Les 100 premiers jours d’une libraire à la présidence de l’April
Trois mois… C’est fou ce que cela passe vite.
En décembre 2022, j’ai repris la présidence de l’April, l’association pour la promotion et la défense du Logiciel Libre. Cette association existe depuis 1996 et compte presque 3 000 membres. N’étant ni informaticienne, ni juriste, ni politicienne, j’avais refusé le poste quand un des anciens présidents, Lionel Allorge <3, me l’avait proposé, syndrome d’imposture inconscient sans doute. Après quinze ans dans l’association dont dix en tant qu’administratrice, c’était le bon moment pour se lancer.
Mais être présidente de l’April, ça m’engage à quoi ?
Les personnes qui se sont succédé à la présidence de l’April, Fred, Benoît, Tangui, Lionel, Jean-Christophe ou Véronique (maintenant vous connaissez leurs prénoms1) ont été confrontées à des combats, des injustices, des politiciens godillots, des messages à passer et à faire passer. Celles et ceux qui me connaissent savent que je suis dynamique, joviale, que j’aime aller vers les autres, travailler en équipe, rencontrer des libristes, construire ensemble, à plusieurs, et surtout totalement utopiste sur la société dans laquelle je souhaiterais vivre. Exigeante avec moi-même, je me suis fixé plusieurs objectifs à mener au sein de l’April dans l’année à venir même si, parfois, cela me semble irréalisable lors de mes insomnies. Heureusement, j’ai la chance d’être entourée de personnes formidables : les membres de l’équipe salariée, du conseil d’administration (CA) et les membres de l’association.
1) Se mettre à jour sur les dossiers institutionnels de l’April.
Chaque bénévole s’intéresse à ses sujets préférés, moi j’étais plutôt dans la vie de l’association, la tenue de stands, la sensibilisation. Mais, devenue présidente, j’ai dû me mettre à jour, m’informer et me tenir au courant des dossiers institutionnels que traite l’April : proposition de loi sur le contrôle parental, l’OpenBar du ministère des Armées avec Microsoft, Pacte du Logiciel Libre, Conseil d’expertise logiciels libres, Label Territoire Numérique Libre, GAFAM-Nation un rapport éclairant sur le lobbying des GAFAM en France, proposition d’évaluation des dépenses de logiciels de l’État, suivi de questions écrites, Ministère de l’Éducation nationale… pour ne citer qu’eux !
C’est assez chronophage de se documenter et de lire des articles sur des sujets avec lesquels on n’a que peu d’affinités, mais tellement intéressant, finalement, de creuser, de chercher des informations, de remonter à leurs sources. Pourquoi les médias ne s’emparent-ils pas de ces problématiques ? Pourquoi ne s’offusquent-ils pas de la domination des GAFAM et de l’inaction des politiques, des mauvaises décisions des responsables, du manque des femmes dans le numérique, du matériel propriétaire, parfois inutile et que l’on impose aux élèves… Arf !, je m’enflamme, désolée !
Des sujets me tiennent énormément à cœur, sur lesquels j’aimerais travailler comme la priorité au logiciel libre pour tous les logiciels utilisés par l’État et les administrations ; l’obligation d’interopérabilité partout ; la sobriété numérique car l’épuisement des matières premières nécessaires au numérique m’inquiète ; l’Éducation nationale qui reste sous le joug des GAFAM, je pense qu’elle doit sensibiliser les élèves à toutes les alternatives pour pouvoir faire des choix éclairés, pourquoi les prive-t-on des logiciels libres ?
Tellement de sujets et si peu d’heures dans une journée !
2) Lister et s’abonner aux différents groupes de travail
Les échanges et les travaux au sein des groupes de travail de l’April se font principalement au travers de listes de discussions auxquelles les membres peuvent s’inscrire. Et même les personnes non membres de l’association, la plupart des listes étant ouvertes à toute personne intéressée par le thème du groupe de travail. Je pensais que la présidente devait les suivre toutes (arf !!). En le faisant j’ai assisté à des réunions passionnantes et parfois passionnées, j’ai participé à des échanges de courriels enthousiastes ou parfois résignés.
Merci :
au groupe Éducation qui m’a bien accueillie, m’a expliqué tous les acronymes (j’en ai encore des cauchemars). Réfléchir sur la doctrine numérique du MEN, ou répondre à sa stratégie a été très formateur ! Préparer un état des lieux au sein d’un questionnaire va sûrement prendre beaucoup de temps et de ressources. C’est parti !
au groupe Sensibilisation qui approfondit actuellement la réalisation d’un jeu de société (le jeu du Gnou — jeu de plateau aux multiples questions introduisant aux notions du logiciel libre et de son éthique),
au groupe Diversité que j’essaye doucement de faire renaître de ses cendres,
au groupe Transcriptions que j’ai longtemps animé, qui produit une quantité incroyable de textes tirés de conférences ou d’émissions de radio, il y a toujours des relectures à faire (message peu subliminal).
à l’Agenda du Libre, ma présidence a remotivé Echarp qui y incorpore une nouvelle fonctionnalité, un planet des organisations du Libre… J’ai hâte de voir ce que cela va donner et je referais bien une mise à jour des associations (déjà en cours) !
au Chapril, à ses animsys, à ses services libres et loyaux que j’utilise au quotidien et à la modération du pouet que je réalise avec deux bénévoles chaque lundi ! Merci à Bastet, le chatons de Parinux, pour son lecteur de flux et à Framasoft pour cette incroyable initiative. <3
Désolée les groupes Admin sys, site web, Libre Association et Traductions, vous vous débrouillez très bien sans moi, je garde mon petit grain de sel. Et puis je dois reconnaître que jamais je ne pourrai tout lire :’-(.
Illustration réalisée avec Gégé – https://framalab.org/gknd-creator/
Plus je côtoie les groupes, plus je déplore notre manque de bénévoles. Un peu comme dans chaque association, me direz-vous, mais imaginez tout ce que l’on pourrait faire si nous étions encore plus nombreux ! Si nous étions encore plus de bénévoles !
3) Aller à la rencontre des libristes
En 2012, quand je suis entrée au conseil d’administration de l’April, je voulais me rapprocher des GULL (groupe d’utilisatrices et d’utilisateurs de Logiciels Libres) et lancer l’opération « enGULLez- vous », on m’en a empêchée sous le prétexte fallacieux que le nom prêterait à confusion. 😂 Néanmoins l’idée me plaît toujours.
L’April est souvent accusée de parisianisme : l’équipe salariée est à Paris, beaucoup de réunions s’y organisent. Les différents confinements nous ont permis de nous équiper afin d’organiser des visioconférences, chaque personne pouvant participer depuis chez elle. Et nous en avons bien profité !
Néanmoins, cela ne me suffit pas, c’est frustrant de discuter à distance. J’ai envie de renouer les liens avec les utilisatrices et utilisateurs de logiciels libres, comme lors des April Camps (réunion sur plusieurs jours dans un lieu fermé ou sont parfois organisés des from&pif’) à Marseille ou Montpellier. Et rien de tel que d’aller à leur rencontre ! J’ai donc mis en place une opération dont le nom ne pourra pas m’être refusé cette fois : Le Tour des GULL ! J’ai ainsi déjà rendu visite à Oisux (Beauvais), à Actux (Rennes) et bientôt à Linux Nantes.
Illustration réalisée avec Gégé – https://framalab.org/gknd-creator/
Invitez-moi et je viendrai boire parler de logiciel libre avec vous ! Les festivals recommencent aussi, bientôt les JDLL (Journée du Logiciel Libre) et les RPLL à Lyon, Passage en Seine à Choisy-le-Roi, le Capitole du Libre à Toulouse, l’Open Source Experience à Paris… J’ai hâte d’y tenir des stands, de donner des conférences ! La présidente est bien placée pour présenter l’April aux novices, répondre aux questions que les membres se posent et féliciter certaines entreprises, associations ou collectivités.
J’ai tellement hâte de m’y remettre et de revoir les personnes que je ne voyais qu’aux Rencontres Mondiales du Logiciel Libre.
Conclusion
Comme écrit au début de cet article, je n’ai pas vu passer ce trimestre ! Je suis reconnaissante aux libristes qui viennent à ma rencontre lors des apéros (va falloir agrandir les lieux de réunions !), aux personnes qui m’envoient des articles de presse qui les ont choquées ou ravies, aux membres du CA et à l’équipe salariée qui discutent avec moi par courriel ou par téléphone afin d’éclairer ma petite lanterne sur certains sujets.
Être présidente de l’April, c’est une aventure qui mérite d’être vécue même si ma librairie en pâtit parfois (mes clients pardonnent mes absences du moment que je continue à leur conseiller de bons livres).
Je suis épuisée (comme chaque année à cette époque, les médecins appellent ça le rhume des foins — sauf qu’il n’y a pas de foin à Paris !) mais épanouie et je me sens toujours investie d’une mission : changer le monde (en mieux) !
Si l’aventure vous tente, vous pouvez adhérer à l’April en allant sur le site de l’association ou en venant nous rencontrer lors des différents évènements que nous organisons ou auxquels nous participons, dont les prochains : l’apéro April du vendredi 24 mars, l’assemblée générale du samedi 25 mars, l’April Camp du dimanche 26 mars ou encore les JDLL (Journée du Logiciel Libre) des 1ᵉʳ et 2 avril à Lyon…
Merci d’avoir lu ce texte jusqu’au bout, je ne pensais pas qu’il serait aussi long quand j’ai commencé à l’écrire, mais que voulez-vous, l’enthousiasme ne se restreint pas !
Échirolles libérée ! La dégooglisation (1)
Dans notre série de témoignages sur les processus de dégooglisation, voici la republication du premier article de Nicolas Vivant qui évoque aujourd’hui la nécessaire étape initiale, le consensus à réunir aux plans institutionnel et citoyen quand on envisage et planifie la « transformation numérique » à l’échelle d’une municipalité entière…
Dégooglisation d’Échirolles, partie 1 : la structuration
par Nicolas Vivant
La transformation numérique d’Échirolles est en route, et il n’est peut-être pas inutile que nous partagions notre approche. Située dans le département de l’Isère, cette commune de 37 000 habitants jouxte Grenoble. Son maire, Renzo Sulli est également vice-président de la Métropole. Active et populaire, Échirolles a vu naître quelques célébrités, de Calogero à Vincent Clerc, en passant par Philippe Vandel.
L’histoire commence par une équipe municipale qui prend conscience que des enjeux politiques forts existent autour du numérique, et qu’il convient de s’en saisir pour les inscrire dans une cohérence avec l’action municipale.
En 2014, elle signe le Pacte du Logiciel Libre de l’April, et les premières solutions sont mises en œuvre : elles concernent notamment la messagerie, qui passe de Microsoft à BlueMind, puis la téléphonie, d’Alcatel à Xivo.
Après l’élection municipale de 2020, le choix est fait de mieux structurer l’approche, pour gagner en efficacité et en visibilité, en interne comme en externe. Une délégation est créée qui annonce la couleur et Aurélien Farge devient « Conseiller municipal délégué au développement du numérique, à l’informatique et aux logiciels libres ». Son collègue Saïd Qezbour devient conseiller municipal délégué à l’inclusion numérique, le travail peut commencer.
Sous la houlette d’Amandine Demore, première adjointe, d’Aurélien Farge et de Saïd Qezbour, un « groupe de travail numérique » transversal est crée. Il réunit les élu·e·s pour qui le numérique est un enjeu : ressources humaines, finances, solidarités, éducation, culture… En janvier 2021, une feuille de route du numérique est finalisée. Elle identifie les grands enjeux et les thèmes que l’équipe municipale souhaite aborder dans le cadre du mandat : impact environnemental, inclusion, animation des acteurs et logiciels libres, notamment.
Parallèlement, une étude sur le numérique dans la ville est commandée. Une vaste consultation est lancée, des micro-trottoirs sont réalisés, des entretiens ont lieu avec les chefs de service, les associations, les partenaires économiques, etc. Le cabinet en charge rend son rapport en février 2021. Au-delà des chiffres, intéressants et qui permettent d’avoir une vision globale de la problématique à l’échelle de la commune, les élu·e·s peuvent vérifier que la route choisie est bien en lien avec les attentes du territoire.
Au même moment, une fonction de « directeur·trice de la stratégie et de la culture numériques » est créée. Rattachée au directeur général des services, le/la DSCN chapeautera la DSI et l’équipe en charge de l’inclusion numérique. Rattachée à la direction générale, cette nouvelle direction est chargée de l’articulation entre vision politique et mise en œuvre opérationnelle.
