Avec un ton acerbe contre les géants du numérique, Aral Balkan nourrit depuis plusieurs années une analyse lucide et sans concession du capitalisme de surveillance. Nous avons maintes fois publié des traductions de ses diatribes.
Ce qui fait la particularité de ce nouvel article, c’est qu’au-delà de l’adieu à Twitter, il retrace les étapes de son cheminement.
Sa trajectoire est mouvementée, depuis l’époque où il croyait (« quel idiot j’étais ») qu’il suffisait d’améliorer le système. Il revient donc également sur ses années de lutte contre les plateformes prédatrices et les startups .
Il explique quelle nouvelle voie constructive il a adoptée ces derniers temps, jusqu’à la conviction qu’il faut d’urgence « construire l’infrastructure technologique alternative qui sera possédée et contrôlée par des individus, pas par des entreprises ou des gouvernements ». Dans cette perspective, le Fediverse a un rôle important à jouer selon lui.
Sur le Fédiverse, ils ont un terme pour Twitter.
Ils l’appellent « le site de l’enfer ».
C’est très approprié.
Lorsque je m’y suis inscrit, il y a environ 15 ans, vers fin 2006, c’était un espace très différent. Un espace modeste, pas géré par des algorithmes, où on pouvait mener des discussions de groupe avec ses amis.
Ce que je ne savais pas à l’époque, c’est que Twitter, Inc. était une start-up financée avec du capital risque.
Même si j’avais su, ça n’aurait rien changé, vu que je n’avais aucune idée sur le financement ou les modèles commerciaux. Je pensais que tout le monde dans la tech essayait simplement de fabriquer les nouvelles choses du quotidien pour améliorer la vie des gens.
Même six ans après, en 2012, j’en étais encore à me concentrer sur l’amélioration de l’expérience des utilisateurs avec le système actuel :
« Les objets ont de la valeur non par ce qu’ils sont, mais par ce qu’ils nous permettent de faire. Et, en tant que personnes qui fabriquons des objets, nous avons une lourde responsabilité. La responsabilité de ne pas tenir pour acquis le temps limité dont chacun d’entre nous dispose en ce monde. La responsabilité de rendre ce temps aussi beau, aussi confortable, aussi indolore, aussi exaltant et aussi agréable que possible à travers les expériences que nous créons.
Parce que c’est tout ce qui compte.
Et il ne tient qu’à nous de le rendre meilleur. »
– C’est tout ce qui compte.
Quel idiot j’étais, pas vrai ?
Vous pouvez prendre autant de temps que nécessaire pour me montrer du doigt et ricaner.
Ok, c’est fait ? Continuons…
Privilège est simplement un autre mot pour dire qu’on s’en fiche
À cette époque, je tenais pour acquis que le système en général est globalement bon. Ou du moins je ne pensais pas qu’il était activement mauvais 1.
Bien sûr, j’étais dans les rues à Londres, avec des centaines de milliers de personnes manifestant contre la guerre imminente en Irak. Et bien sûr, j’avais conscience que nous vivions dans une société inégale, injuste, raciste, sexiste et classiste (j’ai étudié la théorie critique des médias pendant quatre ans, du coup j’avais du Chomsky qui me sortait de partout), mais je pensais, je ne sais comment, que la tech existait en dehors de cette sphère. Enfin, s’il m’arrivait de penser tout court.
Ce qui veut clairement dire que les choses n’allaient pas assez mal pour m’affecter personnellement à un point où je ressentais le besoin de me renseigner à ce sujet. Et ça, tu sais, c’est ce qu’on appelle privilège.
Il est vrai que ça me faisait bizarre quand l’une de ces start-ups faisait quelque chose qui n’était pas dans notre intérêt. Mais ils nous ont dit qu’ils avaient fait une erreur et se sont excusés alors nous les avons crus. Pendant un certain temps. Jusqu’à ce que ça devienne impossible.
Et, vous savez quoi, j’étais juste en train de faire des « trucs cools » qui « améliorent la vie des gens », d’abord en Flash puis pour l’IPhone et l’IPad…
Mais je vais trop vite.
Retournons au moment où j’étais complètement ignorant des modèles commerciaux et du capital risque. Hum, si ça se trouve, vous en êtes à ce point-là aujourd’hui. Il n’y a pas de honte à avoir. Alors écoutez bien, voici le problème avec le capital risque.
Ce qui se passe dans le Capital Risque reste dans le Capital Risque
Le capital risque est un jeu de roulette dont les enjeux sont importants, et la Silicon Valley en est le casino.
Un capital risqueur va investir, disons, 5 millions de dollars dans dix start-ups tout en sachant pertinemment que neuf d’entre elles vont échouer. Ce dont a besoin ce monsieur (c’est presque toujours un « monsieur »), c’est que celle qui reste soit une licorne qui vaudra des milliards. Et il (c’est presque toujours il) n’investit pas son propre argent non plus. Il investit l’argent des autres. Et ces personnes veulent récupérer 5 à 10 fois plus d’argent, parce que ce jeu de roulette est très risqué.
Alors, comment une start-up devient-elle une licorne ? Eh bien, il y a un modèle commercial testé sur le terrain qui est connu pour fonctionner : l’exploitation des personnes.
Voici comment ça fonctionne:
1. Rendez les gens accros
Offrez votre service gratuitement à vos « utilisateurs » et essayez de rendre dépendants à votre produit le plus de gens possible.
Pourquoi?
Parce qu’il vous faut croître de manière exponentielle pour obtenir l’effet de réseau, et vous avez besoin de l’effet de réseau pour enfermer les gens que vous avez attirés au début.
Bon dieu, des gens très importants ont même écrit des guides pratiques très vendus sur cette étape, comme Hooked : comment créer un produit ou un service qui ancre des habitudes.
Voilà comment la Silicon Valley pense à vous.
2. Exploitez-les
Collectez autant de données personnelles que possible sur les gens.
Pistez-les sur votre application, sur toute la toile et même dans l’espace physique, pour créer des profils détaillés de leurs comportements. Utilisez cet aperçu intime de leurs vies pour essayer de les comprendre, de les prédire et de les manipuler.
Monétisez tout ça auprès de vos clients réels, qui vous paient pour ce service.
C’est ce que certains appellent le Big Data, et que d’autres appellent le capitalisme de surveillance.
3. Quittez la scène (vendez)
Une start-up est une affaire temporaire, dont le but du jeu est de se vendre à une start-up en meilleure santé ou à une entreprise existante de la Big Tech, ou au public par le biais d’une introduction en Bourse.
Si vous êtes arrivé jusque-là, félicitations. Vous pourriez fort bien devenir le prochain crétin milliardaire et philanthrope en Bitcoin de la Silicon Valley.
De nombreuses start-ups échouent à la première étape, mais tant que le capital risque a sa précieuse licorne, ils sont contents.
Des conneries (partie 1)
Je ne savais donc pas que le fait de disposer de capital risque signifiait que Twitter devait connaître une croissance exponentielle et devenir une licorne d’un milliard de dollars. Je n’avais pas non plus saisi que ceux d’entre nous qui l’utilisaient – et contribuaient à son amélioration à ce stade précoce – étaient en fin de compte responsables de son succès. Nous avons été trompés. Du moins, je l’ai été et je suis sûr que je ne suis pas le seul à ressentir cela.
Tout cela pour dire que Twitter était bien destiné à devenir le Twitter qu’il est aujourd’hui dès son premier « investissement providentiel » au tout début.
C’est ainsi que se déroule le jeu du capital risque et des licornes dans la Silicon Valley. Voilà ce que c’est. Et c’est tout ce à quoi j’ai consacré mes huit dernières années : sensibiliser, protéger les gens et construire des alternatives à ce modèle.
Voici quelques enregistrements de mes conférences datant de cette période, vous pouvez regarder :
Dans le cadre de la partie « sensibilisation », j’essayais également d’utiliser des plateformes comme Twitter et Facebook à contre-courant.
Comme je l’ai écrit dans Spyware vs Spyware en 2014 : « Nous devons utiliser les systèmes existants pour promouvoir nos alternatives, si nos alternatives peuvent exister tout court. » Même pour l’époque, c’était plutôt optimiste, mais une différence cruciale était que Twitter, au moins, n’avait pas de timeline algorithmique.
Les timelines algorithmiques (ou l’enfumage 2.0)
Qu’est-ce qu’une timeline algorithmique ? Essayons de l’expliquer.
Ce que vous pensez qu’il se passe lorsque vous tweetez: « j’ai 44 000 personnes qui me suivent. Quand j’écris quelque chose, 44 000 personnes vont le voir ».
Ce qui se passe vraiment lorsque vous tweetez : votre tweet pourrait atteindre zéro, quinze, quelques centaines, ou quelques milliers de personnes.
Et ça dépend de quoi?
Dieu seul le sait, putain.
(Ou, plus exactement, seul Twitter, Inc. le sait.)
Donc, une timeline algorithmique est une boîte noire qui filtre la réalité et décide de qui voit quoi et quand, sur la base d’un lot de critères complètement arbitraires déterminés par l’entreprise à laquelle elle appartient.
En d’autres termes, une timeline algorithmique est simplement un euphémisme pour parler d’un enfumage de masse socialement acceptable. C’est de l’enfumage 2.0.
L’algorithme est un trouduc
La nature de l’algorithme reflète la nature de l’entreprise qui en est propriétaire et l’a créé.
Étant donné que les entreprises sont sociopathes par nature, il n’est pas surprenant que leurs algorithmes le soient aussi. En bref, les algorithmes d’exploiteurs de personnes comme Twitter et Facebook sont des connards qui remuent la merde et prennent plaisir à provoquer autant de conflits et de controverses que possible.
Hé, qu’attendiez-vous exactement d’un milliardaire qui a pour bio #Bitcoin et d’un autre qui qualifie les personnes qui utilisent sont utilisées par son service de « pauvres cons » ?
Ces salauds se délectent à vous montrer des choses dont ils savent qu’elles vont vous énerver dans l’espoir que vous riposterez. Ils se délectent des retombées qui en résultent. Pourquoi ? Parce que plus il y a d’« engagement » sur la plateforme – plus il y a de clics, plus leurs accros («utilisateurs») y passent du temps – plus leurs sociétés gagnent de l’argent.
Eh bien, ça suffit, merci bien.
Des conneries (partie 2)
Certes je considère important de sensibiliser les gens aux méfaits des grandes entreprises technologiques, et j’ai probablement dit et écrit tout ce qu’il y a à dire sur le sujet au cours des huit dernières années. Rien qu’au cours de cette période, j’ai donné plus d’une centaine de conférences, sans parler des interviews dans la presse écrite, à la radio et à la télévision.
Voici quelques liens vers une poignée d’articles que j’ai écrits sur le sujet au cours de cette période :
Est-ce que ça a servi à quelque chose ?
Je ne sais pas.
J’espère que oui.
J’ai également interpellé d’innombrables personnes chez les capitalistes de la surveillance comme Google et Facebook sur Twitter et – avant mon départ il y a quelques années – sur Facebook, et ailleurs. (Quelqu’un se souvient-il de la fois où j’ai réussi à faire en sorte que Samuel L. Jackson interpelle Eric Schmidt sur le fait que Google exploite les e-mails des gens?) C’était marrant. Mais je m’égare…
Est-ce que tout cela a servi à quelque chose ?
Je ne sais pas.
J’espère que oui.
Mais voici ce que je sais :
Est-ce que dénoncer les gens me rend malheureux ? Oui.
Est-ce que c’est bien ? Non.
Est-ce que j’aime les conflits ? Non.
Alors, trop c’est trop.
Les gens viennent parfois me voir pour me remercier de « parler franchement ». Eh bien, ce « parler franchement » a un prix très élevé. Alors peut-être que certaines de ces personnes peuvent reprendre là où je me suis arrêté. Ou pas. Dans tous les cas, j’en ai fini avec ça.
Dans ta face
Une chose qu’il faut comprendre du capitalisme de surveillance, c’est qu’il s’agit du courant dominant. C’est le modèle dominant. Toutes les grandes entreprises technologiques et les startups en font partie2. Et être exposé à leurs dernières conneries et aux messages hypocrites de personnes qui s’y affilient fièrement tout en prétendant œuvrer pour la justice sociale n’est bon pour la santé mentale de personne.
C’est comme vivre dans une ferme industrielle appartenant à des loups où les partisans les plus bruyants du système sont les poulets qui ont été embauchés comme chefs de ligne.
J’ai passé les huit dernières années, au moins, à répondre à ce genre de choses et à essayer de montrer que la Big Tech et le capitalisme de surveillance ne peuvent pas être réformés.
Et cela me rend malheureux.
J’en ai donc fini de le faire sur des plates-formes dotées d’algorithmes de connards qui s’amusent à m’infliger autant de misère que possible dans l’espoir de m’énerver parce que cela «fait monter les chiffres».
Va te faire foutre, Twitter !
J’en ai fini avec tes conneries.
« fuck twitter » par mowl.eu, licence CC BY-NC-ND 2.0
Et après ?
À bien des égards, cette décision a été prise il y a longtemps. J’ai créé mon propre espace sur le fediverse en utilisant Mastodon il y a plusieurs années et je l’utilise depuis. Si vous n’avez jamais entendu parler du fediverse, imaginez-le de la manière suivante :
Imaginez que vous (ou votre groupe d’amis) possédez votre propre copie de twitter.com. Mais au lieu de twitter.com, le vôtre se trouve sur votre-place.org. Et à la place de Jack Dorsey, c’est vous qui fixez les règles.
Vous n’êtes pas non plus limité à parler aux gens sur votre-place.org.
Je possède également mon propre espace sur mon-espace.org (disons que je suis @moi@mon-espace.org). Je peux te suivre @toi@ton-espace.org et aussi bien @eux@leur.site et @quelquun-dautre@un-autre.espace. Ça marche parce que nous parlons tous un langage commun appelé ActivityPub.
Donc imaginez un monde où il y a des milliers de twitter.com qui peuvent tous communiquer les uns avec les autres et Jack n’a rien à foutre là-dedans.
Eh bien, c’est ça, le Fediverse.
Et si Mastodon n’est qu’un moyen parmi d’autres d’avoir son propre espace dans le Fediverse, joinmastodon.org est un bon endroit pour commencer à se renseigner sur le sujet et mettre pied à l’étrier de façon simple sans avoir besoin de connaissances techniques. Comme je l’ai déjà dit, je suis sur le Fediverse depuis les débuts de Mastodon et j’y copiais déjà manuellement les posts sur Twitter.
Maintenant j’ai automatisé le processus via moa.party et, pour aller de l’avant, je ne vais plus me connecter sur Twitter ou y répondre3.
Vu que mes posts sur Mastodon sont maintenant automatiquement transférés là-bas, vous pouvez toujours l’utiliser pour me suivre, si vous en avez envie. Mais pourquoi ne pas utiliser cette occasion de rejoindre le Fediverse et vous amuser ?
Small is beautiful
Si je pense toujours qu’avoir des bonnes critiques de la Big Tech est essentiel pour peser pour une régulation efficace, je ne sais pas si une régulation efficace est même possible étant donné le niveau de corruption institutionnelle que nous connaissons aujourd’hui (lobbies, politique des chaises musicales, partenariats public-privé, captation de réglementation, etc.)
Ce que je sais, c’est que l’antidote à la Big Tech est la Small Tech.
Nous devons construire l’infrastructure technologique alternative qui sera possédée et contrôlée par des individus, pas par des entreprises ou des gouvernements. C’est un prérequis pour un futur qui respecte la personne humaine, les droits humains, la démocratie et la justice sociale.
Dans le cas contraire, nous serons confrontés à des lendemains sombres où notre seul recours sera de supplier un roi quelconque, de la Silicon Valley ou autre, « s’il vous plaît monseigneur, soyez gentil ».
Je sais aussi que travailler à la construction de telles alternatives me rend heureux alors que désespérer sur l’état du monde ne fait que me rendre profondément malheureux. Je sais que c’est un privilège d’avoir les compétences et l’expérience que j’ai, et que cela me permet de travailler sur de tels projets. Et je compte bien les mettre à contribution du mieux possible.
Pour aller de l’avant, je prévois de concentrer autant que possible de mon temps et de mon énergie à la construction d’un Small Web.
Si vous avez envie d’en parler (ou d’autre chose), vous pouvez me trouver sur le Fediverse.
Vous pouvez aussi discuter avec moi pendant mes live streams S’update et pendant nos live streams Small is beautiful avec Laura.
Des jours meilleurs nous attendent…
Prenez soin de vous.
Portez-vous bien.
Aimez-vous les uns les autres.
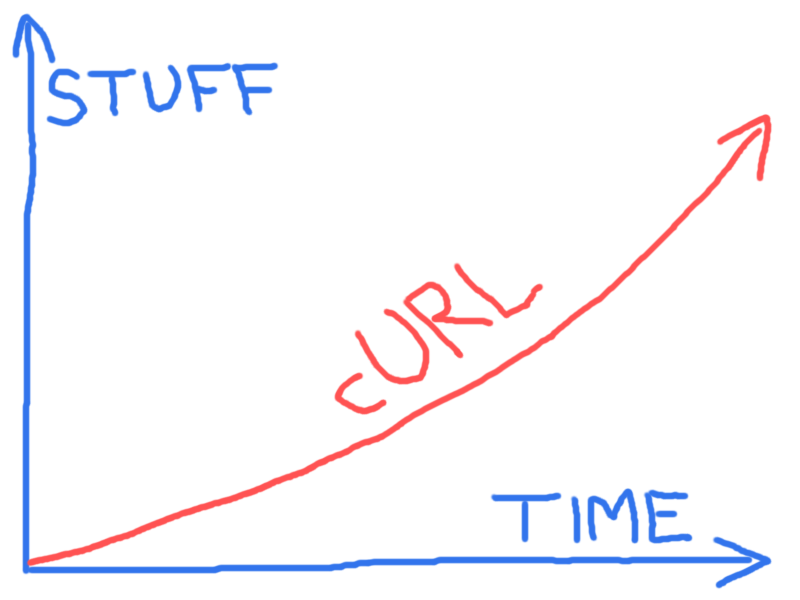
À 23 ans, cURL se rend utile partout
Non, ce n’est pas une marque de biscuits apéritifs aux cacahuètes, mais un outil logiciel méconnu qui mérite pourtant de faire partie de notre culture numérique. On révise ?
Bien qu’ignoré de la plupart des internautes, il est d’un usage familier pour celles et ceux qui travaillent en coulisses pour le Web. L’adage : « si un site web n’est pas « curlable », ce n’est pas du Web » fait de curl un outil majeur pour définir ce qu’est le Web aujourd’hui.
Son développeur principal suédois Daniel Stenberg retrace ici la genèse de cURL, son continu développement et surtout, ce qui devrait intéresser les moins geeks de nos lecteurs, son incroyable diffusion, à travers sa bibliothèque libcurl, au cœur de tant d’objets et appareils familiers. Après des débuts fort modestes, « la quasi-totalité des appareils connectés à Internet exécutent curl » !
