

À petits pas vers le succès (Libres conseils 32/42)
Chaque jeudi à 21h, rendez-vous sur le framapad de traduction, le travail collaboratif sera ensuite publié ici même.
Traduction Framalang :
Les projets trop ambitieux échouent
Jos Poortvliet
Jos Poortvliet travaille en tant que gestionnaire de communauté pour SUSE Linux. Auparavant, il était actif dans la communauté KDE internationale en tant que responsable de l’équipe marketing. Dans sa « vie hors-ligne », il a travaillé dans différentes entreprises en tant que conseiller en stratégie d’entreprise. Il passe son temps libre à expérimenter dans sa cuisine, où il tente de parvenir à quelque chose de comestible.
« Mieux vaut faire beaucoup de petits pas dans la bonne direction qu’un grand bond en avant pour retomber en arrière. » (Vieux proverbe chinois)
Une idée géniale…
Il était une fois, au sein de l’équipe marketing d’un projet de logiciel libre, quelqu’un qui eut une idée géniale pour faire se développer le projet. Un programme serait mis en place pour permettre à des étudiants en informatique de prendre connaissance du projet et de le rejoindre. Des universités seraient contactées et quelqu’un s’adresserait à elles pour susciter leur intérêt. Des ambassadeurs iraient alors dans ces universités pour y donner des cours et encadrer les premiers pas des étudiants dans le monde du logiciel libre. Une fois qu’ils auraient rejoint le projet en ligne, ils seraient encadrés sur des tâches simples et deviendraient finalement des contributeurs chevronnés ! Les universités adoreraient ce programme, bien sûr, et, avec un peu de chance, commenceraient à participer plus activement, en donnant à leurs étudiants du code à écrire pour le projet et bien plus encore.
… qui n’a pas fonctionné…
J’ai vu l’idée développée dans la fiction ci-dessus sous bien des formes dans de nombreuses communautés et projets. C’est une idée géniale et d’un fort potentiel ! Nous savons tous qu’il faut commencer tôt — nos concurrents du logiciel propriétaire sont très bons pour ça. Nous savons également que nous disposons de suffisamment d’arguments pour convaincre les universités et les étudiants de participer — le logiciel libre et open source représente le futur, il offre de très belles possibilités de développement des compétences. Les compétences en programmation ou en administration sous Linux sont davantage demandées que des développeurs Java ou .NET ou que des administrateurs système Windows. Et surtout : c’est plus amusant. Quoi qu’il en soit, si vous allez dans des universités, vous ne verrez pas beaucoup d’affiches vous invitant à rejoindre des projets de logiciels libres. La plupart des professeurs n’en ont jamais entendu parler. Que s’est-il passé ? Permettez-moi de continuer mon histoire.
… pas à cause d’un manque d’efforts…
L’équipe en a discuté longtemps. D’abord en mettant des idées en commun — de nombreuses idées concernant la concrétisation du concept ont fusé. Le responsable de l’équipe les a rassemblées et mises sur le wiki. Un calendrier a été établi avec des échéances et le responsable a réparti les tâches, pour certaines parties. Certains ont commencé à rédiger des supports de cours, d’autres à lister les références des universités. Ils ont régulièrement demandé des suggestions et des idées sur la liste de diffusion et ont reçu beaucoup de réponses proposant d’autres supports de cours, que le responsable a ajoutés à la liste des choses à rédiger. Tout devait être fait pendant le temps libre des volontaires, mais on pouvait toujours compter sur le responsable pour rappeler les échéances aux volontaires.
Après quelques mois, une structure était visible et de nombreuses pages étaient créées sur le wiki.
Entre-temps, néanmoins, le nombre de personnes impliquées depuis la discussion initiale a diminué, passant de plus de 30 à environ cinq qui faisaient encore mine de travailler. Le responsable a décidé de revoir la feuille de route avec des dates butoirs et, après quelques appels lancés sur la liste de diffusion, 10 nouveaux volontaires s’engagèrent à réaliser diverses tâches. Le rythme s’est à nouveau un peu accéléré. Un certain nombre de choses qui avaient déjà été faites ont dû être mises à jour et il y avait d’autres ajustements à faire. Malheureusement, les choses ont continué à s’aggraver et le nombre de personnes impliquées a continué à diminuer. Des sprints mensuels furent mis en place, et ils ont en effet abouti à terminer davantage de choses. Mais il y avait simplement trop à faire. Au bout d’environ un an, les dernières personnes ont jeté l’éponge. Il n’en reste qu’une page wiki obsolète et quelques ressources dépassées…
… mais parce qu’elle était trop ambitieuse
Alors pourquoi ça n’a pas marché ? L’équipe avait pourtant appliqué les meilleures techniques de gestion de projet qu’il est possible de trouver sur le Web : brainstorming, puis mise en place d’un planning avec un échéancier, des objectifs précis ainsi que des responsabilités. Ils ont fait ce qu’il fallait faire sur un projet bénévole : solliciter les personnes, les impliquer, donner la possibilité à chacun d’exprimer son opinion. Ça aurait dû fonctionner !
Ce ne fut pas le cas pour une raison simple : c’était trop ambitieux. C’est une tendance. Des idées géniales reçoivent beaucoup de commentaires, sont inscrites dans de grands plannings qui se terminent en pages wiki incomplètes amenant à une faible implémentation qui finit par s’évanouir dans le néant.
Les responsables doivent admettre que la manière de travailler d’une équipe dans le domaine du logiciel libre et open source n’est pas la même que dans un environnement structuré et dirigé comme peut l’être une entreprise. Les gens ont tendance à être présents lorsque quelque chose d’excitant se produit, comme lors de la sortie d’une version majeure, puis à disparaître jusqu’au prochain gros événement. La création d’une équipe communautaire ne devrait jamais supposer que les gens resteront pleinement impliqués jusqu’à la fin. Il faut prendre en compte le fait qu’ils seront présents pendant un certain temps, puis s’absenteront durant de plus longues périodes avant de revenir. Les arrivées et les départs font qu’il y a beaucoup d’agitation superflue et que le travail avance lentement. Oui, il est possible de diriger des gens, mais il n’est pas possible de les gérer. Dès que vous apprenez à laisser l’aspect gestion de côté, vous pouvez davantage vous concentrer sur les choses à faire dans les plus brefs délais.
Ainsi, au lieu de prévoir les grandes étapes, trouvez quelque chose de plus modeste qui soit réalisable et utile en soi. Non pas une page wiki avec un planning, mais la première étape de ce que vous voulez accomplir. Et ensuite donnez l’impulsion en faisant les choses. Faites le premier brouillon d’un article. Créez la première version d’un dossier. Copiez-collez à partir de n’importe quoi d’existant ou améliorez quelque chose qui existe déjà. Ensuite, présentez le résultat à l’équipe, aussi brouillon qu’il puisse être, et demandez si quelqu’un souhaite l’améliorer. Faites une petite chose et ça fonctionnera.
Ne planifiez pas, agissez…
Comment alors allez-vous réaliser quelque chose d’aussi énorme qu’un programme de recrutement des étudiants avec le concours des universités ? Ne le faites pas ! Du moins, pas directement. Il faut en discuter avec toute l’équipe et le planifier — ça donnera certainement lieu à une discussion sympathique pouvant durer des semaines. Mais ça ne vous mènera pas loin. Gardez plutôt le plan pour vous-même. Sérieusement.
Je ne suis pas en train de dire qu’il ne faudrait pas en parler — vous le pouvez. Faites part de votre ambitieux projet à tous ceux qui sont intéressés. Et c’est tant mieux s’ils font des propositions. Mais n’en attendez pas trop, ne faites pas de plans au-delà de la première ou des deux premières étapes. Allez plutôt de l’avant, construisez sur ce qui existe déjà. Envoyez le brouillon d’un support de communication fraîchement créé ou amélioré à la liste de diffusion. Demandez à quelqu’un ayant donné un cours sur votre projet de partager son support et améliorez-le un peu. Qui sait, les personnes dont le travail vous sert de base pourraient vous venir en aide ! Les gens avec qui vous avez discuté de votre projet et qui partagent votre vision pourraient également vous aider. De cette façon, vous terminerez souvent quelque chose — un prospectus, un site web amélioré ou une présentation utilisable. Et les gens peuvent, peu à peu, commencer à les utiliser. Des ambassadeurs peuvent se rendre dans leur université et utilisant une des choses que vous avez déjà créées. Pour cela, ils auront certainement besoin de créer des éléments manquants — qui pourront ensuite se retrouver sur le wiki. Et vous progressez.
… et vous aurez votre château en Espagne !
En marketing communautaire, la bonne stratégie ne réside pas dans le wiki. Elle ne dépend pas d’un programme ni d’un planning. Elle n’est pas non plus discutée chaque semaine avec l’équipe complète. Elle fait partie d’une vision qui s’est développée au cours du temps. Elle est portée par quelques personnes-clés qui indiquent le planning à court terme ainsi que les objectifs et elle est partagée par l’équipe. Mais elle n’a pas de date butoir ni de risque d’échouer. Elle est flexible et ne dépend de rien ni de personne en particulier. Et ça restera toujours un château en Espagne…
En conséquence, si vous voulez piloter un effort marketing pour une communauté de logiciel libre, faites en sorte que la vision d’ensemble reste une vision d’ensemble. Ne planifiez pas trop, mais faites en sorte que des choses se réalisent !
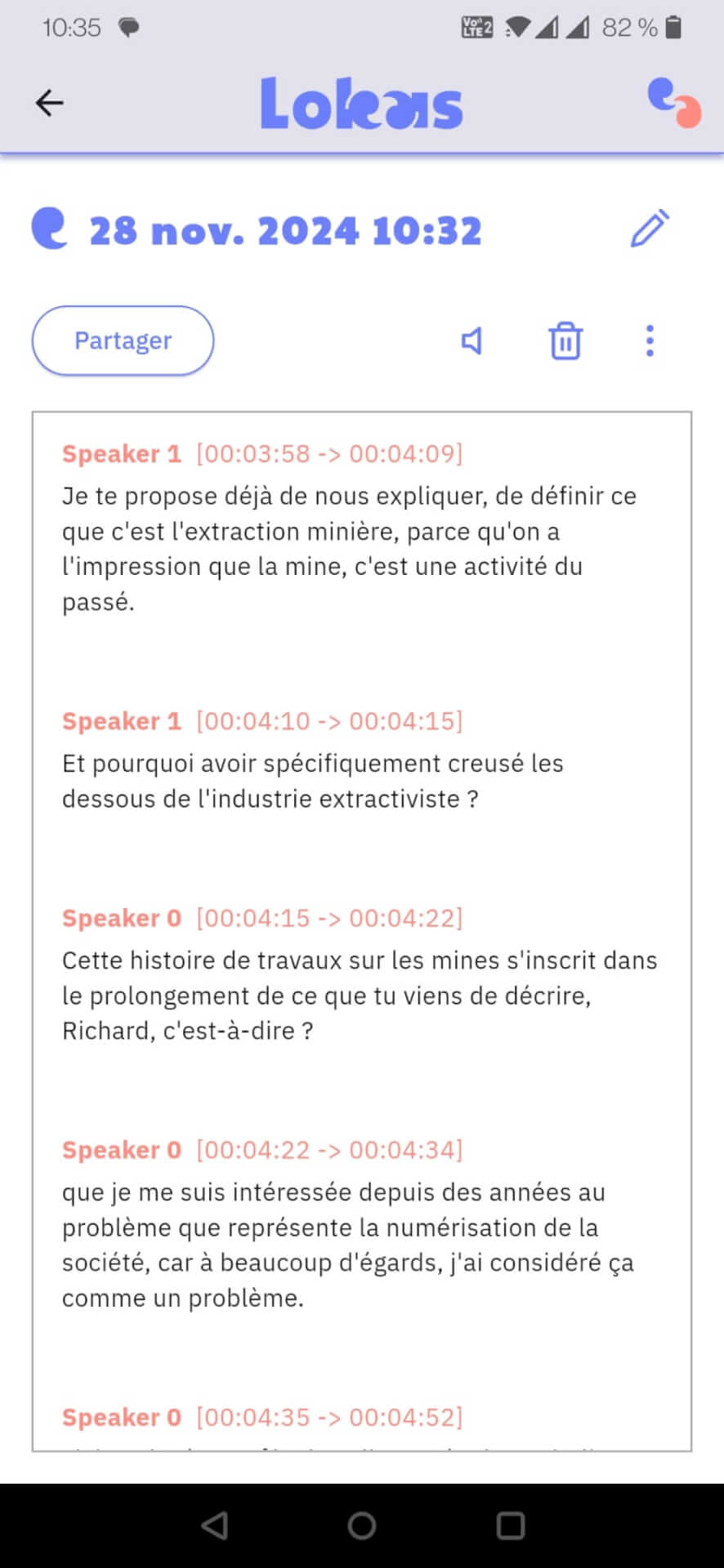
Lokas : l’app pour enregistrer et transcrire vos réunions en toute confidentialité
Framasoft vous propose d’essayer le prototype de Lokas, une nouvelle application de transcription « speech to text » qui respecte votre vie privée. Cette démo fonctionnelle est aussi une expérimentation de Framasoft dans le domaine de l’IA, accompagnée du site Framamia, que l’on présente ici.
🎈 Framasoft a 20 ans🎈 : Contribuez pour financer une 21e année !
Grâce à vos dons (défiscalisables à 66 %), l’association Framasoft agit depuis 20 ans pour faire avancer le Web éthique et convivial. Retrouvez un focus sur certaines de nos actions en 2024 sur le site Soutenir Framasoft.
➡️ Lire la série d’articles de cette campagne (nov. – déc. 2024)
Veuillez noter que cet article est aussi disponible en anglais.
Facilitez vos prises de notes avec Lokas
Lokas est une application (sur smartphone Android ou iOS) qui permet de transcrire le son de voix en fichier texte.
En gros, pour une réunion : vous mettez le téléphone au centre de la table, vous appuyez sur le bouton « Enregistrer » en début de réunion, sur « Arrêter » en fin de réunion, et l’application vous renvoie quelques minutes après un fichier texte reprenant les phrases prononcées par chacun et chacune.
Lokas permet et surtout permettra pas mal d’autres choses, mais nous y reviendrons en fin d’annonce.

