Quand le militantisme déconne : injonctions, pureté militante, attaques… (5/8)
La question compliquée et parfois houleuse du militantisme nous intéresse depuis longtemps à Framasoft, aussi avons-nous demandé à Viciss de Hacking Social, de s’atteler à la tâche.
Voici déjà le cinquième épisode [si vous avez raté les épisodes précédents] de son intéressante contribution, dans laquelle elle examine les différentes facettes de la motivation et comment le militantisme déconnant les dégrade.
Nous publions un nouveau chapitre de son travail chaque vendredi à 13:37 sur le Framablog, mais si vous préférez, vous pouvez télécharger dès maintenant l’essai intégral de Viciss qui comprend une bibliographie revue et augmentée :
Quand le militantisme déconne, format .pdf (5,6 Mo)
Toutes les sources sont sous licence Creative Commons CC-BY-SA et disponibles sur ce dépôt.
Le militantisme déconnant causant une motivation de piètre qualité
Ce sapage des besoins fondamentaux (tant du militant déconnant dans son passé, que chez la cible qu’il vise) va ensuite générer chez celui qui en est cible une motivation de piètre qualité, que sont les régulations introjectées, externes ou une amotivation non autodéterminée.
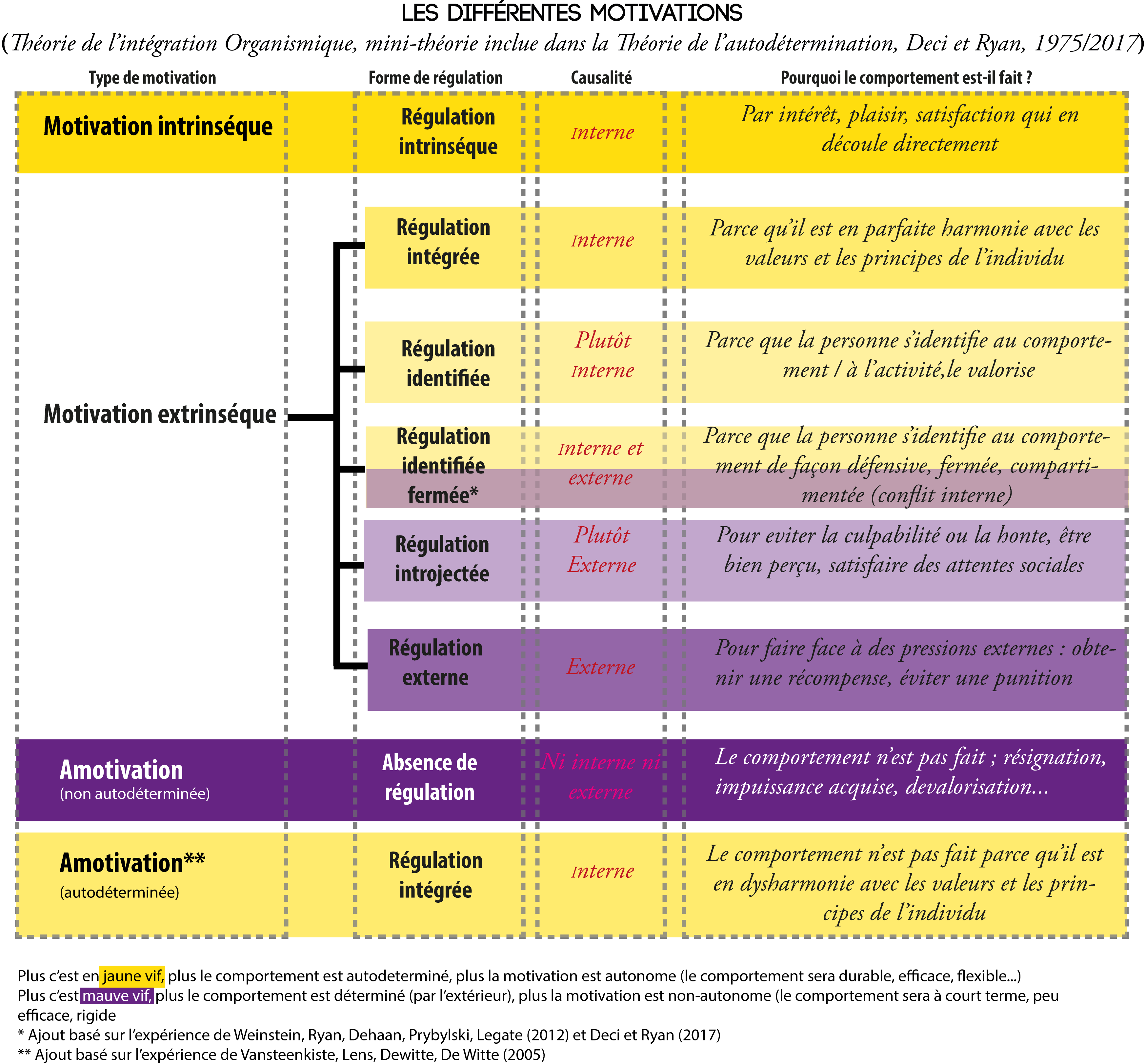
La motivation intrinsèque, détruite par le militantisme contrôlant
La motivation intrinsèque est la motivation la plus puissante qu’on puisse avoir pour quelque chose : c’est la passion, cette activité qu’on fait pour elle-même, qui nous ravit, nous comble, pour laquelle on rêverait de faire carrière. De façon moins épique, toutes les activités qu’on fait pour elles-mêmes et non pour ses résultats sont généralement réalisées par motivation intrinsèque (jouer aux jeux vidéo, regarder des séries, lire, se balader… bref tout ce qu’on peut aimer faire en soi). C’est puissant, parce que l’élan l’est, qu’il n’y a besoin de rien de plus pour nous motiver à la faire.
Or, nos environnements sociaux, s’ils ont un modèle contrôlant sapant les besoins fondamentaux, ont tendance à détruire nos motivations intrinsèques.
