Les nouveaux Leviathans III. Du capitalisme de surveillance à la fin de la démocratie ?
Une chronique de Xavier De La Porte1 sur le site de la radio France Culture pointe une sortie du tout nouveau président Emmanuel Macron parue sur le compte Twitter officiel : « Une start-up nation est une nation où chacun peut se dire qu’il pourra créer une startup. Je veux que la France en soit une ». Xavier De La Porte montre à quel point cette conception de la France en « start-up nation » est en réalité une vieille idée, qui reprend les archaïsmes des penseurs libéraux du XVIIe siècle, tout en provoquant un « désenchantement politique ». La série des Nouveaux Léviathans, dont voici le troisième numéro, part justement de cette idée et cherche à en décortiquer les arguments.
Dans cet article nous allons voir comment ce que Shoshana Zuboff nomme Big Other (cf. article précédent) trouve dans ces archaïques conceptions de l’État un lieu privilégié pour déployer une nouvelle forme d’organisation sociale et politique. L’idéologie-Silicon ne peut plus être aujourd’hui analysée comme un élan ultra-libéral auquel on opposerait des valeurs d’égalité ou de solidarité. Cette dialectique est dépassée car c’est le Contrat Social qui change de nature : la légitimité de l’État repose désormais sur des mécanismes d’expertise2 par lesquels le capitalisme de surveillance impose une logique de marché à tous les niveaux de l’organisation socio-économique, de la décision publique à l’engagement politique. Pour comprendre comment le terrain démocratique a changé à ce point et ce que cela implique dans l’organisation d’une nation, il faut analyser tour à tour le rôle des monopoles numériques, les choix de gouvernance qu’ils impliquent, et comprendre comment cette idéologie est non pas théorisée, mais en quelque sorte auto-légitimée, rendue presque nécessaire, parce qu’aucun choix politique ne s’y oppose. Le capitalisme de surveillance impliquerait-il la fin de la démocratie ?

Libéralisme et Big Other
Dans Les Nouveaux Leviathans II, j’abordais la question du capitalisme de surveillance sous l’angle de la fin du modèle économique du marché libéral. L’utopie dont se réclame ce dernier, que ce soit de manière rhétorique ou réellement convaincue, suppose une auto-régulation du marché, théorie maintenue en particulier par Friedrich Hayek3. À l’opposé de cette théorie qui fait du marché la seule forme (auto-)équilibrée de l’économie, on trouve des auteurs comme Karl Polanyi4 qui, à partir de l’analyse historique et anthropologique, démontre non seulement que l’économie n’a pas toujours été organisée autour d’un marché libéral, mais aussi que le capitalisme « désencastre » l’économie des relations sociales, et provoque un déni du contrat social.
Or, avec le capitalisme de surveillance, cette opposition (qui date tout de même de la première moitié du XXe siècle) a vécu. Lorsque Shoshana Zuboff aborde la genèse du capitalisme de surveillance, elle montre comment, à partir de la logique de rationalisation du travail, on est passé à une société de marché dont les comportements individuels et collectifs sont quantifiés, analysés, surveillés, grâce aux big data, tout comme le (un certain) management d’entreprise quantifie et rationalise les procédures. Pour S. Zuboff, tout ceci concourt à l’avènement de Big Other, c’est-à-dire un régime socio-économique régulé par des mécanismes d’extraction des données, de marchandisation et de contrôle. Cependant, ce régime ne se confronte pas à l’État comme on pourrait le dire du libertarisme sous-jacent au néolibéralisme qui considère l’État au pire comme contraire aux libertés individuelles, au mieux comme une instance limitative des libertés. Encore pourrait-on dire qu’une dialectique entre l’État et le marché pourrait être bénéfique et aboutirait à une forme d’équilibre acceptable. Or, avec le capitalisme de surveillance, le politique lui-même devient un point d’appui pour Big Other, et il le devient parce que nous avons basculé d’un régime politique à un régime a-politique qui organise les équilibres sociaux sur les principes de l’offre marchande. Les instruments de cette organisation sont les big datas et la capacité de modeler la société sur l’offre.
C’est que je précisais en 2016 dans un ouvrage coordonné par Tristan Nitot, Nina Cercy, Numérique : reprendre le contrôle5, en ces termes :
(L)es firmes mettent en œuvre des pratiques d’extraction de données qui annihilent toute réciprocité du contrat avec les utilisateurs, jusqu’à créer un marché de la quotidienneté (nos données les plus intimes et à la fois les plus sociales). Ce sont nos comportements, notre expérience quotidienne, qui deviennent l’objet du marché et qui conditionne même la production des biens industriels (dont la vente dépend de nos comportements de consommateurs). Mieux : ce marché n’est plus soumis aux contraintes du hasard, du risque ou de l’imprédictibilité, comme le pensaient les chantres du libéralisme du XXe siècle : il est devenu malléable parce que ce sont nos comportements qui font l’objet d’une prédictibilité d’autant plus exacte que les big data peuvent être analysées avec des méthodes de plus en plus fiables et à grande échelle.
Si j’écris que nous sommes passés d’un régime politique à un régime a-politique, cela ne signifie pas que cette transformation soit radicale, bien entendu. Il existe et il existera toujours des tensions idéologiques à l’intérieur des institutions de l’État. C’est plutôt une question de proportions : aujourd’hui, la plus grande partie des décisions et des organes opérationnels sont motivés et guidés par des considérations relevant de situations déclarées impératives et non par des perspectives politiques. On peut citer par exemple le grand mouvement de « rigueur » incitant à la « maîtrise » des dépenses publiques imposée par les organismes financiers européens ; des décisions motivées uniquement par le remboursement des dettes et l’expertise financière et non par une stratégie du bien-être social. On peut citer aussi, d’un point de vue plus local et français, les contrats des institutions publiques avec Microsoft, à l’instar de l’Éducation Nationale, à l’encontre de l’avis d’une grande partie de la société civile, au détriment d’une offre différente (comme le libre et l’open source) et dont la justification est uniquement donnée par l’incapacité de la fonction publique à envisager d’autres solutions techniques, non par ignorance, mais à cause du détricotage massif des compétences internes. Ainsi « rationaliser » les dépenses publiques revient en fait à se priver justement de rationalité au profit d’une simple adaptation de l’organisation publique à un état de fait, un déterminisme qui n’est pas remis en question et condamne toute idéologie à être non pertinente.
Ce n’est pas pour autant qu’il faut ressortir les vieilles théories de la fin de l’histoire. Qui plus est, les derniers essais du genre, comme la thèse de Francis Fukuyama6, se sont concentrés justement sur l’avènement de la démocratie libérale conçue comme le consensus ultime mettant fin aux confrontations idéologiques (comme la fin de la Guerre Froide). Or, le capitalisme de surveillance a minima repousse toute velléité de consensus, au-delà du libéralisme, car il finit par définir l’État tout entier comme un instrument d’organisation, quelle que soit l’idéologie : si le nouveau régime de Big Other parvient à organiser le social, c’est aussi parce que ce dernier a désengagé le politique et relègue la décision publique au rang de validation des faits, c’est-à-dire l’acceptation des contrats entre les individus et les outils du capitalisme de surveillance.
