(Si vous avez déjà suivi les épisodes précédents, allez directement au texte de David…)
Comme le savent nos lecteurs, nous défendons volontiers non seulement les logiciels mais aussi la culture libre sous ses multiples formes, y compris dans le domaine artistique :
la position et l’expérimentation d’artistes comme Gwenn Seemel, Amanda Palmer, Neil Jomunsi entre autres multiples exemples (ne risquons pas l’accusation de copinage en mentionnant Pouhiou), nous intéressent et nous passionnent parce qu’elles témoignent d’un monde à la charnière. En effet, un modèle d’édition et de diffusion arrive en bout de course et à bout de souffle, mais il est défendu mordicus à la fois par ses bénéficiaires (c’est cohérent) et parfois par ses victimes, ce qui est plus surprenant. Quant aux modèles émergents, aux variantes nombreuses et inventives, ils cherchent la voie d’une viabilité rendue incertaine par les lois du marché qui s’imposent à eux.
Le mois dernier une annonce nous a fait plaisir, celle de la publication « papier » par Glénat du webcomic Pepper et Carrot de David Revoy, qui n’est pas un inconnu pour les lecteurs du Framablog auquel il a accordé cette interview il y a quelques mois. Voici la page où il détaille sa philosophie.
Un article de Calimaq expose de façon documentée l’intérêt de cette reprise d’une œuvre open source par un éditeur « classique » dans laquelle il voit de façon optimiste une façon de faire bouger les lignes qui bénéficie autant à l’auteur (qui renforce ses sources de mécénat) qu’à l’éditeur et aux lecteurs.
Tout va donc pour le mieux dans le petit monde de la BD ? — Pas vraiment, parce que l’accord passé par David Revoy avec Glénat (lequel s’engage à respecter cette licence Creative Commons) vient de provoquer une levée de boucliers chez un certain nombre d’auteurs de bande dessinée. Ils estiment notamment que cet accord dévalorise l’ensemble d’une profession qui peine déjà à survivre et s’insurgent contre l’idée de donner librement le fruit d’un travail artistique.
Vous pouvez par exemple lire ce billet de Xavier Guilbert pour la revue Du9 qui résume de façon assez équilibrée l’ensemble de la polémique. Si vous souhaitez lire un avis circonstancié carrément libriste, lisez l’excellent coup de gueule de Luc, qui fait notamment le lien avec Framabook, notre maison d’édition qui a fait « le pari du livre libre », mais établit néanmoins des contrats avec les auteurs qui sont rémunérés.
Également du côté des défenseurs du libre Neil Jomunsi sort la grosse artillerie et demande aux auteurs de se sortir les doigts du c**. C’est précisément à la suite de cet article que le principal intéressé s’exprime dans un long commentaire que nous reproduisons ici avec son accord.
(dans un premier temps David s’adresse à Neil Jomunsi)
Photo par Elisa De Castro Guerra
Hello, merci Neil pour cette initiative, j’espère y lire ici des propositions constructives de la part des autres auteurs et non pas seulement des retours des happy few qui vivent confortablement du système éditorial classique. En effet, je prends en considération que ces auteurs ne peuvent pas émettre une pensée libre d’intérêts éditoriaux ou syndicaux sur ce thème (surtout de manière publique). Ils ont aussi très peu d’intérêt à un changement de paradigme…
Pour ma part, je me suis très peu exprimé jusqu’alors. Mais je me sens à l’aise sur ce blog. J’aime le ton de l’article, la police d’écriture et la boîte de commentaire large. Je pense que ça risque de me faire pianoter. Et puis, je n’ai pas de blog français… Je réquisitionne donc cette boîte de commentaire un peu comme un blogpost de réponse.
Voici mon angle de vue que-personne-ne-m’a-demandé-mais-voilà-tout-de-même sur le modèle de Pepper&Carrot et pourquoi, je le répète, il me convient et que je maintiens ma tag-line sur ma page de garde :
(Note : j’utiliserai par raccourcis les termes ‘auteurs’, ‘éditeurs’, ‘lecteurs’, mais je pense bien également aux ‘autrices’, ‘éditrices’, ‘lectrices’ derrière ces termes.)
Donc entendons-nous bien ici : je ne suis pas dans une lutte classique tel qu’on l’entend, voulant la destruction d’organisations, d’entreprises ou autre systèmes en place. Dans « changer l’industrie de la BD », j’entends « sanifier » les relations auteurs/éditeurs par plus de liberté et d’indépendance dans leurs relations. Par sanifier, je n’entends pas l’inversion du rapport de force où l’auteur triomphe de l’éditeur. Non. Dans ma démarche, il n’y a pas de rapport de force entre auteur et éditeur. L’éditeur est un acteur libre qui fait un produit dérivé de ma création. Dans le système classique, il y a un rapport dominant/dominé évident, contractualisé et opaque aux lecteurs. C’est tout là le problème. Avec Pepper&Carrot, je propose un système côte-à-côte. Chacun indépendant.
Ce système marche-t-il ? Sur ma page Philosophie, j’écris
… Et pourquoi Pepper&Carrot ne pourrait-il pas amorcer un changement et ainsi inspirer une industrie en crise ? Essayons !
Ce « essayons » démontre le caractère expérimental de ma démarche. Car oui, je suis en train de créer, oui, c’est nouveau et oui, ça agace quand quelqu’un essaie du nouveau.
Pepper&Carrot est un webcomic numérique en anglais principalement et international. Il est hébergé autant à Paris, qu’au U.S.A, en Asie et sur je-ne-sais-combien de sites miroirs et ça tourne. La France représente 4 % de ses visiteurs et cela me donne un peu de retrait sur le problème actuel. En effet : il serait vraiment malhonnête de penser que je suis dans la même situation qu’un jeune dessinateur amateur français, publiant en français sans audience et qui n’aurait qu’un seul éditeur monolithique comme source de revenus/diffusion, Glénat, pour survivre avec les 350 $ par mois de mécénat de Glénat… C’est pourtant, et à l’origine du buzz, l’angle de communication surprenant qu’a essayé d’orchestrer le syndicat BD SNAC sur sa page Facebook, et ce, bizarrement à quelques dizaines de jours d’une rencontre auteurs/éditeur importante. À part m’y faire traiter littéralement de con dans les commentaires et d’amener un lectorat d’auteurs entier à mépriser ma démarche, rien n’a germé, aucune pensée : stérile. Cependant cela a alimenté de la colère. Ce groupe a-t-il besoin de ça pour s’unifier ? Pepper&Carrot/Glénat est simplement devenu un prétexte du moment. Une opportunité pour eux de « casser de l’éditeur » collectivement et dénigrer un nouvel auteur qui n’a pas choisi de lutter à leur manière. Triste.
Donc ce buzz, dit il la vérité ? En partie, oui, c’est pour ça que ça marche. Il est possible à n’importe qui de faire des produits dérivés de Pepper&Carrot, de façon commerciale, en suivant un ensemble de règles de la Creative CommonsAttribution permissive que j’ai établie. Glénat qui imprime à 10 000 exemplaires mon webcomic n’est qu’un produit dérivé à mes yeux (comme déjà dit). Pour faire un parallèle, je le considère comme si j’avais un film et qu’ils imprimaient la figurine du héros. Rien de plus. Nous avons eu une collaboration que je décris en anglais sur le blog de Pepper&Carrot. J’en suis satisfait, c’est super cool un premier album imprimé, mais cliquez sur le bouton « HD » sur le site de Pepper&Carrot, et vous y aurez plus de détails, plus de couleurs que dans l’album imprimé.
Ma BD principale, mon support de choix n’est pas l’album de Glénat. Ce n’est pas le média principal de Pepper&Carrot. D’autres projets suivront comme l’éditeur allemand Popcom qui vient de rejoindre le mécénat de Pepper&Carrot, le livre de la Krita Foundation ou une édition régionale en Breton de Pepper&Carrot. Ce n’est que le début, le projet n’a que deux ans et je ne compte pas tout ça comme un manque à gagner. Je n’y vois que les effets positifs de personnes qui utilisent la base de ressources que j’ai créée, avec respect, dans les règles qui me conviennent pour créer plus de valeur autour de la série. Et ça fonctionne.
Glénat fait des bénéfices ? Et alors ? Bon pour eux. Le font-il « sur mon dos » ? Non, je ne me sens pas lésé en quoi que ce soit. Pas plus que quand Pepper&Carrot fait la frontpage d’ImgUr, de deviantArt ou de Reddit. (je vous présente ici des nouvelles puissances éditoriales). Le papier, la chaîne graphique, l’impression, l’empaquetage, la distribution, etc. c’est le métier de l’éditeur, il véhicule mon œuvre sur le papier. Pas très différent de ce que ferait un autre site web, pour moi. De mon point de vue, je fais du divertissement numérique sur Internet et je ne vends pas de BD. Si l’éditeur aime la source qui lui permet de vendre du papier, il sait comment me gratifier. Idem pour l’audience. C’est simple et c’est décrit dans l’album papier de Glénat Pepper&Carrot (si certains avaient pris le temps de l’ouvrir). Ce qui m’interpelle vraiment, c’est : Glénat imprime 10 000 exemplaires et aucun petit éditeur ne pense à aller sur mon site télécharger plein de croquis Creative Commons et en faire un artbook d’accompagnement en librairie ? Publier des cartes postales ? Refaire une version « deluxe » du Tome 1 ? Le monde éditorial à moins d’initiative que ce que j’avais prévu.
Je veux un univers collaboratif dont le lecteur puisse s’imprégner et devenir à son tour acteur, entrepreneur. Ici encore la Creative Commons Attribution le permet
J’aimerais aussi faire prendre conscience dans ce débat sur un autre point qui n’est jamais abordé dans les articles : la « culture libre » que permet Pepper&Carrot. Les auteurs ont conquis une place dans les esprits de leurs audiences qui me dérange fondamentalement. Prenez par exemple une BD lambda, distribué sous copyright classique (même d’un webcomic « gratuit » mais propriétaire d’Internet). Tout le monde peut penser l’univers, rêver dedans, rejouer les scènes en pensée, etc. Cet univers existe en nous. Mais dès que cette pensée essaie de germer, de muter, de passer à l’action dans la vraie vie par une création, elle se retrouve anéantie ou réduite aux règles vaseuses du fair-use/fan-art/fan-fiction qui devient illégal en cas de création d’activité commerciale. Combien de cas problématiques sur Internet ces dernières années ! Sans le savoir, les auteurs d’univers propriétaire sont aussi propriétaires d’une part de votre culture, de votre pensée, de vos rêves, de ce qui regroupe les fans…
Avec Pepper&Carrot, je ne veux plus de ce paradigme du tout. Je veux un univers collaboratif dont le lecteur puisse s’imprégner et devenir à son tour acteur, entrepreneur. Ici encore la Creative Commons Attribution le permet, et ainsi j’ai des projets de jeux vidéos, de jeux de sociétés, de jeux de rôles de fan-art et de fan-fictions qui viennent à leur tour enrichir le wiki de l’univers d’Hereva à la base de Pepper&Carrot. Encore une fois, ceci est ma volonté de créer une relation côte-à-côte avec le lecteur, et j’en vois les bénéfices.
je replace l’auteur maître de son œuvre en face de l’éditeur dans un rapport d’égal à égal dans leur liberté et leurs droits.
Vous l’avez donc compris, je ne suis pas intéressé par l’établissement d’une relation d’un contrat classique, dominant-éditeur, dominé-auteur et sous-dominé-lecteur-acheteur. C’est liberticide et nuirait collectivement à notre éditeur-auteur-lecteur, à nos libertés d’agir, d’entreprendre et de penser. Je fonde un écosystème où les acteurs sont libres et côte-à-côte dans un rapport pacifié. La CC-By-Nc ? (la clause non-commerciale de la Creative Commons) désolé, je ne la veux pas pour ma BD, et ce n’est pas parce que ça s’appelle Creative Commons que c’est libre : c’est une licence propriétaire. La CC-By (attribution) est libre et m’intéresse. Avec cette liberté, cette indépendance, j’ai ici un modèle qui fonctionne à ma modeste échelle et tout ceci alimenté financièrement grâce à des héros dans mon audience qui soutiennent mon travail et ma philosophie.
L’image finale de l’épisode 8 récemment publié, l’anniversaire de Pepper
Mais ce n’est pas tout… Ce que je propose est une solution robuste contre la question du piratage de la BD, ce que je propose rend obsolète la création même des DRM pour la diffusion numérique, ce que je propose clarifie les rapports ambigus pour la création de fan-art/fan-fiction et dérivations, et enfin je replace l’auteur maître de son œuvre en face de l’éditeur dans un rapport d’égal à égal dans leur liberté et leurs droits.
Refaites le compte, et réévaluez ma proposition. Libre aussi à chacun de signer un contrat, de le négocier, de savoir quoi faire avec son œuvre. Mais pour moi, cette réflexion est faite. J’aime le libre pour ce qu’il offre pragmatiquement et je suis déjà dans son application à la réalité concernant ma BD depuis deux ans. Il vous reste un dégoût qu’une grosse entreprise genre « gros éditeur » puisse imprimer vos œuvres gratuitement ? Cela fait partie de la licence libre telle qu’elle est et de la liberté qu’elle offre. La licence n’est qu’un outil ne peut pas faire vraiment de différence entre la lectrice/traductrice japonaise, le petit commerçant polonais, l’artisan irlandais, le gros site web australien et le géant industriel de l’édition française… Sinon ce ne serait plus de la vraie liberté.
Il ne me reste plus qu’à continuer d’informer les lecteurs et leur demander de soutenir les artistes libres qu’ils aiment directement via Internet et non de penser que ces artistes touchent un quelconque gros pourcentage opaque sur les produits dérivés que ceux-ci iront acheter. Cette tâche d’information, si on s’y mettait tous collectivement et pratiquement entre artistes, aurait certainement plus d’effets sur nos niveaux et confort de vie que toutes négociations de pourcentages et discussions de frais d’avances autour de réunions et de cocktails.
Darwin par David Revoy, extrait de son portfolio. Cliquer pour agrandir ce portrait à la manière d’Arcimboldo.
Toutes les illustrations de cet article sont de David Revoy, CC-BY
Non, je ne veux pas télécharger votre &@µ$# d’application !
« Ne voulez-vous pas plutôt utiliser notre application ? »…
De plus en plus, les écrans de nos ordiphones et autres tablettes se voient pollués de ce genre de message dès qu’on ose utiliser un bon vieux navigateur web.
Étrangement, c’est toujours « pour notre bien » qu’on nous propose de s’installer sur notre machine parmi les applications que l’on a vraiment choisies…
Ruben Verborgh nous livre ici une toute autre analyse, et nous dévoile les dessous d’une conquête de nos attentions et nos comportements au détriment de nos libertés. Un article blog traduit par Framalang, et sur lequel l’auteur nous a offert encouragements, éclairages et relecture ! Toute l’équipe de Framalang l’en remercie chaleureusement et espère que nous avons fait honneur à son travail 😉
Sous des prétextes mensongers, les applications mobiles natives nous éloignent du Web. Nous ne devrions pas les laisser faire.
Peu de choses m’agacent plus qu’un site quelconque qui me demande « Ne voulez-vous pas utiliser plutôt notre application ? ». Évidemment que je ne veux pas, c’est pour ça que j’utilise votre site web. Certaines personnes aiment les applications et d’autres non, mais au-delà des préférences personnelles, il existe un enjeu plus important. La supplique croissante des applications pour envahir, littéralement, notre espace personnel affaiblit certaines des libertés pour lesquelles nous avons longtemps combattu. Le Web est la première plate-forme dans l’histoire de l’humanité qui nous permette de partager des informations et d’accéder à des services à travers un programme unique : un navigateur. Les applications, quant à elles, contournent joyeusement cette interface universelle, la remplaçant par leur propre environnement. Est-ce vraiment la prétendue meilleure expérience utilisateur qui nous pousse vers les applications natives, ou d’autres forces sont-elles à l’œuvre ?
Il y a 25 ans, le Web commença à tous nous transformer. Aujourd’hui, nous lisons, écoutons et regardons différemment. Nous communiquons à une échelle et à une vitesse inconnues auparavant. Nous apprenons des choses que nous n’aurions pas pu apprendre il y a quelques années, et discutons avec des personnes que nous n’aurions jamais rencontrées. Le Web façonne le monde de façon nouvelle et passionnante, et affecte la vie des gens au quotidien. C’est pour cela que certains se battent pour protéger le réseau Internet qui permet au Web d’exister à travers le globe. Des organisations comme Mozilla s’évertuent à faire reconnaître Internet comme une ressource fondamentale plutôt qu’un bien de luxe, et heureusement, elles y parviennent.
Toutefois, les libertés que nous apporte le Web sont menacées sur plusieurs fronts. L’un des dangers qui m’inquiète particulièrement est le développement agressif des applications natives qui tentent de se substituer au Web. Encore récemment, le directeur de la conception produit de Facebook comparait les sites web aux vinyles : s’éteignant peu à peu sans disparaître complètement. Facebook et d’autres souhaitent en effet que nous utilisions plutôt leurs applications ; mais pas simplement pour nous fournir une « meilleure expérience utilisateur ». Leur façon de nous pousser vers les applications met en danger un écosystème inestimable. Nous devons nous assurer que le Web ne disparaisse jamais, et ce n’est pas juste une question de nostalgie.
Internet, notre réseau global, est une ressource fondamentale. Le web, notre espace d’information mondial, est de loin l’application la plus importante d’Internet. Nous devons aussi le protéger.
Le Web : une interface indépendante ouverte sur des milliards de sources
Pour comprendre pourquoi le Web est si important, il faut s’imaginer le monde d’avant le Web. De nombreux systèmes d’information existaient mais aucun ne pouvait réellement être interfacé avec les autres. Chaque source d’information nécessitait sa propre application. Dans cette situation, on comprend pourquoi la majeure partie de la population ne prenait pas la peine d’accéder à aucun de ces systèmes d’information.
Le Web a permis de libérer l’information grâce à une interface uniforme. Enfin, un seul logiciel – un navigateur web – suffisait pour interagir avec plusieurs sources. Mieux encore, le Web est ouvert : n’importe qui peut créer des navigateurs et des serveurs, et ils sont tous compatibles entre eux grâce à des standards ouverts. Peu après son arrivée, cet espace d’informations qu’était le Web est devenu un espace d’applications, où plus de 3 milliards de personnes pouvaient créer du contenu, passer des commandes et communiquer – le tout grâce au navigateur.
Au fil des années, les gens se mirent à naviguer sur le Web avec une large panoplie d’appareils qui étaient inimaginables à l’époque de la création du Web. Malgré cela, tous ces appareils peuvent accéder au Web grâce à cette interface uniforme. Il suffit de construire un site web une fois pour que celui-ci soit accessible depuis n’importe quel navigateur sur n’importe quel appareil (tant qu’on n’utilise rien de spécial ou qu’on suit au moins les méthodes d’amélioration progressive). De plus, un tel site continuera à fonctionner indéfiniment, comme le prouve le premier site web jamais créé. La compatibilité fonctionne dans les deux sens : mon site fonctionne même dans les navigateurs qui lui préexistaient.
La capacité qu’a le Web à fournir des informations et des services sur différents appareils et de façon pérenne est un don immense pour l’humanité. Pourquoi diable voudrions-nous revenir au temps où chaque source d’information nécessitait son propre logiciel ?
Les applications : des interfaces spécifiques à chaque appareil et une source unique
Après les avancées révolutionnaires du web, les applications natives essaient d’accomplir l’exacte inverse : forcer les gens à utiliser une interface spécifique pour chacune des sources avec lesquelles ils veulent interagir. Les applications natives fonctionnent sur des appareils spécifiques, et ne donnent accès qu’à une seule source (ironiquement, elles passent en général par le web, même s’il s’agit plus précisément d’une API web que vous n’utilisez pas directement). Ainsi elles détricotent des dizaines d’années de progrès dans les technologies de l’information. Au lieu de nous apporter un progrès, elles proposent simplement une expérience que le Web peut déjà fournir sans recourir à des techniques spécifiques à une plate-forme. Pire, les applications parviennent à susciter l’enthousiasme autour d’elles. Mais pendant que nous installons avec entrain de plus en plus d’applications, nous sommes insidieusement privés de notre fenêtre d’ouverture universelle sur l’information et les services du monde entier.
