10 trucs que j’ignorais sur Internet et mon ordi (avant de m’y intéresser…)
Merci à Sualtam, auteur de lectureaudio.fr pour cette contribution active.
1) Tu ne consultes pas une page Internet, tu la copies

Un site web, c’est pas une espèce de journal qu’on aurait mis dans le pays magique d’internet pour que ton navigateur aille le consulter comme tu consulterais le quotidien de ton jour de naissance à la médiathèque du coin.
Pour voir une page web, ton navigateur la copie sur ton ordi. Les textes, les images, les sons : tout ce que tu vois ou entends sur ton écran a été copié sur ton ordinateur (vilain pirate !)
Un ordinateur est un photocopieur dont la trieuse serait une méga fourmilière qui peut faire plein de trucs. La bonne nouvelle, c’est que copier permet de multiplier, que ça ne vole rien à personne, parce que si je te copie un fichier tu l’as toujours.
- La BD « Les Ordinateurs sont des cons » sur GriseBouille
- La chanson « Copier n’est pas voler » sur YouTube
2) Mon navigateur web ne cuisine pas la même page web que le tien.
Sérieux, imagine qu’une page web, c’est une recette de cuisine :
Mettez un titre en gros, en gris et en gras.
Réduisez l’image afin qu’elle fasse un quart de la colonne d’affichage, réservez.
Placez le texte, agrémenté d’une jolie police, aligné à gauche, puis l’image à droite.
Servez chaud.
Le navigateur web (Firefox, Chrome, Safari, Internet Explorer…), c’est le cuisinier. Il va télécharger les ingrédients, et suivre la recette. T’as déjà vu quand on donne la même recette avec les mêmes ingrédients à 4 cuisiniers différents ? Ben ouais, c’est comme dans Top Chef, ça fait 4 plats qui sont pas vraiment pareils.
Surtout quand les assiettes ne sont pas de la même taille (genre l’écran de ton téléphone et celui de ton ordi…) et que pour cuire l’un utilise le four et l’autre un micro-ondes (je te laisse trouver une correspondance métaphorique dans ton esprit, tu peux y arriver, je crois en toi :p !).
Bref : l’article que tu lis aura peu de chance d’avoir la même gueule pour toi et la personne à qui tu le feras passer 😉
- Préfère Firefox si t’as pas envie de filer tes données à Google-Chrome, Apple-Safari ou Microsoft-Edge
- Ou sinon Chromium c’est Chrome sans du Google dedans 😉
3) Le streaming n’existe pas
Nope. Le streaming, c’est du téléchargement qui s’efface au fur et à mesure. Parce qu’un ordinateur est une machine à copier.
Le streaming, c’est du téléchargement que tu ne peux (ou ne sais) pas récupérer, donc tu downloades une vidéo ou un son mais juste pour une seule fois, et si tu veux en profiter à nouveau, il faut encore les télécharger et donc encombrer les tuyaux d’internet.
Tu vois les précieux mégas du forfait data de ton téléphone qui te ruinent chaque mois ? Ce sont des textes, images sons, vidéos et informations qui viennent jusqu’à ton ordi (ordinateur ou ordiphone, hein, c’est pareil). La taille de ces mégas, c’est un peu les litres d’eau que tu récupères au robinet d’internet.
Regarder ou écouter deux fois le même truc en streaming, sur YouTube ou Soundcloud par exemple, c’est comme si tu prenais deux fois le même verre d’eau au robinet.
- Les meilleurs logiciels pour télécharger en pair-à-pair (et décongestionner les tuyaux d’internet)
- 30 sites de torrents aux contenus libres et légaux (en anglais)

