Le projet diaspora* est à un moment charnière et de notre engagement dépend son avenir. Il est temps de s’impliquer pour que le projet se développe, au niveau du code bien sûr, mais aussi en tant que communauté d’un logiciel décentralisé. Découvrons pourquoi à travers l’histoire de Framasphère.
La création
J’ai découvert diaspora* (page wikipédia) en 2011, et ça a été le coup de foudre. Pour une “people person” comme moi, les réseaux sociaux sont un outil magnifique, mais il était hors de question de participer à ce danger qu’est facebook. Le fait que chacun puisse installer son serveur diaspora* (appelé pod) et qu’ils puissent tous communiquer ensemble pour créer un réseau est une excellente réponse à ces problèmes de vie privée. En 2012, je prends donc mon courage à deux mains et j’installe le logiciel sur https://diaspora-fr.org avec mon ami Taratatach. Initialement, nous ne l’avions fait que pour nos amis, mais finalement nous ouvrons les inscriptions à tous, et quelques milliers de personnes rejoignent ainsi l’aventure diaspora* depuis notre pod.
En avril 2014, je retrouve Pyg de Framasoft aux Journées du Logiciel Libre à Lyon, et il me parle d’un projet qu’ils ont dans les cartons, “Dégoogliser Internet”. Il s’agirait de proposer des alternatives aux services fournis par les géants du Web. Diaspora* pourrait être l’alternative à Facebook. Ils me prêtent un serveur Framasoft sur lequel j’installe diaspora* et bingo, Framasphère est née. Nous prévoyons d’annoncer le service en octobre 2014, lors du lancement officiel de la campagne dégooglisons. Mais dans le même temps, l’État Islamique se crée et, vite banni des réseaux traditionnels, il débarque sur diaspora*. Évidemment, diaspora-fr n’est pas épargné, et je me retrouve en contact direct avec la police judiciaire, le serveur étant hébergé en mon nom propre.
Psychologiquement, cela devient dur à gérer, et c’est donc avec soulagement que Framasphère prend le relais de diaspora-fr comme pod principal de la communauté francophone. C’est maintenant une association qui porte légalement la responsabilité des contenus publiés. Plus d’inquiétude. Je ferme les inscriptions sur diaspora-fr, et je deviens officiellement membre de Framasoft. Une belle histoire commence.
La boucle est bouclée
Huit années plus tard, l’association a décidé la fermeture de Framasphère qui aura lieu le 7 octobre 2021 (toutes les infos sur ce post) et nous prenons le chemin inverse : les inscriptions sur Framasphère ferment, et comme il est hors de question pour moi de ne pas proposer un serveur de confiance comme alternative, je rouvre celles de diaspora-fr.
Je m’implique aujourd’hui énormément dans la fonctionnalité d’import d’un compte avec l’aide de Thorsten Claus (encore merci à lui) pour vous permettre de migrer de façon transparente de Framasphère vers diaspora-fr. Comme on vous l’a dit, diaspora* 0.8.0.0 permettant la migration ne sera pas prête avant la fermeture de Framasphère, mais je mettrai quand même le code (encore instable) en ligne sur diaspora-fr. C’est d’ailleurs un premier point où j’aurais besoin d’aide : si vous êtes prêts à faire les béta-testeurs de la migration avec votre compte Framasphère, merci de vous signaler dans les commentaires !
Nous revenons donc à la situation initiale : Framasphère n’est plus là, diaspora-fr est le principal pod francophone, et je suis seul derrière le projet. Cela implique de gérer la maintenance du serveur (assez faible), la modération (assez faible aussi), les mises à jour de diaspora* (je maîtrise), mais aussi potentiellement les requêtes légales (en pratique, je n’en ai plus eu depuis 2014). Cela ne représente très honnêtement pas beaucoup de travail (quelques heures par mois tout au plus), mais tout repose sur moi et si demain je me plante en vélo ou bien plus gentiment je décide de passer une semaine déconnectée à la montagne et qu’il y a un problème sur le serveur, le service sera indisponible.
Les solutions
Cela fait donc longtemps que j’aimerais que d’autres personnes techniques me rejoignent, pour éviter ce bus factor. Le problème, c’est qu’en tant qu’administrateur, nous avons accès à toutes les données des utilisateurs. Or, les gens se sont inscrits sur diaspora-fr parce qu’ils et elles me faisaient confiance. Difficile de donner accès à leurs données à quelqu’un que je ne connaîtrais pas, il me faut moi même trouver quelqu’un de confiance. N’hésitez pas à vous proposer, mais ne soyez pas vexé si je refuse.
L’autre solution, c’est tout simplement que l’on revienne à ce que diaspora* aurait toujours dû être : un réseau décentralisé. La charge est bien moins importante, le nombre d’utilisateurs impactés par une panne bien plus réduit, si au lieu d’un pod avec des dizaines de milliers de personnes, les utilisateurs sont répartis sur des dizaines de pods. Ami(e)s technicien(ne)s, vous êtes la solution ! Si vous croyez au projet, installez votre serveur, vraiment, ce n’est pas très compliqué et la maintenance est facile.
Quand le militantisme déconne : injonctions, pureté militante, attaques… (8/8)
La question compliquée et parfois houleuse du militantisme nous intéresse depuis longtemps à Framasoft, aussi avons-nous demandé à Viciss de Hacking Social, de s’atteler à la tâche.
Voici déjà le huitième et dernier segment [si vous avez raté les épisodes précédents] de son intéressante contribution, dans lequel elle propose à titre de conclusion une série de pistes plutôt positives à suivre pour sortir de la spirale négative du militantisme déconnant.
Nous avons publié un chapitre de son travail chaque vendredi à 13:37 sur le Framablog, mais si vous préférez, vous pouvez télécharger l’essai intégral de Viciss qui comprend une bibliographie revue et augmentée :
D’autres voies pour trouver d’autres façons de faire
Je me suis beaucoup appuyée sur la théorie de l’autodétermination pour analyser et extirper des solutions alternatives au militantisme déconnant, mais c’est juste une perspective parmi d’autres qui pourraient être tout aussi bonnes ; ce n’est pas « la » chose à faire ni « la » perspective qu’il faudrait avoir, bien au contraire. Je l’ai choisie juste parce que je la trouve à la fois suffisamment précise pour entrer dans le détail, et suffisamment libertaire pour que chacun puisse réfléchir à partir de lui-même et non selon ses « règles ». Bref, ce n’est pas une théorie qui ordonne, mais qui laisse le maximum de possibilités et essaye de donner des pistes d’extension à celles-ci, c’est pour cela que j’aime la partager. Mais tout est bon pour trouver d’autres sources d’inspiration.
Rétro-ingénierie du kiff
On pourrait trouver quantité de solutions, d’alternatives, de façons de faire, en analysant dans le détail tout ce qu’on adore, tout ce qui nous a motivés, dans ce qu’on a trouvé de merveilleux et de mémorable. Il s’agit de faire de la rétro-ingénierie du kiff pour tenter de le reproduire un jour au travers de nos activités. Un peu comme le travail de recherche des game-designers lorsqu’ils cherchent les mécaniques qu’ils voudront reproduire dans leur jeu : les conseils de la dev du dimanche sont excellents à ce sujet, et perso je pense qu’on peut les transposer tout à fait à des domaines qui ne sont pas de l’ordre du jeu, si on cherche à créer quelque chose qui générera une expérience motivante :
Journal de bord EP 02 – Coucou, tu veux voir mon pitch ? Voir sur Youtube
J’ai aussi énormément aimé les méthodes et les façons de penser que j’ai trouvées dans « l’art du game design » de Jesse Shell, « Rules of play » de Katie Salen, et globalement le champ du game-design me fascine parce qu’il nous apprend comment construire une structure – un jeu – qui va motiver au maximum autrui, lui faire vivre des expériences mémorables ou des moments sociaux uniques en leur genre.
Rétro-ingénierie de l’adversaire et bidouillage
L’adversaire, surtout si sa création domine, a réussi un truc. Le problème qu’on peut avoir avec lui c’est que sa création génère de la souffrance, de l’injustice, et/ou sert uniquement des intérêts personnels. Cependant, sa manière de faire a eu une puissance d’influence qu’on peut décortiquer et qu’on peut transformer de façon beaucoup plus profitable. Par exemple, bien que je sois assez anti-pub, je sais que lire les publicitaires à travers leurs manuels a été très utile : par exemple, si je veux retenir quelque chose par cœur, j’emploierais les méthodes qu’ils utilisent pour que le consommateur mémorise un message. On peut faire des lectures, des analyses de l’adversaire et déjà commencer à hacker et transformer ses méthodes. Par exemple, je suis très critique du nudge (manipulation des comportements via le design de l’environnement), d’autant que le nudge est souvent utilisée sous une idéologie néo-libérale, mais je le trouve aussi fun et super intéressant ; récemment un doctorant m’a montré son étude1 où il avait hacké le nudge pour en supprimer l’aspect manipulateur et lui substituer à la place de l’autodétermination. Les résultats ont bien été là, c’était jubilatoire. Tout est transformable, hackable et la bonne nouvelle c’est que ce mécanisme de hack et de transformation est ultra fun à vivre lorsqu’on l’opère, mais aussi lorsqu’on y assiste en tant que spectateur, cela nous libère totalement de la colère, de l’énervement, de l’impuissance, et à la place on trouve du fun et de l’empuissantement.
Tout plaquer pour créer
On peut totalement laisser tomber certaines formes de militance (interpersonnelles) pour se consacrer à créer/œuvrer et cela ne fera pas de nous un moins « bon » militant. On peut se donner pour but de créer de meilleurs environnements sociaux (être ce super collègue, ce pote à qui on peut se confier, ce soutien en qui on a confiance…) ; on peut créer ou aider à créer des trucs et bidules ou évènements funs ; on peut être ce mentor qui apprend tout autant qu’il soutient ; on peut être ce spectateur, ce blogueur, ce journaliste qui voit et repère ce truc qui change la face du monde si on le fait connaître. Résister, c’est créer2 ; et créer c’est changer le monde.
Je sais qu’il y a une espèce de bataille de chapelle militante entre ceux qui pensent que seule la confrontation va amener du changement, et ceux qui veulent incarner/créer le changement dès à présent, accusant l’un l’autre de pas avoir la bonne stratégie (on accuse celui qui crée d’être lâche et de ne pas faire front à l’ennemi ; on accuse celui qui se confronte à l’adversaire d’être violent et de ne pas créer le monde qu’il voudrait voir apparaître), mais en fait tout ceci se superpose, se croise, interagit et il n’y a pas à se complexer de ne pas être en confrontation ou de n’être qu’en confrontation (ou de le reprocher aux autres) : au final, c’est l’interaction en système (parfois invisible) qui est productrice de transformation et changement positifs dans la société, sur le long terme.
Tout empuissanter, y compris sur la base de conflits
Ça se confronte entre alliés, envers les spectateurs, dans le mouvement, il y a donc à trouver des façons de gérer les conflits. Et il y aurait besoin d’un mode qui permette de régler les problèmes en interne sans qu’il y ait par la suite des décennies de ressentiments de la part des uns et des autres, prêts à exploser au moindre faux pas. Il y aurait aussi besoin d’une façon de régler les conflits qui ne soit pas autoritaire, car généralement les mouvements militants (excepté fascistes, d’extrême-droite) n’aiment pas trop la justice punitive. Et l’idéal serait évidemment que cette résolution de conflits soit productrice d’empuissantement et d’autodétermination.
Bonne nouvelle, des militants ont déjà bossé dessus et ont déjà établi des tas de protocoles extrêmement empuissantants permettant de gérer les conflits efficacement, au bénéfice de toute le monde, permettant en plus de prévenir d’autres problèmes : c’est la justice transformatrice. Je vous laisse consulter toutes ces ressources ici :
transform harm (transformharm.org/), tout particulièrement les sections « curriculum » de chaque thème (restorative justice, healing justice, etc.) sont emplies de programmes, d’outils très intéressants.
Le processus de responsabilisation : un outil absolument génial quelle que soit sa position ou son rôle dans le conflit, qu’on ait été cible d’un comportement qui nous a été pénible ou cause de cette pénibilité, voire témoin du problème, ou auteur de l’offense. Je trouve vraiment que c’est un outil qui permet de décider en toute autodétermination ce qu’on souhaite pour la suite, ce qui pourrait rétablir des liens de confiance, ce qui permettrait de réparer la situation. Vous trouverez les ressources en anglais ici (je l’ai traduit ici également).
D’autres ressources
J’ai été loin d’être exhaustive dans ce dossier, on aurait pu parler de long en large du conformisme et de son pourquoi, davantage de la réactance, des dynamiques narcissiques qui peuvent aussi poser problème dans la militance (il n’y a généralement pas d’argent à gagner dans ces milieux, mais ça peut attirer des profils en quête de notoriété, de personnes voulant se démarquer et dont l’attitude peut s’opposer au travail collectif), et j’aurais pu aussi parler de ce qui y a au cœur des mécaniques militantes fascistes en parlant de l’autoritaire, du dominateur, etc. Donc, voici d’autres sources potentiellement inspiratrices pour un militantisme qui affronterait l’adversaire et augmenterait la cohésion avec les spectateurs et alliés, en créant, en gueulant, en se posant, en jouant et j’en passe ; ces ressources ne sont pas exhaustives non plus3, il y en a certainement des milliers d’autres.
Dans l’histoire ou la philosophie, témoignages, stratégies et paradigmes de désobéissance :
Magda et André Trocmé, Figures de résistance, texteschoisis par Pierre Boismorand, Cerf, 2008.
Semelin Jacques et Mellon Christian, La non-violence, PUF, 1994.
Semelin Jacques, Sans armes face à Hitler, Les arènes, 1998.
James Haskins et Rosa Parks, Mon histoire, Libertalia 2018.
La Boétie, Discours sur la servitude volontaire, Bossard, 1922 (première édition, 1578) Voir Wikipédia.
Michel Terestchenko, Un si fragile vernis d’humanité, Banalité du mal, banalité du bien, La découverte, 2005.
Samuel P. Oliner, Pearl M. Oliner, The altruistic personnality, rescuers of jews in Nazi Europe, Macmillan USA, 1988 (on en a fait un résumé ici.
Frédéric Gros, Désobéir, Albin Michel, 2017.
Autour du numérique :
Edward Snowden, Mémoires Vives, Seuil, 2019.
Amaëlle Guitton, Hacker : au cœur de la résistance numérique, Au diable Vauvert, 2013.
Nicolas Danet et Frederic Bardeau, Anonymous. Pirates informatiques ou altermondialistes numériques ?, FYP Édtions 2011.
Steven Levy, L’éthique des hackers, Globe, 2013.
Pekka Himanen, L’éthique hacker, Exils, 2001.
De l’activisme :
Srdja Popovic, Comment faire tomber un dictateur quand on est seul, tout petit, et sans armes, Payot, 2015.
Automone A.F.R.I.K.A. Gruppe, Luther Blisset, Sonja Brünzels, Manuel de communication-guérilla, Éditions Zones, disponible en libre accès.
Andrew Boyd et Dave Ashald Mitchell, Joyeux bordel, tactiques et principes et théories pour faire la révolution, Les Liens qui libèrent, 2015 (qui est en fait une partie traduite des tactiques qu’on trouve à libre disposition ici ; le livre en anglais est aussi disponible librement ici, ils en ont même fait un jeu à destinations des militants pour s’aider à construire des actions, par ici.
Non pas parce que je suis de mauvaise volonté ou que je censurerais des ouvrages, mais simplement parce que je suis juste une personne qui n’a qu’une poignée d’heures par jour à disposition, donc je ne peux pas tout lire, tout étudier. Je précise cela parce que j’ai déjà eu des militants me reprochant de ne pas citer untel ou untelle.↩
Si vous avez trouvé ce dossier intéressant, vous pouvez témoigner de votre soutien aux travaux de Hacking Social par un don sur tipee ou sur Liberapay
Le projet Rust et sa gestion collaborative
La gestion d’une communauté de développeurs d’un projet open source est assez délicate. Le langage de programmation Rust, conçu et développé de façon ouverte au sein de Mozilla depuis une bonne dizaine d’années, fait largement appel à sa communauté dans sa structure et son mode de développement.
Son originalité par rapport au management de projet en entreprise apparaît de façon intéressante dans le témoignage et les réflexions de Mara Bos, une jeune développeuse impliquée dans le projet dont Framalang a traduit ci-dessous les propos.
L’année dernière, en tant que contributrice occasionnelle au projet Rust, je n’ai pas trop réfléchi à la structure organisationnelle de l’équipe derrière le projet. J’ai vu une hiérarchie d’équipes et de groupes, de chefs d’équipe, etc. Tout comme n’importe quelle autre organisation. Cette année, après m’être davantage impliquée, et devenue membre de l’équipe Library1 puis cheffe d’équipe, j’ai pris le temps de me demander pourquoi nous avons cette structure et à quoi servent ces équipes.
Pas une entreprise
Dans la plupart des entreprises, on trouve des directeurs et des actionnaires et autres trucs dans le genre en haut de la hiérarchie, qui définissent les buts de l’entreprise. Objectifs, jalons, dates limites, et autres choses qui vont sûrement mener l’entreprise vers le but final quel qu’il soit ; généralement l’argent.
Ensuite il existe plusieurs niveaux de management répartis en départements et en équipes pour diviser la charge de travail. Chaque niveau prend en charge une part des objectifs et s’assure que sa part est faite, en assignant des tâches aux employés en bas de la hiérarchie, tous travaillant d’une manière ou d’une autre à atteindre l’objectif principal commun.
