Google, nouvel avatar du capitalisme, celui de la surveillance
Nous avons la chance d’être autorisés à traduire et publier un long article qui nous tient à cœur : les idées et analyses qu’il développe justifient largement les actions que nous menons avec vous et pour le plus grand nombre.
Avant propos
Par Framatophe.
Dans ses plus récents travaux, Shoshana Zuboff procède à une analyse systématique de ce qu’elle appelle le capitalisme de surveillance. Il ne s’agit pas d’une critique du capitalisme-libéral en tant qu’idéologie, mais d’une analyse des mécanismes et des pratiques des acteurs dans la mesure où elles ont radicalement transformé notre système économique. En effet, avec la fin du XXe siècle, nous avons aussi vu la fin du (néo)libéralisme dans ce qu’il avait d’utopique, à savoir l’idée (plus ou moins vérifiée) qu’en situation d’abondance, chacun pouvait avoir la chance de produire et capitaliser. Cet égalitarisme, sur lequel s’appuient en réalité bien des ressorts démocratiques, est mis à mal par une nouvelle forme de capitalisme : un capitalisme submergé par des monopoles capables d’utiliser les technologies de l’information de manière à effacer la « libre concurrence » et modéliser les marchés à leurs convenances. La maîtrise de la production ne suffit plus : l’enjeu réside dans la connaissance des comportements. C’est de cette surveillance qu’il s’agit, y compris lorsqu’elle est instrumentalisée par d’autres acteurs, comme un effet de bord, telle la surveillance des États par des organismes peu scrupuleux.
La démarche intellectuelle de Shoshana Zuboff est très intéressante. Spécialiste au départ des questions managériales dans l’entreprise, elle a publié un ouvrage en 1988 intitulé In the Age Of The Smart Machine où elle montre comment les mécanismes productivistes, une fois dotés des moyens d’« informationnaliser » la division du travail et son contrôle (c’est-à-dire qu’à chaque fois que vous divisez un travail en plusieurs tâches vous pouvez en renseigner la procédure pour chacune et ainsi contrôler à la fois la production et les hommes), ont progressivement étendu l’usage des technologies de l’information à travers toutes les chaînes de production, puis les services, puis les processus de consommation, etc. C’est à partir de ces clés de lecture que nous pouvons alors aborder l’état de l’économie en général, et on s’aperçoit alors que l’usage (lui même générateur de profit) des Big Data consiste à maîtriser les processus de consommation et saper les mécanismes de concurrence qui étaient auparavant l’apanage revendiqué du libéralisme « classique ».
Ainsi, prenant l’exemple de Google, Shoshana Zuboff analyse les pratiques sauvages de l’extraction de données par ces grands acteurs économiques, à partir des individus, des sociétés, et surtout du quotidien, de nos intimités. Cette appropriation des données comportementales est un processus violent de marchandisation de la connaissance « sur » l’autre et de son contrôle. C’est ce que Shoshana Zuboff nomme Big Other :
« (Big Other) est un régime institutionnel, omniprésent, qui enregistre, modifie, commercialise l’expérience quotidienne, du grille-pain au corps biologique, de la communication à la pensée, de manière à établir de nouveaux chemins vers les bénéfices et les profits. Big Other est la puissance souveraine d’un futur proche qui annihile la liberté que l’on gagne avec les règles et les lois.» 1
Dans l’article ci-dessous, Shoshana Zuboff ne lève le voile que sur un avatar de ce capitalisme de surveillance, mais pas n’importe lequel : Google. En le comparant à ce qu’était General Motors, elle démontre comment l’appropriation des données comportementales par Google constitue en fait un changement de paradigme dans les mécanismes capitalistes : le capital, ce n’est plus le bien ou le stock (d’argent, de produits, de main-d’oeuvre etc.), c’est le comportement et la manière de le renseigner, c’est à dire l’information qu’une firme comme Google peut s’approprier.
Ce qui manquait à la littérature sur ces transformations de notre « société de l’information », c’étaient des clés de lecture capables de s’attaquer à des processus dont l’échelle est globale. On peut toujours en rester à Big Brother, on ne fait alors que se focaliser sur l’état de nos relations sociales dans un monde où le capitalisme de surveillance est un état de fait, comme une donnée naturelle. Au contraire, le capitalisme de surveillance dépasse les États ou toute forme de centralisation du pouvoir. Il est informel et pourtant systémique. Shoshana Zuboff nous donne les clés pour appréhender ces processus globaux, partagé par certaines firmes, où l’appropriation de l’information sur les individus est si totale qu’elle en vient à déposséder l’individu de l’information qu’il a sur lui-même, et même du sens de ses actions.
 Shoshana Zuboff est professeur émérite à Charles Edward Wilson, Harvard Business School. Cet essai a été écrit pour une conférence en 2016 au Green Templeton College, Oxford. Son prochain livre à paraître en novembre 2017 s’intitule Maître ou Esclave : une lutte pour l’âme de notre civilisation de l’information et sera publié par Eichborn en Allemagne, et par Public Affairs aux États-Unis.
Shoshana Zuboff est professeur émérite à Charles Edward Wilson, Harvard Business School. Cet essai a été écrit pour une conférence en 2016 au Green Templeton College, Oxford. Son prochain livre à paraître en novembre 2017 s’intitule Maître ou Esclave : une lutte pour l’âme de notre civilisation de l’information et sera publié par Eichborn en Allemagne, et par Public Affairs aux États-Unis.