Ils trouvent nos navigateurs trop puissants
Pourquoi les éditeurs de contenus préfèrent-ils les applications ? Parce-qu’elles leur donnent bien plus de contrôle sur ce que nous pouvons et ne pouvons pas faire. Le « problème » avec les navigateurs, du point de vue de l’éditeur, est qu’ils appartiennent aux utilisateurs. Cela signifie que nous sommes libres d’utiliser le navigateur de notre choix. Cela signifie que nous pouvons utiliser des plugins qui vont étendre les capacités du navigateur, par exemple pour des raisons d’accessibilité, ou pour ajouter de nouvelles fonctionnalités. Cela signifie que nous pouvons installer des bloqueurs de publicité afin de restreindre à notre guise l’accès de tierces parties à notre activité en ligne. Et plus important encore, cela signifie que nous pouvons nous échapper vers d’autres sites web d’un simple clic.
Si, en revanche, vous utilisez l’application, ce sont eux qui décident à quoi vous avez accès. Votre comportement est pisté sans relâche, les publicités sont affichées sans pitié. Et la protection légale est bien moindre dans ce cadre. L’application offre les fonctionnalités que le fournisseur choisit, à prendre ou à laisser, et vous ne pourrez ni les modifier ni les contourner. Contrairement au Web qui vous donne accès au code source de la page, les applications sont distribuées sous forme de paquets binaires fermés.
« Ne voulez-vous pas plutôt l’application ? »
J’ai procédé à une petite expérience pour mesurer exactement quelle proportion des sites Web les plus visités incitent leurs utilisateurs à installer l’application. J’ai écrit un programme pour déterminer automatiquement si un site web affiche une bannière de promotion de son application. L’outil utilise PhantomJS pour simuler un navigateur d’appareil mobile et capture les popups qui pourraient être insérés dynamiquement. La détection heuristique est basée sur une combinaison de mots-clés et d’indices du langage naturel.
Ce graphique montre combien desites du top Alexa (classés par catégorie) vous proposent d’utiliser leur application :
Plus d’un tiers des 500 sites les plus visités vous proposent d’utiliser leur application.
Les chiffres obtenus sont basés sur une heuristique et sous-estiment probablement la réalité. Dans certaines catégories, au moins un tiers des sites préfèrent que vous utilisiez leur application. Cela signifie qu’un tiers des plus gros sites essaient de nous enfermer dans leur plate-forme propriétaire. Sans surprise, les catégories informations locales, sports et actualités atteignent un pourcentage élevé, puisqu’ils souhaitent être en première ligne pour vous offrir les meilleures publicités. Il est intéressant de noter que les contenus pour adultes sont en bas du classement : soit peu de personnes acceptent d’être vues avec une application classée X, soit les sites pornographiques adorent infecter leurs utilisateurs avec des malwares via le navigateur.
Des prétextes mensongers
Même si les éditeurs de contenu demandent si nous « souhaitons » utiliser leur application, c’est un euphémisme. Ils veulentque nous l’utilisions. En nous privant de la maîtrise plus grande offerte par les navigateurs, ils peuvent mieux influencer les éléments que nous voyons et les choix que nous faisons. Le Web nous appartient à tous, alors que l’application n’est réellement qu’entre les mains de l’éditeur. Généralement, ils justifient l’existence de l’application en plus du site web en marmonnant des arguments autour d’une « expérience utilisateur améliorée », qui serait évidemment « bien plus rapide ». Il est curieux que les éditeurs préfèrent investir dans une technologie complètement différente, plutôt que de prendre la décision logique d’améliorer leur site internet en le rendant plus léger. Leur objectif principal, en réalité, est de nous garder dans l’application. Depuis iOS 9, cliquer sur un lien dans une application permet d’ouvrir un navigateur interne à l’application. Non seulement cette fonctionnalité prête à confusion (depuis quelle application suis-je parti(e), déjà ?), mais surtout elle augmente le contrôle de l’application sur votre activité en ligne. Et une simple pression du doigt vous« ramène » vers l’application que vous n’aviez en fait jamais quittée. Dans ce sens, les applications contribuent sciemment à la « bulle de filtre ».
Les Articles Instantanés de Facebook sont un exemple extrême : un lien normal vous dirige vers la version « optimisée » d’une page à l’intérieur-même de l’application Facebook. Facebook salue cette nouveauté comme un moyen de « créer des articles rapides et interactifs sur Facebook » et ils ne mentent même pas sur ce point : vous ne naviguez même plus sur le vrai Web. Les Articles Instantanés sont vendus comme une expérience « interactive et immersive » avec plus de « flexibilité et de contrôle » (pour les fournisseurs de contenu bien sûr) qui entraînent de nouvelles possibilités de monétisation, et nous rendent une fois de plus « mesurables et traçables ».
Soyons honnêtes sur ce point : le Web fournit déjà des expériences interactives et immersives. Pour preuve, les Articles Instantanés sont développés en HTML5 ! Le Web, en revanche, vous permet de quitter Facebook, de contrôler ce que vous voyez, et de savoir si vous êtes pisté. Le nom « Articles Instantanés » fait référence à la promesse d’une rapidité accrue, et bien qu’ils soient effectivement plus rapides, cette rapidité ne nous est pas vraiment destinée. Facebook explique que les utilisateurs lisent 20% d’articles en plus et ont 70% de chances en moins d’abandonner leur lecture. Ces résultats favorisent principalement les éditeurs… et Facebook, qui a la possibilité de prendre une part des revenus publicitaires.
Rendez-nous le Web
Ne vous y trompez pas : les applications prétendent exister pour notre confort, mais leur véritable rôle est de nous attirer dans un environnement clos pour que les éditeurs de contenu puissent gagner plus d’argent en récoltant nos données et en vendant des publicités auxquelles on ne peut pas échapper. Les développeurs aussi gagnent plus, puisqu’ils sont désormais amenés à élaborer des interfaces pour plusieurs plate-formes au lieu d’une seule, le Web (comme si l’interface de programmation du Web n’était pas déjà assez coûteuse). Et les plate-formes de téléchargement d’applications font également tinter la caisse enregistreuse. Je ne suis pas naïf : les sites web aussi font de l’argent, mais au moins le font-ils dans un environnement ouvert dont nous avons nous-mêmes le contrôle. Pour l’instant, on peut encore souvent choisir entre le site et l’application, mais si ce choix venait à disparaître, l’accès illimité à l’information que nous considérons à juste titre comme normal sur le Web pourrait bien se volatiliser avec.
Certaines voix chez Facebook prédisent déjà la fin des sites web, et ce serait en effet bon pour eux : ils deviendraient enfin l’unique portail d’accès à Internet. Certains ont déjà oublié qu’il existe un Internet au-delà de Facebook ! La réaction logique de certains éditeurs est d’enfermer leur contenu au sein de leur propre application, pour ne plus dépendre de Facebook (ou ne plus avoir à y faire transiter leurs profits). Tout ceci crée exactement ce que je crains : un monde d’applications fragmenté, où un unique navigateur ne suffit plus pour consommer tous les contenus du monde. Nous devenons les prisonniers de leurs applis :
Last thing I remember, I was running for the door.
I had to find the passage back to the place I was before.
“Relax,” said the night man, “we are programmed to receive.”
“You can check out any time you like, but you can never leave!”
Eagles – Hotel California
Mon dernier souvenir, c’est que je courais vers la porte,
Je devais trouver un passage pour retourner d’où je venais
« Relax », m’a dit le gardien, « on est programmés pour recevoir »
« Tu peux rendre ta chambre quand tu veux, mais tu ne pourras jamais partir ! »
Eagles, Hotel California
Cette chanson me rappelle soudain le directeur de Facebook comparant les sites web et le vinyle. L’analogie ne pourrait pas être plus juste. Le Web est un disquaire, les sites sont des disques et le navigateur un tourne-disque : il peut jouer n’importe quel disque, et différents tourne-disques peuvent jouer le même disque. En revanche, une application est une boîte à musique : elle est peut-être aussi rapide qu’un fichier MP3, mais elle ne joue qu’un seul morceau, et contient tout un mécanisme dont vous n’auriez même pas besoin si seulement ce morceau était disponible en disque. Et ai-je déjà mentionné le fait qu’une boîte à musique ne vous laisse pas choisir le morceau qu’elle joue ?
Les sites web sont comme les vinyles : un tourne-disque suffit pour les écouter tous. Image : turntable CC-BY-SA Traaf
C’est la raison pour laquelle je préfère les tourne-disques aux boîtes à musique – et les navigateurs aux applications. Alors à tous les éditeurs qui me demandent d’utiliser leur application, je voudrais répondre : pourquoi n’utilisez-vous pas plutôt le Web ?
À la recherche du téléphone libre… et sans Google !
Vous connaissez l’adage ? « Si le téléphone est intelligent, c’est que l’utilisateur est stupide. » Malheureusement, il se vérifie dans la manière dont les entreprises qui conçoivent ces ordinateurs de poche (avec option téléphone) nous traitent…
Entre la prison dorée qu’est l’Iphone d’Apple (qu’il nous faut « jailbreaker » pour un tout petit peu plus de contrôle, ce qui signifie en Français qu’on en « brise les barreaux »), l’espionnage total de Google sur les Android, les autorisations hallucinantes que nous demandent les applications propriétaires, l’esclavagisme qui se cache derrière les matériaux et la construction, l’obsolescence programmée… difficile de trouver un ordiphone qui convient à nos choix éthiques.
Gee, notre illustrateur-auteur-docteur maison, est parti à la quête d’un smartphone (et de ses logiciels) qui respecterait ce lourd cahier des charges. Nous reproduisons ici un article (libre, bien entendu) paru sur son blog, qui nous offre un retour d’expérience très personnel.
N’hésitez pas à ajouter vos astuces, alternatives, choix et bonnes adresses dans les commentaires !
Aujourd’hui, je vous propose un petit retour sur le Fairphone 2 qui est devenu mon téléphone il y a un mois de cela. Bon, je n’ai jamais fait d’article de ce genre alors désolé si c’est un peu décousu. Je précise d’emblée que ce n’est absolument pas un article sponsorisé ou commandé, c’est juste un retour spontané parce que je pense que cela peut en intéresser certains (les libristes en premier lieu mais pas seulement).
Au départ, c’est tout bête : un téléphone vieillissant mal et la volonté d’en changer. Sauf que les smartphones, outre leurs avantages (oui parce que si j’en ai un, ça reste un choix), m’ont toujours dérangé pour plusieurs choses :
ils sont chers (je n’ai jamais été très à l’aise à l’idée de me trimbaler avec des objets de plusieurs centaines d’euros dans la poche ou à la main) ;
ils sont fragiles et conçus pour durer le moins de temps possible (jusqu’à la sortie du modèle suivant, en gros), obsolescence programmée, tout ça ;
ils sont ultra-verrouillés. Firefox OS plus ou moins enterré, Ubuntu Touch à peine existant, c’est encore Android (et dérivées) qui se rapproche le plus du libre (c’est dire dans quelle merde on est).
Pour le prix, je m’étais toujours dirigé vers du milieu de gamme en faisant des concessions sur les perfs (je ne joue que très peu et ne regarde pas de vidéos de manière prolongée dessus, ça aide).
Pour le second, malgré tous mes efforts pour en prendre soin et pour ne conserver un système stable dans le temps, je n’ai jamais réussi à garder un smartphone bien longtemps. Le dernier en date (Sony Xperia J) va avoir 3 ans et honnêtement, il a déjà des soucis depuis facilement 1 an, c’est justement par pragmatisme que je l’ai gardé. Vous allez me dire, j’aurais pu mettre plus cher et avoir un truc plus solide. M’enfin ma sœur a réussi à péter un Samsung à 500€ avec une Chupa Chups, alors vous m’excuserez si je suis sceptique.
Pour le troisième point, il y a la solution de se lancer dans les joyeusetés du root et de l’install de ROM custom. J’ai testé avec CyanogenMod sur mon Xperia, eh bien c’est incroyablement chiant et compliqué (et je dis ça du point de vue d’un mec qui installe des GNU/Linux tous les 4 matins sur des appareils plus ou moins exotiques). Des ROMS hébergées sur d’immondes sites de direct download (avec 1 tiers de liens morts), des forums à inscription obligatoire pour lire les tutos, des utilitaires Windows-only à tous les étages. Yark. Et après on va me dire que Gnunux, c’est trop compliqué.
Le Fairphone
Bref, l’idée de changer de smartphone ne m’enchante pas vraiment. Forcément, j’en viens à chercher des choses comme « smartphone alternatif » sur Internet. C’est comme ça que je retombe sur le Fairphone (dont j’avais déjà entendu parlé d’une oreille distraite avant). Je ne vous refais pas la description, en gros un smartphone qui se veut un peu plus responsable que la moyenne : pas d’exploitation d’enfants pour l’extraction des matières premières, des circuits type commerce équitable, possibilité de facilement réparer et remplacer les pièces du smartphone pour ne pas devoir le jeter au premier souci, etc. Tout de suite, ça me tente bien.
Mais voilà, tout cela a un prix : 525€. Aïe. Bien plus cher que des téléphones aux caractéristiques équivalentes d’autres marques. Rien de surprenant, quand on paie correctement les travailleurs et qu’on essaie d’avoir des pratiques éthiques, on arrive forcément à un prix total plus élevé que des entreprises sans scrupules plus habituées aux filets anti-suicide pour les exploités au bout de la chaîne et du rouleau à la fois. Mais on est bien au-dessus de mon budget habituel. Non pas que je n’en aie pas les moyens, mais comme je l’ai dit, me balader avec des centaines d’euros à la main ou dans la poche, ça m’embête un peu.
Et là je tombe sur le truc qui va faire basculer ma décision : le Fairphone est vendu de base avec un Android classique… mais ils fournissent également une version d’Android Open Source débarrassée de toutes les apps non libres (dont toutes celles de Google, y compris Play Store). Oh. Alors certes, un Android Open Source, ce n’est pas Fairphone qui l’a inventé. Mais là, on parle d’un truc :
supporté officiellement par le constructeur et prévu pile pour le téléphone en question ;
qui ne fera donc pas péter la garantie si on l’installe ;
qui est (visiblement) installable en un clic (hallelujah hare krishna).
Je demande quelques conseils sur Diaspora* et devant les avis majoritairement positifs, je saute le pas. C’est cher, mais après tout j’aurais réglé 2 de mes 3 problèmes avec les smartphones (l’obsolescence et le verrouillage) en faisant une concession sur le troisième (le prix).
Est-ce que ça marche ?
En bref : oui. Premier allumage, je rentre toutes mes infos, je zappe les parties Google et je remplace direct Android par la version open Source fournie par Fairphone. Deuxième allumage, un Android parfaitement fonctionnel sans Google et avec juste ce qu’il faut (applications téléphone, appareil photo, galerie, musique, etc.). Quand on est habitué au merdier que les constructeurs ajoutent habituellement dans leurs Androids personnalisés, c’est presque reposant.
Côté matos, rien à redire. On n’est sans doute pas au top de la technologie actuelle, mais pour quelqu’un comme moi habitué à du milieu de gamme, c’est parfait. Je ne vous fais pas la fiche technique, c’est dispo partout sur le web.
L’autonomie (le point qui laisse à désirer dans tous les tests) n’est pas fabuleuse mais rien de catastrophique non plus. En utilisation modérée (un peu de communication, quelques SMS, lire ses mails, ses tweets et ses forums de temps en temps), il peut tenir 2 jours voire 3 en utilisation très modérée. Après si on se lance dans les jeux ou de la navigation un peu intensive, on est plus sur 1 jour, c’est vrai. À part ça, il est stable, fluide, aucun ralentissement, appareil photo très performant (deux exemples ci-dessous). L’écran n’est pas mat mais l’affichage est de très bonne qualité.
Après quelques semaines d’utilisation, je m’y sens chez moi. Il y a déjà eu une mise à jour de l’OS depuis que je l’ai installé. Espérons que le support dure.
Android sans Google ?
Cette partie ne concerne pas spécifiquement le Fairphone. Comment on se débrouille avec Android sans compte et sans appli Google ? Comment on se débrouille avec Android quand on veut au maximum utiliser du logiciel libre ?
Déjà, un grand classique que tous les libristes connaissent : F-Droid. C’est un app center alternatif à Google Play Store promu par la Free Software Foundation Europe. Parfait pour n’installer que des applications alternatives et libres. Le logiciel n’est pas des plus sexy (pas de doute, on est bien chez la FSF 🙂 ) mais il fait le boulot très bien. Le plus gros manque, à mon sens, c’est un système de classement : quand on recherche une app, on voudrait savoir laquelle est la plus appréciée ou la plus téléchargée et ce n’est pas possible. On finit toujours par chercher sur le web « best open source photo gallery app android » par exemple. Dommage. Pour le reste, c’est clair, épuré, on installe/désinstalle en un clic, des messages avertissent si l’appli est partiellement non-libre ou promeut des services non-libres, etc. Bref, F-Droid, c’est la supérette bio d’Android.
Ensuite, eh bien il faut juste trouver les applis qui vous conviennent. Le site Droid Break est très bien et donne quelques alternatives à des applications connues.
Un aperçu des applications installées sur mon téléphone :
Bien sûr, dans le tas, il y a des applis pour se connecter à des services non-libres (Twitter, YouTube, etc.). Mais contrairement aux applis officielles, elles ont tendance à vous demander sacrément moins d’autorisations, c’est déjà un plus. En vrac :
TTRSS-Reader : lecteur de flux RSS spécialisé pour Tiny Tiny RSS (branché dans mon cas sur mon compte Framanews) ;
Diaspora : branché sur mon compte Framasphère. Dispensable puisque la version web de Diaspora* est très satisfaisante ;
Twidere : appli alternative pour gérer ses comptes Twitter. Pas de publications promotionnelles, pas de timeline et tout marche bien (manque les sondages pour l’instant). Rien à redire ;
LeafPic : galerie photo bien foutue (je n’étais pas très satisfait de la galerie de base) ;
Firefox : inutile de le présenter mais le panda roux / renard de feu (choisissez votre camp, perso j’en ai rien à carrer) marche bien aussi sur mobile ;
K-9 Mail : excellente appli pour gérer des comptes mails multiples. Les fans de Dr Who apprécieront la référence (perso je n’en ai – encore une fois – rien à carrer) ;
GBCoid : émulateur de GameBoy qui marche très bien et qui est très configurable. Oui, je disais que je ne jouais pas sur smartphone, mais c’est à moitié vrai. Disons que je suis plutôt retrogaming, ce qui se satisfait de perfs modestes en général. Les boutons émulés sur l’écran tactile, faut s’y faire (surtout pour les jeux d’adresse) mais c’est sympa d’avoir un téléphone qui fait GameBoy ;
ScummVM : pour faire tourner les point’n’click des années 90 (particulièrement ceux de LucasArts) dont je suis un fan absolu. Je viens tout juste de me refaire tout Monkey Island 2 (et là je refais le un, OUI C’EST DANS LE DÉSORDRE ET ALORS) ;
NewPipe : lecteur pour YouTube. Simple et efficace ;
Wikipédia : rien à redire, ça marche nickel. J’aime particulièrement le fait que cliquer sur un lien interne ouvre un petit onglet de prévisualisation en bas au lieu d’ouvrir l’article directement ;
Barcode Scanner : lecteur de QR-Code et assimilés. Le genre d’appli que j’utilise toutes les morts d’évêques mais qu’il est bien pratique d’avoir quand même ;
Turbo Editor : éditeur de texte. Je n’en ai pas une grande utilisation (éditer du texte sur un smartphone, faut être motivé), mais ça dépanne bien ;
Tomdroid : gestionnaire de notes. Bien pour relever les compteurs, noter un numéro, etc. Les linuxiens reconnaîtront Tomboy ;
OsmAnd~ : cartes et navigation basé sur OpenStreetMap avec stockage des cartes en local. Une très bonne appli qui mériterait d’être plus connue, parfaite pour remplacer Google Maps ;
ShoLi : gestionnaire de liste de courses. C’est tout con mais c’est très pratique (on prépare une liste puis on coche les éléments en tapotant dessus) et je m’en sers tout le temps ;
DAVdroid : pour gérer les contacts et calendrier de mon compte Owncloud (sur Framadrive) ;
RedReader : pour gérer un compte Reddit ;
ownCloud : client OwnCloud (pour la partie fichiers donc), branché aussi sur mon Framadrive ;
Amaze : l’appli est installée de base, c’est un bon explorateur de fichiers.
