Jour après jour et depuis longtemps, des associations qui promeuvent les logiciels et la culture libre sont au contact de la population et forment un réseau irremplaçable : celui des GUL (Groupes d’Utilisateurs Linux) ou GULL (Groupes d’utilisateurs de Logiciels Libres).
Leurs activités traditionnelles : install’parties, conférences, stands… ont été complétées par une grande variété d’actions adaptées au contexte local et aux évolutions de nos pratiques numériques.
Nous avons choisi de mettre en valeur l’association Montpel’libre parce que (comme d’autres bien sûr) elle offre un exemple intéressant de diversification et de dynamisme (on y trouve même un groupe Framasoft…), et leurs membres ont été assez sympas pour répondre aux 512 questions que nous avions préparées. Voici une sélection de leurs réponses à plusieurs voix…
— Bonjour les Montpel’libristes, est-ce que vous pouvez nous dire un peu à quoi ressemble votre association ?
— Bonjour Frama. En préambule, nous avons remarqué que vous avez utilisé un Framapad pour cette interview, ce que nous comprenons parfaitement. Néanmoins, vous auriez pu utiliser un BIMpad sur nos CHATONS.
BIM pour Bienvenue sur l’Internet Montpelliérain, administré et hébergé localement. Voici la page (en construction) où sont tous les services que nous proposons. Après Dégooglisons, nous sommes aussi passés à Contributopia. 😉
Et pour faire connaissance avec notre association, l’essentiel est sur ce petit flyer
— Avec ce nom d’association on devine que vous rayonnez sur la métropole occitane, mais on voit aussi des événements vers Nîmes ou Béziers, comment vous vous organisez ?
— Effectivement, notre volonté est de faire la promotion des Logiciels Libres, de la Culture Libre et des Biens Communs à l’origine sur Montpellier, mais très vite nous avons pris une dimension régionale. Aujourd’hui nous intervenons sur l’Occitanie, en partie sur PACA, et avons quelques actions sur l’Afrique et le Québec. Nous souhaitons développer ces actions sur ces territoires en y organisant des Jerry-Party, les RMLL, EPN, coworking, ICC et ESS…
Nous sommes créatifs, réactifs, simples et souples. Des personnes viennent vers nous avec des demandes sur les logiciels libres, la culture libre et les biens communs et nous trouvons rapidement et simplement comment faire pour les satisfaire.
Comme nous nous inscrivons dans la durée, nous créons des réseaux que nous mettons en synergie et nous trouvons sur place ou non, les personnes qui peuvent nous aider à mener nos projets : des néophytes qu’on fait monter en compétence comme des personnes chevronnées qui prennent le lead sur les actions à mener. Ce qui les fait adhérer à Montpel’libre et y rester, c’est le fait qu’on écoute leur désir profond et qu’on les accompagne pour créer leur projet, en leur apportant la force du groupe, de ses différentes communautés, personnalités, compétences.
— Quand on lit la liste de des activités de Montpel’libre on est pris d’un léger vertige : mais comment font-ils ? On imagine vu le nombre d’événements, que vous êtes nombreux et nombreuses, et que de nouvelles personnes viennent dans l’asso, comment se passe l’accueil des nouvelles personnes, vous avez une stratégie ou bien ça se fait tout seul ?
— Plutôt que de constater une étanchéité des communautés, comme c’est souvent le cas, nous avons choisi de favoriser au sein de Montpel’libre une collaboration active de plusieurs communautés : April, Blender, Emmabuntüs, Framasoft, OpenStreetMap, Site Web/Internet, Wikipédia…, cela nous permet ipso facto d’organiser plus rapidement des événements tel que les Opérations Libres, qui font intervenir les communautés Wikipédia, OpenStreetMap, Framasoft, Blender… ces communautés étant actives dans l’asso, l’organisation s’en trouve plus aisée, efficiente et du coup largement moins problématique.
— Nous n’avons pas forcément de plan triennal, cela ne nous empêche pas de nous projeter dans l’avenir. Nous établissons déjà les activités pour 2019, même si celles-ci ne sont pas encore publiées, AprilCamp, PyConFr, Escale à l’UM, Libre de Droit, RMLL à Montpellier, en 2020 RMLL à Rabat… Bien sûr certaines propositions ne sont qu’à l’état d’ébauche, blockchain, smart city, iot, icc, ess… Du libre pour tous, tout de suite et partout !
Nous ne sommes pas conscients de tout ce qui nous a permis de réussir, mais nous savons ce qui est important pour nous. En premier lieu, nous sommes respectueux des différences et de la diversité. Bien des personnes nous rejoignent parce qu’elles savent qu’avec et dans Montpel’libre, elles vont pouvoir mettre en place leurs idées de façon simple et efficace, quoiqu’elles sachent faire, et s’accomplir dans une ambiance conviviale. Elles aiment aussi la créativité que démontre le groupe.
— En même temps, pour développer et mener à bien des projets, nous avons dans le Bureau toutes les compétences complémentaires nécessaires : nous sommes tous utilisateurs de logiciels libres et membre de plusieurs communautés. En fait, quand on éprouve un besoin, la réponse arrive à point nommé : cela repose sur un long travail de fond, chacun dans nos domaines, un partage dans l’esprit du Libre et une écoute profonde
— Les adhérents sont très divers et participent tous à notre succès : on retrouve beaucoup d’électrons libres et de hauts profils dans différentes matières qui font le numérique libre au sens large, mais aussi des enfants, des institutions, des entreprises, des associations, d’autres Gull, des personnes âgées, des personnes en situation de handicap, des stagiaires, des étudiants, et des personnes venues de plusieurs continents…
Montpel’libre présente les logiciels libres à la communauté Emmaüs de Montpellier (décembre 2015)
— C’est cette alchimie qui rend l’association étonnante, spécifique, vivante, organique….
— Je crois que ceux qui participent à nos actions (bénévoles, partenaires, fournisseurs) apprécient aussi notre façon de les mettre en valeur : pour nous c’est ensemble que nous faisons les choses et s’il manque une personne, alors l’action ne peut être aussi belle. Nous remercions toujours chacun⋅e en expliquant quelle part il ou elle a pris dans le succès de l’action.
— En conclusion, on pourrait dire : « Il n’est de richesses que de personnes », et nous agissons avec le temps…
— Votre organisation, c’est plutôt cathédrale ou bazar ?
— La contribution collaborative, la prise de décision, l’émergence d’idée, l’esprit critique, le participatif, sont encouragés dans Montpel’libre. Une cathédrale ? Pas forcement. Un bazar structuré, plutôt !
— En fait, ce n’est ni la cathédrale, ni le bazar, c’est autre chose. Plutôt un Ki : l’énergie vitale et primordiale, celle qui est à l’origine de l’action, se transforme et la transforme en permanence.
Nous exprimons. à la fois la diversité de la vie, sa force et sa capacité à se renouveler:)
— C’est quoi les valeurs que vous promouvez, finalement ?
— Montpel’libre considère les Logiciels Libres, la Culture Libre et les Biens Communs (vous remarquerez que nous avons mis des majuscules à chaque mot 🙂 comme l’ADN de l’asso. Notre sacerdoce repose essentiellement sur la liberté 0, que nous qualifions d’accessibilité. Évidemment l’accessibilité au code pour les logiciels, mais aussi l’accessibilité aux ressources, à la culture, au numérique pour les personnes à mobilité réduite, les déficients visuels, mais pas seulement, issus de la diversité, de culture, d’âge ou de genres différents…
Nous rendons accessibles et humains le Logiciel libre, la Culture Libre et les Biens Communs. Entre nous, on en plaisante et on se dit « dealers de bonheur, dis-leur le bonheur ! ». Nous aimons le partage et nous apprécions particulièrement de voir les personnes qui ont participé à l’une de nos actions avec des yeux pleins de lumière et de grands sourires. Nous pratiquons beaucoup l’écoute, le partage et la proximité… mais nous aimons aussi la convivialité : les apéros, les bons repas et danser !
Les bénévoles de Montpel’libre pensent aussi aux plus jeunes (ici atelier jeu vidéo) – Photo Montpel’libre – merci @Natouille
— Votre slogan « Les logiciels logiquement libres » c’est chouette, mais ça laisse supposer que vous ne vous occupez que de la promotion du logiciel libre, alors que vos actions sont bien plus larges...
— L’asso est née en 2008, il y a bientôt 10 ans, vous imaginez bien que nos actions ont évolué, se sont diversifiées, démocratisées et répandues sur un territoire plus élargi. Aujourd’hui, nous nous trouvons à la jonction des secteurs d’activités du numérique, des industries créatives, de l’économie sociale et solidaire, du développement durable, de la recherche et formation ainsi que de l’éducation populaire.
Montpel’libre c’est un jeu de mot qui durera toujours . Montpel’ n’est pas lié : il est libre. Et nous sommes nés à Montpellier, ça, c’est un fait qui ne changera jamais. En revanche aujourd’hui le slogan devrait effectivement changer pour intégrer la Culture libre et les Biens Communs. Il devrait devenir : « Logiquement libres », tout simplement.
— Est-ce que les RMLL à Montpellier ont contribué à booster l’association ou bien était-elle déjà très active et donc a été candidate et choisie pour cela ?
— Bien sûr que les RMLL ont contribué à booster Montpel’libre, en douter serait nier l’évidence, même si nous avions déjà organisé plusieurs fois des salons (confs/stands…) à l’Université de Montpellier. Thierry Stœhr, Christophe Sauthier et d’autres, l’Université de Montpellier, l’Université d’Évry, l’Université Mohammedia de Rabat, 2iE à Ougadougou y ont participé. Nous avons un peu levé le pied là-dessus, car les gens nous demandaient à cette époque des ateliers, des permanences, des confs, bref de la proximité. Nous réfléchissons à relancer ces salons sur la région.
Avant d’organiser les RMLL, nous avions soigneusement travaillé nos réseaux, organisé ou participé à des événements avec les communautés, organisé certains événements comme l’assemblée générale de l’Aful, l’AprilCamp, une étape du tour de France des Logiciels Libres, les assises du Libre… afin de bien connaître et se faire connaître des communautés, des collectivités, des financeurs…
— Les RMLL ont permis d’attirer à Montpel’libre des professions autres que techniques et donc complémentaires et de fédérer les énergies et les bonnes volontés.
En plus, tous ceux qui ont réalisé un événement international le savent, l’organisation en est lourde et des tensions naissent. Le conflit a ceci de bon, quand il est positif, de permettre de s’asseoir à une table, de dire qu’il y a une difficulté et de trouver comment la régler. Montpel’libre a su passer au-dessus des difficultés. Cet événement a été intégrateur de compétences et fédérateur d’énergies et de bonnes volontés.
— C’est quoi le « gros coup » d’après ? Vous avez bien encore un méga-projet dans les cartons ?
— Chut ! Bien sûr, mais comme c’est un projet sensible, nous en discuterons plus tard, si vous le voulez bien.
Hum, mais qui a parlé d’un seul projet ?
— Vous avez une longue liste de partenaires de toutes sortes, est-ce que certains contribuent au financement de l’association ? Et au fait, comment vit financièrement votre association ? Seulement avec les cotisations des membres ?
— Jusqu’à présent, nous ne nous étions pas posé la question, nous avons agi sur fonds propres, c’est à dire des fonds sortis de nos poches ! Aujourd’hui, ce n’est plus possible vu le nombre et la diversité des activités. Il faut donc faire rentrer de l’argent dans les caisses (voyages, hébergement, pérennisation des activités…)
Le premier argent économisé est celui qui n’a pas été dépensé. Nous bénéficions de beaucoup de mécénats en nature (salles gratuites, personnels de service et gardiennage gratuit et dans certains cas cocktail).
Les cotisations de nos membres sont symboliques parce que volontairement nous voulons être accessibles : tout le monde doit pouvoir bénéficier des services de l’association et participer à l’organisation de l’une de ses activités.
Nous réfléchissons à trouver un, voire des modèle(s) économique(s).
— Bon c’est tout de même un peu agaçant, vous cochez toutes les cases de l’asso dynamique et sympathique en plein développement. Vous n’auriez pas un petit truc qui cloche pour tempérer un peu, je ne sais pas moi, un problème, une inquiétude, un truc dont vous regrettez qu’il ne marche pas ?
— Nous avons les mêmes difficultés que tout le monde pour mettre en place des actions et pour les pérenniser. Nous vivons les mêmes joies et questionnements que tout le monde. Nous croyons profondément en notre liberté et nous respectons celle des autres. Si quelqu’un ne veut pas agir avec nous, c’est sa liberté, nous la respectons et nous continuons notre chemin.
Un point qui est à améliorer : nous ne sommes pas assez présents dans des salons sur le logiciel libre (pas assez de stands, conférences, ateliers…).
— Quelle est le projet qui a le mieux réussi à faire venir à vous des Clapassièrs (les habitants de Montpellier) ?
— Ici, dans le Clapàs des Paysannasses notre réputation s’est faite à partir des cartoparties participatives sur l’accessibilité des personnes à mobilité réduite. Nous avons effectivement travaillé trois ans à l’enrichissement d’OpenStreetMap et de l’OpenData de Montpellier avec la ville, les citoyens et les communautés.
Après les cartoparties qui ont fait connaître Montpel’libre, notre association a permis à ceux qui y adhéraient de faire autre chose et autrement, d’où la diversité de ses actions.
Le groupe OSM : réunion de travail mais aussi cartopartie sur le terrain…
— Qu’est-ce que vous souhaitez dire aux habitants qui ne vous connaissent pas encore ? Et plus largement, à tous les libristes et tous les GULL ?
— Osez oser ! Construisez à partir de qui vous êtes, c’est-à-dire des compétences que vous avez, et qui font de vous un individu ou une association différente et unique. Le reste viendra tout seul et vous saurez vous réinventer.
— On vous laisse le mot de la fin mais ce n’est qu’un début, continuez le combat !
Bien sûr :
PeerTube bêta : une graine d’alternative à YouTube vient d’éclore
Le 21 novembre dernier, nous annoncions notre volonté de développer PeerTube, un logiciel libre qui pose les bases d’une alternative aux YouTubes et autres plateformes centralisant les vidéos.
Parmi toutes les actions de notre feuille de route Contributopia, celle-ci a reçu une attention et un soutien tout particulier. Il est temps de vous montrer les premiers résultats, de faire un premier point d’étape à l’occasion de la sortie publique de la version bêta de PeerTube.
« Bêta », cela signifie que ceci n’est qu’un début ! Nous espérons que vous verrez combien il est prometteur.
ATTENTION : cet article est long, car il compile de nombreuses explications. Pour vous aider à aller droit à ce qui vous intéresse, voici un sommaire.
Tout le monde ne suit pas assidûment les nombreux projets de Framasoft, alors on s’explique !
Nous allons parler ici des principes au cœur de PeerTube : un logiciel libre qui allie fédération d’hébergements et diffusion en pair à pair pour publier des vidéos en ligne de manière décentralisée.
Pour qui sait administrer un serveur, PeerTube c’est…
C’est un logiciel que vous installez sur votre serveur pour créer votre site web d’hébergement et de diffusion de vidéos… En gros : vous vous créez votre propre « YouTube maison » !
Il existe déjà des logiciels libres qui vous permettent de faire cela. L’avantage ici, c’est que vous pouvez choisir de relier votre instance PeerTube (votre site web de vidéos), à l’instance PeerTube de Zaïd (où se trouvent les vidéos des conférences de son université populaire), à celle de Catherine (qui héberge les vidéos de son Webmédia), ou encore à l’instance PeerTube de Solar (qui gère le serveur de son collectif de vidéastes).
Du coup, sur votre site web PeerTube, le public pourra voir vos vidéos, mais aussi celles hébergées par Zaïd, Catherine ou Solar… sans que votre site web n’ait à héberger les vidéos des autres ! Cette diversité dans le catalogue de vidéos devient très attractive. C’est ce qui a fait le succès des plateformes centralisatrices à la YouTube : le choix et la variété des vidéos.
Mais PeerTube ne centralise pas : il fédère. Grâce au protocole ActivityPub (utilisé aussi par la fédération Mastodon, une alternative libre à Twitter) PeerTube fédère plein de petits hébergeurs pour ne pas les obliger à acheter des milliers de disques durs afin d’héberger les vidéos du monde entier.
Un autre avantage de cette fédération, c’est que chacun·e est indépendant·e. Zaïd, Catherine, Solar et vous-même pouvez avoir vos propres règles du jeu, et créer vos propres Conditions Générales d’Utilisation (on peut, par exemple, imaginer un MiaouTube où les vidéos de chiens seraient strictement interdites 🙂 ).
Pour qui veut diffuser ses vidéos en ligne PeerTube permet…
Il vous permet de choisir un hébergement qui vous correspond. On l’a vu avec les dérives de YouTube : son hébergeur, Google-Alphabet, peut imposer son système ContentID (le fameux « Robocopyright ») ou ses outils de mise en valeur des vidéos, qui semblent aussi obscurs qu’injustes. Quoi qu’il arrive, il vous impose déjà de lui céder -gracieusement- des droits sur vos vidéos.
Avec PeerTube, vous choisissez l’hébergeur de vos vidéos selon ses conditions d’utilisation, sa politique de modération, ses choix de fédération… Comme vous n’avez pas un géant du web en face de vous, vous pourrez probablement discuter ensemble si vous avez un souci, un besoin, une envie…
L’autre gros avantage de PeerTube, c’est que votre hébergeur n’a pas à craindre le succès soudain d’une de vos vidéos. En effet, PeerTube diffuse les vidéos avec le protocole WebTorrent. Si des centaines de personnes regardent votre vidéo au même moment, leur navigateur envoie automatiquement des bouts de votre vidéo aux autres spectateurs.
Mine de rien, avant cette diffusion en pair-à-pair, les vidéastes à succès (ou les vidéos qui font le buzz) étaient condamnés à s’héberger chez un géant du web dont l’infrastructure peut encaisser des millions de vues simultanées… Ou à payer très cher un hébergement de vidéo indépendant afin qu’il tienne la charge.
Pour qui veut voir des vidéos, PeerTube a pour avantage…
Un des avantages, c’est que vous devenez partie prenante de la diffusion des vidéos que vous êtes en train de regarder. Si d’autres personnes regardent une vidéo PeerTube en même temps que vous, tant que votre onglet reste ouvert, votre navigateur partage des bouts de cette vidéo et vous participez ainsi à une utilisation plus saine d’Internet.
Bien sûr, le lecteur vidéo de PeerTube s’adapte à votre situation : si votre installation ne permet pas la diffusion en pair-à-pair (réseau d’entreprise, navigateur récalcitrant, etc…) la lecture de la vidéo se fera de manière classique.
Mais surtout, PeerTube vous considère comme une personne, et non pas comme un produit qu’il faut pister, profiler, et enfermer dans des boucles vidéos pour mieux vendre votre temps de cerveau disponible. Ainsi, le code source (la recette de cuisine) du logiciel PeerTube est ouvert, ce qui fait que son fonctionnement est transparent.
PeerTube n’est pas juste open-source : il est libre. Sa licence libre garantit nos libertés fondamentales d’utilisateurs ou d’utilisatrices. C’est ce respect de nos libertés qui permet à Framasoft de vous inviter à contribuer à ce logiciel, et de nombreuses évolutions (système de commentaires innovant, etc.) nous ont déjà été soufflées par certain·e·s d’entre vous.
PeerTube, expliqué par MrBidouille, sur PeerTube.
Et sinon, Framatube, ça avance…?
En novembre dernier, la campagne « Framatube » avait pour objectif de permettre à Framasoft d’embaucher Chocobozzz, le développeur de PeerTube, pour qu’il puisse enfin consacrer son temps professionnel à ce projet personnel.
On va pas se mentir : nous avons mis du « Frama » dedans pour mieux faire connaître le projet et susciter les contributions, financières et humaines. Si nous avons voulu mettre notre réputation (et nos savoir-faire) au service de PeerTube, ce n’est clairement pas Framasoft qui importe ici.
Ce qui compte, ce que l’on va raconter ci-dessous, c’est l’évolution qu’a pu connaître le projet PeerTube. Une évolution technique comme pratique, qui a été rendue possible grâce aux personnes qui se sont impliquées dans le projet (et si vous avez déjà tout suivi, passez à la suite en cliquant ici et le sommaire est là).
Sous le capot, le code
Une des plus grosses évolutions du code de PeerTube a été de le rendre plus visuel, et plus agréable. En effet, le logiciel que Chocobozzz a écrit sur son temps libre permettait déjà de nombreuses choses : créer une instance, des comptes pour les vidéastes, etc. Mais une partie de tout cela se faisait en ligne de commande, dans un terminal. Aujourd’hui, l’interface web permet (presque) tout.
On dit « presque », car la nouvelle fonctionnalité d’import de vidéos en masse depuis d’autres plateformes (YouTube, mais aussi Viméo, Dailymotion, et plein plein d’autres) se fait encore en ligne de commande… Si son utilisation reste réservée aux initié·e·s, l’outil reste bien pratique pour qui veut copier sa chaîne YouTube sur son instance PeerTube ;).
Suite à de nombreux échanges sur notre forum des contributions, le système de fédération a été entièrement revu pour adopter le protocole ActivityPub, qui est utilisé, par exemple, par Mastodon (l’alternative à Twitter libre et fédérée). Concrètement, cela permet à PeerTube de communiquer de manière standardisée avec d’autres logiciels fédérés… qui ne font pas forcément de la vidéo (comme Mastodon !). Pour l’instant, les échanges sont expérimentaux, mais ces tests sont prometteurs.
Enfin, nous avons accompagné Chocobozzz afin qu’il puisse mieux définir des cas d’utilisation, ce qui lui a permis de coder divers rôles d’utilisateurs d’une instance PeerTube. Désormais, l’hébergeur d’une instance peut désigner des admins, des modos, et ainsi créer une communauté autour de son instance et des règles qui ont été adoptées.
Cette fonctionnalité de rôles va de pair avec de meilleurs outils pour gérer les utilisateur·ice·s. Par exemple, un hébergeur peut définir un quota d’espace disque par vidéaste, afin de ne pas avoir une personne prenant tout les gigas disponibles sur son serveur. Les hébergeurs ont aussi la possibilité de définir le nombre de comptes disponibles sur leur instance (une fois dépassé, les inscriptions sont fermées).
Tout cela, bien entendu, dépend des règles que chaque instance aura définies. C’est là qu’intervient un nouvel outil qui permettra de décrire le but de son instance (généraliste, réservée à tel types de vidéos, ou de communauté, etc.) et surtout les règles qui régissent cet hébergement dans les conditions générales d’utilisation. Une fédération d’instances diverses ouvre la porte à une diversité de gouvernances et d’identités : mieux vaut avoir un outil pour afficher tout cela en toute transparence !
Les échanges se font aussi en dessous des vidéos. Pour cela, un outil de commentaires a été créé. Grâce au protocole de fédération ActivityPub, les commentaires de votre compte PeerTube sont automatiquement « pouettés » (un Pouet, c’est comme un Tweet qui se serait libéré de Twitter). Si les commentaires sont fonctionnels, ils sont voués à évoluer, car de nombreuses améliorations sont déjà discutées sur notre forum des contributions (merci à Rigelk et Thoumou au passage !).
Enfin, PeerTube a connu une grosse évolution graphique. On peut évoquer l’outil pour envoyer une miniature personnalisée sur sa vidéo, ou de celui qui permet de définir le contenu comme « Not Safe For Work » (« réservé à un public averti »)… Mais c’est surtout la contribution d’Olivier Massain qu’il faut souligner. Ce dernier a repensé le design de PeerTube et a créé les maquettes visuelles que Chocobozzz a intégré dans cette version bêta du logiciel. Désormais, PeerTube est plus évident à utiliser tout en gagnant une identité visuelle claire.
La dimension humaine de PeerTube
On l’oublie souvent mais un projet logiciel, surtout lorsqu’il est contributif, c’est avant tout des personnes qui y mettent de leur temps, de leurs envies, et de leur talent dedans. Suite à sa proposition initiale de design, Olivier Massain a poursuivi son travail avec Chocobozzz, lorsqu’il fallait créer de nouvelles visualisations, et on ne peut que l’en remercier chaleureusement.
De même, la catégorie « PeerTube » de notre forum des contributions s’est enrichie d’un contributeur de qualité en la personne de Rigelk. Sa présence, sa bienveillance et sa pertinence ont alimenté de nombreuses discussions avec pour résultat des propositions collaboratives vraiment intéressantes. De telles contributions permettent à Chocobozzz de gagner du temps qu’il peut consacrer au développement de PeerTube.
Ce ne sont là que deux exemples de personnes qui ont grandement contribué à PeerTube (sans forcément apporter du code, d’ailleurs ^^). Il nous serait impossible de citer toutes les personnes ayant participé par leurs échanges, apports, questionnements, etc. Sachez simplement que PeerTube ne serait pas le même si nous l’avions fait juste « dans notre coin », alors merci à vous.
D’ailleurs, vos contributions financières à notre campagne de dons 2017 nous ont permis de renouveler le contrat de Chocobozzz, initialement embauché pour quatre mois. L’avoir avec nous jusqu’à fin 2018 nous permet d’envisager la poursuite du projet PeerTube jusqu’à une version 1, même si cela reste un pari financier pour Framasoft. Mais sa joyeuse présence, son professionnalisme (et ses connaissances en NodeJS) sont un apport indéniable à notre équipe salariée.
Et pis Chocobozzz, il montre même sur PeerTube comment marchent les commentaires PeerTube.
PeerTube : aujourd’hui et demain
Alors non : ce n’est pas aujourd’hui que vous allez brûler vos comptes YouTube ni libérer vos vidéos des chaînes de Google (quoique… sentez-vous libres ^^). Si la sortie de cette bêta n’est pas une révolution, elle marque une étape importante, une première marche essentielle vers une alternative crédible aux plateformes centralisatrices.
Ici, on va parler ensemble de la base commune que nous avons, expliquer pourquoi PeerTube ne répond pas encore à toutes les attentes (nombreuses et pressantes), et nos envies pour cheminer vers la version 1 de ce logiciel (pour aller direct à la conclusion, c’est ici et le sommaire est là).
De beaux débuts communautaires
C’est un bonheur de l’annoncer : le pari est réussi. PeerTube est un logiciel qui marche, et permet de fédérer des sites hébergeant des vidéos diffusées de pairs à pairs. Vous pouvez regarder, commenter, approuver (ou désapprouver) des vidéos, et même découvrir comment soutenir la personne qui les a mises en ligne (si elle a rempli le texte qui se cache derrière le bouton soutenir ou «support»).
Vous pouvez aussi, si vous en avez les capacités techniques, installer cette solution sur votre serveur et rejoindre la communauté naissante des hébergeurs PeerTube. À ce jour, nous comptons près d’une vingtaine d’instances d’hébergement avec qui nous avons travaillé pour mettre en place une proto-fédération. Une mailing-list et un wiki ont d’ailleurs vu le jour pour partager les expériences et mettre en commun les savoirs de chacun·e, tout est sur le site joinpeertube.org
Les vidéos disponibles sont extrêmement variées : du hacking (matériel comme social) à l’éducation populaire, des conférences gesticulées au let’s play, du data-journalisme au librisme… Il y en a tellement pour tous les goûts que nous allons vous détailler cela dans un autre article !
Par contre, peu d’instances d’hébergement vont ouvrir leurs portes à vos vidéos… Car c’est un travail titanesque que d’héberger, modérer, et prendre la responsabilité de mettre sur son serveur le contenu d’autrui. Si votre envie est de publier vos vidéos sur une instance PeerTube, il va falloir que vous dénichiez une instance d’hébergement qui vous va… ou que vous vous organisiez pour le faire vous-même.
Alors Framatube est là : https://framatube.org , mais le Framatube de vos rêves risque fort d’être… dans vos rêves. Nous l’avions annoncé : Framasoft n’ouvrira pas son hébergement aux vidéos du public. Non seulement par crainte de devenir un point de centralisation dans une solution qui prône la décentralisation, mais aussi parce que nous n’en avons pas les épaules. Entre passer notre énergie à modérer et diffuser vos contenus, et s’investir pour que vous puissiez le faire en toute indépendance, nous avons choisi : nous voulons améliorer l’outil.
Car PeerTube est loin d’être parfait. Déjà, son interface n’existe qu’en anglais. Oui, cela fait râler les amoureuxses du Français que nous sommes (hihi ^^), mais si nous voulons une solution ouverte sur le monde, l’anglais est une base indispensable (et PeerTube dépasse déjà la simple francophonie). Or, le travail d’internationalisation (préparer un logiciel pour pouvoir traduire son interface en plusieurs langues) n’est pas encore fait… (mais on a des idées pour ça aussi, vous verrez !)
De même, nous avons bien compris que la monétisation des vidéos est un sujet qui vous titille. C’est d’ailleurs étrange de noter combien Google a formaté nos façons de voir la diffusion de vidéos en ligne, à ce sujet… Pour l’instant, la seule solution proposée aux personnes qui mettent en ligne des vidéos est de mettre un texte et un lien qui apparaîtront dans le bouton soutenir («Support») sous la vidéo.
