Piwigo, la photo en liberté
Nous avons profité de la sortie d’une nouvelle version de l’application mobile pour interroger l’équipe de Piwigo, et plus particulièrement Pierrick, le créateur de ce logiciel libre qui a fêté ses vingt ans et qui est, c’est incroyable, rentable.
Salut l’équipe de Piwigo ! Nous avons lu avec intérêt la page https://fr.piwigo.com/qui-sommes-nous
Moi je note que «Piwigo» c’est plus sympa que « PhpWebGallery », comme nom de logiciel. Enfin, un logiciel libre qui n’a pas un nom trop tordu. Qu’est-ce que vous pouvez nous apprendre sur Piwigo, le logiciel ?
Piwigo est un logiciel libre de gestion de photothèque. Il s’agit d’une application web, donc accessible depuis un navigateur web, que l’on peut également consulter et administrer avec des applications mobiles. Au-delà des photos, Piwigo permet d’organiser et indexer tout type de média : images, vidéos, documents PDF et autres fichiers de travail des graphistes. Originellement conçu pour les particuliers, il s’est au fil des ans trouvé un public auprès des organisations de toutes tailles.

La gestation du projet PhpWebGallery démarre fin 2001 et la première version sortira aux vacances de Pâques 2002. Pendant les vacances, car j’étais étudiant en école d’ingénieur à Lyon et j’ai eu besoin de temps libre pour finaliser la première version. Le logiciel a tout de suite rencontré un public et des contributeurs ont rejoint l’aventure. En 2009, « PhpWebGallery » est renommé « Piwigo » mais seul le nom a changé, il s’agit du même projet.
Les huit premières années, le projet était entièrement bénévole, avec des contributeurs (de qualité) qui donnaient de leur temps libre et de leurs compétences. Le passage d’étudiant à salarié m’a donné du temps libre, vraiment beaucoup. Je faisais pas mal d’heures pour mon employeur mais en comparaison avec le rythme prépa/école, c’était très tranquille : pas de devoirs à faire le soir ! Donc Piwigo a beaucoup avancé durant cette période. Devenu parent puis propriétaire d’un appartement, avec les travaux à faire… mon temps libre a fondu et il a fallu faire des choix. Soit j’arrêtais le projet et il aurait été repris par la communauté, soit je trouvais un modèle économique viable et compatible avec le projet pour en faire mon métier. Si je suis ici pour en parler douze ans plus tard, c’est que cette deuxième option a été retenue.
En 2010 vous lancez le service piwigo.com ; un logiciel libre dont les auteurs ne crèvent pas de faim, c’est plutôt bien. Est-ce que c’est vrai ? Avez-vous trouvé votre modèle économique ?

Pour ce qui me concerne, je ne crève pas du tout de faim. J’ai pu rapidement retrouver des revenus équivalents à mon ancien salaire. Et davantage aujourd’hui. J’estime vivre très confortablement et ne manquer de rien. Ceci est très subjectif et mon mode de vie pourrait paraître « austère » pour certains et « extravagant » pour d’autres. En tout cas moi cela me convient 🙂
Notre modèle économique a un peu évolué en 12 ans. Si l’objectif est depuis le départ de se concentrer sur la vente d’abonnements, il a fallu quelques années pour que cela couvre mon salaire. J’ai eu l’opportunité de réaliser des prestations de dev en parallèle de Piwigo les premières années pour compenser la croissance lente des ventes d’abonnements.
Ce qui a beaucoup changé c’est notre cible : on est passé d’une cible B2C (à destination des individus) à une cible B2B (à destination des organisations). Et cela a tout changé en terme de chiffre d’affaires. Malheureusement ou plutôt « factuellement » nous plafonnons depuis longtemps sur les particuliers. Nos offres Entreprise quant à elles sont en croissance continue, sans que l’on atteigne encore de plafond. Nous avons donc décidé de communiquer vers cette cible. Piwigo reste utilisable pour des particuliers bien sûr, mais ce sont prioritairement les organisations qui vont orienter notre feuille de route.
