Les nouveaux Léviathans II — Surveillance et confiance (a)
Qu’est-ce qui fait courir Framasoft ? De la campagne Dégooglisons à l’initiative C.H.A.T.O.N.S quelles idées ont en tête les acteurs et soutiens de l’association ? Vous reprendrez bien une tranche de Léviathan ?
Pour vous inviter à aller au-delà des apparences (la sympathique petite tribu d’amateurs gaulois qui veut modestement mettre son grain de sable dans la loi des entreprises hégémoniques) nous vous proposons non seulement un moment de réflexion, mais pour une fois une série de considérations nourries, argumentées et documentées sur l’état de bascule que nous vivons et dans lequel nous prétendons inscrire notre action avec vous.
Jamais le logiciel libre et les valeurs qu’il porte n’ont été autant à la croisée des chemins, car il ne s’agit pas de proposer seulement des alternatives techniques, c’est un défi économique et politique qu’il doit relever.
Entre les États qui nous surveillent et les GAFAM qui nous monétisent, jamais le refuge du secret, celui de l’intime, n’a été aussi attaqué ni menacé. Pour représenter le monstre à plusieurs têtes, Christophe Masutti qui est l’auteur de cette série de réflexions, a choisi la figure emblématique du Léviathan, forgée déjà par Hobbes en particulier pour désigner l’État toujours plus avide de domination.
C’est donc une série de Léviathans nouveaux et anciens que nous vous invitons à découvrir par étapes, tout au long de cette semaine, qui vous conduiront peut-être à comprendre et adopter notre démarche. Car une fois établies les sources du mal et posé le diagnostic, que faire ? Les perspectives que nous proposons seront peut-être les vôtres.
Note de l’auteur :Cette seconde partie (Léviathans II) vise à approfondir les concepts survolés précédemment (Léviathans I). Nous avons vu que les monopoles de l’économie numérique ont changé le paradigme libéral jusqu’à instaurer un capitalisme de surveillance. Pour en rendre compte et comprendre ce nouveau système, il faut brosser plusieurs aspects de nos rapports avec la technologie en général, et les services numériques en particulier, puis voir comment des modèles s’imposent par l’usage des big data et la conformisation du marché (Léviathans IIa). J’expliquerai, à partir de la lecture de S. Zuboff, quelles sont les principales caractéristiques du capitalisme de surveillance. En identifiant ainsi ces nouvelles conditions de l’aliénation des individus, il devient évident que le rétablissement de la confiance aux sources de nos relations contractuelles et démocratiques, passe immanquablement par l’autonomie, le partage et la coopération, sur le modèle du logiciel libre (Léviathans IIb).
Techniques d’anticipation
On pense habituellement les objets techniques et les phénomènes sociaux comme deux choses différentes, voire parfois opposées. En plus de la nature, il y aurait deux autres réalités : d’un côté un monde constitué de nos individualités, nos rapports sociaux, nos idées politiques, la manière dont nous structurons ensemble la société ; et de l’autre côté le monde des techniques qui, pour être appréhendé, réclamerait obligatoirement des compétences particulières (artisanat, ingénierie). Nous refusons même parfois de comprendre nos interactions avec les techniques autrement que par automatisme, comme si notre accomplissement social passait uniquement par le statut d’utilisateur et jamais comme producteurs. Comme si une mise à distance devait obligatoirement s’établir entre ce que nous sommes (des êtres sociaux) et ce que nous produisons. Cette posture est au plus haut point paradoxale puisque non seulement la technologie est une activité sociale mais nos sociétés sont à bien des égards elles-mêmes configurées, transformées, et même régulées par les objets techniques. Certes, la compréhension des techniques n’est pas toujours obligatoire pour comprendre les faits sociaux, mais il faut avouer que bien peu de faits sociaux se comprennent sans la technique.
L’avènement des sociétés industrielles a marqué un pas supplémentaire dans l’interdépendance entre le social et les objets techniques : le travail, comme activité productrice, est en soi un rapport réflexif sur les pratiques et les savoirs qui forment des systèmes techniques. Nous baignons dans une culture technologique, nous sommes des êtres technologiques. Nous ne sommes pas que cela. La technologie n’a pas le monopole du signifiant : nous trouvons dans l’art, dans nos codes sociaux, dans nos intentions, tout un ensemble d’éléments culturels dont la technologie est censée être absente. Nous en usons parfois même pour effectuer une mise à distance des techniques omniprésentes. Mais ces dernières ne se réduisent pas à des objets produits. Elles sont à la fois des pratiques, des savoir-faire et des objets. La raison pour laquelle nous tenons tant à instaurer une mise à distance par rapport aux technologies que nous utilisons, c’est parce qu’elles s’intègrent tellement dans notre système économique qu’elles agissent aussi comme une forme d’aliénation au travail comme au quotidien.