Alors que la structure derrière un gros projet open source comme Rust peut sembler similaire, vue de loin, c’est souvent complètement l’inverse. Dans un tel projet, les objectifs et buts ne sont pas ceux des équipes d’en haut, mais effectivement ceux des contributeurs.
En tant qu’équipe library, nous pourrions par exemple essayer de décider que le mécanisme de formatage (std::fmt) devrait être réécrit pour être plus petit et plus efficace. Mais prendre cette décision ne provoque pas la réécriture. Et nous n’avons pas d’employés à qui assigner les tâches. Ce n’est pas comme ça que ça fonctionne.
Au lieu de cela, un contributeur passionné d’algorithmes de formatage pourrait se manifester, et commencer à travailler sur le problème. Notre travail en tant qu’équipe library est de faire en sorte que cette personne puisse travailler. S’assurer que son projet est en accord avec le reste de la bibliothèque standard, relire son travail et fournir un retour utile et constructif. Si davantage de personnes interviennent pour collaborer sur ce projet, mettre en place un groupe de travail pour aider à tout organiser, etc.
Les entreprises ne font pas travailler le premier venu sur quelque chose. C’est ce qui fait que l’open source est particulier et si génial, si on s’y prend bien.
Objectifs personnels
Idéalement, l’objectif d’un projet open source comme Rust est simplement la combinaison des buts personnels de toutes les personnes travaillant dessus. Et là est la difficulté. Parce que quand une nouvelle personne arrive, on ne lui assigne pas une tâche qui correspond à nos objectifs. Cette personne arrive plutôt avec ses propres objectifs et ses propres idées, les ajoutant à un ensemble déjà assez varié d’objectifs potentiellement conflictuels.
Et c’est pourquoi un projet open source piloté par des bénévoles a besoin d’une structure de management. On ne peut pas juste mettre ensemble une centaine de personnes avec chacune ses propres buts et espérer que tout se passe bien.
Donc ce que fait le management, c’est prendre en considération tous les buts personnels de toutes les personnes travaillant sur un sujet, et essayer de les guider de manière à ce que les choses fonctionnent. Ça peut impliquer le fait de dire non à des idées quand elles seraient incompatibles avec d’autres idées, ou ça peut impliquer beaucoup de discussions pour harmoniser les idées afin qu’elles soient compatibles. C’est exactement l’opposé de la manière dont fonctionne une entreprise typique, où les objectifs viennent d’en haut, et où le management décide de la manière de les répartir et les assigner aux personnes qui effectuent le travail technique.
Alors que beaucoup de projets open source, dont Rust, ont un cap ou un plan d’action, ces derniers doivent reposer sur les objectifs des contributeurs individuels du projet pour que ça fonctionne. Dire « notre objectif principal en 2021 est d’améliorer les mécanismes de formatage dans la bibliothèque standard » devrait faciliter le travail des personnes travaillant déjà dessus, et attirer les personnes qui voulaient déjà travailler sur quelque chose de ce genre. Ça devrait les aider parce que nous priorisons toutes les décisions de management et les révisions de code dont ils ont besoin. Ça devrait permettre aux personnes de se concentrer et d’avancer davantage. Mais sans ces contributeurs, mettre en place de tels objectifs n’a pas de sens. Contrairement à une entreprise, nous n’avons pas à choisir ce sur quoi les personnes passent leur temps, et nous n’employons pas de personnes auxquelles assigner des tâches.
Et c’est une bonne chose.
Le logo du langage de programmation Rust
C’est la raison pour laquelle les gens veulent travailler sur Rust.
Je ne prétends pas qu’un langage de programmation ne pourrait pas être géré « d’en haut » comme une entreprise le ferait. Beaucoup de langages de programmation ont été et sont développés de cette manière avec beaucoup d’efficacité. Ce que je dis, cependant, c’est que personnellement je ne veux pas que le projet Rust fonctionne de cette manière.
Je ne veux pas gérer le département library de l’entreprise Rust. Je veux aider les personnes qui veulent améliorer les bibliothèques du langage Rust.
Un espace pour s’épanouir
Différents contributeurs ont des objectifs très différents, travaillent avec des méthodes très variées, et ont des besoins très différents des structures de management.
Pour certains d’entre eux, nous avons des processus en place destinés à leur rendre le travail plus facile. Une personne qui veut travailler sur une nouvelle fonctionnalité du langage peut soumettre ses idées via une RFC 2 et prendre part dans une discussion avec l’équipe library pour des conseils et de l’aide. Quelqu’un qui veut améliorer une grande partie du code du compilateur 3 peut soumettre une proposition de changement majeur (MCP) et en discuter avec l’équipe du compilateur. Et quelqu’un qui veut résoudre un problème dans la bibliothèque standard peut soumettre une proposition de modification et la voir relue et évaluée par des personnes qui connaissent le contexte.
En d’autres termes, nous avons créé un espace pour ces types de contributeurs. De l’espace pour faire leur travail, de l’espace pour obtenir des retours, de l’espace pour obtenir de l’aide, de l’espace pour obtenir une reconnaissance, tout l’espace dont ils ont besoin pour réussir.
Cependant, il existe malheureusement beaucoup de types de contributeurs pour lesquels nous n’avons pas créé un espace, ou pas le bon espace.
Jusqu’à une époque récente, l’équipe library était principalement concentrée sur la conception de l’API. Les problèmes critiques d’implémentation étaient gérés par l’équipe du compilateur par nécessité. Les modifications de code plus modestes étaient relus et évalués par des relecteurs individuels de l’équipe library. Mais il n’y avait pas de gestion prévue pour de plus gros changements de code. Ça signifiait qu’il n’y avait pas d’espace pour une personne qui aurait voulu remettre à neuf le code de std::fmt. Il n’y avait pas d’équipe qu’elle aurait plus rejoindre pour travailler là-dessus, rendant beaucoup plus difficile, voire impossible, d’atteindre son but.
Faire de la place pour quelque chose peut souvent amener à (accidentellement) retirer de la place pour autre chose. Une personne qui n’est pas très impliquée dans le code mais qui veut appliquer son expérience dans la conception d’API et qui se soucie beaucoup de l’interface de la bibliothèque standard ne s’épanouirait pas dans une équipe qui aime avoir des réunions hebdomadaires à propos des problèmes de correction du code et de la manière avec laquelle résoudre ces problèmes avant la prochaine version publique.
Voilà pourquoi nous avons à présent l’équipe Library API
Nous avons maintenant aussi une équipe de « Contributeurs à Library ». Un endroit pour les personnes qui sont plus impliquées dans le projet que les contributeurs occasionnels, mais qui ne font pas partie des équipes qui prennent les décisions finales. Ça fait de l’espace pour les personnes qui veulent, par exemple, travailler sur seulement un aspect particulier de la bibliothèque, ou aider à relire les modifications proposées. Jusqu’à il y a environ un an, il n’y avait pas d’espace particulier pour qu’une personne relise les changements ou qu’elle s’implique davantage d’autres manières, sans faire directement partie d’une équipe avec beaucoup plus de responsabilités.
J’ai réussi à effectuer ces changements de structure d’équipe avec l’aide des membres des équipes Core et Library, qui m’ont mise en capacité de le faire. En retour, ces changements vont, je l’espère, permettre à des membres de ces nouvelles équipes de s’épanouir, et ainsi permettre à encore plus de personnes de contribuer, pour que finalement cela soit bénéfique pour tous les utilisateurs et utilisatrices du langage.
La mascotte de Rust
Continuer à changer
Je n’ai pas l’impression que nous ayons maintenant un espace pour toute personne souhaitant contribuer. Mais une fois que la poussière de la réorganisation se sera dispersée, je pense que le résultat sera une amélioration par rapport à ce que nous avions auparavant, et que ça correspond mieux au projet tel qu’il est aujourd’hui.
« Aujourd’hui » est le mot important ici. Ces équipes sont faites autour des membres actuels et des personnes qui, je pense, pourraient devenir des membres dans un futur proche. Mais ce groupe de personnes et leurs besoins changent, parfois à une vitesse surprenante. Et dans un projet qui est entièrement défini par les personnes qui y contribuent, ça change le projet en lui-même et la structure dont il a besoin, tout aussi rapidement.
En 2018, l’équipe Library était très impliquée dans l’aide aux auteurs des bibliothèques 4 populaires de l’écosystème. L’équipe a publié un ensemble de guides, et va réviser les bibliothèques et travailler conjointement avec leurs auteurs pour les implémenter. Tout cela pour améliorer la cohérence et la qualité de l’écosystème de librairies Rust.
Il y a quelques jours encore, c’était toujours techniquement une partie des buts affichés de l’équipe, même si en pratique ça n’était plus vraiment le cas ; particulièrement depuis qu’Ashley Mannix a quitté le projet il y a un moment. Sans les personnes qui ont pour but personnel de faire que des choses se produisent, les choses ne se produisent pas.
Et c’est très bien comme ça.
Tout le monde a une longue liste de vœux pour Rust, de choses qui ne se font pas parce que personne ne travaille dessus. Nous ne sommes pas une entreprise avec des dates limites et des jalons qu’il nous faut absolument atteindre. Nous sommes un groupe, divers et fluctuant, de personnes qui essaient de gérer tout ça avec passion, en s’efforçant de faire en sorte que tous les efforts aboutissent harmonieusement.
Il y a beaucoup de choses pour lesquelles nous devrions avoir de l’espace, mais pour lesquelles nous n’avons encore de place. Mais si nous continuons à essayer, si nous continuons à effectuer de petites améliorations. À nous adapter. À prendre en compte les personnes autour de nous qui veulent contribuer elles aussi ; si nous continuons à réfléchir à la façon dont nous pouvons les aider, eux et tous les autres. Alors chaque pas sera un pas dans la bonne direction, ainsi Rust prospérera et toutes les nombreuses personnes qui travaillent sur Rust et avec Rust s’épanouiront.
Photo « Rusty but pretty » par Jeanne à vélo, licence CC-BY-SA
Quand le militantisme déconne : injonctions, pureté militante, attaques… (7/8)
La question compliquée et parfois houleuse du militantisme nous intéresse depuis longtemps à Framasoft, aussi avons-nous demandé à Viciss de Hacking Social, de s’atteler à la tâche.
Voici déjà le septième épisode [si vous avez raté les épisodes précédents] de son intéressante contribution, dans laquelle des alternatives sont envisagées et des pistes proposées pour tenter d’échapper à la fâcheuse tendance au militantisme déconnant.
Nous publions un nouveau chapitre de son travail chaque vendredi à 13:37 sur le Framablog, mais si vous préférez, vous pouvez télécharger dès maintenant l’essai intégral de Viciss qui comprend une bibliographie revue et augmentée :
On a déjà pu apercevoir dans les points précédents qu’on se mettait à avoir des pratiques déconnantes non pas parce qu’on est persuadé que ce sont de bonnes pratiques, mais davantage malgré nous, parce que nos propres besoins sont sapés (par exemple faute d’avoir son autonomie comblée, on tente de contrôler l’autre, ce qui nous donne une satisfaction ponctuelle de notre besoin de compétence), parce que c’est le modèle de fonctionnement majoritaire dans nos environnements sociaux, parce qu’on manque d’informations, qu’on est surmené, etc.
Viser les besoins fondamentaux et vivre sa motivation intrinsèque
La solution est donc pour casser ce cercle vicieux est de commencer à nourrir les besoins fondamentaux à travers nos activités (tous les conseils dans les cadres jaunes des schémas précédents), tant les nôtres que ceux des autres en même temps. S’ensuivront des motivations de plus haute qualité pour l’activité, et celles-ci vont aussi nourrir en retour nos besoins en un cercle cette fois-ci vertueux. Et quand on aime profondément une activité, on cherche à en décupler le plaisir, donc on tente de la partager, les personnes aimant partager des émotions plaisantes écoutent et sont à leur tour entraînées dans une motivation à cette activité. Le truc serait juste de vivre et de communiquer pleinement sa motivation intrinsèque pour telle activité.
Cette transmission de la joie et du vécu positif pour une activité qu’on a avec une motivation intrinsèque (comme peuvent l’être tous les loisirs actifs, les disciplines qui ont pu passionner des personnes dans le monde) peut se faire dès qu’on lève toute crainte quant au jugement de celles et ceux qui pourraient observer ce vécu joyeux, crainte qui peut potentiellement s’effacer lorsqu’on est concentré dans l’activité elle-même. Généralement les gens perçoivent la passion, ressentent les émotions positives sincères lorsqu’elles sont explicitement vécues, de façon authentique (par exemple, on ne se forcerait pas à transmettre la joie de faire ceci, on serait juste effectivement joyeux de faire cela)1. La plus grande difficulté de ce partage de motivation intrinsèque réside dans la crainte des atteintes à la proximité sociale : être authentique, c’est être à nu, donc s’exposer potentiellement au jugement d’autrui, à son mépris, à son indifférence, à sa future ostracisation. On peut donc avoir des réticences à s’exposer sincèrement, tout particulièrement lorsqu’on a déjà vécu des situations de forte indifférence ou de mépris alors qu’on était pleinement authentique et bienveillant. Cela demande alors un même type de courage qu’un saut du plongeoir, on ne peut que se jeter à l’eau, s’immerger (ici dans le sujet, en vivant totalement avec lui), et nager jusqu’à l’atteinte du but. La crainte du regard d’autrui, son jugement potentiel est mis de côté, on se concentre sur son rapport authentique à sa passion. Vivre pleinement sa motivation intrinsèque et l’exposer n’est pas tant un effort, un travail, mais plutôt une immersion de l’attention qui est telle que les craintes liées au sapage de la proximité sociale sont pour le moment comme hors sujet.
Viser les motivations extrinsèques intégrées
Cependant, on sait aussi tous que la vie n’est pas forcément composée d’activité attractive. Changer la litière du chat, descendre les poubelles, suivre le Code de la route… Je ne connais personne qui ait de motivation intrinsèque pour ces activités, et c’est tout à fait normal parce que celles-ci peuvent avoir intrinsèquement des stimuli aversifs (l’odeur de la litière, des poubelles), demander des actions ennuyeuses qui n’apportent rien (attendre au stop n’est en rien une expérience qui nous apprend quelque chose), etc. De même, sans motivation intrinsèque, certaines activités militantes peuvent être tout aussi répulsives en premier lieu.
Toutefois on peut avoir des motivations extrinsèques intégrées pour ces actions répulsives, et celles-ci sont puissantes, durables sur le long terme et rendant l’acte moins pénible ou coûteux en efforts. On change alors la litière pour maintenir un foyer plus agréable pour ses habitants (y compris pour le chat qui vous remerciera en cessant de vous faire découvrir au petit matin de petites surprises puantes sur le sol du salon), on suit le Code de la route parce qu’on ne veut pas causer d’accident, on trie ses poubelles correctement pour faciliter le travail des éboueurs et de tous ceux qui travaillent sur le traitement des déchets.
Et comme c’est particulièrement intégré en nous, ça ne nous coûte rien de le faire, on ne rechigne pas, on n’a plus besoin d’y penser, on n’a pas de crainte d’être jugé, on ne sent pas de menaces, on n’agit pas par injonction.
L’autre avantage de cette motivation à régulation intégrée, c’est la résistance aux tentatives de manipulation/d’influence néfaste : par exemple, une personne à motivation intégrée pour le tri triera non seulement tout le temps sans que personne n’ait à lui ordonner quoique ce soit, sans qu’il y ait une seule pression, mais plus encore elle ne sera pas influencée par les arguments tentant de la convaincre que c’est pathétique de trier, et elle continuera son comportement. On a donc là une motivation très puissante, potentiellement préventive face aux menaces et aux tentatives d’influence.
Mais comment transmettre ça à un autre, sans être injonctif, saoulant, culpabilisant ?
Une expérience de la théorie de l’autodétermination est assez éloquente à ce sujet :
ℹ ⇢ Koestner et coll. (1984). Au travers d’une expérience sur la peinture avec des enfants, il a été testé différentes façons de présenter une règle consistant à respecter la propreté du matériel. Pour soutenir l’autonomie malgré une imposition de règles, il a été vu qu’il fallait présenter les choses ainsi :
Minimiser l’usage d’un langage contrôlant (« tu dois » « il faut »…),
Reconnaître le sentiment des enfants à ne pas vouloir être soigneux avec les outils,
Fournir aux enfants une justification de cette limite/règle (c’est-à-dire expliquer pourquoi on a voulu que les outils restent propres).
En présentant ainsi les limites de façon non contrôlante, la motivation intrinsèque des enfants pour la peinture était préservée et beaucoup plus haute que dans un cadre contrôlant (c’est-à-dire avec juste l’ordre de ne pas salir les outils, sans justification ni reconnaissance du sentiment de l’enfant).
Si on transpose cela à l’acte militant, vous avez plus de chances de réussir à transmettre un changement d’habitude, une nouvelle pratique qui supplante une ancienne, une alternative, en n’étant pas contrôlant dans son langage : on supprime l’impératif, « il faut » « tu dois ». À la place, on peut mettre « on peut », « il est possible de » ; je trouve que le conditionnel est aussi très doux pour montrer des possibilités. Et un discours non injonctif qui connote l’ouverture à des possibilités est un discours qui permettra d’éviter des comportements réactants.
❣ Reconnaître les émotions d’autrui, c’est soit se mettre en empathie cognitive avec l’autre (par exemple, imaginer ce que peut ressentir un militant antivax), soit essayer de comprendre ses émotions en l’écoutant activement, sans jugement.
