C’est Qwant qu’on va où ?
L’actualité récente de Qwant était mouvementée, mais il nous a semblé qu’au-delà des polémiques c’était le bon moment pour faire le point avec Qwant, ses projets et ses valeurs.
Si comme moi vous étiez un peu distrait⋅e et en étiez resté⋅e à Qwant-le-moteur-de-recherche, vous allez peut-être partager ma surprise : en fouinant un peu, on trouve tout un archipel de services, certains déjà en place et disponibles, d’autres en phase expérimentale, d’autres encore en couveuse dans le labo.
Voyons un peu avec Tristan Nitot, Vice-président Advocacy de Qwant, de quoi il retourne et si le principe affiché de respecter la vie privée des utilisateurs et utilisatrices demeure une ligne directrice pour les applications qui arrivent.

Bonjour Tristan, tu es toujours content de travailler pour Qwant malgré les périodes de turbulence ?
Oui, bien sûr ! Je reviens un peu en arrière : début 2018, j’ai déjeuné avec un ancien collègue de chez Mozilla, David Scravaglieri, qui travaillait chez Qwant. Il m’a parlé de tous les projets en logiciel libre qu’il lançait chez Qwant en tant que directeur de la recherche. C’est ce qui m’a convaincu de postuler chez Qwant.
J’étais déjà fan de l’approche liée au respect de la vie privée et à la volonté de faire un moteur de recherche européen, mais là, en plus, Qwant se préparait à faire du logiciel libre, j’étais conquis. À peine arrivé au dessert, j’envoie un texto au président, Eric Léandri pour savoir quand il m’embauchait. Sa réponse fut immédiate : « Quand tu veux ! ». J’étais aux anges de pouvoir travailler sur des projets qui rassemblent mes deux casquettes, à savoir vie privée et logiciel libre.
Depuis, 18 mois ont passé, les équipes n’ont pas chômé et les premiers produits arrivent en version Alpha puis Bêta. C’est un moment très excitant !
Récemment, Qwant a proposé Maps en version Bêta… Vous comptez vraiment rivaliser avec Google Maps ? Parce que moi j’aime bien Street View par exemple, est-ce que c’est une fonctionnalité qui viendra un jour pour Qwant Maps ?
Rivaliser avec les géants américains du capitalisme de surveillance n’est pas facile, justement parce qu’on cherche un autre modèle, respectueux de la vie privée. En plus, ils ont des budgets incroyables, parce que le capitalisme de surveillance est extrêmement lucratif. Plutôt que d’essayer de trouver des financements comparables, on change les règles du jeu et on se rapproche de l’écosystème libre OpenStreetMap, qu’on pourrait décrire comme le Wikipédia de la donnée géographique. C’est une base de données géographiques contenant des données et des logiciels sous licence libre, créée par des bénévoles autour desquels viennent aussi des entreprises pour former ensemble un écosystème. Qwant fait partie de cet écosystème.
En ce qui concerne les fonctionnalités futures, c’est difficile d’être précis, mais il y a plein de choses que nous pouvons mettre en place grâce à l’écosystème OSM. On a déjà ajouté le calcul d’itinéraires il y a quelques mois, et on pourrait se reposer sur Mapillary pour avoir des images façon StreetView, mais libres !
Dis donc, en comparant 2 cartes du même endroit, on voit que Qwant Maps a encore des progrès à faire en précision ! Pourquoi est-ce que Qwant Maps ne reprend pas l’intégralité d’Open Street Maps ?
