David Revoy, un artiste face aux IA génératives
Depuis plusieurs années, Framasoft est honoré et enchanté des illustrations que lui fournit David Revoy, comme sont ravi⋅es les lectrices et lecteurs qui apprécient les aventures de Pepper et Carrot et les graphistes qui bénéficient de ses tutoriels. Ses créations graphiques sont sous licence libre (CC-BY), ce qui est un choix courageux compte tenu des « éditeurs » dépourvus de scrupules comme on peut le lire dans cet article.
Cet artiste talentueux autant que généreux explique aujourd’hui son embarras face aux IA génératives et pourquoi son éthique ainsi que son processus créatif personnel l’empêchent de les utiliser comme le font les « IArtistes »…
Article original en anglais sur le blog de David Revoy
Traduction : Goofy, révisée par l’auteur.
Intelligence artificielle : voici pourquoi je n’utiliserai pas pour mes créations artistiques de hashtag #HumanArt, #HumanMade ou #NoAI
par David REVOY

« C’est cool, vous avez utilisé quel IA pour faire ça ? »
« Son travail est sans aucun doute de l’IA »
« C’est de l’art fait avec de l’IA et je trouve ça déprimant… »
… voilà un échantillon des commentaires que je reçois de plus en plus sur mon travail artistique.
Et ce n’est pas agréable.
Dans un monde où des légions d’IArtistes envahissent les plateformes comme celles des médias sociaux, de DeviantArt ou ArtStation, je remarque que dans l’esprit du plus grand nombre on commence à mettre l’Art-par-IA et l’art numérique dans le même panier. En tant qu’artiste numérique qui crée son œuvre comme une vraie peinture, je trouve cette situation très injuste. J’utilise une tablette graphique, des layers (couches d’images), des peintures numériques et des pinceaux numériques. J’y travaille dur des heures et des heures. Je ne me contente pas de saisir au clavier une invite et d’appuyer sur Entrée pour avoir mes images.
C’est pourquoi j’ai commencé à ajouter les hashtags #HumanArt puis #HumanMade à mes œuvres sur les réseaux sociaux pour indiquer clairement que mon art est « fait à la main » et qu’il n’utilise pas Stable Diffusion, Dall-E, Midjourney ou n’importe quel outil de génération automatique d’images disponible aujourd’hui. Je voulais clarifier cela pour ne plus recevoir le genre de commentaires que j’ai cités au début de mon intro. Mais quel est le meilleur hashtag pour cela ?
Je ne savais pas trop, alors j’ai lancé un sondage sur mon fil Mastodon
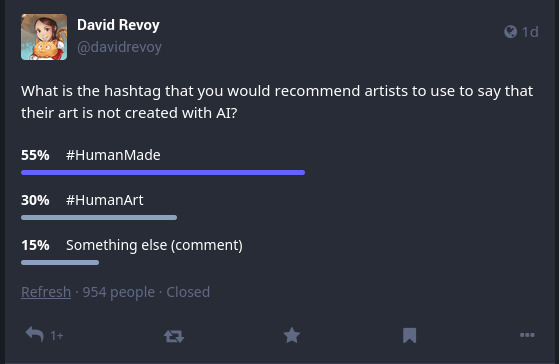
Résultats
Sur 954 personnes qui ont voté (je les remercie), #HumanMade l’emporte par 55 % contre 30 % pour #HumanArt. Mais ce qui m’a fait changer d’idée c’est la diversité et la richesse des points de vue que j’ai reçus en commentaires. Bon nombre d’entre eux étaient privés et donc vous ne pouvez pas les parcourir. Mais ils m’ont vraiment fait changer d’avis sur la question. C’est pourquoi j’ai décidé de rédiger cet article pour en parler un peu.
Critiques des hashtags #HumanMade et #HumanArt
Tout d’abord, #HumanArt sonne comme une opposition au célèbre tag #FurryArt de la communauté Furry. Bien vu, ce n’est pas ce que je veux.
Et puis #HumanMade est un choix qui a été critiqué parce que l’IA aussi était une création humaine, ce qui lui faisait perdre sa pertinence. Mais la plupart des personnes pouvaient facilement comprendre ce que #HumanMade signifierait sous une création artistique. Donc 55 % des votes était un score cohérent.
