Les données que récolte Google – Ch.7 et conclusion
Voici déjà la traduction du septième chapitre et de la brève conclusion de Google Data Collection, l’étude élaborée par l’équipe du professeur Douglas C. Schmidt, spécialiste des systèmes logiciels, chercheur et enseignant à l’Université Vanderbilt. Si vous les avez manqués, retrouvez les chapitres précédents déjà publiés.
Il s’agit cette fois-ci de tous les récents produits de Google (ou plutôt Alphabet) qui investissent nos pratiques et nos habitudes : des pages AMP aux fournisseurs de services tiers en passant par les assistants numériques, tout est prétexte à collecte de données directement ou non.
VII. Des produits avec un haut potentiel futur d’agrégation de données
83. Google a d’autres produits qui pourraient être adoptés par le marché et pourraient bientôt servir à la collecte de données, tels que AMP, Photos, Chromebook Assistant et Google Pay. Il faut ajouter à cela que Google est capable d’utiliser les données provenant de partenaires pour collecter les informations de l’utilisateur. La section suivante les décrit plus en détail.
84. Il existe également d’autres applications Google qui peuvent ne pas être largement utilisées. Toutefois, par souci d’exhaustivité, la collecte de données par leur intermédiaire est présentée dans la section VIIII.B de l’annexe.
A. Pages optimisées pour les mobiles (AMP)
85. Les Pages optimisées pour les mobiles (AMP) sont une initiative open source menée par Google pour réduire le temps de chargement des sites Web et des publicités. AMP convertit le HTML standard et le code JavaScript en une version simplifiée développée par Google1 qui stocke les pages validées dans un cache des serveurs du réseau Google pour un accès plus rapide2. AMP fournit des liens vers les pages grâce aux résultats de la recherche Google mais également via des applications tierces telles que LinkedIn et Twitter. D’après AMP : « L’ecosystème AMP compte 25 millions de domaines, plus de 100 fournisseurs de technologie et plateformes de pointe qui couvrent les secteurs de la publication de contenu, les publicités, le commerce en ligne, les petits commerces, le commerce local etc. »3
86. L’illustration 17a décrit les étapes menant à la fourniture d’une page AMP accessible via la recherche Google. Merci de noter que le fournisseur de contenu à travers AMP n’a pas besoin de fournir ses propres caches serveur, car c’est quelque chose que Google fournit pour garantir un délai optimal de livraison aux utilisateurs. Dans la mesure où le cache AMP est hébergé sur les serveurs de Google, lors d’un clic sur un lien AMP produit par la recherche Google, le nom de domaine vient du domaine google.com et non pas du domaine du fournisseur. Ceci est montré grâce aux captures prises lors d’un exemple de recherche de mots clés dans l’illustration 17b.
Illustration 17 : une page web normale qui devient une page AMP.
87. Les utilisateurs peuvent accéder au contenu depuis de multiples fournisseurs dont les articles apparaissent dans les résultats de recherche pendant qu’ils naviguent dans le carrousel AMP, tout en restant dans le domaine de Google. En effet, le cache AMP opère comme un réseau de distribution de contenu (RDC, ou CDN en anglais) appartenant à Google et géré par Google.
88. En créant un outil open source, complété avec un CDN, Google a attiré une large base d’utilisateurs à qui diffuser les sites mobiles et la publicité et cela constitue une quantité d’information significative (p.ex. le contenu lui-même, les pages vues, les publicités, et les informations de celui à qui ce contenu est fourni). Toutes ces informations sont disponibles pour Google parce qu’elles sont collectées sur les serveurs CDN de Google, fournissant ainsi à Google beaucoup plus de données que par tout autre moyen d’accès.
89. L’AMP est très centré sur l’utilisateur, c’est-à-dire qu’il offre aux utilisateurs une expérience de navigation beaucoup plus rapide et améliorée sans l’encombrement des fenêtres pop-up et des barres latérales. Bien que l’AMP représente un changement majeur dans la façon dont le contenu est mis en cache et transmis aux utilisateurs, la politique de confidentialité de Google associée à l’AMP est assez générale4. En particulier, Google est en mesure de recueillir des informations sur l’utilisation des pages Web (par exemple, les journaux de serveur et l’adresse IP) à partir des requêtes envoyées aux serveurs de cache AMP. De plus, les pages standards sont converties en AMP via l’utilisation des API AMP5. Google peut donc accéder à des applications ou à des sites Web (« clients API ») et utiliser toute information soumise par le biais de l’API conformément à ses politiques générales6.
90. Comme les pages Web ordinaires, les pages Web AMP pistent les données d’utilisation via Google Analytics et DoubleClick. En particulier, elles recueillent des informations sur les données de page (par exemple : domaine, chemin et titre de page), les données d’utilisateur (par exemple : ID client, fuseau horaire), les données de navigation (par exemple : ID et référence de page uniques), l’information du navigateur et les données sur les interactions et les événements7. Bien que les modes de collecte de données de Google n’aient pas changé avec l’AMP, la quantité de données recueillies a augmenté puisque les visiteurs passent 35 % plus de temps sur le contenu Web qui se charge avec Google AMP que sur les pages mobiles standard.8
B. Google Assistant
91. Google Assistant est un assistant personnel virtuel auquel on accède par le biais de téléphones mobiles et d’appareils dits intelligents. C’est un assistant virtuel populaire, comme Siri d’Apple, Alexa d’Amazon et Cortana de Microsoft. 9 Google Assistant est accessible via le bouton d’accueil des appareils mobiles sous Android 6.0 ou versions ultérieures. Il est également accessible via une application dédiée sur les appareils iOS10, ainsi que par l’intermédiaire de haut-parleurs intelligents, tel Google Home, qui offre de nombreuses fonctions telles que l’envoi de textes, la recherche de courriels, le contrôle de la musique, la recherche de photos, les réponses aux questions sur la météo ou la circulation, et le contrôle des appareils domestiques intelligents11.
92. Google collecte toutes les requêtes de Google Assistant, qu’elles soient audio ou saisies au clavier. Il collecte également l’emplacement où la requête a été effectuée. L’illustration 18 montre le contenu d’une requête enregistrée par Google. Outre son utilisation via les haut-parleurs de Google Home, Google Assistant est activé sur divers autres haut-parleurs produits par des tiers (par exemple, les casques sans fil de Bose). Au total, Google Assistant est disponible sur plus de 400 millions d’appareils12. Google peut collecter des données via l’ensemble de ces appareils puisque les requêtes de l’Assistant passent par les serveurs de Google.
Figure 18 : Exemple de détails collectés à partir de la requête Google Assistant.
C. Photos
93. Google Photos est utilisé par plus de 500 millions de personnes dans le monde et stocke plus de 1,2 milliard de photos et vidéos chaque jour13. Google enregistre l’heure et les coordonnées GPS de chaque photo prise.Google télécharge des images dans le Google cloud et effectue une analyse d’images pour identifier un large éventail d’objets, tels que les modes de transport, les animaux, les logos, les points de repère, le texte et les visages14. Les capacités de détection des visages de Google permettent même de détecter les états émotionnels associés aux visages dans les photos téléchargées et stockées dans leur cloud15.
94. Google Photos effectue cette analyse d’image par défaut lors de l’utilisation du produit, mais ne fera pas de distinction entre les personnes, sauf si l’utilisateur donne l’autorisation à l’application16. Si un utilisateur autorise Google à regrouper des visages similaires, Google identifie différentes personnes à l’aide de la technologie de reconnaissance faciale et permet aux utilisateurs de partager des photos grâce à sa technologie de « regroupement de visages »1718. Des exemples des capacités de classification d’images de Google avec et sans autorisation de regroupement des visages de l’utilisateur sont présentés dans l’illustration 19. Google utilise Photos pour assembler un vaste ensemble d’informations d’identifications faciales, qui a récemment fait l’objet de poursuites judiciaires19 de la part de certains États.
Illustration : Exemple de reconnaissance d’images dans Google Photos.
D. Chromebook
95. Chromebook est la tablette-ordinateur de Google qui fonctionne avec le système d’exploitation Chrome (Chrome OS) et permet aux utilisateurs d’accéder aux applications sur le cloud. Bien que Chromebook ne détienne qu’une très faible part du marché des PC, il connaît une croissance rapide, en particulier dans le domaine des appareils informatiques pour la catégorie K-12, où il détenait 59,8 % du marché au deuxième trimestre 201720. La collecte de données de Chromebook est similaire à celle du navigateur Google Chrome, qui est décrite dans la section II.A. Chromebooks permet également aux cookies de Google et de domaines tiers de pister l’activité de l’utilisateur, comme pour tout autre ordinateur portable ou PC.
96. De nombreuses écoles de la maternelle à la terminale utilisent des Chromebooks pour accéder aux produits Google via son service GSuite for Education. Google déclare que les données recueillies dans le cadre d’une telle utilisation ne sont pas utilisées à des fins de publicité ciblée21. Toutefois, les étudiants reçoivent des publicités s’ils utilisent des services supplémentaires (tels que YouTube ou Blogger) sur les Chromebooks fournis par leur établissement d’enseignement.
E. Google Pay
97. Google Pay est un service de paiement numérique qui permet aux utilisateurs de stocker des informations de carte de crédit, de compte bancaire et de PayPal pour effectuer des paiements en magasin, sur des sites Web ou dans des applications utilisant Google Chrome ou un appareil Android connecté22. Pay est le moyen par lequel Google collecte les adresses et numéros de téléphone vérifiés des utilisateurs, car ils sont associés aux comptes de facturation. En plus des renseignements personnels, Pay recueille également des renseignements sur la transaction, comme la date et le montant de la transaction, l’emplacement et la description du marchand, le type de paiement utilisé, la description des articles achetés, toute photo qu’un utilisateur choisit d’associer à la transaction, les noms et adresses électroniques du vendeur et de l’acheteur, la description du motif de la transaction par l’utilisateur et toute offre associée à la transaction23. Google traite ses informations comme des informations personnelles en fonction de sa politique générale de confidentialité. Par conséquent il peut utiliser ces informations sur tous ses produits et services pour fournir de la publicité très ciblée24. Les paramètres de confidentialité de Google l’autorisent par défaut à utiliser ces données collectées25.
F. Données d’utilisateurs collectées auprès de fournisseurs de données tiers
98. Google collecte des données de tiers en plus des informations collectées directement à partir de leurs services et applications. Par exemple, en 2014, Google a annoncé qu’il commencerait à suivre les ventes dans les vrais commerces réels en achetant des données sur les transactions par carte de crédit et de débit. Ces données couvraient 70 % de toutes les opérations de crédit et de débit aux États-Unis26. Elles contenaient le nom de l’individu, ainsi que l’heure, le lieu et le montant de son achat27.
99. Les données de tiers sont également utilisées pour aider Google Pay, y compris les services de vérification, les informations résultant des transactions Google Pay chez les commerçants, les méthodes de paiement, l’identité des émetteurs de cartes, les informations concernant l’accès aux soldes du compte de paiement Google, les informations de facturation des opérateurs et transporteurs et les rapports des consommateurs28. Pour les vendeurs, Google peut obtenir des informations des organismes de crédit aux particuliers ou aux entreprises.
100. Bien que l’information des utilisateurs tiers que Google reçoit actuellement soit de portée limitée, elle a déjà attiré l’attention des autorités gouvernementales. Par exemple, la FTC a annoncé une injonction contre Google en juillet 2017 concernant la façon dont la collecte par Google de données sur les achats des consommateurs porte atteinte à la vie privée électronique29. L’injonction conteste l’affirmation de Google selon laquelle il peut protéger la vie privée des consommateurs tout au long du processus en utilisant son algorithme. Bien que d’autres mesures n’aient pas encore été prises, l’injonction de la FTC est un exemple des préoccupations du public quant à la quantité de données que Google recueille sur les consommateurs.
VIII. CONCLUSION
101. Google compte un pourcentage important de la population mondiale parmi ses clients directs, avec de multiples produits en tête de leurs marchés mondiaux et de nombreux produits qui dépassent le milliard d’utilisateurs actifs par mois. Ces produits sont en mesure de recueillir des données sur les utilisateurs au moyen d’une variété de techniques qui peuvent être difficiles à comprendre pour un utilisateur moyen. Une grande partie de la collecte de données de Google a lieu lorsque l’utilisateur n’utilise aucun de ses produits directement. L’ampleur d’une telle collecte est considérable, en particulier sur les appareils mobiles Android. Et bien que ces informations soient généralement recueillies sans identifier un utilisateur unique, Google a la possibilité d’utiliser les données recueillies auprès d’autres sources pour désanonymiser une telle collecte.
Il s’agit cette fois de comprendre comment Google complète les données collectées avec les données provenant des applications et des comptes connectés des utilisateurs.
VI. Données collectées par les applications clés de Google destinées aux particuliers
67. Google a des dizaines de produits et services qui évoluent en permanence (une liste est disponible dans le tableau 4, section IX.B de l’annexe). On accède souvent à ces produits grâce à un compte Google (ou on l’y associe), ce qui permet à Google de relier directement les détails des activités de l’utilisateur de ses produits et services à un profil utilisateur. En plus des données d’usage de ses produits, Google collecte également des identificateurs et des données de localisation liés aux appareils lorsqu’on accède aux services Google. 30
68. Certaines applications de Google (p.ex. YouTube, Search, Gmail et Maps) occupent une place centrale dans les tâches de base qu’une multitude d’utilisateurs effectuent quotidiennement sur leurs appareils fixes ou mobiles. Le tableau 2 décrit la portée de ces produits clés. Cette section explique comment chacune de ces applications majeures collecte les informations des utilisateurs.
Tableau 2 : Portée mondiale des principales applications Google
Produits
Utilisateurs actifs
Search
Plus d’un milliard d’utilisateurs actifs par mois, 90.6 % de part de marché des moteurs de recherche 31
Youtube
Plus de 1,8 milliard d’utilisateurs inscrits et actifs par mois 32
Maps
Plus d’un milliard d’utilisateurs actifs par mois 33
69. Google Search est le moteur de recherche sur internet le plus populaire au monde 35, avec plus de 11 milliards de requêtes par mois aux États-Unis 36. En plus de renvoyer un classement de pages web en réponse aux requêtes globales des utilisateurs, Google exploite d’autres outils basés sur la recherche, tels que Google Finance, Flights (vols), News (actualités), Scholar (recherche universitaire), Patents (brevets), Books (livres), Images, Videos et Hotels. Google utilise ses applications de recherche afin de collecter des données liées aux recherches, à l’historique de navigation ainsi qu’aux activités d’achats et de clics sur publicités. Par exemple, Google Finance collecte des informations sur le type d’actions que les utilisateurs peuvent suivre, tandis que Google Flight piste leurs réservations et recherches de voyage.
70. Dès lors que Search est utilisé, Google collecte les données de localisation par différents biais, sur ordinateur ou sur mobile, comme décrit dans les sections précédentes. Google enregistre toute l’activité de recherche d’un utilisateur ou utilisatrice et la relie à son compte Google si cette personne est connectée. L’illustration 13 montre un exemple d’informations collectées par Google sur une recherche utilisateur par mot-clé et la navigation associée.