Et la petite appli « L’espace client » dont je n’ai pas parlé ? Eh bien là, c’est la solution de secours en l’absence d’alternative : utiliser un marque-page Firefox et en faire une icône. Là, il s’agit du portail web mobile de ma banque. Ils fournissent une appli non-libre sur le Play Store et c’est typiquement le genre de d’appli que, pour des raisons de sécurité, je n’irai pas télécharger en APK directement sur n’importe quel site venu. Bref, le web mobile, c’est bien, ça marche (quand c’est fait correctement).
Comme ça a tendance à manquer un peu, quelques captures d’écran de la plupart de ces applis :
Alors, est-ce qu’au final, Android sans les applis fermées et sans Google, c’est faisable ? Bien sûr ! Et ça marche même très bien.
Mais est-ce que c’est pareil ? Aussi facile à utiliser ? Aussi pratique ? Alors là, je vais être un peu abrupt : la réponse est non.
Mais au bout d’un moment, il va falloir faire le deuil de ce genre de problématique. Aucune alternative libre n’a la puissance de frappe d’un GAFAM, il est illusoire d’espérer en obtenir la même chose. J’ai parlé de F-Droid comme de la supérette bio d’Android, et ce n’est pas un hasard : je pense que le choix du Libre en informatique, c’est comme le choix du bio en nourriture. Quand tu décides de manger bio, tu sais que les KitKats c’est terminé, tu sais que tes légumes seront peut-être moins brillants et que tu auras moins de choix en prenant des produits locaux (normal, on ne produit pas des bananes n’importe où et à n’importe quel moment de l’année). Mais tu manges bio parce que, quelque part, tu es prêt à faire des concession pour avoir accès à des choses plus saines et que tu sais qu’au final, tu restes « gagnant » par rapport à la bouffe industrielle. Et jamais tu n’exigeras autant de choix et de flexibilité à ta supérette bio qu’au Géant Casino d’à côté.
Le Libre, c’est pareil. Non, je n’aurai pas la dernière appli qui défonce tout, oui je me prive de certaines fonctionnalités hyper-pratiques (Google Maps et Waze pour t’aider à éviter les bouchons quand t’habites près de Nice, c’est un bonheur pourtant). Mais ça vaut le coup. Avoir un téléphone qui vous fout la paix, qui ne vous espionne pas. Des applis qui demandent juste les autorisations qu’il leur faut (c’est-à-dire souvent pas grand-chose). Pas de pub, pas de fonctionnalités payantes cachées, pas de connexion centralisée avec Google, Facebook ou qui sais-je encore. Juste des applis simples qui font le boulot et qui manquent parfois un peu de polish.
On ne démantèlera pas Géant Casino ou Carrefour avec nos petites paluches. Mais, supérette bio après supérette bio, on participe à une alternative de plus en plus viable. C’est pareil pour GAFAM et les petites alternatives qui ne paient pas de mine.
Et comme indiqué au-dessus, ça n’implique pas nécessairement de se couper totalement des services non-libres (type Twitter) dont on reste parfois encore dépendants (je n’ai pas la prétention d’être blanc comme neige sur ce point, je fais comme la plupart des gens : au mieux).
Je conclurais bien en disant que ça me rappelle un certain projet de dégooglisation, mais zut, on va encore dire que je fais de la promo pour les copains 🙂
F-Droid, la plateforme d’applications Android Libre
Droid-Break [EN], pour trouver des applications alternatives.
Ce que valent nos adresses quand nous signons une pétition
Le chant des sirènes de la bonne conscience est hypnotique, et rares sont ceux qui n’ont jamais cédé à la tentation de signer des pétitions en ligne… Surtout quand il s’agit de ces « bonnes causes » qui font appel à nos réactions citoyennes et humanistes, à nos convictions les mieux ancrées ou bien sûr à notre indignation, notre compassion… Bref, dès qu’il nous semble possible d’avoir une action sur le monde avec un simple clic, nous signons des pétitions. Il ne nous semble pas trop grave de fournir notre adresse mail pour vérifier la validité de notre « signature ». Mais c’est alors que des plateformes comme Change.org font de notre profil leur profit…
Voilà ce que dénonce, chiffres à l’appui, la journaliste de l’Espresso Stefania Maurizi. Active entre autres dans la publication en Italie des documents de Wikileaks et de Snowden, elle met ici en lumière ce qui est d’habitude laissé en coulisses : comment Change.org monétise nos données les plus sensibles.
Dans le cadre de notre campagne Dégooglisons, nous sommes sensibles à ce dévoilement, c’est un argument de plus pour vous proposer prochainement un Framapétitions, un outil de création de pétitions libre et open source, respectueux de vos données personnelles…
Voilà comment Change.org vend nos adresses électroniques
L’Espresso a obtenu les tarifs de l’entreprise (de 1,50 euro à 85 centimes) et a contacté certains clients. Entre les réponses embarrassées et les reconnaissances du bout des lèvres, nous avons étudié l’activité de l’« Amazon des pétitions en ligne ». Elle manipule des données extrêmement sensibles telles que les opinions politiques et fait l’objet en Allemagne d’une enquête sur le respect de la vie privée.
On l’a appelée le « Google de la politique moderne ». Change.org, la plateforme populaire pour lancer des pétitions sur les questions politiques et sociales, est un géant qui compte cent cinquante millions d’utilisateurs à travers le monde et ce nombre augmente d’un million chaque semaine : un événement comme le Brexit a déclenché à lui seul 400 pétitions. En Italie, où elle a débarqué il y a quatre ans, Change.org a atteint cinq millions d’utilisateurs. Depuis la pétition lancée par Ilaria Cucchi pour demander l’approbation d’une loi sur la torture, qui a jusqu’à présent recueilli plus de 232 000 signatures, jusqu’à celle sur le référendum constitutionnel, que celui qui n’a jamais apposé une signature sur Change.org dans l’espoir de faire pression sur telle ou telle institution pour changer les choses lève la main. Au 21e siècle, la participation démocratique va inévitablement vers les plateformes en ligne. Et en effet on ne manque pas d’exemples dans lesquels ces pétitions ont vraiment déclenché des changements.
Il suffit de quelques clics : tout le monde peut lancer une pétition et tout le monde peut la signer. Mais il y a un problème : combien de personnes se rendent-elles compte que les données personnelles qu’elles confient à la plateforme en signant les soi-disant « pétitions sponsorisées » — celles qui sont lancées par les utilisateurs qui paient pour les promouvoir (https://www.change.org/advertise) — seront en fait vendues et utilisées pour les profiler ? La question est cruciale, car ce sont des données très sensibles, vu qu’elles concernent des opinions politiques et sociales.
L’Espresso est en mesure de révéler les tarifs que Change.org applique à ceux qui lancent des pétitions sponsorisées : des ONG aux partis politiques qui payent pour obtenir les adresses électroniques des signataires. Les prix vont de un 1,5 € par adresse électronique, si le client en achète moins de dix mille, jusqu’à 85 centimes pour un nombre supérieur à cinq cent mille. Notre journal a aussi demandé à certaines des ONG clientes de Change.org s’il est vrai qu’elles acquièrent les adresses électroniques des signataires. Certaines ont répondu de façon trop évasive pour ne pas susciter d’interrogations. D’autres, comme Oxfam, ont été honnêtes et l’ont confirmé.
Pour Change.org, voici combien vaut votre adresse électronique
Beaucoup croient que Change.org est une association sans but lucratif, animée d’idéaux progressistes. En réalité, c’est une véritable entreprise, Change.org Inc, créée dans le Delaware, un paradis fiscal américain, dont le quartier général est à San Francisco, au cœur de cette Silicon Valley où les données ont remplacé le pétrole. Et c’est vrai qu’elle permet à n’importe qui de lancer gratuitement des pétitions et remplit une fonction sociale : permettre jusqu’au dernier sans domicile fixe de s’exprimer. Mais elle réalise des profits avec les pétitions sponsorisées, là où le client paie pour réussir à contacter ceux qui seront probablement les plus enclins à signer et à donner de l’argent dans les campagnes de récolte de fonds. Comment fait Change.org pour le savoir ? Chaque fois que nous souscrivons à un appel, elle accumule des informations sur nous et nous profile. Et comme l’a expliqué clairement la revue américaine Wired : « si vous avez signé une pétition sur les droits des animaux, l’entreprise sait que vous avez une probabilité 2,29 fois supérieure d’en signer une sur la justice. Et si vous avez signé une pétition sur la justice, vous avez une probabilité 6,3 fois supérieure d’en signer une sur la justice économique, 4,4 d’en signer une sur les droits des immigrés et 4 fois d’en signer une autre encore sur l’éducation. »
Celui qui souscrit à une pétition devrait d’abord lire soigneusement les règles relatives à la vie privée, mais combien le font et combien comprennent réellement que, lorsqu’ils signent une pétition sponsorisée, il suffit qu’ils laissent cochée la mention « Tenez-moi informé de cette pétition » pour que leur adresse électronique soit vendue par Change.org à ses clients qui ont payé pour cela ? Ce n’est pas seulement les tarifs obtenus par L’Espresso qui nous confirment la vente des adresses électroniques, c’est aussi Oxfam, une des rares ONG qui a répondu de façon complètement transparente à nos questions : « c’est seulement au moment où les signataires indiquent qu’ils soutiennent Oxfam qu’il nous est demandé de payer Change.org pour leurs adresses », nous explique l’organisation.
Nous avons demandé ce que signifiait exactement « les signataires ont indiqué vouloir soutenir Oxfam », l’ONG nous a répondu en montrant la case cochée par le signataire, par laquelle il demande à rester informé de la pétition. Interpellée par L’Espresso, l’entreprise Change.org n’a pas démenti les tarifs. De plus elle a confirmé qu’ « ils varient selon le client en fonction du volume de ses achats » ; comme l’a expliqué John Coventry, responsable des Relations publiques de Change.org, une fois que le signataire a choisi de cocher la case, ou l’a laissée cochée, son adresse électronique est transmise à l’organisation qui a lancé la pétition sponsorisée. Coventry est convaincu que la plupart des personnes qui choisissent cette option se rendent compte qu’elles recevront des messages de l’organisation. En d’autres termes, les signataires donnent leur consentement.
Capture d’écran sur le site Change.org
Depuis longtemps, Thilo Weichert, ex-commissaire pour la protection des données du Land allemand de Schleswig-Holstein, accuse l’entreprise de violation de la loi allemande en matière de confidentialité. Weichert explique à l’Espresso que la transparence de Change.org laisse beaucoup à désirer : « ils ne fournissent aucune information fiable sur la façon dont ils traitent les données ». Et quand nous lui faisons observer que ceux qui ont signé ces pétitions ont accepté la politique de confidentialité et ont donc donné leur consentement en toute conscience, Thilo répond que la question du consentement ne résout pas le problème, parce que si une pratique viole la loi allemande sur la protection des données, l’entreprise ne peut pas arguer du consentement des utilisateurs. En d’autres termes, il n’existe pas de consentement éclairé qui rende légal le fait d’enfreindre la loi.
Suite aux accusations de Thilo Weichert, la Commission pour la protection des données de Berlin a ouvert sur Change.org une enquête qui est toujours en cours, comme nous l’a confirmé la porte-parole de la Commission, Anja-Maria Gardain. Et en avril, l’organisation « Digitalcourage », qui en Allemagne organise le « Big Brother Award » a justement décerné ce prix négatif à Change.org. « Elle vise à devenir ce qu’est Amazon pour les livres, elle veut être la plus grande plateforme pour toutes les campagnes politiques » nous dit Tangens Rena de Digitalcourage. Elle explique comment l’entreprise s’est montrée réfractaire aux remarques de spécialistes comme Weichert : par exemple en novembre dernier, celui-ci a fait observer à Change.org que le Safe Harbour auquel se réfère l’entreprise pour sa politique de confidentialité n’est plus en vigueur, puisqu’il a été déclaré invalide par la Cour européenne de justice suite aux révélations d’Edward Snowden. Selon Tangens, « une entreprise comme Change.org aurait dû être en mesure de procéder à une modification pour ce genre de choses. »
L’experte de DigitalCourage ajoute qu’il existe en Allemagne des plateformes autres que Change.org, du type Campact.de : « elles ne sont pas parfaites » précise-t-elle, « et nous les avons également critiquées, mais au moins elles se sont montrées ouvertes au dialogue et à la possibilité d’opérer des modifications ». Bien sûr, pour les concurrents de Change.org, il n’est pas facile de rivaliser avec un géant d’une telle envergure et le défi est presque impossible à relever pour ceux qui choisissent de ne pas vendre les données des utilisateurs. Comment peuvent-ils rester sur le marché s’ils ne monétisent pas la seule denrée dont ils disposent : les données ?
Pour Rena Tagens l’ambition de l’entreprise Change.org, qui est de devenir l’Amazon de la pétition politique et sociale, l’a incitée à s’éloigner de ses tendances progressistes initiales et à accepter des clients et des utilisateurs dont les initiatives sont douteuses. On trouve aussi sur la plateforme des pétitions qui demandent d’autoriser le port d’armes à la Convention républicaine du 18 juillet, aux USA. Et certains l’accusent de faire de l’astroturfing, une pratique qui consiste à lancer une initiative politique en dissimulant qui est derrière, de façon à faire croire qu’elle vient de la base. Avec l’Espresso, Weichert et Tangens soulignent tous les deux que « le problème est que les données qui sont récoltées sont vraiment des données sensibles et que Change.org est située aux Etats-Unis », si bien que les données sont soumises à la surveillance des agences gouvernementales américaines, de la NSA à la CIA, comme l’ont confirmé les fichiers révélés par Snowden.
Mais Rena Tangens et Thilo Weichert, bien que tous deux critiques envers les pratiques de Change.org, soulignent qu’il est important de ne pas jeter le bébé avec l’eau du bain, car ils ne visent pas à détruire l’existence de ces plateformes : « Je crois qu’il est important qu’elles existent pour la participation démocratique, dit Thilo Weichert, mais elles doivent protéger les données ».
Mise à jour du 22 juillet : la traduction de cet article a entraîné une réaction officielle de Change.org France sur leur page Facebook, suite auquel nous leur avons bien évidemment proposé de venir s’exprimer en commentaire sur le blog. Ils ont (sympathiquement) accepté. Nous vous encourageons donc à prendre connaissance de leur réponse, ainsi que les commentaires qui le suivent, afin de poursuivre le débat.
La prise de conscience et la suite
C’est peut-être le début du début de quelque chose : naguère traités de « paranos », les militants pour la vie privée ont désormais une audience croissante dans le grand public, on peut même parler d’une prise de conscience générale partielle et lente mais irréversible…
Dans un article récent traduit pour vous par le groupe Framalang, Cory Doctorow utilise une analogie inattendue avec le déclin du tabagisme et estime qu’un cap a été franchi : celui de l’indifférence générale au pillage de notre vie privée.
Mais le chemin reste long et il nous faut désormais aller au-delà en fournissant des outils et des moyens d’action à tous ceux qui refusent de se résigner. C’est ce qu’à notre modeste échelle nous nous efforçons de mener à bien avec vous.
traduction Framalang : lyn, Julien, cocosushi, goofy, xi
Dès les tout premiers jours de l’accès public à Internet, les militants comme moi n’ont cessé d’alerter sur les risques sérieux pour la vie privée impliqués par les traces des données personnelles que nous laissons derrière nous lors de notre activité quotidienne en ligne. Nous espérions que le grand public réfléchirait sérieusement aux risques potentiels de divulgation à tout va. Que le grand public comprendrait que les inoffensives miettes d’informations personnelles pourraient être minutieusement rassemblées pour notre malheur par des criminels ou des gouvernements répressifs, des harceleurs aux aguets ou des employeurs abusifs, ou encore par des forces de l’ordre bien intentionnées mais qui pourraient tirer des conclusions fallacieuses de leur espionnage de nos vies.
Nous avons complètement échoué.
La popularité et la portée d’Internet n’ont fait qu’augmenter chaque année. Et chaque année ont augmenté aussi les menaces sur la vie privée des utilisateurs.
Pour être honnête, nous, les défenseurs de la vie privée, avons une bonne excuse. Il est vraiment très difficile d’amener les gens à avoir conscience des dangers qui les menacent lorsque ceux-ci sont à venir, surtout quand le comportement qui vous met en danger et ses conséquences sont très éloignés dans le temps et dans l’espace. La divulgation de la vie privée est un problème de santé publique, comme le tabagisme. Ce n’est pas une simple bouffée de cigarette qui va vous donner le cancer, mais inhalez assez de bouffées et, au bout du compte, ce sera le cancer quasi assuré. Une simple divulgation de vos données personnelles ne vous causera pas de préjudice, mais la répétition de ces divulgations sur le long terme engendrera de sérieux problèmes de confidentialité.
Pendant des décennies, les défenseurs de la santé publique ont essayé d’amener les gens à se préoccuper des risques de cancer, sans beaucoup de succès. Ils avaient, eux aussi, une bonne excuse. Fumer procure un bénéfice à court terme (on calme une envie irrésistible) et le coût en est modique. Pire encore, les entreprises qui faisaient du profit avec le tabac ont largement financé des campagnes de désinformation pour que leurs clients aient plus de mal à appréhender les risques à long terme, et surtout évitent de s’en soucier.
Le tabagisme est maintenant en déclin (bien que le vapotage s’avère y conduire efficacement), mais il a fallu pas mal de temps pour en arriver là. Quand ceux qui avaient fumé toute leur vie recevaient le diagnostic de leur cancer, il était déjà trop tard, et beaucoup ont nié la réalité de leur cancer, ont continué à fumer tout au long de leur thérapie, ou bien ont connu une mort lente et cruelle. L’association entre le plaisir à court terme de la fumée et l’absence de moyens significatifs de réparer les dégâts qui se sont déjà produits, telle est l’infaillible moteur du déni : pourquoi se priver des plaisirs de la fumée si finalement ça ne fait aucune différence ?
Cependant, le tabagisme n’est en déclin que parce que les preuves de ses dégâts sont peu à peu devenues indéniables. À un certain moment, l’indifférence aux dangers du tabac a atteint son point culminant – bien avant que le tabagisme lui-même n’atteigne son maximum. L’indifférence maximale représente un tournant. Une fois que le nombre de personnes qui se sentent concernées par le problème commence à grandir indépendamment de vous, sans que vous ayez besoin de présenter encore et toujours ses conséquences à long terme, vous pouvez changer de tactique pour passer à quelque chose de bien plus facile. Plutôt que d’essayer d’impliquer les gens, vous avez maintenant seulement besoin de les inciter à agir sur ce sujet.
Le mouvement contre le tabagisme a réalisé de grandes avancées sur ce terrain. Il a fait en sorte que les personnes atteintes du cancer – ou celles dont les proches l’étaient – comprennent que le fait de fumer n’était pas un phénomène venu de nulle part. Des noms ont été cités, des documents publiés qui ont montré exactement qui conspirait pour détruire des vies avec le cancer afin de s’enrichir. Les militants ont mis au jour et souligné les risques qui pèsent sur la vie des gens non fumeurs : le tabagisme passif, mais aussi le poids qu’il pèse sur la santé publique et la douleur des survivants après le décès de leurs proches. Tous ont demandé des changements structurels – interdiction de fumer – et légaux, économiques et normatifs. Franchir le cap de l’indifférence maximale leur a permis de passer de l’argumentation à la réponse.
Voilà pourquoi il est grand temps que les défenseurs de la vie privée se mettent à réfléchir à une nouvelle tactique. Nous avons franchi et dépassé le cap de l’indifférence à la surveillance en ligne : ce qui signifie qu’à compter d’aujourd’hui, le nombre de gens que la surveillance indigne ne fera que croître.
La mauvaise nouvelle, c’est qu’après 20 ans d’échec pour convaincre les gens des risques liés à leur vie privée, une boite de Pandore s’est construite : toutes les données collectées, actuellement stockées dans des bases de données géants seront, un jour ou l’autre, divulguées et lorsque cela se produira, des vies seront détruites. Ils verront leur maison volée par des usurpateurs d’identité qui falsifient les titres de propriété (ça c’est déjà vu), leur casier judiciaire ne sera plus vierge car des usurpateurs auront pris leur identité pour commettre des délits (ça c’est déjà vu), ils seront accusés de terrorisme ou de crimes terribles parce qu’un algorithme aura scanné leurs données et aura abouti à une conclusion qu’ils ne pourront ni lire ni remettre en question (ça c’est déjà vu) ; leurs appareils seront piratés parce que leurs mots de passe et autres données personnelles auront fuité de vieux comptes, des pirates les espionneront depuis leurs babyphones, leur voitures, leurs décodeurs, leurs implants médicaux (ça c’est déjà vu) ; leurs informations sensibles, fournies au gouvernement pour obtenir des accréditations fuiteront et seront stockées par des états ennemis pour exercer un chantage (ça c’est déjà vu) , leurs employeurs feront faillite après que des informations personnelles auront servies à faire de l’espionnage industriel (ça c’est déjà vu) etc..