J’ai aussi reçu pas mal de propositions d’alternatives comme #HandCrafted, #HandMade, #Art et autres suggestions.
Le succès de #NoAI
J’ai également reçu beaucoup de suggestions en faveur du hashtag #NoAI, ainsi que des variantes plus drôles et surtout plus crues. C’était tout à fait marrant, mais je n’ai pas l’intention de m’attaquer à toute l’intelligence artificielle. Certains de ses usages qui reposent sur des jeux de données éthiques pourraient à l’avenir s’avérer de bons outils. J’y reviendrai plus loin dans cet article.
De toutes façons, j’ai toujours essayé d’avoir un état d’esprit « favorable à » plutôt que « opposé à » quelque chose.
C’est aux artistes qui utilisent l’IA de taguer leur message
Ceci est revenu aussi très fréquemment dans les commentaires. Malheureusement, les IArtistes taguent rarement leur travail, comme on peut le voir sur les réseaux sociaux, DeviantArt ou ArtStation. Et je les comprends, vu le nombre d’avantages qu’ils ont à ne pas le faire.
Pour commencer, ils peuvent se faire passer pour des artistes sans grand effort. Ensuite, ils peuvent conférer à leur art davantage de légitimité à leurs yeux et aux yeux de leur public. Enfin, ils peuvent probablement éviter les commentaires hostiles et les signalements des artistes anti-IA des diverses plateformes.
Je n’ai donc pas l’espoir qu’ils le feront un jour. Je déteste cette situation parce qu’elle est injuste.
Mais récemment j’ai commencé à apprécier ce comportement sous un autre angle, dans la mesure où ces impostures pourraient ruiner tous les jeux de données et les modèles d’apprentissage : les IA se dévorent elles-mêmes.
Quand David propose de saboter les jeux de données… 😛
Pas de hashtag du tout
La dernière suggestion que j’ai fréquemment reçue était de ne pas utiliser de hashtag du tout.
En effet, écrire #HumanArt, #HumanMade ou #NoAI signalerait immédiatement le message et l’œuvre comme une cible de qualité pour l’apprentissage sur les jeux de données à venir. Comme je l’ai écrit plus haut, obtenir des jeux de données réalisées par des humains est le futur défi des IA. Je ne veux surtout pas leur faciliter la tâche.
Il m’est toujours possible d’indiquer mon éthique personnelle en écrivant « Œuvre réalisée sans utilisation de générateur d’image par IA qui repose sur des jeux de données non éthiques » dans la section d’informations de mon profil de média social, ou bien d’ajouter simplement un lien vers l’article que j’écris en ce moment même.
Conclusion et considérations sur les IA
J’ai donc pris ma décision : je n’utiliserai pour ma création artistique aucun hashtag, ni #HumanArt, ni #HumanMade, ni #NoAI.
Je continuerai à publier en ligne mes œuvres numériques, comme je le fais depuis le début des années 2000.
Je continuerai à tout publier sous une licence permissive Creative Commons et avec les fichiers sources, parce que c’est ainsi que j’aime qualifier mon art : libre et gratuit.
Malheureusement, je ne serai jamais en mesure d’empêcher des entreprises dépourvues d’éthique de siphonner complètement mes collections d’œuvres. Le mal est en tout cas déjà fait : des centaines, voire des milliers de mes illustrations et cases de bandes dessinées ont été utilisées pour entraîner leurs IA. Il est facile d’en avoir la preuve (par exemple sur haveibeentrained.com ou bien en parcourant le jeu de données d’apprentissage Laion5B).
Je ne suis pas du tout d’accord avec ça.