Ces dernières années, nous avons vu émerger des technologies qui prétendent prédire nos comportements. Amazon teste à grande échelle des dépôts locaux de produits en prévision des commandes passées par les internautes sur un territoire donné. Les stocks de ces dépôts seront gérés au plus juste par l’exploitation des données inférées à partir de l’analyse de l’attention des utilisateurs (mesurée au clic), les tendances des recherches effectuées sur le site, l’impact des promotions et propositions d’Amazon, etc. De son côté, Google ne cesse d’analyser nos recherches dans son moteur d’indexation, dont les suggestions anticipent nos besoins souvent de manière troublante. En somme, si nous éprouvons parfois cette nécessité d’une mise à distance entre notre être et la technologie, c’est en réponse à cette situation où, intuitivement, nous sentons bien que la technologie n’a pas à s’immiscer aussi profondément dans l’intimité de nos pensées. Mais est-ce vraiment le cas ? Ne conformons-nous pas aussi, dans une certaine mesure, nos envies et nos besoins en fonction de ce qui nous est présenté comme nos envies et nos besoins ? La lutte permanente entre notre volonté d’indépendance et notre adaptation à la société de consommation, c’est-à-dire au marché, est quelque chose qui a parfaitement été compris par les grandes firmes du secteur numérique. Parce que nous laissons tellement de traces transformées en autant d’informations extraites, analysées, quantifiées, ces firmes sont désormais capables d’anticiper et de conformer le marché à leurs besoins de rentabilité comme jamais une firme n’a pu le faire dans l’histoire des sociétés capitalistes modernes.
Productivisme et information
Si vous venez de perdre deux minutes à lire ma prose ci-dessus hautement dopée à l’EPO (Enfonçage de Portes Ouvertes), c’est parce qu’il m’a tout de même paru assez important de faire quelques rappels de base avant d’entamer des considérations qui nous mènerons petit à petit vers une compréhension en détail de ce système. J’ai toujours l’image de cette enseignante de faculté, refusant de lire un mode d’emploi pour appuyer deux touches sur son clavier afin de basculer l’affichage écran vers l’affichage du diaporama, et qui s’exclamait : « il faut appeler un informaticien, ils sont là pour ça, non ? ». Ben non, ma grande, un informaticien a autre chose à faire. C’est une illustration très courante de ce que la transmission des savoirs (activité sociale) dépend éminemment des techniques (un vidéo-projecteur couplé un ordinateur contenant lui-même des supports de cours sous forme de fichiers) et que toute tentative volontaire ou non de mise à distance (ne pas vouloir acquérir un savoir-faire technique) cause un bouleversement a-social (ne plus être en mesure d’assurer une transmission de connaissance, ou plus prosaïquement passer pour quelqu’un de stupide). La place que nous occupons dans la société n’est pas uniquement une affaire de codes ou relations interpersonnelles, elle dépend pour beaucoup de l’ordre économique et technique auquel nous devons plus ou moins nous ajuster au risque de l’exclusion (et la forme la plus radicale d’exclusion est l’absence de travail et/ou l’incapacité de consommer).
Des études déjà anciennes sur les organisations du travail, notamment à propos de l’industrialisation de masse, ont montré comment la technologie, au même titre que l’organisation, détermine les comportements des salariés, en particulier lorsqu’elle conditionne l’automatisation des tâches1. Souvent, cette automatisation a été étudiée sous l’angle des répercussions socio-psychologiques, accroissant les sentiments de perte de sens ou d’aliénation sociale2. D’un point de vue plus populaire, c’est le remplacement de l’homme par la machine qui fut tantôt vécu comme une tragédie (l’apparition du chômage de masse) tantôt comme un bienfait (diminuer la pénibilité du travail). Aujourd’hui, les enjeux sont très différents. On s’interroge moins sur la place de la machine dans l’industrie que sur les taux de productivité et la gestion des flux. C’est qu’un changement de paradigme s’est accompli à partir des années 1970-1980, qui ont vu apparaître l’informatisation quasi totale des systèmes de production et la multiplication des ordinateurs mainframe dans les entreprises pour traiter des quantités sans cesse croissantes de données.
Très peu de sociologues ou d’économistes ont travaillé sur ce qu’une illustre chercheuse de la Harvard Business School, Shoshana Zuboff a identifié dans la transformation des systèmes de production : l’informationnalisation (informating). En effet, dans un livre très visionnaire, In the Age Of The Smart Machine en 19883, S. Zuboff montre que les mécanismes du capitalisme productiviste du XXe siècle ont connu plusieurs mouvements, plus ou moins concomitants selon les secteurs : la mécanisation, la rationalisation des tâches, l’automatisation des processus et l’informationnalisation. Ce dernier mouvement découle des précédents : dès l’instant qu’on mesure la production et qu’on identifie des processus, on les documente et on les programme pour les automatiser. L’informationnalisation est un processus qui transforme la mesure et la description des activités en information, c’est-à-dire en données extractibles et quantifiables, calculatoires et analytiques.