Nous ne sommes pas allé·e·s plus loin car favoriser une solution technique serait imposer une vision des partages culturels et de leurs financements. Or nous avons ici une version bêta : de nombreuses améliorations sont à prévoir… Dont celles qui vous permettraient de créer (et choisir) vous-même les outils de monétisation qui vous intéressent !
En route pour la version 1 !
On aimerait bien pouvoir dire à Chocobozzz « Bon, maintenant, va faire une petite sieste jusqu’à la prochaine ère glacière », mais… Il reste tellement de choses à faire ! Déjà, parce qu’avec la sortie d’une version bêta viennent les retours des bêta-tests. Ensuite parce que nous comptons avancer pour proposer une version 1 d’ici la fin de l’année…
Or ce ne sont pas les envies qui manquent pour améliorer PeerTube vers sa V1 : stabiliser le code, bien sûr, mais aussi travailler sa capacité à passer à l’échelle (comment se comporte PeerTube sur un petit RaspberryPi ou sur des grrrrrrrrros serveurs). Nous souhaitons aussi avoir un système d’internationalisation pour pouvoir traduire l’interface du logiciel, un outil pour mettre en ligne des sous-titres sur les vidéos, travailler le module de commentaires innovant imaginé sur le forum des contributions…
Dans nos rêves les plus fous, il y a aussi des outils statistiques plus poussés, un système de hooks ou de plugin qui permettent de personnaliser son instance PeerTube (changer l’apparence, ajouter un bouton ici ou là, etc.), une application mobile… Mais tout cela dépendra des énergies qui nous rejoindront comme de notre capacité à les accueillir et à collaborer ensemble.
Car tout cela a un coût : humain, associatif et financier. Si nous avons pu prolonger le contrat de Chocobozzz, c’est grâce à des dons qui ont été faits pour l’ensemble des actions de Framasoft. Ainsi, son temps de développement ne sera plus exclusivement consacré à PeerTube, car d’autres logiciels libres ont aussi besoin de ses talents (rassurez-vous, hein : il va quand même continuer à travailler sur son beau bébé ^^).
Longue vie à PeerTube !
Le fait est que nous allons devoir trouver comment pérenniser le poste de Chocobozzz et le projet PeerTube, qui nous semble avoir toutes les qualités pour proposer, à terme, une alternative éthique et astucieuse aux géants de la vidéo sur le web. Si nous cherchons encore comment faire, nous savons que nous ne voulons pas uniquement nous reposer sur la générosité de la communauté francophone.
En attendant, c’est aujourd’hui le jour où nous pouvons rendre publics les efforts qui ont été menés jusqu’à présent, en espérant que cela titille au moins votre curiosité… et au mieux vos envies de contribuer à cette belle aventure (ça se passe sur notre forum !).
Car oui, la route vers une alternative à YouTube est longue… Mais on vient d’en défricher la voie, et on vous assure qu’elle est Libre !
L’équipe Framasoft, qui lève son chapeau à Chocobozzz.
Incroyables comestibles : les communs dans l’assiette
« Les incroyables comestibles » se définissent comme « un mouvement citoyen, une initiative de transition, visant à transformer l’espace public en jardin potager gratuit dans lequel la nourriture devient une ressource mise à disposition par tous et accessible à tout un chacun ». Voilà qui ressemble drôlement à un commun.
Avec eux, l’espace public devient un jardin potager géant, gratuit et à partager librement. On peut alors imaginer de la ciboulette sur les boîtes aux lettres avec les voisins, des courges qui grimpent aux grilles des écoles, des cornichons à côté des arrêts de bus…
Nous avions adoré les rencontrer lors de la journée In-Libe issue de l’imagination de deux amis geeks et jardiniers.
Aujourd’hui c’est Tripou qui interroge les dynamiques d’Amiens.
Salut les Amiénois·e·s !
Vous avez un site sympathique, 100% collaboratif, et qui répertorie même les endroits où il y a des arbres fruitiers sur une OpenStreetMap pour aller les cueillir…miam ! Mais en vrai on ne peut pas se nourrir entièrement/complètement avec de la nourriture en accès libre, si ?
Effectivement, il est difficile de trouver tout ce dont on a besoin en accès libre, surtout en ville. Mais de plus en plus d’associations proposent des découvertes de plantes sauvages comestibles et c’est un bon début!
Combien de temps faut-il pour mettre en place ce type de projet ?
Le temps dépend de pas mal de facteurs aussi me semble-t-il difficile de répondre de manière précise. Le mouvement des IC est en gestation depuis plusieurs années à Amiens, où il a réellement pris son essor il y a un peu plus d’un an.
Et combien de personnes faut-il trouver pour ne pas s’épuiser à s’occuper de tous les bacs à légumes ?
Tout dépend du nombre de bacs, de leur localisation. À Amiens il y a un système de « parrainage » de bac où 2-3 personnes en moyenne prennent en charge leur observation et leur entretien courant néanmoins l’intérêt est que cet entretien ne se cantonne pas aux bénévoles du noyau dur du mouvement mais soit relayé par les habitants ou les publics rattachés aux lieux où ces bacs se trouvent.
Et le tas de compost, il est sous la mairie ?
Pas de compost sous la mairie et pas de dynamique de compostage collectif rattaché à la dynamique. Cependant le bac installé par les étudiants de l’association Nature en Fac à la Fac de Science est situé à proximité immédiate du bac à compost mis en place par les étudiants et la Fac.
Comment réagissent les services municipaux par chez vous ?
La collectivité réserve plutôt un bon accueil à la démarche et travaille également sur le sujet des jardins en ville.
Étant donné que c’est un mouvement mondial, vous êtes en lien avec les autres groupes français ou internationaux ?
Nous avons des échanges avec Incroyables comestibles France et François Rouillay. Nous avons parfois des contacts avec des habitants de la région intéressés pour instiller un mouvement sur leur territoire.
Les gens qui s’engagent dans ce genre d’actions, c’est qui ? Ont-ils un passé de jardinier par exemple ?
Les membres du collectif viennent d’horizons divers ce ne sont pas forcément des jardiniers (même s’il y en a aussi, tout le monde vient avec ses envies et les compétences ou moyens qui peuvent nourrir la démarche)
Quel est votre champ d’action ?
Il est très divers : espace public, bibliothèques, centres culturels, fac …
Les lieux d’implantations doivent être éloignés des zones où il y a des gaz d’échappement, mais en ville il y en a pas mal, non ?
Oui c’est en effet une précaution à observer et une contrainte difficile à éviter. Les bacs installés à Amiens ne bordent pas directement de voies de circulation mais sont situés pour la plupart en retrait ou dans des espaces à moindre circulation.
C’est bio ?
La priorité étant d’avoir un autre regard sur son environnement, de mettre des bacs où cela est possible et faire changer les mentalités en conséquence. C’est bio dans la mesure où ça n’est pas traité chimiquement. Les gaz ne s’arrêtent pas aux limites des chaussées et il faut faire avec en ville pour le moment.
On peut imaginer des vaches à steaks gérées collectivement, des endroits de découpe ou de transformations groupés, des haies de houblon…ça fait rêver, est-ce que c’est possible ?
Bien sur, de plus en plus de communes se penchent sur la question et des initiatives de ce genre voient le jour en France. Cela relève évidemment de la politique de la ville.
Pour moi, voir ce genre de mise en place me permet aussi de me questionner sur la manière dont je me nourris, ce que j’achète et où je le trouve, le goût des choses etc… Vous vous fournissez comment en graines et plants ?
Nous avons eu des dons au départ (kokopelli, jardiniers amateurs…) puis les personnes qui ont pu utiliser nos graines les ont récoltées et nous les ont redonnées.A chaque événement, nous avons le plaisir de recevoir de nouvelles graines.
Vous pouvez m’aiguiller vers des producteur-trice-s locaux si après avoir pillé et mangé tous vos bacs, j’ai encore faim ?
Vous pouvez vous rapprocher des différentes AMAP présentes dans le secteur d’Amiens, les producteurs des Hortillonages sur les marchés d’Amiens et depuis quelques mois l’île aux Fruits qui proposent des fruits et légumes chaque jeudi.
Vous faites aussi des permanences tous les mois à l’université, comment ça se passe concrètement ?
Très bien : un ordre du jour pour garder le fil et s’organiser sur les différents projets, des échanges et discussions avec tous les présents (les permanences sont ouvertes à tous) et un temps de convivialité sur le mode apéro grignote partagée.
Au fait c’est l’hiver ! Un petit conseil pour semer, une préférence de légume ?
Toujours semer plus que ce dont on a besoin. Offrir à son entourage le reste et en planter dans le bacs Incroyables Comestibles. D’abord des salades, radis au jardin, puis tomates courgettes suivront au chaud en attendant les dernières gelées.
Vous pouvez aussi nous suivre sur Facebook (hum) pour les dernières infos.
Nous sommes toujours à la recherche de bénévoles, jardiniers ou non ! Venez nous rencontrez lors de nos prochaines réunions. 🙂
Les nouveaux Léviathans IV. La surveillance qui vient
Dans ce quatrième numéro de la série Nouveaux Léviathans, nous allons voir dans quelle mesure le modèle économique a développé son besoin vital de la captation des données relatives à la vie privée. De fait, nous vivons dans le même scénario dystopique depuis une cinquantaine d’années. Nous verrons comment les critiques de l’économie de la surveillance sont redondantes depuis tout ce temps et que, au-delà des craintes, le temps est à l’action d’urgence.
Note : voici le quatrième volet de la série des Nouveaux (et anciens) Léviathans, initiée en 2016, par Christophe Masutti, alias Framatophe. Pour retrouver les articles précédents, une liste vous est présentée à la fin de celui-ci.
Aujourd’hui
Avons-nous vraiment besoin des utopies et des dystopies pour anticiper les rêves et les cauchemars des technologies appliquées aux comportements humains ? Sempiternellement rabâchés, le Meilleur de mondes et 1984 sont sans doute les romans les plus vendus parmi les best-sellers des dernières années. Il existe un effet pervers des utopies et des dystopies, lorsqu’on les emploie pour justifier des arguments sur ce que devrait être ou non la société : tout argument qui les emploie afin de prescrire ce qui devrait être se trouve à un moment ou à un autre face au mur du réel sans possibilité de justifier un mécanisme crédible qui causerait le basculement social vers la fiction libératrice ou la fiction contraignante. C’est la raison pour laquelle l’île de Thomas More se trouve partout et nulle part, elle est utopique, en aucun lieu. Utopie et dystopie sont des propositions d’expérience et n’ont en soi aucune vocation à prouver ou prédire quoi que ce soit bien qu’elles partent presque toujours de l’expérience commune et dont tout l’intérêt, en particulier en littérature, figure dans le troublant cheminement des faits, plus ou moins perceptible, du réel vers l’imaginaire.
Pourtant, lorsqu’on se penche sur le phénomène de l’exploitation des données personnelles à grande échelle par des firmes à la puissance financière inégalable, c’est la dystopie qui vient à l’esprit. Bien souvent, au gré des articles journalistiques pointant du doigt les dernières frasques des GAFAM dans le domaine de la protection des données personnelles, les discussions vont bon train : « ils savent tout de nous », « nous ne sommes plus libres », « c’est Georges Orwell », « on nous prépare le meilleur des mondes ». En somme, c’est l’angoisse pendant quelques minutes, juste le temps de vérifier une nouvelle fois si l’application Google de notre smartphone a bien enregistré l’adresse du rendez-vous noté la veille dans l’agenda.
Un petit coup d’angoisse ? allez… que diriez-vous si vos activités sur les réseaux sociaux, les sites d’information et les sites commerciaux étaient surveillées et quantifiées de telle manière qu’un système de notation et de récompense pouvait vous permettre d’accéder à certains droits, à des prêts bancaires, à des autorisations officielles, au logement, à des libertés de circulation, etc. Pas besoin de science-fiction. Ainsi que le rapportait Wired en octobre 20171, la Chine a déjà tout prévu d’ici 2020, c’est-à-dire demain. Il s’agit, dans le contexte d’un Internet déjà ultra-surveillé et non-neutre, d’établir un système de crédit social en utilisant les big data sur des millions de citoyens et effectuer un traitement qui permettra de catégoriser les individus, quels que soient les risques : risques d’erreurs, risques de piratage, crédibilité des indicateurs, atteinte à la liberté d’expression, etc.
Évidemment les géants chinois du numérique comme Alibaba et sa filiale de crédit sont déjà sur le coup. Mais il y a deux choses troublantes dans cette histoire. La première c’est que le crédit social existe déjà et partout : depuis des années on évalue en ligne les restaurants et les hôtels sans se priver de critiquer les tenanciers et il existe toute une économie de la notation dans l’hôtellerie et la restauration, des applications terrifiantes comme Peeple2 existent depuis 2015, les banques tiennent depuis longtemps des listes de créanciers, les fournisseurs d’énergie tiennent à jour les historiques des mauvais payeurs, etc. Ce que va faire la Chine, c’est le rêve des firmes, c’est la possibilité à une gigantesque échelle et dans un cadre maîtrisé (un Internet non-neutre) de centraliser des millions de gigabits de données personnelles et la possibilité de recouper ces informations auparavant éparses pour en tirer des profils sur lesquels baser des décisions.
Le second élément troublant, c’est que le gouvernement chinois n’aurait jamais eu cette idée si la technologie n’était pas déjà à l’œuvre et éprouvée par des grandes firmes. Le fait est que pour traiter autant d’informations par des algorithmes complexes, il faut : de grandes banques de données, beaucoup d’argent pour investir dans des serveurs et dans des compétences, et espérer un retour sur investissement de telle sorte que plus vos secteurs d’activités sont variés plus vous pouvez inférer des profils et plus votre marketing est efficace. Il est important aujourd’hui pour des monopoles mondialisés de savoir combien vous avez de chance d’acheter à trois jours d’intervalle une tondeuse à gazon et un canard en mousse. Le profilage de la clientèle (et des utilisateurs en général) est devenu l’élément central du marché à tel point que notre économie est devenue une économie de la surveillance, repoussant toujours plus loin les limites de l’analyse de nos vies privées.
La dystopie est en marche, et si nous pensons bien souvent au cauchemar orwellien lorsque nous apprenons l’existence de projets comme celui du gouvernement chinois, c’est parce que nous n’avons pas tous les éléments en main pour en comprendre le cheminement. Nous anticipons la dystopie mais trop souvent, nous n’avons pas les moyens de déconstruire ses mécanismes. Pourtant, il devient de plus en plus facile de montrer ces mécanismes sans faire appel à l’imaginaire : toutes les conditions sont remplies pour n’avoir besoin de tracer que quelques scénarios alternatifs et peu différents les uns des autres. Le traitement et l’analyse de nos vies privées provient d’un besoin, celui de maximiser les profits dans une économie qui favorise l’émergence des monopoles et la centralisation de l’information. Cela se retrouve à tous les niveaux de l’économie, à commencer par l’activité principale des géants du Net : le démarchage publicitaire. Comprendre ces modèles économiques revient aussi à comprendre les enjeux de l’économie de la surveillance.
Données personnelles : le commerce en a besoin
Dans le petit monde des études en commerce et marketing, Frederick Reichheld fait figure de référence. Son nom et ses publications dont au moins deux best sellers, ne sont pas vraiment connus du grand public, en revanche la plupart des stratégies marketing des vingt dernières années sont fondées, inspirées et même modélisées à partir de son approche théorique de la relation entre la firme et le client. Sa principale clé de lecture est une notion, celle de la fidélité du client. D’un point de vue opérationnel cette notion est déclinée en un concept, celui de la valeur vie client (customer lifetime value) qui se mesure à l’aune de profits réalisés durant le temps de cette relation entre le client et la firme. Pour Reichheld, la principale activité du marketing consiste à optimiser cette valeur vie client. Cette optimisation s’oppose à une conception rétrograde (et qui n’a jamais vraiment existé, en fait3) de la « simple » relation marchande.
En effet, pour bien mener les affaires, la relation avec le client ne doit pas seulement être une série de transactions marchandes, avec plus ou moins de satisfaction à la clé. Cette manière de concevoir les modèles économiques, qui repose uniquement sur l’idée qu’un client satisfait est un client fidèle, a son propre biais : on se contente de donner de la satisfaction. Dès lors, on se place d’un point de vue concurrentiel sur une conception du capitalisme marchand déjà ancienne. Le modèle de la concurrence « non faussée » est une conception nostalgique (fantasmée) d’une relation entre firme et client qui repose sur la rationalité de ce dernier et la capacité des firmes à produire des biens en réponse à des besoins plus ou moins satisfaits. Dès lors la décision du client, son libre arbitre, serait la variable juste d’une économie auto-régulée (la main invisible) et la croissance économique reposerait sur une dynamique de concurrence et d’innovation, en somme, la promesse du « progrès ».
Évidemment, cela ne fonctionne pas ainsi. Il est bien plus rentable pour une entreprise de fidéliser ses clients que d’en chercher de nouveaux. Prospecter coûte cher alors qu’il est possible de jouer sur des variables à partir de l’existant, tout particulièrement lorsqu’on exerce un monopole (et on comprend ainsi pourquoi les monopoles s’accommodent très bien entre eux en se partageant des secteurs) :
on peut résumer la conception de Reichheld à partir de son premier best seller, The Loyalty Effect (1996) : avoir des clients fidèles, des employés fidèles et des propriétaires loyaux. Il n’y a pas de main invisible : tout repose sur a) le rapport entre hausse de la rétention des clients / hausse des dépenses, b) l’insensibilité aux prix rendue possible par la fidélisation (un client fidèle, ayant dépassé le stade du risque de défection, est capable de dépenser davantage pour des raisons qui n’ont rien à voir avec la valeur marchande), c) la diminution des coûts de maintenance (fidélisation des employés et adhésion au story telling), d) la hausse des rendements et des bénéfices. En la matière la firme Apple rassemble tous ces éléments à la limite de la caricature.
Reichheld est aussi le créateur d’un instrument d’évaluation de la fidélisation : le NPS (Net Promoter Score). Il consiste essentiellement à catégoriser les clients, entre promoteurs, détracteurs ou passifs. Son autre best-seller The Ultimate Question 2.0: How Net Promoter Companies Thrive in a Customer-Driven World déploie les applications possibles du contrôle de la qualité des relations client qui devient dès lors la principale stratégie de la firme d’où découlent toutes les autres stratégies (en particulier les choix d’innovation). Ainsi il cite dans son ouvrage les plus gros scores NPS détenus par des firmes comme Apple, Amazon et Costco.
Il ne faut pas sous-estimer la valeur opérationnelle du NPS. Notamment parce qu’il permet de justifier les choix stratégiques. Dans The Ultimate Question 2.0 Reichheld fait référence à une étude de Bain & Co. qui montre que pour une banque, la valeur vie client d’un promoteur (au sens NPS) est estimée en moyenne à 9 500 dollars. Ce modèle aujourd’hui est une illustration de l’importance de la surveillance et du rôle prépondérant de l’analyse de données. En effet, plus la catégorisation des clients est fine, plus il est possible de déterminer les leviers de fidélisation. Cela passe évidemment par un système de surveillance à de multiples niveaux, à la fois internes et externes :
surveiller des opérations de l’organisation pour les rendre plus agiles et surveiller des employés pour augmenter la qualité des relations client,
rassembler le plus de données possibles sur les comportements des clients et les possibilités de déterminer leurs choix à l’avance.
Savoir si cette approche du marketing est née d’un nouveau contexte économique ou si au contraire ce sont les approches de la valeur vie client qui ont configuré l’économie d’aujourd’hui, c’est se heurter à l’éternel problème de l’œuf et de la poule. Toujours est-il que les stratégies de croissance et de rentabilité de l’économie reposent sur l’acquisition et l’exploitation des données personnelles de manière à manipuler les processus de décision des individus (ou plutôt des groupes d’individus) de manière à orienter les comportements et fixer des prix non en rapport avec la valeur des biens mais en rapport avec ce que les consommateurs (ou même les acheteurs en général car tout ne se réduit pas à la question des seuls biens de consommation et des services) sont à même de pouvoir supporter selon la catégorie à laquelle ils appartiennent.
Le fait de catégoriser ainsi les comportements et les influencer, comme nous l’avons vu dans les épisodes précédents de la série Léviathans, est une marque stratégique de ce que Shoshana Zuboff a appelé le capitalisme de surveillance4. Les entreprises ont aujourd’hui un besoin vital de rassembler les données personnelles dans des silos de données toujours plus immenses et d’exploiter ces big data de manière à optimiser leurs modèles économiques. Ainsi, du point de vue des individus, c’est le quotidien qui est scruté et analysé de telle manière que, il y a à peine une dizaine d’années, nous étions à mille lieues de penser l’extrême granularité des données qui cartographient et catégorisent nos comportements. Tel est l’objet du récent rapport publié par Cracked Lab Corporate surveillance in everyday life5 qui montre à quel point tous les aspect du quotidien font l’objet d’une surveillance à une échelle quasi-industrielle (on peut citer les activités de l’entreprise Acxiom), faisant des données personnelles un marché dont la matière première est traitée sans aucun consentement des individus. En effet, tout le savoir-faire repose essentiellement sur le recoupement statistique et la possibilité de catégoriser des milliards d’utilisateurs de manière à produire des représentations sociales dont les caractéristiques ne reflètent pas la réalité mais les comportements futurs. Ainsi par exemple les secteurs bancaires et des assurances sont particulièrement friands des possibilités offertes par le pistage numérique et l’analyse de solvabilité.
Cette surveillance a été caractérisée déjà en 1988 par le chercheur en systèmes d’information Roger Clarke6 :
dans la mesure où il s’agit d’automatiser, par des algorithmes, le traitement des informations personnelles dans un réseau regroupant plusieurs sources, et d’en inférer du sens, on peut la qualifier de « dataveillance », c’est à dire « l’utilisation systématique de systèmes de traitement de données à caractère personnel dans l’enquête ou le suivi des actions ou des communications d’une ou de plusieurs personnes » ;
l’un des attributs fondamentaux de cette dataveillance est que les intentions et les mécanismes sont cachés aux sujets qui font l’objet de la surveillance.
En effet, l’accès des sujets à leurs données personnelles et leurs traitements doit rester quasiment impossible car après un temps très court de captation et de rétention, l’effet de recoupement fait croître de manière exponentielle la somme d’information sur les sujets et les résultats, qu’ils soient erronés ou non, sont imbriqués dans le profilage et la catégorisation de groupes d’individus. Plus le monopole a des secteurs d’activité différents, plus les comportements des mêmes sujets vont pouvoir être quantifiés et analysés à des fins prédictives. C’est pourquoi la dépendance des firmes à ces informations est capitale ; pour citer Clarke en 20177 :
« L’économie de la surveillance numérique est cette combinaison d’institutions, de relations institutionnelles et de processus qui permet aux entreprises d’exploiter les données issues de la surveillance du comportement électronique des personnes et dont les sociétés de marketing deviennent rapidement dépendantes. »
Le principal biais que produit cette économie de la surveillance (pour S. Zuboff, c’est de capitalisme de surveillance qu’il s’agit puisqu’elle intègre une relation d’interdépendance entre centralisation des données et centralisation des capitaux) est qu’elle n’a plus rien d’une démarche descriptive mais devient prédictive par effet de prescription.
Elle n’est plus descriptive (mais l’a-t-elle jamais été ?) parce qu’elle ne cherche pas à comprendre les comportements économiques en fonction d’un contexte, mais elle cherche à anticiper les comportements en maximisant les indices comportementaux. On ne part plus d’un environnement économique pour comprendre comment le consommateur évolue dedans, on part de l’individu pour l’assigner à un environnement économique sur mesure dans l’intérêt de la firme. Ainsi, comme l’a montré une étude de Propublica en 20168, Facebook dispose d’un panel de pas moins de 52 000 indicateurs de profilage individuels pour en établir une classification générale. Cette quantification ne permet plus seulement, comme dans une approche statistique classique, de déterminer par exemple si telle catégorie d’individus est susceptible d’acheter une voiture. Elle permet de déterminer, de la manière la plus intime possible, quelle valeur économique une firme peut accorder à un panel d’individus au détriment des autres, leur valeur vie client.
Tout l’enjeu consiste à savoir comment influencer ces facteurs et c’est en cela que l’exploitation des données passe d’une dimension prédictive à une dimension prescriptive. Pour prendre encore l’exemple de Facebook, cette firme a breveté un système capable de déterminer la solvabilité bancaire des individus en fonction de la solvabilité moyenne de leur réseau de contacts9. L’important ici, n’est pas vraiment d’aider les banques à diminuer les risques d’insolvabilité de leurs clients, car elles savent très bien le faire toutes seules et avec les mêmes procédés d’analyse en big data. En fait, il s’agit d’influencer les stratégies personnelles des individus par le seul effet panoptique10 : si les individus savent qu’ils sont surveillés, toute la stratégie individuelle consistera à choisir ses amis Facebook en fonction de leur capacité à maximiser les chances d’accéder à un prêt bancaire (et cela peut fonctionner pour bien d’autres objectifs). L’intérêt de Facebook n’est pas d’aider les banques, ni de vendre une expertise en statistique (ce n’est pas le métier de Facebook) mais de normaliser les comportements dans l’intérêt économique et augmenter la valeur vie client potentielle de ses utilisateurs : si vous avez des problèmes d’argent, Facebook n’est pas fait pour vous. Dès lors il suffit ensuite de revendre des profils sur-mesure à des banques. On se retrouve typiquement dans un épisode d’anticipation de la série Black Mirror (Chute libre)11.
La fiction, l’anticipation, la dystopie… finalement, c’est-ce pas un biais que de toujours analyser sous cet angle l’économie de la surveillance et le rôle des algorithmes dans notre quotidien ? Tout se passe en quelque sorte comme si nous découvrions un nouveau modèle économique, celui dont nous venons de montrer que les préceptes sont déjà anciens, et comme si nous appréhendions seulement aujourd’hui les enjeux de la captation et l’exploitation des données personnelles. Au risque de décevoir tous ceux qui pensent que questionner la confiance envers les GAFAM est une activité d’avant-garde, la démarche a été initiée dès les prémices de la révolution informatique.
La vie privée à l’époque des pattes d’eph.
Face au constat selon lequel nous vivons dans un environnement où la surveillance fait loi, de nombreux ouvrages, articles de presse et autres témoignages ont sonné l’alarme. En décembre 2017, ce fut le soi-disant repentir de Chamath Palihapitya, ancien vice-président de Facebook, qui affirmait avoir contribué à créer « des outils qui déchirent le tissu social »12. Il ressort de cette lecture qu’après plusieurs décennies de centralisation et d’exploitation des données personnelles par des acteurs économiques ou institutionnels, nous n’avons pas fini d’être surpris par les transformations sociales qu’impliquent les big data. Là où, effectivement, nous pouvons accorder un tant soit peu de de crédit à C. Palihapitya, c’est dans le fait que l’extraction et l’exploitation des données personnelles implique une économie de la surveillance qui modèle la société sur son modèle économique. Et dans ce modèle, l’exercice de certains droits (comme le droit à la vie privée) passe d’un état absolu (un droit de l’homme) à un état relatif (au contexte économique).
Comme cela devient une habitude dans cette série des Léviathans, nous pouvons effectuer un rapide retour dans le temps et dans l’espace. Situons-nous à la veille des années 1970, aux États-Unis, plus exactement dans la période charnière qui vit la production en masse des ordinateurs mainframe (du type IBM 360), à destination non plus des grands laboratoires de recherche et de l’aéronautique, mais vers les entreprises des secteurs de la banque, des assurances et aussi vers les institutions gouvernementales. L’objectif premier de tels investissements (encore bien coûteux à cette époque) était le traitement des données personnelles des citoyens ou des clients.
Comme bien des fois en histoire, il existe des périodes assez courtes où l’on peut comprendre les événements non pas parce qu’ils se produisent suivant un enchaînement logique et linéaire, mais parce qu’ils surviennent de manière quasi-simultanée comme des fruits de l’esprit du temps. Ainsi nous avons d’un côté l’émergence d’une industrie de la donnée personnelle, et, de l’autre l’apparition de nombreuses publications portant sur les enjeux de la vie privée. D’aucuns pourraient penser que, après la publication en 1949 du grand roman de G. Orwell, 1984, la dystopie orwellienne pouvait devenir la clé de lecture privilégiée de l’informationnalisation (pour reprendre le terme de S. Zuboff) de la société américaine dans les années 1960-1970. Ce fut effectivement le cas… plus exactement, si les références à Orwell sont assez courantes dans la littérature de l’époque13, il y avait deux lectures possibles de la vie privée dans une société aussi bouleversée que celle de l’Amérique des années 1960. La première questionnait la hiérarchie entre vie privée et vie publique. La seconde focalisait sur le traitement des données informatiques. Pour mieux comprendre l’état d’esprit de cette période, il faut parcourir quelques références.
