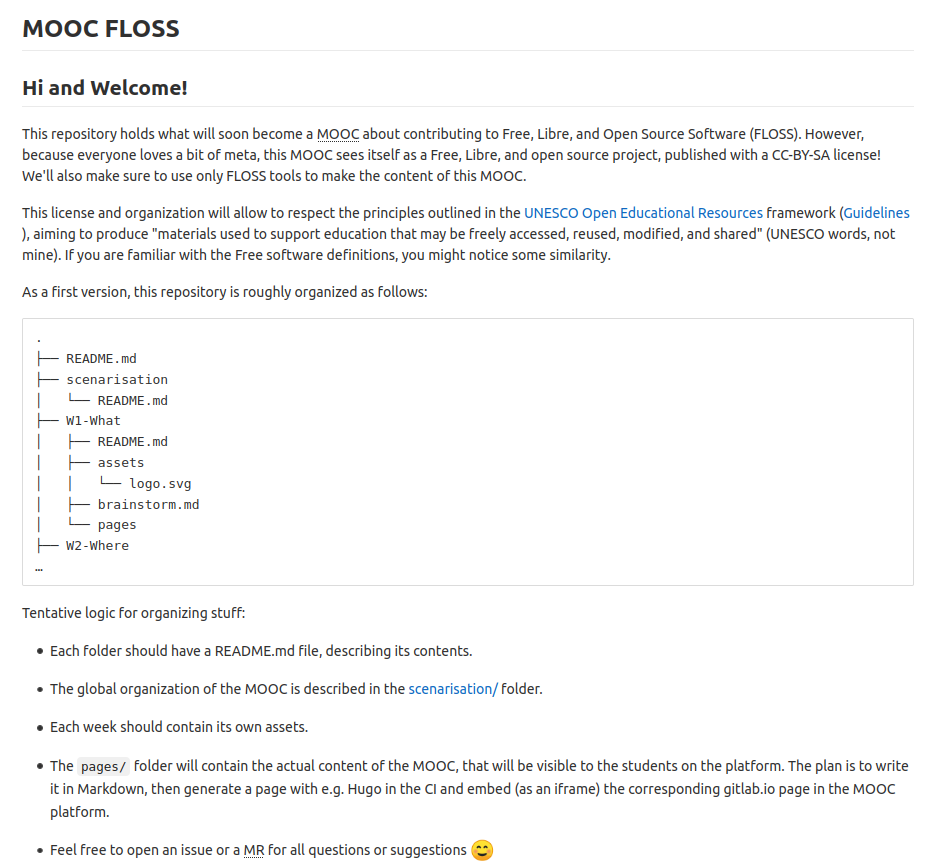
You are invited to contribute to the future « Contributing to Free-Libre Open Source Software » MOOC by Télécom Paris and Framasoft
Interested in contributing to the contents production of a MOOC about FLOSS contribution? You already have a contribution experience and think it can be useful to new contributors? Join us!
Leading Internet users into the world of contribution
Last September we were so delighted to learn that Marc Jeanmougin, a research engineer at Télécom Paris, wanted Framasoft to be associated with his online course projet on FLOSS contributions that had just been funded by the Institut Mines-Télécom.
We have been dreaming about it: a MOOC to learn how to contribute to free-libre software
Developing digital tools that facilitate individuals’ contributions is one of the lines of our Contributopia campaign. On this subject we already have set up Contribateliers (and their online version Confinateliers): workshops to discover how each of us can contribute to free-libre software. Implemented in 2018 in Lyon, those interventions now take place in cities (Lyon, Paris, Toulouse, Grenoble and Nantes) allowing people to contribute to the free-libre software and free culture in a user-friendly way.
This is also the case with the Contribulle project we are hosting: a platform where projects with the same free-libre software values are connected with those without enough skills and contributors who could give them a hand. This nice initiative is slowly taking shape and we think it will be a great success in the coming months.
Finally, the aim with this Contributing to FLOSS MOOC is to allow developers to get both a theoretical (what is it about?) and practical introduction (how to contact somebody? and how to contribute?) to the world of FLOSS contribution.
All these initiatives allow users of free-libre services to learn how to contribute and to stop using a software only as if it were a finished product.
Contributing to develop the Contributing to FLOSS MOOC
After a first day in October, talking about pedagogical sequencing in a small committee, the prefiguration team decided that given the MOOC subject, it would not be totally far-fetched to allow people who want to co-produce contents with us to do so.
We also have created a dedicated Matrix chatroom in order to have a daily and more informal exchange with you. Do not hesitate to join us there to learn more about this project.
We invite you to exchange in video conference on this project on February, 10th at 6:30pm. At the same time we will present you the general organization of the MOOC and the choices we have made both educationally (what angle on FLOSS we will try to take) and technically. We will also discuss how we envisage contributions to contents production.
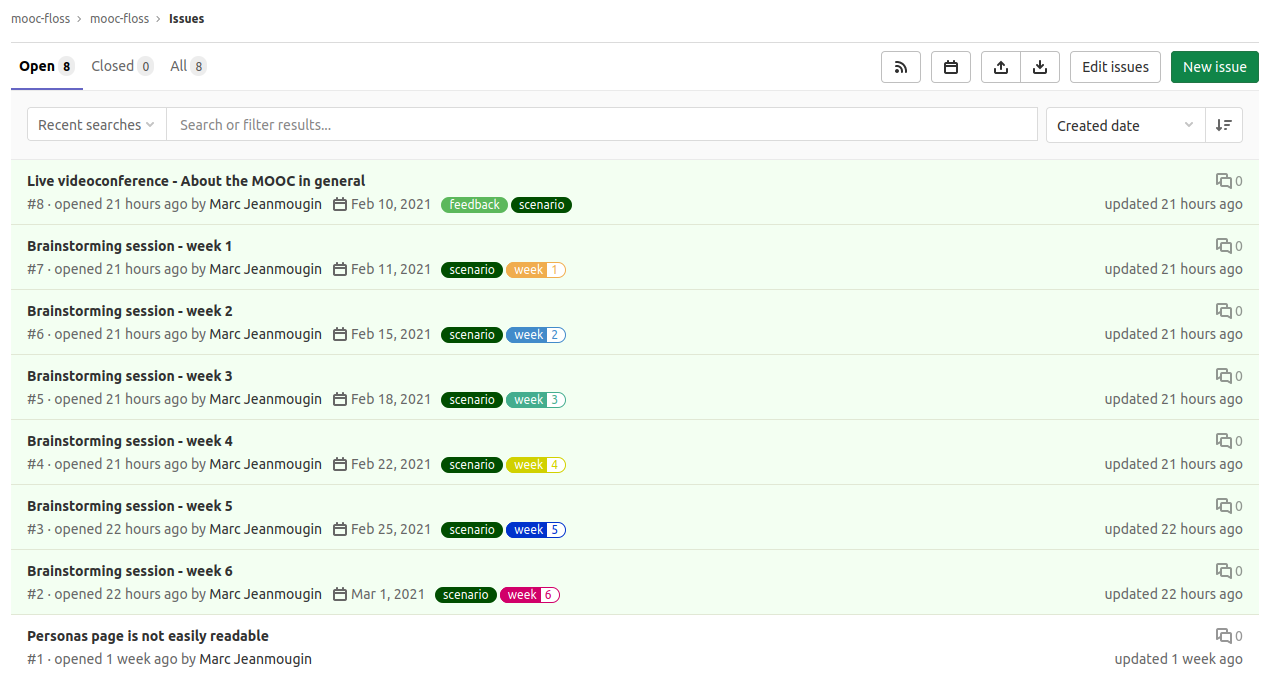
If after this first exchange you want to help us with contents preparation, you can participate in 6 other online brainstorming sessions, each one dedicated to the contents of one week of the MOOC. They will take place on Mondays and Thursdays between 6:30pm and 8pm from February 11th to March 1st (details of access and contents will be published on the gitlab issues with each session).
GitLab issues with details of access and contents of the 6 meetings we offer.
We hope we will see many of you at those different events. But as we know it’s not always easy to be available on a set time slot, we offer to collect your reactions, feedbacks or comments before each session on our repository. Do not hesitate to write down whatever comes to your mind!
Télécom Paris et Framasoft vous invitent à contribuer au futur MOOC « Contributing to Free-Libre and Open Source Software »
Participer à la production des contenus d’un MOOC dont le sujet est la contribution aux logiciels libres, ça vous tente ? Vous avez déjà contribué à des logiciels libres et vous pensez que votre expérience peut aider des apprenti·es contributeur·ices ? Rejoignez-nous !
Continuer à accompagner les internautes dans l’univers de la contribution
Lorsqu’en septembre dernier, Marc Jeanmougin, ingénieur de recherche à Télécom Paris, nous contactait pour nous informer que son projet de cours en ligne sur la contribution au logiciel libre venait d’obtenir un financement de l’Institut Mines-Télécom et qu’il souhaitait que Framasoft soit associé à ce projet, on a été super emballé·es !
Un MOOC (cours en ligne massivement ouvert) pour apprendre à contribuer au logiciel libre, on en rêvait !
C’est d’ailleurs l’un des axes de notre campagne Contributopia que de concrétiser des outils numériques qui facilitent les contributions de chacun·e. Dans ce domaine, nous avons déjà initié les Contribateliers (et leur version en ligne, les Confinateliers), des ateliers pour découvrir comment chacun·e d’entre nous peut contribuer au logiciel libre. Lancé en 2018 à Lyon, ce dispositif existe désormais dans 5 villes (Lyon, Paris, Toulouse, Grenoble et Nantes) et permet à toutes et tous de contribuer aux logiciels libres et à la culture libre en toute convivialité.
C’est aussi ce que nous faisons en offrant un hébergement au projet Contribulle, une plateforme de mise en relation entre des projets partageant les valeurs du logiciel libre et des communs qui manquent de compétences, et des contributeur·rices qui pourraient leur donner un coup de main. Cette chouette initiative prend doucement forme et on ne doute pas qu’elle rencontrera un fort succès dans les mois à venir.
Enfin, avec ce MOOC Contributing to FLOSS, l’objectif est de permettre à des développeur·euses d’avoir une introduction théorique (de quoi parle-t-on ?) comme pratique (comment entrer en contact, comment contribuer ?) à l’univers de la contribution au libre.
Toutes ces initiatives sont l’occasion pour les utilisateur·ices de services libres d’apprendre à contribuer et d’arrêter de consommer simplement le logiciel comme s’il était un produit fini.
Contribuer à la réalisation du MOOC Contributing to FLOSS
Après une première journée en petit comité en octobre pour échanger sur le séquençage pédagogique, l’équipe de préfiguration s’est dit que vu le sujet du MOOC, ce ne serait pas totalement tiré par les cheveux que de permettre à celles et ceux qui le souhaitent de co-produire avec nous les contenus.
Nous avons aussi créé un salon Matrix dédié afin de pouvoir échanger de manière plus informelle avec vous au quotidien. N’hésitez pas à nous y rejoindre pour avoir davantage de précisions sur ce projet.
Nous vous invitons à un temps d’échanges autour du projet le mercredi 10 février à 18h30 en visioconférence. Ce sera l’occasion de vous présenter l’organisation générale du MOOC et les choix que nous avons effectués, tant au plan pédagogique (quel angle sur les FLOSS nous essaierons de prendre) qu’au plan technique. Nous échangerons aussi sur la façon dont nous envisageons les contributions à la production des contenus.
Si à la suite de ce premier temps d’échanges, vous êtes partant·es pour nous aider sur la préparation des contenus, on vous propose de participer à 6 autres sessions de brainstorming en ligne, chacune de ces sessions étant dédiée aux contenus d’une semaine du MOOC. Ces sessions se tiendront les lundis et jeudis entre 18h30 et 20h sur la période du 11 février au 1er mars (les détails d’accès et des contenus discutés seront publiés sur les tickets associés à chaque session).
Tickets sur lesquels vous trouverez détails d’accès et contenus des 6 rendez-vous que nous vous proposons.
On vous espère nombreu·ses lors de ces différents rendez-vous. Mais comme nous savons qu’il n’est pas toujours évident de se libérer sur un créneau fixe, nous proposons de recueillir en amont de chaque session vos réactions, notes ou commentaires. N’hésitez donc pas à aller y noter ce qui vous passe par la tête !
Utilisateurs libres ou domestiqués ? WhatsApp et les autres
Le mois dernier, WhatsApp a publié une nouvelle politique de confidentialité avec cette injonction : acceptez ces nouvelles conditions, ou supprimez WhatsApp de votre smartphone. La transmission de données privées à la maison-mère Facebook a suscité pour WhatsApp un retour de bâton retentissant et un nombre significatif d’utilisateurs et utilisatrices a migré vers d’autres applications, en particulier Signal.
Cet épisode parmi d’autres dans la guerre des applications de communication a suscité quelques réflexions plus larges sur la capture des utilisateurs et utilisatrices par des entreprises qui visent selon Rohan Kumar à nous « domestiquer »…
Je n’ai jamais utilisé WhatsApp et ne l’utiliserai jamais. Et pourtant j’éprouve le besoin d’écrire un article sur WhatsApp car c’est une parfaite étude de cas pour comprendre une certaine catégorie de modèles commerciaux : la « domestication des utilisateurs ».
La domestication des utilisateurs est, selon moi, l’un des principaux problèmes dont souffre l’humanité et il mérite une explication détaillée.
Cette introduction générale étant faite, commençons.
L’ascension de Whatsapp
Pour les personnes qui ne connaissent pas, WhatsApp est un outil très pratique pour Facebook car il lui permet de facilement poursuivre sa mission principale : l’optimisation et la vente du comportement humain (communément appelé « publicité ciblée »). WhatsApp a d’abord persuadé les gens d’y consentir en leur permettant de s’envoyer des textos par Internet, chose qui était déjà possible, en associant une interface simple et un marketing efficace. L’application s’est ensuite développée pour inclure des fonctionnalités comme les appels vocaux et vidéos gratuits. Ces appels gratuits ont fait de WhatsApp une plate-forme de communication de référence dans de nombreux pays.
WhatsApp a construit un effet de réseau grâce à son système propriétaire incompatible avec d’autres clients de messagerie instantanée : les utilisateurs existants sont captifs car quitter WhatsApp signifie perdre la capacité de communiquer avec les utilisateurs de WhatsApp. Les personnes qui veulent changer d’application doivent convaincre tous leurs contacts de changer aussi ; y compris les personnes les moins à l’aise avec la technologie, celles qui avaient déjà eu du mal à apprendre à se servir de WhatsApp.
Dans le monde de WhatsApp, les personnes qui souhaitent rester en contact doivent obéir aux règles suivantes :
• Chacun se doit d’utiliser uniquement le client propriétaire WhatsApp pour envoyer des messages ; développer des clients alternatifs n’est pas possible.
• Le téléphone doit avoir un système d’exploitation utilisé par le client. Les développeurs de WhatsApp ne développant que pour les systèmes d’exploitation les plus populaires, le duopole Android et iOS en sort renforcé.
• Les utilisateurs dépendent entièrement des développeurs de WhatsApp. Si ces derniers décident d’inclure des fonctionnalités hostiles dans l’application, les utilisateurs doivent s’en contenter. Ils ne peuvent pas passer par un autre serveur ou un autre client de messagerie sans quitter WhatsApp et perdre la capacité à communiquer avec leurs contacts WhatsApp.
La domestication des utilisateurs
WhatsApp s’est développé en piégeant dans son enclos des créatures auparavant libres, et en changeant leurs habitudes pour créer une dépendance à leurs maîtres. Avec le temps, il leur est devenu difficile voire impossible de revenir à leur mode de vie précédent. Ce processus devrait vous sembler familier : il est étrangement similaire à la domestication des animaux. J’appelle ce type d’enfermement propriétaire « domestication des utilisateurs » : la suppression de l’autonomie des utilisateurs, pour les piéger et les mettre au service du fournisseur.
J’ai choisi cette métaphore car la domestication animale est un processus graduel qui n’est pas toujours volontaire, qui implique typiquement qu’un groupe devienne dépendant d’un autre. Par exemple, nous savons que la domestication du chien a commencé avec sa sociabilisation, ce qui a conduit à une sélection pas totalement artificielle promouvant des gènes qui favorisent plus l’amitié et la dépendance envers les êtres humains1.
Qu’elle soit délibérée ou non, la domestication des utilisateurs suit presque toujours ces trois mêmes étapes :
1. Un haut niveau de dépendance des utilisateurs envers un fournisseur de logiciel
2. Une incapacité des utilisateurs à contrôler le logiciel, via au moins une des méthodes suivantes :
2.1. Le blocage de la modification du logiciel
2.2. Le blocage de la migration vers une autre plate-forme
3. L’exploitation des utilisateurs désormais captifs et incapables de résister.
L’exécution des deux premières étapes a rendu les utilisateurs de WhatsApp vulnérables à la domestication. Avec ses investisseurs à satisfaire, WhatsApp avait toutes les raisons d’implémenter des fonctionnalités hostiles, sans subir aucune conséquence. Donc, évidemment, il l’a fait.
La chute de WhatsApp
La domestication a un but : elle permet à une espèce maîtresse d’exploiter les espèces domestiquées pour son propre bénéfice. Récemment, WhatsApp a mis à jour sa politique de confidentialité pour permettre le partage de données avec sa maison mère, Facebook. Les personnes qui avaient accepté d’utiliser WhatsApp avec sa précédente politique de confidentialité avaient donc deux options : accepter la nouvelle politique ou perdre l’accès à WhatsApp. La mise à jour de la politique de confidentialité est un leurre classique : WhatsApp a appâté et ferré ses utilisateurs avec une interface élégante et une impression de confidentialité, les a domestiqués pour leur ôter la capacité de migrer, puis est revenu sur sa promesse de confidentialité avec des conséquences minimes. Chaque étape de ce processus a permis la suivante ; sans domestication, il serait aisé pour la plupart des utilisateurs de quitter l’application sans douleur.
Celles et ceux parmi nous qui sonnaient l’alarme depuis des années ont connu un bref moment de félicité sadique quand le cliché à notre égard est passé de « conspirationnistes agaçants et paranoïaques » à simplement « agaçants ».
Une tentative de dérapage contrôlé
L’opération de leurre et de ferrage a occasionné une réaction contraire suffisante pour qu’une minorité significative d’utilisateurs migre ; leur nombre a été légèrement supérieur la quantité négligeable que WhatsApp attendait probablement. En réponse, WhatsApp a repoussé le changement et publié la publicité suivante :
Cette publicité liste différentes données que WhatsApp ne collecte ni ne partage. Dissiper des craintes concernant la collecte de données en listant les données non collectées est trompeur. WhatsApp ne collecte pas d’échantillons de cheveux ou de scans rétiniens ; ne pas collecter ces informations ne signifie pas qu’il respecte la confidentialité parce que cela ne change pas ce que WhatsApp collecte effectivement.
Dans cette publicité WhatsApp nie conserver « l’historique des destinataires des messages envoyés ou des appels passés ». Collecter des données n’est pas la même chose que « conserver l’historique » ; il est possible de fournir les métadonnées à un algorithme avant de les jeter. Un modèle peut alors apprendre que deux utilisateurs s’appellent fréquemment sans conserver l’historique des métadonnées de chaque appel. Le fait que l’entreprise ait spécifiquement choisi de tourner la phrase autour de l’historique implique que WhatsApp soit collecte déjà cette sorte de données soit laisse la porte ouverte afin de les collecter dans le futur.
Une balade à travers la politique de confidentialité réelle de WhatsApp du moment (ici celle du 4 janvier) révèle qu’ils collectent des masses de métadonnées considérables utilisées pour le marketing à travers Facebook.
Liberté logicielle
Face à la domestication des utilisateurs, fournir des logiciels qui aident les utilisateurs est un moyen d’arrêter leur exploitation. L’alternative est simple : que le service aux utilisateurs soit le but en soi.
Pour éviter d’être contrôlés par les logiciels, les utilisateurs doivent être en position de contrôle. Les logiciels qui permettent aux utilisateurs d’être en position de contrôles sont appelés logiciels libres. Le mot « libre » dans ce contexte a trait à la liberté plutôt qu’au prix2. La liberté logicielle est similaire au concept d’open-source, mais ce dernier est focalisé sur les bénéfices pratiques plutôt qu’éthiques. Un terme moins ambigu qui a trait naturellement à la fois à la gratuité et l’open-source est FOSS3.
