#FixCopyright : de bonnes raisons de soutenir le rapport REDA.
Nous entamons ici une série d’articles autour du rapport REDA, une initiative visant à dépoussiérer et harmoniser les lois du droit d’auteur/copyright sur le territoire européen. Il s’agit d’un sujet important et d’une opportunité unique de trouver un compromis qui pourrait favoriser les auteurs, les échanges culturels sur les Internets sans écorcher l’industrie de production et diffusion culturelle.
L’idée de cette série d’articles est de donner la parole à des créateurs de contenus, au nom desquels sociétés de gestion collective de droits et industriels de la culture voudraient lancer une « guerre au partage ».
Ce premier article est signé Greg, dont le blog l’Antre du Greg est à suivre avec attention. Greg est un auteur aux créations Libres. Il a su résumer les points fondamentaux et les enjeux de cette proposition législative qui pourrait (en douceur et avec des compromis) changer la donne dans la relation auteur-audience, d’internaute à internaute.
Le contenu qui suit est donc CC-BY-SA Greg, et a été originellement publié sur l’Antre du Greg.
Pourquoi je soutiens le rapport REDA (et pourquoi vous aussi, vous devriez)

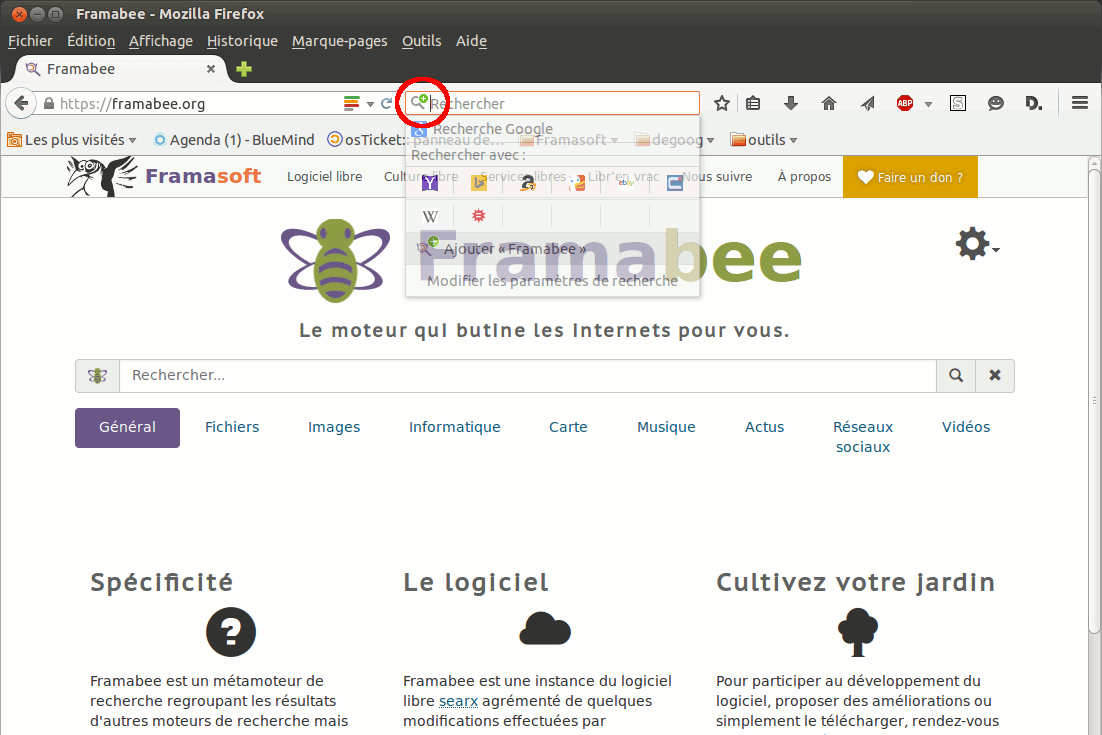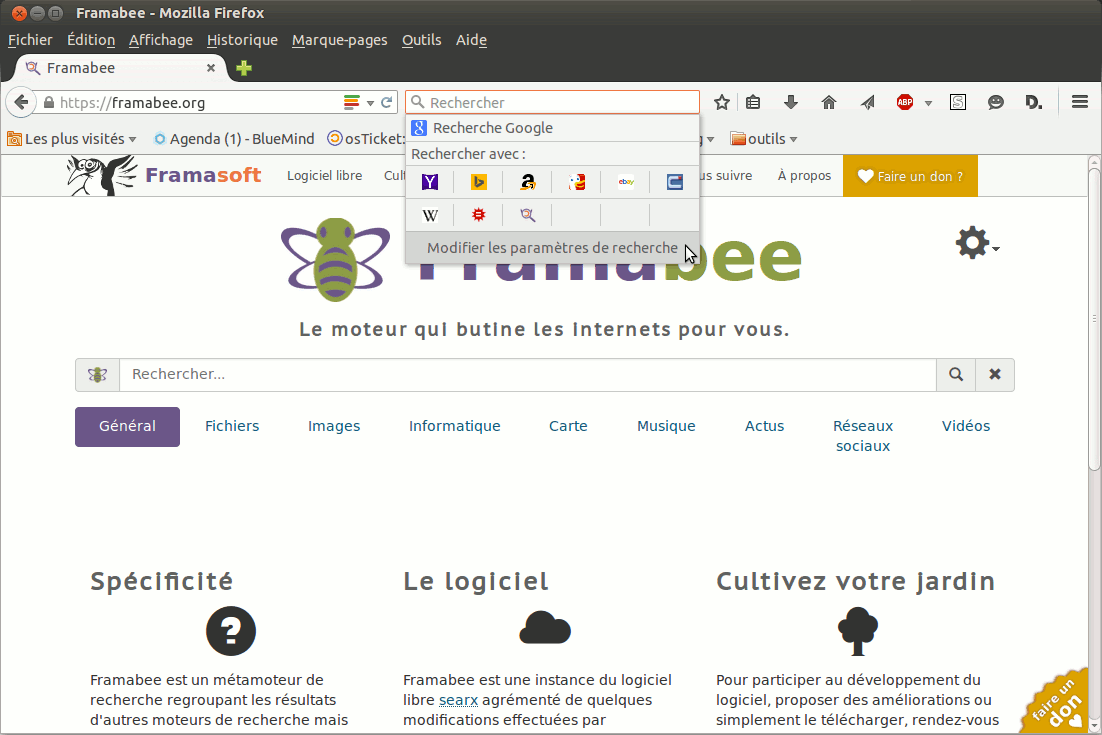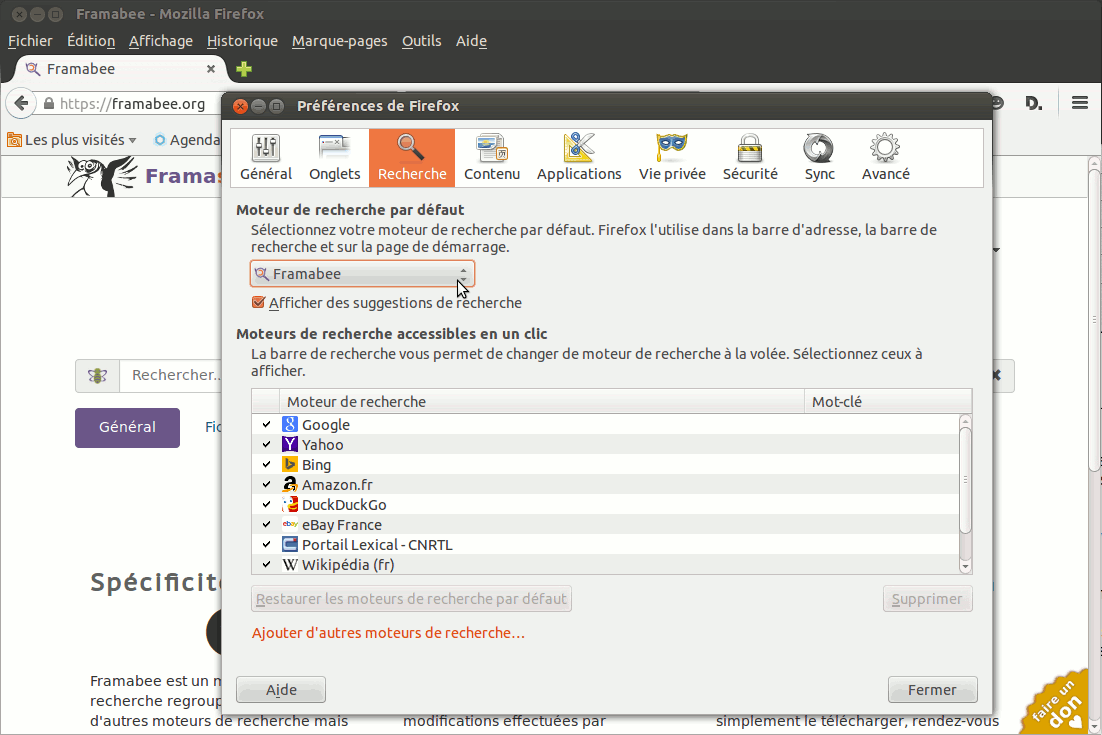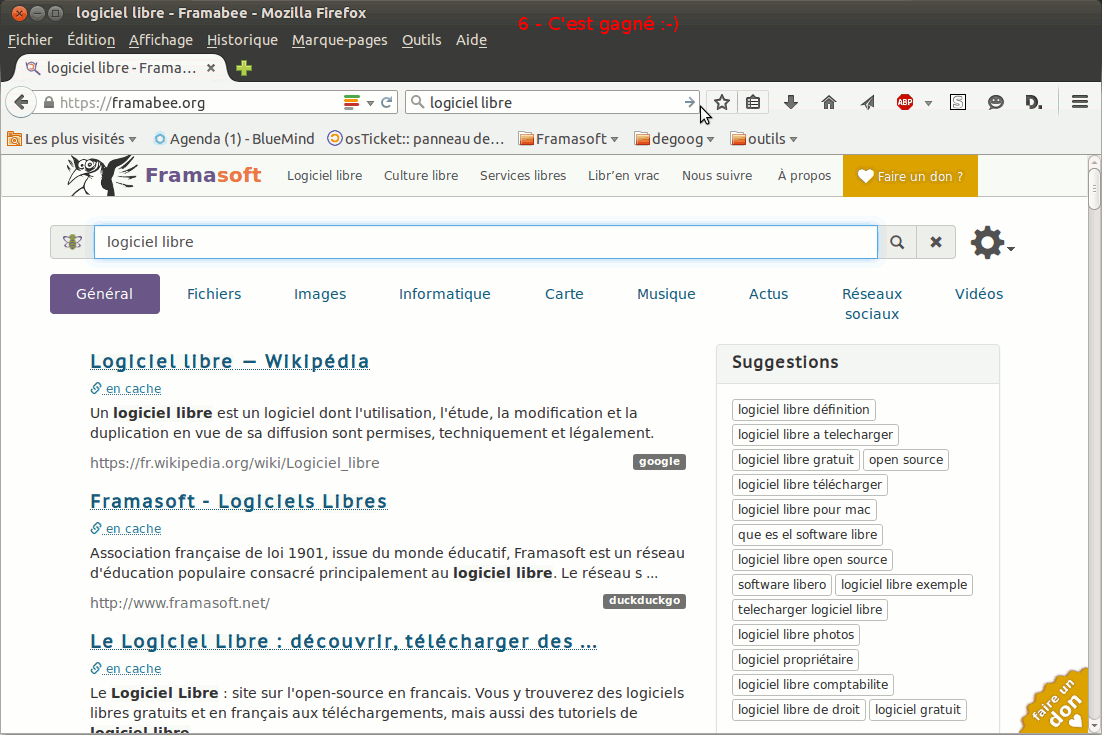
En ce moment, au parlement européen, on prépare la réforme du droit d’auteurs, initiée par le rapport Reda (du nom de la députée Julia Reda, non pour Réforme Européenne pour le Droit d’Auteur (ne riez pas, on m’a pourtant fait cette remarque)). Ce rapport, quoiqu’en disent les grands acteurs de l’industrie culturelle, donne plus de droits aux créateurs, se basant sur les nouvelles technologies, mais aussi aux internautes. Je vous invite à lire une explication du rapport de Julia, si vous ne le connaissez pas, et si vous voulez le texte en détail, c’est par ici. Je voulais vous partager mon ressenti sur les débats qui ont lieu en ce moment, mais aussi vous expliquer pourquoi, selon moi, il est important de le soutenir. La liste n’est cependant pas exhaustive, sinon, je pense que mon plaidoyer atteindrait la taille d’un mini-livre. Voici donc déjà des points essentiels, mais n’hésitez pas à approfondir le sujet.
