On nous demande souvent comment contribuer au Libre sans être un cador en informatique. Voici un projet utile, d’une grande importance et auquel il est très simple de contribuer : il suffit de savoir lire, parler et écouter. On vous explique tout.
On voit émerger à grande allure des objets avec lesquels l’interaction repose sur la reconnaissance vocale : smartphones, assistants connecté, dispositifs de réalité virtuelle…Selon les experts de ce marché, 50 % des recherches toutes plateformes confondues passeront par la voix d’ici 2 à 3 ans. Quant aux objets dits « intelligents », ils atteignent pour les pays favorisés un niveau de prix qui les rend accessibles à un nombre croissant de consommateurs. On peut trouver dès aujourd’hui dans la grande distribution des « enceintes connectées » à l’écoute de vos questions pour moins de 100 euros… Autant dire que ces produits sont en passe d’être des objets de consommation de masse.
Les services vocaux, au-delà des fonctions d’espionnage qui suscitent la méfiance, apporteront des avantages sensibles aux usages numériques du grand public. Ils abaisseront la barrière d’accès à des fonctionnalités utiles pour les personnes handicapées, en difficulté avec la lecture, dont les mains sont occupées ou pour celles qui ont besoin d’assistance immédiate. Dans bien des cas de figure il est ou sera plus efficace ou rapide d’utiliser la voix plutôt qu’une interface tactile ou souris/clavier1
Le problème hélas a un air de déjà-vu : aujourd’hui les systèmes de reconnaissance vocale sont essentiellement propriétaires et reposent sur 4 ou 5 bases de données vocales propriétaires : Cortana (Microsoft), Siri (Apple), Google Now (Google), Vocapia Research (VoxSigma suite)… En d’autres termes, tout est prêt pour assurer à quelques géants du numérique, toujours les mêmes, une suprématie commerciale et technologique. Et l’histoire récente prouve qu’ils n’hésiteront pas longtemps avant de capter les données les plus précieuses, celles de notre vie dans la bulle privée de notre habitation.
Il se trouve qu’un projet qui repose sur des ressources libres (données et code informatique) a été lancé par l’un des acteurs majeurs du monde du Libre : la fondation Mozilla.
Pourquoi Mozilla s’en mêle ?
Parmi les principes qui guident Mozilla et qu’on retrouve dans son manifeste, la santé d’un Web ouvert et l’inclusivité sont des valeurs essentielles. Cette ressource numérique dont l’usage est appelé à se développer rapidement doit être à la disposition du plus grand nombre, à commencer par les entreprises innovantes (déjà sur la brèche par exemple Mycroft et Snips) qui n’ont pas les moyens financiers d’accéder aux bases propriétaires et qui seraient tout simplement marginalisées par les grandes entreprises. Au-delà, bien sûr, c’est pour que des produits reposant sur la reconnaissance vocale soient accessibles à tous, quelle que soit leur langue, leur genre, leur accent local etc.
De quoi s’agit-il ?
De constituer la plus riche base possible d’échantillons sonores qui seront mis à la disposition des développeurs sous une licence libre (licence CC0). Le projet global s’appelle Deep Speech et Mozilla fait travailler des ingénieurs à traiter les données collectées avec des algorithmes, et ainsi alimenter un dispositif d’apprentissage machine.
Comment ça peut marcher ?
Ici nous tentons une description simple donc forcément approximative…
On donne à la machine des fichiers audio en entrée
On calcule la sortie, c’est-à-dire le texte
On compare au texte d’origine et… ben non c’est pas tout à fait ça.
On ajuste un petit peu des millions de paramètres internes pour essayer de se rapprocher de la sortie voulue
On répète sur des milliers d’heures…
Alexandre Lissy, ingénieur Mozilla qui travaille au bureau de Paris pour le projet Deep Speech. Les autres membres de l’équipe sont à Berlin, au Brésil et à San Francisco… (Photo de Samuel Nohra publiée dans Ouest France)
Pourquoi est-ce difficile à réaliser ?
L’entraînement des machines et la transcription nécessitent une grosse puissance de calcul.
Un nombre très important d’heures d’enregistrements valides est nécessaire pour que la reconnaissance vocale soit la plus efficace possible. C’est une somme d’environ 10 000 heures qui est considérée comme souhaitable pour obtenir un résultat.
Il existe peu de gros jeux de données publiquement accessibles en CC0 pour construire des modèles de reconnaissance 100% libres.
Les principes de Common Voice
Tout d’abord le projet est mondial et vise à fonctionner pour le plus grand nombre de langues possible. Le projet est assez récent et pour l’instant, 16 langues seulement sont actives dont bien sûr le Français. On remarque que le projet a de l’importance pour les langues qui peuvent se sentir menacées : le Catalan, le Breton et le Kabyle par exemple sont déjà lancés !
Mais euh… On n’en est que là nous autres les francophones ? Vous avez compris : il est temps de nous y mettre tous ! (copie d’écran de la page des langues)
C’est aussi un projet inclusif pour lequel les intonations diverses sont bienvenues, avec une insistance particulière des ingénieurs responsables du projet pour qu’il y ait une grande diversité de voix : locuteurs et locutrices, de tous âges, avec tous les accents régionaux (oui les accents du sud, du nord etc. sont tout à fait bienvenus, une trentaine d’accents sont retenus), car les machines devront traiter la voix pour le plus grand nombre et pas exclusivement pour une prononciation standard appliquée. il est important de prononcer distinctement, mais le projet n’a pas besoin de textes déclamés professionnellement par des acteurs.
C’est surtout un projet communautaire et collaboratif. Il s’est construit dès le départ avec la communauté Mozilla et ses contributeurs et contributrices. Il fait maintenant appel à la communauté plus large de… tous les francophones. Car comme vous allez le voir, tout le monde 2 peut y participer !
et enregistrer tour à tour une série de 5 brèves phrases
Pas d’inquiétude : on peut choisir « passer » avec un bouton dédié si on rencontre une difficulté de compréhension, prononciation ou autre. Et bien entendu si en se réécoutant on constate que ça peut être mieux, un simple clic permet de recommencer.
2. ÉCOUTER
pour valider ou non une série de 5 phrases
Vous vous demandez peut-être d’où viennent tous ces textes parfois bizarres qu’on doit lire à haute voix ou écouter. Eh bien ce sont des textes dont la licence permet l’utilisation, qui viennent de transcriptions de débats de l’assemblée Nationale, de quelques livres du projet Gutenberg, de quelques pièces de théâtre, d’adresses françaises… Ah tiens, mais s’il faut enrichir la base, les romans de Pouhiou et celui de Frédéric Urbain publiés chez Framabook sont en CC0 ! Ça pourrait donner des phrases de test assez rigolotes.
Quand t’as eu des hémorroïdes, tu peux plus croire à la réincarnation.
Vingt-cinq ans, j’ai été bignole. Vous pensez si je retapisse un poulet.
Le coin des pas contents
Ah et puis ça ne va pas rater, les chevaliers blancs du Libre ne vont pas manquer d’agiter leur drapeau immaculé, donc on vous le dit d’avance : oui malheureusement la page de Common Voice contient du Google Analytics. Et oui encore, amis sourcilleux sur les licences libres, la CC0 va permettre la réutilisation commerciale des voix enregistrées bénévolement. C’est dommage ou pas de placer un travail collectif sous une licence très permissive ?
Cliquez sur l’image pour parcourir la page d’informations sur la CC0
À vous de jouer !
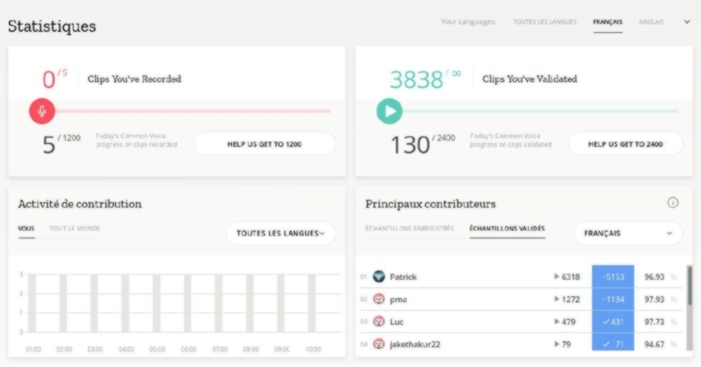
Chaque contribution est précieuse, surtout si elle est réitérée un grand nombre de fois 😉 Pour s’encourager, on peut suivre la progression des objectifs quotidiens, et certain⋅e⋅s ne manquent pas de se prendre au jeu…
Vous l’avez compris, ce projet réclame une participation massive pour avancer, alors si chacun y contribue ne serait-ce que modestement, nous pourrons dire que la voix est libre !
Il s’agit cette fois de comprendre comment Google complète les données collectées avec les données provenant des applications et des comptes connectés des utilisateurs.
VI. Données collectées par les applications clés de Google destinées aux particuliers
67. Google a des dizaines de produits et services qui évoluent en permanence (une liste est disponible dans le tableau 4, section IX.B de l’annexe). On accède souvent à ces produits grâce à un compte Google (ou on l’y associe), ce qui permet à Google de relier directement les détails des activités de l’utilisateur de ses produits et services à un profil utilisateur. En plus des données d’usage de ses produits, Google collecte également des identificateurs et des données de localisation liés aux appareils lorsqu’on accède aux services Google. 3
68. Certaines applications de Google (p.ex. YouTube, Search, Gmail et Maps) occupent une place centrale dans les tâches de base qu’une multitude d’utilisateurs effectuent quotidiennement sur leurs appareils fixes ou mobiles. Le tableau 2 décrit la portée de ces produits clés. Cette section explique comment chacune de ces applications majeures collecte les informations des utilisateurs.
Tableau 2 : Portée mondiale des principales applications Google
Produits
Utilisateurs actifs
Search
Plus d’un milliard d’utilisateurs actifs par mois, 90.6 % de part de marché des moteurs de recherche 4
Youtube
Plus de 1,8 milliard d’utilisateurs inscrits et actifs par mois 5
Maps
Plus d’un milliard d’utilisateurs actifs par mois 6
69. Google Search est le moteur de recherche sur internet le plus populaire au monde 8, avec plus de 11 milliards de requêtes par mois aux États-Unis 9. En plus de renvoyer un classement de pages web en réponse aux requêtes globales des utilisateurs, Google exploite d’autres outils basés sur la recherche, tels que Google Finance, Flights (vols), News (actualités), Scholar (recherche universitaire), Patents (brevets), Books (livres), Images, Videos et Hotels. Google utilise ses applications de recherche afin de collecter des données liées aux recherches, à l’historique de navigation ainsi qu’aux activités d’achats et de clics sur publicités. Par exemple, Google Finance collecte des informations sur le type d’actions que les utilisateurs peuvent suivre, tandis que Google Flight piste leurs réservations et recherches de voyage.
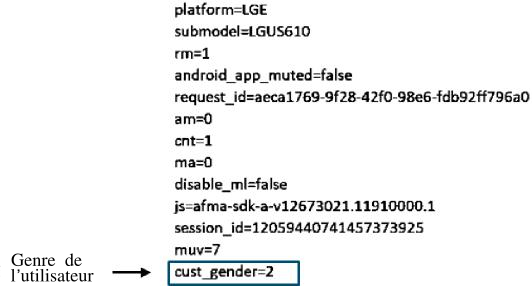
70. Dès lors que Search est utilisé, Google collecte les données de localisation par différents biais, sur ordinateur ou sur mobile, comme décrit dans les sections précédentes. Google enregistre toute l’activité de recherche d’un utilisateur ou utilisatrice et la relie à son compte Google si cette personne est connectée. L’illustration 13 montre un exemple d’informations collectées par Google sur une recherche utilisateur par mot-clé et la navigation associée.
