Berlin, March 2023 : Diary of the first ECHO Network study visit
From 27 to 31 March 2023, the first study visit of the European project ECHO Network took place in Berlin. This report looks back on this week of exchange on the theme of « Young people, social networks and political education« , organised by the Willi Eichler Academy.
In order to promote the values of the Ethical, Commons, Humans, Open-Source Network project, the Framasoft participants wanted to travel to Berlin by train. So Monday and Friday of this exchange week were dedicated to transport.
The day of departure was a national strike day in Germany (where a rail strike = no trains running!). As a result, only 3 of the 4 Framasoft members who had planned to take part in the project were able to make it.
When you think of trains, you think of time, where transport is an integral part of the journey. In fact, it takes 9 hours by train from Paris, or even 13 hours from Nantes… And you should add 1 or 2 hours (or even half a day) for « contingency management » (delays, cancellations, changes of train). Travelling to Germany by train was an adventure in itself (and the feeling seems to be shared!).
Tuesday 28 March: Discoveries and visits off the beaten track
After a brief meeting with the first participants the day before, Tuesday will continue with the aim of getting to know each other (arrivals will continue throughout the day due to changes in the itinerary caused by the strike the day before).
Tuesday morning will begin with a visit to the Jewish Cemetery of Berlin-Weißensee, the largest Jewish cemetery in Europe. Nature takes over in this historic place.
Weißensee Jewish cemetery, between nature and history
In the afternoon we visit a former Stasi prison, Berlin-Hohenschönhausen. This visit made a particularly strong impression on us: the site was created by former prisoners, the prison wasn’t closed until 1990, and many of the people who tortured prisoners were never brought to justice. In short, a dark page of history, but one that needs to be shared (we recommend the visit!)…
The day will end with a convivial meal in a traditional restaurant.
Wednesday 29 March: young, old and social networks
The chandelier in the entrance hall of the cookery school is just right!
Discussion: What do we think about social networks in our organisations?
The first workshop was a round-table discussion in which each participant shared his or her use of and views on social networks, and in particular TikTok, the medium that will be used in the following workshop.
To summarise:
There is little use of social media from a personal point of view in the group.
On the other hand, the majority of the group use social media to promote their organisation’s activities (Facebook, Twitter, Instagram and Mastodon).
No one in the group uses TikTok, which poses a problem for understanding this social media.
As part of their organisation’s activities, the majority of the group would like to reach out more to young people and it seems interesting to find them where they are, i.e. on social media.
The group fully agreed that social media are not neutral tools and try to monopolise the attention of their users.
This time of exchange therefore allowed us to see that we share the same values, difficulties and desires when it comes to social media. However, we felt that the ‘one at a time’ format lacked some dynamism in the exchanges and the opportunity for several people to discuss.
Feedback from a student workshop: raising awareness of social issues in a TikTok video
Alongside our morning discussions on social media, 2 groups of students from the Brillat-Savarin school worked on a video project. They had to produce a TikTok video (one per group) to show the impact of the European Union (1st group) and climate change (2nd group) on their work as chefs. The videos were shown to us (incredible quality in 2 hours of work!) and then we exchanged views on the topic.
What we took away from this workshop:
The students were between 18 and 22 years old and did not use TikTok. According to the students, this social network is aimed at people younger than them (« young » is too broad a term!). However, they had mastered the codes of the platform as they were regularly exposed to TikTok content on other platforms such as Instagram and YouTube.
In any case, they wouldn’t necessarily want to use a social network to watch political content, preferring a more recreational use of the network (like watching videos of kittens!), even if they claim to be political.
They found it particularly interesting to get a message across in videos and to question themselves on issues that directly affect them.
It was an interesting experiment, even if the plenary discussions did not allow everyone to participate.
Photo of the ECHO Network group and some of the school’s students
Thursday 30th March: Politics and Open Source
Reflect EU&US: the Willi Eichler Academy project
Funded to the tune of €500,000 by Marshall Plan leftovers, Reflect EU&US is a 2-year project (2022-2024) by the Willi Eichler Academy. Its aim? To organise discussions between students outside the university environment, remotely and anonymously.
Reflect EU&US project logo
Points to remember:
The project involves 60 students (30 from the United States and 30 from Germany), with a physical meeting planned at the very end of the project to lift the masks.
Topics covered include justice, racism, gender and politics.
Following the discussions, a library of documents will be created, which will allow the various sources (texts, articles, videos, podcasts, etc.) to be validated (or not).
Anonymity makes it easier to accept contradictory opinions.
The management of the groups can be complicated by anonymity, but it is an integral part of the project.
From a technical point of view, the platform is based on the OpenTalk tool and was chosen to provide this space for free exchange, with the creation of coloured cards as avatars, making it possible to guarantee the anonymity of the participants. The choice of open source technologies was made specifically with the aim of reassuring participants so that they could exchange in complete peace of mind. This was followed by a live test of the platform with the students (in German, which didn’t allow us to understand everything!).
Open source meets politics
The afternoon continued with a talk by Peer Heinlein, director of OpenTalk, on « True digital independence and sovereignty are impossible without open source ». You can imagine that we at Framasoft have an opinion on this, even if we don’t feel strongly about it… Discussions with the audience followed on open source software, privacy and data encryption.
The next speaker was Maik Außendorf, representative of the Green Party in the European Parliament. Among other things, we discussed how digital technology can help the ecological transition. We learnt that German parliamentarians do not have a choice when it comes to using digital tools, and that national coherence is difficult to achieve with the decentralised organisation of Germany into Länder.
The study visit ended in a restaurant, where we had the opportunity to talk with a SeaWatch activist, highlighting the common values and reflections of the different organisations (precariousness of associations, the need to propose alternatives to the capitalist world, the need for free and emancipatory digital technologies).
This chandelier will have inspired⋅es (can you see the artistic side too?).
An intense week!
We were particularly surprised and excited by the common visions shared by the participants and organisations, whether it be about emancipatory digital, the desire to move towards a world that is more like us, where cooperation and contribution move forward, and the question of how to share our messages while remaining coherent with what we defend.
Although the majority of the week was built around plenary workshops, which did not always encourage exchange between participants or spontaneous speaking, the informal times (meals, coffee breaks, walks) made it possible to create these essential moments.
What next for the ECHO network? The second study visit took place in Brussels from 12 to 16 June. A summary article will follow on the Framablog (but as always, we’ll take our time!).
We couldn’t go to Berlin without visiting the murals on the Berlin Wall: here’s a photo of the trip to round off this article.
Berlin, mars 2023 : journal de bord de la première visite d’études d’ECHO Network
Du 27 au 31 mars 2023, la première visite d’études du projet européen ECHO Network s’est tenue à Berlin. Ce compte rendu retrace cette semaine d’échanges sur la thématique « jeunes, réseaux sociaux et éducation politique », organisée par Willi Eichler Akademy.
Ambiance fraîche à Berlin pour ce début de printemps !
La route est longue jusque Berlin…!
Pour pousser les valeurs du projet Ethical, Commons, Humans, Open-Source Network (Réseau autour de l’Éthique, les Communs, les Humain⋅es et l’Open-source), les participant⋅es de Framasoft souhaitaient favoriser le train pour se rendre à Berlin. Ainsi, le lundi et le vendredi de cette semaine d’échange étaient banalisés pour le transport.
Les contre-temps faisant partie du voyage, le jour des départs était un jour de grève nationale en Allemagne (où grève ferroviaire = zéro train qui circule !). Ainsi, sur les 4 membres de Framasoft prévu⋅es sur le projet, seul⋅es 3 ont pu se rendre sur place.
Qui dit train dit aussi temps investi, où le transport fait partie intégrante du voyage. En effet, il faut prévoir 9 heures de train depuis Paris, ou encore 13 heures depuis Nantes… Et à cela, il est fortement conseillé d’ajouter 1h ou 2h (voire une demi-journée) de « gestion des imprévus » (retards, annulations, changements de train). Se rendre en Allemagne en train nous a semblé une aventure à part entière (et ce ressenti semble partagé !).
Mardi 28 mars : découvertes et visites hors sentiers touristiques
Après avoir rencontré brièvement la veille les premières et premiers participant⋅es, la journée du mardi continue avec l’objectif de se découvrir les un⋅es les autres (les arrivées se feront au compte-gouttes sur toute la journée suite aux changements d’itinéraire dus à la grève de la veille).
Nous entamons le mardi matin avec une visite du Cimetière juif de Weißensee de Berlin, le plus grand cimetière juif d’Europe. La nature prend le dessus dans ce lieu empreint d’histoire.
Cimetière juif de Weißensee, entre nature et histoire
Nous nous dirigeons ensuite l’après-midi vers une ancienne prison de la Stasi, la prison de Berlin-Hohenschönhausen. Cette visite nous aura particulièrement marqué⋅es : le site a été créé par d’ancien⋅nes prisonnier⋅ères, la prison n’a fermé qu’en 1990, et de nombreuses personnes ayant torturé des prisonnier⋅ères n’ont jamais été jugées. Bref, une page d’histoire sombre mais qu’il est nécessaire de partager (nous conseillons la visite !)…
La journée se terminera par un moment convivial dans un restaurant traditionnel.
Mercredi 29 mars : jeunes, moins jeunes et réseaux sociaux
Lustre du hall de l’école de cuisine, on peut dire qu’il est plutôt adapté !
Discussion : on pense quoi des réseaux sociaux dans nos organisations ?
Le premier atelier a été un tour de table où chaque participant⋅e partageait son utilisation et point de vue sur les réseaux sociaux, et particulièrement TikTok, média sur lequel sera utilisé l’atelier suivant.
Ce que l’on peut résumer :
Il y a peu d’utilisation des médias sociaux d’un point de vue personnel dans le groupe.
Les médias sociaux sont par contre utilisés par la majorité du groupe pour mettre en valeur les actions de son organisation (Facebook, Twitter, Instagram et Mastodon).
Personne dans le groupe n’utilise TikTok ce qui pose problème pour comprendre ce média social.
Dans le cadre des activités de leur organisation, la majorité du groupe souhaiterait toucher davantage les jeunes et il semble intéressant de les trouver là où iels sont, donc sur les médias sociaux.
Le groupe est tout à fait d’accord sur le fait que les médias sociaux ne sont pas des outils neutres et cherchent à monopoliser l’attention de ses utilisateur⋅rices.
Ce temps d’échange a donc permis de voir que nous partageons les mêmes valeurs, difficultés et envies sur les médias sociaux. Cependant, le format « chacun son tour de parole » nous a semblé manquer un peu de dynamisme dans les échanges et de possibilité de discuter à plusieurs.
Retour d’atelier d’étudiant⋅es : sensibiliser sur des sujets de société dans une vidéo TikTok
En parallèle de nos échanges du matin sur les médias sociaux, 2 groupes d’étudiant⋅es de la Brillat-Savarin School ont travaillé sur un projet vidéo. Ils devaient produire une vidéo TikTok (une par groupe) pour montrer l’impact sur leur métier de cuisinier⋅ère de l’Union Européenne (1er groupe) et du changement climatique (2ème groupe). Les vidéos nous ont été présentées (incroyable la qualité en 2 heures de travail !), puis nous avons échangé sur le sujet.
Ce que nous retenons de cet atelier :
Les étudiant⋅es avaient entre 18 et 22 ans, et n’utilisent pas TikTok . Selon les étudiant⋅es, ce réseau social est tourné pour une cible plus jeune qu’elles et eux (« jeunes » est un terme trop large !). Par contre iels maîtrisaient les codes de la plateformes, étant régulièrement exposé⋅es à du contenu issu de TikTok sur d’autres plateformes telles que Instagram ou YouTube .
Iels n’auraient de toute façon pas forcément envie d’utiliser un réseau social pour voir du contenu politique, préférant un usage plus récréatif du réseau (comme regarder des vidéos de chatons par exemple !), même lorsqu’iels se revendiquent politisé⋅es.
Iels ont trouvé la démarche particulièrement intéressante de faire passer un message en vidéos, et se questionner sur des sujets les impliquant directement.
L’expérimentation aura été intéressante, même si les échanges en plénière ne permettaient pas l’implication de chacun et chacune.
Photo du groupe d’ECHO Network et quelques étudiant⋅es de l’école
Jeudi 30 mars : politique et open source
Reflect EU&US : le projet de la Willi Eichler Akademy
Financé à hauteur de 500k€ par des restes du plan Marshall, Reflect EU&US est un projet sur 2 ans (2022-2024) de la Willi Eichler Akademy. L’objectif ? Organiser des discussions entre étudiant⋅es en dehors du cadre universitaire, à distance et en restant dans l’anonymat.
Logo du projet Reflect EU&US
Les points à retenir :
Le projet investit 60 étudiant·es (30 des Etats-Unis et 30 d’Allemagne), une rencontre physique est prévue à la toute fin du projet pour lever les masques.
Des sujets traités tels que : justice, racisme, genre, politique.
Une bibliothèque de documents est alimentée suite aux discussions, permettant de valider (ou non) les différentes sources (textes, articles, vidéos, podcasts, etc).
L’anonymat permet plus facilement d’assumer des opinions contradictoires.
L’animation des groupes peut être compliquée par l’anonymat, mais fait partie intégrante du projet.
D’un point de vue technique, la plateforme est basée sur l’outil OpenTalk et a été choisie pour avoir cet espace d’échange libre, avec la création de cartes de couleurs comme avatar, permettant de garantir l’anonymat des participant⋅es. Le choix de technologies open-source a été fait spécifiquement dans le but de rassurer les participant⋅es pour qu’iels puissent échanger en toute tranquillité. Un test en direct de la plateforme a suivi avec des étudiant⋅es (en allemand, ce qui ne nous a pas permis de tout comprendre !).
Rencontres entre open source et politique
L’après-midi a continué avec l’intervention de Peer Heinlein, directeur d’OpenTalk, sur le sujet « L’indépendance et la souveraineté numérique réelle sont impossibles sans l’open-source ». Vous vous doutez bien qu’à Framasoft, même si ce n’est pas un aspect qui nous tient à cœur, nous avons un avis sur la question… Des échanges ont suivi avec les participant·e·s sur les logiciels open source, la protection des données personnelles, ou encore le chiffrement des données.
C’est ensuite Maik Außendorf, représentant du Green Party au parlement qui est intervenu. Nous avons, entre autre, échangé sur le numérique pour aider la transition écologique. Nous avons appris que les parlementaires allemand⋅es n’ont pas le choix dans leur utilisation d’outils numériques et qu’une cohérence nationale semble compliquée à mettre en place avec l’organisation décentralisée de l’Allemagne en Länder.
La clôture de la visite d’études a eu lieu dans un restaurant, où nous avons pu notamment échanger avec un activiste de SeaWatch, mettant particulièrement en avant valeurs communes et réflexions partagées entre les différentes organisations (précarisation des associations, nécessité de proposer des alternatives au monde capitaliste, nécessité d’un numérique libre et émancipateur).
Ce lustre nous aura inspiré⋅es (vous aussi vous distinguez un côté artistique ?)
Une semaine intense !
Nous avons particulièrement été surpris⋅es et enthousiastes par les visions communes partagées entre participant⋅es et organisations, que ce soit sur le numérique émancipateur, l’envie d’aller vers un monde qui nous ressemble plus, où la coopération et la contribution vont de l’avant et les questionnements sur comment partager nos messages en restant cohérent⋅es avec ce que l’on défend.
Bien que la majorité de la semaine ait été construite sous forme d’ateliers en plénière, ne favorisant pas toujours les échanges entre participant⋅es ou les prises de parole spontanées, les temps informels (repas, pauses café, balades) auront permis de créer ces moments essentiels.
Et la suite d’ECHO Network ? La seconde visite d’études a eu lieu à Bruxelles du 12 au 16 juin. Un article récap’ suivra sur le Framablog (mais comme toujours : on se laisse le temps !).
On ne pouvait pas se rendre à Berlin sans faire un tour par les fresques du mur de Berlin : petite photo de la virée pour boucler cet article.
Dorlotons Dégooglisons, c’est plus de soin, d’énergie et de temps dédié à nos services en ligne. Nous clôturons aujourd’hui la collecte lancée le 23 mai pour nous aider à financer l’épisode 1, et l’objectif a été atteint (et même plus !). Un sincère MERCI : merci de votre soutien pour ce nouveau projet qui ne serait pas réalisable sans vous ❤️.
« Dorlotons Dégooglisons »
Consacrer plus de temps et d’énergie à nos services en ligne, c’est un nouveau cap que nous voulons suivre. Et nous pourrons le garder grâce à vous, grâce à vos dons ! En savoir plus sur le site Soutenir Framasoft.
Dorlotons Dégooglisons, un projet qui NOUS tient à cœur
Le projet à long terme « Dorlotons Dégooglisons » c’est une manière pour nous de montrer le soin que nous consacrons à nos services : de la gestion à l’administration, en passant par le support et la communication, sans oublier l’expertise technique. C’est sortir de l’ombre les 80 petites mains qui s’activent en coulisses pour vous permettre d’utiliser des services éthiques afin de retrouver de l’autonomie, de l’esprit critique et de la liberté dans vos pratiques numériques.
Quelques exemples concrets du travail derrière la scène
« Dorlotons » Dégooglisons, c’est aussi (et surtout !) consacrer plus de temps et d’énergie à nos services en ligne, dont certains peuvent sembler un peu à l’ancienne : nous allons dégager du temps salarié pour la coordination du projet et prendrons le temps de vous faire part des différentes avancées.
Dans ce premier épisode, nous avons mis en lumière les dorlotages déjà réalisés cette année (et souvent un peu passés à la trappe), tout en mettant un coup de projecteur sur le nouveau service Framagroupes (listes de discussions par email), ouvert le 7 juin.
Dorlotons Dégooglisons, un projet qui VOUS tient à cœur
Dorlotons Dégooglisons c’est aussi vous mobiliser : ces services en ligne, gratuits et utiles à près de 1,5 million de personnes par mois ont bien un coût, et il est financé par vous, par vos dons. Lancer cette collecte c’était aussi une manière de savoir si vous trouvez utile que l’on consacre plus de soin, de temps et d’énergie à nos services.
Framasoft prenant plaisir à proposer des outils à celles et ceux voulant s’émanciper ! Illustration de David RevoyCC-By 4.0
Alors on vous le dit haut et fort : MERCI ! Vous avez été au rendez-vous, et en seulement 12 jours l’objectif de 60 000 € était atteint ! À l’heure où nous publions ces lignes et après ces 22 jours d’animation, vous êtes plus de 1 500 personnes a avoir contribué, avec plus de 76 000 € collectés, soit 127 % de l’objectif fixé (et il reste encore quelques heures pour la collecte : elle ne ferme que ce soir à minuit !). Vraiment, encore une fois, MERCI ! Cette mobilisation nous confirme bien que prendre soin de nos services, les améliorer, et les mettre en avant, c’est réellement un projet qui vous motive autant que nous !
Le livre d’or de cette collecte est maintenant en ligne : vous y trouverez les petits mots que certaines et certains d’entre vous nous ont laissés (et que nous avons pris grand plaisir à lire !). Prendre conscience de l’utilité de nos actions, c’est ça qui nous motive à continuer, et le témoignage de Kris l’illustre vraiment très bien (aucun lien avec Khrys, l’autrice du Khrys’presso) (et promis, c’est pas pour frimer que nous le partageons, mais parce qu’il nous touche particulièrement !).
Merci à Framasoft de nous proposer ces services si utiles au quotidien pour fonctionner en groupe à distance : les pads pour les réunions, les framalistes, les framaforms ! On a tellement besoin de ça, de ces outils qui ne nous pistent pas, cherchent juste à être utiles sans vouloir capter du temps de cerveau, ni de l’argent. Merci aussi pour vos contributions à d’autres services, les efforts faits pour nous informer, et nous permettre de cheminer vers d’autres usages, pour vos réflexions partagées, et pour l’accompagnement que vous apportez aux collectifs pour sortir du tout Google. Merci pour votre engagement, et merci de toutes ces initiatives pour un numérique plus éthique, plus émancipateur et plus libre, loin du monopole et du fonctionnement capitaliste. Merci de vos propositions pour réfléchir le monde autrement (collecte et confiance, édition de livres libres…). Vous assurez grave ! Kris
La série va t-elle être reconduite ?
Clairement : OUI ! Tout d’abord, l’enthousiasme de la mobilisation pour cette collecte nous a montré que nous ne nous trompons pas de direction : vous estimez qu’il est nécessaire de consacrer davantage d’énergie à nos services en ligne et nous allons dégager plus de temps pour les améliorer.
Ce temps de collecte pour mettre en avant nos dorlotages réalisés cette année et présenter la démarche à venir nous rassure aussi quant au budget de notre association. Celui-ci repose à 94% sur des dons et dépend actuellement très (trop !) fortement des 3 dernières semaines de décembre, où sont réalisés 50 % des dons de l’année (chiffres de 2022). Animer ce temps de mobilisation en milieu d’année nous permet à la fois :
de continuer l’année plus sereinement et d’être moins « en stress » en fin d’année pour boucler notre budget (enfin, on l’espère !). Cette expérimentation semble donc encourageante sur cet aspect.
de proposer un deuxième rendez-vous dans l’année pour parler de nos actions et faire un bilan (et rendre la fin d’année aussi plus digeste sur la quantité d’info qu’on vous transmet !)
Et alors, c’est quoi la suite pour Dorlotons Dégooglisons ? Nous allons élaborer une feuille de route pour gérer nos priorités, définir les prochains projets et trouver de potentiels prestataires… Bref nous avons encore du pain sur la planche pour les prochaines années. Et nous comptons bien refaire le point sur tout ça l’an prochain…
Encore un immense merci pour votre confiance et pour votre soutien !
À l’heure où dans une dérive policière inquiétante on criminalise les personnes qui veulent protéger leur vie privée, il est plus que jamais important que soient diffusées à une large échelle les connaissances et les pratiques qui permettent de prendre conscience des enjeux et de préserver la confidentialité. Dans cette démarche, l’association Exodus Privacy joue un rôle important en rendant accessible l’analyse des trop nombreux pisteurs qui parasitent nos ordiphones. Cette même association propose aujourd’hui un nouvel outil ou plutôt une boîte à outils tout aussi intéressante…
Bonjour, Exodus Privacy. Chez Framasoft, on vous connaît bien et on vous soutient mais pouvez-vous rappeler à nos lecteurs et lectrices en quoi consiste l’activité de votre association?