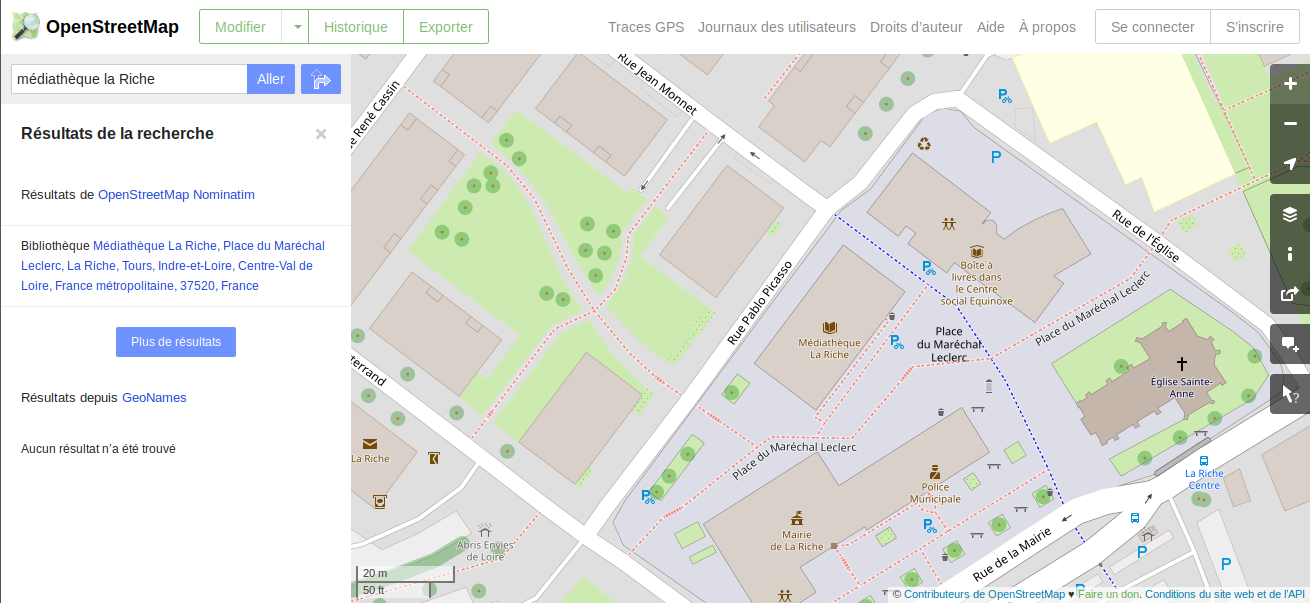

En fait, OSM montre énormément de détails et on a choisi d’en avoir un peu moins mais plus utilisables. On a deux sources de données pour les points d’intérêt (POI) : Pages Jaunes, avec qui on a un contrat commercial et OSM. On n’affiche qu’un seul jeu de POI à un instant t, en fonction de ce que tu as recherché.
Quand tu choisis par exemple « Restaurants » ou « Banques », sans le savoir tu fais une recherche sur les POI Pages Jaunes. Donc tu as un fond de carte OSM avec des POI Pages Jaunes, qui sont moins riches que ceux d’OSM mais plus directement lisibles.
Bon d’accord, Qwant Maps utilise les données d’OSM, c’est tant mieux, mais alors vous vampirisez du travail bénévole et libre ? Quelle est la nature du deal avec OSM ?
 Non, bien sûr, Qwant n’a pas vocation à vampiriser l’écosystème OSM : nous voulons au contraire être un citoyen modèle d’OSM. Nous utilisons les données et logiciels d’OSM conformément à leur licence. Il n’y a donc pas vraiment de deal, juste un respect des licences dans la forme et dans l’esprit. Par exemple, on met un lien qui propose aux utilisateurs de Qwant Maps d’apprendre à utiliser et contribuer à OSM. En ce qui concerne les logiciels libres nécessaires au fonctionnement d’OSM, on les utilise et on y contribue, par exemple avec les projets Mimirsbrunn, Kartotherian et Idunn. Mes collègues ont écrit un billet de blog à ce sujet.
