Ce que valent nos adresses quand nous signons une pétition
Le chant des sirènes de la bonne conscience est hypnotique, et rares sont ceux qui n’ont jamais cédé à la tentation de signer des pétitions en ligne… Surtout quand il s’agit de ces « bonnes causes » qui font appel à nos réactions citoyennes et humanistes, à nos convictions les mieux ancrées ou bien sûr à notre indignation, notre compassion… Bref, dès qu’il nous semble possible d’avoir une action sur le monde avec un simple clic, nous signons des pétitions. Il ne nous semble pas trop grave de fournir notre adresse mail pour vérifier la validité de notre « signature ». Mais c’est alors que des plateformes comme Change.org font de notre profil leur profit…
Voilà ce que dénonce, chiffres à l’appui, la journaliste de l’Espresso Stefania Maurizi. Active entre autres dans la publication en Italie des documents de Wikileaks et de Snowden, elle met ici en lumière ce qui est d’habitude laissé en coulisses : comment Change.org monétise nos données les plus sensibles.
Dans le cadre de notre campagne Dégooglisons, nous sommes sensibles à ce dévoilement, c’est un argument de plus pour vous proposer prochainement un Framapétitions, un outil de création de pétitions libre et open source, respectueux de vos données personnelles…
Voilà comment Change.org vend nos adresses électroniques
L’Espresso a obtenu les tarifs de l’entreprise (de 1,50 euro à 85 centimes) et a contacté certains clients. Entre les réponses embarrassées et les reconnaissances du bout des lèvres, nous avons étudié l’activité de l’« Amazon des pétitions en ligne ». Elle manipule des données extrêmement sensibles telles que les opinions politiques et fait l’objet en Allemagne d’une enquête sur le respect de la vie privée.
On l’a appelée le « Google de la politique moderne ». Change.org, la plateforme populaire pour lancer des pétitions sur les questions politiques et sociales, est un géant qui compte cent cinquante millions d’utilisateurs à travers le monde et ce nombre augmente d’un million chaque semaine : un événement comme le Brexit a déclenché à lui seul 400 pétitions. En Italie, où elle a débarqué il y a quatre ans, Change.org a atteint cinq millions d’utilisateurs. Depuis la pétition lancée par Ilaria Cucchi pour demander l’approbation d’une loi sur la torture, qui a jusqu’à présent recueilli plus de 232 000 signatures, jusqu’à celle sur le référendum constitutionnel, que celui qui n’a jamais apposé une signature sur Change.org dans l’espoir de faire pression sur telle ou telle institution pour changer les choses lève la main. Au 21e siècle, la participation démocratique va inévitablement vers les plateformes en ligne. Et en effet on ne manque pas d’exemples dans lesquels ces pétitions ont vraiment déclenché des changements.
Il suffit de quelques clics : tout le monde peut lancer une pétition et tout le monde peut la signer. Mais il y a un problème : combien de personnes se rendent-elles compte que les données personnelles qu’elles confient à la plateforme en signant les soi-disant « pétitions sponsorisées » — celles qui sont lancées par les utilisateurs qui paient pour les promouvoir (https://www.change.org/advertise) — seront en fait vendues et utilisées pour les profiler ? La question est cruciale, car ce sont des données très sensibles, vu qu’elles concernent des opinions politiques et sociales.
L’Espresso est en mesure de révéler les tarifs que Change.org applique à ceux qui lancent des pétitions sponsorisées : des ONG aux partis politiques qui payent pour obtenir les adresses électroniques des signataires. Les prix vont de un 1,5 € par adresse électronique, si le client en achète moins de dix mille, jusqu’à 85 centimes pour un nombre supérieur à cinq cent mille. Notre journal a aussi demandé à certaines des ONG clientes de Change.org s’il est vrai qu’elles acquièrent les adresses électroniques des signataires. Certaines ont répondu de façon trop évasive pour ne pas susciter d’interrogations. D’autres, comme Oxfam, ont été honnêtes et l’ont confirmé.
Pour Change.org, voici combien vaut votre adresse électronique
Beaucoup croient que Change.org est une association sans but lucratif, animée d’idéaux progressistes. En réalité, c’est une véritable entreprise, Change.org Inc, créée dans le Delaware, un paradis fiscal américain, dont le quartier général est à San Francisco, au cœur de cette Silicon Valley où les données ont remplacé le pétrole. Et c’est vrai qu’elle permet à n’importe qui de lancer gratuitement des pétitions et remplit une fonction sociale : permettre jusqu’au dernier sans domicile fixe de s’exprimer. Mais elle réalise des profits avec les pétitions sponsorisées, là où le client paie pour réussir à contacter ceux qui seront probablement les plus enclins à signer et à donner de l’argent dans les campagnes de récolte de fonds. Comment fait Change.org pour le savoir ? Chaque fois que nous souscrivons à un appel, elle accumule des informations sur nous et nous profile. Et comme l’a expliqué clairement la revue américaine Wired : « si vous avez signé une pétition sur les droits des animaux, l’entreprise sait que vous avez une probabilité 2,29 fois supérieure d’en signer une sur la justice. Et si vous avez signé une pétition sur la justice, vous avez une probabilité 6,3 fois supérieure d’en signer une sur la justice économique, 4,4 d’en signer une sur les droits des immigrés et 4 fois d’en signer une autre encore sur l’éducation. »
Celui qui souscrit à une pétition devrait d’abord lire soigneusement les règles relatives à la vie privée, mais combien le font et combien comprennent réellement que, lorsqu’ils signent une pétition sponsorisée, il suffit qu’ils laissent cochée la mention « Tenez-moi informé de cette pétition » pour que leur adresse électronique soit vendue par Change.org à ses clients qui ont payé pour cela ? Ce n’est pas seulement les tarifs obtenus par L’Espresso qui nous confirment la vente des adresses électroniques, c’est aussi Oxfam, une des rares ONG qui a répondu de façon complètement transparente à nos questions : « c’est seulement au moment où les signataires indiquent qu’ils soutiennent Oxfam qu’il nous est demandé de payer Change.org pour leurs adresses », nous explique l’organisation.
Nous avons demandé ce que signifiait exactement « les signataires ont indiqué vouloir soutenir Oxfam », l’ONG nous a répondu en montrant la case cochée par le signataire, par laquelle il demande à rester informé de la pétition. Interpellée par L’Espresso, l’entreprise Change.org n’a pas démenti les tarifs. De plus elle a confirmé qu’ « ils varient selon le client en fonction du volume de ses achats » ; comme l’a expliqué John Coventry, responsable des Relations publiques de Change.org, une fois que le signataire a choisi de cocher la case, ou l’a laissée cochée, son adresse électronique est transmise à l’organisation qui a lancé la pétition sponsorisée. Coventry est convaincu que la plupart des personnes qui choisissent cette option se rendent compte qu’elles recevront des messages de l’organisation. En d’autres termes, les signataires donnent leur consentement.
Capture d’écran sur le site Change.org
Depuis longtemps, Thilo Weichert, ex-commissaire pour la protection des données du Land allemand de Schleswig-Holstein, accuse l’entreprise de violation de la loi allemande en matière de confidentialité. Weichert explique à l’Espresso que la transparence de Change.org laisse beaucoup à désirer : « ils ne fournissent aucune information fiable sur la façon dont ils traitent les données ». Et quand nous lui faisons observer que ceux qui ont signé ces pétitions ont accepté la politique de confidentialité et ont donc donné leur consentement en toute conscience, Thilo répond que la question du consentement ne résout pas le problème, parce que si une pratique viole la loi allemande sur la protection des données, l’entreprise ne peut pas arguer du consentement des utilisateurs. En d’autres termes, il n’existe pas de consentement éclairé qui rende légal le fait d’enfreindre la loi.
Suite aux accusations de Thilo Weichert, la Commission pour la protection des données de Berlin a ouvert sur Change.org une enquête qui est toujours en cours, comme nous l’a confirmé la porte-parole de la Commission, Anja-Maria Gardain. Et en avril, l’organisation « Digitalcourage », qui en Allemagne organise le « Big Brother Award » a justement décerné ce prix négatif à Change.org. « Elle vise à devenir ce qu’est Amazon pour les livres, elle veut être la plus grande plateforme pour toutes les campagnes politiques » nous dit Tangens Rena de Digitalcourage. Elle explique comment l’entreprise s’est montrée réfractaire aux remarques de spécialistes comme Weichert : par exemple en novembre dernier, celui-ci a fait observer à Change.org que le Safe Harbour auquel se réfère l’entreprise pour sa politique de confidentialité n’est plus en vigueur, puisqu’il a été déclaré invalide par la Cour européenne de justice suite aux révélations d’Edward Snowden. Selon Tangens, « une entreprise comme Change.org aurait dû être en mesure de procéder à une modification pour ce genre de choses. »
L’experte de DigitalCourage ajoute qu’il existe en Allemagne des plateformes autres que Change.org, du type Campact.de : « elles ne sont pas parfaites » précise-t-elle, « et nous les avons également critiquées, mais au moins elles se sont montrées ouvertes au dialogue et à la possibilité d’opérer des modifications ». Bien sûr, pour les concurrents de Change.org, il n’est pas facile de rivaliser avec un géant d’une telle envergure et le défi est presque impossible à relever pour ceux qui choisissent de ne pas vendre les données des utilisateurs. Comment peuvent-ils rester sur le marché s’ils ne monétisent pas la seule denrée dont ils disposent : les données ?
Pour Rena Tagens l’ambition de l’entreprise Change.org, qui est de devenir l’Amazon de la pétition politique et sociale, l’a incitée à s’éloigner de ses tendances progressistes initiales et à accepter des clients et des utilisateurs dont les initiatives sont douteuses. On trouve aussi sur la plateforme des pétitions qui demandent d’autoriser le port d’armes à la Convention républicaine du 18 juillet, aux USA. Et certains l’accusent de faire de l’astroturfing, une pratique qui consiste à lancer une initiative politique en dissimulant qui est derrière, de façon à faire croire qu’elle vient de la base. Avec l’Espresso, Weichert et Tangens soulignent tous les deux que « le problème est que les données qui sont récoltées sont vraiment des données sensibles et que Change.org est située aux Etats-Unis », si bien que les données sont soumises à la surveillance des agences gouvernementales américaines, de la NSA à la CIA, comme l’ont confirmé les fichiers révélés par Snowden.
Mais Rena Tangens et Thilo Weichert, bien que tous deux critiques envers les pratiques de Change.org, soulignent qu’il est important de ne pas jeter le bébé avec l’eau du bain, car ils ne visent pas à détruire l’existence de ces plateformes : « Je crois qu’il est important qu’elles existent pour la participation démocratique, dit Thilo Weichert, mais elles doivent protéger les données ».
Mise à jour du 22 juillet : la traduction de cet article a entraîné une réaction officielle de Change.org France sur leur page Facebook, suite auquel nous leur avons bien évidemment proposé de venir s’exprimer en commentaire sur le blog. Ils ont (sympathiquement) accepté. Nous vous encourageons donc à prendre connaissance de leur réponse, ainsi que les commentaires qui le suivent, afin de poursuivre le débat.
La prise de conscience et la suite
C’est peut-être le début du début de quelque chose : naguère traités de « paranos », les militants pour la vie privée ont désormais une audience croissante dans le grand public, on peut même parler d’une prise de conscience générale partielle et lente mais irréversible…
Dans un article récent traduit pour vous par le groupe Framalang, Cory Doctorow utilise une analogie inattendue avec le déclin du tabagisme et estime qu’un cap a été franchi : celui de l’indifférence générale au pillage de notre vie privée.
Mais le chemin reste long et il nous faut désormais aller au-delà en fournissant des outils et des moyens d’action à tous ceux qui refusent de se résigner. C’est ce qu’à notre modeste échelle nous nous efforçons de mener à bien avec vous.
traduction Framalang : lyn, Julien, cocosushi, goofy, xi
Dès les tout premiers jours de l’accès public à Internet, les militants comme moi n’ont cessé d’alerter sur les risques sérieux pour la vie privée impliqués par les traces des données personnelles que nous laissons derrière nous lors de notre activité quotidienne en ligne. Nous espérions que le grand public réfléchirait sérieusement aux risques potentiels de divulgation à tout va. Que le grand public comprendrait que les inoffensives miettes d’informations personnelles pourraient être minutieusement rassemblées pour notre malheur par des criminels ou des gouvernements répressifs, des harceleurs aux aguets ou des employeurs abusifs, ou encore par des forces de l’ordre bien intentionnées mais qui pourraient tirer des conclusions fallacieuses de leur espionnage de nos vies.
Nous avons complètement échoué.
La popularité et la portée d’Internet n’ont fait qu’augmenter chaque année. Et chaque année ont augmenté aussi les menaces sur la vie privée des utilisateurs.
Pour être honnête, nous, les défenseurs de la vie privée, avons une bonne excuse. Il est vraiment très difficile d’amener les gens à avoir conscience des dangers qui les menacent lorsque ceux-ci sont à venir, surtout quand le comportement qui vous met en danger et ses conséquences sont très éloignés dans le temps et dans l’espace. La divulgation de la vie privée est un problème de santé publique, comme le tabagisme. Ce n’est pas une simple bouffée de cigarette qui va vous donner le cancer, mais inhalez assez de bouffées et, au bout du compte, ce sera le cancer quasi assuré. Une simple divulgation de vos données personnelles ne vous causera pas de préjudice, mais la répétition de ces divulgations sur le long terme engendrera de sérieux problèmes de confidentialité.
Pendant des décennies, les défenseurs de la santé publique ont essayé d’amener les gens à se préoccuper des risques de cancer, sans beaucoup de succès. Ils avaient, eux aussi, une bonne excuse. Fumer procure un bénéfice à court terme (on calme une envie irrésistible) et le coût en est modique. Pire encore, les entreprises qui faisaient du profit avec le tabac ont largement financé des campagnes de désinformation pour que leurs clients aient plus de mal à appréhender les risques à long terme, et surtout évitent de s’en soucier.
Le tabagisme est maintenant en déclin (bien que le vapotage s’avère y conduire efficacement), mais il a fallu pas mal de temps pour en arriver là. Quand ceux qui avaient fumé toute leur vie recevaient le diagnostic de leur cancer, il était déjà trop tard, et beaucoup ont nié la réalité de leur cancer, ont continué à fumer tout au long de leur thérapie, ou bien ont connu une mort lente et cruelle. L’association entre le plaisir à court terme de la fumée et l’absence de moyens significatifs de réparer les dégâts qui se sont déjà produits, telle est l’infaillible moteur du déni : pourquoi se priver des plaisirs de la fumée si finalement ça ne fait aucune différence ?
Cependant, le tabagisme n’est en déclin que parce que les preuves de ses dégâts sont peu à peu devenues indéniables. À un certain moment, l’indifférence aux dangers du tabac a atteint son point culminant – bien avant que le tabagisme lui-même n’atteigne son maximum. L’indifférence maximale représente un tournant. Une fois que le nombre de personnes qui se sentent concernées par le problème commence à grandir indépendamment de vous, sans que vous ayez besoin de présenter encore et toujours ses conséquences à long terme, vous pouvez changer de tactique pour passer à quelque chose de bien plus facile. Plutôt que d’essayer d’impliquer les gens, vous avez maintenant seulement besoin de les inciter à agir sur ce sujet.
Le mouvement contre le tabagisme a réalisé de grandes avancées sur ce terrain. Il a fait en sorte que les personnes atteintes du cancer – ou celles dont les proches l’étaient – comprennent que le fait de fumer n’était pas un phénomène venu de nulle part. Des noms ont été cités, des documents publiés qui ont montré exactement qui conspirait pour détruire des vies avec le cancer afin de s’enrichir. Les militants ont mis au jour et souligné les risques qui pèsent sur la vie des gens non fumeurs : le tabagisme passif, mais aussi le poids qu’il pèse sur la santé publique et la douleur des survivants après le décès de leurs proches. Tous ont demandé des changements structurels – interdiction de fumer – et légaux, économiques et normatifs. Franchir le cap de l’indifférence maximale leur a permis de passer de l’argumentation à la réponse.