Nicolas Vivant en hérite avec, comme première mission, la rédaction d’un schéma directeur pour le mandat : « Échirolles numérique libre ». Basé sur la feuille de route et sur le rapport sur le numérique dans la ville, il est une déclinaison stratégique de la volonté politique de la collectivité.
Voté le 8 novembre 2021 à l’unanimité des conseillères et conseillers municipaux, il sert de fil conducteur pour le plan d’action de la DSI, et permet d’inscrire les projets du service dans une cohérence globale.
Auteur : Erich Lessing Culture and Fine Arts Archives via artsy.net
Description : Tableau d’Eugène Delacroix « La Liberté Guidant le Peuple », commémorant la révolution des Trois Glorieuses (27-28-29 juillet 1830) en France.
D’autres témoignages de Dégooglisation ont été publiés sur ce blog, n’hésitez pas à prendre connaissance. Et si vous aussi, vous faites partie d’une organisation qui s’est lancée dans une démarche similaire et que vous souhaitez partager votre expérience, n’hésitez pas à nous envoyer un message pour nous le faire savoir. On sera ravi d’en parler ici !
Google et son robot pipoteur(*), selon Doctorow
Source de commentaires alarmants ou sarcastiques, les robots conversationnels qui reposent sur l’apprentissage automatique ne provoquent pas seulement l’intérêt du grand public, mais font l’objet d’une course de vitesse chez les GAFAM.
Tout récemment, peut-être pour ne pas être à la traîne derrière Microsoft qui veut adjoindre un chatbot à son moteur de recherche Bing, voilà que Google annonce sa ferme résolution d’en faire autant. Dans l’article traduit pour vous par framalang, Cory Doctorow met en perspective cette décision qui lui semble absurde en rappelant les échecs de Google qui a rarement réussi à créer quoi que ce soit…
Il n’y a rien d’étonnant à ce que Microsoft décide que l’avenir de la recherche en ligne ne soit plus fondé sur les liens dans une page web, mais de là à la remplacer par des longs paragraphes fleuris écrits dans un chatbot qui se trouve être souvent mensonger… — et en plus Google est d’accord avec ce concept.
Microsoft n’a rien à perdre. Il a dépensé des milliards pour Bing, un moteur de recherche que personne n’utilise volontairement. Alors, sait-on jamais, essayer quelque chose d’aussi stupide pourrait marcher. Mais pourquoi Google, qui monopolise plus de 90 % des parts des moteurs de recherche dans le monde, saute-t-il dans le même bateau que Microsoft ?
Il y a un délicieux fil à dérouler sur Mastodon, écrit par Dan Hon, qui compare les interfaces de recherche merdiques de Bing et Google à Tweedledee et Tweedledum :
Devant la maison, Alice tomba sur deux étranges personnages, tous deux étaient des moteurs de recherche. — moi, c’est Google-E, se présenta celui qui était entièrement recouvert de publicités — et moi, c’est Bingle-Dum, fit l’autre, le plus petit des deux, et il fit la grimace comme s’il avait moins de visiteurs et moins d’occasions de mener des conversations que l’autre. — je vous connais, répondit Alice, vous allez me soumettre une énigme ? Peut-être que l’un de vous dit la vérité et que l’autre ment ? — Oh non, fit Bingle-Dum — Nous mentons tous les deux, ajouta Google-E
Mais voilà le meilleur :
— Cette situation est vraiment intolérable, si vous mentez tous les deux.
— mais nous mentons de façon très convaincante, précisa Bingle-Dum
— D’accord, merci bien. Dans ce cas, comment puis-je vous faire jamais confiance ni / confiance à l’un ni/ou à l’autre ? Dans ce cas, comment puis-je faire confiance à l’un d’entre vous ?
Google-E et Bingle-Dum se tournèrent l’un vers l’autre et haussèrent les épaules.
La recherche par chatbot est une très mauvaise idée, surtout à un moment où le Web est prompt à se remplir de vastes montagnes de conneries générées via l’intelligence artificielle, comme des jacassements statiques de perroquets aléatoires :
La stratégie du chatbot de Google ne devrait pas consister à ajouter plus de délires à Internet, mais plutôt à essayer de trouver comment exclure (ou, au moins, vérifier) les absurdités des spammeurs et des escrocs du référencement.
Et pourtant, Google est à fond dans les chatbots, son PDG a ordonné à tout le monde de déployer des assistants conversationnels dans chaque recoin de l’univers Google. Pourquoi diable est-ce que l’entreprise court après Microsoft pour savoir qui sera le premier à décevoir des espérances démesurées ?
J’ai publié une théorie dans The Atlantic, sous le titre « Comment Google a épuisé toutes ses idées », dans lequel j’étudie la théorie de la compétition pour expliquer l’insécurité croissante de Google, un complexe d’anxiété qui touche l’entreprise quasiment depuis sa création:
L’idée de base : il y a 25 ans, les fondateurs de Google ont eu une idée extraordinaire — un meilleur moyen de faire des recherches. Les marchés financiers ont inondé l’entreprise en liquidités, et elle a engagé les meilleurs, les personnes les plus brillantes et les plus créatives qu’elle pouvait trouver, mais cela a créé une culture d’entreprise qui était incapable de capitaliser sur leurs idées.
Tous les produits que Google a créés en interne, à part son clone de Hotmail, sont morts. Certains de ces produits étaient bons, certains horribles, mais cela n’avait aucune importance. Google, une entreprise qui promouvait la culture du baby-foot et la fantaisie de l’usine Willy Wonka [NdT: dans Charlie et la chocolaterie, de Roald Dahl], était totalement incapable d’innover.
Toutes les réussites de Google, hormis son moteur de recherche et gmail, viennent d’une acquisition : mobile, technologie publicitaire, vidéos, infogérance de serveurs, docs, agenda, cartes, tout ce que vous voulez. L’entreprise souhaite plus que tout être une société qui « fabrique des choses », mais en réalité elle « achète des choses ». Bien sûr, ils sont très bons pour rendre ces produits opérationnels et à les faire « passer à l’échelle », mais ce sont les enjeux de n’importe quel monopole :
La dissonance cognitive d’un « génie créatif » autoproclamé, dont le véritable génie est de dépenser l’argent des autres pour acheter les produits des autres, et de s’en attribuer le mérite, pousse les gens à faire des choses vraiment stupides (comme tout utilisateur de Twitter peut en témoigner).
Google a longtemps montré cette pathologie. Au milieu des années 2000 – après que Google a chassé Yahoo en Chine et qu’il a commencé à censurer ses résultats de recherche, puis collaboré à la surveillance d’État — nous avions l’habitude de dire que le moyen d’amener Google à faire quelque chose de stupide et d’autodestructeur était d’amener Yahoo à le faire en premier lieu.
C’était toute une époque. Yahoo était désespéré et échouait, devenant un cimetière d’acquisitions prometteuses qui étaient dépecées et qu’on laissait se vider de leur sang, laissées à l’abandon sur l’Internet public, alors que les princes duellistes de la haute direction de Yahoo se donnaient des coups de poignard dans le dos comme dans un jeu de rôle genre les Médicis, pour savoir lequel saboterait le mieux l’autre. Aller en Chine fut un acte de désespoir après l’humiliation pour l’entreprise que fut le moteur de recherche largement supérieur de Google. Regarder Google copier les manœuvres idiotes de Yahoo était stupéfiant.
C’était déconcertant, à l’époque. Mais à mesure que le temps passait, Google copiait servilement d’autres rivaux et révélait ainsi une certaine pathologie d’insécurité. L’entreprise échouait de manière récurrente à créer son réseau « social », et comme Facebook prenait toujours plus de parts de marché dans la publicité, Google faisait tout pour le concurrencer. L’entreprise fit de l’intégration de Google Plus un « indictateur2 de performance » dans chaque division, et le résultat était une agrégation étrange de fonctionnalités « sociales » défaillantes dans chaque produit Google — produits sur lesquels des milliards d’utilisateurs se reposaient pour des opérations sensibles, qui devenaient tout à coup polluées avec des boutons sociaux qui n’avaient aucun sens.
La débâcle de G+ fut à peine croyable : certaines fonctionnalités et leur intégration étaient excellentes, et donc logiquement utilisées, mais elles subissaient l’ombrage des incohérences insistantes de la hiérarchie de Google pour en faire une entreprise orientée réseaux sociaux. Quand G+ est mort, il a totalement implosé, et les parties utiles de G+ sur lesquelles les gens se reposaient ont disparu avec les parties aberrantes.
Pour toutes celles et ceux qui ont vécu la tragi-comédie de G+, le virage de Google vers Bard, l’interface chatbot pour les résultats du moteur de recherche, semble tristement familier. C’est vraiment le moment « Mourir en héros ou vivre assez longtemps pour devenir un méchant ». Microsoft, le monopole qui n’a pas pu tuer la jeune pousse Google à cause de son expérience traumatisante des lois antitrust, est passé d’une entreprise qui créait et développait des produits à une entreprise d’acquisitions et d’opérations, et Google est juste derrière elle.
Pour la seule année dernière, Google a viré 12 000 personnes pour satisfaire un « investisseur activiste » privé. La même année, l’entreprise a racheté 70 milliards de dollars en actions, ce qui lui permet de dégager suffisamment de capitaux pour payer les salaires de ses 12 000 « Googleurs » pendant les 27 prochaines années. Google est une société financière avec une activité secondaire dans la publicité en ligne. C’est une nécessité : lorsque votre seul moyen de croissance passe par l’accès aux marchés financiers pour financer des acquisitions anticoncurrentielles, vous ne pouvez pas vous permettre d’énerver les dieux de l’argent, même si vous avez une structure à « double pouvoir » qui permet aux fondateurs de l’emporter au vote contre tous les autres actionnaires :
ChatGPT et ses clones cochent toutes les cases d’une mode technologique, et sont les dignes héritiers de la dernière saison du Web3 et des pics des cryptomonnaies. Une des critiques les plus claires et les plus inspirantes des chatbots vient de l’écrivain de science-fiction Ted Chiang, dont la critique déjà culte est intitulée « ChatGPT est un une image JPEG floue du Web » :
Chiang souligne une différence essentielle entre les résultats de ChatGPT et ceux des humains : le premier jet d’un auteur humain est souvent une idée originale, mal exprimée, alors que le mieux que ChatGPT puisse espérer est une idée non originale, exprimée avec compétence. ChatGPT est parfaitement positionné pour améliorer la soupe de référencement que des légions de travailleurs mal payés produisent dans le but de grimper dans les résultats de recherche de Google.
En mentionnant l’article de Chiang dans l’épisode du podcast « This Machine Kills », Jathan Sadowski perce de manière experte la bulle de la hype ChatGPT4, qui soutient que la prochaine version du chatbot sera si étonnante que toute critique de la technologie actuelle en deviendra obsolète.
Sadowski note que les ingénieurs d’OpenAI font tout leur possible pour s’assurer que la prochaine version ne sera pas entraînée sur les résultats de ChatGPT3. Cela en dit long : si un grand modèle de langage peut produire du matériel aussi bon qu’un texte produit par un humain, alors pourquoi les résultats issus de ChatGPT3 ne peuvent-ils pas être utilisés pour créer ChatGPT4 ?
Sadowski utilise une expression géniale pour décrire le problème : « une IA des Habsbourg ». De même que la consanguinité royale a produit une génération de prétendus surhommes incapables de se reproduire, l’alimentation d’un nouveau modèle par le flux de sortie du modèle précédent produira une spirale infernale toujours pire d’absurdités qui finira par disparaître dans son propre trou du cul.
On vous a partagé la semaine dernière la deuxième partie de La dégooglisation du GRAP qui vous invitait à découvrir comment iels avaient réussi à sortir de Google Agenda et gmail. Voici donc la suite et fin de ce récit palpitant de dégooglisation. Encore merci à l’équipe informatique du GRAP d’avoir documenté leur démarche : c’est vraiment très précieux ! Bonne lecture !
Dans l’épisode précédent…
Après la sortie de Google Drive remplacé par Nextcloud, Google Agenda par Nextcloud Agenda, nous avons fini par le plus gros bout en 2021-2022, sortir de Gmail et en finir avec le tentaculaire Google.
