Un Web « low-tech », « sobre », « frugal»… ce n’est pas une mode, mais un mouvement de fond qui va au-delà de la prise de conscience et commence à s’installer dans les pratiques. C’est pourquoi sans doute Nathalie a choisi d’associer recherche d’informations et expérimentation dans sa démarche d’éco-conception, c’est après tout la meilleure façon d’apprendre et progresser. Les commentaires comme toujours sont ouverts et modérés.
Bilan du défi « avance rapide »
par Nathalie
Nous sommes début avril 2021, voilà maintenant un mois que je m’intéresse aux impacts du numérique sur notre planète. Un mois que je lis tout ce que je peux trouver sur ce sujet et plus particulièrement sur l’éco-conception du numérique. Un mois que j’apprends intensivement sur ce sujet passionnant. Un mois que j’écris sur chaque découverte ou inspiration. Ce fut un mois intense et passionnant. Merci à celles et ceux qui ont pris le temps de me lire et d’écrire un commentaire, que ce soit pour m’encourager ou confronter leurs opinions. Certains sont plus en avance que moi sur le sujet et m’ont apporté leur contribution pour enrichir ce blog.
Je vais continuer à apprendre et à écrire ici au fil de mon chemin. De manière moins soutenue et peut-être un contenu un peu différent parfois. J’aimerais mettre en application ce que j’ai appris. Peut-être en commençant par l’analyse de sites web, décortiquer ensemble les choix de design et les confronter à mes récentes connaissances en éco-conception. Tout n’est pas encore décidé, d’ailleurs si vous avez des idées ou des choses que vous aimeriez voir ici, n’hésitez pas à m’en faire part en commentaires.
Bilan du défi “avance rapide”
Voici un bilan de ces 30 jours d’apprentissage intensif, défi que j’avais baptisé “avance rapide” (ici l’article sur le lancement du défi).
Articles publiés
J’ai lu des dizaines et des dizaines d’articles sur le sujet, participé à deux conférences et lu également deux livres pour lesquels j’ai mis le lien des chroniques un peu plus bas. J’ai découvert de nombreuses statistiques dont certaines qui m’ont beaucoup choquée et que j’ai regroupées ici. J’ai publié 29 articles (en excluant les articles sur le lancement et le bilan du défi que vous êtes en train de lire), un mélange entre apprentissage théorique, bonnes pratiques concrètes et inspirations. Je vous remets les liens de chaque article ci-dessous, classés par catégorie.
Au fil de mon apprentissage, j’ai également appliqué concrètement certaines actions sur le blog:
– non utilisation du blanc dans le design du blog (le blanc est la couleur la plus consommatrice en terme d’énergie)
– application de la méthode Marie Kondo, par exemple en utilisant des images uniquement lorsqu’elles servent à la compréhension
– optimisation des images avec ImageOptim (40% de réduction de poids en moyenne)
– mise en place d’un CDN pour réduire la distance à parcourir pour chaque requête (une bonne pratique dont je n’ai pas encore parlé mais j’y dédierai un article prochainement)
– j’essaie de rédiger des titres clairs pour éviter les mauvaises surprises et des chargements de page inutiles
Pour le moment, le score obtenu pour la page d’accueil du blog (www.webdesignfortheplanet.com) est plutôt satisfaisant. J’espère le maintenir dans le futur 🙂
En conclusion
J’espère que vous avez appris aussi et que certains articles vous ont interpellés, fait prendre conscience de l’impact de nos choix UX ou UI notamment dans la construction de nos sites web et, pourquoi pas, carrément donné envie de changer les choses dans nos métiers du numérique. N’hésitez pas à partager vos ressentis avec moi sur tout ça, ça m’intéresse de vous lire 🙂
J’ai encore beaucoup à apprendre sur ce sujet, je vais continuer à creuser, lire, analyser et expérimenter à mon rythme. Si vous avez des recommandations ou des suggestions de sujets que vous aimeriez que je creuse, n’hésitez pas à m’en faire part en commentaires de cet article.
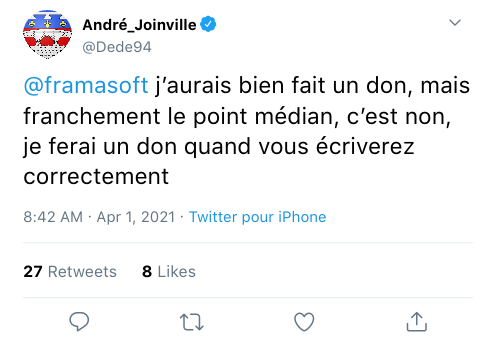
Le point médian m’a tué⋅e : Framasoft met la clef sous la porte
La rumeur courait depuis quelque temps et c’est maintenant confirmé : l’association d’éducation populaire Framasoft dépose le bilan. En cause ? L’effondrement catastrophique du montant des dons au cours des derniers mois, effondrement principalement imputable à un curieux symbole typographique.
Cela fait de nombreuses années maintenant que l’on peut trouver des formes de ce que l’on appelle « l’écriture inclusive » dans les communications de Framasoft. La forme la plus visible de cette écriture est le fameux « point médian » qui permet de détailler les genres lorsqu’un mot inclut des personnes indéterminées (et au genre, par conséquent, indéterminé également). Sauf que voilà, ce point médian est loin de faire l’unanimité. Nous avons rencontré Jean-Mi, président des Promoteurs de l’Écriture Non-Inclusive Systématique (PENIS), en croisade contre le point médian depuis 2017.
« Je crois qu’on ait avant tous des défenseur de la belle langue Francaise » nous écrit Jean-Mi dans un premier mail de contact. « Le point médian agresse l’œil, on a constaté une explosion des frais d’ophtalmologie chez les lecteurs du Framablog ces dernières années, il fallait réagir. » Un problème de santé publique ? Jean-Mi nous répond sans détour :
À 200%. Les anecdotes se comptent par dizaines. Tu vas lire pépouze un article sur le développement de PeerTube et PAF ! Une saloperie de point médian qui surgit plus furtivement qu’un Rattata dans les hautes herbes. La dernière fois, ça m’a fait un haut-le-cœur, j’en ai dégueulé tout mon dîner sur le clavier, 30€ de dégâts. Mon pote Dédé, l’autre jour, sur l’article sur Mobilizon, il était tout prêt à changer le monde, tout ça, et PAF ! Il retrouve de la propagande de connasse de féministe sur un bon vieux blog de tech où on devrait pourtant pouvoir faire de l’entre-couilles en paix. Deux mois de thérapie pour s’en remettre, qu’il lui a fallu, au Dédé. Ils y pensent, à ça, les framaguignols qui pondent du point médian au kilomètre sans respect pour nos petits cœurs fragiles ?
Jean-Mi et Dédé, chevaliers de la liberté et des belles lettres, n’ont jamais caché leur dégoût pour cet odieux symbole typographique et commentent systématiquement les articles incriminés sur le Framablog. Pouhiou, chargé de communication de Framasoft contacté par nos soins, soupire :
Tu bosses comme un fou pour faire des articles bien écrits, avec un ton agréable, tu mets du soin, du cœur à l’ouvrage, et là tu vois le premier commentaire : une remarque insultante sur le point médian. T’as fait 15 000 caractères aux petits oignons et on vient te casser les gonades parce qu’il y en a 3 qui plaisent pas. C’est fatigant.
Les PENIS restent inflexibles :
Si ça le fatigue, qu’il arrête ! Nous aussi ça nous fatigue, leurs conneries, sauf que nous, c’est nous qu’on a raison ! La langue française, y’a des fucking règles, tu les respectes ! #JeSuisAcademieFrancaise
Sauf que cette fois, l’intransigeance a pris un autre détour : le boycott de dons. Jean-Mi nous raconte, ému, la genèse de ce mode d’action :
C’est Dédé qu’a eu l’idée. Un jour je l’ai vu tweeter :
J’me suis dit : putain mais c’est du génie !
