Les nouveaux Léviathans II — Surveillance et confiance (b)
Qu’est-ce qui fait courir Framasoft ? De la campagne Dégooglisons à l’initiative C.H.A.T.O.N.S quelles idées ont en tête les acteurs et soutiens de l’association ? Vous reprendrez bien une tranche de Léviathan ?
Pour vous inviter à aller au-delà des apparences (la sympathique petite tribu d’amateurs gaulois qui veut modestement mettre son grain de sable dans la loi des entreprises hégémoniques) nous vous proposons non seulement un moment de réflexion, mais pour une fois une série de considérations nourries, argumentées et documentées sur l’état de bascule que nous vivons et dans lequel nous prétendons inscrire notre action avec vous.
Jamais le logiciel libre et les valeurs qu’il porte n’ont été autant à la croisée des chemins, car il ne s’agit pas de proposer seulement des alternatives techniques, c’est un défi économique et politique qu’il doit relever.
Entre les États qui nous surveillent et les GAFAM qui nous monétisent, jamais le refuge du secret, celui de l’intime, n’a été aussi attaqué ni menacé. Pour représenter le monstre à plusieurs têtes, Christophe Masutti qui est l’auteur de cette série de réflexions, a choisi la figure emblématique du Léviathan, forgée déjà par Hobbes en particulier pour désigner l’État toujours plus avide de domination.
C’est donc une série de Léviathans nouveaux et anciens que nous vous invitons à découvrir par étapes, tout au long de cette semaine, qui vous conduiront peut-être à comprendre et adopter notre démarche. Car une fois établies les sources du mal et posé le diagnostic, que faire ? Les perspectives que nous proposons seront peut-être les vôtres.
(suite de la section précédente)
Note de l’auteur :
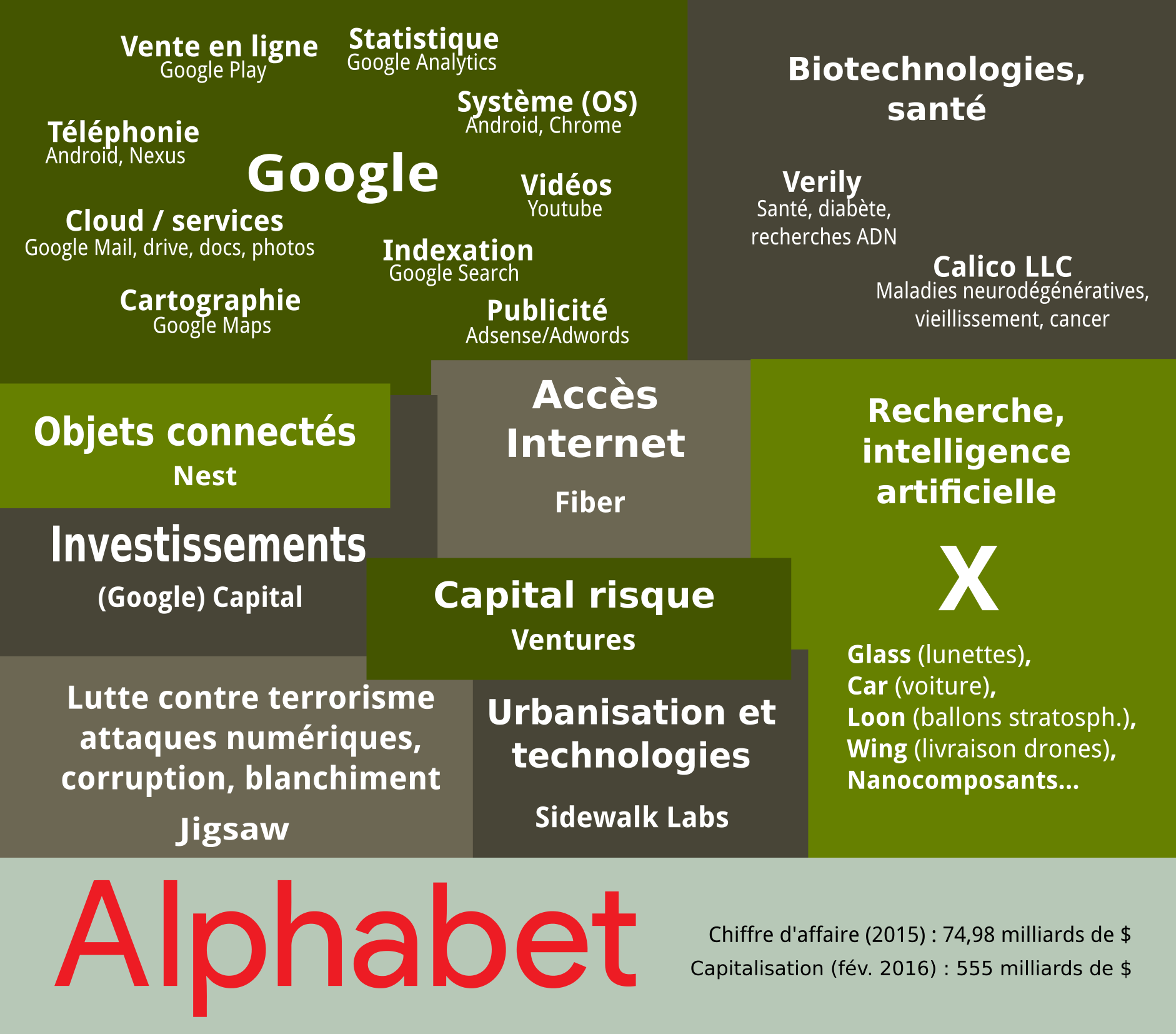
Cette seconde partie (Léviathans II) vise à approfondir les concepts survolés précédemment (Léviathans I). Nous avons vu que les monopoles de l’économie numérique ont changé le paradigme libéral jusqu’à instaurer un capitalisme de surveillance. Pour en rendre compte et comprendre ce nouveau système, il faut brosser plusieurs aspects de nos rapports avec la technologie en général, et les services numériques en particulier, puis voir comment des modèles s’imposent par l’usage des big data et la conformisation du marché (Léviathans IIa). J’expliquerai, à partir de la lecture de S. Zuboff, quelles sont les principales caractéristiques du capitalisme de surveillance. En identifiant ainsi ces nouvelles conditions de l’aliénation des individus, il devient évident que le rétablissement de la confiance aux sources de nos relations contractuelles et démocratiques, passe immanquablement par l’autonomie, le partage et la coopération, sur le modèle du logiciel libre (Léviathans IIb).