Si vous n’êtes pas développeur et que les caractéristiques techniques de curl sont pour vous un peu obscures, allez directement à la deuxième partie de l’article pour en comprendre facilement l’importance.
Article original sur le blog de l’auteur : curl is 23 years old today
Traduction : Fabrice, Goofy, Julien/Sphinx, jums, NGFChristian, tTh,
curl fête son 23e anniversaire
par Daniel Stenberg La date de naissance officielle de curl, le 20 mars 1998, marque le jour de la toute première archive tar qui pouvait installer un outil nommé curl. Je l’ai créé et nommé curl 4.0 car je voulais poursuivre la numérotation de versions que j’avais déjà utilisée pour les noms précédents de l’outil. Ou plutôt, j’ai fait un saut depuis la 3.12, qui était la dernière version que j’avais utilisée avec le nom précédent : urlget.
Bien sûr, curl n’a pas été créé à partir de rien ce jour-là. Son histoire commence une petite année plus tôt : le 11 novembre 1996 a été publié un outil appelé httpget, développé par Rafael Sagula. C’est un projet j’avais trouvé et auquel j’avais commencé à contribuer. httpget 0.1 était un fichier de code C de moins de 300 lignes. (La plus ancienne version dont j’aie encore le code source est httpget 1.3, retrouvée ici)
Comme je l’ai évoqué à de multiples reprises, j’ai commencé à m’attaquer à ce projet parce que je voulais avoir un petit outil pour télécharger des taux de change régulièrement depuis un site internet et les fournir via mon petit bot4 de taux de change sur IRC5.
Ces petites décisions prises rapidement à cette époque allaient avoir plus tard un impact significatif et influencer ma vie. curl a depuis toujours été l’un de mes passe-temps principaux. Et bien sûr il s’agit aussi d’un travail à plein temps depuis quelques années désormais.
En ce même jour de novembre 1996 a été distribué pour la première fois le programme Wget(1.4.0). Ce projet existait déjà sous un autre nom avant d’être distribué, et je crois me souvenir que je ne le connaissais pas, j’utilisais httpget pour mon robogiciel. Peut-être que j’avais vu Wget et que je ne l’utilisais pas à cause de sa taille : l’archive tar de Wget 1.4.0 faisait 171 ko.
Peu de temps après, je suis devenu le responsable de httpget et j’ai étendu ses fonctionnalités. Il a ensuite été renommé urlget quand je lui ai ajouté le support de Gopher et de FTP (ce que j’ai fait parce que j’avais trouvé des taux de change sur des serveurs qui utilisaient ces protocoles). Au printemps 1998, j’ai ajouté le support de l’envoi par FTP et comme le nom du programme ne correspondait plus clairement à ses fonctionnalités j’ai dû le renommer une fois de plus6.
Nommer les choses est vraiment difficile. Je voulais un nom court dans le style d’Unix. Je n’ai pas planché très longtemps puisque j’ai trouvé un mot marrant assez rapidement. L’outil fonctionne avec des URL, et c’est un client Internet. « c » pour client et URL ont fait que « cURL » semblait assez pertinent et marrant. Et court. Bien dans de style d’Unix.
J’ai toujours voulu que curl soit un citoyen qui s’inscrive dans la tradition Unix d’utiliser des pipes7, la sortie standard, etc. Je voulais que curl fonctionne comme la commande cat, mais avec des URL. curl envoie donc par défaut le contenu de l’URL sur la sortie standard dans le terminal. Tout comme le fait cat. Il nous permettra donc de « voir » le contenu de l’URL. La lettre C se prononce si (Ndt : ou see, « voir » en anglais) donc « see URL » fonctionne aussi. Mon esprit blagueur n’en demande pas plus, mais je dis toujours « kurl ».
Le logo original, créé en 1998 par Henrik Hellerstedt
J’ai créé le paquet curl 4.0 et l’ai rendu public ce vendredi-là. Il comprenait alors 2 200 lignes de code. Dans la distribution de curl 4.8 que j’ai faite quelques mois plus tard, le fichier THANKS mentionnait 7 contributeurs[Note] Daniel Stenberg, Rafael Sagula, Sampo Kellomaki, Linas Vepstas, Bjorn Reese, Johan Anderson, Kjell Ericson[/note]. Ça nous a pris presque sept ans pour atteindre une centaine de contributeurs. Aujourd’hui, ce fichier liste plus de 2 300 noms et nous ajoutons quelques centaines de noms chaque année. Ce n’est pas un projet solo !
Il ne s’est rien passé de spécial
curl n’a pas eu un succès massif. Quelques personnes l’ont découvert et deux semaines après cette première distribution, j’ai envoyé la 4.1 avec quelques corrections de bugs et une tradition de plusieurs décennies a commencé : continuer à publier des mises à jour avec des corrections de bug. « Distribuer tôt et souvent » est un mantra auquel nous nous sommes conformés.
Plus tard en 1998, après plus de quinze distributions, notre page web présentait cette excellente déclaration :
Capture d’écran : Liste de diffusion. Pour cause de grande popularité, nous avons lancé une liste de diffusion pour parler de cet outil. (La version 4.8.4 a été téléchargée à elle seule plus de 300 fois depuis ce site.)
Trois cents téléchargements !
Je n’ai jamais eu envie de conquérir le monde ou nourri de visions idylliques pour ce projet et cet outil. Je voulais juste que les transferts sur Internet soient corrects, rapides et fiables, et c’est ce sur quoi j’ai travaillé.
Afin de mieux procurer au monde entier de quoi réaliser de bons transferts sur Internet, nous avons lancé la bibliothèque libcurl, publiée pour la première fois à l’été 2000. Cela a permis au projet de se développer sous un autre angle 8. Avec les années, libcurl est devenue de facto une API de transfert Internet.
Aujourd’hui, alors qu’il fête son 23e anniversaire, c’est toujours principalement sous cet angle que je vois le cœur de mon travail sur curl et ce que je dois y faire. Je crois que si j’ai atteint un certain succès avec curl avec le temps, c’est principalement grâce à une qualité spécifique. En un mot :
Persistance
Nous tenons bon. Nous surmontons les problèmes et continuons à perfectionner le produit. Nous sommes dans une course de fond. Il m’a fallu deux ans (si l’on compte à partir des précurseurs) pour atteindre 300 téléchargements. Il en a fallu dix ou presque pour qu’il soit largement disponible et utilisé.
En 2008, le site web pour curl a servi 100 Go de données par mois. Ce mois-ci, c’est 15 600 Go (soit fait 156 fois plus en 156 mois) ! Mais bien entendu, la plupart des utilisatrices et utilisateurs ne téléchargent rien depuis notre site, c’est leur distribution ou leur système d’exploitation qui leur met à disposition curl.
curl a été adopté au sein de Red Hat Linux à la fin de l’année 1998, c’est devenu un paquet Debian en mai 1999 et faisait partie de Mac OS X 10.1 en août 2001. Aujourd’hui, il est distribué par défaut dans Windows 10 et dans les appareils iOS et Android. Sans oublier les consoles de jeux comme la Nintendo Switch, la Xbox et la PS5 de Sony.
Ce qui est amusant, c’est que libcurl est utilisé par les deux principaux systèmes d’exploitation mobiles mais que ces derniers n’exposent pas d’API pour ses fonctionnalités. Aussi, de nombreuses applications, y compris celles qui sont largement diffusées, incluent-elles leur propre version de libcurl : YouTube, Skype, Instagram, Spotify, Google Photos, Netflix, etc. Cela signifie que la plupart des personnes qui utilisent un smartphone ont curl installé plusieurs fois sur leur téléphone.
Par ailleurs, libcurl est utilisé par certains des jeux vidéos les plus populaires : GTA V, Fortnite, PUBG mobile, Red Dead Redemption 2, etc.
libcurl alimente les fonctionnalités de lecteurs média ou de box comme Roku, Apple TV utilisés par peut-être un demi milliard de téléviseurs.
curl et libcurl sont pratiquement intégrés dans chaque serveur Internet, c’est le moteur de transfert par défaut de PHP qui est lui-même utilisé par environ 80% des deux milliards de sites web.
Maintenant que les voitures sont connectées à Internet, libcurl est utilisé dans presque chaque voiture moderne pour le transfert de données depuis et vers les véhicules.
À cela s’ajoutent les lecteurs média, les appareils culinaires ou médicaux, les imprimantes, les montres intelligentes et les nombreux objets « intelligents » connectés à Internet. Autrement dit, la quasi-totalité des appareils connectés à Internet exécutent curl.
Je suis convaincu que je n’exagère pas quand je déclare que curl existe sur plus de dix milliards d’installations sur la planète.
Seuls et solides
À plusieurs reprises lors de ces années, j’ai essayé de voir si curl pouvait rejoindre une organisation cadre mais aucune n’a accepté et, en fin de compte, je pense que c’est mieux ainsi. Nous sommes complètement seuls et indépendants de toute organisation ou entreprise. Nous faisons comme nous l’entendons et nous ne suivons aucune règle édictée par d’autres. Ces dernières années, les dons et les soutiens financiers se sont vraiment accélérés et nous sommes désormais en situation de pouvoir confortablement payer des récompenses pour la chasse aux bugs de sécurité par exemple.
Le support commercial que nous proposons, wolfSSL et moi-même, a je crois renforcé curl : cela me laisse encore plus de temps pour travailler sur curl, et permet à davantage d’entreprises d’utiliser curl sereinement, ce qui en fin de compte le rend meilleur pour tous.
Ces 300 lignes de code fin 1996 sont devenues 172 000 lignes en mars 2021.
L’avenir
Notre travail le plus important est de ne pas « faire chavirer le navire ». Fournir la meilleure et la plus solide bibliothèque de transfert par Internet, sur le plus de plateformes possible.
Mais pour rester attractifs, nous devons vivre avec notre temps, c’est à dire de nous adapter aux nouveaux protocoles et aux nouvelles habitudes au fur et à mesure qu’ils apparaissent. Prendre en charge de nouvelles versions de protocoles, permettre de meilleures manières de faire les choses et, au fur et à mesure, abandonner les mauvaises choses de manière responsable pour ne pas nuire aux personnes qui utilisent le logiciel.
À court terme je pense que nous voulons travailler à nous assurer du fonctionnement d’HTTP/3, faire de Hyper 9 une brique de très bonne qualité et voir ce que devient la brique rustls.
Après 23 ans, nous n’avons toujours pas de vision idéale ni de feuille de route pour nous guider. Nous allons là où Internet et nos utilisatrices nous mènent. Vers l’avant, toujours plus haut !
La feuille de route de curl 😉
23 ans de curl en 23 nombres
Pendant les jours qui ont précédé cet anniversaire, j’ai tweeté 23 « statistiques de curl » en utilisant le hashtag #curl23. Ci-dessous ces vingt-trois nombres et faits.
2 200 lignes de code en mars 1998 sont devenues 170 000 lignes en 2021 alors que curl fête ses 23 ans
14 bibliothèques TLS différentes sont prises en charge par curl alors qu’il fête ses 23 ans
2 348 contributrices et contributeurs ont participé au développement de curl alors qu’il fête ses 23 ans
197 versions de curl ont été publiées alors que curl fête ses 23 ans
6 787 correctifs de bug ont été enregistrés alors que curl fête ses 23 ans
10 000 000 000 d’installations dans le monde font que curl est l’un des jeunes hommes de 23 ans des plus distribués au monde
871 personnes ont contribué au code de curl pour en faire un projet vieux de 23 ans
935 000 000 récupérations pour l’image docker officielle de curl (83 récupérations par seconde) alors que curl fête ses 23 ans
22 marques de voitures, au moins, exécutent curl dans leurs véhicules alors que curl fête ses 23 ans
100 tâches d’intégration continue sont exécutées pour chaque commit et pull request sur le projet curl alors qu’il fête ses 23 ans
15 000 heures de son temps libre ont été passés sur le projet curl par Daniel alors qu’il fête ses 23 ans
2 systèmes d’exploitation mobile les plus utilisés intègrent et utilisent curl dans leur architecture alors que curl fête ses 23 ans
86 systèmes d’exploitation différents font tourner curl alors qu’il fête ses 23 ans
250 000 000 de télévisions utilisent curl alors qu’il fête ses 23 ans
26 protocoles de transport sont pris en charge alors que curl fête ses 23 ans
36 bibliothèques tierces différentes peuvent être compilées afin d’être utilisées par curl alors qu’il fête ses 23 ans
22 architectures différentes de processeurs exécutent curl alors qu’il fête ses 23 ans
4 400 dollars américains ont été payés au total pour la découverte de bugs alors que curl fête ses 23 ans
240 options de ligne de commandes existent lorsque curl fête ses 23 ans
15 600 Go de données sont téléchargées chaque mois depuis le site web de curl alors que curl fête ses 23 ans
60 passerelles vers d’autres langages existent pour permettre aux programmeurs de transférer des données facilement en utilisant n’importe quel langage alors que curl fête ses 23 ans
1 327 449 mots composent l’ensemble des RFC pertinentes qu’il faut lire pour les opérations effectuées par curl alors que curl fête ses 23 ans
1 fondateur et développeur principal est resté dans les parages du projet alors que curl fête ses 23 ans
J’enseigne, je code et je partage : une série de portraits-entretiens à la rencontre des enseignant⋅es développeur·euses
J’enseigne, je code et je partage est une série de portraits-entretiens à la rencontre des enseignant⋅es développeur·euses réalisée par Hervé Baronnet (enseignant) et Jean-Marc Adolphe (journaliste culture et humanités) pour l’association Faire École Ensemble. Déjà 3 de ces portraits-entretiens ont été publiés et on s’est dit que ça pourrait être chouette d’en savoir un peu plus sur cette initiative. Alors, on a demandé aux interviewers s’ils acceptaient d’être interviewés à leur tour.
Bonjour Hervé et Jean-Marc ! Pouvez-vous vous présenter ?
Bonjour,
Hervé Baronnet, je suis enseignant en maternelle depuis 25 ans, toujours en zone d’éducation prioritaire. Utilisateurs des TICE, notamment de logiciels éducatifs libres mais pas exclusivement. J’ai contribué au projet AbulÉdu en tant que bêta-testeur et auteur de documentations pédagogiques. Je suis actuellement membre du conseil collégial de FÉE.
Bonjour,
Jean-Marc Adolphe, journaliste et conseiller artistique, ex-militant FCPE. Je m’intéresse depuis longtemps à l’éducation aux médias, à mes yeux insuffisamment enseignée à l’école. Et en tant que citoyen, l’école m’engage. La question des « biens communs numériques » me semble essentielle dans tout ce qui ressort du service public, particulièrement au sein de l’Éducation nationale.
Vous êtes tous les deux adhérents de l’association Faire École Ensemble. C’est quoi cette asso ?
L’association Faire École Ensemble est une association collégiale qui facilite les collaborations entre les citoyens et la communauté éducative tout au long de la pandémie. Fée engage des projets collaboratifs en s’appuyant sur 3 spécificités : la convivialité, la documentation et le recours par défaut aux licences ouvertes.
Concrètement, à l’annonce de la fermeture des écoles et de la mise en place généralisée de l’enseignement à distance en mars 2020, nous avons mobilisé 1000 citoyennes et citoyens pour aider les professeurs peu à l’aise avec le numérique. S’en sont suivies d’autres actions autour de la réouverture progressive des écoles avec un protocole sanitaire drastique, les possibilités de faire école à l’extérieur, la préparation d’une rentrée apaisée en passant une nuit à l’école et une action réflexive sur la place du numérique dans l’enseignement (recherche-action ; états généraux du numérique libre et des communs pédagogiques).
Ce que nous faisons avec Faire École Ensemble relève d’une configuration tiers-lieux telle que définie par Antoine Burret (« le tiers-lieu peut-être défini conceptuellement comme : une configuration sociale où la rencontre entre des entités individuées engage intentionnellement à la conception de représentations communes »). Nos projets réunissent des communautés de personnes diverses (parents, profs, designers, chercheurs, élèves, architectes, juristes, militants associatifs, artistes…) autour d’une intention commune (réaménager sa classe, organiser une nuit à l’école, penser la pédagogique en période de crise…). Nous documentons les conversations (formelles et informelles) pour faire émerger un patrimoine informationnel commun, nous prenons soin des liens entre les personnes, sommes garants de la convivialité et accompagnons celles et ceux qui le souhaitent dans le passage à l’action (nous ne faisons pas à leur place).
J’ai cru comprendre que FÉE souhaitait développer une communauté d’enseignant⋅es développeur·euses en informatique. Quel est l’objectif ? Ça s’organise où et comment ? Quelles sont les modalités pour y participer ?
Des webinaires « le logiciel libre par des acteurs de l’éducation pour l’éducation » dans le cadre du cycle sur le libre et les communs sont proposés régulièrement. Les enseignant⋅es développeur·euses sont invité⋅es à y participer.
Il est important de souligner que les « enseignant⋅es développeur·euses » ne sont pas nécessairement des spécialistes en informatique. Ce sont avant tout des enseignant⋅es, soucieu⋅ses de trouver des ressources pédagogiques et « techniques » adaptées à leurs élèves.
Dans ce cadre, vous vous êtes lancés dans une série d’interviews d’enseignant⋅es développeur·euses. Quel est l’objectif de ces interviews ?