Lokas, c’est pour qui ?
Lokas s’adresse à toute personne qui participe à des réunions. Autant dire un paquet de personnes sur la planète 🙂
Nous pouvons cependant partager quelques cas d’usages.
Premier exemple : une AG associative
Imaginons une Assemblée Générale associative. Il y a 15 personnes dans la pièce, 2 animateur⋅ices, 1 personne à la prise de notes. Et une réunion de 2H.
Les soucis :
- La prise de notes est épuisante
- La personne qui prend les notes voit sa participation limitée
- Les notes peuvent être incomplètes (un « trou » dû à une pause pipi)
Ce qu’apporte Lokas ?
Lokas permet d’assister la personne qui prend les notes, et lui permettra de participer plus facilement (tout en autorisant la pause pipi !).
Second exemple : un atelier avec des ados
Un atelier de l’association « Les petits débrouillards ». 3 groupes de 5 adolescent⋅es. Une majorité de filles dans les groupes.
Les soucis :
- La prise de notes peut être très compliquée
- Les garçons monopolisent la parole
Ce qu’apporte Lokas ?
Lokas permet de garder trace (sonore et écrite) de ce qu’il s’est dit. Et permet d’établir des statistiques de temps de paroles, notamment par genre, afin d’objectiver le fait que les garçons ne laissent que peu de temps de paroles aux filles.
Troisième exemple : une réunion de travail en visio, en langue étrangère
Votre collectif militant est proche d’une association espagnole. C’est Camille, une bénévole de votre collectif, qui parle à peu près l’espagnol, qui fera la visio avec son interlocutrice madrilène. La visio a donc lieu dans une langue étrangère.
Les soucis :
- Vous avez besoin de pouvoir réécouter à tête reposée
- Vous avez besoin d’une transcription en français et de la partager aux membres du C.A.
Ce qu’apporte Lokas ?
Avec Lokas, Camille pourra réécouter la visio, la transcrire automatiquement en français, et la partager depuis votre smartphone (par mail, via Signal, Matrix, WhatsApp, Telegram, etc).
L’IA n’est pas magique ✨. Lokas non plus 🤷.
Lokas n’est qu’un outil. Il peut vous assister dans la prise de notes. Cependant, comme tout outil, il ne doit pas vous dispenser d’utiliser votre cerveau !
L’invention de l’écriture (une autre technologie, très perfectionnée) date d’au moins 3 000 ans. Cela fait donc au moins aussi longtemps que l’humanité est capable de se réunir et de garder des traces écrites. Sans IA. Sans smartphone. Ne jetez pas plusieurs millénaires de techniques avec l’eau de l’IA. Un outil comme Lokas pourra être utile dans certains cas, et complètement gadget, voire improductif, dans d’autres cas. Cela n’est pas sans rappeler le concept de Pharmakon, cher au philosophe Bernard Stiegler : Lokas, comme tout objet technique, est à la fois poison, remède, et bouc-émissaire.
Par exemple le web est « à la fois un dispositif technologique associé permettant la participation et un système industriel dépossédant les internautes de leurs données pour les soumettre à un marketing omniprésent et individuellement tracé et ciblé par les technologies du user profiling. ». Remède et poison.
De la même façon, Lokas pourra être émancipateur (en facilitant la participation plutôt que la prise de notes), ou au contraire contraignant (les réunions un peu foutraques dans un bar bruyant ont aussi leur intérêt, il ne faudrait pas s’en passer parce que l’outil fonctionne mieux dans un environnement calme), ou frustrant (« l’application a planté, je n’ai aucune note de secours ! La technologie, c’est de la mârde ! »).
Lokas, comme une voiture, un marteau, un stylo, n’est pas un outil « neutre ». À vous de voir, collectivement, si vous souhaitez l’utiliser, et comment.

« C’est l’histoire d’une app… »
Il nous semble intéressant de pouvoir vous raconter comment est née l’application Lokas. C’est lever un coin de rideau sur les coulisses de Framasoft, comprendre comment nous pouvons prendre la décision de faire (ou de ne pas faire) tel ou tel projet. C’est aussi montrer que parfois, avec un peu de chance et d’huile de coude clavier, on peut faire des choses qui pourraient paraître impossibles. Cependant, comme cette partie n’est pas indispensable, on vous laisse le choix d’en prendre connaissance ou pas.
Cliquez ici pour lire (l’improbable et fabuleuse) histoire de Lokas
Cela fait bien trois ou quatre ans que l’idée de Lokas traîne dans la tête de pyg, membre de Framasoft.
L’idée de départ (nom de code : « Brewawa »), c’était surtout d’imaginer une application qui serait capable de calculer le temps de parole de locuteur⋅ices dans une réunion. Le but (pas du tout caché) était de démontrer facilement que lors d’une discussion avec des personnes de genres différents, ce sont de façon très très majoritairement les hommes qui monopolisent la conversation.
Différents essais ont été réalisés ces dernières années (coucou Gee, coucou bjnbvr !) pour étudier la faisabilité d’une telle application. Mais le fait est qu’en 2020, même si les possibilités techniques étaient présentes, elles n’étaient pas vraiment accessibles pour notre toute petite association, surtout sur un projet parallèle à tous ceux que Framasoft menait déjà.
« C’est l’histoire d’améliorations techniques… »
Cependant, avec le développement de logiciels tels que Vosk ou Whisper, les capacités de transcription audio (c’est-à-dire la capacité à transformer le son de phrases en texte) se sont largement améliorées.
À tel point qu’aujourd’hui, ces technologies sont utilisées par énormément de logiciels (de YouTube à PeerTube, en passant par BigBlueButton ou WhatsApp), et souvent même directement intégrée dans des appareils (Samsung en fait clairement un argument de vente).
Par ailleurs cette dernière décennie a aussi vu s’améliorer les processus de « diarisation ». Ce terme un peu barbare est en fait la technique qui permet d’identifier différent⋅es locuteur⋅ices dans une discussion. Par exemple, si Alex, Camille et Fred font une réunion, la diarisation saura attribuer à chacun⋅e les phrases qu’il ou elle aura prononcées (non, le logiciel ne va pas deviner le prénom de la personne, mais il saura – à peu près – identifier qu’il y avait trois participant⋅es, et dire « Cette phrase a été prononcée par la personne #1. Cette phrase a été prononcée par la personne #2. », etc.
C’est évidemment une phase essentielle pour pouvoir comprendre « qui a dit quoi » dans une réunion.
Ce processus est encore imparfait, mais s’améliore de mois en mois. Il faut donc se projeter en 2026 ou 2027 pour imaginer une diarisation vraiment fiable, mais elle est aujourd’hui « suffisante » dans 60 à 80% des usages en « bonnes conditions ».
« C’est l’histoire d’un alignement de planètes… »
Il se trouve qu’au sein de Framasoft, les compétences nécessaires pour le développement d’une telle application étaient réunies.
Chocobozzz, le développeur de PeerTube, avait déjà beaucoup travaillé sur le processus d’intégration de Whisper à PeerTube, afin de pouvoir générer automatiquement les sous-titres d’une vidéo. Il connait donc bien Whisper, ses options de configuration, ses performances, etc.
Wicklow, le développeur de l’application PeerTube, travaille depuis plusieurs mois avec le langage Dart et le SDK Flutter qui permet de développer en une seule base de code une application pour différents terminaux (Android, iPhone, ordinateur/tablette, web, etc).
Luc, notre administrateur système préféré (c’est pas compliqué, remarquez, nous n’en avons qu’un 😅) gère l’intégralité de l’infrastructure technique de Framasoft (une soixantaine de serveurs informatiques physiques). Donc, mettre en place la machine qui gère les transcriptions, l’installer, la sécuriser, etc, était pour lui un jeu d’enfant.
pyg, anciennement directeur de Framasoft, aujourd’hui coordinateur des services numériques de l’association, a géré d’innombrables projets pour Framasoft ces 20 dernières années. Alors, un de plus, même en pleine campagne, ça n’allait pas l’arrêter.
Entre cet ensemble de compétences, et les capacités techniques des logiciels de transcriptions et diarisation, les planètes étaient donc alignées pour lancer un tel projet.
« C’est une histoire de chance… »
Cependant, comme souvent, il faut un peu compter aussi sur le hasard ou la chance.
En effet, pyg avait un peu laissé tomber l’idée de cette application, tout simplement par ignorance des avancées techniques en termes de diarisation.
C’est en évoquant l’idée de cette application lors du dernier Framacamp, en juillet 2024, que Wicklow a lâché une info au détour de la conversation : « Ah, mais tu sais, Whisper fait maintenant une diarisation correcte. »
BIM 💣
« Ah, super intéressant ! Mais j’imagine qu’il faudrait longtemps pour développer une telle application de transcription libre ? » lui demanda pyg.
« Oh, je dirais qu’en 3 jours, je peux avoir un prototype fonctionnel si Chocobozzz se charge de la partie serveur. »
BOUM 💥
Autant vous dire qu’au lieu de profiter de sa soirée à jouer au poker, pyg a filé dans sa chambre, préparé une présentation d’une douzaine de diapositives sur un potentiel projet d’application, qu’il a présenté à l’association le lendemain matin.
Certain⋅es membres étaient enthousiastes, d’autres moins. Et on les comprend : d’une part, c’était encore ajouter du travail à une association déjà particulièrement chargée et épuisée ; d’autre part, c’était un projet utilisant un logiciel issu de l’intelligence artificielle, une technologie sur laquelle nous sommes (unanimement) très critiques.
Cependant, cette application, qui allait devenir Lokas, nous semblait un bon moyen « d’incarner » l’objet social de Framasoft : faire de l’éducation populaire aux enjeux du numérique et des communs culturels.
Cela nous permettait en effet de sortir de l’aspect discours pédagogique, à la fois indispensable, mais insuffisant en termes d’appropriation et d’autodétermination. En créant un « objet numérique manipulable », nous pouvions faire de Lokas une occasion complémentaire de faire comprendre ce qu’est l’IA, ses possibilités, mais aussi ses faiblesses. Et revenir, donc, à notre « Pharmakon » évoqué plus haut.
Par ailleurs, en plus de pouvoir assister tout collectif faisant des réunions, cela nous permettait de mettre en œuvre, concrètement, une application portant nos valeurs : un outil convivial, n’exploitant pas les données des utilisateur⋅ices, sous licence libre, s’adressant avant tout aux personnes qui changent le monde pour plus de progrès social et de justice sociale.
Au final, la majorité des membres présent⋅es s’est exprimée : « Banco la caravane ! On se lance ! ».
« C’est (aussi) une histoire de contraintes »
Comme évoqué plus haut, les contraintes étaient fortes.
Un projet, ça coûte forcément en temps et en argent. Du temps et de l’argent qui ne pourront pas être utilisés ailleurs.
Or, il ne vous a pas échappé que Framasoft vit des dons. Il faut donc faire des campagnes de dons. Et la fin de l’année était déjà particulièrement chargée par la finalisation de différents projets et leurs annonces
En discutant avec Thomas et Pouhiou, codirecteurs de l’association, il a donc été décidé que Lokas devrait rester un projet sous contraintes fortes : coûter moins de 10 000€ tout compris ; ne pas impacter fortement les missions de Chocobozzz, pyg, ou Wicklow ; être réalisé (à « temps perdu », donc) entre mi-septembre et mi-novembre (notamment à cause des délais de validation des stores Android et iOS, que nous ne maîtrisons pas).
Avec de telles contraintes, impossible pour nous de réaliser un produit bien finalisé. Nous avons donc décidé de viser plutôt la mise à disposition d’un prototype. Voyez ce prototype comme un appartement témoin. Nous avons produit cette version non pas en nous focalisant sur un projet de long terme, avec des fondations solides, mais plutôt comme une « preuve de concept », développée rapidement, pour voir si le concept est suffisamment attirant et intéressant pour qu’en 2025 nous priorisions le développement de cette application (si les dons sont suffisants, donc !).
Afin de vous donner suffisamment « envie » de voir un jour une version 1.0 de Lokas arriver, nous avons fait appel aux compétences de l’Atelier Domino pour la création d’un logotype et d’une charte graphique. Ce qui nous a guidés pour réalisé en interne le site web du projet : lokas.app
En parallèle, Wicklow et Chocobozzz se sont attaqués au développement du prototype, ainsi qu’à la partie serveur de transcription.
« C’est une histoire qui ne demande qu’à être écrite… »
Une quinzaine de jours de travail plus tard (et un coût estimé à 7 500€ tout compris, avec en gros moitié de temps de travail Framasoft, et moitié prestations : Atelier Domino, location du serveur, des noms de domaines, validation des stores), nous pouvons présenter, avec fierté et un peu d’anxiété, notre prototype !
Lokas, comment ça marche ?
1. Se mettre dans les bonnes conditions
Lokas, comme tous les outils de transcription, d’ailleurs, est imparfait. Des bruits extérieurs, une mauvaise articulation, une voix fluette en fond de salle, des personnes qui se coupent la parole… Autant de raisons qui peuvent nuire à la transcription.
En conséquence, prévoyez de vous mettre au calme, de placer le téléphone au centre de la table (meilleure est la qualité sonore, meilleure est la transcription), n’ayez pas plusieurs discussions en même temps, et… prenez des notes « à l’ancienne » à côté (papier+crayon, ordinateur+pad, etc) en cas de souci.
Une fois cela fait, le fonctionnement est très simple.