Trouver les bonnes clés
Cette logique du marché, doit être analysée avec d’autres outils que ceux de l’économie classique. L’impact de l’informationnalisation et la concentration des acteurs de l’économie numérique ont sans doute été largement sous-estimés, non pas pour les risques qu’ils font courir aux économies post-industrielles, mais pour les bouleversements sociaux qu’ils impliquent. Le besoin de défendre les droits et libertés sur Internet et ailleurs n’est qu’un effet collatéral d’une situation contre laquelle il est difficile d’opposer seulement des postures et des principes.
Il faut entendre les mots de Marc Rotenberg, président de l’Electronic Privacy Information Center (EPIC), pour qui le débat dépasse désormais la seule question de la neutralité du réseau ou de la liberté d’expression1. Pour lui, nous avons besoin d’analyser ce qui structure la concentration du marché. Mais le phénomène de concentration dans tous les services de communication que nous utilisons implique des échelles tellement grandes, que nous avons besoin d’instruments de mesure au moins aussi grands. Nous avons besoin d’une nouvelle science pour comprendre Internet, le numérique et tout ce qui découle des formes d’automatisation.

On s’arrête bien souvent sur l’aspect le plus spectaculaire de la fuite d’environ 1,7 millions de documents grâce à Edward Snowden en 2013, qui montrent que les États, à commencer par les États-Unis, ont créé des systèmes de surveillance de leurs populations au détriment du respect de la vie privée. Pour beaucoup de personnes, cette atteinte doit être ramenée à la dimension individuelle : dois-je avoir quelque chose à cacher ? comment échapper à cette surveillance ? implique-t-elle un contrôle des populations ? un contrôle de l’expression ? en quoi ma liberté est-elle en danger ? etc. Mais peu de personnes se sont réellement interrogées sur le fait que si la NSA s’est fait livrer ces quantités gigantesques d’informations par des fournisseurs de services (comme par exemple, la totalité des données téléphoniques de Verizon ou les données d’échanges de courriels du service Hotmail de Microsoft) c’est parce que ces entreprises avaient effectivement les moyens de les fournir et que par conséquent de telles quantités d’informations sur les populations sont tout à fait exploitables et interprétables en premier lieu par ces mêmes fournisseurs.
Face à cela, plusieurs attitudes sont possibles. En les caricaturant, elles peuvent être :
- Positivistes. On peut toujours s’extasier devant les innovations de Google surtout parce que la culture de l’innovation à la Google est une composante du story telling organisé pour capter l’attention des consommateurs. La communication est non seulement exemplaire mais elle constitue un modèle d’après Google qui en donne même les recettes (cf. les deux liens précédents). Que Google, Apple, Microsoft, Facebook ou Amazon possèdent des données me concernant, cela ne serait qu’un détail car nous avons tous l’opportunité de participer à cette grande aventure du numérique (hum !).
- Défaitistes. On n’y peut rien, il faut donc se contenter de protéger sa vie privée par des moyens plus ou moins dérisoires, comme par exemple faire du bruit pour brouiller les pistes et faire des concessions car c’est le prix à payer pour profiter des applications bien utiles. Cette attitude consiste à échanger l’utilité contre l’information, ce que nous faisons à chaque fois que nous validons les clauses d’utilisation des services GAFAM.
- Complotistes. Les procédés de captation des données servent ceux qui veulent nous espionner. Les utilisations commerciales seraient finalement secondaires car c’est contre l’emploi des données par les États qu’il faut lutter. C’est la logique du moins d’État contre la liberté du nouveau monde numérique, comme si le choix consistait à donner notre confiance soit aux États soit aux GAFAM, liberté par contrat social ou liberté par consommation.