Les secrets du capitalisme de surveillance
par Shoshana Zuboff
Article original en anglais paru dans le Franfurter Allgemeine Zeitung : The Secrets of Surveillance Capitalism
Traduction originale : Dr. Virginia Alicia Hasenbalg-Corabianu, révision Framalang : mo, goofy, Mannik, Lumi, lyn
Le contrôle exercé par les gouvernements n’est rien comparé à celui que pratique Google. L’entreprise crée un genre entièrement nouveau de capitalisme, une logique d’accumulation systémique et cohérente que nous appelons le capitalisme de surveillance. Pouvons-nous y faire quelque chose ?

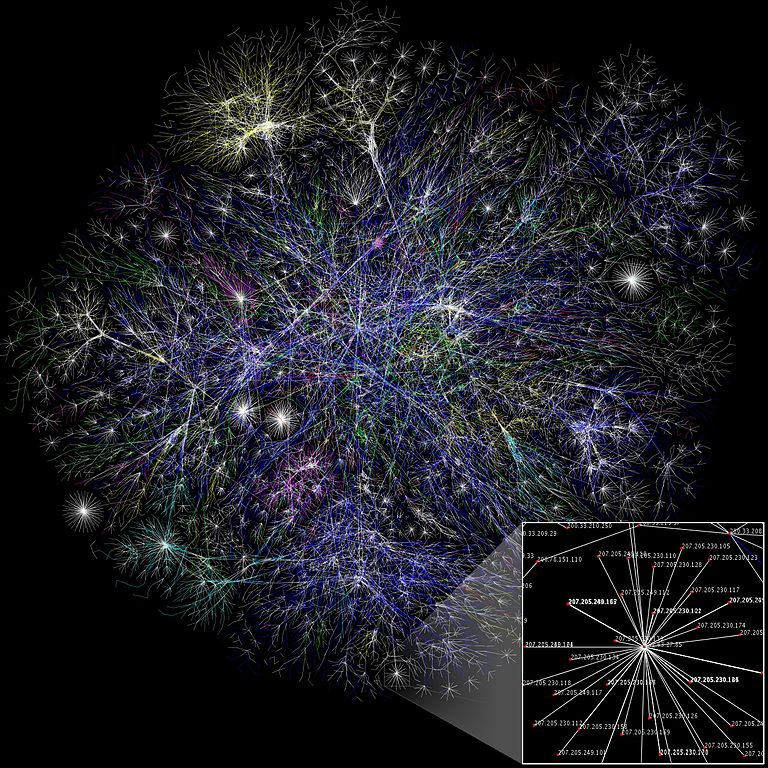
Google a dépassé Apple en janvier en devenant la plus grosse capitalisation boursière du monde, pour la première fois depuis 2010 (à l’époque, chacune des deux entreprises valait moins de 200 milliards de dollars; aujourd’hui, chacune est évaluée à plus de 500 milliards). Même si cette suprématie de Google n’a duré que quelques jours, le succès de cette entreprise a des implications pour tous ceux qui ont accès à Internet. Pourquoi ? Parce que Google est le point de départ pour une toute nouvelle forme de capitalisme dans laquelle les bénéfices découlent de la surveillance unilatérale ainsi que de la modification du comportement humain. Il s’agit d’une intrusion globale. Il s’agit d’un nouveau capitalisme de surveillance qui est inimaginable en dehors des insondables circuits à haute vitesse de l’univers numérique de Google, dont le vecteur est l’Internet et ses successeurs. Alors que le monde est fasciné par la confrontation entre Apple et le FBI, véritable réalité est que les capacités de surveillance d’espionnage en cours d’élaboration par les capitalistes de la surveillance sont enviées par toutes les agences de sécurité des États. Quels sont les secrets de ce nouveau capitalisme, comment les entreprises produisent-elles une richesse aussi stupéfiante, et comment pouvons-nous nous protéger de leur pouvoir envahissant ?
I. Nommer et apprivoiser
La plupart des Américains se rendent compte qu’il y a deux types de personnes qui sont régulièrement surveillées quand elles se déplacent dans le pays. Dans le premier groupe, celles qui sont surveillées contre leur volonté par un dispositif de localisation attaché à la cheville suite à une ordonnance du tribunal. Dans le second groupe, toutes les autres.
Certains estiment que cette affirmation est absolument fondée. D’autres craignent qu’elle ne puisse devenir vraie. Certains doivent penser que c’est ridicule. Ce n’est pas une citation issue d’un roman dystopique, d’un dirigeant de la Silicon Valley, ni même d’un fonctionnaire de la NSA. Ce sont les propos d’un consultant de l’industrie de l’assurance automobile, conçus comme un argument en faveur de « la télématique automobile » et des capacités de surveillance étonnamment intrusives des systèmes prétendument bénins déjà utilisés ou en développement. C’est une industrie qui a eu une attitude notoire d’exploitation de ses clients et des raisons évidentes d’être inquiète, pour son modèle économique, des implications des voitures sans conducteur. Aujourd’hui, les données sur l’endroit où nous sommes et celui où nous allons, sur ce que nous sentons, ce que nous disons, les détails de notre conduite, et les paramètres de notre véhicule se transforment en balises de revenus qui illuminent une nouvelle perspective commerciale. Selon la littérature de l’industrie, ces données peuvent être utilisées pour la modification en temps réel du comportement du conducteur, déclencher des punitions (hausses de taux en temps réel, pénalités financières, couvre-feux, verrouillages du moteur) ou des récompenses (réductions de taux, coupons à collectionner pour l’achat d’avantages futurs).