2. Lancer l’enregistrement
Cliquez simplement sur le bouton « Enregistrement ». Placez le téléphone de façon à ce qu’il puisse capter au mieux les échanges. Et commencez votre réunion.

Afin de limiter les abus, les enregistrements sont limités à 5 par jour et par appareil.
Notez que le modèle de langue géré par Lokas permet de l’utiliser d’ores et déjà dans une cinquantaine de langues, notamment : Néerlandais, espagnol, coréen, italien, allemand, thaïlandais, russe, portugais, polonais, indonésien, mandarin, suédois, tchèque, anglais, japonais et bien entendu français ! D’autres langues sont supportées, mais la reconnaissance sera moins performante.
À la fin de la réunion, cliquez sur « Finaliser ».
3. Envoyez votre fichier pour transcription (et patientez)
Vous pourrez éventuellement réécouter votre fichier avant de cliquer sur « Envoyer ».
Votre fichier est alors envoyé sur notre serveur où il sera placé dans la file d’attente pour sa transcription.
Cette étape pourra prendre de quelques minutes à quelques heures, suivant le nombre de fichiers en attente.
Vous pourrez vérifier manuellement si votre fichier a bien été transcrit, ou attendre tranquillement la notification (dont la tâche de vérification est exécutée toutes les 15mn)

Une fois la transcription reçue
Une fois la transcription reçue, vous pourrez l’afficher dans Lokas.
Vous pourrez évidemment la partager (avec l’application de votre choix : mail, Signal, WhatsApp, etc) pour la corriger.
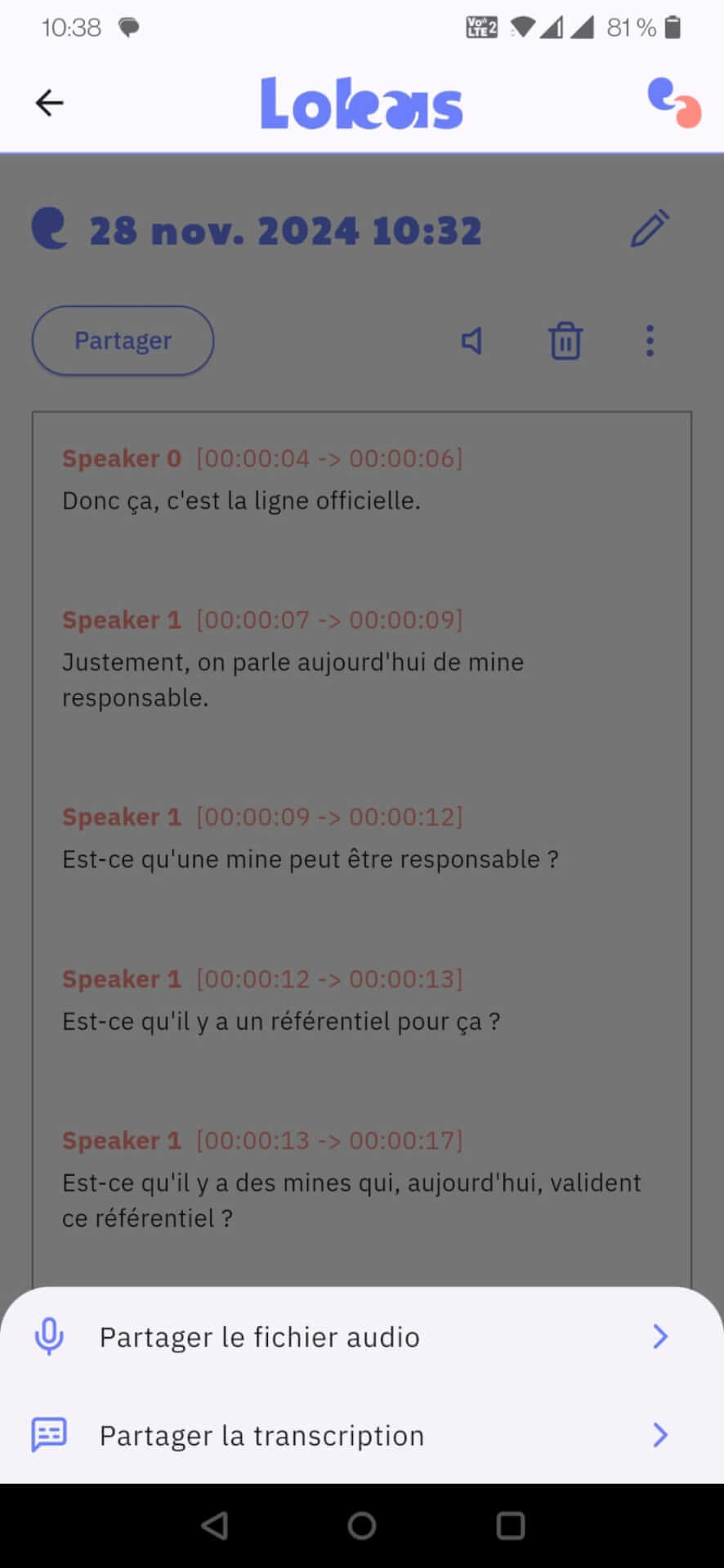
Vous pourrez aussi voir les statistiques de temps de parole (NB : cette fonctionnalité est relativement expérimentale). Si vous le souhaitez, pour une meilleure lecture des notes, vous pouvez attribuer un prénom (ou pseudo) aux participant⋅es. Pour obtenir des temps de parole par genre, vous pouvez aussi les attribuer manuellement, en vous assurant évidemment du consentement des personnes concernées à communiquer cette information. Notez que ces informations sont volontairement manuelles, et ne quittent pas votre téléphone, et ne sont donc pas transmises à Framasoft ou qui que ce soit.

Point confidentialité : l’une des particularités de Lokas est que nous respectons votre vie privée : le fichier audio est enregistré sur votre téléphone. Il est envoyé, à votre demande, sur nos serveurs, qui se chargeront alors de sa transcription. Une fois la transcription terminée, une notification est envoyée sur votre téléphone ; lorsque vous ouvrez (dans « Mes fichiers ») la réunion en question, la transcription est alors téléchargée sur votre téléphone. Une fois cette étape réalisée, et après un léger délai pour s’assurer que tout s’est bien passé techniquement, tout est supprimé de notre serveur : le fichier audio ainsi que la transcription. Par ailleurs, si vous attribuez des noms, pseudos ou genres, pour les statistiques, sachez que ces informations ne font l’objet d’aucun traitement de notre côté.
Et l’IA dans tout ça ?
À Framasoft, nous ne sommes pas fans du tout de l’IA. Nous pensons que cette technologie (ou plutôt cet ensemble de technologies), pose plus de problèmes qu’elle n’apporte de solutions. Nous avons d’ailleurs essayé de présenter une synthèse de notre position sur l’I.A. au sein du site Framamia, que nous présentons ici sur le Framablog.
Alors, n’est-ce pas contradictoire d’utiliser l’IA au sein d’applications Framasoft, comme Lokas ou PeerTube ?
À notre sens, non. Et ce pour plusieurs raisons.
D’abord, comme nous l’écrivions dans le site Framamia, tous les modèles d’intelligence artificielle ne se valent pas. Whisper, le logiciel qui sert à la transcription, est une IA « spécialisée », et non une IA « généraliste » comme ChatGPT par exemple.
« Les modèles spécialisés, quant à eux sont optimisés pour résoudre efficacement une tâche précise. Leur impact est souvent maîtrisé, et peut correspondre à celui d’un autre logiciel. ».
Framasoft, sur le site Framamia.org
Whisper est certes une IA, mais qui tourne « en vase clos » sur nos serveurs.
Les algorithmes utilisés sont plus complexes qu’un filtre « Enlève les yeux rouges de cette photo » avec GIMP ou Photoshop, mais cela reste un modèle relativement simple (avec un processus d’entrées/sorties) infiniment moins énergivore qu’un modèle d’entraînement. En effet, l’inférence (le processus d’utiliser le modèle pour effectuer une tâche) consomme bien moins d’énergie que l’entraînement. Par exemple, exécuter Whisper pour transcrire un fichier audio de quelques minutes nécessite une puissance de calcul relativement modeste.
Ensuite, un projet comme Lokas ne nécessite pas d’acheter 350 000 puces GPU pour 9 milliards de dollars, comme l’a fait récemment Meta/Facebook, ce qui représente en gros le PIB du Togo en 2023. Nous ne pensons pas participer à la croissance de la bulle financière autour de l’IA, ou à faire faire s’emballer le capitalisme algorithmique.
Enfin (et surtout), avec Lokas ou PeerTube, nous demeurons cohérent⋅es avec une des valeurs au cœur de Framasoft, à savoir le respect de la confidentialité de vos données. En effet, nous ne faisons aucune exploitation de vos fichiers, en dehors de la tâche explicitement demandée, par exemple la transcription. Elles ne servent pas à enrichir un modèle d’IA à partir de vos discussions, de votre identité, etc. Nous ne conservons pas les fichiers audio ou texte, nous n’avons pas accès aux noms/prénoms/genres que vous attribuez manuellement aux participant⋅es d’une discussion (ça reste sur votre téléphone), etc. Et, évidemment, vos données ne sont JAMAIS monétisées.
Bref, Framasoft se fiche du contenu de vos données, elles vous appartiennent et ne regardent que vous.
Malgré cela, nous respectons le point de vue des personnes qui souhaitent boycotter l’IA, et nous entendons la contradiction qu’iels pourraient trouver à ce qu’une asso technocritique comme Framasoft propose des projets utilisant l’I.A.
Notre objectif est justement de proposer un outil qui permette d’avoir une réflexion concrète, afin de se forger un avis autonome, permettant à chacun et chacune de se construire sa propre position.