Les objectifs de cette accumulation de données sont effectivement différents que ceux poursuivis par la NSA et ses institutions homologues. La concentration des entreprises crée le besoin crucial d’organiser les monopoles pour conserver un marché stable. Les ententes entre entreprises, repoussant toujours davantage les limites juridiques des autorités de régulations, créent une logique qui ne consiste plus à s’adapter à un marché aléatoire, mais adapter le marché à l’offre en l’analysant en temps réel, en utilisant les données quotidiennes des utilisateurs de services. Il faut donc analyser ce capitalisme de surveillance, ainsi que le nomme Shoshana Zuboff, car comme nous l’avons vu :
- les États ont de moins en moins les capacités de réguler ces activités,
- nous sommes devenus des produits de variables qui configurent nos comportements et nos besoins.
L’ancienne conception libérale du marché, l’acception économique du contrat social, reposait sur l’idée que la démocratie se consolide par l’égalitarisme des acteurs et l’équilibre du marché. Que l’on adhère ou pas à ce point de vue, il reste qu’aujourd’hui le marché ne s’équilibre plus par des mécanismes libéraux mais par la seule volonté de quelques entreprises. Cela pose inévitablement une question démocratique.
Dans son rapport, Antoinette Rouvroy en vient à adresser une série de questions sur les répercutions de cette morphologie du marché. Sans y apporter franchement de réponse, elle en souligne les enjeux :
Ces dispositifs d’« anticipation performative » des intentions d’achat (qui est aussi un court-circuitage du processus de transformation de la pulsion en désir ou en intention énonçable), d’optimisation de la force de travail fondée sur la détection anticipative des performances futures sur base d’indicateurs produits automatiquement au départ d’analyses de type Big Data (qui signifie aussi une chute vertigineuse du « cours de l’expérience » et des mérites individuels sur le marché de l’emploi), posent des questions innombrables. L’anticipation performative des intentions –et les nouvelles possibilités d’actions préemptives fondées sur la détection des intentions – est-elle compatible avec la poursuite de l’autodétermination des personnes ? Ne faut-il pas concevoir que la possibilité d’énoncer par soi-même et pour soi-même ses intentions et motivations constitue un élément essentiel de l’autodétermination des personnes, contre cette utopie, ou cette dystopie, d’une société dispensée de l’épreuve d’un monde hors calcul, d’un monde où les décisions soient autre chose que l’application scrupuleuse de recommandations automatiques, d’un monde où les décisions portent encore la marque d’un engagement subjectif ? Comment déterminer la loyauté de ces pratiques ? L’optimisation de la force de travail fondée sur le profilage numérique est-il compatible avec le principe d’égalité et de non-discrimination ?2
Ce qui est questionné par A. Rouvroy, c’est ce que Zuboff nomme le capitalisme de surveillance, du moins une partie des pratiques qui lui sont inhérentes. Dès lors, au lieu de continuer à se poser des questions, il est important d’intégrer l’idée que si le paradigme a changé, les clés de lecture sont forcément nouvelles.
Déconstruire le capitalisme de surveillance
Shoshana Zuboff a su identifier les pratiques qui déconstruisent l’équilibre originel et créent ce nouveau capitalisme. Elle pose ainsi les jalons de cette nouvelle « science » qu’appelle de ses vœux Marc Rotenberg, et donne des clés de lecture pertinentes. L’essentiel des concepts qu’elle propose se trouve dans son article « Big other: surveillance capitalism and the prospects of an information civilization », paru en 20153. Dans cet article S. Zuboff décortique deux discours de Hal Varian, chef économiste de Google et s’en sert de trame pour identifier et analyser les processus du capitalisme de surveillance. Dans ce qui suit, je vais essayer d’expliquer quelques clés issues du travail de S. Zuboff.
Sur quelle stratégie repose le capitalisme de surveillance ?
Il s’agit de la stratégie de commercialisation de la quotidienneté en modélisant cette dernière en autant de données analysées, inférences et prédictions. La logique d’accumulation, l’automatisation et la dérégulation de l’extraction et du traitement de ces données rendent floues les frontières entre vie privée et consommation, entre les firmes et le public, entre l’intention et l’information.
Qu’est-ce que la quotidienneté ?
Il s’agit de ce qui concerne la sphère individuelle mais appréhendée en réseau. L’informationnalisation de nos profils individuels provient de plusieurs sources. Il peut s’agir des informations conventionnelles (au sens propre) telles que nos données d’identité, nos données bancaires, etc. Elles peuvent résulter de croisements de flux de données et donner lieu à des inférences. Elles peuvent aussi provenir des objets connectés, agissant comme des sensors ou encore résulter des activités de surveillance plus ou moins connues. Si toutes ces données permettent le profilage c’est aussi par elles que nous déterminons notre présence numérique. Avoir une connexion Internet est aujourd’hui reconnu comme un droit : nous ne distinguons plus nos activités d’expression sur Internet des autres activités d’expression. Les activités numériques n’ont plus à être considérées comme des activités virtuelles, distinctes de la réalité. Nos pages Facebook ne sont pas plus virtuelles que notre compte Amazon ou notre dernière déclaration d’impôt en ligne. Si bien que cette activité en réseau est devenue si quotidienne qu’elle génère elle-même de nouveaux comportements et besoins, produisant de nouvelles données analysées, agrégées, commercialisées.