Oui, avec plaisir ! L’association Exodus Privacy a pour but de permettre au plus grand nombre de personnes de mieux protéger sa vie privée sur son smartphone. Pour cela, on propose des outils d’analyse des applications issues du Google Play store ou de F-droid qui permettent de savoir notamment si des pisteurs s’y cachent. On propose donc une application qui permet d’analyser les différentes applications présentes sur son smartphone et une plateforme d’analyse en ligne.
Logo d’Exodus Privacy
Alors ça ne suffisait pas de fournir des outils pour ausculter les applications et d’y détecter les petits et gros espions ? Vous proposez maintenant un outil pédagogique ? Expliquez-nous ça…
Depuis le début de l’association, on anime des ateliers et des conférences et on est régulièrement sollicité·es pour intervenir. Comme on est une petite association de bénévoles, on ne peut être présent·es partout et on s’est dit qu’on allait proposer un kit pour permettre aux personnes intéressées d’animer un atelier « smartphones et vie privée » sans avoir besoin de nous !
Selon vous, dans quels contextes le kit peut-il être utilisé ? Vous vous adressez plutôt aux formatrices ou médiateurs de profession, aux bénévoles d’une asso qui veulent proposer un atelier ou bien directement aux membres de la famille Dupuis-Morizeau ?
Clairement, on s’adresse à deux types de publics : les médiateur·ices numériques professionnel·les qui proposent des ateliers pour leurs publics, qu’ils et elles soient en bibliothèque, en centre social ou en maison de quartier, mais aussi les bénévoles d’associations qui proposent des actions autour de la protection de l’intimité numérique.
Bon en fait qu’est-ce qu’il y a dans ce kit, et comment on peut s’en servir ?
Dans ce kit, il y a tout pour animer un atelier d’1h30 destiné à un public débutant ou peu à l’aise avec le smartphone : un déroulé détaillé pour la personne qui anime, un diaporama, une vidéo pédagogique pour expliquer les pisteurs et une fiche qui permet aux participant·es de repartir avec un récapitulatif de ce qui a été abordé pendant l’atelier.
Par exemple, on propose, à partir d’un faux téléphone, dont on ne connaît que les logos des applications, de deviner des éléments sur la vie de la personne qui possède ce téléphone. On a imaginé des méthodes d’animation ludiques et participatives, mais chacun·e peut adapter en fonction de ses envies et de son aisance !
un faux téléphone pour acquérir de vraies compétences en matière de vie privée
Comment l’avez-vous conçu ? Travail d’une grosse équipe ou d’un petit noyau d’acharnés ?
Nous avons été au total 2-3 bénévoles dans l’association à créer les contenus, dont MeTaL_PoU qui a suivi/piloté le projet, Héloïse de NetFreaks qui s’est occupée du motion-design de la vidéo et _Lila* de la création graphique et de la mise en page. Tout s’est fait à distance ! À chaque réunion mensuelle de l’association, on faisait un point sur l’avancée du projet, qui a mis plus longtemps que prévu à se terminer, sûrement parce qu’on n’avait pas totalement bien évalué le temps nécessaire et qu’une partie du projet reposait sur du bénévolat. Mais on est fier·es de le publier maintenant !
Vous l’avez déjà bêta-testé ? Premières réactions après tests ?
On a fait tester un premier prototype à des médiateur·ices numériques. Les retours ont confirmé que l’atelier fonctionne bien, mais qu’il y avait quelques détails à modifier, notamment des éléments qui manquaient de clarté. C’est l’intérêt des regards extérieurs : au sein d’Exodus Privacy, des choses peuvent nous paraître évidentes alors qu’elles ne le sont pas du tout !
Aspi espion qui aspire vos données privées en vous surveillant du coin de l’œil
Votre kit est disponible pour tout le monde ? Sous quelle licence ? C’est du libre ?
Il est disponible en CC-BY-SA, et c’est du libre, comme tout ce qu’on fait ! Il n’existe pour le moment qu’en français, mais rien n’empêche de contribuer pour l’améliorer !
Tout ça représente un coût, ça justifie un appel aux dons ?
Nous avons eu de la chance : ce projet a été financé en intégralité par la Fondation AFNIC pour un numérique inclusif et on les remercie grandement pour ça ! Le coût de ce kit est quasi-exclusivement lié à la rémunération des professionnel·les ayant travaillé sur le motion design, la mise en page et la création graphique.
Est-ce que vous pensez faire un peu de communication à destination des publics visés, par exemple les médiateur-ices numériques de l’Éducation Nationale, des structures d’éducation populaire comme le CEMEA etc. ?
Mais oui, c’est prévu : on est déjà en contact avec le CEMEA et l’April notamment. Il y a également une communication prévue au sein des ProfDoc. et ce sera diffusé au sein des réseaux de MedNum.
Le travail d’Exodus Privacy va au delà de ce kit et il est important de le soutenir ! Pour découvrir les actions de cette formidable association et y contribuer, c’est sur leur site web : https://exodus-privacy.eu.org/fr/page/contribute On souhaite un franc succès et une large diffusion à ce nouvel outil. Merci pour ça et pour toutes leurs initiatives !
Dorlotons Dégooglisons : pour des framaservices bichonnés !
« Dorlotons Dégooglisons » consiste à prendre soin de nos services en ligne et à mettre en lumière le travail trop peu visible des personnes qui s’en occupent. La collecte en cours nous permettra de voir si ce nouveau cap vous motive autant que nous !
« Dorlotons Dégooglisons »
Consacrer plus de temps et d’énergie à nos services en ligne, c’est un nouveau cap que nous voulons suivre. Et nous pourrons le garder grâce à vous, grâce à vos dons ! En savoir plus sur le site Soutenir Framasoft.
Nous le savons : nos services « Dégooglisons Internet » ne sont pas parfaits.
Oui, Framadate n’est pas idéal sur mobile (avez-vous essayé de basculer votre smartphone à l’horizontale ?).
Oui, mettre des cellules en gras sur Framacalc n’est pas le plus intuitif (mais si ! Vous voyez en haut « Format » ? Ensuite vous repérez « Polices » et vous choisissez dans la liste « Gras & Italique ». Facile !).
Non, le partage d’administration sur Framaforms n’est pas possible (quoi ? Vous avez vraiment besoin d’être plusieurs à modifier vos formulaires ?).
Bref nous avons en interne une « liste au Père Noël » qui s’allonge au fil des ans… Et c’est normal : certains services « Dégooglisons Internet » vont bientôt fêter leurs 10 ans ! Ces services que vous utilisez tant – vous êtes près de 1,5 million de personnes par mois à naviguer sur nos sites (nous on trouve ça dingue !) – nous ne les oublions pas.
Même si nous les chouchoutons déjà, nous souhaitons en faire encore plus. Nous voulons leur consacrer plus de temps et d’énergie. Et du temps, de l’énergie, ce sont des ressources précieuses, qui ne sont pas gratuites. C’est pour cela que nous avons besoin de vous, et de votre soutien !
Nous souhaitons aussi rendre visible le soin humain apporté à nos services, sans lequel la magie n’opérerait pas ! Un « dorlotage » humain essentiel au bon fonctionnement de nos services, que nous voulons mettre en lumière.
Les envoûtements de la gestion. C’est nécessaire pour toute association : des petites mains s’activent au quotidien pour payer les factures (eh oui, louer des serveurs n’est pas gratuit !), faire du lien avec les îles de notre archipel et orchestrer tous ces esprits volontaires. Du boulot essentiel auquel on ne pense pas en écrivant sur un pad !
Les incantations techniques. Que ce soit pour la mise en place d’une belle page d’accueil, pour les mises à jour et en sécurité de services, pour des développements ponctuels ou pour se dépatouiller des problèmes rencontrés avec les géants fournisseurs de mail (calinternets bienvenus dans cette éventualité plus que réaliste !), une expertise technique est indispensable pour le bon fonctionnement de nos services. Sans elle, les services ne dureraient pas !
Les enchantements du support. « Pourquoi mon mail met du temps à être reçu ? », si vous n’avez pas trouvé la réponse dans notre documentation ou notre Foire Aux Questions, il vous arrive de contacter notre support. Et derrière toute réponse envoyée par notre support, ce sont des humains et des humaines qui s’activent pour trouver des solutions à vos questions parfois épineuses (processus souvent accompagné de quelques litres de café pour motiver les troupes lors des heures matinales – mais quelle idée de commencer la journée avant midi…!).
Le charme de la communication. Nos membres s’activent pour sensibiliser à des outils numériques éthiques, rassurent les inquiet⋅es en rappelant que tout changement prend du temps et, lors d’évènements, prennent plaisir à papoter de leurs militances avec passion (qu’elles concernent la défense du secteur associatif, les communs culturels ou le dernier rapport du GIEC).
« Dorlotons Dégooglisons », c’est aussi une manière de financer ce travail de soin à nos services bien trop souvent invisible et pourtant absolument essentiel.
Dès cette année nous bichonnons nos services en ligne, pour qu’ils puissent durer dans le temps et être plus pratiques pour vous, comme pour nous. Concrètement, voilà ce qui s’est passé cette année en coulisses :
Des réparations. Nous avons passé de nombreuses heures à trouver des solutions pour gérer les spams, que ce soit sur Framaforms, Framagit, ou Framalistes (coucou Orange qui ne laisse toujours pas passer nos mails de façon fluide…!). Nous avons aussi dû séparer Framagit sur 2 machines (la base de données du service devenait trop importante et pénalisait l’ensemble du service…). Pour Framacalc, nous avons dû corriger un bug Ethercalc (le logiciel derrière le service) qui générait un problème de saturation de la mémoire et faisait tomber le service.
Des mises à jour conséquentes. Nous avons (enfin !) pu mettre à jour Framavox en début d’année, vers une version récente particulièrement lourde à gérer pour nous (une mise à jour que nous avions reportée d’un an pour non disponibilité interne…), et nous en avons profité pour mettre mettre un bon coup de pinceau sur la page d’accueil du service. Framateam, Framindmap, Framagenda, Framadrive, Mobilizon.fr, mooc.chatons.org et Framapiaf ont également été mis à jour, corrigeant des bugs ou apportant de nouvelles fonctionnalités.
Des contributions aux logiciels libres qui font tourner nos services. Nous avons apporté des contributions à différents logiciels libres qui sont en coulisses de nos services – améliorations qui sont maintenant disponibles pour l’ensemble des utilisateur⋅ices de ces logiciels :
Logiciel uMap, pour Framacartes : résolution d’un souci de pertes de données, et correction d’un problème avec les liens d’édition secrets, qui empêchait l’accès à l’ancien lien
Prioriser nos services en ligne, c’est le choix que feraient 82% des 12 664 répondant⋅es à l’enquête lancée l’année dernière, s’iels étaient aux manettes de notre association. Et ça tombe plutôt bien car nous partageons cette envie !
Cette collecte, c’est aussi pour nous une manière de voir si nous prenons la bonne direction. Nous estimons que cette première année de dorlotage coûte 60 000 € (« estimons », car c’est très difficile de chiffrer précisément un travail de soin humain), et nous vous lançons le défi de les récolter en 3 semaines, du 23 mai au 13 juin. La suite ?
La semaine prochaine, le 7 juin, nous ouvrons et vous présentons le service Framagroupes.
Dans deux semaines, le 13 juin, nous ferons le bilan de ces 3 semaines de collecte.
Vous utilisez nos services en ligne ? C’est parce que d’autres (ou vous !) les ont financés, en nous faisant un don. Vous pouvez, vous aussi, soutenir « Dorlotons Dégooglisons », et nous conforter sur le choix de prendre cette nouvelle direction, celle du soin à nos services et une mise en valeur du travail qu’il demande. D’avance, merci de votre soutien !
Pour relayer ou participer à la collecte, une seule adresse à retenir : soutenir.framasoft.org.
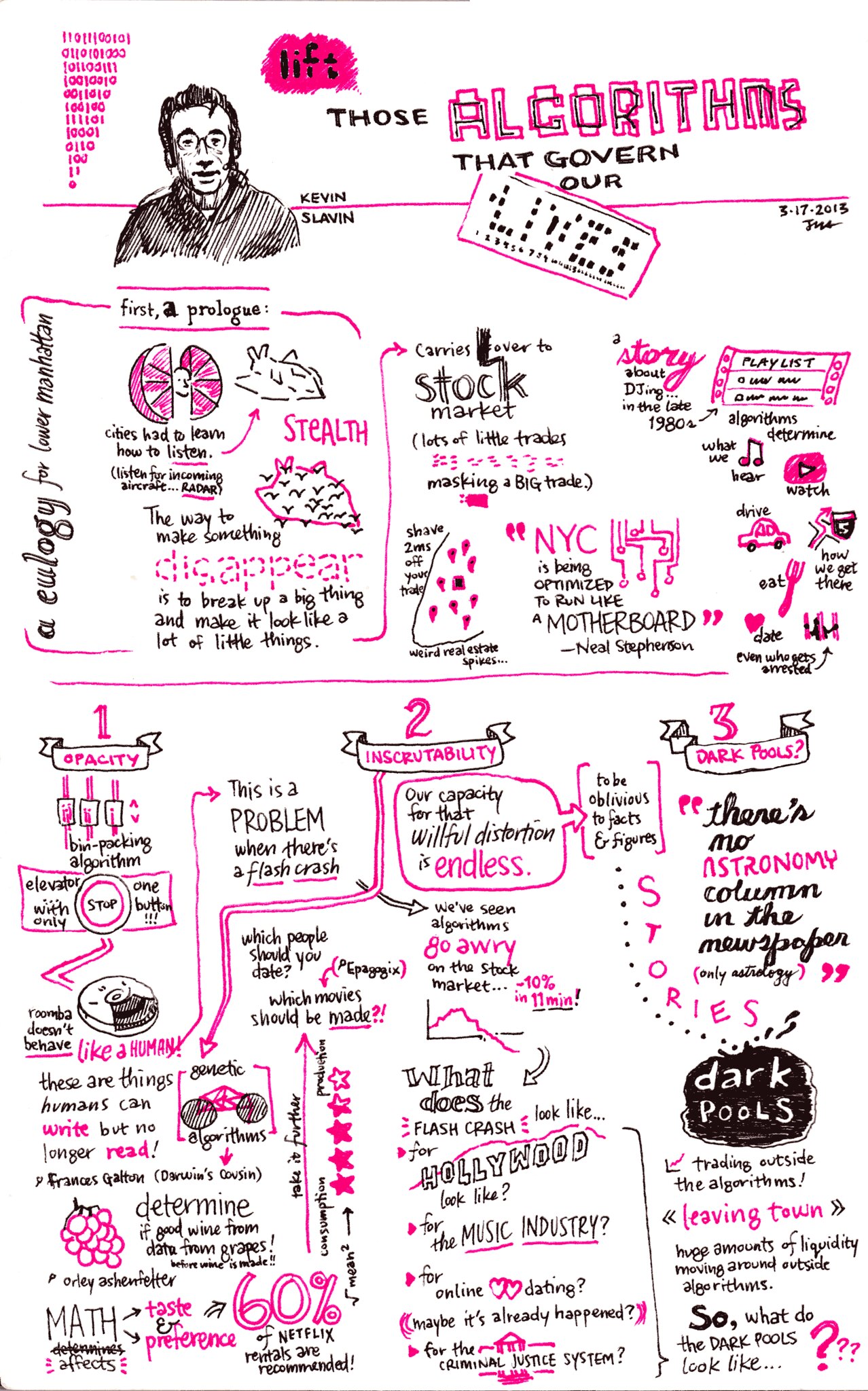
Ouvrir le code des algorithmes ? — oui, mais… (2/2)
Voici le deuxième volet (si vous avez raté le premier) de l’enquête approfondie d’Hubert Guillaud sur l’exploration des algorithmes, et de son analyse des enjeux qui en découlent.
Dans le code source de l’amplification algorithmique : que voulons-nous vraiment savoir ?
par Hubert GUILLAUD
Que voulons-nous vraiment savoir en enquêtant sur l’amplification algorithmique ? C’est justement l’enjeu du projet de recherche qu’Arvind Narayanan mène au Knight Institute de l’université Columbia où il a ouvert un blog dédié et qui vient d’accueillir une grande conférence sur le sujet. Parler d’amplification permet de s’intéresser à toute la gamme des réponses qu’apportent les plateformes, allant de l’amélioration de la portée des discours à leur suppression, tout en se défiant d’une réduction binaire à la seule modération automatisée, entre ce qui doit être supprimé et ce qui ne doit pas l’être. Or, les phénomènes d’amplification ne sont pas sans effets de bord, qui vont bien au-delà de la seule désinformation, à l’image des effets très concrets qu’ont les influenceurs sur le commerce ou le tourisme. Le gros problème, pourtant, reste de pouvoir les étudier sans toujours y avoir accès.
Outre des analyses sur TikTok et les IA génératives, le blog recèle quelques trésors, notamment une monumentale synthèse qui fait le tour du sujet en expliquant les principes de fonctionnements des algorithmes (l’article est également très riche en liens et références, la synthèse que j’en propose y recourra assez peu).
Narayanan rappelle que les plateformes disposent de très nombreux algorithmes entremêlés, mais ceux qui l’intéressent particulièrement sont les algorithmes de recommandation, ceux qui génèrent les flux, les contenus qui nous sont mis à disposition. Alors que les algorithmes de recherche sont limités par le terme recherché, les algorithmes de recommandation sont bien plus larges et donnent aux plateformes un contrôle bien plus grand sur ce qu’elles recommandent à un utilisateur.
La souscription, le réseau et l’algorithme
Pour Narayanan, il y a 3 grands types de leviers de propagation : la souscription (ou abonnement), le réseau et l’algorithme. Dans le modèle par abonnement, le message atteint les personnes qui se sont abonnées à l’auteur du message. Dans le modèle de réseau, il se propage en cascade à travers le réseau tant que les utilisateurs qui le voient choisissent de le propager. Dans le modèle algorithmique, les utilisateurs ayant des intérêts similaires (tels que définis par l’algorithme sur la base de leurs engagements passés) sont représentés plus près les uns des autres. Plus les intérêts d’un utilisateur sont similaires à ceux définis, plus il est probable que le contenu lui sera recommandé.
À l’origine, les réseaux sociaux comme Facebook ou Twitter ne fonctionnaient qu’à l’abonnement : vous ne voyiez que les contenus des personnes auxquelles vous étiez abonnés et vous ne pouviez pas republier les messages des autres ! Dans le modèle de réseau, un utilisateur voit non seulement les messages créés par les personnes auxquelles il s’est abonné, mais aussi les messages que ces utilisateurs choisissent d’amplifier, ce qui crée la possibilité de cascades d’informations et de contenus “viraux”, comme c’était le cas de Twitter jusqu’en 2016, moment où le réseau introduisit le classement algorithmique. Dans le modèle algorithmique, la souscription est bien souvent minorée, le réseau amplifié mais surtout, le flux dépend principalement de ce que l’algorithme estime être le plus susceptible d’intéresser l’utilisateur. C’est ce que Cory Doctorow désigne comme « l’emmerdification » de nos flux, le fait de traiter la liste des personnes auxquelles nous sommes abonnés comme des suggestions et non comme des commandes.
Le passage aux recommandations algorithmiques a toujours généré des contestations, notamment parce que, si dans les modèles d’abonnement et de réseau, les créateurs peuvent se concentrer sur la construction de leur réseau, dans le « modèle algorithmique, cela ne sert à rien, car le nombre d’abonnés n’a rien à voir avec la performance des messages » (mais comme nous sommes dans des mélanges entre les trois modèles, le nombre d’abonnés a encore un peu voire beaucoup d’influence dans l’amplification). Dans le modèle algorithmique, l’audience de chaque message est optimisée de manière indépendante en fonction du sujet, de la « qualité » du message et d’un certain nombre de paramètres pris en compte par le modèle.
Amplification et viralité
La question de l’amplification interroge la question de la viralité, c’est-à-dire le fait qu’un contenu soit amplifié par une cascade de reprises, et non pas seulement diffusé d’un émetteur à son public. Le problème de la viralité est que sa portée reste imprévisible. Pour Narayanan, sur toutes les grandes plateformes, pour la plupart des créateurs, la majorité de l’engagement provient d’une petite fraction de contenu viral. Sur TikTok comme sur YouTube, 20 % des vidéos les plus vues d’un compte obtiennent plus de 70 % des vues. Plus le rôle de l’algorithme dans la propagation du contenu est important, par opposition aux abonnements ou au réseau, plus cette inégalité semble importante.
Parce qu’il est particulièrement repérable dans la masse des contenus, le contenu viral se prête assez bien à la rétropropagation, c’est-à-dire à son déclassement ou à sa suppression. Le problème justement, c’est qu’il y a plein de manières de restreindre le contenu. Facebook classe les posts rétrogradés plus bas dans le fil d’actualité qu’ils ne le seraient s’ils ne l’avaient pas été, afin que les utilisateurs soient moins susceptibles de le rencontrer et de le propager. À son tour, l’effet de la rétrogradation sur la portée peut être imprévisible, non linéaire et parfois radical, puisque le contenu peut devenir parfaitement invisible. Cette rétrogradation est parfaitement opaque, notamment parce qu’une faible portée n’est pas automatiquement suspecte, étant donné qu’il existe une grande variation dans la portée naturelle du contenu.
Amplification et prédiction de l’engagement
Les plateformes ont plusieurs objectifs de haut niveau : améliorer leurs revenus publicitaires bien sûr et satisfaire suffisamment les utilisateurs pour qu’ils reviennent… Mais ces objectifs n’aident pas vraiment à décider ce qu’il faut donner à un utilisateur spécifique à un moment précis ni à mesurer comment ces décisions impactent à long terme la plateforme. D’où le fait que les plateformes observent l’engagement, c’est-à-dire les actions instantanées des utilisateurs, comme le like, le commentaire ou le partage qui permettent de classer le contenu en fonction de la probabilité que l’utilisateur s’y intéresse. « D’une certaine manière, l’engagement est une approximation des objectifs de haut niveau. Un utilisateur qui s’engage est plus susceptible de revenir et de générer des revenus publicitaires pour la plateforme. »
Si l’engagement est vertueux, il a aussi de nombreuses limites qui expliquent que les algorithmes intègrent bien d’autres facteurs dans leur calcul. Ainsi, Facebook et Twitter optimisent les « interactions sociales significatives », c’est-à-dire une moyenne pondérée des likes, des partages et des commentaires. YouTube, lui, optimise en fonction de la durée de visionnage que l’algorithme prédit. TikTok utilise les interactions sociales et valorise les vidéos qui ont été regardées jusqu’au bout, comme un signal fort et qui explique certainement le caractère addictif de l’application et le fait que les vidéos courtes (qui ont donc tendance à obtenir un score élevé) continuent de dominer la plateforme.