Grâce à la réorientation de notre modèle économique, il a été possible de faire grossir l’équipe.
Donc on a Piwigo.org qui fournit le logiciel libre que chacun⋅e peut installer à condition d’en avoir les compétences, et Piwigo.com, service commercial géré par ton équipe et toi. Vous vous chargez de la maintenance, des mises à jour, des sauvegardes.
Qui est vraiment derrière Piwigo.com aujourd’hui ? Et combien de gens est-ce que ça fait vivre ?
Une petite équipe mêlant des salariés, dont plusieurs alternants, des freelances dans les domaines du support, de la communication, du design ou encore de la gestion administrative. Cela représente 8 personnes, certaines à temps plein, d’autres à temps partiel. J’exclus le cabinet comptable, même s’il y passe du temps compte tenu du nombre de transactions que les abonnements représentent…
Qu’est-ce qui est lourd ?
Certains aspects purement comptables de l’activité. La gestion de la TVA par exemple. Non pas le principe de la TVA mais les règles autour de la TVA. Nous vendons en France, dans la zone Euro et hors zone Euro : à chaque situation sa règle d’application des taxes. Les PCA (produits constatés d’avance) sont aussi une petite source de tracas qu’il a fallu gérer proprement. Jamais je n’aurais imaginé passer autant de temps sur ce genre de sujets en lançant le projet commercial.
Qu’est-ce qui est cool ?
Constater que Piwigo est leur principal outil de travail de nombreux clients. On comprend alors que certains choix de design, certaines optimisations de performances font pour eux une grande différence au quotidien.
Nous avons lancé depuis quelques semaines une série d’entretiens utilisateurs durant lesquels des clients nous montrent comment ils utilisent Piwigo et c’est assez génial de les voir utiliser voire détourner les fonctionnalités que l’on a développées.
D’un point de vue vraiment personnel, ce que je trouve cool c’est qu’un projet démarré sur mon temps libre pendant mes études soit devenu créateur d’emplois. Et j’espère un emploi « intéressant » pour les personnes concernées. Qu’elles soient participantes à l’aventure ou utilisatrices dans leur métier. Je crois vraiment au rôle social de l’entreprise et je suis particulièrement fier que Piwigo figure dans le parcours professionnel de nombreuses personnes.
Votre liste de clients https://fr.piwigo.com/clients est impressionnante…
Oui, je suis d’accord : ça claque ! et bien sûr tout est absolument authentique. Évidemment on n’affiche qu’une portion microscopique de notre liste de clients.
Recevez-vous des commandes spécifiques des gros clients pour développer certaines fonctionnalités ?
Pourquoi des « gros » ? Certaines entreprises « pas très grosses » ont des demandes spécifiques aussi. Bon, en pratique c’est vrai que certains « gros » ont l’habitude que l’outil s’adapte à leur besoin et pas le contraire. Donc parfois on adapte : en personnalisant l’interface quasiment toujours, en développant des plugins parfois. C’est moins de 5% de nos clients qui vont payer une prestation de développement. Vendre ce type de prestation n’est pas au cœur de notre modèle économique mais ne pas le proposer pourrait nuire à la vente d’abonnements, donc on est ouverts aux demandes.
 Est-ce que vous refusez de faire certaines choses ?
Est-ce que vous refusez de faire certaines choses ?
D’un point de vue du développement ? Pas souvent. Je n’ai pas souvenir de demandes suffisamment farfelues… pardon « spécifiques » pour qu’on les refuse a priori. En revanche il y a des choses qu’on refuse systématiquement : répondre à des appels d’offre et autre « marchés publics ». Quand une administration nous contacte et nous envoie des « dossiers » avec des listes de questions à rallonge, on s’assure qu’il n’y a pas d’appel d’offre derrière car on ne rentrera pas dans le processus. Nous ne vendons pas assez cher pour nous permettre de répondre à des appels d’offre. Je comprends que les entreprises qui vendent des tickets à 50k€+ se permettent ce genre de démarche administrative, mais avec notre ticket entre 500€ et 4 000€, on serait perdant à tous les coups. Le « coût administratif » d’un appel d’offre est plus élevé que le coût opérationnel de la solution proposée. C’est aberrant et on refuse de rentrer là-dedans.