Extraction des données
S. Zuboff dresse un inventaire des types de données, des pratiques d’extraction, et les enjeux de l’analyse. Il faut cependant comprendre qu’il y a de multiples manières de « traiter » les données. La Directive 95/46/CE (Commission Européenne) en dressait un inventaire, déjà en 19954 :
« traitement de données à caractère personnel » (traitement) : toute opération ou ensemble d’opérations effectuées ou non à l’aide de procédés automatisés et appliquées à des données à caractère personnel, telles que la collecte, l’enregistrement, l’organisation, la conservation, l’adaptation ou la modification, l’extraction, la consultation, l’utilisation, la communication par transmission, diffusion ou toute autre forme de mise à disposition, le rapprochement ou l’interconnexion, ainsi que le verrouillage, l’effacement ou la destruction.
Le processus d’extraction de données n’est pas un processus autonome, il ne relève pas de l’initiative isolée d’une ou quelques firmes sur un marché de niche. Il constitue désormais la norme commune à une multitude de firmes, y compris celles qui n’œuvrent pas dans le secteur numérique. Il s’agit d’un modèle de développement qui remplace l’accumulation de capital. Autant cette dernière était, dans un modèle économique révolu, un facteur de production (par les investissements, par exemple), autant l’accumulation de données est désormais la clé de production de capital, lui-même réinvesti en partie dans des solutions d’extraction et d’analyse de données, et non dans des moyens de production, et pour une autre partie dans la valorisation boursière, par exemple pour le rachat d’autres sociétés, à l’image des multiples rachats de Google.
Neutralité et indifférence
Les données qu’exploite Google sont très diverses. On s’interroge généralement sur celles qui concernent les catégories auxquelles nous accordons de l’importance, comme par exemple lorsque nous effectuons une recherche au sujet d’une mauvaise grippe et que Google Now nous propose une consultation médicale à distance. Mais il y a une multitude de données dont nous soupçonnons à peine l’existence, ou apparemment insignifiantes pour soi, mais qui, ramenées à des millions, prennent un sens tout à fait probant pour qui veut les exploiter. On peut citer par exemple le temps de consultation d’un site. Si Google est prêt à signaler des contenus à l’administration des États-Unis, comme l’a dénoncé Julian Assange ou si les relations publiques de la firme montrent une certaine proximité avec les autorités de différents pays et l’impliquent dans des programmes d’espionnage, il reste que cette attitude coopérante relève essentiellement d’une stratégie économique. En réalité, l’accumulation et l’exploitation des données suppose une indifférence formelle par rapport à leur signification pour l’utilisateur. Quelle que soit l’importance que l’on accorde à l’information, le postulat de départ du capitalisme de surveillance, c’est l’accumulation de quantités de données, non leur qualité. Quant au sens, c’est le marché publicitaire qui le produit.
L’extraction et la confiance
S. Zuboff dresse aussi un court inventaire des pratiques d’extraction de Google. L’exemple emblématique est Google Street View, qui rencontra de multiples obstacles à travers le monde : la technique consiste à s’immiscer sur des territoires et capturer autant de données possible jusqu’à rencontrer de la résistance qu’elle soit juridique, politique ou médiatique. Il en fut de même pour l’analyse du courrier électronique sur Gmail, la capture des communications vocales, les paramètres de confidentialité, l’agrégation des données des comptes sur des services comme Google+, la conservation des données de recherche, la géolocalisation des smartphones, la reconnaissance faciale, etc.
En somme, le processus d’extraction est un processus à sens unique, qui ne tient aucun compte (ou le moins possible) de l’avis de l’utilisateur. C’est l’absence de réciprocité.
On peut ajouter à cela la puissance des Big Data dans l’automatisation des relations entre le consommateur et le fournisseur de service. Google Now propose de se substituer à une grande partie de la confidentialité entre médecin et patient en décelant au moins les causes subjectives de la consultation (en interprétant les recherches). Hal Varian lui-même vante les mérites de l’automatisation de la relation entre assureurs et assurés dans un monde où l’on peut couper à distance le démarrage de la voiture si le client n’a pas payé ses traites. Des assurances santé et même des mutuelles (!) proposent aujourd’hui des applications d’auto-mesure (quantified self)de l’activité physique, dont on sait pertinemment que cela résultera sur autant d’ajustements des prix voire des refus d’assurance pour les moins chanceux.
La relation contractuelle est ainsi automatisée, ce qui élimine d’autant le risque lié aux obligations des parties. En d’autres termes, pour éviter qu’une partie ne respecte pas ses obligations, on se passe de la confiance que le contrat est censé formaliser, au profit de l’automatisation de la sanction. Le contrat se résume alors à l’acceptation de cette automatisation. Si l’arbitrage est automatique, plus besoin de recours juridique. Plus besoin de la confiance dont la justice est censée être la mesure.
Entre l’absence de réciprocité et la remise en cause de la relation de confiance dans le contrat passé avec l’utilisateur, ce sont les bases démocratiques de nos rapports sociaux qui sont remises en question puisque le fondement de la loi et de la justice, c’est le contrat et la formalisation de la confiance.

Qu’implique cette nouvelle forme du marché ?
Plus Google a d’utilisateurs, plus il rassemble des données. Plus il y a de données plus leur valeur predictive augmente et optimise le potentiel lucratif. Pour des firmes comme Google, le marché n’est pas composé d’agents rationnels qui choisissent entre plusieurs offres et configurent la concurrence. La société « à la Google » n’est plus fondée sur des relations de réciprocité, même s’il s’agit de luttes sociales ou de revendications.