Non, bien sûr, Qwant n’a pas vocation à vampiriser l’écosystème OSM : nous voulons au contraire être un citoyen modèle d’OSM. Nous utilisons les données et logiciels d’OSM conformément à leur licence. Il n’y a donc pas vraiment de deal, juste un respect des licences dans la forme et dans l’esprit. Par exemple, on met un lien qui propose aux utilisateurs de Qwant Maps d’apprendre à utiliser et contribuer à OSM. En ce qui concerne les logiciels libres nécessaires au fonctionnement d’OSM, on les utilise et on y contribue, par exemple avec les projets Mimirsbrunn, Kartotherian et Idunn. Mes collègues ont écrit un billet de blog à ce sujet.
Nous avons aussi participé à la réunion annuelle d’OSM, State Of the Map (SOTM) à Montpellier le 14 juin dernier, où j’étais invité à parler justement des relations entre les entreprises comme Qwant et les projets libres de communs numériques comme OSM. Les mauvais exemples ne manquent pas, avec Apple qui, avec Safari et Webkit, a sabordé le projet Konqueror de navigateur libre, ou Google qui reprend de la data de Wikipédia mais ne met pas de lien sur comment y contribuer (alors que Qwant le fait). Chez Qwant, on vise à être en symbiose avec les projets libres qu’on utilise et auxquels on contribue.
Google Maps a commencé à monétiser les emplois de sa cartographie, est-ce qu’un jour Qwant Maps va être payant ?
En réalité, Google Maps est toujours gratuit pour les particuliers (approche B2C Business to consumer). Pour les organisations ou entreprises qui veulent mettre une carte sur leur site web (modèle B2B Business to business), Google Maps a longtemps été gratuit avant de devenir brutalement payant, une fois qu’il a éliminé tous ses concurrents commerciaux. Il apparaît assez clairement que Google a fait preuve de dumping.
Pour le moment, chez Qwant, il n’y a pas d’offre B2B. Le jour où il y en aura une, j’espère que le un coût associé sera beaucoup plus raisonnable que chez Google, qui prend vraiment ses clients pour des vaches à lait. Je comprends qu’il faille financer le service qui a un coût, mais là, c’est exagéré !
Quand j’utilise Qwant Maps, est-ce que je suis pisté par des traqueurs ? J’imagine et j’espère que non, mais qu’est-ce que Qwant Maps « récolte » et « garde » de moi et de ma connexion si je lui demande où se trouve Bure avec ses opposants à l’enfouissement de déchets nucléaires ? Quelles garanties m’offre Qwant Maps de la confidentialité de mes recherches en cartographie ?
C’est un principe fort chez Qwant : on ne veut pas collecter de données personnelles. Bien sûr, à un instant donné, le serveur doit disposer à la fois de la requête (quelle zone de la carte est demandée, à quelle échelle) et l’adresse IP qui la demande. L’adresse IP pourrait permettre de retrouver qui fait quelle recherche, et Qwant veut empêcher cela. C’est pourquoi l’adresse IP est salée et hachée aussitôt que possible et c’est le résultat qui est stocké. Ainsi, il est impossible de faire machine arrière et de retrouver quelle adresse IP a fait quelle recherche sur la carte. C’est cette méthode qui est utilisée dans Qwant Search pour empêcher de savoir qui a recherché quoi dans le moteur de recherche.
Est-ce que ça veut dire qu’on perd aussi le relatif confort d’avoir un historique utile de ses recherches cartographiques ou générales ? Si je veux gagner en confidentialité, j’accepte de perdre en confort ?
Effectivement, Qwant ne veut rien savoir sur la personne qui recherche, ce qui implique qu’on ne peut pas personnaliser les résultats, ni au niveau des recherches Web ni au niveau cartographique : pour une recherche donnée, chaque utilisateur reçoit les mêmes résultats que tout le monde.
