La traduction suivante est la suite et la continuation du travail entamé la semaine dernière sur le long rapport final élaboré par le comité « Digital, Culture, Media and Sport » du Parlement britannique, publié le 14 février dernier, sur la désinformation et la mésinformation.
Il s’agit cette fois de poser le décor. Participants, méthodes de travail, acteurs audités. Une bonne mise en bouche qui vous rendra impatient⋅e de lire les articles suivants.
Le groupe Framalang a en effet entrepris de vous communiquer l’intégralité du rapport en feuilleton suivant l’avancement de la traduction.
La traduction est effectuée par le groupe Framalang, avec l’aide de toutes celles et ceux qui veulent bien participer et pour cet opus : Lumibd, maximefolschette, Alio, wazabyl, Khrys, serici, Barbara + 1 anonyme
Introduction et contexte
1. Le Rapport Provisoire du Comité DCMS, « Désinformation et infox », a été publié en juillet 2018 1. Depuis l’été 2018, le Comité a tenu trois audiences supplémentaires pour y entendre témoigner les organismes de réglementation du Royaume-Uni et le gouvernement, et nous avons reçu 23 autres témoignages écrits 2. Nous avons également tenu un “International Grand Commitee”3 en novembre 2018, auquel ont participé des parlementaires de neuf pays : Argentine, Belgique, Brésil, Canada, France, Irlande, Lettonie, Singapour et Royaume-Uni.
2. Notre longue enquête sur la désinformation et la mésinformation a mis en lumière le fait que les définitions dans ce domaine sont importantes. Nous avons même changé le titre de notre enquête de « infox » à « désinformation et infox », car le terme “infox” a développé sa propre signification très connotée. Comme nous l’avons dit dans notre rapport préliminaire les “infox” ont été utilisées pour décrire un contenu qu’un lecteur pourrait ne pas aimer ou désapprouver. Le président américain Donald Trump a qualifié certains médias de « faux médias d’information » et d’être « les véritables ennemis du peuple »4.
3. Nous sommes donc heureux que le gouvernement ait accepté les recommandations de notre rapport provisoire et, au lieu d’utiliser l’expression “infox”, il utilise l’expression « désinformation » pour décrire « la création et le partage délibérés de renseignements faux ou manipulés qui visent à tromper et à induire en erreur le public, soit dans le but de nuire, soit pour leur procurer un avantage politique, personnel ou financier »5.
4. Ce rapport final s’appuie sur les principales questions mises en évidence dans les sept domaines couverts dans le rapport provisoire : la définition, le rôle et les responsabilités juridiques des plateformes de médias sociaux ; le mauvais usage des données et le ciblage, fondé sur les allégations Facebook, Cambridge Analytica et Aggregate IQ (AIQ), incluant les preuves issues des documents que nous avons obtenus auprès de Six 4 Three à propos de la connaissance de Facebook de donnés de partages et sa participation dans le partage de données ; les campagnes électorales ; l’influence russe dans les élections étrangères l’influence des SCL dans les élections étrangères; et la culture numérique. Nous intégrons également les analyses réalisées par la société de conseil 89up, les données litigieuses relatives à la base de données AIQ que nous avons reçues de Chris Vickery.
5. Dans le présent rapport final, nous nous appuyons sur les recommandations fondées sur des principes formulés dans le rapport provisoire. Nous avons hâte d’entendre la réponse du gouvernement à ces recommandations d’ici deux mois. Nous espérons que cette réponse sera beaucoup plus complète, pratique et constructive que leur réponse au rapport provisoire publié en octobre 2018. 6 Plusieurs de nos recommandations n’ont pas reçu de réponse substantielle et il est maintenant urgent que le gouvernement y réponde. Nous sommes heureux que le Secrétaire d’État, le très honorable député Jeremy Wright, ait décrit nos échanges comme faisant partie d’un « processus itératif » et que ce rapport soit « très utile, franchement, pour pouvoir alimenter nos conclusions futures avant la rédaction du Livre Blanc » et que nos opinions fassent partie des considérations du gouvernement. 7 Nous attendons avec impatience le livre blanc du gouvernement dénommé Online Harms, rédigé par le Ministère du Numérique, de la Culture, des Médias et des Sports et le Ministère de l’Intérieur, qui sera publié au début de 2019, et qui abordera les questions des préjudices en ligne, y compris la désinformation. 8 Nous avons réitéré plusieurs des recommandations figurant dans notre rapport provisoire, demeurées sans réponse de la part du gouvernement auxquelles le gouvernement n’a pas répondu. Nous présumons et nous nous espérons que le gouvernement réponde à la fois aux recommandations du présent rapport final et à celles du rapport provisoire restées sans réponse.
6. Ce rapport final est le fruit de plusieurs mois de collaboration avec d’autres pays, organisations, parlementaires et particuliers du monde entier. Au total, le Comité a tenu 23 séances d’audiences, reçu plus de 170 mémoires écrits, entendu 73 témoins, posé plus de 4 350 questions lors de ces audiences et eu de nombreux échanges de correspondance publique et privée avec des particuliers et des organisations.
7. Il s’agit d’une enquête collaborative, dans le but de s’attaquer aux questions techniques, politiques et philosophiques complexes qui sont en jeu et de trouver des solutions pratiques à ces questions. Comme nous l’avons fait dans notre rapport provisoire, nous remercions les nombreuses personnes et entreprises, tant nationales qu’internationales, y compris nos collègues et associés en Amérique, d’avoir bien voulu nous partager leurs opinions et informations. 9
8. Nous aimerions également souligner le travail réalisé par d’autres parlementaires qui se sont penchés sur des questions semblables en même temps que notre enquête. Le Comité permanent canadien de l’accès à l’information, de la protection des renseignements personnels et de l’éthique a publié en décembre 2018 un rapport intitulé « Démocratie menacée : risques et solutions à l’ère de la désinformation et du monopole des données » 10 . Ce rapport souligne l’étude du Comité canadien sur la violation des données personnelles impliquant Cambridge Analytica et Facebook, et les questions concernant plus largement l’utilisation faite des données personnelles par les média sociaux et leur responsabilité dans la diffusion d’information dites fake news ou dans la désinformation . Leurs recommandations concordent avec bon nombre des nôtres dans le présent rapport.
9. La commission du Sénat américain sur le renseignement mène actuellement une enquête sur l’ampleur de l’ingérence de la Russie dans les élections américaines de 2016. Grâce à l’ensemble des données fournis par Facebook, Twitter et Google au Comité du renseignement, sous la direction de son groupe de conseillers techniques, deux rapports tiers ont été publiés en décembre 2018. New Knowledge , une société travaillant sur l’intégrité de l’information, a publié “The Tactics and Tropes of the Internet Research Agency” (La stratégie et la rhétorique de l’agence de renseignement sur internet), qui met en lumière les tactiques et les messages utilisés par ladite agence pour manipuler et influencer les américains, rapport qui inclus un ensemble de présentations, des statistiques éclairantes, des infographies et un présentation thématique de mèmes 11. The Computational Propaganda Research Project (Le projet de recherche sur la propagande informatique) et Graphikap ont publié le second rapport, qui porte sur les activités de comptes connus de l’Internet Research Agency, utilisant Facebook, Instagram, Twitter et YouTube entre 2013 et 2018, afin d’influencer les utilisateurs américains 12. Ces deux rapports seront intégrés au rapport du Comité du renseignement en 2019.
10. La réunion du Grand Comité International qui s’est tenue en novembre 2018 a été le point culminant de ce travail collaboratif. Ce Grand Comité International était composé de 24 représentants démocratiquement élus de neuf pays, incluant 11 membres du Comité du DCMS, qui représentent au total 447 millions de personnes. Les représentants ont signé un ensemble de principes internationaux lors de cette réunion. 13 Nous avons échangé des idées et des solutions en privé et en public, et nous avons tenu une séance de témoignage oral de sept heures. Nous avons invité Mark Zuckerberg, PDG de Facebook, l’entreprise de média social qui compte plus de 2,25 milliards d’utilisateurs et qui a réalisé un chiffre d’affaires de 40 milliards de dollars en 2017, à témoigner devant nous et devant ce Comité ; il a choisi de refuser, par trois fois14. Cependant, dans les 4 heures qui ont suivi la publication des documents obtenus auprès de Six4Three – concernant la connaissance et la participation au partage de données par Facebook, M. Zuckerberg a répondu par un message sur sa page Facebook 15. Nous remercions nos collègues du “International Grand Commitee” pour leur participation à cette importante session, et nous espérons pouvoir continuer notre collaboration cette année.
Demain, les nains…
Et si les géants de la technologie numérique étaient concurrencés et peut-être remplacés par les nains des technologies modestes et respectueuses des êtres humains ?
Telle est l’utopie qu’expose Aral Balkan ci-dessous. Faut-il préciser que chez Framasoft, nous avons l’impression d’être en phase avec cette démarche et de cocher déjà des cases qui font de nous ce qu’Aral appelle une Small Tech (littéralement : les petites technologies) par opposition aux Big Tech, autrement dit les GAFAM et leurs successeurs déjà en embuscade pour leur disputer les positions hégémoniques.
Les géants du numérique, avec leurs « licornes » à plusieurs milliards de dollars, nous ont confisqué le potentiel d’Internet. Alimentée par la très courte vue et la rapacité du capital-risque et des start-ups, la vision utopique d’une ressource commune décentralisée et démocratique s’est transformée en l’autocratie dystopique des panopticons de la Silicon Valley que nous appelons le capitalisme de surveillance. Cette mutation menace non seulement nos démocraties, mais aussi l’intégrité même de notre personne à l’ère du numérique et des réseaux1.
Alors que la conception éthique décrit sans ambiguïté les critères et les caractéristiques des alternatives éthiques au capitalisme de surveillance, c’est l’éthique elle-même qui est annexée par les Big Tech dans des opérations de relations publiques qui détournent l’attention des questions systémiques centrales2 pour mettre sous les projecteurs des symptômes superficiels3.
Nous avons besoin d’un antidote au capitalisme de surveillance qui soit tellement contradictoire avec les intérêts des Big Tech qu’il ne puisse être récupéré par eux. Il doit avoir des caractéristiques et des objectifs clairs et simples impossibles à mal interpréter. Et il doit fournir une alternative viable et pratique à la mainmise de la Silicon Valley sur les technologies et la société en général.
Cet antidote, c’est la Small Tech.
Small Tech
elle est conçue par des humains pour des humains 4 ;
est la propriété des individus qui la contrôlent, et non des entreprises ou des gouvernements ;
respecte, protège et renforce l’intégrité de la personne humaine, des droits humains, de la justice sociale et de la démocratie à l’ère du numérique en réseau ;
encourage une organisation politique non-hiérarchisée et où les décisions sont prises à l’échelle humaine ;
alimente un bien commun sain ;
est soutenable ;
sera un jour financée par les communs, pour le bien commun.