Illustration 13 : Un exemple de collecte de données de recherche extrait de la page My Activity (Mon Activité) d’un utilisateur
71. Non seulement c’est le moteur de recherche par défaut sur Chrome et les appareils Google, mais Google Search est aussi l’option par défaut sur d’autres navigateurs internet et applications grâce à des arrangements de distribution. Ainsi, Google est récemment devenu le moteur de recherche par défaut sur le navigateur internet Mozilla Firefox 10 dans des régions clés (dont les USA et le Canada), une position occupée auparavant par Yahoo. De même, Apple est passé de Microsoft Bing à Google pour les résultats de recherche via Siri sur les appareils iOS et Mac 11. Google a des accords similaires en place avec des OEM (fabricants d’équipement informatique ou électronique) 12, ce qui lui permet d’atteindre les consommateurs mobiles.
B. YouTube
72. YouTube met à disposition des utilisateurs et utilisatrices une plateforme pour la mise en ligne et la visualisation de contenu vidéo. Il attire plus de 180 millions de personnes rien qu’aux États-Unis et a la particularité d’être le deuxième site le plus visité des États-Unis 13, juste derrière Google Search. Au sein des entreprises de streaming multimédia, YouTube possède près de 80 % de parts de marché en termes de visites mensuelles (comme décrit dans l’illustration 14). La quantité de contenu mis en ligne et visualisé sur YouTube est conséquente : 400 heures de vidéo sont mises en ligne chaque minute 14 et 1 milliard d’heures de vidéo sont visualisées quotidiennement sur la plateforme YouTube.15
Illustration 14 : Comparaison d’audiences mensuelles des principaux sites multimédia aux États-Unis 16
73. Les utilisateurs peuvent accéder à YouTube sur l’ordinateur (navigateur internet), sur leurs appareils mobiles (application et/ou navigateur internet) et sur Google Home (via un abonnement payant appelé YouTube Red). Google collecte et sauvegarde l’historique de recherche, l’historique de visualisation, les listes de lecture, les abonnements et les commentaires aux vidéos. La date et l’horaire de chaque activité sont ajoutés à ces informations.
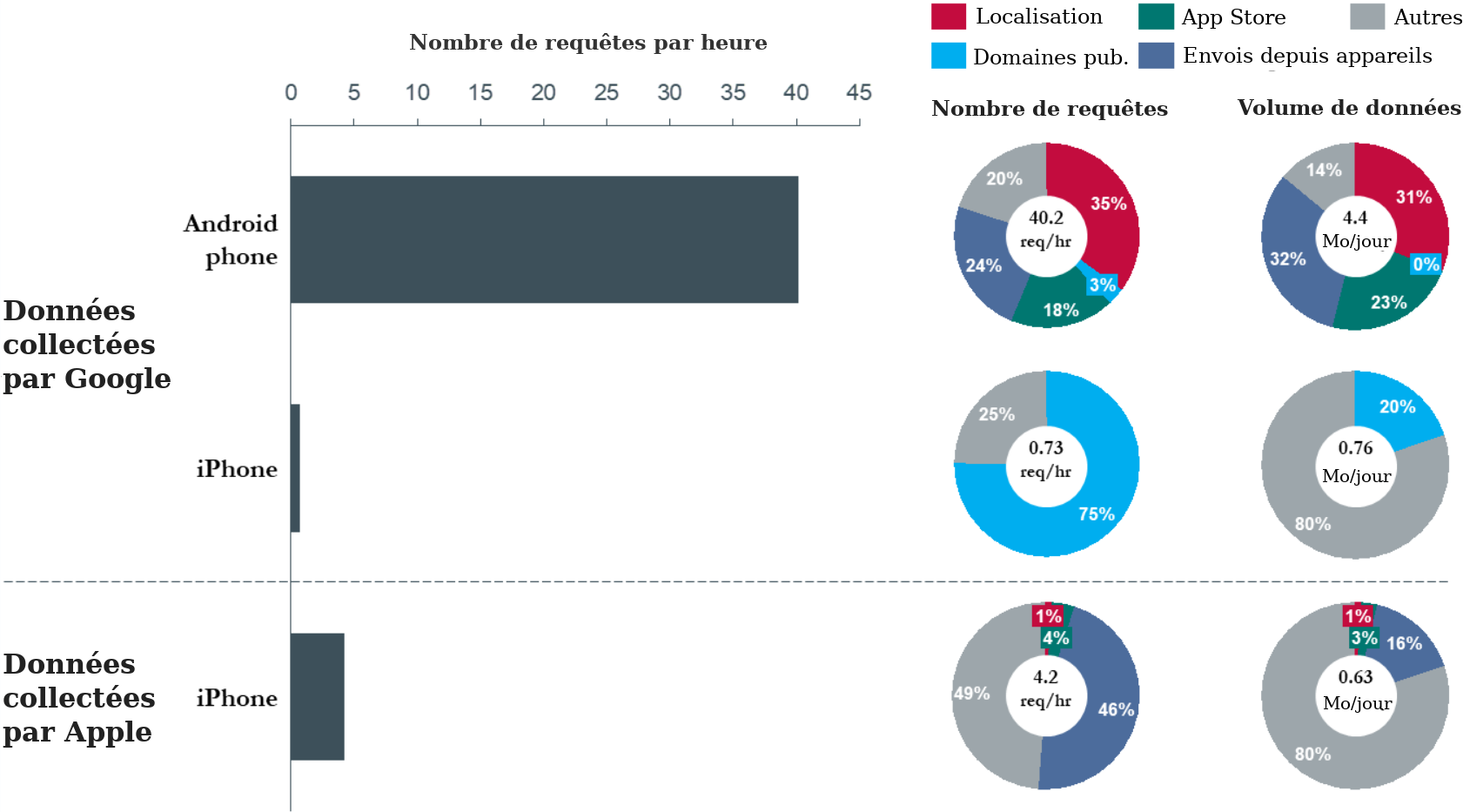
74. Si un utilisateur se connecte à son compte Google pour accéder à n’importe quelle application Google via un navigateur internet (par ex. Chrome, Firefox, Safari), Google reconnaît l’identité de l’utilisateur, même si l’accès à la vidéo est réalisé par un site hors Google (ex. : vidéos YouTube lues sur cnn.com). Cette fonctionnalité permet à Google de pister l’utilisation YouTube d’un utilisateur à travers différentes plateformes tierces. L’illustration 15 montre un exemple de données YouTube collectées.
Illustration 15 : Exemple de collecte de données YouTube dans My Activity (Mon Activité)
75. Google propose également un produit YouTube différencié pour les enfants, appelé YouTube Kids, dans l’intention d’offrir une version « familiale » de YouTube avec des fonctionnalités de contrôle parental et de filtres vidéos. Google collecte des informations de YouTube Kids, notamment le type d’appareil, le système d’exploitation, l’identifiant unique de l’appareil, les informations de journalisation et les détails d’utilisation du service. Google utilise ensuite ces informations pour fournir des annonces publicitaires limitées, qui ne sont pas cliquables et dont le format, la durée et le site sont limités.17.
C. Maps
76. Maps est l’application phare de navigation routière de Google. Google Maps peut déterminer les trajets et la vitesse d’un utilisateur et ses lieux de fréquentation régulière (ex. : domicile, travail, restaurants et magasins). Cette information donne à Google une idée des intérêts (ex. : préférences d’alimentation et d’achats), des déplacements et du comportement de l’utilisateur.
77. Maps utilise l’adresse IP, le GPS, le signal cellulaire et les points d’accès au Wi-Fi pour calculer la localisation d’un appareil. Les deux dernières informations sont collectées par le biais de l’appareil où Maps est utilisé, puis envoyées à Google pour évaluer la localisation via son interface de localisation (Location API). Cette interface fournit de nombreux détails sur un utilisateur, dont les coordonnées géographiques, son état stationnaire ou en mouvement, sa vitesse et la détermination probabiliste de son mode de transport (ex. : en vélo, voiture, train, etc.).
78. Maps sauvegarde un historique des lieux qu’un utilisateur connecté à Maps par son compte Googe a visités. L’illustration 16. montre un exemple d’un tel historique 18. Les points rouges indiquent les coordonnées géographiques recueillies par Maps lorsque l’utilisateur se déplace ; les lignes bleues représentent les projections de Maps sur le trajet réel de l’utilisateur.
Illustration 16 : Exemple d’un historique Google Maps (« Timeline ») d’un utilisateur réel
79. La précision des informations de localisation recueillies par les applications de navigation routière permet à Google de non seulement cibler des audiences publicitaires, mais l’aide aussi à fournir des annonces publicitaires aux utilisateurs lorsqu’ils s’approchent d’un magasin 19. Google Maps utilise de plus ces informations pour générer des données de trafic routier en temps réel.20
D. Gmail
80. Gmail sauvegarde tous les messages (envoyés et reçus), le nom de l’expéditeur, son adresse email et la date et l’heure des messages envoyés ou reçus. Puisque Gmail représente pour beaucoup un répertoire central pour la messagerie électronique, il peut déterminer leurs intérêts en scannant le contenu de leurs courriels, identifier les adresses de commerçants grâce à leurs courriels publicitaires ou les factures envoyées par message électronique, et connaître l’agenda d’un utilisateur (ex. : réservations à dîner, rendez-vous médicaux…). Étant donné que les utilisateurs utilisent leur identifiant Gmail pour des plateformes tierces (Facebook, LinkedIn…), Google peut analyser tout contenu qui leur parvient sous forme de courriel (ex. : notifications, messages).
81. Depuis son lancement en 2004 jusqu’à la fin de l’année 2017 (au moins), Google peut avoir analysé le contenu des courriels Gmail pour améliorer le ciblage publicitaire et les résultats de recherche ainsi que ses filtres de pourriel. Lors de l’été 2016, Google a franchi une nouvelle étape et a modifié sa politique de confidentialité pour s’autoriser à fusionner les données de navigation, autrefois anonymes, de sa filiale DoubleClick (qui fournit des publicités personnalisées sur internet) avec les données d’identification personnelles qu’il amasse à travers ses autres produits, dont Gmail 21. Le résultat : « les annonces publicitaires DoubleClick qui pistent les gens sur Internet peuvent maintenant leur être adaptées sur mesure, en se fondant sur les mots-clés qu’ils ont utilisés dans leur messagerie Gmail. Cela signifie également que Google peut à présent reconstruire le portrait complet d’une utilisatrice ou utilisateur par son nom, en fonction de tout ce qui est écrit dans ses courriels, sur tous les sites visités et sur toutes les recherches menées. » 22
82. Vers la fin de l’année 2017, Google a annoncé qu’il arrêterait la personnalisation des publicités basées sur les messages Gmail 23. Cependant, Google a annoncé récemment qu’il continue à analyser les messages Gmail pour certaines raisons 24.
Les données que récolte Google – Ch.5
Voici déjà la traduction du cinquième chapitre de Google Data Collection, l’étude élaborée par l’équipe du professeur Douglas C. Schmidt, spécialiste des systèmes logiciels, chercheur et enseignant à l’Université Vanderbilt. Si vous les avez manqués, retrouvez les chapitres précédents déjà publiés. Il s’agit cette fois d’explorer la quantité de données que Google collecte lorsque l’on a désactivé tout ce qui pouvait l’être…
V. Quantité de données collectées lors d’une utilisation minimale des produits Google
58. Cette section montre les détails de la collecte de données par Google à travers ses services de publication et d’annonces. Afin de comprendre une telle collecte de données, une expérience est réalisée impliquant un utilisateur qui se sert de son téléphone dans sa vie de tous les jours mais qui évite délibérément d’utiliser les produits Google (Search, Gmail, YouTube, Maps, etc.), exception faite du navigateur Chrome.