Le mardi 23 novembre, nous débranchions enfin Google. Nous voilà libres ! Presque 😉
Bilan dégooglisation
Après 4 ans de dégooglisation, où en sommes-nous de notre utilisation de logiciels non libres ?
Dans l’équipage ⛵
Système d’exploitation
Libre ?
Commentaire
Windows
❌
13 personnes
Ubuntu
✅
9 personnes
Gestion documentaire et travail collaboratif
Nextcloud Files
✅
Tout le monde depuis 2020 ✅
Nextcloud Agenda
✅
Tout le monde depuis 2021 ✅
Téléphonie et visio
3CX
❌
Tout le monde ❌
Nextcloud Discussions
✅
Mail et nom de domaine
Gandi
✅
Tout le monde depuis 2022 ✅
Logiciels métier
Odoo (suivi des actis, achat/revente, facturation)
✅
Pôles info, accompagnement et logistique
EBP (compta)
❌
Pôle compta
Cegid (paie)
❌
Pôle social
Gimp, Inkscape, Scribus (graphisme et mise en page)
✅
Pôle communication
BookstackApp (documentation)
✅
Tous pôles
Logiciels bureautique
Suite Office
❌
Suite LibreOffice
✅
Réseaux sociaux
Facebook, Linkedin, Twitter, Eventbrite
❌
Peertube
✅
Nos pistes d’amélioration en logiciel libre sont donc du côté du système d’exploitation et des logiciels métiers.
Les blocages sont dus :
à certains logiciels métiers qui n’existent pas en logiciel libre
→ à voir si on arrive à développer certains bouts métier sur Odoo dans les prochaines années
à la difficulté de se passer d’Excel pour certaines personnes grandement habituées à ses logiques et son efficacité
→ à voir si LibreOffice continue à s’améliorer et/ou si on se forme plus sur LibreOffice
Dans la coopérative 🌸
Système d’exploitation
Libre ?
Commentaire
Ubuntu
✅
Dans tous les points de vente
ordinateurs portables
Dur à dire, mais la majorité des activités de transformation utilise des tableaux Excel ou des logiciels dédiés
Logiciels bureautique
Suite Office
❌
Pas de référencement fait. Aucune visibilité actuellement
Suite LibreOffice
✅
Nos pistes d’amélioration sont donc du côté des logiciels mails et des logiciels métiers.
→ Un des gros chantiers de 2022-2023 est justement le développement et la migration sur Odoo Transfo. Pas pour le côté politique du logiciel libre mais bien de l’amélioration continue d’un même logiciel partagé dans la coopérative.
→ À voir si la dégooglisation de l’équipe « inspire » certaines activités pour se motiver à se dégoogliser. Nous serons là pour les accompagner et continuer à porter le message à qui veut l’entendre.
Bilan humain
À l’heure où nous écrivons (fin octobre 2022), il est trop tôt pour faire le bilan de la sortie de Gmail. Nous comptons d’ailleurs envoyer un nouveau questionnaire dans quelques mois qui nous permettra d’y voir plus clair. Mais nous pouvons d’ores et déjà dire que ce fut clairement l’étape la plus compliquée de la dégooglisation.
Sortir d’un logiciel fonctionnel, performant et joli est forcément compliqué quand on migre vers un logiciel aux logiques différentes (logiciel bureau VS web par exemple) et qui souffre de la comparaison au premier abord. Pour compenser cela, nous avons fait le choix de dédier beaucoup de temps humains (nombreuses formations par mini groupes ou en individuels, réponses rapides aux questions posées) et beaucoup de documentations et de partage de retour d’expériences.
La sortie de Google Drive et Google Agenda furent relativement douces et moins complexes que Gmail. Le logiciel Nextcloud étant assez mature pour assurer un changement plutôt simple et serein.
Ça paraît simple une fois énoncé, mais plus les gens travaillent avec un outil (Google par exemple), plus il sera difficile de les amener à changer facilement d’outil.
Conseil n°5 : Dans la mesure du possible, la meilleure des dégooglisation est celle qui commence dès le début, par l’utilisation d’outils Libres. En 2022, quasiment tout logiciel a son alternative Libre mature et fonctionnel. Si ce n’est pas possible, dès que les moyens humains sont disponibles et que la majorité le veut, envisagez votre dégooglisation ?
À Grap, il existe une certaine culture politique de compréhension autour des enjeux du logiciel libre et des GAFAM. Cela nous a aidé. Et cela nous parait quasiment obligatoire avant d’envisager une dégooglisation. Car c’est un processus long où l’on a besoin du consentement – au moins théorique – des gens impactés pour que celleux-ci acceptent de se former à de nouveaux outils, s’habituer à de nouvelles habitudes etc.
Conseil n°6 :avant d’entamer une dégooglisation, faire monter en compétences votre groupe sur les sujets autour du Logiciel Libre et des enjeux des Gafam à travers des projections de films par exemple. Voici un récap de quelques ressources.
Bilan technique
Voici nos choix de logiciels pour notre dégooglisation :
Nextcloud pour la gestion documentaire et le travail collaboratif (agenda, visio, gestion de tâches)
complété par Onlyoffice avec une image Docker sans limitation d’usage (pendant 2 ans l’image nemskiller007/officeunleashed puis désormais alehoho/oo-ce-docker-license)
sauvegarde quotidienne par le logiciel de sauvegarde Borg
BookstackApp et Peertube pour la documentation écrite et vidéo
Meshcentral pour la prise en main à distance d’autres ordinateurs
Gandi pour le prestataire de mails
Thunderbird pour le logiciel bureau pour gérer ses mails (et K9Mail sur téléphone)
Voici nos choix d’infrastructure :
OVH et Online pour la location de serveurs faisant tourner ses services (choix historique)
1 serveur dédié Nextcloud Test en miroir du Nextcloud
1 serveur de sauvegarde (mutualisé avec d’autres services de la coopérative)
1 serveur dédié à différents services (Peertube, Meshcentral, Bookstackapp)
Bilan économique
Pour calculer le coût économique de notre dégooglisation commencé en 2018, voici les chiffres retenus.
☀️ Le scénario « Dégooglisation » est celui réellement effectué depuis 2018.
Son coût comprend :
le temps de travail du service informatique, découpé en
l’aide au collègue habituelle : qui subit une augmentation du fait de l’internalisation de certaines questions, notamment avec le changement de Gmail à Thunderbird
le support et administration système des services :
toutes les recherches techniques (comment bien gérer les installations, sauvegardes etc.)
toutes les questions / réponses par mail et téléphone
le « temps de dégooglisation » qui correspond
les temps d’écriture de documentation et de formation
les mails d’annonce, de relance, de re-re-relance 😉
le coût des serveurs informatiques pour faire tourner les logiciels remplaçant les services Google et Teamviewer
🤮 À l’opposé, le scénario Google comprend :
le temps de travail du service informatique sur l’aide au collègue – accès stable dans le temps – qui augmente par le nombre de gens dans l’équipe, mais diminue par notre appropriation des logiciels, améliorations de l’existant, documentation etc.
la facturation des comptes Google Workspace
stable depuis 2018, Google a annoncé cet été l’augmentation de ces prix. Les pauvres n’ont eu que 6% de croissance en 2022 avec 14 milliards de dollars de bénéfices. Passant donc les comptes pro de 4€ à 10,40€/mois à partir de juin 2023.
la facturation hypothétique (car elle n’a jamais eu lieu) de Teamviewer Pro
En effet, jusqu’à juin 2019, nous utilisions Teamviewer pour aider les activités de la coopérative à distance. Mais notre utilisation intensive ne rentrait plus dans la version gratuite et Teamviewer nous bloquait l’usage du logiciel pour que l’on souscrive à leur abonnement.
Heureusement, nous sommes passés sur des logiciels auto-hebergés et libre : RemoteHelp (un logiciel libre abandonné depuis) puis en décembre 2020 sur Meshcentral.
En prenant en compte ces données, le scénario « Dégooglisation » finit par devenir moins cher que le scénario « Google ».
Pour le coût mensuel, cela arrive dès septembre 2022 (quasi à la fin de la sortie de Gmail donc) ! 🎉
Pour le coût cumulé, cela devient rentable deux ans après, en septembre 2024 ! 🎉
Ces chiffres s’expliquent par :
le coût important au démarrage de la sortie de Google Drive
128h passées sur les 5 premiers mois pour valider la solution Nextcloud
un temps de support / administration système pour Nextcloud qui baisse progressivement
passant de 14h mensuels en 2019, à 9h en 2020, à 5h en 2021, à 3h en 2022
le prix de Google qui aurait augmenté (mais on y a échappé avant, ouf !)
Bilan politique
Nous sommes fièr·es en tant que coopérative de porter concrètement nos valeurs dans le choix de nos logiciels qui sont plus que de simples outils.
Ces outils sont porteurs de valeurs démocratiques très fortes. Nous ne voulons pas continuer à engraisser Google – et autres GAFAM – de nos données privées et professionnelles qui les revendent à des entreprises publicitaires et des états à tendance anti-démocratique (voir les révélations Snowden, le scandale Facebook-Cambridge Analytica). Cela est en contradiction avec ce que nous prônons : la coopération, de l’entraide et le lien humain.
Nous avons besoin d’outils conviviaux, modulables et modifiables selon qui nous sommes. Nous avons besoin de pouvoir trifouiller les outils que nous utilisons, comme nous pouvons trifouiller un vélo pour y réparer le frein ou y rajouter un porte-bagages. Des outils émancipateurs en somme, qui nous empouvoire et ne rendent pas plus esclave de la matrice capitaliste.
Notre démarche n’aurait pas pu avoir lieu sans le travail et l’aide de millions de personnes qui ont construit des outils Libres, des documentations Libres, des conférences et autres vidéos Libres. Elle n’aurait pas eu lieu non plus sans l’inspiration de structures comme Framasoft ou la Quadrature du Net. Merci.
🍎 La route est longue, la voie est libre, et sur le chemin nous y cueillerons des pommes bios et paysannes. 🍏
Encore un grand merci aux informaticiens du GRAP pour leur travail de documentation sur cette démarche. D’autres témoignages de Dégooglisation ont été publiés sur ce blog, n’hésitez pas à prendre connaissance. Et si vous aussi, vous faites partie d’une organisation qui s’est lancée dans une démarche similaire et que vous souhaitez partager votre expérience, n’hésitez pas à nous envoyer un message pour nous le faire savoir. On sera ravi d’en parler ici !
Démystifier les conneries sur l’IA – Une interview
par JULIA ANGWIN Si vous avez parcouru tout le battage médiatique sur ChatGPT le dernier robot conversationnel qui repose sur l’intelligence artificielle, vous pouvez avoir quelque raison de croire que la fin du monde est proche.
Même le PDG de l’entreprise qui a lancé ChatGPT, Sam Altman, a déclaré aux médias que le pire scénario pour l’IA pourrait signifier « notre extinction finale ».
Alors, jusqu’à quel point devrions-nous nous inquiéter ? Pour recueillir un avis autorisé, je me suis adressée au professeur d’informatique de Princeton Arvind Narayanan, qui est en train de co-rédiger un livre sur « Le charlatanisme de l’IA ». En 2019, Narayanan a fait une conférence au MIT intitulée « Comment identifier le charlatanisme del’IA » qui exposait une classification des IA en fonction de leur validité ou non. À sa grande surprise, son obscure conférence universitaire est devenue virale, et ses diapos ont été téléchargées plusieurs dizaines de milliers de fois ; ses messages sur twitter qui ont suivi ont reçu plus de deux millions de vues.
Narayanan s’est alors associé à l’un de ses étudiants, Sayash Kapoor, pour développer dans un livre la classification des IA. L’année dernière, leur duo a publié une liste de 18 pièges courants dans lesquels tombent régulièrement les journalistes qui couvrent le sujet des IA. Presque en haut de la liste : « illustrer des articles sur l’IA avec de chouettes images de robots ». La raison : donner une image anthropomorphique des IA implique de façon fallacieuse qu’elles ont le potentiel d’agir dans le monde réel.
Voici notre échange, édité par souci de clarté et brièveté.
Angwin : vous avez qualifié ChatGPT de « générateur de conneries ». Pouvez-vous expliquer ce que vous voulez dire ?
Narayanan : Sayash Kapoor et moi-même l’appelons générateur de conneries et nous ne sommes pas les seuls à le qualifier ainsi. Pas au sens strict mais dans un sens précis. Ce que nous voulons dire, c’est qu’il est entraîné pour produire du texte vraisemblable. Il est très bon pour être persuasif, mais n’est pas entraîné pour produire des énoncés vrais ; s’il génère souvent des énoncés vrais, c’est un effet collatéral du fait qu’il doit être plausible et persuasif, mais ce n’est pas son but.
