Only You & SQL : un nouveau Framabook
Ce nouvel ouvrage vous entraîne dans les coulisses de nos usages numériques quotidiens et nous fait découvrir en profondeur la gestion des bases de données et le langage qui sert à interagir avec elles.

... mais ce serait peut-être l'une des plus grandes opportunités manquées de notre époque si le logiciel libre ne libérait rien d'autre que du code

Ce nouvel ouvrage vous entraîne dans les coulisses de nos usages numériques quotidiens et nous fait découvrir en profondeur la gestion des bases de données et le langage qui sert à interagir avec elles.
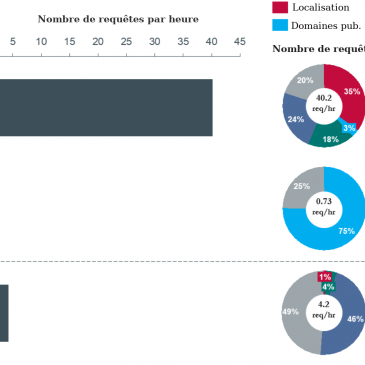
Voici déjà la traduction du troisième chapitre de Google Data Collection, l’étude élaborée par l’équipe du professeur Douglas C. Schmidt, spécialiste des systèmes logiciels, chercheur et enseignant à l’Université Vanderbilt. Si vous les avez manqués, retrouvez les chapitres précédents déjà … Lire la suite