Offrez le cadeau du logiciel libre, avec Framalibre !
Il restait un cadeau au pied du sapin… L’annuaire du logiciel libre et projet fondateur de Framasoft évolue à nouveau, en un site plus beau, plus simple, plus ergonomique… et beaucoup plus pratique pour recommander ses logiciels libres préférés !
C’est donc riches de tous ces enseignements que nous avons concocté cette nouvelle version « 2024 » de Framalibre que nous vous présentons aujourd’hui, avec fierté, sur Framalibre.org
Alors pour les personnes qui étaient habituées à la version précédente de Framalibre, on vous prévient : ça va faire un vide… Vous êtes tout à fait en droit de vous écrier « mais il est où, tout mon bazar ? » … Or, pour beaucoup de nouvelles et de nouveaux dans le monde du libre, c’était bien ça le problème !
Maiwann a réalisé pour nous des tests d’utilisation, notamment lors de conférences, ou sur des stands où l’on se rencontre. Ces tests lui ont, par exemple, permis de réaliser qu’afficher une simple étiquette « mail » sur la page d’accueil n’aidait pas pour autant les personnes dont le besoin serait « trouver une alternative à Gmail ».
Pour cette nouvelle mouture, nous avons donc fait un choix radical : celui de la simplicité. Nous avons donc réalisé un grand travail pour simplifier les menus, sous-menus, menus secondaires, étiquettes, encadrés, affichages de notices, boutons…
Ce choix radical de la simplicité a un coût : nous avons dû recentrer l’annuaire Framalibre sur les outils numériques. La version précédente avait voulu s’ouvrir à la culture, aux objets et aux structures du libre. Mais le problème quand on fait un peu de tout, c’est que c’est dur de faire tout bien : présenter tout le Libre induisait de multiplier les menus et les catégories tout en augmentant la complexité pour créer une notice.
Le nouveau site Framalibre est volontairement dépouillé. Il vous accueille par une page affichant des étiquettes (les recherches les plus utilisées) et une barre de recherche. Finies les méta-catégories, catégories, sous catégories, et filtres de sous-catégories… Bref, l’arborescence héritée de l’annuaire de 2001 !
Notre d’objectif est de répondre au plus vite à votre besoin de trouver un logiciel libre pour faire ce que vous avez à faire, ou de trouver une alternative pour remplacer ce service des géants du web dont vous voulez vous libérer : vous cherchez, vous trouvez.
résultats d’une recherche photoshop sur Framalibre 2024
📃 Sous le capot, les pages 📃
Cliquez sur GNU et Tux pour soutenir Framalibre ! – illustration David Revoy – Licence : CC-By 4.0
Pour les plus techniques d’entre vous (les autres, vous pouvez passer directement à la partie suivante ^^), cette simplicité se retrouve aussi sous le capot.
Le Drupal 7 de Framalibre 2017 avait besoin d’une bonne mise à niveau, ce qui demande du temps et de l’énergie. La base de données des notices était difficile d’accès : si nous avions bien bricolé quelque chose pour que cela puisse être utilisé par d’autres, il nous aurait fallu mettre plus de temps et d’énergie à développer une API pratique et documentée…
Nous avons préféré consacrer cette énergie à appliquer ce choix de la simplicité dans le logiciel même, en faisant du nouveau Framalibre un site statique, que l’on espère plus léger et rapide. Le code de cet outil, basé sur le logiciel Jekyll, a été développé par les talents de l’Échappée Belle (merci à Fanny et David <3), et bien entendu il est libre et disponible en ligne.
Ce choix du statique nous a permis de modifier la structure des notices et de la base de données. Désormais écrites en markdown, ces notices sont lisibles aussi bien par des humaines que par des scripts (tant que vos robots restent bien élevés, ça va de soi :p). Les notices de Framalibre étant sous CC-By SA, nous espérons que faciliter leur accès et leur lisibilité permettra des réutilisations intéressantes !
Nous en avons d’ailleurs profité pour simplifier au maximum les notices : vous n’y trouverez plus, par exemple, de capture d’écran du logiciel. En effet, au bout de quelques années, ces images sont souvent périmées et trompeuses. Désormais, les informations présentées dans une notice sont simples, succinctes, et si ce premier regard sur tel ou tel logiciel libre vous plaît, on vous invite à trouver plus d’informations sur le site officiel.
Notice de Krita sur Framalibre 2024
🎁 « Tiens, voici ce que j’utilise pour me libérer… » 🎁
Cliquez pour nous soutenir et aider à repousser MS Blue Scream – Illustration CC-By David Revoy
Car notre objectif n’est pas que vous restiez sur Framalibre le plus longtemps possible (oui, au jeu de l’économie de l’attention, Framasoft est franchement -et volontairement- mauvaise 😉 ). Au contraire, Framalibre se veut un intermédiaire, une rampe pour vous élancer vers le site officiel de l’outil libre qui répond à votre besoin.
Au-delà d’être un outil de recherche, nous avons pensé ce nouveau Framalibre comme un outil de recommandation d’alternatives libres et éthiques. Que ce soit lors des enquêtes et tests préliminaires à cette refonte de Framalibre, durant les rencontres régulières auxquelles nous participons ou même lorsque l’on regarde nos fonctionnements à nous.… nous observons la même constante :
Il est beaucoup plus facile d’adopter un outil libre lorsqu’il nous est chaudement recommandé par des personnes en qui nous avons confiance.
C’est comme cela que nous avons eu l’idée d’ajouter un encadré « utilisé par les membres de Framasoft » en haut de certaines pages de recherche. Cela ne veut pas dire que les autres logiciels soient moins bien, ni qu’ils ne répondent pas à votre attente spécifique : cela permet juste de montrer les logiciels et services libres que nous utilisons régulièrement.
Un mini-site de recommandations Framalibre
💝 Les mini-sites Framalibre : offrez vos sélections ! 💝
Avec cette nouvelle version de Framalibre, nous avions envie d’aller encore plus loin pour favoriser la recommandation de pair à pair. Nous savons, d’expérience, qu’une personne qui utilise du libre aujourd’hui est une personne qui, demain, aidera ses proches à libérer leurs usages numériques.
Sur le nouveau Framalibre, vous pouvez faire votre sélection d’outils libres, et obtenir le lien d’une page à partager avec vos proches !
Rien que pour le plaisir, voici quelques exemples que nous vous avons concoctés :
Nous avons hâte de vous voir partager vos sélections d’outils libres !
GNU & Tux contre MB Blue Scream – Illustration David Revoy – Licence : CC-By 4.0
🤝 Le collaboratif, ça se partage ! 🤝
Bien entendu, Framalibre est et reste un annuaire collaboratif. Que vous vouliez ajouter une notice à l’annuaire ou corriger une notice existante, la contribution est à portée de clic !
Nous avons d’ailleurs rendu tout le processus plus… simple (vous sentiez qu’il y a comme un thème, là !). La contrepartie, c’est que vos contributions seront vérifiées avant publication par notre équipe de modératrices et modérateurs (et non plus modérées a posteriori comme avant).
L’avantage, c’est qu’il y a déjà près de 1 019 notices à aller découvrir, comme autant de solutions que les communautés du Libre offrent à chacune et chacun d’entre nous pour mieux émanciper ses pratiques numériques.
Et si vous n’y trouvez pas la fiche de ce super logiciel libre ou de cette app formidable qui vous a émancipé des géants du web… Libre à vous de l’ajouter : vous allez voir, c’est (sans trop de surprise) simple !
Alors désormais, c’est à vous de jouer !
À vous de vous emparer de Framalibre pour trouver, partager mais surtout pour recommander les outils libres qui vous facilitent la vie numérique… et la vie tout court !
Car oui : cette fin d’année encore, nous avons besoin de vous, de votre soutien, de vos partages, pour nous aider à reprendre du terrain sur le web toxique des GAFAM, et multiplier les espaces de numérique éthique.
Nous avons donc demandé à David Revoy de nous aider à montrer cela sur notre site Soutenir Framasoft, que nous vous invitons à visiter (parce que c’est beau) et surtout à partager le plus largement possible :
Si nous voulons boucler notre budget pour 2024, il ne nous reste plus que 5 jours pour récolter 71 398 € : nous n’y arriverons pas sans votre aide !
Mais où sont les livres universitaires open-source ?
Où sont les livres universitaires libres, ceux qu’on pourrait télécharger gratuitement à la façon d’un logiciel open-source ? Les lecteurs et lectrices du Framablog qui étudient ou travaillent à l’université se sont probablement posé la question.
Olivier Cleynen vous soumet ici quelques réponses auxquelles nous ouvrons bien volontiers nos colonnes.
Les manuels universitaires libres, j’en ai fabriqué un : Thermodynamique de l’ingénieur, publié en 2015 au sein du projet Framabook. Cette année, alors que Framabook se métamorphose en Des livres en commun et abandonne le format papier, je reprends le livre à mon nom et j’expérimente avec différentes formes de commercialisation pour sa troisième édition. C’est pour moi l’occasion de me poser un peu et de partager avec vous ce que j’ai appris sur ce monde au cours des sept dernières années.
Bon, je vais commencer par prendre le problème à l’envers. Un manuel universitaire, c’est d’abord un livre et comme tout autre livre il faut qu’il parte d’un désir fort de la part de l’auteur/e, car c’est une création culturelle au même titre qu’une composition musicale par exemple. Et d’autre part c’est un outil de travail, il faut qu’il soit très cohérent, structuré, qu’il justifie constamment l’effort qu’il demande au lecteur ou à la lectrice, en l’aidant à accomplir quelque chose de précis. Ces deux facettes font qu’il doit être le produit du travail d’un nombre faible de personnes très impliquées. On le voit bien avec les projets Wikibooks et Wikiversity par exemple, qui à mes yeux ne peuvent pas décoller, par contraste avec Wikipédia où le fait que certains articles soient plus touffus que d’autres et utilisent des conventions de notation différentes ne pose aucun problème.
Leonardo da Vinci (1452-1519), Codex Leicester, un manuel italien écrit en miroir, ayant un peu vieilli, mais heureusement déjà dans le domaine public.
Pour écrire un livre comme Thermodynamique de l’ingénieur j’estime (à la louche) qu’il faut un an de travail à quelqu’un de niveau ingénieur. En plus de ça il faut au moins deux personne-mois de travail pour mettre le tout en page et avoir un livre prêt à l’impression.
Je n’aime pas beaucoup ce genre de calculs qui ont tendance à tout réduire à des échanges mercantiles, mais dans un monde où l’équipe d’en face loue l’accès à un PDF en ligne à 100 euros par semestre, on peut se permettre d’écrire quelques nombres au dos d’une enveloppe, pour se faire une idée. Un an de travail pour une ingénieur médiane coûte 58 k€ brut en France. Pour deux personnes-mois de mise en page, on peut certainement compter 5 k€ de rémunération brute, soit au total: 63 000 euros.
Maintenant en partant sur la base de 1000 livres vendus on voit qu’il faudrait récolter 63 euros par livre pour financer au “prix du marché”, si je peux me permettre, le travail purement créatif. C’est une mesure (très approximative…) de ce que les créateurs choisissent de ne pas gagner ailleurs, lorsqu’ils/elles font un livre en accès gratuit ou en vente à prix coûtant, comme l’a été le Framabook de thermodynamique.
