Il sera peut-être une nouvelle fois traité de Cassandre et de parano, mais Bruce Schneier enfonce le clou !
Sensible aux signaux qu’envoient de façon croissante les faits divers mettant en cause les objets connectés — le fameux Internet des objets pour lequel « se mobilise » (sic) la grande distribution avec la French Tech — ce spécialiste de la sécurité informatique qui a rejoint récemment le comité directeur du projet Tor veut montrer que les risques désormais ne concernent plus seulement la vie numérique mais bien, directement ou non, la vie réelle. Il insiste aussi une fois encore sur les limites de la technologie et la nécessité d’un volontarisme politique.
Quand l’internet des objets menace la sécurité du monde réel
Les récits de catastrophes qui impliquent l’Internet des objets sont à la mode. Ils mettent en scène les voitures connectées (avec ou sans conducteur), le réseau électrique, les barrages hydroélectriques et les conduits d’aération. Un scénario particulièrement réaliste et vivant, qui se déroule dans un avenir proche, a été publié le mois dernier dans New York Magazine, décrivant une cyberattaque sur New York qui comprend le piratage de voitures, du réseau de distribution de l’eau, des hôpitaux, des ascenseurs et du réseau électrique. Dans de tels récits, un chaos total s’ensuit et des milliers de gens meurent. Bien sûr, certains de ces scénarios exagérèrent largement la destruction massive, mais les risques pour les individus sont bien réels. Et la sécurité classique des ordinateurs et des réseaux numériques n’est pas à la hauteur pour traiter de tels problèmes.
La sécurité traditionnelle des informations repose sur un triptyque : la confidentialité, l’intégrité et l’accès. On l’appelle aussi « C.I.A », ce qui, il faut bien le reconnaître, entretient la confusion dans le contexte de la sécurité nationale. Mais fondamentalement, voici les trois choses que je peux faire de vos données : les voler (confidentialité), les modifier (intégrité), ou vous empêcher de les obtenir (accès).
« L’internet des objets permettra des attaques que nous ne pouvons même pas imaginer. »
Jusqu’à présent, les menaces occasionnées par internet ont surtout concerné la confidentialité. Elles peuvent coûter cher; d’après cette étude chaque piratage de données a coûté 3.8 millions de dollars en moyenne. Elles peuvent s’avérer très gênantes, c’était le cas par exemple quand des photos de célébrités ont été volées sur le cloud d’Apple en 2014 ou lors du piratage du site de rencontres Ashley Madison en 2015. Elles peuvent faire des dégâts, comme quand le gouvernement de Corée du Nord a volé des milliers de documents à Sony ou quand des hackers ont piraté 83 millions de comptes de la banque JPMorgan Chase, dans les deux cas en 2014. Elles peuvent menacer la sécurité nationale, on l’a vu dans le cas du piratage de l’Office of Personnel Management par — pense-t-on — la Chine en 2015.
Avec l’Internet des objets, les menaces sur l’intégrité et la disponibilité sont plus importantes que celles concernant la confidentialité. C’est une chose si votre serrure intelligente peut être espionnée pour savoir qui est à la maison. C’est autre chose si elle peut être piratée pour permettre à un cambrioleur d’ouvrir la porte ou vous empêcher de l’ouvrir. Un pirate qui peut vous retirer le contrôle de votre voiture ou en prendre le contrôle est bien plus dangereux que celui qui peut espionner vos conversations ou pister la localisation de votre voiture.
Avec l’avènement de l’internet des objets et des systèmes physiques connectés en général, nous avons donné à Internet des bras et des jambes : la possibilité d’affecter directement le monde physique. Les attaques contre des données et des informations sont devenues des attaques contre la chair, l’acier et le béton.
Les menaces d’aujourd’hui incluent des hackers qui font s’écraser des avions en s’introduisant dans des réseaux informatiques, et qui désactivent à distance des voitures, qu’elles soient arrêtées et garées ou lancées à pleine vitesse sur une autoroute. Nous nous inquiétons à propos des manipulations de comptage des voix des machines de vote électronique, des canalisations d’eau gelées via des thermostats piratés, et de meurtre à distance au travers d’équipements médicaux piratés. Les possibilités sont à proprement parler infinies. L’internet des objets permettra des attaques que nous ne pouvons même pas imaginer.
Thermostat connecté, photo par athriftymrs.com, licence CC BY-SA 2.0
L’accroissement des risques provient de trois choses : le contrôle logiciel des systèmes, les interconnexions entre systèmes, et les systèmes automatiques ou autonomes. Jetons un œil à chacune d’entre elles.
Contrôle logiciel. L’internet des objets est le résultat de la transformation de tous les objets en ordinateurs. Cela nous apporte une puissance et une flexibilité énormes, mais aussi des insécurités par la même occasion. À mesure que les objets deviennent contrôlables de façon logicielle, ils deviennent vulnérables à toutes les attaques dont nous avons été témoins contre les ordinateurs. Mais étant donné qu’un bon nombre de ces objets sont à la fois bon marché et durables, la plupart des systèmes de mise à jour et de correctifs qui fonctionnent pour les ordinateurs et les téléphones intelligents ne fonctionneront pas ici. À l’heure actuelle, la seule manière de mieux sécuriser les routeurs individuels c’est de les jeter à la poubelle pour en acheter de nouveaux. Et la sécurité que vous obtenez en changeant fréquemment d’ordiphone ou d’ordinateur ne servira à rien pour protéger votre thermostat ou votre réfrigérateur : en moyenne vous changez ce dernier tous les 15 ans, et l’autre à peu près… jamais. Une étude récente de Princeton a découvert 500 000 appareils non sécurisés sur Internet. Ce nombre est sur le point d’augmenter de façon explosive.
Interconnexions. Ces systèmes devenant de plus en plus interconnectés, une vulnérabilité de l’un entraîne des attaques contres les autres. Nous avons déjà vu des comptes Gmail compromis à cause d’une vulnérabilité dans un réfrigérateur connecté Samsung, le réseau d’un hôpital compromis à cause de vulnérabilités dans du matériel médical et l’entreprise Target piratée à cause d’une vulnérabilité dans son système d’air conditionné. Les systèmes sont soumis à nombre d’externalités qui affectent d’autres systèmes de façon imprévisible et potentiellement dangereuse. Ce qui peut sembler bénin aux concepteurs d’un système particulier peut s’avérer néfaste une fois combiné à un autre système. Les vulnérabilités d’un système peuvent se répercuter sur un autre système et le résultat sera une vulnérabilité que personne n’a vu venir et que personne ne prendra la responsabilité de corriger. L’internet des objets va rendre les failles exploitables beaucoup plus communes. C’est mathématique. Si 100 systèmes interagissent entre eux, cela fait environ 5000 interactions et 5 000 vulnérabilités potentielles résultant de ces interactions. Si 300 systèmes interagissent entre eux, c’est 45 000 interactions. 1 000 systèmes : 12,5 millions d’interactions. La plupart seront bénignes ou sans intérêt, mais certaines seront très préjudiciables.
Autonomie. Nos systèmes informatiques sont des plus en plus autonomes. Ils achètent et vendent des actions, allument et éteignent la chaudière, régulent les flux d’électricité à travers le réseau et, dans le cas des voitures autonomes, conduisent des véhicules de plusieurs tonnes jusqu’à destination. L’autonomie est une bonne chose pour toutes sortes de raisons, mais du point de vue de la sécurité, cela signifie qu’une attaque peut prendre effet immédiatement et partout à la fois. Plus nous retirons l’humain de la boucle, plus les attaques produiront des effets rapidement et plus nous perdrons notre capacité à compter sur une vraie intelligence pour remarquer que quelque chose ne va pas avant qu’il ne soit trop tard.
« Les risques et les solutions sont trop techniques pour être compris de la plupart des gens. »
Nous construisons des systèmes de plus en plus puissants et utiles. Le revers de la médaille est qu’ils sont de plus en plus dangereux. Une seule vulnérabilité a forcé Chrysler à rappeler 1,4 million de véhicules en 2015. Nous sommes habitués aux attaques à grande échelle contre les ordinateurs, rappelez-vous les infections massives de virus de ces dernières décennies, mais nous ne sommes pas préparés à ce que cela arrive à tout le reste de notre monde.
Les gouvernements en prennent conscience. L’année dernière, les directeurs du renseignement national James Clapper et de la NSA Mike Rogers ont témoigné devant le Congrès, mettant l’accent sur ces menaces. Tous deux pensent que nous sommes vulnérables.
La plupart des discussions sur les menaces numériques traitent de la disponibilité et de la confidentialité des informations ; l’espionnage en ligne s’attaque à la confidentialité, là où les attaques par déni de service ou les effacements de données menacent la disponibilité. À l’avenir, en revanche, nous verrons certainement apparaître des opérations modifiant les informations électroniques dont l’objectif sera de toucher à leur intégrité (c’est à dire leur précision et leur fiabilité) plutôt que de les effacer ou d’empêcher leur accès. Le processus de prise de décision des responsables gouvernementaux (civils ou militaires), des chefs d’entreprises, des investisseurs et d’autres sera handicapé s’ils ne peuvent faire confiance à l’information qu’ils reçoivent.
Le rapport sur l’évaluation de la menace pour 2016 mentionnait quelque chose de similaire :
Les futures opérations cybernétiques attacheront presque à coup sûr une plus grande importance à la modification et à la manipulation des données destinées à compromettre leur intégrité (c’est-à-dire la précision et la fiabilité) pour influencer la prise de décision, réduire la confiance dans les systèmes ou provoquer des effets physiques indésirables. Une plus large adoption des appareils connectés et de l’intelligence artificielle — dans des environnements tels que les services publics et la santé — ne fera qu’exacerber ces effets potentiels.
Les ingénieurs en sécurité travaillent sur des technologies qui peuvent atténuer une grande partie de ce risque, mais de nombreuses solutions ne seront pas déployées sans intervention du gouvernement. Ce n’est pas un problème que peut résoudre le marché. Comme dans le cas de la confidentialité des données, les risques et les solutions sont trop techniques pour être compris de la plupart des gens et des organisations ; les entreprises sont très désireuses de dissimuler le manque de sécurité de leurs propres systèmes à leurs clients, aux utilisateurs et au grand public ; les interconnexions peuvent rendre impossible d’établir le lien entre un piratage et les dégâts qu’il occasionne ; et les intérêts des entreprises coïncident rarement avec ceux du reste de la population.
Il faut que les gouvernements jouent un rôle plus important : fixer des normes, en surveiller le respect et proposer des solutions aux entreprises et aux réseaux. Et bien que le plan national d’action pour la cybersécurité de la Maison Blanche aille parfois dans la bonne direction, il ne va sûrement pas assez loin, parce que beaucoup d’entre nous avons la phobie de toute solution imposée par un gouvernement quelconque.
Le prochain président sera probablement contraint de gérer un désastre à grande échelle sur Internet, qui pourrait faire de nombreuses victimes. J’espère qu’il ou elle y fera face à la fois avec la conscience de ce que peut faire un gouvernement et qui est impossible aux entreprises, et avec la volonté politique nécessaire.
Bruce Schneier est un spécialiste reconnu en matière de sécurité informatique, sur laquelle il a publié plusieurs livres et de nombreux articles sur son blog schneier.com.
Citation recueillie par le site AZ Quotes « Si vous croyez que la technologie peut résoudre vos problèmes de sécurité, c’est que vous ne comprenez pas les problèmes et que vous ne comprenez pas la technologie. »
Les bénéfices d’un combat, témoignage
Il n’est pas toujours facile de militer activement, ça demande du temps, de l’énergie et le courage de surmonter les difficultés.
Mais c’est aussi l’occasion de se confronter à la réalité du monde, de se découvrir aussi, et de tirer une fierté légitime de victoires auxquelles on a contribué. C’est dans cet esprit que nous publions aujourd’hui le témoignage de Bram.
Membre de Framasoft, il fut militant à la Quadrature du net et à la Nurpa, il se concentre aujourd’hui sur des actions plus locales comme la Brique Internet ou encore Neutrinet, une association bruxelloise fournisseur d’accès à Internet et membre de la fédération FDN.
Il nous propose ici un retour d’expérience en définitive plutôt positif et nous explique fort bien quels bénéfices il a tirés de cet épisode militant. Alors bien sûr, face aux lobbies, les formes et stratégies du combat ont évolué depuis la victoire contre ACTA qu’il évoque dans ce témoignage, donc la lutte aux côtés de la Quadrature s’est donné de nouveaux outils et des campagnes moins difficiles à vivre.
Mais l’essentiel demeure : l’action collaborative résolue est déterminante et il est possible de faire une différence.
Le jour où j’ai compris que je pouvais faire une différence en politique
C’est une histoire que je raconte parfois, au coin d’une table, mais que je n’ai jamais eu le courage de mettre par écrit, je profite d’un instant de motivation parce que je pense qu’en ce moment difficile pour nos actions politiques il est important de partager nos histoires et les récits de réussites. Nous manquons d’ailleurs cruellement d’histoires de nos luttes dans nos communautés.
Cela remonte à l’année 2010, le gouvernement français venait de faire passer la loi Hadopi malgré tous ses déboires et j’avais regardé l’ensemble des débats à l’Assemblée nationale, j’étais particulièrement remonté avec l’envie de faire quelque chose et je venais à la fois de rejoindre la Quadrature du Net depuis 6 mois et de co-fonder la Nurpa dans la même période.
À ce moment-là, 4 eurodéputé·e·s venaient de lancer la déclaration écrite numéro 12 qui disait grosso merdo « si la Commission européenne ne rend pas public le texte d’ACTA, le Parlement européen votera contre ». Une déclaration écrite est un texte, qui, s’il est signé par la moitié des eurodéputé·e·s en moins de 6 mois, devient une prise de position officielle du Parlement européen (sans pour autant être contraignante).
Le problème c’est que signer ce texte ne peut se faire que de 2 manières : soit dans une salle obscure que personne ne connait au fin fond du Parlement européen, soit avant d’entrer en séance plénière, au moment où les Eurodéputé·e·s ont franchement beaucoup d’autres choses en tête que d’aller signer un papier — et bien entendu les plénières ne durent que quelques jours une seule fois par mois.
Mais le sujet était important, nous venions de découvrir ACTA, c’était une horreur et il fallait absolument se battre contre ce désastre annoncé
Pour précision, une déclaration écrite est également quelque chose de fort facile à proposer et par son côté non contraignant elle ne représente pas beaucoup d’enjeux. On a donc le droit à toute une série de déclarations écrites farfelues et sans grand intérêt généralement proposées par des Eurodéputé·e·s cherchant un moyen de montrer à leur électorat qu’elles ont foutu quelque chose sur un sujet quelconque. À l’époque nous avions trouvé, entre autres, une déclaration écrite proposant une journée internationale de la glace à Italienne artisanale et une autre demandant la déclassification de documents sur les OVNIs. Mais le sujet était important, nous venions de découvrir ACTA, c’était une horreur et il fallait absolument se battre contre ce désastre annoncé, la Quadrature du Net décida donc de soutenir cette déclaration écrite.
Février 2010, branle-bas de combat, un certain moustachu m’informe via IRC (eh oui) de la situation et me dit en gros : « ça serait bien si tu pouvais trouver quelques personnes et qu’on se rejoigne au Parlement, on a un truc important à faire signer aux Eurodéputé·e·s contre ACTA ». Pas tout à fait sûr de vraiment comprendre de quoi il s’agissait, mais ayant pressenti l’importance de l’événement, je me ramenai avec 4-5 personnes — à l’agréable surprise dudit moustachu. Ce fut alors le début de la bataille.
Une bataille épuisante qui dura plus de 6 mois à raison de une à deux visites au Parlement par mois. Notre action était simple : aller frapper à la porte des bureaux de tous les députés pour les convaincre de signer la déclaration écrite en leur expliquant à quel point c’était important et espérer qu’ils aillent signer, coller des affiches et distribuer mollement des tracts avant la plénière. Bien souvent nous n’avions affaire qu’aux assistants, les députés étant occupés à d’autres choses, quand ce n’était pas un bureau vide.
Ce fut l’occasion pour notre petit groupe (à l’exception du moustachu) de découvrir les rouages de l’advocatie de terrain, les lobbyistes ayant leur propre catégorie de badge au Parlement européen (que nous refusions, nous étions des citoyens, pas des lobbyistes) et les désillusions face aux arguments les plus efficaces… (« ton chef a signé et a dit de signer alors signe » « tous tes potes ont signé sauf toi » « ton adversaire a signé, si tu le fais pas tu vas passer pour un loser » « roh mais dites les Verts, l’ALDE a plus signé que vous ! » mais dit dans leur langue, bref, la cour de récré).
un travail pénible, ingrat et peu visible…
Je n’irai au Parlement que deux ou trois fois, cette activité étant bien trop stressante pour moi (merci les anxiétés sociales), je me suis retrouvé bien vite à m’occuper de quelque chose de fort important mais plus discret : maintenir la liste des signataires (en plus de trouver des bénévoles et de faire de la coordination). Une tâche bien moins simple que prévu à cause de l’incompétence technique du Parlement européen : il a plus de 700 Eurodéputé·e·s, certain·e·s partaient, certain·e·s venaient, les documents de ceux qui avaient signé changeaient tout le temps de forme et les députés parfois de nom (en fait c’était l’époque où le Parlement avait mal inscrit certains noms peu communs en Belgique notamment au niveau des accents) et le terme « opendata » commençait juste à apparaitre. Bref, un travail pénible, ingrat et peu visible, mais au moins on a pu faire des jolis graphiques (mmmh… en matplotlib) qui plaisaient beaucoup aux journalistes et qui étaient utilisés comme argumentaires auprès de certain·e·s Eurodéputé·e·s.
La route fut difficile, nous n’obtenions que peu de signatures au début, car nous préférions viser la droite en premier lieu dans l’espoir que ça ne finisse pas comme « un texte de gauche » que la droite refuserait de signer. Les progrès étaient lents et démotivants et le public était d’une totale indifférence pour cette procédure peu connue, sur un sujet pas encore très en vogue (pas grand-monde avait entendu parler d’ACTA ou saisi son importance). Ainsi, nos appels répétés à contacter les Eurodéputé·e·s restèrent sans grand résultat, pire encore à la plénière d’avril nous n’obtiendrons que 27 signatures. Combinées aux 62 et 57 signatures précédentes, cela nous amenait à 146 signatures : très très loin des 369 dont nous avions besoin alors qu’il ne nous restait que 4 plénières. Le moral était au plus bas et les drames présents.
des listes sur papier des Eurodéputé·e·s
Ce fut également une période intéressante au niveau de l’invention d’outils d’activisme : à partir des données des signataires (que j’avais extraites de memopol, qui à l’époque était une collection de 28 scripts Perl écrivant des pages mediawiki et pas le projet qui existe aujourd’hui) nous nous mîmes à concevoir des listes sur papier des Eurodéputé·e·s que nous prenions avec nous au Parlement européen avec des cases à remplir pour ensuite nous les échanger. Dans le désespoir de l’action « j’inventais » les pads avec la liste de toutes les informations des député·e·s à appeler et des champs à remplir en dessous avec les réponses obtenues (à l’époque le piphone n’existait même pas au stade d’idée, mais en est en partie inspiré) et j’invitais absolument tout le monde à aller dessus, ce fut très ironiquement aussi le moment où nous réalisions que les pads étaient limités par défaut à 14 connexions simultanées. Ce fut aussi l’époque où j’ouvris le compte twitter @UnGarage avec le moustachu.
l’instant magique plein de synergie
Les plénières suivantes ne furent gère meilleures : 39, 34 et 34 signatures soit 253 signatures au total, il nous en manquait 116 pour la dernière plénière, cela nous semblait totalement impossible. Coïncidence heureuse : cette dernière plénière de juillet eut lieu pile pendant les RMLLs 2010 de Bordeaux. La pression était à son comble, nous étions épuisé·e·s et déjà fort occupé·e·s, l’idée était de lancer une séance d’appels au Parlement avec des téléphones SIP mais rien ne marchait. Après 2-3 jours d’engueulades et de tensions intenses (je me rappelle avoir vu Benjamin consoler une permanente en larmes), nous finîmes par occuper un local et mettre en commun tous les téléphones des gens voulant bien nous les prêter (avec la promesse de remboursement des factures) et à faire un atelier d’appels au Eurodéputé·e·s.
Ce fut alors l’instant magique de synergie où plein de participant·e·s des RMLLs se sont mis·es à appeler les Eurodéputé·e·s à la chaîne. Je me rappelle d’un présentateur radio qui avait particulièrement marqué la salle : après avoir appelé impeccablement bien tou·te·s les Français·es et les Belges, nous découvrîmes qu’il était bilingue lorsqu’il se mit à faire pareil avec tou·te·s Bulgares dans leur langue ! De son côté, le moustachu qui était lui au Parlement européen n’était pas en reste et les 4 Eurodéputé·e·s à l’origine de la déclaration non plus. Le résultat fut au rendez-vous : nous obtînmes 100 signatures, ce n’était pas les 116 qu’il nous fallait, mais c’était assez pour pouvoir demander une rallonge à la plénière suivante, qui fut obtenue, et nous savions que les 16 signatures manquantes étaient une formalité (et nous les obtînmes par la suite).
Nous avions gagné.
Les conséquences de cet événement furent également intéressantes : cette victoire nous avait coûté cher matériellement (tout le budget « actions européennes » de la Quadrature y était passé et nous étions à la moitié de l’année) et humainement pour un résultat moyennement intéressant : une déclaration écrite, soit une prise de position officielle mais non contraignante du Parlement européen. Les effets de bord l’ont été bien plus cependant : les personnes que j’avais embarquées dans l’histoire se sont forcément beaucoup politisées (Bouska par exemple se présentera quelques années plus tard en tant que député pour les Français à l’étranger du Benelux et a foutu le bordel sur la question des votes sur Internet), ce fut également une des premières actions politiques de la toute jeune Nurpa qui a beaucoup grandi et on retrouve également l’influence de cette période dans une partie de la boîte à outils de la Quadrature (memopol, piphone) comme dans une partie des méthodes d’action qui furent et sont encore parfois utilisées.
Un travail de groupe avant tout
J’étais personnellement épuisé et ce fut l’un des plus grand soulagements de ma vie mais aussi un accomplissement : je n’avais absolument pas tout fait tout seul, c’était un travail de groupe avant tout mais j’y avais eu un des rôles centraux et je ne sais pas si ça se serait fait sans moi tant la victoire avait été difficile à obtenir. J’avais 22 ans et j’avais eu un rôle central dans un groupe qui avait obtenu une prise de position publique du Parlement européen.