Là où S. Zuboff s’est montrée visionnaire dans les années 1980, c’est qu’elle a montré aussi comment l’informationnalisation modèle en retour les apprentissages et déplace les enjeux de pouvoir. On ne cherche plus à savoir qui a les connaissances suffisantes pour mettre en œuvre telle procédure, mais qui a accès aux données dont l’analyse déterminera la stratégie de développement des activités. Alors que le « vieux » capitalisme organisait une concurrence entre moyens de production et maîtrise de l’offre, ce qui, dans une économie mondialisée n’a plus vraiment de sens, un nouveau capitalisme (dont nous verrons plus loin qu’il se nomme le capitalisme de surveillance) est né, et repose sur la production d’informations, la maîtrise des données et donc des processus.
Pour illustrer, il suffit de penser à nos smartphones. Quelle que soit la marque, ils sont produits de manière plus ou moins redondante, parfois dans les mêmes chaînes de production (au moins en ce qui concerne les composants), avec des méthodes d’automatisation très similaires. Dès lors, la concurrence se place à un tout autre niveau : l’optimisation des procédures et l’identification des usages, tous deux producteurs de données. Si bien que la plus-value ajoutée par la firme à son smartphone pour séduire le plus d’utilisateurs possible va de pair avec une optimisation des coûts de production et des procédures. Cette optimisation relègue l’innovation organisationnelle au moins au même niveau, si ce n’est plus, que l’innovation du produit lui-même qui ne fait que répondre à des besoins d’usage de manière marginale. En matière de smartphone, ce sont les utilisateurs les plus experts qui sauront déceler la pertinence de telle ou telle nouvelle fonctionnalité alors que l’utilisateur moyen n’y voit que des produits similaires.
L’enjeu dépasse la seule optimisation des chaînes de production et l’innovation. S. Zuboff a aussi montré que l’analyse des données plus fines sur les processus de production révèle aussi les comportements des travailleurs : l’attention, les pratiques quotidiennes, les risques d’erreur, la gestion du temps de travail, etc. Dès lors l’informationnalisation est aussi un moyen de rassembler des données sur les aspects sociaux de la production4, et par conséquent les conformer aux impératifs de rentabilité. L’exemple le plus frappant aujourd’hui de cet ajustement comportemental à la rentabilité par les moyens de l’analyse de données est le phénomène d’« Ubérisation » de l’économie5.
Ramené aux utilisateurs finaux des produits, dans la mesure où il est possible de rassembler des données sur l’utilisation elle-même, il devrait donc être possible de conformer les usages et les comportements de consommation (et non plus seulement de production) aux mêmes impératifs de rentabilité. Cela passe par exemple par la communication et l’apprentissage de nouvelles fonctionnalités des objets. Par exemple, si vous aviez l’habitude de stocker vos fichiers MP3 dans votre smartphone pour les écouter comme avec un baladeur, votre fournisseur vous permet aujourd’hui avec une connexion 4G d’écouter de la musique en streaming illimité, ce qui permet d’analyser vos goûts, vous proposer des playlists, et faire des bénéfices. Mais dans ce cas, si vous vous situez dans un endroit où la connexion haut débit est défaillante, voire absente, vous devez vous passer de musique ou vous habituer à prévoir à l’avance cette éventualité en activant un mode hors-connexion. Cette adaptation de votre comportement devient prévisible : l’important n’est pas de savoir ce que vous écoutez mais comment vous le faites, et ce paramètre entre lui aussi en ligne de compte dans la proposition musicale disponible.
Le nouveau paradigme économique du XXIe siècle, c’est le rassemblement des données, leur traitement et leurs valeurs prédictives, qu’il s’agisse des données de production comme des données d’utilisation par les consommateurs.

Big Data
Ces dernières décennies, l’informatique est devenu un média pour l’essentiel de nos activités sociales. Vous souhaitez joindre un ami pour aller boire une bière dans la semaine ? c’est avec un ordinateur que vous l’appelez. Voici quelques étapes grossières de cet épisode :
- votre mobile a signalé vers des antennes relais pour s’assurer de la couverture réseau,
- vous entrez un mot de passe pour déverrouiller l’écran,
- vous effectuez une recherche dans votre carnet d’adresse (éventuellement synchronisé sur un serveur distant),
- vous lancez le programme de composition du numéro, puis l’appel téléphonique (numérique) proprement dit,
- vous entrez en relation avec votre correspondant, convenez d’une date,
- vous envoyez ensuite une notification de rendez-vous avec votre agenda vers la messagerie de votre ami…
- qui vous renvoie une notification d’acceptation en retour,
- l’une de vos applications a géolocalisé votre emplacement et vous indique le trajet et le temps de déplacement nécessaire pour vous rendre au point de rendez-vous, etc.