En plus de ces logiques de base, il existe bien d’autres logiques secondaires, comme par exemple, pour que l’expérience utilisateur ne soit pas ralentie par le calcul, que les suggestions restent limitées, sélectionnées plus que classées, selon divers critères plus que selon des critères uniques (par exemple en proposant des nouveaux contenus et pas seulement des contenus similaires à ceux qu’on a apprécié, TikTok se distingue à nouveau par l’importance qu’il accorde à l’exploration de nouveaux contenus… c’est d’ailleurs la tactique suivie désormais par Instagram de Meta via les Reels, boostés sur le modèle de TikTok, qui ont le même effet que sur TikTok, à savoir une augmentation du temps passé sur l’application)…
« Bien qu’il existe de nombreuses différences dans les détails, les similitudes entre les algorithmes de recommandation des différentes plateformes l’emportent sur leurs différences », estime Narayanan. Les différences sont surtout spécifiques, comme Youtube qui optimise selon la durée de visionnage, ou Spotify qui s’appuie davantage sur l’analyse de contenu que sur le comportement. Pour Narayanan, ces différences montrent qu’il n’y a pas de risque concurrentiel à l’ouverture des algorithmes des plateformes, car leurs adaptations sont toujours très spécifiques. Ce qui varie, c’est la façon dont les plateformes ajustent l’engagement.
Comment apprécier la similarité ?
Mais la grande question à laquelle tous tentent de répondre est la même : « Comment les utilisateurs similaires à cet utilisateur ont-ils réagi aux messages similaires à ce message ? »
Si cette approche est populaire dans les traitements, c’est parce qu’elle s’est avérée efficace dans la pratique. Elle repose sur un double calcul de similarité. D’abord, celle entre utilisateurs. La similarité entre utilisateurs dépend du réseau (les gens que l’on suit ou ceux qu’on commente par exemple, que Twitter valorise fortement, mais peu TikTok), du comportement (qui est souvent plus critique, « deux utilisateurs sont similaires s’ils se sont engagés dans un ensemble de messages similaires ») et les données démographiques (du type âge, sexe, langue, géographie… qui sont en grande partie déduits des comportements).
Ensuite, il y a un calcul sur la similarité des messages qui repose principalement sur leur sujet et qui repose sur des algorithmes d’extraction des caractéristiques (comme la langue) intégrant des évaluations normatives, comme la caractérisation de discours haineux. L’autre signal de similarité des messages tient, là encore, au comportement : « deux messages sont similaires si un ensemble similaire d’utilisateurs s’est engagé avec eux ». Le plus important à retenir, insiste Narayanan, c’est que « l’enregistrement comportemental est le carburant du moteur de recommandation ». La grande difficulté, dans ces appréciations algorithmiques, consiste à faire que le calcul reste traitable, face à des volumes d’enregistrements d’informations colossaux.
Une histoire des évolutions des algorithmes de recommandation
« La première génération d’algorithmes de recommandation à grande échelle, comme ceux d’Amazon et de Netflix au début des années 2000, utilisait une technique simple appelée filtrage collaboratif : les clients qui ont acheté ceci ont également acheté cela ». Le principe était de recommander des articles consultés ou achetés d’une manière rudimentaire, mais qui s’est révélé puissant dans le domaine du commerce électronique. En 2006, Netflix a organisé un concours en partageant les évaluations qu’il disposait sur les films pour améliorer son système de recommandation. Ce concours a donné naissance à la « factorisation matricielle », une forme de deuxième génération d’algorithmes de recommandation, c’est-à-dire capables d’identifier des combinaisons d’attributs et de préférences croisées. Le système n’étiquette pas les films avec des termes interprétables facilement (comme “drôle” ou “thriller” ou “informatif”…), mais avec un vaste ensemble d’étiquettes (de micro-genres obscurs comme « documentaires émouvants qui combattent le système ») qu’il associe aux préférences des utilisateurs. Le problème, c’est que cette factorisation matricielle n’est pas très lisible pour l’utilisateur et se voir dire qu’on va aimer tel film sans savoir pourquoi n’est pas très satisfaisant. Enfin, ce qui marche pour un catalogue de film limité n’est pas adapté aux médias sociaux où les messages sont infinis. La prédominance de la factorisation matricielle explique pourquoi les réseaux sociaux ont tardé à se lancer dans la recommandation, qui est longtemps restée inadaptée à leurs besoins.
Pourtant, les réseaux sociaux se sont tous convertis à l’optimisation basée sur l’apprentissage automatique. En 2010, Facebook utilisait un algorithme appelé EdgeRank pour construire le fil d’actualité des utilisateurs qui consistait à afficher les éléments par ordre de priorité décroissant selon un score d’affinité qui représente la prédiction de Facebook quant au degré d’intérêt de l’utilisateur pour les contenus affichés, valorisant les photos plus que le texte par exemple. À l’époque, ces pondérations étaient définies manuellement plutôt qu’apprises. En 2018, Facebook est passé à l’apprentissage automatique. La firme a introduit une métrique appelée « interactions sociales significatives » (MSI pour meaningful social interactions) dans le système d’apprentissage automatique. L’objectif affiché était de diminuer la présence des médias et des contenus de marque au profit des contenus d’amis et de famille. « La formule calcule un score d’interaction sociale pour chaque élément susceptible d’être montré à un utilisateur donné ». Le flux est généré en classant les messages disponibles selon leur score MSI décroissant, avec quelques ajustements, comme d’introduire de la diversité (avec peu d’indications sur la façon dont est calculée et ajoutée cette diversité). Le score MSI prédit la probabilité que l’utilisateur ait un type d’interaction spécifique (comme liker ou commenter) avec le contenu et affine le résultat en fonction de l’affinité de l’utilisateur avec ce qui lui est proposé. Il n’y a plus de pondération dédiée pour certains types de contenus, comme les photos ou les vidéos. Si elles subsistent, c’est uniquement parce que le système l’aura appris à partir des données de chaque utilisateur, et continuera à vous proposer des photos si vous les appréciez.
« Si l’on pousse cette logique jusqu’à sa conclusion naturelle, il ne devrait pas être nécessaire d’ajuster manuellement la formule en fonction des affinités. Si les utilisateurs préfèrent voir le contenu de leurs amis plutôt que celui des marques, l’algorithme devrait être en mesure de l’apprendre ». Ce n’est pourtant pas ce qu’il se passe. Certainement pour lutter contre la logique de l’optimisation de l’engagement, estime Narayanan, dans le but d’augmenter la satisfaction à long terme, que l’algorithme ne peut pas mesurer, mais là encore sans que les modalités de ces ajustements ne soient clairement documentés.
Est-ce que tout cela est efficace ?
Reste à savoir si ces algorithmes sont efficaces ! « Il peut sembler évident qu’ils doivent bien fonctionner, étant donné qu’ils alimentent des plateformes technologiques qui valent des dizaines ou des centaines de milliards de dollars. Mais les chiffres racontent une autre histoire. Le taux d’engagement est une façon de quantifier le problème : il s’agit de la probabilité qu’un utilisateur s’intéresse à un message qui lui a été recommandé. Sur la plupart des plateformes, ce taux est inférieur à 1 %. TikTok est une exception, mais même là, ce taux dépasse à peine les 5 %. »
Le problème n’est pas que les algorithmes soient mauvais, mais surtout que les gens ne sont pas si prévisibles. Et qu’au final, les utilisateurs ne se soucient pas tant du manque de précision de la recommandation. « Même s’ils sont imprécis au niveau individuel, ils sont précis dans l’ensemble. Par rapport aux plateformes basées sur les réseaux, les plateformes algorithmiques semblent être plus efficaces pour identifier les contenus viraux (qui trouveront un écho auprès d’un grand nombre de personnes). Elles sont également capables d’identifier des contenus de niche et de les faire correspondre au sous-ensemble d’utilisateurs susceptibles d’y être réceptifs. » Si les algorithmes sont largement limités à la recherche de modèles dans les données comportementales, ils n’ont aucun sens commun. Quant au taux de clic publicitaire, il reste encore plus infinitésimal – même s’il est toujours considéré comme un succès !
Les ingénieurs contrôlent-ils encore les algorithmes ?
Les ingénieurs ont très peu d’espace pour contrôler les effets des algorithmes de recommandation, estime Narayanan, en prenant un exemple. En 2019, Facebook s’est rendu compte que les publications virales étaient beaucoup plus susceptibles de contenir des informations erronées ou d’autres types de contenus préjudiciables. En d’autres termes, ils se sont rendu compte que le passage à des interactions sociales significatives (MSI) a eu des effets de bords : les contenus qui suscitaient l’indignation et alimentaient les divisions gagnaient en portée, comme l’a expliqué l’ingénieure et lanceuse d’alerte Frances Haugen à l’origine des Facebook Files, dans ses témoignages. C’est ce que synthétise le tableau de pondération de la formule MSI publié par le Wall Street Journal, qui montrent que certains éléments ont des poids plus forts que d’autres : un commentaire vaut 15 fois plus qu’un like, mais un commentaire signifiant ou un repartage 30 fois plus, chez Facebook. Une pondération aussi élevée permet d’identifier les messages au potentiel viral et de les stimuler davantage. En 2020, Facebook a ramené la pondération des partages à 1,5, mais la pondération des commentaires est restée très élevée (15 à 20 fois plus qu’un like). Alors que les partages et les commentaires étaient regroupés dans une seule catégorie de pondération en 2018, ils ne le sont plus. Cette prime au commentaire demeure une prime aux contenus polémiques. Reste, on le comprend, que le jeu qui reste aux ingénieurs de Facebook consiste à ajuster le poids des paramètres. Pour Narayanan : piloter un système d’une telle complexité en utilisant si peu de boutons ne peut qu’être difficile.
Le chercheur rappelle que le système est censé être neutre à l’égard de tous les contenus, à l’exception de certains qui enfreignent les règles de la plateforme. Utilisateurs et messages sont alors rétrogradés de manière algorithmique suite à signalement automatique ou non. Mais cette neutralité est en fait très difficile à atteindre. Les réseaux sociaux favorisent ceux qui ont déjà une grande portée, qu’elle soit méritée ou non, et sont récompensés par une plus grande portée encore. Par exemple, les 1 % d’auteurs les plus importants sur Twitter reçoivent 80 % des vues des tweets. Au final, cette conception de la neutralité finit par récompenser ceux qui sont capables de pirater l’engagement ou de tirer profit des biais sociaux.
Outre cette neutralité, un deuxième grand principe directeur est que « l’algorithme sait mieux que quiconque ». « Ce principe et celui de la neutralité se renforcent mutuellement. Le fait de confier la politique (concernant le contenu à amplifier) aux données signifie que les ingénieurs n’ont pas besoin d’avoir un point de vue à ce sujet. Et cette neutralité fournit à l’algorithme des données plus propres à partir desquelles il peut apprendre. »
Le principe de l’algorithme qui sait le mieux signifie que la même optimisation est appliquée à tous les types de discours : divertissement, informations éducatives, informations sur la santé, actualités, discours politique, discours commercial, etc. En 2021, FB a fait une tentative de rétrograder tout le contenu politique, ce qui a eu pour effet de supprimer plus de sources d’information de haute qualité que de faible qualité, augmentant la désinformation. Cette neutralité affichée permet également une forme de désengagement des ingénieurs.
En 2021, encore, FB a entraîné des modèles d’apprentissage automatique pour classer les messages en deux catégories : bons ou mauvais pour le monde, en interrogeant les utilisateurs pour qu’ils apprécient des contenus qui leurs étaient proposés pour former les données. FB a constaté que les messages ayant une plus grande portée étaient considérés comme étant mauvais pour le monde. FB a donc rétrogradé ces contenus… mais en trouvant moins de contenus polémique, cette modification a entraîné une diminution de l’ouverture de l’application par les utilisateurs. L’entreprise a donc redéployé ce modèle en lui donnant bien moins de poids. Les corrections viennent directement en conflit avec le modèle d’affaires.
Pourquoi l’optimisation de l’engagement nous nuit-elle ?
« Un grand nombre des pathologies familières des médias sociaux sont, à mon avis, des conséquences relativement directes de l’optimisation de l’engagement », suggère encore le chercheur. Cela explique pourquoi les réformes sont difficiles et pourquoi l’amélioration de la transparence des algorithmes, de la modération, voire un meilleur contrôle par l’utilisateur de ce qu’il voit (comme le proposait Gobo mis en place par Ethan Zuckerman), ne sont pas des solutions magiques (même si elles sont nécessaires).
Les données comportementales, celles relatives à l’engagement passé, sont la matière première essentielle des moteurs de recommandations. Les systèmes privilégient la rétroaction implicite sur l’explicite, à la manière de YouTube qui a privilégié le temps passé sur les rétroactions explicites (les likes). Sur TikTok, il n’y a même plus de sélection, il suffit de swipper.
Le problème du feedback implicite est qu’il repose sur nos réactions inconscientes, automatiques et émotionnelles, sur nos pulsions, qui vont avoir tendance à privilégier une vidéo débile sur un contenu expert.
Pour les créateurs de contenu, cette optimisation par l’engagement favorise la variance et l’imprévisibilité, ce qui a pour conséquence d’alimenter une surproduction pour compenser cette variabilité. La production d’un grand volume de contenu, même s’il est de moindre qualité, peut augmenter les chances qu’au moins quelques-uns deviennent viraux chaque mois afin de lisser le flux de revenus. Le fait de récompenser les contenus viraux se fait au détriment de tous les autres types de contenus (d’où certainement le regain d’attraits pour des plateformes non algorithmiques, comme Substack voire dans une autre mesure, Mastodon).
Au niveau de la société, toutes les institutions sont impactées par les plateformes algorithmiques, du tourisme à la science, du journalisme à la santé publique. Or, chaque institution à des valeurs, comme l’équité dans le journalisme, la précision en science, la qualité dans nombre de domaines. Les algorithmes des médias sociaux, eux, ne tiennent pas compte de ces valeurs et de ces signaux de qualité. « Ils récompensent des facteurs sans rapport, sur la base d’une logique qui a du sens pour le divertissement, mais pas pour d’autres domaines ». Pour Narayanan, les plateformes de médias sociaux « affaiblissent les institutions en sapant leurs normes de qualité et en les rendant moins dignes de confiance ». C’est particulièrement actif dans le domaine de l’information, mais cela va bien au-delà, même si ce n’est pas au même degré. TikTok peut sembler ne pas représenter une menace pour la science, mais nous savons que les plateformes commencent par être un divertissement avant de s’étendre à d’autres sphères du discours, à l’image d’Instagram devenant un outil de communication politique ou de Twitter, où un tiers des tweets sont politiques.
La science des données en ses limites
Les plateformes sont bien conscientes de leurs limites, pourtant, elles n’ont pas fait beaucoup d’efforts pour résoudre les problèmes. Ces efforts restent occasionnels et rudimentaires, à l’image de la tentative de Facebook de comprendre la valeur des messages diffusés. La raison est bien sûr que ces aménagements nuisent aux résultats financiers de l’entreprise. « Le recours à la prise de décision subconsciente et automatique est tout à fait intentionnelle ; c’est ce qu’on appelle la « conception sans friction ». Le fait que les utilisateurs puissent parfois faire preuve de discernement et résister à leurs impulsions est vu comme un problème à résoudre. »
Pourtant, ces dernières années, la réputation des plateformes n’est plus au beau fixe. Narayanan estime qu’il y a une autre limite. « La plupart des inconvénients de l’optimisation de l’engagement ne sont pas visibles dans le cadre dominant de la conception des plateformes, qui accorde une importance considérable à la recherche d’une relation quantitative et causale entre les changements apportés à l’algorithme et leurs effets. »
Si on observe les raisons qui poussent l’utilisateur à quitter une plateforme, la principale est qu’il ne parvient pas à obtenir des recommandations suffisamment intéressantes. Or, c’est exactement ce que l’optimisation par l’engagement est censée éviter. Les entreprises parviennent très bien à optimiser des recommandations qui plaisent à l’utilisateur sur l’instant, mais pas celles qui lui font dire, une fois qu’il a fermé l’application, que ce qu’il y a trouvé l’a enrichi. Elles n’arrivent pas à calculer et à intégrer le bénéfice à long terme, même si elles restent très attentives aux taux de rétention ou aux taux de désabonnement. Pour y parvenir, il faudrait faire de l’A/B testing au long cours. Les plateformes savent le faire. Facebook a constaté que le fait d’afficher plus de notifications augmentait l’engagement à court terme mais avait un effet inverse sur un an. Reste que ce regard sur leurs effets à longs termes ne semble pas être une priorité par rapport à leurs effets de plus courts termes.
Une autre limite repose sur l’individualisme des plateformes. Si les applications sociales sont, globalement, assez satisfaisantes pour chacun, ni les utilisateurs ni les plateformes n’intériorisent leurs préjudices collectifs. Ces systèmes reposent sur l’hypothèse que le comportement de chaque utilisateur est indépendant et que l’effet sur la société (l’atteinte à la démocratie par exemple…) est très difficile à évaluer. Narayanan le résume dans un tableau parlant, où la valeur sur la société n’a pas de métrique associée.
Tableau montrant les 4 niveaux sur lesquels les algorithmes des plateformes peuvent avoir des effets. CTR : Click Through Rate (taux de clic). MSI : Meaningful Social Interactions, interactions sociales significatives, la métrique d’engagement de Facebook. DAU : Daily active users, utilisateurs actifs quotidiens.
Les algorithmes ne sont pas l’ennemi (enfin si, quand même un peu)
Pour répondre à ces problèmes, beaucoup suggèrent de revenir à des flux plus chronologiques ou a des suivis plus stricts des personnes auxquelles nous sommes abonnés. Pas sûr que cela soit une solution très efficace pour gérer les volumes de flux, estime le chercheur. Les algorithmes de recommandation ont été la réponse à la surcharge d’information, rappelle-t-il : « Il y a beaucoup plus d’informations en ligne en rapport avec les intérêts d’une personne qu’elle n’en a de temps disponible. » Les algorithmes de classement sont devenus une nécessité pratique. Même dans le cas d’un réseau longtemps basé sur l’abonnement, comme Instagram : en 2016, la société indiquait que les utilisateurs manquaient 70 % des publications auxquelles ils étaient abonnés. Aujourd’hui, Instagram compte 5 fois plus d’utilisateurs. En fait, les plateformes subissent d’énormes pressions pour que les algorithmes soient encore plus au cœur de leur fonctionnement que le contraire. Et les systèmes de recommandation font leur entrée dans d’autres domaines, comme l’éducation (avec Coursera) ou la finance (avec Robinhood).
Pour Narayanan, l’enjeu reste de mieux comprendre ce qu’ils font. Pour cela, nous devons continuer d’exiger d’eux bien plus de transparence qu’ils n’en livrent. Pas plus que dans le monde des moteurs de recherche nous ne reviendrons aux annuaires, nous ne reviendrons pas aux flux chronologiques dans les moteurs de recommandation. Nous avons encore des efforts à faire pour contrecarrer activement les modèles les plus nuisibles des recommandations. L’enjeu, conclut-il, est peut-être d’esquisser plus d’alternatives que nous n’en disposons, comme par exemple, d’imaginer des algorithmes de recommandations qui n’optimisent pas l’engagement, ou pas seulement. Cela nécessite certainement aussi d’imaginer des réseaux sociaux avec des modèles économiques différents. Un autre internet. Les algorithmes ne sont peut-être pas l’ennemi comme il le dit, mais ceux qui ne sont ni transparents, ni loyaux, et qui optimisent leurs effets en dehors de toute autre considération, ne sont pas nos amis non plus !
Ouvrir le code des algorithmes ? — Oui, mais… (1/2)
Voici le premier des deux articles qu’Hubert Guillaud nous fait le plaisir de partager. Sans s’arrêter à la surface de l’actualité, il aborde la transparence du code des algorithmes, qui entraîne un grand nombre de questions épineuses sur lesquelles il s’est documenté pour nous faire part de ses réflexions.
Dans le code source de l’amplification algorithmique : publier le code ne suffit pas !
par Hubert GUILLAUD
Le 31 mars, Twitter a publié une partie du code source qui alimente son fil d’actualité, comme l’a expliqué l’équipe elle-même dans un billet. Ces dizaines de milliers de lignes de code contiennent pourtant peu d’informations nouvelles. Depuis le rachat de l’oiseau bleu par Musk, Twitter a beaucoup changé et ne cesse de se modifier sous les yeux des utilisateurs. La publication du code source d’un système, même partiel, qui a longtemps été l’un des grands enjeux de la transparence, montre ses limites.
« LZW encoding and decoding algorithms overlapped » par nayukim, licence CC BY 2.0.
Publier le code ne suffit pas
Dans un excellent billet de blog, le chercheur Arvind Narayanan (sa newsletter mérite également de s’y abonner) explique ce qu’il faut en retenir. Comme ailleurs, les règles ne sont pas claires. Les algorithmes de recommandation utilisent l’apprentissage automatique ce qui fait que la manière de classer les tweets n’est pas directement spécifiée dans le code, mais apprise par des modèles à partir de données de Twitter sur la manière dont les utilisateurs ont réagi aux tweets dans le passé. Twitter ne divulgue ni ces modèles ni les données d’apprentissages, ce qui signifie qu’il n’est pas possible d’exécuter ces modèles. Le code ne permet pas de comprendre pourquoi un tweet est ou n’est pas recommandé à un utilisateur, ni pourquoi certains contenus sont amplifiés ou invisibilisés. C’est toute la limite de la transparence. Ce que résume très bien le journaliste Nicolas Kayser-Bril pour AlgorithmWatch (pertinemment traduit par le framablog) : « Vous ne pouvez pas auditer un code seulement en le lisant. Il faut l’exécuter sur un ordinateur. »
« Ce que Twitter a publié, c’est le code utilisé pour entraîner les modèles, à partir de données appropriées », explique Narayanan, ce qui ne permet pas de comprendre les propagations, notamment du fait de l’absence des données. De plus, les modèles pour détecter les tweets qui violent les politiques de Twitter et qui leur donnent des notes de confiance en fonction de ces politiques sont également absentes (afin que les usagers ne puissent pas déjouer le système, comme nous le répètent trop de systèmes rétifs à l’ouverture). Or, ces classements ont des effets de rétrogradation très importants sur la visibilité de ces tweets, sans qu’on puisse savoir quels tweets sont ainsi classés, selon quelles méthodes et surtout avec quelles limites.