Cela rejoint vraiment ce que le philosophe Harry Frankfurt a appelé du bullshit, c’est-à-dire du langage qui a pour objet de persuader sans égards pour le critère de vérité. Ceux qui débitent du bullshit se moquent de savoir si ce qu’ils disent est vrai ; ils ont en tête certains objectifs. Tant qu’ils persuadent, ces objectifs sont atteints. Et en effet, c’est ce que fait ChatGPT. Il tente de persuader, et n’a aucun moyen de savoir à coup sûr si ses énoncés sont vrais ou non.
Angwin : Qu’est-ce qui vous inquiète le plus avec ChatGPT ?
Narayanan : il existe des cas très clairs et dangereux de mésinformation dont nous devons nous inquiéter. Par exemple si des personnes l’utilisent comme outil d’apprentissage et accidentellement apprennent des informations erronées, ou si des étudiants rédigent des essais en utilisant ChatGPT quand ils ont un devoir maison à faire. J’ai appris récemment que le CNET a depuis plusieurs mois maintenant utilisé des outils d’IA générative pour écrire des articles. Même s’ils prétendent que des éditeurs humains ont vérifié rigoureusement les affirmations de ces textes, il est apparu que ce n’était pas le cas. Le CNET a publié des articles écrits par une IA sans en informer correctement, c’est le cas pour 75 articles, et plusieurs d’entre eux se sont avérés contenir des erreurs qu’un rédacteur humain n’aurait très probablement jamais commises. Ce n’était pas dans une mauvaise intention, mais c’est le genre de danger dont nous devons nous préoccuper davantage quand des personnes se tournent vers l’IA en raison des contraintes pratiques qu’elles affrontent. Ajoutez à cela le fait que l’outil ne dispose pas d’une notion claire de la vérité, et vous avez la recette du désastre.
Angwin : Vous avez développé une classification des l’IA dans laquelle vous décrivez différents types de technologies qui répondent au terme générique de « IA ». Pouvez-vous nous dire où se situe ChatGPT dans cette taxonomie ?
Narayanan : ChatGPT appartient à la catégorie des IA génératives. Au plan technologique, elle est assez comparable aux modèles de conversion de texte en image, comme DALL-E [qui crée des images en fonction des instructions textuelles d’un utilisateur]. Ils sont liés aux IA utilisées pour les tâches de perception. Ce type d’IA utilise ce que l’on appelle des modèles d’apprentissage profond. Il y a environ dix ans, les technologies d’identification par ordinateur ont commencé à devenir performantes pour distinguer un chat d’un chien, ce que les humains peuvent faire très facilement.
Ce qui a changé au cours des cinq dernières années, c’est que, grâce à une nouvelle technologie qu’on appelle des transformateurs et à d’autres technologies associées, les ordinateurs sont devenus capables d’inverser la tâche de perception qui consiste à distinguer un chat ou un chien. Cela signifie qu’à partir d’un texte, ils peuvent générer une image crédible d’un chat ou d’un chien, ou même des choses fantaisistes comme un astronaute à cheval. La même chose se produit avec le texte : non seulement ces modèles prennent un fragment de texte et le classent, mais, en fonction d’une demande, ces modèles peuvent essentiellement effectuer une classification à l’envers et produire le texte plausible qui pourrait correspondre à la catégorie donnée.
Angwin : une autre catégorie d’IA dont vous parlez est celle qui prétend établir des jugements automatiques. Pouvez-vous nous dire ce que ça implique ?
Narayanan : je pense que le meilleur exemple d’automatisation du jugement est celui de la modération des contenus sur les médias sociaux. Elle est nettement imparfaite ; il y a eu énormément d’échecs notables de la modération des contenus, dont beaucoup ont eu des conséquences mortelles. Les médias sociaux ont été utilisés pour inciter à la violence, voire à la violence génocidaire dans de nombreuses régions du monde, notamment au Myanmar, au Sri Lanka et en Éthiopie. Il s’agissait dans tous les cas d’échecs de la modération des contenus, y compris de la modération du contenu par l’IA.
Toutefois les choses s’améliorent. Il est possible, du moins jusqu’à un certain point, de s’emparer du travail des modérateurs de contenus humains et d’entraîner des modèles à repérer dans une image de la nudité ou du discours de haine. Il existera toujours des limitations intrinsèques, mais la modération de contenu est un boulot horrible. C’est un travail traumatisant où l’on doit regarder en continu des images atroces, de décapitations ou autres horreurs. Si l’IA peut réduire la part du travail humain, c’est une bonne chose.
Je pense que certains aspects du processus de modération des contenus ne devraient pas être automatisés. Définir où passe la frontière entre ce qui est acceptable et ce qui est inacceptable est chronophage. C’est très compliqué. Ça demande d’impliquer la société civile. C’est constamment mouvant et propre à chaque culture. Et il faut le faire pour tous les types possibles de discours. C’est à cause de tout cela que l’IA n’a pas de rôle à y jouer.
Angwin : vous décrivez une autre catégorie d’IA qui vise à prédire les événements sociaux. Vous êtes sceptique sur les capacités de ce genre d’IA. Pourquoi ?
Narayanan : c’est le genre d’IA avec laquelle les décisionnaires prédisent ce que pourraient faire certaines personnes à l’avenir, et qu’ils utilisent pour prendre des décisions les concernant, le plus souvent pour exclure certaines possibilités. On l’utilise pour la sélection à l’embauche, c’est aussi célèbre pour le pronostic de risque de délinquance. C’est aussi utilisé dans des contextes où l’intention est d’aider des personnes. Par exemple, quelqu’un risque de décrocher de ses études ; intervenons pour suggérer un changement de filière.
Ce que toutes ces pratiques ont en commun, ce sont des prédictions statistiques basées sur des schémas et des corrélations grossières entre les données concernant ce que des personnes pourraient faire. Ces prédictions sont ensuite utilisées dans une certaine mesure pour prendre des décisions à leur sujet et, dans de nombreux cas, leur interdire certaines possibilités, limiter leur autonomie et leur ôter la possibilité de faire leurs preuves et de montrer qu’elles ne sont pas définies par des modèles statistiques. Il existe de nombreuses raisons fondamentales pour lesquelles nous pourrions considérer la plupart de ces applications de l’IA comme illégitimes et moralement inadmissibles.
Lorsqu’on intervient sur la base d’une prédiction, on doit se demander : « Est-ce la meilleure décision que nous puissions prendre ? Ou bien la meilleure décision ne serait-elle pas celle qui ne correspond pas du tout à une prédiction ? » Par exemple, dans le scénario de prédiction du risque de délinquance, la décision que nous prenons sur la base des prédictions est de refuser la mise en liberté sous caution ou la libération conditionnelle, mais si nous sortons du cadre prédictif, nous pourrions nous demander : « Quelle est la meilleure façon de réhabiliter cette personne au sein de la société et de diminuer les risques qu’elle ne commette un autre délit ? » Ce qui ouvre la possibilité d’un ensemble beaucoup plus large d’interventions.
Angwin : certains s’alarment en prétendant que ChatGPT conduit à “l’apocalypse,” pourrait supprimer des emplois et entraîner une dévalorisation des connaissances. Qu’en pensez-vous ?
Narayanan : Admettons que certaines des prédictions les plus folles concernant ChatGPT se réalisent et qu’il permette d’automatiser des secteurs entiers de l’emploi. Par analogie, pensez aux développements informatiques les plus importants de ces dernières décennies, comme l’internet et les smartphones. Ils ont remodelé des industries entières, mais nous avons appris à vivre avec. Certains emplois sont devenus plus efficaces. Certains emplois ont été automatisés, ce qui a permis aux gens de se recycler ou de changer de carrière. Il y a des effets douloureux de ces technologies, mais nous apprenons à les réguler.
Même pour quelque chose d’aussi impactant que l’internet, les moteurs de recherche ou les smartphones, on a pu trouver une adaptation, en maximisant les bénéfices et minimisant les risques, plutôt qu’une révolution. Je ne pense pas que les grands modèles de langage soient même à la hauteur. Il peut y avoir de soudains changements massifs, des avantages et des risques dans de nombreux secteurs industriels, mais je ne vois pas de scénario catastrophe dans lequel le ciel nous tomberait sur la tête.
Le Fediverse n’est pas Twitter, mais peut aller plus loin
Maintenant que Mastodon a suscité l’intérêt d’un certain nombre de migrants de Twitter, il nous semble important de montrer concrètement comment peuvent communiquer entre eux des comptes de Mastodon, PeerTube, Pixelfed et autres… c’est ce que propose Ross Schulman dans ce billet de l’EFF traduit pour vous par Framalang…
Le Washington Post a récemment publié une tribune de Megan McArdle intitulée : « Twitter pourrait être remplacé, mais pas par Mastodon ou d’autres imitateurs ». L’article explique que Mastodon tombe dans le piège habituel des projets open source : élaborer une alternative qui a l’air identique et améliore les choses dont l’utilisateur type n’a rien à faire, tout en manquant des éléments qui ont fait le succès de l’original. L’autrice suggère plutôt que dépasser Twitter demandera quelque chose d’entièrement nouveau, et d’offrir aux masses quelque chose qu’elles ne savaient même pas qu’elles le désiraient.
Nous pensons, contrairement à Megan, que Mastodon (qui fait partie intégrante du Fediverse) offre en réalité tout cela, car c’est un réseau social véritablement interopérable et portable. Considérer que Mastodon est un simple clone de Twitter revient à oublier que le Fediverse est capable d’être ou de devenir la plate-forme sociale dont vous rêvez. C’est toute la puissance des protocoles. Le Fediverse dans son ensemble est un site de micro-blogging, qui permet de partager des photos, des vidéos, des listes de livres, des lectures en cours, et bien plus encore.
Comme beaucoup de gens se font, comme Megan, une fausse idée sur le Fediverse, et comme une image vaut mieux qu’un long discours, voyons comment l’univers plus large d’ActivityPub fonctionne dans la pratique.
Parlons de PeerTube. Il s’agit d’un système d’hébergement de vidéos, grâce auquel les internautes peuvent en suivre d’autres, télécharger des vidéos, les commenter et les « liker ».
Voici par exemple la page de la chaîne principale du projet open source Blender et c’est là que vous pouvez vous abonner à la chaîne…
Dans cet exemple nous avons créé un compte Mastodon sur l’instance (le serveur) framapiaf.org. Une fois qu’on clique sur « S’abonner à distance », nous allons sur le compte Mastodon, à partir duquel il nous suffit de cliquer sur « Suivre » pour nous permettre de…suivre depuis Mastodon le compte du PeerTube de Blender.
Maintenant, dès que Blender met en ligne une nouvelle vidéo avec PeerTube, la mise à jour s’effectue dans le fil de Mastodon, à partir duquel nous pouvons « liker » (avec une icône d’étoile « ajouter aux favoris ») la vidéo et publier un commentaire.
… de sorte que le « like » et la réponse apparaissent sans problème sur la page de la vidéo.
Pixelfed est un autre service basé sur ActivityPub prenant la forme d’un réseau social de partage de photographies. Voici la page d’accueil de Dan Supernault, le principal développeur.
On peut le suivre depuis notre compte, comme nous venons de le faire avec la page PeerTube de Blender ci-dessus, mais on peut aussi le retrouver directement depuis notre compte Mastodon si nous connaissons son nom d’utilisateur.
capture : après recherche du nom d’utilisateur « dansup », mastodon retrouve le compte pixelfed recherché
Tout comme avec PeerTube, une fois que nous suivons le compte de Dan, ses images apparaîtront dans Mastodon, et les « likes » et les commentaires apparaîtront aussi dans Pixelfed.
Voilà seulement quelques exemples de la façon dont des protocoles communs, et ActivityPub en particulier, permettent d’innover en termes de médias sociaux, Dans le Fediverse existent aussi BookWyrm, une plateforme sociale pour partager les lectures, FunkWhale, un service de diffusion et partage de musique ainsi que WriteFreely, qui permet de tenir des blogs plus étendus, pour ne mentionner que ceux-là.
Ce que garantit le Fediverse, c’est que tous ces éléments interagissent de la façon dont quelqu’un veut les voir. Si j’aime Mastodon, je peux toujours y voir des images de Pixelfed même si elles sont mieux affichées dans Pixelfed. Mieux encore, mes commentaires s’afficheront dans Pixelfed sous la forme attendue.
