Peur des robots qui nous remplacent ? Pas forcément, mais comment vivre et travailler avec les robots ?Une des craintes fort répandues à propos de la robotisation consiste à envisager qu’un grand nombre de professions, et pas seulement parmi les moins qualifiées, pourraient être à court ou moyen terme remplacées par des robots, du moins des systèmes automatisés que les progrès relatifs de l’intelligence artificielle rendraient plus performants que les humains dans l’accomplissement de leurs tâches.
Nul n’ignore pour l’instant ce qui va survenir effectivement mais une chose est d’ores et déjà établie : les systèmes robotisés sont déjà là, et plutôt qu’être remplacés, pour l’instant les travailleurs les côtoient, entrent avec eux dans des interactions déjà problématiques. On lira par exemple ce témoignage sur la gestion des livreurs à vélo où le donneur d’ordres et donc de travail est un système informatique qui piste « ses » employés autant que les clients.
À une tout autre échelle, le géant Amazon impose déjà la présence de robots dans ses immenses entrepôts au sein du travail humain, et comme le développe le texte ci-dessous, ce sont les êtres humains qui y travaillent qui doivent s’efforcer de s’adapter à leur présence ! L’anthropologue qui signe l’article que nous avons traduit pour vous analyse ce que représente pour les humains la perte de leur latitude d’action, voire de leur liberté d’initiative, dans une environnement où les robots sont omniprésents.
Les pratiques de l’entreprise Amazon, détestables pour les conditions de travail, sont par ailleurs assez révélatrices d’une dérive qui nous mène peut-être à renoncer peu à peu à notre liberté, pour nous en remettre aux systèmes automatisés dans tous les instants de notre quotidien.
Que sommes-nous prêts à sacrifier pour l’automatisation ?
Par S. A. Applin
Ce que nous apprennent les entrepôts d’Amazon sur un monde où de plus en plus, que ce soit des choses ou des personnes, tout ce qu’il est possible de mesurer finit par être mesuré.
On a l’impression que pratiquement chaque semaine apparaît dans l’actualité une polémique (sinon davantage) autour d’Amazon. Dans les seules deux semaines dernières, il a été question de conversations transcrites et enregistrées avec Echo, d’employés d’Amazon qui protestent contre la faible détermination de leur entreprise au sujet du dérèglement climatique, des efforts de ladite entreprise pour prétendre que les risques liés à la reconnaissance faciale sont « peu significatifs », sans oublier les questions posées par la sénatrice Warren sur les impôts fédéraux de 0 dollar pour un profit de 10 milliards de dollars aux U.S.A. Une entreprise aussi gigantesque qu’Amazon, avec une envergure aussi large en termes de produits et de services, est constamment dans l’actualité. Et malheureusement pour elle, la plupart de ces nouvelles lui donnent l’image d’un manque de compassion, d’intérêt et de sollicitude pour le reste du monde au sens large, en particulier pour les humains qui travaillent pour elle.
Ce qui a retenu mon attention au cours des dernières semaines c’est le témoignage paru dans Vox d’un employé dans un entrepôt, qui s’est plaint des températures qui y régnaient. Selon ce que Rashad Long a indiqué à la publication :
Il fait si chaud dans les troisième et quatrième étages que je transpire dans mes vêtements même s’il fait très froid dehors… Nous avons demandé à l’entreprise de nous fournir de l’air conditionné, mais on nous a indiqué que les robots ne peuvent travailler à basse température.
Alors que Long et d’autres sont impliqués dans des procès avec l’entreprise, et prennent des initiatives pour former un syndicat, les plus importantes plaintes des employés semblent être concentrées sur un seul point : Amazon a la réputation de traiter ses employés comme des robots.
Dans un rapport qui m’a été envoyé après la publication de cette histoire, Amazon contestait ce compte-rendu comme « totalement faux », prétendant que des systèmes et des équipes surveillent constamment les températures dans les centres de traitement des commandes. L’entreprise a indiqué qu’à la mi-décembre, la température moyenne du local où Long travaillait était de 71.04 degrés Fahrenheit (NDT : 21.68 °C).
Le porte-parole d’Amazon a déclaré : « Les collaborateurs d’Amazon sont le cœur et l’âme de nos activités. La sécurité de nos employés est notre première priorité et la santé de chacun de nos employés est évaluée au-delà de toute notion de productivité. Nous sommes fiers de nos conditions de travail sûres, de notre communication transparente et de notre industrie de pointe. »
Un entrepôt d’Amazon, photo par Scott Lewis (CC BY 2.0)
Cependant, vu de l’extérieur, on a l’impression que les entrepôts Amazon mettent en scène le « taylorisme sauvage ». Comme je l’ai déjà écrit, le taylorisme est une théorie de la gestion de l’ingénierie développée au début du XXe siècle et largement adoptée dans les domaines de la gestion et de l’ingénierie jusqu’à présent. Alors qu’à l’origine il était utilisé pour gérer les processus de fabrication et se concentrait sur l’efficacité de l’organisation, avec le temps, le taylorisme s’est intégré dans la culture d’ingénierie et de gestion. Avec l’avènement des outils de calcul pour la mesure quantitative et les métriques et le développement de l’apprentissage machine basé sur les mégadonnées développées par ces métriques, les entreprises dont Amazon, ont abordé une nouvelle phase que j’appellerais « l’analyse extrême des données », dans laquelle tout et quiconque peut être mesuré finit par l’être.
C’est un vrai problème. L’utilisation du comptage, des mesures et de la mise en œuvre des résultats de l’analyse extrême des données destinée à éclairer les décisions pour les êtres humains constitue une menace pour notre bien-être et se traduit par les témoignages dont on nous parle dans les entrepôts et d’autres parties de nos vies, où trop souvent des êtres humains renoncent à leurs initiatives d’action au profit des machines et algorithmes.
Environ 200 travailleurs d’Amazon se sont rassemblés devant leur lieu de travail dans le Minnesota le 18 décembre 2018 pour protester contre leurs conditions de travail qui comprennent le pistage des ordinateurs et l’obligation de travailler à grande vitesse, comme scanner un article toutes les 7 secondes. [Photo : Fibonacci Blue, CC BY 2.0]
Malheureusement, après des décennies où s’est échafaudé ce système de quantification, une entreprise comme Amazon l’a presque intégré à son infrastructure et à sa culture. Il y a des raisons au taylorisme chez Amazon, et une grande partie est liée à ses embauches aux décisions prises par ses cadres en matière de gestion et de développement, et à l’impact de ces décisions sur les personnes qui doivent faire le travail nécessaire pour que ces processus fonctionnent réellement.
Dans un article que j’ai écrit en 2013 avec Michael D. Fischer, nous avons exploré l’idée que les processus étaient une forme de surveillance dans les organisations, en nous concentrant particulièrement sur le fait que lorsque la direction des organisations dicte des processus qui ne fonctionnent pas particulièrement bien pour les employés, ces derniers profitent de l’occasion pour développer des solutions de rechange, ou « agissements cachés ».
Chaque fois que nous utilisons un ordinateur, ou tout autre appareil du même type, nous perdons du pouvoir.
Notre pouvoir en tant qu’humains réside dans notre capacité à faire des choix parmi les options qui s’offrent à nous à un moment donné. La gamme des possibilités évolue avec le temps, mais en tant qu’humains, nous avons le choix. Notre pouvoir c’est la coopération. Nous perdons un peu de notre liberté de choix, quelqu’un d’autre aussi, mais nous pouvons tous les deux parvenir à un compromis efficace.
Chaque fois que nous utilisons un ordinateur, ou tout autre appareil du même type, nous perdons du pouvoir. Nous le faisons quand nous sommes assis ou debout pour utiliser un clavier, à la saisie, ou en cliquant, en faisant défiler, en cochant des cases, en déroulant des menus et en remplissant des données d’une manière telle que la machine puisse comprendre. Si nous ne le faisons pas de la façon dont la machine est conçue pour le traiter, nous cédons notre pouvoir, encore et toujours, pour qu’elle le fasse de façon à pouvoir recueillir les données nécessaires et nous fournir l’article que nous voulons, le service dont nous avons besoin ou la réponse que nous espérons. Les humains abandonnent. Pas les machines.
Lorsque l’action humaine est confrontée à une automatisation difficile à contrôler, il y a des problèmes, et dans des cas extrêmes, ces problèmes peuvent être fatals. L’un d’eux a été mentionné dans le cadre d’enquêtes sur les écrasements de deux Boeing 737 Max, qui se sont concentrées sur les interactions des pilotes avec un système automatisé conçu pour prévenir un décrochage. Alors que le monde continue d’automatiser les choses, les processus et les services, nous les humains sommes mis dans des situations où nous devons constamment nous adapter, car à l’heure actuelle, l’automatisation ne peut et ne veut pas coopérer avec nous au-delà de son répertoire d’actions préprogrammées. Ainsi, dans de nombreux cas, nous devons céder notre initiative et nos choix aux algorithmes ou aux robots, pour atteindre les résultats communs dont nous avons besoin.
Au fil du temps, les humains ont évolué vers le commerce et le troc selon une démarche de coopération, échangeant des ressources pour acquérir ce dont nous avons besoin pour survivre. Nous le faisons par le travail. Dans l’état du marché d’aujourd’hui, si nous sommes à la recherche d’un nouvel emploi, nous devons utiliser un ordinateur pour postuler à un poste affiché sur un site web. Nous devons renoncer à notre initiative personnelle pour utiliser l’ordinateur (nous ne pouvons plus appeler personne), où nous céderons ensuite à un logiciel qui n’est pas nécessairement conçu pour gérer l’enregistrement de notre expérience vécue particulière. Une fois que nous avons fait de notre mieux avec les formulaires, nous appuyons sur un bouton et espérons obtenir une réponse. Les algorithmes en arrière-plan, informés par le système de gestion et les développeurs, vont alors « nous trier », nous transformant en série de données qui sont ensuite évaluées et traitées statistiquement.
C’est seulement si nous passons à travers les filtres qu’une réponse automatisée nous parvient par un courriel (auquel nous ne pouvons pas répondre) pour nous informer du résultat. S’il est positif pour nous, un humain finira par nous contacter, nous demandant d’utiliser une méthode automatisée pour planifier un moment pour un appel, qui utilisera des scripts/processus/lignes directives narratives, qui nous demandent à nouveau de renoncer à notre initiative – même dans une conversation avec un autre humain, où il y a généralement plus de flexibilité. C’est épuisant.
Le coût humain de la « frugalité »
Une fois que les employés des entrepôts d’Amazon ont renoncé à leur liberté pour se plier au processus d’embauche et qu’ils sont embauchés, ils sont également obligés de céder leur liberté d’action dans leur travail. Alors que les employés de bureau cèdent à des partenaires algorithmiques sous forme de logiciels ou de procédures d’entreprises, les employés d’entrepôt cèdent leur liberté d’agir en acceptant les horaires décalés et en travaillant avec des partenaires robots au lieu de partenaires algorithmiques ou à leurs côtés sous forme de logiciels. Les risques pour l’intégrité physique sont beaucoup plus élevés quand on agit dans un entrepôt sans coopérer avec un robot qu’ils ne le sont si on ne coopère pas avec un logiciel dans un travail de bureau.
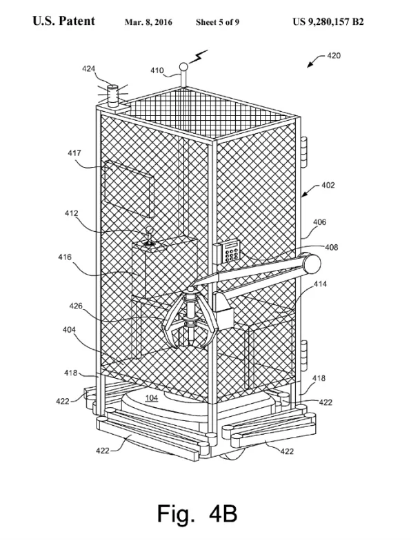
Un brevet déposé par Amazon en 2013, « Système et méthode de transport du personnel dans une environnement de travail industriel. »
Dans certains entrepôts et environnements industriels, les travailleurs doivent se soumettre aux robots parce que les robots sont rapides, faits de métal, et pourraient les blesser ou les tuer. De cette façon, un travailleur qui manœuvre autour d’un robot a moins d’emprise sur son corps au travail que ceux qui, dans les bureaux, prennent les décisions sur la façon dont ces travailleurs vont travailler.
Une solution proposée par Amazon en 2013 a été le brevet U.S. 9,280,157 B2, accordé en 2016. Ce brevet a été décrit comme un « dispositif de transport humain » pour un entrepôt, constitué d’une cage humaine. Une cage, c’est un symbole brutal. Bien que l’idée ait été de protéger les travailleurs humains contre les robots, elle n’a pas été perçue comme elle était probablement prévue. À l’extrême, une cage implique une fois de plus que les humains céderont leur capacité d’agir aux robots, ce qui semble donner raison aux plaintes initiales des magasiniers selon lesquelles les robots bénéficient d’un traitement préférentiel sur le lieu de travail chez Amazon
Amazon a insisté sur le fait que l’entreprise n’avait pas l’intention de mettre en œuvre cette idée. « Parfois même de mauvaises idées sont soumises pour des brevets, m’a dit un porte-parole d’Amazon, après la publication de cette histoire. Cela n’a jamais été utilisé et nous n’avons aucun plan d’utilisation. Nous avons développé une bien meilleure solution qui est un petit gilet que les associés peuvent porter et qui impose à tous les robots à proximité de s’immobiliser. »
Qu’il s’agisse d’une cage ou d’un gilet automatique, de toutes façons, ces interventions de sécurité soulèvent la question de savoir si une installation comme un centre de traitement d’Amazon pourrait être conçue de manière à ne pas obliger les humains à faire ces sacrifices frontaliers – tout en étant encore employés de façon rémunérée.
Fondamentalement, le taylorisme n’est pas forcément une question d’efficacité pour l’efficacité, mais d’économie de temps et, par association, d’argent. Parmi les « principes de leadership » d’Amazon, il y a la frugalité, et c’est cet aspect qui semble avoir dépassé leurs autres idéaux, car « faire plus avec moins » semble être le principe dominant dans la façon dont l’entreprise interagit avec tout, et comment cette interaction affecte ses employés et ses clients à travers le monde.
Si une entreprise pratique ce taylorisme dans l’ensemble de sa culture, des êtres humains vont prendre des décisions sur la façon dont d’autres humains doivent travailler ou interagir avec les systèmes d’une manière qui sera dans l’intérêt des métriques qu’ils servent. Si Amazon récompense la frugalité dans la gestion et la collecte de données sur la façon dont la direction gère (ce qu’elle fait), alors la direction va faire ce qu’elle peut pour maximiser les formes d’automatisation afin de rester pertinente dans l’organisation.
Ce principe particulier, couplé avec le taylorisme, crée l’environnement parfait pour que l’exploration et l’analyse de données deviennent délirantes, et pour que les processus qui ont un impact sur la vie réelle des gens soient ignorés. Ceux qui sont dans les bureaux ne voient pas ceux qui sont dans les entrepôts et ne peuvent pas se rendre compte que leurs indicateurs de rendement du service à la clientèle ou de la chaîne d’approvisionnement ont un coût humain. Dans une version extrême de ce qui se passe dans tant d’entreprises, les bénéfices sont liés à des mesures imbriquées dans la chaîne des parties prenantes. Les 10 milliards de dollars de bénéfices d’Amazon proviennent en partie de millions de minuscules décisions « frugales » influencées par le taylorisme, chacune payée au prix fort : la perte de la dignité et de latitude d’action des humains (ou des autres).
Le fait de céder continuellement à cette analyse extrême des données nous réduira à l’esclavage
Le taylorisme a été conçu et mis en œuvre à une époque où la fabrication était mécanique, et bien que certaines machines aient pu fonctionner plus rapidement que les humains, la plupart des processus qui ont eu un impact sur leur travail étaient analogiques, et au rythme du traitement humain. L’ouvrier de l’entrepôt d’Amazon se trouve au bout de la ligne de l’arbre de décision du taylorisme de la frugalité, et il est soumis à des processus algorithmiques qui contrôlent les données et les machines plus rapidement que de nombreux humains ne peuvent traiter l’information et encore moins agir physiquement sur elle. Ces travailleurs sont dépassés, à un degré inimaginable, mais liés par un mécanisme d’entreprise qui exige toujours plus d’eux et, plus important encore, de la chaîne qui les précède, qu’ils « qui fassent plus avec moins ».
Image d’un site syndical britannique en campagne contre les mauvaises conditions de travail chez Amazon
Ainsi, à un moment donné, le fait de céder continuellement à cette analyse extrême des données nous réduira à l’esclavage. Non pas en restreignant nos bras et nos jambes (bien que cette cage d’Amazon s’en rapproche) mais en créant une vision du monde liée par des mesures quantitatives comme seule mesure justifiable. Le taylorisme a été utile dans un contexte manufacturier au début du siècle dernier. Il n’est plus utile ni approprié aujourd’hui, près d’un siècle plus tard, et son adoption continue crée de réels problèmes pour nous en tant que société mondiale.