Depuis, à chaque article point-médiané, Jean-Mi et Dédé soulignent que Framasoft a perdu un donateur :
Bon okay, on n’avait jamais fait de don avant, mais n’empêche qu’on aurait très bien pu en faire un dans un futur hypothermique ! EH BAH NON. Tout cet argent perdu par Framasoft pour une bête lubie féminazie, c’est triste. Mais c’est bien fait pour eux.
L’association, longtemps restée sourde à ces avertissements, paie aujourd’hui lourdement l’addition : le boycott massif du point médian a mené à un écroulement des dons, et ceux-ci ne suffisent plus à rémunérer les salarié⋅e⋅s. Triste retour à la réalité : Framasoft met aujourd’hui la clef sous la porte. « Ça leur pendait au nez » commente Jean-Mi « et à toi aussi, sale petite merde journalope qui vient d’écrire salarié⋅e⋅s, tu crois que je t’ai pas vu ?! »
Les PENIS se dressent aussi pour la belle langue française à l’Assemblée Nationale (rigolez pas, c’est avec votre pognon)
C’est un triste jour pour l’association qui s’était rendue célèbre par son annuaire de logiciels, ses livres libres, ses services autour du projet Dégooglisons Internet et, plus récemment, par l’initiative Contributopia visant à outiller la société de la contribution. Pierre-Yves Gosset, salarié historique de Framasoft, commente : « ça me fait vraiment mal qu’un truc aussi beau finisse comme ça à cause d’une bande de déglingués de la typo. Ça traite tout le monde de fragile et ça pète une bielle pour trois pixels. » Amer, il arrive malgré tout à en rire : « Enfin au moins, maintenant on sait comment flinguer Google : suffit de leur faire adopter le point médian. »
L’aventure s’arrête donc ici pour l’asso qui avait pour ambition de dégoogliser Internet mais n’aura pas su dépointmédianiser son propre blog. Le jeu en aura-t-il valu la chandelle ? C’est Luc, ancien admin-sys de Framasoft croisé au comptoir de Pôle Emploi, qui conclut : « y’a des poings médians dans la gueule qui se perdent. »
Google chante le requiem pour les cookies, mais le grand chœur du pistage résonnera encore
Google va cesser de nous pister avec des cookies tiers ! Une bonne nouvelle, oui mais… Regardons le projet d’un peu plus près avec un article de l’EFF.
La presse en ligne s’en est fait largement l’écho : par exemple siecledigital, generation-nt ou lemonde. Et de nombreux articles citent un éminent responsable du tout-puissant Google :
Chrome a annoncé son intention de supprimer la prise en charge des cookies tiers et que nous avons travaillé avec l’ensemble du secteur sur le Privacy Sandbox afin de mettre au point des innovations qui protègent l’anonymat tout en fournissant des résultats aux annonceurs et aux éditeurs. Malgré cela, nous continuons à recevoir des questions pour savoir si Google va rejoindre d’autres acteurs du secteur des technologies publicitaires qui prévoient de remplacer les cookies tiers par d’autres identifiants de niveau utilisateur. Aujourd’hui, nous précisons qu’une fois les cookies tiers supprimés, nous ne créerons pas d’identifiants alternatifs pour suivre les individus lors de leur navigation sur le Web et nous ne les utiliserons pas dans nos produits.
David Temkin, Director of Product Management, Ads Privacy and Trust (source)
« Pas d’identifiants alternatifs » voilà de quoi nous réjouir : serait-ce la fin d’une époque ?
Comme d’habitude avec Google, il faut se demander où est l’arnaque lucrative. Car il semble bien que le Béhémoth du numérique n’ait pas du tout renoncé à son modèle économique qui est la vente de publicité.
Dans cet article de l’Electronic Frontier Foundation, que vous a traduit l’équipe de Framalang, il va être question d’un projet déjà entamé de Google dont l’acronyme est FLoC, c’est-à-dire Federated Learning of Cohorts. Vous le trouverez ici traduit AFC pour « Apprentissage Fédéré de Cohorte » (voir l’article de Wikipédia Apprentissage fédéré).
Pour l’essentiel, ce dispositif donnerait au navigateur Chrome la possibilité de créer des groupes de milliers d’utilisateurs ayant des habitudes de navigation similaires et permettrait aux annonceurs de cibler ces « cohortes ».
Les cookies tiers se meurent, mais Google essaie de créer leur remplaçant.
Personne ne devrait pleurer la disparition des cookies tels que nous les connaissons aujourd’hui. Pendant plus de deux décennies, les cookies tiers ont été la pierre angulaire d’une obscure et sordide industrie de surveillance publicitaire sur le Web, brassant plusieurs milliards de dollars ; l’abandon progressif des cookies de pistage et autres identifiants tiers persistants tarde à arriver. Néanmoins, si les bases de l’industrie publicitaire évoluent, ses acteurs les plus importants sont déterminés à retomber sur leurs pieds.
Google veut être en première ligne pour remplacer les cookies tiers par un ensemble de technologies permettant de diffuser des annonces ciblées sur Internet. Et certaines de ses propositions laissent penser que les critiques envers le capitalisme de surveillance n’ont pas été entendues. Cet article se concentrera sur l’une de ces propositions : l’Apprentissage Fédéré de Cohorte (AFC, ou FLoC en anglais), qui est peut-être la plus ambitieuse – et potentiellement la plus dangereuse de toutes.
L’AFC est conçu comme une nouvelle manière pour votre navigateur d’établir votre profil, ce que les pisteurs tiers faisaient jusqu’à maintenant, c’est-à-dire en retravaillant votre historique de navigation récent pour le traduire en une catégorie comportementale qui sera ensuite partagée avec les sites web et les annonceurs. Cette technologie permettra d’éviter les risques sur la vie privée que posent les cookies tiers, mais elle en créera de nouveaux par la même occasion. Une solution qui peut également exacerber les pires attaques sur la vie privée posées par les publicités comportementales, comme une discrimination accrue et un ciblage prédateur.
La réponse de Google aux défenseurs de la vie privée a été de prétendre que le monde de demain avec l’AFC (et d’autres composants inclus dans le « bac à sable de la vie privée » sera meilleur que celui d’aujourd’hui, dans lequel les marchands de données et les géants de la tech pistent et profilent en toute impunité. Mais cette perspective attractive repose sur le présupposé fallacieux que nous devrions choisir entre « le pistage à l’ancienne » et le « nouveau pistage ». Au lieu de réinventer la roue à espionner la vie privée, ne pourrait-on pas imaginer un monde meilleur débarrassé des problèmes surabondants de la publicité ciblée ?
Nous sommes à la croisée des chemins. L’ère des cookies tiers, peut-être la plus grande erreur du Web, est derrière nous et deux futurs possibles nous attendent.
Dans l’un d’entre eux, c’est aux utilisateurs et utilisatrices que revient le choix des informations à partager avec chacun des sites avec lesquels il ou elle interagit. Plus besoin de s’inquiéter du fait que notre historique de navigation puisse être utilisé contre nous-mêmes, ou employé pour nous manipuler, lors de l’ouverture d’un nouvel onglet.
Dans l’autre, le comportement de chacune et chacun est répercuté de site en site, au moyen d’une étiquette, invisible à première vue mais riche de significations pour celles et ceux qui y ont accès. L’historique de navigation récent, concentré en quelques bits, est « démocratisé » et partagé avec les dizaines d’interprètes anonymes qui sont partie prenante des pages web. Les utilisatrices et utilisateurs commencent chaque interaction avec une confession : voici ce que j’ai fait cette semaine, tenez-en compte.
Les utilisatrices et les personnes engagées dans la défense des droits numériques doivent rejeter l’AFC et les autres tentatives malvenues de réinventer le ciblage comportemental. Nous exhortons Google à abandonner cette pratique et à orienter ses efforts vers la construction d’un Web réellement favorable aux utilisateurs.
Qu’est-ce que l’AFC ?