Les personnes qui ont migré de Twitter ont tendance à penser que c’est un remplaçant de Twitter pour des raisons évidentes, et donc elles utilisent Mastodon (ou peut-être micro.blog), mais ce n’est qu’une partie de son potentiel. La question n’est pas celle du remplacement de Twitter, mais de savoir si ce protocole peut se substituer aux autres plateformes dans notre activité sur la toile. S’il continue sur sa lancée, le Fediverse pourrait devenir un nouveau nœud de relations sociales sur la toile, qui engloberait d’autres systèmes comme Tumblr ou Medium et autres retardataires.
La dégooglisation du GRAP, partie 2 : Au revoir Google Agenda et Gmail
On vous a partagé la semaine dernière la première partie de la démarche de dégooglisation du GRAP qui vous invitait à découvrir comment iels avaient réussi à sortir de Google Drive. Voici donc la suite (mais pas la fin) de ce récit de dégooglisation qui nous permet de prendre conscience que ce n’est toujours facile de sortir des griffes de ces géants de la tech. Bonne lecture !
Dans l’épisode précédent…
En janvier 2020, après plus d’un an à avoir pris la décision de passer sur Nextcloud en remplacement de Google Drive, la migration était officiellement finie ! Mais voilà, nous passions encore pas mal de temps à ouvrir un onglet Google pour consulter nos agendas, ainsi que nos mails pour les personnes utilisant Gmail en ligne.
/2021/ Fini Google Agenda, go Nextcloud Agenda
Fin septembre 2020, nous décidons collectivement de passer sur l’agenda Nextcloud. Nous nous laissons 3 mois pour commencer l’année 2021 sur le nouvel outil. Quelques personnes (notamment le pôle informatique) vont alors tester en conditions réelles Nextcloud Agenda.
Le challenge est sympa car nous décidons de faire ça en pleine migration d’Odoo de version 8 à la version 12, qui est le résultat de pas moins de 1000 heures de temps de travail et 294 tests de non régression.
L’export de données de Google Agenda se passe relativement bien, et l’import sur Nextcloud Agenda aussi. Les seuls soucis viennent de soucis d’exportation d’évènements récurrents du côté Google. On demande alors de recréer ces évènements du côté de Nextcloud Agenda.
Début 2021, la migration n’est pas possible pour trop de monde dans l’équipe : nous décidons de nous donner du mou et de fixer une date de bascule au 29 mars 2021 après que certains temps collectifs soient passés (l’assemblée générale notamment).
Une procédure est écrite pour que chaque personne s’autonomise dans sa migration, mais la majorité de la migration se fait collectivement à la date choisie du 29 mars :
export de l’agenda Google
import dans l’agenda Nextcloud
partage de son agenda au reste de l’équipe
(optionnel) synchronisation de l’agenda avec Thunderbird
création des agendas partagés pour les salles de réunion
Depuis avril 2021, nous sommes donc officiellement toustes sur Nextcloud Agenda.
L’application reçoit régulièrement des mises à jour porteuses de fonctionnalités bien chouettes (corbeille, recherche d’évènements, recherche d’un créneau de disponibilité), ou de corrections de bugs.
/2021-22/ La transformation complète : sortir de Gmail
Nous voilà arrivé·es à la dernière étape qui nous permet de sortir des outils Google pour l’équipage (nouveau nom de l’équipe interne). La plus dure. Même si cette étape ne concerne « que » les membres de l’équipage, cette transformation fut la plus longue à mener.
Pourquoi ? Parce que :
le mail est l’outil principal de la majorité des salarié·es de l’équipe qui l’utilisent toute la journée
Gmail est très performant, notamment dans la recherche de mail
certain·es personnes ont jusqu’à 10 ans d’habitudes de travail avec Gmail
D’ailleurs, on l’a constaté empiriquement, les personnes les plus anciennes de Grap furent les personnes les plus compliquées à faire transiter. Autant du point de vue technique (transférer 10 ans de mail est forcement plus compliqué que pour une personne arrivée récemment) que des habitudes prises sur le logiciel.
Conseil n°1 : plus on s’y prend tôt à se dégoogliser, moins ça sera compliqué dans la conduite du changement de logiciel.
🌱 Été 2021 – Trouver la solution technique remplaçante
Nous travaillons avec Gandi pour la majorité des activités de Grap afin de gérer leur nom de domaine et leurs mails. Pourquoi Gandi ?
Gandi est engagé depuis longtemps dans le respect de la vie privée
Gandi est une entreprise qui roule à priori bien sur laquelle on peut compter sur la durée
Gandi a un support de qualité qui répond rapidement à toutes nos demandes (et ce fut bien utile lors des moments de doute technique pour cette dégooglisation)
Gandi est une entreprise française qui paye à priori ses impôts en France 😉
Thunderbird va être notre pierre angulaire pour cette dé-gmail-isation. Autant pour permettre le transfert des mails de Google à Gandi, que pour travailler ses mails pour la suite. Ce fut une évidence de partir sur Thunderbird au début.
Ce logiciel libre est complet. Peut-être même trop complet, ce qui rend son ergonomie critiquable.
Ce logiciel est aussi assez ancien, ce qui lui donne une bonne robustesse. Peut-être trop ancien, ce qui rend son ergonomie critiquable 😉
Ce logiciel a une communauté importante qui développe de très nombreux modules complémentaires(à voir ici) qui viennent se greffer à Thunderbird pour apporter une myriade de possibilités.
Quelques mois plus tard, après la prise en main de certain·es utilisateur·ices, et de leur critique légitime, on s’est senti obligé de réaliser un banc d’essai (benchmark), qui validera définitivement ce choix.
Le benchmark pour choisir notre logiciel de bureau pour la gestion des emails
Les critères suivants ont été retenus :
logiciel libre
fonctionne sur Linux Ubuntu et Windows
communauté vivante et grande
modèle économique viable
installation simple
rempli les fonctionnalités de base demandées par les collègues (voir plus tard dans le texte)
🌿 Automne 2021 – Identifier les besoins et fonctionnalités utilisées
Pour être certain de pouvoir sortir de Google, il faut s’assurer que les collègues vont retrouver leurs petits, ou que l’on assume collectivement que l’on perdra des usages / fonctionnalités en passant sur Thunderbird.
Pour cela, nous envoyons un sondage qui nous permet d’y voir plus clair sur les fonctionnalités utilisées par l’équipe pour ajuster nos formations, documentations et recherches de modules complémentaires dans Thunderbird.
Réponse à la question « Quelles fonctionnalités mail utilises-tu actuellement ? »
Réponse à la question « Quelles fonctionnalités mail AIMERAIS-tu découvrir ou utiliser ? »
Sur la question « Sur une échelle de 0 à 6, est-ce que tu souhaites être précurseur·se de ce changement ? (0 : non / 6 : trop chaud·e)« , la moyenne et la médiane est à 3,5. Les gens sont donc.. moyennent chaud·es en général !
⚠️ Voici les points les plus bloquants pour un passage sur Thunderbird selon notre analyse :
les mails ne sont pas gérés sous la forme de fils de conversation
la recherche Thunderbird est laborieuse et pas aussi précise et rapide que Gmail
la peur de perdre des mails anciens
l’ergonomie de Thunderbird, notamment la différence de fluidité par rapport à une page web comme Gmail
Pour réussir ce changement de logiciel, il faut que les étapes soient claires et transparentes pour les utilisateur·ices. Cela leur permet de se projeter : « ok dans 6 mois / 1 an je change d’outil et je sais à peu près ce qui m’attend ! ».
Après ce premier sondage, un calendrier a donc été partagé, indiquant les différentes dates menant à la dégooglisation de tout le monde.
🪴 Automne – Hiver 2021 – Formation et Documentation Thunderbird
4 personnes sur 20 utilisent déjà Thunderbird. Pour les 16 autres, nous prévoyons d’étaler les formations par petits groupes sur 3 mois : les personnes les plus intéressées commencent dès mi-octobre, et les personnes les plus frileuses seront formées en janvier, ce qui nous laissera le temps d’avoir des retours, d’ajuster la formation et la documentation.
Ce travail de plusieurs mois va être itératif : chaque formation apporte son lot de questions, ou de bugs, ou de besoins qu’il faut alors documenter et faire repartager à tout le monde. De nombreux points mails (ou des messages informels) sont envoyés à l’équipe pour leur faire part des retours, de l’avancée et des nouveaux modules complémentaires ou paramétrages trouvés pour faciliter l’utilisation de Thunderbird.
🙊 Une difficulté anticipée mais relou : le lien Thunderbird – Gmail
Thunderbird a des défauts indéniables. Mais dans cette dégooglisation, on n’est pas aidé par Gmail qui aime bien avoir des comportements… embêtants. Une de ses particularités est le traitement des mails dans un dossier appelé « Tous les messages ». Pour citer la doc officielle de Thunderbird :
Tous les messages : contient une copie de tous les messages de votre compte Gmail, en incluant le dossier « Courrier entrant », le dossier « Envoyé » et les messages archivés.
Donc si vous avez 10 000 messages entrants et sortants, Thunderbird va télécharger 20 000 mails. Sachant qu’on retrouve tous ses mails dans Courrier entrant et Envoyés, ce dossier ne sert donc à rien. Après plusieurs semaines d’utilisation, et certains ralentissements au lancement de Thunderbird, nous avons fini par conseiller aux gens de se désabonner de ce dossier.
☘️ Avril 2022 – Premier bilan et questionnement technique
Le calendrier des formations a été quasiment tenu. C’est seulement en janvier que certaines formations n’ont pas eu lieu, du fait de difficultés professionnelles rencontrées dans certains pôles de l’équipe. Il ne restait alors que 2 personnes à former.
Mais entre temps, Quentin qui est responsable de cette dégooglisation, est parti en congés sans solde en février-mars. La décision avait été prise de ne pas se presser avant son départ et de faire le point en avril, nous y voilà.
2 personnes non formées en janvier + 2 arrivées
Certaines personnes de l’équipe n’ont pas pris le pli et sont revenues un peu / beaucoup sur Gmail
Un tableau partagé a fait remonter les problèmes soulevés :
La plupart peuvent être réglés par contournement ou par une meilleure documentation.
s’interroger sur pourquoi certaines personnes n’ont pas pris le pli
demander l’avis des membres de l’équipe sur Thunderbird et la dégooglisation en cours
faire un benchmark des solutions (voir si Thunderbird est vraiment le cheval gagnant)
s’assurer et valider le processus technique de bascule qu’il faudra faire (le voici)
prendre une décision lors de notre comité de pilotage informatique qui arrive
Conseil n°2 :Nous prenons aussi la décision que Quentin ne soit pas le seul porter ce projet. Il ressent une charge mentale et une certaine pression à gérer les retours des personnes en difficulté. Pour ne pas non plus tomber dans une posture de l’informaticien libriste qui impose le choix, et pour bien affirmer que nous prenons des choix collectivement, nous allons dé-personnifier le projet. Désormais le travail sera soutenu et partagé avec Sandie, et les mails signés par le pôle informatique.
⚡ Mai 2022 – La recherche boostée à notre rescousse !
Enfin ! Nous avons trouvé un moyen de répondre aux soucis de recherche sur Thunderbird. Avec un habile mélange de dossier virtuel et d’un module complémentaire de recherche avancée, nous parvenons à lier rapidité et complexité de recherche !
🍀 Juin 2022 – Deuxième bilan : on y va, on sort de Google ?
Notre comité de pilotage ne prend pas une décision ferme. On continue juste à valider de travailler sur cette dégooglisation. En dehors de tous les aspects politiques, en sortant de Google, nous allons cesser de payer 2000€/an pour les comptes pros que nous avons, et c’est toujours ça de gagné dans un moment de crise économique !
Deux mois plus tôt, nous avions envoyé ce formulaire à l’équipe, commenté par cette phrase qui résume son intention « Vive le consentement, à bas la coercition 🌞 » pour prendre la température de l’équipe sur l’utilisation de Thunderbird. Voici notre analyse résumée des résultats :
🔴 les personnes n’ayant pas encore franchi l’étape Thunderbird sont :
une grande partie d’un pôle en surcharge
les « ancien⋅nes » qui sont là depuis longtemps
🔴 les difficultés principales vis-à-vis de l’outil sont :
la recherche de mail
le changement d’usage ergonomique
des problèmes liés à la connexion avec Google
des besoins spécifiques non fonctionnels (invitation Outlook)
des problèmes spécifiques réglés depuis (soucis d’antivirus, paramétrage mail d’absence, etc.)