Finalement, même avec le désir d’accomplir « plus avec moins », il y a un tel excès de « moins » que cela oblige les humains à être en tension et faire « plus », en épuisant leurs propres réserves internes. Si chaque processus est finalement automatisé et restreint l’action humaine, tout en exigeant simultanément notre servitude pour fonctionner, nous serons cloués au mur sans aucun choix, sans rien à donner et sans aucune alternative pour y faire face.
S. A. Applin, PhD, est une anthropologue dont le champ de recherche couvre les domaines du comportement humain, des algorithmes, de l’IA et de l’automatisation dans le contexte des systèmes sociaux et de la sociabilité. Pour en savoir plus : http://sally.com/wiki @anthropunk et PoSR.org.
La traduction suivante est la suite et la continuation du travail entamé la semaine dernière sur le long rapport final élaboré par le comité « Digital, Culture, Media and Sport » du Parlement britannique, publié le 14 février dernier, sur la désinformation et la mésinformation.
Maintenant que le décor est posé, on aborde les questions réglementaires. Après avoir clairement défini ce qu’est une fake news, que nous avons traduit par « infox » et que les auteurs regroupent sous le terme plus précis de « désinformation », il est question de définir une nouvelle catégorie de fournisseurs de service pour caractériser leur responsabilité dans les préjudices faits à la société ainsi que des solutions pour protéger le public et financer l’action des structures de contrôle.
Le groupe Framalang a en effet entrepris de vous communiquer l’intégralité du rapport en feuilleton suivant l’avancement de la traduction.
La réglementation, le rôle, la définition et la responsabilité juridique des entreprises de technologie
Définitions
11. Dans notre rapport intermédiaire, nous avons désavoué le terme d’« infox » puisqu’il a « pris de nombreux sens, notamment une description de toute affirmation qui n’est pas appréciée ou en accord avec l’opinion du lecteur » et nous avons recommandé à la place les termes de « mésinformation » ou de « désinformation ». Avec ces termes viennent « des directives claires à suivre pour les compagnies, organisations et le Gouvernement » liées à « une cohérence partagée de la définition sur les plateformes, qui peuvent être utilisées comme la base de la régulation et de l’application de la loi »1.
12. Nous avons eu le plaisir de voir que le Gouvernement a accepté notre point de vue sur le fait que le terme « infox » soit trompeur, et ait essayé à la place d’employer les termes de « désinformation » et de « mésinformation ». Dans sa réponse, le gouvernement a affirmé :
Dans notre travail, nous avons défini le mot « désinformation » comme la création et le partage délibérés d’informations fausses et/ou manipulées dans le but de tromper et d’induire en erreur le public, peu importe que ce soit pour porter préjudice, ou pour des raisons politiques, personnelles ou financières. La « mésinformation » se réfère au partage par inadvertance de fausses informations2.
13. Nous avons aussi recommandé une nouvelle catégorie d’entreprises de réseaux sociaux, qui resserrent les responsabilités des entreprises de technologie et qui ne sont pas forcément « une plateforme » ou un « éditeur ». le gouvernement n’a pas du tout répondu à cette recommandation, mais Sharon White, Pdg de Of.com a qualifié cette catégorie de « très soignée » car les « plateformes ont vraiment des responsabilités, même si elles ne génèrent pas les contenus, concernant ce qu’elles hébergent et promeuvent sur leur site ».3.
14. Les entreprises de réseaux sociaux ne peuvent se cacher derrière le fait qu’elles seraient simplement une plateforme, et maintenir qu’elles n’ont elles-mêmes aucune responsabilité sur la régulation du contenu de leurs sites. Nous répétons la recommandation de notre rapport provisoire, qui stipule qu’une nouvelle catégorie d’entreprises technologiques doit être définie qui renforcera les responsabilités des entreprises technologiques et qui ne sont pas forcément « une plateforme » ou un « éditeur ». Cette approche voudrait que les entreprises de technologie prennent leur responsabilité en cas de contenu identifié comme étant abusif après qu’il a été posté par des utilisateurs. Nous demandons au gouvernement de prendre en compte cette nouvelle catégorie de compagnies technologiques dans son livre blanc qui va paraître prochainement.
Préjudices et réglementation en ligne
15. Plus tôt dans le cadre de notre enquête, nous avons écouté le témoignage de Sandy Parakilas et Tristan Harris, qui étaient tous deux à l’époque impliqués dans le Center for Human Technology, situé aux États-Unis. Le centre a compilé un « Recueil de Préjudices » qui résume les « impacts négatifs de la technologie qui n’apparaissent pas dans les bilans des entreprises, mais dans le bilan de la société ».4 Le Recueil de Préjudices contient les impacts négatifs de la technologie, notamment la perte d’attention, les problèmes de santé mentale, les confusions sur les relations personnelles, les risques qui pèsent sur nos démocraties et les problèmes qui touchent les enfants.5.
16. La prolifération des préjudices en ligne est rendu plus dangereuse si on axe des messages spécifiques sur des individus suite à des « messages micro-ciblés », qui jouent souvent sur les opinions négatives qu’ont les gens d’eux-mêmes et des autres et en les déformant. Cette déformation est rendue encore plus extrême par l’utilisation de « deepfakes » 6 audio et vidéos qui sonnent et ressemblent à une personne existante tenant des propos qui ne lui appartiennent pas.7 Comme nous l’avons dit dans notre rapport intermédiaire, la détection de ces exemples ne deviendra que plus complexe et plus difficile à démasquer au fur et à mesure de la sophistication des logiciels 8.
17. Le ministre de la santé, le député Hon Matthew Hancock, a récemment mis en garde les sociétés informatiques, notamment Facebook, Google et Twitter, qu’elles étaient en charge de la suppression des contenus inappropriés, blessants suite à la mort de Molly Russel, qui à 14 ans s’est suicidée en novembre 2017. Son compte Instagram contenait du contenu en lien avec la dépression, l’auto-mutilation et le suicide. Facebook, propriétaire d’Instagram, s’est déclaré profondément désolé de l’affaire.9 Le directeur d’Instagram, Adam Mosseri, a rencontré le secrétaire de la Santé début février 2019 et déclaré qu’Instagram n’était pas « dans une situation où il était nécessaire de traiter le problème de l’auto-mutilation et du suicide » et que cela revenait à arbitrer entre « agir maintenant et agir de manière responsable » 10
18. Nous relevons également que dans son discours du 5 février 2019, la députée Margot James, ministre du numérique dans le département du numérique, de la culture, des médias et du sport a exprimé ses craintes :
La réponse des principales plateformes est depuis trop longtemps inefficace. Il y a eu moins de 15 chartes de bonne conduite mises en place volontairement depuis 2008. Il faut maintenant remettre absolument en cause un système qui n’a jamais été suffisamment encadré par la loi. Le livre blanc, que le DCMS produit en collaboration avec le ministère de l’intérieur sera suivi d’une consultation durant l’été et débouchera sur des mesures législatives permettant de s’assurer que les plateformes supprimeront les contenus illégaux et privilégieront la protection des utilisateurs, particulièrement des enfants, adolescents et adultes vulnérables. 11
Le nouveau Centre pour des algorithmes et des données éthiques
19. Comme nous l’avons écrit dans notre rapport intermédiaire, les sociétés fournissant des réseaux sociaux tout comme celles fournissant des moteurs de recherche utilisent des algorithmes ou des séquences d’instructions pour personnaliser les informations et autres contenus aux utilisateurs. Ces algorithmes sélectionnent le contenu sur la base de facteurs tels que l’activité numérique passée de l’utilisateur, ses connexions sociales et leur localisation. Le modèle de revenus des compagnies d’Internet repose sur les revenus provenant de la vente d’espaces publicitaires et parce qu’il faut faire du profit, toute forme de contenu augmentant celui-ci sera priorisé. C’est pourquoi les histoires négatives seront toujours mises en avant par les algorithmes parce qu’elles sont plus fréquemment partagées que les histoires positives.12
20. Tout autant que les informations sur les compagnies de l’internet, les informations sur leurs algorithmes doivent être plus transparentes. Ils comportent intrinsèquement des travers, inhérents à la façon dont ils ont été développés par les ingénieurs ; ces travers sont ensuite reproduits diffusés et renforcés. Monica Bickert, de Facebook, a admis « que sa compagnie était attentive à toute forme de déviance, sur le genre, la race ou autre qui pourrait affecter les produits de l’entreprise et que cela inclut les algorithmes ». Facebook devrait mettre plus d’ardeur à lutter contre ces défauts dans les algorithmes de ses ingénieurs pour éviter leur propagation. 13
21. Dans le budget de 2017, le Centre des données Ethiques et de l’innovation a été créé par le gouvernement pour conseiller sur « l’usage éthique, respectueux et innovant des données, incluant l’IA ». Le secrétaire d’état a décrit son rôle ainsi:
Le Centre est un composant central de la charte numérique du gouvernement, qui définit des normes et des règles communes pour le monde numérique. Le centre permettra au Royaume-Uni de mener le débat concernant l’usage correct des données et de l’intelligence artificielle.14
22. Le centre agira comme un organisme de recommandation pour le gouvernement et parmi ses fonctions essentielles figurent : l’analyse et l’anticipation des manques en termes de régulation et de gestion; définition et orchestration des bonnes pratiques, codes de conduites et standards d’utilisations de l’Intelligence Artificielle; recommandation au gouvernement sur les règles et actions réglementaires à mettre en place en relation avec l’usage responsable et innovant des données. 15
23. La réponse du gouvernement à notre rapport intermédiaire a mis en lumière certaines réponses à la consultation telle que la priorité de l’action immédiate du centre, telle que « le monopole sur la donnée, l’utilisation d’algorithme prédictifs dans la police, l’utilisation de l’analyse des données dans les campagnes politiques ainsi que l’éventualité de discrimination automatisée dans les décisions de recrutement ». Nous nous félicitons de la création du Centre et nous nous réjouissons à la perspective d’en recueillir les fruits de ses prochaines travaux.
La loi en Allemagne et en France
24. D’autres pays ont légiféré contre le contenu malveillant sur les plateformes numériques. Comme nous l’avons relevé dans notre rapport intermédiaire, les compagnies d’internet en Allemagne ont été contraintes initialement de supprimer les propos haineux en moins de 24 heures. Quand cette auto-régulation s’est montrée inefficace, le gouvernement allemand a voté le Network Enforcement Act, aussi connu sous le nom de NetzDG, qui a été adopté en janvier 2018. Cette loi force les compagnies technologiques à retirer les propos haineux de leurs sites en moins de 24 heures et les condamne à une amende de 20 millions d’euros si ces contenus ne sont pas retirés16. Par conséquent, un modérateur sur six de Facebook travaille désormais en Allemagne, ce qui prouve bien que la loi peut être efficace.17.
25. Une nouvelle loi en France, adoptée en novembre 2018 permet aux juges d’ordonner le retrait immédiat d’articles en ligne s’ils estiment qu’ils diffusent de la désinformation pendant les campagnes d’élection. La loi stipule que les utilisateurs doivent recevoir « d’informations qui sont justes, claires et transparentes » sur l’utilisation de leurs données personnelles, que les sites doivent divulguer les sommes qu’elles reçoivent pour promouvoir des informations, et la loi autorise le CSA français à pouvoir suspendre des chaînes de télévision contrôlées ou sous influence d’un état étranger, s’il estime que cette chaîne dissémine de manière délibérée des fausses informations qui pourraient affecter l’authenticité du vote. Les sanctions imposées en violation de la loi comprennent un an de prison et une amende de 75000 euros18.
Le Royaume-Uni
26. Comme la Commissaire de l’Information du Royaume-Uni, Elisabeth Denham, nous l’a expliqué en novembre 2018, il y a une tension entre le modèle économique des médias sociaux, centré sur la publicité, et les droits humains tels que la protection de la vie privée. « C’est notre situation actuelle et il s’agit d’une tâche importante à la fois pour les régulateurs et le législateur de s’assurer que les bonnes exigences, la surveillance et sanctions sont en place » 19. Elle nous a dit que Facebook, par exemple, devrait en faire plus et devrait faire « l’objet d’une régulation et d’une surveillance plus stricte »20. Les activités de Facebook dans la scène politique sont en augmentation; l’entreprise a récemment lancé un fil d’actualités intitulé « Community Actions » avec une fonctionnalité de pétition pour, par exemple, permettre aux utilisateurs de résoudre des problèmes politiques locaux en créant ou soutenant des pétitions. Il est difficile de comprendre comment Facebook sera capable d’auto-réguler une telle fonctionnalité; plus le problème local va être sujet à controverse et litiges, plus il entrainera de l’engagement sur Facebook et donc de revenus associés grâce aux publicités 21.
Facebook et la loi
27. En dépit de toutes les excuses formulées par Facebook pour ses erreurs passées, il semble encore réticent à être correctement surveillé. Lors de la session de témoignage verbal au « Grand Comité International », Richard Alland, vice-président des solutions politiques de Facebook, a été interrogé à plusieurs reprises sur les opinions de Facebook sur la régulation, et à chaque fois il a déclaré que Facebook était très ouvert au débat sur la régulation, et que travailler ensemble avec les gouvernements seraient la meilleure option possible :
« Je suis ravi, personnellement, et l’entreprise est vraiment engagé, de la base jusqu’à notre PDG — il en a parlé en public — à l’idée d’obtenir le bon type de régulation afin que l’on puisse arrêter d’être dans ce mode de confrontation. Cela ne sert ni notre société ni nos utilisateurs. Essayons de trouver le juste milieu, où vous êtes d’accord pour dire que nous faisons un travail suffisamment bon et où vous avez le pouvoir de nous tenir responsable si nous ne le faisons pas, et nous comprenons quel le travail que nous avons à faire. C’est la partie régulation22. »
28. Ashkan Soltani, un chercheur et consultant indépendant, et ancien Responsable Technologique de la Commission Fédérale du Commerce des USA 23, a questionné la volonté de Facebook à être régulé. À propos de la culture interne de Facebook, il a dit : « Il y a ce mépris — cette capacité à penser que l’entreprise sait mieux que tout le monde et tous les législateurs » 24. Il a discuté de la loi californienne pour la vie privée des consommateurs 25 que Facebook a supporté en public, mais a combattu en coulisses 26.
29. Facebook ne semble pas vouloir être régulé ou surveillé. C’est considéré comme normal pour les ressortissants étrangers de témoigner devant les comités. En effet, en juin 2011, le Comité pour la Culture, les Médias et le Sport 27 a entendu le témoignage de Rupert Murdoch lors de l’enquête sur le hacking téléphonique 28 et le Comité au Trésor 29 a récemment entendu le témoignage de trois ressortissants étrangers 30. En choisissant de ne pas se présenter devant le Comité et en choisissant de ne pas répondre personnellement à aucune de nos invitations, Mark Zuckerberg a fait preuve de mépris envers à la fois le parlement du Royaume-Uni et le « Grand Comité International », qui compte des représentants de neufs législatures dans le monde.
30. La structure managériale de Facebook est opaque pour les personnes extérieures, et semble conçue pour dissimuler la connaissance et la responsabilité de certaines décisions. Facebook a pour stratégie d’envoyer des témoins dont ils disent qu’ils sont les plus adéquats, mais qui n’ont pas été suffisamment informés sur les points cruciaux, et ne peuvent répondre ou choisissent de ne pas répondre à nombre de nos questions. Ils promettent ensuite d’y répondre par lettre, qui —sans surprise— échouent à répondre à toutes nos questions. Il ne fait pas de doute que cette stratégie est délibérée.
Régulateurs britanniques existants
31. Au Royaume-Uni, les principales autorités compétentes — Ofcom, l’autorité pour les standards publicitaires 31, le bureau du commissaire à l’information 32, la commission électorale 33 et l’autorité pour la compétition et le marché 34 — ont des responsabilités spécifiques sur l’utilisation de contenus, données et comportements. Quand Sharon White, responsable de Ofcom, est passé devant le comité en octobre 2018, après la publication de notre rapport intermédiaire, nous lui avons posé la question si leur expérience comme régulateur de diffusion audiovisuelle pourrait être utile pour réguler les contenus en ligne. Elle a répondu :
« On a essayé d’identifier quelles synergies seraient possibles. […] On a été frappé de voir qu’il y a deux ou trois domaines qui pourraient être applicable en ligne. […] Le fait que le Parlement 35 ait mis en place des standards, ainsi que des objectifs plutôt ambitieux, nous a semblé très important, mais aussi durable avec des objectifs clés, que ce soit la protection de l’enfance ou les préoccupations autour des agressions et injures. Vous pouvez le voir comme un processus démocratique sur quels sont les maux que l’on croit en tant que société être fréquent en ligne. L’autre chose qui est très importante dans le code de diffusion audiovisuelle est qu’il explicite clairement le fait que ces choses peuvent varier au cours du temps comme la notion d’agression se modifie et les inquiétudes des consommateurs changent. La mise en œuvre est ensuite déléguée à un régulateur indépendant qui traduit en pratique ces objectifs de standards. Il y a aussi la transparence, le fait que l’on publie nos décisions dans le cas d’infractions, et que tout soit accessible au public. Il y a la surveillance de nos décisions et l’indépendance du jugement 36 ».