Lokas c’est pour quand ?
Vous pouvez d’ores et déjà télécharger l’application Lokas sur le Play Store, iOS (toujours en testflight chez Apple, parce qu’ils sont 🤬… disons tatillons. EDIT : c’est maintenant disponible !), f-droid (en cours), ou avoir l’apk Android en téléchargement direct ici. Notez cependant que Lokas est un prototype (si ce n’est pas déjà fait, prenez deux minutes pour lire « L’histoire de Lokas » et comprendre pourquoi), et il est donc normal que plein plein plein de choses ne fonctionnent pas !
Nous avons déjà pris du temps, de l’énergie, et un peu d’argent sur des ressources pourtant limitées (on vous a déjà dit qu’on ne vivait que de vos dons ? 😉 ). De plus, comme toujours, le code est libre, nous l’avons publié ici sur notre forge logicielle.
Avant d’aller plus loin, nous avons donc besoin de confirmer que ce projet vous intéresse. Si les dons ne sont pas assez importants, ou si les contradictions sont trop fortes : nous nous arrêterons là. (le code est libre, donc ça ne sera pas « perdu »).
Si, par contre, vous trouvez ça pertinent, les possibilités de développements futurs sont innombrables. Citons par exemple :
- Reprendre complètement le design et l’accessibilité (en mode prototypage, nous sommes allé⋅es très vite, et Lokas est donc très perfectible) ;
- Possibilité de (re)transcrire le fichier de son choix (par exemple issu d’une vidéo ou d’une autre application) ;
- Ajouter un mode « web » à l’application. C’est à dire la possibilité d’utiliser Lokas depuis son ordinateur (sur le modèle de ce que fait le serveur Scribe de nos ami⋅es des Céméa) ;
- Ajouter la possibilité de synthèses automatiques des transcriptions, pour retrouver rapidement les points clés ;
- Traduire l’application (et le site web) dans d’autres langues que le français et l’anglais ;
- Possibilité d’éditer et corriger la transcription directement depuis votre téléphone ;
- Donner la possibilité d’obtenir la transcription dans la langue de son choix (par exemple une réunion en anglais, transcrite en français, ou l’inverse) ;
- etc
Mais pour cela, il va nous falloir du temps salarié, et donc de l’argent. Donc, au risque de paraître insistant, nous vous invitons, si vous le pouvez, à nous faire un don.
Faire une don pour soutenir Lokas
Le défi : 20 000 fois 20 € de dons pour les 20 ans de Framasoft !
Framasoft est financée par vos dons ! Chaque tranche de 20 euros de dons sera un nouveau ballon pour célébrer 20 d’aventures et nous aider à continuer et décoller une 21e année.
Framasoft, c’est un modèle solidaire :
- 8000 donatrices en 2023 ;
- plus de 2 millions de bénéficiaires chaque mois ;
- votre don (défiscalisable à 66 %) peut bénéficier à 249 autres personnes.

À ce jour, nous avons collecté 58 625 € sur notre objectif de campagne. Il nous reste 29 jours pour convaincre les copaines et récolter de quoi faire décoller Framasoft.
Alors : défi relevé ?
Lokas : Record and transcribe your meetings in complete confidentiality !
Framasoft invites you to try out the prototype of Lokas, a new speech-to-text transcription application that respects your privacy. This functional demo is also an experiment by Framasoft in the field of AI, accompanied by the Framamia website, which we present here (in French).
🎈Framasoft is 20 years old🎈 : Contribute to finance a 21st year!
Thanks to your donations (66% tax-free), the Framasoft association has been working for 20 years to advance the ethical and user-friendly Web. Find out more about some of our actions in 2024 on the Support Framasoftwebsite .
➡️ Read the series of articles from this campaign (Nov. – Dec. 2024)
Please note that this article is also available in French here.
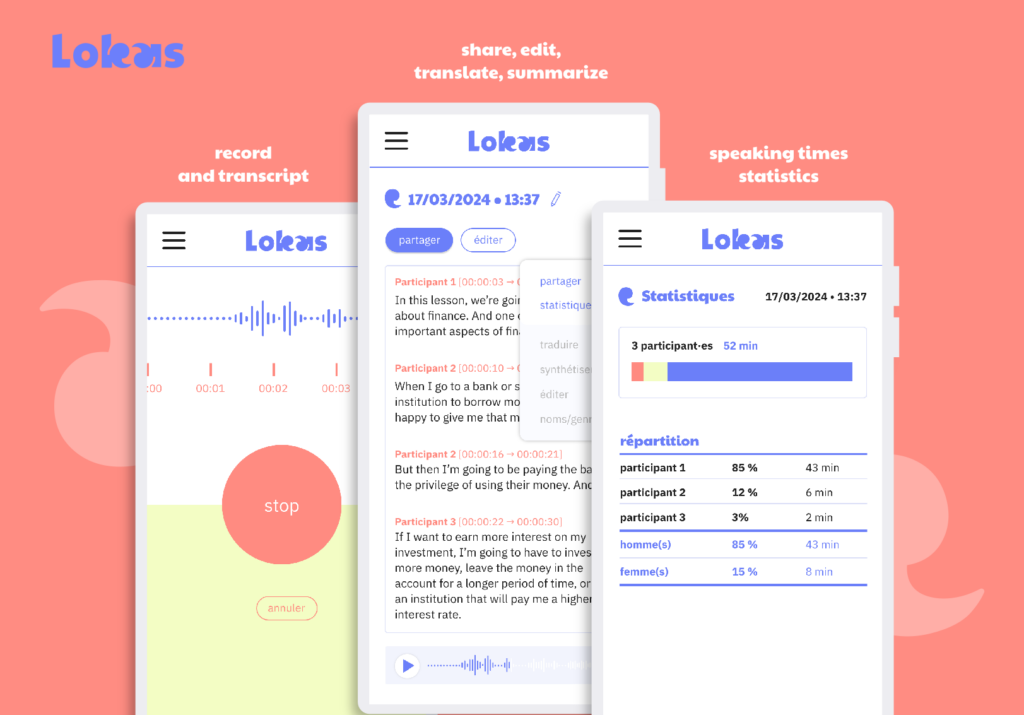
Make note-taking easier with Lokas
Lokas is an application (for Android or iOS smartphones) that allows you to transcribe the sound of your voice into a text file.
Basically, during a meeting: you put the phone in the middle of the table, press the ‘Record’ button at the start of the meeting and the ‘Stop’ button at the end. A few minutes later, the application sends you a text file containing the sentences spoken by everyone.
Lokas can and will do many more things, but we’ll come back to that at the end of this announcement.
Who is Lokas for?
Lokas is aimed at anyone who takes part in meetings. That’s a lot of people on the planet 🙂
However, we can share a few usecases.
First example: a nonprofit’s Annual General Meeting
Let’s imagine a nonprofit AGM. There are 15 people in the room, 2 moderators and 1 note taker. And a 2-hour meeting.
Concerns:
- Note-taking is exhausting
- The person taking the notes has limited participation
- The notes may be incomplete (a ‘blank’ due to a bathroom break).
What does Lokas offer?
Lokas assists the note-taker, making it easier for him or her to participate (while still allowing for a pee break!).
Example of a transcription of a voice exchange using the Lokas application.
Second example: a workshop with teenagers
A workshop run by the ‘ Les petits débrouillards ’ association. 3 groups of 5 teenagers. A majority of girls in the groups.
Concerns:
- Note-taking can be very complicated.
- Boys monopolise the floor
What does Lokas offer?
Lokas makes it possible to keep a record (audio and written) of what was said. It also makes it possible to compile statistics on speaking time, particularly by gender, so that we can see for ourselves that boys leave very little speaking time for girls.
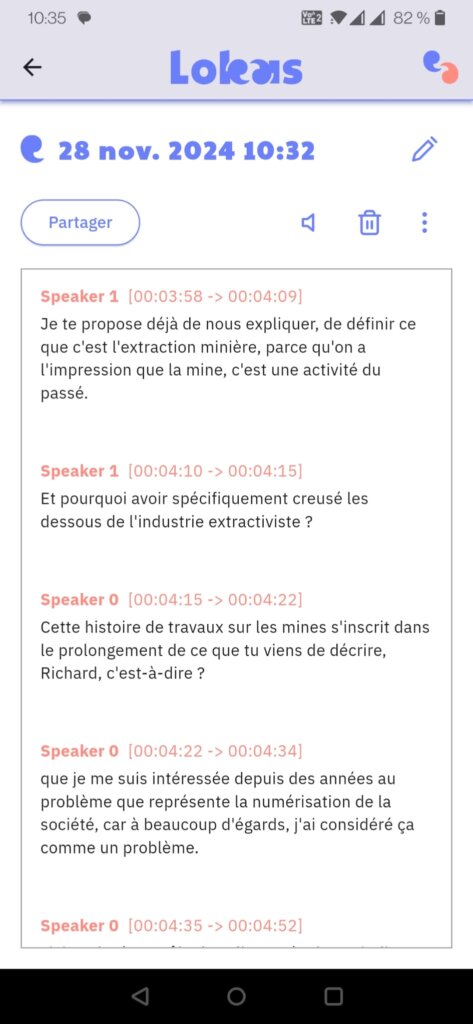
Third example: a video meeting in a foreign language
Your activist collective is close to a Spanish association. Camille, a volunteer from your group, who speaks a little Spanish, will be doing the video with her contact in Madrid. The video will therefore take place in a foreign language.
Concerns :
- You need to be able to listen again with your head down
- You need a French transcript to share with board members.
What does Lokas offer?
With Lokas, Camille will be able to listen to the video again, automatically transcribe it into French, and share it from your smartphone (by email, via Signal, Matrix, WhatsApp, Telegram, etc).
AI isn’t magic ✨. Neither is Lokas 🤷.
Lokas is just a tool. It can assist you in taking notes. However, like any tool, it shouldn’t exempt you from using your brain!
Writing (another highly sophisticated technology) was invented at least 3,000 years ago. So humanity has been able to get together and keep written records for at least that long. Without AI. Without smartphones. Don’t throw away several millennia of technology with the water of AI. A tool like Lokas could be useful in some cases, and completely gimmicky, even unproductive, in others. This is reminiscent of the concept of Pharmakon, a concept dear to the French philosopher Bernard Stiegler: Lokas, like any technical object, is simultaneously poison, remedy and scapegoat.
The web, for example, is both a technological device enabling participation, and an industrial system dispossessing Internet users of their data in order to subject them to omnipresent marketing that is individually traced and targeted by user profiling technologies.
In the same way, Lokas can be emancipating (by facilitating participation rather than note-taking), or on the contrary restrictive (meetings in a noisy bar can be interesting, but we shouldn’t do without them because the tool works better in a quiet environment), or frustrating (« The application has crashed, I don’t have any backup notes! Technology is shite! »)
Lokas, like a car, a hammer or a pen, is not a ‘neutral’ tool. It’s up to you, collectively, to decide whether and how you want to use it.
‘This is the story of an app…’
We thought it would be interesting to tell you how the Lokas app came about. It means lifting the curtain on what goes on behind the scenes at Framasoft, and understanding how we can decide to do (or not to do) such and such a project. It’s also about showing that sometimes, with a bit of luck and a bit of elbow keyboard, you can do things that might seem impossible. However, as this part is not essential, we’ll leave it up to you to decide whether or not you want to read it.
Click here to read the (improbable and fabulous) origin story of Lokas
The idea for Lokas has been in the head of pyg, a member of Framasoft, for three or four years now.
The original idea (code name: ‘ Brewawa ’) was mainly to come up with an application that would be able to calculate the speaking time of participants in a meeting. The (not at all hidden) aim was to easily demonstrate that during a discussion with people of different genders, it is overwhelmingly men who monopolise the conversation.
Various tests have been carried out in recent years (hi Gee, hi bnjbvr !) to study the feasibility of such an application. But the fact is that in 2020, even if the technical possibilities were there, they weren’t really available to our tiny association, especially on a project piling on all those that Framasoft was already carrying out.
‘It’s all about technical improvements…’.
However, with the evolution of softwares such as Vosk and Whisper, audio transcription capabilities (i.e. the ability to transform the sound of sentences into text) have considerably improved.
So much so that today, these technologies are used by a huge number of software applications (from YouTube and PeerTube to BigBlueButton and WhatsApp), and are often even integrated directly into devices (Samsung has clearly made this a selling point).
The last decade has also seen improvements in ‘diarization’ processes. This rather barbaric term is in fact the technique used to identify different⋅es speakers in a discussion. For example, if Alex, Camille and Fred are having a meeting, the diarization will know how to attribute to each their sentences (no, the software won’t guess the person’s first name, but it will know – more or less – identify that there were three participants, and say ‘This sentence was uttered by person #1. This sentence was said by person #2.’, etc.
This is obviously an essential phase in being able to understand ‘who said what’ in a meeting.
This process is still imperfect, but it is improving month by month. We therefore need to look ahead to 2026 or 2027 to imagine truly reliable diarization, but today it is ‘sufficient’ in 60 to 80% of uses under ‘good conditions’.
‘It’s the story of an alignment of planets…’.
It just so happened that Framasoft had the skills needed to develop such an application.
Chocobozzz, developer of PeerTube, had already worked hard on the process of integrating Whisper into PeerTube, in order to be able to automatically generate subtitles for a video. So he’s very familiar with Whisper, its configuration options, its performance and so on.
Wicklow, developer of the PeerTube application, has been working for several months with the Dart language and Flutter SDK, which enables an application to be developed for different terminals (Android, iPhone, computer/tablet, web, etc.) in a single code base.
Luc, our favourite system administrator (it’s not complicated, mind you, we only have the one 😅 ) manages Framasoft’s entire technical infrastructure (around sixty physical computer servers). So setting up the machine that manages the transcriptions, installing it, securing it, etc, was child’s play for him.
pyg, former director of Framasoft, now the association’s digital services coordinator, has managed countless projects for Framasoft over the last 20 years. So one more, even in the middle of a campaign, wasn’t going to stop him.
With this range of skills, and the technical capabilities of the transcription and diarization software, the planets were aligned to launch such a project.
‘It’s all about luck…’
However, as is often the case, you also have to rely a little on chance or luck.
Indeed, pyg had somewhat dropped the idea of this application, simply out of ignorance of the technical advances in terms of diarisation.
It was while discussing the idea of this application at the last Framacamp, in July 2024, that Wicklow dropped a piece of information in the nick of time: ‘Ah, but you know, Whisper now does proper diarization.’
BIM 💣
‘Ah, very interesting! But I imagine it would take a long time to develop such a free transcription application?’ asked pyg.
‘Oh, I’d say in 3 days I can have a working prototype if Chocobozzz takes care of the server part.’
BANG 💥
So instead of enjoying his evening playing poker, pyg went off to his room and prepared a presentation of a dozen slides on a potential application project, which he presented to the association the following morning.
Some members were enthusiastic, others less so. And we can understand them: first, because it was adding yet more work to an already particularly busy and exhausted association. More, this project would use software derived from artificial intelligence, a technology about which we are (unanimously) very critical.
However, this application, which was to become Lokas, seemed to us to be a good way of ‘embodying’ the social purpose of Framasoft: to educate the public about the challenges of digital technology and the cultural commons.
This enabled us to move away from the pedagogical aspect, which is both essential and insufficient in terms of appropriation and self-determination. By creating a ‘manipulable digital object’, we could use Lokas as an additional opportunity to explain what AI is, its possibilities, but also its weaknesses. And so return to our ‘Pharmakon’ mentioned above.
What’s more, as well as being able to assist any collective holding meetings, this enabled us to put into practice, in concrete terms, an application bearing our values: a user-friendly tool, not exploiting users data, under an open licence, aimed above all at people who are changing the world for more social progress and social justice.
In the end, the majority of members present said: ‘Let’s go for it!’.
‘It’s (also) a story of limits’.
As mentioned above, the constraints were considerable.
A project inevitably costs time and money. Time and money that can’t be used elsewhere.
As you know, Framasoft lives off donations. So we have to run donation campaigns. And the end of the year was already particularly busy with the finalisation of various projects and their announcements.
In discussions with Thomas and Pouhiou, co-directors of the association, it was decided that Lokas should remain a project subject to strict limitations: it should cost less than €10,000 all-included; it should not have a major impact on the missions of Chocobozzz, pyg or Wicklow; and it should be completed (in ‘wasted time’) between mid-September and mid-November (in particular because of the validation deadlines for the Android and iOS stores, which we don’t control).
With such constraints, it was impossible for us to produce a well-finished product. So we’ve decided to focus instead on making a prototype available. Think of this prototype as a showroom house. We’ve produced this version not by focusing on a long-term project, with solid foundations, but rather as a ‘proof of concept’, developed rapidly, to see if the concept is sufficiently attractive and interesting for us to priorise the development of this application in 2025 (if donations are sufficient, that is!).
To give you enough ‘desire’ to see a version 1.0 of Lokas arrive one day, we called on the skills of Atelier Domino to create a logotype and a graphic charter. This led us to create the project website in-house : lokas.app
At the same time, Wicklow and Chocobozzz set about developing the prototype and the transcription server.
‘It’s a story just waiting to be written…’.
A fortnight’s work later (and an estimated cost of €7,500 all-in, with roughly half the time spent by Framasoft and half on services: Domino workshop, server hire, domain names, validation of Google & Apple app stores), we can proudly and somewhat anxiously present our prototype!
How does Lokas work?
1. Get in the right conditions
Lokas, like all transcription tools, is imperfect. Outside noise, poor articulation, a faint voice in the background, people cutting each other off… These are just some of the reasons why transcription can be difficult.
As a result, plan to be in a quiet room, place the telephone in the centre of the table (the better the sound quality, the better the transcription), don’t hold several discussions at the same time, and… take ‘old-fashioned’ notes (paper+pencil, computer+pad, etc.) in case of problems.
Once you’ve done that, it’s very simple.
2. Start recording
Simply click on the ‘Record’ button. Position the phone so that it can best pick up the exchanges. And start your meeting.

