Vous en avez sans doute entendu parler : Mickey entre enfin dans le domaine public. Enfin… c’est un peu plus compliqué que ça… Notre dessinateur Gee vous explique tout ça.
Note : cette BD reprend partiellement la chronique que Gee a donnée mardi dernier dans l’émission de radio de l’April, Libre à vous ! (dont le podcast sera disponible prochainement). Si la chronique et la BD partagent une trame commune, elles ne sont pas identiques mais complémentaires.
Mickey dans le domaine public
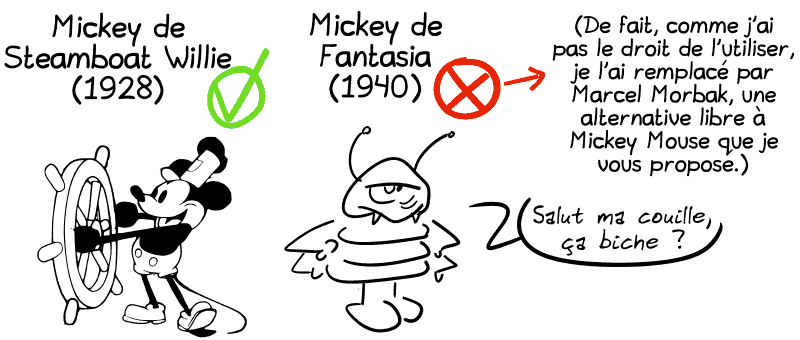
Le copyright étatsunien est un drôle d’animal qui, pendant des décennies, a grandi avec un autre animal : une petite souris.
Bon, je ne suis pas sûr que ce soit un vrai sursaut de décence qui soit à l’origine de cet arrêt de l’augmentation de la durée du copyright…
Quoi qu’il en soit, après bien des années d’attente, cette fois c’est fait :
Mickey Mouse entre dans le domaine public.
Mais alors attention, pas n’importe lequel : juste celui de Steamboat Willie, le fameux film d’animation de 1928.
Ajoutons à ça la tripotée de marques que Disney a pris soin de déposer autour de sa mascotte…
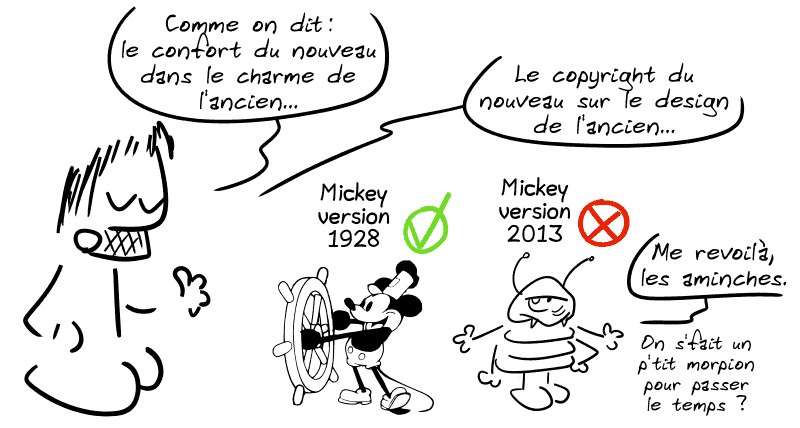
Ajoutons aussi le nouveau design rétro de Mickey, très ressemblant à celui de 1928, que Disney a balancé en 2013, entre le fromage et le dessert. Histoire qu’il y ait toujours un petit doute sur lequel vous utilisez…
Après, ne rigolons pas trop fort sur les délires du copyright étatsunien… de notre côté de l’Atlantique, c’est pas beaucoup plus reluisant.
Je sais, là, vous allez me dire…
Mais POURQUOI cette extension ?
La justification est très simple :
Bon, vous en pensez c’que vous voulez, mais moi je trouve qu’on nous prend un peu pour des moutons dans une boîte, avec cette histoire.
Vous pouvez télécharger le livre dans le domaine public belge depuis saintexupery-domainepublic.be. Sauf si vous êtes en France, bien sûr, je le répète, mais déconnez pas, hein.
De toute façon, chez nous aussi on sait faire joujou avec le droit des marques, donc les héritiers de Saint-Exupéry ont déposé le Petit Prince comme marque de commerce, et c’est plié.
Bref, je suis personnellement d’avis que l’art est libre par essence, parce qu’il forme notre imaginaire collectif et qu’il est donc démocratiquement juste de se l’approprier, de le transformer et de le partager.
Citation extraite du Discours d’ouverture du Congrès Littéraire International du 17 juin 1878 (à retrouver sur Wikisource).
Ateliers Solarpunk – UPLOAD : bientôt des nouvelles de 2042
… et des extraits aujourd’hui pour l’apéritif !
Les ateliers de l’UTC de l’opération #Solarpunk #UPLOAD ont été plus que fructueux ! Si vous avez raté le début, parcourez cet article récent et cet autre…
Sept groupes de participant⋅es ont collectivement imaginé puis scénarisé et finalement… rédigé des nouvelles dont voici quelques échantillons et dont nous publierons l’intégralité ici même au cours de la semaine prochaine.
En attendant, vous pourrez dès ce vendredi 19 janvier les écouter présenter leur travail et interpréter quelques passages sur la radio https://grafhit.net/ (et sur le 94.9 FM si vous êtes dans le Compiègnois). Soyez à l’écoute à partir de 12h !
Une radio punk, des dirigeables, un musée d’avant l’effondrement, des étudiant⋅es les mains dans la terre, d’autres bloqués sans réseau, une ferme et des dortoirs à rénover… C’est parti pour vous mettre l’eau à la bouche !