Quelles sont mes possibilités ? Pas grand-chose… Je ne peux pas supprimer mes créations une à une de leur jeu de données. Elles ont été copiées sur tellement de sites de fonds d’écran, de galeries, forums et autres projets. Je n’ai pas les ressources pour me lancer là-dedans. Je ne peux pas non plus exclure mes créations futures des prochaines moissons par scans. De plus, les méthodes de protection comme Glaze me paraissent une piètre solution au problème, je ne suis pas convaincu. Pas plus que par la perspective d’imposer des filigranes à mes images…
Ne vous y trompez pas : je n’ai rien contre la technologie des IA en elle-même.On la trouve partout en ce moment. Dans le smartphones pour améliorer les photos, dans les logiciels de 3D pour éliminer le « bruit » des processeurs graphiques, dans les outils de traduction [N. de T. la présente traduction a en effet été réalisée avec l’aide DeepL pour le premier jet], derrière les moteurs de recherche etc. Les techniques de réseaux neuronaux et d’apprentissage machine sur les jeux de données s’avèrent très efficaces pour certaines tâches.
Les projets FLOSS (Free Libre and Open Source Software) eux-mêmes comme GMIC développent leurs propres bibliothèques de réseaux neuronaux. Bien sûr elles reposeront sur des jeux de données éthiques. Comme d’habitude, mon problème n’est pas la technologie en elle-même. Mon problème, c’est le mode de gouvernance et l’éthique de ceux qui utilisent de telles technologies.
Pour ma part, je continuerai à ne pas utiliser d’IA génératives dans mon travail (Stable Diffusion, Dall-E, Midjourney et Cie). Je les ai expérimentées sur les médias sociaux par le passé, parfois sérieusement, parfois en étant impressionné, mais le plus souvent de façon sarcastique .
Je n’aime pas du tout le processus des IA…
Quand je crée une nouvelle œuvre, je n’exprime pas mes idées avec des mots.
Quand je crée une nouvelle œuvre, je n’envoie pas l’idée par texto à mon cerveau.
C’est un mixage complexe d’émotions, de formes, de couleurs et de textures. C’est comme saisir au vol une scène éphémère venue d’un rêve passager rendant visite à mon cerveau. Elle n’a nul besoin d’être traduite en une formulation verbale. Quand je fais cela, je partage une part intime de mon rêve intérieur. Cela va au-delà des mots pour atteindre certaines émotions, souvenirs et sensations.
Avec les IA, les IArtistes se contentent de saisir au clavier un certains nombre de mots-clés pour le thème. Ils l’agrémentent d’autres mots-clés, ciblent l’imitation d’un artiste ou d’un style. Puis ils laissent le hasard opérer pour avoir un résultat. Ensuite ils découvrent que ce résultat, bien sûr, inclut des émotions sous forme picturale, des formes, des couleurs et des textures. Mais ces émotions sont-elles les leurs ou bien un sous-produit de leur processus ? Quoi qu’il en soit, ils peuvent posséder ces émotions.
Les IArtistes sont juste des mineurs qui forent dans les œuvres d’art générées artificiellement, c’est le nouveau Readymade numérique de notre temps. Cette technologie recherche la productivité au moindre coût et au moindre effort. Je pense que c’est très cohérent avec notre époque. Cela fournit à beaucoup d’écrivains des illustrations médiocres pour les couvertures de leurs livres, aux rédacteurs pour leurs articles, aux musiciens pour leurs albums et aux IArtistes pour leurs portfolios…
Je comprends bien qu’on ne peut pas revenir en arrière, ce public se sent comme empuissanté par les IA. Il peut finalement avoir des illustrations vite et pas cher. Et il va traiter de luddites tous les artistes qui luttent contre ça…
Mais je vais persister ici à déclarer que personnellement je n’aime pas cette forme d’art, parce qu’elle ne dit rien de ses créateurs. Ce qu’ils pensent, quel est leur goût esthétique, ce qu’ils ont en eux-mêmes pour tracer une ligne ou donner tel coup de pinceau, quelle lumière brille en eux, comment ils masquent leurs imperfections, leurs délicieuses inexactitudes en les maquillant… Je veux voir tout cela et suivre la vie des personnes, œuvre après œuvre.
J’espère que vous continuerez à suivre et soutenir mon travail artistique, les épisodes de mes bandes dessinées, mes articles et tutoriels, pour les mêmes raisons.
Vous pouvez soutenir la travail de David Revoy en devenant un mécène ou en parcourant sa boutique.