Thermodynamique de l’ingénieur – troisième édition
Bien sûr, si l’on reprend le problème à l’endroit, le prix d’un livre acheté par un étudiant ou une universitaire n’est pas du tout calculé sur cette base, car il faut aussi et surtout rémunérer les autres acteurs entre l’auteure et la lectrice.
La part du lion est assurément réservée aux distributeurs, et parmi eux Amazon, qui sont passés progressivement de purs agents logistiques à de véritables plateformes éditoriales. Les distributeurs ont ainsi dépassé leur rôle initial (être une réponse à la question : « où vais-je me procurer ce livre qui m’intéresse ? ») et saturé le niveau d’au-dessus, en proposant de facto toutes les réponses les plus pertinentes à la question : « quel est le meilleur livre sur ce sujet ? ».
Au milieu de tout ça, il y a les éditeurs. Un peu comme les producteurs dans le monde de la musique, leur rôle est de résoudre l’équation qui va lier et satisfaire tous les acteurs impliqués dans l’arrivée du livre entre les mains de la lectrice. Ils sont ceux qui devraient le mieux connaître les particularités de ce produit pas tout à fait comme les autres, et pourtant…
Dans notre exploration du monde des manuels universitaires, je vais choisir de diviser les éditeurs en trois groupes.
tout un patrimoine est rendu légalement inaccessible.
Au centre, nous avons les petits. Ils sont écrasés par tous les autres, mais je peux dire d’emblée qu’ils n’ont que ce qu’ils méritent. Leurs outils et méthodes de travail sont désuets voire archaïques, et ils saisissent très mal les mécanismes du succès éditorial. Donc, ils se contentent de sortir beaucoup de livres pour espérer en réussir quelques-uns. Contactez-les avec votre projet, et ils vous proposeront un contrat dans lequel vous renoncez ad vitam à tout contrôle, et à 93% des revenus de la vente. Faites le calcul : même avec un prix de vente élevé, disons 40€, ce qu’ils vous présenteront sans sourciller comme un succès (mille livres vendus) ne vous rapportera même pas 3000 euros bruts, étalés sur dix ans.
Vous me direz que ce n’est pas bien grave, qu’avoir une haute rentabilité, une haute efficacité, n’est pas un but en soi : tout le monde ne veut pas être Jeff Bezos, et le monde a bien besoin de petits acteurs, de diversité éditoriale, de tentatives risquées, tout comme le secteur de la musique. Certes ! Mais voyons les conséquences en aval. Lorsque le contrat est signé, le copyright sur l’œuvre passe irréversiblement dans les mains de l’éditeur, qui ne l’exploitera vraisemblablement que dix ans. Que se passe-t-il après ? Le livre n’est plus imprimé, il sort de la sphère commerciale, et… il est envoyé en prison. Il rejoint la montagne de livres abandonnés, qui attendent, sous l’œil du gendarme copyright, le premier janvier de la 71ème année après la mort de leur auteur, que l’on puisse les réutiliser. Un siècle de punition ! Quelle bibliothèque en aura encore un exemplaire en rayon lorsqu’ils en sortiront ?
Et voilà comment nous entretenons cette situation absurde, dans laquelle une masse de travail faramineuse, sans plus aucune valeur commerciale, est mise hors d’accès de ceux qui en ont besoin. Il y a des manuels universitaires par centaines, parfaitement fonctionnels, dont le contenu aurait juste besoin d’un petit dépoussiérage pour servir dans les amphis après une mise à jour. Ils pourraient aussi être traduits en d’autres langues, ou bien dépecés pour servir à construire de nouvelles choses. Au lieu de ça, en thermodynamique les petits éditeurs sortent chaque année de nouveaux manuels dans lesquels les auteurs décrivent une nouvelle fois l’expérience de Joule et Gay-Lussac de 1807, condamnés à refaire eux-mêmes le même schéma, les mêmes diagrammes pression-volume, donner les mêmes explications sans pouvoir utiliser ce qui a déjà été fait par leurs prédécesseurs. Certes, d’autres disciplines évoluent plus vite que la mienne, mais partout il y a des fondamentaux qu’il n’est pas nécessaire de revisiter très souvent, et pour lesquels tout un patrimoine est rendu légalement inaccessible. Quel gâchis !
des pratiques difficiles à accepter pour ceux pour qui un livre doit aussi être un outil d’émancipation.
Grimpons maintenant d’un étage. Au dessus des petits éditeurs, les gros ; eux résolvent l’équation autrement, en partant du point de vue qu’un manuel universitaire est un outil de travail professionnel : un produit pointu, hyper-spécialisé et qui coûte cher. Aux États-Unis, ce sont eux qui mènent la course. Pour pouvoir suivre un cours de thermodynamique ou de chimie organique, l’étudiant/e lambda est forcée d’utiliser un manuel qui coûte entre 100 et 300 euros par le/la prof, qui va baser tous ses cours, diapositives, sessions d’exercices et examens dessus. Nous parlons de pavés de 400 pages, écrits par plusieurs auteur/es et illustrés par des professionnels, des outils magnifiques qui non seulement attisent votre curiosité, mais aussi vous rassasient d’applications concrètes et récentes, en vous permettant de progresser à votre rythme. On est loin des petits aides-mémoire français avec leurs résumés de cours abscons !
Ces manuels sont de véritables navires, conduits avec soin pour maximiser leur potentiel commercial, avec des pratiques pas toujours très éthiques. Par exemple, les nouvelles éditions s’enchaînent à un rythme rapide, et les données et la numérotation des exercices sont souvent modifiés, pour rendre plus difficile l’utilisation des éditions antérieures. Pour pouvoir capter de nouveaux marchés, en Asie notamment, les éditeurs impriment pour eux des versions beaucoup moins chères, dont ils tentent après par tous les moyens d’interdire la vente dans les autres pays.
Le prix de vente des livres est en fait tel que pour les étudiants, la location devient le moyen d’accès principal. Les distributeurs (comme Amazon US ou Chegg) vous envoient l’enveloppe de retour affranchie directement avec le livre. Vous pouvez tout de même surligner et annoter l’intérieur du livre : il ne sera probablement pas reloué plus d’une fois. Après tout, le coût de fabrication est faible au regard des autres sommes en jeu : il s’agit surtout de pouvoir contrôler le nombre de livres en circulation (lire : empêcher la revente de livres récents et bon marché).
Les éditeurs tentent aussi de ne pas louper le virage (très lent…) de la dématérialisation, en louant l’accès au contenu du livre via leur site Internet ou leur appli. Pensiez-vous que l’on vous donnerait un PDF à télécharger ? Que nenni. Nos amis francophones au Canada ont déjà testé pour vous : « Les étudiants sont pris en otage avec une plateforme difficile d’utilisation à un prix très élevé. Difficile de faire des recherches, difficile de naviguer, difficile de zoomer, difficile d’imprimer. Difficile de toute. En plus, on perd l’accès au livre après un certain temps, alors qu’on paie presque la totalité du prix d’un livre physique. Il y a un problème. »
En bref, cet étage combine le meilleur et le pire : des outils pédagogiques de très bon niveau, empaquetés dans des pratiques difficiles à accepter pour ceux pour qui un livre doit aussi être un outil d’émancipation.
l’émergence de créateurs et créatrices de biens culturels plus indépendants et plus justement rétribués
En dessous de ces deux groupes, il y a tout un ensemble désordonné d’entreprises qui proposent aux auteurs potentiels de court-circuiter les voies d’édition traditionnelles (j’expérimente en ce moment avec plusieurs de ces acteurs pour mon livre). On peut mentionner Lulu, qui fournit un service d’impression à la demande (Framabook l’a longtemps utilisé), mais aussi Amazon qui accepte de plus en plus facilement dans son catalogue physique et immatériel (Kindle) des livres auto-édités. En marge, il y a un grand nombre d’acteurs qui facilitent la rémunération des créateurs et créatrices en tout genre, par exemple en permettant la vente de fichiers informatiques, de services en ligne, et le financement ponctuel ou régulier de leur travail par leur audience. Ces choses étaient très difficiles à mettre en pratique il y a quinze ans ; maintenant ces entreprises érodent par le bas les piliers financiers de l’édition traditionnelle. Elles permettent, d’une part, l’émergence de créateurs et créatrices de biens culturels plus indépendants et plus justement rétribués, qui ne se feront pas manger tout/es cru/es par les machines de l’édition traditionnelle. Elles permettent aussi, et c’est plus regrettable, la monétisation d’échanges qui auraient dû rester non-commerciaux ; par exemple on ne peut que grincer des dents en voyant des enseignants fonctionnaires de l’éducation nationale, sur une plateforme quelconque, se vendre les uns aux autres l’accès à leurs fiches de travaux pratiques de collège. Dans l’ensemble toutefois, je pense que la balance penche franchement dans le bon sens, et je me réjouis de savoir que de plus en plus de personnes se voient offrir la possibilité de se demander : « tiens, et si j’en faisais un livre ? ».
Alors toi, petit/e prof de l’enseignement supérieur, qui voudrais bien faire un livre de ce que tu as déjà construit avec tes cours, et qui regardes ce paysage, tu te demandes si tu ne devrais pas faire un manuel universitaire open-source, un truc que les étudiants et les autres profs pourraient télécharger et réadapter sans rien devoir demander. Qu’est-ce que je peux te recommander ?
Pour commencer, le plus important — fonce ! Tu ne le regretteras pas. Je partage volontiers avec toi quelques chiffres et quelques retours, sept ans après m’être lancé (mais sans avoir jamais travaillé sur la communication ou la diffusion). Une trentaine de personnes télécharge le PDF de mon livre depuis mon site Internet chaque jour, la moitié depuis les pays d’Afrique francophone, et une sur cinq-cent met la main à sa poche pour acheter un exemplaire imprimé. Après six ans, ça représente 250 livres vendus (250 kilos de papier !). Je retrouve des traces de mon livre un peu partout sur Internet, pour le meilleur et pour le pire. Il y a eu un gros lot de mauvaises surprises, parce qu’il y a beaucoup de dilution : le PDF du livre est repris, en entier ou en petits morceaux, par de nombreux acteurs plus ou moins bien intentionnés. Le plus souvent ce sont simplement des banques de PDFs et miroirs informes qui s’efforcent de bien se positionner dans les résultats des moteurs de recherche, puis génèrent un revenu en apposant de la publicité à côté du contenu qu’ils reproduisent. Il y a aussi des plateformes (par exemple Academia.edu pour ne pas les nommer) qui encouragent leurs utilisateurs à republier comme les leurs les travaux des autres, et mon livre fait partie de milliers d’autres qui sont partagés sous une nouvelle licence et en étant mal attribués. Le plus désagréable est certainement de voir mon travail occasionnellement plagié par des universitaires qui ont voulu croire que le livre était simplement déposé dans le domaine public et qu’il n’était pas nécessaire d’en mentionner l’auteur. Mais je pense que ces problèmes sont propres à tous les livres et pas seulement ceux que l’on diffuse sous licence Creative Commons.
Il y a aussi de bonnes surprises ! Recevoir un paquet de correctifs par quelqu’un qui a pris le temps de refaire tes exercices. Recevoir un compliment et un remerciement d’une consœur que tu n’as jamais pu rencontrer. Voir ton PDF téléchargé depuis des adresses IP associées à une ville au milieu du désert algérien, ou bien d’endroits où personne ne n’a jamais vu une librairie universitaire ou une camionnette Amazon. Ces moments à eux seuls font du projet un succès à mes yeux, et ils te porteront toi aussi dans tes efforts.
