Framalibre : l’annuaire du libre renaît entre vos mains
Notre projet historique, l’annuaire de Framasoft, renaît de ses cendres… pour ouvrir encore plus grandes les portes du Libre.
Au commencement était l’annuaire…
OK : pas besoin de prendre un ton biblique non plus, mais il est vrai que c’est avec une émotion toute particulière qu’on vous présente cette refonte complète du tout premier projet, celui qui a fait naître Framasoft ; et qui, mine de rien, a défini notre identité.
Il y a 16 ans, en 2001, une prof de FRAnçais (Caroline d’Atabekian) et un prof de MAths (Alexis Kauffmann) commencent à s’échanger des listes de logiciels gratuits pour les salles d’ordinateurs de leurs établissements dont le budget informatique était grevé par les licences Windows.
Le projet plaît, et il évolue. On se rend compte que derrière certains logiciels gratuits, il existe des licences libres, des contrats garants de nos libertés et du respect de certaines valeurs. Alors on découvre le monde du Logiciel Libre, fait d’entraide (pour adapter les serveurs au succès croissant du site) et de collaboration (à côté des fiches pour les logiciels fleurissent les tutoriels d’utilisation).
Il faut attendre 2004 pour que ce premier site devienne un annuaire collaboratif de logiciels libres tel qu’on le connaît aujourd’hui. Un outil pratique, fait par et pour des « non-pros » de l’informatique, conçu comme une porte d’entrée vers ce monde numérique où les êtres humains et leurs libertés sont respectés. On y vient pour un besoin logiciel précis, on y retourne pour la chaleur de la communauté, et on se fait délicieusement contaminer par les valeurs du Libre.
Cela fait bien cinq ans que nous savons l’annuaire vieillissant, avec des notices trop détaillées qui deviennent vite obsolètes. Cinq ans que d’atermoiements en hésitations (« Faut-il vraiment repartir de zéro ? », se demandait-on avec des yeux de Chat Potté), d’avancées en marches à reculons, nous nous rendons compte qu’il n’est plus adapté ni au Libre (qui désormais déborde largement du champ des seuls logiciels), ni à nos usages (avec des contributions passant par un wiki, un forum, puis un Spip… c’est pas lourd du tout du tout -_-).
Sauf que voilà : on a toujours une urgence qui vient de tomber (entraînée par un de nos serveurs), un nouveau Framabook ou une nouvelle Framakey sur le feu, un Internet à Dégoogliser… Et puis il est difficile d’admettre que le SPIP qui a vaillamment permis notre annuaire (et donc notre page d’accueil) depuis tant d’années n’était plus l’outil le mieux adapté et le plus accessible pour cet usage précis…
Il nous a donc fallu cinq ans (et de multiples abandons/blocages/coup de fouet/reprises du projet) pour vous proposer cette refonte, cette remise à zéro de l’annuaire. Ne vous inquiétez pas, si vous aimez l’ancien, nous en avons gardé une archive juste à cette adresse archive.framalibre.org 😉 ! Cinq ans, et le travail conjoint de nombreux membres, salariés, mais surtout partenaires : Smile, dans un premier temps, pour leurs templates de visualisation… Mais surtout Makina Corpus, entreprise toulousaine bien connue des visiteurs du Capitole du Libre, qui nous a fait un design et une intégration Drupal aux petits oignons et nous a accompagnés (avec Framatophe tenant vaillamment le cap) sur les derniers efforts que nous ne savions pas fournir nous-mêmes.
Bon, c’est pas tout ça, mais est-ce que ça valait le coup d’attendre ? Que va-t-on trouver en guise d’annuaire Framasoft ?
Déjà on revient à quelque chose de simple. Les notices sont claires, concises, et vous mènent au plus vite vers le lien officiel de la ressource que vous consultez. Finies les notices hyper-détaillées et trop longues qui deviennent désuètes à la moindre mise à jour 😉 ! L’idée principale, c’est de trouver aisément et comme on le souhaite : on peut rechercher une notice selon sa catégorie, utiliser le système de tags, ou même se laisser porter par les suggestions, recommandations, les notices mises en avant, etc.
C’est aussi un annuaire qui facilite la collaboration. Avec un simple compte, vous pouvez voter pour les ressources que vous préférez (et donc les mettre en valeur), corriger ou mettre à jour une notice, en créer une nouvelle dans l’annuaire, ou plus simplement écrire une chronique (un tutoriel, un témoignage, ou bien votre avis sur telle ressource…). Cet annuaire, c’est vous qui le ferez, nous avons donc fait en sorte qu’il vous soit le plus ouvert possible. Et, avec Drupal, gageons que nous pourrons, ensuite, ouvrir les données engrangées via un système d’API (ceci est un souhait, pas une promesse — mais ce serait cool, hein ?)…
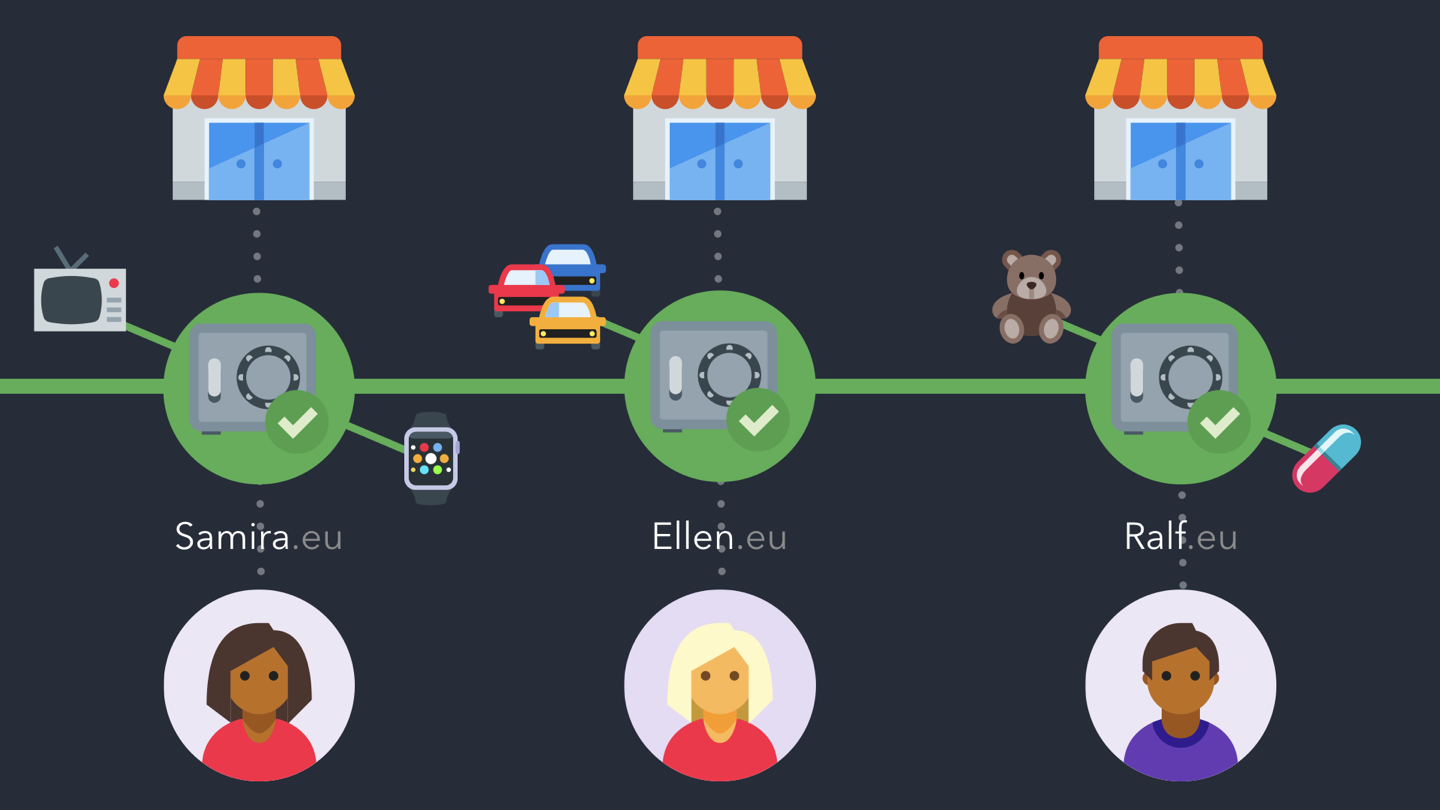
Enfin et surtout, Framalibre se veut un annuaire du Libre, en général, et non pas seulement du Logiciel Libre. Car nos vies numériques ne sont plus uniquement « virtuelles », et les libertés que nous défendons et nourrissons vont au-delà du logiciel.
des logiciels, du matériel et des jeux de données libres, dans S’équiper,
des livres, albums, films et autres œuvres culturelles dans Se cultiver,
et même les entreprises, collectifs, associations et autres initiatives du monde du Libre dans pour bien S’entourer.
Depuis 2004, le monde du Libre a bien grandi… Il était temps d’en agrandir une des portes d’entrée ;).
Ouvrons les portes et nos communautés !
Un annuaire, c’est un bouquet de fleurs capiteuses… Attiré·e par la douce odeur de THE information pratique que l’on vient y chercher, on s’enivre du nectar des autres notices à disposition, on se perd dans la navigation et finit par découvrir un nouveau champ de possibilités et de libertés.