Illustration 13 : Un exemple de collecte de données de recherche extrait de la page My Activity (Mon Activité) d’un utilisateur
71. Non seulement c’est le moteur de recherche par défaut sur Chrome et les appareils Google, mais Google Search est aussi l’option par défaut sur d’autres navigateurs internet et applications grâce à des arrangements de distribution. Ainsi, Google est récemment devenu le moteur de recherche par défaut sur le navigateur internet Mozilla Firefox 37 dans des régions clés (dont les USA et le Canada), une position occupée auparavant par Yahoo. De même, Apple est passé de Microsoft Bing à Google pour les résultats de recherche via Siri sur les appareils iOS et Mac 38. Google a des accords similaires en place avec des OEM (fabricants d’équipement informatique ou électronique) 39, ce qui lui permet d’atteindre les consommateurs mobiles.
B. YouTube
72. YouTube met à disposition des utilisateurs et utilisatrices une plateforme pour la mise en ligne et la visualisation de contenu vidéo. Il attire plus de 180 millions de personnes rien qu’aux États-Unis et a la particularité d’être le deuxième site le plus visité des États-Unis 40, juste derrière Google Search. Au sein des entreprises de streaming multimédia, YouTube possède près de 80 % de parts de marché en termes de visites mensuelles (comme décrit dans l’illustration 14). La quantité de contenu mis en ligne et visualisé sur YouTube est conséquente : 400 heures de vidéo sont mises en ligne chaque minute 41 et 1 milliard d’heures de vidéo sont visualisées quotidiennement sur la plateforme YouTube.42
Illustration 14 : Comparaison d’audiences mensuelles des principaux sites multimédia aux États-Unis 43
73. Les utilisateurs peuvent accéder à YouTube sur l’ordinateur (navigateur internet), sur leurs appareils mobiles (application et/ou navigateur internet) et sur Google Home (via un abonnement payant appelé YouTube Red). Google collecte et sauvegarde l’historique de recherche, l’historique de visualisation, les listes de lecture, les abonnements et les commentaires aux vidéos. La date et l’horaire de chaque activité sont ajoutés à ces informations.
74. Si un utilisateur se connecte à son compte Google pour accéder à n’importe quelle application Google via un navigateur internet (par ex. Chrome, Firefox, Safari), Google reconnaît l’identité de l’utilisateur, même si l’accès à la vidéo est réalisé par un site hors Google (ex. : vidéos YouTube lues sur cnn.com). Cette fonctionnalité permet à Google de pister l’utilisation YouTube d’un utilisateur à travers différentes plateformes tierces. L’illustration 15 montre un exemple de données YouTube collectées.
Illustration 15 : Exemple de collecte de données YouTube dans My Activity (Mon Activité)
75. Google propose également un produit YouTube différencié pour les enfants, appelé YouTube Kids, dans l’intention d’offrir une version « familiale » de YouTube avec des fonctionnalités de contrôle parental et de filtres vidéos. Google collecte des informations de YouTube Kids, notamment le type d’appareil, le système d’exploitation, l’identifiant unique de l’appareil, les informations de journalisation et les détails d’utilisation du service. Google utilise ensuite ces informations pour fournir des annonces publicitaires limitées, qui ne sont pas cliquables et dont le format, la durée et le site sont limités.44.
C. Maps
76. Maps est l’application phare de navigation routière de Google. Google Maps peut déterminer les trajets et la vitesse d’un utilisateur et ses lieux de fréquentation régulière (ex. : domicile, travail, restaurants et magasins). Cette information donne à Google une idée des intérêts (ex. : préférences d’alimentation et d’achats), des déplacements et du comportement de l’utilisateur.
77. Maps utilise l’adresse IP, le GPS, le signal cellulaire et les points d’accès au Wi-Fi pour calculer la localisation d’un appareil. Les deux dernières informations sont collectées par le biais de l’appareil où Maps est utilisé, puis envoyées à Google pour évaluer la localisation via son interface de localisation (Location API). Cette interface fournit de nombreux détails sur un utilisateur, dont les coordonnées géographiques, son état stationnaire ou en mouvement, sa vitesse et la détermination probabiliste de son mode de transport (ex. : en vélo, voiture, train, etc.).
78. Maps sauvegarde un historique des lieux qu’un utilisateur connecté à Maps par son compte Googe a visités. L’illustration 16. montre un exemple d’un tel historique 45. Les points rouges indiquent les coordonnées géographiques recueillies par Maps lorsque l’utilisateur se déplace ; les lignes bleues représentent les projections de Maps sur le trajet réel de l’utilisateur.
Illustration 16 : Exemple d’un historique Google Maps (« Timeline ») d’un utilisateur réel
79. La précision des informations de localisation recueillies par les applications de navigation routière permet à Google de non seulement cibler des audiences publicitaires, mais l’aide aussi à fournir des annonces publicitaires aux utilisateurs lorsqu’ils s’approchent d’un magasin 46. Google Maps utilise de plus ces informations pour générer des données de trafic routier en temps réel.47
D. Gmail
80. Gmail sauvegarde tous les messages (envoyés et reçus), le nom de l’expéditeur, son adresse email et la date et l’heure des messages envoyés ou reçus. Puisque Gmail représente pour beaucoup un répertoire central pour la messagerie électronique, il peut déterminer leurs intérêts en scannant le contenu de leurs courriels, identifier les adresses de commerçants grâce à leurs courriels publicitaires ou les factures envoyées par message électronique, et connaître l’agenda d’un utilisateur (ex. : réservations à dîner, rendez-vous médicaux…). Étant donné que les utilisateurs utilisent leur identifiant Gmail pour des plateformes tierces (Facebook, LinkedIn…), Google peut analyser tout contenu qui leur parvient sous forme de courriel (ex. : notifications, messages).
81. Depuis son lancement en 2004 jusqu’à la fin de l’année 2017 (au moins), Google peut avoir analysé le contenu des courriels Gmail pour améliorer le ciblage publicitaire et les résultats de recherche ainsi que ses filtres de pourriel. Lors de l’été 2016, Google a franchi une nouvelle étape et a modifié sa politique de confidentialité pour s’autoriser à fusionner les données de navigation, autrefois anonymes, de sa filiale DoubleClick (qui fournit des publicités personnalisées sur internet) avec les données d’identification personnelles qu’il amasse à travers ses autres produits, dont Gmail 48. Le résultat : « les annonces publicitaires DoubleClick qui pistent les gens sur Internet peuvent maintenant leur être adaptées sur mesure, en se fondant sur les mots-clés qu’ils ont utilisés dans leur messagerie Gmail. Cela signifie également que Google peut à présent reconstruire le portrait complet d’une utilisatrice ou utilisateur par son nom, en fonction de tout ce qui est écrit dans ses courriels, sur tous les sites visités et sur toutes les recherches menées. » 49
82. Vers la fin de l’année 2017, Google a annoncé qu’il arrêterait la personnalisation des publicités basées sur les messages Gmail 50. Cependant, Google a annoncé récemment qu’il continue à analyser les messages Gmail pour certaines raisons 51.
Framasoft : les chiffres à connaître
Chaque année, nous nous rappelons à votre bon souvenir pour vous inciter à soutenir financièrement nos actions. Vous voyez au fil du temps de nouveaux services et des campagnes ambitieuses se mettre en place. Mais peut-être voudriez-vous savoir en chiffres ce que nous avons réalisé jusqu’à présent. Voilà de quoi vous satisfaire.
Par souci de transparence, nos bilans financiers sont publiés chaque année et nous offrons en temps réel l’accès à certaines statistiques d’usage de nos services. Mais cela ne couvre pas l’ensemble de nos actions et nous nous sommes dit que vous pourriez en vouloir plus que ce qui se trouve sur Framastats.
Libre à vous de picorer un chiffre ou l’autre, d’en faire des quizz ou de les reprendre pour votre argumentaire afin de démontrer l’efficacité du monde associatif. Nous espérons que vous y verrez l’illustration de notre engagement à promouvoir le libre sous toutes ses formes.
1 : Depuis son lancement voilà un an, chaque heure un nouveau site naît sur Framasite.
2,5 : Les 5 000 utilisatrices de Framadrive utilisent 2,5 To de données pour leurs 3 millions de fichiers.
5 : Toutes les 5 secondes en moyenne, un utilisateur se connecte sur les services Framasoft.
10 : Toutes les 10 minutes à peine, une nouvelle visioconférence est créée sur Framatalk, qui accueille environ 400 participant⋅es par jour.
Framatalk, la vision-conférence Libre, vue par Pëhà
11 : C’est le nombre de pizzas, additionné aux 47 plateaux-repas et 25 couscous qu’ont avalé les 25 personnes présentes pendant les 4 jours de l’AG Framasoft 2018.
33 : Framasoft vous propose 33 services en ligne alternatifs, respectueux de vos données et sans publicité.
35 : Grâce aux 300 abonné·e·s à la liste Framalang, ce ne sont pas moins de 35 traductions qui ont été effectuées et publiées sur le Framablog en un an.
252 : http://joinpeertube.org , c’est une fédération de 252 instances (déclarées) affichant 23 017 vidéos libérées de YouTube
750 : Chaque mois, notre support répond à environ 750 demandes, questions et problèmes. Avec un seul salarié !
Framalibre, l’annuaire à l’origine de Framasoft
871 : Framalibre, l’annuaire du libre vous présente 871 projets, logiciels ou créations artistiques sous licence libre à l’aide de courtes notices.
1 000 : Framaforms c’est environ 1000 formulaires créés quotidiennement et plus de 44 000 formulaires hébergés.
1 800 : Chaque jour, ce sont près de 1 800 images qui viennent s’ajouter aux 770 000 déjà présentes sur les serveurs de Framapic.
2 236 : Le Framablog c’est 2 236 articles et 28 919 commentaires depuis 2006, faisant le lien entre logiciel libre et société/culture libres.
3 000 : 4 000 utilisatrices réparties en 250 groupes ont créé plus de 3 000 présentations et conférences grâce à Framaslides alors qu’il n’est encore qu’en beta !
6 000 : Framemo héberge 6 000 tableaux qui ont aidé des utilisateurs à mettre leurs idées au clair, sans avoir à s’inscrire.
Framacarte, pour ne pas se perdre en chemin
6 000 : Sur Framacarte ajoutez votre propre fond de carte aux 6 000 qui existent déjà, en partenariat avec OpenStreetMap.
6 579 : Framapiaf, c’est 6 579 utilisateurs ayant « pouetté » 734 500 messages sur cette instance Mastodon, elle-même fédérée avec près de 4 000 autres instances (totalisant environ 1,5 million de comptes).
11 000 : Avec Framanews, ce sont 500 lecteurs (limite qu’on a nous même fixée pour restreindre la charge du serveur) qui accèdent régulièrement à leurs 11 000 flux RSS.
13 000 : Près de 4 000 utilisatrices accèdent à leur 13 000 notes depuis n’importe quel navigateur, avec un accès sécurisé, sur Framanotes.
15 000 : Avec Framabag 15 000 personnes ont pu sauvegarder et classer 1,5 million d’articles.
Framagit, pour partager librement votre code
25 000 : Notre forge logicielle, Framagit, héberge plus de 25 000 projets (et autant d’utilisateurs).
35 000 : Avec MyFrama, 35 000 utilisatrices partagent librement leurs liens Internet.
43 000 : Accédez à une des 43 000 adresses Web abrégées ou créez-en une grâce au raccourcisseur d’URL Framalink qui ne traque pas vos visiteurs.
52 000 : Découvrez Framasphère, membre du réseau social libre et fédéré Diaspora*, où 52 000 utilisatrices ont échangé environ 600 000 messages et autant de commentaires.
75 000 : Près de 75 000 joueurs ont pu faire une petite pause ludique sans s’exposer à de la publicité sur Framagames.
Framadrop, le partage aisé de gros fichier, en sécurité
100 000 : Sur Framadrop plus de 100 000 fichiers ont pu être échangés en toute confidentialité.
130 000 : Framacalc accueille plus de 130 000 feuilles de calcul, où vos données ne sont pas espionnées ni revendues
142 600 : Sur Framapad, c’est en moyenne plus de 142 600 pads actifs chaque jour et presque 8 millions d’utilisateurs depuis ses débuts.
150 000 : Les serveurs de Framalistes adressent en moyenne 150 000 courriels chaque jour aux 280 000 inscrites à des listes de discussion.
200 000 : Êtes-vous l’une des 200 000 personnes à avoir consulté un des 23 000 messages chiffrés de Framabin ?
500 000 : Framadate c’est plus de 500 000 visites par mois et plus de 1 000 sondages créés chaque jour.
Framapiaf, notre instance Mastodon
2 500 000 : Plus de 2 millions et demi de personnes ont développé leurs idées, échafaudé des projets sur Framindmap depuis sa mise en place.
3 350 000 : Grâce à Framabook, 3 350 000 lecteurs ont pu télécharger en toute légalité un des 47 ouvrages librement publiés.
5 000 000 : Sur Framagenda environ 35 000 utilisateurs gèrent un million de contacts. Ils organisent et partagent près de cinq millions d’événements.
10 000 000 : Comme près de 40 000 personnes, travaillez en équipe sur Framateam et rejoignez un des 80 000 canaux avec presque 10 millions de messages !
Et le chiffre essentiel pour que tout cela soit possible, c’est celui de nos donatrices et donateurs (2381 en moyenne chaque année) : appuyez sur ce bouton pour le faire croître de 1
Ce que peut faire votre Fournisseur d’Accès à l’Internet
Nous sommes ravis et honorés d’accueillir Stéphane Bortzmeyer qui allie une compétence de haut niveau sur des questions assez techniques et une intéressante capacité à rendre assez claires des choses complexes. Nous le remercions de nous expliquer dans cet article quelles pratiques douteuses tentent certains fournisseurs d’accès à l’Internet, quelles menaces cela représente pour la confidentialité comme pour la neutralité du Net, et pourquoi la parade du chiffrement fait l’objet d’attaques répétées de leur part.
Pour vous connecter à l’Internet, vous avez besoin d’un FAI (Fournisseur d’Accès à l’Internet), une entreprise ou une association dont le métier est de relier des individus ou des organisations aux autres FAI. En effet, l’Internet est une coalition de réseaux, chaque FAI a le sien, et ce qui constitue l’Internet global, c’est la connexion de tous ces FAI entre eux. À part devenir soi-même FAI, la seule façon de se connecter à l’Internet est donc de passer par un de ces FAI. La question de la confiance est donc cruciale : qu’est-ce que mon FAI fait sans me le dire ?
Outre son travail visible (vous permettre de regarder Wikipédia, et des vidéos avec des chats mignons), le FAI peut se livrer à des pratiques plus contestables, que cet article va essayer d’expliquer. L’article est prévu pour un vaste public et va donc simplifier une réalité parfois assez compliquée.
Notons déjà tout de suite que je ne prétends pas que tous les FAI mettent en œuvre les mauvaises pratiques décrites ici. Il y a heureusement des FAI honnêtes. Mais toutes ces pratiques sont réellement utilisées aujourd’hui, au moins par certains FAI.