En 2019, Google présentait son bac à sable de la vie privée qui correspond à sa vision du futur de la confidentialité sur le Web. Le point central de ce projet est un ensemble de protocoles, dépourvus de cookies, conçus pour couvrir la multitude de cas d’usage que les cookies tiers fournissent actuellement aux annonceurs. Google a soumis ses propositions au W3C, l’organisme qui forge les normes du Web, où elles ont été principalement examinées par le groupe de commerce publicitaire sur le Web, un organisme essentiellement composé de marchands de technologie publicitaire. Dans les mois qui ont suivi, Google et d’autres publicitaires ont proposé des dizaines de standards techniques portant des noms d’oiseaux : pigeon, tourterelle, moineau, cygne, francolin, pélican, perroquet… et ainsi de suite ; c’est très sérieux ! Chacune de ces propositions aviaires a pour objectif de remplacer différentes fonctionnalités de l’écosystème publicitaire qui sont pour l’instant assurées par les cookies.
L’AFC est conçu pour aider les annonceurs à améliorer le ciblage comportemental sans l’aide des cookies tiers. Un navigateur ayant ce système activé collecterait les informations sur les habitudes de navigation de son utilisatrice et les utiliserait pour les affecter à une « cohorte » ou à un groupe. Les utilisateurs qui ont des habitudes de navigations similaires – reste à définir le mot « similaire » – seront regroupés dans une même cohorte. Chaque navigateur partagera un identifiant de cohorte, indiquant le groupe d’appartenance, avec les sites web et les annonceurs. D’après la proposition, chaque cohorte devrait contenir au moins plusieurs milliers d’utilisatrices et utilisateurs (ce n’est cependant pas une garantie).
Si cela vous semble complexe, imaginez ceci : votre identifiant AFC sera comme un court résumé de votre activité récente sur le Web.
La démonstration de faisabilité de Google utilisait les noms de domaines des sites visités comme base pour grouper les personnes. Puis un algorithme du nom de SimHash permettait de créer les groupes. Il peut tourner localement sur la machine de tout un chacun, il n’y a donc pas besoin d’un serveur central qui collecte les données comportementales. Toutefois, un serveur administrateur central pourrait jouer un rôle dans la mise en œuvre des garanties de confidentialité. Afin d’éviter qu’une cohorte soit trop petite (c’est à dire trop caractéristique), Google propose qu’un acteur central puisse compter le nombre de personnes dans chaque cohorte. Si certaines sont trop petites, elles pourront être fusionnées avec d’autres cohortes similaires, jusqu’à ce qu’elles représentent suffisamment d’utilisateurs.
Pour que l’AFC soit utile aux publicitaires, une cohorte d’utilisateurs ou utilisatrices devra forcément dévoiler des informations sur leur comportement.
Selon la proposition formulée par Google, la plupart des spécifications sont déjà à l’étude. Le projet de spécification prévoit que l’identification d’une cohorte sera accessible via JavaScript, mais on ne peut pas savoir clairement s’il y aura des restrictions, qui pourra y accéder ou si l’identifiant de l’utilisateur sera partagé par d’autres moyens. L’AFC pourra constituer des groupes basés sur l’URL ou le contenu d’une page au lieu des noms domaines ; également utiliser une synergie de « système apprentissage » (comme le sous-entend l’appellation AFC) afin de créer des regroupements plutôt que de se baser sur l’algorithme de SimHash. Le nombre total de cohortes possibles n’est pas clair non plus. Le test de Google utilise une cohorte d’utilisateurs avec des identifiants sur 8 bits, ce qui suppose qu’il devrait y avoir une limite de 256 cohortes possibles. En pratique, ce nombre pourrait être bien supérieur ; c’est ce que suggère la documentation en évoquant une « cohorte d’utilisateurs en 16 bits comprenant 4 caractères hexadécimaux ». Plus les cohortes seront nombreuses, plus elles seront spécialisées – plus les identifiants de cohortes seront longs, plus les annonceurs en apprendront sur les intérêts de chaque utilisatrice et auront de facilité pour cibler leur empreinte numérique.
Mais si l’un des points est déjà clair c’est le facteur temps. Les cohortes AFC seront réévaluées chaque semaine, en utilisant chaque fois les données recueillies lors de la navigation de la semaine précédente.
Ceci rendra les cohortes d’utilisateurs moins utiles comme identifiants à long terme, mais les rendra plus intrusives sur les comportements des utilisatrices dans la durée.
De nouveaux problèmes pour la vie privée.
L’AFC fait partie d’un ensemble qui a pour but d’apporter de la publicité ciblée dans un futur où la vie privée serait préservée. Cependant la conception même de cette technique implique le partage de nouvelles données avec les annonceurs. Sans surprise, ceci crée et ajoute des risques concernant la donnée privée.
Le Traçage par reconnaissance d’ID.
Le premier enjeu, c’est le pistage des navigateurs, une pratique qui consiste à collecter de multiples données distinctes afin de créer un identifiant unique, personnalisé et stable lié à un navigateur en particulier. Le projet Cover Your Tracks (Masquer Vos Traces) de l’Electronic Frontier Foundation (EFF) montre comment ce procédé fonctionne : pour faire simple, plus votre navigateur paraît se comporter ou agir différemment des autres, plus il est facile d’en identifier l’empreinte unique.
Google a promis que la grande majorité des cohortes AFC comprendrait chacune des milliers d’utilisatrices, et qu’ainsi on ne pourra vous distinguer parmi le millier de personnes qui vous ressemblent. Mais rien que cela offre un avantage évident aux pisteurs. Si un pistage commence avec votre cohorte, il doit seulement identifier votre navigateur parmi le millier d’autres (au lieu de plusieurs centaines de millions). En termes de théorie de l’information, les cohortes contiendront quelques bits d’entropie jusqu’à 8, selon la preuve de faisabilité. Cette information est d’autant plus éloquente sachant qu’il est peu probable qu’elle soit corrélée avec d’autres informations exposées par le navigateur. Cela va rendre la tâche encore plus facile aux traqueurs de rassembler une empreinte unique pour les utilisateurs de l’AFC.
Google a admis que c’est un défi et s’est engagé à le résoudre dans le cadre d’un plan plus large, le « Budget vie privée » qui doit régler le problème du pistage par l’empreinte numérique sur le long terme. Un but admirable en soi, et une proposition qui va dans le bon sens ! Mais selon la Foire Aux Questions, le plan est « une première proposition, et n’a pas encore d’implémentation dans un navigateur ». En attendant, Google a commencé à tester l’AFC dès ce mois de mars.
Le pistage par l’empreinte numérique est évidemment difficile à arrêter. Des navigateurs comme Safari et Tor se sont engagés dans une longue bataille d’usure contre les pisteurs, sacrifiant une grande partie de leurs fonctionnalités afin de réduire la surface des attaques par traçage. La limitation du pistage implique généralement des coupes ou des restrictions sur certaines sources d’entropie non nécessaires. Il ne faut pas que Google crée de nouveaux risques d’être tracé tant que les problèmes liés aux risques existants subsistent.
L’exposition croisée
Un second problème est moins facile à expliquer : la technologie va partager de nouvelles données personnelles avec des pisteurs qui peuvent déjà identifier des utilisatrices. Pour que l’AFC soit utile aux publicitaires, une cohorte devra nécessairement dévoiler des informations comportementales.
La page Github du projet aborde ce sujet de manière très directe :
Cette API démocratise les accès à certaines informations sur l’historique de navigation général des personnes (et, de fait, leurs intérêts principaux) à tous les sites qui le demandent… Les sites qui connaissent les Données à Caractère Personnel (c’est-à-dire lorsqu’une personne s’authentifie avec son adresse courriel) peuvent enregistrer et exposer leur cohorte. Cela implique que les informations sur les intérêts individuels peuvent éventuellement être rendues publiques.
Comme décrit précédemment, les cohortes AFC ne devraient pas fonctionner en tant qu’identifiant intrinsèque. Cependant, toute entreprise capable d’identifier un utilisateur d’une manière ou d’une autre – par exemple en offrant les services « identifiez-vous via Google » à différents sites internet – seront à même de relier les informations qu’elle apprend de l’AFC avec le profil de l’utilisateur.
Deux catégories d’informations peuvent alors être exposées :
1. Des informations précises sur l’historique de navigation. Les pisteurs pourraient mettre en place une rétro-ingénierie sur l’algorithme d’assignation des cohortes pour savoir si une utilisatrice qui appartient à une cohorte spécifique a probablement ou certainement visité des sites spécifiques.