Du piratage du site Ashley Madison à la violation de données de l’Office of Personnel Management [le service qui gère les fonctionnaires fédéraux aux USA], ce qui nous attend est clair : dorénavant, tous les quinze jours, un ou deux millions de personnes dont la vie vient d’être détruite par une fuite de données vont régulièrement aller frapper à la porte d’un défenseur de la vie privée, pâles comme un fumeur qui vient d’apprendre qu’il a un cancer, ils lui diront : « Vous aviez raison. On fait quoi, maintenant ? »
Clavier « vie privée » par g4ll4is, (CC BY-SA 2.0)
C’est là que nous pouvons intervenir. Nous pouvons désigner les personnes qui nous ont dit que la notion de vie privée était obsolète alors qu’eux-mêmes dépensent des centaines de millions de dollars pour se prémunir de toute surveillance, en achetant les maisons proches de la leur et en les laissant vides (comme l’a fait le PDG de Facebook, Mark Zuckerberg) ; en menaçant les journalistes qui ont divulgué des données personnelles les concernant (comme l’a fait l’ex-PDG de Google, Eric Schmidt) ; en utilisant des paradis fiscaux pour cacher leurs délits financiers (comme ceux nommés dans les Panama Papers). Toutes ces personnes ont dit un jour : « La vie privée, c’est fini » mais ils voulaient dire « Si vous pensez que c’en est fini de votre vie privée, je serai vraiment beaucoup plus riche. »
Nous devons citer des noms, rendre évident le fait que des personnes vivantes aujourd’hui ont conçu un mouvement de déni de la vie privée sur le modèle du mouvement de déni du cancer conçu par l’industrie du tabac.
Nous devons fournir des moyens d’action : des outils de protection des données personnelles qui permettent aux gens de se défendre contre l’économie de la surveillance ; des campagnes politiques qui exposent et ridiculisent publiquement les politiciens et les espions ; l’opportunité d’obtenir en justice des réparations de ceux qui profitent de la surveillance.
Si nous pouvons donner une perspective d’action aux victimes du pillage de leur vie privée, un mouvement qu’elles puissent rejoindre, elles combattront à nos côtés. Sinon, elles deviendront des nihilistes de la confidentialité et continueront à répandre leurs données personnelles pour gagner un peu de vie sociale à court terme, ce qui en fera des proies faciles pour les espions, les escrocs, les salauds et les voyeurs.
C’est à nous de jouer.
Les anciens Léviathans II — Internet. Pour un contre-ordre social
Qu’est-ce qui fait courir Framasoft ? De la campagne Dégooglisons à l’initiative C.H.A.T.O.N.S quelles idées ont en tête les acteurs et soutiens de l’association ? Vous reprendrez bien une tranche de Léviathan ?
Michel Foucault, disparu il y a trente ans, proposait d’approcher les grandes questions du monde à travers le rapport entre savoir et pouvoir. Cette méthode a l’avantage de contextualiser le discours que l’on est en train d’analyser : quels discours permettent d’exercer quels pouvoirs ? Et quels pouvoirs sont censés induire quelles contraintes et en vertu de quels discours ? Dans un de ses plus célèbres ouvrages, Surveiller et punir[1], Foucault démontre les mécanismes qui permettent de passer de la démonstration publique du pouvoir d’un seul, le monarque qui commande l’exécution publique des peines, à la normativité morale et physique imposée par le contrôle, jusqu’à l’auto-censure. Ce n’est plus le pouvoir qui est isolé dans la forteresse de l’autorité absolue, mais c’est l’individu qui exerce lui-même sa propre coercition. Ainsi, Surveiller et punir n’est pas un livre sur la prison mais sur la conformation de nos rapports sociaux à la fin du XXe siècle.
Deux autres auteurs et œuvres pas du tout importants. Du tout, du tout.
Les modèles économiques ont suivi cet ordre des choses : puisque la société est individualiste, c’est à l’individu que les discours doivent s’adresser. La plupart des modèles économiques qui préexistent à l’apparition de services sur Internet furent considérés, au début du XXIe siècle, comme les seuls capables de générer des bénéfices, de l’innovation et du bien-être social. L’exercice de la contrainte consistait à susciter le consentement des individus-utilisateurs dans un rapport qui, du moins le croyait-on, proposait une hiérarchie entre d’un côté les producteurs de contenus et services et, de l’autre côté, les utilisateurs. Il n’en était rien : les utilisateurs eux-mêmes étaient supposés produire des contenus œuvrant ainsi à la normalisation des rapports numériques où les créateurs exerçaient leur propre contrainte, c’est-à-dire accepter le dévoilement de leur vie privée (leur identité) en guise de tribut à l’expression de leurs idées, de leurs envies, de leurs besoins, de leurs rêves. Que n’avait-on pensé plus tôt au spectaculaire déploiement de la surveillance de masse focalisant non plus sur les actes, mais sur les éléments qui peuvent les déclencher ? Le commerce autant que l’État cherche à renseigner tout comportement prédictible dans la mesure où, pour l’un il permet de spéculer et pour l’autre il permet de planifier l’exercice du pouvoir. La société prédictible est ainsi devenue la force normalisatrice en fonction de laquelle tout discours et tout pouvoir s’exerce désormais (mais pas exclusivement) à travers l’organe de communication le plus puissant qui soit : Internet. L’affaire Snowden n’a fait que focaliser sur l’un de ses aspects relatif aux questions des défenses nationales. Mais l’aspect le plus important est que, comme le dit si bien Eben Moglen dans une conférence donnée à Berlin en 2012[2], « nous n’avons pas créé l’anonymat lorsque nous avons inventé Internet. »
Depuis le milieu des années 1980, les méthodes de collaboration dans la création de logiciels libres montraient que l’innovation devait être collective pour être assimilée et partagée par le plus grand nombre. La philosophie du Libre s’opposait à la nucléarisation sociale et proposait un modèle où, par la mise en réseau, le bien-être social pouvait émerger de la contribution volontaire de tous adhérant à des objectifs communs d’améliorations logicielles, techniques, sociales. Les créations non-logicielles de tout type ont fini par suivre le même chemin à travers l’extension des licences à des œuvres non logicielles. Les campagnes de financement collaboratif, en particulier lorsqu’elles visent à financer des projets sous licence libre, démontrent que dans un seul et même mouvement, il est possible à la fois de valider l’impact social du projet (par l’adhésion du nombre de donateurs) et assurer son développement. Pour reprendre Eben Moglen, ce n’est pas l’anonymat qui manque à Internet, c’est la possibilité de structurer une société de la collaboration qui échappe aux modèles anciens et à la coercition de droit privé qu’ils impliquent. C’est un changement de pouvoir qui est à l’œuvre et contre lequel toute réaction sera nécessairement celle de la punition : on comprend mieux l’arrivée plus ou moins subtile d’organes gouvernementaux et inter-gouvernementaux visant à sanctionner toute incartade qui soit effectivement condamnable en vertu du droit mais aussi à rigidifier les conditions d’arrivée des nouveaux modèles économiques et structurels qui contrecarrent les intérêts (individuels eux aussi, par définition) de quelques-uns. Nous ne sommes pas non plus à l’abri des resquilleurs et du libre-washing cherchant, sous couvert de sympathie, à rétablir une hiérarchie de contrôle.
Dans sa Lettre aux barbus[3], le 5 juin 2014, Laurent Chemla vise juste : le principe selon lequel « la sécurité globale (serait) la somme des sécurités individuelles » implique que la surveillance de masse (rendue possible, par exemple, grâce à notre consentement envers les services gratuits dont nous disposons sur Internet) provoque un déséquilibre entre d’une part ceux qui exercent le pouvoir et en ont les moyens et les connaissances, et d’autre part ceux sur qui s’exerce le pouvoir et qui demeurent les utilisateurs de l’organe même de l’exercice de ce pouvoir. Cette double contrainte n’est soluble qu’à la condition de cesser d’utiliser des outils centralisés et surtout s’en donner les moyens en « (imaginant) des outils qui créent le besoin plutôt que des outils qui répondent à des usages existants ». C’est-à-dire qu’il relève de la responsabilité de ceux qui détiennent des portions de savoir (les barbus, caricature des libristes) de proposer au plus grand nombre de nouveaux outils capables de rétablir l’équilibre et donc de contrecarrer l’exercice illégitime du pouvoir.
Une affaire de compétences
Par bien des aspects, le logiciel libre a transformé la vie politique. En premier lieu parce que les licences libres ont bouleversé les modèles[4] économiques et culturels hérités d’un régime de monopole. En second lieu, parce que les développements de logiciels libres n’impliquent pas de hiérarchie entre l’utilisateur et le concepteur et, dans ce contexte, et puisque le logiciel libre est aussi le support de la production de créations et d’informations, il implique des pratiques démocratiques de décision et de liberté d’expression. C’est en ce sens que la culture libre a souvent été qualifiée de « culture alternative » ou « contre-culture » parce qu’elle s’oppose assez frontalement avec les contraintes et les usages qui imposent à l’utilisateur une fenêtre minuscule pour échanger sa liberté contre des droits d’utilisation.
Contrairement à ce que l’on pouvait croire il y a seulement une dizaine d’années, tout le monde est en mesure de comprendre le paradoxe qu’il y a lorsque, pour pouvoir avoir le droit de communiquer avec la terre entière et 2 amis, vous devez auparavant céder vos droits et votre image à une entreprise comme Facebook. Il en est de même avec les formats de fichiers dont les limites ont vite été admises par le grand public qui ne comprenait et ne comprend toujours pas en vertu de quelle loi universelle le document écrit il y a 20 ans n’est aujourd’hui plus lisible avec le logiciel qui porte le même nom depuis cette époque. Les organisations libristes telles la Free Software Foundation[5], L’Electronic Frontier Foundation[6], l’April[7], l’Aful[8], Framasoft[9] et bien d’autres à travers le monde ont œuvré pour la promotion des formats ouverts et de l’interopérabilité à tel point que la décision publique a dû agir en devenant, la plupart du temps assez mollement, un organe de promotion de ces formats. Bien sûr, l’enjeu pour le secteur public est celui de la manipulation de données sensibles dont il faut assurer une certaine pérennité, mais il est aussi politique puisque le rapport entre les administrés et les organes de l’État doit se faire sans donner à une entreprise privée l’exclusivité des conditions de diffusion de l’information.
Les acteurs associatifs du Libre, sans se positionner en lobbies (alors même que les lobbies privés sont financièrement bien plus équipés) et en œuvrant auprès du public en donnant la possibilité à celui-ci d’agir concrètement, ont montré que la société civile est capable d’expertise dans ce domaine. Néanmoins, un obstacle de taille est encore à franchir : celui de donner les moyens techniques de rendre utilisables les solutions alternatives permettant une émancipation durable de la société. Peine perdue ? On pourrait le croire, alors que des instances comme le CNNum (Conseil National du Numérique) ont tendance à se résigner[10] et penser que les GAFA (Google, Apple, Facebook et Amazon) seraient des autorités incontournables, tout comme la soumission des internautes à cette nouvelle forme de féodalité serait irrémédiable.
Pour ce qui concerne la visibilité, on ne peut pas nier les efforts souvent exceptionnels engagés par les associations et fondations de tout poil visant à promouvoir le Libre et ses usages auprès du large public. Tout récemment, la Free Software Foundation a publié un site web multilingue exclusivement consacré à la question de la sécurité des données dans l’usage des courriels. Intitulé Email Self Defense[11], ce guide explique, étape par étape, la méthode pour chiffrer efficacement ses courriels avec des logiciels libres. Ce type de démarche est en réalité un symptôme, mais il n’est pas seulement celui d’une réaction face aux récentes affaires d’espionnage planétaire via Internet.
Pour reprendre l’idée de Foucault énoncée ci-dessus, le contexte de l’espionnage de masse est aujourd’hui tel qu’il laisse la place à un autre discours : celui de la nécessité de déployer de manière autonome des infrastructures propres à l’apprentissage et à l’usage des logiciels libres en fonction des besoins des populations. Auparavant, il était en effet aisé de susciter l’adhésion aux principes du logiciel libre sans pour autant déployer de nouveaux usages et sans un appui politique concret et courageux (comme les logiciels libres à l’école, dans les administrations, etc.). Aujourd’hui, non seulement les principes sont socialement intégrés mais de nouveaux usages ont fait leur apparition tout en restant prisonniers des systèmes en place. C’est ce que soulève très justement un article récent de Cory Doctorow[12] en citant une étude à propos de l’usage d’Internet chez les jeunes gens. Par exemple, une part non négligeable d’entre eux suppriment puis réactivent au besoin leurs comptes Facebook de manière à protéger leurs données et leur identité. Pour Doctorow, être « natifs du numérique » ne signifie nullement avoir un sens inné des bons usages sur Internet, en revanche leur sens de la confidentialité (et la créativité dont il est fait preuve pour la sauvegarder) est contrecarré par le fait que « Facebook rend extrêmement difficile toute tentative de protection de notre vie privée » et que, de manière plus générale, « les outils propices à la vie privée tendent à être peu pratiques ». Le sous-entendu est évident : même si l’installation logicielle est de plus en plus aisée, tout le monde n’est capable d’installer chez soi des solutions appropriées comme un serveur de courriel chiffré.
Que faire ?
Le diagnostic posé, que pouvons-nous faire ? Le domaine associatif a besoin d’argent. C’est un fait, d’ailleurs remarqué par le gouvernement français, qui avait fait de l’engagement associatif la grande « cause nationale de l’année 2014 ». Cette action[13] a au moins le mérite de valoriser l’économie sociale et solidaire, ainsi que le bénévolat. Les associations libristes sont déjà dans une dynamique similaire depuis un long moment, et parfois s’essoufflent… En revanche, il faut des investissements de taille pour avoir la possibilité de soutenir des infrastructures libres dédiées au public et répondant à ses usages numériques. Ces investissements sont difficiles pour au moins deux raisons :
la première réside dans le fait que les associations ont pour cela besoin de dons en argent. Les bonnes volontés ne suffisent pas et la monnaie disponible dans les seules communautés libristes est à ce jour en quantité insuffisante compte tenu des nombreuses sollicitations ;
la seconde découle de la première : il faut lancer un mouvement de financements participatifs ou des campagnes de dons ciblées de manière à susciter l’adhésion du grand public et proposer des solutions adaptées aux usages.
Pour cela, la première difficulté sera de lutter contre la gratuité. Aussi paradoxal que cela puisse paraître, la gratuité (relative) des services privateurs possède une dimension attractive si puissante qu’elle élude presque totalement l’existence des solutions libres ou non libres qui, elles, sont payantes. Pour rester dans le domaine de la correspondance, il est très difficile aujourd’hui de faire comprendre à Monsieur Dupont qu’il peut choisir un hébergeur de courriel payant, même au prix « participatif » d’1 euro par mois. En effet, Monsieur Dupont peut aujourd’hui utiliser, au choix : le serveur de courriel de son employeur, le serveur de courriel de son fournisseur d’accès à Internet, les serveurs de chez Google, Yahoo et autres fournisseurs disponibles très rapidement sur Internet. Dans l’ensemble, ces solutions sont relativement efficaces, simples d’utilisation, et ne nécessitent pas de dépenses supplémentaires. Autant d’arguments qui permettent d’ignorer la question de la confidentialité des courriels qui peuvent être lus et/ou analysés par son employeur, son fournisseur d’accès, des sociétés tierces…
Pourtant des solutions libres, payantes et respectueuses des libertés, existent depuis longtemps. C’est le cas de Sud-Ouest.org[14], une plate-forme d’hébergement mail à prix libre. Ou encore l’association Lautre.net[15], qui propose une solution d’hébergement de site web, mais aussi une adresse courriel, la possibilité de partager ses documents via FTP, la création de listes de discussion, etc. Pour vivre, elle propose une participation financière à la gestion de son infrastructure, quoi de plus normal ?
Aujourd’hui, il est de la responsabilité des associations libristes de multiplier ce genre de solutions. Cependant, pour dégager l’obstacle de la contrepartie financière systématique, il est possible d’ouvrir gratuitement des services au plus grand nombre en comptant exclusivement sur la participation de quelques-uns (mais les plus nombreux possible). En d’autres termes, il s’agit de mutualiser à la fois les plates-formes et les moyens financiers. Cela ne rend pas pour autant les offres gratuites, simplement le coût total est réparti socialement tant en unités de monnaie qu’en contributions de compétences. Pour cela, il faut savoir convaincre un public déjà largement refroidi par les pratiques des géants du web et qui perd confiance.
Framasoft propose des solutions
Parmi les nombreux projets de Framasoft, il en est un, plus généraliste, qui porte exclusivement sur les moyens techniques (logiciels et matériels) de l’émancipation du web. Il vise à renouer avec les principes qui ont guidé (en des temps désormais très anciens) la création d’Internet, à savoir : un Internet libre, décentralisé (ou démocratique), éthique et solidaire (l.d.e.s.).
Framasoft n’a cependant pas le monopole de ces principes l.d.e.s., loin s’en faut, en particulier parce que les acteurs du Libre œuvrent tous à l’adoption de ces principes. Mais Framasoft compte désormais jouer un rôle d’interface. À l’instar d’un Google qui rachète des start-up pour installer leurs solutions à son compte et constituer son nuage, Framasoft se propose depuis 2010, d’héberger des solutions libres pour les ouvrir gratuitement à tout public. C’est ainsi que par exemple, des particuliers, des syndicats, des associations et des entreprises utilisent les instances Framapad et Framadate. Il s’agit du logiciel Etherpad, un système de traitement de texte collaboratif, et d’un système de sondage issu de l’Université de Strasbourg (Studs) permettant de convenir d’une date de réunion ou créer un questionnaire. Des milliers d’utilisateurs ont déjà bénéficié de ces applications en ligne ainsi que d’autres, qui sont listées sur Framalab.org[16].
Depuis le début de l’année 2014, Framasoft a entamé une stratégie qui, jusqu’à présent est apparue comme un iceberg aux yeux du public. Pour la partie émergée, nous avons tout d’abord commencé par rompre radicalement les ponts avec les outils que nous avions tendance à utiliser par pure facilité. Comme nous l’avions annoncé lors de la campagne de don 2013, nous avons quitté les services de Google pour nos listes de discussion et nos analyses statistiques. Nous avons choisi d’installer une instance Bluemind, ouvert un serveur Sympa, mis en place Piwik ; quant à la publicité et les contenus embarqués, nous pouvons désormais nous enorgueillir d’assurer à tous nos visiteurs que nous ne nourrissons plus la base de données de Google. À l’échelle du réseau Framasoft, ces efforts ont été très importants et ont nécessité des compétences et une organisation technique dont jusque là nous ne disposions pas.
L’état de la Dégooglisation en octobre 2015…
Nous ne souhaitons pas nous arrêter là. La face immergée de l’iceberg est en réalité le déploiement sans précédent de plusieurs services ouverts. Ces services ne sont pas seulement proposés, ils sont accompagnés d’une pédagogie visant à montrer comment[17] installer des instances similaires pour soi-même ou pour son organisation. Nous y attachons d’autant plus d’importance que l’objectif n’est pas de commettre l’erreur de proposer des alternatives centralisées mais d’essaimer au maximum les solutions proposées.
Au mois de juin, nous avons lancé une campagne de financement participatif afin d’améliorer Etherpad (sur lequel est basé notre service Framapad) en travaillant sur un plugin baptisé Mypads : il s’agit d’ouvrir des instances privées, collaboratives ou non, et les regrouper à l’envi, ce qui permettra in fine de proposer une alternative sérieuse à Google Docs. À l’heure où j’écris ces lignes, la campagne est une pleine réussite et le déploiement de Mypads (ainsi que sa mise à disposition pour toute instance Etherpad) est prévue pour le dernier trimestre 2014. Nous avons de même comblé les utilisateurs de Framindmap, notre créateur en ligne de carte heuristiques, en leur donnant une dimension collaborative avec Wisemapping, une solution plus complète.