Nous ne comptons plus le nombre de fois, sur le stand d’une convention libriste, où nous rencontrons un·e convaincu·e, arborant fièrement le logo de sa « distro GNUnux » favorite sur son T-Shirt, et qui s’écrie plein·e de nostalgie :
« Oooh ! Framasoft ! Je me souviens, c’est sur votre site, là, que j’ai découvert mes premiers logiciels libres ! »
Nous, à l’écoute de telles exclamations (allégorie.)
C’est à nous, désormais, de préparer le terrain pour que les futures générations de libristes tombent dans la marmite de potion magique ! D’ailleurs, un énorme merci aux personnes qui ont saisi les 400 premières notices avant la mise en production <3 ! Oh et au fait : vos comptes beta.framalibre.org fonctionnent désormais sur framalibre.org 😉
C’est à nous, donc, de contribuer à cet annuaire et de le nourrir de ce qui nous intéresse et que l’on souhaite partager. Que ce soit des notices, des chroniques, des corrections ou de simples votes : ce sont toutes vos contributions qui pourront faire le succès de cette renaissance…
Une équipe de modération est déjà en place (mais aura vite besoin de nouveaux bras) et des ateliers de contribution commencent à s’organiser (dont un sur Toulouse, le 22 mars, avec le GULL Toulibre). En cette période où le Libre est en fête, faites-vous une joie de mettre en valeur des œuvres (logicielles, culturelles, matérielles, etc.) libres, parce que vous y contribuez ou en bénéficiez, ou simplement parce que vous les aimez et souhaitez les partager avec le plus grand nombre.
Nous, on va écraser une petite larmichette d’émotion sur cette page qui se tourne, et se remettre au boulot !
La création d’un site web depuis votre compte Framagit est beaucoup plus souple, et c’est une belle victoire pour le libre !
Attention : ce billet comporte des éléments techniques… Si vous avez un compte Framagit et/ou si vous vous intéressez à la création d’un site web statique depuis un dépôt Git, il est fait pour vous ! Si vous n’avez pas tout compris à cette phrase, la suite va vous paraître délicieusement absurde :p !
NB : l’édition communautaire de Gitlab est la version libre de la forge logicielle Gitlab, qui existe aussi en version non-libre, appelée version entreprise. Bien évidemment, nous utilisons la version libre pour fournir le service Framagit 🙂
NB : les adresses IP pour utiliser votre propre domaine ont changé. Il faut maintenant faire pointer votre domaine vers les adresses 2a01:4f8:231:4c99::42 et 176.9.183.74 (ou faire un enregistrement CNAME vers frama.io).
Qu’est‐ce que GitLab Pages ?
À l’instar des pages Github, les pages GitLab permettent à toute personne possédant un dépôt sur une instance de GitLab de créer un site Web via un générateur de site statique (Jekyll, Middleman, Hexo, Hugo, Pelican…) et de l’héberger sur l’infrastructure dudit GitLab.
La compilation du site est effectuée lors du push vers le dépôt GitLab, via le système d’intégration continue de GitLab, puis le résultat est publié à l’endroit idoine pour être accessible via le Web. Il est possible d’utiliser un nom de domaine personnel (il n’est pas obligatoire d’utiliser une adresse du style https://username.gitlab.io), ainsi qu’un certificat personnel.
Et ça sert ?
Oui !
Les pages GitHub sont très souvent utilisées par les développeurs pour fournir une page de présentation de leurs projets, même les plus gros : Ruby on Rails, Django, React…
Les pages GitLab sont donc susceptibles d’être tout autant utilisées que les pages GitHub. La demande est là.
Mais on avait pas déjà un truc comme ça ?
Tout à fait ! J’avais créé Fs Pages pour fournir un service similaire mais plus limité que les Gitlab Pages car Gitlab ne souhaitait pas les intégrer à leur édition communautaire.
Il était possible de publier un site statique via Fs Pages mais la génération du site devait se faire avant de pousser le code : point de génération automatique. De plus, il n’était pas possible d’utiliser un nom de domaine personnel. Votre site statique répondait uniquement via l’adresse https://votre_utilisateur.frama.io.
Le long chemin de la libération
Nous n’allons pas refaire l’historique complet de la libération des Gitlab Pages, surtout que celui-ci est disponible sur LinuxFr. Mais un petit résumé succinct ne fera pas de mal.
Tout a commencé par un tweet de votre serviteur demandant à Gitlab s’il était envisageable d’avoir les Gitlab Pages dans l’édition communautaire de Gitlab (pas la peine de chercher les tweets en question, j’ai fermé mon compte twitter). Gitlab a ouvert un ticket pour discuter de cela.
Gitlab a exposé au fil du temps trois arguments :
seules les fonctionnalités utiles aux instances de moins de 100 utilisateurs peuvent aller dans l’édition communautaire (et pour eux, cela n’était pas le cas de Gitlab Pages)
https://gitlab.com, qui utilise la version entreprise — donc avec les Gitlab Pages — est libre d’utilisation pour tout un chacun, et contrairement à Github, les dépôts privés sont gratuits
les Gitlab Pages sont une fonctionnalité qui ajoute une réelle plus-value à l’édition entreprise : comment vendre leur produit si une des fonctionnalités majeures est déjà dans l’édition communautaire ?
Il est à noter que Gitlab nous a proposé d’utiliser la version entreprise avec un rabais, ce qui est tout à leur honneur, mais comme nous ne souhaitons utiliser que du logiciel libre, nous avons décliné (évidemment 😀)
La communauté a fait valoir que Gitlab Pages n’intéressait pas que les grandes instances, qu’utiliser https://gitlab.com ou Github revenait au même puisque cela équivaut à utiliser du logiciel propriétaire, proposa un financement participatif pour financer la libération et enfin avança que les Gitlab Pages feraient une bonne publicité à Gitlab, les développeurs utilisant de plus en plus fréquemment ce genre de solution pour héberger leurs sites ou leurs blogs. Et même si j’ai horreur de cet argument de notoriété, force m’est d’avouer qu’il a su faire mouche (ainsi que les plus de 100 « 👍 » du ticket) : la libération fut annoncée peu de temps après celui-ci !
En tout, la discussion a duré près de onze mois. Les échanges furent cordiaux et la communauté, opiniâtre, a su faire valoir ses arguments.
Bref, une bien belle victoire pour le libre qui voit là un logiciel apprécié se doter d’une nouvelle fonctionnalité très attendue !
Bon, et maintenant ?
Depuis la mise à jour de Framagit du 2 mars dernier, toute personne possédant un dépôt sur Framagit peut, via les Gitlab Pages, créer et héberger un site sur notre infrastructure, que ce soit en sous-domaine de frama.io (comme moi 😊) ou avec un domaine privé (auquel cas il faudra faire pointer un enregistrement DNS vers les IPs de frama.io : 144.76.206.44 et 2a01:4f8:200:1302::44 ou créer un enregistrement DNS de type CNAME vers frama.io.), avec ou sans certificat.
l’utilisation de certificats Let’s Encrypt n’est pas aisée mais un ticket est ouvert chez Gitlab pour intégrer directement Let’s Encrypt aux Gitlab Pages
il n’y a pas de redirection automatique vers la version sécurisée (https) de votre site, quand bien même vous fourniriez un certificat ou que vous utilisiez un sous-domaine de frama.io (ce qui vous fournit automatiquement une version https de votre site grâce à notre achat d’un certificat wildcard (certificat valant pour le domaine et tous ses sous-domaines)). Un ticket est cependant ouvert chez Gitlab à ce sujet. En attendant, pour rediriger vos visiteurs vers la version https de votre site, vous pouvez néanmoins inclure ce petit bout de JavaScript dans vos pages :
<script>
var loc = window.location.href+'';
if (loc.indexOf('http://')==0){
window.location.href = loc.replace('http://','https://');
}
</script>
Le framablog n’étant pas un blog technique, nous ne étendrons pas plus sur les ficelles de Gitlab Pages : on va laisser ça pour notre site dédié à la documentation de nos services.
Au 20 mars, nous sommes déjà 31 (oui, bon, ok, sur 7 560 utilisateurs, ça fait peu) à avoir commencé à bidouiller sur les Gitlab Pages de Framagit (contre 53 quand nous proposions FsPages). Continuez comme ça ! 🙂
28 ans d’existence du World Wide Web : vous reprendrez bien un peu d’exploitation ?
À l’occasion du 28e anniversaire du World Wide Web, son inventeur Tim Berners-Lee a publié une lettre ouverte dans laquelle il expose ses inquiétudes concernant l’évolution du Web, notamment la perte de contrôle sur les données personnelles, la désinformation en ligne et les enjeux de la propagande politique.
Aral Balkan, qui n’est plus à présenter sur ce blog, lui répond par cet article en reprenant le concept de Capitalisme de surveillance. Comment pourrions-nous arrêter de nous faire exploiter en coopérant avec des multinationales surpuissantes, alors que cela va à l’encontre de leurs intérêts ? Réponse : c’est impossible. À moins de changer de paradigme…
Traduction Framalang : Dark Knight, audionuma, bricabrac, dominix, mo, Jerochat, Luc, goofy, lyn, dodosan et des anonymes
Aral Balkan est un militant, concepteur et développeur. Il détient 1/3 de Ind.ie, une petite entreprise sociale qui travaille pour la justice sociale à l’ère du numérique.