La langue française a un seul verbe, « pouvoir », pour désigner à la fois une possibilité technique (« ma voiture peut atteindre 140 km/h ») et un droit (« sur une route ordinaire, je peux aller jusqu’à 80 km/h »). Cette confusion des deux possibilités est très fréquente dans les discussions au sujet de l’Internet. Ici, je parlerais surtout des possibilités techniques. Les règles juridiques et morales encadrant les pratiques décrites ici varient selon les pays et sont parfois complexes (et je ne suis ni juriste ni moraliste) donc elles seront peu citées dans cet article.
Au sujet du numérique
Pour résumer les possibilités du FAI (Fournisseur d’Accès à l’Internet), il faut se rappeler de quelques propriétés essentielles du monde numérique :
Modifier des données numériques ne laisse aucune trace. Contrairement à un message physique, dont l’altération, même faite avec soin, laisse toujours une trace, les messages envoyés sur l’Internet peuvent être changés sans que ce changement ne se voit.
Copier des données numériques, par exemple à des fins de surveillance des communications, ne change pas ces données, et est indécelable. Elle est très lointaine, l’époque où (en tout cas dans les films policiers), on détectait une écoute à un « clic » entendu dans la communication ! Les promesses du genre « nous n’enregistrons pas vos données » sont donc impossibles à vérifier.
Modifier les données ou bien les copier est très bon marché, avec les matériels et logiciels modernes. Le FAI qui voudrait le faire n’a même pas besoin de compétences pointues : les fournisseurs de matériel et de logiciel pour FAI ont travaillé pour lui et leur catalogue est rempli de solutions permettant modification et écoute des données, solutions qui ne sont jamais accompagnées d’avertissements légaux ou éthiques.
Une publicité pour un logiciel d’interception des communications, même chiffrées. Aucun avertissement légal ou éthique dans la page.
Modifier le trafic réseau
Commençons avec la possibilité technique de modification des données numériques. On a vu qu’elle était non seulement faisable, mais en outre facile. Citons quelques exemples où l’internaute ne recevait pas les données qui avaient été réellement envoyées, mais une version modifiée :
de 2011 à 2013 (et peut-être davantage), en France, le FAI SFR modifiait les images envoyées via son réseau, pour en diminuer la taille. Une image perdait donc ainsi en qualité. Si la motivation (diminuer le débit) était compréhensible, le fait que les utilisateurs n’étaient pas informés indique bien que SFR était conscient du caractère répréhensible de cette pratique.
en 2018 (et peut-être avant), Orange Tunisie modifiait les pages Web pour y insérer des publicités. La modification avait un intérêt financier évident pour le FAI, et aucun intérêt pour l’utilisateur. On lit parfois que la publicité sur les pages Web est une conséquence inévitable de la gratuité de l’accès à cette page mais, ici, bien qu’il soit client payant, l’utilisateur voit des publicités qui ne rapportent qu’au FAI. Comme d’habitude, l’utilisateur n’avait pas été notifié, et le responsable du compte Twitter d’Orange, sans aller jusqu’à nier la modification (qui est interdite par la loi tunisienne), la présentait comme un simple problème technique.
en 2015 (et peut-être avant), Verizon Afrique du Sud modifiait les échanges effectués entre le téléphone et un site Web pour ajouter aux demandes du téléphone des informations comme l’IMEI (un identificateur unique du téléphone) ou bien le numéro de téléphone de l’utilisateur. Cela donnait aux gérants des sites Web des informations que l’utilisateur n’aurait pas donné volontairement. On peut supposer que le FAI se faisait payer par ces gérants de sites en échange de ce service.
Il s’agit uniquement des cas connus, c’est-à-dire de ceux où des experts ont décortiqué ce qui se passait et l’ont documenté. Il y a certainement de nombreux autres cas qui passent inaperçus. Ce n’est pas par hasard si la majorité de ces manipulations se déroulent dans les pays du Sud, où il y a moins d’experts disponibles pour l’analyse, et où l’absence de démocratie politique n’encourage pas les citoyens à regarder de près ce qui se passe. Il n’est pas étonnant que ces modifications du trafic qui passe dans le réseau soient la règle en Chine. Ces changements du trafic en cours de route sont plus fréquents sur les réseaux de mobiles (téléphone mobile) car c’est depuis longtemps un monde plus fermé et davantage contrôlé, où les FAI ont pris de mauvaises habitudes.
Quelles sont les motivations des FAI pour ces modifications ? Elles sont variées, souvent commerciales (insertion de publicités) mais peuvent être également légales (obligation de censure passant techniquement par une modification des données).
Mais ces modifications sont une violation directe du principe de neutralité de l’intermédiaire (le FAI). La « neutralité de l’Internet » est parfois présentée à tort comme une affaire financière (répartition des bénéfices entre différents acteurs de l’Internet) alors qu’elle est avant tout une protection des utilisateurs : imaginez si la Poste modifiait le contenu de vos lettres avant de les distribuer !
Les FAI qui osent faire cela le savent très bien et, dans tous les cas cités, aucune information des utilisateurs n’avait été faite. Évidemment, « nous changerons vos données au passage, pour améliorer nos bénéfices » est plus difficile à vendre aux clients que « super génial haut débit, vos vidéos et vos jeux plus rapides ! » Parfois, même une fois les interférences avec le trafic analysées et publiées, elles sont niées, mais la plupart du temps, le FAI arrête ces pratiques temporairement, sans explications ni excuses.
Surveiller le trafic réseau
De même que le numérique permet de modifier les données en cours de route, il rend possible leur écoute, à des fins de surveillance, politique ou commerciale. Récolter des quantités massives de données, et les analyser, est désormais relativement simple. Ne croyez pas que vos données à vous sont perdues dans la masse : extraire l’aiguille de la botte de foin est justement ce que les ordinateurs savent faire le mieux.
Grâce au courage du lanceur d’alerte Edward Snowden, la surveillance exercée par les États, en exploitant ces possibilités du numérique, est bien connue. Mais il n’y a pas que les États. Les grands intermédiaires que beaucoup de gens utilisent comme médiateurs de leurs communications (tels que Google ou Facebook) surveillent également massivement leurs utilisateurs, en profitant de leur position d’intermédiaire. Le FAI est également un intermédiaire, mais d’un type différent. Il a davantage de mal à analyser l’information reçue, car elle n’est pas structurée pour lui. Mais par contre, il voit passer tout le trafic réseau, alors que même le plus gros des GAFA (Google, Apple, Facebook, Amazon) n’en voit qu’une partie.
L’existence de cette surveillance par les FAI ne fait aucun doute, mais est beaucoup plus difficile à prouver que la modification des données. Comme pour la modification des données, c’est parfois une obligation légale, où l’État demande aux FAI leur assistance dans la surveillance. Et c’est parfois une décision d’un FAI.
Les données ainsi récoltées sont parfois agrégées (regroupées en catégories assez vastes pour que l’utilisateur individuel puisse espérer qu’on ne trouve pas trace de ses activités), par exemple quand elles sont utilisées à des fins statistiques. Elles sont dans ce cas moins dangereuses que des données individuelles. Mais attention : le diable est dans les détails. Il faut être sûr que l’agrégation a bien noyé les détails individuels. Quand un intermédiaire de communication proclame bien fort que les données sont « anonymisées », méfiez-vous. Le terme est utilisé à tort et à travers, et désigne souvent des simples remplacements d’un identificateur personnel par un autre, tout aussi personnel.
La solution du chiffrement
Ces pratiques de modification ou de surveillance des données sont parfois légales et parfois pas. Même quand elles sont illégales, on a vu qu’elles étaient néanmoins pratiquées, et jamais réprimées par la justice. Il est donc nécessaire de ne pas compter uniquement sur les protections juridiques mais également de déployer des protections techniques contre la modification et l’écoute. Deux catégories importantes de protections existent : minimiser les données envoyées, et les chiffrer. La minimisation consiste à envoyer moins de données, et elle fait partie des protections imposées par le RGPD (Règlement [européen] Général sur la Protection des Données). Combinée au chiffrement, elle protège contre la surveillance. Le chiffrement, lui, est la seule protection contre la modification des données.
Mais c’est quoi, le chiffrement ? Le terme désigne un ensemble de techniques, issues de la mathématique, et qui permet d’empêcher la lecture ou la modification d’un message. Plus exactement, la lecture est toujours possible, mais elle ne permet plus de comprendre le message, transformé en une série de caractères incompréhensibles si on ne connait pas la clé de déchiffrement. Et la modification reste possible mais elle est détectable : au déchiffrement, on voit que les données ont été modifiées. On ne pourra pas les lire mais, au moins, on ne recevra pas des données qui ne sont pas les données authentiques.
Dans le contexte du Web, la technique de chiffrement la plus fréquente se nomme HTTPS (HyperText Transfer Protocol Secure). C’est celle qui est utilisée quand une adresse Web commence par https:// , ou quand vous voyez un cadenas vert dans votre navigateur, à gauche de l’adresse. HTTPS sert à assurer que les pages Web que vous recevez sont exactement celles envoyées par le serveur Web, et il sert également à empêcher des indiscrets de lire au passage vos demandes et les réponses. Ainsi, dans le cas de la manipulation faite par Orange Tunisie citée plus haut, HTTPS aurait empêché cet ajout de publicités.
Pour toutes ces raisons, HTTPS est aujourd’hui massivement déployé. Vous le voyez de plus en plus souvent par exemple sur ce blog que vous êtes en train de lire.
Tous les sites Web sérieux ont aujourd’hui HTTPS
Le chiffrement n’est pas utilisé que par HTTPS. Si vous utilisez un VPN (Virtual Private Network, « réseau privé virtuel »), celui-ci chiffre en général les données, et la motivation des utilisateurs de VPN est en effet en général d’échapper à la surveillance et à la modification des données par les FAI. C’est particulièrement important pour les accès publics (hôtels, aéroports, Wifi du TGV) où les manipulations et filtrages sont quasi-systématiques.
Comme toute technique de sécurité, le chiffrement n’est pas parfait, et il a ses limites. Notamment, la communication expose des métadonnées (qui communique, quand, même si on n’a pas le contenu de la communication) et ces métadonnées peuvent être aussi révélatrices que la communication elle-même. Le système « Tor », qui peut être vu comme un type de VPN particulièrement perfectionné, réduit considérablement ces métadonnées.
Le chiffrement est donc une technique indispensable aujourd’hui. Mais il ne plait pas à tout le monde. Lors du FIC (Forum International de la Cybersécurité) en 2015, le représentant d’un gros FAI français déplorait en public qu’en raison du chiffrement, le FAI ne pouvait plus voir ce que faisaient ses clients. Et ce raisonnement est apparu dans un document d’une organisation de normalisation, l’IETF (Internet Engineering Task Force). Ce document, nommé « RFC 8404 »52 décrit toutes les pratiques des FAI qui peuvent être rendues difficiles ou impossibles par le chiffrement. Avant le déploiement massif du chiffrement, beaucoup de FAI avaient pris l’habitude de regarder trop en détail le trafic qui circulait sur leur réseau. C’était parfois pour des motivations honorables, par exemple pour mieux comprendre ce qui passait sur le réseau afin de l’améliorer. Mais, aujourd’hui, compte-tenu de ce qu’on sait sur l’ampleur massive de la surveillance, il est urgent de changer ses pratiques, au lieu de simplement regretter que ce qui était largement admis autrefois soit maintenant rejeté.
Cette liste de pratiques de certains FAI est une information intéressante mais il est dommage que ce document de l’IETF les présente comme si elles étaient toutes légitimes, alors que beaucoup sont scandaleuses et ne devraient pas être tolérées. Si le chiffrement les empêche, tant mieux !
Conclusion
Le déploiement massif du chiffrement est en partie le résultat des pratiques déplorables de certains FAI. Il est donc anormal que ceux-ci se plaignent des difficultés que leur pose le chiffrement. Ils sont les premiers responsables de la méfiance des utilisateurs !
La guerre contre les pratiques douteuses, déjà au XIe siècle… – Image retrouvée sur ce site.
J’ai surtout parlé ici des risques que le FAI écoute les messages, ou les modifie. Mais la place cruciale du FAI dans la communication fait qu’il existe d’autres risques, comme celui de censure de certaines activités ou certains services, ou de coupure d’accès. À l’heure où la connexion à l’Internet est indispensable pour tant d’activités, une telle coupure serait très dommageable.
Quelles sont les solutions, alors ? Se passer de FAI n’est pas réaliste. Certes, des bricoleurs peuvent connecter quelques maisons proches en utilisant des techniques fondées sur les ondes radio, mais cela ne s’étend pas à tout l’Internet. Par contre, il ne faut pas croire qu’un FAI est forcément une grosse entreprise commerciale. Ce peut être une collectivité locale, une association, un regroupement de citoyens. Dans certains pays, des règles très strictes imposées par l’État limitent cette activité de FAI, afin de permettre le maintien du contrôle des citoyens. Heureusement, ce n’est pas (encore ?) le cas en France. Par exemple, la FFDN (Fédération des Fournisseurs d’Accès Internet Associatifs) regroupe de nombreux FAI associatifs en France. Ceux-ci se sont engagés à ne pas recourir aux pratiques décrites plus haut, et notamment à respecter le principe de neutralité.
Bien sûr, monter son propre FAI ne se fait pas en cinq minutes dans son garage. Mais c’est possible en regroupant un collectif de bonnes volontés.
Et, si on n’a pas la possibilité de participer à l’aventure de la création d’un FAI, et pas de FAI associatif proche, quelles sont les possibilités ? Peut-on choisir un bon FAI commercial, en tout cas un qui ne viole pas trop les droits des utilisateurs ? Il est difficile de répondre à cette question. En effet, aucun FAI commercial ne donne des informations détaillées sur ce qui est possible et ne l’est pas. Les manœuvres comme la modification des images dans les réseaux de mobiles sont toujours faites en douce, sans information des clients. Même si M. Toutlemonde était prêt à passer son week-end à comparer les offres de FAI, il ne trouverait pas l’information essentielle « est-ce que ce FAI s’engage à rester strictement neutre ? » En outre, contrairement à ce qui existe dans certains secteurs économiques, comme l’agro-alimentaire, il n’existe pas de terminologie standardisée sur les offres des FAI, ce qui rend toute comparaison difficile.
Dans ces conditions, il est difficile de compter sur le marché pour réguler les pratiques des FAI. Une régulation par l’État n’est pas forcément non plus souhaitable (on a vu que c’est parfois l’État qui oblige les FAI à surveiller les communications, ainsi qu’à modifier les données transmises). À l’heure actuelle, la régulation la plus efficace reste la dénonciation publique des mauvaises pratiques : les FAI reculent souvent, lorsque des modifications des données des utilisateurs sont analysées et citées en public. Cela nécessite du temps et des efforts de la part de ceux et celles qui font cette analyse, et il faut donc saluer leur rôle.