2. Des informations générales relatives à la démographie ou aux centres d’intérêts. Par exemple, une cohorte particulière pourrait sur-représenter des personnes jeunes, de sexe féminin, ou noires ; une autre cohorte des personnes d’âge moyen votant Républicain ; une troisième des jeunes LGBTQ+, etc.
Cela veut dire que chaque site que vous visitez se fera une bonne idée de quel type de personne vous êtes dès le premier contact avec ledit site, sans avoir à se donner la peine de vous suivre sur le Net. De plus, comme votre cohorte sera mise à jour au cours du temps, les sites sur lesquels vous êtes identifié⋅e⋅s pourront aussi suivre l’évolution des changements de votre navigation. Souvenez-vous, une cohorte AFC n’est ni plus ni moins qu’un résumé de votre activité récente de navigation.
Vous devriez pourtant avoir le droit de présenter différents aspects de votre identité dans différents contextes. Si vous visitez un site pour des informations médicales, vous pourriez lui faire confiance en ce qui concerne les informations sur votre santé, mais il n’y a pas de raison qu’il ait besoin de connaître votre orientation politique. De même, si vous visitez un site de vente au détail, ce dernier n’a pas besoin de savoir si vous vous êtes renseigné⋅e récemment sur un traitement pour la dépression. L’AFC érode la séparation des contextes et, au contraire, présente le même résumé comportemental à tous ceux avec qui vous interagissez.
Au-delà de la vie privée
L’AFC est conçu pour éviter une menace spécifique : le profilage individuel qui est permis aujourd’hui par le croisement des identifiants contextuels. Le but de l’AFC et des autres propositions est d’éviter de laisser aux pisteurs l’accès à des informations qu’ils peuvent lier à des gens en particulier. Alors que, comme nous l’avons montré, cette technologie pourrait aider les pisteurs dans de nombreux contextes. Mais même si Google est capable de retravailler sur ses conceptions et de prévenir certains risques, les maux de la publicité ciblée ne se limitent pas aux violations de la vie privée. L’objectif même de l’AFC est en contradiction avec d’autres libertés individuelles.
Pouvoir cibler c’est pouvoir discriminer. Par définition, les publicités ciblées autorisent les annonceurs à atteindre certains types de personnes et à en exclure d’autres. Un système de ciblage peut être utilisé pour décider qui pourra consulter une annonce d’emploi ou une offre pour un prêt immobilier aussi facilement qu’il le fait pour promouvoir des chaussures.
Au fur et à mesure des années, les rouages de la publicité ciblée ont souvent été utilisés pour l’exploitation, la discrimination et pour nuire. La capacité de cibler des personnes en fonction de l’ethnie, la religion, le genre, l’âge ou la compétence permet des publicités discriminatoires pour l’emploi, le logement ou le crédit. Le ciblage qui repose sur l’historique du crédit – ou des caractéristiques systématiquement associées – permet de la publicité prédatrice pour des prêts à haut taux d’intérêt. Le ciblage basé sur la démographie, la localisation et l’affiliation politique aide les fournisseurs de désinformation politique et la suppression des votants. Tous les types de ciblage comportementaux augmentent les risques d’abus de confiance.
Au lieu de réinventer la roue du pistage, nous devrions imaginer un monde sans les nombreux problèmes posés par les publicités ciblées.
Google, Facebook et beaucoup d’autres plateformes sont en train de restreindre certains usages sur de leur système de ciblage. Par exemple, Google propose de limiter la capacité des annonceurs de cibler les utilisatrices selon des « catégories de centres d’intérêt à caractère sensible ». Cependant, régulièrement ces tentatives tournent court, les grands acteurs pouvant facilement trouver des compromis et contourner les « plateformes à usage restreint » grâce à certaines manières de cibler ou certains types de publicité.
Même un imaginant un contrôle total sur quelles informations peuvent être utilisées pour cibler quelles personnes, les plateformes demeurent trop souvent incapables d’empêcher les usages abusifs de leur technologie. Or l’AFC utilisera un algorithme non supervisé pour créer ses propres cohortes. Autrement dit, personne n’aura un contrôle direct sur la façon dont les gens seront regroupés.
Idéalement (selon les annonceurs), les cohortes permettront de créer des regroupements qui pourront avoir des comportements et des intérêts communs. Mais le comportement en ligne est déterminé par toutes sortes de critères sensibles : démographiques comme le genre, le groupe ethnique, l’âge ou le revenu ; selon les traits de personnalités du « Big 5 »; et même la santé mentale. Ceci laisse à penser que l’AFC regroupera aussi des utilisateurs parmi n’importe quel de ces axes.
L’AFC pourra aussi directement rediriger l’utilisatrice et sa cohorte vers des sites internet qui traitent l’abus de substances prohibées, de difficultés financières ou encore d’assistance aux victimes d’un traumatisme.
Google a proposé de superviser les résultats du système pour analyser toute corrélation avec ces catégories sensibles. Si l’on découvre qu’une cohorte spécifique est étroitement liée à un groupe spécifique protégé, le serveur d’administration pourra choisir de nouveaux paramètres pour l’algorithme et demander aux navigateurs des utilisateurs concernés de se constituer en un autre groupe.
Cette solution semble à la fois orwellienne et digne de Sisyphe. Pour pouvoir analyser comment les groupes AFC seront associés à des catégories sensibles, Google devra mener des enquêtes gigantesques en utilisant des données sur les utilisatrices : genre, race, religion, âge, état de santé, situation financière. Chaque fois que Google trouvera qu’une cohorte est associée trop fortement à l’un de ces facteurs, il faudra reconfigurer l’ensemble de l’algorithme et essayer à nouveau, en espérant qu’aucune autre « catégorie sensible » ne sera impliquée dans la nouvelle version. Il s’agit d’une variante bien plus compliquée d’un problème que Google s’efforce déjà de tenter de résoudre, avec de fréquents échecs.
Dans un monde numérique doté de l’AFC, il pourrait être plus difficile de cibler directement les utilisatrices en fonction de leur âge, genre ou revenu. Mais ce ne serait pas impossible. Certains pisteurs qui ont accès à des informations secondaires sur les utilisateurs seront capables de déduire ce que signifient les groupes AFC, c’est-à-dire quelles catégories de personnes appartiennent à une cohorte, à force d’observations et d’expérimentations. Ceux qui seront déterminés à le faire auront la possibilité de la discrimination. Pire, les plateformes auront encore plus de mal qu’aujourd’hui à contrôler ces pratiques. Les publicitaires animés de mauvaises intentions pourront être dans un déni crédible puisque, après tout, ils ne cibleront pas directement des catégories protégées, ils viseront seulement les individus en fonction de leur comportement. Et l’ensemble du système sera encore plus opaque pour les utilisatrices et les régulateurs.
Avec Google les instruments changent, mais c’est toujours la même musique…
Google, ne faites pas ça, s’il vous plaît
Nous nous sommes déjà prononcés sur l’AFC et son lot de propositions initiales lorsque tout cela a été présenté pour la première fois, en décrivant l’AFC comme une technologie « contraire à la vie privée ». Nous avons espéré que les processus de vérification des standards mettraient l’accent sur les défauts de base de l’AFC et inciteraient Google à renoncer à son projet. Bien entendu, plusieurs problèmes soulevés sur leur GitHub officiel exposaient exactement les mêmespréoccupations que les nôtres. Et pourtant, Google a poursuivi le développement de son système, sans pratiquement rien changer de fondamental. Ils ont commencé à déployer leur discours sur l’AFC auprès des publicitaires, en vantant le remplacement du ciblage basé sur les cookies par l’AFC « avec une efficacité de 95 % ». Et à partir de la version 89 de Chrome, depuis le 2 mars, la technologie est déployée pour un galop d’essai. Une petite fraction d’utilisateurs de Chrome – ce qui fait tout de même plusieurs millions – a été assignée aux tests de cette nouvelle technologie.
