Framasoft fait son « Ray’s day » avec 8 nouvelles Libres
Depuis sa création, Framasoft s’est donné pour mission de diffuser la culture libre et d’en emprunter la voie — libre elle aussi. Aujourd’hui, c’est le « Ray’s day », l’occasion de fêter l’acte de lecture en célébrant l’anniversaire de feu Ray Bradbury.
L’événement, initié l’année dernière par l’auteur Neil Jomunsi se veut « comme une grande fête d’anniversaire dans le jardin avec ballons et tartes aux myrtilles ». Pas une fête pour « vendre de la culture », juste une grande envie de partager nos lectures.
8 nouvelles Libres
Alors, à Framasoft, comme on aime beaucoup les tartes aux myrtilles, on s’est dit qu’on allait participer. Le temps de cette belle journée, différents membres de l’association ont donc pris la casquette d’écrivain pour vous présenter un livre électronique inédit contenant 8 histoires différentes :
Lisez, partagez, adaptez ou modifiez-les, ces histoires vous appartiennent désormais ! Et si l’envie vous en prend, diffusez le mot sur les réseaux sociaux avec le hashtag #RaysDay… l’occasion aussi de découvrir d’autres initiatives à travers la toile.
Mais ce n’est pas tout…
En effet, suite à un harcèlement textuel et potache sur les réseaux sociaux, Gee et Pouhiou ont repris leur casquettes de Connards Professionnels pour un nouvel épisode de « Bastards, inc. – Le Guide du Connard Professionnel ». L’occasion de relire et/ou télécharger les épisodes précédents, et de lire cet épisode inédit en attendant qu’ils reprennent (dès le 2 septembre) leur rythme de croisière de ce roman/BD/MOOC de connardise.
Cliquez sur l’image pour aller lire ce nouvel épisode
Enfin, le groupe Framalang vient d’achever la traduction d’une nouvelle futuriste sur le copyright et ses dérives : Stop the Music de Charles Duan (initialement publiée sur BoingBoing, un site tenu, entre autres, par Cory Doctorow). La traduction n’a pu être prête à temps pour rejoindre l’epub de cet article, c’est pour cela que vous en retrouverez la première partie dès aujourd’hui ici sur le Framablog !
RaysDay : Stop the Music, une nouvelle sur les libertés. 1/2
À l’occasion du RaysDay 2015, l’équipe de traduction Framalang a choisi de traduire la nouvelle Stop the Music, de Charles Duan, publiée originellement sur Boing Boing. Cette histoire futuriste explore les dérives possibles des lois sur le copyright.
Voici donc la première partie de cette traduction (la seconde et dernière partie sera publiée sur le Framablog la semaine prochaine). Exceptionnellement, nous avons choisi de ne pas traduire le titre (libre à vous de le faire !)
À la Cour fédérale du district central de Californie
Eugene L. Whitman contre Alfred Vail Enterprises, Inc.
Plainte pour violation du droit d’auteur
Le 18 février 2044
Le plaignant, Eugene L. Whitman, représenté par ses avocats, porte plainte contre Alfred Vail Enterprises, Inc. suite aux faits suivants :
1. Le plaignant, M. Whitman, compositeur de son état, a écrit la chanson populaire Taking It Back
2. Le 14 janvier 2044, le défendeur Vail Enterprises a distribué la chanson Straight Focus qui remporte aujourd’hui un grand succès.
3. Straight Focus inclut un fragment de huit notes, extraites de Taking It Back. Par conséquent et au vu de cette œuvre dérivée non autorisée, Vail Enterprises a manqué au droit d’auteur de M. Whitman.
En tout état de cause, M. Whitman requiert que Vail Enterprises :
A. Reçoive une injonction lui interdisant la poursuite de cette infraction au droit d’auteur de M. Whitman ;
B. Détruise l’intégralité des exemplaires de Straight Focus en possession de Vail Enterprises ;
C. Soit ordonnée de supprimer la chanson Straight Focus de la mémoire de l’ensemble des personnes résidant aux États-Unis.
II.
À la Cour fédérale du district central de Californie
Eugene L. Whitman contre Alfred Vail Enterprises, Inc.
Réponse de Alfred Vail Enterprises, Inc.
Le 25 février 2044
Le défendeur, Alfred Vail Enterprises, Inc., répond à la plainte du plaignant, Eugene L. Whitman, en les termes suivants :
1. Vail Enterprises est une société basée dans l’État du Delaware dont le siège se situe à Los Angeles en Californie et qui est intégralement détenue par M. Alfred Vail.
2. À la suite d’une carrière longue et réussie au sein de l’industrie de la neurobio-ingénierie, M. Vail fit le choix d’entrer dans le monde de la musique. Sa première composition Straight Focus est une œuvre musicale unique et innovante, jugée par les critiques comme « digne d’un nouveau siècle technologique » ou comme « une clef de voûte entre l’art et les neurosciences ».
3. En plus d’être un succès massif, la portée de Straight Focus fut internationale. Cette chanson fut vue plus de 350 millions de fois sur les sites de partage de vidéos. Outre cela, le meilleur révélateur de la popularité de cette œuvre reste : les vidéos d’appréciation, les remixes et adaptations diverses réalisées par les amateurs de ce morceau.
4. M. Vail a écrit Straight Focus à la mémoire de sa fille Sarah Vail, décédée l’année dernière en pleine adolescence suite aux complications de sa leucémie. Le morceau est composé de fragments des cinquante œuvres musicales préférées de Mlle. Vail, arrangés par lui-même grâce à sa créativité et à son expérience en neurosciences afin de produire un tour de force émotionnel musical inattendu. L’une de ces œuvres correspond au morceau du plaignant Taking It Back.
5. Le fragment de Taking It Back utilisé dans Straight Focus est minime et n’a pas altéré la valeur de ce morceau. En effet, la popularité de la composition de M. Vail a entraîné un intérêt significatif et une augmentation des ventes pour l’ensemble des œuvres sur lesquelles il s’est basé. Par conséquent, l’utilisation de ce fragment de Taking It Back par M. Vail ne constitue pas une infraction au droit d’auteur ou, a minima, constitue un usage raisonnable au titre de l’article 17 U.S.C. § 107.
6. En outre, la requête du plaignant, M. Whitman, exigeant la suppression de tout souvenir de Straight Focus des pensées des auditeurs, constitue un précédent absurde. Jamais un tribunal n’a ordonné ou autorisé de suppression de mémoire totale, visant l’ensemble du public pour une affaire liée au droit d’auteur. Cet ordre ou cette autorisation ne devrait pas être soumis à la compétence de cette cour.
III.
À la Cour fédérale du district central de Californie
Eugene L. Whitman contre Alfred Vail Enterprises, Inc.
Avis et ordre quant à l’effacement de la mémoire
20 juin 2044 Avis de M. Benson, juge fédéral.
Le jury du tribunal a considéré que l’accusé Vail Enterprises n’a pas respecté le droit d’auteur du plaignant M. Whitman. Le plaignant demande donc à cette cour d’émettre un arrêt obligeant Vail Enterprises à effacer tout souvenir du morceau délictueux Straight Focus des pensées de toutes les personnes résidant aux États-Unis, grâce au système EffaceMem National.
La requête de M. Whitman est une forme de réparation extrêmement inhabituelle et sans précédent. Il est donc nécessaire de procéder à quelques explications concernant le système.
Le système EffaceMem National a été développé à partir de la technologie EffaceMem, inventée par Alfred Vail en 2028. Des avancées antérieures en neurosciences ont révélé que les souvenirs humains pouvaient être modifiés ou effacés en agitant les cellules cérébrales, mais cette procédure était intrusive et risquée, et, de fait, utilisée uniquement dans des cas particulièrement inhabituels de troubles psychiques, comme les troubles de stress post-traumatiques.
M. Vail a découvert que certaines ondes sonores basses fréquences à fluctuation rapide pouvaient être utilisées pour agiter les cellules cérébrales de la même manière, permettant ainsi un effacement de la mémoire sans risque et sans intrusion, avec une excellente précision concernant la date et l’objet des souvenirs. Cette technologie, qu’il appela EffaceMem, fut offerte comme service au consommateur, le plus souvent pour effacer le souvenir d’événements embarrassants, d’ex-amants, et de situations traumatisantes.
De manière inattendue, le service au consommateur devint un élément de sécurité nationale au moment des attaques terroristes contre les États-Unis d’août 2039. L’Agence centrale de renseignement (CIA) avait intercepté une communication chiffrée contenant les détails de la planification de plusieurs bombardements simultanés sur plusieurs grandes villes. La CIA savait que l’attaque aurait lieu durant la semaine suivante, mais ne pouvait pas déchiffrer le reste du message pour identifier les détails du complot. Le temps venant à manquer, la CIA, dans une ultime tentative, se procura des milliers d’énormes haut-parleurs haute-fidélité, les répartit dans les villes, et diffusa à plein volume des enregistrements d’EffaceMem conçus pour effacer les souvenirs de toutes les conversations ayant eu lieu au moment de la diffusion des messages interceptés.
Les résultats furent saisissants : San Francisco et la ville Washington., où EffaceMem était déployé, ne subirent aucun bombardement, alors que la ville de New York, où EffaceMem n’avait pas pu être déployé à temps, fut dévastée.
À la suite de ces attaques, le pays entreprit rapidement de déployer EffaceMem sur l’ensemble du territoire. Le réseau ainsi formé, connu sous le nom de « système EffaceMem National », couvre chaque centimètre carré et chaque habitant des États-Unis, et permet d’assurer la suppression totale d’une idée dans l’esprit de la population. Le système n’a pas été utilisé de manière fréquente, mais plutôt occasionnellement, et sous supervision judiciaire stricte, pour déjouer les complots terroristes et prévenir des crimes, avec d’excellents résultats. La CIA et l’armée ont également étudié d’autres applications.
Mais le système EffaceMem National n’a jamais été utilisé pour servir des intérêts privés. Jusqu’à présent, il a été utilisé uniquement pour effacer des idées de crimes ou des dangers pour le public. Ainsi, la requête de M. Whitman d’utiliser le système pour effacer le souvenir d’un morceau de musique est parfaitement inattendue. Cette cour n’a absolument aucune décision similaire ni aucun précédent sur lequel se baser.
Au premier abord, l’injonction faite à une partie d’utiliser le système EffaceMem National semble inappropriée dans presque tous les cas, car cette cour ne peut obliger une partie à faire quelque chose que si cette partie peut faire cette chose, et utiliser EffaceMem National n’est pas possible pour la plupart des gens. Mais ici, l’accusé est une exception inhabituelle, car Vail Enterprises est propriétaire du système. M. Alfred Vail, inventeur d’EffaceMem, a plus tard fondé Vail Enterprises, qui a financé et construit le système EffaceMem National, et en est toujours propriétaire. Par conséquent, une injonction d’utiliser le système pourrait être émise à son encontre.
M. Whitman soutient que l’article 17 U.S.C. § 503(b) autorise cette cour à ordonner à Vail Enterprises de réaliser une suppression des souvenirs du morceau. Cette loi indique que cette cour « peut ordonner la destruction […] de toutes les copies ou les enregistrements audio faits ou utilisés en violation des droits exclusifs du propriétaire des droits d’auteur ». Comme les neurones qui ont enregistré les souvenirs du morceau sont des « copies ou des enregistrements audio », M. Whitman prétend que cette cour a le pouvoir d’ordonner à Vail Enterprises de procéder à la « destruction » de ces copies en effaçant les souvenirs.
Je comprends la position de M. Whitman. M. Whitman est manifestement très soucieux de protéger ses œuvres musicales, et refuse à quiconque d’en créer des œuvres dérivées ou de les altérer, en accord avec son désir de garantir que sa musique reste « pure ». Cela lui est permis, en tant que propriétaire des droits d’auteur. J’ai déjà ordonné à Vail Enterprises de supprimer toutes les copies physiques du morceau contrefait.
Mais en ce qui me concerne, je ne suis pas certain que l’injonction d’effacer des souvenirs soit raisonnable. Peut-être l’est-elle, peut-être pas ; aucune autre autorité judiciaire ne fournit de conseil sur cette question. Si la Cour d’appel ou la Cour suprême décident que ce type d’injonction est autorisé, alors je l’émettrai. Mais sans le support d’une de ces cours, il me semble nécessaire de rester prudent et de ne pas ordonner à Vail Enterprises d’effacer les souvenirs du morceau contrefait.
Demande rejetée.
IV.
The Washington Post
Audition à la Cour suprême à propos de l’affaire sur l’effacement de mémoire.
Le 12 février 2046
Ce matin, la Cour suprême entendra les plaidoiries dans une affaire très suivie concernant la possibilité pour un auteur de chansons d’utiliser son droit d’auteur pour effacer de la mémoire de tous les Américains une chanson supposée contrevenir au droit d’auteur.
Cette affaire, Whitman contre Vail Enterprises, voit s’affronter le chanteur Gene Whitman et le neurobiologiste (devenu artiste du remix) Alfred Vail, à propos de la chanson à succès Straight Focus. En 2044, un jury a décidé que la chanson de M. Vail violait le droit d’auteur de M. Whitman. Immédiatement, l’Association Américaine de l’Industrie du Disque a diligenté une requête auprès du système fédéral de gestion des droits numériques, déclenchant ainsi un effacement automatique de la chanson de tous les sites internet et des équipements personnels. Straight Focus n’a plus été entendue aux États-Unis depuis plus d’un an maintenant.
Mais M. Whitman considère que la suppression de Straight Focus de tous les équipements personnels n’est pas suffisante. Extrêmement protecteur de ses œuvres, M. Whitman a cherché à obtenir un arrêt de la Cour imposant l’effacement de la chanson Straight Focus de la conscience de tout le monde en utilisant le système EffaceMem National, système qui est la propriété de M. Vail.
La Cour a récusé la requête de M. Whitman, indiquant qu’elle n’ordonnerait pas l’utilisation du système EffaceMem National sans l’avis de la Cour suprême.
