Partagez l’inventaire de votre bibliothèque avec vos proches sur inventaire.io
Inventaire.io est une application web libre qui permet de faire l’inventaire de sa bibliothèque pour pouvoir organiser le don, le prêt ou la vente de livres physiques. Une sorte de méga-bibliothèque communautaire, si l’on veut. Ces derniers mois, Inventaire s’est doté de nouvelles fonctionnalités et on a vu là l’occasion de valoriser ce projet auprès de notre communauté. On a donc demandé à Maxlath et Jums qui travaillent sur le projet de répondre à quelques unes de nos questions.
Chez Framasoft, on a d’ailleurs créé notre inventaire où l’on recense les ouvrages qu’on achète pour se documenter. Cela permet aux membres de l’association d’avoir un accès facile à notre bibliothèque interne. On a aussi fait le choix de proposer ces documents en prêt, pour que d’autres puissent y accéder.
Salut Maxlath et Jums ! Pouvez-vous vous présenter ?
Nous sommes une association de deux ans d’existence, développant le projet Inventaire, centré autour de l’application web inventaire.io, en ligne depuis 2015. On construit Inventaire comme une infrastructure libre, se basant donc autant que possible sur des standards ouverts, et des logiciels et savoirs libres : Wikipédia, Wikidata, et plus largement le web des données ouvertes.
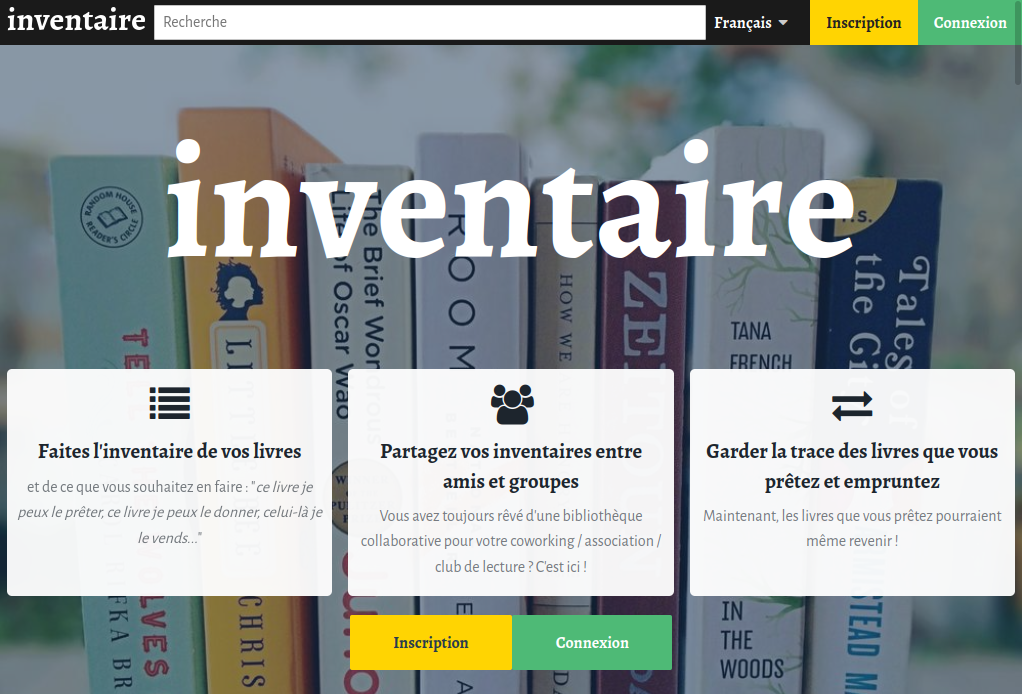
Le projet grandit également au sein de communautés et de lieux : notamment le mouvement Wikimedia, l’archipel framasoftien à travers les Contribateliers, la MYNE et la Maison de l’Économie Circulaire sur Lyon, et Kanthaus en Allemagne.
L’association ne compte aujourd’hui que deux membres, mais le projet ne serait pas où il en est sans les nombreu⋅ses contributeur⋅ices venu⋅es nous prêter main forte, notamment sur la traduction de l’interface, la contribution aux données bibliographiques, le rapport de bugs ou les suggestions des nouvelles fonctionnalités.
Vous pouvez nous en dire plus sur Inventaire.io ? Ça sert à quoi ? C’est pour qui ?