D’autres ont expliqué les concepts soutenant le logiciel libre mieux que moi, je n’irai pas dans les détails. Cela se décline en quatre libertés essentielles :
la liberté d’exécuter le programme comme vous le voulez, quel que soit le but
la liberté d’étudier comment le programme fonctionne, et de le modifier à votre souhait
la liberté de redistribuer des copies pour aider d’autres personnes
la liberté de distribuer des copies de votre version modifiée aux autres
Gagner de l’argent avec des FOSS
L’objection la plus fréquente que j’entends, c’est que gagner de l’argent serait plus difficile avec le logiciel libre qu’avec du logiciel propriétaire.
Pour gagner de l’argent avec les logiciels libres, il s’agit de vendre du logiciel comme un complément à d’autres services plus rentables. Parmi ces services, on peut citer la vente d’assistance, la personnalisation, le conseil, la formation, l’hébergement géré, le matériel et les certifications. De nombreuses entreprises utilisent cette approche au lieu de créer des logiciels propriétaires : Red Hat, Collabora, System76, Purism, Canonical, SUSE, Hashicorp, Databricks et Gradle sont quelques noms qui viennent à l’esprit.
L’hébergement n’est pas un panier dans lequel vous avez intérêt à déposer tous vos œufs, notamment parce que des géants comme Amazon Web Service peuvent produire le même service pour un prix inférieur. Être développeur peut donner un avantage dans des domaines tels que la personnalisation, le support et la formation ; cela n’est pas aussi évident en matière d’hébergement.
Les logiciels libres ne suffisent pas toujours
Le logiciel libre est une condition nécessaire mais parfois insuffisante pour établir une immunité contre la domestication. Deux autres conditions impliquent de la simplicité et des plates-formes ouvertes.
Simplicité
Lorsqu’un logiciel devient trop complexe, il doit être maintenu par une vaste équipe. Les utilisateurs qui ne sont pas d’accord avec un fournisseur ne peuvent pas facilement dupliquer et maintenir une base de code de plusieurs millions de lignes, surtout si le logiciel en question contient potentiellement des vulnérabilités de sécurité. La dépendance à l’égard du fournisseur peut devenir très problématique lorsque la complexité fait exploser les coûts de développement ; le fournisseur peut alors avoir recours à la mise en œuvre de fonctionnalités hostiles aux utilisateurs pour se maintenir à flot.
Un logiciel complexe qui ne peut pas être développé par personne d’autre que le fournisseur crée une dépendance, première étape vers la domestication de l’utilisateur. Cela suffit à ouvrir la porte à des développements problématiques.
Étude de cas : Mozilla et le Web
Mozilla était une lueur d’espoir dans la guerre des navigateurs, un espace dominé par la publicité, la surveillance et le verrouillage par des distributeurs. Malheureusement, le développement d’un moteur de navigation est une tâche monumentale, assez difficile pour qu’Opera et Microsoft abandonnent leur propre moteur et s’équipent de celui de Chromium. Les navigateurs sont devenus bien plus que des lecteurs de documents : ils ont évolué vers des applications dotées de propres technologies avec l’accélération GPU, Bluetooth, droits d’accès, énumération des appareils, codecs de médias groupés, DRM4, API d’extension, outils de développement… la liste est longue. Il faut des milliards de dollars par an pour répondre aux vulnérabilités d’une surface d’attaque aussi massive et suivre des standards qui se développent à un rythme tout aussi inquiétant. Ces milliards doivent bien venir de quelque part.
Mozilla a fini par devoir faire des compromis majeurs pour se maintenir à flot. L’entreprise a passé des contrats de recherche avec des sociétés manifestement hostiles aux utilisateurs et a ajouté au navigateur des publicités (et a fait machine arrière) et des bloatwares, comme Pocket, ce logiciel en tant que service partiellement financé par la publicité. Depuis l’acquisition de Pocket (pour diversifier ses sources de revenus), Mozilla n’a toujours pas tenu ses promesses : mettre le code de Pocket en open-source, bien que les clients soient passés en open-source, le code du serveur reste propriétaire. Rendre ce code open-source, et réécrire certaines parties si nécessaire serait bien sûr une tâche importante en partie à cause de la complexité de Pocket.
Les navigateurs dérivés importants comme Pale Moon sont incapables de suivre la complexité croissante des standards modernes du Web tels que les composants web (Web Components). En fait, Pale Moon a récemment dû migrer son code hors de GitHub depuis que ce dernier a commencé à utiliser des composants Web. Il est pratiquement impossible de commencer un nouveau navigateur à partir de zéro et de rattraper les mastodontes qui ont fonctionné avec des budgets annuels exorbitants pendant des décennies. Les utilisateurs ont le choix entre le moteur de navigation développé par Mozilla, celui d’une entreprise publicitaire (Blink de Google) ou celui d’un fournisseur de solutions monopolistiques (WebKit d’Apple). A priori, WebKit ne semble pas trop mal, mais les utilisateurs seront impuissants si jamais Apple décide de faire marche arrière.
Pour résumer : la complexité du Web a obligé Mozilla, le seul développeur de moteur de navigation qui déclare être « conçu pour les gens, pas pour l’argent », à mettre en place des fonctionnalités hostiles aux utilisateurs dans son navigateur. La complexité du Web a laissé aux utilisateurs un choix limité entre trois grands acteurs en conflit d’intérêts, dont les positions s’enracinent de plus en plus avec le temps.
Attention, je ne pense pas que Mozilla soit une mauvaise organisation ; au contraire, c’est étonnant qu’ils soient capables de faire autant, sans faire davantage de compromis dans un système qui l’exige. Leur produit de base est libre et open-source, et des composants externes très légèrement modifiés suppriment des anti-fonctionnalités.
Plates-formes ouvertes
Pour éviter qu’un effet de réseau ne devienne un verrouillage par les fournisseurs, les logiciels qui encouragent naturellement un effet de réseau doivent faire partie d’une plate-forme ouverte. Dans le cas des logiciels de communication/messagerie, il devrait être possible de créer des clients et des serveurs alternatifs qui soient compatibles entre eux, afin d’éviter les deux premières étapes de la domestication de l’utilisateur.
Étude de cas : Signal
Depuis qu’un certain vendeur de voitures a tweeté « Utilisez Signal », un grand nombre d’utilisateurs ont docilement changé de messagerie instantanée. Au moment où j’écris ces lignes, les clients et les serveurs Signal sont des logiciels libres et open-source, et utilisent certains des meilleurs algorithmes de chiffrement de bout en bout qui existent ; cependant, je ne suis pas fan.
Bien que les clients et les serveurs de Signal soient des logiciels libres et gratuits, Signal reste une plate-forme fermée. Le cofondateur de Signal, Moxie Marlinspike, est très critique à l’égard des plates-formes ouvertes et fédérées. Il décrit dans un article de blog les raisons pour lesquelles Signal reste une plate-forme fermée5. Cela signifie qu’il n’est pas possible de développer un serveur alternatif qui puisse être supporté par les clients Signal, ou un client alternatif qui supporte les serveurs Signal. La première étape de la domestication des utilisateurs est presque achevée.
Outre qu’il n’existe qu’un seul client et qu’un seul serveur, il n’existe qu’un seul fournisseur de serveur Signal : Signal Messenger LLC. La dépendance des utilisateurs vis-à-vis de ce fournisseur de serveur central leur a explosé au visage, lors de la récente croissance de Signal qui a provoqué des indisponibilités de plus d’une journée, mettant les utilisateurs de Signal dans l’incapacité d’envoyer des messages, jusqu’à ce que le fournisseur unique règle le problème.
Certains ont quand même essayé de développer des clients alternatifs : un fork Signal appelé LibreSignal a tenté de faire fonctionner Signal sur des systèmes Android respectueux de la vie privée, sans les services propriétaires Google Play. Ce fork s’est arrêté après que Moxie eut clairement fait savoir qu’il n’était pas d’accord avec une application tierce utilisant les serveurs Signal. La décision de Moxie est compréhensible, mais la situation aurait pu être évitée si Signal n’avait pas eu à dépendre d’un seul fournisseur de serveurs.
Si Signal décide de mettre à jour ses applications pour y inclure une fonction hostile aux utilisateurs, ces derniers seront tout aussi démunis qu’ils le sont actuellement avec WhatsApp. Bien que je ne pense pas que ce soit probable, la plate-forme fermée de Signal laisse les utilisateurs vulnérables à leur domestication.
Même si je n’aime pas Signal, je l’ai tout de même recommandé à mes amis non-techniques, parce que c’était le seul logiciel de messagerie instantanée assez privé pour moi et assez simple pour eux. S’il y avait eu la moindre intégration à faire (création de compte, ajout manuel de contacts, etc.), un de mes amis serait resté avec Discord ou WhatsApp. J’ajouterais bien quelque chose de taquin comme « tu te reconnaîtras » s’il y avait la moindre chance pour qu’il arrive aussi loin dans l’article.
Réflexions
Les deux études de cas précédentes – Mozilla et Signal – sont des exemples d’organisations bien intentionnées qui rendent involontairement les utilisateurs vulnérables à la domestication. La première présente un manque de simplicité mais incarne un modèle de plate-forme ouverte. La seconde est une plate-forme fermée avec un degré de simplicité élevé. L’intention n’entre pas en ligne de compte lorsqu’on examine les trois étapes et les contre-mesures de la domestication des utilisateurs. @paulsnar@mastodon.technology a souligné un conflit potentiel entre la simplicité et les plates-formes ouvertes :
j’ai l’impression qu’il y a une certaine opposition entre simplicité et plates-formes ouvertes ; par exemple Signal est simple précisément parce que c’est une plate-forme fermée, ou du moins c’est ce qu’explique Moxie. À l’inverse, Matrix est superficiellement simple, mais le protocole est en fait (à mon humble avis) assez complexe, précisément parce que c’est une plate-forme ouverte.
Je n’ai pas de réponse simple à ce dilemme. Il est vrai que Matrix est extrêmement complexe (comparativement à des alternatives comme IRC ou même XMPP), et il est vrai qu’il est plus difficile de construire une plate-forme ouverte. Cela étant dit, il est certainement possible de maîtriser la complexité tout en développant une plate-forme ouverte : Gemini, IRC et le courrier électronique en sont des exemples. Si les normes de courrier électronique ne sont pas aussi simples que Gemini ou IRC, elles évoluent lentement ; cela évite aux implémentations de devoir rattraper le retard, comme c’est le cas pour les navigateurs Web ou les clients/serveurs Matrix.
Tous les logiciels n’ont pas besoin de brasser des milliards. La fédération permet aux services et aux réseaux comme le Fediverse et XMPP de s’étendre à un grand nombre d’utilisateurs sans obliger un seul léviathan du Web à vendre son âme pour payer la facture. Bien que les modèles commerciaux anti-domestication soient moins rentables, ils permettent encore la création des mêmes technologies qui ont été rendues possibles par la domestication des utilisateurs. Tout ce qui manque, c’est un budget publicitaire ; la plus grande publicité que reçoivent certains de ces projets, ce sont de longs billets de blog non rémunérés.
Peut-être n’avons-nous pas besoin de rechercher la croissance à tout prix et d’essayer de « devenir énorme ». Peut-être pouvons-nous nous arrêter, après avoir atteint une durabilité et une sécurité financière, et permettre aux gens de faire plus avec moins.
Notes de clôture
Avant de devenir une sorte de manifeste, ce billet se voulait une version étendue d’un commentaire que j’avais laissé suite à un message de Binyamin Green sur le Fediverse.
J’avais décidé, à l’origine, de le développer sous sa forme actuelle pour des raisons personnelles. De nos jours, les gens exigent une explication approfondie chaque fois que je refuse d’utiliser quelque chose que « tout le monde » utilise (WhatsApp, Microsoft Office, Windows, macOS, Google Docs…).
Puis, ils et elles ignorent généralement l’explication, mais s’attendent quand même à en avoir une. La prochaine fois que je les rencontrerai, ils auront oublié notre conversation précédente et recommenceront le même dialogue. Justifier tous mes choix de vie en envoyant des assertions logiques et correctes dans le vide – en sachant que tout ce que je dis sera ignoré – est un processus émotionnellement épuisant, qui a fait des ravages sur ma santé mentale ces dernières années ; envoyer cet article à mes amis et changer de sujet devrait me permettre d’économiser quelques cheveux gris dans les années à venir.
Cet article s’appuie sur des écrits antérieurs de la Free Software Foundation, du projet GNU et de Richard Stallman. Merci à Barna Zsombor de m’avoir fait de bon retours sur IRC.
Mosaïque romaine, Orphée apprivoisant les animaux, photo par mharrsch, licence CC BY-NC-SA 2.0
Mais comme la haute autorité n’a toujours pas atterri dans la poubelle de l’histoire à laquelle elle est pourtant destinée, et enfonce encore une fois le clou avec une nouvelle campagne de pub, notre dessinateur remet le couvert également…
Hadopi dans le formol
Cela fait déjà 11 ans que la Hadopi suce de la finance publique, avec un budget de plus 82 millions d’euros depuis sa création (pour 87 000 € d’amendes émises).
Récemment, la sangsue a publié une nouvelle campagne de communication tonitruante, #TesImpôts, qui reste dans la grande tradition de la haute autorité d’être toujours à côté de la plaque (ou en retard de 15 ans).
Voilà, Hadopi a 11 ans et comme le dit la chanson, le temps ne fait rien à l’affaire…
Car en matière de nostalgie, je me permets de vous rappeler cette première campagne de pub d’Hadopi, datant de 2011 et présentant Emma Leprince, une chanteuse de grosse soupe insipide « néo-électro » dans le futur…
… mais qui est, en 2011, une gamine qui se prend pour Shakira dans sa chambre.
Pour finir, notons que dans cette fameuse pub, Emma Leprince est présentée révélation française de l’année…
2022.
Et puisqu’Emma Leprince n’a pas l’air partie pour être révélation de l’année 2022, je propose qu’on dissolve la Hadopi qui a visiblement failli à sa mission divine.
Le Fediverse et l’avenir des réseaux décentralisés
Le Fediverse est un réseau social multiforme qui repose sur une fédération de serveurs interconnectés. C’est un phénomène assez jeune encore, mais dont la croissance suscite déjà l’intérêt et des questionnements. Parmi les travaux d’analyse qui s’efforcent de prendre une distance critique, nous vous proposons « Sept thèses sur le Fediverse et le devenir du logiciel libre »
Cette traduction Framalang vous arrive aujourd’hui avec presque un an de retard. Le document était intégralement traduit par l’équipe de Framalang dès le printemps 2020, mais nous avons tergiversé sur sa publication, car nous souhaitions un support différent du blog, où les contributions auraient pu se répondre. Mais entre le premier confinement et d’autres projets qui sont venus s’intercaler… Cependant le débat reste possible, non seulement les commentaires sont ouverts (et modérés) comme d’habitude, mais nous serions ravis de recueillir d’autres contributions qui voudraient s’emparer du thème du Fediverse pour apporter un nouvel éclairage sur ce phénomène encore jeune et en devenir. N’hésitez pas à publier votre analyse sur un blog personnel ou à défaut, ici même si vous le souhaitez.
Référence : Aymeric Mansoux et Roel Roscam Abbing, « Seven Theses on the Fediverse and the becoming of FLOSS », dans Kristoffer Gansing et Inga Luchs (éds.), The Eternal Network. The Ends and Becomings of Network Culture, Institute of Network Cultures, Amsterdam, 2020, p. 124-140. En ligne.
Ces dernières années, dans un contexte de critiques constantes et de lassitude généralisée associées aux plates-formes de médias sociaux commerciaux1, le désir de construire des alternatives s’est renforcé. Cela s’est traduit par une grande variété de projets animés par divers objectifs. Les projets en question ont mis en avant leurs différences avec les médias sociaux des grandes plates-formes, que ce soit par leur éthique, leur structure, les technologies qui les sous-tendent, leurs fonctionnalités, l’accès au code source ou encore les communautés construites autour d’intérêts spécifiques qu’ils cherchent à soutenir. Bien que diverses, ces plates-formes tendent vers un objectif commun : remettre clairement en question l’asservissement à une plate-forme unique dans le paysage des médias sociaux dominants. Par conséquent, ces projets nécessitent différents niveaux de décentralisation et d’interopérabilité en termes d’architecture des réseaux et de circulation de données. Ces plates-formes sont regroupées sous le terme de « Fédiverse », un mot-valise composé de « Fédération » et « univers ». La fédération est un concept qui vient de la théorie politique par lequel divers acteurs qui se constituent en réseau décident de coopérer tous ensemble. Les pouvoirs et responsabilités sont distribués à mesure que se forme le réseau. Dans le contexte des médias sociaux, les réseaux fédérés sont portés par diverses communautés sur différents serveurs qui peuvent interagir mutuellement, plutôt qu’à travers un logiciel ou une plate-forme unique. Cette idée n’est pas nouvelle, mais elle a récemment gagné en popularité et a réactivé les efforts visant à construire des médias sociaux alternatifs2.
Les tentatives précédentes de créer des plates-formes de médias sociaux fédérés venaient des communautés FLOSS (Free/Libre and Open Source software, les logiciels libres et open source3) qui avaient traditionnellement intérêt à procurer des alternatives libres aux logiciels propriétaires et privateurs dont les sources sont fermées. En tant que tels, ces projets se présentaient en mettant l’accent sur la similarité de leurs fonctions avec les plates-formes commerciales tout en étant réalisés à partir de FLOSS. Principalement articulées autour de l’ouverture des protocoles et du code source, ces plates-formes logicielles ne répondaient aux besoins que d’une audience modeste d’utilisateurs et de développeurs de logiciels qui étaient en grande partie concernés par les questions typiques de la culture FLOSS.
La portée limitée de ces tentatives a été dépassée en 2016 avec l’apparition de Mastodon, une combinaison de logiciels client et serveur pour les médias sociaux fédérés. Mastodon a été rapidement adopté par une communauté diversifiée d’utilisateurs et d’utilisatrices, dont de nombreuses personnes habituellement sous-représentées dans les FLOSS : les femmes, les personnes de couleur et les personnes s’identifiant comme LGBTQ+. En rejoignant Mastodon, ces communautés moins représentées ont remis en question la dynamique des environnements FLOSS existants ; elles ont également commencé à contribuer autant au code qu’à la contestation du modèle unique dominant des médias sociaux commerciaux dominants. Ce n’est pas une coïncidence si ce changement s’est produit dans le sillage du Gamergate4 en 2014, de la montée de l’alt-right et des élections présidentielles américaines de 2016. Fin 2017, Mastodon a dépassé le million d’utilisateurs qui voulaient essayer le Fédiverse comme une solution alternative aux plates-formes de médias sociaux commerciaux. Ils ont pu y tester par eux-mêmes si une infrastructure différente peut ou non conduire à des discours, des cultures et des espaces sûrs (safe spaces) différents.
Aujourd’hui, le Fédiverse comporte plus de 3,5 millions de comptes répartis sur près de 5 000 serveurs, appelés « instances », qui utilisent des projets logiciels tels que Friendica, Funkwhale, Hubzilla, Mastodon, Misskey, PeerTube, PixelFed et Pleroma, pour n’en citer que quelques-uns5. La plupart de ces instances peuvent être interconnectées et sont souvent focalisées sur une pratique, une idéologie ou une activité professionnelle spécifique. Dans cette optique, le projet Fédiverse démontre qu’il est non seulement techniquement possible de passer de gigantesques réseaux sociaux universels à de petites instances interconnectées, mais qu’il répond également à un besoin concret.
On peut considérer que la popularité actuelle du Fédiverse est due à deux tendances conjointes. Tout d’abord, le désir d’opérer des choix techniques spécifiques pour résoudre les problèmes posés par les protocoles fermés et les plates-formes propriétaires. Deuxièmement, une volonté plus large des utilisateurs de récupérer leur souveraineté sur les infrastructures des médias sociaux. Plus précisément, alors que les plates-formes de médias sociaux commerciaux ont permis à beaucoup de personnes de publier du contenu en ligne, le plus grand impact du Web 2.0 a été le découplage apparent des questions d’infrastructure des questions d’organisation sociale. Le mélange de systèmes d’exploitation et de systèmes sociaux qui a donné naissance à la culture du Net6 a été remplacé par un système de permissions et de privilèges limités pour les utilisateurs. Ceux qui s’engagent dans le Fédiverse travaillent à défaire ce découplage. Ils veulent contribuer à des infrastructures de réseau qui soient plus honnêtes quant à leurs idéologies sous-jacentes.