Nous n’avons pas perdu le contrôle du Web — on nous l’a volé
12 mars 2017. Le Web que nous avons fonctionne bien pour Google et Facebook. Celles et ceux qui nous exploitent ne respectent pas nos vies privées et en sont récompensé·e·s chaque année par des chiffres d’affaires atteignant des dizaines de milliards de dollars. Comment pourraient-ils être nos alliés ?
Le Web que nous connaissons fait parfaitement l’affaire pour Google. Crédit photo : Jeff Roberts
Pour marquer le vingt-huitième anniversaire du World Wide Web, son inventeur Tim Berners-Lee a écrit une lettre ouverte distinguant trois « tendances » principales qui l’inquiètent de plus en plus depuis douze mois :
1. Nous avons perdu le contrôle de nos données personnelles
2. Il est trop facile de répandre la désinformation sur le Web
3. La propagande politique en ligne doit être transparente et comprise
Il est important de noter qu’il ne s’agit pas seulement de tendances et que ce phénomène est en gestation depuis bien plus de douze mois. Ce sont des symptômes inextricablement liés à l’essence même du Web tel qu’il existe dans le contexte socio-technologique où nous vivons aujourd’hui, que nous appelons le capitalisme de surveillance.
C’est le résultat d’un cercle vicieux entre l’accumulation d’informations et celle du capital, qui nous a laissé une oligarchie de plateformes en situation de monopole qui filtrent, manipulent et exploitent nos vies quotidiennes.
Nous n’avons pas perdu le contrôle du Web — on nous l’a volé
Google et Facebook ne sont pas des alliés dans notre combat pour un futur juste : ils sont l’ennemi.
Tim dit que nous avons « perdu le contrôle de nos données personnelles ».
C’est inexact.
Nous n’avons pas perdu le contrôle : la Silicon Valley nous l’a volé.
Ceux qui nous exploitent, les Google et les Facebook du monde entier, nous le volent tous les jours.
Tim touche au cœur du problème dans son billet : « Le modèle commercial actuel appliqué par beaucoup de sites Web est de vous offrir du contenu en échange de vos données personnelles. » (1)
En revanche, aucun exemple ne nous est donné. Aucun nom. Aucune responsabilité n’est attribuée.
Ceux qu’il ne veut pas nommer – Google et Facebook – sont là, silencieux et en retrait, sans être jamais mentionnés, tout juste sont-ils décrits un peu plus loin dans la lettre comme des alliés qui tentent de « combattre le problème » de la désinformation. Il est peut-être stupide de s’attendre à davantage quand on sait que Google est un des plus importants contributeurs aux standards récents du Web du W3C et qu’avec Facebook ils participent tous les deux au financement de la Web Foundation ?
Ceux qui nous exploitent ne sont pas nos alliés
Permettez-moi d’énoncer cela clairement : Google et Facebook ne sont pas des alliés dans notre combat pour un futur juste, ils sont l’ennemi.
Ces plateformes monopolistiques font de l’élevage industriel d’êtres humains et nous exploitent pour extraire jusqu’à la moindre parcelle qu’ils pourront tirer de nous.
Si, comme le déclare Tim, le principal défi pour le Web aujourd’hui est de combattre l’exploitation des personnes, et si nous savons qui sont ces exploiteurs, ne devrions-nous pas légiférer fermement pour refréner leurs abus ?
Le Web, à l’instar du capitalisme de surveillance, a remarquablement réussi.
La Web Foundation va-t-elle enfin encourager une régulation forte de la collecte, de la conservation et de l’utilisation des données personnelles par les Google, Facebook et consorts ? Va-t-elle promouvoir une forme de réglementation visant à interdire la privatisation des données du monde entier par ces derniers de façon à encourager les biens communs ? Aura-t-elle le cran, dont nous avons plus que jamais besoin, de rejeter la responsabilité à qui de droit et de demander à contrer les violations quotidiennes de nos droits humains perpétrées par les partenaires du W3C et de la Web Foundation elle-même ? Ou est-il insensé de s’attendre à de telles choses de la part d’une organisation qui est si étroitement liée à ces mêmes sociétés qu’elle ne peut paraître indépendante de quelque manière que ce soit ?
Le Web n’est pas cassé, il est perdu.
Le Web est perdu mais il n’est pas cassé. La distinction est essentielle.
Le Web, tout comme le capitalisme de surveillance lui-même, a réussi de façon spectaculaire et fonctionne parfaitement pour les entreprises. En revanche, la partie est perdue pour nous en tant qu’individus.
Google, Facebook, et les autres « licornes » multimilliardaires sont toutes des success stories du capitalisme de surveillance. Le capitalisme de surveillance est un système dont, comme le cancer, la réussite se mesure à la capacité d’évolution rapide et infinie dans un contexte de ressources finies. Et tout comme le cancer à son paroxysme, le succès du capitalisme de surveillance aujourd’hui est sur le point de détruire son hôte. D’ailleurs, là encore comme le cancer, non sans nous avoir volé d’abord notre bien-être, notre pouvoir et notre liberté. Le problème est que parmi les critères de réussite du capitalisme de surveillance ne figurent absolument pas notre équité, notre bien-être, notre capacité d’action ni notre liberté individuelle. Nous ne sommes que du bétail à exploiter, une source infinie de matières premières.
Le Web que nous avons n’est pas cassé pour Google et Facebook. Ceux qui nous exploitent sont récompensés à hauteur de dizaines de milliards de chiffre d’affaires pour s’être introduits dans nos vies. Comment pourraient-ils être nos alliés ?
Tim suggère que « nous devons travailler avec les entreprises du Web pour trouver un équilibre qui redonne aux personnes un juste niveau de contrôle de leurs données. »
Quoi de plus naïf que de nous suggérer de travailler avec les plus gros exploiteurs du Web pour leur rendre cette tâche plus difficile et donc réduire leurs bénéfices ? (2)
Quelle raison Google ou Facebook pourraient-ils avoir de réparer le Web que nous avons alors qu’il n’est pas cassé pour eux ? Aucune. Absolument aucune.
Tim écrit : « Pour construire le web, il a fallu notre participation à tous, et c’est à nous tous, désormais, de construire le web que nous voulons – pour tous. »
Je ne suis pas d’accord.
Il a fallu la Silicon Valley (subventionnée par le capital-risque et suivant le modèle commercial de l’exploitation des personnes) pour construire le Web que nous avons.
Et maintenant c’est à nous, qui n’avons aucun lien avec ces entreprises, nous qui ne sommes pas de mèche ou qui ne sommes pas sponsorisé·e·s par ces entreprises, nous qui comprenons que le Big Data est le nouveau nerf de la guerre, de faire pression pour une réglementation forte, de contrer les abus des exploiteurs et de jeter un pont entre le Web que nous avons et celui que nous voulons : du capitalisme de surveillance vers un monde de souveraineté individuelle et de biens communs.
(1) Le problème est que même si vous payez effectivement pour des produits ou des services, il est très probable qu’ils violeront tout de même votre identité numérique, à moins qu’ils ne soient conçus par éthique pour être décentralisés et/ou amnésiques.^^
(2) Avant de vous laisser croire que je m’en prends à Tim, je précise que ce n’est pas le cas. Par deux fois je l’ai rencontré et nous avons discuté, je l’ai trouvé sincèrement honnête, passionné, humble, attentionné, quelqu’un de gentil. Je pense réellement que Tim se soucie des problèmes qu’il soulève et veut les résoudre. Je pense vraiment qu’il veut un Web qui soit un moyen d’encourager la souveraineté individuelle et les communs. Je ne crois pas, néanmoins, qu’il soit humainement possible pour lui, en tant qu’inventeur du Web, de se détacher assez du Web que nous avons afin de devenir le défenseur du Web que nous voulons. Les entreprises qui ont fait du Web ce qu’il est aujourd’hui (un poste de surveillance) sont sensiblement les mêmes qui composent le W3C et soutiennent la Web Foundation. En tant que leader des deux, les conflits d’intérêts sont trop nombreux pour être démêlés. Je ne suis pas jaloux de la position peu enviable de Tim, dans laquelle il ne peut pas délégitimer Google et Facebook sans délégitimer les organisations qu’il conduit et au sein desquelles leur présence est si importante.
En outre, je crois sincèrement que Tim pensait avoir conçu le Web en lien avec sa philosophie sans réaliser qu’une architecture client/serveur, une fois immergée dans un bain de culture capitaliste, aurait pour résultat des pôles (les serveurs) se structurant verticalement et s’unifiant — pour finalement devenir des monopoles — comme les Google et Facebook que nous connaissons aujourd’hui. A posteriori, tout est clair et il est facile de faire la critique de décisions d’architecture qui ont été prises 28 ans plus tôt en soulignant les défauts d’un système que personne n’aurait cru capable de grandir autant ni de prendre un rôle central dans nos vies. Si j’avais conçu le Web à l’époque, non seulement j’aurais été un prodige, mais j’aurais probablement pris exactement les mêmes décisions, sans doute en moins bien. Je ne possède rien qui ressemble au cerveau de Tim. Tim a suivi son intuition, et il l’a fait de façon très élégante en élaborant les choses les plus simples qui pourraient fonctionner. Cela, ainsi que le fait de l’avoir partagé avec le monde entier, et sa compatibilité avec l’architecture du capitalisme, ont été les raisons du succès du Web. S’il y a une leçon à retenir de cela, c’est que les protocoles sociaux et économiques sont au moins aussi importants que les protocoles réseau et que nous devons leur consacrer autant de réflexion et de notoriété dans nos alternatives.^^
Demain, les développeurs… ?