C’était donc possible.
Le militantisme est un sport de combat
Ce que valent nos adresses quand nous signons une pétition
Le chant des sirènes de la bonne conscience est hypnotique, et rares sont ceux qui n’ont jamais cédé à la tentation de signer des pétitions en ligne… Surtout quand il s’agit de ces « bonnes causes » qui font appel à nos réactions citoyennes et humanistes, à nos convictions les mieux ancrées ou bien sûr à notre indignation, notre compassion… Bref, dès qu’il nous semble possible d’avoir une action sur le monde avec un simple clic, nous signons des pétitions. Il ne nous semble pas trop grave de fournir notre adresse mail pour vérifier la validité de notre « signature ». Mais c’est alors que des plateformes comme Change.org font de notre profil leur profit…
Voilà ce que dénonce, chiffres à l’appui, la journaliste de l’Espresso Stefania Maurizi. Active entre autres dans la publication en Italie des documents de Wikileaks et de Snowden, elle met ici en lumière ce qui est d’habitude laissé en coulisses : comment Change.org monétise nos données les plus sensibles.
Dans le cadre de notre campagne Dégooglisons, nous sommes sensibles à ce dévoilement, c’est un argument de plus pour vous proposer prochainement un Framapétitions, un outil de création de pétitions libre et open source, respectueux de vos données personnelles…
Voilà comment Change.org vend nos adresses électroniques
L’Espresso a obtenu les tarifs de l’entreprise (de 1,50 euro à 85 centimes) et a contacté certains clients. Entre les réponses embarrassées et les reconnaissances du bout des lèvres, nous avons étudié l’activité de l’« Amazon des pétitions en ligne ». Elle manipule des données extrêmement sensibles telles que les opinions politiques et fait l’objet en Allemagne d’une enquête sur le respect de la vie privée.
On l’a appelée le « Google de la politique moderne ». Change.org, la plateforme populaire pour lancer des pétitions sur les questions politiques et sociales, est un géant qui compte cent cinquante millions d’utilisateurs à travers le monde et ce nombre augmente d’un million chaque semaine : un événement comme le Brexit a déclenché à lui seul 400 pétitions. En Italie, où elle a débarqué il y a quatre ans, Change.org a atteint cinq millions d’utilisateurs. Depuis la pétition lancée par Ilaria Cucchi pour demander l’approbation d’une loi sur la torture, qui a jusqu’à présent recueilli plus de 232 000 signatures, jusqu’à celle sur le référendum constitutionnel, que celui qui n’a jamais apposé une signature sur Change.org dans l’espoir de faire pression sur telle ou telle institution pour changer les choses lève la main. Au 21e siècle, la participation démocratique va inévitablement vers les plateformes en ligne. Et en effet on ne manque pas d’exemples dans lesquels ces pétitions ont vraiment déclenché des changements.
Il suffit de quelques clics : tout le monde peut lancer une pétition et tout le monde peut la signer. Mais il y a un problème : combien de personnes se rendent-elles compte que les données personnelles qu’elles confient à la plateforme en signant les soi-disant « pétitions sponsorisées » — celles qui sont lancées par les utilisateurs qui paient pour les promouvoir (https://www.change.org/advertise) — seront en fait vendues et utilisées pour les profiler ? La question est cruciale, car ce sont des données très sensibles, vu qu’elles concernent des opinions politiques et sociales.
L’Espresso est en mesure de révéler les tarifs que Change.org applique à ceux qui lancent des pétitions sponsorisées : des ONG aux partis politiques qui payent pour obtenir les adresses électroniques des signataires. Les prix vont de un 1,5 € par adresse électronique, si le client en achète moins de dix mille, jusqu’à 85 centimes pour un nombre supérieur à cinq cent mille. Notre journal a aussi demandé à certaines des ONG clientes de Change.org s’il est vrai qu’elles acquièrent les adresses électroniques des signataires. Certaines ont répondu de façon trop évasive pour ne pas susciter d’interrogations. D’autres, comme Oxfam, ont été honnêtes et l’ont confirmé.
Pour Change.org, voici combien vaut votre adresse électronique
Beaucoup croient que Change.org est une association sans but lucratif, animée d’idéaux progressistes. En réalité, c’est une véritable entreprise, Change.org Inc, créée dans le Delaware, un paradis fiscal américain, dont le quartier général est à San Francisco, au cœur de cette Silicon Valley où les données ont remplacé le pétrole. Et c’est vrai qu’elle permet à n’importe qui de lancer gratuitement des pétitions et remplit une fonction sociale : permettre jusqu’au dernier sans domicile fixe de s’exprimer. Mais elle réalise des profits avec les pétitions sponsorisées, là où le client paie pour réussir à contacter ceux qui seront probablement les plus enclins à signer et à donner de l’argent dans les campagnes de récolte de fonds. Comment fait Change.org pour le savoir ? Chaque fois que nous souscrivons à un appel, elle accumule des informations sur nous et nous profile. Et comme l’a expliqué clairement la revue américaine Wired : « si vous avez signé une pétition sur les droits des animaux, l’entreprise sait que vous avez une probabilité 2,29 fois supérieure d’en signer une sur la justice. Et si vous avez signé une pétition sur la justice, vous avez une probabilité 6,3 fois supérieure d’en signer une sur la justice économique, 4,4 d’en signer une sur les droits des immigrés et 4 fois d’en signer une autre encore sur l’éducation. »
Celui qui souscrit à une pétition devrait d’abord lire soigneusement les règles relatives à la vie privée, mais combien le font et combien comprennent réellement que, lorsqu’ils signent une pétition sponsorisée, il suffit qu’ils laissent cochée la mention « Tenez-moi informé de cette pétition » pour que leur adresse électronique soit vendue par Change.org à ses clients qui ont payé pour cela ? Ce n’est pas seulement les tarifs obtenus par L’Espresso qui nous confirment la vente des adresses électroniques, c’est aussi Oxfam, une des rares ONG qui a répondu de façon complètement transparente à nos questions : « c’est seulement au moment où les signataires indiquent qu’ils soutiennent Oxfam qu’il nous est demandé de payer Change.org pour leurs adresses », nous explique l’organisation.
Nous avons demandé ce que signifiait exactement « les signataires ont indiqué vouloir soutenir Oxfam », l’ONG nous a répondu en montrant la case cochée par le signataire, par laquelle il demande à rester informé de la pétition. Interpellée par L’Espresso, l’entreprise Change.org n’a pas démenti les tarifs. De plus elle a confirmé qu’ « ils varient selon le client en fonction du volume de ses achats » ; comme l’a expliqué John Coventry, responsable des Relations publiques de Change.org, une fois que le signataire a choisi de cocher la case, ou l’a laissée cochée, son adresse électronique est transmise à l’organisation qui a lancé la pétition sponsorisée. Coventry est convaincu que la plupart des personnes qui choisissent cette option se rendent compte qu’elles recevront des messages de l’organisation. En d’autres termes, les signataires donnent leur consentement.
Capture d’écran sur le site Change.org
Depuis longtemps, Thilo Weichert, ex-commissaire pour la protection des données du Land allemand de Schleswig-Holstein, accuse l’entreprise de violation de la loi allemande en matière de confidentialité. Weichert explique à l’Espresso que la transparence de Change.org laisse beaucoup à désirer : « ils ne fournissent aucune information fiable sur la façon dont ils traitent les données ». Et quand nous lui faisons observer que ceux qui ont signé ces pétitions ont accepté la politique de confidentialité et ont donc donné leur consentement en toute conscience, Thilo répond que la question du consentement ne résout pas le problème, parce que si une pratique viole la loi allemande sur la protection des données, l’entreprise ne peut pas arguer du consentement des utilisateurs. En d’autres termes, il n’existe pas de consentement éclairé qui rende légal le fait d’enfreindre la loi.
Suite aux accusations de Thilo Weichert, la Commission pour la protection des données de Berlin a ouvert sur Change.org une enquête qui est toujours en cours, comme nous l’a confirmé la porte-parole de la Commission, Anja-Maria Gardain. Et en avril, l’organisation « Digitalcourage », qui en Allemagne organise le « Big Brother Award » a justement décerné ce prix négatif à Change.org. « Elle vise à devenir ce qu’est Amazon pour les livres, elle veut être la plus grande plateforme pour toutes les campagnes politiques » nous dit Tangens Rena de Digitalcourage. Elle explique comment l’entreprise s’est montrée réfractaire aux remarques de spécialistes comme Weichert : par exemple en novembre dernier, celui-ci a fait observer à Change.org que le Safe Harbour auquel se réfère l’entreprise pour sa politique de confidentialité n’est plus en vigueur, puisqu’il a été déclaré invalide par la Cour européenne de justice suite aux révélations d’Edward Snowden. Selon Tangens, « une entreprise comme Change.org aurait dû être en mesure de procéder à une modification pour ce genre de choses. »
L’experte de DigitalCourage ajoute qu’il existe en Allemagne des plateformes autres que Change.org, du type Campact.de : « elles ne sont pas parfaites » précise-t-elle, « et nous les avons également critiquées, mais au moins elles se sont montrées ouvertes au dialogue et à la possibilité d’opérer des modifications ». Bien sûr, pour les concurrents de Change.org, il n’est pas facile de rivaliser avec un géant d’une telle envergure et le défi est presque impossible à relever pour ceux qui choisissent de ne pas vendre les données des utilisateurs. Comment peuvent-ils rester sur le marché s’ils ne monétisent pas la seule denrée dont ils disposent : les données ?
Pour Rena Tagens l’ambition de l’entreprise Change.org, qui est de devenir l’Amazon de la pétition politique et sociale, l’a incitée à s’éloigner de ses tendances progressistes initiales et à accepter des clients et des utilisateurs dont les initiatives sont douteuses. On trouve aussi sur la plateforme des pétitions qui demandent d’autoriser le port d’armes à la Convention républicaine du 18 juillet, aux USA. Et certains l’accusent de faire de l’astroturfing, une pratique qui consiste à lancer une initiative politique en dissimulant qui est derrière, de façon à faire croire qu’elle vient de la base. Avec l’Espresso, Weichert et Tangens soulignent tous les deux que « le problème est que les données qui sont récoltées sont vraiment des données sensibles et que Change.org est située aux Etats-Unis », si bien que les données sont soumises à la surveillance des agences gouvernementales américaines, de la NSA à la CIA, comme l’ont confirmé les fichiers révélés par Snowden.
Mais Rena Tangens et Thilo Weichert, bien que tous deux critiques envers les pratiques de Change.org, soulignent qu’il est important de ne pas jeter le bébé avec l’eau du bain, car ils ne visent pas à détruire l’existence de ces plateformes : « Je crois qu’il est important qu’elles existent pour la participation démocratique, dit Thilo Weichert, mais elles doivent protéger les données ».
Mise à jour du 22 juillet : la traduction de cet article a entraîné une réaction officielle de Change.org France sur leur page Facebook, suite auquel nous leur avons bien évidemment proposé de venir s’exprimer en commentaire sur le blog. Ils ont (sympathiquement) accepté. Nous vous encourageons donc à prendre connaissance de leur réponse, ainsi que les commentaires qui le suivent, afin de poursuivre le débat.
Les anciens Léviathans II — Internet. Pour un contre-ordre social
Qu’est-ce qui fait courir Framasoft ? De la campagne Dégooglisons à l’initiative C.H.A.T.O.N.S quelles idées ont en tête les acteurs et soutiens de l’association ? Vous reprendrez bien une tranche de Léviathan ?
Michel Foucault, disparu il y a trente ans, proposait d’approcher les grandes questions du monde à travers le rapport entre savoir et pouvoir. Cette méthode a l’avantage de contextualiser le discours que l’on est en train d’analyser : quels discours permettent d’exercer quels pouvoirs ? Et quels pouvoirs sont censés induire quelles contraintes et en vertu de quels discours ? Dans un de ses plus célèbres ouvrages, Surveiller et punir[1], Foucault démontre les mécanismes qui permettent de passer de la démonstration publique du pouvoir d’un seul, le monarque qui commande l’exécution publique des peines, à la normativité morale et physique imposée par le contrôle, jusqu’à l’auto-censure. Ce n’est plus le pouvoir qui est isolé dans la forteresse de l’autorité absolue, mais c’est l’individu qui exerce lui-même sa propre coercition. Ainsi, Surveiller et punir n’est pas un livre sur la prison mais sur la conformation de nos rapports sociaux à la fin du XXe siècle.
Deux autres auteurs et œuvres pas du tout importants. Du tout, du tout.
Les modèles économiques ont suivi cet ordre des choses : puisque la société est individualiste, c’est à l’individu que les discours doivent s’adresser. La plupart des modèles économiques qui préexistent à l’apparition de services sur Internet furent considérés, au début du XXIe siècle, comme les seuls capables de générer des bénéfices, de l’innovation et du bien-être social. L’exercice de la contrainte consistait à susciter le consentement des individus-utilisateurs dans un rapport qui, du moins le croyait-on, proposait une hiérarchie entre d’un côté les producteurs de contenus et services et, de l’autre côté, les utilisateurs. Il n’en était rien : les utilisateurs eux-mêmes étaient supposés produire des contenus œuvrant ainsi à la normalisation des rapports numériques où les créateurs exerçaient leur propre contrainte, c’est-à-dire accepter le dévoilement de leur vie privée (leur identité) en guise de tribut à l’expression de leurs idées, de leurs envies, de leurs besoins, de leurs rêves. Que n’avait-on pensé plus tôt au spectaculaire déploiement de la surveillance de masse focalisant non plus sur les actes, mais sur les éléments qui peuvent les déclencher ? Le commerce autant que l’État cherche à renseigner tout comportement prédictible dans la mesure où, pour l’un il permet de spéculer et pour l’autre il permet de planifier l’exercice du pouvoir. La société prédictible est ainsi devenue la force normalisatrice en fonction de laquelle tout discours et tout pouvoir s’exerce désormais (mais pas exclusivement) à travers l’organe de communication le plus puissant qui soit : Internet. L’affaire Snowden n’a fait que focaliser sur l’un de ses aspects relatif aux questions des défenses nationales. Mais l’aspect le plus important est que, comme le dit si bien Eben Moglen dans une conférence donnée à Berlin en 2012[2], « nous n’avons pas créé l’anonymat lorsque nous avons inventé Internet. »
Depuis le milieu des années 1980, les méthodes de collaboration dans la création de logiciels libres montraient que l’innovation devait être collective pour être assimilée et partagée par le plus grand nombre. La philosophie du Libre s’opposait à la nucléarisation sociale et proposait un modèle où, par la mise en réseau, le bien-être social pouvait émerger de la contribution volontaire de tous adhérant à des objectifs communs d’améliorations logicielles, techniques, sociales. Les créations non-logicielles de tout type ont fini par suivre le même chemin à travers l’extension des licences à des œuvres non logicielles. Les campagnes de financement collaboratif, en particulier lorsqu’elles visent à financer des projets sous licence libre, démontrent que dans un seul et même mouvement, il est possible à la fois de valider l’impact social du projet (par l’adhésion du nombre de donateurs) et assurer son développement. Pour reprendre Eben Moglen, ce n’est pas l’anonymat qui manque à Internet, c’est la possibilité de structurer une société de la collaboration qui échappe aux modèles anciens et à la coercition de droit privé qu’ils impliquent. C’est un changement de pouvoir qui est à l’œuvre et contre lequel toute réaction sera nécessairement celle de la punition : on comprend mieux l’arrivée plus ou moins subtile d’organes gouvernementaux et inter-gouvernementaux visant à sanctionner toute incartade qui soit effectivement condamnable en vertu du droit mais aussi à rigidifier les conditions d’arrivée des nouveaux modèles économiques et structurels qui contrecarrent les intérêts (individuels eux aussi, par définition) de quelques-uns. Nous ne sommes pas non plus à l’abri des resquilleurs et du libre-washing cherchant, sous couvert de sympathie, à rétablir une hiérarchie de contrôle.
Dans sa Lettre aux barbus[3], le 5 juin 2014, Laurent Chemla vise juste : le principe selon lequel « la sécurité globale (serait) la somme des sécurités individuelles » implique que la surveillance de masse (rendue possible, par exemple, grâce à notre consentement envers les services gratuits dont nous disposons sur Internet) provoque un déséquilibre entre d’une part ceux qui exercent le pouvoir et en ont les moyens et les connaissances, et d’autre part ceux sur qui s’exerce le pouvoir et qui demeurent les utilisateurs de l’organe même de l’exercice de ce pouvoir. Cette double contrainte n’est soluble qu’à la condition de cesser d’utiliser des outils centralisés et surtout s’en donner les moyens en « (imaginant) des outils qui créent le besoin plutôt que des outils qui répondent à des usages existants ». C’est-à-dire qu’il relève de la responsabilité de ceux qui détiennent des portions de savoir (les barbus, caricature des libristes) de proposer au plus grand nombre de nouveaux outils capables de rétablir l’équilibre et donc de contrecarrer l’exercice illégitime du pouvoir.
Une affaire de compétences
Par bien des aspects, le logiciel libre a transformé la vie politique. En premier lieu parce que les licences libres ont bouleversé les modèles[4] économiques et culturels hérités d’un régime de monopole. En second lieu, parce que les développements de logiciels libres n’impliquent pas de hiérarchie entre l’utilisateur et le concepteur et, dans ce contexte, et puisque le logiciel libre est aussi le support de la production de créations et d’informations, il implique des pratiques démocratiques de décision et de liberté d’expression. C’est en ce sens que la culture libre a souvent été qualifiée de « culture alternative » ou « contre-culture » parce qu’elle s’oppose assez frontalement avec les contraintes et les usages qui imposent à l’utilisateur une fenêtre minuscule pour échanger sa liberté contre des droits d’utilisation.
Contrairement à ce que l’on pouvait croire il y a seulement une dizaine d’années, tout le monde est en mesure de comprendre le paradoxe qu’il y a lorsque, pour pouvoir avoir le droit de communiquer avec la terre entière et 2 amis, vous devez auparavant céder vos droits et votre image à une entreprise comme Facebook. Il en est de même avec les formats de fichiers dont les limites ont vite été admises par le grand public qui ne comprenait et ne comprend toujours pas en vertu de quelle loi universelle le document écrit il y a 20 ans n’est aujourd’hui plus lisible avec le logiciel qui porte le même nom depuis cette époque. Les organisations libristes telles la Free Software Foundation[5], L’Electronic Frontier Foundation[6], l’April[7], l’Aful[8], Framasoft[9] et bien d’autres à travers le monde ont œuvré pour la promotion des formats ouverts et de l’interopérabilité à tel point que la décision publique a dû agir en devenant, la plupart du temps assez mollement, un organe de promotion de ces formats. Bien sûr, l’enjeu pour le secteur public est celui de la manipulation de données sensibles dont il faut assurer une certaine pérennité, mais il est aussi politique puisque le rapport entre les administrés et les organes de l’État doit se faire sans donner à une entreprise privée l’exclusivité des conditions de diffusion de l’information.
Les acteurs associatifs du Libre, sans se positionner en lobbies (alors même que les lobbies privés sont financièrement bien plus équipés) et en œuvrant auprès du public en donnant la possibilité à celui-ci d’agir concrètement, ont montré que la société civile est capable d’expertise dans ce domaine. Néanmoins, un obstacle de taille est encore à franchir : celui de donner les moyens techniques de rendre utilisables les solutions alternatives permettant une émancipation durable de la société. Peine perdue ? On pourrait le croire, alors que des instances comme le CNNum (Conseil National du Numérique) ont tendance à se résigner[10] et penser que les GAFA (Google, Apple, Facebook et Amazon) seraient des autorités incontournables, tout comme la soumission des internautes à cette nouvelle forme de féodalité serait irrémédiable.
Pour ce qui concerne la visibilité, on ne peut pas nier les efforts souvent exceptionnels engagés par les associations et fondations de tout poil visant à promouvoir le Libre et ses usages auprès du large public. Tout récemment, la Free Software Foundation a publié un site web multilingue exclusivement consacré à la question de la sécurité des données dans l’usage des courriels. Intitulé Email Self Defense[11], ce guide explique, étape par étape, la méthode pour chiffrer efficacement ses courriels avec des logiciels libres. Ce type de démarche est en réalité un symptôme, mais il n’est pas seulement celui d’une réaction face aux récentes affaires d’espionnage planétaire via Internet.
Pour reprendre l’idée de Foucault énoncée ci-dessus, le contexte de l’espionnage de masse est aujourd’hui tel qu’il laisse la place à un autre discours : celui de la nécessité de déployer de manière autonome des infrastructures propres à l’apprentissage et à l’usage des logiciels libres en fonction des besoins des populations. Auparavant, il était en effet aisé de susciter l’adhésion aux principes du logiciel libre sans pour autant déployer de nouveaux usages et sans un appui politique concret et courageux (comme les logiciels libres à l’école, dans les administrations, etc.). Aujourd’hui, non seulement les principes sont socialement intégrés mais de nouveaux usages ont fait leur apparition tout en restant prisonniers des systèmes en place. C’est ce que soulève très justement un article récent de Cory Doctorow[12] en citant une étude à propos de l’usage d’Internet chez les jeunes gens. Par exemple, une part non négligeable d’entre eux suppriment puis réactivent au besoin leurs comptes Facebook de manière à protéger leurs données et leur identité. Pour Doctorow, être « natifs du numérique » ne signifie nullement avoir un sens inné des bons usages sur Internet, en revanche leur sens de la confidentialité (et la créativité dont il est fait preuve pour la sauvegarder) est contrecarré par le fait que « Facebook rend extrêmement difficile toute tentative de protection de notre vie privée » et que, de manière plus générale, « les outils propices à la vie privée tendent à être peu pratiques ». Le sous-entendu est évident : même si l’installation logicielle est de plus en plus aisée, tout le monde n’est capable d’installer chez soi des solutions appropriées comme un serveur de courriel chiffré.
Que faire ?
Le diagnostic posé, que pouvons-nous faire ? Le domaine associatif a besoin d’argent. C’est un fait, d’ailleurs remarqué par le gouvernement français, qui avait fait de l’engagement associatif la grande « cause nationale de l’année 2014 ». Cette action[13] a au moins le mérite de valoriser l’économie sociale et solidaire, ainsi que le bénévolat. Les associations libristes sont déjà dans une dynamique similaire depuis un long moment, et parfois s’essoufflent… En revanche, il faut des investissements de taille pour avoir la possibilité de soutenir des infrastructures libres dédiées au public et répondant à ses usages numériques. Ces investissements sont difficiles pour au moins deux raisons :
la première réside dans le fait que les associations ont pour cela besoin de dons en argent. Les bonnes volontés ne suffisent pas et la monnaie disponible dans les seules communautés libristes est à ce jour en quantité insuffisante compte tenu des nombreuses sollicitations ;
la seconde découle de la première : il faut lancer un mouvement de financements participatifs ou des campagnes de dons ciblées de manière à susciter l’adhésion du grand public et proposer des solutions adaptées aux usages.
