Le point médian m’a tué⋅e : Framasoft met la clef sous la porte
La rumeur courait depuis quelque temps et c’est maintenant confirmé : l’association d’éducation populaire Framasoft dépose le bilan. En cause ? L’effondrement catastrophique du montant des dons au cours des derniers mois, effondrement principalement imputable à un curieux symbole typographique.
Cela fait de nombreuses années maintenant que l’on peut trouver des formes de ce que l’on appelle « l’écriture inclusive » dans les communications de Framasoft. La forme la plus visible de cette écriture est le fameux « point médian » qui permet de détailler les genres lorsqu’un mot inclut des personnes indéterminées (et au genre, par conséquent, indéterminé également). Sauf que voilà, ce point médian est loin de faire l’unanimité. Nous avons rencontré Jean-Mi, président des Promoteurs de l’Écriture Non-Inclusive Systématique (PENIS), en croisade contre le point médian depuis 2017.
« Je crois qu’on ait avant tous des défenseur de la belle langue Francaise » nous écrit Jean-Mi dans un premier mail de contact. « Le point médian agresse l’œil, on a constaté une explosion des frais d’ophtalmologie chez les lecteurs du Framablog ces dernières années, il fallait réagir. » Un problème de santé publique ? Jean-Mi nous répond sans détour :
À 200%. Les anecdotes se comptent par dizaines. Tu vas lire pépouze un article sur le développement de PeerTube et PAF ! Une saloperie de point médian qui surgit plus furtivement qu’un Rattata dans les hautes herbes. La dernière fois, ça m’a fait un haut-le-cœur, j’en ai dégueulé tout mon dîner sur le clavier, 30€ de dégâts. Mon pote Dédé, l’autre jour, sur l’article sur Mobilizon, il était tout prêt à changer le monde, tout ça, et PAF ! Il retrouve de la propagande de connasse de féministe sur un bon vieux blog de tech où on devrait pourtant pouvoir faire de l’entre-couilles en paix. Deux mois de thérapie pour s’en remettre, qu’il lui a fallu, au Dédé. Ils y pensent, à ça, les framaguignols qui pondent du point médian au kilomètre sans respect pour nos petits cœurs fragiles ?
Jean-Mi et Dédé, chevaliers de la liberté et des belles lettres, n’ont jamais caché leur dégoût pour cet odieux symbole typographique et commentent systématiquement les articles incriminés sur le Framablog. Pouhiou, chargé de communication de Framasoft contacté par nos soins, soupire :
Tu bosses comme un fou pour faire des articles bien écrits, avec un ton agréable, tu mets du soin, du cœur à l’ouvrage, et là tu vois le premier commentaire : une remarque insultante sur le point médian. T’as fait 15 000 caractères aux petits oignons et on vient te casser les gonades parce qu’il y en a 3 qui plaisent pas. C’est fatigant.
Les PENIS restent inflexibles :
Si ça le fatigue, qu’il arrête ! Nous aussi ça nous fatigue, leurs conneries, sauf que nous, c’est nous qu’on a raison ! La langue française, y’a des fucking règles, tu les respectes ! #JeSuisAcademieFrancaise
Sauf que cette fois, l’intransigeance a pris un autre détour : le boycott de dons. Jean-Mi nous raconte, ému, la genèse de ce mode d’action :
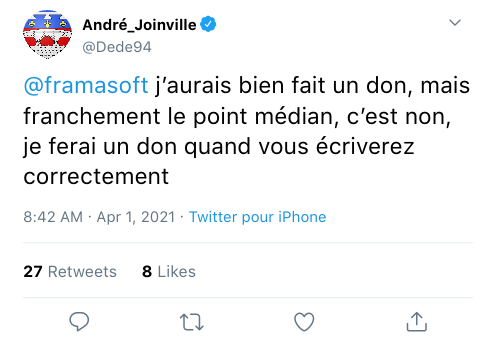
C’est Dédé qu’a eu l’idée. Un jour je l’ai vu tweeter :
J’me suis dit : putain mais c’est du génie !
Depuis, à chaque article point-médiané, Jean-Mi et Dédé soulignent que Framasoft a perdu un donateur :
Bon okay, on n’avait jamais fait de don avant, mais n’empêche qu’on aurait très bien pu en faire un dans un futur hypothermique ! EH BAH NON. Tout cet argent perdu par Framasoft pour une bête lubie féminazie, c’est triste. Mais c’est bien fait pour eux.
L’association, longtemps restée sourde à ces avertissements, paie aujourd’hui lourdement l’addition : le boycott massif du point médian a mené à un écroulement des dons, et ceux-ci ne suffisent plus à rémunérer les salarié⋅e⋅s. Triste retour à la réalité : Framasoft met aujourd’hui la clef sous la porte. « Ça leur pendait au nez » commente Jean-Mi « et à toi aussi, sale petite merde journalope qui vient d’écrire salarié⋅e⋅s, tu crois que je t’ai pas vu ?! »
Les PENIS se dressent aussi pour la belle langue française à l’Assemblée Nationale (rigolez pas, c’est avec votre pognon)
C’est un triste jour pour l’association qui s’était rendue célèbre par son annuaire de logiciels, ses livres libres, ses services autour du projet Dégooglisons Internet et, plus récemment, par l’initiative Contributopia visant à outiller la société de la contribution. Pierre-Yves Gosset, salarié historique de Framasoft, commente : « ça me fait vraiment mal qu’un truc aussi beau finisse comme ça à cause d’une bande de déglingués de la typo. Ça traite tout le monde de fragile et ça pète une bielle pour trois pixels. » Amer, il arrive malgré tout à en rire : « Enfin au moins, maintenant on sait comment flinguer Google : suffit de leur faire adopter le point médian. »
L’aventure s’arrête donc ici pour l’asso qui avait pour ambition de dégoogliser Internet mais n’aura pas su dépointmédianiser son propre blog. Le jeu en aura-t-il valu la chandelle ? C’est Luc, ancien admin-sys de Framasoft croisé au comptoir de Pôle Emploi, qui conclut : « y’a des poings médians dans la gueule qui se perdent. »
Google chante le requiem pour les cookies, mais le grand chœur du pistage résonnera encore
Google va cesser de nous pister avec des cookies tiers ! Une bonne nouvelle, oui mais… Regardons le projet d’un peu plus près avec un article de l’EFF.
La presse en ligne s’en est fait largement l’écho : par exemple siecledigital, generation-nt ou lemonde. Et de nombreux articles citent un éminent responsable du tout-puissant Google :
Chrome a annoncé son intention de supprimer la prise en charge des cookies tiers et que nous avons travaillé avec l’ensemble du secteur sur le Privacy Sandbox afin de mettre au point des innovations qui protègent l’anonymat tout en fournissant des résultats aux annonceurs et aux éditeurs. Malgré cela, nous continuons à recevoir des questions pour savoir si Google va rejoindre d’autres acteurs du secteur des technologies publicitaires qui prévoient de remplacer les cookies tiers par d’autres identifiants de niveau utilisateur. Aujourd’hui, nous précisons qu’une fois les cookies tiers supprimés, nous ne créerons pas d’identifiants alternatifs pour suivre les individus lors de leur navigation sur le Web et nous ne les utiliserons pas dans nos produits.
David Temkin, Director of Product Management, Ads Privacy and Trust (source)
« Pas d’identifiants alternatifs » voilà de quoi nous réjouir : serait-ce la fin d’une époque ?
Comme d’habitude avec Google, il faut se demander où est l’arnaque lucrative. Car il semble bien que le Béhémoth du numérique n’ait pas du tout renoncé à son modèle économique qui est la vente de publicité.
Dans cet article de l’Electronic Frontier Foundation, que vous a traduit l’équipe de Framalang, il va être question d’un projet déjà entamé de Google dont l’acronyme est FLoC, c’est-à-dire Federated Learning of Cohorts. Vous le trouverez ici traduit AFC pour « Apprentissage Fédéré de Cohorte » (voir l’article de Wikipédia Apprentissage fédéré).
Pour l’essentiel, ce dispositif donnerait au navigateur Chrome la possibilité de créer des groupes de milliers d’utilisateurs ayant des habitudes de navigation similaires et permettrait aux annonceurs de cibler ces « cohortes ».
Les cookies tiers se meurent, mais Google essaie de créer leur remplaçant.
Personne ne devrait pleurer la disparition des cookies tels que nous les connaissons aujourd’hui. Pendant plus de deux décennies, les cookies tiers ont été la pierre angulaire d’une obscure et sordide industrie de surveillance publicitaire sur le Web, brassant plusieurs milliards de dollars ; l’abandon progressif des cookies de pistage et autres identifiants tiers persistants tarde à arriver. Néanmoins, si les bases de l’industrie publicitaire évoluent, ses acteurs les plus importants sont déterminés à retomber sur leurs pieds.
Google veut être en première ligne pour remplacer les cookies tiers par un ensemble de technologies permettant de diffuser des annonces ciblées sur Internet. Et certaines de ses propositions laissent penser que les critiques envers le capitalisme de surveillance n’ont pas été entendues. Cet article se concentrera sur l’une de ces propositions : l’Apprentissage Fédéré de Cohorte (AFC, ou FLoC en anglais), qui est peut-être la plus ambitieuse – et potentiellement la plus dangereuse de toutes.
L’AFC est conçu comme une nouvelle manière pour votre navigateur d’établir votre profil, ce que les pisteurs tiers faisaient jusqu’à maintenant, c’est-à-dire en retravaillant votre historique de navigation récent pour le traduire en une catégorie comportementale qui sera ensuite partagée avec les sites web et les annonceurs. Cette technologie permettra d’éviter les risques sur la vie privée que posent les cookies tiers, mais elle en créera de nouveaux par la même occasion. Une solution qui peut également exacerber les pires attaques sur la vie privée posées par les publicités comportementales, comme une discrimination accrue et un ciblage prédateur.
La réponse de Google aux défenseurs de la vie privée a été de prétendre que le monde de demain avec l’AFC (et d’autres composants inclus dans le « bac à sable de la vie privée » sera meilleur que celui d’aujourd’hui, dans lequel les marchands de données et les géants de la tech pistent et profilent en toute impunité. Mais cette perspective attractive repose sur le présupposé fallacieux que nous devrions choisir entre « le pistage à l’ancienne » et le « nouveau pistage ». Au lieu de réinventer la roue à espionner la vie privée, ne pourrait-on pas imaginer un monde meilleur débarrassé des problèmes surabondants de la publicité ciblée ?
Nous sommes à la croisée des chemins. L’ère des cookies tiers, peut-être la plus grande erreur du Web, est derrière nous et deux futurs possibles nous attendent.
Dans l’un d’entre eux, c’est aux utilisateurs et utilisatrices que revient le choix des informations à partager avec chacun des sites avec lesquels il ou elle interagit. Plus besoin de s’inquiéter du fait que notre historique de navigation puisse être utilisé contre nous-mêmes, ou employé pour nous manipuler, lors de l’ouverture d’un nouvel onglet.
Dans l’autre, le comportement de chacune et chacun est répercuté de site en site, au moyen d’une étiquette, invisible à première vue mais riche de significations pour celles et ceux qui y ont accès. L’historique de navigation récent, concentré en quelques bits, est « démocratisé » et partagé avec les dizaines d’interprètes anonymes qui sont partie prenante des pages web. Les utilisatrices et utilisateurs commencent chaque interaction avec une confession : voici ce que j’ai fait cette semaine, tenez-en compte.
Les utilisatrices et les personnes engagées dans la défense des droits numériques doivent rejeter l’AFC et les autres tentatives malvenues de réinventer le ciblage comportemental. Nous exhortons Google à abandonner cette pratique et à orienter ses efforts vers la construction d’un Web réellement favorable aux utilisateurs.
Qu’est-ce que l’AFC ?
En 2019, Google présentait son bac à sable de la vie privée qui correspond à sa vision du futur de la confidentialité sur le Web. Le point central de ce projet est un ensemble de protocoles, dépourvus de cookies, conçus pour couvrir la multitude de cas d’usage que les cookies tiers fournissent actuellement aux annonceurs. Google a soumis ses propositions au W3C, l’organisme qui forge les normes du Web, où elles ont été principalement examinées par le groupe de commerce publicitaire sur le Web, un organisme essentiellement composé de marchands de technologie publicitaire. Dans les mois qui ont suivi, Google et d’autres publicitaires ont proposé des dizaines de standards techniques portant des noms d’oiseaux : pigeon, tourterelle, moineau, cygne, francolin, pélican, perroquet… et ainsi de suite ; c’est très sérieux ! Chacune de ces propositions aviaires a pour objectif de remplacer différentes fonctionnalités de l’écosystème publicitaire qui sont pour l’instant assurées par les cookies.
L’AFC est conçu pour aider les annonceurs à améliorer le ciblage comportemental sans l’aide des cookies tiers. Un navigateur ayant ce système activé collecterait les informations sur les habitudes de navigation de son utilisatrice et les utiliserait pour les affecter à une « cohorte » ou à un groupe. Les utilisateurs qui ont des habitudes de navigations similaires – reste à définir le mot « similaire » – seront regroupés dans une même cohorte. Chaque navigateur partagera un identifiant de cohorte, indiquant le groupe d’appartenance, avec les sites web et les annonceurs. D’après la proposition, chaque cohorte devrait contenir au moins plusieurs milliers d’utilisatrices et utilisateurs (ce n’est cependant pas une garantie).
Si cela vous semble complexe, imaginez ceci : votre identifiant AFC sera comme un court résumé de votre activité récente sur le Web.