1.Un début de vive altercation sur Radio_Padakor, ça risque de tourner au vinaigre entre le jardinier et l’écologue experte de la startup…
… à ce problème de taille, continue Victoire, Écorizon apporte pourtant une solution plus qu’inespérée : l’éradication des écrevisses de Louisiane sera comprise au sein du programme de compensation écologique proposé par la firme. Pour ce faire, nous proposons de relâcher, de manière ciblée, sur une zone limitée et temporairement, une toxine issue des traitements de l’usine dans les eaux de l’Oise. Cette toxine ne viserait que les écrevisses, évidemment. Jarvis est stupéfait : cela n’a aucun sens, il doit encore intervenir. Le vieil homme ne manque donc pas de couper la parole de l’écologue, une nouvelle fois, par un violent « Shut up! » tout droit sorti de son cœur d’Écossais. Il confronte la soi-disant écologue à ses propos, en la questionnant : comment une toxine, prétendument aussi efficace, pourrait-elle ne cibler que les écrevisses ? Victoire, encore, ne se démonte pas : la toxine, prétend-elle, passe uniquement par les branchies des crustacés. Jarvis s’énerve : les poissons aussi ont des branchies, cette toxine leur serait également inoculée !
extrait de Panique à bord de Padakor, récit complet sous licence CC-BY-SA Radio_Padakor, à paraître lundi prochain sur le Framablog
2. à l’UPLOAD, ça discute après l’effort dans le jardin collectif partagé…
« Pas mal, lâcha Émile, pour une première, vous vous en sortez plutôt bien ! — Merci, c’est pas si dur en fait le jardinage ! Il y a des petites techniques à apprendre et puis notre potager se retrouve rempli de bons fruits et légumes, répondit Maura enthousiaste. — C’est vrai, mais il y a aussi toute la partie entretien du potager ! objecta le jardinier. Il y a dans toutes disciplines des parties moins agréables mais essentielles qui nous rendent encore plus fiers du travail accompli. » Puis il se tut, il semblait méditer. Théo saisit cette opportunité pour s’introduire dans la conversation. « Moi quand je travaille sur les dirigeables, je suis toujours fier du travail accompli ! — Oh non, pas encore tes dirigeables ! s’exaspéra Maura. — Vous saviez que les nouveaux dirigeables à panneaux solaires émettaient seulement l’équivalent d’1% des émissions CO2 d’un avion pour du fret- — Théo, reste concentré sur le potager ! lui intima Maura. — Vous ferez moins les malins quand j’aurai un poste d’ingénieur dans une des usines d’assemblage ! — Les usines fluviales ? demanda le jardinier intrigué. »
extrait de Mission dirigeable ! récit complet sous licence CC-BY-SA à paraître mardi prochain sur le Framablog
3. Des enfants de 2042 visitent l’exposition « Compiègne avant la sobriété »…
Louka s’était rapproché d’une ancienne carte de la région, il était surpris car il voyait de longs chemins de couleur sombre qui serpentaient de ville en ville. « C’est quoi Papa ? c’est tout gris, dit l’enfant en pointant du doigt ces longs tracés. – Ça tu vois, c’est une autoroute. Et là ce sont des routes nationales, ici les routes départementales et là les rues de la ville, expliquait Thomas. Thomas poursuivit, décrivant à ces enfants ces voies de transports qu’ils n’avaient pas connues. – À cette époque, nous utilisions des voitures pour nous déplacer. Une voiture c’était 4 sièges plus ou moins mis dans une boite. Puis on mettait cette boite sur quatre roues, on lui ajoutait un moteur avec de l’essence, et ça roulait… Thomas continua en précisant que chaque voiture avait un « propriétaire » et de ce fait, on en faisait un usage individuel la plupart du temps. Il montra une photo où figurait une file de véhicules anciens. – Mais, elle étaient énormes ces voitures ! Pourquoi elles étaient si grosses si on était seul dedans ? … ça sert à rien ! s’étonna Louka. Face à la surprise de son fils, Thomas soupira. Il lui revint en mémoire les heures de bouchon pour aller travailler dans un bureau d’une compagnie d’assurance située à 25 km de chez lui.
extrait de Compiègne avant les années sobres, récit complet sous licence CC-BY-SA à paraître mercredi prochain sur le Framablog
4. Quand on veut profiter de la cantine communautaire de l’UPLOAD, on participe d’abord…
C’était le Corridor, le lieu de livraison de la nourriture. Didier sortit de son gros sac à dos des courgettes, des pommes et des poires. Une étudiante les lui prit, le remercia, et alla les donner en cuisine. Daniel fut surpris qu’elle ne donne pas de l’argent à son ami en échange. « Allons manger maintenant ! s’exclama Didier. – Attends… mais on est pas étudiants, on a pas le droit. Et pourquoi elle ne t’a pas payé ? – Le principe du ReR, la cantine « Rires et Ratatouille », repose sur la collaboration de chacun à son bon fonctionnement. Pour y avoir accès, les élèves suivent des cours et des activités en rapport avec l’agriculture, et les personnes extérieures peuvent y manger si elles apportent de la nourriture ou aident en cuisine. On a apporté des fruits et des légumes, on peut maintenant manger sans payer. Allez, à table ! »
extrait de Jardins de demain, jardins malins, récit complet sous licence CC-BY-SA à paraître jeudi prochain sur le Framablog
5. Dans le bâtiment d’accès sécurisé où ils viennent de travailler toute l’après-midi, un groupe d’étudiant⋅es cherche à quitter les lieux…
Quelques heures passent encore, sans plus aucune interruption. Une fois leur première série d’expériences terminée, tous se dirigent vers la porte. Dylan pose son index sur le lecteur d’empreintes mais celui-ci s’allume en rouge. La sortie lui est refusée. – Et merde, on est bloqués, la porte ne s’ouvre pas ! – Arrête de faire une blague c’est pas drôle, répond Adrien. Les autres essaient à leur tour, en vain. C’est Noah qui comprend tout à coup : – Ah oui ! Ça doit être parce qu’il est plus de 14h. – Comment ça ? chuchote Candice d’une voix blanche. – Vous ne vous souvenez pas de l’annonce des opérateurs de télécom ? Ils avaient décrété que les réseaux de l’Oise allaient devenir intermittents. Internet n’est actif qu’entre 11h et 14h puis entre 22h et 6h. Ça ne vous dit vraiment rien ?