Bloomberg Business Week note que ces systèmes automobiles vont donner aux assureurs la possibilité d’augmenter leurs recettes en vendant des données sur la conduite de leur clientèle de la même manière que Google réalise des profits en recueillant et en vendant des informations sur ceux qui utilisent son moteur de recherche. Le PDG de Allstate Insurance veut être à la hauteur de Google. Il déclare : « Il y a beaucoup de gens qui font de la monétisation des données aujourd’hui. Vous allez chez Google et tout paraît gratuit. Ce n’est pas gratuit. Vous leur donnez des informations ; ils vendent vos informations. Pourrions-nous, devrions-nous vendre ces informations que nous obtenons des conducteurs à d’autres personnes, et réaliser ainsi une source de profit supplémentaire…? C’est une partie à long terme. »
Qui sont ces « autres personnes » et quelle est cette « partie à long terme » ? Il ne s’agit plus de l’envoi d’un catalogue de vente par correspondance ni le ciblage de la publicité en ligne. L’idée est de vendre l’accès en temps réel au flux de votre vie quotidienne – votre réalité – afin d’influencer et de modifier votre comportement pour en tirer profit. C’est la porte d’entrée vers un nouvel univers d’occasions de monétisation : des restaurants qui veulent être votre destination ; des fournisseurs de services qui veulent changer vos plaquettes de frein ; des boutiques qui vous attirent comme les sirènes des légendes. Les « autres personnes », c’est tout le monde, et tout le monde veut acheter un aspect de votre comportement pour leur profit. Pas étonnant, alors, que Google ait récemment annoncé que ses cartes ne fourniront pas seulement l’itinéraire que vous recherchez, mais qu’elles suggéreront aussi une destination.
Le véritable objectif : modifier le comportement réel des gens, à grande échelle.
Ceci est juste un coup d’œil pris au vol d’une industrie, mais ces exemples se multiplient comme des cafards. Parmi les nombreux entretiens que j’ai menés au cours des trois dernières années, l’ingénieur responsable de la gestion et analyse de méga données d’une prestigieuse entreprise de la Silicon Valley qui développe des applications pour améliorer l’apprentissage des étudiants m’a dit : « Le but de tout ce que nous faisons est de modifier le comportement des gens à grand échelle. Lorsque les gens utilisent notre application, nous pouvons cerner leurs comportements, identifier les bons et les mauvais comportements, et développer des moyens de récompenser les bons et punir les mauvais. Nous pouvons tester à quel point nos indices sont fiables pour eux et rentables pour nous. »
L’idée même d’un produit efficace, abordable et fonctionnel puisse suffire aux échanges commerciaux est en train de mourir. L’entreprise de vêtements de sport Under Armour réinvente ses produits comme des technologies que l’on porte sur soi. Le PDG veut lui aussi ressembler à Google. Il dit : « Tout cela ressemble étrangement à ces annonces qui, à cause de votre historique de navigation, vous suivent quand vous êtes connecté à l’Internet (Internet ou l’internet), c’est justement là le problème – à ce détail près que Under Armour traque votre comportement réel, et que les données obtenues sont plus spécifiques… si vous incitez les gens à devenir de meilleurs athlètes ils auront encore plus besoin de notre équipement. » Les exemples de cette nouvelle logique sont infinis, des bouteilles de vodka intelligentes aux thermomètres rectaux reliés à Internet, et littéralement tout ce qu’il y a entre les deux. Un rapport de Goldman Sachs appelle une « ruée vers l’or » cette course vers « de gigantesques quantités de données ».
La bataille des données comportementales
Nous sommes entrés dans un territoire qui était jusqu’alors vierge. L’assaut sur les données de comportement progresse si rapidement qu’il ne peut plus être circonscrit par la notion de vie privée et sa revendication. Il y a un autre type de défi maintenant, celui qui menace l’idéal existentiel et politique de l’ordre libéral moderne défini par les principes de l’autodétermination constitué au cours des siècles, voire des millénaires. Je pense à des notions qui entre autres concernent dès le départ le caractère sacré de l’individu et les idéaux de l’égalité sociale ; le développement de l’identité, l’autonomie et le raisonnement moral ; l’intégrité du marché ; la liberté qui revient à la réalisation et l’accomplissement des promesses ; les normes et les règles de la collectivité ; les fonctions de la démocratie de marché ; l’intégrité politique des sociétés et l’avenir de la souveraineté démocratique. En temps et lieu, nous allons faire un bilan rétrospectif de la mise en place en Europe du « Droit à l’Oubli » et l’invalidation plus récente de l’Union européenne de la doctrine Safe Harbor2 comme les premiers jalons d’une prise en compte progressive des vraies dimensions de ce défi.
Il fut un temps où nous avons imputé la responsabilité de l’assaut sur les données comportementales à l’État et à ses agences de sécurité. Plus tard, nous avons également blâmé les pratiques rusées d’une poignée de banques, de courtiers en données et d’entreprises Internet. Certains attribuent l’attaque à un inévitable « âge des mégadonnées », comme s’il était possible de concevoir des données nées pures et irréprochables, des données en suspension dans un lieu céleste où les faits se subliment dans la vérité.