La démonstration de faisabilité de Google utilisait les noms de domaines des sites visités comme base pour grouper les personnes. Puis un algorithme du nom de SimHash permettait de créer les groupes. Il peut tourner localement sur la machine de tout un chacun, il n’y a donc pas besoin d’un serveur central qui collecte les données comportementales. Toutefois, un serveur administrateur central pourrait jouer un rôle dans la mise en œuvre des garanties de confidentialité. Afin d’éviter qu’une cohorte soit trop petite (c’est à dire trop caractéristique), Google propose qu’un acteur central puisse compter le nombre de personnes dans chaque cohorte. Si certaines sont trop petites, elles pourront être fusionnées avec d’autres cohortes similaires, jusqu’à ce qu’elles représentent suffisamment d’utilisateurs.
Pour que l’AFC soit utile aux publicitaires, une cohorte d’utilisateurs ou utilisatrices devra forcément dévoiler des informations sur leur comportement.
Selon la proposition formulée par Google, la plupart des spécifications sont déjà à l’étude. Le projet de spécification prévoit que l’identification d’une cohorte sera accessible via JavaScript, mais on ne peut pas savoir clairement s’il y aura des restrictions, qui pourra y accéder ou si l’identifiant de l’utilisateur sera partagé par d’autres moyens. L’AFC pourra constituer des groupes basés sur l’URL ou le contenu d’une page au lieu des noms domaines ; également utiliser une synergie de « système apprentissage » (comme le sous-entend l’appellation AFC) afin de créer des regroupements plutôt que de se baser sur l’algorithme de SimHash. Le nombre total de cohortes possibles n’est pas clair non plus. Le test de Google utilise une cohorte d’utilisateurs avec des identifiants sur 8 bits, ce qui suppose qu’il devrait y avoir une limite de 256 cohortes possibles. En pratique, ce nombre pourrait être bien supérieur ; c’est ce que suggère la documentation en évoquant une « cohorte d’utilisateurs en 16 bits comprenant 4 caractères hexadécimaux ». Plus les cohortes seront nombreuses, plus elles seront spécialisées – plus les identifiants de cohortes seront longs, plus les annonceurs en apprendront sur les intérêts de chaque utilisatrice et auront de facilité pour cibler leur empreinte numérique.
Mais si l’un des points est déjà clair c’est le facteur temps. Les cohortes AFC seront réévaluées chaque semaine, en utilisant chaque fois les données recueillies lors de la navigation de la semaine précédente.
Ceci rendra les cohortes d’utilisateurs moins utiles comme identifiants à long terme, mais les rendra plus intrusives sur les comportements des utilisatrices dans la durée.
De nouveaux problèmes pour la vie privée.
L’AFC fait partie d’un ensemble qui a pour but d’apporter de la publicité ciblée dans un futur où la vie privée serait préservée. Cependant la conception même de cette technique implique le partage de nouvelles données avec les annonceurs. Sans surprise, ceci crée et ajoute des risques concernant la donnée privée.
Le Traçage par reconnaissance d’ID.
Le premier enjeu, c’est le pistage des navigateurs, une pratique qui consiste à collecter de multiples données distinctes afin de créer un identifiant unique, personnalisé et stable lié à un navigateur en particulier. Le projet Cover Your Tracks (Masquer Vos Traces) de l’Electronic Frontier Foundation (EFF) montre comment ce procédé fonctionne : pour faire simple, plus votre navigateur paraît se comporter ou agir différemment des autres, plus il est facile d’en identifier l’empreinte unique.
Google a promis que la grande majorité des cohortes AFC comprendrait chacune des milliers d’utilisatrices, et qu’ainsi on ne pourra vous distinguer parmi le millier de personnes qui vous ressemblent. Mais rien que cela offre un avantage évident aux pisteurs. Si un pistage commence avec votre cohorte, il doit seulement identifier votre navigateur parmi le millier d’autres (au lieu de plusieurs centaines de millions). En termes de théorie de l’information, les cohortes contiendront quelques bits d’entropie jusqu’à 8, selon la preuve de faisabilité. Cette information est d’autant plus éloquente sachant qu’il est peu probable qu’elle soit corrélée avec d’autres informations exposées par le navigateur. Cela va rendre la tâche encore plus facile aux traqueurs de rassembler une empreinte unique pour les utilisateurs de l’AFC.
Google a admis que c’est un défi et s’est engagé à le résoudre dans le cadre d’un plan plus large, le « Budget vie privée » qui doit régler le problème du pistage par l’empreinte numérique sur le long terme. Un but admirable en soi, et une proposition qui va dans le bon sens ! Mais selon la Foire Aux Questions, le plan est « une première proposition, et n’a pas encore d’implémentation dans un navigateur ». En attendant, Google a commencé à tester l’AFC dès ce mois de mars.
Le pistage par l’empreinte numérique est évidemment difficile à arrêter. Des navigateurs comme Safari et Tor se sont engagés dans une longue bataille d’usure contre les pisteurs, sacrifiant une grande partie de leurs fonctionnalités afin de réduire la surface des attaques par traçage. La limitation du pistage implique généralement des coupes ou des restrictions sur certaines sources d’entropie non nécessaires. Il ne faut pas que Google crée de nouveaux risques d’être tracé tant que les problèmes liés aux risques existants subsistent.
L’exposition croisée
Un second problème est moins facile à expliquer : la technologie va partager de nouvelles données personnelles avec des pisteurs qui peuvent déjà identifier des utilisatrices. Pour que l’AFC soit utile aux publicitaires, une cohorte devra nécessairement dévoiler des informations comportementales.
La page Github du projet aborde ce sujet de manière très directe :
Cette API démocratise les accès à certaines informations sur l’historique de navigation général des personnes (et, de fait, leurs intérêts principaux) à tous les sites qui le demandent… Les sites qui connaissent les Données à Caractère Personnel (c’est-à-dire lorsqu’une personne s’authentifie avec son adresse courriel) peuvent enregistrer et exposer leur cohorte. Cela implique que les informations sur les intérêts individuels peuvent éventuellement être rendues publiques.
Comme décrit précédemment, les cohortes AFC ne devraient pas fonctionner en tant qu’identifiant intrinsèque. Cependant, toute entreprise capable d’identifier un utilisateur d’une manière ou d’une autre – par exemple en offrant les services « identifiez-vous via Google » à différents sites internet – seront à même de relier les informations qu’elle apprend de l’AFC avec le profil de l’utilisateur.
Deux catégories d’informations peuvent alors être exposées :
1. Des informations précises sur l’historique de navigation. Les pisteurs pourraient mettre en place une rétro-ingénierie sur l’algorithme d’assignation des cohortes pour savoir si une utilisatrice qui appartient à une cohorte spécifique a probablement ou certainement visité des sites spécifiques.
2. Des informations générales relatives à la démographie ou aux centres d’intérêts. Par exemple, une cohorte particulière pourrait sur-représenter des personnes jeunes, de sexe féminin, ou noires ; une autre cohorte des personnes d’âge moyen votant Républicain ; une troisième des jeunes LGBTQ+, etc.
Cela veut dire que chaque site que vous visitez se fera une bonne idée de quel type de personne vous êtes dès le premier contact avec ledit site, sans avoir à se donner la peine de vous suivre sur le Net. De plus, comme votre cohorte sera mise à jour au cours du temps, les sites sur lesquels vous êtes identifié⋅e⋅s pourront aussi suivre l’évolution des changements de votre navigation. Souvenez-vous, une cohorte AFC n’est ni plus ni moins qu’un résumé de votre activité récente de navigation.
Vous devriez pourtant avoir le droit de présenter différents aspects de votre identité dans différents contextes. Si vous visitez un site pour des informations médicales, vous pourriez lui faire confiance en ce qui concerne les informations sur votre santé, mais il n’y a pas de raison qu’il ait besoin de connaître votre orientation politique. De même, si vous visitez un site de vente au détail, ce dernier n’a pas besoin de savoir si vous vous êtes renseigné⋅e récemment sur un traitement pour la dépression. L’AFC érode la séparation des contextes et, au contraire, présente le même résumé comportemental à tous ceux avec qui vous interagissez.
Au-delà de la vie privée
L’AFC est conçu pour éviter une menace spécifique : le profilage individuel qui est permis aujourd’hui par le croisement des identifiants contextuels. Le but de l’AFC et des autres propositions est d’éviter de laisser aux pisteurs l’accès à des informations qu’ils peuvent lier à des gens en particulier. Alors que, comme nous l’avons montré, cette technologie pourrait aider les pisteurs dans de nombreux contextes. Mais même si Google est capable de retravailler sur ses conceptions et de prévenir certains risques, les maux de la publicité ciblée ne se limitent pas aux violations de la vie privée. L’objectif même de l’AFC est en contradiction avec d’autres libertés individuelles.
Pouvoir cibler c’est pouvoir discriminer. Par définition, les publicités ciblées autorisent les annonceurs à atteindre certains types de personnes et à en exclure d’autres. Un système de ciblage peut être utilisé pour décider qui pourra consulter une annonce d’emploi ou une offre pour un prêt immobilier aussi facilement qu’il le fait pour promouvoir des chaussures.
Au fur et à mesure des années, les rouages de la publicité ciblée ont souvent été utilisés pour l’exploitation, la discrimination et pour nuire. La capacité de cibler des personnes en fonction de l’ethnie, la religion, le genre, l’âge ou la compétence permet des publicités discriminatoires pour l’emploi, le logement ou le crédit. Le ciblage qui repose sur l’historique du crédit – ou des caractéristiques systématiquement associées – permet de la publicité prédatrice pour des prêts à haut taux d’intérêt. Le ciblage basé sur la démographie, la localisation et l’affiliation politique aide les fournisseurs de désinformation politique et la suppression des votants. Tous les types de ciblage comportementaux augmentent les risques d’abus de confiance.
Au lieu de réinventer la roue du pistage, nous devrions imaginer un monde sans les nombreux problèmes posés par les publicités ciblées.
Google, Facebook et beaucoup d’autres plateformes sont en train de restreindre certains usages sur de leur système de ciblage. Par exemple, Google propose de limiter la capacité des annonceurs de cibler les utilisatrices selon des « catégories de centres d’intérêt à caractère sensible ». Cependant, régulièrement ces tentatives tournent court, les grands acteurs pouvant facilement trouver des compromis et contourner les « plateformes à usage restreint » grâce à certaines manières de cibler ou certains types de publicité.
Même un imaginant un contrôle total sur quelles informations peuvent être utilisées pour cibler quelles personnes, les plateformes demeurent trop souvent incapables d’empêcher les usages abusifs de leur technologie. Or l’AFC utilisera un algorithme non supervisé pour créer ses propres cohortes. Autrement dit, personne n’aura un contrôle direct sur la façon dont les gens seront regroupés.
Idéalement (selon les annonceurs), les cohortes permettront de créer des regroupements qui pourront avoir des comportements et des intérêts communs. Mais le comportement en ligne est déterminé par toutes sortes de critères sensibles : démographiques comme le genre, le groupe ethnique, l’âge ou le revenu ; selon les traits de personnalités du « Big 5 »; et même la santé mentale. Ceci laisse à penser que l’AFC regroupera aussi des utilisateurs parmi n’importe quel de ces axes.
L’AFC pourra aussi directement rediriger l’utilisatrice et sa cohorte vers des sites internet qui traitent l’abus de substances prohibées, de difficultés financières ou encore d’assistance aux victimes d’un traumatisme.
Google a proposé de superviser les résultats du système pour analyser toute corrélation avec ces catégories sensibles. Si l’on découvre qu’une cohorte spécifique est étroitement liée à un groupe spécifique protégé, le serveur d’administration pourra choisir de nouveaux paramètres pour l’algorithme et demander aux navigateurs des utilisateurs concernés de se constituer en un autre groupe.
Cette solution semble à la fois orwellienne et digne de Sisyphe. Pour pouvoir analyser comment les groupes AFC seront associés à des catégories sensibles, Google devra mener des enquêtes gigantesques en utilisant des données sur les utilisatrices : genre, race, religion, âge, état de santé, situation financière. Chaque fois que Google trouvera qu’une cohorte est associée trop fortement à l’un de ces facteurs, il faudra reconfigurer l’ensemble de l’algorithme et essayer à nouveau, en espérant qu’aucune autre « catégorie sensible » ne sera impliquée dans la nouvelle version. Il s’agit d’une variante bien plus compliquée d’un problème que Google s’efforce déjà de tenter de résoudre, avec de fréquents échecs.
Dans un monde numérique doté de l’AFC, il pourrait être plus difficile de cibler directement les utilisatrices en fonction de leur âge, genre ou revenu. Mais ce ne serait pas impossible. Certains pisteurs qui ont accès à des informations secondaires sur les utilisateurs seront capables de déduire ce que signifient les groupes AFC, c’est-à-dire quelles catégories de personnes appartiennent à une cohorte, à force d’observations et d’expérimentations. Ceux qui seront déterminés à le faire auront la possibilité de la discrimination. Pire, les plateformes auront encore plus de mal qu’aujourd’hui à contrôler ces pratiques. Les publicitaires animés de mauvaises intentions pourront être dans un déni crédible puisque, après tout, ils ne cibleront pas directement des catégories protégées, ils viseront seulement les individus en fonction de leur comportement. Et l’ensemble du système sera encore plus opaque pour les utilisatrices et les régulateurs.