ℹ ⇢ Dans une expérience de Deci, Schwartz, Sheinman et Ryan (1981), 36 professeurs ont été étudiés durant l’été, avant la rentrée scolaire. Il a été testé leur orientation de causalité1 (qui était soit autonome soit contrôlée), les actions qu’ils envisageaient pour le contrôle des élèves (punir, récompenser) ou les actions de soutien (écoute du problème, guide pour le résoudre). À 2 mois de l’année scolaire entamée puis à 8 mois, leurs élèves ont complété des enquêtes évaluant leur motivation et leur perception de soi. Ceux qui avaient eu les professeurs les plus contrôlants avaient une motivation intrinsèque en chute, une estime de soi en baisse et leurs compétences cognitives avaient également chuté. Ces élèves avaient moins de curiosité quant au travail scolaire, ils préféraient les tâches faciles plutôt que difficiles, faisaient preuve de moins d’initiatives scolaires. Ils ont renouvelé cette étude dans un autre district scolaire. Ils ont sélectionné des professeurs soit hautement contrôlants soit soutenant l’autonomie. La motivation intrinsèque des élèves a été testée durant la 2e semaine d’école puis deux mois plus tard. Avec les enseignants soutenant l’autonomie, la motivation intrinsèque a augmenté, ainsi que la compétence perçue. C’était le contraire avec les professeurs contrôlants.
Plus précisément, les façons de faire contrôlantes nous dégoûtent de ce qu’on aimait naturellement faire, puisque la motivation intrinsèque chute lorsqu’on est surveillé2, menacé de punition3, qu’on a un objectif et un temps d’exécution limités4, qu’on est mis en compétition5, évalué avec des feedbacks négatifs6, qu’il y a la présence de personnes totalement indifférentes à notre activité7, qu’on est récompensé⋅e selon une performance donnée8 (par exemple, avoir son salaire/son cadeau/un compliment uniquement si on atteint une performance demandée par le superviseur ; le salaire ne sape pas la motivation intrinsèque s’il est prévu en amont, qu’importent les performances).
À l’inverse, lorsqu’on vise la préservation de la motivation intrinsèque avec sa transmission (par exemple, un militant qui montre tout le fun qu’il y a à une pratique écolo), alors la personne a tendance à s’engager et il y a un effet de débordement9 (ici, elle se mettrait d’elle-même à chercher d’autres pratiques écolos qui pourraient être tout aussi fun). C’est plaisant pour tout le monde, efficace en termes de militance, pas plus coûteux que d’injonctiver.