59. Pour que l’expérience soit aussi réaliste que possible, plusieurs études sur les usages de consommateurs25, 26 ont été utilisées pour créer le profil d’usage journalier d’un utilisateur lambda. Ensuite, toutes les interactions directes avec les services Google ont été retirées du profil. La section IX.F dans les annexes liste les sites internet et applications utilisés pendant l’expérience.
60. L’expérience a été reproduite sur des appareils Android et iOS et les données HTTPS envoyées aux serveurs Google et Apple ont été tracées et analysées en utilisant une méthode similaire à celle expliquée dans la section précédente. Les résultats sont résumés dans la figure 12. Pendant la période de 24 h (qui inclut la période de repos nocturne), la majorité des appels depuis le téléphone Android ont été effectués vers les services Google de localisation et de publication de publicités (DoubleClick, Analytics). Google a enregistré la géolocalisation de l’utilisateur environ 450 fois, ce qui représente 1,4 fois le volume de l’expérience décrite dans la section III.C, qui se basait sur un téléphone immobile.
Figure 12 : Requêtes du téléphone portable durant une journée typique d’utilisation
61. Les serveurs de Google communiquent significativement moins souvent avec un appareil iPhone qu’avec Android (45 % moins). En revanche, le nombre d’appels aux régies publicitaires de Google reste les mêmes pour les deux appareils — un résultat prévisible puisque l’utilisation de pages web et d’applications tierces était la même sur chacun des périphériques. À noter, une différence importante est que l’envoi de données de géolocalisation à Google depuis un appareil iOS est pratiquement inexistant. En absence des plateformes Android et Chrome — ou de l’usage d’un des autres produits de Google — Google perd significativement sa capacité à pister la position des utilisateurs.
62. Le nombre total d’appels aux serveurs Apple depuis un appareil iOS était bien moindre, seulement 19 % des appels aux serveurs de Google depuis l’appareil Android. De plus, il n’y a pas d’appels aux serveurs d’Apple liés à la publicité, ce qui pourrait provenir du fait que le modèle économique d’Apple ne dépend pas autant de la publicité que celui de Google. Même si Apple obtient bien certaines données de localisation des utilisateurs d’appareil iOS, le volume de données collectées est bien moindre (16 fois moins) que celui collecté par Google depuis Android.
63. Au total, les téléphones Android ont communiqué 11.6 Mo de données par jour (environ 350 Mo par mois) avec les serveurs de Google. En comparaison, l’iPhone n’a envoyé que la moitié de ce volume. La quantité de données spécifiques aux régies publicitaires de Google est restée pratiquement identique sur les deux appareils.
64. L’appareil iPhone a communiqué bien moins de données aux serveurs Apple que l’appareil Android n’a échangé avec les serveurs Google.
65. De manière générale, même en l’absence d’interaction utilisateur avec les applications Google les plus populaires, un utilisateur de téléphone Android muni du navigateur Chrome a tout de même tendance à envoyer une quantité non négligeable de données à Google, dont la majorité est liée à la localisation et aux appels aux serveurs de publicité. Bien que, dans le cadre limité de cette expérience, un utilisateur d’iPhone soit protégé de la collecte des données de localisation par Google, Google recueille tout de même une quantité comparable de données liées à la publicité.
66. La section suivante décrit les données collectées par les applications les plus populaires de Google, telles que Gmail, Youtube, Maps et la recherche.
MobiliZon : reprendre le pouvoir sur ce qui nous rassemble
Nous voulons façonner les outils que les géants du Web ne peuvent ni ne veulent créer. Pour y parvenir, nous avons besoin de votre soutien.
Penser hors des sentiers battus par les actionnaires
Pauvre MeetUp ! Pauvre Facebook avec ses événements et ses groupes ! Vous imaginez combien c’est dur, d’être une des plus grandes capitalisations boursières au monde ? Non mais c’est que les actionnaires ils sont jamais contents, alors il faut les arracher avec les dents, ces dividendes !
Nos pauvres petits géants du Web sont o-bli-gés de coder des outils qui ne vous donnent que très peu de contrôle sur vos communautés (familiales, professionnelles, militantes, etc.). Parce qu’au fond, les centres d’intérêt que vous partagez avec d’autres, c’est leur fonds de commerce ! Nos pauvres vendeurs de temps de cerveau disponible sont trop-for-cés de vous enfermer dans leurs plateformes où tout ce que vous ferez sera retenu envers et contre vous. Parce qu’un profil publicitaire complet, ça se vend plus cher, et ça, ça compte, dans leurs actions…
Cliquez sur l’image pour aller voir la conférence « Comment internet a facilité l’organisation des révolutions sociales mais en a compromis la victoire » de Zeynep Tufekci sur TED Talk
Et nous, internautes prétentieuses, on voudrait qu’ils nous fassent en plus un outil complet, éthique et pratique pour nous rassembler…? Mais on leur en demande trop, à ces milliardaires du marketing digital !
Comme on est choubidou chez Framasoft, on s’est dit qu’on allait leur enlever une épine du pied. Oui, il faut un outil pour organiser ces moments où on se regroupe, que ce soit pour le plaisir ou pour changer le monde. Alors on accepte le défi et on se relève les manches.
On ne changera pas le monde depuis Facebook
Lors du lancement de la feuille de route Contributopia, nous avions annoncé une alternative à Meetup, nom de code Framameet. Au départ, nous imaginions vraiment un outil qui puisse servir à se rassembler autour de l’anniversaire du petit dernier, de l’AG de son asso ou de la compète de son club d’Aïkido… Un outil singeant les groupes et événements Facebook, mais la version libre, qui respecte nos sphères d’intimité.
Puis, nous avons vu comment les « Marches pour le climat » se sont organisées sur Facebook, et comment cet outil a limité les personnes qui voulaient s’organiser pour participer à ces manifestations. Cliquera-t-on vraiment sur «ça m’intéresse» si on sait que nos collègues, nos ami·e·s d’enfance et notre famille éloignée peuvent voir et critiquer notre démarche ? Quelle capacité pour les orgas d’envoyer une info aux participant·e·s quand tout le monde est enfermé dans des murs Facebook où c’est l’Algorithme qui décide de ce que vous verrez, de ce que vous ne verrez pas ?
L’outil dont nous rêvons, les entreprises du capitalisme de surveillance sont incapables de le produire, car elles ne sauraient pas en tirer profit. C’est l’occasion de faire mieux qu’elles, en faisant autrement.
Nous avons été contacté·e·s par des personnes des manifestations #OnVautMieuxQueÇa et contre la loi travail, des Nuits Debout, des Marches pour le climat, et des Gilets Jaunes… Et nous travaillons régulièrement avec les Alternatiba, l’association Résistance à l’Agression Publicitaire, le mouvement Colibris ou les CEMÉA (entre autres) : la plupart de ces personnes peinent à trouver des outils permettant de structurer leurs actions de mobilisation, sans perdre le contrôle de leur communauté, du lien qui est créé.
Cliquez sur cette image pour lire « Après avoir liké, les Gilets Jaunes iront-ils voter ? » d’Olivier Ertzschied.
Or « qui peut le plus peut le moins » : si on conçoit un outil qui peut aider un mouvement citoyen à s’organiser, à s’émanciper… cet outil peut servir, en plus, pour gérer l’anniversaire surprise de Tonton Roger !
Ce que MeetUp nous refuse, MobiliZon l’intègrera
Concevoir le logiciel MobiliZon (car ce sera son nom), c’est reprendre le pouvoir qui a été capté par les plateformes centralisatrices des géants du Web. Prendre le pouvoir aux GAFAM pour le remettre entre les mains de… de nous, des gens, des humains, quoi. Nous allons nous inspirer de l’aventure PeerTube, et penser un logiciel réellement émancipateur :
Ce sera un logiciel Libre : la direction que Framasoft lui donne ne vous convient pas ? Vous aurez le pouvoir de l’emmener sur une autre voie.
Comme Mastodon ou PeerTube, ce sera une plateforme fédérée (via ActivityPub). Vous aurez le pouvoir de choisir qui héberge vos données sans vous isoler du reste de la fédération, du « fediverse ».
L’effet « double rainbow » de la fédération, c’est qu’avec MobiliZon vous donnerez à vos événements le pouvoir d’interagir avec les pouets de Mastodon, les vidéosPeerTube, les musiques de FunkWhale…
Vous voulez cloisonner vos rassemblements familiaux de vos activités associatives ou de vos mobilisations militantes ? Vous aurez le pouvoir de créer plusieurs identités depuis le même compte, comme autant de masques sociaux.
Vous voulez créer des événements réellement publics ? Vous donnerez le pouvoir de cliquer sur « je participe » sans avoir à se créer de compte.
Il faut lier votre événement à des outils externes, par exemple (au hasard) à un Framapad ? Vous aurez le pouvoir d’intégrer des outils externes à votre communauté MobiliZon.
La route est longue, mais MobiliZon-nous pour que la voie soit libre !
Nous avons travaillé en amont pour poser des bases au projet, que nous vous présentons aujourd’hui sur JoinMobilizon.org. Au delà des briques logicielles et techniques, nous avons envie de penser à l’expérience utilisateur de l’application que les gens auront en main au final. Et qui, en plus, se doit d’être accessible et compréhensible par des néophytes.
Nous souhaitons éprouver ainsi une nouvelle façon de faire, en contribuant avec des personnes dont c’est le métier (designeurs et designeuses, on parlera très vite de Marie-Cécile et de Geoffrey !) pour œuvrer ensemble au service de causes qui veulent du bien à la société.
Le développement se fera par étapes et itérations, comme cela avait été le cas pour PeerTube, de façon à livrer rapidement (fin 2019) une version fonctionnelle qui soit aussi proche que possible des aspirations de celles et ceux qui ont besoin d’un tel outil pour se mobiliser.
Voilà notre déclaration d’intention. La question est : allez-vous nous soutenir ?
Pour notre campagne de dons de cette année, nous avons fait le choix de ne pas utiliser des outils invasifs qui jouent à vous motiver (genre la barre de dons qu’on a envie de voir se remplir). On a voulu rester sobre, et du coup c’est pas super la fête : on risque d’avoir du mal à ajouter MobiliZon dans notre budget 2019…
Alors si MobiliZon vous fait rêver autant que nous, et si vous le pouvez, pensez à soutenir Framasoft.
Chaque année, nous nous rappelons à votre bon souvenir pour vous inciter à soutenir financièrement nos actions. Vous voyez au fil du temps de nouveaux services et des campagnes ambitieuses se mettre en place. Mais peut-être voudriez-vous savoir en chiffres ce que nous avons réalisé jusqu’à présent. Voilà de quoi vous satisfaire.
Par souci de transparence, nos bilans financiers sont publiés chaque année et nous offrons en temps réel l’accès à certaines statistiques d’usage de nos services. Mais cela ne couvre pas l’ensemble de nos actions et nous nous sommes dit que vous pourriez en vouloir plus que ce qui se trouve sur Framastats.
Libre à vous de picorer un chiffre ou l’autre, d’en faire des quizz ou de les reprendre pour votre argumentaire afin de démontrer l’efficacité du monde associatif. Nous espérons que vous y verrez l’illustration de notre engagement à promouvoir le libre sous toutes ses formes.
1 : Depuis son lancement voilà un an, chaque heure un nouveau site naît sur Framasite.
2,5 : Les 5 000 utilisatrices de Framadrive utilisent 2,5 To de données pour leurs 3 millions de fichiers.
5 : Toutes les 5 secondes en moyenne, un utilisateur se connecte sur les services Framasoft.
10 : Toutes les 10 minutes à peine, une nouvelle visioconférence est créée sur Framatalk, qui accueille environ 400 participant⋅es par jour.