Ces nouvelles infrastructures ne se cachent pas derrière des manipulations d’idées en trompe-l’œil comme l’ouverture, l’accès universel ou l’ingénierie apolitique. Bien qu’il soit trop tôt aujourd’hui pour dire si le Fédiverse sera à la hauteur des attentes de celles et ceux qui la constituent et quel sera son impact à long terme sur les FLOSS, il est déjà possible de dresser la carte des transformations en cours, ainsi que des défis à relever dans ce dernier épisode de la saga sans fin de la culture du Net et de l’informatique. C’est pourquoi nous présentons sept thèses sur le Fédiverse et le devenir des FLOSS, dans l’espoir d’ouvrir le débat autour de certaines des questions les plus urgentes qu’elles soulèvent.
« interlace » par Joachim Aspenlaub Blattboldt, licence CC BY-NC-ND 2.0
Nous reconnaissons volontiers que toute réflexion sérieuse sur la culture du Net aujourd’hui doit traiter de la question des mèmes d’une façon ou d’une autre. Mais que peut-on ajouter au débat sur les mèmes en 2020 ? Il semble que tout ait déjà été débattu, combattu et exploité jusqu’à la corde par les universitaires comme par les artistes. Que nous reste-t-il à faire sinon nous tenir régulièrement au courant des derniers mèmes et de leur signification ? On oublie trop souvent que de façon cruciale, les mèmes ne peuvent exister ex nihilo. Il y a des systèmes qui permettent leur circulation et leur amplification : les plateformes de médias sociaux.
Les plateformes de médias sociaux ont démocratisé la production et la circulation des mèmes à un degré jamais vu jusqu’alors. De plus, ces plateformes se sont développées en symbiose avec la culture des mèmes sur Internet. Les plateformes de médias sociaux commerciaux ont été optimisées et conçues pour favoriser les contenus aptes à devenir des mèmes. Ces contenus encouragent les réactions et la rediffusion, ils participent à une stratégie de rétention des utilisateurs et de participation au capitalisme de surveillance. Par conséquent, dans les environnements en usage aujourd’hui pour la majeure partie des communications en ligne, presque tout est devenu un mème, ou doit afficher l’aptitude à en devenir un pour survivre — du moins pour être visible — au sein d’un univers de fils d’actualités gouvernés par des algorithmes et de flux contrôlés par des mesures7.
Comme les médias sociaux sont concentrés sur la communication et les interactions, on a complètement sous-estimé la façon dont les mèmes deviendraient bien plus que des vecteurs stratégiquement conçus pour implanter des idées, ou encore des trucs amusants et viraux à partager avec ses semblables. Ils sont devenus un langage, un argot, une collection de signes et de symboles à travers lesquels l’identité culturelle ou sous-culturelle peut se manifester. La circulation de tels mèmes a en retour renforcé certains discours politiques qui sont devenus une préoccupation croissante pour les plateformes. En effet, pour maximiser l’exploitation de l’activité des utilisateurs, les médias sociaux commerciaux doivent trouver le bon équilibre entre le laissez-faire et la régulation.
Ils tentent de le faire à l’aide d’un filtrage algorithmique, de retours d’utilisateurs et de conditions d’utilisation. Cependant, les plateformes commerciales sont de plus en plus confrontées au fait qu’elles ont créé de véritables boites de Pétri permettant à toutes sortes d’opinions et de croyances de circuler sans aucun contrôle, en dépit de leurs efforts visant à réduire et façonner le contenu discursif de leurs utilisateurs en une inoffensive et banale substance compatible avec leur commerce.
Malgré ce que les plateformes prétendent dans leurs campagnes de relations publiques ou lors des auditions des législateurs, il est clair qu’aucun solutionnisme technologique ni aucun travail externalisé et précarisé réalisé par des modérateurs humains traumatisés8 ne les aidera à reprendre le contrôle. En conséquence de l’augmentation de la surveillance menée par les plateformes de médias sociaux commerciaux, tous ceux qui sont exclus ou blessés dans ces environnements se sont davantage intéressés à l’idée de migrer sur d’autres plateformes qu’ils pourraient maîtriser eux-mêmes.
Les raisons incitant à une migration varient. Des groupes LGBTQ+ cherchent des espaces sûrs pour éviter l’intimidation et le harcèlement. Des suprémacistes blancs recherchent des plateformes au sein desquelles leur interprétation de la liberté d’expression n’est pas contestée. Raddle, un clone radicalisé, s’est développé à la suite de son exclusion du forum Reddit original ; à l’extrême-droite, il y a Voat, un autre clone de Reddit9. Ces deux plateformes ont développé leurs propres FLOSS en réponse à leur exclusion.
Au-delà de l’accès au code source, ce qui vaut aux FLOSS la considération générale, on ignore étonnamment l’un des avantages essentiels et historiques de la pratique des FLOSS : la capacité d’utiliser le travail des autres et de s’appuyer sur cette base. Il semble important aujourd’hui de développer le même logiciel pour un public réduit, et de s’assurer que le code source n’est pas influencé par les contributions d’une autre communauté. C’est une évolution récente dans les communautés FLOSS, qui ont souvent défendu que leur travail est apolitique.
C’est pourquoi, si nous nous mettons à évoquer les mèmes aujourd’hui, nous devons parler de ces plateformes de médias sociaux. Nous devons parler de ces environnements qui permettent, pour le meilleur comme pour le pire, une sédimentation du savoir : en effet, lorsqu’un discours spécifique s’accumule en ligne, il attire et nourrit une communauté, via des boucles de rétroaction qui forment des assemblages mémétiques. Nous devons parler de ce processus qui est permis par les Floss et qui en affecte la perception dans le même temps. Les plateformes de médias sociaux commerciaux ont décidé de censurer tout ce qui pourrait mettre en danger leurs affaires, tout en restant ambivalentes quant à leur prétendue neutralité10.
Mais contrairement à l’exode massif de certaines communautés et à leur repli dans la conception de leur propre logiciel, le Fédiverse offre plutôt un vaste système dans lequel les communautés peuvent être indépendantes tout en étant connectées à d’autres communautés sur d’autres serveurs. Dans une situation où la censure ou l’exil en isolement étaient les seules options, la fédération ouvre une troisième voie. Elle permet à une communauté de participer aux échanges ou d’entrer en conflit avec d’autres plateformes tout en restant fidèle à son cadre, son idéologie et ses intérêts.
Dès lors, deux nouveaux scénarios sont possibles : premièrement, une culture en ligne localisée pourrait être mise en place et adoptée dans le cadre de la circulation des conversations dans un réseau de communication partagé. Deuxièmement, des propos mémétiques extrêmes seraient susceptibles de favoriser l’émergence d’une pensée axée sur la dualité amis/ennemis entre instances, au point que les guerres de mèmes et la propagande simplistes seraient remplacés par des guerres de réseaux.
« Network » par photobunny, licence CC BY-NC-ND 2.0
Les concepts d’ouverture, d’universalité, et de libre circulation de l’information ont été au cœur des récits pour promouvoir le progrès technologique et la croissance sur Internet et le Web. Bien que ces concepts aient été instrumentalisés pour défendre les logiciels libres et la culture du libre, ils ont aussi été cruciaux dans le développement des médias sociaux, dont le but consistait à créer des réseaux en constante croissance, pour embarquer toujours davantage de personnes communiquant librement les unes avec les autres. En suivant la tradition libérale, cette approche a été considérée comme favorisant les échanges d’opinion fertiles en fournissant un immense espace pour la liberté d’expression, l’accès à davantage d’informations et la possibilité pour n’importe qui de participer.
Cependant, ces systèmes ouverts étaient également ouverts à leur accaparement par le marché et exposés à la culture prédatrice des méga-entreprises. Dans le cas du Web, cela a conduit à des modèles lucratifs qui exploitent à la fois les structures et le contenu circulant11 dans tout le réseau.
Revenons à la situation actuelle : les médias sociaux commerciaux dirigent la surveillance des individus et prédisent leur comportement afin de les convaincre d’acheter des produits et d’adhérer à des idées politiques. Historiquement, des projets de médias sociaux alternatifs tels que GNU Social, et plus précisément Identi.ca/StatusNet, ont cherché à s’extirper de cette situation en créant des plateformes qui contrevenaient à cette forme particulière d’ouverture sur-commercialisée.
Ils ont créé des systèmes interopérables explicitement opposés à la publicité et au pistage par les traqueurs. Ainsi faisant, ils espéraient prouver qu’il est toujours possible de créer un réseau à la croissance indéfinie tout en distribuant la responsabilité de la détention des données et, en théorie, de fournir les moyens à des communautés variées de s’approprier le code source des plateformes ainsi que de contribuer à la conception du protocole.
C’était en somme la conviction partagée sur le Fédiverse vers 2016. Cette croyance n’a pas été remise en question, car le Fédiverse de l’époque n’avait pas beaucoup dévié du projet d’origine d’un logiciel libre de média social fédéré, lancé une décennie plus tôt.
Par conséquent, le Fédiverse était composé d’une foule très homogène, dont les intérêts recoupaient la technologie, les logiciels libres et les idéologies anti-capitalistes. Cependant, alors que la population du Fédiverse s’est diversifiée lorsque Mastodon a attiré des communautés plus hétérogènes, des conflits sont apparus entre ces différentes communautés. Cette fois, il s’agissait de l’idée même d’ouverture du Fédiverse qui était de plus en plus remise en question par les nouveaux venus. Contribuant à la critique, un appel a émergé de la base d’utilisateurs de Mastodon en faveur de la possibilité de bloquer ou « défédérer » d’autres serveurs du Fédiverse.
Bloquer signifie que les utilisateurs ou les administrateurs de serveurs pouvaient empêcher le contenu d’autres serveurs sur le réseau de leur parvenir. « Défédérer », dans ce sens, est devenu une possibilité supplémentaire dans la boîte à outils d’une modération communautaire forte, qui permettait de ne plus être confronté à du contenu indésirable ou dangereux. Au début, l’introduction de la défédération a causé beaucoup de frictions parmi les utilisateurs d’autres logiciels du Fédiverse. Les plaintes fréquentes contre Mastodon qui « cassait la fédération » soulignent à quel point ce changement était vu comme une menace pour le réseau tout entier12. Selon ce point de vue, plus le réseau pouvait grandir et s’interconnecter, plus il aurait de succès en tant qu’alternative aux médias sociaux commerciaux. De la même manière, beaucoup voyaient le blocage comme une contrainte sur les possibilités d’expression personnelle et d’échanges d’idées constructifs, craignant qu’il s’ensuive l’arrivée de bulles de filtres et d’isolement de communautés.
En cherchant la déconnexion sélective et en contestant l’idée même que le débat en ligne est forcément fructueux, les communautés qui se battaient pour la défédération ont aussi remis en cause les présupposés libéraux sur l’ouverture et l’universalité sur lesquels les logiciels précédents du Fédiverse étaient construits. Le fait qu’en parallèle à ces développements, le Fédiverse soit passé de 200 000 à plus de 3,5 millions de comptes au moment d’écrire ces lignes, n’est probablement pas une coïncidence. Plutôt que d’entraver le réseau, la défédération, les communautés auto-gouvernées et le rejet de l’universalité ont permis au Fédiverse d’accueillir encore plus de communautés. La présence de différents serveurs qui représentent des communautés si distinctes qui ont chacune leur propre culture locale et leur capacité d’action sur leur propre partie du réseau, sans être isolée de l’ensemble plus vaste, est l’un des aspects les plus intéressants du Fédiverse. Cependant, presque un million du nombre total de comptes sont le résultat du passage de la plateforme d’extrême-droite Gab aux protocoles du Fédiverse, ce qui montre que le réseau est toujours sujet à la captation et à la domination par une tierce partie unique et puissante13. Dans le même temps, cet événement a immédiatement déclenché divers efforts pour permettre aux serveurs de contrer ce risque de domination.
Par exemple, la possibilité pour certaines implémentations de serveurs de se fédérer sur la base de listes blanches, qui permettent aux serveurs de s’interconnecter au cas par cas, au lieu de se déconnecter au cas par cas. Une autre réponse qui a été proposée consistait à étendre le protocole ActivityPub, l’un des protocoles les plus populaires et discutés du Fédiverse, en ajoutant des méthodes d’autorisation plus fortes à base d’un modèle de sécurité informatique qui repose sur la capacité des objets (Object-capability model). Ce modèle permet à un acteur de retirer, a posteriori, la possibilité à d’autres acteurs de voir ou d’utiliser ses données. Ce qui est unique à propos du Fédiverse c’est cette reconnaissance à la fois culturelle et technique que l’ouverture a ses limites, et qu’elle est elle-même ouverte à des interprétations plus ou moins larges en fonction du contexte, qui n’est pas fixe dans le temps. C’est un nouveau point de départ fondamental pour imaginer de nouveaux médias sociaux.
« interlace » par Interlace Explorer, licence CC BY-NC-SA 2.0
Comme nous l’avons établi précédemment, une des caractéristiques du Fédiverse tient aux différentes couches logicielles et applications qui la constituent et qui peuvent virtuellement être utilisées par n’importe qui et dans n’importe quel but. Cela signifie qu’il est possible de créer une communauté en ligne qui peut se connecter au reste du Fédiverse mais qui opère selon ses propres règles, sa propre ligne de conduite, son propre mode d’organisation et sa propre idéologie. Dans ce processus, chaque communauté est capable de se définir elle-même non plus uniquement par un langage mémétique, un intérêt, une perspective commune, mais aussi par ses relations aux autres, en se différenciant. Une telle spécificité peut faire ressembler le Fédiverse à un assemblage d’infrastructures qui suivrait les principes du pluralisme agonistique. Le pluralisme agonistique, ou agonisme, a d’abord été conçu par Ernesto Laclau et Chantal Mouffe, qui l’ont par la suite développé en une théorie politique. Pour Mouffe, à l’intérieur d’un ordre hégémonique unique, le consensus politique est impossible. Une négativité radicale est inévitable dans un système où la diversité se limite à des groupes antagonistes14.
La thèse de Mouffe s’attaque aux systèmes démocratiques où les politiques qui seraient en dehors de ce que le consensus libéral juge acceptable sont systématiquement exclues. Toutefois, ce processus est aussi à l’œuvre sur les plateformes de médias sociaux commerciaux, dans le sens où ces dernières forment et contrôlent le discours pour qu’il reste acceptable par le paradigme libéral, et qu’il s’aligne sur ses propres intérêts commerciaux. Ceci a conduit à une radicalisation de celles et ceux qui en sont exclus.
Le pari fait par l’agonisme est qu’en créant un système dans lequel un pluralisme d’hégémonies est permis, il devienne possible de passer d’une conception de l’autre en tant qu’ennemi à une conception de l’autre en tant qu’adversaire politique. Pour que cela se produise, il faut permettre à différentes idéologies de se matérialiser par le biais de différents canaux et plateformes. Une condition préalable importante est que l’objectif du consensus politique doit être abandonné et remplacé par un consensus conflictuel, dans lequel la reconnaissance de l’autre devient l’élément de base des nouvelles relations, même si cela signifie, par exemple, accepter des points de vue non occidentaux sur la démocratie, la laïcité, les communautés et l’individu.
Pour ce qui est du Fédiverse, il est clair qu’il contient déjà un paysage politique relativement diversifié et que les transitions du consensus politique au consensus conflictuel peuvent être constatées au travers de la manière dont les communautés se comportent les unes envers les autres. À la base de ces échanges conflictuels se trouvent divers points de vue sur la conception et l’utilisation collectives de toutes les couches logicielles et des protocoles sous-jacents qui seraient nécessaires pour permettre une sorte de pluralisme agonistique en ligne.
Cela dit, les discussions autour de l’usage susmentionné du blocage d’instance et de la défédération sont férocement débattues, et, au moment où nous écrivons ces lignes, avec la présence apparemment irréconciliable de factions d’extrême gauche et d’extrême droite dans l’univers de la fédération, les réalités de l’antagonisme seront très difficiles à résoudre. La conception du Fédiverse comme système dans lequel les différentes communautés peuvent trouver leur place parmi les autres a été concrètement mise à l’épreuve en juillet 2019, lorsque la plateforme explicitement d’extrême droite, Gab, a annoncé qu’elle modifierait sa base de code, s’éloignant de son système propriétaire pour s’appuyer plutôt sur le code source de Mastodon.
En tant que projet qui prend explicitement position contre l’idéologie de Gab, Mastodon a été confronté à la neutralité des licences FLOSS. D’autres projets du Fédiverse, tels que les clients de téléphonie mobile FediLab et Tusky, ont également été confrontés au même problème, peut-être même plus, car la motivation directe des développeurs de Gab pour passer aux logiciels du Fédiverse était de contourner leur interdiction des app stores d’Apple et de Google pour violation de leurs conditions de service. En s’appuyant sur les clients génériques de logiciels libres du Fédiverse, Gab pourrait échapper à de telles interdictions à l’avenir, et aussi forger des alliances avec d’autres instances idéologiquement compatibles sur le Fédiverse15.
Dans le cadre d’une stratégie antifasciste plus large visant à dé-plateformer et à bloquer Gab sur le Fédiverse, des appels ont été lancés aux développeurs de logiciels pour qu’ils ajoutent du code qui empêcherait d’utiliser leurs clients pour se connecter aux serveurs Gab. Cela a donné lieu à des débats approfondis sur la nature des logiciels libres et open source, sur l’efficacité de telles mesures quant aux modifications du code source public, étant donné qu’elles peuvent être facilement annulées, et sur le positionnement politique des développeurs et mainteneurs de logiciels.
Au cœur de ce conflit se trouve la question de la neutralité du code, du réseau et des protocoles. Un client doit-il – ou même peut-il – être neutre ? Le fait de redoubler de neutralité signifie-t-il que les mainteneurs tolèrent l’idéologie d’extrême-droite ? Que signifie bloquer ou ne pas bloquer une autre instance ? Cette dernière question a créé un va-et-vient compliqué où certaines instances demanderont à d’autres instances de prendre part explicitement au conflit, en bloquant d’autres instances spécifiques afin d’éviter d’être elles-mêmes bloquées. La neutralité, qu’elle soit motivée par l’ambivalence, le soutien tacite, l’hypocrisie, le désir de troller, le manque d’intérêt, la foi dans une technologie apolitique ou par un désir agonistique de s’engager avec toutes les parties afin de parvenir à un état de consensus conflictuel… la neutralité donc est très difficile à atteindre. Le Fédiverse est l’environnement le plus proche que nous ayons actuellement d’un réseau mondial diversifié de singularités locales. Cependant, sa topologie complexe et sa lutte pour faire face au tristement célèbre paradoxe de la tolérance – que faire de l’idée de liberté d’expression ? – montre la difficulté d’atteindre un état de consensus conflictuel. Elle montre également le défi que représente la traduction d’une théorie de l’agonisme en une stratégie partagée pour la conception de protocoles, de logiciels et de directives communautaires. La tolérance et la liberté d’expression sont devenues des sujets explosifs après près de deux décennies de manipulation politique et de filtrage au sein des médias sociaux des grandes entreprises ; quand on voit que les plateformes et autres forums de discussion populaires n’ont pas réussi à résoudre ces problèmes, on n’est guère enclin à espérer en des expérimentations futures.
Plutôt que d’atteindre un état de pluralisme agonistique, il se pourrait que le Fédiverse crée au mieux une forme d’agonisme bâtard par le biais de la pilarisation. En d’autres termes, nous pourrions assister à une situation dans laquelle des instances ne formeraient de grandes agrégations agonistes-sans-agonisme qu’entre des communautés et des logiciels compatibles tant sur le plan idéologique que technique, seule une minorité d’entre elles étant capable et désireuse de faire le pont avec des systèmes radicalement opposés. Quelle que soit l’issue, cette question de l’agonisme et de la politique en général est cruciale pour la culture du réseau et de l’informatique. Dans le contexte des systèmes post-politiques occidentaux et de la manière dont ils prennent forme sur le net, un sentiment de déclin de l’esprit partisan et de l’action militante politique a donné l’illusion, ou plutôt la désillusion, qu’il n’y a plus de boussole politique. Si le Fédiverse nous apprend quelque chose, c’est que le réseau et les composants de logiciel libres de son infrastructure n’ont jamais été aussi politisés qu’aujourd’hui. Les positions politiques qui sont générées et hébergées sur le Fédiverse ne sont pas insignifiantes, mais sont clairement articulées. De plus, comme le montre la prolifération de célébrités politiques et de politiciens utilisant activement les médias sociaux, une nouvelle forme de démocratie représentative émerge, dans laquelle le langage mémétique des cultures post-numériques se déplace effectivement dans le monde de la politique électorale et inversement16.