extrait de Un réseau d’émotions, récit complet sous licence CC-BY-SA à paraître vendredi prochain sur le Framablog
Rollot par Bycro- Travail personnel, CC BY-SA 4.0
6. Est-ce que cet éleveur qui veut rénover son exploitation va pouvoir trouver des compétences à l’UPLOAD ?
— je suis dans l’élevage bovin et la production de lait. Mais ça devient dur et j’aimerais bien transformer une partie de mon vieux corps de ferme en un endroit sympa où les gens pourront acheter du fromage, du lait frais, du maroilles ou d’la tome au cidre. En plus de tout cas, j’prévois aussi d’avoir un coin pour avoir du stock… Tout ça, pour mettre en place du circuit court. Ça m’permettrait aussi de vendre les rollots que j’fais à plus juste prix. — Ça me semble de très bonnes idées ! Je suis la responsable projet de l’UPLOAD, et nous recherchons des propositions des collaborations entre nos élèves en dernière année et les habitants de l’agglomération. Avez-vous… Joël, d’une voix franche quelque peu irritée, coupe la parole à son interlocutrice. — Je te coupe tout de suite m’dame, j’pense pas que ce genre de projet puisse être confié à des gamins étudiants. Faut des têtes bien pleines, des gens qui savent faire des calculs de structure, thermique et autres. J’ai pas envie que mon bâtiment tombe sur la tête des clients ou que mes fromages tournent.
extrait de Réno pour les rollots, récit complet sous licence CC-BY-SA à paraître vendredi prochain sur le Framablog
7. Pour rénover les dortoirs délabrés de l’UPLOAD, on choisit lowtech ou hightech ?
Apu, animé par la conviction que des solutions simples pouvaient avoir un impact majeur, commença à partager son histoire.
« Stella, tu sais, à Mumbai, j’ai vu comment des matériaux locaux simples peuvent faire une différence dans la vie quotidienne. Les briques en terre crue, par exemple, sont abondantes et peuvent être produites localement, réduisant ainsi notre empreinte carbone. » Stella, initialement sceptique, écouta attentivement les explications d’Apu tout en esquissant quelques notes sur son propre cahier. « Les briques en terre crue peuvent être une alternative aux matériaux de construction conventionnels, » suggéra Apu, esquissant un plan sur son cahier. « Elles peuvent être produites localement, réduisant ainsi notre empreinte carbone. » Stella répondit: « C’est intéressant, Apu, mais il faut voir au-delà de la simplicité. Moi je verrais bien des panneaux solaire, des éoliennes qui se fondent dans l’architecture, et l’utilisation de l’énergie hydraulique par exemple avec un barrage.
extrait de Renaissance urbaine, récit complet sous licence CC-BY-SA à paraître samedi prochain sur le Framablog
Pourquoi se syndiquer dans l’informatique ?
On le sait, le syndicalisme ne se porte pas formidablement bien dans notre pays. Et dans certains métiers, il ne va pas forcément de soi. C’est pourquoi l’article de Cécile et Thomas, publié initialement sur 24joursdeweb nous a semblé essentiel, et nous sommes ravi⋅es de le partager ici.
Quand on parle de syndicalisme, on a souvent l’image de « Jojo-le-syndiqué-de-la-cégété », qui brûle des pneus devant l’usine en mangeant des merguez en manif. Ou encore de la mafia qui ne travaille que pour ses propres intérêts particuliers.
Dans l’informatique, milieu de cadres, le syndicalisme est tantôt mal vu, tantôt inexistant, souvent considéré comme inutile. Après tout, nous sommes des privilégié·es !
Pourtant quelques bribes commencent à émerger dans notre secteur. Il y a eu le mouvement, plutôt associatif, « On est la tech » d’informaticien·nes, qui se sont mobilisé·es lors des premières manifestations contre le système de la retraite à points.
Dans le milieu du développement de jeux vidéo, bon nombre de syndicats ont agi contre les violences sexistes et sexuelles (on peut penser aux — trop nombreux — scandales chez Ubisoft et Quantic Dream).
Alors pourquoi des gens se syndiquent dans l’informatique ?
Être majoritairement cadres et avoir un salaire à plus de 40 K ne fait pas de nous des patrons. On reste des employé·es qui doivent arriver à l’heure au bureau et qui subissent de gros coups de pression dans les moments de rush.
D’un point de vue marxiste, nous sommes et nous restons du côté des « exploités » et pas des « propriétaires » ! (On vous rassure, on ne va pas vous faire un cours sur le marxisme… quoique !).
Vous allez me dire qu’il y a pire comme exploitation. Et vous avez raison… jusqu’à un certain point (!).
D’abord sur le côté temporaire. S’il est vrai qu’actuellement la conjoncture est plutôt bonne dans notre industrie, nous ne sommes pas à l’abri d’un retournement économique, qui est d’ailleurs dans l’actualité. Celleux qui ont vécu la crise des années 2000 de l’informatique peuvent en témoigner.
Par ailleurs, l’informatique est un métier où l’on vieillit avec ses technologies et ses modes : que vaudra votre expertise Node.js, votre certification Scrum Master ou votre expertise Window Server 2023 dans vingt ans ? Dans quarante ans ?
Parce que oui, au cas où vous ne l’auriez pas vu, vous risquez fortement de bosser jusqu’à soixante-sept ans ! Tout le monde n’aura pas la chance d’être un papy Cobol !
À quoi servent les syndicats ?
L’idée d’un syndicat est de regrouper des personnes qui partagent le même intérêt.