Vie privée vs vie publique
Deux best-sellers parus en été 1964 effectuent un travail introspectif sur la société américaine et son rapport à la vie privée. Le premier, écrit par Myron Brenton, s’intitule The privacy invaders14. Brenton est un ancien détective privé qui dresse un inventaire des techniques de surveillance à l’encontre des citoyens et du droit. Le second livre, écrit par Vance Packard, connut un succès international. Il s’intitule The naked Society15, traduit en français un an plus tard sous le titre Une société sans défense. V. Packard est alors universitaire, chercheur en sociologie et économie. Il est connu pour avoir surtout travaillé sur la société de consommation et le marketing et dénoncé, dans un autre ouvrage (La persuasion clandestine16), les abus des publicitaires en matière de manipulation mentale. Dans The naked Society comme dans The privacy invaders les mêmes thèmes sont déployés à propos des dispositifs de surveillance, entre les techniques d’enquêtes des banques sur leurs clients débiteurs, les écoutes téléphoniques, la surveillance audio et vidéo des employés sur les chaînes de montage, en somme toutes les stratégies privées ou publiques d’espionnage des individus et d’abus en tout genre qui sont autant d’atteintes à la vie privée. Il faut dire que la société américaine des années 1960 a vu aussi bien arriver sur le marché des biens de consommation le téléphone et la voiture à crédit mais aussi l’électronique et la miniaturisation croissante des dispositifs utiles dans ce genre d’activité. Or, les questions que soulignent Brenton et Packard, à travers de nombreux exemples, ne sont pas tant celles, plus ou moins spectaculaires, de la mise en œuvre, mais celles liées au droit des individus face à des puissances en recherche de données sur la vie privée extorquées aux sujets mêmes. En somme, ce que découvrent les lecteurs de ces ouvrages, c’est que la vie privée est une notion malléable, dans la réalité comme en droit, et qu’une bonne part de cette malléabilité est relative aux technologies et au médias. Packard ira légèrement plus loin sur l’aspect tragique de la société américaine en focalisant plus explicitement sur le respect de la vie privée dans le contexte des médias et de la presse à sensation et dans les contradictions apparente entre le droit à l’information, le droit à la vie privée et le Sixième Amendement. De là, il tire une sonnette d’alarme en se référant à Georges Orwell, et dénonçant l’effet panoptique obtenu par l’accessibilité des instruments de surveillance, la généralisation de leur emploi dans le quotidien, y compris pour les besoins du marketing, et leur impact culturel.
En réalité, si ces ouvrages connurent un grand succès, c’est parce que leur approche de la vie privée reposait sur un questionnement des pratiques à partir de la morale et du droit, c’est-à-dire sur ce que, dans une société, on est prêt à admettre ou non au sujet de l’intimité vue comme une part structurelle des relations sociales. Qu’est-ce qui relève de ma vie privée et qu’est-ce qui relève de la vie publique ? Que puis-je exposer sans crainte selon mes convictions, ma position sociale, la classe à laquelle j’appartiens, etc. Quelle est la légitimité de la surveillance des employés dans une usine, d’un couple dans une chambre d’hôtel, d’une star du show-biz dans sa villa ?
Il reste que cette approche manqua la grande révolution informatique naissante et son rapport à la vie privée non plus conçue comme l’image et l’estime de soi, mais comme un ensemble d’informations quantifiables à grande échelle et dont l’analyse peut devenir le mobile de décisions qui impactent la société en entier17. La révolution informatique relègue finalement la légitimité de la surveillance au second plan car la surveillance est alors conçue de manière non plus intentionnelle mais comme une série de faits : les données fournies par les sujets, auparavant dans un contexte fermé comme celui de la banque locale, finirent par se retrouver centralisées et croisées au gré des consortiums utilisant l’informatique pour traiter les données des clients. Le même schéma se retrouva pour ce qui concerne les institutions publiques dans le contexte fédéral américain.
Vie privée vs ordinateurs
Une autre approche commença alors à faire son apparition dans la sphère universitaire. Elle intervient dans la seconde moitié des années 1960. Il s’agissait de se pencher sur la gouvernance des rapports entre la vie privée et l’administration des données personnelles. Suivant au plus près les nouvelles pratiques des grands acteurs économiques et gouvernementaux, les universitaires étudièrent les enjeux de la numérisation des données personnelles avec en arrière-plan les préoccupations juridiques, comme celle de V. Packard, qui faisaient l’objet des réflexions de la décennie qui se terminait. Si, avec la société de consommation venait tout un lot de dangers sur la vie privée, cette dernière devrait être protégée, mais il fallait encore savoir sur quels plans agir. Le début des années 1970, en guise de résultat de ce brainstorming général, marquèrent alors une nouvelle ère de la privacy à l’Américaine à l’âge de l’informatisation et du réseautage des données personnelles. Il s’agissait de comprendre qu’un changement majeur était en train de s’effectuer avec les grands ordinateurs en réseau et qu’il fallait formaliser dans le droit les garde-fou les plus pertinents : on passait d’un monde où la vie privée pouvait faire l’objet d’une intrusion par des acteurs séparés, recueillant des informations pour leur propre compte en fonction d’objectifs différents, à un monde où les données éparses étaient désormais centralisées, avec des machines capables de traiter les informations de manière rapide et automatisée, capables d’inférer des informations sans le consentement des sujets à partir d’informations que ces derniers avaient données volontairement dans des contextes très différents.
La liste des publications de ce domaine serait bien longue. Par exemple, la Rand Corporation publia une longue liste bibliographique annotée au sujet des données personnelles informatisées. Cette liste regroupe près de 300 publications entre 1965 et 1967 sur le sujet18.
Des auteurs universitaires firent école. On peut citer :
Alan F. Westin : Privacy and freedom (1967), Civil Liberties and Computerized Data Systems (1971), Databanks in a Free Society: Computers, Record Keeping and Privacy (1972)19 ;
James B. Rule : Private lives and public surveillance: social control in the computer age (1974)20 ;
Arthur R. Miller : The assault on privacy. Computers, Data Banks and Dossier (1971)21 ;
Malcolm Warner et Mike Stone, The Data Bank Society : Organizations, Computers and Social Freedom (1970)22.
Toutes ces publications ont ceci en commun qu’elles procédèrent en deux étapes. La première consistait à dresser un tableau synthétique de la société américaine face à la captation des informations personnelles. Quatre termes peuvent résumer les enjeux du traitement des informations : 1) la légitimité de la captation des informations, 2) la permanence des données et leurs modes de rétention, 3) la transférabilité (entre différentes organisations), 4) la combinaison ou le recoupement de ces données et les informations ainsi inférées23.
La seconde étape consistait à choisir ce qui, dans cette « société du dossier (dossier society) » comme l’appelait Arthur R. Miller, devait faire l’objet de réformes. Deux fronts venaient en effet de s’ouvrir : l’État et les firmes.
Le premier, évident, était celui que la dystopie orwellienne pointait avec empressement : l’État de surveillance. Pour beaucoup de ces analystes, en effet, le fédéralisme américain et la multiplicité des agences gouvernementales pompaient allègrement la privacy des honnêtes citoyens et s’équipaient d’ordinateurs à temps partagé justement pour rendre interopérables les systèmes de traitement d’information à (trop) grande échelle. Un rapide coup d’œil sur les références citées, montre que, effectivement, la plupart des conclusions focalisaient sur le besoin d’adapter le droit aux impératifs constitutionnels américains. Tels sont par exemple les arguments de A. F. Westin pour lequel l’informatisation des données privées dans les différentes autorités administratives devait faire l’objet non d’un recul, mais de nouvelles règles portant sur la sécurité, l’accès des citoyens à leurs propres données et la pertinence des recoupements (comme par exemple l’utilisation restreinte du numéro de sécurité sociale). En guise de synthèse, le rapport de l’U.S. Department of health, Education and Welfare livré en 197324 (et où l’on retrouve Arthur R. Miller parmi les auteurs) repris ces éléments au titre de ses recommandations. Il prépara ainsi le Privacy Act de 1974, qui vise notamment à prévenir l’utilisation abusive de documents fédéraux et garantir l’accès des individus aux données enregistrées les concernant.
Le second front, tout aussi évident mais moins accessible car protégé par le droit de propriété, était celui de la récolte de données par les firmes, et en particulier les banques. L’un des auteurs les plus connus, Arthur R. Miller dans The assault on privacy, fit la synthèse des deux fronts en focalisant sur le fait que l’informatisation des données personnelles, par les agences gouvernementales comme par les firmes, est une forme de surveillance et donc un exercice du pouvoir. Se poser la question de leur légitimité renvoie effectivement à des secteurs différents du droit, mais c’est pour lui le traitement informatique (il utilise le terme « cybernétique ») qui est un instrument de surveillance par essence. Et cet instrument est orwellien :
« Il y a à peine dix ans, on aurait pu considérer avec suffisance Le meilleur des mondes de Huxley ou 1984 de Orwell comme des ouvrages de science-fiction excessifs qui ne nous concerneraient pas et encore moins ce pays. Mais les révélations publiques répandues au cours des dernières années au sujet des nouvelles formes de pratiques d’information ont fait s’envoler ce manteau réconfortant mais illusoire. »
Pourtant, un an avant la publication de Miller fut voté le Fair Credit Reporting Act, portant sur les obligations déclaratives des banques. Elle fut aussi l’une des premières lois sur la protection des données personnelles, permettant de protéger les individus, en particulier dans le secteur bancaire, contre la tenue de bases de données secrètes, la possibilité pour les individus d’accéder aux données et de les contester, et la limitation dans le temps de la rétention des informations.
Cependant, pour Miller, le Fair Credit Reporting Act est bien la preuve que la bureaucratie informatisée et le réseautage des données personnelles impliquent deux pertes de contrôle de la part de l’individu et pour lesquelles la régulation par le droit n’est qu’un pis-aller (pp. 25-38). On peut de même, en s’autorisant quelque anachronisme, s’apercevoir à quel point les deux types de perte de contrôles qu’il pointe nous sont éminemment contemporains.
The individual loss of control over personal information : dans un contexte où les données sont mises en réseau et recoupées, dès lors qu’une information est traitée par informatique, le sujet et l’opérateur n’ont plus le contrôle sur les usages qui pourront en être faits. Sont en jeu la sécurité et l’intégrité des données (que faire en cas d’espionnage ? que faire en cas de fuite non maîtrisée des données vers d’autres opérateurs : doit-on exiger que les opérateurs en informent les individus ?).
The individual loss of control over the accuracy of his informational profil : la centralisation des données permet de regrouper de multiples aspects de la vie administrative et sociale de la personne, et de recouper toutes ces données pour en inférer des profils. Dans la mesure où nous assistons à une concentration des firmes par rachats successifs et l’émergence de monopoles (Miller prend toujours l’exemple des banques), qu’arrive-t-il si certaines données sont erronées ou si certains recoupements mettent en danger le droit à la vie privée : par exemple le rapport entre les données de santé, l’identité des individus et les crédits bancaires.
Et Miller de conclure (p. 79) :
« Ainsi, l’informatisation, le réseautage et la réduction de la concurrence ne manqueront pas de pousser l’industrie de l’information sur le crédit encore plus profondément dans le marasme du problème de la protection de la vie privée. »
Les échos du passé
La lutte pour la préservation de la vie privée dans une société numérisée passe par une identification des stratégies intentionnelles de la surveillance et par l’analyse des procédés d’extraction, rétention et traitement des données. La loi est-elle une réponse ? Oui, mais elle est loin de suffire. La littérature nord-américaine dont nous venons de discuter montre que l’économie de la surveillance dans le contexte du traitement informatisé des données personnelles est née il y a plus de 50 ans. Et dès le début il fut démontré, dans un pays où les droits individuels sont culturellement associés à l’organisation de l’État fédéral (la Déclaration des Droits), non seulement que la privacy changeait de nature (elle s’étend au traitement informatique des informations fournies et aux données inférées) mais aussi qu’un équilibre s’établissait entre le degré de sanctuarisation de la vie privée et les impératifs régaliens et économiques qui réclament une industrialisation de la surveillance.
Puisque l’intimité numérique n’est pas absolue mais le résultat d’un juste équilibre entre le droit et les pratiques, tout les jeux post-révolution informatique après les années 1960 consistèrent en une lutte perpétuelle entre défense et atteinte à la vie privée. C’est ce que montre Daniel J. Solove dans « A Brief History of Information Privacy Law »25 en dressant un inventaire chronologique des différentes réponses de la loi américaine face aux changements technologiques et leurs répercussions sur la vie privée.
Il reste néanmoins que la dimension industrielle de l’économie de la surveillance a atteint en 2001 un point de basculement à l’échelle mondiale avec le Patriot Act26 dans le contexte de la lutte contre le terrorisme. À partir de là, les principaux acteurs de cette économie ont vu une demande croissante de la part des États pour récolter des données au-delà des limites strictes de la loi sous couvert des dispositions propres à la sûreté nationale et au secret défense. Pour rester sur l’exemple américain, Thomas Rabino écrit à ce sujet27 :
« Alors que le Privacy Act de 1974 interdit aux agences fédérales de constituer des banques de données sur les citoyens américains, ces mêmes agences fédérales en font désormais l’acquisition auprès de sociétés qui, à l’instar de ChoicePoint, se sont spécialisées dans le stockage d’informations diverses. Depuis 2001, le FBI et d’autres agences fédérales ont conclu, dans la plus totale discrétion, de fructueux contrats avec ChoicePoint pour l’achat des renseignements amassés par cette entreprise d’un nouveau genre. En 2005, le budget des États-Unis consacrait plus de 30 millions de dollars à ce type d’activité. »
Dans un contexte plus récent, on peut affirmer que même si le risque terroriste est toujours agité comme un épouvantail pour justifier des atteintes toujours plus fortes à l’encontre de la vie privée, les intérêts économiques et la pression des lobbies ne peuvent plus se cacher derrière la Raison d’État. Si bien que plusieurs pays se mettent maintenant au diapason de l’avancement technologique et des impératifs de croissance économique justifiant par eux-mêmes des pratiques iniques. Ce fut le cas par exemple du gouvernement de Donald Trump qui, en mars 2017 et à la plus grande joie du lobby des fournisseurs d’accès, abroge une loi héritée du gouvernement précédent et qui exigeait que les FAI obtiennent sous conditions la permission de partager des renseignements personnels – y compris les données de localisation28.
Encore en mars 2017, c’est la secrétaire d’État à l’Intérieur Britannique Amber Rudd qui juge publiquement « inacceptable » le chiffrement des communications de bout en bout et demande aux fournisseurs de messagerie de créer discrètement des backdoors, c’est à dire renoncer au chiffrement de bout en bout sans le dire aux utilisateurs29. Indépendamment du caractère moralement discutable de cette injonction, on peut mesurer l’impact du message sur les entreprises comme Google, Facebook et consors : il existe des décideurs politiques capables de demander à ce qu’un fournisseur de services propose à ses utilisateurs un faux chiffrement, c’est-à-dire que le droit à la vie privée soit non seulement bafoué mais, de surcroît, que le mensonge exercé par les acteurs privés soit couvert par les acteurs publics, et donc par la loi.
Comme le montre Shoshana Zuboff, le capitalisme de surveillance est aussi une idéologie, celle qui instaure une hiérarchie entre les intérêts économiques et le droit. Le droit peut donc être une arme de lutte pour la sauvegarde de la vie privée dans l’économie de la surveillance, mais il ne saurait suffire dans la mesure où il n’y pas de loyauté entre les acteurs économiques et les sujets et parfois même encore moins entre les décideurs publics et les citoyens.
Dans ce contexte où la confiance n’est pas de mise, les portes sont restées ouvertes depuis les années 1970 pour créer l’industrie des big data dont le carburant principal est notre intimité, notre quotidienneté. C’est parce qu’il est désormais possible de repousser toujours un peu plus loin les limites de la captation des données personnelles que des théories économique prônent la fidélisation des clients et la prédiction de leurs comportements comme seuls points d’appui des investissements et de l’innovation. C’est vrai dans le marketing, c’est vrai dans les services et l’innovation numériques. Et tout naturellement c’est vrai dans la vie politique, comme le montre par exemple l’affaire des dark posts durant la campagne présidentielle de D. Trump : la possibilité de contrôler l’audience et d’influencer une campagne présidentielle via les réseaux sociaux comme Facebook est désormais démontrée.
Tant que ce modèle économique existera, aucune confiance ne sera possible. La confiance est même absente des pratiques elles-mêmes, en particulier dans le domaine du traitement algorithmique des informations. En septembre 2017, la chercheuse Zeynep Tufekci, lors d’une conférence TED30, reprenait exactement les questions d’Arthur R. Miller dans The assault on privacy, soit 46 ans après. Miller prenait comme étude de cas le stockage d’information bancaire sur les clients débiteurs, et Tufekci prend les cas des réservation de vols aériens en ligne et du streaming vidéo. Dans les deux réflexions, le constat est le même : le traitement informatique de nos données personnelles implique que nous (les sujets et les opérateurs eux-mêmes) perdions le contrôle sur ces données :
« Le problème, c’est que nous ne comprenons plus vraiment comment fonctionnent ces algorithmes complexes. Nous ne comprenons pas comment ils font cette catégorisation. Ce sont d’énormes matrices, des milliers de lignes et colonnes, peut-être même des millions, et ni les programmeurs, ni quiconque les regardant, même avec toutes les données, ne comprend plus comment ça opère exactement, pas plus que vous ne sauriez ce que je pense en ce moment si l’on vous montrait une coupe transversale de mon cerveau. C’est comme si nous ne programmions plus, nous élevons une intelligence que nous ne comprenons pas vraiment. »
Z. Tufekci montre même que les algorithmes de traitement sont en mesure de fournir des conclusions (qui permettent par exemple d’inciter les utilisateurs à visualiser des vidéos sélectionnées d’après leur profil et leur historique) mais que ces conclusions ont ceci de particulier qu’elle modélisent le comportement humain de manière à l’influencer dans l’intérêt du fournisseur. D’après Z. Tufekci : « L’algorithme a déterminé que si vous pouvez pousser les gens à penser que vous pouvez leur montrer quelque chose de plus extrême (nda : des vidéos racistes dans l’exemple cité), ils ont plus de chances de rester sur le site à regarder vidéo sur vidéo, descendant dans le terrier du lapin pendant que Google leur sert des pubs. »
Ajoutons de même que les technologies de deep learning, financées par millions par les GAFAM, se prêtent particulièrement bien au jeu du traitement automatisé en cela qu’elle permettent, grâce à l’extrême croissance du nombre de données, de procéder par apprentissage. Cela permet à Facebook de structurer la grande majorité des données des utilisateurs qui, auparavant, n’était pas complètement exploitable31. Par exemple, sur les milliers de photos de chatons partagées par les utilisateurs, on peut soit se contenter de constater une redondance et ne pas les analyser davantage, soit apprendre à y reconnaître d’autres informations, comme par exemple l’apparition, en arrière-plan, d’un texte, d’une marque de produit, etc. Il en est de même pour la reconnaissance faciale, qui a surtout pour objectif de faire concorder les identités des personnes avec toutes les informations que l’on peut inférer à partir de l’image et du texte.
Si les techniques statistiques ont le plus souvent comme objectif de contrôler les comportements à l’échelle du groupe, c’est parce que le seul fait de catégoriser automatiquement les individus consiste à considérer que leurs données personnelles en constituent l’essence. L’économie de la surveillance démontre ainsi qu’il n’y a nul besoin de connaître une personne pour en prédire le comportement, et qu’il n’y a pas besoin de connaître chaque individu d’un groupe en particulier pour le catégoriser et prédire le comportement du groupe, il suffit de laisser faire les algorithmes : le tout est d’être en mesure de classer les sujets dans les bonnes catégories et même faire en sorte qu’ils y entrent tout à fait. Cela a pour effet de coincer littéralement les utilisateurs des services « capteurs de données » dans des bulles de filtres où les informations auxquelles ils ont accès leur sont personnalisées selon des profils calculés32. Si vous partagez une photo de votre chat devant votre cafetière, et que dernièrement vous avez visité des sites marchands, vous aurez de grandes chance pour vos futures annonces vous proposent la marque que vous possédez déjà et exercent, par effet de répétition, une pression si forte que c’est cette marque que vous finirez par acheter. Ce qui fonctionne pour le marketing peut très bien fonctionner pour d’autres objectifs, même politiques.
En somme tous les déterminants d’une société soumise au capitalisme de surveillance, apparus dès les années 1970, structurent le monde numérique d’aujourd’hui sans que les lois ne puissent jouer de rôle pleinement régulateur. L’usage caché et déloyal des big data, le trafic de données entre organisations, la dégradation des droits individuels (à commencer par la liberté d’expression et le droit à la vie privée), tous ces éléments ont permis à des monopoles d’imposer un modèle d’affaire et affaiblir l’État-nation. Combien de temps continuerons-nous à l’accepter ?
Sortir du marasme
En 2016, à la fin de son article synthétique sur le capitalisme de surveillance33, Shoshana Zuboff exprime personnellement un point de vue selon lequel la réponse ne peut pas être uniquement technologique :
« (…) les faits bruts du capitalisme de surveillance suscitent nécessairement mon indignation parce qu’ils rabaissent la dignité humaine. L’avenir de cette question dépendra des savants et journalistes indignés attirés par ce projet de frontière, des élus et des décideurs indignés qui comprennent que leur autorité provient des valeurs fondamentales des communautés démocratiques, et des citoyens indignés qui agissent en sachant que l’efficacité sans l’autonomie n’est pas efficace, la conformité induite par la dépendance n’est pas un contrat social et être libéré de l’incertitude n’est pas la liberté. »
L’incertitude au sujet des dérives du capitalisme de surveillance n’existe pas. Personne ne peut affirmer aujourd’hui qu’avec l’avènement des big data dans les stratégies économiques, on pouvait ignorer que leur usage déloyal était non seulement possible mais aussi que c’est bien cette direction qui fut choisie d’emblée dans l’intérêt des monopoles et en vertu de la centralisation des informations et des capitaux. Depuis les années 1970, plusieurs concepts ont cherché à exprimer la même chose. Pour n’en citer que quelques-uns : computocracie (M. Warner et M. Stone, 1970), société du dossier (Arthur R. Miller, 1971), surveillance de masse (J. Rule, 1973), dataveillance (R. Clarke, 1988), capitalisme de surveillance (Zuboff, 2015)… tous cherchent à démontrer que la surveillance des comportements par l’usage des données personnelles implique en retour la recherche collective de points de rupture avec le modèle économique et de gouvernance qui s’impose de manière déloyale. Cette recherche peut s’exprimer par le besoin d’une régulation démocratiquement décidée et avec des outils juridiques. Elle peut s’exprimer aussi autrement, de manière violente ou pacifiste, militante et/ou contre-culturelle.
Plusieurs individus, groupes et organisation se sont déjà manifestés dans l’histoire à ce propos. Les formes d’expression et d’action ont été diverses :
institutionnelles : les premières formes d’action pour garantir le droit à la vie privée ont consisté à établir des rapports collectifs préparatoires à des grandes lois, comme le rapport Records, computers and the rights of citizens, de 1973, cité plus haut ;
individualistes, antisociales et violentes : bien que s’inscrivant dans un contexte plus large de refus technologique, l’affaire Theodore Kaczynski (alias Unabomber) de 1978 à 1995 est un bon exemple d’orientation malheureuse que pourraient prendre quelques individus isolés trouvant des justifications dans un contexte paranoïaque ;
collectives – activistes – légitimistes : c’est le temps des manifestes cypherpunk des années 199034, ou plus récemment le mouvement Anonymous, auxquels on peut ajouter des collectifs « événementiels », comme le Jam Echelon Day ;
Les limites de l’attente démocratique sont néanmoins déjà connues. La société ne peut réagir de manière légale, par revendication interposée, qu’à partir du moment où l’exigence de transparence est remplie. Lorsqu’elle ne l’est pas, au pire les citoyens les plus actifs sont taxés de complotistes, au mieux apparaissent de manière épisodique des alertes, à l’image des révélations d’Edward Snowden, mais dont la fréquence est si rare malgré un impact psychologique certain, que la situation a tendance à s’enraciner dans un statu quo d’où sortent généralement vainqueurs ceux dont la capacité de lobbying est la plus forte.
À cela s’ajoute une difficulté technique due à l’extrême complexité des systèmes de surveillance à l’œuvre aujourd’hui, avec des algorithmes dont nous maîtrisons de moins en moins les processus de calcul (cf. Z. Tufekci). À ce propos on peut citer Roger Clarke35 :
« Dans une large mesure, la transparence a déjà été perdue, en partie du fait de la numérisation, et en partie à cause de l’application non pas des approches procédurales et d’outils de développement des logiciels algorithmiques du XXe siècle, mais à cause de logiciels de dernière génération dont la raison d’être est obscure ou à laquelle la notion de raison d’être n’est même pas applicable. »
Une autre option pourrait consister à mettre en œuvre un modèle alternatif qui permette de sortir du marasme économique dans lequel nous sommes visiblement coincés. Sans en faire l’article, le projet Contributopia de Framasoft cherche à participer, à sa mesure, à un processus collectif de réappropriation d’Internet et, partant:
montrer que le code est un bien public et que la transparence, grâce aux principes du logiciel libre (l’ouverture du code), permet de proposer aux individus un choix éclairé, à l’encontre de l’obscurantisme de la dataveillance ;
promouvoir des apprentissages à contre-courant des pratiques de captation des vies privées et vers des usages basés sur le partage (du code, de la connaissance) entre les utilisateurs ;
rendre les utilisateurs autonomes et en même temps contributeurs à un réseau collectif qui les amènera naturellement, par l’attention croissante portée aux pratiques des monopoles, à refuser ces pratiques, y compris de manière active en utilisant des solutions de chiffrement, par exemple.
Mais Contributopia de Framasoft ne concerne que quelques aspects des stratégies de sortie du capitalisme de surveillance. Par exemple, pour pouvoir œuvrer dans cet esprit, une politique rigide en faveur de la neutralité du réseau Internet doit être menée. Les entreprises et les institutions publiques doivent être aussi parmi les premières concernées, car il en va de leur autonomie numérique, que cela soit pour de simples questions économiques (ne pas dépendre de la bonne volonté d’un monopole et de la logique des brevets) mais aussi pour des questions de sécurité. Enfin, le passage du risque pour la vie privée au risque de manipulation sociale étant avéré, toutes les structures militantes en faveur de la démocratie et les droits de l’homme doivent urgemment porter leur attention sur le traitement des données personnelles. Le cas de la britannique Amber Rudd est loin d’être isolé : la plupart des gouvernements collaborent aujourd’hui avec les principaux monopoles de l’économie numérique et, donc, contribuent activement à l’émergence d’une société de la surveillance. Aujourd’hui, le droit à la vie privée, au chiffrement des communications, au secret des correspondances sont des droits à protéger coûte que coûte sans avoir à choisir entre la liberté et les épouvantails (ou les sirènes) agités par les communicants.
Depuis les années 1950 et l’apparition des premiers hackers, l’informatique est porteuse d’un message d’émancipation. Sans ces pionniers, notre dépendance aux grandes firmes technologiques aurait déjà été scellée.
Aujourd’hui, l’avènement de l’Internet des objets remet en question l’autonomisation des utilisateurs en les empêchant de « bidouiller » à leur gré. Pire encore, les modèles économiques apparus ces dernières années remettent même en question la notion de propriété. Les GAFAM et compagnie sont-ils devenus nos nouveaux seigneurs féodaux ?
Une traduction de Framalang : Relec’, Redmood, FranBAG, Ostrogoths, simon, Moutmout, Edgar Lori, Luc, jums, goofy, Piup et trois anonymes
Est-ce vraiment ainsi que se définissent maintenant nos rapports avec les entreprises de technologie numérique ? Queen Mary Master
Les appareils connectés à Internet sont si courants et si vulnérables que des pirates informatiques ont récemment pénétré dans un casino via… son aquarium ! Le réservoir était équipé de capteurs connectés à Internet qui mesuraient sa température et sa propreté. Les pirates sont entrés dans les capteurs de l’aquarium puis dans l’ordinateur utilisé pour les contrôler, et de là vers d’autres parties du réseau du casino. Les intrus ont ainsi pu envoyer 10 gigaoctets de données quelque part en Finlande.
En observant plus attentivement cet aquarium, on découvre le problème des appareils de « l’Internet des objets » : on ne les contrôle pas vraiment. Et il n’est pas toujours évident de savoir qui tire les ficelles, bien que les concepteurs de logiciels et les annonceurs soient souvent impliqués.
Dans mon livre récent intitulé Owned : Property, Privacy, and the New Digital Serfdom (Se faire avoir : propriété, protection de la vie privée et la nouvelle servitude numérique), je définis les enjeux liés au fait que notre environnement n’a jamais été truffé d’autant de capteurs. Nos aquariums, téléviseurs intelligents, thermostats d’intérieur reliés à Internet, Fitbits (coachs électroniques) et autres téléphones intelligents recueillent constamment des informations sur nous et notre environnement. Ces informations sont précieuses non seulement pour nous, mais aussi pour les gens qui veulent nous vendre des choses. Ils veillent à ce que les appareils connectés soient programmés de manière à ce qu’ils partagent volontiers de l’information…
Les atteintes à la sécurité et à la vie privée sont intégrées
Comme le Roomba, d’autres appareils intelligents peuvent être programmés pour partager nos informations privées avec les annonceurs publicitaires par le biais de canaux dissimulés. Dans un cas bien plus intime que le Roomba, un appareil de massage érotique contrôlable par smartphone, appelé WeVibe, recueillait des informations sur la fréquence, les paramètres et les heures d’utilisation. L’application WeVibe renvoyait ces données à son fabricant, qui a accepté de payer plusieurs millions de dollars dans le cadre d’un litige juridique lorsque des clients s’en sont aperçus et ont contesté cette atteinte à la vie privée.