L’« uberisation » de la société (voir le début de cet article) qui nous transforme tous en employés ou la transformation des citoyens en purs consommateurs, c’est exactement le cauchemar d’Hannah Arendt que S. Zuboff cite longuement :
Le dernier stade de la société de travail, la société d’employés, exige de ses membres un pur fonctionnement automatique, comme si la vie individuelle était réellement submergée par le processus global de la vie de l’espèce, comme si la seule décision encore requise de l’individu était de lâcher, pour ainsi dire, d’abandonner son individualité, sa peine et son inquiétude de vivre encore individuellement senties, et d’acquiescer à un type de comportement, hébété, « tranquillisé » et fonctionnel. Ce qu’il y a de fâcheux dans les théories modernes du comportement, ce n’est pas qu’elles sont fausses, c’est qu’elles peuvent devenir vraies, c’est qu’elles sont, en fait, la meilleure mise en concept possible de certaines tendances évidentes de la société moderne. On peut parfaitement concevoir que l’époque moderne (…) s’achève dans la passivité la plus inerte, la plus stérile que l’Histoire ait jamais connue.5
Devant cette anticipation catastrophiste, l’option choisie ne peut être l’impuissance et le laisser-faire. Il faut d’abord nommer ce à quoi nous avons affaire, c’est-à-dire un système (total) face auquel nous devons nous positionner.
Qu’est-ce que Big Other et que peut-on faire ?
Il s’agit des mécanismes d’extraction, marchandisation et contrôle. Ils instaurent une dichotomie entre les individus (utilisateurs) et leur propre comportement (pour les transformer en données) et simultanément ils produisent de nouveaux marchés basés justement sur la prédictibilité de ces comportements.
(Big Other) est un régime institutionnel, omniprésent, qui enregistre, modifie, commercialise l’expérience quotidienne, du grille-pain au corps biologique, de la communication à la pensée, de manière à établir de nouveaux chemins vers les bénéfices et les profits. Big other est la puissance souveraine d’un futur proche qui annihile la liberté que l’on gagne avec les règles et les lois.6
Avoir pu mettre un nom sur ce nouveau régime dont Google constitue un peu plus qu’une illustration (presque initiateur) est la grande force de Shoshana Zuboff. Sans compter plusieurs articles récents de cette dernière dans la Frankfurter Allgemeine Zeitung, il est étonnant que le rapport d’Antoinette Rouvroy, postérieur d’un an, n’y fasse aucune mention. Est-ce étonnant ? Pas vraiment, en réalité, car dans un rapport officiellement remis aux autorités européennes, il est important de préciser que la lutte contre Big Other (ou de n’importe quelle manière dont on peut l’exprimer) ne peut que passer par la légitimité sans faille des institutions. Ainsi, A. Rouvroy oppose les deux seules voies envisageables dans un tel contexte officiel :
À l’approche « law and economics », qui est aussi celle des partisans d’un « marché » des données personnelles, qui tendrait donc à considérer les données personnelles comme des « biens » commercialisables (…) s’oppose l’approche qui consiste à aborder les données personnelles plutôt en fonction du pouvoir qu’elles confèrent à ceux qui les contrôlent, et à tenter de prévenir de trop grandes disparités informationnelles et de pouvoir entre les responsables de traitement et les individus. C’est, à l’évidence, cette seconde approche qui prévaut en Europe.
Or, devant Google (ou devant ce Big Other) nous avons vu l’impuissance des États à faire valoir un arsenal juridique, à commencer par les lois anti-trust. D’une part, l’arsenal ne saurait être exhaustif : il concernerait quelques aspects seulement de l’exploitation des données, la transparence ou une série d’obligations comme l’expression des finalités ou des consentements. Il ne saurait y avoir de procès d’intention. D’autre part, nous pouvons toujours faire valoir que des compagnies telles Microsoft ont été condamnées par le passé, au moins par les instances européennes, pour abus de position dominante, et que quelques millions d’euros de menace pourraient suffire à tempérer les ardeurs. C’est faire peu de cas d’au moins trois éléments :
- l’essentiel des compagnies dont il est question sont nord-américaines, possèdent des antennes dans des paradis fiscaux et sont capables, elles, de menacer financièrement des pays entiers par simples effets de leviers boursiers.
- L’arsenal juridique qu’il faudrait déployer avant même de penser à saisir une cour de justice, devrait être rédigé, voté et décrété en admettant que les jeux de lobbies et autres obstacles formels soient entièrement levés. Cela prendrait un minimum de dix ans, si l’on compte les recours envisageables après une première condamnation.
- Il faut encore caractériser les Big Data dans un contexte où leur nature est non seulement extrêmement diverse mais aussi soumise à des process d’automatisation et calculatoires qui permettent d’en inférer d’autres quantités au moins similaires. Par ailleurs, les sources des données sont sans cesse renouvelées, et leur stockage et analyse connaissent une progression technique exponentielle.
Dès lors, quels sont les moyens de s’échapper de ce Big Other ? Puisque nous avons changé de paradigme économique, nous devons changer de paradigme de consommation et de production. Grâce à des dispositifs comme la neutralité du réseau, garantie fragile et obtenue de longue lutte, il est possible de produire nous même l’écosystème dans lequel nos données sont maîtrisées et les maillons de la chaîne de confiance sont identifiés.