Le thread suivant explique formidablement bien comment on peut communiquer avec « l’adversaire » à sa cause d’une façon qui respecte son autonomie, ses besoins (ici c’est la personne antivax, mais ça pourrait concerner un autre sujet, la méthode d’écoute des émotions et besoins serait tout aussi pertinente).
[Thread] Comment parler à une personne Antivax ? – (le) Deuxième Humain – @DeuxiemeHumain
❭ J’ai vu plein de gens parler de leurs proches qui veulent pas se faire vacciner / ont peur des vaccins / pensent qu’il faut pas faire confiance à la médecine, (4:24 PM · 21 mai 2021 · Twitter)
❭ et qui aimeraient bien les faire changer d’avis ou les pousser à se faire vacciner (pour rester en vie), donc voici quelques astuces pour y arriver :
❭ Précision : tout ce dont je vais parler ici concerne les proches / personnes qu’on connait plutôt bien.
❭ Malheureusement faire changer d’avis un·e inconnu·e sur twitter, surtout un sujet aussi chargé émotionnellement, ce n’est souvent pas un objectif réaliste. Mais si tu as de la patience et du temps, tu peux toujours essayer 🙂
❭ Le plus important c’est de ne pas prendre les personnes antivax pour des idiotes. C’est pas parce qu’on est antivax qu’on est plut bête qu’un·e autre.
❭ Et même si c’était le cas : se faire prendre de haut ça n’a jamais fait évoluer personne. Et ça n’a jamais n’a définitivement jamais fait évoluer personne de façon saine.
❭ Ne monopolisez pas la parole : c’est important d’avoir une vraie discussion où vous écoutez sincèrement la personne en face, sinon elle ne va pas avoir envie de vous écouter en retour et vous risquez de parler dans le vide.
❭ Il faut essayer d’avoir un véritable échange, ne placez pas uniquement les sources avec les faits ou statistiques sur les vaccins qui montrent que c’est mieux de se faire vacciner comme si vous étiez en train de jouer aux échecs.
❭ Écoutez. Écoutez. Écoutez. Personne ne « naît » antivax. Il y a toujours une raison derrière.
❭ Ça peut être une histoire personnelle, une peur des « élites », une peur ou une incompréhension de la science derrière les vaccins, une perte de confiance envers la médecine, des positions politiques ou religieuses…
❭ Et si la personne en face ne rentre pas dans les détails, posez des questions. Intéressez-vous sincèrement à la personne face à vous et aux raisons qui ont poussé à être contre les vaccins.
❭ Ça vous aidera à mieux l’aider à comprendre ce sujet et aussi à mieux la comprendre de manière générale dans la vie (et c’est toujours cool d’être plus proche de ses proches).
❭ Tant que vous y êtes : parlez de vous aussi. Pourquoi est-ce que vous êtes d’accord-vax ? (Je viens d’inventer ce mot, j’en suis très fier)
❭ Est-ce que vous avez eu des doutes à certains moments ? Comment avez-vous fait pour vous renseigner ? Qu’est-ce qui vous a fait vous décider ? Pourquoi vous faites-vous vacciner ?
❭ Je passe beaucoup de temps dessus, parce que c’est très important d’avoir une vraie discussion et de ne pas venir avec son Powerpoint, balancer plein de chiffres ou de noms qui font sérieux puis repartir direct.
❭ Et la deuxième étape, après avoir pris le temps d’écouter et de parler posément avec la personne antivax, c’est d’apporter des réponses ou des solutions à ses problèmes.
❭ La personne que vous souhaitez convaincre ne fait pas confiance aux positions du gouvernement parce que, honnêtement, c’est des positions qui changent toutes les 2 semaines c’est chelou ?
❭ Parlez-lui des recommandations de l’OMS-qui ont d’ailleurs plusieurs fois été gentiment ignorées par le gouvernement.
❭ Vous êtes face à quelqu’un qui a peur des effets secondaires potentiels ? Regardez ensemble quels sont les effets secondaires potentiels des vaccins et les effets primaires du Covid (Spoiler : le Covid a l’air franchement plus violent).
❭ Et vous pouvez aussi regarder la liste d’effets secondaires de médicaments courants ou qu’elle prends, pour lui montrer que ça n’est pas si différent et qu’il s’agit de cas rares. Ils existent, mais sont rares.
❭ Quelqu’un ne veut pas se faire vacciner parce que « c’est chiant je sais pas comment faire avec internet et tout » ? Vous pouvez l’aider à prendre rendez-vous, le faire pour elui voire même l’accompagner si vous êtes disponible !
❭ Rien que proposer de prendre des rendez-vous au même moment ça peut motiver certaines personnes qui n’étaient pas sûres : avec l’effet de groupe on se dit « allez, tant qu’on y est ! » et c’est toujours plus rassurant d’y aller à plusieurs, surtout avec des proches.
❭ Storytime : Quelqu’un dans ma famille (anonymysé·e pour des raisons d’anonymat) vient d’un pays où il y a littéralement eu des tests de vaccins et médocs faits sur la population « pour voir si ça fonctionne bien avant de les envoyer dans les pays riches ».
❭ Allez savoir pourquoi, cette personne n’a pas super méga confiance en la vaccination contre le Covid du coup. Et bah on va se faire vacciner avant elui, comme ça iel pourra voir si on va bien et aller se faire vacciner en ayant confiance.
❭ Le plus important c’est d’écouter les besoins ou peurs des personnes et les aider à les surmonter -et ça, quels que soient ces problèmes et ces peurs, même si elles nous paraissent ridicules : un peu de compassion punaise !
❭ Félicitations, vous êtes arrivé·es à la fin de ce thread ! Pour fêter ça vous pouvez le RT où l’envoyer à des gens que ça pourrait aider. Et pour me soutenir vous pouvez aller sur https://utip.io/vivreavec , ça nous soutient Matthieu et moi !
⚒ Concernant la justification rationnelle à apporter sur « pourquoi » selon le militant il faudrait changer de comportement (ne plus employer tel mot, tel logiciel ; porter le masque, se faire vacciner, ne pas croire ceci, etc.), des méta-analyses révèlent celles les plus convaincantes :
ℹ ⇢ Steingut, Patall et Trimble (2017) ont fait une méta-analyse de 23 expériences portant sur le soutien à l’autonomie qui fournissait une explication ou une justification rationnelle sur la tâche à faire. Ils ont découvert que cette explication augmente la valeur perçue de la tâche, mais peut parfois générer un effet négatif sur le sentiment d’être compétent. En effet, toutes les explications n’ont pas la même valeur autodéterminante, et peuvent être classées en 3 types :
contrôlantes : le comportement est dit important pour des raisons externes, tel que « cela vous rapportera de l’argent, une promotion », ou concernant l’apparence physique ou canalisant le sentiment de culpabilité ;
autonomes : le comportement est dit important pour soi, ses valeurs personnelles, son développement personnel « cela améliorera votre mémoire/votre indépendance/votre esprit critique… » ;
prosociales : le comportement est dit important pour autrui, « cela va apporter du confort et du bien-être à vos proches/aux personnes présentes ».
C’est lorsque l’explication ou la justification est prosociale que le comportement est ensuite le plus efficace, avec une meilleure motivation autonome, un meilleur engagement.
Autrement dit, l’humain étant un animal social, il est davantage motivé de suivre un comportement qui va clairement montrer que ça aide un autre humain ; ça le motive plus que les récompenses, l’argent, l’évitement de la culpabilité, ou la croissance de ces capacités ou compétences personnelles. À mon avis, cette justification prosociale, pour être transmise efficacement, pourrait être formulée au plus concret et proximal possible : dire que le tri des déchets va sauver l’humanité ne sera pas une justification qui motivera le locuteur à changer son comportement, par contre dire que ça facilite le travail de l’éboueur qu’on peut croiser de temps en temps dans sa rue sera bien plus efficace. Parce que la réussite « sauver le monde » est à la fois un défi trop important, quand bien même il serait réussi, il n’y aurait pas de feedback de réussite direct (« ah vous êtes le type qui avait eu une pratique écologique parfaite et depuis nous n’avons plus de pollution, merci beaucoup ! ») ; alors que voir les éboueurs de bonne humeur dans la rue parce qu’il n’y a pas de problème avec les poubelles et les déchets tels que les gens en ont pris soin, est un feedback directement visible, appréciable, concret.
☸ Soutenir l’autonomie (en n’étant pas contrôlant, en donnant des explications rationnelles et prosociales) est stratégiquement le plus approprié si on souhaite transmettre à la personne l’adoption d’un comportement à long terme, qui peut potentiellement « déborder » (Spill Over effect), c’est-à-dire entraîner un comportement analogue (par exemple on apprend un comportement écologique de tri, la personne va faire déborder ce comportement par elle-même en commençant à faire attention à sa production de déchets).
ℹ ⇢ Dolan et Galizzi (2015) ont constaté que cet effet de débordement est au plus fort lorsque les interventions visent la motivation intrinsèque ; et inversement, les interventions basées sur l’augmentation de la culpabilité ont les effets les plus négatifs.
La motivation intrinsèque + la motivation intégrée sont le carburant des résistants et génèrent, selon les situations, un courage, une créativité rebelle et une puissance exceptionnelle, qu’eux-mêmes ne comprennent pas quand elles adviennent2. En cela, il me semble que ce sont les motivations qu’on pourrait davantage tenter de nourrir lorsqu’on est militant ou engagé, puisqu’une seule personne avec une telle motivation peut transformer toute une situation concernant des centaines d’autres.
Un militantisme autodéterminateur plutôt que contrôlant
La théorie de l’autodétermination donne des outils vraiment très accessibles, testables, qui ont déjà démontré une forte efficacité. Mais avant de trop nous emballer, il y a malheureusement à se rappeler que même la militance la plus efficace ne pourra réparer immédiatement tout le mal que des décennies d’environnements sociaux déconnants ont pu générer, ni même réussir à combler les besoins d’individus qui sont encore aux prises d’environnements sociaux sapants. Un oncle peut arriver à rendre joyeux et libre son neveu, mais si l’enfant est battu par ses parents dès qu’il les retrouve, tout le travail de nourrissement des besoins par l’oncle est réduit en miettes. Parfois la meilleure aide à apporter à autrui est de l’aider à fuir des environnements sociaux destructifs, que ce soit la famille maltraitante, le travail où il y a harcèlement, ce village où il n’y a que surveillance, mépris et solitude, etc. Cet exemple peut apparaître éloigné des situations de militance, mais pas tant que ça : lorsqu’on discute, qu’on tente de comprendre l’adversaire ou le spectateur voulant rester dans sa routine et ne rien changer, ceux-ci nous décrivent rapidement des environnements sociaux dans lesquels ils sont sous emprise, parfois de manière très complexe, et dont on peut difficilement les aider à s’extirper pour de meilleurs environnements sociaux (par conséquent, le changement de comportement qu’on propose peut apparaître à la personne comme un effort trop grand, ou ridicule par rapport à la souffrance vécue).
Cependant, pour reprendre cette métaphore familiale, cet oncle qui aura rendu heureux cet enfant maltraité, quand bien même il n’a pas réussi pour le moment à trouver une solution pour libérer cet enfant, lui a tout de même offert un modèle d’environnement social sain, lui aura montré que les choses peuvent fonctionner d’une bien meilleure façon. Cet acte n’est absolument pas anodin, au contraire, il permet d’aider l’enfant à ne pas intérioriser le modèle maltraitant comme étant la bonne chose à reproduire (puisque le modèle concurrent est producteur de bonheur), et ça c’est extrêmement important pour le futur, pour son développement.
Voilà pourquoi ça vaut le coup d’essayer de nourrir les besoins fondamentaux des personnes, surtout dans un travail engagé/militant, quand bien même on n’arrive pas dans l’immédiat à résoudre les grands problèmes, ni à changer aucun comportement ou à convaincre. Il ne s’agit pas de placer un arbre de force, mais de distiller quelques graines ci et là. Si on a nourri un peu les besoins de la personne par notre écoute, c’est déjà beaucoup, parce que c’est montrer concrètement qu’un environnement social peut être nourrissant. Pour donner un exemple concret, des discussions sympas peuvent amener un adversaire à abandonner une idéologie qui le ravageait et se transformer : un incel3 raconte comment le fait d’avoir des discussions banales avec des féministes et autres personnes non-incel lui a apporté quelque chose de libérateur. Le fait de rencontrer d’autres environnements sociaux ne fonctionnant pas de la même manière peut constituer une expérience paradigmatique qui les transforment :
« Quand j’étais un incel je ne sortais jamais. Je n’avais jamais mis un pied dans un bar, un club, je ne connaissais rien de ce style de vie. Du coup, c’était facile de croire tout ce qui se racontait en ligne sur les bars, les clubs, les femmes, parce que je n’avais aucun élément de comparaison issu de la réalité qui m’aurait permis de séparer le vrai du faux.
La première fois que j’ai été dans un bar, j’ai vu un mec faisant bien 10 centimètres de moins que moi et le double de mon poids, installé dans le carré VIP avec plein de femmes sexy gravitant de son côté. Voir ça, ça a anéanti ma vision du monde. Parce que si on en croit la communauté des incels, ce que faisait ce mec, là, c’était littéralement impossible.
En gros, j’ai remplacé ce que j’ai appris des incels par des connaissances tirées d’expériences réelles. » (tiré de reddit.com, traduit par Madmoizelle.com)4.
Voilà ci-dessous tout ce que la théorie de l’autodétermination conseille pour nourrir les besoins et tout ce qui pourrait aider la personne à s’autodéterminer ; il y a aussi tout ce qu’il y a à ne pas faire car cela sape l’autodétermination, envoie les individus vers des motivations de basses qualités. Cependant, si vous êtes autoritaire et si vous visez le contrôle des individus afin d’en faire des pions, que vous avez d’énormes moyens afin de développer ce mode de contrôle (par exemple installer une surveillance massive de tout instant, embaucher de nombreux militants injonctiveurs tels que des chefs, sous-chefs, surveillants, contremaître, black hat trolls5, etc.), évidemment il serait incohérent de suivre les conseils autodéterminateurs puisque cela irait contre vos buts. À noter que ce ne sont pas des conseils juste lancés comme ça, tout a été testé par des expériences et études répliquées.
Recommandations de la SDT pour viser l’autodétermination (= motivation intrinsèque + motivation intégrée + besoins fondamentaux comblés + orientation autonome)
Ce qui aide à l’autodétermination et au bien-être des individus dans les environnements sociaux. (Environnements autodéterminants)
Ce qui empêche l’autodétermination, contribue au mal-être, et pousse les individus à être pion dans les environnements sociaux (Environnements contrôlants)
• Viser le bien-être
• Viser le comblement des besoins
• Chercher à ce que les individus soient autodéterminé, puissent s’émanciper grâce à nos apports ou être libres dans la structure (viser la préservation, le developpement, le maintien de la motivation intrinsèque, la régulation identifiée/intégrée, l’orientation autonome, l’amotivation pour les activités/comporte-ments sapant les besoins des autres/de soi)
• Formuler, transmettre, encourager et nourrir les buts et aspirations intrinsèques, montrer les possibilités de la situation
• Viser le mal-être
• Viser la frustration des besoins pour mieux déterminer son comportement/ses idées…
• Chercher à déterminer totalement les individus, a avoir un contrôle total sur eux (orientation contrôlée/impersonnelle, pas de motivation intrinsèque, introjection, régulation externe, amotivation pour les activi-tés/comportements nourrissant ses ou les besoins des autres)
• Formuler, transmettre, encourager et nourrir les buts et aspirations extrinsèques, éliminer/nier buts intrinsèques, montrer les impossibilités et les contrôles de la situation
Concevoir un environnement favorisant l’autonomie
Concevoir un environnement contrôlant
• transmission autonome de limites (pas de langage contrôlant ; reconnaissance des sentiments négatifs ; justification rationnelle et prosociale de la limite)
• proposition et soutien de vrais choix, pas simplement des options interchangeables
• fournir des explications claires et rationnelles
• permettre à la personne de changer la structure, le cadre, les habitudes si cela est un bienfait pour tous
• ne pas condamner les prises d’initiatives
• modèle horizontal, autogouverné, en appuyant sur le pouvoir constructif de chacun
• punitions
• transmission contrôlée des limites (langage contrôlant, déni des émotions, absence de justification)
• récompenses (conditionné à la performance, conditionnelles)
• mise en compétition menaçant l’ego
• surveillance
• notes / évaluations menaçant l’ego
• objectifs imposés/temps limité induisant une pression
• appuyer sur la comparaison sociale
• évaluation menaçant l’ego
• modèle de pouvoir hiérarchique, en insistant fortement sur son pouvoir dominant
Concevoir un environnement favorisant la proximité sociale
Concevoir un environnement niant le besoin de proximité sociale ou uniquement de façon conditionnelle
• faire confiance
• se préoccuper sincèrement des soucis ou problèmes de l’autre
• dispenser de l’attention et du soin
• exprimer son affection, sa compréhension
• partager du temps ensemble
• savoir s’effacer lorsque la personne n’a pas besoin de nous
• écouter
• ne jamais faire confiance
• être condescendant, exprimer du dédain envers les personnes
• terrifier les personnes
• montrer de l’indifférence pour les autres
• instrumentaliser les relations
• empêcher les liens entre les personnes de se faire
• comparaison sociale
• appuyer sur les mécanismes d’inflation de l’ego (l’orgueil, la fierté d’avoir dépassé les autres)
Concevoir un environnement favorisant la compétence
Concevoir un environnement défavorisant la compétence ou n’orientant que la compétence via la performance
• être clair sur les procédures, la structure, les attentes
• laisser à disposition des défis/tâches optimales, adaptables à chacun
• donner des trucs et astuces pour progresser
• permettre l’autoévaluation
• si besoin, proposer des récompenses « surprises » et congruentes (sans condition)
• donner des feed-back informatif, positif ou négatif, mais sans implication de l’ego.
