Le « gouvernement ouvert » à la française : un leurre ?
Alors que la France s’apprête à accueillir le Sommet mondial du Partenariat pour un Gouvernement Ouvert, plusieurs associations pointent les contradictions du gouvernement. Certaines ne s’y rendront pas.
Bilan du gouvernement ouvert à la française (9 pages), co-signé par les associations et collectifs suivants : April, BLOOM, DemocracyOS France, Fais ta loi, Framasoft, La Quadrature du Net, Ligue des Droits de l’Homme, Regards Citoyens, République citoyenne, SavoirsCom1.
Derrière un apparent « dialogue avec la société civile », la France est loin d’être une démocratie exemplaire
Le « gouvernement ouvert » est une nouvelle manière de collaborer entre les acteurs publics et la société civile, pour trouver des solutions conjointes aux grands défis auxquels les démocraties font face : les droits humains, la préservation de l’environnement, la lutte contre la corruption, l’accès pour tous à la connaissance, etc.
Soixante-dix pays se sont engagés dans cette démarche en adhérant au Partenariat pour un Gouvernement Ouvert (PGO), qui exige de chaque État la conception et la mise en œuvre d’un Plan d’action national, en collaboration étroite avec la société civile.
En tant que « pays des droits de l’Homme », nation co-présidente et hôte du Sommet mondial du PGO, on pourrait attendre de la France qu’elle donne l’exemple en matière de gouvernement ouvert.
Hélas, à ce jour, les actes n’ont pas été à la hauteur des annonces, y compris dans les trois domaines que la France elle-même considère prioritaires (1. Climat et développement durable ; 2. Transparence, intégrité et lutte contre la corruption ; 3. Construction de biens communs numériques) et ce, malgré l’autosatisfaction affichée du gouvernement. Pire, certaines décisions et pratiques, à rebours du progrès démocratique promu par le Partenariat pour un gouvernement ouvert, font régresser la France et la conduisent sur un chemin dangereux.
Les associations signataires de ce communiqué dressent un bilan critique et demandent au gouvernement et aux parlementaires de revoir certains choix qui s’avèrent radicalement incompatibles avec l’intérêt général et l’esprit du PGO, et de mettre enfin en cohérence leurs paroles et leurs actes.
L’April est la principale association de promotion et de défense du logiciel libre dans l’espace francophone. La mobilisation de ses bénévoles et de son équipe de permanents lui permet de mener des actions nombreuses et variées en faveur des libertés informatiques.
BLOOM, Fondée en 2005 par Claire Nouvian, BLOOM est entièrement dévouée aux océans et à ceux qui en vivent. Sa mission est d’œuvrer pour le bien commun en mettant en œuvre un pacte durable entre l’homme et la mer.
DemocracyOS France est une association qui promeut l’usage d’une plateforme web open source permettant de prendre des décisions de manière transparente et collective.
Fais Ta Loi est un collectif qui a pour but d’aider les publics les plus éloignés du débat démocratique à faire entendre leur voix au Parlement.
Framasoft est un réseau dédié à la promotion du « libre » en général et du logiciel libre en particulier.
Ligue des Droits de l’Homme : agit pour la défense des droits et libertés, de toutes et de tous. Elle s’intéresse à la citoyenneté sociale et propose des mesures pour une démocratie forte et vivante, en France et en Europe.
La Quadrature du Net : La Quadrature du Net est une association de défense des droits et libertés des citoyens sur Internet.
Regards Citoyens est un collectif transpartisan né en 2009 qui promeut la transparence démocratique et l’ouverture des données publiques pour alimenter le débat politique. Il est a l’initiative d’une douzaine d’initiatives dont NosDeputés.fr et LaFabriqueDeLaLoi.fr.
République citoyenne est une association, créée en 2013, qui a pour but de stimuler l’esprit critique des citoyens sur les questions démocratiques et notamment sur le gouvernement ouvert.
SavoirsCom1 est un collectif dédié à la défense de politiques publiques en faveur des Communs de la connaissance.
Des routes et des ponts (13) – Des mécènes pour les projets open source
Chaque semaine, l’équipe Framalang vous propose la traduction d’un chapitre de Roads and Bridges de Nadia Eghbal, une enquête fouillée qui explore les problématiques des infrastructures numériques, et en particulier leur intrication avec l’écosystème open source.
Après avoir exploré dans le précédent chapitre différents types de modèles économiques adaptés aux projets open source (retrouvez ici tous les chapitres antérieurs), l’auteure examine ici les cas de projets s’appuyant sur les dons ou le mécénat : du financement participatif au soutien institutionnalisé d’une entreprise, elle analyse les avantages et les limites de chaque solution, et livre les témoignages de nombreux porteurs de projets ou contributeurs qui relatent leur expérience au cœur de projets aussi divers qu’OpenSSL, jQuery ou encore Node.js.
La deuxième option pour financer des projets d’infrastructure numérique consiste à trouver des mécènes ou des donateurs. Il s’agit d’une pratique courante dans les cas de figure suivants :
Il n’existe pas de demande client facturable pour les services proposés par le projet.
Rendre l’accès payant empêcherait l’adoption (on ne pourrait pas, par exemple, faire payer l’utilisation d’un langage de programmation comme Python, car personne ne l’utiliserait ; ce serait comme si parler anglais étant payant).
Le projet n’a pas les moyens de financer des emplois rémunérés, ou bien il n’y a pas de volonté de la part du développeur de s’occuper des questions commerciales.
La neutralité et le refus de la commercialisation sont considérés comme des principes importants en termes de gouvernance.
Dans ce type de situation, un porteur de projet cherchera des mécènes qui croient en la valeur de son travail et qui sont disposés à le soutenir financièrement. À l’heure actuelle, il existe deux sources principales de financement : les entreprises de logiciel et les autres développeurs.
Le financement participatif
Certains travaux de développement obtiennent des fonds grâce à des campagnes de financement participatif (« crowdfunding ») via des plateformes telles que Kickstarter ou Indiegogo. Bountysource, le site de récompenses dont nous parlions dans un chapitre précédent, possède également une plateforme appelée Salt dédiée au financement participatif de projets open source.
Andrew Godwin, un développeur du noyau Django résidant à Londres, a ainsi réussi à récolter sur Kickstarter 17952£ (environ 21000€) de la part de 507 contributeurs, afin de financer des travaux de base de données pour Django. Le projet a été entièrement financé en moins de quatre heures.
Pour expliquer sa décision de lever des fonds pour un projet open source, Godwin écrit :
« Une quantité importante de code open source est écrit gratuitement. Cependant, mon temps libre est limité. Je dispose actuellement d’une seule journée libre par semaine pour travailler, et j’adorerais la consacrer à l’amélioration de Django, plutôt qu’à du conseil ou à de la sous-traitance.
L’objectif est double : d’une part, garantir au projet un temps de travail conséquent et au moins 80 heures environ de temps de codage ; et d’autre part prouver au monde que les logiciels open source peuvent réellement rémunérer le temps de travail des développeurs. »
À l’instar des récompenses, le financement participatif s’avère utile pour financer de nouvelles fonctionnalités, ou des développements aboutissant à un résultat clair et tangible. Par ailleurs, le financement participatif a moins d’effets pervers que les récompenses, notamment parce qu’organiser une campagne de financement demande plus d’efforts que de poster une offre de récompense, et parce que le succès du financement repose en grande partie sur la confiance qu’a le public dans la capacité du porteur de projet à réaliser le travail annoncé. Dans le cas de Godwin, il était l’un des principaux contributeurs au projet Django depuis six ans et était largement reconnu dans la communauté.
Toutefois, le financement participatif ne répond pas à la nécessité de financer les frais de fonctionnement et les frais généraux. Ce n’est pas une source de capital régulière. En outre, planifier et mettre en œuvre une campagne de financement participatif demande à chaque fois un investissement important en temps et en énergie. Enfin, les donateurs pour ces projets sont souvent eux-mêmes des développeurs ou des petites entreprises – et un porteur de projet ne peut pas éternellement aller toquer à la même porte pour financer ses projets.
Avec le recul, Godwin a commenté sa propre expérience :
« Je ne suis pas sûr que le financement participatif soit totalement compatible avec le développement open source en général ; non seulement c’est un apport ponctuel, mais en plus l’idée de rétribution est souvent inadéquate car elle nécessite de promettre quelque chose que l’on puisse garantir et décrire a priori.
S’en remettre uniquement à la bonne volonté du public, cela ne fonctionnera pas. On risque de finir par s’appuyer de manière disproportionnée sur des développeurs, indépendants ou non, à un niveau personnel – et je ne pense pas que ce soit viable. »
À côté des campagnes de financement participatif, plusieurs plateformes ont émergé pour encourager la pratique du « pourboire » (tipping en anglais) pour les contributeurs open source : cela consiste à verser une petite somme de revenu régulier à un contributeur, en signe de soutien à son travail. Deux plateformes populaires se distinguent : Patreon (qui ne se limite pas exclusivement aux contributeurs open source) et Gratipay (qui tend à fédérer une communauté plus technique).
L’idée d’un revenu régulier est alléchante, mais souffre de certains problèmes communs avec le financement participatif. On remarque notamment que les parrains (patrons ou tippers en anglais) sont souvent eux-mêmes des développeurs, avec une quantité limitée de capital à se promettre les uns aux autres. Les dons ont généralement la réputation de pouvoir financer une bière, mais pas un loyer. Gratipay rassemble 122 équipes sur sa plateforme, qui reçoivent collectivement 1000 $ par semaine, ce qui signifie qu’un projet touche en moyenne moins de 40$ par mois.
Même les très gros projets tels que OpenSSL ne généraient que 2000$ de dons annuels avant la faille Heartbleed. Comme expliqué précédemment, après Heartbleed, Steve Marquess, membre de l’équipe, a remarqué « un déferlement de soutien de la part de la base de la communauté OpenSSL » : la première vague de dons a rassemblé environ 200 donateurs pour un total de 9000$.
Marquess a remercié la communauté pour son soutien mais a également ajouté :
« Même si ces donations continuent à arriver au même rythme indéfiniment (ce ne sera pas le cas), et même si chaque centime de ces dons allait directement aux membres de l’équipe OpenSSL, nous serions encore loin de ce qu’il faudrait pour financer correctement le niveau de main-d’œuvre humaine nécessaire à la maintenance d’un projet aussi complexe et aussi crucial. Même s’il est vrai que le projet « appartient au peuple », il ne serait ni réaliste ni correct d’attendre de quelques centaines, ou même de quelques milliers d’individus seulement, qu’ils le financent à eux seuls. Ceux qui devraient apporter les vraies ressources, ce sont les entreprises lucratives et les gouvernements qui utilisent OpenSSL massivement et qui le considèrent comme un acquis. »
(À l’appui de l’argument de Marquess, les dons de la part des entreprises furent par la suite plus importants, les sociétés ayant davantage à donner que les particuliers. La plus grosse donation provint d’un fabricant de téléphone chinois, Smartisan, pour un montant de 160000$. Depuis, Smartisan a continué de faire des dons substantiels au projet OpenSSL.)
Au bout du compte, la réalité est la suivante : il y a trop de projets, tous qualitatifs ou cruciaux à leur manière, et pas assez de donateurs, pour que la communauté technique (entreprises ou individus) soit en mesure de prêter attention et de contribuer significativement à chacun d’eux.
Le mécénat d’entreprises pour les projets d’infrastructure
À plus grande échelle, dans certains cas, la valeur d’un projet devient si largement reconnue qu’une entreprise finit par recruter un contributeur pour travailler à plein temps à son développement.
John Resig est l’auteur de jQuery, une bibliothèque de programmation JavaScript qui est utilisée par près des 2/3 du million de sites web les plus visités au monde. John Resig a développé et publié jQuery en 2006, sous la forme d’un projet personnel. Il a rejoint Mozilla en 2007 en tant que développeur évangéliste, se spécialisant notamment dans les bibliothèques JavaScript.
La popularité de jQuery allant croissante, il est devenu clair qu’en plus des aspects liés au développement technique, il allait falloir formaliser certains aspects liés à la gouvernance du projet. Mozilla a alors proposé à John de travailler à plein temps sur jQuery entre 2009 et 2011, ce qu’il a fait.
À propos de cette expérience, John Resig a écrit :
« Pendant l’année et demi qui vient de s’écouler, Mozilla m’a permis de travailler à plein temps sur jQuery. Cela a abouti à la publication de 9 versions de jQuery… et à une amélioration drastique de l’organisation du projet (nous appartenons désormais à l’organisation à but non lucratif Software Freedom Conservancy, nous avons des réunions d’équipe régulières, des votes publics, fournissons des états des lieux publics et encourageons activement la participation au projet). Heureusement, le projet jQuery se poursuit sans encombre à l’heure actuelle, ce qui me permet de réduire mon implication à un niveau plus raisonnable et de participer à d’autres travaux de développement. »
Après avoir passé du temps chez Mozilla pour donner à jQuery le support organisationnel dont il avait besoin, John a annoncé qu’il rejoindrait la Khan Academy afin de se concentrer sur de nouveaux projets.
Cory Benfield, développeur Python, a suivi un chemin similaire. Après avoir contribué à plusieurs projets open source sur son temps libre, il est devenu un développeur-clé pour une bibliothèque essentielle de Python intitulée Requests. Cory Benfield note que :
« Cette bibliothèque a une importance comparable à celle de Django, dans la mesure où les deux sont des « infrastructures critiques » pour les développeurs Python. Et pourtant, avant que j’arrive sur le projet, elle était essentiellement maintenue par une seule personne. »
Benfield estime qu’il a travaillé bénévolement sur le projet environ 12 heures par semaine pendant presque quatre ans, en plus de son travail à plein temps. Personne n’était payé pour travailler sur Requests.
Pendant ce temps, HP embauchait un employé, Donald Stufft, pour se consacrer spécifiquement aux projets en rapport avec Python, un langage qu’il considère comme indispensable à ses logiciels. (Donald est le développeur cité précédemment qui est payé à plein temps pour travailler sur le packaging Python). Donald a alors convaincu son supérieur d’embaucher Cory pour qu’il travaille à temps plein sur des projets Python. Il y travaille toujours.