On trouve comme cela des syndicats de patron·es (MEDEF, CGPME…) et des syndicats de travailleuses et travailleurs. (Pour les plus connues : CGT, CFDT, SUD/Solidaires, FO…)
Les « intérêts » des salarié·es sont souvent les mêmes un peu partout et depuis toujours ; ça peut se résumer à : gagner plein d’argent, avoir une bonne ambiance au boulot (de préférence, sans harcèlement) et beaucoup de temps libre !
Les syndicats sont donc des personnes qui cherchent à se battre pour cela. Ils vont avoir quatre outils pour le faire :
les instances de négociation dans l’entreprise (on reviendra plus bas sur le CSE);
la loi ;
les pressions diverses ;
la grève.
Le comité social et économique (CSE) et les délégués syndicaux
Dans les entreprises de plus de onze salarié·es, il doit y avoir un CSE. Un lieu où les représentant·es des salarié·es, qui sont élue·es par les salarié·es, discutent avec la direction (qui elle n’est pas élue, mais qui a eu la bonne idée d’être riche au bon moment !) de sujets variés. Toutes les questions peuvent être posées à la direction, qui a pour obligation d’y répondre… avec plus ou moins de bonne foi !
Chaque syndicat ou liste qui a reçu plus de 10 % des voix aux élections va avoir des délégué·es syndicaux (DS). Ces fameux DS vont signer (ou ne pas signer) des accords d’entreprise avec la direction de l’entreprise.
Typiquement, il y a sûrement un accord d’entreprise sur le télétravail, sur l’accueil spécifique des personnes en situation de handicap ou sur les congés menstruels/hormonaux… Grâce à notre bon président (humour noir), les accords d’entreprise peuvent être moins bons que ce que propose le code du travail.
Les délégués syndicaux sont aussi ceux qui négocient les augmentations en fin d’année.
Enfin, c’est le CSE qui gère les activités sociales et culturelles (ASC), c’est-à-dire l’argent qui est donné pour les salarié·es pour les œuvres socioculturelles (les places de ciné, les réductions pour la salle de sport, la colonie de vacances de l’entreprise…).
Warning : dans notre milieu de cadres, il n’est pas rare de trouver des syndicats « jaunes », c’est à dire des syndicats pro-direction qui sont prêts a signer les pires accords d’entreprise pour les salarié·es en échange d’avancement de carrière ou de planques diverses dans la boîte…
Autre point, le CSE a aussi la responsabilité de veiller à la sécurité physique et psychologique des salarié·es. Cela se fait dans le sous-groupe du CSE appelé CSSCT : commission santé, sécurité et conditions de travail.
Bon, habituellement, les métiers de l’informatique ne présentent que peu de risques physiques, si ce n’est des problèmes de dos et aux yeux à rester trop longtemps devant un écran. Cela reste très soft par rapport à des gens travaillant dans d’autres secteurs, comme en usine ou dans le bâtiment.
En revanche, pour les questions psychologiques, c’est autre chose. Les syndicats ont un vrai rôle pour faire remonter les questions de harcèlement, de stress divers et de burnout. Même si la loi n’est pas très précise ni claire sur ces questions, faire remonter que le petit chef X est un harceleur ou qu’il y a eu quatre burnouts dans le service de M. Bidule auprès du PDG de la boîte fait toujours son petit effet.
La loi
Salarié·es comme RH ne connaissent pas toujours le droit du travail ni la loi. Le rôle des syndicats dans l’entreprise est là pour rappeler le droit du travail aux salarié·es, mais aussi à la direction quand elle se trompe ou oublie d’appliquer la loi (oups !). Et le droit du travail en France est assez lourd, mouvant et complexe.
D’ailleurs, il y a aussi une certaine superposition du droit qu’il faut avoir en tête : le Bureau International du Travail (BIT), les directives européennes, la loi française, le droit du travail, les conventions de branche et les accords d’entreprise.
Pour nous, cadres de l’informatique, on dépend très souvent de l’accord de branche qui regroupe les bureaux d’études techniques, les cabinets d’ingénieurs-conseils et les sociétés de conseils. L’accord s’appelle « SYNTEC » et a été mis à jour en mai dernier.
Connaître tout le droit est quasiment impossible. C’est pour cela que les élu·es au CSE ont des jours de délégation pour se former aux bases du droit du travail. Il y a aussi toutes les connaissances légales que les syndiqué·es apprennent et comprennent en discutant avec d’autres syndiqué·es.
Mais le gros du travail est souvent assuré par un avocat spécialiste en droit du travail. En effet toutes les centrales syndicales ont des partenariats avec des avocats qu’ils peuvent mobiliser quand ils ont des demandes juridiques.
D’ailleurs saviez-vous que le statut de cadre (convention SYNTEC) oblige l’employeur à payer le train en première classe lors des voyages professionnels ?
Les pressions diverses
La loi, c’est bien, mais ça ne fait pas tout. Et surtout les procédures légales sont parfois longues, pour à la fin ne pas obtenir grand chose.
On aimerait vivre dans monde de bisounours où en demandant gentiment à la direction, elle nous donnerait des augmentations, des primes de télétravail et des jours de congés payés pour les enfants malades. Dans la réalité, il faut parfois savoir montrer les dents pour négocier.
Soyons francs, il y a des moments où mettre un petit coup de pression à la direction est bien plus efficace que des années de batailles juridiques.
Pour ça, les syndicats ont deux grands types de techniques : la communication interne et la communication externe.
La communication interne
En interne, on a vu que le CSE pouvait faire passer des messages à la direction.
Ces messages et ces questions sont écrites et portées à la connaissance des salarié·es. Cela permet souvent de mettre la direction face à ses contradictions.
Madame la RH, comment expliquez vous l’augmentation des dividendes aux actionnaires de 30 % quand les salarié·es ont une augmentation de 0,5 % en moyenne ?
Mais la communication interne, c’est aussi des mails possibles aux salarié·es : dans une grosse boîte de jeux vidéos très connue, il était de notoriété publique que certains services et certains managers pratiquaient du harcèlement sexuel. Problème : aucune femme ne voulait porter plainte.