« THINK Together » par waynewhuang licence CC BY-NC 2.0
Par le passé, les débats sur les risques des médias sociaux commerciaux se sont focalisés sur les questions de vie privée et de surveillance, surtout depuis les révélations de Snowden en 2013. Par conséquent, de nombreuses réponses techniques, en particulier celles issues des communautés FLOSS, se sont concentrées sur la sécurité des traitements des données personnelles. Cela peut être illustré par la multiplication des applications de messagerie et de courrier électronique chiffrées post-Snowden17. La menace perçue par ces communautés est la possibilité de surveillance du réseau, soit par des agences gouvernementales, soit par de grandes entreprises.
Les solutions proposées sont donc des outils qui implémentent un chiffrement fort à la fois dans le contenu et dans la transmission du message en utilisant idéalement des topologies de réseaux de pair à pair qui garantissent l’anonymat. Ces approches, malgré leur rigueur, requièrent des connaissances techniques considérables de la part des utilisateurs.
Le Fédiverse bascule alors d’une conception à dominante technique vers une conception plus sociale de la vie privée, comme l’ont clairement montré les discussions qui ont eu lieu au sein de l’outil de suivi de bug de Mastodon, lors de ces premières étapes de développement. Le modèle de menace qui y est discuté comprend les autres utilisateurs du réseau, les associations accidentelles entre des comptes et les dynamiques des conversations en ligne elles-mêmes. Cela signifie qu’au lieu de se concentrer sur des caractéristiques techniques telles que les réseaux de pair à pair et le chiffrement de bout en bout, le développement a été axé sur la construction d’outils de modération robustes, sur des paramétrages fins de la visibilité des messages et sur la possibilité de bloquer d’autres instances.
Ces fonctionnalités, qui favorisent une approche plus sociale de la protection de la vie privée, ont été développées et défendues par les membres des communautés marginalisées, dont une grande partie se revendique comme queer. Comme le note Sarah Jamie Lewis :
Une grande partie de la rhétorique actuelle autour des […] outils de protection de la vie privée est axée sur la surveillance de l’État. Les communautés LGBTQI+ souhaitent parfois cacher des choses à certains de leurs parents et amis, tout en pouvant partager une partie de leur vie avec d’autres. Se faire des amis, se rencontrer, échapper à des situations violentes, accéder à des services de santé, s’explorer et explorer les autres, trouver un emploi, pratiquer le commerce du sexe en toute sécurité… sont autant d’aspects de la vie de cette communauté qui sont mal pris en compte par ceux qui travaillent aujourd’hui sur la protection de la vie privée18.
Alors que tout le monde a intérêt à prendre en compte les impacts sur la vie privée d’interactions (non sollicitées) entre des comptes d’utilisateurs, par exemple entre un employeur et un employé, les communautés marginalisées sont affectées de manière disproportionnée par ces formes de surveillance et leurs conséquences. Lorsque la conception de nouvelles plateformes sur le Fédiverse comme Mastodon a commencé — avec l’aide de membre de ces communautés — ces enjeux ont trouvé leur place sur les feuilles de route de développement des logiciels. Soudain, les outils de remontée de défauts techniques sont également devenus un lieu de débat de questions sociales, culturelles et politiques. Nous reviendrons sur ce point dans la section six.
Les technologies qui ont finalement été développées comprennent le blocage au niveau d’une instance, des outils de modérations avancés, des avertissements sur la teneur des contenus et une meilleure accessibilité. Cela a permis à des communautés géographiquement, culturellement et idéologiquement disparates de partager le même réseau selon leurs propres conditions. De ce fait, le Fédiverse peut être compris comme un ensemble de communautés qui se rallient autour d’un serveur, ou une instance, afin de créer un environnement où chacun se sent à l’aise. Là encore, cela constitue une troisième voie : ni un modèle dans lequel seuls ceux qui ont des aptitudes techniques maîtrisent pleinement leurs communications, ni un scénario dans lequel la majorité pense n’avoir « rien à cacher » simplement parce qu’elle n’a pas son mot à dire ni le contrôle sur les systèmes dont elle est tributaire. En effet, le changement vers une perception sociale de la vie privée a montré que le Fédiverse est désormais un laboratoire dans lequel on ne peut plus prétendre que les questions d’organisation sociale et de gouvernance sont détachées des logiciels.
Ce qui compte, c’est que le Fédiverse marque une évolution de la définition des questions de surveillance et de protection de la vie privée comme des problématiques techniques vers leur formulation en tant qu’enjeux sociaux. Cependant, l’accent mis sur la dimension sociale de la vie privée s’est jusqu’à présent limité à placer sa confiance dans d’autres serveurs et administrateurs pour qu’ils agissent avec respect.
Cela peut être problématique dans le cas par exemple des messages directs (privés), par leur confidentialité inhérente, qui seraient bien mieux gérés avec des solutions techniques telles que le chiffrement de bout en bout. De plus, de nombreuses solutions recherchées dans le développement des logiciels du Fédiverse semblent être basées sur le collectif plutôt que sur l’individu. Cela ne veut pas dire que les considérations de sécurité technique n’ont aucune importance. Les serveurs du Fédiverse ont tendance à être équipés de paramètres de « confidentialité par défaut », tels que le nécessaire chiffrement de transport et le proxy des requêtes distantes afin de ne pas exposer les utilisateurs individuels.
Néanmoins, cette évolution vers une approche sociale de la vie privée n’en est qu’à ses débuts, et la discussion doit se poursuivre sur de nombreux autres plans.
« Liseron sur ombelles » par philolep, licence CC BY-NC-SA 2.0
Les grandes plateformes de médias sociaux, qui se concentrent sur l’utilisation de statistiques pour récompenser leur usage et sur la gamification, sont tristement célèbres pour utiliser autant qu’elles le peuvent le travail gratuit. Quelle que soit l’information introduite dans le système, elle sera utilisée pour créer directement ou indirectement des modélisations, des rapports et de nouveaux jeux de données qui possèdent un intérêt économique fondamental pour les propriétaires de ces plateformes : bienvenue dans le monde du capitalisme de surveillance19.
Jusqu’à présent il a été extrêmement difficile de réglementer ces produits et services, en partie à cause du lobbying intense des propriétaires de plateformes et de leurs actionnaires, mais aussi et peut-être de façon plus décisive, à cause de la nature dérivée de la monétisation qui est au cœur des entreprises de médias sociaux. Ce qui est capitalisé par ces plateformes est un sous-produit algorithmique, brut ou non, de l’activité et des données téléchargées par ses utilisateurs et utilisatrices. Cela crée un fossé qui rend toujours plus difficile d’appréhender la relation entre le travail en ligne, le contenu créé par les utilisateurs, le pistage et la monétisation.
Cet éloignement fonctionne en réalité de deux façons. D’abord, il occulte les mécanismes réels qui sont à l’œuvre, ce qui rend plus difficile la régulation de la collecte des données et leur analyse. Il permet de créer des situations dans lesquelles ces plateformes peuvent développer des produits dont elles peuvent tirer profit tout en respectant les lois sur la protection de la vie privée de différentes juridictions, et donc promouvoir leurs services comme respectueux de la vie privée. Cette stratégie est souvent renforcée en donnant à leurs utilisatrices et utilisateurs toutes sortes d’options pour les induire en erreur et leur faire croire qu’ils ont le contrôle de ce dont ils alimentent la machine.
Ensuite, en faisant comme si aucune donnée personnelle identifiable n’était directement utilisée pour être monétisée ; ces plateformes dissimulent leurs transactions financières derrière d’autres sortes de transactions, comme les interactions personnelles entre utilisatrices, les opportunités de carrière, les groupes et discussion gérés par des communautés en ligne, etc. Au bout du compte, les utilisateurs s’avèrent incapables de faire le lien entre leur activité sociale ou professionnelle et son exploitation, parce tout dérive d’autres transactions qui sont devenues essentielles pour nos vies connectées en permanence, en particulier à l’ère de l’« entrepecariat » et de la connectivité quasi obligatoire au réseau.
Nous l’avons vu précédemment : l’approche sociale de la vie privée en ligne a influencé la conception initiale de Mastodon, et le Fédiverse offre une perspective nouvelle sur le problème du capitalisme de surveillance. La question de l’usage des données des utilisateurs et utilisatrices et la façon dont on la traite, au niveau des protocoles et de l’interface utilisateur, sont des points abordés de façon transparente et ouverte. Les discussions se déroulent publiquement à la fois sur le Fédiverse et dans les plateformes de suivi du logiciel. Les utilisateurs expérimentés du Fédiverse ou l’administratrice locale d’un groupe Fédiverse, expliquent systématiquement aux nouveaux utilisateurs la façon dont les données circulent lorsqu’ils rejoignent une instance.
Cet accueil permet généralement d’expliquer comment la fédération fonctionne et ce que cela implique concernant la visibilité et l’accès aux données partagées par ces nouveaux utilisateurs21. Cela fait écho à ce que Robert Gehl désigne comme une des caractéristiques des plateformes de réseaux sociaux alternatifs. Le réseau comme ses coulisses ont une fonction pédagogique. On indique aux nouvelles personnes qui s’inscrivent comment utiliser la plateforme et chacun peut, au-delà des permissions utilisateur limitées, participer à son développement, à son administration et à son organisation22. En ce sens, les utilisateurs et utilisatrices sont incitées par le Fédiverse à participer activement, au-delà de simples publications et « likes » et sont sensibilisés à la façon dont leurs données circulent.
Pourtant, quel que soit le niveau d’organisation, d’autonomie et d’implication d’une communauté dans la maintenance de la plateforme et du réseau (au passage, plonger dans le code est plus facile à dire qu’à faire), rien ne garantit un plus grand contrôle sur les données personnelles. On peut facilement récolter et extraire des données de ces plateformes et cela se fait plus facilement que sur des réseaux sociaux privés. En effet, les services commerciaux des réseaux sociaux privés protègent activement leurs silos de données contre toute exploitation extérieure.
Actuellement, il est très facile d’explorer le Fédiverse et d’analyser les profils de ses utilisatrices et utilisateurs. Bien que la plupart des plateformes du Fédiverse combattent le pistage des utilisateurs et la collecte de leurs données, des tiers peuvent utiliser ces informations. En effet, le Fédiverse fonctionne comme un réseau ouvert, conçu à l’origine pour que les messages soient publics. De plus, étant donné que certains sujets, notamment des discussions politiques, sont hébergées sur des serveurs spécifiques, les communautés de militant⋅e⋅s peuvent être plus facilement exposées à la surveillance. Bien que le Fédiverse aide les utilisateurs à comprendre, ou à se rappeler, que tout ce qui est publié en ligne peut échapper et échappera à leur contrôle, elle ne peut pas empêcher toutes les habitudes et le faux sentiment de sécurité hérités des réseaux sociaux commerciaux de persister, surtout après deux décennies de désinformation au sujet de la vie privée numérique23.
De plus, bien que l’exploitation du travail des utilisateurs et utilisatrices ne soit pas la même que sur les plateformes de médias sociaux commerciaux, il reste sur ce réseau des problèmes autour de la notion de travail. Pour les comprendre, nous devons d’abord admettre les dégâts causés, d’une part, par la merveilleuse utilisation gratuite des réseaux sociaux privés, et d’autre part, par la mécompréhension du fonctionnement des logiciels libres ou open source : à savoir, la manière dont la lutte des travailleurs et la question du travail ont été masquées dans ces processus24.
Cette situation a incité les gens à croire que le développement des logiciels, la maintenance des serveurs et les services en ligne devraient être mis gratuitement à leur disposition. Les plateformes de média sociaux commerciaux sont justement capables de gérer financièrement leurs infrastructures précisément grâce à la monétisation des contenus et des activités de leurs utilisateurs. Dans un système où cette méthode est évitée, impossible ou fermement rejetée, la question du travail et de l’exploitation apparaît au niveau de l’administration des serveurs et du développement des logiciels et concerne tous celles et ceux qui contribuent à la conception, à la gestion et à la maintenance de ces infrastructures.
Pour répondre à ce problème, la tendance sur le Fédiverse consiste à rendre explicites les coûts de fonctionnement d’un serveur communautaire. Tant les utilisatrices que les administrateurs encouragent le financement des différents projets par des donations, reconnaissant ainsi que la création et la maintenance de ces plateformes coûtent de l’argent. Des projets de premier plan comme Mastodon disposent de davantage de fonds et ont mis en place un système permettant aux contributeurs d’être rémunérés pour leur travail25.
Ces tentatives pour compenser le travail des contributeurs sont un pas en avant, cependant étendre et maintenir ces projets sur du long terme demande un soutien plus structurel. Sans financement significatif du développement et de la maintenance, ces projets continueront à dépendre de l’exploitation du travail gratuit effectué par des volontaires bien intentionnés ou des caprices des personnes consacrant leur temps libre au logiciel libre. Dans le même temps, il est de plus en plus admis, et il existe des exemples, que le logiciel libre peut être considéré comme un bien d’utilité publique qui devrait être financé par des ressources publiques26. À une époque où la régulation des médias sociaux commerciaux est débattue en raison de leur rôle dans l’érosion des institutions publiques, le manque de financement public d’alternatives non prédatrices devrait être examiné de manière plus active.
Enfin, dans certains cas, les personnes qui accomplissent des tâches non techniques comme la modération sont rémunérées par les communautés du Fédiverse. On peut se demander pourquoi, lorsqu’il existe une rémunération, certaines formes de travail sont payées et d’autres non. Qu’en est-il par exemple du travail initial et essentiel de prévenance et de critique fourni par les membres des communautés marginalisées qui se sont exprimés sur la façon dont les projets du Fédiverse devraient prendre en compte une interprétation sociale de la protection de la vie privée ? Il ne fait aucun doute que c’est ce travail qui a permis au Fédiverse d’atteindre le nombre d’utilisateurs qu’elle a aujourd’hui.
Du reste comment cette activité peut-elle être évaluée ? Elle se manifeste dans l’ensemble du réseau, dans des fils de méta-discussions ou dans les systèmes de suivi, et n’est donc pas aussi quantifiable ou visible que la contribution au code. Donc, même si des évolutions intéressantes se produisent, il reste à voir si les utilisateurs et les développeuses du Fédiverse peuvent prendre pleinement conscience de ces enjeux et si les modèles économiques placés extérieurs au capitalisme de surveillance peuvent réussir à soutenir une solidarité et une attention sans exploitation sur tous les maillons de la chaîne.
« Liseron sur ombelles » par philolep, licence CC BY-NC-SA 2.0
« basket weaving » par cloudberrynine, licence CC BY-NC-ND 2.0
On peut envisager le Fédiverse comme un ensemble de pratiques, ou plutôt un ensemble d’attentes et de demandes concernant les logiciels de médias sociaux, dans lesquels les efforts disparates de projets de médias sociaux alternatifs convergent en un réseau partagé avec des objectifs plus ou moins similaires. Les différents modèles d’utilisation, partagés entre les serveurs, vont de plateformes d’extrême-droite financées par le capital-risque à des systèmes de publication d’images japonaises, en passant par des collectifs anarcho-communistes, des groupes politiques, des amateurs d’algorithmes de codage en direct, des « espaces sûrs » pour les travailleur⋅euse⋅s du sexe, des forums de jardinage, des blogs personnels et des coopératives d’auto-hébergement. Ces pratiques se forment parallèlement au problème du partage des données et du travail gratuit, et font partie de la transformation continuelle de ce que cela implique d’être utilisateur ou utilisatrice de logiciel.
Les premiers utilisateurs de logiciels, ou utilisateurs d’appareils de calcul, étaient aussi leurs programmeuses et programmeurs, qui fournissaient ensuite les outils et la documentation pour que d’autres puissent contribuer au développement et à l’utilisation de ces systèmes27.
Ce rôle était si important que les premières communautés d’utilisateurs furent pleinement soutenues et prises en charge par les fabricants de matériel.
Avance rapide de quelques décennies et, avec la croissance de l’industrie informatique, la notion d’ « utilisateur » a complètement changé pour signifier « consommateur apprivoisé » avec des possibilités limitées de contribution ou de modification des systèmes qu’ils utilisent, au-delà de personnalisations triviales ou cosmétiques. C’est cette situation qui a contribué à façonner une grande partie de la popularité croissante des FLOSS dans les années 90, en tant qu’adversaires des systèmes d’exploitation commerciaux propriétaires pour les ordinateurs personnels, renforçant particulièrement les concepts antérieurs de liberté des utilisateurs28. Avec l’avènement du Web 2.0, la situation changea de nouveau. En raison de la dimension communicative et omniprésente des logiciels derrière les plateformes de médias sociaux d’entreprises, les fournisseurs ont commencé à offrir une petite ouverture pour un retour de la part de leurs utilisateurs, afin de rendre leur produit plus attrayant et pertinent au quotidien. Les utilisateurs peuvent généralement signaler facilement les bugs, suggérer de nouvelles fonctionnalités ou contribuer à façonner la culture des plateformes par leurs échanges et le contenu partagés. Twitter en est un exemple bien connu, où des fonctionnalités essentielles, telles que les noms d’utilisateur préfixés par @ et les hashtags par #, ont d’abord été suggérés par les utilisateurs. Les forums comme Reddit permettent également aux utilisateurs de définir et modérer des pages, créant ainsi des communautés distinctes et spécifiques.
Sur les plateformes alternatives de médias sociaux comme le Fédiverse, en particulier à ses débuts, ces formes de participation vont plus loin. Les utilisatrices et utilisateurs ne se contentent pas de signaler des bogues ou d’aider a la création d’une culture des produits, ils s’impliquent également dans le contrôle du code, dans le débat sur ses effets et même dans la contribution au code. À mesure que le Fédiverse prend de l’ampleur et englobe une plus grande diversité de cultures et de logiciels, les comportements par rapport à ses usages deviennent plus étendus. Les gens mettent en place des nœuds supplémentaires dans le réseau, travaillent à l’élaboration de codes de conduite et de conditions de service adaptées, qui contribuent à l’application de lignes directrices communautaires pour ces nœuds. Ils examinent également comment rendre ces efforts durables par un financement via la communauté.
Ceci dit, toutes les demandes de changement, y compris les contributions pleinement fonctionnelles au code, ne sont pas acceptées par les principaux développeurs des plateformes. Cela s’explique en partie par le fait que les plus grandes plateformes du Fédiverse reposent sur des paramètres par défaut, bien réfléchis, qui fonctionnent pour ces majorités diverses, plutôt que l’ancien modèle archétypique de FLOSS, pour permettre une personnalisation poussée et des options qui plaisent aux programmeurs, mais en découragent beaucoup d’autres. Grâce à la disponibilité du code source, un riche écosystème de versions modifiées de projets (des forks) existe néanmoins, qui permet d’étendre ou de limiter certaines fonctionnalités tout en conservant un certain degré de compatibilité avec le réseau plus large.
Les débats sur les mérites des fonctionnalités et des logiciels modifiés qu’elles génèrent nourrissent de plus amples discussions sur l’orientation de ces projets, qui à leur tour conduisent à une attention accrue autour de leur gouvernance.
Il est certain que ces développements ne sont ni nouveaux ni spécifiques au Fédiverse. La manière dont les facilitateurs de services sont soutenus sur le Fédiverse, par exemple, est analogue à la manière dont les créateurs de contenu sur les plateformes de streaming au sein des communautés de jeux sont soutenus par leur public. Des appels à une meilleure gouvernance des projets logiciels sont également en cours dans les communautés FLOSS plus largement. L’élaboration de codes de conduite (un document clé pour les instances de la Fédiverse mis en place pour exposer leur vision de la communauté et de la politique) a été introduit dans diverses communautés FLOSS au début des années 2010, en réponse à la misogynie systématique et à la l’exclusion des minorités des espaces FLOSS à la fois en ligne et hors ligne29. Les codes de conduite répondent également au besoin de formes génératrices de résolution des conflits par-delà les barrières culturelles et linguistiques.