En quelques années à peine s’est élevée dans une grande partie de la population la conscience diffuse des menaces que font peser la surveillance et le pistage sur la vie privée.
Mais une fois identifiée avec toujours plus de précision la nature de ces menaces, nous sommes bien en peine le plus souvent pour y échapper. Nous avons tendance surtout à chercher qui accuser… Certes les coupables sont clairement identifiables : les GAFAM et leur hégémonie bien sûr, mais aussi les gouvernements qui abdiquent leur pouvoir politique et se gardent bien de réguler ce qui satisfait leur pulsion sécuritaire. Trop souvent aussi, nous avons tendance à culpabiliser les Dupuis-Morizeau en les accusant d’imprudence et de manque d’hygiène numérique. C’est sur les utilisateurs finaux que l’on fait porter la responsabilité : « problème entre la chaise et le clavier », « si au moins ils utilisaient des mots de passe compliqués ! », « ils ont qu’à chiffrer leur mails », etc. et d’enchaîner sur les 12 mesures qu’ils doivent prendre pour assurer leur sécurité, etc.
L’originalité du billet qui suit consiste à impliquer une autre cible : les développeurs. Par leurs compétences et leur position privilégiée dans le grand bain numérique, ils sont à même selon l’auteur de changer le cours de choses et doivent y œuvrer. Les pistes qu’expose Mo Bitar, lui-même développeur (il travaille sur StandardNotes, une application open source de notes qui met l’accent sur la longévité et la vie privée) paraîtront peut-être un peu vagues et idéalistes. Il n’en pointe pas moins une question intéressante : la communauté des codeurs est-elle consciente de ses responsabilités ?
Qu’en pensent les spécialistes de la cybersécurité, les adminsys, la communauté du développement ? — les commentaires sont ouverts, comme d’habitude.
Voici pourquoi les développeurs de logiciels détiennent la clef d’un nouveau monde
par Mo Bitar
Actuellement, c’est la guerre sur les réseaux, et ça tire de tous les côtés. Vous remportez une bataille, ils en gagnent d’autres. Qui l’emporte ? Ceux qui se donnent le plus de mal, forcément. Dans cette campagne guerrière qui oppose des méga-structures surdimensionnées et des technophiles, nous sommes nettement moins armés.
Des informations. C’est ce que tout le monde a toujours voulu. Pour un gouvernement, c’est un fluide vital. Autrefois, les informations étaient relativement faciles à contrôler et à vérifier. Aujourd’hui, les informations sont totalement incontrôlables.
Les informations circulent à la vitesse de la lumière, la vitesse la plus rapide de l’univers. Comment pourrait-on arrêter une chose pareille ? Impossible. Nos problèmes commencent quand une structure trop avide pense qu’elle peut le faire.
Telle est la partie d’échecs pour la confidentialité que nous jouons tous aujourd’hui. Depuis le contrôle de l’accès à nos profils jusqu’au chiffrement de nos données en passant par un VPN (réseau privé virtuel) pour les rediriger, nous ne sommes que des joueurs de deuxième zone sur le grand échiquier des informations. Quel est l’enjeu ? Notre avenir. Le contrôle de la vie privée c’est le pouvoir, et les actions que nous menons aujourd’hui déterminent l’équilibre des pouvoirs pour les générations et sociétés à venir. Quand ce pouvoir est entre les mains de ceux qui ont le monopole de la police et des forces armées, les massacres de masse en sont le résultat inévitable.
Alors, où se trouve la révolution sur la confidentialité de nos informations que nous attendons tous ? Ce jour d’apothéose où nous déciderons tous de vraiment prendre au sérieux la question de la confidentialité ? Nous disons : « Je garde un œil dessus, mais pour le moment je ne vais pas non plus me déranger outre mesure pour la confidentialité. Quand il le faudra vraiment, je m’y mettrai ». Ce jour, soit n’arrivera jamais, soit sous une forme qui emportera notre pays avec lui. Je parle des États-Unis, mais ceci est valable pour tout pays qui a été construit sur des principes solides et de bonnes intentions. Bâtir un nouveau pays n’est pas facile : des vies sont perdues et du sang est inutilement versé dans le processus. Gardons plutôt notre pays et agissons pour l’améliorer.
Les gouvernements peuvent être envahissants, mais ni eux ni les gens ne sont mauvais par nature : c’est l’échelle qui est problématique. Plus une chose grandit, moins on distingue les actions et les individus qui la composent, jusqu’à ce qu’elle devienne d’elle-même une entité autonome, capable de définir sa propre direction par la seule force de son envergure.
Alors, où est notre révolution ?
— Du côté des développeurs de logiciels.
Les développeurs de logiciels et ceux qui sont profondément immergés dans la technologie numérique sont les seuls actuellement aptes à déjouer les manœuvres des sur-puissants, des sans-limites. Il est devenu trop difficile, ou n’a jamais vraiment été assez facile pour le consommateur moyen de suivre l’évolution des meilleurs moyens de garder le contrôle sur ses informations et sa vie privée. La partie a été facile pour le Joueur 1 à tel point que le recueil des données s’est effectué à l’échelle de milliards d’enregistrements par jour. Ensuite sont arrivés les technophiles, des adversaires à la hauteur, qui sont entrés dans la danse et sont devenus de véritables entraves pour le Joueur 1. Des technologies telles que Tor, les VPN, le protocole Torrent et les crypto-monnaies rendent la tâche extrêmement difficile pour les sur-puissants, les sans-limites. Mais comme dans tous les bons jeux, chaque joueur riposte plus violemment à chaque tour. Et notre équipe perd douloureusement.
Même moi qui suis développeur de logiciels, je dois admettre qu’il n’est pas facile de suivre la cadence des dernières technologies sur la confidentialité. Et si ce n’est pas facile pour nous, ce ne sera jamais facile pour l’utilisateur lambda des technologies informatiques. Alors, quand la révolution des données aura-t-elle lieu ? Jamais, à ce rythme.
Tandis que nous jouissons du luxe procuré par la société moderne, sans cesse lubrifiée par des technologies qui nous libèrent de toutes les corvées et satisfont tous les besoins, nous ne devons pas oublier d’où nous venons. Les révolutions de l’histoire n’ont pas eu lieu en 140 caractères ; elles se sont passées dans le sang, de la sueur et des larmes, et un désir cannibale pour un nouveau monde. Notre guerre est moins tangible, n’existant que dans les impulsions électriques qui voyagent par câble. « Où se trouve l’urgence si je ne peux pas la voir ? » s’exclame aujourd’hui l’être humain imprudent, qui fonctionne avec un système d’exploitation biologique dépassé, incapable de pleinement comprendre le monde numérique.
Mais pour beaucoup d’entre nous, nos vies numériques sont plus réelles que nos vies biologiques. Dans ce cas, quel est l’enjeu ? La manière dont nous parcourons le monde dans nos vies numériques. Imaginez que vous viviez dans un monde où, dès que vous sortez de chez vous pour aller faire des courses, des hommes en costume noir, avec des lunettes de soleil et une oreillette, surveillent votre comportement, notent chacun de vos mouvements et autres détails, la couleur de vos chaussures ce jour-là, votre humeur, le temps que vous passez dans le magasin, ce que vous avez acheté, à quelle vitesse vous êtes rentré·e chez vous, avec qui vous vous déplaciez ou parliez au téléphone – toutes ces métadonnées. Comment vous sentiriez-vous si ces informations étaient recueillies sur votre vie, dans la vraie vie ? Menacé·e, certainement. Biologiquement menacé·e.
Nos vies sont numériques. Bienvenue à l’évolution. Parcourons un peu notre nouveau monde. Il n’est pas encore familier, et ne le sera probablement jamais. Comment devrions-nous entamer nos nouvelles vies dans notre nouveau pays, notre nouveau monde ? Dans un monde où règnent contrôle secret et surveillance de nos mouvements comme de nos métadonnées ? Ou comme dans une nouvelle vieille Amérique, un lieu où être libre, un lieu où on peut voyager sur des milliers de kilomètres : la terre promise.
Construisons notre nouveau monde sur de bonnes bases. Il existe actuellement des applications iPad qui apprennent aux enfants à coder – pensez-vous que cela restera sans conséquences ? Ce qui est aujourd’hui à la pointe de la technologie, compréhensible seulement par quelques rares initiés, sera connu et assimilé demain par des enfants avant leurs dix ans. Nous prétendons que la confidentialité ne sera jamais généralisée parce qu’elle est trop difficile à cerner. C’est vrai. Mais où commence-t-elle ?
Elle commence lorsque ceux qui ont le pouvoir de changer les choses se lèvent et remplissent leur rôle. Heureusement pour nous, cela n’implique pas de se lancer dans une bataille sanglante. Mais cela implique de sortir de notre zone de confort pour faire ce qui est juste, afin de protéger le monde pour nous-mêmes et les générations futures. Nous devons accomplir aujourd’hui ce qui est difficile pour le rendre facile aux autres demain.
Jeune nerd à qui on vient de demander de sauver le monde, dessin de Simon « Dr Gee » Giraudot, Licence Creative Commons BY SA
Développeur ou développeuse, technophile… vous êtes le personnage principal de ce jeu et tout dépend de vos décisions et actions présentes. Il est trop fastidieux de gérer un petit serveur personnel ? Les générations futures ne seront jamais propriétaires de leurs données. Il est trop gênant d’utiliser une application de messagerie instantanée chiffrée, parce qu’elle est légèrement moins belle ? Les générations futures ne connaîtront jamais la confidentialité de leurs données. Vous trouvez qu’il est trop pénible d’installer une application open source sur votre propre serveur ? Alors les générations à venir ne profiteront jamais de la maîtrise libre de leurs données.