Bien que nous refusions de répondre à cette complexité administrative (très française), nous avons de nombreuses administrations comme clients : ministère, mairies, conseils départementaux, offices de tourisme… Comme quoi c’est possible (et légal) de ne pas gaspiller de l’énergie et du temps à remplir des dossiers.
Y a-t-il beaucoup de particuliers qui, comme moi, vous confient leurs photos ? Faites péter les chiffres qui décoiffent !
Environ 2000 particuliers sont clients de notre offre hébergée. Ils sont bien plus nombreux à confier leurs photos à Piwigo, mais ils ne sont pas hébergés sur nos serveurs. Notre dernière enquête en 2020 indiquait qu’environ un utilisateur sur dix était client de Piwigo.com [donc 90% des gens qui utilisent le logiciel Piwigo s’auto-hébergent ou s’hébergent ailleurs, NDLR] .
Si on élargit un peu le champ de vision, on estime qu’il y a entre 50 000 et 500 000 installations de Piwigo dans le monde. Avec une énorme majorité d’installations hors Piwigo.com donc. Difficile à chiffrer précisément car Piwigo ne traque pas les installations.
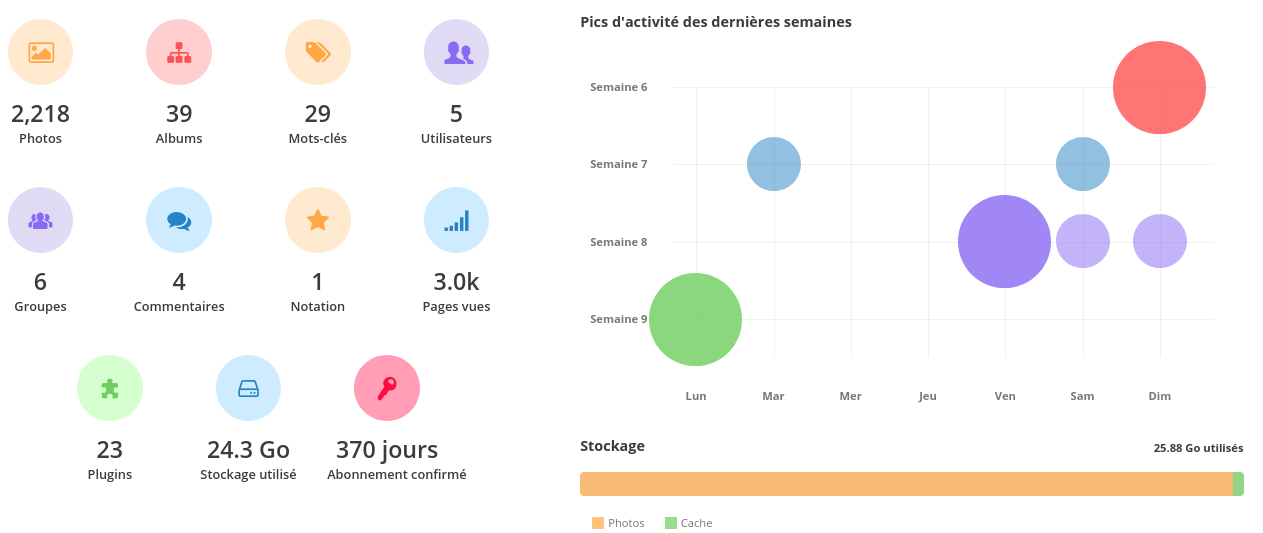
Pour des chiffres qui « décoiffent », je dirais qu’on a fait 30% de croissance en 2020. Puis encore 30% de croissance en 2021 (merci les confinements…) et qu’on revient à notre rythme de croisière de +15% par an en 2022. Dans le contexte actuel de difficulté des entreprises, je trouve qu’on s’en sort bien !