Pour cela, la première difficulté sera de lutter contre la gratuité. Aussi paradoxal que cela puisse paraître, la gratuité (relative) des services privateurs possède une dimension attractive si puissante qu’elle élude presque totalement l’existence des solutions libres ou non libres qui, elles, sont payantes. Pour rester dans le domaine de la correspondance, il est très difficile aujourd’hui de faire comprendre à Monsieur Dupont qu’il peut choisir un hébergeur de courriel payant, même au prix « participatif » d’1 euro par mois. En effet, Monsieur Dupont peut aujourd’hui utiliser, au choix : le serveur de courriel de son employeur, le serveur de courriel de son fournisseur d’accès à Internet, les serveurs de chez Google, Yahoo et autres fournisseurs disponibles très rapidement sur Internet. Dans l’ensemble, ces solutions sont relativement efficaces, simples d’utilisation, et ne nécessitent pas de dépenses supplémentaires. Autant d’arguments qui permettent d’ignorer la question de la confidentialité des courriels qui peuvent être lus et/ou analysés par son employeur, son fournisseur d’accès, des sociétés tierces…
Pourtant des solutions libres, payantes et respectueuses des libertés, existent depuis longtemps. C’est le cas de Sud-Ouest.org[14], une plate-forme d’hébergement mail à prix libre. Ou encore l’association Lautre.net[15], qui propose une solution d’hébergement de site web, mais aussi une adresse courriel, la possibilité de partager ses documents via FTP, la création de listes de discussion, etc. Pour vivre, elle propose une participation financière à la gestion de son infrastructure, quoi de plus normal ?
Aujourd’hui, il est de la responsabilité des associations libristes de multiplier ce genre de solutions. Cependant, pour dégager l’obstacle de la contrepartie financière systématique, il est possible d’ouvrir gratuitement des services au plus grand nombre en comptant exclusivement sur la participation de quelques-uns (mais les plus nombreux possible). En d’autres termes, il s’agit de mutualiser à la fois les plates-formes et les moyens financiers. Cela ne rend pas pour autant les offres gratuites, simplement le coût total est réparti socialement tant en unités de monnaie qu’en contributions de compétences. Pour cela, il faut savoir convaincre un public déjà largement refroidi par les pratiques des géants du web et qui perd confiance.
Framasoft propose des solutions
Parmi les nombreux projets de Framasoft, il en est un, plus généraliste, qui porte exclusivement sur les moyens techniques (logiciels et matériels) de l’émancipation du web. Il vise à renouer avec les principes qui ont guidé (en des temps désormais très anciens) la création d’Internet, à savoir : un Internet libre, décentralisé (ou démocratique), éthique et solidaire (l.d.e.s.).
Framasoft n’a cependant pas le monopole de ces principes l.d.e.s., loin s’en faut, en particulier parce que les acteurs du Libre œuvrent tous à l’adoption de ces principes. Mais Framasoft compte désormais jouer un rôle d’interface. À l’instar d’un Google qui rachète des start-up pour installer leurs solutions à son compte et constituer son nuage, Framasoft se propose depuis 2010, d’héberger des solutions libres pour les ouvrir gratuitement à tout public. C’est ainsi que par exemple, des particuliers, des syndicats, des associations et des entreprises utilisent les instances Framapad et Framadate. Il s’agit du logiciel Etherpad, un système de traitement de texte collaboratif, et d’un système de sondage issu de l’Université de Strasbourg (Studs) permettant de convenir d’une date de réunion ou créer un questionnaire. Des milliers d’utilisateurs ont déjà bénéficié de ces applications en ligne ainsi que d’autres, qui sont listées sur Framalab.org[16].
Depuis le début de l’année 2014, Framasoft a entamé une stratégie qui, jusqu’à présent est apparue comme un iceberg aux yeux du public. Pour la partie émergée, nous avons tout d’abord commencé par rompre radicalement les ponts avec les outils que nous avions tendance à utiliser par pure facilité. Comme nous l’avions annoncé lors de la campagne de don 2013, nous avons quitté les services de Google pour nos listes de discussion et nos analyses statistiques. Nous avons choisi d’installer une instance Bluemind, ouvert un serveur Sympa, mis en place Piwik ; quant à la publicité et les contenus embarqués, nous pouvons désormais nous enorgueillir d’assurer à tous nos visiteurs que nous ne nourrissons plus la base de données de Google. À l’échelle du réseau Framasoft, ces efforts ont été très importants et ont nécessité des compétences et une organisation technique dont jusque là nous ne disposions pas.
L’état de la Dégooglisation en octobre 2015…
Nous ne souhaitons pas nous arrêter là. La face immergée de l’iceberg est en réalité le déploiement sans précédent de plusieurs services ouverts. Ces services ne sont pas seulement proposés, ils sont accompagnés d’une pédagogie visant à montrer comment[17] installer des instances similaires pour soi-même ou pour son organisation. Nous y attachons d’autant plus d’importance que l’objectif n’est pas de commettre l’erreur de proposer des alternatives centralisées mais d’essaimer au maximum les solutions proposées.
Au mois de juin, nous avons lancé une campagne de financement participatif afin d’améliorer Etherpad (sur lequel est basé notre service Framapad) en travaillant sur un plugin baptisé Mypads : il s’agit d’ouvrir des instances privées, collaboratives ou non, et les regrouper à l’envi, ce qui permettra in fine de proposer une alternative sérieuse à Google Docs. À l’heure où j’écris ces lignes, la campagne est une pleine réussite et le déploiement de Mypads (ainsi que sa mise à disposition pour toute instance Etherpad) est prévue pour le dernier trimestre 2014. Nous avons de même comblé les utilisateurs de Framindmap, notre créateur en ligne de carte heuristiques, en leur donnant une dimension collaborative avec Wisemapping, une solution plus complète.
Au mois de juillet, nous avons lancé Framasphère[18], une instance Diaspora* dont l’objectif est de proposer (avec Diaspora-fr[19]) une alternative à Facebook en l’ouvrant cette fois au maximum en direction des personnes extérieures au monde libriste. Nous espérons pouvoir attirer ainsi l’attention sur le fait qu’aujourd’hui, les réseaux sociaux doivent afficher clairement une éthique respectueuse des libertés et des droits, ce que nous pouvons garantir de notre côté.
Enfin, après l’été 2014, nous comptons de même offrir aux utilisateurs un moteur de recherche (Framasearx) et d’ici 2015, si tout va bien, un diaporama en ligne, un service de visioconférence, des services de partage de fichiers anonymes et chiffrés, et puis… et puis…
Aurons-nous les moyens techniques et financiers de supporter la charge ? J’aimerais me contenter de dire que nous avons la prétention de faire ainsi œuvre publique et que nous devons réussir parce qu’Internet a aujourd’hui besoin de davantage de zones libres et partagées. Mais cela ne suffit pas. D’après les derniers calculs, si l’on compare en termes de serveurs, de chiffre d’affaires et d’employés, Framasoft est environ 38.000 fois plus petit que Google[20]. Or, nous n’avons pas peur, nous ne sommes pas résignés, et nous avons nous aussi une vision au long terme pour changer le monde[21]. Nous savons qu’une population de plus en plus importante (presque majoritaire, en fait) adhère aux mêmes principes que ceux du modèle économique, technique et éthique que nous proposons. C’est à la société civile de se mobiliser et nous allons développer un espace d’expression de ces besoins avec les moyens financiers de 200 mètres d’autoroute en équivalent fonds publics. Dans les mois et les années qui viennent, nous exposerons ensemble des méthodes et des exemples concrets pour améliorer Internet. Nous aider et vous investir, c’est rendre possible le passage de la résistance à la réalisation.
Ce document est placé sous Licence Art Libre 1.3 (Document version 1.0) Paru initialement dans Linux Pratique n°85 Septembre/Octobre 2014, avec leur aimable autorisation.
Les anciens Léviathans I — Le contrat social fait 128 bits… ou plus
Qu’est-ce qui fait courir Framasoft ? De la campagne Dégooglisons à l’initiative C.H.A.T.O.N.S quelles idées ont en tête les acteurs et soutiens de l’association ? Vous reprendrez bien une tranche de Léviathan ?
Pour vous inviter à aller au-delà des apparences (la sympathique petite tribu d’amateurs gaulois qui veut modestement mettre son grain de sable dans la loi des entreprises hégémoniques) nous vous proposons non seulement un moment de réflexion, mais pour une fois une série de considérations nourries, argumentées et documentées sur l’état de bascule que nous vivons et dans lequel nous prétendons inscrire notre action avec vous.
Jamais le logiciel libre et les valeurs qu’il porte n’ont été autant à la croisée des chemins, car il ne s’agit pas de proposer seulement des alternatives techniques, c’est un défi économique et politique qu’il doit relever.
Entre les États qui nous surveillent et les GAFAM qui nous monétisent, jamais le refuge du secret, celui de l’intime, n’a été aussi attaqué ni menacé. Pour représenter le monstre à plusieurs têtes, Christophe Masutti qui est l’auteur de cette série de réflexions, a choisi la figure emblématique du Léviathan, forgée déjà par Hobbes en particulier pour désigner l’État toujours plus avide de domination.
C’est donc une série de Léviathans nouveaux et anciens que nous vous invitons à découvrir par étapes, tout au long de cette semaine, qui vous conduiront peut-être à comprendre et adopter notre démarche. Car une fois établies les sources du mal et posé le diagnostic, que faire ? Les perspectives que nous proposons seront peut-être les vôtres.
Note de l’auteur :
Chiffrer nos données est un acte censé protéger nos vies privées. Dans le contexte de la surveillance massive de nos communications, il devient une nécessité.
Mais peut-on mettre en balance la notion de vie privée et la paix entre tous que le contrat social est censé nous garantir ? Le prétendu choix entre liberté et sécurité tendrait à montrer que le pouvoir de l’État ne souffre aucune option. Et pourtant, les anciennes conceptions ont la vie dure.
Quand Manuel Valls s’exprime
Dans un article de RUE 89, le journaliste Andréa Fradin revenait sur une allocution du premier ministre M. Valls, tenue le 16 octobre 2015 à l’occasion de la présentation de la Stratégie nationale pour la sécurité numérique. Durant son discours, M. Valls tenait ces propos :
Mais – s’il était nécessaire de donner à nos services de renseignement les outils indispensables pour assumer leurs missions dans la société numérique – mon gouvernement reste favorable à ce que les acteurs privés continuent de bénéficier pleinement, pour se protéger, de toutes les ressources qu’offre la cryptologie légale.
Et le journaliste de s’interroger sur la signification de ce que pourrait bien être la « cryptologie légale », dans la mesure où le fait de pouvoir chiffrer des communications ne se pose pas en ces termes. Sur son site, l’ANSSI est très claire :
L’utilisation d’un moyen de cryptologie est libre. Il n’y a aucune démarche à accomplir.
En revanche, la fourniture, l’importation, le transfert intracommunautaire et l’exportation d’un moyen de cryptologie sont soumis, sauf exception, à déclaration ou à demande d’autorisation.
Si M. Valls s’adressait essentiellement aux professionnels des communications, une telle déclaration mérite que l’on s’y arrête un peu. Elle résonne particulièrement fort dans le contexte juridique, social et émotionnel très particulier qui a vu se multiplier l’adoption de lois et de procédures qui mettent fortement en danger les libertés de communication et d’expression, sous couvert de lutte contre le terrorisme, ainsi que l’illustrait le Projet de loi renseignement au printemps 2015.
Extrait de la conférence « Dégooglisons Internet »
On note que M. Valls précise que les moyens de « cryptologie légale » sont laissés au libre choix des acteurs privés « pour se protéger ». En effet, comme le rappelle l’ANSSI, le fait de fournir un moyen de chiffrer des communications doit faire l’objet d’une déclaration ou d’une autorisation. C’est uniquement dans le choix des systèmes préalablement autorisés, que M. Valls concède aux acteurs privés qui en ressentent le besoin d’aller piocher le meilleur moyen d’assurer la confidentialité et l’authenticité de leurs échanges ou des échanges de leurs utilisateurs.
C’est sans doute cela qu’il fallait comprendre dans cette phrase. À ceci près que rappeler ce genre d’éléments aussi basiques à des acteurs déjà bien établis dans le secteur des communications numériques, ressemble bien plutôt à une mise en garde : il y a du chiffrement autorisé et il y a du chiffrement qui ne l’est pas. En d’autres termes, du point de vue des fournisseurs comme du point de vue des utilisateurs, tout n’est pas permis, y compris au nom de la protection de la vie privée.
La question du choix entre respect de la vie privée (ou d’autres libertés comme les libertés d’expression et de communication) et l’intérêt suprême de l’État dans la protection de ses citoyens, est une question qui est à l’heure actuelle bien loin d’être tranchée (si elle peut l’être un jour). Habituellement caricaturée sur le mode binaire du choix entre sécurité et liberté, beaucoup ont essayé ces derniers temps de calmer les ardeurs des partisans des deux camps, en oubliant comme nous le verrons dans les prochaines sections, que le choix datait d’au moins des premiers théoriciens du Contrat Social, il y a trois siècles. L’histoire de PGP (Pretty Good Privacy) et du standard OpenPGP est jalonnée de cette dualité (sécurité et liberté) dans notre conception du contrat social.
Autorité et PGP
La première diffusion de PGP était déjà illégale au regard du droit à l’exportation des produits de chiffrement, ce qui a valu à son créateur, Philip Zimmermann quelques ennuis juridiques au début des années 1990. La France a finalement suivi la politique nord-américaine concernant PGP en autorisant l’usage mais en restreignant son étendue. C’est l’esprit du décret 99-200 du 17 mars 1999, qui autorise, sans formalité préalable, l’utilisation d’une clé de chiffrement à condition qu’elle soit inférieure ou égale à 128 bits pour chiffrer des données. Au-delà, il fallait une autorisation jusqu’au vote de la Loi sur l’économie numérique en 2004, qui fait sauter le verrou des 128 bits (art. 30-1) pour l’usage du chiffrement (les moyens, les logiciels, eux, sont soumis à déclaration1).
Si l’on peut aisément mettre le doigt sur les lacunes du système PGP2, il reste qu’une clé de chiffrement à 128 bits, si l’implémentation est correcte, permet déjà de chiffrer très efficacement des données, quelles qu’elles soient. Lorsque les activités de surveillance de masse de la NSA furent en partie révélées par E. Snowden, on apprit que l’une des pratiques consiste à capter et stocker les contenus des communications de manière exhaustive, qu’elles soient chiffrées ou non. En cas de chiffrement, la NSA compte sur les progrès techniques futurs pour pouvoir les déchiffrer un jour où l’autre, selon les besoins. Ce gigantesque travail d’archivage réserve en principe pour l’avenir des questions de droit plutôt inextricables (par exemple l’évaluation du degré de préméditation d’un crime, ou le fait d’être suspect parce qu’on peut établir que 10 ans plus tôt Untel était en relation avec Untel). Mais le principal sujet, face à ce gigantesque travail d’espionnage de tout l’Internet, et d’archivage de données privées lisibles et illisibles, c’est de savoir dans quelle mesure il est possible de réclamer un peu plus que le seul respect de la vie privée. Pour qu’une agence d’État s’octroie le droit de récupérer dans mon intimité des données qu’elle n’est peut-être même pas capable de lire, en particulier grâce à des dispositifs comme PGP, il faut se questionner non seulement sur sa légitimité mais aussi sur la conception du pouvoir que cela suppose.
Si PGP a finalement été autorisé, il faut bien comprendre quelles en sont les limitations légales. Pour rappel, PGP fonctionne sur la base du binôme clé publique / clé privée. Je chiffre mon message avec ma clé de session, générée aléatoirement à 128 bits (ou plus), et cette clé de session est elle-même chiffrée avec la clé publique du destinataire (qui peut largement excéder les 128 bits). J’envoie alors un paquet contenant a) le message chiffré avec ma clé de session, et b) ma clé de session chiffrée par la clé publique de mon destinataire. Puis, comme ce dernier possède la clé privée qui va de pair avec sa clé publique, lui seul va pouvoir déchiffrer le message. On comprend donc que la clé privée et la clé publique ont des rôles bien différents. Alors que la clé privée sert à chiffrer les données, la clé publique sert contrôler l’accès au contenu chiffré. Dans l’esprit du décret de 1999, c’est la clé de session qui était concernée par la limitation à 128 bits.
PGP a donc été autorisé pour au moins trois raisons, que je propose ici à titre de conjectures :
parce que PGP devenait de plus en plus populaire et qu’il aurait été difficile d’en interdire officiellement l’usage, ce qui aurait supposé une surveillance de masse des échanges privés (!),
parce que PGP est une source d’innovation en termes de services et donc porteur d’intérêts économiques,
parce que PGP, limité en chiffrement des contenus à 128 bits, permettait d’avoir un étalon de mesure pour justifier la nécessité de délivrer des autorisations pour des systèmes de chiffrement supérieurs à 128 bits, c’est-à-dire des chiffrements hautement sécurisés, même si la version autorisée de PGP est déjà très efficace. Après 2004, la question ne se pose plus en termes de limitation de puissance mais en termes de surveillance des moyens (ce qui compte, c’est l’intention de chiffrer et à quel niveau).
En somme c’est une manière pour l’État de retourner à son avantage une situation dans laquelle il se trouvait pris en défaut. Je parle en premier lieu des États-Unis, car j’imagine plutôt l’État français (et les États européens en général) en tant que suiveur, dans la mesure où si PGP est autorisé d’un côté de l’Atlantique, il aurait été de toute façon contre-productif de l’interdire de l’autre. En effet, Philip Zimmermann rappelle bien les enjeux dans son texte « Pourquoi j’ai écrit PGP ». La principale raison qui justifie selon lui l’existence de PGP, est qu’une série de dispositions légales entre 1991 et 1994 imposaient aux compagnies de télécommunication américaines de mettre en place des dispositions permettant aux autorités d’intercepter en clair des communications. En d’autres termes, il s’agissait d’optimiser les dispositifs de communication pour faciliter leur accès par les services d’investigation et de surveillance aujourd’hui tristement célèbres. Ces dispositions légales ont été la cause de scandales et furent en partie retirés, mais ces intentions cachaient en vérité un programme bien plus vaste et ambitieux. Les révélations d’E. Snowden nous en ont donné un aperçu concret il y a seulement deux ans.
Inconstitutionnalité de la surveillance de masse
Là où l’argumentaire de Philip Zimmermann devient intéressant, c’est dans la justification de l’intention de créer PGP, au delà de la seule réaction à un contexte politique dangereux. Pour le citer :
[…] Il n’y a rien de mal dans la défense de votre intimité. L’intimité est aussi importante que la Constitution. Le droit à la vie privée est disséminé implicitement tout au long de la Déclaration des Droits. Mais quand la Constitution des États-Unis a été bâtie, les Pères Fondateurs ne virent aucun besoin d’expliciter le droit à une conversation privée. Cela aurait été ridicule. Il y a deux siècles, toutes les conversations étaient privées. Si quelqu’un d’autre était en train d’écouter, vous pouviez aller tout simplement derrière l’écurie et avoir une conversation là. Personne ne pouvait vous écouter sans que vous le sachiez. Le droit à une conversation privée était un droit naturel, non pas seulement au sens philosophique, mais au sens des lois de la physique, étant donné la technologie de l’époque. Mais avec l’arrivée de l’âge de l’information, débutant avec l’invention du téléphone, tout cela a changé. Maintenant, la plupart de nos conversations sont acheminées électroniquement. Cela permet à nos conversations les plus intimes d’être exposées sans que nous le sachions.
L’évocation de la Constitution des États-Unis est tout à fait explicite dans l’argumentaire de Philip Zimmermann, car la référence à laquelle nous pensons immédiatement est le Quatrième amendement (de la Déclaration des Droits) :
Le droit des citoyens d’être garantis dans leurs personne, domicile, papiers et effets, contre les perquisitions et saisies non motivées ne sera pas violé, et aucun mandat ne sera délivré, si ce n’est sur présomption sérieuse, corroborée par serment ou affirmation, ni sans qu’il décrive particulièrement le lieu à fouiller et les personnes ou les choses à saisir.
En d’autres termes, la surveillance de masse est anticonstitutionnelle. Et cela va beaucoup plus loin qu’une simple affaire de loi. Le Quatrième amendement repose essentiellement sur l’adage très britannique my home is my castle, c’est à dire le point de vue de la castle doctrine, une rémanence du droit d’asile romain (puis chrétien). C’est-à-dire qu’il existe un lieu en lequel toute personne peut trouver refuge face à l’adversité, quelle que soit sa condition et ce qu’il a fait, criminel ou non. Ce lieu pouvant être un temple (c’était le cas chez les Grecs), un lieu sacré chez les romains, une église chez les chrétiens, et pour les peuples qui conféraient une importance viscérale à la notion de propriété privée, comme dans l’Angleterre du XVIe siècle, c’est la demeure. La naissance de l’État moderne (et déjà un peu au Moyen Âge) encadra fondamentalement ce droit en y ajoutant des conditions d’exercice, ainsi, par exemple, dans le Quatrième Amendement, l’existence ou non de « présomptions sérieuses ».
Le besoin de limiter drastiquement ce qui ressort de la vie privée, est éminemment lié à la conception de l’État moderne et du contrat social. En effet, ce qui se joue à ce moment de l’histoire, qui sera aussi celui des Lumières, c’est une conception rationnelle de la vie commune contre l’irrationnel des temps anciens. C’est Thomas Hobbes qui, parmi les plus acharnés du pouvoir absolu de l’État, traumatisé qu’il était par la guerre civile, pensait que rien ne devait entraver la survie et l’omnipotence de l’État au risque de retomber dans les âges noirs de l’obscurantisme et du déchaînement des passions. Pour lui, le pacte social ne tient que dans la mesure où, pour le faire respecter, l’État peut exercer une violence incommensurable sur les individus qui composent le tissu social (et ont conféré à l’État l’exercice de cette violence). Le pouvoir de l’État s’exerce par la centralisation et la soumission à l’autorité, ainsi que le résume très bien Pierre Dockès dans son article « Hobbes et le pouvoir »3.