C’est à nous de nous lever et de faire ce qui est difficile pour le bien commun. Ce ne sera pas toujours aussi dur. C’est dur parce que c’est nouveau. Mais lorsque vous et vos ami⋅e⋅s, vos collègues et des dizaines de millions de développeurs et développeuses auront tous ensemble fait ce qui est difficile, cela restera difficile pendant combien de temps, à votre avis ? Pas bien longtemps. Car comme c’est le cas avec les économies de marché, ces dizaines de millions de développeurs et développeuses deviendront un marché, aux besoins desquels il faudra répondre et à qui on vendra des produits. Ainsi pourra s’étendre et s’intensifier dans les consciences le combat pour la confidentialité.
Pas besoin d’attendre 10 ans pour que ça se produise. Pas besoin d’avoir dix millions de développeurs. C’est de vous qu’on a besoin.
Vous pouvez faire un premier pas en utilisant et soutenant les services qui assurent la confidentialité et la propriété des données par défaut. Vous pouvez aussi en faire profiter tout le monde : rendez-vous sur Framalibre, et ajoutez les outils libres et respectueux que vous connaissez, avec une brève notice informative.
Sur la piste du pistage
La revue de presse de Jonas@framasoft, qui paraît quand il a le temps. Épisode No 3/n
Facebook juge de ce qui est fiable ou non
Le nouvel algorithme de Facebook, qui permet de mettre en avant (ou reléguer aux oubliettes) les informations sur votre mur, cherche à faire du fact-checking. C’est logique : plutôt que de donner la maîtrise à l’utilisateur de ses fils de données, pourquoi ne pas rafistoler les bulles de filtre que le réseau social a lui-même créées ?
Le pistage par ultrasons contribue à nous profiler et permet de repérer les utilisateurs de Tor
Les annonceurs et les spécialistes du marketing ont la possibilité d’identifier et de pister des individus en insérant des fréquences audio inaudibles dans une publicité diffusée à la télévision, sur une radio ou en ligne. Ces ultrasons pouvant être captés à proximité par les micros des ordinateurs ou des smartphones, vont alors interpréter les instructions (…) Les annonceurs s’en servent pour lier différents dispositifs au même individu et ainsi créer de meilleurs profils marketing afin de mieux diffuser des publicités ciblées dans le futur.
L’année dernière, des chercheurs ont expliqué que des attaquants pourraient pirater ces ultrasons pour pirater un dispositif (ordinateur ou smartphone). Cette fois-ci, ce sont 6 chercheurs qui ont expliqué que cette technique peut également servir à désanonymiser les utilisateurs de Tor.
Les chercheurs expliquent que les pirates peuvent utiliser un dispositif Bluetooth inclus dans la poupée My Friend Cayla pour écouter les enfants et leur parler pendant qu’ils jouent.
La commissaire européenne à la Justice, à la Consommation et à l’Égalité des sexes, Vera Jourova, a déclaré à la BBC : » je suis inquiète de l’impact des poupées connectées sur la vie privée et la sécurité des enfants ».
Selon les termes de la loi allemande, il est illégal de vendre ou détenir un appareil de surveillance non-autorisé. Enfreindre la loi peut coûter jusqu’à 2 ans de prison.
L’Allemagne a des lois très strictes pour s’apposer à la surveillance. Sans doute parce qu’au siècle dernier le peuple allemand a subi une surveillance abusive, sous le nazisme puis sous le régime communiste de l’Allemagne de l’est.
S’il est de notoriété publique que nos données personnelles sont enregistrées et utilisées par les G.A.F.A.M., il est en revanche moins connu que certaines de ces données sont utilisables par tout le monde. Et c’est bien là le point faible de toute campagne de prévention : on a beau dire que nos données sont utilisées, il est peu fréquent que nos paroles soient illustrées.
x0rz publie sur son blog un billet qui illustre parfaitement ce problème. En effet, il a écrit un petit script Python (moins de 400 lignes de code) qui récupère et synthétise les métadonnées Twitter, accessible par n’importe qui.
Ce billet ouvre deux perspectives :
Concernant le harcèlement numérique : certes ces données sont publiques, mais il faut tout de même quelques capacités en programmation pour les exploiter, ce qui n’est pas à la portée de tout le monde. Imaginons qu’apparaissent de plus en plus de programmes grand public permettant d’accumuler et synthétiser ces données. Il deviendra alors plus facile pour un particulier d’identifier et de traquer une autre personne.
Concernant les métadonnées en général : dans cet exemple, les données analysées restent très basiques (heure et localisation). Nous arrivons toutefois, par l’accumulation et le recoupement, à déduire des informations intéressantes de ces « méta-métadonnées », et à identifier nettement une personne. Imaginons que les métadonnées enregistrées soient plus précises et plus nombreuses, les informations obtenues seraient alors d’une importance et d’une précision inimaginables. Est-ce alors nécessaire de mentionner qu’à la fois les entreprises (ici Twitter) et les agences gouvernementales ont accès à ce genre de métadonnées ?
Article original écrit par x0rz, consultant en sécurité informatique, sur son blog.
Traduction Framalang : mo, mathis, goofy, valvin, Diane, Moriarty, Bromind et des anonymes
Vous serez surpris par tout ce que vos tweets peuvent révéler de vous et de vos habitudes
Une analyse de l’activité des comptes Twitter
J’utilise Twitter tous les jours. Pour moi qui suis consultant en cybersécurité, c’est de loin un des meilleurs outils pour rester informé des dernières actualités et pour partager des informations qu’on estime pertinentes pour d’autres. Avec la récente investiture de Donald Trump, les dingosdeTwitter de la nouvelle administration et l’émergence de groupes de résistance sur Twitter, j’ai décidé de démontrer à quel point il est facile d’exposer des informations révélatrices à partir du compte de quelqu’un d’autre, sans même le pirater.
Métadonnées
Comme tous les réseaux sociaux, Twitter sait beaucoup de choses sur vous, grâce aux métadonnées. En effet, pour un message de 140 caractères, vous aurez un paquet de métadonnées, plus de 20 fois la taille du contenu initial que vous avez saisi ! Et vous savez quoi ? Presque toutes les métadonnées sont accessibles par l’API ouverte de Twitter.
Voici quelques exemples qui peuvent être exploités par n’importe qui (pas seulement les gouvernements) pour pister quelqu’un et en déduire son empreinte numérique :
Fuseau horaire et langue choisie pour l’interface de twitter
Langues détectées dans les tweets
Sources utilisées (application pour mobile, navigateur web…)
Géolocalisation
Hashtags les plus utilisés, utilisateurs les plus retweetés, etc.
Activité quotidienne/hebdomadaire
Un exemple d’analyse de tweet (2010, l’API a beaucoup changé depuis).
Tout le monde connaît les dangers des fuites de géolocalisation et à quel point elles nuisent à la confidentialité. Mais peu de gens se rendent compte que tweeter de façon régulière suffit à en dire beaucoup sur vos habitudes.
Prendre séparément un tweet unique peut révéler des métadonnées intéressantes. Prenez-en quelques milliers et vous allez commencer à voir se dessiner des lignes directrices. C’est là que ça devient amusant.
Méta-métadonnées
Une fois qu’on a collecté suffisamment de tweets d’un compte on peut par exemple identifier ceux qui relèvent d’une entreprise (émettant uniquement pendant les horaires de bureau) et même essayer de deviner combien d’utilisateurs interagissent avec ce compte.
Pour prouver ce que j’avance, j’ai développé un script en python qui récupère tous les derniers tweets de quelqu’un, extrait les métadonnées, et mesure l’activité en fonction de l’heure et du jour de la semaine.
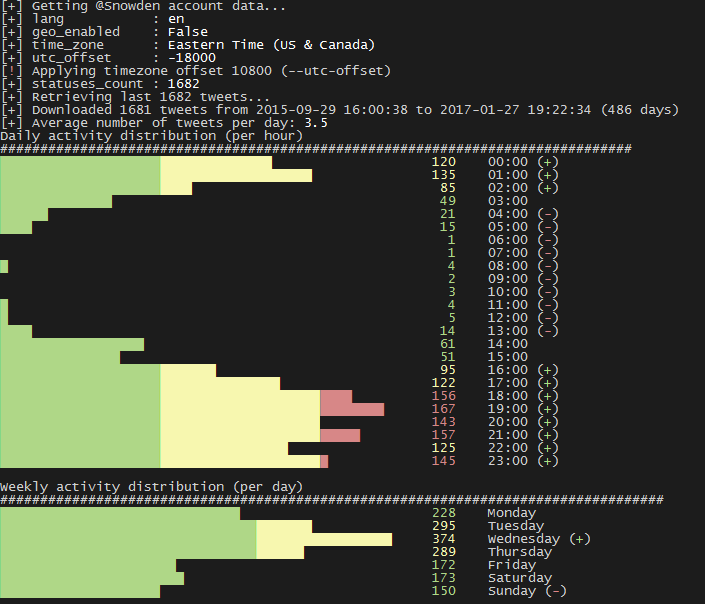
Analyse du compte de @Snowden
Snowden a posté 1682 tweets depuis septembre 2015. Comme on peut le voir ci-dessous, il est facile de déterminer son rythme de sommeil (fuseau horaire de Moscou).