Les mécanismes ne sont pas si nombreux et tiennent en quatre points :
- le fait que les firmes soient des multinationales et surfent sur l’offre de la moins-disance juridique pour s’établir dans les pays (c’est la pratique du law shopping),
- le fait que l’utilisation des données personnelles soit déloyale envers les individus-utilisateurs des services des firmes qui s’approprient les données,
- le fait que les firmes entre elles adoptent des processus loyaux (pactes de non-agression, partage de marchés, acceptation de monopoles, rachats convenus, etc.) et passent des contrats iniques avec les institutions, avec l’appui de l’expertise, faisant perdre aux États leur souveraineté numérique,
- le fait que les monopoles « du numérique » diversifient tellement leurs activités vers les secteurs industriels qu’ils finissent par organiser une grande partie des dynamiques d’innovation et de concurrence à l’échelle mondiale.
Pour résumer les trois conceptions de l’économie dont il vient d’être question, on peut dresser ce tableau :
| Économie | Forme | Individus | État |
|---|---|---|---|
| Économie spontanée | Diversité et créativité des formes d’échanges, du don à la financiarisation | Régulent l’économie par la démocratie ; les échanges sont d’abord des relations sociales | Garant de la redistribution équitable des richesses ; régulateur des échanges et des comportements |
| Marché libéral | Auto-régulation, défense des libertés économiques contre la décision publique (conception libérale de la démocratie : liberté des échanges et de la propriété) | Agents consommateurs décisionnaires dans un milieu concurrentiel | Réguler le marché contre ses dérives inégalitaires ; maintient une démocratie plus ou moins forte |
| Capitalisme de surveillance | Les monopoles façonnent les échanges, créent (tous) les besoins en fonction de leurs capacités de production et des big data | Sont exclusivement utilisateurs des biens et services | Automatisation du droit adapté aux besoins de l’organisation économique ; sécurisation des conditions du marché |
Il est important de comprendre deux aspects de ce tableau :
- il ne cherche pas à induire une progression historique et linéaire entre les différentes formes de l’économie et des rapports de forces : ces rapports sont le plus souvent diffus, selon les époques, les cultures. Il y a une économie spontanée à l’Antiquité comme on pourrait par exemple, comprendre les monnaies alternatives d’aujourd’hui comme des formes spontanées d’organisation des échanges.
- aucune de ces cases ne correspond réellement à des conceptions théorisées. Il s’agit essentiellement de voir comment le capitalisme de surveillance induit une distorsion dans l’organisation économique : alors que dans des formes classiques de l’organisation économique, ce sont les acteurs qui produisent l’organisation, le capitalisme de surveillance induit non seulement la fin du marché libéral (vu comme place d’échange équilibrée de biens et services concurrentiels) mais exclut toute possibilité de régulation par les individus / citoyens : ceux-ci sont vus uniquement comme des utilisateurs de services, et l’État comme un pourvoyeur de services publics. La décision publique, elle, est une affaire d’accord entre les monopoles et l’État.

Les monopoles et l’État
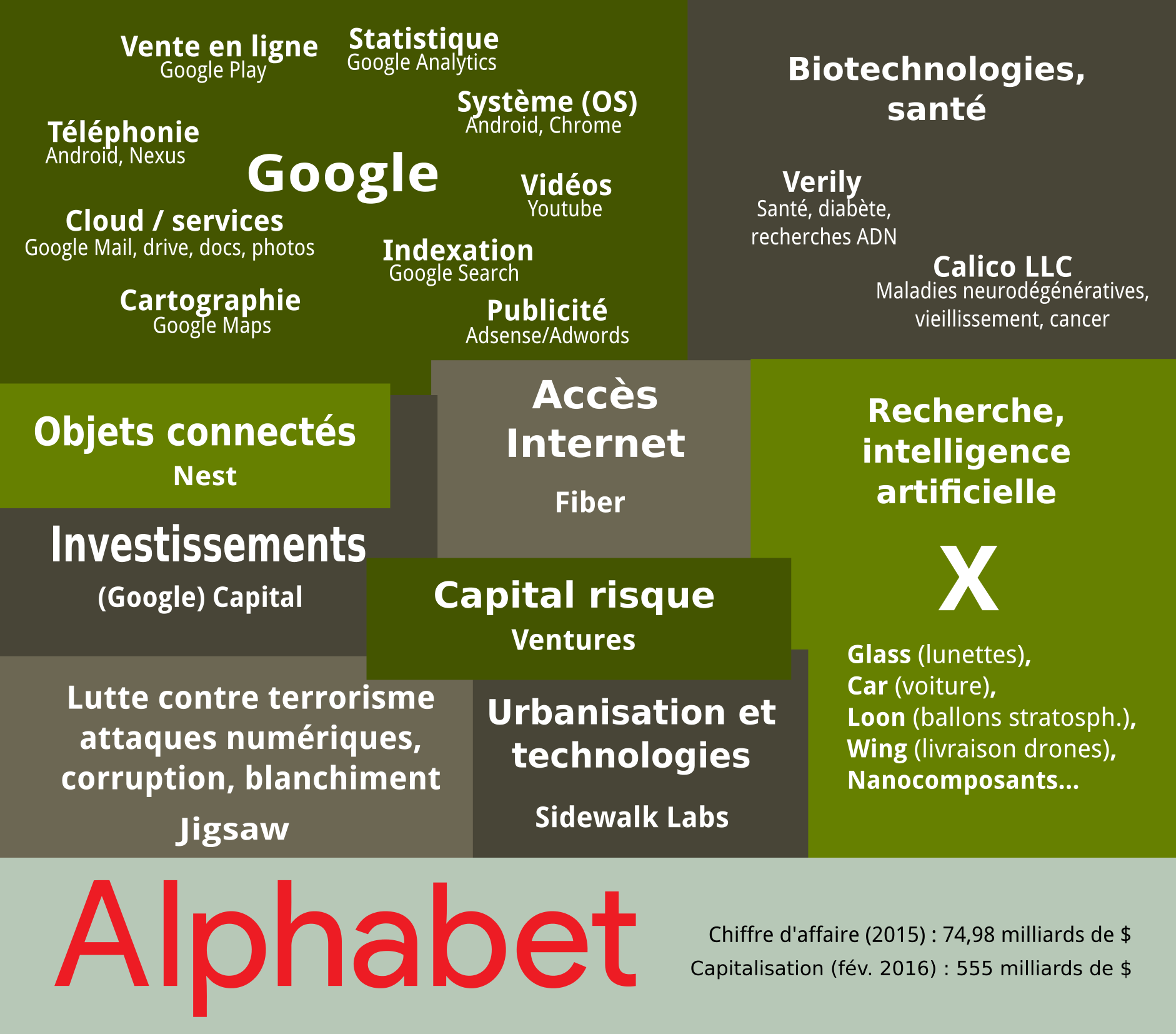
Pour sa première visite en Europe, Sundar Pichai qui était alors en février 2016 le nouveau CEO de Google Inc. , choisit les locaux de Sciences Po. Paris pour tenir une conférence de presse7, en particulier devant les élèves de l’école de journalisme. Le choix n’était pas anodin, puisqu’à ce moment-là Google s’est présenté en grand défenseur de la liberté d’expression (par un ensemble d’outils, de type reverse-proxy que la firme est prête à proposer aux journalistes pour mener leurs investigations), en pourvoyeur de moyens efficaces pour lutter contre le terrorisme, en proposant à qui veut l’entendre des partenariats avec les éditeurs, et de manière générale en s’investissant dans l’innovation numérique en France (voir le partenariat Numa / Google). Tout cela démontre, s’il en était encore besoin, à quel point la firme Google (et Alphabet en général) est capable de proposer une offre si globale qu’elle couvre les fonctions de l’État : en réalité, à Paris lors de cette conférence, alors que paradoxalement elle se tenait dans les locaux où étudient ceux qui demain sont censés remplir des fonctions régaliennes, Sundar Pichai ne s’adressait pas aux autorités de l’État mais aux entreprises (éditeurs) pour leur proposer des instruments qui garantissent leurs libertés. Avec comme sous-entendu : vous évoluez dans un pays dont la liberté d’expression est l’un des fleurons, mais votre gouvernement n’est pas capable de vous le garantir mieux que nous, donc adhérez à Google. Les domaines de la santé, des systèmes d’informations et l’éducation en sont pas exempts de cette offre « numérique ».