Durant cet épisode, quel que soit l’opérateur du réseau que vous utilisez et quel que soit le système d’exploitation de votre mobile (à une ou deux exceptions près), vous avez produit des données exploitables. Par exemple (liste non exhaustive) :
- le bornage de votre mobile indique votre position à l’opérateur, qui peut croiser votre activité d’émission-réception avec la nature de votre abonnement,
- la géolocalisation donne des indications sur votre vitesse de déplacement ou votre propension à utiliser des transports en commun,
- votre messagerie permet de connaître la fréquence de vos contacts, et éventuellement l’éloignement géographique.
Ramené à des millions d’utilisateurs, l’ensemble des données ainsi rassemblées entre dans la catégorie des Big Data. Ces dernières ne concernent pas seulement les systèmes d’informations ou les services numériques proposés sur Internet. La massification des données est un processus qui a commencé il y a longtemps, notamment par l’analyse de productivité dans le cadre de la division du travail, les analyses statistiques des achats de biens de consommation, l’analyse des fréquences de transaction boursières, etc. Tout comme ce fut le cas pour les processus de production qui furent automatisés, ce qui caractérise les Big Data c’est l’obligation d’automatiser leur traitement pour en faire l’analyse.
Prospection, gestion des risques, prédictibilité, etc., les Big Data dépassent le seul degré de l’analyse statistique dite descriptive, car si une de ces données renferme en général très peu d’information, des milliers, des millions, des milliards permettent d’inférer des informations dont la pertinence dépend à la fois de leur traitement et de leur gestion. Le tout dépasse la somme des parties : c’est parce qu’elles sont rassemblées et analysées en masse que des données d’une même nature produisent des valeurs qui dépassent la somme des valeurs unitaires.
Antoinette Rouvroy, dans un rapport récent6 auprès du Conseil de l’Europe, précise que les capacités techniques de stockage et de traitement connaissent une progression exponentielle7. Elle définit plusieurs catégories de data en fonction de leurs sources, et qui quantifient l’essentiel des actions humaines :
- les hard data, produites par les institutions et administrations publiques ;
- les soft data, produites par les individus, volontairement (via les réseaux sociaux, par exemple) ou involontairement (analyse des flux, géolocalisation, etc.) ;
- les métadonnées, qui concernent notamment la provenance des données, leur trafic, les durées, etc. ;
- l’Internet des objets, qui une fois mis en réseau, produisent des données de performance, d’activité, etc.
Les Big Data n’ont cependant pas encore de définition claire8. Il y a des chances pour que le terme ne dure pas et donne lieu à des divisions qui décriront plus précisément des applications et des méthodes dès lors que des communautés de pratiques seront identifiées avec leurs procédures et leurs réseaux. Aujourd’hui, l’acception générique désigne avant tout un secteur d’activité qui regroupe un ensemble de savoir-faire et d’applications très variés. Ainsi, le potentiel scientifique des Big Data est encore largement sous-évalué, notamment en génétique, physique, mathématiques et même en sociologie. Il en est de même dans l’industrie. En revanche, si on place sur un même plan la politique, le marketing et les activités marchandes (à bien des égards assez proches) on conçoit aisément que l’analyse des données optimise efficacement les résultats et permet aussi, par leur dimension prédictible, de conformer les biens et services.
Google fait peur ?
Eric Schmidt, actuellement directeur exécutif d’Alphabet Inc., savait exprimer en peu de mots les objectifs de Google lorsqu’il en était le président. Depuis 1998, les activités de Google n’ont cessé d’évoluer, jusqu’à reléguer le service qui en fit la célébrité, la recherche sur la Toile, au rang d’activité has been pour les internautes. En 2010, il dévoilait le secret de Polichinelle :
Le jour viendra où la barre de recherche de Google – et l’activité qu’on nomme Googliser – ne sera plus au centre de nos vies en ligne. Alors quoi ? Nous essayons d’imaginer ce que sera l’avenir de la recherche (…). Nous sommes toujours contents d’être dans le secteur de la recherche, croyez-moi. Mais une idée est que de plus en plus de recherches sont faites en votre nom sans que vous ayez à taper sur votre clavier.