Framatalk, la vision-conférence Libre, vue par Pëhà
11 : C’est le nombre de pizzas, additionné aux 47 plateaux-repas et 25 couscous qu’ont avalé les 25 personnes présentes pendant les 4 jours de l’AG Framasoft 2018.
33 : Framasoft vous propose 33 services en ligne alternatifs, respectueux de vos données et sans publicité.
35 : Grâce aux 300 abonné·e·s à la liste Framalang, ce ne sont pas moins de 35 traductions qui ont été effectuées et publiées sur le Framablog en un an.
252 : http://joinpeertube.org , c’est une fédération de 252 instances (déclarées) affichant 23 017 vidéos libérées de YouTube
750 : Chaque mois, notre support répond à environ 750 demandes, questions et problèmes. Avec un seul salarié !
Framalibre, l’annuaire à l’origine de Framasoft
871 : Framalibre, l’annuaire du libre vous présente 871 projets, logiciels ou créations artistiques sous licence libre à l’aide de courtes notices.
1 000 : Framaforms c’est environ 1000 formulaires créés quotidiennement et plus de 44 000 formulaires hébergés.
1 800 : Chaque jour, ce sont près de 1 800 images qui viennent s’ajouter aux 770 000 déjà présentes sur les serveurs de Framapic.
2 236 : Le Framablog c’est 2 236 articles et 28 919 commentaires depuis 2006, faisant le lien entre logiciel libre et société/culture libres.
3 000 : 4 000 utilisatrices réparties en 250 groupes ont créé plus de 3 000 présentations et conférences grâce à Framaslides alors qu’il n’est encore qu’en beta !
6 000 : Framemo héberge 6 000 tableaux qui ont aidé des utilisateurs à mettre leurs idées au clair, sans avoir à s’inscrire.
Framacarte, pour ne pas se perdre en chemin
6 000 : Sur Framacarte ajoutez votre propre fond de carte aux 6 000 qui existent déjà, en partenariat avec OpenStreetMap.
6 579 : Framapiaf, c’est 6 579 utilisateurs ayant « pouetté » 734 500 messages sur cette instance Mastodon, elle-même fédérée avec près de 4 000 autres instances (totalisant environ 1,5 million de comptes).
11 000 : Avec Framanews, ce sont 500 lecteurs (limite qu’on a nous même fixée pour restreindre la charge du serveur) qui accèdent régulièrement à leurs 11 000 flux RSS.
13 000 : Près de 4 000 utilisatrices accèdent à leur 13 000 notes depuis n’importe quel navigateur, avec un accès sécurisé, sur Framanotes.
15 000 : Avec Framabag 15 000 personnes ont pu sauvegarder et classer 1,5 million d’articles.
Framagit, pour partager librement votre code
25 000 : Notre forge logicielle, Framagit, héberge plus de 25 000 projets (et autant d’utilisateurs).
35 000 : Avec MyFrama, 35 000 utilisatrices partagent librement leurs liens Internet.
43 000 : Accédez à une des 43 000 adresses Web abrégées ou créez-en une grâce au raccourcisseur d’URL Framalink qui ne traque pas vos visiteurs.
52 000 : Découvrez Framasphère, membre du réseau social libre et fédéré Diaspora*, où 52 000 utilisatrices ont échangé environ 600 000 messages et autant de commentaires.
75 000 : Près de 75 000 joueurs ont pu faire une petite pause ludique sans s’exposer à de la publicité sur Framagames.
Framadrop, le partage aisé de gros fichier, en sécurité
100 000 : Sur Framadrop plus de 100 000 fichiers ont pu être échangés en toute confidentialité.
130 000 : Framacalc accueille plus de 130 000 feuilles de calcul, où vos données ne sont pas espionnées ni revendues
142 600 : Sur Framapad, c’est en moyenne plus de 142 600 pads actifs chaque jour et presque 8 millions d’utilisateurs depuis ses débuts.
150 000 : Les serveurs de Framalistes adressent en moyenne 150 000 courriels chaque jour aux 280 000 inscrites à des listes de discussion.
200 000 : Êtes-vous l’une des 200 000 personnes à avoir consulté un des 23 000 messages chiffrés de Framabin ?
500 000 : Framadate c’est plus de 500 000 visites par mois et plus de 1 000 sondages créés chaque jour.
Framapiaf, notre instance Mastodon
2 500 000 : Plus de 2 millions et demi de personnes ont développé leurs idées, échafaudé des projets sur Framindmap depuis sa mise en place.
3 350 000 : Grâce à Framabook, 3 350 000 lecteurs ont pu télécharger en toute légalité un des 47 ouvrages librement publiés.
5 000 000 : Sur Framagenda environ 35 000 utilisateurs gèrent un million de contacts. Ils organisent et partagent près de cinq millions d’événements.
10 000 000 : Comme près de 40 000 personnes, travaillez en équipe sur Framateam et rejoignez un des 80 000 canaux avec presque 10 millions de messages !
Et le chiffre essentiel pour que tout cela soit possible, c’est celui de nos donatrices et donateurs (2381 en moyenne chaque année) : appuyez sur ce bouton pour le faire croître de 1
Voici déjà la traduction du quatrième chapitre de Google Data Collection, l’étude élaborée par l’équipe du professeur Douglas C. Schmidt, spécialiste des systèmes logiciels, chercheur et enseignant à l’Université Vanderbilt. Si vous les avez manqués, retrouvez les chapitres précédents déjà publiés. Il s’agit cette fois d’explorer les stratégies des régies publicitaires qui opèrent en arrière-plan : des opérations fort discrètes mais terriblement efficaces…
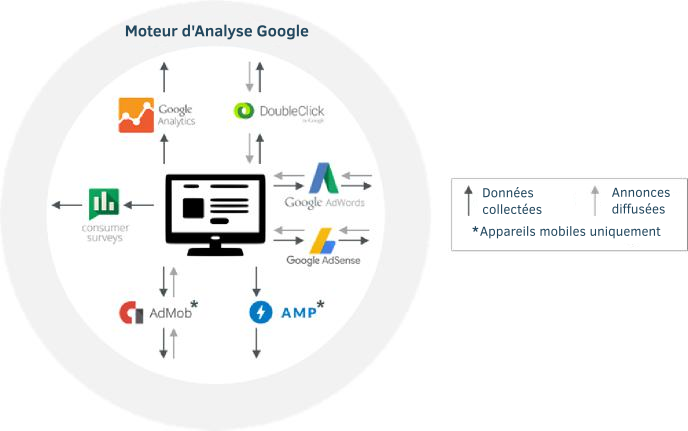
IV. Collecte de données par les outils des annonceurs et des diffuseurs
29. Une source majeure de collecte des données d’activité des utilisateurs provient des outils destinés au annonceurs et aux éditeurs tels que Google Analytics, DoubleClick, AdSense, AdWords et AdMob. Ces outils ont une portée énorme ; par exemple, plus d’un million d’applications mobiles utilisent AdMob27, plus d’un million d’annonceurs utilisent AdWords28, plus de 15 millions de sites internet utilisent AdSense29 et plus de 30 millions de sites utilisent Google Analytics30.
30. Au moment de la rédaction du présent rapport, Google a rebaptisé AdWords « Google Ads » et DoubleClick « Google Ad Manager« , mais aucune modification n’a été apportée aux fonctionnalités principales des produits, y compris la collecte d’informations par ces produits31. Par conséquent, pour les besoins du présent rapport, les premiers noms ont été conservés afin d’éviter toute confusion avec des noms de domaine connexes (tels que doubleclick.net).
31. Voici deux principaux groupes d’utilisateurs des outils de Google axés sur l’édition — et les annonces publicitaires :
Les éditeurs de sites web et d’applications, qui sont des organisations qui possèdent des sites web et créent des applications mobiles. Ces entités utilisent les outils de Google pour (1) gagner de l’argent en permettant l’affichage d’annonces aux visiteurs sur leurs sites web ou applications, et (2) mieux suivre et comprendre qui visite leurs sites et utilise leurs applications. Les outils de Google placent des cookies et exécutent des scripts dans les navigateurs des visiteurs du site web pour aider à déterminer l’identité d’un utilisateur et suivre son intérêt pour le contenu et son comportement en ligne. Les bibliothèques d’applications mobiles de Google suivent l’utilisation des applications sur les téléphones mobiles.
Les annonceurs, qui sont des organisations qui paient pour que des bannières, des vidéos ou d’autres publicités soient diffusées aux utilisateurs lorsqu’ils naviguent sur Internet ou utilisent des applications. Ces entités utilisent les outils de Google pour cibler des profils spécifiques de personnes pour que les publicités augmentent le retour sur leurs investissements marketing (les publicités mieux ciblées génèrent généralement des taux de clics et de conversion plus élevés). De tels outils permettent également aux annonceurs d’analyser leurs audiences et de mesurer l’efficacité de leur publicité numérique en regardant sur quelles annonces les utilisateurs cliquent et à quelle fréquence, et en donnant un aperçu du profil des personnes qui ont cliqué sur les annonces.
32. Ensemble, ces outils recueillent des informations sur les activités des utilisateurs sur les sites web et dans les applications, comme le contenu visité et les annonces cliquées. Ils travaillent en arrière-plan — en général imperceptibles par des utilisateurs. La figure 7 montre certains de ces outils clés, avec des flèches indiquant les données recueillies auprès des utilisateurs et les publicités qui leur sont diffusées.
Figure 7 : Produits Google destinés aux éditeurs et annonceurs32
33. Les informations recueillies par ces outils comprennent un identifiant non personnel que Google peut utiliser pour envoyer des publicités ciblées sans identifier les informations personnelles de la personne concernée. Ces identificateurs peuvent être spécifiques à l’appareil ou à la session, ainsi que permanents ou semi-permanents. Le tableau 1 liste un ensemble de ces identificateurs. Afin d’offrir aux utilisateurs un plus grand anonymat lors de la collecte d’informations pour le ciblage publicitaire, Google s’est récemment tourné vers l’utilisation d’identifiants uniques semi-permanents (par exemple, les GAID)33. Des sections ultérieures décrivent en détail la façon dont ces outils recueillent les données des utilisateurs et l’utilisation de ces identificateurs au cours du processus de collecte des données.
Tableau 1: Identificateurs transmis à Google
Identificateur
Type
Description
GAID/IDFA
Semi-permanent
Chaine de caractères alphanumériques pour appareils Android et iOS, pour permettre les publicités ciblées sur mobile. Réinitialisable par l’utilisateur.
ID client
Semi-permanent
ID créé la première fois qu’un cookie est stocké sur le navigateur. Utilisé pour relier les sessions de navigations. Réinitialisé lorsque les cookies du navigateur sont effacés.
Adresse IP
Semi-permanent
Une unique suite de nombre qui identifie le réseau par lequel un appareil accède à internet.
ID appareil Android
Semi-permanent
Nombre généré aléatoirement au premier démarrage d’un appareil. Utilisé pour identifier l’appareil. En retrait progressif pour la publicité. Réinitialisé lors d’une remise à zéro de l’appareil.
Google Services Framework (GSF)
Semi-permanent
Nombre assigné aléatoirement lorsqu’un utilisateur s’enregistre pour la première fois dans les services Google sur un appareil. Utilisé pour identifier un appareil unique. Réinitialisé lors d’une remise à zéro de l’appareil.
IEMI / MEID
Permanent
Identificateur utilisé dans les standards de communication mobile. Unique pour chaque téléphone portable.
Adresse MAC
Permanent
Identificateur unique de 12 caractères pour un élément matériel (ex. : routeur).
Numéro de série
Permanent
Chaine de caractères alphanumériques utilisée pour identifier un appareil.