4) Quand tu regardes une page web, elle te regarde aussi.
Mon livre ne me dit pas de le sortir du tiroir de la table de nuit. Il ne sait pas où je suis lorsque je le lis, quand je m’arrête, quand je saute des pages ni vers quel chapitre, quand je le quitte et si c’est pour aller lire un autre livre.
Sur Internet, les tuyaux vont dans les deux sens. Une page web sait déjà plein de choses sur toi juste lorsque tu cliques dessus et la vois s’afficher. Elle sait où tu te trouves, parce qu’elle connaît l’adresse de la box internet à laquelle tu t’es connecté. Elle sait combien de temps tu restes. Quand est-ce que tu cliques sur une autre page du même site. Quand et où tu t’en vas.
Netflix, par exemple, est une application web, donc un site web hyper complexe, genre QI d’intello plus plus plus. Netflix sait quel type de film tu préfères voir lors de tes soirées d’insomnie. À partir de quel épisode tu accroches vraiment à la saison d’une série. Ils doivent même pouvoir déterminer quand tu fais ta pause pipi !
Ouaip : Internet te regarde juste pour pouvoir fonctionner, et souvent plus. Ne t’y trompe pas : il prend des notes sur toi.
- Pour équiper ton cuisinier-navigateur d’outils contre l’espionnage publicitaire, suis le guide !
- Surfe anonyme avec le navigateur Tor
5) Pas besoin d’un compte Facebook/Google/etc pour qu’ils aient un dossier sur toi.

Si Internet peut te regarder, ceux qui y gagnent le plus d’argent ont les moyens d’en profiter (logique : ils peuvent se payer les meilleurs spécialistes !)
Tu vois le petit bouton « like » (ou « tweet » ou « +1 » ou…) sur tous les articles web que tu lis ? Ces petits boutons sont des espions, des trous de serrures. Ils donnent à Facebook (ou Twitter ou Google ou…) toutes les infos sur toi dont on parlait juste au dessus. Si tu n’as pas de compte, qu’ils n’ont pas ton nom, ils mettront cela sur l’adresse de ta machine. Le pire, c’est que cela fonctionne aussi avec des choses que tu vois moins (les polices d’écriture fournies par Google et très utilisées par les sites, les framework javascript, les vidéos YouTube incrustées sur un blog…)
Une immense majorité de sites utilisent aussi « Google Analytics » pour analyser tes comportements et mieux savoir quelles pages web marchent bien et comment. Mais du coup, ces infos ne sont pas données qu’à la personne qui a fait le site web : Google les récupère au passage. Là où ça devient marrant, c’est quand on se demande qui décide qu’un site marche « bien » ? C’est quoi ce « bien » ? C’est bien pour qui…?
Oui : avec le blog rank comme avec la YouTube money, Google décide souvent de comment nous devons créer nos contenus.
- Voici 98 choses que Facebook sait sur toi par Anguille sous Roche.
- Découvre les infos que Google a sur toi (compte Google nécessaire -_-…)
6) Un email est une carte postale
On a tendance à comparer les emails (et les SMS) à des lettres, le truc sous enveloppe. Sauf que non : c’est une carte postale. Tout le monde (la poste, le centre de tri, ceux qui gèrent le train ou l’avion, l’autre centre de tri, le facteur…), tous ces gens peuvent lire ton message. J’ai même des pros qui me disent que c’est carrément un poster affiché sur tous les murs de ces intermédiaires, puisque pour transiter par leurs ordis, ton email se… copie. Oui, même si c’est une photo de tes parties intimes…
Si tu veux une enveloppe, il faut chiffrer tes emails (ou tes sms).
Gamin, j’adorais déchiffrer les messages codés dans la page jeux du journal de Mickey. Y’avait une phrase faite d’étoiles, carrés, et autre symboles, et je devais deviner que l’étoile c’est la lettre A, le cœur la lettre B, etc. Lorsque j’avais trouvé toutes les correspondances c’était le sésame magique : j’avais trouvé la clé pour déchiffrer la phrase dans la mystérieuse bulle de Mickey.
Imagine la même chose version calculatrice boostée aux amphètes. C’est ça, le chiffrement. Une petit logiciel prend ton email/SMS, applique la clé des correspondances bizarres pour le chiffrer en un brouillard de symboles, et l’envoie à ton pote. Comme vos logiciels se sont déjà échangé les clés, ton pote peut le déchiffrer. Mais comme il est le seul à avoir la clé, lui seul peut le déchiffrer.
Ben ça, ça te fait une enveloppe en plomb que même le regard laser de Superman il peut pas passer au travers pour lire ta lettre.
- Comment chiffrer ses e-mails avec Open-PGP
- Comment chiffrer très simplement ses appels et SMS avec Signal
7) Le cloud, c’est l’ordinateur d’un autre.