Le capitalisme a été piraté par la surveillance
Je suis arrivée à une conclusion différente : l’assaut auquel nous sommes confronté⋅e⋅s est conduit dans une large mesure par les appétits exceptionnels d’un tout nouveau genre du capitalisme, une nouvelle logique systémique et cohérente de l’accumulation que j’appelle le capitalisme de surveillance. Le capitalisme a été détourné par un projet de surveillance lucrative qui subvertit les mécanismes évolutifs « normaux » associés à son succès historique et qui corrompt le rapport entre l’offre et la demande qui, pendant des siècles, même imparfaitement, a lié le capitalisme aux véritables besoins de ses populations et des sociétés, permettant ainsi l’expansion fructueuse de la démocratie de marché.

Le capitalisme de surveillance est une mutation économique nouvelle, issue de l’accouplement clandestin entre l’énorme pouvoir du numérique avec l’indifférence radicale et le narcissisme intrinsèque du capitalisme financier, et la vision néolibérale qui a dominé le commerce depuis au moins trois décennies, en particulier dans les économies anglo-saxonnes. C’est une forme de marché sans précédent dont les racines se développent dans un espace de non-droit. Il a été découvert et consolidé par Google, puis adopté par Facebook et rapidement diffusé à travers l’Internet. Le cyberespace est son lieu de naissance car, comme le célèbrent Eric Schmidt, Président de Google/Alphabet, et son co-auteur Jared Cohen, à la toute première page de leur livre sur l’ère numérique, « le monde en ligne n’est vraiment pas attaché aux lois terrestres… Il est le plus grand espace ingouvernable au monde ».
Alors que le capitalisme de surveillance découvre les pouvoirs invasifs de l’Internet comme source d’accumulation de capital et de création de richesses, il est maintenant, comme je l’ai suggéré, prêt à transformer aussi les pratiques commerciales au sein du monde réel. On peut établir l’analogie avec la propagation rapide de la production de masse et de l’administration dans le monde industrialisé au début du XXe siècle, mais avec un bémol majeur. La production de masse était en interaction avec ses populations qui étaient ses consommateurs et ses salariés. En revanche, le capitalisme de surveillance se nourrit de populations dépendantes qui ne sont ni ses consommateurs, ni ses employés, mais largement ignorantes de ses pratiques.
L’accès à Internet, un droit humain fondamental
Nous nous étions jetés sur Internet pour y trouver réconfort et solutions, mais nos besoins pour une vie efficace ont été contrecarrés par les opérations lointaines et de plus en plus impitoyables du capitalisme de la fin du XXe siècle. Moins de deux décennies après l’introduction du navigateur web Mosaic auprès du public, qui permettait un accès facile au World Wide Web, un sondage BBC de 2010 a révélé que 79 % des personnes de 26 pays différents considéraient l’accès à l’Internet comme un droit humain fondamental. Tels sont les Charybde et Scylla de notre sort. Il est presque impossible d’imaginer la participation à une vie quotidienne efficace – de l’emploi à l’éducation, en passant par les soins de santé – sans pouvoir accéder à Internet et savoir s’en servir, même si ces espaces en réseau autrefois florissants s’avèrent être une forme nouvelle et plus forte d’asservissement. Il est arrivé rapidement et sans notre accord ou entente préalable. En effet, les préjudices les plus poignants du régime ont été difficiles à saisir ou à théoriser, brouillés par l’extrême vitesse et camouflés par des opérations techniques coûteuses et illisibles, des pratiques secrètes des entreprises, de fausses rhétoriques discursives, et des détournements culturels délibérés.
Apprivoiser cette nouvelle force nécessite qu’elle soit nommée correctement. Cette étroite interdépendance du nom et de l’apprivoisement est clairement illustrée dans l’histoire récente de la recherche sur le VIH que je vous propose comme analogie. Pendant trois décennies, les recherches des scientifiques visaient à créer un vaccin en suivant la logique des guérisons précédentes qui amenaient le système immunitaire à produire des anticorps neutralisants. Mais les données collectées et croisées ont révélé des comportements imprévus du virus VIH défiant les modèles obtenus auprès d’autres maladies infectieuses.
L’analogie avec la recherche contre le SIDA
La tendance a commencé à prendre une autre direction à la Conférence internationale sur le SIDA en 2012, lorsque de nouvelles stratégies ont été présentées reposant sur une compréhension plus adéquate de la biologie des quelques porteurs du VIH, dont le sang produit des anticorps naturels. La recherche a commencé à se déplacer vers des méthodes qui reproduisent cette réponse d’auto-vaccination. Un chercheur de pointe a annoncé : « Nous connaissons le visage de l’ennemi maintenant, et nous avons donc de véritables indices sur la façon d’aborder le problème. »
Ce qu’il nous faut en retenir : chaque vaccin efficace commence par une compréhension approfondie de la maladie ennemie. Nous avons tendance à compter sur des modèles intellectuels, des vocabulaires et des outils mis en place pour des catastrophes passées. Je pense aux cauchemars totalitaires du XXe siècle ou aux prédations monopolistiques du capitalisme de l’Âge d’Or. Mais les vaccins que nous avons développés pour lutter contre ces menaces précédentes ne sont pas suffisants ni même appropriés pour les nouveaux défis auxquels nous sommes confrontés. C’est comme si nous lancions des boules de neige sur un mur de marbre lisse pour ensuite les regarder glisser et ne laisser rien d’autre qu’une trace humide : une amende payée ici, un détour efficace là.