Il s’agit aujourd’hui de mesurer ce que les plateformes les plus populaires recueillent de nos smartphones
Traduction Framalang : Côme, goofy, Khrys, Mika, Piup. Remerciements particuliers à badumtss qui a contribué à la traduction de l’infographie.
La collecte des données par les plateformes Android et Chrome
11. Android et Chrome sont les plateformes clés de Google qui facilitent la collecte massive de données des utilisateurs en raison de leur grande portée et fréquence d’utilisation. En janvier 2018, Android détenait 53 % du marché américain des systèmes d’exploitation mobiles (iOS d’Apple en détenait 45 %)53 et, en mai 2017, il y avait plus de 2 milliards d’appareils Android actifs par mois dans le monde.54
12. Le navigateur Chrome de Google représentait plus de 60 % de l’utilisation mondiale de navigateurs Internet avec plus d’un milliard d’utilisateurs actifs par mois, comme l’indiquait le rapport Q4 10K de 201755. Les deux plateformes facilitent l’usage de contenus de Google et de tiers (p.ex. applications et sites tiers) et fournissent donc à Google un accès à un large éventail d’informations personnelles, d’activité web, et de localisation.
A. Collecte d’informations personnelles et de données d’activité
13. Pour télécharger et utiliser des applications depuis le Google Play Store sur un appareil Android, un utilisateur doit posséder (ou créer) un compte Google, qui devient une passerelle clé par laquelle Google collecte ses informations personnelles, ce qui comporte son nom d’utilisateur, son adresse de messagerie et son numéro de téléphone. Si un utilisateur s’inscrit à des services comme Google Pay56, Android collecte également les données de la carte bancaire, le code postal et la date de naissance de l’utilisateur. Toutes ces données font alors partie des informations personnelles de l’utilisateur associées à son compte Google.
14. Alors que Chrome n’oblige pas le partage d’informations personnelles supplémentaires recueillies auprès des utilisateurs, il a la possibilité de récupérer de telles informations. Par exemple, Chrome collecte toute une gamme d’informations personnelles avec la fonctionnalité de remplissage automatique des formulaires, qui incluent typiquement le nom d’utilisateur, l’adresse, le numéro de téléphone, l’identifiant de connexion et les mots de passe.57 Chrome stocke les informations saisies dans les formulaires sur le disque dur de l’utilisateur. Cependant, si l’utilisateur se connecte à Chrome avec un compte Google et active la fonctionnalité de synchronisation, ces informations sont envoyées et stockées sur les serveurs de Google. Chrome pourrait également apprendre la ou les langues que parle la personne avec sa fonctionnalité de traduction, activée par défaut.58
15. En plus des données personnelles, Chrome et Android envoient tous deux à Google des informations concernant les activités de navigation et l’emploi d’applications mobiles, respectivement. Chaque visite de page internet est automatiquement traquée et collectée par Google si l’utilisateur a un compte Chrome. Chrome collecte également son historique de navigation, ses mots de passe, les permissions particulières selon les sites web, les cookies, l’historique de téléchargement et les données relatives aux extensions.59
16. Android envoie des mises à jour régulières aux serveurs de Google, ce qui comprend le type d’appareil, le nom de l’opérateur, les rapports de bug et des informations sur les applications installées60. Il avertit également Google chaque fois qu’une application est ouverte sur le téléphone (ex. Google sait quand un utilisateur d’Android ouvre son application Uber).
B. Collecte des données de localisation de l’utilisateur
17. Android et Chrome collectent méticuleusement la localisation et les mouvements de l’utilisateur en utilisant une variété de sources, représentées sur la figure 3. Par exemple, un accès à la « localisation approximative » peut être réalisé en utilisant les coordonnées GPS sur un téléphone Android ou avec l’adresse IP sur un ordinateur. La précision de la localisation peut être améliorée (« localisation précise ») avec l’usage des identifiants des antennes cellulaires environnantes ou en scannant les BSSID (’’Basic Service Set IDentifiers’’), identifiants assignés de manière unique aux puces radio des points d’accès Wi-Fi présents aux alentours61. Les téléphones Android peuvent aussi utiliser les informations des balises Bluetooth enregistrées dans l’API Proximity Beacon de Google62. Ces balises non seulement fournissent les coordonnées de géolocalisation de l’utilisateur, mais pourraient aussi indiquer à quel étage exact il se trouve dans un immeuble.63
Figure 3 : Android et Chrome utilisent diverses manières de localiser l’utilisateur d’un téléphone.
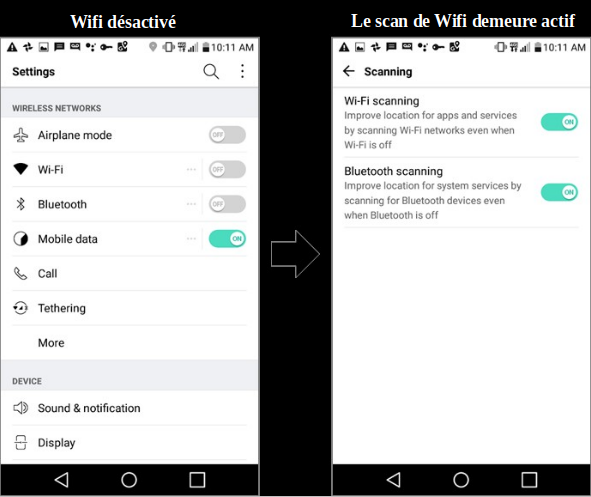
18. Il est difficile pour un utilisateur de téléphone Android de refuser le traçage de sa localisation. Par exemple, sur un appareil Android, même si un utilisateur désactive le Wi-Fi, la localisation est toujours suivie par son signal Wi-Fi. Pour éviter un tel traçage, le scan Wi-Fi doit être explicitement désactivé par une autre action de l’utilisateur, comme montré sur la figure 4.
Figure 4 : Android collecte des données même si le Wi-Fi est éteint par l’utilisateur
19. L’omniprésence de points d’accès Wi-Fi a rendu le traçage de localisation assez fréquent. Par exemple, durant une courte promenade de 15 minutes autour d’une résidence, un appareil Android a envoyé neuf requêtes de localisation à Google. Les requêtes contenaient au total environ 100 BSSID de points d’accès Wi-Fi publics et privés.
20. Google peut vérifier avec un haut degré de confiance si un utilisateur est immobile, s’il marche, court, fait du vélo, ou voyage en train ou en car. Il y parvient grâce au traçage à intervalles de temps réguliers de la localisation d’un utilisateur Android, combiné avec les données des capteurs embarqués (comme l’accéléromètre) sur les téléphones mobiles. La figure 5 montre un exemple de telles données communiquées aux serveurs de Google pendant que l’utilisateur marchait.
Figure 5 : capture d’écran d’un envoi de localisation d’utilisateur à Google.
C. Une évaluation de la collecte passive de données par Google via Android et Chrome
21. Les données actives que les plateformes Android ou Chrome collectent et envoient à Google à la suite des activités des utilisateurs sur ces plateformes peuvent être évaluées à l’aide des outils MyActivity et Takeout. Les données passives recueillies par ces plateformes, qui vont au-delà des données de localisation et qui restent relativement méconnues des utilisateurs, présentent cependant un intérêt potentiellement plus grand. Afin d’évaluer plus en détail le type et la fréquence de cette collecte, une expérience a été menée pour surveiller les données relatives au trafic envoyées à Google par les téléphones mobiles (Android et iPhone) en utilisant la méthode décrite dans la section IX.D de l’annexe. À titre de comparaison, cette expérience comprenait également l’analyse des données envoyées à Apple via un appareil iPhone.
22. Pour des raisons de simplicité, les téléphones sont restés stationnaires, sans aucune interaction avec l’utilisateur. Sur le téléphone Android, une seule session de navigateur Chrome restait active en arrière-plan, tandis que sur l’iPhone, le navigateur Safari était utilisé. Cette configuration a permis une analyse systématique de la collecte de fond que Google effectue uniquement via Android et Chrome, ainsi que de la collecte qui se produit en l’absence de ceux-ci (c’est-à-dire à partir d’un appareil iPhone), sans aucune demande de collecte supplémentaire générée par d’autres produits et applications (par exemple YouTube, Gmail ou utilisation d’applications).
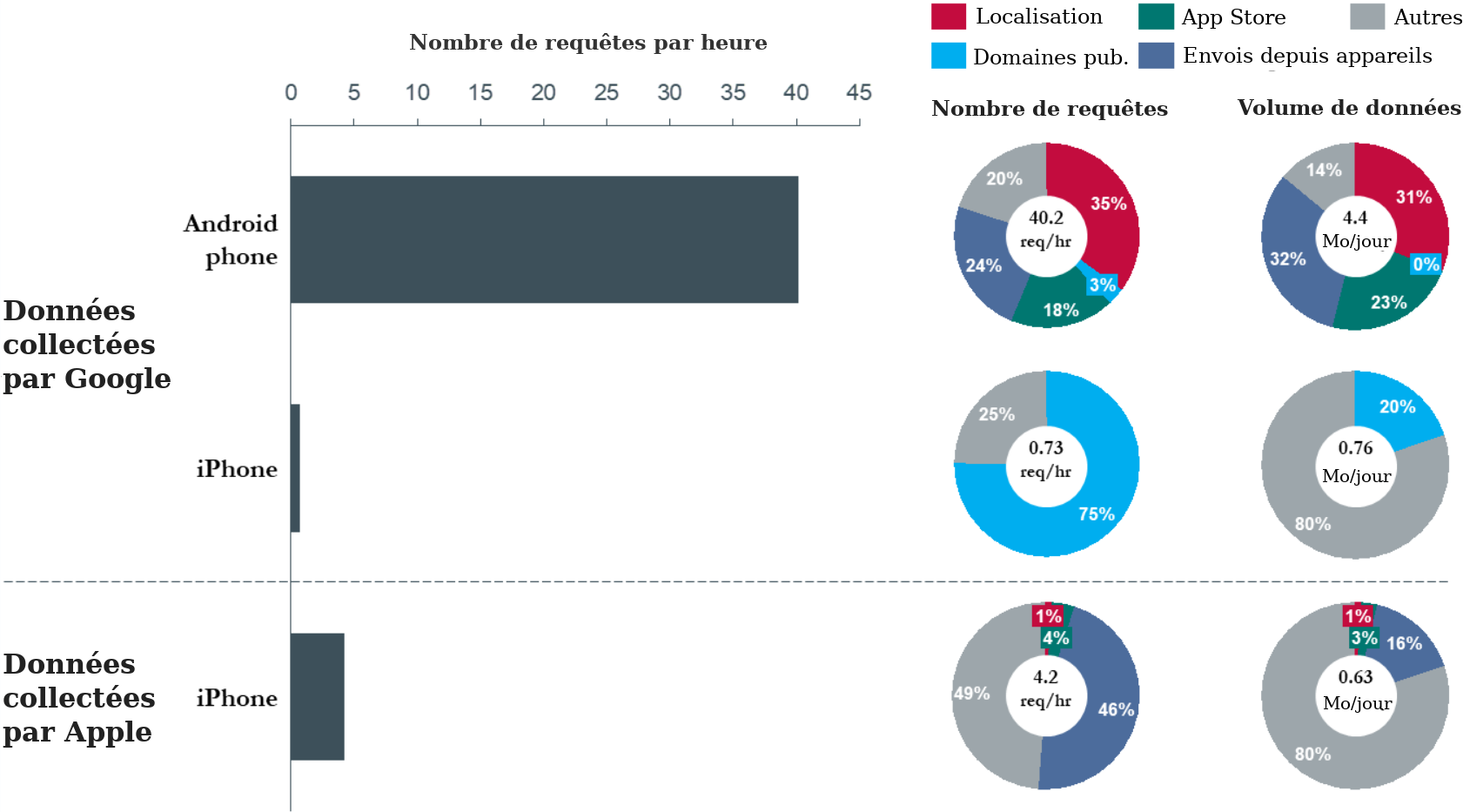
23. La figure 6 présente un résumé des résultats obtenus dans le cadre de cette expérience. L’axe des abscisses indique le nombre de fois où les téléphones ont communiqué avec les serveurs Google (ou Apple), tandis que l’axe des ordonnées indique le type de téléphone (Android ou iPhone) et le type de domaine de serveur (Google ou Apple) avec lequel les paquets de données ont été échangés par les téléphones. La légende en couleur décrit la catégorisation générale du type de demandes de données identifiées par l’adresse de domaine du serveur. Une liste complète des adresses de domaine appartenant à chaque catégorie figure dans le tableau 5 de la section IX.D de l’annexe.
24. Au cours d’une période de 24 heures, l’appareil Android a communiqué environ 900 échantillons de données à une série de terminaux de serveur Google. Parmi ceux-ci, environ 35 % (soit environ 14 par heure) étaient liés à la localisation. Les domaines publicitaires de Google n’ont reçu que 3 % du trafic, ce qui est principalement dû au fait que le navigateur mobile n’a pas été utilisé activement pendant la période de collecte. Le reste (62 %) des communications avec les domaines de serveurs Google se répartissaient grosso modo entre les demandes adressées au magasin d’applications Google Play, les téléchargements par Android de données relatives aux périphériques (tels que les rapports de crash et les autorisations de périphériques), et d’autres données — principalement de la catégorie des appels et actualisations de fond des services Google.
Figure 6 : Données sur le trafic envoyées par les appareils Andoid et les iPhones en veille.
25. La figure 6 montre que l’appareil iPhone communiquait avec les domaines Google à une fréquence inférieure de plus d’un ordre de grandeur (50 fois) à celle de l’appareil Android, et que Google n’a recueilli aucun donnée de localisation utilisateur pendant la période d’expérience de 24 heures via iPhone. Ce résultat souligne le fait que les plateformes Android et Chrome jouent un rôle important dans la collecte de données de Google.
26. De plus, les communications de l’appareil iPhone avec les serveurs d’Apple étaient 10 fois moins fréquentes que les communications de l’appareil Android avec Google. Les données de localisation ne représentaient qu’une très faible fraction (1 %) des données nettes envoyées aux serveurs Apple à partir de l’iPhone, Apple recevant en moyenne une fois par jour des communications liées à la localisation.
27. En termes d’amplitude, les téléphones Android communiquaient 4,4 Mo de données par jour (130 Mo par mois) avec les serveurs Google, soit 6 fois plus que ce que les serveurs Google communiquaient à travers l’appareil iPhone.
28. Pour rappel, cette expérience a été réalisée à l’aide d’un téléphone stationnaire, sans interaction avec l’utilisateur. Lorsqu’un utilisateur commence à bouger et à interagir avec son téléphone, la fréquence des communications avec les serveurs de Google augmente considérablement. La section V du présent rapport résume les résultats d’une telle expérience.
Ce que récolte Google : revue de détail
Le temps n’est plus où il était nécessaire d’alerter sur la prédation opérée par Google et ses nombreux services sur nos données personnelles. Il est fréquent aujourd’hui d’entendre dire sur un ton fataliste : « de toute façon, ils espionnent tout »
Si beaucoup encore proclament à l’occasion « je n’ai rien à cacher » c’est moins par conviction réelle que parce que chacun en a fait l’expérience : « on ne peut rien cacher » dans le monde numérique. Depuis quelques années, les mises en garde, listes de précautions à prendre et solutions alternatives ont été largement exposées, et Framasoft parmi d’autres y a contribué.