Au mois de juillet, nous avons lancé Framasphère[18], une instance Diaspora* dont l’objectif est de proposer (avec Diaspora-fr[19]) une alternative à Facebook en l’ouvrant cette fois au maximum en direction des personnes extérieures au monde libriste. Nous espérons pouvoir attirer ainsi l’attention sur le fait qu’aujourd’hui, les réseaux sociaux doivent afficher clairement une éthique respectueuse des libertés et des droits, ce que nous pouvons garantir de notre côté.
Enfin, après l’été 2014, nous comptons de même offrir aux utilisateurs un moteur de recherche (Framasearx) et d’ici 2015, si tout va bien, un diaporama en ligne, un service de visioconférence, des services de partage de fichiers anonymes et chiffrés, et puis… et puis…
Aurons-nous les moyens techniques et financiers de supporter la charge ? J’aimerais me contenter de dire que nous avons la prétention de faire ainsi œuvre publique et que nous devons réussir parce qu’Internet a aujourd’hui besoin de davantage de zones libres et partagées. Mais cela ne suffit pas. D’après les derniers calculs, si l’on compare en termes de serveurs, de chiffre d’affaires et d’employés, Framasoft est environ 38.000 fois plus petit que Google[20]. Or, nous n’avons pas peur, nous ne sommes pas résignés, et nous avons nous aussi une vision au long terme pour changer le monde[21]. Nous savons qu’une population de plus en plus importante (presque majoritaire, en fait) adhère aux mêmes principes que ceux du modèle économique, technique et éthique que nous proposons. C’est à la société civile de se mobiliser et nous allons développer un espace d’expression de ces besoins avec les moyens financiers de 200 mètres d’autoroute en équivalent fonds publics. Dans les mois et les années qui viennent, nous exposerons ensemble des méthodes et des exemples concrets pour améliorer Internet. Nous aider et vous investir, c’est rendre possible le passage de la résistance à la réalisation.
Ce document est placé sous Licence Art Libre 1.3 (Document version 1.0) Paru initialement dans Linux Pratique n°85 Septembre/Octobre 2014, avec leur aimable autorisation.
Les nouveaux Léviathans II — Surveillance et confiance (b)
Qu’est-ce qui fait courir Framasoft ? De la campagne Dégooglisons à l’initiative C.H.A.T.O.N.S quelles idées ont en tête les acteurs et soutiens de l’association ? Vous reprendrez bien une tranche de Léviathan ?
Pour vous inviter à aller au-delà des apparences (la sympathique petite tribu d’amateurs gaulois qui veut modestement mettre son grain de sable dans la loi des entreprises hégémoniques) nous vous proposons non seulement un moment de réflexion, mais pour une fois une série de considérations nourries, argumentées et documentées sur l’état de bascule que nous vivons et dans lequel nous prétendons inscrire notre action avec vous.
Jamais le logiciel libre et les valeurs qu’il porte n’ont été autant à la croisée des chemins, car il ne s’agit pas de proposer seulement des alternatives techniques, c’est un défi économique et politique qu’il doit relever.
Entre les États qui nous surveillent et les GAFAM qui nous monétisent, jamais le refuge du secret, celui de l’intime, n’a été aussi attaqué ni menacé. Pour représenter le monstre à plusieurs têtes, Christophe Masutti qui est l’auteur de cette série de réflexions, a choisi la figure emblématique du Léviathan, forgée déjà par Hobbes en particulier pour désigner l’État toujours plus avide de domination.
C’est donc une série de Léviathans nouveaux et anciens que nous vous invitons à découvrir par étapes, tout au long de cette semaine, qui vous conduiront peut-être à comprendre et adopter notre démarche. Car une fois établies les sources du mal et posé le diagnostic, que faire ? Les perspectives que nous proposons seront peut-être les vôtres.
Cette seconde partie (Léviathans II) vise à approfondir les concepts survolés précédemment (Léviathans I). Nous avons vu que les monopoles de l’économie numérique ont changé le paradigme libéral jusqu’à instaurer un capitalisme de surveillance. Pour en rendre compte et comprendre ce nouveau système, il faut brosser plusieurs aspects de nos rapports avec la technologie en général, et les services numériques en particulier, puis voir comment des modèles s’imposent par l’usage des big data et la conformisation du marché (Léviathans IIa). J’expliquerai, à partir de la lecture de S. Zuboff, quelles sont les principales caractéristiques du capitalisme de surveillance. En identifiant ainsi ces nouvelles conditions de l’aliénation des individus, il devient évident que le rétablissement de la confiance aux sources de nos relations contractuelles et démocratiques, passe immanquablement par l’autonomie, le partage et la coopération, sur le modèle du logiciel libre (Léviathans IIb).
Trouver les bonnes clés
Cette logique du marché, doit être analysée avec d’autres outils que ceux de l’économie classique. L’impact de l’informationnalisation et la concentration des acteurs de l’économie numérique ont sans doute été largement sous-estimés, non pas pour les risques qu’ils font courir aux économies post-industrielles, mais pour les bouleversements sociaux qu’ils impliquent. Le besoin de défendre les droits et libertés sur Internet et ailleurs n’est qu’un effet collatéral d’une situation contre laquelle il est difficile d’opposer seulement des postures et des principes.
Il faut entendre les mots de Marc Rotenberg, président de l’Electronic Privacy Information Center (EPIC), pour qui le débat dépasse désormais la seule question de la neutralité du réseau ou de la liberté d’expression1. Pour lui, nous avons besoin d’analyser ce qui structure la concentration du marché. Mais le phénomène de concentration dans tous les services de communication que nous utilisons implique des échelles tellement grandes, que nous avons besoin d’instruments de mesure au moins aussi grands. Nous avons besoin d’une nouvelle science pour comprendre Internet, le numérique et tout ce qui découle des formes d’automatisation.
Diapositive extraite de la conférence « Dégooglisons Internet »
On s’arrête bien souvent sur l’aspect le plus spectaculaire de la fuite d’environ 1,7 millions de documents grâce à Edward Snowden en 2013, qui montrent que les États, à commencer par les États-Unis, ont créé des systèmes de surveillance de leurs populations au détriment du respect de la vie privée. Pour beaucoup de personnes, cette atteinte doit être ramenée à la dimension individuelle : dois-je avoir quelque chose à cacher ? comment échapper à cette surveillance ? implique-t-elle un contrôle des populations ? un contrôle de l’expression ? en quoi ma liberté est-elle en danger ? etc. Mais peu de personnes se sont réellement interrogées sur le fait que si la NSA s’est fait livrer ces quantités gigantesques d’informations par des fournisseurs de services (comme par exemple, la totalité des données téléphoniques de Verizon ou les données d’échanges de courriels du service Hotmail de Microsoft) c’est parce que ces entreprises avaient effectivement les moyens de les fournir et que par conséquent de telles quantités d’informations sur les populations sont tout à fait exploitables et interprétables en premier lieu par ces mêmes fournisseurs.
Face à cela, plusieurs attitudes sont possibles. En les caricaturant, elles peuvent être :
Positivistes. On peut toujours s’extasier devant les innovations de Google surtout parce que la culture de l’innovation à la Google est une composante du story telling organisé pour capter l’attention des consommateurs. La communication est non seulement exemplaire mais elle constitue un modèle d’après Google qui en donne même les recettes (cf. les deux liens précédents). Que Google, Apple, Microsoft, Facebook ou Amazon possèdent des données me concernant, cela ne serait qu’un détail car nous avons tous l’opportunité de participer à cette grande aventure du numérique (hum !).
Défaitistes. On n’y peut rien, il faut donc se contenter de protéger sa vie privée par des moyens plus ou moins dérisoires, comme par exemple faire du bruit pour brouiller les pistes et faire des concessions car c’est le prix à payer pour profiter des applications bien utiles. Cette attitude consiste à échanger l’utilité contre l’information, ce que nous faisons à chaque fois que nous validons les clauses d’utilisation des services GAFAM.
Complotistes. Les procédés de captation des données servent ceux qui veulent nous espionner. Les utilisations commerciales seraient finalement secondaires car c’est contre l’emploi des données par les États qu’il faut lutter. C’est la logique du moins d’État contre la liberté du nouveau monde numérique, comme si le choix consistait à donner notre confiance soit aux États soit aux GAFAM, liberté par contrat social ou liberté par consommation.
Les objectifs de cette accumulation de données sont effectivement différents que ceux poursuivis par la NSA et ses institutions homologues. La concentration des entreprises crée le besoin crucial d’organiser les monopoles pour conserver un marché stable. Les ententes entre entreprises, repoussant toujours davantage les limites juridiques des autorités de régulations, créent une logique qui ne consiste plus à s’adapter à un marché aléatoire, mais adapter le marché à l’offre en l’analysant en temps réel, en utilisant les données quotidiennes des utilisateurs de services. Il faut donc analyser ce capitalisme de surveillance, ainsi que le nomme Shoshana Zuboff, car comme nous l’avons vu :
les États ont de moins en moins les capacités de réguler ces activités,
nous sommes devenus des produits de variables qui configurent nos comportements et nos besoins.
L’ancienne conception libérale du marché, l’acception économique du contrat social, reposait sur l’idée que la démocratie se consolide par l’égalitarisme des acteurs et l’équilibre du marché. Que l’on adhère ou pas à ce point de vue, il reste qu’aujourd’hui le marché ne s’équilibre plus par des mécanismes libéraux mais par la seule volonté de quelques entreprises. Cela pose inévitablement une question démocratique.
Dans son rapport, Antoinette Rouvroy en vient à adresser une série de questions sur les répercutions de cette morphologie du marché. Sans y apporter franchement de réponse, elle en souligne les enjeux :
Ces dispositifs d’« anticipation performative » des intentions d’achat (qui est aussi un court-circuitage du processus de transformation de la pulsion en désir ou en intention énonçable), d’optimisation de la force de travail fondée sur la détection anticipative des performances futures sur base d’indicateurs produits automatiquement au départ d’analyses de type Big Data (qui signifie aussi une chute vertigineuse du « cours de l’expérience » et des mérites individuels sur le marché de l’emploi), posent des questions innombrables. L’anticipation performative des intentions –et les nouvelles possibilités d’actions préemptives fondées sur la détection des intentions – est-elle compatible avec la poursuite de l’autodétermination des personnes ? Ne faut-il pas concevoir que la possibilité d’énoncer par soi-même et pour soi-même ses intentions et motivations constitue un élément essentiel de l’autodétermination des personnes, contre cette utopie, ou cette dystopie, d’une société dispensée de l’épreuve d’un monde hors calcul, d’un monde où les décisions soient autre chose que l’application scrupuleuse de recommandations automatiques, d’un monde où les décisions portent encore la marque d’un engagement subjectif ? Comment déterminer la loyauté de ces pratiques ? L’optimisation de la force de travail fondée sur le profilage numérique est-il compatible avec le principe d’égalité et de non-discrimination ?2
Ce qui est questionné par A. Rouvroy, c’est ce que Zuboff nomme le capitalisme de surveillance, du moins une partie des pratiques qui lui sont inhérentes. Dès lors, au lieu de continuer à se poser des questions, il est important d’intégrer l’idée que si le paradigme a changé, les clés de lecture sont forcément nouvelles.
Déconstruire le capitalisme de surveillance
Shoshana Zuboff a su identifier les pratiques qui déconstruisent l’équilibre originel et créent ce nouveau capitalisme. Elle pose ainsi les jalons de cette nouvelle « science » qu’appelle de ses vœux Marc Rotenberg, et donne des clés de lecture pertinentes. L’essentiel des concepts qu’elle propose se trouve dans son article « Big other: surveillance capitalism and the prospects of an information civilization », paru en 20153. Dans cet article S. Zuboff décortique deux discours de Hal Varian, chef économiste de Google et s’en sert de trame pour identifier et analyser les processus du capitalisme de surveillance. Dans ce qui suit, je vais essayer d’expliquer quelques clés issues du travail de S. Zuboff.
Sur quelle stratégie repose le capitalisme de surveillance ?
Il s’agit de la stratégie de commercialisation de la quotidienneté en modélisant cette dernière en autant de données analysées, inférences et prédictions. La logique d’accumulation, l’automatisation et la dérégulation de l’extraction et du traitement de ces données rendent floues les frontières entre vie privée et consommation, entre les firmes et le public, entre l’intention et l’information.
Qu’est-ce que la quotidienneté ?
Il s’agit de ce qui concerne la sphère individuelle mais appréhendée en réseau. L’informationnalisation de nos profils individuels provient de plusieurs sources. Il peut s’agir des informations conventionnelles (au sens propre) telles que nos données d’identité, nos données bancaires, etc. Elles peuvent résulter de croisements de flux de données et donner lieu à des inférences. Elles peuvent aussi provenir des objets connectés, agissant comme des sensors ou encore résulter des activités de surveillance plus ou moins connues. Si toutes ces données permettent le profilage c’est aussi par elles que nous déterminons notre présence numérique. Avoir une connexion Internet est aujourd’hui reconnu comme un droit : nous ne distinguons plus nos activités d’expression sur Internet des autres activités d’expression. Les activités numériques n’ont plus à être considérées comme des activités virtuelles, distinctes de la réalité. Nos pages Facebook ne sont pas plus virtuelles que notre compte Amazon ou notre dernière déclaration d’impôt en ligne. Si bien que cette activité en réseau est devenue si quotidienne qu’elle génère elle-même de nouveaux comportements et besoins, produisant de nouvelles données analysées, agrégées, commercialisées.
Extraction des données
S. Zuboff dresse un inventaire des types de données, des pratiques d’extraction, et les enjeux de l’analyse. Il faut cependant comprendre qu’il y a de multiples manières de « traiter » les données. La Directive 95/46/CE (Commission Européenne) en dressait un inventaire, déjà en 19954 :
« traitement de données à caractère personnel » (traitement) : toute opération ou ensemble d’opérations effectuées ou non à l’aide de procédés automatisés et appliquées à des données à caractère personnel, telles que la collecte, l’enregistrement, l’organisation, la conservation, l’adaptation ou la modification, l’extraction, la consultation, l’utilisation, la communication par transmission, diffusion ou toute autre forme de mise à disposition, le rapprochement ou l’interconnexion, ainsi que le verrouillage, l’effacement ou la destruction.
Le processus d’extraction de données n’est pas un processus autonome, il ne relève pas de l’initiative isolée d’une ou quelques firmes sur un marché de niche. Il constitue désormais la norme commune à une multitude de firmes, y compris celles qui n’œuvrent pas dans le secteur numérique. Il s’agit d’un modèle de développement qui remplace l’accumulation de capital. Autant cette dernière était, dans un modèle économique révolu, un facteur de production (par les investissements, par exemple), autant l’accumulation de données est désormais la clé de production de capital, lui-même réinvesti en partie dans des solutions d’extraction et d’analyse de données, et non dans des moyens de production, et pour une autre partie dans la valorisation boursière, par exemple pour le rachat d’autres sociétés, à l’image des multiples rachats de Google.
Neutralité et indifférence
Les données qu’exploite Google sont très diverses. On s’interroge généralement sur celles qui concernent les catégories auxquelles nous accordons de l’importance, comme par exemple lorsque nous effectuons une recherche au sujet d’une mauvaise grippe et que Google Now nous propose une consultation médicale à distance. Mais il y a une multitude de données dont nous soupçonnons à peine l’existence, ou apparemment insignifiantes pour soi, mais qui, ramenées à des millions, prennent un sens tout à fait probant pour qui veut les exploiter. On peut citer par exemple le temps de consultation d’un site. Si Google est prêt à signaler des contenus à l’administration des États-Unis, comme l’a dénoncé Julian Assange ou si les relations publiques de la firme montrent une certaine proximité avec les autorités de différents pays et l’impliquent dans des programmes d’espionnage, il reste que cette attitude coopérante relève essentiellement d’une stratégie économique. En réalité, l’accumulation et l’exploitation des données suppose une indifférence formelle par rapport à leur signification pour l’utilisateur. Quelle que soit l’importance que l’on accorde à l’information, le postulat de départ du capitalisme de surveillance, c’est l’accumulation de quantités de données, non leur qualité. Quant au sens, c’est le marché publicitaire qui le produit.
L’extraction et la confiance
S. Zuboff dresse aussi un court inventaire des pratiques d’extraction de Google. L’exemple emblématique est Google Street View, qui rencontra de multiples obstacles à travers le monde : la technique consiste à s’immiscer sur des territoires et capturer autant de données possible jusqu’à rencontrer de la résistance qu’elle soit juridique, politique ou médiatique. Il en fut de même pour l’analyse du courrier électronique sur Gmail, la capture des communications vocales, les paramètres de confidentialité, l’agrégation des données des comptes sur des services comme Google+, la conservation des données de recherche, la géolocalisation des smartphones, la reconnaissance faciale, etc.
En somme, le processus d’extraction est un processus à sens unique, qui ne tient aucun compte (ou le moins possible) de l’avis de l’utilisateur. C’est l’absence de réciprocité.
On peut ajouter à cela la puissance des Big Data dans l’automatisation des relations entre le consommateur et le fournisseur de service. Google Now propose de se substituer à une grande partie de la confidentialité entre médecin et patient en décelant au moins les causes subjectives de la consultation (en interprétant les recherches). Hal Varian lui-même vante les mérites de l’automatisation de la relation entre assureurs et assurés dans un monde où l’on peut couper à distance le démarrage de la voiture si le client n’a pas payé ses traites. Des assurances santé et même des mutuelles (!) proposent aujourd’hui des applications d’auto-mesure (quantified self)de l’activité physique, dont on sait pertinemment que cela résultera sur autant d’ajustements des prix voire des refus d’assurance pour les moins chanceux.
La relation contractuelle est ainsi automatisée, ce qui élimine d’autant le risque lié aux obligations des parties. En d’autres termes, pour éviter qu’une partie ne respecte pas ses obligations, on se passe de la confiance que le contrat est censé formaliser, au profit de l’automatisation de la sanction. Le contrat se résume alors à l’acceptation de cette automatisation. Si l’arbitrage est automatique, plus besoin de recours juridique. Plus besoin de la confiance dont la justice est censée être la mesure.
Entre l’absence de réciprocité et la remise en cause de la relation de confiance dans le contrat passé avec l’utilisateur, ce sont les bases démocratiques de nos rapports sociaux qui sont remises en question puisque le fondement de la loi et de la justice, c’est le contrat et la formalisation de la confiance.
Plus Google a d’utilisateurs, plus il rassemble des données. Plus il y a de données plus leur valeur predictive augmente et optimise le potentiel lucratif. Pour des firmes comme Google, le marché n’est pas composé d’agents rationnels qui choisissent entre plusieurs offres et configurent la concurrence. La société « à la Google » n’est plus fondée sur des relations de réciprocité, même s’il s’agit de luttes sociales ou de revendications.
L’« uberisation » de la société (voir le début de cet article) qui nous transforme tous en employés ou la transformation des citoyens en purs consommateurs, c’est exactement le cauchemar d’Hannah Arendt que S. Zuboff cite longuement :
Le dernier stade de la société de travail, la société d’employés, exige de ses membres un pur fonctionnement automatique, comme si la vie individuelle était réellement submergée par le processus global de la vie de l’espèce, comme si la seule décision encore requise de l’individu était de lâcher, pour ainsi dire, d’abandonner son individualité, sa peine et son inquiétude de vivre encore individuellement senties, et d’acquiescer à un type de comportement, hébété, « tranquillisé » et fonctionnel. Ce qu’il y a de fâcheux dans les théories modernes du comportement, ce n’est pas qu’elles sont fausses, c’est qu’elles peuvent devenir vraies, c’est qu’elles sont, en fait, la meilleure mise en concept possible de certaines tendances évidentes de la société moderne. On peut parfaitement concevoir que l’époque moderne (…) s’achève dans la passivité la plus inerte, la plus stérile que l’Histoire ait jamais connue.5
Devant cette anticipation catastrophiste, l’option choisie ne peut être l’impuissance et le laisser-faire. Il faut d’abord nommer ce à quoi nous avons affaire, c’est-à-dire un système (total) face auquel nous devons nous positionner.
Qu’est-ce que Big Other et que peut-on faire ?
Il s’agit des mécanismes d’extraction, marchandisation et contrôle. Ils instaurent une dichotomie entre les individus (utilisateurs) et leur propre comportement (pour les transformer en données) et simultanément ils produisent de nouveaux marchés basés justement sur la prédictibilité de ces comportements.