32. Elle a également ajouté que la fonction du régulateur de contenu en ligne devrait évaluer l’efficacité des compagnies technologiques sur leurs mesures prises contre les contenus qui ont été signalés comme abusifs. « Une approche serait de se dire si les compagnies ont les systèmes, les processus, et la gouvernance en place avec la transparence qui amène la responsabilité publique et la responsabilité devant le Parlement, que le pays serait satisfait du devoir de vigilance ou que les abus seront traités de manière constante et efficace ».37.
33. Cependant, si on demandait à Ofcom de prendre en charge la régulation des capacités des compagnies des réseaux sociaux, il faudrait qu’il soit doté de nouveaux pouvoirs d’enquête. Sharon White a déclaré au comité « qu’il serait absolument fondamental d’avoir des informations statutaires, réunissant des pouvoirs sur un domaine large ».38.
34. UK Council for Internet Safety(UKCIS) est un nouvel organisme, sponsorisé par le Ministère du Numérique, de la Culture, des Médias et du Sport, le Ministère de l’Éducation et le Ministère de l’Intérieur, il réunit plus de 200 organisations qui ont pour but de garantir la sécurité des enfants en ligne. Son site web affirme « si c’est inacceptable hors ligne, c’est inacceptable en ligne ». Son attention tiendra compte des abus en lignes comme le cyberharcèlement et l’exploitation sexuelle, la radicalisation et l’extrémisme, la violence contre les femmes et les jeunes filles, les crimes motivés par la haine et les discours haineux, et les formes de discrimination vis à vis de groupes protégés par l’Equality Act.39. Guy Parker, Pdg d’Advertising Standards Authority nous a informé que le Gouvernement pourrait se décider à intégrer les abus dans la publicité dans leur définition d’abus en ligne40.
35. Nous pensons que UK Council for Internet Safety devrait inclure dans le périmètre de ses attributions « le risque envers la démocratie » tel qu’identifié dans le « Registre des Préjudices » du Center for Human Technology, en particulier par rapport aux reportages profondément faux. Nous notons que Facebook est inclus en tant que membre d’UKCIS, compte tenu de son influence éventuelle, et nous comprenons pourquoi. Cependant, étant donné l’attitude de Facebook dans cette enquête, nous avons des réserves quant à sa bonne foi des affaires et sa capacité à participer au travail d’UKCIS dans l’intérêt du public, par opposition à ses intérêts personnels.
36. Lorsqu’il a été demandé au Secrétaire du Numérique, de la Culture, des Médias et des Sports, le Très Honorable député Jeremy Wright, de formuler un spectre des abus en ligne, sa réponse était limitée. « Ce que nous devons comprendre est à quel point les gens sont induits en erreur ou à quel point les élections ont été entravées de manière délibérée ou influencée, et si elle le sont […] nous devons trouver des réponses appropriées et des moyens de défense. Cela fait partie d’un paysage bien plus global et je ne crois par que c’est juste de le segmenter41. Cependant, une fois que nous avons défini les difficultés autour de la définition, l’étendue et la responsabilité des abus en ligne, le Secrétaire d’État était plus coopératif lorsqu’on lui a posé la question sur la régulation des compagnies de réseaux sociaux, et a déclaré que le Royaume-Uni devrait prendre l’initia
37. Notre rapport intermédiaire recommandait que des responsabilités juridiques claires soient définies pour les compagnies technologiques, afin qu’elles puissent prendre des mesures allant contre des contenus abusifs ou illégaux sur leurs sites. À l’heure actuelle, il est urgent de mettre en œuvre des règlements indépendants. Nous croyons qu’un Code d’Éthique obligatoire doit être implémenté, supervisé par un régulateur indépendant, définissant ce que constitue un contenu abusif. Le régulateur indépendant aurait des pouvoirs conférés par la loi pour surveiller les différentes compagnies technologiques, cela pourrait créer un système réglementaire pour les contenus en ligne qui est aussi effectif que pour ceux des industries de contenu hors ligne.
38. Comme nous l’avons énoncé dans notre rapport intermédiaire, un tel Code d’Éthique devrait ressembler à celui du Broadcasting Code publiée par Ofcom, qui se base sur des lignes directrices définies dans la section 319 du Communications Acts de 2003. Le Code d’Éthique devrait être mis au point par des experts techniques et supervisés par un régulateur indépendant, pour pouvoir mettre noir sur blanc ce qui est acceptable et ce qui ne l’est pas sur les réseaux sociaux, notamment les contenus abusifs et illégaux qui ont été signalés par leurs utilisateurs pour être retirés, ou qu’il aurait été facile d’identifier pour les compagnies technologiques elles-mêmes.
39. Le processus devrait définir une responsabilité juridique claire pour les compagnies technologiques de prendre des mesures contre les contenus abusifs et illégaux sur leur plateforme et ces compagnies devraient mettre en place des systèmes adaptés pour marquer et retirer des « types d’abus » et s’assurer que les structures de cybersécurité soient implémentées. Si les compagnies techniques (y compris les ingénieurs informaticiens en charge de la création des logiciels pour ces compagnies) sont reconnues fautifs de ne pas avoir respecté leurs obligations en vertu d’un tel code, et n’ont pas pris de mesure allant contre la diffusion de contenus abusifs et illégaux, le régulateur indépendant devrait pouvoir engager des poursuites judiciaires à leur encontre, dans l’objectif de les condamner à payer des amendes élevées en cas de non-respect du Code.
40. C’est le même organisme public qui devrait avoir des droits statutaires pour obtenir toute information de la part des compagnies de réseaux sociaux qui sont en lien avec son enquête. Cela pourrait concerner la capacité de vérifier les données qui sont conservées sur un utilisateur, s’il demandait ces informations. Cet organisme devrait avoir accès aux mécanismes de sécurité des compagnies technologiques et aux algorithmes, pour s’assurer qu’ils travaillent de manière responsable. Cet organisme public devrait être accessible au public et recevoir les plaintes sur les compagnies des réseaux sociaux. Nous demandons au gouvernement de soumettre ces propositions dans son prochain livre blanc.
Utilisation des données personnelles et inférence
41. Lorsque Mark Zuckerberg a fourni les preuves au congrès en avril 2018, dans la suite du scandal Cambridge Analytica, il a fait la déclaration suivante : « Vous devriez avoir un contrôle complet sur vos données […] Si nous ne communiquons pas cela clairement, c’est un point important sur lequel nous devons travailler ». Lorsqu’il lui a été demandé à qui était cet « alterego virtuel », Zuckerberg a répondu que les gens eux-mêmes possèdent tout le « contenu » qu’ils hébergent sur la plateforme, et qu’ils peuvent l’effacer à leur gré42. Cependant, le profil publicitaire que Facebook construit sur les utilisateurs ne peut être accédé, contrôlé ni effacé par ces utilisateurs. Il est difficile de concilier ce fait avec l’affirmation que les utilisateurs possèdent tout « le contenu » qu’ils uploadent.
42. Au Royaume-Uni, la protection des données utilisateur est couverte par le RGPD (Règlement Général de Protection des Données)43. Cependant, les données « inférées » ne sont pas protégées ; cela inclut les caractéristiques qui peuvent être inférées sur les utilisateurs et qui ne sont pas basées sur des informations qu’ils ont partagées, mais sur l’analyse des données de leur profil. Ceci, par exemple, permet aux partis politiques d’identifier des sympathisants sur des sites comme Facebook, grâce aux profils correspondants et aux outils de ciblage publicitaire sur les « publics similaires ». Selon la propre description de Facebook des « publics similaires », les publicitaires ont l’avantage d’atteindre de nouvelles personnes sur Facebook « qui ont des chances d’être intéressées par leurs produits car ils sont semblables à leurs clients existants » 44.
43. Le rapport de l’ICO, publié en juillet 2018, interroge sur la présomption des partis politques à ne pas considérer les données inférées comme des données personnelles:
« Nos investigations montrent que les partis politiques n’ont pas considéré les données inférées comme des informations personnelles car ce ne sont pas des informations factuelles. Cependant, le point de vue de l’ICO est que ces informations sont basées sur des hypothèses sur les intérets des personnes et leurs préférences, et peuvent être attribuées à des individus spécifiques, donc ce sont des informations personnelles et elles sont soumises aux contraintes de la protection des données 45. »
44. Les données inférées sont donc considérées par l’ICO comme des données personnelles, ce qui devient un problème lorsque les utilisateurs sont informés qu’ils disposent de leurs propres données, et qu’ils ont un pouvoir sur où les données vont, et ce pour quoi elles sont utilisées. Protéger nos données nous aide à sécuriser le passé, mais protéger les inférences et l’utilisation de l’Intelligence Artificielle (IA) est ce dont nous avons besoin pour protéger notre futur.
45. La commissaire à l’information, Elizabeth Denham, a souligné son intérêt sur l’utilisation des données inférées dans les campagnes politiques lorsqu’elle a fourni des preuves au comité en novembre 2018, déclarant qu’il y a eu :
« Un nombre dérangeant de manque de respect des données personnelles des votants et des votants potentiels. Ce qui s’est passé ici est que le modèle familier aux gens du secteur commercial sur le ciblage des comportements a été transféré – je pense transformé – dans l’arène politique. C’est pour cela que j’appelle à une pause éthique, afin que nous puissions y remédier. Nous ne voulons pas utiliser le même modèle qui nous vend des vacances, des chaussures et des voitures pour collaborer avec des personnes et des votants. Les gens veulent plus que ça. C’est le moment pour faire un pause pour regarder les codes, regarder les pratiques des entreprises de réseaux sociaux, de prendre des mesures là où ils ont enfreint la loi. Pour nous, le principal but de ceci est de lever le rideau et montrer au public ce qu’il advient de leurs données personnelles 46. »
46. Avec des références explicites sur l’utilisation des « publics similaires » de Facebook, Elizabeth Denham a expliqué au comité qu’ils « devaient être transparents envers les [utilisateurs] privés. Ils ont besoin de savoir qu’un parti politique, ou un membre du parlement, fait usage des publics similaires. Le manque de transparence est problématique47. Lorsque nous avons demandé à la commissaire à l’information si elle pensait que l’utilisation des « publics similaires » était légal selon le RGPD, elle a répondu : « Nous avons besoin de l’analyser en détail sous la loupe du RGPD, mais je pense que le public est mal à l’aise avec les publics similaires, et il a besoin que ce soit transparent » 48. Les gens ont besoin de savoir que l’information qu’ils donnent pour un besoin spécifique va être utilisé pour inférer des informations sur eux dans d’autres buts.
47. Le secrétaire d’état, le très honorable membre du parlement Jeremy Wright, nous a également informé que le framework éthique et législatif entourant l’IA devait se développer parallèlement à la technologie, ne pas « courir pour [la] rattraper », comme cela s’est produit avec d’autres technologies dans le passé 49. Nous devons explorer les problèmes entourant l’IA en détail, dans nos enquêtes sur les technologies immersives et d’addictives, qui a été lancée en décembre 2018 50.
48. Nous soutenons la recommandation de l’ICO comme quoi les données inférées devraient être protégées par la loi comme les informations personnelles. Les lois sur la protection de la vie privée devraient être étendues au-delà des informations personnelles pour inclure les modèles utilisés pour les inférences sur les individus. Nous recommandons que le gouvernement étudie les manières dont les protections de la vie privée peuvent être étendues pour inclure les modèles qui sont utilisés pour les inférences sur les individus, en particulier lors des campagnes politiques. Cela nous assurerait que les inférences sur les individus sont traitées de manière aussi importante que les informations personnelles des individus.
Rôle accru de l’OIC et taxe sur les entreprises de technologie
49. Dans notre rapport intérimaire, nous avons demandé que l’OIC soit mieux à même d’être à la fois un « shérif efficace dans le Far West de l’Internet » et d’anticiper les technologies futures. L’OIC doit avoir les mêmes connaissances techniques, sinon plus, que les organisations examinées51. Nous avons recommandé qu’une redevance soit prélevée sur les sociétés de technologie opérant au Royaume-Uni, pour aider à payer ces travaux, dans le même esprit que la façon dont le secteur bancaire paie les frais de fonctionnement de l’autorité de régulation Financière 5253.
50. Lorsque l’on a demandé au secrétaire d’État ce qu’il pensait d’une redevance, il a répondu, en ce qui concerne Facebook en particulier: « Le Comité est rassuré que ce n’est pas parce que Facebook dit qu’il ne veut pas payer une redevance, qu’il ne sera pas question de savoir si nous devrions ou non avoir une redevance »54. Il nous a également dit que « ni moi, ni, je pense franchement, l’OIC, ne pensons qu’elle soit sous-financée pour le travail qu’elle a à faire actuellement. […] Si nous devons mener d’autres activités, que ce soit en raison d’une réglementation ou d’une formation supplémentaires, par exemple, il faudra bien qu’elles soient financées d’une façon ou d’une autre. Par conséquent, je pense que la redevance vaut la peine d’être envisagée »55.
51. Dans notre rapport intermédiaire, nous avons recommandé qu’une redevance soit prélevée sur les sociétés de technologie opérant au Royaume-Uni pour soutenir le travail renforcé de l’OIC. Nous réitérons cette recommandation. La décision du chancelier, dans son budget de 2018, d’imposer une nouvelle taxe de 2% sur les services numériques sur les revenus des grandes entreprises technologiques du Royaume-Uni à partir d’avril 2020, montre que le gouvernement est ouvert à l’idée d’une taxe sur les entreprises technologiques. Dans sa réponse à notre rapport intermédiaire, le gouvernement a laissé entendre qu’il n’appuierait plus financièrement l’OIC, contrairement à notre recommandation. Nous exhortons le gouvernement à réévaluer cette position.
52. Le nouveau système indépendant et la nouvelle réglementation que nous recommandons d’établir doivent être financés adéquatement. Nous recommandons qu’une taxe soit prélevée sur les sociétés de technologie opérant au Royaume-Uni pour financer leur travail.
Désinformation, le rapport – 2
La traduction suivante est la suite et la continuation du travail entamé la semaine dernière sur le long rapport final élaboré par le comité « Digital, Culture, Media and Sport » du Parlement britannique, publié le 14 février dernier, sur la désinformation et la mésinformation.
Il s’agit cette fois de poser le décor. Participants, méthodes de travail, acteurs audités. Une bonne mise en bouche qui vous rendra impatient⋅e de lire les articles suivants.
Le groupe Framalang a en effet entrepris de vous communiquer l’intégralité du rapport en feuilleton suivant l’avancement de la traduction.
La traduction est effectuée par le groupe Framalang, avec l’aide de toutes celles et ceux qui veulent bien participer et pour cet opus : Lumibd, maximefolschette, Alio, wazabyl, Khrys, serici, Barbara + 1 anonyme
Introduction et contexte
1. Le Rapport Provisoire du Comité DCMS, « Désinformation et infox », a été publié en juillet 2018 56. Depuis l’été 2018, le Comité a tenu trois audiences supplémentaires pour y entendre témoigner les organismes de réglementation du Royaume-Uni et le gouvernement, et nous avons reçu 23 autres témoignages écrits 57. Nous avons également tenu un “International Grand Commitee”58 en novembre 2018, auquel ont participé des parlementaires de neuf pays : Argentine, Belgique, Brésil, Canada, France, Irlande, Lettonie, Singapour et Royaume-Uni.
2. Notre longue enquête sur la désinformation et la mésinformation a mis en lumière le fait que les définitions dans ce domaine sont importantes. Nous avons même changé le titre de notre enquête de « infox » à « désinformation et infox », car le terme “infox” a développé sa propre signification très connotée. Comme nous l’avons dit dans notre rapport préliminaire les “infox” ont été utilisées pour décrire un contenu qu’un lecteur pourrait ne pas aimer ou désapprouver. Le président américain Donald Trump a qualifié certains médias de « faux médias d’information » et d’être « les véritables ennemis du peuple »59.
3. Nous sommes donc heureux que le gouvernement ait accepté les recommandations de notre rapport provisoire et, au lieu d’utiliser l’expression “infox”, il utilise l’expression « désinformation » pour décrire « la création et le partage délibérés de renseignements faux ou manipulés qui visent à tromper et à induire en erreur le public, soit dans le but de nuire, soit pour leur procurer un avantage politique, personnel ou financier »60.
4. Ce rapport final s’appuie sur les principales questions mises en évidence dans les sept domaines couverts dans le rapport provisoire : la définition, le rôle et les responsabilités juridiques des plateformes de médias sociaux ; le mauvais usage des données et le ciblage, fondé sur les allégations Facebook, Cambridge Analytica et Aggregate IQ (AIQ), incluant les preuves issues des documents que nous avons obtenus auprès de Six 4 Three à propos de la connaissance de Facebook de donnés de partages et sa participation dans le partage de données ; les campagnes électorales ; l’influence russe dans les élections étrangères l’influence des SCL dans les élections étrangères; et la culture numérique. Nous intégrons également les analyses réalisées par la société de conseil 89up, les données litigieuses relatives à la base de données AIQ que nous avons reçues de Chris Vickery.