Mettre sur le cloud ses fichiers (icloud), ses emails (gmail), ses outils (Office365)… c’est les mettre sur l’ordinateur d’Apple, de Google, de Microsoft.
Alors OK, on parle pas d’un petit PC qui prend la poussière, hein. On parle d’une grosse ferme de serveurs, de milliers d’ordinateurs qui chauffent tellement que des climatiseurs tournent à fond.
Mais c’est le même principe : un serveur, c’est un ordinateur-serviteur en mode Igor, qui est tout le temps allumé, qu’on a enchaîné au plus gros tuyau internet possible. Dès qu’on lui demande une page web, un fichier, un email, une application… on le fouette et il doit répondre au plus vite « Ouiiiiii, Mestre ! »
Tout le truc est de savoir si tu fais confiance aux Igors de savants fous dont le but est de devenir les plus riches et les maîtres du monde, ou au petit Igor du gentil nerd du coin… Voire si tu te paierais pas le luxe d’avoir ton propre Igor, ton propre serveur à la maison.
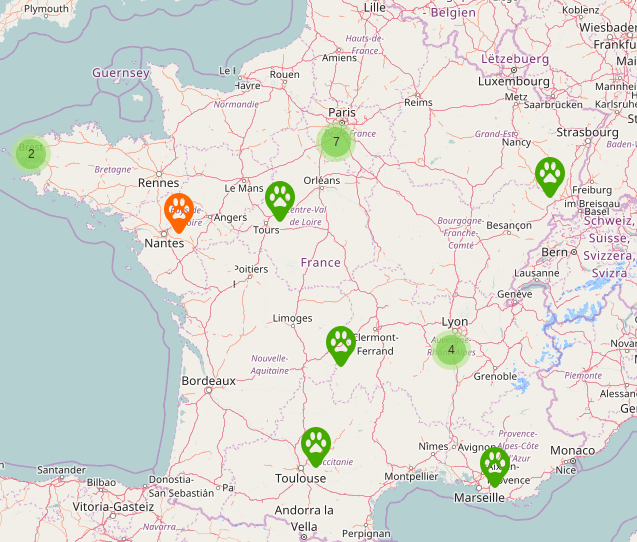
- Utilise les services de Dégooglisons Internet, les Igors de Framasoft…
- …encore mieux : trouve un gentil Igor près de chez toi avec les CHATONS…
- …encore plus mieux : crée ton propre Igor avec Yunohost / La Brique Internet !
8) Facebook est plus fort que ma volonté.

Ouais, je suis faible. J’ai, encore aujourd’hui, le réflexe « je clique sur facebook entre deux trucs à faire ». Ou Twitter. Ou Tumblr. Ou l’autre truc à la con, OSEF, c’est pareil.
Cinq minutes plus tard, je finis dans état de semi zombie, à scroller de la mollette en voyant mon mur défiler des informations devant mes yeux hypnotisés. Je finis par faire ce qu’on attend de moi : cliquer sur un titre putassier, liker, retwetter une notification et répondre à des trucs dont je n’aurais rien à foutre si une vague connaissance venait m’en parler dans un bar.
Ce n’est pas que je manque de volonté : c’est juste que Facebook (et ses collègues de bureau) m’ont bien étudié. Enfin, ils ont plus étudié l’humain que moi, mais pas de bol : j’en fais partie. Du coup ils ont construit leurs sites, leurs applications, etc. de façon à me piéger, à ce que je reste là (afin de bouffer leur pub), et à ce que j’y retourne.
Ces techniques de design qui hackent notre esprit (genre le « scroll infini », le « bandit manchot des notifications » et les « titres clickbait » dont je parle juste au dessus) sont volontaires, étudiées et documentées. Elles utilisent simplement des failles de notre esprit (subconscient, inconscient, biais cognitifs… je laisse les scientifiques définir tout cela) qui court-circuitent nos volontés. Ce n’est pas en croyant qu’on est maître de soi-même qu’on l’est vraiment. C’est souvent le contraire : le code fait la loi jusque dans nos esprits.
Bref, je suis faible, parce que je suis humain, et donc je suis pas le seul. Et ça, les géants du web l’ont bien compris.
- Comment est-ce que le code, c’est la loi.
- Un ex « Philosophe-produit » de chez Google explique comment des millions d’heures de nos vies nous sont volées
- Comment la technologie pirate l’esprit des gens, l’article originel en Anglais de Tristan Harris
9) Internet est ce que j’en ferai