Nous avons un système dans lequel 99.99999% des investissements financent les entreprises qui reposent sur la surveillance et se donnent pour mission de croître de façon exponentielle en violant la vie privée de la population en général [retour]
« Attention » et « addiction ». S’il est vrai que les capitalistes de la surveillance veulent attirer notre attention et nous rendre dépendants à leurs produits, ils ne le font pas comme une fin en soi, mais parce que plus nous utilisons leurs produits, plus ils peuvent nous exploiter pour nos données. Des entreprises comme Google et Facebook sont des fermes industrielles pour les êtres humains. Leurs produits sont les machines agricoles. Ils doivent fournir une façade brillante pour garder notre attention et nous rendre dépendants afin que nous, le bétail, puissions volontairement nous autoriser à être exploités. Ces institutions ne peuvent être réformées. Les Big Tech ne peuvent être réglementées que de la même manière que la Big Tobacco pour réduire ses méfaits sur la société. Nous pouvons et devrions investir dans une alternative éthique : la Small Tech. [retour]
La petite technologie établit une relation d’humain à humain par nature. Plus précisément, elle n’est pas créée par des sociétés à but lucratif pour exploiter les individus – ce qu’on appelle la technologie entreprise vers consommateur. Il ne s’agit pas non plus d’une technologie construite par des entreprises pour d’autres entreprises [retour]
Nous construisons la Small Tech principalement pour le bien commun, pas pour faire du profit. Cela ne signifie pas pour autant que nous ne tenons pas compte du système économique dans lequel nous nous trouvons actuellement enlisés ou du fait que les solutions de rechange que nous élaborons doivent être durables. Même si nous espérons qu’un jour Small Tech sera financé par les deniers publics, pour le bien commun, nous ne pouvons pas attendre que nos politiciens et nos décideurs politiques se réveillent et mettent en œuvre un tel changement social. Alors que nous devons survivre dans le capitalisme, nous pouvons vendre et faire des profits avec la Small Tech. Mais ce n’est pas notre but premier. Nos organisations se préoccupent avant tout des méthodes durables pour créer des outils qui donnent du pouvoir aux gens sans les exploiter, et non de faire du profit. Small Tech n’est pas une organisation caritative, mais une organisation à but non lucratif.[retour]
Les organisations disposant de capitaux propres sont détenues et peuvent donc être vendues. En revanche, les organisations sans capital social (par exemple, les sociétés à responsabilité limitée par garantie en Irlande et au Royaume-Uni) ne peuvent être vendues. De plus, si une organisation a du capital-risque, on peut considérer qu’elle a déjà été vendue au moment de l’investissement car, si elle n’échoue pas, elle doit se retirer (être achetée par une grande société ou par le public en général lors d’une introduction en bourse). Les investisseurs en capital-risque investissent l’argent de leurs clients dans la sortie. La sortie est la façon dont ces investisseurs font leur retour sur investissement. Nous évitons cette pilule toxique dans la Small Tech en créant des organisations sans capitaux propres qui ne peuvent être vendues. La Silicon Valley a des entreprises de jetables qu’ils appellent des startups. Nous avons des organisations durables qui travaillent pour le bien commun que nous appelons Stayups (Note de Traduction : jeu de mots avec le verbe to stay signifie « demeurer »).[retour]
La révolution ne sera pas parrainée par ceux contre qui nous nous révoltons. Small Tech rejette le parrainage par des capitalistes de la surveillance. Nous ne permettrons pas que nos efforts soient utilisés comme des relations publiques pour légitimer et blanchir le modèle d’affaires toxique des Big Tech et les aider à éviter une réglementation efficace pour mettre un frein à leurs abus et donner une chance aux alternatives éthiques de prospérer.[retour]
La vie privée, c’est avoir le droit de décider de ce que vous gardez pour vous et de ce que vous partagez avec les autres. Par conséquent, la seule définition de la protection de la vie privée qui importe est celle de la vie privée par défaut. Cela signifie que nous concevons la Small Tech de sorte que les données des gens restent sur leurs appareils. S’il y a une raison légitime pour laquelle cela n’est pas possible (par exemple, nous avons besoin d’un nœud permanent dans un système de pair à pair pour garantir l’accessibilité et la disponibilité), nous nous assurons que les données sont chiffrées de bout en bout et que l’individu qui possède l’outil possède les clés des informations privées et puisse contrôler seul qui est à chacun des « bouts » (pour éviter le spectre du Ghosting).[retour]
La configuration de base de notre technologie est le pair à pair : un système a-centré dans lequel tous les nœuds sont égaux. Les nœuds sur lesquels les individus n’ont pas de contrôle direct (p. ex., le nœud toujours actif dans le système pair à pair mentionné dans la note précédente) sont des nœuds de relais non fiables et non privilégiés qui n’ont jamais d’accès aux informations personnelles des personnes.[retour]
Afin d’assurer un bien commun sain, nous devons protéger le bien commun contre l’exploitation et de l’enfermement. La Small Tech utilise des licences copyleft pour s’assurer que si vous bénéficiez des biens communs, vous devez redonner aux biens communs. Cela empêche également les Big Tech d’embrasser et d’étendre notre travail pour finalement nous en exclure en utilisant leur vaste concentration de richesse et de pouvoir.[retour]
La Small Tech est influencé en grande partie par la richesse du travail existant des concepteurs et développeurs inspirants de la communauté JavaScript qui ont donné naissance aux communautés DAT et Scuttlebutt. Leur philosophie, qui consiste à créer des composants pragmatiques, modulaires, minimalistes et à l’échelle humaine, aboutit à une technologie qui est accessible aux individus, qui peut être maintenue par eux et qui leur profite. Leur approche, qui est aussi la nôtre, repose sur la philosophie d’UNIX.[retour]
La Small Tech est conçue par des humains, pour des humains ; c’est une approche résolument non-coloniale. Elle n’est pas créée par des humains plus intelligents pour des humains plus bêtes (par exemple, par des développeurs pour des utilisateurs – nous n’utilisons pas le terme utilisateur dans Small Tech. On appelle les personnes, des personnes.) Nous élaborons nos outils aussi simplement que possible pour qu’ils puissent être compris, maintenus et améliorés par le plus grand nombre. Nous n’avons pas l’arrogance de supposer que les gens feront des efforts excessifs pour apprendre nos outils. Nous nous efforçons de les rendre intuitifs et faciles à utiliser. Nous réalisons de belles fonctionnalités par défaut et nous arrondissons les angles. N’oubliez pas : la complexité survient d’elle-même, mais la simplicité, vous devez vous efforcer de l’atteindre. Dans la Small Tech, trop intelligent est une façon de dire stupide. Comme le dit Brian Kernighan : « Le débogage est deux fois plus difficile que l’écriture du premier jet de code. Par conséquent, si vous écrivez du code aussi intelligemment que possible, vous n’êtes, par définition, pas assez intelligent pour le déboguer. » Nous nous inspirons de l’esprit de la citation de Brian et l’appliquons à tous les niveaux : financement, structure organisationnelle, conception du produit, son développement, son déploiement et au-delà.[retour]
Il n’est pas si fréquent que l’équipe Framalang traduise un article depuis la langue italienne, mais la récapitulation bien documentée de Cagizero était une bonne occasion de faire le point sur l’expansion de la Fediverse, un phénomène dont nous nous réjouissons et que nous souhaitons voir gagner plus d’amplitude encore, tant mieux si l’article ci-dessous est très lacunaire dans un an !
Mastodon, la Fediverse et l’avenir des réseaux décentralisés
par Cagizero
Peu de temps après une première vue d’ensemble de Mastodon il est déjà possible d’ajouter quelques observations nouvelles.
Tout d’abord, il faut noter que plusieurs personnes familières de l’usage des principaux médias sociaux commerciaux (Facebook, Twitter, Instagram…) sont d’abord désorientées par les concepts de « décentralisation » et de « réseau fédéré ».
En effet, l’idée des médias sociaux qui est répandue et bien ancrée dans les esprits est celle d’un lieu unique, indifférencié, monolithique, avec des règles et des mécanismes strictement identiques pour tous. Essentiellement, le fait même de pouvoir concevoir un univers d’instances séparées et indépendantes représente pour beaucoup de gens un changement de paradigme qui n’est pas immédiatement compréhensible.
Dans un article précédent où était décrit le média social Mastodon, le concept d’instance fédérée était comparé à un réseau de clubs ou cercles privés associés entre eux.
Certains aspects exposés dans l’article précédent demandent peut-être quelques éclaircissements supplémentaires pour celles et ceux qui abordent tout juste le concept de réseau fédéré.
1. On ne s’inscrit pas « sur Mastodon », mais on s’inscrit à une instance de Mastodon ! La comparaison avec un club ou un cercle s’avère ici bien pratique : adhérer à un cercle permet d’entrer en contact avec tous ceux et celles qui font partie du même réseau : on ne s’inscrit pas à une plateforme, mais on s’inscrit à l’un des clubs de la plateforme qui, avec les autres clubs, constituent le réseau. La plateforme est un logiciel, c’est une chose qui n’existe que virtuellement, alors qu’une instance qui utilise une telle plateforme en est l’aspect réel, matériel. C’est un serveur qui est physiquement situé quelque part, géré par des gens en chair et en os qui l’administrent. Vous vous inscrivez donc à une instance et ensuite vous entrez en contact avec les autres.
2. Les diverses instances ont la possibilité technique d’entrer en contact les unes avec les autres mais ce n’est pas nécessairement le cas. Supposons par exemple qu’il existe une instance qui regroupe 500 utilisateurs et utilisatrices passionné⋅e⋅s de littérature, et qui s’intitule mastodon.litterature : ces personnes se connaissent précisément parce en tant que membres de la même instance et chacun⋅e reçoit les messages publics de tous les autres membres.
Eh bien, chacun d’entre eux aura probablement aussi d’autres contacts avec des utilisateurs enregistrés sur difFerentes instances (nous avons tous des ami⋅e⋅s qui ne font pas partie de notre « cercle restreint », n’est-ce pas ?). Si chacun des 500 membres de maston.litterature suit par exemple 10 membres d’une autre instance, mastodon.litterature aurait un réseau local de 500 utilisateurs, mais aussi un réseau fédéré de 5000 utilisateurs !
Bien. Supposons que parmi ces 5000 il n’y ait même pas un seul membre de l’instance japonaise japan.nuclear.physics dont le thème est la physique nucléaire : cette autre instance pourrait avoir peut-être 800 membres et avoir un réseau fédéré de plus de 8000 membres, mais si entre les réseaux « littérature » et « physique nucléaire » il n’y avait pas un seul ami en commun, ses membres ne pourraient en théorie jamais se contacter entre eux.
En réalité, d’après la loi des grands nombres, il est assez rare que des instances d’une certaine taille n’entrent jamais en contact les unes avec les autres, mais l’exemple sert à comprendre les mécanismes sur lesquels repose un réseau fédéré (ce qui, en se basant justement sur la loi des grands nombres et les principes des degrés de séparation, confirme au contraire l’hypothèse que plus le réseau est grand, moins les utilisateurs et instances seront isolés sur une seule instance).
3. Chaque instance peut décider volontairement de ne pas entrer en contact avec une autre, sur la base des choix, des règles et politiques internes qui lui sont propres. Ce point est évidemment peu compris des différents commentateurs qui ne parviennent pas à sortir de l’idée du « réseau social monolithique ». S’il y avait sur Mastodon une forte concentration de suprémacistes blancs en deuil de Gab, ou de blogueurs porno en deuil de Tumblr, cela ne signifie pas que ce serait l’ensemble du réseau social appelé Mastodon qui deviendrait un « réseau social pour suprémacistes blancs et porno », mais seulement quelques instances qui n’entreraient probablement jamais en contact avec des instances antifascistes ou ultra-religieuses. Comme il est difficile de faire comprendre un tel concept, il est également difficile de faire comprendre les potentialités d’une structure de ce type. Dans un réseau fédéré, une fois donnée la possibilité technique d’interagir entre instances et utilisateurs, chaque instance et chaque utilisateur peut ensuite choisir de façon indépendante l’utilisation qui en sera faite.
Supposons qu’il existe par exemple :
Une instance écologiste, créée, maintenue et soutenue financièrement par un groupe de passionnés qui veulent avoir un lieu où échanger sur la nature et l’écologie, qui pose comme principe qu’on n’y poste ni liens externes ni images pornographiques.
Une instance commerciale, créée par une petite entreprise qui dispose d’un bon serveur et d’une bande passante très confortable, et celui ou celle qui s’y inscrit en payant respecte les règles fixées auparavant par l’entreprise elle-même.
Une instance sociale, créée par un centre social et dont les utilisateurs sont surtout les personnes qui fréquentent ledit centre et se connaissent aussi personnellement.
Une instance vidéoludique, qui était à l’origine une instance interne des employés d’une entreprise de technologie mais qui dans les faits est ouverte à quiconque s’intéresse aux jeux vidéos.
Avec ce scénario à quatre instances, on peut déjà décrire quelques interactions intéressantes : l’instance écologiste pourrait consulter ses utilisateurs et utilisatrices et décider de bannir l’instance commerciale au motif qu’on y diffuse largement une culture contraire à l’écologie, tandis que l’instance sociale pourrait au contraire maintenir le lien avec l’instance commerciale tout en choisissant préventivement de la rendre muette dans son propre fil, laissant le choix personnel à ses membres d’entrer ou non en contact avec les membres de l’instance commerciale. Cependant, l’instance sociale pourrait bannir l’instance de jeu vidéo à cause de la mentalité réactionnaire d’une grande partie de ses membres.
En somme, les contacts « insupportables/inacceptables » sont spontanément limités par les instances sur la base de leurs différentes politiques. Ici, le cadre d’ensemble commence à devenir très complexe, mais il suffit de l’observer depuis une seule instance, la nôtre, pour en comprendre les avantages : les instances qui accueillent des trolls, des agitateurs et des gens avec qui on n’arrive vraiment pas à discuter, nous les avons bannies, alors que celles avec lesquelles on n’avait pas beaucoup d’affinités mais pas non plus de motif de haine, nous les avons rendues muettes. Ainsi, si quelqu’un parmi nous veut les suivre, il n’y a pas de problème, mais ce sera son choix personnel.
