Comment s’organiser contre la domination assistée par ordinateur ? [forum ouvert]
Dans le cadre de l’Université d’Été des Mouvements Sociaux et de la Solidarité (UEMSS) qui se déroulera du 23 au 27 août à Bobigny, et avec les copaines de Attac, Ritimo, Globenet, Convergence Services Publics, Transiscope, l’April, L’Établi numérique, La Dérivation… Nous avons voulu proposer ensemble un forum ouvert pour permettre la rencontre de celles et ceux impliquées dans des luttes et confronter nos expériences et nos réflexions.
Cette journée d’échanges se déroulera le samedi 26 août. Elle nécessite de s’inscrire à l’UEMSS (prix libre).
Forum ouvert : Comment s’organiser contre la domination assistée par ordinateur ?
Amazon utilisant des algorithmes sophistiqués pour imposer des cadences inhumaines aux chauffeurs et aux employé⋅es des centres logistiques. Facebook et al. collectant les opinions politiques des collectifs qui s’organisent dessus et favorisent structurellement la réaction. L’industrie de la tech poussant à acheter toujours plus d’appareils électroniques, générant ainsi toujours plus d’extraction de ressources et de déchets qui finissent par s’entasser dans énormes décharges dans les pays du Sud. La police demandant l’accès à nos communications, la possibilité de nous surveiller en temps réel par la reconnaissance faciale ou la biométrie aux frontières. ParcoursSup organisant la sélection sociale dans un service public de l’enseignement en crise.
Les différentes dominations auxquelles nous faisons face mobilisent maintenant toutes l’infrastructure informatique pour se renforcer, s’amplifier et élargir leurs champs d’actions. Il est devenu difficile de trouver un exemple de lutte où le numérique n’apparaît pas à un moment comme un outil utilisé par celleux d’en face. La domination est maintenant assistée par ordinateur.
Si on ne s’intéresse pas au numérique, le numérique, lui, s’intéresse à nous. Il est donc indispensable de réfléchir ensemble, de nous organiser collectivement pour faire face à cette domination. Les questions sont multiples : pouvons-nous retourner les outils numériques contre le capitalisme ? Comment mieux nous protéger face à la surveillance généralisée permise par la technologie ? À quoi ressemblerait un monde numérique désirable et vivable ?
Le numérique est devenu une réalité politique à part entière, et son évolution ne peut pas être laissée à des prétendu·es expertes et au capitalisme.
Vous avez des pistes d’actions concrètes, des idées, des envies ? Venez avec votre enthousiasme pour les partager !
Rȯse, la mascotte de Mobilizon en avant pour le forum ouvert illustration : David Revoy (CC-By)
Forum ouvert ?
Un forum ouvert se construit à partir des sujets que les personnes y participant souhaitent aborder. Le programme est élaboré ensemble au début de la journée. Le reste se déroule ensuite au rythme des différents groupes qui travaillent en parallèle et des nombreuses discussions informelles qui habitent les couloirs.
4 principes gouvernent un forum ouvert :
les personnes qui se présentent sont les bonnes personnes ;
il arrive ce qui pouvait arriver de mieux ;
ça commence quand ça commence ;
ça finit quand c’est fini.
La loi de la mobilité permet à une personne qui n’est ni en train d’apprendre, ni de contribuer, de changer de groupe.
Pistes de réflexion
Nous proposons quatre textes ou discussions pour alimenter nos réflexions avant l’événement :
Que veut dire « libre » (ou « open source ») pour un grand modèle de langage ?
Le flou entretenu entre open source et libre, déjà ancien et persistant dans l’industrie des technologies de l’information, revêt une nouvelle importance maintenant que les entreprises se lancent dans la course aux IA… Explications, décantation et clarification par Stéphane Bortzmeyer, auquel nous ouvrons bien volontiers nos colonnes.
Vous le savez, les grands modèles de langage (ou LLM, pour « Large Language Model ») sont à la mode. Ces mécanismes, que le marketing met sous l’étiquette vague et sensationnaliste d’IA (Intelligence Artificielle), ont connu des progrès spectaculaires ces dernières années.
Une de leurs applications les plus connues est la génération de textes ou d’images. L’ouverture au public de ChatGPT, en novembre 2022, a popularisé cette application. Chaque grande entreprise de l’informatique sort désormais son propre modèle, son propre LLM.
Il faut donc se distinguer du concurrent et, pour cela, certains utilisent des arguments qui devraient plaire aux lecteurs et lectrices du Framablog, en affirmant que leur modèle est (en anglais dans le texte) « open source ». Est-ce vrai ou bien est-ce du « libre-washing » ?
Et qu’est-ce que cela veut dire pour cet objet un peu particulier qu’est un modèle de langage ?
Tout le monde parle des LLM (ici, avec une faute de frappe).
Source ouverte ?
Traitons d’abord un cas pénible mais fréquent : que veut dire « open source » ? Le terme désigne normalement l’information qui est librement disponible. C’est en ce sens que les diplomates, les chercheurs, les journalistes et les espions parlent de ROSO (Renseignement d’Origine en Sources Ouvertes) ou d’OSINT (Open Source Intelligence). Mais, dans le contexte du logiciel, le terme a acquis un autre sens quand un groupe de personnes, en 1998, a décidé d’essayer de remplacer le terme de « logiciel libre », qui faisait peur aux décideurs, par celui d’« open source ». Ils ont produit une définition du terme qu’on peut considérer comme la définition officielle d’« open source ». Il est intéressant de noter qu’en pratique, cette définition est quasiment équivalente aux définitions classiques du logiciel libre et que des phrases comme « le logiciel X n’est pas libre mais est open source » n’ont donc pas de sens. Ceci dit, la plupart des gens qui utilisent le terme « open source » ne connaissent ni l’histoire, ni la politique, ni la définition « officielle » et ce terme, en réalité, est utilisé pour tout et n’importe quoi. On peut donc se dire « open source » sans risque d’être contredit. Je vais donc plutôt me pencher sur la question « ces modèles sont-ils libres ? ».
Grand modèle de langage ?
Le cas du logiciel est désormais bien connu et, sauf grande malhonnêteté intellectuelle, il est facile de dire si un logiciel est libre ou pas. Mais un modèle de langage ? C’est plus compliqué, Revenons un peu sur le fonctionnement d’un LLM (grand modèle de langage). On part d’une certaine quantité de données, par exemple des textes, le « dataset ». On applique divers traitements à ces données pour produire un premier modèle. Un modèle n’est ni un programme, ni un pur ensemble de données. C’est un objet intermédiaire, qui tient des deux. Après d’éventuels raffinements et ajouts, le modèle va être utilisé par un programme (le moteur) qui va le faire tourner et, par exemple, générer du texte. Le moteur en question peut être libre ou pas. Ainsi, la bibliothèque transformers est clairement libre (licence Apache), ainsi que les bibliothèques dont elle dépend (comme PyTorch). Mais c’est le modèle qu’elle va exécuter qui détermine la qualité du résultat. Et la question du caractère libre ou pas du modèle est bien plus délicate.
Notons au passage que, vu l’importante consommation de ressources matérielles qu’utilisent ces LLM, ils sont souvent exécutés sur une grosse machine distante (le mythique « cloud »). Lorsque vous jouez avec ChatGPT, le modèle (GPT 3 au début, GPT 4 désormais) n’est pas téléchargé chez vous. Vous avez donc le service ChatGPT, qui utilise le modèle GPT.
Mais qui produit ces modèles (on verra plus loin que c’est une tâche non triviale) ? Toutes les grandes entreprises du numérique ont le leur (OpenAI a le GPT qui propulse ChatGPT, Meta a Llama), mais il en existe bien d’autres (Bloom, Falcon, etc), sans compter ceux qui sont dérivés d’un modèle existant. Beaucoup de ces modèles sont disponibles sur Hugging Face (« le GitHub de l’IA », si vous cherchez une « catch phrase ») et vous verrez donc bien des références à Hugging Face dans la suite de cet article. Prenons par exemple le modèle Falcon. Sa fiche sur Hugging Face nous donne ses caractéristiques techniques, le jeu de données sur lequel il a été entrainé (on verra que tous les modèles sont loin d’être aussi transparents sur leur création) et la licence utilisée (licence Apache, une licence libre). Hugging Face distribue également des jeux de données d’entrainement.
Dans cet exemple ci-dessous (trouvé dans la documentation de Hugging Face), on fait tourner le moteur transformers (plus exactement, transformers, plus diverses bibliothèques logicielles) sur le modèle xlnet-base-cased en lui posant la question « Es-tu du logiciel libre ? » :
% python run_generation.py --model_type=xlnet --model_name_or_path=xlnet-base-cased
...
Model prompt >>> Are you free software?
This is a friendly reminder - the current text generation call will exceed the model's predefined maximum length (-1). Depending on the model, you may observe exceptions, performance degradation, or nothing at all.
=== GENERATED SEQUENCE 1 ===
Are you free software? Are you a professional? Are you a Master of Technical Knowledge? Are you a Professional?
Ce modèle, comme vous le voyez, est bien moins performant que celui qui est derrière le service ChatGPT ; je l’ai choisi parce qu’il peut tourner sur un ordinateur ordinaire.
Vous voulez voir du code source en langage Python ? Voici un exemple d’un programme qui fait à peu près la même chose :
from transformers import pipeline
generator = pipeline("text-generation", model="DunnBC22/xlnet-base-cased-finetuned-WikiNeural-PoS")
print(generator("Are you free software?"))
Le modèle utilisé est un raffinement du précédent, DunnBC22/xlnet-base-cased-finetuned-WikiNeural-PoS. Il produit lui aussi du contenu de qualité contestable([{‘generated_text’: « Are you free software? What ever you may have played online over your days? Are you playing these games? Any these these hours where you aren’t wearing any heavy clothing?) mais, bon, c’est un simple exemple, pas un usage intelligent de ces modèles.
Les LLM n’ont pas de corps (comme Scarlett Johansson dans le film « Her ») et ne sont donc pas faciles à illustrer. Plutôt qu’une de ces stupides illustrations de robot (les LLM n’ont pas de corps, bon sang !), je mets une image d’un chat certainement intelligent. Drew Coffman, CC BY 2.0, via Wikimedia Commons
Que veut dire « libre » pour un LLM ?
Les définitions classiques du logiciel libre ne s’appliquent pas telles quelles. Des entreprises (et les journalistes paresseux qui relaient leurs communiqués de presse sans vérifier) peuvent dire que leur modèle est « open source » simplement parce qu’on peut le télécharger et l’utiliser. C’est très loin de la liberté. En effet, cette simple autorisation ne permet pas les libertés suivantes :
Connaître le jeu de données utilisé pour l’entrainement, ce qui permettrait de connaitre les choix effectués par les auteurs du modèle (quels textes ils ont retenu, quels textes ils ont écarté) et savoir qui a écrit les textes en question (et n’était pas forcément d’accord pour cette utilisation).
Connaître les innombrables choix techniques qui ont été faits pour transformer ces textes en un modèle. (Rappelez-vous : un algorithme, ce sont les décisions de quelqu’un d’autre.)
Sans ces informations, on ne peut pas refaire le modèle différemment (alors que la possibilité de modifier le programme est une des libertés essentielles pour qu’un logiciel soit qualifié de libre). Certes, on peut affiner le modèle (« fine-tuning a pre-trained model », diront les documentations) mais cela ne modifie pas le modèle lui-même, certains choix sont irréversibles (par exemple des choix de censure). Vous pouvez créer un nouveau modèle à partir du modèle initial (si la licence prétendument « open source » le permet) mais c’est tout.
Un exemple de libre-washing
Le 18 juillet 2023, l’entreprise Meta a annoncé la disponibilité de la version 2 de son modèle Llama, et le fait qu’il soit « open source ». Meta avait même convaincu un certain nombre de personnalités de signer un appel de soutien, une initiative rare dans le capitalisme. Imagine-t-on Microsoft faire signer un appel de soutien et de félicitations pour une nouvelle version de Windows ? En réalité, la licence est très restrictive, même le simple usage du modèle est limité. Par exemple, on ne peut pas utiliser Llama pour améliorer un autre modèle (concurrent). La démonstration la plus simple de la non-liberté est que, pour utiliser le modèle Llama sur Hugging Face, vous devez soumettre une candidature, que Meta accepte ou pas (« Cannot access gated repo for url https://huggingface.co/meta-llama/Llama-2-7b/resolve/main/config.json. Access to model meta-llama/Llama-2-7b is restricted and you are not in the authorized list. Visit https://huggingface.co/meta-llama/Llama-2-7b to ask for access. »)
Mais la communication dans l’industrie du numérique est telle que très peu de gens ont vérifié. Beaucoup de commentateurs et de gourous ont simplement relayé la propagande de Meta. Les auteurs de la définition originale d’« open source » ont expliqué clairement que Llama n’avait rien d’« open source », même en étant très laxiste sur l’utilisation du terme. Ceci dit, il y a une certaine ironie derrière le fait que les mêmes personnes, celles de cette Open Source Initiative, critiquent Meta alors même qu’elles avaient inventé le terme « open source » pour brouiller les pistes et relativiser l’importance de la liberté.
Au contraire, un modèle comme Falcon coche toutes les cases et peut très probablement être qualifié de libre.
La taille compte
Si une organisation qui crée un LLM publie le jeu de données utilisé, tous les réglages utilisés pendant l’entrainement, et permet ensuite son utilisation, sa modification et sa redistribution, est-ce que le modèle peut être qualifié de libre ? Oui, certainement, mais on peut ajouter une restriction, le problème pratique. En effet, un modèle significatif (disons, permettant des résultats qui ne sont pas ridicules par rapport à ceux de ChatGPT) nécessite une quantité colossale de données et des machines énormes pour l’entrainement. L’exécution du modèle par le moteur peut être plus économe. Encore qu’elle soit hors de portée, par exemple, de l’ordiphone classique. Si une application « utilisant l’IA » tourne soi-disant sur votre ordiphone, c’est simplement parce que le gros du travail est fait par un ordinateur distant, à qui l’application envoie vos données (ce qui pose divers problèmes liés à la vie privée, mais c’est une autre histoire). Même si l’ordiphone avait les capacités nécessaires, faire tourner un modèle non trivial épuiserait vite sa batterie. Certains fabricants promettent des LLM tournant sur l’ordiphone lui-même (« on-device ») mais c’est loin d’être réalisé.