M. Whitmann n’a pas souhaité s’exprimer sur cette affaire. M. Vail, lors d’une interview, a exprimé son « exaspération » que cette affaire aille jusqu’à la Cour suprême.
« Ma chanson Straight Focus signifie beaucoup pour de nombreuses personnes », dit-il. « Pour moi, c’est un souvenir de ma fille que j’ai perdue il y a trois ans. Et les amateurs de cette chanson ont créé leurs propres sens et souvenirs à partir d’elle. Cela dépasse l’imagination que Gene Whitman puisse effacer toutes ces pensées en clamant une sorte de possession du droit d’auteur. »
C’est la deuxième affaire au sujet du système EffaceMem National qui est portée devant la Cour suprême. L’affaire précédente, United States contre Neilson, portait sur la constitutionnalité du système, utilisé pour supprimer l’activité criminelle à la suite des attaques du 7 août 2039. Le système a été jugé constitutionnel par une majorité divisée de 5 voix pour et 4 voix contre.
Au nom de cette majorité, la présidente de la Cour suprême, Mme Diehr, a rejeté les recours basés sur les premier, cinquième et quatorzième amendements, déclarant que le système EffaceMem National est « un outil nécessaire à la société technologique pour la prévention des méfaits et des délits à l’encontre du du public ». Vétéran de l’armée de l’air et également ancienne procureure générale, la présidente s’est vraisemblablement basée sur son expérience au sein de l’armée des États-Unis lorsqu’elle a conclu : « le nombre grandissant de menaces envers notre nation ne peut être contrecarré qu’avec un arsenal défensif renforcé. »Elle écrit par ailleurs « qu’il s’agit d’un devoir de citoyen que d’abandonner ses pensées personnelles si cela protège le plus grand bien, de la même façon qu’il était un devoir, en temps de guerre, que d’abandonner sa liberté ou ses propriétés, pour le bien de la nation ».
Dans un argumentaire vivement opposé, le juge Diamond rejeta l’idée que « la pensée humaine est le jouet du gouvernement fédéral ». Rappelant son passé d’avocat des droits civils et se basant sur la Constitution et la Déclaration des droits, le juge a déduit que celles-ci contenaient, dans une certaine mesure, des garanties sur la vie privée et la liberté de pensée. Selon son point de vue, ces textes entrent en conflit avec un effacement de mémoire sans consentement. Il a fait référence à l’affaire Americans for Digitals Rights contre Gottschalk qui décida que la collecte de données représentait une fouille illégale d’après le quatrième amendement. Il y a 25 ans, le juge Diamond était l’avocat qui représentait ADR lors de cette affaire qui brisa la jurisprudence pré-Internet, jurisprudence qui avait été sérieusement remise en question par le juge Sotomayor en 2012.
Le juge Flook, dans un avis séparé, indiqua qu’il était « indécis » en raison des « conséquences inquiétantes » d’un effacement de mémoire généralisé. Malgré cela, pour lui, les bénéfices de ce système compensent ces inconvénients. C’est probablement son vote qui décidera du sort de cette affaire, tous les yeux seront rivés sur lui lors des débats.
Le juge est un ancien professeur de droit, dont les intérêts et les publications portent sur les lois concernant l’environnement et les ressources naturelles. Au regard de ses prouesses universitaires et de sa passion environnementale, l’opinion du juge dans l’affaire Neilson est, comme pour beaucoup de ses confrères, brillante sur le plan analytique et partagée sur le plan émotionnel. Il a déclaré : « Je crains sincèrement un monde où mes souvenirs et les souvenirs d’innombrables personnes peuvent être effacés en appuyant sur un bouton. Mais je crains autant les attaques terroristes. Dès lors que je peux être sûr que cet effacement de mémoire est limité aux seules situations nécessaires, ma première crainte sera suffisamment restreinte. ».
L’audience débutera à 10 h et portera sur l’affaire n°45-405 : Whitman contre Alfred Vail Enterprises.
Rendez-vous la semaine prochaine pour la suite et conclusion de cette nouvelle !
RMLL 2015 et Résistances : Framasoft en Festivals !
C’est la canicule, on sort les recettes d’eau libre (à consommer avec modération ^^), les stands, les beaux T-shirts… c’est officiel, on arrive à l’été des Rencontres et échanges Libristes !
RMLL 2015 : rendez-vous à Beauvais
Logo RMLL
Rendez-vous incontournable du monde Libre, les « ReuMeuLeuLeu » (ou Rencontres Mondiales du Logiciel Libre) sont cette années accueillies et organisées par Beauvais, et c’est du 4 au 11 Juillet !
Comme nous vous l’avions annoncé, nous ne tiendrons un stand que lors des Journées Grand Public (samedi 4 et dimanche 5 juillet). Ce qui nous nous empêchera pas d’être présents lors du reste des rencontres, que ce soit entre les stands (un indice : repérez les badges « Framateam ») ou durant des conférences.
Car les RMLL proposent un programme complet de conférences, tables rondes et autre réjouissances auxquelles Framasoft se joint avec plaisir… Vous nous retrouverez donc :
Bien entendu, au delà des Framasofteries, TOUT le programme des RMLL est empli de pépites qui sauront faire pétiller votre intérêt, vos neurones et vos processeurs…
Résistances, du cinéma et des idées
Du 3 au 11 juillet, dans la ville de Foix[1] (en Ariège), a lieu un festival de cinéma aussi engageant qu’engagé : Résitances.
L’idée de ce festival, qui fête cette année sa 19e édition, est de mettre en valeur des films qui bousculent notre vision du monde, montrent d’autres façons de vivre, de voir de raconter et de partager… bref : qui nous nourrissent l’esprit comme la société.
Framasoft sera présent lors du week-end final (10 et 11 juillet) à l’occasion de leur thématique Une civilisation du partage. l’occasion pour nous d’échanger avec un public pas forcément rompu aux codes du Libre, et pour Pouhiou de réitérer sa conférence Créateurs, la confiance paye…
Voilà pour les quelques rencontres estivales… promis, il y aura encore plus d’occasions de se voir, de boire de la limonade libre (avec modération ^^) et de parler Dégooglisation dès la rentrée !
Note inutile et donc indispensable :
[1] Et le premier ou la première qui commente « Il était une fois, dans la ville de Foix… » Pouhiou se jure de lui émonder les arquemuses… soyez prévenu-e-s !)
La thermodynamique peut-elle casser des briques ?
L’équipe Framabook est très fière de vous annoncer la sortie de son premier manuel scolaire : Thermodynamique de l’ingénieur. Ce manuel universitaire, à destination des étudiant-e-s comme de leurs enseignant-e-s, est signé Olivier Cleynen, et disponible sous la licence CC-BY-SA…
L’occasion d’une rencontre drôle et intéressante avec cet auteur qui a fait le pari du livre Libre !
Bon, Olivier, je serai honnête, on se demande comment tu as pu en arriver là. Tu n’es pas un poussin de l’année qui découvre le monde du Libre : si j’en crois ton ancien blog, dès ton premier billet en 2007 tu déclares ta flamme au logiciel libre, en établissant du reste un lien très net entre logiciel libre et société libre. Pourrais-tu te présenter succinctement et évoquer ta trajectoire de libriste ?
Ma trajectoire n’est en fait pas réellement exceptionnelle. Je suis ingénieur aéronautique de formation et j’ai découvert le logiciel libre et son univers pendant mes études. Il y a des gens pour qui ça « prend » plus que pour d’autres… en 2006 j’ai co-fondé puis dirigé à plein temps pendant deux ans une association à but non-lucratif de promotion du logiciel libre qui ressemblait un peu à Framasoft. J’ai essayé sans succès d’en vivre, puis, je suis devenu prof en école d’ingénieurs : c’est là que j’ai commencé ce livre. J’effectue maintenant une thèse de doctorat dans l’espoir de me faire une petite place dans l’enseignement supérieur.
Question No124 (mais, à la demande d’Olivier, la voici en 2e position) : pourrais-tu résumer la thermodynamique en un tweet (140 signes) ?
Bon, je tente l’expérience, mais j’ai droit à plusieurs essais, alors…
« Tiens, je me demande comment le frigo fait pour refroidir le pack de bières alors qu’il est déjà plus froid que dehors… »
« Comment ça, le moteur de voiture n’a que 30% d’efficacité ? On est obligés de rejeter 70% de la chaleur par le pot d’échappement ? »
« @JamesPrescottJoule Au fait, c’est quoi, chaud ? Une sorte de fluide bizarre invisible ? Est-ce qu’on peut fabriquer du chaud ? »
« @WilliamThomsonKelvin Et 40°C, c’est deux fois plus chaud que 20°C ? Et si oui, alors qu’est-ce qui est deux fois plus chaud que -10°C ? »
« @LudwigEduardBoltzmann Pourquoi ma tasse de thé chaud va toujours se refroidir toute seule, et jamais se réchauffer ? HEIN, POURQUOI ???? »
La réponse à chacun de ces tweets demande de comprendre ce que c’est que la chaleur, comment on la fabrique, comment on la détruit, comment on la transforme. C’est ce qu’on appelle thermodynamique. De là, les physiciens enchaînent sur tout un tas de questionnements : la notion d’échelle microscopique ou macroscopique, la notion d’état, d’équilibre, le sens des transformations, etc. Les ingénieurs (le camp dont je fais partie) cherchent plutôt à bidouiller la chaleur dans des machines, et se servent de la thermodynamique pour comprendre les moteurs et les rendre plus efficaces, ou plus puissants, ou plus réactifs, etc. Quoi qu’il en soit, c’est passionnant : on commence par étudier de petits ballons de gaz, et on finit par prédire la fin de l’univers ! Ah zut, la réponse fait plus de 140 caractères !
trop facile à comprendre après la lecture de la Thermodynamique de l’Ingénieur (CC-BY-SA Olivier Cleynen)
Pourquoi avoir choisi de porter tout ton effort et pendant si longtemps (plusieurs années tout de même !) sur ce manuel de thermodynamique ? Les livres existants n’étaient pas suffisants ?
Il y deux faces à la réponse. D’une part, je trouve la plupart des livres français de thermodynamique terriblement tristes et ennuyeux. Je trouve dommage de se casser la tête à résoudre des équations qu’on comprend à peine pendant deux semestres, si c’est pour ressortir de la thermodynamique sans jamais avoir étudié le fonctionnement d’un turboréacteur. J’avais envie de faire un cours « pour futur-es ingénieur-es curieux-ses », et avec le temps le cours a pris la forme d’un livre.
Mais la plus grande motivation est que je n’ai rien trouvé de libre à me mettre sous la dent ! La thermodynamique de l’ingénieur est terminée depuis 150 ans et les technologies que l’on y étudie aujourd’hui ont toutes au moins 50 ans : un livre de thermo, c’est donc essentiellement un remix. C’est dur de voir que ces équations, ces raisonnements et ces schémas qui font partie du patrimoine scientifique et public au sens large, sont affublés d’une mention « reproduction interdite ». Dans certains livres, c’est même écrit à toutes les pages…
De ce point de vue, non, les livres existants n’étaient pas suffisants. Je trouve que ce n’est pas assez bien de pousser des étudiants à acheter un livre vendu quarante euros (un par matière…) qui leur défend solennellement d’en repiquer le contenu. C’est triste de voir un éditeur distribuer les JPG des figures aux seuls profs qui engendreront quarante ventes d’un livre. Et c’est frustrant, lorsqu’on débute un cours, de devoir tout ré-écrire et dessiner depuis zéro, du premier diagramme pression-volume jusqu’au dernier schéma de turbine.
J’ai construit le livre que j’avais envie de trouver quand j’ai commencé. Tu peux le copier, le reprendre, le ré-utiliser. Un schéma t’intéresse ? Tu télécharges le PDF, tu cliques sur la légende, et te voilà face au fichier source sur Wikimedia Commons, que tu peux modifier selon tes besoins. Tu préfères un format « polycopié » du chapitre 8 avec des grandes marges ? Tu pointes ton navigateur sur http://thermodynamique.ninja/ et tu imprimes. Tu veux reprendre une série d’équations en LaTeX sans les retaper, ou tu veux soumettre un patch pour corriger une erreur ? La même page web te pointe vers le dépôt git du projet. Tout ça se fait sans demander de permission, il suffit de respecter les termes de la licence Creative Commons : BY-SA pour le texte et la plupart des figures, et CC-0 pour les schémas les plus simples.
Dis-donc je l’ai parcouru ton ouvrage, d’accord il est parfaitement bien rangé dans des tiroirs avec un sommaire et des sous-parties aux petits oignons mais tout de même ça déborde de partout : histoire des sciences, biographies de quelques savants, une série de cours progressifs, des schémas et des croquis, des trucs pour aller plus loin… et surtout des exercices avec des cas de figure qui impliquent l’étudiant… brr ça fait un peu peur tout ça non ?
Alors, il ne faut pas avoir peur : c’est un gros livre, on n’est pas obligé de tout lire ! On s’y retrouve facilement, il est construit pour qu’on puisse aussi le survoler rapidement.
En ce qui concerne les exemples résolus et les exercices, j’admets que c’est parfois un peu riche, mais c’est le prix à payer pour qui veut étudier des cas concrets, car il faut plus de contexte. Six années d’enseignement en école d’ingénieurs ont fait le tri : les exercices qui « percutent » sont aussi ceux pour lesquels il faut un peu s’impliquer. Et puis je trouve juste plus cool d’avoir sous les yeux une photo de l’hélicoptère dont je calcule la consommation de carburant.
Les parties historiques (une par chapitre) sont, elles, parfaitement accessoires. Le but est de se construire une culture d’ingénieur/e et de scientifique : comprendre que pendant longtemps, on comprenait à peine ce que l’on faisait en thermodynamique, et voir aussi comment la technologie des moteurs a chamboulé le monde. Philippe Depondt, enseignant-chercheur en physique (à qui je voue une admiration sans fin pour avoir écrit le génial L’entropie et tout ça), a accepté d’écrire la moitié d’entre elles, et j’ai complété l’autre moitié. Peut-être est-ce que nous nous sommes laissé emporter ? Mais regrette-t-on d’apprendre, après avoir étudié un chapitre difficile, que la première personne à avoir montré que la chaleur n’a pas de poids a aussi été agent secret, architecte, instituteur et ministre de guerre philanthrope ? Ou qu’un geek thermodynamicien frustré s’est construit sa propre turbine à vapeur pour pouvoir ridiculiser toute la Royal Navy avec son bateau ?
et maintenant (roulements de tambour) dis-nous pourquoi c’est devenu un framabook, pourquoi cet éditeur ? tu es grillé chez les éditeurs classiques ? Travailler avec des gens qui n’avaient jamais fait de thermodynamique, ça ne t’a pas posé problème ?