• ne pas communiquer d’attentes claires, ni donner de structures ou procédures concernant les choses à faire
• donner des taches et défis inadaptés aux compétences des personnes voire impossible.
• Évaluer selon la performance
• donner des feedback menaçant l’ego de la personne (humiliation, comparaison sociale)
• donner des feedback flous sans informations
• traduire les réussites et échecs en terme interne allégeant.
• feed-back positif pour quelque chose de trop facile
• valoriser les signes extérieurs superficiels de réussite
Les recherches sur l’autodétermination démontrent que généralement les gens détectent et jugent très positivement les personnes à motivation intrinséque, passionnées, et souhaitant empuissanter autrui. Leur propre motivation intrinsèque augmente aussi via l’exposition à ces profils (que ce soit la ou le conjoint·e, les professeur·es, les coachs, les superviseurs, etc.). Cependant, s’ils sont contrôlants, sapent l’autonomie, cela ne marche pas du tout et fait l’effet inverse. Cf Deci, Schwartz, Sheinman et Ryan (1981) ; Ryan et Grolnick (1986) ; Deci et Ryan (2017).↩
Dans Un si fragile vernis d’humanité, banalité du mal, banalité du bien, Michel Terestchenko rapporte comment un routier, voyant une situation où un groupe de Juifs allait se faire expulser ou incarcérer en camp, s’est d’un coup fait passer pour un diplomate auprès des nazis et a pu interdire aux autorités de nuire à ce groupe. Il a fait ça sans l’avoir prémédité. On trouve quantité d’actes non prémédités d’altruisme hautement stratégique et très efficace également dans « Altruistic personnality » des Oliner (dont on a traduit des morceaux ici ; globalement, cela semble dû à un altruisme à motivation intégrée, ou à une amotivation autodéterminée à faire du mal qui a été forgée dans le passé, notamment grâce au fait que les désobéissants aient eu au moins un proche ou un ami nourrissant leurs besoins fondamentaux et présentant concrètement des actes altruistes.↩
Idéologie anti-femme / anti-couples qui considère (entre autres) que seuls certains hommes exceptionnellement beaux ou riches attireront les femmes, donc qu’ils seront célibataires à jamais. Il y a aussi chez eux un rejet des femmes non-blanches et/ou non-blondes, un rejet des femmes ne suivant pas un modèle traditionnel (par exemple, si elles travaillent, si elles ont fait des études), un rejet du fait qu’elles puissent être des personnes (l’incel considére que s’il rend service à une femme, elle doit coucher avec lui ; il y a une infériorisation de la femme et une objectivation). Ils disent haïr les femmes tout en disant crever d’envie d’être en couple avec elles. Les incels ont commis des tueries de masse à l’encontre des couples et des femmes, cf. le listing sur Wikipédia (il est malheureusement régulièrement mis à jour).↩
Ou « farfadet de la dialectique à chapeau noir ». Ceci n’est pas un terme de l’Académie française pour troll, mais une proposition d’un internaute qui a répertorié d’autres propositions ici.↩
(à suivre…)
Si vous trouvez ce dossier intéressant, vous pouvez témoigner de votre soutien aux travaux de Hacking Social par un don sur tipee ou sur Liberapay
Quand le militantisme déconne : injonctions, pureté militante, attaques… (6/8)
La question compliquée et parfois houleuse du militantisme nous intéresse depuis longtemps à Framasoft, aussi avons-nous demandé à Viciss de Hacking Social, de s’atteler à la tâche.
Voici déjà le sixième épisode [si vous avez raté les épisodes précédents] de son intéressante contribution, dans laquelle elle examine des causes classiques ou plus inattendues du militantisme déconnant.
Nous publions un nouveau chapitre de son travail chaque vendredi à 13:37 sur le Framablog, mais si vous préférez, vous pouvez télécharger dès maintenant l’essai intégral de Viciss qui comprend une bibliographie revue et augmentée :
Quand on est surmené, on essaye de régler les problèmes au plus vite pour en traiter d’autres plus urgents, donc il est totalement logique qu’on en vienne à être plus sec dans notre ton, qu’on ait plus tendance à l’injonction pour obtenir de l’autre un comportement immédiat afin qu’il cesse de nous solliciter. Le problème ce n’est ni nous, ni l’autre qui sollicite ou fait un truc pour lequel on va l’injonctiver en réaction, mais bien la situation de surmenage. Or, c’est extrêmement courant en militance, parce que les mouvements n’ont pas souvent les moyens de gérer tout ce qu’il y a à gérer, parce que la militance mène à affronter des situations particulièrement surmenantes, stressantes, parfois oppressantes et violentes. Et même lorsque la situation surmenante est loin derrière, il y a toujours cette menace qu’elle revienne sous peu, d’autant qu’elle laisse souvent des traces. En conséquence, notre cerveau maintient ce mode « sous tension » par prévention, parce que cela s’est avéré une manière efficace de gérer le moment tendu.
Autrement dit, dans ce cas de figure ce n’est ni la faute du militant, ni de l’allié qui faute ou qui aurait un comportement qui va générer une critique, mais bien un problème situationnel qui demande des solutions organisationnelles. La situation d’urgence, de surmenage peut être inévitable, en ce cas, l’idéal est d’avoir un mode de fonctionnement préétabli pour ces situations particulières, et d’autres modes de fonctionnement pour les autres situations. Ce n’est pas forcément incohérent d’avoir un mode plus « hiérarchique » dans une situation de forte confrontation avec l’adversaire, avec des règles plus serrées, parce que la violence ou les risques peuvent obliger à cela, et parfois le rôle donné à chacun dans un groupe peut avoir des effets protecteurs ; parmi les hackers, j’ai pu voir à l’œuvre à la fois un mode quasi-militaire lors d’opérations risquées impliquant beaucoup de monde, avec des instructions très strictes qui ne laissaient pas de place à de l’initiative personnelle, parce que c’était à la fois le moyen de mener à bien l’opération et de protéger tout le monde de risques très concrets. Mais dès que l’opération était terminée, l’autogestion sans chef, do-ocrate (le pouvoir à celui qui fait/initie un projet), anti-autoritaire, reprenait le dessus pour fomenter de nouvelles opérations. Il s’agit de pouvoir switcher, être flexible dans l’organisation et dans les modes d’agir afin de coller aux besoins particuliers de la situation, et ne pas rester en mode « menaces » lorsque celles-ci ne sont pas présentes.
Quoi qu’il en soit, le surmenage et les dérives que cela entraîne ne peuvent être résolus que par des modes d’organisation qui sont pensés en fonction des situations. Cela n’est pas un problème qui peut être résolu en se focalisant sur un individu « fautif ».
Le manque d’information
Pour reprendre l’exemple de « vous connaissez PeerTube ? » qu’on a eu des centaines de fois, c’était saoulant non pas parce que les gens l’étaient, mais parce qu’il leur manquait l’information que nous étions déjà partisans de PeerTube, que nous avions déjà nos vidéos sur des instances, que des dizaines d’individus avant eux n’arrêtaient pas de nous le dire, et qu’ils ne devinaient pas eux-mêmes qu’il leur manquait ces informations. Et si nous l’avions répété sans cesse, nous aurions été nous-mêmes saoulants, c’est pourquoi nous ne l’avons pas fait. J’ai vu aussi le même genre de problème chez des individus participant à des formes de cancel culture1 – malgré eux : ils se permettaient une certaine agressivité se pensant seuls dans les commentaires à avoir ce ton et ne se rendant pas compte qu’ils contribuaient à rejoindre une meute qui attaquait déjà de toutes parts sur le même ton.
Avant de conseiller, ordonner, critiquer, s’énerver contre quelqu’un ou un groupe, on pourrait tenter de s’informer au préalable des positions de la personne qu’on cible, en regardant ce qu’elle a pu déjà répondre par le passé à ce sujet, si elle a parlé de ses positions quelque part, si elle n’a pas déjà fait ce qu’on voudrait qu’elle fasse, etc. Parfois, cela suffira à combler le manque d’informations et il n’y aura pas besoin d’interpeller la personne (par exemple, on pourra voir qu’elle connaît déjà PeerTube ou qu’elle a déjà exprimé son choix pour/contre en public).
Il s’agirait avant toute interaction de partir du principe qu’on ne sait pas d’emblée les positions des personnes, leur savoir ou leur ignorance d’un sujet, mais d’enquêter avant.
Cela peut fonctionner en situation où l’on initie l’interaction avec un autre sur le Net, comme dans une situation où l’on est attaqué par un autre. Même si on repère que l’autre veut par exemple nous humilier ou nous écraser, on peut partir du principe que ce n’est peut-être pas ça, et tout simplement poser des questions pour bien comprendre sa position2. Par exemple « Vous me dites que d’avoir mis le mot « bonheur » dans ce titre est odieux et insupportable, quel est l’élément associé à bonheur qui vous parait odieux ? » et on cherche à comprendre ce qui a éveillé le sentiment négatif chez l’autre, on enquête sans jugement ni défensivité. Cela peut lever pas mal de malentendus et pacifier l’échange.
Sur Internet, le manque d’informations c’est aussi l’absence de langage non verbal (absence du ton de la voix, des mimiques de visage, des gestes du corps, etc.). Ainsi, on a tous un déficit d’informations parfois énorme sur l’état émotionnel dans lequel a été posté un message et dans quelle visée. Et encore une fois, on oublie totalement qu’il nous manque quantité d’informations pour interpréter ce message parce qu’IRL, lorsqu’on est neurotypique, on a l’habitude d’avoir toutes ces informations automatiquement sans qu’on en ait conscience. Sur la toile, on va alors avoir le même réflexe et interpréter le message automatiquement, en voyant une offense dans une ironie, en voyant de l’ironie dans un message pourtant sérieux, etc. Pour pallier ce manque d’informations non verbales, on va se concentrer sur d’autres indices tels que la ponctuation, y plaquant un sens qui n’est pourtant pas celui du locuteur. D’autant que l’usage et la connotation des ponctuations varient selon des facteurs socio-culturels, tels que l’âge de la personne : les boomers pourront avoir tendance par exemple à terminer tous leurs tweets d’un point, selon l’usage « académique » qu’ils ont profondément intériorisé, sans exclamation ni smiley3, ce qui pourra donner l’impression, selon le propos tenu, à un ton brutal, voire un mode passif-agressif, alors qu’il s’agissait parfois tout simplement d’une volonté de soigner son écriture, sans froisser son interlocuteur. Même chose pour l’usage des points de suspension dans un message, qui pourra être utilisé différemment et suggérer de multiples interprétations contradictoires… On se focalise sur ces petits détails, car on cherche une substitution à ce langage non-verbal qui nous manque cruellement. S’ensuivent donc quantité de malentendus de toutes parts.
Là encore, on peut prévenir la situation en étant très explicite lorsqu’on s’exprime, avec tout ce qu’on a disposition (smiley, formulation de politesse, soin aux styles de la phrase, mots, expression explicite de son émotion/son état/ses buts, etc.).
Ou encore lorsqu’on est l’interlocuteur, demander des précisions sur le message, poser des questions jusqu’à être sûr de bien comprendre, avant de juger son but. Ça peut paraître long dit comme ça, mais en fait poser une question ce n’est parfois qu’une seule phrase. Et parfois la réponse suffit à se faire une idée.
« Ambassadeur : Honte et fierté mélangées. Nos ennemis nous ont appelés « tanks vivants ». Ainsi que par des noms moins flatteurs. » On peut même s’amuser à utiliser la méthode Elcor (dans les jeux Mass Effect, les Elcors sont des êtres qui ne peuvent partager une communication non-verbale avec les autres espèces, ni même faire transparaître leurs émotions dans leurs voix ; pour pallier ce manque, ils commencent systématiquement leur propos par un mot qui donnera la bonne teinte émotionnelle à leur discours). D’autres exemples ici.
La réaction à la notoriété bizarre du Net : les relations parasociales
C’est un terme qui a été formulé en 1956 par Horton et Wohl pour décrire les relations unilatérales d’un·e artiste avec son public : les spectateurs peuvent se sentir comme amis avec ceux-ci, donc croire tout connaître de lui, alors qu’en fait non. Aujourd’hui, ce type de relations est encore plus répandu parce qu’on peut tous être cet « artiste » qui envoie ou partage du contenu avec une communauté qui le suit.
D’une part, la personne qui une petite ou grande notoriété sur le Net ne sait rien de vous et ne peut rien déduire de votre comportement habituel (par exemple, elle ne peut pas savoir que lorsque vous employez des injures, c’est du second degré ou une marque d’amitié ; elle ne sait pas que vous êtes peu versé dans les formules de politesse mais néanmoins cordial), elle peut donc difficilement interpréter des remarques qui seraient à double sens, encore plus sans avoir accès à votre langage non verbal pour comprendre. Le militant déconnant peut croire que cette personne à notoriété va parfaitement le comprendre, qu’il est sympa d’office, qu’importe le style du message, parce que lui, il la connaît bien mais oublie qu’elle, elle ne le connaît pas du tout. Et là peuvent se créer de très forts malentendus.
D’autre part, en tant que spectateur, bien qu’on ait ce sentiment de familiarité avec la personne à notoriété, on ne la connaît pas du tout : on ne peut pas savoir si elle est en dépression ou si elle traverse une phase difficile, elle peut très bien partager quelque chose de sombre tout en étant dans une situation joyeuse dans son quotidien, tout comme partager de la joie en broyant du noir. Là encore, avant d’entamer une démarche qui risque potentiellement d’être dure à digérer pour l’autre, on peut poser des questions, « tâter le terrain » pour savoir si c’est le bon moment ou non de parler de telle chose ; on peut aussi se rappeler qu’on ne connaît la personne qu’à travers son travail/œuvre/partage, pas sa vie tout entière qui peut être radicalement différente. Même des vlogs réguliers qui pourtant renseignent sur la vie de la personne sont sélectifs, ne sont qu’un aperçu de sa vie, ce qu’elle accepte de montrer. Tout comme on ne peut déduire le bien-être d’un vendeur de sandwichs à la qualité dudit sandwich (qui peut par exemple avoir été cuisiné sous une pression énorme), on ne peut pleinement déduire l’état d’esprit d’un partageur à son seul partage. Pour connaître un peu le milieu, je dirais que lorsque vous vous adressez un partageur/créateur sur le Net, il est probable qu’il est en dépression, en burn-out ou surmené, qu’importe la vivacité dont il peut faire preuve dans ses œuvres. Il serait plus prudent d’éviter de partir du principe qu’il peut encaisser toutes les récriminations.
L’autre aspect de cette relation parasociale, c’est que parfois, les spectateurs confondent ces petites célébrités du Net avec les célébrités classiques : c’est-à-dire qu’ils partent du principe que la notoriété est accompagnée d’un statut supérieur (plus de pouvoir, plus de possibilités, plus d’argent, plus de moyens, plus d’influence, etc.), donc qu’elles auraient en quelque sorte pour devoir d’utiliser ce trop-plein de privilèges qu’il leur serait offert, notamment pour vanter ou exercer une pureté militante. Or, même des gens qui ont une forte audience sur le Net peuvent n’avoir aucun privilège matériel par rapport au spectateur moyen, peuvent toujours être salarié smicard, au chômage, voire dans des situations de grande pauvreté, de sérieuses difficultés. Et vous n’en saurez généralement rien.
Cependant je comprends, ça peut être trompeur qu’une petite célébrité sur le Net en galère au quotidien puisse avoir le même nombre de followers4 qu’une petite célébrité de la télévision qui elle, peut avoir des moyens plus importants, le soutien d’une structure, des relations qui la mettent à l’abri, etc. Bref, la notoriété du Net doit être déconnectée dans nos représentations des privilèges, car la notoriété sur la toile n’est pas synonyme d’avantages matériels ou sociaux5.
La suspicion d’infiltrés/d’ennemis
L’infiltration dans un groupe militant est malheureusement une pratique existante, d’autant plus sur le Net où il est souvent facile de rejoindre le Discord d’un autre groupe militant pour glaner des informations ou pour troller en interne (ce que l’on peut retrouver par exemple dans des groupes politiques fortement engagés, notamment entre fascistes et anti-fascistes). La suspicion d’infiltrés (ou la présence effective de ceux-ci) peut nous faire nous méfier des alliés, des spectateurs, et nous mettre en mode paranoïa. C’est un cercle vicieux terrible, et j’avoue que je n’ai pas la solution contre cela d’autant que je l’ai malheureusement déjà vécu dans certains mouvements (présence réelle d’infiltrés professionnels, confirmée par des leaks découverts plus tard et publiés dans certains médias). L’idée serait peut-être de se concentrer davantage sur les actions qui sont proposées, de les évaluer au regard du mouvement et des buts de celui-ci, ce qui permettrait d’éviter des catastrophes. Les infiltrés ou individus malveillants auront tendance à diviser, créer des conflits internes, proposer de s’attaquer aux alliés et spectateurs, chercher à obtenir des postes à pouvoir de décisions, épuiser les éléments les plus doués, proposer des actions honteuses/inefficaces qui ne permettent pas de se confronter à l’adversaire. Donc, ce n’est pas tant qu’il faudrait le traquer pour le virer, mais davantage prendre soin des alliés, des spectateurs car c’est une politique plus puissamment établie : ces projets saboteurs ne seront alors pas suivis parce qu’ils apparaîtront incohérents, inadaptés.
