auteurs et autrices de « papiers » scientifiques puissent conserver leur droit de publication et en permettre le libre accès.
Il y a quelques semaines, nous nous demandions si les éditeurs universitaires essaieraient de faire supprimer l’extraordinaire Index général des publications scientifiques créé par Carl Malamud. Il existe un précédent de ce genre de poursuites judiciaires contre un service du plus grand intérêt pour la société. Depuis 2015, les éditeurs essaient de faire taire Sci-Hub, qui propose près de 90 millions de publications universitaires. Le motif de leur plainte : Sci-Hub viole leurs droits d’auteur2
C’est étrange, car d’après la loi, les droits d’auteur de la vaste majorité de ces 90 millions de publications sont détenus par les chercheur·euse·s qui les ont rédigées.
Et la majorité de ces chercheur·euse·s approuve Sci-Hub, comme l’a clairement montré une étude menée en 2016 par le magazine Science :
Il est probable que l’échantillon retenu pour le sondage soit biaisé par une surreprésentation des fans du site : près de 60 % des personnes interrogées disent avoir déjà utilisé Sci-Hub, et un quart le font quotidiennement ou chaque semaine. De sorte qu’on ne s’étonnera guère si 88 % d’entre elles déclarent ne rien voir de mal dans le téléchargement de publications piratées. Mais notez bien, éditeurs universitaires, que ce ne sont pas seulement des jeunes et de grands utilisateurs de Sci-Hub qui voient les choses ainsi. Un examen plus attentif des données du sondage indiquait que les personnes interrogées de toutes les catégories soutiennent la fronde, même celles qui n’ont jamais utilisé Sci-Hub ou celles âgées de plus de 50 ans – respectivement 84 % et 79 % – n’avaient aucun scrupule à le faire.
Alors, si la plupart des chercheur·euse·s n’ont aucun problème avec Sci-Hub, et l’utilisent eux-mêmes, pourquoi le site est-il poursuivi par les éditeurs ? La réponse à cette question révèle un problème clé crucial, celui des tentatives en cours pour rendre les savoirs universitaires librement accessibles, par le biais de l’open access.
Théoriquement, les chercheur·euse·s peuvent diffuser leurs publications sous une licence Creative Commons, ce qui permet de les lire et de les reproduire librement, et de se baser facilement sur ce travail. En réalité, les auteurs sont souvent « incités » à céder leurs droits aux éditeurs de la revue où apparaît la publication, ce qui conditionne l’accès aux connaissances derrière à des paiements onéreux. Ce n’est pas indispensable, c’est seulement ce qui est devenu habituel. Mais les conséquences en sont importantes. D’abord, les auteurs originaux deviennent réticents à partager leurs articles, parce qu’ils sont « sous copyright », comme le mentionne un précédent article (en anglais) de ce blog. Ensuite, si les droits sont transférés des auteurs vers les éditeurs, alors ces derniers peuvent poursuivre en justice les sites comme Sci-Hub, sans tenir compte de l’avis des chercheur⋅euse⋅s.
La bonne nouvelle, c’est qu’il existe maintenant des efforts coordonnés pour éviter ces problèmes grâce à « la rétention des droits ». Tout en garantissant aux éditeurs le droit de diffuser un article dans leur publication, les auteurs et autrices conservent aussi certains droits pour permettre le libre partage de leurs articles, et leur utilisation par des sites comme Sci-Hub. Un des chefs de file de cette initiative est cOAlition S, un groupe d’organisations de financement de la recherche, avec le soutien de la Commission européenne et du Conseil Européen de la Recherche. Les principes essentiels du « Plan S » de la Coalition précisent :
À compter de 2021, toutes les publications universitaires dont les résultats de recherche sont financés via des fonds publics ou privés au travers d’institutions nationales, continentales, régionales ou internationales, doivent être publiées dans des revues ou sur des plateformes en libre accès, ou bien encore être immédiatement disponibles sur un répertoire en libre accès, et ce sans aucune restriction.
L’un des points-clés de ce Plan S est le suivant :
Les auteurs et autrices ou leurs institutions gardent les droits sur leurs publications. Toute publication doit être placée sous licence ouverte, de préférence la licence Creative Commons Attribution (CC BY).
Ça semble fonctionner. Un récent article de Ross Mounce mettait en évidence le fait suivant :
En tant que personne indépendante de la cOAlition S, j’ai pu observer avec grand intérêt la mise en application de la stratégie de rétention des droits. En utilisant Google Scholar et Paperpile, j’ai relevé plus de 500 papiers publiés sur des centaines de supports différents qui utilisaient la référence à la stratégie de rétention des droits dans les remerciements.