Les entreprises sont des acteurs tout désignés pour soutenir financièrement les projets bénévoles qu’elles considèrent comme indispensables à leurs activités, et quand des cas comme ceux de John Resig ou de Cory Benfield surviennent, ils sont chaleureusement accueillis. Cependant, il y a des complications.
Premièrement, aucune entreprise n’est obligée d’embaucher quelqu’un pour travailler sur des projets en demande de soutien ; ces embauches ont tendance à advenir par hasard de la part de mécènes bienveillants. Et même une fois qu’un employé est embauché, il y a toujours la possibilité de perdre ce financement, notamment parce que l’employé ne contribue pas directement au résultat net de l’entreprise. Une telle situation est particulièrement périlleuse si la viabilité d’un projet dépend entièrement d’un seul contributeur employé à plein temps. Dans le cas de Requests, Cory est le seul contributeur à plein temps (on compte deux autres contributeurs à temps partiel, Ian Cordasco et Kenneth Reitz).
Une telle situation s’est déjà produite dans le cas de « rvm », un composant critique de l’infrastructure Ruby. Michal Papis, son auteur principal, a été engagé par Engine Yard entre 2011 et 2013 pour soutenir le développement de rvm. Mais quand ce parrainage s’est terminé, Papis a dû lancer une campagne de financement participatif pour continuer de financer le développement de rvm.
Le problème, c’est que cela ne concernait pas seulement rvm. Engine Yard avait embauché plusieurs mainteneurs de projets d’infrastructure Ruby, qui travaillaient notamment sur JRuby, Ruby on Rails 3 et bundler. Quand les responsables d’Engine Yard ont été obligés de faire le choix réaliste qui s’imposait pour la viabilité de leur entreprise, c’est-à-dire réduire leur soutien financier, tous ces projets ont perdu leurs mainteneurs à temps plein, et presque tous en même temps.
L’une des autres craintes est qu’une entreprise unique finisse par avoir une influence disproportionnée sur un projet, puisqu’elle en est de facto le seul mécène. Cory Benfield note également que le contributeur ou la contributrice lui-même peut avoir une influence disproportionnée sur le projet, puisqu’il ou elle dispose de beaucoup plus de temps que les autres pour faire des contributions. De fait, une telle décision peut même être prise par une entreprise et un mainteneur, sans consulter le reste de la communauté du projet.
On peut en voir un exemple avec le cas d’Express.js, un framework important pour l’écosystème Node.js. Quand l’auteur du projet a décidé de passer à autre chose, il en a transféré les actifs (en particulier le dépôt du code source et le nom de domaine) à une société appelée StrongLoop dont les employés avaient accepté de continuer à maintenir le projet. Cependant StrongLoop n’a pas fourni le soutien qu’attendait la communauté, et comme les employés de StrongLoop étaient les seuls à avoir un accès administrateur, il est devenu difficile pour la communauté de faire des contributions. Doug Wilson, l’un des principaux mainteneurs (non-affilié à StrongLoop), disposait encore d’un accès commit et a continué de traiter la charge de travail du projet, essayant tant bien que mal de tout gérer à lui seul.
Après l’acquisition de StrongLoop par IBM, Doug déclara que StrongLoop avait bel et bien tué la communauté des contributeurs.
« Au moment où on est passé à StrongLoop, il y avait des membres actifs comme @Fishrock123 qui travaillaient à créer… de la documentation. Et puis tout à coup, je me suis retrouvé tout seul à faire ça sur mon temps libre alors que les demandes de support ne faisaient que se multiplier… et pendant tout ce temps, je me suis tué à la tâche, je me suis engagé pour le compte StrongLoop. Quoi qu’il arrive, jamais plus je ne contribuerai à aucun dépôt logiciel appartenant à StrongLoop. »
Finalement, le projet Express.js a été transféré de StrongLoop à la fondation Node.js, qui aide à piloter des projets appartenant à l’écosystème technologique Node.js.
En revanche, pour les projets open source qui ont davantage d’ampleur et de notoriété, il n’est pas rare d’embaucher des développeurs. La Fondation Linux a fait savoir, par exemple, que 80% du développement du noyau Linux est effectué par des développeurs rémunérés pour leur travail. La fondation Linux emploie également des Fellows [« compagnons » selon un titre consacré, NdT] payés pour travailler à plein temps sur les projets d’infrastructure, notamment Greg Kroah-Hartman, un développeur du noyau Linux, et Linus Torvalds lui-même, le créateur de Linux.
Pourquoi Framasoft n’ira plus prendre le thé au ministère de l’Éducation Nationale
Cet article vise à clarifier la position de Framasoft, sollicitée à plusieurs reprises par le Ministère de l’Éducation Nationale ces derniers mois. Malgré notre indignation, il ne s’agit pas de claquer la porte, mais au contraire d’en ouvrir d’autres vers des acteurs qui nous semblent plus sincères dans leur choix du libre et ne souhaitent pas se cacher derrière une « neutralité et égalité de traitement » complètement biaisée par l’entrisme de Google, Apple ou Microsoft au sein de l’institution.
Pour commencer
Une technologie n’est pas neutre, et encore moins celui ou celle qui fait des choix technologiques. Contrairement à l’affirmation de la Ministre de l’Éducation Mme Najat Vallaud-Belkacem, une institution publique ne peut pas être « neutre technologiquement », ou alors elle assume son incompétence technique (ce qui serait grave). En fait, la position de la ministre est un sophisme déjà bien ancien ; c’est celui du Gorgias de Platon qui explique que la rhétorique étant une technique, il n’y en a pas de bon ou de mauvais usage, elle ne serait qu’un moyen.
Or, lui oppose Socrate, aucune technique n’est neutre : le principe d’efficacité suppose déjà d’opérer des choix, y compris économiques, pour utiliser une technique plutôt qu’une autre ; la possession d’une technique est déjà en soi une position de pouvoir ; enfin, rappelons l’analyse qu’en faisait Jacques Ellul : la technique est un système autonome qui impose des usages à l’homme qui en retour en devient addict. Même s’il est consternant de rappeler de tels fondamentaux à ceux qui nous gouvernent, tout choix technologique suppose donc une forme d’aliénation. En matière de logiciels, censés servir de supports dans l’Éducation Nationale pour la diffusion et la production de connaissances pour les enfants, il est donc plus qu’évident que choisir un système plutôt qu’un autre relève d’une stratégie réfléchie et partisane.
Le tweet confondant neutralité logicielle et choix politique.
Un système d’exploitation n’est pas semblable à un autre, il suffit pour cela de comparer les deux ou trois principaux OS du marché (privateur) et les milliers de distributions GNU/Linux, pour comprendre de quel côté s’affichent la créativité et l’innovation. Pour les logiciels en général, le constat est le même : choisir entre des logiciels libres et des logiciels privateurs implique une position claire qui devrait être expliquée. Or, au moins depuis 1997, l’entrisme de Microsoft dans les organes de l’Éducation Nationale a abouti à des partenariats et des accords-cadres qui finirent par imposer les produits de cette firme dans les moindres recoins, comme s’il était naturel d’utiliser des solutions privatrices pour conditionner les pratiques d’enseignement, les apprentissages et in fine tous les usages numériques. Et ne parlons pas des coûts que ces marchés publics engendrent, même si les solutions retenues le sont souvent, au moins pour commencer, à « prix cassé ».
Depuis quelque temps, au moins depuis le lancement de la première vague de son projet Degooglisons Internet, Framasoft a fait un choix stratégique important : se tourner vers l’éducation populaire, avec non seulement ses principes, mais aussi ses dynamiques propres, ses structures solidaires et les valeurs qu’elle partage. Nous ne pensions pas que ce choix pouvait nous éloigner, même conceptuellement, des structures de l’Éducation Nationale pour qui, comme chacun le sait, nous avons un attachement historique. Et pourtant si… Une rétrospective succincte sur les relations entre Microsoft et l’Éducation Nationale nous a non seulement donné le tournis mais a aussi occasionné un éclair de lucidité : si, malgré treize années d’(h)activisme, l’Éducation Nationale n’a pas bougé d’un iota sa préférence pour les solutions privatrices et a même radicalisé sa position récemment en signant un énième partenariat avec Microsoft, alors nous utiliserions une partie des dons, de notre énergie et du temps bénévole et salarié en pure perte dans l’espoir qu’il y ait enfin une position officielle et des actes concrets en faveur des logiciels libres. Finalement, nous en sommes à la fois indignés et confortés dans nos choix.
Extrait de l’accord-Cadre MS-EN novembre 2015
L’Éducation Nationale et Microsoft, une (trop) longue histoire
En France, les rapports qu’entretient le secteur de l’enseignement public avec Microsoft sont assez anciens. On peut remonter à la fin des années 1990 où eurent lieu les premiers atermoiements à l’heure des choix entre des solutions toutes faites, clés en main, vendues par la société Microsoft, et des solutions de logiciels libres, nécessitant certes des efforts de développement mais offrant à n’en pas douter, des possibilités créatrices et une autonomie du service public face aux monopoles économiques. Une succession de choix délétères nous conduisent aujourd’hui à dresser un tableau bien négatif.
Dans un article paru dans Le Monde du 01/10/1997, quelques mois après la réception médiatisée de Bill Gates par René Monory, alors président du Sénat, des chercheurs de l’Inria et une professeure au CNAM dénonçaient la mainmise de Microsoft sur les solutions logicielles retenues par l’Éducation Nationale au détriment des logiciels libres censés constituer autant d’alternatives fiables au profit de l’autonomie de l’État face aux monopoles américains. Les mots ne sont pas tendres :
(…) Microsoft n’est pas la seule solution, ni la meilleure, ni la moins chère. La communauté internationale des informaticiens développe depuis longtemps des logiciels, dits libres, qui sont gratuits, de grande qualité, à la disposition de tous, et certainement beaucoup mieux adaptés aux objectifs, aux besoins et aux ressources de l’école. Ces logiciels sont largement préférés par les chercheurs, qui les utilisent couramment dans les contextes les plus divers, et jusque dans la navette spatiale. (…) On peut d’ailleurs, de façon plus générale, s’étonner de ce que l’administration, et en particulier l’Éducation Nationale, préfère acheter (et imposer à ses partenaires) des logiciels américains, plutôt que d’utiliser des logiciels d’origine largement européenne, gratuits et de meilleure qualité, qui préserveraient notre indépendance technologique.
D’autres témoignages mettent en lumière des tensions entre logiciels libres et logiciels privateurs dans les décisions d’équipement et dans les intentions stratégiques de l’Éducation Nationale au tout début des années 2000. En revanche, en décembre 2003, l’accord-cadre1 Microsoft et le Ministère de l’Éducation Nationale change radicalement la donne et propose des solutions clés en main intégrant trois aspects :
tous les établissements de l’Éducation Nationale sont concernés, des écoles primaires à l’enseignement supérieur ;
le développement des solutions porte à la fois sur les systèmes d’exploitation et la bureautique, c’est-à-dire l’essentiel des usages ;
la vente des logiciels se fait avec plus de 50% de remise, c’est-à-dire avec des prix résolument tirés vers le bas.
Depuis lors, des avenants à cet accord-cadre sont régulièrement signés. Comme si cela ne suffisait pas, certaines institutions exercent leur autonomie et établissent de leur côté des partenariats « en surplus », comme l’Université Paris Descartes le 9 juillet 2009, ou encore les Villes, comme Mulhouse qui signe un partenariat Microsoft dans le cadre de « plans numériques pour l’école », même si le budget est assez faible comparé au marché du Ministère de l’Éducation.
Il serait faux de prétendre que la société civile ne s’est pas insurgée face à ces accords et à l’entrisme de la société Microsoft dans l’enseignement. On ne compte plus les communiqués de l’April (souvent conjoints avec d’autres associations du Libre) dénonçant ces pratiques. Bien que des efforts financiers (discutables) aient été faits en faveur des logiciels libres dans l’Éducation Nationale, il n’en demeure pas moins que les pratiques d’enseignement et l’environnement logiciel des enfants et des étudiants sont soumis à la microsoftisation des esprits, voire une Gafamisation car la firme Microsoft n’est pas la seule à signer des partenariats dans ce secteur. Le problème ? Il réside surtout dans le coût cognitif des outils logiciels qui, sous couvert d’apprentissage numérique, enferme les pratiques dans des modèles privateurs : « Les enfants qui ont grandi avec Microsoft, utiliseront Microsoft ».
Et si c’était MacDonald’s qui rentrait dans les cantines scolaires…? Les habitudes malsaines peuvent se prendre dès le plus jeune âge.
On ne saurait achever ce tableau sans mentionner le plus récent partenariat Microsoft-EN signé en novembre 2015 et vécu comme une véritable trahison par, entre autres, beaucoup d’acteurs du libre. Il a en effet été signé juste après la grande consultation nationale pour le Projet de Loi Numérique porté par la ministre Axelle Lemaire. La consultation a fait ressortir un véritable plébiscite en faveur du logiciel libre dans les administrations publiques et des amendements ont été discutés dans ce sens, même si le Sénat a finalement enterré l’idée. Il n’en demeure pas moins que les défenseurs du logiciel libre ont cru déceler chez nombre d’élus une oreille attentive, surtout du point de vue de la souveraineté numérique de l’État. Pourtant, la ministre Najat Vallaud-Belkacem a finalement décidé de montrer à quel point l’Éducation Nationale ne saurait être réceptive à l’usage des logiciels libre en signant ce partenariat, qui constitue, selon l’analyse par l’April des termes de l’accord, une « mise sous tutelle de l’informatique à l’école » par Microsoft.