La suspicion qu’il y ait des infiltrés ou qu’untel ait des projets malveillants ou potentiellement destructeurs pour le groupe (par exemple, un membre qu’on pense vouloir nuire au mouvement suite à un conflit mal résolu en interne, ce qui arrive assez fréquemment : tout militant d’expérience aura sans doute en mémoire l’exemple d’un ancien camarade qui, sous l’effet du ressentiment, a pu se mettre à saper activement un mouvement ou à vouloir nuire à ses membres) peut également n’être qu’une simple suspicion qui s’avérera plus tard infondée, et ça serait dommage que l’activité militante soit détournée juste parce qu’on est en mode méfiance et qu’on a peur des menaces internes. Cependant, là aussi, je pense qu’on peut tenter d’éviter les problèmes en se concentrant sur les actions au cœur du mouvement, celles qui sont les plus concrètes et les plus cohérentes.
« Cancel culture » : « pratique qui consiste à dénoncer des individus (ou structures) dans le but de les ostraciser ». Plus d’infos sur Wikipédia, ou sur Neonmag.↩
Ici, je me base sur les pratiques et méthodes de Carl Rogers, psychologue humaniste qui visait l’empuissantement et l’autodétermination des personnes, tant dans des contextes thérapeutiques, de groupes aux buts divers (académique, religieux, politique à visée de résolution de conflits, etc.). Ces écrits sont particulièrement accessibles, y compris pour les personnes non formées à la psychologie, notamment ses ouvrages Liberté pour apprendre, Le développement de la personne.↩
Si vous êtes acolyte des illustres de l’académie française, vous devez dire « binette » ou « frimousse » pour désigner un smiley.↩
Follower = « acolyte des illustres » si votre allégeance va à l’Académie française, quoique je pense qu’elle se fout un peu de la gueule des personnes utilisant Internet, voire de la population tout court, quand on voit qu’elle a rejeté l’usage commun du masculin pour « covid » à la grande joie des Grammar Nazis qui auront une occasion supplémentaire de corriger leurs interlocuteurs. Voir l’explication de l’académie sur cette traduction ; on pourrait dire « abonnés » mais il me semble que cela reste trop associé à l’image de quelqu’un qui a acheté un abonnement pour accéder à un contenu. Le terme « adepte » est utilisé aussi par bing, mais là encore il me semble que cela nous renvoie à une image erronée du follower (qui n’est pas forcément partisan du contenu suivi, encore moins fidèle à lui comme il le serait d’une religion).↩
Une étude sur les vulgarisateurs le montre bien : « Frontiers. French Science Communication on YouTube : A Survey of Individual and Institutional Communicators and Their Channel Characteristics Communication », frontiersin.org ; ou en vidéo : Analyse des vulgarisateurs scientifiques sur Youtube ; ou dans ce thread : « On a analysé plus de 600 chaînes et 70 000 vidéos de vulgarisation scientifique en français, et complété cette analyse par un sondage auprès de 180 youtubeurs. Nos résultats (avec @SciTania @MasselotPierre @tofu89) viennent d’être publiés dans Frontiers in communication », Stéphane Debove sur Twitter ; par exemple seul 12 % des vulgarisateurs (sur 600 chaînes françaises) gagnent plus de 1000 euros par mois, 44 % ne gagnent rien du tout.↩
(à suivre…)
Si vous trouvez ce dossier intéressant, vous pouvez témoigner de votre soutien aux travaux de Hacking Social par un don sur tipee ou sur Liberapay
Apple veut protéger les enfants mais met en danger le chiffrement
Apple vient de subir un tir de barrage nourri de la part des défenseurs de la vie privée alors que ce géant du numérique semble animé des intentions les plus louables…
Qui oserait contester un dispositif destiné à éradiquer les contenus incitant à des abus sexuels sur les enfants ? Après tout, les autres géants du numérique, Google et Microsoft entre autres, ont déjà des outils de détection pour ces contenus (voir ici et là )… Alors comment se fait-il que la lettre ouverte que nous traduisons ici ait réuni en quelques heures autant de signatures d’organisations comme d’individus, dont Edward Snowden ?
Deux raisons au moins.
D’abord, Apple a construit sa réputation de protecteur intransigeant de la vie privée au point d’en faire un cheval de bataille de sa communication : « Ce qui se passe dans votre iPhone reste sur votre iPhone ». Souvenons-nous aussi qu’en février 2016 Apple a fermement résisté aux pressions du FBI et de la NSA qui exigeaient que l’entreprise fournisse un logiciel de déchiffrement des échanges chiffrés (un bon résumé par ici). La surprise et la déception sont donc grandes à l’égard d’un géant qui il y a quelques années à peine co-signait une lettre contre la loi anti-chiffrement que des sénateurs états-uniens voulaient faire passer.
Mais surtout, et c’est sans doute plus grave, Apple risque selon les experts de mettre en péril le chiffrement de bout en bout. Alors oui, on entend déjà les libristes ricaner doucement que c’est bien fait pour les zélateurs inconditionnels d’Apple et qu’ils n’ont qu’à renoncer à leur dispendieuse assuétude… mais peu nous importe ici. Le dispositif envisagé par Apple aura forcément des répercussions sur l’ensemble de l’industrie numérique qui ne mettra que quelques mois pour lui emboîter le pas, et en fin de compte, toute personne qui souhaite protéger sa vie privée sera potentiellement exposée aux risques que mentionnent les personnalités citées dans cette lettre ouverte…
Lettre ouverte contre la technologie de l’analyse du contenu d’Apple qui porte atteinte à la vie privée
Des experts en sécurité et en protection de la vie privée, des spécialistes en cryptographie, des chercheurs, des professeurs, des experts juridiques et des utilisateurs d’Apple dénoncent le projet lancé par Apple qui va saper la vie privée des utilisateurs et le chiffrement de bout en bout.
Cher Apple,
Le 5 août 2021, Apple a annoncé de nouvelles mesures technologiques censées s’appliquer à la quasi-totalité de ses appareils sous le prétexte affiché de « Protections étendues pour les enfants ».
Bien que l’exploitation des enfants soit un problème sérieux, et que les efforts pour la combattre relèvent incontestablement d’intentions louables, la proposition d’Apple introduit une porte dérobée qui menace de saper les protections fondamentales de la vie privée pour tous les utilisateurs de produits Apple.
La technologie que se propose d’employer Apple fonctionne par la surveillance permanente des photos enregistrées ou partagées sur l’iPhone, l’iPad ou le Mac. Un système détecte si un certain nombre de photos répréhensibles sont repérées dans le stockage iCloud et alerte les autorités. Un autre système avertit les parents d’un enfant si iMessage est utilisé pour envoyer ou recevoir des photos qu’un algorithme d’apprentissage automatique considère comme contenant de la nudité.
Comme les deux vérifications sont effectuées sur l’appareil de l’utilisatrice, elles ont le potentiel de contourner tout chiffrement de bout en bout qui permettrait de protéger la vie privée de chaque utilisateur.
Dès l’annonce d’Apple, des experts du monde entier ont tiré la sonnette d’alarme car les dispositifs proposés par Apple pourraient transformer chaque iPhone en un appareil qui analyse en permanence toutes les photos et tous les messages qui y passent pour signaler tout contenu répréhensible aux forces de l’ordre, ce qui crée ainsi un précédent où nos appareils personnels deviennent un nouvel outil radical de surveillance invasive, avec très peu de garde-fous pour empêcher d’éventuels abus et une expansion déraisonnable du champ de la surveillance.
« Il est impossible de construire un système d’analyse côté client qui ne puisse être utilisé que pour les images sexuellement explicites envoyées ou reçues par des enfants. En conséquence, même un effort bien intentionné pour construire un tel système va rompre les promesses fondamentales du chiffrement de la messagerie elle-même et ouvrira la porte à des abus plus importants […] Ce n’est pas une pente glissante ; c’est un système entièrement construit qui n’attend qu’une pression extérieure pour apporter le plus petit changement. »
Le Center for Democracy and Technology a déclaré qu’il était « profondément préoccupé par les changements projetés par Apple qui créent en réalité de nouveaux risques pour les enfants et tous les utilisateurs et utilisatrices, et qui représentent un tournant important par rapport aux protocoles de confidentialité et de sécurité établis de longue date » :
« Apple remplace son système de messagerie chiffrée de bout en bout, conforme aux normes de l’industrie, par une infrastructure de surveillance et de censure, qui sera vulnérable aux abus et à la dérive, non seulement aux États-Unis, mais dans le monde entier », déclare Greg Nojeim, codirecteur du projet Sécurité et surveillance de la CDT. « Apple devrait abandonner ces changements et rétablir la confiance de ses utilisateurs dans la sécurité et l’intégrité de leurs données sur les appareils et services Apple. »
Le Dr. Carmela Troncoso, experte en recherche sur la sécurité et la vie privée et professeur à l’EPFL à Lausanne, en Suisse, a déclaré que « le nouveau système de détection d’Apple pour les contenus d’abus sexuel sur les enfants est promu sous le prétexte de la protection de l’enfance et de la vie privée, mais il s’agit d’une étape décisive vers une surveillance systématique et un contrôle généralisé ».
Matthew D. Green, un autre grand spécialiste de la recherche sur la sécurité et la vie privée et professeur à l’université Johns Hopkins de Baltimore, dans le Maryland, a déclaré :
« Hier encore, nous nous dirigions peu à peu vers un avenir où de moins en moins d’informations devaient être contrôlées et examinées par quelqu’un d’autre que nous-mêmes. Pour la première fois depuis les années 1990, nous récupérions notre vie privée. Mais aujourd’hui, nous allons dans une autre direction […] La pression va venir du Royaume-Uni, des États-Unis, de l’Inde, de la Chine. Je suis terrifié à l’idée de ce à quoi cela va ressembler. Pourquoi Apple voudrait-elle dire au monde entier : « Hé, nous avons cet outil » ?
« Si Apple réussit à introduire cet outil, combien de temps pensez-vous qu’il faudra avant que l’on attende la même chose des autres fournisseurs ? Avant que les applications qui ne le font pas ne soient interdites par des murs de protection ? Avant que cela ne soit inscrit dans la loi ? Combien de temps pensez-vous qu’il faudra avant que la base des données concernées soit étendue pour inclure les contenus « terroristes » ? « les contenus « préjudiciables mais légaux » ? « la censure spécifique d’un État ? »
Le Dr Nadim Kobeissi, chercheur sur les questions de sécurité et de confidentialité, a averti :
« Apple vend des iPhones sans FaceTime en Arabie saoudite, car la réglementation locale interdit les appels téléphoniques chiffrés. Ce n’est qu’un exemple parmi tant d’autres où Apple s’est plié aux pressions locales. Que se passera-t-il lorsque la réglementation locale en Arabie Saoudite exigera que les messages soient scannés non pas pour des abus sexuels sur des enfants, mais pour homosexualité ou pour offenses à la monarchie ? »
La déclaration de l’Electronic Frontier Foundation sur la question va dans le même sens que les inquiétudes exposées ci-dessus et donne des exemples supplémentaires sur la façon dont la technologie proposée par Apple pourrait conduire à des abus généralisés :
« Prenez l’exemple de l’Inde, où des règlements récemment adoptés prévoient des obligations dangereuses pour les plateformes d’identifier l’origine des messages et d’analyser préalablement les contenus. En Éthiopie, de nouvelles lois exigeant le retrait des contenus de « désinformation » sous 24 heures peuvent s’appliquer aux services de messagerie. Et de nombreux autres pays – souvent ceux dont le gouvernement est autoritaire – ont adopté des lois comparables. Les changements projetés par Apple permettraient de procéder à ces filtrages, retraits et signalements dans sa messagerie chiffrée de bout en bout. Les cas d’abus sont faciles à imaginer : les gouvernements qui interdisent l’homosexualité pourraient exiger que l’algorithme de classement soit formé pour restreindre le contenu LGBTQ+ apparent, ou bien un régime autoritaire pourrait exiger que le qu’il soit capable de repérer les images satiriques populaires ou les tracts contestataires. »
En outre, l’Electronic Frontier Foundation souligne qu’elle a déjà constaté cette dérive de mission :
« L’une des technologies conçues à l’origine pour scanner et hacher les images d’abus sexuels sur les enfants a été réutilisée pour créer une base de données de contenus « terroristes » à laquelle les entreprises peuvent contribuer et accéder dans l’objectif d’interdire ces contenus. Cette base de données, gérée par le Global Internet Forum to Counter Terrorism (GIFCT), ne fait l’objet d’aucune surveillance externe, malgré les appels lancés par la société civile. »
Des défauts de conception fondamentaux de l’approche proposée par Apple ont été soulignés par des experts, ils affirment que « Apple peut de façon routinière utiliser différents ensembles de données d’empreintes numériques pour chaque utilisatrice. Pour un utilisateur, il pourrait s’agir d’abus d’enfants, pour un autre, d’une catégorie beaucoup plus large », ce qui permet un pistage sélectif du contenu pour des utilisateurs ciblés.
Le type de technologie qu’Apple propose pour ses mesures de protection des enfants dépend d’une infrastructure extensible qui ne peut pas être contrôlée ou limitée techniquement. Les experts ont averti à plusieurs reprises que le problème n’est pas seulement la protection de la vie privée, mais aussi le manque de responsabilité de l’entreprise, les obstacles techniques au développement, le manque d’analyse ou même de prise en considération du potentiel d’erreurs et de faux positifs.
Kendra Albert, juriste à la Harvard Law School’s Cyberlaw Clinic, a averti que « ces mesures de « protection de l’enfance » vont faire que les enfants homosexuels seront mis à la porte de leur maison, battus ou pire encore », […] Je sais juste (je le dis maintenant) que ces algorithmes d’apprentissage automatique vont signaler les photos de transition. Bonne chance pour envoyer une photo de vous à vos amis si vous avez des « tétons d’aspect féminin » ».
Ce que nous demandons
Nous, les soussignés, demandons :
L’arrêt immédiat du déploiement par Apple de sa technologie de surveillance du contenu proposée.
Une déclaration d’Apple réaffirmant son engagement en faveur du chiffrement de bout en bout et de la protection de la vie privée des utilisateurs.
La voie que choisit aujourd’hui Apple menace de saper des décennies de travail effectué par des spécialistes en technologies numériques, par des universitaires et des militants en faveur de mesures strictes de préservation de la vie privée, pour qu’elles deviennent la norme pour une majorité d’appareils électroniques grand public et de cas d’usage. Nous demandons à Apple de reconsidérer son déploiement technologique, de peur qu’il ne nuise à cet important travail.
Quand le militantisme déconne : injonctions, pureté militante, attaques… (5/8)
La question compliquée et parfois houleuse du militantisme nous intéresse depuis longtemps à Framasoft, aussi avons-nous demandé à Viciss de Hacking Social, de s’atteler à la tâche.
Voici déjà le cinquième épisode [si vous avez raté les épisodes précédents] de son intéressante contribution, dans laquelle elle examine les différentes facettes de la motivation et comment le militantisme déconnant les dégrade.
Nous publions un nouveau chapitre de son travail chaque vendredi à 13:37 sur le Framablog, mais si vous préférez, vous pouvez télécharger dès maintenant l’essai intégral de Viciss qui comprend une bibliographie revue et augmentée :
Le militantisme déconnant causant une motivation de piètre qualité
Ce sapage des besoins fondamentaux (tant du militant déconnant dans son passé, que chez la cible qu’il vise) va ensuite générer chez celui qui en est cible une motivation de piètre qualité, que sont les régulations introjectées, externes ou une amotivation non autodéterminée.
En jaune les motivations qui naissent de situations répétées où nos besoins ont été comblés (ou non sapés) et en mauve les motivations issues des situations répétées où nos besoins ont été sapés (ou non nourris).
La motivation intrinsèque, détruite par le militantisme contrôlant
La motivation intrinsèque est la motivation la plus puissante qu’on puisse avoir pour quelque chose : c’est la passion, cette activité qu’on fait pour elle-même, qui nous ravit, nous comble, pour laquelle on rêverait de faire carrière. De façon moins épique, toutes les activités qu’on fait pour elles-mêmes et non pour ses résultats sont généralement réalisées par motivation intrinsèque (jouer aux jeux vidéo, regarder des séries, lire, se balader… bref tout ce qu’on peut aimer faire en soi). C’est puissant, parce que l’élan l’est, qu’il n’y a besoin de rien de plus pour nous motiver à la faire.
Or, nos environnements sociaux, s’ils ont un modèle contrôlant sapant les besoins fondamentaux, ont tendance à détruire nos motivations intrinsèques.
ℹ ⇢ Dans une expérience de Deci, Schwartz, Sheinman et Ryan (1981), 36 professeurs ont été étudiés durant l’été, avant la rentrée scolaire. Il a été testé leur orientation de causalité1 (qui était soit autonome soit contrôlée), les actions qu’ils envisageaient pour le contrôle des élèves (punir, récompenser) ou les actions de soutien (écoute du problème, guide pour le résoudre). À 2 mois de l’année scolaire entamée puis à 8 mois, leurs élèves ont complété des enquêtes évaluant leur motivation et leur perception de soi. Ceux qui avaient eu les professeurs les plus contrôlants avaient une motivation intrinsèque en chute, une estime de soi en baisse et leurs compétences cognitives avaient également chuté. Ces élèves avaient moins de curiosité quant au travail scolaire, ils préféraient les tâches faciles plutôt que difficiles, faisaient preuve de moins d’initiatives scolaires. Ils ont renouvelé cette étude dans un autre district scolaire. Ils ont sélectionné des professeurs soit hautement contrôlants soit soutenant l’autonomie. La motivation intrinsèque des élèves a été testée durant la 2e semaine d’école puis deux mois plus tard. Avec les enseignants soutenant l’autonomie, la motivation intrinsèque a augmenté, ainsi que la compétence perçue. C’était le contraire avec les professeurs contrôlants.
