La Fée diverse déploie ses ailes
Il n’est pas si fréquent que l’équipe Framalang traduise un article depuis la langue italienne, mais la récapitulation bien documentée de Cagizero était une bonne occasion de faire le point sur l’expansion de la Fediverse, un phénomène dont nous nous réjouissons et que nous souhaitons voir gagner plus d’amplitude encore, tant mieux si l’article ci-dessous est très lacunaire dans un an !
Article original : Mastodon, il Fediverso ed il futuro decentrato delle reti sociali
Traduction Framalang : alainmi, Ezelty, goofy, MO
Mastodon, la Fediverse et l’avenir des réseaux décentralisés
par Cagizero

Peu de temps après une première vue d’ensemble de Mastodon il est déjà possible d’ajouter quelques observations nouvelles.
Tout d’abord, il faut noter que plusieurs personnes familières de l’usage des principaux médias sociaux commerciaux (Facebook, Twitter, Instagram…) sont d’abord désorientées par les concepts de « décentralisation » et de « réseau fédéré ».
En effet, l’idée des médias sociaux qui est répandue et bien ancrée dans les esprits est celle d’un lieu unique, indifférencié, monolithique, avec des règles et des mécanismes strictement identiques pour tous. Essentiellement, le fait même de pouvoir concevoir un univers d’instances séparées et indépendantes représente pour beaucoup de gens un changement de paradigme qui n’est pas immédiatement compréhensible.
Dans un article précédent où était décrit le média social Mastodon, le concept d’instance fédérée était comparé à un réseau de clubs ou cercles privés associés entre eux.
Certains aspects exposés dans l’article précédent demandent peut-être quelques éclaircissements supplémentaires pour celles et ceux qui abordent tout juste le concept de réseau fédéré.
1. On ne s’inscrit pas « sur Mastodon », mais on s’inscrit à une instance de Mastodon ! La comparaison avec un club ou un cercle s’avère ici bien pratique : adhérer à un cercle permet d’entrer en contact avec tous ceux et celles qui font partie du même réseau : on ne s’inscrit pas à une plateforme, mais on s’inscrit à l’un des clubs de la plateforme qui, avec les autres clubs, constituent le réseau. La plateforme est un logiciel, c’est une chose qui n’existe que virtuellement, alors qu’une instance qui utilise une telle plateforme en est l’aspect réel, matériel. C’est un serveur qui est physiquement situé quelque part, géré par des gens en chair et en os qui l’administrent. Vous vous inscrivez donc à une instance et ensuite vous entrez en contact avec les autres.
2. Les diverses instances ont la possibilité technique d’entrer en contact les unes avec les autres mais ce n’est pas nécessairement le cas. Supposons par exemple qu’il existe une instance qui regroupe 500 utilisateurs et utilisatrices passionné⋅e⋅s de littérature, et qui s’intitule mastodon.litterature : ces personnes se connaissent précisément parce en tant que membres de la même instance et chacun⋅e reçoit les messages publics de tous les autres membres.
Eh bien, chacun d’entre eux aura probablement aussi d’autres contacts avec des utilisateurs enregistrés sur difFerentes instances (nous avons tous des ami⋅e⋅s qui ne font pas partie de notre « cercle restreint », n’est-ce pas ?). Si chacun des 500 membres de maston.litterature suit par exemple 10 membres d’une autre instance, mastodon.litterature aurait un réseau local de 500 utilisateurs, mais aussi un réseau fédéré de 5000 utilisateurs !
Bien. Supposons que parmi ces 5000 il n’y ait même pas un seul membre de l’instance japonaise japan.nuclear.physics dont le thème est la physique nucléaire : cette autre instance pourrait avoir peut-être 800 membres et avoir un réseau fédéré de plus de 8000 membres, mais si entre les réseaux « littérature » et « physique nucléaire » il n’y avait pas un seul ami en commun, ses membres ne pourraient en théorie jamais se contacter entre eux.
En réalité, d’après la loi des grands nombres, il est assez rare que des instances d’une certaine taille n’entrent jamais en contact les unes avec les autres, mais l’exemple sert à comprendre les mécanismes sur lesquels repose un réseau fédéré (ce qui, en se basant justement sur la loi des grands nombres et les principes des degrés de séparation, confirme au contraire l’hypothèse que plus le réseau est grand, moins les utilisateurs et instances seront isolés sur une seule instance).
3. Chaque instance peut décider volontairement de ne pas entrer en contact avec une autre, sur la base des choix, des règles et politiques internes qui lui sont propres. Ce point est évidemment peu compris des différents commentateurs qui ne parviennent pas à sortir de l’idée du « réseau social monolithique ». S’il y avait sur Mastodon une forte concentration de suprémacistes blancs en deuil de Gab, ou de blogueurs porno en deuil de Tumblr, cela ne signifie pas que ce serait l’ensemble du réseau social appelé Mastodon qui deviendrait un « réseau social pour suprémacistes blancs et porno », mais seulement quelques instances qui n’entreraient probablement jamais en contact avec des instances antifascistes ou ultra-religieuses. Comme il est difficile de faire comprendre un tel concept, il est également difficile de faire comprendre les potentialités d’une structure de ce type. Dans un réseau fédéré, une fois donnée la possibilité technique d’interagir entre instances et utilisateurs, chaque instance et chaque utilisateur peut ensuite choisir de façon indépendante l’utilisation qui en sera faite.
Supposons qu’il existe par exemple :
- Une instance écologiste, créée, maintenue et soutenue financièrement par un groupe de passionnés qui veulent avoir un lieu où échanger sur la nature et l’écologie, qui pose comme principe qu’on n’y poste ni liens externes ni images pornographiques.
- Une instance commerciale, créée par une petite entreprise qui dispose d’un bon serveur et d’une bande passante très confortable, et celui ou celle qui s’y inscrit en payant respecte les règles fixées auparavant par l’entreprise elle-même.
- Une instance sociale, créée par un centre social et dont les utilisateurs sont surtout les personnes qui fréquentent ledit centre et se connaissent aussi personnellement.
- Une instance vidéoludique, qui était à l’origine une instance interne des employés d’une entreprise de technologie mais qui dans les faits est ouverte à quiconque s’intéresse aux jeux vidéos.
Avec ce scénario à quatre instances, on peut déjà décrire quelques interactions intéressantes : l’instance écologiste pourrait consulter ses utilisateurs et utilisatrices et décider de bannir l’instance commerciale au motif qu’on y diffuse largement une culture contraire à l’écologie, tandis que l’instance sociale pourrait au contraire maintenir le lien avec l’instance commerciale tout en choisissant préventivement de la rendre muette dans son propre fil, laissant le choix personnel à ses membres d’entrer ou non en contact avec les membres de l’instance commerciale. Cependant, l’instance sociale pourrait bannir l’instance de jeu vidéo à cause de la mentalité réactionnaire d’une grande partie de ses membres.