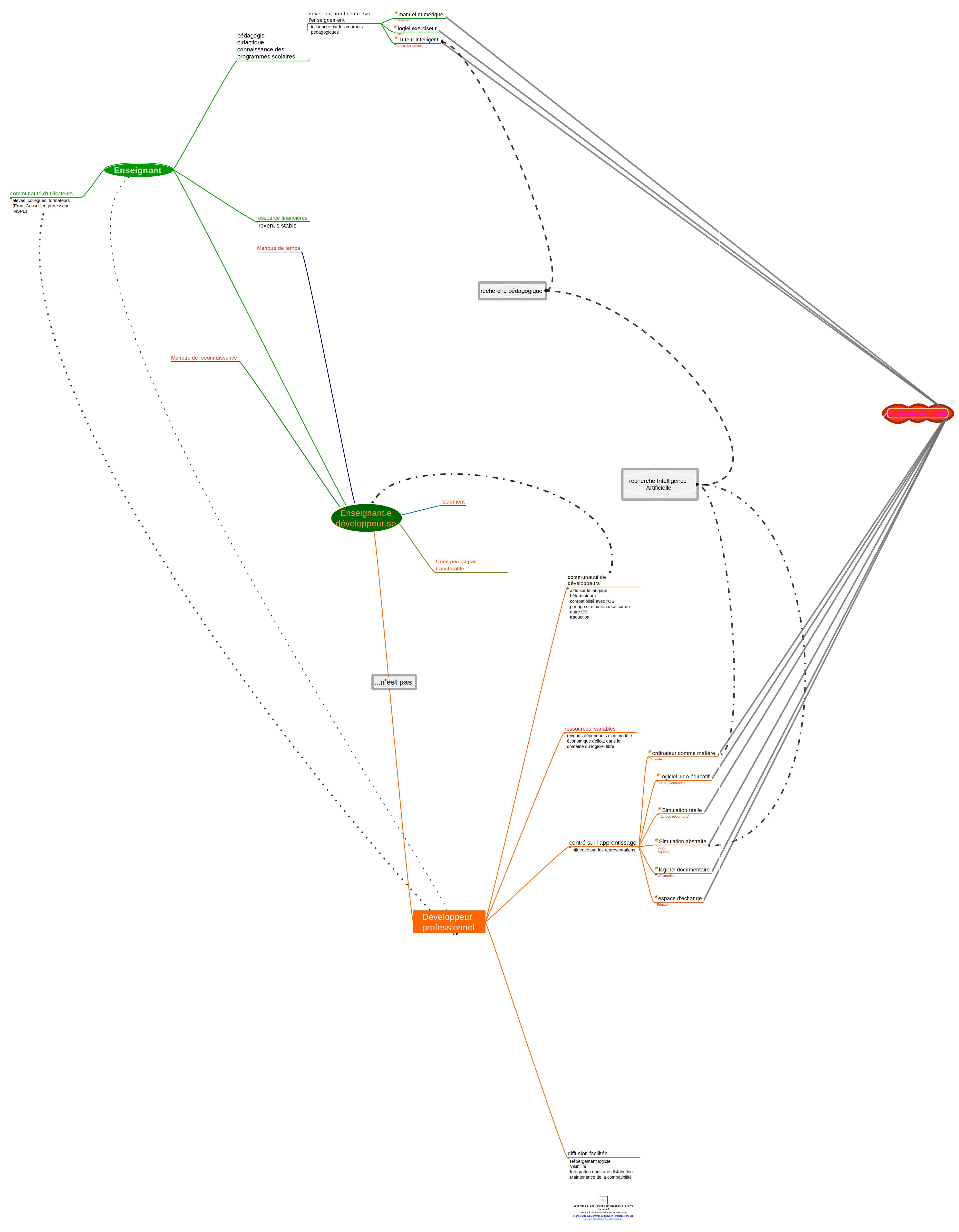
Le premier objectif de cette série d’entretiens-portraits est de faire connaître l’existence de ces personnes, de les valoriser elleux ainsi que les projets sur lesquels ielles travaillent. Ensuite, un portrait type présentant leurs spécificités va pouvoir naître en croisant les réponses.
Carte heuristique pour mettre en évidence les spécificités des enseignant⋅es développeur·euses.
Il s’agit de faire savoir à d’autres enseignant⋅es développeur·euses qu’ielles ne sont pas seul⋅es. À plus long terme, il s’agit de faire prendre conscience de la valeur de ces acteur⋅ices et de lister les freins et les besoins pour aboutir à un soutien institutionnel.
Sur quels critères sélectionnez-vous les enseignant⋅es développeur·euses pour votre série de portraits ?
Nous avons sollicité dans un premier temps des enseignant⋅es qui s’étaient inscrit⋅es sur le forum de FÉE. Puis nous avons réalisé des portraits de personnes au profil plus étendu, avec la double casquette enseignant et développeur au sens large. Le fait de développer ou de contribuer à des logiciels libres est privilégié dans le choix des entretiens.
#ModeTroll : il y a à ce jour 3 entretiens sur le blog et uniquement des hommes. C’est volontaire de ne pas valoriser la gent féminine ?
Il y en a 3 et bientôt 6, tous des hommes, en effet ! FÉE n’y est pour rien (le conseil collégial de l’association devrait être bientôt à parité hommes / femmes). Il se trouve que seuls des enseignants-hommes se sont manifestés à ce jour. Mais nous profitons de cet entretien pour lancer un appel à des enseignantes-développeuses afin qu’elles participent à cette série d’entretiens et qu’elles puissent rejoindre la communauté qui est en train de se former.
Quelle est la place du logiciel libre dans les pratiques des enseignant⋅es développeur·euses ?
La place du logiciel libre est centrale, car la priorité a été donnée aux enseignant⋅es développeur·euses libristes, cette action étant dans la continuité des États Généraux du Numérique Libre organisés par FÉE.
Des développeur·euses qui utilisent des outils non libres ou développant des applications gratuites propriétaires pourront aussi être sollicité⋅es pour mieux définir ce qui les empêche de basculer vers le libre.
Et comme toujours, sur le Framablog, on vous laisse le mot de la fin !
À partir de ces entretiens des caractéristiques communes aux enseignant⋅es développeur·euses peuvent être extraites.
Parmi les points positifs :
+ la motivation à aider les élèves
+ l’éthique comme moteur
+ la valeur ajoutée de leur projet en tant qu’outil métier
Parmi les aspects négatifs :
– le temps, la non-reconnaissance du travail
– le code « amateur » peu ou pas documenté
– l’aspect chronophage des questions des utilisateur⋅ices qui augmente avec le succès des logiciels
Notre contributopie serait de limiter ces freins par l’impulsion de solutions :
Que les institutions qui emploient ces enseignant⋅es développeur·euses reconnaissent l’intérêt de leur travail et leur permettent d’y consacrer du temps. Les enseignant⋅es ne veulent pas devenir développeur·euses à temps plein, le côté passion est leur moteur et les expériences de « professionnalisation » ont été des échecs.
Que la communauté du libre les aide pour améliorer le code sous forme, par exemple, de formations menées par des développeur·euses professionnel⋅les.
La mise en place d’une communauté d’usage permettant de répondre aux questions des utilisateur⋅ices et de créer de la documentation pédagogique.
Merci beaucoup pour vos précisions Hervé et Jean-Marc. Et on espère que de nombreu⋅ses enseignant⋅es et libristes rejoindront votre communauté.
Google chante le requiem pour les cookies, mais le grand chœur du pistage résonnera encore
Google va cesser de nous pister avec des cookies tiers ! Une bonne nouvelle, oui mais… Regardons le projet d’un peu plus près avec un article de l’EFF.
La presse en ligne s’en est fait largement l’écho : par exemple siecledigital, generation-nt ou lemonde. Et de nombreux articles citent un éminent responsable du tout-puissant Google :
Chrome a annoncé son intention de supprimer la prise en charge des cookies tiers et que nous avons travaillé avec l’ensemble du secteur sur le Privacy Sandbox afin de mettre au point des innovations qui protègent l’anonymat tout en fournissant des résultats aux annonceurs et aux éditeurs. Malgré cela, nous continuons à recevoir des questions pour savoir si Google va rejoindre d’autres acteurs du secteur des technologies publicitaires qui prévoient de remplacer les cookies tiers par d’autres identifiants de niveau utilisateur. Aujourd’hui, nous précisons qu’une fois les cookies tiers supprimés, nous ne créerons pas d’identifiants alternatifs pour suivre les individus lors de leur navigation sur le Web et nous ne les utiliserons pas dans nos produits.
David Temkin, Director of Product Management, Ads Privacy and Trust (source)
« Pas d’identifiants alternatifs » voilà de quoi nous réjouir : serait-ce la fin d’une époque ?
Comme d’habitude avec Google, il faut se demander où est l’arnaque lucrative. Car il semble bien que le Béhémoth du numérique n’ait pas du tout renoncé à son modèle économique qui est la vente de publicité.
Dans cet article de l’Electronic Frontier Foundation, que vous a traduit l’équipe de Framalang, il va être question d’un projet déjà entamé de Google dont l’acronyme est FLoC, c’est-à-dire Federated Learning of Cohorts. Vous le trouverez ici traduit AFC pour « Apprentissage Fédéré de Cohorte » (voir l’article de Wikipédia Apprentissage fédéré).
Pour l’essentiel, ce dispositif donnerait au navigateur Chrome la possibilité de créer des groupes de milliers d’utilisateurs ayant des habitudes de navigation similaires et permettrait aux annonceurs de cibler ces « cohortes ».
Les cookies tiers se meurent, mais Google essaie de créer leur remplaçant.
Personne ne devrait pleurer la disparition des cookies tels que nous les connaissons aujourd’hui. Pendant plus de deux décennies, les cookies tiers ont été la pierre angulaire d’une obscure et sordide industrie de surveillance publicitaire sur le Web, brassant plusieurs milliards de dollars ; l’abandon progressif des cookies de pistage et autres identifiants tiers persistants tarde à arriver. Néanmoins, si les bases de l’industrie publicitaire évoluent, ses acteurs les plus importants sont déterminés à retomber sur leurs pieds.
Google veut être en première ligne pour remplacer les cookies tiers par un ensemble de technologies permettant de diffuser des annonces ciblées sur Internet. Et certaines de ses propositions laissent penser que les critiques envers le capitalisme de surveillance n’ont pas été entendues. Cet article se concentrera sur l’une de ces propositions : l’Apprentissage Fédéré de Cohorte (AFC, ou FLoC en anglais), qui est peut-être la plus ambitieuse – et potentiellement la plus dangereuse de toutes.
L’AFC est conçu comme une nouvelle manière pour votre navigateur d’établir votre profil, ce que les pisteurs tiers faisaient jusqu’à maintenant, c’est-à-dire en retravaillant votre historique de navigation récent pour le traduire en une catégorie comportementale qui sera ensuite partagée avec les sites web et les annonceurs. Cette technologie permettra d’éviter les risques sur la vie privée que posent les cookies tiers, mais elle en créera de nouveaux par la même occasion. Une solution qui peut également exacerber les pires attaques sur la vie privée posées par les publicités comportementales, comme une discrimination accrue et un ciblage prédateur.
La réponse de Google aux défenseurs de la vie privée a été de prétendre que le monde de demain avec l’AFC (et d’autres composants inclus dans le « bac à sable de la vie privée » sera meilleur que celui d’aujourd’hui, dans lequel les marchands de données et les géants de la tech pistent et profilent en toute impunité. Mais cette perspective attractive repose sur le présupposé fallacieux que nous devrions choisir entre « le pistage à l’ancienne » et le « nouveau pistage ». Au lieu de réinventer la roue à espionner la vie privée, ne pourrait-on pas imaginer un monde meilleur débarrassé des problèmes surabondants de la publicité ciblée ?
Nous sommes à la croisée des chemins. L’ère des cookies tiers, peut-être la plus grande erreur du Web, est derrière nous et deux futurs possibles nous attendent.
Dans l’un d’entre eux, c’est aux utilisateurs et utilisatrices que revient le choix des informations à partager avec chacun des sites avec lesquels il ou elle interagit. Plus besoin de s’inquiéter du fait que notre historique de navigation puisse être utilisé contre nous-mêmes, ou employé pour nous manipuler, lors de l’ouverture d’un nouvel onglet.
Dans l’autre, le comportement de chacune et chacun est répercuté de site en site, au moyen d’une étiquette, invisible à première vue mais riche de significations pour celles et ceux qui y ont accès. L’historique de navigation récent, concentré en quelques bits, est « démocratisé » et partagé avec les dizaines d’interprètes anonymes qui sont partie prenante des pages web. Les utilisatrices et utilisateurs commencent chaque interaction avec une confession : voici ce que j’ai fait cette semaine, tenez-en compte.
Les utilisatrices et les personnes engagées dans la défense des droits numériques doivent rejeter l’AFC et les autres tentatives malvenues de réinventer le ciblage comportemental. Nous exhortons Google à abandonner cette pratique et à orienter ses efforts vers la construction d’un Web réellement favorable aux utilisateurs.
Qu’est-ce que l’AFC ?
En 2019, Google présentait son bac à sable de la vie privée qui correspond à sa vision du futur de la confidentialité sur le Web. Le point central de ce projet est un ensemble de protocoles, dépourvus de cookies, conçus pour couvrir la multitude de cas d’usage que les cookies tiers fournissent actuellement aux annonceurs. Google a soumis ses propositions au W3C, l’organisme qui forge les normes du Web, où elles ont été principalement examinées par le groupe de commerce publicitaire sur le Web, un organisme essentiellement composé de marchands de technologie publicitaire. Dans les mois qui ont suivi, Google et d’autres publicitaires ont proposé des dizaines de standards techniques portant des noms d’oiseaux : pigeon, tourterelle, moineau, cygne, francolin, pélican, perroquet… et ainsi de suite ; c’est très sérieux ! Chacune de ces propositions aviaires a pour objectif de remplacer différentes fonctionnalités de l’écosystème publicitaire qui sont pour l’instant assurées par les cookies.
L’AFC est conçu pour aider les annonceurs à améliorer le ciblage comportemental sans l’aide des cookies tiers. Un navigateur ayant ce système activé collecterait les informations sur les habitudes de navigation de son utilisatrice et les utiliserait pour les affecter à une « cohorte » ou à un groupe. Les utilisateurs qui ont des habitudes de navigations similaires – reste à définir le mot « similaire » – seront regroupés dans une même cohorte. Chaque navigateur partagera un identifiant de cohorte, indiquant le groupe d’appartenance, avec les sites web et les annonceurs. D’après la proposition, chaque cohorte devrait contenir au moins plusieurs milliers d’utilisatrices et utilisateurs (ce n’est cependant pas une garantie).
Si cela vous semble complexe, imaginez ceci : votre identifiant AFC sera comme un court résumé de votre activité récente sur le Web.
La démonstration de faisabilité de Google utilisait les noms de domaines des sites visités comme base pour grouper les personnes. Puis un algorithme du nom de SimHash permettait de créer les groupes. Il peut tourner localement sur la machine de tout un chacun, il n’y a donc pas besoin d’un serveur central qui collecte les données comportementales. Toutefois, un serveur administrateur central pourrait jouer un rôle dans la mise en œuvre des garanties de confidentialité. Afin d’éviter qu’une cohorte soit trop petite (c’est à dire trop caractéristique), Google propose qu’un acteur central puisse compter le nombre de personnes dans chaque cohorte. Si certaines sont trop petites, elles pourront être fusionnées avec d’autres cohortes similaires, jusqu’à ce qu’elles représentent suffisamment d’utilisateurs.
Pour que l’AFC soit utile aux publicitaires, une cohorte d’utilisateurs ou utilisatrices devra forcément dévoiler des informations sur leur comportement.
Selon la proposition formulée par Google, la plupart des spécifications sont déjà à l’étude. Le projet de spécification prévoit que l’identification d’une cohorte sera accessible via JavaScript, mais on ne peut pas savoir clairement s’il y aura des restrictions, qui pourra y accéder ou si l’identifiant de l’utilisateur sera partagé par d’autres moyens. L’AFC pourra constituer des groupes basés sur l’URL ou le contenu d’une page au lieu des noms domaines ; également utiliser une synergie de « système apprentissage » (comme le sous-entend l’appellation AFC) afin de créer des regroupements plutôt que de se baser sur l’algorithme de SimHash. Le nombre total de cohortes possibles n’est pas clair non plus. Le test de Google utilise une cohorte d’utilisateurs avec des identifiants sur 8 bits, ce qui suppose qu’il devrait y avoir une limite de 256 cohortes possibles. En pratique, ce nombre pourrait être bien supérieur ; c’est ce que suggère la documentation en évoquant une « cohorte d’utilisateurs en 16 bits comprenant 4 caractères hexadécimaux ». Plus les cohortes seront nombreuses, plus elles seront spécialisées – plus les identifiants de cohortes seront longs, plus les annonceurs en apprendront sur les intérêts de chaque utilisatrice et auront de facilité pour cibler leur empreinte numérique.
Mais si l’un des points est déjà clair c’est le facteur temps. Les cohortes AFC seront réévaluées chaque semaine, en utilisant chaque fois les données recueillies lors de la navigation de la semaine précédente.
Ceci rendra les cohortes d’utilisateurs moins utiles comme identifiants à long terme, mais les rendra plus intrusives sur les comportements des utilisatrices dans la durée.
De nouveaux problèmes pour la vie privée.
L’AFC fait partie d’un ensemble qui a pour but d’apporter de la publicité ciblée dans un futur où la vie privée serait préservée. Cependant la conception même de cette technique implique le partage de nouvelles données avec les annonceurs. Sans surprise, ceci crée et ajoute des risques concernant la donnée privée.
Le Traçage par reconnaissance d’ID.
Le premier enjeu, c’est le pistage des navigateurs, une pratique qui consiste à collecter de multiples données distinctes afin de créer un identifiant unique, personnalisé et stable lié à un navigateur en particulier. Le projet Cover Your Tracks (Masquer Vos Traces) de l’Electronic Frontier Foundation (EFF) montre comment ce procédé fonctionne : pour faire simple, plus votre navigateur paraît se comporter ou agir différemment des autres, plus il est facile d’en identifier l’empreinte unique.
Google a promis que la grande majorité des cohortes AFC comprendrait chacune des milliers d’utilisatrices, et qu’ainsi on ne pourra vous distinguer parmi le millier de personnes qui vous ressemblent. Mais rien que cela offre un avantage évident aux pisteurs. Si un pistage commence avec votre cohorte, il doit seulement identifier votre navigateur parmi le millier d’autres (au lieu de plusieurs centaines de millions). En termes de théorie de l’information, les cohortes contiendront quelques bits d’entropie jusqu’à 8, selon la preuve de faisabilité. Cette information est d’autant plus éloquente sachant qu’il est peu probable qu’elle soit corrélée avec d’autres informations exposées par le navigateur. Cela va rendre la tâche encore plus facile aux traqueurs de rassembler une empreinte unique pour les utilisateurs de l’AFC.
Google a admis que c’est un défi et s’est engagé à le résoudre dans le cadre d’un plan plus large, le « Budget vie privée » qui doit régler le problème du pistage par l’empreinte numérique sur le long terme. Un but admirable en soi, et une proposition qui va dans le bon sens ! Mais selon la Foire Aux Questions, le plan est « une première proposition, et n’a pas encore d’implémentation dans un navigateur ». En attendant, Google a commencé à tester l’AFC dès ce mois de mars.
Le pistage par l’empreinte numérique est évidemment difficile à arrêter. Des navigateurs comme Safari et Tor se sont engagés dans une longue bataille d’usure contre les pisteurs, sacrifiant une grande partie de leurs fonctionnalités afin de réduire la surface des attaques par traçage. La limitation du pistage implique généralement des coupes ou des restrictions sur certaines sources d’entropie non nécessaires. Il ne faut pas que Google crée de nouveaux risques d’être tracé tant que les problèmes liés aux risques existants subsistent.
L’exposition croisée
Un second problème est moins facile à expliquer : la technologie va partager de nouvelles données personnelles avec des pisteurs qui peuvent déjà identifier des utilisatrices. Pour que l’AFC soit utile aux publicitaires, une cohorte devra nécessairement dévoiler des informations comportementales.
La page Github du projet aborde ce sujet de manière très directe :
Cette API démocratise les accès à certaines informations sur l’historique de navigation général des personnes (et, de fait, leurs intérêts principaux) à tous les sites qui le demandent… Les sites qui connaissent les Données à Caractère Personnel (c’est-à-dire lorsqu’une personne s’authentifie avec son adresse courriel) peuvent enregistrer et exposer leur cohorte. Cela implique que les informations sur les intérêts individuels peuvent éventuellement être rendues publiques.