Voilà pourquoi il est grand temps que les défenseurs de la vie privée se mettent à réfléchir à une nouvelle tactique. Nous avons franchi et dépassé le cap de l’indifférence à la surveillance en ligne : ce qui signifie qu’à compter d’aujourd’hui, le nombre de gens que la surveillance indigne ne fera que croître.
La mauvaise nouvelle, c’est qu’après 20 ans d’échec pour convaincre les gens des risques liés à leur vie privée, une boite de Pandore s’est construite : toutes les données collectées, actuellement stockées dans des bases de données géants seront, un jour ou l’autre, divulguées et lorsque cela se produira, des vies seront détruites. Ils verront leur maison volée par des usurpateurs d’identité qui falsifient les titres de propriété (ça c’est déjà vu), leur casier judiciaire ne sera plus vierge car des usurpateurs auront pris leur identité pour commettre des délits (ça c’est déjà vu), ils seront accusés de terrorisme ou de crimes terribles parce qu’un algorithme aura scanné leurs données et aura abouti à une conclusion qu’ils ne pourront ni lire ni remettre en question (ça c’est déjà vu) ; leurs appareils seront piratés parce que leurs mots de passe et autres données personnelles auront fuité de vieux comptes, des pirates les espionneront depuis leurs babyphones, leur voitures, leurs décodeurs, leurs implants médicaux (ça c’est déjà vu) ; leurs informations sensibles, fournies au gouvernement pour obtenir des accréditations fuiteront et seront stockées par des états ennemis pour exercer un chantage (ça c’est déjà vu) , leurs employeurs feront faillite après que des informations personnelles auront servies à faire de l’espionnage industriel (ça c’est déjà vu) etc..
Du piratage du site Ashley Madison à la violation de données de l’Office of Personnel Management [le service qui gère les fonctionnaires fédéraux aux USA], ce qui nous attend est clair : dorénavant, tous les quinze jours, un ou deux millions de personnes dont la vie vient d’être détruite par une fuite de données vont régulièrement aller frapper à la porte d’un défenseur de la vie privée, pâles comme un fumeur qui vient d’apprendre qu’il a un cancer, ils lui diront : « Vous aviez raison. On fait quoi, maintenant ? »
Clavier « vie privée » par g4ll4is, (CC BY-SA 2.0)
C’est là que nous pouvons intervenir. Nous pouvons désigner les personnes qui nous ont dit que la notion de vie privée était obsolète alors qu’eux-mêmes dépensent des centaines de millions de dollars pour se prémunir de toute surveillance, en achetant les maisons proches de la leur et en les laissant vides (comme l’a fait le PDG de Facebook, Mark Zuckerberg) ; en menaçant les journalistes qui ont divulgué des données personnelles les concernant (comme l’a fait l’ex-PDG de Google, Eric Schmidt) ; en utilisant des paradis fiscaux pour cacher leurs délits financiers (comme ceux nommés dans les Panama Papers). Toutes ces personnes ont dit un jour : « La vie privée, c’est fini » mais ils voulaient dire « Si vous pensez que c’en est fini de votre vie privée, je serai vraiment beaucoup plus riche. »
Nous devons citer des noms, rendre évident le fait que des personnes vivantes aujourd’hui ont conçu un mouvement de déni de la vie privée sur le modèle du mouvement de déni du cancer conçu par l’industrie du tabac.
Nous devons fournir des moyens d’action : des outils de protection des données personnelles qui permettent aux gens de se défendre contre l’économie de la surveillance ; des campagnes politiques qui exposent et ridiculisent publiquement les politiciens et les espions ; l’opportunité d’obtenir en justice des réparations de ceux qui profitent de la surveillance.
Si nous pouvons donner une perspective d’action aux victimes du pillage de leur vie privée, un mouvement qu’elles puissent rejoindre, elles combattront à nos côtés. Sinon, elles deviendront des nihilistes de la confidentialité et continueront à répandre leurs données personnelles pour gagner un peu de vie sociale à court terme, ce qui en fera des proies faciles pour les espions, les escrocs, les salauds et les voyeurs.
C’est à nous de jouer.
Les nouveaux Léviathans II — Surveillance et confiance (a)
Qu’est-ce qui fait courir Framasoft ? De la campagne Dégooglisons à l’initiative C.H.A.T.O.N.S quelles idées ont en tête les acteurs et soutiens de l’association ? Vous reprendrez bien une tranche de Léviathan ?
Pour vous inviter à aller au-delà des apparences (la sympathique petite tribu d’amateurs gaulois qui veut modestement mettre son grain de sable dans la loi des entreprises hégémoniques) nous vous proposons non seulement un moment de réflexion, mais pour une fois une série de considérations nourries, argumentées et documentées sur l’état de bascule que nous vivons et dans lequel nous prétendons inscrire notre action avec vous.
Jamais le logiciel libre et les valeurs qu’il porte n’ont été autant à la croisée des chemins, car il ne s’agit pas de proposer seulement des alternatives techniques, c’est un défi économique et politique qu’il doit relever.
Entre les États qui nous surveillent et les GAFAM qui nous monétisent, jamais le refuge du secret, celui de l’intime, n’a été aussi attaqué ni menacé. Pour représenter le monstre à plusieurs têtes, Christophe Masutti qui est l’auteur de cette série de réflexions, a choisi la figure emblématique du Léviathan, forgée déjà par Hobbes en particulier pour désigner l’État toujours plus avide de domination.
C’est donc une série de Léviathans nouveaux et anciens que nous vous invitons à découvrir par étapes, tout au long de cette semaine, qui vous conduiront peut-être à comprendre et adopter notre démarche. Car une fois établies les sources du mal et posé le diagnostic, que faire ? Les perspectives que nous proposons seront peut-être les vôtres.
Note de l’auteur :Cette seconde partie (Léviathans II) vise à approfondir les concepts survolés précédemment (Léviathans I). Nous avons vu que les monopoles de l’économie numérique ont changé le paradigme libéral jusqu’à instaurer un capitalisme de surveillance. Pour en rendre compte et comprendre ce nouveau système, il faut brosser plusieurs aspects de nos rapports avec la technologie en général, et les services numériques en particulier, puis voir comment des modèles s’imposent par l’usage des big data et la conformisation du marché (Léviathans IIa). J’expliquerai, à partir de la lecture de S. Zuboff, quelles sont les principales caractéristiques du capitalisme de surveillance. En identifiant ainsi ces nouvelles conditions de l’aliénation des individus, il devient évident que le rétablissement de la confiance aux sources de nos relations contractuelles et démocratiques, passe immanquablement par l’autonomie, le partage et la coopération, sur le modèle du logiciel libre (Léviathans IIb).
Techniques d’anticipation
On pense habituellement les objets techniques et les phénomènes sociaux comme deux choses différentes, voire parfois opposées. En plus de la nature, il y aurait deux autres réalités : d’un côté un monde constitué de nos individualités, nos rapports sociaux, nos idées politiques, la manière dont nous structurons ensemble la société ; et de l’autre côté le monde des techniques qui, pour être appréhendé, réclamerait obligatoirement des compétences particulières (artisanat, ingénierie). Nous refusons même parfois de comprendre nos interactions avec les techniques autrement que par automatisme, comme si notre accomplissement social passait uniquement par le statut d’utilisateur et jamais comme producteurs. Comme si une mise à distance devait obligatoirement s’établir entre ce que nous sommes (des êtres sociaux) et ce que nous produisons. Cette posture est au plus haut point paradoxale puisque non seulement la technologie est une activité sociale mais nos sociétés sont à bien des égards elles-mêmes configurées, transformées, et même régulées par les objets techniques. Certes, la compréhension des techniques n’est pas toujours obligatoire pour comprendre les faits sociaux, mais il faut avouer que bien peu de faits sociaux se comprennent sans la technique.
L’avènement des sociétés industrielles a marqué un pas supplémentaire dans l’interdépendance entre le social et les objets techniques : le travail, comme activité productrice, est en soi un rapport réflexif sur les pratiques et les savoirs qui forment des systèmes techniques. Nous baignons dans une culture technologique, nous sommes des êtres technologiques. Nous ne sommes pas que cela. La technologie n’a pas le monopole du signifiant : nous trouvons dans l’art, dans nos codes sociaux, dans nos intentions, tout un ensemble d’éléments culturels dont la technologie est censée être absente. Nous en usons parfois même pour effectuer une mise à distance des techniques omniprésentes. Mais ces dernières ne se réduisent pas à des objets produits. Elles sont à la fois des pratiques, des savoir-faire et des objets. La raison pour laquelle nous tenons tant à instaurer une mise à distance par rapport aux technologies que nous utilisons, c’est parce qu’elles s’intègrent tellement dans notre système économique qu’elles agissent aussi comme une forme d’aliénation au travail comme au quotidien.
Ces dernières années, nous avons vu émerger des technologies qui prétendent prédire nos comportements. Amazon teste à grande échelle des dépôts locaux de produits en prévision des commandes passées par les internautes sur un territoire donné. Les stocks de ces dépôts seront gérés au plus juste par l’exploitation des données inférées à partir de l’analyse de l’attention des utilisateurs (mesurée au clic), les tendances des recherches effectuées sur le site, l’impact des promotions et propositions d’Amazon, etc. De son côté, Google ne cesse d’analyser nos recherches dans son moteur d’indexation, dont les suggestions anticipent nos besoins souvent de manière troublante. En somme, si nous éprouvons parfois cette nécessité d’une mise à distance entre notre être et la technologie, c’est en réponse à cette situation où, intuitivement, nous sentons bien que la technologie n’a pas à s’immiscer aussi profondément dans l’intimité de nos pensées. Mais est-ce vraiment le cas ? Ne conformons-nous pas aussi, dans une certaine mesure, nos envies et nos besoins en fonction de ce qui nous est présenté comme nos envies et nos besoins ? La lutte permanente entre notre volonté d’indépendance et notre adaptation à la société de consommation, c’est-à-dire au marché, est quelque chose qui a parfaitement été compris par les grandes firmes du secteur numérique. Parce que nous laissons tellement de traces transformées en autant d’informations extraites, analysées, quantifiées, ces firmes sont désormais capables d’anticiper et de conformer le marché à leurs besoins de rentabilité comme jamais une firme n’a pu le faire dans l’histoire des sociétés capitalistes modernes.
Productivisme et information
Si vous venez de perdre deux minutes à lire ma prose ci-dessus hautement dopée à l’EPO (Enfonçage de Portes Ouvertes), c’est parce qu’il m’a tout de même paru assez important de faire quelques rappels de base avant d’entamer des considérations qui nous mènerons petit à petit vers une compréhension en détail de ce système. J’ai toujours l’image de cette enseignante de faculté, refusant de lire un mode d’emploi pour appuyer deux touches sur son clavier afin de basculer l’affichage écran vers l’affichage du diaporama, et qui s’exclamait : « il faut appeler un informaticien, ils sont là pour ça, non ? ». Ben non, ma grande, un informaticien a autre chose à faire. C’est une illustration très courante de ce que la transmission des savoirs (activité sociale) dépend éminemment des techniques (un vidéo-projecteur couplé un ordinateur contenant lui-même des supports de cours sous forme de fichiers) et que toute tentative volontaire ou non de mise à distance (ne pas vouloir acquérir un savoir-faire technique) cause un bouleversement a-social (ne plus être en mesure d’assurer une transmission de connaissance, ou plus prosaïquement passer pour quelqu’un de stupide). La place que nous occupons dans la société n’est pas uniquement une affaire de codes ou relations interpersonnelles, elle dépend pour beaucoup de l’ordre économique et technique auquel nous devons plus ou moins nous ajuster au risque de l’exclusion (et la forme la plus radicale d’exclusion est l’absence de travail et/ou l’incapacité de consommer).
Des études déjà anciennes sur les organisations du travail, notamment à propos de l’industrialisation de masse, ont montré comment la technologie, au même titre que l’organisation, détermine les comportements des salariés, en particulier lorsqu’elle conditionne l’automatisation des tâches1. Souvent, cette automatisation a été étudiée sous l’angle des répercussions socio-psychologiques, accroissant les sentiments de perte de sens ou d’aliénation sociale2. D’un point de vue plus populaire, c’est le remplacement de l’homme par la machine qui fut tantôt vécu comme une tragédie (l’apparition du chômage de masse) tantôt comme un bienfait (diminuer la pénibilité du travail). Aujourd’hui, les enjeux sont très différents. On s’interroge moins sur la place de la machine dans l’industrie que sur les taux de productivité et la gestion des flux. C’est qu’un changement de paradigme s’est accompli à partir des années 1970-1980, qui ont vu apparaître l’informatisation quasi totale des systèmes de production et la multiplication des ordinateurs mainframe dans les entreprises pour traiter des quantités sans cesse croissantes de données.
Très peu de sociologues ou d’économistes ont travaillé sur ce qu’une illustre chercheuse de la Harvard Business School, Shoshana Zuboff a identifié dans la transformation des systèmes de production : l’informationnalisation (informating). En effet, dans un livre très visionnaire, In the Age Of The Smart Machine en 19883, S. Zuboff montre que les mécanismes du capitalisme productiviste du XXe siècle ont connu plusieurs mouvements, plus ou moins concomitants selon les secteurs : la mécanisation, la rationalisation des tâches, l’automatisation des processus et l’informationnalisation. Ce dernier mouvement découle des précédents : dès l’instant qu’on mesure la production et qu’on identifie des processus, on les documente et on les programme pour les automatiser. L’informationnalisation est un processus qui transforme la mesure et la description des activités en information, c’est-à-dire en données extractibles et quantifiables, calculatoires et analytiques.
Là où S. Zuboff s’est montrée visionnaire dans les années 1980, c’est qu’elle a montré aussi comment l’informationnalisation modèle en retour les apprentissages et déplace les enjeux de pouvoir. On ne cherche plus à savoir qui a les connaissances suffisantes pour mettre en œuvre telle procédure, mais qui a accès aux données dont l’analyse déterminera la stratégie de développement des activités. Alors que le « vieux » capitalisme organisait une concurrence entre moyens de production et maîtrise de l’offre, ce qui, dans une économie mondialisée n’a plus vraiment de sens, un nouveau capitalisme (dont nous verrons plus loin qu’il se nomme le capitalisme de surveillance) est né, et repose sur la production d’informations, la maîtrise des données et donc des processus.
Pour illustrer, il suffit de penser à nos smartphones. Quelle que soit la marque, ils sont produits de manière plus ou moins redondante, parfois dans les mêmes chaînes de production (au moins en ce qui concerne les composants), avec des méthodes d’automatisation très similaires. Dès lors, la concurrence se place à un tout autre niveau : l’optimisation des procédures et l’identification des usages, tous deux producteurs de données. Si bien que la plus-value ajoutée par la firme à son smartphone pour séduire le plus d’utilisateurs possible va de pair avec une optimisation des coûts de production et des procédures. Cette optimisation relègue l’innovation organisationnelle au moins au même niveau, si ce n’est plus, que l’innovation du produit lui-même qui ne fait que répondre à des besoins d’usage de manière marginale. En matière de smartphone, ce sont les utilisateurs les plus experts qui sauront déceler la pertinence de telle ou telle nouvelle fonctionnalité alors que l’utilisateur moyen n’y voit que des produits similaires.
L’enjeu dépasse la seule optimisation des chaînes de production et l’innovation. S. Zuboff a aussi montré que l’analyse des données plus fines sur les processus de production révèle aussi les comportements des travailleurs : l’attention, les pratiques quotidiennes, les risques d’erreur, la gestion du temps de travail, etc. Dès lors l’informationnalisation est aussi un moyen de rassembler des données sur les aspects sociaux de la production4, et par conséquent les conformer aux impératifs de rentabilité. L’exemple le plus frappant aujourd’hui de cet ajustement comportemental à la rentabilité par les moyens de l’analyse de données est le phénomène d’« Ubérisation » de l’économie5.