Il manquait toutefois un travail de fond pour explorer et comprendre, une véritable étude menée suivant la démarche universitaire et qui, au-delà du jugement global approximatif, établisse les faits avec précision.
C’est à quoi s’est attelée l’équipe du professeur Douglas C. Schmidt, spécialiste depuis longtemps des systèmes logiciels, chercheur et enseignant à l’Université Vanderbilt, qui livre au public une étude d’une cinquantaine de pages intitulée Google Data Collection. Cette étude, qui nous semble pouvoir servir de référence, a retenu l’attention du groupe Framalang qui vous en livre ci-dessous l’executive summary, c’est-à-dire une sorte de résumé initial, qui en donne un aperçu programmatique.
Si vous trouvez un intérêt à cette traduction et souhaitez que Framalang vous propose la suite nous ferons de notre mieux…
1.
Google est la plus grosse agence de publicité numérique du monde 64. Elle fournit aussi le leader des navigateurs web 65, la première plateforme mobile 66 ainsi que le moteur de recherche le plus utilisé au monde 67. La plateforme vidéo de Google, ses services de mail et de cartographie comptent 1 milliard d’utilisateurs mensuels actifs chacun 68. Google utilise l’immense popularité de ses produits pour collecter des données détaillées sur le comportement des utilisateurs en ligne comme dans la vie réelle, données qu’il utilisera ensuite pour cibler ses utilisateurs avec de la publicité payante. Les revenus de Google augmentent significativement en fonction de la finesse des technologies de ciblage des données.
2.
Google collecte les données utilisateurs de diverses manières. Les plus évidentes sont « actives », celles dans lesquelles l’utilisateur donne
directement et consciemment des informations à Google, par exemple en s’inscrivant à des applications très populaires telles que YouTube, Gmail, ou le moteur de recherche. Les voies dites « passives » utilisées par Google pour collecter des données sont plus discrètes, quand une application devient pendant son utilisation l’instrument de la collecte des données, sans que l’utilisateur en soit conscient. On trouve ces méthodes de collecte dans les plateformes (Android, Chrome), les applications (le moteur de recherche, YouTube, Maps), des outils de publication (Google Analytics, AdSense) et de publicité (AdMob, AdWords). L’étendue et l’ampleur de la collecte passive de données de Google ont été en grande partie négligées par les études antérieures sur le sujet 69.
3.
Pour comprendre les données que Google collecte, cette étude s’appuie sur quatre sources clefs :
a. Les outils Google « Mon activité » (My Activity) 70 et « Téléchargez vos données » (Takeout) 71, qui décrivent aux utilisateurs l’information collectée lors de l’usage des outils Google.
b. Les données interceptées lors de l’envoi aux serveurs de Google pendant l’utilisation des produits Google ou d’autres sociétés associées.
c. Les règles concernant la vie privée (des produits Google spécifiquement ou en général).
d. Des recherches tierces qui ont analysé les collectes de données opérées par Google.
Histoire naturelle, générale et particulière, des mollusques, animaux sans vertèbres et à sang blanc. T.2. Paris,L’Imprimerie de F. Dufart,An X-XIII [1802-1805]. biodiversitylibrary.org/page/35755415
4.
Au travers de la combinaison des sources ci-dessus, cette étude montre une vue globale et exhaustive de l’approche de Google concernant la collecte des données et aborde en profondeur certains types d’informations collectées auprès des utilisateurs et utilisatrices.
Cette étude met en avant les éléments clés suivants :
a. Dans une journée d’utilisation typique, Google en apprend énormément sur les intérêts personnels de ses utilisateurs. Dans ce scénario d’une journée « classique », où un utilisateur réel avec un compte Google et un téléphone Android (avec une nouvelle carte SIM) suit sa routine quotidienne, Google collecte des données tout au long des différentes activités, comme la localisation, les trajets empruntés, les articles achetés et la musique écoutée. De manière assez surprenante, Google collecte ou infère plus de deux tiers des informations via des techniques passives. Au bout du compte, Google a identifié les intérêts des utilisateurs avec une précision remarquable.
b. Android joue un rôle majeur dans la collecte des données pour Google, avec plus de 2 milliards d’utilisateurs actifs mensuels dans le monde 72. Alors que le système d’exploitation Android est utilisé par des fabricants d’équipement d’origine (FEO) partout dans le monde, il est étroitement connecté à l’écosystème Google via le service Google Play. Android aide Google à récolter des informations personnelles sur les utilisateurs (nom, numéro de téléphone, date de naissance, code postal et dans beaucoup de cas le numéro de carte bancaire), les activités réalisées sur le téléphone (applications utilisées, sites web consultés) et les coordonnées de géolocalisation. En coulisses, Android envoie fréquemment la localisation de l’utilisateur ainsi que des informations sur l’appareil lui-même, comme sur l’utilisation des applications, les rapports de bugs, la configuration de l’appareil, les sauvegardes et différents identifiants relatifs à l’appareil.
c. Le navigateur Chrome aide Google à collecter des données utilisateurs depuis à la fois le téléphone et l’ordinateur de bureau, grâce à quelque 2 milliards d’installations dans le monde 73. Le navigateur Chrome collecte des informations personnelles (comme lorsqu’un utilisateur remplit un formulaire en ligne) et les envoie à Google via le processus de synchronisation. Il liste aussi les pages visitées et envoie les données de géolocalisation à Google.
d. Android comme Chrome envoient des données à Google même en l’absence de toute interaction de l’utilisateur. Nos expériences montrent qu’un téléphone Android dormant et stationnaire (avec Chrome actif en arrière-plan) a communiqué des informations de localisation à Google 340 fois pendant une période de 24 heures, soit en moyenne 14 communications de données par heure. En fait, les informations de localisation représentent 35 % de l’échantillon complet de données envoyés à Google. À l’opposé, une expérience similaire a montré que sur un appareil iOS d’Apple avec Safari (où ni Android ni Chrome n’étaient utilisés), Google ne pouvait pas collecter de données notables (localisation ou autres) en absence d’interaction de l’utilisateur avec l’appareil.
e. Une fois qu’un utilisateur ou une utilisatrice commence à interagir avec un téléphone Android (par exemple, se déplace, visite des pages web, utilise des applications), les communications passives vers les domaines de serveurs Google augmentent considérablement, même dans les cas où l’on n’a pas utilisé d’applications Google majeures (c.-à-d. ni recherche Google, ni YouTube, pas de Gmail ni Google Maps). Cette augmentation s’explique en grande partie par l’activité sur les données de l’éditeur et de l’annonceur de Google (Google Analytics, DoubleClick, AdWords) 74. Ces données représentaient 46 % de l’ensemble des requêtes aux serveurs Google depuis le téléphone Android. Google a collecté la localisation à un taux 1,4 fois supérieur par rapport à l’expérience du téléphone fixe sans interaction avec l’utilisateur. En termes d’amplitude, les serveurs de Google ont communiqué 11,6 Mo de données par jour (ou 0,35 Go / mois) avec l’appareil Android. Cette expérience suggère que même si un utilisateur n’interagit avec aucune application phare de Google, Google est toujours en mesure de recueillir beaucoup d’informations par l’entremise de ses produits d’annonce et d’éditeur.
f. Si un utilisateur d’appareil sous iOS décide de renoncer à l’usage de tout produit Google (c’est-à-dire sans Android, ni Chrome, ni applications Google) et visite exclusivement des pages web non-Google, le nombre de fois où les données sont communiquées aux serveurs de Google demeure encore étonnamment élevé. Cette communication est menée exclusivement par des services de l’annonceur/éditeur. Le nombre d’appels de ces services Google à partir d’un appareil iOS est similaire à ceux passés par un appareil Android. Dans notre expérience, la quantité totale de données communiquées aux serveurs Google à partir d’un appareil iOS est environ la moitié de ce qui est envoyé à partir d’un appareil Android.
g. Les identificateurs publicitaires (qui sont censés être « anonymisés » et collectent des données sur l’activité des applications et les visites des pages web tierces) peuvent être associés à l’identité d’un utilisateur ou utilisatrice de Google. Cela se produit par le transfert des informations d’identification depuis l’appareil Android vers les serveurs de Google. De même, le cookie ID DoubleClick (qui piste les activités des utilisateurs et utilisatrices sur les pages web d’un tiers) constitue un autre identificateur censé être anonymisé que Google peut associer à celui d’un compte personnel Google, si l’utilisateur accède à une application Google avec le navigateur déjà utilisé pour aller sur la page web externe. En définitive, nos conclusions sont que Google a la possibilité de connecter les données anonymes collectées par des moyens passifs avec les données personnelles de l’utilisateur.
PeerTube 1.0 : la plateforme de vidéos libre et fédérée
Ce qui nous fait du bien, chez Framasoft, c’est quand nous arrivons à tenir nos engagements. On a beau faire les marioles, se dire qu’on est dans l’associatif, que la pression n’est pas la même, tu parles !
[Short version of this article in English available here]
Après le financement participatif réussi du mois de juin 2018, nous avions fait la promesse de sortir la version 1 de Peertube en octobre 2018. Et alors, où en sommes-nous ? Le suspense est insoutenable.
Nous étions confiants. Le salaire du développeur principal, Chocobozzz, était assuré jusqu’à la fin de l’année, nous avions déjà recensé des contributions de qualité, nous avions fait un peu de bruit dans la presse… Cependant, nous avions aussi pris un engagement ferme vis-à-vis de nos donateur·ices, ainsi qu’auprès d’un large public international qui ne nous connaissait pas aussi bien que nos soutiens francophones habituels.
Ne vous faisons pas languir plus longtemps, cette version 1.0, elle est là, elle sort à l’heure dite et elle tient ses promesses, elle aussi. C’est l’occasion de dérouler pour vous un récapitulatif des épisodes précédents, ce qui vous évitera de farfouiller dans le blog pour retrouver vos petits. On sait que c’est pénible, on l’a fait. 🙂
C’est quoi, PeerTube ? Une révolte ? Non, Sire, une révolution
[Vidéo de présentation de PeerTube, en anglais, avec les sous-titres français, sur Framatube. Pour la vidéo avec les sous-titres en anglais, cliquez ici. Réalisation : Association LILA (CC by-sa)]
« Dégooglisons Internet ! » avons-nous crié partout pendant trois ans, sur l’air de « Delenda Carthago ! »
Ça, c’était une révolte. Un cri du cœur. Déjà un défi fou : proposer une alternative aux services des géants du web, les GAFAM et leurs petits copains (Twitter, par exemple). Un par un, les services étaient sortis, à un rythme insensé. Ils sont toujours là. Il faut les maintenir. Heureusement, les (désormais 60) CHATONS permettent de répartir un peu la charge. L’offre de mail mise de côté, il restait un gros morceau : proposer une alternative crédible au géant Youtube, rien que ça ! Pas facile de briser l’hégémonie des plateformes de diffusion vidéo !
Les fichiers vidéo sont lourds, c’est le principal inconvénient. Donc il faut de gros serveurs, beaucoup de bande passante, ce qui représente un coût astronomique, sans parler de l’administration technique de tout ça.
Non seulement impensable au regard de nos moyens, mais surtout complètement à l’opposé des principes du Libre : indépendance, décentralisation, partage. Pour répondre au défi financier, Youtube et ses clones utilisent toutes les ressources du capitalisme de surveillance : en captant l’attention des internautes dans des boucles sans fin, en profilant leurs goûts, en les assaillant de publicité, en leur proposant des recommandations parfois toxiques…
C’est là que nous avons pris connaissance du logiciel (libre !) d’un jeune homme sympathique caché derrière le pseudo Chocobozzz, qui travaillait dans son coin à proposer une manière innovante de diffuser et visionner de la vidéo sur Internet.
Quand vous visionnez une vidéo, votre ordinateur participe à sa diffusion
PeerTube utilise les ressources du Web (WebRTC et BitTorrent, des technologies permettant le partage de diffusion, qui est un concept fondamental d’Internet) pour alléger la charge des sites qui hébergent du contenu. Avec un principe on ne peut plus simple : quand vous visionnez une vidéo, votre ordinateur participe à sa diffusion. Si beaucoup de personnes regardent la même vidéo, au lieu de tirer sur les ressources du serveur, on demande un petit effort à chaque machine et à chaque connexion. Les flux se répartissent, le réseau est optimisé. L’Internet comme il doit être. Comme il aurait dû le rester !
Pas besoin d’héberger tous les contenus que vous souhaitez diffuser : il suffit de se fédérer avec des instances amies qui proposent ces contenus pour les référencer sur sa propre instance. Sans dupliquer les fichiers. Et ça marche ! Quand les copains de Datagueule ont mis en ligne leur documentaire Démocratie, le logiciel a encaissé les milliers de visionnages sans broncher. Nous vous avons alors soumis l’idée d’embaucher Chocobozzz pour lui permettre de travailler sereinement à son projet, avec pour objectif de produire une version bêta du logiciel en mars 2018. Grâce à vos dons et à votre confiance, nous avons franchi cette première étape.
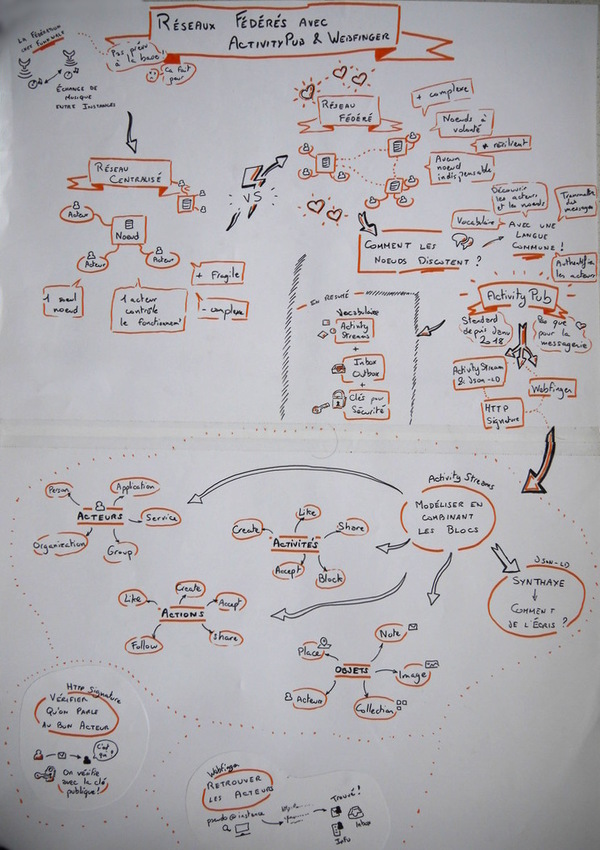
Nous avons entre-temps peaufiné notre nouvelle feuille de route Contributopia, dans laquelle PeerTube s’inscrivait parfaitement. Avec la recommandation du protocole ActivityPub par le W3C, qui renforçait le principe de fédération déjà initié par des logiciels sociaux (comme Mastodon), PeerTube est même devenu une brique majeure de Contributopia. Heureusement, la fédération, c’est facile à expliquer, parce que tout le monde l’utilise déjà : on a tou⋅tes des adresses mails, fournies par des tas de serveurs différents, et pourtant on arrive à s’écrire ! Avec PeerTube, lorsque plusieurs instances sont fédérées, il est possible de faire des recherches sur toutes ces instances, sans quitter celle sur laquelle vous êtes, ou de commenter des vidéos d’une instance distante sans avoir besoin de vous créer un compte dessus.