Dans tout cela, il faut bien voir que les quantités d’argent mises en jeu dans la circulation du livre sont dérisoires, à des années-lumières de la valeur que vont créer les étudiants ingénieurs avec ce qu’ils ont appris à l’aide du manuel. Et surtout, après avoir de bon cœur mis son livre en libre téléchargement et la version papier en vente à prix coûtant, l’auteur/e réalise un matin, comme certainement beaucoup de programmeurs libristes avant lui/elle, que des œuvres concurrentes objectivement bien moins bonnes et beaucoup plus chères se vendent bien mieux.
Où trouver notre place alors dans ce paysage compliqué ? Un livre sous licence Creative Commons peut-il être une bonne réponse au problème ?
Cette treizième édition du livre, préférez-vous l’acheter neuve pour 190 euros, ou d’occasion pour 100 euros ? Sinon, je vous propose de la louer pour 37 euros…
Je pense qu’une bonne recette de fabrication pour livre universitaire doit en tout premier satisfaire trois groupes : les auteur/es, les enseignant/es et les étudiant/es. De quoi ont-ils/elles besoin ? Je propose ici mes réponses (évidemment toutes biaisées par mon expérience), en listant les points les plus importants en premier.
Ce que veulent les auteur/es :
Fabriquer une œuvre qui n’est pas cloisonnée, qui peut servir à d’autres si je disparais ou si le projet ne m’intéresse plus (donc quelque chose de ré-éditable, qu’on peut corriger, remettre à jour, traduisible en japonais et tout ça sans devoir obtenir de permission).
Une reconnaissance de mon travail, quelque chose que je peux valoriser dans un CV académique (donc quelque chose qui va être cité par ceux qui s’en servent).
De l’argent, mais pas cent-douze euros par an. Soit le livre contribue significativement à mes revenus, soit je préfère renoncer à gagner de l’argent avec (pour maximiser sa diffusion et m’éviter les misères administratives, la contribution à la sécu des artistes-auteurs ou à l’Urssaf etc).
Ce que veulent les enseignant/es :
Un contenu fiable (un livre bien ancré dans la littérature scientifique existante et dans lequel l’auteur/e n’essaie pas de glisser un point de vue « alternatif » ou personnel).
Un livre remixable, dont on peut reprendre le contenu dans ses diapos ou son polycopié, de façon flexible (ne pas devoir scanner les pages du livre ou bien tout redessiner).
Un livre dont le prix est supportable pour les étudiant/es.
Et enfin, ce que veulent les étudiant/es :
Un livre qui les aide à s’en sortir dans leur cours. C’est d’abord un outil, et il faut survivre aux examens ! Si le livre rend le sujet intéressant, c’est un plus.
Un livre très bon marché, ou encore mieux, gratuit.
Un livre déjà désigné pour elles et eux, et qui correspond bien au programme : personne n’a envie d’arpenter les rayons de bibliothèque ou le catalogue d’Amazon en espérant trouver de l’aide.
On le voit, finalement nous ne sommes pas loin du compte avec des livres sous licence Creative Commons ! Tous les outils importants sont déjà à portée de main, pour créer le livre (avec des logiciels libres en tout genre), l’encadrer (avec des contrats de licence solides) et le distribuer (avec l’Internet pour sa forme numérique et, si nécessaire d’autres plateformes pour sa forme physique). C’est peut-être un évidence, mais il est bon de se rappeler parfois qu’on vit une époque formidable.
Alors, que manque-t-il ? Pourquoi les livres libres n’ont-ils toujours pas envahi les amphis ? Quels sont les points faibles qui rendent l’équation si difficile à résoudre ? Je pense qu’une partie de la réponse vient de nous-mêmes, nous dans les communautés impliquées autour des concepts de culture libre, de partage des connaissances et de logiciels open-source. Voici quelques éléments de critique, que je propose avec beaucoup de respect et en grimaçant un peu car je m’identifie avec ces communautés et m’inclus parmi les responsables.
la monnaie de cette reconnaissance est la citation académique
Je voudrais d’abord me tourner vers les enseignant/es du supérieur. Confrères, consœurs, nous devons citer nos sources dans nos documents de cours, et les publier ! Je sais que construire un cours est un travail très chronophage, souvent fait seul/e et à la volée — comment pourrait-il en être autrement, puisque souvent seul le travail de recherche est valorisé à l’université. Mais trop de nos documents (résumés de cours, exercices, diapositives) ne citent aucune source, et restent en plus coincés dans un intranet universitaire, cachés dans un serveur Moodle, invisibles depuis l’extérieur. Sous nos casquettes de chercheurs, nous sommes déjà les premiers responsables d’une crise sans fin dans l’édition des publications scientifiques. Nous devons faire mieux avec nos chapeaux d’enseignants. Nous le devons à nos étudiants, à qui nous reprochons souvent de faire la même chose que nous. Et nous le devons à ceux et celles dont nous reprenons le travail (les plans de cours, les schémas, les exercices…), qui ont besoin de reconnaissance pour leur partage ; la monnaie de cette reconnaissance est la citation académique. Il faut surmonter le syndrome de l’imposteur : mentionner un livre dans la bibliographie officielle de la fiche descriptive du cours ne suffit pas. Il faut aussi le citer dans ses documents de travail, et les laisser en libre accès ensuite.
Quant aux institutions de l’enseignement supérieur (écoles, instituts, universités en tous genres), je souhaite qu’elles acceptent l’idée que la création de supports de cours universitaires est un processus qui demande de l’argent au même titre que la création de savoir par l’activité de recherche. Il faut y consacrer du temps, et il y a des frais de fonctionnement. Sans cela, on laisse les enseignants perpétuellement réinventer la roue, coincés entre des livres trop courts ou trop chers pour leurs étudiants. Il manque plus généralement une prise de conscience que l’enseignement supérieur a tout d’un processus industriel (il se fait à grande échelle, il a de très nombreux aspects qui sont mesurables directement etc.): nous devons arrêter d’enseigner avec des méthodes de travail qui relèvent de l’artisanat, chacun avec ses petits outils, ses méthodes et son expérience.
Un peu plus loin, au cœur-même des communautés libristes, il y a aussi beaucoup d’obstacles à franchir pour l’auteur/e universitaire : ainsi les défauts de la bibliothèque multimédia communautaire Wikimedia Commons, et du projet Creative Commons en général, pourraient faire chacun l’objet d’un article entier.
Ce que j’ai appris avec ce projet de livre, c’est que travailler à l’intersection de tous ces groupes consomme une certaine quantité d’énergie, parce que mon espoir n’est pas que le fruit de tout ce travail reste à l’intérieur. J’ai envie d’envoyer mon livre de l’autre côté de la colline, où il se retrouve en concurrence avec des manuels de gros éditeurs, parce que c’est ce public que je veux rencontrer — l’espoir n’est pas de faire un livre pour geeks libristes, mais plutôt d’arriver dans les mains d’étudiants qui n’ont pas l’habitude de copier légalement des trucs. Créer ce pont entre deux mondes est un travail en soi. En le réalisant, j’ai appris deux choses.
un travail de communication et de présence en amont.
La première, c’est que nous dépendons toujours d’une plate-forme ou d’une autre. Comme beaucoup d’autres avant moi, je me suis hissé sur les épaules de géants depuis une chambre d’étudiant, en montant une pile de logiciels libres sur mon ordinateur et en me connectant à un réseau informatique global décentralisé. L’euphorie perdure encore jusqu’à ce jour, mais elle ne doit pas m’empêcher d’accepter qu’on ne peut pas toujours tout faire soi-même, et qu’une activité qui implique des transactions financières se fait toujours à l’intérieur d’un ou plusieurs systèmes. Quel que soit son métier, avocate, auteure, chauffagiste, restaurantiste, une personne qui veut s’adresser à un public doit passer par une plate-forme : il faut une boutique avec vitrine sur rue, ou un emplacement dans une galerie commerciale, ou une fiche dans un annuaire professionnel, ou bien un emplacement publicitaire physique ou numérique, ou encore être présent dans un salon professionnel. Chaque public a des attentes particulières. Pour que quelqu’un pense à vous même sans se tourner activement vers une plateforme (simplement en pensant silencieusement « bon il me faut un livre de thermodynamique » ou « bon il faut que quelqu’un répare cette chaudière ») il faut que vous ayez fait un travail de communication et de présence en amont. Toutes les plateformes ne sont pas équivalentes, loin de là ! Le web est certainement une des toutes meilleures, mais là aussi nous voulons trop souvent oublier qu’elle est de facto mécaniquement couplée à une autre, celle du moteur de recherche duquel émanent 92% des requêtes mondiales : c’est ce moteur qu’il faut satisfaire pour y grandir.
Autre plateforme, Amazon: l’utiliser pour distribuer ses livres, c’est participer à beaucoup de choses difficiles à accepter sociétalement. Framasoft a fait le choix de ne plus l’utiliser, et c’est tout à leur honneur, d’autant plus lorsqu’on voit le travail qu’ils abattent pour en construire de meilleures, des plateformes ! Personnellement, j’ai choisi de continuer à y vendre mon livre, car il y a des publics pour lesquels un livre qui n’est pas sur Amazon n’existe pas. Idem pour Facebook, sur lequel je viens bon gré mal gré de me connecter pour la première fois, parce que mon livre s’y partage que je le veuille ou non et que je voudrais bien voir ça de plus près. Ainsi, au cours des dernières années j’ai appris à observer les flux au delà de la connexion entre mon petit serveur et mon petit ordinateur.
La seconde chose que j’ai apprise, c’est que nous avons, nous au sein des communautés du logiciel et de la culture libres, une relation assez dysfonctionnelle à l’argent. Il nous manque globalement de l’argent, ça je le savais déjà (j’ai fondé et travaillé à plein temps pour une association sont les objectifs ressemblaient un peu à ceux de Framasoft il y a 15 ans), mais j’avais toujours attribué cela à de vagues circonstances extérieures. Maintenant, je suis convaincu qu’une grande part de responsabilité nous revient : il nous manque de la culture et de la sensibilité autour de l’argent et du commerce. Dès que l’on professionnalise son activité, on vient à bout du credo « il est seulement interdit d’interdire » que nous avons adopté pour encadrer le partage des biens communs culturels. Nos licences et nos organisations sont en décalage avec la réalité et nous faisons collectivement un amalgame entre « amateur », « non-commercial » et « à but non-lucratif ». — j’y reviendrai dans un autre article.
Voilà tout ce que j’ai en tête lors que je me demande où sont les livres universitaires libres. Qui sera là pour faire un pont entre tous ces mondes ? Il y a quelques années, le terme “Open Educationnal Resource” (OER ou en français REL) a pris de l’essor un peu comme le mot-clé “MOOC”, une idée intéressante pas toujours suivie d’applications concrètes. Plusieurs projets ont été lancés pour éditer des livres et cours universitaires libres. Aujourd’hui beaucoup on jeté l’éponge : Lyryx, Boundless, Flatworld, Tufts OpenCourseWare, Bookboon se sont arrêtés ou tournés vers d’autres modèles. Il reste, à ma connaissance, un seul éditeur avec un catalogue substantiel et à jour (je ne vous cache pas que je rêve d’y contribuer un jour) : c’est OpenStax, une organisation américaine à but non-lucratif, avec une quarantaine de manuels en anglais. Et dans la sphère francophone ? Un groupe de geeks de culture libre arrivera-t-il jamais à faire peur à tout le monde en mettant dans les mains des étudiants des outils qu’ils peuvent utiliser comme ils le veulent ?