Confiance et espaces de confiance
Comment évoluer dans le monde du capitalisme de surveillance ? telle est la question que nous pouvons nous poser dans la mesure où visiblement nous ne pouvons plus nous extraire d’une situation de soumission à Big Other. Quelles que soient nos compétences en matière de camouflage et de chiffrement, les sources de données sur nos individualités sont tellement diverses que le résultat de la distanciation avec les technologies du marché serait une dé-socialisation. Puisque les technologies sur le marché sont celles qui permettent la production, l’analyse et l’extraction automatisées de données, l’objectif n’est pas tant de s’en passer que de créer un système où leur pertinence est tellement limitée qu’elle laisse place à un autre principe que l’accumulation de données : l’accumulation de confiance.
Voyons un peu : quelles sont les actuelles échappatoires de ce capitalisme de surveillance ? Il se trouve qu’elles impliquent à chaque fois de ne pas céder aux facilités des services proposés pour utiliser des solutions plus complexes mais dont la simplification implique toujours une nouvelle relation de confiance. Illustrons ceci par des exemples relatifs à la messagerie par courrier électronique :
- Si j’utilise Gmail, c’est parce que j’ai confiance en Google pour respecter la confidentialité de ma correspondance privée (no comment !). Ce jugement n’implique pas que moi, puisque mes correspondants auront aussi leurs messages scannés, qu’ils soient utilisateurs ou non de Gmail. La confiance repose exclusivement sur Google et les conditions d’utilisation de ses services.
- L’utilisation de clés de chiffrement pour correspondre avec mes amis demande un apprentissage de ma part comme de mes correspondants. Certains services, comme ProtonMail, proposent de leur faire confiance pour transmettre des données chiffrées tout en simplifiant les procédures avec un webmail facile à prendre en main. Les briques open source de Protonmail permettent un niveau de transparence acceptable sans que j’en aie toutefois l’expertise (si je ne suis pas moi-même un informaticien sérieux).
- Si je monte un serveur chez moi, avec un système libre et/ou open source comme une instance Cozycloud sur un Raspeberry PI, je dois avoir confiance dans tous les domaines concernés et sur lesquels je n’ai pas forcément l’expertise ou l’accès physique (la fabrication de l’ordinateur, les contraintes de mon fournisseur d’accès, la sécurité de mon serveur, etc.), c’est-à-dire tous les aspects qui habituellement font l’objet d’une division du travail dans les entreprises qui proposent de tels services, et que j’ai la prétention de rassembler à moi tout seul.
Les espaces de relative autonomie existent donc mais il faut structurer la confiance. Cela peut se faire en deux étapes.
La première étape consiste à définir ce qu’est un tiers de confiance et quels moyens de s’en assurer. Le blog de la FSFE a récemment publié un article qui résume très bien pourquoi la protection des données privées ne peut se contenter de l’utilisation plus ou moins maîtrisée des technologies de chiffrement7. La FSFE rappelle que tous les usages des services sur Internet nécessitent un niveau de confiance accordé à un tiers. Quelle que soit son identité…
…vous devez prendre en compte :
- la bienveillance : le tiers ne veut pas compromettre votre vie privée et/ou il est lui-même concerné ;
- la compétence : le tiers est techniquement capable de protéger votre vie privée et d’identifier et de corriger les problèmes ;
- l’intégrité : le tiers ne peut pas être acheté, corrompu ou infiltré par des services secrets ou d’autres tiers malveillants ;
Comment s’assurer de ces trois qualités ? Pour les défenseurs et promoteurs du logiciel libre, seules les communautés libristes sont capables de proposer des alternatives en vertu de l’ouverture du code. Sur les quatre libertés qui définissent une licence libre, deux impliquent que le code puisse être accessible, audité, vérifié.
Est-ce suffisant ? non : ouvrir le code ne conditionne pas ces qualités, cela ne fait qu’endosser la responsabilité et l’usage du code (via la licence libre choisie) dont seule l’expertise peut attester de la fiabilité et de la probité.
En complément, la seconde étape consiste donc à définir une chaîne de confiance. Elle pourra déterminer à quel niveau je peux m’en remettre à l’expertise d’un tiers, à ses compétences, à sa bienveillance…. Certaines entreprises semblent l’avoir compris et tentent d’anticiper ce besoin de confiance. Pour reprendre les réflexions du Boston Consulting Group, l’un des plus prestigieux cabinets de conseil en stratégie au monde :
(…) dans un domaine aussi sensible que le Big Data, la confiance sera l’élément déterminant pour permettre à l’entreprise d’avoir le plus large accès possible aux données de ses clients, à condition qu’ils soient convaincus que ces données seront utilisées de façon loyale et contrôlée. Certaines entreprises parviendront à créer ce lien de confiance, d’autres non. Or, les enjeux économiques de ce lien de confiance sont très importants. Les entreprises qui réussiront à le créer pourraient multiplier par cinq ou dix le volume d’informations auxquelles elles sont susceptibles d’avoir accès. Sans la confiance du consommateur, l’essentiel des milliards d’euros de valeur économique et sociale que le Big Data pourrait représenter dans les années à venir risquerait d’être perdu.8
En d’autres termes, il existe un marché de la confiance. En tant que tel, soit il est lui aussi soumis aux effets de Big Other, soit il reste encore dépendant de la rationalité des consommateurs. Dans les deux cas, le logiciel libre devra obligatoirement trouver le créneau de persuasion pour faire adhérer le plus grand nombre à ses principes.