Ne vous y trompez pas, si Google poursuit encore son projet d’implémenter l’AFC dans Chrome, il donnera probablement à chacun les « options » nécessaires. Le système laissera probablement le choix par défaut aux publicitaires qui en tireront bénéfice, mais sera imposé par défaut aux utilisateurs qui en seront affectés. Google se glorifiera certainement de ce pas en avant vers « la transparence et le contrôle par l’utilisateur », en sachant pertinemment que l’énorme majorité de ceux-ci ne comprendront pas comment fonctionne l’AFC et que très peu d’entre eux choisiront de désactiver cette fonctionnalité. L’entreprise se félicitera elle-même d’avoir initié une nouvelle ère de confidentialité sur le Web, débarrassée des vilains cookies tiers, cette même technologie que Google a contribué à développer bien au-delà de sa date limite, engrangeant des milliards de dollars au passage.
Ce n’est pas une fatalité. Les parties les plus importantes du bac-à-sable de la confidentialité comme l’abandon des identificateurs tiers ou la lutte contre le pistage des empreintes numériques vont réellement améliorer le Web. Google peut choisir de démanteler le vieil échafaudage de surveillance sans le remplacer par une nouveauté nuisible.
Nous rejetons vigoureusement le devenir de l’AFC. Ce n’est pas le monde que nous voulons, ni celui que méritent les utilisatrices. Google a besoin de tirer des leçons pertinentes de l’époque du pistage par des tiers et doit concevoir son navigateur pour l’activité de ses utilisateurs et utilisatrices, pas pour les publicitaires.
Remarque : nous avons contacté Google pour vérifier certains éléments exposés dans ce billet ainsi que pour demander davantage d’informations sur le test initial en cours. Nous n’avons reçu aucune réponse à ce jour.
Libres bulles pour que décollent les contributions
Comme beaucoup d’associations libristes, nous recevons fréquemment ce genre de demandes « je vous suis depuis longtemps et je voudrais contribuer un peu au Libre, comment commencer ? »
Pour y répondre, ce qui n’est pas toujours facile, une dynamique équipe s’est constituée avec le soutien de Framasoft et a fondé le projet Contribulle qui propose déjà d’aiguiller chacun⋅e vers des contributions à sa mesure. Pour comprendre comment ça marche et quel intérêt vous avez à les rejoindre, nous leur avons posé des questions…
« Bulles de savon » par Daniel_Hache, licence CC BY-ND 2.0
Bonjour la team Contribulle ! On vous a rencontré⋅e⋅s sur l’archipel de Contributopia, mais pouvez-vous vous présenter, nous dire de quels horizons vous venez ?
– Hello, je suis llaq (ou lelibreauquotidien), je suis dans le logiciel libre depuis quelques années depuis qu’un ami m’a offert un PC sous Linux (bon, quand j’étais sous Windows, j’utilisais déjà des logiciels libres mais c’était pas un argument rédhibitoire).
— Yo ! Oui on se baladait dans le coin, l’horizon qui se présentait à nous paraissait bien prometteur ! Je suis Mélanie mais vous pouvez m’appeler méli, j’ai bientôt 25 ans et je viens du monde du design UX et UI. En explorant le numérique, j’ai pas mal gravité autour du Libre et mon mémoire de master de l’année dernière m’a bien fait plonger dans ce sujet super passionnant ! Fun fact : je me demandais comment rendre le logiciel libre plus ouvert (!), pour mieux accueillir une diversité de contributions et il faut dire que votre campagne Contributopia m’a pas mal guidée héhé. Le projet Contribulle a en partie émergé à cette période-là et je suis contente de le poursuivre, toujours en tant que designeuse UX/UI !
– Hello ! Je suis Maiwann, membre de Framasoft… une petite asso que vous connaissez peut-être ? Et je suis designer.
Laissez-moi deviner : Contribulle, c’est un dispositif pour enfermer les contributeurs et contributrices d’un projet dans une bulle et alors quand ça monte ça éclate et le projet explose ? Non, c’est pas ça ?
llaq : C’est presque ça. Contribulle est une plateforme qui permet de mettre en relation des projets aux besoins assez spécifiques avec des contributeur·rice·s intéressé·e·s, qu’iels soient dans le domaine technique ou non. Un des buts du site est d’ailleurs de permettre aux non-techniques de contribuer à des projets libres et surtout de démontrer que la contribution, c’est pas seulement pour les codeur·se·s.
méli : Haha, ce nom a été voté par jugement majoritaire ! Perso, j’imagine une bulle qui est amenée à grossir grâce aux contributions des personnes et qui sera tellement géante qu’il sera impossible de la rater. Et peut-être qu’elle pourrait attirer d’autres contributions !
Maiwann : … Et moi j’imagine plein de petites bulles comme un nuage de bulles de savon quand on souffle dans le petit cercle ! Et elles s’envolent… loin… loiiiiiin ! Jusqu’à ce qu’on en fasse une nouvelle fournée 🙂
« Bubbles » by bogenfreund, licence CC BY-SA 2.0
Ah mais c’est tout neuf cette plateforme ? Comment est venue l’idée de proposer ça ? Et d’ailleurs ça paraît tellement utile qu’on se demande pourquoi ça n’existait pas avant.
méli : Pendant mon mémoire, j’avais retenu qu’il était compliqué de s’y retrouver parmi tous les projets libres créés et qu’il était encore plus difficile de savoir où et comment contribuer au Libre, surtout en tant que non-développeur·se. J’avais donc rapidement imaginé un site qui recenserait des projets libres à la recherche de compétences et qui permettrait d’attirer des contributeur·rice·s de tous horizons. Je ne savais pas s’il existait déjà une plateforme de ce type dans laquelle je pourrais m’inscrire.
Quelques déambulations plus tard, je suis tombée sur la restitution du fameux événement coorganisé par Framasoft et la Quadrature du Net « Fabulous Contribution Camp » de novembre 2017. J’y ai trouvé une idée similaire au site que j’imaginais et je contacte donc Maiwann pour avoir des nouvelles sur l’évolution de ce projet. On s’appelle en janvier 2020 (merci BigBlueButton) et il s’avère que rien n’avait été mis en place et qu’il manquait un tremplin pour lancer le projet. C’est donc à partir de là que ça a décollé. Si la suite intéresse : J’ai ensuite réalisé une maquette de la plateforme, qui avait pour nom de code « Meetic du Libre ». J’ai pu la présenter au cours d’un Confinatelier en juin 2020 avec Maiwann. On avait pour objectifs de valider la pertinence du projet et ensuite de mobiliser des personnes qui souhaiteraient bien y contribuer. Les retours nous ont rassuré⋅e⋅s et on a pu monter un groupe de travail rapidement.
Cependant, avec l’été qui se profilait, le site était juste débutant jusqu’à ce que Maiwann nous relance fin octobre. Depuis novembre, l’équipe est un peu plus réduite : on est 2 designeuses, 1 développeur front et 1 développeur back et on s’organise des rendez-vous hebdomadaires pour avancer. Des personnes nous ont aussi aidé⋅e⋅s ponctuellement, que ce soit aux niveaux code, graphisme et design, on leur en est super reconnaissant·e·s ! Grâce aux efforts et la bonne humeur de tou·te·s les contributeur·rices, on a pu mettre en ligne Contribulle en février 2021, une grande fierté !
Est-ce qu’il faut s’inscrire avec ses coordonnées et tout ?
llaq : Pour les personnes qui créent une demande de contribution, il n’est pas nécessaire de créer de compte. Il faut simplement renseigner une adresse email valide et un pseudo pour que les contributeur·rice·s qui le souhaitent puissent contacter la personne qui a créé l’annonce.
Maiwann : On a fait en sorte d’être le plus minimalistes possibles dans le nombre d’infos demandées. Du coup, exit la création de compte pour ne pas se farcir un énième identifiant-mot-de-passe ! En revanche, on demande un moyen de contact aux personnes qui recherchent des contributeurices, pour être sûres qu’elles vont pouvoir s’adresser à un humain !