Pourtant, le militant aux pratiques déconnantes va plutôt reproduire le modèle de contrôle (et pas celui de la transmission de la motivation intrinsèque), quand bien même ce modèle a détruit certaines de ces plus belles motivations par le passé10. Pourquoi ? Eh bien parce qu’en plus de détruire notre motivation intrinsèque, ce vécu sous modèle contrôlant peut nous plonger dans des motivations contrôlées de l’extérieur, par exemple la motivation introjectée : l’enfant dans la classe au professeur contrôlant perd non seulement sa motivation intrinsèque, mais cherchant à réussir les objectifs pour ne pas être ostracisé, humilié, il fait alors tout pour éviter la honte, la culpabilité, etc. C’est pourquoi l’estime de soi chute : les résultats scolaires « mauvais » sont sans doute accompagnés des remarques négatives et de la dévalorisation de la part du professeur. Tout jugement militant puriste peut voir des effets similaires sur une personne visée.
La motivation à régulation introjectée, celle du militant déconnant ?
À force d’être dans des environnements qui tentent de contrôler notre comportement, notre comportement général est complètement guidé par le potentiel jugement de l’extérieur, sans même qu’une autorité soit présente : on fait alors les choses prioritairement pour éviter d’avoir honte, de se sentir coupable, d’être pointé du doigt, de perdre encore de la valeur auprès des autres, d’être marginalisé, ridiculisé, etc. La motivation introjectée est la plus répandue chez les personnes, pour à peu près n’importe quelle activité.
Le militant déconnant peut provoquer une motivation introjectée chez autrui en étant contrôlant : « je vais éviter de faire des fautes, sinon les grammar nazis vont encore me tomber dessus », il n’y a aucune motivation intrinsèque qui guide ce comportement (telle que « je ressens de la satisfaction à écrire sans fautes ») ni intégrée (« je vais tenter d’écrire sans fautes pour que les autres comprennent bien mon message »). S’il n’y avait pas de grammar nazi, alors cette personne à motivation introjectée cesserait de faire attention, ce qui signifie que la valeur intrinsèque à l’orthographe n’était absolument pas transmise. Mais on voit bien là-dedans que les militants déconnants vont interpréter ce constat comme une justification de leur contrôle : « si on ne les juge/surveille/injonctive pas, alors les gens font n’importe quoi », or ce n’est pas cela le problème. Le problème c’est que ces grammar nazis n’ont pas transmis l’orthographe d’une façon qui soit perçue comme agréable, fun, socialement utile, connectante, donc pourquoi les gens suivraient-ils leurs recommandations de manière autonome ?
Le militant déconnant peut lui-même être en motivation introjectée pour la cause qu’il défend, donc il est contrôlant envers autrui parce qu’il n’a lui-même aucune motivation intrinsèque ou intégrée pour la cause (comment dès lors transmettre quelque chose dont il ne connaît pas la dynamique et les conséquences positives ?). Par exemple, le grammar nazi a peut-être appris l’orthographe à coup d’humiliation, donc humilie autrui à son tour pensant lui faire « bien » apprendre. Il peut même avoir un authentique élan altruiste à contrôler autrui tel que « il faut que je lui montre comment être parfait sinon il va se faire humilier encore plus » ; cependant quand bien même ce n’est pas méchant ou égoïste, c’est néanmoins la perpétuation d’une pratique qui cause un mal-être, et le légitime. La seule voie de sortie de ce cercle vicieux contrôle ➝ introjection ➝ contrôle ➝ introjection ➝, etc. est de procéder différemment face à un contrôle initial ou de décortiquer ces introjections pour les comprendre, puis décider ce que l’on souhaite vraiment en faire.