Une solution serait de déplacer le curseur de la chaîne de confiance non plus sur les principaux acteurs de services, plus ou moins dotés de bonnes intentions, mais dans la sphère publique. Je ne fais plus confiance à tel service ou telle entreprise parce qu’ils indiquent dans leurs CGU qu’ils s’engagent à ne pas utiliser mes données personnelles, mais parce que cet engagement est non seulement vérifiable mais aussi accessible : en cas de litige, le droit du pays dans lequel j’habite peut s’appliquer, des instances peuvent se porter parties civiles, une surveillance collective ou policière est possible, etc. La question n’est plus tellement de savoir ce que me garantit le fournisseur mais comment il propose un audit public et expose sa responsabilité vis-à-vis des données des utilisateurs.
S’en remettre à l’État pour des services fiables ? Les États ayant démontré leurs impuissances face à des multinationales surfinancées, les tentatives de cloud souverain ont elles aussi été des échecs cuisants. Créer des entreprises de toutes pièces sur fonds publics pour proposer une concurrence directe à des monopoles géants, était inévitablement un suicide : il aurait mieux valu proposer des ressources numériques et en faciliter l’accès pour des petits acteurs capables de proposer de multiples solutions différentes et alternatives adaptées aux besoins de confiance des utilisateurs, éventuellement avec la caution de l’État, la réputation d’associations nationales (association de défense des droits de l’homme, associations de consommateurs, etc.), bref, des assurances concrètes qui impliquent les utilisateurs, c’est-à-dire comme le modèle du logiciel libre qui ne sépare pas utilisation et conception.
Ce que propose le logiciel libre, c’est davantage que du code, c’est un modèle de coopération et de cooptation. C’est la possibilité pour les dynamiques collectives de réinvestir des espaces de confiance. Quel que soit le service utilisé, il dépend d’une communauté, d’une association, ou d’une entreprise qui toutes s’engagent par contrat (les licences libres sont des contrats) à respecter les données des utilisateurs. Le tiers de confiance devient collectif, il n’est plus un, il est multiple. Il ne s’agit pas pour autant de diluer les responsabilités (chaque offre est indépendante et s’engage individuellement) mais de forcer l’engagement public et la transparence des recours.
Chatons solidaires
Si s’échapper seul du marché de Big Other ne peut se faire qu’au prix de l’exclusion, il faut opposer une logique différente capable, devant l’exploitation des données et notre aliénation de consommateurs, de susciter l’action et non la passivité, le collectif et non l’individu. Si je produis des données, il faut qu’elles puissent profiter à tous ou à personne. C’est la logique de l’open data qui garanti le libre accès à des données placées dans le bien commun. Ce commun a ceci d’intéressant que tout ce qui y figure est alors identifiable. Ce qui n’y figure pas relève alors du privé et diffuser une donnée privée ne devrait relever que du seul choix délibéré de l’individu.
Le modèle proposé par le projet CHATONS (Collectif d’Hébergeurs Alternatifs, Transparents, Ouverts, Neutres et Solidaires) de Framasoft repose en partie sur ce principe. En adhérant à la charte, un hébergeur s’engage publiquement à remplir certaines obligations et, parmi celles-ci, l’interdiction d’utiliser les données des utilisateurs pour autre chose que l’évaluation et l’amélioration des services.
Comme écrit dans son manifeste (en version 0.9), l’objectif du collectif CHATONS est simple :
L’objectif de ce collectif est de mailler les initiatives de services basés sur des solutions de logiciels libres et proposés aux utilisateurs de manière à diffuser toutes les informations utiles permettant au public de pouvoir choisir leurs services en fonction de leurs besoins, avec un maximum de confiance vis-à-vis du respect de leur vie privée, sans publicité ni clause abusive ou obscure.
En lançant l’initiative de ce collectif, sans toutefois se placer dans une posture verticale fédérative, Framasoft ouvre une porte d’échappatoire. L’essentiel n’est pas tant de maximiser la venue de consommateurs sur quelques services identifiés mais de maximiser les chances pour les consommateurs d’utiliser des services de confiance qui, eux, pourront essaimer et se multiplier. Le postulat est que l’utilisateur est plus enclin à faire confiance à un hébergeur qu’il connaît et qui s’engage devant d’autres hébergeurs semblables, ses pairs, à respecter ses engagements éthiques. Outre l’utilisation de logiciels libres, cela se concrétise par trois principes
- Mutualiser l’expertise : les membres du collectif s’engagent à partager les informations pour augmenter la qualité des services et pour faciliter l’essaimage des solutions de logiciels libres utilisées. C’est un principe de solidarité qui permettra, à terme, de consolider sérieusement le tissu des hébergeurs concernés.
- Publier et adhérer à une charte commune. Cette charte donne les principaux critères techniques et éthiques de l’activité de membre. L’engagement suppose une réciprocité des échanges tant avec les autres membres du collectif qu’avec les utilisateurs.