Les auteurs s’en servent pour conserver leurs droits sur les prépublications, les articles de revues, les supports de conférences, les chapitres de livres et même des posters sur les affiches, c’est tout à fait logique. La stratégie est rédigée en termes simples et elle est facile à ajouter à des résultats de recherche. Il est aisé de mentionner ses sources de financement des recherches et d’ajouter ce paragraphe : « Afin de maintenir un accès libre, l’auteur⸱ice a appliqué la licence de libre diffusion CC BY à toute version finale évaluée par les pairs découlant de la présente soumission », et donc les autrices et auteurs le font.
Comme souligné ci-dessus, il suffit donc aux chercheur·euse·s d’ajouter la brève mention qui suit à leurs articles pour conserver leurs droits fondamentaux :
« Afin de maintenir un accès libre, l’auteur⸱ice a appliqué la licence de libre diffusion CC BY à toute version finale évaluée par les pairs découlant de cette la présente soumission. »
C’est un si petit pas pour un⸱e chercheur⸱euse, mais un tel pas de géant pour faciliter l’accès universel à la connaissance, que toutes et tous devraient le faire naturellement.
Ce billet de Glyn Moody est sous licence CC BY 4.0




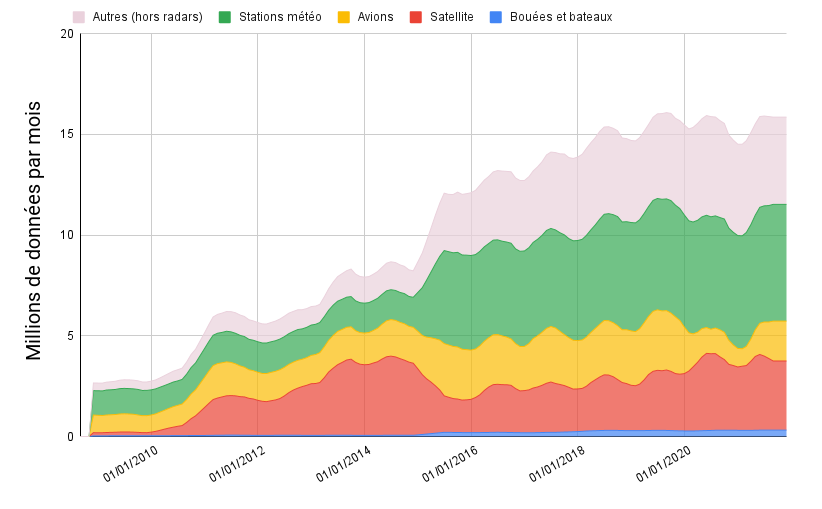
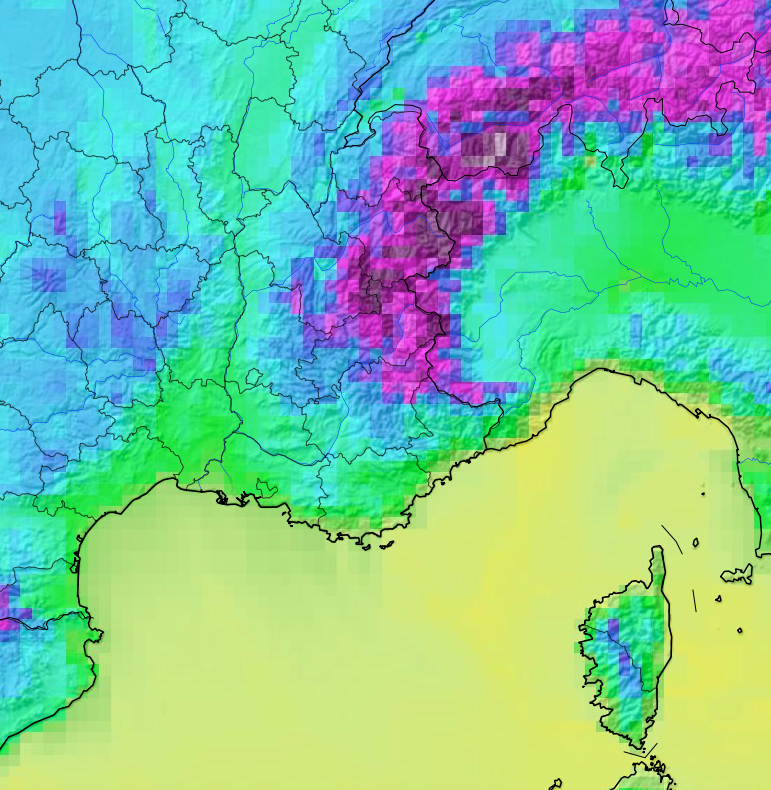