Du côté du secteur public, le meilleur moyen de ne pas perdre la face est de monter dans le train suivant l’adage « Puisque ces mystères nous dépassent, feignons d’en être l’organisateur ». Par exemple, si Google et Facebook ont une telle puissance capable de mener efficacement une lutte, au moins médiatique, contre le terrorisme, à l’instar de leurs campagnes de propagande8, il faut créer des accords de collaboration entre l’État et ces firmes9, quitte à les faire passer comme une exigence gouvernementale (mais quel État ne perdrait pas la face devant le poids financier des GAFAM ?).
… Et tout cela crée un marché de la gouvernance dans lequel on ne compte plus les millions d’investissement des GAFAM. Ainsi, la gouvernance est un marché pour Microsoft, qui lance un Office 2015 spécial « secteur public », ou, mieux, qui sait admirablement se situer dans les appels d’offre en promouvant des solutions pour tous les besoins d’organisation de l’État. Par exemple, la présentation des activités de Microsoft dans le secteur public sur son site comporte ces items :
- Stimulez la transformation numérique du secteur public
- Optimisez l’administration publique
- Transformez des services du secteur public
- Améliorez l’efficacité des employés du secteur public
- Mobilisez les citoyens

D’aucuns diraient que ce que font les GAFAM, c’est proposer un nouveau modèle social. Par exemple dans une enquête percutante sur les entreprises de la Silicon Valley, Philippe Vion-Dury définit ce nouveau modèle comme « politiquement technocratique, économiquement libéral, culturellement libertaire, le tout nimbé de messianisme typiquement américain »10. Et il a entièrement raison, sauf qu’il ne s’agit pas d’un modèle social, c’est justement le contraire, c’est un modèle de gouvernance sans politique, qui considère le social comme la juxtaposition d’utilisateurs et de groupes d’utilisateurs. Comme le montre l’offre de Microsoft, si cette firme est capable de fournir un service propre à « mobiliser les citoyens » et si en même temps, grâce à ce même fournisseur, vous avez les outils pour transformer des services du secteur public, quel besoin y aurait-il de voter, de persuader, de discuter ? si tous les avis des citoyens sont analysés et surtout anticipés par les big datas, et si les seuls outils efficaces de l’organisation publique résident dans l’offre des GAFAM, quel besoin y aurait-il de parler de démocratie ?
En réalité, comme on va le voir, tout cette nouvelle configuration du capitalisme de surveillance n’est pas seulement rendue possible par la puissance novatrice des monopoles du numérique. C’est peut-être un biais : penser que leur puissance d’innovation est telle qu’aucune offre concurrente ne peut exister. En fait, même si l’offre était moindre, elle n’en serait pas moins adoptée car tout réside dans la capacité de la décision publique à déterminer la nécessité d’adopter ou non les services des GAFAM. C’est l’aménagement d’un terrain favorable qui permet à l’offre de la gouvernance numérique d’être proposée. Ce terrain, c’est la décision par l’expertise.

“Work-buy-consume-die”, par Mika Raento, sous licence CC BY 2.0
(trad. : « Participez à l’hilarante aventure d’une vie : travaillez, achetez, consommez, mourez. »)
L’accueil favorable au capitalisme de surveillance
Dans son livre The united states of Google11, Götz Haman fait un compte-rendu d’une conférence durant laquelle interviennent Eric Schmidt, alors président du conseil d’administration de Google, et son collègue Jared Cohen. Ces derniers ont écrit un ouvrage (The New Digital Age) qu’ils présentent dans les grandes lignes. Götz Haman le résume en ces termes : « Aux yeux de Google, les États sont dépassés. Ils n’ont rien qui permette de résoudre les problèmes du XXIe siècle, tels le changement climatique, la pauvreté, l’accès à la santé. Seules les inventions techniques peuvent mener vers le Salut, affirment Schmidt et son camarade Cohen. »
Une fois cette idéologie — celle du capitalisme de surveillance12 — évoquée, il faut s’interroger sur la raison pour laquelle les États renvoient cette image d’impuissance. En fait, les sociétés occidentales modernes ont tellement accru leur consommation de services que l’offre est devenue surpuissante, à tel point, comme le montre Shoshanna Zuboff, que les utilisateurs eux-mêmes sont devenus à la fois les pourvoyeurs de matière première (les données) et les consommateurs. Or, si nous nous plaçons dans une conception de la société comme un unique marché où les relations sociales peuvent être modelées par l’offre de services (ce qui se cristallise aujourd’hui par ce qu’on nomme dans l’expression-valise « Uberisation de la société »), ce qui relève de la décision publique ne peut être motivé que par l’analyse de ce qu’il y a de mieux pour ce marché, c’est-à-dire le calcul de rentabilité, de rendement, d’efficacité… d’utilité. Or cette analyse ne peut être à son tour fournie par une idéologie visionnaire, une utopie ou simplement l’imaginaire politique : seule l’expertise de l’état du monde pour ce qu’il est à un instant T permet de justifier l’action publique. Il faut donc passer du concept de gouvernement politique au concept de gouvernance par les instruments. Et ces instruments doivent reposer sur les GAFAM.
Pour comprendre au mieux ce que c’est que gouverner par les instruments, il faut faire un petit détour conceptuel.
L’expertise et les instruments
Prenons un exemple. La situation politique qu’a connue l’Italie après novembre 2011 pourrait à bien des égards se comparer avec la récente élection en France d’Emmanuel Macron et les élections législatives qui ont suivi. En effet, après le gouvernement de Silvio Berlusconi, la présidence italienne a nommé Mario Monti pour former un gouvernement dont les membres sont essentiellement reconnus pour leurs compétences techniques appliquées en situation de crise économique. La raison du soutien populaire à cette nomination pour le moins discutable (M. Monti a été nommé sénateur à vie, reconnaissance habituellement réservée aux anciens présidents de République Italienne) réside surtout dans le désaveu de la casta, c’est-à-dire le système des partis qui a dominé la vie politique italienne depuis maintes années et qui n’a pas réussi à endiguer les effets de la crise financière de 2008. Si bien que le gouvernement de Mario Monti peut être qualifié de « gouvernement des experts », non pas un gouvernement technocratique noyé dans le fatras administratif des normes et des procédures, mais un gouvernement à l’image de Mario Monti lui-même, ex-commissaire européen au long cours, motivé par la nécessité technique de résoudre la crise en coopération avec l’Union Européenne. Pour reprendre les termes de l’historien Peppino Ortoleva, à propos de ce gouvernement dans l’étude de cas qu’il consacre à l’Italie13 en 2012 :
Le « gouvernement des experts » se présente d’un côté comme le gouvernement de l’objectivité et des chiffres, celui qui peut rendre compte à l’Union européenne et au système financier international, et d’un autre côté comme le premier gouvernement indépendant des partis.