Il a suffi d’un mail à l’ensemble de la boîte (plusieurs milliers de personnes) appelant à dénoncer les violences sexistes et sexuelles qu’elles auraient subies et ce, notamment dans le service bidule de M. X ou machin de M. Z, pour que des femmes aient l’immense courage de porter plainte.
Effet corollaire, au minimum, les managers des services en question ont regardé leurs pompes pendant quelques mois après, ont raté leur augmentation et — après quelques mois — ont enfin fini par se faire virer !
La communication externe, plus compliquée mais aussi très redoutable
Aujourd’hui beaucoup de sections syndicales ont un compte X/Instagram/Mastodon ou un blog plus ou moins actif où ils dénoncent les problèmes de leur boîte. Quand sur le hashtag du nom de la boîte tu trouves diffusés au grand jour tous les problèmes de l’entreprise, tu écorches l’image de la boîte et la « marque employeur ».
Ça fait réfléchir à deux fois les directions avant de faire des saloperies…
Si on va plus loin ou que l’entreprise est connue, on peut aussi avoir des articles dans la presse spécialisée.
La grève
Le dernier outil qui reste aux syndicalistes, c’est la grève. L’arrêt de travail pur et simple. On est sur du classique et du médiatique mais ça reste un outil important pour pouvoir apporter du rapport de forces dans les négociations.
Même lorsque que c’est symbolique, la grève permet de désorganiser, fait prendre du retard sur des projets et, au final, peut faire perdre de l’argent à un actionnaire.
On ne va pas se mentir, jusqu’ici dans l’informatique en France, on n’a pas souvent eu des grèves massives qui ont eu un impact significatif sur le cours de la bourse de nos boîtes.
Mais on constate que, depuis les manifestations sur les retraites, on a des rangs qui grossissent à chaque nouvelle manifestation.
Faut-il avoir un poster de Lénine au-dessus de son lit pour être syndiqué ?
Alors oui et non. Vous le savez sans doute, certains syndicats sont plus « politiques » que d’autres. C’est-à-dire qu’ils vont s’intéresser à des sujets plus ou moins éloignés du monde du travail et de l’entreprise : les OGM, le conflit israélo-palestinien, la lutte contre l’extrême droite…
D’autres, au contraire, vont préférer se « mettre des œillères » et ne s’intéresser qu’à ce qu’il se passe dans l’open-space.
Une autre grille d’analyse est la dichotomie « syndicalisme de service » versus « syndicalisme de lutte ». Les premiers sont souvent dans le « dialogue » avec la direction, les seconds vont plus volontiers aller au conflit. Les premiers sont souvent qualifiés de « syndicalisme mou » voire de « traîtres » et les seconds sont souvent qualifiés « d’excités », de « brailleurs ».
À vous de voir ce qui vous intéresserait comme style de syndicalisme et pour cela, le meilleur moyen c’est d’aller parler avec les gens. Si les grandes organisations syndicales s’inscrivent dans ces axes (plus ou moins politique ; syndicalisme de service ou de lutte), sur le terrain, dans les entreprises, on peut avoir par les personnes des choses totalement différentes.
Oui, un militant Solidaires-Informatique peut être un vendu mou du genou et oui, il est possible qu’une section CFTC organise une grève dans une boîte en solidarité avec le peuple palestinien !
(Bon, c’est rare, mais justement, allez voir par vous-mêmes, sur le terrain, ce qu’il en est !)
Mais au final, pourquoi se syndiquer, qu’est-ce que j’y gagne ?
On peut y voir un intérêt personnel. Se syndiquer, c’est souvent profiter d’un réseau et d’un service juridique. Toutes les organisations syndicales ont des partenariats avec des avocats spécialisés en droit du travail et en cas de coup de dur, ça peut s’avérer très utile.
Se syndiquer, c’est aussi payer une cotisation : tous les mois, on alimente une grande caisse commune, qui permet de compenser les pertes de salaires pendant les grèves.
Et comme les syndicats de l’informatique ne font pas souvent grève, on a souvent des caisses bien garnies, qui permettent de donner à des associations chouettes, à des logiciels libres ou simplement d’autres syndicats qui ont des besoins plus urgents de solidarité.
Certain·es se syndiquent pour faire de la politique sur le terrain, avec des résultats directs et loin des partis politiques. Histoire d’appliquer ses idéaux sur quelque chose de visible : ses collègues de bureau.
D’autres se syndiquent par amitié, parce que c’est les copains de la machine à café, est-ce scandaleux ? D’autres aussi — souvent en fin de carrière — se syndiquent pour changer de travail : parce que les liens humains finissent par intéresser davantage que les lignes de code… À moins que ce ne soit parce que l’expertise technique qu’ils avaient en début de carrière ne vaut plus rien aujourd’hui. En se syndiquant, on trouve une place utile dans la société. On en a connu qui se syndiquent pour des raisons familiales : une tradition de CGTistes qui ont résisté pendant la Seconde Guerre mondiale et qui prennent leur carte de père en fille. Certain·es payent juste leur cotisation et ne s’engagent pas plus. D’autres sont ultra actifs sur le terrain mais refusent de payer leur carte par principe.
Bon, disons le tout net on ne fait pas du syndicalisme « pour gagner quelque chose ». C’est beaucoup d’énergie, beaucoup de temps, des risques sur sa carrière pour de maigres victoires.
Personnellement, j’ai connu quelqu’un qui s’est syndiqué parce qu’un jour je lui ai juste dit que le chef Bidule était un connard notoire. C’était le genre de petit chef qui pousse tout son service à bout en pinaillant sur des détails inutiles qui se transformaient en « manque de professionnalisme » dans ses mots. Ses équipes finissaient par bosser le soir et le week-end, le gars en question avait fini par entrer dans une sorte de dépression. Il m’a dit que mes mots l’avaient rassuré sur ses capacités et son professionnalisme. Je n’aurais jamais pensé que mes bêtes petits mots, assez banals, iraient jusqu’à ce qu’il adhère à un syndicat. Mais ça m’a rendue un peu fière.