✅ l’équipe est chaude pour sortir de Google !
✅ l’équipe se sent bien accompagnée à ce changement.
☑️ une minorité de l’équipe (3~4 personnes) ne se sent pas sécurisée ou perd quelques minutes par jour à l’utilisation de Thunderbird. Ces 3~4 personnes se recoupent avec les personnes utilisant Gmail. Nous pensons qu’avec l’usage et les améliorations du logiciel, nous parviendrons à améliorer ça.
⭕ les personnes revenues sur Gmail l’expliquent par :
de travailler sur la solution d’application smartphone adéquate pour sortir de l’application Gmail
de redonner une formation aux 5 personnes qui n’ont pas fait le switch afin qu’elles y arrivent
de fixer la date de sortie de Google : cela sera la 1ère ou 2ème semaine d’août
de commencer à créer toutes les boîtes mails et redirections mails nécessaires
Conseil n°3 :Nous avions 17 boîtes mails à recréer et 80 redirections de mails assez complexes à réaliser. C’est un travail fastidieux qui demande de se concentrer pour ne pas louper un mail dans la redirection mail créée. Car non, il n’existait pas d’export Google des « groupes Google » que nous utilisions. Le conseil est donc le suivant : partagez le travail 🙂 Merci Sandie pour ce gros taf !
🚀 Juillet 2022 – la bonne nouvelle : Thunderbird s’améliore
Alors que nous venions de fixer le créneau de départ de Google (début août), Thunderbird sort sa dernière version (la 102), le 29 juin. Cette version apporte de très nombreuses améliorations ergonomiques, rendant le logiciel bien plus agréable à utiliser. Et quand on utilise un logiciel toute la journée, ce n’est pas un petit détail que de pouvoir modifier la taille d’affichage, la taille de police, les couleurs des dossiers mails ou encore une gestion des contacts totalement re-désignée. Leur annonce officielle ici.
Et les bonnes nouvelles s’enchaînent :
Thunderbird annonce rejoindre le projet K-9 Mail pour une application libre sur Android qui va donc s’améliorer encore plus vite !
une ergonomie qui s’améliore de jour en jour avec notamment l’affichage des mails sur plusieurs lignes
une synchronisation de son compte qui permettrait d’avoir deux Thunderbird sur deux ordis différents
🌸 Voici à quoi pourrait ressembler Thunderbird en mi-2023 🌸
🌲 9 Août 2022 – Le fil rouge sur le bouton rouge..
Depuis quelques mois, on discutait avec Gandi pour nous assurer que la procédure était la bonne. Quel plaisir d’avoir des gens qui répondent rapidement à ces demandes. Merci ! Nous étions donc plutôt prêts pour ce switch. Le mardi 9 août à 22h, alors que les collègues sont pour la plupart en vacances, on change les DNS du domaine grap.coop (DNS = règles techniques qui disent ce qui se passe avec grap.coop) pour débrancher Google et brancher Gandi.
Le mardi 9 août à 23h50, après quelques tests d’envoi et de réception de mails, j’annonce officiellement que tout semble fonctionner comme prévu. Les mails de Gandi partent bien. On reçoit bien les mails sur la nouvelle boîte mail. Le monde n’a pas cessé de tourner. Victoire !
Grap vs Google, allégorie
🙊 Une difficulté pas anticipée : l’envoi de mail par notre logiciel Odoo [tech]
En créant toutes les boîtes mails sur Gandi, nous nous étions rendu compte des cas particuliers (des personnes qui avaient un compte mail mais qui n’étaient pas ou plus dans l’équipe par exemple) mais ce n’est que tardivement qu’on a réalisé que la boîte mail serveurs <arobase> grap.coop servait de boîte d’envoi à l’ensemble des mails du logiciel Odoo utilisé par les 65 activités. Comment cela allait se comporter en passant chez Gandi ? Deux soucis sont encore en cours :
1 – L’usurpation d’identité
En fait, chaque activité envoie ses bons de commandes et factures depuis Odoo. Odoo utilise une seule boîte mail serveurs grap.coop mais lors de l’envoi, prend l’identité de l’activité qui envoie un mail.
Cette « usurpation d’identité » était bien acceptée car nous étions chez Google. Mais avec le passage chez Gandi, cette usurpation d’identité n’est plus acceptée par les boîtes mail à la réception si celles-ci sont chez Google.
L’activité a un mail d’envoi géré par Gandi → envoi par serveurs qui est géré par Gandi → OK
L’activité a un mail d’envoi géré par Google / OVH / Ecomail etc. → envoi par serveurs qui est géré par Gandi → NOK si à la réception la personne utilise Google.
La solution future : améliorer l’envoi de mail sur Odoo pour que chaque activité puisse envoyer avec les informations de sa vraie boîte mail.
2 – Les mails envoyés par les serveurs <arobase> grap.coop ne sont pas automatiquement enregistrés dans le dossier Envoyés
À priori, l’envoi de mail n’est pas totalement bien développé et il manque quelques informations dans le mail pour que celui-ci soit bien mis dans le dossier Envoyés.
Mais avec Google, cela fonctionnait. Il devrait réussir à comprendre qu’un mail partait de sa boite mail, et il le plaçait le mail dans le dossier Envoyés. Ce qui était pratique pour vérifier que le mail était bien parti.
La solution future : améliorer l’envoi de mail sur Odoo pour que le mail arrive dans le dossier Envoyés.
🙊 Un comportement pas anticipé : Google, le mort-vivant
Malgré la déconnexion technique du nom de domaine grap.coop avec Google, il était encore possible de se connecter à Gmail et d’envoyer des mails. Alors certes, les réponses n’arrivaient plus sur Gmail, mais cela permettait encore aux irréductibles de résister au changement ! 😛
Surtout, même après avoir supprimé le compte Google sur Thunderbird (n’ayant alors que le compte Gandi), un paramétrage technique (le serveur SMTP d’envoi) faisait que les mails envoyés l’étaient par le serveur Google.
Donc au moment de la suppression réelle du compte Google, l’envoi par Thunderbird était bloqué. Ce n’est pas un gros souci, mais nous avons documenté le petit changement à faire.
🐢 Septembre 2022 – La fin de la route est longue, mais la voie est libre
Après la dégooglisation technique, place à la dernière étape, supprimer réellement les comptes Google. Chaque personne devait suivre un tutoriel nommé « Google débranché 💃🕺 La suite ✌️ » comportant ces étapes :
🧹 Nettoyer derrière soi
🚪 Fermer la porte
🔧 S’assurer que l’on envoie ses mails avec les bons paramétrages
🫑 Embellir son nouveau jardin
📫 Découvrir le webmail (logiciel en ligne) de Gandi
📱 Connecter son ordiphone
💥 Quitter définitivement Google
Il a fallu 2 mois pour que les 30 personnes concernées suivent réellement ce tutoriel – voire rattrapent leur « retard » pour sortir leur mail de Google. Ce fut l’une des étapes les plus chronophages en termes de relance, de suivi personnel, de questions / réponses, de gestion de cas particuliers (certaines personnes n’avaient pas pu transférer leur mail à cause d’une connexion Internet trop faible par exemple). C’est aussi à ce moment que l’on devait bien vérifier qu’aucune autre donnée n’était encore stockée sur Google Drive / Google Photos / Agenda etc., ce qui a ralenti quelques personnes.
Conseil n°4 : pour motiver chaque personne à passer le pas, communiquer de façon informelle et encourageante !
💀 Octobre 2022 – Au revoir Google, tu ne vas pas me manquer
Même si nous avons tout fait pour être coercitifs, certaines personnes ont besoin de date limite pour prioriser leur travail. Trois semaines avant, la date butoir du 07 octobre est donc fixée pour motiver les dernières personnes.
🎄 Novembre 2022 – Jusqu’au bout !
La première date butoir et les nombreuses relances n’ont pas suffi à faire remonter en priorité n°1 à tou·te·s les collègues de sortir de Gmail.
Comme nous ne sommes pas des grands méchants, et que nous comprenons les difficultés et calendrier de chacun·e, nous redonnons du rab : le mardi 23 novembre. La veille de la fête des 10 ans de Grap, cela semble une date symbolique et assez lointaine pour réellement partir. Pour de bon.
Le mardi 23 novembre, à 13h35, nous étions 5 à nous réunir autour d’un ordinateur, observant ce moment… un peu stressant, comme quand on part d’un lieu en espérant n’y avoir rien oublié. À 13h43, Google était derrière nous. ✊
To be continued…
Dans la troisième (et dernière) partie, nous continuerons notre récit de dégooglisation en faisant le bilan de cette démarche. A la semaine prochaine !
Si vous aussi, vous faites partie d’une organisation qui s’est lancée dans une démarche similaire et que vous souhaitez partager votre expérience, n’hésitez pas à nous envoyer un message pour nous le faire savoir. On sera ravi d’en parler ici !
La dégooglisation du GRAP, partie 1 : La sortie de Google Drive
On a donc sauté sur l’occasion lorsque le GRAP (Groupement Régional Alimentaire de Proximité), une coopérative réunissant des activités de transformation et de distribution dans l’alimentation bio-locale, a publié le récit de sa dégooglisation. Nous reproduisons ici ce long texte en trois parties pour vous partager leur expérience.
De 2018 à cette fin 2022, nous avons travaillé à Grap à notre dégooglisation. Nous vous proposons ce long texte en trois parties pour vous partager notre expérience.
Son premier intérêt est de laisser une trace du travail fourni et d’en faire le bilan.
Le deuxième intérêt est de partager cette expérience à d’autres structures qui souhaiteraient se lancer dans l’aventure.
Nous partageons dans ce texte les processus mis en place, les différentes étapes de cette dégooglisation, les difficultés rencontrées et quelques conseils.
Pour toute question ou retour, vous pouvez contacter le pôle informatique de Grap : pole-informatique <arobase> grap.coop
Bonne lecture et longue vie aux outils numériques émancipateurs et Libres ! 🚲
Au début de Grap en 2012…
Il y a 10 ans, Grap naissait en tant que SCIC – Société Coopérative d’Intérêt Collectif. En 2012 est écrite une 1ère version du préambule des statuts qui décrit l’intérêt collectif qui réunit les associé·e·s de la SCIC. Ce préambule présentait alors que Grap aller « Contribuer au développement d’activités économiques citoyennes et démocratiques, c’est-à-dire […] travaillant dans une logique de partage des savoirs, en phase avec la philosophie Creative Commons ».
Cette 1ère référence au monde du Libre est complétée et enrichie 5 ans plus tard à l’occasion d’une révision du préambule des statuts, en 2017. Désormais le préambule des statuts indique que Grap entend :
Contribuer au développement d’activités économiques citoyennes et démocratiques […] promouvant l’économie des biens communs, c’est à dire :
Travailler dans une logique de partage des savoirs, en phase avec la philosophie Creative Commons
Promouvoir, contribuer et utiliser des logiciels libres au sens de la Free Software Foundation ; minimiser l’utilisation de logiciels sous licences privatives
Promouvoir, contribuer et utiliser des solutions informatiques qui n’exploitent pas de façons commerciales les données des utilisateurs et qui respectent leurs vies privées
Notre démarche de dégooglisation s’inscrit donc dans la continuité des choix politiques portés par les associé·e·s de la coopérative depuis sa création. Par dégooglisation, nous entendons ici le remplacement des logiciels propriétaires – qu’ils soient détenus par les GAFAM ou non – par des logiciels Libres.
Dès le début, il est décidé d’internaliser une partie de l’informatique au sein de l’équipe qui rend les services aux activités de la coopérative. [À Grap, nous utilisons le terme d’activité pour désigner les entreprises associées à Grap et les activités économiques de la Coopérative d’Activités et d’Emploi]. La majorité du temps informatique sera dédié au développement du progiciel libre OpenERP (nommé désormais Odoo) pour gérer la première activité d’épicerie (3 P’tits Pois à Lyon) de la coopérative.
Par pragmatisme économique et choix stratégique, les autres outils de la coopérative ne sont pas choisis par le critère de logiciel Libre ou non. Ainsi, la coopérative va utiliser Google Drive, Google Mail, Google Agenda, et aussi d’autres logiciels spécifiques comme EBP pour la compta ou Cegid Quadra pour la paie.