De même, bon nombre des pratiques de modération et de gestion communautaire observées dans le Fédiverse ont hérité des expériences d’autres plateformes, des succès et défaillances d’autres outils et systèmes. La synthèse et la coordination de toutes ces pratiques deviennent de plus en plus visibles dans l’univers fédéré.
En retour, les questions et les approches abordées dans le Fédiverse ont créé un précédent pour d’autres projets des FLOSS, en encourageant des transformations des discussions qui étaient jusqu’alors limitées ou difficiles à engager.
Il n’est pas évident, compte tenu de la diversité des modèles d’utilisation, que l’ensemble du Fédiverse fonctionne suivant cette tendance. Les développements décrits ci-dessus suggèrent cependant que de nombreux modèles d’utilisation restent à découvrir et que le Fédiverse est un environnement favorable pour les tester. La nature évolutive de l’utilisation du Fédiverse montre à quel point l’écart est grand entre les extrêmes stéréotypés du modèle capitaliste de surveillance et du martyre auto-infligé des plateformes de bénévolat. Ce qui a des implications sur le rôle des utilisateurs en relation avec les médias sociaux alternatifs, ainsi que pour le développement de la culture des FLOSS30.
« What a tangled web we weave….. » par Pandiyan, licence CC BY-NC 2.0
Jusqu’à présent, la grande majorité des discussions autour des licences FLOSS sont restées enfermées dans une comparaison cliché entre l’accent mis par le logiciel libre sur l’éthique de l’utilisateur et l’approche de l’open source qui repose sur l’économie31.
Qu’ils soient motivés par l’éthique ou l’économie, les logiciels libres et les logiciels open source partagent l’idéal selon lequel leur position est supérieure à celle des logiciels fermés et aux modes de production propriétaires. Toutefois, dans les deux cas, le moteur libéral à la base de ces perspectives éthiques et économiques est rarement remis en question. Il est profondément enraciné dans un contexte occidental qui, au cours des dernières décennies, a favorisé la liberté comme le conçoivent les libéraux et les libertariens aux dépens de l’égalité et du social.
Remettre en question ce principe est une étape cruciale, car cela ouvrirait des discussions sur d’autres façons d’aborder l’écriture, la diffusion et la disponibilité du code source. Par extension, cela mettrait fin à la prétention selon laquelle ces pratiques seraient soit apolitiques, soit universelles, soit neutres.
Malheureusement, de telles discussions ont été difficiles à faire émerger pour des raisons qui vont au-delà de la nature dogmatique des agendas des logiciels libres et open source. En fait, elles ont été inconcevables car l’un des aspects les plus importants des FLOSS est qu’ils ont été conçus comme étant de nature non discriminatoire. Par « non discriminatoire », nous entendons les licences FLOSS qui permettent à quiconque d’utiliser le code source des FLOSS à n’importe quelle fin.
Certains efforts ont été faits pour tenter de résoudre ce problème, par exemple au niveau de l’octroi de licences discriminatoires pour protéger les productions appartenant aux travailleurs, ou pour exclure l’utilisation par l’armée et les services de renseignement32.
Ces efforts ont été mal accueillis en raison de la base non discriminatoire des FLOSS et de leur discours. Pis, la principale préoccupation du plaidoyer en faveur des FLOSS a toujours été l’adoption généralisée dans l’administration, l’éducation, les environnements professionnels et commerciaux, et la dépolitisation a été considérée comme la clé pour atteindre cet objectif. Cependant, plus récemment, la croyance en une dépolitisation, ou sa stratégie, ont commencé à souffrir de plusieurs manières.
Tout d’abord, l’apparition de ce nouveau type d’usager a entraîné une nouvelle remise en cause des modèles archétypaux de gouvernance des projets de FLOSS, comme celui du « dictateur bienveillant ». En conséquence, plusieurs projets FLOSS de longue date ont été poussés à créer des structures de compte-rendu et à migrer vers des formes de gouvernance orientées vers la communauté, telles que les coopératives ou les associations.
Deuxièmement, les licences tendent maintenant à être combinées avec d’autres documents textuels tels que les accords de transfert de droits d’auteur, les conditions de service et les codes de conduite. Ces documents sont utilisés pour façonner la communauté, rendre leur cohérence idéologique plus claire et tenter d’empêcher manipulations et malentendus autour de notions vagues comme l’ouverture, la transparence et la liberté.
Troisièmement, la forte coloration politique du code source remet en question la conception actuelle des FLOSS. Comme indiqué précédemment, certains de ces efforts sont motivés par le désir d’éviter la censure et le contrôle des plateformes sociales des entreprises, tandis que d’autres cherchent explicitement à développer des logiciels à usage antifasciste. Ces objectifs interrogent non seulement l’universalité et l’utilité globale des grandes plateformes de médias sociaux, ils questionnent également la supposée universalité et la neutralité des logiciels. Cela est particulièrement vrai lorsque les logiciels présentent des conditions, codes et accords complémentaires explicites pour leurs utilisateurs et les développeuses.
Avec sa base relativement diversifiée d’utilisatrices, de développeurs, d’agenda, de logiciels et d’idéologies, le Fédiverse devient progressivement le système le plus pertinent pour l’articulation de nouvelles formes de la critique des FLOSS. Il est devenu un endroit où les notions traditionnelles sur les FLOSS sont confrontées et révisées par des personnes qui comprennent son utilisation dans le cadre d’un ensemble plus large de pratiques qui remettent en cause le statu quo. Cela se produit parfois dans un contexte de réflexion, à travers plusieurs communautés, parfois par la concrétisation d’expériences et des projets qui remettent directement en question les FLOSS tels que nous les connaissons. C’est devenu un lieu aux multiples ramifications où les critiques constructives des FLOSS et l’aspiration à leur réinvention sont très vives. En l’état, la culture FLOSS ressemble à une collection rapiécée de pièces irréconciliables provenant d’un autre temps et il est urgent de réévaluer nombre de ses caractéristiques qui étaient considérées comme acquises.
Si nous pouvons accepter le sacrilège nécessaire de penser au logiciel libre sans le logiciel libre, il reste à voir ce qui pourrait combler le vide laissé par son absence.
Consulter Geert Lovink, Sad by Design: On Platform Nihilism (Triste par essence: Du nihilisme des plates-formes, non traduit en français), London: Pluto Press, 2019. ↩
Dans tout ce document nous utiliserons « médias sociaux commerciaux » et « médias sociaux alternatifs » selon les définitions de Robert W. Gehl dans « The Case for Alternative Social Media » (Pour des médias sociaux alternatifs, non traduit en français), Social Media + Society, juillet-décembre 2015, p. 1-12. En ligne. ↩
Danyl Strype, « A Brief History of the GNU Social Fediverse and ‘The Federation’ » (Une brève histoire de GNU Social, du Fédiverse et de la ‘fédération’, non traduit en français), Disintermedia, 1er Avril 2017. En ligne. ↩
Pour une exploration du #GamerGate et des technocultures toxiques, consulter Adrienne Massanari, « #Gamergate and The Fappening: How Reddit’s Algorithm, Governance, and Culture Support Toxic Technocultures » (#GamerGate et Fappening : comment les algorithmes, la gouvernance et la culture de Reddit soutiennent les technocultures toxiques, non traduit en français), New Media & Society, 19(3), 2016, p. 329-346. ↩
En raison de la nature décentralisée du Fédiverse, il n’est pas facile d’obtenir les chiffres exacts du nombre d’utilisateurs, mais quelques projets tentent de mesurer la taille du réseau: The Federation ; Fediverse Network ; Mastodon Users, Bitcoin Hackers. ↩
Pour un exemple de ce type de mélange, consulter Michael Rossman, « Implications of Community Memory » (Implications du projet Community Memory, non traduit en français) SIGCAS – Computers & Society, 6(4), 1975, p. 7-10. ↩
Aymeric Mansoux, « Surface Web Times » (L’ère du Web de surface, non traduit en français), MCD, 69, 2013, p. 50-53. ↩
Burcu Gültekin Punsmann, « What I learned from three months of Content Moderation for Facebook in Berlin » (Ce que j’ai appris de trois mois de modération de contenu pour Facebook à Berlin, non traduit en français), SZ Magazin, 6 January 2018. En ligne. ↩
Gabriella Coleman, « The Political Agnosticism of Free and Open Source Software and the Inadvertent Politics of Contrast » (L’agnosticisme politique des FLOSS et la politique involontaire du contraste, non traduit en français), Anthropological Quarterly, 77(3), 2004, p. 507-519. ↩
Pour une discussion plus approfondie sur les multiples possibilités procurés par l’ouverture mais aussi pour un commentaire sur le librewashing, voyez l’article de Jeffrey Pomerantz and Robin Peek, « Fifty Shades of Open », First Monday, 21(5), 2016. En ligne. ↩
Comme exemple d’arguments contre la défédération, voir le commentaire de Kaiser sous l’article du blog de Robek « rw » World : « Mastodon Socal Is THE Twitter Alternative For… », Robek World, 12 janvier 2017. En ligne. ↩
Au moment où Gab a rejoint le réseau, les statistiques du Fédiverse ont augmenté d’environ un million d’utilisateurs. Ces chiffres, comme tous les chiffres d’utilisation du Fédiverse, sont contestés. Pour le contexte, voir John Dougherty et Michael Edison Hayden, « ‘No Way’ Gab has 800,000 Users, Web Host Says », Southern Poverty Law Center, 14 février 2019. En ligne. Et le message sur Mastodon de emsenn le 10 août 2017, 04:51. ↩
Pour une introduction exhaustive aux écrits de Chantal Mouffe, voir Chantal Mouffe, Agonistique : penser politiquement le monde, Paris, Beaux-Arts de Paris éditions, 2014. On lira aussi avec profit la page Wikipédia consacrée à l’agonisme. ↩
Andrew Torba : « Le passage au protocole ActivityPub pour notre base nous permet d’entrer dans les App Stores mobiles sans même avoir à soumettre ni faire approuver nos propres applications, que cela plaise ou non à Apple et à Google », posté sur Gab, url consultée en mai 2019. ↩
David Garcia, « The Revenge of Folk Politics », transmediale/journal, 1, 2018. En ligne. ↩
hbsc & friends, « Have You Considered the Alternative? », Homebrew Server Club, 9 March 2017. En ligne. ↩
Sarah Jamie Lewis (éd.), Queer Privacy: Essays From The Margin Of Society, Victoria, British Columbia, Lean Pub/Mascherari Press, 2017, p. 2. ↩
Shoshana Zuboff, The Age of Surveillance Capitalism: The Fight for a Human Future at the New Frontier of Power, New York, PublicAffairs, 2019. ↩
Silvio Lorusso, Entreprecariat – Everyone Is an Entrepreneur. Nobody Is Safe, Onomatopee: Eindhoven, 2019. ↩
Pour un exemple d’introduction très souvent citée en lien, rédigée par une utilisatrice, cf. Noëlle Anthony, Joyeusenoelle/GuideToMastodon, 2019. En ligne. ↩
Au sein de ce texte, nous utilisons « média social commercial » (corporate social media) et « média social alternatif » (alternative social media) comme définis par Robert W. Gehl, « The Case for Alternative Social Media », op. cit.. ↩
Pour un relevé permanent de ces problématiques, cf. Pervasive Labour Union Zine, en ligne. ↩
Bien que formulée dans le contexte de Tumblr, pour une discussion à propos des tensions entre le travail numérique, les communautés post-numériques et l’activisme, voyez Cassius Adair et Lisa Nakamura, « The Digital Afterlives of This Bridge Called My Back: Woman of Color Feminism, Digital Labor, and Networked Pedagogy », American Literature, 89(2), 2017, p. 255-278. ↩
Pour des éléments de discussion sur le financement public des logiciels libres, ainsi que quelques analyses des premiers jets de lois concernant l’accès au code source des logiciels achetés avec l’argent public, cf. Jesús M. González-Barahona, Joaquín Seoane Pascual et Gregorio Robles, Introduction to Free Software, Barcelone, Universitat Oberta de Catalunya, 2009. ↩
par exemple, consultez Atsushi Akera, « Voluntarism and the Fruits of Collaboration: The IBM UserGroup, Share », Technology and Culture, 42(4), 2001, p. 710-736. ↩
Sam Williams, Free as in Freedom: Richard Stallman’s Crusade for Free Software, Farnham: O’Reilly, 2002. ↩
Femke Snelting, « Codes of Conduct: Transforming Shared Values into Daily Practice », dans Cornelia Sollfrank (éd.), The Beautiful Warriors: Technofeminist Praxis in the 21st Century, Colchester, Minor Compositions, 2019, pp. 57-72. ↩
Dušan Barok, Privatising Privacy: Trojan Horse in Free Open Source Distributed Social Platforms, Thèse de Master, Networked Media, Piet Zwart Institute, Rotterdam/Netherlands, 2011. ↩
Voyez l’échange de correspondance Stallman-Ghosh-Glott sur l’étude du FLOSS, « Two Communities or Two Movements in One Community? », dans Rishab Aiyer Ghosh, Ruediger Glott, Bernhard Krieger and Gregorio Robles, Free/Libre and Open Source Software: Survey and Study, FLOSS final report, International Institute of Infonomics, University of Maastricht, Netherlands, 2002. En ligne. ↩
Consultez par exemple Felix von Leitner, « Mon Jul 6 2015 », Fefes Blog, 6 July 2015, en ligne. ↩
Qui sont les auteurs
AYMERIC MANSOUX s’amuse avec les ordinateurs et les réseaux depuis bien trop longtemps. Il a été un membre fondateur du collectif GOTO10 (FLOSS+Art anthology, Puredyne distro, make art festival). Parmi les collaborations récentes, citons : Le Codex SKOR, une archive sur l’impossibilité d’archiver ; What Remains, un jeu vidéo 8 bits sur la manipulation des l’opinion publique et les lanceurs d’alerte pour la console Nintendo de 1985 ; et LURK, une une infrastructure de serveurs pour les discussions sur la liberté culturelle, l’art dans les nouveaux médias et la culture du net. Aymeric a obtenu son doctorat au Centre d’études culturelles, Goldsmiths, Université de Londres en 2017, pour son enquête sur le déclin de la diversité culturelle et des formes techno-légales de l’organisation sociale dans le cadre de pratiques culturelles libres et open-source. Il dirige actuellement le Cours de maîtrise en édition expérimentale (XPUB) à l’Institut Piet Zwart, Rotterdam. https://bleu255.com/~aymeric.
ROEL ROSCAM ABBING est un artiste et chercheur dont les travaux portent sur les questions et les cultures entourant les ordinateurs en réseau. Il s’intéresse à des thèmes tels que le réseau, les infrastructures, la politique de la technologie et les approches DIY (NdT : « Faites-le vous-même »). Il est doctorant dans le domaine du design d’interaction à l’université de Malmö.
OpenKeys.science, des clés de détermination pour ouvrir les portes de la biodiversité
Nous avons rencontré les serruriers de la biodiversité, une fine équipe qui veut vous donner les clés du vivant pour apprendre à mieux le connaître…
… et qui veut vous apprendre aussi (vous allez voir, c’est facile et plutôt amusant) à contribuer vous-même à la création et l’enrichissement d’un vaste trousseau de « clés ». Libres, naturellement.
À noter : cet article bénéficie désormais d’une version audio.
Merci à Sualtam, auteur de lectureaudio.fr pour cette contribution active.
Avant même de vous présenter, vous allez tout de suite nous expliquer ce qu’est une clé de détermination et à quoi ça sert, sinon, vous savez comme sont les lecteurs et les lectrices (exigeantes, intelligentes, attentionnées, etc.), ils et elles vont quitter cet article pour se précipiter sur Peertube afin de trouver une vidéo qui leur explique à notre place. Sébastien Une clé de détermination, c’est un peu comme un livre dont on est le héros ! Une succession de questions vous permet d’aboutir à la détermination d’un être vivant. Au fil des questions et de vos réponses, la liste des espèces possibles se réduit progressivement jusqu’à ce qu’il ne reste qu’un seul candidat (ou une liste très réduite). Certaines questions font parfois appel à du vocabulaire spécialisé, pas de panique ! Une illustration et une définition sont systématiquement présentes pour vous guider.
À titre d’exemple, vous pouvez consulter cette clé de détermination des insectes pollinisateurs.
1. Je réponds à des questions qui me sont proposées :
2. et ensuite visualiser les espèces candidates pour découvrir l’insecte que j’observe :
Donc si je dis qu’une clé de détermination c’est une liste de questions qui a pour objectif d’identifier à quelle espèce appartient un animal ou un végétal que j’observe, je simplifie un peu, mais j’ai bon ?
C’est l’idée oui.
Maintenant qu’on a compris de quoi on va parler, vous pouvez vous présenter !
Sébastien Turpin : Je suis enseignant de Sciences de la Vie et de la Terre et je travaille au Muséum national d’Histoire naturelle où je coordonne un programme de sciences participatives pour les scolaires. Et comme Thibaut, j’aime me balader dans la nature même si je n’arrive pas à y aller aussi souvent que je le souhaiterais !
Grégoire Loïs : Je suis naturaliste depuis toujours et j’ai la chance de travailler dans ce même établissement avec Sébastien, mais depuis un peu plus de 25 ans en ce qui me concerne. Je m’occupe comme lui de programmes de sciences participatives et plus particulièrement de bases de données.
Thibaut Arribe : Je suis développeur dans une petite SCOP qui s’appelle Kelis. On édite des solutions documentaires open-source pour produire et diffuser des documents numériques (vous avez peut-être déjà entendu parler de Scenari ou Opale, deux logiciels édités par Kelis). Accessoirement, je suis accompagnateur en montagne. J’emmène des groupes et particuliers se balader dans la nature sauvage des Pyrénées et des Cévennes.
Entrons dans le vif du sujet, c’est quoi OpenKeys.science ?
ThibautOpenKeys.science est un service en ligne qui permet de produire et diffuser des clés de détermination sous la forme de petit sites web autonomes.
Autonomes, ça veut dire qu’ils peuvent aller se promener tout seuls, sans attestation ?
Thibaut C’est exactement ça ! Pour tout un tas de bonnes et moins bonnes raisons, un site web est souvent dépendant de nombreux programmes à installer sur un serveur. Cette complexité rend bien service, mais l’installation de ce genre de site web en devient réservée à un public d’initiés.
Dans notre cas, une fois produit, rendre ce site “autonome” disponible sur le web est simple : n’importe quel espace web perso suffit (qu’il soit fourni par votre CHATON favori ou votre fournisseur d’accès à Internet).
Surtout, ça signifie qu’il est très simple d’en faire une copie pour l’emporter en balade dans la nature, et ça, c’est assez chouette.
Et donc produire des clés ? On a compris que c’était pas des vraies clés avec du métal, mais vous pouvez préciser en quoi ça consiste ?
Thibaut Prenons un exemple simple : tu veux avoir un moyen de différencier à tous les coups un frelon européen (Vespa crabro pour les intimes) d’un frelon asiatique (le fameux Vespa velutina). C’est important de faire la différence, le frelon asiatique est une espèce invasive qui fait des dégats, par exemple dans l’apiculture… (il raffole des boulettes d’abeille à l’automne ! Chacun son truc…)
Bon, avec OpenKeys, je vais commencer par créer une belle fiche illustrée sur le frelon européen dans un éditeur adapté. Ça pourrait ressembler à ça :
Ensuite, je fais la même pour son lointain cousin.
Voilà, toutes les espèces mentionnées par ma clé sont en place, je peux maintenant créer des critères qui vont m’aider à différencier ces deux espèces.
J’ai lu dans un bouquin que le critère le plus facile, c’est de regarder la couleur du thorax (la partie centrale du corps, entre la tête et l’abdomen). Pour les frelons asiatique, le thorax est de couleur unie (noire) et pour le frelon européen, c’est un mélange de bordeaux et noir.
J’associe chaque valeur à la fiche correspondante dans OpenKeys et le tour est joué. Je n’ai plus qu’à générer ma clé, la publier sur le Web et envoyer un email à la Fédération des apiculteurs pour les aider à faire connaître le frelon asiatique, ses risques sur les abeilles, et les moyens de le reconnaître.