Les créateurs sont hors-la-loi…
Les créateurs de vidéos, principalement sur Youtube, sont considérés à l’heure actuelle comme des hors-la-loi en Europe. En effet, il existe aux USA le principe du Fair Use qui permet de mettre un petit extrait d’une œuvre pour illustrer son propos. En Europe ce n’est pas le cas. Mettre un passage d’une chanson, une citation d’un film est une violation du copyright. Oui, votre youtuber préféré, qui a remixé une œuvre, a fait un mash-up, est un criminel aux yeux des ayants droit. Mais plutôt que de vous faire une longue diatribe contre l’état actuel de la législation, je vous invite à regarder cette petite vidéo, pleine de gens bien qui vous expliqueront tout ça bien mieux que moi.

…Mais l’internaute aussi.
La copie a toujours existé. Les moines copistes en sont la preuve. Nous avons tous, dans le passé, pris un peu de temps avec une photocopieuse. Nous avons enregistré des disques sur cassettes audio que nous repassions à nos copains. Pareil pour les films avec les cassettes vidéo. Jamais nous n’aurions pensé que nous serions considérés comme des criminels, que l’on passerait en jugement et que nous risquerions prison ou amende. C’est pourtant ce qui est en train de se passer : la criminalisation du partage. Si vous avez le malheur de mettre la moindre œuvre artistique sur un réseau de peer-to-peer vous êtes considéré comme le pire des criminels. Le rapport REDA propose de renforcer les droits des utilisateurs, avec entre autre, la facilitation du prêt numérique pour les bibliothèques.
Ce n’est pas le piratage qui tue un artiste ou une œuvre, mais bien l’absence d’offre concrète et suffisante. On a souvent l’impression que les grandes maisons d’édition passent plus de temps à lutter contre le piratage qu’à créer une véritable offre : les titres numériques sont très peu nombreux par rapport à leur équivalent papier, et tout un temps, les livres numériques n’étaient que de vulgaires scans. Les grandes maisons d’éditions s’érigent en spécialistes du numérique sans même en connaître tous les tenants et aboutissants : rien que dernièrement, un auteur préconise l’abandon du format epub parce que c’est devenu le standard du piratage : c’est une aberration totale. Un fichier reste un fichier, si un format disparaît, un autre prendra rapidement sa place.
Pour clore ce paragraphe, je terminerai en soulignant une idée défendue aussi par Thierry Crouzet mais aussi Ploum, et beaucoup d’auteurs libres : publier c’est rendre public, mettre à la disposition de tout un chacun et laisser son œuvre vivre sa vie, se propager. Beaucoup d’auteurs se plaignent que le piratage tue leurs œuvres. J’ai vu dernièrement un auteur se plaindre que son livre ne s’était vendu qu’à deux cents exemplaires mais qu’il avait été téléchargé plus de sept cents fois. Je ne comprends pas la plainte : s’il a été téléchargé, c’est que des personnes se sont intéressées à son travail et l’ont propagé. Elles ont aidé à la faire connaître. Je ne trouve pas plus gratifiant de recevoir de l’argent que d’être lu par un plus grand nombre, c’est même le contraire (même s’il est vrai que comme beaucoup d’auteurs, j’aimerais vivre de ma plume, je serai nettement plus honoré de voir mon œuvre se propager sur les sites internet, cela prouve que du monde s’intéresse à ce que je fais et veut le faire découvrir à d’autres). Et si vous ne voulez pas voir votre œuvre se propager sur internet, n’écrivez et ne publiez pas.