Si je veux voir d’autres choses dans ma vie numérique, j’ai le choix : attendre que les autres le fassent jusqu’à ce que des toiles d’araignées collent mes phalanges aux touches de mon clavier, en mode squelette… ou bien je peux bouger mes doigts.
Alors ouais, j’ai pas appris à conduire en vingt heures de cours, j’ai raté plein de gâteaux avant de m’acheter les bons ustensiles et la première écharpe que j’ai faite avait pleins de trous. Mais aujourd’hui, je sais conduire, faire des pâtisseries pas dégueu et même me tricoter un pull.
Ben créer et diffuser des contenus sur Internet, c’est pareil, ça s’apprend. On trouve même facilement les infos et les outils sur Internet (dont des cours de tricot !).
Une fois qu’on sait, on peut proposer autre chose : c’est la mode des articles courts, creux et aux titres putassiers ? Tiens, et si je gardais le coup du titre pour faire un top, mais cette fois-ci dans un article blog long, dense, et condensant une tonne de sujets épars…?
Oh, wait.
- Zeste de savoir, un site pour apprendre et partager de tout.
- OpenClassrooms, un site pour se former au numérique
10) C’est pas la fin du monde, juste le début.
Quand on voit à quel point on a perdu la maîtrise de l’informatique, de nos vies numériques, de notre capacité à simplement imaginer comment on pourrait faire autrement… y’a de quoi déprimer.
Mais avant que tu demandes à ce qu’on t’apporte une corde, une pierre et une rivière, regarde juste un truc : le numérique est une révolution toute jeune dans notre Histoire. C’est comme quand tu découvres le chocolat, le maquillage, ou une fucking nouvelle série qui déboîte : tu t’en fous plein la gueule.
Sociétalement, on vient de se gaver d’ordinateurs (jusqu’à en mettre dans nos poches, ouais, de vrais ordis avec option téléphone !) et de numérique, et là les plus gros marchands de chocolat/maquillage/séries se sont gavés sur notre dos en nous fourguant un truc sucré, gras et qui nous laisse parfois l’estomac au bord des lèvres.
Mais on commence tout juste, et il est encore temps d’apprendre à devenir gourmet, à savoir se maquiller avec finesse, et même à écrire une fan fiction autour de cette nouvelle série.
Il est temps de revenir vers une informatique-amie, à échelle humaine, vers un outil que l’on maîtrise nous ! (et pas l’inverse, parce que moi j’aime pas que mon lave-linge me donne des ordres, nanmého !)
Des gens plus intelligents et spécialistes que moi m’ont dit qu’avec le trio « logiciel libres + chiffrement + services décentralisés », on tenait une bonne piste. J’ai tendance à les croire, et si ça te botte, tu peux venir explorer cette voie avec nous. Cela ne nous empêchera pas d’en cheminer d’autres, ensemble et en même temps, car nous avons un vaste territoire à découvrir.
Alors, t’es prêt pour la terra incognita ?
- Lire Surveillance:// de Tristan Nitot
- Lire Numérique, reprendre le contrôle, ouvrage collectif chez Framabook



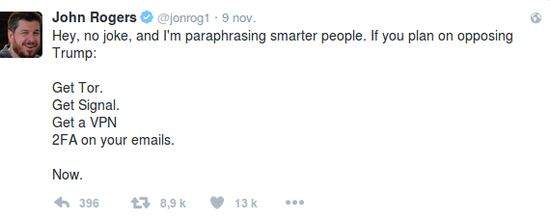



 Depuis un ou deux ans, quelqu’un a sondé les défenses des entreprises qui font tourner des composantes critiques d’Internet. Ces sondes prennent la forme d’attaques précisément calibrées destinées à déterminer exactement comment ces entreprises peuvent se défendre, et ce qui serait nécessaire pour les faire tomber. Nous ne savons pas qui fait cela, mais ça ressemble à un grand État-nation. La Chine ou la Russie seraient mes premières suppositions.
Depuis un ou deux ans, quelqu’un a sondé les défenses des entreprises qui font tourner des composantes critiques d’Internet. Ces sondes prennent la forme d’attaques précisément calibrées destinées à déterminer exactement comment ces entreprises peuvent se défendre, et ce qui serait nécessaire pour les faire tomber. Nous ne savons pas qui fait cela, mais ça ressemble à un grand État-nation. La Chine ou la Russie seraient mes premières suppositions.