En somme, les contacts « insupportables/inacceptables » sont spontanément limités par les instances sur la base de leurs différentes politiques. Ici, le cadre d’ensemble commence à devenir très complexe, mais il suffit de l’observer depuis une seule instance, la nôtre, pour en comprendre les avantages : les instances qui accueillent des trolls, des agitateurs et des gens avec qui on n’arrive vraiment pas à discuter, nous les avons bannies, alors que celles avec lesquelles on n’avait pas beaucoup d’affinités mais pas non plus de motif de haine, nous les avons rendues muettes. Ainsi, si quelqu’un parmi nous veut les suivre, il n’y a pas de problème, mais ce sera son choix personnel.
4. Chaque utilisateur peut décider de rendre muets d’autres utilisateurs, mais aussi des instances entières. Si vous voulez particulièrement éviter les contenus diffusés par les utilisateurs et utilisatrices d’une certaine instance qui n’est cependant pas bannie par l’instance qui vous accueille (mettons que votre instance ne ferme pas la porte à une instance appelée meme.videogamez.lulz, dont la communauté tolère des comportements excessifs et une ambiance de moquerie lourde que certains trouvent néanmoins amusante), vous êtes libres de la rendre muette pour vous seulement. En principe, en présence de groupes d’utilisateurs indésirables venant d’une même instance/communauté, il est possible de bloquer plusieurs dizaines ou centaines d’utilisateurs à la fois en bloquant (pour vous) l’instance entière. Si votre instance n’avait pas un accord unanime sur la manière de traiter une autre instance, vous pourriez facilement laisser le choix aux abonnés qui disposent encore de ce puissant outil. Une instance peut également choisir de modérer seulement ses utilisateurs ou de ne rien modérer du tout, laissant chaque utilisateur complètement libre de faire taire ou d’interdire qui il veut sans jamais interférer ou imposer sa propre éthique.
La Fediverse
Maintenant que nous nous sommes mieux concentrés sur ces aspects, nous pouvons passer à l’étape suivante. Comme déjà mentionné dans le post précédent, Mastodon fait partie de quelque chose de plus vaste appelé la Fediverse (Fédération + Univers).
En gros, Mastodon est un réseau fédéré qui utilise certains outils de communication (il existe plusieurs protocoles mais les principaux sont ActivityPub, Ostatus et Diaspora*, chacun ayant ses avantages, ses inconvénients, ses partisans et ses détracteurs), utilisés aussi par et d’autres réalités fédérées (réseaux sociaux, plateformes de blogs, etc.) qui les mettent en contact pour former une galaxie unique de réseaux fédérés.
Pour vous donner une idée, c’est comme si Mastodon était un système planétaire qui tourne autour d’une étoile (Mastodon est l’étoile et chaque instance est une planète), cependant ce système planétaire fait partie d’un univers dans lequel existent de nombreux systèmes planétaires tous différents mais qui communiquent les uns avec les autres.
Toutes les planètes d’un système planétaire donné (les instances, comme des « clubs ») tournent autour d’un soleil commun (la plate-forme logicielle). L’utilisateur peut choisir la planète qu’il préfère mais il ne peut pas se poser sur le soleil : on ne s’inscrit pas à la plateforme, mais on s’inscrit à l’un des clubs qui, avec tous les autres, forme le réseau.
Dans cet univers, Mastodon est tout simplement le « système planétaire » le plus grand (celui qui a le plus de succès et qui compte le plus grand nombre d’utilisateurs) mais il n’est pas certain qu’il en sera toujours ainsi : d’autres « systèmes planétaires » se renforcent et grandissent.
[NB : chaque plate-forme évoquée ici utilise ses propres noms pour définir les serveurs indépendants sur lesquels elle est hébergée. Mastodon les appelle instances, Hubzilla les appelle hubs et Diaspora* les appelle pods. Toutefois, par souci de simplicité et de cohérence avec l’article précédent, seul le terme « instance » sera utilisé pour tous dans l’article]


Sur Kumu.io on peut trouver une représentation interactive de la Fediverse telle qu’elle apparaît actuellement. Chaque « nœud » représente un réseau différent (ou « système planétaire »). Ce sont les différentes plateformes qui composent la fédération. Mastodon n’est que l’une d’entre elles, la plus grande, en bas au fond. Sur la capture d’écran qui illustre l’article, Mastodon est en bas.
En sélectionnant Mastodon il est possible de voir avec quels autres médias ou systèmes de la Fediverse il est en mesure d’interagir. Comme on peut le voir, il interagit avec la plupart des autres médias mais pas tout à fait avec tous.
En sélectionnant un autre réseau social comme GNU Social, on observe qu’il a différentes interactions : il en partage la majeure partie avec Mastodon mais il en a quelques-unes en plus et d’autres en moins.
Cela dépend principalement du type d’outils de communication (protocoles) que chaque média particulier utilise. Un média peut également utiliser plus d’un protocole pour avoir le plus grand nombre d’interactions, mais cela rend évidemment leur gestion plus complexe. C’est, par exemple, la voie choisie par Friendica et GNU Social.
En raison des différents protocoles utilisés, certains médias ne peuvent donc pas interagir avec tous les autres. Le cas le plus important est celui de Diaspora*, qui utilise son propre protocole (appelé lui aussi Diaspora), qui ne peut interagir qu’avec Friendica et Gnu Social mais pas avec des médias qui reposent sur ActivityPub tels que Mastodon.
Au sein de la Fediverse, les choses sont cependant en constante évolution et l’image qui vient d’être montrée pourrait avoir besoin d’être mise à jour prochainement. En ce moment, la plupart des réseaux semblent s’orienter vers l’adoption d’ActivityPub comme outil unique. Ce ne serait pas mal du tout d’avoir un seul protocole de communication qui permette vraiment tout type de connexion !
Mais revenons un instant à l’image des systèmes planétaires. Kumu.io montre les connexions techniquement possibles entre tous les « systèmes planétaires » et, pour ce faire, relie génériquement les différents soleils. Mais comme nous l’avons bien vu, les vraies connexions ont lieu entre les planètes et non entre les soleils ! Une carte des étoiles montrant les connexions réelles devrait montrer pour chaque planète (c’est-à-dire chaque « moustache » des nœuds de Kum.io), des dizaines ou des centaines de lignes de connexion avec autant de planètes/moustaches, à la fois entre instances de sa plateforme et entre instances de différentes plateformes ! La quantité et la complexité des connexions, comme on peut l’imaginer, formeraient un enchevêtrement qui donnerait mal à la tête serait graphiquement illisible. Le simple fait de l’imaginer donne une idée de la quantité et de la complexité des connexions possibles.