A. Google Analytics et DoubleClick
34. DoubleClick et Google Analytics (GA) sont les produits phares de Google en matière de suivi du comportement des utilisateurs et d’analyse du trafic des pages Web sur les périphériques de bureau et mobiles. GA est utilisé par environ 75 % des 100 000 sites Web les plus visités34. Les cookies DoubleClick sont associés à plus de 1,6 million de sites Web35.
35. GA utilise de petits segments de code de traçage (appelés « balises de page ») intégrés dans le code HTML d’un site Web36. Après le chargement d’une page Web à la demande d’un utilisateur, le code GA appelle un fichier analytics.js qui se trouve sur les serveurs de Google. Ce programme transfère un instantané « par défaut » des données de l’utilisateur à ce moment, qui comprend l’adresse de la page web visitée, le titre de la page, les informations du navigateur, l’emplacement actuel (déduit de l’adresse IP), et les paramètres de langue de l’utilisateur. Les scripts de GA utilisent des cookies pour suivre le comportement des utilisateurs.
36. Le script de GA, la première fois qu’il est exécuté, génère et stocke un cookie spécifique au navigateur sur l’ordinateur de l’utilisateur. Ce cookie a un identificateur de client unique (voir le tableau 1 pour plus de détails)37 Google utilise l’identificateur unique pour lier les cookies précédemment stockés, qui capturent l’activité d’un utilisateur sur un domaine particulier tant que le cookie n’expire pas ou que l’utilisateur n’efface pas les cookies mis en cache dans son navigateur38
37. Alors qu’un cookie GA est spécifique au domaine particulier du site Web que l’utilisateur visite (appelé « cookie de première partie »), un cookie DoubleClick est généralement associé à un domaine tiers commun (tel que doubleclick.net). Google utilise de tels cookies pour suivre l’interaction de l’utilisateur sur plusieurs sites web tiers39 Lorsqu’un utilisateur interagit avec une publicité sur un site web, les outils de suivi de conversion de DoubleClick (par exemple, Floodlight) placent des cookies sur l’ordinateur de l’utilisateur et génèrent un identifiant client unique40 Par la suite, si l’utilisateur visite le site web annoncé, le serveur DoubleClick accède aux informations stockées dans le cookie, enregistrant ainsi la visite comme une conversion valide.
B. AdSense, AdWords et AdMob
38. AdSense et AdWords sont des outils de Google qui diffusent des annonces sur les sites Web et dans les résultats de recherche Google, respectivement. Plus de 15 millions de sites Web ont installé AdSense pour afficher des annonces sponsorisées41 De même, plus de 2 millions de sites web et applications, qui constituent le réseau Google Display Network (GDN) et touchent plus de 90 % des internautes42 affichent des annonces AdWords.
39. AdSense collecte des informations indiquant si une annonce a été affichée ou non sur la page web de l’éditeur. Il recueille également la façon dont l’utilisateur a interagi avec l’annonce, par exemple en cliquant sur l’annonce ou en suivant le mouvement du curseur sur l’annonce43. AdWords permet aux annonceurs de diffuser des annonces de recherche sur Google Search, d’afficher des annonces sur les pages des éditeurs et de superposer des annonces sur des vidéos YouTube. Pour suivre les taux de clics et de conversion des utilisateurs, les publicités AdWords placent un cookie sur les navigateurs des utilisateurs pour identifier l’utilisateur s’il visite par la suite le site web de l’annonceur ou s’il effectue un achat44.
40. Bien qu’AdSense et AdWords recueillent également des données sur les appareils mobiles, leur capacité d’obtenir des renseignements sur les utilisateurs des appareils mobiles est limitée puisque les applications mobiles ne partagent pas de cookies entre elles, une technique d’isolement appelée « bac à sable »45 qui rend difficile pour les annonceurs de suivre le comportement des utilisateurs entre différentes applications mobiles.
41 Pour résoudre ce problème, Google et d’autres entreprises utilisent des « bibliothèques d’annonces » mobiles (comme AdMob) qui sont intégrées dans les applications par leurs développeurs pour diffuser des annonces dans les applications mobiles. Ces bibliothèques compilent et s’exécutent avec les applications et envoient à Google des données spécifiques à l’application à laquelle elles sont intégrées, y compris les emplacements GPS, la marque de l’appareil et le modèle de l’appareil lorsque les applications ont les autorisations appropriées. Comme on peut le voir dans les analyses de trafic de données (Figure 8), et comme on peut trouver confirmation sur les propres pages web des développeurs de Google46, de telles bibliothèques peuvent également envoyer des données personnelles de l’utilisateur, telles que l’âge et le genre, tout cela va vers Google à chaque fois que les développeurs d’applications envoient explicitement leurs valeurs numériques vers la bibliothèque.
Figure 8 : Aperçu des informations renvoyées à Google lorsqu’une application est lancée
C. Association de données recueillies passivement et d’informations à caractère personnel
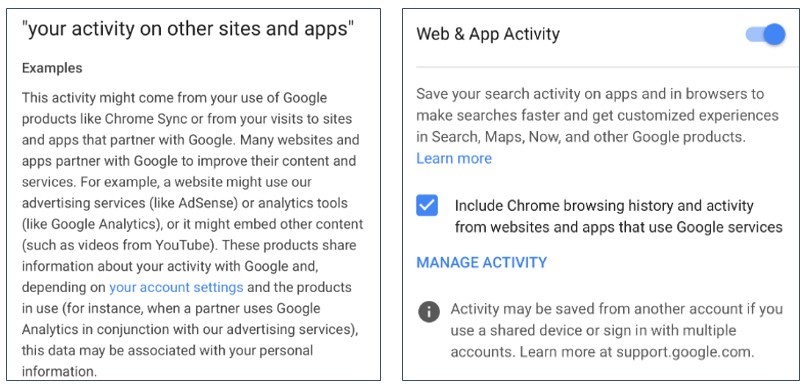
42. Comme nous l’avons vu plus haut, Google recueille des données par l’intermédiaire de produits pour éditeurs et annonceurs, et associe ces données à une variété d’identificateurs semi-permanents et anonymes. Google a toutefois la possibilité d’associer ces identifiants aux informations personnelles d’un utilisateur. C’est ce qu’insinuent les déclarations faites dans la politique de confidentialité de Google, dont des extraits sont présentés à la figure 9. La zone de texte à gauche indique clairement que Google peut associer des données provenant de services publicitaires et d’outils d’analyse aux informations personnelles d’un utilisateur, en fonction des paramètres du compte de l’utilisateur. Cette disposition est activée par défaut, comme indiqué dans la zone de texte à droite.
Figure 9 : Page de confidentialité de Google pour la collecte de sites web tiers et l’association avec des informations personnelles4748.
43. De plus, une analyse du trafic de données échangé avec les serveurs de Google (résumée ci-dessous) a permis d’identifier deux exemples clés (l’un sur Android et l’autre sur Chrome) qui montrent la capacité de Google à corréler les données recueillies de façon anonyme avec les renseignements personnels des utilisateurs.
1) L’identificateur de publicité mobile peut être désanonymé grâce aux données envoyées à Google par Android.
44. Les analyses du trafic de données communiqué entre un téléphone Android et les domaines de serveur Google suggèrent un moyen possible par lequel des identifiants anonymes (GAID dans ce cas) peuvent être associés au compte Google d’un utilisateur. La figure 10 décrit ce processus en une série de trois étapes clés.
45. Dans l’étape 1, une donnée de check-in est envoyée à l’URL android.clients.google.com/checkin. Cette communication particulière fournit une synchronisation de données Android aux serveurs Google et contient des informations du journal Android (par exemple, du journal de récupération), des messages du noyau, des crash dumps, et d’autres identifiants liés au périphérique. Un instantané d’une demande d’enregistrement partiellement décodée envoyée au serveur de Google à partir d’Android est montré en figure 10.
Figure 10 : Les identifiants d’appareil sont envoyés avec les informations de compte dans les requêtes de vérification Android.
46. Comme l’indiquent les zones pointées, Android envoie à Google, au cours du processus d’enregistrement, une variété d’identifiants permanents importants liés à l’appareil, y compris l’adresse MAC de l’appareil, l’IMEI /MEID et le numéro de série du dispositif. En outre, ces demandes contiennent également l’identifiant Gmail de l’utilisateur Android, ce qui permet à Google de relier les informations personnelles d’un utilisateur aux identifiants permanents des appareils Android.
47. À l’étape 2, le serveur de Google répond à la demande d’enregistrement. Ce message contient un identifiant de cadre de services Google (GSF ID)49 qui est similaire à l’« Android ID »50 (voir le tableau 1 pour les descriptions).
48. L’étape 3 implique un autre cas de communication où le même identifiant GSF (de l’étape 2) est envoyé à Google en même temps que le GAID. La figure 10 montre l’une de ces transmissions de données à android.clients.google.com/fdfe/bulkDetails?au=1.
49. Grâce aux trois échanges de données susmentionnés, Google reçoit les informations nécessaires pour connecter un GAID avec des identifiants d’appareil permanents ainsi que les identifiants de compte Google des utilisateurs.
50. Ces échanges de données interceptés avec les serveurs de Google à partir d’un téléphone Android montrent comment Google peut connecter les informations anonymisées collectées sur un appareil mobile Android via les outils DoubleClick, Analytics ou AdMob avec l’identité personnelle de l’utilisateur. Au cours de la collecte de données sur 24 heures à partir d’un téléphone Android sans mouvement ni activité, deux cas de communications d’enregistrement avec des serveurs Google ont été observés. Une analyse supplémentaire est toutefois nécessaire pour déterminer si un tel échange d’informations a lieu avec une certaine périodicité ou s’il est déclenché par des activités spécifiques sur les téléphones.
2) L’ID du cookie DoubleClick est relié aux informations personnelles de l’utilisateur sur le compte Google.
51. La section précédente expliquait comment Google peut désanonymiser l’identité de l’utilisateur via les données passives et anonymisées qu’il collecte à partir d’un appareil mobile Android. Cette section montre comment une telle désanonymisation peut également se produire sur un ordinateur de bureau/ordinateur portable.
52. Les données anonymisées sur les ordinateurs de bureau et portables sont collectées par l’intermédiaire d’identifiants basés sur des cookies (par ex. Cookie ID), qui sont typiquement générés par les produits de publicité et d’édition de Google (par ex. DoubleClick) et stockés sur le disque dur local de l’utilisateur. L’expérience présentée ci-dessous a permis d’évaluer si Google peut établir un lien entre ces identificateurs (et donc les renseignements qui y sont associés) et les informations personnelles d’un utilisateur.
Cette expérience comportait les étapes ordonnées suivantes :
Ouverture d’une nouvelle session de navigation (Chrome ou autre) (pas de cookies enregistrés, par exemple navigation privée ou incognito) ;
Visite d’un site Web tiers qui utilisait le réseau publicitaire DoubleClick de Google ;
Visite du site Web d’un service Google largement utilisé (Gmail dans ce cas) ;
Connexion à Gmail.
53. Au terme des étapes 1 et 2, dans le cadre du processus de chargement des pages, le serveur DoubleClick a reçu une demande lorsque l’utilisateur a visité pour la première fois le site Web tiers. Cette demande faisait partie d’une série de reqêtes comprenant le processus d’initialisation DoubleClick lancé par le site Web de l’éditeur, qui a conduit le navigateur Chrome à installer un cookie pour le domaine DoubleClick. Ce cookie est resté sur l’ordinateur de l’utilisateur jusqu’à son expiration ou jusqu’à ce que l’utilisateur efface manuellement les cookies via les paramètres du navigateur.