4. Chaque utilisateur peut décider de rendre muets d’autres utilisateurs, mais aussi des instances entières. Si vous voulez particulièrement éviter les contenus diffusés par les utilisateurs et utilisatrices d’une certaine instance qui n’est cependant pas bannie par l’instance qui vous accueille (mettons que votre instance ne ferme pas la porte à une instance appelée meme.videogamez.lulz, dont la communauté tolère des comportements excessifs et une ambiance de moquerie lourde que certains trouvent néanmoins amusante), vous êtes libres de la rendre muette pour vous seulement. En principe, en présence de groupes d’utilisateurs indésirables venant d’une même instance/communauté, il est possible de bloquer plusieurs dizaines ou centaines d’utilisateurs à la fois en bloquant (pour vous) l’instance entière. Si votre instance n’avait pas un accord unanime sur la manière de traiter une autre instance, vous pourriez facilement laisser le choix aux abonnés qui disposent encore de ce puissant outil. Une instance peut également choisir de modérer seulement ses utilisateurs ou de ne rien modérer du tout, laissant chaque utilisateur complètement libre de faire taire ou d’interdire qui il veut sans jamais interférer ou imposer sa propre éthique.
La Fediverse
logo de la Fediverse
Maintenant que nous nous sommes mieux concentrés sur ces aspects, nous pouvons passer à l’étape suivante. Comme déjà mentionné dans le post précédent, Mastodon fait partie de quelque chose de plus vaste appelé la Fediverse (Fédération + Univers).
En gros, Mastodon est un réseau fédéré qui utilise certains outils de communication (il existe plusieurs protocoles mais les principaux sont ActivityPub, Ostatus et Diaspora*, chacun ayant ses avantages, ses inconvénients, ses partisans et ses détracteurs), utilisés aussi par et d’autres réalités fédérées (réseaux sociaux, plateformes de blogs, etc.) qui les mettent en contact pour former une galaxie unique de réseaux fédérés.
Pour vous donner une idée, c’est comme si Mastodon était un système planétaire qui tourne autour d’une étoile (Mastodon est l’étoile et chaque instance est une planète), cependant ce système planétaire fait partie d’un univers dans lequel existent de nombreux systèmes planétaires tous différents mais qui communiquent les uns avec les autres.
Toutes les planètes d’un système planétaire donné (les instances, comme des « clubs ») tournent autour d’un soleil commun (la plate-forme logicielle). L’utilisateur peut choisir la planète qu’il préfère mais il ne peut pas se poser sur le soleil : on ne s’inscrit pas à la plateforme, mais on s’inscrit à l’un des clubs qui, avec tous les autres, forme le réseau.
Dans cet univers, Mastodon est tout simplement le « système planétaire » le plus grand (celui qui a le plus de succès et qui compte le plus grand nombre d’utilisateurs) mais il n’est pas certain qu’il en sera toujours ainsi : d’autres « systèmes planétaires » se renforcent et grandissent.
[NB : chaque plate-forme évoquée ici utilise ses propres noms pour définir les serveurs indépendants sur lesquels elle est hébergée. Mastodon les appelle instances, Hubzilla les appelle hubs et Diaspora* les appelle pods. Toutefois, par souci de simplicité et de cohérence avec l’article précédent, seul le terme « instance » sera utilisé pour tous dans l’article]
La structure d’ensemble de la Fediverse
Les interactions de Mastodon avec les autres médias
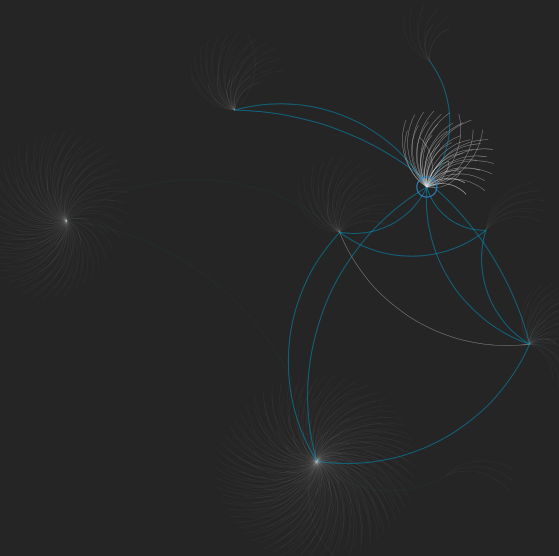
Sur Kumu.io on peut trouver une représentation interactive de la Fediverse telle qu’elle apparaît actuellement. Chaque « nœud » représente un réseau différent (ou « système planétaire »). Ce sont les différentes plateformes qui composent la fédération. Mastodon n’est que l’une d’entre elles, la plus grande, en bas au fond. Sur la capture d’écran qui illustre l’article, Mastodon est en bas.
En sélectionnant Mastodon il est possible de voir avec quels autres médias ou systèmes de la Fediverse il est en mesure d’interagir. Comme on peut le voir, il interagit avec la plupart des autres médias mais pas tout à fait avec tous.
Les interactions de Gnu social avec les autres médias
En sélectionnant un autre réseau social comme GNU Social, on observe qu’il a différentes interactions : il en partage la majeure partie avec Mastodon mais il en a quelques-unes en plus et d’autres en moins.
Cela dépend principalement du type d’outils de communication (protocoles) que chaque média particulier utilise. Un média peut également utiliser plus d’un protocole pour avoir le plus grand nombre d’interactions, mais cela rend évidemment leur gestion plus complexe. C’est, par exemple, la voie choisie par Friendica et GNU Social.
En raison des différents protocoles utilisés, certains médias ne peuvent donc pas interagir avec tous les autres. Le cas le plus important est celui de Diaspora*, qui utilise son propre protocole (appelé lui aussi Diaspora), qui ne peut interagir qu’avec Friendica et Gnu Social mais pas avec des médias qui reposent sur ActivityPub tels que Mastodon.
Au sein de la Fediverse, les choses sont cependant en constante évolution et l’image qui vient d’être montrée pourrait avoir besoin d’être mise à jour prochainement. En ce moment, la plupart des réseaux semblent s’orienter vers l’adoption d’ActivityPub comme outil unique. Ce ne serait pas mal du tout d’avoir un seul protocole de communication qui permette vraiment tout type de connexion !
Mais revenons un instant à l’image des systèmes planétaires. Kumu.io montre les connexions techniquement possibles entre tous les « systèmes planétaires » et, pour ce faire, relie génériquement les différents soleils. Mais comme nous l’avons bien vu, les vraies connexions ont lieu entre les planètes et non entre les soleils ! Une carte des étoiles montrant les connexions réelles devrait montrer pour chaque planète (c’est-à-dire chaque « moustache » des nœuds de Kum.io), des dizaines ou des centaines de lignes de connexion avec autant de planètes/moustaches, à la fois entre instances de sa plateforme et entre instances de différentes plateformes ! La quantité et la complexité des connexions, comme on peut l’imaginer, formeraient un enchevêtrement qui donnerait mal à la tête serait graphiquement illisible. Le simple fait de l’imaginer donne une idée de la quantité et de la complexité des connexions possibles.
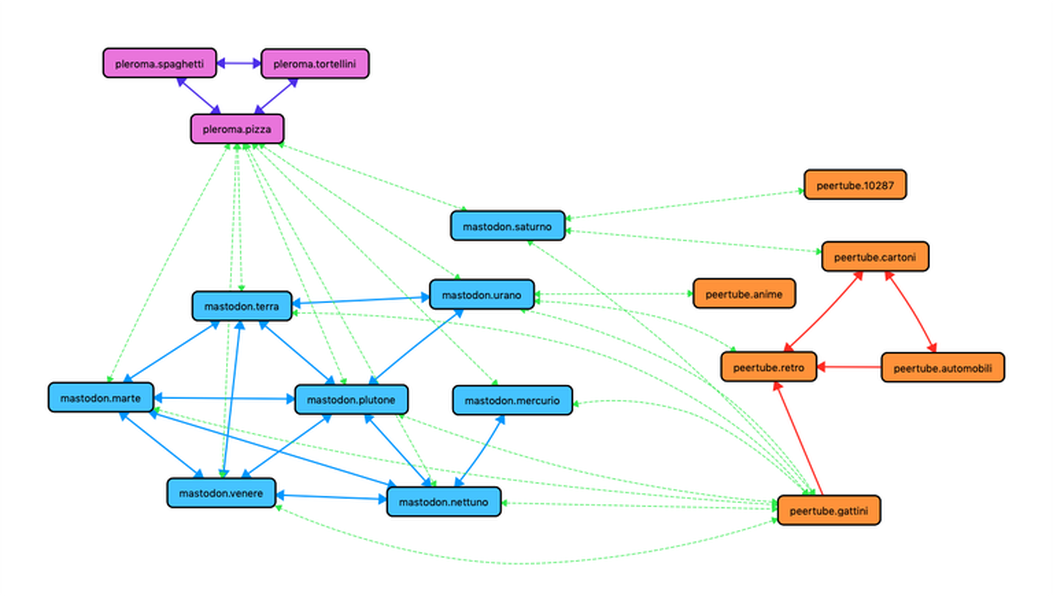
Et cela ne s’arrête pas là : chaque planète peut établir ou interrompre ses contacts avec les autres planètes de son système solaire (c’est-à-dire que l’instance Mastodon A peut décider de ne pas avoir de contact avec l’instance Mastodon B), et de la même manière elle peut établir ou interrompre les contacts avec des planètes de différents systèmes solaires (l’instance Mastodon A peut établir ou interrompre des contacts avec l’instance Pleroma B). Pour donner un exemple radical, nous pouvons supposer que nous avons des cousins qui sont des crétins, mais d’authentiques crétins, que nous avons chassés de notre planète (mastodon.terre) et qu’ensuite ils ont construit leur propre instance (mastodon.saturne) dans notre voisinage parce que ben, ils aiment bien notre soleil « Mastodon ». Nous décidons de nous ignorer les uns les autres tout de suite. Ces cousins, cependant, sont tellement crétins que même nos parents et amis proches des planètes voisines (mastodon.jupiter, mastodon.venus, etc.) ignorent les cousins crétins de mastodon.saturne.
Aucune planète du système Mastodon ne les supporte. Les cousins, cependant, ne sont pas entièrement sans relations et, au contraire, ils ont beaucoup de contacts avec les planètes d’autres systèmes solaires. Par exemple, ils sont en contact avec certaines planètes du système planétaire PeeeTube: peertube.10287, peertube.chatons, peertube.anime, mais aussi avec pleroma.pizza du système Pleroma et friendica.jardinage du système Friendica. En fait, les cousins crétins sont d’accord pour vivre sur leur propre petite planète dans le système Mastodon, mais préfèrent avoir des contacts avec des planètes de systèmes différents.
Nous qui sommes sur mastodon.terre, nous ne nous soucions pas moins des planètes qui leur sont complaisantes : ce sont des crétins tout autant que nos cousins et nous les avons bloquées aussi. Sauf un. Sur pleroma.pizza, nous avons quelques ami⋅e⋅s qui sont aussi des ami⋅e⋅s de certains cousins crétins de mastodon.saturne. Mais ce n’est pas un problème. Oh que non ! Nous avons des connexions interstellaires et nous devrions nous inquiéter d’une chose pareille ? Pas du tout ! Le blocage que nous avons activé sur mastodon.saturne est une sorte de barrière énergétique qui fonctionne dans tout le cosmos ! Si nous étions impliqués dans une conversation entre un ami de pleroma.pizza et un cousin de mastodon.saturne, simplement, ce dernier ne verrait pas ce qui sort de notre clavier et nous ne verrions pas ce qui sort du sien. Chacun d’eux saura que l’autre est là, mais aucun d’eux ne pourra jamais lire l’autre. Bien sûr, nous pourrions déduire quelque chose de ce que notre ami commun de pleroma.pizza dira, mais bon, qu’est-ce qu’on peut en espérer ? 😉
Cette image peut donner une idée de la façon dont les instances (planètes) se connectent entre elles. Si l’on considère qu’il existe des milliers d’instances connues de la Fediverse, on peut imaginer la complexité de l’image. Un aspect intéressant est le fait que les connexions entre une instance et une autre ne dépendent pas de la plateforme utilisée. Sur l’image on peut voir l’instance mastodon.mercure : c’est une instance assez isolée par rapport au réseau d’instances Mastodon, dont les seuls contacts sont mastodon.neptune, peertube.chatons et pleroma.pizza. Rien n’empêche mastodon.mercure de prendre connaissance de toutes les autres instances de Mastodon non par des échanges de messages avec mastodon.neptune, mais par des commentaires sur les vidéos de peertube.chatons. En fait, c’est d’autant plus probable que mastodon.neptune n’est en contact qu’avec trois autres instances Mastodon, alors que peertube.chatons est en contact avec toutes les instances Mastodon.
Essayer d’imaginer comment les différentes instances de cette image qui « ne se connaissent pas » peuvent entrer en contact nous permet d’avoir une idée plus précise du niveau de complexité qui peut être atteint. Dans un système assez grand, avec un grand nombre d’utilisateurs et d’instances, isoler une partie de celui-ci ne compromettra en aucune façon la richesse des connexions possibles.