Activité du compte Twitter de Snowden
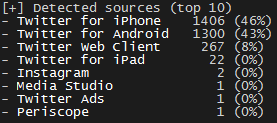
Analyse du compte de @realdonaldtrump
Est-ce que le compte de Donald Trump est géré par plusieurs personnes ? Cette fois en observant le nombre de sources détectées, je vous laisse deviner…
Sources des tweets du compte de Donald Trump
Recommandations générales
Je vous recommande fortement de lire les conseils de sécurité Twitter du Grugq. En plus de ce guide, je vous conseille d’être prudents avec les fuseaux horaires et les langues que vous utilisez, et d’être également conscients que vos tweets peuvent être analysés comme un tout : ne tweetez pas toujours à la même heure si vous ne voulez pas que les gens devinent votre fuseau horaire. Bien sûr, ces principes sont valables seulement si vous souhaitez rester anonyme, ne les appliquez pas à votre compte principal (ce serait une perte de temps) !
Code source
J’ai publié mon script sur GitHub. C’est open source donc n’hésitez pas à contribuer 😉
Facebook n’est pas un réseau social, c’est un scanner qui nous numérise
Aral Balkan est dans le monde de l’informatique une voix singulière, peut-être signe d’un changement de mentalités au sein de cette nébuleuse généralement plus préoccupée de technologie que de la marche du monde.
C’est en effet sur le terrain politique et même idéologique (ça y est, en deux mots on a déjà perdu les startupers !) qu’il place son travail, dans une perspective militante.
Contempteur sans concession du « capitalisme de surveillance » ( voir ce que nous avons publié sur cette question), il se place ici en rupture totale avec le discours à visée hégémonique que vient de tenir Mark Zuckerberg.
Pour Aral Balkan, tous les objets numériques qui nous prolongent sont autant d’émanations fragmentaires de notre personnalité, nous devrions donc en reconquérir la souveraineté et en défendre les droits battus en brèche par les Léviathans qui les captent et les monétisent.
il nous faut selon lui travailler à créer un autre monde (eh oui, carrément) où nous aurions retrouvé la maîtrise de toutes les facettes de nos personnalités numériques, il indique même quelques pistes dont certaines sont « déjà là » : les biens communs, les licences libres, le pair à pair…
Certains ne manqueront pas de traiter sa vision d’utopie avec un haussement d’épaules, avant de se résigner à un statu quo qui mutile notre humanité.
Découvrez plutôt sans préjugés un discours disruptif qui peut-être porte en germe une flexion décisive dans notre rapport au numérique.
Encourager la maîtrise de chacun et la bonne santé des biens communs
Dans son manifeste récent Mark Zuckerberg mettait en valeur sa vision d’une colonie mondiale centralisée dont les règles seraient dictées par l’oligarchie de la Silicon Valley.
J’affirme que nous devons faire exactement l’inverse et œuvrer à un monde fondé sur la souveraineté individuelle et un patrimoine commun sain.
Nous sommes des êtres fragmentés. Construisons un monde où nous détenons et contrôlons toutes les facettes de notre personnalité.
Mark Zuckerberg a publié un manifeste intitulé « Construisons une communauté mondiale » dans lequel il détaille comment lui, un des 8 plus riches milliardaires au monde) et son empire entrepreneurial américain/multinational, Facebook Inc., vont résoudre tous les maux du monde.
Dans sa vision grandiose pour l’humanité, Mark revient sur la façon dont fondamentalement, Facebook « nous rapproche » en « connectant nos amis et nos familles ». Ce que Mark oublie de dire c’est que Facebook ne connecte pas les gens entre eux ; Facebook connecte les gens à Facebook Inc.
Facebook : Le mythe. Mark souhaite que vous pensiez que Facebook vous connecte les uns aux autres.
Facebook : la réalité. Facebook vous connecte à Facebook Inc.
Le modèle économique de Facebook c’est d’être « l’homme du milieu » : il consiste à pister tous vos comportements, votre famille, vos amis, à stocker indéfiniment des informations et les analyser en permanence pour vous connaître, vous exploiter en vous manipulant afin d’en tirer un bénéfice financier ou politique.
Facebook n’est pas un réseau social, c’est un scanner qui numérise les êtres humains. C’est, pour ainsi dire, une caméra qui capte votre âme.
Le business de Facebook consiste à créer un double de vous-même, à s’emparer de ce double et à le contrôler, pour vous posséder et vous contrôler.
Quand Mark vous demande de lui faire confiance pour être un roi bienveillant, je réponds que nous bâtirons un monde sans roi.
Le modèle économique de Facebook, Google et de la cohorte des startups financées par le capital-risque de la Silicon Valley, j’appelle ça de l’élevage d’être humains. Facebook est une ferme industrielle pour les êtres humains. Et le manifeste de Mark n’est rien d’autre que la dernière tentative d’un milliardaire paniqué pour enjoliver un modèle d’affaires répugnant fondé sur la violation des droits humains avec l’objectif faussement moral de se débarrasser de la réglementation et de justifier un désir décomplexé de créer une seigneurie à l’échelle planétaire, en connectant chacun d’entre nous à Facebook, Inc.
Refusons une colonie globale
Le manifeste de Mark ne vise pas à construire une communauté globale, il vise à construire une colonie globale – dont il serait le roi et dont son entreprise et l’oligarchie de la Silicon Valley seraient la cour.
Facebook veut nous faire croire qu’il s’agit d’un parc de loisirs alors qu’il s’agit d’un centre commercial.
Ce n’est pas le rôle d’une entreprise de « développer l’infrastructure sociale d’une communauté » comme Mark veut le faire. L’infrastructure sociale doit faire partie des biens communs, et non pas appartenir aux entreprises monopolistiques géantes comme Facebook. La raison pour laquelle nous nous retrouvons dans un tel bazar avec une surveillance omniprésente, des bulles de filtres et des informations mensongères (de la propagande) c’est que, précisément, la sphère publique a été totalement détruite par un oligopole d’infrastructures privées qui se présente comme un espace public.
Facebook veut nous faire croire qu’il s’agit d’un parc alors qu’il s’agit d’un centre commercial. La dernière chose dont nous ayons besoin c’est d’une infrastructure numérique encore plus centralisée et détenue par des intérêts privés pour résoudre les problèmes créés par une concentration sans précédent de puissance, de richesse et de contrôle entre les mains de quelques-uns. Il est grand temps que nous commencions à financer et à construire l’équivalent numérique de parcs à l’ère du numérique au lieu de construire des centres commerciaux de plus en plus grands.
D’autres ont critiqué en détail le manifeste de Mark. Je ne vais pas répéter ici ce qu’ils ont dit. Je voudrais plutôt me concentrer sur la manière dont nous pouvons construire un univers radicalement différent de celui de la vision de Mark. Un monde dans lequel, nous, individus, au lieu des entreprises, aurons la maîtrise et le contrôle de notre être. En d’autres termes, un monde dans lequel nous aurons la souveraineté individuelle.
Là où Mark vous demande de lui faire confiance en tant que roi bienveillant, je réponds : construisons un monde sans roi. Là où la vision de Mark s’enracine dans le colonialisme et la perpétuation d’un pouvoir et d’un contrôle centralisés, la mienne est fondée sur la souveraineté individuelle et avec des biens communs en bonne santé et distribués.
La souveraineté individuelle et le moi cybernétique.
Nous ne pouvons plus nous offrir le luxe de ne pas comprendre la nature du « moi » à l’âge numérique. L’existence même de nos libertés et de la démocratie en dépend.
Nous sommes (et nous le sommes depuis un moment maintenant) des organismes cybernétiques.
Nous devons résister de toutes nos forces à toute tentative de réduire les personnes à des propriétés.
En cela, je ne veux pas faire référence à la représentation stéréotypée des cyborgs qui prévaut en science-fiction et dans laquelle la technologie se mélange aux tissus humains. Je propose plutôt une définition plus générale dans laquelle le terme s’applique à toute extension de notre esprit et de notre moi biologique par la technologie. Bien que les implants technologiques soient certainement réalisables, possibles et avérés, le principal moyen par lequel nous amplifions aujourd’hui notre moi avec la technologie, ce n’est pas par des implants mais par des explants.
Nous sommes des êtres fragmentés ; la somme de nos différents aspects tels que contenus dans nos êtres biologiques aussi bien que dans la myriade de technologies que nous utilisons pour étendre nos capacités biologiques.
Nous devons protéger par voie constitutionnelle la dignité et le caractère sacro-saint du moi étendu.
Une fois que nous avons compris cela, il s’ensuit que nous devons étendre les protections du moi au-delà de nos limites biologiques pour y inclure toutes ces technologies qui servent à nous prolonger. Par conséquent, toute tentative par des tierces parties de posséder, contrôler et utiliser ces technologies comme une marchandise est une tentative de posséder, contrôler et monétiser les éléments constitutionnels des individus comme des marchandises. Pour faire court, c’est une tentative de posséder, contrôler et utiliser les êtres humains comme des marchandises.
Inutile de dire que nous devons résister avec la plus grande vigueur à toute tentative de réduire les êtres humains à de la marchandise. Car ne pas le faire, c’est donner notre consentement tacite à une nouvelle servitude : une servitude qui ne fait pas commerce des aspects biologiques des êtres humains mais de leurs paramètres numériques. Les deux, bien sûr, n’existent pas séparément et ne sont pas réellement séparables lorsque la manipulation de l’un affecte nécessairement l’autre.