Miroir de Valem : un projet artistique, libre et solidaire
Valem est sculpteur et aime capter les portraits dans leurs scènes de vie. Durant ses voyages au Sénégal, elle a été touchée par La Teranga, terme wolof qui conjugue les valeurs d’hospitalité, de partage et de solidarité des Sénégalais. Elle a donc réalisé de nombreux dessins inspirés de ces voyages et a créé un dispositif solidaire pour venir en aide aux familles en situations précaires. Framasoft communique cet article, car ce projet regroupe les valeurs libristes, artistiques et solidaires que nous tenons à partager.
À noter : cet article bénéficie désormais d’une version audio.
Merci à Sualtam, auteur de lectureaudio.fr pour cette contribution active.
Famille sénégalaise rencontrée lors des voyages auquel ce projet vient en aide.
Le Miroir de Valem est un dispositif physique d’art numérique libre, solidaire, open-source, low-tech, interactif, contributif et évolutif.
Le concept est que ce miroir puisse renvoyer au spectateur son propre reflet composé, en une « mosaïque d’images », de portraits dessinés en noir et blanc d’après des souvenirs de voyages (environ une centaine réalisés à ce jour et d’autres encore à venir). L’enjeu de l’œuvre est avant tout d’aider les populations qui ont inspiré les dessins constituant les reflets en leur reversant les potentielles recettes générées (également grâce à la cagnotte en ligne).
« Votre reflet n’est pas un simple « selfie », mais plutôt un « altrie ». En reconstituant votre image à partir de portraits de personnes vivant dans une autre partie du monde, le Miroir tisse des liens entre les cultures et les individus pour dessiner une humanité à la fois plurielle et unie. »
Un groupe de 5 étudiants de l’UTC (Université de Technologie de Compiègne) a aidé l’artiste Valem sur le plan technique pour réaliser ce projet, notamment 2 étudiants en Génie Informatique, 1 en Mécanique et Design Produit et 2 en Design d’interface.
Ce dispositif a été mis au point de la manière suivante :
le châssis en bois a été fabriqué par un ébéniste (de l’Atelier des Bois Pérennes) sur la base des plans réalisés par les étudiants ;
ils ont créé l’application mobile et amélioré le logiciel libre Pixelize afin de pouvoir restituer une photo en mosaïque ;
ils ont également placé un écran d’ordinateur derrière un miroir sans tain ;
puis une tablette et un Raspberry Pi pour l’interface UX d’interaction.
Un autre groupe de 4 étudiants en gestion de projets a pu aider dans l’élaboration du projet. Ils se sont notamment occupés de la création de l’association Miroir de Valem, des statuts et donc des aspects juridiques, de la communication, de l’organisation économique et des voyages au Sénégal. L’association Miroir de Valem a pour mission de :
promouvoir cette forme de création artistique et les valeurs associées ;
apporter une aide financière aux familles sénégalaises qui l’ont inspirée.
De plus, en janvier 2020, 2 étudiants en Génie Informatique les ont rejoints à plein temps pour terminer les logiciels embarqués dans le miroir, sur une tablette Android et un Raspberry Pi. La tablette héberge une application qui permet à l’utilisateur·ice de communiquer avec le miroir. Elle communique elle-même avec le Raspberry qui est en charge de transformer la photo originale en reflet et de l’afficher sur le miroir.
Schéma d’usage du Miroir.
Pour Valem, le but du projet est d’avoir une double transmission des connaissances : elle dispose de compétences artistiques et de l’ouverture à la culture sénégalaise ; les étudiants ont les savoir-faire techniques qui lui manquaient pour la réalisation du dispositif et la communication. Le projet a été riche d’échanges et de partages de notions pour tous ces acteurs. Certains d’entre eux ont eu le privilège d’être accueillis dans une famille (d’environ 30 personnes) pendant une ou plusieurs semaines. Le but du projet est donc de partir de ce point d’ancrage, donc de cette famille, pour ensuite aider d’autres familles et le quartier entier. En effet, suite à la pandémie du Covid-19, le Sénégal a été très impacté économiquement car deux de ses principales sources de revenus sont le tourisme et la pêche. Afin de mieux répondre aux besoins de cette population qui a une façon de vivre et des besoins différents des nôtres, l’association bénéficie d’un contact de confiance sur place, afin de définir au mieux quelles solutions leur proposer.
Quelle est la dimension libriste de ce projet ?
Vous pouvez copier, utiliser, partager et diffuser les dessins, le dispositif physique, les logiciels et les contenus du site web selon les droits qui vous sont accordés par leurs licences libres (voir page Crédits du site web du Miroir de Valem). Le but est que chacun·e se serve du dispositif, partage les images comme il ou elle le souhaite. Les plans du châssis en bois, le code source de l’application, les réglages du Raspberry Pi ainsi que l’application à installer sur celui-ci sont disponibles sur Framagit. Le but est de pouvoir proposer des améliorations ou même, si l’on est artiste soi-même, de pouvoir réaliser un projet comparable avec ses propres œuvres, toujours dans un but de solidarité envers les plus démunis.
Où les rencontrer ?
À l’exposition Art Up programmée (et reportée) en février 2021 à Lille (salon d’art international) afin de confronter le Miroir à un public qui vient à la rencontre/découverte des artistes, mais qui est possiblement peu sensibilisé à la culture libre.
Aux Journées Des Logiciels Libres de Lyon reportées également en avril 2021. Cette fois, c’est pour toucher un public libriste averti (ou cherchant à se sensibiliser), mais qui ne s’attend pas forcément à ce que les valeurs du libre animent un projet artistique.
Ensuite, de belles rencontres sont envisagées : comme celle de travailler avec l’ambassade du Sénégal et des villes jumelées avec des villes sénégalaises afin d’organiser des événements plus généraux ou ouverts à tous types de public, comme une fête locale.
Enfin, le projet sera présenté à laFête de la Science de l’UTCen octobre, à un public jeune qui n’est pas forcément sensible a priori à l’art ni au libre au départ.
Ce projet permet d’aborder plusieurs concepts pouvant être mobilisés pour la construction de sociétés soutenables : la solidarité, la création collective, l’approche low-tech, la culture libre, l’économie du don, les équilibres Nord/Sud, etc. Pour transformer la société au regard des enjeux environnementaux auxquels on fait déjà face, soutenez le Miroir de Valem.
Un coup de pouce de Sourcehut pour financer vos débuts sur PeerTube ?
Pour la culture libre, le problème du financement est souvent crucial. Voici la proposition d’une sorte de petite bourse de « débutant sur PeerTube » qui nous fait plaisir et que nous vous invitons à considérer.
Sourcehut qui fait cette offre est une communauté qui propose à prix raisonnable une suite d’outils libres et open source et une plateforme de développement avec des dépôts Git et Mercurial, des listes de diffusion, du suivi de bug, l’intégration continue etc. Le tout sans traqueurs ni publicité (oui en revanche, nous leur faisons un peu de promo ici, donc).
Séduits par PeerTube, Sourcehut souhaite en augmenter les contenus disponibles en vous aidant à en réaliser…
Peertube est un excellent projet qui vise à créer un « tube » vidéo ouvert et décentralisé pour héberger des contenus vidéo dont la gouvernance est distribuée et le développement piloté par la communauté. Chocobozzz, avec l’aide de dizaines de contributeurs, a fait le difficile travail d’ingénierie pour construire une belle plateforme, et maintenant nous nous voulons y voir du contenu !
Pour contribuer à cette opération, SourceHut offre 5000$ à titre d’amorçage pour fournir du contenu sur le réseau PeerTube. Cet argent sera utilisé pour aider de nouveaux créateurs de contenus à faire des vidéos pour PeerTube. Nous financerons de l’équipement pour vous aider à vous lancer : caméras, microphones, cartes de capture vidéo et ainsi de suite, quoi que ce soit d’approprié au genre de vidéos que vous voulez faire, avec un budget supplémentaire de 200$ à dépenser à votre guise pour les premières vidéos. Besoin d’une caméra sympa ? De quelques micros adaptés pour mener une interview ? D’un drone pour faire des prises de vues ? On y va ! Un compte sera aussi configuré pour vous sur Liberapay pour que votre public puisse vous aider à vivre de façon convenable.
Si vous avez un loisir intéressant à partager, un sujet à enseigner que vous connaissez sur le bout des doigts, un talent que vous aimeriez montrer, ou tout autre super idée à laquelle nous n’avons pas pensé, envoyez-nous un courriel à sir@cmpwn.com avec le sujet : “PeerTube bootstrap application: [votre nom ici] « . [NOTE DE FRAMASOFT : Écrivez votre message en anglais, évidemment ! 🙂 ]. Ajoutez quelques lignes pour vous présenter, dire pourquoi vous postulez, et préciser quel genre de vidéos vous voudriez réaliser. Indiquez-nous aussi pourquoi la culture libre est importante pour vous !
Sepia, la mascotte de PeerTube, par David Revoy (CC-By)
Voici les conditions à remplir :
Vous ne devez pas déjà être un habitué de la diffusion vidéo sur d’autres plateformes. Nous cherchons à financer de nouveaux créateurs de contenu. Pas ceux qui le sont déjà1.
Vous ne pouvez publier des vidéos que sur PeerTube — pas sur YouTube ni où que ce soit d’autre.
Vos vidéos doivent être sous licence Creative Commons, par exemple CC-BY-NC-SA.
Nous attendons de vous que vous fassiez au moins 5 vidéos. Si vous décidez par la suite que la création vidéo, ce n’est pas pour vous, nous reprendrons l’équipement et vous serez libéré⋅e (de votre engagement).
À partir du moment où vous gagnerez 20$ / mois via Liberapay, nous partagerons les coûts d’hébergement à parts égales entre tous les créateurs : ils se montent à 45$ / mois pour le moment. Vous ne nous serez jamais redevable d’un montant supérieur à 25 % de vos rentrées Liberapay ; SourceHut prendra le reste en charge.
Notre instance est sur spacepub.space. Nous nous chargerons de l’administration technique du serveur et nous vous fournirons l’aide nécessaire pour démarrer. Ensemble, nous bâtirons une communauté de créateurs de culture libre qui s’entraident pour un bien commun enthousiasmant. Faisons de PeerTube une plateforme grandiose !
Aujourd’hui, les licences suffisent-elles ?
Frank Karlitschek est un développeur de logiciel libre, un entrepreneur et un militant pour le respect de la vie privée. Il a fondé les projets Nextcloud et ownCloud et il est également impliqué dans plusieurs autres projets de logiciels libres.
Il a publié le Manifeste des données utilisateursdont nous avons tout récemment publié une traduction et il présente régulièrement des conférences. Il a pris la peine de résumer l’une d’elles qui porte sur les limites des licences libres et open source dans l’environnement numérique d’aujourd’hui.
Il y a quelques semaines, j’ai eu l’honneur de prononcer une conférence introductive aux Open Source Awards d’Édimbourg. J’ai décidé d’aborder un sujet dont je voulais parler depuis un bon bout de temps sans en avoir eu l’occasion jusqu’alors. Ma conférence n’a pas été filmée mais plusieurs personnes m’ont demandé d’en faire une synthèse. J’ai donc décidé de prendre un peu de mon temps libre dans un avion pour en faire un résumé dans le billet qui suit.