Mais l’entraînement d’un modèle non trivial est bien pire. Non seulement il faut télécharger des téra-octets sur son disque dur, et les stocker, mais il faut des dizaines d’ordinateurs rapides équipés de GPU (puces graphiques) pour créer le modèle. Le modèle Llama aurait nécessité des milliers de machines et Bloom une bonne partie d’un super-calculateur. Cette histoire de taille ne remet pas en question le caractère libre du modèle, mais cela limite quand même cette liberté en pratique. Un peu comme si on vous disait « vous êtes libre de passer votre week-end sur la Lune, d’ailleurs voici les plans de la fusée ». Le monde du logiciel libre n’a pas encore beaucoup réfléchi à ce genre de problèmes. (Qui ne touche pas que l’IA : ainsi, un logiciel très complexe, comme un navigateur Web, peut être libre, sans que pour autant les modifications soit une entreprise raisonnable.) En pratique, pour l’instant, il y a donc peu de gens qui ré-entrainent le modèle, faisant au contraire une confiance aveugle à ce qu’ils ont téléchargé (voire utilisé à distance).
Conclusion
Pour l’instant, la question de savoir ce que signifie la liberté pour un modèle de langage reste donc ouverte. L’Open Source Initiative a lancé un projet pour arriver à une définition. Je ne connais pas d’effort analogue du côté de la FSF mais plus tard, peut-être ?
Le X de Musk n’est pas une inconnue…
L’actualité récente nous invite à republier avec son accord l’article de Kazhnuz sur son blog (il est sous licence CC BY-SA 4.0) qui souligne un point assez peu observé de la stratégie d’Elon Musk : elle n’est guère innovante et ne vise qu’à ajouter un X aux GAFAM pour capter une base utilisateur à des fins mercantiles…
L’annonce a été faite le 23 juillet, Twitter va être remplacé par X, le « rêve » de Musk de créer l’app-à-tout-faire à la WeChat en Chine. Le logo va être changé, et la marque Twitter va être abandonnée au profit de celle de X, et le domaine x.com redirige déjà vers Twitter. Le nom a déjà été utilisé jadis par Musk pour sa banque en ligne (qui après moult péripéties deviendra Paypal, justement parce que le nom est nul et pose des tonnes de soucis – ressembler à un nom de site X justement), et cette fois comme y’a personne pour lui dire « stop mec ton idée pue », il le fait.
Cependant, je pense qu’il y a quelques trucs intéressants à dire sur la situation, parce qu’au final, plus qu’une « lubie de Musk », il y a dedans quelque chose qui informe de la transformation faite de twitter, et de la façon dont Musk fait juste partie d’un mouvement fortement présent dans la Silicon Valley.
Encore un
Je pense qu’il ne faut pas voir ce changement de nom comme quelque chose de si surprenant, imprévisible, parce que c’est jouer le jeu de Musk de croire qu’il est l’électron libre qu’il prétend être. Parce que même s’il va plus loin en changeant carrément la marque du produit, Musk ne fait (encore une fois) que copier-coller un comportement déjà présent dans le milieu de la tech.
Parce qu’au final, Twitter appartenant et devenant X Corp, c’est comme Facebook qui devient Meta Plateform, ou Google qui devient Alphabet Inc. Un changement en grande partie pour tenter de forger la « hype », l’idée que le site fait partie de quelque chose de plus grand, du futur, de ce qui va former l’Internet – non la vie – de demain. Bon je pense que ça se voit que je suis un peu sarcastique de tout ça, mais y’a cette idée derrière les grandes entreprises de la tech. Elles ne sont plus dans l’idée de tourner autour de quelques produits, elles se présentent comme le « futur ». X Corp n’est qu’une tentative de créer un autre GAFAM, et fait partie des mêmes mouvements, des mêmes visions, du même aspect « techbro ».
C’est pour ça que le nom « rigolo » est moins mis en avant par rapport au nom plus « générique-mais-cool-regardez ». Meta, pour ceux qui vont au-delà et le métavers. X pour la variable inconnue. Alphabet pour aller de A à Z. Tout cela est de l’esbroufe, parce que plus que vendre un produit, ils vendent de la hype aux investisseurs.
Et le fait que Musk a voulu réutiliser ce nom dans le passé ne change pas grand-chose à tout ça. Le but, l’ego est le même. Donner l’impression qu’on est face à une grosse mégacorporation du futur. Et ce manque d’originalité n’est pas que dans le changement de nom, mais aussi au final dans son plan derrière tout ça : transformer Twitter en une marketplace.
X, une autre marketplace
Le passage de Twitter à X.com, montre le même cœur que les metaverse et crypto… et au final une grande partie des transformations qui se sont produites : tout transformer en marketplace, enrobé dans une esthétique de technofuturisme. Cela se voit encore plus dans le message de Linda Yaccarino, la CEO de Twitter :
X est l’état futur de l’interactivité illimitée – centrée sur l’audio, la vidéo, la messagerie, les paiements/les banques – créant une place de marché globale pour les idées, les biens, les services et les opportunités. Propulsé par l’IA, X va nous connecter d’une manière que nous commençons juste à imaginer.
— Linda Yaccarino, twitter
On peut remarquer deux choses dans ce message :
Le premier est qu’il n’y a rien d’original dedans. Nous y retrouvons exactement la même chose que l’on retrouvait à l’époque des crypto et des NFT : le truc qui fait tout mais surtout des trucs qui existent déjà, et basé sur la technologie du turfu. Y’a déjà 500 plateformes pour faire payer pour des services, que ce soit en crowdfunding, au format « patreon », via des commissions, etc. Des ventes de biens sur internet, y’a aussi des tonnes de moyens, etc. Tout ce qui est rajouté c’est « on va faire tous ces trucs qui existent déjà, et on a dit « IA » dedans donc c’est le futur ça va tout révolutionner tavu ». C’est le modus operandi classique, et il n’y a rien d’original dans ce que propose Twitter. D’ailleurs, le rôle que peut avoir l’IA dedans est très vague : est-ce que c’est pour modifier les algorithmes ? (cela ne sert pas à grand-chose, on les hait tous déjà). Est-ce que c’est pour pouvoir générer des produits par IA pour les vendre ? Le produit que veut proposer X Corp n’a pas besoin d’IA pour fonctionner, elle est là juste pour dire « c’est le futur », et hyper les investisseurs.
Le second est que cela transforme l’idée de base de Twitter (l’endroit où les gens parlent) en avant tout une « place de marché », comme indiqué plus haut. Twitter était le lieu de la discussion, du partage de l’idée à la con qu’on a eue sous la douche. D’où le format du microblogging. Là aussi, même cet aspect devient quelque chose de commercialisable, ce qui rappelle encore une fois le mouvement qu’il y avait eu autour de la crypto et des NFT : tout doit pouvoir devenir commercialisable, tout doit pouvoir devenir un produit. C’est aussi ce mouvement qui fait qu’on a de plus en plus de « jeux-services », qui servent avant tout à vendre des produits dématérialisés n’ayant de valeur qu’à l’intérieur du jeu (et encore). Beaucoup de jeux ne peuvent plus juste « être un jeu », ils doivent être une « marketplace ».
Conclusion
La transformation de twitter en X n’est donc pas une surprise – en plus du fait que c’était annoncé depuis longtemps. Il ne s’agit que d’un phénomène qui arrive tout le temps sur Internet. Une volonté de transformer un site populaire en une « place de marché du futur » pour hyper des investisseurs. Encore une fois.
Et au final, on sait bien ce qu’a acheté Musk quand il a acheté Twitter. Il n’a pas acheté un produit. Il a acheté une userbase (une base d’utilisateurs et utilisatrices) pour l’injecter directement dans le nouveau produit qu’il voulait faire. C’est assez ironique de voir que Twitter a fini de la même manière que certains comptes populaires : revendu pour être renommé et envoyer sa pub à des tonnes d’utilisateurs.
Berlin, March 2023 : Diary of the first ECHO Network study visit
From 27 to 31 March 2023, the first study visit of the European project ECHO Network took place in Berlin. This report looks back on this week of exchange on the theme of « Young people, social networks and political education« , organised by the Willi Eichler Academy.
In order to promote the values of the Ethical, Commons, Humans, Open-Source Network project, the Framasoft participants wanted to travel to Berlin by train. So Monday and Friday of this exchange week were dedicated to transport.
The day of departure was a national strike day in Germany (where a rail strike = no trains running!). As a result, only 3 of the 4 Framasoft members who had planned to take part in the project were able to make it.
When you think of trains, you think of time, where transport is an integral part of the journey. In fact, it takes 9 hours by train from Paris, or even 13 hours from Nantes… And you should add 1 or 2 hours (or even half a day) for « contingency management » (delays, cancellations, changes of train). Travelling to Germany by train was an adventure in itself (and the feeling seems to be shared!).
Tuesday 28 March: Discoveries and visits off the beaten track
After a brief meeting with the first participants the day before, Tuesday will continue with the aim of getting to know each other (arrivals will continue throughout the day due to changes in the itinerary caused by the strike the day before).
Tuesday morning will begin with a visit to the Jewish Cemetery of Berlin-Weißensee, the largest Jewish cemetery in Europe. Nature takes over in this historic place.
Weißensee Jewish cemetery, between nature and history
In the afternoon we visit a former Stasi prison, Berlin-Hohenschönhausen. This visit made a particularly strong impression on us: the site was created by former prisoners, the prison wasn’t closed until 1990, and many of the people who tortured prisoners were never brought to justice. In short, a dark page of history, but one that needs to be shared (we recommend the visit!)…
The day will end with a convivial meal in a traditional restaurant.
Wednesday 29 March: young, old and social networks
The chandelier in the entrance hall of the cookery school is just right!
Discussion: What do we think about social networks in our organisations?
The first workshop was a round-table discussion in which each participant shared his or her use of and views on social networks, and in particular TikTok, the medium that will be used in the following workshop.
To summarise:
There is little use of social media from a personal point of view in the group.
On the other hand, the majority of the group use social media to promote their organisation’s activities (Facebook, Twitter, Instagram and Mastodon).
No one in the group uses TikTok, which poses a problem for understanding this social media.
As part of their organisation’s activities, the majority of the group would like to reach out more to young people and it seems interesting to find them where they are, i.e. on social media.
The group fully agreed that social media are not neutral tools and try to monopolise the attention of their users.
This time of exchange therefore allowed us to see that we share the same values, difficulties and desires when it comes to social media. However, we felt that the ‘one at a time’ format lacked some dynamism in the exchanges and the opportunity for several people to discuss.
Feedback from a student workshop: raising awareness of social issues in a TikTok video
Alongside our morning discussions on social media, 2 groups of students from the Brillat-Savarin school worked on a video project. They had to produce a TikTok video (one per group) to show the impact of the European Union (1st group) and climate change (2nd group) on their work as chefs. The videos were shown to us (incredible quality in 2 hours of work!) and then we exchanged views on the topic.
What we took away from this workshop:
The students were between 18 and 22 years old and did not use TikTok. According to the students, this social network is aimed at people younger than them (« young » is too broad a term!). However, they had mastered the codes of the platform as they were regularly exposed to TikTok content on other platforms such as Instagram and YouTube.
In any case, they wouldn’t necessarily want to use a social network to watch political content, preferring a more recreational use of the network (like watching videos of kittens!), even if they claim to be political.
They found it particularly interesting to get a message across in videos and to question themselves on issues that directly affect them.
It was an interesting experiment, even if the plenary discussions did not allow everyone to participate.
Photo of the ECHO Network group and some of the school’s students
Thursday 30th March: Politics and Open Source
Reflect EU&US: the Willi Eichler Academy project
Funded to the tune of €500,000 by Marshall Plan leftovers, Reflect EU&US is a 2-year project (2022-2024) by the Willi Eichler Academy. Its aim? To organise discussions between students outside the university environment, remotely and anonymously.
Reflect EU&US project logo
Points to remember:
The project involves 60 students (30 from the United States and 30 from Germany), with a physical meeting planned at the very end of the project to lift the masks.
Topics covered include justice, racism, gender and politics.
Following the discussions, a library of documents will be created, which will allow the various sources (texts, articles, videos, podcasts, etc.) to be validated (or not).
Anonymity makes it easier to accept contradictory opinions.
The management of the groups can be complicated by anonymity, but it is an integral part of the project.
From a technical point of view, the platform is based on the OpenTalk tool and was chosen to provide this space for free exchange, with the creation of coloured cards as avatars, making it possible to guarantee the anonymity of the participants. The choice of open source technologies was made specifically with the aim of reassuring participants so that they could exchange in complete peace of mind. This was followed by a live test of the platform with the students (in German, which didn’t allow us to understand everything!).
Open source meets politics
The afternoon continued with a talk by Peer Heinlein, director of OpenTalk, on « True digital independence and sovereignty are impossible without open source ». You can imagine that we at Framasoft have an opinion on this, even if we don’t feel strongly about it… Discussions with the audience followed on open source software, privacy and data encryption.
The next speaker was Maik Außendorf, representative of the Green Party in the European Parliament. Among other things, we discussed how digital technology can help the ecological transition. We learnt that German parliamentarians do not have a choice when it comes to using digital tools, and that national coherence is difficult to achieve with the decentralised organisation of Germany into Länder.
The study visit ended in a restaurant, where we had the opportunity to talk with a SeaWatch activist, highlighting the common values and reflections of the different organisations (precariousness of associations, the need to propose alternatives to the capitalist world, the need for free and emancipatory digital technologies).