Attends, je t’arrête, qui a envie de faire ça ?
Thibaut Très certainement plus de personnes que tu ne le crois ! Assez rapidement, on peut imaginer plusieurs publics :
les chercheuses et chercheurs qui s’intéressent à la biodiversité comme ceux de Vigie-nature
les enseignantes et enseignants (à l’école, en SVT au collège ou à l’université) pour un usage en classe
et au final, toutes les contemplatrices et contemplateurs de la nature et de la biodiversité, qui s’intéressent aux plantes, aux oiseaux, aux insectes, aux champignons… ou juste à ce qu’on peut observer à proximité de la maison.
OK, je vois. Et, une fois les clés produites, qu’en font ces structures et ces gens ?
Thibaut Ça dépend des profils… Le laboratoire Vigie-Nature utilise la clé des insectes pollinisateurs dans son observatoire de sciences participatives SPIPOLL par exemple.
Un⋅e enseignant⋅e va produire une ressource éducative pour sa classe (par exemple ici).
Un⋅e médiateur⋅rice de l’environnement va produire des clés pour le grand public (comme le fait l’ONF ici)
On voit aussi des naturalistes amateur⋅ices mettre leurs connaissances à disposition : le site Champ Yves en est un bon exemple.
De mon côté, j’utilise des clés pour progresser et identifier de nouvelles espèces dans mon activité en montagne. J’en propose aussi aux groupes que j’accompagne pour identifier les espèces de montagne qui les entoureront au cours leurs prochaines randonnées.
Sébastien et Grégoire, pouvez-vous nous expliquer ce qu’est Vigie-nature ? SébastienVigie-Nature est un programme de sciences participatives ouvert à tous. En s’appuyant sur des protocoles simples et rigoureux, il propose à chacun de contribuer à la recherche en découvrant la biodiversité qui nous entoure. Initié il y a plus de 30 ans avec le Suivi Temporel des Oiseaux Communs (STOC), le programme Vigie-Nature s’est renforcé depuis avec le suivi de nouveaux groupes : les papillons, chauves-souris, escargots, insectes pollinisateurs, libellules, plantes sauvages des villes…. En partageant avec les scientifiques des données de terrain essentielles les participants contribuent à l’amélioration des connaissances sur la biodiversité ordinaire et sur ses réponses face aux changements globaux (urbanisation, changement climatique…). Chacun peut y participer qu’il s’y connaisse ou non. À vous de jouer ! Grégoire En participant, on découvre un monde. Nous avons des échanges avec des participants qui se sont pris au jeu et sont devenus de véritables experts passionnés en quelques années alors qu’ils ne prêtaient pas attention aux plantes et aux animaux qui les entouraient. D’autres ont découvert cet univers puis ont butiné de programmes participatifs en programmes participatifs, au gré des découvertes. Enfin, il faut souligner que toute l’année, en ville comme à la campagne, on peut s’impliquer et contribuer à la recherche scientifique en s’enrichissant d’expériences de nature.
Donc si je veux, je peux observer des papillons et des abeilles dans mon jardin, utiliser les clés de détermination pour les identifier correctement, et remonter les résultats à Vigie-Nature ? C’est un peu comme améliorer les cartes d’OpenStreetMap, avec des êtres vivants à la place des bâtiments, mon analogie est bonne ?
Grégoire Oui en quelque sorte. Mais on pourrait même dire que ça va un peu plus loin qu’Open Street Map. C’est un peu comme si l’amélioration permanente d’Open Street Map était cadrée. Comme si, en participant, vous vous engagiez à faire une contribution régulière à Open Street Map, en revenant sur les mêmes lieux et dans les mêmes conditions. La différence est ténue mais elle est importante. En faisant de la sorte, vous pourriez suivre de manière rigoureuse les changements d’occupation du sol. Et en multipliant le nombre de personnes agissant de la sorte, il serait possible de modéliser puis d’extrapoler les divers changements, voire d’en faire des prédictions pour le futur.
Vous nous avez aussi parlé de SPIPOLL, c’est pour espionner les insectes ? (mais espion, ça prend un Y en anglais…) Grégoire Ici, Spipoll signifie Suivi Photographique des Insectes POLLinisteurs.
De quoi s’agit-il ? La pollinisation de laquelle dépend la reproduction des plantes à fleurs peut se faire de plusieurs manières.
Ainsi les graminées ou encore certains arbres profitent du vent pour faire circuler le pollen. C’est malheureusement à l’origine des allergies qu’on regroupe sous le nom de rhume des foins.
Mais pour beaucoup d’espèces, un bénéfice mutuel s’est mis en place entre plantes et insectes il y a un peu plus de 100 millions d’années (sous notre latitude, dans les tropiques, oiseaux et chauves-souris s’en mêlent). La plante fournit en abondance pollen et même nectar, un liquide sucré qui n’a d’autre rôle que d’attirer les insectes. Ces derniers viennent consommer ces deux ressources et passent de fleurs en fleurs chargés de minuscules grains de pollen. Ils assurent ainsi la reproduction sexuée des plantes et tirent bénéfice de ce service sous forme de ressources alimentaires.
Dans certains cas même, la plante ensorcelle littéralement l’insecte puisqu’elle l’attire et se fait passer pour un partenaire sexuel, trompant ainsi les mâles qui passent de fleurs en fleurs en transportant de petits sacs de pollens mais sans bénéficier de victuailles.
Suite aux incroyables bouleversement qu’ont subis les milieux naturels notamment depuis la révolution industrielle, on a pu constater des déclins d’insectes et des difficultés pour les plantes à échanger leurs gamètes. C’est crucial : sans cet échange, pas de fruits, et par exemple, aux États-Unis, les plantations d’orangers ont de grandes difficultés à fructifier. Dans ce cas, les arboriculteurs installent des ruches d’abeilles domestiques mais il semble que la situation soit tout de même critique. Les chercheurs en Écologie fondamentale se posent donc beaucoup de questions sur les communautés de pollinisateurs. On parle ici de communautés parce qu’on estime à entre cinq et dix mille le nombre d’espèces d’invertébrés impliqués dans la pollinisation en France ! Aucun spécialiste des insectes n’est à même d’étudier un si vaste nombre d’espèces, surtout qu’elles appartiennent à des groupes très variés (mouches, guêpes, abeilles et fourmis, coléoptères, papillons diurnes et nocturnes, punaises, etc.).
L’idée du Spipoll est de solliciter les personnes intéressées pour collecter des informations sur les réseaux d’interaction entre plantes et insectes partout sur le territoire. Il s’agit de prendre des photos de tout ce qui s’active sur les parties florales d’une espèce de plante dans un rayon de 5 mètres, puis de trier ces photos pour n’en garder qu’une par “bestiole différente” puis de tenter de ranger ces bestioles au sein d’une simplification taxonomique comptant quand même 630 branches !!! Et c’est là qu’une clé se révèle indispensable…
Vous avez mentionné au début de l’article que vous aimiez contempler la nature, ça fait envie, vous pouvez me décrire concrètement en quoi OpenKeys.science va m’y aider ?
Thibaut Savoir nommer les espèces qui nous entourent, c’est ouvrir une porte sur la complexité du vivant. De découverte en découverte, les paysages que nous contemplons nous apparaissent comme des lieux de vies ou cohabitent des milliers d’espèces. La diversité des espèces, des milieux et des relations entre ces espèces donne le vertige (et une soif d’en découvrir toujours plus).
En fournissant des clés à utiliser chez soi ou à emmener en balade, OpenKeys met le pied à l’étrier pour changer son regard sur la nature et pour découvrir tout ce qui se cache autour de nous.
Avec une clé de détermination dans la poche, je peux prendre le temps de m’arrêter, d’observer les alentours et d’identifier ce qui m’entoure. De découverte en découverte, c’est toute cette richesse de la nature qui s’offrira à vous…
Entre deux confinements, on va pouvoir retourner se balader, quelles clés sont disponibles sur OpenKeys.science pour une débutante ou un débutant ?
Sébastien Une clé des insectes pollinisateurs est déjà disponible, avec laquelle vous devriez pouvoir nommer la plupart des insectes que vous verrez dans votre jardin !
Nous travaillons également à proposer rapidement une clé pour :
Cet interview est aussi l’occasion de faire un appel… Vous voulez partager vos connaissances, venez faire un tour sur OpenKeys.science et créez votre clé. Par exemple, j’adorerais avoir une clé pour progresser dans l’identification des champignons.
Est-ce que vous ne seriez pas en train d’essayer de googliser la clé de détermination ? Et après vous allez capter toutes les données, les monétiser, disrupter, on connaît la suite…
Thibaut Hé hé ! Non, ce n’est pas du tout l’idée. Les contenus sources sont dans des formats libres et ouverts. Il est possible d’importer et exporter ses productions. Le service OpenKeys.science est construit avec des technologies libres (la suite logicielle Scenari et le modèle associé IDKey). Il est donc possible d’héberger ce genre de service ailleurs…
On peut considérer OpenKeys.science comme une îlot en interaction avec d’autres dans l’archipel des connaissances libres. Chez nous, on fabrique et diffuse des ressources pour comprendre la nature qui nous entoure. On utilise des technologies open source et les ressources produites sont sous licence libre pour favoriser la circulation des connaissances.
On a découvert qu’il existait plusieurs clés de détermination sur le site de TelaBotanica. Qu’est-ce que la vôtre aura de plus ?
Thibaut On peut discuter sur le plan technique. Les clés produites sur OpenKeys.science sont plus ergonomiques (ça, c’est pas moi, c’est Anna, l’ergonome qui a travaillé avec moi sur ces clés qui le dit). Elles s’adaptent mieux à l’affichage sur grand et petit écran. Elles utilisent des standards récents du Web pour être installées sur son ordinateur ou téléphone. Elles peuvent donc fonctionner sans Internet…
Après, ce n’est pas vraiment le sujet, je crois. Il ne s’agit pas de concurrencer des sites de référence comme TelaBotanica ou MycoDB par exemple. J’insiste, on ne souhaite pas centraliser les connaissances sur les clés ni challenger le reste du monde. L’idée est plutôt d’aider ces communautés de passionnés à partager. Je serai ravi de donner un coup de main aux autrices et auteurs de ces sites pour migrer techniquement leur contenu et ainsi leur permettre de générer leur clé sur OpenKeys.science ou ailleurs avec les mêmes technologies open-source. Elles ou ils y gagnent une clé plus facile à utiliser et à installer sur leur site ainsi qu’un outil pour mettre à jour et enrichir cette clé facilement.
Je suis nul en smartphone, mais un pote m’a parlé de Pl@ntnet, ça va pas vous couper l’herbe sous le pied ? Est-ce que des IA dans la blockchain avec des drones autonomes connectés 5.0 ne seraient pas plus efficaces que des humains qui se promènent avec des sites statiques ? C’est pas un peu old tech votre histoire ?
Sébastien Mais non 🙂 ! Ce n’est juste pas du tout les mêmes approches ! Une clé de détermination permet de guider le regard, d’apprendre à observer, de prendre son temps, bref de s’intéresser et de découvrir un être vivant… c’est certainement un peu plus long que de prendre une photo et d’attendre qu’une IA du Web 3.0 fasse tout le travail mais tellement plus valorisant !
Et puis, quand on a pris le temps d’observer à fond une espèce, lors de la prochaine rencontre vous vous en rappellerez tout seul et sans aide !
Thibaut Côté technique, plutôt que old tech, je revendiquerais plutôt le terme low tech. Oui, c’est volontairement un objet technique simple. Ça a plein d’avantages. Par exemple, c’est bien moins consommateur d’énergie, ça marchera encore bien après la fin d’un projet comme Pl@ntnet…
Votre projet démontre que logiciel libre et biodiversité peuvent aller de pair, et ça c’est une bonne nouvelle pour les gens qui se préoccupent de l’un et l’autre, et on est pas mal dans ce cas à Framasoft. Est-ce que vous avez d’autres idées dans le genre ? Thibaut Je crois que OpenKeys.science est un bon exemple d’interactions super positives entre ces deux mondes ! Disons que ça valide complètement l’intuition de départ… Oui, mettre en relation l’univers de l’informatique libre et la recherche en biodiversité nous profite à tous.
Je vais donc continuer d’explorer cette piste. D’un côté, rencontrer des chercheurs pour discuter des difficultés technologiques dans leurs travaux. De l’autre, identifier des développeurs qui pourraient les aider. Je pense que ça intéresserait du monde, par exemple pour prendre le temps de découvrir une nouvelle techno en menant un projet sympa, ou une organisation qui cherche un sujet pour créer un démonstrateur de son savoir-faire, ou encore des étudiants et enseignants à la recherche de projets à mener dans un cadre universitaire… les contextes ne manquent pas.
Et pourquoi pas, si tout ça fonctionne et rend service, fédérer la démarche dans une association ou une fondation.
(image d’illustration : CC BY-SA Dominik Stodulski, Wikipédia, https://fr.wikipedia.org/wiki/Coccinellidae)
Le Web est-il devenu trop compliqué ?
Le Web, tout le monde s’en sert et beaucoup en sont très contents. Mais, même parmi ceux et celles qui sont ravi·es de l’utiliser, il y a souvent des critiques. Elles portent sur de nombreux aspects et je ne vais pas essayer de lister ici toutes ces critiques. Je vais parler d’un problème souvent ressenti : le Web n’est-il pas devenu trop compliqué ?
À noter : cet article bénéficie désormais d’une version audio.
Merci à Sualtam, auteur de lectureaudio.fr pour cette contribution active.
Je ne parle pas de la complexité pour l’utilisateur, par exemple des problèmes qu’il ou elle peut avoir avec telle ou telle application Web, ou tel formulaire incompréhensible ou excluant. Non, je parle de la complexité des nombreuses technologies sous-jacentes. Alors, si vous n’êtes pas technicien·ne, vous avez peut-être envie d’arrêter votre lecture ici en pensant qu’on ne parlera que de technique. Mais ce n’est pas le cas, cet article est pour tous et toutes. (Ceci dit, si vous arrêtez votre lecture pour jouer avec le chat, manger un bon plat, lire un livre passionnant ou faire des câlins à la personne appropriée, cela ne me dérange pas et je vous souhaite un agréable moment.)
Mais revenons à l’objection « OK, les techniques utilisées dans le Web sont compliquées mais cela ne concerne que les développeuses et développeurs, non ? » Eh bien non car cette complication a des conséquences pour tous et toutes. Elle se traduit par des logiciels beaucoup plus complexes, donc elle réduit la concurrence, très peu d’organisations pouvant aujourd’hui développer un navigateur Web. Elle a pour conséquence de rendre l’utilisation du Web plus lente : bien que les machines et les réseaux aient nettement gagné en performance, le temps d’affichage d’une page ne cesse d’augmenter. Passer à la fibre ou à la 5G ne se traduira pas forcément par un gain de temps, puisque ce sont souvent les calculs nécessaires à l’affichage qui ralentissent la navigation. Et enfin cette complication augmente l’empreinte environnementale du Web, en imposant davantage d’opérations aux machines, ce qui pousse au remplacement plus rapide des terminaux.
L’insoutenable lourdeur du Web
Une page Web d’aujourd’hui n’est en effet pas une simple description d’un contenu. Elle inclut la « feuille de style », rédigée dans le langage CSS, qui va indiquer comment présenter la page, du JavaScript, un langage de programmation qui va être exécuté pour faire varier le contenu de la page, des vidéos, et d’autres choses qui souvent distraient du contenu lui-même. Je précise que je ne parle pas ici des applications tournant sur le Web (comme une application d’accès au courrier électronique, ou une application de gestion des évènements ou l’application maison utilisée par les employés d’une organisation pour gérer leur travail), non, je parle des pages Web de contenu, qui ne devraient pas avoir besoin de toute cette artillerie.
Du fait de cette complexité, il n’existe aujourd’hui que quatre ou cinq navigateurs Web réellement distincts. Écrire un navigateur Web aujourd’hui est une tâche colossale, hors de portée de la très grande majorité des organisations. La concurrence a diminué sérieusement. La complexité technique a donc des conséquences stratégiques pour le Web. Et ceci d’autant plus qu’il n’existe derrière ces navigateurs que deux moteurs de rendu, le cœur du navigateur, la partie qui interprète le langage HTML et le CSS et dessine la page. Chrome, Edge et Safari utilisent le même moteur de rendu, WebKit (ou l’une de ses variantes).
Et encore tout ne tourne pas sur votre machine. Derrière votre écran, l’affichage de la moindre page Web va déclencher d’innombrables opérations sur des machines que vous ne voyez pas, comme les calculs des entreprises publicitaires qui vont, en temps réel, déterminer les « meilleures » publicités à vous envoyer dans la figure ou comme l’activité de traçage des utilisateurs, notant en permanence ce qu’ils font, d’où elles viennent et de nombreuses autres informations, dont beaucoup sont envoyées automatiquement par votre navigateur Web, qui travaille au moins autant pour l’industrie publicitaire que pour vous. Pas étonnant que la consommation énergétique du numérique soit si importante. Et ces calculs côté serveur ont une grande influence sur la capacité du serveur à tenir face à une charge élevée, comme on l’a vu pendant les confinements Covid-19. Les sites Web de l’Éducation Nationale ne tenaient pas le coup, même quand il s’agissait uniquement de servir du contenu statique.
La surveillance coûte cher
La complexité du Web cache en effet également cette activité de surveillance, pratiquée aussi bien par les entreprises privées que par les États. Autrefois, acheter un journal à un kiosque et le lire étaient des activités largement privées. Aujourd’hui, toute activité sur le Web est enregistrée et sert à nourrir les bases de données du monde de la publicité, ou les fichiers des États. Comme exemple des informations envoyées par votre navigateur, sans que vous en ayez clairement connaissance, on peut citer bien sûr les fameux cookies. Ce sont des petits fichiers choisis par le site Web et envoyés à votre navigateur. Celui-ci les stockera et, lors d’une visite ultérieure au même site Web, renverra le cookie. C’est donc un outil puissant de suivi de l’utilisateur. Et ne croyez pas que, si vous visitez un site Web, seule l’organisation derrière ce site pourra vous pister. La plupart des pages Web incluent en effet des ressources extérieures (images, vidéos, boutons de partage), pas forcément chargés depuis le site Web que vous visitez et qui ont eux aussi leurs cookies. La loi Informatique et Libertés (et, aujourd’hui, le RGPD) impose depuis longtemps que les utilisateurs soient prévenus de ce pistage et puissent s’y opposer, mais il a fallu très longtemps pour que la CNIL tape sur la table et impose réellement cette information des utilisateurs, le « bandeau cookies ». Notez qu’il n’est pas obligatoire. D’abord, si le site Web ne piste pas les utilisateurs, il n’y a pas d’obligation d’un tel bandeau, ensuite, même en cas de pistage, de nombreuses exceptions sont prévues.
Un bandeau cookies. Notez qu’il n’y a pas de bouton Refuser.
Les bandeaux cookies sont en général délibérément conçus pour qu’il soit difficile de refuser. Le but est que l’utilisateur clique rapidement sur « Accepter » pour en être débarrassé, permettant ainsi à l’entreprise qui gère le site Web de prétendre qu’il y a eu consentement.
Désolé de la longueur de ce préambule, d’autant plus qu’il est très possible que, en tant que lectrice ou lecteur du Framablog, vous soyez déjà au courant. Mais il était nécessaire de revenir sur ces problèmes du Web pour mieux comprendre les projets qui visent à corriger le tir. Notez que les évolutions néfastes du Web ne sont pas qu’un problème technique. Elles sont dues à des raisons économiques et politiques et donc aucune approche purement technique ne va résoudre complètement le problème. Cela ne signifie pas que les techniciens et techniciennes doivent rester les bras croisés. Ils et elles peuvent apporter des solutions partielles au problème.
Bloquer les saletés
Première approche possible vers un Web plus léger, tenter de bloquer les services néfastes. Tout bon navigateur Web permet ainsi un certain contrôle de l’usage des cookies. C’est par exemple ce que propose Firefox dans une rubrique justement nommée « Vie privée et sécurité ».