Ces canaux dissimulés constituent également une grave faille de sécurité. Il fut un temps, le fabricant d’ordinateurs Lenovo, par exemple, vendait ses ordinateurs avec un programme préinstallé appelé Superfish. Le programme avait pour but de permettre à Lenovo — ou aux entreprises ayant payé — d’insérer secrètement des publicités ciblées dans les résultats de recherches web des utilisateurs. La façon dont Lenovo a procédé était carrément dangereuse : l’entreprise a modifié le trafic des navigateurs à l’insu de l’utilisateur, y compris les communications que les utilisateurs croyaient chiffrées, telles que des transactions financières via des connexions sécurisées à des banques ou des boutiques en ligne.
Le problème sous-jacent est celui de la propriété
L’une des principales raisons pour lesquelles nous ne contrôlons pas nos appareils est que les entreprises qui les fabriquent semblent penser que ces appareils leur appartiennent toujours et agissent clairement comme si c’était le cas, même après que nous les avons achetés. Une personne peut acheter une jolie boîte pleine d’électronique qui peut fonctionner comme un smartphone, selon les dires de l’entreprise, mais elle achète une licence limitée à l’utilisation du logiciel installé. Les entreprises déclarent qu’elles sont toujours propriétaires du logiciel et que, comme elles en sont propriétaires, elles peuvent le contrôler. C’est comme si un concessionnaire automobile vendait une voiture, mais revendiquait la propriété du moteur.
Ce genre de disposition anéantit le fondement du concept de propriété matérielle. John Deere a déjà annoncé aux agriculteurs qu’ils ne possèdent pas vraiment leurs tracteurs, mais qu’ils ont, en fait, uniquement le droit d’en utiliser le logiciel — ils ne peuvent donc pas réparer leur propre matériel agricole ni même le confier à un atelier de réparation indépendant. Les agriculteurs s’y opposent, mais il y a peut-être des personnes prêtes à l’accepter, lorsqu’il s’agit de smartphones, souvent achetés avec un plan de paiement échelonné et échangés à la première occasion.
Combien de temps faudra-t-il avant que nous nous rendions compte que ces entreprises essaient d’appliquer les mêmes règles à nos maisons intelligentes, aux téléviseurs intelligents dans nos salons et nos chambres à coucher, à nos toilettes intelligentes et à nos voitures connectées à Internet ?
Un retour à la féodalité ?
La question de savoir qui contrôle la propriété a une longue histoire. Dans le système féodal de l’Europe médiévale, le roi possédait presque tout, et l’accès à la propriété des autres dépendait de leurs relations avec le roi. Les paysans vivaient sur des terres concédées par le roi à un seigneur local, et les ouvriers ne possédaient même pas toujours les outils qu’ils utilisaient pour l’agriculture ou d’autres métiers comme la menuiserie et la forge.
Au fil des siècles, les économies occidentales et les systèmes juridiques ont évolué jusqu’à notre système commercial moderne : les individus et les entreprises privées achètent et vendent souvent eux-mêmes des biens de plein droit, possèdent des terres, des outils et autres objets. Mis à part quelques règles gouvernementales fondamentales comme la protection de l’environnement et la santé publique, la propriété n’est soumise à aucune condition.
Ce système signifie qu’une société automobile ne peut pas m’empêcher de peindre ma voiture d’une teinte rose pétard ou de faire changer l’huile dans le garage automobile de mon choix. Je peux même essayer de modifier ou réparer ma voiture moi-même. Il en va de même pour ma télévision, mon matériel agricole et mon réfrigérateur.
Pourtant, l’expansion de l’Internet des objets semble nous ramener à cet ancien modèle féodal où les gens ne possédaient pas les objets qu’ils utilisaient tous les jours. Dans cette version du XXIe siècle, les entreprises utilisent le droit de la propriété intellectuelle — destiné à protéger les idées — pour contrôler les objets physiques dont les utilisateurs croient être propriétaires.
Mainmise sur la propriété intellectuelle
Mon téléphone est un Samsung Galaxy. Google contrôle le système d’exploitation ainsi que les applications Google Apps qui permettent à un smartphone Android de fonctionner correctement. Google en octroie une licence à Samsung, qui fait sa propre modification de l’interface Android et me concède le droit d’utiliser mon propre téléphone — ou du moins c’est l’argument que Google et Samsung font valoir. Samsung conclut des accords avec de nombreux fournisseurs de logiciels qui veulent prendre mes données pour leur propre usage.
Mais ce modèle est déficient, à mon avis. C’est notre droit de pouvoir réparer nos propres biens. C’est notre droit de pouvoir chasser les annonceurs qui envahissent nos appareils. Nous devons pouvoir fermer les canaux d’information détournés pour les profits des annonceurs, pas simplement parce que nous n’aimons pas être espionnés, mais aussi parce que ces portes dérobées constituent des failles de sécurité, comme le montrent les histoires de Superfish et de l’aquarium piraté. Si nous n’avons pas le droit de contrôler nos propres biens, nous ne les possédons pas vraiment. Nous ne sommes que des paysans numériques, utilisant les objets que nous avons achetés et payés au gré des caprices de notre seigneur numérique.
Même si les choses ont l’air sombres en ce moment, il y a de l’espoir. Ces problèmes deviennent rapidement des cauchemars en matière de relations publiques pour les entreprises concernées. Et il y a un appui bipartite important en faveur de projets de loi sur le droit à la réparation qui restaurent certains droits de propriété pour les consommateurs.
Ces dernières années, des progrès ont été réalisés dans la reconquête de la propriété des mains de magnats en puissance du numérique. Ce qui importe, c’est que nous identifiions et refusions ce que ces entreprises essaient de faire, que nous achetions en conséquence, que nous exercions vigoureusement notre droit d’utiliser, de réparer et de modifier nos objets intelligents et que nous appuyions les efforts visant à renforcer ces droits. L’idée de propriété est encore puissante dans notre imaginaire culturel, et elle ne mourra pas facilement. Cela nous fournit une opportunité. J’espère que nous saurons la saisir.
Comment les entreprises surveillent notre quotidien
Vous croyez tout savoir déjà sur l’exploitation de nos données personnelles ? Parcourez plutôt quelques paragraphes de ce très vaste dossier…
Il s’agit du remarquable travail d’enquête procuré par Craked Labs, une organisation sans but lucratif qui se caractérise ainsi :
… un institut de recherche indépendant et un laboratoire de création basé à Vienne, en Autriche. Il étudie les impacts socioculturels des technologies de l’information et développe des innovations sociales dans le domaine de la culture numérique.
… Il a été créé en 2012 pour développer l’utilisation participative des technologies de l’information et de la communication, ainsi que le libre accès au savoir et à l’information – indépendamment des intérêts commerciaux ou gouvernementaux. Cracked Labs se compose d’un réseau interdisciplinaire et international d’experts dans les domaines de la science, de la théorie, de l’activisme, de la technologie, de l’art, du design et de l’éducation et coopère avec des parties publiques et privées.
Bien sûr, vous connaissez les GAFAM omniprésents aux avant-postes pour nous engluer au point que s’en déprendre complètement est difficile… Mais connaissez-vous Acxiom et LiveRamp, Equifax, Oracle, Experian et TransUnion ? Non ? Pourtant il y a des chances qu’ils nous connaissent bien…
Il existe une industrie très rentable et très performante des données « client ».
Dans ce long article documenté et qui déploie une vaste gamme d’exemples dans tous les domaines, vous ferez connaissance avec les coulisses de cette industrie intrusive pour laquelle il semble presque impossible de « passer inaperçu », où notre personnalité devient un profil anonyme mais tellement riche de renseignements que nos nom et prénom n’ont aucun intérêt particulier.
L’article est long, vous pouvez préférer le lire à votre rythme en format .PDF (2,3 Mo)
avec les contributions de : Katharina Kopp, Patrick Urs Riechert / Illustrations de Pascale Osterwalder.
Comment des milliers d’entreprises surveillent, analysent et influencent la vie de milliards de personnes. Quels sont les principaux acteurs du pistage numérique aujourd’hui ? Que peuvent-ils déduire de nos achats, de nos appels téléphoniques, de nos recherches sur le Web, de nos Like sur Facebook ? Comment les plateformes en ligne, les entreprises technologiques et les courtiers en données font-ils pour collecter, commercialiser et exploiter nos données personnelles ?
Ces dernières années, des entreprises dans de nombreux secteurs se sont mises à surveiller, pister et suivre les gens dans pratiquement tous les aspects de leur vie. les comportements, les déplacements, les relations sociales, les centres d’intérêt, les faiblesses et les moments les plus intimes de milliards de personnes sont désormais continuellement enregistrés, évalués et analysés en temps réel. L’exploitation des données personnelles est devenue une industrie pesant plusieurs milliards de dollars. Pourtant, de ce pistage numérique omniprésent, on ne voit que la partie émergée de l’iceberg ; la majeure partie du processus se déroule dans les coulisses et reste opaque pour la plupart d’entre nous.
Ce rapport de Cracked Labs examine le fonctionnement interne et les pratiques en vigueur dans cette industrie des données personnelles. S’appuyant sur des années de recherche et sur un précédent rapport de 2016, l’enquête donne à voir la circulation cachée des données entre les entreprises. Elle cartographie la structure et l’étendue de l’écosystème numérique de pistage et de profilage et explore tout ce qui s’y rapporte : les technologies, les plateformes, les matériels ainsi que les dernières évolutions marquantes.
Le rapport complet (93 pages, en anglais) est disponible en téléchargement au format PDF, et cette publication web en présente un résumé en dix parties.
En 2007, Apple a lancé le smartphone, Facebook a atteint les 30 millions d’utilisateurs, et des entreprises de publicité en ligne ont commencé à cibler les internautes en se basant sur des données relatives à leurs préférences individuelles et leurs centres d’intérêt. Dix ans plus tard, un large ensemble d’entreprises dont le cœur de métier est les données (les data-companies ou entreprises de données en français) a émergé, on y trouve de très gros acteurs comme Facebook ou Google mais aussi des milliers d’autres entreprises, qui sans cesse, se partagent et se vendent les unes aux autres des profils numériques. Certaines entreprises ont commencé à combiner et à relier des données du web et des smartphones avec les données clients et les informations hors-ligne qu’elles avaient accumulées pendant des décennies.
La machine omniprésente de surveillance en temps réel qui a été développée pour la publicité en ligne s’étend rapidement à d’autres domaines, de la tarification à la communication politique en passant par le calcul de solvabilité et la gestion des risques. Des plateformes en ligne énormes, des entreprises de publicité numérique, des courtiers en données et des entreprises de divers secteurs peuvent maintenant identifier, trier, catégoriser, analyser, évaluer et classer les utilisateurs via les plateformes et les matériels. Chaque clic sur un site web et chaque mouvement du doigt sur un smartphone peut activer un large éventail de mécanismes de partage de données distribuées entre plusieurs entreprises, ce qui, en définitive, affecte directement les choix offerts aux gens. Le pistage numérique et le profilage, en plus de la personnalisation ne sont pas seulement utilisés pour surveiller, mais aussi pour influencer les comportements des personnes.
Vous devez vous battre pour votre vie privée, sinon vous la perdrez.
Eric Schmidt, Google/Alphabet, 2013
Analyser les individus
Des études scientifiques démontrent que de nombreux aspects de la personnalité des individus peuvent être déduits des données générées par des recherches sur Internet, des historiques de navigation, des comportements lors du visionnage d’une vidéo, des activités sur les médias sociaux ou des achats. Par exemple, des données personnelles sensibles telles que l’origine ethnique, les convictions religieuses ou politiques, la situation amoureuse, l’orientation sexuelle, ou l’usage d’alcool, de cigarettes ou de drogues peuvent être assez précisément déduites des Like sur Facebook d’une personne. L’analyse des profils de réseaux sociaux peut aussi prédire des traits de personnalité comme la stabilité émotionnelle, la satisfaction individuelle, l’impulsivité, la dépression et l’intérêt pour le sensationnel.
Analyser les like Facebook, les données des téléphones, et les styles de frappe au clavier
Pour plus de détails, se référer à Christl and Spiekermann 2016 (p. 14-20). Sources : Kosinski et al 2013, Chittaranjan et al 2011, Epp at al 2011.
De la même façon, il est possible de déduire certains traits de caractères d’une personne à partir de données sur les sites Web qu’elle a visités, sur les appels téléphoniques qu’elle a passés, et sur les applis qu’elle a utilisées. L’historique de navigation peut donner des informations sur la profession et le niveau d’étude. Des chercheurs canadiens ont même réussi à évaluer des états émotionnels comme la confiance, la nervosité, la tristesse ou la fatigue en analysant la façon dont on tape sur le clavier de l’ordinateur.
Analyser les individus dans la finance, les assurances et la santé
Les résultats des méthodes actuelles d’extraction et d’analyse des données reposent sur des corrélations statistiques avec un certain niveau de probabilité. Bien qu’ils soient significativement plus fiables que le hasard dans la prédiction des caractéristiques ou des traits de caractère d’un individu, ils ne sont évidemment pas toujours exacts. Néanmoins, ces méthodes sont déjà mises en œuvre pour trier, catégoriser, étiqueter, évaluer, noter et classer les personnes, non seulement dans une approche marketing mais aussi pour prendre des décisions dans des domaines riches en conséquence comme la finance, l’assurance, la santé, pour ne citer qu’eux.
L’évaluation de crédit basée sur les données de comportement numérique
Des startups comme Lenddo, Kreditech, Cignifi et ZestFinance utilisent déjà les données récoltées sur les réseaux sociaux, lors de recherches sur le web ou sur les téléphones portables pour calculer la solvabilité d’une personne sans même utiliser de données financières. D’autres se basent sur la façon dont quelqu’un va remplir un formulaire en ligne ou naviguer sur un site web, sur la grammaire et la ponctuation de ses textos, ou sur l’état de la batterie de son téléphone. Certaines entreprises incluent même des données sur les amis avec lesquels une personne est connectée sur un réseau social pour évaluer sa solvabilité.
Cignifi, qui calcule la solvabilité des clients en fonction des horaires et de la fréquence des appels téléphoniques, se présente comme « la plateforme ultime de monétisation des données pour les opérateurs de réseaux mobiles ». De grandes entreprises, notamment MasterCard, le fournisseur d’accès mobile Telefonica, les agences d’évaluation de solvabilité Experian et Equifax, ainsi que le géant chinois de la recherche web Baidu, ont commencé à nouer des partenariats avec des startups de ce genre. L’application à plus grande échelle de services de cette nature est particulièrement en croissance dans les pays du Sud, ainsi qu’auprès de groupes de population vulnérables dans d’autres régions.
Réciproquement, les données de crédit nourrissent le marketing en ligne. Sur Twitter, par exemple, les annonceurs peuvent cibler leurs publicités en fonction de la solvabilité supposée des utilisateurs de Twitter sur la base des données client fournies par le courtier en données Oracle. Allant encore plus loin dans cette logique, Facebook a déposé un brevet pour une évaluation de crédit basée sur la cote de solvabilité de vos amis sur un réseau social. Personne ne sait s’ils ont l’intention de réellement mettre en application cette intégration totale des réseaux sociaux, du marketing et de l’évaluation des risques.
On peut dire que toutes les données sont des données sur le crédit, mais il manque encore la façon de les utiliser.
Douglas Merrill, fondateur de ZestFinance et ancien directeur des systèmes d’informations chez Google, 2012
Prédire l’état de santé à partir des données client
Les entreprises de données et les assureurs travaillent sur des programmes qui utilisent les informations sur la vie quotidienne des consommateurs pour prédire leurs risques de santé. Par exemple, l’assureur Aviva, en coopération avec la société de conseil Deloitte, a utilisé des données clients achetées à un courtier en données et habituellement utilisées pour le marketing, pour prédire les risques de santé individuels (comme le diabète, le cancer, l’hypertension et la dépression) de 60 000 personnes souhaitant souscrire une assurance.
La société de conseil McKinsey a aidé à prédire les coûts hospitaliers de patients en se basant sur les données clients d’une « grande compagnie d’assurance » santé américaine. En utilisant les informations concernant la démographie, la structure familiale, les achats, la possession d’une voiture et d’autres données, McKinsey a déclaré que ces « renseignements peuvent aider à identifier des sous-groupes stratégiques de patients avant que des périodes de coûts élevés ne surviennent ».
L’entreprise d’analyse santé GNS Healthcare a aussi calculé les risques individuels de santé de patients à partir d’un large champ de données tel que la génétique, les dossiers médicaux, les analyses de laboratoire, les appareils de santé mobiles et le comportement du consommateur. Les sociétés partenaires des assureurs tels que Aetna donnent une note qui identifie « les personnes susceptibles de subir une opération » et proposent de prédire l’évolution de la maladie et les résultats des interventions. D’après un rapport sectoriel, l’entreprise « classe les patients suivant le retour sur investissement » que l’assureur peut espérer s’il les cible pour des interventions particulières.
LexisNexis Risk Solutions, à la fois, un important courtier en données et une société d’analyse de risque, fournit un produit d’évaluation de santé qui calcule les risques médicaux ainsi que les frais de santé attendus individuellement, en se basant sur une importante quantité de données consommateurs, incluant les achats.
Collecte et utilisation massives de données client
Les plus importantes plates-formes connectées d’aujourd’hui, Google et Facebook en premier lieu, ont des informations détaillées sur la vie quotidienne de milliards de personnes dans le monde. Ils sont les plus visibles, les plus envahissants et, hormis les entreprises de renseignement, les publicitaires en ligne et les services de détection des fraudes numériques, peut-être les acteurs les plus avancés de l’industrie de l’analyse et des données personnelles. Beaucoup d’autres agissent en coulisse et hors de vue du public.
Le cœur de métier de la publicité en ligne consiste en un écosystème de milliers d’entreprises concentrées sur la traque constante et le profilage de milliards de personnes. À chaque fois qu’une publicité est affichée sur un site web ou une application mobile, un profil d’utilisateur vient juste d’être vendu au plus gros enchérisseur dans les millisecondes précédentes. Contrairement à ces nouvelles pratiques, les agences d’analyse de solvabilité et les courtiers en données clients exploitent des données personnelles depuis des décennies. Ces dernières années, ils ont commencé à combiner les très nombreuses données dont ils disposent sur la vie hors-ligne des personnes avec les bases de données utilisateurs et clients utilisées par de grandes plateformes, par des entreprises de publicité et par une multitude d’autres entreprises dans de nombreuses secteurs.
Les entreprises de données ont des informations détaillées sur des milliards de personnes
Plateformes en ligne grand public
Facebook dispose
des profils de
1,9 milliards d’utilisateurs de Facebook
1,2 milliards d’utilisateurs de Whatsapp
600 millions d’utilisateurs d’Instagram
Google dispose
des profils de
2 milliards d’utilisateurs d’Android
+ d’un milliard d’utilisateurs de Gmail
+ d’un milliard d’utilisateurs de Youtube
Apple dispose
des profils de
1 milliard d’utilisateurs d’iOS
Sociétés d’analyse de la solvabilité
Experian
dispose des données de solvabilité de 918 millions de personnes
dispose des données marketing de 700 millions de personnes
a un “aperçu” sur 2,3 milliards de personnes
Equifax
dispose des données de 820 millions de personnes
et d’1 milliard d’appareils
TransUnion
dispose des données d’1 milliard de personnes
Courtiers en données clients
Acxiom
dispose des données de
700 millions de personnes
1 milliard de cookies et d’appareils mobiles
3,7 milliards de profils clients
Oracle
dispose des données de
1 milliard d’utilisateurs d’appareils mobiles
1,7 milliards d’internautes
donne accès à
5 milliards d’identifiants uniques client
Facebook utilise au moins 52 000 caractéristiques personnelles pour trier et classer ses 1,9 milliard d’utilisateurs suivant, par exemple, leur orientation politique, leur origine ethnique et leurs revenus. Pour ce faire, la plateforme analyse leurs messages, leurs Likes, leurs partages, leurs amis, leurs photos, leurs mouvements et beaucoup d’autres comportements. De plus, Facebook acquiert à d’autres entreprises des données sur ses utilisateurs. En 2013, la plateforme démarre son partenariat avec les quatre courtiers en données Acxiom, Epsilon, Datalogix et BlueKai, les deux derniers ont ensuite été rachetés par le géant de l’informatique Oracle. Ces sociétés aident Facebook à pister et profiler ses utilisateurs bien mieux qu’il le faisait déjà en lui fournissant des données collectées en dehors de sa plateforme.
Les courtiers en données et le marché des données personnelles
Les courtiers en données client ont un rôle clé dans le marché des données personnelles actuel. Ils agrègent, combinent et échangent des quantités astronomiques d’informations sur des populations entières, collectées depuis des sources en ligne et hors-ligne. Les courtiers en données collectent de l’information disponible publiquement et achètent le droit d’utiliser les données clients d’autres entreprises. Leurs données proviennent en général de sources qui ne sont pas les individus eux-mêmes, et sont collectées en grande partie sans que le consommateur soit au courant. Ils analysent les données, en font des déductions, construisent des catégories de personnes et fournissent à leurs clients des informations sur des milliers de caractéristiques par individu.
Dans les profils individuels créés par les courtiers en données, on trouve non seulement des informations à propos de l’éducation, de l’emploi, des enfants, de la religion, de l’origine ethnique, de la position politique, des loisirs, des centres d’intérêts et de l’usage des médias, mais aussi à propos du comportement en ligne, par exemple les recherches sur Internet. Sont également collectées les données sur les achats, l’usage de carte bancaire, le revenu et l’endettement, la gestion bancaire et les polices d’assurance, la propriété immobilière et automobile, et tout un tas d’autres types d’information. Les courtiers en données calculent et attribuent aussi des notes aux individus afin de prédire leur comportement futur, par exemple en termes de stabilité économique, de projet de grossesse ou de changement d’emploi.
Quelques exemples de données clients fournies par Acxiom et Oracle
exemples de données clients fournies par Axciom et Oracle (en avril/mai 2017) – sources : voir le rapport
Acxiom, un important courtier en données
Fondée en 1969, Acxiom gère l’une des plus grandes bases de données client commerciales au monde. Disposant de milliers de sources, l’entreprise fournit jusqu’à 3000 types de données sur 700 millions de personnes réparties dans de nombreux pays, dont les États-Unis, le Royaume-Uni et l’Allemagne. Née sous la forme d’une entreprise de marketing direct, Acxiom a développé ses bases de données client centralisées à la fin des années 1990.
À l’aide de son système Abilitek Link, l’entreprise tient à jour une sorte de registre de la population dans lequel chaque personne, chaque foyer et chaque bâtiment reçoit un identifiant unique. En permanence, l’entreprise met à jour ses bases de données sur la base d’informations concernant les naissances et les décès, les mariages et les divorces, les changements de nom ou d’adresse et aussi bien sûr de nombreuses autres données de profil. Quand on lui demande des renseignements sur une personne, Acxiom peut par exemple donner une appartenance religieuse parmi l’une des 13 retenues comme « catholique », « juif », ou « musulman » et une appartenance ethnique sur quasiment 200 possibles.
Acxiom commercialise l’accès aux profils détaillés des consommateurs et aide ses clients à trouver, cibler, identifier, analyser, trier, noter et classer les gens. L’entreprise gère aussi directement pour ses propres clients 15 000 bases de données clients représentant des milliards de profils consommateurs. Les clients d’Acxiom sont des grandes banques, des assureurs, des services de santé et des organismes gouvernementaux. En plus de son activité de commercialisation de données, Acxiom fournit également des services de vérification d’identité, de gestion du risque et de détection de fraude.
Acxiom et ses fournisseurs de données, ses partenaires et ses services
Axciom et ses fournisseurs de données, ses partenaires et ses clients (en avril/mai 2017) – sources : voir le rapport
Depuis l’acquisition en 2014 de la société de données en ligne LiveRamp, Acxiom a déployé d’importants efforts pour connecter son dépôt de données – couvrant une dizaine d’années – au monde numérique. Par exemple, Acxiom était parmi les premiers courtiers en données à fournir de l’information additionnelle à Facebook, Google et Twitter afin d’aider ces plateformes à mieux pister ou catégoriser les utilisateurs en fonction de leurs achats mais aussi en fonction d’autres comportements qu’ils ne savaient pas encore eux-mêmes pister.
LiveRamp de Acxiom connecte et combine les profils numériques issus de centaines d’entreprises de données et de publicité. Au centre se trouve son système IdentityLink, qui aide à reconnaître les individus et à relier les informations les concernant, dans les bases de données, les plateformes et les appareils en se basant sur leur adresse de courriel, leur numéro de téléphone, l’identifiant de leur téléphone, ou d’autres identifiants. Bien que l’entreprise assure que les correspondances et les associations se fassent de manière « anonyme » et « dé-identifiée », elle dit aussi pouvoir « connecter des données hors-ligne et en ligne sur un seul identifiant ».
Parmi les entreprises qui ont récemment été reconnues comme étant des fournisseurs de données par LiveRamp, on trouve les géants de l’analyse de solvabilité Equifax, Experian et TransUnion. De plus, de nombreux services de pistage numérique collectant des données par Internet, par les applications mobiles, et même par des capteurs placés dans le monde réel, fournissent des données à LiveRamp. Certains d’entre eux utilisent les base de données de LiveRamp, qui permettent aux entreprises « d’acheter et de vendre des données client précieuses ». D’autres fournissent des données afin que Acxiom et LiveRamp puissent reconnaître des individus et relier les informations enregistrées avec les profils numériques d’autres provenances. Mais le plus préoccupant, c’est sans doute le partenariat entre Acxiom et Crossix, une entreprise avec des données détaillées sur la santé de 250 millions de consommateurs américains. Crossix figure parmi les fournisseurs de données de LiveRamp.
Quiconque enregistrant des données sur les consommateurs peut potentiellement être un fournisseur de données. »
Travis May, Directeur général de Acxiom-LiveRamp
Oracle, un géant des technologies de l’information pénètre le marché des données client
En faisant l’acquisition de plusieurs entreprises de données telles que Datalogix, BlueKai, AddThis et CrossWise, Oracle, un des premiers fournisseurs de logiciels d’entreprises et de bases de données dans le monde, est également récemment devenu un des premiers courtiers en données clients. Dans son « cloud », Oracle rassemble 3 milliards de profils utilisateurs issus de 15 millions de sites différents, les données d’un milliard d’utilisateurs mobiles, des milliards d’historiques d’achats dans des chaînes de supermarchés et 1500 détaillants, ainsi que 700 millions de messages par jour issus des réseaux sociaux, des blogs et des sites d’avis de consommateurs.
Oracle rassemble des données sur des milliards de consommateurs
Oracle et ses fournisseurs de données, ses partenaires et ses clients (en avril/mai 2017) – sources : voir le rapport
Oracle catalogue près de 100 fournisseurs de données dans son répertoire de données, parmi lesquels figurent Acxiom et des agences d’analyse de solvabilité telles que Experian et TransUnion, ainsi que des entreprises qui tracent les visites de sites Internet, l’utilisation d’applications mobiles et les déplacements, ou qui collectent des données à partir de questionnaires en ligne. Visa et MasterCard sont également référencés comme fournisseurs de données. En coopération avec ses partenaires, Oracle fournit plus de 30 000 catégories de données différentes qui peuvent être attribuées aux consommateurs. Réciproquement, l’entreprise partage des données avec Facebook et aide Twitter à calculer la solvabilité de ses utilisateurs.
Le Graphe d’Identifiants Oracle détermine et combine des profils utilisateur provenant de différentes entreprises. Il est le « trait d’union entre les interactions » à travers les différentes bases de données, services et appareils afin de « créer un profil client adressable » et « d’identifier partout les clients et les prospects ». D’autres entreprises peuvent envoyer à Oracle, des clés de correspondance construites à partir d’adresses courriel, de numéros de téléphone, d’adresse postale ou d’autres identifiants, Oracle les synchronisera ensuite à son « réseau d’identifiants utilisateurs et statistiques, connectés ensemble dans le Graphe d’Identifiants Oracle ». Bien que l’entreprise promette de n’utiliser que des identifiants utilisateurs anonymisés et des profils d’utilisateurs anonymisés, ceux-ci font tout de même référence à certains individus et peuvent être utilisés pour les reconnaître et les cibler dans de nombreux contextes de la vie.
Le plus souvent, les clients d’Oracle peuvent télécharger dans le « cloud » d’Oracle leurs propres données concernant : leurs clients, les visites sur leur site ou les utilisateurs d’une application ; ils peuvent les combiner avec des données issues de nombreuses autres entreprises, puis les transférer et les utiliser en temps réel sur des centaines d’autres plateformes de commerce et de publicité. Ils peuvent par exemple les utiliser pour trouver et cibler des personnes sur tous les appareils et plateformes, personnaliser leurs interactions, et le cas échéant mesurer la réaction des clients qui ont été personnellement ciblés.