(Big Other) est un régime institutionnel, omniprésent, qui enregistre, modifie, commercialise l’expérience quotidienne, du grille-pain au corps biologique, de la communication à la pensée, de manière à établir de nouveaux chemins vers les bénéfices et les profits. Big other est la puissance souveraine d’un futur proche qui annihile la liberté que l’on gagne avec les règles et les lois.6
Avoir pu mettre un nom sur ce nouveau régime dont Google constitue un peu plus qu’une illustration (presque initiateur) est la grande force de Shoshana Zuboff. Sans compter plusieurs articles récents de cette dernière dans la Frankfurter Allgemeine Zeitung, il est étonnant que le rapport d’Antoinette Rouvroy, postérieur d’un an, n’y fasse aucune mention. Est-ce étonnant ? Pas vraiment, en réalité, car dans un rapport officiellement remis aux autorités européennes, il est important de préciser que la lutte contre Big Other (ou de n’importe quelle manière dont on peut l’exprimer) ne peut que passer par la légitimité sans faille des institutions. Ainsi, A. Rouvroy oppose les deux seules voies envisageables dans un tel contexte officiel :
À l’approche « law and economics », qui est aussi celle des partisans d’un « marché » des données personnelles, qui tendrait donc à considérer les données personnelles comme des « biens » commercialisables (…) s’oppose l’approche qui consiste à aborder les données personnelles plutôt en fonction du pouvoir qu’elles confèrent à ceux qui les contrôlent, et à tenter de prévenir de trop grandes disparités informationnelles et de pouvoir entre les responsables de traitement et les individus. C’est, à l’évidence, cette seconde approche qui prévaut en Europe.
Or, devant Google (ou devant ce Big Other) nous avons vu l’impuissance des États à faire valoir un arsenal juridique, à commencer par les lois anti-trust. D’une part, l’arsenal ne saurait être exhaustif : il concernerait quelques aspects seulement de l’exploitation des données, la transparence ou une série d’obligations comme l’expression des finalités ou des consentements. Il ne saurait y avoir de procès d’intention. D’autre part, nous pouvons toujours faire valoir que des compagnies telles Microsoft ont été condamnées par le passé, au moins par les instances européennes, pour abus de position dominante, et que quelques millions d’euros de menace pourraient suffire à tempérer les ardeurs. C’est faire peu de cas d’au moins trois éléments :
l’essentiel des compagnies dont il est question sont nord-américaines, possèdent des antennes dans des paradis fiscaux et sont capables, elles, de menacer financièrement des pays entiers par simples effets de leviers boursiers.
L’arsenal juridique qu’il faudrait déployer avant même de penser à saisir une cour de justice, devrait être rédigé, voté et décrété en admettant que les jeux de lobbies et autres obstacles formels soient entièrement levés. Cela prendrait un minimum de dix ans, si l’on compte les recours envisageables après une première condamnation.
Il faut encore caractériser les Big Data dans un contexte où leur nature est non seulement extrêmement diverse mais aussi soumise à des process d’automatisation et calculatoires qui permettent d’en inférer d’autres quantités au moins similaires. Par ailleurs, les sources des données sont sans cesse renouvelées, et leur stockage et analyse connaissent une progression technique exponentielle.
Dès lors, quels sont les moyens de s’échapper de ce Big Other ? Puisque nous avons changé de paradigme économique, nous devons changer de paradigme de consommation et de production. Grâce à des dispositifs comme la neutralité du réseau, garantie fragile et obtenue de longue lutte, il est possible de produire nous même l’écosystème dans lequel nos données sont maîtrisées et les maillons de la chaîne de confiance sont identifiés.
Comment évoluer dans le monde du capitalisme de surveillance ? telle est la question que nous pouvons nous poser dans la mesure où visiblement nous ne pouvons plus nous extraire d’une situation de soumission à Big Other. Quelles que soient nos compétences en matière de camouflage et de chiffrement, les sources de données sur nos individualités sont tellement diverses que le résultat de la distanciation avec les technologies du marché serait une dé-socialisation. Puisque les technologies sur le marché sont celles qui permettent la production, l’analyse et l’extraction automatisées de données, l’objectif n’est pas tant de s’en passer que de créer un système où leur pertinence est tellement limitée qu’elle laisse place à un autre principe que l’accumulation de données : l’accumulation de confiance.
Voyons un peu : quelles sont les actuelles échappatoires de ce capitalisme de surveillance ? Il se trouve qu’elles impliquent à chaque fois de ne pas céder aux facilités des services proposés pour utiliser des solutions plus complexes mais dont la simplification implique toujours une nouvelle relation de confiance. Illustrons ceci par des exemples relatifs à la messagerie par courrier électronique :
Si j’utilise Gmail, c’est parce que j’ai confiance en Google pour respecter la confidentialité de ma correspondance privée (no comment !). Ce jugement n’implique pas que moi, puisque mes correspondants auront aussi leurs messages scannés, qu’ils soient utilisateurs ou non de Gmail. La confiance repose exclusivement sur Google et les conditions d’utilisation de ses services.
L’utilisation de clés de chiffrement pour correspondre avec mes amis demande un apprentissage de ma part comme de mes correspondants. Certains services, comme ProtonMail, proposent de leur faire confiance pour transmettre des données chiffrées tout en simplifiant les procédures avec un webmail facile à prendre en main. Les briques open source de Protonmail permettent un niveau de transparence acceptable sans que j’en aie toutefois l’expertise (si je ne suis pas moi-même un informaticien sérieux).
Si je monte un serveur chez moi, avec un système libre et/ou open source comme une instance Cozycloud sur un Raspeberry PI, je dois avoir confiance dans tous les domaines concernés et sur lesquels je n’ai pas forcément l’expertise ou l’accès physique (la fabrication de l’ordinateur, les contraintes de mon fournisseur d’accès, la sécurité de mon serveur, etc.), c’est-à-dire tous les aspects qui habituellement font l’objet d’une division du travail dans les entreprises qui proposent de tels services, et que j’ai la prétention de rassembler à moi tout seul.
Les espaces de relative autonomie existent donc mais il faut structurer la confiance. Cela peut se faire en deux étapes.
La première étape consiste à définir ce qu’est un tiers de confiance et quels moyens de s’en assurer. Le blog de la FSFE a récemment publié un article qui résume très bien pourquoi la protection des données privées ne peut se contenter de l’utilisation plus ou moins maîtrisée des technologies de chiffrement7. La FSFE rappelle que tous les usages des services sur Internet nécessitent un niveau de confiance accordé à un tiers. Quelle que soit son identité…
…vous devez prendre en compte :
la bienveillance : le tiers ne veut pas compromettre votre vie privée et/ou il est lui-même concerné ;
la compétence : le tiers est techniquement capable de protéger votre vie privée et d’identifier et de corriger les problèmes ;
l’intégrité : le tiers ne peut pas être acheté, corrompu ou infiltré par des services secrets ou d’autres tiers malveillants ;
Comment s’assurer de ces trois qualités ? Pour les défenseurs et promoteurs du logiciel libre, seules les communautés libristes sont capables de proposer des alternatives en vertu de l’ouverture du code. Sur les quatre libertés qui définissent une licence libre, deux impliquent que le code puisse être accessible, audité, vérifié.
Est-ce suffisant ? non : ouvrir le code ne conditionne pas ces qualités, cela ne fait qu’endosser la responsabilité et l’usage du code (via la licence libre choisie) dont seule l’expertise peut attester de la fiabilité et de la probité.
En complément, la seconde étape consiste donc à définir une chaîne de confiance. Elle pourra déterminer à quel niveau je peux m’en remettre à l’expertise d’un tiers, à ses compétences, à sa bienveillance…. Certaines entreprises semblent l’avoir compris et tentent d’anticiper ce besoin de confiance. Pour reprendre les réflexions du Boston Consulting Group, l’un des plus prestigieux cabinets de conseil en stratégie au monde :
(…) dans un domaine aussi sensible que le Big Data, la confiance sera l’élément déterminant pour permettre à l’entreprise d’avoir le plus large accès possible aux données de ses clients, à condition qu’ils soient convaincus que ces données seront utilisées de façon loyale et contrôlée. Certaines entreprises parviendront à créer ce lien de confiance, d’autres non. Or, les enjeux économiques de ce lien de confiance sont très importants. Les entreprises qui réussiront à le créer pourraient multiplier par cinq ou dix le volume d’informations auxquelles elles sont susceptibles d’avoir accès. Sans la confiance du consommateur, l’essentiel des milliards d’euros de valeur économique et sociale que le Big Data pourrait représenter dans les années à venir risquerait d’être perdu.8
En d’autres termes, il existe un marché de la confiance. En tant que tel, soit il est lui aussi soumis aux effets de Big Other, soit il reste encore dépendant de la rationalité des consommateurs. Dans les deux cas, le logiciel libre devra obligatoirement trouver le créneau de persuasion pour faire adhérer le plus grand nombre à ses principes.
Une solution serait de déplacer le curseur de la chaîne de confiance non plus sur les principaux acteurs de services, plus ou moins dotés de bonnes intentions, mais dans la sphère publique. Je ne fais plus confiance à tel service ou telle entreprise parce qu’ils indiquent dans leurs CGU qu’ils s’engagent à ne pas utiliser mes données personnelles, mais parce que cet engagement est non seulement vérifiable mais aussi accessible : en cas de litige, le droit du pays dans lequel j’habite peut s’appliquer, des instances peuvent se porter parties civiles, une surveillance collective ou policière est possible, etc. La question n’est plus tellement de savoir ce que me garantit le fournisseur mais comment il propose un audit public et expose sa responsabilité vis-à-vis des données des utilisateurs.
S’en remettre à l’État pour des services fiables ? Les États ayant démontré leurs impuissances face à des multinationales surfinancées, les tentatives de cloud souverain ont elles aussi été des échecs cuisants. Créer des entreprises de toutes pièces sur fonds publics pour proposer une concurrence directe à des monopoles géants, était inévitablement un suicide : il aurait mieux valu proposer des ressources numériques et en faciliter l’accès pour des petits acteurs capables de proposer de multiples solutions différentes et alternatives adaptées aux besoins de confiance des utilisateurs, éventuellement avec la caution de l’État, la réputation d’associations nationales (association de défense des droits de l’homme, associations de consommateurs, etc.), bref, des assurances concrètes qui impliquent les utilisateurs, c’est-à-dire comme le modèle du logiciel libre qui ne sépare pas utilisation et conception.
Ce que propose le logiciel libre, c’est davantage que du code, c’est un modèle de coopération et de cooptation. C’est la possibilité pour les dynamiques collectives de réinvestir des espaces de confiance. Quel que soit le service utilisé, il dépend d’une communauté, d’une association, ou d’une entreprise qui toutes s’engagent par contrat (les licences libres sont des contrats) à respecter les données des utilisateurs. Le tiers de confiance devient collectif, il n’est plus un, il est multiple. Il ne s’agit pas pour autant de diluer les responsabilités (chaque offre est indépendante et s’engage individuellement) mais de forcer l’engagement public et la transparence des recours.
Chatons solidaires
Si s’échapper seul du marché de Big Other ne peut se faire qu’au prix de l’exclusion, il faut opposer une logique différente capable, devant l’exploitation des données et notre aliénation de consommateurs, de susciter l’action et non la passivité, le collectif et non l’individu. Si je produis des données, il faut qu’elles puissent profiter à tous ou à personne. C’est la logique de l’open data qui garanti le libre accès à des données placées dans le bien commun. Ce commun a ceci d’intéressant que tout ce qui y figure est alors identifiable. Ce qui n’y figure pas relève alors du privé et diffuser une donnée privée ne devrait relever que du seul choix délibéré de l’individu.
Le modèle proposé par le projet CHATONS (Collectif d’Hébergeurs Alternatifs, Transparents, Ouverts, Neutres et Solidaires) de Framasoft repose en partie sur ce principe. En adhérant à la charte, un hébergeur s’engage publiquement à remplir certaines obligations et, parmi celles-ci, l’interdiction d’utiliser les données des utilisateurs pour autre chose que l’évaluation et l’amélioration des services.
Comme écrit dans son manifeste (en version 0.9), l’objectif du collectif CHATONS est simple :
L’objectif de ce collectif est de mailler les initiatives de services basés sur des solutions de logiciels libres et proposés aux utilisateurs de manière à diffuser toutes les informations utiles permettant au public de pouvoir choisir leurs services en fonction de leurs besoins, avec un maximum de confiance vis-à-vis du respect de leur vie privée, sans publicité ni clause abusive ou obscure.
En lançant l’initiative de ce collectif, sans toutefois se placer dans une posture verticale fédérative, Framasoft ouvre une porte d’échappatoire. L’essentiel n’est pas tant de maximiser la venue de consommateurs sur quelques services identifiés mais de maximiser les chances pour les consommateurs d’utiliser des services de confiance qui, eux, pourront essaimer et se multiplier. Le postulat est que l’utilisateur est plus enclin à faire confiance à un hébergeur qu’il connaît et qui s’engage devant d’autres hébergeurs semblables, ses pairs, à respecter ses engagements éthiques. Outre l’utilisation de logiciels libres, cela se concrétise par trois principes
Mutualiser l’expertise : les membres du collectif s’engagent à partager les informations pour augmenter la qualité des services et pour faciliter l’essaimage des solutions de logiciels libres utilisées. C’est un principe de solidarité qui permettra, à terme, de consolider sérieusement le tissu des hébergeurs concernés.
Publier et adhérer à une charte commune. Cette charte donne les principaux critères techniques et éthiques de l’activité de membre. L’engagement suppose une réciprocité des échanges tant avec les autres membres du collectif qu’avec les utilisateurs.
Un ensemble de contraintes dans la charte publique implique non seulement de ne s’arroger aucun droit sur les données privées des utilisateurs, mais aussi de rester transparent y compris jusque dans la publication de ses comptes et rapports d’activité. En tant qu’utilisateur je connais les engagements de mon hébergeur, je peux agir pour le contraindre à les respecter tout comme les autres hébergeurs peuvent révoquer de leur collectif un membre mal intentionné.
Le modèle CHATONS n’est absolument pas exclusif. Il constitue même une caricature, en quelque sorte l’alternative contraire mais pertinente à GAFAM. Des entreprises tout à fait bien intentionnées, respectant la majeure partie de la charte, pourraient ne pas pouvoir entrer dans ce collectif à cause des contraintes liées à leur modèle économique. Rien n’empêche ces entreprises de monter leur propre collectif, avec un niveau de confiance différent mais néanmoins potentiellement acceptable. Si le collectif CHATONS décide de restreindre au domaine associatif des acteurs du mouvement, c’est parce que l’idée est d’essaimer au maximum le modèle : que l’association philatélique de Trifouille-le-bas puisse avoir son serveur de courriel, que le club de football de Trifouille-le-haut puisse monter un serveur owncloud et que les deux puissent mutualiser en devenant des CHATONS pour en faire profiter, pourquoi pas, les deux communes (et donc la communauté).
Un chaton, deux chatons… des chatons !
Conclusion
La souveraineté numérique est souvent invoquée par les autorités publiques bien conscientes des limitations du pouvoir qu’implique Big Other. Par cette expression, on pense généralement se situer à armes égales contre les géants du web. Pouvoir économique contre pouvoir républicain. Cet affrontement est perdu d’avance par tout ce qui ressemble de près ou de loin à une procédure institutionnalisée. Tant que les citoyens ne sont pas eux-mêmes porteurs d’alternatives au marché imposé par les GAFAM, l’État ne peut rien faire d’autre que de lutter pour sauvegarder son propre pouvoir, c’est-à-dire celui des partis comme celui des lobbies. Le serpent se mord la queue.
Face au capitalisme de surveillance, qui a depuis longtemps dépassé le stade de l’ultra-libéralisme (car malgré tout il y subsistait encore un marché et une autonomie des agents), c’est à l’État non pas de proposer un cloud souverain mais de se positionner comme le garant des principes démocratiques appliqués à nos données numériques et à Internet : neutralité sans faille du réseau, garantie de l’équité, surveillance des accords commerciaux, politique anti-trust affirmée, etc. L’éducation populaire, la solidarité, l’intelligence collective, l’expertise des citoyens, feront le reste, quitte à ré-inventer d’autres modèles de gouvernance (et de gouvernement).
Nous ne sommes pas des êtres a-technologiques. Aujourd’hui, nos vies sont pleines de données numériques. Avec Internet, nous en usons pour nous rapprocher, pour nous comprendre et mutualiser nos efforts, tout comme nous avons utilisé en leurs temps le téléphone, les voies romaines, le papyrus, et les tablettes d’argile. Nous avons des choix à faire. Nous pouvons nous diriger vers des modèles exclusifs, avec ou sans GAFAM, comme la généralisation de block chains pour toutes nos transactions. En automatisant les contrats, même avec un système ouvert et neutre, nous ferions alors reposer la confiance sur la technologie (et ses failles), en révoquant toute relation de confiance entre les individus, comme si toute relation interpersonnelle était vouée à l’échec. L’autre voie repose sur l’éthique et le partage des connaissances. Le projet CHATONS n’est qu’un exemple de système alternatif parmi des milliers d’autres dans de multiples domaines, de l’agriculture à l’industrie, en passant par la protection de l’environnement. Saurons-nous choisir la bonne voie ? Saurons-nous comprendre que les relations d’interdépendances qui nous unissent sur terre passent aussi bien par l’écologie que par le partage du code ?
Discours prononcé lors d’une conférence intitulée Surveillance capitalism: A new societal condition rising lors du sommet CPDP (Computers Privacy and Data protection), Bruxelles, 27-29 janvier 2016 (video).↩
Shoshana Zuboff, « Big other: surveillance capitalism and the prospects of an information civilization », Journal of Information Technology, 30, 2015, pp. p;75-89.↩
Directive 95/46/CE du Parlement européen et du Conseil, du 24 octobre 1995, relative à la protection des personnes physiques à l’égard du traitement des données à caractère personnel et à la libre circulation de ces données.↩
Hannah Arendt, La condition de l’homme moderne, Paris: Calmann-Lévy, Agora, 1958, pp. 400-401.↩
Shoshana Zuboff, « Big other: surveillance capitalism and the prospects of an information civilization », Journal of Information Technology, 30, 2015, p. p;81.↩
Les nouveaux Léviathans II — Surveillance et confiance (a)
Qu’est-ce qui fait courir Framasoft ? De la campagne Dégooglisons à l’initiative C.H.A.T.O.N.S quelles idées ont en tête les acteurs et soutiens de l’association ? Vous reprendrez bien une tranche de Léviathan ?
Pour vous inviter à aller au-delà des apparences (la sympathique petite tribu d’amateurs gaulois qui veut modestement mettre son grain de sable dans la loi des entreprises hégémoniques) nous vous proposons non seulement un moment de réflexion, mais pour une fois une série de considérations nourries, argumentées et documentées sur l’état de bascule que nous vivons et dans lequel nous prétendons inscrire notre action avec vous.
Jamais le logiciel libre et les valeurs qu’il porte n’ont été autant à la croisée des chemins, car il ne s’agit pas de proposer seulement des alternatives techniques, c’est un défi économique et politique qu’il doit relever.
Entre les États qui nous surveillent et les GAFAM qui nous monétisent, jamais le refuge du secret, celui de l’intime, n’a été aussi attaqué ni menacé. Pour représenter le monstre à plusieurs têtes, Christophe Masutti qui est l’auteur de cette série de réflexions, a choisi la figure emblématique du Léviathan, forgée déjà par Hobbes en particulier pour désigner l’État toujours plus avide de domination.
C’est donc une série de Léviathans nouveaux et anciens que nous vous invitons à découvrir par étapes, tout au long de cette semaine, qui vous conduiront peut-être à comprendre et adopter notre démarche. Car une fois établies les sources du mal et posé le diagnostic, que faire ? Les perspectives que nous proposons seront peut-être les vôtres.
Note de l’auteur :Cette seconde partie (Léviathans II) vise à approfondir les concepts survolés précédemment (Léviathans I). Nous avons vu que les monopoles de l’économie numérique ont changé le paradigme libéral jusqu’à instaurer un capitalisme de surveillance. Pour en rendre compte et comprendre ce nouveau système, il faut brosser plusieurs aspects de nos rapports avec la technologie en général, et les services numériques en particulier, puis voir comment des modèles s’imposent par l’usage des big data et la conformisation du marché (Léviathans IIa). J’expliquerai, à partir de la lecture de S. Zuboff, quelles sont les principales caractéristiques du capitalisme de surveillance. En identifiant ainsi ces nouvelles conditions de l’aliénation des individus, il devient évident que le rétablissement de la confiance aux sources de nos relations contractuelles et démocratiques, passe immanquablement par l’autonomie, le partage et la coopération, sur le modèle du logiciel libre (Léviathans IIb).