Peppino Ortoleva conclut alors que cet exemple italien ne représente que les prémices pour d’autres gouvernements du même acabit dans d’autres pays, avec tous les questionnements que cela suppose en termes de débat politique et démocratique : si en effet la décision publique n’est mue que par la nécessité (ici la crise financière et la réponse aux injonctions de la Commission européenne) quelle place peut encore tenir le débat démocratique et l’autonomie décisionnaire des peuples ?
En son temps déjà le « There is no alternative » de Margaret Thatcher imposait par la force des séries de réformes au nom de la nécessité et de l’expertise économiques. On ne compte plus, en Europe, les gouvernements qui nomment des groupes d’expertise, conseils et autres comités censés répondre aux questions techniques que pose l’environnement économique changeant, en particulier en situation de crise.
Cette expertise a souvent été confondue avec la technocratie, à l’instar de l’ouvrage de Vincent Dubois et Delphine Dulong publié en 2000, La question technocratique14. Lorsqu’en effet la décision publique se justifie exclusivement par la nécessité, cela signifie que cette dernière est définie en fonction d’une certaine compréhension de l’environnement socio-économique. Par exemple, si l’on part du principe que la seule réponse à la crise financière est la réduction des dépenses publiques, les technocrates inventeront les instruments pour rendre opérationnelle la décision publique, les experts identifieront les méthodes et l’expertise justifiera les décisions (on remet en cause un avis issu d’une estimation de ce que devrait être le monde, mais pas celui issu d’un calcul d’expert).
La technocratie comme l’expertise se situent hors des partis, mais la technocratie concerne surtout l’organisation du gouvernement. Elle répond souvent aux contraintes de centralisation de la décision publique. Elle crée des instruments de surveillance, de contrôle, de gestion, etc. capables de permettre à un gouvernement d’imposer, par exemple, une transformation économique du service public. L’illustration convaincante est le gouvernement Thatcher, qui dès 1979 a mis en place plusieurs instruments de contrôle visant à libéraliser le secteur public en cassant les pratiques locales et en imposant un système concurrentiel. Ce faisant, il démontrait aussi que le choix des instruments suppose aussi des choix d’exercice du pouvoir, tels ceux guidés par la croyance en la supériorité des mécanismes de marché pour organiser l’économie15.
Gouverner par l’expertise ne signifie donc pas que le gouvernement manque de compétences en son sein pour prendre les (bonnes ou mauvaises) décisions publiques. Les technocrates existent et sont eux aussi des experts. En revanche, l’expertise permet surtout de justifier les choix, les stratégies publiques, en interprétant le monde comme un environnement qui contraint ces choix, sans alternative.
En parlant d’alternative, justement, on peut s’interroger sur celles qui relèvent de la société civile et portées tant bien que mal à la connaissance du gouvernement. La question du logiciel libre est, là encore, un bon exemple.
En novembre 2016, Framasoft publiait un billet retentissant intitulé « Pourquoi Framasoft n’ira plus prendre le thé au ministère de l’Éducation Nationale ». La raison de ce billet est la prise de conscience qu’après plus de treize ans d’efforts de sensibilisation au logiciel libre envers les autorités publiques, et en particulier l’Éducation Nationale, Framasoft ne pouvait plus dépenser de l’énergie à coopérer avec une telle institution si celle-ci finissait fatalement par signer contrats sur contrats avec Microsoft ou Google. En fait, le raisonnement va plus loin et j’y reviendrai plus tard dans ce texte. Mais il faut comprendre que ce à quoi Framasoft s’est confronté est exactement ce gouvernement par l’expertise. En effet, les communautés du logiciel libre n’apportent une expertise que dans la mesure où elles proposent de changer de modèle : récupérer une autonomie numérique en développant des compétences et des initiatives qui visent à atteindre un fonctionnement idéal (des données protégées, des solutions informatiques modulables, une contribution collective au code, etc.). Or, ce que le gouvernement attend de l’expertise, ce n’est pas un but à atteindre, c’est savoir comment adapter l’organisation au modèle existant, c’est-à-dire celui du marché.
Dans le cadre des élections législatives, l’infatigable association APRIL (« promouvoir et défendre le logiciel libre ») lance sa campagne de promotion de la priorité au logiciel libre dans l’administration publique. À chaque fois, la campagne connaît un certain succès et des députés s’engagent réellement dans cette cause qu’ils plaident même à l’intérieur de l’Assemblée Nationale. Sous le gouvernement de F. Hollande, on a entendu des députés comme Christian Paul ou Isabelle Attard avancer les arguments les plus pertinents et sans ménager leurs efforts, convaincus de l’intérêt du Libre. À leur image, il serait faux de dire que la sphère politique est toute entière hermétique au logiciel libre et aux équilibres numériques et économiques qu’il porte en lui. Peine perdue ? À voir les contrats passés entre le gouvernement et les GAFAM, c’est un constat qu’on ne peut pas écarter et sans doute au profit d’une autre forme de mobilisation, celle du peuple lui-même, car lui seul est capable de porter une alternative là où justement la politique a cédé la place : dans la décision publique.
La rencontre entre la conception du marché comme seule organisation gouvernementale des rapports sociaux et de l’expertise qui détermine les contextes et les nécessités de la prise de décision a permis l’émergence d’un terrain favorable à l’État-GAFAM. Pour s’en convaincre il suffit de faire un tour du côté de ce qu’on a appelé la « modernisation de l’État ».
Les firmes à la gouvernance numérique
Anciennement la Direction des Systèmes d’Information (DSI), la DINSIC (Direction Interministérielle du Numérique et du Système d’Information et de Communication) définit les stratégies et pilote les structures informationnelles de l’État français. Elle prend notamment part au mouvement de « modernisation » de l’État. Ce mouvement est en réalité une cristallisation de l’activité de réforme autour de l’informatisation commencée dans les années 1980. Cette activité de réforme a généré des compétences et assez d’expertise pour être institutionnalisée (DRB, DGME, aujourd’hui DIATP — Direction interministérielle pour l’accompagnement des transformations publiques). On se perd facilement à travers les acronymes, les ministères de rattachement, les changements de noms au rythme des fusions des services entre eux. Néanmoins, le concept même de réforme n’a pas évolué depuis les grandes réformes des années 1950 : il faut toujours adapter le fonctionnement des administrations publiques au monde qui change, en particulier le numérique.
La différence, aujourd’hui, c’est que cette adaptation ne se fait pas en fonction de stratégies politiques, mais en fonction d’un cadre de productivité, dont on dit qu’il est un « contrat de performance » ; cette performance étant évaluée par des outils de contrôle : augmenter le rendement de l’administration en « rationalisant » les effectifs, automatiser les services publics (par exemple déclarer ses impôts en ligne, payer ses amendes en lignes, etc.), expertiser (accompagner) les besoins des systèmes d’informations selon les offres du marché, limiter les instances en adaptant des méthodes agiles de prise de décision basées sur des outils numériques de l’analyse de data, maîtrise des coûts….