54. Ensuite, à l’étape 3, lorsque l’utilisateur visite Gmail, il est invité à se connecter avec ses identifiants Google. Google gère l’identité à l’aide d’une architecture single sign on (SSO) [NdT : authentification unique], dans laquelle les identifiants sont fournis à un service de compte (ici accounts.google.com) en échange d’un « jeton d’authentification », qui peut ensuite être présenté à d’autres services Google pour identifier les utilisateurs. À l’étape 4, lorsqu’un utilisateur accède à son compte Gmail, il se connecte effectivement à son compte Google, qui fournit alors à Gmail un jeton d’autorisation pour vérifier l’identité de l’utilisateur.51 Ce processus est décrit à la figure 24 de la section IX.E de l’annexe.
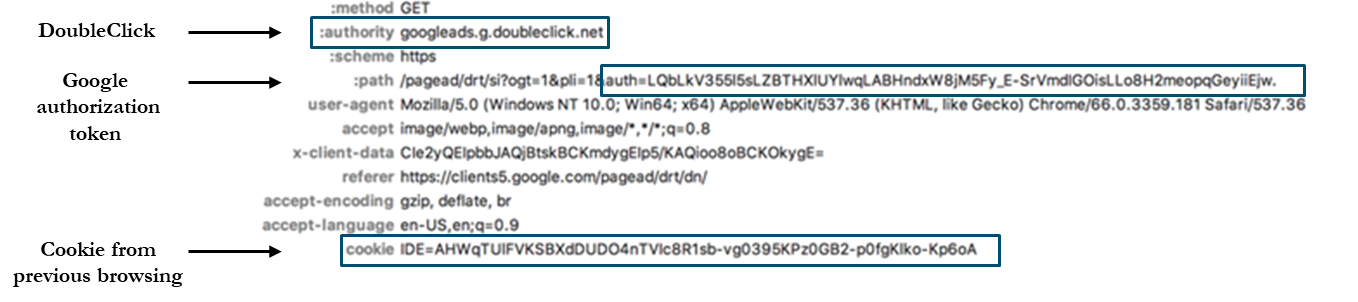
55. Dans la dernière étape de ce processus de connexion, une requête est envoyée au domaine DoubleClick. Cette requête contient à la fois le jeton d’authentification fourni par Google et le cookie de suivi défini lorsque l’utilisateur a visité le site web tiers à l’étape 2 (cette communication est indiquée à la figure 11). Cela permet à Google de relier les informations d’identification Google de l’utilisateur à un cookie DoubleClick. Par conséquent, si les utilisateurs n’effacent pas régulièrement les cookies de leur navigateur, leurs informations de navigation sur les pages Web de tiers qui utilisent les services DoubleClick pourraient être associées à leurs informations personnelles sur Google Account.
Figure 11 : La requête à DoubleClick.net inclut le jeton d’authentification Google et les cookies passés.
56. Il est donc établi à présent que Google recueille une grande variété de données sur les utilisateurs par l’intermédiaire de ses outils d’éditeur et d’annonceur, sans que l’utilisateur en ait une connaissance directe. Bien que ces données soient collectées à l’aide d’identifiants anonymes, Google a la possibilité de relier ces informations collectées aux identifiants personnels de l’utilisateur stockés sur son compte Google.
57. Il convient de souligner que la collecte passive de données d’utilisateurs de Google à partir de pages web tierces ne peut être empêchée à l’aide d’outils populaires de blocage de publicité52, car ces outils sont conçus principalement pour empêcher la présence de publicités pendant que les utilisateurs naviguent sur des pages web tierces53. La section suivante examine de plus près l’ampleur de cette collecte de données.
Ce que peut faire votre Fournisseur d’Accès à l’Internet
Nous sommes ravis et honorés d’accueillir Stéphane Bortzmeyer qui allie une compétence de haut niveau sur des questions assez techniques et une intéressante capacité à rendre assez claires des choses complexes. Nous le remercions de nous expliquer dans cet article quelles pratiques douteuses tentent certains fournisseurs d’accès à l’Internet, quelles menaces cela représente pour la confidentialité comme pour la neutralité du Net, et pourquoi la parade du chiffrement fait l’objet d’attaques répétées de leur part.
Pour vous connecter à l’Internet, vous avez besoin d’un FAI (Fournisseur d’Accès à l’Internet), une entreprise ou une association dont le métier est de relier des individus ou des organisations aux autres FAI. En effet, l’Internet est une coalition de réseaux, chaque FAI a le sien, et ce qui constitue l’Internet global, c’est la connexion de tous ces FAI entre eux. À part devenir soi-même FAI, la seule façon de se connecter à l’Internet est donc de passer par un de ces FAI. La question de la confiance est donc cruciale : qu’est-ce que mon FAI fait sans me le dire ?
Outre son travail visible (vous permettre de regarder Wikipédia, et des vidéos avec des chats mignons), le FAI peut se livrer à des pratiques plus contestables, que cet article va essayer d’expliquer. L’article est prévu pour un vaste public et va donc simplifier une réalité parfois assez compliquée.
Notons déjà tout de suite que je ne prétends pas que tous les FAI mettent en œuvre les mauvaises pratiques décrites ici. Il y a heureusement des FAI honnêtes. Mais toutes ces pratiques sont réellement utilisées aujourd’hui, au moins par certains FAI.
La langue française a un seul verbe, « pouvoir », pour désigner à la fois une possibilité technique (« ma voiture peut atteindre 140 km/h ») et un droit (« sur une route ordinaire, je peux aller jusqu’à 80 km/h »). Cette confusion des deux possibilités est très fréquente dans les discussions au sujet de l’Internet. Ici, je parlerais surtout des possibilités techniques. Les règles juridiques et morales encadrant les pratiques décrites ici varient selon les pays et sont parfois complexes (et je ne suis ni juriste ni moraliste) donc elles seront peu citées dans cet article.
Au sujet du numérique
Pour résumer les possibilités du FAI (Fournisseur d’Accès à l’Internet), il faut se rappeler de quelques propriétés essentielles du monde numérique :
Modifier des données numériques ne laisse aucune trace. Contrairement à un message physique, dont l’altération, même faite avec soin, laisse toujours une trace, les messages envoyés sur l’Internet peuvent être changés sans que ce changement ne se voit.
Copier des données numériques, par exemple à des fins de surveillance des communications, ne change pas ces données, et est indécelable. Elle est très lointaine, l’époque où (en tout cas dans les films policiers), on détectait une écoute à un « clic » entendu dans la communication ! Les promesses du genre « nous n’enregistrons pas vos données » sont donc impossibles à vérifier.
Modifier les données ou bien les copier est très bon marché, avec les matériels et logiciels modernes. Le FAI qui voudrait le faire n’a même pas besoin de compétences pointues : les fournisseurs de matériel et de logiciel pour FAI ont travaillé pour lui et leur catalogue est rempli de solutions permettant modification et écoute des données, solutions qui ne sont jamais accompagnées d’avertissements légaux ou éthiques.
Une publicité pour un logiciel d’interception des communications, même chiffrées. Aucun avertissement légal ou éthique dans la page.
Modifier le trafic réseau
Commençons avec la possibilité technique de modification des données numériques. On a vu qu’elle était non seulement faisable, mais en outre facile. Citons quelques exemples où l’internaute ne recevait pas les données qui avaient été réellement envoyées, mais une version modifiée :
de 2011 à 2013 (et peut-être davantage), en France, le FAI SFR modifiait les images envoyées via son réseau, pour en diminuer la taille. Une image perdait donc ainsi en qualité. Si la motivation (diminuer le débit) était compréhensible, le fait que les utilisateurs n’étaient pas informés indique bien que SFR était conscient du caractère répréhensible de cette pratique.
en 2018 (et peut-être avant), Orange Tunisie modifiait les pages Web pour y insérer des publicités. La modification avait un intérêt financier évident pour le FAI, et aucun intérêt pour l’utilisateur. On lit parfois que la publicité sur les pages Web est une conséquence inévitable de la gratuité de l’accès à cette page mais, ici, bien qu’il soit client payant, l’utilisateur voit des publicités qui ne rapportent qu’au FAI. Comme d’habitude, l’utilisateur n’avait pas été notifié, et le responsable du compte Twitter d’Orange, sans aller jusqu’à nier la modification (qui est interdite par la loi tunisienne), la présentait comme un simple problème technique.
en 2015 (et peut-être avant), Verizon Afrique du Sud modifiait les échanges effectués entre le téléphone et un site Web pour ajouter aux demandes du téléphone des informations comme l’IMEI (un identificateur unique du téléphone) ou bien le numéro de téléphone de l’utilisateur. Cela donnait aux gérants des sites Web des informations que l’utilisateur n’aurait pas donné volontairement. On peut supposer que le FAI se faisait payer par ces gérants de sites en échange de ce service.
Il s’agit uniquement des cas connus, c’est-à-dire de ceux où des experts ont décortiqué ce qui se passait et l’ont documenté. Il y a certainement de nombreux autres cas qui passent inaperçus. Ce n’est pas par hasard si la majorité de ces manipulations se déroulent dans les pays du Sud, où il y a moins d’experts disponibles pour l’analyse, et où l’absence de démocratie politique n’encourage pas les citoyens à regarder de près ce qui se passe. Il n’est pas étonnant que ces modifications du trafic qui passe dans le réseau soient la règle en Chine. Ces changements du trafic en cours de route sont plus fréquents sur les réseaux de mobiles (téléphone mobile) car c’est depuis longtemps un monde plus fermé et davantage contrôlé, où les FAI ont pris de mauvaises habitudes.
Quelles sont les motivations des FAI pour ces modifications ? Elles sont variées, souvent commerciales (insertion de publicités) mais peuvent être également légales (obligation de censure passant techniquement par une modification des données).
Mais ces modifications sont une violation directe du principe de neutralité de l’intermédiaire (le FAI). La « neutralité de l’Internet » est parfois présentée à tort comme une affaire financière (répartition des bénéfices entre différents acteurs de l’Internet) alors qu’elle est avant tout une protection des utilisateurs : imaginez si la Poste modifiait le contenu de vos lettres avant de les distribuer !
Les FAI qui osent faire cela le savent très bien et, dans tous les cas cités, aucune information des utilisateurs n’avait été faite. Évidemment, « nous changerons vos données au passage, pour améliorer nos bénéfices » est plus difficile à vendre aux clients que « super génial haut débit, vos vidéos et vos jeux plus rapides ! » Parfois, même une fois les interférences avec le trafic analysées et publiées, elles sont niées, mais la plupart du temps, le FAI arrête ces pratiques temporairement, sans explications ni excuses.
Surveiller le trafic réseau
De même que le numérique permet de modifier les données en cours de route, il rend possible leur écoute, à des fins de surveillance, politique ou commerciale. Récolter des quantités massives de données, et les analyser, est désormais relativement simple. Ne croyez pas que vos données à vous sont perdues dans la masse : extraire l’aiguille de la botte de foin est justement ce que les ordinateurs savent faire le mieux.
Grâce au courage du lanceur d’alerte Edward Snowden, la surveillance exercée par les États, en exploitant ces possibilités du numérique, est bien connue. Mais il n’y a pas que les États. Les grands intermédiaires que beaucoup de gens utilisent comme médiateurs de leurs communications (tels que Google ou Facebook) surveillent également massivement leurs utilisateurs, en profitant de leur position d’intermédiaire. Le FAI est également un intermédiaire, mais d’un type différent. Il a davantage de mal à analyser l’information reçue, car elle n’est pas structurée pour lui. Mais par contre, il voit passer tout le trafic réseau, alors que même le plus gros des GAFA (Google, Apple, Facebook, Amazon) n’en voit qu’une partie.
L’existence de cette surveillance par les FAI ne fait aucun doute, mais est beaucoup plus difficile à prouver que la modification des données. Comme pour la modification des données, c’est parfois une obligation légale, où l’État demande aux FAI leur assistance dans la surveillance. Et c’est parfois une décision d’un FAI.