Ramené aux utilisateurs finaux des produits, dans la mesure où il est possible de rassembler des données sur l’utilisation elle-même, il devrait donc être possible de conformer les usages et les comportements de consommation (et non plus seulement de production) aux mêmes impératifs de rentabilité. Cela passe par exemple par la communication et l’apprentissage de nouvelles fonctionnalités des objets. Par exemple, si vous aviez l’habitude de stocker vos fichiers MP3 dans votre smartphone pour les écouter comme avec un baladeur, votre fournisseur vous permet aujourd’hui avec une connexion 4G d’écouter de la musique en streaming illimité, ce qui permet d’analyser vos goûts, vous proposer des playlists, et faire des bénéfices. Mais dans ce cas, si vous vous situez dans un endroit où la connexion haut débit est défaillante, voire absente, vous devez vous passer de musique ou vous habituer à prévoir à l’avance cette éventualité en activant un mode hors-connexion. Cette adaptation de votre comportement devient prévisible : l’important n’est pas de savoir ce que vous écoutez mais comment vous le faites, et ce paramètre entre lui aussi en ligne de compte dans la proposition musicale disponible.
Le nouveau paradigme économique du XXIe siècle, c’est le rassemblement des données, leur traitement et leurs valeurs prédictives, qu’il s’agisse des données de production comme des données d’utilisation par les consommateurs.
Ces dernières décennies, l’informatique est devenu un média pour l’essentiel de nos activités sociales. Vous souhaitez joindre un ami pour aller boire une bière dans la semaine ? c’est avec un ordinateur que vous l’appelez. Voici quelques étapes grossières de cet épisode :
votre mobile a signalé vers des antennes relais pour s’assurer de la couverture réseau,
vous entrez un mot de passe pour déverrouiller l’écran,
vous effectuez une recherche dans votre carnet d’adresse (éventuellement synchronisé sur un serveur distant),
vous lancez le programme de composition du numéro, puis l’appel téléphonique (numérique) proprement dit,
vous entrez en relation avec votre correspondant, convenez d’une date,
vous envoyez ensuite une notification de rendez-vous avec votre agenda vers la messagerie de votre ami…
qui vous renvoie une notification d’acceptation en retour,
l’une de vos applications a géolocalisé votre emplacement et vous indique le trajet et le temps de déplacement nécessaire pour vous rendre au point de rendez-vous, etc.
Durant cet épisode, quel que soit l’opérateur du réseau que vous utilisez et quel que soit le système d’exploitation de votre mobile (à une ou deux exceptions près), vous avez produit des données exploitables. Par exemple (liste non exhaustive) :
le bornage de votre mobile indique votre position à l’opérateur, qui peut croiser votre activité d’émission-réception avec la nature de votre abonnement,
la géolocalisation donne des indications sur votre vitesse de déplacement ou votre propension à utiliser des transports en commun,
votre messagerie permet de connaître la fréquence de vos contacts, et éventuellement l’éloignement géographique.
Ramené à des millions d’utilisateurs, l’ensemble des données ainsi rassemblées entre dans la catégorie des Big Data. Ces dernières ne concernent pas seulement les systèmes d’informations ou les services numériques proposés sur Internet. La massification des données est un processus qui a commencé il y a longtemps, notamment par l’analyse de productivité dans le cadre de la division du travail, les analyses statistiques des achats de biens de consommation, l’analyse des fréquences de transaction boursières, etc. Tout comme ce fut le cas pour les processus de production qui furent automatisés, ce qui caractérise les Big Data c’est l’obligation d’automatiser leur traitement pour en faire l’analyse.
Prospection, gestion des risques, prédictibilité, etc., les Big Data dépassent le seul degré de l’analyse statistique dite descriptive, car si une de ces données renferme en général très peu d’information, des milliers, des millions, des milliards permettent d’inférer des informations dont la pertinence dépend à la fois de leur traitement et de leur gestion. Le tout dépasse la somme des parties : c’est parce qu’elles sont rassemblées et analysées en masse que des données d’une même nature produisent des valeurs qui dépassent la somme des valeurs unitaires.
Antoinette Rouvroy, dans un rapport récent6 auprès du Conseil de l’Europe, précise que les capacités techniques de stockage et de traitement connaissent une progression exponentielle7. Elle définit plusieurs catégories de data en fonction de leurs sources, et qui quantifient l’essentiel des actions humaines :
les hard data, produites par les institutions et administrations publiques ;
les soft data, produites par les individus, volontairement (via les réseaux sociaux, par exemple) ou involontairement (analyse des flux, géolocalisation, etc.) ;
les métadonnées, qui concernent notamment la provenance des données, leur trafic, les durées, etc. ;
l’Internet des objets, qui une fois mis en réseau, produisent des données de performance, d’activité, etc.
Les Big Data n’ont cependant pas encore de définition claire8. Il y a des chances pour que le terme ne dure pas et donne lieu à des divisions qui décriront plus précisément des applications et des méthodes dès lors que des communautés de pratiques seront identifiées avec leurs procédures et leurs réseaux. Aujourd’hui, l’acception générique désigne avant tout un secteur d’activité qui regroupe un ensemble de savoir-faire et d’applications très variés. Ainsi, le potentiel scientifique des Big Data est encore largement sous-évalué, notamment en génétique, physique, mathématiques et même en sociologie. Il en est de même dans l’industrie. En revanche, si on place sur un même plan la politique, le marketing et les activités marchandes (à bien des égards assez proches) on conçoit aisément que l’analyse des données optimise efficacement les résultats et permet aussi, par leur dimension prédictible, de conformer les biens et services.
Google fait peur ?
Eric Schmidt, actuellement directeur exécutif d’Alphabet Inc., savait exprimer en peu de mots les objectifs de Google lorsqu’il en était le président. Depuis 1998, les activités de Google n’ont cessé d’évoluer, jusqu’à reléguer le service qui en fit la célébrité, la recherche sur la Toile, au rang d’activité has been pour les internautes. En 2010, il dévoilait le secret de Polichinelle :
Le jour viendra où la barre de recherche de Google – et l’activité qu’on nomme Googliser – ne sera plus au centre de nos vies en ligne. Alors quoi ? Nous essayons d’imaginer ce que sera l’avenir de la recherche (…). Nous sommes toujours contents d’être dans le secteur de la recherche, croyez-moi. Mais une idée est que de plus en plus de recherches sont faites en votre nom sans que vous ayez à taper sur votre clavier.
En fait, je pense que la plupart des gens ne veulent pas que Google réponde à leurs questions. Ils veulent que Google dise ce qu’ils doivent faire ensuite. (…) La puissance du ciblage individuel – la technologie sera tellement au point qu’il sera très difficile pour les gens de regarder ou consommer quelque chose qui n’a pas été adapté pour eux.9
Google n’a pas été la première firme à exploiter des données en masse. Le principe est déjà ancien avec les premiers data centers du milieu des années 1960. Google n’est pas non plus la première firme à proposer une indexation générale des contenus sur Internet, par contre Google a su se faire une place de choix parmi la concurrence farouche de la fin des années 1990 et sa croissance n’a cessé d’augmenter depuis lors, permettant des investissements conséquents dans le développement de technologies d’analyse et dans le rachat de brevets et de plus petites firmes spécialisées. Ce que Google a su faire, et qui explique son succès, c’est proposer une expérience utilisateur captivante de manière à rassembler assez de données pour proposer en retour des informations adaptées aux profils des utilisateurs. C’est la radicalisation de cette stratégie qui est énoncée ici par Eric Schmidt. Elle trouve pour l’essentiel son accomplissement en utilisant les données produites par les utilisateurs du cloud computing. Les Big Data en sont les principaux outils.
D’autres firmes ont emboîté le pas. En résultat, la concentration des dix premières firmes de services numériques génère des bénéfices spectaculaires et limite la concurrence. Cependant, l’exploitation des données personnelles des utilisateurs et la manière dont elles sont utilisées sont souvent mal comprises dans leurs aspects techniques autant que par les enjeux économiques et politiques qu’elles soulèvent. La plupart du temps, la quantité et la pertinence des informations produites par l’utilisateur semblent négligeables à ses yeux, et leur exploitation d’une importance stratégique mineure. Au mieux, si elles peuvent encourager la firme à mettre d’autres services gratuits à disposition du public, le prix est souvent considéré comme largement acceptable. Tout au plus, il semble a priori moins risqué d’utiliser Gmail et Facebook, que d’utiliser son smartphone en pleine manifestation syndicale en France, puisque le gouvernement français a voté publiquement des lois liberticides et que les GAFAM ne livrent aux autorités que les données manifestement suspectes (disent-elles) ou sur demande rogatoire officielle (disent-elles).
Gigantismus
En 2015, Google Analytics couvrait plus de 70% des parts de marché des outils de mesure d’audience. Google Analytics est un outil d’une puissance pour l’instant incomparable dans le domaine de l’analyse du comportement des visiteurs. Cette puissance n’est pas exclusivement due à une supériorité technologique (les firmes concurrentes utilisent des techniques d’analyse elles aussi très performantes), elle est surtout due à l’exhaustivité monopolistique des utilisations de Google Analytics, disponible en version gratuite et premium, avec un haut degré de configuration des variables qui permettent la collecte, le traitement et la production très rapide de rapports (pratiquement en temps réel). La stratégie commerciale, afin d’assurer sa rentabilité, consiste essentiellement à coupler le profilage avec la régie publicitaire (Google AdWords). Ce modèle économique est devenu omniprésent sur Internet. Qui veut être lu ou regardé doit passer l’épreuve de l’analyse « à la Google », mais pas uniquement pour mesurer l’audience : le monopole de Google sur ces outils impose un web rédactionnel, c’est-à-dire une méthode d’écriture des contenus qui se prête à l’extraction de données.
Google n’est pas la seule entreprise qui réussi le tour de force d’adapter les contenus, quelle que soit leur nature et leurs propos, à sa stratégie commerciale. C’est le cas des GAFAM qui reprennent en chœur le même modèle économique qui conforme l’information à ses propres besoins d’information. Que vous écriviez ou non un pamphlet contre Google, l’extraction et l’analyse des données que ce contenu va générer indirectement en produisant de l’activité (visites, commentaires, échanges, temps de connexion, provenance, etc.) permettra de générer une activité commerciale. Money is money, direz-vous. Pourtant, la concentration des activités commerciales liées à l’exploitation des Big Data par ces entreprises qui forment les premières capitalisations boursières du monde, pose un certain nombre répercutions sociales : l’omniprésence mondialisée des firmes, la réduction du marché et des choix, l’impuissance des États, la sur-financiarisation.
Omniprésence
En produisant des services gratuits (ou très accessibles), performants et à haute valeur ajoutée pour les données qu’ils produisent, ces entreprises captent une gigantesque part des activités numériques des utilisateurs. Elles deviennent dès lors les principaux fournisseurs de services avec lesquels les gouvernements doivent composer s’ils veulent appliquer le droit, en particulier dans le cadre de la surveillance des populations et des opérations de sécurité. Ainsi, dans une démarche très pragmatique, des ministères français parmi les plus importants réunirent le 3 décembre 2015 les « les grands acteurs de l’internet et des réseaux sociaux » dans le cadre de la stratégie anti-terroriste10. Plus anciennement, le programme américain de surveillance électronique PRISM, dont bien des aspects furent révélés par Edward Snowden en 2013, a permit de passer durant des années des accords entre la NSA et l’ensemble des GAFAM. Outre les questions liées à la sauvegarde du droit à la vie privée et à la liberté d’expression, on constate aisément que la surveillance des populations par les gouvernements trouve nulle part ailleurs l’opportunité de récupérer des données aussi exhaustives, faisant des GAFAM les principaux prestataires de Big Data des gouvernements, quels que soient les pays11.
Réduction du marché
Le monopole de Google sur l’indexation du web montre qu’en vertu du gigantesque chiffre d’affaires que cette activité génère, celle-ci devient la première et principale interface du public avec les contenus numériques. En 2000, le journaliste Laurent Mauriac signait dans Libération un article élogieux sur Google12. À propos de la méthode d’indexation qui en fit la célébrité, L. Mauriac écrit :
Autre avantage : ce système empêche les sites de tricher. Inutile de farcir la partie du code de la page invisible pour l’utilisateur avec quantité de mots-clés…
Or, en 2016, il devient assez évident de décortiquer les stratégies de manipulation de contenus que les compagnies qui en ont les moyens financiers mettent en œuvre pour dominer l’index de Google en diminuant ainsi la diversité de l’offre13. Que la concentration des entreprises limite mécaniquement l’offre, cela n’est pas révolutionnaire. Ce qui est particulièrement alarmant, en revanche, c’est que la concentration des GAFAM implique par effets de bord la concentration d’autres entreprises de secteurs entièrement différents mais qui dépendent d’elles en matière d’information et de visibilité. Cette concentration de second niveau, lorsqu’elle concerne la presse en ligne, les éditeurs scientifiques ou encore les libraires, pose à l’évidence de graves questions en matière de liberté d’information.
Impuissances
La concentration des services, qu’il s’agisse de ceux de Google comme des autres géants du web, sur des secteurs biens découpés qui assurent les monopoles de chaque acteur, cause bien des soucis aux États qui voient leurs économies impactées selon les revenus fiscaux et l’implantation géographique de ces compagnies. Les lois anti-trust semblent ne plus suffire lorsqu’on voit, par exemple, la Commission Européenne avoir toutes les peines du monde à freiner l’abus de position dominante de Google sur le système Android, sur Google Shopping, sur l’indexation, et de manière générale depuis 2010.
Illustration cynique devant l’impuissance des États à réguler cette concentration, Google a davantage à craindre de ses concurrents directs qui ont des moyens financiers largement supérieurs aux États pour bloquer sa progression sur les marchés. Ainsi, cet accord entre Microsoft et Google, qui conviennent de régler désormais leurs différends uniquement en privé, selon leurs propres règles, pour ne se concentrer que sur leur concurrence de marché et non plus sur la législation. Le message est double : en plus d’instaurer leur propre régulation de marché, Google et Microsoft en organiseront eux-mêmes les conditions juridiques, reléguant le rôle de l’État au second plan, voire en l’éliminant purement et simplement de l’équation. C’est l’avènement des Léviathans dont j’avais déjà parlé dans un article antérieur.
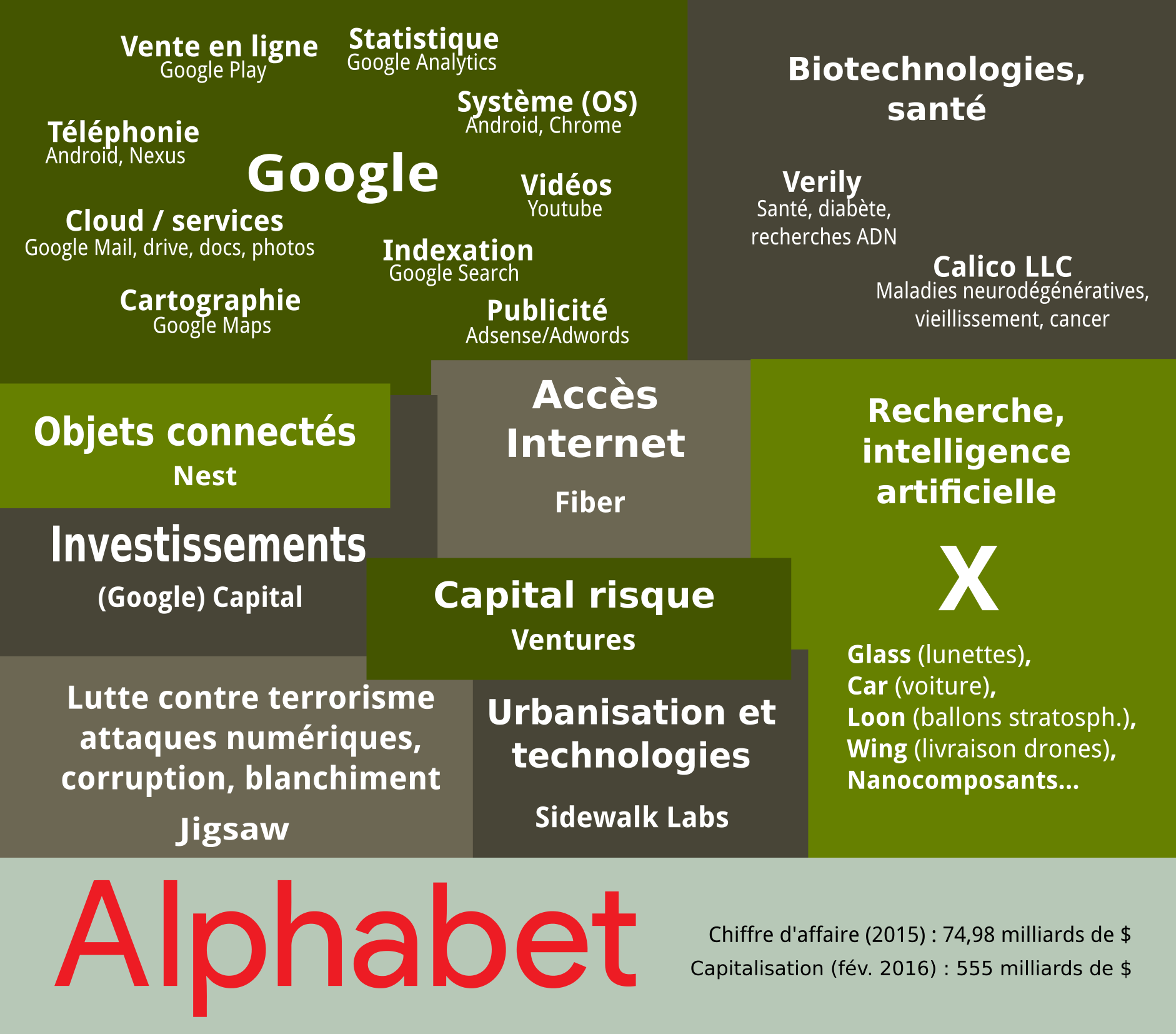
Alphabet. CC-by-sa, Framatophe
Capitaux financiers
La capitalisation boursière des GAFAM a atteint un niveau jamais envisagé jusqu’à présent dans l’histoire, et ces entreprises figurent toutes dans le top 40 de l’année 201514. La valeur cumulée de GAFAM en termes de capital boursier en 2015 s’élève à 1 838 milliards de dollars. À titre de comparaison, le PIB de la France en 2014 était de 2 935 milliards de dollars et celui des Pays Bas 892 milliards de dollars.