En fait, je pense que la plupart des gens ne veulent pas que Google réponde à leurs questions. Ils veulent que Google dise ce qu’ils doivent faire ensuite. (…) La puissance du ciblage individuel – la technologie sera tellement au point qu’il sera très difficile pour les gens de regarder ou consommer quelque chose qui n’a pas été adapté pour eux.9
Google n’a pas été la première firme à exploiter des données en masse. Le principe est déjà ancien avec les premiers data centers du milieu des années 1960. Google n’est pas non plus la première firme à proposer une indexation générale des contenus sur Internet, par contre Google a su se faire une place de choix parmi la concurrence farouche de la fin des années 1990 et sa croissance n’a cessé d’augmenter depuis lors, permettant des investissements conséquents dans le développement de technologies d’analyse et dans le rachat de brevets et de plus petites firmes spécialisées. Ce que Google a su faire, et qui explique son succès, c’est proposer une expérience utilisateur captivante de manière à rassembler assez de données pour proposer en retour des informations adaptées aux profils des utilisateurs. C’est la radicalisation de cette stratégie qui est énoncée ici par Eric Schmidt. Elle trouve pour l’essentiel son accomplissement en utilisant les données produites par les utilisateurs du cloud computing. Les Big Data en sont les principaux outils.
D’autres firmes ont emboîté le pas. En résultat, la concentration des dix premières firmes de services numériques génère des bénéfices spectaculaires et limite la concurrence. Cependant, l’exploitation des données personnelles des utilisateurs et la manière dont elles sont utilisées sont souvent mal comprises dans leurs aspects techniques autant que par les enjeux économiques et politiques qu’elles soulèvent. La plupart du temps, la quantité et la pertinence des informations produites par l’utilisateur semblent négligeables à ses yeux, et leur exploitation d’une importance stratégique mineure. Au mieux, si elles peuvent encourager la firme à mettre d’autres services gratuits à disposition du public, le prix est souvent considéré comme largement acceptable. Tout au plus, il semble a priori moins risqué d’utiliser Gmail et Facebook, que d’utiliser son smartphone en pleine manifestation syndicale en France, puisque le gouvernement français a voté publiquement des lois liberticides et que les GAFAM ne livrent aux autorités que les données manifestement suspectes (disent-elles) ou sur demande rogatoire officielle (disent-elles).
Gigantismus
En 2015, Google Analytics couvrait plus de 70% des parts de marché des outils de mesure d’audience. Google Analytics est un outil d’une puissance pour l’instant incomparable dans le domaine de l’analyse du comportement des visiteurs. Cette puissance n’est pas exclusivement due à une supériorité technologique (les firmes concurrentes utilisent des techniques d’analyse elles aussi très performantes), elle est surtout due à l’exhaustivité monopolistique des utilisations de Google Analytics, disponible en version gratuite et premium, avec un haut degré de configuration des variables qui permettent la collecte, le traitement et la production très rapide de rapports (pratiquement en temps réel). La stratégie commerciale, afin d’assurer sa rentabilité, consiste essentiellement à coupler le profilage avec la régie publicitaire (Google AdWords). Ce modèle économique est devenu omniprésent sur Internet. Qui veut être lu ou regardé doit passer l’épreuve de l’analyse « à la Google », mais pas uniquement pour mesurer l’audience : le monopole de Google sur ces outils impose un web rédactionnel, c’est-à-dire une méthode d’écriture des contenus qui se prête à l’extraction de données.
Google n’est pas la seule entreprise qui réussi le tour de force d’adapter les contenus, quelle que soit leur nature et leurs propos, à sa stratégie commerciale. C’est le cas des GAFAM qui reprennent en chœur le même modèle économique qui conforme l’information à ses propres besoins d’information. Que vous écriviez ou non un pamphlet contre Google, l’extraction et l’analyse des données que ce contenu va générer indirectement en produisant de l’activité (visites, commentaires, échanges, temps de connexion, provenance, etc.) permettra de générer une activité commerciale. Money is money, direz-vous. Pourtant, la concentration des activités commerciales liées à l’exploitation des Big Data par ces entreprises qui forment les premières capitalisations boursières du monde, pose un certain nombre répercutions sociales : l’omniprésence mondialisée des firmes, la réduction du marché et des choix, l’impuissance des États, la sur-financiarisation.