Mais qu’est-ce qui était irrationnel dans ces temps anciens, par exemple dans la République romaine ? Beaucoup de choses à vrai dire, à commencer par le polythéisme. Et justement, l’asylum latin fait partie de ces conceptions absolues contre lesquelles les théoriciens du contrat social se débattront pour trouver des solutions. L’État peut-il ou non supporter l’existence d’un lieu où son pouvoir ne pourrait s’exercer, en aucun cas, même s’il existe des moyens techniques pour le faire ? C’est le tabou, dans la littérature ethnologique, dont la transgression oblige le transgresseur à se soumettre à une forme d’intervention au-delà de la justice des hommes, et par là oblige les autres hommes à l’impuissance face à cette transgression innommable et surnaturelle.
À cet absolu générique s’opposent donc les limitations de l’État de droit. Dans le Code Civil français, l’article 9 stipule : « Chacun a droit au respect de sa vie privée. Tout est dans la notion de respect, que l’on oublie bien vite dans les discussions, ici et là, autour des conditions de la vie privée dans un monde numérique. La définition du respect est une variable d’ajustement, alors qu’un absolu ne se discute pas. Et c’est cette soif d’absolu que l’on entend bien souvent réclamée, car il est tellement insupportable de savoir qu’un ou plusieurs États organisent une surveillance de masse que la seule réaction proportionnellement inverse que peuvent opposer les individus au non-respect de la vie privée relève de l’irrationnel : l’absolu de la vie privée, l’idée qu’une vie privée est non seulement inviolable mais qu’elle constitue aussi l’asylum de nos données numériques.
Qu’il s’agisse de la vie privée, de la propriété privée ou de la liberté d’expression, à lire la Déclaration des droits de l’homme et du citoyen de 1789, elles sont toujours soumises à deux impératifs. Le premier est un dérivé de l’impératif catégorique kantien : « ne fais pas à autrui ce que tu n’aimerais pas qu’on te fasse » (article 4 de la Déclaration), qui impose le pouvoir d’arbitrage de l’État (« Ces bornes ne peuvent être déterminées que par la Loi ») dans les affaires privées comme dans les affaires publiques. L’autre impératif est le principe de souveraineté (article 3 de la Déclaration) selon lequel « Le principe de toute Souveraineté réside essentiellement dans la Nation. Nul corps, nul individu ne peut exercer d’autorité qui n’en émane expressément ». En d’autres termes, il faut choisir : soit les règles de l’État pour la paix entre les individus, soit le retour à l’âge du surnaturel et de l’immoralité.
À l’occasion du vote concernant la Loi Renseignement, c’est en ces termes que furent posés nombre de débats autour de la vie privée sous l’apparent antagonisme entre sécurité et liberté. D’un côté, on opposait la loi comme le moyen sans lequel il ne pouvait y avoir d’autre salut qu’en limitant toujours plus les libertés des individus. De l’autre côté, on voyait la loi comme un moyen d’exercer un pouvoir à d’autres fins (ou profits) que la paix sociale : maintenir le pouvoir de quelques uns ou encore succomber aux demandes insistantes de quelques lobbies.
Mais très peu se sont penché sur la réaction du public qui voyait dans les révélations de Snowden comme dans les lois « scélérates » la transgression du tabou de la vie privée, de l’asylum. Comment ? Une telle conception archaïque n’est-elle pas depuis longtemps dépassée ? Il y aurait encore des gens soumis au diktat de la Révélation divine ? et après tout, qu’est-ce qui fait que j’accorde un caractère absolu à un concept si ce n’est parce qu’il me provient d’un monde d’idées (formelles ou non) sans être le produit de la déduction rationnelle et de l’utilité ? Cette soif d’absolu, si elle ne provient pas des dieux, elle provient du monde des idées. Or, si on en est encore à l’opposition Platon vs. Aristote, comment faire la démonstration de ce qui n’est pas démontrable, savoir : on peut justifier, au nom de la sécurité, que l’État puisse intervenir dans nos vie privées, mais au nom de quoi justifier le caractère absolu de la vie privée ? Saint Augustin, au secours !
À ceci près, mon vieil Augustin, que deux éléments manquent encore à l’analyse et montrent qu’en réalité le caractère absolu du droit à la vie privée, d’où l’État serait exclu quelle que soit sa légitimité, a muté au fil des âges et des pratiques démocratiques.
Dialogue entre droit de savoir et droit au secret
C’est l’autorité judiciaire qui exerce le droit de savoir au nom de la manifestation de la vérité. Et à l’instar de la vie privée, la notion de vérité possède un caractère tout aussi absolu. La vie privée manifeste, au fond, notre soif d’exercer notre droit au secret. Ses limites ? elles sont instituées par la justice (et particulièrement la jurisprudence) et non par le pouvoir de l’État. Ainsi le Rapport annuel 2010 de la Cour de Cassation exprime parfaitement le cadre dans lequel peut s’exercer le droit de savoir en rapport avec le respect de la vie privée :
Dans certains cas, il peut être légitime de prendre connaissance d’une information ayant trait à la vie privée d’une personne indépendamment de son consentement. C’est dire qu’il y a lieu de procéder à la balance des intérêts contraires. Un équilibre doit être trouvé, dans l’édification duquel la jurisprudence de la Cour de cassation joue un rôle souvent important, entre le droit au respect de la vie privée et des aspirations, nombreuses, à la connaissance d’informations se rapportant à la vie privée d’autrui. Lorsqu’elle est reconnue, la primauté du droit de savoir sur le droit au respect de la vie privée se traduit par le droit de prendre connaissance de la vie privée d’autrui soit dans un intérêt privé, soit dans l’intérêt général.
En d’autres termes, il n’y a aucun archaïsme dans la défense de la vie privée face à la décision publique : c’est simplement que le débat n’oppose pas vie privée et sécurité, et en situant le débat dans cette fausse dialectique, on oublie que le premier principe de cohésion sociale, c’est la justice. On retrouve ici aussi tous les contre-arguments avancés devant la tendance néfaste des gouvernements à vouloir automatiser les sanctions sans passer par l’administration de la justice. Ainsi, par exemple, le fait de se passer d’un juge d’instruction pour surveiller et sanctionner le téléchargement « illégal » d’œuvres cinématographiques, ou de vouloir justifier la surveillance de toutes les communications au nom de la sécurité nationale au risque de suspecter tout le monde. C’est le manque (subi ou consenti) de justice qui conditionne toutes les dictatures.
Le paradoxe est le suivant: en situant le débat sur le registre sécurité vs. liberté, au nom de l’exercice légitime du pouvoir de l’État dans la protection des citoyens, on place le secret privé au même niveau que le secret militaire et stratégique, et nous serions alors tous des ennemis potentiels, exactement comme s’il n’y avait pas d’État ou comme si son rôle ne se réduisait qu’à être un instrument de répression à disposition de quelques-uns contre d’autres, ou du souverain contre la Nation. Dans ce débat, il ne faudrait pas tant craindre le « retour à la nature » mais le retour à la servitude.
Le second point caractéristique du droit de savoir, est qu’on ne peut que lui opposer des arguments rationnels. S’il s’exerce au nom d’un autre absolu, la vérité, tout l’exercice consiste à démontrer non pas le pourquoi mais le comment il peut aider à atteindre la vérité (toute relative qu’elle soit). On l’autorise alors, ou pas, à l’aune d’un consentement éclairé et socialement acceptable. On entre alors dans le règne de la déduction logique et de la jurisprudence. Pour illustrer cela, il suffit de se pencher sur les cas où les secrets professionnels ont été cassés au nom de la manifestation de la vérité, à commencer par le secret médical. La Cour de cassation explique à ce sujet, dans son Rapport 2010 :
[…] La chambre criminelle a rendu le 16 février 2010 (Bull. crim. 2010, no 27, pourvoi no 09-86.363) une décision qui, entre les droits fondamentaux que sont la protection des données personnelles médicales d’une part, et l’exercice des droits de la défense d’autre part, a implicitement confirmé l’inopposabilité du secret au juge d’instruction, mais aussi la primauté du droit de la défense qui peut justifier, pour respecter le principe du contradictoire, que ce secret ne soit pas opposable aux différentes parties.
Au risque de rappeler quelques principes évidents, puisque nous sommes censés vivre dans une société rationnelle, toute tentative de casser un secret et s’immiscer dans la vie privée, ne peut se faire a priori que par décision de justice à qui l’on reconnaît une légitimité « prudentielle ». Confier ce rôle de manière unilatérale à l’organe d’exercice du pouvoir de l’État, revient à nier ce partage entre l’absolu et le rationnel, c’est à dire révoquer le contrat social.
La sûreté des échanges est un droit naturel et universel
Comme le remarquait Philip Zimmermann, avant l’invention des télécommunications, le droit à avoir une conversation privée était aussi à comprendre comme une loi physique : il suffisait de s’isoler de manière assez efficace pour pouvoir tenir des échanges d’information de manière complètement privée. Ce n’est pas tout à fait exact. Les communications ont depuis toujours été soumises au risque de la divulgation, à partir du moment où un opérateur et/ou un dispositif entrent en jeu. Un rouleau de parchemin ou une lettre cachetée peuvent toujours être habilement ouverts et leur contenu divulgué. Et d’ailleurs la principale fonction du cachet n’était pas tant de fermer le pli que de l’authentifier.
C’est pour des raisons de stratégie militaire, que les premiers chiffrements firent leur apparition. Créés par l’homme pour l’homme, leur degré d’inviolabilité reposait sur l’habileté intellectuelle de l’un ou l’autre camp. C’est ainsi que le chiffrement ultime, une propriété de la nature (du moins, de la logique algorithmique) a été découvert : le chiffre de Vernam ou système de chiffrement à masque jetable. L’idée est de créer un chiffrement dont la clé (ou masque) est aussi longue que le message à chiffrer, composée de manière aléatoire et utilisable une seule fois. Théoriquement impossible à casser, et bien que présentant des lacunes dans la mise en œuvre pratique, cette méthode de chiffrement était accessible à la puissance de calcul du cerveau humain. C’est avec l’apparition des machines que les dés ont commencés à être pipés, sur trois plans :
en dépassant les seules capacités humaines de calcul,
en rendant extrêmement rapides les procédures de chiffrement et de déchiffrement,
en rendant accessibles des outils puissants de chiffrement à un maximum d’individus dans une société « numérique ».
Dans la mesure où l’essentiel de nos communications, chargées de données complexes et à grande distance, utilisent des machines pour être produites (ou au moins formalisées) et des services de télécommunications pour être véhiculées, le « droit naturel » à un échange privé auquel faisait allusion Philip Zimmermann, passe nécessairement par un système de chiffrement pratique, rapide et hautement efficace. PGP est une solution (il y en a d’autres).
PGP est-il efficace ? Si le contrôle de l’accès à nos données peut toujours nous échapper (comme le montrent les procédures de surveillance), le chiffrement lui-même, ne serait-ce qu’à 128 bits « seulement », reste à ce jour assez crédible. Cette citation de Wikipédia en donne la mesure :
À titre indicatif, l’algorithme AES, dernier standard d’algorithme symétrique choisi par l’institut de standardisation américain NIST en décembre 2001, utilise des clés dont la taille est au moins de 128 bits soit 16 octets, autrement dit il y en a 2128. Pour donner un ordre de grandeur sur ce nombre, cela fait environ 3,4×1038 clés possibles ; l’âge de l’univers étant de 1010 années, si on suppose qu’il est possible de tester 1 000 milliards de clés par seconde (soit 3,2×1019 clés par an), il faudra encore plus d’un milliard de fois l’âge de l’univers. Dans un tel cas, on pourrait raisonnablement penser que notre algorithme est sûr. Toutefois, l’utilisation en parallèle de très nombreux ordinateurs, synchronisés par internet, fragilise la sécurité calculatoire.
Les limites du chiffrement sont donc celles de la physique et des grands nombres, et à ce jour, ce sont des limites déjà largement acceptables. Tout l’enjeu, désormais, parce que les États ont montré leur propension à retourner l’argument démocratique contre le droit à la vie privée, est de disséminer suffisamment les pratiques de chiffrement dans le corps social. Ceci de manière à imposer en pratique la communication privée-chiffrée comme un acte naturel, un libre choix qui borne, en matière de surveillance numérique, les limites du pouvoir de l’État à ce que les individus choisissent de rendre privé et ce qu’ils choisissent de ne pas protéger par le chiffrement.
Conclusion
Aujourd’hui, la définition du contrat social semble passer par un concept supplémentaire, le chiffrement de nos données. L’usage libre des pratiques de chiffrement est borné officiellement à un contrôle des moyens, ce qui semble suffisant, au moins pour nécessiter des procédures judiciaires bien identifiées dans la plupart des cas où le droit de savoir s’impose. Idéalement, cette limite ne devrait pas exister et il devrait être possible de pouvoir se servir de systèmes de chiffrement réputés inviolables, quel que soit l’avis des gouvernements.
L’inviolabilité est une utopie ? pas tant que cela. En 2001, le chercheur Michael Rabin avait montré lors d’un colloque qu’un système réputé inviolable était concevable. En 2005, il a publié un article éclairant sur la technique de l’hyper-chiffrement (hyper encryption) intitulé « Provably unbreakable hyper-encryption in the limited access model », et une thèse (sous la direction de M. Rabin) a été soutenue en 2009 par Jason K. Juang, librement accessible à cette adresse. Si les moyens pour implémenter de tels modèles sont limités à ce jour par les capacités techniques, la sécurité de nos données semble dépendre de notre volonté de diminuer davantage ce qui nous sépare d’un système 100% efficace d’un point de vue théorique.
Le message de M. Valls, à propos de la « cryptologie légale » ne devrait pas susciter de commentaires particuliers puisque, effectivement, en l’état des possibilités techniques et grâce à l’ouverture de PGP, il est possible d’avoir des échanges réputés privés à défaut d’être complètement inviolables. Néanmoins, il faut rester vigilant quant à la tendance à vouloir définir légalement les conditions d’usage du chiffrement des données personnelles. Autant la surveillance de masse est (devrait être) inconstitutionnelle, autant le droit à chiffrer nos données doit être inconditionnel.
Doit-on craindre les pratiques d’un gouvernement plus ou moins bien intentionné ? Le Léviathan semble toutefois vaciller : non pas parce que nous faisons valoir en droit notre intimité, mais parce que d’autres Léviathans se sont réveillés, en dehors du droit et dans une nouvelle économie, sur un marché dont ils maîtrisent les règles. Ces nouveaux Léviathans, il nous faut les étudier avec d’autres concepts que ceux qui définissent l’État moderne.
On peut se reporter au site de B. Depail (Univ. Marne-La-Vallée) de qui expose les aspects juridiques de la signature numérique, en particulier la section « Aspects juridiques relatifs à la cryptographie ».↩
Pierre Dockès, « Hobbes et le pouvoir », Cahiers d’économie politique, 50.1, 2006, pp. 7-25.↩
Les nouveaux Léviathans II — Surveillance et confiance (b)
Qu’est-ce qui fait courir Framasoft ? De la campagne Dégooglisons à l’initiative C.H.A.T.O.N.S quelles idées ont en tête les acteurs et soutiens de l’association ? Vous reprendrez bien une tranche de Léviathan ?
Pour vous inviter à aller au-delà des apparences (la sympathique petite tribu d’amateurs gaulois qui veut modestement mettre son grain de sable dans la loi des entreprises hégémoniques) nous vous proposons non seulement un moment de réflexion, mais pour une fois une série de considérations nourries, argumentées et documentées sur l’état de bascule que nous vivons et dans lequel nous prétendons inscrire notre action avec vous.
Jamais le logiciel libre et les valeurs qu’il porte n’ont été autant à la croisée des chemins, car il ne s’agit pas de proposer seulement des alternatives techniques, c’est un défi économique et politique qu’il doit relever.
Entre les États qui nous surveillent et les GAFAM qui nous monétisent, jamais le refuge du secret, celui de l’intime, n’a été aussi attaqué ni menacé. Pour représenter le monstre à plusieurs têtes, Christophe Masutti qui est l’auteur de cette série de réflexions, a choisi la figure emblématique du Léviathan, forgée déjà par Hobbes en particulier pour désigner l’État toujours plus avide de domination.
C’est donc une série de Léviathans nouveaux et anciens que nous vous invitons à découvrir par étapes, tout au long de cette semaine, qui vous conduiront peut-être à comprendre et adopter notre démarche. Car une fois établies les sources du mal et posé le diagnostic, que faire ? Les perspectives que nous proposons seront peut-être les vôtres.
Cette seconde partie (Léviathans II) vise à approfondir les concepts survolés précédemment (Léviathans I). Nous avons vu que les monopoles de l’économie numérique ont changé le paradigme libéral jusqu’à instaurer un capitalisme de surveillance. Pour en rendre compte et comprendre ce nouveau système, il faut brosser plusieurs aspects de nos rapports avec la technologie en général, et les services numériques en particulier, puis voir comment des modèles s’imposent par l’usage des big data et la conformisation du marché (Léviathans IIa). J’expliquerai, à partir de la lecture de S. Zuboff, quelles sont les principales caractéristiques du capitalisme de surveillance. En identifiant ainsi ces nouvelles conditions de l’aliénation des individus, il devient évident que le rétablissement de la confiance aux sources de nos relations contractuelles et démocratiques, passe immanquablement par l’autonomie, le partage et la coopération, sur le modèle du logiciel libre (Léviathans IIb).
Trouver les bonnes clés
Cette logique du marché, doit être analysée avec d’autres outils que ceux de l’économie classique. L’impact de l’informationnalisation et la concentration des acteurs de l’économie numérique ont sans doute été largement sous-estimés, non pas pour les risques qu’ils font courir aux économies post-industrielles, mais pour les bouleversements sociaux qu’ils impliquent. Le besoin de défendre les droits et libertés sur Internet et ailleurs n’est qu’un effet collatéral d’une situation contre laquelle il est difficile d’opposer seulement des postures et des principes.
Il faut entendre les mots de Marc Rotenberg, président de l’Electronic Privacy Information Center (EPIC), pour qui le débat dépasse désormais la seule question de la neutralité du réseau ou de la liberté d’expression1. Pour lui, nous avons besoin d’analyser ce qui structure la concentration du marché. Mais le phénomène de concentration dans tous les services de communication que nous utilisons implique des échelles tellement grandes, que nous avons besoin d’instruments de mesure au moins aussi grands. Nous avons besoin d’une nouvelle science pour comprendre Internet, le numérique et tout ce qui découle des formes d’automatisation.
Diapositive extraite de la conférence « Dégooglisons Internet »
On s’arrête bien souvent sur l’aspect le plus spectaculaire de la fuite d’environ 1,7 millions de documents grâce à Edward Snowden en 2013, qui montrent que les États, à commencer par les États-Unis, ont créé des systèmes de surveillance de leurs populations au détriment du respect de la vie privée. Pour beaucoup de personnes, cette atteinte doit être ramenée à la dimension individuelle : dois-je avoir quelque chose à cacher ? comment échapper à cette surveillance ? implique-t-elle un contrôle des populations ? un contrôle de l’expression ? en quoi ma liberté est-elle en danger ? etc. Mais peu de personnes se sont réellement interrogées sur le fait que si la NSA s’est fait livrer ces quantités gigantesques d’informations par des fournisseurs de services (comme par exemple, la totalité des données téléphoniques de Verizon ou les données d’échanges de courriels du service Hotmail de Microsoft) c’est parce que ces entreprises avaient effectivement les moyens de les fournir et que par conséquent de telles quantités d’informations sur les populations sont tout à fait exploitables et interprétables en premier lieu par ces mêmes fournisseurs.
Face à cela, plusieurs attitudes sont possibles. En les caricaturant, elles peuvent être :
Positivistes. On peut toujours s’extasier devant les innovations de Google surtout parce que la culture de l’innovation à la Google est une composante du story telling organisé pour capter l’attention des consommateurs. La communication est non seulement exemplaire mais elle constitue un modèle d’après Google qui en donne même les recettes (cf. les deux liens précédents). Que Google, Apple, Microsoft, Facebook ou Amazon possèdent des données me concernant, cela ne serait qu’un détail car nous avons tous l’opportunité de participer à cette grande aventure du numérique (hum !).
Défaitistes. On n’y peut rien, il faut donc se contenter de protéger sa vie privée par des moyens plus ou moins dérisoires, comme par exemple faire du bruit pour brouiller les pistes et faire des concessions car c’est le prix à payer pour profiter des applications bien utiles. Cette attitude consiste à échanger l’utilité contre l’information, ce que nous faisons à chaque fois que nous validons les clauses d’utilisation des services GAFAM.
Complotistes. Les procédés de captation des données servent ceux qui veulent nous espionner. Les utilisations commerciales seraient finalement secondaires car c’est contre l’emploi des données par les États qu’il faut lutter. C’est la logique du moins d’État contre la liberté du nouveau monde numérique, comme si le choix consistait à donner notre confiance soit aux États soit aux GAFAM, liberté par contrat social ou liberté par consommation.
Les objectifs de cette accumulation de données sont effectivement différents que ceux poursuivis par la NSA et ses institutions homologues. La concentration des entreprises crée le besoin crucial d’organiser les monopoles pour conserver un marché stable. Les ententes entre entreprises, repoussant toujours davantage les limites juridiques des autorités de régulations, créent une logique qui ne consiste plus à s’adapter à un marché aléatoire, mais adapter le marché à l’offre en l’analysant en temps réel, en utilisant les données quotidiennes des utilisateurs de services. Il faut donc analyser ce capitalisme de surveillance, ainsi que le nomme Shoshana Zuboff, car comme nous l’avons vu :
les États ont de moins en moins les capacités de réguler ces activités,
nous sommes devenus des produits de variables qui configurent nos comportements et nos besoins.
L’ancienne conception libérale du marché, l’acception économique du contrat social, reposait sur l’idée que la démocratie se consolide par l’égalitarisme des acteurs et l’équilibre du marché. Que l’on adhère ou pas à ce point de vue, il reste qu’aujourd’hui le marché ne s’équilibre plus par des mécanismes libéraux mais par la seule volonté de quelques entreprises. Cela pose inévitablement une question démocratique.