Et cela ne s’arrête pas là : chaque planète peut établir ou interrompre ses contacts avec les autres planètes de son système solaire (c’est-à-dire que l’instance Mastodon A peut décider de ne pas avoir de contact avec l’instance Mastodon B), et de la même manière elle peut établir ou interrompre les contacts avec des planètes de différents systèmes solaires (l’instance Mastodon A peut établir ou interrompre des contacts avec l’instance Pleroma B). Pour donner un exemple radical, nous pouvons supposer que nous avons des cousins qui sont des crétins, mais d’authentiques crétins, que nous avons chassés de notre planète (mastodon.terre) et qu’ensuite ils ont construit leur propre instance (mastodon.saturne) dans notre voisinage parce que ben, ils aiment bien notre soleil « Mastodon ». Nous décidons de nous ignorer les uns les autres tout de suite. Ces cousins, cependant, sont tellement crétins que même nos parents et amis proches des planètes voisines (mastodon.jupiter, mastodon.venus, etc.) ignorent les cousins crétins de mastodon.saturne.
Aucune planète du système Mastodon ne les supporte. Les cousins, cependant, ne sont pas entièrement sans relations et, au contraire, ils ont beaucoup de contacts avec les planètes d’autres systèmes solaires. Par exemple, ils sont en contact avec certaines planètes du système planétaire PeeeTube: peertube.10287, peertube.chatons, peertube.anime, mais aussi avec pleroma.pizza du système Pleroma et friendica.jardinage du système Friendica. En fait, les cousins crétins sont d’accord pour vivre sur leur propre petite planète dans le système Mastodon, mais préfèrent avoir des contacts avec des planètes de systèmes différents.
Nous qui sommes sur mastodon.terre, nous ne nous soucions pas moins des planètes qui leur sont complaisantes : ce sont des crétins tout autant que nos cousins et nous les avons bloquées aussi. Sauf un. Sur pleroma.pizza, nous avons quelques ami⋅e⋅s qui sont aussi des ami⋅e⋅s de certains cousins crétins de mastodon.saturne. Mais ce n’est pas un problème. Oh que non ! Nous avons des connexions interstellaires et nous devrions nous inquiéter d’une chose pareille ? Pas du tout ! Le blocage que nous avons activé sur mastodon.saturne est une sorte de barrière énergétique qui fonctionne dans tout le cosmos ! Si nous étions impliqués dans une conversation entre un ami de pleroma.pizza et un cousin de mastodon.saturne, simplement, ce dernier ne verrait pas ce qui sort de notre clavier et nous ne verrions pas ce qui sort du sien. Chacun d’eux saura que l’autre est là, mais aucun d’eux ne pourra jamais lire l’autre. Bien sûr, nous pourrions déduire quelque chose de ce que notre ami commun de pleroma.pizza dira, mais bon, qu’est-ce qu’on peut en espérer ? 😉
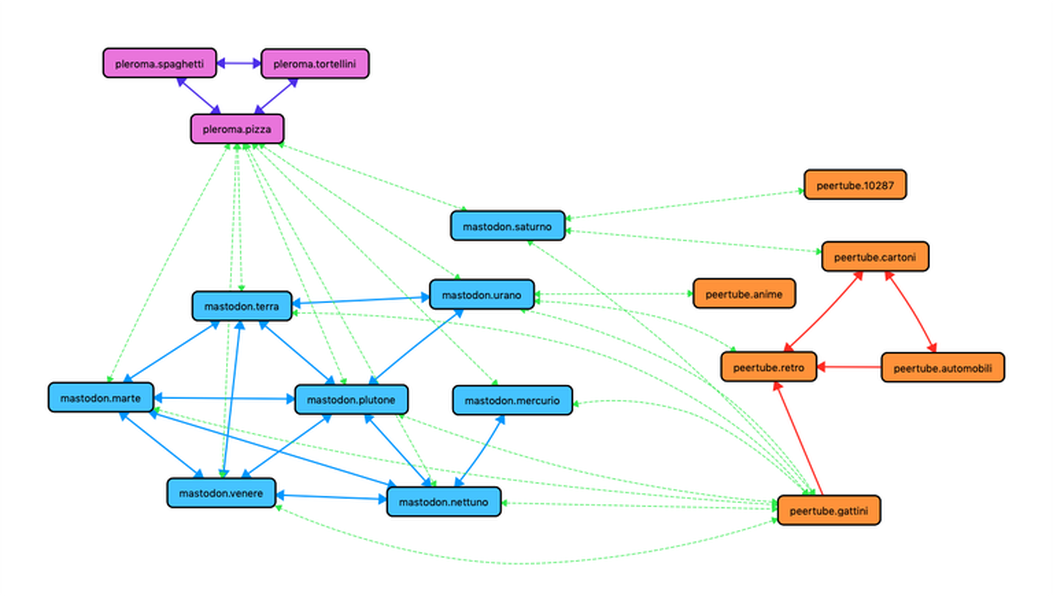
Cette image peut donner une idée de la façon dont les instances (planètes) se connectent entre elles. Si l’on considère qu’il existe des milliers d’instances connues de la Fediverse, on peut imaginer la complexité de l’image. Un aspect intéressant est le fait que les connexions entre une instance et une autre ne dépendent pas de la plateforme utilisée. Sur l’image on peut voir l’instance mastodon.mercure : c’est une instance assez isolée par rapport au réseau d’instances Mastodon, dont les seuls contacts sont mastodon.neptune, peertube.chatons et pleroma.pizza. Rien n’empêche mastodon.mercure de prendre connaissance de toutes les autres instances de Mastodon non par des échanges de messages avec mastodon.neptune, mais par des commentaires sur les vidéos de peertube.chatons. En fait, c’est d’autant plus probable que mastodon.neptune n’est en contact qu’avec trois autres instances Mastodon, alors que peertube.chatons est en contact avec toutes les instances Mastodon.
Essayer d’imaginer comment les différentes instances de cette image qui « ne se connaissent pas » peuvent entrer en contact nous permet d’avoir une idée plus précise du niveau de complexité qui peut être atteint. Dans un système assez grand, avec un grand nombre d’utilisateurs et d’instances, isoler une partie de celui-ci ne compromettra en aucune façon la richesse des connexions possibles.
Une fois toutes les connexions possibles créées, il est également possible de réaliser une expérience différente, c’est-à-dire d’imaginer interrompre des connexions jusqu’à la formation de deux ou plusieurs réseaux parfaitement séparés, contenant chacune des instances Mastodon, Pleroma et Peertube.
Et pour ajouter encore un degré de complexité, on peut faire encore une autre expérience, en raisonnant non plus à l’échelle des instances mais à celle des utilisateurs⋅rices individuel⋅le⋅s des instances (faire l’hypothèse de cinq utilisateurs⋅rices par instance pourrait suffire pour recréer les différentes situations). Quelques cas qu’on peut imaginer :
1) Nous sommes sur une instance de Mastodon et l’utilisatrice Anna vient de découvrir par le commentaire d’une vidéo sur Peertube l’existence d’une nouvelle instance de Pleroma, donc maintenant elle connaît son existence mais, choisissant de ne pas la suivre, elle ne fait pas réellement connaître sa découverte aux autres membres de son instance.
2) Sur cette même instance de Mastodon l’utilisateur Ludo bloque la seule instance Pleroma connue. Conséquence : si cette instance Pleroma devait faire connaître d’autres instances Pleroma avec lesquelles elle est en contact, Ludo devrait attendre qu’un autre membre de son instance les fasse connaître, car il s’est empêché lui-même d’être parmi les premiers de son instance à les connaître.