La motivation compartimentée : ou comment la militance peut devenir violente
La motivation introjectée n’est pas la « pire » pour autant, puisqu’elle n’est généralement pas liée à une violence envers les autres. Si on est militant à motivation introjectée ou qu’on provoque de l’introjection chez les autres par nos introjections, on ne va pas pour autant se transformer ou transformer les autres en combattants violents. On alimentera juste une saoulance générale, et les motivations pour la cause ne seront pas de très bonne qualité11 (tant chez les militants que chez les spectateurs, alliés ou toute cible de cette saoulance).
Par contre d’autres configurations complexes de la motivation amènent à soutenir une violence envers des personnes, voire à l’être soi-même ; c’est le cas de la motivation à identification compartimentée (ou dite fermée, défensive), dont les tenants et aboutissants sont complexes à démêler.
Rassurez-vous, dans les cas cités en introduction, je ne crois pas qu’un seul des exemples déconnants cités n’ait été conduit par ce type de motivation, encore moins il me semble chez les libristes (du moins je n’en ai pas vécu personnellement). Généralement on repère ces motivations malsaines lorsque c’est la haine qui conduit l’activité, qu’il y a un « nous contre eux » ethnocentrique (voir définition dans le cadre ci-dessous) : le groupe zététicien que j’ai évoqué, dont une des activités était de passer des soirées à se foutre d’un autre zététicien, de se gargariser à le haïr tous ensemble, avait tout de même un côté « motivation identifiée compartimentée », puisque l’identification au groupe passait uniquement par le fait de haïr un « ennemi » désigné, sans rien créer. Cependant, je peux difficilement analyser cette dynamique et comprendre son origine, parce qu’on a quitté le groupe dès qu’on a vu ces signaux malsains, et je ne connaissais pas du tout l’histoire personnelle de ses membres.

Dire qu’il y a ethnocentrisme ou identification compartimentée n’explique pas vraiment pourquoi il y a cet élan d’attaque : certes, ces mécaniques se font souvent en groupe, sont animées par une dynamique de groupe, type « bouc-émissaire », certains militants comparent ce genre de situation au harcèlement scolaire12. Mais ce n’est pas parce que c’est répandu que c’est « inévitable », que ce serait sans raison ou que cela s’expliquerait par une prétendue « nature humaine ». Quand on creuse, on trouve des réponses : chez les ados par exemple, l’identité est en pleine construction et c’est pour cela que des individus vont parfois se rassembler pour attaquer les élèves perçus comme marginaux. Cela leur permet de construire/légitimer leur identité à moindres frais, et de compenser le mal-être général lié à l’adolescence elle-même. Autrement dit, on voit poindre des solutions lorsqu’on comprend mieux la cause première : soutenir les ados, créer des climats qui ne soient pas menaçants, leur montrer des voies de constructions personnelles qui ne passent pas par la destruction d’autres personnes13.
ℹ ⇢ L’identification compartimentée peut être totalement connectée à des stéréotypes ancrés dans la société :
Weinstein et al. (2012) ont postulé que lorsque des individus grandissent dans des environnements menaçant l’autonomie, ils peuvent être empêchés d’explorer et d’intégrer certaines valeurs ou identités potentielles, et en conséquence être plus enclins à compartimenter certaines expériences qui sont perçues comme inacceptables.
Comme l’homosexualité est stigmatisée, l’hypothèse des chercheurs a été que les personnes qui ont grandi dans des environnements sapant ou frustrant leur autonomie pourraient être plus enclins à compartimenter leur attirance pour le même sexe autant pour les autres que pour eux-mêmes, ce qui conduit à des processus défensifs. Les quatre études des chercheurs ont consisté à voir le soutien parental de l’autonomie des personnes, prendre note de leur identification sexuelle, puis mesurer leur orientation sexuelle implicite grâce des tests d’association implicite. Ces tests se basent sur le temps de réaction, sans que la personne puisse avoir le temps de mettre en œuvre des mécanismes de défense.
Résultat, il s’est avéré que plus l’environnement paternel avait été contrôlant et homophobe, plus il y avait une forte différence entre leur hétérosexualité annoncée et les résultats aux tests d’association implicite montrant leur attirance sexuelle pour les personnes du même sexe. C’est-à-dire qu’ils n’étaient pas cohérents dans la forte hétérosexualité qu’ils annonçaient alors qu’ils avaient pourtant des désirs homosexuels. En plus, pour protéger cette identification compartimentée, ces individus préconisaient plus d’agression envers les homosexuels.