To limit abuse, recordings are limited to 5 per day and per device.
Note that the language model managed by Lokas means that it can already be used in around fifty languages, including: Dutch, Spanish, Korean, Italian, German, Thai, Russian, Portuguese, Polish, Indonesian, Mandarin, Swedish, Czech, French, Japanese and, of course, English! Other languages are supported, but recognition will be less effective.
At the end of the meeting, click ‘Finish’.
3. Send your file for transcription (and be patient)
You may wish to listen to your file again before clicking on ‘Send’.
Your file will then be sent to our server where it will be queued for transcription.
This stage can take from a few minutes to a few hours, depending on the number of files in the queue.
You can check manually whether your file has been transcribed, or wait quietly for the notification (the verification task is carried out every 15 minutes).

Once the transcript has been received
Once you have received the transcript, you can display it in Lokas.
You can of course share it (with the application of your choice: email, Signal, WhatsApp, etc.) to correct it.
You can also see the speaking time statistics (NB: this feature is relatively experimental). If you wish, you can assign a first name (or pseudonym) to each participants to make it easier to read the notes. To obtain speaking times by gender, you can also allocate them manually, obviously ensuring that you have the consent of the people concerned to communicate this information. Note that this information is voluntarily manual, and does not leave your phone, and is therefore not transmitted to Framasoft nor anyone else.