Entre libre-washing et méthodes douteuses
Pour être complète, l’analyse doit cependant rester honnête : il existe, dans les institutions de l’Éducation Nationale des projets de production de ressources libres. On peut citer par exemple le projet EOLE (Ensemble Ouvert Libre Évolutif), une distribution GNU/Linux basée sur Ubuntu, issue du Pôle de compétence logiciel libre, une équipe du Ministère de l’Éducation Nationale située au rectorat de l’académie de Dijon. On peut mentionner le projet Open Sankoré, un projet de développement de tableau interactif au départ destiné à la coopération auprès de la Délégation Interministérielle à l’Éducation Numérique en Afrique (DIENA), repris par la nouvelle Direction du numérique pour l’éducation (DNE) du Ministère de l’EN, créée en 2014. En ce qui concerne l’information et la formation des personnels, on peut souligner certaines initiatives locales comme le site Logiciels libres et enseignement de la DANE (Délégation Académique au Numérique Éducatif) de l’académie de Versailles. D’autres projets sont parfois maladroits comme la liste de « logiciels libres et gratuits » de l’académie de Strasbourg, qui mélange allègrement des logiciels libres et des logiciels privateurs… pourvus qu’ils soient gratuits.
Les initiatives comme celles que nous venons de recenser se comptent néanmoins sur les doigts des deux mains. En pratique, l’environnement des salles informatiques des lycées et collèges reste aux couleurs Microsoft et les tablettes (réputées inutiles) distribuées çà et là par villes et départements, sont en majorité produites par la firme à la pomme2. Les enseignants, eux, n’ayant que très rarement voix au chapitre, s’épuisent souvent à des initiatives en classe fréquemment isolées bien que créatives et efficaces. Au contraire, les inspecteurs de l’Éducation Nationale sont depuis longtemps amenés à faire la promotion des logiciels privateurs quand ils ne sont pas carrément convoqués chez Microsoft.
Convocation Inspecteurs de l’EN chez Microsoft
L’interprétation balance entre deux possibilités. Soit l’Éducation Nationale est composée exclusivement de personnels incohérents prêts à promouvoir le logiciel libre partout mais ne faisant qu’utiliser des suites Microsoft. Soit des projets libristes au sein de l’Éducation Nationale persistent à exister, composés de personnels volontaires et motivés, mais ne s’affichent que pour mieux mettre en tension les solutions libres et les solutions propriétaires. Dès lors, comme on peut s’attendre à ce que le seul projet EOLE ne puisse assurer toute une migration de tous les postes de l’EN à un système d’exploitation libre, il est logique de voir débouler Microsoft et autres sociétés affiliées présentant des solutions clés en main et économiques. Qu’a-t-on besoin désormais de conserver des développeurs dans la fonction publique puisque tout est pris en charge en externalisant les compétences et les connaissances ? Pour que cela ne se voie pas trop, on peut effectivement s’empresser de mettre en avant les quelques deniers concédés pour des solutions libres, parfois portées par des sociétés à qui on ne laisse finalement aucune chance, telle RyXéo qui proposait la suite Abulédu.
Finalement, on peut en effet se poser la question : le libre ne serait-il pas devenu un alibi, voire une caution bien mal payée et soutenue au plus juste, pour légitimer des solutions privatrices aux coûts exorbitants ? Les décideurs, DSI et autres experts, ne préfèrent-ils pas se reposer sur un contrat Microsoft plutôt que sur le management de développeurs et de projets créatifs ? Les solutions les plus chères sont surtout les plus faciles.
Plus faciles, mais aussi plus douteuses ! On pourra en effet se pencher à l’envi sur les relations discutables entre certains cadres de Microsoft France et leurs postes occupés aux plus hautes fonctions de l’État, comme le montrait le Canard Enchaîné du 30 décembre 2015. Framasoft se fait depuis longtemps l’écho des manœuvres de Microsoft sans que cela ne soulève la moindre indignation chez les décideurs successifs au Ministère3. On peut citer, pêle-mêle :
la stratégie sournoise d’introduction des produits à l’école, selon la technique « embrace and extend », ce qui flirte dangereusement avec les règlements en vigueur, à commencer par le droit des marchés publics (opposé régulièrement pour contrecarrer la préférence donnée au Libre dans les appels d’offres) ;
les frontières imprécises entre promotion marketing et innovation pédagogique, voilant à peine les intentions réelles de Microsoft…
Cette publicité est un vrai tweet Microsoft. Oui. Cliquez sur l’image pour lire l’article de l’APRIL à ce sujet.
Du temps et de l’énergie en pure perte
« Vous n’avez qu’à proposer », c’est en substance la réponse balourde par touittes interposés de Najat Vallaud-Belkacem aux libristes qui dénonçaient le récent accord-cadre signé entre Microsoft et le Ministère. Car effectivement, c’est bien la stratégie à l’œuvre : alors que le logiciel libre suppose non seulement une implication forte des décideurs publics pour en adopter les usages, son efficience repose également sur le partage et la contribution. Tant qu’on réfléchit en termes de pure consommation et de fournisseur de services, le logiciel libre n’a aucune chance. Il ne saurait être adopté par une administration qui n’est pas prête à développer elle-même (ou à faire développer) pour ses besoins des logiciels libres et pertinents, pas plus qu’à accompagner leur déploiement dans des milieux qui ne sont plus habitués qu’à des produits privateurs prêts à consommer.
Au lieu de cela, les décideurs s’efforcent d’oublier les contreparties du logiciel libre, caricaturent les désavantages organisationnels des solutions libres et légitiment la Microsoft-providence pour qui la seule contrepartie à l’usage de ses logiciels et leur « adaptation », c’est de l’argent… public. Les conséquences en termes de hausses de tarifs des mises à jour, de sécurité, de souveraineté numérique et de fiabilité, par contre, sont des sujets laissés vulgairement aux « informaticiens », réduits à un débat de spécialistes dont les décideurs ne font visiblement pas partie, à l’instar du Ministère de la défense lui aussi aux prises avec Microsoft.
Comme habituellement il manque tout de même une expertise d’ordre éthique, et pour peu que des compétences libristes soient nécessaires pour participer au libre-washing institutionnel, c’est vers les associations que certains membres de l’Éducation Nationale se tournent. Framasoft a bien souvent été démarchée soit au niveau local pour intervenir dans des écoles / collèges / lycées afin d’y sensibiliser au Libre, soit pour collaborer à des projets très pertinents, parfois même avec des possibilités de financement à la clé. Ceci depuis les débuts de l’association qui se présente elle-même comme issue du milieu éducatif.
Témoignage : usage de Framapad à l’école
Depuis plus de dix ans Framasoft intervient sur des projets concrets et montre par l’exemple que les libristes sont depuis longtemps à la fois forces de proposition et acteurs de terrain, et n’ont rien à prouver à ceux qui leur reprocheraient de se contenter de dénoncer sans agir. Depuis deux décennies des associations comme l’April ont impulsé des actions, pas seulement revendicatrices mais aussi des conseils argumentés, de même que l’AFUL (mentionnée plus haut). Las… le constat est sans appel : l’Éducation Nationale a non seulement continué à multiplier les relations contractuelles avec des firmes comme Microsoft, barrant la route aux solutions libres, mais elle a radicalisé sa position en novembre 2015 en un ultime pied de nez à ces impertinentes communautés libristes.
Nous ne serons pas revanchards, mais il faut tout de même souligner que lorsque des institutions publiques démarchent des associations composées de membres bénévoles, les tâches demandées sont littéralement considérées comme un dû, voire avec des obligations de rendement. Cette tendance à amalgamer la soi-disant gratuité du logiciel libre et la soi-disant gratuité du temps bénévole des libristes, qu’il s’agisse de développement ou d’organisation, est particulièrement détestable.
Discuter au lieu de faire
À quelles demandes avons-nous le plus souvent répondu ? Pour l’essentiel, il s’agit surtout de réunions, de demandes d’expertises dont les résultats apparaissent dans des rapports, de participation plus ou moins convaincante (quand il s’agit parfois de figurer comme caution) à des comités divers, des conférences… On peut discuter de la pertinence de certaines de ces sollicitations tant les temporalités de la réflexion et des discours n’ont jamais été en phase avec les usages et l’évolution des pratiques numériques.
Le discours de Framasoft a évolué en même temps que grandissait la déception face au décalage entre de timides engagements en faveur du logiciel libre et des faits attestant qu’à l’évidence le marché logiciel de l’Éducation Nationale était structuré au bénéfice des logiques privatrices. Nous en sommes venus à considérer que…
si, en treize ans de sensibilisation des enseignants et des décideurs, aucune décision publique n’a jamais assumé de préférence pour le logiciel libre ;
si, en treize ans, le discours institutionnel s’est même radicalisé en défaveur du Libre : en 2003, le libre n’est « pas souhaitable » ; en 2013 le libre et les formats ouverts pourraient causer des « difficultés juridiques » ; en 2016, le libre ne pourra jamais être prioritaire malgré le plébiscite populaire4…
…une association comme Framasoft ne peut raisonnablement continuer à utiliser l’argent de ses donateurs pour dépenser du temps bénévole et salarié dans des projets dont les objectifs ne correspondent pas aux siens, à savoir la promotion et la diffusion du Libre.
Par contre, faire la nique à Microsoft en proposant du Serious Gaming éducatif, ça c’est concret !
L’éducation populaire : pas de promesses, des actes
Framasoft s’est engagée depuis quelque temps déjà dans une stratégie d’éducation populaire. Elle repose sur les piliers suivants :
social : le mouvement du logiciel libre est un mouvement populaire où tout utilisateur est créateur (de code, de valeur, de connaissance…) ;
technique : par le logiciel libre et son développement communautaire, le peuple peut retrouver son autonomie numérique et retrouver savoirs et compétences qui lui permettront de s’émanciper ;
solidaire : le logiciel libre se partage, mais aussi les compétences, les connaissances et même les ressources. Le projet CHATONS démontre bien qu’il est possible de renouer avec des chaînes de confiance en mobilisant des structures au plus proche des utilisateurs, surtout si ces derniers manquent de compétences et/ou d’infrastructures.
Quelles que soient les positions institutionnelles, nous sommes persuadés qu’en collaborant avec de petites ou grandes structures de l’économie sociale et solidaire (ESS), avec le monde culturel en général, nous touchons bien plus d’individus. Cela sera également bien plus efficace qu’en participant à des projets avec le Ministère de l’Éducation Nationale, qui se révèlent n’avoir au final qu’une portée limitée. Par ailleurs, nous sommes aussi convaincus que c’est là le meilleur moyen de toucher une grande variété de publics, ceux-là mêmes qui s’indigneront des pratiques privatrices de l’Éducation Nationale.
Néanmoins, il est vraiment temps d’agir, car même le secteur de l’ESS commence à se faire « libre-washer » et noyauter par Microsoft : par exemple la SocialGoodWeek a pour partenaires MS et Facebook ; ou ADB Solidatech qui équipe des milliers d’ordinateurs pour associations avec des produits MS à prix cassés.
Page SocialGoodWeek, sponsors
Ce positionnement du « faire, faire sans eux, faire malgré eux » nous a naturellement amenés à développer notre projet Degooglisons Internet. Mais au-delà, nous préférons effectivement entrer en relation directe avec des enseignants éclairés qui, plutôt que de perdre de l’énergie à convaincre la pyramide hiérarchique kafkaïenne, s’efforcent de créer des projets concrets dans leurs (minces) espaces de libertés. Et pour cela aussi le projet Degooglisons Internet fait mouche.
Nous continuerons d’entretenir des relations de proximité et peut-être même d’établir des projets communs avec les associations qui, déjà, font un travail formidable dans le secteur de l’Éducation Nationale, y compris avec ses institutions, telles AbulEdu, Sésamath et bien d’autres. Il s’agit là de relations naturelles, logiques et même souhaitables pour l’avancement du Libre. Fermons-nous définitivement la porte à l’Éducation Nationale ? Non… nous inversons simplement les rôles.
Pour autant, il est évident que nous imposons implicitement des conditions : les instances de l’Éducation Nationale doivent considérer que le logiciel libre n’est pas un produit mais que l’adopter, en plus de garantir une souveraineté numérique, implique d’en structurer les usages, de participer à son développement et de généraliser les compétences en logiciels libres. Dans un système déjà noyauté (y compris financièrement) par les produits Microsoft, la tâche sera rude, très rude, car le coût cognitif est déjà cher payé, dissimulé derrière le paravent brumeux du droit des marchés publics (même si en la matière des procédures négociées peuvent très bien être adaptées au logiciel libre). Ce n’est pas (plus) notre rôle de redresser la barre ou de cautionner malgré nous plus d’une décennie de mauvaises décisions pernicieuses.
Si l’Éducation Nationale décide finalement et officiellement de prendre le bon chemin, avec force décrets et positions de principe, alors, ni partisans ni vindicatifs, nous l’accueillerons volontiers à nos côtés car « la route est longue, mais la voie est libre… ».
— L’association Framasoft
En revanche, si c’est juste pour prendre le thé… merci de se référer à l’erreur 418.
Certes, on pourrait aussi ajouter que, bien qu’il soit le plus familier, Microsoft n’est pas le seul acteur dans la place: Google est membre fondateur de la « Grande École du Numérique » et Apple s’incruste aussi à l’école avec ses tablettes.↩
On pourra aussi noter le rôle joué par l’AFDEL et Syntec Numérique dans cette dernière décision, mais aussi, de manière générale, par les lobbies dans les couloirs de l’Assemblée et du Sénat. Ceci n’est pas un scoop.↩
10 trucs que j’ignorais sur Internet et mon ordi (avant de m’y intéresser…)
Disclaimer : Cet article est sous licence CC-0 car les petits bouts de savoir qu’il contient sont autant d’armes d’auto-défense numérique qu’il faut diffuser. En gros, j’espère vraiment que certains d’entre vous en feront un top youtube, une buzzfeederie, une BD, un truc que j’ai même pas encore imaginé, ce que vous voulez… Mais que vous ferez passer les messages.
À noter : cet article bénéficie désormais d’une version audio.
Merci à Sualtam, auteur de lectureaudio.fr pour cette contribution active.