La liste des acquisitions de Google explique en partie la cumulation de valeurs boursières. Pour une autre partie, la plus importante, l’explication concerne l’activité principale de Google : la valorisation des big data et l’automatisation des tâches d’analyse de données qui réduisent les coûts de production (à commencer par les frais d’infrastructure : Google a besoin de gigantesque data centers pour le stockage, mais l’analyse, elle, nécessite plus de virtualisation que de nouveaux matériels ou d’employés). Bien que les cheminements ne soient pas les mêmes, les entreprises GAFAM ont abouti au même modèle économique qui débouche sur le status quo de monopoles sectorisés. Un élément de comparaison est donné par le Financial Times en août 2014, à propos de l’industrie automobile vs l’économie numérique :
Comparons Detroit en 1990 et la Silicon Valley en 2014. Les 3 plus importantes compagnies de Detroit produisaient des bénéfices à hauteur de 250 milliards de dollars avec 1,2 million d’employés et la cumulation de leurs capitalisations boursières totalisait 36 milliards de dollars. Le 3 premières compagnies de la Silicon Valley en 2014 totalisaient 247 milliards de dollars de bénéfices, avec seulement 137 000 employés, mais un capital boursier de 1,09 mille milliard de dollars.15
La captation d’autant de valeurs par un petit nombre d’entreprises et d’employés, aurait été analysée, par exemple, par Schumpeter comme une chute inévitable vers la stagnation en raison des ententes entre les plus puissants acteurs, la baisse des marges des opérateurs et le manque d’innovation. Pourtant cette approche est dépassée : l’innovation à d’autres buts (produire des services, même à perte, pour capter des données), il est très difficile d’identifier le secteur d’activité concerné (Alphabet regroupe des entreprises ultra-diversifiées) et donc le marché est ultra-malléable autant qu’il ne représente que des données à forte valeur prédictive et possède donc une logique de plus en plus maîtrisée par les grands acteurs.
Voir sur ce point Robert Blauner, Alienation and Freedom. The Factory Worker and His Industry, Chicago: Univ. Chicago Press, 1965.↩
Shoshana Zuboff, In The Age Of The Smart Machine: The Future Of Work And Power, New York: Basic Books, 1988.↩
En guise d’illustration de tests (proof of concepts) discrets menés dans les entreprises aujourd’hui, on peut se reporter à cet article de Rue 89 Strasbourg sur cette société alsacienne qui propose, sous couvert de challenge collectif, de monitorer l’activité physique de ses employés. Rémi Boulle, « Chez Constellium, la collecte des données personnelles de santé des employés fait débat », Rue 89 Strasbourg, juin 2016.↩
Par exemple, dans le cas des livreurs à vélo de plats préparés utilisés par des sociétés comme Foodora ou Take Eat Easy, on constate que ces sociétés ne sont qu’une interface entre les restaurants et les livreurs. Ces derniers sont auto-entrepreneurs, payés à la course et censés assumer toutes les cotisations sociales et leurs salaires uniquement sur la base des courses que l’entreprise principale pourra leur confier. Ce rôle est automatisé par une application de calcul qui rassemble les données géographiques et les performances (moyennes, vitesse, assiduité, etc.) des livreurs et distribue automatiquement les tâches de livraisons. Charge aux livreurs de se trouver au bon endroit au bon moment. Ce modèle économique permet de détacher l’entreprise de toutes les externalités ou tâches habituellement intégrées qui pourraient influer sur son chiffre d’affaires : le matériel du livreur, l’assurance, les cotisations, l’accidentologie, la gestion du temps de travail, etc., seule demeure l’activité elle-même automatisée et le livreur devient un exécutant dont on analyse les performances. L’« Ubérisation » est un processus qui automatise le travail humain, élimine les contraintes sociales et utilise l’information que l’activité produit pour ajuster la production à la demande (quels que soient les risques pris par les livreurs, par exemple pour remonter les meilleures informations concernant les vitesses de livraison et se voir confier les prochaines missions). Sur ce sujet, on peut écouter l’émission Comme un bruit qui court de France Inter qui diffusa le reportage de Giv Anquetil le 11 juin 2016, intitulé « En roue libre ».↩
Même si Apple a déclaré ne pas entrer dans le secteur des Big Data, il n’en demeure pas moins qu’il en soit un consommateur comme un producteur d’envergure mondiale.↩
Les nouveaux Léviathans I — Histoire d’une conversion capitaliste (b)
Qu’est-ce qui fait courir Framasoft ? De la campagne Dégooglisons à l’initiative C.H.A.T.O.N.S quelles idées ont en tête les acteurs et soutiens de l’association ? Vous êtes curieux ? Vous reprendrez bien une tranche de Léviathan ?
Pour vous inviter à aller au-delà des apparences (la sympathique petite tribu d’amateurs gaulois qui veut modestement mettre son grain de sable dans la loi des entreprises hégémoniques) nous vous proposons non seulement un moment de réflexion, mais pour une fois une série de considérations nourries, argumentées et documentées sur l’état de bascule que nous vivons et dans lequel nous prétendons inscrire notre action avec vous.
Jamais le logiciel libre et les valeurs qu’il porte n’ont été autant à la croisée des chemins, car il ne s’agit pas de proposer seulement des alternatives techniques, c’est un défi économique et politique qu’il doit relever.
Entre les États qui nous surveillent et les GAFAM qui nous monétisent, jamais le refuge du secret, celui de l’intime, n’a été aussi attaqué ni menacé. Pour représenter le monstre à plusieurs têtes, Christophe Masutti qui est l’auteur de cette série de réflexions, a choisi la figure emblématique du Léviathan, forgée déjà par Hobbes en particulier pour désigner l’État toujours plus avide de domination.
C’est donc une série de Léviathans nouveaux et anciens que nous vous invitons à découvrir par étapes, tout au long de cette semaine, qui vous conduiront peut-être à comprendre et adopter notre démarche. Car une fois établies les sources du mal et posé le diagnostic, que faire ? Les perspectives que nous proposons seront peut-être les vôtres.
Note de l’auteur :Dans cette première partie (Léviathans I), je tente de synthétiser les transformations des utopies numériques des débuts de l’économie informatique vers ce que S. Zuboff nomme le « capitalisme de surveillance ». Dans cette histoire, le logiciel libre apparaît non seulement comme un élément disruptif présent dès les premiers âges de cette conversion capitaliste (Léviathans Ia), mais aussi comme le moyen de faire valoir la primauté de nos libertés individuelles face aux comportements imposés par un nouvel ordre numérique (Léviathans Ib). La dégooglisation d’Internet n’est plus un souhait, c’est un impératif !
Piller le code, imposer des usages
À la fin des années 1990, c’est au nom de ce réalisme capitaliste, que les promoteurs de l’Open Source Initiative avaient compris l’importance de maintenir des codes sources ouverts pour faciliter un terreau commun permettant d’entretenir le marché. Ils voyaient un frein à l’innovation dans les contraintes des licences du logiciel libre tel que le proposaient Richard Stallman et la Free Software Foundation (par exemple, l’obligation de diffuser les améliorations d’un logiciel libre sous la même licence, comme l’exige la licence GNU GPL – General Public License). Pour eux, l’ouverture du code est une opportunité de création et d’innovation, ce qui n’implique pas forcément de placer dans le bien commun les résultats produits grâce à cette ouverture. Pas de fair play : on pioche dans le bien commun mais on ne redistribue pas, du moins, pas obligatoirement.
Les exemples sont nombreux de ces entreprises qui utilisent du code source ouvert sans même participer à l’amélioration de ce code, voire en s’octroyant des pans entiers de ce que des généreux programmeurs ont choisi de verser dans le bien commun. D’autres entreprises trouvent aussi le moyen d’utiliser du code sous licence libre GNU GPL en y ajoutant tant de couches successives de code privateur que le système final n’a plus rien de libre ni d’ouvert. C’est le cas du système Android de Google, dont le noyau est Linux.
Jamais jusqu’à aujourd’hui le logiciel libre n’avait eu de plus dur combat que celui non plus de proposer une simple alternative à informatique privateur, mais de proposer une alternative au modèle économique lui-même. Pas seulement l’économie de l’informatique, dont on voudrait justement qu’il ne sorte pas, mais un modèle beaucoup plus général qui est celui du pillage intellectuel et physique qui aliène les utilisateurs et, donc, les citoyens. C’est la raison pour laquelle le discours de Richard Stallman est un discours politique avant tout.
La fameuse dualité entre open source et logiciel libre n’est finalement que triviale. On n’a pas tort de la comparer à une querelle d’église même si elle reflète un mal bien plus général. Ce qui est pillé aujourd’hui, ce n’est plus seulement le code informatique ou les libertés des utilisateurs à pouvoir disposer des programmes. Même si le principe est (très) loin d’être encore communément partagé dans l’humanité, le fait de cesser de se voir imposer des programmes n’est plus qu’un enjeu secondaire par rapport à une nouvelle voie qui se dévoile de plus en plus : pour maintenir la pression capitaliste sur un marché verrouillé par leurs produits, les firmes cherchent désormais à imposer des comportements. Elles ne cherchent plus à les induire comme on pouvait dire d’Apple que le design de ses produits provoquait un effet de mode, une attitude « cool ». Non : la stratégie a depuis un moment déjà dépassé ce stade.
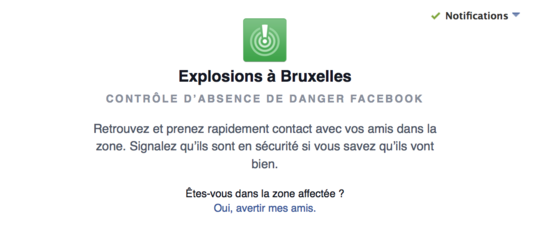
Un exemple révélateur et particulièrement cynique, la population belge en a fait la terrible expérience à l’occasion des attentats commis à Bruxelles en mars 2016 par de sombres crétins, au prix de dizaines de morts et de centaines de blessés. Les médias déclarèrent en chœur, quelques heures à peine après l’annonce des attentats, que Facebook déclenchait le « Safety Check ». Ce dispositif propre à la firme avait déjà été éprouvé lors des attentats de Paris en novembre 2015 et cet article de Slate.fr en montre bien les enjeux. Avec ce dispositif, les personnes peuvent signaler leur statut à leurs amis sur Facebook en situation de catastrophe ou d’attentat. Qu’arrive-t-il si vous n’avez pas de compte Facebook ou si vous n’avez même pas l’application installée sur votre smartphone ? Vos amis n’ont plus qu’à se consumer d’inquiétude pour vous.
Facebook safety check fr
La question n’est pas tant de s’interroger sur l’utilité de ce dispositif de Facebook, mais plutôt de s’interroger sur ce que cela implique du point de vue de nos comportements :
Le devoir d’information : dans les médias, on avait l’habitude, il y a encore peu de temps, d’avoir à disposition un « numéro vert » ou un site internet produits par les services publics pour informer la population. Avec les attentats de Bruxelles, c’est le « Safety Check » qui fut à l’honneur. Ce n’est plus à l’État d’assurer la prise en charge de la détresse, mais c’est à Facebook de le faire. L’État, lui, a déjà prouvé son impuissance puisque l’attentat a eu lieu, CQFD. On retrouve la doctrine du « moins d’État ».
La morale : avec la crainte qu’inspire le contexte du terrorisme actuel, Facebook joue sur le sentiment de sollicitude et propose une solution technique à un problème moral : ai-je le devoir ou non, envers mes proches, de m’inscrire sur Facebook ?
La norme : le comportement normal d’un citoyen est d’avoir un smartphone, de s’inscrire sur Facebook, d’être en permanence connecté à des services qui lui permettent d’être localisé et tracé. Tout comportement qui n’intègre pas ces paramètres est considéré comme déviant non seulement du point de vue moral mais aussi, pourquoi pas, du point de vue sécuritaire.
Ce cas de figure est extrême mais son principe (conformer les comportements) concerne des firmes aussi gigantesques que Google, Apple, Facebook, Amazon, Microsoft (GAFAM) et d’autres encore, parmi les plus grandes capitalisations boursières du monde. Ces dernières sont aujourd’hui capables d’imposer des usages et des comportements parce qu’elles proposent toutes une seule idéologie : leurs solutions techniques peuvent remplacer plus efficacement les pouvoirs publics à la seule condition d’adhérer à la communauté des utilisateurs, de « prendre la citoyenneté » Google, Apple, Facebook, Microsoft. Le rêve californien de renverser le Léviathan est en train de se réaliser.
L’expression a récemment été reprise par Aral Balkan, dans un texte traduit sur le Framablog intitulé : « La nature du ‘soi’ à l’ère numérique ». A. Balkan interroge l’impact du capitalisme de surveillance sur l’intégrité de nos identités, à travers nos pratiques numériques. Pour le citer :
La Silicon Valley est la version moderne du système colonial d’exploitation bâti par la Compagnie des Indes Orientales, mais elle n’est ni assez vulgaire, ni assez stupide pour entraver les individus avec des chaînes en fer. Elle ne veut pas être propriétaire de votre corps, elle se contente d’être propriétaire de votre avatar. Et maintenant, (…) plus ces entreprises ont de données sur vous, plus votre avatar est ressemblant, plus elles sont proches d’être votre propriétaire.
C’est exactement ce que démontre S. Zuboff (y compris à travers toute sa bibliographie). Dans l’article cité, à travers l’exemple des pratiques de Google, elle montre que la collecte et l’analyse des données récoltées sur les utilisateurs permet l’émergence de nouvelles formes contractuelles (personnalisation, expérience immersive, etc.) entre la firme et ses utilisateurs. Cela induit des mécanismes issus de l’extraction des données qui débouchent sur deux principes :
la marchandisation des comportements : par exemple, les sociétés d’assurance ne peuvent que s’émouvoir des données géolocalisées des véhicules ;
le contrôle des comportements : il suffit de penser, par exemple, aux applications de e-health promues par des assurances-vie et des mutuelles, qui incitent l’utilisateur à marcher X heures par jour.
Dans un article paru dans le Frankfurter Allgemeine Zeitung le 24 mars 2016 (« The Secrets of Surveillance Capitalism »), S. Zuboff relate les propos de l’analyste (de données) en chef d’une des plus grandes firmes de la Silicon Valley :
Le but de tout ce que nous faisons est de modifier le comportement des gens à grande échelle. Lorsqu’ils utilisent nos applications, nous pouvons enregistrer leurs comportements, identifier les bons et les mauvais comportements, et développer des moyens de récompenser les bons et pénaliser les mauvais.