Je n’ai pas eu l’occasion de chercher d’autres éditeurs, mais dans la mesure où la publication sous licence libre a toujours fait partie intégrante du projet, j’imagine que je n’aurais pas eu beaucoup de succès. Je suis et soutiens la progression de Framasoft depuis longtemps, et je suis très honoré que le comité ait accepté de produire un Framabook pour étudiants ingénieurs.
Quant au processus d’édition, il n’y a pas que les connaissances en thermodynamique qui comptent. Le comité m’a encouragé pour trouver un confrère, Nicolas Horny, qui veuille bien relire le livre sous son aspect technique (qu’il en soit remercié…). Mais je compte surtout le travail incroyable de Mireille Bernex, qui est à l’origine de centaines d’améliorations de langage et de clarifications dans le livre, et de beaucoup d’autres contributeurs que je n’ai pas la place de citer ici. Enfin, après quinze mois d’édition, je ne suis toujours pas venu à bout de la patience de Christophe Masutti, qui coordonne le projet Framabook. Bref, le plus important est de partager le désir de produire un manuel de qualité, et de ce point de vue, je suis comblé.
On dit souvent que le Libre et l’éducation portent plusieurs valeurs communes. Pour toi, quel est l’intérêt pour les enseignants et les étudiants de disposer d’un ouvrage sous licence libre ?
L’avantage pratique du livre libre est bien sûr sa gratuité. L’étudiant/e et l’enseignant/e peuvent le télécharger à tout moment, sur n’importe quel équipement, et s’en servir, en repiquant/reprenant/remixant le contenu du livre, sans demander la permission à qui que ce soit ni rentrer dans l’illégalité.
Il me semble que cette gratuité est un point important. Dans l’enseignement, le véritable ajout de valeur économique se fait dans la transmission, la réappropriation, et la création du savoir et des connaissances : en classe, en amphithéâtre, pendant le travail de groupe ou le travail personnel. En revanche, il n’y a aucune valeur économique intrinsèque à l’accès à la connaissance : sinon, il suffirait de s’acheter des livres pour devenir ingénieur ! Je préfère donc que l’argent dans l’éducation, privée ou publique, soit consacré aux activités (payer cher les profs et l’environnement de travail) plutôt que l’accès à l’information (faire chuter le coût des livres et ouvrir l’accès aux bibliothèques).
L’utilisation de contenus sous licence libre est aussi, selon moi, une démarche intellectuelle plus claire et pérenne. Lorsqu’un/e prof ou étudiant/e reprend une image du site internet d’Airbus, par exemple, il y a toute une liste de restrictions associées à sa réutilisation : on ne peut s’en servir que pour dire du bien d’Airbus, on ne peut pas la modifier comme on le veut, les conditions de l’utilisation commerciale sont floues, et la permission peut être retirée à tout moment. La reprise de documents dans le cadre de la courte citation française, ou du fair use américain, ou des innombrables accords particuliers passés par l’un ou l’autre éditeur avec tel ou tel gouvernement, est un véritable casse-tête juridique et laisse beaucoup d’incertitudes. Je préfère dire : tiens, reprends mon beau schéma de centrale à vapeur pour en faire ce que tu veux : les termes de la licence CC-BY-SA sont clairs et elle est irrévocable. C’est un bon ingrédient pour cuisiner quelque chose qui, fondamentalement, n’est qu’un remix des connaissances humaines actuelles.
Un autre schéma qui devient évident une fois qu’on a lu le manuel… si, si !
(CC-BY-SA Olivier Cleynen)
Pour vendre beaucoup d’exemplaires, j’espère que tu feras comme certains profs d’université et que ton cours sera incompréhensible si tes étudiants n’achètent pas ton livre…
Ce serait sournois, n’est-ce pas ? Et pourtant, c’est une pratique courante dans les universités aux États-Unis : beaucoup de cours sont ancrés sur un livre particulier, que les étudiants doivent absolument avoir sous la main s’ils veulent réussir.
Avant de nous indigner, il faut comprendre le pourquoi du comment de la chose. Construire un cours universitaire, c’est un travail pharaonique. Structurer un corps de connaissances, le sectionner en morceaux de 120 minutes digestes, ré-exprimer des notions complexes, illustrer tout cela, et construire des exercices intéressants : on peut y consacrer un temps infini, que les profs n’ont pas. Ancrer un cours sur un manuel en particulier, et donc sur une « recette » déjà éprouvée, permet à un/e prof de se consacrer au véritable apport de valeur qu’il/elle doit générer : rendre un cours passionnant, créer un environnement de travail où les étudiants vont se prendre au jeu et s’épanouir. On ne peut tout de même pas demander à chaque prof de ré-écrire toute la thermodynamique !
En enjoignant tous les étudiants à travailler sur un seul livre, le problème de l’accès à l’information est réglé dès le premier cours du semestre, et le reste du temps est consacré à l’exploration, l’appropriation des connaissances. L’alternative classique à la française, le tableau à craie et le maigre polycopié, n’a rien de mirobolant. Qui aurait cru qu’en 2015, l’apprentissage de la thermodynamique puisse encore se faire en recopiant au stylo sur du papier l’information qu’un prof trace avec un caillou blanc poussiéreux sur un mur noir devant 200 personnes ?
En parallèle, les revenus importants qui découlent de ces ventes poussent les éditeurs et les auteurs à produire des manuels de très haute qualité. Nous parlons de pavés de 500 ou 1000 pages, magnifiquement illustrés, soigneusement structurés, hyper accessibles, bref, de vrais outils de travail et de découverte qui donnent immédiatement envie de s’y plonger. On se prend vite de passion pour n’importe quelle discipline avec cela !
Le revers de la médaille est le prix supporté par les étudiants, en termes économiques et de libertés.
L’argent, d’abord : à 200 dollars le livre, l’accès à l’information indispensable au suivi d’un cours devient un obstacle très important à franchir, quel que soit le mode de financement (état, bourses, fonds propres ou emprunts).
En termes de libertés, le coût est plus subtil. Les éditeurs et distributeurs ont tout intérêt à restreindre le marché du livre d’occasion, et font mettre à jour les livres à un rythme effréné ; à chaque fois, la numérotation et l’énoncé de nombreux exercices est modifié (ce qui décourage l’utilisation d’anciennes éditions en cours). Les livres sont couramment proposés en location, sous forme papier (par Amazon notamment) mais aussi sous forme numérique. Voilà des livres dans le nuage, qui ne marchent que lorsqu’on est connecté sur le campus, ou bien seulement pendant un semestre. Certains livres en ligne sont financés avec de la publicité, et on peut imaginer que l’ensemble des données personnelles recueillies à propos des lecteurs est exploité. On retrouve les éditeurs dans les tribunaux et au Congrès, où ils tentent de faire interdire la revente aux USA des livres qu’ils commercialisent au quart du prix en Inde. Bref, on retrouve là l’ensemble des problèmes éthiques et sociétaux associés à un système de distribution fermé, et qui s’immisce dans les ordinateurs et les tablettes des étudiants.
Vu d’ici le problème peut sembler être très étatsunien, mais je suis convaincu que la recherche d’une meilleure qualité d’enseignement nous y confrontera tous tôt ou tard (en fait, à l’instant même où nous abandonnerons cette cochonnerie de tableau à craie…). Je pense que la publication de livres universitaires libres peut être une partie de la réponse. Un programme d’études où tu peux télécharger, remixer, imprimer librement tous les livres ? — Vous pensez, c’est comme construire toute une pile de logiciels libres qui fonctionne sur n’importe quel ordinateur, ou bien écrire toute une encyclopédie sous licence libre : c’est totalement impossible…
Des ordis moins énergivores (mais aussi efficaces) pour les institutions françaises. Libres. assemblés en France ? C’est le pari osé d’une association de Nevers, qui a besoin de sous pour démarrer.
Nous avons voulu en savoir plus avant, peut-être, de mettre la main au portefeuille, et nous sommes allés interroger Émilien Court, l’un des responsables du projet PIQO.
Bonjour, Émilien. Ça vient d’où, ce projet ? Qui êtes-vous ? Comme dirait Isaac : comment justifiez-vous votre existence ?
Je vois qu’on a les mêmes références ! PIQO est le fruit d’un constat : le parc informatique des administrations, entreprises, écoles ou universités est très largement surdimensionné en termes de puissance compte tenu de l’usage qui en est fait. Cela entraîne un coût financier non négligeable en investissement ou consommation électrique. L’impact écologique est également considérable en traitement des déchets électroniques, transport ou production d’énergie. Enfin, tous les équipements informatiques sont actuellement produits en Asie, et il apparaît indispensable de mettre en place un « circuit court » de l’informatique en localisant l’assemblage en France.
PIQO est un projet de synthèse. Ça n’est pas que de l’informatique, c’est aussi un projet social et environnemental.
Je suis tombé dans l’informatique quand j’étais petit, j’en ai même fait mon métier à une époque. Parce que je suis aussi quelqu’un d’engagé et préoccupé par les questions de société, il m’apparaissait normal, dès lors que la technologie le permettait, de la sortir du seul champ de l’informatique pour la mettre au service de l’éducation, de l’économie, de l’environnement ou de l’emploi de façon constructive.
Il n’a pas été difficile de constituer une équipe de personnes issues d’horizons très divers : éducation, économie sociale et solidaire, environnement, industrie, design…
Aujourd’hui, PIQO compte une quinzaine de membres, qui tous voient derrière l’ordinateur un projet de société.
Pourquoi avoir créé une association et faire un crowdfunding ? Vous auriez pu monter une entreprise et démarrer avec un emprunt bancaire…
La question de créer une entreprise ne s’est même pas posée, à vrai dire. PIQO repose sur des technologies libres ou à but non lucratif, et c’est cette philosophie que nous souhaitons porter à grande échelle.
PIQO est aussi un laboratoire. Notre objectif est de démontrer qu’il n’existe pas qu’un seul modèle économique basé sur l’exploitation de l’humain et de la nature. On peut créer de l’activité économique, de l’innovation et des emplois sans recourir au modèle économique libéral. Notre démarche s’inscrit dans l’économie sociale et solidaire, et ce qui peut être fait dans l’informatique peut s’appliquer partout ailleurs.
Dans cette optique de sortie du schéma « capital, dividendes », l’association était la meilleure solution pour garantir l’indépendance et l’autonomie du projet. PIQO n’appartient à personne … ou à tout le monde !
Pourriez vous, nous en dire plus sur les membres de votre association, et ce qui vous a amenés à vous unir ?
Nous sommes issus d’horizons très divers : éducation, santé, technologie, environnement ou encore social. La plupart des membres ne sont pas des pointures en informatique, mais sont cependant tout à fait conscients des enjeux d’un tel projet et de l’impact potentiel sur la société. C’est cette convergence de valeurs qui est la base de notre collaboration, parce que nous avons tous à cœur de proposer une alternative technique, environnementale et sociale.
On a l’impression que le fait que vous êtes tou(te)s Nivernais a une incidence sur la création de PIQO…
La Nièvre, comme beaucoup de départements ruraux, souffre d’une situation économique difficile, d’une baisse de sa population au profit de régions plus prospères, et d’un déficit d’image. La pauvreté de l’offre en matière d’éducation supérieure conduit notamment les bacheliers à quitter le département pour étudier dans les grandes villes, mais peu reviennent finalement sur leur territoire d’origine. La Nièvre offre cependant une excellente qualité de vie et Nevers est une ville à taille humaine dotée de bonnes infrastructures. Parmi les voies de développement, il y a évidemment le numérique. Toutes les villes aujourd’hui essaient de s’équiper pour attirer les entreprises du secteur et cela conduira à une mise en concurrence acharnée des territoires. Je pense que pour être efficaces, ces stratégies doivent tendre à se spécialiser faute de pouvoir affronter les métropoles française ou européennes. L’exemple de Lannion en Bretagne est à suivre. Cette ville de 20 000 habitants a développé son économie autour des technologies de télécommunication, notamment en proposant une offre éducative adaptée.
La Nièvre a ses propres atouts et problématiques. Il serait pertinent de s’appuyer dessus pour développer le numérique : la santé, la prise en charge des personnes âgées ou dépendantes, le tourisme, la compétition automobile et pourquoi pas le logiciel libre. C’est là que PIQO a un rôle à jouer parce que notre volonté est d’offrir au territoire une opportunité de développement qui réponde à des exigences environnementales, éthiques, sociales, et locales.
Je me dis souvent qu’on n’a pas besoin de 4Gio de Ram pour faire de la bureautique. C’est ça, votre postulat de départ ?
Je n’irai pas, comme Bill Gates en 1981, jusqu’à dire que « 640 Ko de mémoire devraient suffire à tout le monde », mais effectivement 4Gio de RAM pour faire de la bureautique c’est trop !
L’informatique a connu une croissance technologique et économique fulgurante. Les ordinateurs sont beaucoup plus puissants qu’hier et beaucoup moins que demain. Pour autant, il faut en mesurer l’impact sur notre civilisation.
Regardons ce qui se passe dans un autre secteur industriel : l’automobile. La notion d’efficience est devenue une nécessité en raison des conséquences environnementales et de l’explosion du coût de l’énergie. La voiture s’adapte de plus en plus aux besoins de l’utilisateur. Il est désormais difficilement concevable d’acheter un véhicule qui consomme 15 litres aux 100km pour faire de petits trajets urbains. Alors que les industriels se livraient par le passé une guerre sur le terrain de la puissance, aujourd’hui ils communiquent sur le confort, la sécurité ou la consommation. Les V8, les V10 ou les V12 disparaissent peu à peu des concessions.