Combien ça coûte ?
llaq : Rien. Plus sérieusement, dans le projet, nous sommes tou·te·s bénévoles et les ressources techniques servant à l’hébergement de contribulle.org nous ont gracieusement été offertes par notre partenaire Framasoft, donc aucun frais pour nous, aucune raison de faire payer la plateforme donc 🙂
méli : Dans la perspective de mettre en avant des projets qui participent à l’émancipation individuelle et collective des individus et qui sont bien évidemment respectueux de nos libertés, on ne souhaite pas faire payer pour poster une annonce. On veut inviter le plus grand nombre à mettre la main à la pâte donc on préfère éviter de poser des contraintes financières dès le départ !
Maiwann : Ça a coûté du temps et de l’énergie à des gens compétents de se retrouver, de décider d’une direction pour le projet, de faire des choix, de les maquetter / coder, + les frais d’hébergement. Et ça va coûter de l’énergie dans le futur pour faire vivre Contribulle, donc si vous en parlez le plus possible autour de vous, ça nous aidera beaucoup et ça contribuera à faire vivre Contribulle !
Si j’ai un projet génial mais que je ne sais rien faire du tout, je peux juste vous donner mon idée géniale et vous allez vous en charger et tout faire pour moi ?
méli : Mmmh Contribulle n’est pas un service de travail gratuit… mais c’est chouette si tu as une bonne idée de projet, si tu sens qu’elle a du potentiel et qu’elle est valide…
À quel(s) besoin(s) répond-elle ?
Quelle est sa valeur ajoutée pour les futur·e·s utilisateur·rices ?
…
…tu peux lister précisément les compétences requises. Contribulle a vocation de faciliter la compréhension de contributions auprès des personnes qui veulent aider. C’est pour ça qu’il nous semble nécessaire dans le formulaire de demande de contribution de bien présenter le projet et de donner plus d’indications sur la contribution souhaitée. Un projet se doit d’être sérieux et conscient du temps et de l’effort qu’un·e contributeur·rice y consacrera.
logo du projet Contribulle
Un point qu’il est important de mentionner est l’accueil des contributeur·rice·s au sein d’un projet. Il ne faut pas prendre l’aide d’une personne externe comme acquise et surtout la surexploiter parce que (friendly reminder) : on a nos vies et nos priorités à gérer.
Un projet doit mettre en place un dispositif pour faciliter l’accès à la contribution, que ce soit une page dédiée, une conversation épistolaire, le format est libre et à adapter selon les parties prenantes !
Attention cependant aux renvois directs vers les forges logicielles comme GitHub ou GitLab qui ne sont pas si accessibles pour les non-techniques. Peut-être qu’un tutorat personnalisé peut s’envisager ?
Bref, soyons plus à l’écoute des contributeur·rice·s ! Et pour les contributeur·rice·s : écoutez-vous et n’hésitez pas à dire quand un truc vous gêne, la communication fait tout.
Comment je vais savoir que d’autres sont intéressée⋅es par mon projet ou que ma contribution intéresse d’autres ?
llaq : On n’a pas de messagerie intégrée, tout se fait par le mail que vous avez indiqué dans votre annonce. Maiwann : comme ça, pas besoin de revenir sur la plateforme, ouf ! Vous postez et c’est réglé !
Attention c’est le moment trollifère : les projets sur lesquels on peut contribuer c’est du libre ou open source ou bien osef ?
llaq : Nous comptons justement implémenter un bandeau qui s’affichera si le projet est libre ou pas (c’est-à-dire bénéficiant d’une licence libre) ! Mais sa place sur Contribulle va dépendre de l’équipe de modération composée de 4 personnes pour l’instant.
méli : La valeur (politique) des projets publiés sera prise en compte. Parmi les questions à se poser : pour qui est le projet ? Participe-t-il au bien collectif ? Comment permettrait-il à tou·te·s les utilisateur·rices de disposer de leurs appareils ainsi que de leurs données personnelles ?
Maiwann : On voudrait que tous les projets soient sous licence libre, mais on est aussi conscient·es que tout le monde n’est pas forcément au clair sur l’intérêt que ça peut avoir, l’importance… donc on se dit qu’on poussera les personnes à s’y intéresser à l’aide du bandeau, mais sans les disqualifier forcément d’entrée (et on verra ça au cas par cas !)
C’est évalué comment et par qui, le « sérieux » ou la pertinence des projets et contributions ? Chacun⋅e s’autonomise et hop ?
llaq : Nous avons décidé de faire de la modération à posteriori. Ton annonce est directement publiée et visible par tout le monde mais si l’équipe de modération estime que le projet n’a pas sa place sur Contribulle, il sera supprimé de la plateforme. Maiwann : et si c’est trop relou, on passera à de la modération a priori ! Et pour faire des choix, ça sera sans doute au doigt mouillé, au « comment chacune le sent » et puis on verra sur le tas comment se structure l’équipe de modération ! Pour l’instant, RAS 🙂
« bubbles » par Mycatkins, licence CC BY 2.0
Et donc si je veux contribuller au projet, je peux faire quoi ?
méli : Pour l’instant, nous faire des retours sur vos usages de Contribulle et la promouvoir autour de vous seraient de belles contributions ! On souhaite l’améliorer au mieux selon les besoins ressentis de chacun·e.
La question de rétribution n’a pas encore été abordée mais selon l’évolution de la plateforme et des ressources mobilisées, des formes sont à réfléchir je pense. Qu’il s’agisse de don financier, d’un retour d’utilisateur·rice, ou autre.
Maiwann : Je pense que ce qui va être primordial ça va être de faire vivre Contribulle. Quelqu’un dit qu’il voudrait aider le Libre ? glissez lui un mot sur Contribulle. Quelqu’un vient à un contrib’atelier ? N’oubliez pas de parler de Contribulle. Comme ça le projet vivra grâce aux visites des contributeurices !
Ah mais il y a déjà un paquet de demandes, ça fait un peu peur, je vois bien que je ne vais servir à rien pour tous ces trucs de techies ! Au secours ! (Pour l’instant dans l’équipe c’est orienté web développement non) ?
méli : c’est 50/50 moitié dev et moitié design/conception. Oui, on a dépassé les 20 annonces depuis sa mise en ligne il y a un mois, c’est trop bien ! Et on cherche vraiment à mettre en avant des contributions non-techniques parce que tu es super utile justement ! Prochainement tu pourras filtrer les annonces selon tes propres savoir-faire, en espérant qu’il y aura des demandes à ce niveau-là. En attendant, on te propose des contributions faciles. Tu seras renvoyé·e vers des sites sélectionnés par nos soins et auxquelles tu peux directement contribuer. Bonne contribution !
Maiwann : C’est tout à fait ça, grâce aux filtres tu vas pouvoir plus facilement mettre de côté les choses qui font peur !
Et si je regarde, il y a déjà quelques projets qui sont chouettes et que tu peux aider sans compétences techniques, par exemple :
La cartographie libre creuse son sillon depuis de nombreuses années déjà. À l’instar de Wikipédia, l’autre grand projet collaboratif du Web dont le succès ne se dément pas, le projet OpenStreetMap (OSM), lancé quelques années après l’encyclopédie libre, est à l’origine de nombreuses applications.
À noter : cet article bénéficie désormais d’une version audio.
Merci à Sualtam, auteur de lectureaudio.fr pour cette contribution active.
L’article que vous allez lire en présente plusieurs avec une grande clarté et insiste en particulier sur la possibilité de les utiliser hors ligne. Parmi celles-ci, l’application Geovélo fait figure de fleuron français. Largement soutenue et promue par les collectivités locales, elle bénéficie d’une relativement importante couverture médiatique.
On peut toutefois s’interroger sur la manière dont ces collectivités appréhendent réellement le modèle des données libres et ouvertes sur lequel repose ce type d’applications. Car pour qu’elles rendent les services qu’on attend d’elles, il faut que les données cartographiques soient de bonne qualité et mises à jour régulièrement. C’est ce que rappelle Julien de Labaca dans « Le vélo a besoin de carto(s) ». Les collectivités locales françaises sont-elles contributrices au projet OSM ? Après tout, en tant que gestionnaires de voirie, leurs services sont les mieux placés pour collaborer efficacement à ce bien commun qu’est une cartographie libre.