3) En fait, la première utilisatrice de l’instance à entrer en contact avec les autres instances Pleroma sera Marianne. Mais elle ne les connaît pas de l’instance Pleroma (celle que Ludo a bloquée) avec laquelle ils sont déjà en contact, mais par son seul contact sur GNU Social.
Cela semble un peu compliqué mais en réalité ce n’est rien de plus qu’une réplique de mécanismes humains auxquels nous sommes tellement habitué⋅e⋅s que nous les tenons pour acquis. On peut traduire ainsi les différents exemples qui viennent d’être exposés :
1) Notre amie Anna, habituée de notre bar, rencontre dans la rue une personne qui lui dit fréquenter un nouveau bar dans une ville proche. Mais Anna n’échange pas son numéro de téléphone avec le type et elle ne pourra donc pas donner d’informations à ses amis dans son bar sur le nouveau bar de l’autre ville.
2) Dans le bar habituel, Ludo de Nancy évite Laura de Metz. Quand Laura amène ses autres amies Solène et Louise de Metz au bar, elle ne les présente pas à Ludo. Ce n’est que plus tard que les amis du bar, devenus amis avec Solène et Louise, pourront les présenter à Ludo indépendamment de Laura.
3) En réalité Marianne avait déjà rencontré Solène et Louise, non pas grâce à Laura, mais grâce à Stéphane, son seul ami à Villers.
Pour avoir une idée de l’ampleur de la Fediverse, vous pouvez jeter un coup d’œil à plusieurs sites qui tentent d’en fournir une image complète. Outre Kumu.io déjà mentionné, qui essaie de la représenter avec une mise en page graphique élégante qui met en évidence les interactions, il y a aussi Fediverse.network qui essaie de lister chaque instance existante en indiquant pour chacune d’elles les protocoles utilisés et le statut du service, ou Fediverse.party, qui est un véritable portail où choisir la plate-forme à utiliser et à laquelle s’enregistrer. Switching.software, une page qui illustre toutes les alternatives gratuites aux médias sociaux et propriétaires, indique également quelques réseaux fédérés parmi les alternatives à Twitter et Facebook.
Pour être tout à fait complet : au début, on avait tendance à diviser tout ce mégaréseau en trois « univers » superposés : celui de la « Fédération » pour les réseaux reposant sur le protocole Diaspora, La « Fediverse » pour ceux qui utilisent Ostatus et « ActivityPub » pour ceux qui utilisent… ActivityPub. Aujourd’hui, au contraire, ils sont tous considérés comme faisant partie de la Fediverse, même si parfois on l’appelle aussi la Fédération.
Tant de réseaux…
Examinons donc les principales plateformes/réseaux et leurs différences. Petites précisions : certaines de ces plateformes sont pleinement actives alors que d’autres sont à un stade de développement plus ou moins avancé. Dans certains cas, l’interaction entre les différents réseaux n’est donc pas encore pleinement fonctionnelle. De plus, en raison de la nature libre et indépendante des différents réseaux, il est possible que des instances apportent des modifications et des personnalisations « non standard » (un exemple en est la limite de caractères sur Mastodon : elle est de 500 caractères par défaut, mais une instance peut décider de définir la limite qu’elle veut ; un autre exemple est l’utilisation des fonctions de mise en favori ou de partage, qu’une instance peut autoriser et une autre interdire). Dans ce paragraphe, ces personnalisations et différences ne sont pas prises en compte.
Mastodon (semblable à : Twitter)
Mastodon est une plateforme de microblogage assez semblable à Twitter parce qu’elle repose sur l’échange de messages très courts. C’est le réseau le plus célèbre de la Fediverse. Il est accessible sur smartphone à travers un certain nombre d’applications tant pour Android que pour iOS. Un de ses points forts est le design bien conçu et le fait qu’il a déjà un « parc d’utilisateurs⋅rices » assez conséquent (presque deux millions d’utilisateurs⋅rices dans le monde, dont quelques milliers en France). En version bureau, il se présente comme une série de colonnes personnalisables, qui montrent les différents « fils », sur le modèle de Tweetdeck. Pour le moment, Mastodon est la seule plateforme sociale fédérée accessible par des applications sur Android et iOS.
Pleroma (semblable à : Twitter et DeviantArt)
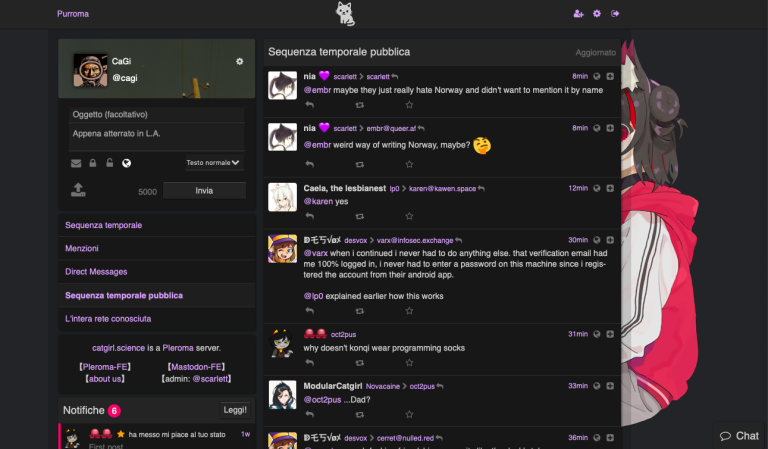
Pleroma est le réseau « sœur » de Mastodon : fondamentalement, c’est la même chose dans deux versions un peu différentes. Pleroma offre quelques fonctionnalités supplémentaires concernant la gestion des images et permet par défaut des messages plus longs. À la différence de Mastodon, Pleroma montre en version bureau une colonne unique avec le fil sélectionné, ce qui le rend beaucoup plus proche de Twitter. Actuellement, de nombreuses instances Pleroma ont un grand nombre d’utilisateurs⋅rices qui s’intéressent à l’illustration et au manga, ce qui, comme ambiance, peut vaguement rappeler l’ambiance de DeviantArt. Les applications pour smartphone de Mastodon peuvent également être utilisées pour accéder à Pleroma.