Une fois toutes les connexions possibles créées, il est également possible de réaliser une expérience différente, c’est-à-dire d’imaginer interrompre des connexions jusqu’à la formation de deux ou plusieurs réseaux parfaitement séparés, contenant chacune des instances Mastodon, Pleroma et Peertube.
Et pour ajouter encore un degré de complexité, on peut faire encore une autre expérience, en raisonnant non plus à l’échelle des instances mais à celle des utilisateurs⋅rices individuel⋅le⋅s des instances (faire l’hypothèse de cinq utilisateurs⋅rices par instance pourrait suffire pour recréer les différentes situations). Quelques cas qu’on peut imaginer :
1) Nous sommes sur une instance de Mastodon et l’utilisatrice Anna vient de découvrir par le commentaire d’une vidéo sur Peertube l’existence d’une nouvelle instance de Pleroma, donc maintenant elle connaît son existence mais, choisissant de ne pas la suivre, elle ne fait pas réellement connaître sa découverte aux autres membres de son instance.
2) Sur cette même instance de Mastodon l’utilisateur Ludo bloque la seule instance Pleroma connue. Conséquence : si cette instance Pleroma devait faire connaître d’autres instances Pleroma avec lesquelles elle est en contact, Ludo devrait attendre qu’un autre membre de son instance les fasse connaître, car il s’est empêché lui-même d’être parmi les premiers de son instance à les connaître.
3) En fait, la première utilisatrice de l’instance à entrer en contact avec les autres instances Pleroma sera Marianne. Mais elle ne les connaît pas de l’instance Pleroma (celle que Ludo a bloquée) avec laquelle ils sont déjà en contact, mais par son seul contact sur GNU Social.
Cela semble un peu compliqué mais en réalité ce n’est rien de plus qu’une réplique de mécanismes humains auxquels nous sommes tellement habitué⋅e⋅s que nous les tenons pour acquis. On peut traduire ainsi les différents exemples qui viennent d’être exposés :
1) Notre amie Anna, habituée de notre bar, rencontre dans la rue une personne qui lui dit fréquenter un nouveau bar dans une ville proche. Mais Anna n’échange pas son numéro de téléphone avec le type et elle ne pourra donc pas donner d’informations à ses amis dans son bar sur le nouveau bar de l’autre ville.
2) Dans le bar habituel, Ludo de Nancy évite Laura de Metz. Quand Laura amène ses autres amies Solène et Louise de Metz au bar, elle ne les présente pas à Ludo. Ce n’est que plus tard que les amis du bar, devenus amis avec Solène et Louise, pourront les présenter à Ludo indépendamment de Laura.
3) En réalité Marianne avait déjà rencontré Solène et Louise, non pas grâce à Laura, mais grâce à Stéphane, son seul ami à Villers.
Pour avoir une idée de l’ampleur de la Fediverse, vous pouvez jeter un coup d’œil à plusieurs sites qui tentent d’en fournir une image complète. Outre Kumu.io déjà mentionné, qui essaie de la représenter avec une mise en page graphique élégante qui met en évidence les interactions, il y a aussi Fediverse.network qui essaie de lister chaque instance existante en indiquant pour chacune d’elles les protocoles utilisés et le statut du service, ou Fediverse.party, qui est un véritable portail où choisir la plate-forme à utiliser et à laquelle s’enregistrer. Switching.software, une page qui illustre toutes les alternatives gratuites aux médias sociaux et propriétaires, indique également quelques réseaux fédérés parmi les alternatives à Twitter et Facebook.
Pour être tout à fait complet : au début, on avait tendance à diviser tout ce mégaréseau en trois « univers » superposés : celui de la « Fédération » pour les réseaux reposant sur le protocole Diaspora, La « Fediverse » pour ceux qui utilisent Ostatus et « ActivityPub » pour ceux qui utilisent… ActivityPub. Aujourd’hui, au contraire, ils sont tous considérés comme faisant partie de la Fediverse, même si parfois on l’appelle aussi la Fédération.
Tant de réseaux…
Examinons donc les principales plateformes/réseaux et leurs différences. Petites précisions : certaines de ces plateformes sont pleinement actives alors que d’autres sont à un stade de développement plus ou moins avancé. Dans certains cas, l’interaction entre les différents réseaux n’est donc pas encore pleinement fonctionnelle. De plus, en raison de la nature libre et indépendante des différents réseaux, il est possible que des instances apportent des modifications et des personnalisations « non standard » (un exemple en est la limite de caractères sur Mastodon : elle est de 500 caractères par défaut, mais une instance peut décider de définir la limite qu’elle veut ; un autre exemple est l’utilisation des fonctions de mise en favori ou de partage, qu’une instance peut autoriser et une autre interdire). Dans ce paragraphe, ces personnalisations et différences ne sont pas prises en compte.
Mastodon (semblable à : Twitter)
Copie d’écran, une instance de Mastodon, Framapiaf
Mastodon est une plateforme de microblogage assez semblable à Twitter parce qu’elle repose sur l’échange de messages très courts. C’est le réseau le plus célèbre de la Fediverse. Il est accessible sur smartphone à travers un certain nombre d’applications tant pour Android que pour iOS. Un de ses points forts est le design bien conçu et le fait qu’il a déjà un « parc d’utilisateurs⋅rices » assez conséquent (presque deux millions d’utilisateurs⋅rices dans le monde, dont quelques milliers en France). En version bureau, il se présente comme une série de colonnes personnalisables, qui montrent les différents « fils », sur le modèle de Tweetdeck. Pour le moment, Mastodon est la seule plateforme sociale fédérée accessible par des applications sur Android et iOS.
Pleroma (semblable à : Twitter et DeviantArt)
Copie d’écran, Pleroma
Pleroma est le réseau « sœur » de Mastodon : fondamentalement, c’est la même chose dans deux versions un peu différentes. Pleroma offre quelques fonctionnalités supplémentaires concernant la gestion des images et permet par défaut des messages plus longs. À la différence de Mastodon, Pleroma montre en version bureau une colonne unique avec le fil sélectionné, ce qui le rend beaucoup plus proche de Twitter. Actuellement, de nombreuses instances Pleroma ont un grand nombre d’utilisateurs⋅rices qui s’intéressent à l’illustration et au manga, ce qui, comme ambiance, peut vaguement rappeler l’ambiance de DeviantArt. Les applications pour smartphone de Mastodon peuvent également être utilisées pour accéder à Pleroma.
Misskey (semblable à : un mélange entre Twitter et DeviantArt)
Copie d’écran, Misskey
Misskey est une sorte de Twitter qui tourne principalement autour d’images. Il offre un niveau de personnalisation supérieur à Mastodon et Pleroma, et une plus grande attention aux galeries d’images. C’est une plateforme qui a eu du succès au Japon et parmi les passionnés de manga (et ça se voit !).
Friendica (semblable à : Facebook)
Friendica est un réseau extrêmement intéressant. Il reprend globalement la structure graphique de Facebook (avec les ami⋅e⋅s, les notifications, etc.), mais il permet également d’interagir avec plusieurs réseaux commerciaux qui ne font pas partie de la Fediverse. Il est donc possible de connecter son compte Friendica à Facebook, Twitter, Tumblr, WordPress, ainsi que de générer des flux RSS, etc. Bref, Friendica se présente comme une sorte de nœud pour diffuser du contenu sur tous les réseaux disponibles, qu’ils soient fédérés ou non. En somme, Friendica est le passe-partout de la Fediverse : une instance Friendica au maximum de ses fonctions se connecte à tout et dialogue avec tout le monde.
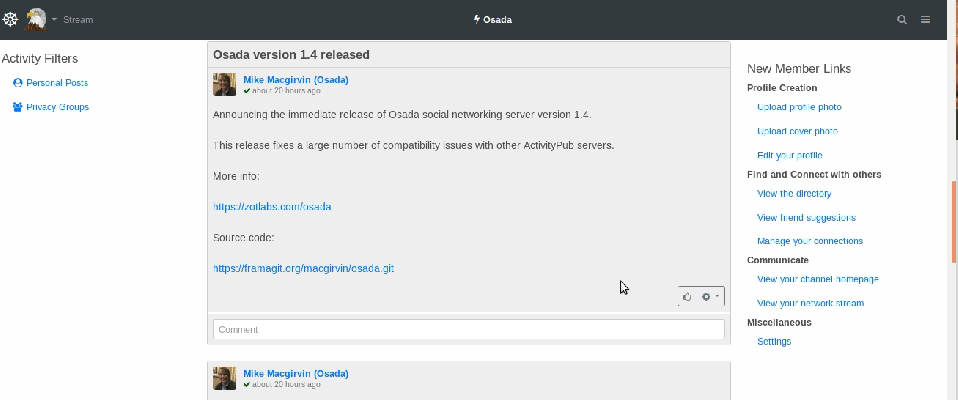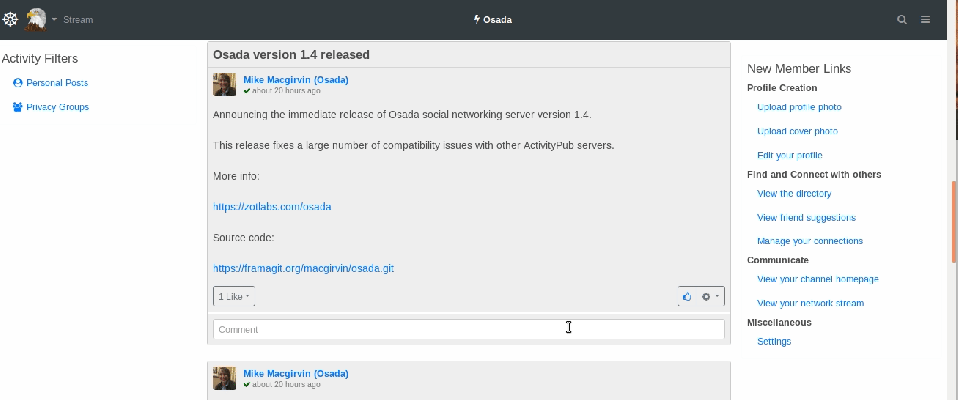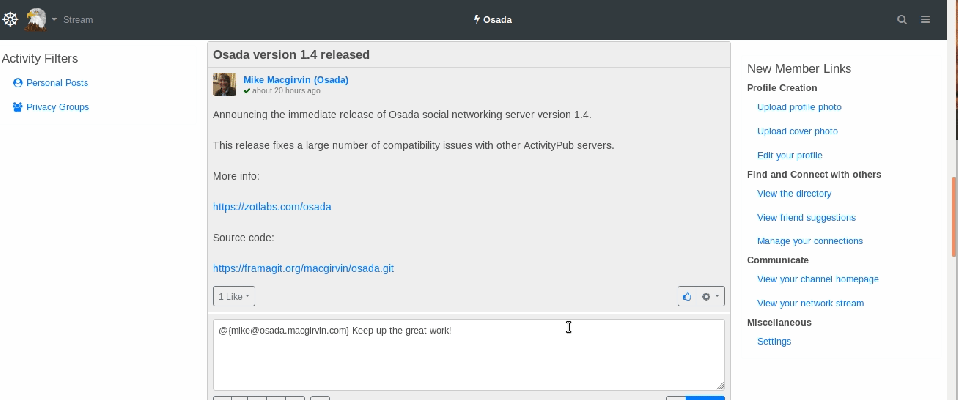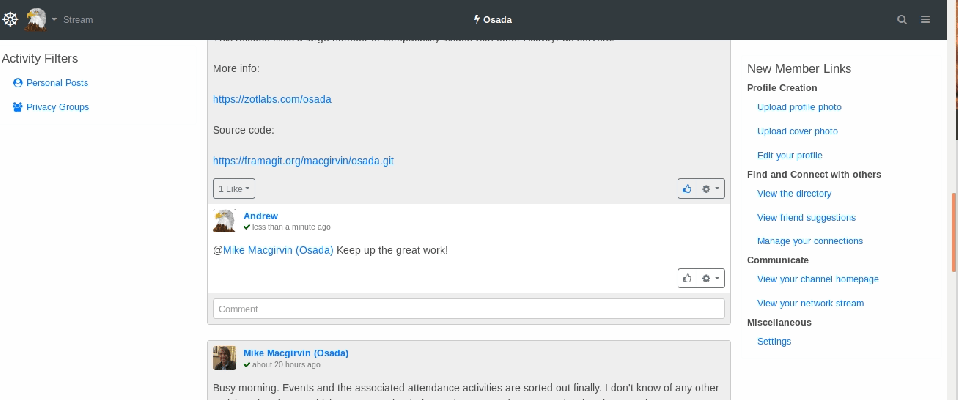
Osada (semblable à : un mélange entre Twitter et Facebook)
Image animée, réponse à un commentaire sur Osada
Osada est un autre réseau dont la configuration peut faire penser à un compromis entre Twitter et Facebook. De toutes les plateformes qui rappellent Facebook, c’est celle dont le design est le plus soigné.