5. Dans le présent rapport final, nous nous appuyons sur les recommandations fondées sur des principes formulés dans le rapport provisoire. Nous avons hâte d’entendre la réponse du gouvernement à ces recommandations d’ici deux mois. Nous espérons que cette réponse sera beaucoup plus complète, pratique et constructive que leur réponse au rapport provisoire publié en octobre 2018. 61 Plusieurs de nos recommandations n’ont pas reçu de réponse substantielle et il est maintenant urgent que le gouvernement y réponde. Nous sommes heureux que le Secrétaire d’État, le très honorable député Jeremy Wright, ait décrit nos échanges comme faisant partie d’un « processus itératif » et que ce rapport soit « très utile, franchement, pour pouvoir alimenter nos conclusions futures avant la rédaction du Livre Blanc » et que nos opinions fassent partie des considérations du gouvernement. 62 Nous attendons avec impatience le livre blanc du gouvernement dénommé Online Harms, rédigé par le Ministère du Numérique, de la Culture, des Médias et des Sports et le Ministère de l’Intérieur, qui sera publié au début de 2019, et qui abordera les questions des préjudices en ligne, y compris la désinformation. 63 Nous avons réitéré plusieurs des recommandations figurant dans notre rapport provisoire, demeurées sans réponse de la part du gouvernement auxquelles le gouvernement n’a pas répondu. Nous présumons et nous nous espérons que le gouvernement réponde à la fois aux recommandations du présent rapport final et à celles du rapport provisoire restées sans réponse.
6. Ce rapport final est le fruit de plusieurs mois de collaboration avec d’autres pays, organisations, parlementaires et particuliers du monde entier. Au total, le Comité a tenu 23 séances d’audiences, reçu plus de 170 mémoires écrits, entendu 73 témoins, posé plus de 4 350 questions lors de ces audiences et eu de nombreux échanges de correspondance publique et privée avec des particuliers et des organisations.
7. Il s’agit d’une enquête collaborative, dans le but de s’attaquer aux questions techniques, politiques et philosophiques complexes qui sont en jeu et de trouver des solutions pratiques à ces questions. Comme nous l’avons fait dans notre rapport provisoire, nous remercions les nombreuses personnes et entreprises, tant nationales qu’internationales, y compris nos collègues et associés en Amérique, d’avoir bien voulu nous partager leurs opinions et informations. 64
8. Nous aimerions également souligner le travail réalisé par d’autres parlementaires qui se sont penchés sur des questions semblables en même temps que notre enquête. Le Comité permanent canadien de l’accès à l’information, de la protection des renseignements personnels et de l’éthique a publié en décembre 2018 un rapport intitulé « Démocratie menacée : risques et solutions à l’ère de la désinformation et du monopole des données » 65 . Ce rapport souligne l’étude du Comité canadien sur la violation des données personnelles impliquant Cambridge Analytica et Facebook, et les questions concernant plus largement l’utilisation faite des données personnelles par les média sociaux et leur responsabilité dans la diffusion d’information dites fake news ou dans la désinformation . Leurs recommandations concordent avec bon nombre des nôtres dans le présent rapport.
9. La commission du Sénat américain sur le renseignement mène actuellement une enquête sur l’ampleur de l’ingérence de la Russie dans les élections américaines de 2016. Grâce à l’ensemble des données fournis par Facebook, Twitter et Google au Comité du renseignement, sous la direction de son groupe de conseillers techniques, deux rapports tiers ont été publiés en décembre 2018. New Knowledge , une société travaillant sur l’intégrité de l’information, a publié “The Tactics and Tropes of the Internet Research Agency” (La stratégie et la rhétorique de l’agence de renseignement sur internet), qui met en lumière les tactiques et les messages utilisés par ladite agence pour manipuler et influencer les américains, rapport qui inclus un ensemble de présentations, des statistiques éclairantes, des infographies et un présentation thématique de mèmes 66. The Computational Propaganda Research Project (Le projet de recherche sur la propagande informatique) et Graphikap ont publié le second rapport, qui porte sur les activités de comptes connus de l’Internet Research Agency, utilisant Facebook, Instagram, Twitter et YouTube entre 2013 et 2018, afin d’influencer les utilisateurs américains 67. Ces deux rapports seront intégrés au rapport du Comité du renseignement en 2019.
10. La réunion du Grand Comité International qui s’est tenue en novembre 2018 a été le point culminant de ce travail collaboratif. Ce Grand Comité International était composé de 24 représentants démocratiquement élus de neuf pays, incluant 11 membres du Comité du DCMS, qui représentent au total 447 millions de personnes. Les représentants ont signé un ensemble de principes internationaux lors de cette réunion. 68 Nous avons échangé des idées et des solutions en privé et en public, et nous avons tenu une séance de témoignage oral de sept heures. Nous avons invité Mark Zuckerberg, PDG de Facebook, l’entreprise de média social qui compte plus de 2,25 milliards d’utilisateurs et qui a réalisé un chiffre d’affaires de 40 milliards de dollars en 2017, à témoigner devant nous et devant ce Comité ; il a choisi de refuser, par trois fois69. Cependant, dans les 4 heures qui ont suivi la publication des documents obtenus auprès de Six4Three – concernant la connaissance et la participation au partage de données par Facebook, M. Zuckerberg a répondu par un message sur sa page Facebook 70. Nous remercions nos collègues du “International Grand Commitee” pour leur participation à cette importante session, et nous espérons pouvoir continuer notre collaboration cette année.
Le Libre peut-il faire le poids ?
Dans un article assez lucide de son blog que nous reproduisons ici, Dada remue un peu le fer dans la plaie.
Faiblesse économique du Libre, faiblesse encore des communautés actives dans le développement et la maintenance des logiciels et systèmes, manque de visibilité hors du champ de perception de beaucoup de DSI. En face, les forces redoutables de l’argent investi à perte pour tuer la concurrence, les forces tout aussi redoutables des entreprises-léviathans qui phagocytent lentement mais sûrement les fleurons du Libre et de l’open source…
Lucide donc, mais aussi tout à fait convaincu depuis longtemps de l’intérêt des valeurs du Libre, Dada appelle de ses vœux l’émergence d’entreprises éthiques qui permettraient d’y travailler sans honte et d’y gagner sa vie décemment. Elles sont bien trop rares semble-t-il.
D’où ses interrogations, qu’il nous a paru pertinent de vous faire partager. Que cette question cruciale soit l’occasion d’un libre débat : faites-nous part de vos réactions, observations, témoignages dans les commentaires qui comme toujours sont ouverts et modérés. Et pourquoi pas dans les colonnes de ce blog si vous désirez plus longuement exposer vos réflexions.
Avec des projets plein la tête, ou plutôt des envies, et le temps libre que j’ai choisi de me donner en n’ayant pas de boulot depuis quelques mois, j’ai le loisir de m’interroger sur l’économie du numérique. Je lis beaucoup d’articles et utilise énormément Mastodon pour me forger des opinions.
Je vous invite à vraiment prendre le temps de l’écouter, c’est franchement passionnant. On y apprend, en gros, que l’économie des géants du numérique est, pour certains, basée sur une attitude extrêmement agressive : il faut être le moins cher possible, perdre de l’argent à en crever et lever des fonds à tire-larigot pour abattre ses concurrents avec comme logique un pari sur la quantité d’argent disponible à perdre par participants. Celui qui ne peut plus se permettre de vider les poches de ses actionnaires a perdu. Tout simplement. Si ces entreprises imaginent, un jour, remonter leurs prix pour envisager d’être à l’équilibre ou rentable, l’argument du « ce n’est pas possible puisque ça rouvrira une possibilité de concurrence » sortira du chapeau de ces génies pour l’interdire. Du capitalisme qui marche sur la tête.
L’investissement sécurisé
La deuxième grande technique des géants du numérique est basée sur la revente de statistiques collectées auprès de leurs utilisateurs. Ces données privées que vous fournissez à Google, Facebook Inc,, Twitter & co permettent à ces sociétés de disposer d’une masse d’informations telle que des entreprises sont prêtes à dégainer leurs portefeuilles pour en dégager des tendances.
Je m’amuse souvent à raconter que si les séries et les films se ressemblent beaucoup, ce n’est pas uniquement parce que le temps passe et qu’on se lasse des vieilles ficelles, c’est aussi parce que les énormes investissements engagés dans ces productions culturelles sont basés sur des dossiers mettant en avant le respect d’un certain nombre de « bonnes pratiques » captant l’attention du plus gros panel possible de consommateurs ciblés.
Avec toutes ces données, il est simple de savoir quel acteur ou quelle actrice est à la mode, pour quelle tranche d’âge, quelle dose d’action, de cul ou de romantisme dégoulinant il faut, trouver la période de l’année pour la bande annonce, sortie officielle, etc. Ça donne une recette presque magique. Comme les investisseurs sont friands de rentabilité, on se retrouve avec des productions culturelles calquées sur des besoins connus : c’est rassurant, c’est rentable, c’est à moindre risque. Pas de complot autour de l’impérialisme américain, juste une histoire de gros sous.
Cette capacité de retour sur investissement est aussi valable pour le monde politique, avec Barack OBAMA comme premier grand bénéficiaire ou encore cette histoire de Cambridge Analytica.
C’est ça, ce qu’on appelle le Big Data, ses divers intérêts au service du demandeur et la masse de pognon qu’il rapporte aux grands collecteurs de données.
La pub
Une troisième technique consiste à reprendre les données collectées auprès des utilisateurs pour afficher de la pub ciblée, donc plus efficace, donc plus cher. C’est une technique connue, alors je ne développe pas. Chose marrante, quand même, je ne retrouve pas l’étude (commentez si vous mettez la main dessus !) mais je sais que la capacité de ciblage est tellement précise qu’elle peut effrayer les consommateurs. Pour calmer l’angoisse des internautes, certaines pubs sans intérêt vous sont volontairement proposées pour corriger le tir.
Les hommes-sandwichs
Une autre technique est plus sournoise. Pas pour nous autres, vieux loubards, mais pour les jeunes : le placement produit. Même si certain Youtubeurs en font des blagues pas drôles (Norman…), ce truc est d’un vicieux.
Nos réseaux sociaux n’attirent pas autant de monde qu’espéré pour une raison assez basique : les influenceurs et influenceuses. Ces derniers sont des stars, au choix parce qu’ils sont connus de par leurs activités précédentes (cinéma, série, musique, sport, etc.) ou parce que ces personnes ont réussi à amasser un tel nombre de followers qu’un simple message sur Twitter, Youtube ou Instagram se cale sous les yeux d’un monstrueux troupeau. Ils gagnent le statut d’influenceur de par la masse de gens qui s’intéresse à leurs vies (lapsus, j’ai d’abord écrit vide à la place de vie). J’ai en tête l’histoire de cette jeune Léa, par exemple. Ces influenceurs sont friands de plateformes taillées pour leur offrir de la visibilité et clairement organisées pour attirer l’œil des Directeurs de Communication des marques. Mastodon, Pixelfed, diaspora* et les autres ne permettent pas de spammer leurs utilisateurs, n’attirent donc pas les marques, qui sont la cible des influenceurs, ces derniers n’y dégageant, in fine, aucun besoin d’y être présents.
Ces gens-là deviennent les nouveaux « hommes-sandwichs ». Ils ou elles sont contacté⋅e⋅s pour porter tel ou tel vêtement, boire telle boisson ou pour seulement poster un message avec le nom d’un jeu. Les marques les adorent et l’argent coule à flot.
On peut attendre
Bref, l’économie du numérique n’est pas si difficile que ça à cerner, même si je ne parle pas de tout. Ce qui m’intéresse dans toutes ces histoires est la stabilité de ces conneries sur le long terme et la possibilité de proposer autre chose. On peut attendre que les Uber se cassent la figure calmement, on peut attendre que le droit décide enfin de protéger les données des utilisateurs, on peut aussi attendre le jour où les consommateurs comprendront qu’ils sont les seuls responsables de l’inintérêt de ce qu’ils regardent à la télé, au cinéma, en photos ou encore que les mastodontes du numérique soient démantelés. Bref, on peut attendre. La question est : qu’aurons-nous à proposer quand tout ceci finira par se produire ?
La LowTech
Après la FinTech, la LegalTech, etc, faites place à la LowTech ou SmallTech. Je ne connaissais pas ces expressions avant de tomber sur cet article dans le Framablog et celui de Ubsek & Rica d’Aral. On y apprend que c’est un mouvement qui s’oppose frontalement aux géants, ce qui est fantastique. C’est une vision du monde qui me va très bien, en tant que militant du Libre depuis plus de 10 ans maintenant. On peut visiblement le rapprocher de l’initiative CHATONS.
Cependant, j’ai du mal à saisir les moyens qui pourraient être mis en œuvre pour sa réussite.
Les mentalités
Les mentalités actuelles sont cloisonnées : le Libre, même s’il s’impose dans quelques domaines, reste mal compris. Rien que l’idée d’utiliser un programme au code source ouvert donne des sueurs froides à bon nombre de DSI. Comment peut-on se protéger des méchants si tout le monde peut analyser le code et en sortir la faille de sécurité qui va bien ? Comment se démarquer des concurrents si tout le monde se sert du même logiciel ? Regardez le dernier changelog : il est plein de failles béantes : ce n’est pas sérieux !
Parlons aussi de son mode de fonctionnement : qui se souvient d’OpenSSL utilisé par tout le monde et abandonné pendant des années au bénévolat de quelques courageux qui n’ont pas pu empêcher l’arrivée de failles volontaires ? Certains projets sont fantastiques, vraiment, mais les gens ont du mal à réaliser qu’ils sont, certes, très utilisés mais peu soutenus. Vous connaissez beaucoup d’entreprises pour lesquelles vous avez bossé qui refilent une petite partie de leurs bénéfices aux projets libres qui les font vivre ?
Le numérique libre et la Presse
Les gens, les éventuels clients des LowTech, ont plus ou moins grandi dans une société du gratuit. L’autre jour, je m’amusais à comparer les services informatiques à la Presse. Les journaux ont du mal à se sortir du modèle gratuit. Certains y arrivent (Mediapart, Arrêts sur Image : abonnez-vous !), d’autres, largement majoritaires, non.
Il n’est pas difficile de retrouver les montants des subventions que l’État français offre à ces derniers. Libération en parle ici. Après avoir noué des partenariats tous azimuts avec les GAFAM, après avoir noyé leurs contenus dans de la pub, les journaux en ligne se tournent doucement vers le modèle payant pour se sortir du bourbier dans lequel ils se sont mis tout seuls. Le résultat est très moyen, si ce n’est mauvais. Les subventions sont toujours bien là, le mirage des partenariats avec les GAFAM aveugle toujours et les rares qui s’en sont sortis se comptent sur les doigts d’une main.
On peut faire un vrai parallèle entre la situation de la Presse en ligne et les services numériques. Trouver des gens pour payer l’accès à un Nextcloud, un Matomo ou que sais-je est une gageure. La seule différence qui me vient à l’esprit est que des services en ligne arrivent à s’en sortir en coinçant leurs utilisateurs dans des silos : vous avez un Windows ? Vous vous servirez des trucs de Microsoft. Vous avez un compte Gmail, vous vous servirez des trucs de Google. Les premiers Go sont gratuits, les autres seront payants. Là où les journaux généralistes ne peuvent coincer leurs lecteurs, les géants du numérique le peuvent sans trop de souci.
Et le libre ?
Profil de libriste sur Mastodon.
Dans tout ça, les LowTech libres peuvent essayer de s’organiser pour subvenir aux besoins éthiques de leurs clients. Réflexion faite, cette dernière phrase n’a pas tant que ça de sens : comment une entreprise peut-elle s’en sortir alors que l’idéologie derrière cette mouvance favorise l’adhésion à des associations ou à rejoindre des collectifs ? Perso, je l’ai déjà dit, j’adhère volontiers à cette vision du monde horizontale et solidaire. Malgré tout, mon envie de travailler, d’avoir un salaire, une couverture sociale, une activité rentable, et peut-être un jour une retraite, me poussent à grimacer. Si les bribes d’idéologie LowTech orientent les gens vers des associations, comment fait-on pour sortir de terre une entreprise éthique, rentable et solidaire ?
On ne s’en sort pas, ou très difficilement, ou je n’ai pas réussi à imaginer comment. L’idée, connue, serait de s’attaquer au marché des entreprises et des collectivités pour laisser celui des particuliers aux associations sérieuses. Mais là encore, on remet un pied dans le combat pour les logiciels libres contre les logiciels propriétaires dans une arène encerclée par des DSI pas toujours à jour. Sans parler de la compétitivité, ce mot adoré par notre Président, et de l’état des finances de ces entités. Faire le poids face à la concurrence actuelle, même avec les mots « éthique, solidaire et responsable » gravés sur le front, n’est pas évident du tout.
Proie
Si je vous parle de tout ça, c’est parce que j’estime que nous sommes dans une situation difficile : celle d’une proie. Je ne vais pas reparler de l’achat de Nginx, de ce qu’il se passe avec ElasticSearch ou du comportement de Google qui forke à tout va pour ses besoins dans Chrome. Cette conférence vue au FOSDEM, The Cloud Is Just Another Sun, résonne terriblement en moi. L’intervenant y explique que les outils libres que nous utilisons dans le cloud sont incontrôlables. Qui vous certifie que vous tapez bien dans un MariaDB ou un ES quand vous n’avez accès qu’a une boite noire qui ne fait que répondre à vos requêtes ? Rien.