Techniques d’anticipation
On pense habituellement les objets techniques et les phénomènes sociaux comme deux choses différentes, voire parfois opposées. En plus de la nature, il y aurait deux autres réalités : d’un côté un monde constitué de nos individualités, nos rapports sociaux, nos idées politiques, la manière dont nous structurons ensemble la société ; et de l’autre côté le monde des techniques qui, pour être appréhendé, réclamerait obligatoirement des compétences particulières (artisanat, ingénierie). Nous refusons même parfois de comprendre nos interactions avec les techniques autrement que par automatisme, comme si notre accomplissement social passait uniquement par le statut d’utilisateur et jamais comme producteurs. Comme si une mise à distance devait obligatoirement s’établir entre ce que nous sommes (des êtres sociaux) et ce que nous produisons. Cette posture est au plus haut point paradoxale puisque non seulement la technologie est une activité sociale mais nos sociétés sont à bien des égards elles-mêmes configurées, transformées, et même régulées par les objets techniques. Certes, la compréhension des techniques n’est pas toujours obligatoire pour comprendre les faits sociaux, mais il faut avouer que bien peu de faits sociaux se comprennent sans la technique.
L’avènement des sociétés industrielles a marqué un pas supplémentaire dans l’interdépendance entre le social et les objets techniques : le travail, comme activité productrice, est en soi un rapport réflexif sur les pratiques et les savoirs qui forment des systèmes techniques. Nous baignons dans une culture technologique, nous sommes des êtres technologiques. Nous ne sommes pas que cela. La technologie n’a pas le monopole du signifiant : nous trouvons dans l’art, dans nos codes sociaux, dans nos intentions, tout un ensemble d’éléments culturels dont la technologie est censée être absente. Nous en usons parfois même pour effectuer une mise à distance des techniques omniprésentes. Mais ces dernières ne se réduisent pas à des objets produits. Elles sont à la fois des pratiques, des savoir-faire et des objets. La raison pour laquelle nous tenons tant à instaurer une mise à distance par rapport aux technologies que nous utilisons, c’est parce qu’elles s’intègrent tellement dans notre système économique qu’elles agissent aussi comme une forme d’aliénation au travail comme au quotidien.
Ces dernières années, nous avons vu émerger des technologies qui prétendent prédire nos comportements. Amazon teste à grande échelle des dépôts locaux de produits en prévision des commandes passées par les internautes sur un territoire donné. Les stocks de ces dépôts seront gérés au plus juste par l’exploitation des données inférées à partir de l’analyse de l’attention des utilisateurs (mesurée au clic), les tendances des recherches effectuées sur le site, l’impact des promotions et propositions d’Amazon, etc. De son côté, Google ne cesse d’analyser nos recherches dans son moteur d’indexation, dont les suggestions anticipent nos besoins souvent de manière troublante. En somme, si nous éprouvons parfois cette nécessité d’une mise à distance entre notre être et la technologie, c’est en réponse à cette situation où, intuitivement, nous sentons bien que la technologie n’a pas à s’immiscer aussi profondément dans l’intimité de nos pensées. Mais est-ce vraiment le cas ? Ne conformons-nous pas aussi, dans une certaine mesure, nos envies et nos besoins en fonction de ce qui nous est présenté comme nos envies et nos besoins ? La lutte permanente entre notre volonté d’indépendance et notre adaptation à la société de consommation, c’est-à-dire au marché, est quelque chose qui a parfaitement été compris par les grandes firmes du secteur numérique. Parce que nous laissons tellement de traces transformées en autant d’informations extraites, analysées, quantifiées, ces firmes sont désormais capables d’anticiper et de conformer le marché à leurs besoins de rentabilité comme jamais une firme n’a pu le faire dans l’histoire des sociétés capitalistes modernes.
Productivisme et information
Si vous venez de perdre deux minutes à lire ma prose ci-dessus hautement dopée à l’EPO (Enfonçage de Portes Ouvertes), c’est parce qu’il m’a tout de même paru assez important de faire quelques rappels de base avant d’entamer des considérations qui nous mènerons petit à petit vers une compréhension en détail de ce système. J’ai toujours l’image de cette enseignante de faculté, refusant de lire un mode d’emploi pour appuyer deux touches sur son clavier afin de basculer l’affichage écran vers l’affichage du diaporama, et qui s’exclamait : « il faut appeler un informaticien, ils sont là pour ça, non ? ». Ben non, ma grande, un informaticien a autre chose à faire. C’est une illustration très courante de ce que la transmission des savoirs (activité sociale) dépend éminemment des techniques (un vidéo-projecteur couplé un ordinateur contenant lui-même des supports de cours sous forme de fichiers) et que toute tentative volontaire ou non de mise à distance (ne pas vouloir acquérir un savoir-faire technique) cause un bouleversement a-social (ne plus être en mesure d’assurer une transmission de connaissance, ou plus prosaïquement passer pour quelqu’un de stupide). La place que nous occupons dans la société n’est pas uniquement une affaire de codes ou relations interpersonnelles, elle dépend pour beaucoup de l’ordre économique et technique auquel nous devons plus ou moins nous ajuster au risque de l’exclusion (et la forme la plus radicale d’exclusion est l’absence de travail et/ou l’incapacité de consommer).
Des études déjà anciennes sur les organisations du travail, notamment à propos de l’industrialisation de masse, ont montré comment la technologie, au même titre que l’organisation, détermine les comportements des salariés, en particulier lorsqu’elle conditionne l’automatisation des tâches1. Souvent, cette automatisation a été étudiée sous l’angle des répercussions socio-psychologiques, accroissant les sentiments de perte de sens ou d’aliénation sociale2. D’un point de vue plus populaire, c’est le remplacement de l’homme par la machine qui fut tantôt vécu comme une tragédie (l’apparition du chômage de masse) tantôt comme un bienfait (diminuer la pénibilité du travail). Aujourd’hui, les enjeux sont très différents. On s’interroge moins sur la place de la machine dans l’industrie que sur les taux de productivité et la gestion des flux. C’est qu’un changement de paradigme s’est accompli à partir des années 1970-1980, qui ont vu apparaître l’informatisation quasi totale des systèmes de production et la multiplication des ordinateurs mainframe dans les entreprises pour traiter des quantités sans cesse croissantes de données.
Très peu de sociologues ou d’économistes ont travaillé sur ce qu’une illustre chercheuse de la Harvard Business School, Shoshana Zuboff a identifié dans la transformation des systèmes de production : l’informationnalisation (informating). En effet, dans un livre très visionnaire, In the Age Of The Smart Machine en 19883, S. Zuboff montre que les mécanismes du capitalisme productiviste du XXe siècle ont connu plusieurs mouvements, plus ou moins concomitants selon les secteurs : la mécanisation, la rationalisation des tâches, l’automatisation des processus et l’informationnalisation. Ce dernier mouvement découle des précédents : dès l’instant qu’on mesure la production et qu’on identifie des processus, on les documente et on les programme pour les automatiser. L’informationnalisation est un processus qui transforme la mesure et la description des activités en information, c’est-à-dire en données extractibles et quantifiables, calculatoires et analytiques.
Là où S. Zuboff s’est montrée visionnaire dans les années 1980, c’est qu’elle a montré aussi comment l’informationnalisation modèle en retour les apprentissages et déplace les enjeux de pouvoir. On ne cherche plus à savoir qui a les connaissances suffisantes pour mettre en œuvre telle procédure, mais qui a accès aux données dont l’analyse déterminera la stratégie de développement des activités. Alors que le « vieux » capitalisme organisait une concurrence entre moyens de production et maîtrise de l’offre, ce qui, dans une économie mondialisée n’a plus vraiment de sens, un nouveau capitalisme (dont nous verrons plus loin qu’il se nomme le capitalisme de surveillance) est né, et repose sur la production d’informations, la maîtrise des données et donc des processus.
Pour illustrer, il suffit de penser à nos smartphones. Quelle que soit la marque, ils sont produits de manière plus ou moins redondante, parfois dans les mêmes chaînes de production (au moins en ce qui concerne les composants), avec des méthodes d’automatisation très similaires. Dès lors, la concurrence se place à un tout autre niveau : l’optimisation des procédures et l’identification des usages, tous deux producteurs de données. Si bien que la plus-value ajoutée par la firme à son smartphone pour séduire le plus d’utilisateurs possible va de pair avec une optimisation des coûts de production et des procédures. Cette optimisation relègue l’innovation organisationnelle au moins au même niveau, si ce n’est plus, que l’innovation du produit lui-même qui ne fait que répondre à des besoins d’usage de manière marginale. En matière de smartphone, ce sont les utilisateurs les plus experts qui sauront déceler la pertinence de telle ou telle nouvelle fonctionnalité alors que l’utilisateur moyen n’y voit que des produits similaires.
L’enjeu dépasse la seule optimisation des chaînes de production et l’innovation. S. Zuboff a aussi montré que l’analyse des données plus fines sur les processus de production révèle aussi les comportements des travailleurs : l’attention, les pratiques quotidiennes, les risques d’erreur, la gestion du temps de travail, etc. Dès lors l’informationnalisation est aussi un moyen de rassembler des données sur les aspects sociaux de la production4, et par conséquent les conformer aux impératifs de rentabilité. L’exemple le plus frappant aujourd’hui de cet ajustement comportemental à la rentabilité par les moyens de l’analyse de données est le phénomène d’« Ubérisation » de l’économie5.
Ramené aux utilisateurs finaux des produits, dans la mesure où il est possible de rassembler des données sur l’utilisation elle-même, il devrait donc être possible de conformer les usages et les comportements de consommation (et non plus seulement de production) aux mêmes impératifs de rentabilité. Cela passe par exemple par la communication et l’apprentissage de nouvelles fonctionnalités des objets. Par exemple, si vous aviez l’habitude de stocker vos fichiers MP3 dans votre smartphone pour les écouter comme avec un baladeur, votre fournisseur vous permet aujourd’hui avec une connexion 4G d’écouter de la musique en streaming illimité, ce qui permet d’analyser vos goûts, vous proposer des playlists, et faire des bénéfices. Mais dans ce cas, si vous vous situez dans un endroit où la connexion haut débit est défaillante, voire absente, vous devez vous passer de musique ou vous habituer à prévoir à l’avance cette éventualité en activant un mode hors-connexion. Cette adaptation de votre comportement devient prévisible : l’important n’est pas de savoir ce que vous écoutez mais comment vous le faites, et ce paramètre entre lui aussi en ligne de compte dans la proposition musicale disponible.
Le nouveau paradigme économique du XXIe siècle, c’est le rassemblement des données, leur traitement et leurs valeurs prédictives, qu’il s’agisse des données de production comme des données d’utilisation par les consommateurs.
Ces dernières décennies, l’informatique est devenu un média pour l’essentiel de nos activités sociales. Vous souhaitez joindre un ami pour aller boire une bière dans la semaine ? c’est avec un ordinateur que vous l’appelez. Voici quelques étapes grossières de cet épisode :
votre mobile a signalé vers des antennes relais pour s’assurer de la couverture réseau,
vous entrez un mot de passe pour déverrouiller l’écran,
vous effectuez une recherche dans votre carnet d’adresse (éventuellement synchronisé sur un serveur distant),
vous lancez le programme de composition du numéro, puis l’appel téléphonique (numérique) proprement dit,
vous entrez en relation avec votre correspondant, convenez d’une date,
vous envoyez ensuite une notification de rendez-vous avec votre agenda vers la messagerie de votre ami…
qui vous renvoie une notification d’acceptation en retour,
l’une de vos applications a géolocalisé votre emplacement et vous indique le trajet et le temps de déplacement nécessaire pour vous rendre au point de rendez-vous, etc.
Durant cet épisode, quel que soit l’opérateur du réseau que vous utilisez et quel que soit le système d’exploitation de votre mobile (à une ou deux exceptions près), vous avez produit des données exploitables. Par exemple (liste non exhaustive) :
le bornage de votre mobile indique votre position à l’opérateur, qui peut croiser votre activité d’émission-réception avec la nature de votre abonnement,
la géolocalisation donne des indications sur votre vitesse de déplacement ou votre propension à utiliser des transports en commun,
votre messagerie permet de connaître la fréquence de vos contacts, et éventuellement l’éloignement géographique.
Ramené à des millions d’utilisateurs, l’ensemble des données ainsi rassemblées entre dans la catégorie des Big Data. Ces dernières ne concernent pas seulement les systèmes d’informations ou les services numériques proposés sur Internet. La massification des données est un processus qui a commencé il y a longtemps, notamment par l’analyse de productivité dans le cadre de la division du travail, les analyses statistiques des achats de biens de consommation, l’analyse des fréquences de transaction boursières, etc. Tout comme ce fut le cas pour les processus de production qui furent automatisés, ce qui caractérise les Big Data c’est l’obligation d’automatiser leur traitement pour en faire l’analyse.
Prospection, gestion des risques, prédictibilité, etc., les Big Data dépassent le seul degré de l’analyse statistique dite descriptive, car si une de ces données renferme en général très peu d’information, des milliers, des millions, des milliards permettent d’inférer des informations dont la pertinence dépend à la fois de leur traitement et de leur gestion. Le tout dépasse la somme des parties : c’est parce qu’elles sont rassemblées et analysées en masse que des données d’une même nature produisent des valeurs qui dépassent la somme des valeurs unitaires.
Antoinette Rouvroy, dans un rapport récent6 auprès du Conseil de l’Europe, précise que les capacités techniques de stockage et de traitement connaissent une progression exponentielle7. Elle définit plusieurs catégories de data en fonction de leurs sources, et qui quantifient l’essentiel des actions humaines :
les hard data, produites par les institutions et administrations publiques ;
les soft data, produites par les individus, volontairement (via les réseaux sociaux, par exemple) ou involontairement (analyse des flux, géolocalisation, etc.) ;
les métadonnées, qui concernent notamment la provenance des données, leur trafic, les durées, etc. ;
l’Internet des objets, qui une fois mis en réseau, produisent des données de performance, d’activité, etc.
Les Big Data n’ont cependant pas encore de définition claire8. Il y a des chances pour que le terme ne dure pas et donne lieu à des divisions qui décriront plus précisément des applications et des méthodes dès lors que des communautés de pratiques seront identifiées avec leurs procédures et leurs réseaux. Aujourd’hui, l’acception générique désigne avant tout un secteur d’activité qui regroupe un ensemble de savoir-faire et d’applications très variés. Ainsi, le potentiel scientifique des Big Data est encore largement sous-évalué, notamment en génétique, physique, mathématiques et même en sociologie. Il en est de même dans l’industrie. En revanche, si on place sur un même plan la politique, le marketing et les activités marchandes (à bien des égards assez proches) on conçoit aisément que l’analyse des données optimise efficacement les résultats et permet aussi, par leur dimension prédictible, de conformer les biens et services.
Google fait peur ?
Eric Schmidt, actuellement directeur exécutif d’Alphabet Inc., savait exprimer en peu de mots les objectifs de Google lorsqu’il en était le président. Depuis 1998, les activités de Google n’ont cessé d’évoluer, jusqu’à reléguer le service qui en fit la célébrité, la recherche sur la Toile, au rang d’activité has been pour les internautes. En 2010, il dévoilait le secret de Polichinelle :
Le jour viendra où la barre de recherche de Google – et l’activité qu’on nomme Googliser – ne sera plus au centre de nos vies en ligne. Alors quoi ? Nous essayons d’imaginer ce que sera l’avenir de la recherche (…). Nous sommes toujours contents d’être dans le secteur de la recherche, croyez-moi. Mais une idée est que de plus en plus de recherches sont faites en votre nom sans que vous ayez à taper sur votre clavier.
En fait, je pense que la plupart des gens ne veulent pas que Google réponde à leurs questions. Ils veulent que Google dise ce qu’ils doivent faire ensuite. (…) La puissance du ciblage individuel – la technologie sera tellement au point qu’il sera très difficile pour les gens de regarder ou consommer quelque chose qui n’a pas été adapté pour eux.9
Google n’a pas été la première firme à exploiter des données en masse. Le principe est déjà ancien avec les premiers data centers du milieu des années 1960. Google n’est pas non plus la première firme à proposer une indexation générale des contenus sur Internet, par contre Google a su se faire une place de choix parmi la concurrence farouche de la fin des années 1990 et sa croissance n’a cessé d’augmenter depuis lors, permettant des investissements conséquents dans le développement de technologies d’analyse et dans le rachat de brevets et de plus petites firmes spécialisées. Ce que Google a su faire, et qui explique son succès, c’est proposer une expérience utilisateur captivante de manière à rassembler assez de données pour proposer en retour des informations adaptées aux profils des utilisateurs. C’est la radicalisation de cette stratégie qui est énoncée ici par Eric Schmidt. Elle trouve pour l’essentiel son accomplissement en utilisant les données produites par les utilisateurs du cloud computing. Les Big Data en sont les principaux outils.
D’autres firmes ont emboîté le pas. En résultat, la concentration des dix premières firmes de services numériques génère des bénéfices spectaculaires et limite la concurrence. Cependant, l’exploitation des données personnelles des utilisateurs et la manière dont elles sont utilisées sont souvent mal comprises dans leurs aspects techniques autant que par les enjeux économiques et politiques qu’elles soulèvent. La plupart du temps, la quantité et la pertinence des informations produites par l’utilisateur semblent négligeables à ses yeux, et leur exploitation d’une importance stratégique mineure. Au mieux, si elles peuvent encourager la firme à mettre d’autres services gratuits à disposition du public, le prix est souvent considéré comme largement acceptable. Tout au plus, il semble a priori moins risqué d’utiliser Gmail et Facebook, que d’utiliser son smartphone en pleine manifestation syndicale en France, puisque le gouvernement français a voté publiquement des lois liberticides et que les GAFAM ne livrent aux autorités que les données manifestement suspectes (disent-elles) ou sur demande rogatoire officielle (disent-elles).
Gigantismus
En 2015, Google Analytics couvrait plus de 70% des parts de marché des outils de mesure d’audience. Google Analytics est un outil d’une puissance pour l’instant incomparable dans le domaine de l’analyse du comportement des visiteurs. Cette puissance n’est pas exclusivement due à une supériorité technologique (les firmes concurrentes utilisent des techniques d’analyse elles aussi très performantes), elle est surtout due à l’exhaustivité monopolistique des utilisations de Google Analytics, disponible en version gratuite et premium, avec un haut degré de configuration des variables qui permettent la collecte, le traitement et la production très rapide de rapports (pratiquement en temps réel). La stratégie commerciale, afin d’assurer sa rentabilité, consiste essentiellement à coupler le profilage avec la régie publicitaire (Google AdWords). Ce modèle économique est devenu omniprésent sur Internet. Qui veut être lu ou regardé doit passer l’épreuve de l’analyse « à la Google », mais pas uniquement pour mesurer l’audience : le monopole de Google sur ces outils impose un web rédactionnel, c’est-à-dire une méthode d’écriture des contenus qui se prête à l’extraction de données.
Google n’est pas la seule entreprise qui réussi le tour de force d’adapter les contenus, quelle que soit leur nature et leurs propos, à sa stratégie commerciale. C’est le cas des GAFAM qui reprennent en chœur le même modèle économique qui conforme l’information à ses propres besoins d’information. Que vous écriviez ou non un pamphlet contre Google, l’extraction et l’analyse des données que ce contenu va générer indirectement en produisant de l’activité (visites, commentaires, échanges, temps de connexion, provenance, etc.) permettra de générer une activité commerciale. Money is money, direz-vous. Pourtant, la concentration des activités commerciales liées à l’exploitation des Big Data par ces entreprises qui forment les premières capitalisations boursières du monde, pose un certain nombre répercutions sociales : l’omniprésence mondialisée des firmes, la réduction du marché et des choix, l’impuissance des États, la sur-financiarisation.