Ça peut être un problème pour certaines personnes, qui aimeraient bien disposer de personnalisation. Mais Qwant n’a pas dit son dernier mot : c’est exactement pour ça que nous avons fait « Masq by Qwant ». Masq, c’est une application Web en logiciel libre qui permet de stocker localement dans le navigateur (en LocalStorage)1 et de façon chiffrée des données pour la personnalisation de l’expérience utilisateur. Masq est encore en Alpha et il ne permet pour l’instant que de stocker (localement !) ses favoris cartographiques. À terme, nous voulons que les différents services de Qwant utilisent Masq pour faire de la personnalisation respectueuse de la vie privée.
Ah bon alors c’est fini le cloud, on met tout sur sa machine locale ? Et si on vient fouiner dans mon appareil alors ? N’importe quel intrus peut voir mes données personnelles stockées ?
Effectivement, tes données étant chiffrées, et comme tu es le seul à disposer du mot de passe, c’est ta responsabilité de conserver précieusement ledit mot de passe. Quant à la sauvegarde des données, tu as bien pensé à faire une sauvegarde, non ? 😉

Ah mais vous avez aussi un projet de reconnaissance d’images ? Comment ça marche ? Et à quoi ça peut être utile ?
C’est le résultat du travail de chercheurs de Qwant Research, une intelligence artificielle (plus concrètement un réseau de neurones) qu’on a entraînée avec Pytorch sur des serveurs spécialisés DGX-1 en vue de proposer des images similaires à celles que tu décris ou que tu téléverses.

Ah tiens j’ai essayé un peu, ça donne effectivement des résultats rigolos : si on cherche des saucisses, on a aussi des carottes, des crevettes et des dents…

C’est encore imparfait comme tu le soulignes, et c’est bien pour ça que ça n’est pas encore un produit en production ! On compte utiliser cette technologie de pointe pour la future version de notre moteur de recherche d’images.
Comment je fais pour signaler à l’IA qu’elle s’est plantée sur telle ou telle image ? C’est prévu de faire collaborer les bêta-testeurs ? Est-ce que Qwant accueille les contributions bénévoles ou militantes ?
Il est prévu d’ajouter un bouton pour que les utilisateurs puissent valider ou invalider une image par rapport à une description. Pour des projets de plus en plus nombreux, Qwant produit du logiciel libre et donc publie le code. Par exemple pour la recherche d’image, c’est sur https://github.com/QwantResearch/text-image-similarity. Les autres projets sont hébergés sur les dépôts https://github.com/QwantResearch : les contributions au code (Pull requests) et les descriptions de bugs (issues) sont les bienvenus !
Bon je vois que Qwant a l’ambition de couvrir autant de domaines que Google ? C’est pas un peu hégémonique tout ça ? On se croirait dans Dégooglisons Internet !
- Qwant Music (depuis juin 2016)
- Boards, des « carnets » personnels en ligne
- Qwant Junior
- et encore ce projet-là parmi d’autres…
Effectivement, nos utilisateurs attendent de Qwant tout un univers de services. La recherche est pour nous une tête de pont, mais on travaille à de nouveaux services. Certains sont des moteurs de recherche spécialisés comme Qwant Junior, pour les enfants de 6 à 12 ans (pas de pornographie, de drogues, d’incitation à la haine ou à la violence).
Comment c’est calculé, les épineuses questions de résultats de recherche ou non avec Qwant Junior ? Ça doit être compliqué de filtrer…
Nous avons des équipes qui gèrent cela et s’assurent que les sujets sont abordables par les enfants de 6 à 12 ans, qui sont notre cible pour Junior.
Ça n’est pas facile effectivement, mais nous pensons que c’est important. C’est une idée qui nous est venue au lendemain des attentats du Bataclan où trop d’images choquantes étaient publiées par les moteurs de recherche. C’était insupportable pour les enfants. Et puis Junior, comme je le disais, n’a pas vocation à afficher de publicité ni à capturer de données personnelles. C’est aussi pour cela que Qwant Junior est très utilisé dans les écoles, où il donne visiblement satisfaction aux enseignants et enseignantes.
Mais euh… « filtrer » les résultats, c’est le job d’un moteur de recherche ?