Nous n’avons pas trouvé le moyen de nous protéger dans le monde dans lequel nous vivons. Des licences ralentissent le processus de digestion en cours par les géants du numérique et c’est tout. Notre belle vision du monde, globalement, se fait bouffer et les poches de résistance sont minuscules.
Le Libre est-il sur une pente dangereuse ou en train de négocier brillamment un virage ? Page d’accueil du site d’entreprise https://befox.fr/
Pour finir
Pour finir, ne mettons pas complètement de côté l’existence réelle d’un marché : Nextcloud en est la preuve, tout comme Dolibarr et la campagne de financement réussie d’OpenDSI. Tout n’est peut-être pas vraiment perdu. C’est juste très compliqué.
La bonne nouvelle, s’il y en a bien une, c’est qu’en parlant de tout ça dans Mastodon, je vous assure que si une entreprise du libre se lançait demain, nous serions un bon nombre prêt à tout plaquer pour y travailler. À attendre d’hypothétiques clients, qu’on cherche toujours, certes, mais dans la joie et la bonne humeur.
Enfin voilà, des réflexions, des idées, beaucoup de questions. On arrive à plus de 1900 mots, de quoi faire plaisir à Cyrille BORNE.
Des bisous.
Demain, les nains…
Et si les géants de la technologie numérique étaient concurrencés et peut-être remplacés par les nains des technologies modestes et respectueuses des êtres humains ?
Telle est l’utopie qu’expose Aral Balkan ci-dessous. Faut-il préciser que chez Framasoft, nous avons l’impression d’être en phase avec cette démarche et de cocher déjà des cases qui font de nous ce qu’Aral appelle une Small Tech (littéralement : les petites technologies) par opposition aux Big Tech, autrement dit les GAFAM et leurs successeurs déjà en embuscade pour leur disputer les positions hégémoniques.
Les géants du numérique, avec leurs « licornes » à plusieurs milliards de dollars, nous ont confisqué le potentiel d’Internet. Alimentée par la très courte vue et la rapacité du capital-risque et des start-ups, la vision utopique d’une ressource commune décentralisée et démocratique s’est transformée en l’autocratie dystopique des panopticons de la Silicon Valley que nous appelons le capitalisme de surveillance. Cette mutation menace non seulement nos démocraties, mais aussi l’intégrité même de notre personne à l’ère du numérique et des réseaux1.
Alors que la conception éthique décrit sans ambiguïté les critères et les caractéristiques des alternatives éthiques au capitalisme de surveillance, c’est l’éthique elle-même qui est annexée par les Big Tech dans des opérations de relations publiques qui détournent l’attention des questions systémiques centrales2 pour mettre sous les projecteurs des symptômes superficiels3.
Nous avons besoin d’un antidote au capitalisme de surveillance qui soit tellement contradictoire avec les intérêts des Big Tech qu’il ne puisse être récupéré par eux. Il doit avoir des caractéristiques et des objectifs clairs et simples impossibles à mal interpréter. Et il doit fournir une alternative viable et pratique à la mainmise de la Silicon Valley sur les technologies et la société en général.
Cet antidote, c’est la Small Tech.
Small Tech
elle est conçue par des humains pour des humains 4 ;
est la propriété des individus qui la contrôlent, et non des entreprises ou des gouvernements ;
respecte, protège et renforce l’intégrité de la personne humaine, des droits humains, de la justice sociale et de la démocratie à l’ère du numérique en réseau ;
encourage une organisation politique non-hiérarchisée et où les décisions sont prises à l’échelle humaine ;
alimente un bien commun sain ;
est soutenable ;
sera un jour financée par les communs, pour le bien commun.
Nous avons un système dans lequel 99.99999% des investissements financent les entreprises qui reposent sur la surveillance et se donnent pour mission de croître de façon exponentielle en violant la vie privée de la population en général [retour]
« Attention » et « addiction ». S’il est vrai que les capitalistes de la surveillance veulent attirer notre attention et nous rendre dépendants à leurs produits, ils ne le font pas comme une fin en soi, mais parce que plus nous utilisons leurs produits, plus ils peuvent nous exploiter pour nos données. Des entreprises comme Google et Facebook sont des fermes industrielles pour les êtres humains. Leurs produits sont les machines agricoles. Ils doivent fournir une façade brillante pour garder notre attention et nous rendre dépendants afin que nous, le bétail, puissions volontairement nous autoriser à être exploités. Ces institutions ne peuvent être réformées. Les Big Tech ne peuvent être réglementées que de la même manière que la Big Tobacco pour réduire ses méfaits sur la société. Nous pouvons et devrions investir dans une alternative éthique : la Small Tech. [retour]
La petite technologie établit une relation d’humain à humain par nature. Plus précisément, elle n’est pas créée par des sociétés à but lucratif pour exploiter les individus – ce qu’on appelle la technologie entreprise vers consommateur. Il ne s’agit pas non plus d’une technologie construite par des entreprises pour d’autres entreprises [retour]
Nous construisons la Small Tech principalement pour le bien commun, pas pour faire du profit. Cela ne signifie pas pour autant que nous ne tenons pas compte du système économique dans lequel nous nous trouvons actuellement enlisés ou du fait que les solutions de rechange que nous élaborons doivent être durables. Même si nous espérons qu’un jour Small Tech sera financé par les deniers publics, pour le bien commun, nous ne pouvons pas attendre que nos politiciens et nos décideurs politiques se réveillent et mettent en œuvre un tel changement social. Alors que nous devons survivre dans le capitalisme, nous pouvons vendre et faire des profits avec la Small Tech. Mais ce n’est pas notre but premier. Nos organisations se préoccupent avant tout des méthodes durables pour créer des outils qui donnent du pouvoir aux gens sans les exploiter, et non de faire du profit. Small Tech n’est pas une organisation caritative, mais une organisation à but non lucratif.[retour]
Les organisations disposant de capitaux propres sont détenues et peuvent donc être vendues. En revanche, les organisations sans capital social (par exemple, les sociétés à responsabilité limitée par garantie en Irlande et au Royaume-Uni) ne peuvent être vendues. De plus, si une organisation a du capital-risque, on peut considérer qu’elle a déjà été vendue au moment de l’investissement car, si elle n’échoue pas, elle doit se retirer (être achetée par une grande société ou par le public en général lors d’une introduction en bourse). Les investisseurs en capital-risque investissent l’argent de leurs clients dans la sortie. La sortie est la façon dont ces investisseurs font leur retour sur investissement. Nous évitons cette pilule toxique dans la Small Tech en créant des organisations sans capitaux propres qui ne peuvent être vendues. La Silicon Valley a des entreprises de jetables qu’ils appellent des startups. Nous avons des organisations durables qui travaillent pour le bien commun que nous appelons Stayups (Note de Traduction : jeu de mots avec le verbe to stay signifie « demeurer »).[retour]
La révolution ne sera pas parrainée par ceux contre qui nous nous révoltons. Small Tech rejette le parrainage par des capitalistes de la surveillance. Nous ne permettrons pas que nos efforts soient utilisés comme des relations publiques pour légitimer et blanchir le modèle d’affaires toxique des Big Tech et les aider à éviter une réglementation efficace pour mettre un frein à leurs abus et donner une chance aux alternatives éthiques de prospérer.[retour]
La vie privée, c’est avoir le droit de décider de ce que vous gardez pour vous et de ce que vous partagez avec les autres. Par conséquent, la seule définition de la protection de la vie privée qui importe est celle de la vie privée par défaut. Cela signifie que nous concevons la Small Tech de sorte que les données des gens restent sur leurs appareils. S’il y a une raison légitime pour laquelle cela n’est pas possible (par exemple, nous avons besoin d’un nœud permanent dans un système de pair à pair pour garantir l’accessibilité et la disponibilité), nous nous assurons que les données sont chiffrées de bout en bout et que l’individu qui possède l’outil possède les clés des informations privées et puisse contrôler seul qui est à chacun des « bouts » (pour éviter le spectre du Ghosting).[retour]
La configuration de base de notre technologie est le pair à pair : un système a-centré dans lequel tous les nœuds sont égaux. Les nœuds sur lesquels les individus n’ont pas de contrôle direct (p. ex., le nœud toujours actif dans le système pair à pair mentionné dans la note précédente) sont des nœuds de relais non fiables et non privilégiés qui n’ont jamais d’accès aux informations personnelles des personnes.[retour]
Afin d’assurer un bien commun sain, nous devons protéger le bien commun contre l’exploitation et de l’enfermement. La Small Tech utilise des licences copyleft pour s’assurer que si vous bénéficiez des biens communs, vous devez redonner aux biens communs. Cela empêche également les Big Tech d’embrasser et d’étendre notre travail pour finalement nous en exclure en utilisant leur vaste concentration de richesse et de pouvoir.[retour]
La Small Tech est influencé en grande partie par la richesse du travail existant des concepteurs et développeurs inspirants de la communauté JavaScript qui ont donné naissance aux communautés DAT et Scuttlebutt. Leur philosophie, qui consiste à créer des composants pragmatiques, modulaires, minimalistes et à l’échelle humaine, aboutit à une technologie qui est accessible aux individus, qui peut être maintenue par eux et qui leur profite. Leur approche, qui est aussi la nôtre, repose sur la philosophie d’UNIX.[retour]
La Small Tech est conçue par des humains, pour des humains ; c’est une approche résolument non-coloniale. Elle n’est pas créée par des humains plus intelligents pour des humains plus bêtes (par exemple, par des développeurs pour des utilisateurs – nous n’utilisons pas le terme utilisateur dans Small Tech. On appelle les personnes, des personnes.) Nous élaborons nos outils aussi simplement que possible pour qu’ils puissent être compris, maintenus et améliorés par le plus grand nombre. Nous n’avons pas l’arrogance de supposer que les gens feront des efforts excessifs pour apprendre nos outils. Nous nous efforçons de les rendre intuitifs et faciles à utiliser. Nous réalisons de belles fonctionnalités par défaut et nous arrondissons les angles. N’oubliez pas : la complexité survient d’elle-même, mais la simplicité, vous devez vous efforcer de l’atteindre. Dans la Small Tech, trop intelligent est une façon de dire stupide. Comme le dit Brian Kernighan : « Le débogage est deux fois plus difficile que l’écriture du premier jet de code. Par conséquent, si vous écrivez du code aussi intelligemment que possible, vous n’êtes, par définition, pas assez intelligent pour le déboguer. » Nous nous inspirons de l’esprit de la citation de Brian et l’appliquons à tous les niveaux : financement, structure organisationnelle, conception du produit, son développement, son déploiement et au-delà.[retour]
Il n’est pas si fréquent que l’équipe Framalang traduise un article depuis la langue italienne, mais la récapitulation bien documentée de Cagizero était une bonne occasion de faire le point sur l’expansion de la Fediverse, un phénomène dont nous nous réjouissons et que nous souhaitons voir gagner plus d’amplitude encore, tant mieux si l’article ci-dessous est très lacunaire dans un an !
Mastodon, la Fediverse et l’avenir des réseaux décentralisés
par Cagizero
Peu de temps après une première vue d’ensemble de Mastodon il est déjà possible d’ajouter quelques observations nouvelles.
Tout d’abord, il faut noter que plusieurs personnes familières de l’usage des principaux médias sociaux commerciaux (Facebook, Twitter, Instagram…) sont d’abord désorientées par les concepts de « décentralisation » et de « réseau fédéré ».
En effet, l’idée des médias sociaux qui est répandue et bien ancrée dans les esprits est celle d’un lieu unique, indifférencié, monolithique, avec des règles et des mécanismes strictement identiques pour tous. Essentiellement, le fait même de pouvoir concevoir un univers d’instances séparées et indépendantes représente pour beaucoup de gens un changement de paradigme qui n’est pas immédiatement compréhensible.
Dans un article précédent où était décrit le média social Mastodon, le concept d’instance fédérée était comparé à un réseau de clubs ou cercles privés associés entre eux.
Certains aspects exposés dans l’article précédent demandent peut-être quelques éclaircissements supplémentaires pour celles et ceux qui abordent tout juste le concept de réseau fédéré.
1. On ne s’inscrit pas « sur Mastodon », mais on s’inscrit à une instance de Mastodon ! La comparaison avec un club ou un cercle s’avère ici bien pratique : adhérer à un cercle permet d’entrer en contact avec tous ceux et celles qui font partie du même réseau : on ne s’inscrit pas à une plateforme, mais on s’inscrit à l’un des clubs de la plateforme qui, avec les autres clubs, constituent le réseau. La plateforme est un logiciel, c’est une chose qui n’existe que virtuellement, alors qu’une instance qui utilise une telle plateforme en est l’aspect réel, matériel. C’est un serveur qui est physiquement situé quelque part, géré par des gens en chair et en os qui l’administrent. Vous vous inscrivez donc à une instance et ensuite vous entrez en contact avec les autres.
2. Les diverses instances ont la possibilité technique d’entrer en contact les unes avec les autres mais ce n’est pas nécessairement le cas. Supposons par exemple qu’il existe une instance qui regroupe 500 utilisateurs et utilisatrices passionné⋅e⋅s de littérature, et qui s’intitule mastodon.litterature : ces personnes se connaissent précisément parce en tant que membres de la même instance et chacun⋅e reçoit les messages publics de tous les autres membres.
Eh bien, chacun d’entre eux aura probablement aussi d’autres contacts avec des utilisateurs enregistrés sur difFerentes instances (nous avons tous des ami⋅e⋅s qui ne font pas partie de notre « cercle restreint », n’est-ce pas ?). Si chacun des 500 membres de maston.litterature suit par exemple 10 membres d’une autre instance, mastodon.litterature aurait un réseau local de 500 utilisateurs, mais aussi un réseau fédéré de 5000 utilisateurs !
Bien. Supposons que parmi ces 5000 il n’y ait même pas un seul membre de l’instance japonaise japan.nuclear.physics dont le thème est la physique nucléaire : cette autre instance pourrait avoir peut-être 800 membres et avoir un réseau fédéré de plus de 8000 membres, mais si entre les réseaux « littérature » et « physique nucléaire » il n’y avait pas un seul ami en commun, ses membres ne pourraient en théorie jamais se contacter entre eux.
En réalité, d’après la loi des grands nombres, il est assez rare que des instances d’une certaine taille n’entrent jamais en contact les unes avec les autres, mais l’exemple sert à comprendre les mécanismes sur lesquels repose un réseau fédéré (ce qui, en se basant justement sur la loi des grands nombres et les principes des degrés de séparation, confirme au contraire l’hypothèse que plus le réseau est grand, moins les utilisateurs et instances seront isolés sur une seule instance).
3. Chaque instance peut décider volontairement de ne pas entrer en contact avec une autre, sur la base des choix, des règles et politiques internes qui lui sont propres. Ce point est évidemment peu compris des différents commentateurs qui ne parviennent pas à sortir de l’idée du « réseau social monolithique ». S’il y avait sur Mastodon une forte concentration de suprémacistes blancs en deuil de Gab, ou de blogueurs porno en deuil de Tumblr, cela ne signifie pas que ce serait l’ensemble du réseau social appelé Mastodon qui deviendrait un « réseau social pour suprémacistes blancs et porno », mais seulement quelques instances qui n’entreraient probablement jamais en contact avec des instances antifascistes ou ultra-religieuses. Comme il est difficile de faire comprendre un tel concept, il est également difficile de faire comprendre les potentialités d’une structure de ce type. Dans un réseau fédéré, une fois donnée la possibilité technique d’interagir entre instances et utilisateurs, chaque instance et chaque utilisateur peut ensuite choisir de façon indépendante l’utilisation qui en sera faite.
Supposons qu’il existe par exemple :
Une instance écologiste, créée, maintenue et soutenue financièrement par un groupe de passionnés qui veulent avoir un lieu où échanger sur la nature et l’écologie, qui pose comme principe qu’on n’y poste ni liens externes ni images pornographiques.
Une instance commerciale, créée par une petite entreprise qui dispose d’un bon serveur et d’une bande passante très confortable, et celui ou celle qui s’y inscrit en payant respecte les règles fixées auparavant par l’entreprise elle-même.
Une instance sociale, créée par un centre social et dont les utilisateurs sont surtout les personnes qui fréquentent ledit centre et se connaissent aussi personnellement.
Une instance vidéoludique, qui était à l’origine une instance interne des employés d’une entreprise de technologie mais qui dans les faits est ouverte à quiconque s’intéresse aux jeux vidéos.
Avec ce scénario à quatre instances, on peut déjà décrire quelques interactions intéressantes : l’instance écologiste pourrait consulter ses utilisateurs et utilisatrices et décider de bannir l’instance commerciale au motif qu’on y diffuse largement une culture contraire à l’écologie, tandis que l’instance sociale pourrait au contraire maintenir le lien avec l’instance commerciale tout en choisissant préventivement de la rendre muette dans son propre fil, laissant le choix personnel à ses membres d’entrer ou non en contact avec les membres de l’instance commerciale. Cependant, l’instance sociale pourrait bannir l’instance de jeu vidéo à cause de la mentalité réactionnaire d’une grande partie de ses membres.