Comme décrit précédemment, les cohortes AFC ne devraient pas fonctionner en tant qu’identifiant intrinsèque. Cependant, toute entreprise capable d’identifier un utilisateur d’une manière ou d’une autre – par exemple en offrant les services « identifiez-vous via Google » à différents sites internet – seront à même de relier les informations qu’elle apprend de l’AFC avec le profil de l’utilisateur.
Deux catégories d’informations peuvent alors être exposées :
1. Des informations précises sur l’historique de navigation. Les pisteurs pourraient mettre en place une rétro-ingénierie sur l’algorithme d’assignation des cohortes pour savoir si une utilisatrice qui appartient à une cohorte spécifique a probablement ou certainement visité des sites spécifiques.
2. Des informations générales relatives à la démographie ou aux centres d’intérêts. Par exemple, une cohorte particulière pourrait sur-représenter des personnes jeunes, de sexe féminin, ou noires ; une autre cohorte des personnes d’âge moyen votant Républicain ; une troisième des jeunes LGBTQ+, etc.
Cela veut dire que chaque site que vous visitez se fera une bonne idée de quel type de personne vous êtes dès le premier contact avec ledit site, sans avoir à se donner la peine de vous suivre sur le Net. De plus, comme votre cohorte sera mise à jour au cours du temps, les sites sur lesquels vous êtes identifié⋅e⋅s pourront aussi suivre l’évolution des changements de votre navigation. Souvenez-vous, une cohorte AFC n’est ni plus ni moins qu’un résumé de votre activité récente de navigation.
Vous devriez pourtant avoir le droit de présenter différents aspects de votre identité dans différents contextes. Si vous visitez un site pour des informations médicales, vous pourriez lui faire confiance en ce qui concerne les informations sur votre santé, mais il n’y a pas de raison qu’il ait besoin de connaître votre orientation politique. De même, si vous visitez un site de vente au détail, ce dernier n’a pas besoin de savoir si vous vous êtes renseigné⋅e récemment sur un traitement pour la dépression. L’AFC érode la séparation des contextes et, au contraire, présente le même résumé comportemental à tous ceux avec qui vous interagissez.
Au-delà de la vie privée
L’AFC est conçu pour éviter une menace spécifique : le profilage individuel qui est permis aujourd’hui par le croisement des identifiants contextuels. Le but de l’AFC et des autres propositions est d’éviter de laisser aux pisteurs l’accès à des informations qu’ils peuvent lier à des gens en particulier. Alors que, comme nous l’avons montré, cette technologie pourrait aider les pisteurs dans de nombreux contextes. Mais même si Google est capable de retravailler sur ses conceptions et de prévenir certains risques, les maux de la publicité ciblée ne se limitent pas aux violations de la vie privée. L’objectif même de l’AFC est en contradiction avec d’autres libertés individuelles.
Pouvoir cibler c’est pouvoir discriminer. Par définition, les publicités ciblées autorisent les annonceurs à atteindre certains types de personnes et à en exclure d’autres. Un système de ciblage peut être utilisé pour décider qui pourra consulter une annonce d’emploi ou une offre pour un prêt immobilier aussi facilement qu’il le fait pour promouvoir des chaussures.
Au fur et à mesure des années, les rouages de la publicité ciblée ont souvent été utilisés pour l’exploitation, la discrimination et pour nuire. La capacité de cibler des personnes en fonction de l’ethnie, la religion, le genre, l’âge ou la compétence permet des publicités discriminatoires pour l’emploi, le logement ou le crédit. Le ciblage qui repose sur l’historique du crédit – ou des caractéristiques systématiquement associées – permet de la publicité prédatrice pour des prêts à haut taux d’intérêt. Le ciblage basé sur la démographie, la localisation et l’affiliation politique aide les fournisseurs de désinformation politique et la suppression des votants. Tous les types de ciblage comportementaux augmentent les risques d’abus de confiance.
Au lieu de réinventer la roue du pistage, nous devrions imaginer un monde sans les nombreux problèmes posés par les publicités ciblées.
Google, Facebook et beaucoup d’autres plateformes sont en train de restreindre certains usages sur de leur système de ciblage. Par exemple, Google propose de limiter la capacité des annonceurs de cibler les utilisatrices selon des « catégories de centres d’intérêt à caractère sensible ». Cependant, régulièrement ces tentatives tournent court, les grands acteurs pouvant facilement trouver des compromis et contourner les « plateformes à usage restreint » grâce à certaines manières de cibler ou certains types de publicité.
Même un imaginant un contrôle total sur quelles informations peuvent être utilisées pour cibler quelles personnes, les plateformes demeurent trop souvent incapables d’empêcher les usages abusifs de leur technologie. Or l’AFC utilisera un algorithme non supervisé pour créer ses propres cohortes. Autrement dit, personne n’aura un contrôle direct sur la façon dont les gens seront regroupés.
Idéalement (selon les annonceurs), les cohortes permettront de créer des regroupements qui pourront avoir des comportements et des intérêts communs. Mais le comportement en ligne est déterminé par toutes sortes de critères sensibles : démographiques comme le genre, le groupe ethnique, l’âge ou le revenu ; selon les traits de personnalités du « Big 5 »; et même la santé mentale. Ceci laisse à penser que l’AFC regroupera aussi des utilisateurs parmi n’importe quel de ces axes.
L’AFC pourra aussi directement rediriger l’utilisatrice et sa cohorte vers des sites internet qui traitent l’abus de substances prohibées, de difficultés financières ou encore d’assistance aux victimes d’un traumatisme.
Google a proposé de superviser les résultats du système pour analyser toute corrélation avec ces catégories sensibles. Si l’on découvre qu’une cohorte spécifique est étroitement liée à un groupe spécifique protégé, le serveur d’administration pourra choisir de nouveaux paramètres pour l’algorithme et demander aux navigateurs des utilisateurs concernés de se constituer en un autre groupe.
Cette solution semble à la fois orwellienne et digne de Sisyphe. Pour pouvoir analyser comment les groupes AFC seront associés à des catégories sensibles, Google devra mener des enquêtes gigantesques en utilisant des données sur les utilisatrices : genre, race, religion, âge, état de santé, situation financière. Chaque fois que Google trouvera qu’une cohorte est associée trop fortement à l’un de ces facteurs, il faudra reconfigurer l’ensemble de l’algorithme et essayer à nouveau, en espérant qu’aucune autre « catégorie sensible » ne sera impliquée dans la nouvelle version. Il s’agit d’une variante bien plus compliquée d’un problème que Google s’efforce déjà de tenter de résoudre, avec de fréquents échecs.
Dans un monde numérique doté de l’AFC, il pourrait être plus difficile de cibler directement les utilisatrices en fonction de leur âge, genre ou revenu. Mais ce ne serait pas impossible. Certains pisteurs qui ont accès à des informations secondaires sur les utilisateurs seront capables de déduire ce que signifient les groupes AFC, c’est-à-dire quelles catégories de personnes appartiennent à une cohorte, à force d’observations et d’expérimentations. Ceux qui seront déterminés à le faire auront la possibilité de la discrimination. Pire, les plateformes auront encore plus de mal qu’aujourd’hui à contrôler ces pratiques. Les publicitaires animés de mauvaises intentions pourront être dans un déni crédible puisque, après tout, ils ne cibleront pas directement des catégories protégées, ils viseront seulement les individus en fonction de leur comportement. Et l’ensemble du système sera encore plus opaque pour les utilisatrices et les régulateurs.
Avec Google les instruments changent, mais c’est toujours la même musique…
Google, ne faites pas ça, s’il vous plaît
Nous nous sommes déjà prononcés sur l’AFC et son lot de propositions initiales lorsque tout cela a été présenté pour la première fois, en décrivant l’AFC comme une technologie « contraire à la vie privée ». Nous avons espéré que les processus de vérification des standards mettraient l’accent sur les défauts de base de l’AFC et inciteraient Google à renoncer à son projet. Bien entendu, plusieurs problèmes soulevés sur leur GitHub officiel exposaient exactement les mêmespréoccupations que les nôtres. Et pourtant, Google a poursuivi le développement de son système, sans pratiquement rien changer de fondamental. Ils ont commencé à déployer leur discours sur l’AFC auprès des publicitaires, en vantant le remplacement du ciblage basé sur les cookies par l’AFC « avec une efficacité de 95 % ». Et à partir de la version 89 de Chrome, depuis le 2 mars, la technologie est déployée pour un galop d’essai. Une petite fraction d’utilisateurs de Chrome – ce qui fait tout de même plusieurs millions – a été assignée aux tests de cette nouvelle technologie.
Ne vous y trompez pas, si Google poursuit encore son projet d’implémenter l’AFC dans Chrome, il donnera probablement à chacun les « options » nécessaires. Le système laissera probablement le choix par défaut aux publicitaires qui en tireront bénéfice, mais sera imposé par défaut aux utilisateurs qui en seront affectés. Google se glorifiera certainement de ce pas en avant vers « la transparence et le contrôle par l’utilisateur », en sachant pertinemment que l’énorme majorité de ceux-ci ne comprendront pas comment fonctionne l’AFC et que très peu d’entre eux choisiront de désactiver cette fonctionnalité. L’entreprise se félicitera elle-même d’avoir initié une nouvelle ère de confidentialité sur le Web, débarrassée des vilains cookies tiers, cette même technologie que Google a contribué à développer bien au-delà de sa date limite, engrangeant des milliards de dollars au passage.
Ce n’est pas une fatalité. Les parties les plus importantes du bac-à-sable de la confidentialité comme l’abandon des identificateurs tiers ou la lutte contre le pistage des empreintes numériques vont réellement améliorer le Web. Google peut choisir de démanteler le vieil échafaudage de surveillance sans le remplacer par une nouveauté nuisible.
Nous rejetons vigoureusement le devenir de l’AFC. Ce n’est pas le monde que nous voulons, ni celui que méritent les utilisatrices. Google a besoin de tirer des leçons pertinentes de l’époque du pistage par des tiers et doit concevoir son navigateur pour l’activité de ses utilisateurs et utilisatrices, pas pour les publicitaires.
Remarque : nous avons contacté Google pour vérifier certains éléments exposés dans ce billet ainsi que pour demander davantage d’informations sur le test initial en cours. Nous n’avons reçu aucune réponse à ce jour.
Libres bulles pour que décollent les contributions
Comme beaucoup d’associations libristes, nous recevons fréquemment ce genre de demandes « je vous suis depuis longtemps et je voudrais contribuer un peu au Libre, comment commencer ? »
Pour y répondre, ce qui n’est pas toujours facile, une dynamique équipe s’est constituée avec le soutien de Framasoft et a fondé le projet Contribulle qui propose déjà d’aiguiller chacun⋅e vers des contributions à sa mesure. Pour comprendre comment ça marche et quel intérêt vous avez à les rejoindre, nous leur avons posé des questions…
« Bulles de savon » par Daniel_Hache, licence CC BY-ND 2.0
Bonjour la team Contribulle ! On vous a rencontré⋅e⋅s sur l’archipel de Contributopia, mais pouvez-vous vous présenter, nous dire de quels horizons vous venez ?
– Hello, je suis llaq (ou lelibreauquotidien), je suis dans le logiciel libre depuis quelques années depuis qu’un ami m’a offert un PC sous Linux (bon, quand j’étais sous Windows, j’utilisais déjà des logiciels libres mais c’était pas un argument rédhibitoire).
— Yo ! Oui on se baladait dans le coin, l’horizon qui se présentait à nous paraissait bien prometteur ! Je suis Mélanie mais vous pouvez m’appeler méli, j’ai bientôt 25 ans et je viens du monde du design UX et UI. En explorant le numérique, j’ai pas mal gravité autour du Libre et mon mémoire de master de l’année dernière m’a bien fait plonger dans ce sujet super passionnant ! Fun fact : je me demandais comment rendre le logiciel libre plus ouvert (!), pour mieux accueillir une diversité de contributions et il faut dire que votre campagne Contributopia m’a pas mal guidée héhé. Le projet Contribulle a en partie émergé à cette période-là et je suis contente de le poursuivre, toujours en tant que designeuse UX/UI !
– Hello ! Je suis Maiwann, membre de Framasoft… une petite asso que vous connaissez peut-être ? Et je suis designer.
Laissez-moi deviner : Contribulle, c’est un dispositif pour enfermer les contributeurs et contributrices d’un projet dans une bulle et alors quand ça monte ça éclate et le projet explose ? Non, c’est pas ça ?
llaq : C’est presque ça. Contribulle est une plateforme qui permet de mettre en relation des projets aux besoins assez spécifiques avec des contributeur·rice·s intéressé·e·s, qu’iels soient dans le domaine technique ou non. Un des buts du site est d’ailleurs de permettre aux non-techniques de contribuer à des projets libres et surtout de démontrer que la contribution, c’est pas seulement pour les codeur·se·s.
méli : Haha, ce nom a été voté par jugement majoritaire ! Perso, j’imagine une bulle qui est amenée à grossir grâce aux contributions des personnes et qui sera tellement géante qu’il sera impossible de la rater. Et peut-être qu’elle pourrait attirer d’autres contributions !
Maiwann : … Et moi j’imagine plein de petites bulles comme un nuage de bulles de savon quand on souffle dans le petit cercle ! Et elles s’envolent… loin… loiiiiiin ! Jusqu’à ce qu’on en fasse une nouvelle fournée 🙂
« Bubbles » by bogenfreund, licence CC BY-SA 2.0
Ah mais c’est tout neuf cette plateforme ? Comment est venue l’idée de proposer ça ? Et d’ailleurs ça paraît tellement utile qu’on se demande pourquoi ça n’existait pas avant.
méli : Pendant mon mémoire, j’avais retenu qu’il était compliqué de s’y retrouver parmi tous les projets libres créés et qu’il était encore plus difficile de savoir où et comment contribuer au Libre, surtout en tant que non-développeur·se. J’avais donc rapidement imaginé un site qui recenserait des projets libres à la recherche de compétences et qui permettrait d’attirer des contributeur·rice·s de tous horizons. Je ne savais pas s’il existait déjà une plateforme de ce type dans laquelle je pourrais m’inscrire.
Quelques déambulations plus tard, je suis tombée sur la restitution du fameux événement coorganisé par Framasoft et la Quadrature du Net « Fabulous Contribution Camp » de novembre 2017. J’y ai trouvé une idée similaire au site que j’imaginais et je contacte donc Maiwann pour avoir des nouvelles sur l’évolution de ce projet. On s’appelle en janvier 2020 (merci BigBlueButton) et il s’avère que rien n’avait été mis en place et qu’il manquait un tremplin pour lancer le projet. C’est donc à partir de là que ça a décollé. Si la suite intéresse : J’ai ensuite réalisé une maquette de la plateforme, qui avait pour nom de code « Meetic du Libre ». J’ai pu la présenter au cours d’un Confinatelier en juin 2020 avec Maiwann. On avait pour objectifs de valider la pertinence du projet et ensuite de mobiliser des personnes qui souhaiteraient bien y contribuer. Les retours nous ont rassuré⋅e⋅s et on a pu monter un groupe de travail rapidement.
Cependant, avec l’été qui se profilait, le site était juste débutant jusqu’à ce que Maiwann nous relance fin octobre. Depuis novembre, l’équipe est un peu plus réduite : on est 2 designeuses, 1 développeur front et 1 développeur back et on s’organise des rendez-vous hebdomadaires pour avancer. Des personnes nous ont aussi aidé⋅e⋅s ponctuellement, que ce soit aux niveaux code, graphisme et design, on leur en est super reconnaissant·e·s ! Grâce aux efforts et la bonne humeur de tou·te·s les contributeur·rices, on a pu mettre en ligne Contribulle en février 2021, une grande fierté !
Est-ce qu’il faut s’inscrire avec ses coordonnées et tout ?
llaq : Pour les personnes qui créent une demande de contribution, il n’est pas nécessaire de créer de compte. Il faut simplement renseigner une adresse email valide et un pseudo pour que les contributeur·rice·s qui le souhaitent puissent contacter la personne qui a créé l’annonce.
Maiwann : On a fait en sorte d’être le plus minimalistes possibles dans le nombre d’infos demandées. Du coup, exit la création de compte pour ne pas se farcir un énième identifiant-mot-de-passe ! En revanche, on demande un moyen de contact aux personnes qui recherchent des contributeurices, pour être sûres qu’elles vont pouvoir s’adresser à un humain !
Combien ça coûte ?
llaq : Rien. Plus sérieusement, dans le projet, nous sommes tou·te·s bénévoles et les ressources techniques servant à l’hébergement de contribulle.org nous ont gracieusement été offertes par notre partenaire Framasoft, donc aucun frais pour nous, aucune raison de faire payer la plateforme donc 🙂
méli : Dans la perspective de mettre en avant des projets qui participent à l’émancipation individuelle et collective des individus et qui sont bien évidemment respectueux de nos libertés, on ne souhaite pas faire payer pour poster une annonce. On veut inviter le plus grand nombre à mettre la main à la pâte donc on préfère éviter de poser des contraintes financières dès le départ !
Maiwann : Ça a coûté du temps et de l’énergie à des gens compétents de se retrouver, de décider d’une direction pour le projet, de faire des choix, de les maquetter / coder, + les frais d’hébergement. Et ça va coûter de l’énergie dans le futur pour faire vivre Contribulle, donc si vous en parlez le plus possible autour de vous, ça nous aidera beaucoup et ça contribuera à faire vivre Contribulle !
Si j’ai un projet génial mais que je ne sais rien faire du tout, je peux juste vous donner mon idée géniale et vous allez vous en charger et tout faire pour moi ?
méli : Mmmh Contribulle n’est pas un service de travail gratuit… mais c’est chouette si tu as une bonne idée de projet, si tu sens qu’elle a du potentiel et qu’elle est valide…
À quel(s) besoin(s) répond-elle ?
Quelle est sa valeur ajoutée pour les futur·e·s utilisateur·rices ?
…
…tu peux lister précisément les compétences requises. Contribulle a vocation de faciliter la compréhension de contributions auprès des personnes qui veulent aider. C’est pour ça qu’il nous semble nécessaire dans le formulaire de demande de contribution de bien présenter le projet et de donner plus d’indications sur la contribution souhaitée. Un projet se doit d’être sérieux et conscient du temps et de l’effort qu’un·e contributeur·rice y consacrera.
logo du projet Contribulle
Un point qu’il est important de mentionner est l’accueil des contributeur·rice·s au sein d’un projet. Il ne faut pas prendre l’aide d’une personne externe comme acquise et surtout la surexploiter parce que (friendly reminder) : on a nos vies et nos priorités à gérer.
Un projet doit mettre en place un dispositif pour faciliter l’accès à la contribution, que ce soit une page dédiée, une conversation épistolaire, le format est libre et à adapter selon les parties prenantes !
Attention cependant aux renvois directs vers les forges logicielles comme GitHub ou GitLab qui ne sont pas si accessibles pour les non-techniques. Peut-être qu’un tutorat personnalisé peut s’envisager ?