Misskey (semblable à : un mélange entre Twitter et DeviantArt)
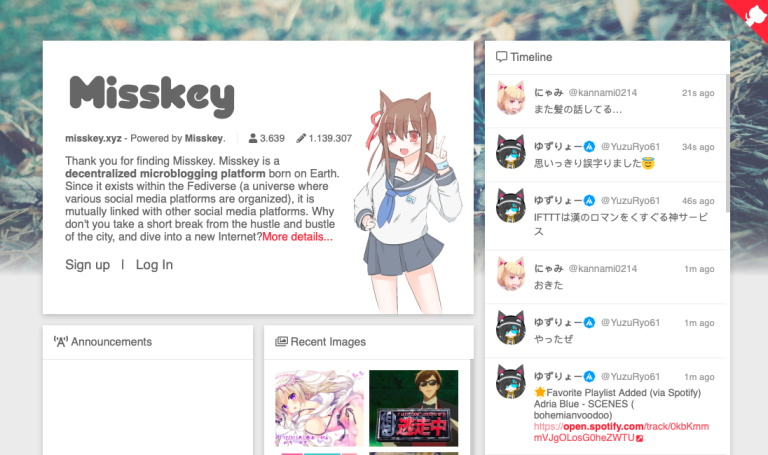
Misskey est une sorte de Twitter qui tourne principalement autour d’images. Il offre un niveau de personnalisation supérieur à Mastodon et Pleroma, et une plus grande attention aux galeries d’images. C’est une plateforme qui a eu du succès au Japon et parmi les passionnés de manga (et ça se voit !).
Friendica (semblable à : Facebook)
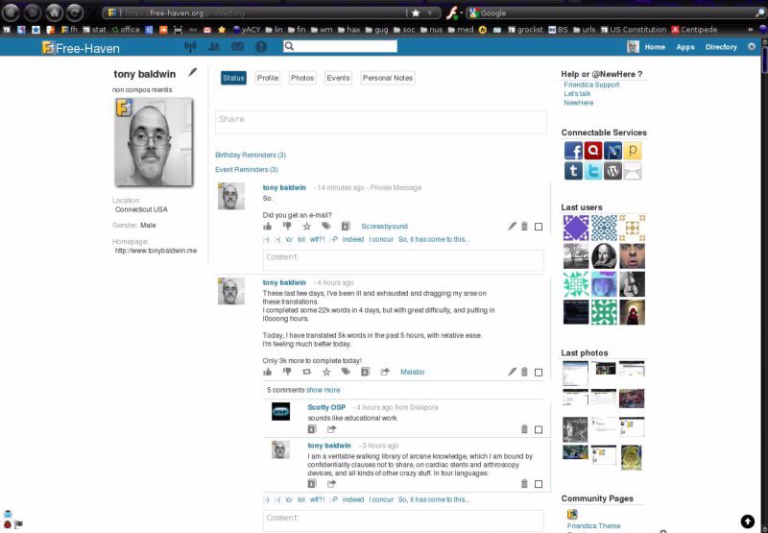
Friendica est un réseau extrêmement intéressant. Il reprend globalement la structure graphique de Facebook (avec les ami⋅e⋅s, les notifications, etc.), mais il permet également d’interagir avec plusieurs réseaux commerciaux qui ne font pas partie de la Fediverse. Il est donc possible de connecter son compte Friendica à Facebook, Twitter, Tumblr, WordPress, ainsi que de générer des flux RSS, etc. Bref, Friendica se présente comme une sorte de nœud pour diffuser du contenu sur tous les réseaux disponibles, qu’ils soient fédérés ou non. En somme, Friendica est le passe-partout de la Fediverse : une instance Friendica au maximum de ses fonctions se connecte à tout et dialogue avec tout le monde.
Osada (semblable à : un mélange entre Twitter et Facebook)
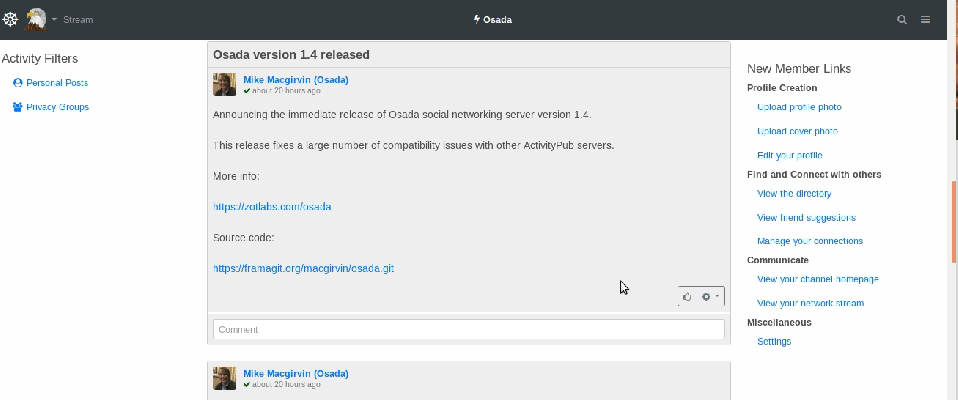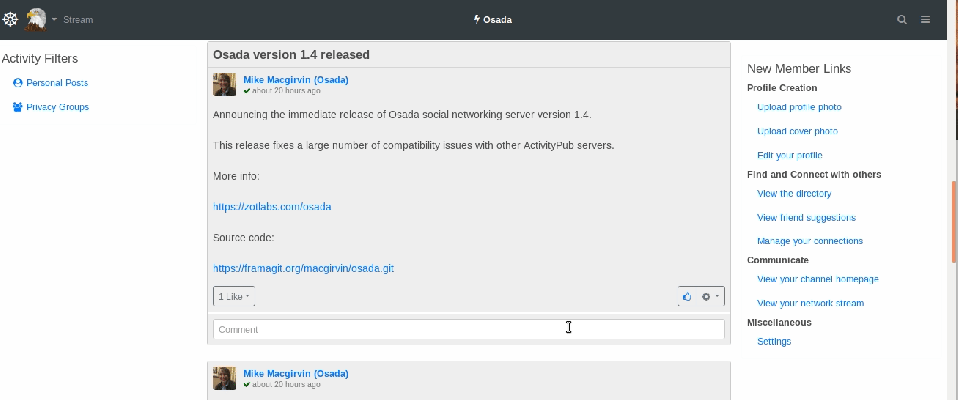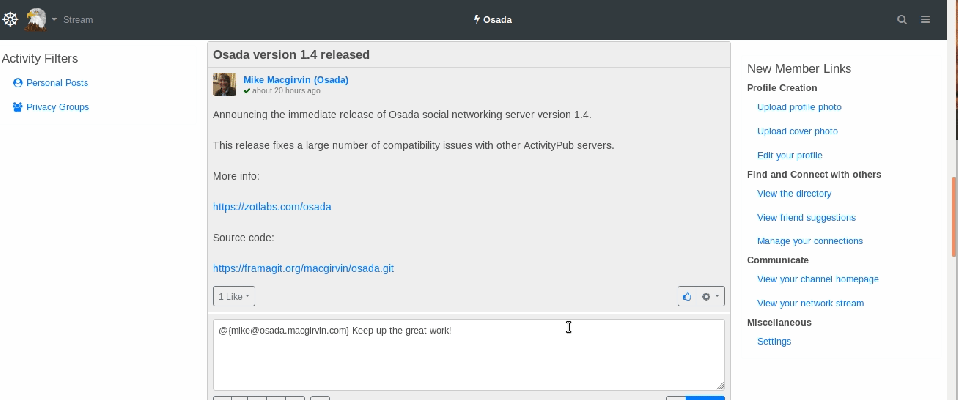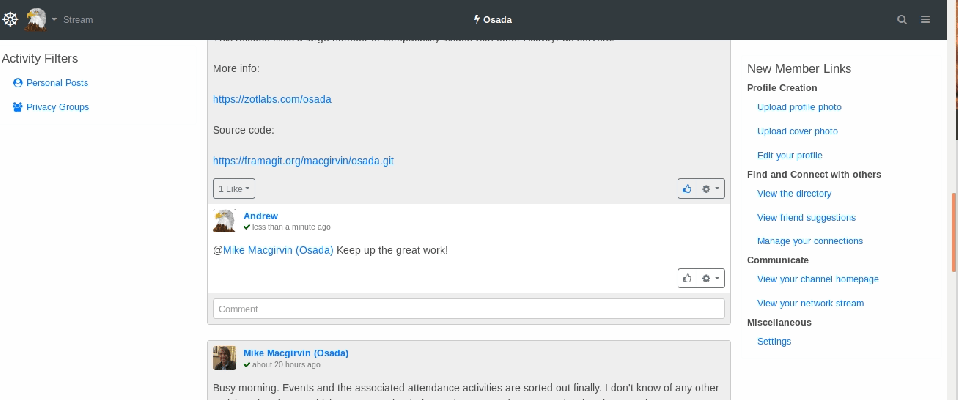
Osada est un autre réseau dont la configuration peut faire penser à un compromis entre Twitter et Facebook. De toutes les plateformes qui rappellent Facebook, c’est celle dont le design est le plus soigné.