Une impasse de l’évolution
Je tiens à dire clairement que le capitalisme de surveillance n’est pas la seule modalité actuelle du capitalisme de l’information, ni le seul modèle possible pour l’avenir. Son raccourci vers l’accumulation du capital et l’institutionnalisation rapide, cependant, en a fait le modèle par défaut du capitalisme de l’information. Les questions que je pose sont les suivantes : est-ce que le capitalisme de surveillance devient la logique dominante de l’accumulation dans notre temps, ou ira-t-il vers une impasse dans son évolution – une poule avec des dents au terme de l’évolution capitaliste ? Qu’est-ce qu’un vaccin efficace impliquerait ? Quel pourrait être ce vaccin efficace ?
Le succès d’un traitement dépend de beaucoup d’adaptations individuelles, sociales et juridiques, mais je suis convaincue que la lutte contre la « maladie hostile » ne peut commencer sans une compréhension des nouveaux mécanismes qui rendent compte de la transformation réussie de l’investissement en capital par le capitalisme de surveillance. Cette problématique a été au centre de mon travail dans un nouveau livre, Maître ou Esclave : une lutte pour le cœur de notre civilisation de l’information, qui sera publié au début de l’année prochaine. Dans le court espace de cet essai, je voudrais partager certaines de mes réflexions sur ce problème.
II. L’avenir : le prédire et le vendre
Les nouvelles logiques économiques et leurs modèles commerciaux sont élaborés dans un temps et lieu donnés, puis perfectionnés par essais et erreurs. Ford a mis au point et systématisé la production de masse. General Motors a institutionnalisé la production en série comme une nouvelle phase du développement capitaliste avec la découverte et l’amélioration de l’administration à grande échelle et la gestion professionnelle. De nos jours, Google est au capitalisme de surveillance ce que Ford et General Motors étaient à la production en série et au capitalisme managérial il y a un siècle : le découvreur, l’inventeur, le pionnier, le modèle, le praticien chef, et le centre de diffusion.
Plus précisément, Google est le vaisseau amiral et le prototype d’une nouvelle logique économique basée sur la prédiction et sa vente, un métier ancien et éternellement lucratif qui a exploité la confrontation de l’être humain avec l’incertitude depuis le début de l’histoire humaine. Paradoxalement, la certitude de l’incertitude est à la fois une source durable d’anxiété et une de nos expériences les plus fructueuses. Elle a produit le besoin universel de confiance et de cohésion sociale, des systèmes d’organisation, de liaison familiale, et d’autorité légitime, du contrat comme reconnaissance formelle des droits et obligations réciproques, la théorie et la pratique de ce que nous appelons « le libre arbitre ». Quand nous éliminons l’incertitude, nous renonçons au besoin humain de lancer le défi de notre prévision face à un avenir toujours inconnu, au profit de la plate et constante conformité avec ce que d’autres veulent pour nous.
La publicité n’est qu’un facteur parmi d’autres
La plupart des gens attribuent le succès de Google à son modèle publicitaire. Mais les découvertes qui ont conduit à la croissance rapide du chiffre d’affaires de Google et à sa capitalisation boursière sont seulement incidemment liées à la publicité. Le succès de Google provient de sa capacité à prédire l’avenir, et plus particulièrement, l’avenir du comportement. Voici ce que je veux dire :
Dès ses débuts, Google a recueilli des données sur le comportement lié aux recherches des utilisateurs comme un sous-produit de son moteur de recherche. À l’époque, ces enregistrements de données ont été traités comme des déchets, même pas stockés méthodiquement ni mis en sécurité. Puis, la jeune entreprise a compris qu’ils pouvaient être utilisés pour développer et améliorer continuellement son moteur de recherche.
Le problème était le suivant : servir les utilisateurs avec des résultats de recherche incroyables « consommait » toute la valeur que les utilisateurs produisaient en fournissant par inadvertance des données comportementales. C’est un processus complet et autonome dans lequel les utilisateurs sont des « fins-en-soi ». Toute la valeur que les utilisateurs produisent était réinvestie pour simplifier l’utilisation sous forme de recherche améliorée. Dans ce cycle, il ne restait rien à transformer en capital, pour Google. L’efficacité du moteur de recherche avait autant besoin de données comportementales des utilisateurs que les utilisateurs de la recherche. Faire payer des frais pour le service était trop risqué. Google était sympa, mais il n’était pas encore du capitalisme – seulement l’une des nombreuses startups de l’Internet qui se vantaient de voir loin, mais sans aucun revenu.
Un tournant dans l’usage des données comportementales
L’année 2001 a été celle de l’effervescence dans la bulle du dot.com avec des pressions croissantes des investisseurs sur Google. À l’époque, les annonceurs sélectionnaient les pages du terme de recherche pour les afficher. Google a décidé d’essayer d’augmenter ses revenus publicitaires en utilisant ses capacités analytiques déjà considérables dans l’objectif d’accroître la pertinence d’une publicité pour les utilisateurs – et donc sa valeur pour les annonceurs. Du point de vue opérationnel cela signifiait que Google allait enfin valoriser son trésor croissant de données comportementales. Désormais, les données allaient être aussi utilisées pour faire correspondre les publicités avec les des mots-clés, en exploitant les subtilités que seul l’accès à des données comportementales, associées à des capacités d’analyse, pouvait révéler.