This chandelier will have inspired⋅es (can you see the artistic side too?).
An intense week!
We were particularly surprised and excited by the common visions shared by the participants and organisations, whether it be about emancipatory digital, the desire to move towards a world that is more like us, where cooperation and contribution move forward, and the question of how to share our messages while remaining coherent with what we defend.
Although the majority of the week was built around plenary workshops, which did not always encourage exchange between participants or spontaneous speaking, the informal times (meals, coffee breaks, walks) made it possible to create these essential moments.
What next for the ECHO network? The second study visit took place in Brussels from 12 to 16 June. A summary article will follow on the Framablog (but as always, we’ll take our time!).
We couldn’t go to Berlin without visiting the murals on the Berlin Wall: here’s a photo of the trip to round off this article.
Berlin, mars 2023 : journal de bord de la première visite d’études d’ECHO Network
Du 27 au 31 mars 2023, la première visite d’études du projet européen ECHO Network s’est tenue à Berlin. Ce compte rendu retrace cette semaine d’échanges sur la thématique « jeunes, réseaux sociaux et éducation politique », organisée par Willi Eichler Akademy.
Ambiance fraîche à Berlin pour ce début de printemps !
La route est longue jusque Berlin…!
Pour pousser les valeurs du projet Ethical, Commons, Humans, Open-Source Network (Réseau autour de l’Éthique, les Communs, les Humain⋅es et l’Open-source), les participant⋅es de Framasoft souhaitaient favoriser le train pour se rendre à Berlin. Ainsi, le lundi et le vendredi de cette semaine d’échange étaient banalisés pour le transport.
Les contre-temps faisant partie du voyage, le jour des départs était un jour de grève nationale en Allemagne (où grève ferroviaire = zéro train qui circule !). Ainsi, sur les 4 membres de Framasoft prévu⋅es sur le projet, seul⋅es 3 ont pu se rendre sur place.
Qui dit train dit aussi temps investi, où le transport fait partie intégrante du voyage. En effet, il faut prévoir 9 heures de train depuis Paris, ou encore 13 heures depuis Nantes… Et à cela, il est fortement conseillé d’ajouter 1h ou 2h (voire une demi-journée) de « gestion des imprévus » (retards, annulations, changements de train). Se rendre en Allemagne en train nous a semblé une aventure à part entière (et ce ressenti semble partagé !).
Mardi 28 mars : découvertes et visites hors sentiers touristiques
Après avoir rencontré brièvement la veille les premières et premiers participant⋅es, la journée du mardi continue avec l’objectif de se découvrir les un⋅es les autres (les arrivées se feront au compte-gouttes sur toute la journée suite aux changements d’itinéraire dus à la grève de la veille).
Nous entamons le mardi matin avec une visite du Cimetière juif de Weißensee de Berlin, le plus grand cimetière juif d’Europe. La nature prend le dessus dans ce lieu empreint d’histoire.
Cimetière juif de Weißensee, entre nature et histoire
Nous nous dirigeons ensuite l’après-midi vers une ancienne prison de la Stasi, la prison de Berlin-Hohenschönhausen. Cette visite nous aura particulièrement marqué⋅es : le site a été créé par d’ancien⋅nes prisonnier⋅ères, la prison n’a fermé qu’en 1990, et de nombreuses personnes ayant torturé des prisonnier⋅ères n’ont jamais été jugées. Bref, une page d’histoire sombre mais qu’il est nécessaire de partager (nous conseillons la visite !)…
La journée se terminera par un moment convivial dans un restaurant traditionnel.
Mercredi 29 mars : jeunes, moins jeunes et réseaux sociaux
Lustre du hall de l’école de cuisine, on peut dire qu’il est plutôt adapté !
Discussion : on pense quoi des réseaux sociaux dans nos organisations ?
Le premier atelier a été un tour de table où chaque participant⋅e partageait son utilisation et point de vue sur les réseaux sociaux, et particulièrement TikTok, média sur lequel sera utilisé l’atelier suivant.
Ce que l’on peut résumer :
Il y a peu d’utilisation des médias sociaux d’un point de vue personnel dans le groupe.
Les médias sociaux sont par contre utilisés par la majorité du groupe pour mettre en valeur les actions de son organisation (Facebook, Twitter, Instagram et Mastodon).
Personne dans le groupe n’utilise TikTok ce qui pose problème pour comprendre ce média social.
Dans le cadre des activités de leur organisation, la majorité du groupe souhaiterait toucher davantage les jeunes et il semble intéressant de les trouver là où iels sont, donc sur les médias sociaux.
Le groupe est tout à fait d’accord sur le fait que les médias sociaux ne sont pas des outils neutres et cherchent à monopoliser l’attention de ses utilisateur⋅rices.
Ce temps d’échange a donc permis de voir que nous partageons les mêmes valeurs, difficultés et envies sur les médias sociaux. Cependant, le format « chacun son tour de parole » nous a semblé manquer un peu de dynamisme dans les échanges et de possibilité de discuter à plusieurs.
Retour d’atelier d’étudiant⋅es : sensibiliser sur des sujets de société dans une vidéo TikTok
En parallèle de nos échanges du matin sur les médias sociaux, 2 groupes d’étudiant⋅es de la Brillat-Savarin School ont travaillé sur un projet vidéo. Ils devaient produire une vidéo TikTok (une par groupe) pour montrer l’impact sur leur métier de cuisinier⋅ère de l’Union Européenne (1er groupe) et du changement climatique (2ème groupe). Les vidéos nous ont été présentées (incroyable la qualité en 2 heures de travail !), puis nous avons échangé sur le sujet.
Ce que nous retenons de cet atelier :
Les étudiant⋅es avaient entre 18 et 22 ans, et n’utilisent pas TikTok . Selon les étudiant⋅es, ce réseau social est tourné pour une cible plus jeune qu’elles et eux (« jeunes » est un terme trop large !). Par contre iels maîtrisaient les codes de la plateformes, étant régulièrement exposé⋅es à du contenu issu de TikTok sur d’autres plateformes telles que Instagram ou YouTube .
Iels n’auraient de toute façon pas forcément envie d’utiliser un réseau social pour voir du contenu politique, préférant un usage plus récréatif du réseau (comme regarder des vidéos de chatons par exemple !), même lorsqu’iels se revendiquent politisé⋅es.
Iels ont trouvé la démarche particulièrement intéressante de faire passer un message en vidéos, et se questionner sur des sujets les impliquant directement.
L’expérimentation aura été intéressante, même si les échanges en plénière ne permettaient pas l’implication de chacun et chacune.
Photo du groupe d’ECHO Network et quelques étudiant⋅es de l’école
Jeudi 30 mars : politique et open source
Reflect EU&US : le projet de la Willi Eichler Akademy
Financé à hauteur de 500k€ par des restes du plan Marshall, Reflect EU&US est un projet sur 2 ans (2022-2024) de la Willi Eichler Akademy. L’objectif ? Organiser des discussions entre étudiant⋅es en dehors du cadre universitaire, à distance et en restant dans l’anonymat.
Logo du projet Reflect EU&US
Les points à retenir :
Le projet investit 60 étudiant·es (30 des Etats-Unis et 30 d’Allemagne), une rencontre physique est prévue à la toute fin du projet pour lever les masques.
Des sujets traités tels que : justice, racisme, genre, politique.
Une bibliothèque de documents est alimentée suite aux discussions, permettant de valider (ou non) les différentes sources (textes, articles, vidéos, podcasts, etc).
L’anonymat permet plus facilement d’assumer des opinions contradictoires.
L’animation des groupes peut être compliquée par l’anonymat, mais fait partie intégrante du projet.
D’un point de vue technique, la plateforme est basée sur l’outil OpenTalk et a été choisie pour avoir cet espace d’échange libre, avec la création de cartes de couleurs comme avatar, permettant de garantir l’anonymat des participant⋅es. Le choix de technologies open-source a été fait spécifiquement dans le but de rassurer les participant⋅es pour qu’iels puissent échanger en toute tranquillité. Un test en direct de la plateforme a suivi avec des étudiant⋅es (en allemand, ce qui ne nous a pas permis de tout comprendre !).
Rencontres entre open source et politique
L’après-midi a continué avec l’intervention de Peer Heinlein, directeur d’OpenTalk, sur le sujet « L’indépendance et la souveraineté numérique réelle sont impossibles sans l’open-source ». Vous vous doutez bien qu’à Framasoft, même si ce n’est pas un aspect qui nous tient à cœur, nous avons un avis sur la question… Des échanges ont suivi avec les participant·e·s sur les logiciels open source, la protection des données personnelles, ou encore le chiffrement des données.
C’est ensuite Maik Außendorf, représentant du Green Party au parlement qui est intervenu. Nous avons, entre autre, échangé sur le numérique pour aider la transition écologique. Nous avons appris que les parlementaires allemand⋅es n’ont pas le choix dans leur utilisation d’outils numériques et qu’une cohérence nationale semble compliquée à mettre en place avec l’organisation décentralisée de l’Allemagne en Länder.
La clôture de la visite d’études a eu lieu dans un restaurant, où nous avons pu notamment échanger avec un activiste de SeaWatch, mettant particulièrement en avant valeurs communes et réflexions partagées entre les différentes organisations (précarisation des associations, nécessité de proposer des alternatives au monde capitaliste, nécessité d’un numérique libre et émancipateur).
Ce lustre nous aura inspiré⋅es (vous aussi vous distinguez un côté artistique ?)
Une semaine intense !
Nous avons particulièrement été surpris⋅es et enthousiastes par les visions communes partagées entre participant⋅es et organisations, que ce soit sur le numérique émancipateur, l’envie d’aller vers un monde qui nous ressemble plus, où la coopération et la contribution vont de l’avant et les questionnements sur comment partager nos messages en restant cohérent⋅es avec ce que l’on défend.
Bien que la majorité de la semaine ait été construite sous forme d’ateliers en plénière, ne favorisant pas toujours les échanges entre participant⋅es ou les prises de parole spontanées, les temps informels (repas, pauses café, balades) auront permis de créer ces moments essentiels.
Et la suite d’ECHO Network ? La seconde visite d’études a eu lieu à Bruxelles du 12 au 16 juin. Un article récap’ suivra sur le Framablog (mais comme toujours : on se laisse le temps !).
On ne pouvait pas se rendre à Berlin sans faire un tour par les fresques du mur de Berlin : petite photo de la virée pour boucler cet article.
Nous ouvrons volontiers nos colonnes aux témoignages de dégooglisation, en particulier quand il s’agit de structures locales tournées vers le public. C’est le cas pour l’interview que nous a donnée Fabrice, qui a entrepris de « dégafamiser » au sein de son association. Il évoque ici le cheminement suivi, depuis les constats jusqu’à l’adoption progressive d’outils libres et éthiques, avec les résistances et les passages délicats à négocier, ainsi que les alternatives qui se sont progressivement imposées. Nous souhaitons que l’exemple de son action puisse donner envie et courage (il en faut, certes) à d’autres de mener à leur tour cette « migration » émancipatrice.
Bonjour, peux-tu te présenter brièvement pour le Framablog ?
Je m’appelle Fabrice, j’ai 60 ans et après avoir passé près de 30 années sur Paris en tant que DSI, je suis venu me reposer au vert, à la grande campagne… Framasoft ? Je connais depuis très longtemps… Linux ? Aussi puisque je l’ai intégré dans une grande entreprise française, y compris sur des postes de travail, il y a fort longtemps…
Ce n’est que plus tard que j’ai pris réellement conscience du pouvoir néfaste des GAFAM et que je défends désormais un numérique Libre, simple, accessible à toutes et à tous et respectueux de nos libertés individuelles. Ayant du temps désormais à accorder aux autres, j’ai intégré une association en tant que bénévole, une asso qui compte un peu moins de 10 salariés et un budget annuel avoisinant les 400 K€.
Quel a été le déclencheur de l’opération de dégafamisation ?
En fait, quand je suis arrivé au sein de l’association le constat était un peu triste :
des postes de travail (PC sous Windows 7, 8, 10) poussifs, voire inutilisables, avec 2 ou 3 antivirus qui se marchaient dessus, sans compter les utilitaires en tout genre (Ccleaner, TurboMem, etc.)
une multitude de comptes Gmail à gérer (plus que le nb d’utilisateurs réels dans l’asso.)
des partages de Drive incontrôlables
des disques durs portables et autres clés USB qui faisaient office aussi de « solutions de partage »
un niveau assez faible de compréhension de toutes ces « technologies »
Il devenait donc urgent de « réparer » et j’ai proposé à l’équipe de remettre tout cela en ordre mais en utilisant des outils libres à chaque fois que cela était possible. À ce stade-là, je pense que mes interlocuteurs ne comprenaient pas exactement de quoi je parlais, ils n’étaient pas très sensibles à la cause du Libre et surtout, ils ne voyaient pas clairement en quoi les GAFAM posaient un problème…
Quand on lance une dégafamisation, ce n’est pas simplement pour changer la couche de peinture…
En amont de votre « dégafamisation », avez-vous organisé en interne des moments pour créer du consensus sur le sujet et passer collectivement à l’action (lever aussi les éventuelles résistances au changement) ? Réunions pour présenter le projet, ateliers de réflexion, autres ?
Le responsable de la structure avait compris qu’il allait y avoir du mieux – personne ne s’occupait du numérique dans l’asso auparavant – et il a dit tout simplement « banco » à la suite de quelques démos que j’ai pu faire avec l’équipe :
démo d’un poste de travail sous Linux (ici c’est Mint)
démo de LibreOffice…
Pour être très franc, je ne pense pas que ces démos aient emballé qui que ce soit…
Franchement, il était difficile d’expliquer les mises à jour de Linux Mint à un utilisateur de Windows qui ne les faisait de toutes façons jamais, d’expliquer LibreOffice Writer à une personne qui utilise MS Word comme un bloc-notes et qui met des espaces pour centrer le titre de son document…
Néanmoins, après avoir dressé le portrait peu glorieux des GAFAM, j’ai tout de même réussi à faire passer un message : les valeurs de l’association (ici une MJC) sont à l’opposé des valeurs des GAFAM ! Sous-entendu, moins on se servira des GAFAM et plus on sera en adéquation avec nos valeurs !