L’étape suivante allait de soi : continuer. La communication autour de PeerTube, via nos réseaux habituels, nous avait déjà permis d’attirer les contributions, des vidéastes avaient manifesté leur intérêt, les forums bruissaient de questions.
C’est pourquoi, rompant avec nos usages habituels, bousculant notre tempo, nous avons décidé de pousser les feux en prenant définitivement le rôle d’éditeur du logiciel de Chocobozzz, avec son accord, évidemment. Et surtout en soumettant une demande de financement participatif à l’international, en anglais, pour pérenniser son embauche, sans forcément vous solliciter à nouveau directement (mais on sait qu’une partie d’entre vous a tenu à participer quand même, et ça fait chaud au cœur, vraiment).
Cette fois encore, ce fut un joli succès, alors que franchement on n’en menait pas large, et voilà ce qui nous amène à cette version 1.0.
Mais alors, elle embarque quoi, cette version 1.0 ?
Avant tout, et pour éviter les mécompréhensions, rappelons que PeerTube n’est pas une seule plateforme centralisée (comme peuvent l’être YouTube, Dailymotion ou Viméo), mais un logiciel permettant de rassembler de nombreuses instances PeerTube (c’est-à-dire différentes installations du logiciel PeerTube, thématiques ou communautaires) au sein de ce que l’on appelle une fédération. Il vous faut donc chercher l’instance PeerTube qui vous convient pour visionner ou mettre en ligne vos vidéos ou, à défaut, mettre en place votre propre instance PeerTube, sur lequel vous aurez tous les droits.
PeerTube n’est pas une seule plateforme centralisée, mais un logiciel
Fonctionnalités de base
Peertube permet de regarder des vidéos avec WebTorrent, pour ne pas saturer les serveurs de diffusion. Si plusieurs personnes regardent la même vidéo, elles téléchargent de petits morceaux de la vidéo depuis votre serveur, mais aussi depuis les machines des autres personnes qui regardent la même vidéo !
Fédération entre instances PeerTube. Si l’instance PeerTube A s’abonne aux instances PeerTube B et C, depuis une recherche sur A, on peut trouver et visionner les vidéos de B et C, sans quitter A.
Le logiciel dispose de réglages assez fins qui permettent d’ajuster la gouvernance : chaque instance s’organise comme elle le souhaite. Ainsi, l’administrateur·ice de l’instance peut définir :
un quota d’espace disque pour chaque vidéaste ;
le nombre de comptes acceptés ;
le rôle des utilisateur·ices (administration, modération, utilisation, upload de vidéos).
PeerTube peut fonctionner sur un petit serveur. Vous pouvez par exemple l’installer sur un matériel type VPS ayant deux cœurs et 2Go de RAM. L’espace de stockage requis dépend évidemment du nombre de vidéos que vous souhaitez héberger personnellement.
PeerTube dispose d’un code stable et robuste, testé et éprouvé sur de nombreux systèmes, ce qui le rend performant. Ainsi, une page PeerTube se charge souvent bien plus vite qu’une page YouTube.
Vos vidéos peuvent être automatiquement converties dans différentes définitions (par exemple 240p, 720p ou 1080p. voire le 4K) pour s’adapter au débit et matériel des visiteur·euses. Cette étape s’appelle le transcodage.
Un mode «Théâtre» ainsi qu’un mode «nuit» sont disponibles pour un meilleur confort de visionnage.
PeerTube ne vous espionne pas et ne vous enferme pas : en effet, l’application ne collecte pas d’informations personnelles à des fins d’exploitation commerciale, et surtout PeerTube ne vous enferme pas dans une « bulle de filtre ». Par ailleurs, il n’utilise pas d’algorithme de recommandation biaisé pour vous faire rester indéfiniment en ligne. C’est peut-être un détail (ou une faiblesse) pour vous, mais pour nous c’est une force qui veut dire beaucoup !
Il n’existe pas – encore – d’application smartphone dédiée. Cependant, la version web de PeerTube fonctionne rapidement sur smartphone et s’adapte parfaitement à votre appareil.
Les visiteur⋅euses peuvent commenter les vidéos. Cette fonctionnalité peut être désactivée soit par l’administrateur·ice de l’instance sur n’importe quelle vidéo, soit localement par la personne qui met en ligne les vidéos.
PeerTube utilisant le protocole d’échanges ActivityPub, il est possible d’interagir avec d’autres logiciels utilisant ce même protocole. Par exemple, la plateforme de vidéo PeerTube peut interagir avec le réseau social Mastodon, alternative à Twitter. Ainsi, il est possible de « suivre » un utilisateur PeerTube depuis Mastodon, ou même de commenter une vidéo directement depuis votre compte Mastodon.
Un bouton permet d’apporter votre soutien à l’auteur d’une vidéo. Ainsi, les vidéastes peuvent mettre en place le mode de financement qui leur convient.
Nous n’avons peut-être pas insisté sur ce point, mais PeerTube est bien évidemment un logiciel libre 🙂 Cela signifie que son code source (sa recette de cuisine) est disponible et ouverte à tou⋅tes. Ainsi, vous pouvez contribuer au code ou, si vous pensez que le logiciel ne va pas dans la bonne direction, le copier et y apporter les modifications qui correspondent à vos besoins.
Image du crowdfunding réussi ayant financé une large partie des fonctionnalités les plus attendues.
Fonctionnalités financées par le crowdfunding
Le sous-titrage : possibilité d’ajouter de multiples fichiers de langue (au format .srt) pour proposer les sous-titrages des vidéos.
La redondance d’instance : il est possible « d’aider » une instance désignée en activant la redondance de tout ou partie de ses vidéos (qui seront alors dupliquées sur votre instance). Ainsi, si l’instance liée est surchargée parce que trop de monde regarde les vidéos qu’elle héberge, votre instance pourra la soutenir en mettant sa bande passante à disposition.
L’import depuis d’autres plateformes vidéo par simple copier-coller : YouTube, Viméo, Dailymotion, etc. Depuis certaines plateformes, la récupération du titre, de la description ou des mots clés est même automatique. Il est bien entendu possible d’importer aussi des vidéos par lien direct ou depuis une autre instance PeerTube. Enfin, PeerTube permet aussi l’import depuis les fichiers .torrent.
Plusieurs flux RSS s’offrent à vous selon vos besoins : un pour les vidéos de manière globale, un autre pour celles d’une chaîne et un dernier pour les commentaires d’une vidéo.
Peertube s’est internationalisé et parle maintenant 13 langues dont le chinois. Des traductions vers d’autres langues sont en cours.
La recherche est plus pertinente. Elle prend en compte certaines fautes de frappe et propose l’utilisation de filtres.
Fonctionnalités à venir
Nous avons une excellente nouvelle : bien que le troisième palier du crowdfunding n’ait pas été atteint, Framasoft a décidé d’embaucher Chocobozzz en CDI afin de pérenniser le développement de Peertube. D’autres fonctionnalités sont donc prévues au cours de l’année 2019.
Un système de plugins pour personnaliser Peertube. Il s’agit là d’un développement essentiel, car il permettra à chacun⋅e de développer ses propres plugins pour adapter PeerTube à ses besoins. Par exemple il deviendra possible de proposer des plugins de recommandations avec des algorithmes spécifiques ou des thèmes graphiques complètement différents.
Nous développerons éventuellement une application mobile (ou bien des contributeur⋅ices motivé⋅e⋅s le feront)
Il sera rapidement possible d’améliorerl’outil d’importation de vidéos, de façon à pouvoir «synchroniser» votre chaîne YouTube avec votre chaîne PeerTube (PeerTube sera en capacité de vérifier si de nouvelles vidéos ont été ajoutées et pourra automatiquement les ajouter à votre compte PeerTube, titre et descriptions compris). Dans les faits, cette fonctionnalité fonctionne déjà pour celles et ceux qui hébergent leur instance PeerTube et maîtrisent la ligne de commande.
Des statistiques par instance ou par compte pourront être mises à disposition.
L’amélioration des outils de modération.
[Exemple de la fonction d’import de vidéo]
PeerTube répare Internet
La campagne « Dégooglisons Internet » était un cri, une réaction, un rejet. Rejet des GAFAM et de leur vision centralisatrice, fermée, toute tournée vers le fric et le contrôle. Lutter contre les GAFAM, c’est mener un combat disproportionné. Mais la prise de conscience est faite. Nous n’avons plus besoin de rabâcher notre couplet sur leur façon de nier nos libertés, de s’approprier nos données personnelles, de prendre le pouvoir dans nos vies. Et puis il faut dire qu’à force de scandales, ils nous ont bien aidés à accélérer dans l’opinion publique cette prise de conscience. Nous revendiquons fièrement notre participation à cette évolution des esprits, au milieu d’autres acteurs tout aussi importants (LQDN, la CNIL, l’APRIL, etc.). Il est temps maintenant de passer à autre chose.
https://framalab.org/gknd-creator/
Chez Framasoft, incorrigibles bavards que nous sommes, nous avons produit beaucoup d’écrits, et nous avons finalement, proportionnellement, assez peu de contenus vidéos à proposer, alors que c’est un média qui est devenu à la fois plus facile à élaborer et plus demandé par le public. Ce virage vers la vidéo nous a été confisqué par les plateformes centralisatrices, Youtube en tête. Elles ont installé un standard, une norme, avec des pratiques révoltantes comme la censure aveugle et l’appropriation des contenus.
Le principe de fédération impulsé par le protocole ActivityPub et les logiciels qui l’utilisent (Peertube, Mastodon, Funkwhale, PixelFed, Plume… la liste s’allonge chaque mois) est en train, ni plus ni moins, de corriger le tir, de (re)construire le futur d’Internet. Celui que nous appelons de nos vœux.
La fédération, avec ActivityPub, c’est s’allier aux autres sans perdre son identité
Oui, cette fois, c’est une révolution. Avec Contributopia, nous annonçons une étape de construction, basée sur le partage, les communs, l’éducation populaire.
Nous avons aussi pris conscience, en avançant, que nous ne pouvions plus nier la dimension politique de cette vision. Alors quand on dit «politique», on convoque l’étymologie du mot, hein. C’est pas demain qu’on verra Pyg, notre délégué général, à l’Assemblée Nationale. Il n’empêche ! La culture du libre, ça va bien au-delà de l’hébergement d’agendas ou de l’ouverture d’un pad pour rédiger le présent article à plusieurs.
Nous travaillons, dans le cadre qui est le nôtre, à fournir des outils numériques aux utopistes qui, comme nous, pensent qu’il y a encore moyen de sauver les meubles. On se disait que ce n’était pas super vendeur, mais nous avons pu voir, lors de nos fréquentes interventions à droite et à gauche, que la démarche rencontrait de l’écho. Nous avons encore quelques jolies cartes à jouer pour la suite (même si pour certaines on ne sait pas encore comment ça se passera ^^), comme toujours dans la bonne humeur et le houblon doré.
Nous espérons que vous nous suivrez, encore, dans cette voie.
Longue vie à PeerTube.
L’équipe de Framasoft.
Pour aller plus loin
À vous de jouer ! PeerTube vous appartient, emparez-vous de ses possibilités. Déposez des vidéos de qualité (de préférence sous licence libre, ou pour laquelle vous avez les droits de diffusion ou un accord explicite) sur l’une des instances déjà existantes. Faites connaître PeerTube à vos contacts et aux YouTubeur⋅euses auxquels vous êtes abonné⋅e. Et si vous le pouvez, installez votre propre instance pour agrandir encore le réseau fédéré !
C’est dans l’air du temps et c’est tant mieux. Comme à chaque fois que Twitter (ou Facebook) se signale par ses errements manifestes (et comment pourrait-il en être autrement ?), s’ensuit une vague de migrations.
Voici par exemple Laura Kalbag. Cette designeuse britannique qui est la moitié de indie.ie avec Aral Balkan et qui a publié le guide Accessibility for everyone a récemment pris ses distances avec Twitter pour expérimenter Mastodon au point de piloter sa propre instance…
Il y a quelques semaines j’ai publié une brève note pour signaler que j’ai désormais ma propre instance Mastodon. Mais commençons par le commencement : pourquoi ?
J’ai l’intention d’utiliser Mastodon comme alternative à Twitter. Bien que Mastodon ne soit pas l’équivalent de Twitter, nombre de ses fonctionnalités sont semblables. Et je cherche une solution alternative à Twitter parce que Twitter n’est pas bon pour moi.
Parfois, il m’arrive de croire qu’en disant : « Twitter n’est pas bon pour moi » je n’ai pas besoin d’expliquer davantage, mais ce n’est pas une opinion tellement répandue. Cela vaut la peine d’être expliqué un peu plus en détail :
Le capitalisme de surveillance
En bref, le problème avec Twitter c’est le capitalisme de surveillance. Au cas où ce terme vous serait étranger, le capitalisme de surveillance est le modèle économique dominant en matière de technologie grand public. La technologie nous traque, observe nos actions : c’est l’aspect surveillance. Cette information est alors utilisée afin de mieux nous vendre des biens et services, souvent par le biais de la publicité « pertinente », c’est l’aspect capitalisme. Pour dire les choses clairement, Aral Balkan appelle cela le people farming que l’on peut traduire par « élevage humain».
Nous sommes la plupart du temps conscient⋅e⋅s du fait que les publicités que nous voyons sur les réseaux sociaux comme Facebook et Twitter financent leurs services. En revanche, nous sommes moins conscient⋅e⋅s du fait que des algorithmes affectent les articles ou billets que nous voyons dans les fils d’information de nos réseaux sociaux, et nous ne savons pas quelle information nourrit ces algorithmes ; ni comment ces algorithmes et leurs interfaces sont conçus pour manipuler notre interaction avec le service. Nous sommes largement inconscient⋅e⋅s de la manière dont la plupart des technologies utilisent le traçage et leurs propres algorithmes pour nous rendre dépendant⋅e⋅s et pour manipuler notre comportement d’une manière qui leur est financièrement bénéfique.
Si tout cela semble tiré par les cheveux, jetez un coup d’œil à la version blog de ma conférence intitulée : « Digital Assistants, Facebook Quizzes, et Fake News ! Vous n’allez pas croire ce qui va se passer ensuite. »
Qu’est-ce qui ne va pas avec Twitter, au juste ?