Avec Google les instruments changent, mais c’est toujours la même musique…
Google, ne faites pas ça, s’il vous plaît
Nous nous sommes déjà prononcés sur l’AFC et son lot de propositions initiales lorsque tout cela a été présenté pour la première fois, en décrivant l’AFC comme une technologie « contraire à la vie privée ». Nous avons espéré que les processus de vérification des standards mettraient l’accent sur les défauts de base de l’AFC et inciteraient Google à renoncer à son projet. Bien entendu, plusieurs problèmes soulevés sur leur GitHub officiel exposaient exactement les mêmespréoccupations que les nôtres. Et pourtant, Google a poursuivi le développement de son système, sans pratiquement rien changer de fondamental. Ils ont commencé à déployer leur discours sur l’AFC auprès des publicitaires, en vantant le remplacement du ciblage basé sur les cookies par l’AFC « avec une efficacité de 95 % ». Et à partir de la version 89 de Chrome, depuis le 2 mars, la technologie est déployée pour un galop d’essai. Une petite fraction d’utilisateurs de Chrome – ce qui fait tout de même plusieurs millions – a été assignée aux tests de cette nouvelle technologie.
Ne vous y trompez pas, si Google poursuit encore son projet d’implémenter l’AFC dans Chrome, il donnera probablement à chacun les « options » nécessaires. Le système laissera probablement le choix par défaut aux publicitaires qui en tireront bénéfice, mais sera imposé par défaut aux utilisateurs qui en seront affectés. Google se glorifiera certainement de ce pas en avant vers « la transparence et le contrôle par l’utilisateur », en sachant pertinemment que l’énorme majorité de ceux-ci ne comprendront pas comment fonctionne l’AFC et que très peu d’entre eux choisiront de désactiver cette fonctionnalité. L’entreprise se félicitera elle-même d’avoir initié une nouvelle ère de confidentialité sur le Web, débarrassée des vilains cookies tiers, cette même technologie que Google a contribué à développer bien au-delà de sa date limite, engrangeant des milliards de dollars au passage.
Ce n’est pas une fatalité. Les parties les plus importantes du bac-à-sable de la confidentialité comme l’abandon des identificateurs tiers ou la lutte contre le pistage des empreintes numériques vont réellement améliorer le Web. Google peut choisir de démanteler le vieil échafaudage de surveillance sans le remplacer par une nouveauté nuisible.
Nous rejetons vigoureusement le devenir de l’AFC. Ce n’est pas le monde que nous voulons, ni celui que méritent les utilisatrices. Google a besoin de tirer des leçons pertinentes de l’époque du pistage par des tiers et doit concevoir son navigateur pour l’activité de ses utilisateurs et utilisatrices, pas pour les publicitaires.
Remarque : nous avons contacté Google pour vérifier certains éléments exposés dans ce billet ainsi que pour demander davantage d’informations sur le test initial en cours. Nous n’avons reçu aucune réponse à ce jour.
Libres bulles pour que décollent les contributions
Comme beaucoup d’associations libristes, nous recevons fréquemment ce genre de demandes « je vous suis depuis longtemps et je voudrais contribuer un peu au Libre, comment commencer ? »
Pour y répondre, ce qui n’est pas toujours facile, une dynamique équipe s’est constituée avec le soutien de Framasoft et a fondé le projet Contribulle qui propose déjà d’aiguiller chacun⋅e vers des contributions à sa mesure. Pour comprendre comment ça marche et quel intérêt vous avez à les rejoindre, nous leur avons posé des questions…
« Bulles de savon » par Daniel_Hache, licence CC BY-ND 2.0
Bonjour la team Contribulle ! On vous a rencontré⋅e⋅s sur l’archipel de Contributopia, mais pouvez-vous vous présenter, nous dire de quels horizons vous venez ?
– Hello, je suis llaq (ou lelibreauquotidien), je suis dans le logiciel libre depuis quelques années depuis qu’un ami m’a offert un PC sous Linux (bon, quand j’étais sous Windows, j’utilisais déjà des logiciels libres mais c’était pas un argument rédhibitoire).
— Yo ! Oui on se baladait dans le coin, l’horizon qui se présentait à nous paraissait bien prometteur ! Je suis Mélanie mais vous pouvez m’appeler méli, j’ai bientôt 25 ans et je viens du monde du design UX et UI. En explorant le numérique, j’ai pas mal gravité autour du Libre et mon mémoire de master de l’année dernière m’a bien fait plonger dans ce sujet super passionnant ! Fun fact : je me demandais comment rendre le logiciel libre plus ouvert (!), pour mieux accueillir une diversité de contributions et il faut dire que votre campagne Contributopia m’a pas mal guidée héhé. Le projet Contribulle a en partie émergé à cette période-là et je suis contente de le poursuivre, toujours en tant que designeuse UX/UI !
– Hello ! Je suis Maiwann, membre de Framasoft… une petite asso que vous connaissez peut-être ? Et je suis designer.
Laissez-moi deviner : Contribulle, c’est un dispositif pour enfermer les contributeurs et contributrices d’un projet dans une bulle et alors quand ça monte ça éclate et le projet explose ? Non, c’est pas ça ?
llaq : C’est presque ça. Contribulle est une plateforme qui permet de mettre en relation des projets aux besoins assez spécifiques avec des contributeur·rice·s intéressé·e·s, qu’iels soient dans le domaine technique ou non. Un des buts du site est d’ailleurs de permettre aux non-techniques de contribuer à des projets libres et surtout de démontrer que la contribution, c’est pas seulement pour les codeur·se·s.
méli : Haha, ce nom a été voté par jugement majoritaire ! Perso, j’imagine une bulle qui est amenée à grossir grâce aux contributions des personnes et qui sera tellement géante qu’il sera impossible de la rater. Et peut-être qu’elle pourrait attirer d’autres contributions !
Maiwann : … Et moi j’imagine plein de petites bulles comme un nuage de bulles de savon quand on souffle dans le petit cercle ! Et elles s’envolent… loin… loiiiiiin ! Jusqu’à ce qu’on en fasse une nouvelle fournée 🙂
« Bubbles » by bogenfreund, licence CC BY-SA 2.0
Ah mais c’est tout neuf cette plateforme ? Comment est venue l’idée de proposer ça ? Et d’ailleurs ça paraît tellement utile qu’on se demande pourquoi ça n’existait pas avant.
méli : Pendant mon mémoire, j’avais retenu qu’il était compliqué de s’y retrouver parmi tous les projets libres créés et qu’il était encore plus difficile de savoir où et comment contribuer au Libre, surtout en tant que non-développeur·se. J’avais donc rapidement imaginé un site qui recenserait des projets libres à la recherche de compétences et qui permettrait d’attirer des contributeur·rice·s de tous horizons. Je ne savais pas s’il existait déjà une plateforme de ce type dans laquelle je pourrais m’inscrire.
Quelques déambulations plus tard, je suis tombée sur la restitution du fameux événement coorganisé par Framasoft et la Quadrature du Net « Fabulous Contribution Camp » de novembre 2017. J’y ai trouvé une idée similaire au site que j’imaginais et je contacte donc Maiwann pour avoir des nouvelles sur l’évolution de ce projet. On s’appelle en janvier 2020 (merci BigBlueButton) et il s’avère que rien n’avait été mis en place et qu’il manquait un tremplin pour lancer le projet. C’est donc à partir de là que ça a décollé. Si la suite intéresse : J’ai ensuite réalisé une maquette de la plateforme, qui avait pour nom de code « Meetic du Libre ». J’ai pu la présenter au cours d’un Confinatelier en juin 2020 avec Maiwann. On avait pour objectifs de valider la pertinence du projet et ensuite de mobiliser des personnes qui souhaiteraient bien y contribuer. Les retours nous ont rassuré⋅e⋅s et on a pu monter un groupe de travail rapidement.
Cependant, avec l’été qui se profilait, le site était juste débutant jusqu’à ce que Maiwann nous relance fin octobre. Depuis novembre, l’équipe est un peu plus réduite : on est 2 designeuses, 1 développeur front et 1 développeur back et on s’organise des rendez-vous hebdomadaires pour avancer. Des personnes nous ont aussi aidé⋅e⋅s ponctuellement, que ce soit aux niveaux code, graphisme et design, on leur en est super reconnaissant·e·s ! Grâce aux efforts et la bonne humeur de tou·te·s les contributeur·rices, on a pu mettre en ligne Contribulle en février 2021, une grande fierté !
Est-ce qu’il faut s’inscrire avec ses coordonnées et tout ?
llaq : Pour les personnes qui créent une demande de contribution, il n’est pas nécessaire de créer de compte. Il faut simplement renseigner une adresse email valide et un pseudo pour que les contributeur·rice·s qui le souhaitent puissent contacter la personne qui a créé l’annonce.
Maiwann : On a fait en sorte d’être le plus minimalistes possibles dans le nombre d’infos demandées. Du coup, exit la création de compte pour ne pas se farcir un énième identifiant-mot-de-passe ! En revanche, on demande un moyen de contact aux personnes qui recherchent des contributeurices, pour être sûres qu’elles vont pouvoir s’adresser à un humain !
Combien ça coûte ?
llaq : Rien. Plus sérieusement, dans le projet, nous sommes tou·te·s bénévoles et les ressources techniques servant à l’hébergement de contribulle.org nous ont gracieusement été offertes par notre partenaire Framasoft, donc aucun frais pour nous, aucune raison de faire payer la plateforme donc 🙂
méli : Dans la perspective de mettre en avant des projets qui participent à l’émancipation individuelle et collective des individus et qui sont bien évidemment respectueux de nos libertés, on ne souhaite pas faire payer pour poster une annonce. On veut inviter le plus grand nombre à mettre la main à la pâte donc on préfère éviter de poser des contraintes financières dès le départ !
Maiwann : Ça a coûté du temps et de l’énergie à des gens compétents de se retrouver, de décider d’une direction pour le projet, de faire des choix, de les maquetter / coder, + les frais d’hébergement. Et ça va coûter de l’énergie dans le futur pour faire vivre Contribulle, donc si vous en parlez le plus possible autour de vous, ça nous aidera beaucoup et ça contribuera à faire vivre Contribulle !
Si j’ai un projet génial mais que je ne sais rien faire du tout, je peux juste vous donner mon idée géniale et vous allez vous en charger et tout faire pour moi ?
méli : Mmmh Contribulle n’est pas un service de travail gratuit… mais c’est chouette si tu as une bonne idée de projet, si tu sens qu’elle a du potentiel et qu’elle est valide…
À quel(s) besoin(s) répond-elle ?
Quelle est sa valeur ajoutée pour les futur·e·s utilisateur·rices ?
…
…tu peux lister précisément les compétences requises. Contribulle a vocation de faciliter la compréhension de contributions auprès des personnes qui veulent aider. C’est pour ça qu’il nous semble nécessaire dans le formulaire de demande de contribution de bien présenter le projet et de donner plus d’indications sur la contribution souhaitée. Un projet se doit d’être sérieux et conscient du temps et de l’effort qu’un·e contributeur·rice y consacrera.
logo du projet Contribulle
Un point qu’il est important de mentionner est l’accueil des contributeur·rice·s au sein d’un projet. Il ne faut pas prendre l’aide d’une personne externe comme acquise et surtout la surexploiter parce que (friendly reminder) : on a nos vies et nos priorités à gérer.
Un projet doit mettre en place un dispositif pour faciliter l’accès à la contribution, que ce soit une page dédiée, une conversation épistolaire, le format est libre et à adapter selon les parties prenantes !
Attention cependant aux renvois directs vers les forges logicielles comme GitHub ou GitLab qui ne sont pas si accessibles pour les non-techniques. Peut-être qu’un tutorat personnalisé peut s’envisager ?
Bref, soyons plus à l’écoute des contributeur·rice·s ! Et pour les contributeur·rice·s : écoutez-vous et n’hésitez pas à dire quand un truc vous gêne, la communication fait tout.
Comment je vais savoir que d’autres sont intéressée⋅es par mon projet ou que ma contribution intéresse d’autres ?
llaq : On n’a pas de messagerie intégrée, tout se fait par le mail que vous avez indiqué dans votre annonce. Maiwann : comme ça, pas besoin de revenir sur la plateforme, ouf ! Vous postez et c’est réglé !
Attention c’est le moment trollifère : les projets sur lesquels on peut contribuer c’est du libre ou open source ou bien osef ?
llaq : Nous comptons justement implémenter un bandeau qui s’affichera si le projet est libre ou pas (c’est-à-dire bénéficiant d’une licence libre) ! Mais sa place sur Contribulle va dépendre de l’équipe de modération composée de 4 personnes pour l’instant.
méli : La valeur (politique) des projets publiés sera prise en compte. Parmi les questions à se poser : pour qui est le projet ? Participe-t-il au bien collectif ? Comment permettrait-il à tou·te·s les utilisateur·rices de disposer de leurs appareils ainsi que de leurs données personnelles ?
Maiwann : On voudrait que tous les projets soient sous licence libre, mais on est aussi conscient·es que tout le monde n’est pas forcément au clair sur l’intérêt que ça peut avoir, l’importance… donc on se dit qu’on poussera les personnes à s’y intéresser à l’aide du bandeau, mais sans les disqualifier forcément d’entrée (et on verra ça au cas par cas !)
C’est évalué comment et par qui, le « sérieux » ou la pertinence des projets et contributions ? Chacun⋅e s’autonomise et hop ?
llaq : Nous avons décidé de faire de la modération à posteriori. Ton annonce est directement publiée et visible par tout le monde mais si l’équipe de modération estime que le projet n’a pas sa place sur Contribulle, il sera supprimé de la plateforme. Maiwann : et si c’est trop relou, on passera à de la modération a priori ! Et pour faire des choix, ça sera sans doute au doigt mouillé, au « comment chacune le sent » et puis on verra sur le tas comment se structure l’équipe de modération ! Pour l’instant, RAS 🙂
« bubbles » par Mycatkins, licence CC BY 2.0
Et donc si je veux contribuller au projet, je peux faire quoi ?
méli : Pour l’instant, nous faire des retours sur vos usages de Contribulle et la promouvoir autour de vous seraient de belles contributions ! On souhaite l’améliorer au mieux selon les besoins ressentis de chacun·e.