Comment avez-vous organisé votre dégafamisation ? Plan stratégique machiavélique puis passage à l’opérationnel ? Ou par itérations et petit à petit, au fil de l’eau ?
Pour montrer que j’avais envie de bien faire et que mon bénévolat s’installerait dans la durée, j’ai candidaté pour participer au Conseil d’Administration et j’ai été élu. J’ai présenté le projet aux membres du C.A sans véritable plan, si ce n’est de remettre tout d’équerre avec du logiciel Libre ! Là encore, les membres du C.A n’avaient pas forcément une exacte appréhension le projet mais à partir du moment où je leur proposais mieux, ils étaient partants !
Le plan (étalé sur 12 mois) :
Priorité no1 : remettre en route les postes de travail (PC portables) afin qu’ils soient utilisables dans de bonnes conditions. Certains postes de moins de 5 ans avaient été mis au rebut car ils « ramaient »…
choix de la distribution : Linux Mint Cinnamon ou Linux Mint XFCE pour les machines les moins puissantes
choix du socle logiciel : sélection des logiciels nécessaires après analyse des besoins / observations
Priorité no 2 : stopper l’utilisation de Gmail pour la messagerie et mettre en place des boites mail (avec le nom de domaine de l’asso), boites qui avaient été achetées mais jamais utilisées…
Priorité no 3 : augmenter le niveau des compétences de base sur les outils numériques
Prorité no 4 : mettre en place un cloud privé afin de stocker, partager, gérer toutes les données de l’asso (350Go) et cesser d’utiliser les clouds des GAFAM…
Est-ce que vous avez rencontré des résistances que vous n’aviez pas anticipées, qui vous ont pris par surprise ?
Bizarrement, les plus réticents à un poste de travail Libre étaient ceux qui maîtrisaient le moins l’utilisation d’un PC… « Nan mais tu comprends, Windows c’est quand même vachement mieux… Ah bon, pourquoi ? Ben j’sais pô…c’est mieux quoi… »
* Quand on représente la plus grosse association de sa ville, il y a de nombreux échanges avec les collectivités territoriales et, on s’arrache les cheveux à la réception des docx ou pptx tout pourris… Il en est de même avec les services de l’État et l’utilisation de certains formulaires PDF qui ont un comportement étrange…
* Quand un utilisateur resté sous Windows utilise encore des solutions Google alors que nous avons désormais tout en interne pour remplacer les services Google, je ne me bats pas…
* Quand certains matériels (un Studio de podcast par exemple) requièrent l’utilisation de Windows et ne peuvent pas fonctionner sous Linux, c’est désormais à prendre en compte dans nos achats…
* Quand Il faut aussi composer avec les services civiques et autres stagiaires qui débarquent, ne jurent que par les outils d’Adobe et expliquent au directeur que sans ces outils, leur création est diminuée…
* Quand le directeur commence à douter sur le choix des logiciels libres, je lui rappelle gentiment que le véhicule de l’asso est une Dacia et non une Tesla…
* Quand on se rend compte qu’un mail provenant des serveurs Gmail est rarement considéré comme SPAM par les autres alors que nos premiers mails avec OVH et avec notre nom de domaine ont eu du mal à « passer » les premières semaines…et de temps en temps encore maintenant…
Est-ce qu’au contraire, il y a eu des changements que vous redoutiez et qui se sont passés comme sur des roulettes ?
Rassembler toutes les données de l’asso. et de ses utilisateurs au sein de notre cloud privé (Nextcloud) était vraiment la chose qui me faisait le plus peur et qui est « passée crème » ! Peut-être tout simplement parce que certaines personnes avaient un peu « oublié » où étaient rangées leurs affaires auparavant…
… et finalement quels outils ou services avez-vous remplacés par lesquels ?
Messagerie Google –> Messagerie OVH + Client Thunderbird ou Client mail de Nextcloud (pour les petits utilisateurs)
Gestion des Contacts Google –> Nextcloud Contacts
Calendrier Google –> Nextcloud Calendrier
MS Office –> LibreOffice
Drive Google, Microsoft, Apple –> Nextcloud pour les fichiers personnels et tous ceux à partager en interne comme en externe
Doodle –> Nextcloud Poll
Google Forms –> Nextcloud Forms
NB : Concernant les besoins en création graphique ou vidéo on utilise plusieurs solutions libres selon les besoins (Gimp, Krita, Inkscape, OpenShotVideo,…) et toutes les autres solutions qui étaient utilisées de manière « frauduleuse » ont été mises à la poubelle ! Nous avons néanmoins un compte payant sur canva.com
À combien estimez-vous le coût de ce changement ? Y compris les coûts indirects : perte de temps, formation, perte de données, des trucs qu’on faisait et qu’on ne peut plus faire ?
Il s’agit essentiellement de temps, que j’estime à 150 heures dont 2/3 passées en « formation/accompagnement/documentation » et 1/3 pour la mise au point des outils (postes de travail, configuration du Nextcloud).
Côté coûts directs : notre serveur Nextcloud dédié, hébergé par un CHATONS pour 360 €/an et, c’est tout, puisque les boîtes mail avaient déjà été achetées avec un hébergement web mais non utilisées…
Il n’y a eu aucune perte de données, au contraire on en a retrouvé !
À noter que les anciens mails des utilisateurs (stockés chez Google donc) n’ont pas été récupérés, à la demande des utilisateurs eux-mêmes ! Pour eux c’était l’occasion de repartir sur un truc propre !
À ma connaissance, il n’y a rien que l’on ne puisse plus faire aujourd’hui, mais nous avons conservé deux postes de travail sous Windows pour des problèmes de compatibilité matérielle.
Cerise sur le gâteau : des PC portables ont été ressuscités grâce à une distribution Linux, du coup, nous en avons trop et n’en avons pas acheté cette année !
Est-ce que votre dégafamisation a un impact direct sur votre public ou utilisez-vous des services libres uniquement en interne ? Si le public est en contact avec des solutions libres, comment y réagit-il ? Est-il informé du fait que c’est libre ?
Un impact direct ? Oui et non…
En fait, en plus de notre démarche, on invite les collectivités et autres assos à venir « voir » comment on a fait et à leur prouver que c’est possible, ce n’est pas pour autant qu’on nous a demandé de l’aide.
Pour eux, la marche peut s’avérer trop haute et ils n’ont pas forcément les compétences pour franchir le pas sans aide. Imaginez un peu, notre mairie continue de sonder la population à coups de GoogleForms alors qu’on leur a dit quantité de fois qu’il existe des alternatives plus éthiques et surtout plus légales !
Et encore oui, bien que nous utilisions essentiellement ces outils en interne le public en est informé, les « politiques » et autres collectivités qui nous soutiennent le sont aussi et ils sont toujours curieux et, de temps en temps, admiratifs ! La gestion même de nos adhérents et de nos activités se fait au travers d’une application client / serveur développée par nos soins avec LibreOffice Base. Les données personnelles de nos adhérents sont ainsi entre nos mains uniquement.
Est-ce qu’il reste des outils auxquels vous n’avez pas encore pu trouver une alternative libre et pourquoi ?
Oui… nos équipes continuent à utiliser Facebook et WhatsApp… Facebook pour promouvoir nos activités, actions et contenus auprès du grand public et WhatsApp pour discuter instantanément ensemble (en interne) ou autour d’un « projet »avec des externes. Dans ces deux cas, il y a certes de très nombreuses alternatives, mais elles sont soit incomplètes (ne couvrent pas tous les besoins), soit inconnues du grand public (donc personne n’adhère), soit trop complexes à utiliser (ex. Matrix) mais je garde un œil très attentif sur tout cela, car les usages changent vite…
Entrée de la MJC
Quels conseils donneriez-vous à des structures comparables à la vôtre (MJC, Maison de quartier, centre culturel…) qui voudrait se dégafamiser aussi ? Des erreurs à ne pas commettre, des bonnes pratiques éprouvées à l’usage ?
Commencer par déployer une solution comme Nextcloud est une étape très fondatrice sur le thème « reprendre le contrôle de ses données » surtout dans des structures comme les nôtres où il y a une rotation de personnels assez importante (contrats courts/aidés, services civiques, volontaires européens, stagiaires, apprentis…).
Pour un utilisateur, le fait de retrouver ses affaires, ou les affaires des autres, dans une armoire bien rangée et bien sécurisée est un vrai bonheur. Une solution comme Nextcloud, avec ses clients de synchronisation, représente une mécanique bien huilée désormais et, accessible à chacun. L’administration de Nextcloud peut très bien être réalisée par une personne avertie (un utilisateur ++), c’est à dire une personne qui sait lire une documentation et qui est rigoureuse dans la gestion de ses utilisateurs et de leurs droits associés. Ne vous lancez pas dans l’auto-hébergement si vous n’avez pas les compétences requises ! De nombreuses structures proposent désormais « du Nextcloud » à des prix très abordables.
À partir du moment où ce type de solution est installée, basculez-y la gestion des contacts, la gestion des calendriers et faites la promotion, en interne, des autres outils disponibles (gestion de projets, de budget, formulaires…)
Fort de ce déploiement et, si votre messagerie est encore chez les GAFAM, commencez à chercher une solution ailleurs en sachant qu’il y aura des coûts, des coups et des pleurs… Cela reste un point délicat compte-tenu des problèmes exposés plus haut… Cela prend du temps mais c’est tout à fait possible ! Pour les jeunes, le mail est « ringard », pour les administratifs c’est le principal outil de communication avec le monde extérieur… Là aussi, avant de vous lancer, analysez bien les usages… Si Google vous autorise à envoyer un mail avec 50 destinataires, ce ne sera peut-être pas le cas de votre nouveau fournisseur…
Le poste de travail (le PC) est, de loin, un sujet sensible : c’est comme prendre la décision de jeter à la poubelle le doudou de votre enfant, doudou qui l’a endormi depuis de longues années… Commencez par recycler des matériels “obsolètes” pour Windows mais tout à fait corrects pour une distribution Linux et faites des heureux ! Montrer aux autres qu’il s’agit de systèmes non intrusifs, simple, rapides et qui disposent d’une logithèque de solutions libres et éthiques incommensurable !
Cela fait deux ans que notre asso. est dans ce mouvement et si je vous dis que l’on utilise FFMPEG pour des traitements lourds sur les médias de notre radio FM associative, traitements que l’on n’arrivait pas à faire auparavant avec un logiciel du commerce ? Si je vous dis qu’avec un simple clic-droit sur une image, un utilisateur appose le logo de notre asso en filigrane (merci nemo-action !). Si je vous dis que certains utilisateurs utilisent des scripts en ligne de commande afin de leur faciliter des traitements fastidieux sur des fichiers images, audios ou vidéos ? Elle est pas belle la vie ?
Néanmoins, cela n’empêche pas des petites remarques de-ci de-là sur l’utilisation de solutions libres plutôt que de « faire comme tout le monde » mais ça, j’en fais mon affaire et tant que je leur trouverai une solution libre et éthique pour répondre à leurs besoins alors on s’en sortira tous grandis !
Ah, j’oubliais : cela fait bien longtemps maintenant qu’il n’est plus nécessaire de mettre les mains dans le cambouis pour déployer un poste de travail sous Linux, le support est quasi proche du zéro !
Merci Fabrice d’avoir piloté cette opération et d’en avoir partagé l’expérience au lectorat du Framablog !
Ouvrir le code des algorithmes ? — oui, mais… (2/2)
Voici le deuxième volet (si vous avez raté le premier) de l’enquête approfondie d’Hubert Guillaud sur l’exploration des algorithmes, et de son analyse des enjeux qui en découlent.
Dans le code source de l’amplification algorithmique : que voulons-nous vraiment savoir ?
par Hubert GUILLAUD
Que voulons-nous vraiment savoir en enquêtant sur l’amplification algorithmique ? C’est justement l’enjeu du projet de recherche qu’Arvind Narayanan mène au Knight Institute de l’université Columbia où il a ouvert un blog dédié et qui vient d’accueillir une grande conférence sur le sujet. Parler d’amplification permet de s’intéresser à toute la gamme des réponses qu’apportent les plateformes, allant de l’amélioration de la portée des discours à leur suppression, tout en se défiant d’une réduction binaire à la seule modération automatisée, entre ce qui doit être supprimé et ce qui ne doit pas l’être. Or, les phénomènes d’amplification ne sont pas sans effets de bord, qui vont bien au-delà de la seule désinformation, à l’image des effets très concrets qu’ont les influenceurs sur le commerce ou le tourisme. Le gros problème, pourtant, reste de pouvoir les étudier sans toujours y avoir accès.
Outre des analyses sur TikTok et les IA génératives, le blog recèle quelques trésors, notamment une monumentale synthèse qui fait le tour du sujet en expliquant les principes de fonctionnements des algorithmes (l’article est également très riche en liens et références, la synthèse que j’en propose y recourra assez peu).
Narayanan rappelle que les plateformes disposent de très nombreux algorithmes entremêlés, mais ceux qui l’intéressent particulièrement sont les algorithmes de recommandation, ceux qui génèrent les flux, les contenus qui nous sont mis à disposition. Alors que les algorithmes de recherche sont limités par le terme recherché, les algorithmes de recommandation sont bien plus larges et donnent aux plateformes un contrôle bien plus grand sur ce qu’elles recommandent à un utilisateur.