Bref, soyons plus à l’écoute des contributeur·rice·s ! Et pour les contributeur·rice·s : écoutez-vous et n’hésitez pas à dire quand un truc vous gêne, la communication fait tout.
Comment je vais savoir que d’autres sont intéressée⋅es par mon projet ou que ma contribution intéresse d’autres ?
llaq : On n’a pas de messagerie intégrée, tout se fait par le mail que vous avez indiqué dans votre annonce. Maiwann : comme ça, pas besoin de revenir sur la plateforme, ouf ! Vous postez et c’est réglé !
Attention c’est le moment trollifère : les projets sur lesquels on peut contribuer c’est du libre ou open source ou bien osef ?
llaq : Nous comptons justement implémenter un bandeau qui s’affichera si le projet est libre ou pas (c’est-à-dire bénéficiant d’une licence libre) ! Mais sa place sur Contribulle va dépendre de l’équipe de modération composée de 4 personnes pour l’instant.
méli : La valeur (politique) des projets publiés sera prise en compte. Parmi les questions à se poser : pour qui est le projet ? Participe-t-il au bien collectif ? Comment permettrait-il à tou·te·s les utilisateur·rices de disposer de leurs appareils ainsi que de leurs données personnelles ?
Maiwann : On voudrait que tous les projets soient sous licence libre, mais on est aussi conscient·es que tout le monde n’est pas forcément au clair sur l’intérêt que ça peut avoir, l’importance… donc on se dit qu’on poussera les personnes à s’y intéresser à l’aide du bandeau, mais sans les disqualifier forcément d’entrée (et on verra ça au cas par cas !)
C’est évalué comment et par qui, le « sérieux » ou la pertinence des projets et contributions ? Chacun⋅e s’autonomise et hop ?
llaq : Nous avons décidé de faire de la modération à posteriori. Ton annonce est directement publiée et visible par tout le monde mais si l’équipe de modération estime que le projet n’a pas sa place sur Contribulle, il sera supprimé de la plateforme. Maiwann : et si c’est trop relou, on passera à de la modération a priori ! Et pour faire des choix, ça sera sans doute au doigt mouillé, au « comment chacune le sent » et puis on verra sur le tas comment se structure l’équipe de modération ! Pour l’instant, RAS 🙂
« bubbles » par Mycatkins, licence CC BY 2.0
Et donc si je veux contribuller au projet, je peux faire quoi ?
méli : Pour l’instant, nous faire des retours sur vos usages de Contribulle et la promouvoir autour de vous seraient de belles contributions ! On souhaite l’améliorer au mieux selon les besoins ressentis de chacun·e.
La question de rétribution n’a pas encore été abordée mais selon l’évolution de la plateforme et des ressources mobilisées, des formes sont à réfléchir je pense. Qu’il s’agisse de don financier, d’un retour d’utilisateur·rice, ou autre.
Maiwann : Je pense que ce qui va être primordial ça va être de faire vivre Contribulle. Quelqu’un dit qu’il voudrait aider le Libre ? glissez lui un mot sur Contribulle. Quelqu’un vient à un contrib’atelier ? N’oubliez pas de parler de Contribulle. Comme ça le projet vivra grâce aux visites des contributeurices !
Ah mais il y a déjà un paquet de demandes, ça fait un peu peur, je vois bien que je ne vais servir à rien pour tous ces trucs de techies ! Au secours ! (Pour l’instant dans l’équipe c’est orienté web développement non) ?
méli : c’est 50/50 moitié dev et moitié design/conception. Oui, on a dépassé les 20 annonces depuis sa mise en ligne il y a un mois, c’est trop bien ! Et on cherche vraiment à mettre en avant des contributions non-techniques parce que tu es super utile justement ! Prochainement tu pourras filtrer les annonces selon tes propres savoir-faire, en espérant qu’il y aura des demandes à ce niveau-là. En attendant, on te propose des contributions faciles. Tu seras renvoyé·e vers des sites sélectionnés par nos soins et auxquelles tu peux directement contribuer. Bonne contribution !
Maiwann : C’est tout à fait ça, grâce aux filtres tu vas pouvoir plus facilement mettre de côté les choses qui font peur !
Et si je regarde, il y a déjà quelques projets qui sont chouettes et que tu peux aider sans compétences techniques, par exemple :
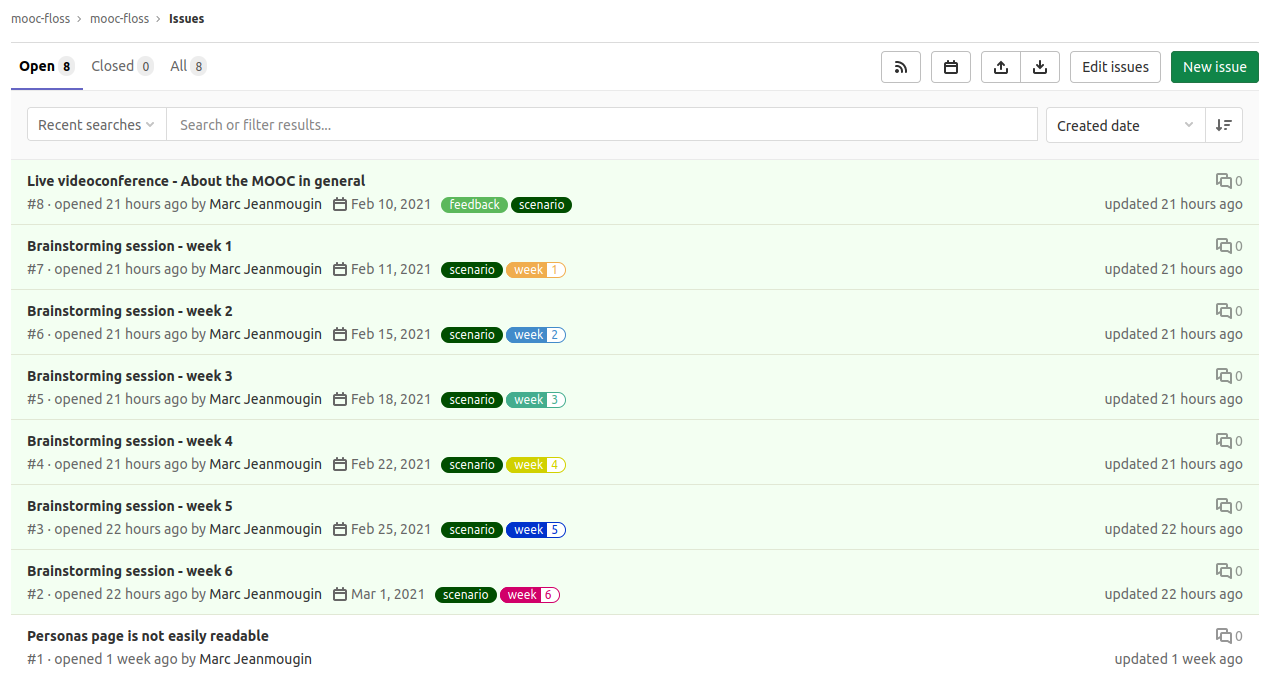
You are invited to contribute to the future « Contributing to Free-Libre Open Source Software » MOOC by Télécom Paris and Framasoft
Interested in contributing to the contents production of a MOOC about FLOSS contribution? You already have a contribution experience and think it can be useful to new contributors? Join us!
Leading Internet users into the world of contribution
Last September we were so delighted to learn that Marc Jeanmougin, a research engineer at Télécom Paris, wanted Framasoft to be associated with his online course projet on FLOSS contributions that had just been funded by the Institut Mines-Télécom.
We have been dreaming about it: a MOOC to learn how to contribute to free-libre software
Developing digital tools that facilitate individuals’ contributions is one of the lines of our Contributopia campaign. On this subject we already have set up Contribateliers (and their online version Confinateliers): workshops to discover how each of us can contribute to free-libre software. Implemented in 2018 in Lyon, those interventions now take place in cities (Lyon, Paris, Toulouse, Grenoble and Nantes) allowing people to contribute to the free-libre software and free culture in a user-friendly way.
This is also the case with the Contribulle project we are hosting: a platform where projects with the same free-libre software values are connected with those without enough skills and contributors who could give them a hand. This nice initiative is slowly taking shape and we think it will be a great success in the coming months.
Finally, the aim with this Contributing to FLOSS MOOC is to allow developers to get both a theoretical (what is it about?) and practical introduction (how to contact somebody? and how to contribute?) to the world of FLOSS contribution.
All these initiatives allow users of free-libre services to learn how to contribute and to stop using a software only as if it were a finished product.
Contributing to develop the Contributing to FLOSS MOOC
After a first day in October, talking about pedagogical sequencing in a small committee, the prefiguration team decided that given the MOOC subject, it would not be totally far-fetched to allow people who want to co-produce contents with us to do so.
We also have created a dedicated Matrix chatroom in order to have a daily and more informal exchange with you. Do not hesitate to join us there to learn more about this project.
We invite you to exchange in video conference on this project on February, 10th at 6:30pm. At the same time we will present you the general organization of the MOOC and the choices we have made both educationally (what angle on FLOSS we will try to take) and technically. We will also discuss how we envisage contributions to contents production.
If after this first exchange you want to help us with contents preparation, you can participate in 6 other online brainstorming sessions, each one dedicated to the contents of one week of the MOOC. They will take place on Mondays and Thursdays between 6:30pm and 8pm from February 11th to March 1st (details of access and contents will be published on the gitlab issues with each session).
GitLab issues with details of access and contents of the 6 meetings we offer.
We hope we will see many of you at those different events. But as we know it’s not always easy to be available on a set time slot, we offer to collect your reactions, feedbacks or comments before each session on our repository. Do not hesitate to write down whatever comes to your mind!
Télécom Paris et Framasoft vous invitent à contribuer au futur MOOC « Contributing to Free-Libre and Open Source Software »
Participer à la production des contenus d’un MOOC dont le sujet est la contribution aux logiciels libres, ça vous tente ? Vous avez déjà contribué à des logiciels libres et vous pensez que votre expérience peut aider des apprenti·es contributeur·ices ? Rejoignez-nous !
Continuer à accompagner les internautes dans l’univers de la contribution
Lorsqu’en septembre dernier, Marc Jeanmougin, ingénieur de recherche à Télécom Paris, nous contactait pour nous informer que son projet de cours en ligne sur la contribution au logiciel libre venait d’obtenir un financement de l’Institut Mines-Télécom et qu’il souhaitait que Framasoft soit associé à ce projet, on a été super emballé·es !
Un MOOC (cours en ligne massivement ouvert) pour apprendre à contribuer au logiciel libre, on en rêvait !
C’est d’ailleurs l’un des axes de notre campagne Contributopia que de concrétiser des outils numériques qui facilitent les contributions de chacun·e. Dans ce domaine, nous avons déjà initié les Contribateliers (et leur version en ligne, les Confinateliers), des ateliers pour découvrir comment chacun·e d’entre nous peut contribuer au logiciel libre. Lancé en 2018 à Lyon, ce dispositif existe désormais dans 5 villes (Lyon, Paris, Toulouse, Grenoble et Nantes) et permet à toutes et tous de contribuer aux logiciels libres et à la culture libre en toute convivialité.
C’est aussi ce que nous faisons en offrant un hébergement au projet Contribulle, une plateforme de mise en relation entre des projets partageant les valeurs du logiciel libre et des communs qui manquent de compétences, et des contributeur·rices qui pourraient leur donner un coup de main. Cette chouette initiative prend doucement forme et on ne doute pas qu’elle rencontrera un fort succès dans les mois à venir.
Enfin, avec ce MOOC Contributing to FLOSS, l’objectif est de permettre à des développeur·euses d’avoir une introduction théorique (de quoi parle-t-on ?) comme pratique (comment entrer en contact, comment contribuer ?) à l’univers de la contribution au libre.
Toutes ces initiatives sont l’occasion pour les utilisateur·ices de services libres d’apprendre à contribuer et d’arrêter de consommer simplement le logiciel comme s’il était un produit fini.
Contribuer à la réalisation du MOOC Contributing to FLOSS
Après une première journée en petit comité en octobre pour échanger sur le séquençage pédagogique, l’équipe de préfiguration s’est dit que vu le sujet du MOOC, ce ne serait pas totalement tiré par les cheveux que de permettre à celles et ceux qui le souhaitent de co-produire avec nous les contenus.
Nous avons aussi créé un salon Matrix dédié afin de pouvoir échanger de manière plus informelle avec vous au quotidien. N’hésitez pas à nous y rejoindre pour avoir davantage de précisions sur ce projet.
Nous vous invitons à un temps d’échanges autour du projet le mercredi 10 février à 18h30 en visioconférence. Ce sera l’occasion de vous présenter l’organisation générale du MOOC et les choix que nous avons effectués, tant au plan pédagogique (quel angle sur les FLOSS nous essaierons de prendre) qu’au plan technique. Nous échangerons aussi sur la façon dont nous envisageons les contributions à la production des contenus.
Si à la suite de ce premier temps d’échanges, vous êtes partant·es pour nous aider sur la préparation des contenus, on vous propose de participer à 6 autres sessions de brainstorming en ligne, chacune de ces sessions étant dédiée aux contenus d’une semaine du MOOC. Ces sessions se tiendront les lundis et jeudis entre 18h30 et 20h sur la période du 11 février au 1er mars (les détails d’accès et des contenus discutés seront publiés sur les tickets associés à chaque session).
Tickets sur lesquels vous trouverez détails d’accès et contenus des 6 rendez-vous que nous vous proposons.
On vous espère nombreu·ses lors de ces différents rendez-vous. Mais comme nous savons qu’il n’est pas toujours évident de se libérer sur un créneau fixe, nous proposons de recueillir en amont de chaque session vos réactions, notes ou commentaires. N’hésitez donc pas à aller y noter ce qui vous passe par la tête !
Le Fediverse et l’avenir des réseaux décentralisés
Le Fediverse est un réseau social multiforme qui repose sur une fédération de serveurs interconnectés. C’est un phénomène assez jeune encore, mais dont la croissance suscite déjà l’intérêt et des questionnements. Parmi les travaux d’analyse qui s’efforcent de prendre une distance critique, nous vous proposons « Sept thèses sur le Fediverse et le devenir du logiciel libre »
Cette traduction Framalang vous arrive aujourd’hui avec presque un an de retard. Le document était intégralement traduit par l’équipe de Framalang dès le printemps 2020, mais nous avons tergiversé sur sa publication, car nous souhaitions un support différent du blog, où les contributions auraient pu se répondre. Mais entre le premier confinement et d’autres projets qui sont venus s’intercaler… Cependant le débat reste possible, non seulement les commentaires sont ouverts (et modérés) comme d’habitude, mais nous serions ravis de recueillir d’autres contributions qui voudraient s’emparer du thème du Fediverse pour apporter un nouvel éclairage sur ce phénomène encore jeune et en devenir. N’hésitez pas à publier votre analyse sur un blog personnel ou à défaut, ici même si vous le souhaitez.
Référence : Aymeric Mansoux et Roel Roscam Abbing, « Seven Theses on the Fediverse and the becoming of FLOSS », dans Kristoffer Gansing et Inga Luchs (éds.), The Eternal Network. The Ends and Becomings of Network Culture, Institute of Network Cultures, Amsterdam, 2020, p. 124-140. En ligne.
Ces dernières années, dans un contexte de critiques constantes et de lassitude généralisée associées aux plates-formes de médias sociaux commerciaux1, le désir de construire des alternatives s’est renforcé. Cela s’est traduit par une grande variété de projets animés par divers objectifs. Les projets en question ont mis en avant leurs différences avec les médias sociaux des grandes plates-formes, que ce soit par leur éthique, leur structure, les technologies qui les sous-tendent, leurs fonctionnalités, l’accès au code source ou encore les communautés construites autour d’intérêts spécifiques qu’ils cherchent à soutenir. Bien que diverses, ces plates-formes tendent vers un objectif commun : remettre clairement en question l’asservissement à une plate-forme unique dans le paysage des médias sociaux dominants. Par conséquent, ces projets nécessitent différents niveaux de décentralisation et d’interopérabilité en termes d’architecture des réseaux et de circulation de données. Ces plates-formes sont regroupées sous le terme de « Fédiverse », un mot-valise composé de « Fédération » et « univers ». La fédération est un concept qui vient de la théorie politique par lequel divers acteurs qui se constituent en réseau décident de coopérer tous ensemble. Les pouvoirs et responsabilités sont distribués à mesure que se forme le réseau. Dans le contexte des médias sociaux, les réseaux fédérés sont portés par diverses communautés sur différents serveurs qui peuvent interagir mutuellement, plutôt qu’à travers un logiciel ou une plate-forme unique. Cette idée n’est pas nouvelle, mais elle a récemment gagné en popularité et a réactivé les efforts visant à construire des médias sociaux alternatifs2.
Les tentatives précédentes de créer des plates-formes de médias sociaux fédérés venaient des communautés FLOSS (Free/Libre and Open Source software, les logiciels libres et open source3) qui avaient traditionnellement intérêt à procurer des alternatives libres aux logiciels propriétaires et privateurs dont les sources sont fermées. En tant que tels, ces projets se présentaient en mettant l’accent sur la similarité de leurs fonctions avec les plates-formes commerciales tout en étant réalisés à partir de FLOSS. Principalement articulées autour de l’ouverture des protocoles et du code source, ces plates-formes logicielles ne répondaient aux besoins que d’une audience modeste d’utilisateurs et de développeurs de logiciels qui étaient en grande partie concernés par les questions typiques de la culture FLOSS.
La portée limitée de ces tentatives a été dépassée en 2016 avec l’apparition de Mastodon, une combinaison de logiciels client et serveur pour les médias sociaux fédérés. Mastodon a été rapidement adopté par une communauté diversifiée d’utilisateurs et d’utilisatrices, dont de nombreuses personnes habituellement sous-représentées dans les FLOSS : les femmes, les personnes de couleur et les personnes s’identifiant comme LGBTQ+. En rejoignant Mastodon, ces communautés moins représentées ont remis en question la dynamique des environnements FLOSS existants ; elles ont également commencé à contribuer autant au code qu’à la contestation du modèle unique dominant des médias sociaux commerciaux dominants. Ce n’est pas une coïncidence si ce changement s’est produit dans le sillage du Gamergate4 en 2014, de la montée de l’alt-right et des élections présidentielles américaines de 2016. Fin 2017, Mastodon a dépassé le million d’utilisateurs qui voulaient essayer le Fédiverse comme une solution alternative aux plates-formes de médias sociaux commerciaux. Ils ont pu y tester par eux-mêmes si une infrastructure différente peut ou non conduire à des discours, des cultures et des espaces sûrs (safe spaces) différents.