1) Tu ne consultes pas une page Internet, tu la copies
Toute ressemblance avec les métaphores de Terry Pratchett n’est que pure admiration de ma part ;)
Un site web, c’est pas une espèce de journal qu’on aurait mis dans le pays magique d’internet pour que ton navigateur aille le consulter comme tu consulterais le quotidien de ton jour de naissance à la médiathèque du coin.
Pour voir une page web, ton navigateur la copie sur ton ordi. Les textes, les images, les sons : tout ce que tu vois ou entends sur ton écran a été copié sur ton ordinateur (vilain pirate !)
Un ordinateur est un photocopieur dont la trieuse serait une méga fourmilière qui peut faire plein de trucs. La bonne nouvelle, c’est que copier permet de multiplier, que ça ne vole rien à personne, parce que si je te copie un fichier tu l’as toujours.
2) Mon navigateur web ne cuisine pas la même page web que le tien.
Sérieux, imagine qu’une page web, c’est une recette de cuisine :
Mettez un titre en gros, en gris et en gras.
Réduisez l’image afin qu’elle fasse un quart de la colonne d’affichage, réservez.
Placez le texte, agrémenté d’une jolie police, aligné à gauche, puis l’image à droite.
Servez chaud.
Le navigateur web (Firefox, Chrome, Safari, Internet Explorer…), c’est le cuisinier. Il va télécharger les ingrédients, et suivre la recette. T’as déjà vu quand on donne la même recette avec les mêmes ingrédients à 4 cuisiniers différents ? Ben ouais, c’est comme dans Top Chef, ça fait 4 plats qui sont pas vraiment pareils.
Surtout quand les assiettes ne sont pas de la même taille (genre l’écran de ton téléphone et celui de ton ordi…) et que pour cuire l’un utilise le four et l’autre un micro-ondes (je te laisse trouver une correspondance métaphorique dans ton esprit, tu peux y arriver, je crois en toi :p !).
Bref : l’article que tu lis aura peu de chance d’avoir la même gueule pour toi et la personne à qui tu le feras passer 😉
Préfère Firefox si t’as pas envie de filer tes données à Google-Chrome, Apple-Safari ou Microsoft-Edge
Ou sinon Chromium c’est Chrome sans du Google dedans 😉
3) Le streaming n’existe pas
Nope. Le streaming, c’est du téléchargement qui s’efface au fur et à mesure. Parce qu’un ordinateur est une machine à copier.
Le streaming, c’est du téléchargement que tu ne peux (ou ne sais) pas récupérer, donc tu downloades une vidéo ou un son mais juste pour une seule fois, et si tu veux en profiter à nouveau, il faut encore les télécharger et donc encombrer les tuyaux d’internet.
Tu vois les précieux mégas du forfait data de ton téléphone qui te ruinent chaque mois ? Ce sont des textes, images sons, vidéos et informations qui viennent jusqu’à ton ordi (ordinateur ou ordiphone, hein, c’est pareil). La taille de ces mégas, c’est un peu les litres d’eau que tu récupères au robinet d’internet.
Regarder ou écouter deux fois le même truc en streaming, sur YouTube ou Soundcloud par exemple, c’est comme si tu prenais deux fois le même verre d’eau au robinet.
4) Quand tu regardes une page web, elle te regarde aussi.
Mon livre ne me dit pas de le sortir du tiroir de la table de nuit. Il ne sait pas où je suis lorsque je le lis, quand je m’arrête, quand je saute des pages ni vers quel chapitre, quand je le quitte et si c’est pour aller lire un autre livre.
Sur Internet, les tuyaux vont dans les deux sens. Une page web sait déjà plein de choses sur toi juste lorsque tu cliques dessus et la vois s’afficher. Elle sait où tu te trouves, parce qu’elle connaît l’adresse de la box internet à laquelle tu t’es connecté. Elle sait combien de temps tu restes. Quand est-ce que tu cliques sur une autre page du même site. Quand et où tu t’en vas.
Netflix, par exemple, est une application web, donc un site web hyper complexe, genre QI d’intello plus plus plus. Netflix sait quel type de film tu préfères voir lors de tes soirées d’insomnie. À partir de quel épisode tu accroches vraiment à la saison d’une série. Ils doivent même pouvoir déterminer quand tu fais ta pause pipi !
Ouaip : Internet te regarde juste pour pouvoir fonctionner, et souvent plus. Ne t’y trompe pas : il prend des notes sur toi.
5) Pas besoin d’un compte Facebook/Google/etc pour qu’ils aient un dossier sur toi.
Dès qu’on te parle de « service personnalisé » c’est qu’on te vend ça -_-…
Si Internet peut te regarder, ceux qui y gagnent le plus d’argent ont les moyens d’en profiter (logique : ils peuvent se payer les meilleurs spécialistes !)
Tu vois le petit bouton « like » (ou « tweet » ou « +1 » ou…) sur tous les articles web que tu lis ? Ces petits boutons sont des espions, des trous de serrures. Ils donnent à Facebook (ou Twitter ou Google ou…) toutes les infos sur toi dont on parlait juste au dessus. Si tu n’as pas de compte, qu’ils n’ont pas ton nom, ils mettront cela sur l’adresse de ta machine. Le pire, c’est que cela fonctionne aussi avec des choses que tu vois moins (les polices d’écriture fournies par Google et très utilisées par les sites, les framework javascript, les vidéos YouTube incrustées sur un blog…)
Une immense majorité de sites utilisent aussi « Google Analytics » pour analyser tes comportements et mieux savoir quelles pages web marchent bien et comment. Mais du coup, ces infos ne sont pas données qu’à la personne qui a fait le site web : Google les récupère au passage. Là où ça devient marrant, c’est quand on se demande qui décide qu’un site marche « bien » ? C’est quoi ce « bien » ? C’est bien pour qui…?
Oui : avec le blog rank comme avec la YouTube money, Google décide souvent de comment nous devons créer nos contenus.
On a tendance à comparer les emails (et les SMS) à des lettres, le truc sous enveloppe. Sauf que non : c’est une carte postale. Tout le monde (la poste, le centre de tri, ceux qui gèrent le train ou l’avion, l’autre centre de tri, le facteur…), tous ces gens peuvent lire ton message. J’ai même des pros qui me disent que c’est carrément un poster affiché sur tous les murs de ces intermédiaires, puisque pour transiter par leurs ordis, ton email se… copie. Oui, même si c’est une photo de tes parties intimes…
Si tu veux une enveloppe, il faut chiffrer tes emails (ou tes sms).
Gamin, j’adorais déchiffrer les messages codés dans la page jeux du journal de Mickey. Y’avait une phrase faite d’étoiles, carrés, et autre symboles, et je devais deviner que l’étoile c’est la lettre A, le cœur la lettre B, etc. Lorsque j’avais trouvé toutes les correspondances c’était le sésame magique : j’avais trouvé la clé pour déchiffrer la phrase dans la mystérieuse bulle de Mickey.
Imagine la même chose version calculatrice boostée aux amphètes. C’est ça, le chiffrement. Une petit logiciel prend ton email/SMS, applique la clé des correspondances bizarres pour le chiffrer en un brouillard de symboles, et l’envoie à ton pote. Comme vos logiciels se sont déjà échangé les clés, ton pote peut le déchiffrer. Mais comme il est le seul à avoir la clé, lui seul peut le déchiffrer.
Ben ça, ça te fait une enveloppe en plomb que même le regard laser de Superman il peut pas passer au travers pour lire ta lettre.
Mettre sur le cloud ses fichiers (icloud), ses emails (gmail), ses outils (Office365)… c’est les mettre sur l’ordinateur d’Apple, de Google, de Microsoft.
Alors OK, on parle pas d’un petit PC qui prend la poussière, hein. On parle d’une grosse ferme de serveurs, de milliers d’ordinateurs qui chauffent tellement que des climatiseurs tournent à fond.
Mais c’est le même principe : un serveur, c’est un ordinateur-serviteur en mode Igor, qui est tout le temps allumé, qu’on a enchaîné au plus gros tuyau internet possible. Dès qu’on lui demande une page web, un fichier, un email, une application… on le fouette et il doit répondre au plus vite « Ouiiiiii, Mestre ! »
Tout le truc est de savoir si tu fais confiance aux Igors de savants fous dont le but est de devenir les plus riches et les maîtres du monde, ou au petit Igor du gentil nerd du coin… Voire si tu te paierais pas le luxe d’avoir ton propre Igor, ton propre serveur à la maison.
Moi, après quelques minutes de Facebook (allégorie.)
Ouais, je suis faible. J’ai, encore aujourd’hui, le réflexe « je clique sur facebook entre deux trucs à faire ». Ou Twitter. Ou Tumblr. Ou l’autre truc à la con, OSEF, c’est pareil.
Cinq minutes plus tard, je finis dans état de semi zombie, à scroller de la mollette en voyant mon mur défiler des informations devant mes yeux hypnotisés. Je finis par faire ce qu’on attend de moi : cliquer sur un titre putassier, liker, retwetter une notification et répondre à des trucs dont je n’aurais rien à foutre si une vague connaissance venait m’en parler dans un bar.
Ce n’est pas que je manque de volonté : c’est juste que Facebook (et ses collègues de bureau) m’ont bien étudié. Enfin, ils ont plus étudié l’humain que moi, mais pas de bol : j’en fais partie. Du coup ils ont construit leurs sites, leurs applications, etc. de façon à me piéger, à ce que je reste là (afin de bouffer leur pub), et à ce que j’y retourne.
Ces techniques de design qui hackent notre esprit (genre le « scroll infini », le « bandit manchot des notifications » et les « titres clickbait » dont je parle juste au dessus) sont volontaires, étudiées et documentées. Elles utilisent simplement des failles de notre esprit (subconscient, inconscient, biais cognitifs… je laisse les scientifiques définir tout cela) qui court-circuitent nos volontés. Ce n’est pas en croyant qu’on est maître de soi-même qu’on l’est vraiment. C’est souvent le contraire : le code fait la loi jusque dans nos esprits.
Bref, je suis faible, parce que je suis humain, et donc je suis pas le seul. Et ça, les géants du web l’ont bien compris.
Si je veux voir d’autres choses dans ma vie numérique, j’ai le choix : attendre que les autres le fassent jusqu’à ce que des toiles d’araignées collent mes phalanges aux touches de mon clavier, en mode squelette… ou bien je peux bouger mes doigts.
Alors ouais, j’ai pas appris à conduire en vingt heures de cours, j’ai raté plein de gâteaux avant de m’acheter les bons ustensiles et la première écharpe que j’ai faite avait pleins de trous. Mais aujourd’hui, je sais conduire, faire des pâtisseries pas dégueu et même me tricoter un pull.
Ben créer et diffuser des contenus sur Internet, c’est pareil, ça s’apprend. On trouve même facilement les infos et les outils sur Internet (dont des cours de tricot !).
Une fois qu’on sait, on peut proposer autre chose : c’est la mode des articles courts, creux et aux titres putassiers ? Tiens, et si je gardais le coup du titre pour faire un top, mais cette fois-ci dans un article blog long, dense, et condensant une tonne de sujets épars…?
Oh, wait.
Zeste de savoir, un site pour apprendre et partager de tout.
Quand on voit à quel point on a perdu la maîtrise de l’informatique, de nos vies numériques, de notre capacité à simplement imaginer comment on pourrait faire autrement… y’a de quoi déprimer.
Mais avant que tu demandes à ce qu’on t’apporte une corde, une pierre et une rivière, regarde juste un truc : le numérique est une révolution toute jeune dans notre Histoire. C’est comme quand tu découvres le chocolat, le maquillage, ou une fucking nouvelle série qui déboîte : tu t’en fous plein la gueule.
Sociétalement, on vient de se gaver d’ordinateurs (jusqu’à en mettre dans nos poches, ouais, de vrais ordis avec option téléphone !) et de numérique, et là les plus gros marchands de chocolat/maquillage/séries se sont gavés sur notre dos en nous fourguant un truc sucré, gras et qui nous laisse parfois l’estomac au bord des lèvres.
Mais on commence tout juste, et il est encore temps d’apprendre à devenir gourmet, à savoir se maquiller avec finesse, et même à écrire une fan fiction autour de cette nouvelle série.
Il est temps de revenir vers une informatique-amie, à échelle humaine, vers un outil que l’on maîtrise nous ! (et pas l’inverse, parce que moi j’aime pas que mon lave-linge me donne des ordres, nanmého !)
Des gens plus intelligents et spécialistes que moi m’ont dit qu’avec le trio « logiciel libres + chiffrement + services décentralisés », on tenait une bonne piste. J’ai tendance à les croire, et si ça te botte, tu peux venir explorer cette voie avec nous. Cela ne nous empêchera pas d’en cheminer d’autres, ensemble et en même temps, car nous avons un vaste territoire à découvrir.
Allez, viens, on va explorer le monde des possibles !
Des routes et des ponts (10) – Les enjeux de la démocratisation de l’open source
L’open source est de plus en plus populaire et répandu parmi les développeurs. Grâce à des plate-formes comme GitHub, qui ont standardisé la manière de contribuer à un projet, l’open source est devenu plus accessible, au point de devenir une norme. Mais cette nouvelle configuration n’est pas sans poser certains problèmes.
Dans ce nouveau chapitre de son ouvrage Des Routes et des ponts (traduit chapitre après chapitre par l’équipe Framalang), Nadia Eghbal s’intéresse aux enjeux de la standardisation et de la démocratisation de l’open source – notamment à l’inflation parfois anarchique du nombre de projets et de contributeurs : pour elle, l’enjeu est d’éviter que l’écosystème numérique ne se transforme en un fragile château de cartes.