Pour S. Zuboff, cette logique d’accumulation et de traitement des données aboutit à un projet de surveillance lucrative qui change radicalement les mécanismes habituels entre l’offre et la demande du capitalisme classique. En cela, le capitalisme de surveillance modifie radicalement les principes de la concurrence libérale qui pensait les individus autonomes et leurs choix individuels, rationnels et libres, censés équilibrer les marchés. Qu’on ait adhéré ou non à cette logique libérale (plus ou moins utopiste, elle aussi, sur certains points) le fait est que, aujourd’hui, ce capitalisme de surveillance est capable de bouleverser radicalement les mécanismes démocratiques. J’aurai l’occasion de revenir beaucoup plus longuement sur le capitalisme de surveillance dans le second volet des Nouveaux Léviathans, mais on peut néanmoins affirmer sans plus d’élément qu’il pose en pratique des questions politiques d’une rare envergure.
Ce ne serait rien, si, de surcroît certains décideurs politiques n’étaient particulièrement pro-actifs, face à cette nouvelle forme du capitalisme. En France, par exemple, la première version du projet de Loi Travail soutenu par la ministre El Khomri en mars 2016 entrait parfaitement en accord avec la logique du capitalisme de surveillance. Dans la première version du projet, au chapitre Adaptation du droit du travail à l’ère numérique, l’article 23 portait sur les plateformes collaboratives telles Uber. Cet article rendait impossible la possibilité pour les « contributeurs » de Uber (les chauffeurs VTC) de qualifier leur emploi au titre de salariés de cette firme, ceci afin d’éviter les luttes sociales comme les travailleurs de Californie qui se sont retournés contre Uber dans une bataille juridique mémorable. Si le projet de loi El Khomri cherche à éliminer le salariat du rapport entre travail et justice, l’enjeu dépasse largement le seul point de vue juridique.
Google est l’un des actionnaires majoritaires de Uber, et ce n’est pas pour rien : d’ici 5 ou 6 ans, nous verrons sans doute les premières voitures sans chauffeur de Google arriver sur le marché. Dès lors, que faire de tous ces salariés chauffeurs de taxi ? La meilleure manière de s’en débarrasser est de leur supprimer le statut de salariés : en créant une communauté de contributeurs Uber à leur propre compte , il devient possible de se passer des chauffeurs puisque ce métier n’existera plus (au sens de corporation) ou sera en voie d’extinction. Ce faisant, Uber fait d’une pierre deux coups : il crée aussi une communauté d’utilisateurs, habitués à utiliser une plate-forme de service de voiturage pour accomplir leurs déplacements. Uber connaît donc les besoins, analyse les déplacements, identifie les trajets et rassemble un nombre incroyable de données qui prépareront efficacement la venue de la voiture sans chauffeur de Google. Que cela n’arrange pas l’émission de pollution et empêche de penser à des moyens plus collectifs de déplacement n’est pas une priorité (quoique Google a déjà son service de bus).
Il faut dégoogliser !
Parmi les moyens qui viennent à l’esprit pour s’en échapper, on peut se demander si le capitalisme de surveillance est soluble dans la bataille pour le chiffrement qui refait surface à l’occasion des vagues terroristes successives. L’idée est tentante : si tous les utilisateurs étaient en mesure de chiffrer leurs communications, l’extraction de données de la part des firmes n’en serait que contrariée. Or, la question du chiffrement n’est presque déjà plus d’actualité que pour les représentants politiques en mal de sensations. Tels certains ministres qui ressassent le sempiternel refrain selon lequel le chiffrement permet aux terroristes de communiquer.
Outre le fait que la pratique « terroriste » du chiffrement reste encore largement à prouver, on se rappelle la bataille récente entre le FBI et Apple dans le cadre d’une enquête terroriste, où le FBI souhaitait obtenir de la part d’Apple un moyen (exploitation de backdoor) de faire sauter le chiffrement d’un IPhone. Le FBI ayant finalement trouvé une solution alternative, que nous apprend cette dispute ? Certes, Apple veut garder la confiance de ses utilisateurs. Certes, le chiffrement a bien d’autres applications bénéfiques, en particulier lorsqu’on consulte à distance son compte en banque ou que l’on transfère des données médicales. Dès lors, la mesure est vite prise entre d’un côté des gouvernements cherchant à déchiffrer des communications (sans même être sûr d’y trouver quoi que ce soit d’intéressant) et la part gigantesque de marché que représente le transfert de données chiffrées. Peu importe ce qu’elles contiennent, l’essentiel est de comprendre non pas ce qui est échangé, mais qui échange avec qui, pour quelles raisons, et comment s’immiscer en tant qu’acteur de ces échanges. Ainsi, encore un exemple parmi d’autres, Google a déployé depuis longtemps des systèmes de consultation médicale à distance, chiffrées bien entendu : « si vous voulez un tel service, nous sommes capables d’en assurer la sécurité, contrairement à un État qui veut déchiffrer vos communications ». Le chiffrement est un élément essentiel du capitalisme de surveillance, c’est pourquoi Apple y tient tant : il instaure un degré de confiance et génère du marché.
Nous pourrions passer en revue plusieurs systèmes alternatifs qui permettraient de s’émanciper plus ou moins du capitalisme de surveillance. Les solutions ne sont pas uniquement techniques : elles résident dans le degré de connaissance des enjeux de la part des populations. Il ne suffit pas de ne plus utiliser les services de courriel de Google, surtout si on apprécie l’efficacité de ce service. Il faut se poser la question : « si j’ai le choix d’utiliser ou non Gmail, dois-je pour autant imposer à mon correspondant qu’il entre en relation avec Google en me répondant à cette adresse ? ». C’est exactement le même questionnement qui s’impose lorsque j’envoie un document en format Microsoft en exigeant indirectement de mon correspondant qu’il ait lui aussi le même logiciel pour l’ouvrir.
L’enjeu est éthique. Dans la Règle d’Or, c’est la réciprocité qui est importante (« ne fais pas à autrui ce que tu n’aimerais pas qu’on te fasse »). Appliquer cette règle à nos rapports technologiques permet une prise de conscience, l’évaluation des enjeux qui dépasse le seul rapport individuel, nucléarisé, que j’ai avec mes pratiques numériques et que le capitalisme de surveillance cherche à m’imposer. Si je choisis d’installer sur mon smartphone l’application de géolocalisation que m’offre mon assureur en guise de test contre un avantage quelconque, il faut que je prenne conscience que je participe directement à une mutation sociale qui imposera des comportements pour faire encore davantage de profits. C’est la même logique à l’œuvre avec l’ensemble des solutions gratuites que nous offrent les GAFAM, à commencer par le courrier électronique, le stockage en ligne, la cartographie et la géolocalisation.
Faut-il se passer de toutes ces innovations ? Bien sûr que non ! le retranchement anti-technologique n’est jamais une solution. D’autant plus qu’il ne s’agit pas non plus de dénigrer les grands bienfaits d’Internet. Par contre, tant que subsisteront dans l’ADN d’Internet les concepts d’ouverture et de partage, il sera toujours possible de proposer une alternative au capitalisme de surveillance. Comme le phare console le marin dans la brume, le logiciel libre et les modèles collaboratifs qu’il véhicule représentent l’avenir de nos libertés. Nous ne sommes plus libres si nos comportements sont imposés. Nous ne sommes pas libres non plus dans l’ignorance technologique.
Il est donc plus que temps de Dégoogliser Internet en proposant non seulement d’autres services alternatifs et respectueux des utilisateurs, mais surtout les moyens de multiplier les solutions et décentraliser les usages. Car ce qu’il y a de commun entre le capitalisme classique et le capitalisme de surveillance, c’est le besoin centralisateur, qu’il s’agisse des finances ou des données. Ah ! si tous les CHATONS du monde pouvaient se donner la patte…
Le chiffrement, s’il n’est pas encore dans tous nos usages — et loin s’en faut, chez la plupart des utilisateurs, est nettement devenu un argument marketing et une priorité pour les entreprises qui distribuent logiciels et services. En effet, le grand public est beaucoup plus sensible désormais à l’argument de la sécurité de la vie privée. Donc les services qui permettent la communication en ligne rivalisent d’annonces pour promettre et garantir une sécurité toujours plus grande et que l’on puisse activer d’un simple clic.
Que faut-il croire, à qui et quoi pouvons-nous confier nos communications ?
L’article de Hannes Hauswedell que nous avons traduit nous aide à faire un tri salutaire entre les solutions logicielles du marché, pointe les faux-semblants et les failles, puis nous conduit tranquillement à envisager des solutions fédérées et pair à pair reposant sur des logiciels libres. Des réseaux de confiance en somme, ce qui est proche de l’esprit de l’initiative C.H.A.T.O.N.S portée par Framasoft et qui suscite déjà un intérêt grandissant.
Comme d’habitude les commentaires sont ouverts et libres si vous souhaitez par exemple ajouter vos découvertes à ce recensement critique forcément incomplet.
Au cours de l’année dernière on a pu croire que les poules avaient des dents quand les grandes entreprises hégémoniques comme Apple, Google et Facebook ont toutes mis en œuvre le chiffrement à un degré ou un autre. Pour Facebook avec WhatsApp et Google avec Allo, le chiffrement de la messagerie a même été implémenté par rien moins que le célèbre Moxie Marlinspike, un hacker anarchiste qui a la bénédiction d’Edward Snowden !
Donc tout est pour le mieux sur le front de la défense de la vie privée !… Euh, vraiment ?
J’ai déjà développé mon point de vue sur la sécurité de la messagerie mobile et j’en ai parlé dans un podcast (en allemand). Mais j’ai pensé qu’il fallait que j’y revienne, car il existe une certaine confusion sur ce que signifient sécurité et confidentialité (en général, mais particulièrement dans le contexte de la messagerie), et parce que les récentes annonces dans ce domaine ne donnent selon moi qu’un sentiment illusoire de sécurité.
Je vais parler de WhatsApp et de Facebook Messenger (tous deux propriétés de Facebook), de Skype (possédé par Microsoft), de Telegram, de Signal (Open Whisper systems), Threema (Threema GmbH), Allo (possédé par Google) et de quelques clients XMPP, je dirai aussi un mot de ToX et Briar. Je n’aborderai pas les diverses fonctionnalités mêmes si elles sont liées à la confidentialité, comme les notifications évidemment mal conçues du type « le message a été lu ». Je n’aborderai pas non plus les questions d’anonymat qui sont connexes, mais selon moi moins importantes lorsqu’il s’agit d’applis de substitution aux SMS, puisque vous connaissez vos contacts de toutes façons.
Le chiffrement
Quand on parle de confidentialité ou de sécurité des communications dans les messageries, il s’agit souvent de chiffrement ou, plus précisément, du chiffrement des données qui se déplacent, de la protection de vos messages pendant qu’ils voyagent vers vos contacts.
Il existe trois moyens classiques pour faire cela :
pas de chiffrement : tout le monde sur votre réseau WIFI local ou un administrateur système quelconque du réseau internet peut lire vos données
le chiffrement en transit : la connexion au et à partir du fournisseur de service, par exemple les serveurs WhatsApp, et entre les fournisseurs de services est sécurisée, mais le fournisseur de service peut lire le message
le chiffrement de bout en bout : le message est lisible uniquement par ceux à qui la conversation est adressée, mais le moment de la communication et les participants sont connus du fournisseur de service
Il y a aussi une propriété appelée « confidentialité persistante » (perfect forward secrecy en anglais) qui assure que les communications passées ne peuvent être déchiffrées, même si la clef à long terme est révélée ou volée.
À l’époque, la plupart des applications, même WhatsApp, appartenaient à la première catégorie. Mais aujourd’hui presque toutes les applications sont au moins dans la deuxième. La probabilité d’un espionnage insoupçonné en est réduite (c’est toujours possible pour les courriels par exemple), mais ce n’est évidemment pas suffisant, puisque le fournisseur de service peut être malveillant ou forcé de coopérer avec des gouvernements malveillants ou des agences d’espionnage sans contrôle démocratique.
C’est pour cela que vous voulez que votre messagerie fasse du chiffrement de bout en bout. Actuellement, les messageries suivantes le font (classées par taille supposée) : WhatsApp, Signal, Threema, les clients XMPP avec GPG/OTR/Omemo (ChatSecure, Conversations, Kontalk).
Les messageries qui disposent d’un mode spécifique (« chat secret » ou « mode incognito ») sont Telegram et Google Allo. Il est vraiment dommage qu’il ne soit pas activé par défaut, donc je ne vous les recommande pas. Si vous devez utiliser l’un de ces programmes, assurez-vous toujours d’avoir sélectionné le mode privé. Il est à noter que les experts considèrent que le chiffrement de bout en bout de Telegram est moins robuste, même s’ils s’accordent à dire que les attaques concrètes pour récupérer le texte d’un message ne sont pas envisageables.
D’autres programmes populaires, comme la messagerie de Facebook ou Skype n’utilisent pas de chiffrement de bout en bout, et devraient être évités. Il a été prouvé que Skype analyse vos messages, je ne m’attarderai donc pas sur ces deux-là.
Logiciels libres et intégrité des appareils
Donc maintenant, les données sont en sécurité tant qu’elles voyagent de vous à votre ami. Mais qu’en est-il avant et après leur envoi ? Ne pouvez-vous pas aussi tenter d’espionner le téléphone de l’expéditeur ou du destinataire avant qu’elles ne soient envoyées et après leur réception ? Oui c’est possible et en Allemagne le gouvernement a déjà activement utilisé la « Quellen-Telekommunikationsüberwachung » (surveillance des communications à la source) précisément pour passer outre le chiffrement.
Revenons à la distinction entre (2) et (3). La différence principale entre le chiffrement en transit et de bout en bout est que vous n’avez plus besoin de faire confiance au fournisseur de service… FAUX : Dans presque tous les cas, la personne qui fait tourner le serveur est la même que celle qui fournit le programme. Donc forcément, vous devez croire que le logiciel fait bien ce qu’il dit faire. Ou plutôt, il doit y avoir des moyens sociaux et techniques qui vous donnent suffisamment de certitude que le logiciel est digne de confiance. Sinon, la valeur ajoutée du chiffrement de bout en bout est bien maigre.
La liberté des logiciels
C’est maintenant que le logiciel libre entre en jeu. Si le code source est publié, il y aura un grand nombre de hackers et de volontaires pour vérifier que le programme chiffre vraiment le contenu. Bien que ce contrôle public ne puisse vous donner une sécurité parfaite, ce processus est largement reconnu comme étant le meilleur pour assurer qu’un programme est globalement sûr et que les problèmes de sécurité sont découverts (et aussi corrigés). Le logiciel libre permet aussi de créer des versions non officielles ou rivales de l’application de messagerie, qui seront compatibles. S’il y a certaines choses que vous n’aimez pas ou auxquelles vous ne faites pas confiance dans l’application officielle, vous pourrez alors toujours en choisir une autre et continuer de chatter avec vos amis.
Certaines compagnies comme Threema qui ne fournissent pas leurs sources assurent évidemment qu’elles ne sont pas nécessaires pour avoir confiance. Elles affirment que leur code a été audité par une autre compagnie (qu’ils ont généralement payée pour cela), mais si vous ne faites pas confiance à la première, pourquoi faire confiance à une autre engagée par celle-ci ? Plus important, comment savoir que la version vérifiée par le tiers est bien la même version que celle installée sur votre téléphone ? (Vous recevez des mises à jours régulières ou non ?)
Cela vaut aussi pour les gouvernements et les entités publiques qui font ce genre d’audits. En fonction de votre modèle de menace ou de vos suppositions sur la société, vous pourriez être enclins à faire confiance aux institutions publiques plus qu’aux institutions privées (ou inversement), mais si vous regardez vers l’Allemagne par exemple, avec le TÜV il n’y a en fait qu’une seule organisation vérificatrice, que ce soit sur la valeur de confiance des applications de messagerie ou concernant la quantité de pollution émise par les voitures. Et nous savons bien à quoi cela a mené !