La souscription, le réseau et l’algorithme
Pour Narayanan, il y a 3 grands types de leviers de propagation : la souscription (ou abonnement), le réseau et l’algorithme. Dans le modèle par abonnement, le message atteint les personnes qui se sont abonnées à l’auteur du message. Dans le modèle de réseau, il se propage en cascade à travers le réseau tant que les utilisateurs qui le voient choisissent de le propager. Dans le modèle algorithmique, les utilisateurs ayant des intérêts similaires (tels que définis par l’algorithme sur la base de leurs engagements passés) sont représentés plus près les uns des autres. Plus les intérêts d’un utilisateur sont similaires à ceux définis, plus il est probable que le contenu lui sera recommandé.
À l’origine, les réseaux sociaux comme Facebook ou Twitter ne fonctionnaient qu’à l’abonnement : vous ne voyiez que les contenus des personnes auxquelles vous étiez abonnés et vous ne pouviez pas republier les messages des autres ! Dans le modèle de réseau, un utilisateur voit non seulement les messages créés par les personnes auxquelles il s’est abonné, mais aussi les messages que ces utilisateurs choisissent d’amplifier, ce qui crée la possibilité de cascades d’informations et de contenus “viraux”, comme c’était le cas de Twitter jusqu’en 2016, moment où le réseau introduisit le classement algorithmique. Dans le modèle algorithmique, la souscription est bien souvent minorée, le réseau amplifié mais surtout, le flux dépend principalement de ce que l’algorithme estime être le plus susceptible d’intéresser l’utilisateur. C’est ce que Cory Doctorow désigne comme « l’emmerdification » de nos flux, le fait de traiter la liste des personnes auxquelles nous sommes abonnés comme des suggestions et non comme des commandes.
Le passage aux recommandations algorithmiques a toujours généré des contestations, notamment parce que, si dans les modèles d’abonnement et de réseau, les créateurs peuvent se concentrer sur la construction de leur réseau, dans le « modèle algorithmique, cela ne sert à rien, car le nombre d’abonnés n’a rien à voir avec la performance des messages » (mais comme nous sommes dans des mélanges entre les trois modèles, le nombre d’abonnés a encore un peu voire beaucoup d’influence dans l’amplification). Dans le modèle algorithmique, l’audience de chaque message est optimisée de manière indépendante en fonction du sujet, de la « qualité » du message et d’un certain nombre de paramètres pris en compte par le modèle.
Amplification et viralité
La question de l’amplification interroge la question de la viralité, c’est-à-dire le fait qu’un contenu soit amplifié par une cascade de reprises, et non pas seulement diffusé d’un émetteur à son public. Le problème de la viralité est que sa portée reste imprévisible. Pour Narayanan, sur toutes les grandes plateformes, pour la plupart des créateurs, la majorité de l’engagement provient d’une petite fraction de contenu viral. Sur TikTok comme sur YouTube, 20 % des vidéos les plus vues d’un compte obtiennent plus de 70 % des vues. Plus le rôle de l’algorithme dans la propagation du contenu est important, par opposition aux abonnements ou au réseau, plus cette inégalité semble importante.
Parce qu’il est particulièrement repérable dans la masse des contenus, le contenu viral se prête assez bien à la rétropropagation, c’est-à-dire à son déclassement ou à sa suppression. Le problème justement, c’est qu’il y a plein de manières de restreindre le contenu. Facebook classe les posts rétrogradés plus bas dans le fil d’actualité qu’ils ne le seraient s’ils ne l’avaient pas été, afin que les utilisateurs soient moins susceptibles de le rencontrer et de le propager. À son tour, l’effet de la rétrogradation sur la portée peut être imprévisible, non linéaire et parfois radical, puisque le contenu peut devenir parfaitement invisible. Cette rétrogradation est parfaitement opaque, notamment parce qu’une faible portée n’est pas automatiquement suspecte, étant donné qu’il existe une grande variation dans la portée naturelle du contenu.
Amplification et prédiction de l’engagement
Les plateformes ont plusieurs objectifs de haut niveau : améliorer leurs revenus publicitaires bien sûr et satisfaire suffisamment les utilisateurs pour qu’ils reviennent… Mais ces objectifs n’aident pas vraiment à décider ce qu’il faut donner à un utilisateur spécifique à un moment précis ni à mesurer comment ces décisions impactent à long terme la plateforme. D’où le fait que les plateformes observent l’engagement, c’est-à-dire les actions instantanées des utilisateurs, comme le like, le commentaire ou le partage qui permettent de classer le contenu en fonction de la probabilité que l’utilisateur s’y intéresse. « D’une certaine manière, l’engagement est une approximation des objectifs de haut niveau. Un utilisateur qui s’engage est plus susceptible de revenir et de générer des revenus publicitaires pour la plateforme. »
Si l’engagement est vertueux, il a aussi de nombreuses limites qui expliquent que les algorithmes intègrent bien d’autres facteurs dans leur calcul. Ainsi, Facebook et Twitter optimisent les « interactions sociales significatives », c’est-à-dire une moyenne pondérée des likes, des partages et des commentaires. YouTube, lui, optimise en fonction de la durée de visionnage que l’algorithme prédit. TikTok utilise les interactions sociales et valorise les vidéos qui ont été regardées jusqu’au bout, comme un signal fort et qui explique certainement le caractère addictif de l’application et le fait que les vidéos courtes (qui ont donc tendance à obtenir un score élevé) continuent de dominer la plateforme.
En plus de ces logiques de base, il existe bien d’autres logiques secondaires, comme par exemple, pour que l’expérience utilisateur ne soit pas ralentie par le calcul, que les suggestions restent limitées, sélectionnées plus que classées, selon divers critères plus que selon des critères uniques (par exemple en proposant des nouveaux contenus et pas seulement des contenus similaires à ceux qu’on a apprécié, TikTok se distingue à nouveau par l’importance qu’il accorde à l’exploration de nouveaux contenus… c’est d’ailleurs la tactique suivie désormais par Instagram de Meta via les Reels, boostés sur le modèle de TikTok, qui ont le même effet que sur TikTok, à savoir une augmentation du temps passé sur l’application)…
« Bien qu’il existe de nombreuses différences dans les détails, les similitudes entre les algorithmes de recommandation des différentes plateformes l’emportent sur leurs différences », estime Narayanan. Les différences sont surtout spécifiques, comme Youtube qui optimise selon la durée de visionnage, ou Spotify qui s’appuie davantage sur l’analyse de contenu que sur le comportement. Pour Narayanan, ces différences montrent qu’il n’y a pas de risque concurrentiel à l’ouverture des algorithmes des plateformes, car leurs adaptations sont toujours très spécifiques. Ce qui varie, c’est la façon dont les plateformes ajustent l’engagement.
Comment apprécier la similarité ?
Mais la grande question à laquelle tous tentent de répondre est la même : « Comment les utilisateurs similaires à cet utilisateur ont-ils réagi aux messages similaires à ce message ? »
Si cette approche est populaire dans les traitements, c’est parce qu’elle s’est avérée efficace dans la pratique. Elle repose sur un double calcul de similarité. D’abord, celle entre utilisateurs. La similarité entre utilisateurs dépend du réseau (les gens que l’on suit ou ceux qu’on commente par exemple, que Twitter valorise fortement, mais peu TikTok), du comportement (qui est souvent plus critique, « deux utilisateurs sont similaires s’ils se sont engagés dans un ensemble de messages similaires ») et les données démographiques (du type âge, sexe, langue, géographie… qui sont en grande partie déduits des comportements).
Ensuite, il y a un calcul sur la similarité des messages qui repose principalement sur leur sujet et qui repose sur des algorithmes d’extraction des caractéristiques (comme la langue) intégrant des évaluations normatives, comme la caractérisation de discours haineux. L’autre signal de similarité des messages tient, là encore, au comportement : « deux messages sont similaires si un ensemble similaire d’utilisateurs s’est engagé avec eux ». Le plus important à retenir, insiste Narayanan, c’est que « l’enregistrement comportemental est le carburant du moteur de recommandation ». La grande difficulté, dans ces appréciations algorithmiques, consiste à faire que le calcul reste traitable, face à des volumes d’enregistrements d’informations colossaux.
Une histoire des évolutions des algorithmes de recommandation
« La première génération d’algorithmes de recommandation à grande échelle, comme ceux d’Amazon et de Netflix au début des années 2000, utilisait une technique simple appelée filtrage collaboratif : les clients qui ont acheté ceci ont également acheté cela ». Le principe était de recommander des articles consultés ou achetés d’une manière rudimentaire, mais qui s’est révélé puissant dans le domaine du commerce électronique. En 2006, Netflix a organisé un concours en partageant les évaluations qu’il disposait sur les films pour améliorer son système de recommandation. Ce concours a donné naissance à la « factorisation matricielle », une forme de deuxième génération d’algorithmes de recommandation, c’est-à-dire capables d’identifier des combinaisons d’attributs et de préférences croisées. Le système n’étiquette pas les films avec des termes interprétables facilement (comme “drôle” ou “thriller” ou “informatif”…), mais avec un vaste ensemble d’étiquettes (de micro-genres obscurs comme « documentaires émouvants qui combattent le système ») qu’il associe aux préférences des utilisateurs. Le problème, c’est que cette factorisation matricielle n’est pas très lisible pour l’utilisateur et se voir dire qu’on va aimer tel film sans savoir pourquoi n’est pas très satisfaisant. Enfin, ce qui marche pour un catalogue de film limité n’est pas adapté aux médias sociaux où les messages sont infinis. La prédominance de la factorisation matricielle explique pourquoi les réseaux sociaux ont tardé à se lancer dans la recommandation, qui est longtemps restée inadaptée à leurs besoins.
Pourtant, les réseaux sociaux se sont tous convertis à l’optimisation basée sur l’apprentissage automatique. En 2010, Facebook utilisait un algorithme appelé EdgeRank pour construire le fil d’actualité des utilisateurs qui consistait à afficher les éléments par ordre de priorité décroissant selon un score d’affinité qui représente la prédiction de Facebook quant au degré d’intérêt de l’utilisateur pour les contenus affichés, valorisant les photos plus que le texte par exemple. À l’époque, ces pondérations étaient définies manuellement plutôt qu’apprises. En 2018, Facebook est passé à l’apprentissage automatique. La firme a introduit une métrique appelée « interactions sociales significatives » (MSI pour meaningful social interactions) dans le système d’apprentissage automatique. L’objectif affiché était de diminuer la présence des médias et des contenus de marque au profit des contenus d’amis et de famille. « La formule calcule un score d’interaction sociale pour chaque élément susceptible d’être montré à un utilisateur donné ». Le flux est généré en classant les messages disponibles selon leur score MSI décroissant, avec quelques ajustements, comme d’introduire de la diversité (avec peu d’indications sur la façon dont est calculée et ajoutée cette diversité). Le score MSI prédit la probabilité que l’utilisateur ait un type d’interaction spécifique (comme liker ou commenter) avec le contenu et affine le résultat en fonction de l’affinité de l’utilisateur avec ce qui lui est proposé. Il n’y a plus de pondération dédiée pour certains types de contenus, comme les photos ou les vidéos. Si elles subsistent, c’est uniquement parce que le système l’aura appris à partir des données de chaque utilisateur, et continuera à vous proposer des photos si vous les appréciez.
« Si l’on pousse cette logique jusqu’à sa conclusion naturelle, il ne devrait pas être nécessaire d’ajuster manuellement la formule en fonction des affinités. Si les utilisateurs préfèrent voir le contenu de leurs amis plutôt que celui des marques, l’algorithme devrait être en mesure de l’apprendre ». Ce n’est pourtant pas ce qu’il se passe. Certainement pour lutter contre la logique de l’optimisation de l’engagement, estime Narayanan, dans le but d’augmenter la satisfaction à long terme, que l’algorithme ne peut pas mesurer, mais là encore sans que les modalités de ces ajustements ne soient clairement documentés.
Est-ce que tout cela est efficace ?
Reste à savoir si ces algorithmes sont efficaces ! « Il peut sembler évident qu’ils doivent bien fonctionner, étant donné qu’ils alimentent des plateformes technologiques qui valent des dizaines ou des centaines de milliards de dollars. Mais les chiffres racontent une autre histoire. Le taux d’engagement est une façon de quantifier le problème : il s’agit de la probabilité qu’un utilisateur s’intéresse à un message qui lui a été recommandé. Sur la plupart des plateformes, ce taux est inférieur à 1 %. TikTok est une exception, mais même là, ce taux dépasse à peine les 5 %. »
Le problème n’est pas que les algorithmes soient mauvais, mais surtout que les gens ne sont pas si prévisibles. Et qu’au final, les utilisateurs ne se soucient pas tant du manque de précision de la recommandation. « Même s’ils sont imprécis au niveau individuel, ils sont précis dans l’ensemble. Par rapport aux plateformes basées sur les réseaux, les plateformes algorithmiques semblent être plus efficaces pour identifier les contenus viraux (qui trouveront un écho auprès d’un grand nombre de personnes). Elles sont également capables d’identifier des contenus de niche et de les faire correspondre au sous-ensemble d’utilisateurs susceptibles d’y être réceptifs. » Si les algorithmes sont largement limités à la recherche de modèles dans les données comportementales, ils n’ont aucun sens commun. Quant au taux de clic publicitaire, il reste encore plus infinitésimal – même s’il est toujours considéré comme un succès !
Les ingénieurs contrôlent-ils encore les algorithmes ?