La question de rétribution n’a pas encore été abordée mais selon l’évolution de la plateforme et des ressources mobilisées, des formes sont à réfléchir je pense. Qu’il s’agisse de don financier, d’un retour d’utilisateur·rice, ou autre.
Maiwann : Je pense que ce qui va être primordial ça va être de faire vivre Contribulle. Quelqu’un dit qu’il voudrait aider le Libre ? glissez lui un mot sur Contribulle. Quelqu’un vient à un contrib’atelier ? N’oubliez pas de parler de Contribulle. Comme ça le projet vivra grâce aux visites des contributeurices !
Ah mais il y a déjà un paquet de demandes, ça fait un peu peur, je vois bien que je ne vais servir à rien pour tous ces trucs de techies ! Au secours ! (Pour l’instant dans l’équipe c’est orienté web développement non) ?
méli : c’est 50/50 moitié dev et moitié design/conception. Oui, on a dépassé les 20 annonces depuis sa mise en ligne il y a un mois, c’est trop bien ! Et on cherche vraiment à mettre en avant des contributions non-techniques parce que tu es super utile justement ! Prochainement tu pourras filtrer les annonces selon tes propres savoir-faire, en espérant qu’il y aura des demandes à ce niveau-là. En attendant, on te propose des contributions faciles. Tu seras renvoyé·e vers des sites sélectionnés par nos soins et auxquelles tu peux directement contribuer. Bonne contribution !
Maiwann : C’est tout à fait ça, grâce aux filtres tu vas pouvoir plus facilement mettre de côté les choses qui font peur !
Et si je regarde, il y a déjà quelques projets qui sont chouettes et que tu peux aider sans compétences techniques, par exemple :
Marie-Cécile Godwin : « les usages prévalent sur tout »
Un internaute nous dit : J’ai été particulièrement intéressé par les propos de Marie Cécile Godwin sur ses interactions avec les utilisateurs de PeerTube et les vidéastes qui utilisent déjà YouTube, ainsi que sur ses retours sur la communauté du libre… Dis, Framablog, tu nous ferais un entretien avec elle pour en parler plus longuement ?
Mais avec grand plaisir ! Marie-Cécile, 39 ans, amatrice de Rice Krispies et de tricot, designer UX quand il faut payer les factures. Diplômée de communication visuelle en 2004 (oui, ça date !), j’ai peu à peu navigué vers la stratégie de conception et l’étude des usages, à l’époque où on ne parlait pas encore d’UX. Aujourd’hui, je passe la plupart de mon temps à coller des post-it partout, écouter des personnes me parler de leurs usages numériques et faire de mon mieux pour déconstruire les clichés sur le numérique des étudiant·es durant les cours que je donne. D’ailleurs, je leur propose régulièrement de prendre les logiciels libres comme sujets d’étude !
Détournement de la photo officielle de Marie-Cécile
Qu’est-ce que tu savais du logiciel libre et de la culture geek avant de nous rencontrer ?
Pas grand chose. J’utilisais certains d’entre eux, mais je n’avais pas encore fourré le nez dans la culture libre et ses valeurs. En bonne designer graphique, je capitulais devant le poids des grandes firmes et de leurs logiciels propriétaires pour respecter la chaîne de production tout autour de moi. Puis, avec l’arrivée des plateformes sociales et la découverte des enjeux liés, entre autres, à l’Anthropocène, j’ai enfin pu déconstruire mes préconceptions au sujet des libertés individuelles, et de ce que nous pouvons faire pour nous prémunir de leur destruction. Pour ce qui est des logiciels propriétaires, j’ai récemment décidé de passer à la suite Affinity Serif qui n’est pas libre, mais qui propose leurs logiciels à prix fixe, une rareté dans l’industrie où il ne reste que des programmes « cloud » à abonnement.
Est-ce que tu avais une vision réaliste des vidéastes qui publient sur le web, ou est-ce que tu as eu des surprises en bossant sur PeerTube ?
Très peu consommatrice de contenus vidéos, je n’ai pas bien suivi le phénomène de l’explosion des vidéastes. Certainement dû à mon grand âge, en tout cas sur l’échelle du Web 😀
Du coup, pas tellement de surprises en découvrant l’univers gravitant autour de Peertube, mais de belles rencontres, notamment au fil des entretiens menés pour découvrir les usages de chacune et chacun.
Tu dis que tu es designer, en quoi ça consiste ?
Ah ça, c’est LA question piège à chaque fois qu’on me demande ce que je fais. Il y a des clichés très persistants sur le design, qui est vu comme la discipline de l’apparence et du beau. Si je devais revenir aux fondements de ma pratique, je suis la personne chargée de (re)cadrer le besoin initial, d’analyser le contexte et le terrain, puis de prendre toute la complexité recueillie, l’ordonner et lui donner LA forme qui conviendra.
Que ce soit du travail de graphisme (UI) pour adapter une identité graphique à un wireframe, ou du travail de conception dudit wireframe, ou encore la création d’un « service blueprint » (un plan technique d’un service ou d’une organisation destiné à faciliter l’identification des problèmes ou des frictions) d’après des données de terrain ou d’entretiens, tout part des mêmes méthodes : cadrer, analyser, ordonner puis choisir la forme de restitution qui conviendra.
Ce processus est à la base de tout, c’est ce qui s’appelle la « pensée design », et qui fait les beaux jours des cabinets de consulting sous le très à la mode « design thinking« . Mais qu’on appelle ça « design thinking« , « UX design » ou un quelconque néologisme bullshit, cela m’importe peu. Je me dis souvent « UX designer » ou « UX researcher » parce que ce sont des termes qui sont maintenant entrés dans le langage commun et qui ont un vague sens pour les personnes à qui je le dis. Mais au final, je suis bien « conceptrice » un peu comme je pourrais être « ingénieure ». C’est une façon de penser, réfléchir et faire les choses, puis de leur donner la juste apparence en fonction de tous ces paramètres. J’assiste la conception de systèmes et de services.
Est-ce que tu as changé de façon de « faire du design » au cours de ta vie professionnelle ?
Ouh là là oui ! À l’époque où j’ai fait mes études (le tout début du siècle !), le monde était radicalement différent et les inégalités et oppressions systémiques amplifiées par le numérique étaient beaucoup moins saillantes qu’aujourd’hui. Mon propre privilège m’était également invisible.
je me suis frottée au capitalisme de surveillance
Je me contentais de faire ce que l’on m’avait appris : obéir aux exigences d’un⋅e client·e et faire de mon mieux pour contribuer à atteindre ses objectifs, la plupart du temps ceux-ci étant résumables à « vendre plus de trucs ». Depuis, je me suis frottée au capitalisme de surveillance, à la surconsommation, au dérèglement climatique, aux oppressions systémiques et j’ai découvert que le design et les designers étaient loin d’être innocentes dans tout ça. Il m’a fallu du temps, mais aujourd’hui j’essaie de faire de mon mieux pour parler de ces aspects et les appliquer au quotidien dans ma manière de travailler et les personnes avec qui je travaille.
Pourquoi as-tu accepté de contribuer à Framasoft (On n’en revient toujours pas qu’une pointure comme toi accepte de nous aider) ?
Une « pointure » ? mais non enfin 😀
Hé bien justement, pour toutes les raisons susmentionnées. Il n’est pas possible de lutter individuellement contre des choses aussi complexes et insidieuses que le dérèglement climatique et le capitalisme de surveillance. Par contre, on peut faire plein de petits choix conscients qui feront avancer petit à petit les choses. Collaborer avec Framasoft, que ce soit via des prestations rémunérées ou du bénévolat, me permet d’avoir la sensation de faire une petite part du travail à accomplir pour que le monde soit un poil moins pourri chaque jour.
Aussi, parce que Framasoft est blindée de personnes formidables que j’aime beaucoup côtoyer (toujours à 2 mètres de distance et avec un masque :P) et que j’apprends énormément à leurs côtés.
Quand tu as commencé à regarder ce qui n’allait pas en termes d’UX / UI chez Framasoft, qu’est-ce qui t’a choquée le plus ?
Le mot « choquée » est un peu fort. 😛
Ce qui me donne le plus de fil à retordre, c’est tout le travail de « change management« , pour employer un terme très startup nation. Le modèle mental des designers est radicalement différent, dans la manière d’aborder la conception d’un outil, par exemple d’un logiciel. Nous n’allons pas nous appuyer sur nos propres perceptions pour prendre des décisions, mais nous allons d’abord étudier le contexte, aller voir des personnes qui ont le même besoin, et essayer de trouver un modèle de conception qui serve le plus de monde possible.
Ce travail, s’il n’est pas fait en amont, pose deux problèmes : l’outil une fois conçu ne va pas « parler » aux personnes qu’il est censé aider. Par exemple, le vocabulaire verbal ou visuel de l’interface induira les personnes qui l’utilisent en erreur, soit parce qu’il est trop technique ou qu’il n’emploie pas les bonnes métaphores visuelles. Le deuxième problème, plus structurel, se traduit dans la manière dont le projet est mené et conçu. Si vous avez passé votre vie à concevoir des programmes, qu’ils vous conviennent bien, et qu’en plus personne n’a jamais vraiment râlé, vous n’allez pas avoir besoin de vous remettre en question. Comme je le raconte souvent quand je parle de conception / design dans le libre, en tant qu’UX designer j’arrive avec un constat inconfortable : « ton logiciel ne prend pas le problème dans le bon sens… ». Si on s’arrête là, c’est sûr que ça donne l’impression qu’on va tout péter à coups de masse et que tout le boulot fait jusqu’à présent est à jeter aux oubliettes. La suite du constat est plus cool : « …mais c’est pas grave, on va trouver ensemble des manières de le faire évoluer pour qu’il parle à davantage de gens ».
Comment s’est déroulé ton travail sur PeerTube ?
À la différence de Mobilizon, où le projet commençait à peine et où la team Frama m’a intégrée tout de suite, PeerTube a déjà tout un existant avec lequel j’ai dû me familiariser : l’histoire du projet, de son concepteur, les évolutions, les contributions, les dynamiques autour du projet. J’étais dans mes petits souliers au début ! Ce n’est pas facile de débarquer comme une fleur avec un œil de designer, souvent notre travail est perçu comme l’arrivée d’un chien dans un jeu de quilles, un peu à la « c’est moche, on refait tout ». Il est important de prendre en compte l’histoire du projet et tout le bagage émotionnel qui va avec. On a commencé doucement avec une première phase où j’ai fait l’éponge en posant des questions à l’équipe et à Chocobozzz, puis où j’ai mené des entretiens pour nous faire une meilleure idée de ce que les utilisatrices et utilisateurs de PeerTube en faisaient et ce dont elles et ils avaient besoin. J’ai réalisé en tout une quinzaine d’entretiens, desquels sont sortis non seulement plein d’idées d’améliorations à très court terme, mais aussi de quoi nourrir des orientations stratégiques sur le temps long.
Ce qui m’intéresse beaucoup dans ce projet, c’est d’accompagner Chocobozzz dans les futures évolutions du logiciel en lui apportant la facette « UX ». Outre des petites choses simples comme l’aider à justifier des décisions ergonomiques ou graphiques grâce aux heuristiques de design graphique ou d’utilisabilité, on essaie de bien cadrer les problèmes identifiés, de se faire une bonne idée des usages qui vont autour et de prendre les décisions qui y correspondent.
La grande satisfaction jusqu’à présent, c’est de sentir que je suis utile et que mon travail ne génère pas de défiance dans l’équipe. Chocobozzz m’a dit que ça lui faisait du bien de bosser avec une designer, lui qui a été bien seul sur l’immense majorité de son projet et qui a dû faire des choix ergonomiques sans réellement savoir si c’était la bonne voie ou pas.
les libristes, c’est comme un bol de M&M’s
Qu’est-ce que tu trouves de génial et qu’est-ce que tu trouves de détestable dans la communauté du Libre ?
Ce qui est absolument génial, ce sont ces valeurs partagées et cette ouverture vers des alternatives. La radicalité politique de la communauté est très appréciable. Pour s’intéresser au libre, il faut avoir fait un chemin individuel qui implique forcément de la réflexion, une prise de recul sur l’existant, et l’audace de s’orienter vers quelque chose de différent de la norme.
Pour ce qui est « détestable », je ne sais pas si le mot est juste, mais j’ai eu à me frotter à un cactus bien piquant, celui qui découle du modèle mental dominant dans le libre : celui du développeur / ingénieur (homme cis hétérosexuel, éduqué, très souvent valide et entouré de gens qui lui ressemblent bien trop (ce ne sont que des faits démographiques, pas un jugement)) dans son armure de certitudes. Concrètement, je me suis fait empailler un nombre incalculable de fois, notamment sur Mastodon que j’ai laissé tomber pour cette raison, parce que j’avais eu l’audace d’utiliser une solution non-libre tout en osant travailler avec Frama. Il existe deux problèmes à mon sens : le premier relève de l’allégeance au libre qui est souvent interprétée en décalage avec la réalité des choses (l’existence d’intercompatibilité entre des solutions ou pas, le monde du travail, les habitudes, les possibilités financières, physiques, cognitives de chacun·e). Résultat, je suis une « vendue » si un jour j’ai osé publier un lien vers un Google Doc. Sauf que la petite asso sans moyen à qui je file un coup de main n’a pas vraiment eu d’autre choix que de se rabattre sur cette solution, pour des raisons qui sont les siennes et que je ne dois pas me permettre de critiquer (les usages prévalent sur tout, c’est la réalité, même si on aimerait parfois que ce soit différent).