C’est que nous dit en substance la Synthèse présentant le Cadre stratégique commun du système d’information de l’Etat, c’est-à-dire la feuille de route de la DINSIC. Dans une section intitulée « Pourquoi se transformer est une nécessite ? », on trouve :
Continuer à faire évoluer les systèmes d’information est nécessaire pour répondre aux enjeux publics de demain : il s’agit d’un outil de production de l’administration, qui doit délivrer des services plus performants aux usagers, faciliter et accompagner les réformes de l’État, rendre possible les politiques publiques transverses à plusieurs administrations, s’intégrer dans une dimension européenne.
Cette feuille de route concerne en fait deux grandes orientations : l’amélioration de l’organisation interne aux institutions gouvernementales et les interfaces avec les citoyens. Il est flagrant de constater que, pour ce qui concerne la dimension interne, certains projets que l’on trouve mentionnés dans le Panorama des grands projets SI de l’Etat font appel à des solutions open source et les opérateurs sont publics, notamment par souci d’efficacité, comme c’est le cas, par exemple pour le projet VITAM, relatif à l’archivage. En revanche, lorsqu’il s’agit des relations avec les citoyens-utilisateurs, c’est-à-dires les « usagers », ce sont des entreprises comme Microsoft qui entrent en jeu et se substituent à l’État, comme c’est le cas par exemple du grand projet France Connect, dont Microsoft France est partenaire.
En effet, France Connect est une plateforme centralisée visant à permettre aux citoyens d’effectuer des démarches en ligne (pour les particuliers, pour les entreprises, etc.). Pour permettre aux collectivités et aux institutions qui mettent en place une « offre » de démarche en ligne, Microsoft propose en open source des « kit de démarrage », c’est à dire des modèles, qui vont permettre à ces administrations d’offrir ces services aux usagers. En d’autres termes, c’est chaque collectivité ou administration qui va devenir fournisseur de service, dans un contexte de développement technique mutualisé (d’où l’intérêt ici de l’open source). Ce faisant, l’État n’agit plus comme maître d’œuvre, ni même comme arbitre : c’est Microsoft qui se charge d’orchestrer (par les outils techniques choisis, et ce n’est jamais neutre) un marché de l’offre de services dont les acteurs sont les collectivités et administrations. De là, il est tout à fait possible d’imaginer une concurrence, par exemple entre des collectivités comme les mairies, entre celles qui auront une telle offre de services permettant d’attirer des contribuables et des entreprises sur son territoire, et celles qui resteront coincées dans les procédures administratives réputées archaïques.
En se plaçant ainsi non plus en prestataire de produits mais en tuteur, Microsoft organise le marché de l’offre de service public numérique. Mais la firme va beaucoup plus loin, car elle bénéficie désormais d’une grande expérience, reconnue, en matière de service public. Ainsi, lorsqu’il s’agit d’anticiper les besoins et les changements, elle est non seulement à la pointe de l’expertise mais aussi fortement enracinée dans les processus de la décision publique. Sur le site Econocom en 2015, l’interview de Raphaël Mastier16, directeur du pôle Santé de Microsoft France, est éloquent sur ce point. Partant du principe que « historiquement le numérique n’a pas été considéré comme stratégique dans le monde hospitalier », Microsoft propose des outils « d’analyse et de pilotage », et même l’utilisation de l’analyse prédictive des big data pour anticiper les temps d’attentes aux urgences : « grâce au machine learning, il sera possible de s’organiser beaucoup plus efficacement ». Avec de tels arguments, en effet, qui irait à l’encontre de l’expérience microsoftienne dans les services publics si c’est un gage d’efficacité ? on comprend mieux alors, dans le monde hospitalier, l’accord-cadre CAIH-Microsoft qui consolide durablement le marché Microsoft avec les hôpitaux.
Au-delà de ces exemples, on voit bien que cette nouvelle forme de gouvernance à la Big Other rend ces instruments légitimes car ils produisent le marché et donc l’organisation sociale. Cette transformation de l’État est parfaitement assumée par les autorités, arguant par exemple dans un billet sur gouvernement.fr intitulé « Le numérique : instrument de la transformation de l’État », en faveur de l’allégement des procédures, de la dématérialisation, de la mise à disposition des bases de données (qui va les valoriser ?), etc. En somme autant d’arguments dont il est impossible de nier l’intérêt collectif et qui font, en règle générale, l’objet d’un consensus.
Le groupe canadien CGI, l’un des leaders mondiaux en technologies et gestion de l’information, œuvre aussi en France, notamment en partenariat avec l’UGAP (Union des Groupements d’Achats Publics). Sur son blog, dans un Billet du 2 mai 201717, CGI résume très bien le discours dominant de l’action publique dans ce domaine (et donc l’intérêt de son offre de services), en trois points :
- Réduire les coûts. Le sous-entendu consiste à affirmer que si l’État organise seul sa transformation numérique, le budget sera trop conséquent. Ce qui reste encore à prouver au vu des montants en jeu dans les accords de partenariat entre l’État et les firmes, et la nature des contrats (on peut souligner les clauses concernant les mises à jour chez Microsoft) ;
- Le secteur public accuse un retard numérique. C’est l’argument qui justifie la délégation du numérique sur le marché, ainsi que l’urgence des décisions, et qui, par effet de bord, contrevient à la souveraineté numérique de l’État.
- Il faut améliorer « l’expérience citoyen ». C’est-à-dire que l’objectif est de transformer tous les citoyens en utilisateurs de services publics numériques et, comme on l’a vu plus haut, organiser une offre concurrentielle de services entre les institutions et les collectivités.
Du côté des décideurs publics, les choix et les décisions se justifient sur un mode Thatchérien (il n’y a pas d’alternative). Lorsqu’une alternative est proposée, tel le logiciel libre, tout le jeu consiste à donner une image politique positive pour ensuite orienter la stratégie différemment.
Sur ce point, l’exemple de Framasoft est éloquent et c’est quelque chose qui n’a pas forcément été perçu lors de la publication de la déclaration « Pourquoi Framasoft n’ira plus prendre le thé…» (citée précédemment). Il s’agit de l’utilisation de l’alternative libriste pour légitimer l’appel à une offre concurrentielle sur le marché des firmes. En effet, les personnels de l’Éducation Nationale utilisent massivement les services que Framasoft propose dans le cadre de sa campagne « Degooglisons Internet ». Or, l’institution pourrait très bien, sur le modèle promu par Framasoft, installer ces mêmes services, et ainsi offrir ces solutions pour un usage généralisé dans les écoles, collèges et lycées. C’est justement le but de la campagne de Framasoft que de proposer une vaste démonstration pour que des organisations retrouvent leur autonomie numérique. Les contacts que Framasoft a noué à ce propos avec différentes instances de l’Éducation Nationale se résumaient finalement soit à ce que Framasoft et ses bénévoles proposent un service à la carte dont l’ambition est bien loin d’une offre de service à l’échelle institutionnelle, soit participe à quelques comités d’expertise sur le numérique à l’école. L’idée sous-jacente est que l’Éducation Nationale ne peut faire autrement que de demander à des prestataires de mettre en place une offre numérique clé en main et onéreuse, alors même que Framasoft propose tous ses services au grand public avec des moyens financiers et humains ridiculement petits.