Le menu de Firefox pour contrôler notamment les cookies
On peut ainsi bloquer une partie du système de surveillance. Cette approche est très recommandée mais notez que Firefox vous avertit que cela risque d’ « empêcher certains sites de fonctionner ». Cet avertissement peut faire hésiter certains utilisateurs, d’autant plus qu’avec les sites en question, il n’y aura aucun message clair, uniquement des dysfonctionnements bizarres. La plupart des sites Web commerciaux sont en effet développés sans tenir compte de la possibilité que le visiteur ait activé ces options. Si le site de votre banque ne marche plus après avoir changé ces réglages, ne comptez pas sur le support technique de la banque pour vous aider à analyser le problème, on vous dira probablement uniquement d’utiliser Google Chrome et de ne pas toucher aux réglages. D’un côté, les responsables du Web de surveillance disent qu’on a le choix, qu’on peut changer les réglages, d’un autre côté ils exercent une pression sociale intense pour qu’on ne le fasse pas. Et puis, autant on peut renoncer à regarder le site Web d’un journal lorsqu’il ne marche pas sans cookies, autant on ne peut guère en faire autant lorsqu’il s’agit de sa banque.
De même qu’on peut contrôler, voire débrayer les cookies, on peut supprimer le code Javascript. À ma connaissance, Firefox ne permet pas en standard de le faire, mais il existe une extension nommée NoScript pour le faire. Comme avec les cookies, cela posera des problèmes avec certains sites Web et, pire, ces problèmes ne se traduiront pas par des messages clairs mais par des dysfonctionnements. Là encore, peu de chance que le logiciel que l’entreprise en question a chargé de répondre aux questions sur Twitter vous aide.
Enfin, un troisième outil pour limiter les divers risques du Web est le bloqueur de publicité. (Personnellement, j’utilise uBlock Origin.)
uBlock Origin sur le site du Monde, où il a bloqué trois pisteurs et publicités. On voit aussi à gauche la liste des sites chargés automatiquement par votre navigateur quand vous regardez Le Monde.
Absolument indispensable à la fois pour éviter de consacrer du temps de cerveau à regarder les publicités, pour la sécurité (les réseaux de distribution de la publicité sont l’endroit idéal pour diffuser du logiciel malveillant) et aussi pour l’empreinte environnementale, le bloqueur empêchant le chargement de contenus qui feront travailler votre ordinateur pour le profit des agences de publicité et des annonceurs.
Un navigateur Web léger ?
Une solution plus radicale est de changer de navigateur Web. On peut ainsi préférer le logiciel Dillo, explicitement conçu pour la légèreté, les performances et la vie privée. Dillo marche parfaitement avec des sites Web bien conçus, mais ceux-ci ne sont qu’une infime minorité. La plupart du temps, le site sera affiché de manière bizarre. Et on ne peut pas le savoir à l’avance ; naviguer sur le Web avec Dillo, c’est avoir beaucoup de mauvaises surprises et seulement quelques bonnes (le Framablog, que vous lisez en ce moment, marche très bien avec Dillo).
Le site de l’Élysée vu par Dillo. Inutilisable (et pas par la faute de Dillo mais par le choix de l’Élysée d’un site spectaculaire plutôt qu’informatif).
Autre navigateur « alternatif », le Tor Browser. C’est un Firefox modifié, avec NoScript inclus et qui, surtout, ne se connecte pas directement au site Web visité mais passe par plusieurs relais du réseau Tor, supprimant ainsi un moyen de pistage fréquent, l’adresse IP de votre ordinateur. Outre que certains sites ne réagissent pas bien aux réglages du Tor Browser, le passage par le réseau Tor se traduit par des performances décrues.
Toutes ces solutions techniques, du bloqueur de publicités au navigateur léger et protecteur de la vie privée, ont un problème commun : elles sont perçues par les sites Web comme « alternatives » voire « anormales ». Non seulement le site Web risque de ne pas fonctionner normalement mais surtout, on n’est pas prévenu à l’avance, et même après on n’a pas de diagnostic clair. Le Web, pourtant devenu un écosystème très complexe, n’a pas de mécanismes permettant d’exprimer des préférences et d’être sûr qu’elles sont suivies. Certes, il existe des techniques comme l’en-tête « Do Not Track » où votre navigateur annonce qu’il ne souhaite pas être pisté mais il est impossible de garantir qu’il sera respecté et, vu le manque d’éthique de la grande majorité des sites Web, il vaut mieux ne pas compter dessus.
Gemini, une solution de rupture
Cela a mené à une approche plus radicale, sur laquelle je souhaitais terminer cet article, le projet Gemini. Gemini est un système complet d’accès à l’information, alternatif au Web, même s’il en reprend quelques techniques. Gemini est délibérément très simple : le protocole, le langage parlé entre le navigateur et le serveur, est très limité, afin d’éviter de transmettre des informations pouvant servir au pistage (comme l’en-tête User-Agent du Web) et il n’est pas extensible. Contrairement au Web, aucun mécanisme n’est prévu pour ajouter des fonctions, l’expérience du Web ayant montré que ces fonctions ne sont pas forcément dans l’intérêt de l’utilisateur. Évidemment, il n’y a pas l’équivalent des cookies. Et le format des pages est également très limité, à la fois pour permettre des navigateurs simples (pas de CSS, pas de Javascript), pour éviter de charger des ressources depuis un site tiers et pour diminuer la consommation de ressources informatiques par le navigateur. Il n’y a même pas d’images. Voici deux exemples de navigateurs Gemini :
Le client Gemini Lagrange
Le même site Gemini, vu par un client différent, Elpher
Gemini est un système récent, s’inspirant à la fois de systèmes anciens (comme le Web des débuts) et de choses plus récentes (ainsi, contrairement au Web, le chiffrement du trafic, pour compliquer la surveillance, est systématique). Il reprend notamment le concept d’URL donc par exemple le site d’informations sur les alertes de tempêtes solaires utilisé plus haut à titre d’exemple est gemini://gemini.bortzmeyer.org/presto/. Gemini est actuellement en cours de développement, de manière très ouverte, notamment sur la liste de diffusion publique du projet. Tout le monde peut participer à sa définition. (Mais, si vous voulez le faire, merci de lire la FAQ d’abord, pour ne pas recommencer une question déjà discutée.) Conformément aux buts du projet, écrire un client ou un serveur Gemini est facile et des dizaines de logiciels existent déjà. Le nom étant une allusion aux missions spatiales étatsuniennes Gemini, mais signifiant également « jumeaux » en latin, beaucoup de ces logiciels ont un nom qui évoque le spatial ou la gémellité. Pour la même raison spatiale, les sites Gemini se nomment des capsules, et il y en a actuellement quelques centaines opérationnelles. (Mais, en général, avec peu de contenu original. Gemini ressemble pour l’instant au Web des débuts, avec du contenu importé automatiquement d’autres services, et du contenu portant sur Gemini lui-même.)
On a vu que Gemini est une solution très disruptive et qui ne sera pas facilement adoptée, tant le marketing a réussi à convaincre que, sans vidéos incluses dans la page, on ne peut pas être vraiment heureux. Gemini ne prétend pas à remplacer le Web pour tous ses usages. Par exemple, un CMS, logiciel de gestion de contenu, comme le WordPress utilisé pour cet article, ne peut pas être fait avec Gemini, et ce n’est pas son but. Son principal intérêt est de nous faire réfléchir sur l’accès à l’information : de quoi avons-nous besoin pour nous informer ?
Quand bien même nous exercerions un contrôle démocratique sur nos États et les forcerions à arrêter de piller les silos de données comportementales du capitalisme de surveillance, ce dernier continuera à nous maltraiter. Nous vivons une époque parfaitement éclairée par Zuboff. Son chapitre sur le sanctuaire – ce sentiment de ne pas être observé – est une magnifique ode à l’introspection, au calme, à la pleine conscience et à la tranquillité.
Quand nous sommes observé⋅e, quelque chose change. N’importe quel parent sait ce que cela signifie. Vous pouvez lever la tête de votre bouquin (ou plus vraisemblablement de votre téléphone) et observer votre enfant dans un état profond de réalisation de soi et d’épanouissement, un instant où il est en train d’apprendre quelque chose à la limite de ses capacités, qui demande une concentration intense. Pendant un court laps de temps, vous êtes sidéré⋅e, et vous observez ce moment rare et beau de concentration qui se déroule devant vos yeux, et puis votre enfant lève la tête, vous voit le regarder, et ce moment s’évanouit. Pour grandir, vous devez être vous-même et donner à voir votre moi authentique, c’est à ce moment que vous devenez vulnérable, tel un bernard-l’hermite entre deux coquilles.
Cette partie de vous, tendre et fragile, que vous exposez au monde dans ces moments-là, est bien trop délicate pour être révélée à autrui, pas même à une personne à laquelle vous faites autant confiance qu’un enfant à ses parents.
À l’ère numérique, notre moi authentique est inextricablement mêlé à de notre vie en ligne. Votre historique de recherche est un enregistrement en continu des questions que vous vous posez. Votre historique de géolocalisation est un registre des endroits que vous cherchiez et des expériences que vous avez vécues en ces lieux. Votre réseau social révèle les différentes facettes de votre personnalité ainsi que les gens avec qui vous êtes en contact.
Être observé pendant ces activités, c’est perdre le sanctuaire de votre moi authentique. Mais il y a une autre manière pour le capitalisme de surveillance de nous dérober notre capacité d’être véritablement nous-même : nous rendre anxieux. Ce capitalisme de surveillance n’est pas vraiment un rayon de contrôle mental, pas besoin de ça pour rendre quelqu’un anxieux. Après tout, l’anxiété est le synonyme d’agitation, et pour qu’une personne se sente agitée, il n’y a pas vraiment besoin de la secouer. Il suffit d’aiguillonner et de piquer et de notifier et de bourdonner autour et de bombarder de manière intermittente et juste assez aléatoire pour que notre système limbique ne puisse jamais vraiment s’y habituer.
Nos appareils et nos services sont polyvalents dans le sens où ils peuvent connecter n’importe quoi ou n’importe qui à n’importe quoi ou à n’importe qui d’autre, et peuvent aussi exécuter n’importe quel programme. Cela signifie que ces rectangles de distractions dans nos poches détiennent nos plus précieux moments avec nos proches, tout comme les communications les plus urgentes et les plus sensibles (de « je suis en retard, peux-tu aller chercher les gamins ? » jusqu’à « mauvaise nouvelle du docteur, il faut qu’on parle TOUT DE SUITE »), mais aussi les pubs pour les frigos et les messages de recrutement nazis.
À toute heure du jour ou de la nuit, nos poches sonnent, font voler en éclat notre concentration, détruisent le fragile maillage de nos réflexions quand nous avons besoin de penser des situations difficiles. Si vous enfermiez quelqu’un dans une cellule et que vous l’agitiez de la sorte, on appellerait ça de la torture par privation de sommeil, et ce serait considéré comme un crime de guerre par la Convention de Genève.
Affliger les affligés
Les effets de la surveillance sur notre capacité à être nous-mêmes ne sont pas les mêmes pour tout le monde. Certain⋅e⋅s d’entre nous ont la chance de vivre à une époque et dans un lieu où tous les faits les plus importants de leur vie sont socialement acceptés et peuvent être exposés au grand jour sans en craindre les conséquences sociales.
Mais pour beaucoup d’entre nous, ce n’est pas le cas. Rappelez-vous que, d’aussi loin qu’on s’en souvienne, de nombreuses façons d’être, considérées aujourd’hui comme socialement acceptables, ont donné lieu à de terribles condamnations sociales, voire à des peines d’emprisonnement. Si vous avez 65 ans, vous avez connu une époque où les personnes vivant dans des « sociétés libres » pouvaient être emprisonnées ou punies pour s’être livrées à des pratiques homosexuelles, pour être tombées amoureuses d’une personne dont la peau était d’une couleur différente de la leur, ou pour avoir fumé de l’herbe.
Aujourd’hui, non seulement ces pratiques sont dépénalisées dans une grande partie du monde, mais en plus, elles sont considérées comme normales, et les anciennes prohibitions sont alors vues comme des vestiges d’un passé honteux et regrettable.
Comment sommes-nous passés de la prohibition à la normalisation ? Par une activité privée et personnelle : les personnes dont l’homosexualité étaient secrète ou qui fumaient de l’herbe en secret, ou qui aimaient quelqu’un d’une couleur de peau différente de la leur en secret, étaient susceptibles de représailles si elles dévoilaient leur moi authentique. On les empêchait de défendre leur droit à exister dans le monde et à être en accord avec elles-mêmes. Mais grâce à la sphère privée, ces personnes pouvaient former des liens forts avec leurs amis et leurs proches qui ne partageaient pas leurs manières de vivre mal vues par la société. Elles avaient des conversations privées dans lesquelles elles se dévoilaient, elles révélaient leur moi authentique à leurs proches, puis les ralliaient à leur cause au fil des conversations.
Le droit de choisir le moment et la manière d’aborder ces conversations a joué un rôle fondamental dans le renversement des normes. C’est une chose de faire son coming out à son père au cours d’une sortie de pêche à l’écart du monde, c’en est une autre de tout déballer pendant le repas de Noël, en présence de son oncle raciste sur Facebook prêt à faire une scène.
Sans sphère privée, il est possible qu’aucun de ces changements n’aurait eu lieu et que les personnes qui en ont bénéficié auraient subi une condamnation sociale pour avoir fait leur coming out face à un monde hostile ou alors elles n’auraient jamais pu révéler leur moi authentique aux personnes qu’elles aiment.
Et donc, à moins que vous ne pensiez que notre société ait atteint la perfection sociale – et que vos petits-enfants vous demanderont dans 50 ans de leur raconter comment, en 2020, toutes les injustices ont été réparées et qu’il n’y avait plus eu de changement à apporter –, vous devez vous attendre à ce qu’en ce moment même figurent parmi vos proches des personnes, dont le bonheur est indissociable du vôtre, et dont le cœur abrite un secret qui les empêche toujours de dévoiler leur moi authentique en votre présence. Ces personnes souffrent et emporteront leur chagrin secret dans leur tombe, et la source de ce chagrin, ce sera les relations faussées qu’elles entretenaient avec vous.
Une sphère privée est nécessaire au progrès humain.
Toute donnée collectée et conservée finit par fuiter
L’absence de vie privée peut empêcher les personnes vulnérables d’exprimer leur moi authentique et limiter nos actions en nous privant d’un sanctuaire. Mais il existe un autre risque, encouru par tous et pas seulement par les personnes détenant un secret : la criminalité.
Les informations d’identification personnelle présentent un intérêt très limité pour contrôler l’esprit des gens, mais le vol d’identité – terme fourre-tout pour désigner toute une série de pratiques délictueuses graves, susceptibles de détruire vos finances, de compromettre votre intégrité personnelle, de ruiner votre réputation, voire de vous exposer à un danger physique – est en pleine expansion.
Les attaquants ne se limitent pas à utiliser des données issues de l’intrusion dans une seule et même source.
De nombreux services ont subi des violations qui ont révélé des noms, des adresses, des numéros de téléphone, des mots de passe, des préférences sexuelles, des résultats scolaires, des réalisations professionnelles, des démêlés avec la justice, des informations familiales, des données génétiques, des empreintes digitales et autres données biométriques, des habitudes de lecture, des historiques de recherche, des goûts littéraires, des pseudonymes et autres données sensibles. Les attaquants peuvent fusionner les données provenant de ces violations pour constituer des dossiers très détaillés sur des sujets choisis au hasard, puis utiliser certaines parties des données pour commettre divers délits.
Les attaquants peuvent, par exemple, utiliser des combinaisons de noms d’utilisateur et de mots de passe dérobés pour détourner des flottes entières de véhicules commerciaux équipés de systèmes de repérage GPS et d’immobilisation antivol, ou pour détourner des babyphones afin de terroriser les tout-petits en diffusant du contenu audio pornographique. Les attaquants utilisent les données divulguées pour tromper les opérateurs téléphoniques afin qu’ils leur communiquent votre numéro de téléphone, puis ils interceptent des codes d’authentification à deux facteurs par SMS pour pirater votre courrier électronique, votre compte bancaire ou vos portefeuilles de crypto-monnaie.
Les attaquants rivalisent de créativité pour trouver des moyens de transformer les données divulguées en armes. Ces données sont généralement utilisées pour pénétrer dans les entreprises afin d’accéder à davantage de données.
Tout comme les espions, les fraudeurs en ligne dépendent entièrement des entreprises qui collectent et conservent nos données à outrance. Les agences d’espionnage paient voire intimident parfois des entreprises pour avoir accès à leurs données, elles peuvent aussi se comporter comme des délinquants et dérober du contenu de bases de données d’entreprises.
La collecte excessive de données entraîne de graves conséquences sociales, depuis la destruction de notre moi authentique jusqu’au recul du progrès social, de la surveillance de l’État à une épidémie de cybercriminalité. La surveillance commerciale est également une aubaine pour les personnes qui organisent des campagnes d’influence, mais c’est le cadet de nos soucis.
L’exceptionnalisme technologique critique reste un exceptionnalisme technologique
Les géants de la tech ont longtemps pratiqué un exceptionnalisme technologique : cette idée selon laquelle ils ne devraient pas être soumis aux lois et aux normes du commun des mortels. Des devises comme celle de Facebook « Move fast and break things » [avancer vite et casser des choses, NdT] ont provoqué un mépris compréhensible envers ces entreprises à la rhétorique égoïste.
L’exceptionnalisme technologique nous a tous mis dans le pétrin. Il est donc assez ironique et affligeant de voir les critiques des géants de la tech commettre le même péché.
Les géants de la tech ne forment pas un « capitalisme voyou » qui ne peut être guéri par les remèdes traditionnels anti-monopole que sont le démantèlement des trusts (forcer les entreprises à se défaire des concurrents qu’elles ont acquis) et l’interdiction des fusions monopolistiques et autres tactiques anticoncurrentielles. Les géants de la tech n’ont pas le pouvoir d’utiliser l’apprentissage machine pour influencer notre comportement de manière si approfondie que les marchés perdent la capacité de punir les mauvais acteurs et de récompenser les concurrents vertueux. Les géants de la tech n’ont pas de rayon de contrôle mental qui réécrit les règles, si c’était le cas, nous devrions nous débarrasser de notre vieille boîte à outils.
Cela fait des siècles que des gens prétendent avoir mis au point ce rayon de contrôle mental et cela s’est toujours avéré être une arnaque, même si parfois les escrocs se sont également arnaqués entre eux.
Depuis des générations, le secteur de la publicité améliore constamment sa capacité à vendre des services publicitaires aux entreprises, tout en ne réalisant que des gains marginaux sur la vente des produits de ces entreprises. La complainte de John Wanamaker selon laquelle « La moitié de l’argent que je dépense en publicité est gaspillée, mais je ne sais pas quelle moitié » témoigne du triomphe des directeurs de la publicité qui ont réussi à convaincre Wanamaker que la moitié seulement de ce qu’il dépense était gaspillée.
L’industrie technologique a fait d’énormes progrès dans la capacité à convaincre les entreprises qu’elles sont douées pour la publicité, alors que leurs améliorations réelles en matière de publicité, par opposition au ciblage, ont été plutôt modestes. La vogue de l’apprentissage machine – et l’invocation mystique de l’« intelligence artificielle » comme synonyme de techniques d’inférence statistique directe – a considérablement renforcé l’efficacité du discours commercial des géants de la tech, car les spécialistes du marketing ont exploité le manque de connaissance technique des clients potentiels pour s’en tirer avec énormément de promesses et peu de résultats.
Il est tentant de penser que si les entreprises sont prêtes à déverser des milliards dans un projet, celui-ci doit être bon. Pourtant, il arrive souvent que cette règle empirique nous fasse faire fausse route. Par exemple, on n’a pratiquement jamais entendu dire que les fonds d’investissement surpassent les simples fonds indiciels, et les investisseurs qui confient leur argent à des gestionnaires de fonds experts s’en sortent généralement moins bien que ceux qui confient leur épargne à des fonds indiciels. Mais les fonds gérés représentent toujours la majorité de l’argent investi sur les marchés, et ils sont soutenus par certains des investisseurs les plus riches et les plus pointus du monde. Leur vote de confiance dans un secteur aussi peu performant est une belle leçon sur le rôle de la chance dans l’accumulation de richesses, et non un signe que les fonds de placement sont une bonne affaire.