Autre chiffre qui décoiffe : on n’a pas levé un seul euro. Aucun business angel, aucune levée de fonds auprès d’investisseurs. Notre croissance est douce mais sereine. Attention pour autant : je ne dénigre pas le principe de lever des fonds. Cela permet d’aller beaucoup plus vite. Vers le succès ou l’échec, mais beaucoup plus vite ! Rien ne dit que si c’était à refaire, je n’essaierais pas de lever des fonds.
Encore un chiffre respectable : Piwigo a soufflé sa vingtième bougie en 2022. Le projet a connu plusieurs phases et nous vivons actuellement celle de la professionnalisation. Beaucoup de projets libres s’arrêtent avant et disparaissent car ils ne franchissent pas cette étape. Si certains voient dans l’arrivée de l’argent une « trahison » de la communauté, je trouve au contraire que c’est sain et gage de pérennité. Lorsque les fondateurs d’un projet ont besoin d’un modèle économique viable pour payer leurs propres factures, vous pouvez être sûrs que le projet ne va pas être abandonné sur un coup de tête.
Est-ce que les réseaux sociaux axés sur la photographie concurrencent Piwigo ? On pense à Instagram mais aussi à Pixelfed, évidemment.
J’ai regardé rapidement ce qu’était Pixelfed. Ma conclusion au bout de quelques minutes : c’est un clone opensource à Instagram, en mode décentralisé.
Piwigo n’est pas un réseau social. Pour certains utilisateurs, Piwigo a perdu de son intérêt dès lors que Facebook et ses albums photos sont arrivés. Pour d’autres, Piwigo constitue au contraire une solution pour ceux qui refusent la centralisation/uniformisation telle que proposée par Facebook ou Google. Enfin pour de nombreux clients pro (photographes ou entreprises) Piwigo est un outil à usage interne de l’équipe communication pour organiser les ressources média qui seront ensuite utilisées sur les réseaux sociaux. Il faut comprendre que pour les chargés de communication d’un office de tourisme, mettre sa photothèque sur Facebook n’a aucun sens. Ils ou elles publient quelques photos sur Facebook, sur Instagram ou autres, mais leur photothèque est organisée sur leur Piwigo.
Bref, même si les premières années je me suis demandé si Piwigo était encore pertinent face à l’émergence de ces nouvelles formes de communication, je sais aujourd’hui que Piwigo n’est pas en concurrence frontale avec ces derniers mais qu’au contraire, l’existence de ces réseaux nécessite pour les marques/entreprises qu’elles organisent leurs photothèques. Piwigo est là pour les y aider.
Quelles sont les différences ?
La toute première des choses, c’est la temporalité. Les réseaux sociaux sont excellents pour obtenir une exposition forte et éphémère de votre « actualité ». À l’inverse, Piwigo va exceller pour vous permettre de retrouver un lot de photos parmi des centaines de milliers, organisées au fil des années. Piwigo permet de gérer son patrimoine photo (et autres médias) sur le temps long.
L’autre aspect important c’est le travail en équipe. Un réseau social est généralement conçu autour d’une seule personne qui administre le compte. Dans Piwigo, plusieurs administrateurs collaborent (à un instant T ou dans la durée) pour construire la photothèque : classification, indexation (tags, titre, descriptions…)
Enfin, certaines fonctionnalités n’ont tout simplement rien à voir. Par exemple, dans un réseau social le cœur de métier va être d’obtenir des likes. Dans un Piwigo, vous allez pouvoir mettre en place un moteur de recherche multicritères avec vos propres critères. Par exemple on a un client qui fabrique des matériaux acoustiques. Ses critères de recherche sont collection, coloris, lieu d’implantation… Cela n’aurait aucun sens sur l’interface uniformisée d’un Instagram.