Dans son rapport, Antoinette Rouvroy en vient à adresser une série de questions sur les répercutions de cette morphologie du marché. Sans y apporter franchement de réponse, elle en souligne les enjeux :
Ces dispositifs d’« anticipation performative » des intentions d’achat (qui est aussi un court-circuitage du processus de transformation de la pulsion en désir ou en intention énonçable), d’optimisation de la force de travail fondée sur la détection anticipative des performances futures sur base d’indicateurs produits automatiquement au départ d’analyses de type Big Data (qui signifie aussi une chute vertigineuse du « cours de l’expérience » et des mérites individuels sur le marché de l’emploi), posent des questions innombrables. L’anticipation performative des intentions –et les nouvelles possibilités d’actions préemptives fondées sur la détection des intentions – est-elle compatible avec la poursuite de l’autodétermination des personnes ? Ne faut-il pas concevoir que la possibilité d’énoncer par soi-même et pour soi-même ses intentions et motivations constitue un élément essentiel de l’autodétermination des personnes, contre cette utopie, ou cette dystopie, d’une société dispensée de l’épreuve d’un monde hors calcul, d’un monde où les décisions soient autre chose que l’application scrupuleuse de recommandations automatiques, d’un monde où les décisions portent encore la marque d’un engagement subjectif ? Comment déterminer la loyauté de ces pratiques ? L’optimisation de la force de travail fondée sur le profilage numérique est-il compatible avec le principe d’égalité et de non-discrimination ?2
Ce qui est questionné par A. Rouvroy, c’est ce que Zuboff nomme le capitalisme de surveillance, du moins une partie des pratiques qui lui sont inhérentes. Dès lors, au lieu de continuer à se poser des questions, il est important d’intégrer l’idée que si le paradigme a changé, les clés de lecture sont forcément nouvelles.
Déconstruire le capitalisme de surveillance
Shoshana Zuboff a su identifier les pratiques qui déconstruisent l’équilibre originel et créent ce nouveau capitalisme. Elle pose ainsi les jalons de cette nouvelle « science » qu’appelle de ses vœux Marc Rotenberg, et donne des clés de lecture pertinentes. L’essentiel des concepts qu’elle propose se trouve dans son article « Big other: surveillance capitalism and the prospects of an information civilization », paru en 20153. Dans cet article S. Zuboff décortique deux discours de Hal Varian, chef économiste de Google et s’en sert de trame pour identifier et analyser les processus du capitalisme de surveillance. Dans ce qui suit, je vais essayer d’expliquer quelques clés issues du travail de S. Zuboff.
Sur quelle stratégie repose le capitalisme de surveillance ?
Il s’agit de la stratégie de commercialisation de la quotidienneté en modélisant cette dernière en autant de données analysées, inférences et prédictions. La logique d’accumulation, l’automatisation et la dérégulation de l’extraction et du traitement de ces données rendent floues les frontières entre vie privée et consommation, entre les firmes et le public, entre l’intention et l’information.
Qu’est-ce que la quotidienneté ?
Il s’agit de ce qui concerne la sphère individuelle mais appréhendée en réseau. L’informationnalisation de nos profils individuels provient de plusieurs sources. Il peut s’agir des informations conventionnelles (au sens propre) telles que nos données d’identité, nos données bancaires, etc. Elles peuvent résulter de croisements de flux de données et donner lieu à des inférences. Elles peuvent aussi provenir des objets connectés, agissant comme des sensors ou encore résulter des activités de surveillance plus ou moins connues. Si toutes ces données permettent le profilage c’est aussi par elles que nous déterminons notre présence numérique. Avoir une connexion Internet est aujourd’hui reconnu comme un droit : nous ne distinguons plus nos activités d’expression sur Internet des autres activités d’expression. Les activités numériques n’ont plus à être considérées comme des activités virtuelles, distinctes de la réalité. Nos pages Facebook ne sont pas plus virtuelles que notre compte Amazon ou notre dernière déclaration d’impôt en ligne. Si bien que cette activité en réseau est devenue si quotidienne qu’elle génère elle-même de nouveaux comportements et besoins, produisant de nouvelles données analysées, agrégées, commercialisées.
Extraction des données
S. Zuboff dresse un inventaire des types de données, des pratiques d’extraction, et les enjeux de l’analyse. Il faut cependant comprendre qu’il y a de multiples manières de « traiter » les données. La Directive 95/46/CE (Commission Européenne) en dressait un inventaire, déjà en 19954 :
« traitement de données à caractère personnel » (traitement) : toute opération ou ensemble d’opérations effectuées ou non à l’aide de procédés automatisés et appliquées à des données à caractère personnel, telles que la collecte, l’enregistrement, l’organisation, la conservation, l’adaptation ou la modification, l’extraction, la consultation, l’utilisation, la communication par transmission, diffusion ou toute autre forme de mise à disposition, le rapprochement ou l’interconnexion, ainsi que le verrouillage, l’effacement ou la destruction.
Le processus d’extraction de données n’est pas un processus autonome, il ne relève pas de l’initiative isolée d’une ou quelques firmes sur un marché de niche. Il constitue désormais la norme commune à une multitude de firmes, y compris celles qui n’œuvrent pas dans le secteur numérique. Il s’agit d’un modèle de développement qui remplace l’accumulation de capital. Autant cette dernière était, dans un modèle économique révolu, un facteur de production (par les investissements, par exemple), autant l’accumulation de données est désormais la clé de production de capital, lui-même réinvesti en partie dans des solutions d’extraction et d’analyse de données, et non dans des moyens de production, et pour une autre partie dans la valorisation boursière, par exemple pour le rachat d’autres sociétés, à l’image des multiples rachats de Google.
Neutralité et indifférence
Les données qu’exploite Google sont très diverses. On s’interroge généralement sur celles qui concernent les catégories auxquelles nous accordons de l’importance, comme par exemple lorsque nous effectuons une recherche au sujet d’une mauvaise grippe et que Google Now nous propose une consultation médicale à distance. Mais il y a une multitude de données dont nous soupçonnons à peine l’existence, ou apparemment insignifiantes pour soi, mais qui, ramenées à des millions, prennent un sens tout à fait probant pour qui veut les exploiter. On peut citer par exemple le temps de consultation d’un site. Si Google est prêt à signaler des contenus à l’administration des États-Unis, comme l’a dénoncé Julian Assange ou si les relations publiques de la firme montrent une certaine proximité avec les autorités de différents pays et l’impliquent dans des programmes d’espionnage, il reste que cette attitude coopérante relève essentiellement d’une stratégie économique. En réalité, l’accumulation et l’exploitation des données suppose une indifférence formelle par rapport à leur signification pour l’utilisateur. Quelle que soit l’importance que l’on accorde à l’information, le postulat de départ du capitalisme de surveillance, c’est l’accumulation de quantités de données, non leur qualité. Quant au sens, c’est le marché publicitaire qui le produit.
L’extraction et la confiance
S. Zuboff dresse aussi un court inventaire des pratiques d’extraction de Google. L’exemple emblématique est Google Street View, qui rencontra de multiples obstacles à travers le monde : la technique consiste à s’immiscer sur des territoires et capturer autant de données possible jusqu’à rencontrer de la résistance qu’elle soit juridique, politique ou médiatique. Il en fut de même pour l’analyse du courrier électronique sur Gmail, la capture des communications vocales, les paramètres de confidentialité, l’agrégation des données des comptes sur des services comme Google+, la conservation des données de recherche, la géolocalisation des smartphones, la reconnaissance faciale, etc.
En somme, le processus d’extraction est un processus à sens unique, qui ne tient aucun compte (ou le moins possible) de l’avis de l’utilisateur. C’est l’absence de réciprocité.
On peut ajouter à cela la puissance des Big Data dans l’automatisation des relations entre le consommateur et le fournisseur de service. Google Now propose de se substituer à une grande partie de la confidentialité entre médecin et patient en décelant au moins les causes subjectives de la consultation (en interprétant les recherches). Hal Varian lui-même vante les mérites de l’automatisation de la relation entre assureurs et assurés dans un monde où l’on peut couper à distance le démarrage de la voiture si le client n’a pas payé ses traites. Des assurances santé et même des mutuelles (!) proposent aujourd’hui des applications d’auto-mesure (quantified self)de l’activité physique, dont on sait pertinemment que cela résultera sur autant d’ajustements des prix voire des refus d’assurance pour les moins chanceux.
La relation contractuelle est ainsi automatisée, ce qui élimine d’autant le risque lié aux obligations des parties. En d’autres termes, pour éviter qu’une partie ne respecte pas ses obligations, on se passe de la confiance que le contrat est censé formaliser, au profit de l’automatisation de la sanction. Le contrat se résume alors à l’acceptation de cette automatisation. Si l’arbitrage est automatique, plus besoin de recours juridique. Plus besoin de la confiance dont la justice est censée être la mesure.
Entre l’absence de réciprocité et la remise en cause de la relation de confiance dans le contrat passé avec l’utilisateur, ce sont les bases démocratiques de nos rapports sociaux qui sont remises en question puisque le fondement de la loi et de la justice, c’est le contrat et la formalisation de la confiance.
Plus Google a d’utilisateurs, plus il rassemble des données. Plus il y a de données plus leur valeur predictive augmente et optimise le potentiel lucratif. Pour des firmes comme Google, le marché n’est pas composé d’agents rationnels qui choisissent entre plusieurs offres et configurent la concurrence. La société « à la Google » n’est plus fondée sur des relations de réciprocité, même s’il s’agit de luttes sociales ou de revendications.
L’« uberisation » de la société (voir le début de cet article) qui nous transforme tous en employés ou la transformation des citoyens en purs consommateurs, c’est exactement le cauchemar d’Hannah Arendt que S. Zuboff cite longuement :
Le dernier stade de la société de travail, la société d’employés, exige de ses membres un pur fonctionnement automatique, comme si la vie individuelle était réellement submergée par le processus global de la vie de l’espèce, comme si la seule décision encore requise de l’individu était de lâcher, pour ainsi dire, d’abandonner son individualité, sa peine et son inquiétude de vivre encore individuellement senties, et d’acquiescer à un type de comportement, hébété, « tranquillisé » et fonctionnel. Ce qu’il y a de fâcheux dans les théories modernes du comportement, ce n’est pas qu’elles sont fausses, c’est qu’elles peuvent devenir vraies, c’est qu’elles sont, en fait, la meilleure mise en concept possible de certaines tendances évidentes de la société moderne. On peut parfaitement concevoir que l’époque moderne (…) s’achève dans la passivité la plus inerte, la plus stérile que l’Histoire ait jamais connue.5
Devant cette anticipation catastrophiste, l’option choisie ne peut être l’impuissance et le laisser-faire. Il faut d’abord nommer ce à quoi nous avons affaire, c’est-à-dire un système (total) face auquel nous devons nous positionner.
Qu’est-ce que Big Other et que peut-on faire ?
Il s’agit des mécanismes d’extraction, marchandisation et contrôle. Ils instaurent une dichotomie entre les individus (utilisateurs) et leur propre comportement (pour les transformer en données) et simultanément ils produisent de nouveaux marchés basés justement sur la prédictibilité de ces comportements.
(Big Other) est un régime institutionnel, omniprésent, qui enregistre, modifie, commercialise l’expérience quotidienne, du grille-pain au corps biologique, de la communication à la pensée, de manière à établir de nouveaux chemins vers les bénéfices et les profits. Big other est la puissance souveraine d’un futur proche qui annihile la liberté que l’on gagne avec les règles et les lois.6
Avoir pu mettre un nom sur ce nouveau régime dont Google constitue un peu plus qu’une illustration (presque initiateur) est la grande force de Shoshana Zuboff. Sans compter plusieurs articles récents de cette dernière dans la Frankfurter Allgemeine Zeitung, il est étonnant que le rapport d’Antoinette Rouvroy, postérieur d’un an, n’y fasse aucune mention. Est-ce étonnant ? Pas vraiment, en réalité, car dans un rapport officiellement remis aux autorités européennes, il est important de préciser que la lutte contre Big Other (ou de n’importe quelle manière dont on peut l’exprimer) ne peut que passer par la légitimité sans faille des institutions. Ainsi, A. Rouvroy oppose les deux seules voies envisageables dans un tel contexte officiel :
À l’approche « law and economics », qui est aussi celle des partisans d’un « marché » des données personnelles, qui tendrait donc à considérer les données personnelles comme des « biens » commercialisables (…) s’oppose l’approche qui consiste à aborder les données personnelles plutôt en fonction du pouvoir qu’elles confèrent à ceux qui les contrôlent, et à tenter de prévenir de trop grandes disparités informationnelles et de pouvoir entre les responsables de traitement et les individus. C’est, à l’évidence, cette seconde approche qui prévaut en Europe.
Or, devant Google (ou devant ce Big Other) nous avons vu l’impuissance des États à faire valoir un arsenal juridique, à commencer par les lois anti-trust. D’une part, l’arsenal ne saurait être exhaustif : il concernerait quelques aspects seulement de l’exploitation des données, la transparence ou une série d’obligations comme l’expression des finalités ou des consentements. Il ne saurait y avoir de procès d’intention. D’autre part, nous pouvons toujours faire valoir que des compagnies telles Microsoft ont été condamnées par le passé, au moins par les instances européennes, pour abus de position dominante, et que quelques millions d’euros de menace pourraient suffire à tempérer les ardeurs. C’est faire peu de cas d’au moins trois éléments :
l’essentiel des compagnies dont il est question sont nord-américaines, possèdent des antennes dans des paradis fiscaux et sont capables, elles, de menacer financièrement des pays entiers par simples effets de leviers boursiers.
L’arsenal juridique qu’il faudrait déployer avant même de penser à saisir une cour de justice, devrait être rédigé, voté et décrété en admettant que les jeux de lobbies et autres obstacles formels soient entièrement levés. Cela prendrait un minimum de dix ans, si l’on compte les recours envisageables après une première condamnation.
Il faut encore caractériser les Big Data dans un contexte où leur nature est non seulement extrêmement diverse mais aussi soumise à des process d’automatisation et calculatoires qui permettent d’en inférer d’autres quantités au moins similaires. Par ailleurs, les sources des données sont sans cesse renouvelées, et leur stockage et analyse connaissent une progression technique exponentielle.
Dès lors, quels sont les moyens de s’échapper de ce Big Other ? Puisque nous avons changé de paradigme économique, nous devons changer de paradigme de consommation et de production. Grâce à des dispositifs comme la neutralité du réseau, garantie fragile et obtenue de longue lutte, il est possible de produire nous même l’écosystème dans lequel nos données sont maîtrisées et les maillons de la chaîne de confiance sont identifiés.
Comment évoluer dans le monde du capitalisme de surveillance ? telle est la question que nous pouvons nous poser dans la mesure où visiblement nous ne pouvons plus nous extraire d’une situation de soumission à Big Other. Quelles que soient nos compétences en matière de camouflage et de chiffrement, les sources de données sur nos individualités sont tellement diverses que le résultat de la distanciation avec les technologies du marché serait une dé-socialisation. Puisque les technologies sur le marché sont celles qui permettent la production, l’analyse et l’extraction automatisées de données, l’objectif n’est pas tant de s’en passer que de créer un système où leur pertinence est tellement limitée qu’elle laisse place à un autre principe que l’accumulation de données : l’accumulation de confiance.
Voyons un peu : quelles sont les actuelles échappatoires de ce capitalisme de surveillance ? Il se trouve qu’elles impliquent à chaque fois de ne pas céder aux facilités des services proposés pour utiliser des solutions plus complexes mais dont la simplification implique toujours une nouvelle relation de confiance. Illustrons ceci par des exemples relatifs à la messagerie par courrier électronique :
Si j’utilise Gmail, c’est parce que j’ai confiance en Google pour respecter la confidentialité de ma correspondance privée (no comment !). Ce jugement n’implique pas que moi, puisque mes correspondants auront aussi leurs messages scannés, qu’ils soient utilisateurs ou non de Gmail. La confiance repose exclusivement sur Google et les conditions d’utilisation de ses services.
L’utilisation de clés de chiffrement pour correspondre avec mes amis demande un apprentissage de ma part comme de mes correspondants. Certains services, comme ProtonMail, proposent de leur faire confiance pour transmettre des données chiffrées tout en simplifiant les procédures avec un webmail facile à prendre en main. Les briques open source de Protonmail permettent un niveau de transparence acceptable sans que j’en aie toutefois l’expertise (si je ne suis pas moi-même un informaticien sérieux).
Si je monte un serveur chez moi, avec un système libre et/ou open source comme une instance Cozycloud sur un Raspeberry PI, je dois avoir confiance dans tous les domaines concernés et sur lesquels je n’ai pas forcément l’expertise ou l’accès physique (la fabrication de l’ordinateur, les contraintes de mon fournisseur d’accès, la sécurité de mon serveur, etc.), c’est-à-dire tous les aspects qui habituellement font l’objet d’une division du travail dans les entreprises qui proposent de tels services, et que j’ai la prétention de rassembler à moi tout seul.
Les espaces de relative autonomie existent donc mais il faut structurer la confiance. Cela peut se faire en deux étapes.
La première étape consiste à définir ce qu’est un tiers de confiance et quels moyens de s’en assurer. Le blog de la FSFE a récemment publié un article qui résume très bien pourquoi la protection des données privées ne peut se contenter de l’utilisation plus ou moins maîtrisée des technologies de chiffrement7. La FSFE rappelle que tous les usages des services sur Internet nécessitent un niveau de confiance accordé à un tiers. Quelle que soit son identité…
…vous devez prendre en compte :
la bienveillance : le tiers ne veut pas compromettre votre vie privée et/ou il est lui-même concerné ;
la compétence : le tiers est techniquement capable de protéger votre vie privée et d’identifier et de corriger les problèmes ;
l’intégrité : le tiers ne peut pas être acheté, corrompu ou infiltré par des services secrets ou d’autres tiers malveillants ;
Comment s’assurer de ces trois qualités ? Pour les défenseurs et promoteurs du logiciel libre, seules les communautés libristes sont capables de proposer des alternatives en vertu de l’ouverture du code. Sur les quatre libertés qui définissent une licence libre, deux impliquent que le code puisse être accessible, audité, vérifié.
Est-ce suffisant ? non : ouvrir le code ne conditionne pas ces qualités, cela ne fait qu’endosser la responsabilité et l’usage du code (via la licence libre choisie) dont seule l’expertise peut attester de la fiabilité et de la probité.
En complément, la seconde étape consiste donc à définir une chaîne de confiance. Elle pourra déterminer à quel niveau je peux m’en remettre à l’expertise d’un tiers, à ses compétences, à sa bienveillance…. Certaines entreprises semblent l’avoir compris et tentent d’anticiper ce besoin de confiance. Pour reprendre les réflexions du Boston Consulting Group, l’un des plus prestigieux cabinets de conseil en stratégie au monde :
(…) dans un domaine aussi sensible que le Big Data, la confiance sera l’élément déterminant pour permettre à l’entreprise d’avoir le plus large accès possible aux données de ses clients, à condition qu’ils soient convaincus que ces données seront utilisées de façon loyale et contrôlée. Certaines entreprises parviendront à créer ce lien de confiance, d’autres non. Or, les enjeux économiques de ce lien de confiance sont très importants. Les entreprises qui réussiront à le créer pourraient multiplier par cinq ou dix le volume d’informations auxquelles elles sont susceptibles d’avoir accès. Sans la confiance du consommateur, l’essentiel des milliards d’euros de valeur économique et sociale que le Big Data pourrait représenter dans les années à venir risquerait d’être perdu.8
En d’autres termes, il existe un marché de la confiance. En tant que tel, soit il est lui aussi soumis aux effets de Big Other, soit il reste encore dépendant de la rationalité des consommateurs. Dans les deux cas, le logiciel libre devra obligatoirement trouver le créneau de persuasion pour faire adhérer le plus grand nombre à ses principes.
Une solution serait de déplacer le curseur de la chaîne de confiance non plus sur les principaux acteurs de services, plus ou moins dotés de bonnes intentions, mais dans la sphère publique. Je ne fais plus confiance à tel service ou telle entreprise parce qu’ils indiquent dans leurs CGU qu’ils s’engagent à ne pas utiliser mes données personnelles, mais parce que cet engagement est non seulement vérifiable mais aussi accessible : en cas de litige, le droit du pays dans lequel j’habite peut s’appliquer, des instances peuvent se porter parties civiles, une surveillance collective ou policière est possible, etc. La question n’est plus tellement de savoir ce que me garantit le fournisseur mais comment il propose un audit public et expose sa responsabilité vis-à-vis des données des utilisateurs.
S’en remettre à l’État pour des services fiables ? Les États ayant démontré leurs impuissances face à des multinationales surfinancées, les tentatives de cloud souverain ont elles aussi été des échecs cuisants. Créer des entreprises de toutes pièces sur fonds publics pour proposer une concurrence directe à des monopoles géants, était inévitablement un suicide : il aurait mieux valu proposer des ressources numériques et en faciliter l’accès pour des petits acteurs capables de proposer de multiples solutions différentes et alternatives adaptées aux besoins de confiance des utilisateurs, éventuellement avec la caution de l’État, la réputation d’associations nationales (association de défense des droits de l’homme, associations de consommateurs, etc.), bref, des assurances concrètes qui impliquent les utilisateurs, c’est-à-dire comme le modèle du logiciel libre qui ne sépare pas utilisation et conception.
Ce que propose le logiciel libre, c’est davantage que du code, c’est un modèle de coopération et de cooptation. C’est la possibilité pour les dynamiques collectives de réinvestir des espaces de confiance. Quel que soit le service utilisé, il dépend d’une communauté, d’une association, ou d’une entreprise qui toutes s’engagent par contrat (les licences libres sont des contrats) à respecter les données des utilisateurs. Le tiers de confiance devient collectif, il n’est plus un, il est multiple. Il ne s’agit pas pour autant de diluer les responsabilités (chaque offre est indépendante et s’engage individuellement) mais de forcer l’engagement public et la transparence des recours.
Chatons solidaires
Si s’échapper seul du marché de Big Other ne peut se faire qu’au prix de l’exclusion, il faut opposer une logique différente capable, devant l’exploitation des données et notre aliénation de consommateurs, de susciter l’action et non la passivité, le collectif et non l’individu. Si je produis des données, il faut qu’elles puissent profiter à tous ou à personne. C’est la logique de l’open data qui garanti le libre accès à des données placées dans le bien commun. Ce commun a ceci d’intéressant que tout ce qui y figure est alors identifiable. Ce qui n’y figure pas relève alors du privé et diffuser une donnée privée ne devrait relever que du seul choix délibéré de l’individu.
Le modèle proposé par le projet CHATONS (Collectif d’Hébergeurs Alternatifs, Transparents, Ouverts, Neutres et Solidaires) de Framasoft repose en partie sur ce principe. En adhérant à la charte, un hébergeur s’engage publiquement à remplir certaines obligations et, parmi celles-ci, l’interdiction d’utiliser les données des utilisateurs pour autre chose que l’évaluation et l’amélioration des services.