Autrement dit, cette identification « hétérosexuelle » était fortement ancrée dans ce qu’ils annonçaient mais elle était fermée et défensive, parce que l’individu avait des désirs, des besoins sexuels homosexuels plus forts que ce qu’ils annonçaient. Ce qui entraînait des processus défensifs, c’est-à-dire qu’il défendait l’identification hétérosexuelle en préconisant l’agression des homosexuels : on voit là comme une projection sur la société de leur lutte interne contre leurs propres désirs et envies.
Attention, afin d’éviter un malentendu que l’on peut lire ci ou là14 quand on évoque les études portant sur l’homophobie en psycho, précisons que ce type d’études ne consiste pas à dépolitiser le problème, à tout plaquer sur l’individu. C’est même l’exact opposé puisque les études montrent les conséquences de l’environnement culturel, politique et social sur le développement de la personne ; de plus, étudier les facteurs qui poussent un individu à une agressivité homophobe ne consiste pas à l’excuser, à lui trouver des circonstances atténuantes : les sciences humaines et sociales, telles que la socio ou la psycho, consistent à comprendre, non à excuser (n’en déplaise à Monsieur Valls). Et lorsqu’on comprend dans le détail, on peut ajuster ces stratégies militantes, les optimiser, voire tenter de nouvelles actions en fonction de ces nouvelles informations issues de la recherche.
Cela peut apparaître comme assez contre-intuitif, et très complexe à démêler/deviner chez autrui puisque dans ces identifications compartimentées se niche une histoire secrète de l’individu qui se confronte à des pressions environnementales, puis endosse ces pressions de la société comme « bonnes » quand bien même son corps et des parties de lui-même lui signifient que non, qu’au contraire, elles sont sources de mal-être. Quand on étudie la déshumanisation15, on peut tomber aussi sur ce genre de mécanismes très contre-intuitifs où ce n’est pas parce que la personne déshumanise une autre personne qu’elle va recommander de la violence contre lui, mais plutôt parce qu’elle doit être violente contre lui qu’elle va le déshumaniser. Il y a un besoin qui commande la violence contre un autre, alors advient ensuite la déshumanisation qui permet de supprimer toute empathie pour la personne visée. La grande question est alors : quel est ce besoin ? La réponse varie évidemment selon la situation et des influences distales : par exemple, si un autoritaire influent interprète une crise économique comme étant de la faute d’un groupe ethnique particulier qui s’accaparerait richesses et emplois, alors les gens, par besoin matériel, peuvent s’accrocher à cette interprétation et s’attaquer à ce groupe, même si l’interprétation ne tient pas debout. C’est pour cela qu’en temps de crise on assiste à une plus grande crédulité quant à ce type d’interprétation discriminante, car fondamentalement les besoins de la population ayant été sapés ou étant menacés de l’être, l’interprétation donnant la plus grande promesse de « défense » à moindre coût recueillera bien plus d’adhésion.
Il y a donc d’abord toujours un besoin chez l’individu, parfois détourné, parfois extrêmement caché, et donc très difficile à deviner pour le tiers.
Il se peut aussi que l’individu qui recommande de la violence contre un autre veuille parfois supprimer quelque chose chez l’autre, parce que c’est précisément ce quelque chose qu’il veut supprimer en lui ; la vidéo de Contrapoints sur le Cringe est assez éloquente à ce sujet.
Non seulement les pratiques déconnantes sont donc le reflet d’un mal-être (besoins sapés, besoins frustrés que la personne ne s’avoue pas, motivations de piètre qualité), mais mettent aussi ceux qui les reçoivent dans un mal-être, et sont du même coup inefficaces pour l’avancée de la cause qui est décrédibilisée par la déconnance. De plus, un mouvement militant veut généralement une transformation des comportements sur le long terme, et non juste ponctuellement sous la pression d’un ordre (motivation externe) ou sous la pression sociale (utiliser Firefox un seul jour pour être perçu comme quelqu’un de bien parce qu’il y a des libristes chez soi), or c’est précisément ce que génère la militance déconnante. La militance déconnante, par son comportement, endosse aussi un modèle de contrôle extrêmement conformiste, conservateur : ce faisant, le militant déconnant démontre à autrui qu’il ne veut rien changer de structurel, si ce n’est tenter simplement d’avoir sa part de domination en prenant le contrôle sur autrui. C’est une dynamique cohérente lorsqu’on soutient une idéologie autoritaire, mais c’est incohérent si on vise un changement de paradigme progressiste et ouvert, puisqu’on répète alors un vieux paradigme autoritaire. Être « pur » dans ses pratiques ne compense pas le fait que les autres verront dans l’injonction, l’attaque, la répétition d’un vieux paradigme contrôlant, et donc n’y trouveront rien de bien séduisant.