Il est maintenant clair que ce changement dans l’utilisation des données comportementales a été un tournant historique. Les données comportementales qui avaient été rejetées ou ignorées ont été redécouvertes et sont devenues ce que j’appelle le surplus de comportement. Le succès spectaculaire de Google obtenu en faisant correspondre les annonces publicitaires aux pages a révélé la valeur transformationnelle de ce surplus comportemental comme moyen de générer des revenus et, finalement, de transformer l’investissement en capital. Le surplus comportemental était l’actif à coût zéro qui changeait la donne, et qui pouvait être détourné de l’amélioration du service au profit d’un véritable marché. La clé de cette formule, cependant, est que ce nouveau marché n’est pas le fruit d’un échange avec les utilisateurs, mais plutôt avec d’autres entreprises qui ont compris comment faire de l’argent en faisant des paris sur le comportement futur des utilisateurs. Dans ce nouveau contexte, les utilisateurs ne sont plus une fin en soi. Au contraire, ils sont devenus une source de profit d’un nouveau type de marché dans lequel ils ne sont ni des acheteurs ni des vendeurs ni des produits. Les utilisateurs sont la source de matière première gratuite qui alimente un nouveau type de processus de fabrication.

Bien que ces faits soient connus, leur importance n’a pas été pleinement évaluée ni théorisée de manière adéquate. Ce qui vient de se passer a été la découverte d’une équation commerciale étonnamment rentable – une série de relations légitimes qui ont été progressivement institutionnalisées dans la logique économique sui generis du capitalisme de surveillance. Cela ressemble à une planète nouvellement repérée avec sa propre physique du temps et de l’espace, ses journées de soixante-sept heures, un ciel d’émeraude, des chaînes de montagnes inversées et de l’eau sèche.
Une forme de profit parasite
L’équation : tout d’abord, il est impératif de faire pression pour obtenir plus d’utilisateurs et plus de canaux, des services, des dispositifs, des lieux et des espaces de manière à avoir accès à une gamme toujours plus large de surplus de comportement. Les utilisateurs sont la ressource humaine naturelle qui fournit cette matière première gratuite.
En second lieu, la mise en œuvre de l’apprentissage informatique, de l’intelligence artificielle et de la science des données pour l’amélioration continue des algorithmes constitue un immense « moyen de production » du XXIe siècle coûteux, sophistiqué et exclusif.
Troisièmement, le nouveau processus de fabrication convertit le surplus de comportement en produits de prévision conçus pour prédire le comportement actuel et à venir.
Quatrièmement, ces produits de prévision sont vendus dans un nouveau type de méta-marché qui fait exclusivement commerce de comportements à venir. Plus le produit est prédictif, plus faible est le risque pour les acheteurs et plus le volume des ventes augmente. Les profits du capitalisme de surveillance proviennent principalement, sinon entièrement, de ces marchés du comportement futur.
Alors que les annonceurs ont été les acheteurs dominants au début de ce nouveau type de marché, il n’y a aucune raison de fond pour que de tels marchés soient réservés à ce groupe. La tendance déjà perceptible est que tout acteur ayant un intérêt à monétiser de l’information probabiliste sur notre comportement et/ou à influencer le comportement futur peut payer pour entrer sur un marché où sont exposées et vendues les ressources issues du comportement des individus, des groupes, des organismes, et les choses. Voici comment dans nos propres vies nous observons le capitalisme se déplacer sous nos yeux : au départ, les bénéfices provenaient de produits et services, puis de la spéculation, et maintenant de la surveillance. Cette dernière mutation peut aider à expliquer pourquoi l’explosion du numérique a échoué, jusqu’à présent, à avoir un impact décisif sur la croissance économique, étant donné que ses capacités sont détournées vers une forme de profit fondamentalement parasite.
III. Un péché non originel
L’importance du surplus de comportement a été rapidement camouflée, à la fois par Google et mais aussi par toute l’industrie de l’Internet, avec des étiquettes comme « restes numériques », « miettes numériques », et ainsi de suite. Ces euphémismes pour le surplus de comportement fonctionnent comme des filtres idéologiques, à l’instar des premières cartes géographiques du continent nord-américain qui marquaient des régions entières avec des termes comme « païens », « infidèles », « idolâtres », « primitifs », « vassaux » ou « rebelles ». En vertu de ces étiquettes, les peuples indigènes, leurs lieux et leurs revendications ont été effacés de la pensée morale et juridique des envahisseurs, légitimant leurs actes d’appropriation et de casse au nom de l’Église et la Monarchie.
Nous sommes aujourd’hui les peuples autochtones dont les exigences implicites d’autodétermination ont disparu des cartes de notre propre comportement. Elles sont effacées par un acte étonnant et audacieux de dépossession par la surveillance, qui revendique son droit d’ignorer toute limite à sa soif de connaissances et d’influence sur les nuances les plus fines de notre comportement. Pour ceux qui s’interrogent sur l’achèvement logique du processus global de marchandisation, la réponse est qu’ils achèvent eux-mêmes la spoliation de notre réalité quotidienne intime, qui apparaît maintenant comme un comportement à surveiller et à modifier, à acheter et à vendre.