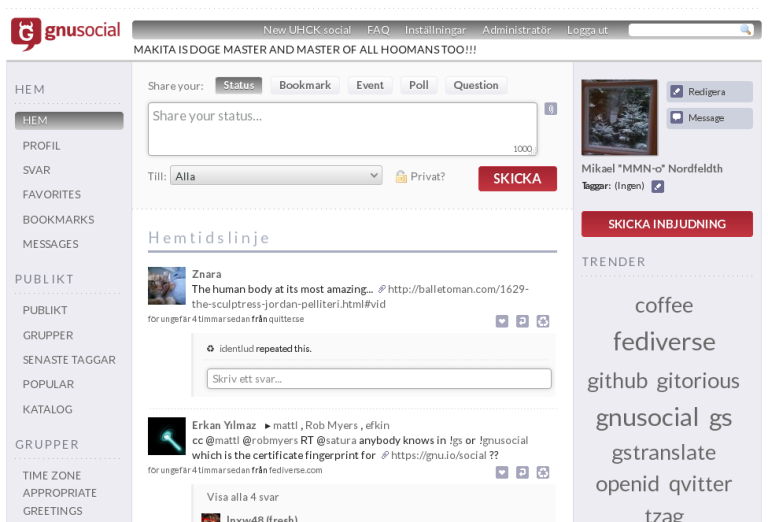
GNUsocial (semblable à : un mélange entre Twitter et Facebook)
Copie d’écran : GNUsocial avec une interface en suédois.
GNUsocial est un peu le « grand-père » des médias sociaux listés ici, en particulier de Friendica et d’Osada, dont il est le prédécesseur.
Aardwolf (semblable à : Twitter, éventuellement)
Copie d’écran : logo et slogan d’Aardwolf
Aardwolf n’est pas encore prêt, mais il est annoncé comme une sorte d’alternative à Twitter. On attend de voir.
PeerTube (semblable à : YouTube)
Capture d’écran, une instance de PeerTube, aperi.tube
PeerTube est le réseau fédéré d’hébergement de vidéo vraiment, mais vraiment très semblable à YouTube, Vimeo et d’autres services de ce genre. Avec un catalogue en cours de construction, Peertube apparaît déjà comme un projet très solide.
Pixelfed (semblable à : Instagram)
Copie d’écran, Pixelfed
Pixelfed est essentiellement l’Instagram de la Fédération. Il est en phase de développement mais semble être plutôt avancé. Il lui manque seulement des applications pour smartphone pour être adopté à la place d’Instagram. Pixelfed a le potentiel pour devenir un membre extrêmement important de la Fédération !
NextCloud (semblable à : iCloud, Dropbox, GDrive)
Logo de Owncloud
NextCloud, né du projet plus ancien ownCloud, est un service d’hébergement de fichiers assez semblable à Dropbox. Tout le monde peut faire tourner NextCloud sur son propre serveur. NextCloud offre également des services de partage de contacts (CardDAV) ou de calendriers (CalDAV), de streaming de médias, de marque-page, de sauvegarde, et d’autres encore. Il tourne aussi sur Window et OSX et est accessible sur smartphone à travers des applications officielles. Il fait partie de la Fediverse dans la mesure où il utilise ActivityPub pour communiquer différentes informations à ses utilisateurs, comme des changements dans les fichiers, les activités du calendrier, etc.
Diaspora* (semblable à : Facebook, et aussi un peu Tumblr)
Copie d’écran, un « pod » de Diaspora*, Framasphere
Diaspora* est un peu le « cousin » de la Fediverse. Il fonctionne avec un protocole bien à lui et dialogue avec le reste de la Fediverse principalement via GNU social et Friendica, le réseau passe-partout, même s’il semble qu’il circule l’idée de faire utiliser à Diaspora* (l’application) aussi bien son propre protocole qu’ActivityPub. Il s’agit d’un grand et beau projet, avec une base solide d’utilisateurs⋅rices fidèles. Au premier abord, il peut faire penser à une version extrêmement minimaliste de Facebook, mais son attention aux images et son système intéressant d’organisation des posts par tag permet également de le comparer, d’une certaine façon, à Tumblr.
Funkwhale (semblable à : SoundCloud et Grooveshark)
Copie d’écran, Funkwhale
Funkwhale ressemble à SoundCloud, Grooveshark et d’autre services semblables. Comme une sorte de YouTube pour l’audio, il permet de partager des pistes audio mais au sein d’un réseau fédéré. Avec quelques fonctionnalités en plus, il pourrait devenir un excellent service d’hébergement de podcasts audio.
Plume, Write Freely et Write.as (plateformes de blog)
Copie d’écran, Write freely
Plume, Write Freely et Write.as sont des plateformes de blog assez minimalistes qui font partie de la Fédération. Elles n’ont pas toute la richesse, les fonctions, les thèmes et la personnalisation de WordPress ou de Blogger, mais elles font leur travail avec légèreté.
Hubzilla (semblable à : …TOUT !!)
Page d’accueil de Hubzilla
Hubzilla est un projet très riche et complexe qui permet de gérer aussi bien des médias sociaux que de l’hébergement de fichiers, des calendriers partagés, de l’hébergement web, et le tout de manière décentralisée. En bref, Hubzilla se propose de faire tout à la fois ce que font plusieurs des services listés ici. C’est comme avoir une seule instance qui fait à la fois Friendica, Peertube et NextCloud. Pas mal ! Un projet à surveiller !
GetTogether (semblable à : MeetUp)
Copie d’écran, GetTogether
GetTogether est une plateforme servant à planifier des événements. Semblable à MeetUp, elle sert à mettre en relation des personnes différentes unies par un intérêt commun, et à amener cet intérêt dans le monde réel. Pour le moment, GetTogether ne fait pas encore partie de la Fediverse, mais il est en train de mettre en place ActivityPub et sera donc bientôt des nôtres.
Mobilizon (semblable à : MeetUp)
Mobilizon est une nouvelle plateforme en cours de développement, qui se propose comme une alternative libre à MeetUp et à d’autres logiciels servant à organiser des réunions et des rencontres en tout genre. Dès le départ, le projet naît avec l’intention d’utiliser ActivityPub et de faire partie de la Fediverse, en conformité avec les valeurs de Framasoft, association française née avec l’objectif de diffuser l’usage des logiciels libres et des réseaux décentralisés. Voir la présentation de Mobilizon en italien.
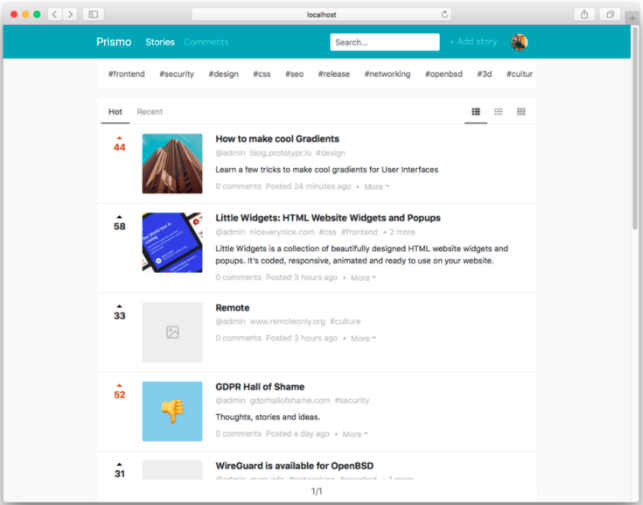
Prismo est une application encore en phase de développement, qui se propose de devenir un sorte de version décentralisée de Reddit, c’est-à-dire un média social centré sur le partage de liens, mais qui pourrait potentiellement évoluer en quelque chose qui ressemble à Pocket ou Evernote. Les fonctions de base sont déjà opérationnelles.
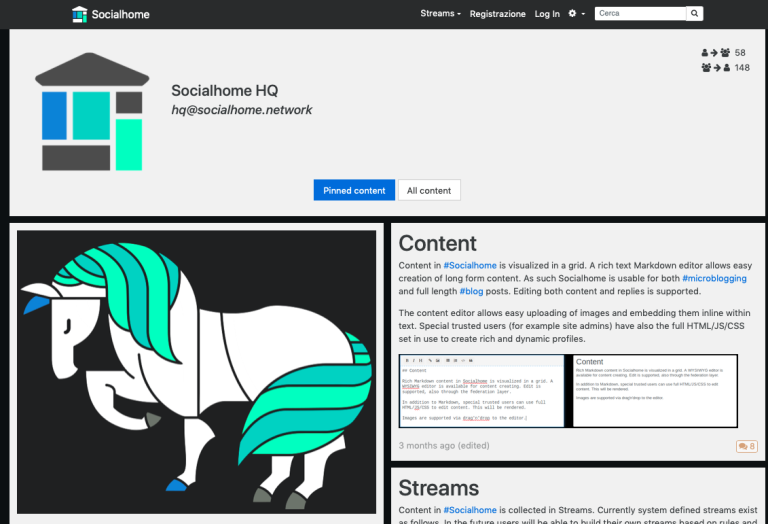
Socialhome
Capture d’écran, Socialhome
Socialhome est un média social qui utilise une interface par « blocs », affichant les messages comme dans un collage de photos de Pinterest. Pour le moment, il communique seulement via le protocole de Diaspora, mais il devrait bientôt mettre en place ActivityPub.
Et ce n’est pas tout !
Les recommandations du W3C pour ActivityPub, page d’accueil
Il existe encore d’autres applications et médias sociaux qui adoptent ou vont adopter ActivityPub, ce qui rendra la Fediverse encore plus structurée. Certains sont assez semblables à ceux déjà évoqués, alors que d’autres sont encore en phase de développement, on ne peut donc pas encore les conseiller pour remplacer des systèmes commerciaux plus connus. Il y a cependant des plateformes déjà prêtes et fonctionnelles qui pourraient entrer dans la Fediverse en adoptant ActivityPub : NextCloud en est un exemple (il était déjà constitué quand il a décidé d’entrer dans la Fediverse) ; le plugin de WordPress est pour sa part un outil qui permet de fédérer une plateforme qui existe déjà ; GetTogether est un autre service qui est en train d’être fédéré. Des plateformes déjà en place (je pense à Gitter, mais c’est juste un exemple parmi tant d’autres) pourraient trouver un avantage à se fédérer et à entrer dans une grande famille élargie. Bref : ça bouge dans la Fediverse et autour d’elle !
… un seul Grand Réseau !
Jusqu’ici, nous avons vu de nombreuses versions alternatives d’outils connus qui peuvent aussi être intéressant pris individuellement, mais qui sont encore meilleurs quand ils collaborent. Voici maintenant le plus beau : le fait qu’ils partagent les mêmes protocoles de communication élimine l’effet « cage dorée » de chaque réseau !
Maintenant qu’on a décrit chaque plateforme, on peut donner quelques exemples concrets :
Je suis sur Mastodon, où apparaît le message d’une personne que je « suis ». Rien d’étrange à cela, si ce n’est que cette personne n’est pas utilisatrice de Mastodon, mais de Peertube ! En effet, il s’agit de la vidéo d’un panorama. Toujours depuis Mastodon, je commente en écrivant « joli » et cette personne verra apparaître mon commentaire sous sa vidéo, sur Peertube.
Je suis sur Osada et je poste une réflexion ouverte un peu longue. Cette réflexion est lue par une de mes amies sur Friendica, qui la partage avec ses followers, dont certains sont sur Friendica, mais d’autres sont sur d’autres plateformes. Par exemple, l’un d’eux est sur Pleroma, il me répond et nous commençons à dialoguer.
Je publie une photo sur Pixelfed qui est vue et commentée par un de mes abonnés sur Mastodon.
En somme, chacun peut garder contact avec ses ami⋅e⋅s/abonné⋅e⋅s depuis son réseau préféré, mêmes si ces personnes en fréquentent d’autres.
Pour établir une comparaison avec les réseaux commerciaux, c’est comme si l’on pouvait recevoir sur Facebook les tweets d’un ami qui est sur Twitter, les images postées par quelqu’un d’autre sur Instagram, les vidéos d’une chaîne YouTube, les pistes audio sur SoundCloud, les nouveaux posts de divers blogs et sites personnels, et commenter et interagir avec chacun d’eux parce que tous ces réseaux collaborent et forment un seul grand réseau !
Chacun de ces réseaux pourra choisir la façon dont il veut gérer ces interactions : par exemple, si je voulais une vie sociale dans un seul sens, je pourrais choisir une instance Pixelfed où les autres utilisateurs⋅rices peuvent me contacter seulement en commentant les photos que je publie, ou bien je pourrais choisir une instance Peertube et publier des vidéos qui ne pourraient pas être commentées mais qui pourraient tourner dans toute la Fediverse, ou choisir une instance Mastodon qui oblige mes interlocuteurs à communiquer avec moi de manière concise.