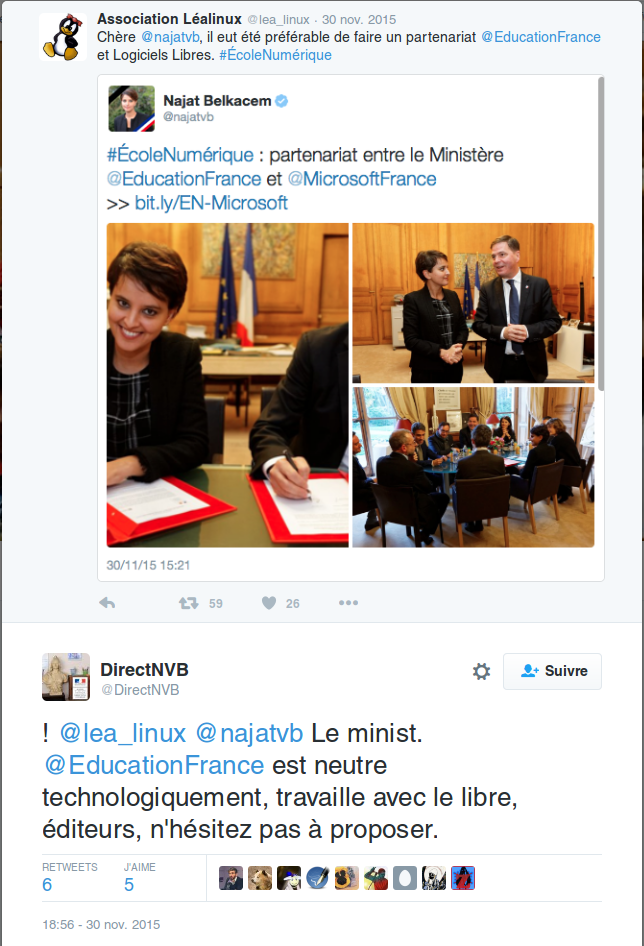
Dès lors, après la signature du partenariat entre le MEN et Microsoft, le message a été clairement formulé à Framasoft (et aux communautés du Libre en général), par un Tweet de la Ministre Najat Vallaud-Belkacem exprimant en substance la « neutralité technologique » du ministère (ce qui justifie donc le choix de Microsoft comme objectivement la meilleure offre du marché) et l’idée que les « éditeurs de logiciels libres » devraient proposer eux aussi leurs solutions, c’est-à-dire entrer sur le marché concurrentiel. Cette distorsion dans la compréhension de ce que sont les alternatives libres (non pas un produit mais un engagement) a été confirmée à plusieurs reprises par la suite : les solutions libres et leurs usages à l’Éducation Nationale peuvent être utilisées pour « mettre en tension » le marché et négocier des tarifs avec les firmes comme Microsoft, ou du moins servir d’épouvantail (dont on peut s’interroger sur l’efficacité réelle devant la puissance promotionnelle et lobbyiste des firmes en question).
On peut conclure de cette histoire que si la décision publique tient à ce point à discréditer les solutions alternatives qui échappent au marché des monopoles, c’est qu’une idéologie est à l’œuvre qui empêche toute forme d’initiative qui embarquerait le gouvernement dans une dynamique différente. Elle peut par exemple placer les décideurs devant une incapacité structurelle18 de choisir des alternatives proposant des logiciels libres, invoquant par exemple le droit des marchés publics voire la Constitution, alors que l’exclusion du logiciel libre n’est pas réglementaire19.
L’idéologie de Silicon
En février 2017, quelques jours à peine après l’élection de Donald Trump à présidence des États-Unis, le PDG de Facebook, Mark Zuckerberg, publie sur son blog un manifeste20 remarquable à l’encontre de la politique isolationniste et réactionnaire du nouveau président. Il cite notamment tous les outils que Facebook déploie au service des utilisateurs et montre combien ils sont les vecteurs d’une grande communauté mondiale unie et solidaire. Tous les concepts de la cohésion sociale y passent, de la solidarité à la liberté de l’information, c’est-à-dire ce que le gouvernement est, aux yeux de Zuckerberg, incapable de garantir correctement à ses citoyens, et ce que les partisans de Trump en particulier menacent ouvertement.
Au moins, si les idées de Mark Zuckerberg semblent pertinentes aux yeux des détracteurs de Donald Trump, on peut néanmoins s’interroger sur l’idéologie à laquelle se rattache, de son côté, le PDG de Facebook. En réalité, pour lui, Donald Trump est la démonstration évidente que l’État ne devrait occuper ni l’espace social ni l’espace économique et que seul le marché et l’offre numérique sont en mesure d’intégrer les relations sociales.
Cette idéologie a déjà été illustrée par Fred Tuner, dans son ouvrage Aux sources de l’utopie numérique21. À propos de ce livre, j’écrivais en 201622 :
(…) Fred Turner montre comment les mouvements communautaires de contre-culture ont soit échoué par désillusion, soit se sont recentrés (surtout dans les années 1980) autour de techno-valeurs, en particulier portées par des leaders charismatiques géniaux à la manière de Steve Jobs un peu plus tard. L’idée dominante est que la revendication politique a échoué à bâtir un monde meilleur ; c’est en apportant des solutions techniques que nous serons capables de résoudre nos problèmes.
Cette analyse un peu rapide passe sous silence la principale clé de lecture de Fred Tuner : l’émergence de nouveaux modes d’organisation économique du travail, en particulier le freelance et la collaboration en réseau. Comme je l’ai montré, le mouvement de la contre-culture californienne des années 1970 a permis la création de nouvelles pratiques d’échanges numériques utilisant les réseaux existants, comme le projet Community Memory, c’est-à-dire des utopies de solidarité, d’égalité et de liberté d’information dans une Amérique en proie au doute et à l’autoritarisme, notamment au sortir de la Guerre du Vietnam. Mais ce faisant, les années 1980, elles, ont développé à partir de ces idéaux la vision d’un monde où, en réaction à un État conservateur et disciplinaire, ce dernier se trouverait dépossédé de ses prérogatives de régulation, au profit de l’autonomie des citoyens dans leurs choix économiques et leurs coopérations. C’est l’avènement des principes du libertarisme grâce aux outils numériques. Et ce que montre Fred Turner, c’est que ce mouvement contre-culturel a ainsi paradoxalement préparé le terrain aux politiques libérales de dérégulation économique des années 1980-1990. C’est la volonté de réduire au strict minimum le rôle de l’État, garant des libertés individuelles, afin de permettre aux individus d’exercer leurs droits de propriété (sur leurs biens et sur eux-mêmes) dans un ordre social qui se définit uniquement comme un marché. À ce titre, pour ce qu’il est devenu, ce libertarisme est une résurgence radicale du libéralisme à la Hayek (la société démocratique libérale est un marché concurrentiel) doublé d’une conception utilitaire des individus et de leurs actions.
Néanmoins, tels ne sont pas exactement les principes du libertarisme, mais ceux-ci ayant cours dans une économie libérale, ils ne peuvent qu’aboutir à des modèles économiques basés sur une forme de collaboration dérégulée, anti-étatique, puisque la forme du marché, ici, consiste à dresser la liberté des échanges et de la propriété contre un État dont les principes du droit sont vécus comme arbitrairement interventionnistes. Les concepts tels la solidarité, l’égalité, la justice sont remplacés par l’utilité, le choix, le droit.