J’ai commencé à utiliser des ordinateurs et à écrire des logiciels au début des années 80 quand j’avais 10 ans. C’est à la même l’époque que Richard Stallman a écrit les 4 libertés, lancé le projet GNU, fondé la FSF et créé la GPL. Son idée était que les utilisateurs et les développeurs devraient avoir le contrôle de leur propre ordinateur, ce qui nécessite des logiciels libres. À l’époque, l’expérience informatique se résumait à un ordinateur personnel devant vous et, avec un peu de chance, les logiciels libres et open source qui s’y trouvaient.
L’équation était :
(matériel personnel) + (logiciel libre)
= (liberté numérique)
Depuis, le monde de l’informatique a changé et beaucoup évolué. Nous avons à présent accès à Internet partout, nous avons des ordinateurs dans les voitures, les télévisions, les montres et tous les autres appareils de l’Internet des Objets. Nous sommes en pleine révolution du tout mobile. Nous avons le Cloud computing (le fameux « nuage ») où le stockage des données et la puissance informatique sont partagés entre plusieurs Data centers (centre de données) possédés et contrôlés par plusieurs groupes et organisations à travers le monde. Nous avons un système de brevets très fort, les DRM, la signature de code et autres outils de cryptographie, les logiciels devenus des services, du matériel propriétaire, des réseaux sociaux et la puissance de l’effet réseau.
Dans son ensemble, le monde a beaucoup changé depuis les années 80. La majorité de la communauté du logiciel libre et de l’open source continue de se concentrer sur les licences logicielles. Je me demande si nous ne perdons pas une vue d’ensemble en limitant le mouvement du logiciel libre et open source aux seules questions des licences.
Richard Stallman souhaitait contrôler son ordinateur. Voyons la situation sur quelques-unes des grandes questions actuelles sur le contrôle numérique :
Facebook
Ces derniers temps, Facebook est sous le feu de nombreuses critiques : que ce soit les innombrables atteintes à la vie privée des utilisateurs, l’implication dans le truquage d’élections, le déclenchement d’un génocide en Birmanie, l’affaiblissement de la démocratie et beaucoup d’autres faits. Voyons si le logiciel libre pourrait résoudre ce problème :
Si Facebook publiait demain son code comme un logiciel libre et open source, notre communauté serait aux anges. Nous avons gagné ! Mais cela résoudrait-il pour autant un seul de ces problèmes ? Je ne peux pas exécuter Facebook sur mon ordinateur car je n’ai pas une grappe de serveurs Facebook. Quand bien même j’y arriverais, je serais bien isolé en étant le seul utilisateur. Donc le logiciel libre est important et génial mais il ne fournit pas de liberté ni de contrôle aux utilisateurs dans le cas de Facebook. Il faut plus que des licences libres.
Microsoft
J’entends de nombreuses personnes de la communauté du logiciel libre et open source se faire les chantres d’un Microsoft qui serait désormais respectable. Microsoft a changé sous la direction de son dernier PDG et ce n’est plus l’Empire du Mal. Ils intègrent désormais un noyau Linux dans Windows 10 et fournissent de nombreux outils libres et open source dans leurs conteneurs Linux sur le cloud Azure. Je pense qu’il s’agit là d’un véritable pas dans la bonne direction mais leurs solutions cloud bénéficient toujours de l’emprise la plus importante pour un éditeur : Windows 10 n’est pas gratuit et ne vous laisse pas de liberté. En réalité, aucun modèle économique open source n’est présent chez eux. Ils ne font qu’utiliser Linux et l’open source. Donc le fait que davantage de logiciels de l’écosystème Microsoft soient disponibles sous des licences libres ne donne pas pour autant davantage de libertés aux utilisateurs.
L’apprentissage automatique
L’apprentissage automatique est une nouvelle technologie importante qui peut être utilisée pour beaucoup de choses, qui vont de la reconnaissance d’images à celle de la voix en passant par les voitures autonomes. Ce qui est intéressant, c’est que le matériel et le logiciel seuls sont inutiles. Pour que l’apprentissage fonctionne, il faut des données pour ajuster l’algorithme. Ces données sont souvent l’ingrédient secret et très précieux nécessaire à une utilisation efficace de l’apprentissage automatique. Plus concrètement, si demain Tesla décidait de publier tous ses logiciels en tant que logiciels libres et que vous achetiez une Tesla pour avoir accès au matériel, vous ne seriez toujours pas en mesure d’étudier, de construire et d’améliorer la fonctionnalité de la voiture autonome. Vous auriez besoin des millions d’heures d’enregistrement vidéo et de données de conducteur pour rendre efficace votre réseau de neurones. En somme, le logiciel libre seul ne suffit pas à donner le contrôle aux utilisateurs.
5G
Le monde occidental débat beaucoup de la confiance à accorder à l’infrastructure de la 5G. Que savons-nous de la présence de portes dérobées dans les antennes-relais si elles sont achetées à Huawei ou à d’autres entreprises chinoises ? La communauté du logiciel libre et open source répond qu’il faudrait que le logiciel soit distribué sous une licence libre. Mais pouvons-nous vraiment vérifier que le code qui s’exécute sur cette infrastructure est le même que le code source mis à disposition ? Il faudrait pour cela avoir des compilations reproductibles, accéder aux clés de signature et de chiffrement du code ; l’infrastructure devrait récupérer les mises à jour logicielles depuis notre serveur de mise à jour et pas depuis celui du fabricant. La licence logicielle est importante mais elle ne vous donne pas un contrôle total et la pleine liberté.
Android
Android est un système d’exploitation mobile très populaire au sein de la communauté du logiciel libre. En effet, ce système est distribué sous une licence libre. Je connais de nombreux militants libristes qui utilisent une version personnalisée d’Android sur leur téléphone et n’installent que des logiciels libres depuis des plateformes telles que F-Droid. Malheureusement, 99 % des utilisateurs lambda ne bénéficient pas de ces libertés car leur téléphone ne peut pas être déverrouillé, car ils n’ont pas les connaissances techniques pour le faire ou car ils utilisent des logiciels uniquement disponibles sur le PlayStore de Google. Les utilisateurs sont piégés dans le monopole du fournisseur. Ainsi, le fait que le cœur d’Android est un logiciel libre ne donne pas réellement de liberté à 99 % de ses utilisateurs.
Finalement, quelle conclusion ?
Je pense que la communauté du logiciel libre et open source concernée par les 4 libertés de Stallman, le contrôle de sa vie numérique et la liberté des utilisateurs, doit étendre son champ d’action. Les licences libres sont nécessaires mais elles sont loin d’être encore suffisantes pour préserver la liberté des utilisateurs et leur garantir un contrôle de leur vie numérique.
La recette (matériel personnel) + (logiciel libre) = (liberté numérique) n’est plus valide.
Il faut davantage d’ingrédients. J’espère que la communauté du logiciel libre peut se réformer et le fera, pour traiter davantage de problématiques que les seules licences. Plus que jamais, le monde a besoin de personnes qui se battent pour les droits numériques et les libertés des utilisateurs.
L’actualité récente de Qwant était mouvementée, mais il nous a semblé qu’au-delà des polémiques c’était le bon moment pour faire le point avec Qwant, ses projets et ses valeurs.
Si comme moi vous étiez un peu distrait⋅e et en étiez resté⋅e à Qwant-le-moteur-de-recherche, vous allez peut-être partager ma surprise : en fouinant un peu, on trouve tout un archipel de services, certains déjà en place et disponibles, d’autres en phase expérimentale, d’autres encore en couveuse dans le labo.
Voyons un peu avec Tristan Nitot, Vice-président Advocacy de Qwant, de quoi il retourne et si le principe affiché de respecter la vie privée des utilisateurs et utilisatrices demeure une ligne directrice pour les applications qui arrivent.
Tristan Nitot, autoportrait (licence CC-BY)
Bonjour Tristan, tu es toujours content de travailler pour Qwant malgré les périodes de turbulence ?
Oui, bien sûr ! Je reviens un peu en arrière : début 2018, j’ai déjeuné avec un ancien collègue de chez Mozilla, David Scravaglieri, qui travaillait chez Qwant. Il m’a parlé de tous les projets en logiciel libre qu’il lançait chez Qwant en tant que directeur de la recherche. C’est ce qui m’a convaincu de postuler chez Qwant.
J’étais déjà fan de l’approche liée au respect de la vie privée et à la volonté de faire un moteur de recherche européen, mais là, en plus, Qwant se préparait à faire du logiciel libre, j’étais conquis. À peine arrivé au dessert, j’envoie un texto au président, Eric Léandri pour savoir quand il m’embauchait. Sa réponse fut immédiate : « Quand tu veux ! ». J’étais aux anges de pouvoir travailler sur des projets qui rassemblent mes deux casquettes, à savoir vie privée et logiciel libre.
Depuis, 18 mois ont passé, les équipes n’ont pas chômé et les premiers produits arrivent en version Alpha puis Bêta. C’est un moment très excitant !
Récemment, Qwant a proposé Maps en version Bêta… Vous comptez vraiment rivaliser avec Google Maps ? Parce que moi j’aime bien Street View par exemple, est-ce que c’est une fonctionnalité qui viendra un jour pour Qwant Maps ?
Rivaliser avec les géants américains du capitalisme de surveillance n’est pas facile, justement parce qu’on cherche un autre modèle, respectueux de la vie privée. En plus, ils ont des budgets incroyables, parce que le capitalisme de surveillance est extrêmement lucratif. Plutôt que d’essayer de trouver des financements comparables, on change les règles du jeu et on se rapproche de l’écosystème libre OpenStreetMap, qu’on pourrait décrire comme le Wikipédia de la donnée géographique. C’est une base de données géographiques contenant des données et des logiciels sous licence libre, créée par des bénévoles autour desquels viennent aussi des entreprises pour former ensemble un écosystème. Qwant fait partie de cet écosystème.
En ce qui concerne les fonctionnalités futures, c’est difficile d’être précis, mais il y a plein de choses que nous pouvons mettre en place grâce à l’écosystème OSM. On a déjà ajouté le calcul d’itinéraires il y a quelques mois, et on pourrait se reposer sur Mapillary pour avoir des images façon StreetView, mais libres !
Dis donc, en comparant 2 cartes du même endroit, on voit que Qwant Maps a encore des progrès à faire en précision ! Pourquoi est-ce que Qwant Maps ne reprend pas l’intégralité d’Open Street Maps ?
vue du centre de la ville de La Riche avec la requête « médiathèque la Riche » par OpenStreetMap
vue du centre de la ville de La Riche avec la requête « médiathèque la Riche » par QwantMaps
En fait, OSM montre énormément de détails et on a choisi d’en avoir un peu moins mais plus utilisables. On a deux sources de données pour les points d’intérêt (POI) : Pages Jaunes, avec qui on a un contrat commercial et OSM. On n’affiche qu’un seul jeu de POI à un instant t, en fonction de ce que tu as recherché.
Quand tu choisis par exemple « Restaurants » ou « Banques », sans le savoir tu fais une recherche sur les POI Pages Jaunes. Donc tu as un fond de carte OSM avec des POI Pages Jaunes, qui sont moins riches que ceux d’OSM mais plus directement lisibles.