Omniprésence
En produisant des services gratuits (ou très accessibles), performants et à haute valeur ajoutée pour les données qu’ils produisent, ces entreprises captent une gigantesque part des activités numériques des utilisateurs. Elles deviennent dès lors les principaux fournisseurs de services avec lesquels les gouvernements doivent composer s’ils veulent appliquer le droit, en particulier dans le cadre de la surveillance des populations et des opérations de sécurité. Ainsi, dans une démarche très pragmatique, des ministères français parmi les plus importants réunirent le 3 décembre 2015 les « les grands acteurs de l’internet et des réseaux sociaux » dans le cadre de la stratégie anti-terroriste10. Plus anciennement, le programme américain de surveillance électronique PRISM, dont bien des aspects furent révélés par Edward Snowden en 2013, a permit de passer durant des années des accords entre la NSA et l’ensemble des GAFAM. Outre les questions liées à la sauvegarde du droit à la vie privée et à la liberté d’expression, on constate aisément que la surveillance des populations par les gouvernements trouve nulle part ailleurs l’opportunité de récupérer des données aussi exhaustives, faisant des GAFAM les principaux prestataires de Big Data des gouvernements, quels que soient les pays11.
Réduction du marché
Le monopole de Google sur l’indexation du web montre qu’en vertu du gigantesque chiffre d’affaires que cette activité génère, celle-ci devient la première et principale interface du public avec les contenus numériques. En 2000, le journaliste Laurent Mauriac signait dans Libération un article élogieux sur Google12. À propos de la méthode d’indexation qui en fit la célébrité, L. Mauriac écrit :
Autre avantage : ce système empêche les sites de tricher. Inutile de farcir la partie du code de la page invisible pour l’utilisateur avec quantité de mots-clés…
Or, en 2016, il devient assez évident de décortiquer les stratégies de manipulation de contenus que les compagnies qui en ont les moyens financiers mettent en œuvre pour dominer l’index de Google en diminuant ainsi la diversité de l’offre13. Que la concentration des entreprises limite mécaniquement l’offre, cela n’est pas révolutionnaire. Ce qui est particulièrement alarmant, en revanche, c’est que la concentration des GAFAM implique par effets de bord la concentration d’autres entreprises de secteurs entièrement différents mais qui dépendent d’elles en matière d’information et de visibilité. Cette concentration de second niveau, lorsqu’elle concerne la presse en ligne, les éditeurs scientifiques ou encore les libraires, pose à l’évidence de graves questions en matière de liberté d’information.
Impuissances
La concentration des services, qu’il s’agisse de ceux de Google comme des autres géants du web, sur des secteurs biens découpés qui assurent les monopoles de chaque acteur, cause bien des soucis aux États qui voient leurs économies impactées selon les revenus fiscaux et l’implantation géographique de ces compagnies. Les lois anti-trust semblent ne plus suffire lorsqu’on voit, par exemple, la Commission Européenne avoir toutes les peines du monde à freiner l’abus de position dominante de Google sur le système Android, sur Google Shopping, sur l’indexation, et de manière générale depuis 2010.
Illustration cynique devant l’impuissance des États à réguler cette concentration, Google a davantage à craindre de ses concurrents directs qui ont des moyens financiers largement supérieurs aux États pour bloquer sa progression sur les marchés. Ainsi, cet accord entre Microsoft et Google, qui conviennent de régler désormais leurs différends uniquement en privé, selon leurs propres règles, pour ne se concentrer que sur leur concurrence de marché et non plus sur la législation. Le message est double : en plus d’instaurer leur propre régulation de marché, Google et Microsoft en organiseront eux-mêmes les conditions juridiques, reléguant le rôle de l’État au second plan, voire en l’éliminant purement et simplement de l’équation. C’est l’avènement des Léviathans dont j’avais déjà parlé dans un article antérieur.
Alphabet. CC-by-sa, Framatophe
Capitaux financiers
La capitalisation boursière des GAFAM a atteint un niveau jamais envisagé jusqu’à présent dans l’histoire, et ces entreprises figurent toutes dans le top 40 de l’année 201514. La valeur cumulée de GAFAM en termes de capital boursier en 2015 s’élève à 1 838 milliards de dollars. À titre de comparaison, le PIB de la France en 2014 était de 2 935 milliards de dollars et celui des Pays Bas 892 milliards de dollars.
La liste des acquisitions de Google explique en partie la cumulation de valeurs boursières. Pour une autre partie, la plus importante, l’explication concerne l’activité principale de Google : la valorisation des big data et l’automatisation des tâches d’analyse de données qui réduisent les coûts de production (à commencer par les frais d’infrastructure : Google a besoin de gigantesque data centers pour le stockage, mais l’analyse, elle, nécessite plus de virtualisation que de nouveaux matériels ou d’employés). Bien que les cheminements ne soient pas les mêmes, les entreprises GAFAM ont abouti au même modèle économique qui débouche sur le status quo de monopoles sectorisés. Un élément de comparaison est donné par le Financial Times en août 2014, à propos de l’industrie automobile vs l’économie numérique :
Comparons Detroit en 1990 et la Silicon Valley en 2014. Les 3 plus importantes compagnies de Detroit produisaient des bénéfices à hauteur de 250 milliards de dollars avec 1,2 million d’employés et la cumulation de leurs capitalisations boursières totalisait 36 milliards de dollars. Le 3 premières compagnies de la Silicon Valley en 2014 totalisaient 247 milliards de dollars de bénéfices, avec seulement 137 000 employés, mais un capital boursier de 1,09 mille milliard de dollars.15
La captation d’autant de valeurs par un petit nombre d’entreprises et d’employés, aurait été analysée, par exemple, par Schumpeter comme une chute inévitable vers la stagnation en raison des ententes entre les plus puissants acteurs, la baisse des marges des opérateurs et le manque d’innovation. Pourtant cette approche est dépassée : l’innovation à d’autres buts (produire des services, même à perte, pour capter des données), il est très difficile d’identifier le secteur d’activité concerné (Alphabet regroupe des entreprises ultra-diversifiées) et donc le marché est ultra-malléable autant qu’il ne représente que des données à forte valeur prédictive et possède donc une logique de plus en plus maîtrisée par les grands acteurs.
Voir sur ce point Robert Blauner, Alienation and Freedom. The Factory Worker and His Industry, Chicago: Univ. Chicago Press, 1965.↩
Shoshana Zuboff, In The Age Of The Smart Machine: The Future Of Work And Power, New York: Basic Books, 1988.↩
En guise d’illustration de tests (proof of concepts) discrets menés dans les entreprises aujourd’hui, on peut se reporter à cet article de Rue 89 Strasbourg sur cette société alsacienne qui propose, sous couvert de challenge collectif, de monitorer l’activité physique de ses employés. Rémi Boulle, « Chez Constellium, la collecte des données personnelles de santé des employés fait débat », Rue 89 Strasbourg, juin 2016.↩
Par exemple, dans le cas des livreurs à vélo de plats préparés utilisés par des sociétés comme Foodora ou Take Eat Easy, on constate que ces sociétés ne sont qu’une interface entre les restaurants et les livreurs. Ces derniers sont auto-entrepreneurs, payés à la course et censés assumer toutes les cotisations sociales et leurs salaires uniquement sur la base des courses que l’entreprise principale pourra leur confier. Ce rôle est automatisé par une application de calcul qui rassemble les données géographiques et les performances (moyennes, vitesse, assiduité, etc.) des livreurs et distribue automatiquement les tâches de livraisons. Charge aux livreurs de se trouver au bon endroit au bon moment. Ce modèle économique permet de détacher l’entreprise de toutes les externalités ou tâches habituellement intégrées qui pourraient influer sur son chiffre d’affaires : le matériel du livreur, l’assurance, les cotisations, l’accidentologie, la gestion du temps de travail, etc., seule demeure l’activité elle-même automatisée et le livreur devient un exécutant dont on analyse les performances. L’« Ubérisation » est un processus qui automatise le travail humain, élimine les contraintes sociales et utilise l’information que l’activité produit pour ajuster la production à la demande (quels que soient les risques pris par les livreurs, par exemple pour remonter les meilleures informations concernant les vitesses de livraison et se voir confier les prochaines missions). Sur ce sujet, on peut écouter l’émission Comme un bruit qui court de France Inter qui diffusa le reportage de Giv Anquetil le 11 juin 2016, intitulé « En roue libre ».↩
Même si Apple a déclaré ne pas entrer dans le secteur des Big Data, il n’en demeure pas moins qu’il en soit un consommateur comme un producteur d’envergure mondiale.↩
 la position et l’expérimentation d’artistes comme Gwenn Seemel, Amanda Palmer, Neil Jomunsi entre autres multiples exemples (ne risquons pas l’accusation de copinage en mentionnant Pouhiou), nous intéressent et nous passionnent parce qu’elles témoignent d’un monde à la charnière. En effet, un modèle d’édition et de diffusion arrive en bout de course et à bout de souffle, mais il est défendu mordicus à la fois par ses bénéficiaires (c’est cohérent) et parfois par ses victimes, ce qui est plus surprenant. Quant aux modèles émergents, aux variantes nombreuses et inventives, ils cherchent la voie d’une viabilité rendue incertaine par les lois du marché qui s’imposent à eux.
la position et l’expérimentation d’artistes comme Gwenn Seemel, Amanda Palmer, Neil Jomunsi entre autres multiples exemples (ne risquons pas l’accusation de copinage en mentionnant Pouhiou), nous intéressent et nous passionnent parce qu’elles témoignent d’un monde à la charnière. En effet, un modèle d’édition et de diffusion arrive en bout de course et à bout de souffle, mais il est défendu mordicus à la fois par ses bénéficiaires (c’est cohérent) et parfois par ses victimes, ce qui est plus surprenant. Quant aux modèles émergents, aux variantes nombreuses et inventives, ils cherchent la voie d’une viabilité rendue incertaine par les lois du marché qui s’imposent à eux.






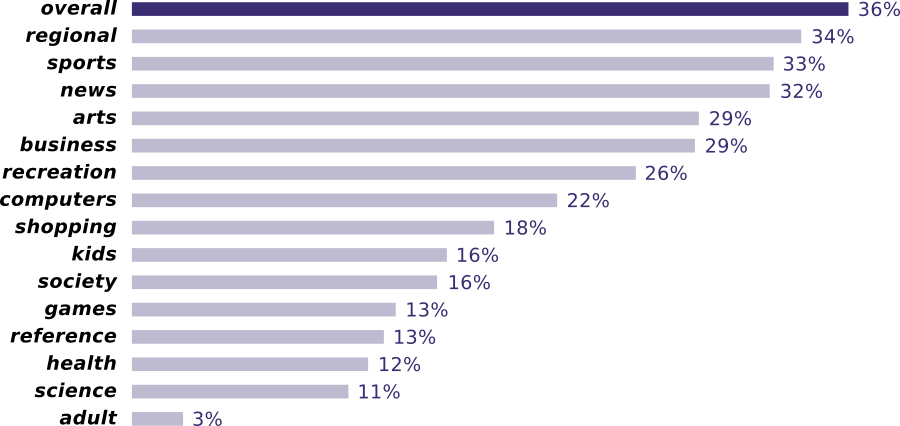





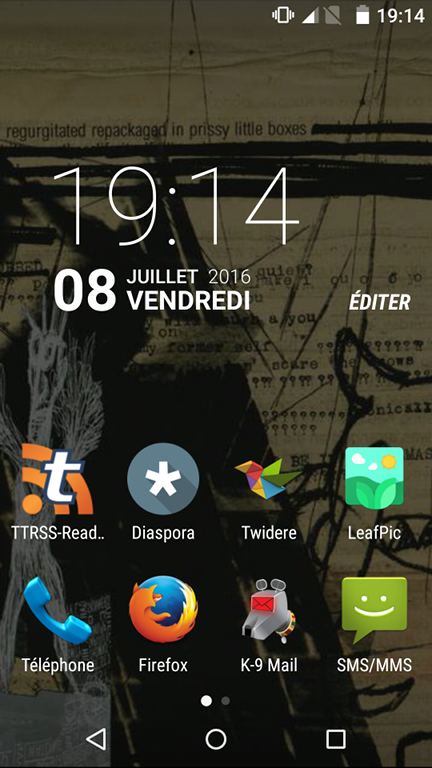

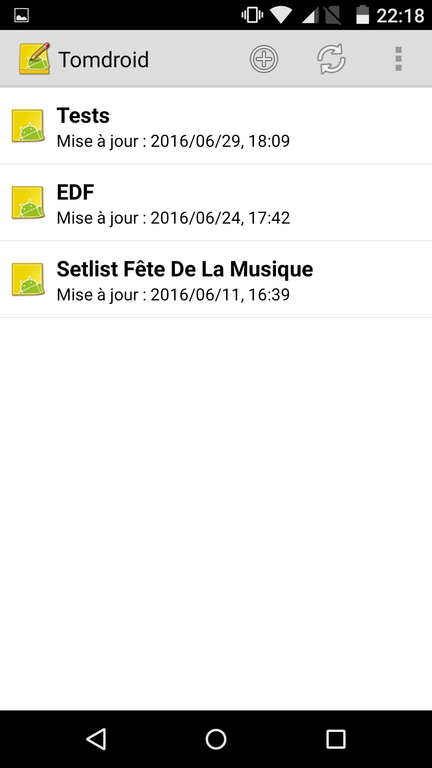
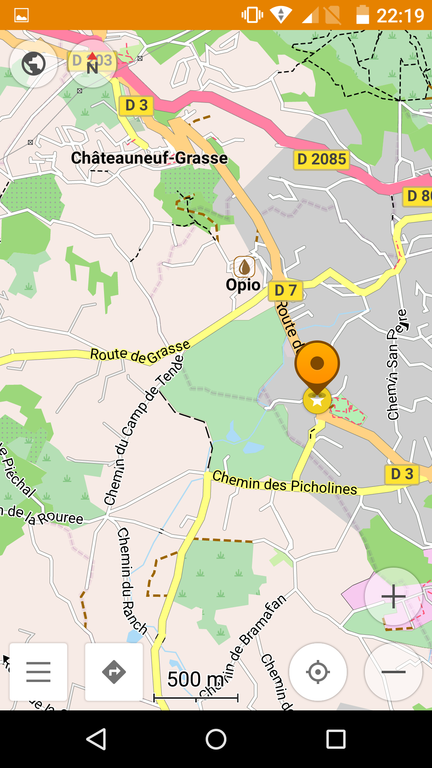
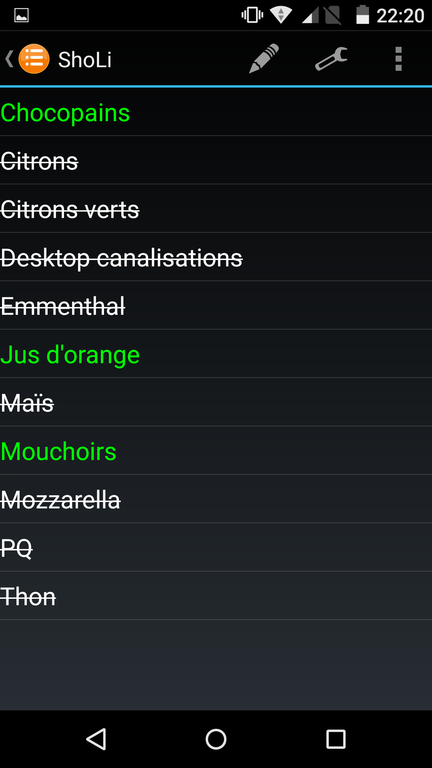
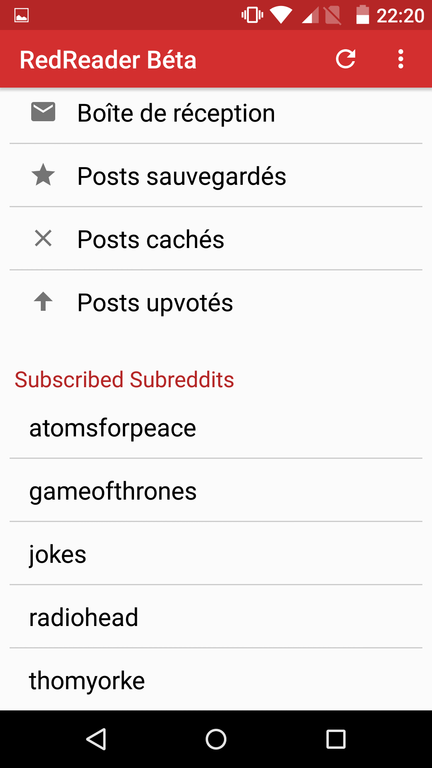
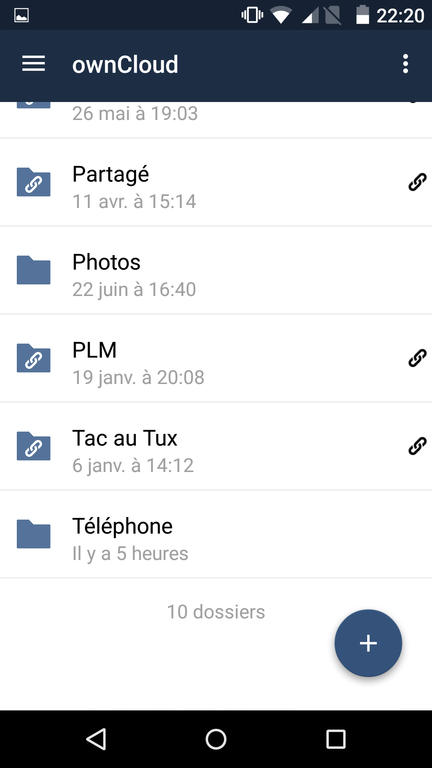
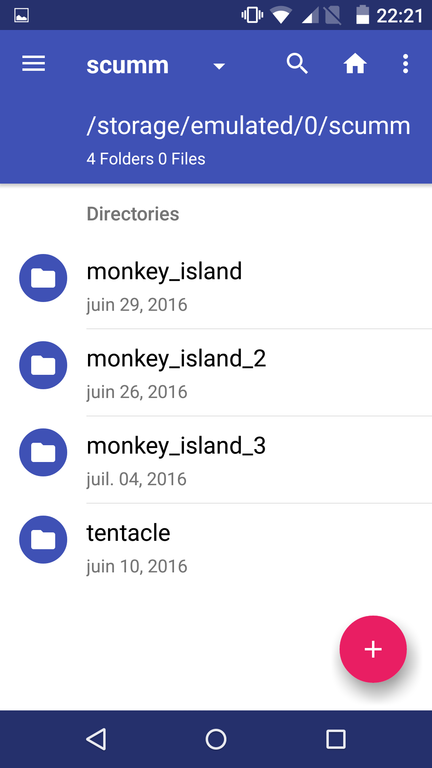
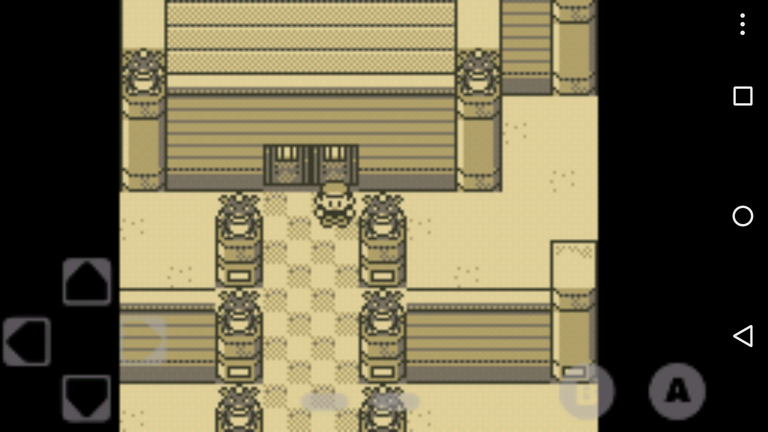
 L’Espresso a obtenu les tarifs de l’entreprise (de 1,50 euro à 85 centimes) et a contacté certains clients. Entre les réponses embarrassées et les reconnaissances du bout des lèvres, nous avons étudié l’activité de l’« Amazon des pétitions en ligne ». Elle manipule des données extrêmement sensibles telles que les opinions politiques et fait l’objet en Allemagne d’une enquête sur le respect de la vie privée.
L’Espresso a obtenu les tarifs de l’entreprise (de 1,50 euro à 85 centimes) et a contacté certains clients. Entre les réponses embarrassées et les reconnaissances du bout des lèvres, nous avons étudié l’activité de l’« Amazon des pétitions en ligne ». Elle manipule des données extrêmement sensibles telles que les opinions politiques et fait l’objet en Allemagne d’une enquête sur le respect de la vie privée.