Au-delà du capitalisme de surveillance
À partir du moment où nous comprenons que notre relation à la technologie n’est pas une relation maître/esclave mais une relation organisme cybernétique/organe ; à partir du moment où nous comprenons que nous étendons notre moi par la technologie et que notre technologie et nos données font partie des limites de notre moi, alors nous devons nous battre pour que légalement les protections constitutionnelles du moi que nous avons gravées dans la Déclaration universelle des droits de l’homme et mises en application dans la myriade des législations nationales soient étendues à la protection du moi en tant qu’être cybernétique.
Il s’ensuit également que toute tentative de violation des limites de ce moi doit être considérée comme une attaque du moi cybernétique. C’est précisément cette violation qui constitue aujourd’hui le modèle économique quotidien de Facebook, Google et des majors de la technologie de la Sillicon Valley. Dans ce modèle, que Shoshana Zuboff appelle le capitalisme de surveillance, ce que nous avons perdu, c’est notre souveraineté individuelle. Les personnes sont à nouveau redevenues des possessions, bien que sous forme numérique et non biologique.
Pour contrer cela, nous devons construire une nouvelle infrastructure pour permettre aux personnes de regagner cette souveraineté individuelle. Ces aspects de l’infrastructure qui concernent le monde qui nous entoure doivent appartenir aux biens communs et les aspects qui concernent les gens – qui constituent les organes de notre être cybernétique – doivent être détenus et contrôlés par les individus eux-mêmes.
Ainsi, par exemple, l’architecture d’une ville intelligente et les données sur le monde qui nous entoure (les données sur notre environnement) doivent appartenir aux biens communs, tandis que votre voiture intelligente, votre smartphone, votre montre connectée, votre peluche intelligente, etc. et les données qu’ils collectent (les données sur les individus) doivent rester votre propriété.
Pour un Internet des individus
Imaginez un monde où chacun possède son propre espace sur Internet, fondé sur les biens communs. Cela représente un espace privé (un organe de notre être cybernétique) auquel nos appareils dits intelligents (qui sont aussi des organes), peuvent se connecter.
Au lieu d’envisager cet espace comme un nuage personnel, nous devons le considérer comme un nœud particulier, permanent, dans une infrastructure de pair à pair dans laquelle nos appareils divers (nos organes) se connectent les uns aux autres. En pratique, ce nœud permanent est utilisé pour garantir la possibilité de trouver la localisation (à l’origine en utilisant des noms de domaine) et la disponibilité (car il est hébergé/toujours en service) tandis que nous passerons de l’architecture client/serveur du Web actuel à l’architecture de pair à pair de la prochaine génération d’Internet.
Chacun a son propre espace sur Internet, auquel tous ses objets se connectent.
Un Internet des individus
L’infrastructure que nous construirons doit être fondée sur les biens communs, appartenir aux biens communs et être interopérable. Les services eux-mêmes doivent être construits et hébergés par une pléthore d’organisations individuelles, non par des gouvernements ou par des entreprises gigantesques, travaillant avec des protocoles interopérables et en concurrence pour apporter à ceux qu’elles servent le meilleur service possible. Ce n’est pas un hasard : ce champ sévèrement limité du pouvoir des entreprises résume l’intégralité de leur rôle dans une démocratie telle que je la conçois.
L’unique but d’une entreprise devrait être de rivaliser avec d’autres organisations pour fournir aux personnes qu’elles servent le meilleur service possible. Cela contraste radicalement avec les énormes dispositifs que les entreprises utilisent aujourd’hui pour attirer les individus (qu’ils appellent des « utilisateurs ») sous de faux prétextes (des services gratuits à l’intérieur desquels ils deviennent les produits destinés à la vente) dans le seul but de les rendre dépendants, de les piéger et de les enfermer dans des technologies propriétaires, en faire l’élevage, manipuler leur comportement et les exploiter pour en tirer un bénéfice financier et politique.
Dans l’entreprenocratie d’aujourd’hui, nous – les individus – sommes au service des entreprises. Dans la démocratie de demain, les entreprises devront être à notre service.
Les fournisseurs de services doivent, naturellement, être libres d’étendre les fonctionnalités du système tant qu’ils partagent les améliorations en les remettant dans les biens communs (« partage à l’identique »), évitant ainsi le verrouillage. Afin de fournir des services au-dessus et au-delà des services de base fondés sur les biens communs, les organisations individuelles doivent leur attribuer un prix et faire payer les services selon leur valeur ajoutée. De cette manière, nous pouvons construire une économie saine basée sur la compétition reposant sur un socle éthiquement sain à la place du système de monopoles que nous rencontrons aujourd’hui reposant sur une base éthiquement pourrie. Nous devons le faire sans compliquer le système tout entier dans une bureaucratie gouvernementale compliquée qui étoufferait l’expérimentation, la compétition et l’évolution décentralisée et organique du système.
Une économie saine fondée sur un base éthique
Interopérabilité, technologies libres avec des licences « partage à l’identique », architecture de pair à pair (par opposition à une architecture client/serveur), et un cœur fondé sur les biens communs : tels sont les garde-fous fondamentaux pour empêcher le nouveau système de se dégrader en une nouvelle version du Web de surveillance monopolistique, tel que nous connaissons aujourd’hui. C’est notre manière d’éviter les économies d’échelle et de rompre la boucle de rétroaction entre l’accumulation d’informations et la richesse qui est le moteur principal du capitalisme de la surveillance.
Pour être tout à fait clair, nous ne parlons pas d’un système qui peut s’épanouir sous le diktat du dernier round d’un capitalisme de surveillance. C’est un système néanmoins, qui peut être construit dans les conditions actuelles pour agir comme un pont entre le statu quo et un monde post-capitaliste durable.
Construire le monde dans lequel vous voulez vivre
Dans un discours que j’ai tenu récemment lors d’un événement de la Commission européenne à Rome, je disais aux auditeurs que nous devions « construire le monde dans lequel nous voulons vivre ». Pour moi, ce n’est pas un monde détenu et contrôlé par une poignée d’oligarques de la Silicon Valley. C’est un monde avec des biens communs sains, dans lequel – en tant que communauté – nous possédons et contrôlons collectivement ces aspects de notre existence qui nous appartiennent à tous, et dans lequel aussi — en tant qu’individus — nous sommes maîtres et avons le contrôle des aspects de notre existence qui n’appartiennent qu’à nous.
Imaginez un monde où vous et ceux que vous aimez disposeraient d’une capacité d’action démocratique ; un monde où nous bénéficierions tous d’un bien-être de base, de droits et de libertés favorables à notre dignité d’êtres cybernétiques. Imaginez un monde durable libéré de l’avidité destructrice et à court terme du capitalisme et dans lequel nous ne récompenserions plus les sociopathes lorsqu’ils trouvent des moyens encore plus impitoyables et destructeurs d’accumuler les richesses et la puissance aux dépens des autres. Imaginez un monde libre, soustrait (non plus soumis) à la boucle de rétroaction de la peur fabriquée et de la surveillance omniprésente qui nous entraîne de plus en plus profondément dans un nouveau vortex du fascisme. Imaginez un monde dans lequel nous nous octroierions la grâce d’une existence intellectuellement riche où nous serions libres d’explorer le potentiel de notre espèce parmi les étoiles.
Tel est le monde pour lequel je me lève chaque jour afin d’y travailler. Non par charité. Non pas parce que je suis un philanthrope. En fait sans aucune autre raison que celle-ci : c’est le monde dans lequel je veux vivre.
– – –
Aral Balkan est un militant, concepteur et développeur. Il détient 1/3 de Ind.ie, une petite entreprise sociale qui travaille pour la justice sociale à l’ère du numérique.
Être un géant du mail, c’est faire la loi…
Google, Yahoo, Microsoft (Outlook.com & Hotmail) voient forcément vos emails. Que vous soyez chez eux ou pas, nombre de vos correspondant·e·s y sont (c’est mathématique !), ce qui fait que vos échanges finissent forcément par passer sur leurs serveurs. Mais ce n’est pas là le seul problème.
Ça, c’est côté public : « Tout le monde est chez eux, alors au final, que j’y sois ou pas, qu’est-ce que ça change ? ». En coulisses, côté serveurs justement, ça change tout. La concentration des utilisateurs est telle qu’ils peuvent de fait imposer des pratiques aux « petits » fournisseurs d’emails, de listes de diffusion, etc. Ben oui : si vous ne respectez pas les exigences de Gmail, les emails que vous enverrez vers tou·te·s leurs utilisateurs et utilisatrices peuvent passer en spam, voire être tout bonnement bloqués.
Comme pour Facebook, on se trouve face à un serpent qui se mord la queue : « Tous mes amis sont dessus, alors je peux pas aller sur un autre réseau… » (phrase entendue lors des début de Twitter, Instagram, Snapchat, et Framasphère*…). Sauf qu’en perdurant chez eux, on devient aussi une part de la masse qui leur confère un pouvoir sur la gouvernance – de fait – d’Internet !
Il n’y a pas de solutions idéale (et, s’il vous plaît, ne jugeons pas les personnes qui participent à ces silos… elles sont souvent pas très loin dans le miroir 😄) ; mais nous pensons que prendre conscience des enjeux, c’est faire avancer sa réflexion et sa démarche vers plus de libertés.