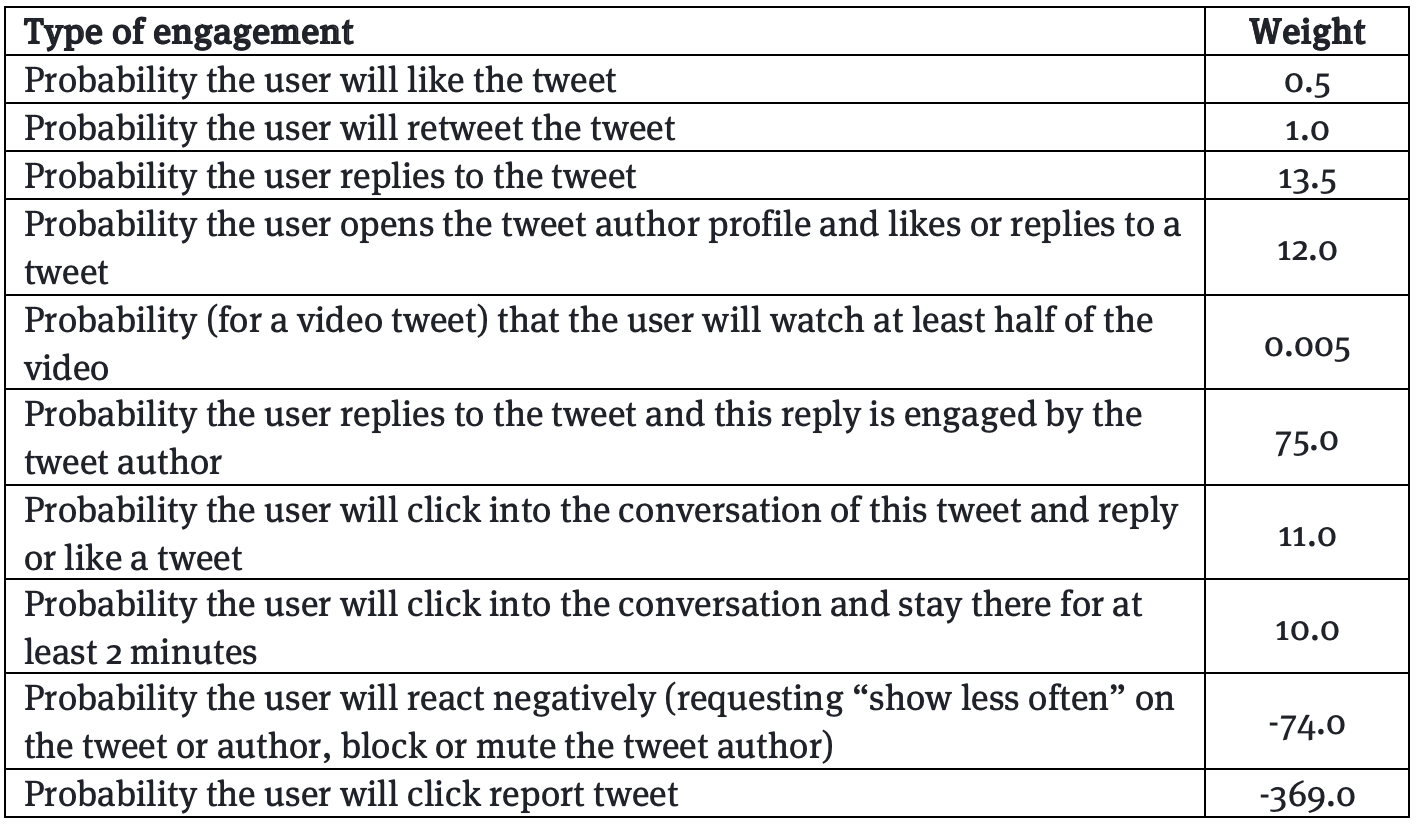
La chose la plus importante que Twitter a révélée en publiant son code, c’est la formule qui spécifie comment les différents types d’engagement (likes, retweets, réponses, etc.) sont pondérés les uns par rapport aux autres… Mais cette formule n’est pas vraiment dans le code. Elle est publiée séparément, notamment parce qu’elle n’est pas statique, mais qu’elle doit être modifiée fréquemment.
Sans surprise, le code révèle ainsi que les abonnés à Twitter Blue, ceux qui payent leur abonnement, bénéficient d’une augmentation de leur portée (ce qui n’est pas sans poser un problème de fond, comme le remarque pertinemment sur Twitter, Guillaume Champeau, car cette préférence pourrait mettre ces utilisateurs dans la position d’être annonceurs, puisqu’ils payent pour être mis en avant, sans que l’interface ne le signale clairement, autrement que par la pastille bleue). Reste que le code n’est pas clair sur l’ampleur de cette accélération. Les notes attribuées aux tweets des abonnés Blue sont multipliées par 2 ou 4, mais cela ne signifie pas que leur portée est pareillement multipliée. « Une fois encore, le code ne nous dit pas le genre de choses que nous voudrions savoir », explique Narayanan.
Reste que la publication de la formule d’engagement est un événement majeur. Elle permet de saisir le poids des réactions sur un tweet. On constate que la réponse à tweet est bien plus forte que le like ou que le RT. Et la re-réponse de l’utilisateur originel est prédominante, puisque c’est le signe d’une conversation forte. À l’inverse, le fait qu’un lecteur bloque, mute ou se désabonne d’un utilisateur suite à un tweet est un facteur extrêmement pénalisant pour la propagation du tweet.
Tableau du poids attribué en fonction des types d’engagement possibles sur Twitter.
Ces quelques indications permettent néanmoins d’apprendre certaines choses. Par exemple que Twitter ne semble pas utiliser de prédictions d’actions implicites (comme lorsqu’on s’arrête de faire défiler son fil), ce qui permet d’éviter l’amplification du contenu trash que les gens ne peuvent s’empêcher de regarder, même s’ils ne s’y engagent pas. La formule nous apprend que les retours négatifs ont un poids très élevé, ce qui permet d’améliorer son flux en montrant à l’algorithme ce dont vous ne voulez pas – même si les plateformes devraient permettre des contrôles plus explicites pour les utilisateurs. Enfin, ces poids ont des valeurs souvent précises, ce qui signifie que ce tableau n’est valable qu’à l’instant de la publication et qu’il ne sera utile que si Twitter le met à jour.
Les algorithmes de recommandation qui optimisent l’engagement suivent des modèles assez proches. La publication du code n’est donc pas très révélatrice. Trois éléments sont surtout importants, insiste le chercheur :
« Le premier est la manière dont les algorithmes sont configurés : les signaux utilisés comme entrée, la manière dont l’engagement est défini, etc. Ces informations doivent être considérées comme un élément essentiel de la transparence et peuvent être publiées indépendamment du code. La seconde concerne les modèles d’apprentissage automatique qui, malheureusement, ne peuvent généralement pas être divulgués pour des raisons de protection de la vie privée. Le troisième est la boucle de rétroaction entre les utilisateurs et l’algorithme ».
Autant d’éléments qui demandent des recherches, des expériences et du temps pour en comprendre les limites.
Si la transparence n’est pas une fin en soi, elle reste un moyen de construire un meilleur internet en améliorant la responsabilité envers les utilisateurs, rappelle l’ingénieur Gabriel Nicholaspour le Center for Democracy & Technology. Il souligne néanmoins que la publication d’une partie du code source de Twitter ne contrebalance pas la fermeture du Consortium de recherche sur la modération, ni celle des rapports de transparence relatives aux demandes de retraits des autorités ni celle de l’accès à son API pour chercheurs, devenue extrêmement coûteuse.
« Twitter n’a pas exactement ’ouvert son algorithme’ comme certains l’ont dit. Le code est lourdement expurgé et il manque plusieurs fichiers de configuration, ce qui signifie qu’il est pratiquement impossible pour un chercheur indépendant d’exécuter l’algorithme sur des échantillons ou de le tester d’une autre manière. Le code publié n’est en outre qu’un instantané du système de recommandation de Twitter et n’est pas réellement connecté au code en cours d’exécution sur ses serveurs. Cela signifie que Twitter peut apporter des modifications à son code de production et ne pas l’inclure dans son référentiel public, ou apporter des modifications au référentiel public qui ne sont pas reflétées dans son code de production. »
L’algorithme publié par Twitter est principalement son système de recommandation. Il se décompose en 3 parties, explique encore Nicholas :
Un système de génération de contenus candidats. Ici, Twitter sélectionne 1500 tweets susceptibles d’intéresser un utilisateur en prédisant la probabilité que l’utilisateur s’engage dans certaines actions pour chaque tweet (c’est-à-dire qu’il RT ou like par exemple).
Un système de classement. Une fois que les 1 500 tweets susceptibles d’être servis sont sélectionnés, ils sont notés en fonction de la probabilité des actions d’engagement, certaines actions étant pondérées plus fortement que d’autres. Les tweets les mieux notés apparaîtront généralement plus haut dans le fil d’actualité de l’utilisateur.
Un système de filtrage. Les tweets ne sont pas classés strictement en fonction de leur score. Des heuristiques et des filtres sont appliqués pour, par exemple, éviter d’afficher plusieurs tweets du même auteur ou pour déclasser les tweets d’auteurs que l’utilisateur a déjà signalés pour violation de la politique du site.
Le score final est calculé en additionnant la probabilité de chaque action multipliée par son poids (en prenant certainement en compte la rareté ou la fréquence d’action, le fait de répondre à un tweet étant moins fréquent que de lui attribuer un like). Mais Twitter n’a pas publié la probabilité de base de chacune de ces actions ce qui rend impossible de déterminer l’importance de chacune d’elles dans les recommandations qui lui sont servies.
Twitter a également révélé quelques informations sur les autres facteurs qu’il prend en compte en plus du classement total d’un tweet. Par exemple, en équilibrant les recommandations des personnes que vous suivez avec celles que vous ne suivez pas, en évitant de recommander les tweets d’un même auteur ou en donnant une forte prime aux utilisateurs payants de Twitter Blue.
Il y a aussi beaucoup de code que Twitter n’a pas partagé. Il n’a pas divulgué beaucoup d’informations sur l’algorithme de génération des tweets candidats au classement ni sur ses paramètres et ses données d’entraînement. Twitter n’a pas non plus explicitement partagé ses algorithmes de confiance et de sécurité pour détecter des éléments tels que les abus, la toxicité ou les contenus pour adultes, afin d’empêcher les gens de trouver des solutions de contournement, bien qu’il ait publié certaines des catégories de contenu qu’il signale.
« 20120212-NodeXL-Twitter-socbiz network graph » par Marc_Smith; licence CC BY 2.0.
Pour Gabriel Nicholas, la transparence de Twitter serait plus utile si Twitter avait maintenu ouverts ses outils aux chercheurs. Ce n’est pas le cas.
En conclusion de son article, Narayanan pointe vers un très intéressant article qui dresse une liste d’options de transparence pour ceux qui produisent des systèmes de recommandation, publiée par les chercheurs Priyanjana Bengani, Jonathan Stray et Luke Thorburn. Ils rappellent que les plateformes ont mis en place des mesures de transparence, allant de publications statistiques à des interfaces de programmation, en passant par des outils et des ensembles de données protégés. Mais ces mesures, très techniques, restent insuffisantes pour comprendre les algorithmes de recommandation et leur influence sur la société. Une grande partie de cette résistance à la transparence ne tient pas tant aux risques commerciaux qui pourraient être révélés qu’à éviter l’embarras d’avoir à se justifier de choix qui ne le sont pas toujours. D’une manière très pragmatique, les trois chercheurs proposent un menu d’actions pour améliorer la transparence et l’explicabilité des systèmes.
Documenter
L’un des premiers outils, et le plus simple, reste la documentation qui consiste à expliquer en termes clairs – selon différentes échelles et niveaux, me semble-t-il – ce qui est activé par une fonction. Pour les utilisateurs, c’est le cas du bouton « Pourquoi je vois ce message » de Facebook ou du panneau « Fréquemment achetés ensemble » d’Amazon. L’idée ici est de fourbir un « compte rendu honnête ». Pour les plus évoluées de ces interfaces, elles devraient permettre non seulement d’informer et d’expliquer pourquoi on nous recommande ce contenu, mais également, permettre de rectifier et mieux contrôler son expérience en ligne, c’est-à-dire d’avoir des leviers d’actions sur la recommandation.
Une autre forme de documentation est celle sur le fonctionnement général du système et ses décisions de classement, à l’image des rapports de transparence sur les questions de sécurité et d’intégrité que doivent produire la plupart des plateformes (voir celui de Google, par exemple). Cette documentation devrait intégrer des informations sur la conception des algorithmes, ce que les plateformes priorisent, minimisent et retirent, si elles donnent des priorités et à qui, tenir le journal des modifications, des nouvelles fonctionnalités, des changements de politiques. La documentation doit apporter une information solide et loyale, mais elle reste souvent insuffisante.
Les données
Pour comprendre ce qu’il se passe sur une plateforme, il est nécessaire d’obtenir des données. Twitter ou Facebook en ont publié (accessibles sous condition de recherche, ici pour Twitter, là pour Facebook). Une autre approche consiste à ouvrir des interfaces de programmation, à l’image de CrowdTangle de Facebook ou de l’API de Twitter. Depuis le scandale Cambridge Analytica, l’accès aux données est souvent devenu plus difficile, la protection de la vie privée servant parfois d’excuse aux plateformes pour éviter d’avoir à divulguer leurs pratiques. L’accès aux données, même pour la recherche, s’est beaucoup refermé ces dernières années. Les plateformes publient moins de données et CrowdTangle propose des accès toujours plus sélectifs. Chercheurs et journalistes ont été contraints de développer leurs propres outils, comme des extensions de navigateurs permettant aux utilisateurs de faire don de leurs données (à l’image du Citizen Browser de The Markup) ou des simulations automatisées (à l’image de l’analyse robotique de TikTok produite par le Wall Street Journal), que les plateformes ont plutôt eu tendance à bloquer en déniant les résultats obtenus sous prétexte d’incomplétude – ce qui est justement le problème que l’ouverture de données cherche à adresser.
Le code
L’ouverture du code des systèmes de recommandation pourrait être utile, mais elle ne suffit pas, d’abord parce que dans les systèmes de recommandation, il n’y a pas un algorithme unique. Nous sommes face à des ensembles complexes et enchevêtrés où « différents modèles d’apprentissage automatique formés sur différents ensembles de données remplissent diverses fonctions ». Même le classement ou le modèle de valeur pour déterminer le score n’explique pas tout. Ainsi, « le poids élevé sur un contenu d’un type particulier ne signifie pas nécessairement qu’un utilisateur le verra beaucoup, car l’exposition dépend de nombreux autres facteurs, notamment la quantité de ce type de contenu produite par d’autres utilisateurs. »
Peu de plateformes offrent une grande transparence au niveau du code source. Reddit a publié en 2008 son code source, mais a cessé de le mettre à jour. En l’absence de mesures de transparence, comprendre les systèmes nécessite d’écluser le travail des journalistes, des militants et des chercheurs pour tenter d’en obtenir un aperçu toujours incomplet.
La recherche
Les plateformes mènent en permanence une multitude de projets de recherche internes voire externes et testent différentes approches pour leurs systèmes de recommandation. Certains des résultats finissent par être accessibles dans des revues ou des articles soumis à des conférences ou via des fuites d’informations. Quelques efforts de partenariats entre la recherche et les plateformes ont été faits, qui restent embryonnaires et ne visent pas la transparence, mais qui offrent la possibilité à des chercheurs de mener des expériences et donc permettent de répondre à des questions de nature causale, qui ne peuvent pas être résolues uniquement par l’accès aux données.
Enfin, les audits peuvent être considérés comme un type particulier de recherche. À l’heure actuelle, il n’existe pas de bons exemples d’audits de systèmes de recommandation menés à bien. Reste que le Digital Service Act (DSA) européen autorise les audits externes, qu’ils soient lancés par l’entreprise ou dans le cadre d’une surveillance réglementaire, avec des accès élargis par rapport à ceux autorisés pour l’instant. Le DSA exige des évaluations sur le public mineur, sur la sécurité, la santé, les processus électoraux… mais ne précise ni comment ces audits doivent être réalisés ni selon quelles normes. Des méthodes spécifiques ont été avancées pour contrôler la discrimination, la polarisation et l’amplification dans les systèmes de recommandation.
En principe, on pourrait évaluer n’importe quel préjudice par des audits. Ceux-ci visent à vérifier si « la conception et le fonctionnement d’un système de recommandation respectent les meilleures pratiques et si l’entreprise fait ce qu’elle dit qu’elle fait. S’ils sont bien réalisés, les audits pourraient offrir la plupart des avantages d’un code source ouvert et d’un accès aux données des utilisateurs, sans qu’il soit nécessaire de les rendre publics. » Reste qu’il est peu probable que les audits imposés par la surveillance réglementaire couvrent tous les domaines qui préoccupent ceux qui sont confrontés aux effets des outils de recommandations.
Autres moteurs de transparence : la gouvernance et les calculs
Les chercheurs concluent en soulignant qu’il existe donc une gamme d’outils à disposition, mais qu’elle manque de règles et de bonnes pratiques partagées. Face aux obligations de transparence et de contrôles qui arrivent (pour les plus gros acteurs d’abord, mais parions que demain, elles concerneront bien d’autres acteurs), les entreprises peinent à se mettre en ordre de marche pour proposer des outillages et des productions dans ces différents secteurs qui leur permettent à la fois de se mettre en conformité et de faire progresser leurs outils. Ainsi, par exemple, dans le domaine des données, documenter les jeux et les champs de données, à défaut de publier les jeux de données, pourrait déjà permettre un net progrès. Dans le domaine de la documentation, les cartes et les registres permettent également d’expliquer ce que les calculs opèrent (en documentant par exemple leurs marges d’erreurs).
Reste que l’approche très technique que mobilisent les chercheurs oublie quelques leviers supplémentaires. Je pense notamment aux conseils de surveillance, aux conseils éthiques, aux conseils scientifiques, en passant par les organismes de contrôle indépendants, aux comités participatifs ou consultatifs d’utilisateurs… à tous les outils institutionnels, participatifs ou militants qui permettent de remettre les parties prenantes dans le contrôle des décisions que les systèmes prennent. Dans la lutte contre l’opacité des décisions, tous les leviers de gouvernance sont bons à prendre. Et ceux-ci sont de très bons moyens pour faire pression sur la transparence, comme l’expliquait très pertinemment David Robinson dans son livre Voices in the Code.
Un autre levier me semble absent de nombre de propositions… Alors qu’on ne parle que de rendre les calculs transparents, ceux-ci sont toujours absents des discussions. Or, les règles de traitements sont souvent particulièrement efficaces pour améliorer les choses. Il me semble qu’on peut esquisser au moins deux moyens pour rendre les calculs plus transparents et responsables : la minimisation et les interdictions.
La minimisation vise à rappeler qu’un bon calcul ne démultiplie pas nécessairement les critères pris en compte. Quand on regarde les calculs, bien souvent, on est stupéfait d’y trouver des critères qui ne devraient pas être pris en compte, qui n’ont pas de fondements autres que d’être rendus possibles par le calcul. Du risque de récidive au score de risque de fraude à la CAF, en passant par l’attribution de greffes ou aux systèmes de calculs des droits sociaux, on trouve toujours des éléments qui apprécient le calcul alors qu’ils n’ont aucune justification ou pertinence autres que d’être rendu possibles par le calcul ou les données. C’est le cas par exemple du questionnaire qui alimente le calcul de risque de récidive aux Etats-Unis, qui repose sur beaucoup de questions problématiques. Ou de celui du risque de fraude à la CAF, dont les anciennes versions au moins (on ne sait pas pour la plus récente) prenaient en compte par exemple le nombre de fois où les bénéficiaires se connectaient à leur espace en ligne (sur cette question, suivez les travaux de la Quadrature et de Changer de Cap). La minimisation, c’est aussi, comme l’explique l’ex-chercheur de chez Google, El Mahdi El Mhamdi, dans une excellente interview, limiter le nombre de paramètres pris en compte par les calculs et limiter l’hétérogénéité des données.
L’interdiction, elle, vise à déterminer que certains croisements ne devraient pas être autorisés, par exemple, la prise en compte des primes dans les logiciels qui calculent les données d’agenda du personnel, comme semble le faire le logiciel Orion mis en place par la Sncf, ou Isabel, le logiciel RH que Bol.com utilise pour gérer la main-d’œuvre étrangère dans ses entrepôts de logistique néerlandais. Ou encore, comme le soulignait Narayanan, le temps passé sur les contenus sur un réseau social par exemple, ou l’analyse de l’émotion dans les systèmes de recrutement (et ailleurs, tant cette technologie pose problème). A l’heure où tous les calculs sont possibles, il va être pertinent de rappeler que selon les secteurs, certains croisements doivent rester interdits parce qu’ils sont trop à risque pour être mobilisés dans le calcul ou que certains calculs ne peuvent être autorisés.
Priyanjana Bengani, Jonathan Stray et Luke Thorburn, pour en revenir à eux, notent enfin que l’exigence de transparence reste formulée en termes très généraux par les autorités réglementaires. Dans des systèmes vastes et complexes, il est difficile de savoir ce que doit signifier réellement la transparence. Pour ma part, je milite pour une transparence “projective”, active, qui permette de se projeter dans les explications, c’est-à-dire de saisir ses effets et dépasser le simple caractère narratif d’une explication loyale, mais bien de pouvoir agir et reprendre la main sur les calculs.
Coincés dans les boucles de l’amplification
Plus récemment, les trois mêmes chercheurs, passé leur article séminal, ont continué à documenter leur réflexion. Ainsi, dans « Rendre l’amplification mesurable », ils expliquent que l’amplification est souvent bien mal définie (notamment juridiquement, ils ont consacré un article entier à la question)… mais proposent d’améliorer les propriétés permettant de la définir. Ils rappellent d’abord que l’amplification est relative, elle consiste à introduire un changement par rapport à un calcul alternatif ou précédent qui va avoir un effet sans que le comportement de l’utilisateur n’ait été, lui, modifié.