On doit se poser les mêmes questions dans l’informatique. Lorsque j’achète un ordinateur, quelles sont les conséquences sur l’environnement, sur mon portefeuille, sur les ouvriers qui l’ont fabriqué ?
Certains commentateurs émettent des doutes en se référant au prix du Raspberry Pi 2, qui est le socle de votre solution. Que leur répondez-vous ?
Effectivement, de façon très surprenante nous sommes la cible d’attaques en règle sur ce point. Il nous est souvent opposé que le prix d’un Raspberry Pi 2 n’est que de 35-40€, ce qui est totalement vrai !
Restons pragmatiques. Le coût global d’un produit ne dépend malheureusement pas que du prix d’un seul de ses composants, fut-il aussi essentiel. Si nous pouvions vendre PIQO sous les 50€ nous le ferions avec plaisir, notre objectif n’étant pas le profit. Nous envisageons par ailleurs la possibilité d’une version moins chère dotée d’une mémoire de 8Gio.
Il faut bien comprendre que le Raspberry PI 2 est le socle de notre solution, mais c’est une carte inerte et pour en faire un ordinateur fonctionnel et plug and play pour tout le monde, nous devons lui ajouter d’autres éléments : 32 Gio de mémoire, une alimentation électrique, un boîtier, un OS, un conditionnement etc. Le prix de revient double presque au passage.
Ensuite, il y a des charges liées à la production et à la commercialisation de PIQO : les locaux, le matériel, la logistique ou le service après-vente pour en citer quelques-unes. Les contraintes économiques ne sont pas les mêmes que lorsqu’on bricole à la maison.
Comme toute activité économique, PIQO est soumis à la TVA, ça représente 16,5 € par exemplaire, ainsi qu’à l’IS et à la CFE.
Enfin, « but non lucratif » ne signifie pas « bénévole ». Les dirigeants de l’association ne sont pas rémunérés, mais pour assembler et distribuer PIQO, il faut créer des emplois, et c’est même l’une de nos missions en favorisant l’insertion et la formation des plus précaires.
Par ailleurs, PIQO est une association ouverte à laquelle tout le monde peut adhérer pour prendre part aux décisions ou élire le conseil d’administration.
Ce qui est évident, c’est que notre solution ne convient pas aux besoins des technophiles, il leur suffit d’acheter un Rasperry Pi et de bidouiller. On retrouve le même principe chez ceux qui préfèrent montent leur PC et ceux qui l’achètent assemblé au supermarché du coin. Mais le grand public, les administrations ou les entreprises ont besoin de solutions clés en main, d’un service après-vente et de conseils. C’est ce que nous proposons.
D’accord, mais il a quelle valeur ajoutée, le PIQO, par rapport à des solutions qui existent déjà, comme le Linutop et le Cubox ? Qu’est-ce qu’on y trouve de plus ?
Linutop est deux à trois fois plus cher pour des performances similaires voire moindres. Cubox est un beau produit et affiche des prix nettement plus proches, mais sous Android, un OS peu adapté à l’usage desktop auquel nous destinons PIQO, sans parler de l’ingérence de Google dans cet environnement.
Notre objectif est clairement de proposer un ordinateur bureautique, qui prenne en compte les questions sociales, environnementales, et qui soit proche de ses utilisateurs particuliers, professionnels ou institutionnels.
PIQO sera un ordinateur déjà rempli de logiciels… libres. Ce choix du logiciel libre (outre son avantage financier), c’est aussi un choix éthique ? Et du coup, allez-vous mettre votre distribution maison à disposition des bidouilleurs et bidouilleuses qui veulent faire leur PIQO de leurs propres mimines ?
Le choix du logiciel libre est effectivement éthique. La contrainte financière est réelle aussi puisqu’il serait impossible de proposer PIQO à un tel prix avec des logiciels propriétaires. Nous aimons particulièrement l’idée que des milliers de personnes à travers le monde ont travaillé pendant toutes ces années pour aboutir à cet éventail de logiciels, sans rien attendre en retour que la satisfaction d’avoir été utiles à la collectivité. Nous travaillons avec la même philosophie et notre distribution basée sur Xubuntu sera évidemment disponible en téléchargement (c’est déjà le cas de la pre-alpha).
Par ailleurs, il n’y a pas de LUG actif dans la Nièvre, est ce que le projet PIQO, ou des membres de votre association, prévoient de développer des actions autour du Logiciel Libre ?
Nevers comme capitale française du logiciel libre, l’idée est séduisante ! Certains membres de l’association utilisent le Libre depuis longtemps, d’autres le découvrent et sont surpris de voir qu’il est en fait tout à fait possible de s’extraire des systèmes propriétaires. La vocation de PIQO est de faire cette démonstration à grande échelle, et cela passe par des actions de terrain. J’aimerais personnellement beaucoup pouvoir organiser des install-parties ou des conférences dans la Nièvre pour expliquer ce qu’est la philosophie du libre et sensibiliser les utilisateurs aux risques des logiciels propriétaires. On a de la place pour accueillir du monde et le cadre est sympa !
En fait en soutenant PIQO, on soutient indirectement des actions en faveur du logiciel libre et de l’open hardware dans la Nièvre ?
On peut dire ça. Le principe de réciprocité est selon moi indissociable du Libre. Si PIQO rencontre le succès, il est normal qu’à son tour l’association se fasse le porte-voix de cette philosophie et fédère autours d’elle d’autres utilisateurs, acteurs ou curieux.
Émilien, du projet PIQO. Photo Jérémie Nestel – Licences Art Libre
Supposons que la Mairie de Paris, qui vient d’adhérer à l’APRIL, vous passe commande pour 20.000 PIQO. Vous pouvez fournir ?
Vous me l’apprenez, c’est une grande nouvelle ! Nous sommes déjà en discussion avec des collectivités pour des volumes de 1500 pièces par an. 20 000 pièces d’un coup c’est une commande énorme, et un investissement considérable. Mais avec l’appui de nos partenaires institutionnels, et un délai raisonnable, nous serions en mesure de relever le défi.
Un dernier mot pour nous convaincre de participer à votre financement participatif ?
Le Libre est mûr pour faire son entrée dans la cour des grands ! Nous tâchons modestement à notre échelle d’œuvrer dans ce sens, tout en développant une activité économique qui soit socialement et moralement responsable.
Ça demande parfois un petit effort d’imagination pour certains, mais c’est possible !
Merci à Jérémie Nestel d’être allé enquêter sur place.
Plus d’erreurs de grammaire ni de typographie avec Grammalecte
Si vous utilisez un traitement de texte avec des élèves, vous avez sûrement déjà entendu cette phrase « Il n’y a pas d’erreurs car ce n’est pas souligné. » En effet, trop souvent, seul le correcteur orthographique est utilisé. Et comme son nom l’indique, il ne corrige que l’orthographe. Si vous voulez que vos élèves (et même les plus grands) questionnent leurs productions, une petite, que dis-je, une grande extension deviendra vite indispensable : Grammalecte. Laissons Olivier nous en dire un peu plus.
Bonjour Olivier, j’ai l’habitude de dire que Grammalecte est une extension qui permet d’apprendre de ses erreurs. Peux-tu nous la présenter ?
Grammalecte est un correcteur grammatical dédié à la langue française. Pour l’instant, il n’existe que pour LibreOffice et OpenOffice, mais j’ai lancé une campagne de financement pour porter l’application dans Firefox et Thunderbird.
Le but du programme, c’est bien sûr de signaler les erreurs grammaticales, mais selon le principe suivant : le moins de fausses alertes possible, car les faux positifs irritent et distraient inutilement les utilisateurs. Ce n’est pas facile à faire, car dans la langue française il y a beaucoup d’incertitudes et les confusions possibles sont innombrables. Songez par exemple que l’adjectif « évident » est aussi une forme verbale du verbe « évider » et vous aurez une idée du genre de difficultés auxquelles il faut faire face. J’en ai parlé dans un long billet sur LinuxFR, alors je préfère ne pas me répéter ici.
Entendre que Grammalecte permet d’apprendre de ses erreurs me fait plaisir, car il n’est pas toujours facile de faire en sorte que le message d’erreur soit instructif. La place est limitée, et parfois l’imagination fait défaut pour écrire un message à la fois simple et instructif. Par ailleurs, les explications ne sont pas toujours comprises (tout le monde ne sait pas ce qu’est un COD ou un participe passé). Les exemples, ce n’est pas toujours clair. Les messages trop longs ne sont probablement pas toujours lus. Et, pour des raisons techniques, il n’est pas toujours possible d’être explicite. Il y a encore du progrès à faire sur ce point. Si je le peux, je place un hyperlien vers une page web plus complète, mais les pages web sont parfois longues et les explications ne concernent pas toujours spécifiquement l’erreur concernée. Mais il est vrai que, contrairement à Word (qui ne fournit qu’une correction sans indication), Grammalecte tente souvent d’expliquer. Car le meilleur moyen d’éviter les erreurs grammaticales, c’est d’enseigner petit à petit à l’utilisateur à ne plus en faire. Le meilleur service que puisse rendre un correcteur grammatical, c’est de devenir de moins en moins utile. Mais il le sera toujours à cause des erreurs d’inattention que même les plus doués font.
Pour aider l’utilisateur à s’y retrouver dans la langue française, il y a deux outils :
— le « lexicographe », qui, avec un clic droit sur n’importe quel mot, renseigne sur sa nature grammaticale : un nom, un adjectif, participe passé, un verbe, un article, etc.
— le conjugueur, qui est, lui aussi, accessible avec un simple clic droit sur n’importe quel verbe.
Ce n’est pas beaucoup par rapport à ce que font des logiciels comme Cordial et Antidote, mais c’est bien mieux que ce que fait Word.
Les correcteurs du Framablog et de Framabook me soufflent également que c’est un allié particulièrement efficace pour les « typo nazis »…
Oui, j’espère qu’il l’est, attendu que c’est avant tout pour des questions de typographie que j’ai commencé ce logiciel. Grammalecte est en effet assez strict sur ce chapitre. Au tout début, la décision de signaler les apostrophes droites avait beaucoup surpris certaines personnes, mais ça me semblait parfaitement normal. J’ai finalement mis cette règle en option pour ceux que ça gênait le plus. Grammalecte peut paraître pointilleux pour beaucoup de gens.
Mais pour soulager l’utilisateur des fastidieuses corrections typographiques, le logiciel possède un outil, appelé « formateur de texte », capable d’automatiser en quelques clics la correction des multitudes d’erreurs typographiques. Il peut par exemple :
— supprimer les espaces surnuméraires en fin de ligne, entre les mots, avant les virgules, etc.
— ajouter les espaces insécables là où elles sont requises,
— transformer les apostrophes droites en apostrophes typographiques,
— placer des tirets cadratins pour les dialogues,
et toutes sortes d’autres choses pénibles à faire manuellement, une par une.
C’est très utile quand on récupère des textes mal formatés sur le Net, car ça fait économiser un temps considérable de mise en forme.
Le formateur de texte de Grammalecte
Cela dit, Grammalecte n’intégrera pas tout à fait les mêmes règles de contrôle typographique dans Firefox, attendu que, dans ce contexte, certaines seront plus une gêne qu’une aide. Ce qui sera supprimé ou modifié reste encore à déterminer. Par exemple, il est possible que je change ou supprime certaines règles sur les espaces.
De manière générale, peux-tu nous présenter les personnes derrière Grammalecte ? Tu travailles seul ?
Alors, oui, je travaille seul sur le moteur interne de Grammalecte. Mais ça ne signifie pas que je sois le seul à avoir travaillé dessus, indirectement ou directement. Le logiciel est un dérivé de Lightproof, un correcteur grammatical minimaliste (d’où son nom, qu’on pourrait traduire par « vérificateur léger ») écrit pour LibreOffice par un Hongrois, mais qui est peu utilisé en raison du manque de ressources lexicales. Ce correcteur fait appel à Hunspell, le correcteur orthographique, mais la plupart des dictionnaires orthographiques n’étant pas grammaticalement étiquetés, son potentiel est limité et il sert surtout pour des corrections basiques ou typographiques. D’ailleurs, tel quel, il ne pouvait être d’une grande utilité pour le français, même avec un dictionnaire étiqueté, c’est pourquoi il a fallu que je triture le code pour pouvoir en faire un correcteur plus puissant (et moins léger). Mais je ne blâme pas Lightproof d’être léger et rudimentaire. Au contraire, ça m’a permis de mettre le pied à l’étrier et de constater que beaucoup de choses n’étaient pas si compliquées à faire. Ensuite, peu à peu, j’ai commencé à réfléchir à des choses plus complexes et à avoir des idées plus vastes que ce que j’avais imaginé faire en premier lieu.
Cependant il y a pas mal d’autres personnes qui ont travaillé et travaillent sur la base indispensable de Grammalecte : le dictionnaire orthographique grammaticalement étiqueté. Ça peut paraître anecdotique, mais gérer un dictionnaire c’est une tâche qui requiert un temps considérable et certains contributeurs y ont consacré une énergie qui méritent toute votre estime. Il y a quelques années, j’avais confié l’administration du dictionnaire à d’autres personnes, ce qui m’a permis d’avoir du temps pour améliorer le site web dédié à l’amélioration du dictionnaire et surtout pour concevoir les premières versions du correcteur grammatical. Gérer une base lexicale, c’est très loin d’être négligeable, c’est pourquoi Grammalecte et LanguageTool utilisent la même ressource. L’un des plus gros contributeurs au dictionnaire, c’est d’ailleurs le mainteneur de la partie française de LanguageTool. Quant aux autres, c’est une petite poignée de passionnés très investis ou de simples passants qui avaient besoin qu’on ajoute certains mots au dico. Mais je n’ai jamais demandé de comptes à quiconque, je ne sais pas qui ils sont. Un pseudo, une adresse e-mail, parfois un nom, c’est tout ce que je sais d’eux. À présent, il y a beaucoup moins de contributeurs, ce projet connaît un certain ralentissement. Il faut dire que le dictionnaire est bien plus fourni qu’autrefois, même s’il y a sans doute encore beaucoup à faire pour les domaines spécialisés comme la médecine, la biologie ou la chimie. Les nouveaux mots qu’on ajoute maintenant concernent surtout les sciences, ou bien des vieilleries peu utilisées.