Il y a deux questions en fait. Pour un moteur de recherche pour enfants, ça me parait légitime de proposer aux parents un moteur qui ne propose pas de contenus choquants. Qwant Junior n’a pas vocation à être neutre : c’est un service éditorialisé qui fait remonter des contenus à valeur pédagogique pour les enfants. C’est aux parents de décider s’ils l’utilisent ou pas.
Pour un moteur de recherche généraliste revanche, la question est plutôt d’être neutre dans l’affichage des résultats, dans les limites de la loi.
Tiens vous avez même des trucs comme Causes qui propose de reverser l’argent des clics publicitaires à de bonnes causes ? Pour cela il faut désactiver les bloqueurs de pub auxquels nous sommes si attachés, ça va pas plaire aux antipubs…
En ce qui concerne Qwant Causes, c’est le moteur de recherche Qwant mais avec un peu plus de publicité. Et quand tu cliques dessus, cela rapporte de l’argent qui est donné à des associations que tu choisis. C’est une façon de donner à ces associations en faisant des recherches. Bien sûr si tu veux utiliser un bloqueur de pub, c’est autorisé chez Qwant, mais ça n’a pas de sens pour Qwant Causes, c’est pour ça qu’un message d’explication est affiché.
Est-ce que tous ces services sont là pour durer ou bien seront-ils fermés au bout d’un moment s’ils sont trop peu employés, pas rentables, etc. ?
Tous les services n’ont pas vocation à être rentables. Par exemple, il n’y a pas de pub sur Qwant Junior, parce que les enfants y sont déjà trop exposés. Mais Qwant reste une entreprise qui a vocation à générer de l’argent et à rémunérer ses actionnaires, donc la rentabilité est pour elle une chose importante. Et il y a encore de la marge pour concurrencer les dizaines de services proposés par Framasoft et les CHATONS 😉
Est-ce que Qwant est capable de dire combien de personnes utilisent ses services ? Qwant publie-t-elle des statistiques de fréquentation ?
Non. D’abord, on n’identifie pas nos utilisateurs, donc c’est impossible de les compter : on peut compter le nombre de recherches qui sont faites, mais pas par combien de personnes. Et c’est très bien comme ça ! Tout ce que je peux dire, c’est que le nombre de requêtes évolue très rapidement : on fait le point en comité de direction chaque semaine, et nous battons presque à chaque fois un nouveau record !
Bon venons-en aux questions que se posent souvent nos lecteurs et lectrices : Qwant et ses multiples services, c’est libre, open source, ça dépend ?
Non, tout n’est pas en logiciel libre chez Qwant, mais si tu vas sur les dépôts de Qwant et Qwant Research tu verras qu’il y a déjà plein de choses qui sont sous licence libre, y compris des choses stratégiques comme Graphee (calcul de graphe du Web) ou Mermoz (robot d’indexation du moteur). Et puis les nouveaux projets comme Qwant Maps et Masq y sont aussi.
La publicité est une source de revenus dans votre modèle économique, ou bien vous vendez des services à des entreprises ou institutions ? Qwant renonce à un modèle économique lucratif qui a fait les choux gras de Google, mais alors comment gagner de l’argent ?
Oui, Qwant facture aussi des services à des institutions dans le domaine de l’open data par exemple, mais l’essentiel du revenu vient de la publicité contextuelle, à ne pas confondre avec la publicité ciblée telle que faite par les géants américains du Web. C’est très différent.
La publicité ciblée, c’est quand tu sais tout de la personne (ses goûts, ses habitudes, ses déplacements, ses amis, son niveau de revenu, ses recherches web, son historique de navigation, et d’autres choses bien plus indiscrètes telles que ses opinions politiques, son orientation sexuelle ou religieuse, etc.). Alors tu vends à des annonceurs le droit de toucher avec de la pub des personnes qui sont ciblées. C’est le modèle des géants américains.