Je crois qu’il y a parfois un côté « psychanalyste de comptoir d’entreprise » dans le syndicalisme. Et peut-être que c’est cela ma raison de me syndiquer.
Qu’importe votre motivation, qu’importe vos raisons profondes et vos besoins.
Se syndiquer, dans l’informatique ou ailleurs, c’est engager un contre-pouvoir, c’est créer de l’espoir pour soi, pour le bureau, et pour un monde meilleur.
Mais déjà les participations sont lancées sur le média social Mastodon et on a laissé libre cours à l’imagination, en voici quelques échantillons, en suivant les hashtags #UTC #solarpunk #UPLOAD :
et voici même un exemple de synopsis élaboré collectivement ce mardi après-midi par un groupe qui a choisi pour thème « Fermer la voiture à Compiègne »
Nous sommes en 2042 à Compiègne, l’UPLOAD : Université Populaire Libre Ouverte Accessible et Décentralisée permet de former des ingénieur⋅es de tout âge et accueille aussi simplement les curieux voulant s’instruire dans certains domaines.
Maura, 22 ans, fan de bricolage, se réveille en retard à cause de son réveil cassé, mais elle sait qu’elle pourra le réparer au fablab de l’UPLOAD.
À travers les cours sur les transports, les ateliers de recyclage de Grégoire, papy ronchon mais gentil de 64 ans ayant des connaissances sur le monde d’avant, ou bien le temps de partage de savoir-faire en jardinage supervisés par Émile, nous en découvrirons un peu plus sur l’UPLOAD et la vie à Compiègne depuis l’effondrement.
Nos personnages réalisent que l’anniversaire de leur ami Théo passionné par les dirigeables approche à grands pas. Ils s’embarquent alors dans un voyage nocturne à la déchetterie de la ville pour y chercher les matériaux nécessaires à la confection du cadeau d’anniversaire de Théo: un dirigeable miniature.
Au fil de leur aventure, nous découvrons que la voiture n’existe plus, les modes de transports ont évolué : entre tramway, vélo hybride, tic-tic, tyrolienne et dirigeable, ils devront choisir le moyen le plus rapide pour arriver à destination. Ils feront aussi la découverte d’un objet surprenant du passé qui pourrait changer la donne. Arriveront-ils à surmonter les différentes épreuves qui se présenteront à eux ?
à suivre …
Après les synopsis, demain et les jours suivants : lectures-arpentage, documentation associée au thème choisi, personnages, scénario avancé et rédaction collective dans ce cadre pédagogique.
Vous pouvez participer par des suggestions ou synopsis sur le média Mastodon ou sur une instance du Fediverse en utilisant les hashtags #UPLOAD #Solarpunk
Des ateliers solarpunk pour imaginer un avenir low-tech
Cette semaine, à l’Université de Technologie de Compiègne, des ateliers originaux vont mobiliser une quarantaine de participant⋅es (dont plusieurs membres de Framasoft) pour imaginer un monde low-tech en 2042 !
Dans cette université qui forme des ingénieurs existe une unité de valeur « lowtechisation et numérique » animée par Stéphane Crozat, qui par ailleurs est membre de Framasoft et l’initiateur de l’atelier pédagogique UPLOAD/solarpunk. De quoi s’agit-il exactement ?
Solarpunk ?
Dérèglement climatique, pollution, inégalités sociales, extinction des énergies fossiles… dans un monde menacé, à quoi peut ressembler une civilisation durable et comment y parvenir ? Le solarpunk est un genre de la science-fiction qui envisage des réponses à cette question dans une perspective utopique ou simplement optimiste, sans jamais être dystopique.
Voici les trois premiers articles du manifeste solarpunk :
Nous sommes solarpunk parce que l’optimisme nous a été volé et que nous cherchons à le récupérer.
Nous sommes solarpunk parce que les seules autres options sont le déni et le désespoir.
L’essence du Solarpunk est une vision de l’avenir qui incarne le meilleur de ce que l’humanité peut accomplir : un monde post-pénurie, post-hiérarchie, post-capitalisme où l’humanité se considère comme une partie de la nature et où les énergies propres remplacent les combustibles fossiles.
Si vous souhaitez en savoir plus, le manifeste est à votre disposition.
Low-tech ?
On comprend mieux pourquoi proposer d’imaginer des fictions low-techà de futurs ingénieurs, qui seront plus enclins à agir en génération frugale (suivant ce scénario pour 2050 de l’ADEME) qu’en technosolutionnistes.
Le principe de lowtechisation est résumé en une formule dans le cours de Stéphane :
Vaste programme, bigrement idéaliste, direz-vous, mais pourquoi ne pas envisager collectivement et concrètement des scénarios possibles qui répondent à ces idéaux ? Voici la proposition-cadre qui est faite aux participant⋅es (et à vous si vous souhaitez y ajouter votre contribution) :
Nous sommes en 2042. La mauvaise nouvelle c’est que l’effondrement est vécu au quotidien (pénurie, épidémies, énergie et matières premières raréfiées, réchauffement climatique…). La bonne nouvelle c’est que notre société n’investit plus majoritairement sur le techno-solutionnisme et la croissance […] mais que peuvent émerger de nouveaux projets désirables : réappropriation de savoir-faire technologiques, réaffectation des ressources, création de communs, décentralisation, autonomisation, débats publics…
Parmi ces initiatives qui émergent, il y a la création de l’UPLOAD (Université Populaire Libre Ouverte Autonome Décentralisée, à Compiègne). On imaginera et publiera des récits courts qui mettront en scène une activité pédagogique (un cours sur la post-croissance ? des ateliers d’imagination de nouveaux métiers ?), un projet low-tech (un éco-bâtiment passif à réaliser soi-même ?) ou high-tech (une IA pour parler avec des animaux ?).