- Un ensemble de contraintes dans la charte publique implique non seulement de ne s’arroger aucun droit sur les données privées des utilisateurs, mais aussi de rester transparent y compris jusque dans la publication de ses comptes et rapports d’activité. En tant qu’utilisateur je connais les engagements de mon hébergeur, je peux agir pour le contraindre à les respecter tout comme les autres hébergeurs peuvent révoquer de leur collectif un membre mal intentionné.
Le modèle CHATONS n’est absolument pas exclusif. Il constitue même une caricature, en quelque sorte l’alternative contraire mais pertinente à GAFAM. Des entreprises tout à fait bien intentionnées, respectant la majeure partie de la charte, pourraient ne pas pouvoir entrer dans ce collectif à cause des contraintes liées à leur modèle économique. Rien n’empêche ces entreprises de monter leur propre collectif, avec un niveau de confiance différent mais néanmoins potentiellement acceptable. Si le collectif CHATONS décide de restreindre au domaine associatif des acteurs du mouvement, c’est parce que l’idée est d’essaimer au maximum le modèle : que l’association philatélique de Trifouille-le-bas puisse avoir son serveur de courriel, que le club de football de Trifouille-le-haut puisse monter un serveur owncloud et que les deux puissent mutualiser en devenant des CHATONS pour en faire profiter, pourquoi pas, les deux communes (et donc la communauté).

Conclusion
La souveraineté numérique est souvent invoquée par les autorités publiques bien conscientes des limitations du pouvoir qu’implique Big Other. Par cette expression, on pense généralement se situer à armes égales contre les géants du web. Pouvoir économique contre pouvoir républicain. Cet affrontement est perdu d’avance par tout ce qui ressemble de près ou de loin à une procédure institutionnalisée. Tant que les citoyens ne sont pas eux-mêmes porteurs d’alternatives au marché imposé par les GAFAM, l’État ne peut rien faire d’autre que de lutter pour sauvegarder son propre pouvoir, c’est-à-dire celui des partis comme celui des lobbies. Le serpent se mord la queue.
Face au capitalisme de surveillance, qui a depuis longtemps dépassé le stade de l’ultra-libéralisme (car malgré tout il y subsistait encore un marché et une autonomie des agents), c’est à l’État non pas de proposer un cloud souverain mais de se positionner comme le garant des principes démocratiques appliqués à nos données numériques et à Internet : neutralité sans faille du réseau, garantie de l’équité, surveillance des accords commerciaux, politique anti-trust affirmée, etc. L’éducation populaire, la solidarité, l’intelligence collective, l’expertise des citoyens, feront le reste, quitte à ré-inventer d’autres modèles de gouvernance (et de gouvernement).
Nous ne sommes pas des êtres a-technologiques. Aujourd’hui, nos vies sont pleines de données numériques. Avec Internet, nous en usons pour nous rapprocher, pour nous comprendre et mutualiser nos efforts, tout comme nous avons utilisé en leurs temps le téléphone, les voies romaines, le papyrus, et les tablettes d’argile. Nous avons des choix à faire. Nous pouvons nous diriger vers des modèles exclusifs, avec ou sans GAFAM, comme la généralisation de block chains pour toutes nos transactions. En automatisant les contrats, même avec un système ouvert et neutre, nous ferions alors reposer la confiance sur la technologie (et ses failles), en révoquant toute relation de confiance entre les individus, comme si toute relation interpersonnelle était vouée à l’échec. L’autre voie repose sur l’éthique et le partage des connaissances. Le projet CHATONS n’est qu’un exemple de système alternatif parmi des milliers d’autres dans de multiples domaines, de l’agriculture à l’industrie, en passant par la protection de l’environnement. Saurons-nous choisir la bonne voie ? Saurons-nous comprendre que les relations d’interdépendances qui nous unissent sur terre passent aussi bien par l’écologie que par le partage du code ?
- La série d’articles sur le framablog
- La série d’article au complet (fichier .epub)
- Discours prononcé lors d’une conférence intitulée Surveillance capitalism: A new societal condition rising lors du sommet CPDP (Computers Privacy and Data protection), Bruxelles, 27-29 janvier 2016 (video).↩
- Antoinette Rouvroy, Des données et des hommes. Droits et libertés fondamentaux dans un monde de données massives, Bureau du comité consultatif de la convention pour la protection des personnes à l’égard du traitement automatisé des données à caractère personnel, janvier 2016.↩
- Shoshana Zuboff, « Big other: surveillance capitalism and the prospects of an information civilization », Journal of Information Technology, 30, 2015, pp. p;75-89.↩
- Directive 95/46/CE du Parlement européen et du Conseil, du 24 octobre 1995, relative à la protection des personnes physiques à l’égard du traitement des données à caractère personnel et à la libre circulation de ces données.↩
- Hannah Arendt, La condition de l’homme moderne, Paris: Calmann-Lévy, Agora, 1958, pp. 400-401.↩
- Shoshana Zuboff, « Big other: surveillance capitalism and the prospects of an information civilization », Journal of Information Technology, 30, 2015, p. p;81.↩
- h2, « Why Privacy is more than Crypto », blog Emergency Exit, FSFE, 31 mai 2016.↩
- Carol Umhoefer et al., Le Big Data face au défi de la confiance, The Boston Consulting Group, juin 2014.↩

















{kind=link}