L’open source, grâce à ses points forts cités plus tôt dans ce rapport, est rapidement en train de devenir un standard pour les projets d’infrastructure numérique et dans le développement logiciel en général. Black Duck, une entreprise qui aide ses clients à gérer des programmes open source, dirige une enquête annuelle qui interroge les entreprises sur leur utilisation de l’open source. (Cette enquête est l’un des rares projets de banque de données qui existe sur le sujet.) Dans leur étude de 2015, 78% des 1300 entreprises interrogées déclarent que les logiciels qu’elles ont créés pour leurs clients sont construits grâce à l’open source, soit presque le double du chiffre de 2010.
L’open source a vu sa popularité s’accroître de manière impressionnante ces cinq dernières années, pas seulement grâce à ses avantages évidents pour les développeurs et les consommateurs, mais également grâce à de nouveaux outils qui rendent la collaboration plus facile. Pour comprendre pourquoi les infrastructures numériques rencontrent des problèmes de support grandissants, nous devons comprendre la manière dont le développement de logiciels open source prolifère.
Github, un espace standardisé pour collaborer sur du code
On n’insistera jamais trop sur le rôle clé de GitHub dans la diffusion de l’open source auprès d’une audience grand public. L’open source a beau exister depuis près de 30 ans, jusqu’en 2008, contribuer à des projets open source n’était pas si facile. Le développeur motivé devait d’abord découvrir qui était le mainteneur du projet, trouver une manière de le contacter, puis proposer ses changements en utilisant le format choisi par le mainteneur (par exemple une liste courriel ou un forum). GitHub a standardisé ces méthodes de communication : les mainteneurs sont listés de façon transparente sur la page du projet, et les discussions sur les changements proposés ont lieu sur la plate-forme GitHub.
GitHub a aussi créé un vocabulaire qui est désormais standard parmi les contributeurs à l’open source, tels que la « pull request » (où un développeur soumet à l’examen de ses pairs une modification à un projet), et changé le sens du terme « fork » (historiquement, créer une copie d’un projet et le modifier pour le transformer en un nouveau projet) [littéralement « fork » signifie « bifurcation », Ndt.]. Avant GitHub, forker un projet revenait à dire qu’il y avait un différend irréconciliable au sujet de la direction qu’un projet devrait prendre. Forker était considéré comme une action grave : si un groupe de développeurs décidait de forker un projet, cela signifiait qu’il se scindait en deux factions idéologiques. Forker était aussi utilisé pour développer un nouveau projet qui pouvait avoir une utilisation radicalement différente du projet initial.
Ce type de « fork de projet » existe toujours, mais GitHub a décidé d’utiliser le terme « fork » pour encourager à davantage d’activité sur sa plate-forme. Un fork GitHub, contrairement à un fork de projet, est une copie temporaire d’un projet sur laquelle on effectue des modifications, et qui est généralement re-fusionnée au projet. Le fork en tant que pratique quotidienne sur GitHub a ajouté une connotation positive, légère au terme : c’est l’idée de prendre l’idée de quelqu’un et de l’améliorer.
GitHub a aussi aidé à standardiser l’utilisation d’un système de contrôle de version appelé Git. Les systèmes de contrôle de versions sont un outil qui permet de garder une trace de chaque contribution apportée sur un morceau de code précis. Par exemple, si le Développeur 1 et le Développeur 2 corrigent différentes parties du même code en même temps, enregistrer chaque changement dans un système de contrôle de version permet de faire en sorte que leurs changements n’entrent pas en conflit. Il existe plusieurs systèmes de contrôle de versions, par exemple Apache Subversion et Concurrent Versions System (CVS). Avant GitHub, Git était un système de contrôle de version assez méconnu. En 2010, Subversion était utilisé dans 60% des projets logiciels, contre 11%pour Git.
C’est Linus Torvalds, le créateur de Linux, qui a conçu Git en 2005. Son intention était de mettre à disposition un outil à la fois plus efficace et plus rapide, qui permette de gérer de multiples contributions apportées par de nombreux participants. Git était vraiment différent des systèmes de contrôle de version précédents, et donc pas forcément facile à adopter, mais son workflowdécentralisé a résolu un vrai problème pour les développeurs.
GitHub a fourni une interface utilisateur intuitive pour les projets open source qui utilisent Git, ce qui rend l’apprentissage plus facile pour les développeurs. Plus les développeurs utilisent GitHub, plus cela les incite à continuer d’utiliser Git. Aujourd’hui, en 2016, Git est utilisé par 38% des projets de logiciels, tandis que la part de Subversion est tombée à 47%. Bien que Subversion soit encore le système de contrôle de version le plus populaire, son usage décline. L’adoption généralisée de Git rend plus facile pour un développeur la démarche de se joindre à un projet sur GitHub, car la méthode pour faire des modifications et pour les communiquer est la même sur tous les projets. Apprendre à contribuer sur un seul des projets vous permet d’acquérir les compétences pour contribuer à des centaines d’autres. Ce n’était pas le cas avant GitHub, où des systèmes de contrôle de versions différents étaient utilisés pour chaque projet.
Enfin, GitHub a créé un espace sociabilité, qui permet de discuter et de tisser des liens au-delà de la stricte collaboration sur du code. La plate-forme est devenue de facto une sorte de communauté pour les développeurs, qui l’utilisent pour communiquer ensemble et exposer leur travail. Ils peuvent y démontrer leur influence et présenter un portfolio de leur travail comme jamais auparavant.
Les usages de GitHub sont un reflet de son ascension vertigineuse. En 2011 il n’y avait que 2 millions de dépôts (« repository »). Aujourd’hui, GitHub a 14 millions d’utilisateurs et plus de 35 millions de dépôts (ce qui inclut aussi les dépôts forkés, le compte des dépôts uniques est plutôt aux environs de 17 millions.) Brian Doll, de chez GitHub, a noté qu’il a fallu 4 ans pour atteindre le million de dépôts, mais que passer de neuf millions à dix millions n’a pris que 48 jours.
En comparaison, SourceForge, la plate-forme qui était la plus populaire pour héberger du code open source avant l’apparition de GitHub, avait 150 000 projets en 2008. Environ 18 000 projets étaient actifs.
Stack Overflow, un espace standard pour s’entraider sur du code
L’une des autres plate-formes importantes de l’open source est Stack Overflow, un site de question/réponse populaire parmi les développeurs, créé en 2008 par Jeff Atwood (développeur déjà mentionné précédemment) et par le blogueur Joel Spolsky. En Avril 2014, Stack Overflow avait plus de 4 millions d’utilisateurs enregistrés et plus de 11 millions de questions résolues (à noter qu’il n’est pas nécessaire de s’enregistrer pour voir les questions ou leurs réponses).
Stack Overflow est devenu de facto une plate-forme d’entraide pour les développeurs, qui peuvent poser des questions de programmation, trouver des réponses à des problèmes de code spécifiques, ou juste échanger des conseils sur la meilleure façon de créer un aspect précis d’un logiciel. On pourrait définir la plate-forme comme un « support client » participatif pour les développeurs à travers le monde. Même si Stack Overflow n’est pas un endroit où l’on écrit directement du code, c’est un outil de collaboration essentiel pour les développeurs individuels, qui facilite grandement la résolution de problèmes et permet de coder plus efficacement. Cela signifie qu’un développeur individuel est capable de produire plus, en moins de temps, ce qui améliore le rendement global. Stack Overflow a également permis à certains utilisateurs d’apprendre de nouveaux concepts de développement (ou même de s’initier au code tout court), et a rendu le codage plus facile et plus accessible à tous.
Tendances macro dans un paysage en mutation constante
La popularité hors-normes de l’open source a amené à des changements significatifs dans la manière dont les développeurs d’aujourd’hui parlent, pensent et collaborent sur des logiciels.
Premièrement, les attentes et exigences en termes de licences ont changé, reflétant un monde qui considère désormais l’open source comme une norme, et pas l’exception : un triomphe sur l’univers propriétaire des années 1980. Les politiques de GitHub et de Stack Overflow reflètent toutes deux cette réalité.
Dès le départ, Stack Overflow a choisi d’utiliser une licence Creative Commons appelée CC-BY-SA pour tous les contenus postés sur son site. La licence était cependant limitante, car elle requérait des utilisateurs qu’ils mentionnent l’auteur de chaque morceau de code qu’ils utilisaient, et qu’ils placent leurs propres contributions sous la même licence.
Beaucoup d’utilisateurs choisissaient d’ignorer la licence ou n’étaient même pas au courant de ses restrictions, mais pour les développeurs travaillant avec des contraintes plus strictes (par exemple dans le cadre d’une entreprise), elle rendait Stack Overflow compliqué à utiliser. S’ils postaient une question demandant de l’aide sur leur code, et qu’une personne extérieure réglait le problème, alors légalement, ils devaient attribuer le code à cette personne.
En conséquence, les dirigeants de Stack Overflow ont annoncé leur volonté de déplacer toutes les nouvelles contributions de code sous la Licence MIT, qui est une licence open source comportant moins de restrictions. En Avril 2016, ils débattent encore activement et sollicitent des retours de leur communauté pour déterminer le meilleur moyen de mettre en œuvre un système plus permissif. Cette démarche est un encouragement à la fois pour la popularité de Stack Overflow et pour la prolifération de l’open source en général. Qu’un développeur travaillant dans une grosse entreprise de logiciel puisse légalement inclure le code d’une personne complètement extérieure dans un produit pour lequel il est rémunéré est en effet un accomplissement pour l’open source.
A l’inverse, GitHub fit initialement le choix de ne pas attribuer de licence par défaut aux projets postés sur sa plateforme, peut-être par crainte que cela ne freine son adoption par les utilisateurs et sa croissance. Ainsi, les projets postés sur GitHub accordent le droit de consulter et de forker le projet, mais sont à part ça sous copyright, sauf si le développeur spécifie qu’il s’agit d’une licence open source.
En 2013, GitHub décida enfin de prendre davantage position sur la question des licences, avec notamment la création et la promotion d’un micro-site, choosealicense.com(« choisissez-une-licence »), pour aider les utilisateurs à choisir une licence pour leur projet. Ils encouragent aussi désormais leurs utilisateurs à choisir une licence parmi une liste d’options au moment de créer un nouveau « repository » (dépôt).
Ce qui est intéressant, cependant, c’est que la plupart des développeurs ne se préoccupaient pas de la question des licences : soit ignoraient que leurs projets « open source » n’étaient pas légalement protégés, soit ils s’en fichaient. Une étude informelle réalisée en 2013 par le Software Freedom Law Center (Centre du Droit de la Liberté des Logiciels) sur un échantillon de 1,6 million de dépôts GitHub révéla que seuls 15% d’entre eux avaient spécifié une licence. Aussi, les entretiens avec des développeurs réalisés pour ce rapport suggèrent que beaucoup se fichent de spécifier une licence, ou se disent que si quelqu’un demande, ils pourront toujours en ajouter une plus tard.
Ce manque d’intérêt pour les licences a amené James Governor, cofondateur de la firme d’analyse de développeurs Red Monk, à constater en 2012 que « les jeunes dévs aujourd’hui font du POSS – Post open source software. Envoie chier les licences et la gestion, contribue juste à GitHub » [en anglais « commit to GitHub » signifie littéralement « s’engager dans GitHub » mais fait également référence à la commande « commit » qui permet de valider les modifications apportées à un projet, NdT.]. En d’autres termes, faire de l’information ouverte par défaut est devenu une telle évidence culturelle aujourd’hui que les développeurs ne s’imaginent plus faire les choses autrement – un contexte bien différent de celui des rebelles politisés du logiciel libre des années 1980. Ce retournement des valeurs, quoi qu’inspirant au niveau global, peut cependant amener à des complications légales pour les individus quand leurs projets gagnent en popularité ou sont utilisés à des fins commerciales.
Mais, en rendant le travail collaboratif sur le code aussi facile et standardisé, l’open source se retrouve aux prises avec une série d’externalités perverses.
L’open source a rendu le codage plus facile et plus accessible au monde. Cette accessibilité accrue, à son tour, a engendré une nouvelle catégorie de développeurs, moins expérimentés, mais qui savent comment utiliser les composants préfabriqués par d’autres pour construire ce dont ils ont besoin.
En 2012, Jeff Atwood, cofondateur de Stack Overflow, rédigea un article de blog intitulé ironiquement « Pitié n’apprenez pas à coder », où il se plaint de la mode des stages et des écoles de code. Tout en se félicitant du désir des personnes non-techniciennes de comprendre le code d’un point de vue conceptuel, Atwood met en garde contre l’idée qu’« introduire parmi la main-d’œuvre ces codeurs naïfs, novices, voire même-pas-vraiment-sûrs-d’aimer-ce-truc-de-programmeur, ait vraiment des effets positifs pour le monde ».
Dans ces circonstances, le modèle de développement de l’open source change de visage. Avant l’ascension de GitHub, il y avait moins de projets open source. Les développeurs étaient donc un groupe plus petit, mais en moyenne plus expérimenté : ceux qui utilisaient du code partagé par d’autres étaient susceptibles d’être également ceux qui contribuent en retour.
Aujourd’hui, l’intense développement de l’éducation au code implique que de nombreux développeurs inexpérimentés inondent le marché. Cette dernière génération de développeurs novices emprunte du code libre pour écrire ce dont elle a besoin, mais elle est rarement capable, en retour, d’apporter des contributions substantielles aux projets. Beaucoup sont également habitués à se considérer comme des « utilisateurs » de projets open source, davantage que comme les membres d’une communauté. Les outils open source étant désormais plus standardisés et faciles à utiliser, il est bien plus simple aujourd’hui pour un néophyte de débarquer sur un forum GitHub et d’y faire un commentaire désobligeant ou une requête exigeante – ce qui épuise et exaspère les mainteneurs.