Certains détails sont encore à définir (par exemple : je pourrais envoyer un message direct depuis Mastodon vers une plateforme qui ne permet pas à ses utilisateurs⋅rices de recevoir des messages directs, sans jamais être averti du fait que le/la destinataire n’aura aucun moyen de savoir que je lui ai envoyé quelque chose). Il s’agit de situations bien compréhensibles à l’intérieur d’un écosystème qui doit s’adapter à des réalités très diverses, mais dans la majorité des cas il s’agit de détails faciles à gérer. Ce qui compte, c’est que les possibilités d’interactions sont potentiellement infinies !
Connectivité totale, exposition dosée
Toute cette connectivité partagée doit être observée en gardant à l’esprit que, même si par simplicité les différents réseaux ont été traités ici comme des réseaux centralisés, ce sont en réalité des réseaux d’instances indépendantes qui interagissent directement avec les instances des autres réseaux : mon instance Mastodon filtrera les instances Peertube qui postent des vidéos racistes mais se connectera à toutes les instances Peertube qui respectent sa politique ; si je suis un certain ami sur Pixelfed je verrai seulement ses posts, sans que personne m’oblige à voir toutes les photos de couchers de soleil et de chatons de ses ami⋅e⋅s sur ce réseau.
La combinaison entre autonomie des instances, grande interopérabilité entre celles-ci et liberté de choix permet une série de combinaisons extrêmement intéressantes dont les réseaux commerciaux ne peuvent même pas rêver : ici, l’utilisateur⋅rice est membre d’un seul grand réseau où chacun⋅e peut choisir :
Son outil d’accès préféré (Mastodon, Pleroma, Friendica) ;
La communauté dans laquelle il ou elle se sent le plus à l’aise (l’instance) ;
La fermeture aux communautés indésirables et l’ouverture aux communautés qui l’intéressent.
Tout cela sans pour autant renoncer à être connecté à des utilisateurs⋅rices qui ont choisi des outils et des communautés différents. Par exemple, je peux choisir une certaine instance Pleroma parce que j’aime son design, la communauté qu’elle accueille, ses règles et la sécurité qu’elle procure mais, à partir de là, suivre et interagir principalement avec des utilisateurs⋅rices d’une instance Pixelfed particulière et en importer les contenus et l’esthétique dans mon instance.
À cela on peut ajouter que des instances individuelles peuvent littéralement être installées et administrées par chaque utilisateur individuel sur ses propres machines, ce qui permet un contrôle total du contenu. Les instances minuscules auto-hébergées « à la maison » et les instances de travail plus robustes, les instances scolaires et les instances collectives, les instances avec des milliers d’utilisateurs et les instances avec un seul utilisateur, les instances à l’échelle d’un quartier ou d’un immeuble, toutes sont unies pour former un réseau complexe et personnalisable, qui vous permet de vous connecter pratiquement à n’importe qui mais aussi de vous éviter la surcharge d’information.
C’est une sorte de retour aux origines d’Internet, mais un retour à un âge de maturité, celui du Web 2.0, qui a tiré les leçons de l’expérience : être passé par la centralisation de la communication entre les mains de quelques grands acteurs internationaux a renforcé la conviction que la structure décentralisée est la plus humaine et la plus enrichissante.
Rejoignez la fédération !
Nous devons nous passer de Chrome
Chrome, de navigateur internet novateur et ouvert, est devenu au fil des années un rouage essentiel de la domination d’Internet par Google. Cet article détaille les raisons pour lesquelles Chrome asphyxie le Web ouvert et pourquoi il faudrait passer sur un autre navigateur tel Vivaldi ou Firefox.
Il y a dix ans, nous avons eu besoin de Google Chrome pour libérer le Web de l’hégémonie des entreprises, et nous avons réussi à le faire pendant une courte période. Aujourd’hui, sa domination étouffe la plateforme même qu’il a autrefois sauvée des griffes de Microsoft. Et personne, à part Google, n’a besoin de ça.
Nous sommes en 2008. Microsoft a toujours une ferme emprise sur le marché des navigateurs web. Six années se sont écoulées depuis que Mozilla a sorti Firefox, un concurrent direct d’Internet Explorer. Google, l’entreprise derrière le moteur de recherche que tout le monde aimait à ce moment-là, vient d’annoncer qu’il entre dans la danse. Chrome était né.
Au bout de deux ans, Chrome représentait 15 % de l’ensemble du trafic web sur les ordinateurs fixes — pour comparer, il a fallu 6 ans à Firefox pour atteindre ce niveau. Google a réussi à fournir un navigateur rapide et judicieusement conçu qui a connu un succès immédiat parmi les utilisateurs et les développeurs Web. Les innovations et les prouesses d’ingénierie de leur produit étaient une bouffée d’air frais, et leur dévouement à l’open source la cerise sur le gâteau. Au fil des ans, Google a continué à montrer l’exemple en adoptant les standards du Web.
Avançons d’une décennie. Le paysage des navigateurs Web est très différent. Chrome est le navigateur le plus répandu de la planète, faisant de facto de Google le gardien du Web, à la fois sur mobile et sur ordinateur fixe, partout sauf dans une poignée de régions du monde. Le navigateur est préinstallé sur la plupart des téléphones Android vendus hors de Chine, et sert d’interface utilisateur pour Chrome OS, l’incursion de Google dans les systèmes d’exploitation pour ordinateurs fixe et tablettes. Ce qui a commencé comme un navigateur d’avant-garde respectant les standards est maintenant une plateforme tentaculaire qui n’épargne aucun domaine de l’informatique moderne.
Bien que le navigateur Chrome ne soit pas lui-même open source, la plupart de ses composantes internes le sont. Chromium, la portion non-propriétaire de Chrome, a été rendue open source très tôt, avec une licence laissant de larges marges de manœuvre, en signe de dévouement à la communauté du Web ouvert. En tant que navigateur riche en fonctionnalités, Chromium est devenu très populaire auprès des utilisateurs de Linux. En tant que projet open source, il a de nombreux adeptes dans l’écosystème open source, et a souvent été utilisé comme base pour d’autres navigateurs ou applications.
Tant Chrome que Chromium se basent sur Blink, le moteur de rendu qui a démarré comme un fork de WebKit en 2013, lorsque l’insatisfaction de Google grandissait envers le projet mené par Apple. Blink a continué de croître depuis lors, et va continuer de prospérer lorsque Microsoft commencera à l’utiliser pour son navigateur Edge.
La plateforme Chrome a profondément changé le Web. Et plus encore. L’adoption des technologies web dans le développement des logiciels PC a connu une augmentation sans précédent dans les 5 dernières années, avec des projets comme Github Electron, qui s’imposent sur chaque OS majeur comme les standards de facto pour des applications multiplateformes. ChromeOS, quoique toujours minoritaire comparé à Windows et MacOS, s’installe dans les esprits et gagne des parts de marché.
Chrome est, de fait, partout. Et c’est une mauvaise nouvelle
Don’t Be Evil
L’hégémonie de Chrome a un effet négatif majeur sur le Web en tant que plateforme ouverte : les développeurs boudent de plus en plus les autres navigateurs lors de leurs tests et de leurs débogages. Si cela fonctionne comme prévu sur Chrome, c’est prêt à être diffusé. Cela engendre en retour un afflux d’utilisateurs pour le navigateur puisque leurs sites web et applications favorites ne marchent plus ailleurs, rendant les développeurs moins susceptibles de passer du temps à tester sur les autres navigateurs. Un cercle vicieux qui, s’il n’est pas brisé, entraînera la disparition de la plupart des autres navigateurs et leur oubli. Et c’est exactement comme ça que vous asphyxiez le Web ouvert.
Quand il s’agit de promouvoir l’utilisation d’un unique navigateur Web, Google mène la danse. Une faible assurance de qualité et des choix de conception discutables sont juste la surface visible de l’iceberg quand on regarde les applications de Google et ses services en dehors de l’écosystème Chrome. Pour rendre les choses encore pires, le blâme retombe souvent sur les autres concurrents car ils « retarderaient l’avancée du Web ». Le Web est actuellement le terrain de jeu de Google ; soit vous faites comme ils disent, soit on vous traite de retardataire.
Sans une compétition saine et équitable, n’importe quelle plateforme ouverte régressera en une organisation dirigiste. Pour le Web, cela veut dire que ses points les plus importants — la liberté et l’accessibilité universelle — sont sapés pour chaque pour-cent de part de marché obtenu par Chrome. Rien que cela est suffisant pour s’inquiéter. Mais quand on regarde de plus près le modèle commercial de Google, la situation devient beaucoup plus effrayante.
La raison d’être de n’importe quelle entreprise est de faire du profit et de satisfaire les actionnaires. Quand la croissance soutient une bonne cause, c’est considéré comme un avantage compétitif. Dans le cas contraire, les services marketing et relations publiques sont mis au travail. Le mantra de Google, « Don’t be evil« , s’inscrivait parfaitement dans leur récit d’entreprise quand leur croissance s’accompagnait de rendre le Web davantage ouvert et accessible.
Hélas, ce n’est plus le cas.
Logos de Chrome
L’intérêt de l’entreprise a dérivé petit à petit pour transformer leur domination sur le marché des navigateurs en une croissance du chiffre d’affaires. Il se trouve que le modèle commercial de Google est la publicité sur leur moteur de recherche et Adsense. Tout le reste représente à peine 10 % de leur revenu annuel. Cela n’est pas forcément un problème en soi, mais quand la limite entre navigateur, moteur de recherche et services en ligne est brouillée, nous avons un problème. Et un gros.
Les entreprises qui marchent comptent sur leurs avantages compétitifs. Les moins scrupuleuses en abusent si elles ne sont pas supervisées. Quand votre navigateur vous force à vous identifier, à utiliser des cookies que vous ne pouvez pas supprimer et cherche à neutraliser les extensions de blocage de pub et de vie privée, ça devient très mauvais16. Encore plus quand vous prenez en compte le fait que chaque site web contient au moins un bout de code qui communique avec les serveurs de Google pour traquer les visiteurs, leur montrer des publicités ou leur proposer des polices d’écriture personnalisées.
En théorie, on pourrait fermer les yeux sur ces mauvaises pratiques si l’entreprise impliquée avait un bon bilan sur la gestion des données personnelles. En pratique cependant, Google est structurellement flippant, et ils n’arrivent pas à changer. Vous pouvez penser que vos données personnelles ne regardent que vous, mais ils ne semblent pas être d’accord.
Le modèle économique de Google requiert un flot régulier de données qui puissent être analysées et utilisées pour créer des publicités ciblées. Du coup, tout ce qu’ils font a pour but ultime d’accroître leur base utilisateur et le temps passé par ces derniers sur leurs outils. Même quand l’informatique s’est déplacée de l’ordinateur de bureau vers le mobile, Chrome est resté un rouage important du mécanisme d’accumulation des données de Google. Les sites web que vous visitez et les mots-clés utilisés sont traqués et mis à profit pour vous offrir une expérience plus « personnalisée ». Sans une limite claire entre le navigateur et le moteur de recherche, il est difficile de suivre qui connaît quoi à votre propos. Au final, on accepte le compromis et on continue à vivre nos vies, exactement comme les ingénieurs et concepteurs de produits de Google le souhaitent.
En bref, Google a montré à plusieurs reprises qu’il n’avait aucune empathie envers ses utilisateurs finaux. Sa priorité la plus claire est et restera les intérêts des publicitaires.
Voir au-delà
Une compétition saine centrée sur l’utilisateur est ce qui a provoqué l’arrivée des meilleurs produits et expériences depuis les débuts de l’informatique. Avec Chrome dominant 60 % du marché des navigateurs et Chromium envahissant la bureautique sur les trois plateformes majeures, on confie beaucoup à une seule entreprise et écosystème. Un écosystème qui ne semble plus concerné par la performance, ni par l’expérience utilisateur, ni par la vie privée, ni par les progrès de l’informatique.
Mais on a encore la possibilité de changer les choses. On l’a fait il y a une décennie et on peut le faire de nouveau.
Mozilla et Apple font tous deux un travail remarquable pour combler l’écart des standards du Web qui s’est élargi dans les premières années de Chrome. Ils sont même sensiblement en avance sur les questions de performance, utilisation de la batterie, vie privée et sécurité.
Si vous êtes coincés avec des services de Google qui ne marchent pas sur d’autres navigateurs, ou comptez sur Chrome DevTools pour faire votre travail, pensez à utiliser Vivaldi17 à la place. Ce n’est pas l’idéal —Chromium appartient aussi à Google—, mais c’est un pas dans la bonne direction néanmoins. Soutenir des petits éditeurs et encourager la diversité des navigateurs est nécessaire pour renverser, ou au moins ralentir, la croissance malsaine de Chrome.