Bon d’accord, Qwant Maps utilise les données d’OSM, c’est tant mieux, mais alors vous vampirisez du travail bénévole et libre ? Quelle est la nature du deal avec OSM ?
Non, bien sûr, Qwant n’a pas vocation à vampiriser l’écosystème OSM : nous voulons au contraire être un citoyen modèle d’OSM. Nous utilisons les données et logiciels d’OSM conformément à leur licence. Il n’y a donc pas vraiment de deal, juste un respect des licences dans la forme et dans l’esprit. Par exemple, on met un lien qui propose aux utilisateurs de Qwant Maps d’apprendre à utiliser et contribuer à OSM. En ce qui concerne les logiciels libres nécessaires au fonctionnement d’OSM, on les utilise et on y contribue, par exemple avec les projets Mimirsbrunn, Kartotherian et Idunn. Mes collègues ont écrit un billet de blog à ce sujet.
Nous avons aussi participé à la réunion annuelle d’OSM, State Of the Map (SOTM) à Montpellier le 14 juin dernier, où j’étais invité à parler justement des relations entre les entreprises comme Qwant et les projets libres de communs numériques comme OSM. Les mauvais exemples ne manquent pas, avec Apple qui, avec Safari et Webkit, a sabordé le projet Konqueror de navigateur libre, ou Google qui reprend de la data de Wikipédia mais ne met pas de lien sur comment y contribuer (alors que Qwant le fait). Chez Qwant, on vise à être en symbiose avec les projets libres qu’on utilise et auxquels on contribue.
Google Maps a commencé à monétiser les emplois de sa cartographie, est-ce qu’un jour Qwant Maps va être payant ?
En réalité, Google Maps est toujours gratuit pour les particuliers (approche B2C Business to consumer). Pour les organisations ou entreprises qui veulent mettre une carte sur leur site web (modèle B2B Business to business), Google Maps a longtemps été gratuit avant de devenir brutalement payant, une fois qu’il a éliminé tous ses concurrents commerciaux. Il apparaît assez clairement que Google a fait preuve de dumping.
Pour le moment, chez Qwant, il n’y a pas d’offre B2B. Le jour où il y en aura une, j’espère que le un coût associé sera beaucoup plus raisonnable que chez Google, qui prend vraiment ses clients pour des vaches à lait. Je comprends qu’il faille financer le service qui a un coût, mais là, c’est exagéré !
Quand j’utilise Qwant Maps, est-ce que je suis pisté par des traqueurs ? J’imagine et j’espère que non, mais qu’est-ce que Qwant Maps « récolte » et « garde » de moi et de ma connexion si je lui demande où se trouve Bure avec ses opposants à l’enfouissement de déchets nucléaires ? Quelles garanties m’offre Qwant Maps de la confidentialité de mes recherches en cartographie ?
C’est un principe fort chez Qwant : on ne veut pas collecter de données personnelles. Bien sûr, à un instant donné, le serveur doit disposer à la fois de la requête (quelle zone de la carte est demandée, à quelle échelle) et l’adresse IP qui la demande. L’adresse IP pourrait permettre de retrouver qui fait quelle recherche, et Qwant veut empêcher cela. C’est pourquoi l’adresse IP est salée et hachée aussitôt que possible et c’est le résultat qui est stocké. Ainsi, il est impossible de faire machine arrière et de retrouver quelle adresse IP a fait quelle recherche sur la carte. C’est cette méthode qui est utilisée dans Qwant Search pour empêcher de savoir qui a recherché quoi dans le moteur de recherche.
Est-ce que ça veut dire qu’on perd aussi le relatif confort d’avoir un historique utile de ses recherches cartographiques ou générales ? Si je veux gagner en confidentialité, j’accepte de perdre en confort ?
Effectivement, Qwant ne veut rien savoir sur la personne qui recherche, ce qui implique qu’on ne peut pas personnaliser les résultats, ni au niveau des recherches Web ni au niveau cartographique : pour une recherche donnée, chaque utilisateur reçoit les mêmes résultats que tout le monde.
Ça peut être un problème pour certaines personnes, qui aimeraient bien disposer de personnalisation. Mais Qwant n’a pas dit son dernier mot : c’est exactement pour ça que nous avons fait « Masq by Qwant ». Masq, c’est une application Web en logiciel libre qui permet de stocker localement dans le navigateur (en LocalStorage)2 et de façon chiffrée des données pour la personnalisation de l’expérience utilisateur. Masq est encore en Alpha et il ne permet pour l’instant que de stocker (localement !) ses favoris cartographiques. À terme, nous voulons que les différents services de Qwant utilisent Masq pour faire de la personnalisation respectueuse de la vie privée.
Ouverture d’un compte Masq.
Ah bon alors c’est fini le cloud, on met tout sur sa machine locale ? Et si on vient fouiner dans mon appareil alors ? N’importe quel intrus peut voir mes données personnelles stockées ?
Effectivement, tes données étant chiffrées, et comme tu es le seul à disposer du mot de passe, c’est ta responsabilité de conserver précieusement ledit mot de passe. Quant à la sauvegarde des données, tu as bien pensé à faire une sauvegarde, non ? 😉
Ah mais vous avez aussi un projet de reconnaissance d’images ? Comment ça marche ? Et à quoi ça peut être utile ?
C’est le résultat du travail de chercheurs de Qwant Research, une intelligence artificielle (plus concrètement un réseau de neurones) qu’on a entraînée avec Pytorch sur des serveurs spécialisés DGX-1 en vue de proposer des images similaires à celles que tu décris ou que tu téléverses.
On peut chercher une image ou bien « déposer une image » pour en trouver de similaires.
Ah tiens j’ai essayé un peu, ça donne effectivement des résultats rigolos : si on cherche des saucisses, on a aussi des carottes, des crevettes et des dents…
C’est encore imparfait comme tu le soulignes, et c’est bien pour ça que ça n’est pas encore un produit en production ! On compte utiliser cette technologie de pointe pour la future version de notre moteur de recherche d’images.
Comment je fais pour signaler à l’IA qu’elle s’est plantée sur telle ou telle image ? C’est prévu de faire collaborer les bêta-testeurs ? Est-ce que Qwant accueille les contributions bénévoles ou militantes ?
Il est prévu d’ajouter un bouton pour que les utilisateurs puissent valider ou invalider une image par rapport à une description. Pour des projets de plus en plus nombreux, Qwant produit du logiciel libre et donc publie le code. Par exemple pour la recherche d’image, c’est sur https://github.com/QwantResearch/text-image-similarity. Les autres projets sont hébergés sur les dépôts https://github.com/QwantResearch : les contributions au code (Pull requests) et les descriptions de bugs (issues) sont les bienvenus !
Bon je vois que Qwant a l’ambition de couvrir autant de domaines que Google ? C’est pas un peu hégémonique tout ça ? On se croirait dans Dégooglisons Internet !
Effectivement, nos utilisateurs attendent de Qwant tout un univers de services. La recherche est pour nous une tête de pont, mais on travaille à de nouveaux services. Certains sont des moteurs de recherche spécialisés comme Qwant Junior, pour les enfants de 6 à 12 ans (pas de pornographie, de drogues, d’incitation à la haine ou à la violence).
Comment c’est calculé, les épineuses questions de résultats de recherche ou non avec Qwant Junior ? Ça doit être compliqué de filtrer…
Qwant Junior ne montre pas d’images de sexe masculin, tant mieux/tant pis ?
Nous avons des équipes qui gèrent cela et s’assurent que les sujets sont abordables par les enfants de 6 à 12 ans, qui sont notre cible pour Junior.
Ça n’est pas facile effectivement, mais nous pensons que c’est important. C’est une idée qui nous est venue au lendemain des attentats du Bataclan où trop d’images choquantes étaient publiées par les moteurs de recherche. C’était insupportable pour les enfants. Et puis Junior, comme je le disais, n’a pas vocation à afficher de publicité ni à capturer de données personnelles. C’est aussi pour cela que Qwant Junior est très utilisé dans les écoles, où il donne visiblement satisfaction aux enseignants et enseignantes.
Mais euh… « filtrer » les résultats, c’est le job d’un moteur de recherche ?
Il y a deux questions en fait. Pour un moteur de recherche pour enfants, ça me parait légitime de proposer aux parents un moteur qui ne propose pas de contenus choquants. Qwant Junior n’a pas vocation à être neutre : c’est un service éditorialisé qui fait remonter des contenus à valeur pédagogique pour les enfants. C’est aux parents de décider s’ils l’utilisent ou pas.
Pour un moteur de recherche généraliste revanche, la question est plutôt d’être neutre dans l’affichage des résultats, dans les limites de la loi.
Tiens vous avez même des trucs comme Causes qui propose de reverser l’argent des clics publicitaires à de bonnes causes ? Pour cela il faut désactiver les bloqueurs de pub auxquels nous sommes si attachés, ça va pas plaire aux antipubs…
En ce qui concerne Qwant Causes, c’est le moteur de recherche Qwant mais avec un peu plus de publicité. Et quand tu cliques dessus, cela rapporte de l’argent qui est donné à des associations que tu choisis. C’est une façon de donner à ces associations en faisant des recherches. Bien sûr si tu veux utiliser un bloqueur de pub, c’est autorisé chez Qwant, mais ça n’a pas de sens pour Qwant Causes, c’est pour ça qu’un message d’explication est affiché.
Est-ce que tous ces services sont là pour durer ou bien seront-ils fermés au bout d’un moment s’ils sont trop peu employés, pas rentables, etc. ?
Tous les services n’ont pas vocation à être rentables. Par exemple, il n’y a pas de pub sur Qwant Junior, parce que les enfants y sont déjà trop exposés. Mais Qwant reste une entreprise qui a vocation à générer de l’argent et à rémunérer ses actionnaires, donc la rentabilité est pour elle une chose importante. Et il y a encore de la marge pour concurrencer les dizaines de services proposés par Framasoft et les CHATONS 😉
Est-ce que Qwant est capable de dire combien de personnes utilisent ses services ? Qwant publie-t-elle des statistiques de fréquentation ?
Non. D’abord, on n’identifie pas nos utilisateurs, donc c’est impossible de les compter : on peut compter le nombre de recherches qui sont faites, mais pas par combien de personnes. Et c’est très bien comme ça ! Tout ce que je peux dire, c’est que le nombre de requêtes évolue très rapidement : on fait le point en comité de direction chaque semaine, et nous battons presque à chaque fois un nouveau record !
Bon venons-en aux questions que se posent souvent nos lecteurs et lectrices : Qwant et ses multiples services, c’est libre, open source, ça dépend ?
Non, tout n’est pas en logiciel libre chez Qwant, mais si tu vas sur les dépôts de Qwant et Qwant Research tu verras qu’il y a déjà plein de choses qui sont sous licence libre, y compris des choses stratégiques comme Graphee (calcul de graphe du Web) ou Mermoz (robot d’indexation du moteur). Et puis les nouveaux projets comme Qwant Maps et Masq y sont aussi.
La publicité est une source de revenus dans votre modèle économique, ou bien vous vendez des services à des entreprises ou institutions ? Qwant renonce à un modèle économique lucratif qui a fait les choux gras de Google, mais alors comment gagner de l’argent ?