Aujourd’hui, le Fédiverse comporte plus de 3,5 millions de comptes répartis sur près de 5 000 serveurs, appelés « instances », qui utilisent des projets logiciels tels que Friendica, Funkwhale, Hubzilla, Mastodon, Misskey, PeerTube, PixelFed et Pleroma, pour n’en citer que quelques-uns5. La plupart de ces instances peuvent être interconnectées et sont souvent focalisées sur une pratique, une idéologie ou une activité professionnelle spécifique. Dans cette optique, le projet Fédiverse démontre qu’il est non seulement techniquement possible de passer de gigantesques réseaux sociaux universels à de petites instances interconnectées, mais qu’il répond également à un besoin concret.
On peut considérer que la popularité actuelle du Fédiverse est due à deux tendances conjointes. Tout d’abord, le désir d’opérer des choix techniques spécifiques pour résoudre les problèmes posés par les protocoles fermés et les plates-formes propriétaires. Deuxièmement, une volonté plus large des utilisateurs de récupérer leur souveraineté sur les infrastructures des médias sociaux. Plus précisément, alors que les plates-formes de médias sociaux commerciaux ont permis à beaucoup de personnes de publier du contenu en ligne, le plus grand impact du Web 2.0 a été le découplage apparent des questions d’infrastructure des questions d’organisation sociale. Le mélange de systèmes d’exploitation et de systèmes sociaux qui a donné naissance à la culture du Net6 a été remplacé par un système de permissions et de privilèges limités pour les utilisateurs. Ceux qui s’engagent dans le Fédiverse travaillent à défaire ce découplage. Ils veulent contribuer à des infrastructures de réseau qui soient plus honnêtes quant à leurs idéologies sous-jacentes.
Ces nouvelles infrastructures ne se cachent pas derrière des manipulations d’idées en trompe-l’œil comme l’ouverture, l’accès universel ou l’ingénierie apolitique. Bien qu’il soit trop tôt aujourd’hui pour dire si le Fédiverse sera à la hauteur des attentes de celles et ceux qui la constituent et quel sera son impact à long terme sur les FLOSS, il est déjà possible de dresser la carte des transformations en cours, ainsi que des défis à relever dans ce dernier épisode de la saga sans fin de la culture du Net et de l’informatique. C’est pourquoi nous présentons sept thèses sur le Fédiverse et le devenir des FLOSS, dans l’espoir d’ouvrir le débat autour de certaines des questions les plus urgentes qu’elles soulèvent.
« interlace » par Joachim Aspenlaub Blattboldt, licence CC BY-NC-ND 2.0
Nous reconnaissons volontiers que toute réflexion sérieuse sur la culture du Net aujourd’hui doit traiter de la question des mèmes d’une façon ou d’une autre. Mais que peut-on ajouter au débat sur les mèmes en 2020 ? Il semble que tout ait déjà été débattu, combattu et exploité jusqu’à la corde par les universitaires comme par les artistes. Que nous reste-t-il à faire sinon nous tenir régulièrement au courant des derniers mèmes et de leur signification ? On oublie trop souvent que de façon cruciale, les mèmes ne peuvent exister ex nihilo. Il y a des systèmes qui permettent leur circulation et leur amplification : les plateformes de médias sociaux.
Les plateformes de médias sociaux ont démocratisé la production et la circulation des mèmes à un degré jamais vu jusqu’alors. De plus, ces plateformes se sont développées en symbiose avec la culture des mèmes sur Internet. Les plateformes de médias sociaux commerciaux ont été optimisées et conçues pour favoriser les contenus aptes à devenir des mèmes. Ces contenus encouragent les réactions et la rediffusion, ils participent à une stratégie de rétention des utilisateurs et de participation au capitalisme de surveillance. Par conséquent, dans les environnements en usage aujourd’hui pour la majeure partie des communications en ligne, presque tout est devenu un mème, ou doit afficher l’aptitude à en devenir un pour survivre — du moins pour être visible — au sein d’un univers de fils d’actualités gouvernés par des algorithmes et de flux contrôlés par des mesures7.
Comme les médias sociaux sont concentrés sur la communication et les interactions, on a complètement sous-estimé la façon dont les mèmes deviendraient bien plus que des vecteurs stratégiquement conçus pour implanter des idées, ou encore des trucs amusants et viraux à partager avec ses semblables. Ils sont devenus un langage, un argot, une collection de signes et de symboles à travers lesquels l’identité culturelle ou sous-culturelle peut se manifester. La circulation de tels mèmes a en retour renforcé certains discours politiques qui sont devenus une préoccupation croissante pour les plateformes. En effet, pour maximiser l’exploitation de l’activité des utilisateurs, les médias sociaux commerciaux doivent trouver le bon équilibre entre le laissez-faire et la régulation.
Ils tentent de le faire à l’aide d’un filtrage algorithmique, de retours d’utilisateurs et de conditions d’utilisation. Cependant, les plateformes commerciales sont de plus en plus confrontées au fait qu’elles ont créé de véritables boites de Pétri permettant à toutes sortes d’opinions et de croyances de circuler sans aucun contrôle, en dépit de leurs efforts visant à réduire et façonner le contenu discursif de leurs utilisateurs en une inoffensive et banale substance compatible avec leur commerce.
Malgré ce que les plateformes prétendent dans leurs campagnes de relations publiques ou lors des auditions des législateurs, il est clair qu’aucun solutionnisme technologique ni aucun travail externalisé et précarisé réalisé par des modérateurs humains traumatisés8 ne les aidera à reprendre le contrôle. En conséquence de l’augmentation de la surveillance menée par les plateformes de médias sociaux commerciaux, tous ceux qui sont exclus ou blessés dans ces environnements se sont davantage intéressés à l’idée de migrer sur d’autres plateformes qu’ils pourraient maîtriser eux-mêmes.
Les raisons incitant à une migration varient. Des groupes LGBTQ+ cherchent des espaces sûrs pour éviter l’intimidation et le harcèlement. Des suprémacistes blancs recherchent des plateformes au sein desquelles leur interprétation de la liberté d’expression n’est pas contestée. Raddle, un clone radicalisé, s’est développé à la suite de son exclusion du forum Reddit original ; à l’extrême-droite, il y a Voat, un autre clone de Reddit9. Ces deux plateformes ont développé leurs propres FLOSS en réponse à leur exclusion.
Au-delà de l’accès au code source, ce qui vaut aux FLOSS la considération générale, on ignore étonnamment l’un des avantages essentiels et historiques de la pratique des FLOSS : la capacité d’utiliser le travail des autres et de s’appuyer sur cette base. Il semble important aujourd’hui de développer le même logiciel pour un public réduit, et de s’assurer que le code source n’est pas influencé par les contributions d’une autre communauté. C’est une évolution récente dans les communautés FLOSS, qui ont souvent défendu que leur travail est apolitique.
C’est pourquoi, si nous nous mettons à évoquer les mèmes aujourd’hui, nous devons parler de ces plateformes de médias sociaux. Nous devons parler de ces environnements qui permettent, pour le meilleur comme pour le pire, une sédimentation du savoir : en effet, lorsqu’un discours spécifique s’accumule en ligne, il attire et nourrit une communauté, via des boucles de rétroaction qui forment des assemblages mémétiques. Nous devons parler de ce processus qui est permis par les Floss et qui en affecte la perception dans le même temps. Les plateformes de médias sociaux commerciaux ont décidé de censurer tout ce qui pourrait mettre en danger leurs affaires, tout en restant ambivalentes quant à leur prétendue neutralité10.
Mais contrairement à l’exode massif de certaines communautés et à leur repli dans la conception de leur propre logiciel, le Fédiverse offre plutôt un vaste système dans lequel les communautés peuvent être indépendantes tout en étant connectées à d’autres communautés sur d’autres serveurs. Dans une situation où la censure ou l’exil en isolement étaient les seules options, la fédération ouvre une troisième voie. Elle permet à une communauté de participer aux échanges ou d’entrer en conflit avec d’autres plateformes tout en restant fidèle à son cadre, son idéologie et ses intérêts.
Dès lors, deux nouveaux scénarios sont possibles : premièrement, une culture en ligne localisée pourrait être mise en place et adoptée dans le cadre de la circulation des conversations dans un réseau de communication partagé. Deuxièmement, des propos mémétiques extrêmes seraient susceptibles de favoriser l’émergence d’une pensée axée sur la dualité amis/ennemis entre instances, au point que les guerres de mèmes et la propagande simplistes seraient remplacés par des guerres de réseaux.
« Network » par photobunny, licence CC BY-NC-ND 2.0
Les concepts d’ouverture, d’universalité, et de libre circulation de l’information ont été au cœur des récits pour promouvoir le progrès technologique et la croissance sur Internet et le Web. Bien que ces concepts aient été instrumentalisés pour défendre les logiciels libres et la culture du libre, ils ont aussi été cruciaux dans le développement des médias sociaux, dont le but consistait à créer des réseaux en constante croissance, pour embarquer toujours davantage de personnes communiquant librement les unes avec les autres. En suivant la tradition libérale, cette approche a été considérée comme favorisant les échanges d’opinion fertiles en fournissant un immense espace pour la liberté d’expression, l’accès à davantage d’informations et la possibilité pour n’importe qui de participer.
Cependant, ces systèmes ouverts étaient également ouverts à leur accaparement par le marché et exposés à la culture prédatrice des méga-entreprises. Dans le cas du Web, cela a conduit à des modèles lucratifs qui exploitent à la fois les structures et le contenu circulant11 dans tout le réseau.
Revenons à la situation actuelle : les médias sociaux commerciaux dirigent la surveillance des individus et prédisent leur comportement afin de les convaincre d’acheter des produits et d’adhérer à des idées politiques. Historiquement, des projets de médias sociaux alternatifs tels que GNU Social, et plus précisément Identi.ca/StatusNet, ont cherché à s’extirper de cette situation en créant des plateformes qui contrevenaient à cette forme particulière d’ouverture sur-commercialisée.
Ils ont créé des systèmes interopérables explicitement opposés à la publicité et au pistage par les traqueurs. Ainsi faisant, ils espéraient prouver qu’il est toujours possible de créer un réseau à la croissance indéfinie tout en distribuant la responsabilité de la détention des données et, en théorie, de fournir les moyens à des communautés variées de s’approprier le code source des plateformes ainsi que de contribuer à la conception du protocole.
C’était en somme la conviction partagée sur le Fédiverse vers 2016. Cette croyance n’a pas été remise en question, car le Fédiverse de l’époque n’avait pas beaucoup dévié du projet d’origine d’un logiciel libre de média social fédéré, lancé une décennie plus tôt.
Par conséquent, le Fédiverse était composé d’une foule très homogène, dont les intérêts recoupaient la technologie, les logiciels libres et les idéologies anti-capitalistes. Cependant, alors que la population du Fédiverse s’est diversifiée lorsque Mastodon a attiré des communautés plus hétérogènes, des conflits sont apparus entre ces différentes communautés. Cette fois, il s’agissait de l’idée même d’ouverture du Fédiverse qui était de plus en plus remise en question par les nouveaux venus. Contribuant à la critique, un appel a émergé de la base d’utilisateurs de Mastodon en faveur de la possibilité de bloquer ou « défédérer » d’autres serveurs du Fédiverse.
Bloquer signifie que les utilisateurs ou les administrateurs de serveurs pouvaient empêcher le contenu d’autres serveurs sur le réseau de leur parvenir. « Défédérer », dans ce sens, est devenu une possibilité supplémentaire dans la boîte à outils d’une modération communautaire forte, qui permettait de ne plus être confronté à du contenu indésirable ou dangereux. Au début, l’introduction de la défédération a causé beaucoup de frictions parmi les utilisateurs d’autres logiciels du Fédiverse. Les plaintes fréquentes contre Mastodon qui « cassait la fédération » soulignent à quel point ce changement était vu comme une menace pour le réseau tout entier12. Selon ce point de vue, plus le réseau pouvait grandir et s’interconnecter, plus il aurait de succès en tant qu’alternative aux médias sociaux commerciaux. De la même manière, beaucoup voyaient le blocage comme une contrainte sur les possibilités d’expression personnelle et d’échanges d’idées constructifs, craignant qu’il s’ensuive l’arrivée de bulles de filtres et d’isolement de communautés.
En cherchant la déconnexion sélective et en contestant l’idée même que le débat en ligne est forcément fructueux, les communautés qui se battaient pour la défédération ont aussi remis en cause les présupposés libéraux sur l’ouverture et l’universalité sur lesquels les logiciels précédents du Fédiverse étaient construits. Le fait qu’en parallèle à ces développements, le Fédiverse soit passé de 200 000 à plus de 3,5 millions de comptes au moment d’écrire ces lignes, n’est probablement pas une coïncidence. Plutôt que d’entraver le réseau, la défédération, les communautés auto-gouvernées et le rejet de l’universalité ont permis au Fédiverse d’accueillir encore plus de communautés. La présence de différents serveurs qui représentent des communautés si distinctes qui ont chacune leur propre culture locale et leur capacité d’action sur leur propre partie du réseau, sans être isolée de l’ensemble plus vaste, est l’un des aspects les plus intéressants du Fédiverse. Cependant, presque un million du nombre total de comptes sont le résultat du passage de la plateforme d’extrême-droite Gab aux protocoles du Fédiverse, ce qui montre que le réseau est toujours sujet à la captation et à la domination par une tierce partie unique et puissante13. Dans le même temps, cet événement a immédiatement déclenché divers efforts pour permettre aux serveurs de contrer ce risque de domination.
Par exemple, la possibilité pour certaines implémentations de serveurs de se fédérer sur la base de listes blanches, qui permettent aux serveurs de s’interconnecter au cas par cas, au lieu de se déconnecter au cas par cas. Une autre réponse qui a été proposée consistait à étendre le protocole ActivityPub, l’un des protocoles les plus populaires et discutés du Fédiverse, en ajoutant des méthodes d’autorisation plus fortes à base d’un modèle de sécurité informatique qui repose sur la capacité des objets (Object-capability model). Ce modèle permet à un acteur de retirer, a posteriori, la possibilité à d’autres acteurs de voir ou d’utiliser ses données. Ce qui est unique à propos du Fédiverse c’est cette reconnaissance à la fois culturelle et technique que l’ouverture a ses limites, et qu’elle est elle-même ouverte à des interprétations plus ou moins larges en fonction du contexte, qui n’est pas fixe dans le temps. C’est un nouveau point de départ fondamental pour imaginer de nouveaux médias sociaux.
« interlace » par Interlace Explorer, licence CC BY-NC-SA 2.0
Comme nous l’avons établi précédemment, une des caractéristiques du Fédiverse tient aux différentes couches logicielles et applications qui la constituent et qui peuvent virtuellement être utilisées par n’importe qui et dans n’importe quel but. Cela signifie qu’il est possible de créer une communauté en ligne qui peut se connecter au reste du Fédiverse mais qui opère selon ses propres règles, sa propre ligne de conduite, son propre mode d’organisation et sa propre idéologie. Dans ce processus, chaque communauté est capable de se définir elle-même non plus uniquement par un langage mémétique, un intérêt, une perspective commune, mais aussi par ses relations aux autres, en se différenciant. Une telle spécificité peut faire ressembler le Fédiverse à un assemblage d’infrastructures qui suivrait les principes du pluralisme agonistique. Le pluralisme agonistique, ou agonisme, a d’abord été conçu par Ernesto Laclau et Chantal Mouffe, qui l’ont par la suite développé en une théorie politique. Pour Mouffe, à l’intérieur d’un ordre hégémonique unique, le consensus politique est impossible. Une négativité radicale est inévitable dans un système où la diversité se limite à des groupes antagonistes14.
La thèse de Mouffe s’attaque aux systèmes démocratiques où les politiques qui seraient en dehors de ce que le consensus libéral juge acceptable sont systématiquement exclues. Toutefois, ce processus est aussi à l’œuvre sur les plateformes de médias sociaux commerciaux, dans le sens où ces dernières forment et contrôlent le discours pour qu’il reste acceptable par le paradigme libéral, et qu’il s’aligne sur ses propres intérêts commerciaux. Ceci a conduit à une radicalisation de celles et ceux qui en sont exclus.
Le pari fait par l’agonisme est qu’en créant un système dans lequel un pluralisme d’hégémonies est permis, il devienne possible de passer d’une conception de l’autre en tant qu’ennemi à une conception de l’autre en tant qu’adversaire politique. Pour que cela se produise, il faut permettre à différentes idéologies de se matérialiser par le biais de différents canaux et plateformes. Une condition préalable importante est que l’objectif du consensus politique doit être abandonné et remplacé par un consensus conflictuel, dans lequel la reconnaissance de l’autre devient l’élément de base des nouvelles relations, même si cela signifie, par exemple, accepter des points de vue non occidentaux sur la démocratie, la laïcité, les communautés et l’individu.
Pour ce qui est du Fédiverse, il est clair qu’il contient déjà un paysage politique relativement diversifié et que les transitions du consensus politique au consensus conflictuel peuvent être constatées au travers de la manière dont les communautés se comportent les unes envers les autres. À la base de ces échanges conflictuels se trouvent divers points de vue sur la conception et l’utilisation collectives de toutes les couches logicielles et des protocoles sous-jacents qui seraient nécessaires pour permettre une sorte de pluralisme agonistique en ligne.
Cela dit, les discussions autour de l’usage susmentionné du blocage d’instance et de la défédération sont férocement débattues, et, au moment où nous écrivons ces lignes, avec la présence apparemment irréconciliable de factions d’extrême gauche et d’extrême droite dans l’univers de la fédération, les réalités de l’antagonisme seront très difficiles à résoudre. La conception du Fédiverse comme système dans lequel les différentes communautés peuvent trouver leur place parmi les autres a été concrètement mise à l’épreuve en juillet 2019, lorsque la plateforme explicitement d’extrême droite, Gab, a annoncé qu’elle modifierait sa base de code, s’éloignant de son système propriétaire pour s’appuyer plutôt sur le code source de Mastodon.
En tant que projet qui prend explicitement position contre l’idéologie de Gab, Mastodon a été confronté à la neutralité des licences FLOSS. D’autres projets du Fédiverse, tels que les clients de téléphonie mobile FediLab et Tusky, ont également été confrontés au même problème, peut-être même plus, car la motivation directe des développeurs de Gab pour passer aux logiciels du Fédiverse était de contourner leur interdiction des app stores d’Apple et de Google pour violation de leurs conditions de service. En s’appuyant sur les clients génériques de logiciels libres du Fédiverse, Gab pourrait échapper à de telles interdictions à l’avenir, et aussi forger des alliances avec d’autres instances idéologiquement compatibles sur le Fédiverse15.
Dans le cadre d’une stratégie antifasciste plus large visant à dé-plateformer et à bloquer Gab sur le Fédiverse, des appels ont été lancés aux développeurs de logiciels pour qu’ils ajoutent du code qui empêcherait d’utiliser leurs clients pour se connecter aux serveurs Gab. Cela a donné lieu à des débats approfondis sur la nature des logiciels libres et open source, sur l’efficacité de telles mesures quant aux modifications du code source public, étant donné qu’elles peuvent être facilement annulées, et sur le positionnement politique des développeurs et mainteneurs de logiciels.