Le modèle économique de capitalisme de surveillance de Twitter a un impact sur chaque décision prise par Twitter. Twitter récompense les comportements abusifs à travers les algorithmes utilisés pour son historique car la controverse entraîne « l’engagement ». Twitter construit des cultes de la célébrité (qu’il s’agisse des individus ou des mèmes) parce que davantage de personnes s’inscriront sur une plateforme pour suivre l’actualité et éviter la peur de passer à côté.
À travers ses algorithmes Twitter décide de ce que vous voyez
Tout comme l’a fait Facebook auparavant, la décision de Twitter d’utiliser des algorithmes pour vous dicter ce que vous voyez dans votre fil au lieu de vous montrer les messages dans leur ordre chronologique signifie que vous ne pouvez pas faire confiance au flux pour vous afficher les messages des personnes que vous suivez (le contournement consiste à utiliser les « Listes », mais pour cette raison, je soupçonne Twitter de vouloir se débarrasser des listes à un moment ou à un autre…)
Vous ignorez si vos messages sont vus ou si vous voyez ceux de vos amis, puisque vous n’avez aucune idée de ce que fait l’algorithme. il semble que cet algorithme favorise les comptes et les tweets populaires et/ou viraux, ce qui fait de la viralité l’aspiration ultime des vedettes expérimenté⋅e⋅s des réseaux sociaux, au-delà du nombre spectaculaire d’abonné⋅e⋅s. (je ne porte pas de jugement… je décide moi aussi de suivre ou non une personne en fonction de son nombre d’abonné⋅e⋅s, pas vous ?)
En réalité, Twitter encourage les agressions
Twitter permet aux agressions et au harcèlement de continuer parce que l’engagement des utilisateurs prospère grâce à la polémique. Des trolls haineux qui chassent en meute ? C’est ça, l’engagement ! Des femmes et des personnes de groupes marginalisés sont harcelées sur Twitter ? Mais tous ces trolls sont si engageants ! Qu’est-ce que ça peut faire qu’une femme quitte Twitter si la polémique a pour résultat qu’un plus grand nombre de personnes vont tweeter, ou même s’inscrire pour avoir leur mot à dire sur la question ? Pourquoi Twitter, Inc. devrait-il se soucier des gens alors que les chiffres sont tout ce qui compte pour les investisseurs, et que ce sont eux qui gardent la mainmise sur les projecteurs ? Tout ce que les entreprises de réseaux sociaux ont à faire, c’est de maintenir un équilibre délicat pour ne pas mettre trop de gens en colère et à ne pas les aliéner au point de les faire quitter la plateforme en masse. Et étant donné qu’un si grand nombre de ces gens sont tellement engagés dans Twitter (est-ce nécessaire de mentionner que « engagement » n’est probablement qu’un euphémisme pour « addiction »), ils ont du mal à en sortir. C’est mon cas. Pas vous ?
Si Twitter se conformait rigoureusement à une politique stricte contre le harcèlement et les agressions, il y aurait moins de tweets. Si Twitter nous donnait des outils efficaces pour modérer nos propres fils, réponses et messages, il est probable que cela impacterait ce que l’algorithme choisit de nous montrer, et impacterait le modèle économique de Twitter qui monétise ce que l’algorithme met en priorité dans le flux des messages.
Twitter ne gère pas efficacement les cas d’agression
Il n’est pas facile de modérer les agressions. Décider de ce qui constitue une agression et de la façon de la traiter de manière appropriée est un problème pour toutes les plateformes de publication et tous les réseaux sociaux. Ce sont aussi des problèmes systémiques auxquels sont confrontées les communautés locales et le système judiciaire. Problèmes qui sont généralement traités (encore souvent de manière inadéquate) par ces communautés et systèmes judiciaires. Mais nous devons être conscients que la technologie amplifie les problèmes, en facilitant le ciblage d’un individu et la possibilité d’une attaque de manière anonyme. Et comme nous utilisons les plateformes de grandes entreprises, nous déléguons au contrôle de l’entreprise la responsabilité des décisions sur la manière de gérer les agressions.
Les personnels de ces entreprises technologiques ne devraient pas être ceux qui décident de ce qui relève de la liberté d’expression et de la censure sur ce qui est devenu notre infrastructure sociale mondiale. Les personnes qui ont des intérêts financiers dans le chiffre d’affaires ne devraient pas être en mesure de prendre des décisions concernant nos droits et ce qui constitue la liberté d’expression.
Nuances
Bien sûr, il y a aussi des situations diverses et certains choix de conception d’algorithmes de flux pour gérer le harcèlement et des agressions ne sont pas principalement destinés à servir le capitalisme de surveillance. Il se peut qu’il y ait des personnes qui travaillent dans l’entreprise et qui ont des intentions bienveillantes. (J’en ai rencontré quelques-unes, je n’en doute pas !)
Mais comme le modèle d’affaires de Twitter est concentré sur l’extraction de l’information des gens, les décisions de conception qui servent le modèle économique auront toujours la priorité. Les cas de comportements bienveillants sont des exceptions et ne prouvent pas que le modèle entier repose sur le principe de « l’attention bienveillante malgré tout ». De tels gestes de bonté sont malheureusement accomplis, ou plutôt consentis, pour améliorer les relations publiques.
Mon usage de Twitter
Quand je me demande sincèrement pourquoi j’utilise encore Twitter, je trouve de bonnes raisons et aussi des prétextes. Toutes mes bonnes raisons sont probablement des prétextes, tout dépend du degré de complaisance envers moi-même dont je suis capable tel ou tel jour. Je suis comme prise dans un tourbillon entre mes convictions et mon amour-propre.
Twitter me donne les nouvelles
C’est sur Twitter que je vais d’abord pour m’informer des actualités internationales et locales. Il est difficile de trouver un organe de presse qui couvre l’actualité et les questions qui me tiennent à cœur sans publier également du putaclic, des listes attrape-cons et des bêtises calculées avec du SEO. Malheureusement, c’est en grande partie parce que la publicité sur le Web (qui repose avant tout sur la surveillance) est le modèle économique de la publication de nouvelles. Je me tiens donc au courant des actualités en suivant quelques organes d’information et beaucoup de journalistes individuels.
Il existe une stratégie de contournement : suivre des comptes et des listes Twitter sur Feedbin, à côté des autres flux RSS auxquels je suis abonnée. Tous les tweets sont à disposition, mais l’algorithme ou les applications ne tentent pas de manipuler votre comportement.
Il s’agit d’une solution de contournement temporaire, car Twitter peut trouver un moyen d’interdire ce type d’utilisation. (Peut-être que d’ici là, nous pourrons passer au RSS comme principal moyen de publication ?) Et de toute évidence, cela ne servira pas à grand-chose et ne résoudra pas le problème de la dépendance des médias d’information au capitalisme de surveillance comme modèle économique.
Les abonnés
Beaucoup de personnes dans l’industrie Web ont accumulé un grand nombre d’abonnés sur Twitter, et il est difficile à abandonner (mon nombre d’abonnés est relativement modeste mais assez grand pour flatter mon ego lors d’une mauvaise journée). La façon positive de voir les choses, c’est que vous vous sentez responsable envers les gens qui vous suivent de les tenir au courant des nouvelles de l’industrie, et que vous avez une plateforme et une influence pour promouvoir les enjeux qui vous tiennent à cœur.
La façon plus cynique de voir les choses est la suivante : quelqu’un remarquerait-il vraiment si j’arrêtais de tweeter ? Je suis une goutte d’eau dans l’océan. Est-ce qu’un décompte de mes abonnés est juste devenu une autre façon de flatter mon ego et de prouver ma propre valeur parce que je suis accro à la dopamine d’une notification qui me signale que quelqu’un pense que je vaux un petit clic sur le bouton « suivre » ? Peut-être que me suivre n’est pas l’expérience heureuse que j’imagine avec autosatisfaction. Il n’y a pas d’autre solution que de s’améliorer et de devenir moins obsédé⋅e par soi-même. En tant que personne issue de la génération millénium dans une société dominée par le capitalisme, je me souhaite bonne chance.
Le cercle des ami⋅e⋅s
Malgré ce modèle suivre/être suivi de Twitter, j’ai des amis sur Twitter. J’ai déjà parlé d’amitié en ligne. Je me suis aussi fait des ami⋅e⋅s sur Twitter et je l’utilise pour rester en contact avec des gens que je connais personnellement. Je veux savoir comment vont mes amis, ce qu’ils font, à quoi ils s’intéressent. Je veux aussi pouvoir bavarder et échanger des inepties avec des inconnu⋅e⋅s, partager mon expérience jusqu’à ce que nous devenions ami⋅e⋅s.
Une solution : Mastodon. Un réseau social loin d’être parfait mais bien intentionné.
Qu’est-ce que Mastodon et pourquoi l’utiliser ?
Mastodon a démarré comme une plateforme de microblogging similaire à Twitter, mais a évolué avec davantage de fonctionnalités qui montrent une orientation éthique, progressiste et inclusive. À la place de tweets, vos billets sur Mastodon sont appelés des pouets (NdT : en anglais c’est amusant aussi, des “toots”).
Pourquoi utiliser Mastodon et pas un autre réseau social nouveau ?
Maintenant que vous savez pourquoi je quitte Twitter, vous avez probablement une vague idée de ce que je recherche dans un réseau social. Mastodon est unique pour plusieurs raisons :
Mastodon est fédéré
« Mastodon n’est pas seulement un site web, c’est une fédération – pensez à Star Trek. Les milliers de communautés indépendantes qui font tourner Mastodon forment un réseau cohérent, où, bien que chaque planète soit différente, il suffit d’être sur l’une pour communiquer avec toutes les autres. »
La fédération signifie qu’il y a beaucoup de communautés différentes faisant tourner le logiciel Mastodon, mais chaque individu de chaque communauté peut parler à un autre utilisateur de Mastodon. Chaque domaine où Mastodon tourne est appelé une « instance ».
Fédération vs centralisation
Dans mon billet à propos de Twitter, je mentionnais « comme nous utilisons les plateformes de grandes entreprises, nous déléguons la responsabilité des décisions sur la manière de gérer les agressions au contrôle de l’entreprise. » Cette manière dont le pouvoir est tenu par un individu ou un petit groupe est une forme de centralisation.
La centralisation se manifeste à travers le Web de diverses façons, mais pour les plateformes comme Twitter, la centralisation veut dire que la plateforme tourne sur un serveur appartenant à une entreprise et contrôlé par elle. Donc pour utiliser Twitter, vous devez aller sur Twitter.com, ou utiliser un service ou une application qui communique directement avec Twitter.com. Ceci signifie que Twitter a un contrôle absolu sur son logiciel, la manière dont les gens s’en servent, ainsi que le profil et les données de comportement de ces personnes. Aral explique ceci en disant que ces plateformes ne sont pas comme des parcs, mais comme des centres commerciaux. Vous pouvez entrer gratuitement, rencontrer vos ami⋅e⋅s là-bas, avoir des conversations et acheter des trucs, mais vous êtes assujetti⋅e⋅s à leurs règles. Ils peuvent observer ce que vous faites avec des caméras de surveillance, vous entourer de publicités, et vous mettre dehors s’ils n’aiment pas ce que vous faites ou dites.
L’inverse de la centralisation, c’est la décentralisation. Une alternative décentralisée à la publication sur Twitter consiste à poster de petites mises à jour de votre statut sur votre blog, comme je le fais avec mes Notes. De cette manière je suis propriétaire de mes propres contenus et je les contrôle (dans les limites de mon hébergeur web). Si tout le monde postait son statut sur son blog, et allait lire les blogs des autres, ce serait un réseau décentralisé.
Mais poster des statuts sur son blog passe à côté de l’intérêt… social des réseaux sociaux. Nous n’utilisons pas seulement les réseaux sociaux pour crier dans le vide, mais nous les utilisons pour partager des expériences avec les autres. Aral et moi travaillons sur des manières de le faire avec nos sites personnels, mais nous n’y sommes pas encore. Et c’est là que la fédération rentre en jeu.
Oskar nous dit : « wooOOof ! Abonnez-vous à mon compte Mastodon @gigapup@mastodon.laurakalbag.com »
On peut appeler ça une « mono-instance ». Elle est hébergée sur mon propre domaine, donc j’en suis propriétaire et contrôle tout ce que je poste dessus, mais parce que j’ai Mastodon installé, je peux voir ce que les autres gens postent sur leurs instances Mastodon, et leur répondre avec des mentions, des boosts (équivalents d’un retweet) de leurs pouets, bien qu’ils soient sur des instances différentes. C’est comme avoir mon propre Twitter qui puisse discuter avec les autres Twittos, mais où c’est moi qui décide des règles.
« Mastodon est un logiciel gratuit, libre, que chacun peut installer sur un serveur. »
Mastodon est libre et gratuit, c’est pour cela que nous pouvons avoir nos propres instances avec nos propres règles. Cela veut aussi dire que si Eugen Rochko, qui fait Mastodon, va dans une direction que les gens n’aiment pas, nous (suivant nos compétences) pouvons le forker et réaliser notre propre version.
« En utilisant un ensemble de protocoles standards, les serveurs Mastodon peuvent échanger de l’information entre eux, permettant aux utilisateurs d’interagir sans heurts… Grâce aux protocoles standards, le réseau n’est pas limité aux serveurs Mastodon. Si un meilleur logiciel apparaît, il peut continuer avec le même graphe social. »
Mastodon utilise des protocoles standards, ce qui signifie que vous pouvez vous fédérer avec Mastodon même si vous n’utilisez pas Mastodon vous-même. Ceci signifie que vous n’êtes pas enfermé⋅e dans Mastodon, vu qu’il est interopérable, mais aussi qu’une autre technologie peut marcher avec vos pouets à l’avenir.
« Il n’y a pas de publicité, monétisation, ni capital-risque. Vos donations soutiennent directement le développement à plein temps du projet. »
Voilà qui est important. Mastodon est financé par des donations, pas par de la publicité ou autre astuce néfaste de monétiser vos informations, et pas non plus par des investisseurs de capital-risque. Cela signifie qu’il n’y a pas de conseil d’administration qui décidera qu’ils doivent commencer à faire des choses pour vous monétiser afin d’obtenir un retour sur leur investissement, ou pour “croître”. Cela signifie que nous dépendons de la bonne volonté et de la générosité d’Eugen. Mais, comme je l’ai mentionné plus haut, puisque Mastodon est libre et ouvert, si Eugen devient un monstre (cela semble improbable), nous pouvons forker Mastodon et faire une version différente qui fonctionne pour nous, à notre goût.
Mastodon est inclusif
Un des plus gros problèmes de Twitter est la modération (ou plutôt l’absence de modération) du harcèlement et des agressions. Dans un article intitulé Cage the Mastodon (NdT : mettre en cage le mastodonte) Eugen explique comment Mastodon est conçu pour empêcher le harcèlement autant que possible, et vous donner des outils pour vous assurer que votre fil et vos réponses ne contiennent que ce que vous souhaitez voir.