L’aberration des hyperliens
Un hyperlien est un lien que vous faites pour illustrer votre propos vers un autre article. C’est le fondement de l’internet, faire des liens vers d’autres ressources qui approfondissent le sujet. Sans ces derniers, le net serait nettement moins vivant. Vous ne copiez pas l’information, vous dirigez vos lecteurs vers l’information, vers « le propriétaire » de son contenu (je n’aime pas cette façon de voir les choses, une idée, pour moi, n’appartient à personne, mais j’y reviendrai dans un billet ultérieur). Vous ne violez donc pas le droit d’auteur de cette personne. Julia Reda demande donc que l’hyperlien ne soit pas soumis à des droits exclusifs. Petit exemple, qui pourrait se généraliser. J’écris un article sur un sujet X et pour montrer ce que j’explique, je fais un lien vers un site d’une société de l’audio-visuel belge. Je suis bien dans l’illégalité, si on regarde les conditions d’utilisation de ce site :

Je n’ai pourtant pas copié le contenu de l’article. Je n’ai fait qu’un simple lien. En réalité, cette société devrait être reconnaissante envers quelqu’un qui fait un lien vers elle. Elle gagne en visibilité, gagne des visiteurs qui sont intéressés par le sujet. Mais non. Selon eux, une telle pratique reste une violation du droit d’auteur.
« Vendre » de la culture, c’est comme vendre des poires
Dès la présentation du rapport, une levée de bouclier a eu lieu de la part d’eurodéputés. Le député le plus virulent, Jean-Marie Cavada, s’est farouchement opposé au rapport de Julia Reda. Neil Jomunsi, auteur et propriétaire de la maison d’édition Walrus, a voulu lui expliquer ce que le rapport apportait, et en quoi il est important pour les auteurs. Mais la réaction de Cavada fut totalement consternante : premièrement, on a clairement eu l’impression qu’il n’avait pas lu la moindre ligne de la lettre, répondant des phrases préformatées, comme si elle avait été dictée par des lobbyistes. Il souligne que des jeunes « Robin des bois des temps modernes » veulent abolir le copyright, alors que ce n’est pas du tout le cas : il s’agit d’un renforcement DES droits des auteurs et des utilisateurs. On remarque bien dans sa réponse que sa préoccupation n’est pas l’auteur mais bien l’industrie. Il en vient même à comparer un bien culturel à un produit que l’on vend sur les marchés. Même si un bien culturel nourrit l’esprit, je ne suis pas sûr que le comparer à une poire ou une carotte soit très gratifiant.
Vous n’êtes considéré comme auteur que si vous êtes publié par une grande maison
J’aime écrire. J’écris des petites histoires, que je mets ici, sur mon blog, ou sur d’autres réseaux. Je mets des mini-livres numériques à disposition de tout un chacun. Pour des tas de raisons, je n’ai pas cherché à prendre un éditeur. Pour un député européen, Monsieur Cavada (oui, toujours le même), je ne suis donc rien. Je n’ai droit à aucune considération. J’aimerais cependant paraphraser Arnaud Lavalade et Manuel Darcemont, les fondateurs de Scribay :
«Un auteur le devient dès la première ligne.
N’importe qui est auteur dès qu’il se met à écrire. Personne n’a le droit de dire qui est auteur et qui ne l’est pas. C’est l’acte de création qui détermine un auteur, pas sa validation par une quelconque autorité.»
Je constate ici un mépris de chaque internaute qui se lance dans une activité créative et fait partager son art. Mais on remarque une fois de plus la volonté de protéger une industrie qui a du mal à s’adapter aux évolutions technologiques plutôt que de protéger tout acte de création, sans laquelle cette industrie ne pourrait de toute façon pas survivre.
Ce que vous avez financé, ne vous appartient pas et vous pouvez vous asseoir dessus.