En somme, les contacts « insupportables/inacceptables » sont spontanément limités par les instances sur la base de leurs différentes politiques. Ici, le cadre d’ensemble commence à devenir très complexe, mais il suffit de l’observer depuis une seule instance, la nôtre, pour en comprendre les avantages : les instances qui accueillent des trolls, des agitateurs et des gens avec qui on n’arrive vraiment pas à discuter, nous les avons bannies, alors que celles avec lesquelles on n’avait pas beaucoup d’affinités mais pas non plus de motif de haine, nous les avons rendues muettes. Ainsi, si quelqu’un parmi nous veut les suivre, il n’y a pas de problème, mais ce sera son choix personnel.
4. Chaque utilisateur peut décider de rendre muets d’autres utilisateurs, mais aussi des instances entières. Si vous voulez particulièrement éviter les contenus diffusés par les utilisateurs et utilisatrices d’une certaine instance qui n’est cependant pas bannie par l’instance qui vous accueille (mettons que votre instance ne ferme pas la porte à une instance appelée meme.videogamez.lulz, dont la communauté tolère des comportements excessifs et une ambiance de moquerie lourde que certains trouvent néanmoins amusante), vous êtes libres de la rendre muette pour vous seulement. En principe, en présence de groupes d’utilisateurs indésirables venant d’une même instance/communauté, il est possible de bloquer plusieurs dizaines ou centaines d’utilisateurs à la fois en bloquant (pour vous) l’instance entière. Si votre instance n’avait pas un accord unanime sur la manière de traiter une autre instance, vous pourriez facilement laisser le choix aux abonnés qui disposent encore de ce puissant outil. Une instance peut également choisir de modérer seulement ses utilisateurs ou de ne rien modérer du tout, laissant chaque utilisateur complètement libre de faire taire ou d’interdire qui il veut sans jamais interférer ou imposer sa propre éthique.
La Fediverse
logo de la Fediverse
Maintenant que nous nous sommes mieux concentrés sur ces aspects, nous pouvons passer à l’étape suivante. Comme déjà mentionné dans le post précédent, Mastodon fait partie de quelque chose de plus vaste appelé la Fediverse (Fédération + Univers).
En gros, Mastodon est un réseau fédéré qui utilise certains outils de communication (il existe plusieurs protocoles mais les principaux sont ActivityPub, Ostatus et Diaspora*, chacun ayant ses avantages, ses inconvénients, ses partisans et ses détracteurs), utilisés aussi par et d’autres réalités fédérées (réseaux sociaux, plateformes de blogs, etc.) qui les mettent en contact pour former une galaxie unique de réseaux fédérés.
Pour vous donner une idée, c’est comme si Mastodon était un système planétaire qui tourne autour d’une étoile (Mastodon est l’étoile et chaque instance est une planète), cependant ce système planétaire fait partie d’un univers dans lequel existent de nombreux systèmes planétaires tous différents mais qui communiquent les uns avec les autres.
Toutes les planètes d’un système planétaire donné (les instances, comme des « clubs ») tournent autour d’un soleil commun (la plate-forme logicielle). L’utilisateur peut choisir la planète qu’il préfère mais il ne peut pas se poser sur le soleil : on ne s’inscrit pas à la plateforme, mais on s’inscrit à l’un des clubs qui, avec tous les autres, forme le réseau.
Dans cet univers, Mastodon est tout simplement le « système planétaire » le plus grand (celui qui a le plus de succès et qui compte le plus grand nombre d’utilisateurs) mais il n’est pas certain qu’il en sera toujours ainsi : d’autres « systèmes planétaires » se renforcent et grandissent.
[NB : chaque plate-forme évoquée ici utilise ses propres noms pour définir les serveurs indépendants sur lesquels elle est hébergée. Mastodon les appelle instances, Hubzilla les appelle hubs et Diaspora* les appelle pods. Toutefois, par souci de simplicité et de cohérence avec l’article précédent, seul le terme « instance » sera utilisé pour tous dans l’article]
La structure d’ensemble de la Fediverse
Les interactions de Mastodon avec les autres médias
Sur Kumu.io on peut trouver une représentation interactive de la Fediverse telle qu’elle apparaît actuellement. Chaque « nœud » représente un réseau différent (ou « système planétaire »). Ce sont les différentes plateformes qui composent la fédération. Mastodon n’est que l’une d’entre elles, la plus grande, en bas au fond. Sur la capture d’écran qui illustre l’article, Mastodon est en bas.
En sélectionnant Mastodon il est possible de voir avec quels autres médias ou systèmes de la Fediverse il est en mesure d’interagir. Comme on peut le voir, il interagit avec la plupart des autres médias mais pas tout à fait avec tous.
Les interactions de Gnu social avec les autres médias
En sélectionnant un autre réseau social comme GNU Social, on observe qu’il a différentes interactions : il en partage la majeure partie avec Mastodon mais il en a quelques-unes en plus et d’autres en moins.
Cela dépend principalement du type d’outils de communication (protocoles) que chaque média particulier utilise. Un média peut également utiliser plus d’un protocole pour avoir le plus grand nombre d’interactions, mais cela rend évidemment leur gestion plus complexe. C’est, par exemple, la voie choisie par Friendica et GNU Social.
En raison des différents protocoles utilisés, certains médias ne peuvent donc pas interagir avec tous les autres. Le cas le plus important est celui de Diaspora*, qui utilise son propre protocole (appelé lui aussi Diaspora), qui ne peut interagir qu’avec Friendica et Gnu Social mais pas avec des médias qui reposent sur ActivityPub tels que Mastodon.
Au sein de la Fediverse, les choses sont cependant en constante évolution et l’image qui vient d’être montrée pourrait avoir besoin d’être mise à jour prochainement. En ce moment, la plupart des réseaux semblent s’orienter vers l’adoption d’ActivityPub comme outil unique. Ce ne serait pas mal du tout d’avoir un seul protocole de communication qui permette vraiment tout type de connexion !
Mais revenons un instant à l’image des systèmes planétaires. Kumu.io montre les connexions techniquement possibles entre tous les « systèmes planétaires » et, pour ce faire, relie génériquement les différents soleils. Mais comme nous l’avons bien vu, les vraies connexions ont lieu entre les planètes et non entre les soleils ! Une carte des étoiles montrant les connexions réelles devrait montrer pour chaque planète (c’est-à-dire chaque « moustache » des nœuds de Kum.io), des dizaines ou des centaines de lignes de connexion avec autant de planètes/moustaches, à la fois entre instances de sa plateforme et entre instances de différentes plateformes ! La quantité et la complexité des connexions, comme on peut l’imaginer, formeraient un enchevêtrement qui donnerait mal à la tête serait graphiquement illisible. Le simple fait de l’imaginer donne une idée de la quantité et de la complexité des connexions possibles.
Et cela ne s’arrête pas là : chaque planète peut établir ou interrompre ses contacts avec les autres planètes de son système solaire (c’est-à-dire que l’instance Mastodon A peut décider de ne pas avoir de contact avec l’instance Mastodon B), et de la même manière elle peut établir ou interrompre les contacts avec des planètes de différents systèmes solaires (l’instance Mastodon A peut établir ou interrompre des contacts avec l’instance Pleroma B). Pour donner un exemple radical, nous pouvons supposer que nous avons des cousins qui sont des crétins, mais d’authentiques crétins, que nous avons chassés de notre planète (mastodon.terre) et qu’ensuite ils ont construit leur propre instance (mastodon.saturne) dans notre voisinage parce que ben, ils aiment bien notre soleil « Mastodon ». Nous décidons de nous ignorer les uns les autres tout de suite. Ces cousins, cependant, sont tellement crétins que même nos parents et amis proches des planètes voisines (mastodon.jupiter, mastodon.venus, etc.) ignorent les cousins crétins de mastodon.saturne.
Aucune planète du système Mastodon ne les supporte. Les cousins, cependant, ne sont pas entièrement sans relations et, au contraire, ils ont beaucoup de contacts avec les planètes d’autres systèmes solaires. Par exemple, ils sont en contact avec certaines planètes du système planétaire PeeeTube: peertube.10287, peertube.chatons, peertube.anime, mais aussi avec pleroma.pizza du système Pleroma et friendica.jardinage du système Friendica. En fait, les cousins crétins sont d’accord pour vivre sur leur propre petite planète dans le système Mastodon, mais préfèrent avoir des contacts avec des planètes de systèmes différents.
Nous qui sommes sur mastodon.terre, nous ne nous soucions pas moins des planètes qui leur sont complaisantes : ce sont des crétins tout autant que nos cousins et nous les avons bloquées aussi. Sauf un. Sur pleroma.pizza, nous avons quelques ami⋅e⋅s qui sont aussi des ami⋅e⋅s de certains cousins crétins de mastodon.saturne. Mais ce n’est pas un problème. Oh que non ! Nous avons des connexions interstellaires et nous devrions nous inquiéter d’une chose pareille ? Pas du tout ! Le blocage que nous avons activé sur mastodon.saturne est une sorte de barrière énergétique qui fonctionne dans tout le cosmos ! Si nous étions impliqués dans une conversation entre un ami de pleroma.pizza et un cousin de mastodon.saturne, simplement, ce dernier ne verrait pas ce qui sort de notre clavier et nous ne verrions pas ce qui sort du sien. Chacun d’eux saura que l’autre est là, mais aucun d’eux ne pourra jamais lire l’autre. Bien sûr, nous pourrions déduire quelque chose de ce que notre ami commun de pleroma.pizza dira, mais bon, qu’est-ce qu’on peut en espérer ? 😉
Cette image peut donner une idée de la façon dont les instances (planètes) se connectent entre elles. Si l’on considère qu’il existe des milliers d’instances connues de la Fediverse, on peut imaginer la complexité de l’image. Un aspect intéressant est le fait que les connexions entre une instance et une autre ne dépendent pas de la plateforme utilisée. Sur l’image on peut voir l’instance mastodon.mercure : c’est une instance assez isolée par rapport au réseau d’instances Mastodon, dont les seuls contacts sont mastodon.neptune, peertube.chatons et pleroma.pizza. Rien n’empêche mastodon.mercure de prendre connaissance de toutes les autres instances de Mastodon non par des échanges de messages avec mastodon.neptune, mais par des commentaires sur les vidéos de peertube.chatons. En fait, c’est d’autant plus probable que mastodon.neptune n’est en contact qu’avec trois autres instances Mastodon, alors que peertube.chatons est en contact avec toutes les instances Mastodon.
Essayer d’imaginer comment les différentes instances de cette image qui « ne se connaissent pas » peuvent entrer en contact nous permet d’avoir une idée plus précise du niveau de complexité qui peut être atteint. Dans un système assez grand, avec un grand nombre d’utilisateurs et d’instances, isoler une partie de celui-ci ne compromettra en aucune façon la richesse des connexions possibles.
Une fois toutes les connexions possibles créées, il est également possible de réaliser une expérience différente, c’est-à-dire d’imaginer interrompre des connexions jusqu’à la formation de deux ou plusieurs réseaux parfaitement séparés, contenant chacune des instances Mastodon, Pleroma et Peertube.
Et pour ajouter encore un degré de complexité, on peut faire encore une autre expérience, en raisonnant non plus à l’échelle des instances mais à celle des utilisateurs⋅rices individuel⋅le⋅s des instances (faire l’hypothèse de cinq utilisateurs⋅rices par instance pourrait suffire pour recréer les différentes situations). Quelques cas qu’on peut imaginer :
1) Nous sommes sur une instance de Mastodon et l’utilisatrice Anna vient de découvrir par le commentaire d’une vidéo sur Peertube l’existence d’une nouvelle instance de Pleroma, donc maintenant elle connaît son existence mais, choisissant de ne pas la suivre, elle ne fait pas réellement connaître sa découverte aux autres membres de son instance.
2) Sur cette même instance de Mastodon l’utilisateur Ludo bloque la seule instance Pleroma connue. Conséquence : si cette instance Pleroma devait faire connaître d’autres instances Pleroma avec lesquelles elle est en contact, Ludo devrait attendre qu’un autre membre de son instance les fasse connaître, car il s’est empêché lui-même d’être parmi les premiers de son instance à les connaître.
3) En fait, la première utilisatrice de l’instance à entrer en contact avec les autres instances Pleroma sera Marianne. Mais elle ne les connaît pas de l’instance Pleroma (celle que Ludo a bloquée) avec laquelle ils sont déjà en contact, mais par son seul contact sur GNU Social.
Cela semble un peu compliqué mais en réalité ce n’est rien de plus qu’une réplique de mécanismes humains auxquels nous sommes tellement habitué⋅e⋅s que nous les tenons pour acquis. On peut traduire ainsi les différents exemples qui viennent d’être exposés :
1) Notre amie Anna, habituée de notre bar, rencontre dans la rue une personne qui lui dit fréquenter un nouveau bar dans une ville proche. Mais Anna n’échange pas son numéro de téléphone avec le type et elle ne pourra donc pas donner d’informations à ses amis dans son bar sur le nouveau bar de l’autre ville.
2) Dans le bar habituel, Ludo de Nancy évite Laura de Metz. Quand Laura amène ses autres amies Solène et Louise de Metz au bar, elle ne les présente pas à Ludo. Ce n’est que plus tard que les amis du bar, devenus amis avec Solène et Louise, pourront les présenter à Ludo indépendamment de Laura.
3) En réalité Marianne avait déjà rencontré Solène et Louise, non pas grâce à Laura, mais grâce à Stéphane, son seul ami à Villers.
Pour avoir une idée de l’ampleur de la Fediverse, vous pouvez jeter un coup d’œil à plusieurs sites qui tentent d’en fournir une image complète. Outre Kumu.io déjà mentionné, qui essaie de la représenter avec une mise en page graphique élégante qui met en évidence les interactions, il y a aussi Fediverse.network qui essaie de lister chaque instance existante en indiquant pour chacune d’elles les protocoles utilisés et le statut du service, ou Fediverse.party, qui est un véritable portail où choisir la plate-forme à utiliser et à laquelle s’enregistrer. Switching.software, une page qui illustre toutes les alternatives gratuites aux médias sociaux et propriétaires, indique également quelques réseaux fédérés parmi les alternatives à Twitter et Facebook.
Pour être tout à fait complet : au début, on avait tendance à diviser tout ce mégaréseau en trois « univers » superposés : celui de la « Fédération » pour les réseaux reposant sur le protocole Diaspora, La « Fediverse » pour ceux qui utilisent Ostatus et « ActivityPub » pour ceux qui utilisent… ActivityPub. Aujourd’hui, au contraire, ils sont tous considérés comme faisant partie de la Fediverse, même si parfois on l’appelle aussi la Fédération.
Tant de réseaux…
Examinons donc les principales plateformes/réseaux et leurs différences. Petites précisions : certaines de ces plateformes sont pleinement actives alors que d’autres sont à un stade de développement plus ou moins avancé. Dans certains cas, l’interaction entre les différents réseaux n’est donc pas encore pleinement fonctionnelle. De plus, en raison de la nature libre et indépendante des différents réseaux, il est possible que des instances apportent des modifications et des personnalisations « non standard » (un exemple en est la limite de caractères sur Mastodon : elle est de 500 caractères par défaut, mais une instance peut décider de définir la limite qu’elle veut ; un autre exemple est l’utilisation des fonctions de mise en favori ou de partage, qu’une instance peut autoriser et une autre interdire). Dans ce paragraphe, ces personnalisations et différences ne sont pas prises en compte.
Mastodon (semblable à : Twitter)
Copie d’écran, une instance de Mastodon, Framapiaf
Mastodon est une plateforme de microblogage assez semblable à Twitter parce qu’elle repose sur l’échange de messages très courts. C’est le réseau le plus célèbre de la Fediverse. Il est accessible sur smartphone à travers un certain nombre d’applications tant pour Android que pour iOS. Un de ses points forts est le design bien conçu et le fait qu’il a déjà un « parc d’utilisateurs⋅rices » assez conséquent (presque deux millions d’utilisateurs⋅rices dans le monde, dont quelques milliers en France). En version bureau, il se présente comme une série de colonnes personnalisables, qui montrent les différents « fils », sur le modèle de Tweetdeck. Pour le moment, Mastodon est la seule plateforme sociale fédérée accessible par des applications sur Android et iOS.
Pleroma (semblable à : Twitter et DeviantArt)
Copie d’écran, Pleroma
Pleroma est le réseau « sœur » de Mastodon : fondamentalement, c’est la même chose dans deux versions un peu différentes. Pleroma offre quelques fonctionnalités supplémentaires concernant la gestion des images et permet par défaut des messages plus longs. À la différence de Mastodon, Pleroma montre en version bureau une colonne unique avec le fil sélectionné, ce qui le rend beaucoup plus proche de Twitter. Actuellement, de nombreuses instances Pleroma ont un grand nombre d’utilisateurs⋅rices qui s’intéressent à l’illustration et au manga, ce qui, comme ambiance, peut vaguement rappeler l’ambiance de DeviantArt. Les applications pour smartphone de Mastodon peuvent également être utilisées pour accéder à Pleroma.
Misskey (semblable à : un mélange entre Twitter et DeviantArt)
Copie d’écran, Misskey
Misskey est une sorte de Twitter qui tourne principalement autour d’images. Il offre un niveau de personnalisation supérieur à Mastodon et Pleroma, et une plus grande attention aux galeries d’images. C’est une plateforme qui a eu du succès au Japon et parmi les passionnés de manga (et ça se voit !).