Nous reprenons donc ici un article de Luc, notre administrateur-système, qui a partagé sur son blog son expérience de « petit » serveur d’email (à savoir Framasoft, principalement pour Framalistes) face à ces Léviathans. Luc ayant placé son blog dans le domaine public, nous nous sommes permis de remixer cet article avec des précisions qu’il a faites en commentaires et des simplifications/explications sur les parties les plus techniques (à grands coups de notes intempestives 😜 ).
Quand on pense aux GAFAM, on pense surtout à leur vilaine habitude d’aspirer les données de leurs utilisateurs (et des autres aussi d’ailleurs) mais on ne pense pas souvent à leur poids démesuré dans le domaine du mail.
Google, c’est gmail, Microsoft, c’est hotmail, live, msn et je ne sais quels autres domaines, etc. [Outlook.com. On l’oublie souvent. – Note du Framablog]
Tout ça représente un nombre plus que conséquent d’utilisateurs. Google revendiquait en 2015 900 millions de comptes Gmail. Bon OK, il y en a une part qui ne doit servir qu’à avoir un compte pour son téléphone Android, mais quand même. C’est énorme.
Ce qui nous ramène à une situation des plus déplaisantes où un petit nombre d’acteurs peut en em***er une multitude.
WARNING : la liste à puce qui suit contient des exemples techniques un poil velus. Nos notes vous aideront à y survivre, mais vous avez le droit de la passer pour lire la suite des réflexions de Luc. Ah, et puis il a son franc-parler, le loustic. ^^ – NdF.
Petits exemples vécus :
Microsoft bloque tout nouveau serveur mail qu’il ne connaît pas. C’est arrivé pour mon serveur perso, le serveur de mail de Framasoft que j’ai mis en place, sa nouvelle IP [l’adresse qui permet d’indiquer où trouver un serveur – NdF] quand je l’ai migré, le serveur de listes de Framasoft et sa nouvelle IP quand je l’ai migré. Ça me pétait une erreur 554 Message not allowed (de mémoire, je n’ai plus le message sous la main) [erreur qui fait que l’email est tout bonnement refusé – NdF]. Et pour trouver comment s’en débrouiller, bon courage : la page d’erreur de Microsoft n’indiquait rien. Je n’ai même pas trouvé tout seul (et pourtant j’ai cherché) : c’est un ami qui m’a trouvé la bonne adresse où se faire dé-blacklister (notez au passage qu’il est impossible de faire dé-blacklister une adresse ou un bloc d’adresses IPv6 [la nouvelle façon d’écrire les adresses IP, indispensable face à la croissance du nombre de machines connectées à Internet – NdF]).
Gmail qui, du jour au lendemain, décide de mettre tous les mails de mon domaine personnel en spam. Ce qui ne serait pas trop gênant (hé, les faux positifs, ça existe) si ce n’était pour une raison aberrante (ou alors c’est une sacrée coïncidence) : ça s’est passé à partir du moment où j’ai activé DNSSEC[une façon de sécuriser les échanges avec les serveurs DNS [ces serveurs sont les annuaires qui font correspondre une adresse web avec l’adresse IP difficile à retenir pour les humains – NdF²]] sur mon domaine. Et ça s’est terminé dès que j’ai ajouté un enregistrement SPF[une vérification que les emails envoyés ne sont pas usurpés – NdF] à ce domaine. Or le DNSSEC et le SPF n’ont rien à voir ! Surtout pas dans cet ordre-là ! Qu’on ne fasse confiance à un enregistrement SPF que dès lors que le DNS est de confiance (grâce à DNSSEC), soit, mais pourquoi nécessiter du SPF si on a du DNSSEC ? [Oui, pourquoi ? – NdF qui laisse cette question aux spécialistes]
Yahoo. Ah, Yahoo. Yahoo a décidé de renforcer la lutte contre le spam (bien) mais a de fait cassé le fonctionnement des listes de diffusion tel qu’il était depuis des lustres (pas bien). En effet, quand vous envoyez un mail à une liste de diffusion, le mail arrive dans les boîtes des abonnés avec votre adresse comme expéditeur, tout en étant envoyé par le serveur de listes [le serveur de listes se fait passer pour vous, puisque c’est bien vous qui l’avez envoyé par son intermédiaire… vous suivez ? – NdF]. Et Yahoo a publié un enregistrement DMARC[une sécurité de plus pour l’email… heureusement que Luc a mis des liens wikipédia, hein ? – NdF] indiquant que tout mail ayant pour expéditeur une adresse Yahoo doit impérativement provenir d’un serveur de Yahoo. C’est bien gentil, mais non seulement ça fout en l’air le fonctionnement des listes de diffusion, mais surtout ça met le bazar partout : les serveurs de mail qui respectent les enregistrements DMARC appliquent cette règle, pas que les serveurs de Yahoo. Notez qu’AOL fait la même chose.
Orange fait aussi son chieur à coup d’erreurs Too many connections, slow down. OFR004_104 [104][« trop de connexions, ralentissement », une erreur qui fait la joie des petits et des grands admin-sys – NdF]. C’est tellement connu que le moteur de recherche Google suggère de lui-même wanadoo quand on cherche Too many connections, slow down. Voici la solution que j’ai utilisée.
Pour s’en remettre, voici une image qui fait plaisir…
On peut le voir, le pouvoir de nuisance de ces silos est énorme. Et plus encore dans le cas de Yahoo qui n’impacte pas que les communications entre ses serveurs et votre serveur de listes de diffusion, mais entre tous les serveurs et votre serveur de listes, pour peu que l’expéditeur utilise une adresse Yahoo [on confirme : dès qu’une personne chez Yahoo utilisait Framalistes, ça devenait un beau bord… Bref, vous comprenez. Mais Luc a lutté et a fini par arranger tout cela. – NdF]. Et comme il y a encore pas mal de gens possédant une adresse Yahoo, il y a des chances que vous vous rencontriez le problème un jour ou l’autre.
Je sais bien que c’est pour lutter contre le spam, et que la messagerie propre devient si compliquée que ça pourrait limite devenir un champ d’expertise à part entière, mais le problème est que quand un de ces gros acteurs tousse, ce sont tous les administrateurs de mail qui s’enrhument.
Si ces acteurs étaient de taille modeste, l’ensemble de la communauté pourrait soit leur dire d’arrêter leurs bêtises, soit les laisser crever dans leurs forteresses injoignables. Mais ce n’est malheureusement pas le cas. 🙁 « À grand pouvoir, grandes responsabilités »… Je crois avoir montré leur pouvoir de nuisance, j’aimerais qu’ils prennent leurs responsabilités.
Ils peuvent dicter leur loi, de la même façon qu’Internet Explorer 6 le faisait sur le web il y a des années et que Chrome le fait aujourd’hui (n’ayez pas peur, le titre de la vidéo est en anglais, mais la vidéo est en français). C’est surtout ça qui me dérange.
Une seule solution pour faire cesser ce genre d’abus : la dégooglisation ! Une décentralisation du net, le retour à un Internet d’avant, fait de petites briques et pas d’immenses pans de béton.
PS : ne me lancez pas sur MailInBlack, ça me donne des envies de meurtre.








 J’utilise Twitter tous les jours. Pour moi qui suis consultant en cybersécurité, c’est de loin un des meilleurs outils pour rester informé des dernières actualités et pour partager des informations qu’on estime pertinentes pour d’autres. Avec la récente investiture de Donald Trump, les
J’utilise Twitter tous les jours. Pour moi qui suis consultant en cybersécurité, c’est de loin un des meilleurs outils pour rester informé des dernières actualités et pour partager des informations qu’on estime pertinentes pour d’autres. Avec la récente investiture de Donald Trump, les 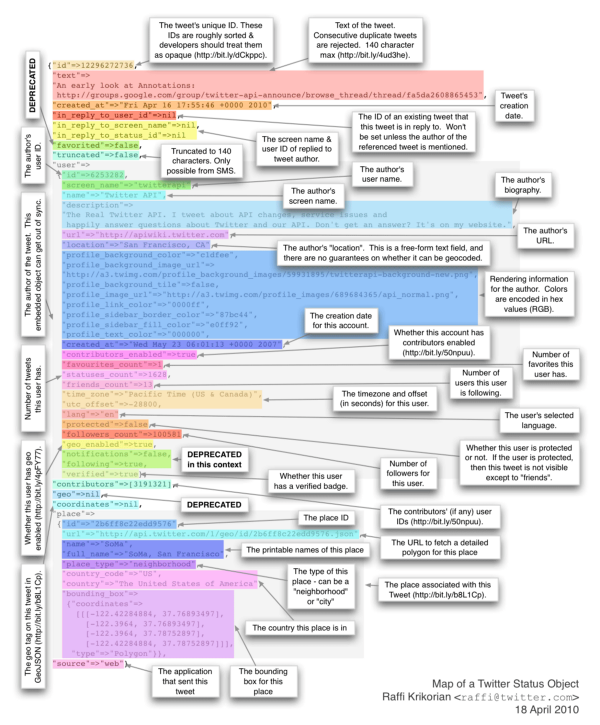
 Dans son manifeste récent Mark Zuckerberg mettait en valeur sa vision d’une colonie mondiale centralisée dont les règles seraient dictées par l’oligarchie de la Silicon Valley.
Dans son manifeste récent Mark Zuckerberg mettait en valeur sa vision d’une colonie mondiale centralisée dont les règles seraient dictées par l’oligarchie de la Silicon Valley.





{kind=link}
{kind=link}
{kind=link}
{kind=link}