Republication de l’article original publié sur le blog de Damien Une famille à vélo, consacré au cyclotourisme en famille et riche en récits de voyages illustrés, en conseils et fiches pratiques…
Itinéraires 2.0
C’est bien beau de pédaler, mais il est aussi utile de savoir où on va. Tous les ordiphones ont une application de cartographie pré-installée, plus ou moins respectueuse de la vie privée, mais qui en général ne fonctionne pas hors-ligne (ou partiellement).
Je ne m’attarderai pas sur ces applications natives.
OpenStreetMap
Nous allons parler d’OpenStreetMap et de son écosystème. Pour ceux qui n’en ont jamais entendu parler voici ce qu’en dit Wikipédia :
OpenStreetMap (OSM) est un projet collaboratif de cartographie en ligne qui vise à constituer une base de données géographiques libre du monde (permettant par exemple de créer des cartes sous licence libre), en utilisant le système GPS et d’autres données libres.
Vous pouvez bien sûr consulter directement la carte OSM avec ses différents fonds de carte (dont certains sont dédiés au vélo). Les données étant sous licence libre, de nombreuses autres applications utilisent les données OSM. C’est très souvent le cas des applications de randonnée.
Des itinéraires vélo à découvrir dans les « couches » de carte OSM
OsmAnd
L’application OsmAnd repose sur les cartes OpenStreetMap. Elle est disponible sur Android et IOS. Le site est en anglais mais – rassurez vous – l ‘application est disponible en français. Voici quelques-unes de ses fonctionnalités :
calcul d’itinéraire et guidage avec différents profils (voiture, vélo, randonnée) ;
recherche de points d’intérêts (exemple l’épicerie la plus proche, avec les horaires d’ouverture) ;
enregistrement d’itinéraires ;
import d’itinéraires ;
ajouts de points favoris.
Copie d’écran OsmAnd
L’application profite de toute la richesse d’OpenStreetMap : cartes détaillées avec différents fonds de carte (routes, itinéraires cyclables, itinéraires de randonnée, courbes de niveau) et les points d’intérêts (commerces, gares, logements, hôpitaux…) L’application utilise aussi la base des points d’intérêt de Wikipédia.
Copie d’écran OsmAnd
Il s’agit d’une application open source qui ne vous obligera pas à créer un compte. Point important, elle fonctionne hors-connexion une fois qu’on a téléchargé les cartes (possibilité limitée à 7 cartes dans la version gratuite). Utile quand vous ne voulez pas exploser votre forfait à l’étranger, ou même autour de chez vous. C’est utile aussi pour économiser la batterie.
N’hésitez pas à prendre le temps de jouer avec les menus. Ils sont assez riches, on s’y perd un peu au début mais il y a tout un tas d’options intéressantes. On trouve des tutoriels assez bien faits sur Internet.
Waymarked Trails
Waymarked Trails présente les itinéraires de randonnée depuis l’échelon local jusqu’au niveau international, avec des cartes et des informations de OpenStreetMap ainsi qu’un profil d’altitude. Le site permet d’afficher les chemins de randonnée à pied, à vélo, à vtt, en rollers, à cheval et à ski.
Zoomer et cliquer sur un itinéraire pour voir le détail. Une fois l’itinéraire sélectionné, il est possible de l’exporter aux formats GPX et KML. Vous n’avez plus qu’à importer l’itinéraire dans votre application GPS préférée.
Les itinéraires touristiques classiques ne sont pas encore tous référencés sur OSM. Dans ce cas vous les trouvez généralement sur les sites internet dédiées aux itinéraires, ou encore sur les sites des offices du tourisme. Exemple l’Alsace à vélo.
Bien sûr, il existe des sites de partage avec des centaines d’itinéraires. Si ces bases sont très riches, elles contiennent essentiellement des tracés fournis par des utilisateurs individuels, qui ne correspondent pas forcément aux itinéraires officiels. C’est intéressant pour des sorties sportives, mais ça ne vous garantit pas de passer par des voies sécurisées ou à faible trafic. Mieux vaut étudier les itinéraires avant de les suivre la tête dans le guidon.
Open Camping Map
Sur le même principe que Waymarked Trails pour les itinéraires, Open Camping Map est une extraction de la base OSM qui présente les campings. Ceux-ci étant référencés sur OSM, c’est plutôt une application qui s’utilise pour avoir une vue dédiée aux campings lorsque vous préparez vos itinéraires.
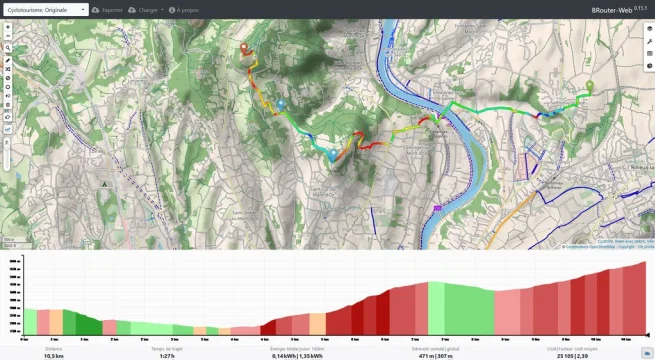
BRouter
BRouter est un bon calculateur d’itinéraire à vélo open source, avec de nombreux profils (route, cyclotourisme, …). Il fonctionne soit en ligne avec possibilité d’exporter l’itinéraire créé, soit en tant qu’application Android qui peut s’utiliser avec OsmAnd, Locus-Maps ou OruxMaps.
Un itinéraire sur BRouter avec son profil
Exemple d’utilisation
Maintenant que nous avons tous les éléments, nous pouvons nous lancer dans la préparation d’un voyage à vélo.
Téléchargement de la carte OSM de la région dans l’application OsmAnd ;
Téléchargement de l’itinéraire vélo principal depuis Waymarked Trails ou autre source ;
Création manuelle de nouveaux itinéraires sur B.Router (détours et autres variantes) ;
Ajout de marques sur la carte (campings, châteaux, musées, piscines…) ;
Import des différents fichiers GPX dans l’application OSM. L’application permet maintenant d’afficher tous les itinéraires et points d’intérêts, et de naviguer hors-ligne.
GéoVélo est un calculateur d’itinéraire (site web et application) pour les villes françaises. L’application fonctionne hors-ligne une fois qu’on a téléchargé la carte de la ville. Le guidage est bien pensé avec un zoom automatique à chaque changement de direction. Petit bémol, on est obligé de créer un compte pour pouvoir mémoriser des lieux et des trajets.
[EDIT par Framasoft] Plusieurs commentaires ci-dessous mettent en garde contre cette application qui ouvre des connexions avec google-analytics.com, doubleclick.net, facebook.net et cdn-apple.com… entre autres]
Participer avec StreetComplete
À la différence des autres cartes, OpenStreetMap est entièrement créé par des gens comme vous, et chacun est libre de le modifier, le mettre à jour, le télécharger et l’utiliser. Vous pouvez donc participer vous aussi à la construction de cet outil communautaire.
Il n’est pas nécessaire d’avoir une licence en géographie ni d’être expert en informatique. Le moyen le plus simple pour commencer est sans doute l’application StreetComplete qui vous permet de contribuer au projet OpenStreetMap en effectuant des « quêtes ». L’application vous propose d’ajouter des informations manquantes sur des zones près de votre position. L’application est destinée aux utilisateurs qui ne connaissent rien aux systèmes de marquage OSM mais souhaitent tout de même contribuer à OpenStreetMap en explorant leur quartier ou d’autres lieux. Vous pouvez le présenter de façon ludique aux enfants, comme une chasse au trésor. Ceci leur apprend à se repérer sur une carte, à s’orienter, à trouver le nom d’une rue, les horaires d’un magasin.
You are invited to contribute to the future « Contributing to Free-Libre Open Source Software » MOOC by Télécom Paris and Framasoft
Interested in contributing to the contents production of a MOOC about FLOSS contribution? You already have a contribution experience and think it can be useful to new contributors? Join us!