Les affirmations du système de contrôle mental des géants de la tech laissent à penser que cette pratique est une arnaque. Par exemple, avec le recours aux traits de personnalité des « cinq grands » comme principal moyen d’influencer les gens, même si cette théorie des cinq grands n’est étayée par aucune étude à grande échelle évaluée par des pairs, et qu’elle est surtout l’apanage des baratineurs en marketing et des psychologues pop.
Le matériel promotionnel des géants de la tech prétend aussi que leurs algorithmes peuvent effectuer avec précision une « analyse des sentiments » ou détecter l’humeur des gens à partir de leurs « micro-expressions », mais il s’agit là d’affirmations marketing et non scientifiques. Ces méthodes n’ont pas été testées par des scientifiques indépendants, et lorsqu’elles l’ont été, elles se sont révélées très insuffisantes. Les micro-expressions sont particulièrement suspectes car il a été démontré que les entreprises spécialisées dans la formation de personnes pour les détecter sont moins performantes que si on laissait faire le hasard.
Les géants de la tech ont été si efficaces pour commercialiser leurs soi-disant super-pouvoirs qu’il est facile de croire qu’elles peuvent commercialiser tout le reste avec la même habileté, mais c’est une erreur de croire au baratin du marketing. Aucune déclaration d’une entreprise sur la qualité de ses produits n’est évidemment impartiale. Le fait que nous nous méfions de tout ce que disent les géants de la tech sur le traitement des données, le respect des lois sur la protection de la vie privée, etc. est tout à fait légitime, car pourquoi goberions-nous la littérature marketing comme s’il s’agissait d’une vérité d’évangile ? Les géants de la tech mentent sur à peu près tout, y compris sur le fonctionnement de leurs systèmes de persuasion alimentés par l’apprentissage automatique.
Ce scepticisme devrait imprégner toutes nos évaluations des géants de la tech et de leurs capacités supposées, y compris à la lecture attentive de leurs brevets. Zuboff confère à ces brevets une importance énorme, en soulignant que Google a revendiqué de nouvelles capacités de persuasion dans ses dépôts de brevets. Ces affirmations sont doublement suspectes : d’abord parce qu’elles sont très intéressées, et ensuite parce que le brevet lui-même est notoirement une invitation à l’exagération.
Les demandes de brevet prennent la forme d’une série de revendications et vont des plus étendues aux plus étroites. Un brevet typique commence par affirmer que ses auteurs ont inventé une méthode ou un système permettant de faire absolument tout ce qu’il est possible d’imaginer avec un outil ou un dispositif. Ensuite, il réduit cette revendication par étapes successives jusqu’à ce que nous arrivions à l’« invention » réelle qui est le véritable objet du brevet. L’espoir est que la personne qui passe en revue les demandes de brevets – qui est presque certainement surchargée de travail et sous-informée – ne verra pas que certaines (ou toutes) ces revendications sont ridicules, ou du moins suspectes, et qu’elle accordera des prétentions plus larges du brevet. Les brevets portant sur des choses non brevetables sont tout de même très utiles, car ils peuvent être utilisés contre des concurrents qui pourraient accorder une licence sur ce brevet ou se tenir à l’écart de ses revendications, plutôt que de subir le long et coûteux processus de contestation.
De plus, les brevets logiciels sont couramment accordés même si le déposant n’a aucune preuve qu’il peut faire ce que le brevet prétend. C’est-à-dire que vous pouvez breveter une « invention » que vous n’avez pas réellement faite et que vous ne savez pas comment faire.
Avec ces considérations en tête, il devient évident que le fait qu’un Géant de la tech ait breveté ce qu’il qualifie de rayon efficace de contrôle mental ne permet nullement de savoir si cette entreprise peut effectivement contrôler nos esprits.
Les géants de la tech collectent nos données pour de nombreuses raisons, y compris la diminution du rendement des stocks de données existants. Mais de nombreuses entreprises technologiques collectent également des données en raison d’une croyance exceptionnaliste erronée aux effets de réseau des données. Les effets de réseau se produisent lorsque chaque nouvel utilisateur d’un système augmente sa valeur. L’exemple classique est celui des télécopieurs [des fax NdT] : un seul télécopieur ne sert à rien, deux télécopieurs sont d’une utilité limitée, mais chaque nouveau télécopieur mis en service après le premier double le nombre de liaisons possibles de télécopie à télécopie.
Les données exploitées pour les systèmes prédictifs ne produisent pas nécessairement ces bénéfices. Pensez à Netflix : la valeur prédictive des données extraites d’un million d’utilisateurs anglophones de Netflix n’est guère améliorée par l’ajout des données de visualisation d’un utilisateur supplémentaire. La plupart des données que Netflix acquiert après ce premier échantillon minimum viable font double emploi avec des données existantes et ne produisent que des gains minimes. En attendant, le recyclage des modèles avec de nouvelles données devient plus cher à mesure que le nombre de points de données augmente, et les tâches manuelles comme l’étiquetage et la validation des données ne deviennent pas moins chères lorsqu’on augmente l’ordre de grandeur.
Les entreprises font tout le temps la course aux modes au détriment de leurs propres profits, surtout lorsque ces entreprises et leurs investisseurs ne sont pas motivés par la perspective de devenir rentables mais plutôt par celle d’être rachetés par un Géant de la tech ou d’être introduits en Bourse. Pour ces entreprises, cocher des cases à la mode comme « collecte autant de données que possible » pourrait permettre d’obtenir un meilleur retour sur investissement que « collecte une quantité de données adaptée à l’entreprise ».
C’est un autre dommage causé par l’exceptionnalisme technologique : la croyance selon laquelle davantage de données produit toujours plus de profits sous la forme de plus d’informations qui peuvent être traduites en de meilleurs rayons de contrôle mental. Cela pousse les entreprises à collecter et à conserver des données de manière excessive, au-delà de toute rationalité. Et comme les entreprises se comportent de manière irrationnelle, bon nombre d’entre elles vont faire faillite et devenir des navires fantômes dont les cales sont remplies de données qui peuvent nuire aux gens de multiples façons, mais dont personne n’est plus responsable. Même si les entreprises ne font pas faillite, les données qu’elles collectent sont maintenues en-deça de la sécurité minimale viable – juste assez de sécurité pour maintenir la viabilité de l’entreprise en attendant d’être rachetées par un Géant de la tech, un montant calculé pour ne pas dépenser un centime de trop pour la protection des données.
Comment les monopoles, et non le contrôle de la pensée, conduisent à la surveillance capitaliste : le cas de Snapchat
Pendant la première décennie de son existence, Facebook est entré en concurrence avec les réseaux sociaux de l’époque (Myspace, Orkut, etc) en se présentant comme l’alternative respectant de la vie privée. De fait, Facebook a justifié son jardin clos, qui permet aux utilisateurs d’y amener des données du Web, mais empêche les services tels que Google Search d’indexer et de mémoriser les pages Facebook, en tant que mesure de respect de la vie privée qui protège les utilisateurs des heureux gagnants de la bataille des réseaux sociaux comme Myspace.
En dépit des fréquentes promesses disant qu’il ne collecterait ou n’analyserait jamais les données de ses utilisateurs, Facebook a lancé à intervalles réguliers des initiatives exactement dans ce but, comme le sinistre Beacon tool, qui vous espionne lorsque vous surfez sur le Web puis ajoute vos activités sur le web à votre timeline publique, permettant à vos amis de surveiller vos habitudes de navigation. Beacon a suscité une révolte des utilisateurs. À chaque fois, Facebook a renoncé à ses actions de surveillance, mais jamais complètement ; inévitablement, le nouveau Facebook vous surveillera plus que l’ancien Facebook, mais moins que le Facebook intermédiaire qui suit le lancement d’un nouveau produit ou service.
Le rythme auquel Facebook a augmenté ses efforts de surveillance semble lié au climat compétitif autour de Facebook. Plus Facebook avait de concurrents, mieux il se comportait. À chaque fois qu’un concurrent majeur s’est effondré, le comportement de Facebook s’est notablement dégradé.
Dans le même temps, Facebook a racheté un nombre prodigieux d’entreprises, y compris une société du nom de Onavo. À l’origine, Onavo a créé une application mobile pour suivre l’évolution de la batterie. Mais les permissions que demandaient Onavo étaient telles que l’appli était capable de recueillir de façon très précise l’intégralité de ce que les utilisateurs font avec leurs téléphones, y compris quelles applis ils utilisent et comment.
Avec l’exemple d’Onavo, Facebook a découvert qu’il était en train de perdre des parts de marché au profit de Snapchat, une appli qui, comme Facebook une décennie plus tôt, se vend comme l’alternative qui respecte la vie privée par rapport au statu quo . À travers Onavo, Facebook a pu extraire des données des appareils des utilisateurs de Snapchat, que ce soient des utilisateurs actuels ou passés. Cela a poussé Facebook à racheter Instagram, dont certaines fonctionnalités sont concurrentes de Snapchat, et a permis à Facebook d’ajuster les fonctionnalités d’Instagram ainsi que son discours marketing dans le but d’éroder les gains de Snapchat et s’assurer que Facebook n’aurait pas à faire face aux pressions de la concurrence comme celles subies par le passé par Myspace et Orkut.
La manière dont Facebook a écrasé Snapchat révèle le lien entre le monopole et le capitalisme de surveillance. Facebook a combiné la surveillance avec une application laxiste des lois antitrust pour repérer de loin la menace de la concurrence par Snapchat et pour prendre des mesures décisives à son encontre. Le capitalisme de surveillance de Facebook lui a permis d’éviter la pression de la concurrence avec des tactiques anti-compétitives. Les utilisateurs de Facebook veulent toujours de la confidentialité, Facebook n’a pas utilisé la surveillance pour les convaincre du contraire, mais ils ne peuvent pas l’obtenir car la surveillance de Facebook lui permet de détruire tout espoir d’émergence d’un rival qui lui fait concurrence sur les fonctionnalités de confidentialité.
Un monopole sur vos amis
Un mouvement de décentralisation a essayé d’éroder la domination de Facebook et autres entreprises des géants de la tech en proposant des alternatives sur le Web indépendant (indieweb) : Mastodon en alternative à Twitter, Diaspora en alternative à Facebook, etc, mais ces efforts ont échoué à décoller.
Fondamentalement, chacun de ces services est paralysé par le même problème : tout utilisateur potentiel d’une alternative de Facebook ou Twitter doit convaincre tous ses amis de le suivre sur une alternative décentralisée pour pouvoir continuer à avoir les bénéfices d’un média social. Pour beaucoup d’entre nous, la seule raison pour laquelle nous avons un compte Facebook est parce que nos amis ont des comptes Facebook, et la raison pour laquelle ils ont des comptes Facebook est que nous avons des comptes Facebook.
Tout cela a contribué à faire de Facebook, et autres plateformes dominantes, des « zones de tir à vue » dans lesquelles aucun investisseur ne financera un nouveau venu.
Et pourtant, tous les géants d’aujourd’hui sont apparus malgré l’avantage bien ancré des entreprises qui existaient avant eux. Pour comprendre comment cela a été possible, il nous faut comprendre l’interopérabilité et l’interopérabilité antagoniste.
Le gros problème de nos espèces est la coordination.
L’« interopérabilité » est la capacité qu’ont deux technologies à fonctionner l’une avec l’autre : n’importe qui peut fabriquer un disque qui jouera sur tous les lecteurs de disques, n’importe qui peut fabriquer un filtre que vous pourrez installer sur la ventilation de votre cuisinière, n’importe qui peut fabriquer l’essence pour votre voiture, n’importe qui peut fabriquer un chargeur USB pour téléphone qui fonctionnera dans votre allume-cigare, n’importe qui peut fabriquer une ampoule qui marchera dans le culot de votre lampe, n’importe qui peut fabriquer un pain qui grillera dans votre grille-pain.
L’interopérabilité est souvent une source d’innovation au bénéfice du consommateur : Apple a fabriqué le premier ordinateur personnel viable commercialement, mais des millions de vendeurs de logiciels indépendants ont fait des programmes interopérables qui fonctionnaient sur l’Apple II Plus. La simple antenne pour les entrées analogiques à l’arrière des téléviseurs a d’abord permis aux opérateurs de câbles de se connecter directement aux télévisions, puis ont permis aux entreprises de consoles de jeux et ensuite aux ordinateurs personnels d’utiliser une télévision standard comme écran. Les prises téléphoniques RJ11 standardisées ont permis la production de téléphones par divers vendeurs avec divers formes, depuis le téléphone en forme de ballon de foot reçu en cadeau d’abonnement de Sports Illustrated, aux téléphones d’affaires avec haut-parleurs, mise en attente, et autres, jusqu’aux répondeurs et enfin les modems, ouvrant la voie à la révolution d’Internet.
On utilise souvent indifféremment « interopérabilité » et « standardisation », qui est le processus pendant lequel les fabricants et autres concernés négocient une liste de règles pour l’implémentation d’une technologie, comme les prises électriques de vos murs, le bus de données CAN utilisé par le système de votre voiture, ou les instructions HTML que votre navigateur internet interprète.
Mais l’interopérabilité ne nécessite pas la standardisation, en effet la standardisation émerge souvent du chaos de mesures d’interopérabilité ad hoc. L’inventeur du chargeur USB dans l’allume-cigare n’a pas eu besoin d’avoir la permission des fabricants de voitures ou même des fabricants des pièces du tableau de bord. Les fabricants automobiles n’ont pas mis en place des contre-mesures pour empêcher l’utilisation de ces accessoires d’après-vente par leurs consommateurs, mais ils n’ont pas non plus fait en sorte de faciliter la vie des fabricants de chargeurs. Il s’agit d’une forme d’« interopérabilité neutre ».
Au-delà de l’interopérabilité neutre, il existe l’« interopérabilité antagoniste ». C’est quand un fabricant crée un produit qui interagit avec le produit d’un autre fabricant en dépit des objections du deuxième fabricant, et cela même si ça nécessite de contourner un système de sécurité conçu pour empêcher l’interopérabilité.
Le type d’interopérabilité antagoniste le plus usuel est sans doute les cartouches d’encre d’imprimantes par des fournisseurs tiers. Les fabricants d’imprimantes affirment qu’ils vendent les imprimantes en-dessous de leur coût et que leur seul moyen de récupérer les pertes est de se constituer une marge élevée sur les encres. Pour empêcher les propriétaires d’imprimantes d’acheter leurs cartouches ailleurs, les entreprises d’imprimantes appliquent une série de systèmes de sécurité anti-consommateurs qui détectent et rejettent les cartouches re-remplies ou par des tiers.
Les propriétaires d’imprimantes quant à eux défendent le point de vue que HP et Epson et Brother ne sont pas des œuvres caritatives et que les consommateurs de leurs produits n’ont aucune obligation à les aider à survivre, et donc que si ces entreprises choisissent de vendre leurs produits à perte, il s’agit de leur choix stupide et à eux d’assumer les conséquences. De même, les compétiteurs qui fabriquent des cartouches ou les re-remplissent font remarquer qu’ils ne doivent rien aux entreprises d’imprimantes, et que le fait qu’ils érodent les marges de ces entreprises est le problème de celles-ci et non celui de leurs compétiteurs. Après tout, les entreprises d’imprimantes n’ont aucun scrupule à pousser un re-remplisseur à fermer boutique, donc pourquoi est-ce que les re-remplisseurs devraient se soucier de la bonne santé économique des entreprises d’imprimantes ?
L’interopérabilité antagoniste a joué un rôle hors normes dans l’histoire de l’industrie tech : depuis la création du « alt.* » dans l’architecture de Usenet (qui a commencé à l’encontre des souhaits des responsables de Usenet et qui s’est développé au point d’être plus important que tout le Usenet combiné) à la guerre des navigateurs (lorsque Netscape et Microsoft ont dépensé d’énormes ressources en ingénierie pour faire en sorte que leur navigateur soit incompatible avec les fonctionnalités spéciales et autres peccadilles de l’autre) à Facebook (dont le succès a entre autres été dû au fait qu’il a aidé ses nouveaux utilisateurs en leur permettant de rester en contact avec les amis qu’ils ont laissés sur Myspace parce que Facebook leur a fourni un outil pour s’emparer des messages en attente sur Myspace et les importer sur Facebook, créant en pratique un lecteur Myspace basé sur Facebook).
Aujourd’hui, la validation par le nombre est considérée comme un avantage inattaquable. Facebook est là où tous vos amis sont, donc personne ne peut fonder un concurrent à Facebook. Mais la compatibilité antagoniste retourne l’avantage concurrentiel : si vous êtes autorisés à concurrencer Facebook en proposant un outil qui importe les messages en attente sur Facebook de tous vos utilisateurs dans un environnement qui est compétitif sur des terrains que Facebook ne pourra jamais atteindre, comme l’élimination de la surveillance et des pubs, alors Facebook serait en désavantage majeur. Vous aurez rassemblé tous les potentiels ex-utilisateurs de Facebook sur un unique service facile à trouver. Vous les auriez éduqués sur la façon dont un service Facebook-like fonctionne et quels sont ses potentiels avantages, et vous aurez fourni un moyen simple aux utilisateurs mécontents de Facebook pour dire à leurs amis où ils peuvent trouver un meilleur traitement.
L’interopérabilité antagoniste a été la norme pendant un temps et une contribution clef à une scène tech dynamique et vibrante, mais à présent elle est coincée derrière une épaisse forêt de lois et règlements qui ajoutent un risque légal aux tactiques éprouvées de l’interopérabilité antagoniste. Ces nouvelles règles et les nouvelles interprétations des règles existantes signifient qu’un potentiel « interopérateur » antagoniste aura besoin d’échapper aux réclamations de droits d’auteurs, conditions de service, secret commercial, ingérence et brevets.
En l’absence d’un marché concurrentiel, les faiseurs de lois ont délégué des tâches lourdes et gouvernementales aux sociétés de Big Tech, telles que le filtrage automatique des contributions des utilisateurs pour la violation des droits d’auteur ou pour des contenus terroristes et extrémistes ou pour détecter et empêcher le harcèlement en temps réel ou encore pour contrôler l’accès au contenu sexuel.
Ces mesures ont fixé une taille minimale à partir de laquelle on peut faire du Big Tech, car seules les très grandes entreprises peuvent se permettre les filtres humains et automatiques nécessaires pour se charger de ces tâches.
Mais ce n’est pas la seule raison pour laquelle rendre les plateformes responsables du maintien de l’ordre parmi leurs utilisateurs mine la compétition. Une plateforme qui est chargée de contrôler le comportement de ses utilisateurs doit empêcher de nombreuses techniques vitales à l’interopérabilité antagoniste de peur qu’elles ne contreviennent à ses mesures de contrôle. Par exemple si quelqu’un utilisant un remplaçant de Twitter tel que Mastodon est capable de poster des messages sur Twitter et de lire des messages hors de Twitter, il pourrait éviter les systèmes automatiques qui détectent et empêchent le harcèlement (tels que les systèmes qui utilisent le timing des messages ou des règles basées sur les IP pour estimer si quelqu’un est un harceleur).
Au point que nous sommes prêts à laisser les géants de la tech s’autocontrôler, plutôt que de faire en sorte que leur industrie soit suffisamment limitée pour que les utilisateurs puissent quitter les mauvaises plateformes pour des meilleures et suffisamment petites pour qu’une réglementation qui ferait fermer une plateforme ne détruirait pas l’accès aux communautés et données de milliards d’utilisateurs, nous avons fait en sorte que les géants de la tech soient en mesure de bloquer leurs concurrents et qu’il leur soit plus facile de demander un encadrement légal des outils pour bannir et punir les tentatives à l’interopérabilité antagoniste.
En définitive, nous pouvons essayer de réparer les géants de la tech en les rendant responsables pour les actes malfaisants de ses utilisateurs, ou bien nous pouvons essayer de réparer Internet en réduisant la taille de géants. Mais nous ne pouvons pas faire les deux. Pour pouvoir remplacer les produits des géants d’aujourd’hui, nous avons besoin d’éclaircir la forêt légale qui empêche l’interopérabilité antagoniste de façon à ce que les produits de demain, agiles, personnels, de petite échelle, puissent se fédérer sur les géants tels que Facebook, permettant aux utilisateurs qui sont partis à continuer à communiquer avec les utilisateurs qui ne sont pas encore partis, envoyant des vignes au-dessus du mur du jardin de Facebook afin que les utilisateurs piégés de Facebook puissent s’en servir afin de grimper aux murs et de s’enfuir, accédant au Web ouvert et global.