Confidentiality point: one of the special features of Lokas is that we respect your privacy: the audio file is recorded on your phone. At your request, it is sent to our servers, which will then transcribe it. Once the transcription is complete, a notification is sent to your phone; when you open (in ‘My files’) the meeting in question, the transcription is then downloaded to your phone. Once this stage has been completed, and after a slight delay to ensure that everything has gone well technically, everything is deleted from our server: the audio file as well as the transcript. And if you give us names, pseudonyms or genres for statistical purposes, please note that we do not process this information in any way.
What about AI?
At Framasoft, we are not at all fans of AI. We think that this technology (or rather this set of technologies) poses more problems than it solves. In fact, we tried to summarise our position on AI on the Framamia website, which we present here on the Framablog (in French).
So, isn’t it contradictory to use AI in Framasoft applications such as Lokas or PeerTube?
In our opinion, no. For several reasons.
Firstly, as we wrote on the Framamia website, not all artificial intelligence models are created equal. Whisper, the software used for transcription, is a ‘specialised’ AI, not a ‘generalist’ AI like ChatGPT, for example.
‘Specialised models are optimised to solve a specific task efficiently. Their impact is often controlled, and may correspond to that of other software’.
Framasoft, on the Framamia.org website
Whisper is certainly an AI, but it runs ‘in isolation’ on our servers.
The algorithms used are more complex than a ‘Remove the red eyes from this photo’ filter with GIMP or Photoshop, but it remains a relatively simple model (with an input/output process) that uses infinitely less energy than a training model. In fact, inference (the process of using the model to perform a task) consumes much less energy than training. For example, running Whisper to transcribe an audio file lasting a few minutes requires relatively modest computing power.
Secondly, a project like Lokas does not require the purchase of 350,000 GPU chips for $9 billion, as Meta/Facebook recently did, which is roughly equivalent to Togo’s GDP in 2023. We don’t think we’ll be taking part in the growth of the AI financial bubble, or in the runaway growth of algorithmic capitalism.
Finally (and most importantly), with Lokas or PeerTube, we remain consistent with one of the values at the heart of Framasoft, namely respect for the confidentiality of your data. Indeed, we do not make any use of your files, apart from the task explicitly requested, for example transcription. They are not used to enrich an AI model based on your discussions, your identity, etc. We don’t keep audio or text files, we don’t have access to the names/first names/genders that you manually assign to participants⋅es in a discussion (that stays on your phone), etc. And, of course, your data is NEVER monetised.
In short, Framasoft doesn’t care about the content of your data, it belongs to you and is nobody’s business but yours.
Despite this, we respect the point of view of people who wish to boycott AI, and we understand the contradiction they might find in a technocritical association like Framasoft proposing projects using AI.
Our aim is to offer a tool that will enable people to think about the issues in a concrete way, so that they can form their own opinions and come to their own conclusions.
When is Lokas coming?
You can Download the Lokas app on the Play Store, iOS (still in TestFlight on iOS, because they are 🤬… let’s say picky EDIT : it’s now available), (and soon on f-droid), or get the android apk directly from us here. But keep in mind it is a prototype (if you haven’t already, take two minutes to read ‘The Lokas Story ’ and understand why), so it’s normal that lots and lots of things don’t work!
We’ve already taken time, energy and a bit of money out of limited resources (did anyone ever tell you that we only live off your donations? 😉 ). And, obviously, this POC is open source, the code is publish here on our forge.
So before going any further, we need to confirm that you are interested in this project. If the donations aren’t big enough, or if the contradictions are too strong: we’ll stop there (the code is free, so it won’t be ‘lost’).
If, on the other hand, you find it relevant, there are countless possibilities for future developments. For example:
- Complete redesign and accessibility (in prototyping mode, we went very fast, and Lokas is therefore very perfectible);
- Ability to (re)transcribe the file of your choice (from Lokas, a video or another application, for example);
- Add a ‘web’ mode to the application. This means you can use Lokas from your computer (similar to the Scribe server used by our friends at the Céméa);
- Add the possibility of automatic summaries of the transcripts, to quickly find the key points;
- Translate the application (and the website) into languages other than French and English;
- Ability to edit and correct the transcript directly from your phone;
- Provide the option of obtaining the transcript in the language of your choice (e.g. a meeting in English transcribed into French, or vice versa);
- etc
But to do this, we’re going to need some staff time, and therefore money. So, at the risk of sounding insistent, we invite you, if you can, to make a donation.
Make a donation to support Lokas
The challenge: 20,000 times €20 donations for Framasoft’s 20th anniversary!
Framasoft is funded by your donations! Every €20 you donate will be a new balloon to celebrate 20 years of adventures and help us continue and take off for a21st year.
Framasoft is a model of solidarity:
- 8,000 donors in 2023 ;
- over 2 million beneficiaries every month;
- your donation (66% tax deductible) can benefit 249 other people.
To date, we have raised €58,625 of our campaign target. We still have 29 days to convince our friends and raise enough money to get Framasoft off the ground.
So, challenge accepted?
L’IA Open Source existe-t-elle vraiment ?
À l’heure où tous les mastodontes du numérique, GAFAM comme instituts de recherche comme nouveaux entrants financés par le capital risque se mettent à publier des modèles en masse (la plateforme Hugging Face a ainsi dépassé le million de modèles déposés le mois dernier), la question du caractère « open-source » de l’IA se pose de plus en plus.
Ainsi, l’Open Source Initiative (OSI) vient de publier une première définition de l’IA Open-Source, et la Linux Foundation (dont le nom peut prêter à confusion, mais qui ne représente surtout qu’une oligarchie d’entreprises du secteur) s’interroge également sur le terme.
Au milieu de tout cela, OpenAI devient de manière assez prévisible de moins en moins « open », et si Zuckerberg et Meta s’efforcent de jouer la carte de la transparence en devenant des hérauts de l’« IA Open-Source », c’est justement l’OSI qui leur met des bâtons dans les roues en ayant une vision différente de ce que devrait être une IA Open-Source, avec en particulier un pré-requis plus élevé sur la transparence des données d’entraînement.
Néanmoins, la définition de l’OSI, si elle embête un peu certaines entreprises, manque selon la personne ayant écrit ce billet (dont le pseudo est « tante ») d’un élément assez essentiel, au point qu’elle se demande si « l’IA open source existe-t-elle vraiment ? ».
Note : L’article originel a été publié avant la sortie du texte final de l’OSI, mais celui-ci n’a semble t-il pas changé entre la version RC1 et la version finale.
L’IA Open Source existe-t-elle vraiment ?
Par tante, sous licence CC BY-SA (article originel).
Une traduction Framalang par tcit et deux contributeur·ices anonymes.
Photo de la bannière par Robert Couse-Baker.
L’Open Source Initiative (OSI) a publié la RC1 (« Release Candidate 1 » signifiant : cet écrit est pratiquement terminé et sera publié en tant que tel à moins que quelque chose de catastrophique ne se produise) de la « Définition de l’IA Open Source ».
D’aucuns pourraient se demander en quoi cela est important. Plein de personnes écrivent sur l’IA, qu’est-ce que cela apporte de plus ? C’est la principale activité sur LinkedIn à l’heure actuelle. Mais l’OSI joue un rôle très particulier dans l’écosystème des logiciels libres. En effet, l’open source n’est pas seulement basé sur le fait que l’on peut voir le code, mais aussi sur la licence sous laquelle le code est distribué : Vous pouvez obtenir du code que vous pouvez voir mais que vous n’êtes pas autorisé à modifier (pensez au débat sur la publication récente de celui de WinAMP). L’OSI s’est essentiellement chargée de définir parmi les différentes licences utilisées partout lesquelles sont réellement « open source » et lesquelles sont assorties de restrictions qui sapent cette idée.
C’est très important : le choix d’une licence est un acte politique lourd de conséquences. Elle peut autoriser ou interdire différents modes d’interaction avec un objet ou imposer certaines conditions d’utilisation. La célèbre GPL, par exemple, vous permet de prendre le code mais vous oblige à publier vos propres modifications. D’autres licences n’imposent pas cette exigence. Le choix d’une licence a des effets tangibles.
Petit aparté : « open source » est déjà un terme un peu problématique, c’est (à mon avis) une façon de dépolitiser l’idée de « Logiciel libre ». Les deux partagent certaines idées, mais là où « open source » encadre les choses d’une manière plus pragmatique « les entreprises veulent savoir quel code elles peuvent utiliser », le logiciel libre a toujours été un mouvement plus politique qui défend les droits et la liberté de l’utilisateur. C’est une idée qui a probablement été le plus abimée par les figures les plus visibles de cet espace et qui devraient aujourd’hui s’effacer.
Qu’est-ce qui fait qu’une chose est « open source » ? L’OSI en dresse une courte liste. Vous pouvez la lire rapidement, mais concentrons-nous sur le point 2 : le code source :
Le programme doit inclure le code source et doit permettre la distribution du code source et de la version compilée. Lorsqu’une quelconque forme d’un produit n’est pas distribuée avec le code source, il doit exister un moyen bien connu d’obtenir le code source pour un coût de reproduction raisonnable, de préférence en le téléchargeant gratuitement sur Internet. Le code source doit être la forme préférée sous laquelle un programmeur modifierait le programme. Le code source délibérément obscurci n’est pas autorisé. Les formes intermédiaires telles que la sortie d’un préprocesseur ou d’un traducteur ne sont pas autorisées.
Open Source Initiative
Pour être open source, un logiciel doit donc être accompagné de ses sources. D’accord, ce n’est pas surprenant. Mais les rédacteurs ont vu pas mal de conneries et ont donc ajouté que le code obfusqué (c’est-à-dire le code qui a été manipulé pour être illisible) ou les formes intermédiaires (c’est-à-dire que vous n’obtenez pas les sources réelles mais quelque chose qui a déjà été traité) ne sont pas autorisés. Très bien. C’est logique. Mais pourquoi les gens s’intéressent-ils aux sources ?
Les sources de la vérité
L’open source est un phénomène de masse relativement récent. Nous avions déjà des logiciels, et même certains pour lesquels nous ne devions pas payer. À l’époque, on les appelait des « Freeware », des « logiciels gratuits ». Les freewares sont des logiciels que vous pouvez utiliser gratuitement mais dont vous n’obtenez pas le code source. Vous ne pouvez pas modifier le programme (légalement), vous ne pouvez pas l’auditer, vous ne pouvez pas le compléter. Mais il est gratuit. Et il y avait beaucoup de cela dans ma jeunesse. WinAMP, le lecteur audio dont j’ai parlé plus haut, était un freeware et tout le monde l’utilisait. Alors pourquoi se préoccuper des sources ?
Pour certains, il s’agissait de pouvoir modifier les outils plus facilement, surtout si le responsable du logiciel ne travaillait plus vraiment dessus ou commençait à ajouter toutes sortes de choses avec lesquelles ils n’étaient pas d’accord (pensez à tous ces logiciels propriétaires que vous devez utiliser aujourd’hui pour le travail et qui contiennent de l’IA derrière tous les autres boutons). Mais il n’y a pas que les demandes de fonctionnalités. Il y a aussi la confiance.
Lorsque j’utilise un logiciel, je dois faire confiance aux personnes qui l’ont écrit. Leur faire confiance pour qu’ils fassent du bon travail, pour qu’ils créent des logiciels fiables et robustes. Qu’ils n’ajoutent que les fonctionnalités décrites dans la documentation et rien de caché, de potentiellement nuisible.
Les questions de confiance sont de plus en plus importantes, d’autant plus qu’une grande partie de notre vie réelle repose sur des infrastructures numériques. Nous savons tous que nos infrastructures doivent comporter des algorithmes de chiffrement entièrement ouverts, évalués par des pairs et testés sur le terrain, afin que nos communications soient à l’abri de tout danger.
L’open source est – en particulier pour les systèmes et infrastructures critiques – un élément clé de l’établissement de cette confiance : Parce que vous voulez que (quelqu’un) soit en mesure de vérifier ce qui se passe. On assiste depuis longtemps à une poussée en faveur d’une plus grande reproductibilité des processus de construction. Ces processus de compilation garantissent essentiellement qu’avec le même code d’entrée, on obtient le même résultat compilé. Cela signifie que si vous voulez savoir si quelqu’un vous a vraiment livré exactement ce qu’il a dit, vous pouvez le vérifier. Parce que votre processus de construction créerait un artefact identique.

Le projet est notamment financé par le Sovereign Tech Fund.
Bien entendu, tout le monde n’effectue pas ce niveau d’analyse. Et encore moins de personnes n’utilisent que des logiciels issus de processus de construction reproductibles – surtout si l’on considère que de nombreux logiciels ne sont pas compilés aujourd’hui. Mais les relations sont plus nuancées que le code et la confiance est une relation : si vous me parlez ouvertement de votre code et de la manière dont la version binaire a été construite, il me sera beaucoup plus facile de vous faire confiance. Savoir ce que contient le logiciel que j’exécute sur la machine qui contient également mes relevés bancaires ou mes clés de chiffrement.
Mais quel est le rapport avec l’IA ?
Les systèmes d’IA et les 4 libertés
Les systèmes d’IA sont un peu particuliers. En effet, les systèmes d’IA – en particulier les grands systèmes qui fascinent tout le monde – ne contiennent pas beaucoup de code par rapport à leur taille. La mise en œuvre d’un réseau neuronal se résume à quelques centaines de lignes de Python, par exemple. Un « système d’IA » ne consiste pas seulement en du code, mais en un grand nombre de paramètres et de données.
Un LLM moderne (ou un générateur d’images) se compose d’un peu de code. Vous avez également besoin d’une architecture de réseau, c’est-à-dire de la configuration des neurones numériques utilisés et de la manière dont ils sont connectés. Cette architecture est ensuite paramétrée avec ce que l’on appelle les « poids » (weights), qui sont les milliards de chiffres dont vous avez besoin pour que le système fasse quelque chose. Mais ce n’est pas tout.
Pour traduire des syllabes ou des mots en nombres qu’une « IA » peut consommer, vous avez besoin d’une intégration, une sorte de table de recherche qui vous indique à quel « jeton » (token) correspond le nombre « 227 ». Si vous prenez le même réseau neuronal mais que vous lui appliquez une intégration différente de celle avec laquelle il a été formé, tout tomberait à l’eau. Les structures ne correspondraient pas.

{kind=link}
Ensuite, il y a le processus de formation, c’est-à-dire le processus qui a créé tous les « poids ». Pour entraîner une « IA », vous lui fournissez toutes les données que vous pouvez trouver et, après des millions et des milliards d’itérations, les poids commencent à émerger et à se cristalliser. Le processus de formation, les données utilisées et la manière dont elles le sont sont essentiels pour comprendre les capacités et les problèmes d’un système d’apprentissage automatique : si vous voulez réduire les dommages dans un réseau, vous devez savoir s’il a été formé sur Valeurs Actuelles ou non, pour donner un exemple.
Et c’est là qu’est le problème.
L’OSI « The Open Source AI Definition – 1.0-RC1 » exige d’une IA open source qu’elle offre quatre libertés à ses utilisateurs :
- Utiliser le système à n’importe quelle fin et sans avoir à demander la permission.
- Étudier le fonctionnement du système et inspecter ses composants.
- Modifier le système dans n’importe quel but, y compris pour changer ses résultats.
- Partager le système pour que d’autres puissent l’utiliser, avec ou sans modifications, dans n’importe quel but.
Jusqu’ici tout va bien. Cela semble raisonnable, n’est-ce pas ? Vous pouvez inspecter, modifier, utiliser et tout ça. Génial. Tout est couvert dans les moindre détails, n’est-ce pas ? Voyons rapidement ce qu’un système d’IA doit offrir. Le code : Check. Les paramètres du modèle (poids, configurations) : Check ! Nous sommes sur la bonne voie. Qu’en est-il des données ?
Informations sur les données : Informations suffisamment détaillées sur les données utilisées pour entraîner le système, de manière à ce qu’une personne compétente puisse construire un système substantiellement équivalent. Les informations sur les données sont mises à disposition dans des conditions approuvées par l’OSI.
En particulier, cela doit inclure (1) une description détaillée de toutes les données utilisées pour la formation, y compris (le cas échéant) des données non partageables, indiquant la provenance des données, leur portée et leurs caractéristiques, la manière dont les données ont été obtenues et sélectionnées, les procédures d’étiquetage et les méthodes de nettoyage des données ; (2) une liste de toutes les données de formation accessibles au public et l’endroit où les obtenir ; et (3) une liste de toutes les données de formation pouvant être obtenues auprès de tiers et l’endroit où les obtenir, y compris à titre onéreux.
Open Source Initiative
Que signifie « informations suffisamment détaillées » ? La définition de l’open source ne parle jamais de « code source suffisamment détaillé ». Vous devez obtenir le code source. Tout le code source. Et pas sous une forme obscurcie ou déformée. Le vrai code. Sinon, cela ne veut pas dire grand-chose et ne permet pas d’instaurer la confiance.
La définition de l’« IA Open Source » donnée par l’OSI porte un grand coup à l’idée d’open source : en rendant une partie essentielle du modèle (les données d’entraînement) particulière de cette manière étrange et bancale, ils qualifient d’« open source » toutes sortes de choses qui ne le sont pas vraiment, sur la base de leur propre définition de ce qu’est l’open source et de ce à quoi elle sert.
Les données d’apprentissage d’un système d’IA font à toutes fins utiles partie de son « code ». Elles sont aussi pertinentes pour le fonctionnement du modèle que le code littéral. Pour les systèmes d’IA, elles le sont probablement encore plus, car le code n’est qu’une opération matricielle générique avec des illusions de grandeur.
L’OSI met une autre cerise sur le gâteau : les utilisateurs méritent une description des « données non partageables » qui ont été utilisées pour entraîner un modèle. Qu’est-ce que c’est ? Appliquons cela au code à nouveau : si un produit logiciel nous donne une partie essentielle de ses fonctionnalités simplement sous la forme d’un artefact compilé et nous jure ensuite que tout est totalement franc et honnête, mais que le code n’est pas « partageable », nous n’appellerions pas ce logiciel « open source ». Parce qu’il n’ouvre pas toutes les sources.
Une « description » de données partiellement « non partageables » vous aide-t-elle à reproduire le modèle ? Non. Vous pouvez essayer de reconstruire le modèle et il peut sembler un peu similaire, mais il est significativement différent. Cela vous aide-t-il d’« étudier le système et d’inspecter ses composants » ? Seulement à un niveau superficiel. Mais si vous voulez vraiment analyser ce qu’il y a dans la boîte de statistiques magiques, vous devez savoir ce qu’il y a dedans. Qu’est-ce qui a été filtré exactement, qu’est-ce qui est entré ?
Cette définition semble très étrange venant de l’OSI, n’est-ce pas ? De toute évidence, cela va à l’encontre des idées fondamentales de ce que les gens pensent que l’open source est et devrait être. Alors pourquoi le faire ?
L’IA (non) open source
Voici le truc. À l’échelle où nous parlons aujourd’hui de ces systèmes statistiques en tant qu’« IA », l’IA open source ne peut pas exister.
De nombreux modèles plus petits ont été entraînés sur des ensembles de données publics explicitement sélectionnés et organisés. Ceux-ci peuvent fournir toutes les données, tout le code, tous les processus et peuvent être appelés IA open-source. Mais ce ne sont pas ces systèmes qui font s’envoler l’action de NVIDIA.
Ces grands systèmes que l’on appelle « IA » – qu’ils soient destinés à la génération d’images, de texte ou multimodaux – sont tous basés sur du matériel acquis et utilisé illégalement. Parce que les ensembles de données sont trop volumineux pour effectuer un filtrage réel et garantir leur légalité. C’est tout simplement trop.
Maintenant, les plus naïfs d’entre vous pourraient se demander : « D’accord, mais si vous ne pouvez pas le faire légalement, comment pouvez-vous prétendre qu’il s’agit d’une entreprise légitime ? » et vous auriez raison, mais nous vivons aussi dans un monde étrange où l’espoir qu’une innovation magique et / ou de l’argent viendront de la reproduction de messages Reddit, sauvant notre économie et notre progrès.
L’« IA open source » est une tentative de « blanchir » les systèmes propriétaires. Dans leur article « Repenser l’IA générative open source : l’openwashing et le règlement sur l’IA de l’UE », Andreas Liesenfeld et Mark Dingemanse ont montré que de nombreux modèles d’IA « Open-Source » n’offrent guère plus que des poids de modèles ouverts. Signification : Vous pouvez faire fonctionner la chose mais vous ne savez pas vraiment ce que c’est.
Cela ressemble à quelque chose que nous avons déjà eu : c’est un freeware. Les modèles open source que nous voyons aujourd’hui sont des blobs freeware propriétaires. Ce qui est potentiellement un peu mieux que l’approche totalement fermée d’OpenAI, mais seulement un peu.
Certains modèles proposent des fiches de présentation du modèle ou d’autres documents, mais la plupart vous laissent dans l’ignorance. Cela s’explique par le fait que la plupart de ces modèles sont développés par des entreprises financées par le capital-risque qui ont besoin d’une voie théorique vers la monétisation.
L’« open source » est devenu un autocollant comme le « Commerce équitable », quelque chose qui donne l’impression que votre produit est bon et digne de confiance. Pour le positionner en dehors du diabolique espace commercial, en lui donnant un sentiment de proximité. « Nous sommes dans le même bateau » et tout le reste. Mais ce n’est pas le cas. Nous ne sommes pas dans le même bateau que Mark fucking Zuckerberg, même s’il distribue gratuitement des poids de LLM parce que cela nuit à ses concurrents. Nous, en tant que personnes normales vivant sur cette planète qui ne cesse de se réchauffer, ne sommes avec aucune de ces personnes.