Le deuxième problème est fait d’un mélange de patriarcat bien ancré dans l’informatique mixé au manque quasi-total d’occasions de se remettre en question dont souffrent nombre de personnages dans le libre. Je ne suis pas en train de critiquer des individus, ce serait trop simple et cela effacerait l’aspect systémique du problème. En pratique, cela se traduit en discussions unilatérales où mon interlocuteur est en incapacité d’imaginer que je puisse avoir une autre perception et une autre expérience de la vie que lui, encore moins de reconnaître ses torts. Une fois entrevue la possibilité que je puisse lui mettre le nez dans son étron, il va redoubler d’effort car mieux vaut se défendre que d’avouer ses erreurs. Il y a aussi cette insupportable certitude qu’on est dans la vérité et que toute personne qui fait autrement a foncièrement tort. Une des conséquences c’est l’infini tsunami de conseils non sollicités que moi et mes consœurs nous prenons dans la courge quand on ose émettre la moindre critique de quoi que ce soit sur Internet. Je n’ai pas l’énergie de gérer les egos de ceux qui viennent m’apprendre la vie, alors qu’en faisant l’effort de lire ma bio ou de consacrer quelques secondes à se renseigner sur ce que je publie, ils se seraient vite rendu compte que leur intervention était au mieux inutile, au pire franchement toxique.
Du coup, les libristes, c’est comme un bol de M&M’s. On te dit qu’au milieu du bol, y’en a 2 ou 3 qui sont toxiques du genre mortel, mais qu’on ne sait pas lesquels. Je souhaite bon courage à la personne qui osera en manger. Cela peut expliquer que je perde patience et qu’il m’arrive de bloquer allègrement, ou d’envoyer de bons vieux mèmes féministes pour clore une discussion non sollicitée.
Extrait d’une vidéo. On est encore tombé sur une hyperactive.
Es-tu une louve solitaire du design et de l’expérience utilisateur dans le monde du libre, ou bien y a-t-il une communauté de UI/UX designers qui ont une affinité avec le libre ?
De plus en plus de consœurs et confrères s’intéressent au libre. Maiwann a commencé bien avant moi ! Je suis loin d’avoir le monopole. Il y a encore un fossé qui nous empêche, nous designers, de vraiment contribuer au libre. On ne s’y sent pas forcément à notre place ou bien accueilli·es. Il faut déjà passer la barrière des outils et méthodes qu’utilisent les libristes pour travailler (GitHub, forums, etc.) et ensuite faire comprendre que nous ne sommes pas juste des peinteresses en bâtiment qui vont pouvoir donner un petit coup de propre à notre vieux Bootstrap UI.
J’essaie de motiver des personnes autour de moi dans l’industrie du design et de l’UX pour contribuer, j’espère que ma présence dans ce milieu va rassurer les gens du libre (non, les designers ne viennent pas tout casser !) et les designers (oui, les gens du libre peuvent écouter !).
Question annexe : je participe à un super projet libre (site Web ou applications pour le Web/ordiphone/ordinateur), mais je suis nul en UX/UI. Vers qui me tourner ? De manière générale, comment aborder cette problématique quand on n’est pas soi-même designer ?
La toute première étape pour aborder la problématique de la conception et de l’expérience d’usage, c’est déjà de se rendre compte qu’on a besoin d’aide 🙂 Ensuite, je dirais qu’intégrer un·e designer le plus tôt possible dans le projet est très important. Comme tu l’as sûrement compris, plus on peut absorber de contraintes, mieux on peut aider.
Il existe plein de ressources pour s’approprier les règles de base afin de créer une interface accessible, lisible, utilisable et logique. Ce n’est pas si dur que ça, promis ! Le tout c’est d’arriver avant la fin du projet où il ne reste plus qu’à « mettre un coup de peinture au Bootstrap« .
En travaillant avec des vidéastes utilisant des plateformes privatrices, as-tu vu des problèmes impossibles à résoudre pour eux (pour le moment) avec les logiciels libres et/ou PeerTube ? (Je pose cette question parce que j’ai récemment lu un article de Robin Wong expliquant qu’il devait publier deux vidéos sur YouTube chaque semaine sous peine de disparaître des écrans, la faute à un algorithme secret et féroce… et j’ai trouvé ça particulièrement triste et aimerais bien qu’il existe une solution libre pour éviter cela)
Il existe nombre de problématiques d’usage pour lesquelles le logiciel libre ne pourra pas grand chose. Avec Mobilizon, par exemple, on s’est frotté·es au phénomène du « no-show« , ou de ces personnes qui prennent une place pour un événement, pour finalement ne pas y venir. C’est un grand classique pour toute personne qui organise des événements, et ça peut être très difficile de gérer la logistique derrière. Cela implique des questionnements sur le nombre de bouteilles de jus de fruit à prévoir jusqu’à la taille même de la salle à louer. C’est un souci humain, et on aura beau se creuser la tête et ajouter tout un tas de petite fonctionnalités pour inciter au maximum ces personnes à céder leur place réservée si elles ne viennent pas, l’informatique a ses limites.
Pour la rémunération, ce ne sont pas les logiciels libres qui vont faire office de solution
Pour ce qui est de la vidéo, il est clair que deux forces jouent en la défaveur des vidéastes : le modèle financier imposé par les plateformes, et les algorithmes qui changent en permanence la donne sur ce qui sera promu et pourquoi. Pour la rémunération, ce ne sont pas les logiciels libres qui vont faire office de solution. C’est à nous de nous poser la question, de manière politique, en décortiquant qui rémunère qui, en fonction de quoi, et en décidant collectivement de nouvelles manières de faire en s’affranchissant des plateformes. Pour le coup des algorithmes de sélection de contenu, ils existent pour un seul objectif : forcer les créatrices et créateurs de contenu à payer pour être vues. Le dommage collatéral terrible, c’est qu’ils les forcent aussi à standardiser ce qu’elles produisent, depuis la tronche de l’image de prévisualisation jusqu’au rythme de publication. Ce diktat est très inconfortable pour elles, et je les comprends. Mais de là à abandonner une audience en apparence captive et une plateforme qui te rémunère sans que tes fans n’aient à débourser un seul euro (ou en tout cas c’est ce dont on a l’impression), il y a un fossé à survoler avant d’y arriver.
La transition vers de nouveaux modèles de publication et de rémunération est loin d’être facile, ni rapide. C’est à nous de promouvoir des modèles alternatifs et toute la pédagogie qui va autour, en ne perdant pas de vue que les logiciels en eux-mêmes ne sont pas une fin.
Quel(s) conseil(s) donnerais-tu aux créateurs de logiciels libres pour obtenir de bons retours qui leur permettent d’améliorer leurs logiciels et de les rendre plus accessibles (pas seulement en termes d’accessibilité comme on l’entend sur le Web, mais tout simplement pour qu’ils soit utiles au plus grand nombre).
Il y a deux niveaux sur lesquels agir :
la stratégie de conception du logiciel,
son apparence, son utilisabilité et son accessibilité.
Pour le deuxième niveau (le plus simple pour commencer), il existe de nombreuses ressources pour s’auto-former en bases du graphisme : la théorie des couleurs, les contrastes, les principes du design visuel, les heuristiques d’utilisabilité d’interface (en anglais), parmi tant d’autres. Rien qu’avec ces basiques, on peut éviter énormément d’erreurs d’UI (apparence de l’interface) ou d’UX (comment l’interface fonctionne et s’enchaîne avec le reste d’un flow).
Il est également possible de faire un peu de « guérilla UX » à moindre frais. La méthode la plus simple consiste à interroger des utilisatrices ou utilisateurs de votre logiciel, voire carrément d’organiser une petite session de partage d’écran, de leur demander d’accomplir telle ou telle action, et de les observer en silence : frissons garantis ! Vous en apprendrez énormément sur la manière dont les personnes utilisent votre logiciel, sur les objectifs qu’elles cherchent à remplir avec, et sur les modèles mentaux qu’elles utilisent et que vous n’aviez pas imaginés.
En ce qui concerne la stratégie de conception, c’est un peu plus compliqué. La remettre en question demande une certaine maturité sur le projet, et l’acceptation qu’il est possible qu’on se soit trompé à la base… Jamais agréable. Ensuite, c’est un long travail à faire que de revenir aux origines de l’usage de votre logiciel. Étudier le besoin original, explorer ce besoin pour voir quel périmètre d’usage choisir, pour quels objectifs, pour promouvoir quelles valeurs, puis comment structurer la conception pour appliquer ces valeurs à l’ensemble des décisions prises. C’est ce qu’on appelle l’assistance à maîtrise d’usage, et c’est ce à quoi je passe la plupart de mon temps. Là, c’est un peu plus difficile de s’auto-former. J’essaie, dans la mesure du temps que je peux dégager, de donner des coups de main à droite à gauche pour débloquer ce genre de situations. C’est ce qu’on avait fait avec Marien sur Lessy, par exemple.
Des recommandations de lectures ou de visionnages pour en découvrir plus sur ton métier et sur les bonnes pratiques de UI/UX en général ?
La cartographie libre creuse son sillon depuis de nombreuses années déjà. À l’instar de Wikipédia, l’autre grand projet collaboratif du Web dont le succès ne se dément pas, le projet OpenStreetMap (OSM), lancé quelques années après l’encyclopédie libre, est à l’origine de nombreuses applications.
À noter : cet article bénéficie désormais d’une version audio.
Merci à Sualtam, auteur de lectureaudio.fr pour cette contribution active.
L’article que vous allez lire en présente plusieurs avec une grande clarté et insiste en particulier sur la possibilité de les utiliser hors ligne. Parmi celles-ci, l’application Geovélo fait figure de fleuron français. Largement soutenue et promue par les collectivités locales, elle bénéficie d’une relativement importante couverture médiatique.
On peut toutefois s’interroger sur la manière dont ces collectivités appréhendent réellement le modèle des données libres et ouvertes sur lequel repose ce type d’applications. Car pour qu’elles rendent les services qu’on attend d’elles, il faut que les données cartographiques soient de bonne qualité et mises à jour régulièrement. C’est ce que rappelle Julien de Labaca dans « Le vélo a besoin de carto(s) ». Les collectivités locales françaises sont-elles contributrices au projet OSM ? Après tout, en tant que gestionnaires de voirie, leurs services sont les mieux placés pour collaborer efficacement à ce bien commun qu’est une cartographie libre.
Republication de l’article original publié sur le blog de Damien Une famille à vélo, consacré au cyclotourisme en famille et riche en récits de voyages illustrés, en conseils et fiches pratiques…
Itinéraires 2.0
C’est bien beau de pédaler, mais il est aussi utile de savoir où on va. Tous les ordiphones ont une application de cartographie pré-installée, plus ou moins respectueuse de la vie privée, mais qui en général ne fonctionne pas hors-ligne (ou partiellement).
Je ne m’attarderai pas sur ces applications natives.
OpenStreetMap
Nous allons parler d’OpenStreetMap et de son écosystème. Pour ceux qui n’en ont jamais entendu parler voici ce qu’en dit Wikipédia :
OpenStreetMap (OSM) est un projet collaboratif de cartographie en ligne qui vise à constituer une base de données géographiques libre du monde (permettant par exemple de créer des cartes sous licence libre), en utilisant le système GPS et d’autres données libres.
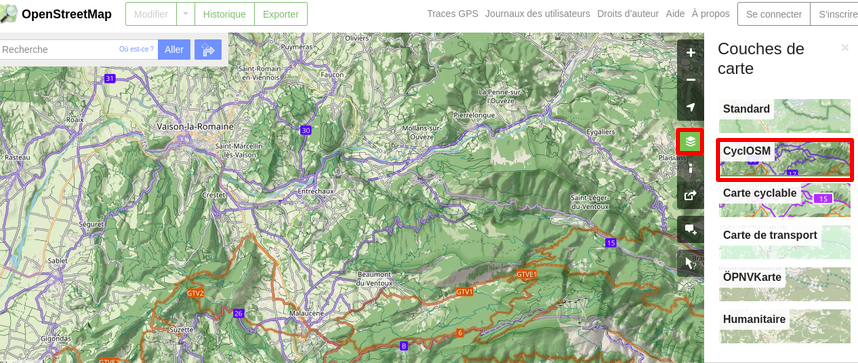
Vous pouvez bien sûr consulter directement la carte OSM avec ses différents fonds de carte (dont certains sont dédiés au vélo). Les données étant sous licence libre, de nombreuses autres applications utilisent les données OSM. C’est très souvent le cas des applications de randonnée.
Des itinéraires vélo à découvrir dans les « couches » de carte OSM
OsmAnd
L’application OsmAnd repose sur les cartes OpenStreetMap. Elle est disponible sur Android et IOS. Le site est en anglais mais – rassurez vous – l ‘application est disponible en français. Voici quelques-unes de ses fonctionnalités :
calcul d’itinéraire et guidage avec différents profils (voiture, vélo, randonnée) ;
recherche de points d’intérêts (exemple l’épicerie la plus proche, avec les horaires d’ouverture) ;
enregistrement d’itinéraires ;
import d’itinéraires ;
ajouts de points favoris.