4 dictionnaires orthographiques proposés
Quant à moi, on pourrait croire que je suis un passionné d’orthographe et de grammaire, et que je m’amuse à faire des concours de dictée. Pas du tout. Pour tout dire, la grammaire ne m’intéresse que parce que je conçois un correcteur grammatical, c’est tout. Ce que j’aime avant tout, ce sont les livres, la littérature et l’informatique. Il y a une douzaine d’années, je récupérais sur le Web pas mal de textes anciens introuvables en librairie, et je les mettais en forme pour mon usage.
En 2005, quand j’ai découvert l’existence d’OpenOffice.org, j’ai immédiatement été impressionné par Writer, qui permettait de concevoir des textes de manière bien plus cohérente et propre que Word. Par ailleurs, Word me fâchait par son incapacité à relire correctement les anciens documents conçus avec lui (j’ai commencé avec Word 6). Il fallait souvent refaire certaines mises en page. Et le format binaire ne permettait guère de retrouver ses petits si le document était corrompu. La qualité de Writer et le format ouvert de documents sont les raisons pour lesquelles j’ai migré vers OOo.
Mais il y avait quand même un aspect de Writer qui était en deçà de son concurrent : le correcteur orthographique. Il était très lacunaire. C’est la raison pour laquelle j’ai commencé à m’intéresser à la question. Finalement, j’ai d’abord cherché à remplir mes besoins d’utilisateur. En 2006-2007, j’ai retroussé mes manches et j’ai d’abord amélioré le dictionnaire, j’ai repris les différentes versions disponibles sur le Net, et j’ai conçu un site web pour recevoir les propositions des utilisateurs. En 2008, j’ai fini par réécrire toutes les règles du dictionnaire pour normaliser les données (avant ça, c’était vraiment le bordel), et j’ai posé des étiquettes grammaticales dessus, avec l’idée que ça servirait un jour à celui ou celle qui aurait l’idée saugrenue de faire un correcteur grammatical, puis j’ai recréé le site web (parce que le premier était mal foutu). À l’époque, je n’avais pas du tout l’intention de concevoir un correcteur grammatical. Je ne me sentais pas assez fou pour me lancer là-dedans.
J’avais bien sûr essayé LanguageTool, mais il ne me convenait pas du tout, car il y avait vraiment trop de faux positifs. En 2010, j’ai tenté d’améliorer LanguageTool pour le français, mais j’y ai finalement renoncé à cause d’une histoire de typographie et de mon désamour pour Java et le XML. C’est alors que j’ai découvert Lightproof, capable d’interroger les dictionnaires dans Writer. Tiens, tiens, intéressant, me suis-je dit, et si je faisais un petit test ? Au commencement, j’ai pas mal galéré pour diverses raisons plus ou moins complexes, mais j’ai eu assez vite un correcteur typographique auquel j’ai ajouté quelques règles simples concernant la grammaire. Encore une fois, je ne faisais que satisfaire mes propres exigences d’utilisateur. Puis, comme ça a plu, j’ai continué à améliorer le moteur interne du correcteur, peu à peu, en ajoutant des mécanismes plus complexes et en polissant peu à peu les rugosités du logiciel.
Cela dit, cela va vous paraître bizarre, mais j’éprouve un doute de nature philosophique sur la pertinence de concevoir un correcteur grammatical. Je ne juge pas qu’un correcteur grammatical soit inutile, mais à force de plancher sur la question, la grammaire française a commencé à me paraître inutilement compliquée et incohérente. On écrit par exemple : Je commence, tu commences, il commence. Mais on écrit : Je finis, tu finis, il finit. Il est étonnant qu’on juge utile de distinguer la deuxième personne du singulier au premier groupe, mais au deuxième groupe on préfère distinguer la troisième personne du singulier. À l’impératif, dans le deuxième groupe, la graphie de la deuxième personne du singulier est la même que celle à l’indicatif (« finis »), mais au premier groupe la graphie de la deuxième personne du singulier est différente à l’indicatif (« commences ») et à l’impératif (« commence »), ce qui trompe d’ailleurs beaucoup de monde. Pire : au deuxième groupe, la première et la deuxième personnes du singulier (« finis ») ont la même graphie qu’un participe passé. Encore une belle occasion de semer la confusion.
On va me rétorquer que c’est notre « héritage », que ça vient des origines de la langue, que l’étymologie, c’est important. Oui, mais c’est un argument creux. D’abord, qui connaît l’origine de la variation des graphies des conjugaisons ? Pas grand-monde, je parie. Un coup d’œil sur la question sur Wikisource. Les anciens étaient-ils parfaitement logiques et cohérents ? C’est très discutable. La langue n’a pas évolué de manière uniforme. Un autre exemple : habiter vient du latin habitare, c’est pour ça qu’il y a un h au début du mot. Habitare dérive lui-même du mot habere, qui signifie avoir. Ah, tiens, le h a disparu sur avoir. Autrement dit, l’histoire préserve et altère les graphies très diversement. Pourtant, préserver le h sur avoir aurait été bien utile, car ça éviterait que certaines formes verbales de avoir soient identiques ou semblables à d’autres mots sans rapport avec ce verbe, comme a, as, avions, aura, ais (qui n’est pas une forme conjuguée de avoir). Absurde de rajouter h à avoir, pensez-vous ? Pourtant, on a autrefois ajouté des lettres aux graphies des mots pour mieux les distinguer. On a ajouté un d à pied (parce que ça vient de pedis), un g à doigt (parce que ça vient de digitus), etc. Personnellement, j’aimerais bien que avoir retrouve son h…
Le français est plein de confusions, d’ambiguïtés et de bizarreries. Il y a tellement de choses à retenir. Savez-vous à quoi ressemble la somme de la connaissance sur la grammaire française ? À un pavé de 1600 pages écrit en petites lettres qui s’appelle Le Bon Usage de Grevisse (au format poche, ça ferait plus de 3500 pages, je pense). Et encore, on n’y trouve pas tout.
Couverture de la 15ᵉ édition du Bon usage
Récemment, une de mes amies s’indignait que ses enfants dussent apprendre par cœur les pluriels irréguliers de caillou, genou, hibou, etc. Pourtant ces mots ne dérivent pas de mots plus anciens contenant des x. Ce x n’est dû qu’à une écriture abrégée employée il y a longtemps, où un X remplaçait “us”. Au lieu d’écrire chous, certains écrivaient choX. (référence sur Wikipédia). Personnellement, il me paraît bien plus grave de confondre “on” et “ont”, “à” et “a”, “se” et “ce”, que de se tromper sur le pluriel de caillou ou d’écrire “tu commence”. Mais le français est si plein de choses à retenir qu’on voit régulièrement des gens ne pas se tromper sur des questions accessoires et écrire des phrases dont la syntaxe fait mal aux yeux.
Voilà pourquoi j’éprouve un doute sur la pertinence de concevoir un correcteur grammatical en l’état des choses. Je crains d’aider à figer une langue dans toutes ses incohérences et ambiguïtés. (Mais ceux qui vendent des correcteurs y trouvent probablement leur compte.) Il me semblerait plus utile que les experts se réunissent pour concevoir un français avec le moins possible d’incohérences, d’ambiguïtés et d’irrégularités. Je comprends que c’est pour certains un scandale de toucher à la langue. C’est pourtant ce que font souvent ceux qui créent des langages de programmation, quand ils veulent les améliorer. Ils modifient la syntaxe, ils ajoutent du vocabulaire, font les modifications qu’ils jugent utiles. Résultat : un langage plus lisible, moins ambigu et plus cohérent.
De toute façon, si l’on ne fait rien, le français évoluera. De manière incohérente probablement, comme jusqu’à présent. Et on appellera ça notre culture.
Mais rassurez-vous, je n’ai aucunement l’intention d’imposer mes idées, et le correcteur grammatical essayera de faire respecter les règles actuelles. 🙂 Actuellement, Grammalecte est disponible pour les suites bureautiques libres (LibreOffice, Apache OpenOffice, OOo4kids et OOoLight), j’ai cru comprendre que la prochaine étape était de couper le cordon et de l’adapter pour d’autres logiciels.
Avant de répondre à cette question, une remarque sur les suites bureautiques : je ne sais pas du tout ce qui se passe du côté d’OOo4Kids et OOoLight. Je pensais que le développement de ces logiciels avait cessé. Je crois savoir qu’ils utilisent Python 2.6, et je ne fournis plus de nouvelles extensions pour cette version de Python depuis assez longtemps. C’est déjà assez contrariant de fournir une version utilisable par OpenOffice (qui n’intègre que la version 2.7 de Python). Le problème, ce n’est pas OpenOffice, c’est cette version de Python dont le module d’expressions régulières est un peu bogué, ce qui rend Grammalecte moins efficace et génère parfois des faux positifs indépendants de mon contrôle. En fait, je teste tout avec LibreOffice, puis l’extension est convertie pour OpenOffice.
Mais, oui, la prochaine étape, c’est de désimbriquer Grammalecte de l’écosystème LibreOffice/OpenOffice, notamment pour pouvoir greffer le correcteur grammatical sur Firefox et Thunderbird. Ça fait longtemps que j’y songe, mais il y a pas mal de prérequis à cela. Il faut refondre et réorganiser une très grosse partie du code, transformer toutes les données, optimiser pas mal de choses, écrire les fonctionnalités qui manqueront après s’être détaché de LibreOffice/OpenOffice, améliorer certains points de la correction grammaticale, convertir en JavaScript (le langage de programmation des navigateurs), concevoir une interface adaptée, et j’en oublie certainement. En bref, il y a des eaux tumultueuses à traverser avant de pouvoir reprendre une navigation sereine. C’est pourquoi j’ai monté une campagne de financement participatif pour pouvoir m’y consacrer sereinement.
Et tu ne comptes pas t’arrêter aux logiciels mozilliens. Quel est ton objectif ultime ?
Produire une extension pour Firefox et Thunderbird fait déjà partie de mon but « ultime », c’est déjà à mes yeux une très importante finalité en elle-même, mais en effet ce n’est pas tout.
Séparer Grammalecte de Writer a aussi pour dessein de bâtir une application autonome, un serveur capable de renvoyer les erreurs à toute autre application qui lui transmettrait du texte, ce qui permettrait à ces applications de proposer des corrections grammaticales. Charge à elles de concevoir l’interface. Après, idéalement, j’aurais aimé revoir complètement la gestion des ressources lexicales, refaire le site web du dictionnaire de fond en comble, mais ce n’est pas indispensable et ça demanderait beaucoup de travail. Alors j’ai préféré être plus raisonnable en proposant de concevoir divers outils annexes.
Parmi ceux-ci, il y a notamment un assistant pour proposer de nouveaux mots à la base de données en ligne, pour simplifier toute la procédure. Il y a aussi un outil pour détecter les répétitions et compter les mots en les regroupant par lemme. Je prévois aussi d’améliorer le « lexicographe » afin de fournir sur les mots toutes les données dans la base, comme le champ sémantique auxquels ils appartiennent, leur indice de fréquence, leur origine étymologique et toute information potentiellement utile.
En fait, toutes ces choses (les extensions, le serveur et les outils annexes) sont plus liées qu’il n’y paraît. Elles ne sont séparées dans la campagne de financement que pour que celle-ci ait plus de chances d’aboutir. La véritable finalité, c’est de bâtir un écosystème grammatical libre.
Nous pouvons donc soutenir le développement financièrement. Si certains de nos lecteurs souhaitent t’aider d’une autre manière, comment peuvent-ils faire ?
Le point sur lequel il est possible d’aider, c’est la gestion du dictionnaire qui sert de base lexicale au correcteur. Ce n’est malheureusement pas une tâche très enthousiasmante, car c’est répétitif. Mais ajouter les mots qui manquent, les étiqueter, c’est pourtant indispensable. Quand un mot n’est pas identifié, le correcteur est aveugle. Plusieurs fois, j’ai laissé le rôle d’administrateur à des personnes motivées qui ont fait du très bon boulot. Tout le monde peut participer, et si quelqu’un se sent motivé pour administrer, il suffit d’apprendre comment ça fonctionne, se faire la main sur le système et de savoir grosso modo quelle est la politique suivie.
Quant au code, je préfère travailler seul, question de tempérament, mais quand j’aurai fini la réorganisation du projet et que les tests seront mis en place pour éviter les régressions, je serai plus ouvert à la collaboration.
Traditionnellement, nous laissons le mot de la fin à l’interviewé. Y a-t-il une question que tu aurais souhaité qu’on te pose ?
On ne m’a pas encore posé de questions sur le potentiel futur du correcteur, s’il peut encore beaucoup progresser dans la détection des erreurs.
La réponse est oui, il peut encore progresser de manière significative. Il est difficile de faire des prédictions avec une grande fiabilité, mais je suis optimiste sur la distance que celui-ci peut parcourir avant d’arriver au point où il sera difficile d’améliorer les choses sans revoir de fond en comble son fonctionnement.
Pour l’instant, il existe 929 règles de contrôle (qui recherchent les erreurs) et 535 règles de transformation (qui aident les premières à s’y retrouver dans le texte). Ces règles font énormément de choses, mais je n’ai pas encore implémenté nombre de vérifications, parce que c’est parfois compliqué à faire (il faut tester, refaire, vérifier, refaire, revérifier), mais aussi parce qu’il existe nombre d’erreurs auxquelles je n’ai pas pensé. Concevoir les règles de détection, c’est parfois simple, mais ça requiert parfois aussi de l’inventivité.