Inventaire.io se compose de deux parties distinctes :
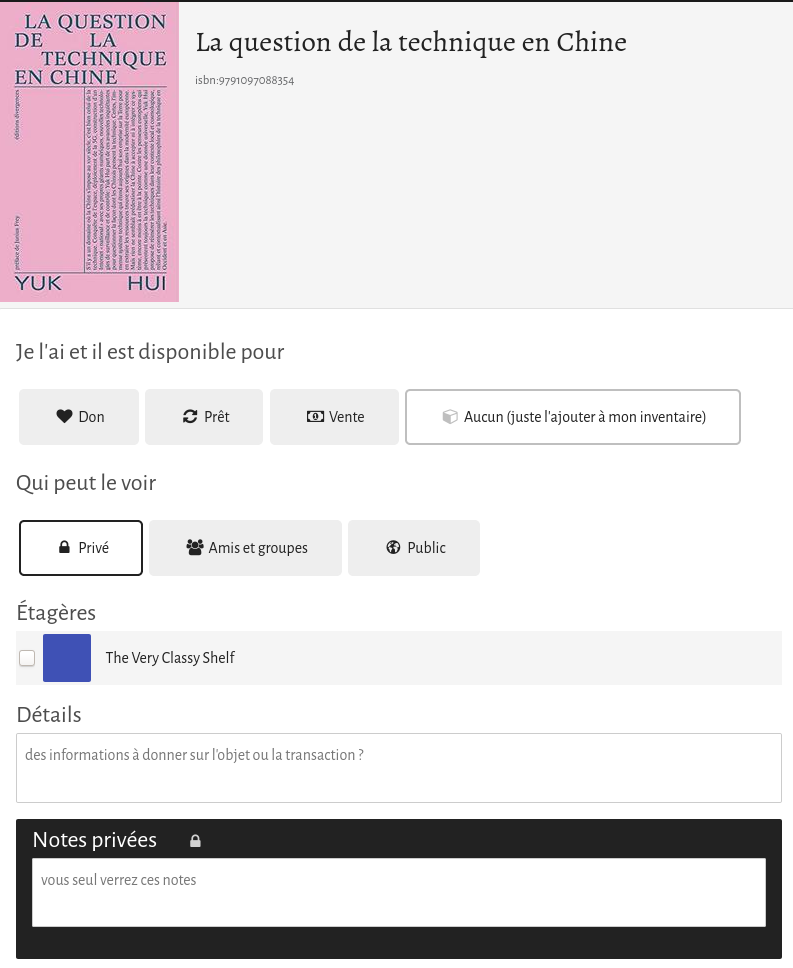
- D’une part, une application web qui permet à chacun⋅e de répertorier ses livres en scannant le code barre par exemple. Une fois constitué, cet inventaire est rendu accessible à ses ami⋅es et groupes, ou publiquement, en indiquant pour chaque livre si l’on souhaite le donner, le prêter, ou le vendre. Il est ensuite possible d’envoyer des demandes pour ces livres et les utilisateur⋅ices peuvent prendre contact entre elleux pour faire l’échange (en main propre, par voie postale, peu importe, Inventaire n’est plus concerné).
- D’autre part, une base de données publique sur les auteurs, les œuvres, les maisons d’éditions, etc, qui permet à chacun⋅e de venir enrichir les données, un peu comme dans un wiki. Le tout organisé autour des communs de la connaissance (voir plus bas) que sont Wikipédia et Wikidata. Cette base de données bibliographiques permet d’adosser les inventaires à un immense graphe de données dont nous ne faisons encore qu’effleurer les possibilités (voir plus bas).
Inventaire.io permettant de constituer des bibliothèques distribuées, le public est extrêmement large : tou⋅tes celleux qui ont envie de partager des livres ! On a donc très envie de dire que c’est un outil pour tout le monde ! Mais comme beaucoup d’outils numériques, l’outil d’inventaire peut être trop compliqué pour des personnes qui ne baignent pas régulièrement dans ce genre d’applications. C’est encore pire une fois que l’on rentre dans la contribution aux données bibliographiques, où on aimerait concilier richesse de la donnée et facilité de la contribution. Cela dit, on peut inventorier ses livres sans trop se soucier des données, et y revenir plus tard une fois qu’on se sent plus à l’aise avec l’outil.
Par ailleurs, on rêverait de pouvoir intégrer les inventaires des professionnel⋅les du livre, bibliothèques et librairies, à cette carte des ressources, mais cela suppose soit de l’interopérabilité avec leurs outils existants, soit de leur proposer d’utiliser notre outil (ce que font déjà de petites bibliothèques, associatives par exemple), mais inventaire.io nous semble encore jeune pour une utilisation à plusieurs milliers de livres.