Une semaine de réflexions, échanges, créations
Du lundi au vendredi un programme diversifié et appétissant est proposé sur place… il sera question bien sûr de low-tech, de décroissance, de décentralisation d’internet, de lectures partagées, de divers scénarios pour demain, souhaitables ou non, et d’élaborer par étapes et ensemble des récits grands ou petits qui seront résumés sur Mastodon et publiés une fois élaborés… ici même sur le Framablog !
À suivre : dès mardi, les groupes auront choisi un thème et le publieront sur Mastodon…
Il y a déjà des suggestions qu’on peut utiliser, dépasser ou ignorer…
Crédits de l’illustration : CC BY-NC-SA 4.0 · par Cix · Bâtir aussi, Ateliers de l’Antémonde · https://antemonde.org/ (adaptée par stph)
et vous, le clavier vous démange ?
Bien sûr, vous n’êtes pas à Compiègne, mais l’idée de proposer un avenir qui ne soit pas post-apocalyptique vous plaît… vous pouvez apporter une contribution à ce projet avec une fiction solarpunk en élaborant :
un format 500 caractères pour Mastodon avec les hashtag #solarPunk et #UPLOAD
un atelier collaboratif informel ou non au sein de votre université ou toute autre structure
…
Selon le volume des textes recueillis, ils seront publiés progressivement ici (sous licence libre CC-BY-SA bien sûr) et peut-être réunis en recueil…
À vos plumes d’oie, stylets, crayons et claviers low-tech 😉
To end the year in style !
Once again this year, we asked David Revoy to illustrate our year-end campaign. And on this last day of 2023, it’s time to give a little nod to this important work!
🦆 VS 😈: Let’s take back some ground from the tech giants!
Cliquez sur l’image pour soutenir l’ensemble des mascottes de Framasoft – Illustration CC-By David Revoy
An animated donation bar
Did you notice? The monsters started the campaign very serenely, enjoying grilled data skewers. But as you donated more and more, they became more than a little concerned…
Our cheerful mascots face off against some rather repulsive Datavöres
Each Framasoft mascot, representing one of our projects, stood up to a monstrous, unattractive GAFAM. But did you notice that our mascots were showing signs of life?
Once again, we’d like to extend our warmest thanks to David Revoy, who has been working with us since 2017 to illustrate our work and hopes with talent, heart and intelligence.
Speaking of success, last night, we’ve reached our fundraising goal to meet our 2024 budget!
We’d like to take this last day of our review to thank all those who have worked, discussed, shared, supported, encouraged, criticized… and contributed to our actions. The Internet isn’t big enough to mention all of you at least as much as you deserve, but you know who you are and from the depths of our little hearts we modestly say: thank you.
Thanks ! – Clock to visit the « Support Framasoft » website
Thanks to you, we’ll have the means to continue our work over the coming year (well, if some of you want to give us a bit more means, we won’t say no… but that’s not the point!). Above all, thanks to you, we feel supported.
We hope you have a wonderful end to the year, and we send you ou best wishes of emancipation, joy and freedom in 2024,
The members of the Framasoft association
Pour finir l’année en toute beauté !
Cette année encore, nous avons fait appel à David Revoy pour illustrer notre campagne de fin d’année. Et en ce dernier jour de 2023, c’est le moment de faire un petit clin d’œil à cet important travail !
Cliquez sur l’image pour soutenir l’ensemble des mascottes de Framasoft – Illustration CC-By David Revoy
Une barre de don animée
L’aviez-vous remarqué ? Les monstres ont commencé très sereinement la campagne en dégustant des brochettes de données grillées. Mais, au fur et à mesure de vos dons, ils se sont plus qu’inquiétés de la situation…
Nos joyeuses mascottes face à des Datavöres plutôt repoussants
Chaque mascotte de Framasoft, représentant un de nos projets, a pris tête face à un monstrueux GAFAM peu attirant. Mais avez-vous remarqué que nos mascottes montraient signes de vie ?
Après 7 semaines à vous présenter nos projets via nos mascottes, nous vous proposons de les retrouver sous forme de fonds d’écran, disponibles en trois formats : paysage HD, paysage 4K, et portrait (mobile).
Une fois encore, nous tenons à remercier chaleureusement David Revoy, qui travaille avec nous depuis 2017 pour illustrer avec talent, cœur et intelligence notre travail et nos espoirs.
En parlant de succès, hier soir, nous avons atteint l’objectif de récolte de cette campagne qui nous permettra de boucler le budget 2024 !
Nous profitons de ce dernier jour de bilan pour remercier toutes les personnes qui ont travaillé, discuté, partagé, soutenu, encouragé, critiqué… et contribué à nos actions. Internet n’est pas assez grand pour vous citer toustes au moins autant que vous le méritez, mais vous savez qui vous êtes et du plus profond de nos petits cœurs on vous dit pudiquement : merci.
Merci ! – Cliquez aller voir le site « Soutenir Framasoft »
Grâce à vous, nous aurons les moyens de poursuivre notre travail l’année à venir (bon alors si certain·es d’entre vous veulent nous attribuer un peu plus de moyens, on ne dit pas non, hein… mais là n’est pas le propos !). Et surtout, grâce à vous, nous nous sentons soutenues.
Nous espérons que vous vivrez une très belle fin d’année, et nous vous souhaitons tous nos vœux d’émancipation, de joie et de libertés pour 2024,
Les membres de l’association Framasoft
Give the gift of free software with Framalibre !
There was one more present left at the foot of the Christmas tree… The French free software directory and founding project of Framasoft is evolving once again, into a site that’s nicer, simpler, more ergonomic… and a lot more practical for recommending your favourite free software!
🦆 VS 😈: Let’s take back some ground from the tech giants!
There was one more present left at the foot of the Christmas tree… The free software directory and founding project of Framasoft is evolving once again, into a site that’s nicer, simpler, more ergonomic… and a lot more practical for recommending your favourite free software!