Les ingénieurs ont très peu d’espace pour contrôler les effets des algorithmes de recommandation, estime Narayanan, en prenant un exemple. En 2019, Facebook s’est rendu compte que les publications virales étaient beaucoup plus susceptibles de contenir des informations erronées ou d’autres types de contenus préjudiciables. En d’autres termes, ils se sont rendu compte que le passage à des interactions sociales significatives (MSI) a eu des effets de bords : les contenus qui suscitaient l’indignation et alimentaient les divisions gagnaient en portée, comme l’a expliqué l’ingénieure et lanceuse d’alerte Frances Haugen à l’origine des Facebook Files, dans ses témoignages. C’est ce que synthétise le tableau de pondération de la formule MSI publié par le Wall Street Journal, qui montrent que certains éléments ont des poids plus forts que d’autres : un commentaire vaut 15 fois plus qu’un like, mais un commentaire signifiant ou un repartage 30 fois plus, chez Facebook. Une pondération aussi élevée permet d’identifier les messages au potentiel viral et de les stimuler davantage. En 2020, Facebook a ramené la pondération des partages à 1,5, mais la pondération des commentaires est restée très élevée (15 à 20 fois plus qu’un like). Alors que les partages et les commentaires étaient regroupés dans une seule catégorie de pondération en 2018, ils ne le sont plus. Cette prime au commentaire demeure une prime aux contenus polémiques. Reste, on le comprend, que le jeu qui reste aux ingénieurs de Facebook consiste à ajuster le poids des paramètres. Pour Narayanan : piloter un système d’une telle complexité en utilisant si peu de boutons ne peut qu’être difficile.
Le chercheur rappelle que le système est censé être neutre à l’égard de tous les contenus, à l’exception de certains qui enfreignent les règles de la plateforme. Utilisateurs et messages sont alors rétrogradés de manière algorithmique suite à signalement automatique ou non. Mais cette neutralité est en fait très difficile à atteindre. Les réseaux sociaux favorisent ceux qui ont déjà une grande portée, qu’elle soit méritée ou non, et sont récompensés par une plus grande portée encore. Par exemple, les 1 % d’auteurs les plus importants sur Twitter reçoivent 80 % des vues des tweets. Au final, cette conception de la neutralité finit par récompenser ceux qui sont capables de pirater l’engagement ou de tirer profit des biais sociaux.
Outre cette neutralité, un deuxième grand principe directeur est que « l’algorithme sait mieux que quiconque ». « Ce principe et celui de la neutralité se renforcent mutuellement. Le fait de confier la politique (concernant le contenu à amplifier) aux données signifie que les ingénieurs n’ont pas besoin d’avoir un point de vue à ce sujet. Et cette neutralité fournit à l’algorithme des données plus propres à partir desquelles il peut apprendre. »
Le principe de l’algorithme qui sait le mieux signifie que la même optimisation est appliquée à tous les types de discours : divertissement, informations éducatives, informations sur la santé, actualités, discours politique, discours commercial, etc. En 2021, FB a fait une tentative de rétrograder tout le contenu politique, ce qui a eu pour effet de supprimer plus de sources d’information de haute qualité que de faible qualité, augmentant la désinformation. Cette neutralité affichée permet également une forme de désengagement des ingénieurs.
En 2021, encore, FB a entraîné des modèles d’apprentissage automatique pour classer les messages en deux catégories : bons ou mauvais pour le monde, en interrogeant les utilisateurs pour qu’ils apprécient des contenus qui leurs étaient proposés pour former les données. FB a constaté que les messages ayant une plus grande portée étaient considérés comme étant mauvais pour le monde. FB a donc rétrogradé ces contenus… mais en trouvant moins de contenus polémique, cette modification a entraîné une diminution de l’ouverture de l’application par les utilisateurs. L’entreprise a donc redéployé ce modèle en lui donnant bien moins de poids. Les corrections viennent directement en conflit avec le modèle d’affaires.
Pourquoi l’optimisation de l’engagement nous nuit-elle ?
« Un grand nombre des pathologies familières des médias sociaux sont, à mon avis, des conséquences relativement directes de l’optimisation de l’engagement », suggère encore le chercheur. Cela explique pourquoi les réformes sont difficiles et pourquoi l’amélioration de la transparence des algorithmes, de la modération, voire un meilleur contrôle par l’utilisateur de ce qu’il voit (comme le proposait Gobo mis en place par Ethan Zuckerman), ne sont pas des solutions magiques (même si elles sont nécessaires).
Les données comportementales, celles relatives à l’engagement passé, sont la matière première essentielle des moteurs de recommandations. Les systèmes privilégient la rétroaction implicite sur l’explicite, à la manière de YouTube qui a privilégié le temps passé sur les rétroactions explicites (les likes). Sur TikTok, il n’y a même plus de sélection, il suffit de swipper.
Le problème du feedback implicite est qu’il repose sur nos réactions inconscientes, automatiques et émotionnelles, sur nos pulsions, qui vont avoir tendance à privilégier une vidéo débile sur un contenu expert.
Pour les créateurs de contenu, cette optimisation par l’engagement favorise la variance et l’imprévisibilité, ce qui a pour conséquence d’alimenter une surproduction pour compenser cette variabilité. La production d’un grand volume de contenu, même s’il est de moindre qualité, peut augmenter les chances qu’au moins quelques-uns deviennent viraux chaque mois afin de lisser le flux de revenus. Le fait de récompenser les contenus viraux se fait au détriment de tous les autres types de contenus (d’où certainement le regain d’attraits pour des plateformes non algorithmiques, comme Substack voire dans une autre mesure, Mastodon).
Au niveau de la société, toutes les institutions sont impactées par les plateformes algorithmiques, du tourisme à la science, du journalisme à la santé publique. Or, chaque institution à des valeurs, comme l’équité dans le journalisme, la précision en science, la qualité dans nombre de domaines. Les algorithmes des médias sociaux, eux, ne tiennent pas compte de ces valeurs et de ces signaux de qualité. « Ils récompensent des facteurs sans rapport, sur la base d’une logique qui a du sens pour le divertissement, mais pas pour d’autres domaines ». Pour Narayanan, les plateformes de médias sociaux « affaiblissent les institutions en sapant leurs normes de qualité et en les rendant moins dignes de confiance ». C’est particulièrement actif dans le domaine de l’information, mais cela va bien au-delà, même si ce n’est pas au même degré. TikTok peut sembler ne pas représenter une menace pour la science, mais nous savons que les plateformes commencent par être un divertissement avant de s’étendre à d’autres sphères du discours, à l’image d’Instagram devenant un outil de communication politique ou de Twitter, où un tiers des tweets sont politiques.
La science des données en ses limites
Les plateformes sont bien conscientes de leurs limites, pourtant, elles n’ont pas fait beaucoup d’efforts pour résoudre les problèmes. Ces efforts restent occasionnels et rudimentaires, à l’image de la tentative de Facebook de comprendre la valeur des messages diffusés. La raison est bien sûr que ces aménagements nuisent aux résultats financiers de l’entreprise. « Le recours à la prise de décision subconsciente et automatique est tout à fait intentionnelle ; c’est ce qu’on appelle la « conception sans friction ». Le fait que les utilisateurs puissent parfois faire preuve de discernement et résister à leurs impulsions est vu comme un problème à résoudre. »
Pourtant, ces dernières années, la réputation des plateformes n’est plus au beau fixe. Narayanan estime qu’il y a une autre limite. « La plupart des inconvénients de l’optimisation de l’engagement ne sont pas visibles dans le cadre dominant de la conception des plateformes, qui accorde une importance considérable à la recherche d’une relation quantitative et causale entre les changements apportés à l’algorithme et leurs effets. »
Si on observe les raisons qui poussent l’utilisateur à quitter une plateforme, la principale est qu’il ne parvient pas à obtenir des recommandations suffisamment intéressantes. Or, c’est exactement ce que l’optimisation par l’engagement est censée éviter. Les entreprises parviennent très bien à optimiser des recommandations qui plaisent à l’utilisateur sur l’instant, mais pas celles qui lui font dire, une fois qu’il a fermé l’application, que ce qu’il y a trouvé l’a enrichi. Elles n’arrivent pas à calculer et à intégrer le bénéfice à long terme, même si elles restent très attentives aux taux de rétention ou aux taux de désabonnement. Pour y parvenir, il faudrait faire de l’A/B testing au long cours. Les plateformes savent le faire. Facebook a constaté que le fait d’afficher plus de notifications augmentait l’engagement à court terme mais avait un effet inverse sur un an. Reste que ce regard sur leurs effets à longs termes ne semble pas être une priorité par rapport à leurs effets de plus courts termes.
Une autre limite repose sur l’individualisme des plateformes. Si les applications sociales sont, globalement, assez satisfaisantes pour chacun, ni les utilisateurs ni les plateformes n’intériorisent leurs préjudices collectifs. Ces systèmes reposent sur l’hypothèse que le comportement de chaque utilisateur est indépendant et que l’effet sur la société (l’atteinte à la démocratie par exemple…) est très difficile à évaluer. Narayanan le résume dans un tableau parlant, où la valeur sur la société n’a pas de métrique associée.
Tableau montrant les 4 niveaux sur lesquels les algorithmes des plateformes peuvent avoir des effets. CTR : Click Through Rate (taux de clic). MSI : Meaningful Social Interactions, interactions sociales significatives, la métrique d’engagement de Facebook. DAU : Daily active users, utilisateurs actifs quotidiens.
Les algorithmes ne sont pas l’ennemi (enfin si, quand même un peu)
Pour répondre à ces problèmes, beaucoup suggèrent de revenir à des flux plus chronologiques ou a des suivis plus stricts des personnes auxquelles nous sommes abonnés. Pas sûr que cela soit une solution très efficace pour gérer les volumes de flux, estime le chercheur. Les algorithmes de recommandation ont été la réponse à la surcharge d’information, rappelle-t-il : « Il y a beaucoup plus d’informations en ligne en rapport avec les intérêts d’une personne qu’elle n’en a de temps disponible. » Les algorithmes de classement sont devenus une nécessité pratique. Même dans le cas d’un réseau longtemps basé sur l’abonnement, comme Instagram : en 2016, la société indiquait que les utilisateurs manquaient 70 % des publications auxquelles ils étaient abonnés. Aujourd’hui, Instagram compte 5 fois plus d’utilisateurs. En fait, les plateformes subissent d’énormes pressions pour que les algorithmes soient encore plus au cœur de leur fonctionnement que le contraire. Et les systèmes de recommandation font leur entrée dans d’autres domaines, comme l’éducation (avec Coursera) ou la finance (avec Robinhood).
Pour Narayanan, l’enjeu reste de mieux comprendre ce qu’ils font. Pour cela, nous devons continuer d’exiger d’eux bien plus de transparence qu’ils n’en livrent. Pas plus que dans le monde des moteurs de recherche nous ne reviendrons aux annuaires, nous ne reviendrons pas aux flux chronologiques dans les moteurs de recommandation. Nous avons encore des efforts à faire pour contrecarrer activement les modèles les plus nuisibles des recommandations. L’enjeu, conclut-il, est peut-être d’esquisser plus d’alternatives que nous n’en disposons, comme par exemple, d’imaginer des algorithmes de recommandations qui n’optimisent pas l’engagement, ou pas seulement. Cela nécessite certainement aussi d’imaginer des réseaux sociaux avec des modèles économiques différents. Un autre internet. Les algorithmes ne sont peut-être pas l’ennemi comme il le dit, mais ceux qui ne sont ni transparents, ni loyaux, et qui optimisent leurs effets en dehors de toute autre considération, ne sont pas nos amis non plus !
Ouvrir le code des algorithmes ? — Oui, mais… (1/2)
Voici le premier des deux articles qu’Hubert Guillaud nous fait le plaisir de partager. Sans s’arrêter à la surface de l’actualité, il aborde la transparence du code des algorithmes, qui entraîne un grand nombre de questions épineuses sur lesquelles il s’est documenté pour nous faire part de ses réflexions.
Dans le code source de l’amplification algorithmique : publier le code ne suffit pas !
par Hubert GUILLAUD
Le 31 mars, Twitter a publié une partie du code source qui alimente son fil d’actualité, comme l’a expliqué l’équipe elle-même dans un billet. Ces dizaines de milliers de lignes de code contiennent pourtant peu d’informations nouvelles. Depuis le rachat de l’oiseau bleu par Musk, Twitter a beaucoup changé et ne cesse de se modifier sous les yeux des utilisateurs. La publication du code source d’un système, même partiel, qui a longtemps été l’un des grands enjeux de la transparence, montre ses limites.
« LZW encoding and decoding algorithms overlapped » par nayukim, licence CC BY 2.0.
Publier le code ne suffit pas
Dans un excellent billet de blog, le chercheur Arvind Narayanan (sa newsletter mérite également de s’y abonner) explique ce qu’il faut en retenir. Comme ailleurs, les règles ne sont pas claires. Les algorithmes de recommandation utilisent l’apprentissage automatique ce qui fait que la manière de classer les tweets n’est pas directement spécifiée dans le code, mais apprise par des modèles à partir de données de Twitter sur la manière dont les utilisateurs ont réagi aux tweets dans le passé. Twitter ne divulgue ni ces modèles ni les données d’apprentissages, ce qui signifie qu’il n’est pas possible d’exécuter ces modèles. Le code ne permet pas de comprendre pourquoi un tweet est ou n’est pas recommandé à un utilisateur, ni pourquoi certains contenus sont amplifiés ou invisibilisés. C’est toute la limite de la transparence. Ce que résume très bien le journaliste Nicolas Kayser-Bril pour AlgorithmWatch (pertinemment traduit par le framablog) : « Vous ne pouvez pas auditer un code seulement en le lisant. Il faut l’exécuter sur un ordinateur. »
« Ce que Twitter a publié, c’est le code utilisé pour entraîner les modèles, à partir de données appropriées », explique Narayanan, ce qui ne permet pas de comprendre les propagations, notamment du fait de l’absence des données. De plus, les modèles pour détecter les tweets qui violent les politiques de Twitter et qui leur donnent des notes de confiance en fonction de ces politiques sont également absentes (afin que les usagers ne puissent pas déjouer le système, comme nous le répètent trop de systèmes rétifs à l’ouverture). Or, ces classements ont des effets de rétrogradation très importants sur la visibilité de ces tweets, sans qu’on puisse savoir quels tweets sont ainsi classés, selon quelles méthodes et surtout avec quelles limites.
La chose la plus importante que Twitter a révélée en publiant son code, c’est la formule qui spécifie comment les différents types d’engagement (likes, retweets, réponses, etc.) sont pondérés les uns par rapport aux autres… Mais cette formule n’est pas vraiment dans le code. Elle est publiée séparément, notamment parce qu’elle n’est pas statique, mais qu’elle doit être modifiée fréquemment.
