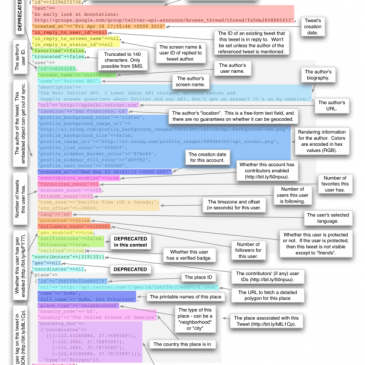
Les médias sociaux ne sont pas des espaces démocratiques
On peut rêver d’une solution technologique ou juridique pour limiter ou interdire l’utilisation d’un logiciel à des groupes ou personnes qui ne partagent pas les valeurs auxquelles on tient ou pire veulent les détruire.