Friendica (semblable à : Facebook)
Friendica est un réseau extrêmement intéressant. Il reprend globalement la structure graphique de Facebook (avec les ami⋅e⋅s, les notifications, etc.), mais il permet également d’interagir avec plusieurs réseaux commerciaux qui ne font pas partie de la Fediverse. Il est donc possible de connecter son compte Friendica à Facebook, Twitter, Tumblr, WordPress, ainsi que de générer des flux RSS, etc. Bref, Friendica se présente comme une sorte de nœud pour diffuser du contenu sur tous les réseaux disponibles, qu’ils soient fédérés ou non. En somme, Friendica est le passe-partout de la Fediverse : une instance Friendica au maximum de ses fonctions se connecte à tout et dialogue avec tout le monde.
Osada (semblable à : un mélange entre Twitter et Facebook)
Image animée, réponse à un commentaire sur Osada
Osada est un autre réseau dont la configuration peut faire penser à un compromis entre Twitter et Facebook. De toutes les plateformes qui rappellent Facebook, c’est celle dont le design est le plus soigné.
GNUsocial (semblable à : un mélange entre Twitter et Facebook)
Copie d’écran : GNUsocial avec une interface en suédois.
GNUsocial est un peu le « grand-père » des médias sociaux listés ici, en particulier de Friendica et d’Osada, dont il est le prédécesseur.
Aardwolf (semblable à : Twitter, éventuellement)
Copie d’écran : logo et slogan d’Aardwolf
Aardwolf n’est pas encore prêt, mais il est annoncé comme une sorte d’alternative à Twitter. On attend de voir.
PeerTube (semblable à : YouTube)
Capture d’écran, une instance de PeerTube, aperi.tube
PeerTube est le réseau fédéré d’hébergement de vidéo vraiment, mais vraiment très semblable à YouTube, Vimeo et d’autres services de ce genre. Avec un catalogue en cours de construction, Peertube apparaît déjà comme un projet très solide.
Pixelfed (semblable à : Instagram)
Copie d’écran, Pixelfed
Pixelfed est essentiellement l’Instagram de la Fédération. Il est en phase de développement mais semble être plutôt avancé. Il lui manque seulement des applications pour smartphone pour être adopté à la place d’Instagram. Pixelfed a le potentiel pour devenir un membre extrêmement important de la Fédération !
NextCloud (semblable à : iCloud, Dropbox, GDrive)
Logo de Owncloud
NextCloud, né du projet plus ancien ownCloud, est un service d’hébergement de fichiers assez semblable à Dropbox. Tout le monde peut faire tourner NextCloud sur son propre serveur. NextCloud offre également des services de partage de contacts (CardDAV) ou de calendriers (CalDAV), de streaming de médias, de marque-page, de sauvegarde, et d’autres encore. Il tourne aussi sur Window et OSX et est accessible sur smartphone à travers des applications officielles. Il fait partie de la Fediverse dans la mesure où il utilise ActivityPub pour communiquer différentes informations à ses utilisateurs, comme des changements dans les fichiers, les activités du calendrier, etc.
Diaspora* (semblable à : Facebook, et aussi un peu Tumblr)
Copie d’écran, un « pod » de Diaspora*, Framasphere
Diaspora* est un peu le « cousin » de la Fediverse. Il fonctionne avec un protocole bien à lui et dialogue avec le reste de la Fediverse principalement via GNU social et Friendica, le réseau passe-partout, même s’il semble qu’il circule l’idée de faire utiliser à Diaspora* (l’application) aussi bien son propre protocole qu’ActivityPub. Il s’agit d’un grand et beau projet, avec une base solide d’utilisateurs⋅rices fidèles. Au premier abord, il peut faire penser à une version extrêmement minimaliste de Facebook, mais son attention aux images et son système intéressant d’organisation des posts par tag permet également de le comparer, d’une certaine façon, à Tumblr.
Funkwhale (semblable à : SoundCloud et Grooveshark)
Copie d’écran, Funkwhale
Funkwhale ressemble à SoundCloud, Grooveshark et d’autre services semblables. Comme une sorte de YouTube pour l’audio, il permet de partager des pistes audio mais au sein d’un réseau fédéré. Avec quelques fonctionnalités en plus, il pourrait devenir un excellent service d’hébergement de podcasts audio.
Plume, Write Freely et Write.as (plateformes de blog)
Copie d’écran, Write freely
Plume, Write Freely et Write.as sont des plateformes de blog assez minimalistes qui font partie de la Fédération. Elles n’ont pas toute la richesse, les fonctions, les thèmes et la personnalisation de WordPress ou de Blogger, mais elles font leur travail avec légèreté.
Hubzilla (semblable à : …TOUT !!)
Page d’accueil de Hubzilla
Hubzilla est un projet très riche et complexe qui permet de gérer aussi bien des médias sociaux que de l’hébergement de fichiers, des calendriers partagés, de l’hébergement web, et le tout de manière décentralisée. En bref, Hubzilla se propose de faire tout à la fois ce que font plusieurs des services listés ici. C’est comme avoir une seule instance qui fait à la fois Friendica, Peertube et NextCloud. Pas mal ! Un projet à surveiller !
GetTogether (semblable à : MeetUp)
Copie d’écran, GetTogether
GetTogether est une plateforme servant à planifier des événements. Semblable à MeetUp, elle sert à mettre en relation des personnes différentes unies par un intérêt commun, et à amener cet intérêt dans le monde réel. Pour le moment, GetTogether ne fait pas encore partie de la Fediverse, mais il est en train de mettre en place ActivityPub et sera donc bientôt des nôtres.
Mobilizon (semblable à : MeetUp)
Mobilizon est une nouvelle plateforme en cours de développement, qui se propose comme une alternative libre à MeetUp et à d’autres logiciels servant à organiser des réunions et des rencontres en tout genre. Dès le départ, le projet naît avec l’intention d’utiliser ActivityPub et de faire partie de la Fediverse, en conformité avec les valeurs de Framasoft, association française née avec l’objectif de diffuser l’usage des logiciels libres et des réseaux décentralisés. Voir la présentation de Mobilizon en italien.
Prismo est une application encore en phase de développement, qui se propose de devenir un sorte de version décentralisée de Reddit, c’est-à-dire un média social centré sur le partage de liens, mais qui pourrait potentiellement évoluer en quelque chose qui ressemble à Pocket ou Evernote. Les fonctions de base sont déjà opérationnelles.
Socialhome
Capture d’écran, Socialhome
Socialhome est un média social qui utilise une interface par « blocs », affichant les messages comme dans un collage de photos de Pinterest. Pour le moment, il communique seulement via le protocole de Diaspora, mais il devrait bientôt mettre en place ActivityPub.
Et ce n’est pas tout !
Les recommandations du W3C pour ActivityPub, page d’accueil
Il existe encore d’autres applications et médias sociaux qui adoptent ou vont adopter ActivityPub, ce qui rendra la Fediverse encore plus structurée. Certains sont assez semblables à ceux déjà évoqués, alors que d’autres sont encore en phase de développement, on ne peut donc pas encore les conseiller pour remplacer des systèmes commerciaux plus connus. Il y a cependant des plateformes déjà prêtes et fonctionnelles qui pourraient entrer dans la Fediverse en adoptant ActivityPub : NextCloud en est un exemple (il était déjà constitué quand il a décidé d’entrer dans la Fediverse) ; le plugin de WordPress est pour sa part un outil qui permet de fédérer une plateforme qui existe déjà ; GetTogether est un autre service qui est en train d’être fédéré. Des plateformes déjà en place (je pense à Gitter, mais c’est juste un exemple parmi tant d’autres) pourraient trouver un avantage à se fédérer et à entrer dans une grande famille élargie. Bref : ça bouge dans la Fediverse et autour d’elle !
… un seul Grand Réseau !
Jusqu’ici, nous avons vu de nombreuses versions alternatives d’outils connus qui peuvent aussi être intéressant pris individuellement, mais qui sont encore meilleurs quand ils collaborent. Voici maintenant le plus beau : le fait qu’ils partagent les mêmes protocoles de communication élimine l’effet « cage dorée » de chaque réseau !
Maintenant qu’on a décrit chaque plateforme, on peut donner quelques exemples concrets :
Je suis sur Mastodon, où apparaît le message d’une personne que je « suis ». Rien d’étrange à cela, si ce n’est que cette personne n’est pas utilisatrice de Mastodon, mais de Peertube ! En effet, il s’agit de la vidéo d’un panorama. Toujours depuis Mastodon, je commente en écrivant « joli » et cette personne verra apparaître mon commentaire sous sa vidéo, sur Peertube.
Je suis sur Osada et je poste une réflexion ouverte un peu longue. Cette réflexion est lue par une de mes amies sur Friendica, qui la partage avec ses followers, dont certains sont sur Friendica, mais d’autres sont sur d’autres plateformes. Par exemple, l’un d’eux est sur Pleroma, il me répond et nous commençons à dialoguer.
Je publie une photo sur Pixelfed qui est vue et commentée par un de mes abonnés sur Mastodon.
En somme, chacun peut garder contact avec ses ami⋅e⋅s/abonné⋅e⋅s depuis son réseau préféré, mêmes si ces personnes en fréquentent d’autres.
Pour établir une comparaison avec les réseaux commerciaux, c’est comme si l’on pouvait recevoir sur Facebook les tweets d’un ami qui est sur Twitter, les images postées par quelqu’un d’autre sur Instagram, les vidéos d’une chaîne YouTube, les pistes audio sur SoundCloud, les nouveaux posts de divers blogs et sites personnels, et commenter et interagir avec chacun d’eux parce que tous ces réseaux collaborent et forment un seul grand réseau !
Chacun de ces réseaux pourra choisir la façon dont il veut gérer ces interactions : par exemple, si je voulais une vie sociale dans un seul sens, je pourrais choisir une instance Pixelfed où les autres utilisateurs⋅rices peuvent me contacter seulement en commentant les photos que je publie, ou bien je pourrais choisir une instance Peertube et publier des vidéos qui ne pourraient pas être commentées mais qui pourraient tourner dans toute la Fediverse, ou choisir une instance Mastodon qui oblige mes interlocuteurs à communiquer avec moi de manière concise.
Certains détails sont encore à définir (par exemple : je pourrais envoyer un message direct depuis Mastodon vers une plateforme qui ne permet pas à ses utilisateurs⋅rices de recevoir des messages directs, sans jamais être averti du fait que le/la destinataire n’aura aucun moyen de savoir que je lui ai envoyé quelque chose). Il s’agit de situations bien compréhensibles à l’intérieur d’un écosystème qui doit s’adapter à des réalités très diverses, mais dans la majorité des cas il s’agit de détails faciles à gérer. Ce qui compte, c’est que les possibilités d’interactions sont potentiellement infinies !
Connectivité totale, exposition dosée
Toute cette connectivité partagée doit être observée en gardant à l’esprit que, même si par simplicité les différents réseaux ont été traités ici comme des réseaux centralisés, ce sont en réalité des réseaux d’instances indépendantes qui interagissent directement avec les instances des autres réseaux : mon instance Mastodon filtrera les instances Peertube qui postent des vidéos racistes mais se connectera à toutes les instances Peertube qui respectent sa politique ; si je suis un certain ami sur Pixelfed je verrai seulement ses posts, sans que personne m’oblige à voir toutes les photos de couchers de soleil et de chatons de ses ami⋅e⋅s sur ce réseau.
La combinaison entre autonomie des instances, grande interopérabilité entre celles-ci et liberté de choix permet une série de combinaisons extrêmement intéressantes dont les réseaux commerciaux ne peuvent même pas rêver : ici, l’utilisateur⋅rice est membre d’un seul grand réseau où chacun⋅e peut choisir :
Son outil d’accès préféré (Mastodon, Pleroma, Friendica) ;
La communauté dans laquelle il ou elle se sent le plus à l’aise (l’instance) ;
La fermeture aux communautés indésirables et l’ouverture aux communautés qui l’intéressent.
Tout cela sans pour autant renoncer à être connecté à des utilisateurs⋅rices qui ont choisi des outils et des communautés différents. Par exemple, je peux choisir une certaine instance Pleroma parce que j’aime son design, la communauté qu’elle accueille, ses règles et la sécurité qu’elle procure mais, à partir de là, suivre et interagir principalement avec des utilisateurs⋅rices d’une instance Pixelfed particulière et en importer les contenus et l’esthétique dans mon instance.
À cela on peut ajouter que des instances individuelles peuvent littéralement être installées et administrées par chaque utilisateur individuel sur ses propres machines, ce qui permet un contrôle total du contenu. Les instances minuscules auto-hébergées « à la maison » et les instances de travail plus robustes, les instances scolaires et les instances collectives, les instances avec des milliers d’utilisateurs et les instances avec un seul utilisateur, les instances à l’échelle d’un quartier ou d’un immeuble, toutes sont unies pour former un réseau complexe et personnalisable, qui vous permet de vous connecter pratiquement à n’importe qui mais aussi de vous éviter la surcharge d’information.
C’est une sorte de retour aux origines d’Internet, mais un retour à un âge de maturité, celui du Web 2.0, qui a tiré les leçons de l’expérience : être passé par la centralisation de la communication entre les mains de quelques grands acteurs internationaux a renforcé la conviction que la structure décentralisée est la plus humaine et la plus enrichissante.
Rejoignez la fédération !
Nous devons nous passer de Chrome
Chrome, de navigateur internet novateur et ouvert, est devenu au fil des années un rouage essentiel de la domination d’Internet par Google. Cet article détaille les raisons pour lesquelles Chrome asphyxie le Web ouvert et pourquoi il faudrait passer sur un autre navigateur tel Vivaldi ou Firefox.
Il y a dix ans, nous avons eu besoin de Google Chrome pour libérer le Web de l’hégémonie des entreprises, et nous avons réussi à le faire pendant une courte période. Aujourd’hui, sa domination étouffe la plateforme même qu’il a autrefois sauvée des griffes de Microsoft. Et personne, à part Google, n’a besoin de ça.
Nous sommes en 2008. Microsoft a toujours une ferme emprise sur le marché des navigateurs web. Six années se sont écoulées depuis que Mozilla a sorti Firefox, un concurrent direct d’Internet Explorer. Google, l’entreprise derrière le moteur de recherche que tout le monde aimait à ce moment-là, vient d’annoncer qu’il entre dans la danse. Chrome était né.
Au bout de deux ans, Chrome représentait 15 % de l’ensemble du trafic web sur les ordinateurs fixes — pour comparer, il a fallu 6 ans à Firefox pour atteindre ce niveau. Google a réussi à fournir un navigateur rapide et judicieusement conçu qui a connu un succès immédiat parmi les utilisateurs et les développeurs Web. Les innovations et les prouesses d’ingénierie de leur produit étaient une bouffée d’air frais, et leur dévouement à l’open source la cerise sur le gâteau. Au fil des ans, Google a continué à montrer l’exemple en adoptant les standards du Web.
Avançons d’une décennie. Le paysage des navigateurs Web est très différent. Chrome est le navigateur le plus répandu de la planète, faisant de facto de Google le gardien du Web, à la fois sur mobile et sur ordinateur fixe, partout sauf dans une poignée de régions du monde. Le navigateur est préinstallé sur la plupart des téléphones Android vendus hors de Chine, et sert d’interface utilisateur pour Chrome OS, l’incursion de Google dans les systèmes d’exploitation pour ordinateurs fixe et tablettes. Ce qui a commencé comme un navigateur d’avant-garde respectant les standards est maintenant une plateforme tentaculaire qui n’épargne aucun domaine de l’informatique moderne.
Bien que le navigateur Chrome ne soit pas lui-même open source, la plupart de ses composantes internes le sont. Chromium, la portion non-propriétaire de Chrome, a été rendue open source très tôt, avec une licence laissant de larges marges de manœuvre, en signe de dévouement à la communauté du Web ouvert. En tant que navigateur riche en fonctionnalités, Chromium est devenu très populaire auprès des utilisateurs de Linux. En tant que projet open source, il a de nombreux adeptes dans l’écosystème open source, et a souvent été utilisé comme base pour d’autres navigateurs ou applications.
Tant Chrome que Chromium se basent sur Blink, le moteur de rendu qui a démarré comme un fork de WebKit en 2013, lorsque l’insatisfaction de Google grandissait envers le projet mené par Apple. Blink a continué de croître depuis lors, et va continuer de prospérer lorsque Microsoft commencera à l’utiliser pour son navigateur Edge.
La plateforme Chrome a profondément changé le Web. Et plus encore. L’adoption des technologies web dans le développement des logiciels PC a connu une augmentation sans précédent dans les 5 dernières années, avec des projets comme Github Electron, qui s’imposent sur chaque OS majeur comme les standards de facto pour des applications multiplateformes. ChromeOS, quoique toujours minoritaire comparé à Windows et MacOS, s’installe dans les esprits et gagne des parts de marché.