Quelle est l’actualité du projet ? Vous prévoyez quoi pour les prochains mois / années ?
L’actualité de ces derniers mois, c’est tout d’abord de nouvelles fonctionnalités :
- les étagères, qui permettent de grouper des livres en sous-catégories, et qui semble rencontrer un certain succès ;
- la mise en place de rôles, qui va permettre notamment d’ouvrir les taches avancées d’administration des données bibliographiques (fusions/suppressions d’édition, d’œuvre, d’auteur etc.) ;
- l’introduction des collections d’éditeurs, qui permettent de valoriser le travail de curation des maisons d’édition.
Pas mal de transitions techniques sous le capot aussi. On n’est pas du genre à changer de framework tous les quatre matins, mais certains choix techniques faits au départ du projet en 2014 – CoffeeScript, Brunch, Backbone – peuvent maintenant être avantageusement remplacés par des alternatives plus récentes – dernière version de Javascript (ES2020), Webpack, Svelte – ce qui augmente la maintenabilité et le confort, voire le plaisir de coder.
Autre transition en cours, notre wiki de documentation est maintenant une instance MediaWiki choisie entre autres pour sa gestion des traductions.
Le programme des prochains mois et années n’est pas arrêté, mais il y a des idées insistantes qu’on espère voir germer prochainement :
- la décentralisation et la fédération (voir plus bas) ;
- les recommandations entre lectrices : aujourd’hui on peut partager de l’information sur les livres que l’on possède, mais pas les livres que l’on apprécie, recommande ou recherche. Même si une utilisation détournée de l’outil est possible en ce sens et nous met aussi en joie (oui, c’est marrant de voir des humains détourner une utilisation), on devrait pouvoir proposer quelque chose pensé pour ;
- des paramètres de visibilité d’un livre ou d’une étagère plus élaborés : aujourd’hui, les seuls modes de partage possible sont privé/amis et groupes/public, or amis et groupes ça peut être des personnes très différentes avec qui on n’a pas nécessairement envie de partager les mêmes choses.
Enfin tout ça c’est ce qu’on fait cachés derrière un écran, mais on aimerait bien aussi expérimenter avec des formats d’évènements, type BiblioParty : venir dans un lieu avec une belle bibliothèque et aider le lieu à en faire l’inventaire.
C’est quoi le modèle économique derrière inventaire.io ? Quelles sont/seront vos sources de financement ?
Pendant les premières années, l’aspect « comment on gagne de l’argent » était une question volontairement laissée de côté, on vivait avec quelques prestations en micro-entrepreneurs, notamment l’année dernière où nous avons réalisé une preuve de concept pour l’ABES (l’Agence bibliographique pour l’enseignement supérieur) et la Bibliothèque Nationale de France. Peu après, nous avons fondé une association loi 1901 à activité économique (voir les statuts), ce qui devrait nous permettre de recevoir des dons, que l’on pourra compléter si besoin par de la prestation de services. Pour l’instant, on compte peu sur les dons individuels car on est financé par NLNet via le NGI0 Discovery Fund.
Et sous le capot, ça fonctionne comment ? Vous utilisez quoi comme technos pour faire tourner le service ?
Le serveur est en NodeJS, avec une base de données CouchDB, synchronisé à un Elasticsearch pour la recherche, et LevelDB pour les données en cache. Ce serveur produit une API JSON (documentée sur https://api.inventaire.io) consommée principalement par le client : une webapp qui a la responsabilité de tout ce qui est rendu de l’application dans le navigateur. Cette webapp consiste en une bonne grosse pile de JS, de templates, et de CSS, initialement organisée autour des framework Backbone.Marionnette et Handlebars, lesquels sont maintenant dépréciés en faveur du framework Svelte. Une visualisation de l’ensemble de la pile technique peut être trouvée sur https://stack.inventaire.io.
Le nom est assez français… est-ce que ça ne pose pas de problème pour faire connaître le site et le logiciel à l’international ? Et d’ailleurs, est-ce que vous avez une idée de la répartition linguistique de vos utilisatrices ? (francophones, anglophones, germanophones, etc.)