Au cœur de ce conflit se trouve la question de la neutralité du code, du réseau et des protocoles. Un client doit-il – ou même peut-il – être neutre ? Le fait de redoubler de neutralité signifie-t-il que les mainteneurs tolèrent l’idéologie d’extrême-droite ? Que signifie bloquer ou ne pas bloquer une autre instance ? Cette dernière question a créé un va-et-vient compliqué où certaines instances demanderont à d’autres instances de prendre part explicitement au conflit, en bloquant d’autres instances spécifiques afin d’éviter d’être elles-mêmes bloquées. La neutralité, qu’elle soit motivée par l’ambivalence, le soutien tacite, l’hypocrisie, le désir de troller, le manque d’intérêt, la foi dans une technologie apolitique ou par un désir agonistique de s’engager avec toutes les parties afin de parvenir à un état de consensus conflictuel… la neutralité donc est très difficile à atteindre. Le Fédiverse est l’environnement le plus proche que nous ayons actuellement d’un réseau mondial diversifié de singularités locales. Cependant, sa topologie complexe et sa lutte pour faire face au tristement célèbre paradoxe de la tolérance – que faire de l’idée de liberté d’expression ? – montre la difficulté d’atteindre un état de consensus conflictuel. Elle montre également le défi que représente la traduction d’une théorie de l’agonisme en une stratégie partagée pour la conception de protocoles, de logiciels et de directives communautaires. La tolérance et la liberté d’expression sont devenues des sujets explosifs après près de deux décennies de manipulation politique et de filtrage au sein des médias sociaux des grandes entreprises ; quand on voit que les plateformes et autres forums de discussion populaires n’ont pas réussi à résoudre ces problèmes, on n’est guère enclin à espérer en des expérimentations futures.
Plutôt que d’atteindre un état de pluralisme agonistique, il se pourrait que le Fédiverse crée au mieux une forme d’agonisme bâtard par le biais de la pilarisation. En d’autres termes, nous pourrions assister à une situation dans laquelle des instances ne formeraient de grandes agrégations agonistes-sans-agonisme qu’entre des communautés et des logiciels compatibles tant sur le plan idéologique que technique, seule une minorité d’entre elles étant capable et désireuse de faire le pont avec des systèmes radicalement opposés. Quelle que soit l’issue, cette question de l’agonisme et de la politique en général est cruciale pour la culture du réseau et de l’informatique. Dans le contexte des systèmes post-politiques occidentaux et de la manière dont ils prennent forme sur le net, un sentiment de déclin de l’esprit partisan et de l’action militante politique a donné l’illusion, ou plutôt la désillusion, qu’il n’y a plus de boussole politique. Si le Fédiverse nous apprend quelque chose, c’est que le réseau et les composants de logiciel libres de son infrastructure n’ont jamais été aussi politisés qu’aujourd’hui. Les positions politiques qui sont générées et hébergées sur le Fédiverse ne sont pas insignifiantes, mais sont clairement articulées. De plus, comme le montre la prolifération de célébrités politiques et de politiciens utilisant activement les médias sociaux, une nouvelle forme de démocratie représentative émerge, dans laquelle le langage mémétique des cultures post-numériques se déplace effectivement dans le monde de la politique électorale et inversement16.
« THINK Together » par waynewhuang licence CC BY-NC 2.0
Par le passé, les débats sur les risques des médias sociaux commerciaux se sont focalisés sur les questions de vie privée et de surveillance, surtout depuis les révélations de Snowden en 2013. Par conséquent, de nombreuses réponses techniques, en particulier celles issues des communautés FLOSS, se sont concentrées sur la sécurité des traitements des données personnelles. Cela peut être illustré par la multiplication des applications de messagerie et de courrier électronique chiffrées post-Snowden17. La menace perçue par ces communautés est la possibilité de surveillance du réseau, soit par des agences gouvernementales, soit par de grandes entreprises.
Les solutions proposées sont donc des outils qui implémentent un chiffrement fort à la fois dans le contenu et dans la transmission du message en utilisant idéalement des topologies de réseaux de pair à pair qui garantissent l’anonymat. Ces approches, malgré leur rigueur, requièrent des connaissances techniques considérables de la part des utilisateurs.
Le Fédiverse bascule alors d’une conception à dominante technique vers une conception plus sociale de la vie privée, comme l’ont clairement montré les discussions qui ont eu lieu au sein de l’outil de suivi de bug de Mastodon, lors de ces premières étapes de développement. Le modèle de menace qui y est discuté comprend les autres utilisateurs du réseau, les associations accidentelles entre des comptes et les dynamiques des conversations en ligne elles-mêmes. Cela signifie qu’au lieu de se concentrer sur des caractéristiques techniques telles que les réseaux de pair à pair et le chiffrement de bout en bout, le développement a été axé sur la construction d’outils de modération robustes, sur des paramétrages fins de la visibilité des messages et sur la possibilité de bloquer d’autres instances.
Ces fonctionnalités, qui favorisent une approche plus sociale de la protection de la vie privée, ont été développées et défendues par les membres des communautés marginalisées, dont une grande partie se revendique comme queer. Comme le note Sarah Jamie Lewis :
Une grande partie de la rhétorique actuelle autour des […] outils de protection de la vie privée est axée sur la surveillance de l’État. Les communautés LGBTQI+ souhaitent parfois cacher des choses à certains de leurs parents et amis, tout en pouvant partager une partie de leur vie avec d’autres. Se faire des amis, se rencontrer, échapper à des situations violentes, accéder à des services de santé, s’explorer et explorer les autres, trouver un emploi, pratiquer le commerce du sexe en toute sécurité… sont autant d’aspects de la vie de cette communauté qui sont mal pris en compte par ceux qui travaillent aujourd’hui sur la protection de la vie privée18.
Alors que tout le monde a intérêt à prendre en compte les impacts sur la vie privée d’interactions (non sollicitées) entre des comptes d’utilisateurs, par exemple entre un employeur et un employé, les communautés marginalisées sont affectées de manière disproportionnée par ces formes de surveillance et leurs conséquences. Lorsque la conception de nouvelles plateformes sur le Fédiverse comme Mastodon a commencé — avec l’aide de membre de ces communautés — ces enjeux ont trouvé leur place sur les feuilles de route de développement des logiciels. Soudain, les outils de remontée de défauts techniques sont également devenus un lieu de débat de questions sociales, culturelles et politiques. Nous reviendrons sur ce point dans la section six.
Les technologies qui ont finalement été développées comprennent le blocage au niveau d’une instance, des outils de modérations avancés, des avertissements sur la teneur des contenus et une meilleure accessibilité. Cela a permis à des communautés géographiquement, culturellement et idéologiquement disparates de partager le même réseau selon leurs propres conditions. De ce fait, le Fédiverse peut être compris comme un ensemble de communautés qui se rallient autour d’un serveur, ou une instance, afin de créer un environnement où chacun se sent à l’aise. Là encore, cela constitue une troisième voie : ni un modèle dans lequel seuls ceux qui ont des aptitudes techniques maîtrisent pleinement leurs communications, ni un scénario dans lequel la majorité pense n’avoir « rien à cacher » simplement parce qu’elle n’a pas son mot à dire ni le contrôle sur les systèmes dont elle est tributaire. En effet, le changement vers une perception sociale de la vie privée a montré que le Fédiverse est désormais un laboratoire dans lequel on ne peut plus prétendre que les questions d’organisation sociale et de gouvernance sont détachées des logiciels.
Ce qui compte, c’est que le Fédiverse marque une évolution de la définition des questions de surveillance et de protection de la vie privée comme des problématiques techniques vers leur formulation en tant qu’enjeux sociaux. Cependant, l’accent mis sur la dimension sociale de la vie privée s’est jusqu’à présent limité à placer sa confiance dans d’autres serveurs et administrateurs pour qu’ils agissent avec respect.
Cela peut être problématique dans le cas par exemple des messages directs (privés), par leur confidentialité inhérente, qui seraient bien mieux gérés avec des solutions techniques telles que le chiffrement de bout en bout. De plus, de nombreuses solutions recherchées dans le développement des logiciels du Fédiverse semblent être basées sur le collectif plutôt que sur l’individu. Cela ne veut pas dire que les considérations de sécurité technique n’ont aucune importance. Les serveurs du Fédiverse ont tendance à être équipés de paramètres de « confidentialité par défaut », tels que le nécessaire chiffrement de transport et le proxy des requêtes distantes afin de ne pas exposer les utilisateurs individuels.
Néanmoins, cette évolution vers une approche sociale de la vie privée n’en est qu’à ses débuts, et la discussion doit se poursuivre sur de nombreux autres plans.
« Liseron sur ombelles » par philolep, licence CC BY-NC-SA 2.0
Les grandes plateformes de médias sociaux, qui se concentrent sur l’utilisation de statistiques pour récompenser leur usage et sur la gamification, sont tristement célèbres pour utiliser autant qu’elles le peuvent le travail gratuit. Quelle que soit l’information introduite dans le système, elle sera utilisée pour créer directement ou indirectement des modélisations, des rapports et de nouveaux jeux de données qui possèdent un intérêt économique fondamental pour les propriétaires de ces plateformes : bienvenue dans le monde du capitalisme de surveillance19.
Jusqu’à présent il a été extrêmement difficile de réglementer ces produits et services, en partie à cause du lobbying intense des propriétaires de plateformes et de leurs actionnaires, mais aussi et peut-être de façon plus décisive, à cause de la nature dérivée de la monétisation qui est au cœur des entreprises de médias sociaux. Ce qui est capitalisé par ces plateformes est un sous-produit algorithmique, brut ou non, de l’activité et des données téléchargées par ses utilisateurs et utilisatrices. Cela crée un fossé qui rend toujours plus difficile d’appréhender la relation entre le travail en ligne, le contenu créé par les utilisateurs, le pistage et la monétisation.
Cet éloignement fonctionne en réalité de deux façons. D’abord, il occulte les mécanismes réels qui sont à l’œuvre, ce qui rend plus difficile la régulation de la collecte des données et leur analyse. Il permet de créer des situations dans lesquelles ces plateformes peuvent développer des produits dont elles peuvent tirer profit tout en respectant les lois sur la protection de la vie privée de différentes juridictions, et donc promouvoir leurs services comme respectueux de la vie privée. Cette stratégie est souvent renforcée en donnant à leurs utilisatrices et utilisateurs toutes sortes d’options pour les induire en erreur et leur faire croire qu’ils ont le contrôle de ce dont ils alimentent la machine.
Ensuite, en faisant comme si aucune donnée personnelle identifiable n’était directement utilisée pour être monétisée ; ces plateformes dissimulent leurs transactions financières derrière d’autres sortes de transactions, comme les interactions personnelles entre utilisatrices, les opportunités de carrière, les groupes et discussion gérés par des communautés en ligne, etc. Au bout du compte, les utilisateurs s’avèrent incapables de faire le lien entre leur activité sociale ou professionnelle et son exploitation, parce tout dérive d’autres transactions qui sont devenues essentielles pour nos vies connectées en permanence, en particulier à l’ère de l’« entrepecariat » et de la connectivité quasi obligatoire au réseau.
Nous l’avons vu précédemment : l’approche sociale de la vie privée en ligne a influencé la conception initiale de Mastodon, et le Fédiverse offre une perspective nouvelle sur le problème du capitalisme de surveillance. La question de l’usage des données des utilisateurs et utilisatrices et la façon dont on la traite, au niveau des protocoles et de l’interface utilisateur, sont des points abordés de façon transparente et ouverte. Les discussions se déroulent publiquement à la fois sur le Fédiverse et dans les plateformes de suivi du logiciel. Les utilisateurs expérimentés du Fédiverse ou l’administratrice locale d’un groupe Fédiverse, expliquent systématiquement aux nouveaux utilisateurs la façon dont les données circulent lorsqu’ils rejoignent une instance.
Cet accueil permet généralement d’expliquer comment la fédération fonctionne et ce que cela implique concernant la visibilité et l’accès aux données partagées par ces nouveaux utilisateurs21. Cela fait écho à ce que Robert Gehl désigne comme une des caractéristiques des plateformes de réseaux sociaux alternatifs. Le réseau comme ses coulisses ont une fonction pédagogique. On indique aux nouvelles personnes qui s’inscrivent comment utiliser la plateforme et chacun peut, au-delà des permissions utilisateur limitées, participer à son développement, à son administration et à son organisation22. En ce sens, les utilisateurs et utilisatrices sont incitées par le Fédiverse à participer activement, au-delà de simples publications et « likes » et sont sensibilisés à la façon dont leurs données circulent.
Pourtant, quel que soit le niveau d’organisation, d’autonomie et d’implication d’une communauté dans la maintenance de la plateforme et du réseau (au passage, plonger dans le code est plus facile à dire qu’à faire), rien ne garantit un plus grand contrôle sur les données personnelles. On peut facilement récolter et extraire des données de ces plateformes et cela se fait plus facilement que sur des réseaux sociaux privés. En effet, les services commerciaux des réseaux sociaux privés protègent activement leurs silos de données contre toute exploitation extérieure.
Actuellement, il est très facile d’explorer le Fédiverse et d’analyser les profils de ses utilisatrices et utilisateurs. Bien que la plupart des plateformes du Fédiverse combattent le pistage des utilisateurs et la collecte de leurs données, des tiers peuvent utiliser ces informations. En effet, le Fédiverse fonctionne comme un réseau ouvert, conçu à l’origine pour que les messages soient publics. De plus, étant donné que certains sujets, notamment des discussions politiques, sont hébergées sur des serveurs spécifiques, les communautés de militant⋅e⋅s peuvent être plus facilement exposées à la surveillance. Bien que le Fédiverse aide les utilisateurs à comprendre, ou à se rappeler, que tout ce qui est publié en ligne peut échapper et échappera à leur contrôle, elle ne peut pas empêcher toutes les habitudes et le faux sentiment de sécurité hérités des réseaux sociaux commerciaux de persister, surtout après deux décennies de désinformation au sujet de la vie privée numérique23.
De plus, bien que l’exploitation du travail des utilisateurs et utilisatrices ne soit pas la même que sur les plateformes de médias sociaux commerciaux, il reste sur ce réseau des problèmes autour de la notion de travail. Pour les comprendre, nous devons d’abord admettre les dégâts causés, d’une part, par la merveilleuse utilisation gratuite des réseaux sociaux privés, et d’autre part, par la mécompréhension du fonctionnement des logiciels libres ou open source : à savoir, la manière dont la lutte des travailleurs et la question du travail ont été masquées dans ces processus24.
Cette situation a incité les gens à croire que le développement des logiciels, la maintenance des serveurs et les services en ligne devraient être mis gratuitement à leur disposition. Les plateformes de média sociaux commerciaux sont justement capables de gérer financièrement leurs infrastructures précisément grâce à la monétisation des contenus et des activités de leurs utilisateurs. Dans un système où cette méthode est évitée, impossible ou fermement rejetée, la question du travail et de l’exploitation apparaît au niveau de l’administration des serveurs et du développement des logiciels et concerne tous celles et ceux qui contribuent à la conception, à la gestion et à la maintenance de ces infrastructures.
Pour répondre à ce problème, la tendance sur le Fédiverse consiste à rendre explicites les coûts de fonctionnement d’un serveur communautaire. Tant les utilisatrices que les administrateurs encouragent le financement des différents projets par des donations, reconnaissant ainsi que la création et la maintenance de ces plateformes coûtent de l’argent. Des projets de premier plan comme Mastodon disposent de davantage de fonds et ont mis en place un système permettant aux contributeurs d’être rémunérés pour leur travail25.
Ces tentatives pour compenser le travail des contributeurs sont un pas en avant, cependant étendre et maintenir ces projets sur du long terme demande un soutien plus structurel. Sans financement significatif du développement et de la maintenance, ces projets continueront à dépendre de l’exploitation du travail gratuit effectué par des volontaires bien intentionnés ou des caprices des personnes consacrant leur temps libre au logiciel libre. Dans le même temps, il est de plus en plus admis, et il existe des exemples, que le logiciel libre peut être considéré comme un bien d’utilité publique qui devrait être financé par des ressources publiques26. À une époque où la régulation des médias sociaux commerciaux est débattue en raison de leur rôle dans l’érosion des institutions publiques, le manque de financement public d’alternatives non prédatrices devrait être examiné de manière plus active.
Enfin, dans certains cas, les personnes qui accomplissent des tâches non techniques comme la modération sont rémunérées par les communautés du Fédiverse. On peut se demander pourquoi, lorsqu’il existe une rémunération, certaines formes de travail sont payées et d’autres non. Qu’en est-il par exemple du travail initial et essentiel de prévenance et de critique fourni par les membres des communautés marginalisées qui se sont exprimés sur la façon dont les projets du Fédiverse devraient prendre en compte une interprétation sociale de la protection de la vie privée ? Il ne fait aucun doute que c’est ce travail qui a permis au Fédiverse d’atteindre le nombre d’utilisateurs qu’elle a aujourd’hui.
Du reste comment cette activité peut-elle être évaluée ? Elle se manifeste dans l’ensemble du réseau, dans des fils de méta-discussions ou dans les systèmes de suivi, et n’est donc pas aussi quantifiable ou visible que la contribution au code. Donc, même si des évolutions intéressantes se produisent, il reste à voir si les utilisateurs et les développeuses du Fédiverse peuvent prendre pleinement conscience de ces enjeux et si les modèles économiques placés extérieurs au capitalisme de surveillance peuvent réussir à soutenir une solidarité et une attention sans exploitation sur tous les maillons de la chaîne.
« Liseron sur ombelles » par philolep, licence CC BY-NC-SA 2.0
« basket weaving » par cloudberrynine, licence CC BY-NC-ND 2.0
On peut envisager le Fédiverse comme un ensemble de pratiques, ou plutôt un ensemble d’attentes et de demandes concernant les logiciels de médias sociaux, dans lesquels les efforts disparates de projets de médias sociaux alternatifs convergent en un réseau partagé avec des objectifs plus ou moins similaires. Les différents modèles d’utilisation, partagés entre les serveurs, vont de plateformes d’extrême-droite financées par le capital-risque à des systèmes de publication d’images japonaises, en passant par des collectifs anarcho-communistes, des groupes politiques, des amateurs d’algorithmes de codage en direct, des « espaces sûrs » pour les travailleur⋅euse⋅s du sexe, des forums de jardinage, des blogs personnels et des coopératives d’auto-hébergement. Ces pratiques se forment parallèlement au problème du partage des données et du travail gratuit, et font partie de la transformation continuelle de ce que cela implique d’être utilisateur ou utilisatrice de logiciel.
Les premiers utilisateurs de logiciels, ou utilisateurs d’appareils de calcul, étaient aussi leurs programmeuses et programmeurs, qui fournissaient ensuite les outils et la documentation pour que d’autres puissent contribuer au développement et à l’utilisation de ces systèmes27.
Ce rôle était si important que les premières communautés d’utilisateurs furent pleinement soutenues et prises en charge par les fabricants de matériel.