- Les individus en orientation contrôlée ont tendance à contrôler autrui, à ne voir que les contrôles dans une situation ; les personnes en orientation autonome ont tendance à voir les possibilités, les potentiels d’une situation, les espaces de liberté/de créativité possible et ont tendance à nourrir l’autonomie, la liberté des autres. L’orientation d’une personne dépend de comment la situation actuelle et passée est nourrissante ou sapante des besoins (quand bien même on peut être très autonome, on peut être en orientation contrôlée dans une situation autoritaire par exemple, parce qu’il n’y a aucune place laissée à l’initiative. Inversement, on peut être en orientation contrôlée dans une situation pourtant très libre, non contrôlante)↩
- Pittman, Davey, Alafat, Wetherill, et Kramer (1980) ; Lepper & Greene (1975) ; Plant & Ryan (1985) ; Ryan et al. (1991) ; Enzle et Anderson (1993).↩
- Deci et Cascio (1972).↩
- Amabile, DeJong, et Lepper (1976) ; Reader and Dollinger (1982).↩
- Deci, Betley, Kahle, Abrams, and Porac (1981).↩
- Anderson et Rodin (1989) ; Baumeister and Tice (1985).↩
- Anderson, Mancogian, Reznick (1976)↩
- Deci (1975) ; Lepper, Greene et Nisbett Ross (1975).↩
- Dolan et Galizzi (2015).↩
- Quantité d’études (Deci et Ryan 2017) montrent que l’école, le travail, ou d’autres situations sociales ont tendance, majoritairement, à détruire nos motivations intrinsèques. On a donc tous probablement connu un nombre plus ou moins grand de sapages de nos motivations intrinsèques.↩
- La motivation introjectée est liée à une baisse de vitalité, une augmentation de l’anxiété, plus de sentiments de honte, de culpabilité, parfois à la dépression, à la somatisation et à une faiblesse face à la manipulation Vallerand et Carducci (1996) Koestner, Houlfort, Paquet et Knight (2001) Ryan et al. (1993) Assor et al. (2004) Moller, Roth, Niemiec, Kanat-Maymon et Deci, (2018).↩
- Pauline Grand d’Esnon, « Pureté militante, culture du ’callout’ : quand les activistes s’entre-déchirent », Neonmag, 13/02/2021.↩
- ça peut passer par la pratique d’un sport, l’apprentissage des compétences socio-émotionnelles, une éducation systémique sur la façon de créer son bien-être, comprendre son mal-être (psychologie, sociologie), une éducation basée sur la coopération et le soutien entre personnes, un enseignement des sciences humaines et sociales dès le collège, etc.↩
- Comme ici : Maëlle Le Corre, « Pourquoi il faut en finir avec le cliché du « mec homophobe qui est en réalité un gay refoulé », Madmoizelle.com, 30/03/2021.↩
- Cf Semelin (1994 ; 1983 ; 2005 ; 1998) ; Straub (2003) ; Hatzfeld (2003) ; Terestchenko (2005).↩
(à suivre…)
| Si vous trouvez ce dossier intéressant, vous pouvez témoigner de votre soutien aux travaux de Hacking Social par un don sur tipee ou sur Liberapay |






![Effet du témoin. [XP] Peut-on compter sur un groupe pour nous porter secours ?](https://framablog.org/wp-content/uploads/2021/07/effettemoin-1.jpg)

















{kind=link}
{kind=link}