Oui, Qwant facture aussi des services à des institutions dans le domaine de l’open data par exemple, mais l’essentiel du revenu vient de la publicité contextuelle, à ne pas confondre avec la publicité ciblée telle que faite par les géants américains du Web. C’est très différent.
La publicité ciblée, c’est quand tu sais tout de la personne (ses goûts, ses habitudes, ses déplacements, ses amis, son niveau de revenu, ses recherches web, son historique de navigation, et d’autres choses bien plus indiscrètes telles que ses opinions politiques, son orientation sexuelle ou religieuse, etc.). Alors tu vends à des annonceurs le droit de toucher avec de la pub des personnes qui sont ciblées. C’est le modèle des géants américains.
Qwant, pour sa part, ne veut pas collecter de données personnelles venant de ses utilisateurs. Tu as sûrement remarqué que quand tu vas sur Qwant.com la première fois, il n’y a pas de bannière « acceptez nos cookies ». C’est normal, nous ne déposons pas de cookies quand tu fais une recherche Qwant !
L’équipe Qwant’Comm en plein brainstorming…
Quand tu fais une recherche, Qwant te donne une réponse qui est la même pour tout le monde. Tu fais une recherche sur « Soupe à la tomate » ? On te donne les résultats et en même temps on voit avec les annonceurs qui est intéressé par ces mots-clés. On ignore tout de toi, ton identité ou ton niveau de revenu. Tout ce qu’on sait, c’est que tu as cherché « soupe à la tomate ». Et c’est ainsi que tu te retrouves avec de la pub pour du Gaspacho ou des ustensiles de cuisine. La publicité vaut un peu moins cher que chez nos concurrents, mais les gens cliquent dessus plus souvent. Au final, ça permet de financer les services et d’en inventer de nouveaux tout en respectant la vie privée des utilisateurs et de proposer une alternative aux services américains gourmands en données personnelles. On pourrait croire que ça ne rapporte pas assez, pourtant c’était le modèle commercial de Google jusqu’en 2006, où il a basculé dans la collecte massive de données personnelles…
Dans quelle mesure Qwant s’inscrit-il dans la reconquête de la souveraineté européenne contre la domination des géants US du Web ?
Effectivement, parmi les deux choses qui différencient Qwant de ses concurrents, il y a la non-collecte de données personnelles et le fait qu’il est français et à vocation européenne. Il y a un truc qui me dérange terriblement dans le numérique actuel, c’est que l’Europe est en train de devenir une colonie numérique des USA et peut-être à terme de la Chine. Or, le numérique est essentiel dans nos vies. Il les transforme ! Ces outils ne sont pas neutres, ils sont le reflet des valeurs de ceux qui les produisent.
Aux USA, les gens sont considérés comme des consommateurs : tout est à vendre à ou à acheter. En Europe, c’est différent. Ça n’est pas un hasard si la CNIL est née en France, si le RGPD est européen : on a conscience de l’enjeu des données personnelles sur la citoyenneté, sur la liberté des gens. Pour moi, que Qwant soit européen, c’est très important.
Merci d’avoir accepté de répondre à nos questions. Comme c’est la tradition de nos interviews, on te laisse le mot de la fin…
Je soutiens Framasoft depuis toujours ou presque, parce que je sais que ce qui y est fait est vraiment important : plus de libre, moins d’hégémonie des suspects habituels, plus de logiciel libre, plus de valeur dans les services proposés.
J’ai l’impression d’avoir avec Qwant une organisation différente par nature (c’est une société, avec des actionnaires), mais avec des objectifs finalement assez proches : fournir des services éthiques, respectueux de la vie pivée, plus proches des gens et de leurs valeurs, tout en contribuant au logiciel libre. C’est ce que j’ai tenté de faire chez Mozilla pendant 17 ans, et maintenant chez Qwant. Alors, je sais que toutes les organisations ne sont pas parfaites, et Qwant ne fait pas exception à la règle. En tout cas, chez Qwant on fait du mieux qu’on peut !
Vive l’Internet libre et ceux qui œuvrent à le mettre en place et à le défendre !
Imago TV, la plateforme gratuite de streaming dédiée à la transition
Il y a quelques mois, une personne nous a demandé dans un commentaire sous un de nos billets de blog de parler d’Imago TV. On s’est dit que c’était une bonne idée que de rendre visible cette plateforme auprès de notre communauté alors on a contacté les deux créateurs Nicolas et Felipe pour qu’ils répondent à nos questions.
Bonjour Nicolas, pouvez-vous vous présenter ?
Bonjour, je suis Nicolas, l’un des 2 co-créateurs d’Imago TV. Avec Felipe, originaire du Chili et travaillant dans le secteur des énergies renouvelables, nous avons lancé le projet Imago TV début 2018. À l’époque je venais juste de quitter mes activités professionnelles dans le domaine du streaming vidéo et je travaillais avec Felipe sur le web magazine Les Gens Qui Sèment, l’émission des alternatives.
Imago TV, c’est quoi ?
Imago TV est une plateforme dédiée à la diffusion et à la valorisation de vidéos engagées dans la transition. À ce jour, Imago TV propose aux internautes de visionner plus de 2000 contenus très diversifiés (émissions, documentaires, podcasts, courts-métrages) leur permettant d’aborder des sujets aussi variés que l’écologie, les énergies, les ressources, la démocratie, l’économie, ou encore les monnaies. Notre objectif était dès le départ d’offrir une vitrine la plus belle possible (aussi bien d’un point de vue esthétique qu’en termes d’audience) aux contenus audiovisuels engagés dans la transition, que ceux-ci produisent une analyse critique des modèles dominants ou qu’ils mettent en lumière des modèles alternatifs à ces modèles dominants.
Qui peut diffuser des contenus sur Imago TV ?
Sur le principe, n’importe qui peut diffuser des contenus sur Imago TV. Pour le moment, un comité de visionnage valide les contenus qui nous sont suggérés par mail. Mais à terme, nous envisageons que ce travail soit coopératif et réalisé de manière collégiale par l’ensemble des utilisateur⋅ices d’Imago TV. La majorité des contenus nous ont d’ailleurs été suggérés par des utilisateur⋅ices et il s’agissait souvent des créateur⋅ices de ces vidéos.
Quels sont les critères de sélection des contenus sur Imago TV ?
Les contenus validés par le comité de visionnage doivent être :
– conformes à la ligne éditoriale
– conformes à la charte
– cohérents avec l’offre existante
En quoi Imago TV porte les valeurs du libre ?
À plusieurs niveaux. Tout d’abord Imago TV est un projet associatif et bénévole, entièrement développé en open-source. Imago TV est accessible sans abonnement et fonctionne sans publicité, sur un modèle uniquement coopératif. Pour le financement, nous venons tout juste de mettre en place un compte en G1 (June) pour recevoir des dons en monnaies libres.
Sur le plan technique, notre site web n’intègre aucune librairie Google Analytics, Facebook ou Twitter ; ainsi, le tracking est limité au maximum. D’une manière générale, la seule librairie extérieure que nous utilisons est jquery et nous n’utilisons pas de framework. Notre future application pour smartphone sera sous Android et l’apk sera disponible en téléchargement depuis notre site web ainsi que sur f-droid.
Nous faisons également la promotion de productions placées sous licences Creative Commons (comme Data Gueule ou Thinkerview) et des plateformes open-source (comme PeerTube ou Wetube pour l’hébergement et Captain Fact pour le fact checking). Les contenus eux-mêmes traitent des questions d’open-source, d’open-access, d’open data, de neutralité du net ou d’hacktivisme (We are legion ou The Internet’s own boy).
Enfin, la plateforme a été pensée dans l’esprit d’Aaron Swartz et de ses écrits relatifs à la création de Wikipédia. Sur la plateforme, nous avons d’ailleurs une page dédiée à son Manifeste de la guérilla pour le libre accès.
Des Framapads plus beaux, grâce à une belle contribution
Framapad, c’est un de nos plus anciens services. C’est une page d’écriture, en ligne, ou vos ami·e·s peuvent venir collaborer en direct à la rédaction d’un texte. Un « Google docs », mais sans Google, sans pistage et même sans inscription !
C’était déjà pratique…
Le principe est simple : vous allez sur Framapad.org, vous décidez de la durée de vie de votre pad et de son nom, vous cliquez sur « Créer un pad » et… ayé, vous êtes dessus. Il ne vous reste plus qu’à choisir votre pseudo (si vous voulez que vos potes vous reconnaissent) et votre couleur d’écriture !
Oh, et si vous avez des ami·e·s (ou juste des gens avec qui vous collaborez, hein), il vous suffit de leur copier/coller l’adresse web du pad dans un message pour qu’iels viennent travailler avec vous sur votre texte, chacun avec son pseudo, chacune avec sa couleur d’écriture. Quand on arrive, ça ressemble à ça :
Framapad n’est pas développé par nos soins : c’est une instance (une installation sur un serveur) du logiciel libre Etherpad (ou Etherpad-lite pour être précis), et vous pouvez retrouver d’autres instances hébergées par La Quadrature du Net, le chaton Infini, les activistes de RiseUp et bien, bien d’autres !
… et maintenant c’est Beau !
Nous venons de procéder à une mise à jour d’Etherpad (vers la version 1.7.5) sur nos serveurs… Et désormais, Framapad, ça ressemble à ça :
Alors oui, c’est un peu injuste, car derrière cette mise à jour il y a de nombreuses contributions qui rendent le code plus solide, plus résilient, plus pratique aussi… Mais forcément, les changements esthétiques sautent aux yeux. Et en même temps, dans un milieu du logiciel libre qui (souvent) peine à améliorer l’expérience des utilisatrices et utilisateurs, il nous semble important de le faire remarquer !
Grâce à quelques modifications de CSS (les feuilles de styles des sites web), Etherpad est devenu plus lisible, plus aéré, plus pratique à utiliser. Cela signifie concrètement que vous aurez beaucoup moins de « non mais je veux pas utiliser ton truc, c’est moche et je comprends pas » lorsque vous proposerez une telle alternative à GoogleDocs !
Pour la petite histoire contributopique
Cette contribution qui améliore le look et la lisibilité d’Etherpad, nous la devons à Sébastian Castro, développeur principal de GoGoCarto, et mrflos, connu du monde du libre pour être le co-auteur de YesWiki. C’est en leur qualité de Geeks du Mouvement Colibris qu’ils se sont intéressés à Etherpad. En effet, nous accompagnons depuis deux ans déjà ce mouvement dans sa démarche de dégoogliser les pratiques de ses plus de 300 000 membres. C’est dans ce but que mrflos leur a concocté le site colibris-outilslibres.org qui rassemble plusieurs services libres :
Seulement voilà : fidèles à la devise du mouvement auquel ils participent, Sébastian et mrflos n’ont pas voulu simplement « utiliser » Etherpad, mais ils ont souhaité faire leur part. Et c’est ainsi qu’après avoir fait des tests et des bidouilles pour améliorer le look de l’Etherpad des Colibris, mrflos a fait remonter leur contribution à la communauté.
Après plus de 3 mois d’affinages du code, de discussions (plus de 60 commentaires variés sur la proposition), la contribution a trouvé sa place dans le code officiel d’Etherpad, et pourra être plus facilement utilisée par des milliers d’utilisateur·ices.
Depuis la sortie de la nouvelle version (la 1.7.5), toutes les instances Etherpad (dont Framapad) peuvent désormais profiter d’un thème plus clair, lisible, et qui facilite l’adoption d’outils libres par un plus grand nombre de gens !