Leading Internet users into the world of contribution
Last September we were so delighted to learn that Marc Jeanmougin, a research engineer at Télécom Paris, wanted Framasoft to be associated with his online course projet on FLOSS contributions that had just been funded by the Institut Mines-Télécom.
We have been dreaming about it: a MOOC to learn how to contribute to free-libre software
Developing digital tools that facilitate individuals’ contributions is one of the lines of our Contributopia campaign. On this subject we already have set up Contribateliers (and their online version Confinateliers): workshops to discover how each of us can contribute to free-libre software. Implemented in 2018 in Lyon, those interventions now take place in cities (Lyon, Paris, Toulouse, Grenoble and Nantes) allowing people to contribute to the free-libre software and free culture in a user-friendly way.
This is also the case with the Contribulle project we are hosting: a platform where projects with the same free-libre software values are connected with those without enough skills and contributors who could give them a hand. This nice initiative is slowly taking shape and we think it will be a great success in the coming months.
Finally, the aim with this Contributing to FLOSS MOOC is to allow developers to get both a theoretical (what is it about?) and practical introduction (how to contact somebody? and how to contribute?) to the world of FLOSS contribution.
All these initiatives allow users of free-libre services to learn how to contribute and to stop using a software only as if it were a finished product.
Contributing to develop the Contributing to FLOSS MOOC
After a first day in October, talking about pedagogical sequencing in a small committee, the prefiguration team decided that given the MOOC subject, it would not be totally far-fetched to allow people who want to co-produce contents with us to do so.
We also have created a dedicated Matrix chatroom in order to have a daily and more informal exchange with you. Do not hesitate to join us there to learn more about this project.
We invite you to exchange in video conference on this project on February, 10th at 6:30pm. At the same time we will present you the general organization of the MOOC and the choices we have made both educationally (what angle on FLOSS we will try to take) and technically. We will also discuss how we envisage contributions to contents production.
If after this first exchange you want to help us with contents preparation, you can participate in 6 other online brainstorming sessions, each one dedicated to the contents of one week of the MOOC. They will take place on Mondays and Thursdays between 6:30pm and 8pm from February 11th to March 1st (details of access and contents will be published on the gitlab issues with each session).
GitLab issues with details of access and contents of the 6 meetings we offer.
We hope we will see many of you at those different events. But as we know it’s not always easy to be available on a set time slot, we offer to collect your reactions, feedbacks or comments before each session on our repository. Do not hesitate to write down whatever comes to your mind!
Télécom Paris et Framasoft vous invitent à contribuer au futur MOOC « Contributing to Free-Libre and Open Source Software »
Participer à la production des contenus d’un MOOC dont le sujet est la contribution aux logiciels libres, ça vous tente ? Vous avez déjà contribué à des logiciels libres et vous pensez que votre expérience peut aider des apprenti·es contributeur·ices ? Rejoignez-nous !
Continuer à accompagner les internautes dans l’univers de la contribution
Lorsqu’en septembre dernier, Marc Jeanmougin, ingénieur de recherche à Télécom Paris, nous contactait pour nous informer que son projet de cours en ligne sur la contribution au logiciel libre venait d’obtenir un financement de l’Institut Mines-Télécom et qu’il souhaitait que Framasoft soit associé à ce projet, on a été super emballé·es !
Un MOOC (cours en ligne massivement ouvert) pour apprendre à contribuer au logiciel libre, on en rêvait !
C’est d’ailleurs l’un des axes de notre campagne Contributopia que de concrétiser des outils numériques qui facilitent les contributions de chacun·e. Dans ce domaine, nous avons déjà initié les Contribateliers (et leur version en ligne, les Confinateliers), des ateliers pour découvrir comment chacun·e d’entre nous peut contribuer au logiciel libre. Lancé en 2018 à Lyon, ce dispositif existe désormais dans 5 villes (Lyon, Paris, Toulouse, Grenoble et Nantes) et permet à toutes et tous de contribuer aux logiciels libres et à la culture libre en toute convivialité.
C’est aussi ce que nous faisons en offrant un hébergement au projet Contribulle, une plateforme de mise en relation entre des projets partageant les valeurs du logiciel libre et des communs qui manquent de compétences, et des contributeur·rices qui pourraient leur donner un coup de main. Cette chouette initiative prend doucement forme et on ne doute pas qu’elle rencontrera un fort succès dans les mois à venir.
Enfin, avec ce MOOC Contributing to FLOSS, l’objectif est de permettre à des développeur·euses d’avoir une introduction théorique (de quoi parle-t-on ?) comme pratique (comment entrer en contact, comment contribuer ?) à l’univers de la contribution au libre.
Toutes ces initiatives sont l’occasion pour les utilisateur·ices de services libres d’apprendre à contribuer et d’arrêter de consommer simplement le logiciel comme s’il était un produit fini.
Contribuer à la réalisation du MOOC Contributing to FLOSS
Après une première journée en petit comité en octobre pour échanger sur le séquençage pédagogique, l’équipe de préfiguration s’est dit que vu le sujet du MOOC, ce ne serait pas totalement tiré par les cheveux que de permettre à celles et ceux qui le souhaitent de co-produire avec nous les contenus.
Nous avons aussi créé un salon Matrix dédié afin de pouvoir échanger de manière plus informelle avec vous au quotidien. N’hésitez pas à nous y rejoindre pour avoir davantage de précisions sur ce projet.
Nous vous invitons à un temps d’échanges autour du projet le mercredi 10 février à 18h30 en visioconférence. Ce sera l’occasion de vous présenter l’organisation générale du MOOC et les choix que nous avons effectués, tant au plan pédagogique (quel angle sur les FLOSS nous essaierons de prendre) qu’au plan technique. Nous échangerons aussi sur la façon dont nous envisageons les contributions à la production des contenus.
Si à la suite de ce premier temps d’échanges, vous êtes partant·es pour nous aider sur la préparation des contenus, on vous propose de participer à 6 autres sessions de brainstorming en ligne, chacune de ces sessions étant dédiée aux contenus d’une semaine du MOOC. Ces sessions se tiendront les lundis et jeudis entre 18h30 et 20h sur la période du 11 février au 1er mars (les détails d’accès et des contenus discutés seront publiés sur les tickets associés à chaque session).
Tickets sur lesquels vous trouverez détails d’accès et contenus des 6 rendez-vous que nous vous proposons.
On vous espère nombreu·ses lors de ces différents rendez-vous. Mais comme nous savons qu’il n’est pas toujours évident de se libérer sur un créneau fixe, nous proposons de recueillir en amont de chaque session vos réactions, notes ou commentaires. N’hésitez donc pas à aller y noter ce qui vous passe par la tête !
Mais comme la haute autorité n’a toujours pas atterri dans la poubelle de l’histoire à laquelle elle est pourtant destinée, et enfonce encore une fois le clou avec une nouvelle campagne de pub, notre dessinateur remet le couvert également…
Hadopi dans le formol
Cela fait déjà 11 ans que la Hadopi suce de la finance publique, avec un budget de plus 82 millions d’euros depuis sa création (pour 87 000 € d’amendes émises).
Récemment, la sangsue a publié une nouvelle campagne de communication tonitruante, #TesImpôts, qui reste dans la grande tradition de la haute autorité d’être toujours à côté de la plaque (ou en retard de 15 ans).
Voilà, Hadopi a 11 ans et comme le dit la chanson, le temps ne fait rien à l’affaire…
Car en matière de nostalgie, je me permets de vous rappeler cette première campagne de pub d’Hadopi, datant de 2011 et présentant Emma Leprince, une chanteuse de grosse soupe insipide « néo-électro » dans le futur…
… mais qui est, en 2011, une gamine qui se prend pour Shakira dans sa chambre.
Pour finir, notons que dans cette fameuse pub, Emma Leprince est présentée révélation française de l’année…
2022.
Et puisqu’Emma Leprince n’a pas l’air partie pour être révélation de l’année 2022, je propose qu’on dissolve la Hadopi qui a visiblement failli à sa mission divine.