Qui apporte des contributions à Piwigo ? Est-ce que c’est surtout la core team ?
Cela a beaucoup changé avec le temps. Et même ce qu’on appelle aujourd’hui « équipe » n’est plus la même chose que ce qu’on appelait « équipe » il y a 10 ans. Aujourd’hui, l’équipe c’est essentiellement celle du projet commercial. Pas uniquement mais quand même pas mal.
On a donc beaucoup de contributions « internes » mais ce serait trop simplificateur d’ignorer l’énorme apport de la communauté de contributeurs au sens large. Déjà parce que l’état actuel de Piwigo repose sur les fondations créées par une communauté de développeurs bénévoles. Ensuite parce qu’on reçoit bien sûr des contributions sous forme de rapports de bugs, des pull-requests mais aussi grâce à des bénévoles qui aident des utilisateurs sur les forums communautaires, les bêta-testeurs… sans oublier les centaines de traducteurs.
Petite anecdote dont je suis fier : Rasmus Lerdorf, créateur de PHP (le langage de programmation principalement utilisé dans Piwigo) nous a plusieurs fois envoyé des patches pour que Piwigo soit compatibles avec les dernières versions de PHP.
Quel est votre lien avec le monde du Libre ? (<troll>y a-t-il un monde du Libre ?</troll>)
Je ne sais pas s’il y a un « monde du libre ». Historiquement Les contributeurs sont d’abord des utilisateurs du logiciel qui ont voulu le faire évoluer. Je ne suis pas certain qu’il s’agisse de fervents défenseurs du logiciel libre.
Franchement je ne sais pas trop comment répondre à cette question. Je sais que Piwigo est une brique de ce monde du libre mais je ne suis pas sûr que l’on conscientise le fait de faire partie d’un mouvement global. Je pense qu’on est pragmatique plutôt qu’idéologique.
En tant que client, je viens de recevoir le mail qui annonce le changement de tarif. Pouvez-vous nous expliquer l’origine de cette décision ?
Là on est vraiment sur l’actualité « à chaud ». Le changement de tarif pour les nouveaux/futurs clients a fait l’objet d’une longue réflexion et préparation. Je dirais qu’on le prépare depuis 18 mois.
Si j’ai bien compris la clientèle particulière est un tout petit pourcentage de la clientèle de Piwigo.com ?
Les clients de l’ancienne offre « individuelle » représentent 30 % du chiffre d’affaires des abonnements pour 91% des clients. J’exclus les prestations de dev, qui sont exclusivement ordonnées par des entreprises. Donc « tout petit pourcentage », ça dépend du point de vue 🙂
Est-ce que l’offre de stockage illimité devient trop chère ?
En moyenne sur l’ensemble des clients individuels, on est à ~30 Go de stockage utilisé. La médiane est quant à elle de 5Go. Si la marge financière dégagée n’est pas folle, on ne perd pas d’argent pour autant, car nous avons réussi à ne pas payer le stockage trop cher. Pour faire simple : on n’utilise pas de stockage cloud type Amazon Web Services, Google Cloud ou Microsoft Azure. Sinon on serait clairement perdant.
Ceci est vrai tant qu’on propose de l’illimité sur les photos. Sauf que la première demande au support, devant toutes les autres, c’est : « puis-je ajouter mes vidéos ? », et cela change la donne. Hors de question de proposer de l’illimité sur les vidéos. De l’autre côté, on entend et on comprend la demande des utilisateurs concernant les vidéos. Donc on veut proposer les vidéos, mais il faut en parallèle introduire un quota de stockage.
Ensuite nous avions un souci de cohérence entre l’offre individuelle (stockage illimité mais photos uniquement) et les offres entreprise (quota de stockage et tout type de fichiers). La solution qui nous paraît la meilleure est d’imposer un quota pour toutes les offres, mais un quota généreux. L’offre « Perso » est à 50 Go de stockage, donc largement au-delà de la conso moyenne.