Les données ainsi récoltées sont parfois agrégées (regroupées en catégories assez vastes pour que l’utilisateur individuel puisse espérer qu’on ne trouve pas trace de ses activités), par exemple quand elles sont utilisées à des fins statistiques. Elles sont dans ce cas moins dangereuses que des données individuelles. Mais attention : le diable est dans les détails. Il faut être sûr que l’agrégation a bien noyé les détails individuels. Quand un intermédiaire de communication proclame bien fort que les données sont « anonymisées », méfiez-vous. Le terme est utilisé à tort et à travers, et désigne souvent des simples remplacements d’un identificateur personnel par un autre, tout aussi personnel.
La solution du chiffrement
Ces pratiques de modification ou de surveillance des données sont parfois légales et parfois pas. Même quand elles sont illégales, on a vu qu’elles étaient néanmoins pratiquées, et jamais réprimées par la justice. Il est donc nécessaire de ne pas compter uniquement sur les protections juridiques mais également de déployer des protections techniques contre la modification et l’écoute. Deux catégories importantes de protections existent : minimiser les données envoyées, et les chiffrer. La minimisation consiste à envoyer moins de données, et elle fait partie des protections imposées par le RGPD (Règlement [européen] Général sur la Protection des Données). Combinée au chiffrement, elle protège contre la surveillance. Le chiffrement, lui, est la seule protection contre la modification des données.
Mais c’est quoi, le chiffrement ? Le terme désigne un ensemble de techniques, issues de la mathématique, et qui permet d’empêcher la lecture ou la modification d’un message. Plus exactement, la lecture est toujours possible, mais elle ne permet plus de comprendre le message, transformé en une série de caractères incompréhensibles si on ne connait pas la clé de déchiffrement. Et la modification reste possible mais elle est détectable : au déchiffrement, on voit que les données ont été modifiées. On ne pourra pas les lire mais, au moins, on ne recevra pas des données qui ne sont pas les données authentiques.
Dans le contexte du Web, la technique de chiffrement la plus fréquente se nomme HTTPS (HyperText Transfer Protocol Secure). C’est celle qui est utilisée quand une adresse Web commence par https:// , ou quand vous voyez un cadenas vert dans votre navigateur, à gauche de l’adresse. HTTPS sert à assurer que les pages Web que vous recevez sont exactement celles envoyées par le serveur Web, et il sert également à empêcher des indiscrets de lire au passage vos demandes et les réponses. Ainsi, dans le cas de la manipulation faite par Orange Tunisie citée plus haut, HTTPS aurait empêché cet ajout de publicités.
Pour toutes ces raisons, HTTPS est aujourd’hui massivement déployé. Vous le voyez de plus en plus souvent par exemple sur ce blog que vous êtes en train de lire.
Tous les sites Web sérieux ont aujourd’hui HTTPS
Le chiffrement n’est pas utilisé que par HTTPS. Si vous utilisez un VPN (Virtual Private Network, « réseau privé virtuel »), celui-ci chiffre en général les données, et la motivation des utilisateurs de VPN est en effet en général d’échapper à la surveillance et à la modification des données par les FAI. C’est particulièrement important pour les accès publics (hôtels, aéroports, Wifi du TGV) où les manipulations et filtrages sont quasi-systématiques.
Comme toute technique de sécurité, le chiffrement n’est pas parfait, et il a ses limites. Notamment, la communication expose des métadonnées (qui communique, quand, même si on n’a pas le contenu de la communication) et ces métadonnées peuvent être aussi révélatrices que la communication elle-même. Le système « Tor », qui peut être vu comme un type de VPN particulièrement perfectionné, réduit considérablement ces métadonnées.
Le chiffrement est donc une technique indispensable aujourd’hui. Mais il ne plait pas à tout le monde. Lors du FIC (Forum International de la Cybersécurité) en 2015, le représentant d’un gros FAI français déplorait en public qu’en raison du chiffrement, le FAI ne pouvait plus voir ce que faisaient ses clients. Et ce raisonnement est apparu dans un document d’une organisation de normalisation, l’IETF (Internet Engineering Task Force). Ce document, nommé « RFC 8404 »54 décrit toutes les pratiques des FAI qui peuvent être rendues difficiles ou impossibles par le chiffrement. Avant le déploiement massif du chiffrement, beaucoup de FAI avaient pris l’habitude de regarder trop en détail le trafic qui circulait sur leur réseau. C’était parfois pour des motivations honorables, par exemple pour mieux comprendre ce qui passait sur le réseau afin de l’améliorer. Mais, aujourd’hui, compte-tenu de ce qu’on sait sur l’ampleur massive de la surveillance, il est urgent de changer ses pratiques, au lieu de simplement regretter que ce qui était largement admis autrefois soit maintenant rejeté.
Cette liste de pratiques de certains FAI est une information intéressante mais il est dommage que ce document de l’IETF les présente comme si elles étaient toutes légitimes, alors que beaucoup sont scandaleuses et ne devraient pas être tolérées. Si le chiffrement les empêche, tant mieux !
Conclusion
Le déploiement massif du chiffrement est en partie le résultat des pratiques déplorables de certains FAI. Il est donc anormal que ceux-ci se plaignent des difficultés que leur pose le chiffrement. Ils sont les premiers responsables de la méfiance des utilisateurs !
La guerre contre les pratiques douteuses, déjà au XIe siècle… – Image retrouvée sur ce site.
J’ai surtout parlé ici des risques que le FAI écoute les messages, ou les modifie. Mais la place cruciale du FAI dans la communication fait qu’il existe d’autres risques, comme celui de censure de certaines activités ou certains services, ou de coupure d’accès. À l’heure où la connexion à l’Internet est indispensable pour tant d’activités, une telle coupure serait très dommageable.
Quelles sont les solutions, alors ? Se passer de FAI n’est pas réaliste. Certes, des bricoleurs peuvent connecter quelques maisons proches en utilisant des techniques fondées sur les ondes radio, mais cela ne s’étend pas à tout l’Internet. Par contre, il ne faut pas croire qu’un FAI est forcément une grosse entreprise commerciale. Ce peut être une collectivité locale, une association, un regroupement de citoyens. Dans certains pays, des règles très strictes imposées par l’État limitent cette activité de FAI, afin de permettre le maintien du contrôle des citoyens. Heureusement, ce n’est pas (encore ?) le cas en France. Par exemple, la FFDN (Fédération des Fournisseurs d’Accès Internet Associatifs) regroupe de nombreux FAI associatifs en France. Ceux-ci se sont engagés à ne pas recourir aux pratiques décrites plus haut, et notamment à respecter le principe de neutralité.
Bien sûr, monter son propre FAI ne se fait pas en cinq minutes dans son garage. Mais c’est possible en regroupant un collectif de bonnes volontés.
Et, si on n’a pas la possibilité de participer à l’aventure de la création d’un FAI, et pas de FAI associatif proche, quelles sont les possibilités ? Peut-on choisir un bon FAI commercial, en tout cas un qui ne viole pas trop les droits des utilisateurs ? Il est difficile de répondre à cette question. En effet, aucun FAI commercial ne donne des informations détaillées sur ce qui est possible et ne l’est pas. Les manœuvres comme la modification des images dans les réseaux de mobiles sont toujours faites en douce, sans information des clients. Même si M. Toutlemonde était prêt à passer son week-end à comparer les offres de FAI, il ne trouverait pas l’information essentielle « est-ce que ce FAI s’engage à rester strictement neutre ? » En outre, contrairement à ce qui existe dans certains secteurs économiques, comme l’agro-alimentaire, il n’existe pas de terminologie standardisée sur les offres des FAI, ce qui rend toute comparaison difficile.
Dans ces conditions, il est difficile de compter sur le marché pour réguler les pratiques des FAI. Une régulation par l’État n’est pas forcément non plus souhaitable (on a vu que c’est parfois l’État qui oblige les FAI à surveiller les communications, ainsi qu’à modifier les données transmises). À l’heure actuelle, la régulation la plus efficace reste la dénonciation publique des mauvaises pratiques : les FAI reculent souvent, lorsque des modifications des données des utilisateurs sont analysées et citées en public. Cela nécessite du temps et des efforts de la part de ceux et celles qui font cette analyse, et il faut donc saluer leur rôle.
Il s’agit aujourd’hui de mesurer ce que les plateformes les plus populaires recueillent de nos smartphones
Traduction Framalang : Côme, goofy, Khrys, Mika, Piup. Remerciements particuliers à badumtss qui a contribué à la traduction de l’infographie.
La collecte des données par les plateformes Android et Chrome
11. Android et Chrome sont les plateformes clés de Google qui facilitent la collecte massive de données des utilisateurs en raison de leur grande portée et fréquence d’utilisation. En janvier 2018, Android détenait 53 % du marché américain des systèmes d’exploitation mobiles (iOS d’Apple en détenait 45 %)55 et, en mai 2017, il y avait plus de 2 milliards d’appareils Android actifs par mois dans le monde.56
12. Le navigateur Chrome de Google représentait plus de 60 % de l’utilisation mondiale de navigateurs Internet avec plus d’un milliard d’utilisateurs actifs par mois, comme l’indiquait le rapport Q4 10K de 201757. Les deux plateformes facilitent l’usage de contenus de Google et de tiers (p.ex. applications et sites tiers) et fournissent donc à Google un accès à un large éventail d’informations personnelles, d’activité web, et de localisation.
A. Collecte d’informations personnelles et de données d’activité
13. Pour télécharger et utiliser des applications depuis le Google Play Store sur un appareil Android, un utilisateur doit posséder (ou créer) un compte Google, qui devient une passerelle clé par laquelle Google collecte ses informations personnelles, ce qui comporte son nom d’utilisateur, son adresse de messagerie et son numéro de téléphone. Si un utilisateur s’inscrit à des services comme Google Pay58, Android collecte également les données de la carte bancaire, le code postal et la date de naissance de l’utilisateur. Toutes ces données font alors partie des informations personnelles de l’utilisateur associées à son compte Google.
14. Alors que Chrome n’oblige pas le partage d’informations personnelles supplémentaires recueillies auprès des utilisateurs, il a la possibilité de récupérer de telles informations. Par exemple, Chrome collecte toute une gamme d’informations personnelles avec la fonctionnalité de remplissage automatique des formulaires, qui incluent typiquement le nom d’utilisateur, l’adresse, le numéro de téléphone, l’identifiant de connexion et les mots de passe.59 Chrome stocke les informations saisies dans les formulaires sur le disque dur de l’utilisateur. Cependant, si l’utilisateur se connecte à Chrome avec un compte Google et active la fonctionnalité de synchronisation, ces informations sont envoyées et stockées sur les serveurs de Google. Chrome pourrait également apprendre la ou les langues que parle la personne avec sa fonctionnalité de traduction, activée par défaut.60
15. En plus des données personnelles, Chrome et Android envoient tous deux à Google des informations concernant les activités de navigation et l’emploi d’applications mobiles, respectivement. Chaque visite de page internet est automatiquement traquée et collectée par Google si l’utilisateur a un compte Chrome. Chrome collecte également son historique de navigation, ses mots de passe, les permissions particulières selon les sites web, les cookies, l’historique de téléchargement et les données relatives aux extensions.61
16. Android envoie des mises à jour régulières aux serveurs de Google, ce qui comprend le type d’appareil, le nom de l’opérateur, les rapports de bug et des informations sur les applications installées62. Il avertit également Google chaque fois qu’une application est ouverte sur le téléphone (ex. Google sait quand un utilisateur d’Android ouvre son application Uber).