Comme écrit dans son manifeste (en version 0.9), l’objectif du collectif CHATONS est simple :
L’objectif de ce collectif est de mailler les initiatives de services basés sur des solutions de logiciels libres et proposés aux utilisateurs de manière à diffuser toutes les informations utiles permettant au public de pouvoir choisir leurs services en fonction de leurs besoins, avec un maximum de confiance vis-à-vis du respect de leur vie privée, sans publicité ni clause abusive ou obscure.
En lançant l’initiative de ce collectif, sans toutefois se placer dans une posture verticale fédérative, Framasoft ouvre une porte d’échappatoire. L’essentiel n’est pas tant de maximiser la venue de consommateurs sur quelques services identifiés mais de maximiser les chances pour les consommateurs d’utiliser des services de confiance qui, eux, pourront essaimer et se multiplier. Le postulat est que l’utilisateur est plus enclin à faire confiance à un hébergeur qu’il connaît et qui s’engage devant d’autres hébergeurs semblables, ses pairs, à respecter ses engagements éthiques. Outre l’utilisation de logiciels libres, cela se concrétise par trois principes
Mutualiser l’expertise : les membres du collectif s’engagent à partager les informations pour augmenter la qualité des services et pour faciliter l’essaimage des solutions de logiciels libres utilisées. C’est un principe de solidarité qui permettra, à terme, de consolider sérieusement le tissu des hébergeurs concernés.
Publier et adhérer à une charte commune. Cette charte donne les principaux critères techniques et éthiques de l’activité de membre. L’engagement suppose une réciprocité des échanges tant avec les autres membres du collectif qu’avec les utilisateurs.
Un ensemble de contraintes dans la charte publique implique non seulement de ne s’arroger aucun droit sur les données privées des utilisateurs, mais aussi de rester transparent y compris jusque dans la publication de ses comptes et rapports d’activité. En tant qu’utilisateur je connais les engagements de mon hébergeur, je peux agir pour le contraindre à les respecter tout comme les autres hébergeurs peuvent révoquer de leur collectif un membre mal intentionné.
Le modèle CHATONS n’est absolument pas exclusif. Il constitue même une caricature, en quelque sorte l’alternative contraire mais pertinente à GAFAM. Des entreprises tout à fait bien intentionnées, respectant la majeure partie de la charte, pourraient ne pas pouvoir entrer dans ce collectif à cause des contraintes liées à leur modèle économique. Rien n’empêche ces entreprises de monter leur propre collectif, avec un niveau de confiance différent mais néanmoins potentiellement acceptable. Si le collectif CHATONS décide de restreindre au domaine associatif des acteurs du mouvement, c’est parce que l’idée est d’essaimer au maximum le modèle : que l’association philatélique de Trifouille-le-bas puisse avoir son serveur de courriel, que le club de football de Trifouille-le-haut puisse monter un serveur owncloud et que les deux puissent mutualiser en devenant des CHATONS pour en faire profiter, pourquoi pas, les deux communes (et donc la communauté).
Un chaton, deux chatons… des chatons !
Conclusion
La souveraineté numérique est souvent invoquée par les autorités publiques bien conscientes des limitations du pouvoir qu’implique Big Other. Par cette expression, on pense généralement se situer à armes égales contre les géants du web. Pouvoir économique contre pouvoir républicain. Cet affrontement est perdu d’avance par tout ce qui ressemble de près ou de loin à une procédure institutionnalisée. Tant que les citoyens ne sont pas eux-mêmes porteurs d’alternatives au marché imposé par les GAFAM, l’État ne peut rien faire d’autre que de lutter pour sauvegarder son propre pouvoir, c’est-à-dire celui des partis comme celui des lobbies. Le serpent se mord la queue.
Face au capitalisme de surveillance, qui a depuis longtemps dépassé le stade de l’ultra-libéralisme (car malgré tout il y subsistait encore un marché et une autonomie des agents), c’est à l’État non pas de proposer un cloud souverain mais de se positionner comme le garant des principes démocratiques appliqués à nos données numériques et à Internet : neutralité sans faille du réseau, garantie de l’équité, surveillance des accords commerciaux, politique anti-trust affirmée, etc. L’éducation populaire, la solidarité, l’intelligence collective, l’expertise des citoyens, feront le reste, quitte à ré-inventer d’autres modèles de gouvernance (et de gouvernement).
Nous ne sommes pas des êtres a-technologiques. Aujourd’hui, nos vies sont pleines de données numériques. Avec Internet, nous en usons pour nous rapprocher, pour nous comprendre et mutualiser nos efforts, tout comme nous avons utilisé en leurs temps le téléphone, les voies romaines, le papyrus, et les tablettes d’argile. Nous avons des choix à faire. Nous pouvons nous diriger vers des modèles exclusifs, avec ou sans GAFAM, comme la généralisation de block chains pour toutes nos transactions. En automatisant les contrats, même avec un système ouvert et neutre, nous ferions alors reposer la confiance sur la technologie (et ses failles), en révoquant toute relation de confiance entre les individus, comme si toute relation interpersonnelle était vouée à l’échec. L’autre voie repose sur l’éthique et le partage des connaissances. Le projet CHATONS n’est qu’un exemple de système alternatif parmi des milliers d’autres dans de multiples domaines, de l’agriculture à l’industrie, en passant par la protection de l’environnement. Saurons-nous choisir la bonne voie ? Saurons-nous comprendre que les relations d’interdépendances qui nous unissent sur terre passent aussi bien par l’écologie que par le partage du code ?
Discours prononcé lors d’une conférence intitulée Surveillance capitalism: A new societal condition rising lors du sommet CPDP (Computers Privacy and Data protection), Bruxelles, 27-29 janvier 2016 (video).↩
Shoshana Zuboff, « Big other: surveillance capitalism and the prospects of an information civilization », Journal of Information Technology, 30, 2015, pp. p;75-89.↩
Directive 95/46/CE du Parlement européen et du Conseil, du 24 octobre 1995, relative à la protection des personnes physiques à l’égard du traitement des données à caractère personnel et à la libre circulation de ces données.↩
Hannah Arendt, La condition de l’homme moderne, Paris: Calmann-Lévy, Agora, 1958, pp. 400-401.↩
Shoshana Zuboff, « Big other: surveillance capitalism and the prospects of an information civilization », Journal of Information Technology, 30, 2015, p. p;81.↩
Les nouveaux Léviathans II — Surveillance et confiance (a)
Qu’est-ce qui fait courir Framasoft ? De la campagne Dégooglisons à l’initiative C.H.A.T.O.N.S quelles idées ont en tête les acteurs et soutiens de l’association ? Vous reprendrez bien une tranche de Léviathan ?
Pour vous inviter à aller au-delà des apparences (la sympathique petite tribu d’amateurs gaulois qui veut modestement mettre son grain de sable dans la loi des entreprises hégémoniques) nous vous proposons non seulement un moment de réflexion, mais pour une fois une série de considérations nourries, argumentées et documentées sur l’état de bascule que nous vivons et dans lequel nous prétendons inscrire notre action avec vous.
Jamais le logiciel libre et les valeurs qu’il porte n’ont été autant à la croisée des chemins, car il ne s’agit pas de proposer seulement des alternatives techniques, c’est un défi économique et politique qu’il doit relever.
Entre les États qui nous surveillent et les GAFAM qui nous monétisent, jamais le refuge du secret, celui de l’intime, n’a été aussi attaqué ni menacé. Pour représenter le monstre à plusieurs têtes, Christophe Masutti qui est l’auteur de cette série de réflexions, a choisi la figure emblématique du Léviathan, forgée déjà par Hobbes en particulier pour désigner l’État toujours plus avide de domination.
C’est donc une série de Léviathans nouveaux et anciens que nous vous invitons à découvrir par étapes, tout au long de cette semaine, qui vous conduiront peut-être à comprendre et adopter notre démarche. Car une fois établies les sources du mal et posé le diagnostic, que faire ? Les perspectives que nous proposons seront peut-être les vôtres.
Note de l’auteur :Cette seconde partie (Léviathans II) vise à approfondir les concepts survolés précédemment (Léviathans I). Nous avons vu que les monopoles de l’économie numérique ont changé le paradigme libéral jusqu’à instaurer un capitalisme de surveillance. Pour en rendre compte et comprendre ce nouveau système, il faut brosser plusieurs aspects de nos rapports avec la technologie en général, et les services numériques en particulier, puis voir comment des modèles s’imposent par l’usage des big data et la conformisation du marché (Léviathans IIa). J’expliquerai, à partir de la lecture de S. Zuboff, quelles sont les principales caractéristiques du capitalisme de surveillance. En identifiant ainsi ces nouvelles conditions de l’aliénation des individus, il devient évident que le rétablissement de la confiance aux sources de nos relations contractuelles et démocratiques, passe immanquablement par l’autonomie, le partage et la coopération, sur le modèle du logiciel libre (Léviathans IIb).
Techniques d’anticipation
On pense habituellement les objets techniques et les phénomènes sociaux comme deux choses différentes, voire parfois opposées. En plus de la nature, il y aurait deux autres réalités : d’un côté un monde constitué de nos individualités, nos rapports sociaux, nos idées politiques, la manière dont nous structurons ensemble la société ; et de l’autre côté le monde des techniques qui, pour être appréhendé, réclamerait obligatoirement des compétences particulières (artisanat, ingénierie). Nous refusons même parfois de comprendre nos interactions avec les techniques autrement que par automatisme, comme si notre accomplissement social passait uniquement par le statut d’utilisateur et jamais comme producteurs. Comme si une mise à distance devait obligatoirement s’établir entre ce que nous sommes (des êtres sociaux) et ce que nous produisons. Cette posture est au plus haut point paradoxale puisque non seulement la technologie est une activité sociale mais nos sociétés sont à bien des égards elles-mêmes configurées, transformées, et même régulées par les objets techniques. Certes, la compréhension des techniques n’est pas toujours obligatoire pour comprendre les faits sociaux, mais il faut avouer que bien peu de faits sociaux se comprennent sans la technique.
L’avènement des sociétés industrielles a marqué un pas supplémentaire dans l’interdépendance entre le social et les objets techniques : le travail, comme activité productrice, est en soi un rapport réflexif sur les pratiques et les savoirs qui forment des systèmes techniques. Nous baignons dans une culture technologique, nous sommes des êtres technologiques. Nous ne sommes pas que cela. La technologie n’a pas le monopole du signifiant : nous trouvons dans l’art, dans nos codes sociaux, dans nos intentions, tout un ensemble d’éléments culturels dont la technologie est censée être absente. Nous en usons parfois même pour effectuer une mise à distance des techniques omniprésentes. Mais ces dernières ne se réduisent pas à des objets produits. Elles sont à la fois des pratiques, des savoir-faire et des objets. La raison pour laquelle nous tenons tant à instaurer une mise à distance par rapport aux technologies que nous utilisons, c’est parce qu’elles s’intègrent tellement dans notre système économique qu’elles agissent aussi comme une forme d’aliénation au travail comme au quotidien.
Ces dernières années, nous avons vu émerger des technologies qui prétendent prédire nos comportements. Amazon teste à grande échelle des dépôts locaux de produits en prévision des commandes passées par les internautes sur un territoire donné. Les stocks de ces dépôts seront gérés au plus juste par l’exploitation des données inférées à partir de l’analyse de l’attention des utilisateurs (mesurée au clic), les tendances des recherches effectuées sur le site, l’impact des promotions et propositions d’Amazon, etc. De son côté, Google ne cesse d’analyser nos recherches dans son moteur d’indexation, dont les suggestions anticipent nos besoins souvent de manière troublante. En somme, si nous éprouvons parfois cette nécessité d’une mise à distance entre notre être et la technologie, c’est en réponse à cette situation où, intuitivement, nous sentons bien que la technologie n’a pas à s’immiscer aussi profondément dans l’intimité de nos pensées. Mais est-ce vraiment le cas ? Ne conformons-nous pas aussi, dans une certaine mesure, nos envies et nos besoins en fonction de ce qui nous est présenté comme nos envies et nos besoins ? La lutte permanente entre notre volonté d’indépendance et notre adaptation à la société de consommation, c’est-à-dire au marché, est quelque chose qui a parfaitement été compris par les grandes firmes du secteur numérique. Parce que nous laissons tellement de traces transformées en autant d’informations extraites, analysées, quantifiées, ces firmes sont désormais capables d’anticiper et de conformer le marché à leurs besoins de rentabilité comme jamais une firme n’a pu le faire dans l’histoire des sociétés capitalistes modernes.
Productivisme et information
Si vous venez de perdre deux minutes à lire ma prose ci-dessus hautement dopée à l’EPO (Enfonçage de Portes Ouvertes), c’est parce qu’il m’a tout de même paru assez important de faire quelques rappels de base avant d’entamer des considérations qui nous mènerons petit à petit vers une compréhension en détail de ce système. J’ai toujours l’image de cette enseignante de faculté, refusant de lire un mode d’emploi pour appuyer deux touches sur son clavier afin de basculer l’affichage écran vers l’affichage du diaporama, et qui s’exclamait : « il faut appeler un informaticien, ils sont là pour ça, non ? ». Ben non, ma grande, un informaticien a autre chose à faire. C’est une illustration très courante de ce que la transmission des savoirs (activité sociale) dépend éminemment des techniques (un vidéo-projecteur couplé un ordinateur contenant lui-même des supports de cours sous forme de fichiers) et que toute tentative volontaire ou non de mise à distance (ne pas vouloir acquérir un savoir-faire technique) cause un bouleversement a-social (ne plus être en mesure d’assurer une transmission de connaissance, ou plus prosaïquement passer pour quelqu’un de stupide). La place que nous occupons dans la société n’est pas uniquement une affaire de codes ou relations interpersonnelles, elle dépend pour beaucoup de l’ordre économique et technique auquel nous devons plus ou moins nous ajuster au risque de l’exclusion (et la forme la plus radicale d’exclusion est l’absence de travail et/ou l’incapacité de consommer).
Des études déjà anciennes sur les organisations du travail, notamment à propos de l’industrialisation de masse, ont montré comment la technologie, au même titre que l’organisation, détermine les comportements des salariés, en particulier lorsqu’elle conditionne l’automatisation des tâches1. Souvent, cette automatisation a été étudiée sous l’angle des répercussions socio-psychologiques, accroissant les sentiments de perte de sens ou d’aliénation sociale2. D’un point de vue plus populaire, c’est le remplacement de l’homme par la machine qui fut tantôt vécu comme une tragédie (l’apparition du chômage de masse) tantôt comme un bienfait (diminuer la pénibilité du travail). Aujourd’hui, les enjeux sont très différents. On s’interroge moins sur la place de la machine dans l’industrie que sur les taux de productivité et la gestion des flux. C’est qu’un changement de paradigme s’est accompli à partir des années 1970-1980, qui ont vu apparaître l’informatisation quasi totale des systèmes de production et la multiplication des ordinateurs mainframe dans les entreprises pour traiter des quantités sans cesse croissantes de données.
Très peu de sociologues ou d’économistes ont travaillé sur ce qu’une illustre chercheuse de la Harvard Business School, Shoshana Zuboff a identifié dans la transformation des systèmes de production : l’informationnalisation (informating). En effet, dans un livre très visionnaire, In the Age Of The Smart Machine en 19883, S. Zuboff montre que les mécanismes du capitalisme productiviste du XXe siècle ont connu plusieurs mouvements, plus ou moins concomitants selon les secteurs : la mécanisation, la rationalisation des tâches, l’automatisation des processus et l’informationnalisation. Ce dernier mouvement découle des précédents : dès l’instant qu’on mesure la production et qu’on identifie des processus, on les documente et on les programme pour les automatiser. L’informationnalisation est un processus qui transforme la mesure et la description des activités en information, c’est-à-dire en données extractibles et quantifiables, calculatoires et analytiques.
Là où S. Zuboff s’est montrée visionnaire dans les années 1980, c’est qu’elle a montré aussi comment l’informationnalisation modèle en retour les apprentissages et déplace les enjeux de pouvoir. On ne cherche plus à savoir qui a les connaissances suffisantes pour mettre en œuvre telle procédure, mais qui a accès aux données dont l’analyse déterminera la stratégie de développement des activités. Alors que le « vieux » capitalisme organisait une concurrence entre moyens de production et maîtrise de l’offre, ce qui, dans une économie mondialisée n’a plus vraiment de sens, un nouveau capitalisme (dont nous verrons plus loin qu’il se nomme le capitalisme de surveillance) est né, et repose sur la production d’informations, la maîtrise des données et donc des processus.
Pour illustrer, il suffit de penser à nos smartphones. Quelle que soit la marque, ils sont produits de manière plus ou moins redondante, parfois dans les mêmes chaînes de production (au moins en ce qui concerne les composants), avec des méthodes d’automatisation très similaires. Dès lors, la concurrence se place à un tout autre niveau : l’optimisation des procédures et l’identification des usages, tous deux producteurs de données. Si bien que la plus-value ajoutée par la firme à son smartphone pour séduire le plus d’utilisateurs possible va de pair avec une optimisation des coûts de production et des procédures. Cette optimisation relègue l’innovation organisationnelle au moins au même niveau, si ce n’est plus, que l’innovation du produit lui-même qui ne fait que répondre à des besoins d’usage de manière marginale. En matière de smartphone, ce sont les utilisateurs les plus experts qui sauront déceler la pertinence de telle ou telle nouvelle fonctionnalité alors que l’utilisateur moyen n’y voit que des produits similaires.
L’enjeu dépasse la seule optimisation des chaînes de production et l’innovation. S. Zuboff a aussi montré que l’analyse des données plus fines sur les processus de production révèle aussi les comportements des travailleurs : l’attention, les pratiques quotidiennes, les risques d’erreur, la gestion du temps de travail, etc. Dès lors l’informationnalisation est aussi un moyen de rassembler des données sur les aspects sociaux de la production4, et par conséquent les conformer aux impératifs de rentabilité. L’exemple le plus frappant aujourd’hui de cet ajustement comportemental à la rentabilité par les moyens de l’analyse de données est le phénomène d’« Ubérisation » de l’économie5.
Ramené aux utilisateurs finaux des produits, dans la mesure où il est possible de rassembler des données sur l’utilisation elle-même, il devrait donc être possible de conformer les usages et les comportements de consommation (et non plus seulement de production) aux mêmes impératifs de rentabilité. Cela passe par exemple par la communication et l’apprentissage de nouvelles fonctionnalités des objets. Par exemple, si vous aviez l’habitude de stocker vos fichiers MP3 dans votre smartphone pour les écouter comme avec un baladeur, votre fournisseur vous permet aujourd’hui avec une connexion 4G d’écouter de la musique en streaming illimité, ce qui permet d’analyser vos goûts, vous proposer des playlists, et faire des bénéfices. Mais dans ce cas, si vous vous situez dans un endroit où la connexion haut débit est défaillante, voire absente, vous devez vous passer de musique ou vous habituer à prévoir à l’avance cette éventualité en activant un mode hors-connexion. Cette adaptation de votre comportement devient prévisible : l’important n’est pas de savoir ce que vous écoutez mais comment vous le faites, et ce paramètre entre lui aussi en ligne de compte dans la proposition musicale disponible.
Le nouveau paradigme économique du XXIe siècle, c’est le rassemblement des données, leur traitement et leurs valeurs prédictives, qu’il s’agisse des données de production comme des données d’utilisation par les consommateurs.
Ces dernières décennies, l’informatique est devenu un média pour l’essentiel de nos activités sociales. Vous souhaitez joindre un ami pour aller boire une bière dans la semaine ? c’est avec un ordinateur que vous l’appelez. Voici quelques étapes grossières de cet épisode :
votre mobile a signalé vers des antennes relais pour s’assurer de la couverture réseau,
vous entrez un mot de passe pour déverrouiller l’écran,
vous effectuez une recherche dans votre carnet d’adresse (éventuellement synchronisé sur un serveur distant),
vous lancez le programme de composition du numéro, puis l’appel téléphonique (numérique) proprement dit,
vous entrez en relation avec votre correspondant, convenez d’une date,
vous envoyez ensuite une notification de rendez-vous avec votre agenda vers la messagerie de votre ami…
qui vous renvoie une notification d’acceptation en retour,
l’une de vos applications a géolocalisé votre emplacement et vous indique le trajet et le temps de déplacement nécessaire pour vous rendre au point de rendez-vous, etc.
Durant cet épisode, quel que soit l’opérateur du réseau que vous utilisez et quel que soit le système d’exploitation de votre mobile (à une ou deux exceptions près), vous avez produit des données exploitables. Par exemple (liste non exhaustive) :
le bornage de votre mobile indique votre position à l’opérateur, qui peut croiser votre activité d’émission-réception avec la nature de votre abonnement,
la géolocalisation donne des indications sur votre vitesse de déplacement ou votre propension à utiliser des transports en commun,
votre messagerie permet de connaître la fréquence de vos contacts, et éventuellement l’éloignement géographique.
Ramené à des millions d’utilisateurs, l’ensemble des données ainsi rassemblées entre dans la catégorie des Big Data. Ces dernières ne concernent pas seulement les systèmes d’informations ou les services numériques proposés sur Internet. La massification des données est un processus qui a commencé il y a longtemps, notamment par l’analyse de productivité dans le cadre de la division du travail, les analyses statistiques des achats de biens de consommation, l’analyse des fréquences de transaction boursières, etc. Tout comme ce fut le cas pour les processus de production qui furent automatisés, ce qui caractérise les Big Data c’est l’obligation d’automatiser leur traitement pour en faire l’analyse.
Prospection, gestion des risques, prédictibilité, etc., les Big Data dépassent le seul degré de l’analyse statistique dite descriptive, car si une de ces données renferme en général très peu d’information, des milliers, des millions, des milliards permettent d’inférer des informations dont la pertinence dépend à la fois de leur traitement et de leur gestion. Le tout dépasse la somme des parties : c’est parce qu’elles sont rassemblées et analysées en masse que des données d’une même nature produisent des valeurs qui dépassent la somme des valeurs unitaires.
Antoinette Rouvroy, dans un rapport récent6 auprès du Conseil de l’Europe, précise que les capacités techniques de stockage et de traitement connaissent une progression exponentielle7. Elle définit plusieurs catégories de data en fonction de leurs sources, et qui quantifient l’essentiel des actions humaines :
les hard data, produites par les institutions et administrations publiques ;
les soft data, produites par les individus, volontairement (via les réseaux sociaux, par exemple) ou involontairement (analyse des flux, géolocalisation, etc.) ;
les métadonnées, qui concernent notamment la provenance des données, leur trafic, les durées, etc. ;
l’Internet des objets, qui une fois mis en réseau, produisent des données de performance, d’activité, etc.