Pour l’instant, j’ai assez peu travaillé sur certaines erreurs grossières, comme les confusions entre “sa” et “ça”, “on” et “ont”, “a” et “à”, etc. parce que j’en vois peu dans les textes sur LibreOffice. Ce n’est pas le genre d’erreurs qui me vient automatiquement à l’esprit. En revanche, sur le web, ces erreurs sont bien plus fréquentes, et il faudra que je veille à renforcer les contrôles sur ces confusions qui trahissent une méconnaissance assez grave de la grammaire française. Il existe bien sûr déjà des règles pour signaler ces confusions, mais c’est encore à améliorer.
Sans rien changer aux mécanismes internes, il y a encore beaucoup de choses faisables. Mais j’avance prudemment, car la difficulté ce n’est pas de trouver de nouvelles erreurs à signaler, c’est d’en détecter sans se tromper trop souvent. Comme la « devise » de Grammalecte, c’est d’éviter autant que possible les faux positifs, la montée en puissance se fait à un rythme raisonnable, afin de corriger ce qui peut l’être au fur et à mesure et d’éviter d’être submergé par des signalements intempestifs.
Par ailleurs, à l’avenir, va être mis en place un système de désambiguïsation (cf. l’article sur LinuxFR) qui va rendre l’analyse du texte plus sûre et mécaniquement augmenter le taux de détection.
Ensuite, il n’est pas exclu de créer des mécanismes plus complexes, mais c’est une autre affaire. Grammalecte n’en est pas encore arrivé à ce stade.
La Marmotte veut le chocolat, et l’argent du chocolat
Aryeom et Jehan se sont lancés dans un projet de film d’animation sous licence libre.
Pas un truc d’amateurs ! Tous deux munis d’un solide bagage (elle : dessinatrice et réalisatrice ; lui : acteur et développeur), ils veulent en mettre plein la vue et courir les festivals avec une belle œuvre.
Ils souhaitent aussi séduire assez de donateurs pour produire leur film en financement participatif.
Comme les premières images sont impressionnantes, nous avons voulu en savoir plus. C’est surtout Jehan qui parle parce qu’il est le plus bavard des deux, et puis Aryeom peine encore à parler français, alors nous l’avons interrogée en anglais.
Vous vous présentez sur le site du studio Girin, mais pouvez-vous nous parler de votre rencontre ?
Jehan, qu’est-ce qui t’a pris de traverser le monde à moto ?
Jehan : Je me suis cassé la clavicule dans une chute à moto. Pendant quelques mois, j’ai pris le métro matin et soir, dans la foule, les bruits et odeurs des transports en commun parisiens, tout ça pour se planter devant un bureau toute la journée. Cela m’a fait me demander « mais qu’est-ce que je fais là ? ». C’est là que j’ai décidé de partir. Quelques mois plus tard, je pose donc ma démission de mon boulot d’ingé, vends ma belle moto neuve et achète à la place une moto de 1991 (que j’utilise encore quotidiennement à ce jour !), rends mon appartement, me débarrasse de ce qui n’est pas utile et prends la route.
Je n’ai jamais eu de plan exact. En fait je ne savais pas pour sûr où j’allais ni par quel chemin avant d’y être. J’ai pris les visas au fur et à mesure. C’est aussi pour cela que je préfère parler de « vagabondage » plutôt que de « voyage ». Le premier terme a une connotation assez péjorative en français, mais je le trouve au contraire très sympathique et j’ai envie qu’il s’applique à moi, surtout après avoir lu Knulp de Hermann Hesse.
Au contraire « voyageur » a cette connotation méliorative. On va entendre des absurdités du genre « les voyageurs sont des gens ouverts », etc. Je peux vous dire que j’ai croisé des très grands voyageurs qui étaient de beaux salauds, tout comme j’ai connu des gens super sympas et ouverts qui n’avaient jamais quitté leur bled. En d’autres termes, ça n’a absolument rien à voir. On peut être un voyageur ouvert ou non, comme pour tout. Par contre le voyage, dans notre société, c’est beaucoup associé à du tourisme pur et dur où des gens vont aller une semaine dans un endroit, voir quelques lieux touristiques, faire quelques remarques bateau, puis revenir chez eux en étant persuadés d’avoir tout compris sur un pays et tous ses habitants. Bien que cette vision du voyage soit bien vue dans nos sociétés, je préfère me poser un peu en rupture avec cette façon d’aller sur les routes. Il n’est pas nécessaire de comprendre ou savoir quoi que ce soit quand on va quelque part ou quand on rencontre quelqu’un. On peut se contenter d’y être. Vouloir tout intellectualiser, c’est peut-être ça d’ailleurs le contraire de l’ouverture.
Je suis donc un vagabond, et je ne réfléchis pas ni ne sais d’où je viens, ni où je vais, tout comme Marmotte. 🙂
Après avoir traversé l’Asie centrale (à travers Kazakhstan, Russie, Mongolie…), je suis resté un an au Japon, puis suis allé en Corée.
C’est là que j’ai rencontré Aryeom.
Aryeom, why did you decide to come in France, while things seemed to work well for you in Asia? (Aryeom, pourquoi as-tu décidé de venir en France, alors que ça semblait marcher pour toi en Asie ?)
Aryeom : France is known as an art country. So I wanted to live in France someday, and the chance came earlier than I thought. Jehan has an association for libre art and suggested a residency artist program with his association. And the principles of the association are so nice for the world. I thought it was a very good chance for me. So I caught it.
(Le rayonnement de la France sur les arts est reconnu. Je m’étais dit que ce serait bien de venir vivre en France un de ces jours ; l’occasion s’est présentée plus tôt que prévu. Jehan fait partie d’une association d’art libre et il m’a proposé un programme d’artiste en résidence. Les principes de son association sont tellement sympathiques que j’ai pensé que sa proposition était une vraie chance pour moi, et j’ai accepté.)
Le personnage principal de votre film d’animation est une marmotte voyageuse, qui décide de partir découvrir le monde au lieu de roupiller devant son terrier. On a bien compris que c’était votre animal totem. Elle illustre votre façon de voir la vie ?
Jehan : Oui et non. Oui j’adore cet animal et c’est un peu mon totem, si on veut. Non je n’y ai pas mis tellement de réflexion (encore une fois !) ou de « théorie bullshit » sur la vie. Au final c’est surtout un animal que je trouve cool et marrant. Ça ne va pas chercher beaucoup plus loin. 🙂
J’ai toujours beaucoup aimé les marmottes et suis allé régulièrement dans les Alpes, donc j’en ai croisé pas mal. J’ai un jour acheté une peluche marmotte (lors d’un séjour au ski, si ma mémoire est bonne), et elle m’a tout bêtement suivi dans tous mes vagabondages depuis. Donc vous pouvez le voir, ça ne vole pas dans de grandes sphères philosophiques ou symboliques !
Je ne l’exhibe pas forcément beaucoup, donc les gens ne le savent pas forcément, mais si vous me rencontrez, il y a de grandes chances qu’elle épie depuis mon sac. 😉
C’était mon copilote, on lui a fait un petit casque en simili-cuir avant mon départ, et il avait sa place sur le guidon de la moto. Cette peluche a visité plusieurs dizaines de pays !
C’est donc l’idée de base du film : et si la marmotte décidait de partir en voyage seule ?
Vous voulez gérer tout le projet uniquement avec des logiciels libres. Ça ne rend pas les choses moins faciles ?
Jehan : Bien sûr. Il existe de très bons logiciels proprios et il n’y a pas eu ou très peu de projets sérieux qui ont utilisé des logiciels Libres. Donc tout ce qui existe pour l’animation n’est qu’à l’état de prototype en gros. Notre projet sera donc clairement un des pionniers.
Mais j’utilise essentiellement les systèmes GNU/Linux depuis une dizaine d’années au moins et avec Aryeom, on a pensé que c’était l’occasion de faire un film d’animation et de créer les logiciels adéquats (ou les sortir de l’état de prototype). Il faut un vrai projet pour rendre les logiciels fonctionnels. La théorie a toujours des limites qui se cognent à la réalité dans de vrais projets.
Je me considère comme un relativement capable développeur. Non pas un expert, mais par contre un touche-à-tout et surtout méticuleux (le mainteneur de GIMP me traite de « pedantic hacker » pour signifier qu’il me fait confiance pour trouver des bugs et problèmes que d’autres ne voient pas !). Donc je pense être capable d’améliorer les choses si on m’en donne les moyens. Sans compter que la base est déjà plutôt bonne. On ne part pas non plus de rien et l’état et la stabilité des logiciels Libres pour le dessin et partiellement l’animation sont très bons de nos jours, bien qu’il y ait encore pas mal de manques.
Aryeom, do you never dream to work with a good old Adobe suite? 🙂
Is it very much complicated to draw with free softwares? Or is it cool because you know a Gimp developer and you can ask directly to Jehan the fonctionnalities/features you want?
(Aryeom, tu ne rêves jamais de bosser avec une bonne vieille suite Adobe ? Est-ce que c’est beaucoup plus compliqué de dessiner avec des logiciels libres ? Ou alors c’est sympa parce que tu connais l’un des développeurs de Gimp et que tu peux demander à Jehan les options dont tu as envie ?)
The first year when I started to use GIMP, there were times I wanted to throw my tablet pen through the window. But now I got used to it.
This is just a different software and I just have had to learn the basics, as for any software.
There are still things I miss. In particular there are no programs which I can use like After effects. This is very tough for me.
And all software in Adobe suite are well connected. We don’t have this in Free Software. Working with GIMP and Blender can be a pain sometimes because of this. I hope that with more users, these connections will be implemented.
(La première année, quand j’ai commencé à travailler avec Gimp, j’ai eu des envies de balancer ma tablette graphique par la fenêtre. Mais maintenant je me suis habituée. C’est simplement un logiciel différent, il a fallu que j’apprenne les fondamentaux, comme avec n’importe quel logiciel, voilà tout.
Il me manque quand même encore des trucs. Particulièrement After Effects, qui n’a pas d’équivalent. Ça, c’est dur.
Et puis tous les logiciels de la suite Adobe sont bien liés entre eux. Nous n’avons pas ça dans le Libre. Du coup, travailler avec Gimp et Blender peut devenir compliqué. J’espère que ces liens seront mis en place quand nous serons plus nombreux à les utiliser.)
L’autre particularité du projet, c’est que vous ne voulez surtout pas faire du boulot d’amateur. Vous souhaitez un résultat de qualité professionnelle et que tout les artistes soient payés. Dans votre demande de contribution, vous dites « ce n’est pas un appel à venir bosser gratos » !
Vous pensez vraiment y arriver ?
Dans le circuit « traditionnel », c’est déjà compliqué de sortir des projets !
Jehan : Nous espérons en tous cas ! Il est vraiment important pour moi de ne pas rester dans l’amateurisme. Attention ce n’est pas parce que je considère l’amateurisme comme inférieur. Bien au contraire, j’en suis un fervent défenseur et il ne faudrait surtout pas déconsidérer le travail amateur. J’ai connu des amateurs qui pourraient aisément être pros et des pros qui font vraiment un boulot de merde. On voit cela pour tout métier.
Néanmoins pour ce projet en particulier, déjà je veux prouver qu’on peut faire un vrai boulot, pour l’image du Libre, mais aussi parce que ce projet nous tient à cœur.
Ce n’est pas non plus juste une « démo technique » comme on peut le voir par ailleurs dans d’autres projets du Libre portés par des gens intéressés seulement par le software. Non c’est un vrai projet de film aussi.
En outre on veut pouvoir y bosser à temps plein. Or pour faire cela, on doit pouvoir se payer, et si on se paye, c’est aussi normal de payer les autres (je ne trouverais pas sain de se payer tout en demandant à des volontaires de bosser gratos).
Quel est le secret de ce bel optimisme ? (How can you be so optimistic?)
Jehan : si vous êtes pessimiste, vous ne pouvez rien faire. Toute personne a tout intérêt à être optimiste en toute chose pour pouvoir « faire des choses ». C’est pour moi un principe de base.
À propos de la musique, j’ai lu que vous deviez refuser les propositions des membres de la SACEM, parce qu’ils ne sont plus libres de diffuser leurs œuvres comme ils le souhaitent. Ubuesque, non ?
Jehan : Oui. Les membres transfèrent la gestion de leurs droits d’auteur à la SACEM. En gros vous n’avez plus de « droit » sur vos droits, ce qui est plutôt ironique. Un adhérent SACEM ne peut plus négocier ou signer de contrat sur ses droits d’auteur, et n’a donc pas le droit de mettre ses œuvres sous une licence de son choix (sauf accord spécifique). De même qu’un adhérent n’a même pas le droit de déposer ses morceaux sur son site perso (ou aucun site de manière générale). À vrai dire, de nombreux membres SACEM sont en violation pure et simple de leur contrat en essayant de faire la pub pour leur morceau (en le faisant écouter, en le mettant sur leur site, etc.). Si même vous faites écouter vos propres morceaux à un public, vous devez payer (pour ensuite toucher théoriquement des droits sur l’écoute, sauf que comme la SACEM prend sa part au passage, il ne reste plus grand chose). Ubuesque, oui. Ridicule même.
Maintenant qu’on sait tout ça, comment est-ce qu’on peut vous aider ? Vous prenez tout le monde ? Moi, je recadre déjà mes photos de famille avec The Gimp. Encore un ou deux tutos à lire et je viens !
Jehan : Effectivement pour ce projet en particulier, la question peut se poser puisqu’on veut faire un film de qualité. De même que la Blender Foundation fait une sélection draconienne pour les participants à ses Open Movies. Ce serait pareil pour nous. Ensuite comme je disais, je n’aurais aucun blème à engager un amateur très qualifié (de même que je n’aurais aucun remord à refuser l’aide d’un professionnel au travail bâclé).
Par contre notre assoce en elle-même prévoit des ateliers pour expliquer les logiciels Libres créatifs à monsieur Tout-le-Monde (ou à des pros habitués à des logiciels propriétaires), et aider les gens à les utiliser. Par exemple à l’Ubuntu Party ainsi qu’aux RMLL, nous aurons (normalement) un atelier de ce genre pour fabriquer tous ensemble « l’album d’autocollants des libristes » dans un contexte « d’impression pro chez un imprimeur ». Tu as peut-être entendu parler de ce projet initié par LDN. D’ailleurs si Framasoft a des autocollants, faut les envoyer ! Clairement vous devez faire partie de l’album. 🙂
La flatterie ne te mènera nulle part.