Un exemple intéressant de ce renversement concernant le droit, est celui du droit de la concurrence appliqué à la question de la neutralité des plateformes, des réseaux, etc. Regardons les plateformes de service. Pourquoi assistons-nous à une forme de schizophrénie entre une Commission européenne pour qui la neutralité d’internet et des plateformes est une condition d’ouverture de l’économie numérique et la bataille contre cette même neutralité appliquée aux individus censés être libres de disposer de leurs données et les protéger, notamment grâce au chiffrement ? Certes, les mesures de lutte contre le terrorisme justifient de s’interroger sur la pertinence d’une neutralité absolue (s’interroger seulement, car le chiffrement ne devrait jamais être remis en cause), mais la question est surtout de savoir quel est le rôle de l’État dans une économie numérique ouverte reposant sur la neutralité d’Internet et des plateformes. Dès lors, nous avons d’un côté la nécessité que l’État puisse intervenir sur la circulation de l’information dans un contexte de saisie juridique et de l’autre celle d’une volontaire absence du Droit dans le marché numérique.
Pour preuve, on peut citer le président de l’Autorité de la concurrence en France, Bruno Lassere, auditionné à l’Assemblée Nationale le 7 juillet 201523. Ce dernier cite le Droit de la Concurrence et ses applications comme un instrument de lutte contre les distorsions du marché, comme les monopoles à l’image de Google/Alphabet. Mais d’un autre côté, le Droit de la Concurrence est surtout vu comme une solution d’auto-régulation dans le contexte de la neutralité des plates-formes :
(…) Les entreprises peuvent prendre des engagements par lesquels elles remédient elles-mêmes à certains dysfonctionnements. Il me semble important que certains abus soient corrigés à l’intérieur du marché et non pas forcément sur intervention législative ou régulatrice. C’est ainsi que Booking, Expedia et HRS se sont engagées à lever la plupart des clauses de parité tarifaire qui interdisent une véritable mise en compétition de ces plateformes de réservation hôtelières. Comment fonctionnent ces clauses ? Si un hôtel propose à Booking douze nuitées au prix de 100 euros la chambre, il ne peut offrir de meilleures conditions – en disponibilité ou en tarif – aux autres plateformes. Il ne peut pas non plus pratiquer un prix différent à ses clients directs. Les engagements signés pour lever ces contraintes sont gagnants-gagnants : ils respectent le modèle économique des plateformes, et donc l’incitation à investir et à innover, tout en rétablissant plus de liberté de négociation. Les hôtels pourront désormais mettre les plateformes en concurrence.
Sur ce point, il ne faut pas s’interroger sur le mécanisme de concurrence qu’il s’agit de promouvoir mais sur l’implication d’une régulation systématique de l’économie numérique par le Droit de la Concurrence. Ainsi le rapport Numérique et libertés présenté Christian Paul et Christiane Féral-Schuhl, propose un long développement sur la question des données personnelles mais cite cette partie de l’audition de Bruno Lasserre à propos du Droit de la Concurrence sans revenir sur la conception selon laquelle l’alpha et l’omega du Droit consiste à aménager un environnement concurrentiel « sain » à l’intérieur duquel les mécanismes de concurrence suffisent à eux-seuls à appliquer des principes de loyauté, d’équité ou d’égalité.
Cette absence de questionnement politique sur le rôle du Droit dans un marché où la concentration des services abouti à des monopoles finit par produire immanquablement une forme d’autonomie absolue de ces monopoles dans les mécanismes concurrentiels, entre une concurrence acceptable et une concurrence non-souhaitable. Tel est par exemple l’objet de multiples pactes passés entre les grandes multinationales du numérique, ainsi entre Microsoft et AOL, entre AOL / Yahoo et Microsoft, entre Intertrust et Microsoft, entre Apple et Google (pacte géant), entre Microsoft et Android, l’accord entre IBM et Apple en 1991 qui a lancé une autre vague d’accords du côté de Microsoft tout en définissant finalement l’informatique des années 1990, etc.
La liste de tels accords peut donner le tournis à n’importe quel juriste au vu de leurs implications en termes de Droit, surtout lorsqu’ils sont déclinés à de multiples niveaux nationaux. L’essentiel est de retenir que ce sont ces accords entre monopoles qui définissent non seulement le marché mais aussi toutes nos relations avec le numérique, à tel point que c’est sur le même modèle qu’agit le politique aujourd’hui.
Ainsi, face à la puissance des GAFAM et consorts, les gouvernements se placent en situation de demandeurs. Pour prendre un exemple récent, à propos de la lutte anti-terroriste en France, le gouvernement ne fait pas que déléguer une partie de ses prérogatives (qui pourraient consister à mettre en place lui-même un système anti-propagande efficace), mais se repose sur la bonne volonté des Géants, comme c’est le cas de l’accord avec Google, Facebook, Microsoft et Twitter, conclu par le Ministre Bernard Cazeneuve, se rendant lui-même en Californie en février 2015. On peut citer, dans un autre registre, celui de la maîtrise des coûts, l’accord-cadre CAIH-Microsoft cité plus haut, qui finalement ne fait qu’entériner la mainmise de Microsoft sur l’organisation hospitalière, et par extension à de multiples secteurs de la santé.
Certes, on peut arguer que ce type d’accord entre un gouvernement et des firmes est nécessaire dans la mesure où ce sont les opérateurs les mieux placés pour contribuer à une surveillance efficace des réseaux ou modéliser les échanges d’information. Cependant, on note aussi que de tels accords relèvent du principe de transfert du pouvoir du politique aux acteurs numériques. Tel est la thèse que synthétise Mark Zuckerberg dans son plaidoyer de février 2017. Elle est acceptée à de multiples niveaux de la décision et de l’action publique.
C’est par une analyse du rôle et de l’emploi du Droit aujourd’hui, en particulier dans ce contexte où ce sont les firmes qui définissent le droit (par exemple à travers leurs accords de loyauté) que Alain Supiot démontre comment le gouvernement par les nombres, c’est-à-dire ce mode de gouvernement par le marché (celui des instruments, de l’expertise, de la mesure et du contrôle) et non plus par le Droit, est en fait l’avènement du Big Other de Shoshanna Zuboff, c’est-à-dire un monde où ce n’est plus le Droit qui règle l’organisation sociale, mais c’est le contrat entre les individus et les différentes offres du marché. Alain Supiot l’exprime en deux phrases24 :
Référée à un nouvel objet fétiche – non plus l’horloge, mais l’ordinateur –, la gouvernance par les nombres vise à établir un ordre qui serait capable de s’autoréguler, rendant superflue toute référence à des lois qui le surplomberaient. Un ordre peuplé de particules contractantes et régi par le calcul d’utilité, tel est l’avenir radieux promis par l’ultralibéralisme, tout entier fondé sur ce que Karl Polanyi a appelé le solipsisme économique.
Le rêve de Mark Zuckerberg et, avec lui, les grands monopoles du numérique, c’est de pouvoir considérer l’État lui-même comme un opérateur économique. C’est aussi ce que les tenants new public management défendent : appliquer à la gestion de l’État les mêmes règles que l’économie privée. De cette manière, ce sont les acteurs privés qui peuvent alors prendre en charge ce qui était du domaine de l’incalculable, c’est-à-dire ce que le débat politique est normalement censé orienter mais qui finit par être approprié par des mécanismes privés : la protection de l’environnement, la gestion de l’état-civil, l’organisation de la santé, la lutte contre le terrorisme, la régulation du travail, etc.