La surveillance en temps réel des comportements quotidiens
Les plateformes en ligne, les fournisseurs de technologies publicitaires, les courtiers en données, et les négociants de toutes sortes d’industries peuvent maintenant surveiller, reconnaître et analyser des individus dans de nombreuses situations. Ils peuvent étudier ce qui intéresse les gens, ce qu’ils ont fait aujourd’hui, ce qu’ils vont sûrement faire demain, et leur valeur en tant que client.
Les données concernant les vies en ligne et hors ligne des personnes
Une large spectre d’entreprises collecte des informations sur les personnes depuis des décennies. Avant l’existence d’Internet, les agences de crédit et les agences de marketing direct servaient de point d’intégration principal entre les données provenant de différentes sources. Une première étape importante dans la surveillance systématique des consommateurs s’est produite dans les années 1990, par la commercialisation de bases de données, les programmes de fidélité et l’analyse poussée de solvabilité. Après l’essor d’Internet et de la publicité en ligne au début des années 2000, et la montée des réseaux sociaux, des smartphones et de la publicité en ligne à la fin des années 2000, on voit maintenant dans les années 2010 l’industrie des données clients s’intégrer avec le nouvel écosystème de pistage et de profilage numérique.
Cartographie de la collecte de données clients
Différents niveaux, domaines et sources de collecte de données clients par les entreprises
De longue date, les courtiers en données clients et d’autres entreprises acquièrent des informations sur les abonnés à des journaux et à des magazines, sur les membres de clubs de lecture et de ciné-clubs, sur les acheteurs de catalogues de vente par correspondance, sur les personnes réservant dans les agences de voyage, sur les participants à des séminaires et à des conférences, et sur les consommateurs qui remplissent les cartes de garantie pour leurs achats. La collecte de données d’achats grâce à des programmes de fidélité est, de ce point de vue, une pratique établie depuis longtemps.
En complément des données provenant directement des individus, sont utilisées, par exemple les informations concernant le type quartiers et d’immeubles où résident les personnes afin de décrire, étiqueter, trier et catégoriser ces personnes. De même, les entreprises utilisent maintenant des profils de consommateurs s’appuyant sur les métadonnées concernant le type de sites Internet fréquentés, les vidéos regardées, les applications utilisées et les zones géographiques visitées. Au cours de ces dernières années, l’échelle et le niveau de détail des flux de données comportementales générées par toutes sortes d’activités du quotidien, telles que l’utilisation d’Internet, des réseaux sociaux et des équipements, ont rapidement augmenté.
Ce n’est pas un téléphone, c’est mon mouchard /pisteur/. New York Times, 2012
Un pistage et un profilage omniprésents
Une des principales raisons pour lesquelles le pistage et le profilage commerciaux sont devenus si généralisés c’est que quasiment tous les sites Internet, les fournisseurs d’applications mobiles, ainsi que de nombreux vendeurs d’équipements, partagent activement des données comportementales avec d’autres entreprises.
Il y a quelques années, la plupart des sites Internet ont commencé à inclure dans leur propre site des services de pistage qui transmettent des données à des tiers. Certains de ces services fournissent des fonctions visibles aux utilisateurs. Par exemple, lorsqu’un site Internet montre un bouton Facebook « j’aime » ou une vidéo YouTube encapsulée, des données utilisateur sont transmises à Facebook ou à Google. En revanche, de nombreux autres services ayant trait à la publicité en ligne demeurent cachés et, pour la plupart, ont pour seul objectif de collecter des données utilisateur. Le type précis de données utilisateur partagées par les éditeurs numériques et la façon dont les tierces parties utilisent ces données reste largement méconnus. Une partie de ces activités de pistage peut être analysée par n’importe qui ; par exemple en installant l’extension pour navigateur Lightbeam, il est possible de visualiser le réseau invisible des trackers des parties tierces.
Une étude récente a examiné un million de sites Internet différents et a trouvé plus de 80 000 services tiers recevant des données concernant les visiteurs de ces sites. Environ 120 de ces services de pistage ont été trouvés sur plus de 10 000 sites, et six entreprises surveillent les utilisateurs sur plus de 100 000 sites, dont Google, Facebook, Twitter et BlueKai d’Oracle. Une étude sur 200 000 utilisateurs allemands visitant 21 millions de pages Internet a montré que les trackers tiers étaient présents sur 95 % des pages visitées. De même, la plupart des applications mobiles partagent des informations sur leurs utilisateurs avec d’autres entreprises. Une étude menée en 2015 sur les applications à la mode en Australie, en Allemagne et aux États-Unis a trouvé qu’entre 85 et 95 % des applications gratuites, et même 60 % des applications payantes se connectaient à des tierces parties recueillant des données personnelles.
Une carte interactive des services cachés de pistage tiers sur les applications Android créée par des chercheurs européens et américains peut être explorée à l’adresse suivante : haystack.mobi/panopticon
En matière d’appareils, ce sont peut-être les smartphones qui actuellement contribuent le plus au recueil omniprésent données. L’information enregistrée par les téléphones portables fournit un aperçu détaillé de la personnalité et de la vie quotidienne d’un utilisateur. Puisque les consommateurs ont en général besoin d’un compte Google, Apple ou Microsoft pour les utiliser, une grande partie de l’information est déjà reliée à l’identifiant d’une des principales plateformes.
La vente de données utilisateurs ne se limite pas aux éditeurs de sites Internet et d’applications mobiles. Par exemple, l’entreprise d’intelligence commerciale SimilarWeb reçoit des données issues non seulement de centaines de milliers de sources de mesures directes depuis les sites et les applications, mais aussi des logiciels de bureau et des extensions de navigateur. Au cours des dernières années, de nombreux autres appareils avec des capteurs et des connexions réseau ont intégré la vie de tous les jours, cela va des liseuses électroniques et autres accessoires connectés aux télés intelligentes, compteurs, thermostats, détecteurs de fumée, imprimantes, réfrigérateurs, brosses à dents, jouets et voitures. À l’instar des smartphones, ces appareils donnent aux entreprises un accès sans précédent au comportement des consommateurs dans divers contextes de leur vie.
Publicité programmatique et technologie marketing
La plus grande partie de la publicité numérique prend aujourd’hui la forme d’enchères en temps réel hautement automatisées entre les éditeurs et les publicitaires ; on appelle cela la publicité programmatique. Lorsqu’une personne se rend sur un site Internet, les données utilisateur sont envoyées à une kyrielle de services tiers, qui cherchent ensuite à reconnaître la personne et extraire l’information disponible sur le profil. Les publicitaires souhaitant livrer une publicité à cet individu, en particulier du fait de certains attributs ou comportements, placent une enchère. En quelques millisecondes, le publicitaire le plus offrant gagne et place la pub. Les publicitaires peuvent de la même façon enchérir sur les profils utilisateurs et le placement de publicités au sein des applications mobiles.
Néanmoins, ce processus ne se déroule pas, la plupart du temps, entre les éditeurs et les publicitaires. L’écosystème est constitué d’une pléthore de toutes sortes de données différentes et de fournisseurs de technologies en interaction les uns avec les autres, parmi lesquels des réseaux publicitaires, des marchés publicitaires, des plateformes côté vente et des plateformes côté achat. Certains se spécialisent dans le pistage et la publicité suivant les résultats de recherche, dans la publicité généraliste sur Internet, dans la pub sur mobile, dans les pubs vidéos, dans les pubs sur les réseaux sociaux, ou dans les pubs au sein des jeux. D’autres se concentrent sur l’approvisionnement en données, en analyse ou en services de personnalisation.
Pour tracer le portrait des utilisateurs d’Internet et d’applications mobiles, toutes les parties impliquées ont développé des méthodes sophistiquées pour accumuler, regrouper et relier les informations provenant de différentes entreprises afin de suivre les individus dans tous les aspects de leur vie. Nombre d’entre elles recueillent et utilisent des profils numériques sur des centaines de millions de consommateurs, leurs navigateurs Internet et leurs appareils.
De nombreux secteurs rejoignent l’économie de pistage
Au cours de ces dernières années, des entreprises dans plusieurs secteurs ont commencé à partager et à utiliser à très grande échelle des données concernant leurs utilisateurs et clients.
La plupart des détaillants vendent des formes agrégées de données sur les habitudes d’achat auprès des entreprises d’études de marchés et des courtiers en données. Par exemple, l’entreprise de données IRI accède aux données de plus de 85 000 magasins (‘alimentation, grande distribution, médicaments, d’alcool et d’animaux de compagnie, magasin à prix unique et magasin de proximité). Nielsen déclare recueillir les informations concernant les ventes de 900 000 magasins dans le monde dans plus de 100 pays. L’enseigne de grande distribution britannique Tesco sous-traite son programme de fidélité et ses activités en matière de données auprès d’une filiale, Dunnhumby, dont le slogan est « transformer les données consommateur en régal pour le consommateur ». Lorsque Dunnhumby a fait l’acquisition de l’entreprise technologique de publicité allemande Sociomantic, il a été annoncé que Dunnhumby « conjuguerait ses connaissances étendues au sujet sur les préférences d’achat de 400 millions de consommateurs » avec les « données en temps réel de plus de 700 millions de consommateurs en ligne » de Sociomantic afin personnaliser et d’évaluer les publicités.
Cartographie de l’écosystème du pistage et du profilage commercial
Aujourd’hui de nombreux industriels dans divers secteurs ont rejoint l’écosystème de pistage et de profilage numérique, aux cotés des grandes plateformes en ligne et des professionnels de l’analyse des données clients.
De grands groupes médiatiques sont aussi fortement intégrés dans l’écosystème de pistage et de profilage numérique actuel. Par exemple, Time Inc. a fait l’acquisition d’Adelphic, une importante société de pistage et de technologies publicitaires multi-support, mais aussi de Viant, une entreprise qui déclare avoir accès à plus de 1,2 milliard d’utilisateurs enregistrés. La plateforme de streaming Spotify est un exemple célèbre d’éditeur numérique qui vend les données de ses utilisateurs. Depuis 2016, la société partage avec le département données du géant du marketing WPP des informations à propos de ce que les utilisateurs écoutent, sur leur humeur ainsi que sur leur comportement et leur activité en termes de playlist. WPP a maintenant accès « aux préférences et comportements musicaux des 100 millions d’utilisateurs de Spotify ».
De nombreuses grandes entreprises de télécom et de fournisseurs d’accès Internet ont fait l’acquisition d’entreprises de technologies publicitaires et de données. Par exemple, Millennial Media, une filiale d’AOL-Verizon, est une plateforme de publicité mobile qui collecte les données de plus de 65 000 applications de différents développeurs, et prétend avoir accès à environ 1 milliard d’utilisateurs actifs distincts dans le monde. Singtel, l’entreprise de télécoms basée à Singapour, a acheté Turn, une plateforme de technologies publicitaires qui donne accès aux distributeurs à 4,3 milliards d’appareils pouvant être ciblés et d’identifiants de navigateurs et à 90 000 attributs démographiques, comportementaux et psychologiques.
Comme les compagnies aériennes, les hôtels, les commerces de détail et les entreprises de beaucoup d’autres secteur, le secteur des services financiers a commencé à agréger et utiliser des données clients supplémentaires grâce à des programmes de fidélité dans les années 80 et 90. Les entreprises dont la clientèle cible est proche et complémentaires partagent depuis longtemps certaines de leurs données clients entre elles, un processus souvent géré par des intermédiaires. Aujourd’hui, l’un de ces intermédiaires est Cardlytics, une entreprise qui gère des programmes de fidélité pour plus de 1 500 institutions financières, telles que Bank of America et MasterCard. Cardlytics s’engage auprès des institutions financières à « générer des nouvelles sources de revenus en exploitant le pouvoir de [leurs] historiques d’achat ». L’entreprise travaille aussi en partenariat avec LiveRamp, la filiale d’Acxiom qui combine les données en ligne et hors ligne des consommateurs.
Pour MasterCard, la vente de produits et de services issus de l’analyse de données pourrait même devenir son cœur de métier, sachant que la production d’informations, dont la vente de données, représentent une part considérable et croissante de ses revenus. Google a récemment déclaré qu’il capture environ 70 % des transactions par carte de crédit aux États-Unis via « partenariats tiers » afin de tracer les achats, mais n’a pas révélé ses sources.
Ce sont vos données. Vous avez le droit de les contrôler, de les partager et de les utiliser comme bon vous semble.
C’est ainsi que le courtier en données Lotame s’adresse sur son site Internet à ses entreprises clientes en 2016.
Relier, faire correspondre et combiner des profils numériques
Jusqu’à récemment, les publicitaires, sur Facebook, Google ou d’autres réseaux de publicité en ligne, ne pouvaient cibler les individus qu’en analysant leur comportement en ligne. Mais depuis quelques années, grâce aux moyens offerts par les entreprises de données, les profils numériques issus de différentes plateformes, de différentes bases de données clients et du monde de la publicité en ligne peuvent désormais être associés et combinés entre eux.
Connecter les identités en ligne et hors ligne
Cela a commencé en 2012, quand Facebook a permis aux entreprises de télécharger leurs propres listes d’adresses de courriel et de numéros de téléphone sur la plateforme. Bien que les adresses et numéros de téléphone soient convertis en pseudonyme, Facebook est en mesure de relier directement ces données client provenant d’entreprises tierces avec ses propres comptes utilisateur. Cela permet par exemple aux entreprises de trouver et de cibler très précisément sur Facebook les personnes dont elles possèdent les adresses de courriel ou les numéros de téléphone. De la même façon, il leur est éventuellement possible d’exclure certaines personnes du ciblage de façon sélective, ou de déléguer à la plateforme le repérage des personnes qui ont des caractéristiques, centre d’intérêts, et comportements communs.
C’est une fonctionnalité puissante, peut-être plus qu’il n’y paraît au premier abord. Elle permet en effet aux entreprises d’associer systématiquement leurs données client avec les données Facebook. Mieux encore, d’autres publicitaires et marchands de données peuvent également synchroniser leurs bases avec celles de la plateforme et en exploiter les ressources, ce qui équivaut à fournir une sorte de télécommande en temps réel pour manipuler l’univers des données Facebook. Les entreprises peuvent maintenant capturer en temps réel des données comportementales extrêmement précises comme un clic de souris sur un site, le glissement d’un doigt sur une application mobile ou un achat en magasin, et demander à Facebook de trouver et de cibler aussitôt les personnes qui viennent de se livrer à ces activités. Google et Twitter ont mis en place des fonctionnalités similaires en 2015.
Les plateformes de gestion de données
De nos jours, la plupart des entreprises de technologie publicitaire croisent en continu plusieurs sources de codage relatives aux individus. Les plateformes de gestion de données permettent aux entreprises de tous les domaines d’associer et de relier leurs propres données clients, comprenant des informations en temps réel sur les achats, les sites web consultés, les applications utilisées et les réponses aux courriels, avec des profils numériques fournis par une multitude de fournisseurs tiers de données. Les données associées peuvent alors être analysées, triées et classées, puis utilisées pour envoyer un message donné à des personnes précises via des réseaux ou des appareils particuliers. Une entreprise peut, par exemple, cibler un groupe de clients existants ayant visité une page particulière sur son site ; ils sont alors perçus comme pouvant devenir de bons clients, bénéficiant alors de contenus personnalisés ou d’une réduction, que ce soit sur Facebook, sur une appli mobile ou sur le site même de l’entreprise.
L’émergence des plateformes de gestion de données marque un tournant dans le développement d’un envahissant pistage des comportements d’achat. Avec leur aide, les entreprises dans tous les domaines et partout dans le monde peuvent très facilement associer et relier les données qu’elles ont collectées depuis des années sur leurs clients et leurs prospects avec les milliards de profils collectés dans le monde numérique. Les principales entreprises faisant tourner ces plateformes sont : Oracle, Adobe, Salesforce (Krux), Wunderman (KBM Group/Zipline), Neustar, Lotame et Cxense.
Nous vous afficherons des publicités basées sur votre identité, mais cela ne veut pas dire que vous serez identifiable.
Erin Egan, Directeur de la protection de la vie privée chez Facebook, 2012
Identifier les gens et relier les profils numériques
Pour surveiller et suivre les gens dans les différentes situations de leur vie, pour leur associer des profils et toujours les reconnaître comme un seul et même individu, les entreprises amassent une grande variété de types de données qui, en quelque sorte, les identifient.
Parce qu’il est ambigu, le nom d’une personne a toujours été un mauvais identifiant pour un recueil de données. L’adresse postale, par contre, a longtemps été et est encore, une indication clé qui permet d’associer et de relier des données de différentes origines sur les consommateurs et leur famille. Dans le monde numérique, les identifiants les plus pertinents pour relier les profils et les comportements sur les différentes bases de données, plateformes et appareils sont : l’adresse de courriel, le numéro de téléphone, et le code propre à chaque smartphone ou autre appareil.
Les identifiants de compte utilisateur sur les immenses plateformes comme Google, Facebook, Apple et Microsoft jouent aussi un rôle important dans le suivi des gens sur Internet. Google, Apple, Microsoft et Roku attribuent un « identifiant publicitaire » aux individus, qui est maintenant largement utilisé pour faire correspondre et relier les données d’appareils tels que les smartphones avec les autres informations issues du monde numérique. Verizon utilise son propre identifiant pour pister les utilisateurs sur les sites web et les appareils. Certaines grandes entreprises de données comme Acxiom, Experian et Oracle disposent, au niveau mondial, d’un identifiant unique par personne qu’elles utilisent pour relier des dizaines d’années de données clients avec le monde numérique. Ces identifiants d’entreprise sont constitués le plus souvent de deux identifiants ou plus qui sont attachés à différents aspects de la vie en ligne et hors ligne d’une personne et qui peuvent être d’une certaine façon reliés l’un à l’autre.
Des Identifiants utilisés pour pister les gens sur les sites web, les appareils et les lieux de vie
Comment les entreprises identifient les consommateurs et les relient à des informations de profils – sources : voir le rapport
Les entreprises de pistage utilisent également des identifiants plus ou moins temporaires, comme les cookies qui sont attachés aux utilisateurs surfant sur le web. Depuis que les utilisateurs peuvent ne pas autoriser ou supprimer les cookies dans leur navigateur, elles ont développé des méthodes sophistiquées permettant de calculer une empreinte numérique unique basée sur diverses caractéristiques du navigateur et de l’ordinateur d’une personne. De la même manière, les entreprises amassent les empreintes sur les appareils tels que les smartphones. Les cookies et les empreintes numériques sont continuellement synchronisés entre les différents services de pistage et ensuite reliés à des identifiants plus permanents.
D’autres entreprises fournissent des services de pistage multi-appareils qui utilisent le machine learning (voir Wikipédia) pour analyser de grandes quantités de données. Par exemple, Tapad, qui a été acheté par le géant des télécoms norvégiens Telenor, analyse les données de deux milliards d’appareils dans le monde et utilise des modèles basés sur les comportements et les relations pour trouver la probabilité qu’un ordinateur, une tablette, un téléphone ou un autre appareil appartienne à la même personne.
Un profilage « anonyme » ?
Les entreprises de données suppriment les noms dans leurs profils détaillés et utilisent des fonctions de hachage (voir Wikipedia) pour convertir les adresses de courriel et les numéros de téléphone en code alphanumérique comme “e907c95ef289”. Cela leur permet de déclarer sur leur site web et dans leur politique de confidentialité qu’elles recueillent, partagent et utilisent uniquement des données clients « anonymisées » ou « dé-identifiées ».
Néanmoins, comme la plupart des entreprises utilisent les mêmes process déterministes pour calculer ces codes alphanumériques, on devrait les considérer comme des pseudonymes qui sont en fait bien plus pratiques que les noms réels pour identifier les clients dans le monde numérique. Même si une entreprise partage des profils contenant uniquement des adresses de courriels ou des numéros de téléphones chiffrés, une personne peut toujours être reconnue dès qu’elle utilise un autre service lié avec la même adresse de courriel ou le même numéro de téléphone. De cette façon, bien que chaque service de pistage impliqué ne connaissent qu’une partie des informations du profil d’une personne, les entreprises peuvent suivre et interagir avec les gens au niveau individuel via les services, les plateformes et les appareils.
Si une entreprise peut vous suivre et interagir avec vous dans le monde numérique – et cela inclut potentiellement votre téléphone mobile ou votre télé – alors son affirmation que vous êtes anonyme n’a aucun sens, en particulier quand des entreprises ajoutent de temps à autre des informations hors-ligne aux données en ligne et masquent simplement le nom et l’adresse pour rendre le tout « anonyme ».
Joseph Turow, spécialiste du marketing et de la vie privée dans son livre « The Daily You », 2011
Gérer les clients et les comportements : personnalisation et évaluation
S’appuyant sur les méthodes sophistiquées d’interconnexion et de combinaison de données entre différents services, les entreprises de tous les secteurs d’activité peuvent utiliser les flux de données comportementales actuellement omniprésents afin de surveiller et d’analyser une large gamme d’activités et de comportements de consommateurs pouvant être pertinents vis-à-vis de leurs intérêts commerciaux.
Avec l’aide des vendeurs de données, les entreprises tentent d’entrer en contact avec les clients tout au long de leurs parcours autant de fois que possible, à travers les achats en ligne ou en boutique, le publipostage, les pubs télé et les appels des centres d’appels. Elles tentent d’enregistrer et de mesurer chaque interaction avec un consommateur, y compris sur les sites Internet, plateformes et appareils qu’ils ne contrôlent pas eux-mêmes. Elles peuvent recueillir en continu une abondance de données concernant leurs clients et d’autres personnes, les améliorer avec des informations provenant de tiers, et utiliser les profils améliorés au sein de l’écosystème de commercialisation et de technologie publicitaire. À l’heure actuelle, les plateformes de gestion des données clients permettent la définition de jeux complexes de règles qui régissent la façon de réagir automatiquement à certains critères tels que des activités ou des personnes données ou une combinaison des deux.
Par conséquent, les individus ne savent jamais si leur comportement a déclenché une réaction de l’un de ces réseaux de pistage et de profilage constamment mis à jour, interconnectés et opaques, ni, le cas échéant, comment cela influence les options qui leur sont proposées à travers les canaux de communication et dans les situations de vie.
Tracer, profiler et influencer les individus en temps réel
Chaque interaction enclenche un large éventail de flux de données entre de nombreuses entreprises.
Personnalisation en série
Les flux de données échangés entre les publicitaires en ligne, les courtiers en données, et les autres entreprises ne sont pas seulement utilisés pour diffuser de la publicité ciblée sur les sites web ou les applis mobiles. Ils sont de plus en plus utilisés pour personnaliser les contenus, les options et les choix offerts aux consommateurs sur le site d’une entreprise par exemple. Les entreprises de technologie des données, comme par exemple Optimizely, peuvent aider à personnaliser un site web spécialement pour les personnes qui le visitent pour la première fois, en s’appuyant sur les profils numériques de ces visiteurs fournis par Oracle.
Les boutiques en ligne, par exemple, personnalisent l’accueil des visiteurs : quels produits seront mis en évidence, quelles promotions seront proposées, et même le prix et des produits ou des services peuvent être différents selon la personne qui visite le site. Les services de détection de la fraude évaluent les utilisateurs en temps réel et décident quels moyens de paiement et de transport peuvent être proposés.
Les entreprises développent des technologies pour calculer et évaluer en continu le potentiel de valeur à long terme d’un client en s’appuyant sur son historique de navigation, de recherche et de localisation, mais aussi sur son usage des applis, sur les produits achetés et sur ses amis sur les réseaux sociaux. Chaque clic, chaque glissement de doigt, chaque Like, chaque partage est susceptible d’influencer la manière dont une personne est traitée en tant que client, combien de temps elle va attendre avant que la hotline ne lui réponde, ou si elle sera complètement exclue des relances et des services marketing.
L’Internet des riches n’est pas le même que celui des pauvres.
Michael Fertik, fondateur de reputation.com, 2013
Trois types de plateformes technologiques jouent un rôle important dans cette sorte de personnalisation instantanée. Premièrement, les entreprises utilisent des systèmes de gestion de la relation client pour gérer leurs données sur les clients et les prospects. Deuxièmement, elles utilisent des plateformes de gestion de données pour connecter leurs propres données à l’écosystème de publicité numérique et obtiennent ainsi des informations supplémentaires sur le profil de leurs clients. Troisièmement, elles peuvent utiliser des plateformes de marketing prédictif qui les aident à produire le bon message pour la bonne personne au bon moment, calculant comment convaincre quelqu’un en exploitant ses faiblesses et ses préjugés.
Par exemple, l’entreprise de données RocketFuel promet à ses clients de « leur apporter des milliers de milliards de signaux numériques ou non pour créer des profils individuels et pour fournir aux consommateurs une expérience personnalisée, toujours actualisée et toujours pertinente » s’appuyant sur les 2,7 milliards de profils uniques de son dépôt de données. Selon RocketFuel, il s’agit « de noter chaque signal selon sa propension à influencer le consommateur ».
La plateforme de marketing prédictif TellApart, qui appartient à Twitter, associe une valeur à chaque couple client/produit acheté, une « synthèse entre la probabilité d’achat, l’importance de la commande et la valeur à long terme », s’appuyant sur « des centaines de signaux en ligne et en magasin sur un consommateur anonyme unique ». En conséquence, TellApart regroupe automatiquement du contenu tel que « l’image du produit, les logos, les offres et toute autre métadonnée » pour construire des publicités, des courriels, des sites web et des offres personnalisées.
Tarifs personnalisés et campagnes électorales
Des méthodes identiques peuvent être utilisées pour personnaliser les tarifs dans les boutiques en ligne, par exemple, en prédisant le niveau d’achat d’un client à long terme ou le montant qu’il sera probablement prêt à payer un peu plus tard. Des preuves sérieuses suggèrent que les boutiques en ligne affichent déjà des tarifs différents selon les consommateurs, ou même des prix différents pour le même produit, en s’appuyant sur leur comportement et leurs caractéristiques. Un champ d’action similaire est la personnalisation lors des campagnes électorales. Le ciblage des électeurs avec des messages personnalisés, adaptés à leur personnalité, et à leurs opinions politiques sur des problèmes donnés a fait monter les débats sur une possible manipulation politique.
Utiliser les données, les analyser et les personnaliser pour gérer les consommateurs
Actuellement, dans tous les domaines, les entreprises peuvent mobiliser les réseaux de suivi et de profilage pour trouver, évaluer, contacter, trier et gérer les consommateurs
Tests et expériences sur les personnes
La personnalisation s’appuyant sur de riches informations de profil et sur du suivi invasif en temps réel est devenue un outil puissant pour influencer le comportement du consommateur quand il visite une page web, clique sur une pub, s’inscrit à un service, s’abonne à une newsletter, télécharge une application ou achète un produit.
Pour améliorer encore cela, les entreprises ont commencé à faire des expériences en continu sur les individus. Elles procèdent à des tests en faisant varier les fonctionnalités, le design des sites web, l’interface utilisateur, les titres, les boutons, les images ou mêmes les tarifs et les remises, surveillent et mesurent avec soin comment les différents groupes d’utilisateurs interagissent avec ces modifications. De cette façon, les entreprises optimisent sans arrêt leur capacité à encourager les personnes à agir comme elles veulent qu’elles agissent.
Les organes de presse, y compris à grand tirage comme le Washington Post, utilisent différentes versions des titres de leurs articles pour voir laquelle est la plus performante. Optimizely, un des principaux fournisseurs de technologies pour ce genre de tests, propose à ses clients la capacité de « faire des tests sur l’ensemble de l’expérience client sur n’importe quel canal, n’importe quel appareil, et n’importe quelle application ». Expérimenter sur des usagers qui l’ignorent est devenu la nouvelle norme.
En 2014, Facebook a déclaré faire tourner « plus d’un millier d’expérimentations chaque jour » afin « d’optimiser des résultats précis » ou pour « affiner des décisions de design sur le long terme ». En 2010 et 2012, la plateforme a mené des expérimentations sur des millions d’utilisateurs et montré qu’en manipulant l’interface utilisateur, les fonctionnalités et le contenu affiché, Facebook pouvait augmenter significativement le taux de participation électorale d’un groupe de personnes. Leur célèbre expérimentation sur l’humeur des internautes, portant sur 700 000 individus, consistait à manipuler secrètement la quantité de messages émotionnellement positifs ou négatifs présents dans les fils d’actualité des utilisateurs : il s’avéra que cela avait un impact sur le nombre de messages positifs ou négatifs que les utilisateurs postaient ensuite eux-mêmes.
Suite à la critique massive de Facebook par le public concernant cette expérience, la plateforme de rendez-vous OkCupid a publié un article de blog provocateur défendant de telles pratiques, déclarant que « nous faisons des expériences sur les êtres humains » et « c’est ce que font tous les autres ». OkCupid a décrit une expérimentation dans laquelle a été manipulé le pourcentage de « compatibilité » montré à des paires d’utilisateurs. Quand on affichait un taux de 90 % entre deux utilisateurs qui en fait étaient peu compatibles, les utilisateurs échangeaient nettement plus de messages entre eux. OkCupid a déclaré que quand elle « dit aux gens » qu’ils « vont bien ensemble », alors ils « agissent comme si c’était le cas ».