So, for people who were used to the previous version of Framalibre, we warn you: it’s going to leave a gap… You have every right to exclaim “but where’s all my junk?” … But for many newcomers to the world of free software, that was the problem!
Maiwann has done a lot of usability testing for us, especially at conferences and at the stands where we meet. These tests helped her to realise, for example, that putting a simple ‘mail’ label on the home page wasn’t helping people who were ‘looking for an alternative to Gmail’.
So for this new version, we’ve made a radical choice: simplicity. So we’ve gone to great lengths to simplify menus, sub-menus, drop-down menus, labels, boxes, notes, buttons, and so on.
This radical choice for simplicity came at a price: we had to refocus the Framalibre directory on digital tools. The previous version wanted to open up to free culture, objects and structures. But the problem with doing a bit of everything is that it’s hard to do everything well: presenting all open source resources meant multiplying menus and categories, while increasing the complexity of creating a listing.
The new Framalibre site is deliberately bare bones. It welcomes you with a page displaying tags (the most frequently used search terms) and a search bar. Goodbye the meta-categories, categories, sub-categories and sub-category filters… In short, the tree structure inherited from the 2001 directory!
Our aim is to respond as quickly as possible to your need to find free software to do what you need to do, or to find an alternative to the service provided by the web giants that you want to free yourself from: you search, you find.
Results for Photoshop search on Framalibre 2024
📃 Under the hood, the pages 📃
Click on GNU and Tux to support Framalibre! – illustration David Revoy – License : CC-By 4.0
For the more technical among you (the rest of you can skip straight to the next part ^^), this simplicity can also be found under the hood.
Framalibre 2017’s Drupal 7 needed a good upgrade, which takes time and energy. The entries database was difficult to access: while we’d done a good job of tinkering with something so that it could be used by others, we would have had to spend more time and energy developing a practical, documented API…
Instead, we decided to devote this energy to applying this choice of simplicity to the software itself, by making the new Framalibre a static site, which we hope will be lighter and faster. The code for this tool, based on Jekyll software, was developed by the talents of l’Échappée Belle (thanks to Fanny and David <3), and of course it’s free and available online.
This choice of static allowed us to modify the structure of the entries and the database. Now written in markdown, these records can be read by both humans and scripts (as long as your robots remain well-behaved, of course :p). As the Framalibre records are CC-By SA, we hope that making them more accessible and readable will lead to some interesting re-uses!
We’ve also taken the opportunity to simplify the manuals as much as possible: you won’t find any screenshots of the software, for example. After a few years, these images are often outdated and misleading. From now on, the information presented in a manual will be simple and concise, and if you like this first look at a particular free software product, we invite you to find out more on the official website.
Entry for Krita on Framalibre 2024
🎁 “Here, this is what I use to free myself…” 🎁.
Click to support us and help to push back MS Blue Scream – Illustration CC-By David Revoy
Because our goal is not for you to stay on Framalibre as long as possible (yes, in the game of attention economy, Framasoft is frankly – and deliberately – bad 😉 ). On the contrary, Framalibre aims to be a mediator, a ramp to take you to the official site of the free tool that meets your needs.
In addition to being a search tool, we have designed this new Framalibre as a tool for recommending free and ethical alternatives. Whether it’s during the preliminary surveys and tests for this redesign of Framalibre, during the regular meetings we attend, or even when we look at how we operate ourselves… we observe the same constant:
It’s much easier to adopt a free tool when it comes highly recommended by people we trust.
This is how we came up with the idea of adding a “used by Framasoft members” box at the top of certain search pages. This doesn’t mean that other software isn’t as good, or that it won’t meet your specific needs: it just shows the free software and services that we use regularly.
[capture mini-site]
💝 Framalibre mini-sites: offer your choices! 💝
With this new version of Framalibre, we wanted to go even further to encourage peer-to-peer recommendations. We know from experience that a person who uses free software today is a person who will help those around him or her to liberate their digital use tomorrow.
On the new Framalibre, you can make your own selection of free tools and get a link to a page that you can share with your friends and family!
Just for fun, here are a few examples we’ve put together for you:
We look forward to hearing your choice of free tools!
GNU and Tux against MB Blue Scream – Illustration David Revoy – License : CC-By 4.0
🤝 Collaboration is about sharing! 🤝
Of course, Framalibre is and will remain a collaborative directory. Whether you want to add a record to the directory or correct an existing record, contributions are just a click away!
What’s more, we’ve made the whole process a lot easier (you can see there’s a theme here!). The downside is that your submissions will be reviewed by our team of moderators before they are published (rather than being moderated after submission, as was previously the case).
The upside is that there are already almost 1,019 entries to discover, like so many of the solutions that open source communities offer each of us to make our digital practices better.
And if you can’t find the entry for that great free software or application that freed you from the web giants… feel free to add it: you’ll see, it’s (unsurprisingly) easy!
So now it’s up to you!
It’s up to you to use Framalibre to find, share and, above all, recommend the free tools that make your digital life easier… and life in general!
Because, yes, at the end of the year, we need you, your support and your sharing to help us regain ground on the toxic GAFAM web and create more ethical digital spaces.
So we’ve asked David Revoy to help us present this on our ‘Support Framasoft’ page, which we invite you to visit (because it’s beautiful) and above all to share as widely as possible:
If we are to balance our budget for 2024, we have just 5 days left to raise € 71 398 : we can’t do it without your help !

















![[Marie] Comment la ville a-t-elle pu autant changer depuis la dernière fois où elle s’y est aventurée ? Les voitures à chaque coin de rue ont disparu, les arbres ont poussé pour agrémenter les chaussées qui ont été réhabilitées pour les piétons. Et cette école autrefois si différente qui aujourd’hui ne semble faire qu’une avec la nature. Qui aurait pu penser que ces murs en béton allaient un jour disparaître au profit de jardins ?](https://framablog.org/wp-content/uploads/2024/01/jardins.png)