Omniprésence
En produisant des services gratuits (ou très accessibles), performants et à haute valeur ajoutée pour les données qu’ils produisent, ces entreprises captent une gigantesque part des activités numériques des utilisateurs. Elles deviennent dès lors les principaux fournisseurs de services avec lesquels les gouvernements doivent composer s’ils veulent appliquer le droit, en particulier dans le cadre de la surveillance des populations et des opérations de sécurité. Ainsi, dans une démarche très pragmatique, des ministères français parmi les plus importants réunirent le 3 décembre 2015 les « les grands acteurs de l’internet et des réseaux sociaux » dans le cadre de la stratégie anti-terroriste10. Plus anciennement, le programme américain de surveillance électronique PRISM, dont bien des aspects furent révélés par Edward Snowden en 2013, a permit de passer durant des années des accords entre la NSA et l’ensemble des GAFAM. Outre les questions liées à la sauvegarde du droit à la vie privée et à la liberté d’expression, on constate aisément que la surveillance des populations par les gouvernements trouve nulle part ailleurs l’opportunité de récupérer des données aussi exhaustives, faisant des GAFAM les principaux prestataires de Big Data des gouvernements, quels que soient les pays11.
Réduction du marché
Le monopole de Google sur l’indexation du web montre qu’en vertu du gigantesque chiffre d’affaires que cette activité génère, celle-ci devient la première et principale interface du public avec les contenus numériques. En 2000, le journaliste Laurent Mauriac signait dans Libération un article élogieux sur Google12. À propos de la méthode d’indexation qui en fit la célébrité, L. Mauriac écrit :
Autre avantage : ce système empêche les sites de tricher. Inutile de farcir la partie du code de la page invisible pour l’utilisateur avec quantité de mots-clés…
Or, en 2016, il devient assez évident de décortiquer les stratégies de manipulation de contenus que les compagnies qui en ont les moyens financiers mettent en œuvre pour dominer l’index de Google en diminuant ainsi la diversité de l’offre13. Que la concentration des entreprises limite mécaniquement l’offre, cela n’est pas révolutionnaire. Ce qui est particulièrement alarmant, en revanche, c’est que la concentration des GAFAM implique par effets de bord la concentration d’autres entreprises de secteurs entièrement différents mais qui dépendent d’elles en matière d’information et de visibilité. Cette concentration de second niveau, lorsqu’elle concerne la presse en ligne, les éditeurs scientifiques ou encore les libraires, pose à l’évidence de graves questions en matière de liberté d’information.
Impuissances
La concentration des services, qu’il s’agisse de ceux de Google comme des autres géants du web, sur des secteurs biens découpés qui assurent les monopoles de chaque acteur, cause bien des soucis aux États qui voient leurs économies impactées selon les revenus fiscaux et l’implantation géographique de ces compagnies. Les lois anti-trust semblent ne plus suffire lorsqu’on voit, par exemple, la Commission Européenne avoir toutes les peines du monde à freiner l’abus de position dominante de Google sur le système Android, sur Google Shopping, sur l’indexation, et de manière générale depuis 2010.
Illustration cynique devant l’impuissance des États à réguler cette concentration, Google a davantage à craindre de ses concurrents directs qui ont des moyens financiers largement supérieurs aux États pour bloquer sa progression sur les marchés. Ainsi, cet accord entre Microsoft et Google, qui conviennent de régler désormais leurs différends uniquement en privé, selon leurs propres règles, pour ne se concentrer que sur leur concurrence de marché et non plus sur la législation. Le message est double : en plus d’instaurer leur propre régulation de marché, Google et Microsoft en organiseront eux-mêmes les conditions juridiques, reléguant le rôle de l’État au second plan, voire en l’éliminant purement et simplement de l’équation. C’est l’avènement des Léviathans dont j’avais déjà parlé dans un article antérieur.