Le processus qui a commencé dans le cyberespace reflète les développements capitalistes du dix-neuvième siècle qui ont précédé l’ère de l’impérialisme. À l’époque, comme Hannah Arendt le décrit dans Les Origines du totalitarisme, « les soi-disant lois du capitalisme ont été effectivement autorisées à créer des réalités » ainsi on est allé vers des régions moins développées où les lois n’ont pas suivi. « Le secret du nouvel accomplissement heureux », a-t-elle écrit, « était précisément que les lois économiques ne bloquaient plus la cupidité des classes possédantes. » Là, « l’argent pouvait finalement engendrer de l’argent », sans avoir à passer par « le long chemin de l’investissement dans la production… »
Le péché originel du simple vol
Pour Arendt, ces aventures du capital à l’étranger ont clarifié un mécanisme essentiel du capitalisme. Marx avait développé l’idée de « l’accumulation primitive » comme une théorie du Big-Bang – Arendt l’a appelé « le péché originel du simple vol » – dans lequel l’appropriation de terres et de ressources naturelles a été l’événement fondateur qui a permis l’accumulation du capital et l’émergence du système de marché. Les expansions capitalistes des années 1860 et 1870 ont démontré, écrit Arendt, que cette sorte de péché originel a dû être répété encore et encore, « de peur que le moteur de l’accumulation de capital ne s’éteigne soudainement ».
Dans son livre The New Imperialism, le géographe et théoricien social David Harvey s’appuie sur ce qu’il appelle « accumulation par dépossession ». « Ce que fait l’accumulation par dépossession » écrit-il, « c’est de libérer un ensemble d’actifs… à un très faible (et dans certains cas, zéro) coût ». Le capital sur-accumulé peut s’emparer de ces actifs et les transformer immédiatement en profit… Il peut aussi refléter les tentatives de certains entrepreneurs… de « rejoindre le système » et rechercher les avantages de l’accumulation du capital.
Brèche dans le « système »
Le processus qui permet que le « surplus de comportement » conduise à la découverte du capitalisme de surveillance illustre cette tendance. C’est l’acte fondateur de la spoliation au profit d’une nouvelle logique du capitalisme construite sur les bénéfices de la surveillance, qui a ouvert la possibilité pour Google de devenir une entreprise capitaliste. En effet, en 2002, première année rentable Google, le fondateur Sergey Brin savoura sa percée dans le « système », comme il l’a dit à Levy,
« Honnêtement, quand nous étions encore dans les jours du boom dot-com, je me sentais comme un idiot. J’avais une startup – comme tout le monde. Elle ne générait pas de profit, c’était le cas des autres aussi, était-ce si dur ? Mais quand nous sommes devenus rentables, j’ai senti que nous avions construit une véritable entreprise « .
Brin était un capitaliste, d’accord, mais c’était une mutation du capitalisme qui ne ressemblait à rien de tout ce que le monde avait vu jusqu’alors.
Une fois que nous comprenons ce raisonnement, il devient clair qu’exiger le droit à la vie privée à des capitalistes de la surveillance ou faire du lobbying pour mettre fin à la surveillance commerciale sur l’Internet c’est comme demander à Henry Ford de faire chaque modèle T à la main. C’est comme demander à une girafe de se raccourcir le cou ou à une vache de renoncer à ruminer. Ces exigences sont des menaces existentielles qui violent les mécanismes de base de la survie de l’entité. Comment pouvons-nous nous espérer que des entreprises dont l’existence économique dépend du surplus du comportement cessent volontairement la saisie des données du comportement ? C’est comme demander leur suicide.
Toujours plus de surplus comportemental avec Google
Les impératifs du capitalisme de surveillance impliquent qu’il faudra toujours plus de surplus comportemental pour que Google et d’autres les transforment en actifs de surveillance, les maîtrisent comme autant de prédictions, pour les vendre dans les marchés exclusifs du futur comportement et les transformer en capital. Chez Google et sa nouvelle société holding appelée Alphabet, par exemple, chaque opération et investissement vise à accroître la récolte de surplus du comportement des personnes, des organismes, de choses, de processus et de lieux à la fois dans le monde virtuel et dans le monde réel. Voilà comment un jour de soixante-sept heures se lève et obscurcit un ciel d’émeraude. Il faudra rien moins qu’une révolte sociale pour révoquer le consensus général à des pratiques visant à la dépossession du comportement et pour contester la prétention du capitalisme de surveillance à énoncer les données du destin.
Quel est le nouveau vaccin ? Nous devons ré-imaginer comment intervenir dans les mécanismes spécifiques qui produisent les bénéfices de la surveillance et, ce faisant, réaffirmer la primauté de l’ordre libéral dans le projet capitaliste du XXIe siècle. Dans le cadre de ce défi, nous devons être conscients du fait que contester Google, ou tout autre capitaliste de surveillance pour des raisons de monopole est une solution du XXe siècle à un problème du 20e siècle qui, tout en restant d’une importance vitale, ne perturbe pas nécessairement l’équation commerciale du capitalisme de surveillance. Nous avons besoin de nouvelles interventions qui interrompent, interdisent ou réglementent : 1) la capture initiale du surplus du comportement, 2) l’utilisation du surplus du comportement comme matière première gratuite, 3) des concentrations excessives et exclusives des nouveaux moyens de production, 4) la fabrication de produits de prévision, 5) la vente de produits de prévision, 6) l’utilisation des produits de prévision par des tiers pour des opérations de modification, d’influence et de contrôle, et 5) la monétisation des résultats de ces opérations. Tout cela est nécessaire pour la société, pour les personnes, pour l’avenir, et c’est également nécessaire pour rétablir une saine évolution du capitalisme lui-même.