Cette évolution démographique a aussi conduit à un réseau de logiciels bien plus fragmenté, avec de nombreux développeurs qui publient de nouveaux projets et qui créent un réseau embrouillé d’interdépendances. Se qualifiant lui-même de « développeur-pie en rémission » [« pie » est un surnom pour les développeurs-opportunistes, d’après le nom de l’oiseau, la pie réputée voleuse, NdT], Drew Hamlett a écrit en janvier 2016 un post de blog devenu très populaire intitulé « Le triste état du développement web ». L’article traite de l’évolution du développement web, se référant spécifiquement à l’écosystème Node.js :
« Les gens qui sont restés dans la communauté Node ont sans aucun doute créé l’écosystème le plus techniquement compliqué [sic] qui ait jamais existé. Personne n’arrive à y créer une bibliothèque qui fasse quoi que ce soit. Chaque projet qui émerge est encore plus ambitieux que le précédent… mais personne ne construit rien qui fonctionne concrètement. Je ne comprends vraiment pas. La seule explication que j’ai trouvée, c’est que les gens sont juste continuellement en train d’écrire et de réécrire en boucle des applis Node.js. »
Aujourd’hui, il y a tellement de projets qui s’élaborent et se publient qu’il est tout simplement impossible pour chacun d’eux de développer une communauté suffisamment importante et viable, avec des contributeurs réguliers qui discuteraient avec passion des modifications à apporter lors de débats approfondis sur des listes courriels. Au lieu de cela, beaucoup de projets sont maintenus par une ou deux personnes seulement, alors même que la demande des utilisateurs pour ces projets peut excéder le travail nécessaire à leur simple maintenance.
GitHub a rendu simples la création et la contribution à de nouveaux projets. Cela a été une bénédiction pour l’écosystème open source, car les projets se développent plus rapidement. Mais cela peut aussi parfois tourner à la malédiction pour les mainteneurs de projets, car davantage de personnes peuvent facilement signaler des problèmes ou réclamer de nouvelles fonctionnalités, sans pour autant contribuer elles-mêmes en retour. Ces interactions superficielles ne font qu’alourdir la charge de travail des mainteneurs, dont on attend qu’ils répondent à une quantité croissante de requêtes.
Il ne serait pas déraisonnable d’affirmer qu’un monde « post-open source » implique une réflexion non seulement autour des licences, ainsi que James Governor l’exprimait dans son commentaire originel, mais aussi autour du processus de développement lui-même.
Noah Kantrowitz, développeur Python de longue date et membre de la Python Software Foundation, a résumé ce changement dans un post de blog souvent cité :
« Dans les débuts du mouvement open source, il y avait assez peu de projets, et en général, la plupart des gens qui utilisaient un projet y contribuaient en retour d’une façon ou d’une autre. Ces deux choses ont changé à un point difficilement mesurable.
[…] Alors même que nous allons de plus en plus vers des outils de niche, il devient difficile de justifier l’investissement en temps requis pour devenir contributeur. « Combler son propre besoin » est toujours une excellente motivation, mais il est difficile de construire un écosystème là-dessus.
L’autre problème est le déséquilibre de plus en plus important entre producteurs et consommateurs. Avant, cela s’équilibrait à peu près. Tout le monde investissait du temps et des efforts dans les Communs et tout le monde en récoltait les bénéfices. Ces temps-ci, très peu de personnes font cet effort et la grande majorité ne fait que bénéficier du travail de ceux qui s’impliquent.
Ce déséquilibre s’est tellement enraciné qu’il est presque impensable pour une entreprise de rendre (en temps ou en argent) ne serait-ce qu’une petite fraction de la valeur qu’elle dérive des Communs. »
Cela ne veut pas dire qu’il n’existe plus de grands projets open source avec des communautés de contributeurs fortes (Node.js, dont on parlera plus tard dans ce rapport, est un exemple de projet qui est parvenu à ce statut.) Cela signifie qu’à côté de ces réussites, il y a une nouvelle catégorie de projets qui est défavorisée par les normes et les attentes actuelles de l’open source, et que le comportement qui dérive de ces nouvelles normes affecte même des projets plus gros et plus anciens.
Hynek Schlawack, Fellow de la Python Software Foundation et contributeur sur des projets d’infrastructure Python, exprime ses craintes au sujet d’un futur où il y aurait une demande plus forte, mais seulement une poignée de contributeurs solides :
« Ce qui me frustre le plus, c’est que nous n’avons jamais eu autant de développeurs Python et aussi peu de contributions de haute qualité. […] Dès que des développeurs clefs comme Armin Ronacher ralentissent leur travail, la communauté toute entière le ressent aussitôt. Le jour où Paul Kehrer arrête de travailler sur PyCA, on est très mal. Si Hawkowl arrête son travail de portage, Twisted ne sera jamais sur Python 3 et Git.
La communauté est en train de se faire saigner par des personnes qui créent plus de travail qu’elles n’en fournissent. […] En ce moment, tout le monde bénéficie de ce qui a été construit mais la situation se détériore à cause du manque de financements et de contributions. Ça m’inquiète, parce Python est peut-être très populaire en ce moment mais une fois que les conséquences se feront sentir, les opportunistes partiront aussi vite qu’ils étaient arrivés. »
Pour la plupart des développeurs, il n’y a guère que 5 ans peut-être que l’open source est devenu populaire. La large communauté des concepteurs de logiciel débat rarement de la pérennité à long terme de l’open source, et n’a parfois même pas conscience du problème. Avec l’explosion du nombre de nouveaux développeurs qui utilisent du code partagé sans contribuer en retour, nous construisons des palaces sur une infrastructure en ruines.
Des routes et des ponts (7) – pour une infrastructure durable
Une question épineuse pour les projets libres et open source est leur maintenance à long terme, et bien évidemment les ressources, tant financières qu’humaines, que l’on peut y consacrer. Tel est le sujet qu’aborde ce nouveau chapitre de l’ouvrage de Nadia Eghbal Des routes et des ponts que le groupe Framalang vous traduit semaine après semaine (si vous avez raté les épisodes précédents)
Elle examine ici une série de cas de figures en fonction de l’origine de l’origine projet.
Comment les projets d’infrastructure numérique sont-ils gérés et maintenus ?
Nous avons établi que les infrastructures numériques sont aussi nécessaires à la société moderne que le sont les infrastructures physiques. Bien qu’elles ne soient pas sujettes aux coûts élevés et aux obstacles politiques auxquels sont confrontées ces dernières, leur nature décentralisée les rend cependant plus difficiles à cerner. Sans une autorité centrale, comment les projets open source trouvent-ils les ressources dont ils ont besoin ?
En un mot, la réponse est différente pour chaque projet. Cependant, on peut identifier plusieurs lieux d’où ces projets peuvent émaner : au sein d’une entreprise, via une startup, de développeurs individuels ou collaborant en communauté.
Au sein d’une entreprise
Parfois, le projet commence au sein d’une entreprise. Voici quelques exemples qui illustrent par quels moyens variés un projet open source peut être soutenu par les ressources d’une entreprise :
Go, le nouveau langage de programmation évoqué précédemment, a été développé au sein de Google en 2007 par les ingénieurs Robert Griesemer, Rob Pike, et Ken Thompson, pour qui la création de Go était une expérimentation. Go est open source et accepte les contributions de la communauté dans son ensemble. Cependant, ses principaux mainteneurs sont employés à plein temps par Google pour travailler sur le langage.
React est une nouvelle bibliothèque JavaScript dont la popularité grandit de jour en jour.
React a été créée par Jordan Walke, ingénieur logiciel chez Facebook, pour un usage interne sur le fil d’actualités Facebook. Un employé d’Instagram (qui est une filiale de Facebook) a également souhaité utiliser React, et finalement, React a été placée en open source, deux ans après son développement initial.
Facebook a dédié une équipe d’ingénieurs à la maintenance du projet, mais React accepte aussi les contributions de la communauté publique des développeurs.
Swift, le langage de programmation utilisé pour iOS, OS X et les autres projets d’Apple, est un exemple de projet qui n’a été placé en open source que récemment. Swift a été développé par Apple en interne pendant quatre ans et publié en tant que langage propriétaire en 2014. Les développeurs pouvaient utiliser Swift pour écrire des programmes pour les appareils d’Apple, mais ne pouvaient pas contribuer au développement du cœur du langage. En 2015, Swift a été rendu open source sous la licence Apache 2.0.
Pour une entreprise, les incitations à maintenir un projet open source sont nombreuses. Ouvrir un projet au public peut signifier moins de travail pour l’entreprise, grâce essentiellement aux améliorations de la collaboration de masse.
Cela stimule la bonne volonté et l’intérêt des développeurs, qui peuvent alors être incités à utiliser d’autres ressources de l’entreprise pour construire leurs projets.
Disposer d’une communauté active de programmeurs crée un vivier de talents à recruter. Et parfois, l’ouverture du code d’un projet aide une entreprise à renforcer sa base d’utilisateurs et sa marque, ou même à l’emporter sur la concurrence. Plus une entreprise peut capter de parts de marché, même à travers des outils qu’elle distribue gratuitement, plus elle devient influente. Ce n’est pas très différent du concept commercial de « produit d’appel ».
Même quand un projet est créé en interne, s’il est open source, alors il peut être librement utilisé ou modifié selon les termes d’une licence libre, et n’est pas considéré comme relevant de la propriété intellectuelle de l’entreprise au sens traditionnel du terme. De nombreux projets d’entreprise utilisent des licences libres standard qui sont considérées comme acceptables par la communauté des développeurs telles que les licences Apache 2.0 ou BSD. Cependant, dans certains cas, les entreprises ajoutent leurs propres clauses. La licence de React, par exemple, comporte une clause additionnelle qui pourrait potentiellement créer des conflits de revendications de brevet avec les utilisateurs de React.
En conséquence, certaines entreprises et individus sont réticents à utiliser React, et cette décision est fréquemment décrite comme un exemple de conflit avec les principes de l’open source.
Via une startup
Certains projets d’infrastructures empruntent la voie traditionnelle de la startup, ce qui inclut des financements en capital-risque. Voici quelques exemples : Docker, qui est peut-être l’exemple contemporain le plus connu, aide les applications logicielles à fonctionner à l’intérieur d’un conteneur. (Les conteneurs procurent un environnement propre et ordonné pour les applications logicielles, ce qui permet de les faire fonctionner plus facilement partout). Docker est né en tant que projet interne chez dotCloud, une société de Plate-forme en tant que service (ou PaaS, pour platform as a service en anglais), mais le projet est devenu si populaire que ses fondateurs ont décidé d’en faire la principale activité de l’entreprise. Le projet Docker a été placé en open source en 2013. Docker a collecté 180 millions de dollars, avec une valeur estimée à plus d’1 milliard de dollars.
Leur modèle économique repose sur du support technique, des projets privés et des services. Les revenus de Docker pour l’année 2014 ne dépassaient pas 10 millions de dollars.
Npm est un gestionnaire de paquets sorti en 2010 pour aider les développeurs de Node.js à partager et à gérer leurs projets. Npm a collecté près de 11 millions de dollars de financements depuis 2014 de la part de True Ventures et de Bessemer Ventures, entre autres. Leur modèle économique se concentre sur des fonctionnalités payantes en faveur de la vie privée et de la sécurité.
Meteor est un framework JavaScript publié pour la première fois en 2012. Il a bénéficié d’un programme d’incubation au sein de Y Combinator, un prestigieux accélérateur de startups qui a également été l’incubateur d’entreprises comme AirBnB et Dropbox. À ce jour, Meteor a reçu plus de 30 millions de dollars de financements de la part de firmes comme Andreessen Horowitz ou Matrix Partners. Le modèle économique de Meteor se base sur une plateforme d’entreprise nommée Galaxy, sortie en Octobre 2015, qui permet de faire fonctionner et de gérer les applications Meteor.
L’approche basée sur le capital-risque est relativement nouvelle, et se développe rapidement.
Lightspeed Venture Partners a constaté qu’entre 2010 et 2015, les sociétés de capital-risque ont investi plus de 4 milliards de dollars dans des entreprises open source, soit dix fois plus que sur les cinq années précédentes.
Le recours aux fonds de capital-risque pour soutenir les projets open source a été accueilli avec scepticisme par les développeurs (et même par certains acteurs du capital-risque eux-mêmes), du fait de l’absence de modèles économiques ou de revenus prévisibles pour justifier les estimations. Steve Klabnik, un mainteneur du langage Rust, explique le soudain intérêt des capital-risqueurs pour le financement de l’open source :
« Je suis un investisseur en capital-risque. J’ai besoin qu’un grand nombre d’entreprises existent pour gagner de l’argent… J’ai besoin que les coûts soient bas et les profits élevés. Pour cela, il me faut un écosystème de logiciels open source en bonne santé. Donc je fais quoi? … Les investisseurs en capital-risque sont en train de prendre conscience de tout ça, et ils commencent à investir dans les infrastructures. […]
Par bien des aspects, le matériel open source est un produit d’appel, pour que tu deviennes accro…puis tu l’utilises pour tout, même pour ton code propriétaire. C’est une très bonne stratégie commerciale, mais cela place GitHub au centre de ce nouvel univers. Donc pour des raisons similaires, a16z a besoin que GitHub soit génial, pour servir de tremplin à chacun des écosystèmes open source qui existeront à l’avenir… Et a16z a suffisamment d’argent pour en «gaspiller » en finançant un projet sur lequel ils ne récupéreront pas de bénéfices directs, parce qu’ils sont suffisamment intelligents pour investir une partie de leurs fonds dans le développement de l’écosystème. »
GitHub, créé en 2008, est une plateforme de partage/stockage de code, disponible en mode public ou privé, doté d’un environnement ergonomique. Il héberge de nombreux projets open source populaires et, surtout, il est devenu l’épicentre culturel de la croissance explosive de l’open source (dont nous parlerons plus loin dans ce rapport). GitHub n’a reçu aucun capital-risque avant 2012, quatre ans après sa création. Avant cette date, GitHub était une entreprise rentable. Depuis 2012, GitHub a reçu au total 350 millions de dollars de financements en capital-risque.
Andreessen Horowitz (alias a16z), la firme d’investissement aux 4 millards de dollars qui a fourni l’essentiel du capital de leur première levée de fonds de 100 millions de dollars, a déclaré qu’il s’agissait là de l’investissement le plus important qu’elle ait jamais fait jusqu’alors.