Toutes ces expériences qui posent de vraies questions éthiques montrent le pouvoir de la personnalisation basée sur les données pour influer sur les comportements.
Dans les mailles du filet : vie quotidienne, données commerciales et analyse du risque
Les données concernant les comportements des personnes, les liens sociaux, et les moments les plus intimes sont de plus en plus utilisées dans des contextes ou à des fins complètement différents de ceux dans lesquels elles ont été enregistrées. Notamment, elles sont de plus en plus utilisées pour prendre des décisions automatisées au sujet d’individus dans des domaines clés de la vie tels que la finance, l’assurance et les soins médicaux.
Données relatives aux risques pour le marketing et la gestion client
Les agences d’évaluation de la solvabilité, ainsi que d’autres acteurs clés de l’évaluation du risque, principalement dans des domaines tels que la vérification des identités, la prévention des fraudes, les soins médicaux et l’assurance fournissent également des solutions commerciales. De plus, la plupart des courtiers en données s’échangent divers types d’informations sensibles, par exemple des informations concernant la situation financière d’un individu, et ce à des fins commerciales. L’utilisation de l’évaluation de solvabilité à des fins de marketing afin soit de cibler soit d’exclure des ensembles vulnérables de la population a évolué pour devenir des produits qui associent le marketing et la gestion du risque.
L’agence d’évaluation de la solvabilité TransUnion fournit, par exemple, un produit d’aide à la décision piloté par les données à destination des commerces de détail et des services financiers qui leur permet « de mettre en œuvre des stratégies de marketing et de gestion du risque sur mesure pour atteindre les objectifs en termes de clients, canaux de vente et résultats commerciaux », il inclut des données de crédit et promet « un aperçu inédit du comportement, des préférences et des risques du consommateur. » Les entreprises peuvent alors laisser leurs clients « choisir parmi une gamme complète d’offres sur mesure, répondant à leurs besoins, leurs préférences et leurs profils de risque » et « évaluer leurs clients sur divers produits et canaux de vente et leur présenter uniquement la ou les offres les plus pertinente pour eux et les plus rentables » pour l’entreprise. De même, Experian fournit un produit qui associe « crédit à la consommation et informations commerciales, fourni avec plaisir par Experian. »
En matière de surveillance, il n’est pas question de connaître vos secrets, mais de gérer des populations, de gérer des personnes.
Katarzyna Szymielewicz, Vice-Présidente EDRi, 2015
Vérification des identités en ligne et détection de la fraude
Outre la machine de surveillance en temps réel qui a été développée au travers de la publicité en ligne, d’autres formes de pistage et de profilage généralisées ont émergé dans les domaines de l’analyse de risque, de la détection de fraudes et de la cybersécurité.
De nos jours, les services de détection de fraude en ligne utilisent des technologies hautement intrusives afin d’évaluer des milliards de transactions numériques. Ils recueillent d’énormes quantités d’informations concernant les appareils, les individus et les comportements. Les fournisseurs habituels dans l’évaluation de solvabilité, la vérification d’identité, et la prévention des fraudes ont commencé à surveiller et à évaluer la façon dont les personnes surfent sur le web et utilisent leurs appareils mobiles. En outre, ils ont entrepris de relier les données comportementales en ligne avec l’énorme quantité d’information hors-connexion qu’ils recueillent depuis des dizaines d’années.
Avec l’émergence de services passant par l’intermédiaire d’objets technologiques, la vérification de l’identité des consommateurs et la prévention de la fraude sont devenues de plus en plus importantes et de plus en plus contraignantes, notamment au vu de la cybercriminalité et de la fraude automatisée. Dans un même temps, les systèmes actuels d’analyse du risque ont agrégé des bases de données gigantesques contenant des informations sensibles sur des pans entiers de population. Nombre de ces systèmes répondent à un grand nombre de cas d’utilisation, parmi lesquels la preuve d’identité pour les services financiers, l’évaluation des réclamations aux compagnies d’assurance et des demandes d’indemnités, de l’analyse des transactions financières et l’évaluation de milliards de transactions en ligne.
De tels systèmes d’analyse du risque peuvent décider si une requête ou une transaction est acceptée ou rejetée ou décider des options de livraison disponibles pour une personne lors d’une transaction en ligne. Des services marchands de vérification d’identité et d’analyse de la fraude sont également employés dans des domaines tels que les forces de l’ordre et la sécurité nationale. La frontière entre les applications commerciales de l’analyse de l’identité et de la fraude et celles utilisées par les agences gouvernementales de renseignement est de plus en plus floue.
Lorsque des individus sont ciblés par des systèmes aussi opaques, ils peuvent être signalés comme étant suspects et nécessitant un traitement particulier ou une enquête, ou bien ils peuvent être rejetés sans plus d’explication. Ils peuvent recevoir un courriel, un appel téléphonique, une notification, un message d’erreur, ou bien le système peut tout simplement ne pas indiquer une option, sans que l’utilisateur ne connaisse son existence pour d’autres. Des évaluations erronées peuvent se propager d’un système à l’autre. Il est souvent difficile, voire impossible de faire recours contre ces évaluations négatives qui excluent ou rejettent, notamment à cause de la difficulté de s’opposer à quelque chose dont on ne connaît pas l’existence.
Exemples de détection de fraude en ligne et de service d’analyse des risques
L’entreprise de cybersécurité ThreatMetrix traite les données concernant 1,4 milliard de « comptes utilisateur uniques » sur des « milliers de sites dans le monde. » Son Digital Identity Network (Réseau d’Identité Numérique) enregistre des « millions d’opérations faites par des consommateurs chaque jour, notamment des connexions, des paiements et des créations de nouveaux comptes », et cartographie les « associations en constante évolution entre les individus et leurs appareils, leurs positions, leurs identifiants et leurs comportements » à des fins de vérification des identités et de prévention des fraudes. L’entreprise collabore avec Equifax et TransUnion. Parmi ses clients se trouvent Netflix, Visa et des entreprises dans des secteurs tels que le jeu vidéo, les services gouvernementaux et la santé.
De façon analogue, l’entreprise de données ID Analytics, qui a récemment été achetée par Symantec, exploite un Réseau d’Identifiants fait de « 100 millions de nouveaux éléments d’identité quotidiens issus des principales organisations interprofessionnelles. ». L’entreprise agrège des données concernant 300 millions de consommateurs, sur les prêts à haut risque, les achats en ligne et les demandes de carte de crédit ou de téléphone portable. Son Indice d’Identité, ID Score, prend en compte les appareils numériques ainsi que les noms, les numéros de sécurité sociale et les adresses postales et courriel.
Trustev, une entreprise en ligne de détection de la fraude dont le siège se situe en Irlande et qui a été rachetée par l’agence d’évaluation de la solvabilité TransUnion en 2015, juge des transactions en ligne pour des clients dans les secteurs des services financiers, du gouvernement, de la santé et de l’assurance en s’appuyant sur l’analyse des comportements numériques, les identités et les appareils tels que les téléphones, les tablettes, les ordinateurs portables, les consoles de jeux, les télés et même les réfrigérateurs. L’entreprise propose aux entreprises clientes la possibilité d’analyser la façon dont les visiteurs cliquent et interagissent avec les sites Internets et les applications. Elle utilise une large gamme de données pour évaluer les utilisateurs, y compris les numéros de téléphone, les adresses courriel et postale, les empreintes de navigateur et d’appareil, les vérifications de la solvabilité, les historiques d’achats sur l’ensemble des vendeurs, les adresses IP, les opérateurs mobiles et la géolocalisation des téléphones. Afin d’aider à « accepter les transactions futures », chaque appareil se voit attribuer une empreinte digitale d’appareil unique. Trustev propose aussi une technologie de marquage d’empreinte digitale sociale qui analyse le contenu des réseaux sociaux, notamment une « analyse de la liste d’amis » et « l’identification des schémas ». TransUnion a intégré la technologie Trustev dans ses propres solutions identifiantes et anti-fraude.
Selon son site Internet, Trustev utilise une large gamme de données pour évaluer les personnes
Capture d’écran du site Internet de Trustev, 2 juin 2016
De façon similaire, l’agence d’évaluation de la solvabilité Equifax affirme qu’elle possède des données concernant près de 1 milliard d’appareils et peut affirmer « l’endroit où se situe en fait un appareil et s’il est associé à d’autres appareils utilisés dans des fraudes connues ». En associant ces données avec « des milliards d’identités et d’événements de crédit pour trouver les activités douteuses » dans tous les secteurs, et en utilisant des informations concernant la situation d’emploi et les liens entre les ménages, les familles et les partenaires, Equifax prétend être capable « de distinguer les appareils ainsi que les individus ».
Je ne suis pas un robot
Le produit reCaptcha de Google fournit en fait un service similaire, du moins en partie. Il est incorporé dans des millions de sites Internets et aide les fournisseurs de sites Internets à décider si un visiteur est un être humain ou non. Jusqu’à récemment, les utilisateurs devaient résoudre diverses sortes de défis rapides tels que le déchiffrage de lettres dans une image, la sélection d’images dans une grille, ou simplement en cochant la case « Je ne suis pas un robot ». En 2017, Google a présenté une version invisible de reCaptcha, en expliquant qu’à partir de maintenant, les utilisateurs humains pourront passer « sans aucune interaction utilisateur, contrairement aux utilisateurs douteux et aux robots ». L’entreprise ne révèle pas le type de données et de comportements utilisateurs utilisés pour reconnaître les humains. Des analyses laissent penser que Google, outre les adresses IP, les empreintes de navigateur, la façon dont l’utilisateur frappe au clavier, déplace la souris ou utilise l’écran tactile « avant, pendant et après » une interaction reCaptcha, utilise plusieurs témoins Google. On ne sait pas exactement si les individus sans compte utilisateur sont désavantagés, si Google est capable d’identifier des individus particuliers plutôt que des « humains » génériques, ou si Google utilise les données enregistrées par reCaptcha à d’autres fins que la détection de robots.
Le pistage numérique à des fins publicitaires et de détection de la fraude ?
Les flux omniprésents de données comportementales enregistrées pour la publicité en ligne s’écoulent vers les systèmes de détection de la fraude. Par exemple, la plateforme de données commerciales Segment propose à ses clients des moyens faciles d’envoyer des données concernant leurs clients, leur site Internet et les utilisateurs mobiles à une kyrielle de services de technologies commerciales, ainsi qu’à des entreprises de détection de fraude. Castle est l’une d’entre-elles et utilise « les données comportementales des consommateurs pour prédire les utilisateurs qui présentent vraisemblablement un risque en matière de sécurité ou de fraude ». Une autre entreprise, Smyte, aide à « prévenir les arnaques, les messages indésirables, le harcèlement et les fraudes par carte de crédit ».
La grande agence d’analyse de la solvabilité Experian propose un service de pistage multi-appareils qui fournit de la reconnaissance universelle d’appareils, sur mobile, Internet et les applications pour le marketing numérique. L’entreprise s’engage à concilier et à associer les « identifiants numériques existants » de leurs clients, y compris des « témoins, identifiants d’appareil, adresses IP et d’autres encore », fournissant ainsi aux commerciaux un « lien omniprésent, cohérent et permanent sur tous les canaux ».
La technologie d’identification d’appareils provient de 41st parameter (le 41e paramètre), une entreprise de détection de la fraude rachetée par Experian en 2013. En s’appuyant sur la technologie développée par 41st parameter, Experian propose aussi une solution d’intelligence d’appareil pour la détection de la fraude au cours des paiements en ligne. Cette solution qui « créé un identifiant fiable pour l’appareil et recueille des données appareil abondantes » « identifie en quelques millisecondes chaque appareil à chaque visite » et « fournit une visibilité jamais atteinte de l’individu réalisant le paiement ». On ne sait pas exactement si Experian utilise les mêmes données pour ses services d’identification d’appareils pour détecter la fraude que pour le marketing.
Cartographie de l’écosystème du pistage et du profilage commercial
Au cours des dernières années, les pratiques déjà existantes de surveillance commerciale ont rapidement muté en un large éventail d’acteurs du secteur privé qui surveillent en permanence des populations entières. Certains des acteurs de l’écosystème actuel de pistage et de profilage, tels que les grandes plateformes et d’autres entreprises avec un grand nombre de clients, tiennent une position unique en matière d’étendue et de niveau de détail de leurs profils de consommateurs. Néanmoins, les données utilisées pour prendre des décisions concernant les individus sur de nombreux sujets ne sont généralement pas centralisées en un lieu, mais plutôt assemblées en temps réel à partir de plusieurs sources selon les besoins.
Un large éventail d’entreprises de données et de services d’analyse en marketing, en gestion client et en analyse du risque recueillent, analysent, partagent et échangent de façon uniforme des données client et les associent avec des informations supplémentaires issues de milliers d’autres entreprises. Tandis que l’industrie des données et des services d’analyse fournissent les moyens pour déployer ces puissantes technologies, les entreprises dans de nombreuses industries contribuent à augmenter la quantité et le niveau de détail des données collectées ainsi que la capacité à les utiliser.
Cartographie de l’écosystème du pistage et du profilage commercial numérique
En plus des grandes plateformes en ligne et de l’industrie des données et des services d’analyse des consommateurs, des entreprises dans de nombreux secteurs ont rejoint les écosystèmes de pistage et de profilage numérique généralisé.
Google et Facebook, ainsi que d’autres grandes plateformes telles que Apple, Microsoft, Amazon et Alibaba ont un accès sans précédent à des données concernant les vies de milliards de personnes. Bien qu’ils aient des modèles commerciaux différents et jouent par conséquent des rôles différents dans l’industrie des données personnelles, ils ont le pouvoir de dicter dans une large mesure les paramètres de base des marchés numériques globaux. Les grandes plateformes limitent principalement la façon dont les autres entreprises peuvent obtenir leurs données. Ainsi, ils les obligent à utiliser les données utilisateur de la plateforme dans leur propre écosystème et recueillent des données au-delà de la portée de la plateforme.
Bien que les grandes multinationales de différents secteurs ayant des interactions fréquentes avec des centaines de millions de consommateurs soient en quelque sorte dans une situation semblable, elles ne font pas qu’acheter des données clients recueillies par d’autres, elles en fournissent aussi. Bien que certaines parties des secteurs des services financiers et des télécoms ainsi que des domaines sociétaux critiques tels que la santé, l’éducation et l’emploi soient soumis à une réglementation plus stricte dans la plupart des juridictions, un large éventail d’entreprises a commencé à utiliser ou fournissent des données aux réseaux actuels de surveillance commerciale.
Les détaillants et d’autres entreprises qui vendent des produits et services aux consommateurs vendent pour la plupart les données concernant les achats de leurs clients. Les conglomérats médiatiques et les éditeurs numériques vendent des données au sujet de leur public qui sont ensuite utilisées par des entreprises dans la plupart des autres secteurs. Les fournisseurs de télécoms et d’accès haut débit ont entrepris de suivre leurs clients sur Internet. Les grandes groupes de distribution, de médias et de télécoms ont acheté ou achètent des entreprises de données, de pistage et de technologie publicitaire. Avec le rachat de NBC Universal par Comcast et le rachat probable de Time Warner par AT&T, les grands groupes de télécoms aux États-Unis sont aussi en train de devenir des éditeurs gigantesques, créant par là même des portefeuilles puissants de contenu, de données et de capacité de pistage. Avec l’acquisition de AOL et de Yahoo, Verizon aussi est devenu une « plateforme ».
Les institutions financières ont longtemps utilisé des données sur les consommateurs pour la gestion du risque, notamment dans l’évaluation de la solvabilité et la détection de fraude, ainsi que pour le marketing, l’acquisition et la rétention de clientèle. Elles complètent leurs propres données avec des données externes issues d’agences d’évaluation de la solvabilité, de courtiers en données et d’entreprises de données commerciales. PayPal, l’entreprise de paiements en ligne la plus connue, partage des informations personnelles avec plus de 600 tiers, parmi lesquels d’autres fournisseurs de paiements, des agences d’évaluation de la solvabilité, des entreprises de vérification de l’identité et de détection de la fraude, ainsi qu’avec les acteurs les plus développés au sein de l’écosystème de pistage numérique. Tandis que les réseaux de cartes de crédit et les banques ont partagé des informations financières sur leurs clients avec les fournisseurs de données de risque depuis des dizaines d’années, ils ont maintenant commencé à vendre des données sur les transactions à des fins publicitaires.
Une myriade d’entreprises, grandes ou petites, fournissant des sites Internets, des applications mobiles, des jeux et d’autres solutions sont étroitement liées à l’écosystème de données commerciales. Elles utilisent des services qui leur permettent de facilement transmettre à des services tiers des données concernant leurs utilisateurs. Pour nombre d’entre elles, la vente de flux de données comportementales concernant leurs utilisateurs constitue un élément clé de leur business model. De façon encore plus inquiétante, les entreprises qui fournissent des services tels que les enregistreurs d’activité physique intègrent des services qui transmettent les données utilisateurs à des tierces parties.
L’envahissante machine de surveillance en temps réel qui a été développée pour la publicité en ligne est en train de s’étendre vers d’autres domaines dont la politique, la tarification, la notation des crédits et la gestion des risques. Partout dans le monde, les assureurs commencent à proposer à leurs clients des offres incluant du suivi en temps réel de leur comportement : comment ils conduisent, quelles sont leurs activités santé ou leurs achats alimentaires et quand ils se rendent au club de gym. Des nouveaux venus dans l’analyse assurantielle et les technologies financières prévoient les risques de santé d’un individu en s’appuyant sur les données de consommation, mais évaluent aussi la solvabilité à partir de données de comportement via les appels téléphoniques ou les recherches sur Internet.
Les courtiers en données sur les consommateurs, les entreprises de gestion de clientèle et les agences de publicité comme Acxiom, Epsilon, Merkle ou Wunderman/WPP jouent un rôle prépondérant en assemblant et reliant les données entre les plateformes, les multinationales et le monde de la technologie publicitaire. Les agences d’évaluation de crédit comme Experian qui fournissent de nombreux services dans des domaines très sensibles comme l’évaluation de crédit, la vérification d’identité et la détection de la fraude jouent également un rôle prépondérant dans l’actuel envahissant écosystème de la commercialisation des données.
Des entreprises particulièrement importantes qui fournissent des données, des analyses et des solutions logicielles sont également appelées « plateforme ». Oracle, un fournisseur important de logiciel de base de données est, ces dernières années, devenu un courtier en données de consommation. Salesforce, le leader sur le marché de la gestion de la relation client qui gère les bases de données commerciales de millions de clients qui ont chacun de nombreux clients, a récemment acquis Krux, une grande entreprise de données, connectant et combinant des données venant de l’ensemble du monde numérique. L’entreprise de logiciels Adobe joue également un rôle important dans le domaine des technologies de profilage et de publicité.
En plus, les principales grandes entreprises du conseil, de l’analyse et du logiciel commercial, comme IBM, Informatica, SAS, FICO, Accenture, Capgemini, Deloitte et McKinsey et même des entreprises spécialisées dans le renseignement et la défense comme Palantir, jouent également un rôle significatif dans la gestion et l’analyse des données personnelles, de la gestion de la relation client à celle de l’identité, du marketing à l’analyse de risque pour les assureurs, les banques et les gouvernements.
Vers une société du contrôle social numérique généralisé ?
Ce rapport montre qu’aujourd’hui, les réseaux entre plateformes en ligne, fournisseurs de technologies publicitaires, courtiers en données, et autres peuvent suivre, reconnaître et analyser des individus dans de nombreuses situations de la vie courante. Les informations relatives aux comportements et aux caractéristiques d’un individu sont reliées entre elles, assemblées, et utilisées en temps réel par des entreprises, des bases de données, des plateformes, des appareils et des services. Des acteurs uniquement motivés par des buts économiques ont fait naître un environnement de données dans lequel les individus sont constamment sondés et évalués, catégorisés et regroupés, notés et classés, numérotés et comptés, inclus ou exclus, et finalement traités de façon différente.
Ces dernières années, plusieurs évolutions importantes ont donné de nouvelles capacités sans précédent à la surveillance omniprésente par les entreprises. Cela comprend l’augmentation des médias sociaux et des appareils en réseau, le pistage et la mise en relation en temps réel de flux de données comportementales, le rapprochement des données en ligne et hors ligne, et la consolidation des données commerciales et de gestion des risques. L’envahissant pistage et profilage numériques, mélangé à la personnalisation et aux tests, ne sont pas seulement utilisés pour surveiller, mais aussi pour influencer systématiquement le comportement des gens. Quand les entreprises utilisent les données sur les situations du quotidien pour prendre des décisions parfois triviales, parfois conséquente sur les gens, cela peut conduire à des discriminations, et renforcer voire aggraver des inégalités existantes.
Malgré leur omniprésence, seul le haut de l’iceberg des données et des activités de profilage est visible pour les particuliers. La plupart d’entre elles restent opaques et à peine compréhensible par la majorité des gens. Dans le même temps, les gens ont de moins en moins de solutions pour résister au pouvoir de cet ecosystème de données ; quitter le pistage et le profilage envahissant, est devenu synonyme de quitter la vie moderne. Bien que les responsables des entreprises affirment que la vie privée est morte (tout en prenant soin de préserver leur propre vie privée), Mark Andrejevic suggère que les gens perçoivent en fait l’asymétrie du pouvoir dans le monde numérique actuel, mais se sentent « frustrés par un sentiment d’impuissance face à une collecte et à une exploitation de données de plus en plus sophistiquées et exhaustives. »
Au regard de cela, ce rapport se concentre sur le fonctionnement interne et les pratiques en vigueur dans l’actuelle industrie des données personnelles. Bien que l’image soit devenue plus nette, de larges portions du système restent encore dans le noir. Renforcer la transparence sur le traitement des données par les entreprises reste un prérequis indispensable pour résoudre le problème de l’asymétrie entre les entreprises de données et les individus. Avec un peu de chance, les résultats de ce rapport encourageront des travaux ultérieurs de la part de journalistes, d’universitaires, et d’autres personnes concernés par les libertés civiles, la protection des données et celle des consommateurs ; et dans l’idéal des travaux des législateurs et des entreprises elles-mêmes.
En 1999, Lawrence Lessig, avait bien prédit que, laissé à lui-même, le cyberespace, deviendrait un parfait outil de contrôle façonné principalement par la « main invisible » du marché. Il avait dit qu’il était possible de « construire, concevoir, ou programmer le cyberespace pour protéger les valeurs que nous croyons fondamentales, ou alors de construire, concevoir, ou programmer le cyberespace pour permettre à toutes ces valeurs de disparaître. » De nos jours, la deuxième option est presque devenue réalité au vu des milliards de dollars investis dans le capital-risque pour financer des modèles économiques s’appuyant sur une exploitation massive et sans scrupule des données. L’insuffisance de régulation sur la vie privée aux USA et l’absence de son application en Europe ont réellement gêné l’émergence d’autres modèles d’innovation numérique, qui seraient fait de pratiques, de technologies, de modèles économiques qui protègent la liberté, la démocratie, la justice sociale et la dignité humaine.
À un niveau plus global, la législation sur la protection des données ne pourra pas, à elle seule, atténuer les conséquences qu’un monde « conduit par les données » a sur les individus et la société que ce soit aux USA ou en Europe. Bien que le consentement et le choix soient des principes cruciaux pour résoudre les problèmes les plus urgents liés à la collecte massive de données, ils peuvent également mener à une illusion de volontarisme. En plus d’instruments de régulation supplémentaires sur la non-discrimination, la protection du consommateur, les règles de concurrence, il faudra en général un effort collectif important pour donner une vision positive d’une future société de l’information. Sans quoi, on pourrait se retrouver bientôt dans une société avec un envahissant contrôle social numérique, dans la laquelle la vie privée deviendrait, si elle existe encore, un luxe pour les riches. Tous les éléments en sont déjà en place.
La production de ce rapport, matériaux web et illustrations a été soutenue par Open Society Foundations.
Bibliographie
Christl, W. (2017, juin). Corporate surveillance in everyday life. Cracked Labs.
Christl, W., & Spiekermann, S. (2016). Networks of Control, a Report on Corporate Surveillance, Digital Tracking, Big Data & Privacy (p. 14‑20). Consulté à l’adresse https://www.privacylab.at/wp-content/uploads/2016/09/Christl-Networks__K_o.pdf
Epp, C., Lippold, M., & Mandryk, R. L. (2011). Identifying emotional states using keystroke dynamics (p. 715). ACM Press. https://doi.org/10.1145/1978942.1979046
Kosinski, M., Stillwell, D., & Graepel, T. (2013). Private traits and attributes are predictable from digital records of human behavior. Proceedings of the National Academy of Sciences, 110(15), 5802‑5805. https://doi.org/10.1073/pnas.1218772110
Turow, J. (s. d.). Daily You | Yale University Press. Consulté 25 septembre 2017, à l’adresse https://yalebooks.yale.edu/book/9780300188011/daily-you
Papiray fait du Komascript
Raymond Rochedieu est, depuis des années, un pilier de l’équipe bénévole qui relit et corrige les framabooks. Quand ce perfectionniste a annoncé vouloir s’attaquer à la traduction et l’adaptation d’un ouvrage kolossal, personne ne pouvait imaginer la masse de travail qui l’attendait. Surtout pas lui ! Personnage haut en couleur et riche d’une vie déjà bien remplie, ce papi du Libre nous offre aujourd’hui le fruit d’un travail acharné de plusieurs années. Framabook renoue ainsi le temps d’un précieux ouvrage avec sa tradition de manuels et guides.
Bonjour Raymond, si tu aidais nos lecteurs à faire connaissance avec toi ?
Bonjour, je m’appelle Raymond Rochedieu et depuis une quinzaine d’année, lors de la naissance de mon premier petit fils, tout le monde m’appelle Papiray. Je suis âgé de 72 ans, marié depuis 51 ans, j’ai deux garçons et 6 petits-enfants.
Je suis à la retraite, après avoir exercé des métiers aussi variés que : journaliste sportif vacataire (1959-1963), agent SNCF titulaire (1963-1967), VRP en machines-outils bois Guilliet (1967-1968), éducateur spécialisé (1968-1970, école d’éducateur de Reims), artisan imprimeur en sérigraphie (1970-1979), VRP (Textiles Florimond Peugnet – Cambrai, Éditions Paris-Match, Robert Laffont et Quillet, Laboratoires Messegué, Électro-ménager Vorwerk et Electrolux, Matra-Horlogerie JAZ…), puis ingénieur conseil, directeur commercial, artisan menuisier aluminier, avant de reprendre des études à 52 ans et de passer en 10 mois un BTS d’informaticien de gestion. Malgré les apparences, je ne suis pas instable, seulement curieux, « jusqu’auboutiste » et surtout socialement et individuellement responsable mais (très) indépendant, ce que j’appelle mon « Anarchie Utopiste » (expression qui, comme chacun le sait, vaut de l’or) : je rêve d’un monde où tous seraient responsables et égaux… mais ce n’est qu’un rêve !
J’ai terminé ma carrière professionnelle comme intervenant en informatique, installateur, dépanneur, créateur de sites internet, formateur agréé éducation nationale, chambre de commerces et chambre des métiers et même jury BTS à l’IUT de Reims.
Ton projet de traduction et de Framabook a été une œuvre de longue haleine et aboutit à un ouvrage massif. Comment tout cela a-t-il commencé ? Pourquoi as-tu entamé seul ce gigantesque labeur ?
Je me suis tout d’abord intéressé à l’ouvrage de Vincent Lozano Tout ce que vous avez toujours voulu savoir sur LATEX sans jamais oser le demander (Ou comment utiliser LATEX quand on n’y connaît goutte) auquel j’ai participé, à l’époque, en qualité de correcteur. Mais 2008, c’est aussi, pour moi, une rupture d’anévrisme et 14 jours de coma dont je suis sorti indemne, bien que physiquement diminué.
Puis j’ai enchaîné opération du genou droit, infection nosocomiale, prothèse du genou gauche, phlébite, re-opération pour éviter l’amputation, bref vous comprenez pourquoi j’ai mis du temps pour poursuivre le travail !
J’ai cependant connu quelques moments de bonheur : deux stages de tourneur sur bois, à l’école Jean-François Escoulen d’Aiguines (83630) avec le « Maître » qui m’ont conduit à un premier projet : construire un tour à bois fonctionnant à l’ancienne sans électricité et raconter mon ouvrage, projet toujours d’actualité mais qui s’est fait croquer, l’âge aidant, par l’envie d’écrire mes souvenirs, moins de sport… car même la marche m’est devenue pénible… un refuge, mon bureau… l’ordi…et KOMA-Script…
En réalité, ce n’est pas tout à fait ça. Début 2014, je rencontre une amie qui se plaint de l’utilisation du logiciel Word, inadapté à son besoin actuel : à 72 ans, elle a repris ses études et prépare un doctorat de théologie. Chapeau, Françoise… elle a aujourd’hui 75 ans et elle est, je crois, en dernière année…
Je cherche donc quels sont les outils utilisés par les « thésards » et les « doctorants », et je découvre LaTeX que l’on dit « créé par les Américains, pour les Américains » et mal adapté à la typographie du reste du monde. J’achète le livre de Maïeul Rouquette et découvre finalement cette perle qu’est KOMA-Script, à travers « Les fiches de Bébert » (voir liste de références plus bas).