Avance rapide de quelques décennies et, avec la croissance de l’industrie informatique, la notion d’ « utilisateur » a complètement changé pour signifier « consommateur apprivoisé » avec des possibilités limitées de contribution ou de modification des systèmes qu’ils utilisent, au-delà de personnalisations triviales ou cosmétiques. C’est cette situation qui a contribué à façonner une grande partie de la popularité croissante des FLOSS dans les années 90, en tant qu’adversaires des systèmes d’exploitation commerciaux propriétaires pour les ordinateurs personnels, renforçant particulièrement les concepts antérieurs de liberté des utilisateurs28. Avec l’avènement du Web 2.0, la situation changea de nouveau. En raison de la dimension communicative et omniprésente des logiciels derrière les plateformes de médias sociaux d’entreprises, les fournisseurs ont commencé à offrir une petite ouverture pour un retour de la part de leurs utilisateurs, afin de rendre leur produit plus attrayant et pertinent au quotidien. Les utilisateurs peuvent généralement signaler facilement les bugs, suggérer de nouvelles fonctionnalités ou contribuer à façonner la culture des plateformes par leurs échanges et le contenu partagés. Twitter en est un exemple bien connu, où des fonctionnalités essentielles, telles que les noms d’utilisateur préfixés par @ et les hashtags par #, ont d’abord été suggérés par les utilisateurs. Les forums comme Reddit permettent également aux utilisateurs de définir et modérer des pages, créant ainsi des communautés distinctes et spécifiques.
Sur les plateformes alternatives de médias sociaux comme le Fédiverse, en particulier à ses débuts, ces formes de participation vont plus loin. Les utilisatrices et utilisateurs ne se contentent pas de signaler des bogues ou d’aider a la création d’une culture des produits, ils s’impliquent également dans le contrôle du code, dans le débat sur ses effets et même dans la contribution au code. À mesure que le Fédiverse prend de l’ampleur et englobe une plus grande diversité de cultures et de logiciels, les comportements par rapport à ses usages deviennent plus étendus. Les gens mettent en place des nœuds supplémentaires dans le réseau, travaillent à l’élaboration de codes de conduite et de conditions de service adaptées, qui contribuent à l’application de lignes directrices communautaires pour ces nœuds. Ils examinent également comment rendre ces efforts durables par un financement via la communauté.
Ceci dit, toutes les demandes de changement, y compris les contributions pleinement fonctionnelles au code, ne sont pas acceptées par les principaux développeurs des plateformes. Cela s’explique en partie par le fait que les plus grandes plateformes du Fédiverse reposent sur des paramètres par défaut, bien réfléchis, qui fonctionnent pour ces majorités diverses, plutôt que l’ancien modèle archétypique de FLOSS, pour permettre une personnalisation poussée et des options qui plaisent aux programmeurs, mais en découragent beaucoup d’autres. Grâce à la disponibilité du code source, un riche écosystème de versions modifiées de projets (des forks) existe néanmoins, qui permet d’étendre ou de limiter certaines fonctionnalités tout en conservant un certain degré de compatibilité avec le réseau plus large.
Les débats sur les mérites des fonctionnalités et des logiciels modifiés qu’elles génèrent nourrissent de plus amples discussions sur l’orientation de ces projets, qui à leur tour conduisent à une attention accrue autour de leur gouvernance.
Il est certain que ces développements ne sont ni nouveaux ni spécifiques au Fédiverse. La manière dont les facilitateurs de services sont soutenus sur le Fédiverse, par exemple, est analogue à la manière dont les créateurs de contenu sur les plateformes de streaming au sein des communautés de jeux sont soutenus par leur public. Des appels à une meilleure gouvernance des projets logiciels sont également en cours dans les communautés FLOSS plus largement. L’élaboration de codes de conduite (un document clé pour les instances de la Fédiverse mis en place pour exposer leur vision de la communauté et de la politique) a été introduit dans diverses communautés FLOSS au début des années 2010, en réponse à la misogynie systématique et à la l’exclusion des minorités des espaces FLOSS à la fois en ligne et hors ligne29. Les codes de conduite répondent également au besoin de formes génératrices de résolution des conflits par-delà les barrières culturelles et linguistiques.
De même, bon nombre des pratiques de modération et de gestion communautaire observées dans le Fédiverse ont hérité des expériences d’autres plateformes, des succès et défaillances d’autres outils et systèmes. La synthèse et la coordination de toutes ces pratiques deviennent de plus en plus visibles dans l’univers fédéré.
En retour, les questions et les approches abordées dans le Fédiverse ont créé un précédent pour d’autres projets des FLOSS, en encourageant des transformations des discussions qui étaient jusqu’alors limitées ou difficiles à engager.
Il n’est pas évident, compte tenu de la diversité des modèles d’utilisation, que l’ensemble du Fédiverse fonctionne suivant cette tendance. Les développements décrits ci-dessus suggèrent cependant que de nombreux modèles d’utilisation restent à découvrir et que le Fédiverse est un environnement favorable pour les tester. La nature évolutive de l’utilisation du Fédiverse montre à quel point l’écart est grand entre les extrêmes stéréotypés du modèle capitaliste de surveillance et du martyre auto-infligé des plateformes de bénévolat. Ce qui a des implications sur le rôle des utilisateurs en relation avec les médias sociaux alternatifs, ainsi que pour le développement de la culture des FLOSS30.
« What a tangled web we weave….. » par Pandiyan, licence CC BY-NC 2.0
Jusqu’à présent, la grande majorité des discussions autour des licences FLOSS sont restées enfermées dans une comparaison cliché entre l’accent mis par le logiciel libre sur l’éthique de l’utilisateur et l’approche de l’open source qui repose sur l’économie31.
Qu’ils soient motivés par l’éthique ou l’économie, les logiciels libres et les logiciels open source partagent l’idéal selon lequel leur position est supérieure à celle des logiciels fermés et aux modes de production propriétaires. Toutefois, dans les deux cas, le moteur libéral à la base de ces perspectives éthiques et économiques est rarement remis en question. Il est profondément enraciné dans un contexte occidental qui, au cours des dernières décennies, a favorisé la liberté comme le conçoivent les libéraux et les libertariens aux dépens de l’égalité et du social.
Remettre en question ce principe est une étape cruciale, car cela ouvrirait des discussions sur d’autres façons d’aborder l’écriture, la diffusion et la disponibilité du code source. Par extension, cela mettrait fin à la prétention selon laquelle ces pratiques seraient soit apolitiques, soit universelles, soit neutres.
Malheureusement, de telles discussions ont été difficiles à faire émerger pour des raisons qui vont au-delà de la nature dogmatique des agendas des logiciels libres et open source. En fait, elles ont été inconcevables car l’un des aspects les plus importants des FLOSS est qu’ils ont été conçus comme étant de nature non discriminatoire. Par « non discriminatoire », nous entendons les licences FLOSS qui permettent à quiconque d’utiliser le code source des FLOSS à n’importe quelle fin.
Certains efforts ont été faits pour tenter de résoudre ce problème, par exemple au niveau de l’octroi de licences discriminatoires pour protéger les productions appartenant aux travailleurs, ou pour exclure l’utilisation par l’armée et les services de renseignement32.
Ces efforts ont été mal accueillis en raison de la base non discriminatoire des FLOSS et de leur discours. Pis, la principale préoccupation du plaidoyer en faveur des FLOSS a toujours été l’adoption généralisée dans l’administration, l’éducation, les environnements professionnels et commerciaux, et la dépolitisation a été considérée comme la clé pour atteindre cet objectif. Cependant, plus récemment, la croyance en une dépolitisation, ou sa stratégie, ont commencé à souffrir de plusieurs manières.
Tout d’abord, l’apparition de ce nouveau type d’usager a entraîné une nouvelle remise en cause des modèles archétypaux de gouvernance des projets de FLOSS, comme celui du « dictateur bienveillant ». En conséquence, plusieurs projets FLOSS de longue date ont été poussés à créer des structures de compte-rendu et à migrer vers des formes de gouvernance orientées vers la communauté, telles que les coopératives ou les associations.
Deuxièmement, les licences tendent maintenant à être combinées avec d’autres documents textuels tels que les accords de transfert de droits d’auteur, les conditions de service et les codes de conduite. Ces documents sont utilisés pour façonner la communauté, rendre leur cohérence idéologique plus claire et tenter d’empêcher manipulations et malentendus autour de notions vagues comme l’ouverture, la transparence et la liberté.
Troisièmement, la forte coloration politique du code source remet en question la conception actuelle des FLOSS. Comme indiqué précédemment, certains de ces efforts sont motivés par le désir d’éviter la censure et le contrôle des plateformes sociales des entreprises, tandis que d’autres cherchent explicitement à développer des logiciels à usage antifasciste. Ces objectifs interrogent non seulement l’universalité et l’utilité globale des grandes plateformes de médias sociaux, ils questionnent également la supposée universalité et la neutralité des logiciels. Cela est particulièrement vrai lorsque les logiciels présentent des conditions, codes et accords complémentaires explicites pour leurs utilisateurs et les développeuses.
Avec sa base relativement diversifiée d’utilisatrices, de développeurs, d’agenda, de logiciels et d’idéologies, le Fédiverse devient progressivement le système le plus pertinent pour l’articulation de nouvelles formes de la critique des FLOSS. Il est devenu un endroit où les notions traditionnelles sur les FLOSS sont confrontées et révisées par des personnes qui comprennent son utilisation dans le cadre d’un ensemble plus large de pratiques qui remettent en cause le statu quo. Cela se produit parfois dans un contexte de réflexion, à travers plusieurs communautés, parfois par la concrétisation d’expériences et des projets qui remettent directement en question les FLOSS tels que nous les connaissons. C’est devenu un lieu aux multiples ramifications où les critiques constructives des FLOSS et l’aspiration à leur réinvention sont très vives. En l’état, la culture FLOSS ressemble à une collection rapiécée de pièces irréconciliables provenant d’un autre temps et il est urgent de réévaluer nombre de ses caractéristiques qui étaient considérées comme acquises.
Si nous pouvons accepter le sacrilège nécessaire de penser au logiciel libre sans le logiciel libre, il reste à voir ce qui pourrait combler le vide laissé par son absence.
Consulter Geert Lovink, Sad by Design: On Platform Nihilism (Triste par essence: Du nihilisme des plates-formes, non traduit en français), London: Pluto Press, 2019. ↩
Dans tout ce document nous utiliserons « médias sociaux commerciaux » et « médias sociaux alternatifs » selon les définitions de Robert W. Gehl dans « The Case for Alternative Social Media » (Pour des médias sociaux alternatifs, non traduit en français), Social Media + Society, juillet-décembre 2015, p. 1-12. En ligne. ↩
Danyl Strype, « A Brief History of the GNU Social Fediverse and ‘The Federation’ » (Une brève histoire de GNU Social, du Fédiverse et de la ‘fédération’, non traduit en français), Disintermedia, 1er Avril 2017. En ligne. ↩
Pour une exploration du #GamerGate et des technocultures toxiques, consulter Adrienne Massanari, « #Gamergate and The Fappening: How Reddit’s Algorithm, Governance, and Culture Support Toxic Technocultures » (#GamerGate et Fappening : comment les algorithmes, la gouvernance et la culture de Reddit soutiennent les technocultures toxiques, non traduit en français), New Media & Society, 19(3), 2016, p. 329-346. ↩
En raison de la nature décentralisée du Fédiverse, il n’est pas facile d’obtenir les chiffres exacts du nombre d’utilisateurs, mais quelques projets tentent de mesurer la taille du réseau: The Federation ; Fediverse Network ; Mastodon Users, Bitcoin Hackers. ↩
Pour un exemple de ce type de mélange, consulter Michael Rossman, « Implications of Community Memory » (Implications du projet Community Memory, non traduit en français) SIGCAS – Computers & Society, 6(4), 1975, p. 7-10. ↩
Aymeric Mansoux, « Surface Web Times » (L’ère du Web de surface, non traduit en français), MCD, 69, 2013, p. 50-53. ↩
Burcu Gültekin Punsmann, « What I learned from three months of Content Moderation for Facebook in Berlin » (Ce que j’ai appris de trois mois de modération de contenu pour Facebook à Berlin, non traduit en français), SZ Magazin, 6 January 2018. En ligne. ↩
Gabriella Coleman, « The Political Agnosticism of Free and Open Source Software and the Inadvertent Politics of Contrast » (L’agnosticisme politique des FLOSS et la politique involontaire du contraste, non traduit en français), Anthropological Quarterly, 77(3), 2004, p. 507-519. ↩
Pour une discussion plus approfondie sur les multiples possibilités procurés par l’ouverture mais aussi pour un commentaire sur le librewashing, voyez l’article de Jeffrey Pomerantz and Robin Peek, « Fifty Shades of Open », First Monday, 21(5), 2016. En ligne. ↩
Comme exemple d’arguments contre la défédération, voir le commentaire de Kaiser sous l’article du blog de Robek « rw » World : « Mastodon Socal Is THE Twitter Alternative For… », Robek World, 12 janvier 2017. En ligne. ↩
Au moment où Gab a rejoint le réseau, les statistiques du Fédiverse ont augmenté d’environ un million d’utilisateurs. Ces chiffres, comme tous les chiffres d’utilisation du Fédiverse, sont contestés. Pour le contexte, voir John Dougherty et Michael Edison Hayden, « ‘No Way’ Gab has 800,000 Users, Web Host Says », Southern Poverty Law Center, 14 février 2019. En ligne. Et le message sur Mastodon de emsenn le 10 août 2017, 04:51. ↩
Pour une introduction exhaustive aux écrits de Chantal Mouffe, voir Chantal Mouffe, Agonistique : penser politiquement le monde, Paris, Beaux-Arts de Paris éditions, 2014. On lira aussi avec profit la page Wikipédia consacrée à l’agonisme. ↩
Andrew Torba : « Le passage au protocole ActivityPub pour notre base nous permet d’entrer dans les App Stores mobiles sans même avoir à soumettre ni faire approuver nos propres applications, que cela plaise ou non à Apple et à Google », posté sur Gab, url consultée en mai 2019. ↩
David Garcia, « The Revenge of Folk Politics », transmediale/journal, 1, 2018. En ligne. ↩
hbsc & friends, « Have You Considered the Alternative? », Homebrew Server Club, 9 March 2017. En ligne. ↩
Sarah Jamie Lewis (éd.), Queer Privacy: Essays From The Margin Of Society, Victoria, British Columbia, Lean Pub/Mascherari Press, 2017, p. 2. ↩
Shoshana Zuboff, The Age of Surveillance Capitalism: The Fight for a Human Future at the New Frontier of Power, New York, PublicAffairs, 2019. ↩
Silvio Lorusso, Entreprecariat – Everyone Is an Entrepreneur. Nobody Is Safe, Onomatopee: Eindhoven, 2019. ↩
Pour un exemple d’introduction très souvent citée en lien, rédigée par une utilisatrice, cf. Noëlle Anthony, Joyeusenoelle/GuideToMastodon, 2019. En ligne. ↩
Au sein de ce texte, nous utilisons « média social commercial » (corporate social media) et « média social alternatif » (alternative social media) comme définis par Robert W. Gehl, « The Case for Alternative Social Media », op. cit.. ↩
Pour un relevé permanent de ces problématiques, cf. Pervasive Labour Union Zine, en ligne. ↩
Bien que formulée dans le contexte de Tumblr, pour une discussion à propos des tensions entre le travail numérique, les communautés post-numériques et l’activisme, voyez Cassius Adair et Lisa Nakamura, « The Digital Afterlives of This Bridge Called My Back: Woman of Color Feminism, Digital Labor, and Networked Pedagogy », American Literature, 89(2), 2017, p. 255-278. ↩
Pour des éléments de discussion sur le financement public des logiciels libres, ainsi que quelques analyses des premiers jets de lois concernant l’accès au code source des logiciels achetés avec l’argent public, cf. Jesús M. González-Barahona, Joaquín Seoane Pascual et Gregorio Robles, Introduction to Free Software, Barcelone, Universitat Oberta de Catalunya, 2009. ↩
par exemple, consultez Atsushi Akera, « Voluntarism and the Fruits of Collaboration: The IBM UserGroup, Share », Technology and Culture, 42(4), 2001, p. 710-736. ↩
Sam Williams, Free as in Freedom: Richard Stallman’s Crusade for Free Software, Farnham: O’Reilly, 2002. ↩
Femke Snelting, « Codes of Conduct: Transforming Shared Values into Daily Practice », dans Cornelia Sollfrank (éd.), The Beautiful Warriors: Technofeminist Praxis in the 21st Century, Colchester, Minor Compositions, 2019, pp. 57-72. ↩
Dušan Barok, Privatising Privacy: Trojan Horse in Free Open Source Distributed Social Platforms, Thèse de Master, Networked Media, Piet Zwart Institute, Rotterdam/Netherlands, 2011. ↩
Voyez l’échange de correspondance Stallman-Ghosh-Glott sur l’étude du FLOSS, « Two Communities or Two Movements in One Community? », dans Rishab Aiyer Ghosh, Ruediger Glott, Bernhard Krieger and Gregorio Robles, Free/Libre and Open Source Software: Survey and Study, FLOSS final report, International Institute of Infonomics, University of Maastricht, Netherlands, 2002. En ligne. ↩
Consultez par exemple Felix von Leitner, « Mon Jul 6 2015 », Fefes Blog, 6 July 2015, en ligne. ↩
Qui sont les auteurs
AYMERIC MANSOUX s’amuse avec les ordinateurs et les réseaux depuis bien trop longtemps. Il a été un membre fondateur du collectif GOTO10 (FLOSS+Art anthology, Puredyne distro, make art festival). Parmi les collaborations récentes, citons : Le Codex SKOR, une archive sur l’impossibilité d’archiver ; What Remains, un jeu vidéo 8 bits sur la manipulation des l’opinion publique et les lanceurs d’alerte pour la console Nintendo de 1985 ; et LURK, une une infrastructure de serveurs pour les discussions sur la liberté culturelle, l’art dans les nouveaux médias et la culture du net. Aymeric a obtenu son doctorat au Centre d’études culturelles, Goldsmiths, Université de Londres en 2017, pour son enquête sur le déclin de la diversité culturelle et des formes techno-légales de l’organisation sociale dans le cadre de pratiques culturelles libres et open-source. Il dirige actuellement le Cours de maîtrise en édition expérimentale (XPUB) à l’Institut Piet Zwart, Rotterdam. https://bleu255.com/~aymeric.
ROEL ROSCAM ABBING est un artiste et chercheur dont les travaux portent sur les questions et les cultures entourant les ordinateurs en réseau. Il s’intéresse à des thèmes tels que le réseau, les infrastructures, la politique de la technologie et les approches DIY (NdT : « Faites-le vous-même »). Il est doctorant dans le domaine du design d’interaction à l’université de Malmö.
 Sur le Fédiverse, ils ont un terme pour Twitter.
Sur le Fédiverse, ils ont un terme pour Twitter.