Plus précisément, les façons de faire contrôlantes nous dégoûtent de ce qu’on aimait naturellement faire, puisque la motivation intrinsèque chute lorsqu’on est surveillé2, menacé de punition3, qu’on a un objectif et un temps d’exécution limités4, qu’on est mis en compétition5, évalué avec des feedbacks négatifs6, qu’il y a la présence de personnes totalement indifférentes à notre activité7, qu’on est récompensé⋅e selon une performance donnée8 (par exemple, avoir son salaire/son cadeau/un compliment uniquement si on atteint une performance demandée par le superviseur ; le salaire ne sape pas la motivation intrinsèque s’il est prévu en amont, qu’importent les performances).
À l’inverse, lorsqu’on vise la préservation de la motivation intrinsèque avec sa transmission (par exemple, un militant qui montre tout le fun qu’il y a à une pratique écolo), alors la personne a tendance à s’engager et il y a un effet de débordement9 (ici, elle se mettrait d’elle-même à chercher d’autres pratiques écolos qui pourraient être tout aussi fun). C’est plaisant pour tout le monde, efficace en termes de militance, pas plus coûteux que d’injonctiver.
Pourtant, le militant aux pratiques déconnantes va plutôt reproduire le modèle de contrôle (et pas celui de la transmission de la motivation intrinsèque), quand bien même ce modèle a détruit certaines de ces plus belles motivations par le passé10. Pourquoi ? Eh bien parce qu’en plus de détruire notre motivation intrinsèque, ce vécu sous modèle contrôlant peut nous plonger dans des motivations contrôlées de l’extérieur, par exemple la motivation introjectée : l’enfant dans la classe au professeur contrôlant perd non seulement sa motivation intrinsèque, mais cherchant à réussir les objectifs pour ne pas être ostracisé, humilié, il fait alors tout pour éviter la honte, la culpabilité, etc. C’est pourquoi l’estime de soi chute : les résultats scolaires « mauvais » sont sans doute accompagnés des remarques négatives et de la dévalorisation de la part du professeur. Tout jugement militant puriste peut voir des effets similaires sur une personne visée.
La motivation à régulation introjectée, celle du militant déconnant ?
À force d’être dans des environnements qui tentent de contrôler notre comportement, notre comportement général est complètement guidé par le potentiel jugement de l’extérieur, sans même qu’une autorité soit présente : on fait alors les choses prioritairement pour éviter d’avoir honte, de se sentir coupable, d’être pointé du doigt, de perdre encore de la valeur auprès des autres, d’être marginalisé, ridiculisé, etc. La motivation introjectée est la plus répandue chez les personnes, pour à peu près n’importe quelle activité.
Le militant déconnant peut provoquer une motivation introjectée chez autrui en étant contrôlant : « je vais éviter de faire des fautes, sinon les grammar nazis vont encore me tomber dessus », il n’y a aucune motivation intrinsèque qui guide ce comportement (telle que « je ressens de la satisfaction à écrire sans fautes ») ni intégrée (« je vais tenter d’écrire sans fautes pour que les autres comprennent bien mon message »). S’il n’y avait pas de grammar nazi, alors cette personne à motivation introjectée cesserait de faire attention, ce qui signifie que la valeur intrinsèque à l’orthographe n’était absolument pas transmise. Mais on voit bien là-dedans que les militants déconnants vont interpréter ce constat comme une justification de leur contrôle : « si on ne les juge/surveille/injonctive pas, alors les gens font n’importe quoi », or ce n’est pas cela le problème. Le problème c’est que ces grammar nazis n’ont pas transmis l’orthographe d’une façon qui soit perçue comme agréable, fun, socialement utile, connectante, donc pourquoi les gens suivraient-ils leurs recommandations de manière autonome ?
Le militant déconnant peut lui-même être en motivation introjectée pour la cause qu’il défend, donc il est contrôlant envers autrui parce qu’il n’a lui-même aucune motivation intrinsèque ou intégrée pour la cause (comment dès lors transmettre quelque chose dont il ne connaît pas la dynamique et les conséquences positives ?). Par exemple, le grammar nazi a peut-être appris l’orthographe à coup d’humiliation, donc humilie autrui à son tour pensant lui faire « bien » apprendre. Il peut même avoir un authentique élan altruiste à contrôler autrui tel que « il faut que je lui montre comment être parfait sinon il va se faire humilier encore plus » ; cependant quand bien même ce n’est pas méchant ou égoïste, c’est néanmoins la perpétuation d’une pratique qui cause un mal-être, et le légitime. La seule voie de sortie de ce cercle vicieux contrôle ➝ introjection ➝ contrôle ➝ introjection ➝, etc. est de procéder différemment face à un contrôle initial ou de décortiquer ces introjections pour les comprendre, puis décider ce que l’on souhaite vraiment en faire.
La motivation compartimentée : ou comment la militance peut devenir violente
La motivation introjectée n’est pas la « pire » pour autant, puisqu’elle n’est généralement pas liée à une violence envers les autres. Si on est militant à motivation introjectée ou qu’on provoque de l’introjection chez les autres par nos introjections, on ne va pas pour autant se transformer ou transformer les autres en combattants violents. On alimentera juste une saoulance générale, et les motivations pour la cause ne seront pas de très bonne qualité11 (tant chez les militants que chez les spectateurs, alliés ou toute cible de cette saoulance).
Par contre d’autres configurations complexes de la motivation amènent à soutenir une violence envers des personnes, voire à l’être soi-même ; c’est le cas de la motivation à identification compartimentée (ou dite fermée, défensive), dont les tenants et aboutissants sont complexes à démêler.
Rassurez-vous, dans les cas cités en introduction, je ne crois pas qu’un seul des exemples déconnants cités n’ait été conduit par ce type de motivation, encore moins il me semble chez les libristes (du moins je n’en ai pas vécu personnellement). Généralement on repère ces motivations malsaines lorsque c’est la haine qui conduit l’activité, qu’il y a un « nous contre eux » ethnocentrique (voir définition dans le cadre ci-dessous) : le groupe zététicien que j’ai évoqué, dont une des activités était de passer des soirées à se foutre d’un autre zététicien, de se gargariser à le haïr tous ensemble, avait tout de même un côté « motivation identifiée compartimentée », puisque l’identification au groupe passait uniquement par le fait de haïr un « ennemi » désigné, sans rien créer. Cependant, je peux difficilement analyser cette dynamique et comprendre son origine, parce qu’on a quitté le groupe dès qu’on a vu ces signaux malsains, et je ne connaissais pas du tout l’histoire personnelle de ses membres.
Je pense qu’on pourrait ajouter qu’il y a aussi ethnocentrisme lorsque l’endogroupe veut dominer (et qu’il ne domine pas forcément objectivement un environnement social) ou subordonner un autre groupe (qu’un tiers pourrait ne même pas voir comme différent tant ils semblent proches à de nombreux titres). Les militants ethnocentriques ne vont donc plus chercher à diminuer une domination, ne vont pas remettre en cause la hiérarchie, mais au contraire vont se conformer aux modèles habituels, les reproduire à leur propre niveau, causant de la souffrance. Ils font sans doute cela parce que c’est un moyen d’obtenir enfin de la valeur auprès d’autrui ou pensent que cela va combler les besoins fondamentaux (spoiler : non, c’est cette mécanique qui génère des sapages, qu’importe qui est placé dans cette hiérarchie illusoire).
Dire qu’il y a ethnocentrisme ou identification compartimentée n’explique pas vraiment pourquoi il y a cet élan d’attaque : certes, ces mécaniques se font souvent en groupe, sont animées par une dynamique de groupe, type « bouc-émissaire », certains militants comparent ce genre de situation au harcèlement scolaire12. Mais ce n’est pas parce que c’est répandu que c’est « inévitable », que ce serait sans raison ou que cela s’expliquerait par une prétendue « nature humaine ». Quand on creuse, on trouve des réponses : chez les ados par exemple, l’identité est en pleine construction et c’est pour cela que des individus vont parfois se rassembler pour attaquer les élèves perçus comme marginaux. Cela leur permet de construire/légitimer leur identité à moindres frais, et de compenser le mal-être général lié à l’adolescence elle-même. Autrement dit, on voit poindre des solutions lorsqu’on comprend mieux la cause première : soutenir les ados, créer des climats qui ne soient pas menaçants, leur montrer des voies de constructions personnelles qui ne passent pas par la destruction d’autres personnes13.
ℹ ⇢ L’identification compartimentée peut être totalement connectée à des stéréotypes ancrés dans la société :
Weinstein et al. (2012) ont postulé que lorsque des individus grandissent dans des environnements menaçant l’autonomie, ils peuvent être empêchés d’explorer et d’intégrer certaines valeurs ou identités potentielles, et en conséquence être plus enclins à compartimenter certaines expériences qui sont perçues comme inacceptables.
Comme l’homosexualité est stigmatisée, l’hypothèse des chercheurs a été que les personnes qui ont grandi dans des environnements sapant ou frustrant leur autonomie pourraient être plus enclins à compartimenter leur attirance pour le même sexe autant pour les autres que pour eux-mêmes, ce qui conduit à des processus défensifs. Les quatre études des chercheurs ont consisté à voir le soutien parental de l’autonomie des personnes, prendre note de leur identification sexuelle, puis mesurer leur orientation sexuelle implicite grâce des tests d’association implicite. Ces tests se basent sur le temps de réaction, sans que la personne puisse avoir le temps de mettre en œuvre des mécanismes de défense.
Résultat, il s’est avéré que plus l’environnement paternel avait été contrôlant et homophobe, plus il y avait une forte différence entre leur hétérosexualité annoncée et les résultats aux tests d’association implicite montrant leur attirance sexuelle pour les personnes du même sexe. C’est-à-dire qu’ils n’étaient pas cohérents dans la forte hétérosexualité qu’ils annonçaient alors qu’ils avaient pourtant des désirs homosexuels. En plus, pour protéger cette identification compartimentée, ces individus préconisaient plus d’agression envers les homosexuels.
Autrement dit, cette identification « hétérosexuelle » était fortement ancrée dans ce qu’ils annonçaient mais elle était fermée et défensive, parce que l’individu avait des désirs, des besoins sexuels homosexuels plus forts que ce qu’ils annonçaient. Ce qui entraînait des processus défensifs, c’est-à-dire qu’il défendait l’identification hétérosexuelle en préconisant l’agression des homosexuels : on voit là comme une projection sur la société de leur lutte interne contre leurs propres désirs et envies.
Attention, afin d’éviter un malentendu que l’on peut lire ci ou là14 quand on évoque les études portant sur l’homophobie en psycho, précisons que ce type d’études ne consiste pas à dépolitiser le problème, à tout plaquer sur l’individu. C’est même l’exact opposé puisque les études montrent les conséquences de l’environnement culturel, politique et social sur le développement de la personne ; de plus, étudier les facteurs qui poussent un individu à une agressivité homophobe ne consiste pas à l’excuser, à lui trouver des circonstances atténuantes : les sciences humaines et sociales, telles que la socio ou la psycho, consistent à comprendre, non à excuser (n’en déplaise à Monsieur Valls). Et lorsqu’on comprend dans le détail, on peut ajuster ces stratégies militantes, les optimiser, voire tenter de nouvelles actions en fonction de ces nouvelles informations issues de la recherche.
Cela peut apparaître comme assez contre-intuitif, et très complexe à démêler/deviner chez autrui puisque dans ces identifications compartimentées se niche une histoire secrète de l’individu qui se confronte à des pressions environnementales, puis endosse ces pressions de la société comme « bonnes » quand bien même son corps et des parties de lui-même lui signifient que non, qu’au contraire, elles sont sources de mal-être. Quand on étudie la déshumanisation15, on peut tomber aussi sur ce genre de mécanismes très contre-intuitifs où ce n’est pas parce que la personne déshumanise une autre personne qu’elle va recommander de la violence contre lui, mais plutôt parce qu’elle doit être violente contre lui qu’elle va le déshumaniser. Il y a un besoin qui commande la violence contre un autre, alors advient ensuite la déshumanisation qui permet de supprimer toute empathie pour la personne visée. La grande question est alors : quel est ce besoin ? La réponse varie évidemment selon la situation et des influences distales : par exemple, si un autoritaire influent interprète une crise économique comme étant de la faute d’un groupe ethnique particulier qui s’accaparerait richesses et emplois, alors les gens, par besoin matériel, peuvent s’accrocher à cette interprétation et s’attaquer à ce groupe, même si l’interprétation ne tient pas debout. C’est pour cela qu’en temps de crise on assiste à une plus grande crédulité quant à ce type d’interprétation discriminante, car fondamentalement les besoins de la population ayant été sapés ou étant menacés de l’être, l’interprétation donnant la plus grande promesse de « défense » à moindre coût recueillera bien plus d’adhésion.
Il y a donc d’abord toujours un besoin chez l’individu, parfois détourné, parfois extrêmement caché, et donc très difficile à deviner pour le tiers.
Il se peut aussi que l’individu qui recommande de la violence contre un autre veuille parfois supprimer quelque chose chez l’autre, parce que c’est précisément ce quelque chose qu’il veut supprimer en lui ; la vidéo de Contrapoints sur le Cringe est assez éloquente à ce sujet.
Non seulement les pratiques déconnantes sont donc le reflet d’un mal-être (besoins sapés, besoins frustrés que la personne ne s’avoue pas, motivations de piètre qualité), mais mettent aussi ceux qui les reçoivent dans un mal-être, et sont du même coup inefficaces pour l’avancée de la cause qui est décrédibilisée par la déconnance. De plus, un mouvement militant veut généralement une transformation des comportements sur le long terme, et non juste ponctuellement sous la pression d’un ordre (motivation externe) ou sous la pression sociale (utiliser Firefox un seul jour pour être perçu comme quelqu’un de bien parce qu’il y a des libristes chez soi), or c’est précisément ce que génère la militance déconnante. La militance déconnante, par son comportement, endosse aussi un modèle de contrôle extrêmement conformiste, conservateur : ce faisant, le militant déconnant démontre à autrui qu’il ne veut rien changer de structurel, si ce n’est tenter simplement d’avoir sa part de domination en prenant le contrôle sur autrui. C’est une dynamique cohérente lorsqu’on soutient une idéologie autoritaire, mais c’est incohérent si on vise un changement de paradigme progressiste et ouvert, puisqu’on répète alors un vieux paradigme autoritaire. Être « pur » dans ses pratiques ne compense pas le fait que les autres verront dans l’injonction, l’attaque, la répétition d’un vieux paradigme contrôlant, et donc n’y trouveront rien de bien séduisant.
Les individus en orientation contrôlée ont tendance à contrôler autrui, à ne voir que les contrôles dans une situation ; les personnes en orientation autonome ont tendance à voir les possibilités, les potentiels d’une situation, les espaces de liberté/de créativité possible et ont tendance à nourrir l’autonomie, la liberté des autres. L’orientation d’une personne dépend de comment la situation actuelle et passée est nourrissante ou sapante des besoins (quand bien même on peut être très autonome, on peut être en orientation contrôlée dans une situation autoritaire par exemple, parce qu’il n’y a aucune place laissée à l’initiative. Inversement, on peut être en orientation contrôlée dans une situation pourtant très libre, non contrôlante)↩
Pittman, Davey, Alafat, Wetherill, et Kramer (1980) ; Lepper & Greene (1975) ; Plant & Ryan (1985) ; Ryan et al. (1991) ; Enzle et Anderson (1993).↩
Quantité d’études (Deci et Ryan 2017) montrent que l’école, le travail, ou d’autres situations sociales ont tendance, majoritairement, à détruire nos motivations intrinsèques. On a donc tous probablement connu un nombre plus ou moins grand de sapages de nos motivations intrinsèques.↩
La motivation introjectée est liée à une baisse de vitalité, une augmentation de l’anxiété, plus de sentiments de honte, de culpabilité, parfois à la dépression, à la somatisation et à une faiblesse face à la manipulation Vallerand et Carducci (1996) Koestner, Houlfort, Paquet et Knight (2001) Ryan et al. (1993) Assor et al. (2004) Moller, Roth, Niemiec, Kanat-Maymon et Deci, (2018).↩
ça peut passer par la pratique d’un sport, l’apprentissage des compétences socio-émotionnelles, une éducation systémique sur la façon de créer son bien-être, comprendre son mal-être (psychologie, sociologie), une éducation basée sur la coopération et le soutien entre personnes, un enseignement des sciences humaines et sociales dès le collège, etc.↩
Si vous trouvez ce dossier intéressant, vous pouvez témoigner de votre soutien aux travaux de Hacking Social par un don sur tipee ou sur Liberapay
Quand le militantisme déconne : injonctions, pureté militante, attaques… (4/8)
La question compliquée et parfois houleuse du militantisme nous intéresse depuis longtemps à Framasoft, aussi avons-nous demandé à Viciss de Hacking Social, de s’atteler à la tâche.
Voici déjà le quatrième épisode [si vous avez raté les épisodes précédents] de son intéressante contribution, dans laquelle elle examine ce qui est au cœur du militantisme déconnant : la destruction des besoins fondamentaux que sont l’autonomie, la compétence et la proximité sociale.
Nous publions un nouveau chapitre de son travail chaque vendredi à 13:37 sur le Framablog, mais si vous préférez, vous pouvez télécharger dès maintenant l’essai intégral de Viciss qui comprend une bibliographie revue et augmentée :
Le militantisme déconnant, un sapage des besoins fondamentaux ?