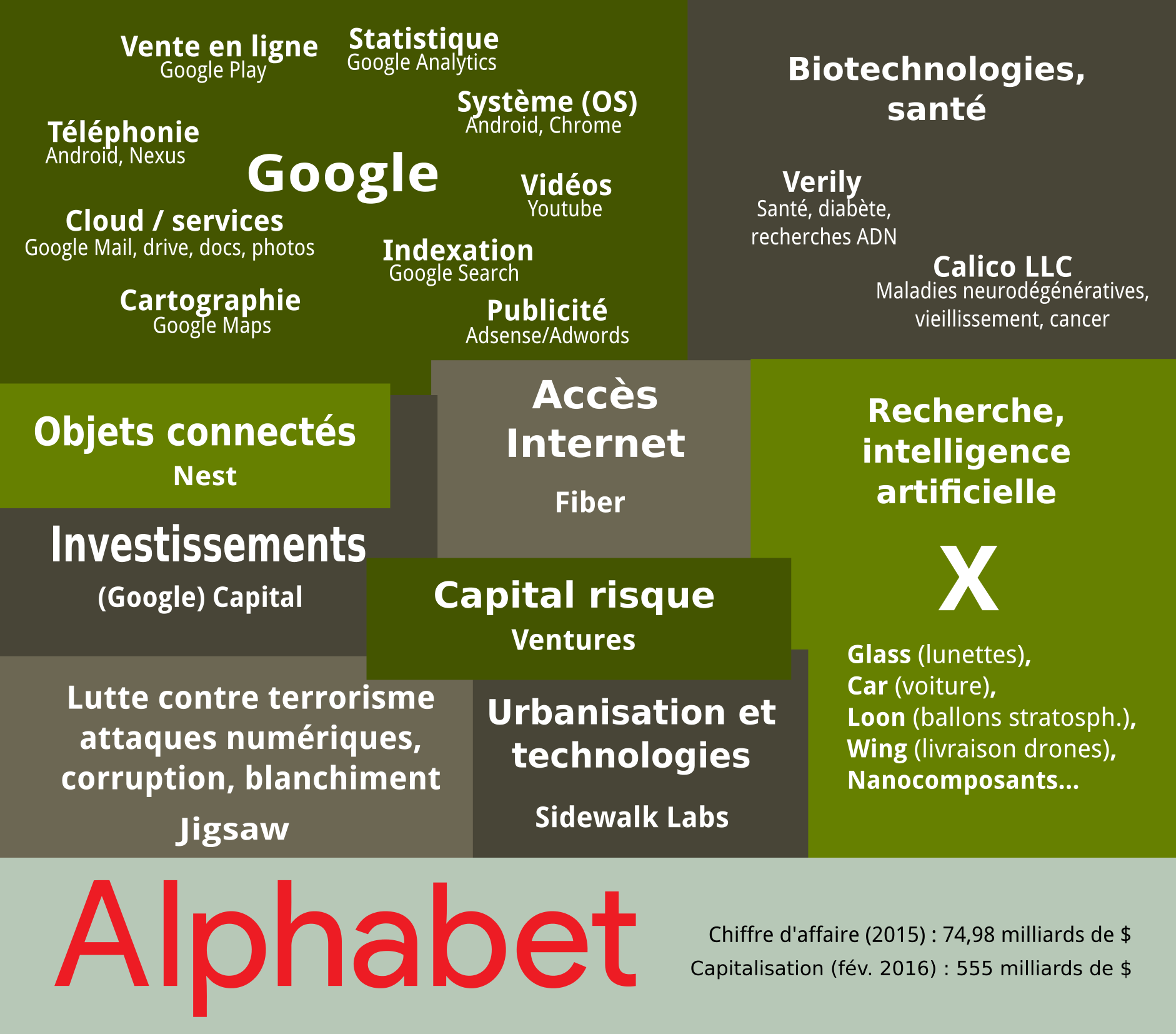
Capitaux financiers
La capitalisation boursière des GAFAM a atteint un niveau jamais envisagé jusqu’à présent dans l’histoire, et ces entreprises figurent toutes dans le top 40 de l’année 201514. La valeur cumulée de GAFAM en termes de capital boursier en 2015 s’élève à 1 838 milliards de dollars. À titre de comparaison, le PIB de la France en 2014 était de 2 935 milliards de dollars et celui des Pays Bas 892 milliards de dollars.
La liste des acquisitions de Google explique en partie la cumulation de valeurs boursières. Pour une autre partie, la plus importante, l’explication concerne l’activité principale de Google : la valorisation des big data et l’automatisation des tâches d’analyse de données qui réduisent les coûts de production (à commencer par les frais d’infrastructure : Google a besoin de gigantesque data centers pour le stockage, mais l’analyse, elle, nécessite plus de virtualisation que de nouveaux matériels ou d’employés). Bien que les cheminements ne soient pas les mêmes, les entreprises GAFAM ont abouti au même modèle économique qui débouche sur le status quo de monopoles sectorisés. Un élément de comparaison est donné par le Financial Times en août 2014, à propos de l’industrie automobile vs l’économie numérique :
Comparons Detroit en 1990 et la Silicon Valley en 2014. Les 3 plus importantes compagnies de Detroit produisaient des bénéfices à hauteur de 250 milliards de dollars avec 1,2 million d’employés et la cumulation de leurs capitalisations boursières totalisait 36 milliards de dollars. Le 3 premières compagnies de la Silicon Valley en 2014 totalisaient 247 milliards de dollars de bénéfices, avec seulement 137 000 employés, mais un capital boursier de 1,09 mille milliard de dollars.15
La captation d’autant de valeurs par un petit nombre d’entreprises et d’employés, aurait été analysée, par exemple, par Schumpeter comme une chute inévitable vers la stagnation en raison des ententes entre les plus puissants acteurs, la baisse des marges des opérateurs et le manque d’innovation. Pourtant cette approche est dépassée : l’innovation à d’autres buts (produire des services, même à perte, pour capter des données), il est très difficile d’identifier le secteur d’activité concerné (Alphabet regroupe des entreprises ultra-diversifiées) et donc le marché est ultra-malléable autant qu’il ne représente que des données à forte valeur prédictive et possède donc une logique de plus en plus maîtrisée par les grands acteurs.