Ce qu’il en écrit me donne envie d’aller plus loin dans la connaissance de l’ouvrage de Markus KOHM, mais pour moi, c’est l’horreur : l’original en langue allemande n’existe que dans une traduction en langue anglaise.
Et qu’est-ce qu’y fait, Papiray ? Hein ? Qu’est-ce qu’y fait ?
Ben y contacte Markus Kohm pour lui demander l’autorisation de passer l’ouvrage en langue française et y demande à ses « amis » de Framasoft ce qu’ils en pensent… ou l’inverse… toujours est-il que Markus m’y autorise en date du 19 juillet 2014 et que mes amis de Framasoft me disent « vas-y, fonce », le début d’une aventure commencée en réalité en mai de la même année.
Dans l’absolu, je n’ai pas l’impression d’avoir été réellement seul. La curiosité, la découverte des différents systèmes, les réponses – surtout par Christophe Masutti – aux questions posées, les lectures des multiples articles et ouvrages consacrés au sujet, les tests permanents des codes (dont les résultats n’étaient pas toujours ce que j‘en attendais), les erreurs de compilation non identifiées et dont il me fallait corriger la source…
Et puis, pour tout avouer, je ne savais pas réellement où je mettais les doigts… une fois la machine lancée, fallait bien assurer et assumer…
Tu as travaillé dur pendant longtemps et par-dessus le marché, les passes de révision des bénévoles de Framabook ont été nombreuses et t’ont souvent obligé à reprendre des détails, version après version. Comment tu as vécu ça, tu ne t’es jamais découragé ?
Vu dans l’instance Framapiaf du 26 juillet 2017 à propos de l’utilisation d’une varwidth dans une fbox :
Ce sont surtout les modifications de versions dues à Markus qui m’ont « obligé ».
Comme je l’ai indiqué ci-dessus, j’ai démarré ce travail, en mai 2014, sur la base de la version de l’époque qui a évolué le 16 avril, le 15 septembre, le 3 octobre 2015, avant de devenir la v3.20 en date du 10 mai 2016, la v3.21 le 14 juin puis la v3.22 le 2 janvier 2017, enfin la v3.23 le 13 avril 2017 et chaque fois, pour coller à la réalité, je me suis adapté en intégrant ces modifications.
De plus, Markus Kohm a multiplié des extensions et additifs publiés sur internet et j’ai décidé de les intégrer dans la version française de l’ouvrage. KOMA-Script est bien entendu le noyau, mais LaTeX, le système d’encodage abordé, m’était totalement inconnu. Je me suis inspiré, pour le découvrir à travers XƎLATEX, des ouvrages suivants qu’il m’a fallu ingérer, sinon comprendre :
le site Renouvo, réseau pour la nouvelle orthographe du français qui diffuse l’information sur les rectifications orthographiques proposées et recommandées par les instances francophones compétentes (entre autres, l’Académie française et « les » Conseil supérieur de la langue française) ;
Et j’ai navigué au hasard de mes hésitations (merci Mozilla), sur de nombreux sites que je n’ai pas cités dans mes références.
Que leurs auteurs et animateurs ne m’en tiennent pas rigueur.
Tu es donc passionné de LaTeX ? Pourquoi donc, quels avantages présente ce langage ?
LaTeX — prononcer « latèk » ou « latèr » comme avec le « j » espagnol de « rota » ou le « ch » allemand de « maren » (machen), selon votre goût — est un langage de description de document, permettant de créer des écrits de grande qualité : livres, articles, mémoires, thèses, présentations projetées…
On peut considérer LaTeX comme un collaborateur spécialisé dans la mise en forme du travail en typographie tandis que l’auteur se consacre au contenu. La fameuse séparation de la forme et du fond : chacun sa spécialité !
Et ce KOMA-Script c’est quoi au juste par rapport à LaTeX ?
LaTeX a été écrit par des Américains pour des Américains. Pour pouvoir l’utiliser convenablement il nous faut charger des paqs qui permettent de l’adapter à notre langue car les formats de papiers américains et européens sont très différents et les mises en page par défaut de LaTeX ne sont adaptées ni à notre format a4, ni à notre typographie.
L’utilisation de KOMA-Script, outil universel d’écriture, permet de gérer la mise en page d’un ensemble de classes et de paqs polyvalents adaptés, grâce au paq babel, à de multiples langues et pratiques d’écriture, dont le français. Le paq KOMA-Script fonctionne avec XƎLATEX, il fournit des remplacements pour les classes LaTeX et met l’accent sur la typographie.
Les classes KOMA-Script permettent la gestion des articles, livres, documents, lettres, rapports et intègrent de nombreux paqs faciles à identifier : toutes et tous commencent par les trois lettres scr : scrbook, scrartcl, scrextend, scrlayer…
Tous ces paqs peuvent être utilisés non seulement avec les classes KOMA-Script, mais aussi avec les classes LaTeX standard et chaque paq a son propre numéro de version.
Donc ça peut être un ouvrage très utile, mais quel est le public visé particulièrement ?
j’ai envie de répondre tout le monde, même si, apparemment, ce système évolué s’adresse d’avantage aux étudiants investis dans des études supérieures en sciences dites « humaines » (Géographie, Histoire, Information et communication, Philosophie, Psychologie, Sciences du langage, Sociologie, Théologie…) et préparant un DUT, une licence, une thèse et même un doctorat plutôt qu’aux utilisateurs des sciences « exactes » qui peuvent être néanmoins traitées.
En réalité, je le pense aussi destiné aux utilisateurs basiques de MSWord, LibreOffice ou de logiciels équivalents de traitement de texte, amoureux de la belle écriture, respectueux des règles typographiques utilisées dans leur pays, désireux de se libérer des carcans plus ou moins imposés par la culture anglo-saxonne, même s’il n’est pas évident, au départ, d’abandonner son logiciel wysiwyg pour migrer vers d’autres habitudes liées à la séparation du fond et de la forme.
Est-ce que tu as d’autres projets pour faire partager des savoirs et savoir-faire à nos amis libristes ?
Oui, dans le même genre, j’ai sous le coude un ouvrage intitulé « Utiliser XƎLATEX c’est facile, même pour le 3e âge » écrit avec la complicité de Paul Bartholdi et Denis Mégevand, tous deux retraités de l’université de Genève, l’Unige. Ces derniers sont les co-auteurs, en octobre 2005, d’un didacticiel destiné à leurs étudiants « Débuter avec LaTeX » simple, clair, plutôt bien écrit et dont je m’inspire, avec leurs autorisations, pour composer la trame de mon ouvrage qui sera enrichi (l’original compte 98 pages) et portera – comme son titre le laisse supposer – sur l’usage de XƎLATEX, incluant des développements et surtout des exemples de codes détaillés et commentés de diverses applications (mon objectif est de me limiter à 400 pages), mais ne le répétez pas…
La notion de commun semble recouvrir aujourd’hui un (trop) large éventail de significations, ce qui sans doute rend confus son usage. Cet article vous propose d’examiner à quelles conditions on peut considérer les logiciels libres comme des communs.
Nous vous proposons aujourd’hui la republication d’un article bien documenté qui a pu vous échapper au moment de sa publication en juin dernier et qui analyse les diverses dimensions de la notion de Communs lorsqu’on l’associe aux logiciels libres. Nous remercions Emmanuelle Helly pour la qualité de son travail : outre le nombre important de liens vers des ressources théoriques et des exemples concrets, son texte a le mérite de montrer que les nuances sont nombreuses et notamment que la notion de gouvernance communautaire est aussi indispensable que les 4 libertés que nous nous plaisons à réciter…
Qu’est-ce qu’un « Commun » ?
Par Emmanuelle Helly
Article publié initialement le 19/06/2017 sur cette page du site de Makina Corpus Contributeurs : Merci à Enguerran Colson, Éric Bréhault, Bastien Guerry, Lionel Maurel et draft pour la relecture et les suggestions d’amélioration. Licence CC-By-SA-3.0
On parle de commun dans le cas d’un système qui se veut le plus ouvert possible avec au centre une ou plusieurs ressources partagées, gérées collectivement par une communauté, celle-ci établit des règles et une gouvernance dans le but de préserver et pérenniser cette ressource.
Cette notion de res communis existe en réalité depuis les Romains, et a perduré en occident durant le Moyen Âge, avec par exemple la gestion commune des forêts, et dans le reste du monde avant sa colonisation par les Européens. Mais depuis la fin du 18e siècle dans nos sociétés occidentales, la révolution industrielle et avec elle la diffusion du mode de production capitaliste dans toutes les couches de la société ont imposé une dichotomie dans la notion de propriété : un bien appartient soit à l’État, soit au privé.
La théorie de la tragédie des communs par Garett Hardin en 1968, selon laquelle les humains sont incapables de gérer une ressource collectivement sans la détruire, contribue à mettre le concept des communs en sommeil pendant un moment dans nos sociétés occidentales.
En réponse Elinor Ostrom, prix Nobel d’économie en 2009, explique que les ressources qui sont mentionnées dans la «tragédie des communs» ne sont pas des biens communs, mais des biens non gérés. Grâce aux travaux qu’elle mène par la suite avec Vincent Ostrom, les communs redeviennent une voie concrète pour gérer collectivement une ressource, entre l’État et le privé. En France et ailleurs on met en avant ces pratiques de gestion de communs, les recherches universitaires en sciences humaines et sociales sur le sujet sont en augmentation, et même la ville de Gand en Belgique fait appel à un économiste spécialiste pour recenser les communs de son territoire.
On peut distinguer en simplifiant trois types de ressources pouvant être gérées en commun :
les ressources naturelles (une réserve de pêche ou une forêt) ;
les ressources matérielles (un hackerspace ou un fablab) ;
les ressources immatérielles (l’encyclopédie Wikipédia, ou encore OpenStreetMap).
Le logiciel libre, et plus largement les projets libres tels que Wikipédia, est une ressource immatérielle, mais peut-on dire que c’est un commun au sens défini plus haut ? Qu’en est-il de sa gestion, de la communauté qui le maintient et l’utilise, des règles que cette communauté a élaborées pour le développer et partager ?
Outre le fait que la ressource est partagée d’une manière ou d’une autre, les règles appliquées doivent être décidées par l’ensemble de la communauté gérant le logiciel, et l’un des objectifs de la communauté est la pérennité de cette ressource.
Une ressource partagée
Richard Stallman
Un logiciel libre est basé sur quatre libertés fondamentales, qui sont :
la liberté de l’utiliser,
de l’étudier,
de le copier,
de redistribuer des versions modifiées de ce logiciel.