Chrome est, de fait, partout. Et c’est une mauvaise nouvelle
Don’t Be Evil
L’hégémonie de Chrome a un effet négatif majeur sur le Web en tant que plateforme ouverte : les développeurs boudent de plus en plus les autres navigateurs lors de leurs tests et de leurs débogages. Si cela fonctionne comme prévu sur Chrome, c’est prêt à être diffusé. Cela engendre en retour un afflux d’utilisateurs pour le navigateur puisque leurs sites web et applications favorites ne marchent plus ailleurs, rendant les développeurs moins susceptibles de passer du temps à tester sur les autres navigateurs. Un cercle vicieux qui, s’il n’est pas brisé, entraînera la disparition de la plupart des autres navigateurs et leur oubli. Et c’est exactement comme ça que vous asphyxiez le Web ouvert.
Quand il s’agit de promouvoir l’utilisation d’un unique navigateur Web, Google mène la danse. Une faible assurance de qualité et des choix de conception discutables sont juste la surface visible de l’iceberg quand on regarde les applications de Google et ses services en dehors de l’écosystème Chrome. Pour rendre les choses encore pires, le blâme retombe souvent sur les autres concurrents car ils « retarderaient l’avancée du Web ». Le Web est actuellement le terrain de jeu de Google ; soit vous faites comme ils disent, soit on vous traite de retardataire.
Sans une compétition saine et équitable, n’importe quelle plateforme ouverte régressera en une organisation dirigiste. Pour le Web, cela veut dire que ses points les plus importants — la liberté et l’accessibilité universelle — sont sapés pour chaque pour-cent de part de marché obtenu par Chrome. Rien que cela est suffisant pour s’inquiéter. Mais quand on regarde de plus près le modèle commercial de Google, la situation devient beaucoup plus effrayante.
La raison d’être de n’importe quelle entreprise est de faire du profit et de satisfaire les actionnaires. Quand la croissance soutient une bonne cause, c’est considéré comme un avantage compétitif. Dans le cas contraire, les services marketing et relations publiques sont mis au travail. Le mantra de Google, « Don’t be evil« , s’inscrivait parfaitement dans leur récit d’entreprise quand leur croissance s’accompagnait de rendre le Web davantage ouvert et accessible.
Hélas, ce n’est plus le cas.
Logos de Chrome
L’intérêt de l’entreprise a dérivé petit à petit pour transformer leur domination sur le marché des navigateurs en une croissance du chiffre d’affaires. Il se trouve que le modèle commercial de Google est la publicité sur leur moteur de recherche et Adsense. Tout le reste représente à peine 10 % de leur revenu annuel. Cela n’est pas forcément un problème en soi, mais quand la limite entre navigateur, moteur de recherche et services en ligne est brouillée, nous avons un problème. Et un gros.
Les entreprises qui marchent comptent sur leurs avantages compétitifs. Les moins scrupuleuses en abusent si elles ne sont pas supervisées. Quand votre navigateur vous force à vous identifier, à utiliser des cookies que vous ne pouvez pas supprimer et cherche à neutraliser les extensions de blocage de pub et de vie privée, ça devient très mauvais71. Encore plus quand vous prenez en compte le fait que chaque site web contient au moins un bout de code qui communique avec les serveurs de Google pour traquer les visiteurs, leur montrer des publicités ou leur proposer des polices d’écriture personnalisées.
En théorie, on pourrait fermer les yeux sur ces mauvaises pratiques si l’entreprise impliquée avait un bon bilan sur la gestion des données personnelles. En pratique cependant, Google est structurellement flippant, et ils n’arrivent pas à changer. Vous pouvez penser que vos données personnelles ne regardent que vous, mais ils ne semblent pas être d’accord.
Le modèle économique de Google requiert un flot régulier de données qui puissent être analysées et utilisées pour créer des publicités ciblées. Du coup, tout ce qu’ils font a pour but ultime d’accroître leur base utilisateur et le temps passé par ces derniers sur leurs outils. Même quand l’informatique s’est déplacée de l’ordinateur de bureau vers le mobile, Chrome est resté un rouage important du mécanisme d’accumulation des données de Google. Les sites web que vous visitez et les mots-clés utilisés sont traqués et mis à profit pour vous offrir une expérience plus « personnalisée ». Sans une limite claire entre le navigateur et le moteur de recherche, il est difficile de suivre qui connaît quoi à votre propos. Au final, on accepte le compromis et on continue à vivre nos vies, exactement comme les ingénieurs et concepteurs de produits de Google le souhaitent.
En bref, Google a montré à plusieurs reprises qu’il n’avait aucune empathie envers ses utilisateurs finaux. Sa priorité la plus claire est et restera les intérêts des publicitaires.
Voir au-delà
Une compétition saine centrée sur l’utilisateur est ce qui a provoqué l’arrivée des meilleurs produits et expériences depuis les débuts de l’informatique. Avec Chrome dominant 60 % du marché des navigateurs et Chromium envahissant la bureautique sur les trois plateformes majeures, on confie beaucoup à une seule entreprise et écosystème. Un écosystème qui ne semble plus concerné par la performance, ni par l’expérience utilisateur, ni par la vie privée, ni par les progrès de l’informatique.
Mais on a encore la possibilité de changer les choses. On l’a fait il y a une décennie et on peut le faire de nouveau.
Mozilla et Apple font tous deux un travail remarquable pour combler l’écart des standards du Web qui s’est élargi dans les premières années de Chrome. Ils sont même sensiblement en avance sur les questions de performance, utilisation de la batterie, vie privée et sécurité.
Si vous êtes coincés avec des services de Google qui ne marchent pas sur d’autres navigateurs, ou comptez sur Chrome DevTools pour faire votre travail, pensez à utiliser Vivaldi72 à la place. Ce n’est pas l’idéal —Chromium appartient aussi à Google—, mais c’est un pas dans la bonne direction néanmoins. Soutenir des petits éditeurs et encourager la diversité des navigateurs est nécessaire pour renverser, ou au moins ralentir, la croissance malsaine de Chrome.
Je me suis libéré de Chrome en 2014, et je n’y ai jamais retouché. Il est probable que vous vous en tirerez aussi bien que moi. Vous pouvez l’apprécier en tant que navigateur. Et vous pouvez ne pas vous préoccuper des compromissions en termes de vie privée qui viennent avec. Mais l’enjeu est bien plus important que nos préférences personnelles et nos affinités ; une plateforme entière est sur le point de devenir un nouveau jardin clos. Et on en a déjà assez. Donc, faisons ce que nous pouvons, quand nous le pouvons, pour éviter ça.
Glyn Moody sur l’article 13 – Une aberration judiciaire
Glyn Moody est infatigable dans son combat contre les dispositions néfastes de la directive européenne sur le droit d’auteur dont le vote est maintenant imminent. Il y consacre une série d’articles dont nous avons déjà proposé deux traductions.
Voici un troisième volet où l’auteur expose notamment le danger de plaintes injustifiées et automatisées de la part de cyberdélinquants.
Traduction Framalang : jums , Khrys, goofy, Barbara
L’article 13 est criminel et irresponsable
par Glyn Moody
Dans un éditorial précédent, j’ai souligné qu’il existe un gros mensonge au cœur de l’Article 13 de la proposition de directive européenne au sujet du droit d’auteur : il est possible de vérifier les téléversements de matériels non-autorisés sans pouvoir inspecter chaque fichier. L’UE s’est retrouvée dans cette position absurde car elle sait que de nombreux parlementaires européens rejetteraient l’idée d’imposer une obligation de suivi général sur les services en ligne, ne serait-ce que parce que la directive sur le commerce en ligne l’interdit de manière explicite. Au lieu de cela, le texte de l’article 13 prétend simplement que des alternatives techniques peuvent être trouvées, sans les préciser. La session parue récemment de « Q & R sur la proposition de directive au sujet du Copyright numérique » par le Parlement Européen explique encore que si les services ne sont pas assez intelligents pour trouver des solutions et utiliser des filtres sur les téléversements de contenu, c’est forcément de leur faute.
Image par Sheila Sund.
Imposer des obligations légales qu’il est impossible de remplir, c’est avoir une conception totalement irresponsable de la chose judiciaire. Mais il existe un autre aspect de l’article 13 qui est pire encore : c’est qu’il va encourager une nouvelle vague de criminalité. On a du mal à imaginer un plus grand échec qu’une loi qui augmente l’absence de loi.
Une fois encore, le problème vient de l’idée erronée qu’il faut contraindre les entreprises à installer des filtres d’upload (c’est-à-dire de mise en ligne par téléversement). De même que les législateurs européens semblent incapables de comprendre l’idée que les services en ligne seront obligés de mener une surveillance généralisée pour se conformer à l’article 13, de même leur manque de connaissances techniques les rend incapables de comprendre les immenses défis pratiques que représente l’implémentation de cette forme de surveillance généralisée.
Au moins le gouvernement français est bien plus cohérent et honnête sur ce point. Il veut aller encore plus loin que l’accord conclu avec le gouvernement allemand, qui a fini par donner la base de l’article 13 sous le nouveau mandat de la présidence roumaine du Conseil, adopté le vendredi 8 février. La France veut supprimer les références à l’article 15 de la directive sur le e-commerce, qui interdit aux États membres d’imposer des obligations de contrôle généralisé, de manière à rendre plus « clair » que ces catégories d’obligations sont parfaitement justifiées quand il s’agit de protéger des contenus sous droits d’auteur.
Un autre éditorial soulignait certains des défis pratiques que pose la mise en œuvre de cette forme de surveillance généralisée. L’article 13 s’appliquera à tous les supports imaginables. Cela signifie que les services en ligne auront besoin de filtres pour le texte, la musique, l’audio, les images, les cartes, les diagrammes, les photos, les vidéos, les films, les logiciels, les modèles 3D, etc. L’article ne peut être filtré que s’il existe une liste de choses qui doivent être bloquées. Ainsi, dans la pratique, l’article 13 signifie que tout site important acceptant les téléversements d’utilisateurs doit avoir des listes de blocage pour chaque type de matériel. Même lorsqu’elles existent, ces listes sont incomplètes. Pour de nombreux domaines – photos, cartes, logiciels, etc. – elles n’existent tout simplement pas. En outre, pour une grande partie du contenu qui devrait être surveillé, les filtres n’existent pas non plus. En un nouvel exemple de législation irresponsable et paresseuse, l’article 13 demande l’impossible.
Que feront les services en ligne dans une telle situation ? La directive sur le droit d’auteur n’est d’aucune aide, elle dit seulement ce qui doit être fait, pas comment le faire. Cela incitera les entreprises à mettre en place des systèmes susceptibles d’offrir la meilleure protection lorsqu’elles seront confrontées à d’inévitables poursuites judiciaires. La principale préoccupation sera de bloquer avec un matériel d’une efficacité maximale ce qui est censé être bloqué, plutôt que de choisir les approches les moins intrusives possible qui maximisent la liberté d’expression pour les utilisateurs. L’absence de systèmes pour se protéger de cette responsabilité pourrait également signifier que certaines plateformes utiliseront le géoblocage, disparaîtront ou s’éloigneront de l’UE, et que d’autres ne seront, en premier lieu, jamais créées en Europe.
Cette injonction va encourager la mise en place de systèmes permettant à quiconque de soumettre des réclamations sur du contenu, qui sera ensuite bloqué. En adoptant ce système, les entreprises seront en mesure de traiter du contenu pour lequel il n’existe pas de listes de blocage générales et pourront ainsi éviter toute responsabilité en cas de téléchargement non autorisé. En plus d’être le seul moyen pratique de relever l’énorme défi que représente le filtrage de tous les types de contenus protégés par le droit d’auteur, cette approche a l’avantage d’avoir déjà été utilisée ailleurs, bien qu’à une plus petite échelle.
Par exemple, YouTube permet à quiconque de prétendre qu’il est le détenteur des droits d’auteur du contenu qui a été posté sur le service Google, et de le faire supprimer automatiquement. Les conséquences négatives de cette fonctionnalité ont été discutées précédemment ; il suffit de dire ici que le matériel légitime est souvent retiré par erreur, et que faire appel contre ces décisions est difficile et prend du temps, et les résultats sont très imprévisibles. La même chose se produira inévitablement avec les filtres de téléchargement de l’article 13, avec ce détail supplémentaire que le contenu sera bloqué avant même qu’il ne soit affiché, alors que le système automatisé de retrait créé par la Digital Millennium Copyright Act (DMCA) des États-Unis ne fonctionne qu’après que le contenu soit affiché en ligne. Cependant, un article récent sur TorrentFreak révèle une autre possibilité troublante :
Par un horrible abus du système de copyright de YouTube, un YouTubeur rapporte que des arnaqueurs utilisent le système des « 3 coups »73 de la plate-forme pour extorquer de l’argent. Après avoir déposé deux fausses plaintes contre ObbyRaidz, les escrocs l’ont contacté et exigé de l’argent comptant pour éviter un troisième – et la résiliation de son canal.
Avec l’article 13, trois avertissements ne sont même pas nécessaires : si votre téléchargement est repéré par le filtre, votre contenu sera bloqué à jamais. On semble penser qu’il importe peu que des erreurs soient commises, parce que les gens peuvent tout bonnement faire appel. Mais comme nous l’avons déjà mentionné, les processus d’appel sont lents, ne fonctionnent pas et ne sont pas utilisés par les gens ordinaires, qui sont intimidés par le processus dans son ensemble. Ainsi, même la menace de revendiquer du contenu sera beaucoup plus forte avec l’article 13 qu’avec YouTube.
Ce qui veut dire que personne ne peut garantir que son contenu pourra seulement paraître en ligne, sauf pour les grosses sociétés de droits de diffusion (américaines) qui forceront les principales plateformes américaines à passer des accords de licence. Même si votre contenu arrive à passer le filtre sur les téléversements, vous allez encore courir le risque d’être racketté par les arnaqueurs au droit d’auteur qui abusent du système. Les obligations de suspension de l’article 13, qui impliquent que le matériel protégé par le droit d’auteur qui a été signalé par les titulaires de droits (ou les arnaqueurs) ne puisse plus être re-téléchargé, rendent les tentatives de réclamer du contenu ou de remettre quelque chose en ligne avec l’article 13 plus difficiles qu’elles ne le sont actuellement sur YouTube.
C’est vraiment une mauvaise nouvelle pour les nouveaux artistes, qui ont absolument besoin de visibilité et qui n’ont pas les poches pleines pour payer des avocats qui règlent ce genre de problèmes, ou pas assez de temps pour s’en occuper eux-mêmes. Les artistes plus établis perdront des revenus à chaque fois que leur contenu sera bloqué, donc ils décideront peut-être aussi de payer des arnaqueurs qui déposeront des fausses plaintes d’infraction au droit d’auteur. Avec cette nouvelle menace, les militants qui utilisent des sites permettant le téléversement public seront aussi sérieusement touchés : beaucoup de campagnes en ligne sont liées à des événements ou des journées particulières. Elles perdent la majeure partie de leur efficacité si leurs actions sont retardées de plusieurs semaines ou même de plusieurs jours, ce que les procédures d’appel ne manqueront pas de faire valoir. C’est plus simple de payer celui qui vous fait chanter.
Ce problème révèle une autre faille de l’Article 13 : il n’y a aucune pénalité pour avoir injustement prétendu être le détenteur des droits sur un contenu, ce qui empêche la mise en ligne de contenus légitimes bloqués par les filtres. Cela veut dire qu’il n’existe presque aucun obstacle si l’on veut envoyer des milliers, voire des millions, de menaces contre des artistes, des militants et autres. Il est clair que c’est de l’extorsion, évidemment illégale. Mais comme les forces de police sont dépassées aujourd’hui, il est à parier qu’elles ne dédieront que des ressources réduites à chasser les fantômes sur Internet. Il est facile pour les gens de se cacher derrière de faux noms, des comptes temporaires et d’utiliser des systèmes de paiement anonymisés tels que le Bitcoin. Avec assez de temps, il est possible d’établir qui se trouve derrière ces comptes, mais si la somme demandée est trop faible, les autorités ne s’en occuperont pas.
En d’autres termes, la nature trop peu réfléchie de l’Article 13 sur les filtres à l’upload crée une nouvelle catégorie de « crime parfait » en ligne. D’une part, tout le monde peut déposer plainte, pourvu d’avoir une connexion Internet, et ce depuis n’importe où dans le monde, et de l’autre cette plainte est prise sans aucun risque pratiquement. Une combinaison particulièrement séduisante et mortelle. Loin d’aider les artistes, la Directive Copyright pourrait créer un obstacle majeur sur la route de leurs succès.
[MISE À JOUR 13/02 22:50]
Dernières nouvelles de l’article 13 : Julia Reda (Parti Pirate européen) explique ici juliareda.eu/2019/02/eu-copyri où on en est et termine en expliquant ce qu’on peut faire (=intervenir auprès des parlementaires européens)
Voir aussi ce que propose saveyourinternet.eu/fr/

 Environ 200 travailleurs d’Amazon se sont rassemblés devant leur lieu de travail dans le Minnesota le 18 décembre 2018 pour protester contre leurs conditions de travail qui comprennent le pistage des ordinateurs et l’obligation de travailler à grande vitesse, comme scanner un article toutes les 7 secondes.
Environ 200 travailleurs d’Amazon se sont rassemblés devant leur lieu de travail dans le Minnesota le 18 décembre 2018 pour protester contre leurs conditions de travail qui comprennent le pistage des ordinateurs et l’obligation de travailler à grande vitesse, comme scanner un article toutes les 7 secondes.