En d’autres termes, la théorie de Steve Klabnik est que les sociétés de capital-risque qui investissent dans les infrastructures open source promeuvent ces plateformes en tant que « produit d’appel », même quand il n’y a pas de modèle économique viable ou de rentabilité à en tirer, parce que cela permet de faire croître l’ensemble de l’écosystème. Plus GitHub a de ressources, plus l’open source est florissant. Plus l’open source est florissant, et mieux se portent les startups. À lui seul, l’intérêt que portent les sociétés d’investissement à l’open source, particulièrement quand on considère l’absence de véritable retour financier, est une preuve du rôle-clé que joue l’open source dans l’écosystème plus large des startups.
Par ailleurs, il est important de noter que la plateforme GitHub en elle-même n’est pas un projet open source, et n’est donc pas un exemple de capital-risque finançant directement l’open source. GitHub est une plateforme à code propriétaire qui héberge des projets open source. C’est un sujet controversé pour certains contributeurs open source.
Par des personnes ou un groupe de personnes
Enfin, de nombreux projets d’infrastructures numériques sont intégralement développés et maintenus par des développeurs indépendants ou des communautés de développeurs. Voici quelques exemples :
Python, un langage de programmation, a été développé et publié par un informaticien, Guido van Rossum, en 1991.
Van Rossum déclarait qu’il « était à la recherche d’un projet de programmation « passe-temps », qui [le] tiendrait occupé pendant la semaine de Noël. »
Le projet a décollé, et Python est désormais considéré comme l’un des langages de programmation les plus populaires de nos jours.
Van Rossum reste le principal auteur de Python (aussi connu parmi les développeurs sous le nom de « dictateur bienveillant à vie » et il est actuellement employé par Dropbox, dont les logiciels reposent fortement sur Python.
Python est en partie géré par la Python Software Foundation (NdT: Fondation du logiciel Python), créée en 2001, qui bénéficie de nombreux sponsors commerciaux, parmi lesquel Intel, HP et Google.
RubyGems est un gestionnaire de paquets qui facilite la distribution de programmes et de bibliothèques associés au langage de programmation Ruby.
C’est une pièce essentielle de l’infrastructure pour tout développeur Ruby. Parmi les sites web utilisant Ruby, on peut citer par exemple Hulu, AirBnB et Bloomberg. RubyGems a été créé en 2003 et est géré par une communauté de développeurs. Certains travaux de développement sont financés par Ruby Together, une fondation qui accepte les dons d’entreprises et de particuliers.
Twisted, une bibliothèque Python, fut créée en 2002 par un programmeur nommé Glyph Lefkowitz. Depuis lors, son usage s’est largement répandu auprès d’individus et d’organisations, parmi lesquelles Lucasfilm et la NASA.
Twisted continue d’être géré par un groupe de volontaires. Le projet est soutenu par des dons corporatifs/commerciaux et individuels ; Lefkowitz en reste l’architecte principal et gagne sa vie en proposant ses services de consultant.
Comme le montrent tous ces exemples, les projets open source peuvent provenir de pratiquement n’importe où. Ce qui est en général considéré comme une bonne chose. Cela signifie que les projets utiles ont le plus de chances de réussir, car ils évitent d’une part les effets de mode futiles inhérents aux startups, et d’autre part la bureaucratie propre aux gouvernements. La nature décentralisée de l’infrastructure numérique renforce également les valeurs de démocratie et d’ouverture d’Internet, qui permet en principe à chacun de créer le prochain super projet, qu’il soit une entreprise ou un individu.
D’un autre côté, un grand nombre de projets utiles proviendront de développeurs indépendants qui se trouveront tout à coup à la tête d’un projet à succès, et qui devront prendre des décisions cruciales pour son avenir. Une étude de 2015 menée par l’Université fédérale de Minas Gerai au Brésil a examiné 133 des projets les plus activement utilisés sur Github, parmi les langages de programmation, et a découvert que 64 % d’entre eux, presque les deux tiers, dépendaient pour leur survie d’un ou deux développeurs seulement.
Bien qu’il puisse y avoir une longue traîne de contributeurs occasionnels ou ponctuels pour de nombreux projets, les responsabilités principales de la gestion du projet ne reposent que sur un très petit nombre d’individus.
Coordonner des communautés internationales de contributeurs aux avis arrêtés, tout en gérant les attentes d’entreprises classées au Fortune 500 qui utilisent votre projet, voilà des tâches qui seraient des défis pour n’importe qui. Il est impressionnant de constater combien de projets ont déjà été accomplis de cette manière. Ces tâches sont particulièrement difficiles dans un contexte où les développeurs manquent de modèles clairement établis, mais aussi de soutien institutionnel pour mener ce travail à bien. Au cours d’interviews menées pour ce rapport, beaucoup de développeurs se sont plaints en privé qu’ils n’avaient aucune idée de qui ils pouvaient solliciter pour avoir de l’aide, et qu’ils préféreraient « juste coder ».
Pourquoi continuent-ils à le faire ? La suite de ce rapport se concentrera sur pourquoi et comment les contributeurs de l’open source maintiennent des projets à grande échelle, et sur les raisons pour lesquelles c’est important pour nous tous.
Une initiative d’éducation populaire au numérique à Damgan
Damgan est un petit village d’environ 1650 habitants dans le sud du Morbihan, région Bretagne. L’Université Populaire du Numérique de Damgan y est née le 27 septembre 2016, c’est une association qui compte déjà 48 adhérents au bout d’un mois.
Transparence : cet article est une reformulation des réponses que j’ai rédigées avec mon ami Pierre Bleiberg pour un article de Ouest France, mais très largement tronquées à la publication.
Qu’est ce qui vous a poussé à créer cette Université Populaire du Numérique de Damgan ?
Je pense qu’il y a urgence. Et depuis longtemps. La révolution numérique est d’ordre culturel, or la population dans sa grande majorité se sent exclue de cette culture. Les ordinateurs, les tablettes, les smartphones sont entrés dans les foyers et beaucoup se sentent démunis face à ce matériel informatique. Bien sûr il y a la nécessité d’apprendre des bases « techniques », mais surtout de se frotter à de nouveaux usages, à une nouvelle façon de faire société dans un monde où nous sommes tous connectés à tous les autres et où chacun, même celui qui se croit déconnecté, a une partie de sa vie stockée quelque part sous forme de 0 et de 1.
Une éducation est nécessaire et ce n’est pas l’état qui peut en être le moteur : comme partout ailleurs, une grande partie des responsables n’ont pas eux-mêmes cette culture. C’est un phénomène transversal qui touche toutes les populations, tous les milieux sociaux, et contrairement à ce que les plus anciens peuvent croire, tous les âges. Les jeunes sont plus à l’aise face à la machine, mais ils ne sont pas pour autant plus cultivés sur le numérique.
Cela fait déjà longtemps qu’on parle de fracture numérique. Je lisais dans un magazine informatique qu’il y a en France entre 8 et 10 millions de Français incapables de naviguer sur le net ou d’envoyer un mail ; c’est aussi handicapant que de ne pas savoir lire. Cette fracture n’a jamais été réduite. Une des raisons est que cette culture porte en elle un modèle de partage et d’horizontalité qui s’oppose violemment à celui de nos sociétés ultra-hiérarchisées. C’est pourquoi je pense que l’effort doit venir de la société civile, que nous devons nous éduquer nous-mêmes dans l’échange.
À qui s’adresse cette association ? Comment organisez-vous les ateliers ?
Nous sommes au tout début de l’aventure, nous ne pouvons pas encore parler d’organisation précise. Nous avons mis en place deux premiers ateliers avec à chaque fois une quarantaine de participants. D’abord un sur les forums car nous avons décidé de nous former sur un outil commun avant toute autre chose (notre forum). S’il n’y a pas d’interaction entre nous, l’objectif est manqué. Nous avons une composante locale, on se rencontre pour créer une sphère de confiance, mais il faut aussi pouvoir se retrouver en ligne en dehors des ateliers.
Nous avons également des listes de diffusion et un blog. Nous ne sommes pas encore présents sur les réseaux sociaux, on va y venir mais ensemble, doucement. Nous pensons créer les comptes en atelier.
La seconde séance a été consacrée aux notions de base de la micro-informatique : les ordinateurs et leurs composants. J’ai également refait l’atelier sur les forums avec d’autres adhérents.
Le public est le plus varié possible. La moyenne d’âge est assez élevée pour l’instant car elle correspond à la population de Damgan, mais nous avons quelques jeunes et espérons bien en trouver d’autres. Et nous avons déjà des personnes qui n’habitent pas Damgan qui participent, d’autres qui sont intéressées. Et je répète que nous accueillons tous les âges, tous les niveaux avec bienveillance.
Le logo et la devise de l’Université populaire de Damgan (cliquer sur l’image pour accéder au site)
Notre démarche s’appuie sur celle de l’éducation populaire, sur l’échange et le partage de connaissances. Si la grande majorité des premiers adhérents a « besoin d’apprendre », nous espérons bien que demain les mêmes pourront partager à leur tour leurs connaissances et leur expérience. Des adhérents ont déjà proposé des sujets qu’ils pourraient nous présenter dans une section du forum consacrée aux « offres ».
Comment gérez-vous les différents niveaux des participant-e-s ?
C’est la grande difficulté. Avec ces premières rencontres on apprend à se connaître et on débat ensemble de la façon dont on va pouvoir s’organiser. Nous avons eu beaucoup de monde et nous sommes bien conscients qu’il va falloir essayer de faire des ateliers plus petits et plus ciblés. Nous demandons à tous d’être un peu patients et nous remercions nos adhérents d’essuyer les plâtres. Ce qui est sûr c’est que le besoin est réel, les gens sont motivés et je suis certain que nous allons faire de grandes choses.
Faut-il amener son matériel ? Faut-il être « connecté-e » ?
Pour l’instant les gens sont venus en grande majorité avec des portables ou des tablettes. Nous allons certainement devoir consacrer des ateliers différents pour ce qui est de la pratique entre l’ordinateur d’un côté et les tablettes/smartphones de l’autre. Mais cela dépend du sujet. On parle beaucoup de pratique mais nos ambitions sont très larges. Si nous organisons des débats sur les données personnelles, il n’y pas besoin de matériel.
Nous souhaitons également nous mettre au service des gens « déconnectés », inviter ceux qui n’ont ni matériel ni internet, pour par exemple faire avec eux des démarches administratives en ligne. Pour ceux qui veulent venir voir et qui n’ont pas de matériel, c’est évidemment possible. Et pourquoi pas créer des créneaux de « libre accès » pour ceux qui en ont le besoin. Nous verrons, ça dépendra aussi de nos moyens financiers et humains.
Ressentez-vous l’appréhension face à cet univers ?
L’appréhension face au numérique, elle est omniprésente. Pour les plus anxieux, quand les gens viennent c’est déjà qu’ils ont fait un grand pas. Nous avons récemment accueilli une dame qui était totalement perdue et très émue de cette situation. Mais elle va s’accrocher et on va voir avec elle pour démarrer en douceur avec des ateliers très basiques.
Nous savons également qu’il nous faudra aller chercher ceux qui n’osent pas venir.
Nous ferons tout pour dédramatiser et casser cette peur avec un maximum de convivialité et d’entraide.
Avez-vous des objectifs, des projets, un plan pour l’avenir ?
Je ne vois aucune limite à nos projets, il y a tant de choses à faire. Rien n’est planifié mais c’est le fruit d’années de réflexions et d’implication dans le domaine du partage de connaissances et de la passion du numérique. Nous avons choisi de nous lancer avant même de savoir comment on allait faire car cela faisait trop longtemps qu’on y réfléchissait, à un moment on s’est dit que si on attendait de pouvoir embrasser tout le spectre des besoins et des possibilités, d’avoir tout planifié, on ne démarrerait jamais. Alors on a fait le grand saut, et on a confiance en l’avenir !
Des routes et des ponts (6) – créer une infrastructure numérique
Dans ce nouveau chapitre de l’ouvrage de Nadia Eghbal Des routes et des ponts que le groupe Framalang vous traduit semaine après semaine (si vous avez raté les épisodes précédents), l’autrice(1) établit cette fois-ci une comparaison éclairante entre l’infrastructure physique dont nous dépendons sans toujours en avoir conscience et l’infrastructure numérique dont la conception et le processus sont bien différents.
Qu’est-ce qu’une infrastructure numérique, et comment est-elle construite ?
Dans un chapitre précédent de ce rapport, nous avons comparé la création d’un logiciel à la construction d’un bâtiment. Ces logiciels publiquement disponibles contribuent à former notre infrastructure numérique. Pour comprendre ce concept, regardons comment les infrastructures physiques fonctionnent.
Tout le monde dépend d’un certain nombre d’infrastructures physiques qui facilitent notre vie quotidienne. Allumer les lumières, aller au travail, faire la vaisselle : nous ne pensons pas souvent à l’endroit d’où viennent notre eau ou notre électricité, mais heureusement que nous pouvons compter sur les infrastructures physiques. Les partenaires publics et privés travaillent de concert pour construire et maintenir nos infrastructures de transport, d’adduction des eaux propres et usées, nos réseaux d’électricité et de communication.
De même, même si nous ne pensons pas souvent aux applications et aux logiciels que nous utilisons quotidiennement, tous utilisent du code libre et public pour fonctionner. Ensemble, dans une société où le numérique occupe une place croissante, ces projets open source forment notre infrastructure numérique. Toutefois, il existe plusieurs différences majeures entre les infrastructures physiques et numériques, qui affectent la manière dont ces dernières sont construites et maintenues. Il existe en particulier des différences de coût, de maintenance, et de gouvernance.
Les infrastructures numériques sont plus rapides et moins chères à construire.
C’est connu, construire des infrastructures matérielles coûte très cher. Les projets sont physiquement de grande envergure et peuvent prendre des mois ou des années à réaliser.