B. Collecte des données de localisation de l’utilisateur
17. Android et Chrome collectent méticuleusement la localisation et les mouvements de l’utilisateur en utilisant une variété de sources, représentées sur la figure 3. Par exemple, un accès à la « localisation approximative » peut être réalisé en utilisant les coordonnées GPS sur un téléphone Android ou avec l’adresse IP sur un ordinateur. La précision de la localisation peut être améliorée (« localisation précise ») avec l’usage des identifiants des antennes cellulaires environnantes ou en scannant les BSSID (’’Basic Service Set IDentifiers’’), identifiants assignés de manière unique aux puces radio des points d’accès Wi-Fi présents aux alentours63. Les téléphones Android peuvent aussi utiliser les informations des balises Bluetooth enregistrées dans l’API Proximity Beacon de Google64. Ces balises non seulement fournissent les coordonnées de géolocalisation de l’utilisateur, mais pourraient aussi indiquer à quel étage exact il se trouve dans un immeuble.65
Figure 3 : Android et Chrome utilisent diverses manières de localiser l’utilisateur d’un téléphone.
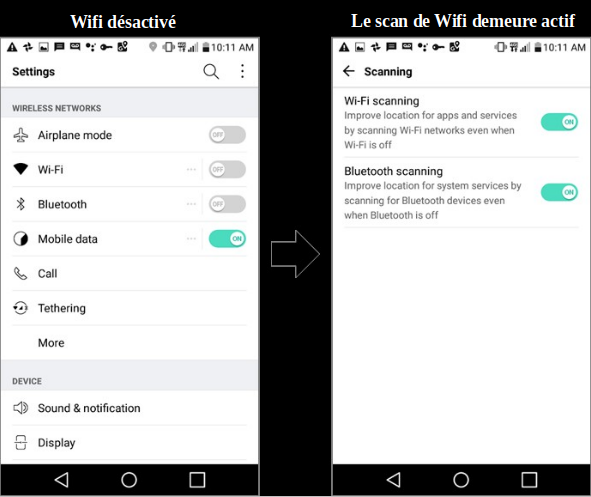
18. Il est difficile pour un utilisateur de téléphone Android de refuser le traçage de sa localisation. Par exemple, sur un appareil Android, même si un utilisateur désactive le Wi-Fi, la localisation est toujours suivie par son signal Wi-Fi. Pour éviter un tel traçage, le scan Wi-Fi doit être explicitement désactivé par une autre action de l’utilisateur, comme montré sur la figure 4.
Figure 4 : Android collecte des données même si le Wi-Fi est éteint par l’utilisateur
19. L’omniprésence de points d’accès Wi-Fi a rendu le traçage de localisation assez fréquent. Par exemple, durant une courte promenade de 15 minutes autour d’une résidence, un appareil Android a envoyé neuf requêtes de localisation à Google. Les requêtes contenaient au total environ 100 BSSID de points d’accès Wi-Fi publics et privés.
20. Google peut vérifier avec un haut degré de confiance si un utilisateur est immobile, s’il marche, court, fait du vélo, ou voyage en train ou en car. Il y parvient grâce au traçage à intervalles de temps réguliers de la localisation d’un utilisateur Android, combiné avec les données des capteurs embarqués (comme l’accéléromètre) sur les téléphones mobiles. La figure 5 montre un exemple de telles données communiquées aux serveurs de Google pendant que l’utilisateur marchait.
Figure 5 : capture d’écran d’un envoi de localisation d’utilisateur à Google.
C. Une évaluation de la collecte passive de données par Google via Android et Chrome
21. Les données actives que les plateformes Android ou Chrome collectent et envoient à Google à la suite des activités des utilisateurs sur ces plateformes peuvent être évaluées à l’aide des outils MyActivity et Takeout. Les données passives recueillies par ces plateformes, qui vont au-delà des données de localisation et qui restent relativement méconnues des utilisateurs, présentent cependant un intérêt potentiellement plus grand. Afin d’évaluer plus en détail le type et la fréquence de cette collecte, une expérience a été menée pour surveiller les données relatives au trafic envoyées à Google par les téléphones mobiles (Android et iPhone) en utilisant la méthode décrite dans la section IX.D de l’annexe. À titre de comparaison, cette expérience comprenait également l’analyse des données envoyées à Apple via un appareil iPhone.
22. Pour des raisons de simplicité, les téléphones sont restés stationnaires, sans aucune interaction avec l’utilisateur. Sur le téléphone Android, une seule session de navigateur Chrome restait active en arrière-plan, tandis que sur l’iPhone, le navigateur Safari était utilisé. Cette configuration a permis une analyse systématique de la collecte de fond que Google effectue uniquement via Android et Chrome, ainsi que de la collecte qui se produit en l’absence de ceux-ci (c’est-à-dire à partir d’un appareil iPhone), sans aucune demande de collecte supplémentaire générée par d’autres produits et applications (par exemple YouTube, Gmail ou utilisation d’applications).
23. La figure 6 présente un résumé des résultats obtenus dans le cadre de cette expérience. L’axe des abscisses indique le nombre de fois où les téléphones ont communiqué avec les serveurs Google (ou Apple), tandis que l’axe des ordonnées indique le type de téléphone (Android ou iPhone) et le type de domaine de serveur (Google ou Apple) avec lequel les paquets de données ont été échangés par les téléphones. La légende en couleur décrit la catégorisation générale du type de demandes de données identifiées par l’adresse de domaine du serveur. Une liste complète des adresses de domaine appartenant à chaque catégorie figure dans le tableau 5 de la section IX.D de l’annexe.
24. Au cours d’une période de 24 heures, l’appareil Android a communiqué environ 900 échantillons de données à une série de terminaux de serveur Google. Parmi ceux-ci, environ 35 % (soit environ 14 par heure) étaient liés à la localisation. Les domaines publicitaires de Google n’ont reçu que 3 % du trafic, ce qui est principalement dû au fait que le navigateur mobile n’a pas été utilisé activement pendant la période de collecte. Le reste (62 %) des communications avec les domaines de serveurs Google se répartissaient grosso modo entre les demandes adressées au magasin d’applications Google Play, les téléchargements par Android de données relatives aux périphériques (tels que les rapports de crash et les autorisations de périphériques), et d’autres données — principalement de la catégorie des appels et actualisations de fond des services Google.
Figure 6 : Données sur le trafic envoyées par les appareils Andoid et les iPhones en veille.
25. La figure 6 montre que l’appareil iPhone communiquait avec les domaines Google à une fréquence inférieure de plus d’un ordre de grandeur (50 fois) à celle de l’appareil Android, et que Google n’a recueilli aucun donnée de localisation utilisateur pendant la période d’expérience de 24 heures via iPhone. Ce résultat souligne le fait que les plateformes Android et Chrome jouent un rôle important dans la collecte de données de Google.
26. De plus, les communications de l’appareil iPhone avec les serveurs d’Apple étaient 10 fois moins fréquentes que les communications de l’appareil Android avec Google. Les données de localisation ne représentaient qu’une très faible fraction (1 %) des données nettes envoyées aux serveurs Apple à partir de l’iPhone, Apple recevant en moyenne une fois par jour des communications liées à la localisation.
27. En termes d’amplitude, les téléphones Android communiquaient 4,4 Mo de données par jour (130 Mo par mois) avec les serveurs Google, soit 6 fois plus que ce que les serveurs Google communiquaient à travers l’appareil iPhone.
28. Pour rappel, cette expérience a été réalisée à l’aide d’un téléphone stationnaire, sans interaction avec l’utilisateur. Lorsqu’un utilisateur commence à bouger et à interagir avec son téléphone, la fréquence des communications avec les serveurs de Google augmente considérablement. La section V du présent rapport résume les résultats d’une telle expérience.


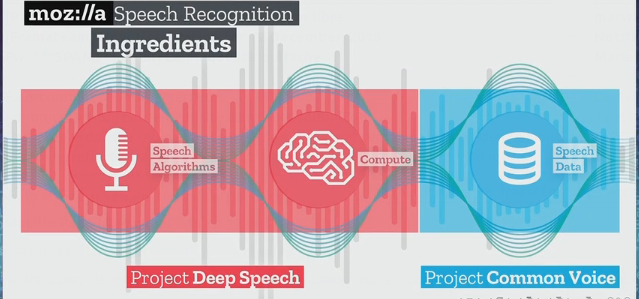

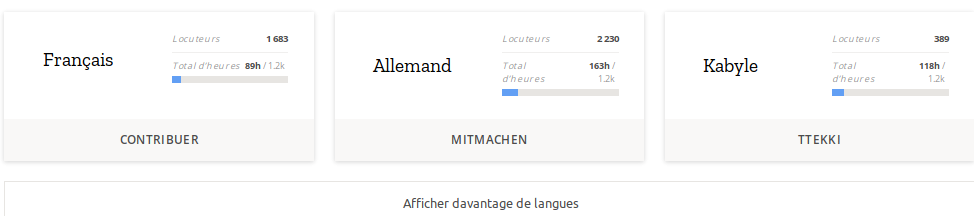
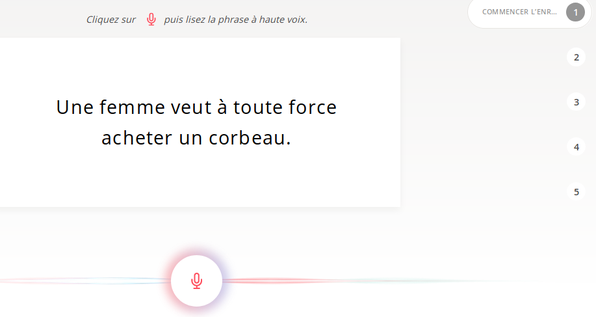 Pas d’inquiétude : on peut choisir « passer » avec un bouton dédié si on rencontre une difficulté de compréhension, prononciation ou autre. Et bien entendu si en se réécoutant on constate que ça peut être mieux, un simple clic permet de recommencer.
Pas d’inquiétude : on peut choisir « passer » avec un bouton dédié si on rencontre une difficulté de compréhension, prononciation ou autre. Et bien entendu si en se réécoutant on constate que ça peut être mieux, un simple clic permet de recommencer.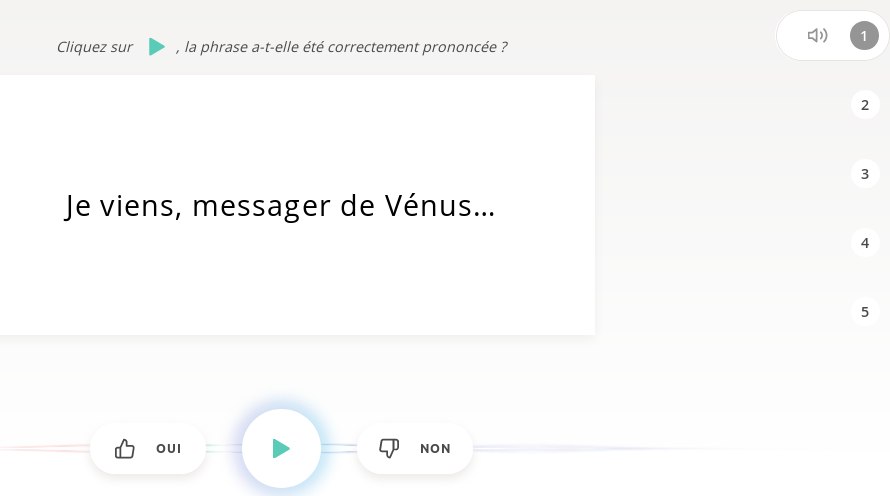
 Et oui encore, amis sourcilleux sur les licences libres, la CC0 va permettre la réutilisation commerciale des voix enregistrées bénévolement. C’est dommage ou pas de placer un travail collectif sous une licence très permissive ?
Et oui encore, amis sourcilleux sur les licences libres, la CC0 va permettre la réutilisation commerciale des voix enregistrées bénévolement. C’est dommage ou pas de placer un travail collectif sous une licence très permissive ?