Mais il y a un autre aspect à cette question, en dehors de redorer l’image des grands noms de la technologie et de leurs entreprises. Il s’agit de la légalité. Au moins en Allemagne, il existe des exceptions à certaines lois qui concernent normalement les auteurs de LLM : si vous le faites à des fins de recherche, vous êtes autorisé à récupérer pratiquement n’importe quoi. Vous pouvez ensuite entraîner des modèles et publier ces poids, et même s’il y a des contenus de Disney là-dedans, vous n’avez rien à craindre. C’est là que l’idée de l’IA open source joue un rôle important : il s’agit d’un moyen de légitimer un comportement probablement illégal par le biais de l’openwashing : en tant qu’entreprise, vous prenez de l’« IA open source » qui est basée sur tous les éléments que vous ne seriez pas légalement autorisé à toucher et vous l’utilisez pour construire votre produit. Faites de l’entraînement supplémentaire avec des données sous licence, par exemple.
L’Open Source Initiative a attrapé le syndrome FOMO (N.d.T : Fear of Missing Out) – tout comme le jury du prix Nobel. Elle souhaite également participer à l’engouement pour l’« IA ».
Mais pour les systèmes que nous appelons aujourd’hui « IA », l’IA open source n’est pas possible dans la pratique. En effet, nous ne pourrons jamais télécharger toutes les données d’entraînement réelles.
« Mais tante, nous n’aurons jamais d’IA open source ». C’est tout à fait exact. C’est ainsi que fonctionne la réalité. Si vous ne pouvez pas remplir les critères d’une catégorie, vous n’appartenez pas à cette catégorie. La solution n’est pas de changer les critères. C’est comme jouer aux échecs avec les pigeons.
Zikapanam : une asso de musiciens amateurs qui organise des jams
Depuis plusieurs années, nous publions régulièrement (tant que faire se peut du moins !) des articles témoignant de la dégafamisation de structures associatives ou relevant de l’économie sociale et solidaire. Dans le cadre du lancement de emancipasso.org, notre nouvelle initiative pour accompagner les associations vers un numérique plus éthique (lire l’article de lancement), nous avons eu envie de reprendre la publication de ces témoignages.
Pour ce faire, nous avons lancé un appel à participation sur nos réseaux sociaux et quelques structures nous ont répondu (vous pouvez continuer à le faire en nous contactant) ! Nous sommes donc ravis de reprendre une nouvelle série d’articles de dégafamisation avec aujourd’hui le témoignage de Zikapanam, qui organise et participe à des jams, répétitions, scènes ouvertes et concerts. Merci à Laurent pour son témoignage riche, et bonne lecture !


La nouvelle #solarpunk du jour : « Archipel »
Pour la deuxième fois, Framasoft participe, au sein de l’Université de Technologie de Compiègne (UTC), à une semaine de cours sur le thème des lowtechs et du Solarpunk.
Les étudiant⋅es ont pour mission d’écrire (sans se faire aider par l’I.A. !) des nouvelles dans cet univers, qui sont publiées ici et participeront à un concours organisé par Low-Tech Journal. Ces nouvelles ont été lues en direct sur la radio indépendante Graf’Hit. La lecture de cette nouvelle est écoutable ici :
Aujourd’hui, on fuit un monde dystopique pour découvrir une société organisée en villages interdépendants…
Archipel
Auteur·rices : MT, M, Paul, KC, Léa et Loul
Ce document est disponible sous licence CC-BY-SA.
— Bonjour Zaden, il est huit heures.
— Bonjour Alann, ouvre les volets, allume la lumière.
— Bien sûr ! Pour votre petit-déjeuner, souhaitez-vous de la confiture ?
— Du beurre. Ah ! Allume la salle de bain et lance la playlist.
— Tout de suite. Vos vêtements sont prêts, dans le tiroir du bas.
— Alann, quelles sont les nouvelles aujourd’hui ?
— Aujourd’hui 15 janvier 2042, 8h23, il fait 16°C et il pleut, la qualité de l’air est bonne. Le pic de particules epsilon se maintient au-dessus de la ville à cause d’un anticyclone. L’entreprise Tomaframe a annoncé le lancement des tests du projet ITER et le gouvernement déclare travailler sur l’exploitation durable des ressources aquifères du satellite Encelade.
— Merci, Alann. Il faut que j’y aille. Déverrouille la porte d’entrée.
— Zaden, avant que vous ne partiez, je viens de recevoir des informations à propos de votre ami Dariux.
— Hein ?

— Votre ami est décédé dans un accident de voiture hier soir.
Cette nouvelle m’assomme.
— Dis-moi où il est !
— Son corps a déjà été incinéré, je peux prévenir ses parents de votre arrivée si vous le voulez.
— D’accord, fais ça !
Déjà incinéré ? Mais pourquoi ? Jamais je n’ai parcouru le trajet reliant ma maison à celle de Dariux aussi rapidement. J’arrive devant sa porte mais quelque chose m’interpelle : elle est ouverte. Je m’interroge, cela pourrait être les militants écologistes de la TREV qui viennent encore faire pression sur la société de son père. Je glisse mon regard dans l’entrebâillement et je reconnais l’uniforme noir de deux membres du gouvernement ONAIME. Que peuvent-ils faire là ? Haletant, je m’approche sans faire de bruit.
« N’oubliez pas, les vraies circonstances de la mort de votre fils doivent rester secrètes… Tout ce que vous devez dire c’est que votre fils est mort d’un accident de voiture ». Cela me semble étrange. Qu’est-ce qu’il se passe ?
Les deux hommes continuent : « D’autant plus qu’un groupe TREV se rassemblerait sur le Belvédère. Il ne faudrait pas leur fournir un prétexte. »
Un prétexte à quoi ? Je ne comprends rien. Justement un tract du TREV a été collé sur le mur de la propriété. Je le reconnais, même si je ne les lis jamais. Cette fois j’en prends connaissance. « NOTRE GOUVERNEMENT NOUS MENT » dit-il. Bien que quelqu’un ait tenté de l’arracher, je peux déchiffrer ces quelques mots : epsilon, intoxication, écologie. La rage et l’incompréhension au ventre, je prends ma course. Je n’ai qu’une envie, celle de parler à une personne qui ne me mentira pas. Je n’entends plus que les battements de mon cœur à mesure que je me dirige vers le point culminant de la ville. Quelques personnes discutent. Une femme aux cheveux gris vient à ma rencontre, l’air soupçonneux.
— Bonjour, jeune homme. Tu t’es perdu ?
— Bonjour madame, c’est vous qui distribuez les tracts ? Mon ami est mort, et le gouvernement semble vouloir en dissimuler la cause… Ils ont aussi parlé de vous, je me suis dit que vous auriez peut-être des réponses.
Elle m’explique.
— Si le gouvernement s’en mêle, c’est sûrement que ton ami est mort à cause des particules epsilon.
Encore une pseudo-solution dite « verte » pour préserver cette maudite croissance.
— Alors Dariux serait mort à cause des epsilon ? Celles que le gouvernement juge inoffensives ? J’ai entendu les uniformes noirs. Ils savent que vous êtes là, c’est comme ça que je vous ai trouvés.
La femme alerte immédiatement ses amis.
— Il faut qu’on bouge ! Heureusement, ils sont lourdauds alors que nous, on voyage léger. Petit, tu peux venir avec nous si tu veux mais c’est maintenant !
D’autorité, le groupe m’embarque dans sa fuite.
°°°
Cela fait trois jours que nous marchons. Je suis éreinté. Manque d’entraînement. Nous arrivons enfin dans un camp. Une nommée Dalia nous accueille, nous fait visiter. Elle m’explique que leur société est constituée de plusieurs îlots d’individus organisés sous forme d’archipel.
— Ici nous sommes à Luton. Chaque îlot, ce que toi tu appelles « village », a des principes qui varient. Par exemple, ici nous ne renions pas totalement la technologie, mais nous la conservons dans son état, le plus lowtech possible. Dans l’îlot voisin, on vit encore plus proche de la nature. Ils refusent tout appareil électrique. Nos micro-sociétés sont interconnectées, communiquent entre elles et s’entraident pour répondre à des besoins communs. Tu savais que c’est comme cela que font les arbres ? Tu pourras choisir l’îlot dont les valeurs te correspondront le plus. Il y a tout de même trois enseignements communs que nous, archipéliens, nous efforçons d’honorer. Premièrement, respecter la Terre et toute forme de vie. Deuxièmement, partager. Troisièmement, ne pas retomber dans les pièges du passé. Bien sûr, chacun peut s’exprimer librement et nous votons pour des propositions formulées dans la « boite à idées ».