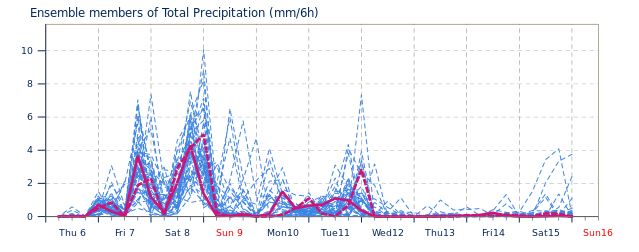
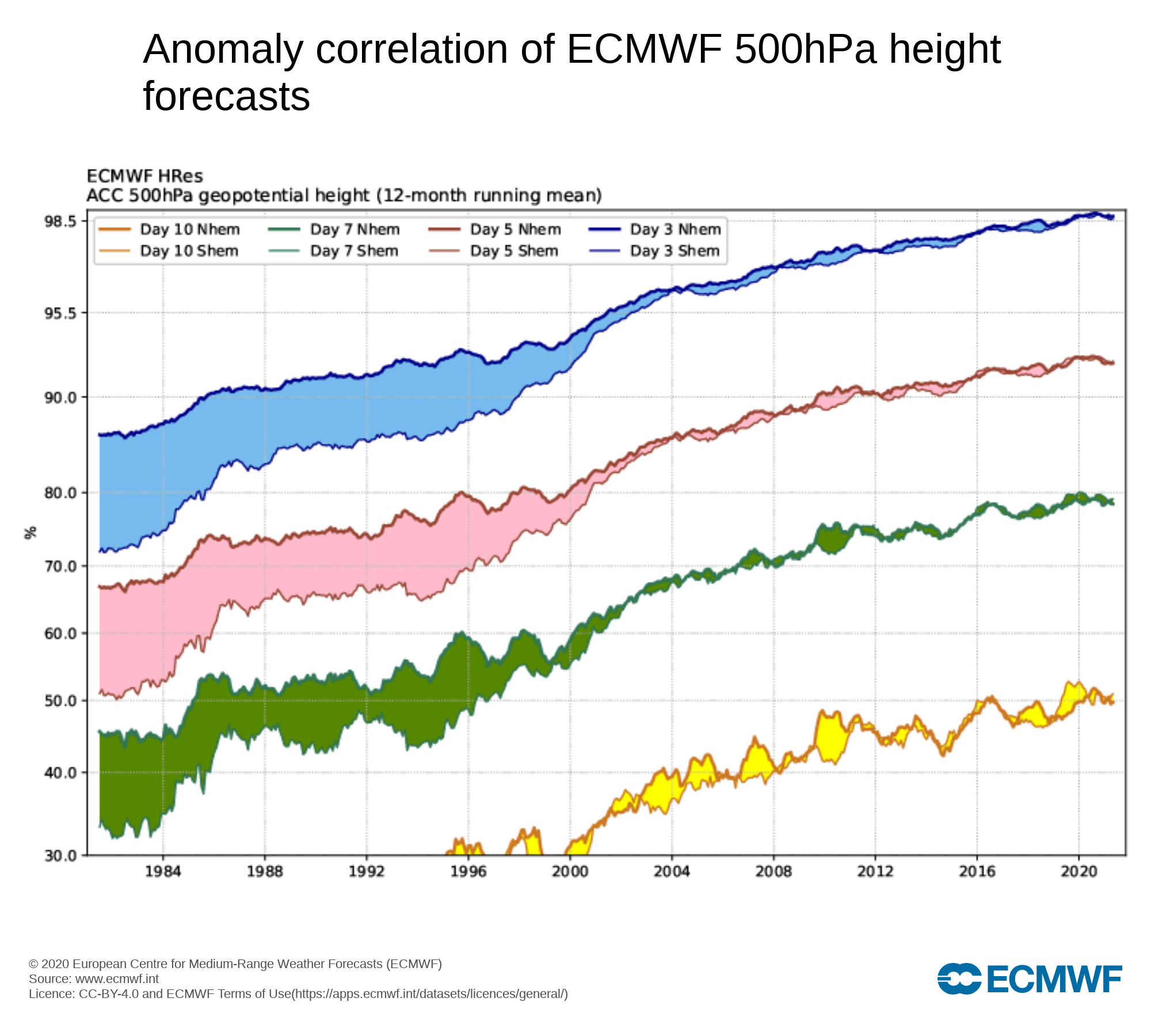

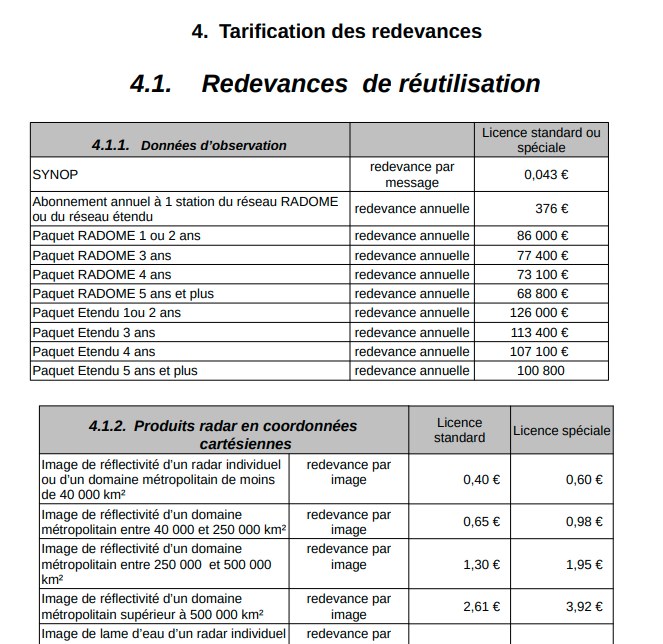





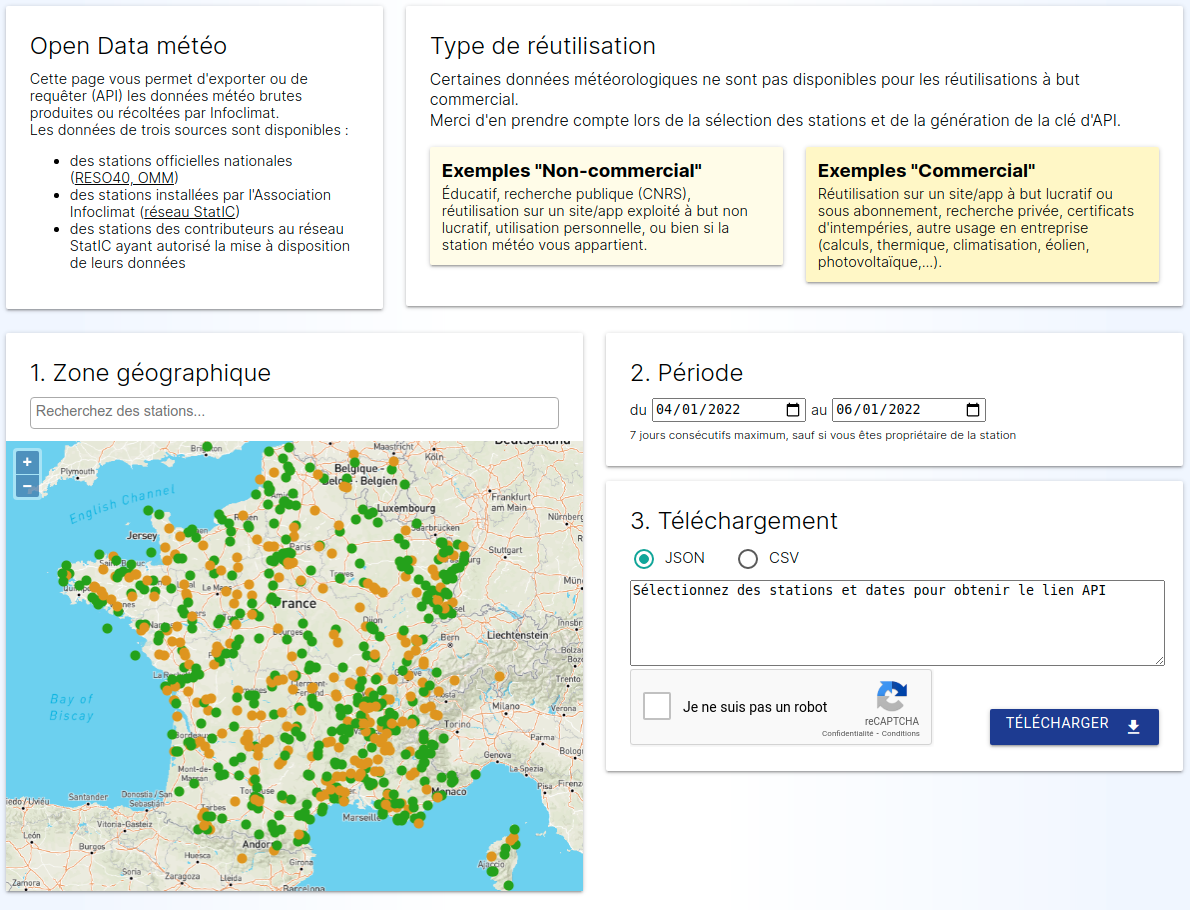

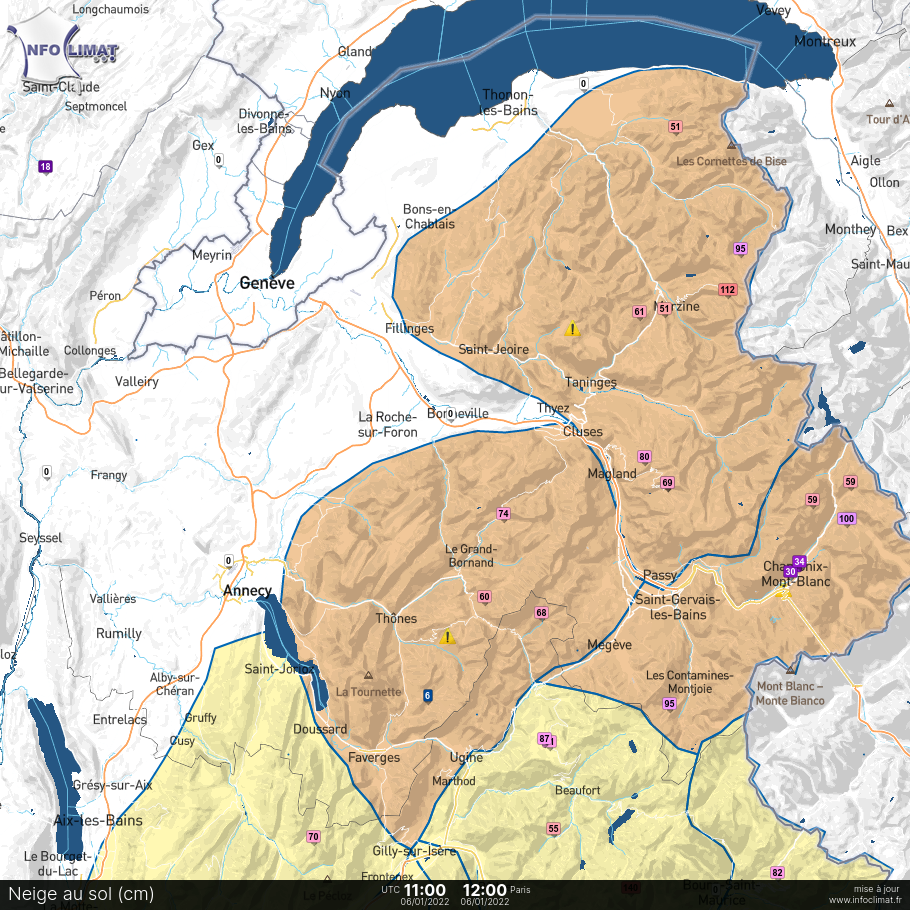

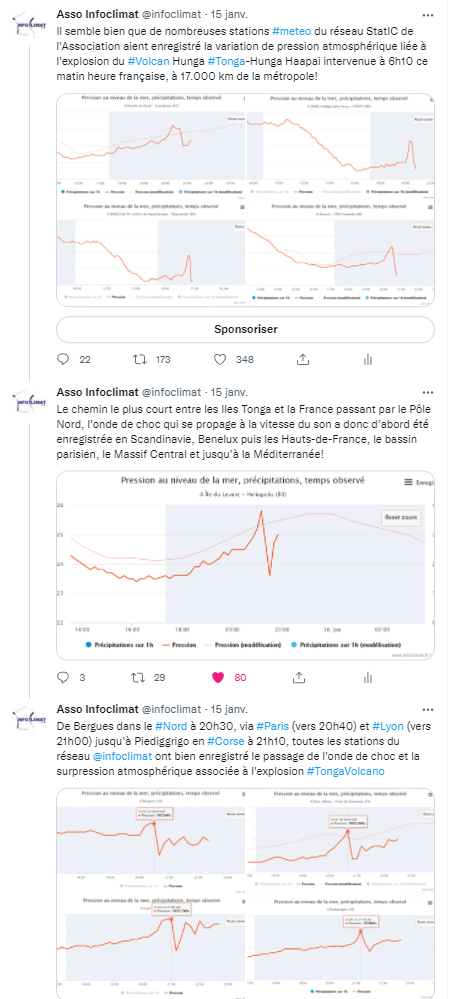



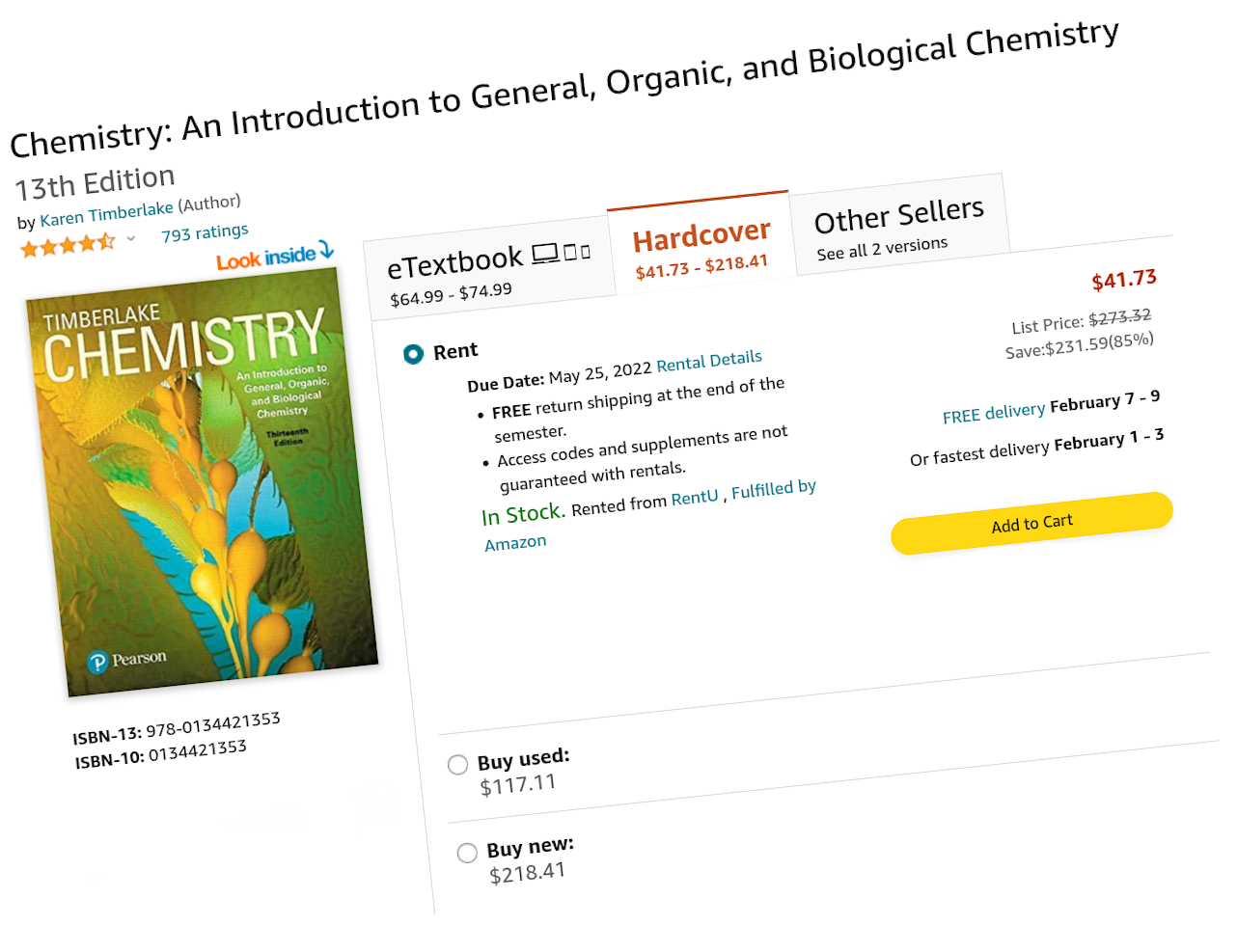

















{kind=link}