On pourrait encore arguer que même si tout ceci ressemble à un sabotage de l’OSS, il n’en reste pas moins que les cibles finissent par adopter les bons mots, par faire attention à leurs comportements, sont plus « pures » dans leurs pratiques. Il y a plus de perfection, plus de conscienciosité, un tri dans les membres les plus capables de conscienciosité vertueuse, le combat ne comporte plus ces zones grises portées par ses membres les plus faillibles. On aurait en quelque sorte une « éducation » parfaite où seuls les meilleurs resteraient en course et obtiendraient leur diplôme de « militant méritant sa place », une élite de chevaliers blancs à l’alignement « loyal bon », qui serait ensuite la plus à même de partir en croisade en ne laissant rien passer.
Les croisades étaient hautement « impures », c’était un bain de sang et une multitude d’horreurs que je n’oserais même pas rapporter tant c’est insupportable… Dans The psychology of genocide, massacre, and extreme violence : why normal people come to commit atrocities, Donald D. Dutton a donné tous les détails de ces horreurs si cela vous intéresse ; mais à choisir (et pour éviter la dissociation, les traumatismes) je vous conseille la biblio de Semelin qui explique de façon moins traumatique les mécanismes de haute violence, génocidaire.
Cependant, ces techniques, en plus de saboter l’efficacité d’un mouvement, sapent aussi les besoins psychologiques fondamentaux de ceux qui en sont cibles (spectateurs, alliés, adversaires). Ces techniques, notamment lorsqu’elles sont employées par des militants ne voulant pas saboter (mais le faisant néanmoins malgré eux, avec une justification de pureté) sont aussi révélatrices que leurs besoins psychologiques fondamentaux sont peut-être sapés, et que c’est pour cela qu’ils adoptent ces techniques dysfonctionnelles.
La théorie de l’autodétermination1, issue de la psychologie sociale de la motivation, a sélectionné trois besoins psychologiques fondamentaux chez l’humain qui, lorsqu’ils sont comblés par un environnement social, vont l’aider à se développer de façon autodéterminée (et aucunement selon un modèle préétabli par des normes). La personne autodéterminée évolue, développe des motivations puissantes, dans un bien-être qui a un impact positif sur la société (les autodéterminés vont chercher à susciter l’autodétermination et le bien-être chez les autres, ils sont très motivants, prosociaux, altruistes et n’ont pas peur de s’exposer à des adversaires très effrayants).
La théorie de l’autodétermination
Autrement dit, un militant autodéterminé serait bienfaiteur dans un mouvement parce qu’il va transmettre sa motivation, soutenir les alliés, comprendre comment informer les spectateurs sans les démotiver, avoir assez de courage pour prendre le risque de se confronter à l’adversaire/l’adversité.
Mais pour espérer développer son autodétermination, il est nécessaire que quelques environnements sociaux nourrissent ces trois besoins fondamentaux, que sont l’autonomie, la compétence, la proximité sociale. Est-ce que le militantisme puritain2 y répond ?
L’autonomie
☸ C’est pour l’individu être à l’origine de ses actions, pouvoir choisir, pouvoir décider, ne pas être contrôlé tel un pion. Cela ne veut pas dire être indépendant, vivre seul : on peut être dépendant d’autrui tout en étant autonome ; par exemple, on peut être dépendant d’autrui pour se nourrir (c’est-à-dire ne pas cultiver sa propre nourriture, et devoir aller en acheter) tout en étant autonome (on choisit ces lieux de vente de nourriture selon ses valeurs, on décide de consommer ceci et pas cela, etc.). C’est différent aussi du fait de vivre une situation de liberté : on peut vivre objectivement une situation où toutes nos fantaisies seraient possibles, où personne ne nous contraint à quoi que ce soit et nous laisse décider, mais pour une raison ou une autre, on ne parvient pas à faire ce qu’on voudrait faire, on n’arrive pas à décider quoi faire, etc.
Lorsqu’un individu nous injonctive « tu dois/tu ne dois pas ; il faut/il ne faut pas ! » le besoin d’autonomie est sapé parce qu’on se sent sous contrôle de l’autre. Même si on refuse cette injonction, on sent qu’on réagit automatiquement, et non selon notre propre décision ; pensez à l’ado à qui on interdit de regarder tel film et qui, dès qu’il le pourra, ne saura résister à l’envie de le visionner, aurait-il eu envie de voir ce film si on ne le lui avait pas interdit en premier lieu ? Moi-même je n’ai jamais eu autant envie de sortir que lorsque le premier confinement a été mis en place.
On réagit automatiquement à l’interdit, au censuré, à l’inaccessible, en voulant y accéder encore plus parce que l’injonction est un sapage de notre besoin d’autonomie. On veut pouvoir décider, choisir, être libre, maintenir ouvertes des possibilités, donc dès lors qu’un environnement social coupe un pan de possibilités, surtout sur le ton de l’injonction, automatiquement on peut vouloir faire l’exact inverse. Le militantisme puritain déconnant va donc probablement nous pousser à faire l’inverse de ce qu’il recommande, à cause de la réactance. Par exemple, si un créateur sur la toile ne cesse de recevoir des injonctions militantes l’incitant à rejoindre telle plateforme libre, cette insistance catégorique fera office de repoussoir : le créateur associera ces injonctions déplaisantes à la plateforme vantée et s’en détournera définitivement alors qu’il était pourtant à la base pleinement ouvert à l’idée de s’y installer. Donc sa stratégie est totalement contre-productive et sabote la croisade du militant puritain, sauf s’il visait secrètement à énerver tout le monde.
L’injonction faite à autrui, lorsqu’il ne demande pas à être évalué, guidé, est une tentative de contrôle de son comportement et, que le militant le conscientise ou non, ça va saper la personne visée. Par conséquent, l’injonctivé va soit réagir d’une façon réactante, ou à terme voir l’injonctiveur et les valeurs qu’il porte en ennemi (qui aime les grammar nazis et leur « combat » ?) ; soit l’injonctivé va obéir, mais avec du mal-être (cette sensation déplaisante dans le ventre, cette gêne qui nous donne l’impression d’avancer à reculons, ce sentiment contradictoire où on accepte à la fois de se lancer dans un projet tout en espérant secrètement pouvoir emprunter dès que possible la première porte de sortie). Il va alors se sentir pion, s’inférioriser, culpabiliser, avoir honte, puis autocontrôler son comportement avec un stress et une pression qu’il aura intériorisés. C’est ce qu’on appelle une introjection (qu’on expliquera plus tard en détail) et qui génère une motivation très médiocre pour le combat, peu efficace, créant plus de mal-être chez les personnes, n’étant pas durable dans le temps et peu efficace.
Mais l’autonomie n’est pas uniquement sapée par les injonctions : toutes les manœuvres autoritaires qui vont tenter de contrôler l’individu, qui sont perçues comme des contrôles, vont le saper et en conséquence provoquer soit une obéissance « introjectée » soit une réactance, mais certainement pas une motivation de haute qualité (par exemple, devenir si fan d’orthographe que corriger des erreurs générerait un plaisir et une efficacité aussi intenses que si on jouait à un jeu vidéo).
Parfois, selon le niveau de violence de la tentative de contrôle, de sapage de l’autonomie de l’autre, cela peut conduire l’individu à une amotivation totale, et détruire tout élan. Je me rappelle un informaticien avec qui j’avais échangé par mail, passionné par le domaine, avec ce genre de passion qui éveille une vocation et guide votre vie. Il avait perdu toute motivation après avoir connu une entreprise extrêmement pressante, injonctive, harcelante. De même dans l’enseignement, Gull me rapportait avoir entendu de nombreux collègues qui avaient le cœur à l’ouvrage à leur entrée dans la profession, des projets plein les yeux, une motivation inébranlable… et qui, à force de contrôles sur leur travail, de nouvelles procédures à respecter, de surveillance et d’évaluation, de refus ou de complication de la part de la hiérarchie et des parents qui semblaient savoir mieux qu’eux comment faire cours, avait perdu toute motivation, ne proposaient plus aucun projet, parfois quittaient l’enseignement ou attendaient impatiemment, pour les plus anciens, la retraite. L’autoritarisme, le contrôle, détruisent l’élan des personnes qui étaient les plus susceptibles d’être extrêmement performantes si on les avait laissées tranquilles.
L’injonction ne fonctionne que pour se faire obéir sur le court terme, mais reste néanmoins utile dans une situation de haut danger : quand un pompier vous hurle de vous éloigner de ce trottoir parce qu’il y a un feu à proximité, il y a tout intérêt à ne pas être réactant. Et c’est exactement pour cette raison aussi que je pense que les militants n’ont pas nécessairement une volonté malsaine de contrôle des autres, et qu’ils ne cherchent pas à dominer lorsqu’ils ordonnent : pour eux, il y a un feu que personne ne voit et ils endossent le rôle de pompier. Ils peuvent être comme ça pour des raisons de surmenage, de climat social menaçant3, ou comble du comble, parce que leur propre besoin d’autonomie est sapé… Effectivement, tenter de contrôler l’autre, c’est décider, faire un choix, agir : le militant puritain peut se sentir ponctuellement comme restauré dans son autonomie, dans son besoin de compétence quand il contrôle l’autre. Cependant comme cela ne mène généralement à rien, il va recommencer sans cesse pour sentir à nouveau cette petite dose de satisfaction, le plongeant dans un cercle infini ou rien ne se règle, ni ses besoins, ni les besoins d’autrui, ni les buts de la militance. C’est assez proche d’une mécanique d’addiction au final : le militant a trouvé un moyen de satisfaire un besoin, sauf que la solution n’est qu’illusoire (comme le shoot d’une drogue qui finira par disparaître), que le besoin n’est jamais comblé, donc la personne insiste encore plus fort dans sa stratégie illusoire, ça ne donne rien, il continue plus fort, etc. C’est un cercle vicieux qui ne prendra fin que lorsqu’une voie totalement différente sera envisagée.
L’autre raison de ces tentatives de contrôle d’autrui chez les militants puritains sapant l’autonomie des personnes (et frustrant leurs propres besoins) s’explique tout simplement parce que quasi tous nos environnements sociaux fonctionnent de la sorte : école, travail, champ politique, champ culturel, messages médiatiques… Tous injonctivent, ordonnent des comportements, y compris hautement contradictoires4, alors on pense que c’est la chose à faire pour changer les comportements des autres afin qu’ils soient plus vertueux. On valorise le « bon » comportement en le rehaussant dans une espèce de hiérarchie sociale, voire en le récompensant, et le mauvais est infériorisé et puni. On reproduit ce modèle de contrôle par crainte d’être en bas de cette pyramide ou pour rester en haut, garder une valeur, ne pas être ostracisé, parce qu’il n’y a que très peu d’environnements où les choses fonctionnent différemment. En cela, la militance déconnante reproduit les logiques dominantes, et pourrait perdre son titre de déconnante ou de puritaine pour celle de conformiste.
Voici un petit schéma qui résume le besoin d’autonomie avec ce qui le menace ou le soutient :
Par supervision, on peut entendre toute personne qui va tenter d’avoir une influence sur le comportement de l’autre. On peut menacer l’autonomie en étant contrôlant (cadre mauve à gauche), mais même si je n’en parle pas dans cet article, on peut aussi la saper en étant manipulateur (cadre marron en bas). En militance déconnante, ça pourrait être perçu par la cible comme de la manipulation. Par exemple, une injonction enrobée dans des étiquetages positifs « toi qui es si engagé, tu devrais être exclusivement sur PeerTube », que ça soit volontairement manipulateur ou non, pourra être perçu par la cible comme une tentative de sapage de son autonomie, un contrôle manipulateur sur elle.
La proximité sociale
▚ C’est pour l’individu le besoin d’être connecté à d’autres humains, de résonner dans la société humaine, de recevoir de l’attention et des soins par autrui, de se sentir appartenir à un groupe, à une communauté par son propre apport significatif et reconnu comme tel ; à l’inverse, une proximité sociale est sapée par l’exclusion, l’ostracisation, les humiliations, les dévalorisations, l’indifférence, les insultes, le mépris, l’absence d’écoute, etc. Elle peut être frustrée par le manque de contacts sociaux signifiants/ résonnants (par exemple, une interaction d’achat n’est généralement pas très résonnante ni comblante ; un moment avec des proches qui ne réagiraient à rien de ce qu’on dit ou qui n’écouteraient même pas serait très frustrante). Le fait d’avoir un profil particulier concernant les rapports sociaux (par exemple introverti VS extraverti) n’a aucun impact sur le fait d’avoir plus ou moins besoin de proximité sociale : c’est simplement que l’extraverti ou l’introverti n’auront pas les mêmes modes relationnels préférés pour combler ce besoin (par exemple, l’extraverti peut préférer échanger avec un groupe, l’introverti échanger avec une seule personne à la fois). Mais tout le monde a besoin d’une connexion positive avec d’autres5 humains, qu’importe son logiciel de base et les modalités sociales préférées pour y accéder.
Je pense qu’il n’est pas nécessaire de revenir sur les exemples déjà évoqués pour montrer en quoi l’injonction ou d’autres pratiques déconnantes (les soirées foutage de gueule d’un collègue…), surtout quand elle advient dans un contexte particulier (rappelez-vous l’exemple des condoléances, de la femme violentée cherchant de l’aide, etc.), sont un énorme sapage de proximité sociale, puisque l’échange social est rendu impossible, tout du moins fort déplaisant.
Dans les cas où la proximité sociale est nourrie, on a un schéma de communication qui ressemble à ceci :
Schéma issu de : Moïra Mikolajczak, Les compétences émotionnelles, Paris, Dunod, 2009. « la dynamique interpersonnelle du partage social des émotions d’après Rimé (2009)
Or, dans un militantisme déconnant, tout ceci s’arrête à la première étape et à la place « Batman corrige/critique/injonctive/, etc. Aquaman6 » : l’émotion d’Aquaman est niée ou non prise en compte, il n’y a aucun mécanisme d’empathie à son égard. Or, si à chaque fois qu’une personne veut partager une émotion (y compris positive, par exemple un intérêt pour un sujet scientifique), et qu’elle est rembarrée parce qu’elle a fait une faute, alors je parie qu’elle va se mettre à déprimer. Et si Batman ne cherche qu’à partager, exprimer son émotion en répliquant à l’expression d’Aquaman, par injonction ou remarques hors sujet, alors il n’y aura jamais la suite positive de ce schéma puisque soit Aquaman déprime/se tait, soit il se met en colère contre lui. Tout le monde est sapé dans sa proximité sociale. Batman et Aquaman ne rejoindront jamais la Justice League.
Mais ça peut être aussi exactement pour cette raison que des militants de certaines mouvances peuvent déconner et avoir des attitudes contrôlantes/autoritaires : ils savent que ça va faire taire les Aquaman qui cherchent à partager leurs émotions et c’est le but (par exemple, les militants d’extrême-droite n’hésitent pas à être très sapants parce qu’ils veulent vraiment détruire l’autre). Et si Aquaman s’énerve, ce militant peut voir cela comme une victoire car l’énervement d’Aquaman met en lumière le propos et la cause de Batman, captant potentiellement l’audimat d’Aquaman. Cela peut devenir une tactique pour gagner en visibilité, mais parfois aussi c’est une réponse désespérée à des sapages passés : mieux vaut vivre une guerre avec les autres qu’être fantôme auprès d’eux. C’est aussi pour cette raison qu’une des premières règles d’Internet a été don’t feed the troll, cela permettait de ponctuellement casser le cercle vicieux : cependant ce n’est pas une stratégie pérenne ni adaptée à toutes les situations (faire comme si de rien n’était face à un harcèlement massif est tout aussi sapant, puisqu’on dénie soi-même sa souffrance).
Schéma issu de : Moïra Mikolajczak, Les compétences émotionnelles… version corrigée
Tout ceci est un sacré cercle vicieux tant que Batman persiste à ne s’exprimer qu’en s’appuyant sur l’expression d’Aquaman (et non en s’appuyant sur lui-même, via son sujet partagé), mais le problème c’est que lorsqu’on est en posture A, il n’y a parfois aucune écoute, ce qui peut nous amener nous-mêmes à devenir un B déconnant. Une solution serait tout simplement d’être un Batman écoutant jusqu’au bout (parce que la relation sera plus sympa, enrichissante, qu’on construit une amitié, un respect mutuel) ou un Aquaman partageant d’une façon nouvelle pour laquelle des patterns n’ont pas été encore automatisés chez les militants déconnants. Et cela a pour conséquences de prendre soin des spectateurs, des alliés voire des adversaires qui verront peut-être que ce membre d’un mouvement adverse nourrit sa proximité sociale plutôt qu’il ne la sape, et donc peut être que ce mouvement est profitable. C’est une action qui serait alors de l’ordre d’une construction.
La proximité sociale
La compétence
⚒ C’est pour l’individu, se sentir efficace dans son action, exercer ses capacités, maîtriser les défis, se sentir compétent. Ce besoin est très connecté à l’autonomie : si l’individu est sous contrôle de l’environnement, il ne peut pas pleinement exercer ses compétences, parce qu’il a besoin lui-même d’avoir du contrôle sur ses actions. Et il peut se sentir autonome ou chercher plus d’autonomie par besoin d’exprimer ses compétences.