Enfin la principe de l’illimité est problématique. En 12 ans, la perception du grand public sur le numérique a évolué. Je parle spécifiquement de la consommation de ressources que le numérique représente. Le cloud, ce sont des serveurs dans des centres de données qui consomment de l’électricité, etc. En 2023, je pense que tout le monde a intégré le fait que nous vivons dans un monde fini. Ceci n’est pas compatible avec la notion de stockage infini. Je peux vous assurer que certains utilisateurs n’ont pas conscience de cette finitude.
Est-ce que des pros ont utilisé cette offre destinée aux particuliers pour «abuser» ?
Il y a des abus sur l’utilisation de l’espace de stockage, mais pas spécialement par des pros. On a des particuliers qui scannent des documents en haute résolution par dizaine de milliers pour des téraoctets stockés… On a des particuliers qui sont fans de telle ou telle star de cinéma et qui font des captures d’écran chaque seconde de chaque film de cet acteur. Ne rigolez pas, cela existe.
En revanche on avait un soucis de positionnement : l’offre « individuelle » n’était pas très appropriée pour les photographes pros mais l’offre entreprise était trop chère. On a maintenant des offres mieux étagées et on espère que cela sera plus pertinent pour ce type de client.
Enfin on a des entreprises qui essaient de prendre l’offre individuelle en se faisant passer pour des particuliers. Et là on est obligés de faire les gendarmes. On a même détecté des « patterns » de ses entreprises et on annulait les commandes « individuelles » de ces clients. J’en avais personnellement un petit peu ras le bol 🙂
Les nouvelles offres, même « Perso » sont accessibles même à des multinationales. Évidemment, les limites qu’on a fixées devraient naturellement les orienter vers nos offres Entreprise (nouvelle génération) voire VIP.
Est-ce qu’il s’agissait d’une offre qui se voulait temporaire et que vous avez laissé filer parce que vous étiez sur autre chose ?
Pendant 12 ans ? Non non, le choix de proposer de l’illimité en 2010 était réfléchi et « à durée indéterminée ». Les besoins et les possibilités et surtout les demandes ont changé. On s’adapte. On espère ne pas se tromper et si c’est le cas on fera des ajustements.
L’important c’est de pas mettre nos clients au pied du mur : ils peuvent renouveler sur leur offre d’origine. On a toujours proposé cela et on ne compte pas changer cette règle. C’est assez unique dans notre secteur d’activité mais on y tient.
Nous avons vu que votre actualité c’était la nouvelle version de Piwigo NG. Je crois que vous avez besoin d’aide. Vous pouvez nous en parler ?
Nous avons plusieurs actualités et effectivement côté logiciel, c’est la sortie de la version 2 de l’application mobile pour Android. Piwigo NG (comme Next Generation) est le résultat du travail de Rémi, qui travaille sur Piwigo depuis deux ans. Après avoir voulu faire évoluer l’application « native » sans succès, il a créé en deux semaines un prototype d’application mobile en Flutter. Ce qu’il avait fait en deux semaines était meilleur que ce que l’on galérait à obtenir avec l’application native en plusieurs mois. On a donc décidé de basculer sur cette nouvelle technologie. Un an après la sortie de Piwigo NG, Rémi sort une version 2 toujours sur Flutter mais avec une nouvelle architecture « plus propice aux évolutions ». Le fameux « il faut refactorer tous les six mois », devise des développeurs Java.
En effet nous avons besoin d’aide pour bêta-tester cette version 2 de Piwigo NG. Plus nous avons de retours, plus nous pouvons la stabiliser.
Pour aller plus loin
- Vous pouvez auto-héberger votre Piwigo, rendez-vous sur cette page
- ou vous pouvez prendre un abonnement ici
- Piwigo est également une application intégrée à la solution d’auto-hébergement Yunohost