Sans surprise, le code révèle ainsi que les abonnés à Twitter Blue, ceux qui payent leur abonnement, bénéficient d’une augmentation de leur portée (ce qui n’est pas sans poser un problème de fond, comme le remarque pertinemment sur Twitter, Guillaume Champeau, car cette préférence pourrait mettre ces utilisateurs dans la position d’être annonceurs, puisqu’ils payent pour être mis en avant, sans que l’interface ne le signale clairement, autrement que par la pastille bleue). Reste que le code n’est pas clair sur l’ampleur de cette accélération. Les notes attribuées aux tweets des abonnés Blue sont multipliées par 2 ou 4, mais cela ne signifie pas que leur portée est pareillement multipliée. « Une fois encore, le code ne nous dit pas le genre de choses que nous voudrions savoir », explique Narayanan.
Reste que la publication de la formule d’engagement est un événement majeur. Elle permet de saisir le poids des réactions sur un tweet. On constate que la réponse à tweet est bien plus forte que le like ou que le RT. Et la re-réponse de l’utilisateur originel est prédominante, puisque c’est le signe d’une conversation forte. À l’inverse, le fait qu’un lecteur bloque, mute ou se désabonne d’un utilisateur suite à un tweet est un facteur extrêmement pénalisant pour la propagation du tweet.
Tableau du poids attribué en fonction des types d’engagement possibles sur Twitter.
Ces quelques indications permettent néanmoins d’apprendre certaines choses. Par exemple que Twitter ne semble pas utiliser de prédictions d’actions implicites (comme lorsqu’on s’arrête de faire défiler son fil), ce qui permet d’éviter l’amplification du contenu trash que les gens ne peuvent s’empêcher de regarder, même s’ils ne s’y engagent pas. La formule nous apprend que les retours négatifs ont un poids très élevé, ce qui permet d’améliorer son flux en montrant à l’algorithme ce dont vous ne voulez pas – même si les plateformes devraient permettre des contrôles plus explicites pour les utilisateurs. Enfin, ces poids ont des valeurs souvent précises, ce qui signifie que ce tableau n’est valable qu’à l’instant de la publication et qu’il ne sera utile que si Twitter le met à jour.
Les algorithmes de recommandation qui optimisent l’engagement suivent des modèles assez proches. La publication du code n’est donc pas très révélatrice. Trois éléments sont surtout importants, insiste le chercheur :
« Le premier est la manière dont les algorithmes sont configurés : les signaux utilisés comme entrée, la manière dont l’engagement est défini, etc. Ces informations doivent être considérées comme un élément essentiel de la transparence et peuvent être publiées indépendamment du code. La seconde concerne les modèles d’apprentissage automatique qui, malheureusement, ne peuvent généralement pas être divulgués pour des raisons de protection de la vie privée. Le troisième est la boucle de rétroaction entre les utilisateurs et l’algorithme ».
Autant d’éléments qui demandent des recherches, des expériences et du temps pour en comprendre les limites.
Si la transparence n’est pas une fin en soi, elle reste un moyen de construire un meilleur internet en améliorant la responsabilité envers les utilisateurs, rappelle l’ingénieur Gabriel Nicholaspour le Center for Democracy & Technology. Il souligne néanmoins que la publication d’une partie du code source de Twitter ne contrebalance pas la fermeture du Consortium de recherche sur la modération, ni celle des rapports de transparence relatives aux demandes de retraits des autorités ni celle de l’accès à son API pour chercheurs, devenue extrêmement coûteuse.
« Twitter n’a pas exactement ’ouvert son algorithme’ comme certains l’ont dit. Le code est lourdement expurgé et il manque plusieurs fichiers de configuration, ce qui signifie qu’il est pratiquement impossible pour un chercheur indépendant d’exécuter l’algorithme sur des échantillons ou de le tester d’une autre manière. Le code publié n’est en outre qu’un instantané du système de recommandation de Twitter et n’est pas réellement connecté au code en cours d’exécution sur ses serveurs. Cela signifie que Twitter peut apporter des modifications à son code de production et ne pas l’inclure dans son référentiel public, ou apporter des modifications au référentiel public qui ne sont pas reflétées dans son code de production. »
L’algorithme publié par Twitter est principalement son système de recommandation. Il se décompose en 3 parties, explique encore Nicholas :
Un système de génération de contenus candidats. Ici, Twitter sélectionne 1500 tweets susceptibles d’intéresser un utilisateur en prédisant la probabilité que l’utilisateur s’engage dans certaines actions pour chaque tweet (c’est-à-dire qu’il RT ou like par exemple).
Un système de classement. Une fois que les 1 500 tweets susceptibles d’être servis sont sélectionnés, ils sont notés en fonction de la probabilité des actions d’engagement, certaines actions étant pondérées plus fortement que d’autres. Les tweets les mieux notés apparaîtront généralement plus haut dans le fil d’actualité de l’utilisateur.
Un système de filtrage. Les tweets ne sont pas classés strictement en fonction de leur score. Des heuristiques et des filtres sont appliqués pour, par exemple, éviter d’afficher plusieurs tweets du même auteur ou pour déclasser les tweets d’auteurs que l’utilisateur a déjà signalés pour violation de la politique du site.
Le score final est calculé en additionnant la probabilité de chaque action multipliée par son poids (en prenant certainement en compte la rareté ou la fréquence d’action, le fait de répondre à un tweet étant moins fréquent que de lui attribuer un like). Mais Twitter n’a pas publié la probabilité de base de chacune de ces actions ce qui rend impossible de déterminer l’importance de chacune d’elles dans les recommandations qui lui sont servies.
Twitter a également révélé quelques informations sur les autres facteurs qu’il prend en compte en plus du classement total d’un tweet. Par exemple, en équilibrant les recommandations des personnes que vous suivez avec celles que vous ne suivez pas, en évitant de recommander les tweets d’un même auteur ou en donnant une forte prime aux utilisateurs payants de Twitter Blue.
Il y a aussi beaucoup de code que Twitter n’a pas partagé. Il n’a pas divulgué beaucoup d’informations sur l’algorithme de génération des tweets candidats au classement ni sur ses paramètres et ses données d’entraînement. Twitter n’a pas non plus explicitement partagé ses algorithmes de confiance et de sécurité pour détecter des éléments tels que les abus, la toxicité ou les contenus pour adultes, afin d’empêcher les gens de trouver des solutions de contournement, bien qu’il ait publié certaines des catégories de contenu qu’il signale.
« 20120212-NodeXL-Twitter-socbiz network graph » par Marc_Smith; licence CC BY 2.0.
Pour Gabriel Nicholas, la transparence de Twitter serait plus utile si Twitter avait maintenu ouverts ses outils aux chercheurs. Ce n’est pas le cas.
En conclusion de son article, Narayanan pointe vers un très intéressant article qui dresse une liste d’options de transparence pour ceux qui produisent des systèmes de recommandation, publiée par les chercheurs Priyanjana Bengani, Jonathan Stray et Luke Thorburn. Ils rappellent que les plateformes ont mis en place des mesures de transparence, allant de publications statistiques à des interfaces de programmation, en passant par des outils et des ensembles de données protégés. Mais ces mesures, très techniques, restent insuffisantes pour comprendre les algorithmes de recommandation et leur influence sur la société. Une grande partie de cette résistance à la transparence ne tient pas tant aux risques commerciaux qui pourraient être révélés qu’à éviter l’embarras d’avoir à se justifier de choix qui ne le sont pas toujours. D’une manière très pragmatique, les trois chercheurs proposent un menu d’actions pour améliorer la transparence et l’explicabilité des systèmes.
Documenter
L’un des premiers outils, et le plus simple, reste la documentation qui consiste à expliquer en termes clairs – selon différentes échelles et niveaux, me semble-t-il – ce qui est activé par une fonction. Pour les utilisateurs, c’est le cas du bouton « Pourquoi je vois ce message » de Facebook ou du panneau « Fréquemment achetés ensemble » d’Amazon. L’idée ici est de fourbir un « compte rendu honnête ». Pour les plus évoluées de ces interfaces, elles devraient permettre non seulement d’informer et d’expliquer pourquoi on nous recommande ce contenu, mais également, permettre de rectifier et mieux contrôler son expérience en ligne, c’est-à-dire d’avoir des leviers d’actions sur la recommandation.
Une autre forme de documentation est celle sur le fonctionnement général du système et ses décisions de classement, à l’image des rapports de transparence sur les questions de sécurité et d’intégrité que doivent produire la plupart des plateformes (voir celui de Google, par exemple). Cette documentation devrait intégrer des informations sur la conception des algorithmes, ce que les plateformes priorisent, minimisent et retirent, si elles donnent des priorités et à qui, tenir le journal des modifications, des nouvelles fonctionnalités, des changements de politiques. La documentation doit apporter une information solide et loyale, mais elle reste souvent insuffisante.
Les données
Pour comprendre ce qu’il se passe sur une plateforme, il est nécessaire d’obtenir des données. Twitter ou Facebook en ont publié (accessibles sous condition de recherche, ici pour Twitter, là pour Facebook). Une autre approche consiste à ouvrir des interfaces de programmation, à l’image de CrowdTangle de Facebook ou de l’API de Twitter. Depuis le scandale Cambridge Analytica, l’accès aux données est souvent devenu plus difficile, la protection de la vie privée servant parfois d’excuse aux plateformes pour éviter d’avoir à divulguer leurs pratiques. L’accès aux données, même pour la recherche, s’est beaucoup refermé ces dernières années. Les plateformes publient moins de données et CrowdTangle propose des accès toujours plus sélectifs. Chercheurs et journalistes ont été contraints de développer leurs propres outils, comme des extensions de navigateurs permettant aux utilisateurs de faire don de leurs données (à l’image du Citizen Browser de The Markup) ou des simulations automatisées (à l’image de l’analyse robotique de TikTok produite par le Wall Street Journal), que les plateformes ont plutôt eu tendance à bloquer en déniant les résultats obtenus sous prétexte d’incomplétude – ce qui est justement le problème que l’ouverture de données cherche à adresser.
Le code
L’ouverture du code des systèmes de recommandation pourrait être utile, mais elle ne suffit pas, d’abord parce que dans les systèmes de recommandation, il n’y a pas un algorithme unique. Nous sommes face à des ensembles complexes et enchevêtrés où « différents modèles d’apprentissage automatique formés sur différents ensembles de données remplissent diverses fonctions ». Même le classement ou le modèle de valeur pour déterminer le score n’explique pas tout. Ainsi, « le poids élevé sur un contenu d’un type particulier ne signifie pas nécessairement qu’un utilisateur le verra beaucoup, car l’exposition dépend de nombreux autres facteurs, notamment la quantité de ce type de contenu produite par d’autres utilisateurs. »
Peu de plateformes offrent une grande transparence au niveau du code source. Reddit a publié en 2008 son code source, mais a cessé de le mettre à jour. En l’absence de mesures de transparence, comprendre les systèmes nécessite d’écluser le travail des journalistes, des militants et des chercheurs pour tenter d’en obtenir un aperçu toujours incomplet.
La recherche
Les plateformes mènent en permanence une multitude de projets de recherche internes voire externes et testent différentes approches pour leurs systèmes de recommandation. Certains des résultats finissent par être accessibles dans des revues ou des articles soumis à des conférences ou via des fuites d’informations. Quelques efforts de partenariats entre la recherche et les plateformes ont été faits, qui restent embryonnaires et ne visent pas la transparence, mais qui offrent la possibilité à des chercheurs de mener des expériences et donc permettent de répondre à des questions de nature causale, qui ne peuvent pas être résolues uniquement par l’accès aux données.
Enfin, les audits peuvent être considérés comme un type particulier de recherche. À l’heure actuelle, il n’existe pas de bons exemples d’audits de systèmes de recommandation menés à bien. Reste que le Digital Service Act (DSA) européen autorise les audits externes, qu’ils soient lancés par l’entreprise ou dans le cadre d’une surveillance réglementaire, avec des accès élargis par rapport à ceux autorisés pour l’instant. Le DSA exige des évaluations sur le public mineur, sur la sécurité, la santé, les processus électoraux… mais ne précise ni comment ces audits doivent être réalisés ni selon quelles normes. Des méthodes spécifiques ont été avancées pour contrôler la discrimination, la polarisation et l’amplification dans les systèmes de recommandation.
En principe, on pourrait évaluer n’importe quel préjudice par des audits. Ceux-ci visent à vérifier si « la conception et le fonctionnement d’un système de recommandation respectent les meilleures pratiques et si l’entreprise fait ce qu’elle dit qu’elle fait. S’ils sont bien réalisés, les audits pourraient offrir la plupart des avantages d’un code source ouvert et d’un accès aux données des utilisateurs, sans qu’il soit nécessaire de les rendre publics. » Reste qu’il est peu probable que les audits imposés par la surveillance réglementaire couvrent tous les domaines qui préoccupent ceux qui sont confrontés aux effets des outils de recommandations.
Autres moteurs de transparence : la gouvernance et les calculs
Les chercheurs concluent en soulignant qu’il existe donc une gamme d’outils à disposition, mais qu’elle manque de règles et de bonnes pratiques partagées. Face aux obligations de transparence et de contrôles qui arrivent (pour les plus gros acteurs d’abord, mais parions que demain, elles concerneront bien d’autres acteurs), les entreprises peinent à se mettre en ordre de marche pour proposer des outillages et des productions dans ces différents secteurs qui leur permettent à la fois de se mettre en conformité et de faire progresser leurs outils. Ainsi, par exemple, dans le domaine des données, documenter les jeux et les champs de données, à défaut de publier les jeux de données, pourrait déjà permettre un net progrès. Dans le domaine de la documentation, les cartes et les registres permettent également d’expliquer ce que les calculs opèrent (en documentant par exemple leurs marges d’erreurs).