Le gouvernement fédéral des États-Unis a dépensé 96 milliards de dollars en projets d’infrastructure en 2014 et les gouvernements des différents états ont dépensé au total 320 milliards de dollars cette même année. Un peu moins de la moitié de ces dépenses (43 pour cent) a été affectée à de nouvelles constructions ; le reste a été dépensé dans des opérations de maintenance de l’infrastructure existante.
Proposer puis financer des projets de nouvelles infrastructures physiques peut être un processus politique très long. Le financement des infrastructures de transport a été un sujet délicat aux États-Unis d’Amérique au cours de la dernière décennie lorsque le gouvernement fédéral a été confronté à un manque de 16 milliards de dollars pour les financer.
Le Congrès a récemment voté la première loi pluriannuelle de financement des transports depuis 10 ans, affectant 305 milliards de dollars aux autoroutes et autres voies rapides après des années d’oppositions politiques empêchant la budgétisation des infrastructures au-delà de deux années.
Même après qu’un nouveau projet d’infrastructure a été validé et a reçu les fonds nécessaires, il faut souvent des années pour le terminer, à cause des incertitudes et des obstacles imprévus auxquels il faut faire face.
Dans le cas du projet Artère Centrale/Tunnel à Boston, dans le Massachusetts, connu aussi sous le nom de Big Dig, neuf ans se sont écoulés entre la planification et le début des travaux. Son coût prévu était de 2,8 milliards de dollars, et il devait être achevé en 1998. Finalement, le projet a coûté 14,6 milliards de dollars et n’a pas été terminé avant 2007, ce qui en fait le projet d’autoroute le plus cher des États-Unis.
En revanche, les infrastructures numériques ne souffrent pas des coûts associés à la construction des infrastructures physiques comme le zonage ou l’achat de matériels. Il est donc plus facile pour tout le monde de proposer une nouvelle idée et de l’appliquer en un temps très court. MySQL, le second système de gestion de base de données le plus utilisé dans le monde et partie intégrante d’une collection d’outils indispensables qui aidèrent à lancer le premier boum technologique, fut lancé par ses créateurs, Michael Widenius & David Axmark, en mai 1995. Ils mirent moins de deux années à le développer.
Il a fallu à Ruby, un langage de programmation, moins de trois ans entre sa conception initiale en février 1993 et sa publication en décembre 1995. Son auteur, l’informaticien Yukihiro Matsumoto, a décidé de créer le langage après une discussion avec ses collègues.
Les infrastructures numériques se renouvellent fréquemment
Comme l’infrastructure numérique est peu coûteuse à mettre en place, les barrières à l’entrée sont plus basses et les outils de développement changent plus fréquemment.
L’infrastructure physique est construite pour durer, c’est pourquoi ces projets mettent si longtemps à être planifiés, financés et construits. Le métro de Londres, le système de transport en commun rapide de la ville, fut construit en 1863 ; les tunnels creusés à l’époque sont encore utilisés aujourd’hui.
Le pont de Brooklyn, qui relie les arrondissements de Brooklyn et de Manhattan à New York City, fut achevé en 1883 et n’a pas subi de rénovations majeures avant 2010, plus de cent ans plus tard. L’infrastructure numérique nécessite non seulement une maintenance et un entretien fréquents pour être compatible avec d’autres logiciels, mais son utilisation et son adoption changent également fréquemment. Un pont construit au milieu de New York City aura un usage garanti et logique, en proportion de la hausse ou la diminution de la population. Mais un langage de programmation ou un framework peut être extrêmement populaire durant plusieurs années, puis tomber en désuétude lorsque apparaît quelque chose de plus rapide, plus efficace, ou simplement plus à la mode.
Par exemple, le graphique ci-dessous montre l’activité des développeurs de code source selon plusieurs langages différents. Le langage C, l’un des langages les plus fondamentaux et les plus utilisés, a vu sa part de marché diminuer alors que de nouveaux langages apparaissaient. Python et JavaScript, deux langages très populaires en ce moment, ont vu leur utilisation augmenter régulièrement avec le temps. Go, développé en 2007, a connu plus d’activité dans les dernières années.
Tim Hwang, dirigeant du Bay Area Infrastructure Observatory, qui organise des visites de groupe sur des sites d’infrastructures physiques, faisait remarquer la différence dans une interview de 2015 donnée au California Sunday Magazine :
« Beaucoup de membres de notre groupe travaillent dans la technologie, que ce soit sur le web ou sur des logiciels. En conséquence, ils travaillent sur des choses qui ne durent pas longtemps. Leur approche c’est ‘On a juste bidouillé ça, et on l’a mis en ligne’ ou : ‘On l’a simplement publié, on peut travailler sur les bogues plus tard’. Beaucoup d’infrastructures sont construites pour durer 100 ans. On ne peut pas se permettre d’avoir des bogues. Si on en a, le bâtiment s’écroule. On ne peut pas l’itérer. C’est une façon de concevoir qui échappe à l’expérience quotidienne de nos membres. »
Cependant, comme l’infrastructure numérique change très fréquemment, les projets plus anciens ont plus de mal à trouver des contributeurs, parce que beaucoup de développeurs préfèrent travailler sur des projets plus récents et plus excitants. Ce phénomène est parfois référencé comme le « syndrome de la pie » chez les développeurs, ces derniers étant attirés par les choses « nouvelles et brillantes », et non par les technologies qui fonctionnent le mieux pour eux et pour leurs utilisateurs.
Les infrastructures numériques n’ont pas besoin d’autorité organisatrice pour déterminer ce qui doit être construit ou utilisé
En définitive, la différence la plus flagrante entre une infrastructure physique et une infrastructure numérique, et c’est aussi un des défis majeurs pour sa durabilité, c’est qu’il n’existe aucune instance décisionnelle pour déterminer ce qui doit être créé et utilisé dans l’infrastructure numérique. Les transports, les réseaux d’adduction des eaux propres et usées sont généralement gérés et possédés par des collectivités, qu’elles soient fédérales, régionales ou locales. Les réseaux électriques et de communication sont plutôt gérés par des entreprises privées. Dans les deux cas, les infrastructures sont créées avec une participation croisée des acteurs publics et privés, que ce soit par le budget fédéral, par les entreprises privées ou les contributions payées par les usagers.
Dans un État stable et développé, nous nous demandons rarement comment une route est construite ou un bâtiment électrifié. Même pour des projets financés ou propriétés du privé, le gouvernement fédéral a un intérêt direct à ce que les infrastructures physiques soient construites et maintenues.
De leur côté, les projets d’infrastructures numériques sont conçus et construits en partant du bas. Cela ressemble à un groupe de citoyens qui se rassemblent et décident de construire un pont ou de créer leur propre système de recyclage des eaux usées. Il n’y a pas d’organe officiel de contrôle auquel il faut demander l’autorisation pour créer une nouvelle infrastructure numérique.
Internet lui-même possède deux organes de contrôle qui aident à définir des standards : l’IETF (Internet Engineering Task Force) et le W3C (World Wide Web Consortium). L’IETF aide à développer et définit des standards recommandés sur la façon dont les informations sont transmises sur Internet. Par exemple, ils sont la raison pour laquelle les URL commencent par “HTTP”. Ils sont aussi la raison pour laquelle nous avons des adresses IP – des identifiants uniques assignés à votre ordinateur lorsqu’il se connecte à un réseau. À l’origine, en 1986, il s’agissait d’un groupe de travail au sein du gouvernement des USA mais l’IETF est devenue une organisation internationale indépendante en 1993.
L’IETF elle-même fonctionne grâce à des bénévoles et il n’y a pas d’exigences pour adhérer : n’importe qui peut joindre l’organisation en se désignant comme membre. Le W3C (World Wide Web Consortium) aide à créer des standards pour le World Wide Web. Ce consortium a été fondé en 1994 par Tim Berners-Lee. Le W3C a tendance à se concentrer exclusivement sur les pages web et les documents (il est, par exemple, à l’origine de l’utilisation du HTML pour le formatage basique des pages web). Il maintient les standards autour du langage de balisage HTML et du langage de formatage de feuilles de style CSS, deux des composants de base de n’importe quelle page web. L’adhésion au W3C, légèrement plus formalisée, nécessite une inscription payante. Ses membres vont des entreprises aux étudiants en passant par des particuliers.
L’IETF et le W3C aident à gérer les standards utilisés par les pièces les plus fondamentales d’Internet, mais la couche du dessus – les choix concernant le langage utilisé pour créer le logiciel, quels frameworks utiliser pour les créer, ainsi que les bibliothèques à utiliser – sont entièrement auto-gérés dans le domaine public (bien entendu, de nombreux projets de logiciels propriétaires, particulièrement ceux qui sont régis par de très nombreuses normes, tels que l’aéronautique ou la santé peuvent avoir des exigences concernant les outils utilisés. Ils peuvent même développer des outils propriétaires pour leur propre utilisation).
Avec les infrastructures physiques, si le gouvernement construit un nouveau pont entre San Francisco et Oakland, ce pont sera certainement utilisé. De la même façon, lorsque le W3C décide d’un nouveau standard, tel qu’une nouvelle version de HTML, il est formellement publié et annoncé. Par exemple, en 2014, le W3C a annoncé HTML 5, la première révision majeure de HTML depuis 1997, qui a été développé pendant sept ans.
En revanche, lorsqu’un informaticien souhaite créer un nouveau langage de programmation, il ou elle est libre de le publier et ce langage peut ou peut ne pas être adopté. La barre d’adoption est encore plus basse pour les frameworks et bibliothèques : parce qu’ils sont plus faciles à créer, et plus facile pour un utilisateur à apprendre et implémenter, ces outils sont itérés plus fréquemment.
Mais le plus important c’est que personne ne force ni même n’encourage fortement quiconque à utiliser ces projets. Certains projets restent plus théoriques que pratiques, d’autres sont totalement ignorés. Il est difficile de prédire ce qui sera véritablement utilisé avant que les gens ne commencent à l’utiliser.
Les développeurs aiment se servir de l’utilité comme indicateur de l’adoption ou non d’un projet. Les nouveaux projets doivent améliorer un projet existant, ou résoudre un problème chronique pour être considérés comme utiles et dignes d’être adoptés. Si vous demandez aux développeurs pourquoi leur projet est devenu si populaire, beaucoup hausseront les épaules et répondront : « C’était la meilleure chose disponible ». Contrairement aux startups technologiques, les nouveaux projets d’infrastructure numérique reposent sur les effets de réseau pour être adoptés par le plus grand nombre.
L’existence d’un groupe noyau de développeurs motivés par le projet, ou d’une entreprise de logiciels qui l’utilise, contribue à la diffusion du projet. Un nom facilement mémorisable, une bonne promotion, ou un beau site Internet peuvent ajouter au facteur « nouveauté » du projet. La réputation d’un développeur dans sa communauté est aussi un facteur déterminant dans la diffusion d’un projet.
Mais en fin de compte, une nouvelle infrastructure numérique peut venir d’à peu près n’importe où, ce qui veut dire que chaque projet est géré et maintenu d’une façon qui lui est propre.

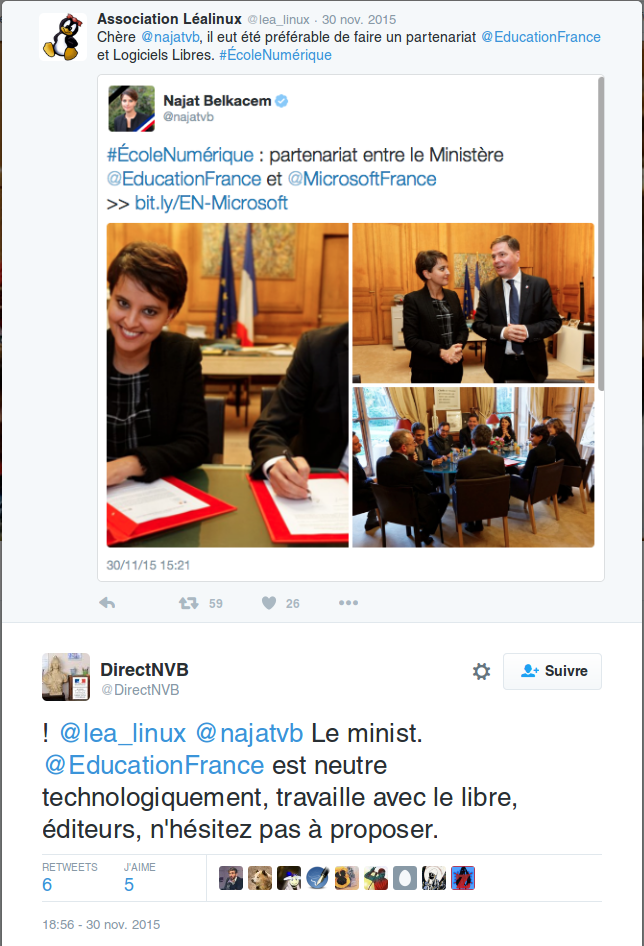




















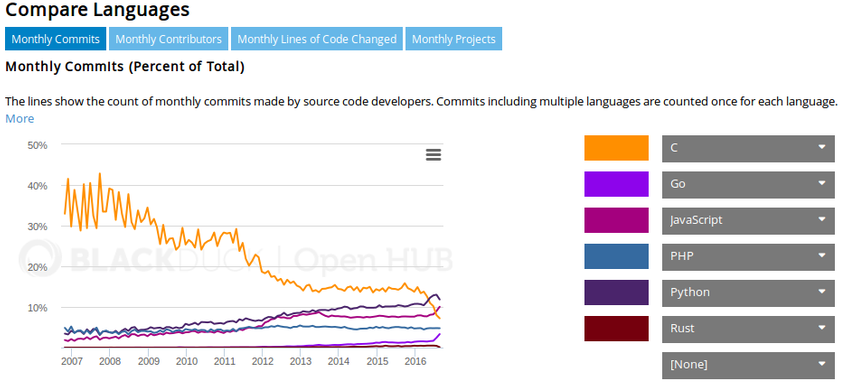
{kind=link}