Pour aller plus loin :
- La série d’articles sur le framablog
- La série d’article au complet (fichier .epub)
- Michel Liu, « Technologie, organisation du travail et comportement des salariés », Revue française de sociologie, 22/2 1981, pp. 205-221.↩
- Voir sur ce point Robert Blauner, Alienation and Freedom. The Factory Worker and His Industry, Chicago: Univ. Chicago Press, 1965.↩
- Shoshana Zuboff, In The Age Of The Smart Machine: The Future Of Work And Power, New York: Basic Books, 1988.↩
- En guise d’illustration de tests (proof of concepts) discrets menés dans les entreprises aujourd’hui, on peut se reporter à cet article de Rue 89 Strasbourg sur cette société alsacienne qui propose, sous couvert de challenge collectif, de monitorer l’activité physique de ses employés. Rémi Boulle, « Chez Constellium, la collecte des données personnelles de santé des employés fait débat », Rue 89 Strasbourg, juin 2016.↩
- Par exemple, dans le cas des livreurs à vélo de plats préparés utilisés par des sociétés comme Foodora ou Take Eat Easy, on constate que ces sociétés ne sont qu’une interface entre les restaurants et les livreurs. Ces derniers sont auto-entrepreneurs, payés à la course et censés assumer toutes les cotisations sociales et leurs salaires uniquement sur la base des courses que l’entreprise principale pourra leur confier. Ce rôle est automatisé par une application de calcul qui rassemble les données géographiques et les performances (moyennes, vitesse, assiduité, etc.) des livreurs et distribue automatiquement les tâches de livraisons. Charge aux livreurs de se trouver au bon endroit au bon moment. Ce modèle économique permet de détacher l’entreprise de toutes les externalités ou tâches habituellement intégrées qui pourraient influer sur son chiffre d’affaires : le matériel du livreur, l’assurance, les cotisations, l’accidentologie, la gestion du temps de travail, etc., seule demeure l’activité elle-même automatisée et le livreur devient un exécutant dont on analyse les performances. L’« Ubérisation » est un processus qui automatise le travail humain, élimine les contraintes sociales et utilise l’information que l’activité produit pour ajuster la production à la demande (quels que soient les risques pris par les livreurs, par exemple pour remonter les meilleures informations concernant les vitesses de livraison et se voir confier les prochaines missions). Sur ce sujet, on peut écouter l’émission Comme un bruit qui court de France Inter qui diffusa le reportage de Giv Anquetil le 11 juin 2016, intitulé « En roue libre ».↩
- Antoinette Rouvroy, Des données et des hommes. Droits et libertés fondamentaux dans un monde de données massives, Bureau du comité consultatif de la convention pour la protection des personnes à l’égard du traitement automatisé des données à caractère personnel, Conseil de l’Europe, janvier 2016.↩
- En même temps qu’une réduction de leur coût de production (leur coût d’exploitation ou d’analyse, en revanche, explose).↩
- On peut s’intéresser à l’origine de l’expression en lisant cet article de Francis X. Diebold, « On the Origin(s) and Development of the Term ‘Big Data’ », Penn Institute For Economic Research, Working Paper 12-037, 2012.↩
- Holman W. Jenkins, « Google and the Search for the Future The Web icon’s CEO on the mobile computing revolution, the future of newspapers, and privacy in the digital age », The Wall Street Journal, 14/08/2010.↩
- Communiqué du Premier ministre, Réunion de travail avec les grands acteurs de l’Internet et des réseaux sociaux, Paris : Hôtel Matignon, 3/12/2015.↩
- Même si Apple a déclaré ne pas entrer dans le secteur des Big Data, il n’en demeure pas moins qu’il en soit un consommateur comme un producteur d’envergure mondiale.↩
- Laurent Mauriac, « Google, moteur en explosion », Libération, 29 juin 2000.↩
- Vincent Abry, « Au revoir la diversité. Quand 16 compagnies dominent complètement l’index Google », article de Blog personnel, voir la version archivée.↩
- PwC, Global Top 100 Companies by market capitalisation, (31/03/2015). Ces données sont à revoir en raison de l’éclatement de Google dans une sorte de holding nommée Alphabet début 2016.↩
- James Manyika et Michael Chui, « Digital era brings hyperscale challenges » (image), The Financial Times, 13/08/2014. Cité par S. Zuboff, « Big Other… », op. cit..↩

















{kind=link}