Ces règles constituent la base des licences libres, elles ont été établies par Richard Stallmann en 1983, et la Free Software Foundation est l’organisation qui promeut et défend ces libertés. D’autres licences sont basées sur ces 4 libertés comme les licences Creative Commons, ou encore l’Open Database Licence (ODbL), qui peuvent s’appliquer aux ressources immatérielles autres que les logiciels.
On peut évoquer le partage sous la même licence (partage à l’identique, ou copyleft) qui garantit que le logiciel modifié sera sous la même licence.
Un logiciel peut être placé sous une telle licence dès le début de sa conception, comme le CMS Drupal, ou bien être « libéré » par les membres de sa communauté, comme l’a été le logiciel de création 3D Blender.
Si un changement dans les règles de partage intervient, il peut être décidé par les membres de la communauté, développeurs, voire tous les contributeurs. Par exemple avant qu’OpenStreetMap ne décide d’utiliser la licence ODbL, la discussion a pris environ quatre ans, puis chaque contributeur était sollicité pour entériner cette décision en validant les nouvelles conditions d’utilisation et de contribution.
Mais ça n’est pas systématique, on peut évoquer pour certains projets libres la personnalisation de leur créateur de certains projets libres, « dictateur bienveillant » comme Guido Van Rossum, créateur et leader du projet python ou « monarque constitutionnel » comme Jimy Wales fondateur de Wikipédia. Même si dans les faits les contributeurs ont leur mot à dire il arrive souvent que des tensions au sein de la communauté ou des luttes de pouvoir mettent en péril la pérennité du projet. Les questions de communauté et de gouvernance se posent donc assez rapidement.
La gouvernance du logiciel libre
Les quatre libertés décrivent la façon dont le logiciel est partagé, et garantissent que la ressource est disponible pour les utilisateurs. Mais si les choix inhérents à son développement tels que la roadmap (feuille de route), les conventions de codage, les choix technologiques ne sont le fait que d’une personne ou une société, ce logiciel peut-il être considéré comme un commun ? Qu’est-ce qui peut permettre à une communauté d’utilisatrices / contributeurs d’influer sur ces choix ?
Dans La Cathédrale et le Bazar, Eric S. Raymond décrit le modèle de gouvernance du bazar, tendant vers l’auto-gestion, en opposition avec celui de la cathédrale, plus hiérarchisée.
À travers le développement de Fetchmail qu’il a géré pendant un moment, il met en avant quelques bonnes pratiques faisant d’un logiciel libre un bon logiciel.
Un certain nombre d’entre elles sont très orientées vers la communauté :
6. Traiter ses utilisateurs en tant que co-développeurs est le chemin le moins semé d’embûches vers une amélioration rapide du code et un débogage efficace. » ;
ou encore
10. Si vous traitez vos bêta-testeurs comme ce que vous avez de plus cher au monde, ils réagiront en devenant effectivement ce que vous avez de plus cher au monde. » ;
et
11. Il est presque aussi important de savoir reconnaître les bonnes idées de vos utilisateurs que d’avoir de bonnes idées vous-même. C’est même préférable, parfois. ».
Du point de vue d’Eric Raymond, le succès rencontré par Fetchmail tient notamment au fait qu’il a su prendre soin des membres de la communauté autant que du code du logiciel lui-même.
D’autres projets libres sont remarquables du point de vue de l’attention apportée à la communauté, et de l’importance de mettre en place une gouvernance permettant d’attirer et d’impliquer les contributeurs.
Le projet Debian fondé en 1993 en est un des exemples les plus étudiés par des sociologues tels que Gabriela Coleman ou Nicolas Auray. Décédé en 2015, son créateur Ian Murdock a amené une culture de la réciprocité et un cadre permettant une large contribution tout en conservant un haut niveau de qualité, comme le rappelle Gabriela Coleman dans ce billet hommage.
A contrario, il existe des exemples de logiciels dont le code source est bien ouvert, mais dans lesquels subsistent plusieurs freins à la contribution et à l’implication dans les décisions : difficile de dire s’ils sont vraiment gérés comme des communs.
Bien souvent, si un trop grand nombre de demandes provenant de contributeurs n’ont pas été satisfaites, si de nouvelles règles plus contraignantes sont imposées aux développeurs, un fork est créé, une partie des contributeurs rejoignent la communauté nouvellement créée autour du clone. Cela a été le cas pour LibreOffice peu après le rachat de Sun par Oracle, ou la création de Nextcloud par le fondateur de Owncloud en 2016, qui a mené à la fermeture de la filiale américaine de Owncloud.
Du logiciel libre au commun
Il est donc difficile de dire qu’un logiciel libre est systématiquement un commun à part entière. La licence régissant sa diffusion et sa réutilisation ne suffit pas, il faut également que le mode de gouvernance implique l’ensemble de la communauté contribuant à ce logiciel dans les décisions à son sujet.
1/ délimitation claire de l’objet de la communauté et de ses membres
2/ cohérence entre les règles relatives à la ressource commune et la nature de cette ressource
Nous l’avons vu la définition de « communauté » pose question : celle qui réunit les développeurs, les contributeurs ou la communauté élargie aux utilisateurs ? Existe-t’il une différence entre les contributeurs qui sont rémunérés et les bénévoles ? Les règles varient-elles selon la taille des logiciels ou projets libres ?
De même sur la « ressource » plusieurs questions peuvent se poser : qu’est-ce qui est possible de contribuer, et par qui ? Les règles de contribution peuvent être différentes pour le cœur d’un logiciel et pour ses modules complémentaires, c’est le cas bien souvent pour les CMS (Drupal, Plone et WordPress ne font pas exception).
La question prend son importance dans les processus de décision, décrits par le troisième principe :
3/ un système permettant aux individus de participer à la définition et à la modification des règles
Dans certains cas en effet, seule une portion des membres les plus actifs de la communauté seront consultés pour la mise à jour des règles, et pour d’autres tous les membres seront concernés : c’est un équilibre difficile à trouver.
On peut aussi mettre dans la balance la ou les entités parties prenantes dans le développement du logiciel libre : si c’est une seule entreprise derrière la fondation, elle peut du jour au lendemain faire des choix contraires aux souhaits des utilisateurs, comme dans le cas de Owncloud.
4/ des moyens de supervision du respect de ces règles par des membres de la communauté
5/ un système gradué de sanction pour des appropriations de ressources qui violent les règles de la communauté
On peut citer pour l’application de ces deux principes le fonctionnement de modération a posteriori des pages Wikipédia, des moyens de monitoring sont en place pour suivre les modifications, et certains membres ont le pouvoir de figer des pages en cas de guerre d’édition par exemple.
6/ un système peu coûteux de résolution des conflits
C’est peut-être l’un des principes les plus complexes à mettre en place pour des communautés dispersées dans le monde. Un forum ou une liste de discussion regroupant la communauté est très rapide d’accès, mais ne sont pas toujours pertinents pour la résolution de conflits. Parfois des moyens de communication plus directs sont nécessaires, il serait intéressant d’étudier les moyens mis en place par les communautés.
7/ la reconnaissance par les institutions extérieures de cette auto-organisation
Les 4 libertés d’un logiciel libre sont reconnues dans le droit français, c’est un point important. On peut également relever les diverses formes juridiques prises par les structures qui gèrent le développement de projets libres. Les projets soutenus par la Free Software Foundation (FSF) ont la possibilité de s’appuyer sur l’assistance juridique de la Fondation.
8/ Dans le cas de ressources communes étendues, une organisation à plusieurs niveaux, avec pour base les ressources communes au niveau local.
Rares sont les projets libres qui sont exclusivement développés localement, ce dernier principe est donc important puisque les communautés sont dispersées géographiquement. Des grands projets tels que Debian ou Wikimedia se dotent d’instances plus locales au niveau des pays ou de zones plus restreintes, permettant aux membres de se rencontrer plus facilement.
Au niveau fonctionnel il peut également se créer des groupes spécialisés dans un domaine particulier comme la traduction ou la documentation, ou encore une délégation peut être mise en œuvre.
Conclusion
On se rend bien compte que les 4 libertés, bien que suffisantes pour assurer le partage et la réutilisation d’un logiciel libre, ne garantissent pas que la communauté des contributrices ou d’utilisateurs soit partie prenante de la gouvernance.
Les bonnes pratiques décrites par Eric S. Raymond sont une bonne approche pour assurer le succès d’un projet libre, de même que les principes de gestion de ressources communes d’Elinor Ostrom. Il serait intéressant d’étudier plus précisément les communautés gérant des logiciels libres au prisme de ces deux approches.
« Le système des paquets n’a pas été conçu pour gérer les logiciels mais pour faciliter la collaboration » – Ian Murdock (1973-2015)
Pour creuser la question des communs, n’hésitez pas à visiter le site les communs et le blog Les Communs d’Abord, ainsi que la communauthèque qui recense de nombreux livres et articles livres sur le sujet. En anglais vous trouverez beaucoup d’information sur le site de la P2P Foundation initié par l’économiste Michel Bauwens.






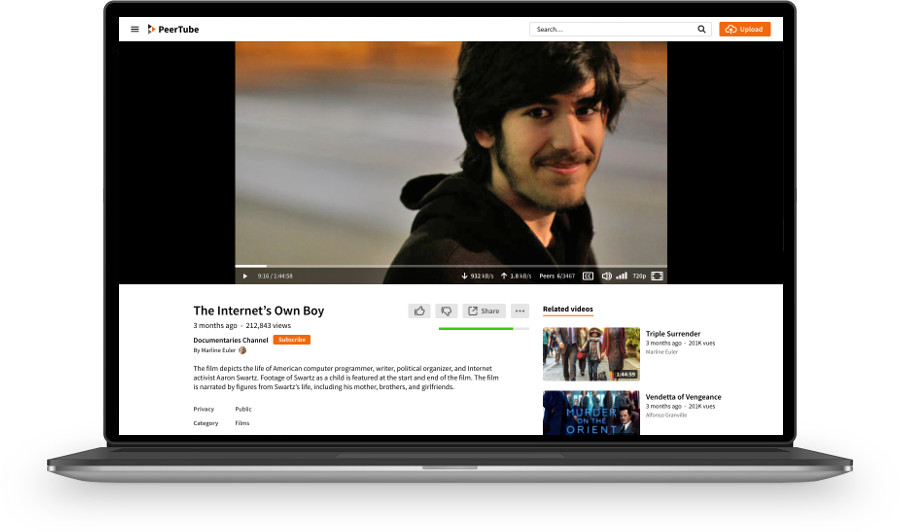

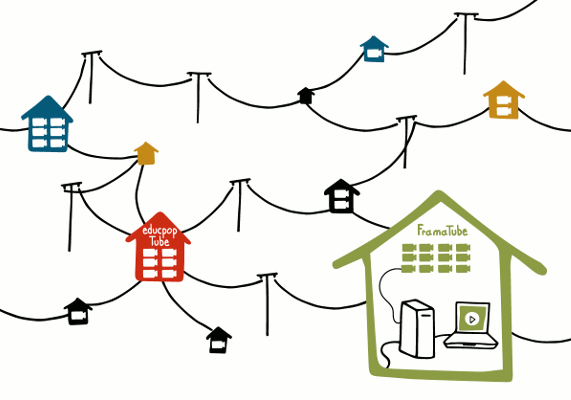
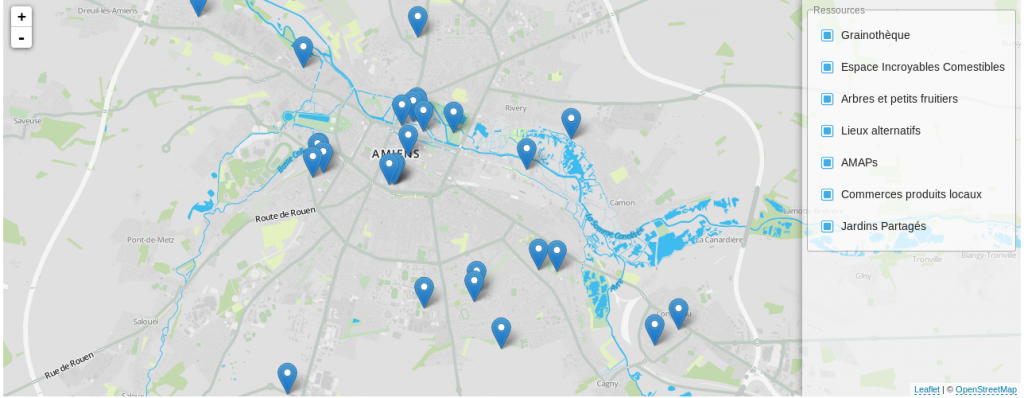









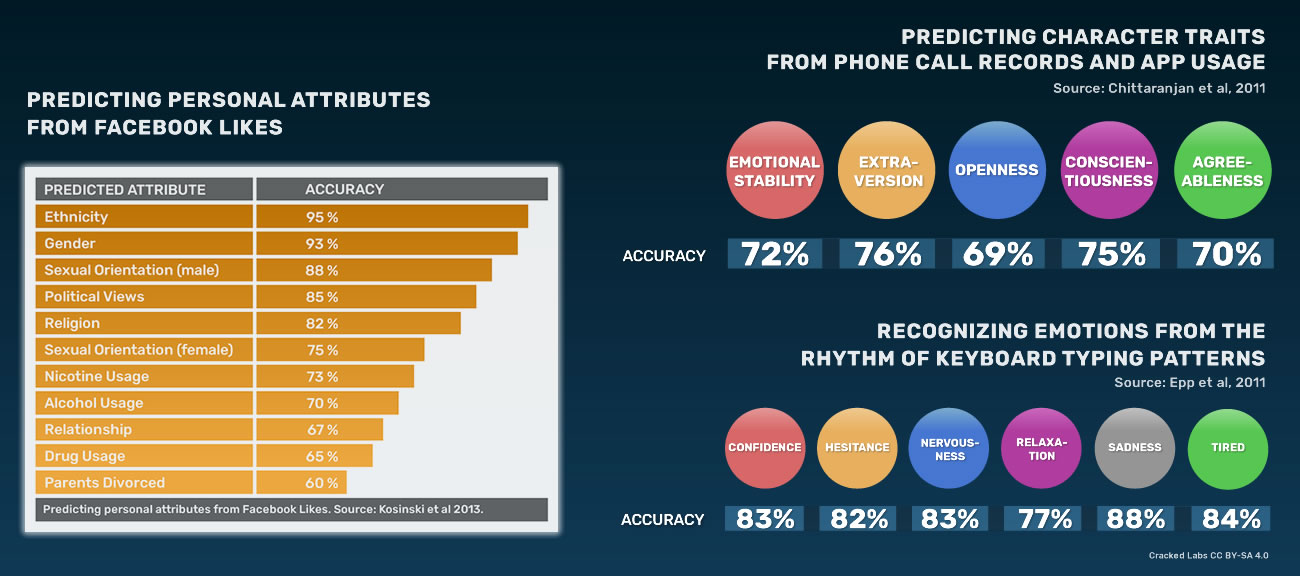
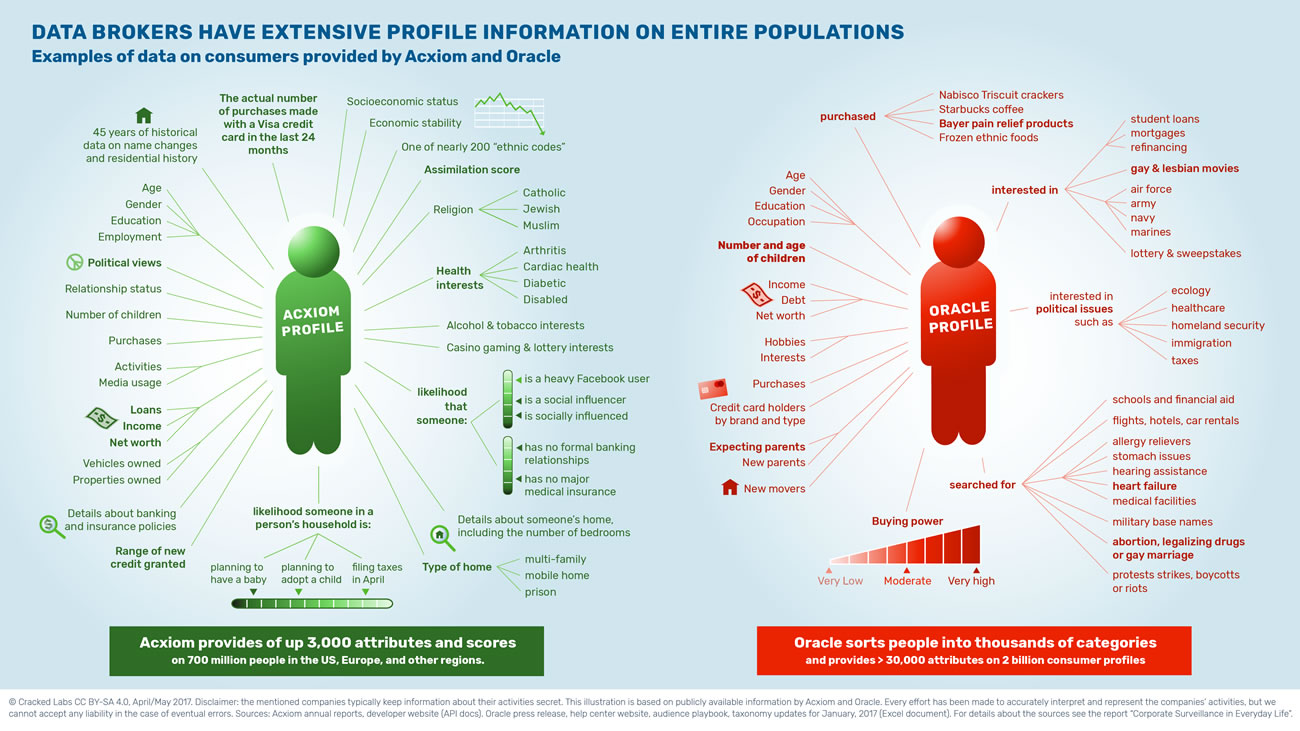
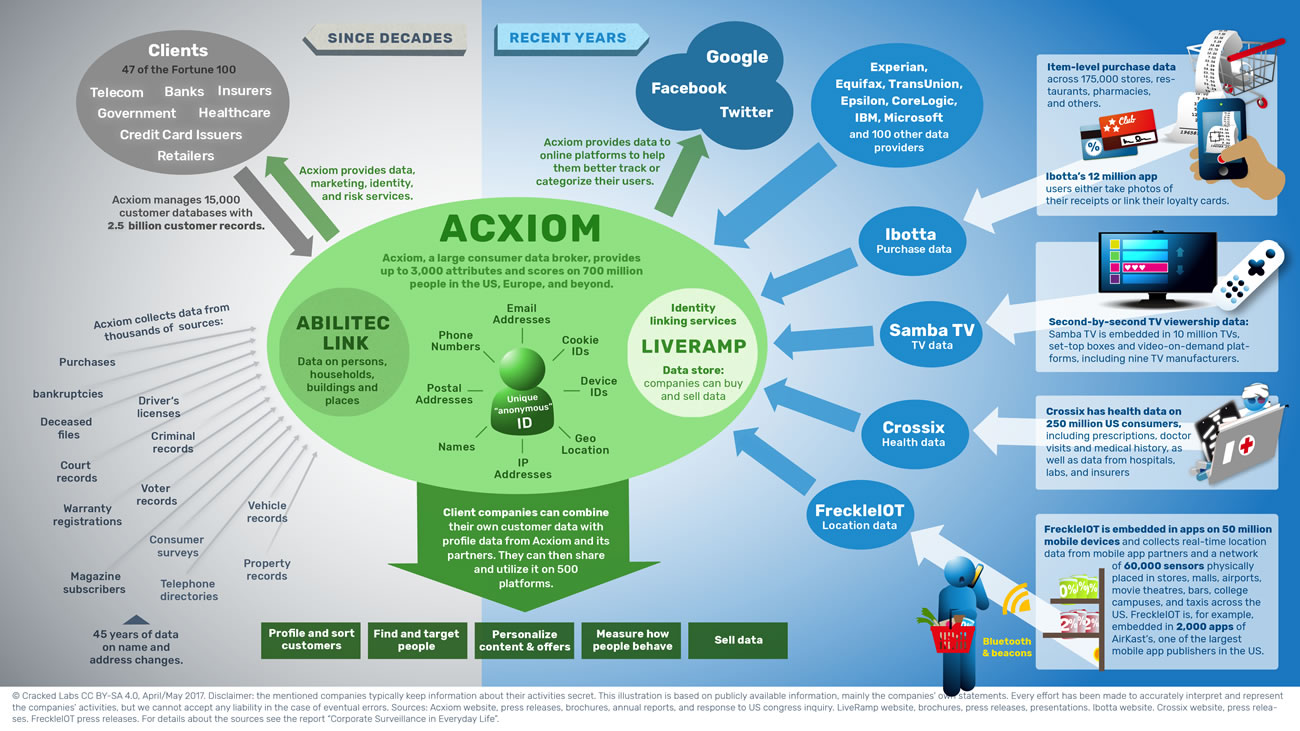
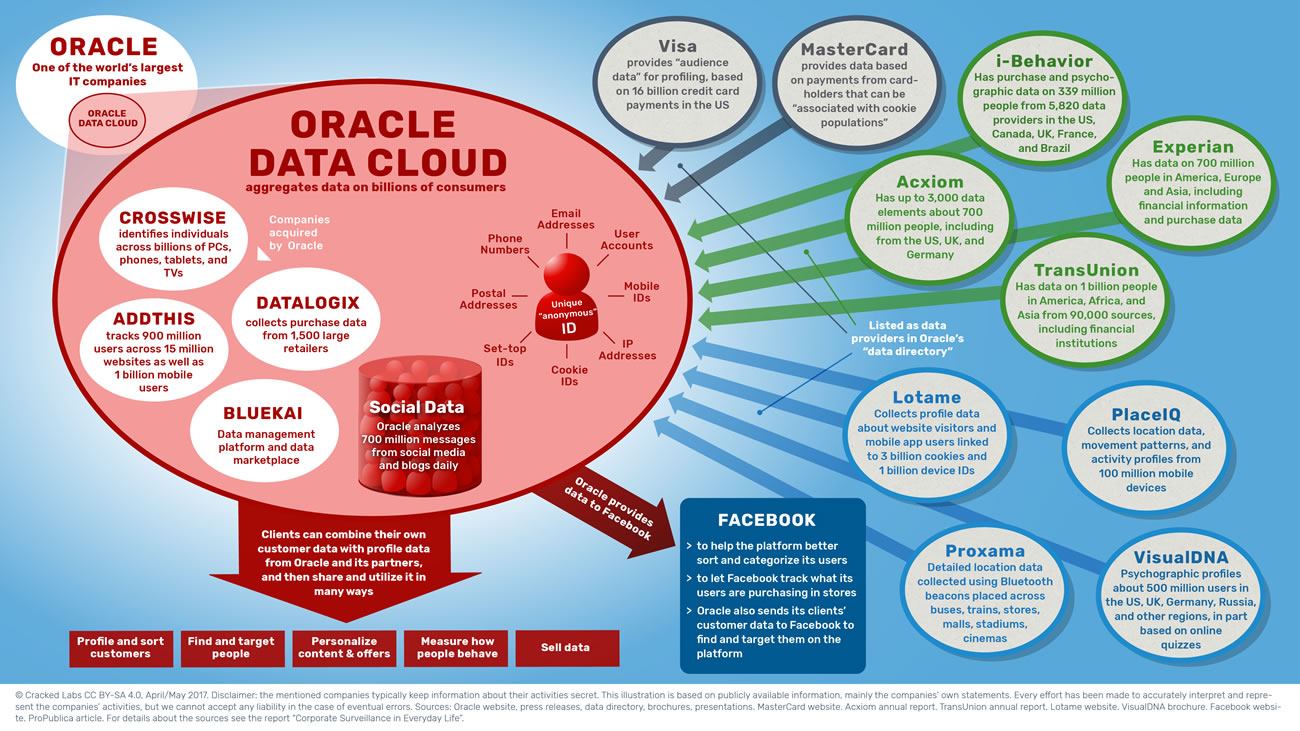
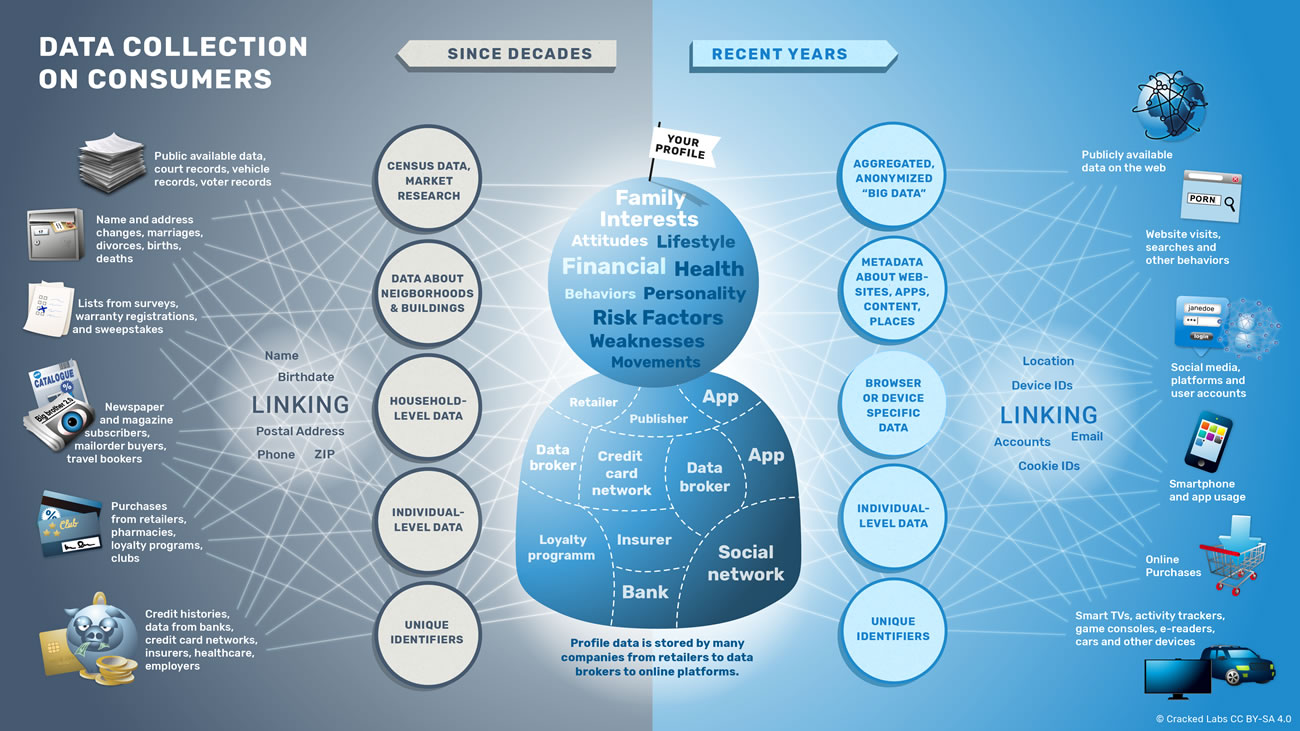

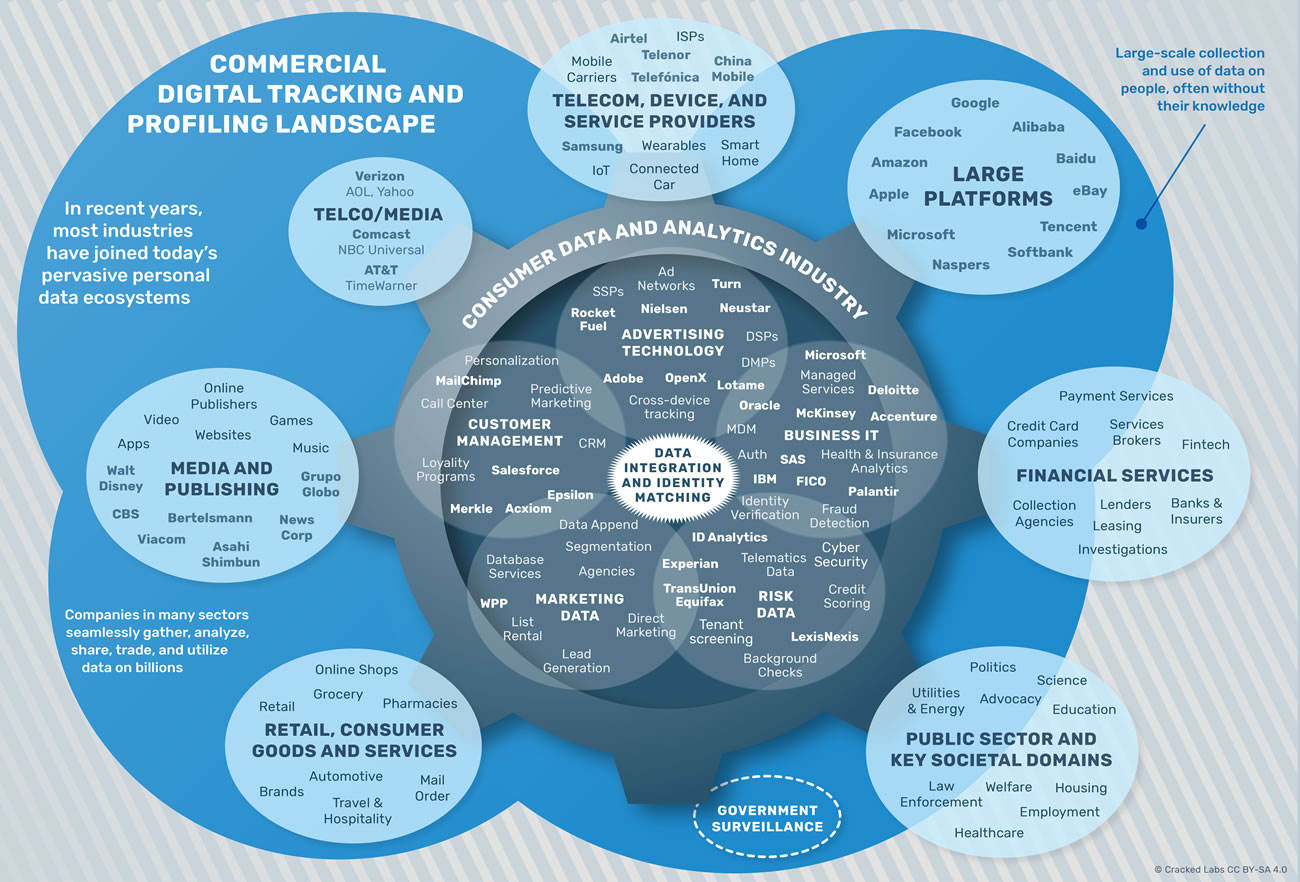
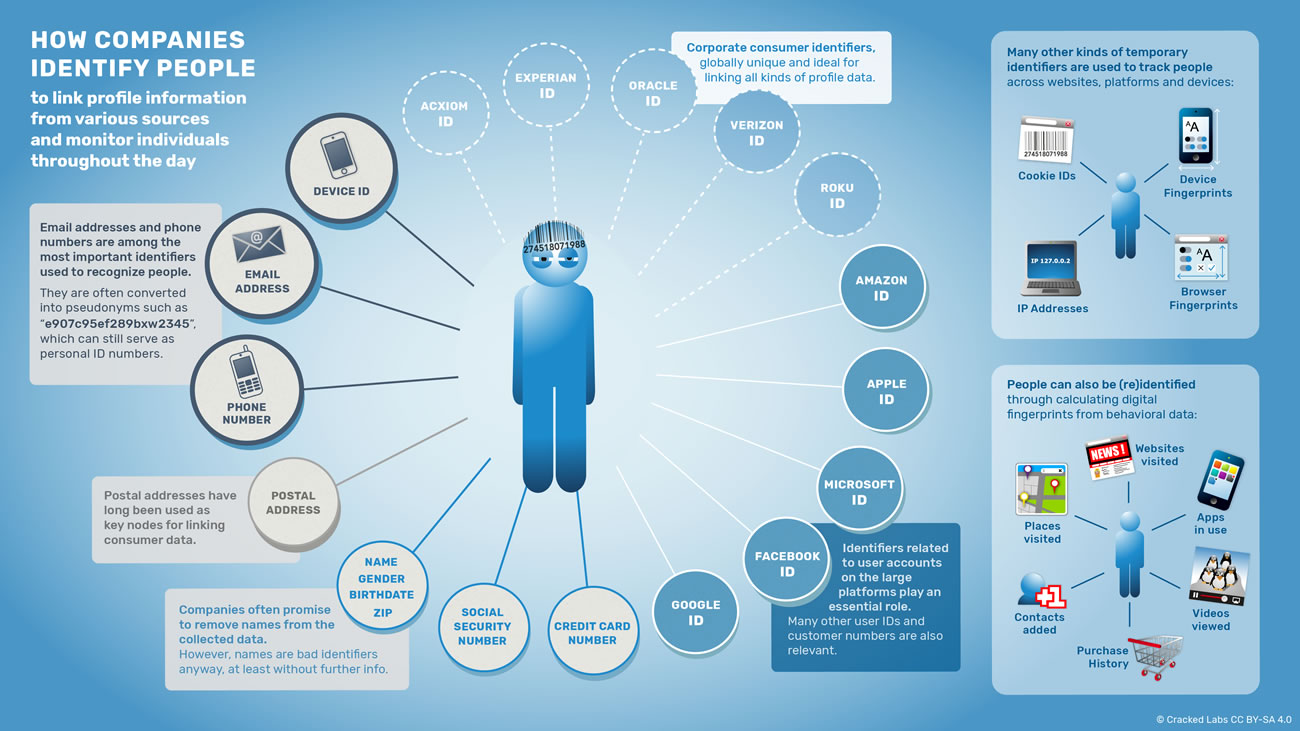
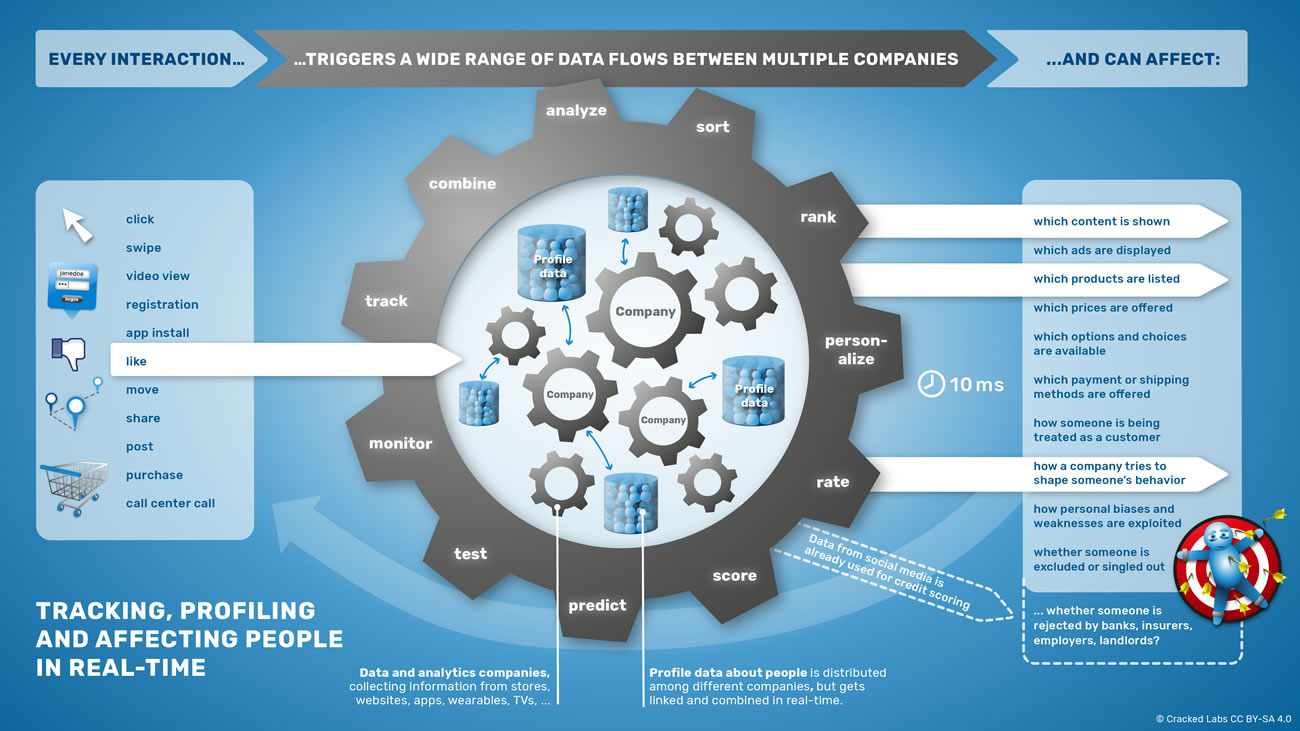
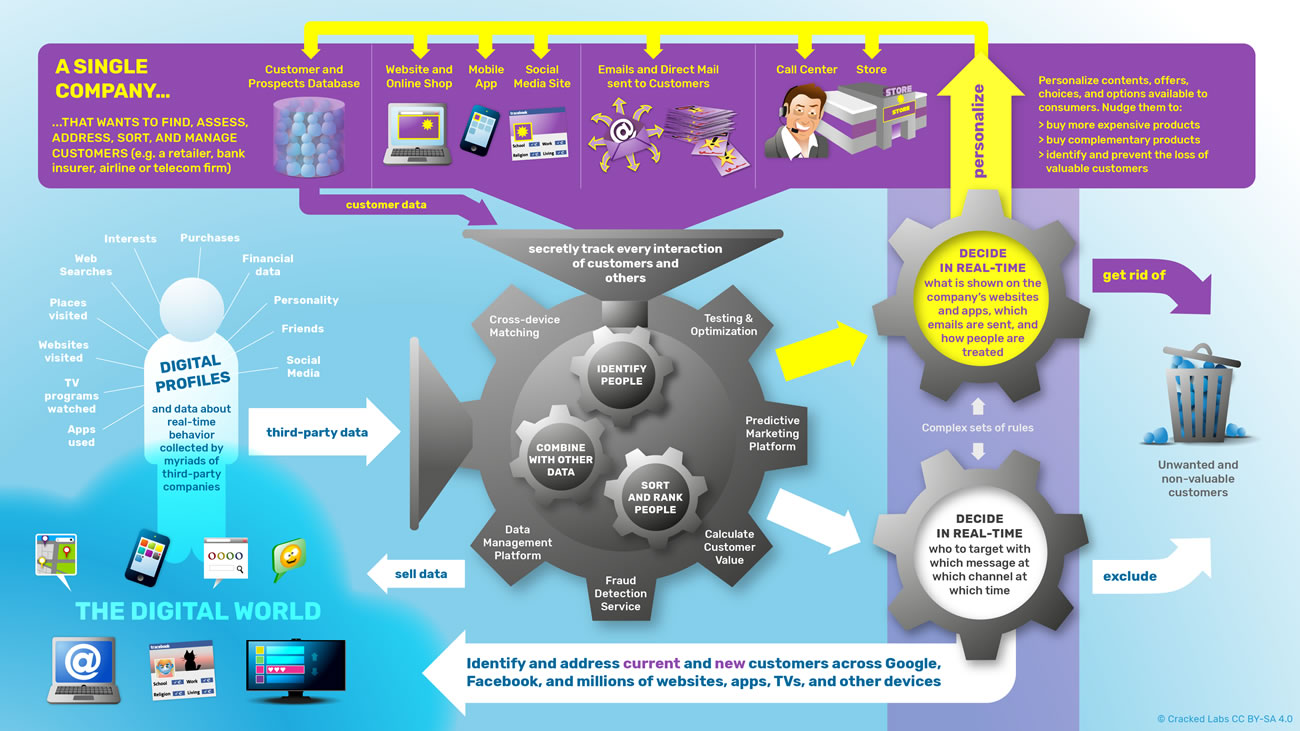
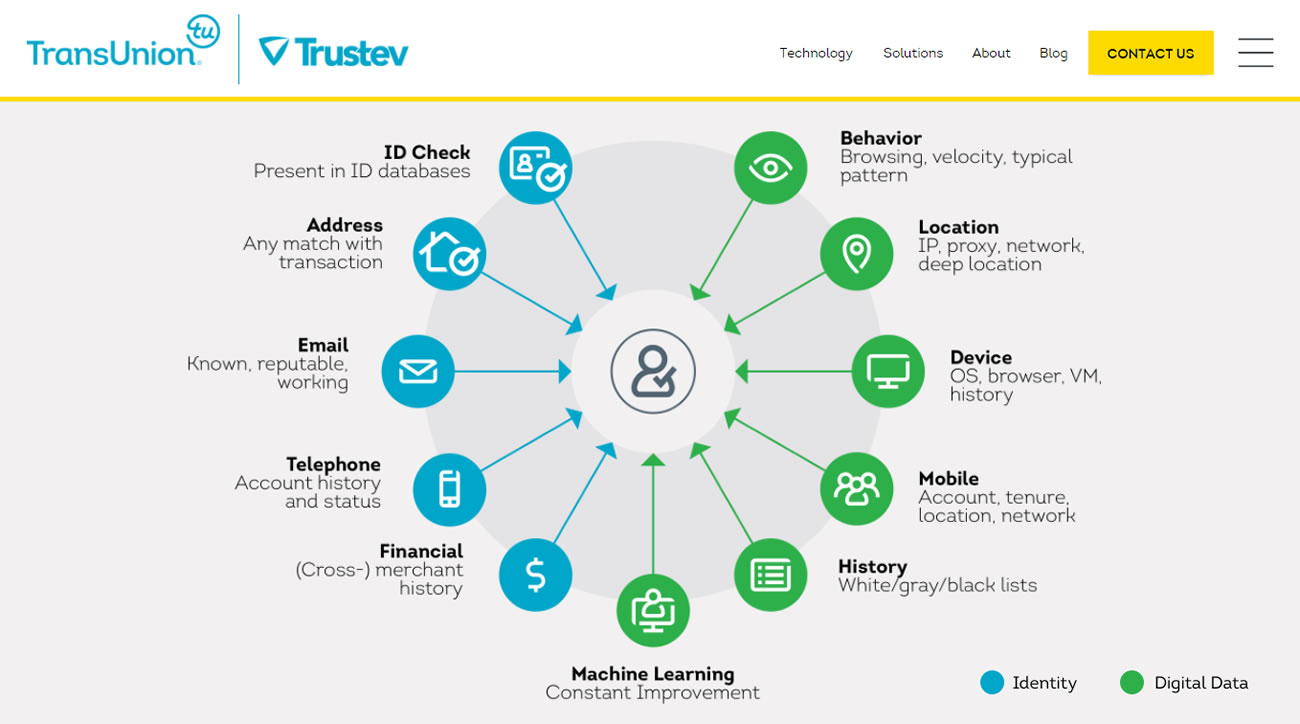
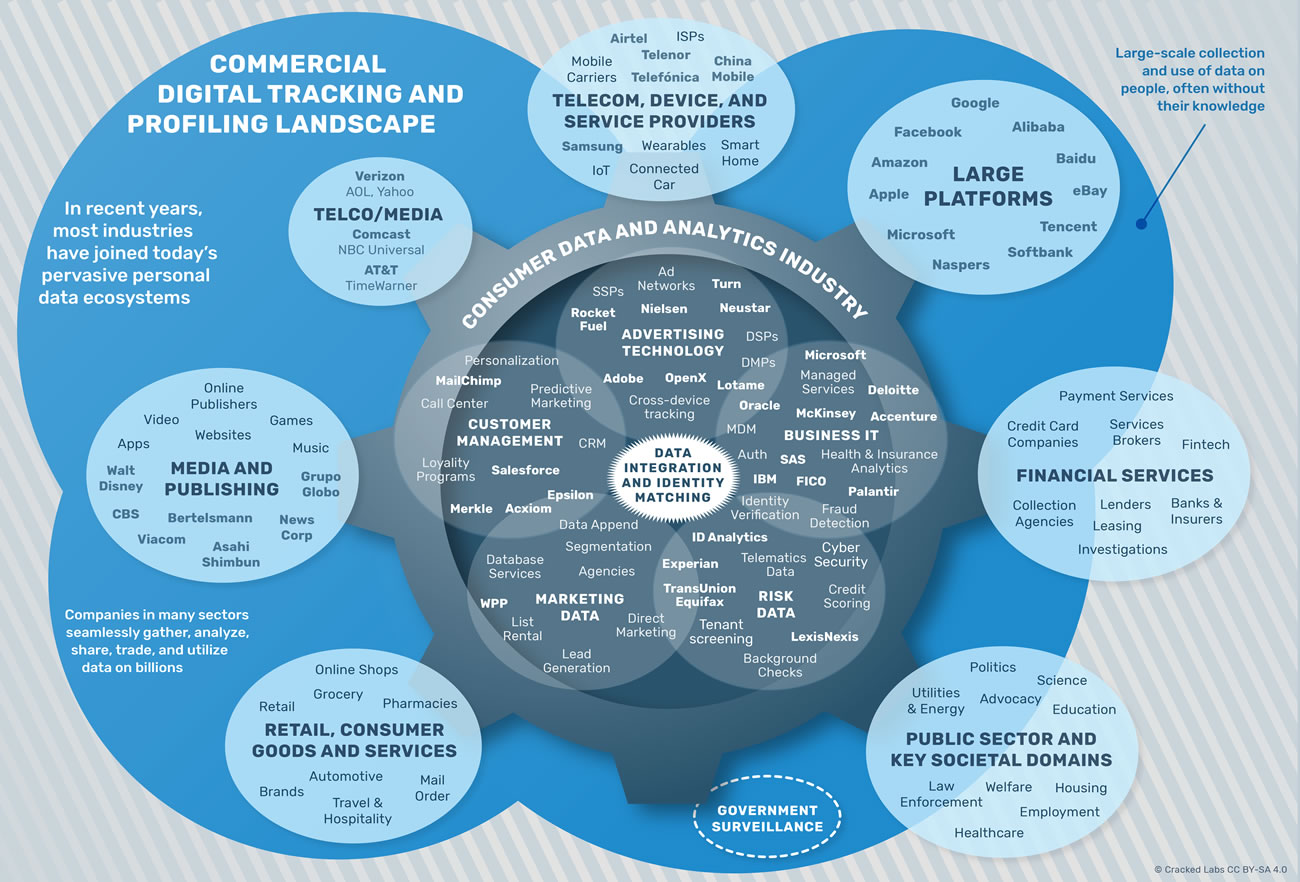

 Bonjour, je m’appelle Raymond Rochedieu et depuis une quinzaine d’année, lors de la naissance de mon premier petit fils, tout le monde m’appelle Papiray. Je suis âgé de 72 ans, marié depuis 51 ans, j’ai deux garçons et 6 petits-enfants.
Bonjour, je m’appelle Raymond Rochedieu et depuis une quinzaine d’année, lors de la naissance de mon premier petit fils, tout le monde m’appelle Papiray. Je suis âgé de 72 ans, marié depuis 51 ans, j’ai deux garçons et 6 petits-enfants.






{kind=link}