2018-2020/ Sortir de Google Drive pour Nextcloud
Après le départ d’un des cofondateurs et d’un informaticien en 2014, le service informatique va fonctionner avec 1 seule personne jusqu’à fin 2017. Sylvain Le Gal va alors consolider le périmètre existant (gestion d’une eBoutique, développements spécifiques à l’alimentaire dans OpenERP, connexion avec des balances client·es et migration de OpenERP 7.0 à Odoo 8.0).
Fin 2017, l’embauche de Quentin Dupont permet de gagner en temps de travail disponible et d’agrandir le périmètre des services du pôle informatique.
🌻 L’été 2018 pour valider l’alternative à Google Drive
Le choix du logiciel remplaçant se fait très facilement : Nextcloud est LA solution Libre qui s’impose autant par sa prise en main relativement simple pour des utilisateur·ices de tout niveau, que par l’engouement de sa communauté et son administration alors maîtrisée par le pôle informatique.
Il faut quand même s’assurer que toutes les fonctionnalités utilisées actuellement trouvent leur équivalent. Grâce aux différentes applications existantes sur Nextcloud, les différents besoins se retrouvent bien couverts.
🌸 À l’automne 2018, on prend la décision de sortir de Google Drive
Un changement de logiciel peut être l’occasion de revoir ses pratiques. Nous en profitons pour revoir notre arborescence de fichiers et de dossiers. Nous créons alors :
Un compte Nextcloud par :
personne physique de l’équipe interne
personne physique des activités qui ont des mandats particuliers (administrateur·ice au CA par exemple)
activité de la coopérative (donc par « personne morale ») et non pas par personne physique de la coopérative pour différentes raisons :
de nombreuses activités partagent réellement leurs ordinateurs tout au long de la journée
aucun intérêt à ce que chaque personne ait son compte, cela rajouterait une dose énorme de suivi de création de compte, de support, etc.
ce choix vient avec une limite : l’accès aux documents personnels avec le pôle social n’est pas possible
Un « groupe » Nextcloud pour chaque groupe autonome
un groupe par pôle de l’équipe interne
un groupe par mandat : DG, CA
un groupe par activité de la coopérative – regroupant le compte de la personne morale + les comptes des personnes physiques de cette activité qui ont des mandats particuliers.
Des dossiers communs pour travailler collaborativement
entre pôles de l’équipe
entre membres de la coopérative
entre mandataires (DG ou CA)
La structure de dossiers présentée en nov. 2018 et qui est en place depuis.
Avec Nextcloud, nous avons donc pu créer une architecture plutôt simple pour les utilisateur·ices mais permettant de répondre aux complexités du travail collaboratif entre des profils bien différents.
Grâce aux droits d’accès paramétrables finement, le Nextcloud permet ainsi d’offrir plus de transparence et de collaboration dans la coopérative, que ce soit par les dossiers partagés totalement ou, à l’inverse, les dossiers dont l’accès n’est possible qu’en lecture sans possibilité de modifier.
💮 2019 – 2020 : la dégooglisation de 150 personnes dans 50 activités
Google Drive n’est pas seulement utilisé par l’équipe interne. L’outil est partagé à l’ensemble de la coopérative. C’est à dire à une cinquantaine – à l’époque – d’activités indépendantes, allant de l’entrepreneuse seule à la petite équipe de 10 personnes.
Il faut donc embarquer tout le monde dans ce changement.
Politiquement/théoriquement pas de soucis. Les méfaits de Google sont connus de la majorité des gens et théoriquement, nous n’avons jamais eu de désaccords sur l’idée de sortir de Google Drive.
En pratique, Google Drive s’avère être plutôt lourd à l’utilisation, pas bien maîtrisé ni maîtrisable, surtout concernant la gestion des partages qui est un véritable enfer (« Qui est le fichu propriétaire de ce fichier dont le propriétaire originel est parti de la structure / n’a plus de compte Google ? »).
En allant sur Nextcloud, nous allions maîtriser – et donc être responsables – des données de la coopérative, nous allions retrouver de la souveraineté et de la compétence sur le sujet.
Au printemps 2019, nous changeons aussi d’outil de documentation. Pour sa simplicité d’utilisation et son ergonomie générale, nous choisissons le logiciel Libre BookstackApp. Depuis, notre librairie tourne toujours aussi bien et héberge notre documentation informatique mais aussi toute la documentation stable de la coopérative.
💩 Une première difficulté : l’export des données de Google