L’amplification agit d’abord sur un contenu et nécessite de répondre à la question de savoir ce qui a été amplifié. Mais même dire que les fake news sont amplifiées n’est pas si simple, à défaut d’avoir une définition précise et commune des fake news qui nécessite de comprendre les classifications opérées. Ensuite, l’amplification se mesure par rapport à un point de référence précédent qui est rarement précisé. Enfin, quand l’amplification atteint son but, elle produit un résultat qui se voit dans les résultats liés à l’engagement (le nombre de fois où le contenu a été apprécié ou partagé) mais surtout ceux liés aux impressions (le nombre de fois où le contenu a été vu). Enfin, il faut saisir ce qui relève de l’algorithme et du comportement de l’utilisateur. Si les messages d’un parti politique reçoivent un nombre relativement important d’impressions, est-ce parce que l’algorithme est biaisé en faveur du parti politique en question ou parce que les gens ont tendance à s’engager davantage avec le contenu de ce parti ? Le problème, bien sûr, est de distinguer l’un de l’autre d’une manière claire, alors qu’une modification de l’algorithme entraîne également une modification du comportement de l’utilisateur. En fait, cela ne signifie pas que c’est impossible, mais que c’est difficile, expliquent les chercheurs. Cela nécessite un système d’évaluation de l’efficacité de l’algorithme et beaucoup de tests A/B pour comparer les effets des évolutions du calcul. Enfin, estiment-ils, il faut regarder les effets à long terme, car les changements dans le calcul prennent du temps à se diffuser et impliquent en retour des réactions des utilisateurs à ces changements, qui s’adaptent et réagissent aux transformations.
Dans un autre article, ils reviennent sur la difficulté à caractériser l’effet bulle de filtre des médias sociaux, notamment du fait de conceptions élastiques du phénomène. S’il y a bien des boucles de rétroaction, leur ampleur est très discutée et dépend beaucoup du contexte. Ils en appellent là encore à des mesures plus précises des phénomènes. Certes, ce que l’on fait sur les réseaux sociaux influe sur ce qui est montré, mais il est plus difficile de démontrer que ce qui est montré affecte ce que l’on pense. Il est probable que les effets médiatiques des recommandations soient faibles pour la plupart des gens et la plupart du temps, mais beaucoup plus importants pour quelques individus ou sous-groupes relativement à certaines questions ou enjeux. De plus, il est probable que changer nos façons de penser ne résulte pas d’une exposition ponctuelle, mais d’une exposition à des récits et des thèmes récurrents, cumulatifs et à long terme. Enfin, si les gens ont tendance à s’intéresser davantage à l’information si elle est cohérente avec leur pensée existante, il reste à savoir si ce que l’on pense affecte ce à quoi l’on s’engage. Mais cela est plus difficile à mesurer car cela suppose de savoir ce que les gens pensent et pas seulement constater leurs comportements en ligne. En général, les études montrent plutôt que l’exposition sélective a peu d’effets. Il est probable cependant que là encore, l’exposition sélective soit faible en moyenne, mais plus forte pour certains sous-groupes de personnes en fonction des contextes, des types d’informations.
Bref, là encore, les effets des réseaux sociaux sont difficiles à percer.
Pour comprendre les effets de l’amplification algorithmique, peut-être faut-il aller plus avant dans la compréhension que nous avons des évolutions de celle-ci, afin de mieux saisir ce que nous voulons vraiment savoir. C’est ce que nous tenterons de faire dans la suite de cet article…
Infrastructures numériques de communication pour les anarchistes (et tous les autres…)
Des moyens sûrs de communiquer à l’abri de la surveillance ? Évitons l’illusion de la confidentialité absolue et examinons les points forts et limites des applications…
PRÉAMBULE
Nous avons des adversaires, ils sont nombreux. Depuis la première diffusion de Pretty Good Privacy (PGP) en 1991 par Philip Zimmermann, nombreuses furent les autorités publiques ou organisations privées à s’inquiéter du fait que des individus puissent échanger des messages rigoureusement indéchiffrables en vertu de lois mathématiques (c’est moins vrai avec les innovations en calculateurs quantiques). Depuis lors, les craintes ne cessèrent d’alimenter l’imaginaire du bloc réactionnaire.
On a tout envisagé, surtout en se servant de la lutte contre le terrorisme et la pédopornographie, pour mieux faire le procès d’intention des réseaux militants, activistes, anarchistes. Jusqu’au jour où les révélations d’E. Snowden (et bien d’autres à la suite) montrèrent à quel point la vie privée était menacée (elle l’est depuis 50 ans de capitalisme de surveillance), d’autant plus que les outils de communication des multinationales du numérique sont largement utilisés par les populations.
Les libertariens s’enivrèrent de cette soif de protection de nos correspondances. Ils y voyaient (et c’est toujours le cas) un point d’ancrage de leur idéologie capitaliste, promouvant une « liberté » contre l’État mais de fait soumise aux logiques débridées du marché. Dès lors, ceux qu’on appelle les crypto-anarchistes, firent feu de ce bois, en connectant un goût certain pour le solutionnisme technologique (blockchain et compagnie) et un modèle individualiste de communication entièrement chiffré où les crypto-monnaies remplissent le rôle central dans ce marché prétendu libre, mais ô combien producteur d’inégalités.
Alimentant le mélange des genres, certains analystes, encore très récemment, confondent allègrement les anarchistes et les crypto-anarchistes, pour mieux dénigrer l’importance que nous accordons à la légitimité sociale, solidaire et égalitaire des protocoles de communication basés sur le chiffrement. Or, ce sont autant de moyens d’expression et de mobilisation démocratique et ils occupent une place centrale dans les conditions de mobilisation politique.
Les groupes anarchistes figurent parmi les plus concernés, surtout parce que les logiques d’action et les idées qui y sont partagées sont de plus en plus insupportables aux yeux des gouvernements, qu’il s’agisse de dictatures, d’illibéralisme, ou de néofascisme. Pour ces adversaires, le simple fait d’utiliser des communications chiffrées (sauf quand il s’agit de protéger leurs corruptions et leurs perversions) est une activité suspecte. Viennent alors les moyens de coercition, de surveillance et de contrôle, la technopolice. Dans cette lutte qui semble sans fin, il faut néanmoins faire preuve de pondération autant que d’analyse critique. Bien souvent on se précipite sur des outils apparemment sûrs mais peu résilients. Gratter la couche d’incertitude ne consiste pas à décourager l’usage de ces outils mais montrer combien leur usage ne fait pas l’économie de mises en garde.
Dans le texte qui suit, issu de la plateforme d’information et de médias It’s Going Down, l’auteur prend le parti de la prévention. Par exemple, ce n’est pas parce que le créateur du protocole Signal et co-fondateur de la Signal Foundation est aussi un anarchiste (quoique assez individualiste) que l’utilisation de Signal est un moyen fiable de communication pour un groupe anarchiste ou plus simplement militant. La convivialité d’un tel outil est certes nécessaire pour son adoption, mais on doit toujours se demander ce qui a été sacrifié en termes de failles de sécurité. Le même questionnement doit être adressé à tous les autres outils de communication chiffrée.
C’est à cette lourde tâche que s’attelle l’auteur de ce texte, et il ne faudra pas lui tenir rigueur de l’absence de certains protocoles tels Matrix ou XMPP. Certes, on ne peut pas aborder tous les sujets, mais il faut aussi lire cet article d’après l’expérience personnelle de l’auteur. Si Signal et Briar sont les objets centraux de ses préoccupations, son travail cherche surtout à produire une vulgarisation de concepts difficiles d’accès. C’est aussi l’occasion d’une mise au point actuelle sur nos rapports aux outils de communication chiffrée et la manière dont ces techniques et leurs choix conditionnent nos communications. On n’oubliera pas son message conclusif, fort simple : lorsqu’on le peut, mieux vaut éteindre son téléphone et rencontrer ses amis pour de vrai…
Framatophe / Christophe Masutti
Pour lire le document (50 pages) qui suit hors-connexion, ou pour l’imprimer, voici quatre liens de téléchargement :
Format .EPUB (3 Mo)Impression format A4 imposé .PDF (2 Mo)Impression format Letter imposé .PDF (2 Mo)Lecture simple .PDF (2 Mo)
Infrastructures numériques de communication pour les anarchistes
(et tous les autres…)
Un aperçu détaillé et un guide des diverses applications qui utilisent le pair-à-pair, le chiffrement et Tor
Les applications de chat sécurisées avec chiffrement constituent une infrastructure numérique essentielle pour les anarchistes. Elles doivent donc être examinées de près. Signal est un outil de chiffrement sécurisé très utilisé par les anarchistes aujourd’hui. Au-delà des rumeurs complotistes, l’architecture de base et les objectifs de développement de Signal présentent certaines implications en termes de sécurité pour les anarchistes. Signal est un service de communication centralisé. La centralisation peut avoir des conséquences sur la sécurité, en particulier lorsque elle est mise en perspective avec l’éventail des menaces. D’autres applications de chat sécurisées, comme Briar et Cwtch, sont des outils de communication pair-à-pair qui, en plus d’être chiffrés comme Signal, font transiter tout le trafic par Tor (appelé aussi CPT pour communication Chiffrée en Pair-à-pair via Tor). Cette conception de communication sécurisée offre de grands avantages en termes de sécurité, d’anonymat et de respect de la vie privée, par rapport à des services plus courants tels que Signal, malgré quelques réserves. Cependant, les anarchistes devraient sérieusement envisager d’essayer et d’utiliser Briar et/ou Cwtch, pour pouvoir former une infrastructure de communication plus résiliente et plus sûre.
Malgré tout, la meilleure façon de communiquer en toute sécurité demeure le face à face.
Chhhhuuut…
Il est ici question des outils numériques qui permettent de communiquer en toute sécurité et en toute confidentialité. Pour bien commencer, il s’agit d’insister sur le fait que le moyen le plus sûr de communiquer reste une rencontre en face à face, à l’abri des caméras et hors de portée sonore d’autres personnes et appareils. Les anarchistes se promenaient pour discuter bien avant que les textos chiffrés n’existent, et ils devraient continuer à le faire aujourd’hui, à chaque fois que c’est possible.
Ceci étant dit, il est indéniable que les outils de communication numérique sécurisés font maintenant partie de notre infrastructure anarchiste. Peut-être que nous sommes nombreux à nous appuyer sur eux plus que nous ne le devrions, mais ils sont devenus incontournables pour se coordonner, collaborer et rester en contact. Puisque ces outils constituent une infrastructure indispensable, il est vital pour nous d’examiner et réévaluer constamment leur sécurité et leur aptitude à protéger nos communications contre nos adversaires.
Au cours des dix ou vingt dernières années, les anarchistes ont été les premiers à adopter ces outils et ces techniques de communication chiffrée. Ils ont joué un rôle majeur dans la banalisation et la diffusion de leur utilisation au sein de nos propres communautés, ou auprès d’autres communautés engagées dans la résistance et la lutte. Le texte qui suit a pour but de présenter aux anarchistes les nouveaux outils de communication chiffrée et sécurisée. Il s’agit de démontrer que nous devrions les adopter afin de renforcer la résilience et l’autonomie de notre infrastructure. Nous pouvons étudier les avantages de ces nouvelles applications, voir comment elles peuvent nous aider à échapper à la surveillance et à la répression – et par la suite les utiliser efficacement dans nos mouvements et les promouvoir plus largement.
Le plus simple est de présenter les nouvelles applications de chat sécurisé en les comparant avec celle que tout le monde connaît : Signal. Signal est de facto l’infrastructure de communication sécurisée de beaucoup d’utilisatrices, du moins en Amérique du Nord. Et de plus en plus, elle devient omniprésente en dehors des cercles anarchistes. Si vous lisez ceci, vous utilisez probablement Signal, et il y a de fortes chances que votre mère ou qu’un collègue de travail l’utilise également. L’utilisation de Signal a explosé en janvier 2021 (à tel point que le service a été interrompu pendant 24 heures), atteignant 40 millions d’utilisateurs quotidiens. Signal permet aux utilisateurs d’échanger très facilement des messages chiffrés. Il est issu d’un projet antérieur appelé TextSecure, qui permettait de chiffrer les messages SMS (les textos à l’ancienne, pour les baby zoomers qui nous lisent). TextSecure, et plus tard Signal, ont très tôt bénéficié de la confiance des anarchistes, en grande partie grâce au réseau de confiance IRL entre le développeur principal, Moxie Marlinspike, et d’autres anarchistes.
Au début de l’année 2022, Moxie a quitté Signal, ce qui a déclenché une nouvelle vague de propos alarmistes à tendance complotiste. Le PDG anarchiste de Signal a démissionné. Signal est neutralisé. Un article intitulé « Signal Warning », publié sur It’s Going Down, a tenté de dissiper ces inquiétudes et ces hypothèses complotistes, tout en discutant de la question de savoir si les anarchistes peuvent encore « faire confiance » à Signal (ils le peuvent, avec des mises en garde comme toujours). L’article a réitéré les raisons pour lesquelles Signal est, en fait, tout à fait sûr et digne de confiance (il est minutieusement audité et examiné par des experts en sécurité).
Cependant, l’article a laissé entendre que le départ de Moxie établissait, à tout le moins, une piqûre de rappel sur la nécessité d’un examen critique et sceptique permanent de Signal, et qu’il en va de même pour tout outil ou logiciel tiers utilisé par les anarchistes.
« Maintenant que la couche de vernis est enlevée, notre capacité à analyser Signal et à évaluer son utilisation dans nos milieux peut s’affranchir des distorsions que la confiance peut parfois engendrer. Nous devons désormais considérer l’application et son protocole sous-jacent tels qu’ils sont : un code utilisé dans un ordinateur, avec tous les avantages et les inconvénients que cela comporte. On en est encore loin, et, à ce jour, on ne va même pas dans cette direction. Mais, comme tous les systèmes techniques, nous devons les aborder de manière sceptique et rationnelle »
Signal continue de jouir d’une grande confiance, et aucune contre-indication irréfutable n’a encore été apportée en ce qui concerne la sécurité de Signal. Ce qui suit n’est pas un appel à abandonner Signal – Signal reste un excellent outil. Mais, étant donné son rôle prépondérant dans l’infrastructure anarchiste et l’intérêt renouvelé pour la question de savoir si nous pouvons ou devons faire confiance à Signal, nous pouvons profiter de cette occasion pour examiner de près l’application, son fonctionnement, la manière dont nous l’utilisons, et explorer les alternatives. Un examen minutieux de Signal ne révèle pas de portes dérobées secrètes (backdoors), ni de vulnérabilités béantes. Mais il révèle une priorité donnée à l’expérience utilisateur et à la rationalisation du développement par rapport aux objectifs de sécurité les plus solides. Les objectifs et les caractéristiques du projet Signal ne correspondent peut-être pas exactement à notre modèle de menace. Et en raison du fonctionnement structurel de Signal, les anarchistes dépendent d’un service centralisé pour l’essentiel de leurs communications sécurisées en ligne. Cela a des conséquences sur la sécurité, la vie privée et la fiabilité.
Il existe toutefois des alternatives développées en grande partie pour répondre spécifiquement à ces problèmes. Briar et Cwtch sont deux nouvelles applications de chat sécurisé qui, comme Signal, permettent également l’échange de messages chiffrés. Elles sont en apparence très proches de Signal, mais leur fonctionnement est très différent. Alors que Signal est un service de messagerie chiffrée, Briar et Cwtch sont des applications qui permettent l’échange de messages Chiffrés et en Pair-à-pair via Tor (CPT). Ces applications CPT et leur fonctionnement seront présentés en détail. Mais la meilleure façon d’expliquer leurs avantages (et pourquoi les anarchistes devraient s’intéresser à d’autres applications de chat sécurisées alors que nous avons déjà Signal) passe par une analyse critique approfondie de Signal.
Modèle de menace et avertissements
Avant d’entrer dans le vif du sujet, il est important de replacer cette discussion dans son contexte en définissant un modèle de menace pertinent. Dans le cadre de cette discussion, nos adversaires sont les forces de l’ordre au niveau national ou bien les forces de l’ordre locales qui ont un accès aux outils des forces de l’ordre nationale. Malgré le chiffrement de bout en bout qui dissimule le contenu des messages en transit, ces adversaires disposent de nombreuses ressources qui pourraient être utilisées pour découvrir ou perturber nos activités, nos communications ou nos réseaux afin de pouvoir nous réprimer. Il s’agit des ressources suivantes :
Ils ont un accès facile aux sites de médias sociaux et à toutes autres informations publiques.
Dans certains cas, ils peuvent surveiller l’ensemble du trafic internet du domicile d’une personne ciblée ou de son téléphone.
Ils peuvent accéder à des données ou à des métadonnées « anonymisées » qui proviennent d’applications, d’opérateurs de téléphonique, de fournisseurs d’accès à Internet, etc.
Ils peuvent accéder au trafic réseau collecté en masse à partir des nombreux goulots d’étranglement de l’infrastructure internet.
Avec plus ou moins de succès, ils peuvent combiner, analyser et corréler ces données et ce trafic réseau afin de désanonymiser les utilisateurs, de cartographier les réseaux sociaux ou de révéler d’autres informations potentiellement sensibles sur des individus ou des groupes et sur leurs communications.
Ils peuvent compromettre l’infrastructure de l’internet (FAI, fournisseurs de services, entreprises, développeurs d’applications) par la coercition ou le piratage1.
Le présent guide vise à atténuer les capacités susmentionnées de ces adversaires, mais il en existe bien d’autres qui ne peuvent pas être abordées ici :
Ils peuvent infecter à distance les appareils des personnes ciblées avec des logiciels malveillants d’enregistrement de frappe au clavier et de pistage, dans des cas extrêmes.
Ils peuvent accéder à des communications chiffrées par l’intermédiaire d’informateurs confidentiels ou d’agents infiltrés.
Ils peuvent exercer de fortes pressions ou recourir à la torture pour contraindre des personnes à déverrouiller leur téléphone ou leur ordinateur ou à donner leurs mots de passe.
Bien qu’ils ne puissent pas casser un système de chiffrement robuste dans un délai raisonnable, ils peuvent, en cas de saisie, être en mesure d’obtenir des données à partir d’appareils apparemment chiffrés grâce à d’autres vulnérabilités (par exemple, dans le système d’exploitation de l’appareil) ou de défaillances de la sécurité opérationnelle.
Toute méthode de communication sécurisée dépend fortement des pratiques de sécurité de l’utilisateur. Peu importe que vous utilisiez l’Application de Chat Sécurisée Préférée d’Edward SnowdenTM si votre adversaire a installé un enregistreur de frappe sur votre téléphone, ou si quelqu’un partage des captures d’écran de vos messages chiffrés sur Twitter, ou encore si votre téléphone a été saisi et n’est pas correctement sécurisé.
Une explication détaillée de la sécurité opérationnelle, de la culture de la sécurité, des concepts connexes et des meilleures pratiques dépasse le cadre de ce texte – cette analyse n’est qu’une partie de la sécurité opérationnelle pertinente pour le modèle de menace concerné. Vous devez envisager une politique générale de sécurité pour vous protéger contre la menace des infiltrés et des informateurs. Comment utiliser en toute sécurité des appareils, comme les téléphones et les ordinateurs portables, pour qu’ils ne puissent pas servir à monter un dossier s’ils sont saisis, et comment adopter des bonnes habitudes pour réduire au minimum les données qui se retrouvent sur les appareils électroniques (rencontrez-vous face à face et laissez votre téléphone à la maison !)
La « cybersécurité » évolue rapidement : il y a une guerre d’usure entre les menaces et les développeurs d’applications. Les informations fournies ici seront peut-être obsolètes au moment où vous lirez ces lignes. Les caractéristiques ou la mise en œuvre des applications peuvent changer, qui invalident partiellement certains des arguments avancés ici (ou qui les renforcent). Si la sécurité de vos communications électroniques est cruciale pour votre sécurité, vous ne devriez pas vous croire sur parole n’importe quelle recommandation, ici ou ailleurs.
Perte de Signal
Vous avez probablement utilisé Signal aujourd’hui. Et Signal ne pose pas vraiment de gros problèmes. Il est important de préciser que malgré les critiques qui suivent, l’objectif n’est pas d’inciter à la panique quant à l’utilisation de Signal. Il ne s’agit pas de supprimer l’application immédiatement, de brûler votre téléphone et de vous enfuir dans les bois. Cela dit, peut-être pourriez-vous le faire pour votre santé mentale, mais en tout cas pas seulement à cause de ce guide. Vous pourriez envisager de faire une petite randonnée au préalable.
Une parenthèse pour répondre à certaines idées complotistes
Une rapide recherche sur DuckDuckGo (ou peut-être une recherche sur Twitter ? Je ne saurais dire) avec les termes « Signal CIA », donnera lieu à de nombreuses désinformations et théories complotistes à propos de Signal. Compte tenu de la nature déjà critique de ce guide et de l’importance d’avoir un avis nuancé, penchons-nous un peu sur ces théories.
La plus répandue nous dit que Signal aurait été développé secrètement par la CIA et qu’il serait donc backdoorisé. Par conséquent, la CIA (ou parfois la NSA) aurait la possibilité d’accéder facilement à tout ce que vous dites sur Signal en passant par leur porte dérobée secrète.
« L’étincelle de vérité qui a embrasé cette théorie complotiste est la suivante : entre 2013 et 2016, les développeurs de Signal ont reçu un peu moins de 3 millions de dollars américains de financement de la part de l’Open Technology Fund (OTF). L’OTF était à l’origine un programme de Radio Free Asia, supervisé par l’Agence américaine pour les médias mondiaux (U. S. Agency for Global Media, USAGM – depuis 2019, l’OTF est directement financé par l’USAGM). L’USAGM est une « agence indépendante du gouvernement américain », qui promeut les intérêts nationaux des États-Unis à l’échelle internationale et qui est financée et gérée directement par le gouvernement américain. Donc ce dernier gère et finance USAGM/Radio Free Asia, qui finance l’OTF, qui a financé le développement de Signal (et Hillary Clinton était secrétaire d’État à l’époque !!) : c’est donc la CIA qui aurait créé Signal… »
L’USAGM (et tous ses projets tels que Radio Free Asia et l’OTF) promeut les intérêts nationaux américains en sapant ou en perturbant les gouvernements avec lesquels les États-Unis sont en concurrence ou en conflit. Outre la promotion de contre-feux médiatiques (via le soutien à une « presse libre et indépendante » dans ces pays), cela implique également la production d’outils pouvant être utilisés pour contourner la censure et résister aux « régimes oppressifs ».
Les bénéficiaires de la FTO sont connus et ce n’est un secret pour personne que l’objectif affiché de la FTO consiste à créer des outils pour subvertir les régimes qui s’appuient fortement sur la répression en ligne, sur la surveillance généralisée et sur la censure massive de l’internet pour se maintenir au pouvoir (et que ces régimes sont ceux dont le gouvernement américain n’est pas fan). Comment et pourquoi cela se produit en relation avec des projets tels que Signal est clairement rapporté par des médias grand public tels que le Wall Street Journal. Des médias comme RT rapportent également ces mêmes informations hors contexte et en les embellissant de manière sensationnelle, ce qui conduit à ces théories complotistes.
