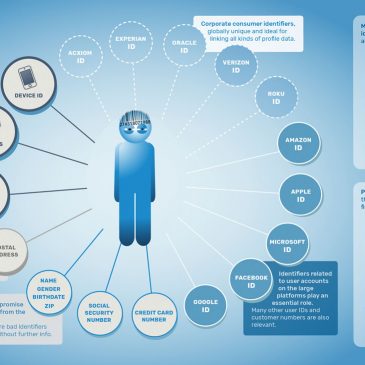
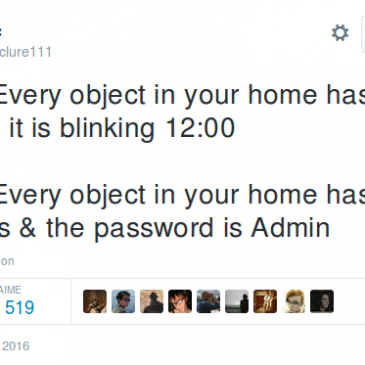
Aujourd’hui, les licences suffisent-elles ?
Classé dans : Droits numériques, Enjeux du numérique, G.A.F.A.M., Libertés numériques, Logiciel libre |
7
Frank Karlitschek est un développeur de logiciel libre, un entrepreneur et un militant pour le respect de la vie privée. Il a fondé les projets Nextcloud et ownCloud et il est également impliqué dans plusieurs autres projets de logiciels libres.