On s’est dit que c’était vraiment un projet sympa, car pas trop complexe (le « contenu » existe déjà, c’est globalement les autocollants existants des assoces françaises), qui permettrait d’expliquer les bases de la mise en page (pour impression physique, pas web), mais aussi des questions sur les couleurs (CMYK/RGB, que sont les profils de couleur ? Sur ce sujet, on aimerait un peu décortiquer le mythe du vrai d’ailleurs car on rencontre foultitude de « graphistes pros » qui n’y pigent rien et répètent les conneries qu’on se répète probablement de graphiste senior à graphiste junior parce qu’ils ne comprennent rien à la technologie sous-jacente).
On pense qu’on devrait pouvoir créer cet album entièrement collaborativement en plusieurs ateliers. Comprendre : nous on fera absolument que dalle !
On ne sera là que pour montrer aux gens comment faire, guider, et répondre aux questions ! Alors, dans un an peut-être, la communauté pourrait lancer une impression de son album créé intégralement collectivement. Moi je trouve ça cool.
Pour ce genre d’atelier, tu pourras venir avec ton background impressionnant de retouche de photos de famille ! Pour le film, c’est moins sûr. 😉
Bon, OK, c’est peut-être mieux si je donne un peu de sous. Où ça ?
Et le film, on le verra quand ? Ça doit prendre du temps à fabriquer, non ? Vous allez donner des nouvelles tout au long de la production ? Montrer des petits morceaux ? Faudrait pas non plus nous gâcher le plaisir de la découverte…
On en saura plus à la fin du financement, notamment quelle sera la durée du film, et donc la durée de la production (ou tout simplement en fonction du support reçu : pourrons-nous faire le film ?). Si on arrive à bien le financer et qu’on peut en faire un projet à temps plein, alors ce serait idéal.
En tous les cas, oui on prévoit de donner des nouvelles régulières. On montrera des images, mais je ne pense pas que l’on montrerait trop de « morceaux » du film publiquement par contre, non parce qu’on veut cacher le film, mais simplement pour le côté « spoiler ». Si on a montré l’ensemble du film par petits morceaux décousus tout au long de la production, non seulement c’est moins impressionnant (car « non fini », donc ça peut avoir un aspect décevant), mais en plus à la fin les gens auront déjà presque tout vu par bouts incohérents et pourraient être déçus de ne pas voir de nouveauté dans le film final. Donc ça gâcherait le visionnage.
Je pense qu’une meilleure stratégie est de ne pas bloquer l’accès aux fichiers (quelqu’un de passionné pourrait alors accéder aux fichiers), sans pour autant gâcher le film final pour ceux qui préfèrent attendre le film fini.
En tous cas, oui une animation prend beaucoup de temps à fabriquer. C’est simple à calculer : 24 images par seconde, ça fait 1440 (24 * 60) images pour une minute de film ! Donc pour juste une seule minute, imaginez que vous devez faire 1440 dessins, les colorier… En plus les dessins doivent être précisément calculés pour obtenir une animation réaliste et/ou drôle/intéressante, ce qui demande aussi un travail et un savoir faire considérable. Bien sûr vous ne redessinez pas tout à chaque dessin (les arrière-plans par exemple peuvent être réutilisés tout au long d’un plan statique), de même que selon la qualité d’animation désirée, il est courant de descendre à 12 images par seconde.
Mais cela reste quand même un gros boulot, et surtout une organisation très importante (avec autant de dessins, ne pas être organisé peut marcher pour une courte animation, mais à partir de quelques minutes, ce n’est plus gérable).
D’ailleurs un aspect du projet est aussi de financer du développement. J’ai plusieurs projets liés à l’animation :
un logiciel de gestion de projet d’animation, ce qui inclut le storyboard, les feuilles d’exposition, etc.;
le plugin d’animation de GIMP pour en faire plus qu’un plugin de création de GIFs animés de chatons;
je prévois de travailler sur l’import des fichiers dans Blender (pour l’instant travailler avec des fichiers générés par GIMP, Krita ou MyPaint et les importer dans Blender n’est absolument pas adapté et vraiment laborieux).
L’un des gros avantages d’une suite comme Adobe n’est pas seulement des logiciels bons individuellement mais aussi leur intégration les uns avec les autres.
Oui, c’est ce que dit Aryeom aussi.
Il est ainsi extrêmement simple de travailler sur des images dans Photoshop, puis charger le fichier PSD (les « images » de Photoshop) dans After Effects, ce qui permet de travailler sur les calques comme des images séparées, puis modifier l’image dans Photoshop et voir les changements dans After Effects, puis travailler dans Première, etc. Tout est lié. On n’a pas ça dans le Libre et c’est quelque chose qu’on aimerait vraiment pouvoir apporter. C’est à peu près aussi important que la qualité des logiciels eux-mêmes : comment les divers logiciels peuvent communiquer efficacement?
En conclusion : oui, c’est un travail de longue haleine. Et on avisera sur la longueur du projet en fonction du financement.
Le grain de sel de Pouhiou : ce film, vous projetez de le sortir sous licence libre… Vous n’avez pas peur qu’on vous vole votre bébé 😛 ?
Plus sérieusement, la licence libre vous semble un pendant naturel au financement collaboratif ?
Oui cela me paraît naturel de rendre à la communauté ce qu’elle a financé. C’est l’inverse qui me paraît difficilement normal. Par exemple lorsqu’un musée public vous empêche de prendre des photos d’œuvres dans le domaine public depuis des centaines d’années, alors même que c’est vous qui payez entièrement ce musée par vos taxes et impôts ! Je sais que beaucoup de gens vont pourtant financer sans problème des œuvres propriétaires. Je n’ai rien à y redire, chacun est libre de dépenser son argent comme il le souhaite. Après tout si le fait que l’œuvre sorte est suffisant pour les financeurs, pourquoi pas. Mais dans mon petit cerveau idéaliste, je rêve de plus. Je rêve d’un marché de l’art sans frontière ni limites auto-imposées et totalement artificielles.
Si on regarde le problème sous un angle plus traditionnel, un investisseur qui met de l’argent dans un film ou une société espère faire fructifier son investissement. Mais dans notre cas, tout ce que nous y gagnons serait quelques t-shirts ou autres bagatelles ? Et si l’investissement des financeurs collaboratifs existait, sauf qu’au lieu d’une forme monétaire uniquement, il a aussi une forme culturelle, artistique et communautaire ? Au lieu de plus d’argent, nous rendons du partage de connaissance et le droit pour tous de voir, partager et faire ce qu’on veut de l’œuvre qu’on a contribué à faire exister !
C’est une œuvre de biens communs.
Quelqu’un veut utiliser notre œuvre ? Très bien !
Est-ce vraiment du « vol » (ou pour être plus précis en termes légaux, de la contrefaçon) si on a déjà été payé pour produire l’œuvre ? C’est aussi pourquoi plus haut, lorsque vous demandez pourquoi c’est important de payer les gens (nous même et autrui), c’est une autre bonne raison. Un vrai travail est produit, un travail compliqué, long (des mois et des mois à temps plein pour créer des dizaines de milliers d’images !). Donc c’est normal de le payer, et si possible pas au lance-pierre. Par contre après cela, les artistes peuvent passer à autre chose, quant à l’œuvre, elle peut continuer à vivre sa vie. Vous voulez la présenter dans un cinéma ? Génial ! Bien sûr si vous souhaitez rémunérer les artistes davantage avec un pourcentage des recettes, c’est très bien, et on acceptera avec joie (vous pourriez alors utiliser un « Creator endorsed » logo comme Nina Paley, par exemple.
Mais si vous ne souhaitez pas le faire, c’est acceptable. On aura déjà été payé après tout. Par contre dans ce cas, ce serait cool que le prix du ticket soit raisonnable (les tarifs de places de cinéma sont de plus en plus absurdes !), mais ça reste votre choix.
Revenant ainsi sur ma réponse plus haut, j’ajouterai donc que je pense qu’il est important de bien payer les gens pour un travail, surtout pour produire une œuvre qui vous plaît. Par contre, une fois l’œuvre sortie, elle pourrait appartenir au public, au monde même. C’est bien plus sain que le système actuel où les coûts sont bien plus mesquins, cachés, et en même temps plus imposants, tout en donnant l’impression d’être gratuits. Non les services web des grosses compagnies du web ne sont pas gratuits (vous le payez avec la pub que vous regardez, votre vie privée que vous échangez, la vie privée de vos proches que vous divulguez, même lorsqu’ils n’ont rien demandé…). Vous en savez quelque chose chez Framasoft (cf. votre projet Dégooglisons Internet) ! Ben pareil, vous payez sans arrêt les œuvres du divertissement de masse (redevance télé, taxes sur la copie privée sur chaque support de stockage…). Saviez-vous que les bars, cafés, restaurants et commerces qui passent de la musique payent des redevances à la SACEM, et la Spré ? Les frais sont versés par les commerçants mais bien entendu répercutés sur les tarifs des produits ou services vendus !
On paye tous constamment au nom de la sacro-sainte « copie privée » et du « droit d’auteur » pour l’industrie du divertissement. Pourtant cela ne signifie pas pour autant que les artistes touchent beaucoup. Ces systèmes sont faits de telle sorte que les intermédiaires (sociétés de gestion de droits elle mêmes, les majors…) touchent une grosse part quoi qu’il advienne (ils ont des locaux, des charges, des employés…), et puis les gros ayant-droits (ils sont un faible pourcentage, ceux qu’on nommera « stars ») récupèrent ce qui reste en laissant des miettes de droits d’auteur pour les artistes restants.
Quand je lis des affirmations aussi attristantes que cela sur sacem.fr :
Vous ne le savez peut-être pas mais les auteurs, compositeurs et éditeurs ne touchent aucun salaire lorsqu’ils créent. Ils vivent de la diffusion de leur musique et c’est la répartition qui leur permet de recevoir leurs droits d’auteur. Ce système consiste à leur reverser leurs droits selon l’utilisation réelle et précise de leurs œuvres sur la base de relevés de diffusions. Des auteurs peu diffusés sont ainsi assurés de toucher, quoi qu’il arrive, ce qui leur revient de droit. La Sacem est réputée pour assurer une redistribution parmi les plus précises au monde.
Heureusement ce n’est pas entièrement vrai (je doute que beaucoup d’auteurs accepteraient de bosser sans être payé du tout à la création), mais tout de même cela donne une idée de l’état d’esprit par lequel on peut essayer de diminuer les tarifs d’un artiste : « vous toucherez plus tard avec les droits d’auteur ».
J’imagine bien la tête des maçons si on leur baissait leurs salaires pour leur dire que plus la maison sera utilisée, plus ils toucheront (avec une société de collecte qui géreraient cela et prendrait sa confortable part au passage).
Et si plutôt que faire cela pour des artistes, on pouvait payer convenablement tout le monde pour le travail effectué puis libérer les œuvres et on passe à autre chose ?
Cela ne serait-il pas plus sain et mieux pour tout le monde ? Les artistes, le public… Bien sûr, les intermédiaires seraient mécontents par contre !
La marmotte vous remerciera
Aryeom, you are guest in France, so the last word is for you! Feel free!(Aryeom, en tant qu’invitée en France, le dernier mot est pour toi. Lâche-toi !)
Why don’t you invest in a small step for our and your good world? Donate for our project <ZeMarmot> please!
(Pourquoi ne pas investir pour que notre monde, à tous, avance d’un petit pas ? Donnez pour notre projet ZeMarmot, s’il vous plaît !)
MyPads point de la semaine 17
Comme annoncé la semaine dernière, c’est désormais un point hebdomadaire qui émaillera le travail autour de MyPads. Cette semaine n’aura pas été de tout repos et les avancées visibles sont malheureusement peu nombreuses. Explications.
Les travaux
La mise en place des tests fonctionnels client, simulant une navigation réelle, a occupé les premiers jours de développement. Ensuite MyPads a subi quelques modifications pour fonctionner avec la version 4 d’Express, le cadre de développement sur lequel repose Etherpad et donc MyPads. Cette migration a été initiée par le tout premier contributeur externe au plugin, et a été rendue nécessaire par la migration d’Etherpad une semaine plus tôt.
Cette migration a été l’occasion de tester à nouveau la compatibilité de MyPads avec Eherpad. Cela peut sembler étonnant, mais MyPads est développé de manière autonome vis à vis d’Etherpad et est régulièrement testé en tant que plugin Etherpad, pour les raisons suivantes :
accélérer le développement et éviter de devoir relancer Etherpad voire réinstaller le plugin à chaque modification;
permettre les tests unitaires et fonctionnels serveur, très difficile sinon à partir d’un plugin Etherpad, isoler une base de tests du reste de l’instance;
conserver une forme d’indépendance vis à vis du cœur d’Etherpad : afin de ne pas nécessiter des modifications d’Etherpad lui-même et de limiter les régressions en cas de changements internes de ce dernier.
Malheureusement le fonctionnement de MyPads s’est révélé erratique : parfois correct, parfois non. Pour les techniciens, seules les méthodes GET et HEAD sont autorisées et toute autre méthode HTTP est refusée. Le problème, nouveau, est intimement lié au logiciel intermédiaire (middleware) yajsml, lequel est employé par Etherpad afin d’optimiser les requêtes des fichiers dits statiques (scripts, images, styles etc). En théorie, les requêtes prises en charge par MyPads ne devraient pas être impactées par ce logiciel intermédiaire, mais pour une raison mal comprise, elles le sont parfois.
Le problème, c’est que MyPads fonctionne autour d’une interface de programmation standard, une API HTTP REST, sur laquelle se connecte le client Web, et qui permettra à d’autres clients ou à des outils tiers de voir le jour. La résolution du soucis n’est pas aisée : l’anomalie intervient de manière aléatoire. Peu de plugins sont touchés car la plupart ne définissent pas leurs propres routes HTTP. Même si yajsml est modifié pour résoudre le soucis, il faudra que la fondation Etherpad accepte le patch et l’intègre avant de pouvoir retrouver une fonctionnement correct de MyPads. Or, il semble que yajsml sera bientôt remplacé par une technologie plus standard.