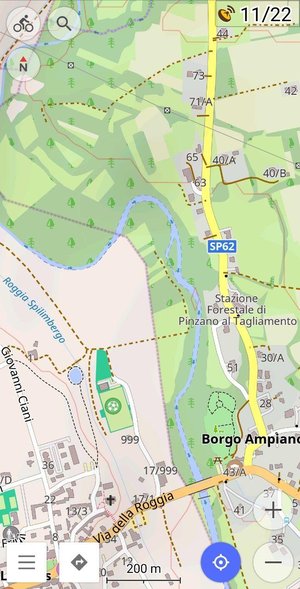
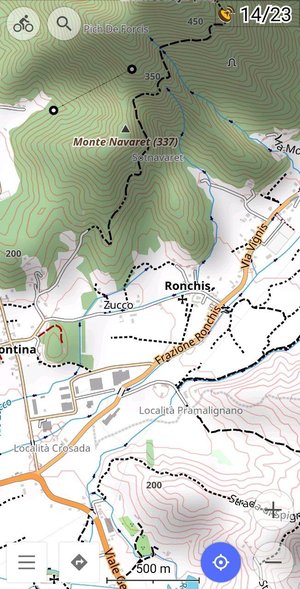
Copie d’écran OsmAnd
L’application profite de toute la richesse d’OpenStreetMap : cartes détaillées avec différents fonds de carte (routes, itinéraires cyclables, itinéraires de randonnée, courbes de niveau) et les points d’intérêts (commerces, gares, logements, hôpitaux…) L’application utilise aussi la base des points d’intérêt de Wikipédia.
Copie d’écran OsmAnd
Il s’agit d’une application open source qui ne vous obligera pas à créer un compte. Point important, elle fonctionne hors-connexion une fois qu’on a téléchargé les cartes (possibilité limitée à 7 cartes dans la version gratuite). Utile quand vous ne voulez pas exploser votre forfait à l’étranger, ou même autour de chez vous. C’est utile aussi pour économiser la batterie.
N’hésitez pas à prendre le temps de jouer avec les menus. Ils sont assez riches, on s’y perd un peu au début mais il y a tout un tas d’options intéressantes. On trouve des tutoriels assez bien faits sur Internet.
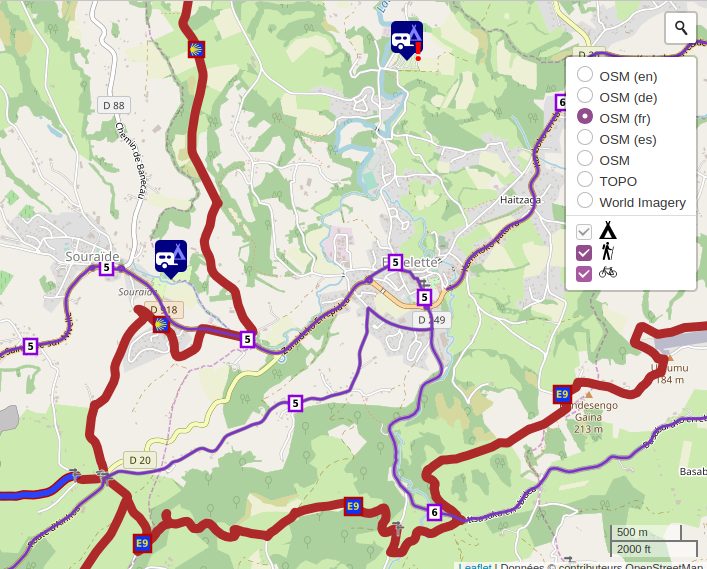
Waymarked Trails
Waymarked Trails présente les itinéraires de randonnée depuis l’échelon local jusqu’au niveau international, avec des cartes et des informations de OpenStreetMap ainsi qu’un profil d’altitude. Le site permet d’afficher les chemins de randonnée à pied, à vélo, à vtt, en rollers, à cheval et à ski.
Zoomer et cliquer sur un itinéraire pour voir le détail. Une fois l’itinéraire sélectionné, il est possible de l’exporter aux formats GPX et KML. Vous n’avez plus qu’à importer l’itinéraire dans votre application GPS préférée.
Les itinéraires touristiques classiques ne sont pas encore tous référencés sur OSM. Dans ce cas vous les trouvez généralement sur les sites internet dédiées aux itinéraires, ou encore sur les sites des offices du tourisme. Exemple l’Alsace à vélo.
Bien sûr, il existe des sites de partage avec des centaines d’itinéraires. Si ces bases sont très riches, elles contiennent essentiellement des tracés fournis par des utilisateurs individuels, qui ne correspondent pas forcément aux itinéraires officiels. C’est intéressant pour des sorties sportives, mais ça ne vous garantit pas de passer par des voies sécurisées ou à faible trafic. Mieux vaut étudier les itinéraires avant de les suivre la tête dans le guidon.
Open Camping Map
Sur le même principe que Waymarked Trails pour les itinéraires, Open Camping Map est une extraction de la base OSM qui présente les campings. Ceux-ci étant référencés sur OSM, c’est plutôt une application qui s’utilise pour avoir une vue dédiée aux campings lorsque vous préparez vos itinéraires.
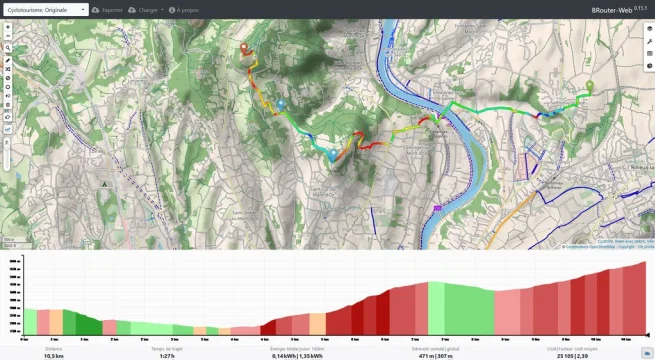
BRouter
BRouter est un bon calculateur d’itinéraire à vélo open source, avec de nombreux profils (route, cyclotourisme, …). Il fonctionne soit en ligne avec possibilité d’exporter l’itinéraire créé, soit en tant qu’application Android qui peut s’utiliser avec OsmAnd, Locus-Maps ou OruxMaps.
Un itinéraire sur BRouter avec son profil
Exemple d’utilisation
Maintenant que nous avons tous les éléments, nous pouvons nous lancer dans la préparation d’un voyage à vélo.
Téléchargement de la carte OSM de la région dans l’application OsmAnd ;
Téléchargement de l’itinéraire vélo principal depuis Waymarked Trails ou autre source ;
Création manuelle de nouveaux itinéraires sur B.Router (détours et autres variantes) ;
Ajout de marques sur la carte (campings, châteaux, musées, piscines…) ;
Import des différents fichiers GPX dans l’application OSM. L’application permet maintenant d’afficher tous les itinéraires et points d’intérêts, et de naviguer hors-ligne.
GéoVélo est un calculateur d’itinéraire (site web et application) pour les villes françaises. L’application fonctionne hors-ligne une fois qu’on a téléchargé la carte de la ville. Le guidage est bien pensé avec un zoom automatique à chaque changement de direction. Petit bémol, on est obligé de créer un compte pour pouvoir mémoriser des lieux et des trajets.
[EDIT par Framasoft] Plusieurs commentaires ci-dessous mettent en garde contre cette application qui ouvre des connexions avec google-analytics.com, doubleclick.net, facebook.net et cdn-apple.com… entre autres]
Participer avec StreetComplete
À la différence des autres cartes, OpenStreetMap est entièrement créé par des gens comme vous, et chacun est libre de le modifier, le mettre à jour, le télécharger et l’utiliser. Vous pouvez donc participer vous aussi à la construction de cet outil communautaire.
Il n’est pas nécessaire d’avoir une licence en géographie ni d’être expert en informatique. Le moyen le plus simple pour commencer est sans doute l’application StreetComplete qui vous permet de contribuer au projet OpenStreetMap en effectuant des « quêtes ». L’application vous propose d’ajouter des informations manquantes sur des zones près de votre position. L’application est destinée aux utilisateurs qui ne connaissent rien aux systèmes de marquage OSM mais souhaitent tout de même contribuer à OpenStreetMap en explorant leur quartier ou d’autres lieux. Vous pouvez le présenter de façon ludique aux enfants, comme une chasse au trésor. Ceci leur apprend à se repérer sur une carte, à s’orienter, à trouver le nom d’une rue, les horaires d’un magasin.
You are invited to contribute to the future « Contributing to Free-Libre Open Source Software » MOOC by Télécom Paris and Framasoft
Interested in contributing to the contents production of a MOOC about FLOSS contribution? You already have a contribution experience and think it can be useful to new contributors? Join us!
Leading Internet users into the world of contribution
Last September we were so delighted to learn that Marc Jeanmougin, a research engineer at Télécom Paris, wanted Framasoft to be associated with his online course projet on FLOSS contributions that had just been funded by the Institut Mines-Télécom.
We have been dreaming about it: a MOOC to learn how to contribute to free-libre software
Developing digital tools that facilitate individuals’ contributions is one of the lines of our Contributopia campaign. On this subject we already have set up Contribateliers (and their online version Confinateliers): workshops to discover how each of us can contribute to free-libre software. Implemented in 2018 in Lyon, those interventions now take place in cities (Lyon, Paris, Toulouse, Grenoble and Nantes) allowing people to contribute to the free-libre software and free culture in a user-friendly way.
This is also the case with the Contribulle project we are hosting: a platform where projects with the same free-libre software values are connected with those without enough skills and contributors who could give them a hand. This nice initiative is slowly taking shape and we think it will be a great success in the coming months.
Finally, the aim with this Contributing to FLOSS MOOC is to allow developers to get both a theoretical (what is it about?) and practical introduction (how to contact somebody? and how to contribute?) to the world of FLOSS contribution.
All these initiatives allow users of free-libre services to learn how to contribute and to stop using a software only as if it were a finished product.
Contributing to develop the Contributing to FLOSS MOOC
After a first day in October, talking about pedagogical sequencing in a small committee, the prefiguration team decided that given the MOOC subject, it would not be totally far-fetched to allow people who want to co-produce contents with us to do so.
We also have created a dedicated Matrix chatroom in order to have a daily and more informal exchange with you. Do not hesitate to join us there to learn more about this project.
We invite you to exchange in video conference on this project on February, 10th at 6:30pm. At the same time we will present you the general organization of the MOOC and the choices we have made both educationally (what angle on FLOSS we will try to take) and technically. We will also discuss how we envisage contributions to contents production.
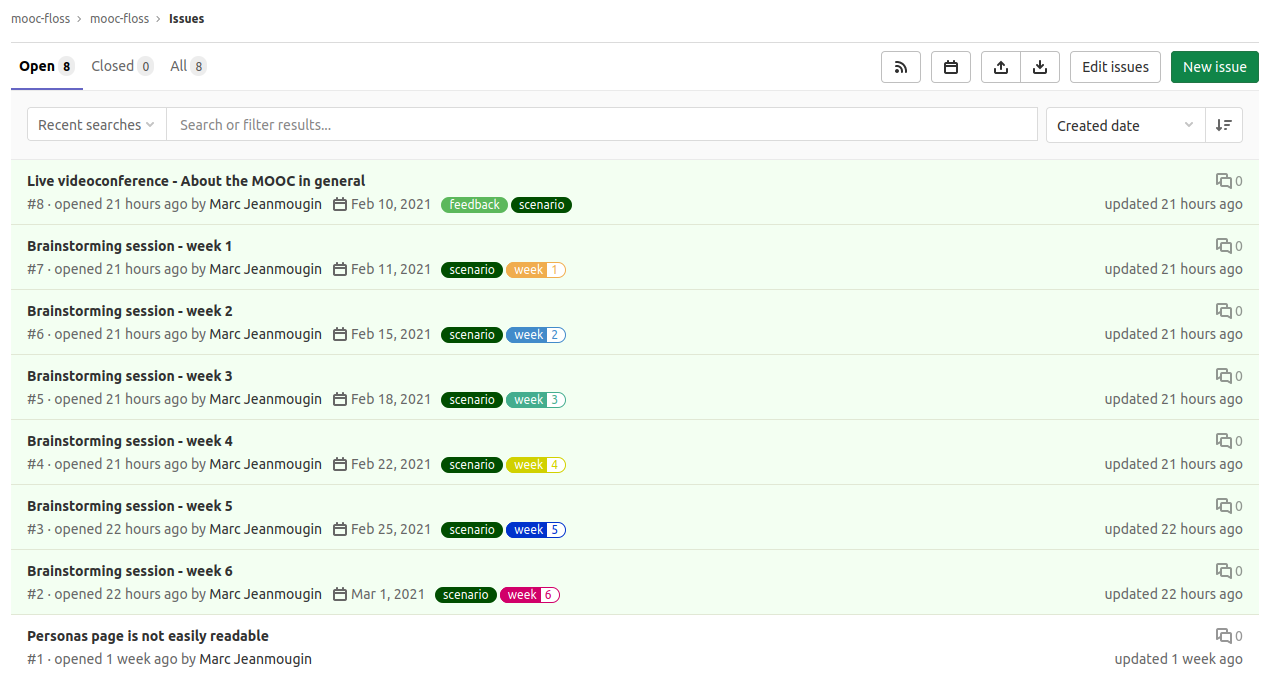
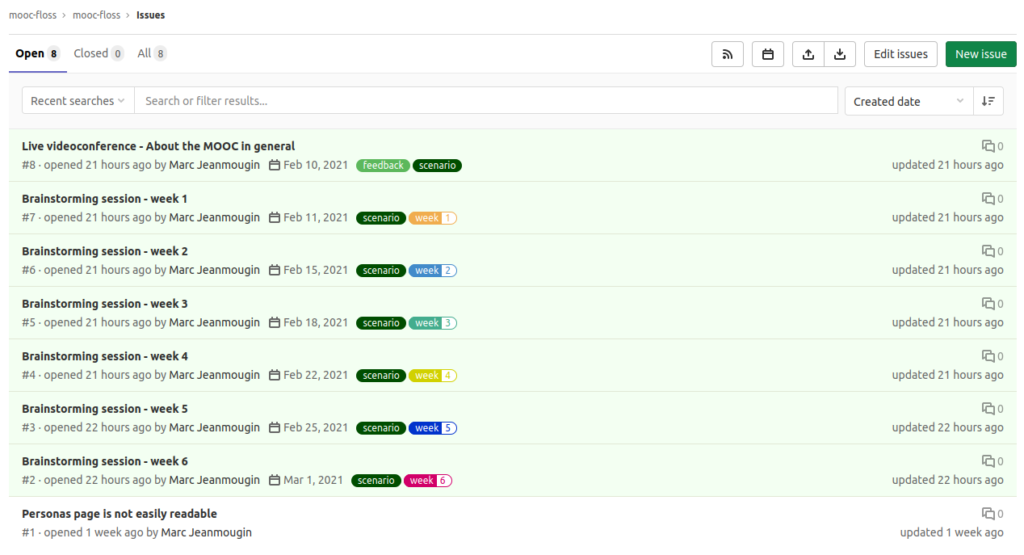
If after this first exchange you want to help us with contents preparation, you can participate in 6 other online brainstorming sessions, each one dedicated to the contents of one week of the MOOC. They will take place on Mondays and Thursdays between 6:30pm and 8pm from February 11th to March 1st (details of access and contents will be published on the gitlab issues with each session).