Conclusion : l’État est-il soluble dans les GAFAM ?
Nous ne perdons pas seulement notre souveraineté numérique mais nous changeons de souveraineté. Pour appréhender ce changement, on ne peut pas se limiter à pointer les monopoles, les effets de la concentration des services numériques et l’exploitation des big data. Il faut aussi se questionner sur la réception de l’idéologie issue à la fois de l’ultra-libéralisme et du renversement social qu’impliquent les techniques numériques à l’épreuve du politique. Le terrain favorable à ce renversement est depuis longtemps prêt, c’est l’avènement de la gouvernance par les instruments (par les nombres, pour reprendre Alain Supiot). Dès lors que la décision publique est remplacée par la technique, cette dernière est soumise à une certaine idéologie du progrès, celle construite par les firmes et structurée par leur marché.
Qu’on ne s’y méprenne pas : la transformation progressive de la gouvernance et cette idéologie-silicone sont l’objet d’une convergence plus que d’un enchaînement logique et intentionnel. La convergence a des causes multiples, de la crise financière en passant par la formation des décideurs, les conjonctures politiques… autant de potentielles opportunités par lesquelles des besoins nouveaux structurels et sociaux sont nés sans pour autant trouver dans la décision publique de quoi les combler, si bien que l’ingéniosité des GAFAM a su configurer un marché où les solutions s’imposent d’elles-mêmes, par nécessité.
Le constat est particulièrement sombre. Reste-t-il malgré tout une possibilité à la fois politique et technologique capable de contrer ce renversement ? Elle réside évidemment dans le modèle du logiciel libre. Premièrement parce qu’il renoue technique et Droit (par le droit des licences, avant tout), établit des chaînes de confiance là où seules des procédures régulent les contrats, ne construit pas une communauté mondiale uniforme mais des groupes sociaux en interaction impliqués dans des processus de décision, induit une diversité numérique et de nouveaux équilibres juridiques. Deuxièmement parce qu’il suppose des apprentissages à la fois techniques et politiques et qu’il est possible par l’éducation populaire de diffuser les pratiques et les connaissances pour qu’elles s’imposent à leur tour non pas sur le marché mais sur l’économie, non pas sur la gouvernance mais dans le débat public.
Pour aller plus loin :
- La série d’articles sur le framablog
- La série d’article au complet (fichier .epub)
- Xavier De La Porte, « Start-up ou Etat-plateforme : Macron a des idées du 17e siècle », Chroniques La Vie Numérique, France Culture, 19/06/2017.↩
- C’est ce que montre, d’un point de vue sociologique Corinne Delmas, dans Sociologie politique de l’expertise, Paris : La Découverte, 2011. Alain Supiot, dans La gouvernance par les nombres (cité plus loin), choisit quant à lui une approche avec les clés de lecture du Droit.↩
- Voir Friedrich Hayek, La route de la servitude, Paris : PUF, (réed.) 2013.↩
- Voir Karl Polanyi, La Grande Transformation, Paris : Gallimard, 2009.↩
- Christophe Masutti, « du software au soft power », dans : Tristan Nitot, Nina Cercy (dir.), Numérique : reprendre le contrôle, Lyon : Framasoft, 2016, pp. 99-107.↩
- Francis Fukuyama, La Fin de l’Histoire et le dernier homme, Paris : Flammarion, 1992.↩
- Corentin Durand, « ‘L’ADN de la France, c’est la liberté de la presse’, clame le patron de Google », Numerama, 26/02/2016.↩
- Les Échos, « Google intensifie sa lutte contre la propagande terroriste », 19/06/2017.↩
- Sandrine Cassini, « Terrorisme : accord entre la France et les géants du Net », Les Echos, 23/04/2015.↩
- Philippe Vion-Dury, La nouvelle servitude volontaire, Enquête sur le projet politique de la Silicon Valley, Editions FYP, 2016.↩
- Götz Hamman, The United States of Google, Paris : Premier Parallèle, 2015.↩
- On pourrait ici affirmer que ce qui est en jeu ici est le solutionnisme technologique, tel que le critique Evgeny Morozov. Certes, c’est aussi ce que Götz Haman démontre : à vouloir adopter des solutions web-centrées et du data mining pour mécaniser les interactions sociales, cela revient à les privatiser par les GAFAM. Mais ce que je souhaite montrer ici, c’est que la racine du capitalisme de surveillance est une idéologie dont le solutionnisme technologique n’est qu’une résurgence (un rhizome, pour filer la métaphore végétale). Le phénomène qu’il nous faut comprendre, c’est que l’avènement du capitalisme de surveillance n’est pas dû uniquement à cette tendance solutionniste, mais il est le résultat d’une convergence entre des renversements idéologiques (fin du libéralisme classique et dénaturation du néo-libéralisme), des nouvelles organisations (du travail, de la société, du droit), des innovations technologiques (le web, l’extraction et l’exploitation des données), de l’abandon du politique. On peut néanmoins lire avec ces clés le remarquable ouvrage de Evgeny Morozov, Pour tout résoudre cliquez ici : L’aberration du solutionnisme technologique, Paris : FYP éditions, 2014.↩
- Peppino Ortoleva, « Qu’est-ce qu’un gouvernement d’experts ? Le cas italien », dans : Hermès, 64/3, 2012, pp. 137-144.↩
- Vincent Dubois et Delphine Dulong, La question technocratique. De l’invention d’une figure aux transformations de l’action publique, Strasbourg : Presses Universitaires de Strasbourg, 2000.↩
- Pierre Lascoumes et Patrick Le Galès (dir.), Gouverner par les instruments, Paris : Les Presses de Sciences Po., 2004, chap. 6, pp. 237 sq.↩
- « Raphaël Mastier, Microsoft France : le secteur hospitalier doit industrialiser sa modernisation numérique », Econocom, 29/05/2015.↩
- « Services aux citoyens, simplification, innovation : les trois axes stratégiques du secteur public », CGI : Blog De la Suite dans les Idées, 02/05/2017.↩
- Ariane Beky, « Loi numérique : les amendements sur le logiciel libre divisent », Silicon.fr, 14/01/2016.↩
- Marc Rees, « La justice annule un marché public excluant le logiciel libre », Next Inpact, 10/01/2011.↩
- Mark Zuckerberg, « Building Global Community », Facebook.com, 16/02/2017.↩
- Fred Tuner, Aux sources de l’utopie numérique. De la contre-culture à la cyberculture. Stewart Brand, un homme d’influence, Caen : C&F Éditions, 2013.↩
- Christophe Masutti, « Les nouveaux Léviathans I — Histoire d’une conversion capitaliste », Framablog, 04/07/2016.↩
- Compte-rendu de l’audition deBruno Lasserre, président de l’Autorité de la concurrence, sur la régulation et la loyauté des plateformes numériques, devant la Commission de réflexion et de propositions sur le droit et les libertés à l’âge du numérique, Mardi 7 juillet 2015 (lien).↩
- Alain Supiot, La gouvernance par les nombres. Cours au Collège de France (2012-2014), Paris : Fayard, 2015, p. 206.↩