Qwant, pour sa part, ne veut pas collecter de données personnelles venant de ses utilisateurs. Tu as sûrement remarqué que quand tu vas sur Qwant.com la première fois, il n’y a pas de bannière « acceptez nos cookies ». C’est normal, nous ne déposons pas de cookies quand tu fais une recherche Qwant !

Quand tu fais une recherche, Qwant te donne une réponse qui est la même pour tout le monde. Tu fais une recherche sur « Soupe à la tomate » ? On te donne les résultats et en même temps on voit avec les annonceurs qui est intéressé par ces mots-clés. On ignore tout de toi, ton identité ou ton niveau de revenu. Tout ce qu’on sait, c’est que tu as cherché « soupe à la tomate ». Et c’est ainsi que tu te retrouves avec de la pub pour du Gaspacho ou des ustensiles de cuisine. La publicité vaut un peu moins cher que chez nos concurrents, mais les gens cliquent dessus plus souvent. Au final, ça permet de financer les services et d’en inventer de nouveaux tout en respectant la vie privée des utilisateurs et de proposer une alternative aux services américains gourmands en données personnelles. On pourrait croire que ça ne rapporte pas assez, pourtant c’était le modèle commercial de Google jusqu’en 2006, où il a basculé dans la collecte massive de données personnelles…
Dans quelle mesure Qwant s’inscrit-il dans la reconquête de la souveraineté européenne contre la domination des géants US du Web ?
Effectivement, parmi les deux choses qui différencient Qwant de ses concurrents, il y a la non-collecte de données personnelles et le fait qu’il est français et à vocation européenne. Il y a un truc qui me dérange terriblement dans le numérique actuel, c’est que l’Europe est en train de devenir une colonie numérique des USA et peut-être à terme de la Chine. Or, le numérique est essentiel dans nos vies. Il les transforme ! Ces outils ne sont pas neutres, ils sont le reflet des valeurs de ceux qui les produisent.
Aux USA, les gens sont considérés comme des consommateurs : tout est à vendre à ou à acheter. En Europe, c’est différent. Ça n’est pas un hasard si la CNIL est née en France, si le RGPD est européen : on a conscience de l’enjeu des données personnelles sur la citoyenneté, sur la liberté des gens. Pour moi, que Qwant soit européen, c’est très important.
Merci d’avoir accepté de répondre à nos questions. Comme c’est la tradition de nos interviews, on te laisse le mot de la fin…
Je soutiens Framasoft depuis toujours ou presque, parce que je sais que ce qui y est fait est vraiment important : plus de libre, moins d’hégémonie des suspects habituels, plus de logiciel libre, plus de valeur dans les services proposés.
J’ai l’impression d’avoir avec Qwant une organisation différente par nature (c’est une société, avec des actionnaires), mais avec des objectifs finalement assez proches : fournir des services éthiques, respectueux de la vie pivée, plus proches des gens et de leurs valeurs, tout en contribuant au logiciel libre. C’est ce que j’ai tenté de faire chez Mozilla pendant 17 ans, et maintenant chez Qwant. Alors, je sais que toutes les organisations ne sont pas parfaites, et Qwant ne fait pas exception à la règle. En tout cas, chez Qwant on fait du mieux qu’on peut !
Vive l’Internet libre et ceux qui œuvrent à le mettre en place et à le défendre !










#/media/Fichier:H96566k.jpg){kind=link}
{kind=link}
![Kae [CC BY-SA 3.0 (https://creativecommons.org/licenses/by-sa/3.0)], via Wikimedia Commons](https://commons.wikimedia.org/wiki/File:Power_connector_Legrand_32A.jpg){kind=link}
_-_Google_Art_Project_-_edited.jpg){kind=link}
![Codex Bodmer – Frater Rufillus (wohl tätig im Weißenauer Skriptorium) [Public domain]](https://commons.wikimedia.org/wiki/File:Codex_Bodmer_127_244r_detail_Rufillus.jpg){kind=link}