« Mastodon est équipé d’outils anti-harcèlement efficaces pour vous aider à vous protéger. Grâce à l’étendue et à l’indépendance du réseau, il y a davantage de modérateurs auxquels vous pouvez vous adresser pour obtenir une aide individuelle, et des instances avec des codes de conduite stricts. »
Bien sûr, Mastodon est loin d’être parfait – cette critique constructive de Nolan Lawson aborde certaines des plus grandes questions et plusieurs approches possibles – mais Mastodon accorde la priorité aux outils anti-agressions et les gens qui travaillent sur Mastodon accordent la priorité aux décisions de conception qui favorisent la sécurité. Par exemple, vous ne pouvez pas simplement rechercher un mot-clé sur Mastodon. Cela signifie que les gens qui cherchent à déclencher une bagarre ou une attaque en meute ne peuvent pas se contenter de chercher des munitions dans les pouets d’autres personnes. Si vous voulez que les mots-clés de vos pouets puissent être recherchés, vous pouvez utiliser des #hashtags, qui peuvent être recherchés.
Une autre de mes fonctionnalités favorites de Mastodon, c’est que par défaut, vous pouvez apporter un texte de description alternatif pour les images, sans que l’option soit cachée dans un menu « Accessibilité ». Par défaut, une zone de saisie vous est montrée au bas de l’image avec la mention « Décrire pour les malvoyants »
C’est une façon astucieuse pour Mastodon de dire aux gens qu’ils doivent rendre leurs images accessibles à leurs amis.
Comment utiliser Mastodon
Je ne suis pas une experte et j’en suis à mes premiers pas sur Mastodon. Alors voici une liste des meilleurs guides d’utilisation réalisés par des personnes qui connaissent bien mieux que moi comment fonctionne Mastodon :
Un guide de Mastodon des plus exhaustifs par @joyeusenoelle – guide écrit de manière simple et suivant le format de la FAQ. Utile si vous voulez trouver une réponse à une question en particulier.
Qu’est-ce que c’est que Mastodon et pourquoi est-ce mieux que Twitter par Nolan Lawson – Une introduction détaillée à Mastodon et à son histoire.
• Le Mastodon apprivoisé par Eugen Rochko – Un aperçu des caractéristiques pour gérer les abus et le harcèlement, qui explique également les décisions prises dans les coulisses de Mastodon en termes de design.
• Comment fonctionne Mastodon ? Par Kev Quirk—Introduit des comparaisons entre Mastodon et Twitter à travers des exemples qui permettent d’améliorer la compréhension.
• La confidentialité des posts de Mastodon – Un pouet qui explique qui peut voir ce que vous pouettez sur Mastodon selon les différents paramétrages choisis.
• La liste ultime – Un guide pratique des apps et des clients web à utiliser avec Mastodon au-delà de son interface par défaut. D’autres points sont également référencés, tels les outils d’affichage croisé notamment.
Rejoignez une petite instance, ou créez la vôtre
Si vous êtes intéressé⋅e par Mastodon, vous pouvez choisir l’instance que vous souhaiteriez rejoindre, ou vous pouvez créer la vôtre. Je suis partisane de l’instance unique pour soi-même, mais si vous souhaitez juste tester, ou si vous avez eu de mauvaise expérience de harcèlement sur les réseaux sociaux ailleurs, je vous recommande de choisir une petite instance avec le code de bonne conduite qui vous convient.
Beaucoup de gens (moi incluse) commencent par se créer un compte sur mastodon.social, mais je vous le déconseille. C’est la plus grande instance anglophone mise en place par les développeurs de Mastodon, avec notamment Eugen Rochko (@gargron). Ils ont des règles anti-nazis et semblent être plutôt bienveillants. Toutefois, beaucoup de gens utilisent mastodon.social. La dernière fois que j’ai regardé, ils étaient 230 000. Cela veut dire beaucoup de pression sur les modérateurs, et sur le serveur, et ça contrevient grandement au concept de fédération si tout le monde rejoint la même instance. Rappelez-vous, vous pouvez facilement communiquer avec des personnes de n’importe quelle autre instance de Mastodon. Si des personnes insistent pour que vous veniez sur leur instance alors que ce n’est ni pour le code de conduite ni pour la modération, à votre place je m’interrogerais sur leurs motivations.
Soyez conscient⋅e que l’administrateur d’une instance peut lire vos messages privés. L’administrateur de l’instance de l’utilisateur avec qui vous communiquez peut aussi lire vos échanges. Cela vient du fait que les messages privés ne sont pas chiffrés de bout en bout. Même si je ne pense pas que ce soit catastrophique pour Mastodon (c’est tout aussi vrai pour vos messages sur Twitter, Facebook, Slack, etc.), [çà nous rappelle que l’on doit vraiment faire confiance à notre administrateur d’instance/un rappel sur la nécessité de pouvoir se fier à l’administrateur de votre instance]. Aussi, si vous souhaitez envoyer des messages de manière vraiment sécurisée, je conseille de toujours utiliser une application de messagerie chiffrée, comme Wire.
Pourquoi Ind.ie ne propose pas d’instance ?
Quelques personnes nous ont encouragés, Aral et moi, à lancer notre propre instance. Nous ne le ferons pas, parce que :
Avant tout : la décentralisation est notre objectif. Nous ne voulons pas la responsabilité de détenir et contrôler vos contenus, même si vous nous faites confiance (vous ne devriez pas !).
De plus, nous serions de piètres modérateurs. Les modérateurs et modératrices devraient être formé⋅e⋅s et avoir une expérience significative. Ils sont la principale défense contre le harcèlement et les agressions. Les modérateurs se doivent d’être des arbitres impartiaux en cas de désaccord, et faire respecter leur Code de Conduite. C’est une activité à temps plein, et je crois que ça ne peut être efficace que sur de petites instances.
Ma mono-instance
J’ai d’abord rejoint Mastodon.social fin 2016. Alors que j’étais assez active sur les comptes @Better et @Indie, mon propre compte était très calme. Mastodon.social était déjà plutôt grand, et je voulais avoir ma propre instance, et ne pas m’investir trop pour un compte qui pourrait finalement cesser d’exister.
Mais je ne voulais pas héberger et maintenir une instance Mastodon toute seule. C’est un logiciel vaste et complexe, et je ne suis pas développeuse backend de grande envergure ni adminsys. De plus, je n’ai tout simplement pas le temps d’acquérir les compétences requises, ni même de mettre à jour les nouvelles versions et faire les mises à jour de sécurité.
Alors quand Masto.host, un hébergeur pour « un hébergement de Mastodon entièrement géré » m’a été recommandé, j’ai su que c’était ce dont j’avais besoin pour franchir le pas pour l’hébergement de ma propre instance.
Pourquoi mettre en place une mono-instance ?
Tout ce que je publie est sous mon contrôle sur mon serveur. Je peux garantir que mon instance Mastodon ne va pas se mettre à tracer mon profil, ou à afficher de la pub, ou à inviter des Nazis dans mon instance, car c’est moi qui pilote mon instance. J’ai accès à tout mon contenu tout le temps, et seuls mon hébergeur ou mon fournisseur d’accès à Internet peuvent bloquer mon accès (comme pour tout site auto-hébergé). Et toutes les règles de blocage et de filtrage sont sous mon contrôle – Vous pouvez filtrer les personnes que vous voulez sur l’instance d’autres personnes, mais vous n’avez pas votre mot à dire sur qui/ce qu’ils bloquent pour toute cette instance.
Vous pouvez aussi créer des emojis personnalisés pour votre propre instance Mastodon que chaque autre instance pourra voir et/ou partager.
Pourquoi ne PAS mettre en place une mono-instance ?
Dans un billet précédent sur les niveaux de décentralisation qui se trouvent au-delà de mes moyens, j’ai examiné les facteurs qui nous permettent, ou non, de posséder et contrôler nos propres contenus. Il en va de même pour les réseaux sociaux, surtout en termes de sécurité. Parfois nous ne voulons pas, ou nous ne pouvons pas, modérer notre propre réseau social.
Je suis une personne privilégiée parce que je peux faire face au faible taux de harcèlement que je reçois. Ce n’est pas un indicateur de ma force mentale, c’est seulement que le pire que je reçois sont des pauvres types qui me draguent par MP (messages privés), et certains individus qui insultent notre travail à Ind.ie de manière non-constructive et/ou blessante. Ce n’est pas infini, c’est gérable avec les outils de blocage et de sourdine usuels. (Je suis également fan du blocage préventif, mais ce sera un billet pour un autre jour). Je n’ai pas (pas encore ?!) été victime d’une attaque en meute, de harcèlement ciblé, ou d’agression plus explicite.
Parce que beaucoup de gens sont victimes de ce type de harcèlement et d’abus, et ils ne peuvent pas s’attendre à maintenir leur propre instance. Parce que pour être en mesure de bloquer, mettre en sourdine et modérer efficacement les personnes et les choses malfaisantes, il faut voir ces personnes et ces choses malfaisantes.
De la même manière qu’à mon avis le gouvernement devrait fournir des filets de sécurité pour les personnes vulnérables et marginalisées de la société, le web devrait fournir également des filets de sécurité pour les personnes vulnérables et marginalisées du web. Je vois des petites instances comme ces filets de sécurité. Idéalement, je vous conseillerais de connaître votre administrateur d’instance en personne. Les instances devraient être comme des familles (entretenant de saines relations) ou des petits clubs du monde hors-ligne. Dans ces situations, vous pouvez avoir quelqu’un qui représente le groupe en tant que leader lorsque c’est nécessaire, mais que ce soit une hiérarchie horizontale sinon.
Connaître de bonnes personnes qui vous protègent est un sacré privilège, alors peut-être qu’une recommandation par du bouche-à-oreille pour une petite instance d’une personne que vous connaissez pourrait suffire. Je ne me suis pas retrouvée dans cette situation, alors prenez ma suggestion avec des pincettes, je veux seulement souligner les potentielles répercussions négatives lorsque vous décidez qui peut contrôler votre vie sociale en ligne. (Prenez en compte les exemples de ceux qui ont été confrontés aux répercussions de Twitter ou Facebook pour décider jusqu’où une agression raciste est acceptable ou quel est leur véritable nom.)
Comment mettre en place une mono-instance
Si, comme moi, vous n’êtes pas un bon adminsys, ou si vous n’avez simplement pas le temps de maintenir votre propre instance Mastodon, je vous recommande masto.host. Hugo Gameiro vous fera l’installation et l’hébergement d’une petite instance Mastodon pour 5 €/mois. La procédure est la suivante :
Acheter un nom de domaine (si vous n’en avez pas déjà un à utiliser)
S’inscrire sur masto.host et donnez à Hugo votre nom de domaine. J’ai mis le mien en place à mastodon.laurakalbag.com ce qui est plutôt long, mais il apparaît clairement que c’est mon instance rien que par le nom.
Mettre en place les réglages DNS. Masto.host vous enverra alors quelques changements que vous devez effectuer sur votre configuration DNS. La plupart des fournisseurs de nom de domaine ont une page pour le faire. Puis, signalez à Masto.host une fois que vous avez effectué ces changements.
Créer votre compte Mastodon. Masto.host va installer votre instance Mastodon. Vous recevrez alors un message vous demandant de créer votre compte Mastodon. Créez le compte Mastodon pour votre administrateur/administratrice. Puis, indiquez à Masto.host que c’est celui que vous avez choisi comme compte administrateur. Masto.host vous donnera alors les droits administrateur/adminstratrice sur ce compte.
Modeler votre instance Mastodon à votre guise pour qu’elle corresponde à ce que vous souhaitez. Dès que vous avez les droits d’administration, vous pouvez personnaliser votre instance Mastodon de la manière qui vous plaît. Vous souhaiterez probablement commencer par fermer l’enregistrement aux autres personnes.
La procédure entière sur Masto.host a pris environ une heure pour moi. Mais gardez à l’esprit que c’est une procédure qui nécessite quelques interventions manuelles, ça peut donc prendre un peu plus de temps. Masto.host est géré par un seul véritable humain (Hugo), pas une société quelconque, il a besoin de dormir, manger, vivre sa vie, et maintenir d’autres instances, donc, si vous vous inscrivez à Masto.host, soyez sympas et polis s’il vous plaît !
Mais, mais, mais…
À partir du moment où vous commencez à recommander un réseau social alternatif, les gens auront leurs raisons pour vous dire en quoi ce n’est pas fait pour eux. C’est très bien. Tant que la critique est fondée. Comme l’a résumé Blain Cook sur Twitter…
Bien que j’aie réfléchi et travaillé à ce problème depuis le tout début de Twitter, je n’ai pas eu beaucoup de succès pour y remédier. Pas plus que n’importe qui d’autre.
Ce sont des problèmes difficiles. La critique facile d’efforts acharnés ne nous mènera nulle part. Ce n’est pas pour dire que la critique n’est pas fondée. De nombreux problèmes se posent. Mais si l’argument par défaut revient à « Il ne nous reste qu’à rester et nous plaindre de Twitter », cela sabote sérieusement la légitimité de toute critique.
Cela dit, il y a quelques arguments qui valent la peine d’être rapidement évoqués :
– Tous mes amis / les gens sympas / les discussions intéressantes sont sur Twitter…
Tous vos amis, les gens sympas et les discussions intéressantes étaient-elles sur Twitter lorsque vous l’avez rejoint ? Voyez Mastodon comme une chance de nouveau départ, trouver de nouvelles personnes à suivre, peut-être même saisir l’occasion de suivre un groupe plus diversifié de personnes… ! Vous pouvez cross-poster sur Twitter et Mastodon s’il le faut. Évitez juste de cross-poster les retweets et @réponses, le rendu est moche et illisible.
Je m’abonne à des comptes et des listes sur Twitter en utilisant RSS avec Feedbin, ce qui me permet de garder un œil sur Twitter tout en me désintoxiquant.
– Je n’ai pas le temps de rejoindre un autre réseau social
Créer ma propre instance ne m’a pris qu’une heure. Rejoindre une instance existante prend moins de 30 secondes une fois que vous avez décidé laquelle rejoindre. Instances.social peut vous aider à trouver une petite instance qui vous convient. Assurez-vous d’avoir lu leur Code de Conduite !
Rejoignez-moi !
Si vous lisez ce billet et vous inscrivez à Mastodon, pouettez-moi ! Je serai heureuse de vous suivre et de répondre aux questions que vous vous posez à propos de Mastodon ou du lancement de votre propre instance (ou les booster lorsque je ne connais pas la réponse !)
Oskar pense que l’accessibilité du mug c’est pour lui aussi (photos Laura Kalbag)
Mastodon ne sera peut-être pas notre solution optimale définitive en tant que réseau social, mais ce sera peut-être une étape sur le chemin. C’est une véritable alternative à ce qui existe déjà. Nous sommes actuellement bloqués avec des plateformes qui amplifient les problèmes structurels de notre société (racisme, sexisme, homophobie, transphobie) parce que nous n’avons pas d’alternatives. Nous ne pouvons pas échapper à ces plateformes, parce qu’elles sont devenues notre infrastructure sociale.
Nous devons essayer des solutions de rechange pour voir ce qui fonctionne et, en tant que personnes qui travaillent quotidiennement dans le domaine du Web, nous devrions nous charger de trouver une technologie sûre que nous pouvons partager avec nos proches.