Typiquement, plus un environnement social contrôle le moindre geste/mot d’un individu – par exemple, comme peuvent l’être des environnements de travail qui imposent des scripts pour parler aux clients – plus le besoin de compétence est sapé, puisqu’on ne peut pas développer ses propres manières de faire, son art singulier, son expérience de la compétence, sa créativité. Et dans ces environnements très sapants, l’une des voies rapides pour restaurer ce besoin de compétence est… de dominer l’autre, de le contrôler. Nous voici encore face à un cercle vicieux : on va tenter de contrôler l’activité de l’autre parce que nous-mêmes avons été contrôlés et qu’exercer ce contrôle satisfait un peu notre besoin de compétence et d’autonomie qu’on nous a préalablement refusé.
Je prends un exemple : sur un Discord, j’ai vu une personne qui accusait de volonté de domination un diagnostic très précis de neuro’ et y voyait là un risque énorme d’emprise. Là, j’ai senti en moi comme une pulsion de correction, mes mains se sont approchées du clavier instantanément, l’argumentaire galopait dans ma tête, prêt à sortir pour le « corriger ». J’allais entrer dans le débat pour lui dire que c’était totalement faux, qu’il n’avait rien compris à ce diagnostic et j’allais lui balancer à la tête des tas de sources de neuropsycho. Vraiment de la pure militance déconnante, conformiste, puritaine, alors que je ne suis même pas neuropsy, ni militante dans une association défendant la vérité vraie. Finalement, je ne l’ai pas fait parce que je savais d’expérience que ça ne servait absolument à rien ni à moi, ni aux autres, et ça aurait été juste un moment pénible pour tout le monde. Mais pourquoi cette pulsion ? Eh bien, si je remonte à la source de mon apprentissage sommaire de la neuro en fac de psycho’, il y a des professeurs formidables qui étaient vraiment extrêmement intéressants en cours magistral. Mais ceux-ci faisaient aussi officiellement des partiels visant à éliminer le maximum d’entre nous (ils prévenaient que le barème serait volontairement très dur, voire injuste, parce qu’on était trop nombreux), ainsi aucune minuscule erreur n’était tolérée : sur plus d’une centaine d’étudiants, les meilleures notes en neuro étaient des 10. Mais cela n’avait même pas une « vraie » valeur académique, puisque j’ai vu des collègues continuer en cursus neuropsy avec des moyennes de 3 à cette matière, l’institution ne prenait en compte que la moyenne générale.
Mon cerveau a bien enregistré le message menaçant qu’était « faute minime = sanction lourde et injuste », et je peux reproduire ce schéma sans m’en rendre compte. Non pas que j’adhère au fait de juger durement les personnes, mais aussi parce qu’au fond je souhaite protéger autrui des punitions lourdes associées à cette faute. Tout comme on corrige le collègue de travail de ses fautes pour lui éviter la sanction du chef qu’on sait encore plus intolérant et violent dans son jugement.
Autrement dit, on peut avoir tendance à corriger autrui parce qu’on a soi-même parfois été corrigé de façon encore plus menaçante pour des fautes encore moins lourdes. On s’en est généralement sorti et on a réussi à faire avec, alors croyant protéger autrui et l’aider à réussir, on reproduit l’évaluation, le jugement pour lui apprendre à mieux faire les choses, lui éviter les menaces. Et là encore, vous voyez le cercle vicieux : on maintient un même système en le reproduisant soi-même.
La compétence
Deci et Ryan, 2017 (revue du champ de la recherche sur l’autodétermination, mais cela a commencé en 1985 et de nombreux autres chercheurs s’y sont joints)↩
« Personne qui montre une pureté morale scrupuleuse, un respect rigoureux des principes » selon le Petit Robert. La militance déconnante a pour particularité de viser cette pureté morale chez autrui (pas forcément chez elle), en le corrigeant, lui reprochant le moindre détail impur, etc.↩
Et nous vivons tous depuis un an dans un climat social hautement susceptible d’être perçu comme menaçant, que ce soit d’un point de vue sanitaire, économique, écologique, politique ou autre.↩
Pensez à l’époque pas si lointaine où l’on nous disait qu’il ne fallait absolument pas porter de masque puis ensuite qu’il fallait absolument porter le masque.↩
Le besoin de proximité sociale est aussi universel (cf Chen et al. (2015)).↩
J’ai mis des noms suivant ces lettres, parce que sinon se représenter un « a » ou un « b » me semble peu chaleureux. Je préfère imaginer pour ma part une confrontation ou une interaction positive entre Batman et Aquaman. Libre à vous de remplacer les lettres par d’autres personnages, tels que Bilbo et Aragorn ou Bigard et Astier.↩
(à suivre…)
Si vous trouvez ce dossier intéressant, vous pouvez témoigner de votre soutien aux travaux de Hacking Social par un don sur tipee ou sur Liberapay








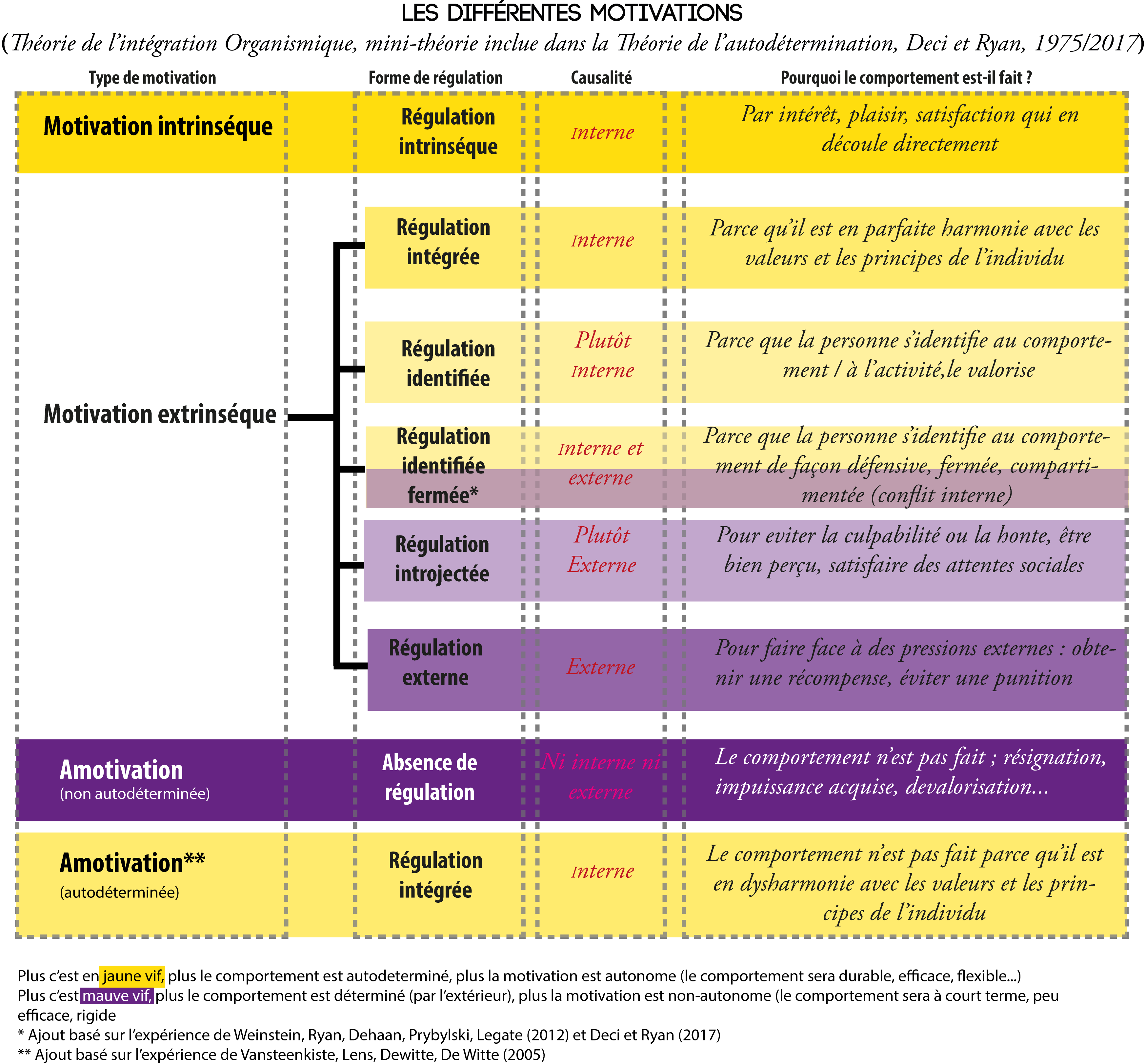


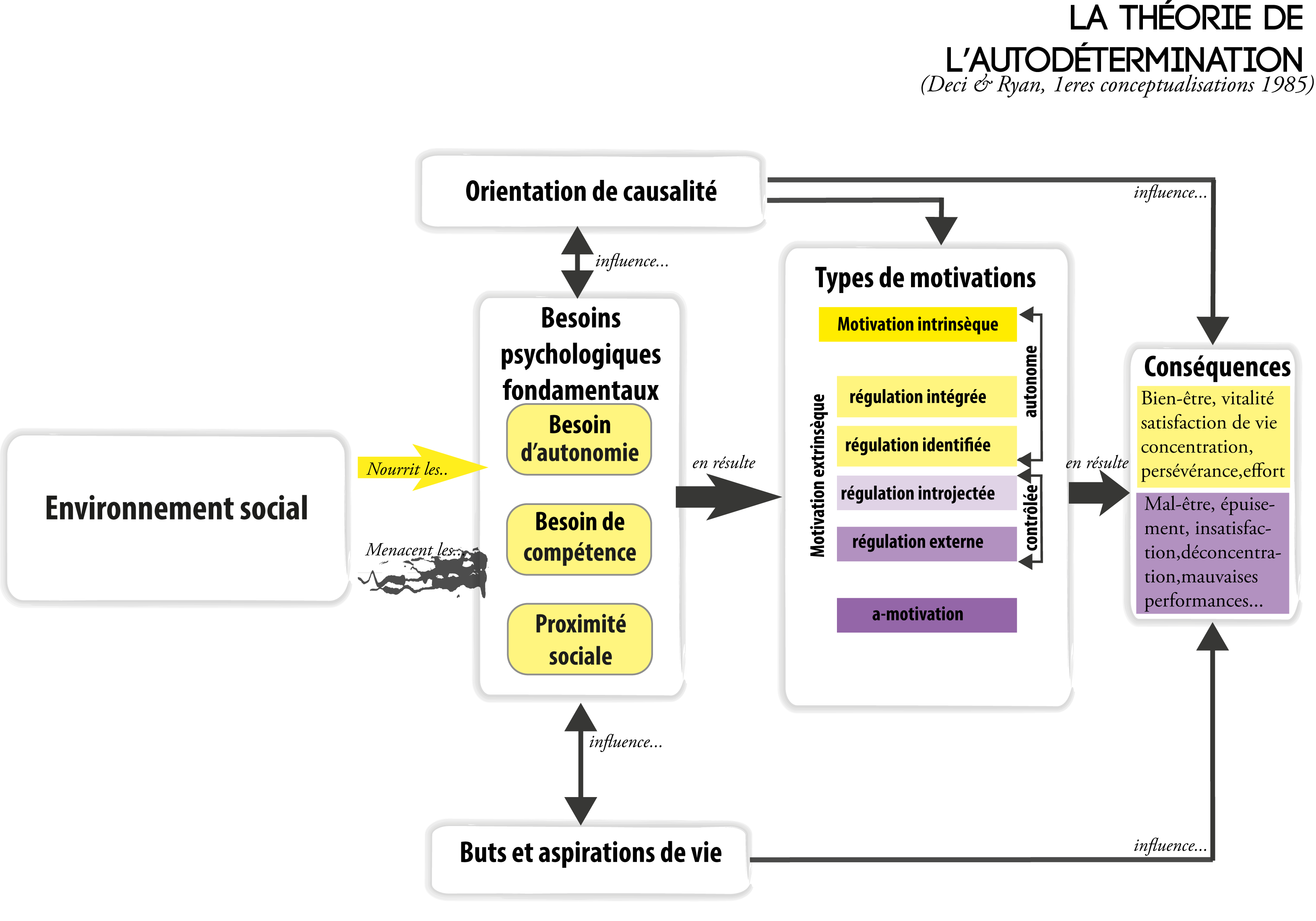


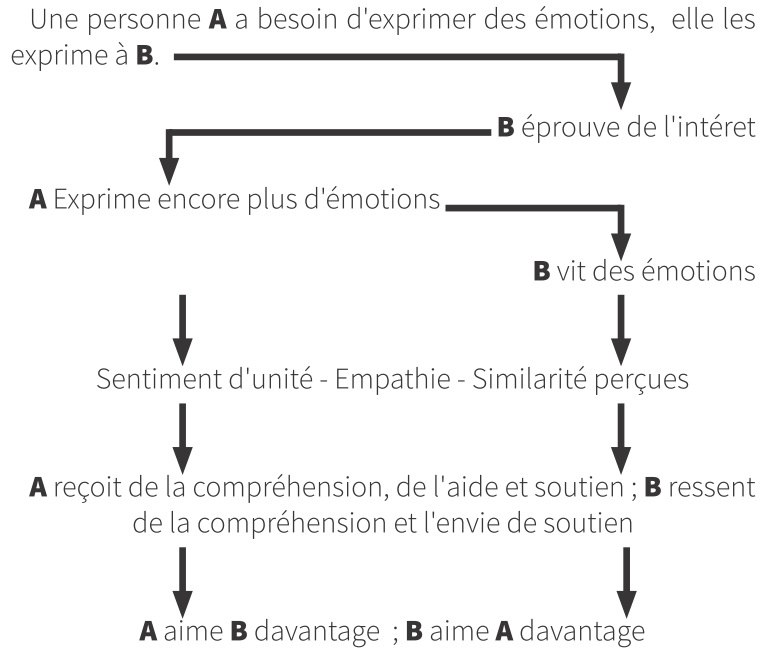
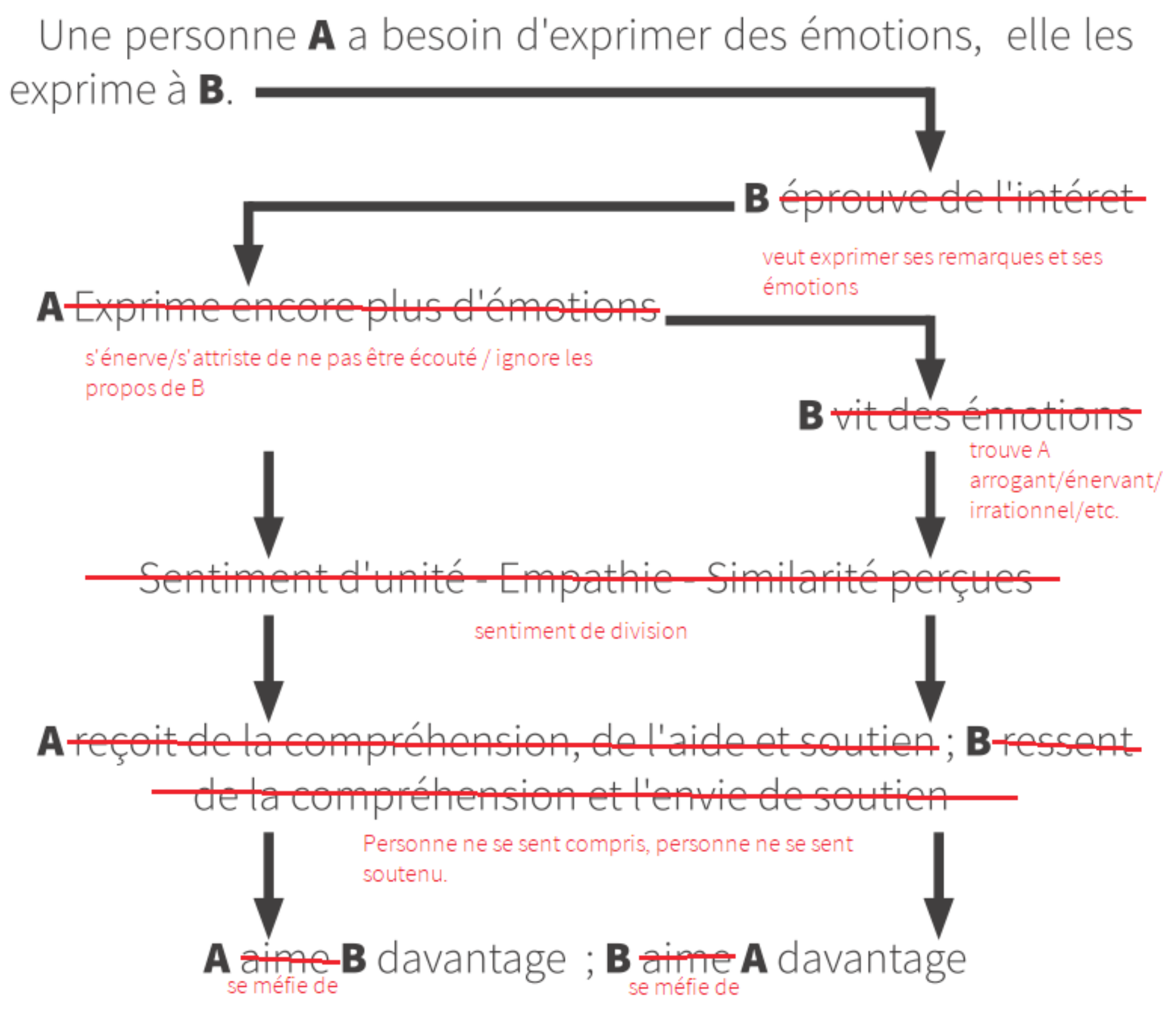


{kind=link}