Oui, le nom peut être un problème au début pour les non-francophones, lequel⋅les ne savent pas toujours comment l’écrire ou le prononcer. Cela fait donc un moment qu’on réfléchit à en changer, mais après le premier contact, ça ne semble plus poser de problème à l’utilisation (l’un des comptes les plus actifs étant par exemple une bibliothèque associative allemande), alors pour le moment on fait avec ce qu’on a.

En termes de répartition linguistique, une bonne moitié des utilisateur⋅ices et contributeur⋅ices sont francophones, un tiers anglophones, puis viennent, en proportion beaucoup plus réduite (autour de 2%), l’allemand, l’espagnol, l’italien, suivi d’une longue traîne de langues européennes mais aussi : arabe, néerlandais, portugais, russe, polonais, danois, indonésien, chinois, suédois, turc, etc. À noter que la plupart de ces langues ne bénéficiant pas d’une traduction complète de l’interface à ce jour, il est probable qu’une part conséquente des utilisatrices utilisent l’anglais, faute d’une traduction de l’interface satisfaisante dans leur langue (malgré les 15 langues traduites à plus de 50%).
À ce que je comprends, vous utilisez donc des données provenant de Wikidata. Pouvez-vous expliquer à celles et ceux qui parmi nous ne sont pas très au point sur la notion de web de données quels sont les enjeux et les applications possibles de Wikidata ?
Tout comme le web a introduit l’hypertexte pour pouvoir lier les écrits humains entre eux (par exemple un article de blog renvoie vers un autre article de blog quelque part sur le web), le web des données ouvertes permet aux bases de données de faire des liens entre elles. Cela permet par exemple à des bibliothèques nationales de publier des données bibliographiques que l’on peut recouper : « Je connais cette auteure avec tel identifiant unique dans ma base. Je sais aussi qu’une autre base de données lui a donné cet autre identifiant unique ; vous pouvez donc aller voir là-bas s’ils en savent plus ». Beaucoup d’institutions s’occupent de créer ces liens, mais la particularité de Wikidata, c’est que, tout comme Wikipédia, tout le monde peut participer, discuter, commenter ce travail de production de données et de mise en relation.

Est-ce qu’il serait envisageable d’établir un lien vers la base de données de https://www.recyclivre.com/ quand l’ouvrage recherché ne figure dans aucun « inventaire » de participant⋅es ?
Ça pose au moins deux problèmes :
- Ce service et d’autres qui peuvent être sympathiques, telles que les plateformes mutualisées de librairies indépendantes (leslibraires.fr, placedeslibraires.fr, librairiesindependantes.com, etc.), ne semblent pas intéressés par l’inter-connexion avec le reste du web, construisant leurs URL avec des identifiants à eux (seul le site librairiesindependantes.com semble permettre de construire une URL avec un ISBN, ex : https://www.librairiesindependantes.com/product/9782253260592/) et il n’existe aucune API publique pour interroger leurs bases de données : il est donc impossible, par exemple, d’afficher l’état des stocks de ces différents services.
- D’autre part, recyclivre est une entreprise à but lucratif (SAS), sans qu’on leur connaisse un intérêt pour les communs (code et base de données propriétaires). Alors certes ça cartonne, c’est efficace, tout ça, mais ce n’est pas notre priorité : on aimerait être mieux connecté avec celleux qui, dans le monde du livre, veulent participer aux communs : les bibliothèques nationales, les projets libres comme OpenLibrary, lib.reviews, Bookwyrm, Readlebee, etc.
Cependant la question de la connexion avec des organisations à but lucratif pose un vrai problème : l’objectif de l’association Inventaire — cartographier les ressources où qu’elles soient — implique à un moment de faire des liens vers des organisations à but lucratif. En suivant l’esprit libriste, il n’y a aucune raison de refuser a priori l’intégration de ces liens, les développeuses de logiciels libres n’étant pas censé contraindre les comportements des utilisatrices ; mais ça pique un peu de travailler gratuitement, sans contrepartie pour les communs.
En quoi inventaire.io participe à un mouvement plus large qui est celui des communs de la connaissance ?
Inventaire, dans son rôle d’annuaire des ressources disponibles, essaye de valoriser les communs de la connaissance, en mettant des liens vers les articles Wikipédia, vers les œuvres dans le domaine public disponibles en format numérique sur des sites comme Wikisource, Gutenberg ou Internet Archive. En réutilisant les données de Wikidata, Inventaire contribue également à valoriser ce commun de la connaissance et à donner à chacun une bonne raison de l’enrichir.