IV. Un coup d’en haut
Dans la représentation classique des menaces sur la vie privée, le secret institutionnel a augmenté, et les droits à la vie privée ont été érodés. Mais ce cadrage est trompeur, car la vie privée et le secret ne sont pas opposés, mais plutôt des moments dans une séquence. Le secret est une conséquence ; la vie privée est la cause. L’exercice du droit à la vie privée a comme effet la possibilité de choisir, et l’on peut choisir de garder quelque chose en secret ou de le partager. Les droits à la vie privée confèrent donc les droits de décision, mais ces droits de décision ne sont que le couvercle sur la boîte de Pandore de l’ordre libéral. À l’intérieur de la boîte, les souverainetés politiques et économiques se rencontrent et se mélangent avec des causes encore plus profondes et plus subtiles : l’idée de l’individu, l’émergence de soi, l’expérience ressentie du libre arbitre.
Le capitalisme de surveillance ne dégrade pas ces droits à la décision – avec leurs causes et leurs conséquences – il les redistribue plutôt. Au lieu de nombreuses personnes ayant quelques « droits », ces derniers ont été concentrés à l’intérieur du régime de surveillance, créant ainsi une toute nouvelle dimension de l’inégalité sociale. Les implications de cette évolution me préoccupent depuis de nombreuses années, et mon sens du danger s’intensifie chaque jour. L’espace de cet essai ne me permet pas de poursuivre jusqu’à la conclusion, mais je vous propose d’en résumer l’essentiel.
Le capitalisme de surveillance va au-delà du terrain institutionnel classique de l’entreprise privée. Il accumule non seulement les actifs de surveillance et des capitaux, mais aussi des droits. Cette redistribution unilatérale des droits soutient un régime de conformité administré en privé fait de récompenses et des punitions en grande partie déliée de toute sanction. Il opère sans mécanismes significatifs de consentement, soit sous la forme traditionnelle d’un « exit, voice or loyalty »3 associé aux marchés, soit sous la forme d’un contrôle démocratique exprimé par des lois et des règlements.
Un pouvoir profondément antidémocratique
En conséquence, le capitalisme de surveillance évoque un pouvoir profondément anti-démocratique que l’on peut qualifier de coup d’en haut : pas un coup d’état, mais plutôt un coup contre les gens, un renversement de la souveraineté du peuple. Il défie les principes et les pratiques de l’autodétermination – dans la vie psychique et dans les relations sociales, le politique et la gouvernance – pour lesquels l’humanité a souffert longtemps et sacrifié beaucoup. Pour cette seule raison, ces principes ne doivent pas être confisqués pour la poursuite unilatérale d’un capitalisme défiguré. Pire encore serait leur forfait par notre propre ignorance, impuissance apprise, inattention, inconvenance, force de l’habitude, ou laisser aller. Tel est, je crois, le terrain sur lequel notre lutte pour l’avenir devra se dérouler.
Hannah Arendt a dit un jour que l’indignation est la réponse naturelle de l’homme à ce qui dégrade la dignité humaine. Se référant à son travail sur les origines du totalitarisme, elle a écrit : « Si je décris ces conditions sans permettre à mon indignation d’y intervenir, alors j’ai soulevé ce phénomène particulier hors de son contexte dans la société humaine et l’ai ainsi privé d’une partie de sa nature, privé de l’une de ses qualités intrinsèques importantes. »
C’est donc ainsi pour moi et peut-être pour vous : les faits bruts du capitalisme de surveillance suscitent nécessairement mon indignation parce qu’ils rabaissent la dignité humaine. L’avenir de cette question dépendra des savants et journalistes indignés attirés par ce projet de frontière, des élus et des décideurs indignés qui comprennent que leur autorité provient des valeurs fondamentales des communautés démocratiques, et des citoyens indignés qui agissent en sachant que l’efficacité sans l’autonomie n’est pas efficace, la conformité induite par la dépendance n’est pas un contrat social et être libéré de l’incertitude n’est pas la liberté.
—–
1. Shoshana Zuboff, « Big other : surveillance capitalism and the prospects of an information civilization », Journal of Information Technology, 30, 2015, p. 81.↩
2. Le 6 octobre 2015, la Cour de justice de l’Union européenne invalide l’accord Safe Harbor. La cour considère que les États-Unis n’offrent pas un niveau de protection adéquat aux données personnelles transférées et que les états membres peuvent vérifier si les transferts de données personnelles entre cet état et les États-Unis respectent les exigences de la directive européenne sur la protection des données personnelles.↩
3. Référence aux travaux de A. O. Hirschman sur la manière de gérer un mécontentement auprès d’une entreprise : faire défection (exit), ou prendre la parole (voice). La loyauté ayant son poids dans l’une ou l’autre décision.↩


















{kind=link}
{kind=link}
{kind=link}
{kind=link}