GitLab issues with details of access and contents of the 6 meetings we offer.
We hope we will see many of you at those different events. But as we know it’s not always easy to be available on a set time slot, we offer to collect your reactions, feedbacks or comments before each session on our repository. Do not hesitate to write down whatever comes to your mind!
Télécom Paris et Framasoft vous invitent à contribuer au futur MOOC « Contributing to Free-Libre and Open Source Software »
Participer à la production des contenus d’un MOOC dont le sujet est la contribution aux logiciels libres, ça vous tente ? Vous avez déjà contribué à des logiciels libres et vous pensez que votre expérience peut aider des apprenti·es contributeur·ices ? Rejoignez-nous !
Continuer à accompagner les internautes dans l’univers de la contribution
Lorsqu’en septembre dernier, Marc Jeanmougin, ingénieur de recherche à Télécom Paris, nous contactait pour nous informer que son projet de cours en ligne sur la contribution au logiciel libre venait d’obtenir un financement de l’Institut Mines-Télécom et qu’il souhaitait que Framasoft soit associé à ce projet, on a été super emballé·es !
Un MOOC (cours en ligne massivement ouvert) pour apprendre à contribuer au logiciel libre, on en rêvait !
C’est d’ailleurs l’un des axes de notre campagne Contributopia que de concrétiser des outils numériques qui facilitent les contributions de chacun·e. Dans ce domaine, nous avons déjà initié les Contribateliers (et leur version en ligne, les Confinateliers), des ateliers pour découvrir comment chacun·e d’entre nous peut contribuer au logiciel libre. Lancé en 2018 à Lyon, ce dispositif existe désormais dans 5 villes (Lyon, Paris, Toulouse, Grenoble et Nantes) et permet à toutes et tous de contribuer aux logiciels libres et à la culture libre en toute convivialité.
C’est aussi ce que nous faisons en offrant un hébergement au projet Contribulle, une plateforme de mise en relation entre des projets partageant les valeurs du logiciel libre et des communs qui manquent de compétences, et des contributeur·rices qui pourraient leur donner un coup de main. Cette chouette initiative prend doucement forme et on ne doute pas qu’elle rencontrera un fort succès dans les mois à venir.
Enfin, avec ce MOOC Contributing to FLOSS, l’objectif est de permettre à des développeur·euses d’avoir une introduction théorique (de quoi parle-t-on ?) comme pratique (comment entrer en contact, comment contribuer ?) à l’univers de la contribution au libre.
Toutes ces initiatives sont l’occasion pour les utilisateur·ices de services libres d’apprendre à contribuer et d’arrêter de consommer simplement le logiciel comme s’il était un produit fini.
Contribuer à la réalisation du MOOC Contributing to FLOSS
Après une première journée en petit comité en octobre pour échanger sur le séquençage pédagogique, l’équipe de préfiguration s’est dit que vu le sujet du MOOC, ce ne serait pas totalement tiré par les cheveux que de permettre à celles et ceux qui le souhaitent de co-produire avec nous les contenus.
Nous avons aussi créé un salon Matrix dédié afin de pouvoir échanger de manière plus informelle avec vous au quotidien. N’hésitez pas à nous y rejoindre pour avoir davantage de précisions sur ce projet.
Nous vous invitons à un temps d’échanges autour du projet le mercredi 10 février à 18h30 en visioconférence. Ce sera l’occasion de vous présenter l’organisation générale du MOOC et les choix que nous avons effectués, tant au plan pédagogique (quel angle sur les FLOSS nous essaierons de prendre) qu’au plan technique. Nous échangerons aussi sur la façon dont nous envisageons les contributions à la production des contenus.
Si à la suite de ce premier temps d’échanges, vous êtes partant·es pour nous aider sur la préparation des contenus, on vous propose de participer à 6 autres sessions de brainstorming en ligne, chacune de ces sessions étant dédiée aux contenus d’une semaine du MOOC. Ces sessions se tiendront les lundis et jeudis entre 18h30 et 20h sur la période du 11 février au 1er mars (les détails d’accès et des contenus discutés seront publiés sur les tickets associés à chaque session).
Tickets sur lesquels vous trouverez détails d’accès et contenus des 6 rendez-vous que nous vous proposons.
On vous espère nombreu·ses lors de ces différents rendez-vous. Mais comme nous savons qu’il n’est pas toujours évident de se libérer sur un créneau fixe, nous proposons de recueillir en amont de chaque session vos réactions, notes ou commentaires. N’hésitez donc pas à aller y noter ce qui vous passe par la tête !
Utilisateurs libres ou domestiqués ? WhatsApp et les autres
Le mois dernier, WhatsApp a publié une nouvelle politique de confidentialité avec cette injonction : acceptez ces nouvelles conditions, ou supprimez WhatsApp de votre smartphone. La transmission de données privées à la maison-mère Facebook a suscité pour WhatsApp un retour de bâton retentissant et un nombre significatif d’utilisateurs et utilisatrices a migré vers d’autres applications, en particulier Signal.
Cet épisode parmi d’autres dans la guerre des applications de communication a suscité quelques réflexions plus larges sur la capture des utilisateurs et utilisatrices par des entreprises qui visent selon Rohan Kumar à nous « domestiquer »…
Je n’ai jamais utilisé WhatsApp et ne l’utiliserai jamais. Et pourtant j’éprouve le besoin d’écrire un article sur WhatsApp car c’est une parfaite étude de cas pour comprendre une certaine catégorie de modèles commerciaux : la « domestication des utilisateurs ».
La domestication des utilisateurs est, selon moi, l’un des principaux problèmes dont souffre l’humanité et il mérite une explication détaillée.
Cette introduction générale étant faite, commençons.
L’ascension de Whatsapp
Pour les personnes qui ne connaissent pas, WhatsApp est un outil très pratique pour Facebook car il lui permet de facilement poursuivre sa mission principale : l’optimisation et la vente du comportement humain (communément appelé « publicité ciblée »). WhatsApp a d’abord persuadé les gens d’y consentir en leur permettant de s’envoyer des textos par Internet, chose qui était déjà possible, en associant une interface simple et un marketing efficace. L’application s’est ensuite développée pour inclure des fonctionnalités comme les appels vocaux et vidéos gratuits. Ces appels gratuits ont fait de WhatsApp une plate-forme de communication de référence dans de nombreux pays.
WhatsApp a construit un effet de réseau grâce à son système propriétaire incompatible avec d’autres clients de messagerie instantanée : les utilisateurs existants sont captifs car quitter WhatsApp signifie perdre la capacité de communiquer avec les utilisateurs de WhatsApp. Les personnes qui veulent changer d’application doivent convaincre tous leurs contacts de changer aussi ; y compris les personnes les moins à l’aise avec la technologie, celles qui avaient déjà eu du mal à apprendre à se servir de WhatsApp.
Dans le monde de WhatsApp, les personnes qui souhaitent rester en contact doivent obéir aux règles suivantes :
• Chacun se doit d’utiliser uniquement le client propriétaire WhatsApp pour envoyer des messages ; développer des clients alternatifs n’est pas possible.
• Le téléphone doit avoir un système d’exploitation utilisé par le client. Les développeurs de WhatsApp ne développant que pour les systèmes d’exploitation les plus populaires, le duopole Android et iOS en sort renforcé.
• Les utilisateurs dépendent entièrement des développeurs de WhatsApp. Si ces derniers décident d’inclure des fonctionnalités hostiles dans l’application, les utilisateurs doivent s’en contenter. Ils ne peuvent pas passer par un autre serveur ou un autre client de messagerie sans quitter WhatsApp et perdre la capacité à communiquer avec leurs contacts WhatsApp.
La domestication des utilisateurs
WhatsApp s’est développé en piégeant dans son enclos des créatures auparavant libres, et en changeant leurs habitudes pour créer une dépendance à leurs maîtres. Avec le temps, il leur est devenu difficile voire impossible de revenir à leur mode de vie précédent. Ce processus devrait vous sembler familier : il est étrangement similaire à la domestication des animaux. J’appelle ce type d’enfermement propriétaire « domestication des utilisateurs » : la suppression de l’autonomie des utilisateurs, pour les piéger et les mettre au service du fournisseur.
J’ai choisi cette métaphore car la domestication animale est un processus graduel qui n’est pas toujours volontaire, qui implique typiquement qu’un groupe devienne dépendant d’un autre. Par exemple, nous savons que la domestication du chien a commencé avec sa sociabilisation, ce qui a conduit à une sélection pas totalement artificielle promouvant des gènes qui favorisent plus l’amitié et la dépendance envers les êtres humains1.
Qu’elle soit délibérée ou non, la domestication des utilisateurs suit presque toujours ces trois mêmes étapes :
1. Un haut niveau de dépendance des utilisateurs envers un fournisseur de logiciel
2. Une incapacité des utilisateurs à contrôler le logiciel, via au moins une des méthodes suivantes :
2.1. Le blocage de la modification du logiciel
2.2. Le blocage de la migration vers une autre plate-forme
3. L’exploitation des utilisateurs désormais captifs et incapables de résister.
L’exécution des deux premières étapes a rendu les utilisateurs de WhatsApp vulnérables à la domestication. Avec ses investisseurs à satisfaire, WhatsApp avait toutes les raisons d’implémenter des fonctionnalités hostiles, sans subir aucune conséquence. Donc, évidemment, il l’a fait.
La chute de WhatsApp
La domestication a un but : elle permet à une espèce maîtresse d’exploiter les espèces domestiquées pour son propre bénéfice. Récemment, WhatsApp a mis à jour sa politique de confidentialité pour permettre le partage de données avec sa maison mère, Facebook. Les personnes qui avaient accepté d’utiliser WhatsApp avec sa précédente politique de confidentialité avaient donc deux options : accepter la nouvelle politique ou perdre l’accès à WhatsApp. La mise à jour de la politique de confidentialité est un leurre classique : WhatsApp a appâté et ferré ses utilisateurs avec une interface élégante et une impression de confidentialité, les a domestiqués pour leur ôter la capacité de migrer, puis est revenu sur sa promesse de confidentialité avec des conséquences minimes. Chaque étape de ce processus a permis la suivante ; sans domestication, il serait aisé pour la plupart des utilisateurs de quitter l’application sans douleur.
Celles et ceux parmi nous qui sonnaient l’alarme depuis des années ont connu un bref moment de félicité sadique quand le cliché à notre égard est passé de « conspirationnistes agaçants et paranoïaques » à simplement « agaçants ».
Une tentative de dérapage contrôlé
L’opération de leurre et de ferrage a occasionné une réaction contraire suffisante pour qu’une minorité significative d’utilisateurs migre ; leur nombre a été légèrement supérieur la quantité négligeable que WhatsApp attendait probablement. En réponse, WhatsApp a repoussé le changement et publié la publicité suivante :
Cette publicité liste différentes données que WhatsApp ne collecte ni ne partage. Dissiper des craintes concernant la collecte de données en listant les données non collectées est trompeur. WhatsApp ne collecte pas d’échantillons de cheveux ou de scans rétiniens ; ne pas collecter ces informations ne signifie pas qu’il respecte la confidentialité parce que cela ne change pas ce que WhatsApp collecte effectivement.
Dans cette publicité WhatsApp nie conserver « l’historique des destinataires des messages envoyés ou des appels passés ». Collecter des données n’est pas la même chose que « conserver l’historique » ; il est possible de fournir les métadonnées à un algorithme avant de les jeter. Un modèle peut alors apprendre que deux utilisateurs s’appellent fréquemment sans conserver l’historique des métadonnées de chaque appel. Le fait que l’entreprise ait spécifiquement choisi de tourner la phrase autour de l’historique implique que WhatsApp soit collecte déjà cette sorte de données soit laisse la porte ouverte afin de les collecter dans le futur.