Je me suis libéré de Chrome en 2014, et je n’y ai jamais retouché. Il est probable que vous vous en tirerez aussi bien que moi. Vous pouvez l’apprécier en tant que navigateur. Et vous pouvez ne pas vous préoccuper des compromissions en termes de vie privée qui viennent avec. Mais l’enjeu est bien plus important que nos préférences personnelles et nos affinités ; une plateforme entière est sur le point de devenir un nouveau jardin clos. Et on en a déjà assez. Donc, faisons ce que nous pouvons, quand nous le pouvons, pour éviter ça.
Vous avez sans doute remarqué que lorsque les médias grand public évoquent les entreprises dominantes du numérique on entend « les GAFA » et on a tendance à oublier le M de Microsoft. Et pourtant…On sait depuis longtemps à quel point Microsoft piste ses utilisateurs, mais des mesures précises faisaient défaut. Le bref article que Framalang vous propose évoque les données d’une analyse approfondie de tout ce que Windows 10 envoie vers ses serveurs pratiquement à l’insu de ses utilisateurs…
Selon les services allemands de cybersécurité, Windows 10 vous surveille de 534 façons
par Derek Zimmer
L’Office fédéral de la sécurité des technologies de l’information (ou BSI) a publié un rapport18 (PDF, 3,4 Mo) qui détaille les centaines de façons dont Windows 10 piste les utilisateurs, et montre qu’à moins d’avoir la version Entreprise de Windows, les multiples paramètres de confidentialité ne font pratiquement aucune différence.
Seules les versions Entreprise peuvent les arrêter
Les versions normales de Windows ont seulement trois niveaux différents de télémétrie. Le BSI a trouvé qu’entre la version Basic et la version Full on passe de 503 à 534 procédés de surveillance. La seule véritable réduction de télémétrie vient des versions Entreprise de Windows qui peuvent utiliser un réglage supplémentaire de « sécurité » pour leur télémétrie qui réduit le nombre de traqueurs actifs à 13.
C’est la première investigation approfondie dans les processus et dans la base de registre de Windows pour la télémétrie
L’analyse est très détaillée, et cartographie le système Event Tracing for Windows (ETW), la manière dont Windows enregistre les données de télémétrie, comment et quand ces données sont envoyées aux serveurs de Microsoft, ainsi que la différence entre les différents niveaux de paramétrage de la télémétrie.
Cette analyse va jusqu’à montrer où sont contrôlés les réglages pour modifier individuellement les composants d’enregistrement dans la base de registre de Windows, et comment ils initialisent Windows.
Voici quelques faits intéressants issus de ce document :
• Windows envoie vos données vers les serveurs Microsoft toutes les 30 minutes ;
• La taille des données enregistrées équivaut à 12 à 16 Ko par heure sur un ordinateur inactif (ce qui, pour donner une idée, représente chaque jour à peu près le volume de données d’un petit roman comme Le Vieil homme et la mer d’Hemingway) ;
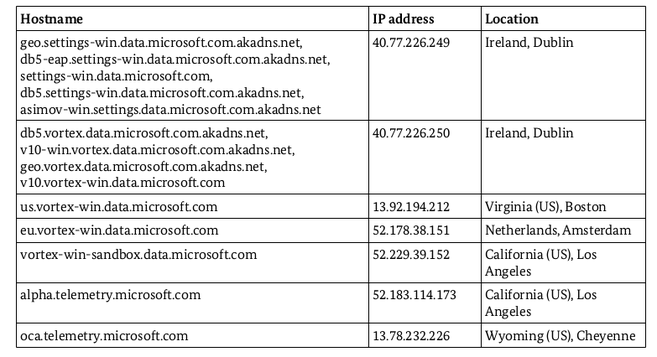
• Il envoie des informations à sept endroits différents, y compris l’Irlande, le Wyoming et la petite ville de Boston en Virginie. C’est la première « plongée en eaux profondes » que je voie où sont énumérés tous les enregistrements, ainsi que les endroits où va le trafic et à quelle fréquence.
Logiquement l’étape suivante consiste à découvrir ce qui figure dans ces 300 Ko de données quotidiennes. J’aimerais aussi savoir à quel point l’utilisation de Windows Media Player, Edge et les autres applications intégrées influe sur l’empreinte laissée par les données, ainsi que le nombre d’éléments actifs d’enregistrement.
Difficile de se prémunir
Au sein des communautés dédiées à l’administration des systèmes ou à la vie privée, la télémétrie Windows est l’objet de nombreuses discussions et il existe plusieurs guides sur les méthodes qui permettent de la désactiver complètement.
Comme toujours, la meilleure défense consiste à ne pas utiliser Windows. La deuxième meilleure défense semble être d’utiliser la version de Windows pour les entreprises où l’on peut désactiver la télémétrie d’une manière officielle. La troisième est d’essayer de la bloquer en changeant les paramètres et clefs de registre ainsi qu’en modifiant vos pare-feux (en dehors de Windows, parce que le pare-feu Windows ignorera les filtres qui bloquent les IP liées à la télémétrie Microsoft) ; en sachant que tout sera réactivé à chaque mise à jour majeure de Windows.
À propos de Derek Zimmer Derek est cryptanalyste, expert en sécurité et militant pour la protection de la vie privée. Fort de douze années d’expérience en sécurité et six années d’expérience en design et implémentation de systèmes respectant la vie privée, il a fondé le Open Source Technology Improvement Fund (OSTIF, Fond d’Amélioration des Technologies Open Source) qui vise à créer et améliorer les solutions de sécurité open source par de l’audit, du bug bounty, ainsi que par la collecte et la gestion de ressources.
Un navigateur pour diffuser votre site web en pair à pair
Les technologies qui permettent la décentralisation du Web suscitent beaucoup d’intérêt et c’est tant mieux. Elles nous permettent d’échapper aux silos propriétaires qui collectent et monétisent les données que nous y laissons.
Vous connaissez probablement Mastodon, peerTube, Pleroma et autres ressources qui reposent sur le protocole activityPub. Mais connaissez-vous les projets Aragon, IPFS, ou ScuttleButt ?
Aujourd’hui nous vous proposons la traduction d’un bref article introducteur à une technologie qui permet de produire et héberger son site web sur son ordinateur et de le diffuser sans le moindre serveur depuis un navigateur.
Nous sommes Blue Link Labs, une équipe de trois personnes qui travaillent à améliorer le Web avec le protocole Dat et un navigateur expérimental pair à pair qui s’appelle Beaker.
L’équipe Blue Link Labs
Nous travaillons sur Beaker car publier et partager est l’essence même du Web. Cependant pour publier votre propre site web ou seulement diffuser un document, vous avez besoin de savoir faire tourner un serveur ou de pouvoir payer quelqu’un pour le faire à votre place.
Nous nous sommes donc demandé « Pourquoi ne pas partager un site Internet directement depuis votre navigateur ? »
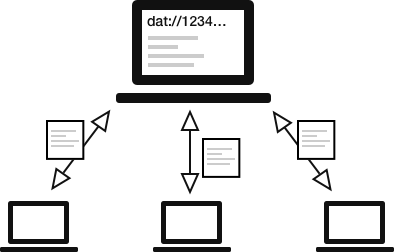
Un protocole pair-à-pair comme dat:// permet aux appareils des utilisateurs ordinaires d’héberger du contenu, donc nous utilisons dat:// dans Beaker pour pouvoir publier depuis le navigateur et donc au lieu d’utiliser un serveur, le site web d’un auteur et ses visiteurs l’aident à héberger ses fichiers. C’est un peu comme BitTorrent, mais pour les sites web !
Architecture
Beaker utilise un réseau pair-à-pair distribué pour publier des sites web et des jeux de données (parfois nous appelons ça des « dats »).
Les sites web dat:// sont joignables avec une clé publique faisant office d’URL, et chaque donnée ajoutée à un site web dat:// est attachée à un log signé.
Les visiteurs d’un site web dat:// peuvent se retrouver grâce à une table de hachage distribuée19, puis ils synchronisent les données entre eux, agissant à la fois comme téléchargeurs et téléverseurs, et vérifiant que les données n’ont pas été altérées pendant le transit.
Une illustration basique du réseau dat://
Techniquement, un site Web dat:// n’est pas tellement différent d’un site web https:// . C’est une collection de fichiers et de dossiers qu’un navigateur Internet va interpréter suivant les standards du Web. Mais les sites web dat:// sont spéciaux avec Beaker parce que nous avons ajouté une API (interface de programmation) qui permet aux développeurs de faire des choses comme lire, écrire, regarder des fichiers dat:// et construire des applications web pair-à-pair.
Créer un site Web pair-à-pair
Beaker rend facile pour quiconque de créer un nouveau site web dat:// en un clic (faire le tour des fonctionnalités). Si vous êtes familier avec le HTML, les CSS ou le JavaScript (même juste un peu !) alors vous êtes prêt⋅e à publier votre premier site Web dat://.
L’exemple ci-dessous montre comment fabriquer le site Web lui-même via la création et la sauvegarde d’un fichier JSON. Cet exemple est fictif mais fournit un modèle commun pour stocker des données, des profils utilisateurs, etc. pour un site Web dat:// : au lieu d’envoyer les données de l’application sur un serveur, elles peuvent être stockées sur le site web lui-même !
// index.js // first get an instance of the website's files var files = new DatArchive(window.location) document.getElementById('create-json-button').addEventListener('click', saveMessage) async function saveMessage () { var timestamp = Date.now() var filename = timestamp + '.json' var content = { timestamp, message: document.getElementById('message').value }
// write the message to a JSON file // this file can be read later using the DatArchive.readFile API await files.writeFile(filename, JSON.stringify(content)) }
Pour aller plus loin
Nous avons hâte de voir ce que les gens peuvent faire de dat:// et de Beaker. Nous apprécions tout spécialement quand quelqu’un crée un site web personnel ou un blog, ou encore quand on expérimente l’interface de programmation pour créer une application.
Beaucoup de choses sont à explorer avec le Web pair-à-pair !
Tara est la co-créatrice du navigateur Beaker. Elle a travaillé précédemment chez Cloudflare et participé au Recurse Center.
Les données que récolte Google – Ch.7 et conclusion
Voici déjà la traduction du septième chapitre et de la brève conclusion de Google Data Collection, l’étude élaborée par l’équipe du professeur Douglas C. Schmidt, spécialiste des systèmes logiciels, chercheur et enseignant à l’Université Vanderbilt. Si vous les avez manqués, retrouvez les chapitres précédents déjà publiés.
Il s’agit cette fois-ci de tous les récents produits de Google (ou plutôt Alphabet) qui investissent nos pratiques et nos habitudes : des pages AMP aux fournisseurs de services tiers en passant par les assistants numériques, tout est prétexte à collecte de données directement ou non.
VII. Des produits avec un haut potentiel futur d’agrégation de données
83. Google a d’autres produits qui pourraient être adoptés par le marché et pourraient bientôt servir à la collecte de données, tels que AMP, Photos, Chromebook Assistant et Google Pay. Il faut ajouter à cela que Google est capable d’utiliser les données provenant de partenaires pour collecter les informations de l’utilisateur. La section suivante les décrit plus en détail.
84. Il existe également d’autres applications Google qui peuvent ne pas être largement utilisées. Toutefois, par souci d’exhaustivité, la collecte de données par leur intermédiaire est présentée dans la section VIIII.B de l’annexe.
A. Pages optimisées pour les mobiles (AMP)
85. Les Pages optimisées pour les mobiles (AMP) sont une initiative open source menée par Google pour réduire le temps de chargement des sites Web et des publicités. AMP convertit le HTML standard et le code JavaScript en une version simplifiée développée par Google20 qui stocke les pages validées dans un cache des serveurs du réseau Google pour un accès plus rapide21. AMP fournit des liens vers les pages grâce aux résultats de la recherche Google mais également via des applications tierces telles que LinkedIn et Twitter. D’après AMP : « L’ecosystème AMP compte 25 millions de domaines, plus de 100 fournisseurs de technologie et plateformes de pointe qui couvrent les secteurs de la publication de contenu, les publicités, le commerce en ligne, les petits commerces, le commerce local etc. »22
86. L’illustration 17a décrit les étapes menant à la fourniture d’une page AMP accessible via la recherche Google. Merci de noter que le fournisseur de contenu à travers AMP n’a pas besoin de fournir ses propres caches serveur, car c’est quelque chose que Google fournit pour garantir un délai optimal de livraison aux utilisateurs. Dans la mesure où le cache AMP est hébergé sur les serveurs de Google, lors d’un clic sur un lien AMP produit par la recherche Google, le nom de domaine vient du domaine google.com et non pas du domaine du fournisseur. Ceci est montré grâce aux captures prises lors d’un exemple de recherche de mots clés dans l’illustration 17b.