Illustration 2: Le journaliste Kit Klarenburg se plaît à produire des articles farfelus sur Signal pour des médias tels que RT.
Signal est un logiciel open source, ce qui signifie que l’ensemble de son code est vérifié et examiné par des experts. C’est l’application-phare où tout le monde cherche une porte dérobée de la CIA. Or, en ce qui concerne la surveillance de masse, il est plus facile et plus efficace pour nos adversaires de dissimuler des dispositifs de surveillance dans des applications et des infrastructures internet fermées et couramment utilisées, avec la coopération d’entreprises complices. Et en termes de surveillance ciblée, il est plus facile d’installer des logiciels malveillants sur votre téléphone.
De nombreux projets de logiciels open-source, comme Signal, ont été financés par des moyens similaires. La FTO finance ou a financé de nombreux autres projets dont vous avez peut-être entendu parler : Tor (au sujet duquel il existe des théories complotistes similaires), K-9 Mail, NoScript, F-Droid, Certbot et Tails (qui compte des anarchistes parmi ses développeurs).
Ces financements sont toujours révélés de manière transparente. Il suffit de consulter la page des sponsors de Tails, où l’on peut voir que l’OTF est un ancien sponsor (et que son principal sponsor actuel est… le département d’État des États-Unis !) Les deux applications CPT dont il est question dans ce guide sont en partie financées par des sources similaires.
On peut débattre sans fin sur les sources de financement des projets open source qui renforcent la protection de la vie privée ou la résistance à la surveillance : conflits d’intérêts, éthique, crédibilité, développement de tels outils dans un contexte de géopolitique néolibérale… Il est bon de faire preuve de scepticisme et de critiquer la manière dont les projets sont financés, mais cela ne doit pas nous conduire à des théories complotistes qui obscurcissent les discussions sur leur sécurité dans la pratique. Signal a été financé par de nombreuses sources « douteuses » : le développement initial de Signal a été financé par la vente du projet précurseur (TextSecure) à Twitter, pour un montant inconnu. Plus récemment, Signal a bénéficié d’un prêt de 50 millions de dollars à taux zéro de la part du fondateur de WhatsApp, qui est aujourd’hui directeur général de la Signal Foundation. Il existe de nombreuses preuves valables qui expliquent pourquoi et comment Signal a été financé par une initiative des États-Unis visant à dominer le monde, mais elles ne suggèrent ni n’impliquent d’aucune façon l’existence d’une porte dérobée, impossible à dissimuler, conçue par la CIA pour cibler les utilisatrices de Signal.
– Alors, Signal c’est bien, en fait ?
Si Signal n’est pas une opération secrète de la CIA, alors tout va bien, non ? Les protocoles de chiffrement de Signal sont communément considérés comme sûrs. En outre, Signal a l’habitude d’améliorer ses fonctionnalités et de remédier aux vulnérabilités en temps voulu, de manière transparente. Signal a réussi à rendre les discussions chiffrées de bout en bout suffisamment faciles pour devenir populaires. L’adoption généralisée de Signal est très certainement une bonne chose.
Thèses complotistes mises à part, les anarchistes ont toutefois de bonnes raisons d’être sceptiques à l’égard de Signal. Pendant le développement de Signal, Moxie a adopté une approche quelque peu dogmatique à l’égard de nombreux choix structurels et d’ingénierie logicielle. Ces décisions ont été prises intentionnellement (comme expliqué dans des articles de blog, lors de conférences ou dans divers fils de discussion sur GitHub) afin de faciliter l’adoption généralisée de Signal Messenger parmi les utilisateurs les moins avertis, mais aussi pour préparer la croissance du projet à long terme, et ainsi permettre une évolution rationalisée tout en ajoutant de nouvelles fonctionnalités.
Les adeptes de la cybersécurité en ligne ont longtemps critiqué ces décisions comme étant des compromis qui sacrifient la sécurité, la vie privée ou l’anonymat de l’utilisateur au profit des propres objectifs de Moxie pour Signal. S’aventurer trop loin risquerait de nous entraîner sur le terrain des débats dominés par les mâles prétentieux du logiciel libre (si ce n’est pas déjà le cas). Pour être bref, les justifications de Moxie se résument à maintenir la compétitivité de Signal dans l’écosystème capitaliste de la Silicon Valley, axé sur le profit. Mise à part les stratégies de développement logiciel dans le cadre du capitalisme moderne, les caractéristiques concrètes de Signal les plus souvent critiquées sont les suivantes :
Signal s’appuie sur une infrastructure de serveurs centralisée.
Signal exige que chaque compte soit lié à un numéro de téléphone.
Signal dispose d’un système de paiement en crypto-monnaie intégré.
Peut-être que Moxie a eu raison et que ses compromis en valaient la peine : aujourd’hui, Signal est extrêmement populaire, l’application s’est massivement développée avec un minimum de problèmes de croissance, de nombreuses nouvelles fonctionnalités (à la fois pour la convivialité et la sécurité) ont été facilement introduites, et elle semble être durable dans un avenir prévisible2. Mais l’omniprésence de Signal en tant qu’infrastructure anarchiste exige un examen minutieux de ces critiques, en particulier lorsqu’elles s’appliquent à nos cas d’utilisation et à notre modèle de menace dans un monde en mutation. Cet examen permettra d’expliquer comment les applications CPT comme Briar et Cwtch, qui utilisent une approche complètement différente de la communication sécurisée, nous apportent potentiellement plus de résilience et de sécurité.
Signal en tant que service centralisé
Signal est moins une application qu’un service. Signal (Open Whisper Systems/The Signal Foundation) fournit l’application Signal (que vous pouvez télécharger et exécuter sur votre téléphone ou votre ordinateur) et gère un serveur Signal3. L’application Signal ne peut rien faire en soi. Le serveur Signal fournit la couche de service en traitant et en relayant tous les messages envoyés et reçus via l’application Signal. C’est ainsi que fonctionnent la plupart des applications de chat. Discord, WhatsApp, iMessage, Instagram/Facebook Messenger et Twitter dms sont tous des services de communication centralisés, où vous exécutez une application sur votre appareil et où un serveur centralisé, exploité par un tiers, relaie les messages entre les individus. Une telle centralisation présente de nombreux avantages pour l’utilisateur : vous pouvez synchroniser vos messages et votre profil sur le serveur pour y accéder sur différents appareils ; vous pouvez envoyer un message à votre ami même s’il n’est pas en ligne et le serveur stockera le message jusqu’à ce que votre ami se connecte et le récupère ; les discussions de groupe entre plusieurs utilisateurs fonctionnent parfaitement, même si les utilisateurs sont en ligne ou hors ligne à des moments différents.
Signal utilise le chiffrement de bout en bout, ce qui signifie que le serveur Signal ne peut lire aucun de vos messages. Mais qu’il soit un service de communication centralisé a de nombreuses implications importantes en termes de sécurité et de fiabilité.
Le bureau de poste de Signal
Signal-en-tant-que-service est comparable à un service postal. Il s’agit d’un très bon service postal, comme il en existe peut-être quelque part en Europe. Dans cet exemple, le serveur Signal est un bureau de poste. Vous écrivez une lettre à votre ami et la scellez dans une enveloppe avec une adresse (disons que personne d’autre que votre ami ne peut ouvrir l’enveloppe – c’est le chiffrement). À votre convenance, vous déposez toutes les lettres que vous envoyez au bureau de poste Signal, où elles sont triées et envoyées aux différents amis auxquels elles sont destinées. Si un ami n’est pas là, pas de problème ! Le bureau de poste Signal conservera la lettre jusqu’à ce qu’il trouve votre ami à la maison, ou votre ami peut simplement la récupérer au bureau de poste le plus proche. Le bureau de poste Signal est vraiment bien (c’est l’Europe, hein !) et vous permet même de faire suivre votre courrier partout où vous souhaitez le recevoir.
Peut-être aurez-vous remarqué qu’un problème de sécurité potentiel se pose sur le fait de confier tout son courrier au bureau de poste Signal. Les enveloppes scellées signifient qu’aucun facteur ou employé ne peut lire vos lettres (le chiffrement les empêche d’ouvrir les enveloppes). Mais celles et ceux qui côtoient régulièrement leur facteur savent qu’il peut en apprendre beaucoup sur vous, simplement en traitant votre courrier : il sait de qui vous recevez des lettres, il connaît tous vos abonnements à des magazines, mais aussi quand vous êtes à la maison ou non, tous les différents endroits où vous faites suivre votre courrier et toutes les choses embarrassantes que vous commandez en ligne. C’est le problème d’un service centralisé qui s’occupe de tout votre courrier – je veux dire de vos messages !
Les métadonnées, c’est pour toujours
Les informations que tous les employés du bureau de poste Signal connaissent sur vous et votre courrier sont des métadonnées. Les métadonnées sont des données… sur les données. Elles peuvent inclure des éléments tels que l’expéditeur et le destinataire d’un message, l’heure à laquelle il a été envoyé et le lieu où il a été distribué. Tout le trafic sur Internet génère intrinsèquement ce type de métadonnées. Les serveurs centralisés constituent un point d’entrée facile pour observer ou collecter toutes ces métadonnées, puisque tous les messages passent par un point unique. Il convient de souligner que l’exemple ci-dessus du bureau de poste Signal n’est qu’une métaphore pour illustrer ce que sont les métadonnées et pourquoi elles constituent une préoccupation importante pour les services de communication centralisés. Signal est en fait extrêmement doué pour minimiser ou masquer les métadonnées. Grâce à la magie noire du chiffrement et à une conception intelligente du logiciel, il y a très peu de métadonnées auxquelles le serveur Signal peut facilement accéder. Selon les propres termes de Signal :
« Les éléments que nous ne stockons pas comprennent tout ce qui concerne les contacts d’un utilisateur (tels que les contacts eux-mêmes, un hachage des contacts, ou toute autre information dérivée sur les contacts), tout ce qui concerne les groupes d’un utilisateur (les groupes auxquels il appartient, leur nombre, les listes de membres des groupes, etc.), ou tout enregistrement des personnes avec lesquelles un utilisateur a communiqué. »
Il n’existe que deux parties de métadonnées connues pour être stockées de manière persistante, et qui permettent de savoir :
si un numéro de téléphone est enregistré auprès d’un compte Signal
la dernière fois qu’un compte Signal a été connecté au serveur.
C’est une bonne chose ! En théorie, c’est tout ce qu’un employé curieux du bureau de poste Signal peut savoir sur vous. Mais cela est dû, en partie, à l’approche « Moi, je ne le vois pas » du serveur lui-même. Dans une certaine mesure, nous devons croire sur parole ce que le serveur Signal prétend faire…
Bien obligés de faire confiance
Tout comme l’application Signal sur votre téléphone ou votre ordinateur, le serveur Signal est également basé sur du code principalement4 open source. Il est donc soumis à des contrôles similaires par des experts en sécurité. Cependant, il y a une réalité importante et inévitable à prendre en compte : nous sommes obligés de croire que le serveur de Signal exécute effectivement le même code open source que celui qui est partagé avec nous. Il s’agit là d’un problème fondamental lorsque l’on se fie à un serveur centralisé géré par une tierce partie.
« Nous ne collectons ni ne stockons aucune information sensible sur nos utilisateurs, et cela ne changera jamais. » (blog de Signal)
En tant que grande association à but non lucratif, Signal ne peut pas systématiquement se soustraire aux ordonnances ou aux citations à comparaître qui concerne les données d’utilisateurs. Signal dispose même d’une page sur son site web qui énumère plusieurs citations à comparaître et les réponses qu’elle y a apportées. Mais rappelons-nous des deux types de métadonnées stockées par le serveur Signal qui peuvent être divulguées :
Illustration 3: Les réponses de Signal indiquent la date de la dernière connexion, la date de création du compte et le numéro de téléphone (caviardé)
À l’heure où nous écrivons ces lignes, il n’y a aucune raison de douter de ce qui a été divulgué, mais il faut noter que Signal se conforme également à des procédures-bâillon qui l’empêchent de révéler qu’elle a reçu une citation à comparaître ou un mandat. Historiquement, Signal se bat contre ces injonctions, mais nous ne pouvons savoir ce qui nous est inconnu, notamment car Signal n’emploie pas de warrant canary, ces alertes en creux qui annoncent aux utilisateurs qu’aucun mandat spécifique n’a été émis pour le moment [une manière détournée d’annoncer des mandats dans le cas où cette annonce disparaisse, NDLR]. Il n’y a aucune raison sérieuse de penser que Signal a coopéré avec les autorités plus fréquemment qu’elle ne le prétend, mais il y a trois scénarios à envisager :
Des modifications de la loi pourraient contraindre Signal, sur demande, à collecter et à divulguer davantage d’informations sur ses utilisateurs et ce, à l’insu du public.
Signal pourrait être convaincu par des arguments éthiques, moraux, politiques ou patriotiques de coopérer secrètement avec des adversaires.
Signal pourrait être infiltré ou piraté par ces adversaires afin de collecter secrètement davantage de données sur les utilisateurs ou afin que le peu de métadonnées disponibles puissent leur être plus facilement transmis.
Tous ces scénarios sont concevables, ils ont des précédents historiques ailleurs, mais ils ne sont pas forcément probables ni vraisemblables. En raison de la « magie noire du chiffrement » susmentionnée et de la complexité des protocoles des réseaux, même si le serveur Signal se retrouvait altéré pour devenir malveillant, il y aurait toujours une limite à la quantité de métadonnées qui peuvent être collectées sans que les utilisatrices ou les observateurs ne s’en aperçoivent. Cela n’équivaudrait pas, par exemple, à ce que le bureau de poste Signal laisse entrer un espion (par une véritable « porte dérobée installée par la CIA ») qui viendrait lire et enregistrer toutes les métadonnées de chaque message qui passe par ce bureau. Des changements dans les procédures et le code pourraient avoir pour conséquence que des quantités faibles, mais toujours plus importantes de métadonnées (ou autres informations), deviennent facilement disponibles pour des adversaires, et cela pourrait se produire sans que nous en soyons conscients. Il n’y a pas de raison particulière de se méfier du serveur Signal à ce stade, mais les anarchistes doivent évaluer la confiance qu’ils accordent à un tiers, même s’il est historiquement digne de confiance comme Signal.
Illustration 4: Intelligence Community Comprehensive National Initiative Data Center (Utah)
Mégadonnées
De nombreux et puissants ennemis sont capables d’intercepter et de stocker des quantités massives de trafic sur Internet. Il peut s’agir du contenu de messages non chiffré, mais avec l’utilisation généralisée du chiffrement, ce sont surtout des métadonnées et l’activité internet de chacun qui sont ainsi capturées et stockées.
Nous pouvons choisir de croire que Signal n’aide pas activement nos adversaires à collecter des métadonnées sur les communications des utilisateurs et utilisatrices, mais nos adversaires disposent de nombreux autres moyens pour collecter ces données : la coopération avec des entreprises comme Amazon ou Google (Signal est actuellement hébergé par Amazon Web Services), ou bien en ciblant ces hébergeurs sans leur accord, ou tout simplement en surveillant le trafic internet à grande échelle.
Les métadonnées relatives aux activités en ligne sont également de plus en plus accessibles à des adversaires moins puissants, ceux qui peuvent les acheter, sous forme brute ou déjà analysées, à des courtiers de données, qui à leur tour les achètent ou les acquièrent via des sociétés spécialisées dans le développement d’applications ou les fournisseurs de téléphones portables.
Les métadonnées ainsi collectées donnent lieu à des jeux de données volumineux et peu maniables qui étaient auparavant difficiles à analyser. Mais de plus en plus, nos adversaires (et même des organisations ou des journalistes) peuvent s’emparer de ces énormes jeux de données, les combiner et leur appliquer de puissants outils d’analyse algorithmique pour obtenir des corrélations utiles sur des personnes ou des groupes de personnes (c’est ce que l’on appelle souvent le « Big Data »). Même l’accès à de petites quantités de ces données et à des techniques d’analyse rudimentaires permet de désanonymiser des personnes et de produire des résultats utiles.
Histoire des messages de Jean-Michel
Voici un scénario fictif qui montre comment l’analyse du trafic et la corrélation des métadonnées peuvent désanonymiser un utilisateur de Signal.
Imaginez un cinéphile assidu, mais mal élevé, disons Jean-Michel, qui passe son temps à envoyer des messages via Signal pendant la projection. Les reflets de l’écran de son téléphone (Jean-Michel n’utilise pas le mode sombre) gênent tout le monde dans la salle. Mais la salle est suffisamment sombre pour que Lucie, la gérante qui s’occupe de tout, ne puisse pas savoir exactement qui envoie des messages en permanence. Lucie commence alors à collecter toutes les données qui transitent par le réseau Wi-Fi du cinéma, à la recherche de connexions au serveur Signal. Les connexions fréquentes de Jean-Michel à ce serveur apparaissent immédiatement. Lucie est en mesure d’enregistrer l’adresse MAC (un identifiant unique associé à chaque téléphone) et peut confirmer que c’est le même appareil qui utilise fréquemment Signal sur le réseau Wi-Fi du cinéma pendant les heures de projection. Lucie est ensuite en mesure d’établir une corrélation avec les relevés de transactions par carte bancaire de la billetterie et d’identifier une carte qui achète toujours des billets de cinéma à l’heure où l’appareil utilise fréquemment Signal (le nom du détenteur de la carte est également révélé : Jean-Michel). Avec l’adresse MAC de son téléphone, son nom et sa carte de crédit, Lucie peut fournir ces informations à un détective privé véreux, qui achètera l’accès à de vastes jeux de données collectées par des courtiers de données (auprès des fournisseurs de téléphones portables et des applications mobiles), et déterminera un lieu où le même téléphone portable est le plus fréquemment utilisé. Outre le cinéma, il s’agit du domicile de Jean-Michel. Lucie se rend chez Jean-Michel de nuit et fait exploser sa voiture (car la salle de cinéma était en fait une couverture pour les Hell’s Angels du coin).
Des métadonnées militarisées
Général Michael Hayden
« Nous tuons des gens en nous appuyant sur des métadonnées… mais ce n’est pas avec les métadonnées que nous les tuons ! » (dit avec un sourire en coin, les rires fusent dans l’assistance)
– Général Michael Hayden, ancien Directeur de la NSA (1999-2005) et Directeur de la CIA (2006-2009).
Sur un Internet où les adversaires ont les moyens de collecter et d’analyser d’énormes volumes de métadonnées et de données de trafic, l’utilisation de serveurs centralisés peut s’avérer dangereuse. Ils peuvent facilement cibler les appareils qui communiquent avec le serveur Signal en surveillant le trafic internet en général, au niveau des fournisseurs d’accès, ou éventuellement aux points de connexion avec le serveur lui-même. Ils peuvent ensuite essayer d’utiliser des techniques d’analyse pour révéler des éléments spécifiques sur les utilisatrices individuelles ou leurs communications via Signal.
Dans la pratique, cela peut s’avérer difficile. Vous pourriez vous demander si un adversaire qui observe tout le trafic entrant et sortant du serveur Signal pourrait déterminer que vous et votre ami échangez des messages en notant qu’un message a été envoyé de votre adresse IP au serveur de signal à 14:01 et que le serveur de Signal a ensuite envoyé un message de la même taille à l’adresse IP de votre ami à 14:02. Heureusement, une analyse corrélationnelle très simple comme celle-ci n’est pas possible en raison de l’importance du trafic entrant et sortant en permanence du serveur de Signal et de la manière dont ce trafic est traité à ce niveau. C’est moins vrai pour les appels vidéo/voix où les protocoles internet utilisés rendent plus plausible l’analyse corrélationnelle du trafic pour déterminer qui a appelé qui. Il n’en reste pas moins que la tâche reste très difficile pour qui observe l’ensemble du trafic entrant et sortant du serveur de Signal afin d’essayer de déterminer qui parle à qui. Peut-être même que cette tâche est impossible à ce jour.
Pourtant, les techniques de collecte de données et les outils d’analyse algorithmique communément appelés « Big Data » deviennent chaque jour plus puissants. Nos adversaires sont à la pointe de cette évolution. L’utilisation généralisée du chiffrement dans toutes les télécommunications a rendu l’espionnage illicite traditionnel beaucoup moins efficace et, par conséquent, nos adversaires sont fortement incités à accroître leurs capacités de collecte et d’analyse des métadonnées. Ils le disent clairement : « Si vous avez suffisamment de métadonnées, vous n’avez pas vraiment besoin du contenu »5. Ils tuent des gens sur la base de métadonnées.
Ainsi, bien qu’il ne soit peut-être pas possible de déterminer avec certitude une information aussi fine que « qui a parlé à qui à un moment précis », nos adversaires continuent d’améliorer à un rythme soutenu leur aptitude à extraire, à partir des métadonnées, toutes les informations sensibles qu’ils peuvent. Certaines fuites nous apprennent régulièrement qu’ils étaient en possession de dispositifs de surveillance plus puissants ou plus invasifs qu’on ne le pensait jusqu’à présent. Il n’est pas absurde d’en déduire que leurs possibilités sont bien étendues que ce que nous en savons déjà.
Signal est plus vulnérable à ce type de surveillance et d’analyse parce qu’il s’agit d’un service centralisé. Le trafic de Signal sur Internet n’est pas difficile à repérer et le serveur Signal est un élément central facile à observer ou qui permet de collecter des métadonnées sur les utilisateurs et leurs activités. D’éventuelles compromissions de Signal, des modifications dans les conditions d’utilisation ou encore des évolutions législatives pourraient faciliter les analyses de trafic et la collecte des métadonnées de Signal, pour que nos adversaires puissent les analyser.
Les utilisateurs individuels peuvent mettre en œuvre certaines mesures de protection, comme faire transiter leur trafic Signal par Tor ou un VPN, mais cela peut s’avérer techniquement difficile à mettre en œuvre et propice aux erreurs. Tout effort visant à rendre plus difficile la liaison d’une utilisatrice de Signal à une personne donnée est également rendu complexe par le fait que Signal exige de chaque compte qu’il soit lié à un numéro de téléphone (nous y reviendrons plus tard).
Dépendances et points faibles
Un service centralisé signifie non seulement qu’il existe un point de contrôle central, mais aussi un point faible unique : Signal ne fonctionne pas si le serveur Signal est en panne. Il est facile de l’oublier jusqu’au jour où cela se produit. Signal peut faire une erreur de configuration ou faire face à un afflux de nouveaux utilisateurs à cause d’un tweet viral et tout à coup Signal ne fonctionne carrément plus.