Quand vous décidez si vous faites confiance à un tiers, vous devez donc prendre en compte :
la bienveillance : le tiers ne veut pas compromettre votre vie privée et/ou il est lui-même concerné
la compétence : le tiers est techniquement capable de protéger votre vie privée et d’identifier et de corriger les problèmes
l’intégrité : le tiers ne peut pas être acheté, corrompu ou infiltré par des services secrets ou d’autres tiers malveillants
Après les révélations de Snowden, il est évident que le public est le seul tiers qui peut remplir collectivement ces prérequis ; donc la mise à disposition publique du code source est cruciale. Cela écarte d’emblée WhatsApp, Google Allo et Threema.
« Attendez une minute… mais n’existe-t-il aucun autre moyen de vérifier que les données qui transitent sont bien chiffrées ? » Ah, bien sûr qu’il en existe, comme Threema le fera remarquer, ou d’autres personnes pour WhatsApp. Mais l’aspect important, c’est que le fournisseur de service contrôle l’application sur votre appareil, et peut intercepter les messages avant le chiffrement ou après le déchiffrement, ou simplement « voler » vos clés de chiffrement. « Je ne crois pas que X fasse une chose pareille. » Gardez bien à l’esprit que, même si vous faites confiance à Facebook ou Google (et vous ne devriez pas), pouvez-vous vraiment leur faire confiance pour ne pas obéir à des décisions de justice ? Si oui, alors pourquoi vouliez-vous du chiffrement de bout en bout ? « Quelqu’un s’en apercevrait, non ? » Difficile à dire ; s’ils le faisaient tout le temps, vous pourriez être capable de vous en apercevoir en analysant l’application. Mais peut-être qu’ils font simplement ceci :
si (listeDeSuspects.contient(utilisateurID))
envoyerClefSecreteAuServeur() ;
Alors seules quelques personnes sont affectées, et le comportement ne se manifeste jamais dans des « conditions de laboratoire ». Ou bien la génération de votre clé est trafiquée, de sorte qu’elle soit moins aléatoire, ou qu’elle adopte une forme plus facile à pirater. Il existe plusieurs approches, et la plupart peuvent facilement être déployées dans une mise à jour ultérieure, ou cachée parmi d’autres fonctionnalités. Notez bien également qu’il est assez facile de se retrouver dans la liste de suspects, car le règlement actuel de la NSA assure de pouvoir y ajouter plus de 25 000 personnes pour chaque suspect « originel ».
À la lumière de ces informations, on comprend qu’il est très regrettable que Open Whisper Systems et Moxie Marlinspike (le célèbre auteur de Signal, mentionné précédemment) fassent publiquement les louanges de Facebook et de Google, augmentant ainsi la confiance en leurs applications [bien qu’il ne soit pas mauvais en soi qu’ils aient aidé à mettre en place le chiffrement, bien sûr]. Je suis assez confiant pour dire qu’ils ne peuvent pas exclure un des scénarios précédents, car ils n’ont pas vu le code source complet des applications, et ne savent pas non plus ce que vont contenir les mises à jour à l’avenir – et nous ne voudrions de toutes façons pas dépendre d’eux pour nous en assurer !
La messagerie Signal
« OK, j’ai compris. Je vais utiliser des logiciels libres et open source. Comme le Signal d’origine ». C’est là que ça se complique. Bien que le code source du logiciel client Signal soit libre/ouvert, il dépend d’autres composants non libres/fermés/propriétaires pour fonctionner. Ces composants ne sont pas essentiels au fonctionnement, mais ils (a) fournissent des métadonnées à Google (plus de détails sur les métadonnées plus loin) et (b) compromettent l’intégrité de votre appareil.
Le dernier point signifie que si même une petite partie de votre application n’est pas digne de confiance, alors le reste ne l’est pas non plus. C’est encore plus critique pour les composants qui ont des privilèges système, puisqu’ils peuvent faire tout et n’importe quoi sur votre téléphone. Et il est particulièrement impossible de faire confiance à ces composants non libres qui communiquent régulièrement des données à d’autres ordinateurs, comme ces services Google. Certes, il est vrai que ces composants sont déjà inclus dans la plupart des téléphones Android dans le monde, et il est aussi vrai qu’il y a très peu d’appareils qui fonctionnent vraiment sans aucun composant non libre, donc de mon point de vue, ce n’est pas problématique en soi de les utiliser quand ils sont disponibles. Mais rendre leur utilisation obligatoire implique d’exclure les personnes qui ont besoin d’un niveau de sécurité supérieur (même s’ils sont disponibles !) ; ou qui utilisent des versions alternatives plus sécurisées d’Android, comme CopperheadOS ; ou simplement qui ont un téléphone sans ces services Google (très courant dans les pays en voie de développement). Au final, Signal créé un « effet réseau » qui dissuade d’améliorer la confiance globale d’un appareil mobile, parce qu’il punit les utilisateurs qui le font. Cela discrédite beaucoup de promesses faites par ses auteurs.
Et voici le pire : Open Whisper Systems, non seulement, ne supporte pas les systèmes complètements libres, mais a également menacé de prendre des mesures légales afin d’empêcher les développeurs indépendants de proposer une version modifiée de l’application client Signal qui fonctionnerait sans les composants propriétaires de Google et pourrait toujours interagir avec les autres utilisateurs de Signal ([1] [2] [3]). À cause de cela, des projets indépendants comme LibreSignal sont actuellement bloqués. En contradiction avec leur licence libre, ils s’opposent à tout client du réseau qu’ils ne distribuent pas. De ce point de vue, l’application Signal est moins utilisable et moins fiable que par exemple Telegram qui encourage les clients indépendants à utiliser leurs serveurs et qui propose des versions entièrement libres.
Juste pour que je ne donne pas de mauvaise impression : je ne crois pas qu’il y ait une sorte de conspiration entre Google et Moxie Marlinspike, et je les remercie de mettre au clair leur position de manière amicale (au moins dans leur dernière déclaration), mais je pense que la protection agressive de leur marque et leur insistance à contrôler tous les logiciels clients de leur réseau met à mal la lutte globale pour des communications fiables.
Décentralisation, contrôle par les distributeurs et métadonnées
Un aspect important d’un réseau de communication est sa topologie, c’est-à-dire la façon dont le réseau est structuré. Comme le montre l’image ci-dessous, il y a plusieurs approches, toutes (plus ou moins) largement répandues. La section précédente concernait ce qui se passe sur votre téléphone, alors que celle-ci traite de ce qui se passe sur les serveurs, et du rôle qu’ils jouent. Il est important de noter que, même dans des réseaux centralisés, certaines communications ont lieu en pair-à-pair (c’est-à-dire sans passer par le centre) ; mais ce qui fait la différence, c’est qu’il nécessitent des serveurs centraux pour fonctionner.
Réseaux centralisés
Les réseaux centralisés sont les plus courants : toutes les applications mentionnées plus haut (WhatsApp, Telegram, Signal, Threema, Allo) reposent sur des réseaux centralisés. Bien que beaucoup de services Internet ont été décentralisés dans le passé, comme l’e-mail ou le World Wide Web, beaucoup de services centralisés ont vu le jour ces dernières années. On peut dire, par exemple, que Facebook est un service centralisé construit sur la structure WWW, à l’origine décentralisée.
Les réseaux centralisés font souvent partie d’une marque ou d’un produit plus global, présenté comme une seule solution (au problème des SMS, dans notre cas). Pour les entreprises qui vendent ou qui offrent ces solutions, cela présente l’avantage d’avoir un contrôle total sur le système, et de pouvoir le changer assez rapidement, pour offrir (ou imposer) de nouvelles fonctionnalités à tous les utilisateurs.
Même si l’on suppose que le service fournit un chiffrement de bout en bout, et même s’il existe une application cliente en logiciel libre, il reste toujours les problèmes suivants :
métadonnées : le contenu de vos messages est chiffré, mais l’information qui/quand/où est toujours accessible pour votre fournisseur de service
déni de service : le fournisseur de service ou votre gouvernement peuvent bloquer votre accès au service
Il y a également ce problème plus général : un service centralisé, géré par un fournisseur privé, peut décider quelles fonctionnalités ajouter, indépendamment du fait que ses utilisateurs les considèrent vraiment comme des fonctionnalités ou des « anti-fonctionnalités », par exemple en indiquant aux autres utilisateurs si vous êtes « en ligne » ou non. Certaines de ces fonctionnalités peuvent être supprimées de l’application sur votre téléphone si c’est du logiciel libre, mais d’autres sont liées à la structure centralisée. J’écrirai peut-être un jour un autre article sur ce sujet.
Métadonnées
Comme expliqué précédemment, les métadonnées sont toutes les données qui ne sont pas le message. On pourrait croire que ce ne sont pas des données importantes, mais de récentes études montrent l’inverse. Voici des exemples de ce qu’incluent les métadonnées : quand vous êtes en ligne, si votre téléphone a un accès internet, la date et l’heure d’envoi des messages et avec qui vous communiquez, une estimation grossière de la taille du message, votre adresse IP qui peut révéler assez précisément où vous vous trouvez (au travail, à la maison, hors de la ville, et cætera), éventuellement aussi des informations liées à la sécurité de votre appareil (le système d’exploitation, le modèle…). Ces informations sont une grande menace contre votre vie privée et les services secrets américains les utilisent réellement pour justifier des meurtres ciblés (voir ci-dessus).
La quantité de métadonnées qu’un service centralisé peut voir dépend de leur implémentation précise. Par exemple, les discussions de groupe avec Signal et probablement Threema sont implémentées dans le client, donc en théorie le serveur n’est pas au courant. Cependant, le serveur a l’horodatage de vos communications et peut probablement les corréler. De nouveau, il est important de noter que si le fournisseur de service n’enregistre pas ces informations par défaut (certaines informations doivent être préservées, d’autres peuvent être supprimées immédiatement), il peut être forcé à enregistrer plus de données par des agences de renseignement. Signal (comme nous l’avons vu) ne fonctionne qu’avec des composants non-libres de Google ou Apple qui ont alors toujours une part de vos métadonnées, en particulier votre adresse IP (et donc votre position géographique) et la date à laquelle vous avez reçu des messages.
Pour plus d’informations sur les métadonnées, regardez ici ou là.
Déni de service
Un autre inconvénient majeur des services centralisés est qu’ils peuvent décider de ne pas vous servir du tout s’ils le veulent ou qu’ils y sont contraints par la loi. Comme nombre de services demandent votre numéro lors de l’enregistrement et sont opérés depuis les États-Unis, ils peuvent vous refuser le service si vous êtes cubain par exemple. C’est particulièrement important puisqu’on parle de chiffrement qui est grandement régulé aux États-Unis.
L’Allemagne vient d’introduire une nouvelle loi antiterroriste dont une partie oblige à décliner son identité lors de l’achat d’une carte SIM, même prépayée. Bien que l’hypothèse soit peu probable, cela permettrait d’établir une liste noire de personnes et de faire pression sur les entreprises pour les exclure du service.
Plutôt que de travailler en coopération avec les entreprises, un gouvernement mal intentionné peut bien sûr aussi cibler le service directement. Les services opérés depuis quelques serveurs centraux sont bien plus vulnérables à des blocages nationaux. C’est ce qui s’est passé pour Signal et Telegram en Chine.
Réseaux déconnectés
Lorsque le code source du serveur est libre, vous pouvez monter votre propre service si vous n’avez pas confiance dans le fournisseur. Ça ressemble à un gros avantage, et Moxie Marlinspike le défend ainsi :
Avant vous pouviez changer d’hébergeur, ou même décider d’utiliser votre propre serveur, maintenant les utilisateurs changent simplement de réseau complet. […] Si un fournisseur centralisé avec une infrastructure ouverte modifiait affreusement ses conditions, ceux qui ne seraient pas d’accord ont le logiciel qu’il faut pour utiliser leur propre alternative à la place.
Et bien sûr, c’est toujours mieux que de ne pas avoir le choix, mais la valeur intrinsèque d’un réseau « social » vient des gens qui l’utilisent et ce n’est pas évident de changer si vous perdez le lien avec vos amis. C’est pour cela que les alternatives à Facebook ont tant de mal. Mme si elles étaient meilleures sur tous les aspects, elles n’ont pas vos amis.
Certes, c’est plus simple pour les applications mobiles qui identifient les gens via leur numéro, parce qu’au moins vous pouvez trouver vos amis rapidement sur un nouveau réseau, mais pour toutes les personnes non techniciennes, c’est très perturbant d’avoir 5 applications différentes juste pour rester en contact avec la plupart de ses amis, donc changer de réseau ne devrait qu’être un dernier recours.
Notez qu’OpenWhisperSystems se réclame de cette catégorie, mais en fait ils ne publient que des parties du code du serveur de Signal, de sorte que vous ne soyez pas capables de monter un serveur avec les mêmes fonctionnalités (plus précisément la partie téléphonie manque).
Centralisation, réseaux déconnectés, fédération, décentralisation en pair à pair
La fédération
La fédération est un concept qui résout le problème mentionné plus haut en permettant en plus aux fournisseurs de service de communiquer entre eux. Donc vous pouvez changer de fournisseur, et peut-être même d’application, tout en continuant à communiquer avec les personnes enregistrées sur votre ancien serveur. L’e-mail est un exemple typique d’un système fédéré : peu importe que vous soyez tom@gmail.com ou jeanne@yahoo.com ou même linda@serveur-dans-ma-cave.com, tout le monde peut parler avec tout le monde. Imaginez combien cela serait ridicule, si vous ne pouviez communiquer qu’avec les personnes qui utilisent le même fournisseur que vous ?
L’inconvénient, pour un développeur et/ou une entreprise, c’est de devoir définir publiquement les protocoles de communication, et comme le processus de standardisation peut être compliqué et très long, vous avez moins de flexibilité pour modifier le système. Je reconnais qu’il devient plus difficile de rendre les bonnes fonctionnalités rapidement disponibles pour la plupart des gens, mais comme je l’ai dit plus haut, je pense que, d’un point de vue de la vie privée et de la sécurité, c’est vraiment une fonctionnalité, car plus de gens sont impliqués et plus cela diminue la possibilité pour le fournisseur d’imposer des fonctionnalités non souhaitées aux utilisateurs ; mais surtout car cela fait disparaître « l’effet d’enfermement ». Cerise sur le gâteau, ce type de réseau produit rapidement plusieurs implémentations du logiciel, à la fois pour l’application utilisateur et pour le logiciel serveur. Cela rend le système plus robuste face aux attaques et garantit que les failles ou les bugs présents dans un logiciel n’affectent pas le système dans son ensemble.
Et, bien sûr, comme évoqué précédemment, les métadonnées sont réparties entre plusieurs fournisseurs (ce qui rend plus difficile de tracer tous les utilisateurs à la fois), et vous pouvez choisir lequel aura les vôtres, voire mettre en place votre propre serveur. De plus, il devient très difficile de bloquer tous les fournisseurs, et vous pouvez en changer si l’un d’entre eux vous rejette (voir « Déni de service » ci-dessus).
Une remarque au passage : il faut bien préciser que la fédération n’impose pas que des métadonnées soient vues par votre fournisseur d’accès et celui de votre pair. Dans le cas de la messagerie électronique, cela représente beaucoup, mais ce n’est pas une nécessité pour la fédération par elle-même, c’est-à-dire qu’une structure fédérée bien conçue peut éviter de partager les métadonnées dans les échanges entre fournisseurs d’accès, si l’on excepte le fait qu’il existe un compte utilisateur avec un certain identifiant sur le serveur.
Alors est-ce qu’il existe un système identique pour la messagerie instantanée et les SMS ? Oui, ça existe, et ça s’appelle XMPP. Alors qu’initialement ce protocole n’incluait pas de chiffrement fort, maintenant on y trouve un chiffrement du même niveau de sécurité que pour Signal. Il existe aussi de très bonnes applications pour mobile sous Android (« Conversations ») et sous iOS (« ChatSecure »), et pour d’autres plateformes dans le monde également.
Inconvénients ? Comme pour la messagerie électronique, il faut d’abord vous enregistrer pour créer un compte quelque part et il n’existe aucune association automatique avec les numéros de téléphone, vous devez donc convaincre vos amis d’utiliser ce chouette nouveau programme, mais aussi trouver quels fournisseur d’accès et nom d’utilisateur ils ont choisis. L’absence de lien avec le numéro de téléphone peut être considérée par certains comme une fonctionnalité intéressante, mais pour remplacer les SMS ça ne fait pas l’affaire.