Illustration 17 : une page web normale qui devient une page AMP.
87. Les utilisateurs peuvent accéder au contenu depuis de multiples fournisseurs dont les articles apparaissent dans les résultats de recherche pendant qu’ils naviguent dans le carrousel AMP, tout en restant dans le domaine de Google. En effet, le cache AMP opère comme un réseau de distribution de contenu (RDC, ou CDN en anglais) appartenant à Google et géré par Google.
88. En créant un outil open source, complété avec un CDN, Google a attiré une large base d’utilisateurs à qui diffuser les sites mobiles et la publicité et cela constitue une quantité d’information significative (p.ex. le contenu lui-même, les pages vues, les publicités, et les informations de celui à qui ce contenu est fourni). Toutes ces informations sont disponibles pour Google parce qu’elles sont collectées sur les serveurs CDN de Google, fournissant ainsi à Google beaucoup plus de données que par tout autre moyen d’accès.
89. L’AMP est très centré sur l’utilisateur, c’est-à-dire qu’il offre aux utilisateurs une expérience de navigation beaucoup plus rapide et améliorée sans l’encombrement des fenêtres pop-up et des barres latérales. Bien que l’AMP représente un changement majeur dans la façon dont le contenu est mis en cache et transmis aux utilisateurs, la politique de confidentialité de Google associée à l’AMP est assez générale23. En particulier, Google est en mesure de recueillir des informations sur l’utilisation des pages Web (par exemple, les journaux de serveur et l’adresse IP) à partir des requêtes envoyées aux serveurs de cache AMP. De plus, les pages standards sont converties en AMP via l’utilisation des API AMP24. Google peut donc accéder à des applications ou à des sites Web (« clients API ») et utiliser toute information soumise par le biais de l’API conformément à ses politiques générales25.
90. Comme les pages Web ordinaires, les pages Web AMP pistent les données d’utilisation via Google Analytics et DoubleClick. En particulier, elles recueillent des informations sur les données de page (par exemple : domaine, chemin et titre de page), les données d’utilisateur (par exemple : ID client, fuseau horaire), les données de navigation (par exemple : ID et référence de page uniques), l’information du navigateur et les données sur les interactions et les événements26. Bien que les modes de collecte de données de Google n’aient pas changé avec l’AMP, la quantité de données recueillies a augmenté puisque les visiteurs passent 35 % plus de temps sur le contenu Web qui se charge avec Google AMP que sur les pages mobiles standard.27
B. Google Assistant
91. Google Assistant est un assistant personnel virtuel auquel on accède par le biais de téléphones mobiles et d’appareils dits intelligents. C’est un assistant virtuel populaire, comme Siri d’Apple, Alexa d’Amazon et Cortana de Microsoft. 28 Google Assistant est accessible via le bouton d’accueil des appareils mobiles sous Android 6.0 ou versions ultérieures. Il est également accessible via une application dédiée sur les appareils iOS29, ainsi que par l’intermédiaire de haut-parleurs intelligents, tel Google Home, qui offre de nombreuses fonctions telles que l’envoi de textes, la recherche de courriels, le contrôle de la musique, la recherche de photos, les réponses aux questions sur la météo ou la circulation, et le contrôle des appareils domestiques intelligents30.
92. Google collecte toutes les requêtes de Google Assistant, qu’elles soient audio ou saisies au clavier. Il collecte également l’emplacement où la requête a été effectuée. L’illustration 18 montre le contenu d’une requête enregistrée par Google. Outre son utilisation via les haut-parleurs de Google Home, Google Assistant est activé sur divers autres haut-parleurs produits par des tiers (par exemple, les casques sans fil de Bose). Au total, Google Assistant est disponible sur plus de 400 millions d’appareils31. Google peut collecter des données via l’ensemble de ces appareils puisque les requêtes de l’Assistant passent par les serveurs de Google.
Figure 18 : Exemple de détails collectés à partir de la requête Google Assistant.
C. Photos
93. Google Photos est utilisé par plus de 500 millions de personnes dans le monde et stocke plus de 1,2 milliard de photos et vidéos chaque jour32. Google enregistre l’heure et les coordonnées GPS de chaque photo prise.Google télécharge des images dans le Google cloud et effectue une analyse d’images pour identifier un large éventail d’objets, tels que les modes de transport, les animaux, les logos, les points de repère, le texte et les visages33. Les capacités de détection des visages de Google permettent même de détecter les états émotionnels associés aux visages dans les photos téléchargées et stockées dans leur cloud34.
94. Google Photos effectue cette analyse d’image par défaut lors de l’utilisation du produit, mais ne fera pas de distinction entre les personnes, sauf si l’utilisateur donne l’autorisation à l’application35. Si un utilisateur autorise Google à regrouper des visages similaires, Google identifie différentes personnes à l’aide de la technologie de reconnaissance faciale et permet aux utilisateurs de partager des photos grâce à sa technologie de « regroupement de visages »3637. Des exemples des capacités de classification d’images de Google avec et sans autorisation de regroupement des visages de l’utilisateur sont présentés dans l’illustration 19. Google utilise Photos pour assembler un vaste ensemble d’informations d’identifications faciales, qui a récemment fait l’objet de poursuites judiciaires38 de la part de certains États.
Illustration : Exemple de reconnaissance d’images dans Google Photos.
D. Chromebook
95. Chromebook est la tablette-ordinateur de Google qui fonctionne avec le système d’exploitation Chrome (Chrome OS) et permet aux utilisateurs d’accéder aux applications sur le cloud. Bien que Chromebook ne détienne qu’une très faible part du marché des PC, il connaît une croissance rapide, en particulier dans le domaine des appareils informatiques pour la catégorie K-12, où il détenait 59,8 % du marché au deuxième trimestre 201739. La collecte de données de Chromebook est similaire à celle du navigateur Google Chrome, qui est décrite dans la section II.A. Chromebooks permet également aux cookies de Google et de domaines tiers de pister l’activité de l’utilisateur, comme pour tout autre ordinateur portable ou PC.
96. De nombreuses écoles de la maternelle à la terminale utilisent des Chromebooks pour accéder aux produits Google via son service GSuite for Education. Google déclare que les données recueillies dans le cadre d’une telle utilisation ne sont pas utilisées à des fins de publicité ciblée40. Toutefois, les étudiants reçoivent des publicités s’ils utilisent des services supplémentaires (tels que YouTube ou Blogger) sur les Chromebooks fournis par leur établissement d’enseignement.
E. Google Pay
97. Google Pay est un service de paiement numérique qui permet aux utilisateurs de stocker des informations de carte de crédit, de compte bancaire et de PayPal pour effectuer des paiements en magasin, sur des sites Web ou dans des applications utilisant Google Chrome ou un appareil Android connecté41. Pay est le moyen par lequel Google collecte les adresses et numéros de téléphone vérifiés des utilisateurs, car ils sont associés aux comptes de facturation. En plus des renseignements personnels, Pay recueille également des renseignements sur la transaction, comme la date et le montant de la transaction, l’emplacement et la description du marchand, le type de paiement utilisé, la description des articles achetés, toute photo qu’un utilisateur choisit d’associer à la transaction, les noms et adresses électroniques du vendeur et de l’acheteur, la description du motif de la transaction par l’utilisateur et toute offre associée à la transaction42. Google traite ses informations comme des informations personnelles en fonction de sa politique générale de confidentialité. Par conséquent il peut utiliser ces informations sur tous ses produits et services pour fournir de la publicité très ciblée43. Les paramètres de confidentialité de Google l’autorisent par défaut à utiliser ces données collectées44.
F. Données d’utilisateurs collectées auprès de fournisseurs de données tiers
98. Google collecte des données de tiers en plus des informations collectées directement à partir de leurs services et applications. Par exemple, en 2014, Google a annoncé qu’il commencerait à suivre les ventes dans les vrais commerces réels en achetant des données sur les transactions par carte de crédit et de débit. Ces données couvraient 70 % de toutes les opérations de crédit et de débit aux États-Unis45. Elles contenaient le nom de l’individu, ainsi que l’heure, le lieu et le montant de son achat46.
99. Les données de tiers sont également utilisées pour aider Google Pay, y compris les services de vérification, les informations résultant des transactions Google Pay chez les commerçants, les méthodes de paiement, l’identité des émetteurs de cartes, les informations concernant l’accès aux soldes du compte de paiement Google, les informations de facturation des opérateurs et transporteurs et les rapports des consommateurs47. Pour les vendeurs, Google peut obtenir des informations des organismes de crédit aux particuliers ou aux entreprises.
100. Bien que l’information des utilisateurs tiers que Google reçoit actuellement soit de portée limitée, elle a déjà attiré l’attention des autorités gouvernementales. Par exemple, la FTC a annoncé une injonction contre Google en juillet 2017 concernant la façon dont la collecte par Google de données sur les achats des consommateurs porte atteinte à la vie privée électronique48. L’injonction conteste l’affirmation de Google selon laquelle il peut protéger la vie privée des consommateurs tout au long du processus en utilisant son algorithme. Bien que d’autres mesures n’aient pas encore été prises, l’injonction de la FTC est un exemple des préoccupations du public quant à la quantité de données que Google recueille sur les consommateurs.
VIII. CONCLUSION
101. Google compte un pourcentage important de la population mondiale parmi ses clients directs, avec de multiples produits en tête de leurs marchés mondiaux et de nombreux produits qui dépassent le milliard d’utilisateurs actifs par mois. Ces produits sont en mesure de recueillir des données sur les utilisateurs au moyen d’une variété de techniques qui peuvent être difficiles à comprendre pour un utilisateur moyen. Une grande partie de la collecte de données de Google a lieu lorsque l’utilisateur n’utilise aucun de ses produits directement. L’ampleur d’une telle collecte est considérable, en particulier sur les appareils mobiles Android. Et bien que ces informations soient généralement recueillies sans identifier un utilisateur unique, Google a la possibilité d’utiliser les données recueillies auprès d’autres sources pour désanonymiser une telle collecte.
Framasoft en 2019 pour les gens pressés
Vous avez aimé Dégooglisons Internet et pensez le plus grand bien de Contributopia ? Vous aimeriez savoir en quelques mots où notre feuille de route nous mènera en 2019 ? Cet article est fait pour vous, les décideurs pressés 🙂
Cet article présente de façon synthétique et ramassée ce que nous avons développé dans l’article de lancement de la campagne 2018-2019 : «Changer le monde, un octet à la fois».
Un octet à la fois, oui, parce qu’avec nos pattounes, ça prend du temps.
Depuis 4 ans, Framasoft montre qu’il est possible de décentraliser Internet avec l’opération « Dégooglisons Internet ». Le propos n’est ni de critiquer ni de culpabiliser, mais d’informer et de mettre en avant des alternatives qui existaient déjà, mais demeuraient difficiles d’accès ou d’usage.
De façon à ne pas devenir un nouveau nœud de centralisation, l’initiative CHATONS a été lancée, proposant de relier les hébergeurs de services en ligne qui partagent nos valeurs.
Depuis l’année dernière, avec sa feuille de route Contributopia, Framasoft a décidé d’affirmer clairement qu’il fallait aller au-delà du logiciel libre, qui n’était pas une fin en soi, mais un moyen de faire advenir un monde que nous appelons de nos vœux.
Il faut donc encourager la société de contribution et dépasser celle de la consommation, y compris en promouvant des projets qui ne soient plus seulement des alternatives aux GAFAM, mais qui soient porteurs d’une nouvelle façon de faire. Cela se fera aussi en se rapprochant de structures (y compris en dehors du mouvement traditionnel du libre) avec lesquelles nous partageons certaines valeurs, de façon à apprendre et diffuser nos savoirs.
Cette année a vu naître la version 1.0 de PeerTube, logiciel phare qui annonce une nouvelle façon de diffuser des médias vidéos, en conservant le contrôle de ses données sans se couper du monde, qu’on soit vidéaste ou spectateur.
Le monde des services de Contributopia. Illustration de David Revoy – Licence : CC-By 4.0
Avenir
La campagne de don actuelle est aussi l’occasion de de rappeler des éléments d’importance pour Framasoft : nous ne sommes pas une grosse multinationale, mais un petit groupe d’amis épaulé par quelques salarié·e·s, et une belle communauté de contributeurs et contributrices.
Cette petite taille et notre financement basé sur vos dons nous offrent souplesse et indépendance. Ils nous permettront de mettre en place de nouveaux projets comme MobilZon (mobilisation par le numérique), un Mooc CHATONS (tout savoir et comprendre sur pourquoi et comment devenir un chaton) ou encore Framapétitions (plateforme de pétitions n’exploitant pas les données des signataires).
Nous voulons aussi tenter d’en appeler à votre générosité sans techniques manipulatoires, en vous exposant simplement d’où nous venons et où nous allons. Nous espérons que cela vous motivera à nous faire un don.