Signal pourrait également tomber en panne à la suite d’actions intentées par un adversaire. Imaginons une attaque par déni de service (ou tout autre cyberattaque) qui viserait à perturber le fonctionnement de Signal lors d’une rébellion massive. Les fournisseurs de services qui hébergent le serveur Signal pourraient également décider de le mettre hors service sans avertissement pour diverses raisons : sous la pression d’un adversaire, sous une pression politique, sous la pression de l’opinion publique ou pour des raisons financières.
Des adversaires qui contrôlent directement l’infrastructure Internet locale peuvent tout aussi bien perturber un service centralisé. Lorsque cela se produit dans certains endroits, Signal réagit en général rapidement en mettant en œuvre des solutions de contournement ou des modifications créatives, ce qui donne lieu à un jeu du chat et de la souris entre Signal et l’État qui tente de bloquer Signal dans la zone qu’il contrôle. Une fois encore, il s’agit de rester confiant dans le fait que les intérêts de Signal s’alignent toujours sur les nôtres lorsqu’un adversaire tente de perturber Signal de cette manière dans une région donnée.
Cryptocontroverse
En 2021, Signal a entrepris d’intégrer un nouveau système de paiement dans l’application en utilisant la crypto-monnaie MobileCoin. Si vous ne le saviez pas, vous n’êtes probablement pas le seul, mais c’est juste là, sur la page de vos paramètres.
MobileCoin est une crypto-monnaie peu connue, qui privilégie la protection de la vie privée, et que Moxie a également contribué à développer. Au-delà des débats sur les systèmes pyramidaux de crypto-monnaies, le problème est qu’en incluant ce type de paiements dans l’application, Signal s’expose à des vérifications de légalité beaucoup plus approfondies de la part des autorités. En effet, les crypto-monnaies étant propices à la criminalité et aux escroqueries, le gouvernement américain se préoccupe de plus en plus d’encadrer leur utilisation. Signal n’est pas une bande de pirates, c’est une organisation à but non lucratif très connue. Elle ne peut pas résister longtemps aux nouvelles lois que le gouvernement américain pourrait adopter pour réglementer les crypto-monnaies.
Si les millions d’utilisateurs de Signal utilisaient effectivement MobileCoin pour leurs transactions quotidiennes, il ne serait pas difficile d’imaginer que Signal fasse l’objet d’un plus grand contrôle de la part de l’organisme fédéral américain de réglementation (la Securities and Exchange Commission) ou autres autorités. Le gouvernement n’aime pas les systèmes de chiffrement, mais il aime encore moins les gens ordinaires qui paient pour de la drogue ou échappent à l’impôt. Imaginez un scénario dans lequel les cybercriminels s’appuieraient sur Signal et MobileCoin pour accepter les paiements des victimes de rançongiciels. Cela pourrait vraiment mettre le feu aux poudres et dégrader considérablement l’image de Signal en tant qu’outil de communication fiable et sécurisé.
Un mouchard en coulisses
Cette frustration devrait déjà être familière aux anarchistes qui utilisent Signal. En effet, les comptes Signal nécessitent un numéro de téléphone. Quel que soit le numéro de téléphone auquel un compte est lié, il est également divulgué à toute personne avec laquelle vous vous connectez sur Signal. En outre, il est très facile de déterminer si un numéro de téléphone donné est lié à un compte Signal actif.
Il existe des solutions pour contourner ce problème, mais elles impliquent toutes d’obtenir un numéro de téléphone qui n’est pas lié à votre identité afin de pouvoir l’utiliser pour ouvrir un compte Signal. En fonction de l’endroit où vous vous trouvez, des ressources dont vous disposez et de votre niveau de compétence technique, cette démarche peut s’avérer peu pratique, voire bien trop contraignante. Signal ne permet pas non plus d’utiliser facilement plusieurs comptes à partir du même téléphone ou ordinateur. Configurer plusieurs comptes Signal pour différentes identités, ou pour les associer à différents projets, devient une tâche énorme, d’autant plus que vous avez besoin d’un numéro de téléphone distinct pour chacun d’entre eux.
Pour des adversaires qui disposent de ressources limitées, il est toujours assez facile d’identifier une personne sur la base de son numéro de téléphone. En outre, s’ils se procurent un téléphone qui n’est pas correctement éteint ou chiffré, ils ont accès aux numéros de téléphone des contacts et des membres du groupe. Il s’agit évidemment d’un problème de sécurité opérationnelle qui dépasse le cadre de Signal, mais le fait que Signal exige que chaque compte soit lié à un numéro de téléphone accroît considérablement la possibilité de pouvoir cartographier le réseau, ce qui entraîne des conséquences dommageables.
On ignore si Signal permettra un jour l’existence de comptes sans qu’ils soient liés à un numéro de téléphone ou à un autre identifiant de la vie réelle. On a pu dire qu’ils ne le feront jamais, ou que le projet est en cours mais perdu dans les limbes6. Quoi qu’il en soit, il s’agit d’un problème majeur pour de nombreux cas d’utilisation par des anarchistes.
Vers une pratique plus stricte
Après avoir longuement discuté de Signal, il est temps de présenter quelques alternatives qui répondent à certains de ces problèmes : Briar et Cwtch. Briar et Cwtch sont, par leur conception même, extrêmement résistants aux métadonnées et offrent un meilleur anonymat. Ils sont également plus résilients, car ils ne disposent pas de serveur central ou de risque de défaillance en un point unique. Mais ces avantages ont un coût : une plus grande sécurité s’accompagne de quelques bizarreries d’utilisation auxquelles il faut s’habituer.
Rappelons que Cwtch et Briar sont des applications CPT :
C : comme Signal, les messages sont chiffrés de bout en bout,
P : pour la transmission en pair-à-pair,
T : les identités et les activités des utilisatrices sont anonymisées par l’envoi de tous messages via Tor.
Parce qu’elles partagent une architecture de base, elles ont de nombreuses fonctionnalités et caractéristiques communes.
Pair-à-pair
Signal est un service de communication centralisé, qui utilise un serveur pour relayer et transmettre chaque message que vous envoyez à vos amis. Les problèmes liés à ce modèle ont été longuement discutés ! Vous êtes probablement lassés d’en entendre parler maintenant. Le P de CPT signifie pair-à-pair. Dans un tel modèle, vous échangez des messages directement avec vos amis. Il n’y a pas de serveur central intermédiaire géré par un tiers. Chaque connexion directe s’appuie uniquement sur l’infrastructure plus large d’Internet.
Vous vous souvenez du bureau de poste Signal ? Avec un modèle pair-à-pair, vous ne passez pas par un service postal pour traiter votre courrier. Vous remettez vous-même chaque lettre directement à votre ami. Vous l’écrivez, vous la scellez dans une enveloppe (chiffrement de bout en bout), vous la mettez dans votre sac et vous traversez la ville à vélo pour la remettre en main propre.
La communication pair-à-pair offre une grande résistance aux métadonnées. Il n’y a pas de serveur central qui traite chaque message auquel des métadonnées peuvent être associées. Il est ainsi plus difficile pour les adversaires de collecter en masse des métadonnées sur les communications que de surveiller le trafic entrant et sortant de quelques serveurs centraux connus. Il n’y a pas non plus de point de défaillance unique. Tant qu’il existe une route sur Internet pour que vous et votre amie puissiez vous connecter, vous pouvez discuter.
Synchronisation
Il y a un point important à noter à propos de la communication pair-à-pair : comme il n’y a pas de serveur central pour stocker et relayer les messages, vous et votre ami devez tous deux avoir l’application en cours d’exécution et avoir une connexion en ligne pour échanger des messages. C’est pourquoi ces applications CPT privilégient la communication synchrone. Que se passe-t-il si vous traversez la ville à vélo pour remettre une lettre à vos amis et… qu’ils ne sont pas chez eux ? Si vous voulez vraiment faire du pair-à-pair, vous devez remettre la lettre en main propre. Vous ne pouvez pas simplement la déposer quelque part (il n’y a pas d’endroit assez sûr !). Vous devez être en mesure de joindre directement vos amis pour leur transmettre le message – c’est l’aspect synchrone de la communication de pair à pair.
Un appel téléphonique est un bon exemple de communication synchrone. Vous ne pouvez pas avoir de conversation téléphonique si vous n’êtes pas tous les deux au téléphone en même temps. Mais qui passe encore des appels téléphoniques ? De nos jours, nous sommes beaucoup plus habitués à un mélange de messagerie synchrone et asynchrone, et les services de communication centralisés comme Signal sont parfaits pour cela. Il arrive que vous et votre ami soyez tous deux en ligne et échangiez des messages en temps réel, mais le plus souvent, il y a un long décalage entre les messages envoyés et reçus. Au moins pour certaines personnes… Vous avez peut-être, en ce moment, votre téléphone allumé, à portée de main à tout moment. Vous répondez immédiatement à tous les messages que vous recevez, à toute heure de la journée. Donc toute communication est et doit être synchrone… si vous êtes dans ce cas, vous vous reconnaîtrez certainement.
Le passage à la communication textuelle synchrone peut être une vraie difficulté au début. Certaines lectrices et lecteurs se souviendront peut-être de ce que c’était lorsque on utilisait AIM, ICQ ou MSN Messenger (si vous vous en souvenez, vous avez mal au dos). Vous devez savoir si la personne est réellement en ligne ou non. Si la personne n’est pas en ligne, vous ne pouvez pas envoyer de messages pour plus tard. Si l’une d’entre vous ne laisse pas l’application en ligne en permanence, vous devez prendre l’habitude de prévoir des horaires pour discuter. Cela peut s’avérer très agréable. Paradoxalement, la normalisation de la communication asynchrone a entraîné le besoin d’être toujours en ligne et réactif. La communication synchrone encourage l’intentionnalité de nos communications, en les limitant aux moments où nous sommes réellement en ligne, au lieu de s’attendre à être en permanence plus ou moins disponibles.
Une autre conséquence importante de la synchronisation des connexions pair-à-pair est qu’elle peut rendre les discussions de groupe un peu bizarres. Que se passe-t-il si tous les membres du groupe ne sont pas en ligne au même moment ? Briar et Cwtch gèrent ce problème différemment, un sujet abordé plus bas, dans les sections relatives à chacune de ces applications.
Tor
Bien que la communication pair-à-pair soit très résistante aux métadonnées et évite d’autres écueils liés à l’utilisation d’un serveur central, elle ne protège pas à elle seule contre la collecte de métadonnées et l’analyse du trafic dans le cadre du « Big Data ». Tor est un très bon moyen de limiter ce problème, et les applications CPT font transiter tout le trafic par Tor.
Si vous êtes un⋅e anarchiste et que vous lisez ces lignes, vous devriez déjà connaître Tor et la façon dont il peut être utilisé pour assurer l’anonymat (ou plutôt la non-associativité). Les applications CPT permettent d’établir des connexions directes pair-à-pair pour échanger des messages par l’intermédiaire de Tor. Il est donc beaucoup plus difficile de vous observer de manière ciblée ou de vous pister et de corréler vos activités sur Internet, de savoir qui parle à qui ou de faire d’autres analyses utiles. Il est ainsi bien plus difficile de relier un utilisateur donné d’une application CPT à une identité réelle. Tout ce qu’un observateur peut voir, c’est que vous utilisez Tor.
Tor n’est pas un bouclier à toute épreuve et des failles potentielles ou des attaques sur le réseau Tor sont possibles. Entrer dans les détails du fonctionnement de Tor prendrait trop de temps ici, et il existe de nombreuses ressources en ligne pour vous informer. Il est également important de comprendre les mises en garde générales en ce qui concerne l’utilisation de Tor. Comme Signal, le trafic Tor peut également être altéré par des interférences au niveau de l’infrastructure Internet, ou par des attaques par déni de service qui ciblent l’ensemble du réseau Tor. Toutefois, il reste beaucoup plus difficile pour un adversaire de bloquer ou de perturber Tor que de mettre hors service ou de bloquer le serveur central de Signal.
Il faut souligner que dans certaines situations, l’utilisation de Tor peut vous singulariser. Si vous êtes la seule à utiliser Tor dans une région donnée ou à un moment donné, vous pouvez vous faire remarquer. Mais il en va de même pour toute application peu courante. Le fait d’avoir Signal sur votre téléphone vous permet également de vous démarquer. Plus il y a de gens qui utilisent Tor, mieux c’est, et s’il est utilisé correctement, Tor offre une meilleure protection contre les tentatives d’identification des utilisateurs que s’il n’était pas utilisé. Les applications CPT utilisent Tor pour tout, par défaut, de manière presque infaillible.
Pas de téléphone, pas de problème
Un point facilement gagné pour les deux applications CPT présentées ici : elles ne réclament pas de numéro de téléphone pour l’enregistrement d’un compte. Votre compte est créé localement sur votre appareil et l’identifiant du compte est une très longue chaîne de caractères aléatoires que vous partagez avec vos amis pour qu’ils deviennent des contacts. Vous pouvez facilement utiliser ces applications sur un ordinateur, sur un téléphone sans carte SIM ou sur un téléphone mais sans lien direct avec votre numéro de téléphone.
Mises en garde générales concernant les applications CPT
La fuite de statut
Les communications pair-à-pair laissent inévitablement filtrer un élément particulier de métadonnées : le statut en ligne ou hors ligne d’un utilisateur. Toute personne que vous avez ajoutée en tant que contact ou à qui vous avez confié votre identifiant (ou tout adversaire ayant réussi à l’obtenir) peut savoir si vous êtes en ligne ou hors ligne à un moment donné. Cela ne s’applique pas vraiment à notre modèle de menace, sauf si vous êtes particulièrement négligent avec les personnes que vous ajoutez en tant que contact, ou pour des événements publics qui affichent les identifiants d’utilisateurs. Mais cela vaut la peine d’être noté, parce qu’il peut parfois arriver que vous ne vouliez pas que tel ami sache que vous êtes en ligne !
Un compte par appareil
Lorsque vous ouvrez ces applications pour la première fois, vous créez un mot de passe qui sera utilisé pour chiffrer votre profil, vos contacts et l’historique de vos messages (si vous choisissez de le sauvegarder). Ces données restent chiffrées sur votre appareil lorsque vous n’utilisez pas l’application.
Comme il n’y a pas de serveur central, vous ne pouvez pas synchroniser votre compte sur plusieurs appareils. Vous pouvez migrer manuellement votre compte d’un appareil à l’autre, par exemple d’un ancien téléphone à un nouveau, mais il n’y a pas de synchronisation magique dans le cloud. Le fait d’avoir un compte distinct sur chaque appareil est une solution de contournement facile, qui encourage la compartimentation. Le fait de ne pas avoir à se soucier d’une version synchronisée sur un serveur central (même s’il est chiffré) ou sur un autre appareil est également un avantage. Cela oblige à considérer plus attentivement où se trouvent vos données et comment vous y accédez plutôt que de tout garder « dans le nuage » (c’est-à-dire sur l’ordinateur de quelqu’un d’autre). Il n’existe pas non plus de copie de vos données utilisateur qui serait sauvegardée sur un serveur tiers afin de restaurer votre compte en cas d’oubli de votre mot de passe ou de perte de votre appareil. Si c’est perdu… c’est perdu !.
Les seuls moyens de contourner ce problème sont : soit de confier à un serveur central une copie de vos contacts et de votre compte de média social, soit de faire confiance à un autre média social, de la même manière que Signal utilise votre liste de contacts composée de numéros de téléphone. Nous ne devrions pas faire confiance à un serveur central pour stocker ces informations (même sous forme chiffrée), ni utiliser quelque chose comme des numéros de téléphone. La possibilité de devoir reconstruire vos comptes de médias sociaux à partir de zéro est le prix à payer pour éviter ces problèmes de sécurité, et encourage la pratique qui consiste à maintenir et à rétablir des liens de confiance avec nos amis.
Durée de la batterie
Exécuter des connexions pair-à-pair avec Tor signifie que l’application doit être connectée et à l’écoute en permanence au cas où l’un de vos amis vous enverrait un message. Cela peut s’avérer très gourmand en batterie sur des téléphones anciens. Le problème se pose de moins en moins, car il y a une amélioration générale de l’utilisation des batteries et ces dernières sont de meilleure qualité.
Rien pour les utilisateurs d’iOS
Aucune de ces applications ne fonctionne sur iOS, principalement en raison de l’hostilité d’Apple à l’égard de toute application qui permet d’établir des connexions pair-à-pair avec Tor. Il est peu probable que cela change à l’avenir (mais ce n’est pas impossible).
Le bestiaire CPT
Il est temps de faire connaissance avec ces applications CPT. Elles disposent toutes les deux d’excellents manuels d’utilisation qui fournissent des informations complètes, mais voici un bref aperçu de leur fonctionnement, de leurs fonctionnalités et de la manière dont on les peut les utiliser.
Briar est développé par le Briar Project, un collectif de développeurs, de hackers et de partisans du logiciel libre, principalement basé en Europe. En plus de résister à la surveillance et à la censure, la vision globale du projet consiste à construire une infrastructure de communication et d’outils à utiliser en cas de catastrophe ou de panne d’Internet. Cette vision est évidemment intéressante pour les anarchistes qui se trouvent dans des régions où il y a un risque élevé de coupure partielle ou totale d’Internet lors d’une rébellion, ou bien là où l’infrastructure générale peut s’effondrer (c.-à-d. partout). Si les connexions à Internet sont coupées, Briar peut synchroniser les messages par Wi-Fi ou Bluetooth. Briar permet également de partager l’application elle-même directement avec un ami. Elle peut même former un réseau maillé rudimentaire entre pairs, de sorte que certains types de messages peuvent passer d’un utilisateur à l’autre.
À l’heure où nous écrivons ces lignes, Briar est disponible pour Android et la version actuelle est la 1.4.9.
Une version desktop bêta est disponible pour Linux (version actuelle 0.2.1.), bien qu’il lui manque de nombreuses fonctionnalités.
Des versions Windows et macOS du client desktop sont prévues.
Utiliser Briar
Conversation basique
Le clavardage de base fonctionne très bien. Les amis doivent s’ajouter mutuellement pour pouvoir se connecter. Briar dispose d’une petite interface agréable pour effectuer cette opération en présentiel en scannant les codes QR de l’autre. Mais il est également possible de le faire à distance en partageant les identifiants (sous la forme d’un « lien briar:// »), ou bien un utilisateur peut en « présenter » d’autres dans l’application, ce qui permet à deux utilisatrices de devenir des contacts l’une pour l’autre par l’intermédiaire de leur amie commune. Cette petite contrainte dans la manière d’ajouter des contacts peut sembler gênante, mais pensez à la façon dont ce modèle encourage des meilleures pratiques, notamment sur la confiance que l’on s’accorde en ajoutant des contacts. Briar a même un petit indicateur à côté de chaque nom d’utilisateur pour vous rappeler comment vous le « connaissez » (en personne, via des liens de partage, ou via un intermédiaire).
Actuellement, dans les discussions directes, vous pouvez envoyer des fichiers, utiliser des émojis, supprimer des messages ou les faire disparaître automatiquement au bout de sept jours. Si votre ami n’est pas en ligne, vous pouvez lui écrire un message qui sera envoyé automatiquement la prochaine fois que vous le verrez en ligne.
Groupes privés
Les groupes privés de Briar sont des groupes de discussion de base. Seul le créateur du groupe peut inviter d’autres membres. La création de groupes privés est donc très pensée en amont et destinée à un usage spécifique. Ils prennent en charge un affichage par fil de discussion (vous pouvez répondre directement à un message spécifique, même s’il ne s’agit pas du message le plus récent de la discussion), mais il s’agit d’un système assez rudimentaire. Il n’est pas possible d’envoyer des images dans un groupe privé, ni de supprimer des messages.
Avec Briar, les discussions de groupe étant véritablement sans serveur, les choses peuvent être un peu bizarres lorsque tous les membres du groupe ne sont pas en ligne en même temps. Vous vous souvenez de la synchronicité ? Tout message de groupe sera envoyé à tous les membres du groupe qui sont en ligne à ce moment-là. Briar s’appuie sur tous les membres d’un groupe pour relayer les messages aux autres membres qui ne sont pas en ligne. Si vous avez manqué certains messages dans une discussion de groupe, n’importe quel autre membre qui a reçu ces messages peut vous les transmettre lorsque vous êtes tous les deux en ligne.
Forums
Briar dispose également d’une fonction appelée Forums. Les forums fonctionnent de la même manière que les groupes privés, sauf que tout membre peut inviter d’autres membres.
Blog
La fonction de blog de Briar est plutôt sympa ! Chaque utilisateur dispose par défaut d’un flux de blog. Les articles de blog publiés par vos contacts s’affichent dans votre propre flux. Vous pouvez également commenter un billet, ou « rebloguer » le billet d’un contact pour qu’il soit partagé avec tous vos contacts (avec votre commentaire). En bref, c’est un réseau social rudimentaire qui fonctionne uniquement sur Briar.
Lecteur de flux RSS
Briar dispose également d’un lecteur de flux rss intégré qui récupère les nouveaux messages des sites d’information via Tor. Cela peut être un excellent moyen de lire le dernier communiqué de votre site de contre-information anarchiste préféré (qui fournit sûrement un flux rss, si vous ne le saviez pas déjà !). Les nouveaux messages qui proviennent des flux rss que vous avez ajoutés apparaissent dans le flux Blog, et vous pouvez les « rebloguer » pour les partager avec tous vos contacts.
Devenez un maillon
Briar propose de nombreux outils pour faire circuler des messages entre contacts, sans avoir recours à des serveurs centraux. Les forums et les blogs sont relayés d’un contact à l’autre, à l’instar des groupes privés qui synchronisent les messages entre les membres sans serveur. Tous vos contacts peuvent recevoir une copie d’un billet de blog ou de forum même si vous n’êtes pas en ligne en même temps – les contacts partagés transmettent le message pour vous. Briar ne crée pas de réseau maillé où les messages sont transmis via d’autres utilisateurs (ce qui pourrait permettre à un adversaire d’exploiter plusieurs comptes malveillants et de collecter des métadonnées). Briar ne confie aucun de vos messages à des utilisateurs auxquels ils ne sont pas destinés. Au contraire, chaque utilisatrice censée recevoir un message participe également à la transmission de ce message, et uniquement grâce à ses propres contacts. Cela peut s’avérer particulièrement utile pour créer un réseau de communication fiable qui fonctionne même si Internet est indisponible. Les utilisatrices de Briar peuvent synchroniser leurs messages par Wi-Fi ou Bluetooth. Vous pouvez vous rendre au café internet local, voir quelques amis et synchroniser divers messages de blogs et de forums. Puis une fois rentré, vos colocataires peuvent se synchroniser avec vous pour obtenir les mêmes mises à jour de tous vos contacts mutuels partagés.