La solution : Kontalk, un client de messagerie qui repose sur XMPP et qui automatise les contacts via votre carnet d’adresses. Malheureusement, cette application n’est pas encore aussi avancée que d’autres mentionnées plus haut. Par exemple, il lui manque la gestion des groupes de discussion et la compatibilité avec iOS. Mais Kontalk est une preuve tangible qu’il est possible d’avoir avec XMPP les mêmes fonctionnalités que l’on trouve avec WhatsApp ou Telegram. Selon moi, donc, ce n’est qu’une question de temps avant que ces solutions fédérées ne soient au même niveau et d’une ergonomie équivalente. Certains partagent ce point de vue, d’autres non.
Réseaux pair à pair
Les réseaux pair à pair éliminent complètement le serveur et par conséquent toute concentration centralisée de métadonnées. Ce type de réseaux est sans égal en termes de liberté et il est pratiquement impossible à bloquer par une autorité. ToX est un exemple d’application pair à pair, ou encore Ricochet (pas pour mobile cependant), et il existe aussi Briar qui est encore en cours de développement, mais ajoute l’anonymat, de sorte que même votre pair ne connaît pas votre adresse IP. Malheureusement il existe des problèmes de principe liés aux appareils mobiles qui rendent difficile de maintenir les nombreuses connexions que demandent ces réseaux. De plus il semble impossible pour le moment d’associer un numéro de téléphone à un utilisateur, si bien qu’il est impossible d’avoir recours à la détection automatique des contacts.
Je ne crois pas actuellement qu’il soit possible que ce genre d’applications prenne des parts de marché à WhatsApp, mais elles peuvent être utiles dans certains cas, en particulier si vous êtes la cible de la surveillance et/ou membre d’un groupe qui décide collectivement de passer à ces applications pour communiquer, une organisation politique par exemple.
En deux mots
La confidentialité de nos données privées est l’objet d’un intérêt accru et les utilisateurs cherchent activement à se protéger mieux.
On peut considérer que c’est un bon signe quand les distributeurs principaux de logiciels comprennent qu’ils doivent réagir à cette situation en ajoutant du chiffrement à leurs logiciels ; et qui sait, il est possible que ça complique un peu la tâche de la NSA.
Toutefois, il n’y a aucune raison de leur faire plus confiance qu’auparavant, puisqu’il n’existe aucun moyen à notre disposition pour savoir ce que font véritablement les applications, et parce qu’il leur reste beaucoup de façons de nous espionner.
Si en ce moment vous utilisez WhatsApp, Skype, Threema ou Allo et que vous souhaitez avoir une expérience comparable, vous pouvez envisager de passer à Telegram ou Signal. Ils valent mieux que les précédents (pour diverses raisons), mais ils sont loin d’être parfaits, comme je l’ai montré. Nous avons besoin à moyen et long terme d’une fédération.
Même s’ils nous paraissent des gens sympas et des hackers surdoués, nous ne pouvons faire confiance à OpenWhisperSystemspour nous délivrer de la surveillance, car ils sont aveugles à certains problèmes et pas très ouverts à la coopération avec la communauté.
Des trucs assez sympas se préparent du côté du XMPP, surveillez Conversations, chatSecure et Kontalk. Si vous le pouvez, soutenez-les avec du code, des dons et des messages amicaux.
Si vous souhaitez une approche sans aucune métadonnée et/ou anonymat, essayez Tor ou ToX, ou attendez Briar.
AbulÉdu : début d’une renaissance ?
Si vous vous intéressez au libre pour l’école primaire, vous connaissez forcément AbulÉdu. Si ce n’est pas le cas, vous pouvez vous rafraîchir la mémoire avec les précédents articles parus ici même : le premier et le deuxième. Deux grosses annonces sont tombées ces derniers jours dans l’écosystème AbulÉdu ; une mauvaise et une bonne qui, nous l’espérons, deviendra excellente. Pour nous expliquer tout cela, rencontrons les membres de l’association AbulEdu-fr
Commençons tout de suite par la mauvaise nouvelle, la société RyXeo, qui édite la solution libre AbulÉdu, est en liquidation judiciaire après 13 ans d’existence. Pour quelles raisons ?
RyXéo, la fin d’une histoire, mais l’aventure continue !
Les grandes catastrophes sont souvent provoquées par une multitude de petits problèmes, c’est ce qui est arrivé à RyXéo :
un projet sans doute trop grand pour une petite équipe de 8 personnes sans ressource financière autre que ses clients et quelques petites subventions alors que le budget annuel devrait tourner dans les 500 000 €, on s’en est tiré avec à peu près la moitié,
des partenaires qui ne portent pas les valeurs du libre et avec lesquels nous avons perdu beaucoup de temps à essayer de faire comprendre que c’est pourtant la seule chose importante pour l’école,
des clients (mairies) qui n’utilisent pas ce pourquoi ils paient et ont tendance à chercher où gratter quelques centaines d’euros par an pour réduire leurs dépenses (réduction liée à la baisse des dotations de l’état)
des politiques publiques chaotiques : parfois on annonce que le libre est une bonne chose (1er ministre) et ensuite on signe un partenariat avec Microsoft (Éducation nationale), les utilisateurs sont perdus et les responsables des commandes publiques ne savent plus ce qu’il faut faire ;
il en va de même sur les annonces des dotations budgétaires : exemple le 2 juin le président annonce que finalement la dotation aux mairies sera réévaluée … conséquence les mairies ne savent pas si elles peuvent investir ou non, et l’école passe souvent dans les derniers choix d’investissements… et l’informatique scolaire encore bien après,
une « trop grande » éthique de la part de nos relais à l’intérieur de l’institution qui sont toujours un peu embêtés lorsqu’ils parlent d’AbulÉdu et ont l’impression d’être le « commercial de RyXéo » alors que leurs collègues ne se privent pas de faire de la pub pour les GAFAM à tour de bras. La fin de Ryxeo va leur donner beaucoup d’oxygène, ils ne risqueront plus d’être coincés entre leur devoir de réserve de fonctionnaire et l’existence d’une société commerciale qui vend AbulÉdu,
quasi zéro budget communication pour Ryxeo, seul le bouche à oreille nous a permis de nous développer,
une trop grande gentillesse et « compréhension » pour toutes ces « petites mairies à petit budget » à qui nous avons consenti des heures de hotline sans les facturer alors qu’il fallait bien payer les salaires correspondant à ce service,
l’impossibilité de licencier un membre de l’équipe, chacun étant indispensable et surtout le coût lié à un licenciement économique n’était pas possible (ce genre de calcul est un peu complexe à comprendre mais grosso-modo quand on licencie un salarié pour raison économique, il coûte d’un coup environ 4 mois de salaire… ce qui représente une dépense instantanée souvent impossible à assumer sur la trésorerie disponible),
le lancement des tablettes, produit super prometteur mais pour lequel nous avions besoin d’un investissement … qui n’est jamais venu.
Bref, tout ceci mis bout à bout nous a conduit à la catastrophe qu’on connaît. Ajoutez une baisse d’implication commerciale du patron de la boite qui s’est recentré sur la technique depuis plusieurs mois et vous avez malheureusement un cocktail détonant.
Une des difficultés n’est-elle pas également de s’adresser aux écoles primaires et donc aux mairies ? Les sociétés qui proposent des solutions aux collèges et lycées ont plus de facilité.
Je ne pense hélas pas que nous verrons beaucoup de collèges équipés avec des solutions basées sur le logiciel libre. Effectivement certains collèges sont équipés avec des serveurs basés sur des solutions libres mais la plupart des postes individuels sont sous windows. Et le récent accord n’est pas prêt de changer la donne.
Treize ans, cela reste une superbe aventure. Une anecdote, un souvenir particulier à nous faire partager ?
Des tonnes. La plus intéressante c’est l’anecdote qui porte le nom de… RyXéo tout simplement : c’est qu’on a prouvé que c’était possible de vivre correctement d’un rêve, d’une utopie, qu’on peut facturer pour du logiciel libre, qu’on peut le faire, qu’il ne faut pas être résigné à acheter des produits en conserve et à les consommer comme des programmes télévisés. Qu’on peut se prendre en main et qu’on peut prendre en main l’avenir numérique des outils d’éducation de nos enfants… C’est possible, on l’a fait, on le prouvait jour après jour. Une boite de 8 personnes qui tient plus de 10 ans c’est pas une coïncidence, c’est pas un hasard, c’est pas un « accident », c’est que ça marche pour de vrai.
RyXeo étant en liquidation, c’est la fin d’AbulÉdu ?
Le projet AbulÉdu n’est pas mort, c’est un projet issu du monde associatif et porté par une communauté. RyXéo en était certes le moteur, puisqu’il a permis de salarier développeurs et graphistes et de faire avancer ce projet tout en le rendant attractif, mais il continuera sa route avec deux autres moteurs identifiés, les associations AbulÉdu-fr et Abul et peut-être d’autres. C’est une des forces du logiciel libre, il nous permet cette continuité et de rebondir.
Quel va être justement le rôle de l’association AbulÉdu-fr ?
Pour être complet, il y a deux associations qui unissent leurs forces pour la continuité du projet AbulÉdu : l’association AbulÉdu-Fr mais aussi l’Abul qui compte parmi les pionniers dans la promotion du logiciel libre en France. Dans cette nouvelle gouvernance qu’il va falloir inventer, AbulÉdu-fr peut s’appuyer sur son savoir faire autour des usages et des relations avec les utilisateurs, l’Abul quant à elle pourra se concentrer sur l’infrastructure technique.
Abul et AbulÉdu-fr : deux associations pour soutenir le projet AbulÉdu avec vous.
Sans être exhaustif, pouvez-vous nous présenter quelques grands projets mis en place par AbulÉdu-fr ?
Le premier qui me vient à l’esprit est Babytwit tant son succès a été rapide et grandissant. Il s’agit d’un site de micro-blogging libre et éthique dédié principalement à la communauté éducative. Une alternative à Twitter dont la publicité est absente et où les données personnelles des utilisateurs ne sont pas monnayées. Je pourrais également citer QiRo, site de questions-réponses où tout le monde peut poser une question ou apporter une réponse. Comment ne pas également parler de data.abuledu.org, banque de ressources brutes sous licences libres (dont Framasoft héberge d’ailleurs un miroir) ?
À ce propos, j’aimerais souligner la partie plus « invisible » de l’activité des membres de l’association : « data » rassemble 30 000 ressources qui ont toutes été proposées, décrites, indexées et modérées par la communauté. Certains membres de l’association accompagnent régulièrement des classes dans la mise en œuvre de projets numériques, d’autres sont très présents sur Babytwit et y animent des activités ou répondent aux messages des élèves.
Comme il ne s’agit pas d’être exhaustif, je ne parlerai pas de la rédaction de tutoriels ou de documentations, des comptes-rendus d’expérimentation, de la prescription de nouveaux services…
Qiro, le service de questions / réponses de l’association AbulÉdu-fr
Vous lancez donc, et c’est la bonne nouvelle, une campagne de financement participatif. Avec quels objectifs ?
L’enjeu primordial est de rendre accessibles un ensemble de ressources pédagogiques et d’outils numériques en dehors de toutes pressions commerciales, au nom de la neutralité, de l’éthique et de l’idée que l’on se fait de l’éducation. Pour y contribuer nous pensons essentiel de passer d’un modèle économique d’éditeur de logiciels à un modèle associatif où chaque nouveau développement ne sera financé qu’une seule fois pour être ensuite disponible pour tous. Cela implique de trouver d’autres moyens de développement de nos ressources, mais aussi d’adapter les ressources actuelles à ce nouveau fonctionnement. C’est pourquoi nous visons deux paliers (l’un à 25000€ et l’autre à 50000€) dont vous trouverez les détails ici sur la page de la campagne.
Il faut sauver AbulÉdu et nous avons besoin de votre aide financière pour cela.
Campagne de financement participatif pour le projet AbulÉdu.
Cette année (oui, dans l’éducation nationale on parle en année scolaire) on a beaucoup entendu parler de l’éducation nationale pour ses liens très étroits avec des logiciels privateurs. Le ministère a-t-il connaissance du projet AbulÉdu et de sa pertinence pour ses écoles ?
Oui, le projet AbulÉdu est connu au ministère. Le serveur AbulÉdu par exemple est référencé dans le guide pratique de mise en place du filtrage des sites Internet sur le site EducNet.
De plus, suite à l’accord passé entre Microsoft et le ministère au mois de novembre dernier nous avons écrit au ministère pour exprimer notre sentiment vis à vis de ce partenariat et également rappeler l’existence du projet AbulÉdu. Au mois de janvier nous avons été reçus par un représentant de la Direction du Numérique Éducatif. Nous avons pu présenter le projet AbulÉdu dans son ensemble, notre interlocuteur était très attentif. Enfin, nous avons constitué un dossier de demande de subvention au mois de mars. La balle est maintenant dans le camp du ministère, nous saurons prochainement si un projet tel qu’AbulÉdu a sa place dans les écoles françaises.
À votre avis, quels sont les principaux freins de la percée du logiciel libre dans l’éducation ?
À mon avis, le souci principal est lié au « point de vue » ou plutôt au paradigme : le logiciel libre porte des valeurs là où le logiciel propriétaire s’appréhende d’un point de vue économique. Le logiciel libre ouvre son code source pour que chacun puisse se l’approprier, le modifier selon ses besoins et bien sûr le redistribuer là où le logiciel propriétaire verrouille tout, empêche toute diffusion autrement que par ses réseaux et tant pis s’il ne correspond pas tout à fait à tes besoins : soit tu changes de besoin, soit tu achètes la prochaine version.
Le logiciel libre refuse l’exploitation et la revente des données des utilisateurs, là où le logiciel propriétaire en fait un commerce démesuré.
Malheureusement, de nos jours, on préfère parler de données économiques brutes que de valeurs éthiques.
Comme vous le savez, à Framasoft, on essaie de sensibiliser à l’emprise croissante des GAFAM (Google, Apple, Facebook, Amazon, Microsoft) dans tous les aspects de notre vie. Quand on parle GAFAM et éducation, on pense naturellement à Microsoft ou Apple. Mais Google perce de plus en plus avec des solutions comme Classrooms ou OpenOnline. Pour l’instant, Google Education vise plutôt le marché universitaire, mais n’a pas caché son ambition de couvrir l’ensemble des cycles. Les solutions Google commencent-elles à apparaître sur vos radars ?
Actuellement, le 1er degré (élèves de maternelle jusqu’au CM2) n’est pas concerné par Google Classrooms ou OpenOnline. Je devrais dire, n’est pas encore concerné. En effet, un appel à projet visant l’équipement des collégiens et des écoliers en EIM (équipement mobile individuel) a été lancé par le ministère, on en est maintenant à la 3e phase. Il y a fort à parier que de nombreux équipements seront basés sur Android offrant ainsi à Google une porte d’entrée dans les écoles.
La tradition musicale du requiem est dès l’origine inhérente à la liturgie chrétienne au point qu’il faut attendre le XVIIIe siècle pour assister à la création de requiems « de concert », donc exécutés en dehors d’une célébration funèbre à caractère religieux.
Aujourd’hui, Denis Raffin propose d’aller plus loin encore et vient de passer plusieurs années à l’élaboration d’un requiem athée, qui comme il nous l’explique, vise à rendre hommage au souvenir des disparus en exaltant plutôt… la vie, hors de toute transcendance.
Qui plus est, sa création musicale est non seulement libre de références à la divinité mais aussi libre de droits et élaborée avec des logiciels libres. De bonnes raisons pour lui donner la parole et prêter une oreille curieuse à son requiem.
Peux-tu te présenter brièvement et nous dire par quel parcours tu en arrivé à ce projet un peu surprenant ?
Je suis un compositeur amateur, épris de musique classique depuis mon enfance. Jusqu’à présent, j’ai surtout composé de courtes pièces pour mon entourage. C’est la première fois que je me lance dans une œuvre d’une telle ampleur. J’ai composé les premières notes en 2013 (il y a 3 ans, oui oui…) et je viens enfin de terminer d’ébaucher les 5 mouvements qui constituent l’œuvre.