Il y a des tas de créations qui n’ont pu avoir lieu qu’avec l’aide de financement public. Prenons un petit exemple : les universités, dans le cadre de leurs travaux, reçoivent de l’argent public (donc oui, votre argent, puisque vous payez des impôts). Les résultats de ces travaux, les thèses, les découvertes, devraient donc être dans le domaine public, puisque tout un chacun les a financés. Mais non, ils restent la propriété de la personne ou l’institut. On pourrait même aller plus loin, mais ici c’est une interprétation purement personnelle, avec la presse. Elle est grandement financée par l’argent public, et elle s’écroulerait si elle ne recevait plus aucun subside. Là c’est même pire, vous devez payer une seconde fois pour accéder à l’information (en plus de donner du temps de cerveau disponible pour les nombreuses publicités qui inondent les pages ou sites internet).
Le lobbying porte ses fruits, dénaturant tout le rapport.
À peine publié, directement dénaturé. Des tas d’amendements furent directement modifiés par nombre de députés, vidant pratiquement tout le rapport de sa substance. Je vous les ai cités plus haut, les hyperliens, où les députés demandent de créer «un droit d’auteur » pour ces derniers. Alors que le rapport demande l’abandon des DRMs, des députés modifient le paragraphe pour les mettre en avant ; alors que le rapport demande une harmonisation des règles pour toute l’Union Européenne, facilitant donc la vie de tous les acteurs hors industrie, on le supprime. Dans le cas où le rapport est voté avec ces modifications, on obtiendrait le statu quo, voire pire plus de droits pour l’industrie et non pour les petits auteurs et les utilisateurs. Je vous invite à lire ce billet : Reda report: the 10 worst and the 5 best amendments (en anglais).
#CopyrightForFreedom, ou se battre pour l’industrie du livre et non l’auteur
Le lobbying de l’industrie continue de se mobiliser. Lors de la Foire du Livre de Paris, la Fédération des Éditeurs Européens lance la campagne « Copyright For Freedom », avec la création d’une pétition en ligne demandant justement de renforcer le copyright. Mais renforcer le droit d’auteur, le prolonger à 70 ans voire plus, n’est-ce pas à l’opposé de la liberté ? Dans le cas de cette prolongation du droit d’auteur et des droits voisins après la mort d’un auteur, ce n’est pas l’auteur qui est protégé, mais bien l’industrie. Oui, cette campagne ne sert qu’à protéger cette industrie. Je suis un auteur, et je le clame haut et fort : pas en mon nom. Et je vous le demande à tous, ne signez pas cette pétition.
Mais pour moi, le rapport aurait pu encore aller plus loin.
Je vais terminer par ce qui m’a le plus déçu dans le rapport Reda, bien que certaines nuances aient pu m’échapper. J’aurais aimé voir une reconnaissance et une harmonisation des systèmes de financement alternatifs tels que Flattr, Tipeee et autre. Rien que pour la Belgique (je pense que c’est pareil pour la France avec Flattr), il y a un flou juridique total à ce sujet, personne ne sait ce qu’il convient de faire pour travailler avec ce type de donation, si on doit les considérer comme des dons ou des revenus (et ce n’est pas faute de poser la question à droite et à gauche). Mais peut-être que cette question dépasse le cadre du rapport Reda.
Continuer à creuser…
Voici pour moi les points essentiels, ce que j’ai retenu sur ce rapport. Je vous invite cependant à prendre connaissance des avis d’autres créateurs. Ce lundi 20 avril s’est tenue la conférence Meet The New Authors, au parlement européen. Voici la vidéo des débats organisés par Julia Reda, vous aurez donc des avis différents, complémentaires aux miens, et des problèmes plus spécifiques aux autres secteurs de l’édition.
Merci de m’avoir lu. Bien sûr, ce texte est sous licence Creative Commons BY-SA. Partagez-le, modifiez-le. Propagez les informations. Pour que les auteurs, mais vous aussi, internautes, ayez plus de droits. Pour que nous ne soyons plus hors-la-loi.
Greg.