Inventaire est aussi un commun en soi : le code est sous licence AGPL, les données bibliographiques sous licence CC0. L’organisation légale en association vise à ouvrir la gouvernance de ce commun à ses contributeur⋅ices. Le statut associatif garantit par ailleurs qu’il ne sera pas possible de transférer les droits sur ce commun à autre chose qu’une association poursuivant les mêmes objectifs.
Si je suis une organisation ou un particulier qui héberge des services en ligne, est-ce que je peux installer ma propre instance d’inventaire.io ?
C’est possible, mais déconseillé en l’état. Notamment car les bases de données bibliographiques de ces différentes instances ne seraient pas synchronisées, ce qui multiplie par autant le travail nécessaire à l’amélioration des données. Comme il n’y a pas encore de mécanisme de fédération des inventaires, les comptes de votre instance seraient donc isolés. Sur ces différents sujets, voir cette discussion : https://github.com/inventaire/inventaire/issues/187 (en anglais).
Cela dit, si vous ne souhaitez pas vous connecter à inventaire.io, pour quelque raison que ce soit, et malgré les mises en garde ci-dessus, vous pouvez vous rendre sur https://github.com/inventaire/inventaire-deploy/ pour déployer votre propre instance « infédérable ». On va travailler sur le sujet dans les mois à venir pour tendre vers plus de décentralisation.
A l’heure où il est de plus en plus urgent de décentraliser le web, envisagez-vous qu’à terme, il sera possible d’installer plusieurs instances d’inventaire.io et de les connecter les unes aux autres ?
Pour la partie réseau social d’inventaires, une décentralisation devrait être possible, même si cela pose des questions auquel le protocole ActivityPub ne semble pas proposer de solution. Ensuite, pour la partie base de données contributives, c’est un peu comme si on devait maintenir plusieurs instances d’OpenStreetMap en parallèle. C’est difficile et il semble préférable de garder cette partie centralisée, mais puisqu’il existe plein de services bibliographiques différents, il va bien falloir s’interconnecter un jour.
Vous savez sûrement que les Chevaliers Blancs du Web Libre sont à cran et vont vous le claironner : vous restez vraiment sur GitHub pour votre dépôt de code https://github.com/inventaire ou bien… ?
La pureté militante n’a jamais été notre modèle. Ce compte date de 2014, à l’époque Github avait peu d’alternatives… Cela étant, il est certain que nous ne resterons pas éternellement chez Microsoft, ni chez Transifex ou Trello, mais les solutions auto-hébergées c’est du boulot, et celles hébergées par d’autres peuvent se révéler instables.
Si on veut contribuer à Inventaire.io, on fait ça où ? Quels sont les différentes manière d’y contribuer ?
Il y a plein de manières de venir contribuer, et pas que sur du code, loin de là : on peut améliorer la donnée sur les livres, la traduction, la documentation et plus généralement venir boire des coups et discuter avec nous de la suite ! Rendez-vous sur https://wiki.inventaire.io/wiki/How_to_contribute/fr.
Est-ce que vous avez déjà eu vent d’outils tiers qui utilisent l’API ? Si oui, vous pouvez donner des noms ? À quoi servent-ils ?
Readlebee et Bookwyrm sont des projets libres d’alternatives à GoodReads. Le premier tape régulièrement dans les données bibliographiques d’Inventaire. Le second vient de mettre en place un connecteur pour chercher de la donnée chez nous. A noter : cela apporte une complémentarité puisque ces deux services sont orientés vers les critiques de livres, ce qui reste très limité sur Inventaire.
Et comme toujours, sur le Framablog, on vous laisse le mot de la fin !
Inventaire est une app faite pour utiliser moins d’applications, pour passer du temps à lire des livres, papier ou non, et partager les dernières trouvailles. Pas de capture d’attention ici, si vous venez deux fois par an pour chiner des bouquins, ça nous va très bien ! Notre contributopie c’est un monde où l’information sur la disponibilité des objets qui nous entoure nous affranchit d’une logique de marché généralisée. Un monde où tout le monde peut contribuer à casser les monopoles de l’information sur les ressources que sont les géants du web et de la distribution. Pouvoir voir ce qui est disponible dans un endroit donné, sans pour autant dépendre ni d’un système cybernétique central, ni d’un marché obscur où les entreprises qui payent sont dorlotées par un algorithme de recommandations.
Merci beaucoup Maxlath et Jums pour ces explications et on souhaite longue vie à Inventaire. Et si vous aussi vous souhaitez mettre en commun votre bibliothèque, n’hésitez pas !