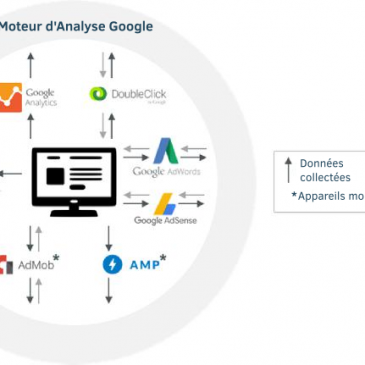
Détruire le capitalisme de surveillance (3)
Voici une troisième partie de l’essai que consacre Cory Doctorow au capitalisme de surveillance (parcourir sur le blog les épisodes précédents – parcourir les trois premiers épisodes en PDF : doctorow-1-2-3). Il s’attache ici à démonter les mécanismes utilisés par les … Lire la suite