Bernard Spragg. NZ (CC0)
Nous traversons le Jardin commun, où plusieurs personnes de tous les âges s’affairent. Dalia salue un homme qui prépare des boutures. Un autre demande des informations à une jeune femme sur le fonctionnement technique du système de récupération d’eau en circuit fermé. Cette eau, une fois propre, est réutilisée dans le jardin, dans les habitations, partout. Je comprends que, malgré un solide bagage théorique, il vient chercher des compétences pratiques. L’entraide est un principe clé de cette civilisation.
C’est contraire à tout ce que j’ai pu vivre. De là où je viens, les connaissances étaient surtout descendantes, une personne enseignant à des centaines. Ici, le partage de connaissance est pluridisciplinaire et se fait lors de situations concrètes, en petits groupes.
— Au commencement, m’explique Dalia, nous n’étions qu’une dizaine ; chacun apportait son expertise dans son domaine. Cuisine, mécanique, organisation, bâtiment… Mais c’était limité. Aujourd’hui que nous sommes plus nombreux, nous avons gardé ce modèle et l’effet en est démultiplié.
— Pourquoi le savoir et les compétences ne seraient-ils pas communs à tous, de sorte qu’ils ne se perdent pas ?
— Poste ça dans la boite à idées, me taquine Dalia.
°°°
Cela fait maintenant cinq ans que je suis là. Je ne m’ennuie jamais. La communauté s’élargit. Nous sommes passés à dix îlots. Ma proposition s’est concrétisée, voici ALANN, l’Académie Libre pour l’Accès aux Nouvelles Notions. Nous y développons les solutions de demain en mettant l’accent sur la collaboration, l’accès libre aux savoirs et la pluralité des idées. Aujourd’hui j’y anime l’atelier panneaux solaires, pour réparer ceux que nous avons récupérés l’été dernier.
— Euh, Zaden… je comprends pas pourquoi ça ne marche pas.
— Il faut y aller pas à pas, Jorj. Regarde, une des cellules sur cette ligne est morte. Le plus simple, c’est d’en récupérer une bonne sur un panneau irréparable.
— D’accord, je vais chercher le fer à souder. On le fait ensemble ?
— Bien sûr !
J’ai moi-même appris les rudiments de l’électronique avec Dalia.
— J’y pense, Jorj, après je te montrerai comment on transforme un vieux panneau en chauffe-eau solaire. On en a besoin pour l’habitation du nouvel arrivant.
— J’suis partant !
Je trouve fascinant que les connaissances puissent ruisseler de façon aussi fluide entre les archipéliens. Depuis son arrivée dans l’îlot, j’ai assisté avec fierté à l’évolution de Jorj. Il déborde d’enthousiasme. Dariux était comme lui. Il aurait adoré cette vie. En préparant un petit sac dans ma chambre, je me souviens de ma première leçon : voyager léger. Demain, avec un groupe d’amis, on s’en va explorer les autres îlots. J’ai hâte.

La nouvelle #solarpunk du jour : « Le Compromis »
Pour la deuxième fois, Framasoft participe, au sein de l’Université de Technologie de Compiègne (UTC), à une semaine de cours sur le thème des lowtechs et du Solarpunk.
Les étudiant⋅es ont pour mission d’écrire (sans se faire aider par l’I.A. !) des nouvelles dans cet univers, qui sont publiées ici et participeront à un concours organisé par Low-Tech Journal. Ces nouvelles ont été lues en direct sur la radio indépendante Graf’Hit. La lecture de cette nouvelle est écoutable ici :
Aujourd’hui, nous assistons à un choc des générations et des modes de transports (plus ou moins) lowtechs…
Le Compromis
Auteur·rices : Mathéo, Chrisbé, Inas, Chanerle, Liu, Lénaeile
Ce document est disponible sous licence CC-BY-SA.
Chapitre 1 : Les retrouvailles
En 2032, André 65 ans, un jeune retraité des sociétés de chemins de fer profite d’une journée ensoleillée sur la terrasse de sa maison. Vieux de la vieille sur la mécanique des trains, André a passé quarante-quatre ans de sa vie à réparer des trains. Voyant défiler au fil des années, tous les types de trains du Gasoil à l’électrique. La retraite arrive à point nommé pour lui, qui veut se détacher du monde industriel et du transport de masse. Son fils, Jaurel, 25 ans, ingénieur en informatique fraîchement diplômé de l’université a rejoint ses parents pour l’été :
— Belle journée, pas vrai papa ?
— Tu l’as dit ! Tu as prévu des choses à faire pour aujourd’hui ?
— Je me disais que ça serait bien que nous allions à la plage. Cela fait longtemps, propose Jaurel.
— C’est bien vrai, la dernière fois, tu devais avoir 10 ans ! Je m’en souviens, tu avais ton petit bob rouge et tes lunettes de soleil rondes.
— Oui, mais surtout, ce jour-là, nous avions remporté le concours du château de sable. Que de bons souvenirs ! Je conduis, si tu veux, suggère Jaurel.
— Conduire ? Pourquoi pas en vélo ? Demande André, l’air assez surpris.
André se souvient que Jaurel a acheté une nouvelle voiture électrique. Bien que très jolie et confortable, André n’est pas totalement convaincu par cette solution. En effet, sa femme et lui ont subi les effets du réchauffement climatique. . La mer est entrée de plus de 20 kilomètres dans les terres et les cours d’eau ont débordé dans toute la région, e qui a failli tuer sa femme. Profondément marqué par cette catastrophe, André a adopté un mode de vie plus respectueux de l’environnement . Il a réduit son l’empreinte carbone et a favorisé les solutions durables.

— Tu ne veux pas qu’on y aille comme au bon vieux temps ? À vélo, en famille ? demande André.
— C’est loin, papa, ça va nous prendre au moins 2 heures à vélo. En plus, j’ai vu que la météo ne va pas rester comme ça . On prévoit de la pluie en milieu de journée.
En effet, la station balnéaire de Estra Kanté est située à 30 kilomètres du centre de la ville de Mutrus City.
— Nous avons le temps d’y réfléchir, il est encore tôt. Viens avec moi chercher de quoi manger ce midi. C’est à l’épicerie du centre, cela n’est pas trop loin pour toi, quand même ?
— Ne sois pas condescendant non plus, papa. Bien sûr que je viens.
André a l’habitude de marcher jusqu’à l’épicerie un matin sur deux pour faire ses courses. C’est une sorte de thérapie pour lui, qui est encore traumatisé.
en chemin la discussion se poursuit entre père et fils :
— Pourquoi est-ce que tu ne veux pas que je conduise ? Ça t’éviterait de faire des efforts sous cette chaleur, se questionne Jaurel.
— Je sais que je ne suis plus de toute jeunesse, mais je ne suis pas encore dans le cercueil, cher fils. Je pensais juste prendre un peu de temps avec toi comme avant, répond le père avec un sourire nostalgique.
— Je me doute, mais ça serait plus pratique en voiture,non ?
— Pour être franc, je ne suis pas convaincu par l’électrique. Tu le sais, en plus. Je comprends l’idée, mais est-ce vraiment la solution à nos problèmes actuels ?
— Eh bien, sans voiture, comment je fais pour mon travail, venir ici, voir mes amis ?
— C’est peut-être ça le problème, plutôt. Rien n’est à taille humaine.
Sur cette remarque, tous deux arrivent à l’épicerie du village. À l’entrée, ils rencontrent Christophe, un ami d’André. Christophe est un ancien agriculteur intensif qui dépendait lourdement des machines et des produits chimiques pour maximiser ses rendements. Plus tard, il s’est converti à une agriculture low-tech au vu des changements climatiques. Il est revenu à des méthodes simples et à la fois enrichies avec des connaissances modernes.
— Mon vieil André ! s’exclame Christophe. Tu te fais rare ces derniers temps ! Laisse-moi deviner, c’est le fiston Jaurès ?
— Pas loin, Jaurel ! Ah écoute, il faut que je m’habitue à tout ce temps libre que j’ai maintenant. C’est dur, tu sais !
— Je ne te le fais pas dire ! Alors fiston, toujours dans l’informatique ?
— Oui, monsieur. Comment va votre exploitation ?
— J’ai su rebondir, on va dire. Je suis reparti de zéro, ça m’a permis de me poser les bonnes questions. C’est ça le plus compliqué, Jaurel, savoir poser les bonnes questions et trouver des solutions ensemble. Maintenant je réfléchis à des projets utiles, accessibles et durables pour la population.
André, Jaurel et Christophe continuent de discuter pendant quelques minutes sur les projets que Christophe réalise en ce moment. Christophe sort de l’épicerie, tout comme André et Jaurel après avoir acheté de quoi manger. Sur le chemin du retour, André explique à son fils son point de vue :
— Tu sais fils, je sais que depuis peu, tu t’intéresses aux problématiques climatiques. Cependant, je crois que tu te trompes de méthode pour répondre au problème. J’ai vu que les machines se voulant écologiques ne le sont pas tout le temps. Tu connais l’effet rebond ? Une voiture, un train, c’est pas différent. Regarde, quand j’étais jeune, les trains électriques débarquaient. Tout le monde était époustouflé par ces nouvelles machines, plus performantes, plus économes, mais qui savait qu’on utilisait du gaz ou du charbon pour produire l’électricité du train ?
— Très bien, mais maintenant, l’électricité est en partie produite par du renouvelable chez nous ! réfute Jaurel, un air de défi dans ses yeux.
— Chez nous, oui ! Mais ailleurs ? Le problème est mondial, pas local. Et puis une partie ne vaut pas 100 %. André s’arrête un instant, posant une main sur l’épaule de son fils.
— 100 % d’énergie renouvelable, c’est un mythe, papa, et tu le sais, un soupçon de frustration dans la voix.
— Sans doute, mais en réduisant notre consommation, en réfléchissant plus au but de nos créations, de nos besoins, il y a une possibilité que ça marche.
— Tout le monde n’est pas prêt à ça.
— Si c’est un effort collectif, alors oui j’en suis persuadé. Regarde, si tu fais l’effort de partir à vélo, tu ne consommes pas d’électricité. Cette énergie peut être utilisée ailleurs par un système qui est vital pour d’autres personnes. Pense à ta santé. Pense aux économies que tu ferais si tu utilisais des moyens de transport alternatifs ou partagés. Au-delà des transports alternatifs, tu te rends compte du nombre d’heures que tu dois travailler pour payer une voiture ? Certes, la voiture est plus rapide, mais seulement à des moments précis. Tu ne vis pas sur l’autoroute à ce que je sache ? En supposant une consommation d’énergie de cinquante centimes par kilomètre, on doit non seulement conduire pendant une demi-heure pour parcourir les trente kilomètres, mais aussi travailler pendant une heure et demie pour gagner les quinze euros pour couvrir les frais de ce trajet. Au total, on consacre deux heures pour parcourir trente kilomètres en voiture. Tu te rends compte ? Jaurel prenant le temps de cogiter sur ce que son père vient de lui dire, finit par céder.
— OK, on prendra le vélo.
Chapitre 2 : Le trajet
L’un des vélos d’André est en très bon état et l’autre demande une petite touche de Il est onze heures quand les deux partent de la maison. Le réseau de pistes cyclables a été grandement amélioré et sécurisé après l’inondation de 2026. Les riverains touchés par l’inondation ont souhaité réduire l’imperméabilisation des sols en améliorant le réseau cyclable. La piste vers la plage est pittoresque, bordée de champs verdoyants et de maisons colorées, promettant une belle journée.
Cependant, après vingt-cinq minutes de route, la pluie annoncée par les prévisions météorologiques s’invita.
— La pluie n’est pas un obstacle ! s’exclame André. D’autant plus que la chaussée n’est pas glissante et le faible vent permet de poursuivre ce trajet à vélo. D’ailleurs, les grands tours sont rarement perturbées par la pluie.

On aurait dit un général d’armée galvanisant ses troupes. L’intensité de la pluie et celle du vent augmentent soudain. En un laps de temps, la visibilité se réduit à tel point que Jaurel à du mal à voir son père qui se trouve à cinq mètres devant lui. Ces conditions les obligent à stopper loin de toute habitation et à s’abriter sous un arbre. D’un air stupéfait, Jaurel interpelle son père :
— C’est à n’y plus rien comprendre, ce temps ! Les prévisions météo ne servent plus à rien !
— Le réchauffement climatique, malheureusement. Ça me rappelle l’inondation, je suis un peu inquiet pour ta mère.
— Nous sommes à mi-chemin, la pluie va nous ralentir, mais nous pouvons être rentrés dans une heure et demie à vue de nez.
— Pas sûr que ce soit une bonne idée, nous risquons d’être emportés avec toute cette eau. Je dois bien l’avouer, je n’ai pas d’autres solutions pour rentrer.
— Si j’avais su, je t’aurais forcé à prendre la voiture. Nous aurions pu arriver plus rapidement auprès de maman.
— Même s’il nous arrive des problèmes, le principal, c’est d’avancer, de se poser les bonnes questions. Quoi qu’il arrive, on ne doit pas abandonner ! Je pense qu’on peut inventer une application pour fournir des informations sur la météo, la qualité de l’air, etc. pour les cyclistes. Combiner high-tech et low-tech afin de favoriser le low-tech, c’est acceptable non ?
— Eh bien non ! L’application donnera les mêmes mauvais résultats que le site de la météo ! C’est du solutionnisme technologique, ton affaire, rien d’autre !