Justement, en prenant connaissance de ton projet, maintenant en phase finale, on ne peut s’empêcher de se dire que tu es soit très courageux soit inconscient : s’attaquer à un tel format musical demande de l’estomac, non ? et je ne parle même pas des monuments du genre (Mozart, Brahms, Berlioz, Verdi et tant d’autres… ) qui peuvent impressionner. Tu veux t’inscrire dans l’histoire de la musique à leur suite ?
J’ai toujours adoré les grandes œuvres religieuses, notamment funèbres. On y trouve une noirceur plus ou moins désespérée, mêlée à un fort besoin de consolation et de lumière (de résilience). Il y a peut-être un peu de mégalomanie dans mon projet, je ne le nie pas. Mais en réalité, il s’agit surtout de répondre à un double besoin : celui de m’obliger à dépasser le stade de compositeur du dimanche et celui d’aborder frontalement un thème qui me hante depuis mon adolescence : celui de la finitude de nos existences. J’ai voulu célébrer par une œuvre monumentale un événement très important dans ma propre existence : j’ai fini par admettre que j’allais mourir.
Brrr ce n’est pas très gai tout ça… On peut concevoir le désir de rendre hommage aux disparus, mais pourquoi célébrer la mort ?
Attention, pas de contre-sens ! Je ne célèbre pas la mort ! Mais assumer ma finitude m’a permis de comprendre des choses simples. D’abord que la vie est un bien précieux car éphémère et fragile. En ce sens, il faut savoir la respecter, la protéger, refuser de se contenter d’une vie où on se « laisse vivre ». Et surtout résister aux vols de nos existences que constituent le sur-travail, les guerres, la consommation, etc. Ensuite, nos existences si courtes prennent beaucoup plus de sens quand on les replace au sein de cycles naturels et historiques qui les dépassent. J’appelle, dans Un requiem athée, à « cultiver le grand jardin du monde ». À agir, humblement, chacun à son échelle, à construire un monde meilleur, tout en profitant au mieux de celui qui nous est offert. Il n’y a rien de morbide dans tout ça, non ?
Un requiem athée et libre, mais pas triste !
Comme tu l’exposes en détails sur cette page tu n’es pas le premier à vouloir créer un Requiem athée. Pourquoi ajouter ta version, est-ce qu’il te semble qu’il y a ces dernières années une urgence (la question toujours vive de la laïcité ?) ou bien la naissance de ton projet correspond-elle à un cheminement plus personnel ?
La question de la laïcité, et en particulier de la cohabitation entre religieux et non-religieux, ne fait pas partie de ma démarche. Simplement, il y avait un manque dans l’histoire de la musique : il existe très peu d’œuvres athées traitant du thème de la mort.
Parler aux athées en général n’est d’ailleurs pas une mince affaire, car les athées ne constituent pas une école de pensée homogène. Le cheminement que je propose dans le texte est nécessairement très personnel. Par exemple dans sa dénonciation de l’immanence ou dans son appel non voilé à la rébellion (« La colère de l’Homme »). Cela dit, je n’ai pas hésité à réécrire le 2e mouvement de mon requiem (« Non credo ») lorsque ceux qui ont suivi sa composition l’ont accusé d’un trop grand dogmatisme. J’espère sincèrement que mon texte ne constitue pas un obstacle à l’appréciation de la musique, quels que soient les points de désaccord que puissent avoir mes auditeurs avec mes idées.
Comment définirais-tu ta musique ? On dit souvent que la musique contemporaine est difficile d’accès pour les oreilles non-initiées, est-ce le cas pour ton requiem ?
Pour les connaisseurs, il s’agit d’une écriture qui s’autorise tous les langages : tonal, modal, chromatique et atonal. Pour ceux qui ne sont pas habitués à écouter de la musique classique, disons que c’est une œuvre globalement facile à suivre, mais avec des passages assez ouvertement dissonants. La durée totale est raisonnable pour le néophyte (environ 45 minutes), tout en laissant le temps de s’imprégner d’un univers musical que je souhaite assez riche.
Pourquoi faire le choix de logiciels libres et placer ton œuvre en gestation dans le domaine public ?
Faire-part de liberté sur le site du projet
La principale raison du choix de la licence CC-0 est philanthropique : c’est un cadeau que je souhaite faire à l’humanité. Par ailleurs, je suis intimement convaincu que le modèle actuel des droits d’auteur freine la création au lieu de la protéger. Il y a une excellente conférence de Pouhiou sur ce thème.
D’ailleurs, c’est un peu grâce à Pouhiou que je me suis décidé à créer un blog pour présenter ma composition en cours de réalisation. Dans son premier tome du cycle des Noénautes, il expose les interactions qu’il a pu avoir avec ses lecteurs sur son blog tout au long de l’écriture du roman et je me suis dit : et pourquoi pas utiliser ce dispositif pour mon requiem aussi ? Pour ceux que ça intéresse, j’ai exposé ma position dans cet article : vive la musique libre, à bas les droits d’auteur !
Pour ce qui est du choix des logiciels libres pour composer, il s’est imposé de lui-même : j’ai toujours milité pour la diffusion des logiciels libres (y compris dans l’Éducation Nationale à l’époque où j’y ai travaillé) et ça n’aurait pas été cohérent d’utiliser des logiciels privateurs pour réaliser une telle œuvre, non ? J’utilise essentiellement Musescore. même si les fonctionnalités sont un peu limitées par rapport aux gros logiciels payants du commerce. J’envisage d’utiliser Lilypond pour les dernières étapes de la composition (orchestration, cadences non mesurées, mise en page, etc.).
Tu as une formation musicale (on s’en doutait) et tu as donc été un temps professeur dans l’Éducation Nationale, mais en ce moment de quoi vis-tu, car on imagine bien que créer un requiem n’est pas une activité très lucrative ?
J’ai été successivement ingénieur du son, professeur de physique-chimie en collège et grand voyageur. Je suis actuellement ouvrier agricole (dans le maraîchage bio). Je compose sur mes temps libres, soir et week-end. Au début du projet, je m’étais mis à temps partiel pour trouver le temps de composer. Clairement, j’aimerais consacrer plus de temps à la composition dans les années qui viennent. Pour une raison simple : si je ne prends pas le temps de composer mes œuvres, qui le fera à ma place ?
De quoi as-tu besoin maintenant pour mener ton projet vers sa phase finale : de contributions techniques, musicales, d’interprètes, d’argent… ? C’est le moment de lancer un appel…
L’étape la plus importante est terminée : toute l’œuvre est ébauchée. On peut d’ailleurs écouter des exports (avec des sons synthétiques) sur le site du projet. Il reste deux étapes avant de pouvoir entendre l’œuvre pour de bon.
D’abord, il faut que j’écrive l’orchestration de l’œuvre. Je n’ai encore jamais eu à faire ça et c’est assez technique. J’apprécierai une aide pour cette étape : j’ai besoin de quelqu’un d’un peu expérimenté pour me relire, me corriger, me faire des suggestions, etc. Je pense m’adresser aux classes d’orchestration des conservatoires pour trouver ce genre de profils.
Ensuite, il faudra réunir des interprètes. Et là, les choses se compliquent… Car il faudra trouver de l’argent pour rémunérer tout ce monde (un orchestre, un chœur et 4 solistes). J’ai plus de questions que de réponses : mon œuvre pourrait-elle intéresser une institution ? Aurais-je un public suffisamment motivé pour réussir un crowdfunding ? J’avoue que ça me soulagerait grandement si quelqu’un de plus compétent que moi pouvait prendre en charge cette partie-là du travail !
Allez on s’écoute le « Non credo » ? Les autres mouvements sont disponibles sur le site de Denis.
Que nos lecteurs mélomanes et musiciens se manifestent et fassent passer le mot : ce projet original et libre mérite d’aboutir à des interprétations publiques et pourquoi pas des enregistrements. À vous de jouer ♫ !
Opération « Dégooglisons » à Nevers les 24/25/26 juin
Mi-avril, les services de la ville de Nevers, dans le cadre de leur Année du Numérique, ont pris contact avec nous pour nous proposer d’animer, avec Nevers Libre (le tout récent GULL local) un événement d’envergure autour de la thématique de la décentralisation d’internet.
On y parlera donc essentiellement de la concentration des pouvoirs des GAFAM (Google, Apple, Facebook, Amazon, Microsoft), mais aussi auto-hébergement, biens communs, et bien évidemment logiciels libres !
La journée débutera par une introduction au logiciel libre (April), et se poursuivra par la présentation des enjeux de la décentralisation (Framasoft), la démonstration d’outils (Cozy Cloud, notamment), et le cas d’un secteur « non-informatique » impacté (celui de la presse, avec nos amis de NextINpact).
Le dimanche verra sa matinée consacrée à une « carte blanche à Louis Pouzin » inventeur du datagramme, précurseur d’internet et natif de la Nièvre. Il participera notamment à une table ronde sur l’enjeu de la question d’un internet neutre et décentralisé, au côté le La Quadrature, de la Fédération FDN, et bien d’autres. Enfin, le week-end s’achèvera par une dernière table ronde qui visera à prendre un peu de recul en abordant la question des « communs numériques » à l’heure de GAFAM.
Le « off »
Le samedi soir, un BarCamp sera organisé. Pour rappel, un BarCamp est une « non-conférence », donc les sujets ne sont évidemment pas définis, car c’est vous qui décidez 😉
Par ailleurs, en parallèle des conférences, des ateliers s’enchaîneront le samedi et le dimanche, autour du thème de ces journées : contributions à OpenStreetMap ou Wikipédia, utilisation de Cozy Cloud, démonstration d’outils Framasoft, ateliers d’auto-hébergement, etc.
Ces temps sont volontairement ouverts à tou-te-s afin d’avoir un programme « souple » permettant à chacun de participer et de partager ses questions et ses connaissances.
Venez !
Pour nous retrouver, rien de tel qu’une Framacarte 😉
Lieu : Lycée Raoul Follereau, 9 Bd St-Exupéry, Nevers
14H Intervention « Internet et vie privée : je t’aime, moi non plus ? » (Framasoft)
SOIRÉE
Lieu CinéMAZARIN, 120 rue de Charleville, Nevers
20H à 20H30: Conférence de presse : Annonce manifeste et charte CHATONS, par Framasoft.
20H30 : projection-débat du documentaire « Les Nouveaux Loups du Web », de Cullen Hoback (1h15)
Avez vous déjà lu les conditions générales d’utilisation des données privées présentes sur chaque site internet que vous visitez, ou sur les applications que vous utilisez ? Bien sûr que non. Et pourtant, ces mentions autorisent les entreprises à utiliser vos informations personnelles dans un cadre au delà de votre imagination. Le film vous révèle ce que les entreprises et les gouvernements vous soustraient en toute légalité, à partir du moment où vous avez cliqué sur « J’accepte », et les conséquences scandaleuses qui en découlent. La projection du film sera suivie d’un débat animé par l’association Framasoft.
Samedi 25/06
Lieu : l’Inkub, site Pittié, 5 rue du 13eme de ligne, Nevers
Tout au long de la journée, retrouvez sur le « village associatif » différentes associations qui pourront vous présenter différents aspects du logiciel et de la culture libres. Différents ateliers animés par ces mêmes structures pourront vous permettre de pratiquer (« Comment contribuer à Wikipédia ou OpenStreetMap ? », « Utilisation de CozyCloud », « Créer un fournisseur d’accès à internet libre de proximité », « Mieux contrôler sa vie privée avec Firefox », etc.)
MATIN
10/12H : Conférence « Qu’est ce que le Logiciel libre ? »
Cette conférence vise à présenter au grand public ce qu’est le logiciel libre, son histoire, ainsi que les enjeux de ce mouvement qui est loin de n’être que technique.
Intervenantes : Magali Garnero, Odile Benassy, Association April
APRÈS MIDI
14H/15H30 : conférence « Nos vies privées sont-elles solubles dans les silos de données de Google ? »
L’emprise de Google, Apple, Facebook, Amazon ou Microsoft ne cesse de croître. Non seulement sur internet, mais aussi dans bien d’autres domaines (robotique, automobile, santé, presse, média, etc). L’association Framasoft s’est fixé l’ambitieuse mission de montrer qu’il était possible – grâce au logiciel libre – de résister à la colonisation d’internet et à marchandisation de notre vie privée.
Intervenants : Pierre-Yves Gosset, Pouhiou, Association Framasoft
16H00/17H30 : conférence « Google, un big brother aux pieds d’argile ! »
Cozy permet à n’importe qui d’avoir son serveur web et de l’administrer à travers une interface très simple. Il offre la possibilité d’installer des applications web et de stocker ses données personnelles sur un matériel que l’on maîtrise. Contacts, calendriers, fichiers… Tout est au même endroit !
Intervenant : Benjamin André, CEO et co-fondateur de Cozy Cloud
18H00/19H30 : Paroles croisées « La presse à l’heure des GAFAM »
Tous les secteurs sont impactés par l’omniprésence et la puissance des géants du numérique (Google, Apple, Facebook, Amazon, Microsoft, etc.). La presse n’est pas épargnée. Comment s’adapter aux changements de pratiques des lecteurs ? Comment résister à la pression des plateformes ? Quels sont les modèles économiques existants ou à inventer ? Quels sont les impacts sur le métier de journaliste ? En croisant les expériences d’un journal historiquement « papier » à dimension régional et celui d’un site d’informations spécialisé né sur internet, nous essaieront de mettre en valeur les enjeux d’une presse à traversée par le numérique.
Intervenants : David Legrand, directeur des rédactions de NextInpact, Jean Philippe Berthin, rédacteur en chef du Journal du Centre
Animateur : Pierre-Yves Gosset, Framasoft
A partir de 20H : BARCAMP : « Venez découvrir et contribuer à des projets libres (OpenStreetMap, Wikipédia, Firefox, Cozy, etc.) »
Wikipédia définit le barcamp comme « une non-conférence ouverte qui prend la forme d’ateliers-événements participatifs où le contenu est fourni par les participants qui doivent tous, à un titre ou à un autre, apporter quelque chose au Barcamp. C’est le principe pas de spectateur, tous participants. »
Dimanche 26
Lieu : l’Inkub, site Pittié, 5 rue du 13eme de ligne, Nevers
MATIN
10h à 10h45 : Carte blanche à Louis Pouzin
11H/13h00 : Table ronde citoyenne : « Un internet neutre et relocalisé : quels enjeux pour les territoires ? »
« Le « cloud », c’est l’ordinateur de quelqu’un d’autre. ». Au travers des regards et expériences de différents acteurs tentant – chacun à leur façon – de promouvoir un internet et des services de proximité au service des citoyen, la table ronde vise à explorer les pistes de résistance à une appropriation d’internet par quelques entreprises.
Intervenants : Fédération FDN, Association April, La Quadrature du Net, Stéphane Bernier(DSI Ville de Nevers),Quentin Bouteiller(NeversLibre),Louis Pouzin
Animateur : Benjamin Jean (Inno3)
APRES MIDI
14H/16H : table ronde « Les communs numériques »
Pour conclure ces journées, cette table ronde vise à « prendre de la hauteur » en posant la question essentielle de la présence des « communs » à l’heure du numérique, mais aussi des pressions sociétales, lobbyistes, économiques auquel ces ressources doivent faire face.
Nous remercions chaleureusement tous les partenaires de cet événement (Ville/agglo de Nevers, Nevers Libre, PIQO, etc.) ainsi que toutes les structures ayant répondu présentes, et nous espérons vous voir nombreuses et nombreux pour partager ce moment avec nous !
 L’Espresso a obtenu les tarifs de l’entreprise (de 1,50 euro à 85 centimes) et a contacté certains clients. Entre les réponses embarrassées et les reconnaissances du bout des lèvres, nous avons étudié l’activité de l’« Amazon des pétitions en ligne ». Elle manipule des données extrêmement sensibles telles que les opinions politiques et fait l’objet en Allemagne d’une enquête sur le respect de la vie privée.
L’Espresso a obtenu les tarifs de l’entreprise (de 1,50 euro à 85 centimes) et a contacté certains clients. Entre les réponses embarrassées et les reconnaissances du bout des lèvres, nous avons étudié l’activité de l’« Amazon des pétitions en ligne ». Elle manipule des données extrêmement sensibles telles que les opinions politiques et fait l’objet en Allemagne d’une enquête sur le respect de la vie privée.