GNUsocial (semblable à : un mélange entre Twitter et Facebook)
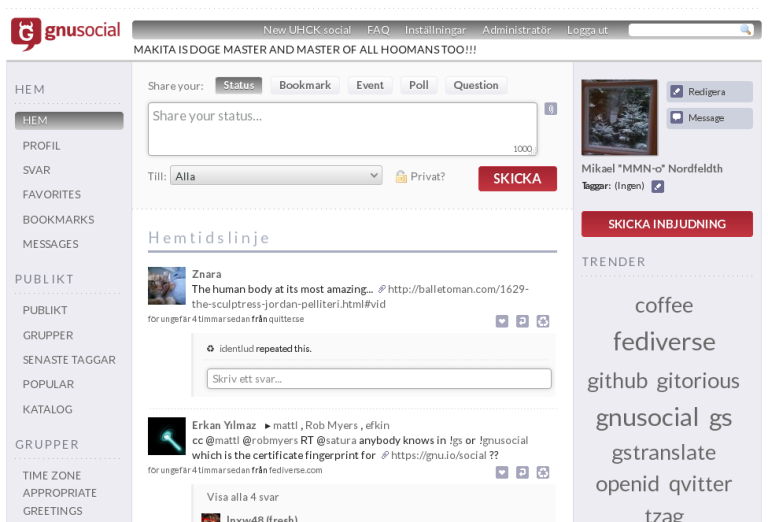
GNUsocial est un peu le « grand-père » des médias sociaux listés ici, en particulier de Friendica et d’Osada, dont il est le prédécesseur.
Aardwolf (semblable à : Twitter, éventuellement)

Aardwolf n’est pas encore prêt, mais il est annoncé comme une sorte d’alternative à Twitter. On attend de voir.
PeerTube (semblable à : YouTube)
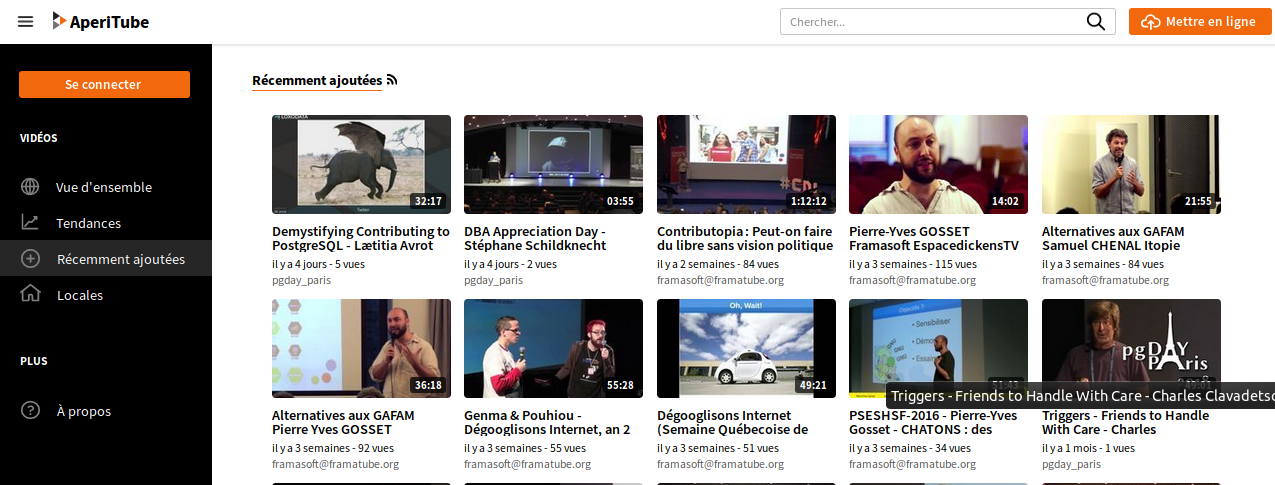
PeerTube est le réseau fédéré d’hébergement de vidéo vraiment, mais vraiment très semblable à YouTube, Vimeo et d’autres services de ce genre. Avec un catalogue en cours de construction, Peertube apparaît déjà comme un projet très solide.
Pixelfed (semblable à : Instagram)
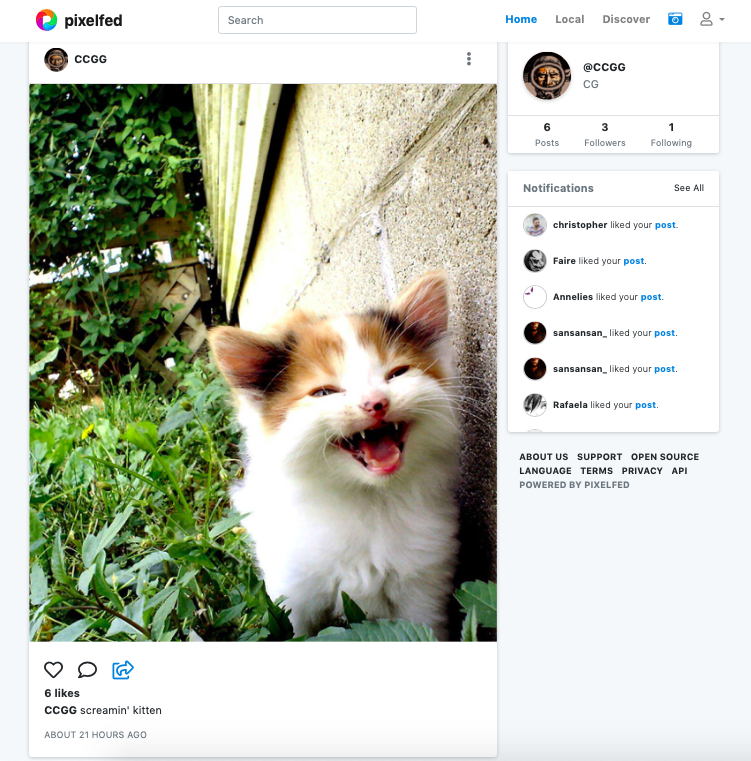
Pixelfed est essentiellement l’Instagram de la Fédération. Il est en phase de développement mais semble être plutôt avancé. Il lui manque seulement des applications pour smartphone pour être adopté à la place d’Instagram. Pixelfed a le potentiel pour devenir un membre extrêmement important de la Fédération !