Une balade à travers la politique de confidentialité réelle de WhatsApp du moment (ici celle du 4 janvier) révèle qu’ils collectent des masses de métadonnées considérables utilisées pour le marketing à travers Facebook.
Liberté logicielle
Face à la domestication des utilisateurs, fournir des logiciels qui aident les utilisateurs est un moyen d’arrêter leur exploitation. L’alternative est simple : que le service aux utilisateurs soit le but en soi.
Pour éviter d’être contrôlés par les logiciels, les utilisateurs doivent être en position de contrôle. Les logiciels qui permettent aux utilisateurs d’être en position de contrôles sont appelés logiciels libres. Le mot « libre » dans ce contexte a trait à la liberté plutôt qu’au prix2. La liberté logicielle est similaire au concept d’open-source, mais ce dernier est focalisé sur les bénéfices pratiques plutôt qu’éthiques. Un terme moins ambigu qui a trait naturellement à la fois à la gratuité et l’open-source est FOSS3.
D’autres ont expliqué les concepts soutenant le logiciel libre mieux que moi, je n’irai pas dans les détails. Cela se décline en quatre libertés essentielles :
la liberté d’exécuter le programme comme vous le voulez, quel que soit le but
la liberté d’étudier comment le programme fonctionne, et de le modifier à votre souhait
la liberté de redistribuer des copies pour aider d’autres personnes
la liberté de distribuer des copies de votre version modifiée aux autres
Gagner de l’argent avec des FOSS
L’objection la plus fréquente que j’entends, c’est que gagner de l’argent serait plus difficile avec le logiciel libre qu’avec du logiciel propriétaire.
Pour gagner de l’argent avec les logiciels libres, il s’agit de vendre du logiciel comme un complément à d’autres services plus rentables. Parmi ces services, on peut citer la vente d’assistance, la personnalisation, le conseil, la formation, l’hébergement géré, le matériel et les certifications. De nombreuses entreprises utilisent cette approche au lieu de créer des logiciels propriétaires : Red Hat, Collabora, System76, Purism, Canonical, SUSE, Hashicorp, Databricks et Gradle sont quelques noms qui viennent à l’esprit.
L’hébergement n’est pas un panier dans lequel vous avez intérêt à déposer tous vos œufs, notamment parce que des géants comme Amazon Web Service peuvent produire le même service pour un prix inférieur. Être développeur peut donner un avantage dans des domaines tels que la personnalisation, le support et la formation ; cela n’est pas aussi évident en matière d’hébergement.
Les logiciels libres ne suffisent pas toujours
Le logiciel libre est une condition nécessaire mais parfois insuffisante pour établir une immunité contre la domestication. Deux autres conditions impliquent de la simplicité et des plates-formes ouvertes.
Simplicité
Lorsqu’un logiciel devient trop complexe, il doit être maintenu par une vaste équipe. Les utilisateurs qui ne sont pas d’accord avec un fournisseur ne peuvent pas facilement dupliquer et maintenir une base de code de plusieurs millions de lignes, surtout si le logiciel en question contient potentiellement des vulnérabilités de sécurité. La dépendance à l’égard du fournisseur peut devenir très problématique lorsque la complexité fait exploser les coûts de développement ; le fournisseur peut alors avoir recours à la mise en œuvre de fonctionnalités hostiles aux utilisateurs pour se maintenir à flot.
Un logiciel complexe qui ne peut pas être développé par personne d’autre que le fournisseur crée une dépendance, première étape vers la domestication de l’utilisateur. Cela suffit à ouvrir la porte à des développements problématiques.
Étude de cas : Mozilla et le Web
Mozilla était une lueur d’espoir dans la guerre des navigateurs, un espace dominé par la publicité, la surveillance et le verrouillage par des distributeurs. Malheureusement, le développement d’un moteur de navigation est une tâche monumentale, assez difficile pour qu’Opera et Microsoft abandonnent leur propre moteur et s’équipent de celui de Chromium. Les navigateurs sont devenus bien plus que des lecteurs de documents : ils ont évolué vers des applications dotées de propres technologies avec l’accélération GPU, Bluetooth, droits d’accès, énumération des appareils, codecs de médias groupés, DRM4, API d’extension, outils de développement… la liste est longue. Il faut des milliards de dollars par an pour répondre aux vulnérabilités d’une surface d’attaque aussi massive et suivre des standards qui se développent à un rythme tout aussi inquiétant. Ces milliards doivent bien venir de quelque part.
Mozilla a fini par devoir faire des compromis majeurs pour se maintenir à flot. L’entreprise a passé des contrats de recherche avec des sociétés manifestement hostiles aux utilisateurs et a ajouté au navigateur des publicités (et a fait machine arrière) et des bloatwares, comme Pocket, ce logiciel en tant que service partiellement financé par la publicité. Depuis l’acquisition de Pocket (pour diversifier ses sources de revenus), Mozilla n’a toujours pas tenu ses promesses : mettre le code de Pocket en open-source, bien que les clients soient passés en open-source, le code du serveur reste propriétaire. Rendre ce code open-source, et réécrire certaines parties si nécessaire serait bien sûr une tâche importante en partie à cause de la complexité de Pocket.
Les navigateurs dérivés importants comme Pale Moon sont incapables de suivre la complexité croissante des standards modernes du Web tels que les composants web (Web Components). En fait, Pale Moon a récemment dû migrer son code hors de GitHub depuis que ce dernier a commencé à utiliser des composants Web. Il est pratiquement impossible de commencer un nouveau navigateur à partir de zéro et de rattraper les mastodontes qui ont fonctionné avec des budgets annuels exorbitants pendant des décennies. Les utilisateurs ont le choix entre le moteur de navigation développé par Mozilla, celui d’une entreprise publicitaire (Blink de Google) ou celui d’un fournisseur de solutions monopolistiques (WebKit d’Apple). A priori, WebKit ne semble pas trop mal, mais les utilisateurs seront impuissants si jamais Apple décide de faire marche arrière.
Pour résumer : la complexité du Web a obligé Mozilla, le seul développeur de moteur de navigation qui déclare être « conçu pour les gens, pas pour l’argent », à mettre en place des fonctionnalités hostiles aux utilisateurs dans son navigateur. La complexité du Web a laissé aux utilisateurs un choix limité entre trois grands acteurs en conflit d’intérêts, dont les positions s’enracinent de plus en plus avec le temps.
Attention, je ne pense pas que Mozilla soit une mauvaise organisation ; au contraire, c’est étonnant qu’ils soient capables de faire autant, sans faire davantage de compromis dans un système qui l’exige. Leur produit de base est libre et open-source, et des composants externes très légèrement modifiés suppriment des anti-fonctionnalités.
Plates-formes ouvertes
Pour éviter qu’un effet de réseau ne devienne un verrouillage par les fournisseurs, les logiciels qui encouragent naturellement un effet de réseau doivent faire partie d’une plate-forme ouverte. Dans le cas des logiciels de communication/messagerie, il devrait être possible de créer des clients et des serveurs alternatifs qui soient compatibles entre eux, afin d’éviter les deux premières étapes de la domestication de l’utilisateur.
Étude de cas : Signal
Depuis qu’un certain vendeur de voitures a tweeté « Utilisez Signal », un grand nombre d’utilisateurs ont docilement changé de messagerie instantanée. Au moment où j’écris ces lignes, les clients et les serveurs Signal sont des logiciels libres et open-source, et utilisent certains des meilleurs algorithmes de chiffrement de bout en bout qui existent ; cependant, je ne suis pas fan.
Bien que les clients et les serveurs de Signal soient des logiciels libres et gratuits, Signal reste une plate-forme fermée. Le cofondateur de Signal, Moxie Marlinspike, est très critique à l’égard des plates-formes ouvertes et fédérées. Il décrit dans un article de blog les raisons pour lesquelles Signal reste une plate-forme fermée5. Cela signifie qu’il n’est pas possible de développer un serveur alternatif qui puisse être supporté par les clients Signal, ou un client alternatif qui supporte les serveurs Signal. La première étape de la domestication des utilisateurs est presque achevée.
Outre qu’il n’existe qu’un seul client et qu’un seul serveur, il n’existe qu’un seul fournisseur de serveur Signal : Signal Messenger LLC. La dépendance des utilisateurs vis-à-vis de ce fournisseur de serveur central leur a explosé au visage, lors de la récente croissance de Signal qui a provoqué des indisponibilités de plus d’une journée, mettant les utilisateurs de Signal dans l’incapacité d’envoyer des messages, jusqu’à ce que le fournisseur unique règle le problème.
Certains ont quand même essayé de développer des clients alternatifs : un fork Signal appelé LibreSignal a tenté de faire fonctionner Signal sur des systèmes Android respectueux de la vie privée, sans les services propriétaires Google Play. Ce fork s’est arrêté après que Moxie eut clairement fait savoir qu’il n’était pas d’accord avec une application tierce utilisant les serveurs Signal. La décision de Moxie est compréhensible, mais la situation aurait pu être évitée si Signal n’avait pas eu à dépendre d’un seul fournisseur de serveurs.
Si Signal décide de mettre à jour ses applications pour y inclure une fonction hostile aux utilisateurs, ces derniers seront tout aussi démunis qu’ils le sont actuellement avec WhatsApp. Bien que je ne pense pas que ce soit probable, la plate-forme fermée de Signal laisse les utilisateurs vulnérables à leur domestication.
Même si je n’aime pas Signal, je l’ai tout de même recommandé à mes amis non-techniques, parce que c’était le seul logiciel de messagerie instantanée assez privé pour moi et assez simple pour eux. S’il y avait eu la moindre intégration à faire (création de compte, ajout manuel de contacts, etc.), un de mes amis serait resté avec Discord ou WhatsApp. J’ajouterais bien quelque chose de taquin comme « tu te reconnaîtras » s’il y avait la moindre chance pour qu’il arrive aussi loin dans l’article.
Réflexions
Les deux études de cas précédentes – Mozilla et Signal – sont des exemples d’organisations bien intentionnées qui rendent involontairement les utilisateurs vulnérables à la domestication. La première présente un manque de simplicité mais incarne un modèle de plate-forme ouverte. La seconde est une plate-forme fermée avec un degré de simplicité élevé. L’intention n’entre pas en ligne de compte lorsqu’on examine les trois étapes et les contre-mesures de la domestication des utilisateurs. @paulsnar@mastodon.technology a souligné un conflit potentiel entre la simplicité et les plates-formes ouvertes :
j’ai l’impression qu’il y a une certaine opposition entre simplicité et plates-formes ouvertes ; par exemple Signal est simple précisément parce que c’est une plate-forme fermée, ou du moins c’est ce qu’explique Moxie. À l’inverse, Matrix est superficiellement simple, mais le protocole est en fait (à mon humble avis) assez complexe, précisément parce que c’est une plate-forme ouverte.
Je n’ai pas de réponse simple à ce dilemme. Il est vrai que Matrix est extrêmement complexe (comparativement à des alternatives comme IRC ou même XMPP), et il est vrai qu’il est plus difficile de construire une plate-forme ouverte. Cela étant dit, il est certainement possible de maîtriser la complexité tout en développant une plate-forme ouverte : Gemini, IRC et le courrier électronique en sont des exemples. Si les normes de courrier électronique ne sont pas aussi simples que Gemini ou IRC, elles évoluent lentement ; cela évite aux implémentations de devoir rattraper le retard, comme c’est le cas pour les navigateurs Web ou les clients/serveurs Matrix.
Tous les logiciels n’ont pas besoin de brasser des milliards. La fédération permet aux services et aux réseaux comme le Fediverse et XMPP de s’étendre à un grand nombre d’utilisateurs sans obliger un seul léviathan du Web à vendre son âme pour payer la facture. Bien que les modèles commerciaux anti-domestication soient moins rentables, ils permettent encore la création des mêmes technologies qui ont été rendues possibles par la domestication des utilisateurs. Tout ce qui manque, c’est un budget publicitaire ; la plus grande publicité que reçoivent certains de ces projets, ce sont de longs billets de blog non rémunérés.
Peut-être n’avons-nous pas besoin de rechercher la croissance à tout prix et d’essayer de « devenir énorme ». Peut-être pouvons-nous nous arrêter, après avoir atteint une durabilité et une sécurité financière, et permettre aux gens de faire plus avec moins.
Notes de clôture
Avant de devenir une sorte de manifeste, ce billet se voulait une version étendue d’un commentaire que j’avais laissé suite à un message de Binyamin Green sur le Fediverse.
J’avais décidé, à l’origine, de le développer sous sa forme actuelle pour des raisons personnelles. De nos jours, les gens exigent une explication approfondie chaque fois que je refuse d’utiliser quelque chose que « tout le monde » utilise (WhatsApp, Microsoft Office, Windows, macOS, Google Docs…).
Puis, ils et elles ignorent généralement l’explication, mais s’attendent quand même à en avoir une. La prochaine fois que je les rencontrerai, ils auront oublié notre conversation précédente et recommenceront le même dialogue. Justifier tous mes choix de vie en envoyant des assertions logiques et correctes dans le vide – en sachant que tout ce que je dis sera ignoré – est un processus émotionnellement épuisant, qui a fait des ravages sur ma santé mentale ces dernières années ; envoyer cet article à mes amis et changer de sujet devrait me permettre d’économiser quelques cheveux gris dans les années à venir.
Cet article s’appuie sur des écrits antérieurs de la Free Software Foundation, du projet GNU et de Richard Stallman. Merci à Barna Zsombor de m’avoir fait de bon retours sur IRC.
Mosaïque romaine, Orphée apprivoisant les animaux, photo par mharrsch, licence CC BY-NC-SA 2.0