Les Big Data n’ont cependant pas encore de définition claire8. Il y a des chances pour que le terme ne dure pas et donne lieu à des divisions qui décriront plus précisément des applications et des méthodes dès lors que des communautés de pratiques seront identifiées avec leurs procédures et leurs réseaux. Aujourd’hui, l’acception générique désigne avant tout un secteur d’activité qui regroupe un ensemble de savoir-faire et d’applications très variés. Ainsi, le potentiel scientifique des Big Data est encore largement sous-évalué, notamment en génétique, physique, mathématiques et même en sociologie. Il en est de même dans l’industrie. En revanche, si on place sur un même plan la politique, le marketing et les activités marchandes (à bien des égards assez proches) on conçoit aisément que l’analyse des données optimise efficacement les résultats et permet aussi, par leur dimension prédictible, de conformer les biens et services.
Google fait peur ?
Eric Schmidt, actuellement directeur exécutif d’Alphabet Inc., savait exprimer en peu de mots les objectifs de Google lorsqu’il en était le président. Depuis 1998, les activités de Google n’ont cessé d’évoluer, jusqu’à reléguer le service qui en fit la célébrité, la recherche sur la Toile, au rang d’activité has been pour les internautes. En 2010, il dévoilait le secret de Polichinelle :
Le jour viendra où la barre de recherche de Google – et l’activité qu’on nomme Googliser – ne sera plus au centre de nos vies en ligne. Alors quoi ? Nous essayons d’imaginer ce que sera l’avenir de la recherche (…). Nous sommes toujours contents d’être dans le secteur de la recherche, croyez-moi. Mais une idée est que de plus en plus de recherches sont faites en votre nom sans que vous ayez à taper sur votre clavier.
En fait, je pense que la plupart des gens ne veulent pas que Google réponde à leurs questions. Ils veulent que Google dise ce qu’ils doivent faire ensuite. (…) La puissance du ciblage individuel – la technologie sera tellement au point qu’il sera très difficile pour les gens de regarder ou consommer quelque chose qui n’a pas été adapté pour eux.9
Google n’a pas été la première firme à exploiter des données en masse. Le principe est déjà ancien avec les premiers data centers du milieu des années 1960. Google n’est pas non plus la première firme à proposer une indexation générale des contenus sur Internet, par contre Google a su se faire une place de choix parmi la concurrence farouche de la fin des années 1990 et sa croissance n’a cessé d’augmenter depuis lors, permettant des investissements conséquents dans le développement de technologies d’analyse et dans le rachat de brevets et de plus petites firmes spécialisées. Ce que Google a su faire, et qui explique son succès, c’est proposer une expérience utilisateur captivante de manière à rassembler assez de données pour proposer en retour des informations adaptées aux profils des utilisateurs. C’est la radicalisation de cette stratégie qui est énoncée ici par Eric Schmidt. Elle trouve pour l’essentiel son accomplissement en utilisant les données produites par les utilisateurs du cloud computing. Les Big Data en sont les principaux outils.
D’autres firmes ont emboîté le pas. En résultat, la concentration des dix premières firmes de services numériques génère des bénéfices spectaculaires et limite la concurrence. Cependant, l’exploitation des données personnelles des utilisateurs et la manière dont elles sont utilisées sont souvent mal comprises dans leurs aspects techniques autant que par les enjeux économiques et politiques qu’elles soulèvent. La plupart du temps, la quantité et la pertinence des informations produites par l’utilisateur semblent négligeables à ses yeux, et leur exploitation d’une importance stratégique mineure. Au mieux, si elles peuvent encourager la firme à mettre d’autres services gratuits à disposition du public, le prix est souvent considéré comme largement acceptable. Tout au plus, il semble a priori moins risqué d’utiliser Gmail et Facebook, que d’utiliser son smartphone en pleine manifestation syndicale en France, puisque le gouvernement français a voté publiquement des lois liberticides et que les GAFAM ne livrent aux autorités que les données manifestement suspectes (disent-elles) ou sur demande rogatoire officielle (disent-elles).
Gigantismus
En 2015, Google Analytics couvrait plus de 70% des parts de marché des outils de mesure d’audience. Google Analytics est un outil d’une puissance pour l’instant incomparable dans le domaine de l’analyse du comportement des visiteurs. Cette puissance n’est pas exclusivement due à une supériorité technologique (les firmes concurrentes utilisent des techniques d’analyse elles aussi très performantes), elle est surtout due à l’exhaustivité monopolistique des utilisations de Google Analytics, disponible en version gratuite et premium, avec un haut degré de configuration des variables qui permettent la collecte, le traitement et la production très rapide de rapports (pratiquement en temps réel). La stratégie commerciale, afin d’assurer sa rentabilité, consiste essentiellement à coupler le profilage avec la régie publicitaire (Google AdWords). Ce modèle économique est devenu omniprésent sur Internet. Qui veut être lu ou regardé doit passer l’épreuve de l’analyse « à la Google », mais pas uniquement pour mesurer l’audience : le monopole de Google sur ces outils impose un web rédactionnel, c’est-à-dire une méthode d’écriture des contenus qui se prête à l’extraction de données.
Google n’est pas la seule entreprise qui réussi le tour de force d’adapter les contenus, quelle que soit leur nature et leurs propos, à sa stratégie commerciale. C’est le cas des GAFAM qui reprennent en chœur le même modèle économique qui conforme l’information à ses propres besoins d’information. Que vous écriviez ou non un pamphlet contre Google, l’extraction et l’analyse des données que ce contenu va générer indirectement en produisant de l’activité (visites, commentaires, échanges, temps de connexion, provenance, etc.) permettra de générer une activité commerciale. Money is money, direz-vous. Pourtant, la concentration des activités commerciales liées à l’exploitation des Big Data par ces entreprises qui forment les premières capitalisations boursières du monde, pose un certain nombre répercutions sociales : l’omniprésence mondialisée des firmes, la réduction du marché et des choix, l’impuissance des États, la sur-financiarisation.
Omniprésence
En produisant des services gratuits (ou très accessibles), performants et à haute valeur ajoutée pour les données qu’ils produisent, ces entreprises captent une gigantesque part des activités numériques des utilisateurs. Elles deviennent dès lors les principaux fournisseurs de services avec lesquels les gouvernements doivent composer s’ils veulent appliquer le droit, en particulier dans le cadre de la surveillance des populations et des opérations de sécurité. Ainsi, dans une démarche très pragmatique, des ministères français parmi les plus importants réunirent le 3 décembre 2015 les « les grands acteurs de l’internet et des réseaux sociaux » dans le cadre de la stratégie anti-terroriste10. Plus anciennement, le programme américain de surveillance électronique PRISM, dont bien des aspects furent révélés par Edward Snowden en 2013, a permit de passer durant des années des accords entre la NSA et l’ensemble des GAFAM. Outre les questions liées à la sauvegarde du droit à la vie privée et à la liberté d’expression, on constate aisément que la surveillance des populations par les gouvernements trouve nulle part ailleurs l’opportunité de récupérer des données aussi exhaustives, faisant des GAFAM les principaux prestataires de Big Data des gouvernements, quels que soient les pays11.
Réduction du marché
Le monopole de Google sur l’indexation du web montre qu’en vertu du gigantesque chiffre d’affaires que cette activité génère, celle-ci devient la première et principale interface du public avec les contenus numériques. En 2000, le journaliste Laurent Mauriac signait dans Libération un article élogieux sur Google12. À propos de la méthode d’indexation qui en fit la célébrité, L. Mauriac écrit :
Autre avantage : ce système empêche les sites de tricher. Inutile de farcir la partie du code de la page invisible pour l’utilisateur avec quantité de mots-clés…
Or, en 2016, il devient assez évident de décortiquer les stratégies de manipulation de contenus que les compagnies qui en ont les moyens financiers mettent en œuvre pour dominer l’index de Google en diminuant ainsi la diversité de l’offre13. Que la concentration des entreprises limite mécaniquement l’offre, cela n’est pas révolutionnaire. Ce qui est particulièrement alarmant, en revanche, c’est que la concentration des GAFAM implique par effets de bord la concentration d’autres entreprises de secteurs entièrement différents mais qui dépendent d’elles en matière d’information et de visibilité. Cette concentration de second niveau, lorsqu’elle concerne la presse en ligne, les éditeurs scientifiques ou encore les libraires, pose à l’évidence de graves questions en matière de liberté d’information.
Impuissances
La concentration des services, qu’il s’agisse de ceux de Google comme des autres géants du web, sur des secteurs biens découpés qui assurent les monopoles de chaque acteur, cause bien des soucis aux États qui voient leurs économies impactées selon les revenus fiscaux et l’implantation géographique de ces compagnies. Les lois anti-trust semblent ne plus suffire lorsqu’on voit, par exemple, la Commission Européenne avoir toutes les peines du monde à freiner l’abus de position dominante de Google sur le système Android, sur Google Shopping, sur l’indexation, et de manière générale depuis 2010.
Illustration cynique devant l’impuissance des États à réguler cette concentration, Google a davantage à craindre de ses concurrents directs qui ont des moyens financiers largement supérieurs aux États pour bloquer sa progression sur les marchés. Ainsi, cet accord entre Microsoft et Google, qui conviennent de régler désormais leurs différends uniquement en privé, selon leurs propres règles, pour ne se concentrer que sur leur concurrence de marché et non plus sur la législation. Le message est double : en plus d’instaurer leur propre régulation de marché, Google et Microsoft en organiseront eux-mêmes les conditions juridiques, reléguant le rôle de l’État au second plan, voire en l’éliminant purement et simplement de l’équation. C’est l’avènement des Léviathans dont j’avais déjà parlé dans un article antérieur.
Alphabet. CC-by-sa, Framatophe
Capitaux financiers
La capitalisation boursière des GAFAM a atteint un niveau jamais envisagé jusqu’à présent dans l’histoire, et ces entreprises figurent toutes dans le top 40 de l’année 201514. La valeur cumulée de GAFAM en termes de capital boursier en 2015 s’élève à 1 838 milliards de dollars. À titre de comparaison, le PIB de la France en 2014 était de 2 935 milliards de dollars et celui des Pays Bas 892 milliards de dollars.
La liste des acquisitions de Google explique en partie la cumulation de valeurs boursières. Pour une autre partie, la plus importante, l’explication concerne l’activité principale de Google : la valorisation des big data et l’automatisation des tâches d’analyse de données qui réduisent les coûts de production (à commencer par les frais d’infrastructure : Google a besoin de gigantesque data centers pour le stockage, mais l’analyse, elle, nécessite plus de virtualisation que de nouveaux matériels ou d’employés). Bien que les cheminements ne soient pas les mêmes, les entreprises GAFAM ont abouti au même modèle économique qui débouche sur le status quo de monopoles sectorisés. Un élément de comparaison est donné par le Financial Times en août 2014, à propos de l’industrie automobile vs l’économie numérique :
Comparons Detroit en 1990 et la Silicon Valley en 2014. Les 3 plus importantes compagnies de Detroit produisaient des bénéfices à hauteur de 250 milliards de dollars avec 1,2 million d’employés et la cumulation de leurs capitalisations boursières totalisait 36 milliards de dollars. Le 3 premières compagnies de la Silicon Valley en 2014 totalisaient 247 milliards de dollars de bénéfices, avec seulement 137 000 employés, mais un capital boursier de 1,09 mille milliard de dollars.15
La captation d’autant de valeurs par un petit nombre d’entreprises et d’employés, aurait été analysée, par exemple, par Schumpeter comme une chute inévitable vers la stagnation en raison des ententes entre les plus puissants acteurs, la baisse des marges des opérateurs et le manque d’innovation. Pourtant cette approche est dépassée : l’innovation à d’autres buts (produire des services, même à perte, pour capter des données), il est très difficile d’identifier le secteur d’activité concerné (Alphabet regroupe des entreprises ultra-diversifiées) et donc le marché est ultra-malléable autant qu’il ne représente que des données à forte valeur prédictive et possède donc une logique de plus en plus maîtrisée par les grands acteurs.
Voir sur ce point Robert Blauner, Alienation and Freedom. The Factory Worker and His Industry, Chicago: Univ. Chicago Press, 1965.↩
Shoshana Zuboff, In The Age Of The Smart Machine: The Future Of Work And Power, New York: Basic Books, 1988.↩
En guise d’illustration de tests (proof of concepts) discrets menés dans les entreprises aujourd’hui, on peut se reporter à cet article de Rue 89 Strasbourg sur cette société alsacienne qui propose, sous couvert de challenge collectif, de monitorer l’activité physique de ses employés. Rémi Boulle, « Chez Constellium, la collecte des données personnelles de santé des employés fait débat », Rue 89 Strasbourg, juin 2016.↩
Par exemple, dans le cas des livreurs à vélo de plats préparés utilisés par des sociétés comme Foodora ou Take Eat Easy, on constate que ces sociétés ne sont qu’une interface entre les restaurants et les livreurs. Ces derniers sont auto-entrepreneurs, payés à la course et censés assumer toutes les cotisations sociales et leurs salaires uniquement sur la base des courses que l’entreprise principale pourra leur confier. Ce rôle est automatisé par une application de calcul qui rassemble les données géographiques et les performances (moyennes, vitesse, assiduité, etc.) des livreurs et distribue automatiquement les tâches de livraisons. Charge aux livreurs de se trouver au bon endroit au bon moment. Ce modèle économique permet de détacher l’entreprise de toutes les externalités ou tâches habituellement intégrées qui pourraient influer sur son chiffre d’affaires : le matériel du livreur, l’assurance, les cotisations, l’accidentologie, la gestion du temps de travail, etc., seule demeure l’activité elle-même automatisée et le livreur devient un exécutant dont on analyse les performances. L’« Ubérisation » est un processus qui automatise le travail humain, élimine les contraintes sociales et utilise l’information que l’activité produit pour ajuster la production à la demande (quels que soient les risques pris par les livreurs, par exemple pour remonter les meilleures informations concernant les vitesses de livraison et se voir confier les prochaines missions). Sur ce sujet, on peut écouter l’émission Comme un bruit qui court de France Inter qui diffusa le reportage de Giv Anquetil le 11 juin 2016, intitulé « En roue libre ».↩
Même si Apple a déclaré ne pas entrer dans le secteur des Big Data, il n’en demeure pas moins qu’il en soit un consommateur comme un producteur d’envergure mondiale.↩
Le chiffrement, s’il n’est pas encore dans tous nos usages — et loin s’en faut, chez la plupart des utilisateurs, est nettement devenu un argument marketing et une priorité pour les entreprises qui distribuent logiciels et services. En effet, le grand public est beaucoup plus sensible désormais à l’argument de la sécurité de la vie privée. Donc les services qui permettent la communication en ligne rivalisent d’annonces pour promettre et garantir une sécurité toujours plus grande et que l’on puisse activer d’un simple clic.
Que faut-il croire, à qui et quoi pouvons-nous confier nos communications ?
L’article de Hannes Hauswedell que nous avons traduit nous aide à faire un tri salutaire entre les solutions logicielles du marché, pointe les faux-semblants et les failles, puis nous conduit tranquillement à envisager des solutions fédérées et pair à pair reposant sur des logiciels libres. Des réseaux de confiance en somme, ce qui est proche de l’esprit de l’initiative C.H.A.T.O.N.S portée par Framasoft et qui suscite déjà un intérêt grandissant.
Comme d’habitude les commentaires sont ouverts et libres si vous souhaitez par exemple ajouter vos découvertes à ce recensement critique forcément incomplet.
Au cours de l’année dernière on a pu croire que les poules avaient des dents quand les grandes entreprises hégémoniques comme Apple, Google et Facebook ont toutes mis en œuvre le chiffrement à un degré ou un autre. Pour Facebook avec WhatsApp et Google avec Allo, le chiffrement de la messagerie a même été implémenté par rien moins que le célèbre Moxie Marlinspike, un hacker anarchiste qui a la bénédiction d’Edward Snowden !
Donc tout est pour le mieux sur le front de la défense de la vie privée !… Euh, vraiment ?
J’ai déjà développé mon point de vue sur la sécurité de la messagerie mobile et j’en ai parlé dans un podcast (en allemand). Mais j’ai pensé qu’il fallait que j’y revienne, car il existe une certaine confusion sur ce que signifient sécurité et confidentialité (en général, mais particulièrement dans le contexte de la messagerie), et parce que les récentes annonces dans ce domaine ne donnent selon moi qu’un sentiment illusoire de sécurité.
Je vais parler de WhatsApp et de Facebook Messenger (tous deux propriétés de Facebook), de Skype (possédé par Microsoft), de Telegram, de Signal (Open Whisper systems), Threema (Threema GmbH), Allo (possédé par Google) et de quelques clients XMPP, je dirai aussi un mot de ToX et Briar. Je n’aborderai pas les diverses fonctionnalités mêmes si elles sont liées à la confidentialité, comme les notifications évidemment mal conçues du type « le message a été lu ». Je n’aborderai pas non plus les questions d’anonymat qui sont connexes, mais selon moi moins importantes lorsqu’il s’agit d’applis de substitution aux SMS, puisque vous connaissez vos contacts de toutes façons.
Le chiffrement
Quand on parle de confidentialité ou de sécurité des communications dans les messageries, il s’agit souvent de chiffrement ou, plus précisément, du chiffrement des données qui se déplacent, de la protection de vos messages pendant qu’ils voyagent vers vos contacts.
Il existe trois moyens classiques pour faire cela :
pas de chiffrement : tout le monde sur votre réseau WIFI local ou un administrateur système quelconque du réseau internet peut lire vos données
le chiffrement en transit : la connexion au et à partir du fournisseur de service, par exemple les serveurs WhatsApp, et entre les fournisseurs de services est sécurisée, mais le fournisseur de service peut lire le message
le chiffrement de bout en bout : le message est lisible uniquement par ceux à qui la conversation est adressée, mais le moment de la communication et les participants sont connus du fournisseur de service
Il y a aussi une propriété appelée « confidentialité persistante » (perfect forward secrecy en anglais) qui assure que les communications passées ne peuvent être déchiffrées, même si la clef à long terme est révélée ou volée.
À l’époque, la plupart des applications, même WhatsApp, appartenaient à la première catégorie. Mais aujourd’hui presque toutes les applications sont au moins dans la deuxième. La probabilité d’un espionnage insoupçonné en est réduite (c’est toujours possible pour les courriels par exemple), mais ce n’est évidemment pas suffisant, puisque le fournisseur de service peut être malveillant ou forcé de coopérer avec des gouvernements malveillants ou des agences d’espionnage sans contrôle démocratique.
C’est pour cela que vous voulez que votre messagerie fasse du chiffrement de bout en bout. Actuellement, les messageries suivantes le font (classées par taille supposée) : WhatsApp, Signal, Threema, les clients XMPP avec GPG/OTR/Omemo (ChatSecure, Conversations, Kontalk).
Les messageries qui disposent d’un mode spécifique (« chat secret » ou « mode incognito ») sont Telegram et Google Allo. Il est vraiment dommage qu’il ne soit pas activé par défaut, donc je ne vous les recommande pas. Si vous devez utiliser l’un de ces programmes, assurez-vous toujours d’avoir sélectionné le mode privé. Il est à noter que les experts considèrent que le chiffrement de bout en bout de Telegram est moins robuste, même s’ils s’accordent à dire que les attaques concrètes pour récupérer le texte d’un message ne sont pas envisageables.
D’autres programmes populaires, comme la messagerie de Facebook ou Skype n’utilisent pas de chiffrement de bout en bout, et devraient être évités. Il a été prouvé que Skype analyse vos messages, je ne m’attarderai donc pas sur ces deux-là.
Logiciels libres et intégrité des appareils
Donc maintenant, les données sont en sécurité tant qu’elles voyagent de vous à votre ami. Mais qu’en est-il avant et après leur envoi ? Ne pouvez-vous pas aussi tenter d’espionner le téléphone de l’expéditeur ou du destinataire avant qu’elles ne soient envoyées et après leur réception ? Oui c’est possible et en Allemagne le gouvernement a déjà activement utilisé la « Quellen-Telekommunikationsüberwachung » (surveillance des communications à la source) précisément pour passer outre le chiffrement.
Revenons à la distinction entre (2) et (3). La différence principale entre le chiffrement en transit et de bout en bout est que vous n’avez plus besoin de faire confiance au fournisseur de service… FAUX : Dans presque tous les cas, la personne qui fait tourner le serveur est la même que celle qui fournit le programme. Donc forcément, vous devez croire que le logiciel fait bien ce qu’il dit faire. Ou plutôt, il doit y avoir des moyens sociaux et techniques qui vous donnent suffisamment de certitude que le logiciel est digne de confiance. Sinon, la valeur ajoutée du chiffrement de bout en bout est bien maigre.
La liberté des logiciels
C’est maintenant que le logiciel libre entre en jeu. Si le code source est publié, il y aura un grand nombre de hackers et de volontaires pour vérifier que le programme chiffre vraiment le contenu. Bien que ce contrôle public ne puisse vous donner une sécurité parfaite, ce processus est largement reconnu comme étant le meilleur pour assurer qu’un programme est globalement sûr et que les problèmes de sécurité sont découverts (et aussi corrigés). Le logiciel libre permet aussi de créer des versions non officielles ou rivales de l’application de messagerie, qui seront compatibles. S’il y a certaines choses que vous n’aimez pas ou auxquelles vous ne faites pas confiance dans l’application officielle, vous pourrez alors toujours en choisir une autre et continuer de chatter avec vos amis.
Certaines compagnies comme Threema qui ne fournissent pas leurs sources assurent évidemment qu’elles ne sont pas nécessaires pour avoir confiance. Elles affirment que leur code a été audité par une autre compagnie (qu’ils ont généralement payée pour cela), mais si vous ne faites pas confiance à la première, pourquoi faire confiance à une autre engagée par celle-ci ? Plus important, comment savoir que la version vérifiée par le tiers est bien la même version que celle installée sur votre téléphone ? (Vous recevez des mises à jours régulières ou non ?)