NextCloud (semblable à : iCloud, Dropbox, GDrive)

NextCloud, né du projet plus ancien ownCloud, est un service d’hébergement de fichiers assez semblable à Dropbox. Tout le monde peut faire tourner NextCloud sur son propre serveur. NextCloud offre également des services de partage de contacts (CardDAV) ou de calendriers (CalDAV), de streaming de médias, de marque-page, de sauvegarde, et d’autres encore. Il tourne aussi sur Window et OSX et est accessible sur smartphone à travers des applications officielles. Il fait partie de la Fediverse dans la mesure où il utilise ActivityPub pour communiquer différentes informations à ses utilisateurs, comme des changements dans les fichiers, les activités du calendrier, etc.
Diaspora* (semblable à : Facebook, et aussi un peu Tumblr)
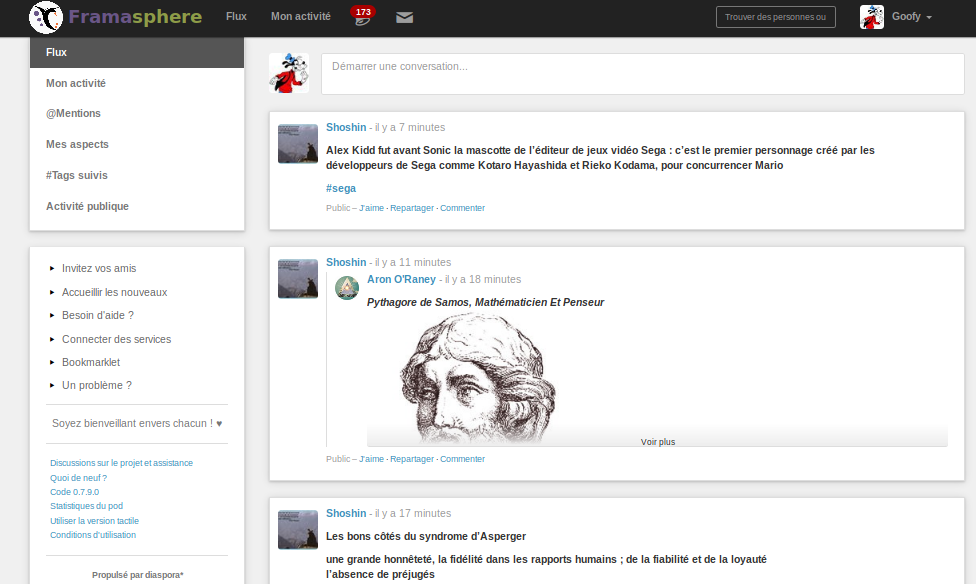
Diaspora* est un peu le « cousin » de la Fediverse. Il fonctionne avec un protocole bien à lui et dialogue avec le reste de la Fediverse principalement via GNU social et Friendica, le réseau passe-partout, même s’il semble qu’il circule l’idée de faire utiliser à Diaspora* (l’application) aussi bien son propre protocole qu’ActivityPub. Il s’agit d’un grand et beau projet, avec une base solide d’utilisateurs⋅rices fidèles. Au premier abord, il peut faire penser à une version extrêmement minimaliste de Facebook, mais son attention aux images et son système intéressant d’organisation des posts par tag permet également de le comparer, d’une certaine façon, à Tumblr.
Funkwhale (semblable à : SoundCloud et Grooveshark)

Funkwhale ressemble à SoundCloud, Grooveshark et d’autre services semblables. Comme une sorte de YouTube pour l’audio, il permet de partager des pistes audio mais au sein d’un réseau fédéré. Avec quelques fonctionnalités en plus, il pourrait devenir un excellent service d’hébergement de podcasts audio.
Plume, Write Freely et Write.as (plateformes de blog)
Plume, Write Freely et Write.as sont des plateformes de blog assez minimalistes qui font partie de la Fédération. Elles n’ont pas toute la richesse, les fonctions, les thèmes et la personnalisation de WordPress ou de Blogger, mais elles font leur travail avec légèreté.
Hubzilla (semblable à : …TOUT !!)

Hubzilla est un projet très riche et complexe qui permet de gérer aussi bien des médias sociaux que de l’hébergement de fichiers, des calendriers partagés, de l’hébergement web, et le tout de manière décentralisée. En bref, Hubzilla se propose de faire tout à la fois ce que font plusieurs des services listés ici. C’est comme avoir une seule instance qui fait à la fois Friendica, Peertube et NextCloud. Pas mal ! Un projet à surveiller !
GetTogether (semblable à : MeetUp)

GetTogether est une plateforme servant à planifier des événements. Semblable à MeetUp, elle sert à mettre en relation des personnes différentes unies par un intérêt commun, et à amener cet intérêt dans le monde réel. Pour le moment, GetTogether ne fait pas encore partie de la Fediverse, mais il est en train de mettre en place ActivityPub et sera donc bientôt des nôtres.
Mobilizon (semblable à : MeetUp)
Mobilizon est une nouvelle plateforme en cours de développement, qui se propose comme une alternative libre à MeetUp et à d’autres logiciels servant à organiser des réunions et des rencontres en tout genre. Dès le départ, le projet naît avec l’intention d’utiliser ActivityPub et de faire partie de la Fediverse, en conformité avec les valeurs de Framasoft, association française née avec l’objectif de diffuser l’usage des logiciels libres et des réseaux décentralisés. Voir la présentation de Mobilizon en italien.
Plugin ActivityPub pour WordPress
 Plugin activityPub pour WordPress
Plugin activityPub pour WordPress
On trouve plusieurs plugins pour WordPress qui en font un membre à part entière de la Fédération ! Il existe également des plugins comme Mastodon AutoPost, Mastodon Auto Share, mais aussi Mastodon Embed, Ostatus for WordPress, Pterotype, Nodeinfo et Mastalab comments.
Prismo (semblable à : Pocket, Evernote, Reddit)
Prismo est une application encore en phase de développement, qui se propose de devenir un sorte de version décentralisée de Reddit, c’est-à-dire un média social centré sur le partage de liens, mais qui pourrait potentiellement évoluer en quelque chose qui ressemble à Pocket ou Evernote. Les fonctions de base sont déjà opérationnelles.