Mises en garde pour Briar
Chaque instance de l’application ne prend en charge qu’un seul compte. Il n’est donc pas possible d’avoir plusieurs comptes sur le même appareil. Ce n’est pas un problème si vous utilisez Briar uniquement pour parler avec un groupe d’amis proches, mais cela rend difficile l’utilisation de Briar avec des groupes différents que vous voudriez compartimenter. Briar fournit pour cela plusieurs arguments basés sur la sécurité, dont l’un est simple : si le même appareil utilise plusieurs comptes, il pourrait théoriquement être plus facile pour un adversaire de déterminer que ces comptes sont liés, malgré l’utilisation de Tor. Si deux comptes ne sont jamais en ligne en même temps, il y a de fortes chances qu’ils utilisent le même téléphone portable pour leurs comptes Briar individuels. Il existe d’autres raisons, et aussi des solutions de contournement, toujours est-il qu’il n’est pas possible, pour le moment, d’avoir plusieurs profils sur le même appareil.
Le protocole Briar exige également que deux utilisatrices s’ajoutent mutuellement en tant que contacts, ou qu’ils soient parrainés par un ami commun, avant de pouvoir interagir. Cela empêche de publier une adresse Briar pour recevoir des messages anonymes. Par exemple, vous voudriez publier votre identifiant Briar pour recevoir des commentaires honnêtes sur un article qui compare différentes applications de chat sécurisées.
Briar et la communication asynchrone
De manière générale, les utilisateurs et utilisatrices apprécient beaucoup la communication asynchrone. Le projet Briar travaille sur une autre application : une boîte aux lettres (Briar Mailbox) qui pourrait être utilisée facilement sur un vieux téléphone Android ou tout autre machine bon marché. Cette boîte aux lettres resterait en ligne principalement pour recevoir des messages pour vous, puis se synchroniserait avec votre appareil principal via Tor lorsque vous êtes connecté. C’est une idée intéressante. Une seule boîte aux lettres Briar pourrait potentiellement être utilisée par plusieurs utilisateurs qui se font confiance, comme des colocataires dans une maison collective, ou les clients réguliers d’un magasin d’information local. Plutôt que de s’appuyer sur un serveur central pour faciliter les échanges asynchrones, un petit serveur facile à configurer et contrôlé par vous-même serait utilisé pour stocker les messages entrants pour vous et vos amis lorsque vous n’êtes pas en ligne. Ce système étant encore en cours de développement, son degré de sécurité (par exemple, savoir si les messages stockés ou d’autres métadonnées seraient suffisamment sûrs si un adversaire accédait à la boîte aux lettres) n’est pas connu et devra faire l’objet d’une évaluation.
Alors oui ce nom pas facile à prononcer… ça rime avec « butch ». Apparemment, il s’agit d’un mot gallois qui signifie une étreinte offrant comme un refuge dans les bras de quelqu’un.
Cwtch est développé par l’Open Privacy Research Society, une organisation à but non lucratif basée à Vancouver. Dans l’esprit, Cwtch pourrait être décrit comme un « Signal queer ». Open Privacy s’investit beaucoup dans la création d’outils destinés à « servir les communautés marginalisées » et à résister à l’oppression. Elle a également travaillé sur d’autres projets intéressants, comme la conception d’un outil appelé « Shatter Secrets », destiné à protéger les secrets contre les scénarios dans lesquels les individus peuvent être contraints de révéler un mot de passe (comme lors d’un passage de frontière).
Cwtch est également un logiciel open source et son protocole repose en partie sur le projet CPT antérieur nommé Ricochet. Cwtch est un projet plus récent que Briar, mais son développement est rapide et de nouvelles versions sortent fréquemment.
À l’heure où nous écrivons ces lignes, la version actuelle est la 1.8.0.
Cwtch est disponible pour Android, Windows, Linux et macOS.
Utiliser Cwtch
Lorsque vous ouvrez Cwtch pour la première fois, vous créez votre profil, protégé par un mot de passe. Votre nouveau profil se voit attribuer un mignon petit avatar et une adresse Cwtch. Contrairement à Briar, Cwtch peut prendre en charge plusieurs profils sur le même appareil, et vous pouvez en avoir plusieurs déverrouillés en même temps. C’est idéal si vous voulez avoir des identités séparées pour différents projets ou réseaux sans avoir à passer d’un appareil à l’autre (mais dans ce cas attention aux possibles risques de sécurité !).
Pour ajouter un ami, il suffit de lui donner votre adresse Cwtch. Il n’est pas nécessaire que vous et votre ami échangiez d’abord vos adresses pour discuter. Cela signifie qu’avec Cwtch, vous pouvez publier une adresse Cwtch publiquement et vos ami⋅e⋅s’ou non peuvent vous contacter de manière anonyme. Vous pouvez également configurer Cwtch pour qu’il bloque automatiquement les messages entrants provenant d’inconnus. Voici une adresse Cwtch pour contacter l’auteur de cet article si vous avez des commentaires ou envie d’écrire un quelconque message haineux :
En mode conversation directe, Cwtch propose un formatage de texte riche, des emojis et des réponses. Chaque conversation peut être configurée pour « enregistrer l’historique » ou « supprimer l’historique » à la fermeture de Cwtch.
C’est le strict minimum et cela fonctionne très bien. Pour l’instant, toutes les autres fonctionnalités de Cwtch sont « expérimentales » et vous pouvez les choisir en y accédant par les paramètres. Cela comprend les discussions de groupe, le partage de fichiers, l’envoi de photos, les photos de profil, les aperçus d’images et les liens cliquables avec leurs aperçus. Le développement de Cwtch a progressé assez rapidement, donc au moment où vous lirez ces lignes, toutes ces fonctionnalités seront peut-être entièrement développées et disponibles par défaut.
Discussions de groupe
Cwtch propose également des discussions de groupe en tant que « fonction expérimentale ». Pour organiser cela, Cwtch utilise actuellement des serveurs gérés par les utilisateurs, ce qui est très différent de l’approche de Briar. Open Privacy considère que la résistance aux métadonnées des discussions de groupe est un problème ouvert, et j’espère qu’en lisant ce qui précède, vous comprendrez pourquoi. Tout comme le serveur Signal, les serveurs Cwtch sont conçus de telle sorte qu’ils soient toujours considérés comme « non fiables » et qu’ils puissent en apprendre le moins possible sur le contenu des messages ou les métadonnées. Mais bien entendu, ces serveurs sont gérés par des utilisateurs individuels et non par une tierce partie centrale.
Tout utilisateur de Cwtch peut devenir le « serveur » d’une discussion de groupe. C’est idéal pour les groupes à usage unique, où un utilisateur peut devenir l’« hôte » d’une réunion ou d’une discussion rapide. Les serveurs de discussion de groupe de Cwtch permettent également la transmission asynchrone des messages, de sorte qu’un groupe ou une communauté peut exploiter son propre serveur en permanence pour rendre service à ses membres. La façon dont Cwtch aborde les discussions de groupe est encore en cours de développement et pourrait changer à l’avenir, mais il s’agit pour l’instant d’une solution très prometteuse et sympathique.
Correspondance asynchrone avec Cwtch
Les discussions de groupe dans Cwtch permettent la correspondance asynchrone (tant que le serveur/hôte est en ligne), mais comme Briar, Cwtch exige que les deux contacts soient en ligne pour l’envoi de messages directs. Contrairement à Briar, Cwtch ne permet pas de mettre en file d’attente les messages à envoyer à un contact une fois qu’il est en ligne.
Cwtch et la question des crypto-monnaies
Fin 2019, Open Privacy, qui développe Cwtch, a reçu un don sans conditions de 40 000 dollars canadiens de la part de la fondation Zcash. Zcash est une autre crypto-monnaie centrée sur la vie privée, similaire mais nettement inférieure à Monero7. En 2019, Cwtch en était au tout début de son développement, et Open Privacy a mené quelques expériences exploratoires sur l’utilisation de Zcash ou de crypto-monnaies blockchain similaires comme des solutions créatives à divers défis relatifs au chiffrement, avec l’idée qu’elles pourraient être incorporées dans Cwtch à un moment ou à un autre. Depuis lors, aucun autre travail de développement avec Zcash ou d’autres crypto-monnaies n’a été associé à Cwtch, et il semble que ce ne soit pas une priorité ou un domaine de recherche pour Open Privacy. Toutefois, il convient de mentionner ce point comme un signal d’alarme potentiel pour les personnes qui se méfient fortement des systèmes de crypto-monnaies. Rappelons que Signal dispose déjà d’une crypto-monnaie entièrement fonctionnelle intégrée à l’application, qui permet aux utilisateurs d’envoyer et de recevoir des MobileCoin.
Conclusions
(… « X a quitté le groupe »)
De nombreux lecteurs se disent peut-être : « Les applications CPT ne semblent pas très bien prendre en charge les discussions de groupe… et j’adore les discussions de groupe ! »… Premièrement, qui aime vraiment les discussions de groupe ? Deuxièmement, c’est l’occasion de soulever des critiques sur la façon dont les anarchistes finissent par utiliser les discussions de groupe dans Signal, pour faire valoir que la façon dont elles sont mises en œuvre dans Briar et Cwtch ne devrait pas être un obstacle.
Signal, Cwtch et Briar vous permettent tous les trois d’organiser facilement un groupe en temps réel (synchrone !) pour une réunion ou une discussion collective rapide qui ne pourrait pas avoir lieu en présentiel. Mais lorsque les gens parlent de « discussion de groupe » (en particulier dans le contexte de Signal), ce n’est pas vraiment ce qu’ils veulent dire. Les discussions de groupe dans Signal deviennent souvent d’énormes flux continus de mises à jour semi-publiques, de « shitposts », de liens repartagés, etc. qui s’apparentent davantage à des pratiques de médias sociaux. Il y a plus de membres qu’il n’est possible d’en avoir pour une conversation vraiment fonctionnelle, sans parler de la prise de décision. La diminution de l’utilité et de la sécurité selon l’augmentation de la taille, de la portée et de la persistance des groupes Signal a été bien décrite dans l’excellent article Signal Fails. Plus un groupe de discussion s’éloigne de la petite taille, du court terme, de l’intention et de l’objectif principal, plus il est difficile à mettre en œuvre avec Briar et Cwtch — et ce n’est pas une mauvaise chose. Briar et Cwtch favorisent des habitudes plus saines et plus sûres, sans les « fonctionnalités » de Signal qui encouragent la dynamique des discussions de groupe critiquées dans des articles tels que « Signal Fails ».
Proposition
Briar et Cwtch sont deux initiatives encore jeunes. Certains anarchistes en ont déjà entendu parler et essaient d’utiliser l’un ou l’autre pour des projets ou des cas d’utilisation spécifiques. Les versions actuelles peuvent sembler plus lourdes à utiliser que Signal, et elles souffrent de l’effet de réseau – tout le monde utilise Signal, donc personne ne veut utiliser autre chose 8. Il est intéressant de souligner que les obstacles apparents à l’utilisation de Cwtch et Briar (encore en version bêta, effet de réseau, différent de ce à quoi vous êtes habitué, sans version iOS) sont exactement les mêmes que ceux qui ont découragé les premiers utilisateurs de Signal (alias TextSecure !).
Il est difficile d’amener les gens à se familiariser avec un nouvel outil et à commencer à l’utiliser. Surtout lorsque l’outil auquel ils sont habitués semble fonctionner à merveille ! Le défi est indéniable. Ce guide a pris des pages et des pages pour tenter de convaincre les anarchistes, qui sont peut-être ceux qui se préoccupent le plus de ces questions, qu’ils ont intérêt à utiliser ces applications.
Les anarchistes ont déjà réussi à adopter de nouveaux outils électroniques prometteurs, à les diffuser et à les utiliser efficacement lors des actions de lutte et de résistance. La normalisation de l’utilisation des applications CPT en plus ou à la place de Signal pour la communication électronique renforcera la résilience de nos communautés et de ceux que nous pouvons convaincre d’utiliser ces outils. Ils nous aideront à nous protéger de la collecte et de l’analyse de métadonnées de plus en plus puissantes, à ne pas dépendre d’un service centralisé et à rendre plus facile l’accès à l’anonymat.
Voici donc la proposition. Après avoir lu ce guide, mettez-le en pratique et partagez-le. Vous ne pouvez pas essayer Cwtch ou Briar seul, vous avez besoin d’au moins un ami pour cela. Installez-ces applications avec votre équipe et essayez d’utiliser l’une ou l’autre pour un projet spécifique qui vous convient. Organisez une réunion hebdomadaire avec les personnes qui ne peuvent pas se rencontrer en personne pour échanger des nouvelles qui, autrement, auraient été partagées dans un groupe de discussion agglutiné sur Signal. Gardez le contact avec quelques amis éloignés ou avec une équipe dont les membres sont distants. Vous n’êtes pas obligé de supprimer Signal (et vous ne le devriez probablement pas), mais vous contribuerez au minimum à renforcer la résilience en établissant des connexions de secours avec vos réseaux. Alors que la situation s’échauffe, la probabilité d’une répression intensive ou de fractures sociétales telles que celles qui perturbent Signal dans d’autres pays est de plus en plus grande partout, et nous aurons tout intérêt à mettre en place nos moyens de communication alternatifs le plus tôt possible !
Briar et Cwtch sont tous deux en développement actif, par des anarchistes et des sympathisants à nos causes. En les utilisant, que ce soit sérieusement ou pour le plaisir, nous pouvons contribuer à leur développement en signalant les bogues et les vulnérabilités, et en incitant leurs développeurs à continuer, sachant que leur projet est utilisé. Peut-être même que les plus férus d’informatique d’entre nous peuvent contribuer directement, en vérifiant le code et les protocoles ou même en participant à leur développement.
Outre la lecture de ce guide, essayer d’utiliser ces applications en tant que groupe d’utilisateurs curieux est le meilleur moyen d’apprécier en quoi elles sont structurellement différentes de Signal. Même si vous ne pouvez pas vous résoudre à utiliser ces applications régulièrement, le fait d’essayer différents outils de communication sécurisés et de comprendre comment, pourquoi et en quoi ils sont différents de ceux qui vous sont familiers améliorera vos connaissances en matière de sécurité numérique. Il n’est pas nécessaire de maîtriser les mathématiques complexes qui sous-tendent l’algorithme de chiffrement à double cliquet de Signal, mais une meilleure connaissance et une meilleure compréhension du fonctionnement théorique et pratique de ces outils permettent d’améliorer la sécurité opérationnelle dans son ensemble. Tant que nous dépendons d’une infrastructure pour communiquer, nous devrions essayer de comprendre comment cette infrastructure fonctionne, comment elle nous protège ou nous rend vulnérables, et explorer activement les moyens de la renforcer.
Le mot de la fin
Toute cette discussion a porté sur les applications de communication sécurisées qui fonctionnent sur nos téléphones et nos ordinateurs. Le mot de la fin doit rappeler que même si l’utilisation d’outils de chiffrement et d’anonymisation des communications en ligne peut vous protéger contre vos adversaires, vous ne devez jamais saisir ou dire quoi que ce soit sur une application ou un appareil sans savoir que cela pourrait être interprété devant un tribunal. Rencontrer vos amis, face à face, en plein air et loin des caméras et autres appareils électroniques est de loin le moyen le plus sûr d’avoir une conversation qui doit être sécurisée et privée. Éteignez votre téléphone, posez-le et sortez !
Appendice : d’autres applications dont vous n’avez pas forcément entendu parler
Ricochet Refresh
Ricochet était une toute première application CPT de bureau financée par le Blueprint for Free Speech, basé en Europe. Ricochet Refresh est la version actuelle. Fondamentalement, elle est très similaire à Cwtch et Briar, mais assez rudimentaire – elle dispose d’un système basique de conversation directe et de transfert de fichiers, et ne fonctionne que sur MacOS, Linux et Windows. Cette application est fonctionnelle, mais dépouillée, et n’a pas de version pour mobiles.
OnionShare
OnionShare est un projet fantastique qui fonctionne sur n’importe quel ordinateur de bureau et qui est fourni avec Tails et d’autres systèmes d’exploitation. Il permet d’envoyer et de recevoir facilement des fichiers ou d’avoir un salon de discussion éphémère rudimentaire via Tor. Il est également CPT !
Telegram
Telegram est en fait comme Twitter. Il peut s’avérer utile d’y être présent dans certains scénarios, mais il ne devrait pas être utilisé pour des communications sécurisées car il y a des fuites de métadonnées partout. Il n’est probablement pas utile de passer plus de temps à critiquer Telegram ici, mais il ne devrait pas être utilisé là où la vie privée ou la sécurité sont exigées.
Tox
Tox est un projet similaire à Briar et Cwtch, mais il n’utilise pas Tor – c’est juste CP. Tox peut être routé manuellement à travers Tor. Aucune des applications développées pour Tox n’est particulièrement conviviale.
Session
Session mérite qu’on s’y attarde un peu. L’ambiance y est très libertarienne, et activiste façon « free-speech movement ». Session utilise le protocole de chiffrement robuste de Signal, est en pair-à-pair pour les messages directs et utilise également le routage Onion pour l’anonymat (le même principe que celui qui est à la base de Tor). Cependant, au lieu de Tor, Session utilise son propre réseau de routage Onion pour lequel une « participation financière » est nécessaire afin de faire fonctionner un nœud de service qui constitue le réseau Onion. Point essentiel, cette participation financière prend la forme d’une crypto-monnaie administrée par la fondation qui développe Session. Le projet est intéressant d’un point de vue technologique, astucieux même, mais il s’agit d’une solution très « web3 » drapée dans une culture cryptobro. Malgré tout ce qu’ils prétendent, leurs discussions de groupe ne sont pas conçues pour être particulièrement résistantes à la collecte de métadonnées, et les grandes discussions de groupe semi-publiques sont simplement hébergées sur des serveurs centralisés (et apparemment envahis par des cryptobros d’extrême-droite). Peut-être que si la blockchain finit par s’imposer, ce sera une bonne option, mais pour l’instant, on ne peut pas la recommander en toute bonne conscience.
Molly
Molly est un fork du client Signal pour Android. Il utilise toujours le serveur Signal mais propose un peu plus de sécurité et de fonctionnalités sur l’appareil.
Contact
Cet article a été écrit originellement en août 2022. Courriel de l’auteur : pettingzoo riseup net ou via Cwtch : g6px2uyn5tdg2gxpqqktnv7qi2i5frr5kf2dgnyielvq4o4emry4qzid
Cependant, Signal semble vraiment vouloir obtenir davantage de dons de la part des utilisateurs, malgré le prêt de 50 millions de dollars contracté par l’entreprise. ¯_(ツ)_/¯↩
Au lieu d’un serveur physique unique, il s’agit en fait d’un énorme réseau de serveurs loués dans les datacenters d’Amazon un peu partout aux États-Unis – ce qui peut être résumé à un serveur Signal unique pour les besoins de notre discussion.↩
Récemment, Signal a choisi de fermer une partie du code de son serveur, soi-disant pour lui permettre de lutter contre le spam sur la plateforme. Cela signifie que désormais, une petite partie du code du serveur Signal n’est pas partagée publiquement. Ce changement dénote également une augmentation, bien qu’extrêmement minime, de la collecte de métadonnées côté serveur, puisqu’elle est nécessaire pour faciliter la lutte efficace contre le spam, même de manière basique. Il n’y a aucune raison de suspecter une manœuvre malveillante, mais il est important de noter qu’il s’agit là encore d’une décision stratégique qui sacrifie les questions de sécurité dans l’intérêt de l’expérience de l’utilisateur.↩
Pardonnez ce pavé sur les numéros de téléphone. Bien que, dans les fils de questions-réponses sur Github, Signal ait mentionné être ouvert à l’idée de ne plus exiger de numéro de téléphone, il n’y a pas eu d’annonce officielle indiquant qu’il s’agissait d’une fonctionnalité à venir et en cours de développement. Il semblerait que l’un des problèmes liés à l’abandon des numéros de téléphone pour l’enregistrement soit la rupture de la compatibilité avec les anciens comptes Signal, en raison de la manière dont les choses étaient mises en œuvre à l’époque de TextSecure. C’est paradoxal, étant donné que le principal argument de Moxie contre les modèles décentralisés est qu’il serait trop difficile d’aller vite – il y a trop de travail à faire avant de pouvoir mettre en œuvre de nouvelles fonctionnalités. Et pourtant, Signal est bloqué par un problème très embarrassant à cause d’un ancien code concernant l’enregistrement des comptes auprès d’un serveur central. Moxie a également expliqué que les numéros de téléphone sont utilisés comme point de référence de votre identité dans Signal pour faciliter la préservation de votre « graphe social ». Au lieu que Signal ait à maintenir une sorte de réseau social en votre nom, tous vos contacts sont identifiés par leur numéro de téléphone dans le carnet d’adresses de votre téléphone, ce qui facilite le maintien et la conservation de votre liste de contacts lorsque vous passez d’autres applications à Signal, ou si vous avez un nouveau téléphone, ou que sais-je encore. Pour Moxie, il semble qu’avoir à « redécouvrir » ses contacts régulièrement et en tout lieu soit un horrible inconvénient. Pour les anarchistes, cela devrait être considéré comme un avantage d’avoir à maintenir intentionnellement notre « graphe social » basé sur nos affinités, nos désirs et notre confiance. Nous devrions constamment réévaluer et réexaminer qui fait partie de notre « graphe social » pour des raisons de sécurité (est-ce que je fais encore confiance à tous ceux qui ont mon numéro de téléphone d’il y a 10 ans ?) et pour encourager des relations sociales intentionnelles (suis-je toujours ami avec tous ceux qui ont mon numéro de téléphone d’il y a 10 ans ?). Dernière anecdote sur l’utilisation des numéros de téléphone par Signal : Signal dépense plus d’argent pour la vérification des numéros de téléphone que pour l’hébergement du reste du service : 1 017 990 dollars pour Twillio, le service de vérification des numéros de téléphone, contre 887 069 dollars pour le service d’hébergement web d’Amazon.↩
Le créateur de Zcash, un cypherpunk du nom de Zooko Wilcox-O’Hearn, semble prétendre que Zcash est privé mais ne peut pas être utilisé dans un but criminel…↩
Avez-vous un moment pour parler d’interopérabilité et de fédération ? Peut-être plus tard…↩