D’autres résolutions ont été envisagées, du fait de la situation de yajsml, et entre autres :
Substituer, comme certains plugins le font, l’API HTTP REST par une API basée sur socket.io, la technologie employée par Etherpad pour la collaboration en temps réel et qui repose en premier lieu sur le standard WebSocket. Cette voie a été expérimentée cette semaine mais représente une charge considérable de travail et la réécriture de nombreux modules. De plus, il ne s’agit pas d’un remplacement propre : MyPads y perd une méthode de communication plus standard ainsi que son système d’authentification, lequel avait été choisi pour permettre à terme une connexion depuis des comptes externes ou encore un annuaire LDAP, OpenID etc
Faire de MyPads une application indépendante, de fait non plus un plugin, qui gèrerait les accès des utilisateurs aux pads en fonction des groupes définis. Le problème de cette solution est de complexifier l’installation de MyPads et de risquer des incompatibilités avec certains autres plugins. Aussi, nous sortirions de fait du cadre du cahier des charges initial.
Il a été décidé que la dernière piste ne serait à employer qu’en cas de dernier recours et c’est la migration vers socket.io qui a été d’abord privilégiée. Néanmoins, à la vue du travail nécessaire et surtout des pertes fonctionnelles que cela risque d’amener, cette solution ne sera pas poursuivie.
La semaine prochaine
Le travail va reprendre sur la version HTTP REST standard qui a été développée jusqu’ici. Il est prévu :
qu’étant donné que la suppression du yajsml n’arrivera qu’à un terme inconnu, il faudra dépister l’anomalie et la résoudre, ou au moins proposer un contournement simple;
de poursuivre le développement, moins actif que prévu cette semaine, avec notamment
le passage d’une authentification en propre classique vers JSON Web Token, dont le travail a commencé cette semaine avec le test de socket.io, de manière à renforcer la sécurité des échanges de données chiffrées entre serveur et client;
les groupes et pads, évidemment.
Rendez-vous jeudi prochain pour le point de la semaine 18.
MyPads week 17
As announced last week, we now give some news about MyPads development weekly. Last couple of days haven’t been picnic and few enhancements are visible. Explanations below.
Work
Frontend functional testing setup, aiming to simulate real navigation, has filled the first days. Then MyPads has been updated to work with Express version 4. Express is the framework which powers Etherpad and so MyPads. This migration has been introduced by the very first MyPads external contributor, and was necessary because of the Etherpad migration a week earlier.
These modifications were a good moment to test MyPads’compatibility towards Eherpad. That can be surprising but MyPads has been programmed independently from Etherpad and is regularly tested as an Etherpad plugin, here’s why :
speeding up the development and avoiding Etherpad reboot or plugin re-installation at each update;
allowing unit and functional server testing, quite hard from an Etherpad plugin, and isolate a test database from the whole node;
retaining a distance regarding Etherpad core in order to avoid need of Etherpad updates and limit regressions in case of internal modifications of it.
Sadly MyPads behavior becomes erratic : sometimes correct, sometimes buggy. For technicians : only GET and HEAD HTTP verbs were allowed and all other method has been forbidden. This problem seems to be linked to the yajsml middleware, used by Etherpad in order to optimize static files requests (scripts, images, styles etc). In theory, MyPads handled routes should not be impacted by this middleware, but for an misunderstood reason, they sometimes are.
Problem is that MyPads is based on a standard home-defined HTTP REST API, which the Web client connects to. This interface may allow other clients and third party tools to be created more easily. Debugging the problem is not an easy task, due to the randomness of the behavior. Few plugins should be concerned because most of them don’t define their own routes. Even if yajsml is updated to fix the issue, the Etherpad developers will have to accept the patch and merge it before we have MyPads working correctly. Now it seems that yajsml will be soon replaced by a more standard technology.
Others resolutions have been considered, regarding to yajsml situation :
Replace, as others plugins do, the HTTP REST API by a socket.io one. socket.io is the technology used by Etherpad for realtime collaboration, that use as a first class citizen the WebSocket protocol. This approach has been tried this week but requires a considerable amount of work and many modules rewriting. Moreover, it’s not a proper replacement : MyPads loses its more standard communication method but in addition its authentication system, which have been chosen to allow, later, connection through external accounts, LDAP directory, OpenID etc
Move MyPads from a plugin to a standalone application, which handle user access according to created groups and pads. Problem with this solution : harden the MyPads installation, risks of incompatibilities with some other plugins. Also, making a standalone app won’t conform to the initial specifications.
We have decided to follow the last proposition only as a last resort. The migration to socket.io has been preferred but, with the light of required work and moreover functional looses, it won’t continue.
Next week
Work will be resumed on the HTTP REST version, the one developed until now. We expect :
because yajsml removal won’t happen before an unknown time, it will be important to find and fix the bug, or at least to provide a simple workaround;
move forward, with
migration from a classical authentication to JSON Web Token, which has been partially done this week as part of socket.io test, in order to harden encrypted data exchanges between client and server;






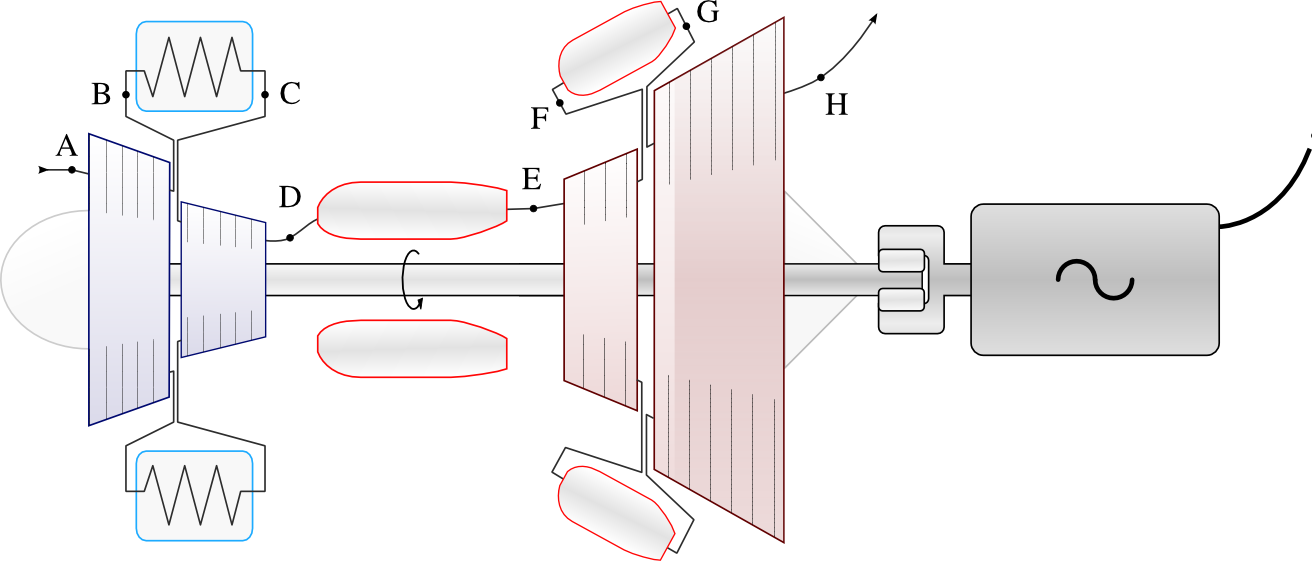





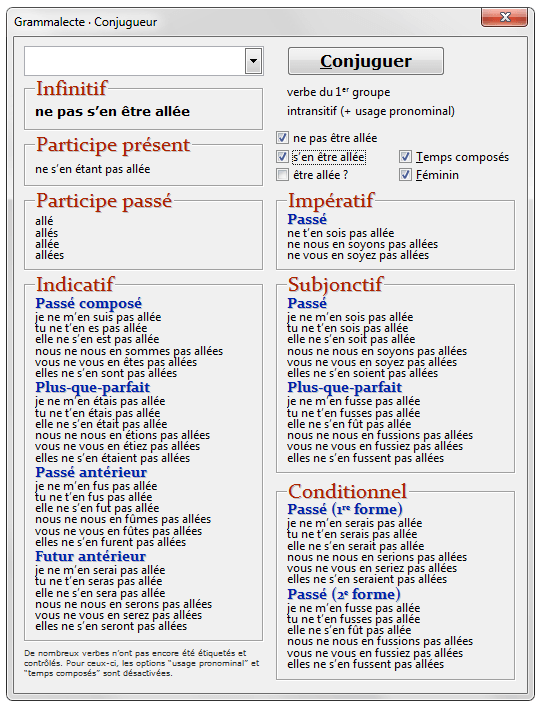
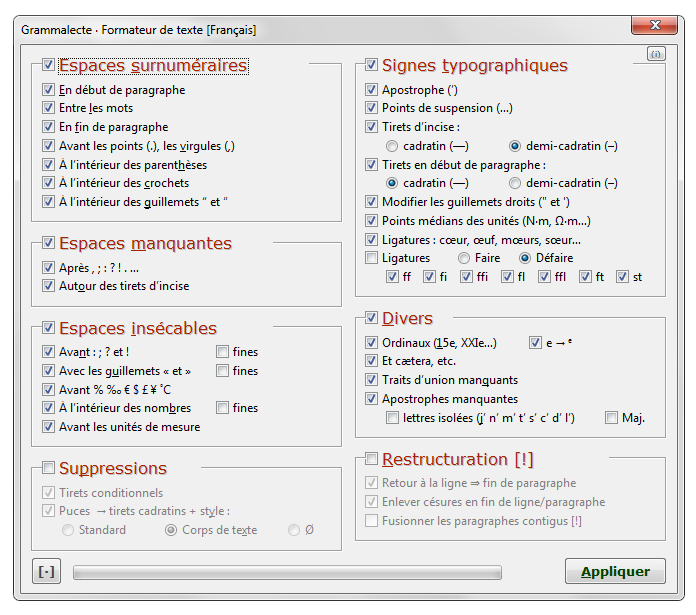




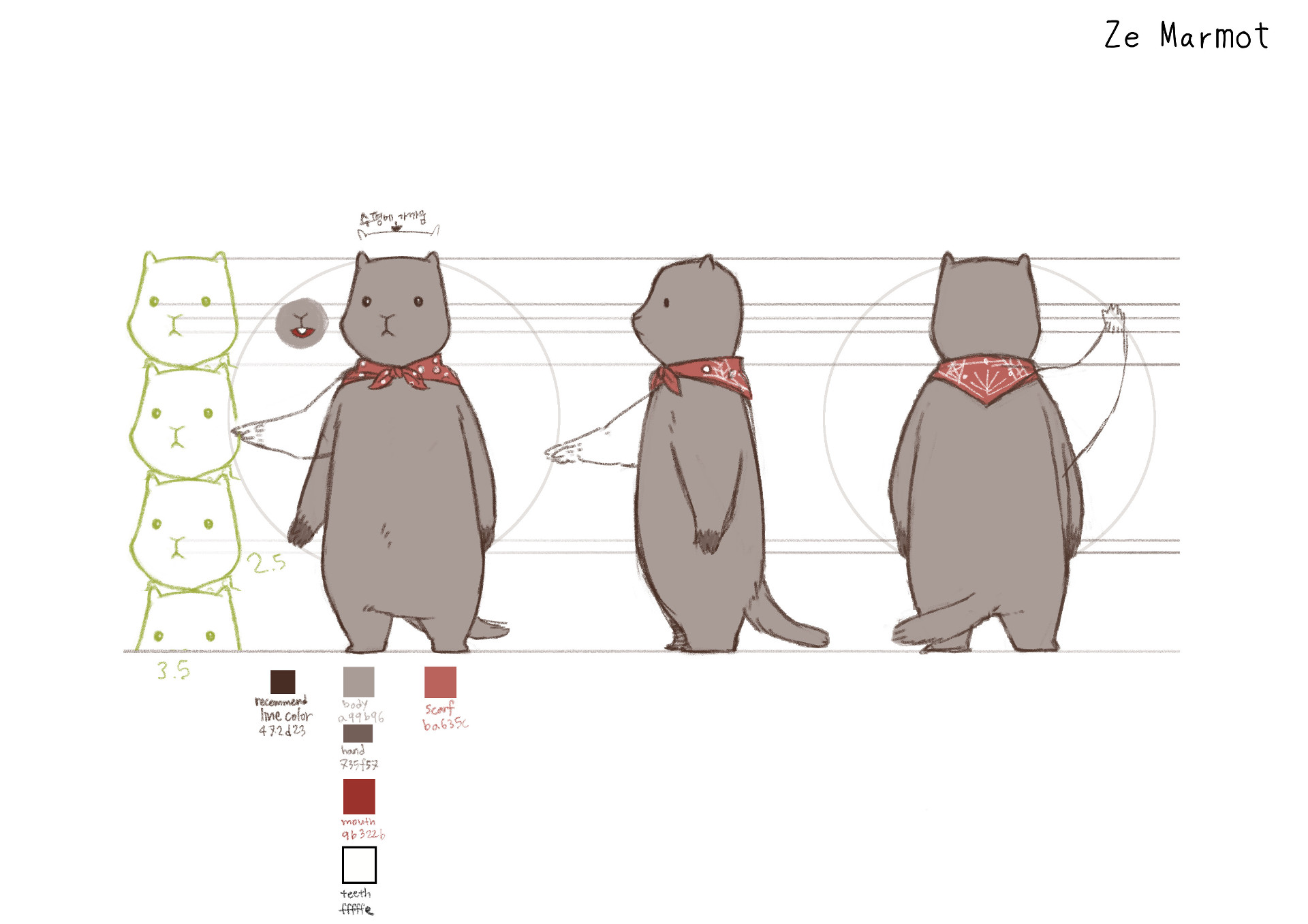


{kind=link}