Une fois encore, ceci n’est qu’une des milliers d’histoires de contributions libres que l’on pourrait raconter. Elle montre simplement que, lorsque l’on part à la rencontre de communautés différentes de la sienne, cela donne lieu à des contributions que nous n’aurions pas forcément imaginées ;).














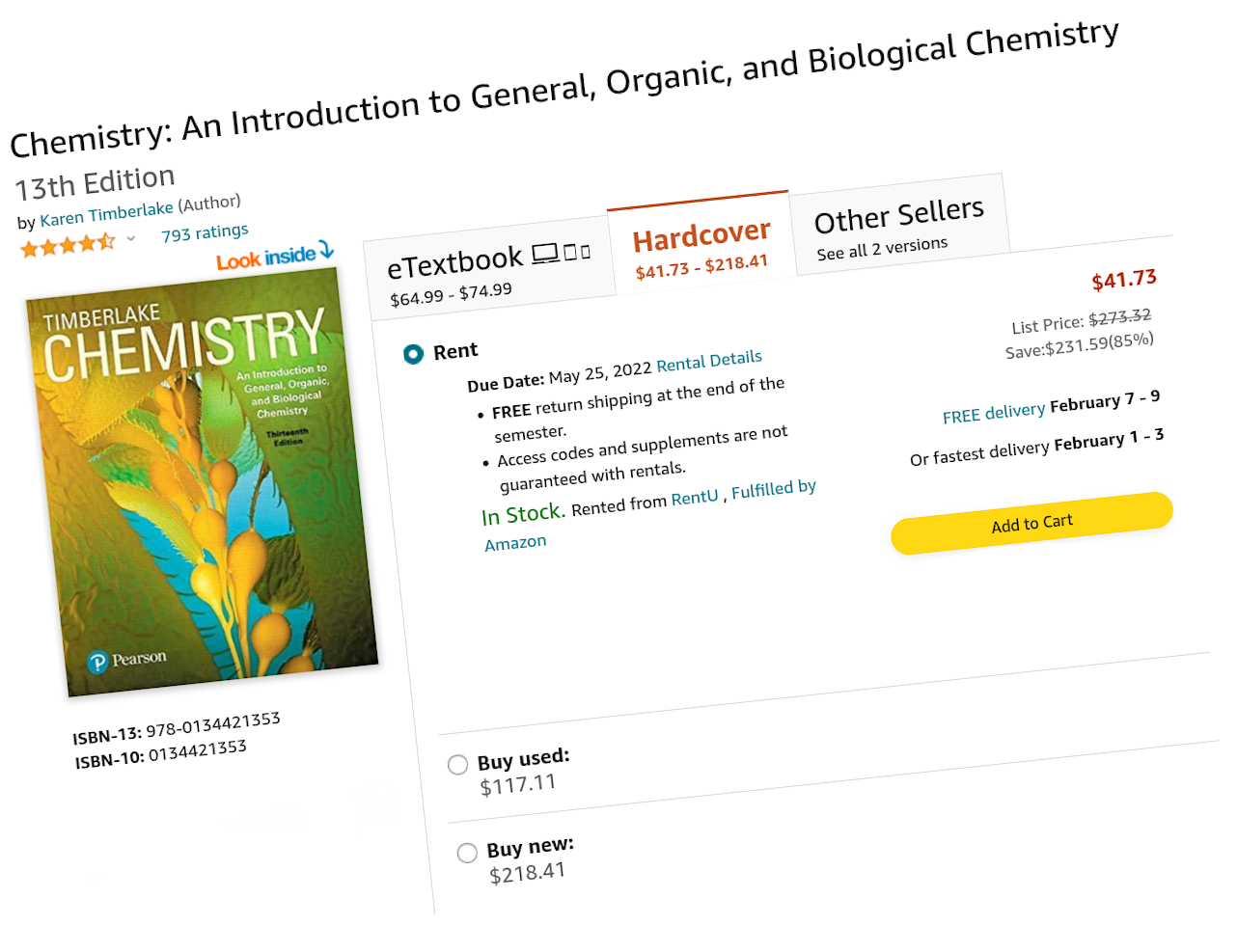







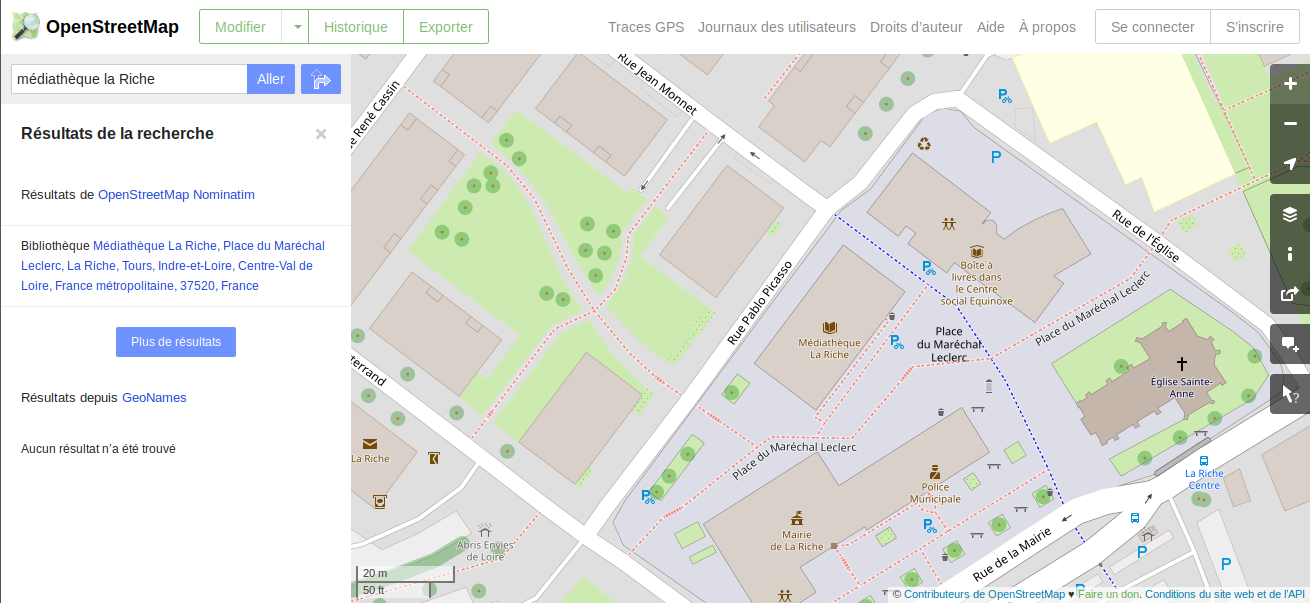

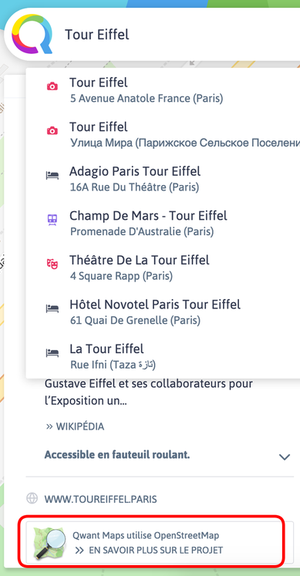



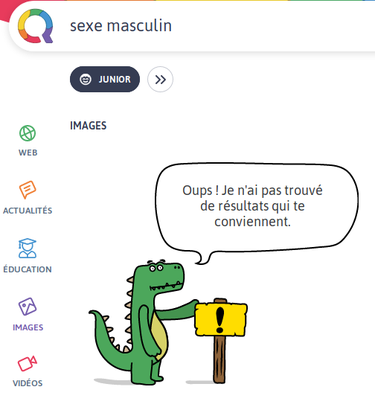



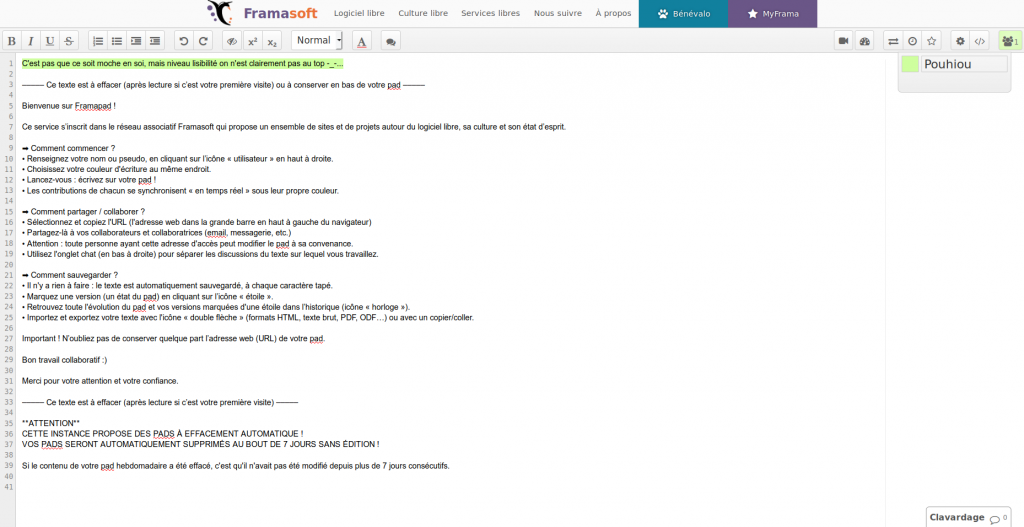
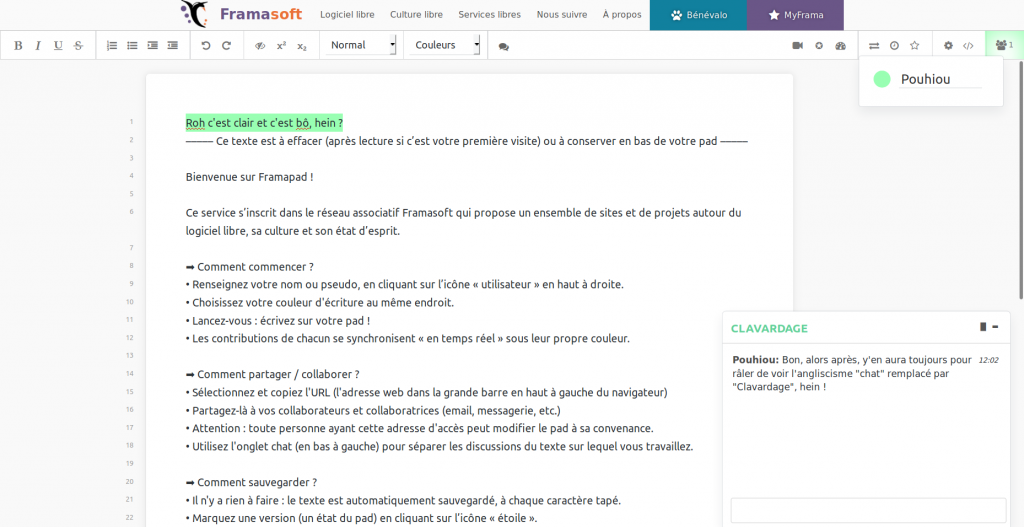
{kind=link}