Cela vaut aussi pour les gouvernements et les entités publiques qui font ce genre d’audits. En fonction de votre modèle de menace ou de vos suppositions sur la société, vous pourriez être enclins à faire confiance aux institutions publiques plus qu’aux institutions privées (ou inversement), mais si vous regardez vers l’Allemagne par exemple, avec le TÜV il n’y a en fait qu’une seule organisation vérificatrice, que ce soit sur la valeur de confiance des applications de messagerie ou concernant la quantité de pollution émise par les voitures. Et nous savons bien à quoi cela a mené !
Quand vous décidez si vous faites confiance à un tiers, vous devez donc prendre en compte :
la bienveillance : le tiers ne veut pas compromettre votre vie privée et/ou il est lui-même concerné
la compétence : le tiers est techniquement capable de protéger votre vie privée et d’identifier et de corriger les problèmes
l’intégrité : le tiers ne peut pas être acheté, corrompu ou infiltré par des services secrets ou d’autres tiers malveillants
Après les révélations de Snowden, il est évident que le public est le seul tiers qui peut remplir collectivement ces prérequis ; donc la mise à disposition publique du code source est cruciale. Cela écarte d’emblée WhatsApp, Google Allo et Threema.
« Attendez une minute… mais n’existe-t-il aucun autre moyen de vérifier que les données qui transitent sont bien chiffrées ? » Ah, bien sûr qu’il en existe, comme Threema le fera remarquer, ou d’autres personnes pour WhatsApp. Mais l’aspect important, c’est que le fournisseur de service contrôle l’application sur votre appareil, et peut intercepter les messages avant le chiffrement ou après le déchiffrement, ou simplement « voler » vos clés de chiffrement. « Je ne crois pas que X fasse une chose pareille. » Gardez bien à l’esprit que, même si vous faites confiance à Facebook ou Google (et vous ne devriez pas), pouvez-vous vraiment leur faire confiance pour ne pas obéir à des décisions de justice ? Si oui, alors pourquoi vouliez-vous du chiffrement de bout en bout ? « Quelqu’un s’en apercevrait, non ? » Difficile à dire ; s’ils le faisaient tout le temps, vous pourriez être capable de vous en apercevoir en analysant l’application. Mais peut-être qu’ils font simplement ceci :
si (listeDeSuspects.contient(utilisateurID))
envoyerClefSecreteAuServeur() ;
Alors seules quelques personnes sont affectées, et le comportement ne se manifeste jamais dans des « conditions de laboratoire ». Ou bien la génération de votre clé est trafiquée, de sorte qu’elle soit moins aléatoire, ou qu’elle adopte une forme plus facile à pirater. Il existe plusieurs approches, et la plupart peuvent facilement être déployées dans une mise à jour ultérieure, ou cachée parmi d’autres fonctionnalités. Notez bien également qu’il est assez facile de se retrouver dans la liste de suspects, car le règlement actuel de la NSA assure de pouvoir y ajouter plus de 25 000 personnes pour chaque suspect « originel ».
À la lumière de ces informations, on comprend qu’il est très regrettable que Open Whisper Systems et Moxie Marlinspike (le célèbre auteur de Signal, mentionné précédemment) fassent publiquement les louanges de Facebook et de Google, augmentant ainsi la confiance en leurs applications [bien qu’il ne soit pas mauvais en soi qu’ils aient aidé à mettre en place le chiffrement, bien sûr]. Je suis assez confiant pour dire qu’ils ne peuvent pas exclure un des scénarios précédents, car ils n’ont pas vu le code source complet des applications, et ne savent pas non plus ce que vont contenir les mises à jour à l’avenir – et nous ne voudrions de toutes façons pas dépendre d’eux pour nous en assurer !
La messagerie Signal
« OK, j’ai compris. Je vais utiliser des logiciels libres et open source. Comme le Signal d’origine ». C’est là que ça se complique. Bien que le code source du logiciel client Signal soit libre/ouvert, il dépend d’autres composants non libres/fermés/propriétaires pour fonctionner. Ces composants ne sont pas essentiels au fonctionnement, mais ils (a) fournissent des métadonnées à Google (plus de détails sur les métadonnées plus loin) et (b) compromettent l’intégrité de votre appareil.
Le dernier point signifie que si même une petite partie de votre application n’est pas digne de confiance, alors le reste ne l’est pas non plus. C’est encore plus critique pour les composants qui ont des privilèges système, puisqu’ils peuvent faire tout et n’importe quoi sur votre téléphone. Et il est particulièrement impossible de faire confiance à ces composants non libres qui communiquent régulièrement des données à d’autres ordinateurs, comme ces services Google. Certes, il est vrai que ces composants sont déjà inclus dans la plupart des téléphones Android dans le monde, et il est aussi vrai qu’il y a très peu d’appareils qui fonctionnent vraiment sans aucun composant non libre, donc de mon point de vue, ce n’est pas problématique en soi de les utiliser quand ils sont disponibles. Mais rendre leur utilisation obligatoire implique d’exclure les personnes qui ont besoin d’un niveau de sécurité supérieur (même s’ils sont disponibles !) ; ou qui utilisent des versions alternatives plus sécurisées d’Android, comme CopperheadOS ; ou simplement qui ont un téléphone sans ces services Google (très courant dans les pays en voie de développement). Au final, Signal créé un « effet réseau » qui dissuade d’améliorer la confiance globale d’un appareil mobile, parce qu’il punit les utilisateurs qui le font. Cela discrédite beaucoup de promesses faites par ses auteurs.
Et voici le pire : Open Whisper Systems, non seulement, ne supporte pas les systèmes complètements libres, mais a également menacé de prendre des mesures légales afin d’empêcher les développeurs indépendants de proposer une version modifiée de l’application client Signal qui fonctionnerait sans les composants propriétaires de Google et pourrait toujours interagir avec les autres utilisateurs de Signal ([1] [2] [3]). À cause de cela, des projets indépendants comme LibreSignal sont actuellement bloqués. En contradiction avec leur licence libre, ils s’opposent à tout client du réseau qu’ils ne distribuent pas. De ce point de vue, l’application Signal est moins utilisable et moins fiable que par exemple Telegram qui encourage les clients indépendants à utiliser leurs serveurs et qui propose des versions entièrement libres.
Juste pour que je ne donne pas de mauvaise impression : je ne crois pas qu’il y ait une sorte de conspiration entre Google et Moxie Marlinspike, et je les remercie de mettre au clair leur position de manière amicale (au moins dans leur dernière déclaration), mais je pense que la protection agressive de leur marque et leur insistance à contrôler tous les logiciels clients de leur réseau met à mal la lutte globale pour des communications fiables.
Décentralisation, contrôle par les distributeurs et métadonnées
Un aspect important d’un réseau de communication est sa topologie, c’est-à-dire la façon dont le réseau est structuré. Comme le montre l’image ci-dessous, il y a plusieurs approches, toutes (plus ou moins) largement répandues. La section précédente concernait ce qui se passe sur votre téléphone, alors que celle-ci traite de ce qui se passe sur les serveurs, et du rôle qu’ils jouent. Il est important de noter que, même dans des réseaux centralisés, certaines communications ont lieu en pair-à-pair (c’est-à-dire sans passer par le centre) ; mais ce qui fait la différence, c’est qu’il nécessitent des serveurs centraux pour fonctionner.
Réseaux centralisés
Les réseaux centralisés sont les plus courants : toutes les applications mentionnées plus haut (WhatsApp, Telegram, Signal, Threema, Allo) reposent sur des réseaux centralisés. Bien que beaucoup de services Internet ont été décentralisés dans le passé, comme l’e-mail ou le World Wide Web, beaucoup de services centralisés ont vu le jour ces dernières années. On peut dire, par exemple, que Facebook est un service centralisé construit sur la structure WWW, à l’origine décentralisée.
Les réseaux centralisés font souvent partie d’une marque ou d’un produit plus global, présenté comme une seule solution (au problème des SMS, dans notre cas). Pour les entreprises qui vendent ou qui offrent ces solutions, cela présente l’avantage d’avoir un contrôle total sur le système, et de pouvoir le changer assez rapidement, pour offrir (ou imposer) de nouvelles fonctionnalités à tous les utilisateurs.
Même si l’on suppose que le service fournit un chiffrement de bout en bout, et même s’il existe une application cliente en logiciel libre, il reste toujours les problèmes suivants :
métadonnées : le contenu de vos messages est chiffré, mais l’information qui/quand/où est toujours accessible pour votre fournisseur de service
déni de service : le fournisseur de service ou votre gouvernement peuvent bloquer votre accès au service
Il y a également ce problème plus général : un service centralisé, géré par un fournisseur privé, peut décider quelles fonctionnalités ajouter, indépendamment du fait que ses utilisateurs les considèrent vraiment comme des fonctionnalités ou des « anti-fonctionnalités », par exemple en indiquant aux autres utilisateurs si vous êtes « en ligne » ou non. Certaines de ces fonctionnalités peuvent être supprimées de l’application sur votre téléphone si c’est du logiciel libre, mais d’autres sont liées à la structure centralisée. J’écrirai peut-être un jour un autre article sur ce sujet.
Métadonnées
Comme expliqué précédemment, les métadonnées sont toutes les données qui ne sont pas le message. On pourrait croire que ce ne sont pas des données importantes, mais de récentes études montrent l’inverse. Voici des exemples de ce qu’incluent les métadonnées : quand vous êtes en ligne, si votre téléphone a un accès internet, la date et l’heure d’envoi des messages et avec qui vous communiquez, une estimation grossière de la taille du message, votre adresse IP qui peut révéler assez précisément où vous vous trouvez (au travail, à la maison, hors de la ville, et cætera), éventuellement aussi des informations liées à la sécurité de votre appareil (le système d’exploitation, le modèle…). Ces informations sont une grande menace contre votre vie privée et les services secrets américains les utilisent réellement pour justifier des meurtres ciblés (voir ci-dessus).
La quantité de métadonnées qu’un service centralisé peut voir dépend de leur implémentation précise. Par exemple, les discussions de groupe avec Signal et probablement Threema sont implémentées dans le client, donc en théorie le serveur n’est pas au courant. Cependant, le serveur a l’horodatage de vos communications et peut probablement les corréler. De nouveau, il est important de noter que si le fournisseur de service n’enregistre pas ces informations par défaut (certaines informations doivent être préservées, d’autres peuvent être supprimées immédiatement), il peut être forcé à enregistrer plus de données par des agences de renseignement. Signal (comme nous l’avons vu) ne fonctionne qu’avec des composants non-libres de Google ou Apple qui ont alors toujours une part de vos métadonnées, en particulier votre adresse IP (et donc votre position géographique) et la date à laquelle vous avez reçu des messages.
Pour plus d’informations sur les métadonnées, regardez ici ou là.
Déni de service
Un autre inconvénient majeur des services centralisés est qu’ils peuvent décider de ne pas vous servir du tout s’ils le veulent ou qu’ils y sont contraints par la loi. Comme nombre de services demandent votre numéro lors de l’enregistrement et sont opérés depuis les États-Unis, ils peuvent vous refuser le service si vous êtes cubain par exemple. C’est particulièrement important puisqu’on parle de chiffrement qui est grandement régulé aux États-Unis.
L’Allemagne vient d’introduire une nouvelle loi antiterroriste dont une partie oblige à décliner son identité lors de l’achat d’une carte SIM, même prépayée. Bien que l’hypothèse soit peu probable, cela permettrait d’établir une liste noire de personnes et de faire pression sur les entreprises pour les exclure du service.
Plutôt que de travailler en coopération avec les entreprises, un gouvernement mal intentionné peut bien sûr aussi cibler le service directement. Les services opérés depuis quelques serveurs centraux sont bien plus vulnérables à des blocages nationaux. C’est ce qui s’est passé pour Signal et Telegram en Chine.
Réseaux déconnectés
Lorsque le code source du serveur est libre, vous pouvez monter votre propre service si vous n’avez pas confiance dans le fournisseur. Ça ressemble à un gros avantage, et Moxie Marlinspike le défend ainsi :
Avant vous pouviez changer d’hébergeur, ou même décider d’utiliser votre propre serveur, maintenant les utilisateurs changent simplement de réseau complet. […] Si un fournisseur centralisé avec une infrastructure ouverte modifiait affreusement ses conditions, ceux qui ne seraient pas d’accord ont le logiciel qu’il faut pour utiliser leur propre alternative à la place.
Et bien sûr, c’est toujours mieux que de ne pas avoir le choix, mais la valeur intrinsèque d’un réseau « social » vient des gens qui l’utilisent et ce n’est pas évident de changer si vous perdez le lien avec vos amis. C’est pour cela que les alternatives à Facebook ont tant de mal. Mme si elles étaient meilleures sur tous les aspects, elles n’ont pas vos amis.
Certes, c’est plus simple pour les applications mobiles qui identifient les gens via leur numéro, parce qu’au moins vous pouvez trouver vos amis rapidement sur un nouveau réseau, mais pour toutes les personnes non techniciennes, c’est très perturbant d’avoir 5 applications différentes juste pour rester en contact avec la plupart de ses amis, donc changer de réseau ne devrait qu’être un dernier recours.
Notez qu’OpenWhisperSystems se réclame de cette catégorie, mais en fait ils ne publient que des parties du code du serveur de Signal, de sorte que vous ne soyez pas capables de monter un serveur avec les mêmes fonctionnalités (plus précisément la partie téléphonie manque).
Centralisation, réseaux déconnectés, fédération, décentralisation en pair à pair
La fédération
La fédération est un concept qui résout le problème mentionné plus haut en permettant en plus aux fournisseurs de service de communiquer entre eux. Donc vous pouvez changer de fournisseur, et peut-être même d’application, tout en continuant à communiquer avec les personnes enregistrées sur votre ancien serveur. L’e-mail est un exemple typique d’un système fédéré : peu importe que vous soyez tom@gmail.com ou jeanne@yahoo.com ou même linda@serveur-dans-ma-cave.com, tout le monde peut parler avec tout le monde. Imaginez combien cela serait ridicule, si vous ne pouviez communiquer qu’avec les personnes qui utilisent le même fournisseur que vous ?
L’inconvénient, pour un développeur et/ou une entreprise, c’est de devoir définir publiquement les protocoles de communication, et comme le processus de standardisation peut être compliqué et très long, vous avez moins de flexibilité pour modifier le système. Je reconnais qu’il devient plus difficile de rendre les bonnes fonctionnalités rapidement disponibles pour la plupart des gens, mais comme je l’ai dit plus haut, je pense que, d’un point de vue de la vie privée et de la sécurité, c’est vraiment une fonctionnalité, car plus de gens sont impliqués et plus cela diminue la possibilité pour le fournisseur d’imposer des fonctionnalités non souhaitées aux utilisateurs ; mais surtout car cela fait disparaître « l’effet d’enfermement ». Cerise sur le gâteau, ce type de réseau produit rapidement plusieurs implémentations du logiciel, à la fois pour l’application utilisateur et pour le logiciel serveur. Cela rend le système plus robuste face aux attaques et garantit que les failles ou les bugs présents dans un logiciel n’affectent pas le système dans son ensemble.
Et, bien sûr, comme évoqué précédemment, les métadonnées sont réparties entre plusieurs fournisseurs (ce qui rend plus difficile de tracer tous les utilisateurs à la fois), et vous pouvez choisir lequel aura les vôtres, voire mettre en place votre propre serveur. De plus, il devient très difficile de bloquer tous les fournisseurs, et vous pouvez en changer si l’un d’entre eux vous rejette (voir « Déni de service » ci-dessus).
Une remarque au passage : il faut bien préciser que la fédération n’impose pas que des métadonnées soient vues par votre fournisseur d’accès et celui de votre pair. Dans le cas de la messagerie électronique, cela représente beaucoup, mais ce n’est pas une nécessité pour la fédération par elle-même, c’est-à-dire qu’une structure fédérée bien conçue peut éviter de partager les métadonnées dans les échanges entre fournisseurs d’accès, si l’on excepte le fait qu’il existe un compte utilisateur avec un certain identifiant sur le serveur.
Alors est-ce qu’il existe un système identique pour la messagerie instantanée et les SMS ? Oui, ça existe, et ça s’appelle XMPP. Alors qu’initialement ce protocole n’incluait pas de chiffrement fort, maintenant on y trouve un chiffrement du même niveau de sécurité que pour Signal. Il existe aussi de très bonnes applications pour mobile sous Android (« Conversations ») et sous iOS (« ChatSecure »), et pour d’autres plateformes dans le monde également.
Inconvénients ? Comme pour la messagerie électronique, il faut d’abord vous enregistrer pour créer un compte quelque part et il n’existe aucune association automatique avec les numéros de téléphone, vous devez donc convaincre vos amis d’utiliser ce chouette nouveau programme, mais aussi trouver quels fournisseur d’accès et nom d’utilisateur ils ont choisis. L’absence de lien avec le numéro de téléphone peut être considérée par certains comme une fonctionnalité intéressante, mais pour remplacer les SMS ça ne fait pas l’affaire.
La solution : Kontalk, un client de messagerie qui repose sur XMPP et qui automatise les contacts via votre carnet d’adresses. Malheureusement, cette application n’est pas encore aussi avancée que d’autres mentionnées plus haut. Par exemple, il lui manque la gestion des groupes de discussion et la compatibilité avec iOS. Mais Kontalk est une preuve tangible qu’il est possible d’avoir avec XMPP les mêmes fonctionnalités que l’on trouve avec WhatsApp ou Telegram. Selon moi, donc, ce n’est qu’une question de temps avant que ces solutions fédérées ne soient au même niveau et d’une ergonomie équivalente. Certains partagent ce point de vue, d’autres non.
Réseaux pair à pair
Les réseaux pair à pair éliminent complètement le serveur et par conséquent toute concentration centralisée de métadonnées. Ce type de réseaux est sans égal en termes de liberté et il est pratiquement impossible à bloquer par une autorité. ToX est un exemple d’application pair à pair, ou encore Ricochet (pas pour mobile cependant), et il existe aussi Briar qui est encore en cours de développement, mais ajoute l’anonymat, de sorte que même votre pair ne connaît pas votre adresse IP. Malheureusement il existe des problèmes de principe liés aux appareils mobiles qui rendent difficile de maintenir les nombreuses connexions que demandent ces réseaux. De plus il semble impossible pour le moment d’associer un numéro de téléphone à un utilisateur, si bien qu’il est impossible d’avoir recours à la détection automatique des contacts.
Je ne crois pas actuellement qu’il soit possible que ce genre d’applications prenne des parts de marché à WhatsApp, mais elles peuvent être utiles dans certains cas, en particulier si vous êtes la cible de la surveillance et/ou membre d’un groupe qui décide collectivement de passer à ces applications pour communiquer, une organisation politique par exemple.
En deux mots
La confidentialité de nos données privées est l’objet d’un intérêt accru et les utilisateurs cherchent activement à se protéger mieux.
On peut considérer que c’est un bon signe quand les distributeurs principaux de logiciels comprennent qu’ils doivent réagir à cette situation en ajoutant du chiffrement à leurs logiciels ; et qui sait, il est possible que ça complique un peu la tâche de la NSA.
Toutefois, il n’y a aucune raison de leur faire plus confiance qu’auparavant, puisqu’il n’existe aucun moyen à notre disposition pour savoir ce que font véritablement les applications, et parce qu’il leur reste beaucoup de façons de nous espionner.
Si en ce moment vous utilisez WhatsApp, Skype, Threema ou Allo et que vous souhaitez avoir une expérience comparable, vous pouvez envisager de passer à Telegram ou Signal. Ils valent mieux que les précédents (pour diverses raisons), mais ils sont loin d’être parfaits, comme je l’ai montré. Nous avons besoin à moyen et long terme d’une fédération.
Même s’ils nous paraissent des gens sympas et des hackers surdoués, nous ne pouvons faire confiance à OpenWhisperSystemspour nous délivrer de la surveillance, car ils sont aveugles à certains problèmes et pas très ouverts à la coopération avec la communauté.
Des trucs assez sympas se préparent du côté du XMPP, surveillez Conversations, chatSecure et Kontalk. Si vous le pouvez, soutenez-les avec du code, des dons et des messages amicaux.
Si vous souhaitez une approche sans aucune métadonnée et/ou anonymat, essayez Tor ou ToX, ou attendez Briar.




 Cela remonte à l’année 2010, le gouvernement français venait de faire passer la loi Hadopi malgré tous ses déboires et j’avais regardé l’ensemble des débats à l’Assemblée nationale, j’étais particulièrement remonté avec l’envie de faire quelque chose et je venais à la fois de rejoindre
Cela remonte à l’année 2010, le gouvernement français venait de faire passer la loi Hadopi malgré tous ses déboires et j’avais regardé l’ensemble des débats à l’Assemblée nationale, j’étais particulièrement remonté avec l’envie de faire quelque chose et je venais à la fois de rejoindre 
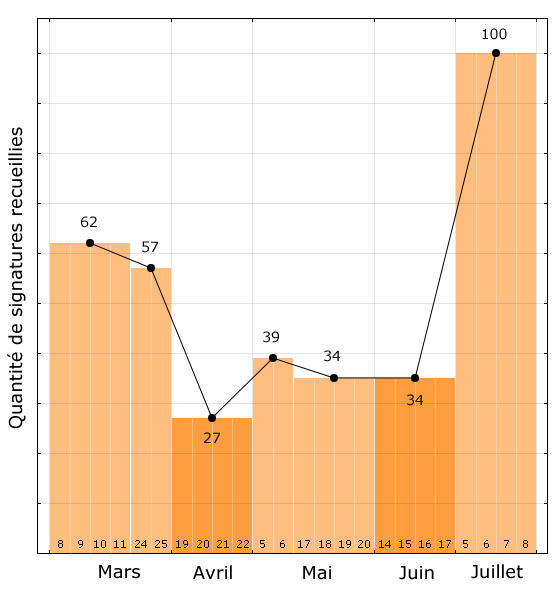

 L’Espresso a obtenu les tarifs de l’entreprise (de 1,50 euro à 85 centimes) et a contacté certains clients. Entre les réponses embarrassées et les reconnaissances du bout des lèvres, nous avons étudié l’activité de l’« Amazon des pétitions en ligne ». Elle manipule des données extrêmement sensibles telles que les opinions politiques et fait l’objet en Allemagne d’une enquête sur le respect de la vie privée.
L’Espresso a obtenu les tarifs de l’entreprise (de 1,50 euro à 85 centimes) et a contacté certains clients. Entre les réponses embarrassées et les reconnaissances du bout des lèvres, nous avons étudié l’activité de l’« Amazon des pétitions en ligne ». Elle manipule des données extrêmement sensibles telles que les opinions politiques et fait l’objet en Allemagne d’une enquête sur le respect de la vie privée.