Socialhome
Socialhome est un média social qui utilise une interface par « blocs », affichant les messages comme dans un collage de photos de Pinterest. Pour le moment, il communique seulement via le protocole de Diaspora, mais il devrait bientôt mettre en place ActivityPub.
Et ce n’est pas tout !

Il existe encore d’autres applications et médias sociaux qui adoptent ou vont adopter ActivityPub, ce qui rendra la Fediverse encore plus structurée. Certains sont assez semblables à ceux déjà évoqués, alors que d’autres sont encore en phase de développement, on ne peut donc pas encore les conseiller pour remplacer des systèmes commerciaux plus connus. Il y a cependant des plateformes déjà prêtes et fonctionnelles qui pourraient entrer dans la Fediverse en adoptant ActivityPub : NextCloud en est un exemple (il était déjà constitué quand il a décidé d’entrer dans la Fediverse) ; le plugin de WordPress est pour sa part un outil qui permet de fédérer une plateforme qui existe déjà ; GetTogether est un autre service qui est en train d’être fédéré. Des plateformes déjà en place (je pense à Gitter, mais c’est juste un exemple parmi tant d’autres) pourraient trouver un avantage à se fédérer et à entrer dans une grande famille élargie. Bref : ça bouge dans la Fediverse et autour d’elle !
… un seul Grand Réseau !
Jusqu’ici, nous avons vu de nombreuses versions alternatives d’outils connus qui peuvent aussi être intéressant pris individuellement, mais qui sont encore meilleurs quand ils collaborent. Voici maintenant le plus beau : le fait qu’ils partagent les mêmes protocoles de communication élimine l’effet « cage dorée » de chaque réseau !
Maintenant qu’on a décrit chaque plateforme, on peut donner quelques exemples concrets :
Je suis sur Mastodon, où apparaît le message d’une personne que je « suis ». Rien d’étrange à cela, si ce n’est que cette personne n’est pas utilisatrice de Mastodon, mais de Peertube ! En effet, il s’agit de la vidéo d’un panorama. Toujours depuis Mastodon, je commente en écrivant « joli » et cette personne verra apparaître mon commentaire sous sa vidéo, sur Peertube.
Je suis sur Osada et je poste une réflexion ouverte un peu longue. Cette réflexion est lue par une de mes amies sur Friendica, qui la partage avec ses followers, dont certains sont sur Friendica, mais d’autres sont sur d’autres plateformes. Par exemple, l’un d’eux est sur Pleroma, il me répond et nous commençons à dialoguer.
Je publie une photo sur Pixelfed qui est vue et commentée par un de mes abonnés sur Mastodon.
En somme, chacun peut garder contact avec ses ami⋅e⋅s/abonné⋅e⋅s depuis son réseau préféré, mêmes si ces personnes en fréquentent d’autres.
Pour établir une comparaison avec les réseaux commerciaux, c’est comme si l’on pouvait recevoir sur Facebook les tweets d’un ami qui est sur Twitter, les images postées par quelqu’un d’autre sur Instagram, les vidéos d’une chaîne YouTube, les pistes audio sur SoundCloud, les nouveaux posts de divers blogs et sites personnels, et commenter et interagir avec chacun d’eux parce que tous ces réseaux collaborent et forment un seul grand réseau !
Chacun de ces réseaux pourra choisir la façon dont il veut gérer ces interactions : par exemple, si je voulais une vie sociale dans un seul sens, je pourrais choisir une instance Pixelfed où les autres utilisateurs⋅rices peuvent me contacter seulement en commentant les photos que je publie, ou bien je pourrais choisir une instance Peertube et publier des vidéos qui ne pourraient pas être commentées mais qui pourraient tourner dans toute la Fediverse, ou choisir une instance Mastodon qui oblige mes interlocuteurs à communiquer avec moi de manière concise.
Certains détails sont encore à définir (par exemple : je pourrais envoyer un message direct depuis Mastodon vers une plateforme qui ne permet pas à ses utilisateurs⋅rices de recevoir des messages directs, sans jamais être averti du fait que le/la destinataire n’aura aucun moyen de savoir que je lui ai envoyé quelque chose). Il s’agit de situations bien compréhensibles à l’intérieur d’un écosystème qui doit s’adapter à des réalités très diverses, mais dans la majorité des cas il s’agit de détails faciles à gérer. Ce qui compte, c’est que les possibilités d’interactions sont potentiellement infinies !
Connectivité totale, exposition dosée
Toute cette connectivité partagée doit être observée en gardant à l’esprit que, même si par simplicité les différents réseaux ont été traités ici comme des réseaux centralisés, ce sont en réalité des réseaux d’instances indépendantes qui interagissent directement avec les instances des autres réseaux : mon instance Mastodon filtrera les instances Peertube qui postent des vidéos racistes mais se connectera à toutes les instances Peertube qui respectent sa politique ; si je suis un certain ami sur Pixelfed je verrai seulement ses posts, sans que personne m’oblige à voir toutes les photos de couchers de soleil et de chatons de ses ami⋅e⋅s sur ce réseau.
La combinaison entre autonomie des instances, grande interopérabilité entre celles-ci et liberté de choix permet une série de combinaisons extrêmement intéressantes dont les réseaux commerciaux ne peuvent même pas rêver : ici, l’utilisateur⋅rice est membre d’un seul grand réseau où chacun⋅e peut choisir :
- Son outil d’accès préféré (Mastodon, Pleroma, Friendica) ;
- La communauté dans laquelle il ou elle se sent le plus à l’aise (l’instance) ;
- La fermeture aux communautés indésirables et l’ouverture aux communautés qui l’intéressent.
Tout cela sans pour autant renoncer à être connecté à des utilisateurs⋅rices qui ont choisi des outils et des communautés différents. Par exemple, je peux choisir une certaine instance Pleroma parce que j’aime son design, la communauté qu’elle accueille, ses règles et la sécurité qu’elle procure mais, à partir de là, suivre et interagir principalement avec des utilisateurs⋅rices d’une instance Pixelfed particulière et en importer les contenus et l’esthétique dans mon instance.
À cela on peut ajouter que des instances individuelles peuvent littéralement être installées et administrées par chaque utilisateur individuel sur ses propres machines, ce qui permet un contrôle total du contenu. Les instances minuscules auto-hébergées « à la maison » et les instances de travail plus robustes, les instances scolaires et les instances collectives, les instances avec des milliers d’utilisateurs et les instances avec un seul utilisateur, les instances à l’échelle d’un quartier ou d’un immeuble, toutes sont unies pour former un réseau complexe et personnalisable, qui vous permet de vous connecter pratiquement à n’importe qui mais aussi de vous éviter la surcharge d’information.
C’est une sorte de retour aux origines d’Internet, mais un retour à un âge de maturité, celui du Web 2.0, qui a tiré les leçons de l’expérience : être passé par la centralisation de la communication entre les mains de quelques grands acteurs internationaux a renforcé la conviction que la structure décentralisée est la plus humaine et la plus enrichissante.