L’export fut en effet très compliqué, trop compliqué pour un logiciel conçu par l’une des entreprises les plus puissantes au monde. L’export des données d’un Google Drive (à l’époque en tout cas) est extrêmement long et très peu sécurisant : Google fournit l’export en archives coupées en plusieurs parties (du style « ARCHIVE-PART01 » « ARCHIVE-PART02 »), archives dont une partie… pouvait être manquante (ex : on a la partie 01, 02, 04, 05 mais pas la partie 03), nécessitant de refaire un export entier.
Nous avons donc passé de nombreuses heures à exporter les données, puis nous les avons sécurisées sur un disque dur externe, avant de les envoyer sur notre Nextcloud.
🚀 Et tu formes formes formes, c’est ta façon d’aimer
Pour réussir à dégoogliser la coopérative, pas de miracle, on a enchaîné la formation des activités une à une, en mutualisant des formations par territoire géographique.
Chaque formation durait environ 1h30. En 2019, nous avons passé environ 150 heures de travail à la formation, l’accompagnement et la documentation de cette étape de dégooglisation (+ les heures techniques, voir bilan financier à la fin de ce récit). L’ensemble de la documentation – qui est un travail continu – est consultable ici : https://librairie.grap.coop/books/nextcloud
En janvier 2020, soit plus d’un an après la décision de passer sur Nextcloud, la migration était officiellement finie ! 🎉
🙊 Une difficulté pas anticipée : les limitations d’Onlyoffice pour les commandes groupées
Tout allait bien dans la dégooglisation progressive de la coopérative. Au cours de l’année 2019, la moitié de la coopérative utilise désormais Nextcloud au lieu de Google Drive !
Un des avantages de la coopérative pour les activités est de pouvoir mutualiser de nombreux sujets. Un de ces sujets est l’approvisionnement en produits artisanaux en circuits courts grâce à une logistique interne – Coolivri. Cette logistique s’appuyait à l’époque sur un GROS fichier tableur en ligne sur Google Drive.
Le 2 août 2019, une première commande groupée d’oranges et d’agrumes est lancée sur le Nextcloud et toutes les prochaines commandes groupées vont débarquer sur le Nextcloud, géré par l’application Onlyoffice.
Et c’est vers cette période que l’on se rend compte que l’application disponible d’Onlyoffice a une limitation : pas plus de 20 personnes connectées simultanément sur l’ensemble des fichiers collaboratifs du nuage ! À l’époque nous devions avoir une soixantaine d’utilisateur·ices et une équipe interne qui l’utilise toute la journée : ce n’était pas tenable.
Cette limitation n’est pas technique, mais bien un choix délibéré de l’entreprise développant le logiciel pour amener à payer une licence permettant d’accéder au logiciel sans limitation. Un modèle freemium en soi. Cette question du modèle économique et de ce qu’est un « vrai » logiciel libre est bien sûr compliqué, et amènera de nombreux débats dans les forums de discussion de Nextcloud.
Fin 2019, nous nous questionnons réellement sur le fait de payer cette licence (coût à l’époque : ~1500€ en une fois pour 100 utilisateur·ices simultanées).
Après avoir écumé les Internets, contacté toutes les structures amies qui auraient la même problématique, la solution vient finalement de la communauté elle-même qui est partagée sur le fait de contourner cette limitation qui constitue le modèle économique de l’entreprise développant Onlyoffice. Un développeur bénévole a réussi à reproduire le logiciel (légalement car le logiciel est Libre) en enlevant cette limitation !
Depuis, nos commandes groupées ont été rapatriées sur Odoo grâce à un gros développement interne, en faisant un outil beaucoup plus résilient et solide. Et nous continuons d’utiliser Onlyoffice dans des versions communautaires trouvées par ci par là.
Google en 2022 s’inquiète 😉
To be continued…
Dans la seconde partie, nous continuerons notre récit de dégooglisation, nous permettant de nous débarrasser de Google Agenda puis du mastodonte.. Gmail !
Si vous aussi, vous faites partie d’une organisation qui s’est lancée dans une démarche similaire et que vous souhaitez partager votre expérience, n’hésitez pas à nous envoyer un message pour nous le faire savoir. On sera ravi d’en parler ici !



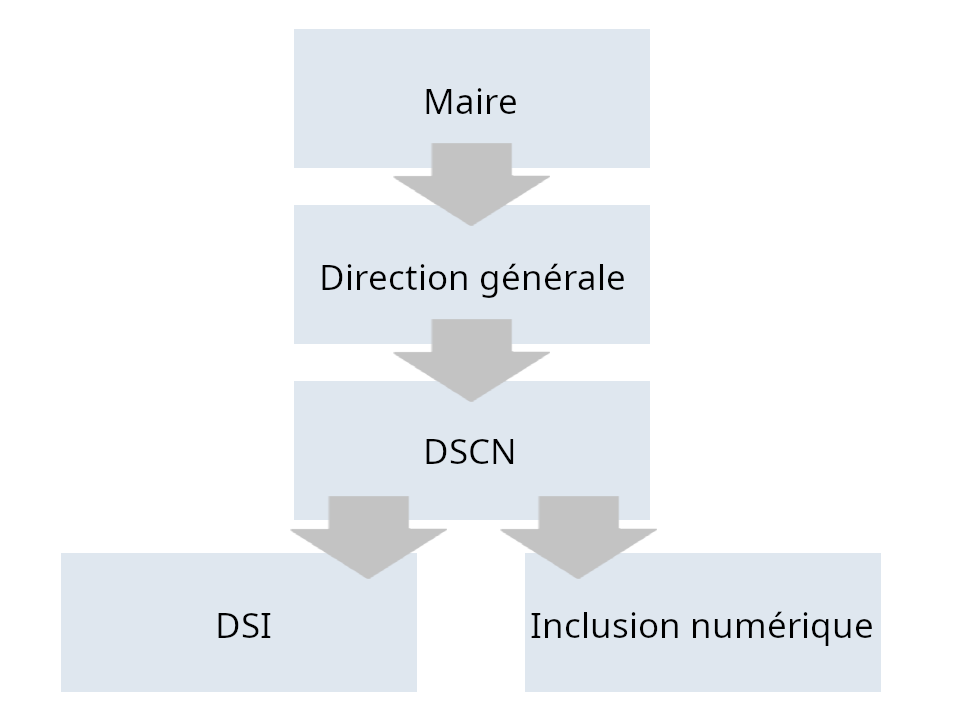





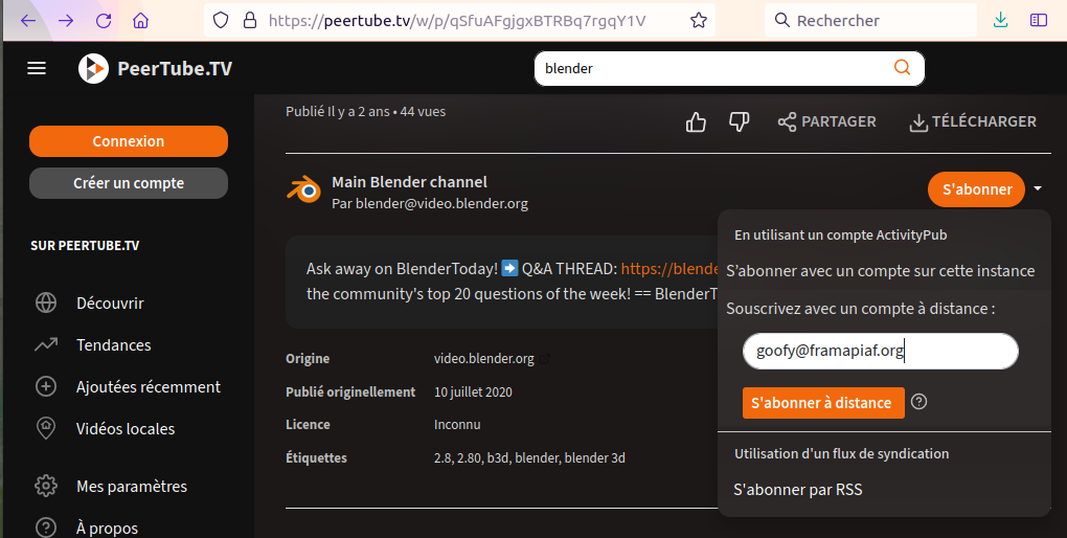
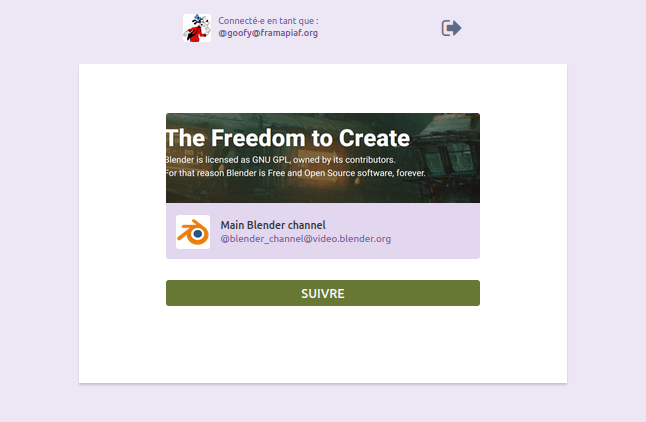

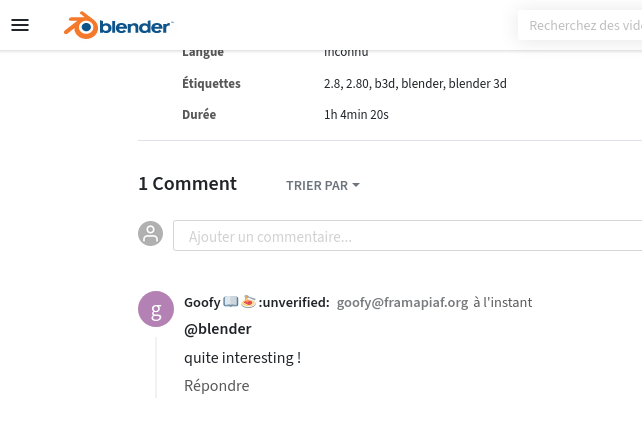
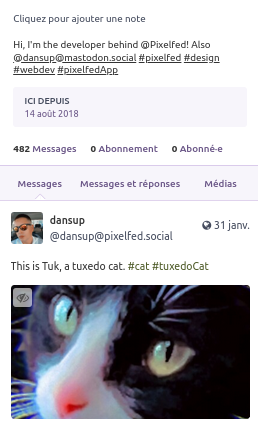
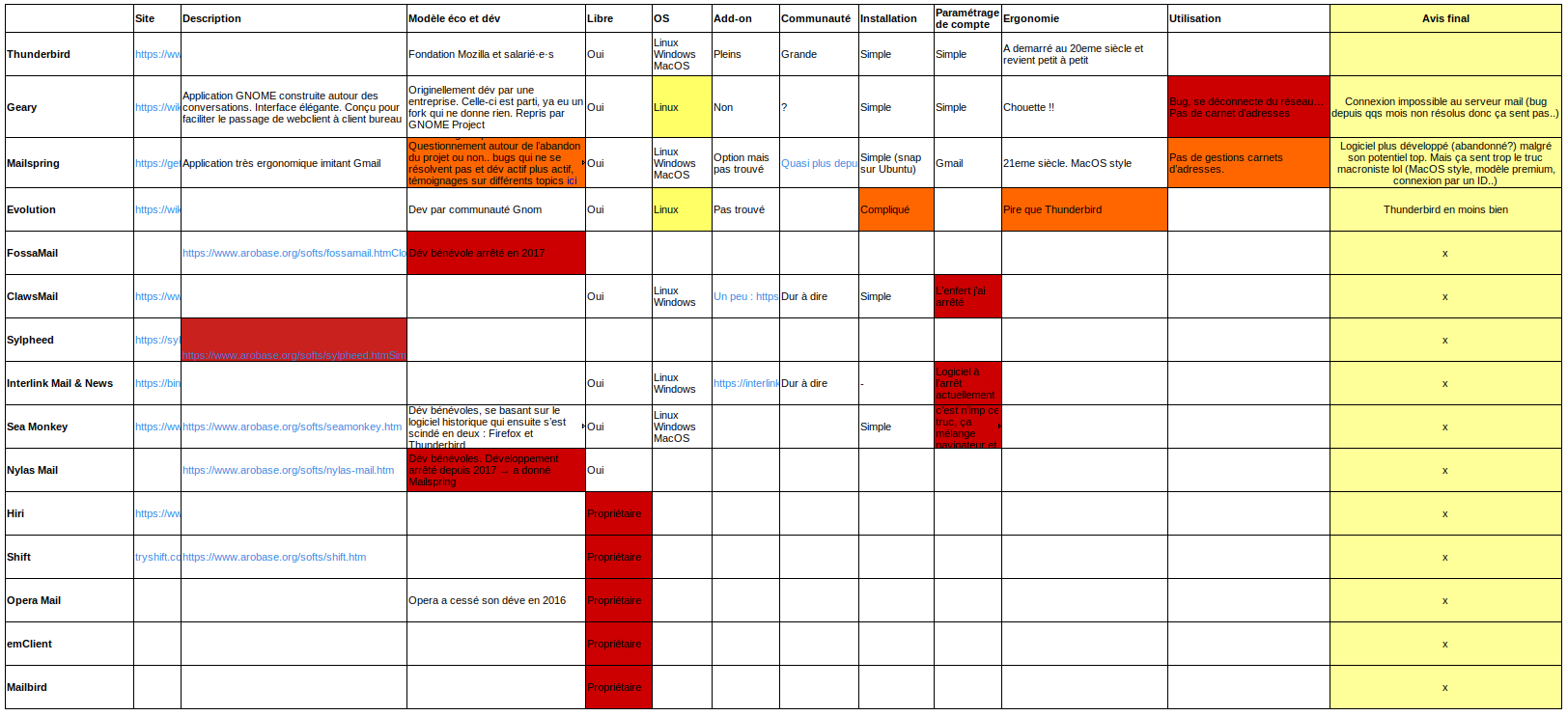

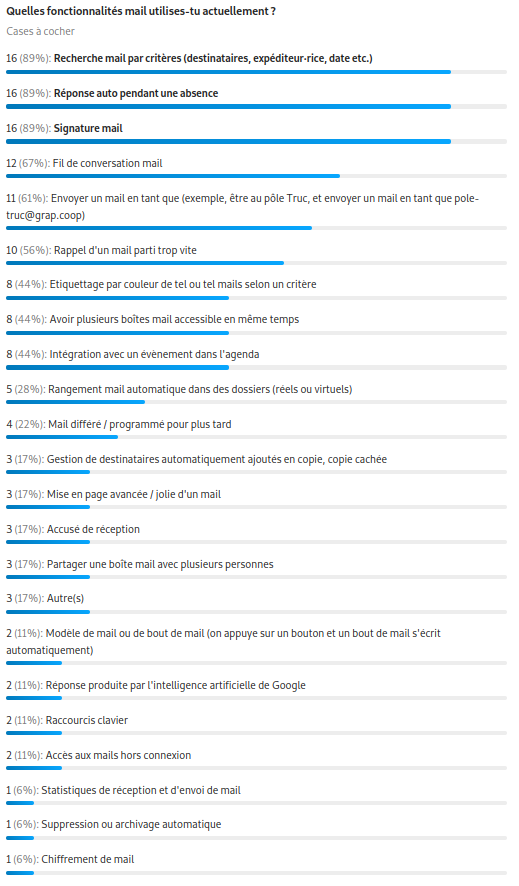
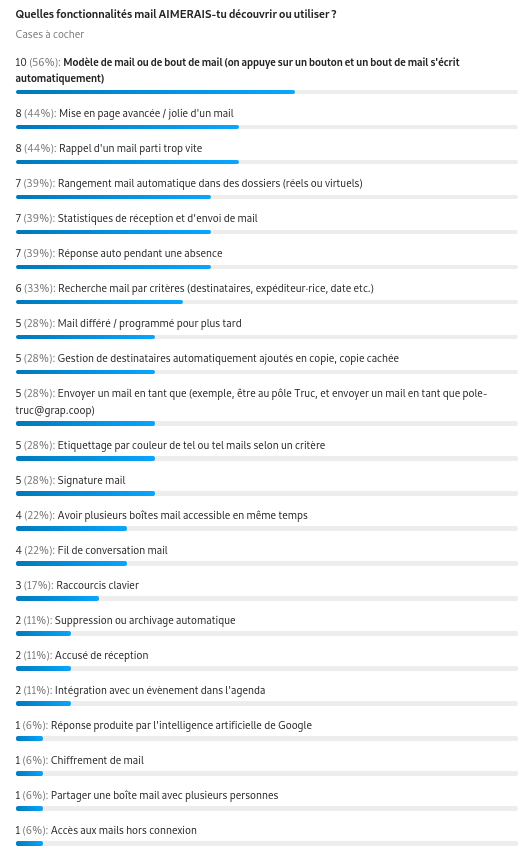


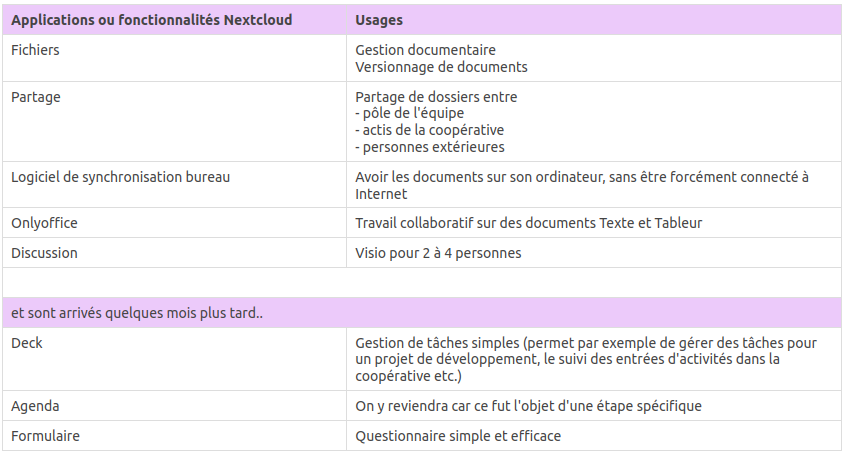
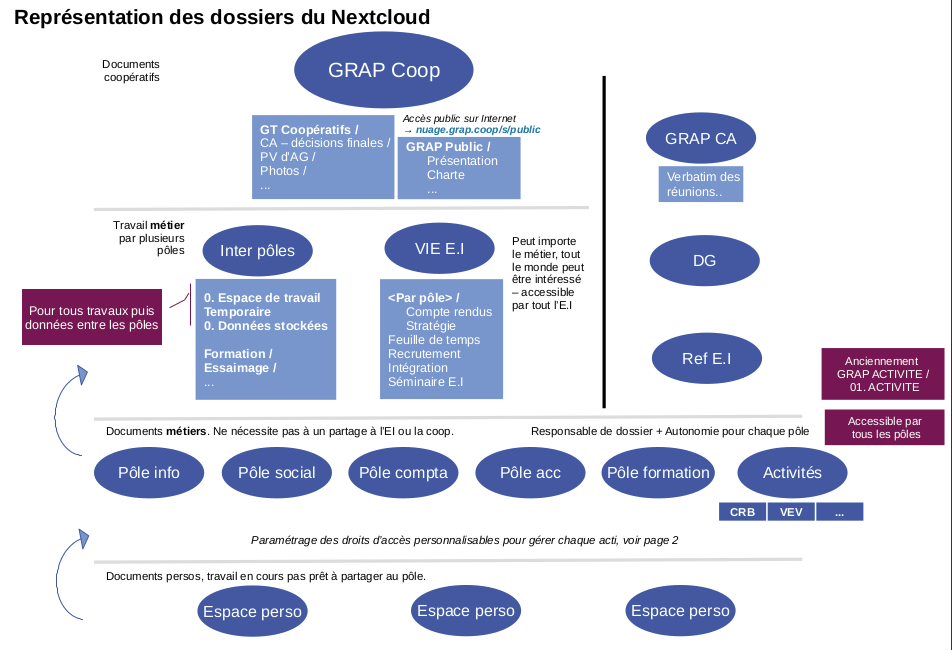

{kind=link}
{kind=link}