Reste que l’approche très technique que mobilisent les chercheurs oublie quelques leviers supplémentaires. Je pense notamment aux conseils de surveillance, aux conseils éthiques, aux conseils scientifiques, en passant par les organismes de contrôle indépendants, aux comités participatifs ou consultatifs d’utilisateurs… à tous les outils institutionnels, participatifs ou militants qui permettent de remettre les parties prenantes dans le contrôle des décisions que les systèmes prennent. Dans la lutte contre l’opacité des décisions, tous les leviers de gouvernance sont bons à prendre. Et ceux-ci sont de très bons moyens pour faire pression sur la transparence, comme l’expliquait très pertinemment David Robinson dans son livre Voices in the Code.
Un autre levier me semble absent de nombre de propositions… Alors qu’on ne parle que de rendre les calculs transparents, ceux-ci sont toujours absents des discussions. Or, les règles de traitements sont souvent particulièrement efficaces pour améliorer les choses. Il me semble qu’on peut esquisser au moins deux moyens pour rendre les calculs plus transparents et responsables : la minimisation et les interdictions.
La minimisation vise à rappeler qu’un bon calcul ne démultiplie pas nécessairement les critères pris en compte. Quand on regarde les calculs, bien souvent, on est stupéfait d’y trouver des critères qui ne devraient pas être pris en compte, qui n’ont pas de fondements autres que d’être rendus possibles par le calcul. Du risque de récidive au score de risque de fraude à la CAF, en passant par l’attribution de greffes ou aux systèmes de calculs des droits sociaux, on trouve toujours des éléments qui apprécient le calcul alors qu’ils n’ont aucune justification ou pertinence autres que d’être rendu possibles par le calcul ou les données. C’est le cas par exemple du questionnaire qui alimente le calcul de risque de récidive aux Etats-Unis, qui repose sur beaucoup de questions problématiques. Ou de celui du risque de fraude à la CAF, dont les anciennes versions au moins (on ne sait pas pour la plus récente) prenaient en compte par exemple le nombre de fois où les bénéficiaires se connectaient à leur espace en ligne (sur cette question, suivez les travaux de la Quadrature et de Changer de Cap). La minimisation, c’est aussi, comme l’explique l’ex-chercheur de chez Google, El Mahdi El Mhamdi, dans une excellente interview, limiter le nombre de paramètres pris en compte par les calculs et limiter l’hétérogénéité des données.
L’interdiction, elle, vise à déterminer que certains croisements ne devraient pas être autorisés, par exemple, la prise en compte des primes dans les logiciels qui calculent les données d’agenda du personnel, comme semble le faire le logiciel Orion mis en place par la Sncf, ou Isabel, le logiciel RH que Bol.com utilise pour gérer la main-d’œuvre étrangère dans ses entrepôts de logistique néerlandais. Ou encore, comme le soulignait Narayanan, le temps passé sur les contenus sur un réseau social par exemple, ou l’analyse de l’émotion dans les systèmes de recrutement (et ailleurs, tant cette technologie pose problème). A l’heure où tous les calculs sont possibles, il va être pertinent de rappeler que selon les secteurs, certains croisements doivent rester interdits parce qu’ils sont trop à risque pour être mobilisés dans le calcul ou que certains calculs ne peuvent être autorisés.
Priyanjana Bengani, Jonathan Stray et Luke Thorburn, pour en revenir à eux, notent enfin que l’exigence de transparence reste formulée en termes très généraux par les autorités réglementaires. Dans des systèmes vastes et complexes, il est difficile de savoir ce que doit signifier réellement la transparence. Pour ma part, je milite pour une transparence “projective”, active, qui permette de se projeter dans les explications, c’est-à-dire de saisir ses effets et dépasser le simple caractère narratif d’une explication loyale, mais bien de pouvoir agir et reprendre la main sur les calculs.
Coincés dans les boucles de l’amplification
Plus récemment, les trois mêmes chercheurs, passé leur article séminal, ont continué à documenter leur réflexion. Ainsi, dans « Rendre l’amplification mesurable », ils expliquent que l’amplification est souvent bien mal définie (notamment juridiquement, ils ont consacré un article entier à la question)… mais proposent d’améliorer les propriétés permettant de la définir. Ils rappellent d’abord que l’amplification est relative, elle consiste à introduire un changement par rapport à un calcul alternatif ou précédent qui va avoir un effet sans que le comportement de l’utilisateur n’ait été, lui, modifié.
L’amplification agit d’abord sur un contenu et nécessite de répondre à la question de savoir ce qui a été amplifié. Mais même dire que les fake news sont amplifiées n’est pas si simple, à défaut d’avoir une définition précise et commune des fake news qui nécessite de comprendre les classifications opérées. Ensuite, l’amplification se mesure par rapport à un point de référence précédent qui est rarement précisé. Enfin, quand l’amplification atteint son but, elle produit un résultat qui se voit dans les résultats liés à l’engagement (le nombre de fois où le contenu a été apprécié ou partagé) mais surtout ceux liés aux impressions (le nombre de fois où le contenu a été vu). Enfin, il faut saisir ce qui relève de l’algorithme et du comportement de l’utilisateur. Si les messages d’un parti politique reçoivent un nombre relativement important d’impressions, est-ce parce que l’algorithme est biaisé en faveur du parti politique en question ou parce que les gens ont tendance à s’engager davantage avec le contenu de ce parti ? Le problème, bien sûr, est de distinguer l’un de l’autre d’une manière claire, alors qu’une modification de l’algorithme entraîne également une modification du comportement de l’utilisateur. En fait, cela ne signifie pas que c’est impossible, mais que c’est difficile, expliquent les chercheurs. Cela nécessite un système d’évaluation de l’efficacité de l’algorithme et beaucoup de tests A/B pour comparer les effets des évolutions du calcul. Enfin, estiment-ils, il faut regarder les effets à long terme, car les changements dans le calcul prennent du temps à se diffuser et impliquent en retour des réactions des utilisateurs à ces changements, qui s’adaptent et réagissent aux transformations.
Dans un autre article, ils reviennent sur la difficulté à caractériser l’effet bulle de filtre des médias sociaux, notamment du fait de conceptions élastiques du phénomène. S’il y a bien des boucles de rétroaction, leur ampleur est très discutée et dépend beaucoup du contexte. Ils en appellent là encore à des mesures plus précises des phénomènes. Certes, ce que l’on fait sur les réseaux sociaux influe sur ce qui est montré, mais il est plus difficile de démontrer que ce qui est montré affecte ce que l’on pense. Il est probable que les effets médiatiques des recommandations soient faibles pour la plupart des gens et la plupart du temps, mais beaucoup plus importants pour quelques individus ou sous-groupes relativement à certaines questions ou enjeux. De plus, il est probable que changer nos façons de penser ne résulte pas d’une exposition ponctuelle, mais d’une exposition à des récits et des thèmes récurrents, cumulatifs et à long terme. Enfin, si les gens ont tendance à s’intéresser davantage à l’information si elle est cohérente avec leur pensée existante, il reste à savoir si ce que l’on pense affecte ce à quoi l’on s’engage. Mais cela est plus difficile à mesurer car cela suppose de savoir ce que les gens pensent et pas seulement constater leurs comportements en ligne. En général, les études montrent plutôt que l’exposition sélective a peu d’effets. Il est probable cependant que là encore, l’exposition sélective soit faible en moyenne, mais plus forte pour certains sous-groupes de personnes en fonction des contextes, des types d’informations.
Bref, là encore, les effets des réseaux sociaux sont difficiles à percer.
Pour comprendre les effets de l’amplification algorithmique, peut-être faut-il aller plus avant dans la compréhension que nous avons des évolutions de celle-ci, afin de mieux saisir ce que nous voulons vraiment savoir. C’est ce que nous tenterons de faire dans la suite de cet article…

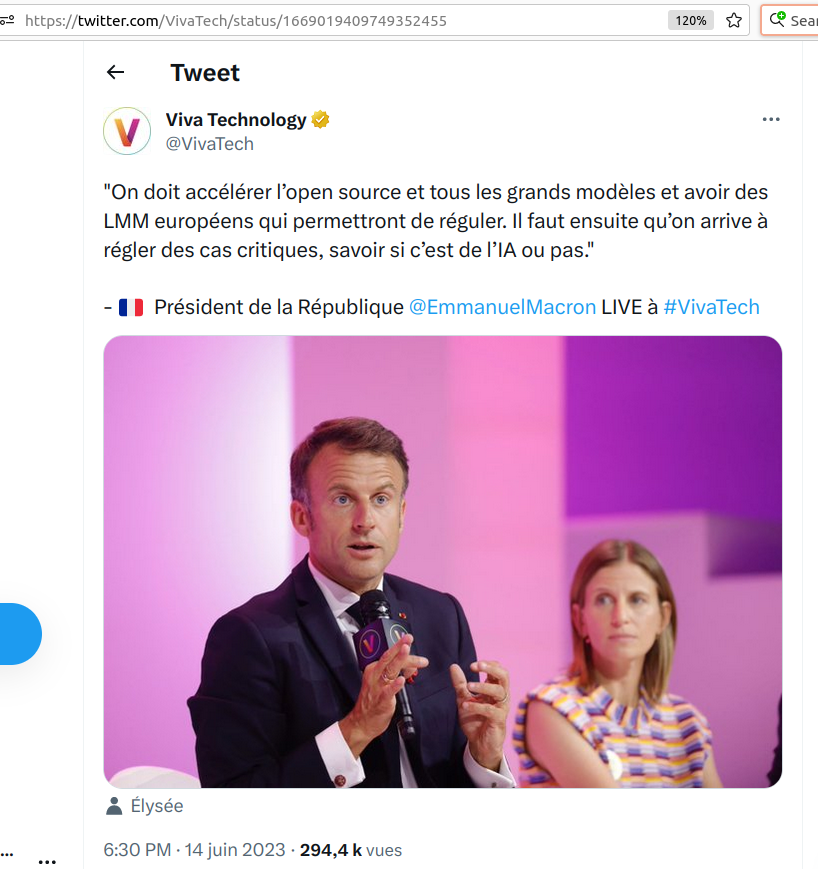

















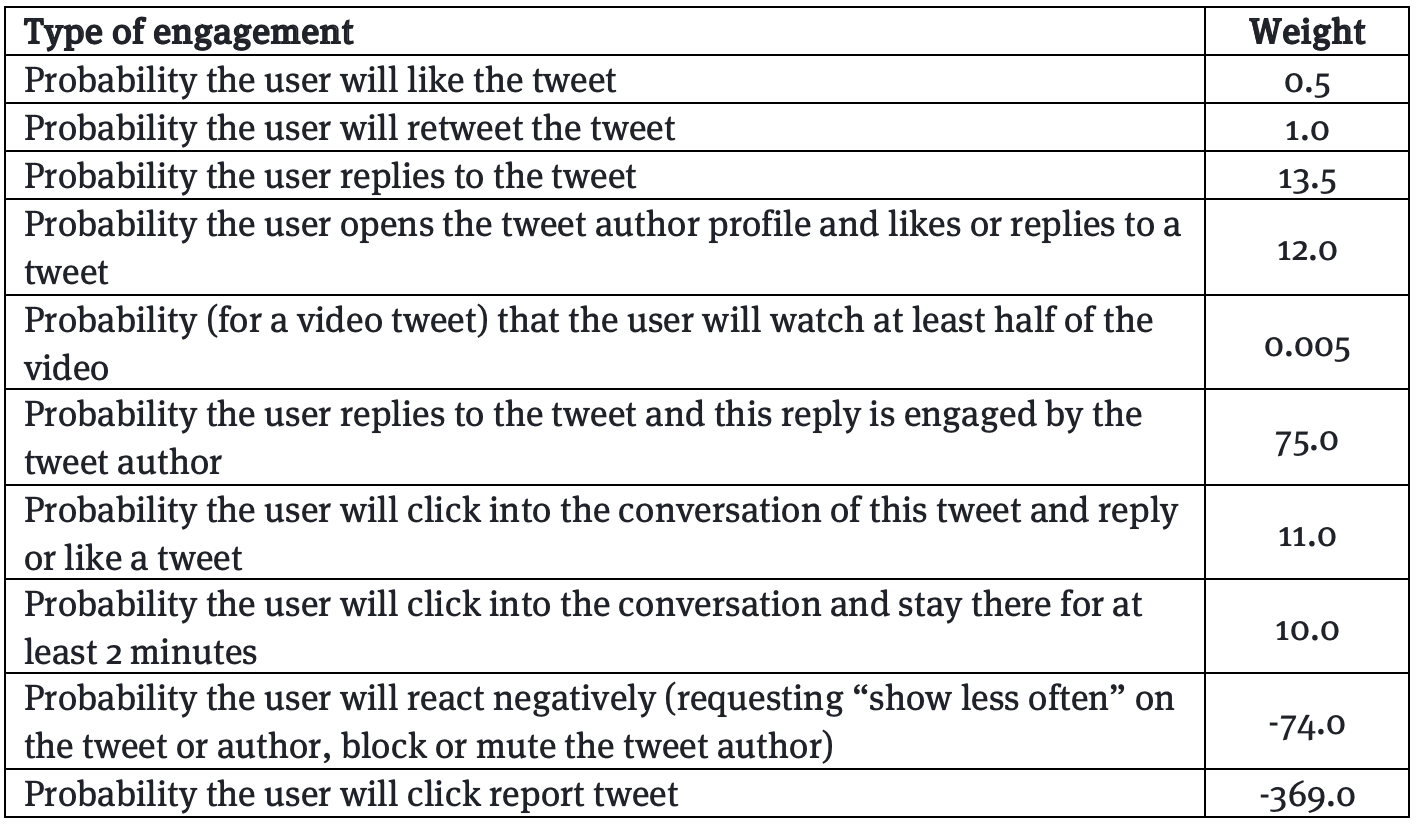
{kind=link}